







原文:Hands-On Meta Learning with Python
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
一、元学习导论
元学习是当前人工智能领域最有前途和趋势的研究领域之一。 它被认为是获得广义人工智能(AGI)的垫脚石。 在本章中,我们将了解什么是元学习以及为什么元学习是当前人工智能中最令人振奋的研究。 我们将了解什么是少拍,单拍和零拍学习,以及如何在元学习中使用它。 我们还将学习不同类型的元学习技术。 然后,我们将探索学习通过梯度下降学习梯度下降的概念,其中我们了解如何使用元学习器来学习梯度下降优化。 继续进行,我们还将学习优化作为少样本学习的模型,我们将了解如何在少样本学习设置中将元学习器用作优化算法。
在本章中,您将了解以下内容:
- 元学习
- 元学习和少样本学习
- 元学习的类型
- 通过梯度下降来元学习梯度下降
- 为少样本学习优化模型
元学习
目前,元学习是 AI 领域中令人振奋的研究领域。 凭借大量的研究论文和进步,元学习显然在 AI 领域取得了重大突破。 在进行元学习之前,让我们看看我们当前的 AI 模型是如何工作的。
近年来,借助强大的算法(如生成对抗网络和胶囊网络),深度学习取得了飞速的发展。 但是深度神经网络的问题在于,我们需要拥有大量的训练集来训练我们的模型,而当我们只有很少的数据点时,它将突然失败。 假设我们训练了一个深度学习模型来执行任务A。 现在,当我们有一个新任务B,与A密切相关时,我们不能使用相同的模型。 我们需要从头开始为任务B训练模型。 因此,对于每项任务,我们都需要从头开始训练模型,尽管它们可能是相关的。
深度学习真的是真正的 AI 吗? 好吧,不是。 人类如何学习? 我们将学习概括为多个概念并从中学习。 但是当前的学习算法仅能完成一项任务。 这就是元学习的用武之地。元学习产生了一个通用的 AI 模型,该模型可以学习执行各种任务,而无需从头开始进行训练。 我们使用很少的数据点在各种相关任务上训练我们的元学习模型,因此对于新的相关任务,它可以利用从先前任务中获得的学习知识,而不必从头开始进行训练。 许多研究人员和科学家认为,元学习可以使我们更接近实现 AGI。 在接下来的部分中,我们将确切学习元学习模型如何元学习过程。
元学习和少样本
从较少的数据点中学习称为少样本学习或 K 样本学习,其中k表示数据集中每个类的数据点的数量。 假设我们正在对猫和狗进行图像分类。 如果我们正好有一只狗和一只猫的图像,那么它被称为单样本学习,也就是说,我们每个类仅从一个数据点开始学习。 如果我们有 10 张狗的图像和 10 张猫的图像,则称为 10 样本学习。 因此, K 样本学习中的k意味着每个类都有许多数据点。 还有零样本学习,每个类没有任何数据点。 等待。 什么? 根本没有数据点时,我们如何学习? 在这种情况下,我们将没有数据点,但是将获得有关每个类的元信息,并且将从元信息中学习。 由于我们的数据集中有两个类别,即狗和猫,因此可以将其称为双向学习k样本学习; 因此n路表示我们在数据集中拥有的类的数量。
为了使我们的模型从一些数据点中学习,我们将以相同的方式对其进行训练。 因此,当我们有一个数据集D时,我们从数据集中存在的每个类中采样一些数据点,并将其称为支持集。 同样,我们从每个类中采样一些不同的数据点,并将其称为查询集。 因此,我们使用支持集训练模型,并使用查询集进行测试。 我们以剧集形式训练模型-也就是说,在每个剧集中,我们从数据集中D中采样一些数据点,准备支持集和查询集,然后在支持集上训练,并在查询集上进行测试。 因此,在一系列剧集中,我们的模型将学习如何从较小的数据集中学习。 我们将在接下来的章节中对此进行更详细的探讨。
元学习的类型
从找到最佳权重集到学习优化器,可以通过多种方式对元学习进行分类。 我们将元学习分为以下三类:
- 学习度量空间
- 学习初始化
- 学习优化器
学习度量空间
在基于度量的元学习设置中,我们将学习适当的度量空间。 假设我们要学习两个图像之间的相似性。 在基于度量的设置中,我们使用一个简单的神经网络从两个图像中提取特征,并通过计算这两个图像的特征之间的距离来找到相似性。 这种方法广泛用于我们没有很多数据点的少样本学习设置中。 在接下来的章节中,我们将学习基于度量的学习算法,例如连体网络,原型网络和关系网络。
学习初始化
在这种方法中,我们尝试学习最佳的初始参数值。 那是什么意思? 假设我们正在建立一个神经网络来对图像进行分类。 首先,我们初始化随机权重,计算损失,并通过梯度下降使损失最小化。 因此,我们将通过梯度下降找到最佳权重,并将损失降到最低。 代替随机初始化权重,如果我们可以使用最佳值或接近最佳值来初始化权重,那么我们可以更快地达到收敛,并且可以很快学习。 在接下来的章节中,我们将看到如何使用 MAML,Reptile 和元 SGD 等算法精确找到这些最佳初始权重。
学习优化器
在这种方法中,我们尝试学习优化器。 我们通常如何优化神经网络? 我们通过在大型数据集上进行训练来优化神经网络,并使用梯度下降来最大程度地减少损失。 但是在少数学习设置中,梯度下降失败了,因为我们将拥有较小的数据集。 因此,在这种情况下,我们将学习优化器本身。 我们将有两个网络:一个实际尝试学习的基础网络和一个优化该基础网络的元网络。 在接下来的部分中,我们将探讨其工作原理。
通过梯度下降来元学习梯度下降
现在,我们将看到一种有趣的元学习算法,称为“通过梯度下降来元学习梯度下降”。 这个名字不是很令人生畏吗? 好吧,事实上,它是最简单的元学习算法之一。 我们知道,在元学习中,我们的目标是元学习过程。 通常,我们如何训练神经网络? 我们通过计算损失并通过梯度下降使损失最小化来训练我们的网络。 因此,我们使用梯度下降来优化模型。 除了使用梯度下降,我们还能自动学习此优化过程吗?
但是我们如何学习呢? 我们用循环神经网络(RNN)取代了传统的优化器(梯度下降)。 但这如何工作? 如何用 RNN 代替梯度下降? 如果您仔细研究,我们在梯度下降中到底在做什么? 这基本上是从输出层到输入层的一系列更新,我们将这些更新存储在一个状态中。 因此,我们可以使用 RNN 并将更新存储在 RNN 单元中。
因此,该算法的主要思想是用 RNN 代替梯度下降。 但是问题是 RNN 如何学习? 我们如何优化 RNN? 为了优化 RNN,我们使用梯度下降。 因此,简而言之,我们正在学习通过 RNN 执行梯度下降,并且 RNN 通过梯度下降进行了优化,这就是所谓的通过梯度下降学习梯度下降的名称。
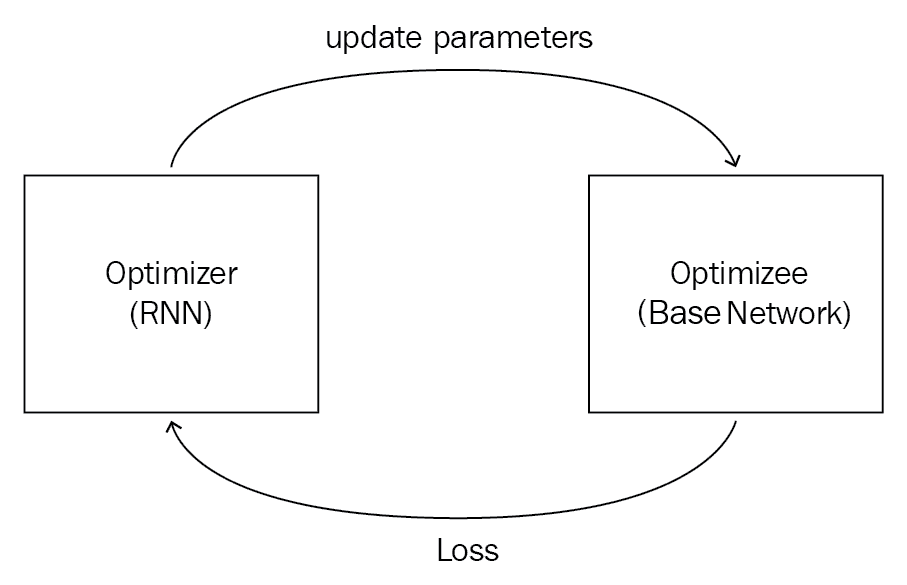
我们称我们的 RNN 为优化器,而将我们的基础网络称为优化器。 假设我们有一个由某些参数θ参数化的模型f。 我们需要找到最佳参数θ,以使损失最小化。 通常,我们通过梯度下降找到最佳参数,但是现在我们使用 RNN 来找到最佳参数。 因此,RNN(优化器)找到最佳参数,并将其发送到最优化(基础网络); 优化器使用此参数,计算损失,然后将损失发送到 RNN。 基于损失,RNN 通过梯度下降进行优化,并更新模型参数θ。
令人困惑? 查看下图:通过优化器(RNN)优化了我们的 Optimize(基础网络)。 优化器将更新后的参数(即权重)发送给优化器,优化器使用这些权重,计算损失,然后将损失发送给优化器。 基于损失,优化器通过梯度下降改进自身:
假设我们的基础网络(优化器)由θ参数化,而我们的 RNN(优化器)由φ参数化。 优化器的损失函数是什么? 我们知道优化器的作用(RNN)是减少优化器(基础网络)的损失。 因此,优化器的损失是优化器的平均损失,可以表示为:
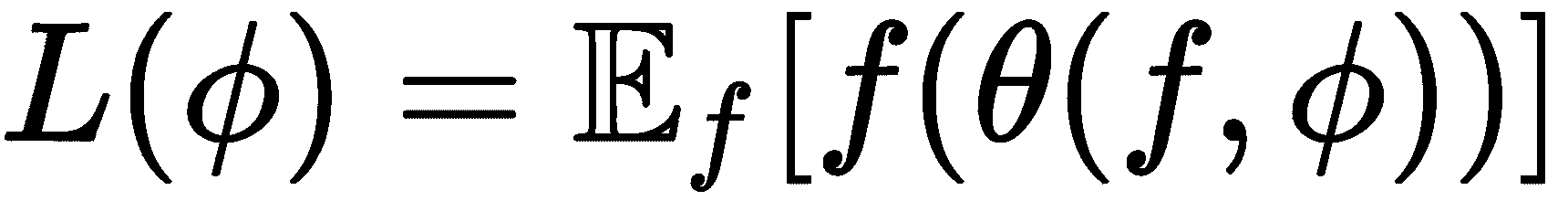
我们如何最小化这种损失? 通过找到正确的φ,我们可以通过梯度下降使这种损失最小化。 好的,RNN 作为输入是什么,它将返回什么输出? 我们的优化器,即我们的 RNN,将优化器ᐁ[t]的梯度及其先前状态h[t]作为输入,并返回输出,即更新g[t],该更新可将优化器的损失降到最低。 让我们用函数m表示我们的 RNN:
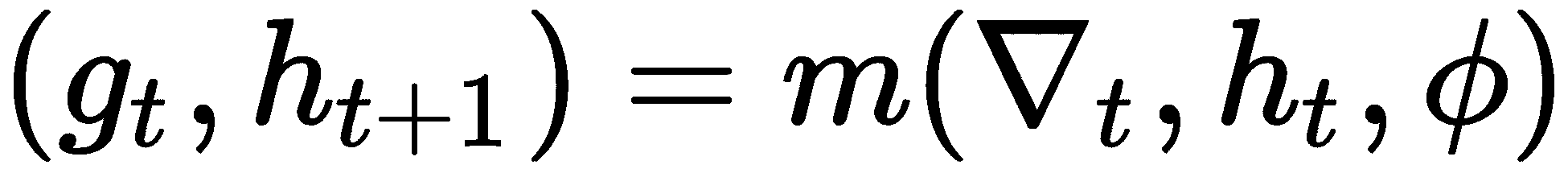
在前面的公式中,适用以下条件:
ᐁ[t]是我们模型(优化程序)f的梯度,即ᐁ[t] = ᐁ[t](f(θ[t]))h[t]是 RNN 的隐藏状态φ是 RNN 的参数- 输出
g[t]和h[t + 1]分别是 RNN 的更新和下一个状态
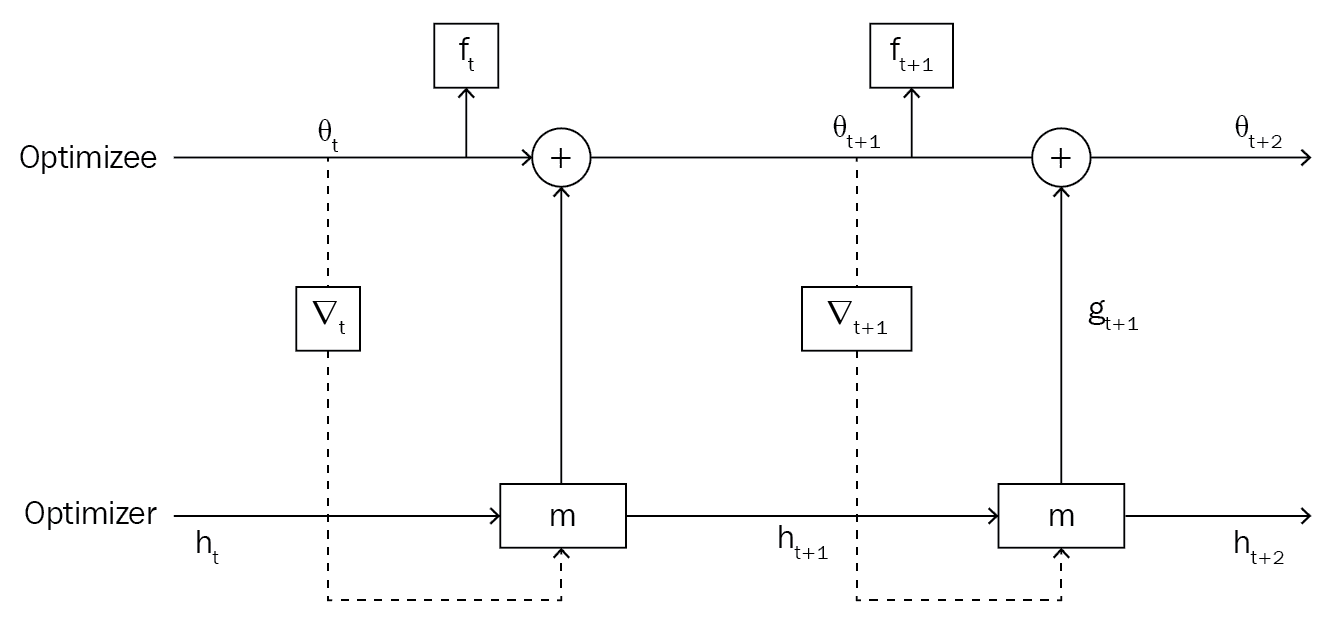
因此,我们使用θ[t + 1] = θ[t] + g[t]更新了模型参数值。
如下图所示,我们的优化器m,将隐藏状态h[t]和θ[t]的梯度ᐁ[t]作为输入,计算g[t]并将其发送到我们的优化器,然后在其中添加θ[t],并在接下来的时间步骤中成为θ[t + 1]进行更新:
因此,通过这种方式,我们通过梯度下降学习梯度下降优化。
为少样本学习优化模型
我们知道,在少样本学习中,我们从较少的数据点中学习,但是如何在少样本学习环境中应用梯度下降呢? 在少样本学习设置中,由于数据点很少,梯度下降突然失败。 梯度下降优化需要更多的数据点才能达到收敛并最大程度地减少损失。 因此,我们需要在少数情况下获得更好的优化技术。 假设我们有一个由某些参数θ参数化的f模型。 我们使用一些随机值初始化此参数θ,并尝试使用梯度下降法找到最佳值。 让我们回想一下梯度下降的更新方程:
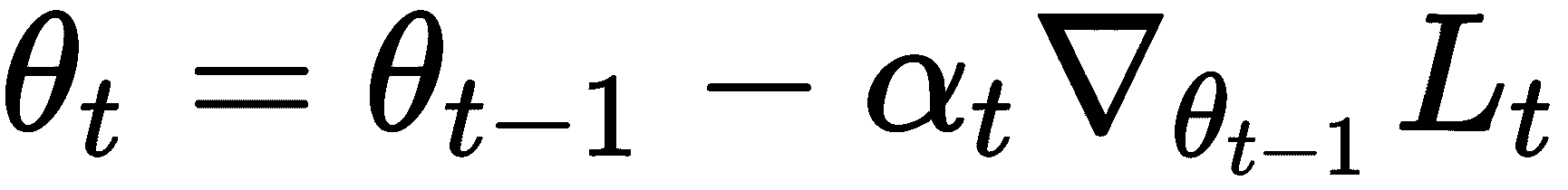
在前面的公式中,适用以下条件:
θ[t]是更新的参数θ[t - 1]是上一个时间步的参数值α[t]是学习率ᐁ[θ[t - 1]]L[t]是损失函数相对于θ[t - 1]的梯度
梯度下降的更新方程看起来不熟悉吗? 是的,您猜对了:它类似于 LSTM 的单元状态更新方程式,可以这样写:
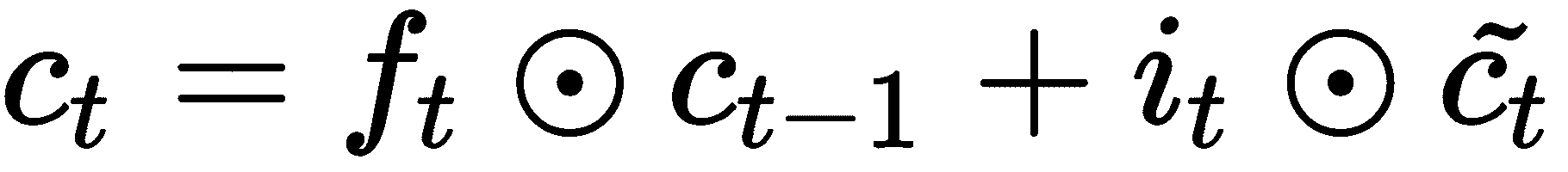
我们可以将 LSTM 单元更新方程与梯度下降完全相关,例如f[t] = 1,则适用以下条件:
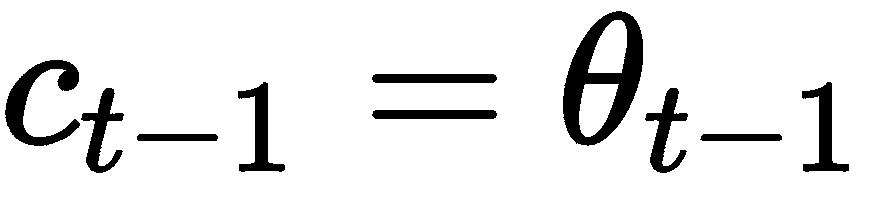

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VsbBENDH-1681653478823)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/24750401-81a6-4f3f-9b3e-60ef2017b393.png)]
因此,我们可以使用 LSTM 作为优化器,而不是在少数学习机制中使用梯度下降作为优化器。 我们的元学习器是 LSTM,它学习用于训练模型的更新规则。 因此,我们使用两个网络:一个是我们的基础学习器,它学习执行任务,另一个是元学习器,它试图找到最佳参数。 但这如何工作?
我们知道,在 LSTM 中,我们使用了一个“遗忘门”来丢弃内存中不需要的信息,它可以表示为:
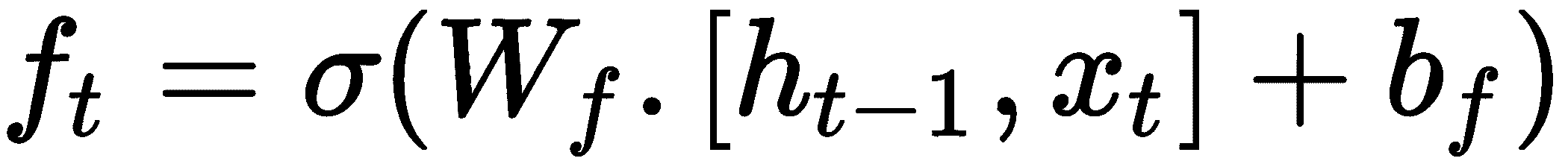
这个遗忘门在我们的优化设置中如何发挥作用? 假设我们处于损失高的位置,并且梯度接近零。 我们如何摆脱这个位置? 在这种情况下,我们可以缩小模型的参数,而忽略其先前值的某些部分。 因此,我们可以使用我们的遗忘门做到这一点,它将当前参数值θ[t - 1],当前损失L[t],当前梯度ᐁ[θ[t - 1]]和先前的遗忘门作为输入; 它可以表示如下:
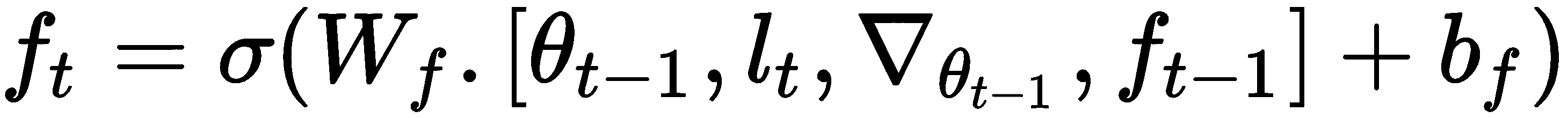
现在让我们进入输入门。 我们知道,LSTM 中的输入门用于确定要更新的值,它可以表示为:
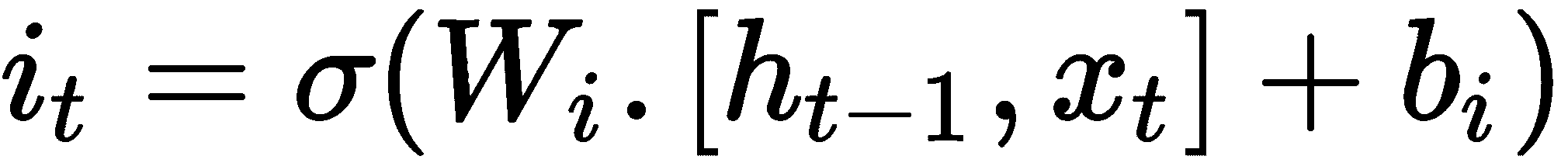
在少样本学习设置中,我们可以使用此输入门来调整学习速度,以快速学习,同时防止出现差异:
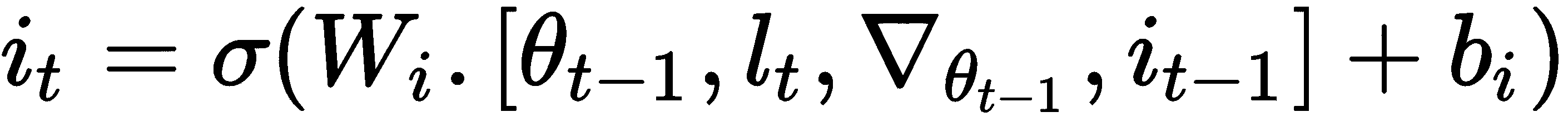
因此,我们的元学习器经过几次更新后即可学习i[t]和f[t]的最佳值。
但是,这如何工作?
假设我们有一个由Θ参数化的基础网络,和M参数化的 LSTM 元学习器R。 假设我们有一个数据集D。 我们将数据集分为D_train和D_test分别进行训练和测试。 首先,我们随机初始化元学习器参数φ。
对于某些T迭代次数,我们从D_train中随机采样数据点,计算损失,然后相对于模型参数Θ计算损失的梯度。 现在,我们将此梯度,损失和元学习器参数φ输入到我们的元学习器。 我们的元学习器R将返回单元状态c[t],然后我们将时间t的基础网络M的参数Θ[t]更新为c[t]。 我们重复N次,如下图所示:

因此,在T次迭代之后,我们将获得一个最佳参数θ[T]。 但是,我们如何检查θ[T]的表现以及如何更新元学习器参数? 我们采用测试集,并使用参数θ[T]计算测试集的损失。 然后,我们根据元学习器参数φ计算损失的梯度,然后更新φ,如下所示:

我们对n个迭代进行此操作,并更新了元学习器。 总体算法如下所示:

总结
我们首先了解了元学习是什么,以及元学习中如何使用单发,少发和零发学习。 我们了解到,支持集和查询集更像是训练集和测试集,但每个类中都有k个数据点。 我们还看到了n-方式 k 次的含义。 后来,我们了解了不同类型的元学习技术。 然后,我们探索了通过梯度下降学习梯度下降的学习方法,其中我们看到了 RNN 如何用作优化器来优化基础网络。 后来,我们将优化视为快速学习的模型,其中我们使用 LSTM 作为元学习器,以在快速学习环境中进行优化。
在下一章中,我们将学习称为连体网络的基于度量的元学习算法,并且将了解如何使用连体网络执行人脸和音频识别。
问题
- 什么是元学习?
- 什么是少样本学习?
- 什么是支持集?
- 什么是查询集?
- 基于度量的学习称为什么?
- 我们如何进行元学习训练?
进一步阅读
二、使用连体网络的人脸和音频识别
在上一章中,我们了解了什么是元学习和不同类型的元学习技术。 我们还看到了如何通过梯度下降和优化来学习梯度下降,这是一次快速学习的模型。 在本章中,我们将学习一种称为连体网络的最常用的基于度量的单样本学习算法。 我们将看到连体网络如何从很少的数据点学习以及如何将它们用于解决低数据问题。 之后,我们将详细探讨连体网络的架构,并看到连体网络的一些应用。 在本章的最后,我们将学习如何使用连体网络构建人脸和音频识别模型。
在本章中,您将学习以下内容:
- 什么是连体网络?
- 连体网络的架构
- 连体网络的应用
- 将连体网络用于人脸识别
- 使用连体网络构建音频识别模型
什么是连体网络?
连体网络是神经网络的一种特殊类型,它是最简单且使用最广泛的单发学习算法之一。 正如我们在上一章中学到的,单样本学习是一种技术,其中我们每个类仅从一个训练示例中学习。 因此,在每个类别中没有很多数据点的应用中主要使用连体网络。 例如,假设我们要为我们的组织建立一个人脸识别模型,并且在组织中有大约 500 个人在工作。 如果我们想从头开始使用卷积神经网络(CNN)建立人脸识别模型,那么我们需要这 500 人中的许多人来训练网络并获得准确率良好的图像。 但是显然,我们不会为这 500 个人提供很多图像,因此除非有足够的数据点,否则使用 CNN 或任何深度学习算法构建模型都是不可行的。 因此,在这种情况下,我们可以求助于复杂的单样本学习算法,例如连体网络,该算法可以从更少的数据点进行学习。
但是,连体网络如何工作? 连体网络基本上由两个对称的神经网络组成,它们共享相同的权重和结构,并且都使用能量函数E最终结合在一起。 我们的连体网络的目标是了解两个输入值是相似还是相异。 假设我们有两个图像X[1]和X2,我们想了解两个图像是相似还是相异。
如下图所示,我们将图像X[1]馈送到网络A和图像X[2]到另一个网络B。 这两个网络的作用是为输入图像生成嵌入(特征向量)。 因此,我们可以使用任何可以嵌入我们的网络。 由于我们的输入是图像,因此我们可以使用卷积网络来生成嵌入,即用于提取特征。 请记住,CNN 在这里的作用仅仅是提取特征而不是进行分类。 我们知道这些网络应该具有相同的权重和架构,如果我们的网络A是三层 CNN,那么我们的网络B也应该是三层 CNN,我们这两个网络必须使用相同的权重集。 因此,网络A和网络B将为我们提供输入图像X[1]和X[2]的嵌入。 然后,我们会将这些嵌入信息提供给能量函数,从而告诉我们两个输入的相似程度。 能量函数基本上是任何相似性度量,例如欧几里得距离和余弦相似性。
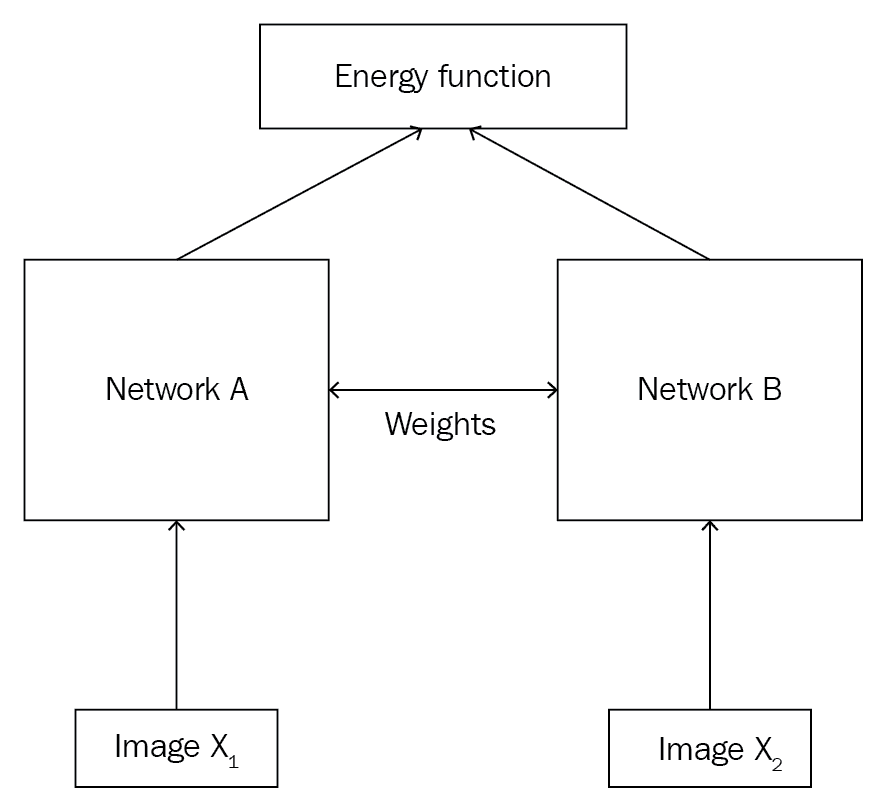
连体网络不仅用于人脸识别,而且还广泛用于我们没有很多数据点和任务需要学习两个输入之间相似性的应用中。 连体网络的应用包括签名验证,相似问题检索,对象跟踪等。 我们将在下一部分中详细研究连体网络。
连体网络的架构
现在,我们对连体网络有了基本的了解,我们将详细探讨它们。 下图显示了连体网络的架构:
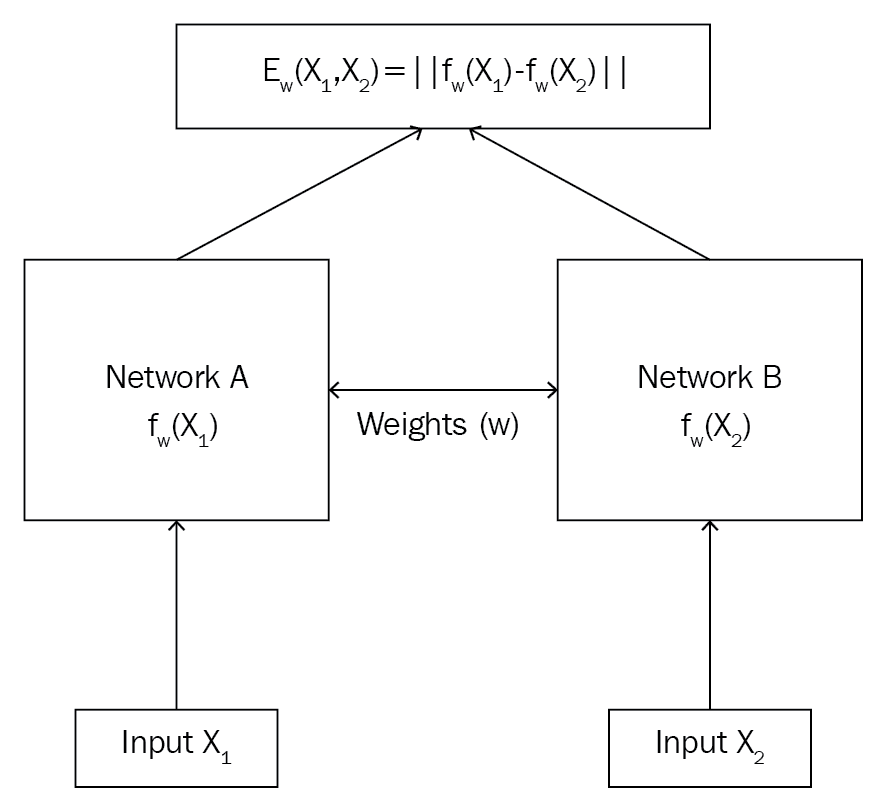
如上图所示,连体网络由两个相同的网络组成,它们共享相同的权重和架构。 假设我们有两个输入,X[1]和X[2]。 我们将输入X[1]馈送到网络A,即f[w](X[1]),然后将输入的X[2]馈送到网络B,即f[w](X[2])。 您会注意到,这两个网络的权重相同w,它们将为我们的输入X[1]和X[2]生成嵌入。 然后,我们将这些嵌入提供给能量函数E,这将使我们在两个输入之间具有相似性。
可以表示为:
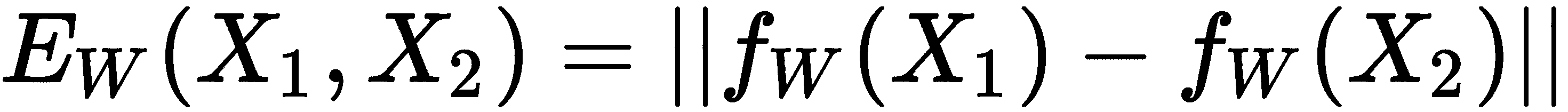
假设我们使用欧几里得距离作为能量函数,那么如果X[1]和X[2]相似。 如果输入值不相同,则E的值将很大。
假设您有两个句子,句子 1 和句子 2。我们将句子 1 馈送到网络A,将句子 2 馈送到网络B。 假设我们的网络A和网络B都是 LSTM 网络,它们共享相同的权重。 因此,网络A和网络B将分别为句子 1 和句子 2 生成单词嵌入。 然后,我们将这些嵌入提供给能量函数,从而为我们提供两个句子之间的相似度得分。 但是我们如何训练我们的连体网络呢? 数据应该如何? 有哪些特征和标签? 我们的目标函数是什么?
连体网络的输入应该成对出现(X[1], X[2])以及它们的二进制标签Y ∈ (0, 1),指出输入对是真对(相同)还是非对(不同)。 正如您在下表中所看到的,我们将句子成对存在,并且标签暗示句子对是真实的(1)还是假的(0):

那么,我们的连体网络的损失函数是什么? 由于连体网络的目标不是执行分类任务而是为了了解两个输入值之间的相似性,因此我们使用对比损失函数。
可以表示为:
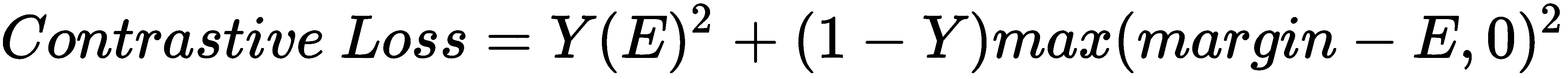
在前面的公式中,Y的值是真实的标签,如果两个输入值相似,则为1;如果两个输入值为0是不同的,E是我们的能量函数,可以是任何距离度量。 术语边距用于保持约束,也就是说,当两个输入值互不相同时,并且如果它们的距离大于边距,则不会造成损失。
连体网络的应用
如我们所知,连体网络通过使用相同的架构找到两个输入值之间的相似性来学习。 它是涉及两个实体之间的计算相似性的任务中最常用的单样本学习算法之一。 它功能强大,可作为低数据问题的解决方案。
在发表连体网络的第一篇论文中,作者描述了网络对于签名验证任务的重要性。 签名验证任务的目的是识别签名的真实性。 因此,作者用真正的和不正确的签名对训练了连体网络,并使用了卷积网络从签名中提取特征。 提取特征后,他们测量了两个特征向量之间的距离以识别相似性。 因此,当出现新的签名时,我们提取特征并将其与签名者存储的特征向量进行比较。 如果距离小于某个阈值,则我们接受签名为真实签名,否则我们拒绝签名。
连体网络也广泛用于 NLP 任务。 有一篇有趣的论文,作者使用连体网络来计算文本相似度。 他们使用连体网络作为双向单元,并使用余弦相似度作为能量函数来计算文本之间的相似度。
连体网络的应用是无止境的。 它们已经堆叠了用于执行各种任务的各种架构,例如人类动作识别,场景更改检测和机器翻译。
将连体网络用于人脸识别
我们将通过建立人脸识别模型来了解连体网络。 我们网络的目标是了解两个面孔是相似还是相异。 我们使用 AT&T 人脸数据库,可以从此处下载。
下载并解压缩存档后,可以看到文件夹s1,s2,最高到s40,如下所示:
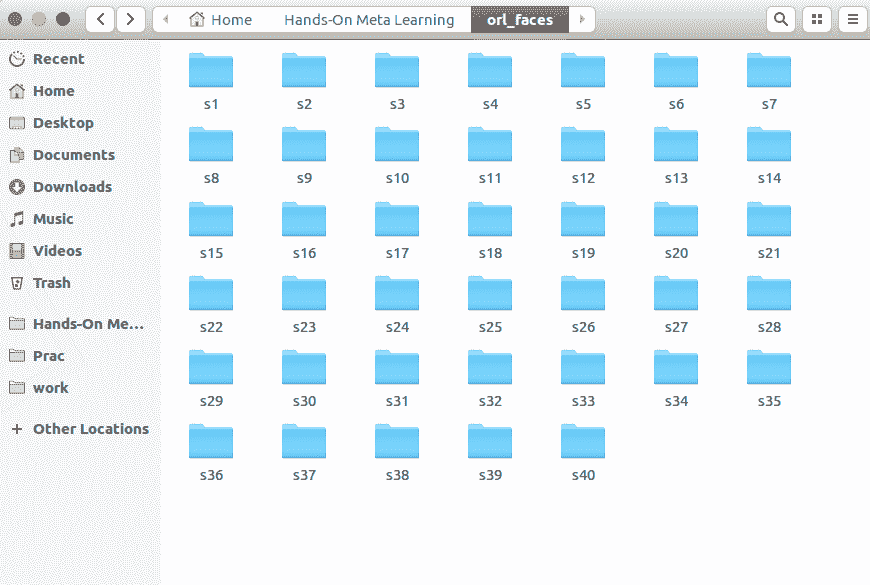
这些文件夹中的每一个都有从不同角度拍摄的 10 个人的不同图像。 例如,打开文件夹s1。 如您所见,一个人有 10 张不同的图像:
我们打开并检查文件夹s13:
我们知道,连体网络需要输入值和标签一起作为一对,因此我们必须以这种方式创建数据。 因此,我们将从同一文件夹中随机获取两张图像,并将它们标记为真正的一对,而我们将从两个不同文件夹中获取单幅图像,并将它们标记为不正确的一对。 以下屏幕快照显示了一个示例; 如您所见,一对真实的人具有相同的人的形象,而一对不真实的人具有不同的人的形象:

一旦我们将数据与它们的标签配对在一起,就可以训练我们的连体网络。 从图像对中,我们将一个图像馈入网络A,将另一个图像馈入网络B。这两个网络的作用仅仅是提取特征向量。 因此,我们使用具有整流线性单元(ReLU)激活的两个卷积层来提取特征。 一旦了解了特征,就将来自两个网络的合成特征向量馈入能量函数,以测量相似度。 我们使用欧几里得距离作为我们的能量函数。 因此,我们通过提供图像对来训练我们的网络,以了解它们之间的语义相似性。 现在,我们将逐步看到这一点。
为了更好地理解,您可以检查完整的代码,该代码可以在 Jupyter 笔记本中找到,并在此处进行解释。
首先,我们将导入所需的库:
import re
import numpy as np
from PIL import Image
from sklearn.model_selection import train_test_split
from keras import backend as K
from keras.layers import Activation
from keras.layers import Input, Lambda, Dense, Dropout, Convolution2D, MaxPooling2D, Flatten
from keras.models import Sequential, Model
from keras.optimizers import RMSprop
现在,我们定义了一个用于读取输入图像的函数。 read_image函数将图像作为输入并返回一个 NumPy 数组:
def read_image(filename, byteorder='>'):
#first we read the image, as a raw file to the buffer
with open(filename, 'rb') as f:
buffer = f.read()
#using regex, we extract the header, width, height and maxval of the image
header, width, height, maxval = re.search(
b"(^P5\s(?:\s*#.*[\r\n])*"
b"(\d+)\s(?:\s*#.*[\r\n])*"
b"(\d+)\s(?:\s*#.*[\r\n])*"
b"(\d+)\s(?:\s*#.*[\r\n]\s)*)", buffer).groups()
#then we convert the image to numpy array using np.frombuffer which interprets buffer as one dimensional array
return np.frombuffer(buffer,
dtype='u1' if int(maxval) < 256 else byteorder+'u2',
count=int(width)*int(height),
offset=len(header)
).reshape((int(height), int(width)))
例如,我们打开一个图像:
Image.open("data/orl_faces/s1/1.pgm")

当我们将此图像提供给read_image函数时,它将作为 NumPy 数组返回:
img = read_image('data/orl_faces/s1/1.pgm')
img.shape
(112, 92)
现在,我们定义另一个函数get_data,用于生成我们的数据。 众所周知,对于连体网络,数据应采用带有二进制标签的成对形式(正版和非正版)。
首先,我们从同一目录中读取(img1和img2)图像,并将它们存储在x_genuine_pair数组中,然后将y_genuine分配给1。 接下来,我们从不同目录中读取(img1,img2)图像,并将它们存储在x_imposite对中,并将y_imposite分配给0。
最后,我们将x_genuine_pair和x_imposite都连接到X以及y_genuine和y_imposite都连接到Y:
size = 2
total_sample_size = 10000
def get_data(size, total_sample_size):
#read the image
image = read_image('data/orl_faces/s' + str(1) + '/' + str(1) + '.pgm', 'rw+')
#reduce the size
image = image[::size, ::size]
#get the new size
dim1 = image.shape[0]
dim2 = image.shape[1]
count = 0
#initialize the numpy array with the shape of [total_sample, no_of_pairs, dim1, dim2]
x_geuine_pair = np.zeros([total_sample_size, 2, 1, dim1, dim2]) # 2 is for pairs
y_genuine = np.zeros([total_sample_size, 1])
for i in range(40):
for j in range(int(total_sample_size/40)):
ind1 = 0
ind2 = 0
#read images from same directory (genuine pair)
while ind1 == ind2:
ind1 = np.random.randint(10)
ind2 = np.random.randint(10)
# read the two images
img1 = read_image('data/orl_faces/s' + str(i+1) + '/' + str(ind1 + 1) + '.pgm', 'rw+')
img2 = read_image('data/orl_faces/s' + str(i+1) + '/' + str(ind2 + 1) + '.pgm', 'rw+')
#reduce the size
img1 = img1[::size, ::size]
img2 = img2[::size, ::size]
#store the images to the initialized numpy array
x_geuine_pair[count, 0, 0, :, :] = img1
x_geuine_pair[count, 1, 0, :, :] = img2
#as we are drawing images from the same directory we assign label as 1\. (genuine pair)
y_genuine[count] = 1
count += 1
count = 0
x_imposite_pair = np.zeros([total_sample_size, 2, 1, dim1, dim2])
y_imposite = np.zeros([total_sample_size, 1])
for i in range(int(total_sample_size/10)):
for j in range(10):
#read images from different directory (imposite pair)
while True:
ind1 = np.random.randint(40)
ind2 = np.random.randint(40)
if ind1 != ind2:
break
img1 = read_image('data/orl_faces/s' + str(ind1+1) + '/' + str(j + 1) + '.pgm', 'rw+')
img2 = read_image('data/orl_faces/s' + str(ind2+1) + '/' + str(j + 1) + '.pgm', 'rw+')
img1 = img1[::size, ::size]
img2 = img2[::size, ::size]
x_imposite_pair[count, 0, 0, :, :] = img1
x_imposite_pair[count, 1, 0, :, :] = img2
#as we are drawing images from the different directory we assign label as 0\. (imposite pair)
y_imposite[count] = 0
count += 1
#now, concatenate, genuine pairs and imposite pair to get the whole data
X = np.concatenate([x_geuine_pair, x_imposite_pair], axis=0)/255
Y = np.concatenate([y_genuine, y_imposite], axis=0)
return X, Y
现在,我们生成数据并检查数据大小。 如您所见,我们有 20,000 个数据点,其中 10,000 个是真实对,而 10,000 个是非对:
X, Y = get_data(size, total_sample_size)
X.shape
(20000, 2, 1, 56, 46)
Y.shape
(20000, 1)
接下来,我们将训练和测试的数据划分为 75% 的训练和 25% 的测试比例:
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=.25)
现在我们已经成功地生成了数据,我们就建立了连体网络。 首先,我们定义基础网络,该网络基本上是用于特征提取的卷积网络。 我们使用 ReLU 激活和最大池化以及一个平坦层来构建两个卷积层:
def build_base_network(input_shape):
seq = Sequential()
nb_filter = [6, 12]
kernel_size = 3
#convolutional layer 1
seq.add(Convolution2D(nb_filter[0], kernel_size, kernel_size, input_shape=input_shape,
border_mode='valid', dim_ordering='th'))
seq.add(Activation('relu'))
seq.add(MaxPooling2D(pool_size=(2, 2)))
seq.add(Dropout(.25))
#convolutional layer 2
seq.add(Convolution2D(nb_filter[1], kernel_size, kernel_size, border_mode='valid', dim_ordering='th'))
seq.add(Activation('relu'))
seq.add(MaxPooling2D(pool_size=(2, 2), dim_ordering='th'))
seq.add(Dropout(.25))
#flatten
seq.add(Flatten())
seq.add(Dense(128, activation='relu'))
seq.add(Dropout(0.1))
seq.add(Dense(50, activation='relu'))
return seq
接下来,我们将图像对馈送到基础网络,该基础网络将返回嵌入,即特征向量:
input_dim = x_train.shape[2:]
img_a = Input(shape=input_dim)
img_b = Input(shape=input_dim)
base_network = build_base_network(input_dim)
feat_vecs_a = base_network(img_a)
feat_vecs_b = base_network(img_b)
feat_vecs_a和feat_vecs_b是我们图像对的特征向量。 接下来,我们将这些特征向量馈入能量函数以计算它们之间的距离,然后使用欧几里得距离作为能量函数:
def euclidean_distance(vects):
x, y = vects
return K.sqrt(K.sum(K.square(x - y), axis=1, keepdims=True))
def eucl_dist_output_shape(shapes):
shape1, shape2 = shapes
return (shape1[0], 1)
distance = Lambda(euclidean_distance, output_shape=eucl_dist_output_shape)([feat_vecs_a, feat_vecs_b])
现在,我们将周期长度设置为13,并使用 RMS 属性进行优化并定义我们的模型:
epochs = 13
rms = RMSprop()
model = Model(input=[input_a, input_b], output=distance)
接下来,我们将损失函数定义为contrastive_loss函数并编译模型:
def contrastive_loss(y_true, y_pred):
margin = 1
return K.mean(y_true * K.square(y_pred) + (1 - y_true) * K.square(K.maximum(margin - y_pred, 0)))
model.compile(loss=contrastive_loss, optimizer=rms)
现在,我们训练模型:
img_1 = x_train[:, 0]
img_2 = x_train[:, 1]
model.fit([img_1, img_2], y_train, validation_split=.25, batch_size=128, verbose=2, nb_epoch=epochs)
您会看到损失随着时间的推移而减少:
Train on 11250 samples, validate on 3750 samples
Epoch 1/13
- 60s - loss: 0.2179 - val_loss: 0.2156
Epoch 2/13
- 53s - loss: 0.1520 - val_loss: 0.2102
Epoch 3/13
- 53s - loss: 0.1190 - val_loss: 0.1545
Epoch 4/13
- 55s - loss: 0.0959 - val_loss: 0.1705
Epoch 5/13
- 52s - loss: 0.0801 - val_loss: 0.1181
Epoch 6/13
- 52s - loss: 0.0684 - val_loss: 0.0821
Epoch 7/13
- 52s - loss: 0.0591 - val_loss: 0.0762
Epoch 8/13
- 52s - loss: 0.0526 - val_loss: 0.0655
Epoch 9/13
- 52s - loss: 0.0475 - val_loss: 0.0662
Epoch 10/13
- 52s - loss: 0.0444 - val_loss: 0.0469
Epoch 11/13
- 52s - loss: 0.0408 - val_loss: 0.0478
Epoch 12/13
- 52s - loss: 0.0381 - val_loss: 0.0498
Epoch 13/13
- 54s - loss: 0.0356 - val_loss: 0.0363
现在,我们使用测试数据进行预测:
pred = model.predict([x_test[:, 0], x_test[:, 1]])
接下来,我们定义一个用于计算精度的函数:
def compute_accuracy(predictions, labels):
return labels[predictions.ravel() < 0.5].mean()
现在,我们对模型的准确率:
compute_accuracy(pred, y_test)
0.9779092702169625
使用连体网络构建音频识别模型
在上一教程中,我们了解了如何使用连体网络识别人脸。 现在,我们将看到如何使用连体网络来识别音频。 我们将训练我们的网络,以区分狗的声音和猫的声音。 可以从此处下载猫和狗音频的数据集。
下载数据后,我们将数据分成三个文件夹:Dogs,Sub_dogs和Cats。 在Dogs和Sub_dogs中,放置狗的吠叫音频,在Cats文件夹中,放置猫的音频。 我们网络的目标是识别音频是狗的吠叫还是其他声音。 众所周知,对于连体网络,我们需要成对输入输入。 我们从Dogs和Sub_dogs文件夹中选择一个音频并将其标记为真正对,并从Dogs和Cats文件夹中选择一个音频并将它们标记为非对。 即,(Dogs, Sub_dogs)是真正的对,(Dogs, Cats)是非配对的。
现在,我们将逐步展示如何训练连体网络以识别音频是狗的吠叫声还是其他声音。
为了更好地理解,您可以检查完整的代码,该代码可以在 Jupyter 笔记本中找到,并在此处进行解释。
首先,我们将加载所有必需的库:
#basic imports
import glob
import IPython
from random import randint
#data processing
import librosa
import numpy as np
#modelling
from sklearn.model_selection import train_test_split
from keras import backend as K
from keras.layers import Activation
from keras.layers import Input, Lambda, Dense, Dropout, Flatten
from keras.models import Model
from keras.optimizers import RMSprop
在继续之前,我们加载并收听音频片段:
IPython.display.Audio("data/audio/Dogs/dog_barking_0.wav")
IPython.display.Audio("data/audio/Cats/cat_13.wav")
那么,如何将这些原始音频馈送到我们的网络? 我们如何从原始音频中提取有意义的特征? 众所周知,神经网络仅接受向量化输入,因此我们需要将音频转换为特征向量。 我们该怎么做? 嗯,我们可以通过几种机制生成音频的嵌入。 这样的流行机制之一是梅尔频率倒谱系数(MFCC)。 MFCC 使用对数功率谱在频率的非线性梅尔尺度上的线性余弦变换来转换音频的短期功率谱。 要了解有关 MFCC 的更多信息,请查看此不错的教程。
我们将使用librosa库中的 MFCC 函数来生成音频嵌入。 因此,我们定义了一个名为audio2vector的函数,该函数在给定音频文件的情况下返回音频嵌入:
def audio2vector(file_path, max_pad_len=400):
#read the audio file
audio, sr = librosa.load(file_path, mono=True)
#reduce the shape
audio = audio[::3]
#extract the audio embeddings using MFCC
mfcc = librosa.feature.mfcc(audio, sr=sr)
#as the audio embeddings length varies for different audio, we keep the maximum length as 400
#pad them with zeros
pad_width = max_pad_len - mfcc.shape[1]
mfcc = np.pad(mfcc, pad_width=((0, 0), (0, pad_width)), mode='constant')
return mfcc
我们将加载一个音频文件并查看嵌入内容:
audio_file = 'data/audio/Dogs/dog_barking_0.wav'
audio2vector(audio_file)
array([[-297.54905127, -288.37618855, -314.92037769, ..., 0\. ,
0\. , 0\. ],
[ 23.05969394, 9.55913148, 37.2173831 , ..., 0\. ,
0\. , 0\. ],
[-122.06299523, -115.02627567, -108.18703056, ..., 0\. ,
0\. , 0\. ],
...,
[ -6.40930836, -2.8602708 , -2.12551478, ..., 0\. ,
0\. , 0\. ],
[ 0.70572914, 4.21777791, 4.62429301, ..., 0\. ,
0\. , 0\. ],
[ -6.08997702, -11.40687886, -18.2415214 , ..., 0\. ,
0\. , 0\. ]])
现在我们已经了解了如何生成音频嵌入,我们需要为我们的连体网络创建数据。 众所周知,连体网络可以成对接受数据,因此我们定义了获取数据的函数。 我们将创建一个真正的对(Dogs,Sub_dogs),并将标签指定为1,将非正当对创建为(Dogs,Cats),并将标签指定为0:
def get_data():
pairs = []
labels = []
Dogs = glob.glob('data/audio/Dogs/*.wav')
Sub_dogs = glob.glob('data/audio/Sub_dogs/*.wav')
Cats = glob.glob('data/audio/Cats/*.wav')
np.random.shuffle(Sub_dogs)
np.random.shuffle(Cats)
for i in range(min(len(Cats),len(Sub_dogs))):
#imposite pair
if (i % 2) == 0:
pairs.append([audio2vector(Dogs[randint(0,3)]),audio2vector(Cats[i])])
labels.append(0)
#genuine pair
else:
pairs.append([audio2vector(Dogs[randint(0,3)]),audio2vector(Sub_dogs[i])])
labels.append(1)
return np.array(pairs), np.array(labels)
X, Y = get_data("/home/sudarshan/sudarshan/Experiments/oneshot-audio/data/")
接下来,我们将训练和测试的数据划分为 75% 的训练和 25% 的测试比例:
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2)
现在我们已经成功地生成了数据,我们就建立了连体网络。 我们定义了用于特征提取的基本网络,我们使用了三个密集层,中间有一个丢弃层:
def build_base_network(input_shape):
input = Input(shape=input_shape)
x = Flatten()(input)
x = Dense(128, activation='relu')(x)
x = Dropout(0.1)(x)
x = Dense(128, activation='relu')(x)
x = Dropout(0.1)(x)
x = Dense(128, activation='relu')(x)
return Model(input, x)
接下来,我们将音频对馈送到基础网络,基础网络将返回特征:
input_dim = X_train.shape[2:]
audio_a = Input(shape=input_dim)
audio_b = Input(shape=input_dim)
base_network = build_base_network(input_dim)
feat_vecs_a = base_network(audio_a)
feat_vecs_b = base_network(audio_b)
feat_vecs_a和feat_vecs_b是我们音频对的特征向量。 接下来,我们将这些特征向量馈入能量函数以计算它们之间的距离,然后使用欧几里得距离作为能量函数:
def euclidean_distance(vects):
x, y = vects
return K.sqrt(K.sum(K.square(x - y), axis=1, keepdims=True))
def eucl_dist_output_shape(shapes):
shape1, shape2 = shapes
return (shape1[0], 1)
distance = Lambda(euclidean_distance, output_shape=eucl_dist_output_shape)([feat_vecs_a, feat_vecs_b])
接下来,我们将周期长度设置为13,并使用 RMS 属性进行优化:
epochs = 13
rms = RMSprop()
model = Model(input=[audio_a, audio_b], output=distance)
最后,我们将损失函数定义为contrastive_loss并编译模型:
def contrastive_loss(y_true, y_pred):
margin = 1
return K.mean(y_true * K.square(y_pred) + (1 - y_true) * K.square(K.maximum(margin - y_pred, 0)))
model.compile(loss=contrastive_loss, optimizer=rms)
现在,我们训练模型:
audio1 = X_train[:, 0]
audio2 = X_train[:, 1]
model.fit([audio_1, audio_2], y_train, validation_split=.25,
batch_size=128, verbose=2, nb_epoch=epochs)
您可以了解历代的损失:
Train on 8 samples, validate on 3 samples
Epoch 1/13
- 0s - loss: 23594.8965 - val_loss: 1598.8439
Epoch 2/13
- 0s - loss: 62360.9570 - val_loss: 816.7302
Epoch 3/13
- 0s - loss: 17967.6230 - val_loss: 970.0378
Epoch 4/13
- 0s - loss: 20030.3711 - val_loss: 358.9078
Epoch 5/13
- 0s - loss: 11196.0547 - val_loss: 339.9991
Epoch 6/13
- 0s - loss: 3837.2898 - val_loss: 381.9774
Epoch 7/13
- 0s - loss: 2037.2965 - val_loss: 303.6652
Epoch 8/13
- 0s - loss: 1434.4321 - val_loss: 229.1388
Epoch 9/13
- 0s - loss: 2553.0562 - val_loss: 215.1207
Epoch 10/13
- 0s - loss: 1046.6870 - val_loss: 197.1127
Epoch 11/13
- 0s - loss: 569.4632 - val_loss: 183.8586
Epoch 12/13
- 0s - loss: 759.0131 - val_loss: 162.3362
Epoch 13/13
- 0s - loss: 819.8594 - val_loss: 120.3017
总结
在本章中,我们学习了什么是连体网络,以及如何使用连体网络构建人脸和音频识别模型。 我们探索了连体网络的架构,该网络基本上由两个相同的神经网络组成,它们具有相同的权重和架构,并且将这些网络的输出插入到一些能量函数中以了解相似性。
在下一章中,我们将学习原型网络及其变种,例如高斯原型网络和半原型网络。 我们还将看到如何使用原型网络进行全方位字符集分类。
问题
- 什么是连体网络?
- 什么是对比损失函数?
- 能量函数是什么?
- 连体网络所需的数据格式是什么?
- 连体网络有哪些应用?
进一步阅读
三、原型网络及其变体
在上一章中,我们了解了什么是连体网络以及如何将它们用于执行少量学习任务。 我们还探讨了如何使用连体网络进行人脸和音频识别。 在本章中,我们将介绍另一种有趣的少样本学习算法,称为原型网络,该算法能够将其推广到训练集中没有的类。 我们将从了解什么是原型网络开始,然后我们将了解如何使用原型网络在 omniglot 数据集中执行分类任务。 然后,我们将看到原型网络的不同变体,例如高斯原型网络和半原型网络。
在本章中,您将了解以下内容:
- 原型网络
- 原型网络算法
- 将原型网络用于分类
- 高斯原型网络
- 高斯原型网络算法
- 半原型网络
原型网络
原型网络是另一种简单,高效,很少的镜头学习算法。 像连体网络一样,原型网络尝试学习度量空间以执行分类。 原型网络的基本思想是创建每个类的原型表示形式,并根据类原型与查询点之间的距离对查询点(即新点)进行分类。
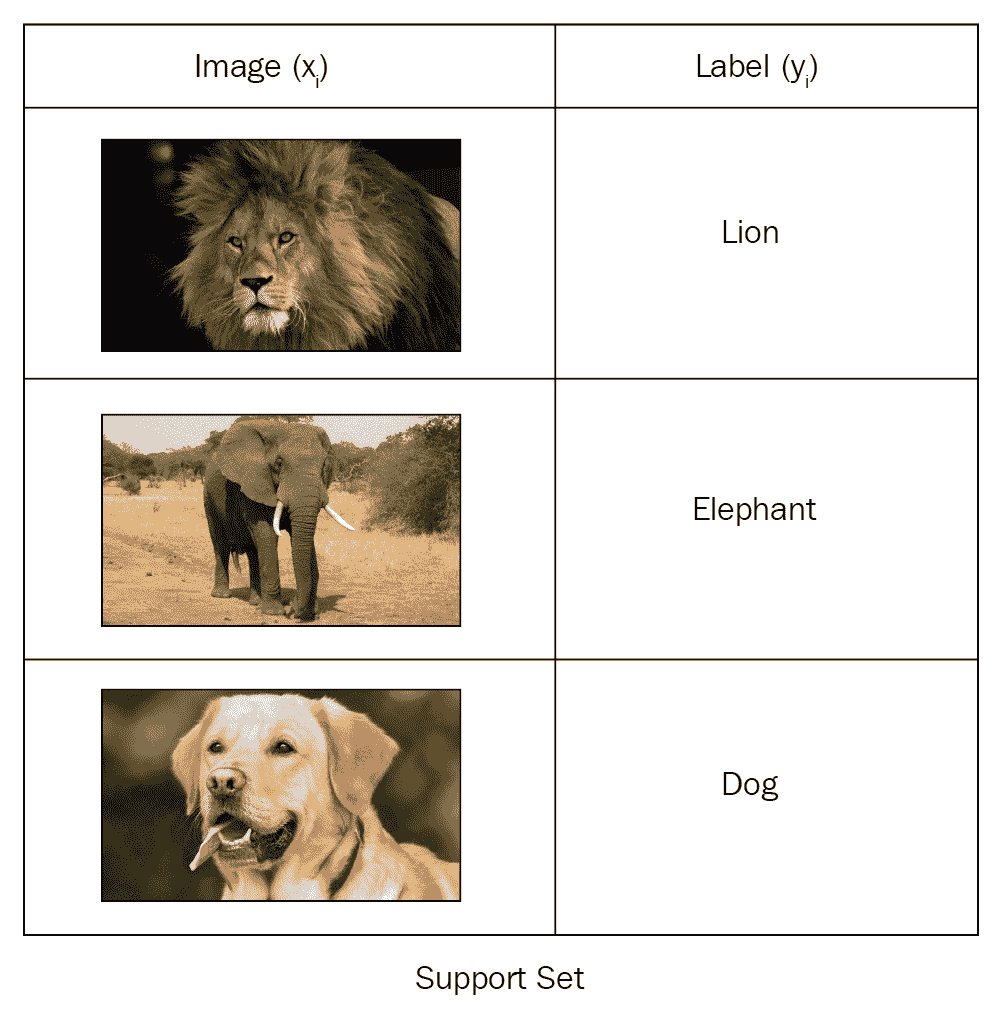
假设我们有一个包含狮子,大象和狗的图像的支持集,如下图所示:

因此,我们分为三类: {Lion, Eleph, Dog}。 现在,我们需要为这三个类中的每一个创建一个原型表示。 我们如何构建这三个类的原型? 首先,我们将使用嵌入函数来学习每个数据点的嵌入。 嵌入函数f[φ]()可以是可用于提取特征的任何函数。 由于我们的输入是图像,因此我们可以使用卷积网络作为嵌入函数,该函数将从输入图像中提取特征:

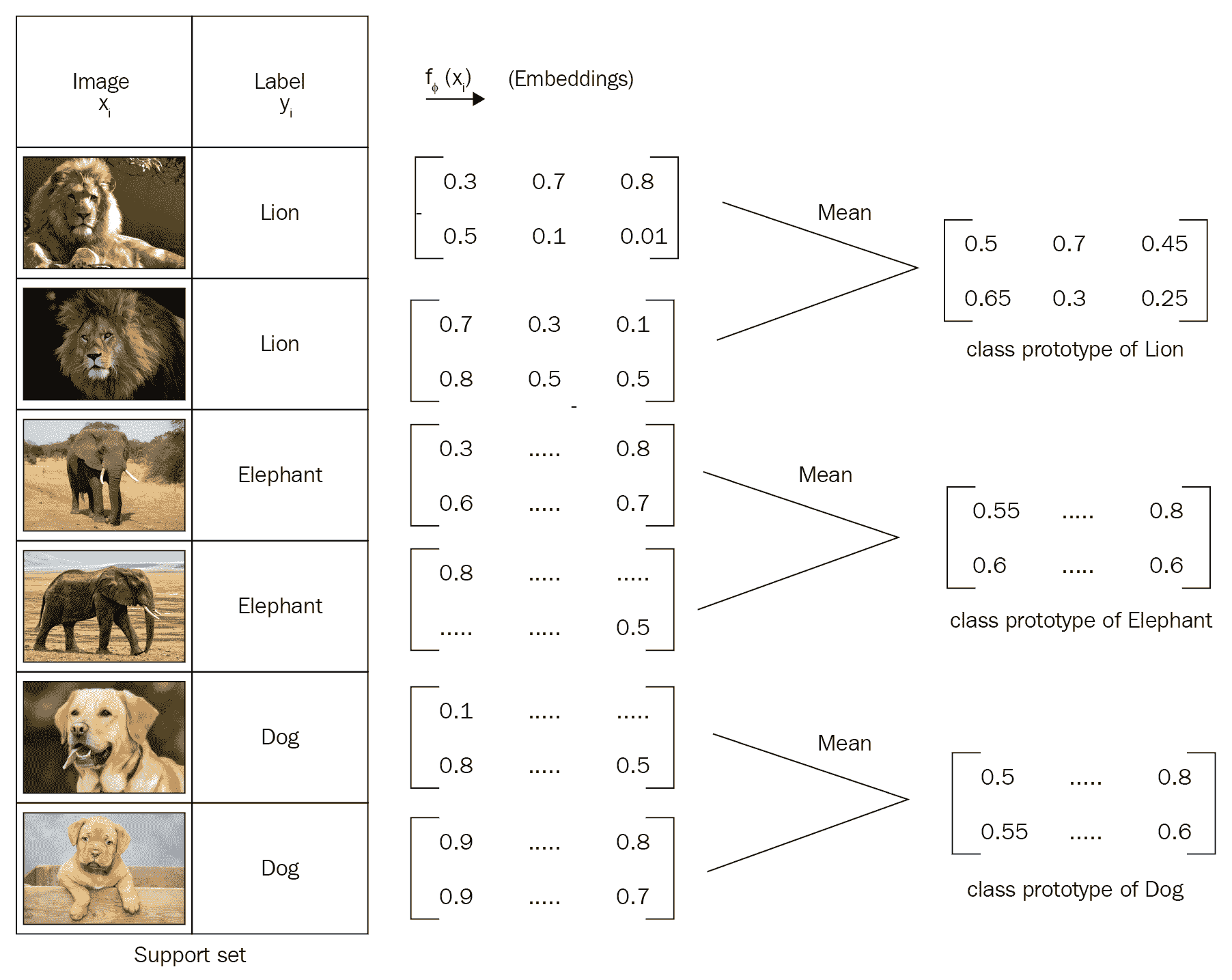
一旦了解了每个数据点的嵌入,就可以将每个类中数据点的均值嵌入并形成类原型,如下图所示。 因此,类原型基本上就是在类中数据点的平均嵌入:
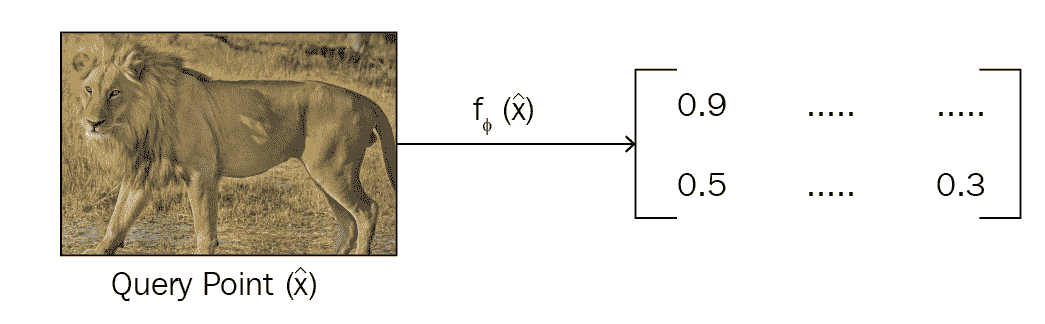
同样,当有新的数据点(即我们要为其预测标签的查询点)进入时,我们将使用与创建类原型相同的嵌入函数为该新数据点生成嵌入。 是,我们使用卷积网络为查询点生成嵌入:
对查询点进行嵌入后,我们将比较类原型和查询点嵌入之间的距离,以查找查询点所属的类。 我们可以使用欧几里得距离作为查找类原型与查询点嵌入之间距离的度量,如下所示:
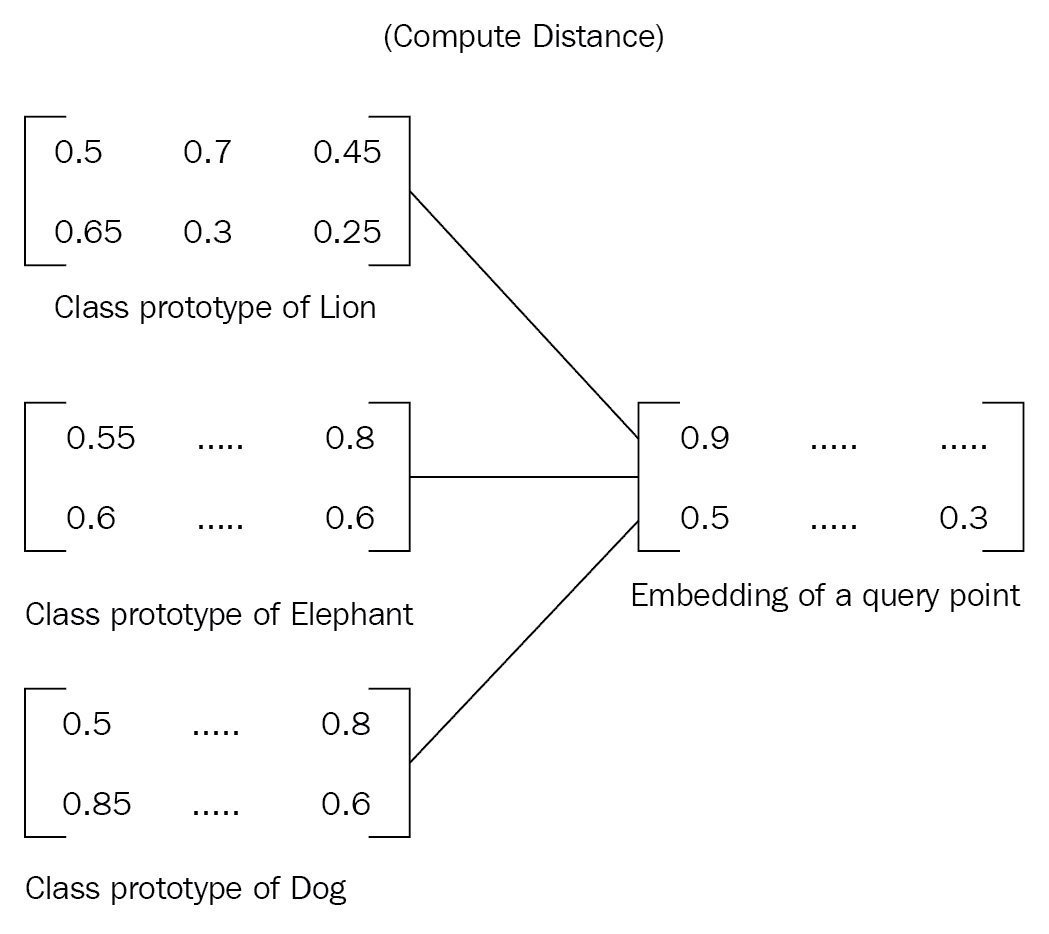
在找到类原型与查询点嵌入之间的距离后,我们将 softmax 应用于该距离并获得概率。 由于我们有狮子,大象和狗这三个类,因此我们将获得三个概率。 因此,概率最高的类别将是我们查询点的类别。
由于我们希望网络从几个数据点中学习,也就是说,我们希望执行几次快照学习,因此我们以相同的方式训练网络。 因此,我们使用了间歇式训练-对于每个剧集,我们从数据集中的每个类随机采样一些数据点,我们称其为支持集,仅使用支持集而不是整个数据集来训练网络。 同样,我们从数据集中随机抽取一个点作为查询点,并尝试预测其类别。 因此,通过这种方式,我们的网络受到了如何从较小的数据点集中学习的训练。
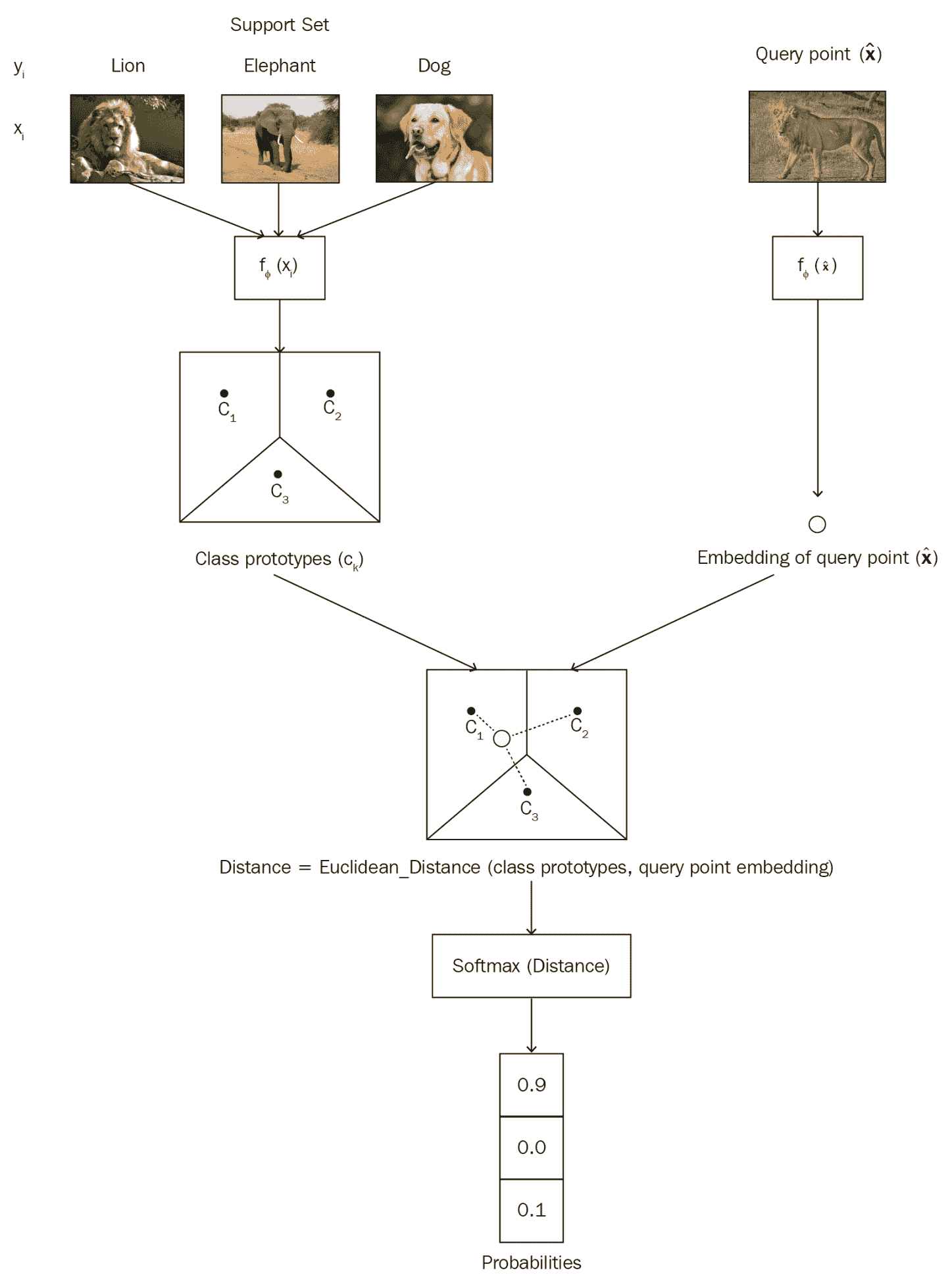
下图显示了我们原型网络的整体流程。 如您所见,首先,我们将为支持集中的所有数据点生成嵌入,并通过在类中获取数据点的平均嵌入来构建类原型。 我们还为查询点生成嵌入。 然后,我们计算类原型与查询点嵌入之间的距离。 我们使用欧几里得距离作为距离度量。 然后,我们将 softmax 应用于此距离并获得概率。 如下图所示,由于我们的查询点是狮子,因此狮子的概率很高,为 0.9:
原型网络不仅用于单样本/少样本学习,而且还用于零样本学习。 考虑以下情况:每个类没有数据点,但是您具有包含每个类的高级描述的元信息。 因此,在这些情况下,我们从每个类的元信息中学习嵌入,以形成类原型,然后使用该类原型进行分类。
算法
原型网络的算法如下所示:
- 假设我们有数据集
D,其中包含{(x1, y1), (x2, y2), ..., (xn, yn)}其中x是特征,y是类别标签。 - 由于我们进行了间歇式训练,因此我们从数据集中
D中随机抽取每个类别的n个数据点数,并准备了支持集S。 - 同样,我们选择
n个数据点,并准备我们的查询集Q。 - 我们使用嵌入函数
f[∅]来学习数据点在支持集中的嵌入。 嵌入函数可以是任何特征提取器,例如,用于图像的卷积网络和用于文本的 LSTM 网络。 - 一旦获得每个数据点的嵌入,就可以通过获取每个类下数据点的平均嵌入来计算每个类的原型:
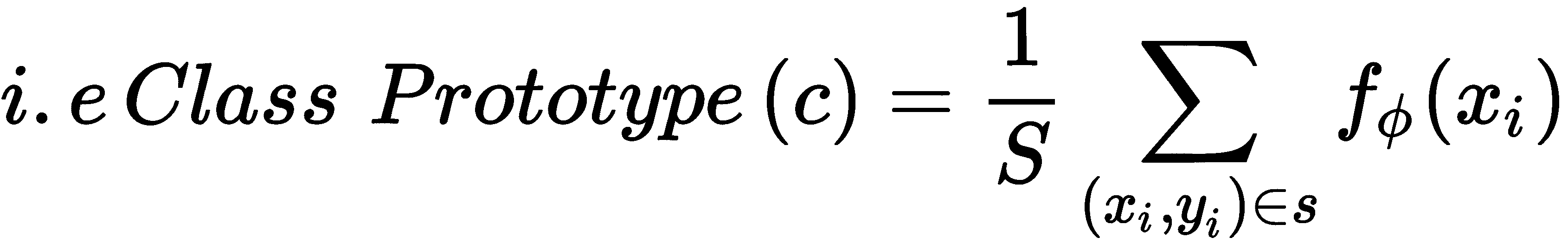
- 同样,我们学习查询集嵌入。
- 我们计算查询集嵌入和类原型之间的欧几里德距离
d。 - 我们通过在距离
d上应用 softmax 来预测查询集类别的概率p [∅](y = k | x):
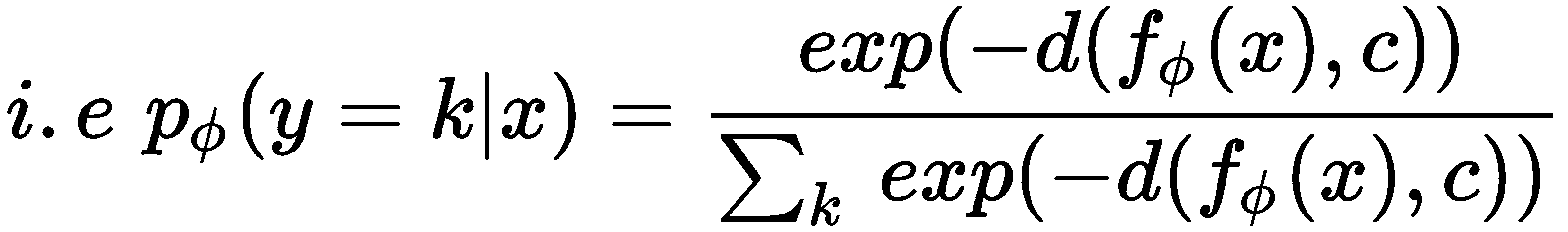
- 我们将损失函数
J(∅)计算为负对数概率J(∅) = -logp[∅](y = k | x),我们尝试使用随机梯度下降法将损失降到最低。
使用原型网络执行分类
现在,我们将看到如何使用原型网络执行分类任务。 我们使用 omniglot 数据集进行分类。 该数据集包含来自 50 个不同字母的 1,623 个手写字符,每个字符都有 20 个不同的示例,这些示例是由不同的人编写的。 由于我们希望我们的网络从数据中学习,因此我们以相同的方式对其进行训练。 我们从每个类中采样五个示例,并将其用作我们的支持集。 我们使用四个卷积块作为编码器来学习支持集的嵌入,并构建类原型。 同样,我们从每个类中为我们的查询集采样五个示例,学习查询集嵌入,并通过比较查询集嵌入和类原型之间的欧式距离来预测查询集类。 让我们逐步了解它会更好地理解这一点。
您还可以在此处查看 Jupyter 笔记本中可用的代码并进行解释。
首先,我们导入所有必需的库:
import os
import glob
from PIL import Image
import numpy as np
import tensorflow as tf
现在,我们将探索并查看我们从数据中得到的结果。 众所周知,我们有不同字母的不同字符,每个字符有二十种不同的字母,由不同的人书写。 让我们绘制并检查其中的一些。
让我们从日语字母中绘制一个字符:
Image.open('dahttps://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/Japanese_(katakana)/character13/0608_01.png')
相同字母的不同变化:
Image.open('dahttps://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/Japanese_(katakana)/character13/0608_13.png')
让我们看一下梵文字母中的一个字符:
Image.open('dahttps://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/Sanskrit/character13/0863_09.png')
Image.open('dahttps://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/Sanskrit/character13/0863_13.png')
我们如何将图像转换为数组? 我们可以使用np.array将这些图像转换为数组并将其重塑为 28 x 28:
image_name = 'dahttps://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/Sanskrit/character13/0863_13.png'
alphabet, character, rotation = 'Sanskrit/character13/rot000'.split('/')
rotation = float(rotation[3:])
您可以看到如下输出:
array([[1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 0., 1., 1., 1., 1., 1., 1., 0., 1., 1., 1., 0., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], [1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1., 1.]],dtype=float32)
现在我们已经了解了数据集中的内容,我们将加载数据集:
root_dir = 'data/'
我们在/data/omniglot/splits/train.txt文件中有拆分的详细信息,该文件中的语言名称,字符号,旋转信息和/data/omniglot/data/中的图像是:
train_split_path = os.path.join(root_dir, 'splits', 'train.txt')
with open(train_split_path, 'r') as train_split:
train_classes = [line.rstrip() for line in train_split.readlines()]
我们发现类的数量如下:
#number of classes
no_of_classes = len(train_classes)
现在,我们将示例数量设置为 20,因为我们的数据集中每个类有 20 个示例,并将图像的宽度和高度设置为28 x 28:
#number of examples
num_examples = 20
#image width
img_width = 28
#image height
img_height = 28
channels = 1
接下来,我们将训练数据集的形状初始化为多个类,示例数以及图像的高度和宽度:
train_dataset = np.zeros([no_of_classes, num_examples, img_height, img_width], dtype=np.float32)
现在,我们读取所有图像,将它们转换为 NumPy 数组,并将它们的标签和值(即train_dataset = [label, values])存储在train_dataset数组中:
for label, name in enumerate(train_classes):
alphabet, character, rotation = name.split('/')
rotation = float(rotation[3:])
img_dir = os.path.join(root_dir, 'data', alphabet, character)
img_files = sorted(glob.glob(os.path.join(img_dir, '*.png')))
for index, img_file in enumerate(img_files):
values = 1\. - np.array(Image.open(img_file).rotate(rotation).resize((img_width, img_height)), np.float32, copy=False)
train_dataset[label, index] = values
训练数据的形状如下:
train_dataset.shape
(4112, 20, 28, 28)
现在我们已经加载了训练数据,我们需要为它们创建嵌入。 我们使用卷积运算生成嵌入,因为我们的输入值是图像。 因此,我们定义了一个具有 64 个过滤器的卷积块,其中批量标准化和 ReLU 作为激活函数。 接下来,我们执行最大池化操作:
def convolution_block(inputs, out_channels, name='conv'):
conv = tf.layers.conv2d(inputs, out_channels, kernel_size=3, padding='SAME')
conv = tf.contrib.layers.batch_norm(conv, updates_collections=None, decay=0.99, scale=True, center=True)
conv = tf.nn.relu(conv)
conv = tf.contrib.layers.max_pool2d(conv, 2)
return conv
现在,我们定义嵌入函数,该函数为我们提供了包含四个卷积块的嵌入:
def get_embeddings(support_set, h_dim, z_dim, reuse=False):
net = convolution_block(support_set, h_dim)
net = convolution_block(net, h_dim)
net = convolution_block(net, h_dim)
net = convolution_block(net, z_dim)
net = tf.contrib.layers.flatten(net)
return net
请记住,我们不会使用整个数据集进行训练; 由于我们使用的是单样本学习,因此我们从每个类中抽取一些数据点作为支持集,并以情景方式使用支持集训练网络。
现在,我们定义一些重要的变量-我们考虑 50 路五样本学习场景:
#number of classes
num_way = 50
#number of examples per class in a support set
num_shot = 5
#number of query points for query set
num_query = 5
#number of examples
num_examples = 20
h_dim = 64
z_dim = 64
接下来,我们为支持和查询集初始化占位符:
support_set = tf.placeholder(tf.float32, [None, None, img_height, img_width, channels])
query_set = tf.placeholder(tf.float32, [None, None, img_height, img_width, channels])
并且我们分别在support_set_shape和query_set_shape中存储支持和查询集的形状:
support_set_shape = tf.shape(support_set)
query_set_shape = tf.shape(query_set)
我们获得了用于初始化我们的支持和查询集的类数,支持集中的数据点数以及查询集中的数据点数:
num_classes, num_support_points = support_set_shape[0], support_set_shape[1]
num_query_points = query_set_shape[1]
接下来,我们为标签定义占位符:
y = tf.placeholder(tf.int64, [None, None])
#convert the label to one hot
y_one_hot = tf.one_hot(y, depth=num_classes)
现在,我们使用嵌入函数为支持集生成嵌入:
support_set_embeddings = get_embeddings(tf.reshape(support_set, [num_classes * num_support_points, img_height, img_width, channels]), h_dim, z_dim)
我们计算每个类的原型,这是该类支持集嵌入的均值向量:
embedding_dimension = tf.shape(support_set_embeddings)[-1]
class_prototype = tf.reduce_mean(tf.reshape(support_set_embeddings, [num_classes, num_support_points, embedding_dimension]), axis=1)
接下来,我们使用相同的嵌入函数来获取查询集的嵌入:
query_set_embeddings = get_embeddings(tf.reshape(query_set, [num_classes * num_query_points, img_height, img_width, channels]), h_dim, z_dim, reuse=True)
现在我们有了类原型和查询集嵌入,我们定义了一个距离函数,该距离函数为我们提供了类原型和查询集嵌入之间的距离:
def euclidean_distance(a, b):
N, D = tf.shape(a)[0], tf.shape(a)[1]
M = tf.shape(b)[0]
a = tf.tile(tf.expand_dims(a, axis=1), (1, M, 1))
b = tf.tile(tf.expand_dims(b, axis=0), (N, 1, 1))
return tf.reduce_mean(tf.square(a - b), axis=2)
我们计算类原型与查询集嵌入之间的距离:
distance = euclidean_distance(class_prototype,query_set_embeddings)
接下来,我们将每个类别的概率作为距离的 softmax:
predicted_probability = tf.reshape(tf.nn.log_softmax(-distance), [num_classes, num_query_points, -1])
然后,我们计算损失:
loss = -tf.reduce_mean(tf.reshape(tf.reduce_sum(tf.multiply(y_one_hot, predicted_probability), axis=-1), [-1]))
我们计算精度如下:
accuracy = tf.reduce_mean(tf.to_float(tf.equal(tf.argmax(predicted_probability, axis=-1), y)))
然后,我们使用 Adam 优化器将损失降到最低:
train = tf.train.AdamOptimizer().minimize(loss)
现在,我们开始 TensorFlow 会话并训练模型:
sess = tf.InteractiveSession()
init = tf.global_variables_initializer()
sess.run(init)
我们定义周期数和剧集数:
num_epochs = 20
num_episodes = 100
接下来,我们开始进行情景式训练-也就是说,对于每个剧集,我们都对数据点进行采样,构建支持和查询集,并训练模型:
for epoch in range(num_epochs):
for episode in range(num_episodes):
# select 60 classes
episodic_classes = np.random.permutation(no_of_classes)[:num_way]
support = np.zeros([num_way, num_shot, img_height, img_width], dtype=np.float32)
query = np.zeros([num_way, num_query, img_height, img_width], dtype=np.float32)
for index, class_ in enumerate(episodic_classes):
selected = np.random.permutation(num_examples)[:num_shot + num_query]
support[index] = train_dataset[class_, selected[:num_shot]]
# 5 querypoints per classs
query[index] = train_dataset[class_, selected[num_shot:]]
support = np.expand_dims(support, axis=-1)
query = np.expand_dims(query, axis=-1)
labels = np.tile(np.arange(num_way)[:, np.newaxis], (1, num_query)).astype(np.uint8)
_, loss_, accuracy_ = sess.run([train, loss, accuracy], feed_dict={support_set: support, query_set: query, y:labels})
if (episode+1) % 20 == 0:
print('Epoch {} : Episode {} : Loss: {}, Accuracy: {}'.format(epoch+1, episode+1, loss_, accuracy_))
高斯原型网络
现在,我们将研究一种原型网络的变体,称为高斯原型网络。 我们刚刚学习了原型网络如何学习数据点的嵌入以及如何通过获取每个类的均值嵌入并使用类原型进行分类来构建类原型的。
在高斯原型网络中,连同为数据点生成嵌入,我们在它们周围添加一个以高斯协方差矩阵为特征的置信区域。 拥有置信度区域有助于表征单个数据点的质量,并且在嘈杂且不太均匀的数据中很有用。
因此,在高斯原型网络中,编码器的输出将是嵌入以及协方差矩阵。 除了使用完整的协方差矩阵之外,我们还包括来自协方差矩阵的半径或对角线分量以及嵌入:
- 半径分量:如果我们使用协方差矩阵的半径分量,则我们的协方差矩阵的维数将为 1,因为半径只是一个整数。
- 对角分量:如果我们使用协方差矩阵的对角分量,则我们的协方差矩阵的维数将与嵌入矩阵的维数相同。
此外,我们使用协方差矩阵的逆矩阵来代替直接使用协方差矩阵。 我们可以使用以下任何一种方法将原始协方差矩阵转换为逆协方差矩阵。 令S_ori为协方差矩阵,S为逆协方差矩阵:
S = 1 + Softplus(S_ori)S = 1 + Sigmoid(S_ori)S = 1 + 4 * Sigmoid(S_ori)S = Bias + Scale * softplus(S_ori),其中Bias和Scale是可训练的参数
因此,编码器,以及为输入生成嵌入,还返回协方差矩阵。 我们使用协方差矩阵的对角线或半径分量。 同样,我们使用逆协方差矩阵代替直接使用协方差矩阵。
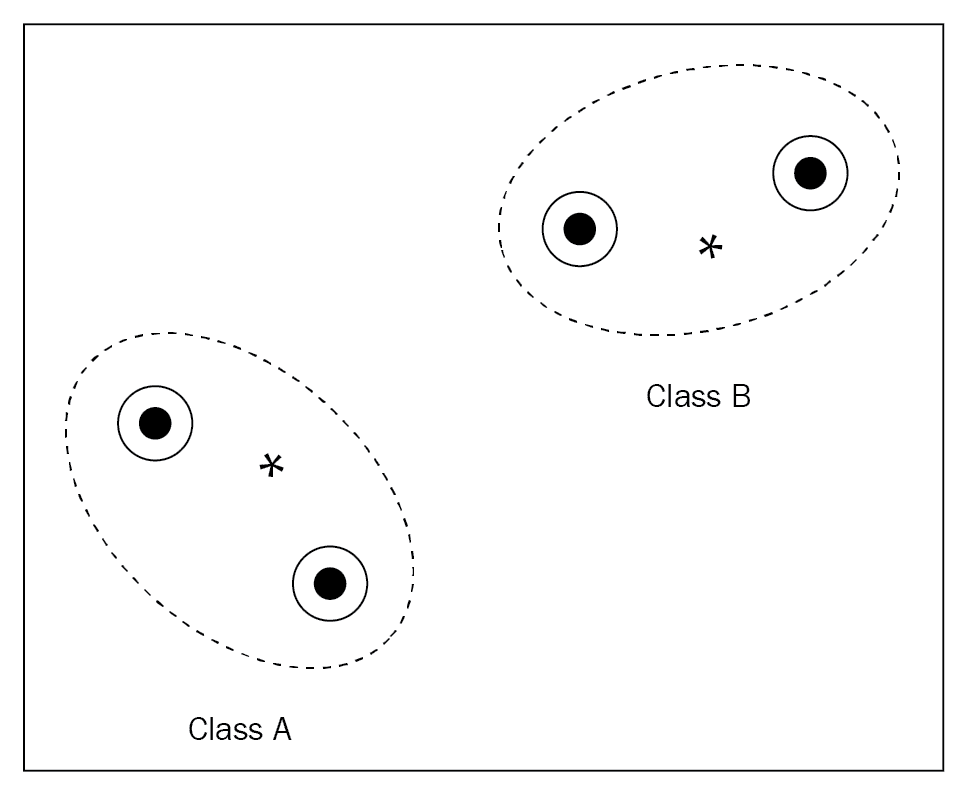
但是将协方差矩阵与嵌入一起使用有什么用? 如前所述,它在数据点周围添加了置信区域,在嘈杂的数据中非常有用。 看下图。 假设我们有两个类,A和B。 黑点表示数据点的嵌入,黑点周围的圆圈表示协方差矩阵。 大的虚线圆表示一个类的整体协方差矩阵。 中间的星星表示类的原型。 如您所见,在嵌入周围有这个协方差矩阵,这给了我们围绕数据点和类原型的置信度区域:
让我们通过查看代码更好地理解这一点。 假设我们有一个图像X,我们想为该图像生成嵌入。 让我们用 sigma 表示协方差矩阵。 首先,我们选择要使用协方差矩阵的哪个分量,即我们要使用对角分量还是半径分量。 如果我们使用半径分量,那么我们的协方差矩阵维将仅为 1。 如果我们选择对角线分量,则协方差矩阵的大小将与嵌入维数相同:
if component =='radius':
covariance_matrix_dim = 1
else:
covariance_matrix_dim = embedding_dim
现在,我们定义编码器。 由于我们的输入是图像,因此我们使用卷积块作为编码器。 因此,我们定义了过滤器的大小,过滤器的数量以及池化层的大小:
filters = [3,3,3,3]
num_filters = [64,64,64,embedding_dim +covariance_matrix_dim]
pools = [2,2,2,2]
我们将嵌入初始化为我们的图片X:
previous_channels = 1
embeddings = X
weight = []
bias = []
conv_relu = []
conv = []
conv_pooled = []
然后,我们执行卷积运算并获得嵌入:
for i in range(len(filters)):
filter_size = filters[i]
num_filter = num_filters[i]
pool = pools[i]
weight.append(tf.get_variable("weights_"+str(i), shape=[filter_size, filter_size, previous_channels, num_filter])
bias.append(tf.get_variable("bias_"+str(i), shape=[num_filter]))
conv.append(tf.nn.conv2d(embeddings, weight[i], strides=[1,1,1,1], padding='SAME') + bias[i])
conv_relu.append(tf.nn.relu(conv[i]))
conv_pooled.append(tf.nn.max_pool(conv_relu[i], ksize = [1,pool,pool,1], strides=[1,pool,pool,1], padding = "VALID"))
previous_channels = num_filter
embeddings = conv_pooled [i]
我们将最后一个卷积层的输出作为我们的嵌入,并对结果进行整形以具有嵌入以及协方差矩阵:
X_encoded = tf.reshape(embeddings,[-1,embedding_dim + covariance_matrix_dim ])
现在,我们将嵌入和原始协方差矩阵拆分,因为我们需要将原始协方差矩阵转换为逆协方差矩阵:
embeddings, raw_covariance_matrix = tf.split(X_encoded, [embedding_dim, covariance_matrix_dim], 1)
接下来,我们使用任何讨论的方法来计算协方差矩阵的逆:
if inverse_transform_type == "softplus":
offset = 1.0
scale = 1.0
inv_covariance_matrix = offset + scale * tf.nn.softplus(raw_covariance_matrix)
elif inverse_transform_type == "sigmoid":
offset = 1.0
scale = 1.0
inv_covariance_matrix = offset + scale * tf.sigmoid(raw_covariance_matrix)
elif inverse_transform_type == "sigmoid_2":
offset = 1.0
scale = 4.0
inv_covariance_matrix = offset + scale * tf.sigmoid(raw_covariance_matrix)
elif inverse_transform_type == "other":
init = tf.constant(1.0)
scale = tf.get_variable("scale", initializer=init)
div = tf.get_variable("div", initializer=init)
offset = tf.get_variable("offset", initializer=init)
inv_covariance_matrix = offset + scale * tf.nn.softplus(raw_covariance_matrix/div)
到目前为止,我们已经看到我们可以计算协方差矩阵以及输入的嵌入。 下一步是什么? 我们如何计算类原型? 类原型p[c]可以如下计算:
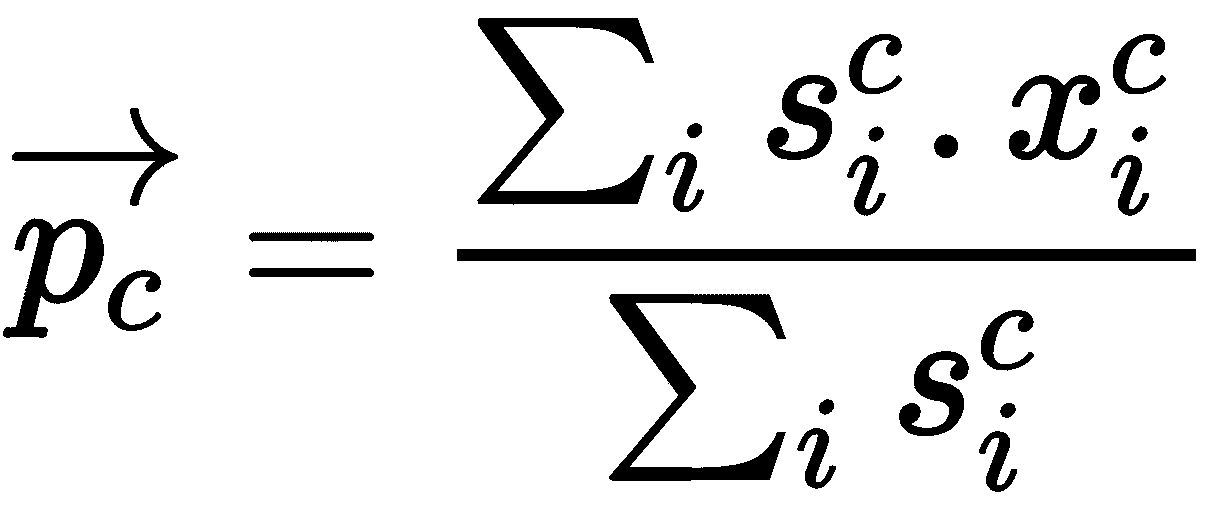
在该方程式中,s[i]^c是逆协方差矩阵的对角线,x[i]^c表示嵌入,上标c表示类别。
在为每个类计算原型之后,我们学习了查询点的嵌入。 令x'为查询点的嵌入。 然后,我们计算查询点嵌入和类原型之间的距离,如下所示:
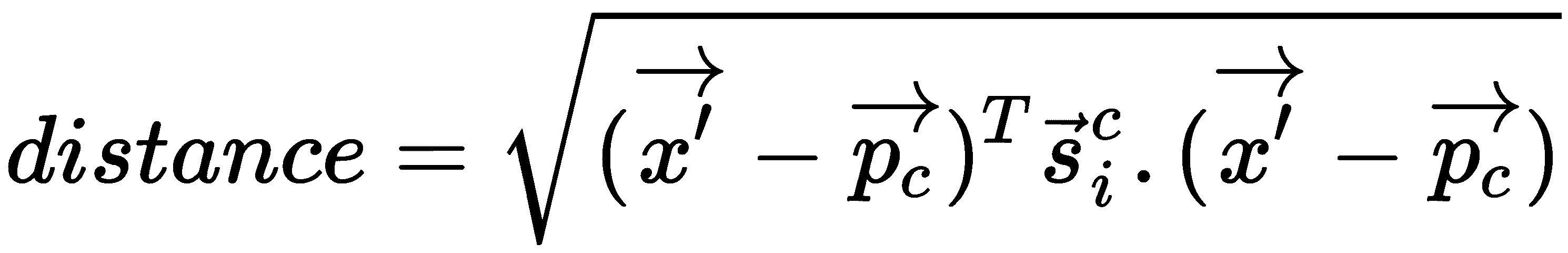
最后,我们预测查询集的类别(y_hat),该类别与类别原型的距离最小:
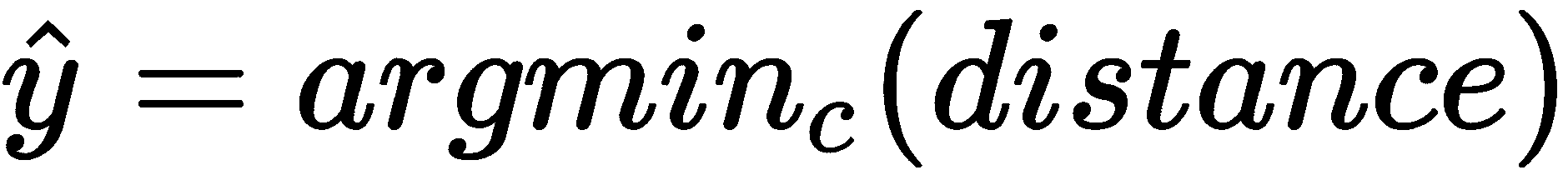
算法
现在,我们将通过逐步了解它来更好地理解高斯原型网络:
- 假设我们有一个数据集,
D = {(x1, y1), (x2, y2), ..., (xi, yi)},其中x是特征,y是标签。 假设我们有一个二进制标签,这意味着我们只有两个类,0和1。 我们将对数据点D中的每个类进行随机抽样,而不用替换它们,并创建我们的支持集S。 - 同样,我们按类随机抽取数据点,然后创建查询集
Q。 - 我们会将支持集传递给我们的嵌入函数
f()。 嵌入函数将为我们的支持集以及协方差矩阵生成嵌入。 - 我们计算协方差矩阵的逆。
- 我们如下计算支持集中每个类的原型:
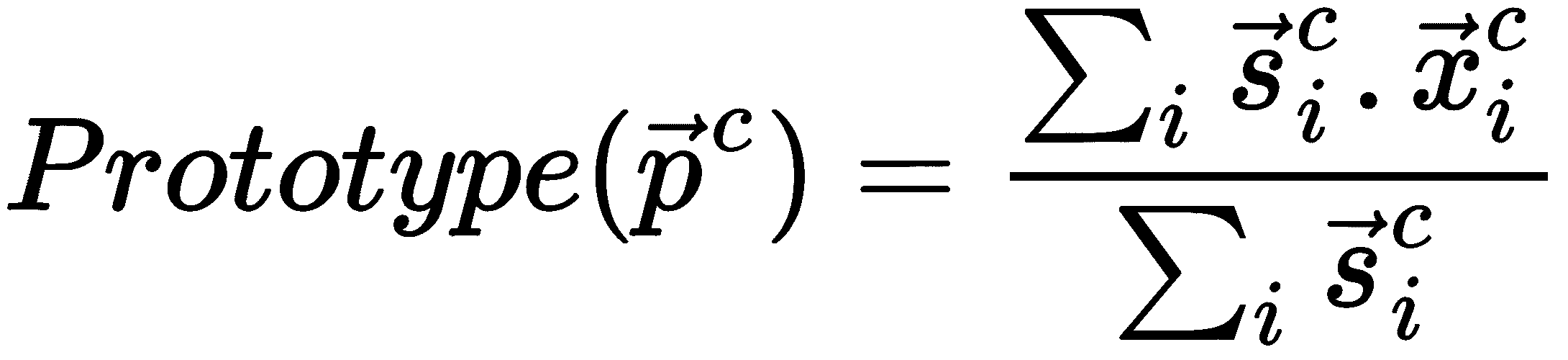
在该等式中,s[i]^c是逆协方差矩阵的对角线,x[i]^c表示支持集的嵌入,上标c表示类别。
- 在计算支持集中每个类的原型之后,我们学习了查询集
Q的嵌入。 假设x'是查询点的嵌入。 - 我们计算查询点嵌入与类原型的距离,如下所示:
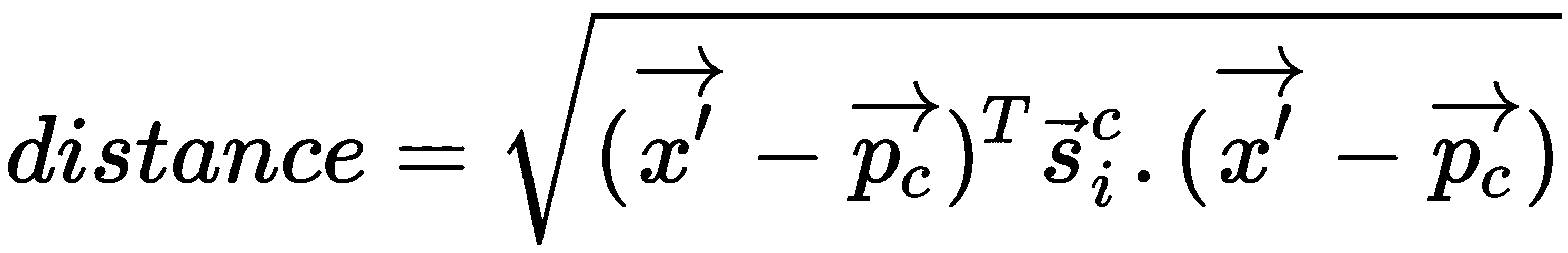
- 在计算出类原型与查询集嵌入之间的距离之后,我们将查询集的类预测为具有最小距离的类,如下所示:
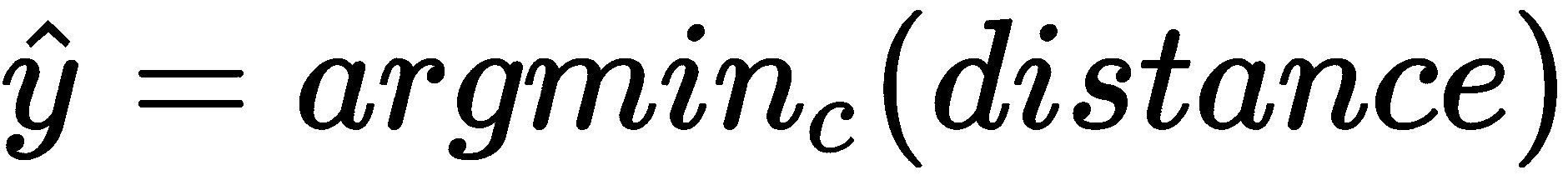
半原型网络
现在,我们将看到原型网络的另一个有趣的变体,即半原型网络。 它处理未标记的示例。 众所周知,在原型网络中,我们通过获取每个类的均值嵌入来计算每个类的原型,然后通过查找查询点与类原型之间的距离来预测查询集的类。
考虑一下我们的数据集包含一些未标记数据点的情况:我们如何计算这些未标记数据点的类原型?
假设我们有一个支持集S = (x1, y1), (x2, y2), ..., (xk, yk),其中x是特征,y是标签,还有一个查询集Q = (x1', y1'), (x2', y2'), ..., (xk', yk')。 伴随着这些,我们还有另外一个称为未标记集R的集合,在这里,我们只有未标记的例子R = (x_tilde1, y_tilde1), (x_tilde2, y_tilde2), ..., (x_tildek, y_tildek)。
那么,我们该如何处理这个未标记的集呢?
首先,我们将使用支持集中给出的所有示例来计算类原型。 接下来,我们使用软 k 均值并为R中的未标记示例分配类别-也就是说,我们通过计算类原型之间的欧式距离来为R中的未标记示例分配类别。
但是,这种方法的问题在于,由于我们使用的是软 k 均值,因此所有未标记的示例将属于任何类原型。 让我们说,我们的支持集中有三个类别,{Lion, Eleph, Dog}; 如果我们的未标记示例具有代表猫的数据点,则将猫放置在支持集中的任何类别中是没有意义的。 因此,我们没有将数据点添加到现有的类中,而是为未标记的示例分配了一个新类,称为Distractor类。
但是即使采用这种方法,我们也会遇到另一个问题,因为干扰项类别本身将具有很大的差异。 例如,考虑我们的未标记集合R包含完全不相关的数据点,例如{cats, helicopter, bus, others}; 在这种情况下,建议不要将所有未标记的示例都放在一个称为“干扰项”的类中,因为它们已经不纯且彼此无关。
因此,我们将分心器类重塑为示例,这些示例不在所有类原型的某个阈值距离之内。 我们如何计算该阈值? 首先,我们计算所有类原型的未标记集合R中未标记示例之间的标准化距离。 接下来,我们通过将归一化距离的各种统计数据(例如最小,最大,偏度和峰度)输入神经网络来计算每个类原型的阈值。 基于此阈值,我们向类原型添加或忽略未标记的示例。
总结
在本章中,我们从原型网络开始,我们了解了原型网络如何使用嵌入函数计算类原型,并通过比较类原型和查询集嵌入之间的欧几里得距离来预测查询集的类标签。 之后,我们通过对 omniglot 数据集进行分类,对原型网络进行了实验。 然后,我们了解了高斯原型网络,该网络与嵌入一起还使用协方差矩阵来计算类原型。 之后,我们探索了半原型网络,该网络用于处理半监督类。 在下一章中,我们将学习关系和匹配网络。
问题
- 什么是原型网络?
- 计算嵌入有什么用?
- 我们如何计算类原型?
- 什么是高斯原型网络?
- 高斯原型网络与普通网络有何不同?
- 高斯原型网络中使用的协方差矩阵的不同成分是什么?
进一步阅读
四、使用 TensorFlow 的关系和匹配网络
在上一章中,我们了解了原型网络,以及如何将原型网络的变体(例如高斯原型网络和半原型网络)用于单样本学习。 我们已经看到原型网络如何利用嵌入来执行分类任务。
在本章中,我们将学习关系网络和匹配网络。 首先,我们将了解什么是关系网络以及如何在单样本,少样本和零样本学习设置中使用它,然后,我们将学习如何使用 TensorFlow 建立关系网络。 在本章的后面,我们将学习匹配网络以及如何在少样本学习中使用它们。 我们还将看到在匹配网络中使用的不同类型的嵌入函数。 在本章的最后,我们将看到如何在 Tensorflow 中构建匹配的网络。
在本章中,我们将学习以下内容:
- 关系网络
- 单样本,少样本和零样本设置的关系网络
- 使用 TensorFlow 建立关系网络
- 匹配网络
- 匹配网络的嵌入函数
- 匹配网络的架构
- TensorFlow 中的匹配网络
关系网络
现在,我们将看到另一种有趣的单样本学习算法,称为关系网络。 它是最简单,最有效的单发学习算法之一。 我们将探讨在单发,少发和零发学习设置中如何使用关系网络。
单样本学习中的关系网络
关系网络由两个重要函数组成:以f[φ]表示的嵌入函数和以g[φ]表示的关系函数。 嵌入函数用于从输入中提取特征。 如果输入是图像,则可以使用卷积网络作为嵌入函数,这将为我们提供图像的特征向量/嵌入。 如果我们的输入是文本,那么我们可以使用 LSTM 网络获取文本的嵌入。
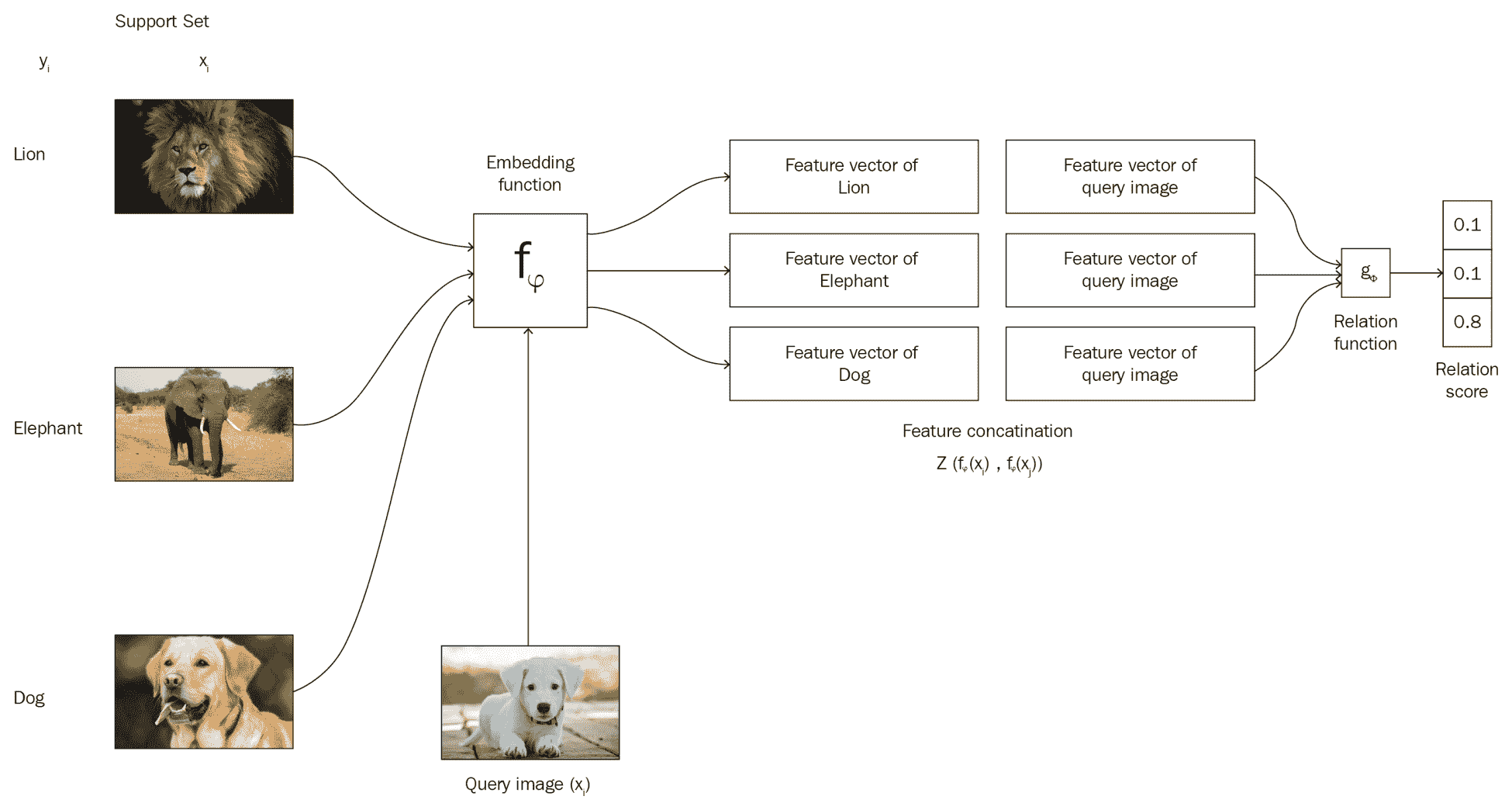
众所周知,在单样本学习中,每个类只有一个示例。 例如,假设我们的支持集包含三个类,每个类一个示例。 如下图所示,我们有一个包含三个类别的支持集,{Lion, Eleph, Dog}:
假设我们有一个查询图像x[j],如下图所示,我们希望预测该查询图像的类:

首先,我们从支持集中获取每个图像x[i],并将其传递给嵌入函数f[φ](x[i]),以提取特征。 由于我们的支持集包含图像,因此我们可以使用卷积网络作为我们的嵌入函数来学习嵌入。 嵌入函数将为我们提供支持集中每个数据点的特征向量。 类似地,我们将把查询图像x[j]传递给嵌入函数f[φ](x[j])来学习其嵌入。
因此,一旦有了支持集f[φ](x[i])和查询集f[φ](x[j])的特征向量,就可以使用运算符Z组合它们。 Z可以是任何组合运算符; 我们使用连接作为运算符,以合并支持和查询集的特征向量,即Z(f[φ](x[i]), f[φ](x[j]))。
如下图所示,我们将合并支持集f[φ](x[i])和查询集f[φ](x[j])的特征向量。 但是这样的组合有什么用呢? 这将帮助我们理解支持集中图像的特征向量与查询图像的特征向量之间的关系。 在我们的示例中,它将帮助我们理解狮子,大象和狗的图像的特征向量与查询图像的特征向量之间的关系:

但是我们如何衡量这种关联性呢? 这就是为什么我们使用关系函数g[φ]的原因。 我们将这些组合的特征向量传递给关系函数,该函数将生成从 0 到 1 的关系得分,代表支持集x[i]中的样本与查询集x[j]中的样本之间的相似性。
以下等式说明了我们如何计算关系网络中的关系得分:
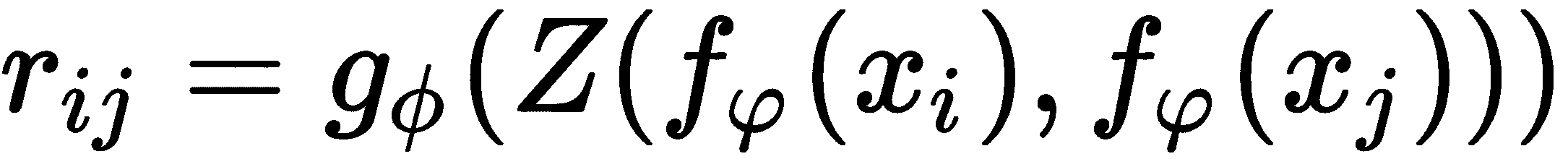
在该等式中,r[ij]表示表示在支持集中的每个类别和查询图像之间的相似性的关系分数。 由于我们在支持集中有 3 个类别,在查询集中有 1 个图像,因此我们将获得 3 个分数,表明支持集中的所有 3 个类别与查询图像的相似程度。
下图显示了在单样本学习设置中关系网络的整体表示:
少样本学习中的关系网络
我们已经看到了如何拍摄属于支持集中每个类别的单个图像,并在关系网络的单样本学习设置中将它们与查询集中图像的关系进行比较。 但是,在少样本学习设置中,每个类将有多个数据点。 我们如何使用嵌入函数在此处学习特征表示?
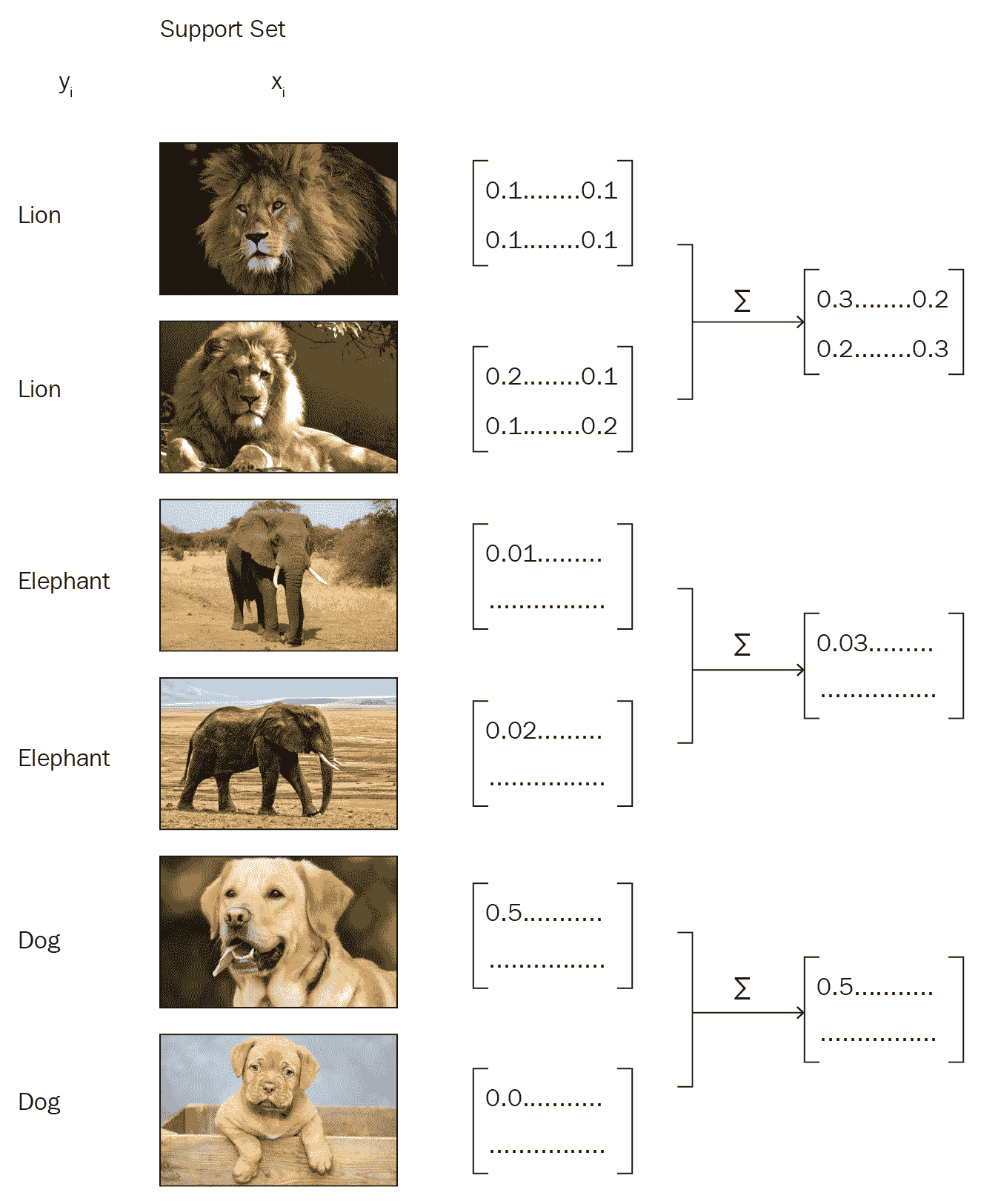
假设我们有一个支持集,每个类包含一个以上的图像,如下图所示:

在这种情况下,我们将学习支持集中每个点的嵌入,并对属于每个类的所有数据点进行元素逐级添加。 因此,我们将为每个类都有嵌入,这是该类中所有数据点的逐元素求和的嵌入:
我们可以像往常一样使用嵌入函数来提取查询图像的特征向量。 接下来,我们使用连接运算符Z组合支持和查询集的特征向量。 我们执行级联,然后将级联的特征向量输入到关系函数并获得关系得分,该关系得分表示支持集和查询集中每个类之间的相似性。
下图显示了关系网络在少样本学习设置中的整体表示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GQUWTBsg-1681653478840)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/61827802-face-4bba-9b33-1a79c5d2deaf.png)]
零样本学习中的关系网络
既然我们已经了解了如何在单发和少发学习任务中使用关系网络,我们将看到如何在零发学习设置中使用关系网络,在这种情况下,每个类别下都没有任何数据点。 但是,在零射击学习中,我们将具有元信息,该元信息是有关每个类的属性的信息,并将被编码到语义向量v[c]中,其中下标c表示类。
我们没有使用单个嵌入函数来学习支持和查询集的嵌入,而是分别使用了两个不同的嵌入函数f[φ1]和f[φ2]。 首先,我们将使用f[φ1]学习语义向量v[c]的嵌入,并使用f[φ2]学习查询集x[j]的嵌入。 现在,我们将使用连接操作Z来连接这些嵌入:
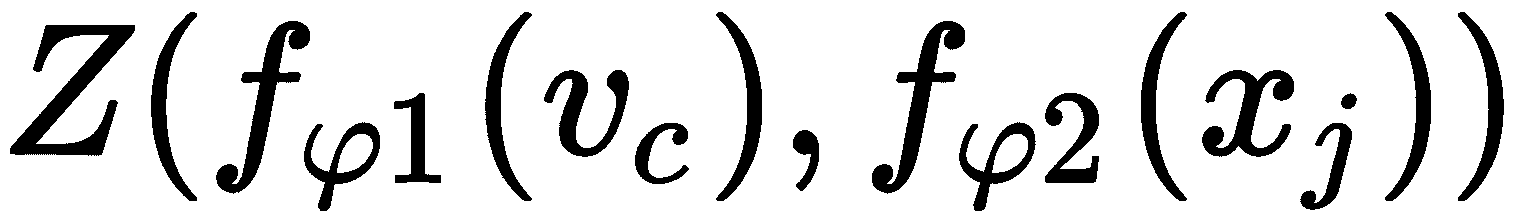
然后,我们将此结果馈入关联函数并计算关联分数,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bb8TAct5-1681653478840)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/79ed7a01-bf4f-447a-b3a6-adc736e08ec7.png)]
损失函数
关系网络的损失函数是什么? 我们将使用均方误差(MSE)作为损失函数。 尽管这是一个分类问题,而 MSE 并不是分类问题的标准度量,但关系网络的作者表示,由于我们正在预测关系得分,因此可以将其视为回归问题。 尽管如此,对于基本事实,我们只能自动生成{0, 1}目标。
因此,我们的损失函数可以表示为:
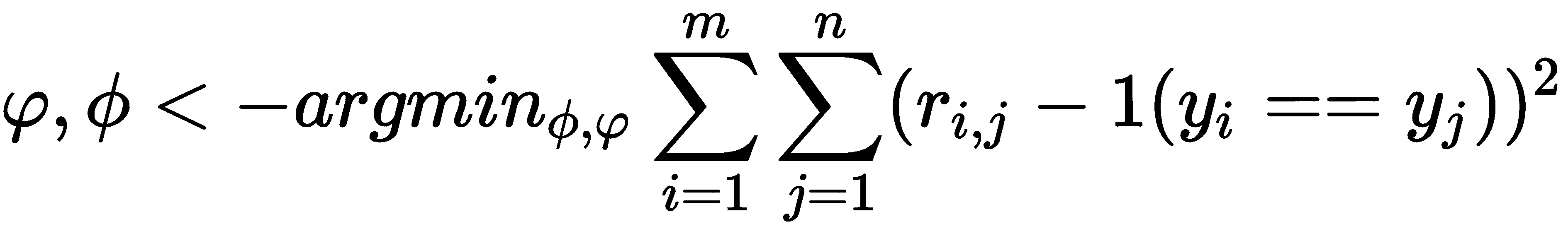
其中φ, φ分别是我们嵌入函数f和关联函数g的参数。
使用 TensorFlow 建立关系网络
关系函数非常简单,对吧? 通过在 TensorFlow 中实现一个关系网络,我们将更好地理解关系网络。
您还可以在此处查看 Jupyter 笔记本中可用的代码并进行解释。
首先,我们导入所有必需的库:
import tensorflow as tf
import numpy as np
我们将随机生成数据点。 假设我们的数据集中有两个类; 我们将为这些类别中的每一个随机生成约 1,000 个数据点:
classA = np.random.rand(1000,18)
ClassB = np.random.rand(1000,18)
我们通过结合以下两个类来创建数据集:
data = np.vstack([classA, ClassB])
现在,我们设置标签; 我们为classA分配1标签,为classB分配0标签:
label = np.vstack([np.ones((len(classA),1)),np.zeros((len(ClassB),1))])
因此,我们的数据集将有 2,000 条记录:
data.shape
(2000, 18)
现在,我们将为支持和查询集定义占位符:
xi = tf.placeholder(tf.float32, [None, 9])
xj = tf.placeholder(tf.float32, [None, 9])
定义y标签的占位符,如下所示:
y = tf.placeholder(tf.float32, [None, 1])
现在,我们将定义我们的嵌入函数,该函数将学习支持和查询集的嵌入。 我们将使用普通的前馈网络作为嵌入函数:
def embedding_function(x):
weights = tf.Variable(tf.truncated_normal([9,1]))
bias = tf.Variable(tf.truncated_normal([1]))
a = (tf.nn.xw_plus_b(x,weights,bias))
embeddings = tf.nn.relu(a)
return embeddings
我们计算支持集的嵌入量:
f_xi = embedding_function(xi)
我们计算查询集的嵌入量:
f_xj = embedding_function(xj)
现在我们已经计算了嵌入并有了特征向量,我们将支持集和查询集特征向量结合起来:
Z = tf.concat([f_xi,f_xj],axis=1)
我们将关系函数定义为具有 ReLU 激活的三层神经网络:
def relation_function(x):
w1 = tf.Variable(tf.truncated_normal([2,3]))
b1 = tf.Variable(tf.truncated_normal([3]))
w2 = tf.Variable(tf.truncated_normal([3,5]))
b2 = tf.Variable(tf.truncated_normal([5]))
w3 = tf.Variable(tf.truncated_normal([5,1]))
b3 = tf.Variable(tf.truncated_normal([1]))
#layer1
z1 = (tf.nn.xw_plus_b(x,w1,b1))
a1 = tf.nn.relu(z1)
#layer2
z2 = tf.nn.xw_plus_b(a1,w2,b2)
a2 = tf.nn.relu(z2)
#layer3
z3 = tf.nn.xw_plus_b(z2,w3,b3)
#output
y = tf.nn.sigmoid(z3)
return y
现在,我们将支持集和查询集的连接特征向量传递给关系函数,并获得关系得分:
relation_scores = relation_function(Z)
我们将loss_function计算为 MSE,即relation_scores与实际y值之间的squared_difference:
loss_function = tf.reduce_mean(tf.squared_difference(relation_scores,y))
我们可以使用AdamOptimizer将损失降到最低:
optimizer = tf.train.AdamOptimizer(0.1)
train = optimizer.minimize(loss_function)
现在,让我们开始 TensorFlow 会话:
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
现在,我们随机抽取支持集xi和查询集xj的数据点,并训练网络:
for episode in range(1000):
_, loss_value = sess.run([train, loss_function],
feed_dict={xi:data[:,0:9]+np.random.randn(*np.shape(data[:,0:9]))*0.05,
xj:data[:,9:]+np.random.randn(*np.shape(data[:,9:]))*0.05,
y:label})
if episode % 100 == 0:
print("Episode {}: loss {:.3f} ".format(episode, loss_value))
我们可以看到如下输出:
Episode 0: loss 0.495
Episode 100: loss 0.250
Episode 200: loss 0.250
Episode 300: loss 0.250
Episode 400: loss 0.250
Episode 500: loss 0.250
Episode 600: loss 0.250
Episode 700: loss 0.250
Episode 800: loss 0.250
Episode 900: loss 0.250
匹配网络
匹配网络是 Google 的 DeepMind 团队发布的另一种简单高效的单样本学习算法。 它甚至可以为数据集中未观察到的类生成标签。
假设我们有一个支持集S,其中包含K示例作为(x1, y1), (x2, y2), ..., (xk, yk)。 给定查询点(一个新的看不见的示例)x_hat时,匹配网络通过将其与支持集进行比较来预测x_hat的类别。
我们可以将其定义为P(y_hat | x_hat, S),其中P是参数化神经网络,y_hat是查询点的预测类,x_hat和S是支持集。 P(y_hat | x_hat, S)将返回x_hat属于数据集中每个类别的概率。 然后,我们选择x_hat的类别作为可能性最高的类别。 但是,这到底如何工作? 如何计算此概率? 让我们现在看看。
查询点x_hat的输出y_hat可以预测如下:
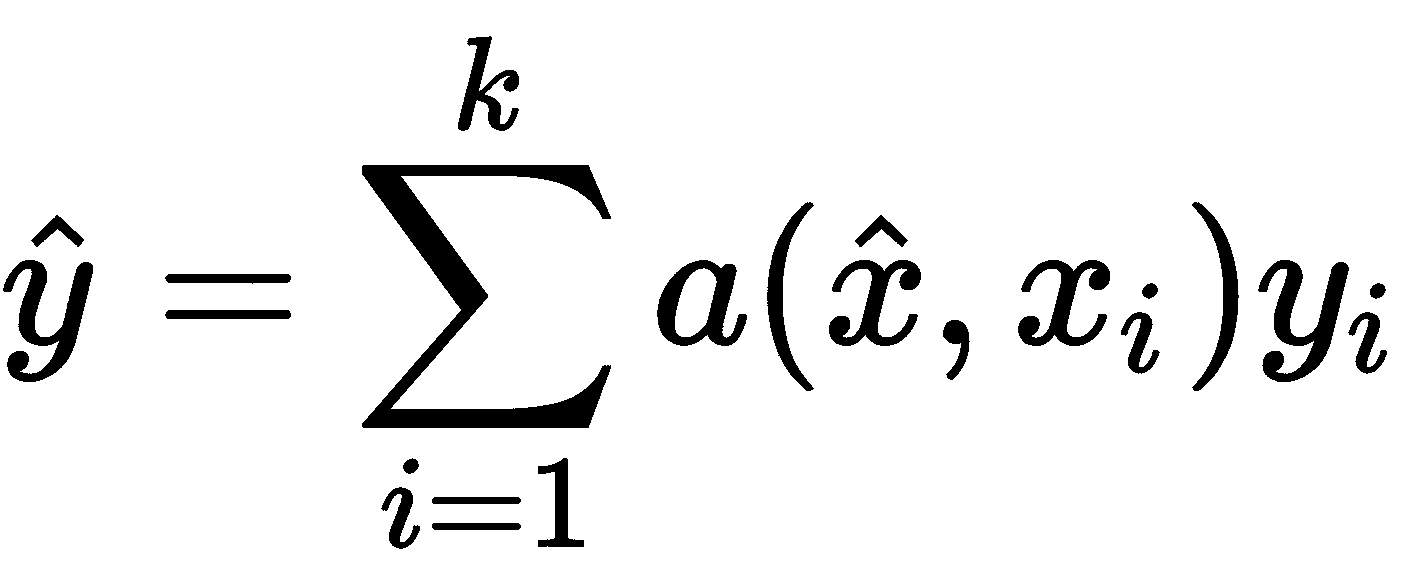
让我们破译这个方程式。 x[i]和y[i]是支持集的输入和标签。 x_hat是查询输入,即我们要预测标签的输入。 a是x_hat和x[i]之间的注意力机制。 但是,我们该如何进行关注呢? 在这里,我们使用一种简单的注意机制,即x_hat和x[i]之间的余弦距离上的 softmax 函数(即a(·, ·) = softmax(cosine(·, ·)))。
我们无法直接计算原始输入x_hat和x[i]之间的余弦距离。 因此,首先,我们将学习它们的嵌入并计算嵌入之间的余弦距离。 我们使用两种不同的嵌入f和g来分别学习查询输入x_hat和支持集输入x[i]的嵌入。 我们将在接下来的部分中详细了解f和g这两个嵌入函数。
因此,我们可以如下重写注意力方程:
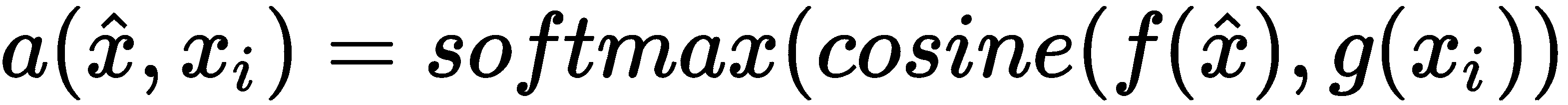
我们可以将前面的等式重写如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ro6E3Vub-1681653478841)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/fd6aef37-dfe5-45f4-87a3-799cfd6e7c43.png)]
因此,在计算注意力矩阵a(x_hat, x[i])之后,我们将注意力矩阵与支持集标签y[i]相乘。 但是,如何将支持集标签与注意力矩阵相乘呢? 首先,我们将支持集标签转换为单热编码值,然后将它们与我们的注意力矩阵相乘,结果,我们获得了y_hat属于支持集中每个类的概率。 然后,我们应用 argmax 并选择y_hat作为具有最大概率值的那个。
您是否还不清楚匹配网络? 看下图; 如您所见,我们的支持集中有 3 个类,即{Lion, Eleph, Dog},还有一个新的查询图像x_hat。 首先,将支持集提供给嵌入函数g,将查询图像提供给嵌入函数f,然后学习它们的嵌入并计算它们之间的余弦距离; 然后,我们在这个余弦距离上施加 softmax 注意。 然后,将注意力矩阵与一键编码支持集标签相乘,得到概率,然后选择y_hat作为概率最高的那个。 如下图所示,查询集图像是一头大象,我们在索引 1 处的概率很高,因此我们将y_hat的类别预测为 1(大象):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PxkAlsR1-1681653478841)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/92322e5f-a6ae-42d2-b3e4-6d4820b5dde8.png)]
嵌入函数
我们了解到,我们使用两个嵌入函数f和g分别学习x_hat和y_hat的嵌入。 现在,我们将确切地看到这两个函数如何学习嵌入。
支持集嵌入函数(g)
我们使用嵌入函数g来学习支持集的嵌入。 我们使用双向 LSTM 作为我们的嵌入函数g。
我们可以如下定义嵌入函数g:
def g(X):
#forward cell
forward_cell = rnn.BasicLSTMCell(32)
#backward cell
backward_cell = rnn.BasicLSTMCell(32)
#bidirectional LSTM
outputs, state_forward, state_backward = rnn.static_bidirectional_rnn(forward_cell, backward_cell, X, dtype=tf.float32)
return tf.add(tf.stack(X), tf.stack(outputs))
查询集嵌入函数(f)
我们使用嵌入函数f来学习查询点x_hat的嵌入。 我们使用 LSTM 作为编码函数。 与x_hat作为输入一起,我们还将传递支持集嵌入的嵌入g(x),还将传递另一个名为K的参数,该参数定义了处理步骤的数量。 让我们逐步了解如何计算查询集嵌入。
首先,我们将初始化 LSTM 单元:
cell = rnn.BasicLSTMCell(64)
previous_state = cell.zero_state(batch_size, tf.float32)
然后,对于处理步骤数,我们执行以下操作:
for step in xrange(K):
我们通过将查询集x_hat馈送到 LSTM 单元来计算其嵌入:
output, state = cell(XHat, previous_state)
h_k = tf.add(output, XHat)
现在,我们对支持集嵌入(即g_embedings)执行 softmax 注意。 它可以帮助我们避免不必要的元素:
content_based_attention = tf.nn.softmax(tf.multiply(previous_state[1], g_embedding))
r_k = tf.reduce_sum(tf.multiply(content_based_attention, g_embedding), axis=0)
我们更新previous_state,并在许多处理步骤K中重复这些步骤:
previous_state = rnn.LSTMStateTuple(state[0], tf.add(h_k, r_k))
计算f_embeddings的完整代码如下:
def f(XHat, g_embedding, K):
cell = rnn.BasicLSTMCell(64)
previous_state = cell.zero_state(batch_size, tf.float32)
for step in xrange(K):
output, state = cell(XHat, previous_state)
h_k = tf.add(output, XHat)
#Soft max attention
content_based_attention = tf.nn.softmax(tf.multiply(previous_state[1], g_embedding))
r_k = tf.reduce_sum(tf.multiply(content_based_attention, g_embedding), axis=0)
previous_state = rnn.LSTMStateTuple(state[0], tf.add(h_k, r_k))
return output
匹配网络的架构
下图显示了匹配网络的整体流程,它与我们已经看到的图像不同。 您会注意到如何分别通过嵌入函数g和f计算支持集x[i]和查询集y[i]。 如您所见,嵌入函数f将查询集以及支持集嵌入作为输入:
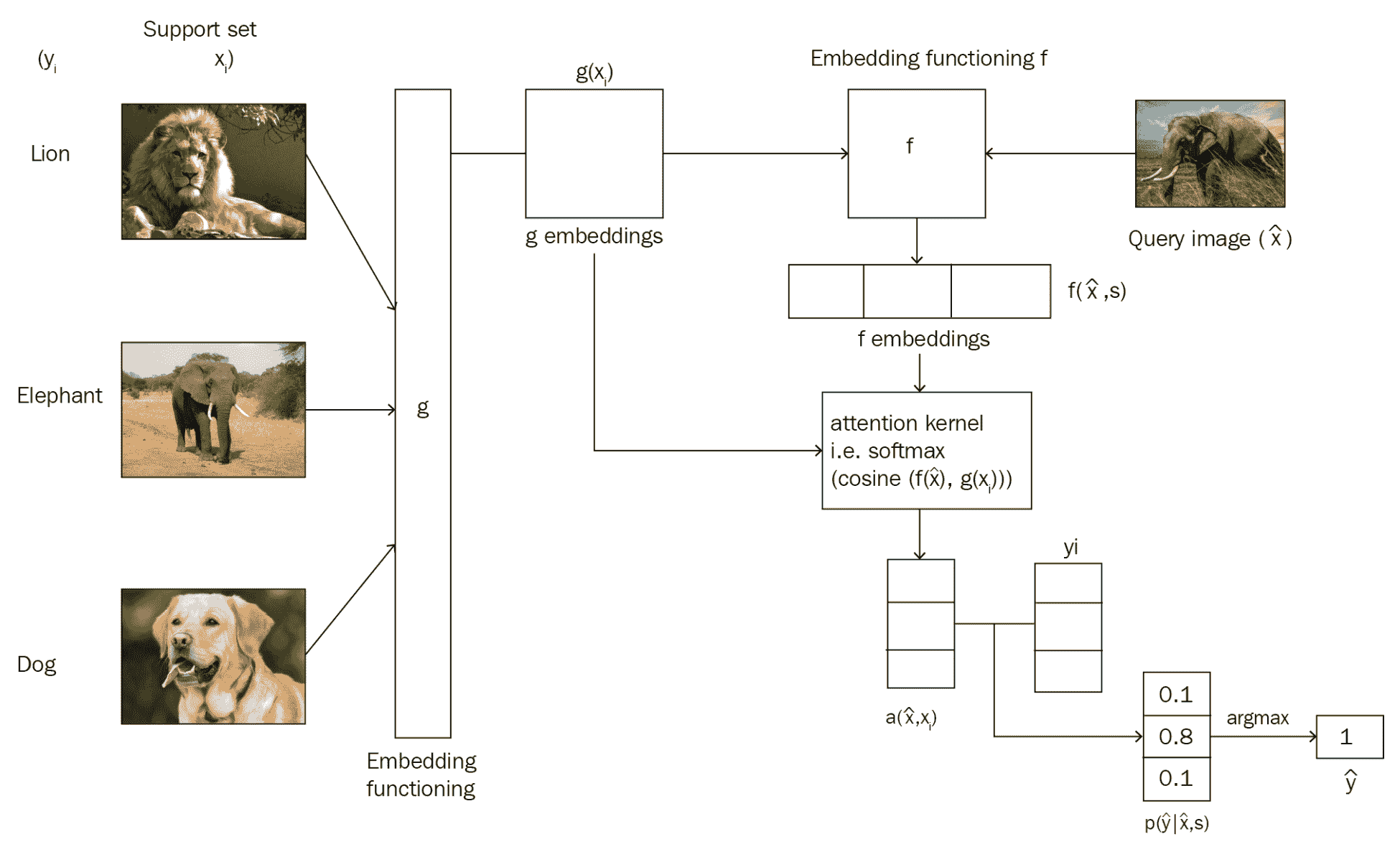
TensorFlow 中的匹配网络
现在,我们将逐步了解如何在 TensorFlow 中构建匹配的网络。 我们将在最后看到最终代码。
首先,我们导入库:
import tensorflow as tf
slim = tf.contrib.slim
rnn = tf.contrib.rnn
现在,我们定义一个名为Matching_network的类,在其中定义我们的网络:
class Matching_network():
我们定义__init__方法,在其中初始化所有变量:
def __init__(self, lr, n_way, k_shot, batch_size=32):
#placeholder for support set
self.support_set_image = tf.placeholder(tf.float32, [None, n_way * k_shot, 28, 28, 1])
self.support_set_label = tf.placeholder(tf.int32, [None, n_way * k_shot, ])
#placeholder for query set
self.query_image = tf.placeholder(tf.float32, [None, 28, 28, 1])
self.query_label = tf.placeholder(tf.int32, [None, ])
假设我们的支持集和查询集包含图片。 在将此原始图像提供给嵌入函数之前,首先,我们将使用卷积网络从图像中提取特征,然后将支持集和查询集的提取特征提供给嵌入函数g和f。
因此,我们将定义一个名为image_encoder的函数,该函数用于对图像中的特征进行编码。 我们使用具有最大池化操作的四层卷积网络作为图像编码器:
def image_encoder(self, image):
with slim.arg_scope([slim.conv2d], num_outputs=64, kernel_size=3, normalizer_fn=slim.batch_norm):
#conv1
net = slim.conv2d(image)
net = slim.max_pool2d(net, [2, 2])
#conv2
net = slim.conv2d(net)
net = slim.max_pool2d(net, [2, 2])
#conv3
net = slim.conv2d(net)
net = slim.max_pool2d(net, [2, 2])
#conv4
net = slim.conv2d(net)
net = slim.max_pool2d(net, [2, 2])
return tf.reshape(net, [-1, 1 * 1 * 64])
现在,我们定义嵌入函数; 我们已经看到在“嵌入函数”部分中如何定义嵌入函数f和g。 因此,我们可以直接定义它们如下:
#embedding function for extracting support set embeddings
def g(self, x_i):
forward_cell = rnn.BasicLSTMCell(32)
backward_cell = rnn.BasicLSTMCell(32)
outputs, state_forward, state_backward = rnn.static_bidirectional_rnn(forward_cell, backward_cell, x_i, dtype=tf.float32)
return tf.add(tf.stack(x_i), tf.stack(outputs))
#embedding function for extracting query set embeddings
def f(self, XHat, g_embedding):
cell = rnn.BasicLSTMCell(64)
prev_state = cell.zero_state(self.batch_size, tf.float32)
for step in xrange(self.processing_steps):
output, state = cell(XHat, prev_state)
h_k = tf.add(output, XHat)
content_based_attention = tf.nn.softmax(tf.multiply(prev_state[1], g_embedding))
r_k = tf.reduce_sum(tf.multiply(content_based_attention, g_embedding), axis=0)
prev_state = rnn.LSTMStateTuple(state[0], tf.add(h_k, r_k))
return output
现在,我们定义一个名为cosine_similarity的函数,用于学习支持集和查询集嵌入之间的余弦相似度:
def cosine_similarity(self, target, support_set):
target_normed = target
sup_similarity = []
for i in tf.unstack(support_set):
i_normed = tf.nn.l2_normalize(i, 1)
similarity = tf.matmul(tf.expand_dims(target_normed, 1), tf.expand_dims(i_normed, 2))
sup_similarity.append(similarity)
return tf.squeeze(tf.stack(sup_similarity, axis=1))
最后,我们使用一个名为train的函数来执行我们的训练操作-让我们逐步看一下:
def train(self, support_set_image, support_set_label, query_image):
首先,我们使用图像编码器对支持集图像的特征进行编码:
support_set_image_encoded = [self.image_encoder(i) for i in tf.unstack(support_set_image, axis=1)]
然后,我们还将使用图像编码器对查询集图像的特征进行编码:
query_image_encoded = self.image_encoder(query_image)
接下来,我们将使用嵌入函数g了解支持集的嵌入:
g_embedding = self.g(support_set_image_encoded)
同样,我们还将使用嵌入函数f了解查询集的嵌入内容:
f_embedding = self.f(query_image_encoded, g_embedding)
现在,我们在这两个嵌入之间计算cosine_similarity:
embeddings_similarity = self.cosine_similarity(f_embedding, g_embedding)
然后,我们对这种相似性进行 softmax 注意:
attention = tf.nn.softmax(embeddings_similarity)
我们通过将注意力矩阵乘以一热编码的支持集标签来预测查询集标签:
y_hat = tf.matmul(tf.expand_dims(attention, 1), tf.one_hot(support_set_label, self.n_way))
接下来,我们得到probabilities:
probabilities = tf.squeeze(y_hat)
我们选择概率最高的索引作为查询图像的类别:
predictions = tf.argmax(self.logits, 1)
最后,我们定义损失函数; 我们使用 softmax 交叉熵作为我们的损失函数:
loss_function = tf.losses.sparse_softmax_cross_entropy(label, self.probabilities)
我们使用AdamOptimizer最小化损失函数:
tf.train.AdamOptimizer(self.lr).minimize(self.loss_op)
现在,我们将看到整个匹配网络的最终代码:
class Matching_network():
#initialize all the variables
def __init__(self, lr, n_way, k_shot, batch_size=32):
#placeholder for support set
self.support_set_image = tf.placeholder(tf.float32, [None, n_way * k_shot, 28, 28, 1])
self.support_set_label = tf.placeholder(tf.int32, [None, n_way * k_shot, ])
#placeholder for query set
self.query_image = tf.placeholder(tf.float32, [None, 28, 28, 1])
self.query_label = tf.placeholder(tf.int32, [None, ])
#encoder function for extracting features from the image
def image_encoder(self, image):
with slim.arg_scope([slim.conv2d], num_outputs=64, kernel_size=3, normalizer_fn=slim.batch_norm):
#conv1
net = slim.conv2d(image)
net = slim.max_pool2d(net, [2, 2])
#conv2
net = slim.conv2d(net)
net = slim.max_pool2d(net, [2, 2])
#conv3
net = slim.conv2d(net)
net = slim.max_pool2d(net, [2, 2])
#conv4
net = slim.conv2d(net)
net = slim.max_pool2d(net, [2, 2])
return tf.reshape(net, [-1, 1 * 1 * 64])
#embedding function for extracting support set embeddings
def g(self, x_i):
forward_cell = rnn.BasicLSTMCell(32)
backward_cell = rnn.BasicLSTMCell(32)
outputs, state_forward, state_backward = rnn.static_bidirectional_rnn(forward_cell, backward_cell, x_i, dtype=tf.float32)
return tf.add(tf.stack(x_i), tf.stack(outputs))
#embedding function for extracting query set embeddings
def f(self, XHat, g_embedding):
cell = rnn.BasicLSTMCell(64)
prev_state = cell.zero_state(self.batch_size, tf.float32)
for step in xrange(self.processing_steps):
output, state = cell(XHat, prev_state)
h_k = tf.add(output, XHat)
content_based_attention = tf.nn.softmax(tf.multiply(prev_state[1], g_embedding))
r_k = tf.reduce_sum(tf.multiply(content_based_attention, g_embedding), axis=0)
prev_state = rnn.LSTMStateTuple(state[0], tf.add(h_k, r_k))
return output
#cosine similarity function for calculating cosine similarity between support set and query set embeddings
def cosine_similarity(self, target, support_set):
target_normed = target
sup_similarity = []
for i in tf.unstack(support_set):
i_normed = tf.nn.l2_normalize(i, 1)
similarity = tf.matmul(tf.expand_dims(target_normed, 1), tf.expand_dims(i_normed, 2))
sup_similarity.append(similarity)
return tf.squeeze(tf.stack(sup_similarity, axis=1))
def train(self, support_set_image, support_set_label, query_image):
#encode the features of query set images using our image encoder
query_image_encoded = self.image_encoder(query_image)
#encode the features of support set images using our image encoder
support_set_image_encoded = [self.image_encoder(i) for i in tf.unstack(support_set_image, axis=1)]
#generate support set embeddings using our embedding function g
g_embedding = self.g(support_set_image_encoded)
#generate query set embeddings using our embedding function f
f_embedding = self.f(query_image_encoded, g_embedding)
#calculate the cosine similarity between both of these embeddings
embeddings_similarity = self.cosine_similarity(f_embedding, g_embedding)
#perform attention over the embedding similarity
attention = tf.nn.softmax(embeddings_similarity)
#now predict query set label by multiplying attention matrix with one hot encoded support set labels
y_hat = tf.matmul(tf.expand_dims(attention, 1), tf.one_hot(support_set_label, self.n_way))
#get the probabilities
probabilities = tf.squeeze(y_hat)
#select the index which has the highest probability as a class of query image
predictions = tf.argmax(self.probabilities, 1)
#we use softmax cross entropy loss as our loss function
loss_function = tf.losses.sparse_softmax_cross_entropy(label, self.probabilities)
#we minimize the loss using adam optimizer
tf.train.AdamOptimizer(self.lr).minimize(self.loss_op)
总结
在本章中,我们学习了在少样本学习中如何使用匹配网络和关系网络。 我们看到了一个关系网络如何学习支持和查询集的嵌入,并将这些嵌入进行组合并将其馈送到关系函数以计算关系得分。 我们还看到了匹配的网络如何使用两种不同的嵌入函数来学习我们的支持集和查询集的嵌入,以及它如何预测查询集的类。
在下一章中,我们将通过存储和检索内存中的信息来学习神经图灵机和记忆增强型神经网络的工作方式。
问题
- 关系网络中使用的特征有哪些不同类型?
- 关系网络中的运算符
Z是什么? - 关系函数是什么?
- 关系网络的损失函数是什么?
- 匹配网络中使用哪些不同类型的嵌入函数?
- 如何在匹配网络中预测查询点的类别?
进一步阅读
五、记忆增强神经网络
到目前为止,在前面的章节中,我们已经学习了几种基于距离的度量学习算法。 我们从连体网络开始,了解了连体网络如何学会区分两个输入,然后我们研究了原型网络以及原型网络的变体,例如高斯原型网络和半原型网络。 展望未来,我们探索了有趣的匹配网络和关系网络。
在本章中,我们将学习用于单样本学习的记忆增强神经网络(MANN)。 在进入 MANN 之前,我们将了解他们的前身神经图灵机(NTM)。 我们将学习 NTM 如何使用外部存储器来存储和检索信息,并且还将看到如何使用 NTM 执行复制任务。
在本章中,我们将学习以下内容:
- NTM
- NTM 中的读写
- 寻址机制
- 使用 NTM 复制任务
- MANN
- MANN 中的读写
NTM
NTM 是一种有趣的算法,能够存储和检索内存中的信息。 NTM 的想法是用外部存储器来增强神经网络-也就是说,它不是使用隐藏状态作为存储器,而是使用外部存储器来存储和检索信息。 NTM 的架构如下图所示:
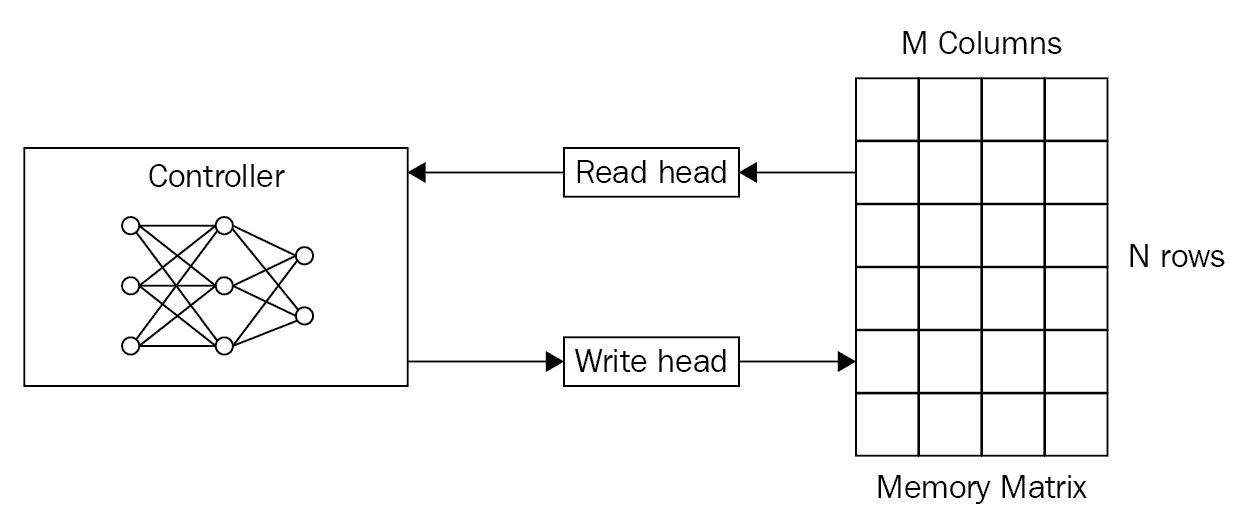
NTM 的重要组成部分如下:
- 控制器:这基本上是前馈神经网络或循环神经网络。 它从内存中读取和写入。
- 内存:我们将在其中存储信息的存储矩阵或存储库,或简称为存储。 内存基本上是由内存单元组成的二维矩阵。 存储器矩阵包含
N行和M列。 使用控制器,我们可以从内存中访问内容。 因此,控制器从外部环境接收输入,并通过与存储矩阵进行交互来发出响应。 - 读写头:读写头是包含必须从其读取和写入的存储器地址的指针。
好的,但是我们如何从内存中访问信息? 我们是否可以通过指定行索引和列索引来访问内存中的信息? 我们可以。 但是问题在于,如果我们按索引访问信息,则无法使用梯度下降来训练 NTM,因为我们无法计算索引的梯度。 因此,NTM 的作者定义了使用控制器进行读写的模糊操作。 模糊操作将在某种程度上与内存中的所有元素进行交互。 基本上,它是一种关注机制,主要关注内存中对读/写很重要的特定位置,而忽略了对其他位置的关注。 因此,我们使用特殊的读取和写入操作来确定要聚焦在存储器上的哪个位置。 我们将在接下来的部分中探索更多有关读写操作的信息。
在 NTM 中读写
现在,我们将看到如何读取和写入内存矩阵。
读取操作
读取操作从内存中读取一个值。 但是,由于我们的存储矩阵中有许多存储块,我们需要选择从存储器中读取哪一个? 这由权重向量确定。 权重向量指定内存中哪个区域比其他区域更重要。 我们使用一种注意力机制来获得该权重向量。 我们将在接下来的部分中进一步探讨如何精确计算此权重向量。 权重向量已归一化,这意味着其值的范围从零到一,并且值的总和等于一。 下图显示了长度的权重向量N:
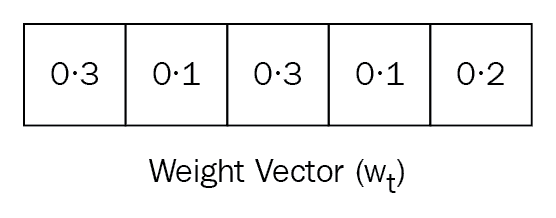
让我们用w[t]表示归一化权重向量,其中下标t表示时间,w[t](i)表示权重向量中的元素,其索引为i,和时间t:
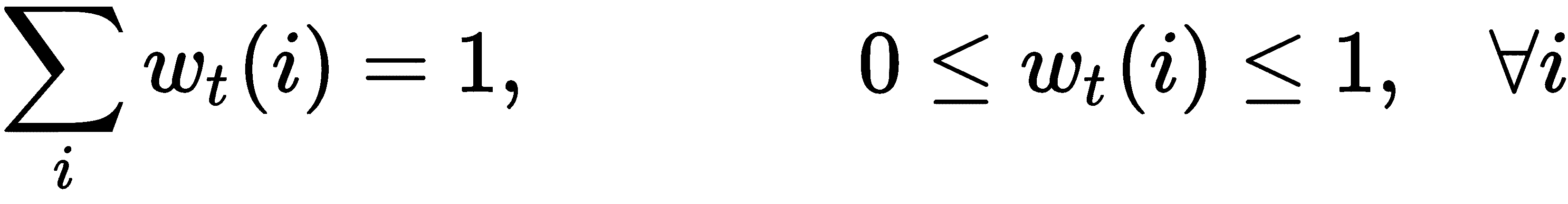
我们的存储矩阵由N行和M列组成,如下图所示。 让我们将t时的存储矩阵表示M[t]:
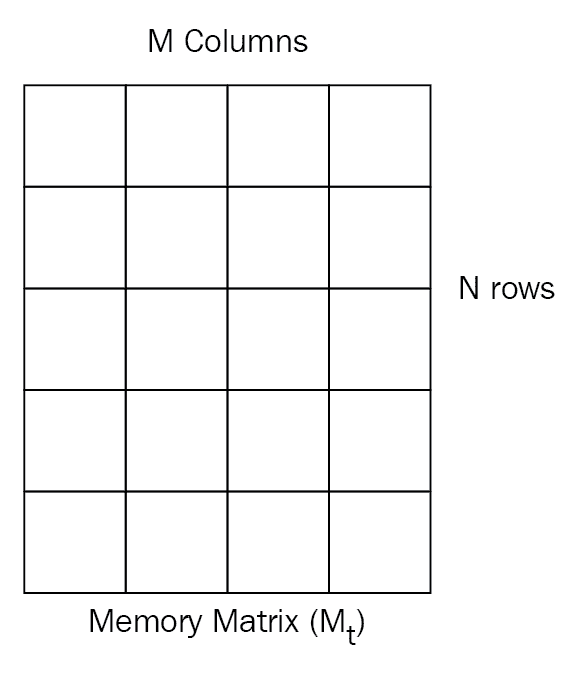
现在我们有了权重向量和存储矩阵,我们执行了存储矩阵M[t]和权重向量w[t],以获取读取向量r[t],如下图所示:
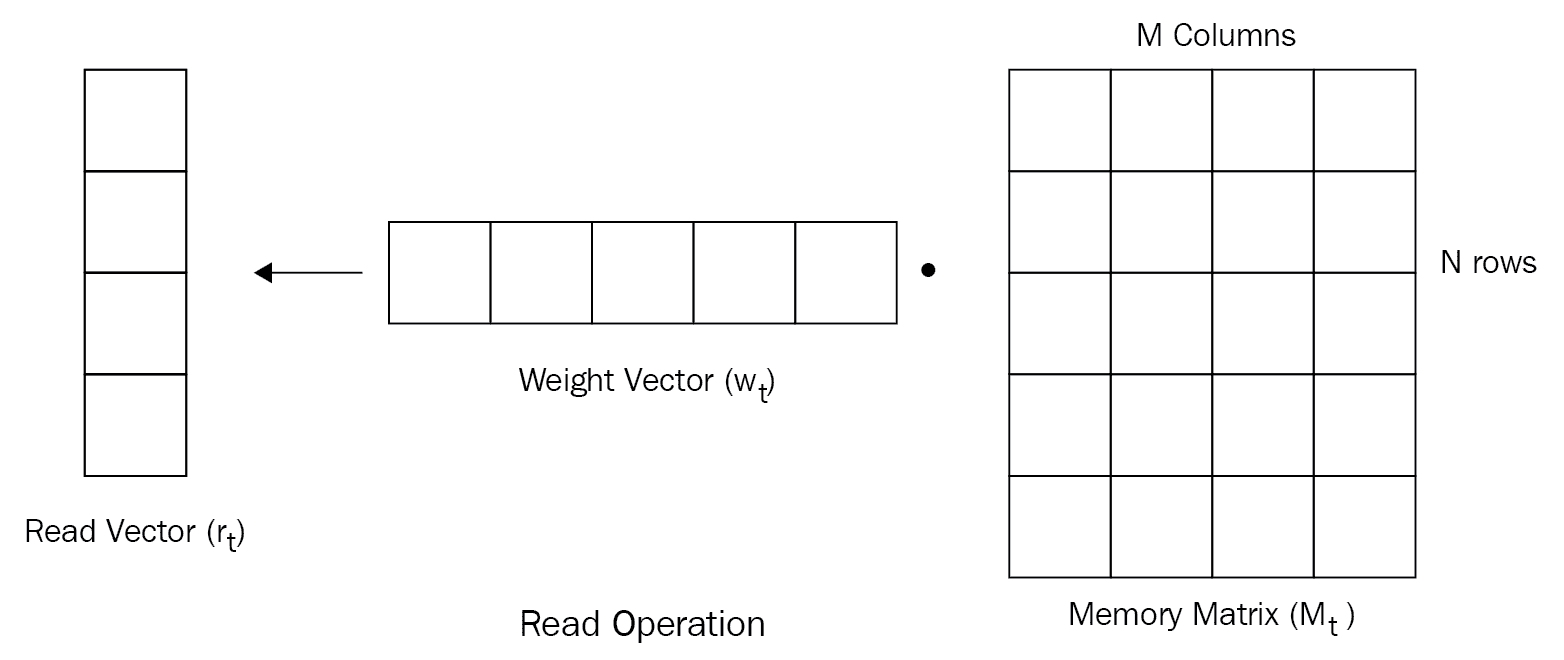
可以表示为以下形式:
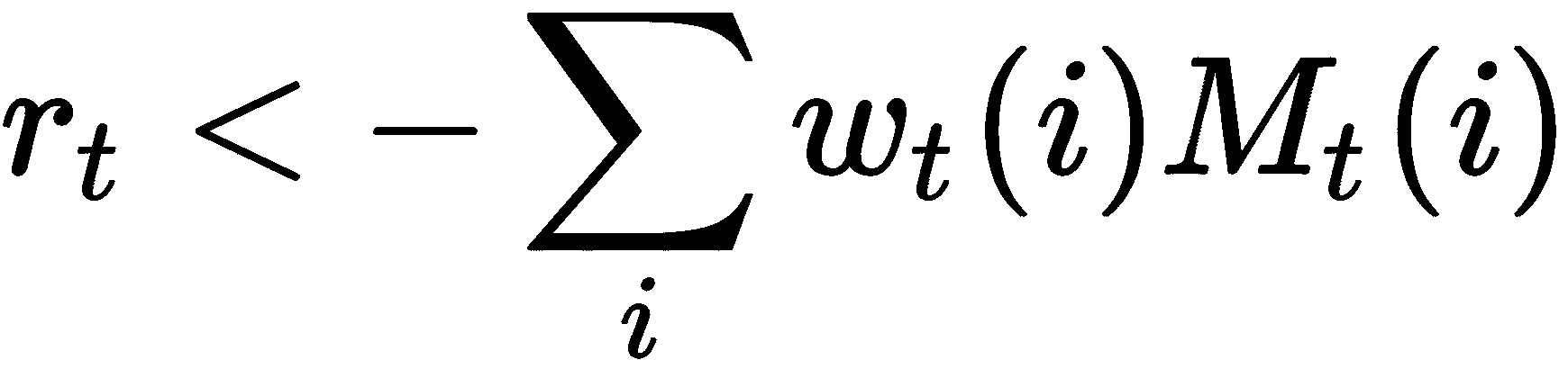
如上图所示,我们具有N行和M列的存储矩阵,大小为N的权重向量包含所有N个位置。 执行这两个的线性组合,我们得到长度为M的读取向量。
写入操作
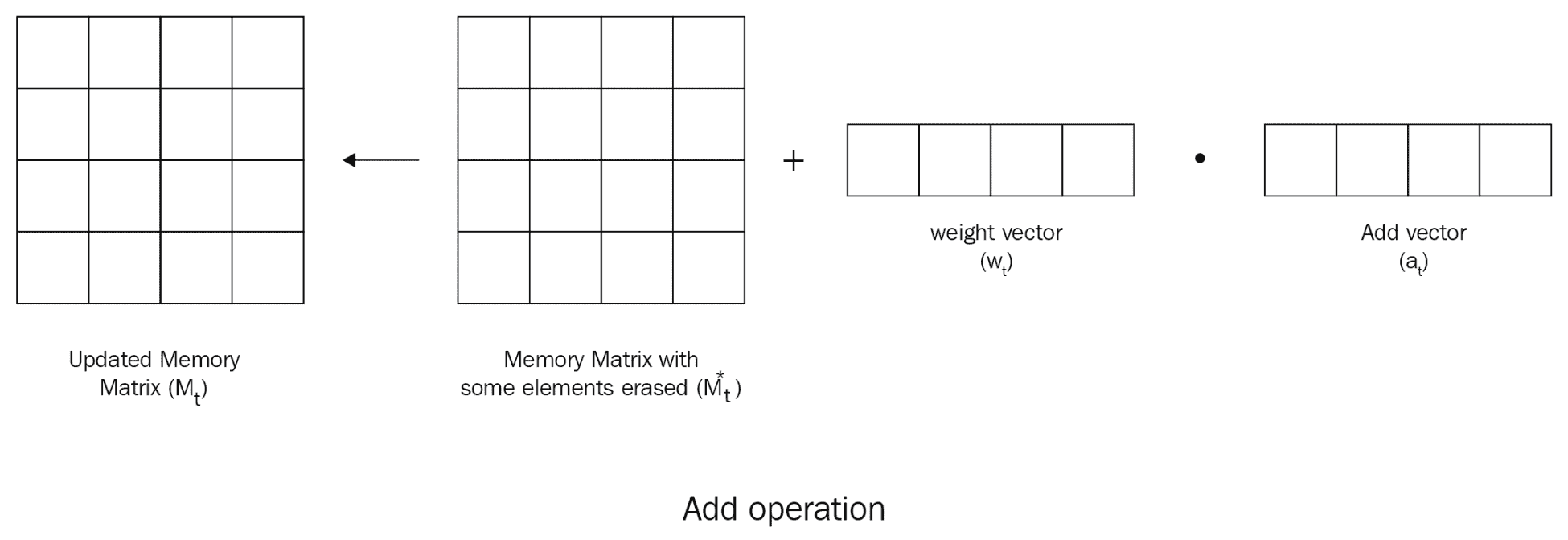
与读取操作不同,写入操作由两个称为擦除和添加操作的子操作组成,这两个子操作分别擦除旧信息并将新信息添加到存储器。
擦除操作
我们使用擦除操作来删除内存中不需要的信息。 执行擦除操作后,我们将拥有一个新的更新的存储矩阵,其中的存储器中的某些元素将被擦除。 我们如何擦除存储矩阵中特定单元的值? 在这里,我们引入了另一种称为擦除向量e[t]的向量,其长度与权重向量w[t]相同。 擦除向量由 0s 和 1s 组成。
好的。 我们有一个擦除向量。 但是,我们如何擦除值并获取更新的存储矩阵? 在上一步M[t - 1]中,我们将(1 - w[t]e[t])与我们的存储矩阵相乘,得到更新后的存储矩阵M[t]*。
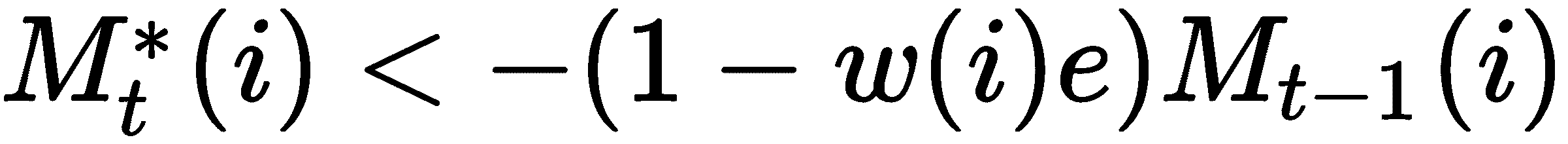
但这如何工作? 仅当索引为i的权重元素和擦除元素都为 1 时,存储器中的特定元素才会被设置为 0,换言之,被擦除; 否则,它将保留自己的值。 例如,查看下图。 首先,我们将权重向量w[t]和擦除向量w[t]相乘:

然后,我们从中减去 1,即(1 - w[t](i)e[t]),然后得到一个新的向量,如下所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-75OqCfQL-1681653478844)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/1584c3bc-b5d9-4d86-8a49-789514b6fd58.png)]
接下来,我们将(1 - w[t]e[t])与上一个时间步M[t - 1]的存储矩阵相乘,得到更新后的存储矩阵M[t]*:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j40jxB4z-1681653478844)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/1e27ee5e-77f2-4515-b584-491c4bf2c6a7.png)]
添加操作
完成擦除操作后,我们获得了更新的存储矩阵M[t]*,其中存储器中的某些元素将被擦除。 现在,我们要向存储矩阵中添加新信息。 我们该怎么做? 我们引入了另一个向量,称为加法向量a[t],该向量具有要添加到存储器中的值。 我们将权重向量w[t]的元素相乘,然后将向量a[t]相加,然后将它们添加到内存中,即:
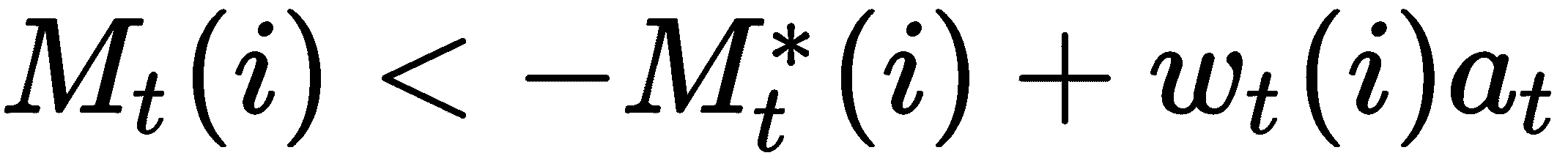
寻址机制
到目前为止,我们已经了解了如何执行读写操作,还了解了如何使用权重向量执行这些操作。 但是我们如何计算这个权重向量呢? 我们使用注意力机制和不同的寻址方案来计算它。 我们使用两种寻址机制来访问内存中的信息:
- 基于内容的寻址
- 基于位置的寻址
基于内容的寻址
在基于内容的寻址中,我们基于相似性从内存中选择值。 控制器返回一个称为k[t]的键向量。 我们将这个关键向量k[t]与存储矩阵M[t]中的每一行进行比较,以了解相似性。 我们使用余弦相似度作为检查相似度的相似度度量,可以表示为:
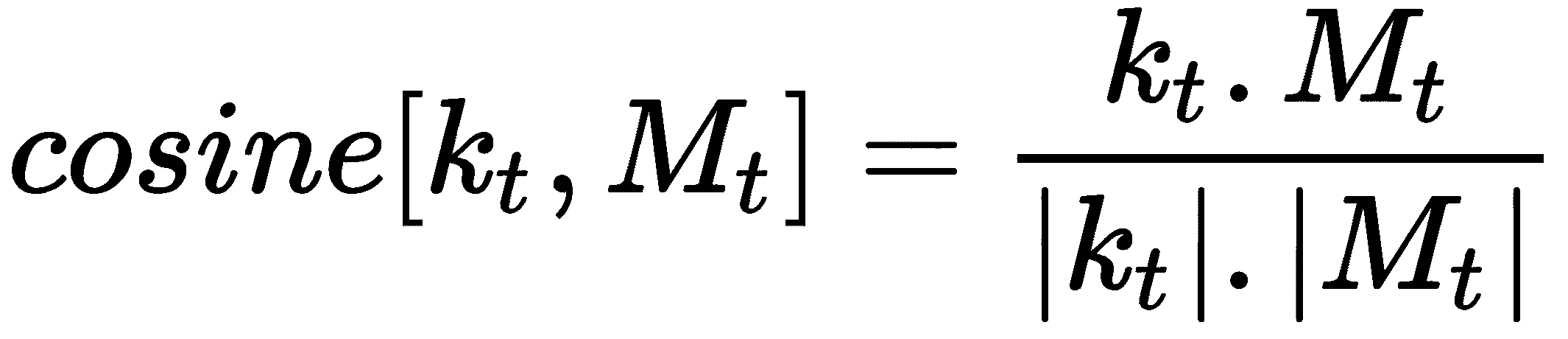
我们引入了一个称为β的新参数,称为键强度。 它决定了我们的权重向量应有多集中。 基于β的值,我们可以增加或减小焦点-也就是说,我们可以基于按键强度β的值将注意力转移到特定位置。 当β的值较低时,我们将同等地关注所有位置; 当β的值较高时,我们将重点放在特定位置。
因此,我们的权重向量变为:
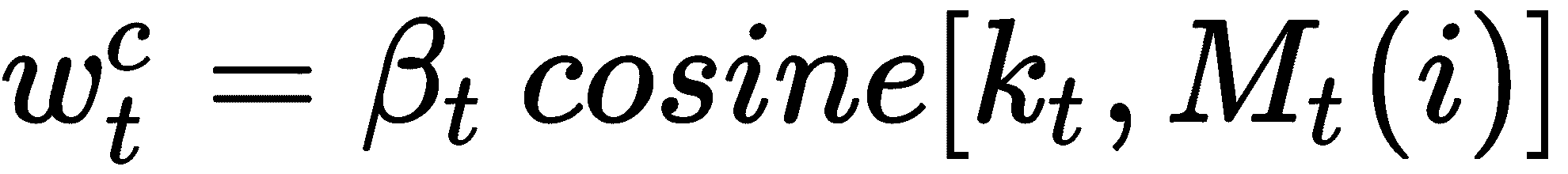
也就是说,键向量k[t]和存储矩阵M[t]之间的余弦相似度乘以键强度β。 w[t]^c中的上标c表示它们是基于内容的权重。 代替直接使用它,我们对权重应用 softmax。 因此,我们的最终权重如下:
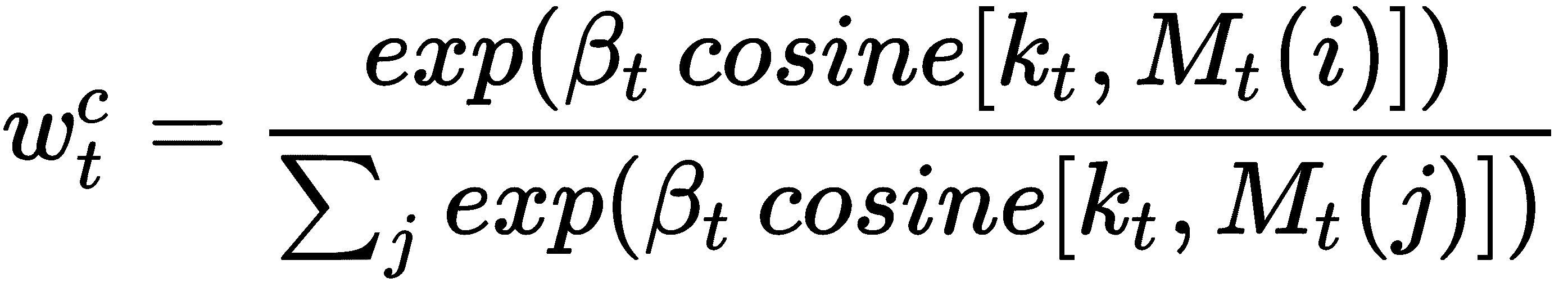
基于位置的寻址
与基于内容的寻址不同,在基于位置的寻址中,我们专注于位置而不是内容相似性。 它包括三个步骤:
- 插值
- 卷积移位
- 锐化
插值
基于位置的寻址的第一步称为插值。 它用于决定我们应该使用在上一个时间步获得的权重w[t - 1],还是使用通过基于内容的寻址获得的权重w[t]^c。 但是我们如何决定呢? 我们使用一个新的标量参数g[t],该参数用于确定应使用的权重。 g[t]的值可以为 0 或 1。
我们可以表示权重向量的计算如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YktBcjBf-1681653478845)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/b7e0ca28-2e27-4adf-a9a0-a393e859a82e.png)]
- 当
g[t]的值为 0 时,我们的方程变为w[t]^g < - w[t - 1],这意味着我们的权重向量是我们在上一个时间步获得的权重向量。 - 当
g[t]的值为 1 时,我们的方程变为w[t]^g < -w[t]^c,这意味着我们的权重向量是我们通过基于内容的寻址获得的权重向量。
因此,g[t]的值用作在我们必须使用的权重之间进行切换的门。
卷积移位
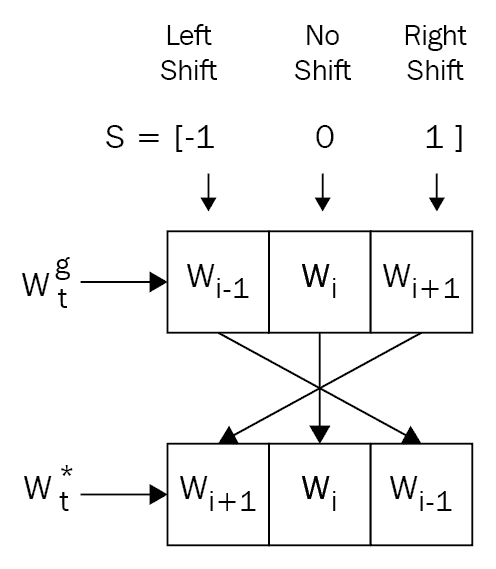
下一步称为卷积移位。 用于移动头部位置。 即,它用于将焦点从一个位置转移到另一位置。 每个磁头发出一个称为移位权重s[t]的参数,该参数为我们提供了一个分布,在该分布上可以执行允许的整数移位。 例如,假设我们在 -1 和 1 之间进行了转换,那么s[t]的长度将变为 3,包括{-1, 0, 1}。
那么,这些转变究竟意味着什么? 假设权重向量w[t]^g中有三个元素 – 即w[i - 1]^g, w[i - 2]^g, w[i - 3]^g,而移位权重向量中有三个元素s[t] = [-1, 0, 1]。
移位 -1 表示我们将w[t]^g中的元素从左向右移动。 移位 0 将元素保持在相同位置,而移位+1 意味着我们将元素从右移到左。 在下图中可以看到:
现在,看下面的图,其中我们有移位权重s[t] = [1, 0, 0],这意味着我们执行了左移位,因为在其他位置移位值为 0:
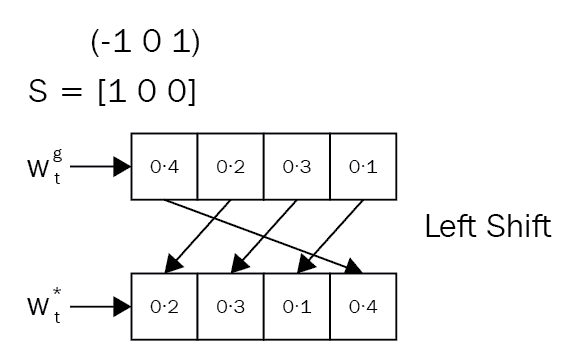
同样,当s[t] = [0, 0, 1]时,我们执行右移,因为在其他位置上的移位值为 0,如下图所示:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-QCSr8PJR-1681653478846)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/51f8b11f-7921-424a-a41f-1fcc6c03314f.png)]
因此,以这种方式,我们对权重矩阵中的元素执行卷积移位。 如果我们将 0 到N-1个存储位置,则可以表示卷积移位如下:
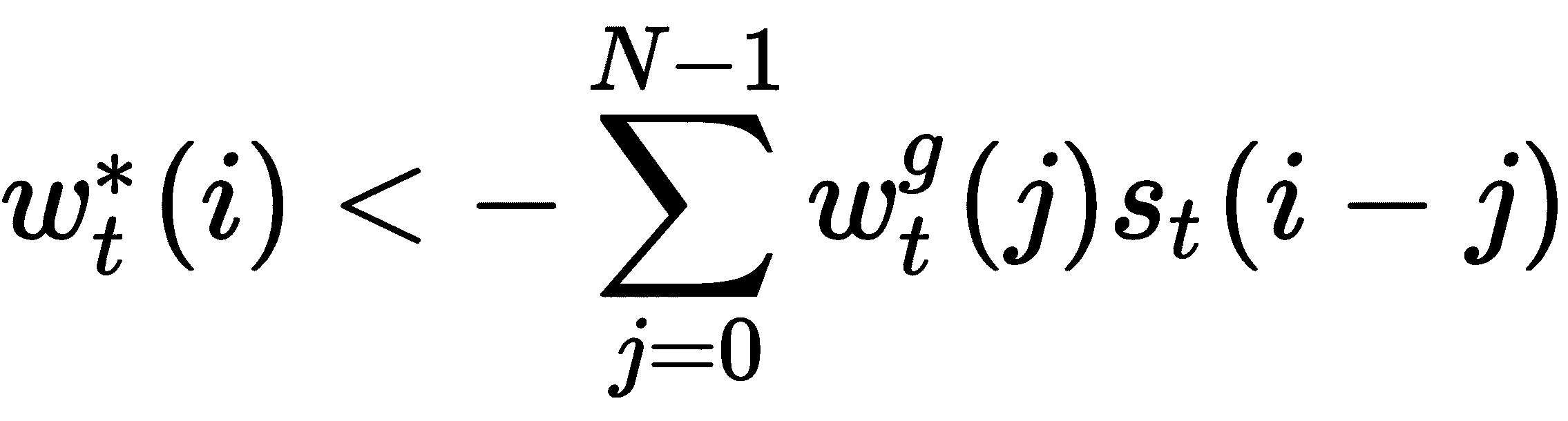
锐化
最后一步称为锐化。 卷积移位的结果是,权重w[t]*不会很尖锐,换句话说,由于移位,聚焦在单个位置的权重将分散到其他位置。 为了减轻这种影响,我们执行锐化。 我们使用一个称为γ[t]的新参数,该参数应大于或等于 1 以进行锐化,并且可以表示为:
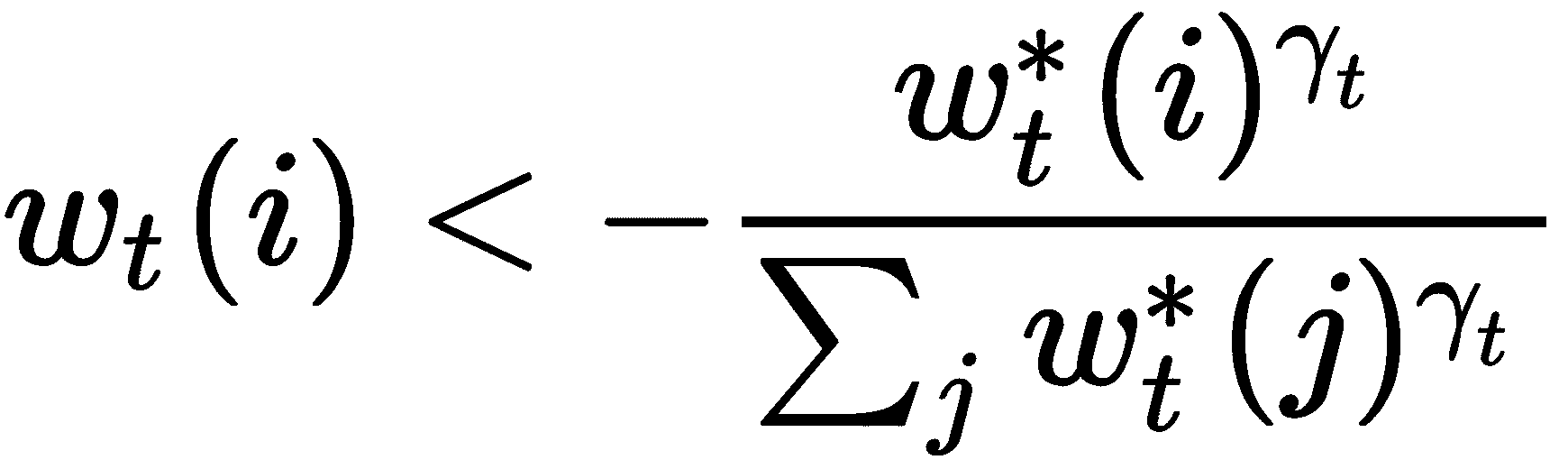
使用 NTM 执行复制任务
现在,我们将看到如何使用 NTM 执行复制任务。 复制任务的目的是了解 NTM 如何存储和调用任意长度的序列。 我们将为网络提供一个随机序列,以及一个指示序列结束的标记。 它必须学习输出给定的输入序列。 因此,网络会将输入序列存储在内存中,然后从内存中回读。 现在,我们将逐步了解如何执行复制任务,然后在最后看到整个最终代码。
您还可以在此处查看 Jupyter 笔记本中提供的代码,并附带说明。
首先,我们将了解如何实现 NTM 单元。 而不是查看整个代码,我们将逐行查看它。
我们定义NTMCell类,在其中实现整个 NTM 单元:
class NTMCell():
首先,我们定义init函数,在其中初始化所有变量:
def __init__(self, rnn_size, memory_size, memory_vector_dim, read_head_num, write_head_num,
addressing_mode='content_and_location', shift_range=1, reuse=False, output_dim=None):
#initialize all the variables
self.rnn_size = rnn_size
self.memory_size = memory_size
self.memory_vector_dim = memory_vector_dim
self.read_head_num = read_head_num
self.write_head_num = write_head_num
self.addressing_mode = addressing_mode
self.reuse = reuse
self.step = 0
self.output_dim = output_dim
self.shift_range = shift_range
#initialize controller as the basic rnn cell
self.controller = tf.nn.rnn_cell.BasicRNNCell(self.rnn_size)
接下来,我们定义__call__方法,在其中实现 NTM 操作:
def __call__(self, x, prev_state):
我们通过将x输入与先前读取的向量列表组合来获得控制器输入:
prev_read_vector_list = prev_state['read_vector_list']
prev_controller_state = prev_state['controller_state']
controller_input = tf.concat([x] + prev_read_vector_list, axis=1)
我们通过输入controller_input和prev_controller_state作为输入来构建控制器,即 RNN 单元:
with tf.variable_scope('controller', reuse=self.reuse):
controller_output, controller_state = self.controller(controller_input, prev_controller_state)
现在,我们初始化读写头:
num_parameters_per_head = self.memory_vector_dim + 1 + 1 + (self.shift_range * 2 + 1) + 1
num_heads = self.read_head_num + self.write_head_num
total_parameter_num = num_parameters_per_head * num_heads + self.memory_vector_dim * 2 * self.write_head_num
接下来,我们初始化权重矩阵并进行偏置并使用前馈操作计算参数:
with tf.variable_scope("o2p", reuse=(self.step > 0) or self.reuse):
o2p_w = tf.get_variable('o2p_w', [controller_output.get_shape()[1], total_parameter_num],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.5))
o2p_b = tf.get_variable('o2p_b', [total_parameter_num],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.5))
parameters = tf.nn.xw_plus_b(controller_output, o2p_w, o2p_b)
head_parameter_list = tf.split(parameters[:, :num_parameters_per_head * num_heads], num_heads, axis=1)
erase_add_list = tf.split(parameters[:, num_parameters_per_head * num_heads:], 2 * self.write_head_num, axis=1)
接下来,我们获得先前的权重向量和先前的内存:
#previous weight vector
prev_w_list = prev_state['w_list']
#previous memory
prev_M = prev_state['M']
w_list = []
p_list = []
现在,我们将初始化一些用于寻址的重要参数:
for i, head_parameter in enumerate(head_parameter_list):
#key vector
k = tf.tanh(head_parameter[:, 0:self.memory_vector_dim])
#key strength(beta)
beta = tf.sigmoid(head_parameter[:, self.memory_vector_dim]) * 10
#interpolation gate
g = tf.sigmoid(head_parameter[:, self.memory_vector_dim + 1])
#shift matrix
s = tf.nn.softmax(
head_parameter[:, self.memory_vector_dim + 2:self.memory_vector_dim + 2 + (self.shift_range * 2 + 1)]
)
#sharpening factor
gamma = tf.log(tf.exp(head_parameter[:, -1]) + 1) + 1
with tf.variable_scope('addressing_head_%d' % i):
w = self.addressing(k, beta, g, s, gamma, prev_M, prev_w_list[i])
w_list.append(w)
p_list.append({'k': k, 'beta': beta, 'g': g, 's': s, 'gamma': gamma})
读取操作:
选择读取头,如下所示:
read_w_list = w_list[:self.read_head_num]
我们知道read操作是权重和内存的线性组合:
read_vector_list = []
for i in range(self.read_head_num):
#linear combination of the weights and memory
read_vector = tf.reduce_sum(tf.expand_dims(read_w_list[i], dim=2) * prev_M, axis=1)
read_vector_list.append(read_vector)
写入操作:
与读取操作不同,写入操作涉及擦除和添加两个步骤。
选择要写入的头,如下所示:
write_w_list = w_list[self.read_head_num:]
#update the memory
M = prev_M
执行擦除和添加操作:
for i in range(self.write_head_num):
#the erase vector will be multipled with weight vector to denote which location to erase or keep unchanged
w = tf.expand_dims(write_w_list[i], axis=2)
erase_vector = tf.expand_dims(tf.sigmoid(erase_add_list[i * 2]), axis=1)
#next we perform the add operation
add_vector = tf.expand_dims(tf.tanh(erase_add_list[i * 2 + 1]), axis=1)
M = M * (tf.ones(M.get_shape()) - tf.matmul(w, erase_vector)) + tf.matmul(w, add_vector)
获取控制器输出:
if not self.output_dim:
output_dim = x.get_shape()[1]
else:
output_dim = self.output_dim
with tf.variable_scope("o2o", reuse=(self.step > 0) or self.reuse):
o2o_w = tf.get_variable('o2o_w', [controller_output.get_shape()[1], output_dim],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.5))
o2o_b = tf.get_variable('o2o_b', [output_dim],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.5))
NTM_output = tf.nn.xw_plus_b(controller_output, o2o_w, o2o_b)
state = {
'controller_state': controller_state,
'read_vector_list': read_vector_list,
'w_list': w_list,
'p_list': p_list,
'M': M
}
self.step += 1
寻址机制:
众所周知,我们使用两种寻址方式:基于内容的寻址和基于位置的寻址。
基于内容的寻址:
计算关键向量和存储矩阵之间的余弦相似度:
k = tf.expand_dims(k, axis=2)
inner_product = tf.matmul(prev_M, k)
k_norm = tf.sqrt(tf.reduce_sum(tf.square(k), axis=1, keepdims=True))
M_norm = tf.sqrt(tf.reduce_sum(tf.square(prev_M), axis=2, keepdims=True))
norm_product = M_norm * k_norm
K = tf.squeeze(inner_product / (norm_product + 1e-8))
现在,我们根据相似度和关键强度(beta)生成归一化的权重向量。 beta用于调整头部聚焦的精度:
K_amplified = tf.exp(tf.expand_dims(beta, axis=1) * K)
w_c = K_amplified / tf.reduce_sum(K_amplified, axis=1, keepdims=True) # eq (5)
基于位置的寻址:
基于位置的寻址涉及其他三个步骤:
- 插值
- 卷积移位
- 锐化
插值:
这用于决定我们应该使用在上一个时间步获得的权重prev_w还是使用通过基于内容的寻址获得的权重w_c。 但是我们如何决定呢? 我们使用一个新的标量参数g,该参数用于确定应使用的权重:
g = tf.expand_dims(g, axis=1)
w_g = g * w_c + (1 - g) * prev_w
卷积移位:
插值后,我们执行卷积移位,以便控制器可以专注于其他行:
s = tf.concat([s[:, :self.shift_range + 1],
tf.zeros([s.get_shape()[0], self.memory_size - (self.shift_range * 2 + 1)]),
s[:, -self.shift_range:]], axis=1)
t = tf.concat([tf.reverse(s, axis=[1]), tf.reverse(s, axis=[1])], axis=1)
s_matrix = tf.stack(
[t[:, self.memory_size - i - 1:self.memory_size * 2 - i - 1] for i in range(self.memory_size)],
axis=1
)
w_ = tf.reduce_sum(tf.expand_dims(w_g, axis=1) * s_matrix, axis=2) # eq (8)
锐化:
最后,我们执行锐化操作以防止偏移的权重向量模糊:
w_sharpen = tf.pow(w_, tf.expand_dims(gamma, axis=1))
w = w_sharpen / tf.reduce_sum(w_sharpen, axis=1, keepdims=True)
接下来,我们定义一个名为zero_state的函数,用于初始化控制器的所有状态,读取向量,权重和内存:
def zero_state(self, batch_size, dtype):
def expand(x, dim, N):
return tf.concat([tf.expand_dims(x, dim) for _ in range(N)], axis=dim)
with tf.variable_scope('init', reuse=self.reuse):
state = {
'controller_state': expand(tf.tanh(tf.get_variable('init_state', self.rnn_size,
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.5))),
dim=0, N=batch_size),
'read_vector_list': [expand(tf.nn.softmax(tf.get_variable('init_r_%d' % i, [self.memory_vector_dim],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.5))),
dim=0, N=batch_size)
for i in range(self.read_head_num)],
'w_list': [expand(tf.nn.softmax(tf.get_variable('init_w_%d' % i, [self.memory_size],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.5))),
dim=0, N=batch_size) if self.addressing_mode == 'content_and_loaction'
else tf.zeros([batch_size, self.memory_size])
for i in range(self.read_head_num + self.write_head_num)],
'M': expand(tf.tanh(tf.get_variable('init_M', [self.memory_size, self.memory_vector_dim],
initializer=tf.random_normal_initializer(mean=0.0, stddev=0.5))),
dim=0, N=batch_size)
}
return state
接下来,我们定义一个名为generate_random_strings的函数,该函数会生成一个长度为seq_length的随机序列,并将这些序列馈送到复制任务的 NTM 输入:
def generate_random_strings(batch_size, seq_length, vector_dim):
return np.random.randint(0, 2, size=[batch_size, seq_length, vector_dim]).astype(np.float32)
现在,我们创建NTMCopyModel以执行整个复制任务:
class NTMCopyModel():
def __init__(self, args, seq_length, reuse=False):
#input sequence
self.x = tf.placeholder(name='x', dtype=tf.float32, shape=[args.batch_size, seq_length, args.vector_dim])
#output sequence
self.y = self.x
#end of the sequence
eof = np.zeros([args.batch_size, args.vector_dim + 1])
eof[:, args.vector_dim] = np.ones([args.batch_size])
eof = tf.constant(eof, dtype=tf.float32)
zero = tf.constant(np.zeros([args.batch_size, args.vector_dim + 1]), dtype=tf.float32)
if args.model == 'LSTM':
def rnn_cell(rnn_size):
return tf.nn.rnn_cell.BasicLSTMCell(rnn_size, reuse=reuse)
cell = tf.nn.rnn_cell.MultiRNNCell([rnn_cell(args.rnn_size) for _ in range(args.rnn_num_layers)])
elif args.model == 'NTM':
cell = NTMCell(args.rnn_size, args.memory_size, args.memory_vector_dim, 1, 1,
addressing_mode='content_and_location',
reuse=reuse,
output_dim=args.vector_dim)
#initialize all the states
state = cell.zero_state(args.batch_size, tf.float32)
self.state_list = [state]
for t in range(seq_length):
output, state = cell(tf.concat([self.x[:, t, :], np.zeros([args.batch_size, 1])], axis=1), state)
self.state_list.append(state)
#get the output and states
output, state = cell(eof, state)
self.state_list.append(state)
self.o = []
for t in range(seq_length):
output, state = cell(zero, state)
self.o.append(output[:, 0:args.vector_dim])
self.state_list.append(state)
self.o = tf.sigmoid(tf.transpose(self.o, perm=[1, 0, 2]))
eps = 1e-8
#calculate loss as cross entropy loss
self.copy_loss = -tf.reduce_mean(self.y * tf.log(self.o + eps) + (1 - self.y) * tf.log(1 - self.o + eps))
#optimize using RMS prop optimizer
with tf.variable_scope('optimizer', reuse=reuse):
self.optimizer = tf.train.RMSPropOptimizer(learning_rate=args.learning_rate, momentum=0.9, decay=0.95)
gvs = self.optimizer.compute_gradients(self.copy_loss)
capped_gvs = [(tf.clip_by_value(grad, -10., 10.), var) for grad, var in gvs]
self.train_op = self.optimizer.apply_gradients(capped_gvs)
self.copy_loss_summary = tf.summary.scalar('copy_loss_%d' % seq_length, self.copy_loss)
我们使用以下命令重置 TensorFlow 图:
tf.reset_default_graph()
然后,我们将所有参数定义如下:
parser = argparse.ArgumentParser()
parser.add_argument('--mode', default="train")
parser.add_argument('--restore_training', default=False)
parser.add_argument('--test_seq_length', type=int, default=5)
parser.add_argument('--model', default="NTM")
parser.add_argument('--rnn_size', default=16)
parser.add_argument('--rnn_num_layers', default=3)
parser.add_argument('--max_seq_length', default=5)
parser.add_argument('--memory_size', default=16)
parser.add_argument('--memory_vector_dim', default=5)
parser.add_argument('--batch_size', default=5)
parser.add_argument('--vector_dim', default=8)
parser.add_argument('--shift_range', default=1)
parser.add_argument('--num_epoches', default=100)
parser.add_argument('--learning_rate', default=1e-4)
parser.add_argument('--save_dir', default= os.getcwd())
parser.add_argument('--tensorboard_dir', default=os.getcwd())
args = parser.parse_args(args = [])
最后,我们定义training函数:
def train(args):
model_list = [NTMCopyModel(args, 1)]
for seq_length in range(2, args.max_seq_length + 1):
model_list.append(NTMCopyModel(args, seq_length, reuse=True))
with tf.Session() as sess:
if args.restore_training:
saver = tf.train.Saver()
ckpt = tf.train.get_checkpoint_state(args.save_dir + '/' + args.model)
saver.restore(sess, ckpt.model_checkpoint_path)
else:
saver = tf.train.Saver(tf.global_variables())
tf.global_variables_initializer().run()
#initialize summary writer for visualizing in tensorboard
train_writer = tf.summary.FileWriter(args.tensorboard_dir, sess.graph)
plt.ion()
plt.show()
for b in range(args.num_epoches):
#initialize the sequence length
seq_length = np.random.randint(1, args.max_seq_length + 1)
model = model_list[seq_length - 1]
#generate our random input sequence as an input
x = generate_random_strings(args.batch_size, seq_length, args.vector_dim)
#feed our input to the model
feed_dict = {model.x: x}
if b % 100 == 0:
p = 0
print("First training batch sample",x[p, :, :])
#compute model output
print("Model output",sess.run(model.o, feed_dict=feed_dict)[p, :, :])
state_list = sess.run(model.state_list, feed_dict=feed_dict)
if args.model == 'NTM':
w_plot = []
M_plot = np.concatenate([state['M'][p, :, :] for state in state_list])
for state in state_list:
w_plot.append(np.concatenate([state['w_list'][0][p, :], state['w_list'][1][p, :]]))
#plot the weight matrix to see the attention
plt.imshow(w_plot, interpolation='nearest', cmap='gray')
plt.draw()
plt.pause(0.001)
#compute loss
copy_loss = sess.run(model.copy_loss, feed_dict=feed_dict)
#write to summary
merged_summary = sess.run(model.copy_loss_summary, feed_dict=feed_dict)
train_writer.add_summary(merged_summary, b)
print('batches %d, loss %g' % (b, copy_loss))
else:
sess.run(model.train_op, feed_dict=feed_dict)
#save the model
if b % 5000 == 0 and b > 0:
saver.save(sess, args.save_dir + '/' + args.model + '/model.tfmodel', global_step=b)
然后,我们开始使用以下命令训练 NTM:
train(args)
我们可以看到输出如下,其中可以看到注意力集中在权重矩阵上:
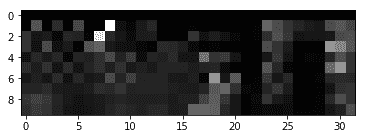
记忆增强神经网络(MANN)
现在,我们将看到一个有趣的 NTM 变体,称为 MANN。 它广泛用于一键式学习任务。 MANN 旨在使 NTM 在单样本学习任务中表现更好。 我们知道 NTM 可以使用基于内容的寻址或基于位置的寻址。 但是在 MANN 中,我们仅使用基于内容的寻址。
MANN 使用一种称为最少最近访问的新寻址方案。 顾名思义,它写入最近最少使用的内存位置。 等待。 什么? 我们刚刚了解到 MANN 不是基于位置的,那么为什么我们要写入最近最少使用的位置? 这是因为最近最少使用的存储位置由读取操作确定,而读取操作由基于内容的寻址执行。 因此,我们基本上执行基于内容的寻址,以读取和写入最近最少使用的位置。
读写操作
现在,我们将看到如何在 MANN 中执行读写操作以及它们与 NTM 的区别。
读取操作
与 NTM 不同,在 MANN 中,我们使用两个不同的权重向量执行读取和写入操作。 MANN 中的读取操作与 NTM 相同。 因为我们知道,在 MANN 中,我们使用基于内容的相似度执行读取操作,所以我们将控制器发出的键向量k[t]与存储矩阵M[t]中的每一行进行比较,以了解相似度 。 我们使用余弦相似度作为检查相似度的相似度度量,可以表示为:
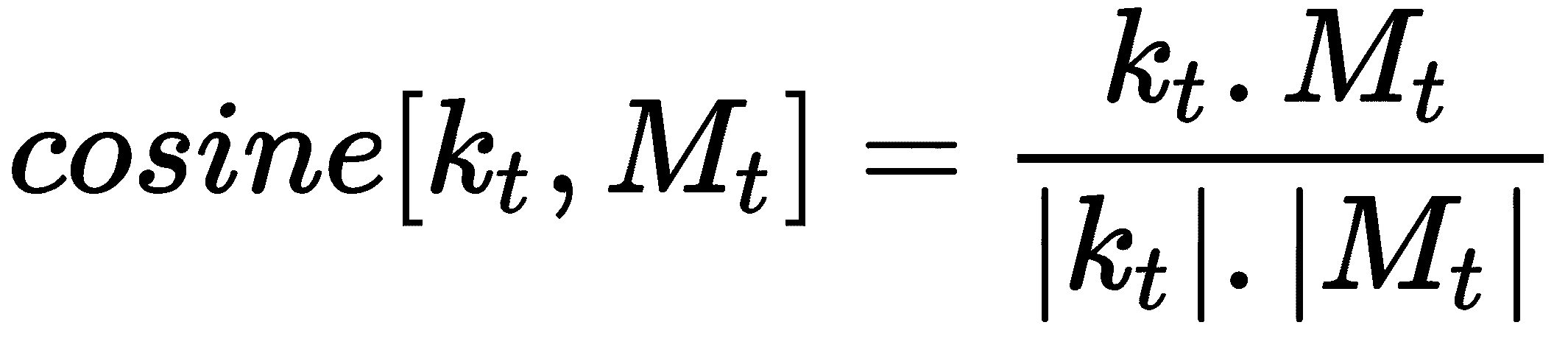
因此,我们的权重向量变为:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Uh22T937-1681653478850)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-meta-learn-py/img/c820a84a-3694-4a00-af7b-8442b29b3142.png)]
但是,与 NTM 不同,我们在这里不使用键强度β。 w[t]^r中的上标r表示它是读取的权重向量。 我们最终的权重向量是权重上的 softmax,即:
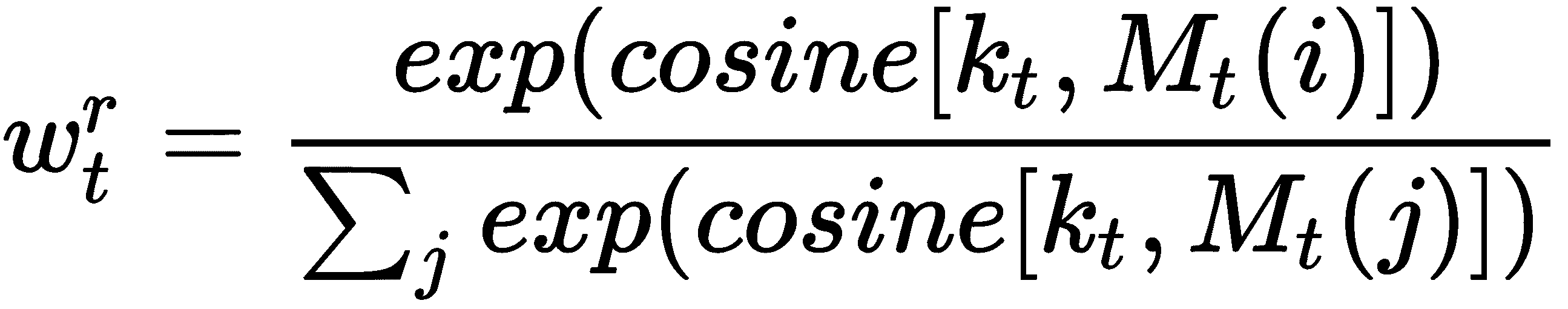
我们的读取向量是权重w[t]^r和存储矩阵M[t]的线性组合,如下所示:
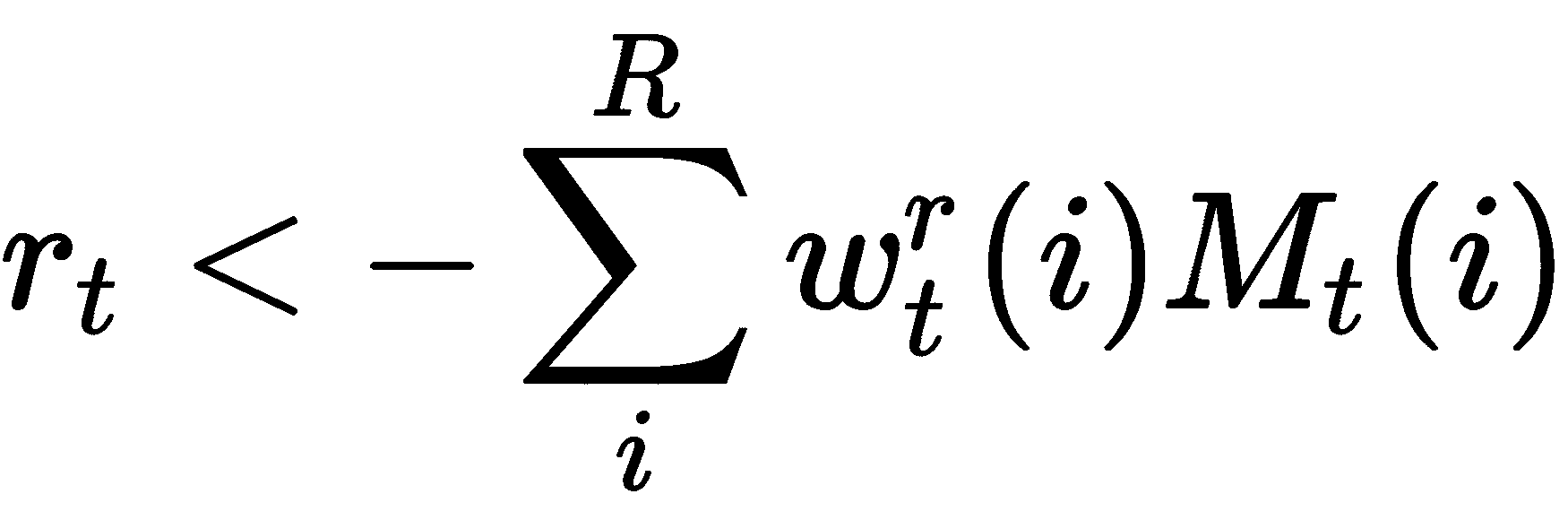
让我们看看如何在 TensorFlow 中构建它。
首先,我们使用基于内容的相似度计算读取权重向量:
def read_head_addressing(k, prev_M):
k = tf.expand_dims(k, axis=2)
inner_product = tf.matmul(prev_M, k)
k_norm = tf.sqrt(tf.reduce_sum(tf.square(k), axis=1, keep_dims=True))
M_norm = tf.sqrt(tf.reduce_sum(tf.square(prev_M), axis=2, keep_dims=True))
norm_product = M_norm * k_norm
K = tf.squeeze(inner_product / (norm_product + 1e-8))
K_exp = tf.exp(K)
w = K_exp / tf.reduce_sum(K_exp, axis=1, keep_dims=True)
return w
然后,我们获得读取的权重向量:
w_r = read_head_addressing(k, prev_M)
我们执行读取操作,这是读取的权重向量和内存的线性组合:
read_vector_list = []
with tf.variable_scope('reading'):
for i in range(self.head_num):
read_vector = tf.reduce_sum(tf.expand_dims(w_r_list[i], dim=2) * M, axis=1)
read_vector_list.append(read_vector)
写入操作
在执行写操作之前,我们要找到最近最少使用的内存位置,因为这是我们必须写的位置。 我们如何找到最近最少使用的内存位置? 为了找到这一点,我们计算了一个新的向量,称为使用权重向量。 它由w[t]^u表示,并将在每个读取和写入步骤之后进行更新。 它只是读取权重向量和写入权重向量的总和,即w[t]^u < -w[t]^r + w[t]^w。
除了添加读取和权重向量外,我们还通过添加衰减的先前使用权重向量w[t - 1]^u来更新使用权重向量。 我们使用称为γ的衰减参数,该参数用于确定以前的使用权重必须如何衰减。 因此,我们最终的使用权重向量是衰减的先前使用权重向量,读取权重向量和写入权重向量的总和:
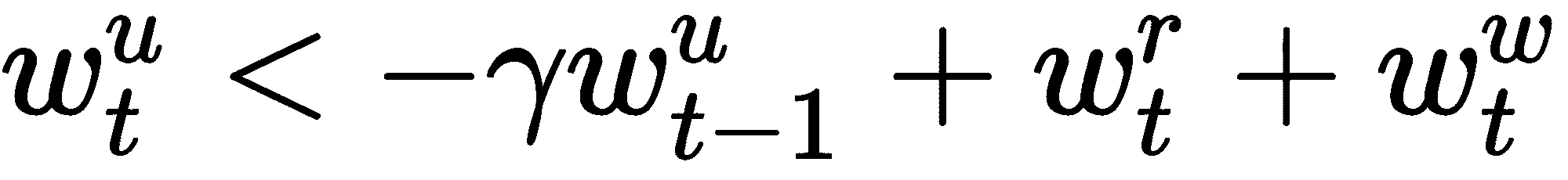
现在我们已经计算了使用权重向量,如何计算最近最少使用的位置? 为此,我们引入了另一个权重向量,称为最不常用的权重向量w[t]^(lu)。
从使用权重向量w[t]^u计算最少使用的权重向量w[t]^(lu)非常简单。 我们只需将使用权重向量中的最低值的索引设置为 1,将其余值设置为 0,因为使用权重向量中的最低值意味着它最近最少使用:

好的,接下来是什么? 我们已经计算出最少使用的权重向量。 现在,我们如何计算写权重向量w[t]^w? 我们使用 Sigmoid 门计算写入权重向量,它用于计算先前读取的权重向量w[t - 1]^r和先前最少使用的权重向量w[t - 1]^(lu)的凸组合:
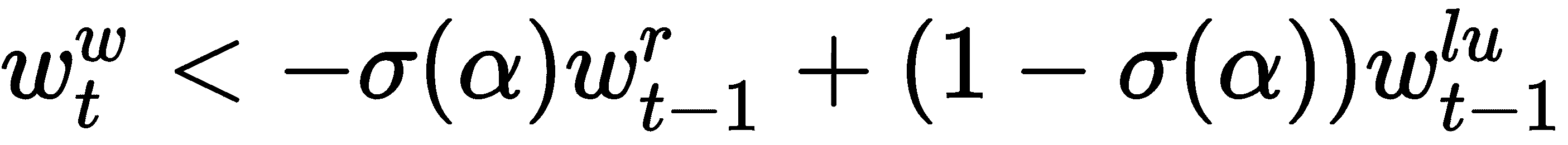
在计算写权重向量之后,我们最终更新我们的存储矩阵:
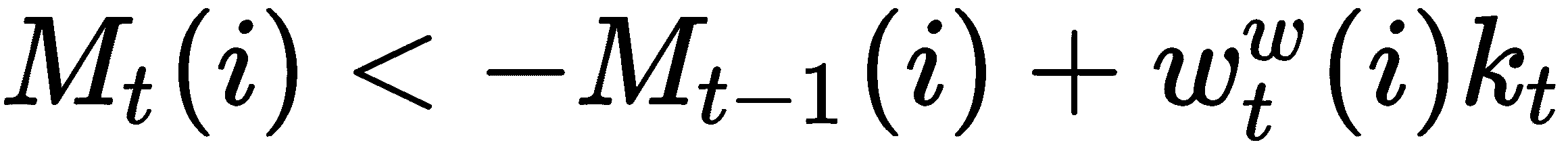
我们将看到如何在 TensorFlow 中构建它。
我们计算使用权重向量:
w_u = self.gamma * prev_w_u + tf.add_n(w_r_list) + tf.add_n(w_w_list)
然后,我们计算最少使用的权重向量:
def least_used(w_u):
_, indices = tf.nn.top_k(w_u, k=self.memory_size)
w_lu = tf.reduce_sum(tf.one_hot(indices[:, -self.head_num:], depth=self.memory_size), axis=1)
return indices, w_lu
我们存储先前的索引和先前最少使用的权重向量:
prev_indices, prev_w_lu = least_used(prev_w_u)
我们计算写权重向量:
def write_head_addressing(sig_alpha, prev_w_r, prev_w_lu):
return sig_alpha * prev_w_r + (1\. - sig_alpha) * prev_w_lu
然后,我们更新内存:
M_ = prev_M * tf.expand_dims(1\. - tf.one_hot(prev_indices[:, -1], self.memory_size), dim=2)
我们执行写操作:
M = M_
with tf.variable_scope('writing'):
for i in range(self.head_num):
w = tf.expand_dims(w_w_list[i], axis=2)
k = tf.expand_dims(k_list[i], axis=1)
M = M + tf.matmul(w, k)
总结
我们看到了神经图灵机如何从内存中存储和检索信息,以及它如何使用不同的寻址机制(例如基于位置和基于内容的寻址)来读写信息。 我们还学习了如何使用 TensorFlow 实现 NTM 以执行复制任务。 然后,我们了解了 MANN 以及 MANN 与 NTM 的不同之处。 我们还了解了 MANN 如何使用最近最少使用的访问方法来克服 NTM 的缺点。
在下一章中,我们将学习模型不可知元学习(MAML)以及如何在监督和强化学习环境中使用它。
问题
- 什么是 NTM?
- NTM 中的控制器是什么?
- 为什么我们使用读写头?
- 什么叫记忆?
- NTM 中使用哪些不同类型的寻址机制?
- 什么叫插值门?
- 如何从使用权重向量中计算出最少使用的权重向量?

















 2304
2304

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









