






始智AI wisemodel.cn社区已上线3个月,是类huggingface社区的产品,将努力打造成中国最活跃的中立AI开源社区。“源享计划”即开源共享计划,大家自己研发的开源模型和数据集,以及基于开源成果衍生的开源模型和数据集等,欢迎同步发布到国内wisemodel.cn社区,方便大家更容易获取和使用。
2023年12月15日清华&智谱AI团队在始智AI wisemodel.cn开源社区发布了最新研究成果CogAgent-Chat。CogAgent是一个基于180亿参数规模的视觉语言模型(VLM)的图形用户界面(GUI)智能体,专注于GUI图形交互界面的理解和导航,最大可处理1120×1120像素的分辨率图像。CogAgent使用屏幕截图作为输入,在PC和Android GUI导航任务上超越了基于语言模型的方法,如Mind2Web和AITW,引领GUI理解领域的最新技术发展。
https://wisemodel.cn/models/ZhipuAI/cogagent-chat (模型地址)
CogAgent研究背景
随着计算机和智能手机的广泛使用,图形用户界面(GUI)已经成为人们日常生活和工作中不可或缺的一部分,开发能够理解和与GUI进行交互的智能体具有很高的实际应用价值。
由于图形用户界面(GUI)通常缺少标准的API接口,一些重要信息如图标、图片、图表等难以直接转换成文字表达等,以及文本渲染的GUI(如网页)中,如canvas和iframe等元素的功能也无法通过HTML解析来理解,这导致纯粹基于语言模型的Agents在实际的GUI场景中有很大的局限。
视觉语言模型(VLMs)结合了视觉和语言处理能力,无需依赖文本输入,可以直接感知视觉GUI信号,并且VLMs还具有快速阅读、编程等能力,这使得基于VLMs的Agent在处理GUI任务时具有很大的潜力。
CogAgent的架构及训练
CogAgent是在CogVLM视觉语言模型的基础上增加了一个高分辨率跨注意力模块(High-Resolution Cross-Module),提取高分辨率图像的特征,CogVLM可以继续处理低分辨率图像的输入。
