







原文:System Design Interview – An Insider’s Guide
译者:飞龙
九、设计网络爬虫
在这一章中,我们关注网络爬虫设计:一个有趣而经典的系统设计面试问题。
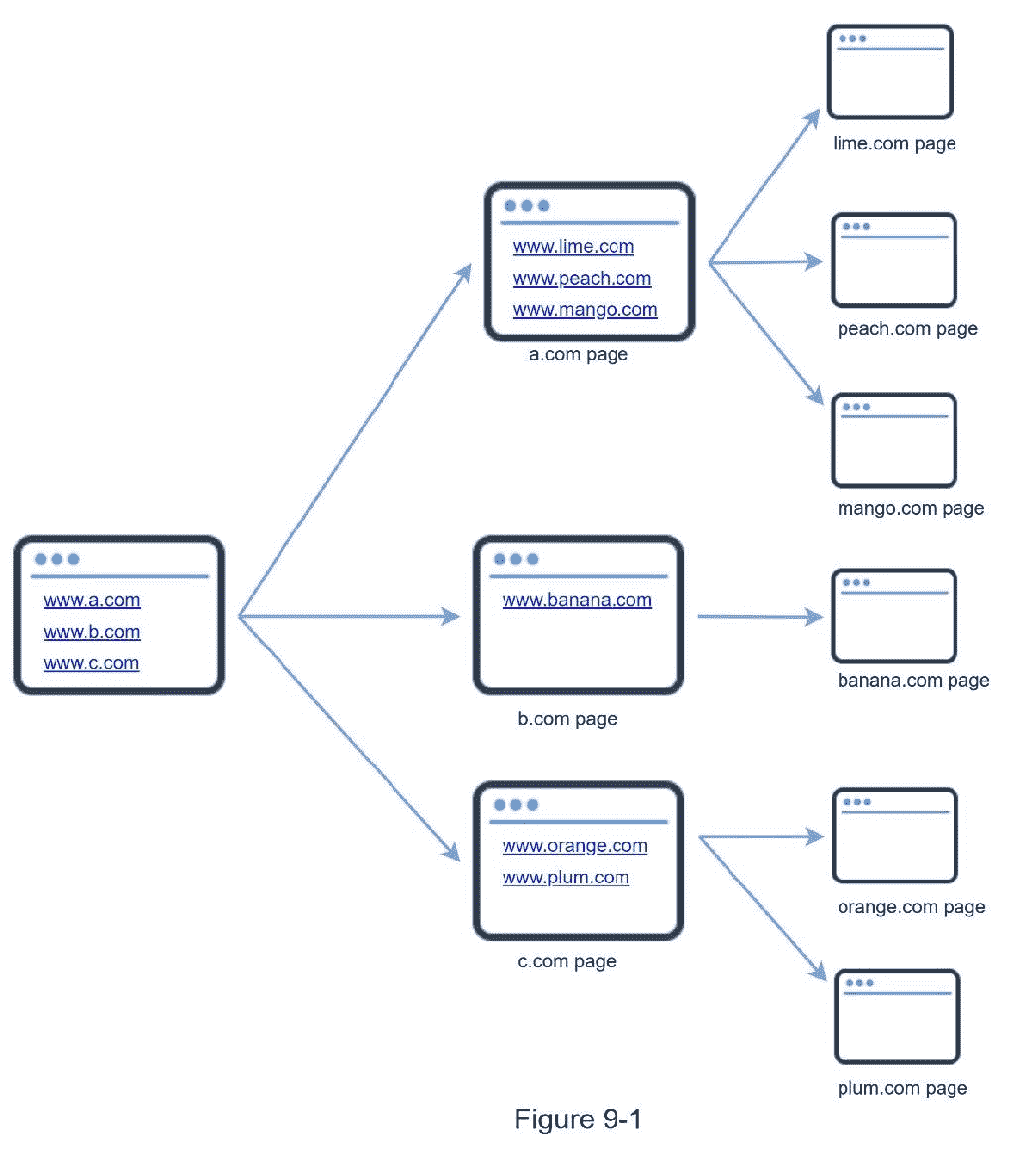
网络爬虫被称为机器人或蜘蛛。搜索引擎广泛使用它来发现 web 上新的或更新的内容。内容可以是网页、图像、视频、PDF 文件等。网络爬虫从收集一些网页开始,然后跟随这些网页上的链接来收集新的内容。图 9-1 显示了爬行过程的一个可视化例子。
爬虫有多种用途:
搜索引擎索引:这是最常见的用例。爬虫收集网页来为搜索引擎创建本地索引。例如,Googlebot 是谷歌搜索引擎背后的网络爬虫。
网络存档:这是从网络上收集信息以保存数据供将来使用的过程。例如,许多国家图书馆运行爬虫来存档网站。著名的例子是美国国会图书馆[1]和欧盟网络档案馆[2]。
Web 挖掘:Web 的爆炸式增长为数据挖掘带来了前所未有的机遇。Web 挖掘有助于从互联网上发现有用的知识。例如,顶级金融公司使用爬虫下载股东会议和年度报告,以了解关键的公司举措。
网络监控。这些爬虫帮助监控互联网上的版权和商标侵权行为。例如,Digimarc [3]利用爬虫来发现盗版作品和报告。
开发一个网络爬虫的复杂性取决于我们打算支持的规模。它可以是一个只需要几个小时就能完成的小型学校项目,也可以是一个需要专业工程团队不断改进的大型项目。由此,我们将在下面探讨尺度和特性来支持 。
步骤 1 -了解问题并确定设计范围
网络爬虫的基本算法很简单:
1。给定一组 URL,下载由这些 URL 寻址的所有网页。
2。从这些网页中提取网址
3。向要下载的 URL 列表中添加新的 URL。重复这三个步骤。
网络爬虫的工作真的像这个基本算法这么简单吗?不完全是。设计一个高度可扩展的网络爬虫是一项极其复杂的任务。任何人都不太可能在面试时间内设计出一个庞大的网络爬虫。在跳入设计之前,我们必须提出问题,了解需求,建立设计范围:
候选 : 爬虫的主要用途是什么?是用于搜索引擎索引,数据挖掘,还是其他?
面试官 : 搜索引擎索引。
候选 : 网络爬虫每月收集多少网页?
面试官:10 亿页。
候选 : 包含哪些内容类型?仅 HTML 还是 pdf 和图像等其他内容类型?
面试官 :只有 HTML。
候选 : 我们要考虑新增或编辑的网页吗?
面试官 : 是的,要考虑新增加或编辑的网页。
候选人 : 我们需要存储从 web 上抓取的 HTML 页面吗?
面试官 : 是的,最多 5 年
候选人 : 我们如何处理内容重复的网页?
面试官 : 内容重复的页面应忽略。
以上是你可以问面试官的一些问题。理解需求和澄清歧义是很重要的。即使你被要求设计一个像网络爬虫这样简单明了的产品,你和你的面试官可能也不会有相同的假设。
除了向你的面试官澄清功能之外,记下一个好的网络爬虫的以下特征也很重要
可扩展性:web 非常大。外面有数十亿的网页。
健壮性:网络充满陷阱。糟糕的 HTML,没有反应的服务器,崩溃,恶意链接等。都很常见。爬虫必须处理所有这些边缘情况。
礼貌:爬虫不要在短时间间隔内向一个网站提出太多请求。
可扩展性 :系统非常灵活,只需很小的改动就能支持新的内容类型。例如,如果我们将来想要抓取图像文件,我们应该不需要重新设计整个系统。
信封估算的背面
下面的估计是基于许多假设的,与面试官沟通以达成共识是很重要的。
假设每月有 10 亿个网页被下载。
QPS:30 天 / 24 小时 / 3600 秒 = 每秒 ~400 页。
峰值 QPS = 2 * QPS = 800
假设平均网页大小为 500k。
10 亿页 x 500k = 每月 500 TB存储。如果你对数字存储单元不清楚,请再次阅读第二章的“2 的幂”一节。
假设数据存储五年,500 TB * 12 个月 * 5 年 = 30 PB。需要 30 PB 的存储空间来存储五年的内容。
第二步-提出高层次设计并获得认同
一旦明确了需求,我们就进入高层次的设计。受之前关于网页抓取的研究的启发[4] [5],我们提出了一个如图 9-2 所示的高级设计。
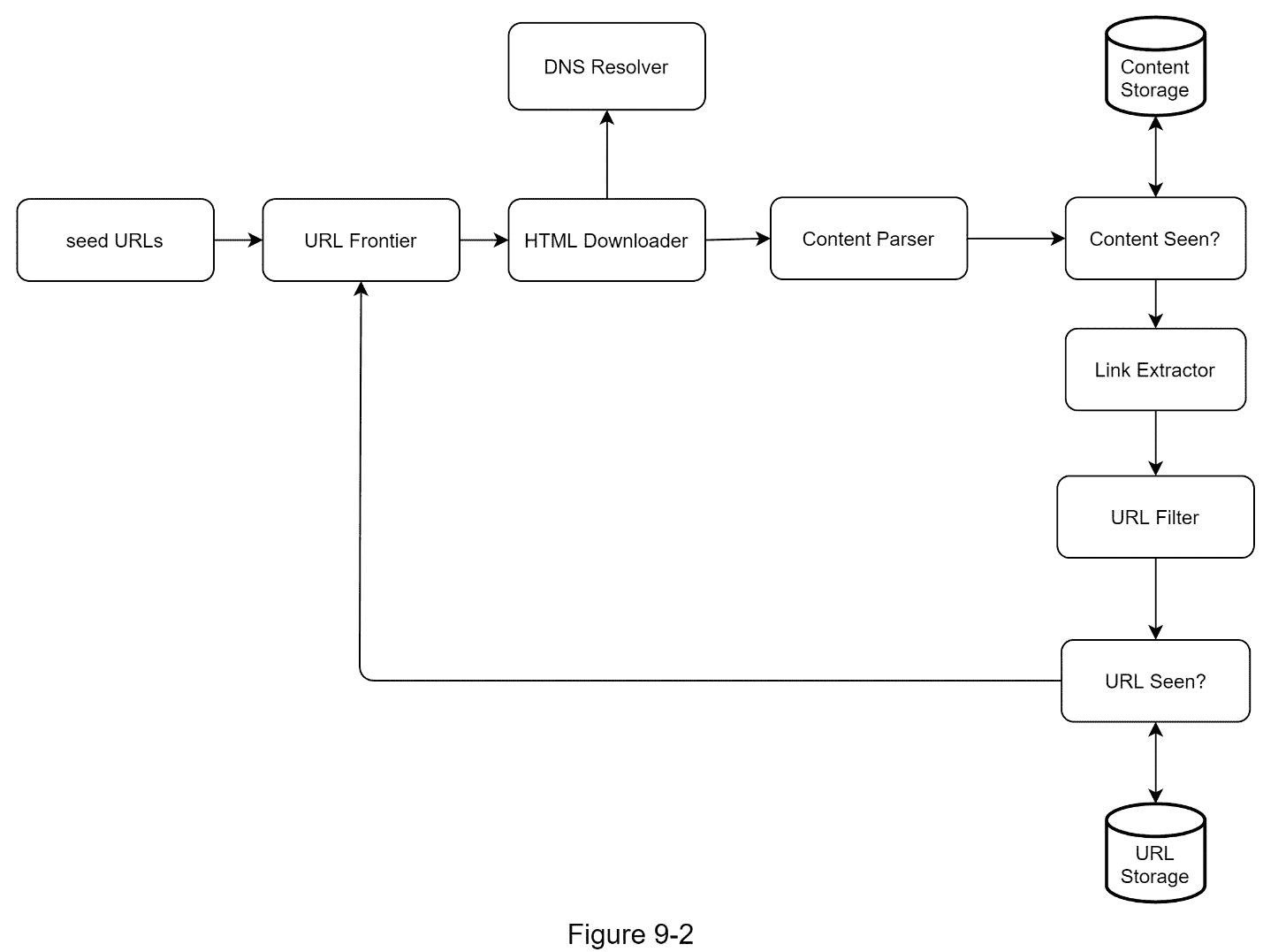
首先,我们探索每个设计组件,了解它们的功能。然后,我们一步一步地检查爬虫工作流。
种子网址
网络爬虫使用种子 URL 作为爬行过程的起点。例如,要从一所大学的网站抓取所有网页,选择种子 URL 的直观方法是使用该大学的域名。
为了抓取整个网络,我们需要在选择种子 URL 时有创意。一个好的种子 URL 是一个好的起点,爬虫可以利用它遍历尽可能多的链接。一般的策略是将整个 URL 空间分成更小的空间。第一种提出的方法是基于位置的,因为不同的国家可能有不同的流行网站。另一种方式是根据主题选择种子 URLs 例如,我们可以将 URL 空间划分为购物、运动、医疗保健等。种子 URL 选择是一个开放式问题。不指望你给出完美的答案。大声想出来。
URL 边界
大多数现代网络爬虫将抓取状态分为两种:待下载和已下载。存储要下载的 URL 的组件称为 URL Frontier。你可以称之为先进先出(FIFO)队列。有关 URL 边界的详细信息,请参考深入探讨。
HTML 下载程序
HTML 下载程序从互联网上下载网页。这些 URL 由 URL Frontier 提供。
DNS 解析器
要下载网页,必须将 URL 转换成 IP 地址。HTML 下载程序调用 DNS 解析器来获取 URL 的相应 IP 地址。例如,从 2019 年 3 月 5 日起,URL www.wikipedia.org 将转换为 IP 地址 198.35.26.96。
内容解析器
下载网页后,必须对其进行解析和验证,因为格式错误的网页会引发问题并浪费存储空间。 在爬行服务器中实现内容解析器会减慢爬行过程。因此,内容解析器是一个独立的组件。
看过的内容?
在线研究[6]显示,29%的网页是重复的内容,这可能导致相同的内容被多次存储。我们介绍“内容看过了吗?”数据结构来消除数据冗余并缩短处理时间。它有助于检测系统中先前存储的新内容。要比较两个 HTML 文档,我们可以逐字符比较。然而,这种方法既慢又耗时,尤其是当涉及数十亿个网页时。完成这项任务的有效方法是比较两个网页的哈希值[7]。
内容存储
它是一个存储 HTML 内容的存储系统。存储系统的选择取决于数据类型、数据大小、访问频率、生命周期等因素。磁盘和内存都要用。
大部分内容都存储在磁盘上,因为数据集太大,内存放不下。
流行内容被保存在内存中以减少延迟。
网址提取器
URL 提取器解析并提取 HTML 页面中的链接。图 9-3 显示了一个链接提取过程的例子。通过添加“https://en.wikipedia.org”前缀,相对路径被转换为绝对 URL。

URL 过滤器
URL 过滤器排除“黑名单”网站中的某些内容类型、文件扩展名、错误链接和 URL。
网址见过?
“网址看到了吗?”是一种数据结构,用于跟踪之前访问过的 URL 或已经在前沿访问过的 URL。"看到网址了吗?"有助于避免多次添加相同的 URL,因为这可能会增加服务器负载并导致潜在的无限循环。
布隆过滤器和哈希表是实现“URL 是否可见?”的常用技术组件。我们不会在这里讨论 bloom filter 和 hash 表的详细实现。有关更多信息,请参考参考资料[4] [8]。
网址存储
URL 存储存储已经访问过的 URL。
到目前为止,我们已经讨论了每个系统组件。接下来,我们将它们放在一起解释工作流程。
网络爬虫工作流程
为了更好地解释工作流程,在设计图中增加了顺序号,如图 9-4 所示。
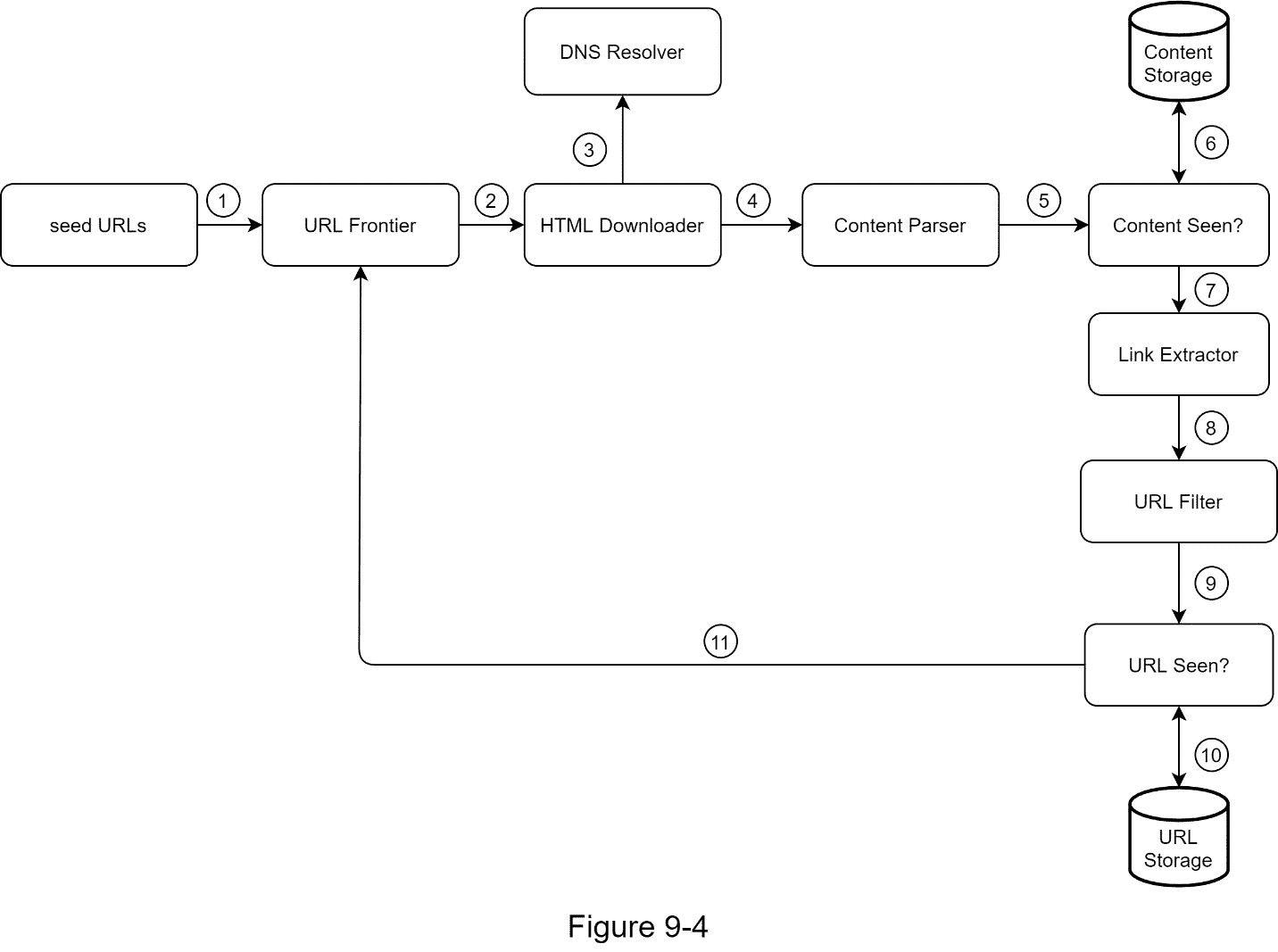
步骤 1:将种子 URL 添加到 URL 边界
步骤 2: HTML 下载程序从 URL Frontier 获取一个 URL 列表。
第三步:HTML Downloader 从 DNS 解析器获取 URL 的 IP 地址,开始下载。
步骤 4:内容解析器解析 HTML 页面并检查页面是否格式错误。
步骤 5:在内容被解析和验证之后,它被传递给“内容是否被看到?”组件。
步骤 6:“内容可见”组件检查 HTML 页面是否已经在存储器中。
如果在存储中,这意味着不同 URL 中的相同内容已经被处理。在这种情况下,HTML 页面将被丢弃。
如果不在存储中,系统之前没有处理过相同的内容。内容被传递到链接提取器。
第 7 步:链接提取器从网页中提取链接。
步骤 8:提取的链接被传递给 URL 过滤器。
步骤 9:在链接被过滤后,它们被传递给“URL 是否可见?”组件。
步骤 10:“URL Seen”组件检查一个 URL 是否已经在存储器中,如果是,则它之前被处理过,并且不需要做任何事情。
步骤 11:如果一个 URL 以前没有被处理过,它被添加到 URL 边界。
步骤 3 -设计深度潜水
到目前为止,我们已经讨论了高层设计。接下来,我们将深入讨论最重要的建筑构件和技术:
深度优先搜索(DFS) vs 广度优先搜索(BFS)
网址前沿
HTML 下载工具
鲁棒性
扩展性
检测并避免有问题的内容
DFS 与 BFS 的比较
你可以把网络想象成一个有向图,网页作为节点,超链接(URL)作为边。爬行过程可以被视为从一个网页到另一个网页遍历有向图。两种常见的图遍历算法是 DFS 和 BFS。但是,DFS 通常不是一个好的选择,因为 DFS 的深度可能非常深。
BFS 通常由网络爬虫使用,并通过先进先出(FIFO)队列来实现。在 FIFO 队列中,URL 按照它们入队的顺序出队。然而,这种实现有两个问题:
来自同一个网页的大多数链接都链接回同一个主机。在图 9-5 中,wikipedia.com 的所有链接都是内部链接,使得爬虫忙于处理来自同一主机(wikipedia.com)的 URL。当爬虫试图并行下载网页时,维基百科服务器会被请求淹没。这被认为是“不礼貌的”。

