







1. 作用
增强模型的领域知识: 原始的大模型可能已经具备了通用的语言理解能力,但它可能不具备专门领域(如《原神》)的具体知识。通过使用与原神角色和国家相关的问答数据集微调模型,可以让模型更加了解这一领域,增强它对《原神》角色和国家等特定知识的掌握。
提升问答能力: 问答数据集的设计可以帮助模型更好地理解和生成符合预期的回答。在微调之后,模型不仅能够识别用户提出的关于原神角色的问题,还能提供准确的回答。例如,用户问“刻晴是哪个国家的角色?”时,模型可以准确返回“璃月”。
定制化模型: 微调是对已有模型进行定制化的过程。通过加入特定领域的数据集(如游戏角色、国家、道具等问答对),你可以使大模型在面对类似的特定场景时表现出色,从而得到一个更符合你实际需求的模型。
2.代码解读
1.数据读取部分
import pandas as pd
import json
# 读取数据文件路径,使用pandas读取CSV文件
file_path = './test.csv'
df = pd.read_csv(file_path)
# 如果数据是Excel文件,则可以使用以下代码读取
# df = pd.read_excel(file_path)
-
导入
pandas和json模块,pandas用于读取CSV文件,json用于后续保存数据为JSON格式。 -
使用
pd.read_csv(file_path)读取指定路径的CSV文件,并将其存储到df变量中。如果文件是Excel格式,也可以使用pd.read_excel()读取。
2.生成问答部分
# 准备训练集的空列表,用于存储生成的问答对
training_data = []
# 遍历每一行数据,并为每个角色生成对应的问答对
for index, row in df.iterrows():
# 获取角色名和国家名
role = row['原神角色']
country = row['国家']
# 生成问题,例如:刻晴是原神哪个国家的角色?
question = f"{role}是原神哪个国家的角色?"
# 生成答案,例如:刻晴是璃月的角色。
answer = f"{role}是{country.strip()}的角色。" # 去掉多余的空格或换行
# 将生成的问题和答案以字典的形式添加到训练集列表
training_data.append({
"question": question,
"answer": answer
})
-
创建一个空列表
training_data,用于生成存储的问答对。 -
使用
df.iterrows()遍历每一行数据,row代表每一行的内容,index代表行号。 -
对每一行数据,提取
原神角色和国家两列的内容,分别存储在变量role和country中。 -
根据提取的数据,生成问题和答案。例如,
刻晴问题是“刻晴是原神哪个国家的角色?”,答案是“刻晴是原神哪个国家的角色”。 -
使用
strip()方法去掉国家名中的空白空格或换行符。 -
将生成的问题和答案组成一个字典,格式为
{"question": question, "answer": answer},将字典添加到training_data列表中。
3.保存问答对为JSON文件部分
