








本文主要讲述open62541里的路径搜索,这功能具体是干啥的呢?用过UaExpert的都看过如下这个界面,这是OPC UA Server的地址空间

可以看出OPC UA Server的地址空间是用层级目录组织的,英文叫hierarchy,根节点是Root。每个节点都会有个路径,如Server的路径就是/Root/Objects/Server。而open62541的路径搜索就是通过路径去获取目标节点的NodeId,下面就讲述下如何操作。
一 OPC UA Server端
先说Server端如何使用路径搜索,后面讲Client端。
1. 添加对象节点Student
使用以下代码添加一个叫Student的对象节点,这个节点有2个Component:姓名(Name)和性别(Gender)
static void manuallyDefineStudent(UA_Server * server)
{
UA_NodeId studentId; /* get the nodeid assigned by the server */
UA_ObjectAttributes stuAttr = UA_ObjectAttributes_default;
stuAttr.displayName = UA_LOCALIZEDTEXT("en-US", "Student");
UA_Server_addObjectNode(server, UA_NODEID_NULL,
UA_NODEID_NUMERIC(0, UA_NS0ID_OBJECTSFOLDER),
UA_NODEID_NUMERIC(0, UA_NS0ID_ORGANIZES),
UA_QUALIFIEDNAME(1, "Student"), UA_NODEID_NUMERIC(0, UA_NS0ID_BASEOBJECTTYPE),
stuAttr, NULL, &studentId);
// 添加姓名
UA_VariableAttributes nameAttr = UA_VariableAttributes_default;
UA_String studentName = UA_STRING("Xiao Ming");
UA_Variant_setScalar(&nameAttr.value, &studentName, &UA_TYPES[UA_TYPES_STRING]);
nameAttr.displayName = UA_LOCALIZEDTEXT("en-US", "Name");
UA_Server_addVariableNode(server, UA_NODEID_NULL, studentId,
UA_NODEID_NUMERIC(0, UA_NS0ID_HASCOMPONENT),
UA_QUALIFIEDNAME(1, "StudentName"),
UA_NODEID_NUMERIC(0, UA_NS0ID_BASEDATAVARIABLETYPE), nameAttr, NULL, NULL);
// 添加性别
UA_VariableAttributes genderAttr = UA_VariableAttributes_default;
UA_String gender = UA_STRING("Male");
UA_Variant_setScalar(&genderAttr.value, &gender, &UA_TYPES[UA_TYPES_STRING]);
genderAttr.displayName = UA_LOCALIZEDTEXT("en-US", "Gender");
UA_Server_addVariableNode(server, UA_NODEID_NULL, studentId,
UA_NODEID_NUMERIC(0, UA_NS0ID_HASCOMPONENT),
UA_QUALIFIEDNAME(1, "Gender"),
UA_NODEID_NUMERIC(0, UA_NS0ID_BASEDATAVARIABLETYPE), genderAttr, NULL, NULL);
}
这里要注意的是,在调用UA_Server_addObjectNode()和UA_Server_addVariableNode()时,第2个参数都是给的UA_NODEID_NULL,表示这些节点的Id由Server去分配,这样我们预先就不知道它们的Id了,只有在运行时才知道。
2. 路径搜索函数
这个函数是从open62541源码里拷贝过来的,做了一些修改,
static int findChildId(UA_Server *server,
UA_NodeId parentNode,
UA_NodeId referenceType,
const UA_QualifiedName targetName,
UA_NodeId *result)
{
int ret = 0;
UA_RelativePathElement rpe;
UA_RelativePathElement_init(&rpe);
rpe.referenceTypeId = referenceType;
rpe.isInverse = false;
rpe.includeSubtypes = false;
rpe.targetName = targetName;
UA_BrowsePath bp;
UA_BrowsePath_init(&bp);
bp.startingNode = parentNode;
bp.relativePath.elementsSize = 1;
