







Reinforcement Learning(强化学习)
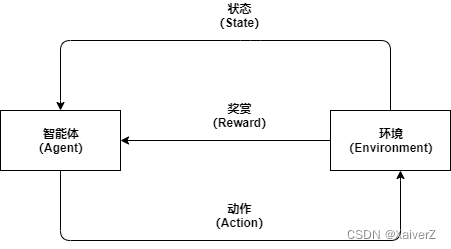
强化学习(Reinforcement Learning)是机器学习(Machine Learning)中的一个领域,本质上是一种无监督学习,其目的是让软件智能体(Agent)在特定环境(Environment)中的某一状态(State)下能够采取回报(Reward)最大化的行为(Action)
流行的强化学习方法包括自适应动态规划(ADP)、时间差分(TD)学习、状态-动作-回报-状态-动作(SARSA)算法、Q-Learning等;其应用包括下棋类游戏、机器人控制和工作调度等。
-
智能体(Agent):可以采取行动的智能个体。如强化学习的算法可以认为是一个我们人为创造的智能体。
-
行动(Action):智能体可以采取的行动的集合。如Flappy Bird游戏中智能体“Bird”可以采取的行动为“跳跃”与“无操作”。
-
环境(Environment):智能体所处的世界。如Flappy Bird中环境就是游戏的背景环境----一个充满障碍物的世界,它接受智能体的状态和行动作为输入,输出智能体该步动作的奖励以及下一步的状态。
-
状态(State):智能体所处的具体即时状态。如Flappy Bird中我们可以将智能体“Bird”所处的背景图片当作即时状态。
-
奖励(Reward):衡量智能体行动好坏的反馈。如Flappy Bird中,若智能体“Bird”采取“跳跃”动作后没有碰到障碍物,那么环境对智能体的反馈奖励可以认为是一个较大的值。反之,若碰到了障碍物,则环境对智能体的反馈奖励可以认为是一个较小的值。
K-摇臂赌博机
K-armed Bandit
Model-Based
通过构建一个虚拟环境,和虚拟环境交互得出最佳策略
Model-Free
直接与真实环境进行交互
-
Q-Learning
-
Sarsa
On-Policy
Comparison Between On-Policy & Off-Policy
在线学习:行为策略和评估策略一致
-
Sarsa
-
Policy Gradient
- REINFORCE
Off-Policy
Comparison Between On-Policy & Off-Policy
离线学习:行为策略和评估策略不一致
- Q-Learning
Monte-Carlo Update
回合更新
-
Policy Gradient
- REINFORCE
Temporal-Difference Update
单步更新














 2193
2193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









