






一、motivation
重点在于,作者发现了一对多和一对一的差异和互补性
detr的缺点在于是一对一(一个GT对应一个query),正查询的数量少,影响
(1)encoder的潜在特征的产生
(2)decoder的attention learning
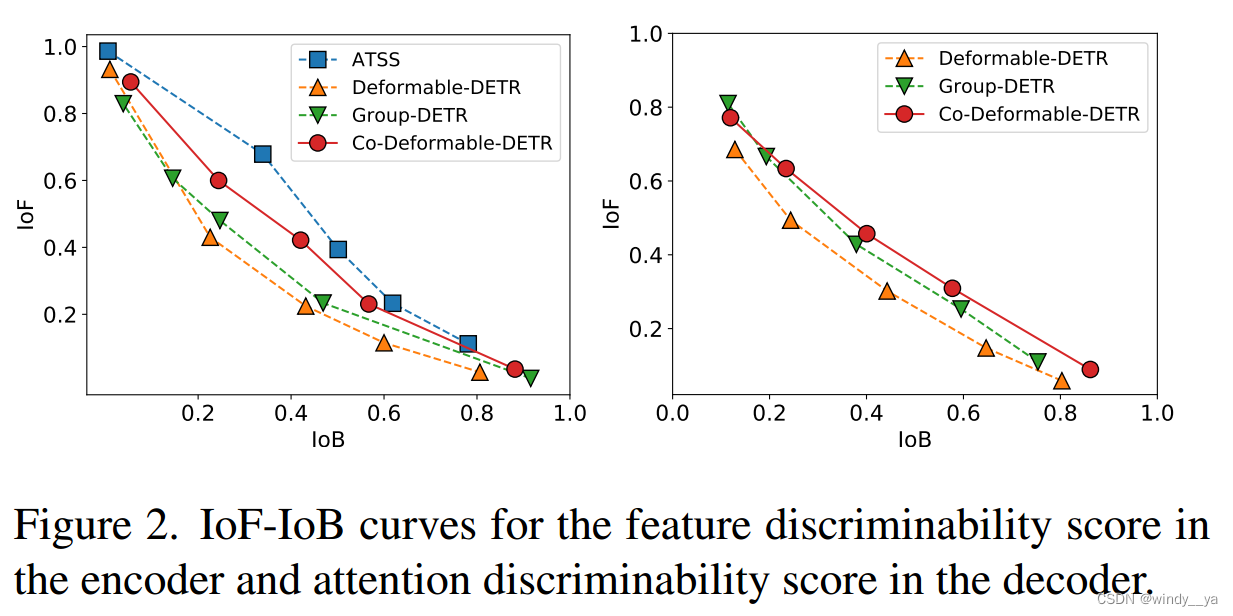
【坐标图中可以看出,(左,encoder)一对多方式更能区分前景和背景;(右,decoder)group和deformable引入更多position query可以提高解码器识别前景和背景能力,即缓解少正查询带来的影响】

【可视化(判别行评分图)可以看出,一对多可以有更多显著特征信息。】
在保持detr端到端优点的情况下让其性能优于传统检测器。
二、innovation
1、Collaborative Hybrid Assignments Training协作式混合分配训练:
将辅助头和encoder输出集成起来,采用一对多的标签分配来进行监督(不同标签分配方法丰富了对编码器输出的监督,增强判别性,加快辅助头的收敛),缓解encoder的稀疏监督。
motivation:decoder中少正查询导致encoder输出的稀疏监督。
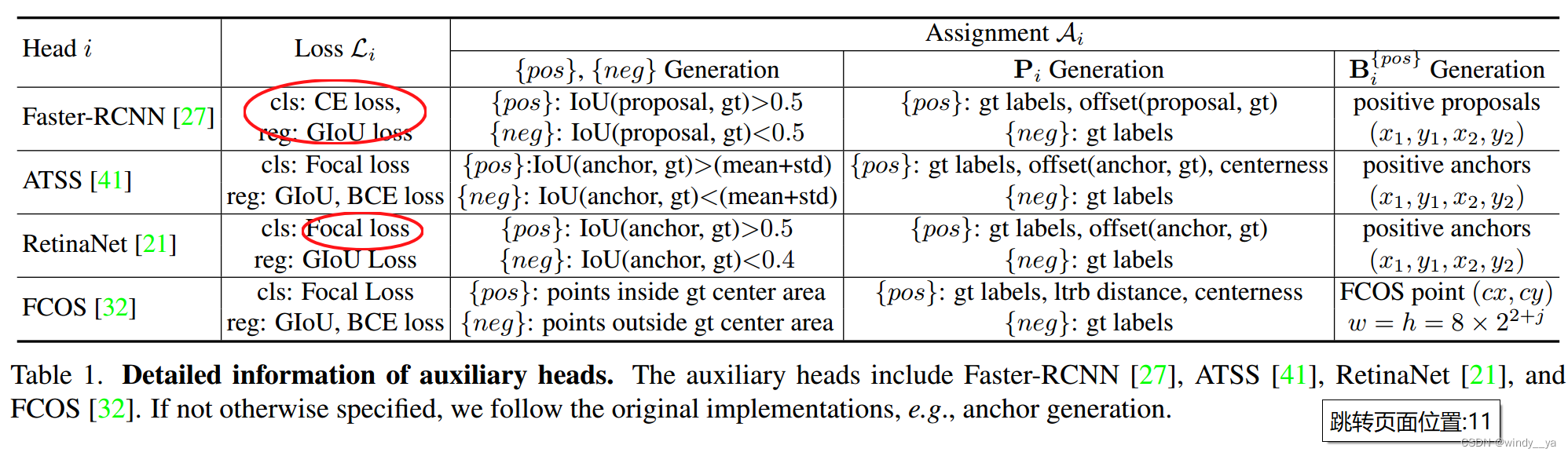
以下是不同辅助头的分配策略:
2、引入正查询(正查询来源于辅助头生成的预测与相应GT的匹配关系)
motivation:少量的正查询带来低效的cross attention learning。