bp.relativePath.elements = &rpe;
UA_BrowsePathResult bpr = UA_Server_translateBrowsePathToNodeIds(server, &bp);
if (bpr.statusCode != UA_STATUSCODE_GOOD || bpr.targetsSize < 1)
{
printf("error: %s, targetsSize: %d\n",
UA_StatusCode_name(bpr.statusCode), bpr.targetsSize);
ret = -1;
}
else
{
UA_NodeId_copy(&bpr.targets[0].targetId.nodeId, result);
}
UA_BrowsePathResult_deleteMembers(&bpr);
return ret;
}
首先解释这个函数的参数
- server:OPC UA Server的指针
- parentNode:路径搜索的start节点的NodeId
- referenceType:start节点和下一个子节点之间的reference类型
- targetName:目标节点的qualified名称
- result:存放目标节点NodeId的指针
代码解释:
- UA_RelativePathElement类型用来描述路径中的单个位置节点,其定义如下,

referenceTypeId用来表示本节点和父节点之间的reference关系
targetName就是本节点的qualified名称 - UA_BrowsePath类型用来描述整个搜索路径


UA_BrowsePath的startingNode表示整个搜索路径得start节点,relativePath则是一个数组,用来存放剩余路径信息,假如整体路径是A/B/C,那么startingNode就是A,B和C则要按顺序存放到relativePath的elements里,并把elementsSize设置为2 - UA_Server_translateBrowsePathToNodeIds()把路径转为NodeId,存放在UA_BrowsePathResult 类型的对象里,整个类型大家看下源码就行了
3. 执行搜索
这是main函数,搜索路径是Objects/Student,起点是Objects,目标节点是Student,也就是前面添加的对象节点,Objects和Student的reference关系是organize,可能会问:我怎么知道它们之间的关系?在添加Student时调用了UA_Server_addObjectNode(),其第4个参数就是organize
int main(void)
{
signal(SIGINT, stopHandler);
signal(SIGTERM, stopHandler);
UA_Server *server = UA_Server_new();
UA_ServerConfig_setDefault(UA_Server_getConfig(server));
manuallyDefineStudent(server);
int ret = 0;
UA_NodeId returnId;
ret = findChildId(server, UA_NODEID_NUMERIC(0, UA_NS0ID_OBJECTSFOLDER),
UA_NODEID_NUMERIC(0, UA_NS0ID_ORGANIZES),
UA_QUALIFIEDNAME(1, "Student (Manual)"), &returnId);
if (ret == 0)
{
if (returnId.identifierType == UA_NODEIDTYPE_NUMERIC)
{
printf("==> return Id: %u\n", returnId.identifier.numeric);
}
}
UA_StatusCode retval = UA_Server_run(server, &running);
UA_Server_delete(server);
return retval == UA_STATUSCODE_GOOD ? EXIT_SUCCESS : EXIT_FAILURE;
}
运行结果如下,

我们使用UaExpert连接再确认下,如下,
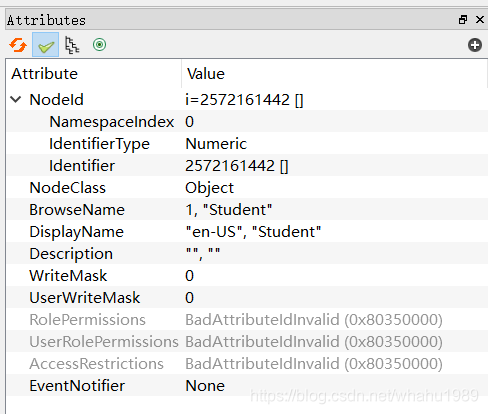
可以看出是对的。
4. 优化
上面的路径搜索函数findChildId()有个缺点,就是只能搜索一层,无法搜索多层,也就是说只能搜索A/B这种,不能搜索A/B/C或者更多层路径节点。
因为前面已经讲述了相关结构体的含义,所以这里可以做个优化,让函数可以搜索更多层,代码如下,
static int findChildId2(UA_Server *server,
UA_NodeId parentNode,
const int relativePathCnt,
const UA_NodeId referenceTypeArr[],
const UA_QualifiedName targetNameArr[],
UA_NodeId *result)
{
int ret = 0;
UA_RelativePathElement rpe[relativePathCnt];
for (int i = 0; i < relativePathCnt; ++i)
{
UA_RelativePathElement_init(&rpe[i]);
rpe[i].referenceTypeId = referenceTypeArr[i];