标准 BFS 不考虑 URL 的优先级。网络很大,不是每个页面都有相同的质量和重要性。因此,我们可能希望根据 URL 的页面排名、web 流量、更新频率等来确定它们的优先级。
URL 边界
URL frontier 有助于解决这些问题 。URL 边界是存储要下载的 URL 的数据结构。URL 边界是确保礼貌、URL 优先级和新鲜度的重要组成部分。参考资料[5] [9]中提到了几篇值得注意的关于 URL 边界的论文。这些论文的研究结果如下:
礼貌
一般来说,网络爬虫应该避免在短时间内向同一个主机服务器发送太多请求。发送过多的请求被认为是“不礼貌的”,甚至会被视为拒绝服务(DOS)攻击。例如,在没有任何约束的情况下,爬虫每秒钟可以向同一个网站发送数千个请求。这可能会使 web 服务器不堪重负。
加强礼貌的总体思路是从同一个主机上一次下载一个页面。可以在两个下载任务之间添加延迟。通过维护从网站主机名到下载(工作)线程映射来实现礼貌约束。每个下载器线程都有一个单独的 FIFO 队列,并且只下载从该队列获得的 URL。图 9-6 显示了管理礼貌的设计。
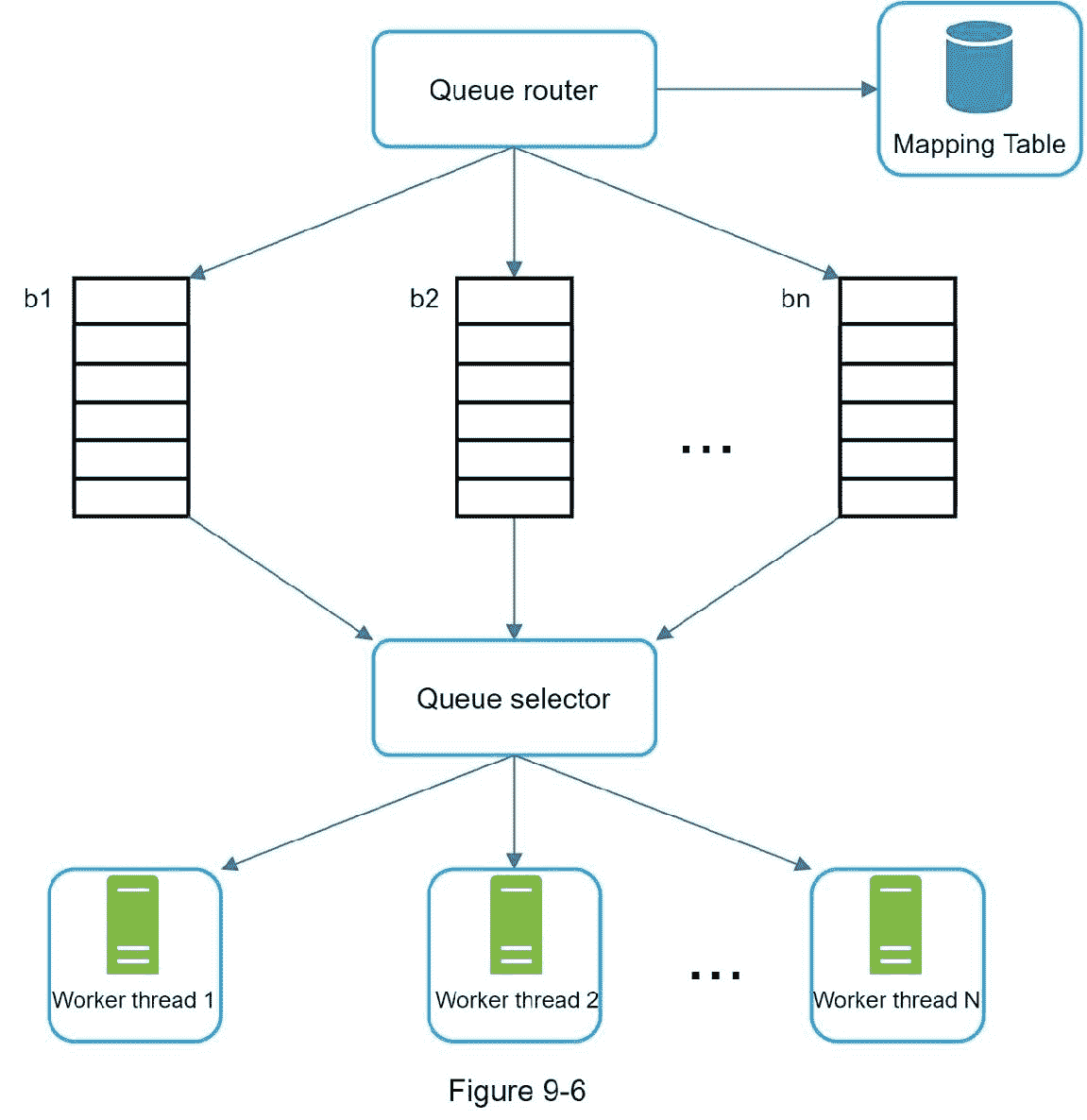
队列路由器:它确保每个队列(b1,b2,… bn)只包含来自同一个主机的 URL。
映射表:将每台主机映射到一个队列。
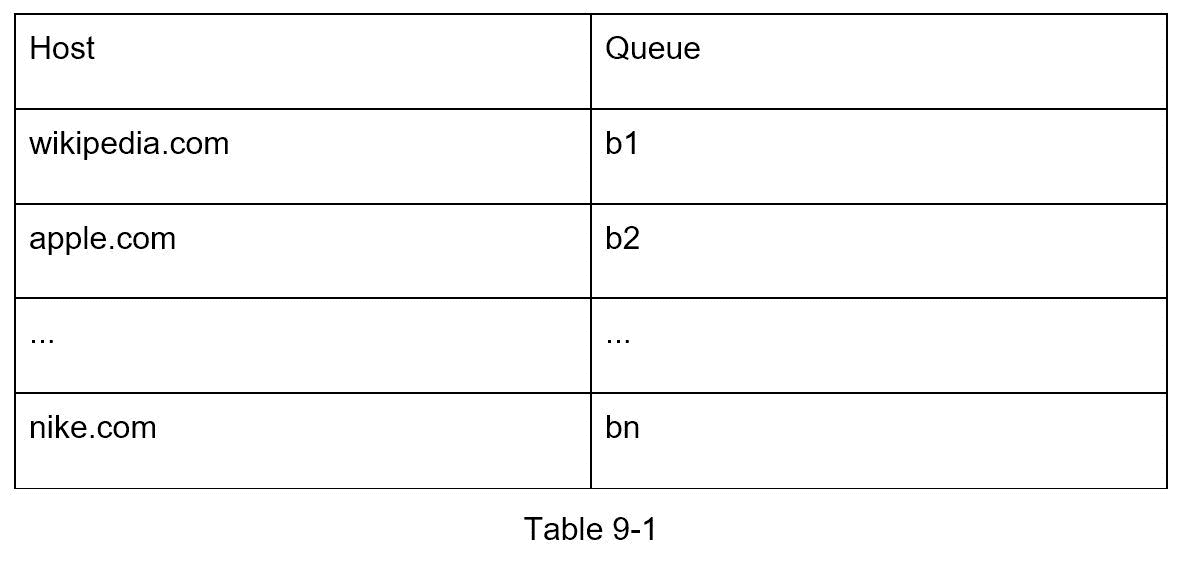
FIFO 队列 b1、b2 到 bn:每个队列包含来自同一主机的 URL。
队列选择器:每个工作线程被映射到一个 FIFO 队列,它只从那个队列下载 URL。队列选择逻辑由队列选择器完成。
工作线程 1 到 n 一个工作线程从同一个主机上一个接一个的下载网页。可以在两个下载任务之间添加延迟。
优先级
来自苹果产品论坛的随机帖子与苹果主页上的帖子具有非常不同的权重。尽管它们都有“Apple”关键字,但对于爬虫来说,首先爬取 Apple 主页是明智的。
我们根据有用性对 URL 进行优先排序,有用性可以通过 PageRank [10]、网站流量、更新频率等来衡量。“优先排序器”是处理 URL 优先排序的组件。请参考参考资料[5] [10]以深入了解这一概念。
图 9-7 显示了管理 URL 优先级的设计。
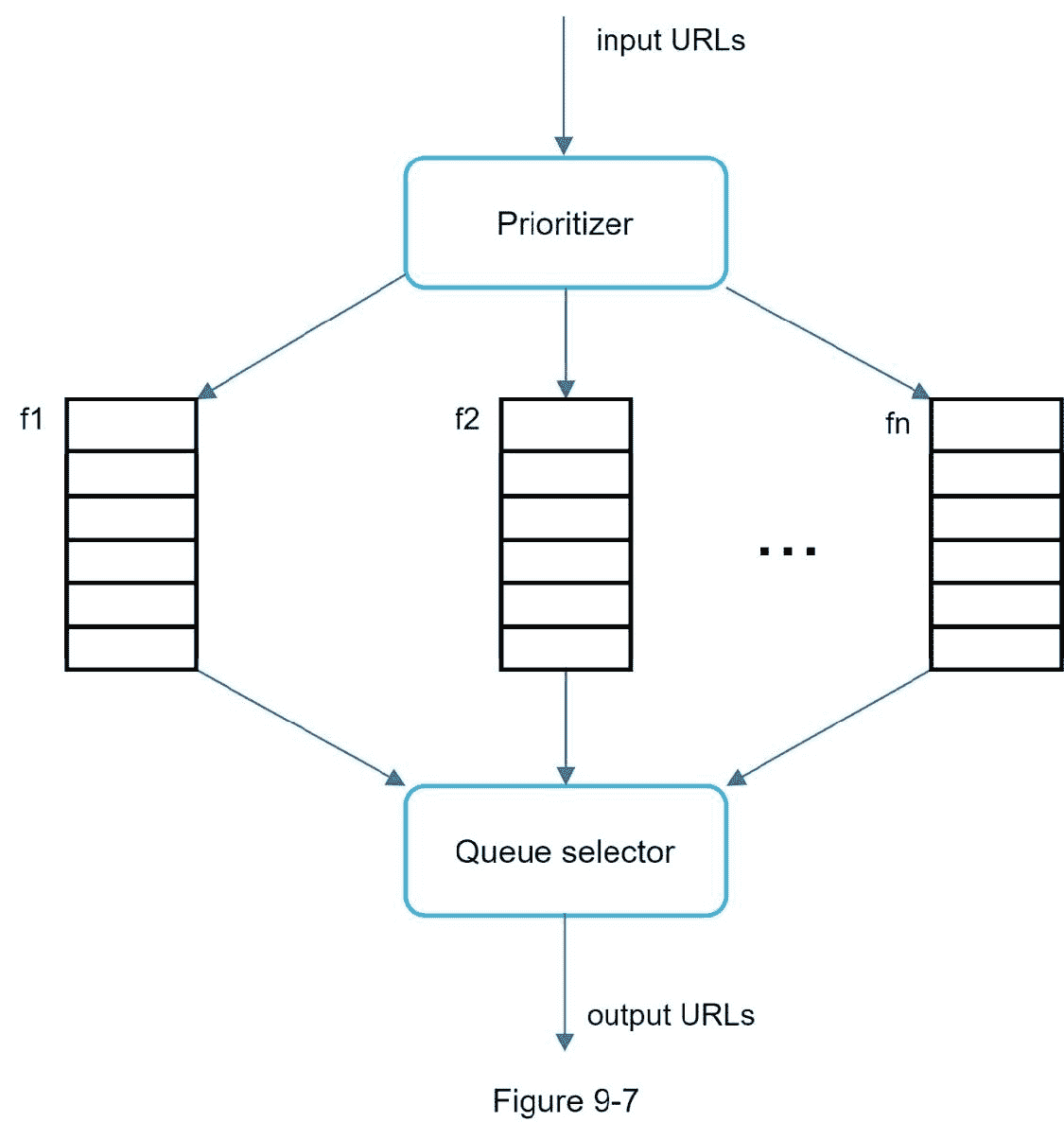
优先级排序器:它将 URL 作为输入并计算优先级。
队列 f1 到 fn:每个队列都有一个指定的优先级。具有高优先级的队列以较高的概率被选择。
队列选择器:随机选择一个偏向高优先级队列的队列。
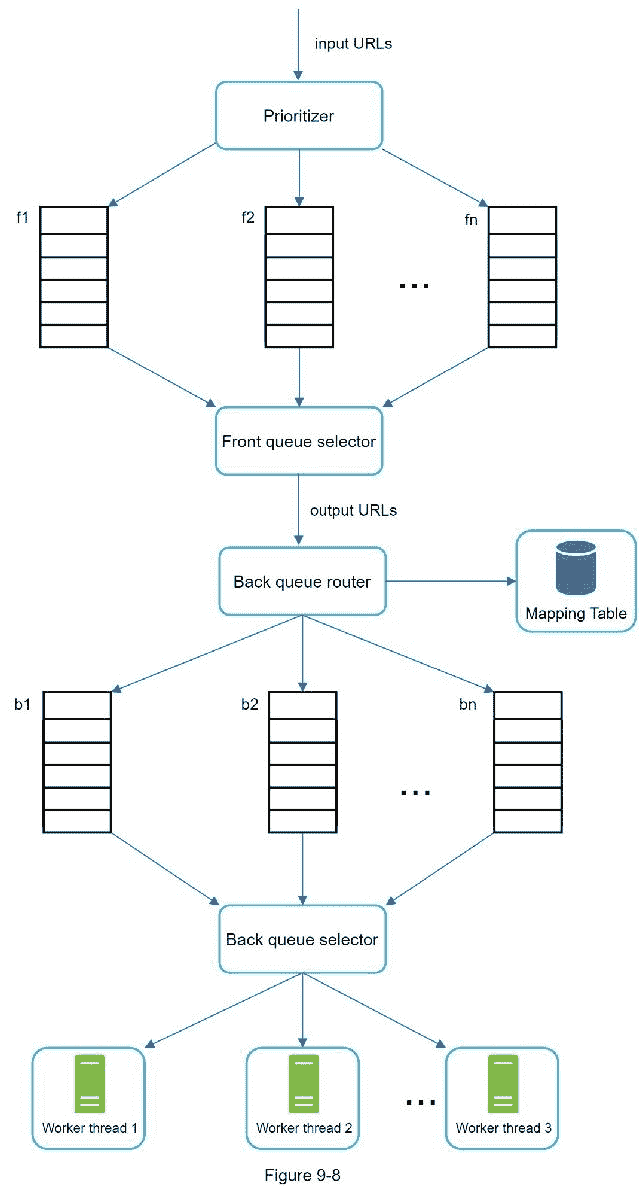
图 9-8 展示了 URL 边界设计,它包含两个模块:
前排队列:管理优先级
后排:管理礼貌
新鲜度
网页不断地被添加、删除和编辑。网络爬虫必须定期重新抓取下载的页面,以保持我们的数据集新鲜。重新搜索所有的 URL 既耗时又耗费资源。下面列出了一些优化新鲜度的策略:
基于网页更新历史重新抓取。
优先处理网址,首先更频繁地重新抓取重要网页。
URL 边界的存储
在搜索引擎的真实世界抓取中,前沿的 URL 数量可能是数亿个[4]。把所有东西都放在内存中既不耐用也不可伸缩。将所有东西都保存在磁盘中也是不可取的,因为磁盘很慢;这很容易成为爬行的瓶颈。
我们采用了混合方法。大多数 URL 都存储在磁盘上,所以存储空间不是问题。为了降低从磁盘读取和向磁盘写入的成本,我们在内存中维护用于入队/出队操作的缓冲区。缓冲区中的数据会定期写入磁盘。
HTML 下载程序
HTML 下载器使用 HTTP 协议从互联网下载网页。在讨论 HTML 下载器之前,我们先来看看 Robots 排除协议。
Robots.txt
Robots.txt,称为 Robots Exclusion Protocol,是网站用来与爬虫通信的标准。它指定允许爬虫下载哪些页面。在尝试对网站进行爬网之前,爬网程序应首先检查其对应的 robots.txt 并遵循其规则。
为了避免重复下载 robots.txt 文件,我们缓存了该文件的结果。文件会定期下载并保存到缓存中。这里有一段来自 https://www.amazon.com/robots.txt的 robots.txt 文件,其中一些目录如 creatorhub 是谷歌机器人不允许的。
User Agent: Googlebot
Disallow: /creatorhub/*
Disallow: /rss/people/*/reviews
Disallow: /gp/pdp/rss/*/reviews
Disallow: /gp/CDP/会员评论/
Disallow: /gp/aw/cr/
除了 robots.txt,性能优化是我们将为 HTML 下载器介绍的另一个重要概念。
性能优化
下面是 HTML 下载程序的性能优化列表。
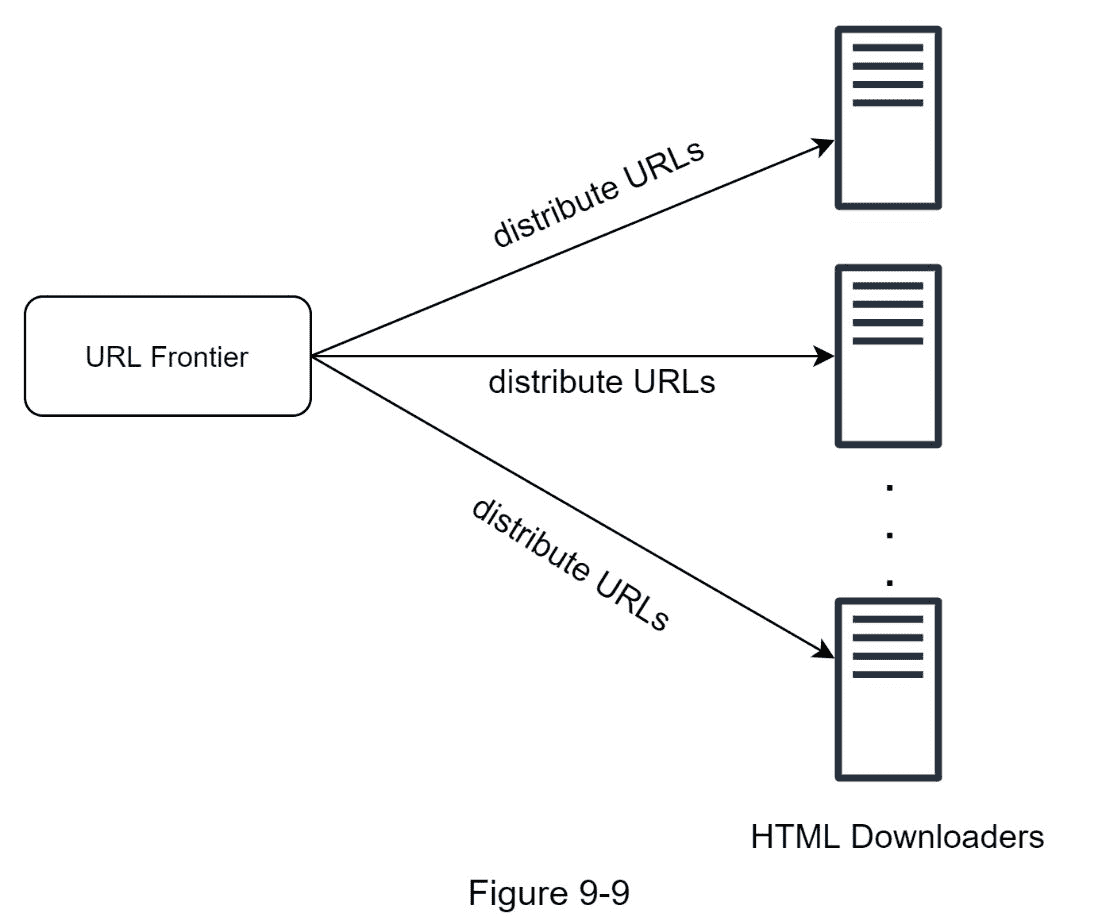
1。分布式抓取
为了实现高性能,爬行作业被分布到多个服务器上,并且每个服务器运行多个线程。URL 空间被分割成更小的部分;因此,每个下载器负责 URL 的一个子集。图 9-9 显示了一个分布式抓取的例子。
2。缓存 DNS 解析器
DNS 解析器是爬虫的瓶颈,因为由于许多 DNS 接口的同步性质,DNS 请求可能需要时间。DNS 响应时间从 10 毫秒到 200 毫秒不等。一旦 crawler 线程执行了对 DNS 的请求,其他线程就会被阻塞,直到第一个请求完成。维护我们的 DNS 缓存以避免频繁调用 DNS 是一种有效的速度优化技术。我们的 DNS 缓存保存域名到 IP 地址的映射,并由 cron 作业定期更新。
3。地点
在地理上分布爬行服务器。当爬网服务器离网站主机越近,爬网程序的下载时间就越快。设计局部性适用于大多数系统组件:爬网服务器、缓存、队列、存储等。
4。短暂超时
一些网络服务器响应缓慢或者根本没有响应。为了避免长时间等待,规定了最大等待时间。如果主机在预定义的时间内没有响应,crawler 将停止作业并搜索其他一些页面。
鲁棒性
除了性能优化,健壮性也是一个重要的考虑因素。我们提出了几种提高系统鲁棒性的方法:
一致哈希:这有助于在下载者之间分配负载。可以使用一致哈希来添加或删除新的下载器服务器。更多细节请参考第五章:设计一致哈希。
保存抓取状态和数据:为了防止失败,抓取状态和数据被写入存储系统。通过加载保存的状态和数据,可以轻松重启中断的爬网。
异常处理:在大规模系统中,错误是不可避免的,也是常见的。爬虫必须在不使系统崩溃的情况下优雅地处理异常。
数据验证:这是防止系统出错的重要措施。
扩展性
随着几乎每个系统的发展,设计目标之一是使系统足够灵活以支持新的内容类型。爬行器可以通过插入新模块来扩展。图 9-10 显示了如何添加新模块。
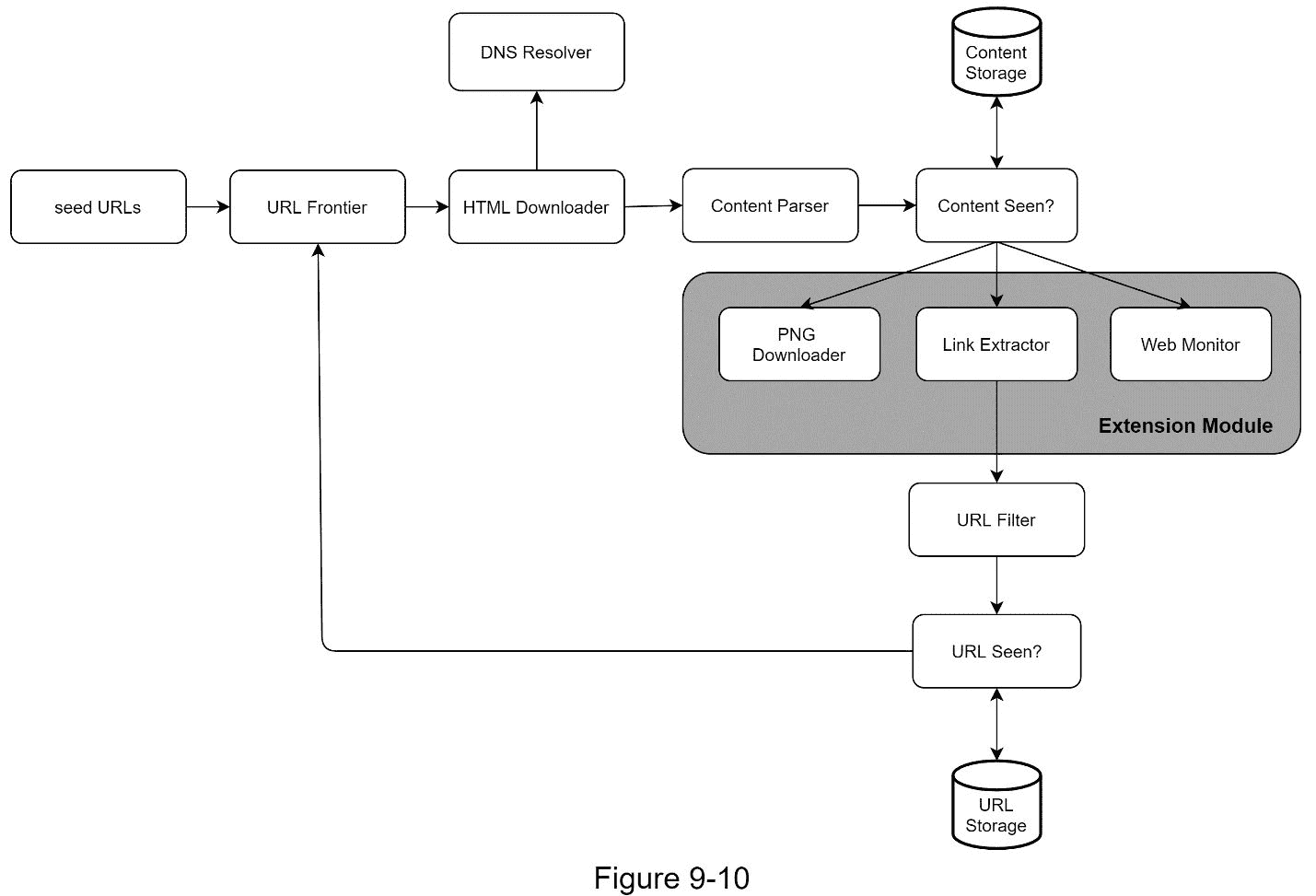
插入 PNG 下载器模块,下载 PNG 文件。
新增网络监控模块,监控网络,防止侵犯版权和商标。
检测并避免有问题的内容
本节讨论检测和预防多余的、 无意义的或有害的内容。
1。冗余内容
如前所述,近 30%的网页是重复的。哈希或校验和有助于检测重复[11]。
2。蜘蛛陷阱
蜘蛛陷阱是一个网页,它会使爬虫陷入无限循环。例如,一个无限深的目录结构如下所示:www.spidertrapexample.com/foo/bar/foo/bar/foo/bar/…
通过设置 URL 的最大长度可以避免这种蜘蛛陷阱。然而,不存在一种通用的解决方案来检测蜘蛛陷阱。包含蜘蛛陷阱的网站很容易识别,因为在此类网站上发现的网页异常多。很难开发自动算法来避免蜘蛛陷阱;但是,用户可以手动验证和识别蜘蛛陷阱,并从 crawler 中排除这些网站或应用一些定制的 URL 过滤器。
3。数据噪声
有些内容几乎没有价值,例如广告、代码片段、垃圾网址等。这些内容对爬网程序没有用,应该尽可能排除。
第四步——总结
在这一章中,我们首先讨论了优秀爬虫的特征:可伸缩性、礼貌性、可扩展性和健壮性。然后,我们提出了一个设计方案,并讨论了关键部件。构建一个可伸缩的网络爬虫并不是一个简单的任务,因为网络非常庞大,充满了陷阱。尽管我们已经涵盖了许多主题,但我们仍然错过了许多相关的话题:
服务器端渲染:许多网站使用 JavaScript、AJAX 等脚本动态生成链接。如果我们直接下载和解析网页,我们将无法检索动态生成的链接。为了解决这个问题,我们在解析页面之前先执行服务器端渲染(也称为动态渲染)[12]。
过滤掉不想要的页面:在有限的存储容量和抓取资源下,反垃圾邮件组件有利于过滤掉低质量和垃圾页面[13] [14]。
数据库复制和分片:复制和分片等技术用于提高数据层的可用性、可伸缩性和可靠性。
横向扩展:对于大规模的抓取,需要数百甚至数千台服务器来执行下载任务。关键是保持服务器无状态。
可用性、一致性和可靠性:这些概念是任何大型系统成功的核心。我们在第一章中详细讨论了这些概念。请回忆一下这些话题。
分析:收集和分析数据是任何系统的重要组成部分,因为数据是微调的关键因素。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] US Library of Congress: https://www.loc.gov/websites/
[2] EU Web Archive: http://data.europa.eu/webarchive
[3] Digimarc: https://www.digimarc.com/products/digimarc-services/piracy-intelligence
[4] Heydon A., Najork M. Mercator: A scalable, extensible web crawler World Wide Web, 2 (4) (1999), pp. 219-229
[5] By Christopher Olston, Marc Najork: Web Crawling. http://infolab.stanford.edu/~olston/publications/crawling_survey.pdf
[6] 29% Of Sites Face Duplicate Content Issues: https://tinyurl.com/y6tmh55y
[7] Rabin M.O., et al. Fingerprinting by random polynomials Center for Research in Computing Techn., Aiken Computation Laboratory, Univ. (1981)
[8] B. H. Bloom, “Space/time trade-offs in hash coding with allowable errors,”
Communications of the ACM, vol. 13, no. 7, pp. 422–426, 1970.
[9] Donald J. Patterson, Web Crawling:
https://www.ics.uci.edu/~lopes/teaching/cs221W12/slides/Lecture05.pdf
[10] L. Page, S. Brin, R. Motwani, and T. Winograd, “The PageRank citation
ranking: Bringing order to the web,” Technical Report, Stanford University,
1998.
[11] Burton Bloom. Space/time trade-offs in hash coding with allowable errors. Communications of the ACM, 13(7), pages 422--426, July 1970.
[12] Google Dynamic Rendering: https://developers.google.com/search/docs/guides/dynamic-rendering
[13] T. Urvoy, T. Lavergne, and P. Filoche, “Tracking web spam with hidden style similarity,” in Proceedings of the 2nd International Workshop on Adversarial Information Retrieval on the Web, 2006.
[14] H.-T. Lee, D. Leonard, X. Wang, and D. Loguinov, “IRLbot: Scaling to 6 billion pages and beyond,” in Proceedings of the 17th International World Wide Web Conference, 2008.
十、设计通知系统
近年来,通知系统已经成为许多应用程序中非常流行的功能。通知提醒用户重要信息,如突发新闻、产品更新、事件、产品等。它已经成为我们日常生活中不可或缺的一部分。在这一章中,你被要求设计一个通知系统。
通知不仅仅是移动推送通知。三种通知格式是:移动推送通知、SMS 消息和电子邮件。图 10-1 显示了这些通知的一个例子。
第一步——了解问题并确定设计范围
构建一个每天发送数百万条通知的可扩展系统并不是一件容易的事情。它需要对通知生态系统有深刻的理解。面试问题特意设计成开放式的,模棱两可的,你有责任提问明确要求。
候选人 :系统支持什么类型的通知?
面试官 :推送通知、短信、邮件。
候选: 是实时系统吗?
面试官: 姑且说是软实时系统吧。我们希望用户尽快收到通知。但是,如果系统工作负载较高,稍微延迟是可以接受的。
候选: 支持哪些设备?
面试官: iOS 设备,android 设备,以及笔记本电脑/台式机。
候选: 什么触发通知?
面试官: 客户端应用程序可以触发通知。它们也可以在服务器端进行调度。
候选人: 用户可以选择退出吗?
面试官: 是的,选择退出的用户将不再收到通知。
候选人: 每天发出多少通知?
面试官:1000 万条移动推送通知,100 万条短信,500 万封邮件。
第二步——提出高水平的设计并获得认同
本节展示了支持各种通知类型的高级设计:iOS 推送通知、Android 推送通知、短信和电子邮件。其结构如下:
不同类型的通知
联系信息采集流程
通知收发流程
不同类型的通知
我们先来看看每种通知类型在高层次上是如何工作的。
iOS 推送通知
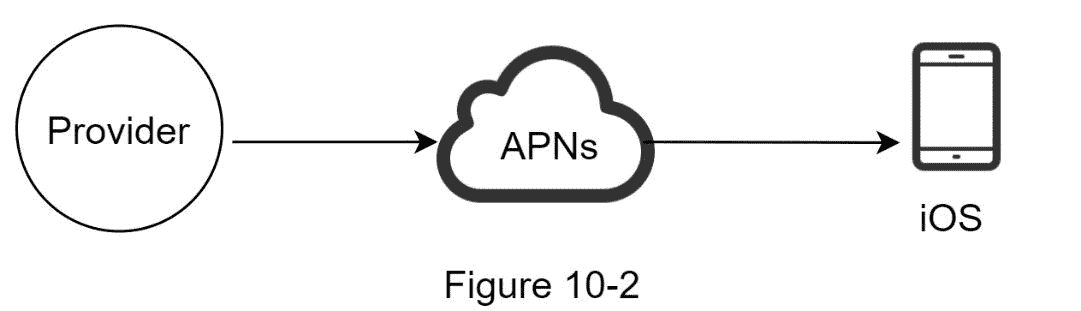
我们主要需要三个组件来发送 iOS 推送通知:
提供者。提供商构建通知请求并将其发送给苹果推送通知服务(APNS)。为了构造推送通知,提供商提供以下数据:
设备令牌:这是用于发送推送通知的唯一标识符。
有效负载:这是一个 JSON 字典,包含通知的有效负载。下面是一个例子:

APNS:这是苹果提供的一项远程服务,用于向 iOS 设备传播推送通知。
iOS 设备:是终端客户端,接收推送通知。
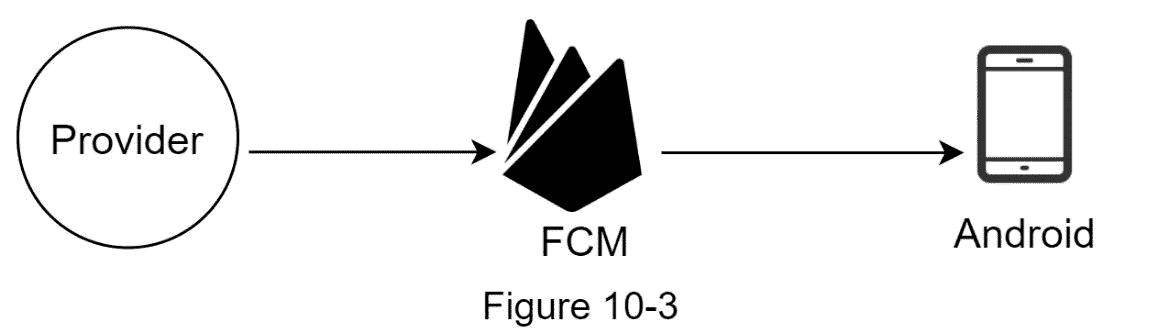
安卓推送通知
Android 采用了类似的通知流程。Firebase Cloud Messaging (FCM)通常用于向 android 设备发送推送通知,而不是使用 APN。
短信
对于短信,通常使用 Twilio [1]、Nexmo [2]等第三方短信服务。大部分是商业服务。
电子邮件
虽然公司可以建立自己的电子邮件服务器,但许多公司选择商业电子邮件服务。Sendgrid [3]和 Mailchimp [4]是最受欢迎的电子邮件服务,它们提供更好的投递率和数据分析。
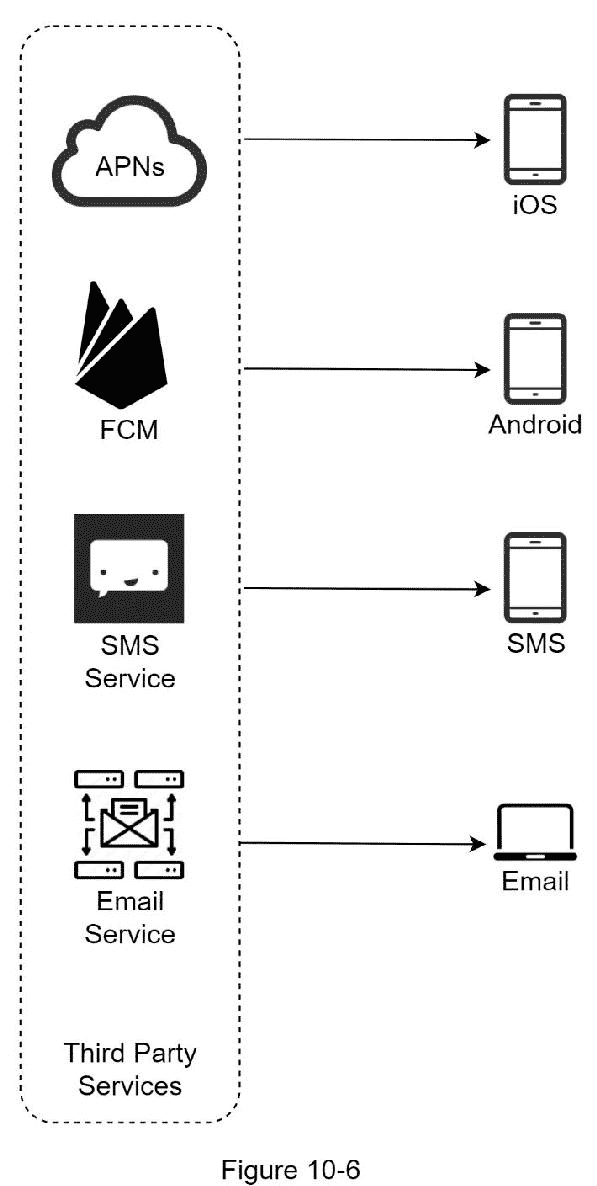
图 10-6 显示了包含所有第三方服务后的设计。
联系信息收集流程
为了发送通知,我们需要收集移动设备令牌、电话号码或电子邮件地址。如图 10-7 所示,当用户安装我们的应用程序或者第一次注册时,API 服务器收集用户的联系信息并存储在数据库中。
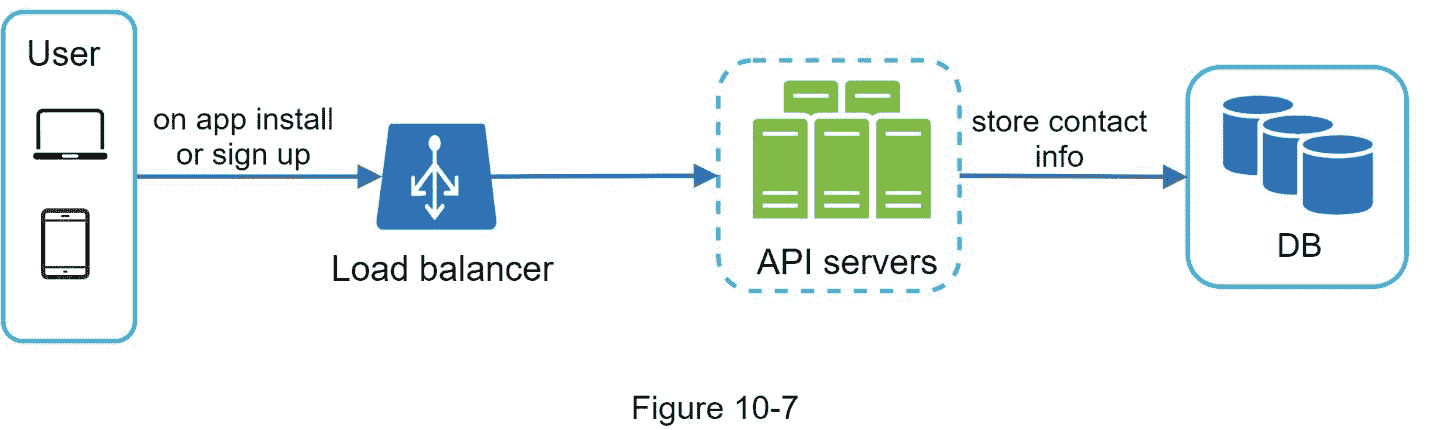
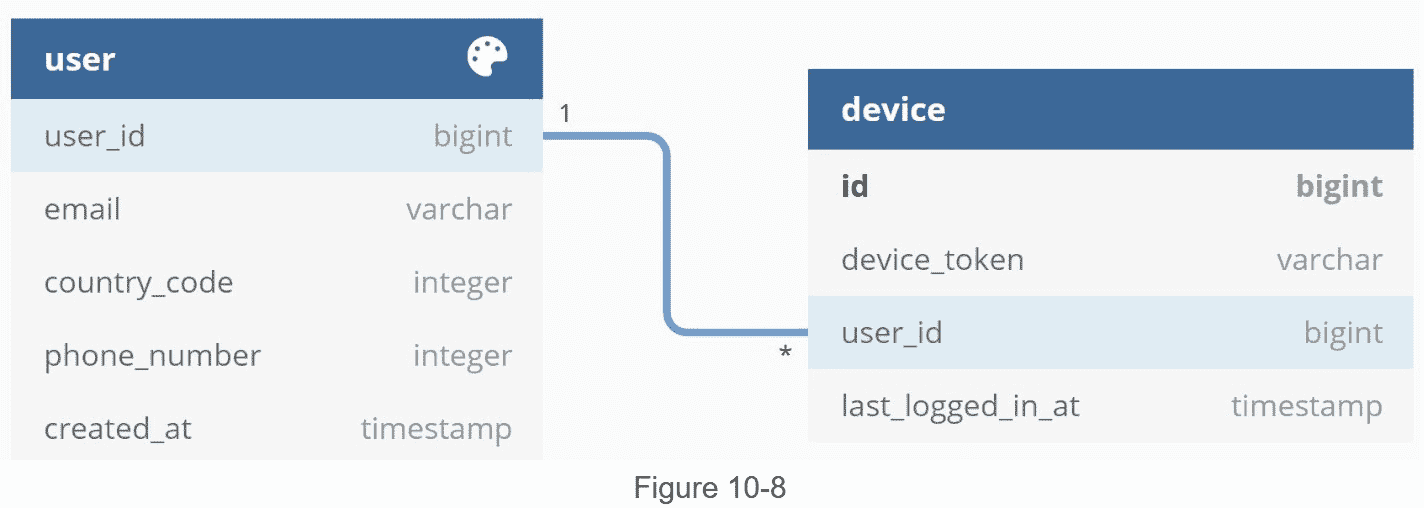
图 10-8 显示了存储联系信息的简化数据库表。电子邮件地址和电话号码存储在 用户 表中,而设备令牌存储在 设备 表中。一个用户可以有多个设备,这表明推送通知可以被发送到所有的用户设备。
通知发送/接收流程
我们将首先展示最初的设计;然后,提出一些优化。
高–水平设计
图 10-9 显示了设计,每个系统组件解释如下。
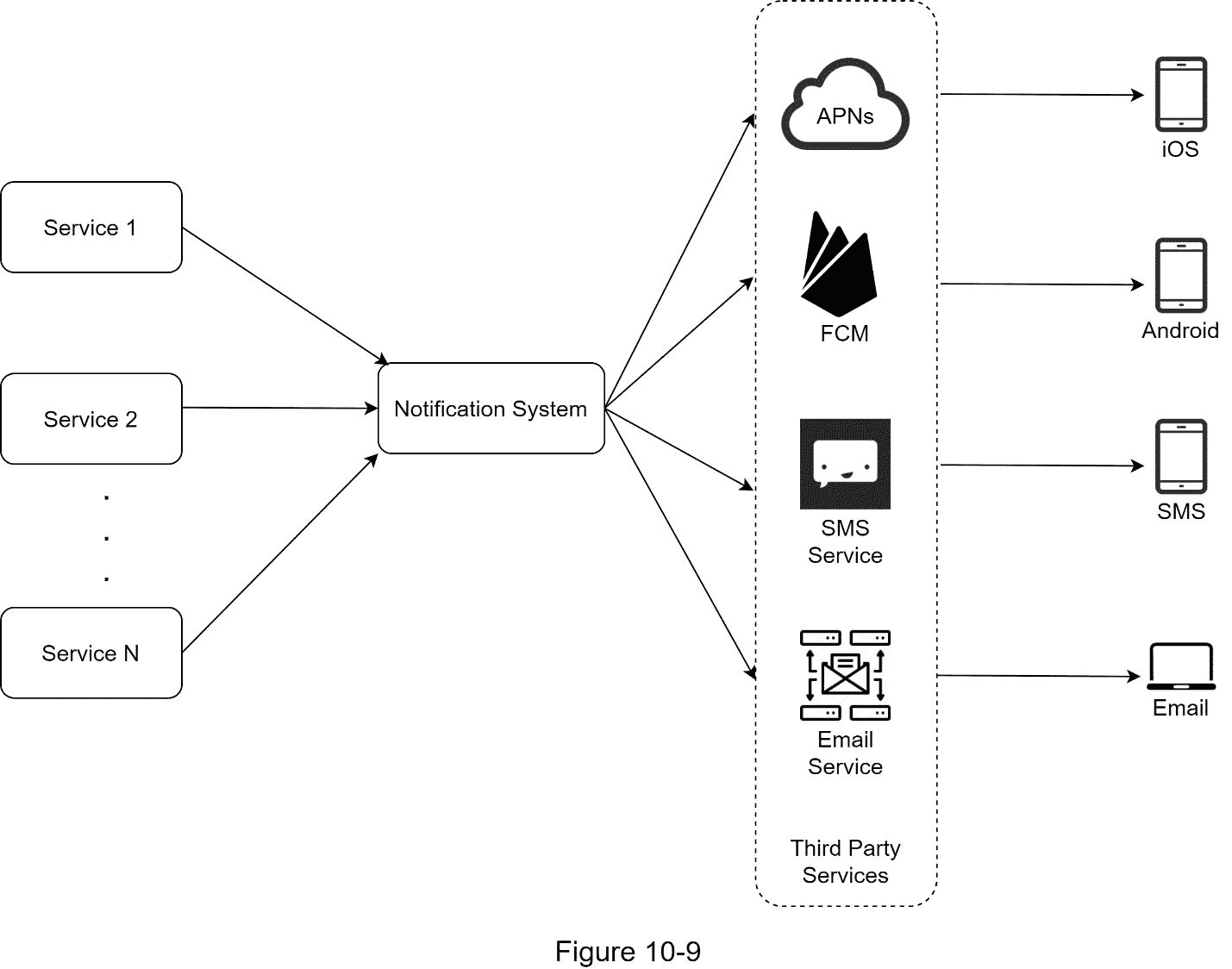
服务 1 到 N :服务可以是微服务、cron 作业,也可以是触发通知发送事件的分布式系统。例如,一个账单服务发送电子邮件提醒客户他们的到期付款,或者一个购物网站通过短信告诉客户他们的包裹将于明天送达。
通知系统 :通知系统是发送/接收通知的核心。从简单的开始,只使用一个通知服务器。它为服务 1 到 N 提供 API,并为第三方服务构建通知有效负载。
第三方服务: 第三方服务负责向用户发送通知。在与第三方服务集成的同时,我们需要额外关注可扩展性。良好的可扩展性意味着一个灵活的系统,可以很容易地插入或拔出第三方服务。另一个重要的考虑是,第三方服务可能在新的市场或未来不可用。例如,FCM 在中国是不可用的。因此,替代的第三方服务,如 Jpush,PushY 等,在那里使用。
iOS、Android、短信、电子邮件 :用户在其设备上接收通知。
在本设计中发现了三个问题:
单点故障(SPOF):单一通知服务器是指 SPOF。
难以扩展:通知系统在一台服务器上处理与推送通知相关的一切。独立扩展数据库、缓存和不同的通知处理组件是一项挑战。
性能瓶颈:处理和发送通知可能是资源密集型的。例如,构建 HTML 页面和等待第三方服务的响应可能需要时间。在一个系统中处理所有事情会导致系统过载,尤其是在高峰时段。
高级设计(改进)
在列举了初始设计中的挑战后,我们对设计进行了如下改进:
将数据库和缓存移出通知服务器。
添加更多通知服务器并设置自动水平缩放。
引入消息队列来分离系统组件。
图 10-10 显示了改进的高层设计。
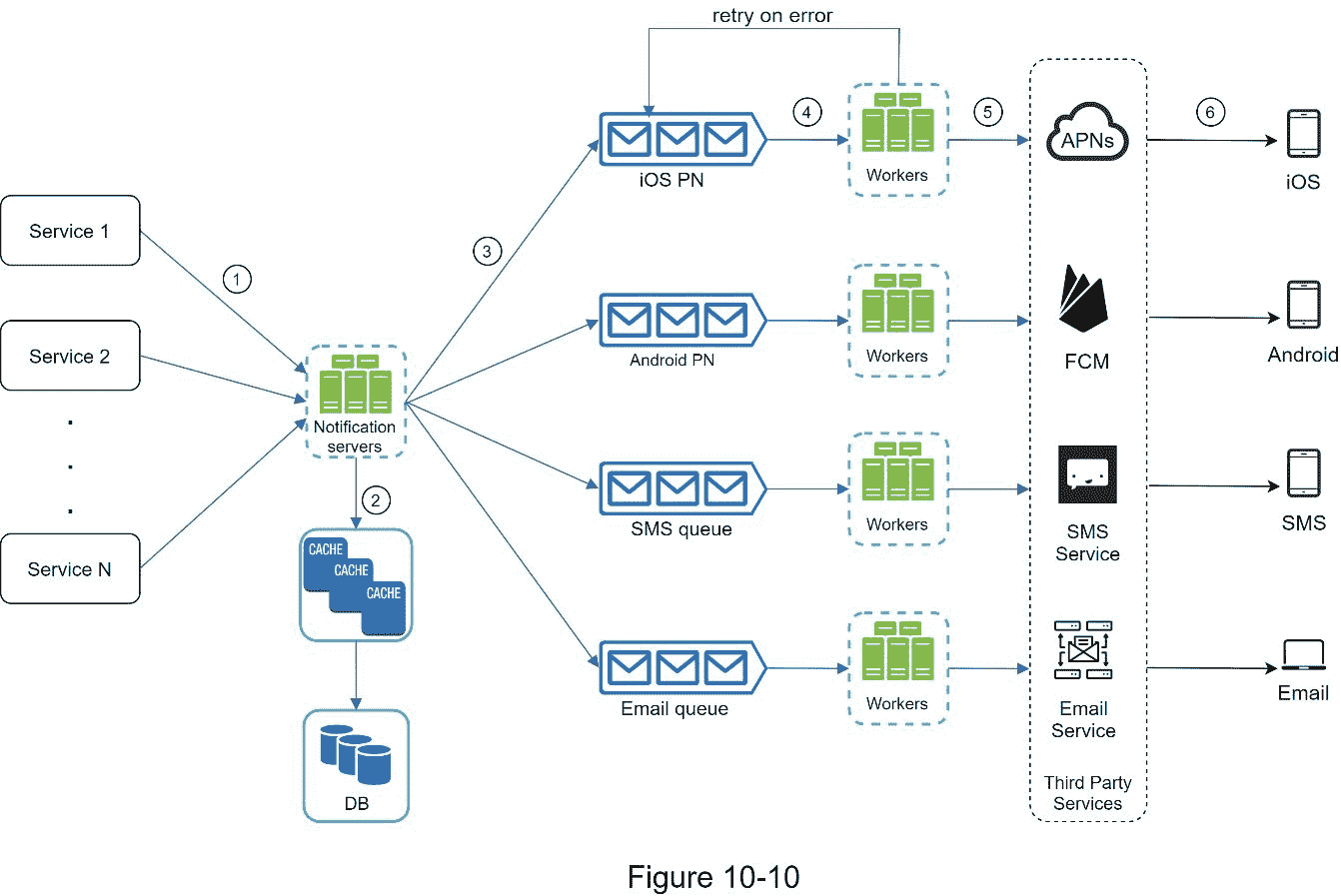
浏览上图的最佳方式是从左到右:
服务 1 到 N :它们代表通过通知服务器提供的 API 发送通知的不同服务。
通知服务器 :提供以下功能:
为发送通知的服务提供 API。这些 API 只能在内部访问或由经过验证的客户端访问,以防止垃圾邮件。
进行基本验证,以验证电子邮件、电话号码等。
查询数据库或缓存以获取呈现通知所需的数据。
将通知数据放入消息队列进行并行处理。
下面是发送电子邮件的 API 示例:
职务
请求体

