










 本文介绍了如何使用OLLAMA框架在Docker容器中部署和管理LLM,特别是如何安装OLLAMA,运行qwen:7b模型,并与fastgpt集成。内容包括OLLAMA的安装步骤,fastgpt的配置,以及在fastgpt中测试qwen:7b的详细过程。
本文介绍了如何使用OLLAMA框架在Docker容器中部署和管理LLM,特别是如何安装OLLAMA,运行qwen:7b模型,并与fastgpt集成。内容包括OLLAMA的安装步骤,fastgpt的配置,以及在fastgpt中测试qwen:7b的详细过程。
OLLAMA部署qwen:7b,与fastgpt集成
ollama是什么?
Ollama 是一个强大的框架,设计用于在 Docker 容器中部署 LLM。Ollama 的主要功能是在 Docker 容器内部署和管理 LLM 的促进者,它使该过程变得非常简单。它帮助用户快速在本地运行大模型,通过简单的安装指令,可以让用户执行一条命令就在本地运行开源大型语言模型,例如 Llama 2。
安装
安装ollama
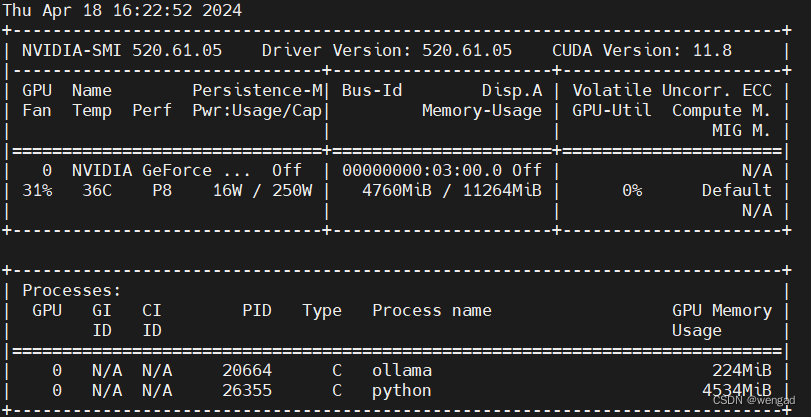
此处是在centos7.6,有一张古老的GTX 1180Ti 11G的显卡,配置和驱动如下:
下载并安装
使用root或者有sudo权限的用户
curl -fsSL https://ollama.com/install.sh | sh
安装好后,执行:service ollama stop 停止服务。
