







图注意力网络
GAT(Graph Attention Network)
Paper : Graph Attention Networks
GAT
- GAT由堆叠简单的图注意力层(Graph Attentional Layer)来实现。图注意力层针对节点对 ( i , j ) (i,j) (i,j)计算注意力系数,计算方式如下:
α i j = e x p ( L e a k y R e L U ( a T [ W h i ∣ ∣ W h j ] ) ) ∑ k ∈ N i e x p ( L e a k y R e L U ( a T [ W h i ∣ ∣ W h k ] ) ) \bm{ α_{ij} = \frac{exp(LeakyReLU(a^T[Wh_i || Wh_j]))}{\sum_{k \in N_i}exp(LeakyReLU(a^T[Wh_i || Wh_k]))} } αij=∑k∈Niexp(LeakyReLU(aT[Whi∣∣Whk]))exp(LeakyReLU(aT[Whi∣∣Whj]))
h i ′ = σ ( ∑ j ∈ N i α i j W h j ) \bm{ h_i^{'} = σ(\sum\limits_{j \in N_i}{α_{ij}Wh_j}) } hi′=σ(j∈Ni∑αijWhj)
- GAT还利用Multi-Head Attention稳定学习过程:Concat or Mean
h i ′ = ∣ ∣ k = 1 K σ ( ∑ j ∈ N i α i j W h j ) \bm{ h_i^{'} = {||}_{k=1}^K σ(\sum\limits_{j \in N_i}{α_{ij}Wh_j}) } hi′=∣∣k=1Kσ(j∈Ni∑αijWhj)
h i ′ = σ ( 1 K ∑ k = 1 K ∑ j ∈ N i α i j k W k h j ) \bm{ h_i^{'} = σ(\frac{1}{K} \sum\limits_{k=1}^K \sum\limits_{j \in N_i}{α_{ij}^kW^kh_j}) } hi′=σ(K1k=1∑Kj∈Ni∑αijkWkhj)
GaAN(Gated Attention Network)
GaAN
-
GaAN也使用Multi-Head Attention。GaAN与GAT在注意力聚合器方面的区别在于,GaAN使用键-值注意力机制和点积注意力机制,而GAT使用全连接层计算注意力系数
-
GaAN通过额外的软门控计算来为不同的注意力头分配不同的权重。该聚合器称为门控注意力聚合器。具体地说,GaAN使用卷积网络,该卷积网络聚合中心节点及其相邻节点的特征以生成门控值
图残差网络
- 动机:在Message Passing Network中,多层GNN能使每个节点都能从k跳远的相邻节点处收集更多信息(因为一层Message Passing只能将信息传递给1跳邻居节点),所以人们开始考虑堆叠多层GNN。然而,单纯的增加模型深度无法改善性能,更深的模型甚至可能表现得更差。这主要是因为,更多的层可能从成倍增加的领域成员中传播噪声信息。
Highway GCN
HN
T ( h t ) = σ ( W t h t + b t ) \bm{ T(h^t) = σ(W^th^t + b^t) } T(ht)=σ(Wtht+bt)
h t + 1 = h t + 1 ⊙ T ( h t ) + h t ⊙ ( 1 − T ( h t ) ) \bm{ h^{t+1} = h^{t+1} ⊙ T(h^t) + h^t ⊙ (1 - T(h^t)) } ht+1=ht+1⊙T(ht)+ht⊙(1−T(ht))
Jump Knowledge Network