innovation:
给定正坐标集合Bi,则Qi可以由以下生成,从Bi中得到位置编码[PE],从F1-k中的正坐标提取特征【个人感觉有点像得到position query和content query】
![]()
3、IOF-IOB的计算
三、模型架构

(1)backbone和传统detr一样,生成分辨率小的特征图(一般C=2048,H/32,W/32)
(2)协同混合分配训练:编码器输出的潜在特征F,采用Multi-scale Adapter转换为金字塔 {F1, · · · , FJ },K个辅助头用A1-k来分配标签。将F1-j送进第i个协作head得到P^,通过Ai计算Pi的正负样本
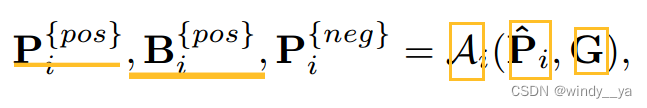 P{pos} :正样本的分类和回归偏移量;P {neg}:负样本的分类;B{pos}:正样本的坐标box;
P{pos} :正样本的分类和回归偏移量;P {neg}:负样本的分类;B{pos}:正样本的坐标box;
这里要注意,用的是单个特征图进行上采样&下采样直接生成金字塔(在VitDet中有提到,FPN其实是不必要的),这里放一下原论文的三个生成特征金字塔的对比吧,采用的就是c啦,对于单尺度输出的encoder,上采样是通过双线性插值和3x3卷积实现的,然后下采样就是通过3x3和stride=2的Conv;对于多尺度输出的encoder,直接进行下采样产生金字塔。

encoder loss的计算:![]()
(3)辅助头得到正查询后放到decoder里面train,辅助头的损失为![]()