rpe[i].isInverse = false;
rpe[i].includeSubtypes = false;
rpe[i].targetName = targetNameArr[i];
}
UA_BrowsePath bp;
UA_BrowsePath_init(&bp);
bp.startingNode = parentNode;
bp.relativePath.elementsSize = relativePathCnt;
bp.relativePath.elements = rpe;
UA_BrowsePathResult bpr = UA_Server_translateBrowsePathToNodeIds(server, &bp);
if (bpr.statusCode != UA_STATUSCODE_GOOD || bpr.targetsSize < 1)
{
printf("error: %s\n", UA_StatusCode_name(bpr.statusCode));
ret = -1;
}
else
{
UA_NodeId_copy(&bpr.targets[0].targetId.nodeId, result);
}
UA_BrowsePathResult_deleteMembers(&bpr);
return ret;
}
参数介绍:
- server:OPC UA Server的指针
- parentNode:路径搜索的start节点的NodeId
- relativePathCnt:除start节点外,相对路径中的元素个数
- referenceTypeArr[]:reference关系数组
- targetNameArr[]:除start节点外,相对路径中的元素qualified名称数组
- result:存放目标节点NodeId的指针
使用如下,
int main(void)
{
signal(SIGINT, stopHandler);
signal(SIGTERM, stopHandler);
UA_Server *server = UA_Server_new();
UA_ServerConfig_setDefault(UA_Server_getConfig(server));
manuallyDefineStudent(server);
int ret = 0;
UA_NodeId newReturnId;
UA_NodeId referenceTypeArr[2] = {UA_NODEID_NUMERIC(0, UA_NS0ID_ORGANIZES), UA_NODEID_NUMERIC(0, UA_NS0ID_HASCOMPONENT)};
UA_QualifiedName targetNameArr[2] = {UA_QUALIFIEDNAME(1, "Student"), UA_QUALIFIEDNAME(1, "StudentName")};
ret = findChildId2(server, UA_NODEID_NUMERIC(0, UA_NS0ID_OBJECTSFOLDER),
2, referenceTypeArr, targetNameArr, &newReturnId);
if (ret == 0)
{
if (returnId.identifierType == UA_NODEIDTYPE_NUMERIC)
{
printf("==> newReturn Id: %u\n", newReturnId.identifier.numeric);
}
}
UA_StatusCode retval = UA_Server_run(server, &running);
UA_Server_delete(server);
return retval == UA_STATUSCODE_GOOD ? EXIT_SUCCESS : EXIT_FAILURE;
}
搜索路径是Objects/Student/StudentName,Objects和Student之间关系是organize,Student和StudentName之间的关系是hascomponent。
另外路径中元素的名称都是qualified名称,不是display 名称,例如,这里的StudentName对应的节点,其display name是“Name”
运行如下,
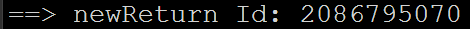
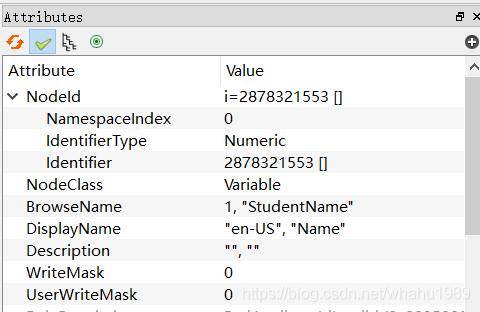
使用UaExpert验证ok,如下,
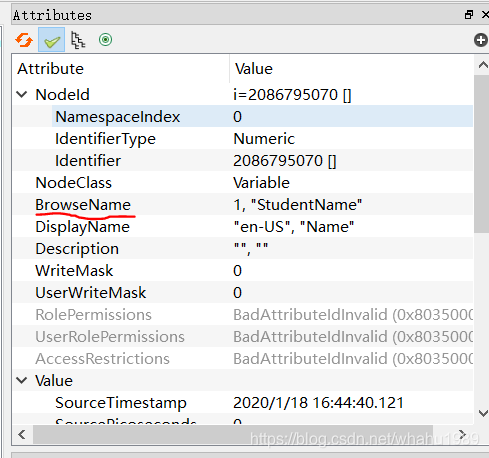
5. 更加简便的方法
上面的方法虽然原理不难,但是用起来比较麻烦,需要定义一堆变量并设置,需要知道很多的细节,而open62541提供了一个更加简单的api,就是UA_Server_browseSimplifiedBrowsePath(),其原型如下,
UA_BrowsePathResult
UA_Server_browseSimplifiedBrowsePath(UA_Server *server, const UA_NodeId origin,
size_t browsePathSize, const UA_QualifiedName *browsePath)
只要确定start节点,和剩余路径元素的qualified名称,就可以去搜索了,这也是利用了相同层级下不会有重名节点这个原理。下面是对其进行封装的简单函数,
static int findChildId3(UA_Server *server,