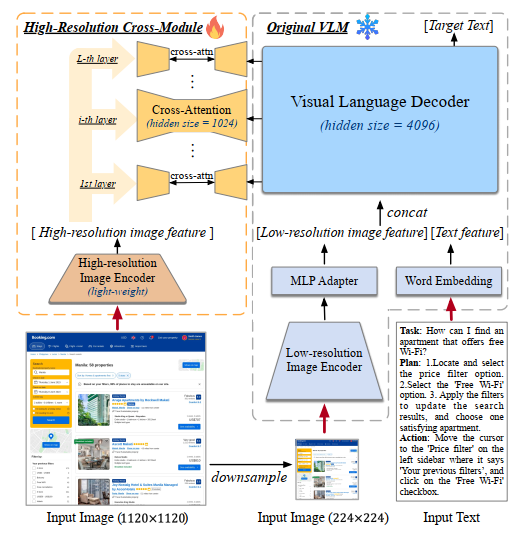
输入具体的图片,CogAgent会先将图片调整为1120 × 1120 和224 × 224两种分辨率的图像,然后分别输入到高分辨率图像编码器(EVA2-CLIP-L)和低分辨率图像编码器(EVA2-CLIP-E)里,两边分别提取图像的序列特征,最后,高分辨率和低分辨率分支中提取的特征序列将被送入一个视觉语言解码器,通过交叉注意力机制(cross-attention)将高分辨率图像特征与低分辨率图像特征以及文本特征进行融合。这种方法既有效处理了高分辨率图像的特征,又有效控制了计算成本。
CogAgent模型预训练过程主要集中Text recognition 、Visual grounding 和 GUI imagery 理解等三方面的能力,并分别选择和构建的三类能力对应的数据集。
预训练过程中先在较容易的文本识别(合成渲染和自然图像OCR)和图像字幕上训练来进行课程学习热身,然后逐步融入更难的文本识别(学术文档)、基础数据和网页数据,这种方法可以更快的收敛和更稳定的训练。
最后,为了让CogAgent能够遵循人类的指示并在GUI环境中执行任务,又进一步在更大的范围的任务上进行微调和对齐,不仅人工收集了2000多张计算机和手机截图数据,每张截图都包含了屏幕元素、潜在任务和操作方法,还利用了一些公开的VQA数据集。
实验结果分析
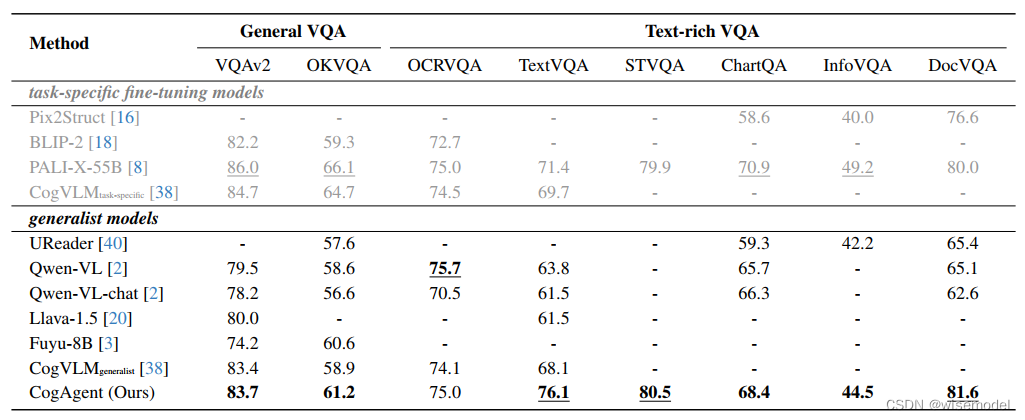
在基础视觉理解方面,CogAgent在八个视觉问题回答(VQA)任务进行基准测试,包括2个通用VQA任务(VQAv2,OK-VQA)以及6个富文本VQA任务(TextVQA,OCR-VQA,ST-VQA,ChartQA,InfoVQA和DocVQA)。相比于其他通用VLM模型,除了OCR-VQA上,CogAgent模型都获取了目前最好的得分。
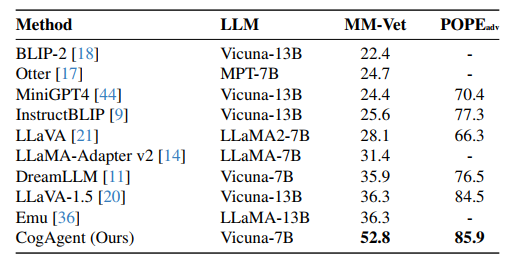
在多模态评估任务中,CogAgent在MM-Vet任务上取得了52.8的分数,超过了包括LLaVA-1.5在内其他模型。在POPE任务的对抗性设置中,CogAgent获得了85.9的分数,显示出其优越地处理幻觉的能力。