整个网络的loss可以表示为:

【记得在汇报论文的时候被问decoder是不是共享权重的:论文里有提到原始分支和辅助分支的L层decoder都是共享参数的。】
work:
(1)one-many增强encoder的监督,更能分辨前景/背景,即提取特征更好。还是这幅图,可以看到在相同的IOB下,co-detr的IOF更高。

(2)提高cross attention的学习(cross attention可以让正查询得到更多object的信息)和降低匹配的不稳定性:如下图,co可以提高匹配的稳定性(匈牙利匹配因为GT和query匹配的不稳定性,会导致训练时间很长);如上图,可以看出在查询较多的情况下,分辨前景和背景的能力较好,说明cross attention learning提高了,所以query可以得到更多的信息。
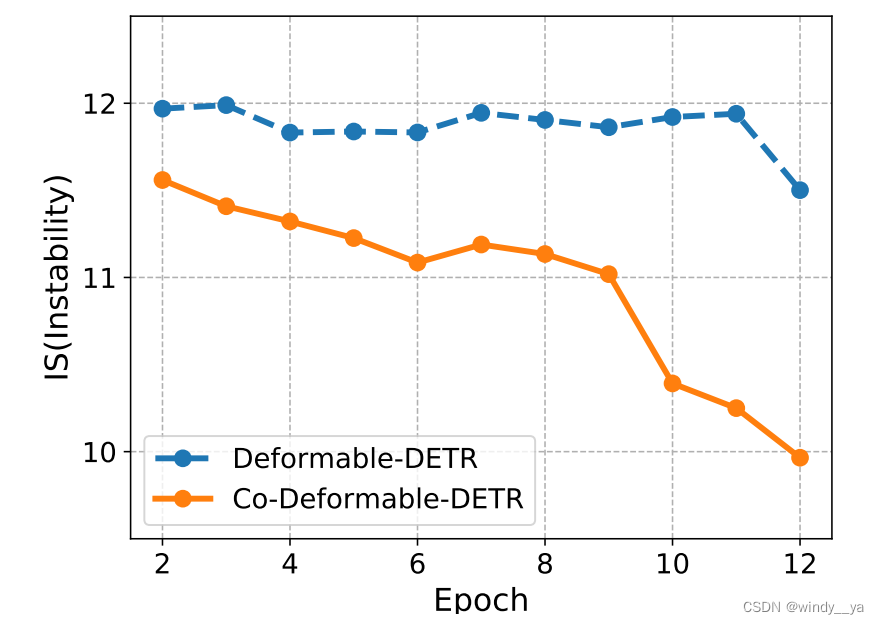
(3)decoder只针对正查询,忽略了负样本,可以减少内存,红框可以看出H-detr由于重复query所以不可避免引入了负查询,内存更高。

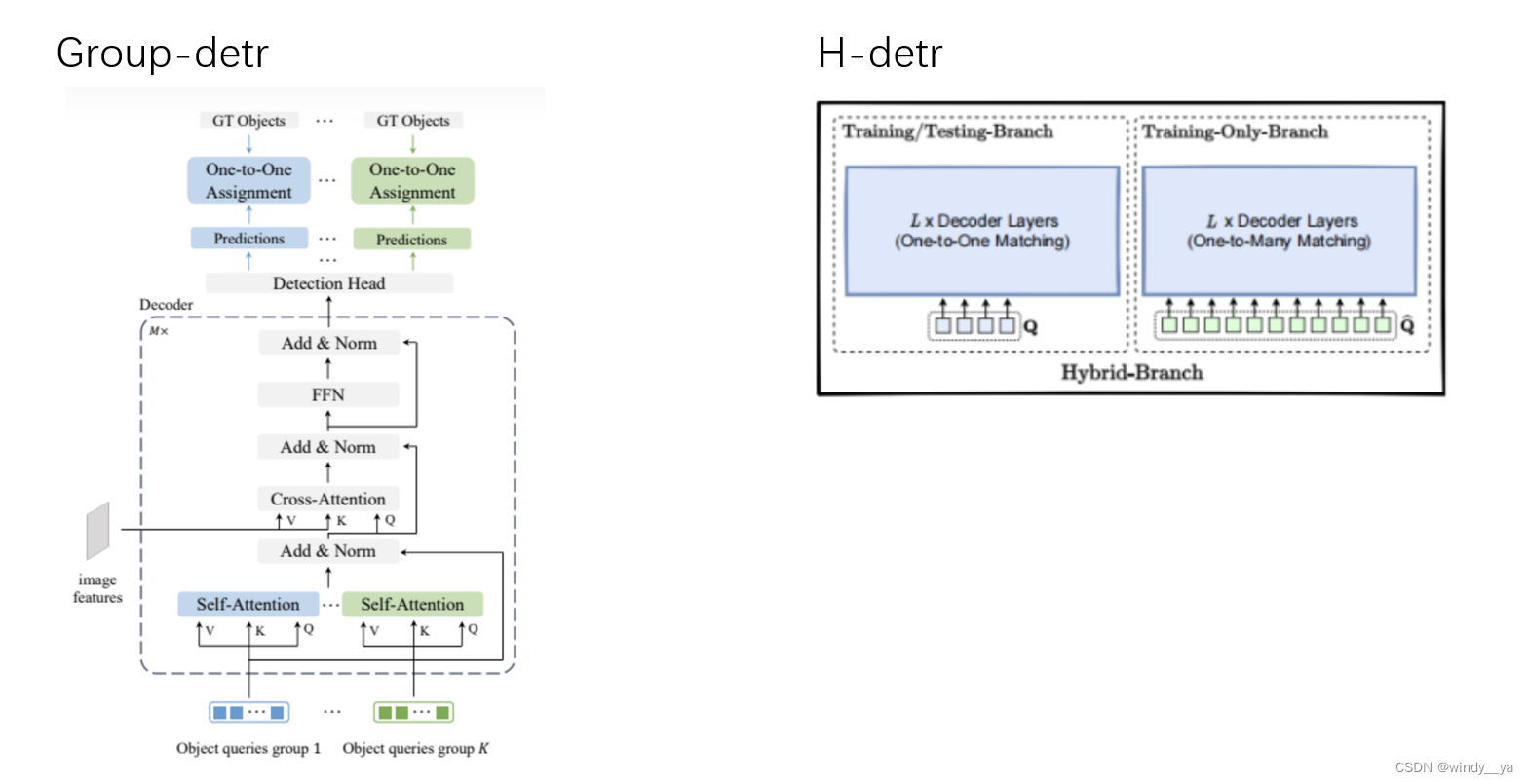
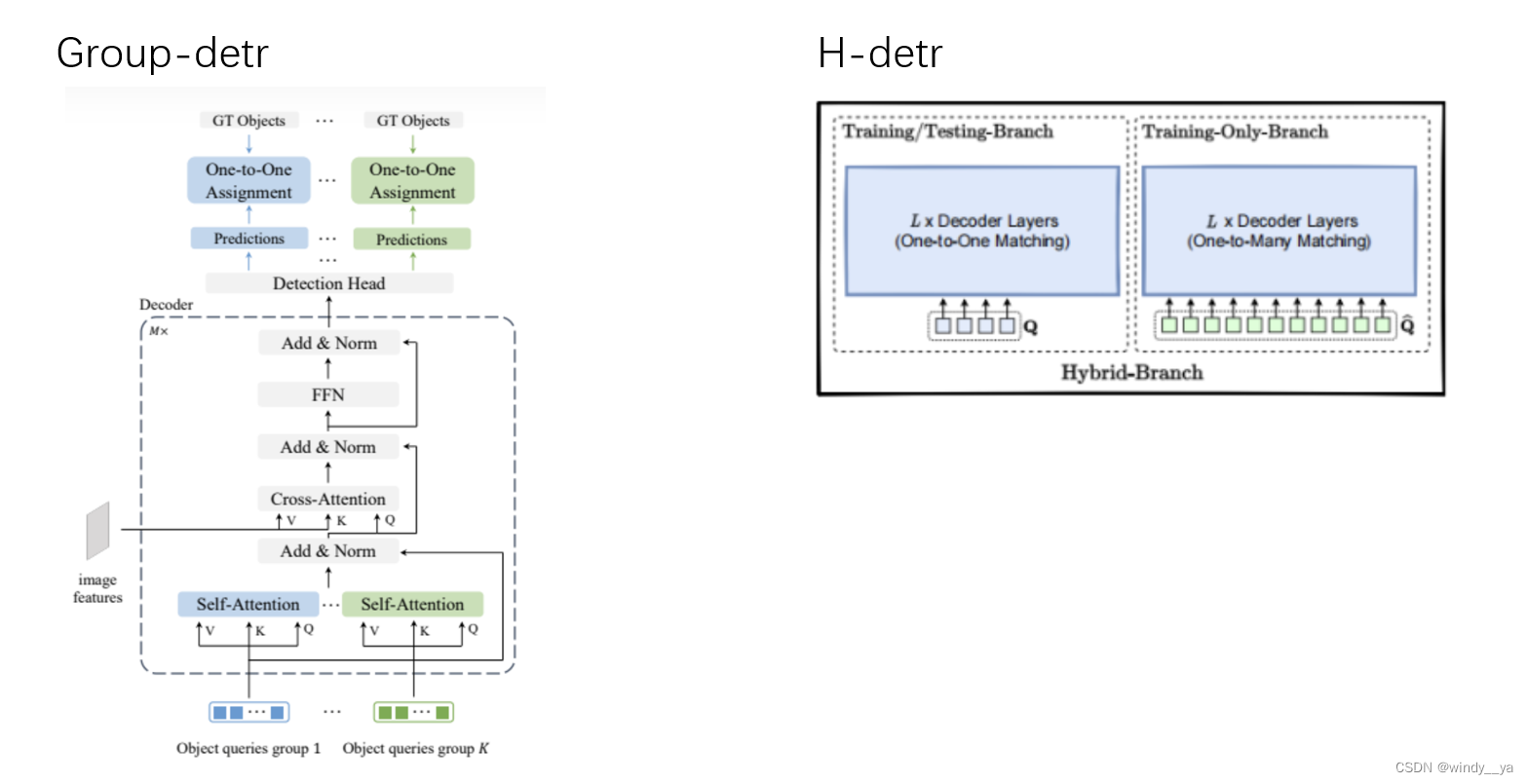
再提一下H-detr&group-detr:通过重复组的方式引入更多的正查询,但是本质上还是相当于是解耦的一对一分配,不可避免地会有匈牙利匹配带来的不稳定性影响收敛速度;而且,该种方式不可避免地会引入负查询。
三、实验