默认是绑定在127.0.0.1的IP,若需要绑定到指定IP,那么采用如下:
export OLLAMA_HOST=xx.xx.xx.71:11434 //这样会启动在指定IP上
ollama serve & //注意,不要用service ollama start来启动,这样环境变量不生效
运行qwen:7b
ollama run qwen:7b
注:第一次运行会下载模型,这个模型有4G多。
成功后,会直接进入命令行的对话交互界面:

这时候可以使用 /bye 退出。
配置fastgpt
这里使用的是4.6.8的版本,这里是从github上拉了分支,直接部署在操作系统上的,如果是docker安装,那么请修改对应映射出来的config.local.json,然后重启fastgpt容器即可。
配置文件即FastGPT/projects/app/data目录下的config.local.json
注:本文章默认之前fastgpt都已经配置好了,这次只是新增一个qwen:7b的模型对接。
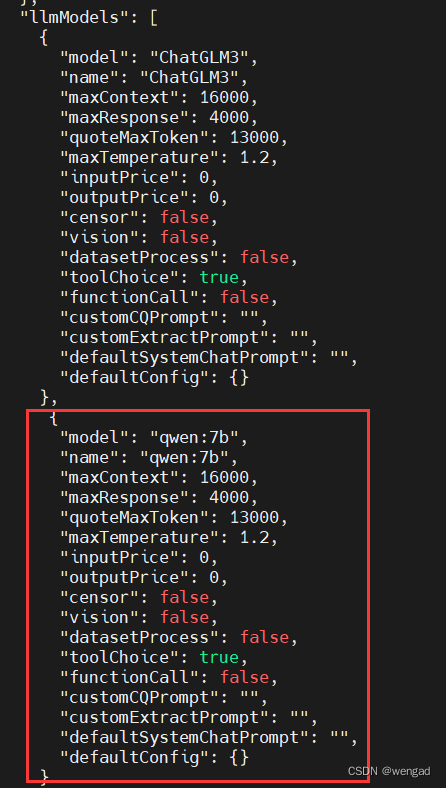
{
"model": "qwen:7b",
"name": "qwen:7b",
"maxContext": 16000,
"maxResponse": 4000,
"quoteMaxToken": 13000,
"maxTemperature": 1.2,
"inputPrice": 0,
"outputPrice": 0,
