






K-means聚类是一种常见的无监督学习算法,主要用于将数据集划分成若干个簇(cluster),使得每个簇内的数据点尽可能相似,而簇间的数据点尽可能不同。
应用场景
K-means聚类应用广泛,尤其适合以下场景:
-
客户分群:根据用户行为特征(如消费习惯、购买频率)将客户划分为不同组别。
-
图像分割:将图像像素根据颜色或纹理分为若干区域。
-
文档分类:将文本向量化后(如TF-IDF表示)进行聚类。
-
生物信息学:分析基因表达数据或其他生物数据模式。
算法的核心思想
目标函数:K-means算法通过最小化簇内数据点到簇中心的总距离(即误差平方和)来进行优化。数学公式为:
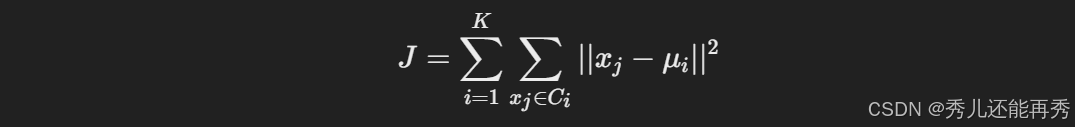
其中:
-
Ci:第 i个簇
-
μi:第 i 个簇的中心(即该簇所有数据点的均值)
通过不断迭代更新簇中心和重新分配数据点来最小化目标函数 J。
K-means 聚类算法的步骤
1、初始化中心点(或称质心)
-
方法1:随机初始化
随机从数据集中选择 KKK 个数据点作为初始簇中心。 -
方法2:K-means++初始化
选择第一个簇中心后,后续簇中心的选择倾向于与当前中心距离较远的点,确保初始簇中心尽可能分散。
2、分配数据点:将数据集中的每个数据点分配到距离其最近的簇中心所代表的簇。常用的距离度量是欧氏距离。(或其他距离公式,本文使用欧氏距离为例)
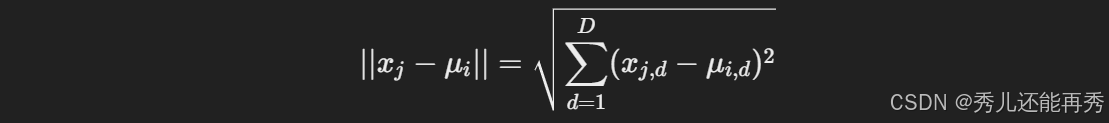
其中:
- D:数据点的维度
:数据点
的第 d 维特征
:簇中心 μi 的第 d 维特征
3、更新簇中心:对于每个簇,计算簇内所有点的均值,新的均值将成为该簇的中心。
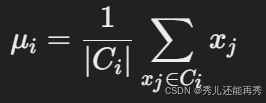
4、重复步骤2和步骤3:重复分配数据点和更新簇中心的步骤,直到簇中心不再发生显著变化(即收敛)或达到设定的最大迭代次数。
优缺点
优点:
1、简单易实现
2、结果可解释性强:输出的簇中心和分配结果容易理解和可视化。
缺点:
1、依赖初始中心:不同的初始簇中心可能导致不同的聚类结果(局部最优解)
2、K值需要预先设定:K值的选择对结果影响较大,通常需要使用肘部法则或轮廓系数等方法。
3、对异常值敏感:离群点可能导致簇中心偏移,影响聚类效果。
4、簇形状假设:K-means假设簇是球形的,对复杂形状的数据(比如环形或不规则簇)效果较差。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