1、ps.一个十字架是deformable用5scale;两个十字架就是用swin-L的backbone;
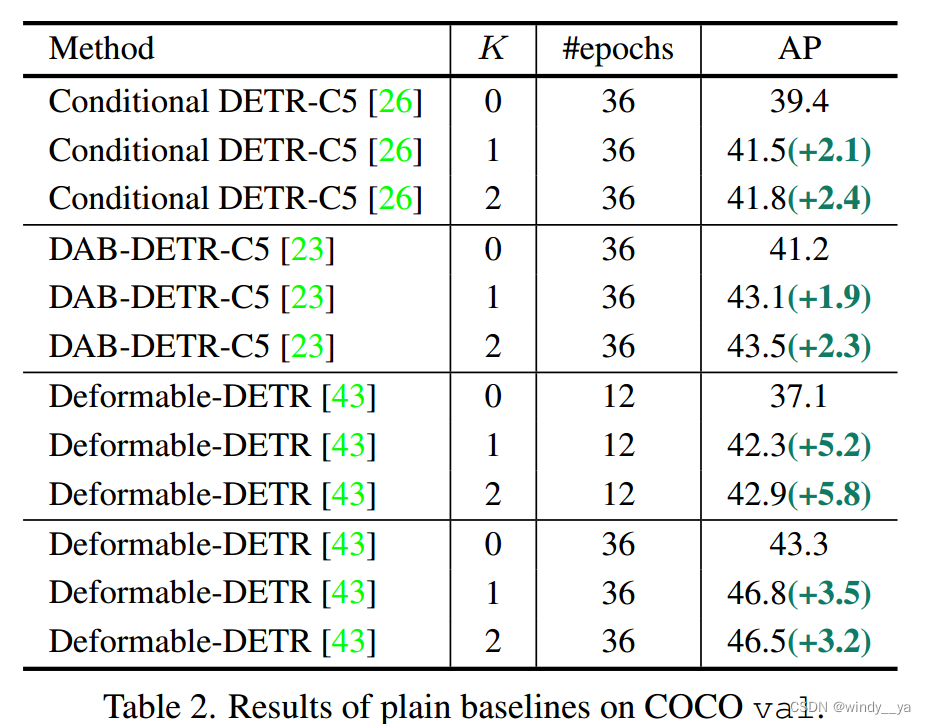
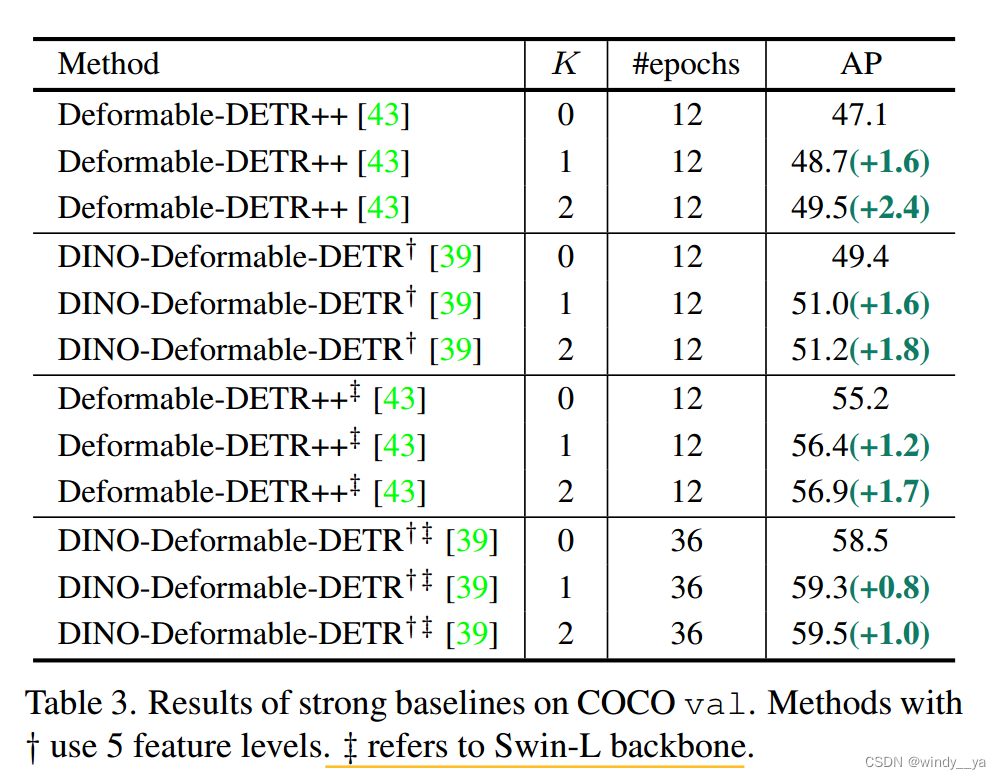
用了更强的backbone依然AP上升
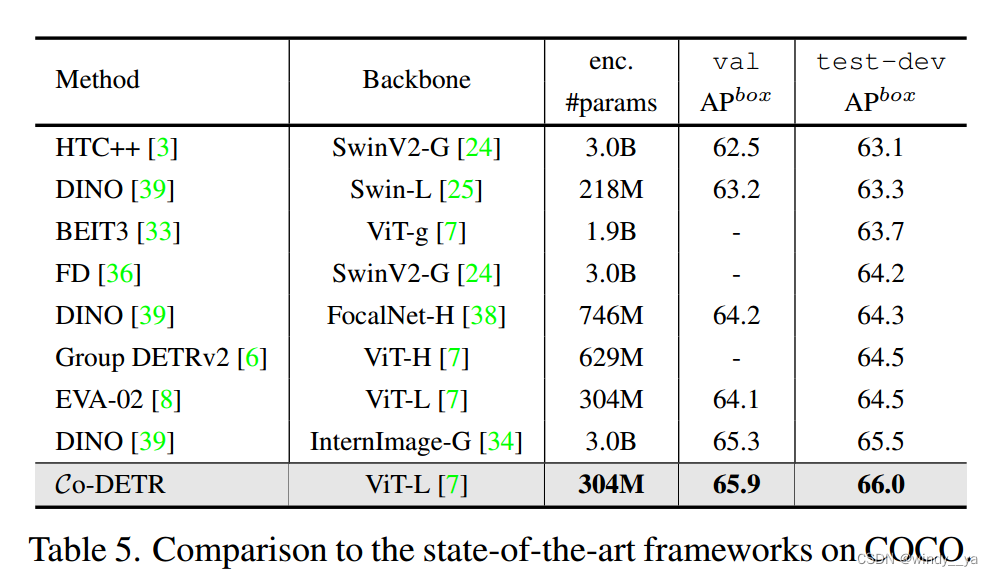
2、sota
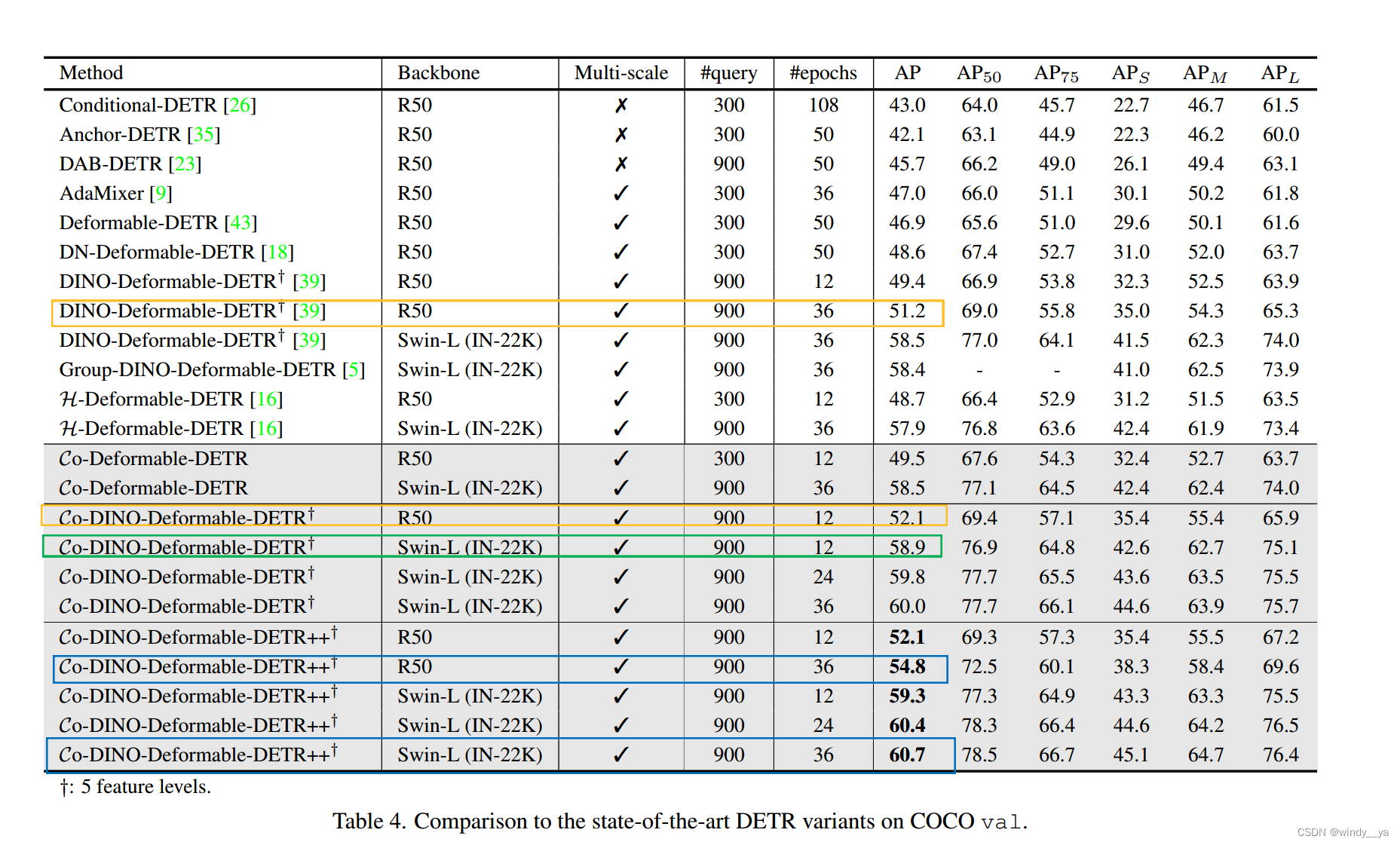
(1)黄框:都是Resnet50下12个epoch都可以达到52.1,收敛快
(2)绿框:用SwinL12个epoch就可以达到比其他好的精度。
(3)蓝框:优于具有相同主干的现有的检测器。
3、扩展性
[骨干容量扩展到3.04亿个参数。使用自监督学习方法(EVA-02[8])对该大型主干ViT-L[8]进行预训练。我们首先在Objects365上使用vitl预训练Co-DINO-Deformable-DETR 26个epoch,然后在COCO数据集上进行12个epoch的微调。在微调阶段,输入分辨率在480×2400和1536×2400之间随机选择。]
在更小的模型尺寸下实现最好的性能。
消融实验:
1、可以看到k>3AP高,而一旦大于3之后产生冲突:这个在附录里是有房消融实验的引入了一个距离度量,可以看到Hi和Hj的距离较大,导致优化不一致;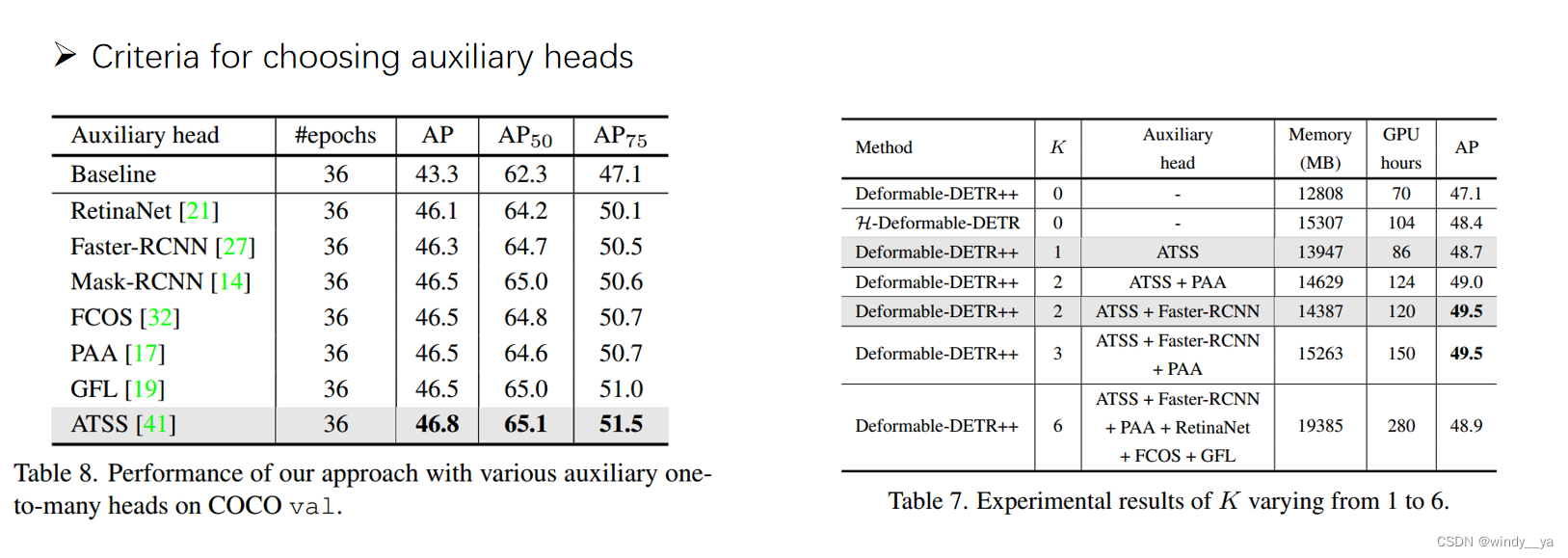
-------------------------分割线----------------------------