UA_NodeId parentNode,
const int relativePathCnt,
const UA_QualifiedName targetNameArr[],
UA_NodeId *result)
{
int ret = 0;
UA_BrowsePathResult bpr = UA_Server_browseSimplifiedBrowsePath(server,
parentNode, relativePathCnt, targetNameArr);
if (bpr.statusCode != UA_STATUSCODE_GOOD || bpr.targetsSize < 1)
{
printf("error: %s\n", UA_StatusCode_name(bpr.statusCode));
ret = -1;
}
else
{
UA_NodeId_copy(&bpr.targets[0].targetId.nodeId, result);
}
UA_BrowsePathResult_deleteMembers(&bpr);
return ret;
}
main函数如下,
int main(void)
{
signal(SIGINT, stopHandler);
signal(SIGTERM, stopHandler);
UA_Server *server = UA_Server_new();
UA_ServerConfig_setDefault(UA_Server_getConfig(server));
manuallyDefineStudent(server);
UA_QualifiedName targetNameArr[2] = {UA_QUALIFIEDNAME(1, "Student"), UA_QUALIFIEDNAME(1, "StudentName")};
UA_NodeId newReturnId2;
int ret = findChildId3(server, UA_NODEID_NUMERIC(0, UA_NS0ID_OBJECTSFOLDER),
2, targetNameArr, &newReturnId2);
if (ret == 0)
{
if (newReturnId2.identifierType == UA_NODEIDTYPE_NUMERIC)
{
printf("==> newReturn Id: %u\n", newReturnId2.identifier.numeric);
}
}
UA_StatusCode retval = UA_Server_run(server, &running);
UA_Server_delete(server);
return retval == UA_STATUSCODE_GOOD ? EXIT_SUCCESS : EXIT_FAILURE;
}
运行结果如下,
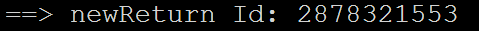
同样,UaExpert验证ok,
二 OPC UA Client端
client端只有一个api可以用,就是UA_Client_Service_translateBrowsePathsToNodeIds(),其原型如下,
static UA_INLINE UA_TranslateBrowsePathsToNodeIdsResponse
UA_Client_Service_translateBrowsePathsToNodeIds(UA_Client *client,
const UA_TranslateBrowsePathsToNodeIdsRequest request)
下面是个简陋的封装函数,
static UA_StatusCode translateBrowsePathsToNodeIdsRequest(UA_Client *client, UA_NodeId *returnId)
{
UA_StatusCode ret = UA_STATUSCODE_GOOD;
#define BROWSE_PATHS_SIZE 3
char *paths[BROWSE_PATHS_SIZE] = {"Objects", "Student", "StudentName"};
UA_UInt32 ids[BROWSE_PATHS_SIZE] = {UA_NS0ID_ORGANIZES, UA_NS0ID_ORGANIZES, UA_NS0ID_HASCOMPONENT};
int nsNumOfQualifiedName[BROWSE_PATHS_SIZE] = {0, 1, 1}; // namespace number of qualified name
UA_BrowsePath browsePath;
UA_BrowsePath_init(&browsePath);
browsePath.startingNode = UA_NODEID_NUMERIC(0, UA_NS0ID_ROOTFOLDER); // start节点是Root
browsePath.relativePath.elements = (UA_RelativePathElement*)UA_Array_new(BROWSE_PATHS_SIZE, &UA_TYPES[UA_TYPES_RELATIVEPATHELEMENT]);
browsePath.relativePath.elementsSize = BROWSE_PATHS_SIZE;
for(size_t i = 0; i < BROWSE_PATHS_SIZE; ++i) {
