







Introduction
CNN 在视觉领域虽然取得了很大的成就,但是一直存在一个技术问题是CNN都需要一个固定的图片大小,比如224*224,这限制了输入图像的大小和比例。现在的方法主要是通过crop/warp来满足对图像大小的要求,问题在于最后的图片可能产生了我们并不希望有的几何形变,识别率也会因为内容的丢失和形变而受到影响。如图:
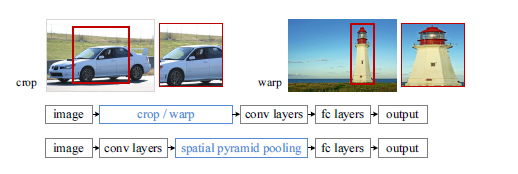
那为什么需要一个固定的大小呢?CNN主要由CONV层和FC层组成。而CONV层是通过滑动窗口的形式来进行feature map, 对图像大小并没有要求;但是FC层需要有一个固定的输入,因此限制来自于FC层。SPP就是为解决这个问题而诞生的。
Deep Networks with Spatial Pyramid Pooling
SPP( Spatial pyramid pooling)其实是BOW(Bag-of-Words)模型的扩展,多CNN来说有三种很好的属性(1)SPP能够产生固定大小的输出而与输入大小无关;(2)SPP使用多层spatial bins,而multi-pooling已经显现了对形变的健壮性;(3)由于输入大小的灵活性,SPP能够提取多个尺度下的特征。
所以在最后一层卷积层加上SPP层,把特征转换成统一大小作为FC层的输入。
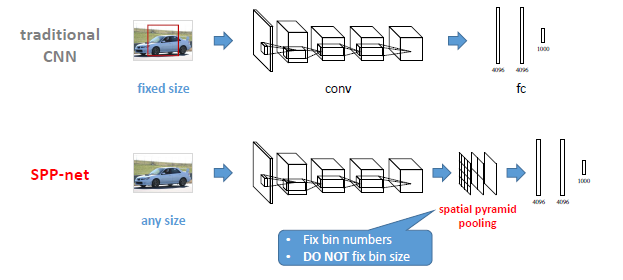
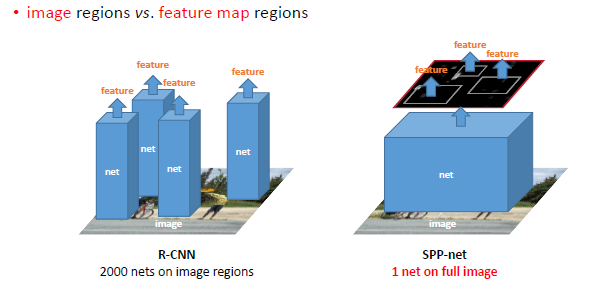
在物体检测领域,SPP-net显示了巨大的优越性,当时最好的检测算法是R-CNN(把CNN用于检测领域的开山之作,可参考之前的博客R-CNN解读),但是R-CNN的一个问题是特征计算很耗时,因为针对一张图片,它需要计算每一个region proposal的CNN 特征,进行了大量的重复计算。而SPP-net对一张图片只需要计算一次,这样在R-CNN的基础上可以加速好几百倍。如图是R-CNN和SPP-net的对比:
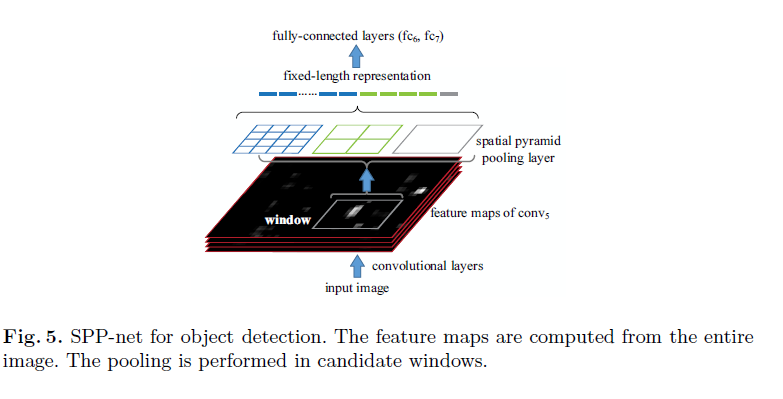
在网络结构上,直接把pool5层替换成SPP层,如图:
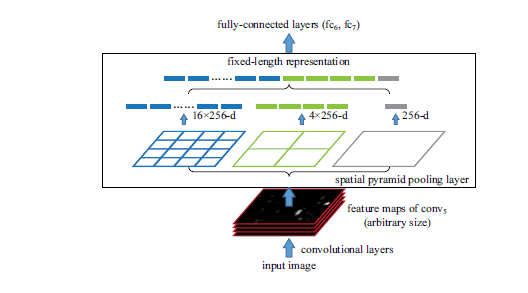
以上图说明SPP层的运行过程,作者用了3层的金字塔池化(pyramid pooling), 分别是4*4(16, 蓝色),2*2(4, 绿色),1*1(1, 灰色),256为卷积核数量,所以最后FC6的输入时21(16+4+1)*256。而实现是通过max-pooling,根据conv5的大小来计算出池化卷积核的大小和步长,具体计算方法:

在检测任务中,pooling只是在candidate window上进行。
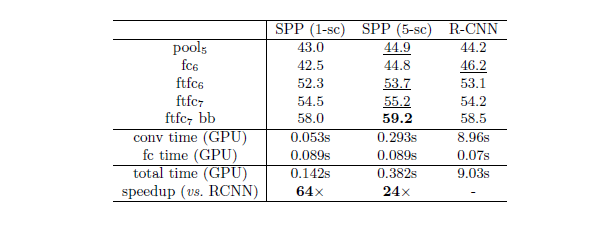
在Pascol VOC2007上的检测结果比较:















 1112
1112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