BASIC
1.L1&L2:正则化
参考:什么是范数(norm)?以及L1,L2范数的简单介绍-CSDN博客
L1有稀疏的作用;
L2是通过抑制不重要权重更新的来正则防止过拟合,具有平滑,符合高斯分布。
2.RCNN&Fast RCNN&Faster RCNN
(1)RCNN:用selective search算法对一张输入图片提取很多候选框,即锚框,然后放到CNN里去提取特征-->到SVM中进行分类(IOU小于阈值为负样本,加上label做损失训练SVM)-->用NMS非极大值抑制去除重复框(对IOU值进行排序,最大的标记保留,剩下的删去)
【SVM】详解如下图。
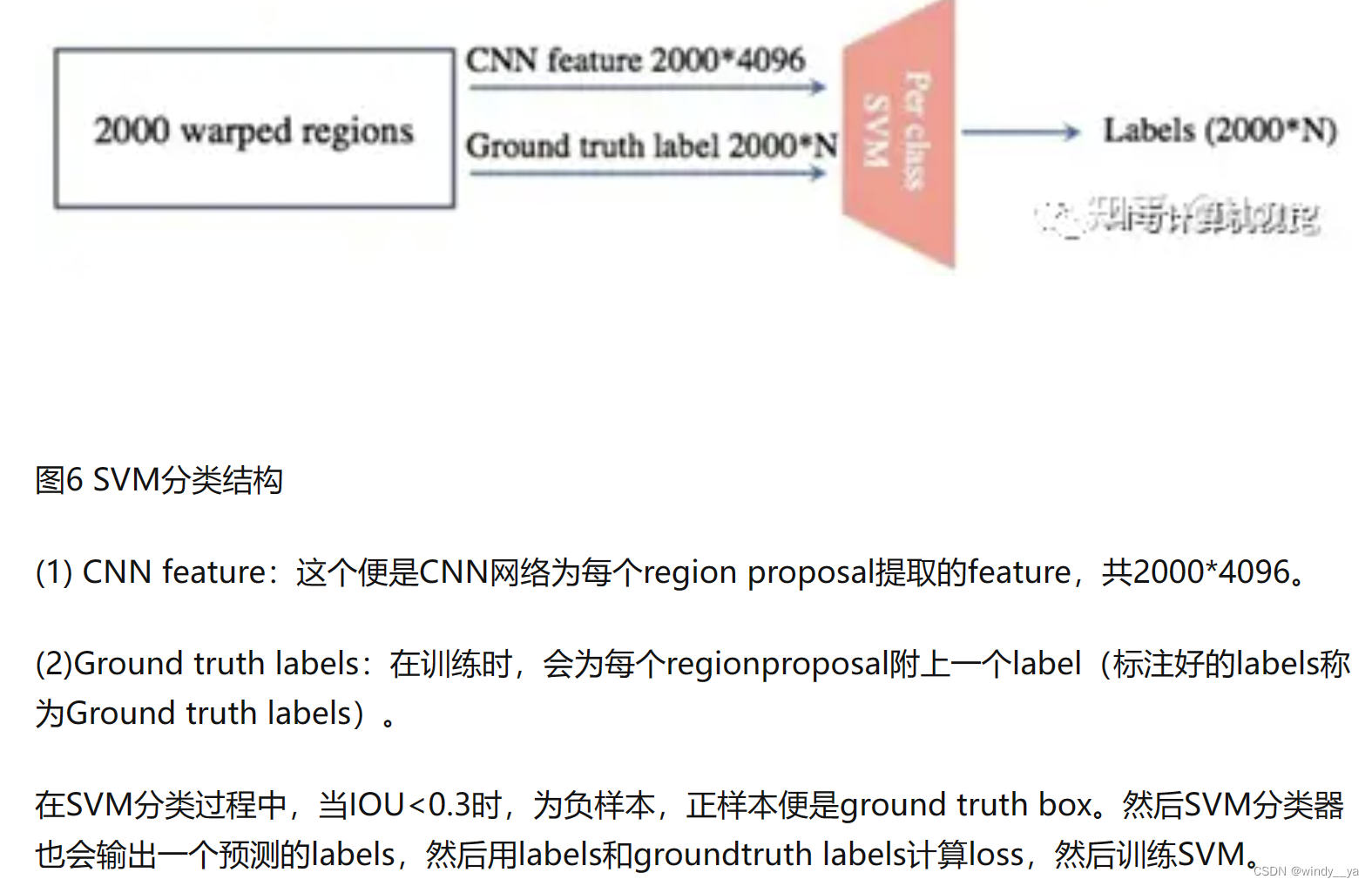
这里解释一下为啥先CNN进行分类正负样本后再SVM分类:因为二者对于正负样本的要求不一样,CNN有可能过拟合,需要较多的数据,即对于正负样本较不严格egIOU=0.5,只有物体的一小部分也可能判为正样本;而SVM适用于少样本,要求较严格egIOU=0.8,筛选的正样本需包含整个物体。
shortback:但是由于RCNN是对每个锚框去用CNN提取feature,所以当有若干个很接近的锚框,会对该区域重复提取特征导致速度很慢,因此有了Fast RCNN。
(2)Fast RCNN
改进:a.对整张图像用CNN提取特征,而非对单独的anchor。b.采用ROI池化(即对每个锚框进行maxpool),从而保证大小一致可以放入全连接层进行下一步的分类回归。