缓存 :缓存用户信息、设备信息、通知模板。
DB :存储用户、通知、设置等数据。
消息队列 :它们移除组件之间的依赖关系。当要发送大量通知时,消息队列充当缓冲区。每种通知类型都分配有不同的消息队列,因此一个第三方服务的中断不会影响其他通知类型。
Workers:Workers 是从消息队列中拉出通知事件并发送给相应的第三方服务的服务器列表。
第三方服务 :已在初步设计中说明。
iOS、Android、短信、邮箱 :在初步设计中已经说明。
接下来,让我们看看每个组件如何协同工作来发送通知:
1。服务调用通知服务器提供的 API 来发送通知。
2。通知服务器从缓存或数据库中获取元数据,如用户信息、设备令牌和通知设置。
3。通知事件被发送到相应的队列进行处理。例如,iOS 推送通知事件被发送到 iOS PN 队列。
4。工作人员从消息队列中提取通知事件。
5。工作人员向第三方服务发送通知。
6。第三方服务向用户设备发送通知。
步骤 3 -设计深度潜水
在概要设计中,我们讨论了不同类型的通知、联系信息收集流程和通知发送/接收流程。我们将深入探讨以下内容:
可靠性。
附加组件和考虑事项:通知模板、通知设置、速率限制、重试机制、推送通知中的安全性、监控排队通知和事件跟踪。
更新设计。
可靠性
在分布式环境中设计通知系统时,我们必须回答几个重要的可靠性问题。
如何防止数据丢失?
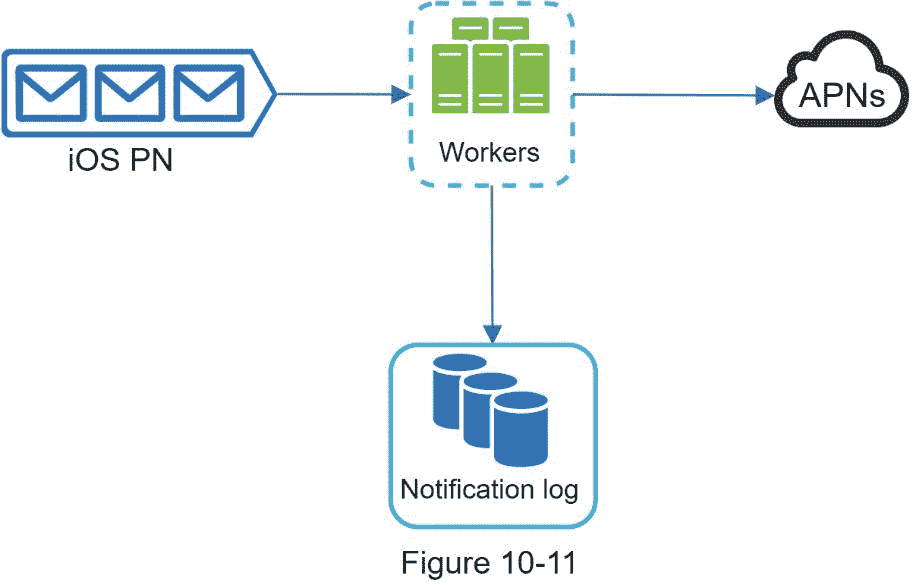
通知系统中最重要的要求之一是不能丢失数据。通知通常可以延迟或重新排序,但永远不会丢失。为了满足这一要求,通知系统将通知数据保存在数据库中,并实现重试机制。如图 10-11 所示,包含通知日志数据库是为了数据持久化。
收件人会收到一次通知吗?
简短的回答是否定的。尽管大多数情况下通知只发送一次,但分布式的本质可能会导致重复的通知。为了减少重复的发生,我们引入了重复数据删除机制,并仔细处理每个故障情况。下面是一个简单的重复数据删除逻辑:
当一个通知事件第一次到达时,我们通过检查事件 ID 来检查它以前是否被看到过。如果是之前看到的,就丢弃。否则,我们将发出通知。感兴趣的读者可以参考参考资料[5],探究为什么我们不能一次交货。
附加组件和注意事项
我们已经讨论了如何收集用户联系信息、发送和接收通知。通知系统远不止于此。这里我们讨论其他组件,包括模板重用、通知设置、事件跟踪、系统监控、速率限制等。
通知模板
大型通知系统每天会发出数百万条通知,其中许多通知都遵循相似的格式。引入通知模板是为了避免从头开始构建每个通知。通知模板是一种预先格式化的通知,通过自定义参数、样式、跟踪链接等来创建您的独特通知。下面是推送通知的一个示例模板。
正文:
你梦见了它。我们敢于挑战。[项目名称]已恢复—仅到[日期]为止。
CTA:
现在订购。或者,保存我的【物品名称】
使用通知模板的好处包括保持格式一致、减少误差和节省时间。
通知设置
用户通常每天会收到太多的通知,他们很容易感到不知所措。因此,许多网站和应用程序允许用户对通知设置进行精细控制。该信息存储在通知设置表中,具有以下字段:
用户标识 bigInt
channel varchar #推送通知、电子邮件或短信
opt_in boolean # opt-in 接收通知
在向用户发送任何通知之前,我们首先检查用户是否选择接收此类通知。
速率限制
为了避免过多的通知让用户不知所措,我们可以限制用户可以接收的通知数量。这很重要,因为如果我们发送得太频繁,接收者可能会完全关闭通知。
重试机制
当第三方服务未能发送通知时,该通知将被添加到消息队列中进行重试。如果问题仍然存在,将向开发人员发出警告。
推送通知中的安全性
对于 iOS 或 Android 应用,appKey 和 appSecret 用于保护推送通知 API[6]。只有经过认证或验证的客户端才允许使用我们的 API 发送推送通知。感兴趣的用户可以参考参考资料[6]。
监控排队通知
要监控的一个关键指标是排队通知的总数。如果数量很大,则工作线程处理通知事件的速度不够快。为了避免通知传递的延迟,需要更多的工人。图 10-12 显示了一个待处理的排队消息的例子。
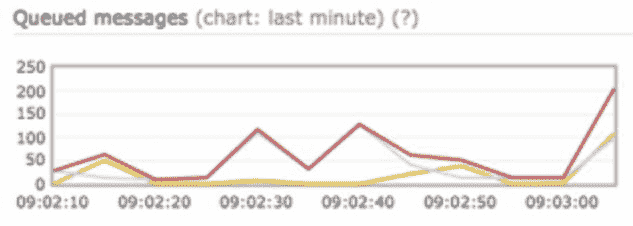
图 10-12
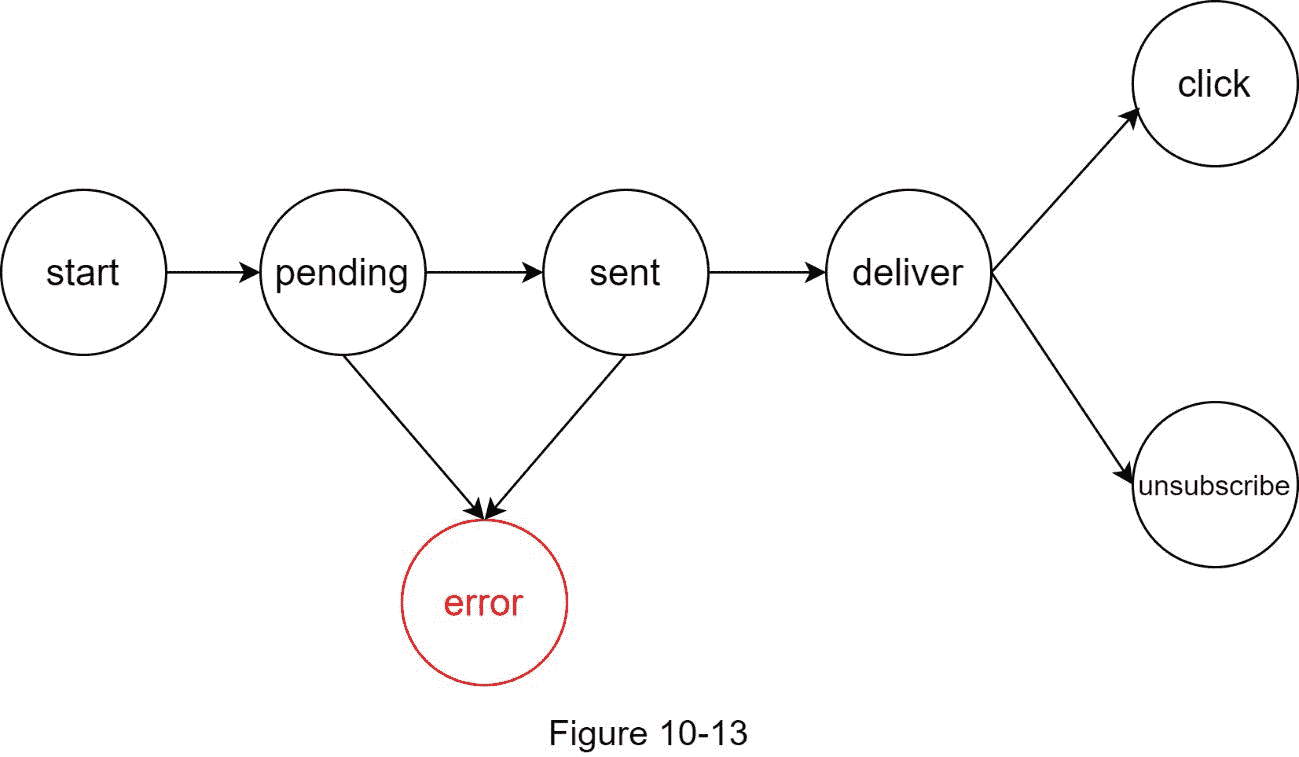
事件跟踪
打开率、点击率和参与度等通知指标对于了解客户行为非常重要。分析服务实现事件跟踪。通知系统和分析服务之间的集成通常是必需的。图 10-13 显示了出于分析目的可能被跟踪的事件的例子。
更新设计
图 10-14 显示了更新后的通知系统设计。
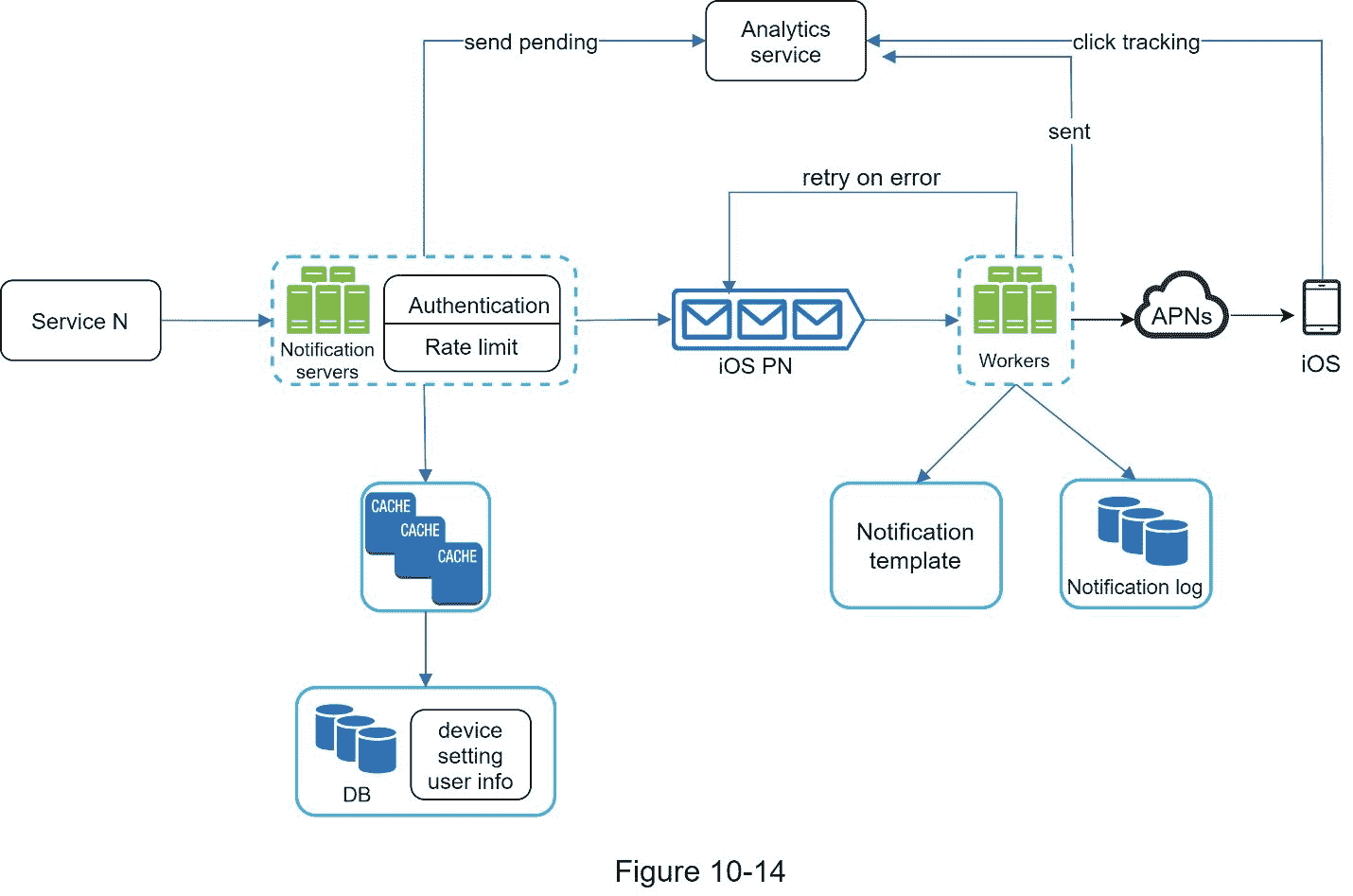
与之前的设计相比,本次设计增加了许多新部件。
通知服务器配备了两个更关键的功能:身份验证和速率限制。
我们还增加了重试机制来处理通知失败。如果系统未能发送通知,它们将被放回消息队列,工作人员将重试预定义的次数。
此外,通知模板提供了一致且高效的通知创建流程。
最后,增加了监控和跟踪系统,用于系统健康检查和未来改进。
步骤 4 -总结
通知是必不可少的,因为它们让我们了解重要的信息。它可能是网飞上关于你最喜欢的电影的推送通知,一封关于新产品折扣的电子邮件,或者一条关于你的网上购物支付确认的消息。
在本章中,我们描述了支持多种通知格式的可扩展通知系统的设计:推送通知、SMS 消息和电子邮件。我们采用消息队列来分离系统组件。
除了高级设计,我们还深入研究了更多组件和优化。
可靠性:我们提出了一个健壮的重试机制来最小化故障率。
安全性:AppKey/appSecret 对用于确保只有经过验证的客户端才能发送通知。
跟踪和监控:这些在通知流的任何阶段都可以实现,以捕获重要的统计数据。
尊重用户设置:用户可以选择不接收通知。我们的系统在发送通知前会先检查用户设置。
速率限制:用户会喜欢对他们收到的通知数量设置频率上限。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] Twilio SMS: https://www.twilio.com/sms
[2] Nexmo SMS: https://www.nexmo.com/products/sms
[3] Sendgrid: https://sendgrid.com/
[4] Mailchimp: https://mailchimp.com/
[5] You Cannot Have Exactly-Once Delivery: https://bravenewgeek.com/you-cannot-have-exactly-once-delivery/
[6] Security in Push Notifications: https://cloud.ibm.com/docs/services/mobilepush?topic=mobile-pushnotification-security-in-push-notifications
[7] RadditMQ: https://bit.ly/2sotIa6
十一、设计新闻订阅系统
在这一章中,你被要求设计一个新闻订阅系统。什么是新闻订阅源?根据脸书的帮助页面,“新闻提要是在你的主页中间不断更新的故事列表。新闻源包括状态更新、照片、视频、链接、应用活动 、 ,以及你在脸书上关注的人、页面和群组的赞。这是一个常见的面试问题。常见的类似问题有:设计脸书新闻提要、Instagram 提要、Twitter 时间线等。

第一步——了解问题并确定设计范围
第一组澄清性问题是当面试官让你设计一个新闻反馈系统时,你要明白她在想什么。至少,您应该弄清楚要支持哪些特性。下面是一个应聘者与面试官互动的例子:
考生 :这是手机 app 吗?还是一个 web app?还是两者都有?
面试官 :双方
候选人 :有哪些重要特征?
采访: 用户可以发表帖子,并在新闻订阅页面上看到她朋友的帖子。
候选人 : 新闻提要是按时间倒序排序还是按话题分数等任何特定顺序排序?例如,来自你亲密朋友的帖子得分更高。
面试官 : 为了简单起见,我们假设提要是按时间倒序排序的。
候选人 : 一个用户可以有多少好友?
面试官 : 5000
候选人 :车流量是多少?
面试官:1000 万 DAU
候选:feed 可以包含图片、视频,或者只是文字?
面试官 :可以包含媒体文件,包括图片和视频。
现在你已经收集了需求,我们集中精力设计系统。
第二步——提出高水平的设计并获得认同
设计分为两个流程:feed 发布和新闻 feed 构建。
Feed 发布:当用户发布帖子时,相应的数据被写入缓存和数据库。她朋友的新闻订阅源上有一个帖子。
新闻提要构建:为了简单起见,我们假设新闻提要是通过按时间倒序聚合朋友的帖子构建的。
新闻源 API
新闻提要 API 是客户端与服务器通信的主要方式。这些 API 是基于 HTTP 的,允许客户端执行操作,包括发布状态、检索新闻提要、添加好友等。我们讨论两个最重要的 API:提要发布 API 和新闻提要检索 API。
Feed 发布 API
要发布帖子,将向服务器发送 HTTP POST 请求。API 如下所示:
后/v1/me/进给
参数:
内容:内容是帖子的正文。
auth _ token:用于认证 API 请求。
新闻订阅源检索 API
检索新闻提要的 API 如下所示:
GET /v1/me/feed
参数:
auth _ token:用于认证 API 请求。
饲料出版
图 11-2 显示了提要发布流程的高层设计。

用户:用户可以在浏览器或移动应用程序上查看新闻源。一个用户通过 API 发布了一个内容为“你好”的帖子:
/v1/me/feed?内容=你好&认证令牌= {认证令牌}
负载均衡器:将流量分配给 web 服务器。
Web 服务器:Web 服务器将流量重定向到不同的内部服务。
Post 服务:在数据库和缓存中持久保存帖子。
Fanout 服务:向好友的新闻推送新内容。新闻订阅源数据存储在缓存中,以便快速检索。
通知服务:通知好友有新内容,发送推送通知。
新闻大楼
在本节中,我们将讨论新闻提要是如何在幕后构建的。图 11-3 显示了高层设计:
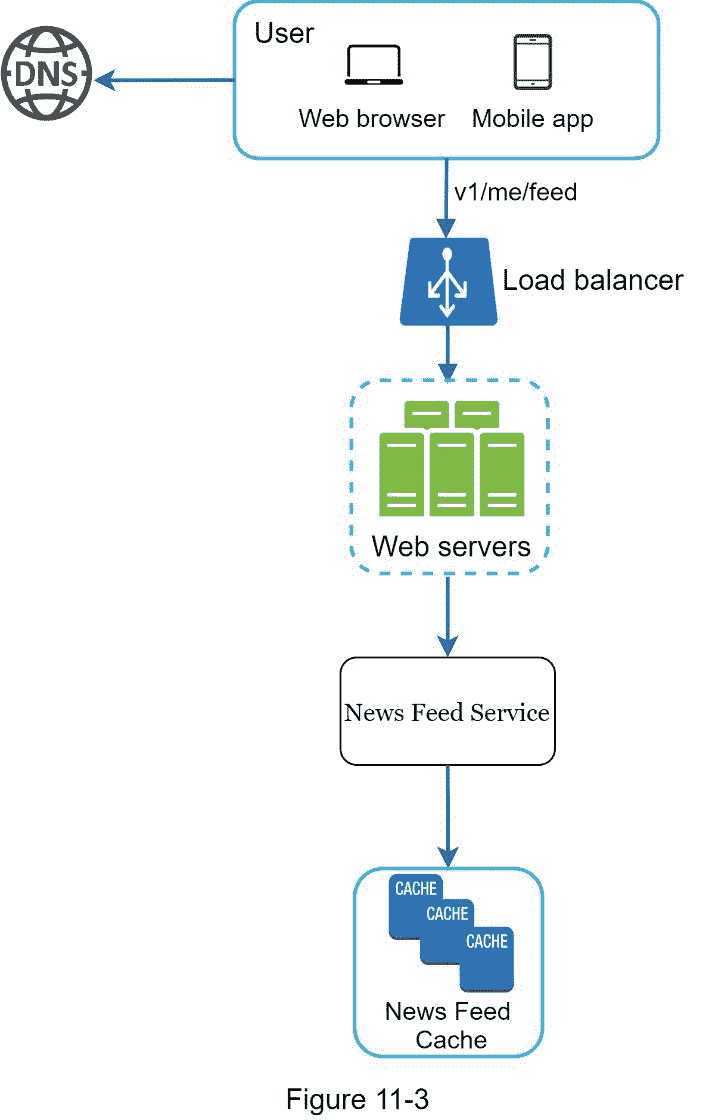
用户:用户发送请求来检索她的新闻提要。请求看起来是这样的: / v1/me/feed。
负载平衡器:负载平衡器将流量重定向到 web 服务器。
Web 服务器:Web 服务器将请求路由到新闻订阅服务。
新闻订阅服务:新闻订阅服务从缓存中获取新闻订阅。
新闻提要缓存:存储呈现新闻提要所需的新闻提要 id。
第三步——设计深潜
概要设计简要地涵盖了两个流程:提要发布和新闻提要构建。在这里,我们更深入地讨论这些话题。
供稿出版深潜
图 11-4 概述了 feed 发布的详细设计。我们已经讨论了高层设计中的大部分组件,我们将集中讨论两个组件:web 服务器和扇出服务。

网络服务器
除了与客户端通信之外,web 服务器还执行身份验证和速率限制。只有使用有效 auth_token 登录的用户才可以发帖。该系统限制用户在一定时间内可以发布的帖子数量,这对防止垃圾邮件和滥用内容至关重要。
扇出服务
扇出是向所有朋友发送帖子的过程。两种类型的扇出模型是:写时扇出(也称为推模型)和读时扇出(也称为拉模型)。两种模式各有利弊。我们解释他们的工作流程,并探索支持我们系统的最佳方法。
写时扇出。 用这种方法, 新闻提要是在编写时间内预先计算好的。新帖子发布后会立即发送到朋友的缓存中。
优点:
新闻提要实时生成,可以立即推送给朋友。
获取新闻提要的速度很快,因为新闻提要是在编写时预先计算的。
缺点:
如果一个用户有很多朋友,那么获取他们的好友列表并为他们生成新闻提要会非常缓慢和耗时。叫做热键问题。
对于不活跃的用户或者很少登录的用户来说,预先计算的新闻提要浪费了计算资源。
扇出上读 。新闻提要是在读取时生成的。这是一种随需应变的模式。当用户加载她的主页时,最近的帖子被拉出来。
优点:
对于不活跃的用户或者那些很少登录的用户来说,读取上的扇出工作得更好,因为它不会在他们身上浪费计算资源。
数据不会推送给朋友,所以不存在热键问题。
缺点:
获取新闻提要很慢,因为新闻提要不是预先计算的。
我们采用了一种混合方法,以获得两种方法的优点并避免其中的缺陷。因为快速获取新闻提要至关重要,所以我们对大多数用户使用推送模型。对于有很多朋友/关注者的名人或用户,我们让关注者按需拉新闻内容,以避免系统过载。一致哈希是一种缓解热键问题的有用技术,因为它有助于更均匀地分布请求/数据。
让我们仔细看看扇出服务,如图 11-5 所示。

扇出服务的工作方式如下:
1。从图形数据库中获取朋友 id。图形数据库适合于管理朋友关系和朋友推荐。有兴趣的读者希望了解更多关于这个概念的信息,可以参考参考资料[2]。
2。从用户缓存中获取朋友信息。然后,系统会根据用户设置过滤掉朋友。例如,如果你将某人设为静音,即使你们仍然是朋友,她的帖子也不会显示在你的新闻订阅源上。帖子可能不会显示的另一个原因是,用户可以有选择地与特定的朋友分享信息,或者对其他人隐藏信息。
3。将好友列表和新帖子 ID 发送到消息队列。
4。扇出工作器从消息队列获取数据,并将新闻提要数据存储在新闻提要缓存中。你可以把新闻提要缓存想象成一个 <post_id, user_id>的映射表。每当一个新的文章发表,它将被附加到新闻提要表中,如图 11-6 所示。如果我们将整个用户和 post 对象存储在缓存中,内存消耗会变得非常大。因此,只存储 id。为了保持较小的内存大小,我们设置了一个可配置的限制。用户在新闻订阅中滚动浏览数千条帖子的可能性很小。大部分用户只对最新的内容感兴趣,所以缓存缺失率很低。
5。在新闻提要缓存中存储<post_id, user_id>。图 11-6 显示了新闻提要在缓存中的样子。

新闻提要检索深度剖析
图 11-7 展示了新闻提要检索的详细设计。
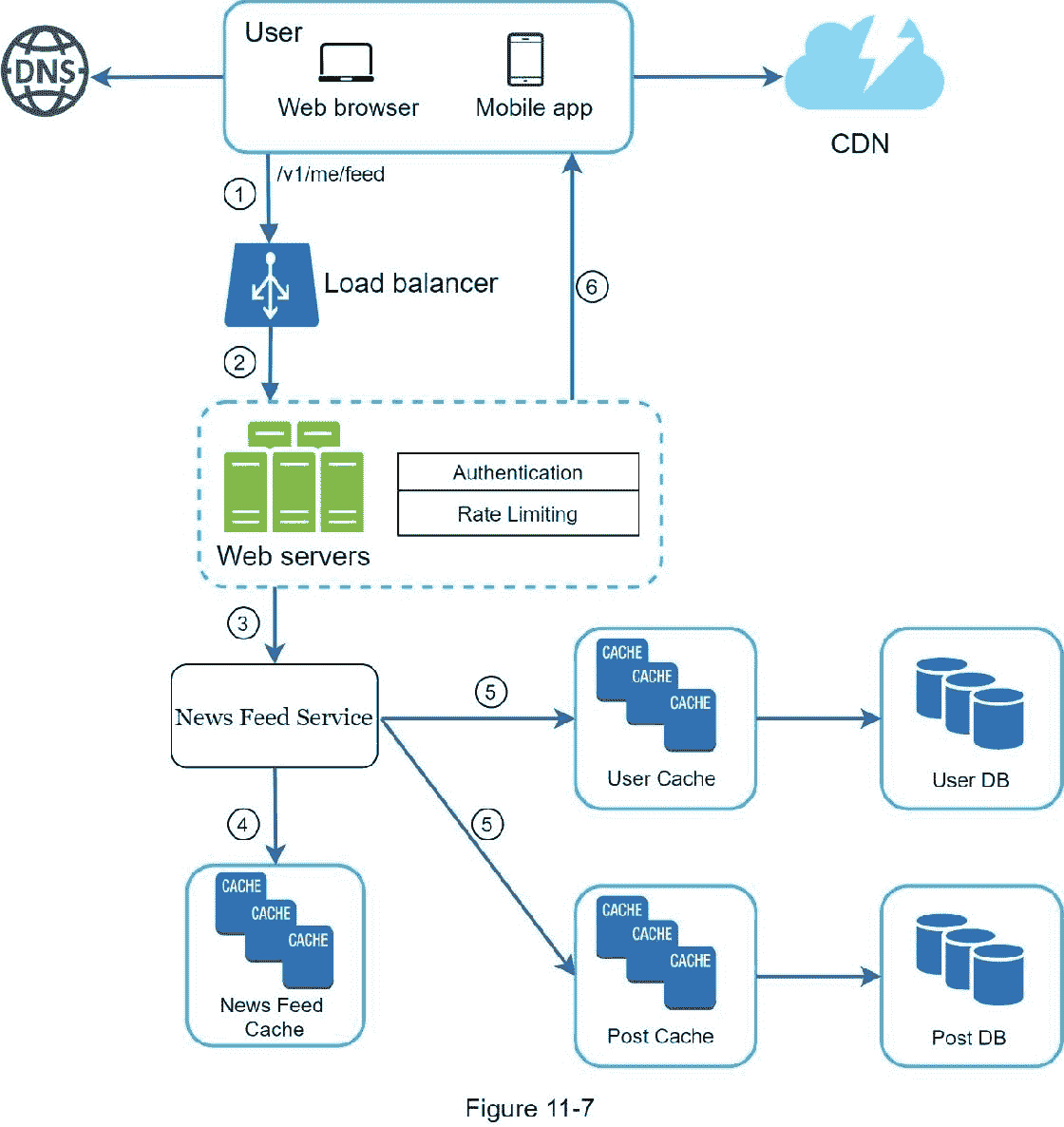
如图 11-7 所示,媒体内容(图片、视频等。)存储在 CDN 中,以便快速检索。让我们看看客户机如何检索新闻提要。
1。用户发送请求来检索她的新闻提要。请求看起来是这样的: /v1/me/feed
2。负载平衡器将请求重新分配给 web 服务器。
3。Web 服务器调用新闻提要服务来获取新闻提要。
4。新闻提要服务从新闻提要缓存中获取一个帖子 id 列表。
5。用户的新闻提要不仅仅是一个提要 id 列表。它包含用户名,个人资料图片,帖子内容,帖子图片等。因此,新闻提要服务从缓存(用户缓存和帖子缓存)中获取完整的用户和帖子对象,以构建完整的新闻提要。
6。完整的新闻提要以 JSON 格式返回给客户端进行呈现。
高速缓存架构
对于新闻订阅系统来说,缓存非常重要。我们将缓存层分为 5 层,如图 11-8 所示。
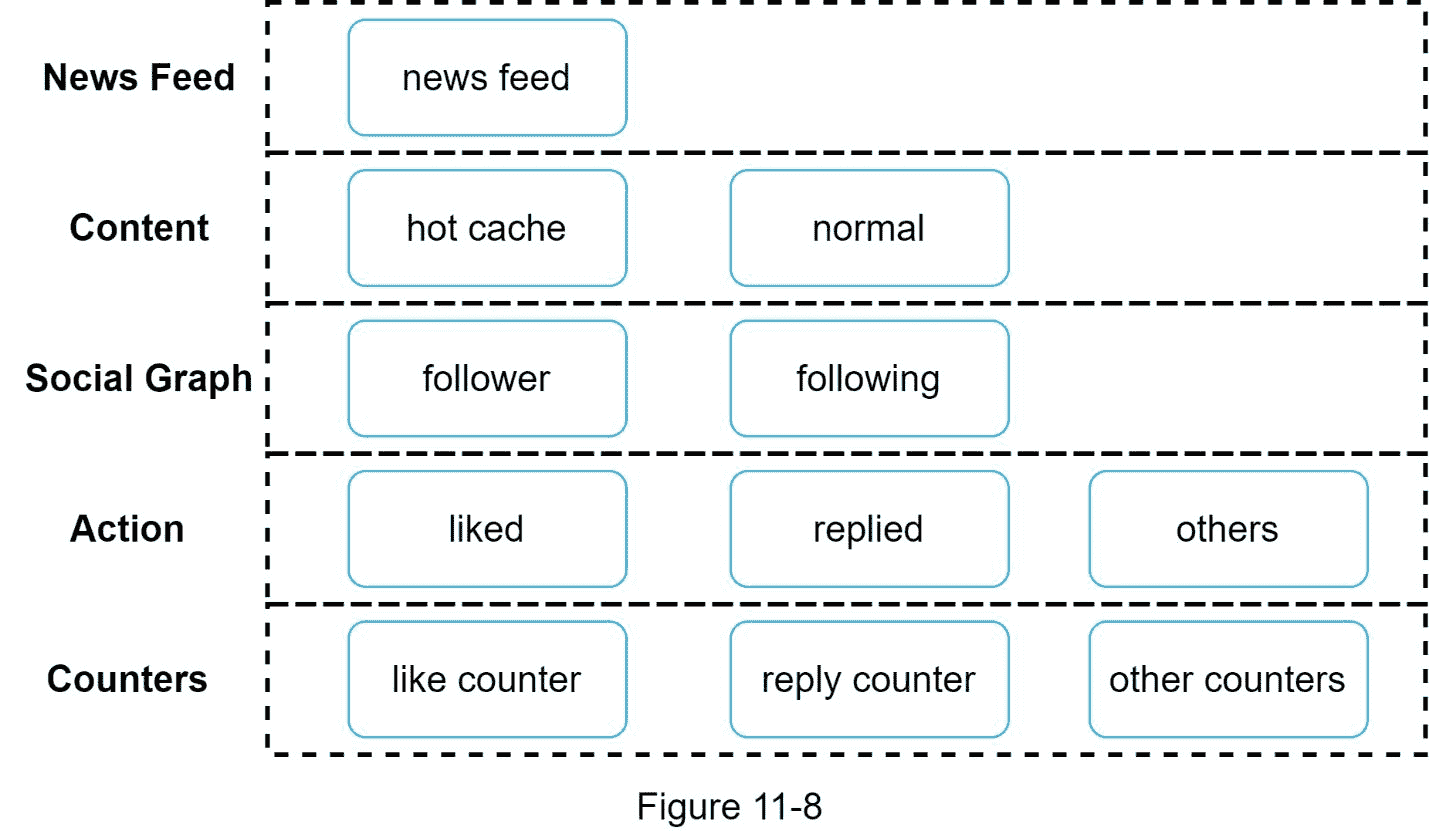
新闻提要:存储新闻提要的 id。
内容:存储每条帖子的数据。热门内容存储在热缓存中。
社交图:存储用户关系数据。
动作:它存储了用户是否喜欢某个帖子、回复某个帖子或对某个帖子采取其他动作的信息。
计数器:存储点赞、回复、关注者、关注等计数器。
步骤 4 -总结
在这一章中,我们设计了一个新闻订阅系统。我们的设计包含两个流程:提要发布和新闻提要检索。
和任何系统设计面试问题一样,设计一个系统没有完美的方法。每个公司都有其独特的限制,你必须设计一个系统来适应这些限制。理解设计和技术选择的权衡非常重要。如果还有几分钟,可以谈谈可伸缩性问题。为了避免重复讨论,下面只列出了高层次的话题。
缩放数据库:
垂直缩放与水平缩放
SQL vs NoSQL
主从复制
读取副本
一致性模型
数据库分片
其他谈话要点:
保持 web 层无状态
尽可能多地缓存数据
支持多个数据中心
丢失消息队列的几个组件
监控关键指标。例如,用户刷新新闻提要时的高峰时间和延迟时间的 QPS 值得关注。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] How News Feed Works:
https://www.facebook.com/help/327131014036297/
[2] Friend of Friend recommendations Neo4j and SQL Sever:
http://geekswithblogs.net/brendonpage/archive/2015/10/26/friend-of-friend-recommendations-with-neo4j.aspx
十二、设计聊天系统
在这一章中,我们将探索一个聊天系统的设计。几乎每个人都使用聊天应用。图 12-1 显示了市场上一些最流行的应用程序。