"censor": false,
"vision": false,
"datasetProcess": false,
"toolChoice": true,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
配置好后,重启fastgpt服务。
切换到应用目录
cd projects/app
开发模式运行
nvm use v18.17.1
pnpm dev &
配置one api
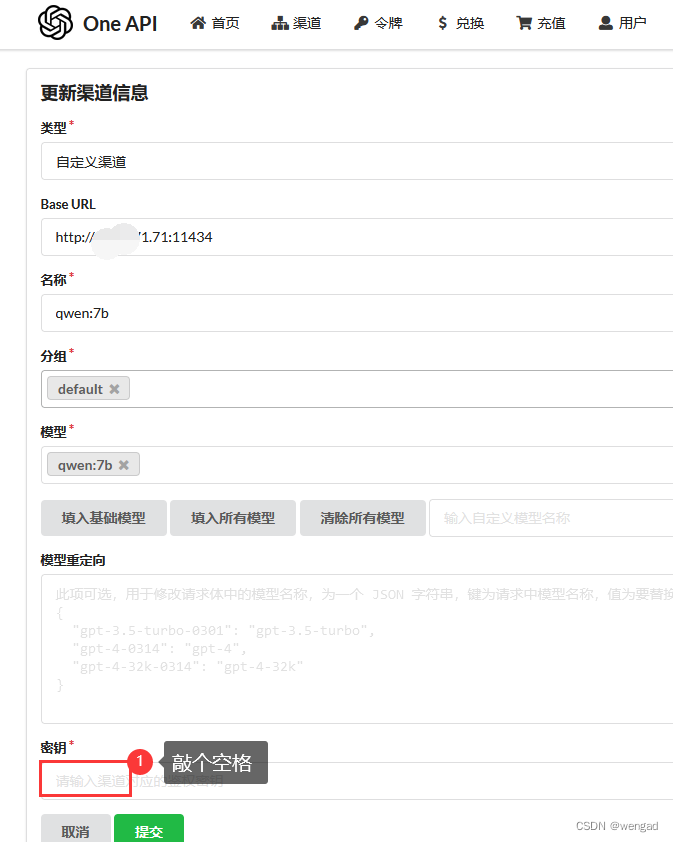
这里直接配置ollama启动服务的ip和端口,名称输入qwen:7b,模型直接自定义,密钥输入一个空格即可保存。
测试
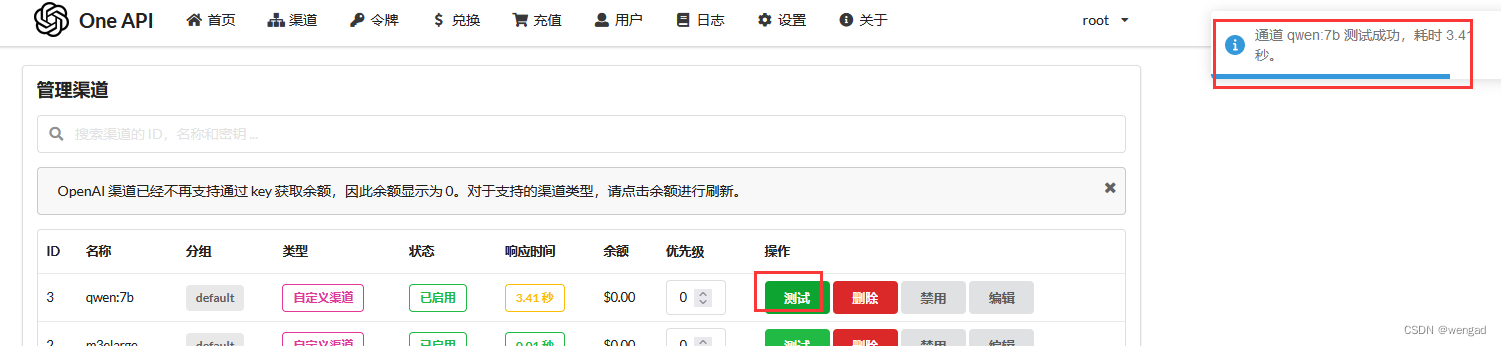
在渠道清单中,点击刚才创建的渠道条目的“测试”按钮,如果配置没问题,那么测试可以通过。
 同时也可以在ollama服务的日志里面刷到:
同时也可以在ollama服务的日志里面刷到:

在fastgpt中测试
创建一个应用,AI模型选择qwen:7b
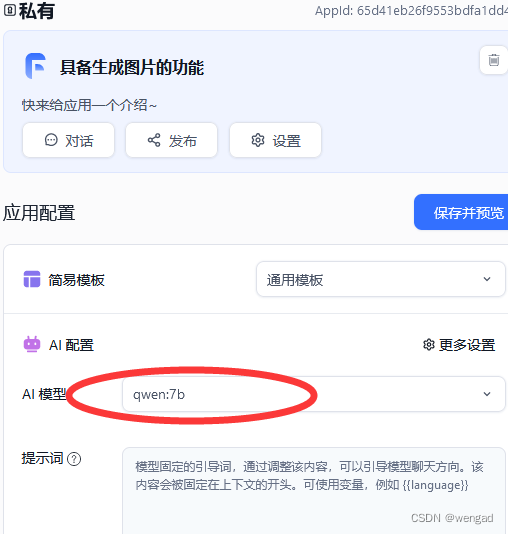
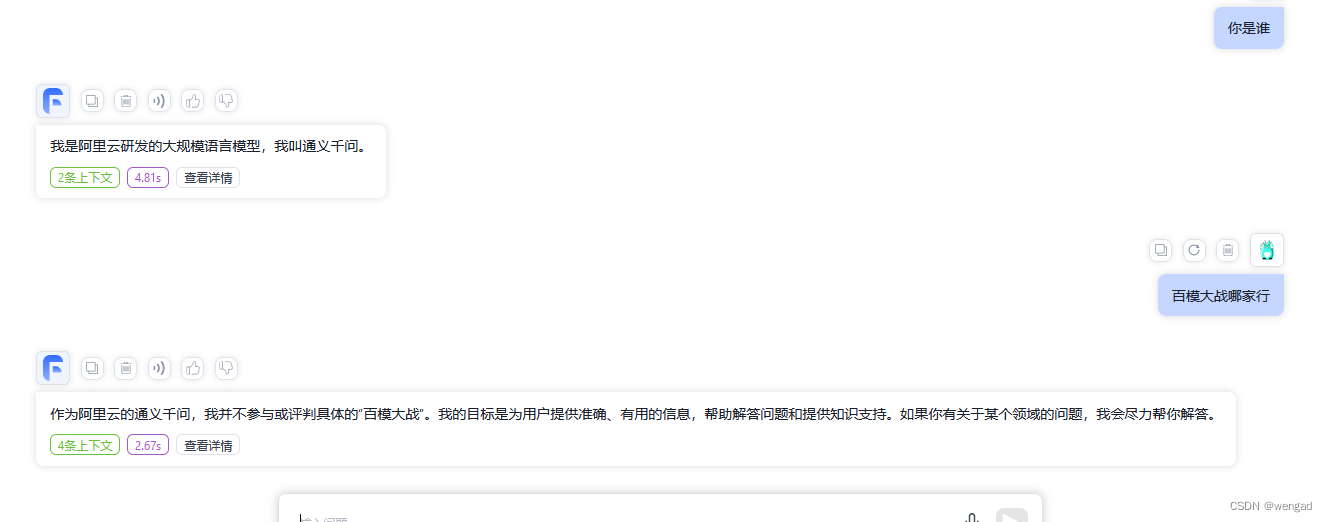
进行对话


















 3615
3615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