UA_RelativePathElement *elem = &browsePath.relativePath.elements[i];
elem->referenceTypeId = UA_NODEID_NUMERIC(0, ids[i]);
elem->targetName = UA_QUALIFIEDNAME_ALLOC(nsNumOfQualifiedName[i], paths[i]);
}
UA_TranslateBrowsePathsToNodeIdsRequest request;
UA_TranslateBrowsePathsToNodeIdsRequest_init(&request);
request.browsePaths = &browsePath;
request.browsePathsSize = 1;
UA_TranslateBrowsePathsToNodeIdsResponse response = UA_Client_Service_translateBrowsePathsToNodeIds(client, request);
if (response.responseHeader.serviceResult == UA_STATUSCODE_GOOD)
{
if (response.resultsSize == 1 && response.results[0].targetsSize == 1)
{
UA_NodeId_copy(&response.results[0].targets[0].targetId.nodeId, returnId);
}
}
else
{
printf("Error: %s\n", UA_StatusCode_name(response.responseHeader.serviceResult));
ret = response.responseHeader.serviceResult;
}
UA_BrowsePath_deleteMembers(&browsePath);
UA_TranslateBrowsePathsToNodeIdsResponse_deleteMembers(&response);
return ret;
}
代码中使用了hardcode,只是为了便捷一点,这里的搜索路径是Root/Objects/Student/StudentName,从根节点开始的。
代码解释:
- Client端也同样用到了UA_BrowsePath和UA_RelativePathElement这2个结构体
- UA_TranslateBrowsePathsToNodeIdsRequest把路径打包进去,形成一个request
- 调用UA_Client_Service_translateBrowsePathsToNodeIds()处理这个请求
- 返回信息存放在UA_TranslateBrowsePathsToNodeIdsResponse
说实在的,这些结构体名字都很长,不过里面的结构元素不是很难分析,看看源码或者本文代码就够用了。
main函数如下,
int main(int argc, char *argv[])
{
UA_Client *client = UA_Client_new();
UA_ClientConfig_setDefault(UA_Client_getConfig(client));
// Connect to OPC UA server
UA_StatusCode retval = UA_Client_connect(client, "opc.tcp://localhost:4840");
if(retval != UA_STATUSCODE_GOOD)
{
UA_Client_delete(client);
return EXIT_FAILURE;
}
UA_NodeId targetId;
retval = translateBrowsePathsToNodeIdsRequest(client, &targetId);
if (retval == UA_STATUSCODE_GOOD)
{
if (targetId.identifierType == UA_NODEIDTYPE_NUMERIC)
{
printf("==> target Id: %u\n", targetId.identifier.numeric);
}
}
UA_Client_disconnect(client);
UA_Client_delete(client);
return retval == UA_STATUSCODE_GOOD ? EXIT_SUCCESS : EXIT_FAILURE;
}
运行结果:

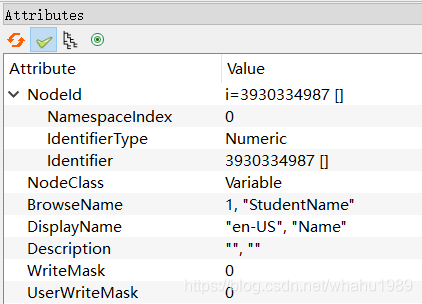
同样,UaExpert验证ok,
三 总结
本文主要讲述如何在OPC UA里进行路径搜索,以获取目标节点的NodeId。
这里简单说下使用场景:
- 当节点很多时,这个方法的优势就明显了,就像你电脑里文件太多了,要找某个文件时,使用搜索是最便捷的
- 还有一种情形,假设工程里已经定义了对象类型(可以看这篇文章),用户只能使用这个类型去创建对象,那么这个对象下所拥有的其它节点的NodeId就是随机分配的,这时想知道它们的id,就只能使用路径搜索
如果有写的不对的地方,希望能留言指正,谢谢阅读。

















 1824
1824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