聊天应用为不同的人执行不同的功能。明确具体的要求是非常重要的。例如,当面试官想到的是一对一的聊天时,你不希望设计一个专注于群聊的系统。重要的是探究特征需求 。
步骤 1 -了解问题并确定设计范围
就聊天应用的设计类型达成一致至关重要。在市场上,有像 Facebook Messenger、微信和 WhatsApp 这样的一对一聊天应用程序,像 Slack 这样专注于群聊的办公聊天应用程序,或者像 Discord 这样专注于大型群体互动和低语音聊天延迟的游戏聊天应用程序。
当面试官让你设计一个聊天系统时,第一组澄清性问题应该明确她到底在想什么。至少,弄清楚你应该专注于一对一聊天还是群聊应用。你可能会问的一些问题如下:
候选人 :我们要设计什么样的聊天应用?1 对 1 还是基于小组?
面试官 :应该支持 1 对 1 和群聊。
考生 :这是手机 app 吗?还是一个 web app?还是两者都有?
面试官 :都有。
候选人 :这个 app 的规模有多大?创业 app 还是海量规模?
面试官 :应该支持 5000 万日活跃用户(DAU)。
候选人 :群聊,群成员限制是多少?
面试官 :最多 100 人
候选人 :聊天 app 有哪些重要的功能?它能支持附件吗?
面试官 : 1 对 1 聊天,群聊,在线指标。系统只支持短信。
候选人 :邮件大小有限制吗?
面试官 :是的,文字长度要小于 10 万字。
候选人 :需要端到端加密吗?
采访者 :现在不需要,但是如果时间允许的话,我们会讨论的。
候选人 :聊天记录要保存多久?
面试官 :永远。
在本章中,我们将重点设计一个像脸书信使这样的聊天应用,重点是以下功能:
低交付延迟的一对一聊天
小型群聊(最多 100 人)
在线状态
多设备支持。同一个账号可以同时登录多个账号。
推送通知
就设计规模达成一致也很重要。我们将设计一个支持 5000 万 DAU 的系统。
第二步——提出高水平的设计并获得认同
为了开发高质量的设计,我们应该对客户机和服务器如何通信有一个基本的了解。在聊天系统中,客户端可以是移动应用程序,也可以是 web 应用程序。客户端之间不直接通信。相反,每个客户端连接到一个聊天服务,它支持上面提到的所有功能。让我们把注意力集中在基本操作上。聊天服务必须支持以下功能:
接收其他客户端的消息。
为每条消息找到合适的收件人,并将消息转发给收件人。
如果收件人不在线,将该收件人的邮件保存在服务器上,直到她在线。
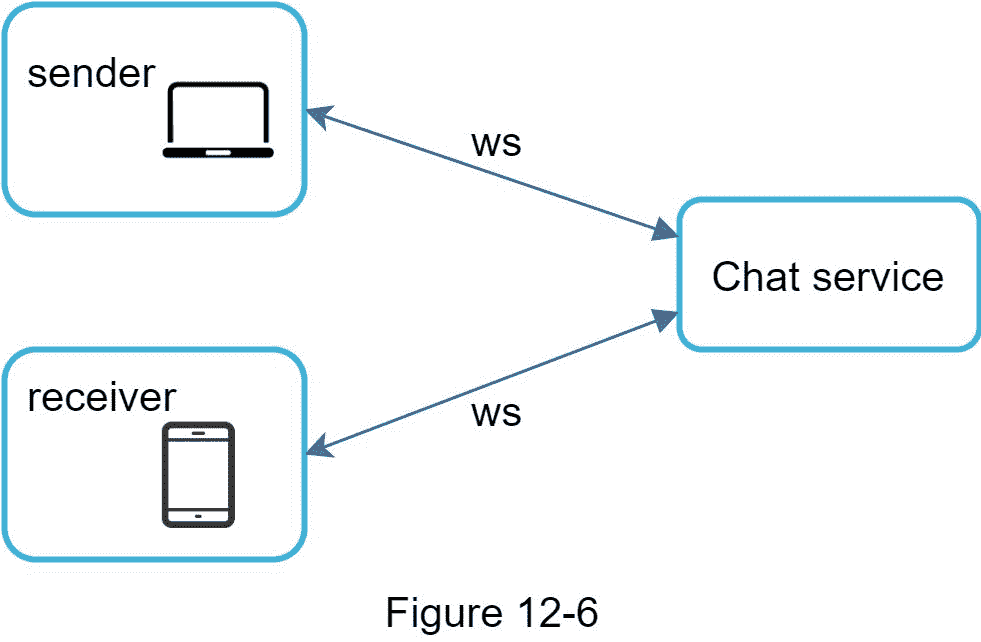
图 12-2 显示了客户端(发送者和接收者)和聊天服务之间的关系。

当客户端想要开始聊天时,它使用一个或多个网络协议连接聊天服务。对于聊天服务来说,网络协议的选择很重要。让我们和面试官讨论一下这个问题。
对于大多数客户机/服务器应用程序,请求是由客户机发起的。对于聊天应用程序的发送方来说也是如此。在图 12-2 中,当发送者通过聊天服务向接收者发送消息时,它使用了久经考验的 HTTP 协议,这是最常见的 web 协议。在这个场景中,客户端打开一个与聊天服务的 HTTP 连接并发送消息,通知服务将消息发送给接收者。为此,保持活动是有效的,因为保持活动头部允许客户端保持与聊天服务的持久连接。它还减少了 TCP 握手的次数。HTTP 是发送方的一个很好的选择,许多流行的聊天应用程序如脸书[1]最初使用 HTTP 发送消息。
然而,接收端要复杂一些。因为 HTTP 是客户端发起的,所以从服务器发送消息并不简单。多年来,许多技术被用来模拟服务器发起的连接:轮询、长轮询和 WebSocket。这些都是在系统设计面试中广泛使用的重要技术,所以让我们来检查一下它们。
投票
如图 12-3 所示,轮询是一种客户端定期询问服务器是否有消息可用的技术。根据轮询频率的不同,轮询的成本可能会很高。回答一个大多数情况下答案为“否”的问题可能会消耗宝贵的服务器资源。

长轮询
因为轮询可能是低效的,下一步是长轮询(图 12-4)。
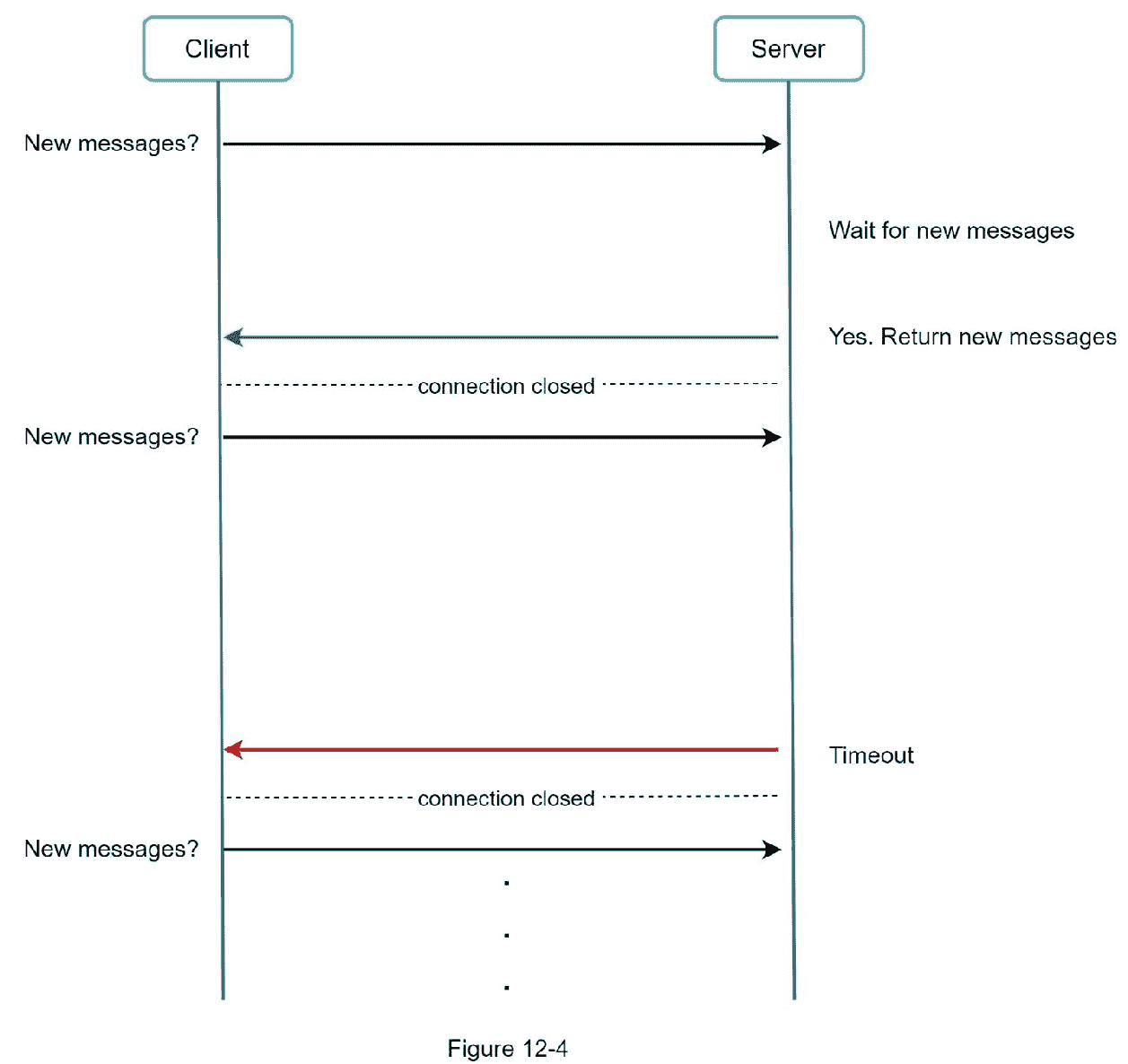
在长轮询中,客户端保持连接打开,直到有新消息可用或达到超时阈值。一旦客户端收到新消息,它会立即向服务器发送另一个请求,重新开始这个过程。长轮询有一些缺点:
发送者和接收者不能连接到同一个聊天服务器。基于 HTTP 的服务器通常是无状态的。如果使用循环法进行负载平衡,接收消息的服务器可能不会与接收消息的客户端建立长轮询连接。
服务器无法判断客户端是否断开。
效率低下。如果用户聊天不多,长轮询仍然会在超时后进行定期连接。
WebSocket
WebSocket 是从服务器向客户端发送异步更新的最常见的解决方案。图 12-5 显示了它是如何工作的。
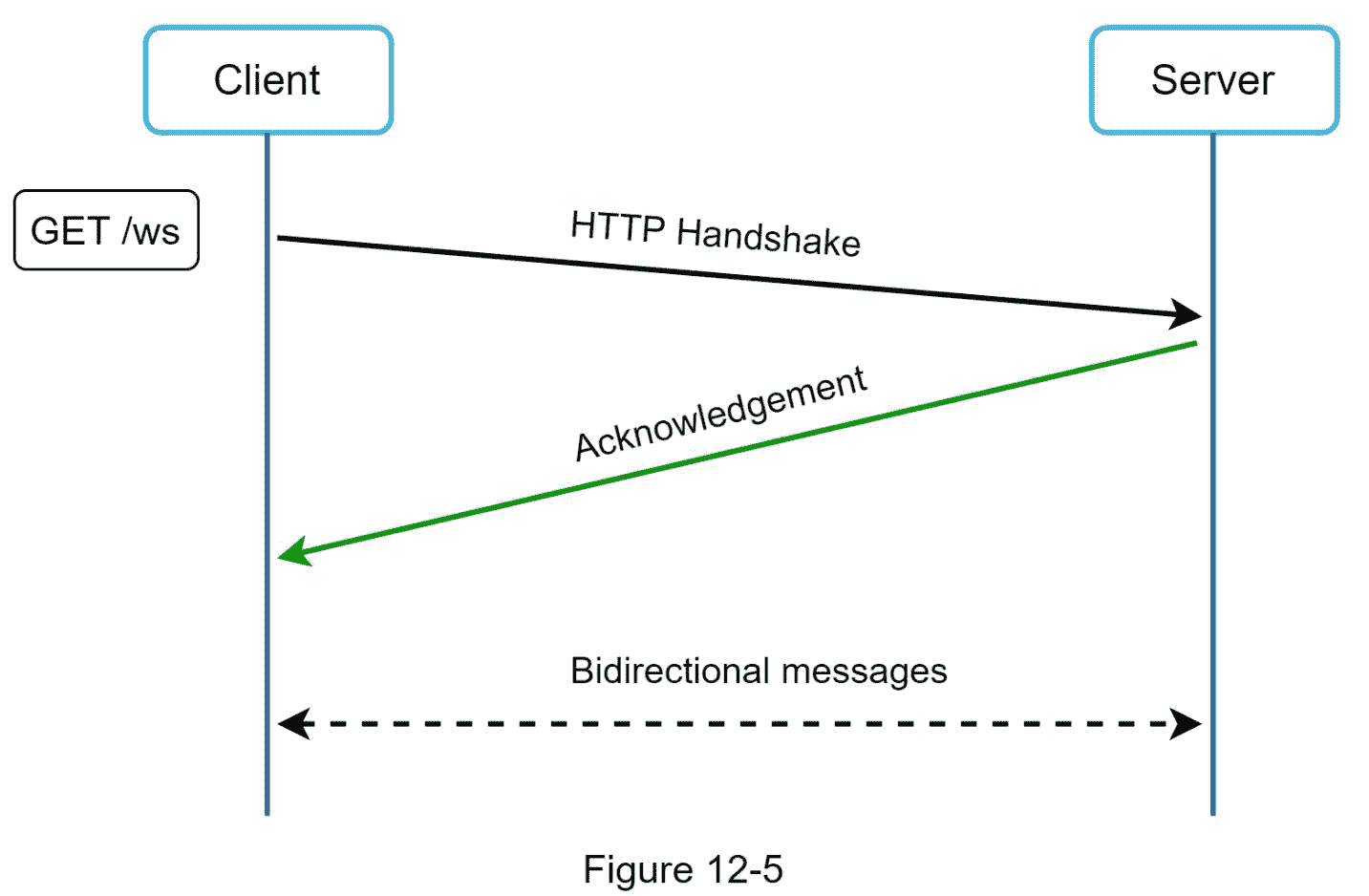
WebSocket 连接由客户端发起。它是双向的和持久的。它最初是一个 HTTP 连接,可以通过一些定义明确的握手“升级”为 WebSocket 连接。通过这种持久连接,服务器可以向客户机发送更新。即使有防火墙,WebSocket 连接通常也能工作。这是因为它们使用 HTTP/HTTPS 连接也使用的端口 80 或 443。
前面我们说过,在发送端,HTTP 是一个很好的协议,但是由于 WebSocket 是双向的,没有很强的技术理由不把它也用于接收。图 12-6 显示了 WebSockets (ws)是如何用于发送方和接收方的。
通过使用 WebSocket 进行发送和接收,它简化了设计,并使客户端和服务器端的实现更加简单。由于 WebSocket 连接是持久的,因此高效的连接管理在服务器端至关重要。
高层设计
刚才我们提到,WebSocket 被选为客户端和服务器之间双向通信的主要通信协议,需要注意的是,其他一切都不一定是 WebSocket。事实上,聊天应用程序的大多数功能(注册、登录、用户资料等)都可以使用传统的 HTTP 请求/响应方法。让我们深入了解一下系统的高级组件。
如图 12-7 所示,聊天系统分为三大类:无状态服务、有状态服务和第三方集成。
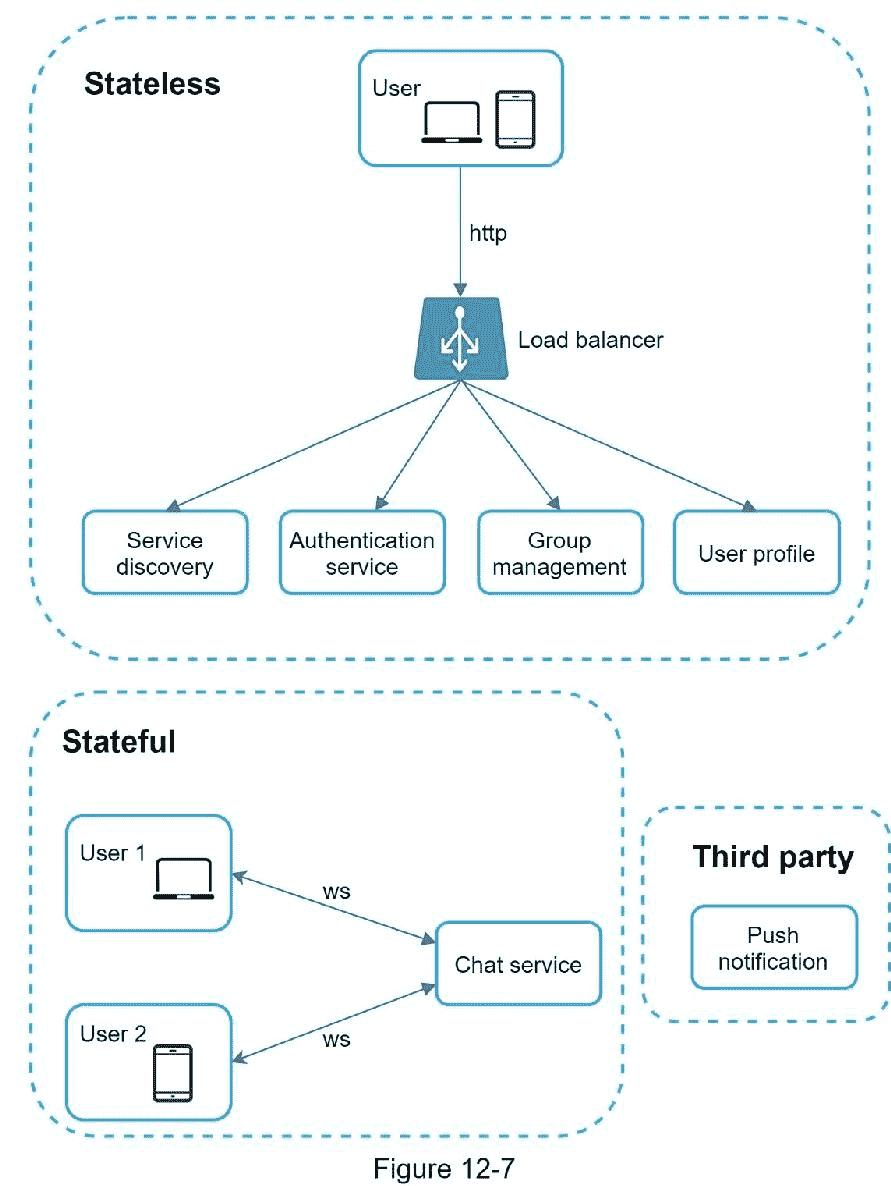
无状态服务
无状态服务是传统的面向公众的请求/响应服务,用于管理登录、注册、用户档案等。这些是许多网站和应用程序的共同特征。
无状态服务 位于负载均衡器之后,其工作是根据请求路径将请求路由到正确的服务。这些服务可以是整体的或单独的微服务。我们不需要自己构建许多这样的无状态服务,因为市场上有可以轻松集成的服务。我们将深入讨论的一项服务是服务发现。它的主要工作是给客户端一个聊天服务器的 DNS 主机名列表,客户端可以连接到这些服务器。
有状态服务
唯一有状态的服务是聊天服务。该服务是有状态的,因为每个客户端都保持与聊天服务器的持久网络连接。在这种服务中,只要服务器仍然可用,客户通常不会切换到另一个聊天服务器。服务发现与聊天服务密切配合,以避免服务器过载。我们将深入探讨细节。
第三方整合
对于一个聊天 app 来说,推送通知是最重要的第三方整合。 恰当的整合推送通知至关重要。更多信息请参考第十章设计通知系统。
可扩展性
在小范围内,上面列出的所有服务都可以放在一台服务器上。即使在我们设计的规模下,理论上也有可能在一个现代云服务器中容纳所有用户连接。服务器可以处理的并发连接数很可能是限制因素。在我们的场景中,在 100 万并发用户的情况下,假设每个用户连接都需要服务器上的 10K 内存(这是一个非常粗略的数字,并且非常依赖于语言选择),它只需要大约 10GB 的内存来容纳一个机器上的所有连接。
如果我们提出一个所有东西都放在一台服务器上的设计,这可能会在面试官的脑海中升起一面大红旗。没有哪个技术专家会在一台服务器上设计出如此大的规模。单服务器设计是一个交易破坏者,原因有很多。其中单点故障是最大的。
然而,从单一服务器设计开始也是非常好的。确保面试官知道这是一个起点。把我们提到的所有东西放在一起,图 12-8 显示了调整后的高层设计。
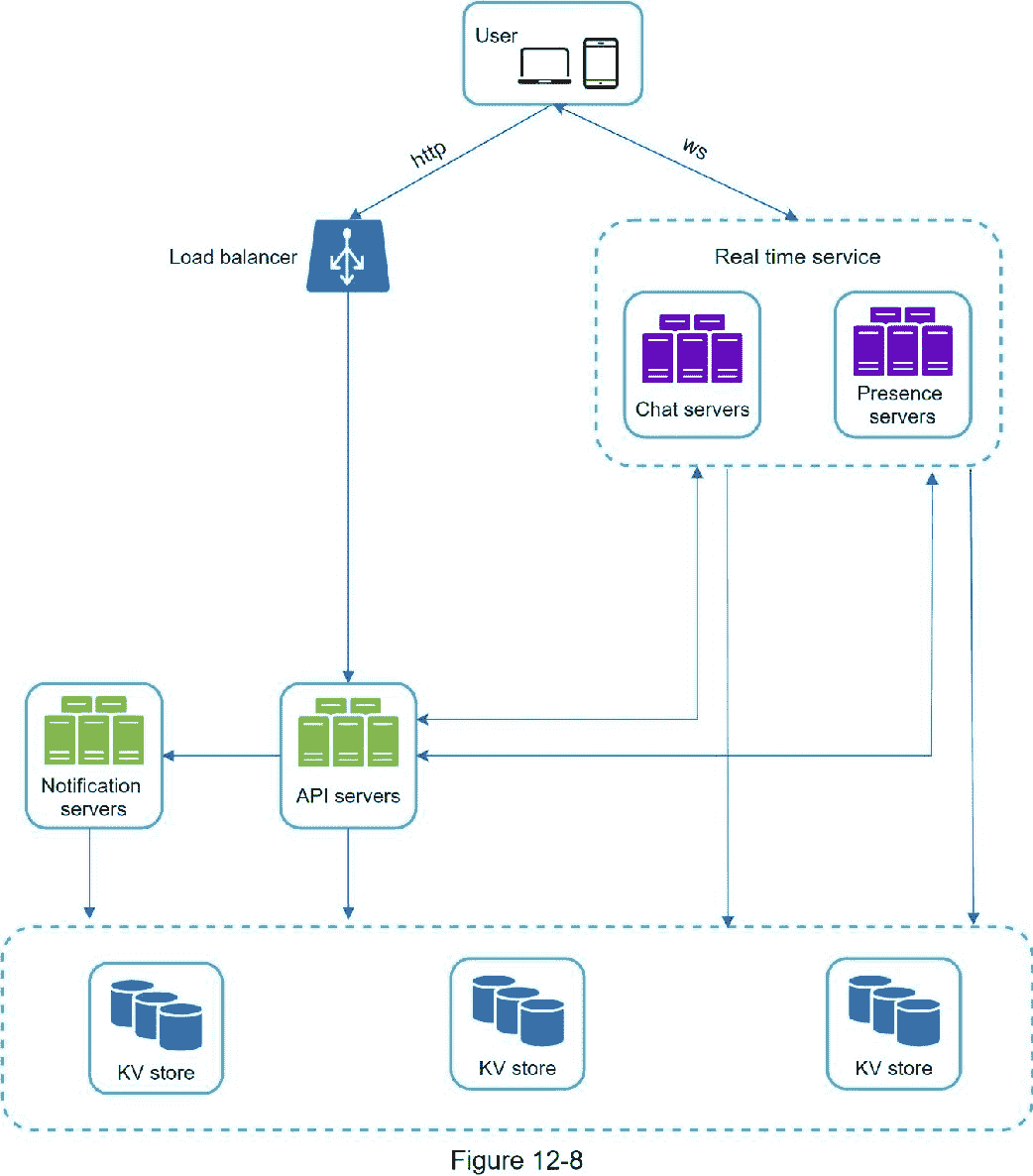
在图 12-8 中,客户端维护一个持久的 WebSocket 连接到一个聊天服务器,用于实时消息传递。
聊天服务器方便消息发送/接收。
呈现服务器管理在线/离线状态。
API 服务器处理一切事务,包括用户登录、注册、更改个人资料等。
通知服务器发送推送通知。
最后,键值存储用于存储聊天历史。当离线用户在线时,她将看到她以前的所有聊天记录。
存储
现在,我们已经准备好了服务器,启动了服务,完成了第三方集成。技术堆栈的最底层是数据层。数据层通常需要一些努力来使它正确。我们必须做出的一个重要决定是决定使用哪种类型的数据库:关系数据库还是 NoSQL 数据库?为了做出明智的决定,我们将检查数据类型和读/写模式。
典型的聊天系统中存在两种类型的数据。第一种是通用数据,如用户资料、设置、用户好友列表。这些数据存储在健壮可靠的关系数据库中。复制和分片是满足可用性和可伸缩性需求的常用技术。
第二个是聊天系统特有的:聊天历史数据。理解读/写模式很重要。
聊天系统的数据量巨大。之前的一项研究[2]显示,脸书信使和 Whatsapp 每天处理 600 亿条信息。
只经常访问最近的聊天记录。用户通常不会查找旧聊天。
虽然在大多数情况下会查看最近的聊天记录,但用户可能会使用需要随机访问数据的功能,如搜索、查看您的提及、跳转到特定消息等。这些情况应该得到数据访问层的支持。
一对一聊天应用的读写比例约为 1:1。
选择支持我们所有使用情形的正确存储系统至关重要。我们推荐键值存储的原因如下:
键值存储允许简单的横向扩展。
键值存储提供非常低的数据访问延迟。
关系数据库不能很好地处理数据的长尾效应。当索引变大时,随机访问的代价很高。
键值存储被其他经过验证的可靠聊天应用所采用。例如,脸书信使和不和谐都使用键值存储。脸书信使用 HBase [4],不和用卡珊德拉[5]。
数据模型
刚才,我们谈到了使用键值存储作为我们的存储层。最重要的数据是消息数据。让我们仔细看看。
一对一聊天的消息表
图 12-9 显示了一对一聊天的消息表。主键是 message_id ,帮助决定消息顺序。我们不能依靠 created _ at 来决定消息顺序,因为可以同时创建两条消息。

群聊消息表
图 12-10 显示了群聊的消息表。复合主键是 (channel_id, message_id)。 渠道和集团在这里代表同一个意思。channel_id是分区键,因为群聊中的所有查询都在一个频道中操作。

