






始智AI wisemodel.cn社区将努力打造成huggingface之外最活跃的中立开放的AI开源社区。“源享计划”即开源共享计划,自研的开源模型和数据集,以及基于开源成果衍生的开源模型和数据集等,欢迎发布到wisemodel.cn社区,方便大家更容易获取和使用。
北京智源人工智能研究院近期在始智AI wisemodel.cn开源社区Aquila2系列模型,包括34B和70B两个尺寸的模型,其中34B模型在10月已开源,包含了Chat模型的标准版和16K版本;70B模型是最近刚发布的异构训练实验版。大家可以前往wisemodel开源社区了解更多关于Aquila系列模型的情况:
模型地址:
https://wisemodel.cn/organization/BAAI
Aquila2-70B-Expr异构实验版
Aquila2-70B-Expr(异构实验版)系列开源模型扩充了70B参数量级的中英双语大模型阵列,为学界和业界提供一个较为优秀的探索起点。虽然只经过1.2T数据训练,但Aquila2-70B-Expr基座模型仍然表现了出色的潜力。基于Aquila2-70B-Expr模型,开发者可以在同构或异构芯片集群上面,进行继续预训练或微调。
虽然Aquila2-70B-Expr目前已经训练的英文数据量仅为LLama2-70B的大约三分之一,但是除了在MMLU上还落后于LLama2-70B,其他主要评测集上的表现已经超过了LLama2-70B。对Aquila2-70B-Expr以MMLU训练集进行一小段持续训练的实验,Aquila2-70B-Expr迅速在MMLU的总体评测上提升至80.7分,可见该基础模型极为出色的学习能力。Aquila2-70B-Expr的更大价值在于给后续使用者一个泛化能力强大、后续学习能力强大的基座模型。
为了展现对下游任务的学习能力,基于同样的指令数据集微调训练得出的AquilaChat2-70B-Expr模型,在主观能力评测中,超过了经过2T数据训练的AquilaChat2-34B,也超过了其它模型在CLCC v2.0主观能力评测的得分。
异构混合训练
为支持多厂商异构算力合池训练,智源升级了FlagScale框架,实现了异构流水线并行及异构数据并行两种模式。实验证明,两种异构方案的实现均不影响70B模型的训练效率及模型性能。
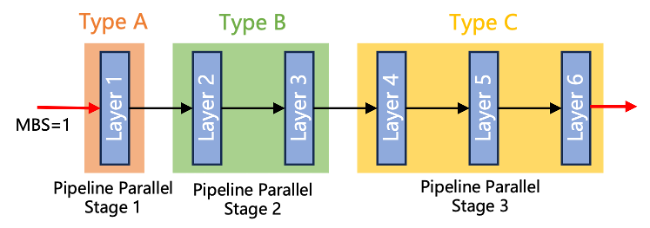
异构流水线并行:不同类型设备处理不同的网络层,同一类型设备处理相同网络层,所有类型只使用单一的微批次大小(microbatch size),具体流程如下图所示。实际训练时,异构流水线并行模式可以跟数据并行、张量并行以及序列并行进行混合来实现高效训练。根据反向传播算法内存使用特点,该模式适合将内存比较大的设备放在流水线并行靠前的阶段,内存小的设备放在流水线并行靠后的阶段,然后根据再设备的算力来分配不同的网络层来实现负载均衡。