先将整个图像放入CNN提取feature --> 将anchor直接缩放映射到提取出来的feature中 --> 用ROI池化 --> 全连接层分类回归。
short back:在这里还是用selective search。
(3)Faster RCNN:参考博客一文读懂Faster RCNN - 知乎 (zhihu.com)
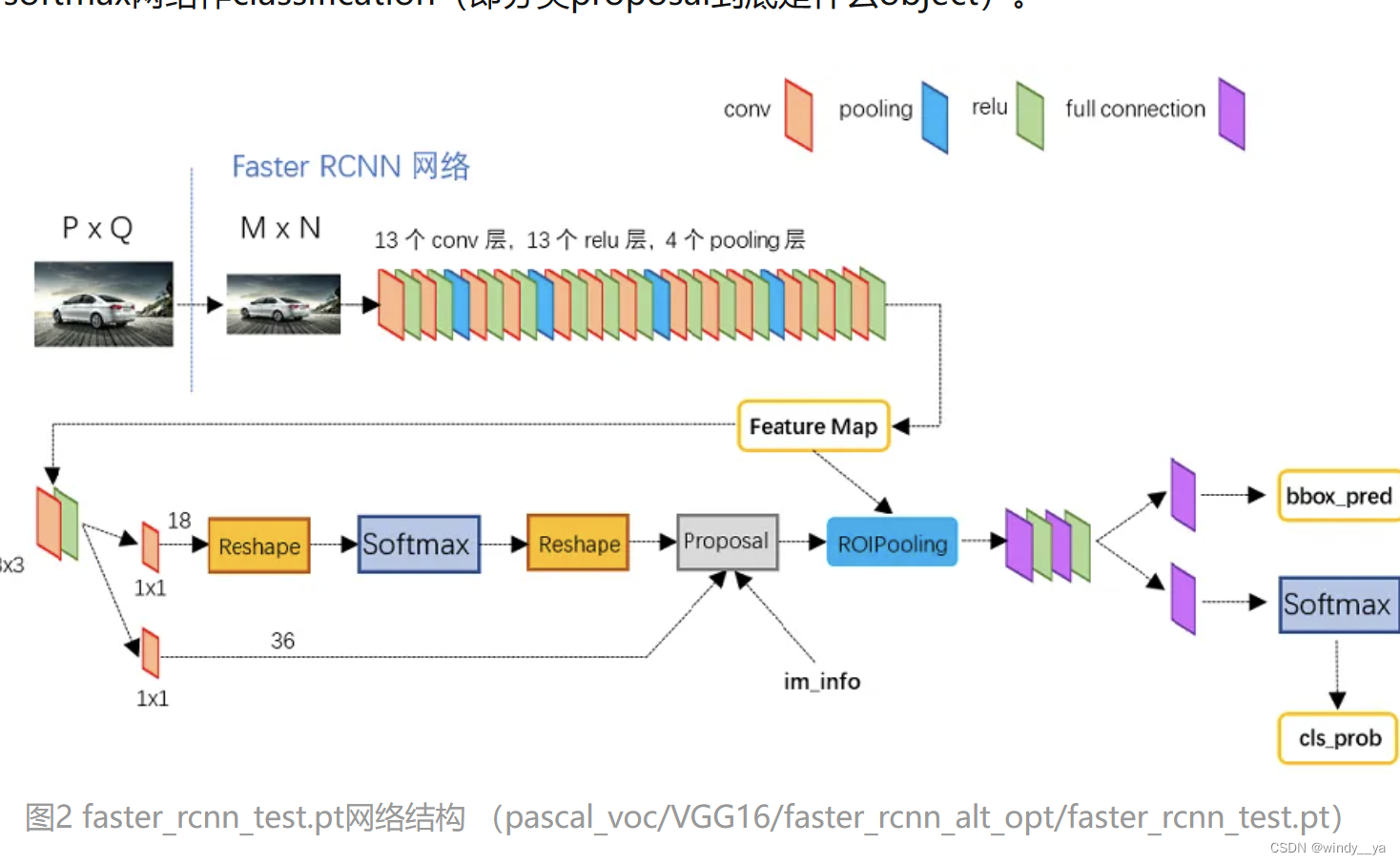
1.先用卷积提取feature
2.RPN(region proposal),如图4,先3x3,然后两个分支的1x1,上面送分题max做二分类分类正负样本,下面计算bounding Box偏移量;然后一起到proposal层(包括NMS),proposal层负责将positive anchor和offset一起得到最终的proposals并剔除太小或超出边界的,其实在这里就完成了目标定位。
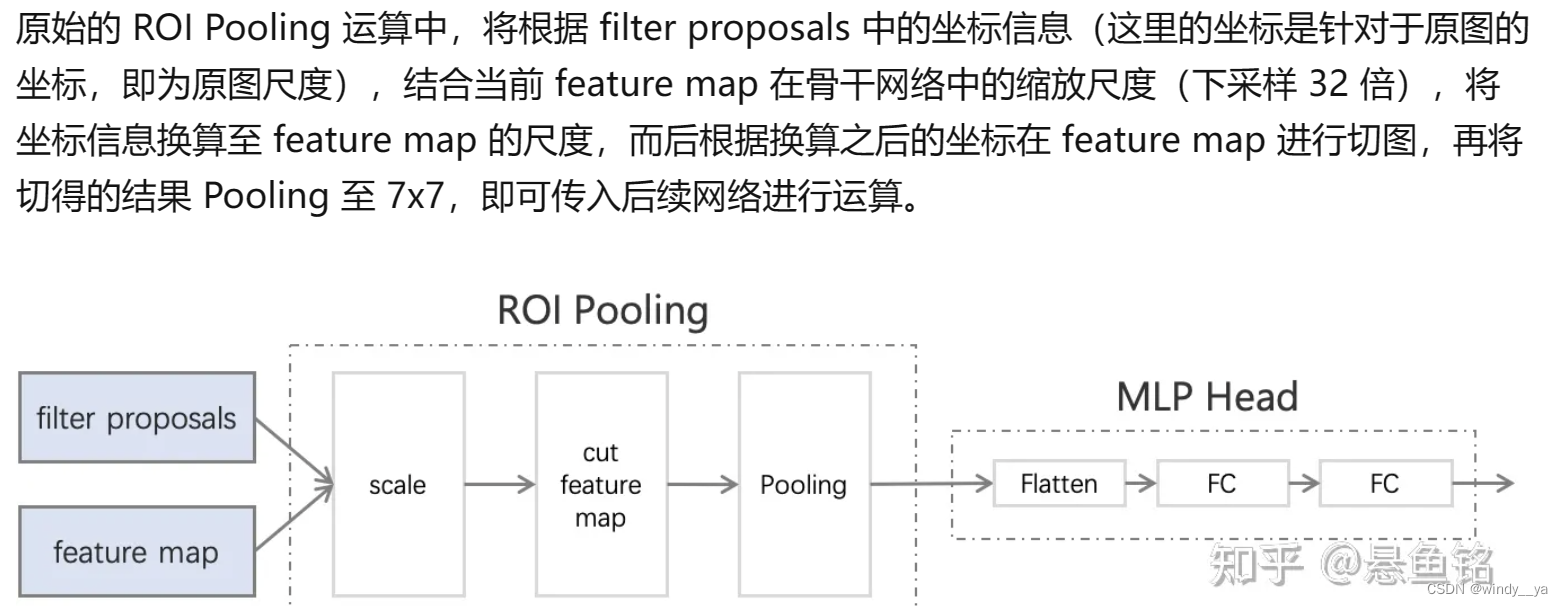
3.ROI pooling:整合proposals和feature map,因为proposals大小不同。
4.classification:上面的分支再次对propoals进行boudingbox回归,进一步获得更精确的框;下面的分支用softmax对目标具体的object进行分类(即识别物体)。
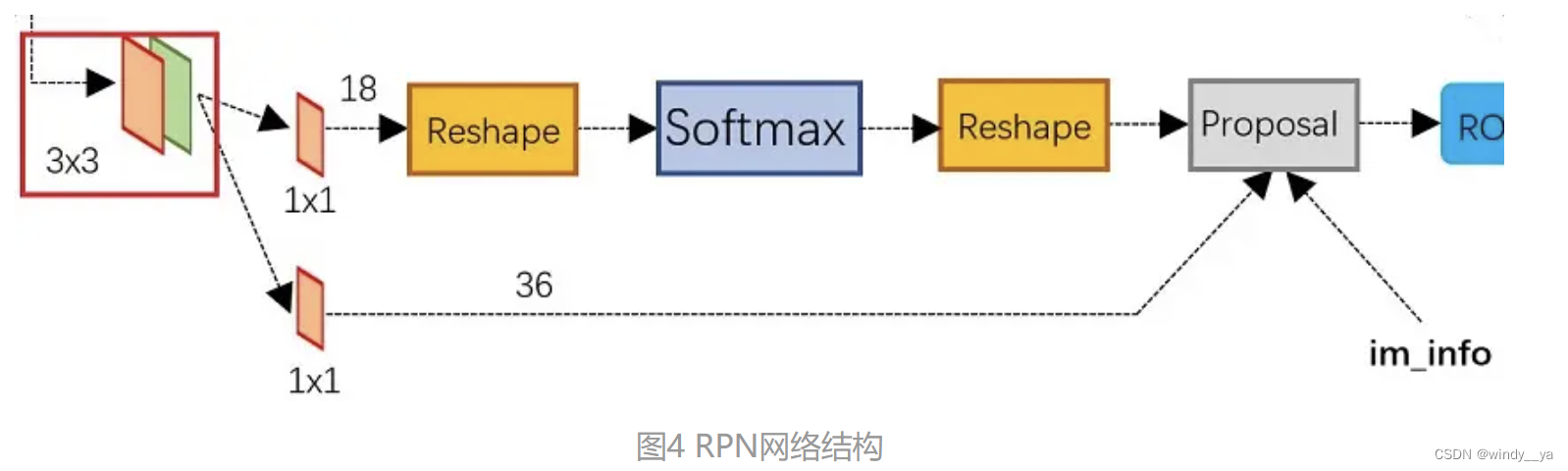