消息 ID
如何生成 消息 _id 是一个值得探讨的有趣话题。 Message_id 承载着保证消息顺序的责任。为了确定消息的顺序, message_id 必须满足以下两个要求:
id 必须唯一。
id 应该可以按时间排序,这意味着新行比旧行具有更高的 id。
我们如何实现这两个保证?首先想到的是 MySql 中的“ auto_increment ”关键字。然而,NoSQL 数据库通常不提供这样的功能。
第二种方法是使用一个全局 64 位序列号生成器,如雪花[6]。这将在“第七章:在分布式系统中设计唯一的 ID 生成器”中讨论。
最后一种方法是使用本地序列号生成器。本地意味着 id 在一个组中是唯一的。本地 IDs 工作的原因是在一对一通道或组通道内维护消息序列就足够了。与全局 ID 实现相比,这种方法更容易实现。
步骤 3 -设计深度潜水
在系统设计面试中,通常你会深入了解概要设计中的一些组件。对于聊天系统,服务发现、消息传递流和在线/离线指标值得深入研究。
服务发现
服务发现的主要作用是根据地理位置、服务器容量等标准为客户推荐最佳的聊天服务器。Apache Zookeeper [7]是一个流行的服务发现开源解决方案。它注册所有可用的聊天服务器,并根据预定义的标准为客户选择最佳的聊天服务器。
图 12-11 显示了服务发现(Zookeeper)是如何工作的。
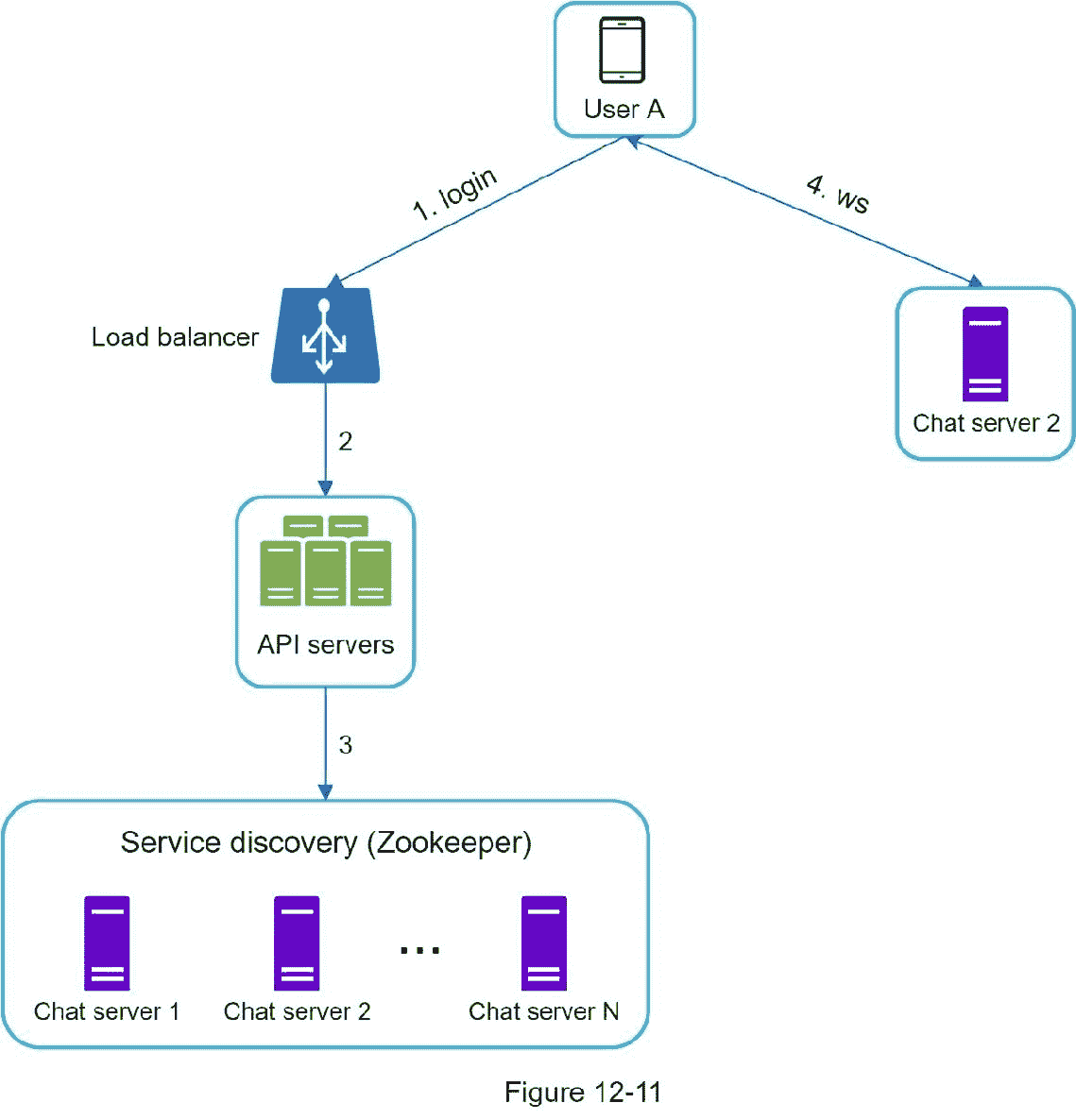
1。用户 A 尝试登录应用程序。
2。负载平衡器将登录请求发送到 API 服务器。
3。在后端对用户进行身份验证后,服务发现会为用户 a 找到最佳的聊天服务器。在本例中,选择了服务器 2,并将服务器信息返回给用户 a。
4。用户 A 通过 WebSocket 连接到聊天服务器 2。
消息流
理解一个聊天系统的端到端流程是很有趣的。在本节中,我们将探讨一对一聊天流程、跨多个设备的消息同步以及群聊流程。
一对一聊天流程
图 12-12 解释了当用户 A 给用户 b 发送消息时会发生什么。
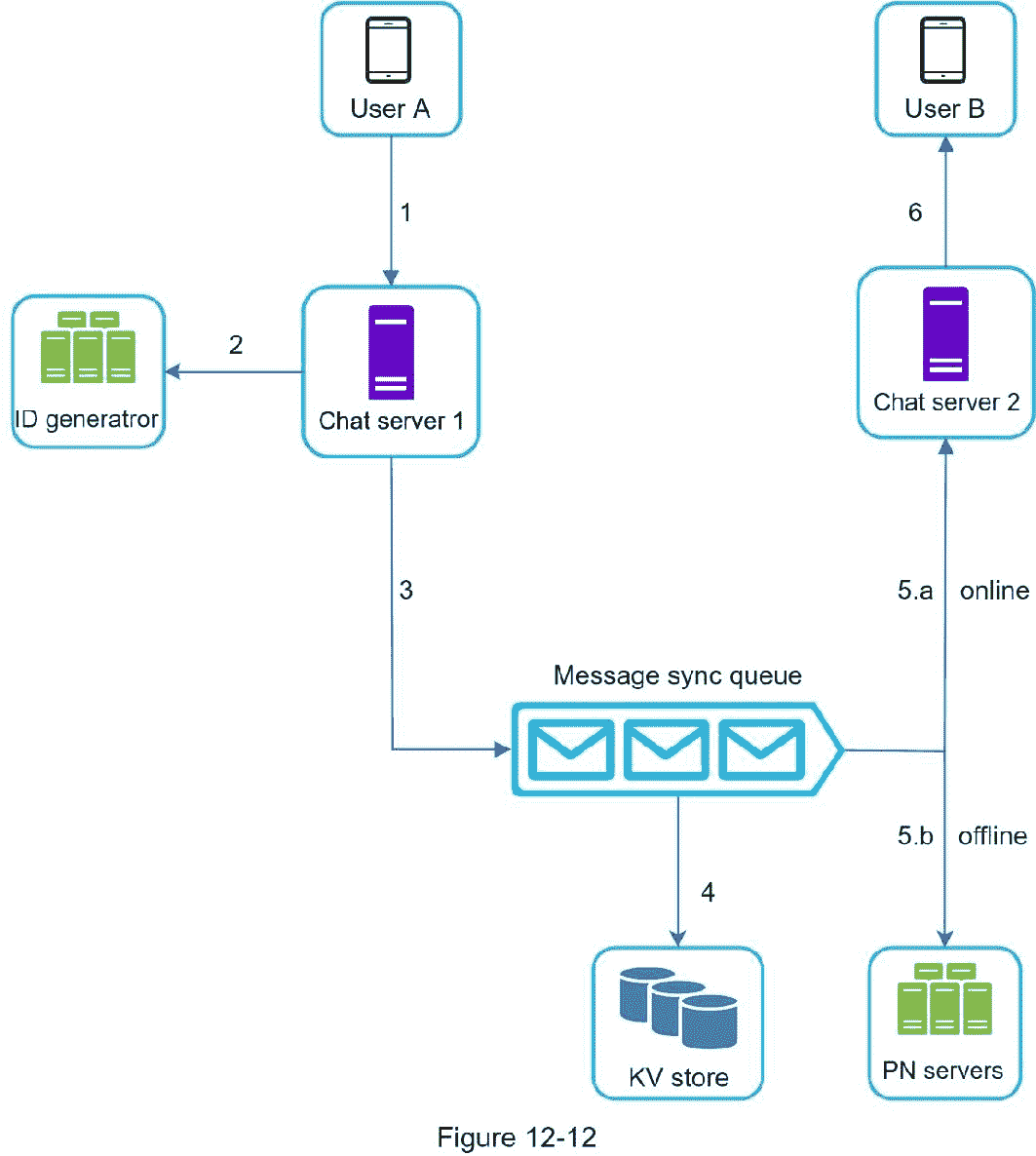
1。用户 A 向聊天服务器 1 发送聊天消息。
2。聊天服务器 1 从 ID 生成器获得消息 ID。
3。聊天服务器 1 将消息发送到消息同步队列。
4。消息存储在键值存储中。
5.a .如果用户 B 在线,则消息被转发到用户 B 所连接的聊天服务器 2。
5.b .如果用户 B 离线,则从推送通知(PN)服务器发送推送通知。
6。聊天服务器 2 将消息转发给用户 B。在用户 B 和聊天服务器 2 之间存在持久的 WebSocket 连接。
跨多个设备的消息同步
许多用户拥有多台设备。我们将解释如何在多个设备之间同步消息。图 12-13 显示了一个消息同步的例子。
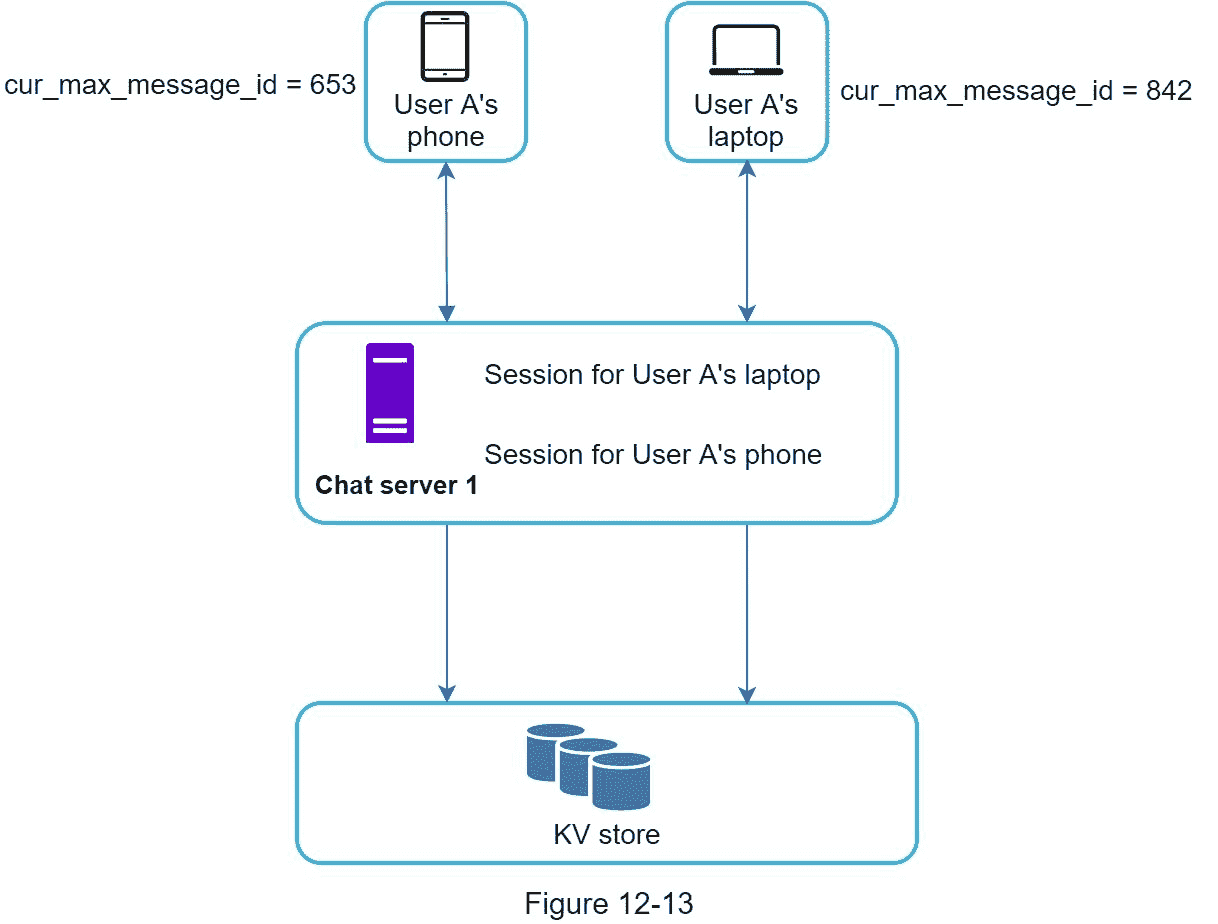
在图 12-13 中,用户 A 有两台设备:一台电话和一台笔记本电脑。当用户 A 用她的电话登录聊天应用时,它与聊天服务器 1 建立 WebSocket 连接。类似地,在膝上型电脑和聊天服务器 1 之间存在连接。
每个设备维护一个名为 cur_max_message_id 的变量,该变量跟踪设备上的最新消息 ID。满足以下两个条件的消息被认为是新闻消息:
收件人 ID 等于当前登录的用户 ID。
键值存储中的消息 ID 大于cur_max_Message_Id。
由于每个设备上都有不同的 cur_max_message_id,因此消息同步很容易,因为每个设备都可以从 KV store 获得新消息。
小组聊天流程
与一对一聊天相比,群聊的逻辑更加复杂。图 12-14 和 12-15 解释了这个流程。
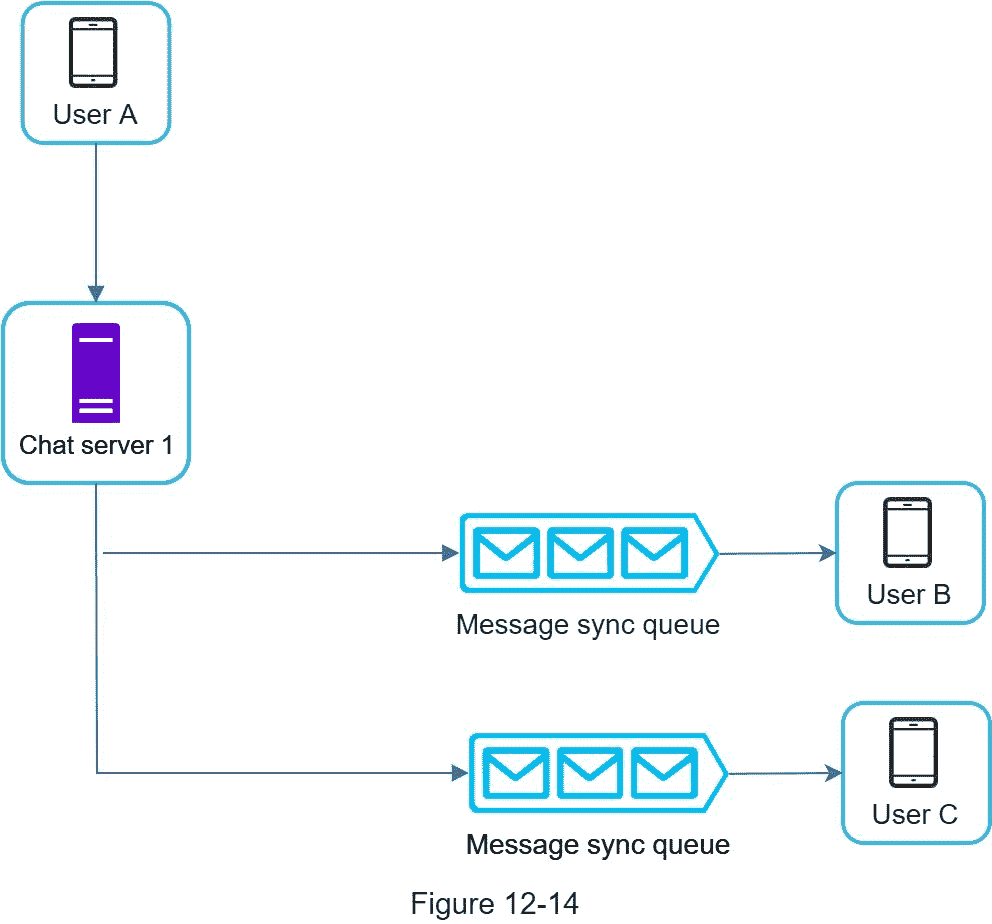
图 12-14 解释了当用户 A 在群聊中发送消息时会发生什么。假设组中有 3 个成员(用户 A、用户 B 和用户 C)。首先,来自用户 A 的邮件被复制到每个组成员的邮件同步队列中:一个是用户 B 的,另一个是用户 c 的。您可以将邮件同步队列视为收件人的收件箱。这种设计选择对小组聊天很有好处,因为:
它简化了消息同步流程,因为每个客户端只需查看自己的收件箱即可获得新消息。
当群组数量较少时,在每个收件人的收件箱中存储一份副本并不太昂贵。
微信使用了类似的方法,它将一个群的成员限制在 500 人[8]。但是,对于有很多用户的组,为每个成员存储一个消息副本是不可接受的。
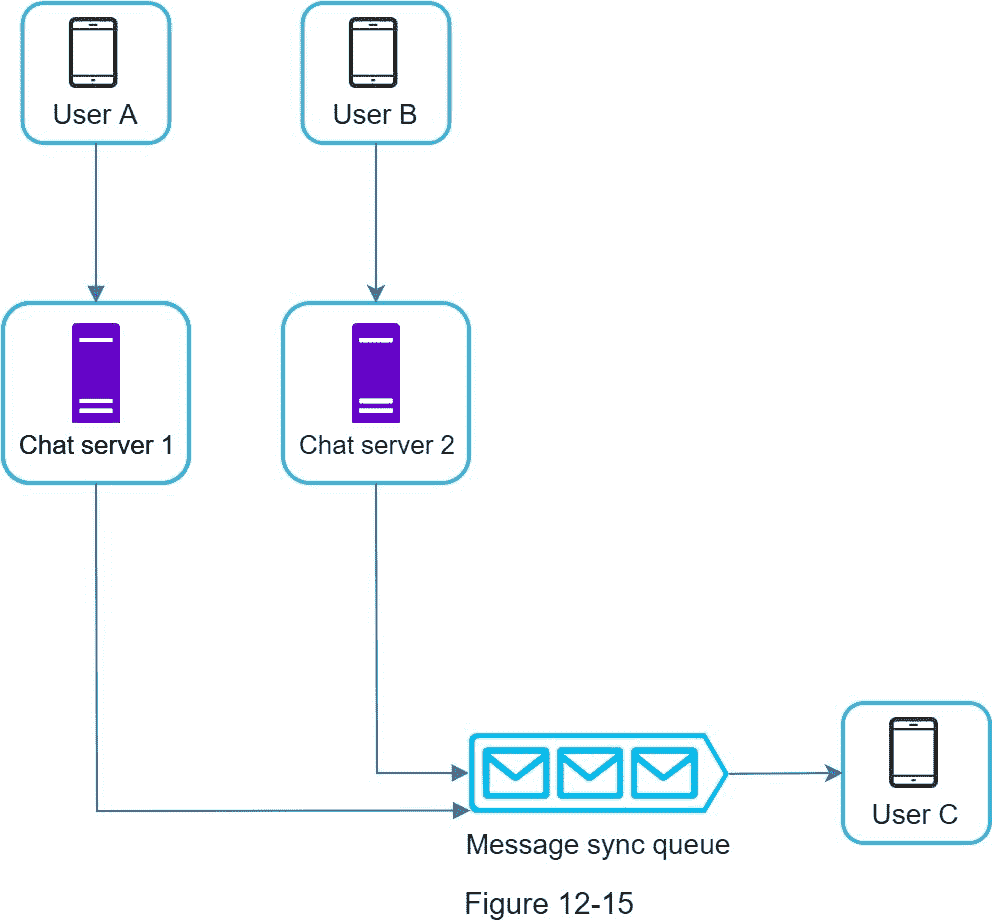
在接收方,一个接收方可以接收来自多个用户的消息。每个收件人都有一个收件箱(邮件同步队列),其中包含来自不同发件人的邮件。图 12-15 说明了这种设计。
在线存在感
在线状态指示器是许多聊天应用程序的基本功能。通常,您可以在用户的个人资料图片或用户名旁边看到一个绿点。本节解释了幕后发生的事情。
在高级设计中,在线状态服务器负责管理在线状态,并通过 WebSocket 与客户端通信。有几个流会触发在线状态更改。让我们逐一检查一下。
用户登录
用户登录流程在“服务发现”一节中解释。客户端与实时服务建立 WebSocket 连接后,用户 A 的在线状态和 last_active_at 时间戳保存在 KV 存储中。在线状态指示器显示用户登录后在线。
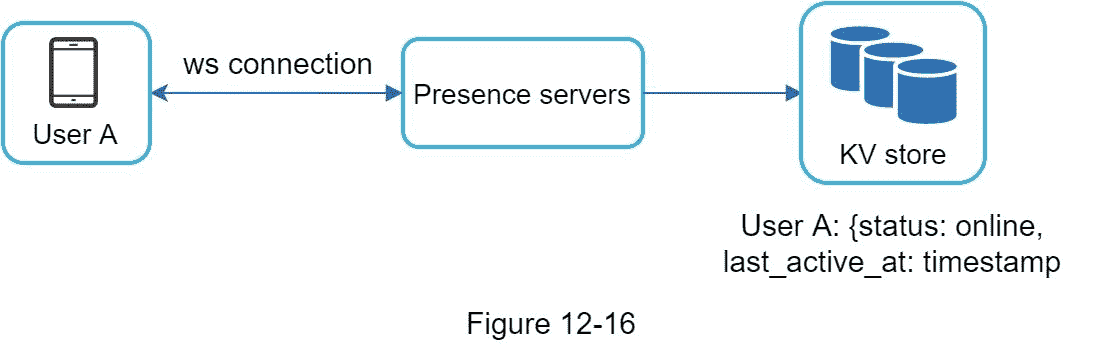
用户注销
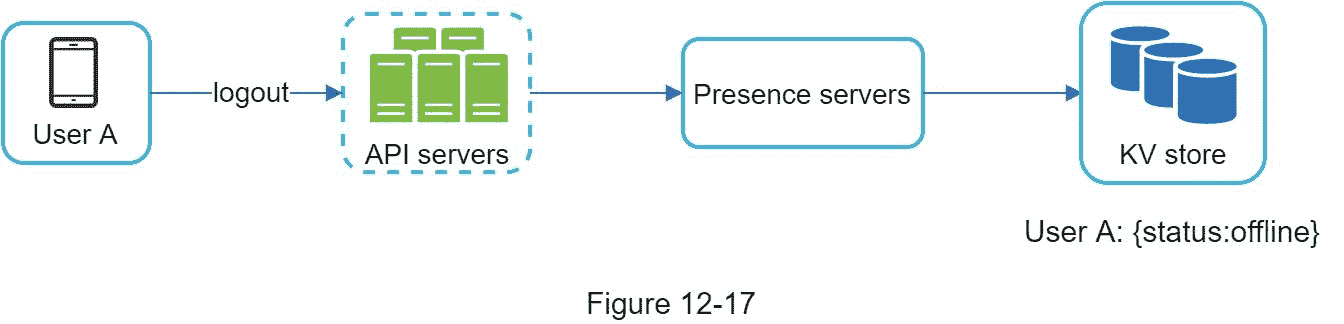
当用户注销时,会经历如图 12-17 所示的用户注销流程。KV 商店中的在线状态更改为离线。在线状态指示器显示用户离线。
用户断开
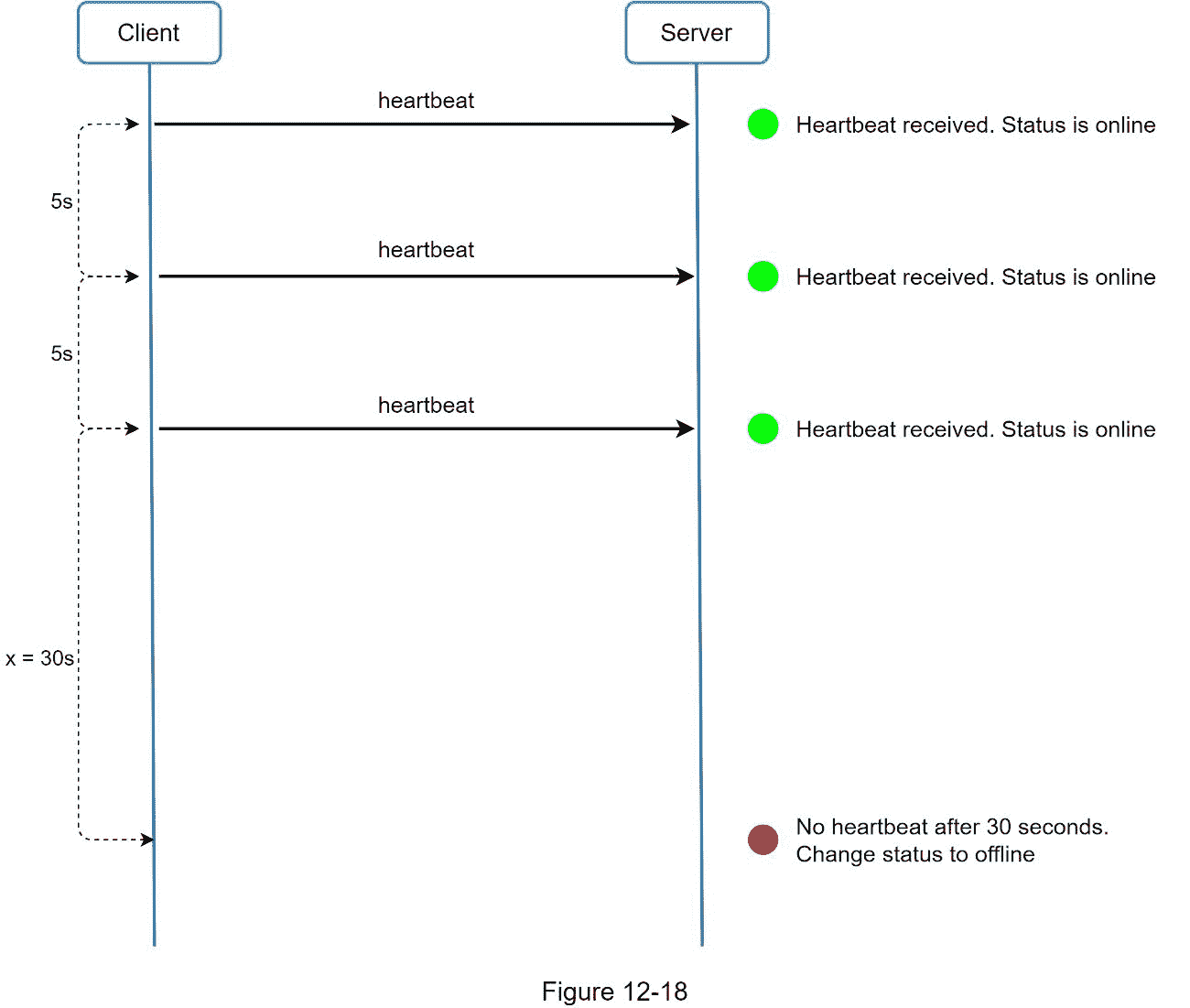
我们都希望我们的互联网连接稳定可靠。然而,情况并非总是如此;因此,我们必须在设计中解决这个问题。当用户断开与互联网的连接时,客户端和服务器之间的持久连接就会丢失。处理用户断开连接的一个简单方法是将用户标记为脱机,并在连接重新建立时将状态更改为联机。然而,这种方法有一个重大缺陷。用户在短时间内频繁断开和重新连接互联网是很常见的。例如,当用户通过隧道时,网络连接可以打开和关闭。在每次断开/重新连接时更新在线状态会使在线指示器改变得太频繁,从而导致较差的用户体验。
我们引入了心跳机制来解决这个问题。在线客户端定期向在线服务器发送心跳事件。如果存在服务器在特定时间内(比如说 x 秒)从客户端接收到心跳事件,则认为用户在线。否则,它是脱机的。
在图 12-18 中,客户端每 5 秒向服务器发送一次心跳事件。发送 3 个心跳事件后,客户端断开连接,不重新连接,inx = 30 秒(这个数字是任意选择的,用来演示逻辑)。联机状态更改为脱机。
在线状态扇出
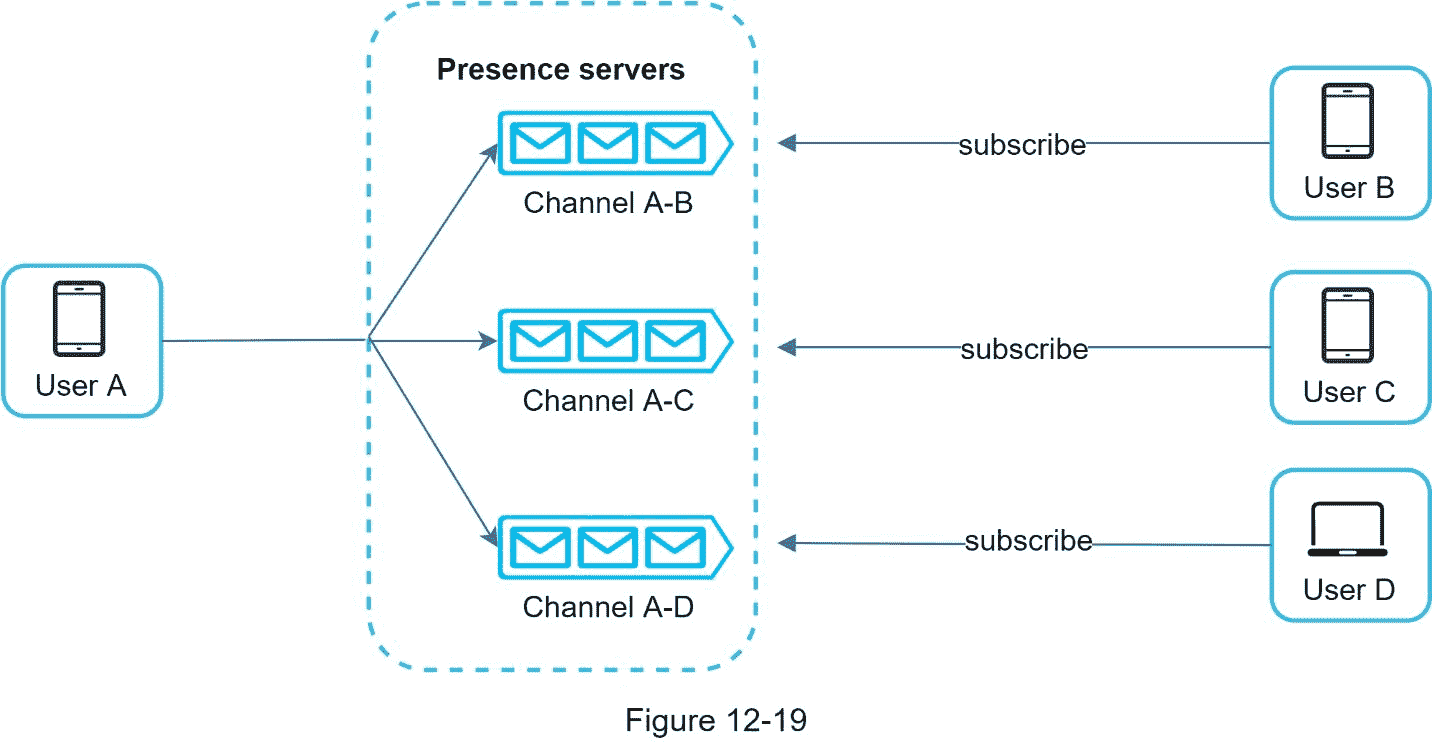
用户 A 的好友是如何知道状态变化的?图 12-19 解释了它是如何工作的。存在服务器使用发布-订阅模型,其中每个朋友对维护一个通道。当用户 A 的在线状态改变时,它将事件发布到三个通道,通道 A-B、A-C 和 A-D。这三个通道分别由用户 B、C 和 D 订阅。因此,朋友很容易获得在线状态更新。客户端和服务器之间的通信是通过实时 WebSocket 进行的。
以上设计对小用户群有效。例如,微信使用类似的方法,因为其用户群上限为 500 人。对于较大的群组,通知所有成员在线状态是昂贵且耗时的。假设一个团体有 100,000 名成员。每个状态变化将产生 100,000 个事件。为了解决性能瓶颈,一个可能的解决方案是仅当用户进入一个组或手动刷新好友列表时获取在线状态。
步骤 4 -总结
在本章中,我们介绍了一个支持一对一聊天和小组聊天的聊天系统架构。WebSocket 用于客户端和服务器之间的实时通信。聊天系统包含以下组件:用于实时消息传递的聊天服务器、用于管理在线状态的状态服务器、用于发送推送通知的推送通知服务器、用于聊天历史持久性的键值存储以及用于其他功能的 API 服务器。
如果你在采访结束时有额外的时间,以下是额外的谈话要点:
扩展聊天 app,支持照片、视频等媒体文件。媒体文件的大小远远大于文本。压缩、云存储和缩略图是有趣的话题。
端到端加密。Whatsapp 支持消息的端到端加密。只有发件人和收件人可以阅读邮件。感兴趣的读者可以参考参考资料[9]中的文章。
在客户端缓存消息可以有效减少客户端和服务器之间的数据传输。
提高加载时间。Slack 建立了一个地理上分散的网络来缓存用户的数据、频道等。为了更好的加载时间[10]。
错误处理。
聊天服务器出错。可能有几十万个,甚至更多的持久连接到聊天服务器。如果聊天服务器离线,service discovery (Zookeeper)将为客户端提供一个新的聊天服务器来建立新的连接。
消息重发机制。重试和排队是重新发送消息的常用技术。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] Erlang at Facebook: https://www.erlang-factory.com/upload/presentations/31/EugeneLetuchy-ErlangatFacebook.pdf
[2] Messenger and WhatsApp process 60 billion messages a day: https://www.theverge.com/2016/4/12/11415198/facebook-messenger-whatsapp-number-messages-vs-sms-f8-2016
[3] Long tail: https://en.wikipedia.org/wiki/Long_tail
[4] The Underlying Technology of Messages: https://www.facebook.com/notes/facebook-engineering/the-underlying-technology-of-messages/454991608919/
[5] How Discord Stores Billions of Messages: https://blog.discordapp.com/how-discord-stores-billions-of-messages-7fa6ec7ee4c7
[6] Announcing Snowflake: https://blog.twitter.com/engineering/en_us/a/2010/announcing-snowflake.html
[7] Apache ZooKeeper: https://zookeeper.apache.org/
[8] From nothing: the evolution of WeChat background system (Article in Chinese): https://www.infoq.cn/article/the-road-of-the-growth-weixin-background
[9] End-to-end encryption: https://faq.whatsapp.com/en/android/28030015/
[10] Flannel: An Application-Level Edge Cache to Make Slack Scale: https://slack.engineering/flannel-an-application-level-edge-cache-to-make-slack-scale-b8a6400e2f6b
十三、设计搜索自动补全系统
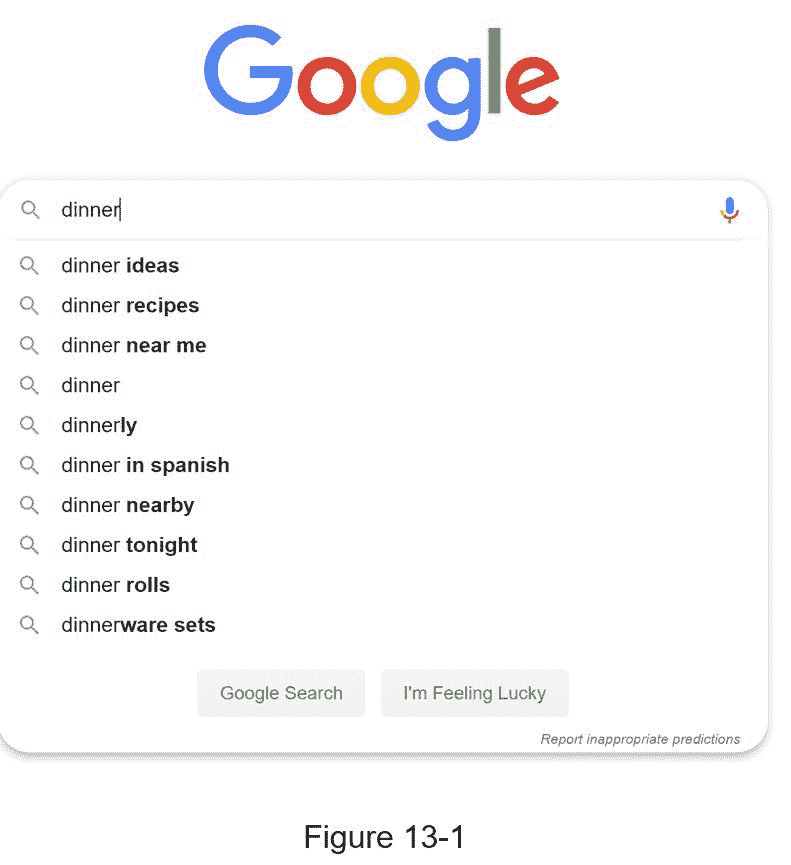
在谷歌上搜索或在亚马逊购物时,当你在搜索框中输入时,一个或多个匹配的搜索词就会呈现在你面前。此功能被称为自动完成、提前键入、随键入搜索或增量搜索。图 13-1 展示了一个谷歌搜索的例子,当在搜索框中输入“晚餐”时,显示了一个自动完成的结果列表。搜索自动完成是许多产品的重要功能。这就引出了面试问题:设计一个搜索自动完成系统,也叫“设计 top k”或“设计 top k 最常搜索的查询”。
步骤 1 -了解问题并确定设计范围
解决任何系统设计面试问题的第一步是问足够多的问题来澄清需求。下面是一个应聘者与面试官互动的例子:
候选人 :是只支持搜索查询开头的匹配,还是也支持中间的匹配?
面试官 :只在搜索查询的开头。
候选人 :系统应该返回多少个自动完成建议?
面试官 : 5
候选人 :系统如何知道返回哪 5 条建议?
面试官 :这个是由人气决定的,由历史查询频率决定的。
考生 :系统支持拼写检查吗?
面试官 :不,不支持拼写检查或自动更正。
候选人 :搜索查询是英文的吗?
面试官 :是的。如果最后时间允许,可以讨论多语言支持。
候选人 :我们允许大写和特殊字符吗?
面试官 :不,我们假设所有的搜索查询都有小写字母字符。
候选人 :有多少用户使用该产品?
面试官:1000 万 DAU。
要求
下面是对需求的总结:
快速响应时间:当用户键入搜索查询时,自动补全建议必须足够快地出现。一篇关于脸书的自动完成系统的文章[1]揭示了该系统需要在 100 毫秒内返回结果。否则会造成口吃。
相关:自动完成建议应该与搜索词相关。
排序:系统返回的结果必须按人气或其他排名模型排序。
可扩展:系统可以处理高流量。
高可用:当系统的一部分离线、变慢或遇到意外网络错误时,系统应保持可用和可访问。
信封估算的背面
假设日活跃用户 1000 万(DAU)。
一个普通人每天会进行 10 次搜索。
每个查询字符串 20 字节数据:
假设我们使用 ASCII 字符编码。1 个字符= 1 个字节
假设一个查询包含 4 个单词,每个单词平均包含 5 个字符。
即每次查询 4×5 = 20 字节。
对于搜索框中输入的每个字符,客户端都会向后端发送一个请求,请求自动完成建议。平均而言,每个搜索查询发送 20 个请求。例如,当您输入完“晚餐”时,以下 6 个请求将被发送到后端。
search?q=d
search?q=di
search?q=din
search?q=dinn
search?q=dinne
search?q =dinner
~每秒 24000 次查询(QPS) = 1000 万用户 * 10 次查询/天 * 20 个字符 / 24 小时 / 3600 秒。
高峰 QPS = QPS * 2 = ~ 4.8 万
假设 20%的日常查询是新的。1000 万 * 10 次查询/天 * 每次查询 20 字节 * 20% = 0.4 GB。这意味着每天有 0.4GB 的新数据添加到存储中。
第二步——提出高水平的设计并获得认同
在高层,系统被分成两部分:
数据收集服务:收集用户输入的查询,并实时汇总。对于大型数据集,实时处理是不实际的;然而,这是一个很好的起点。我们将在深潜中探索更现实的解决方案。
查询服务:给定一个搜索查询或前缀,返回 5 个最常搜索的词语。
数据收集服务
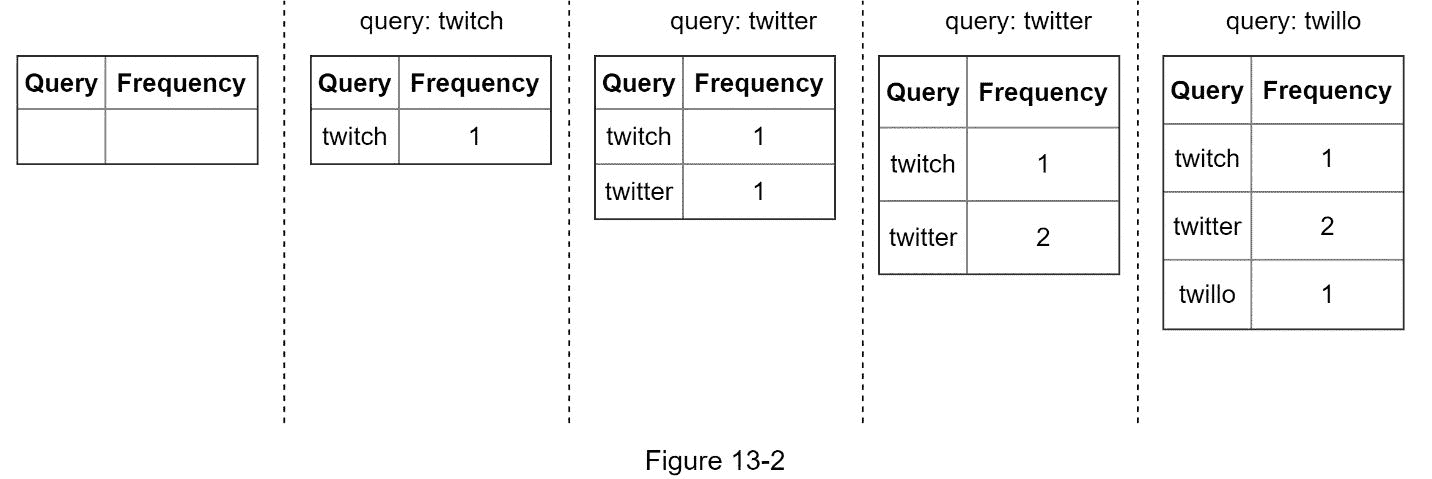
让我们用一个简单的例子来看看数据收集服务是如何工作的。假设我们有一个存储查询字符串及其频率的频率表,如图 13-2 所示。一开始,频率表是空的。之后,用户依次输入查询twitch、twitter、twitter和twillo。图 13-2 显示了频率表是如何更新的。
查询服务
假设我们有一个频率表,如表 13-1 所示。它有两个字段。
查询:存储查询字符串。
频率:表示查询被搜索的次数。

当用户在搜索框中键入“tw”时,会显示以下前 5 个搜索到的查询(图 13-3),假设频率表基于表 13-1。

要获得前 5 个最常搜索的查询,请执行以下 SQL 查询:

当数据集很小时,这是一个可接受的解决方案。当它很大时,访问数据库成为一个瓶颈。我们将深入探讨优化。
第三步——设计深潜
在概要设计中,我们讨论了数据收集服务和查询服务。高层次的设计并不是最佳的,但它是一个很好的起点。在本节中,我们将深入探讨几个组件,并探索如下优化:
特里数据结构
数据收集服务
查询服务
扩展存储
特里运算
Trie 数据结构
关系数据库用于高层设计中的存储。然而,从关系数据库中获取前 5 个搜索查询是低效的。数据结构 trie(前缀树)用于克服这个问题。由于 trie 数据结构对系统至关重要,我们将投入大量时间来设计定制的 trie。请注意,有些想法来自文章[2]和[3]。
理解基本的 trie 数据结构对这个面试问题至关重要。然而,这与其说是系统设计问题,不如说是数据结构问题。况且网上很多资料都在解释这个概念。在本章中,我们将只讨论 trie 数据结构的概述,并重点讨论如何优化基本 trie 以提高响应时间。
Trie(读作“try”)是一种树状数据结构,可以紧凑地存储字符串。这个名字来自单词 re trie val,表明它是为字符串检索操作而设计的。trie 的主要思想包括以下内容:
trie 是一种树状的数据结构。
词根代表空字符串。
每个节点存储一个字符,有 26 个子节点,每个子节点对应一个可能的字符。为了节省空间,我们不画空链接。
每个树节点代表一个单词或一个前缀串。
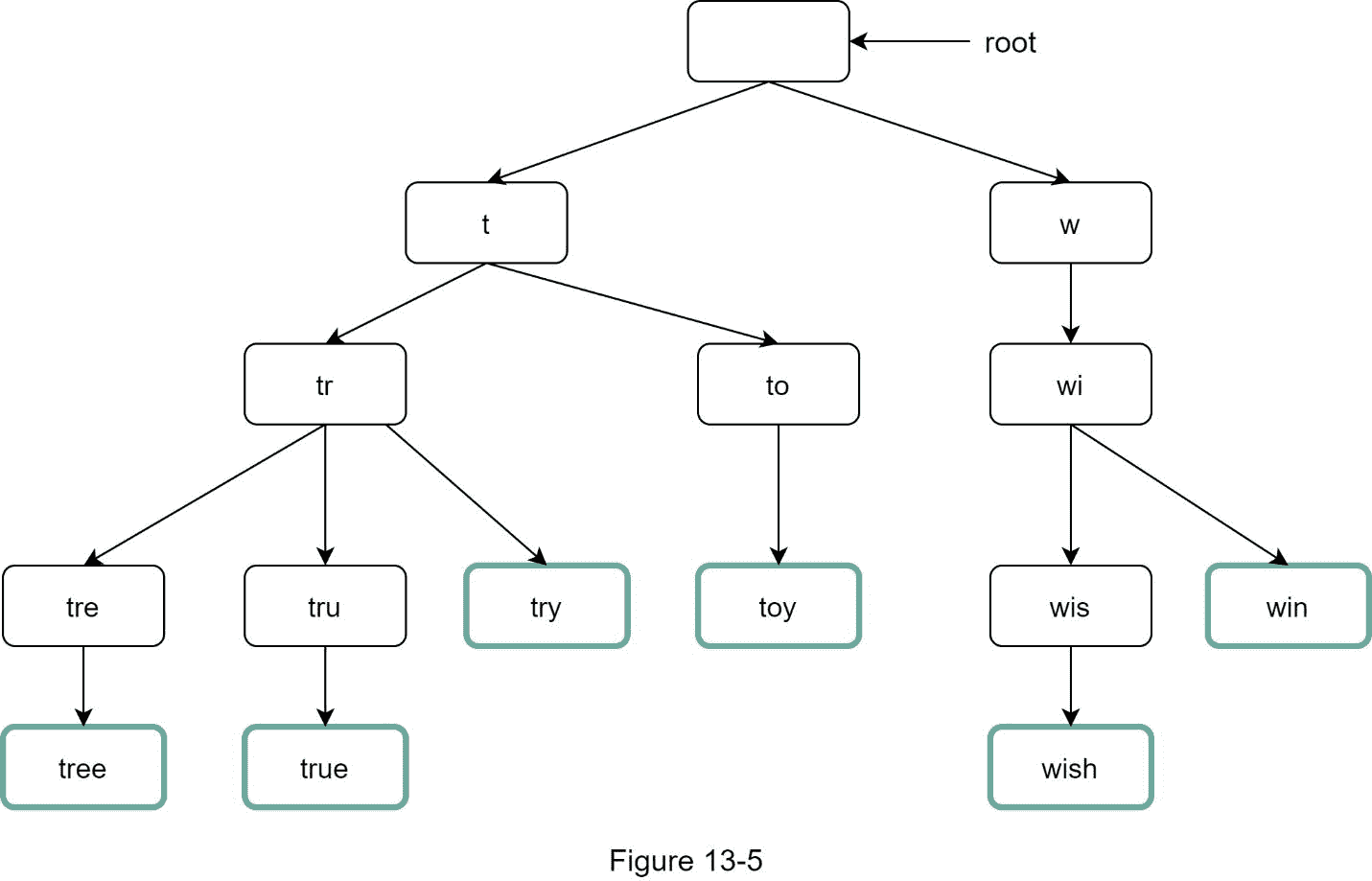
图 13-5 显示了带有搜索查询“树”、“尝试”、“真实”、“玩具”、“愿望”、“胜利”的 trie。搜索查询用粗边框突出显示。
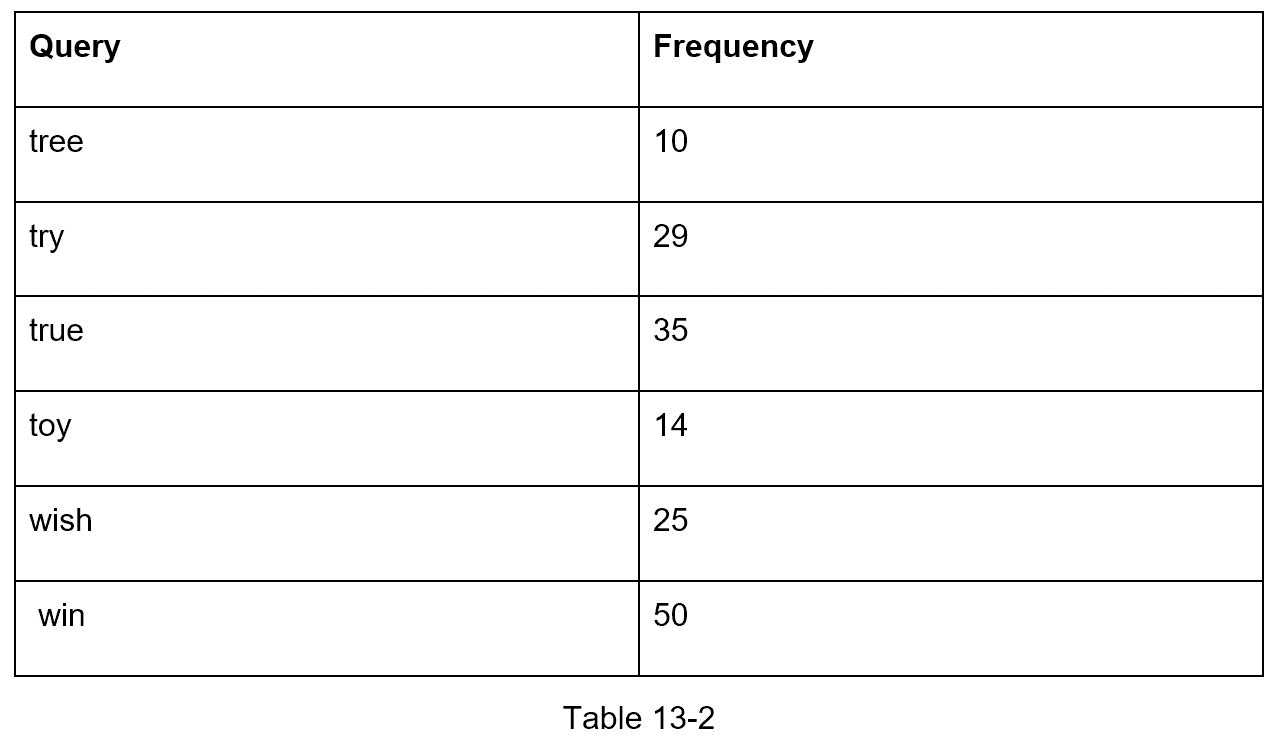
基本的 trie 数据结构在节点中存储字符。为了支持按频率排序,需要在节点中包含频率信息。假设我们有下面的频率表。
向节点添加频率信息后,更新后的 trie 数据结构如图 13-6 所示。
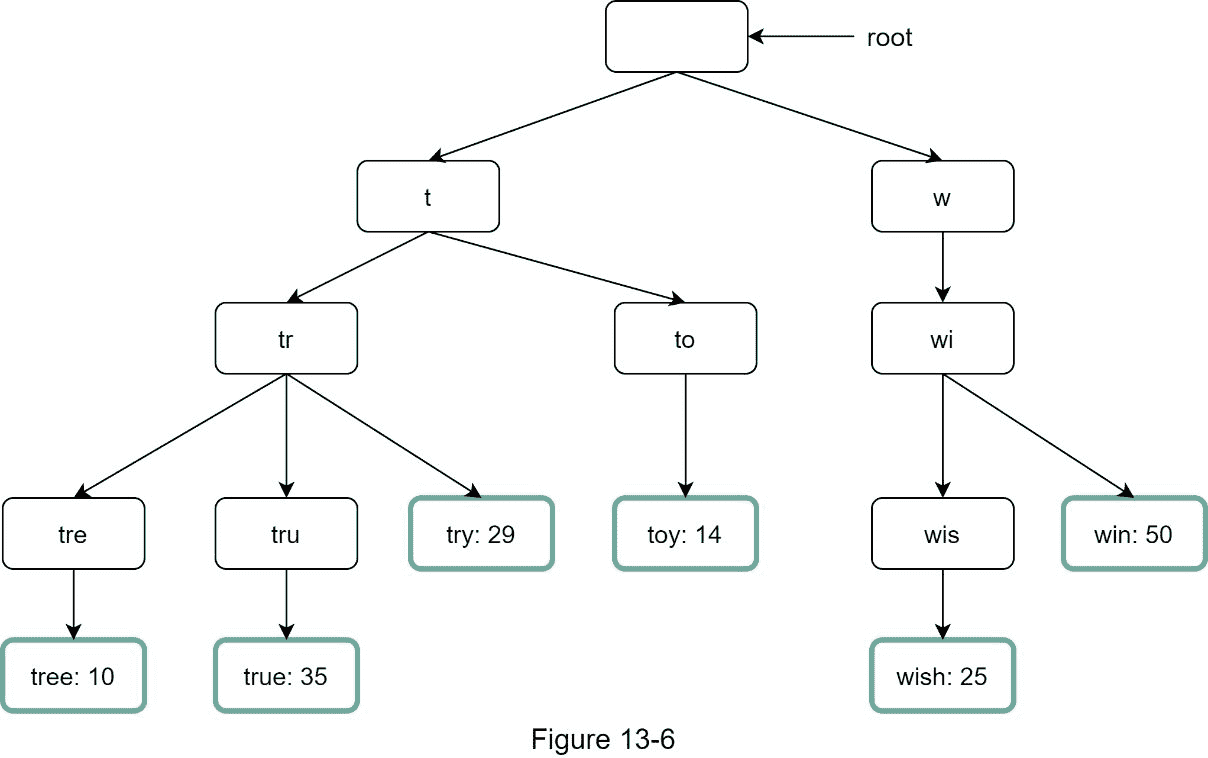
自动完成如何与 trie 一起工作?在深入算法之前,让我们定义一些术语。
p
n:一个 trie 的节点总数
c:给定节点的子节点数量
获得 top k 的步骤下面列出了搜索次数最多的查询:
1。找到前缀。时间复杂度: O(p) 。
2。从前缀节点开始遍历子树以获取所有有效的子节点。如果子元素可以形成有效的查询字符串,则它是有效的。时间复杂度:O(c)
3。给孩子排序,得到 top k 。时间复杂度: O(clogc)
让我们用一个如图 13-7 所示的例子来解释这个算法。假设 k 等于 2,并且用户在搜索框中键入tr。算法工作如下:
第一步:找到前缀节点tr”。
第二步:遍历子树,得到所有有效子树。在这种情况下,节点[tree: 10]、[true: 35]、[try: 29]是有效的。
第三步:对孩子进行排序,得到 top 2。[true: 35]和[try: 29]是前缀为tr的前 2 个查询。
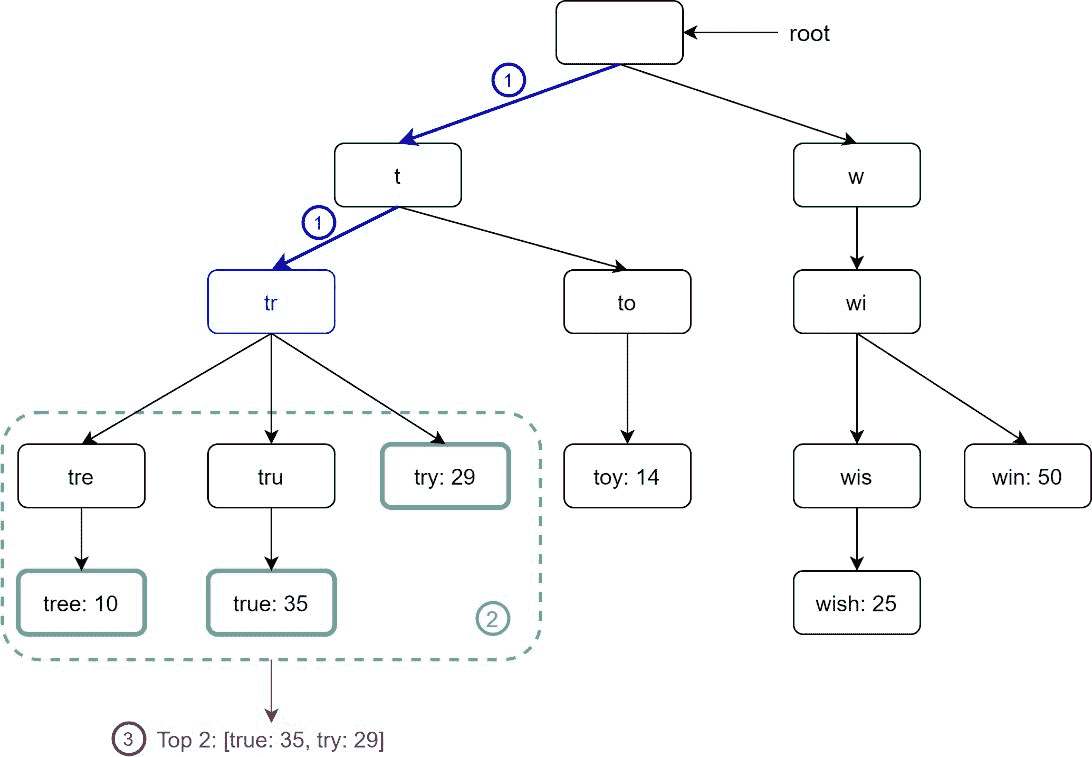
图 13-7
这个算法的时间复杂度是上面提到的每一步花费的时间之和: O(p) + O(c) + O(clogc)
上面的算法很简单。然而,它太慢了,因为我们需要遍历整个 trie 来得到最坏情况下的 top k 结果。下面是两个优化:
1。限制前缀的最大长度
2。在每个节点缓存热门搜索查询
让我们来逐一看看这些优化。
限制前缀的最大长度
用户很少在搜索框中键入长搜索查询。因此,可以肯定地说 p 是一个小整数,比如说 50。如果我们限制前缀的长度,那么“查找前缀”的时间复杂度可以从 降低到 O(小常数) 又名 O(1) 。
在每个节点缓存热门搜索查询
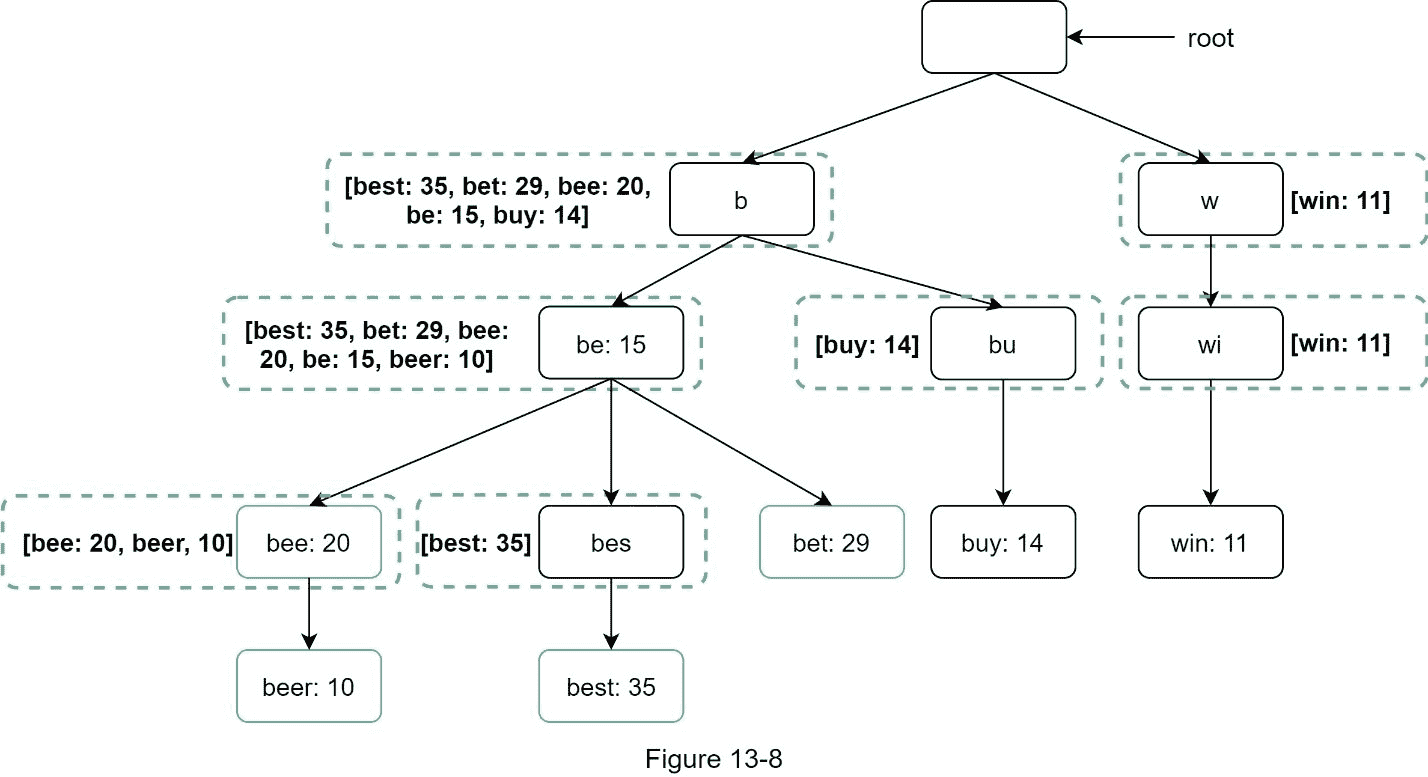
为了避免遍历整个 trie,我们在每个节点存储 top k 最常用的查询。由于 5 到 10 个自动完成建议对用户来说已经足够了, k 是一个相对较小的数字。在我们的具体例子中,只有前 5 个搜索查询被缓存。
通过在每个节点缓存前 5 个搜索查询,我们显著降低了检索前 5 个查询的时间复杂度。然而,这种设计需要大量空间来存储每个节点上的 top 查询。用空间换取时间是非常值得的,因为快速响应时间非常重要。
图 13-8 显示了更新后的 trie 数据结构。前 5 个查询存储在每个节点上。例如,前缀为“be”的节点存储以下内容:[best: 35, bet: 29, bee: 20, be: 15, beer: 10]。
让我们在应用了这两种优化之后再来看看算法的时间复杂度:
1。找到前缀节点。时间复杂度:O(1)
2。返顶 k 。由于 top k 查询被缓存,这一步的时间复杂度为 O(1) 。
由于每一步的时间复杂度降低到了 O(1) ,我们的算法只需要 O(1)就可以获取 top k 查询。
数据收集服务
在我们之前的设计中,无论用户何时输入搜索查询,数据都会实时更新。由于以下两个原因,这种方法不实用:
用户每天可能会输入数十亿次查询。在每次查询时更新 trie 会大大降低查询服务的速度。
一旦构建好 trie,顶级建议可能不会有太大变化。因此,不需要频繁更新 trie。
为了设计一个可扩展的数据收集服务,我们检查数据来自哪里以及如何使用数据。像 Twitter 这样的实时应用程序需要最新的自动完成建议。然而,许多谷歌关键词的自动完成建议可能不会每天都有很大变化。
尽管使用案例不同,但数据收集服务的基础仍然相同,因为用于构建 trie 的数据通常来自分析或日志服务。
图 13-9 显示了重新设计的数据收集服务。每个组件都被逐一检查。

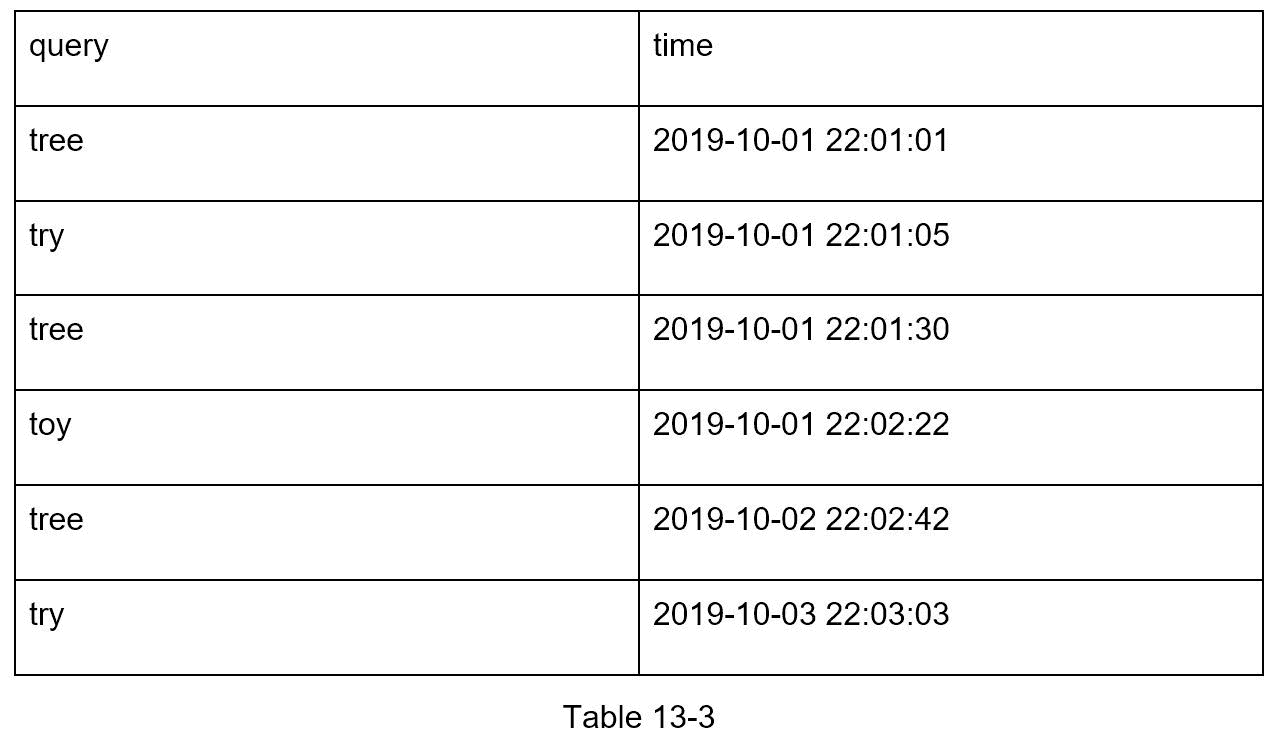
分析日志。 它存储关于搜索查询的原始数据。日志是只追加的,没有索引。表 13-3 显示了一个日志文件的例子。
聚合器。 分析日志通常非常大,并且数据格式不正确。我们需要汇总数据,以便我们的系统能够轻松处理这些数据。
根据不同的使用情况,我们可能会以不同的方式汇总数据。对于 Twitter 这样的实时应用程序,我们在更短的时间间隔内聚合数据,因为实时结果很重要。另一方面,不太频繁地聚合数据,比如每周一次,对于许多用例来说可能已经足够了。在面试过程中,验证实时结果是否重要。我们假设 trie 每周重建一次。
汇总数据。
表 13-4 显示了一个汇总的每周数据的例子。“时间”字段表示一周的开始时间。“频率”字段是该周相应查询的出现次数的总和。

工人。 Workers 是一组定期执行异步作业的服务器。他们构建 trie 数据结构并将其存储在 Trie DB 中。
Trie 缓存。 Trie Cache 是一个分布式缓存系统,将 Trie 保存在内存中,以供快速读取。它每周拍摄一次数据库快照。
特里 DB。 Trie DB 是持久存储。存储数据有两种选择:
1。文档存储:由于每周都会构建一个新的 trie,所以我们可以定期对其进行快照、序列化,并将序列化后的数据存储在数据库中。像 MongoDB [4]这样的文档存储非常适合序列化数据。
2。键值存储:通过应用以下逻辑,可以用哈希表的形式[4]来表示 trie:
trie 中的每个前缀都映射到哈希表中的一个键。
每个 trie 节点上的数据映射到哈希表中的一个值。
图 13-10 显示了 trie 和哈希表之间的映射。
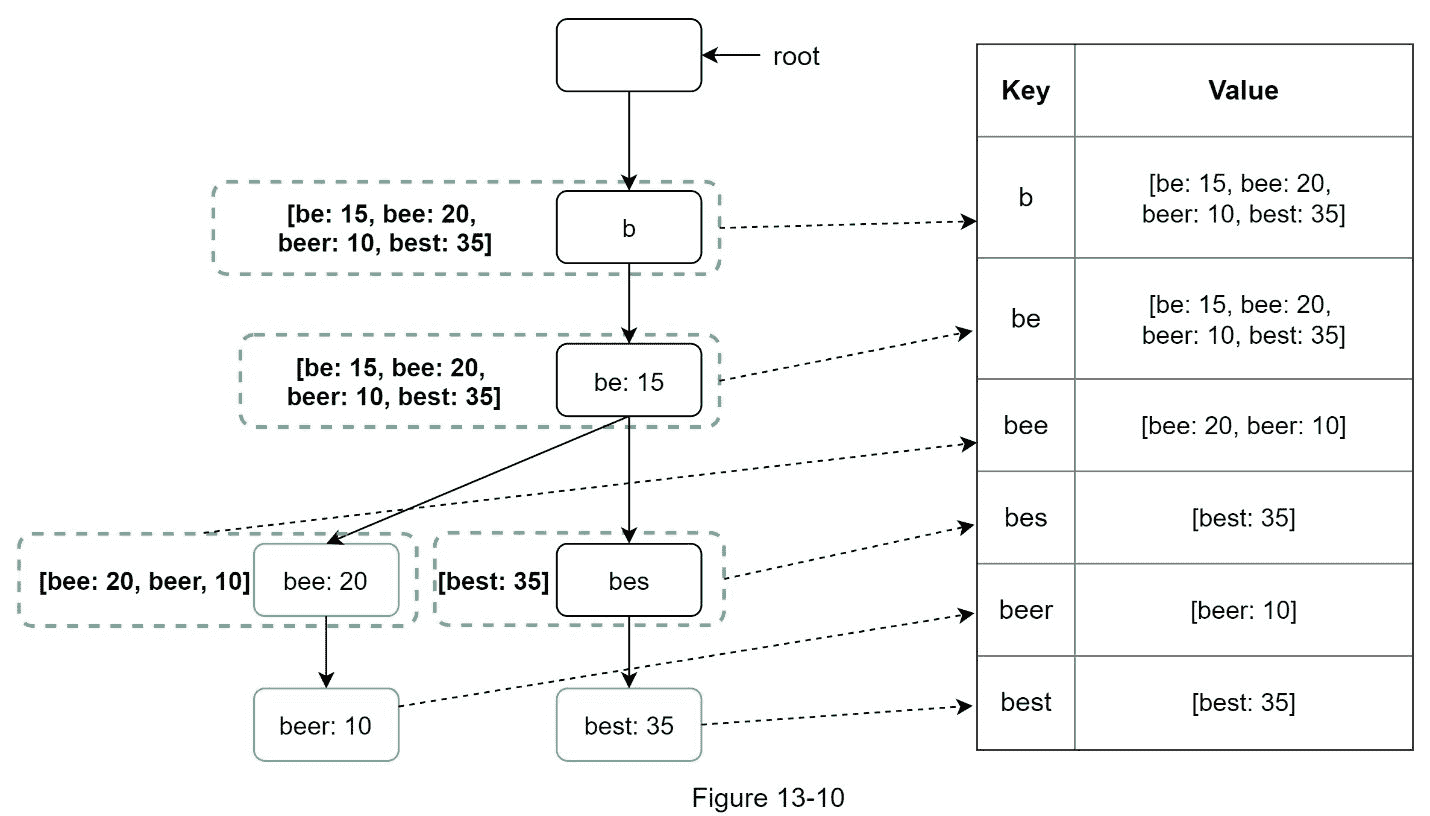
在图 13-10 中,左边的每个 trie 节点映射到右边的键值对。如果你不清楚键值存储是如何工作的,请参考第六章:设计键值存储。
查询服务
在高级设计中,查询服务直接调用数据库来获取前 5 个结果。图 13-11 显示了改进的设计,因为以前的设计效率很低。
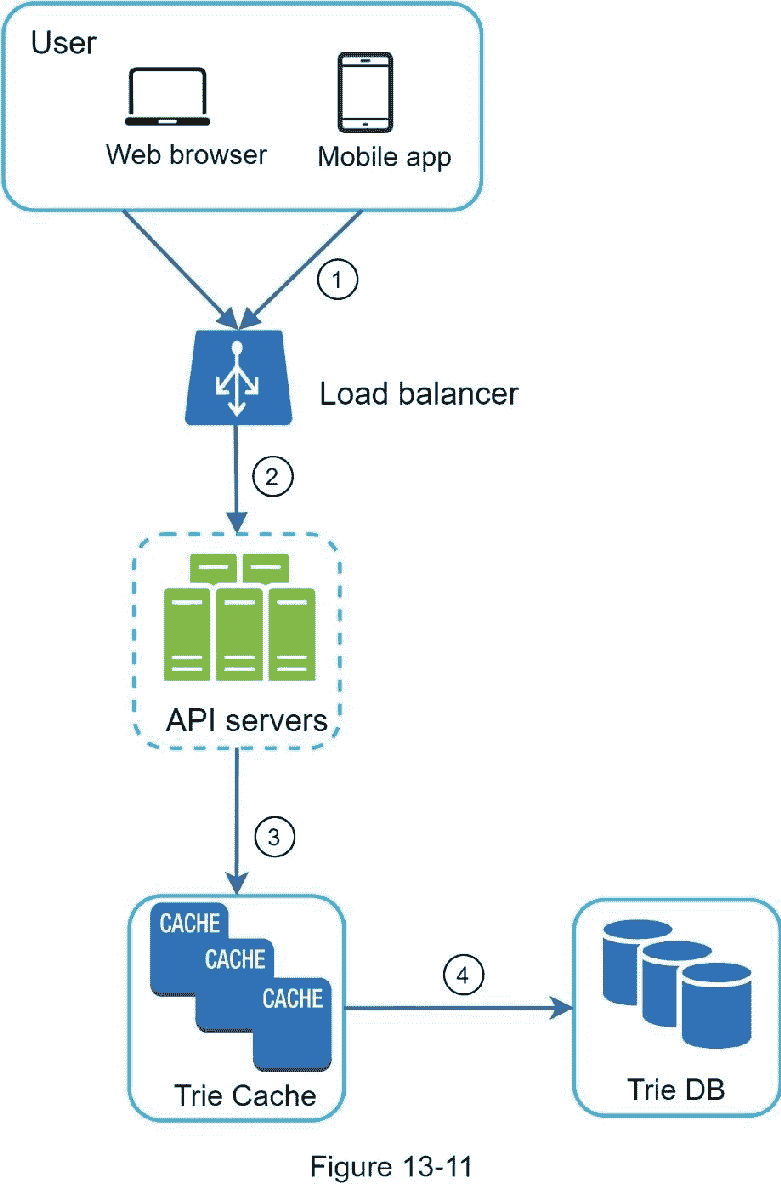
1。搜索查询被发送到负载平衡器。
2。负载平衡器将请求路由到 API 服务器。
3。API 服务器从 trie 缓存中获取 Trie 数据,并为客户端构造自动完成建议。
4。如果数据不在缓存中,我们将数据补充回缓存中。这样,对同一前缀的所有后续请求都将从缓存中返回。当缓存服务器内存不足或脱机时,可能会发生缓存未命中。
查询服务要求闪电般的速度。我们建议进行以下优化:
AJAX 请求。对于 web 应用程序,浏览器通常发送 AJAX 请求来获取自动完成结果。AJAX 的主要好处是发送/接收请求/响应不会刷新整个网页。
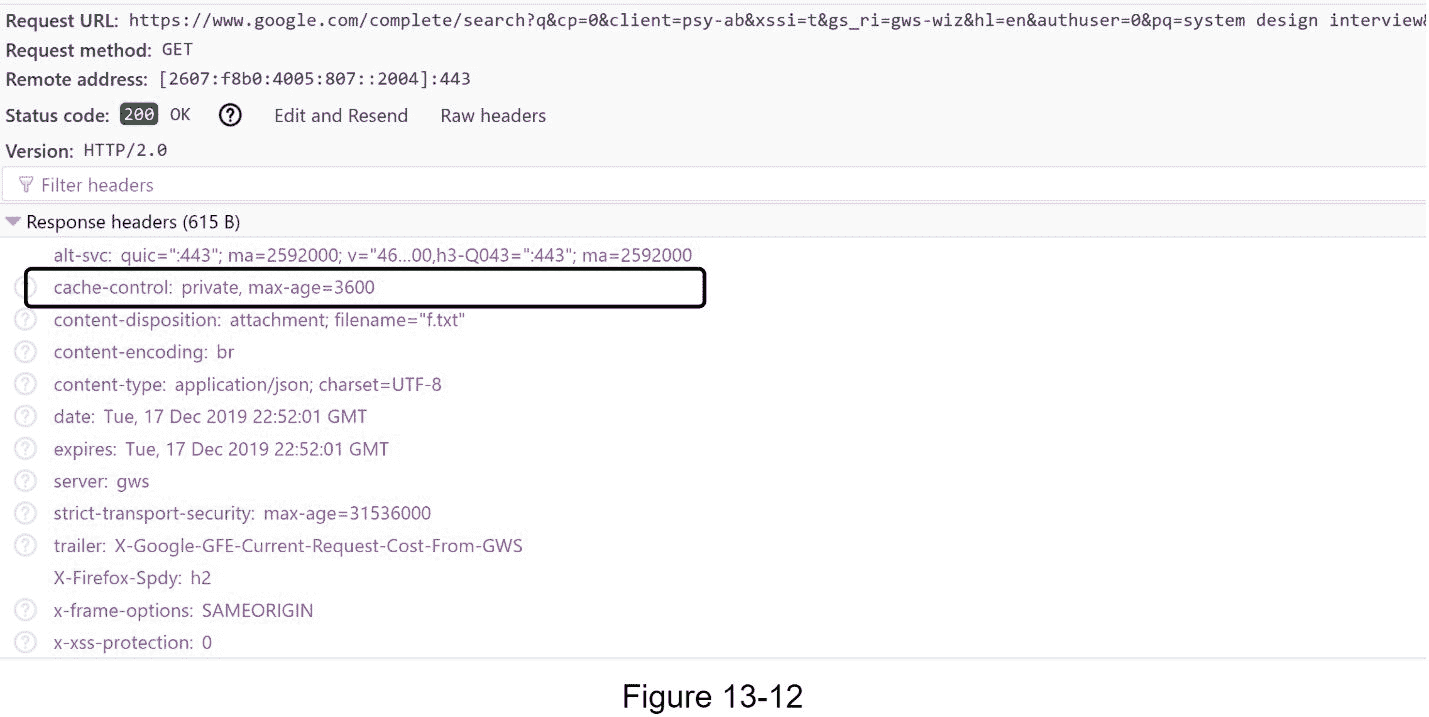
浏览器缓存。对于许多应用程序,自动完成搜索建议可能不会在短时间内发生太大变化。因此,自动完成建议可以保存在浏览器缓存中,以允许后续请求直接从缓存中获得结果。谷歌搜索引擎使用相同的缓存机制。图 13-12 显示了当你在谷歌搜索引擎上输入“系统设计面试”时的回复标题。如你所见,谷歌在浏览器中缓存结果 1 小时。请注意:cache-control 中的private表示结果是为单个用户准备的,不得由共享缓存进行缓存。max-age=3600意味着缓存的有效期为 3600 秒,也就是一个小时。
数据采样:对于大规模系统来说,记录每个搜索查询需要大量的处理能力和存储。数据采样很重要。例如,每 N 个请求中只有 1 个被系统记录。
Trie 操作
Trie 是自动完成系统的核心组件。让我们看看操作(创建、更新和删除)是如何工作的。
创建
工作人员使用聚合数据创建 Trie。数据来源于分析日志/数据库。
更新
有两种方法可以更新 trie。
选项 1:每周更新 trie。一旦创建了新的 trie,新的 trie 就会替换旧的 trie。
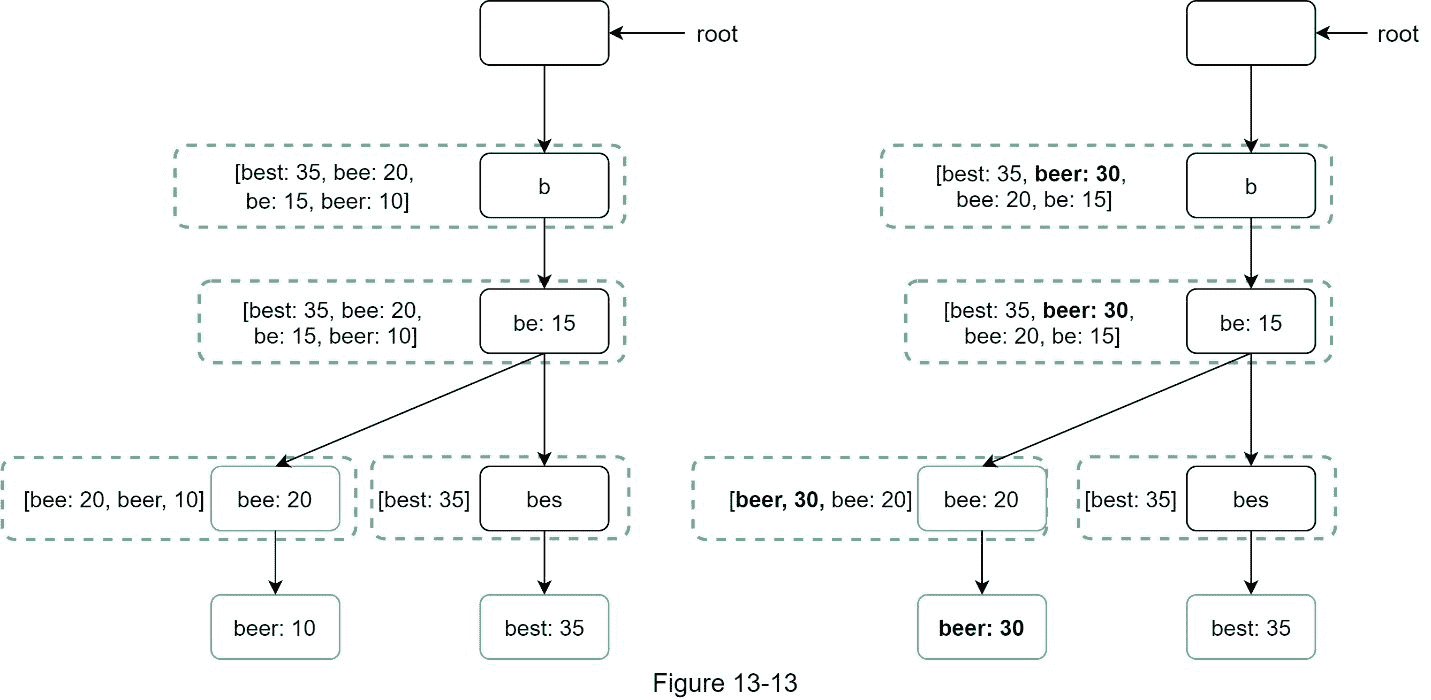
选项 2:直接更新单个 trie 节点。我们尽量避免这种操作,因为它很慢。然而,如果 trie 的大小很小,这是一个可接受的解决方案。当我们更新一个 trie 节点时,它的祖先一直到根都必须被更新,因为祖先存储了子节点的顶部查询。 显示了一个更新操作如何工作的例子。在左侧,搜索查询“啤酒”的原始值为 10。在右侧,它被更新为 30。如您所见,该节点及其祖先的beer值更新为 30。
删除
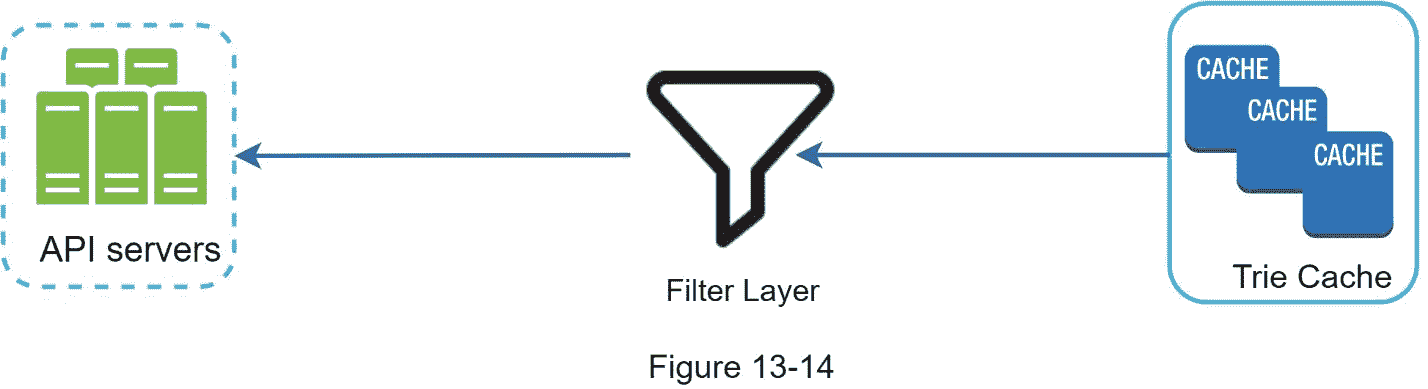
我们必须删除可恶的、暴力的、露骨的或危险的自动完成建议。我们在 Trie 缓存前面添加了一个过滤层(图 13-14 ),过滤掉不想要的建议。有了过滤层,我们可以根据不同的过滤规则灵活地移除结果。不需要的建议被异步地从数据库中物理移除,因此正确的数据集将被用于在下一个更新周期中构建 trie。
扩展存储
既然我们已经开发了一个为用户提供自动完成查询的系统,当 trie 变得太大而不适合一台服务器时,是时候解决可伸缩性问题了。
由于英语是唯一受支持的语言,一种简单的方法是基于第一个字符进行切分。这里有一些例子。
如果我们需要两台服务器进行存储,我们可以在第一台服务器上存储以a-m开头的查询,在第二台服务器上存储以n-z开头的查询。
如果我们需要三台服务器,我们可以将查询拆分为a-i,j-r和s-z。
按照这个逻辑,我们可以将查询拆分到 26 台服务器上,因为英语中有 26 个字母字符。让我们将基于第一个字符的分片定义为一级分片。为了存储超过 26 台服务器的数据,我们可以在第二层甚至第三层进行分片。比如以’ a 开头的数据查询,可以拆分成 4 个服务器:aa-ag、 ah-an、 ao-au、以及av-az。
乍看之下,这种方法似乎很合理,直到你意识到以字母c开头的单词比以字母 x开头的单词多得多。这就造成了分配不均。
为了缓解数据不平衡问题,我们分析了历史数据分布模式,并应用了更智能的分片逻辑,如图 13-15 所示。碎片映射管理器维护一个查找数据库,用于标识行应该存储在哪里。例如,如果对s和u, v, w, x, y, z有相似数量的历史查询