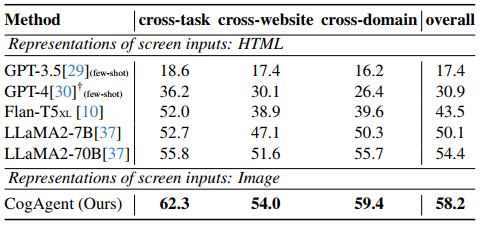
在计算机界面理解方面,CogAgent在Mind2Web数据集上进行了评估,该数据集包含从31个域名137个真实的网站里超过2000个开放任务。除了CogAgent是直接输入图片之外,GPT-4等其他模型都只能接受经过清洗之后的HTML文本,在cross-website 、cross-domain 、cross-task 三方面的测试,CogAgent都显著优于其他模型的表现。
在智能手机界面理解方面,CogAgent在AITW数据集上进行了评测,AITW包含了715,000个操作序列,涵盖了30,000个不同的任务指令、四个Android版本和八种设备类型。每个操作序列包括一个自然语言描述的目标、一个动作序列以及相应的截图。模型需要根据给定的目标、历史动作和截图来预测下一个动作。在五个子集(Google Apps、Install、WebShop、General和Single)上,CogAgent的得分都显著优纯基于文本输入的模型如GPT-3.5等。相比于同样基于视觉语言的Auto-UI模型,CogAgent整体还是具有明显的优势。

鉴于CogAgent在计算机界面(Computer Interface)和智能手机界面(Smartphone Interface)理解方面的出色性能,CogAgent可以根据用户指令自动完成各种操作任务,未来在各种GUI界面交互的场景中都可能可以交给CogAgent来完成具体操作。
DEMO演示
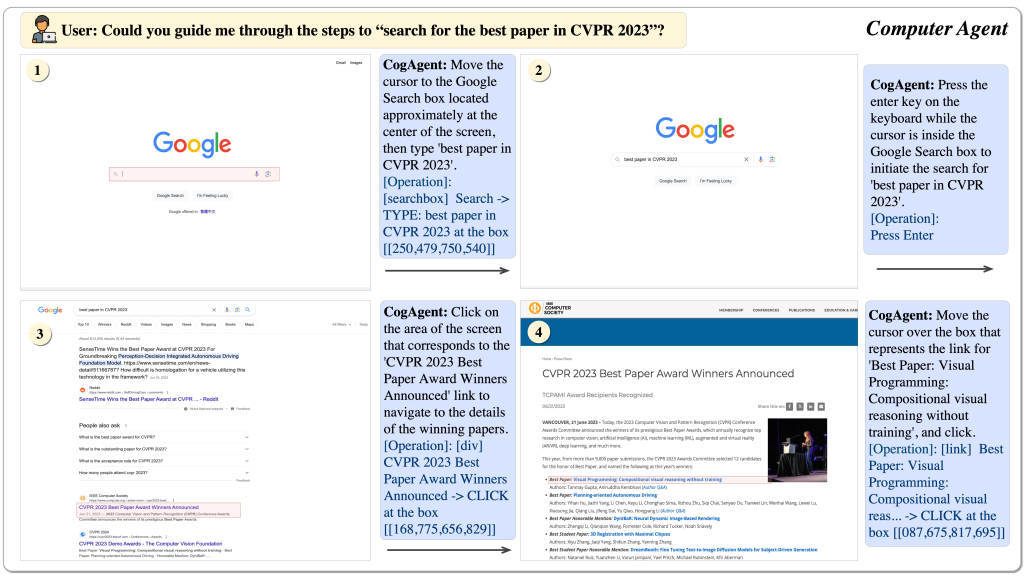

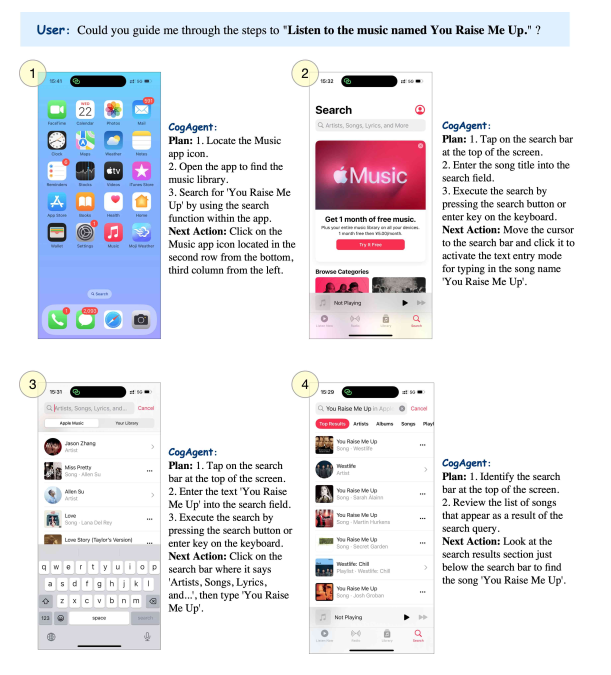
更详细内容大家可以参考论文:https://arxiv.org/pdf/2312.08914.pdf

















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