综上,先用backbone提取图像特征 --> 再用RPN层取二分类和boundingbox回归获得proposals,即得到一堆密集anchor --> 用ROI获得proposal map --> 再次boundingbox回归并且识别物体类别。注意,整个过程中一共经过两次boundingbox回归,所以不用害怕前面的一堆anchor生成归于随便之类的。
3.ATSS:
对于正负样本的选择,提出用mean和标准差得到IOU的阈值来实现动态自适应

4.FPN特征金字塔&FPN与FasterRCNN结合
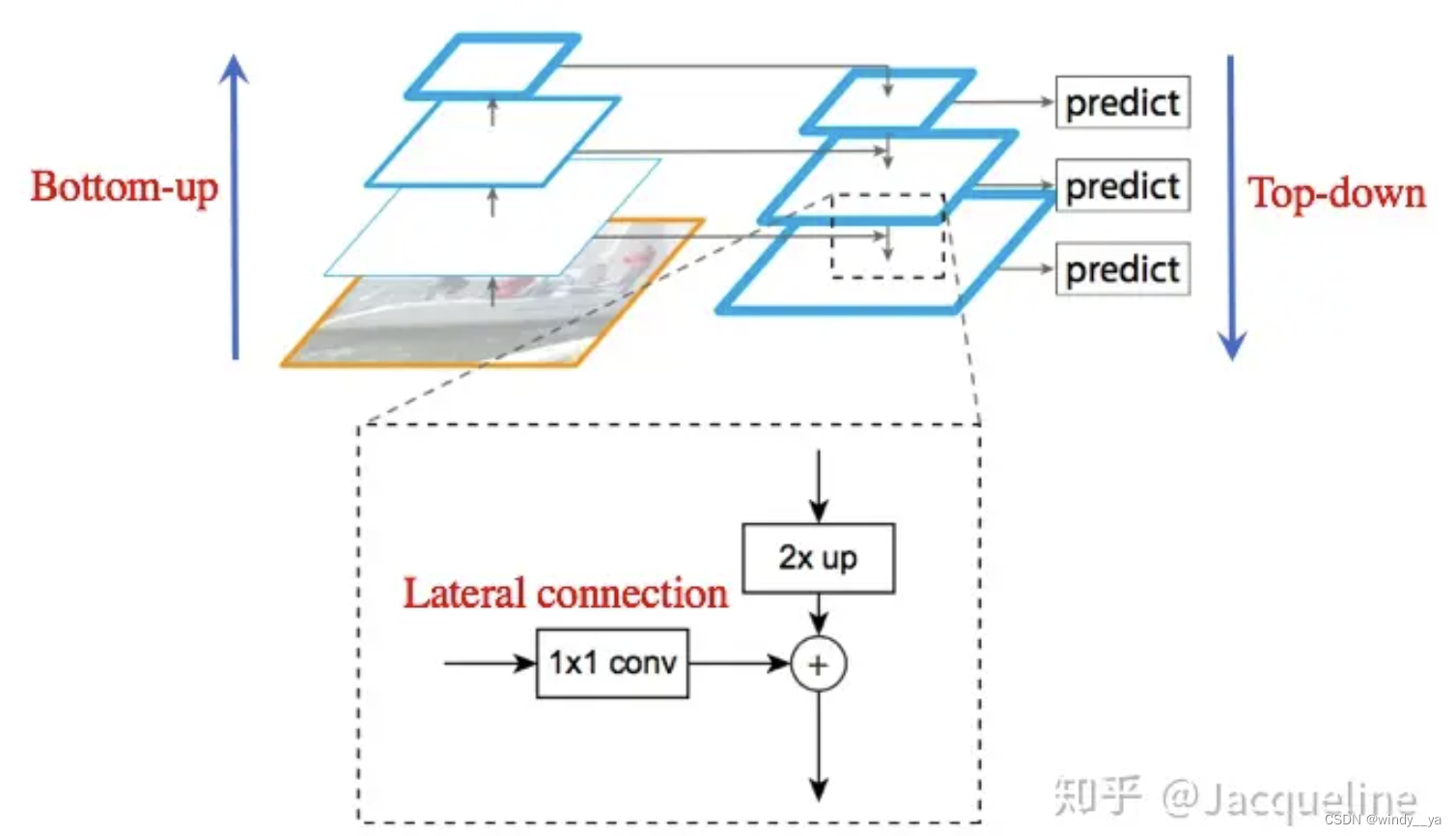
(1)Bottom-up:对feature map进行下采样,不断x0.5进行下采样。得到(C2,C3,C4,C5)
(2)Top-down:将最后的特征图进行x2上采样(最邻近插值,我认为这里是为了最大限度的保留原语义信息/当然我也在想是不是单纯的为了减少计算量),这样高层的语义信息就可以传到低层。
(3)Lateral connection:(具体如下图)将Ci通过1x1Conv改变维度后与Mi+1上采样后的特征图相加。相加融合后需要经过3x3卷积(消除因为最近插值造成灰度不连续的锯齿状)后就得到了P。
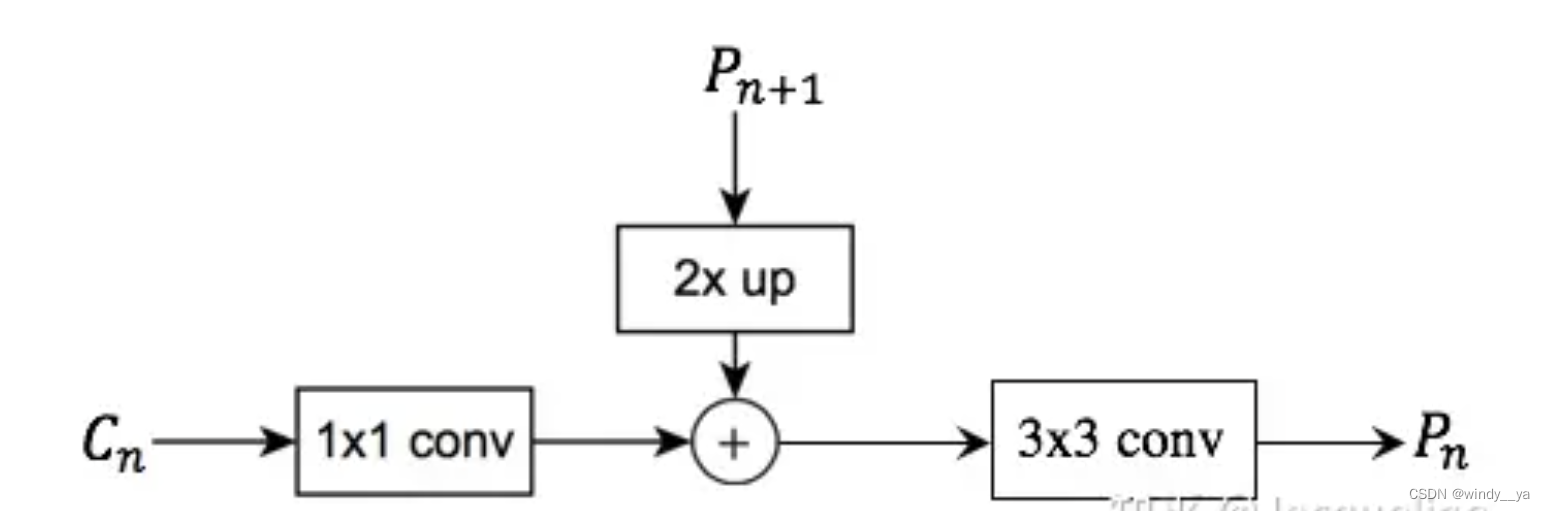
OK接下来就是FPN与Faster-RCNN应用于目标检测的RPN结合
首先引入一下单尺度的RPN:feature map先通过3x3卷积-->然后在feature mqp上生成3个不同尺度的anchor,每个anchor又有3个不同尺度的宽高比,所以一共就有9个anchor--> l两个分支并行通过1x1卷积后分别进行预测label和回归。