第四步——总结
完成深度调查后,面试官可能会问你一些后续问题。
面试官:你是如何扩展你的设计来支持多种语言的?
为了支持其他非英语查询,我们将 Unicode 字符存储在 trie 节点中。如果你不熟悉 Unicode,下面是它的定义:“一个编码标准涵盖了世界上所有书写系统的所有字符,现代的和古代的”[5]。
采访者:如果一个国家的顶级搜索查询与其他国家不同呢?
在这种情况下,我们可以为不同的国家建立不同的尝试。为了缩短响应时间,我们可以将尝试存储在 cdn 中。
采访者:我们如何支持趋势(实时)搜索查询?
假设一个新闻事件爆发,一个搜索查询突然流行起来。我们最初的设计行不通,因为:
离线工作人员尚未计划更新 trie,因为计划每周运行一次。
即使是预定的,构建 trie 的时间也太长了。
构建一个实时搜索自动完成是复杂的,超出了本书的范围,所以我们只给出一些想法:
通过分片减少工作数据集。
改变排名模型,给最近的搜索查询分配更多的权重。
数据可能以数据流的形式出现,所以我们无法一次访问所有数据。流数据意味着数据是连续生成的。流处理需要一套不同的系统:Apache Hadoop MapReduce [6],Apache Spark Streaming [7],Apache Storm [8],Apache Kafka [9]等。因为所有这些主题都需要特定的领域知识,所以我们在这里不做详细介绍。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] The Life of a Typeahead Query: https://www.facebook.com/notes/facebook-engineering/the-life-of-a-typeahead-query/389105248919/
[2] How We Built Prefixy: A Scalable Prefix Search Service for Powering Autocomplete: https://medium.com/@prefixyteam/how-we-built-prefixy-a-scalable-prefix-search-service-for-powering-autocomplete-c20f98e2eff1
[3] Prefix Hash Tree An Indexing Data Structure over Distributed Hash Tables: https://people.eecs.berkeley.edu/~sylvia/papers/pht.pdf
[4] MongoDB wikipedia: https://en.wikipedia.org/wiki/MongoDB
[5] Unicode frequently asked questions: https://www.unicode.org/faq/basic_q.html
[6] Apache hadoop: https://hadoop.apache.org/
[7] Spark streaming: https://spark.apache.org/streaming/
[8] Apache storm: https://storm.apache.org/
[9] Apache kafka: https://kafka.apache.org/docum
十四、设计 YouTube
在这一章中,你被要求设计 YouTube。这个问题的解决方案可以应用于其他面试问题,比如设计一个视频分享平台,如网飞和 Hulu。图 14-1 显示了 YouTube 主页。

YouTube 看起来很简单:内容创作者上传视频,观众点击播放。真的这么简单吗?不完全是。简单的背后有很多复杂的技术。让我们看看 2020 年 YouTube 的一些令人印象深刻的统计数据、人口统计数据和有趣的事实[1] [2]。
月活跃用户总数:20 亿。
每天观看的视频数量:50 亿。
73%的美国成年人使用 YouTube。
YouTube 上 5000 万创作者。
2019 年全年,YouTube 的广告收入为 151 亿美元,比 2018 年增长 36%。
YouTube 负责所有移动互联网流量的 37%。
YouTube 有 80 种不同的语言版本。
从这些统计数据中,我们知道 YouTube 是巨大的,全球化的,赚了很多钱。
步骤 1 -了解问题并确定设计范围
如图 14-1 所示,除了看视频,你还可以在 YouTube 上做很多事情。例如,评论、分享或喜欢视频、将视频保存到播放列表、订阅频道等。在 45 分钟或 60 分钟的采访中不可能设计出所有的东西。因此,提问以缩小范围是很重要的。
候选 : 什么特征重要?
面试官 : 上传视频和观看视频的能力。
候选人 : 我们需要支持哪些客户?
面试官 : 手机应用、网页浏览器、智能电视。
候选人 : 我们有多少日活跃用户?
面试官:500 万
候选 : 平均每天花在产品上的时间是多少?
面试官 : 30 分钟。
候选 : 我们需要支持国际用户吗?
面试官 : 是的,很大比例的用户是国际用户。
候选 : 支持的视频分辨率有哪些?
面试官 : 系统接受大部分的视频分辨率和格式。
候选 : 需要加密吗?
面试官 :是
候选 : 对视频文件大小有什么要求吗?
面试官 : 我们平台专注于中小视频。允许的最大视频大小为 1GB。
候选人 : 我们能否利用亚马逊、谷歌或微软提供的一些现有云基础设施?
面试官 : 这个问题问得好。对于大多数公司来说,从头开始构建一切是不现实的,建议利用一些现有的云服务。
在本章中,我们重点设计一个具有以下特点的视频流服务:
能够快速上传视频
流畅视频流
能够改变视频质量
基础设施成本低
高可用性、可扩展性和可靠性要求
支持的客户端:移动应用、网络浏览器和智能电视
信封估算的背面
下面的估计是基于许多假设,所以与面试官沟通以确保她同意是很重要的。
假设产品有 500 万日活跃用户(DAU)。
用户每天观看 5 个视频。
10%的用户每天上传 1 个视频。
假设平均视频大小为 300 MB。
每日所需总存储空间:500 万 * 10% * 300 MB = 150TB
CDN 费用。
当云 CDN 提供视频时,你要为从 CDN 传输出去的数据付费。
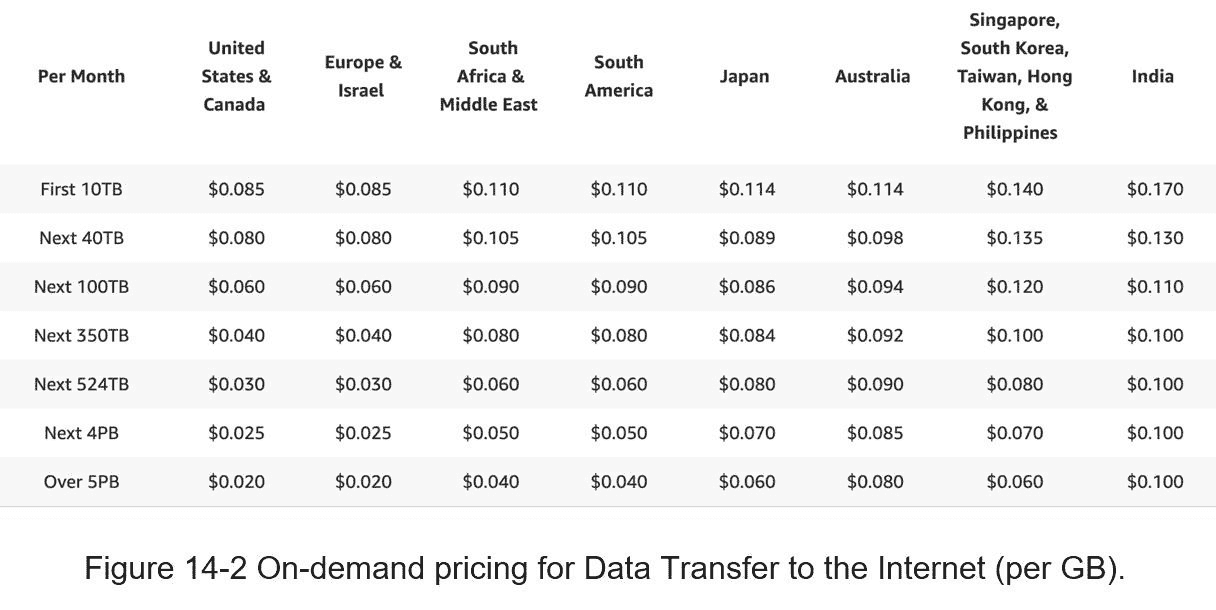
让我们用亚马逊的 CDN CloudFront 进行成本估算(图 14-2) [3]。假设 100%的流量来自美国。每 GB 的平均成本为 0.02 美元。为简单起见,我们只计算视频流的成本。
每天 500 万 * 5 个视频 * 0.3 GB * 0.02 美元 = 15 万美元。
从粗略的成本估算中,我们知道从 CDN 提供视频服务要花费很多钱。尽管云提供商愿意为大客户大幅降低 CDN 成本,但成本仍然很高。我们将深入探讨降低 CDN 成本的方法。
第二步-提出高层次设计并获得认同
如前所述,采访者建议利用现有的云服务,而不是从头开始构建一切。CDN 和 blob 存储是我们将利用的云服务。有些读者可能会问,为什么不自己动手建造一切呢?原因如下:
系统设计面试不是从零开始构建一切。在有限的时间内,选择正确的技术来正确地完成工作比详细解释技术如何工作更重要。例如,提到用于存储源视频的 blob 存储就足够了。谈论 blob 存储的详细设计可能有些矫枉过正。
构建可扩展的 blob 存储或 CDN 极其复杂且成本高昂。即使像网飞或脸书这样的大公司也不会自己建造所有的东西。网飞利用亚马逊的云服务[4],脸书使用 Akamai 的 CDN [5]。
从高层次来看,该系统由三个部分组成(图 14-3)。
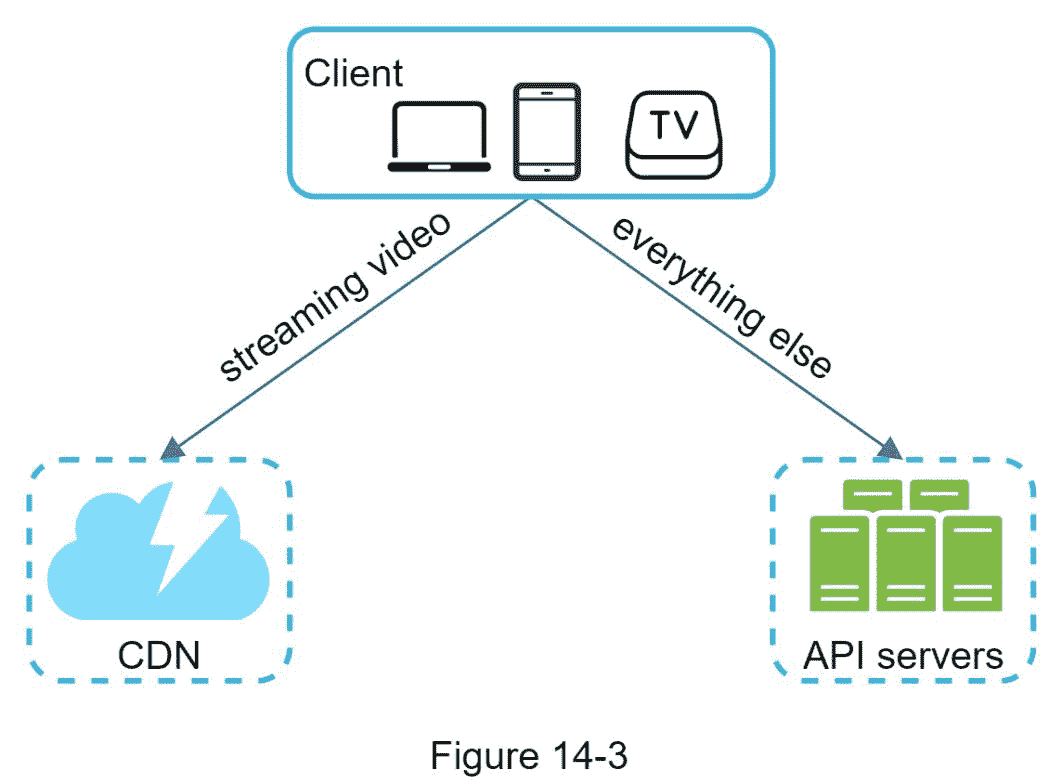
客户端 :可以在电脑、手机、智能电视上看 YouTube。
CDN :视频存储在 CDN 中。当您按下播放按钮时,视频将从 CDN 中流出。
API 服务器 :除了视频流,其他都通过 API 服务器。这包括提要推荐、生成视频上传 URL、更新元数据数据库和缓存、用户注册等。
在问答环节,面试官表现出对两个流程的兴趣:
视频上传流程
视频流
我们将探讨其中每一个的高层设计。
视频上传流程
图 14-4 显示了视频上传的概要设计。
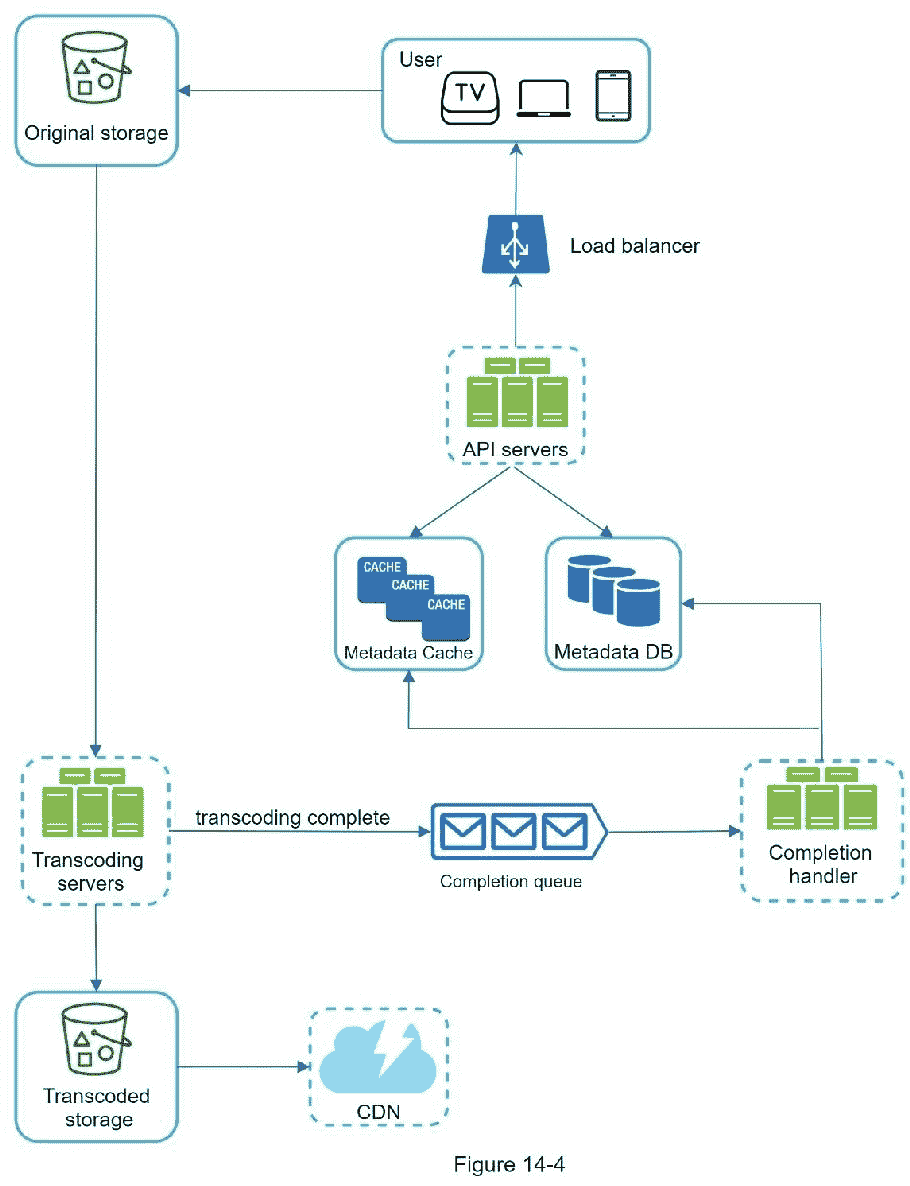
它由以下部件组成:
用户:用户在电脑、手机、智能电视等设备上观看 YouTube。
负载平衡器:负载平衡器在 API 服务器之间平均分配请求。
API 服务器:除了视频流,所有用户请求都要经过 API 服务器。
元数据 DB:视频元数据存储在元数据 DB 中。它经过分片和复制,以满足性能和高可用性要求。
元数据缓存:为了更好的性能,缓存视频元数据和用户对象。
原始存储:blob 存储系统用于存储原始视频。维基百科中关于 blob 存储的一段引文显示:“二进制大型对象(BLOB)是在数据库管理系统中作为单个实体存储的二进制数据的集合”[6]。
转码服务器:视频转码也叫视频编码。它是将一种视频格式转换为其他格式(MPEG、HLS 等)的过程,可以为不同的设备和带宽能力提供最佳的视频流。
转码存储:是一个 blob 存储,存储转码后的视频文件。
CDN:视频缓存在 CDN 中。当您单击播放按钮时,视频将从 CDN 流出。
完成队列:存储视频转码完成事件信息的消息队列。
完成处理程序:它由从完成队列中提取事件数据并更新元数据缓存和数据库的工作者列表组成。
现在我们已经分别了解了每个组件,让我们来看看视频上传流程是如何工作的。该流程分为两个并行运行的流程。
a .上传实际视频。
b .更新视频元数据。元数据包含视频 URL、大小、分辨率、格式、用户信息等信息。
流程 a:上传实际视频
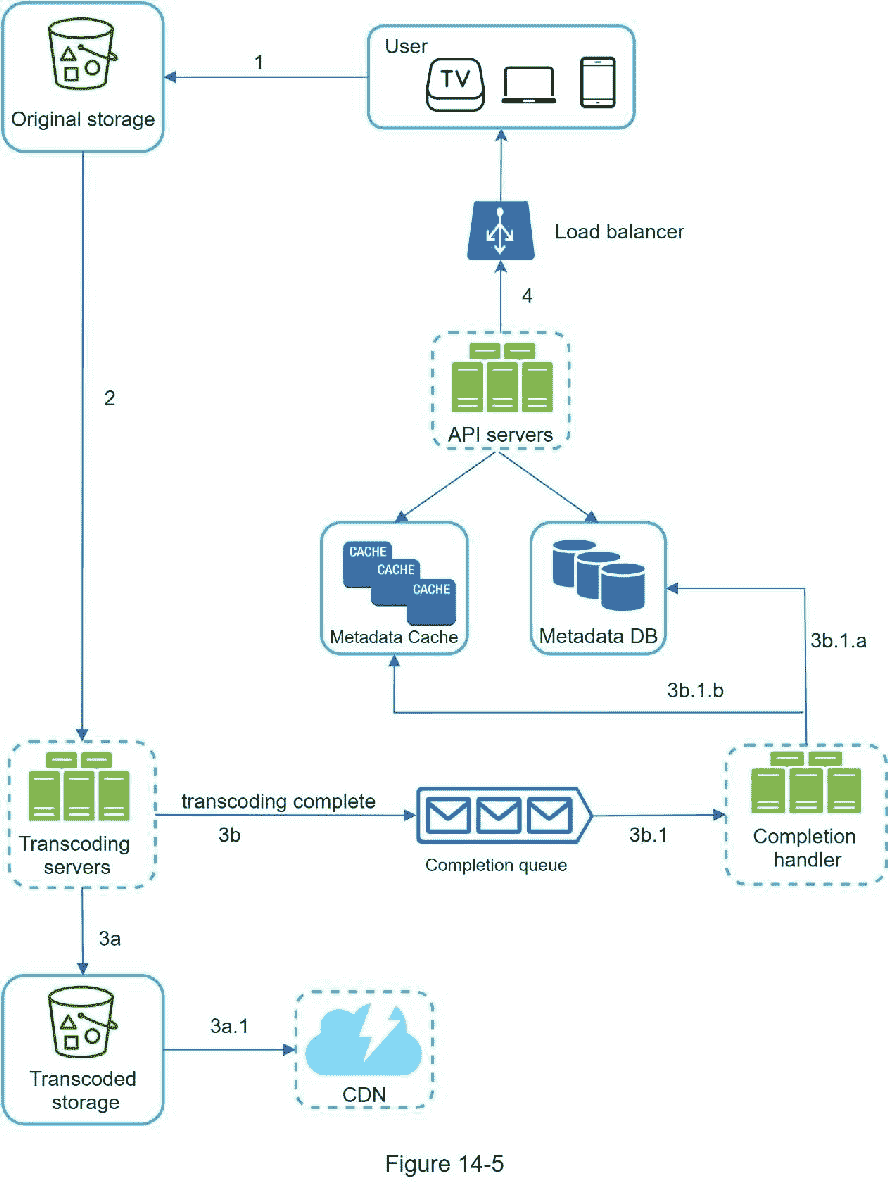
图 14-5 显示了如何上传实际视频。解释如下:
1。视频被上传到原始存储器。
2。转码服务器从原始存储中获取视频并开始转码。
3。一旦代码转换完成,并行执行以下两个步骤:
3a。转码后的视频被发送到转码后的存储器。
3b。代码转换完成事件在完成队列中排队。
3a.1 .转码后的视频分发到 CDN。
3b.1 .完成处理程序包含一群从队列中持续提取事件数据的工人。
3b.1.a .和 3b.1.b .完成处理器在视频转码完成时更新元数据数据库和缓存。
4。API 服务器通知客户端视频已成功上传,可以进行流式传输。
流程 b:更新元数据
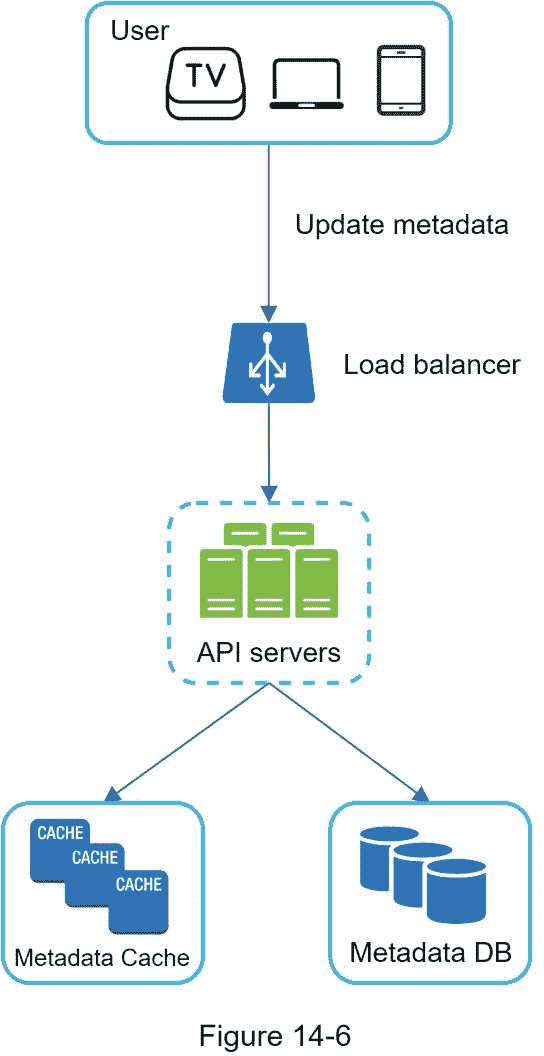
当一个文件被上传到原始存储器时,客户端并行发送一个更新视频元数据的请求,如图 14-6 所示。该请求包含视频元数据,包括文件名、大小、格式等。API 服务器更新元数据缓存和数据库。
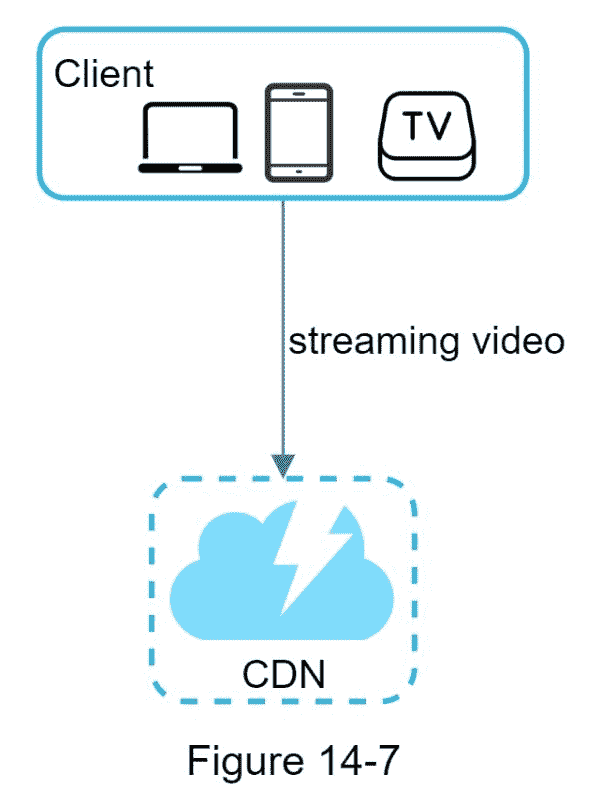
视频流流量
每当你在 YouTube 上观看视频时,它通常会立即开始播放,而不是等到整个视频下载完毕。下载意味着整个视频被复制到您的设备,而流意味着您的设备不断地从远程源视频接收视频流。当您观看流媒体视频时,您的客户端会一次加载一点数据,以便您可以立即连续观看视频。
在讨论视频流之前,我们先来看一个重要的概念:流协议。这是控制视频流数据传输的标准化方式。流行的流媒体协议有:
MPEG-DASH。MPEG 代表“运动图像专家组”,DASH 代表“HTTP 上的动态自适应流”。
苹果 HLS。HLS 代表“HTTP 直播流”。
微软流畅流媒体。
Adobe HTTP 动态流媒体(HDS)。
您不需要完全理解甚至记住这些流媒体协议名称,因为它们是需要特定领域知识的低级细节。这里重要的是理解不同的流协议支持不同的视频编码和回放播放器。当我们设计视频流服务时,我们必须选择正确的流协议来支持我们的用例。要了解更多关于流协议的信息,这里有一篇优秀的文章[7]。
视频直接从 CDN 流出。离你最近的边缘服务器会传送视频。因此,延迟非常小。图 14-7 显示了视频流的高级设计。
第三步——设计深潜
在高层设计中,整个系统被分解为两部分:视频上传流程和视频流传输流程。在这一节中,我们将通过重要的优化改进这两个流,并引入错误处理机制。
视频转码
录制视频时,设备(通常是手机或相机)会赋予视频文件某种格式。如果希望视频在其他设备上流畅播放,则必须将视频编码为兼容的比特率和格式。比特率是一段时间内处理比特的速率。更高的比特率通常意味着更高的视频质量。高比特率流需要更多的处理能力和快速的互联网速度。
视频转码很重要,原因如下:
原始视频消耗大量存储空间。以每秒 60 帧的速度录制的长达一小时的高清视频可能会占用数百 GB 的空间。
许多设备和浏览器只支持特定类型的视频格式。因此,出于兼容性原因,将视频编码为不同的格式是很重要的。
为了确保用户观看高质量的视频,同时保持流畅的播放,一个好主意是向具有高网络带宽的用户提供较高分辨率的视频,而向具有低带宽的用户提供较低分辨率的视频。
网络条件可能会发生变化,尤其是在移动设备上。为了确保视频连续播放,根据网络条件自动或手动切换视频质量对于流畅的用户体验至关重要。
许多类型的编码格式可用;但是,它们大多包含两个部分:
容器:这就像一个篮子,里面装着视频文件、音频和元数据。可以通过文件扩展名来判断容器格式,比如 AVI,MOV 或 MP4。
编解码器:这些是压缩和解压缩算法,旨在减少视频大小,同时保持视频质量。最常用的视频编解码器是 H.264、VP9 和 HEVC。
有向无环图(DAG)模型
对视频进行代码转换在计算上既昂贵又耗时。此外,不同的内容创作者可能有不同的视频处理要求。例如,一些内容创建者要求在他们的视频上添加水印,一些内容创建者自己提供缩略图,一些内容创建者上传高清视频,而其他内容创建者则不需要。
为了支持不同的视频处理管道并保持高并行性,添加某种程度的抽象并让客户端程序员定义要执行的任务是很重要的。例如,脸书的流媒体视频引擎使用有向无环图(DAG)编程模型,该模型分阶段定义任务,因此它们可以顺序或并行执行[8]。在我们的设计中,我们采用了类似的 DAG 模型来实现灵活性和并行性。图 14-8 显示了一个用于视频转码的 DAG。
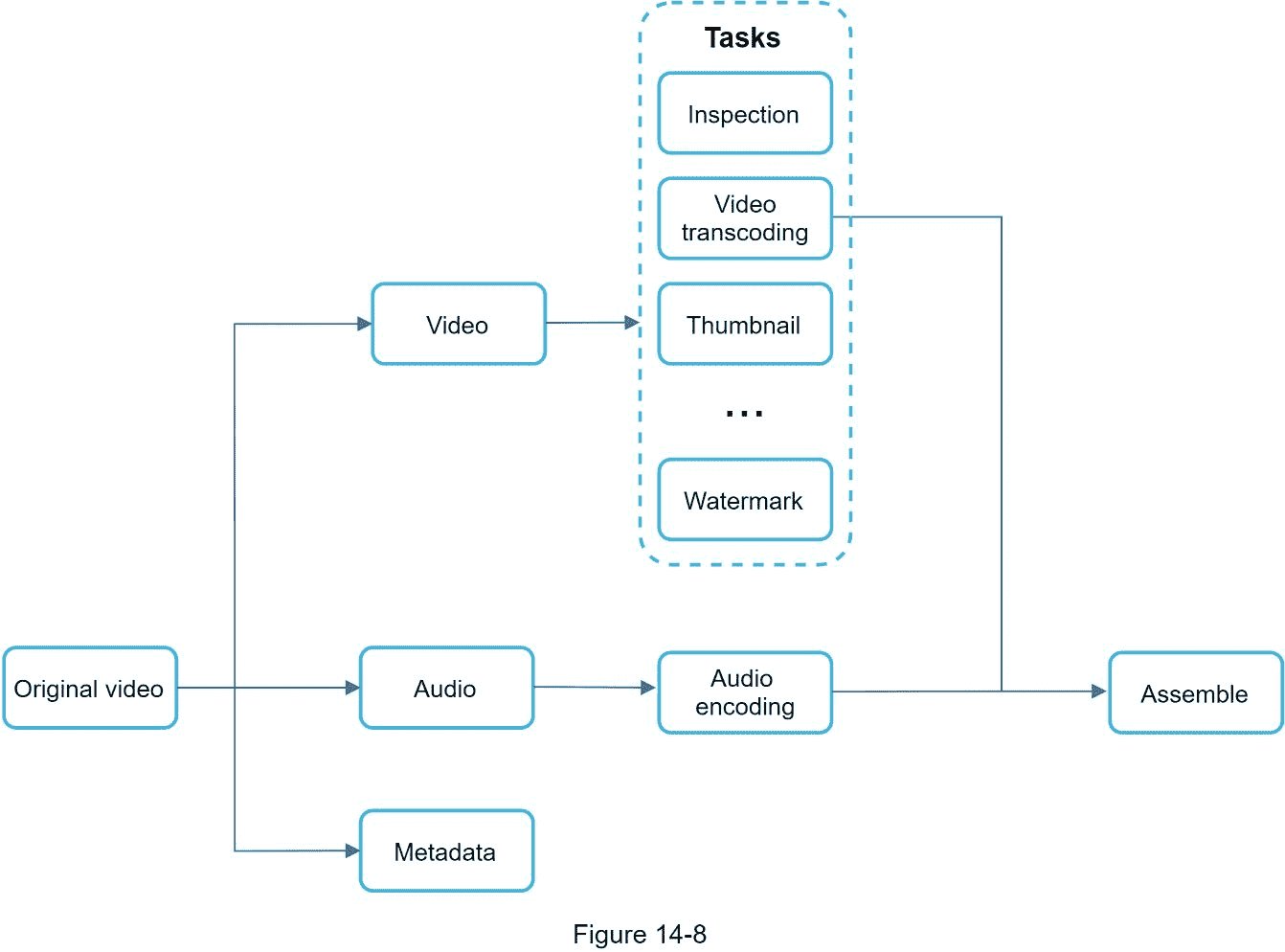
在图 14-8 中,原始视频被分成视频、音频和元数据。以下是一些可以应用于视频文件的任务:
检查:确保视频质量良好,没有畸形。
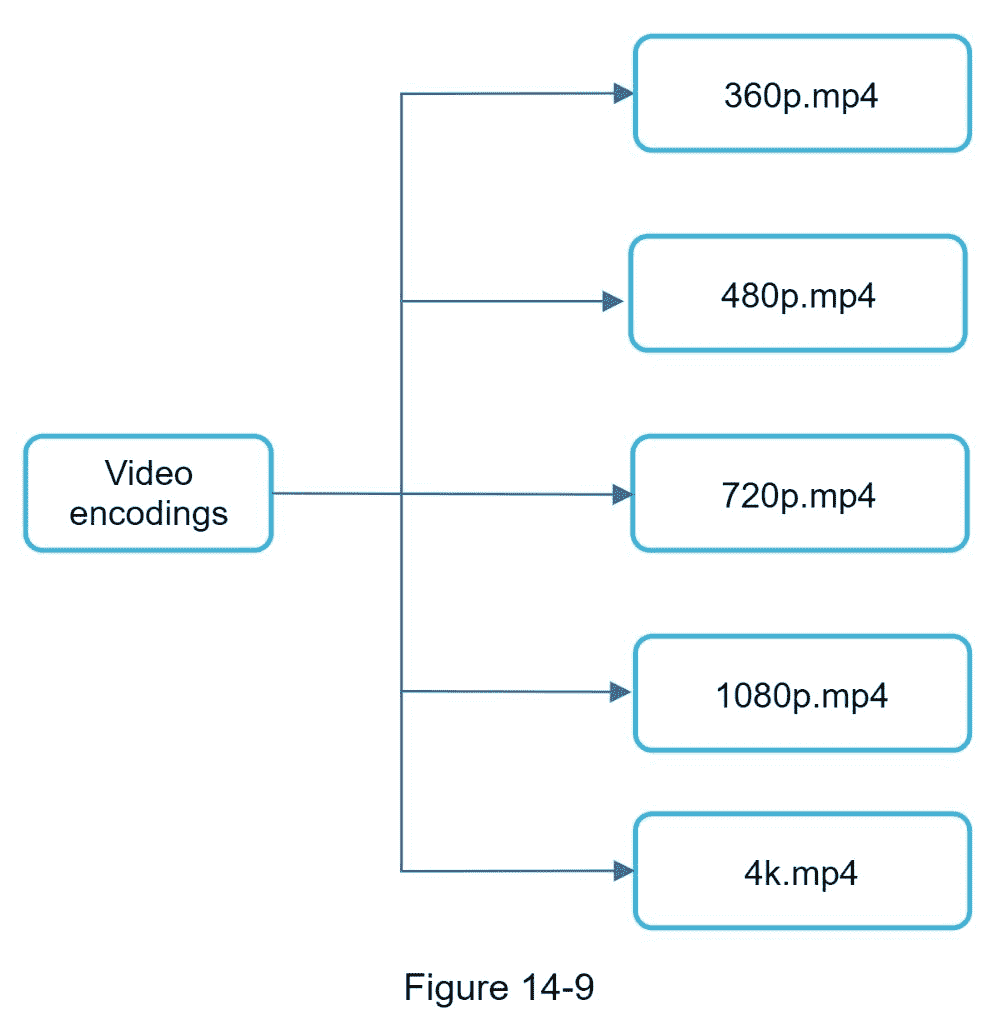
视频编码:视频被转换以支持不同的分辨率、编解码器、比特率等。图 14-9 显示了一个视频编码文件的例子。
。缩略图可以由用户上传,也可以由系统自动生成。
水印:覆盖在视频顶部的图像包含视频的识别信息。
视频转码架构
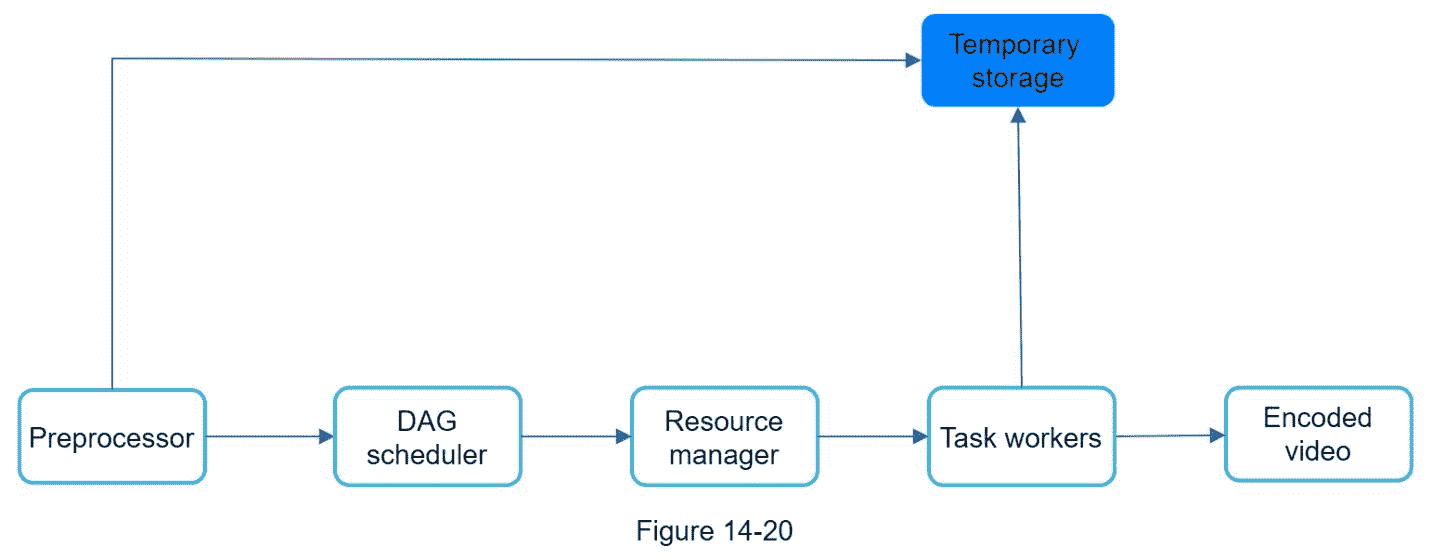
图 14-10 显示了提议的利用云服务的视频转码架构。
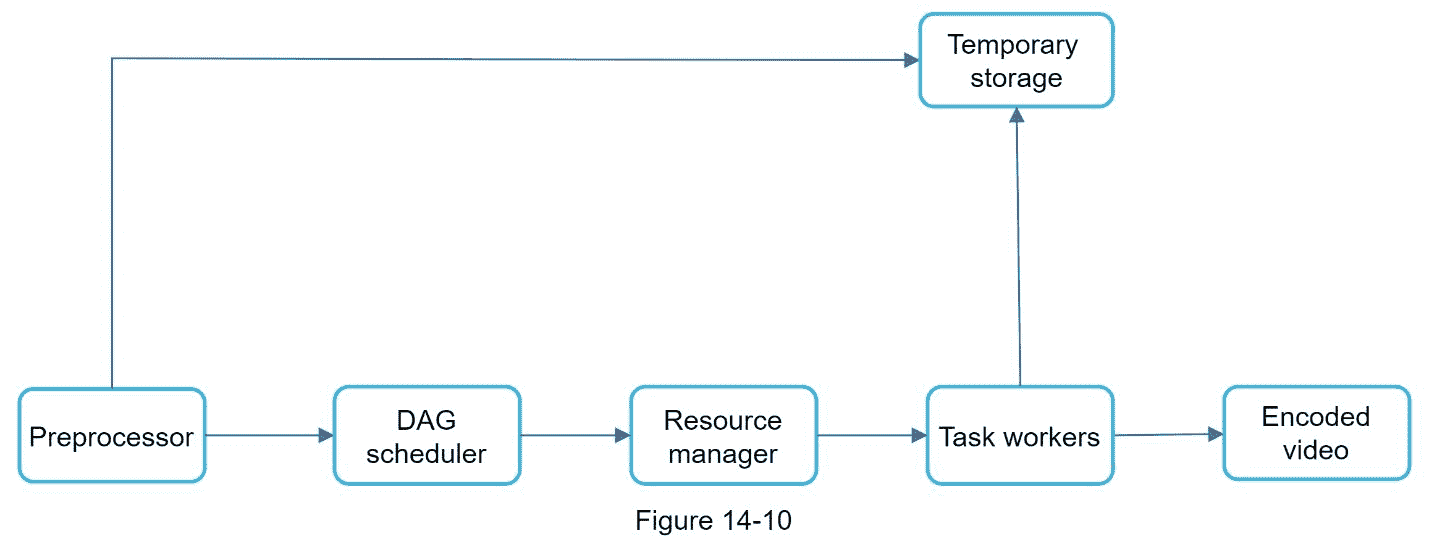
该架构有六个主要组件:预处理器、DAG 调度器、资源管理器、任务工作器、临时存储器和作为输出的编码视频。让我们仔细看看每个组件。
预处理器
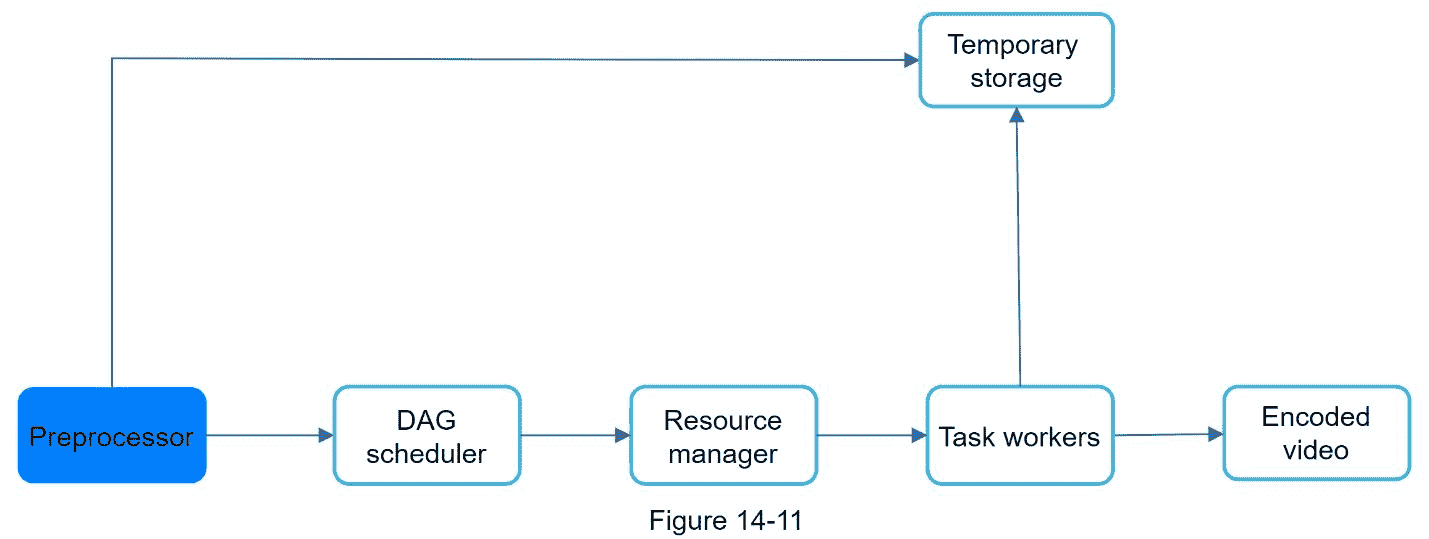
预处理器有 4 个职责:
1。视频分割。视频流被分割或进一步分割成较小图像组(GOP)排列。GOP 是按特定顺序排列的一组/一大块帧。每个区块都是一个独立的游戏单元,长度通常只有几秒钟。
2。一些旧的移动设备或浏览器可能不支持视频分割。预处理器分割视频的 GOP 对齐老客户端。
3。DAG 一代。处理器基于客户端程序员编写的配置文件生成 DAG。图 14-12 是一个简化的 DAG 表示,它有两个节点和一条边:
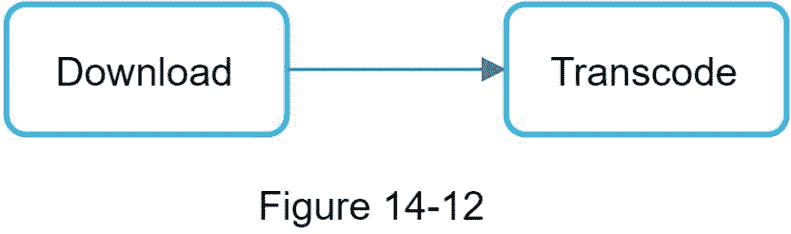
这个 DAG 表示由下面的两个配置文件生成(图 14-13):

