






当编程语言学习越深入,就会接触到各种各样的数据集读取的问题,数据集的格式有很多种,例如:.tar、cfg.....格式,本文是针对于cifar10数据集的训练具体情况
1.加载数据集
 在这里,我把数据集分成了训练集和测试集,以便于后面的测试,然后对训练和测试集进行类型转换(这一步也可以适当省略),但是需要注意奥:在无网络情况下就不能这么去读取了奥,需要把相关的安装包移到相关路径进行读取。
在这里,我把数据集分成了训练集和测试集,以便于后面的测试,然后对训练和测试集进行类型转换(这一步也可以适当省略),但是需要注意奥:在无网络情况下就不能这么去读取了奥,需要把相关的安装包移到相关路径进行读取。
2.构建模型
 构建模型的方式有很多种,我是采用自定义按顺序层的方式,Conv2D为卷积层,MaxPooling2D为最大池化层,当然还可以试试均值池化层,不同的池化的影响作用都是不一样的。padding是模型的边缘处理格式,activation为激活函数(常见的激活函数:Sigmoid、Tanh、Relu)。
构建模型的方式有很多种,我是采用自定义按顺序层的方式,Conv2D为卷积层,MaxPooling2D为最大池化层,当然还可以试试均值池化层,不同的池化的影响作用都是不一样的。padding是模型的边缘处理格式,activation为激活函数(常见的激活函数:Sigmoid、Tanh、Relu)。
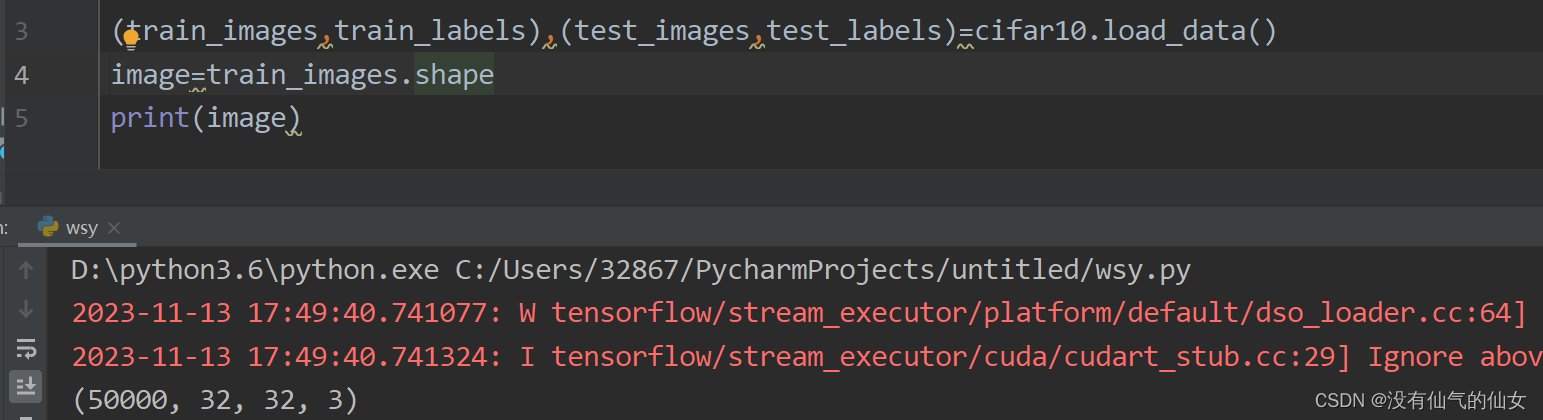
第一层的池化也叫输入层,imput_shape输入的大小根据自己加载的数据集情况,若不知数据集的大小问题,可以通过以下方式查看
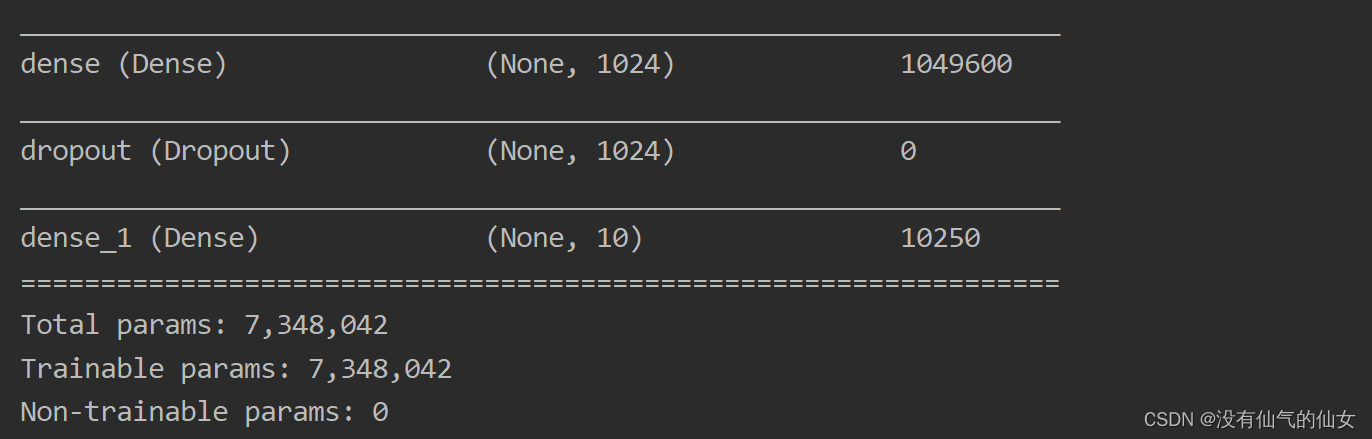
另外,Dropout仅在池化层后使用,例如上述Dropout的值为0.2,则保留概率为0.8,然后 则使用全连接层,也相当于输出层,最后用model.summary()进行模型的查看
3.定义损失函数和优化器并对模型进行训练
涉及的损失函数很多,可以看看数据预处理的相关知识,不同的损失函数的损失值是不一样的,我采用的是绝对值的计算方式