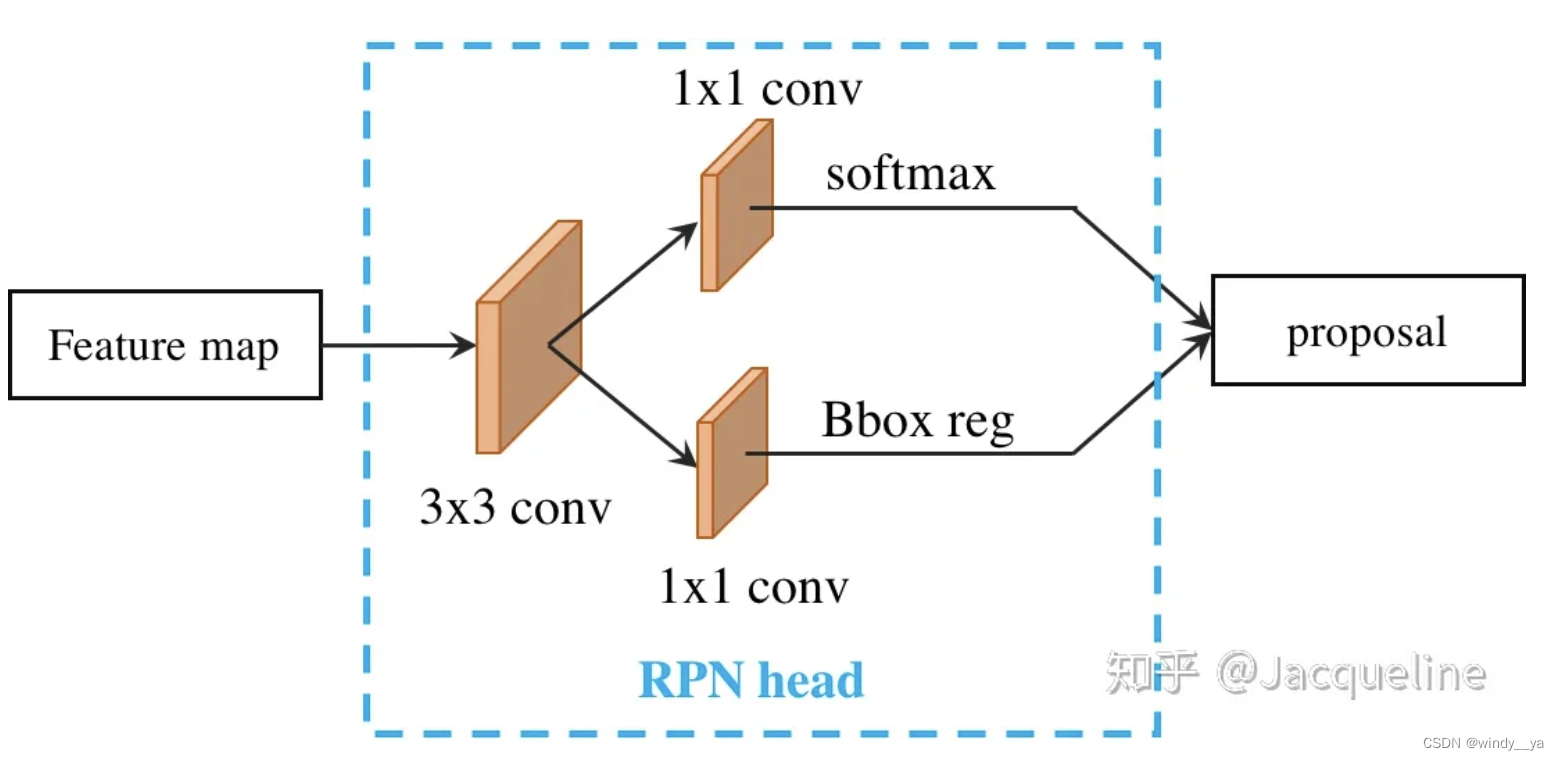
而在多尺度下,即运用前面提到的FPN生成多尺度特征图然后作为不同的RPN head,此时得到的featuremap已经是多尺度的了,所以不需要多尺度的anchor,只需要不同高宽比的anchor,所以一共只需要15个anchor。
如下图,
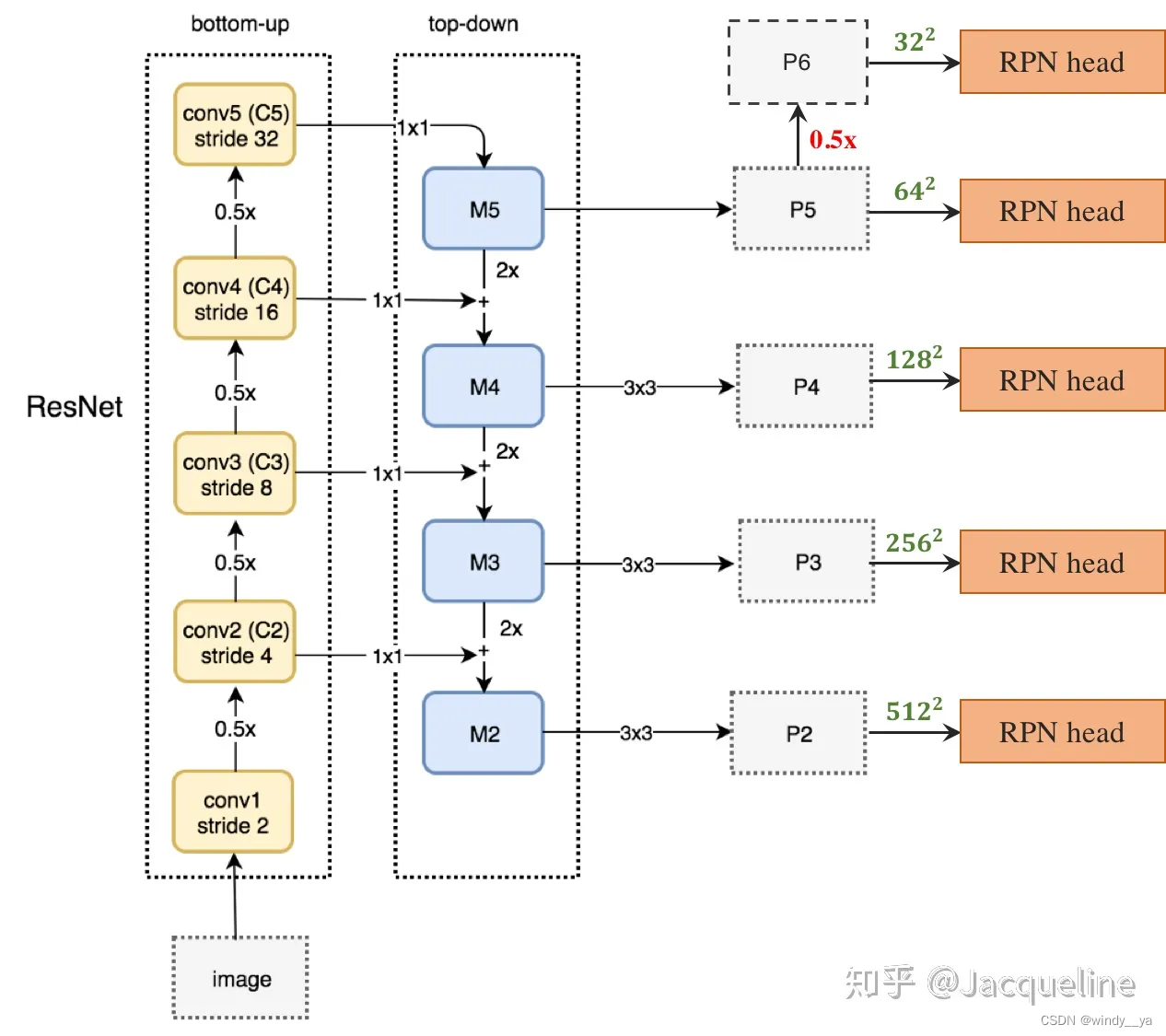
(1)先对image做下采样提取feature map(C2,C3,C4,C5) -->
(2) 取语义信息最丰富的最后一层即C进行1x1卷积变换维度 后为M5 -->
(3) Ci 通过1x1卷积变换维度后与Mi+1上采样相加进行信息融合得到Mi -->
(4)Mi通过3x3卷积消除像素不连续得到Pi -->
(5)将Pi送入RPN head
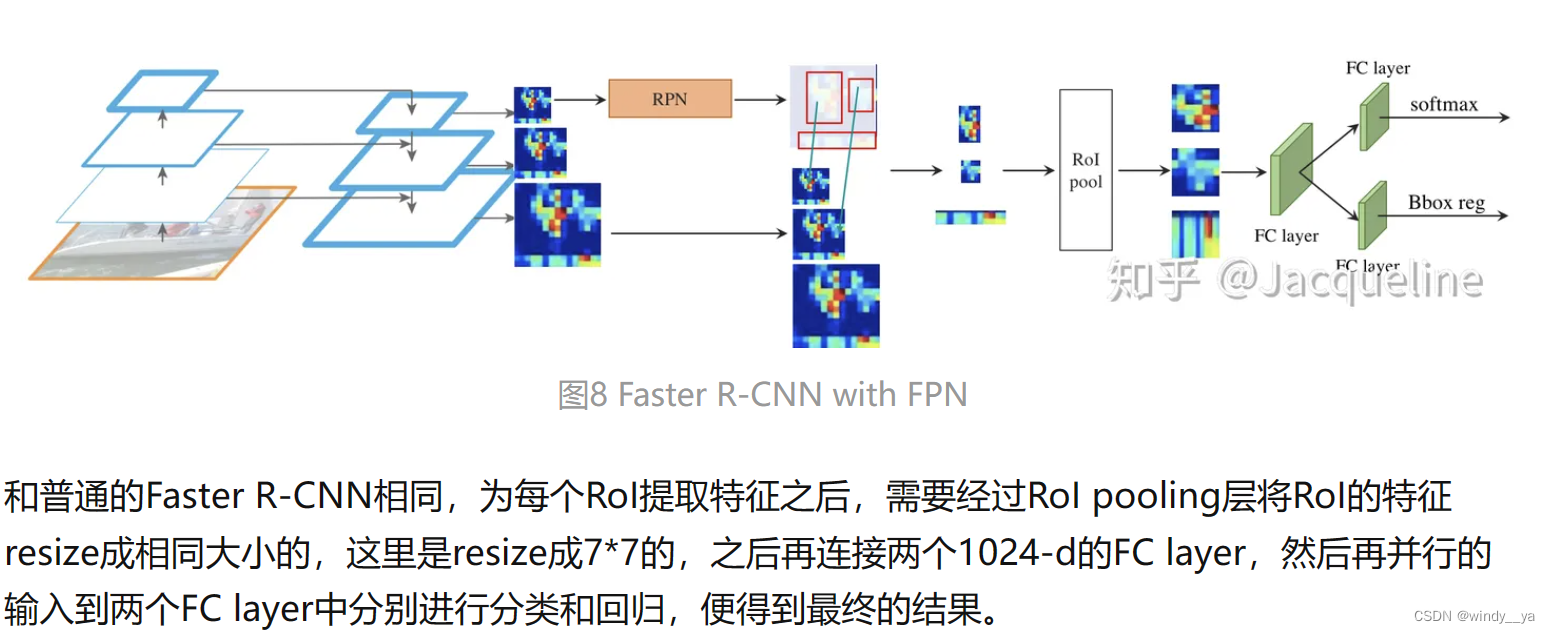
这里,输出的proposal用ROI池化的话,就让大的ROI对应后面的map,C5;小的对应前面的C4;这样 在小的特征图上学习检测大物体,在大的特征图上可以检测小物体。【POI的输入是原始的特征图和RPN的proposal box】
5、group-detr&H-detr














 1886
1886











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