Paper : Representation Learning on Graphs with Jumping Knowledge Networks
JKN
-
动机:对于图中的中心节点,其相邻节点的数量会随层数增加而呈指数级增长,这意味着学习更多的噪声,并使得表示更平滑。然而,对于图中的边缘节点,即使拓展其感受野,它的相邻节点也很少。因此,这些节点缺乏足够的信息来学习好的表示
-
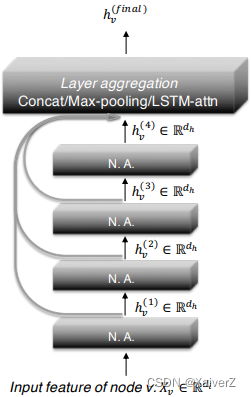
在JKN中,最后一层的每个节点都从所有中间层表示中选择,这使每个节点都可以根据需要选择合适的领域大小。汇总各层信息的方式包括但不限于拼接、最大池化、LSTM注意力机制。
DeepGCN
Paper : DeepGCNs: Can GCNs Go as Deep as CNNs?
DeepGCN
-
GNN堆叠网络层两大挑战
-
梯度消失
- 解决:残差和密集连接(ResNet、DenseNet)
-
过度平滑
- 解决:空洞卷积
-
-
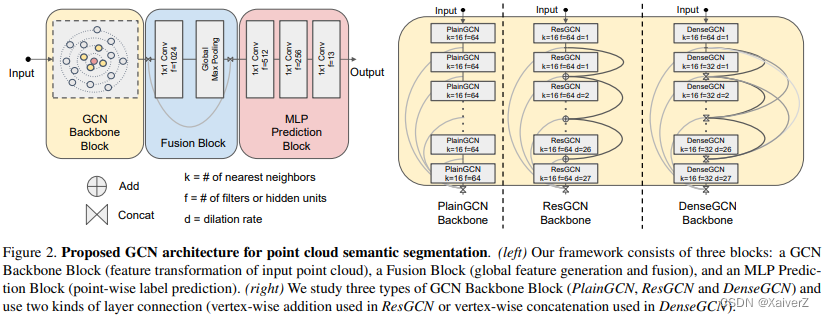
将原GCN模型记为PlainGCN,并进一步提出ResGCN、DenseGCN。这三个架构组成了DeepGCN模块。在PlainGCN中,隐状态的计算公式如下:
H t + 1 = F ( H t , W t ) \bm{ H^{t+1} = F(H^t, W^t) } Ht+1=F(Ht,Wt)
对于ResGCN,计算过程为:
H R e s t + 1 = H t + 1 + H t = F ( H t , W t ) + H t \bm{ H^{t+1}_{Res} = H^{t+1} + H^t = F(H^t, W^t) + H^t } HRest+1=Ht+1+Ht=F(Ht,Wt)+Ht
对于DenseGCN,计算过程为:
H D e n s e t + 1 = T ( H t + 1 , H t , . . . , H 0 ) = T ( F ( H t , W t ) , F ( H t − 1 , W t − 1 ) , . . . , H 0 ) \bm{ H^{t+1}_{Dense} = T(H^{t+1}, H^t, ..., H^0) = T(F(H^t, W^t), F(H^{t-1}, W^{t-1}), ..., H^0) } HDenset+1=T(Ht+1,Ht,...,H0)=T(F(Ht,Wt),F(Ht−1,Wt−1),...,H0)
其中, F F F为卷积操作, T T T为拼接操作 -
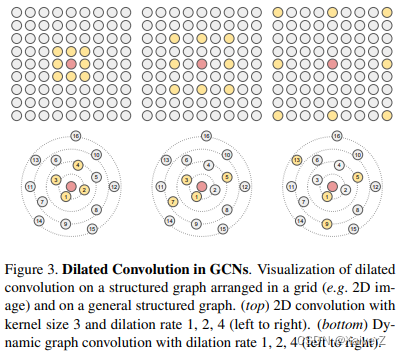
GCN中的空洞卷积和CNN中的空洞卷积类似,本文使用的是扩张k近邻的方法,扩张率为d。对每个节点,总共选择 k ∗ d k * d k∗d个邻居节点,每次选择都会跳过d个相邻节点。邻居节点的选择遵循如下操作:
-
如果相邻节点为 ( u 1 , u 2 , . . . , u k ∗ d ) (u_1, u_2, ..., u_{k*d}) (u1,u2,...,uk∗d),则节点v经过扩张化后的相邻节点为 ( u 1 , u 1 + d , u 1 + 2 d , . . . , u 1 + ( k − 1 ) d ) (u_1, u_{1+d}, u_{1+2d}, ..., u_{1+(k-1)d}) (u1,u1+d,u1+2d,...,u1+(k−1)d)
-
扩张卷积使用不同上下文的信息,增大了节点v的感受野
-














 742
742











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