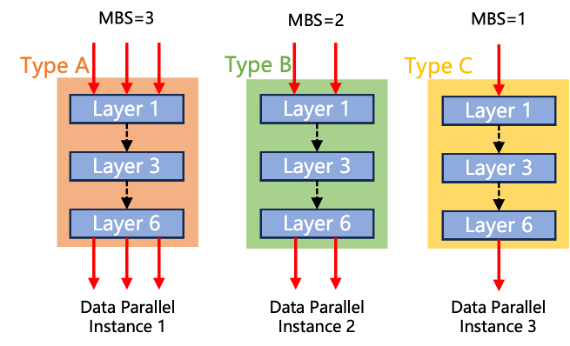
异构数据并行模式:不同类型硬件处理不同数据并行实例,同一类型设备处理相同且完整的神经网络层,但不同类型设备将使用不同微批次大小,参考类似的工作,具体流程如下图所示。实际训练时,异构数据并行模式可以跟张量并行、流水线并行以及序列并行进行混合来实现大规模高效训练。在该模式下,算力和内存都比较大的设备将处理较大的微批次大小,而算力和内存都比较小的设备将处理较小的微批次大小,从而实现不同设备上的负载均衡。
通过实验证明,不管是在NVIDIA芯片还是在国产芯片上进行异构混合训练,都有性能收益;使用FlagScale进行混合异构训练效率接近上限,并且由于混合后资源变多,在某些情况能解锁新的优化空间。FlagScale v0.2 提供的异构流水线并行与异构数据并行实现,都可以很好地保持模型性能,在NVIDIA异构训练或国产芯片上异构训练,对模型性能影响甚微,国产芯片集群上的同构训练能够达到NVIDIA同构训练上的模型性能(尽管国产机器训练会对ckpt进行重切分,无法完全保持随机初始状态一致)。
Aquila2-34B系列模型
2023年10月上旬,北京智源人工智能研究院开源了Aquila2-34B系列模型,Aquila2 在中英文综合能力方面效果显著,Aquila2-34B 基座模型取得了22个评测基准的综合排名先前,包括语言、理解、推理、代码、考试等多个维度。经指令微调得到了AquilaChat2-34B对话模型系列,在主观+客观综合评测中效果领先。
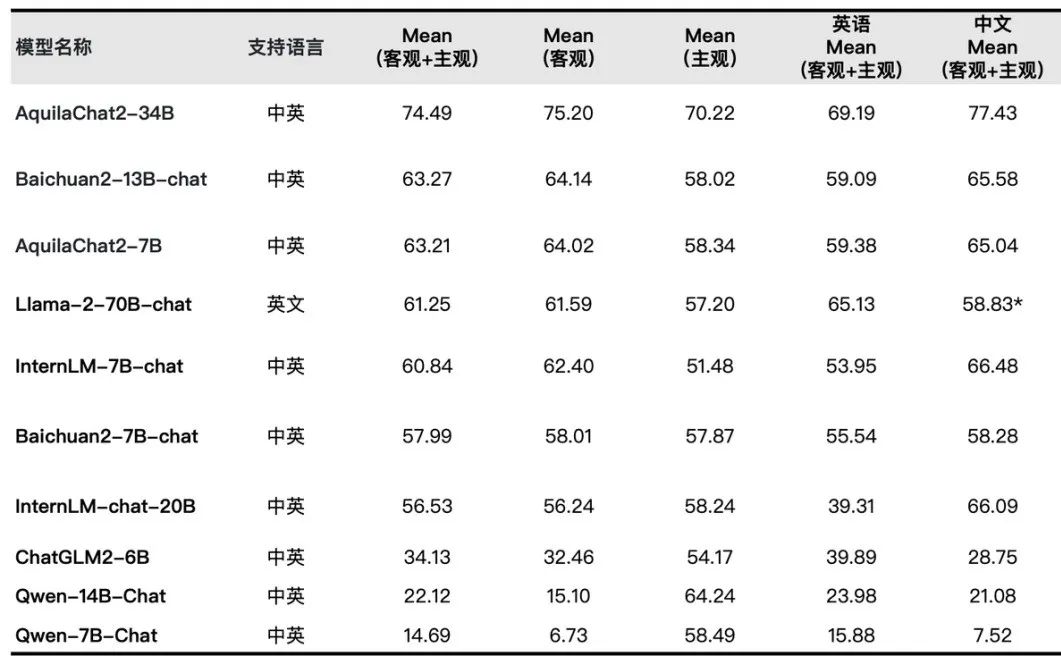
AquilaChat2-34B-16K 以 Aquila2-34B 为基座,经过位置编码内插法处理,并在 20W 条优质长文本对话数据集上做了 SFT,将模型的有效上下文窗口长度扩展至 16K。在 LongBench 的四项中英文长文本问答、长文本总结任务的评测效果显示,AquilaChat2-34B-16K 处于开源长文本模型的前列水平。
长度外延能力不足是制约大模型成文本能力的普遍问题。为此,智源团队创新提出 NLPE(Non-Linearized Position Embedding, 非线性位置编码)方法,在 RoPE 方法的基础上,通过调整相对位置编码、约束最大相对长度来提升模型外延能力。在代码、中英文Few-Shot Leaning、电子书等多个领域上的文本续写实验显示,NLPE 可以将 4K 的 Aquila2-34B 模型外延到 32K 长度,且续写文本的连贯性远好于 Dynamic-NTK、位置插值等方法。
了解更多,可以参考:
https://github.com/FlagAI-Open/Aquila2















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