优化器:
optimizer:优化器,用于控制梯度裁剪,常见的优化器:RMSprop、Adagrad、 Adam/Adamax/Nadam、
loss:损失函数,计算模型在训练期间应寻求最小化的数量
metrics:评价函数用于评估当前训练模型的性能。当模型编译后(compile),评价函数应该作为 metrics 的参数来输入。评价函数和损失函数相似,只不过评价函数的结果不会用于训练 过程中。
训练模型:
model.fit( )函数返回一个History的对象,即记录了loss和其他指标的数值随epoch变化的情况

x:输入(train_images)
y:输出(train_labels)
batch_size:每一个batch的大小(批尺寸),即训练一次网络所用的样本数
epochs:迭代次数,即全部样本数据将被“轮”多少次,轮完训练停止
validation_split:(0,1)的浮点数,分割数据当验证数据,其它当训练数据(不设置也没有太大的影响)
validation_data:指定验证数据,该数据将覆盖validation_spilt设定的数据
4.loss函数和accuracy函数的变化图象
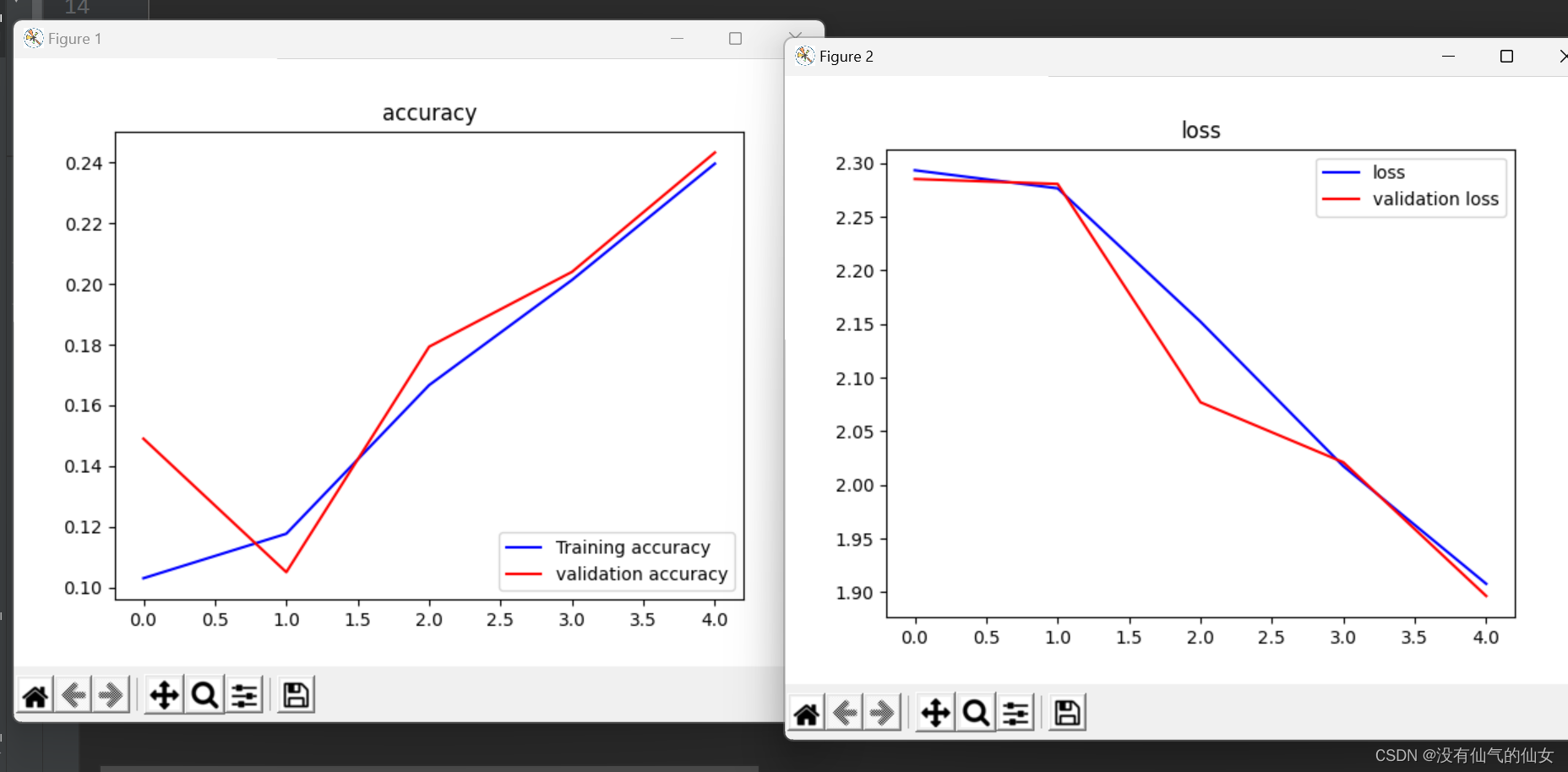 以上我取了一部分数据,所以准确率不是特别高,要想准确率较高,可以增加迭代次数或者增加数据集,然后调试相应的训练模型和参数
以上我取了一部分数据,所以准确率不是特别高,要想准确率较高,可以增加迭代次数或者增加数据集,然后调试相应的训练模型和参数
5.回调函数
 首先建立训练和测试数据集的存储(不需要自己去创文件夹),建立了可视化数据再引用到训练模型中
首先建立训练和测试数据集的存储(不需要自己去创文件夹),建立了可视化数据再引用到训练模型中
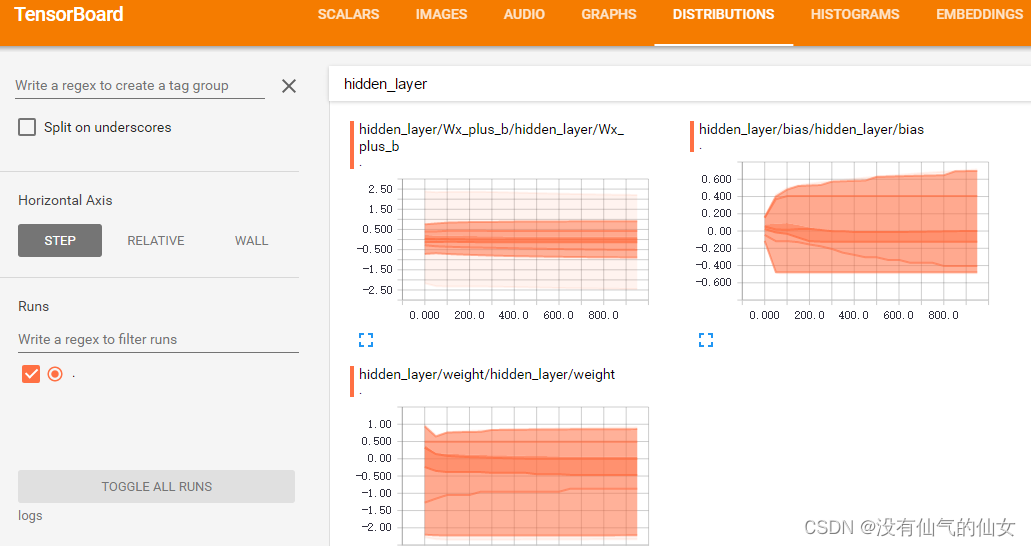
 在pycharm 的终端输入命令查看可视化内容,这里可能会出现输入命令报错的情况,我是采用python的绝对使用命令去执行,会出来一个网址,点击进去就是如下内容
在pycharm 的终端输入命令查看可视化内容,这里可能会出现输入命令报错的情况,我是采用python的绝对使用命令去执行,会出来一个网址,点击进去就是如下内容















 1707
1707











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