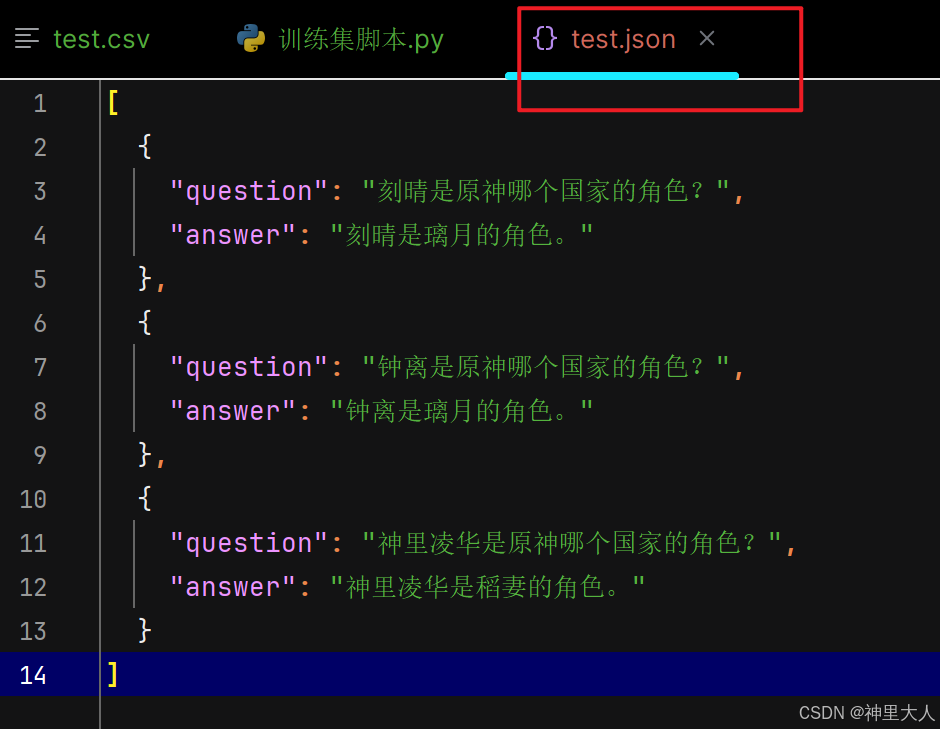
# 将生成的训练数据保存为JSON文件
with open('./test.json', 'w', encoding='utf-8') as f:
json.dump(training_data, f, ensure_ascii=False, indent=2)
# 打印提示,表示训练集生成完毕
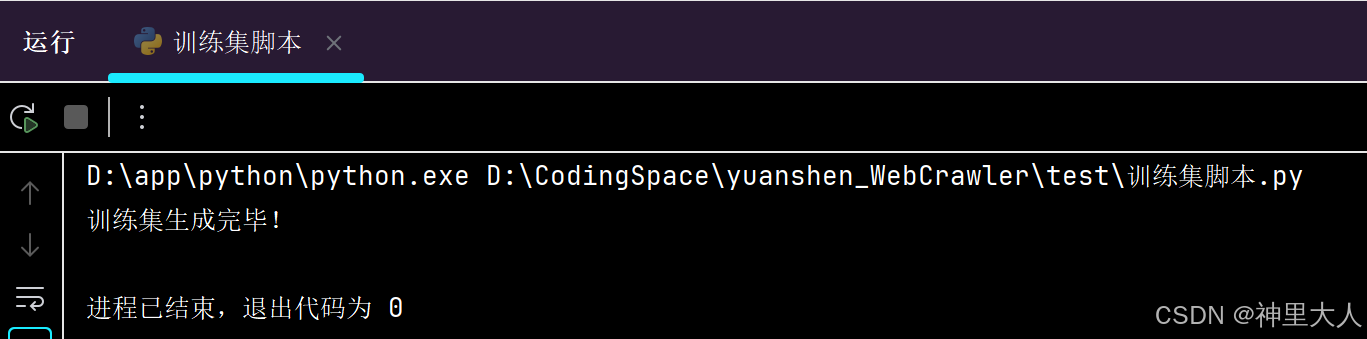
print("训练集生成完毕!")
- 使用
open()函数打开(或创建)一个名为test.json的文件,以写入模式 ('w') 和utf-8编码格式打开。 - 使用
json.dump()将training_data列表转换为JSON格式并读取文件。ensure_ascii=False保证中文字符不被编码,indent=2让JSON文件格式更加美观、易读。 - 写入完成后,关闭文件,并打印提示信息“训练集生成完毕!”。
3.具体步骤
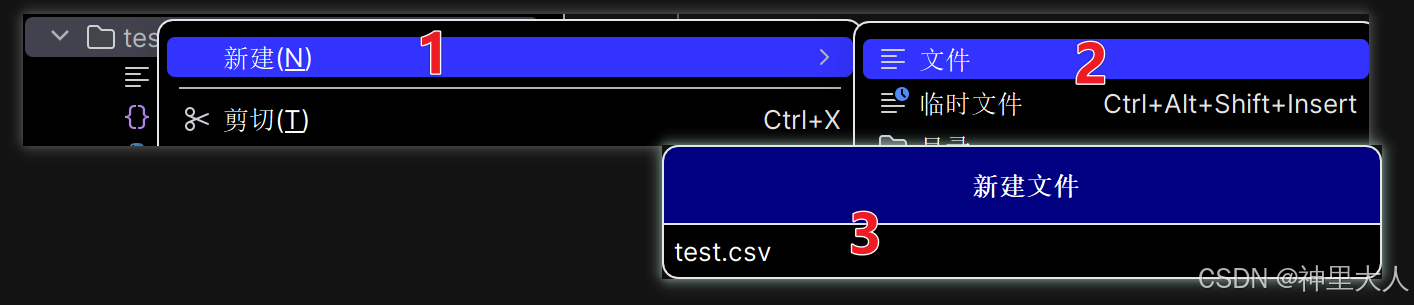
1.新建一个csv文件,复制粘贴数据
原神角色,国家
刻晴,璃月
钟离,璃月
神里凌华,稻妻
2.新建一个py文件,如果不在同一个目录下需要修改路径
import pandas as pd
import json
# 读取数据文件路径,使用pandas读取CSV文件
file_path = './test.csv'
df = pd.read_csv(file_path)
# 如果数据是Excel文件,则可以使用以下代码读取
# df = pd.read_excel(file_path)
# 准备训练集的空列表,用于存储生成的问答对
training_data = []
# 遍历每一行数据,并为每个角色生成对应的问答对
for index, row in df.iterrows():
# 获取角色名和国家名
role = row['原神角色']
country = row['国家']
# 生成问题,例如:刻晴是原神哪个国家的角色?
question = f"{role}是原神哪个国家的角色?"
# 生成答案,例如:刻晴是璃月的角色。
answer = f"{role}是{country.strip()}的角色。" # 去掉多余的空格或换行
# 将生成的问题和答案以字典的形式添加到训练集列表
training_data.append({
"question": question,
"answer": answer
})
# 将生成的训练数据保存为JSON文件
with open('./test.json', 'w', encoding='utf-8') as f:
json.dump(training_data, f, ensure_ascii=False, indent=2)
# 打印提示,表示训练集生成完毕
print("训练集生成完毕!")
3.运行代码即可,会生成一个test.json文件

















 9389
9389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