4。缓存数据。预处理器是分段视频的缓存。为了提高可靠性,预处理器将 GOP 和元数据存储在临时存储中。如果视频编码失败,系统可以使用持久数据进行重试操作。
天调度器
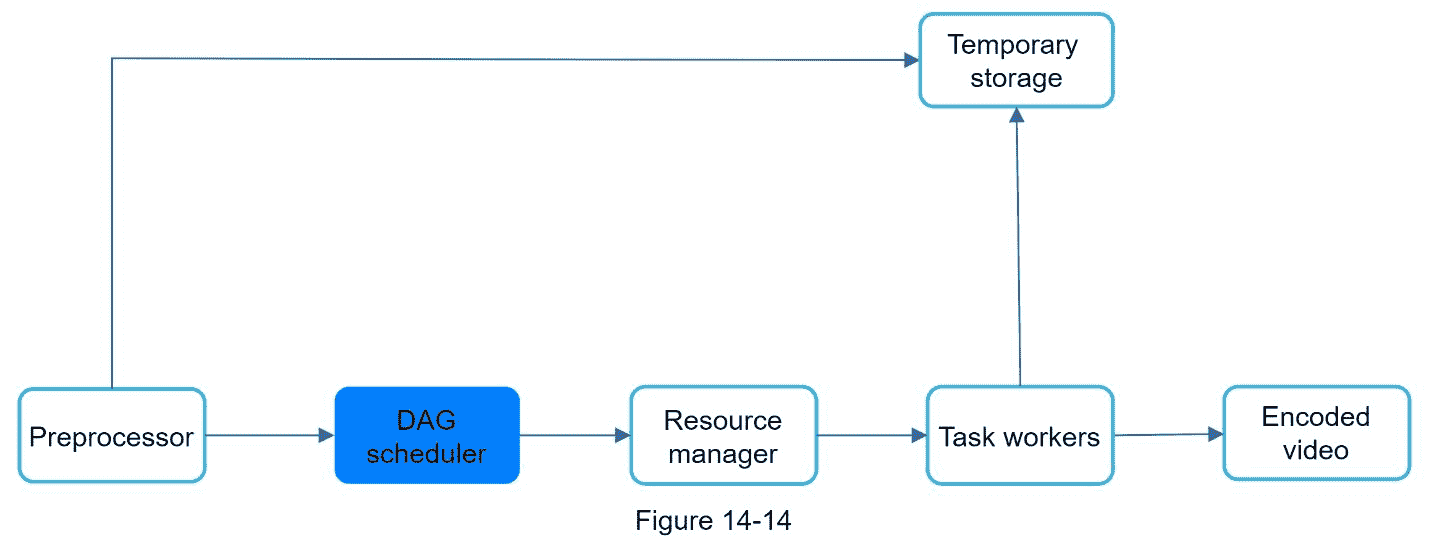
DAG 调度程序将 DAG 图分割成任务阶段,并将它们放入资源管理器的任务队列中。图 14-15 显示了 DAG 调度程序如何工作的示例。
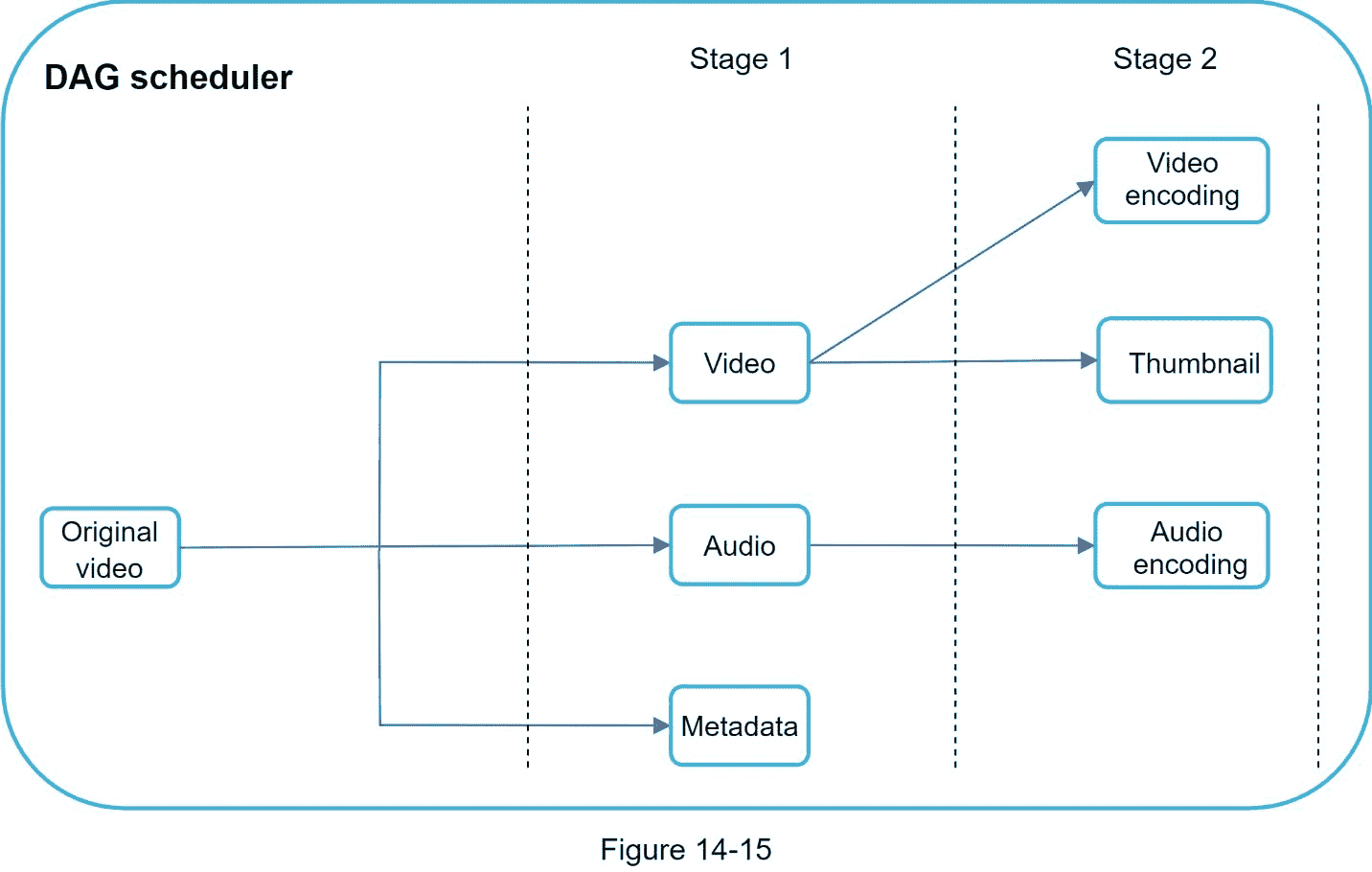
如图 14-15 所示,原始视频被分成两个阶段:阶段 1:视频、音频和元数据。在阶段 2 中,视频文件被进一步分成两个任务:视频编码和缩略图。作为阶段 2 任务的一部分,音频文件需要音频编码。
资源经理
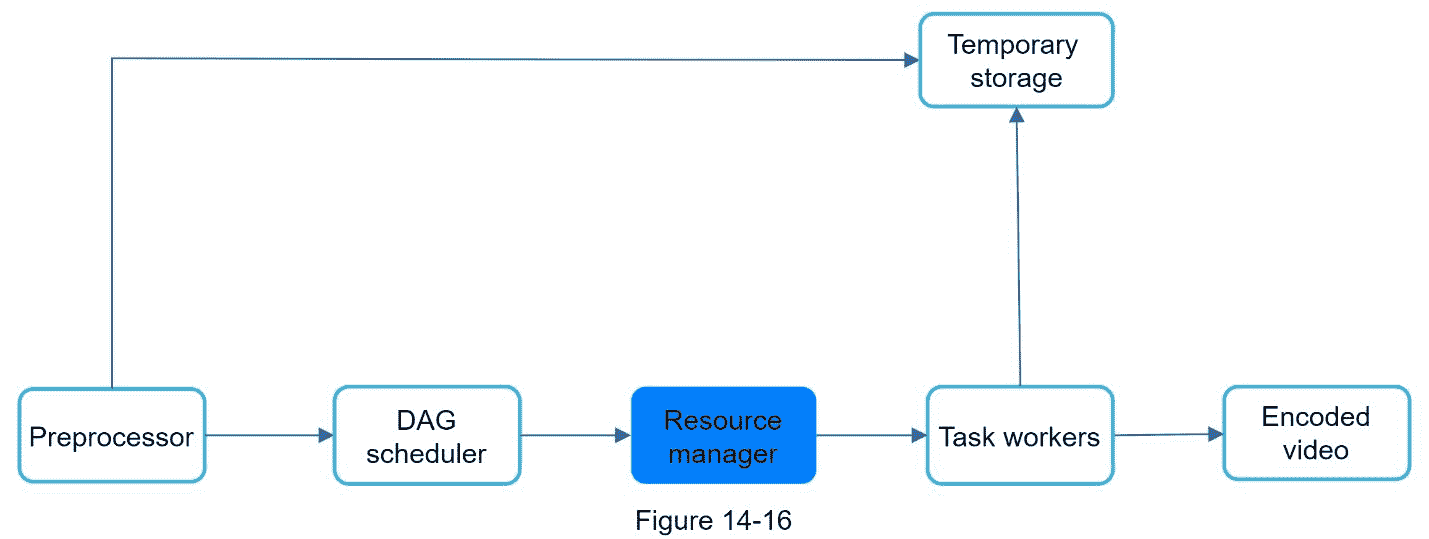
资源经理负责管理资源分配的效率。它包含 3 个队列和一个任务调度器,如图 14-17 所示。
任务队列:是一个优先级队列,包含要执行的任务。
工人队列:包含工人使用信息的优先队列。
运行队列:包含当前正在运行的任务以及运行这些任务的工作人员的信息。
任务调度器:挑选最优的任务/工作者,并指示所选的任务工作者执行作业。
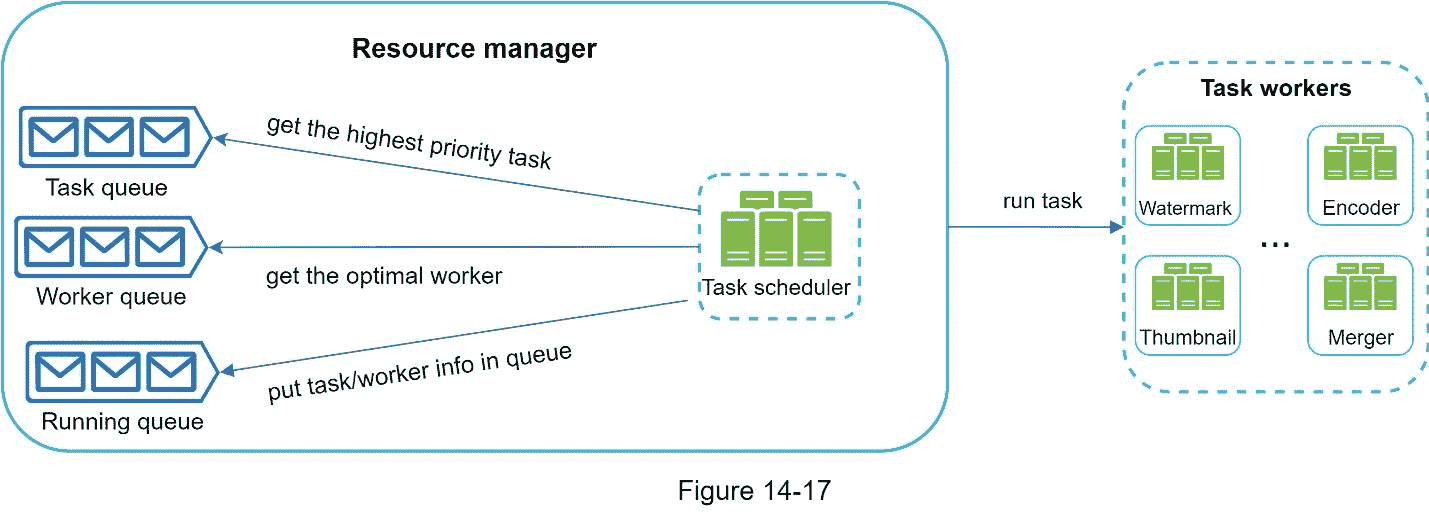
资源管理器的工作方式如下:
任务调度器从任务队列中获取优先级最高的任务。
任务调度器从工作者队列中获取最优的任务工作者来运行任务。
任务调度器指示选择的任务工作者运行任务。
任务调度器绑定任务/工作者信息,放入运行队列。
一旦任务完成,任务调度器就将任务从运行队列中删除。
任务工人

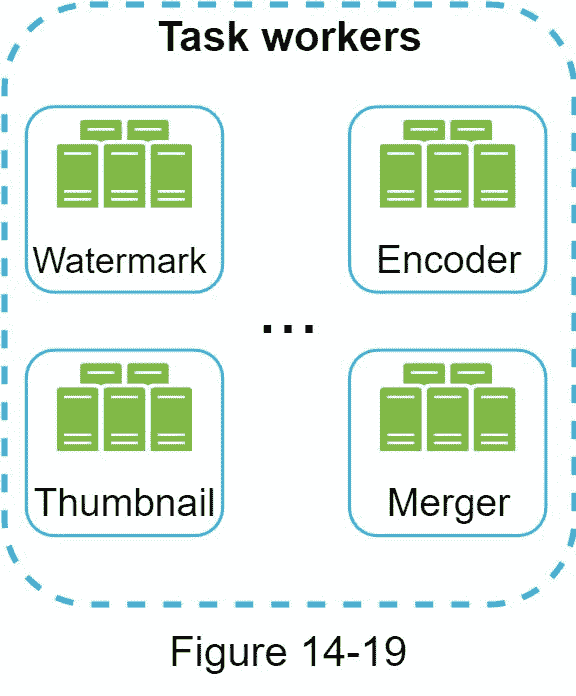
任务工作者运行 DAG 中定义的任务。不同的任务工作者可能运行不同的任务,如图 14-19 所示。
临时存储
这里使用了多个存储系统。存储系统的选择取决于数据类型、数据大小、访问频率、数据生命周期等因素。例如,工作人员经常访问元数据,并且数据大小通常很小。因此,在内存中缓存元数据是一个好主意。对于视频或音频数据,我们将它们放在 blob 存储中。一旦相应的视频处理完成,临时存储器中的数据被释放。
编码视频
编码视频是编码管道的最终输出。下面是一个输出的例子: 滑稽 _720p.mp 4 。
系统优化
至此,你应该对视频上传流程、视频流流程和视频转码有了很好的理解。接下来,我们将优化系统,包括速度、安全和成本节约。
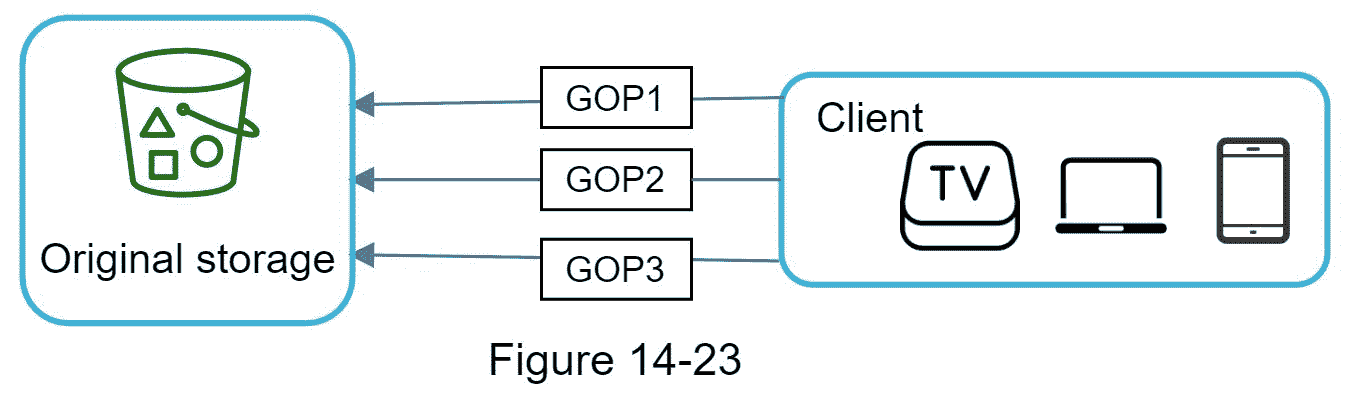
速度优化:并行上传视频
整体上传一个视频效率很低。我们可以通过 GOP 对齐将一个视频分割成更小的块,如图 14-22 所示。

这允许在先前上传失败时快速恢复上传。按 GOP 分割视频文件的工作可以由客户端实现,以提高上传速度,如图 14-23 所示。
速度优化:将上传中心放在离用户近的地方
另一种提高上传速度的方法是在全球设立多个上传中心(图 14-24)。美国的人可以上传视频到北美上传中心,中国的人可以上传视频到亚洲上传中心。为了实现这一点,我们使用 CDN 作为上传中心。

速度优化:并行无处不在
实现低延迟需要付出巨大努力。另一个优化是构建一个松散耦合的系统,并实现高并行性。
我们的设计需要一些修改来实现高并行性。让我们放大视频从原始存储转移到 CDN 的流程。流程如图 14-25 所示,显示了输出依赖于前一步的输入。这种依赖性使得并行变得困难。
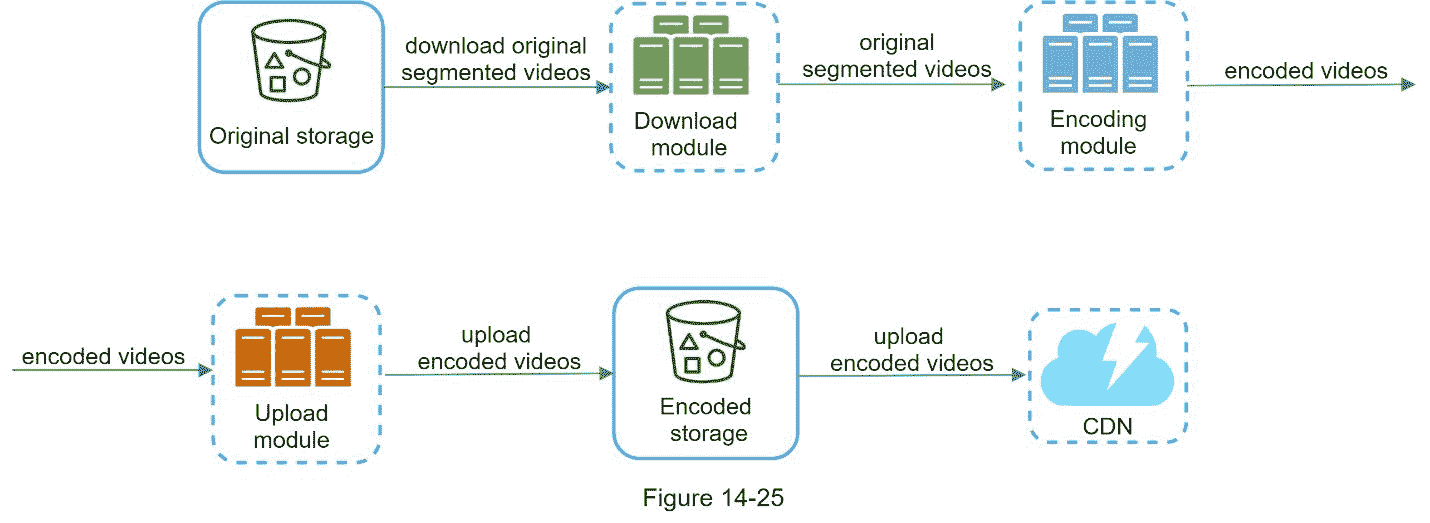
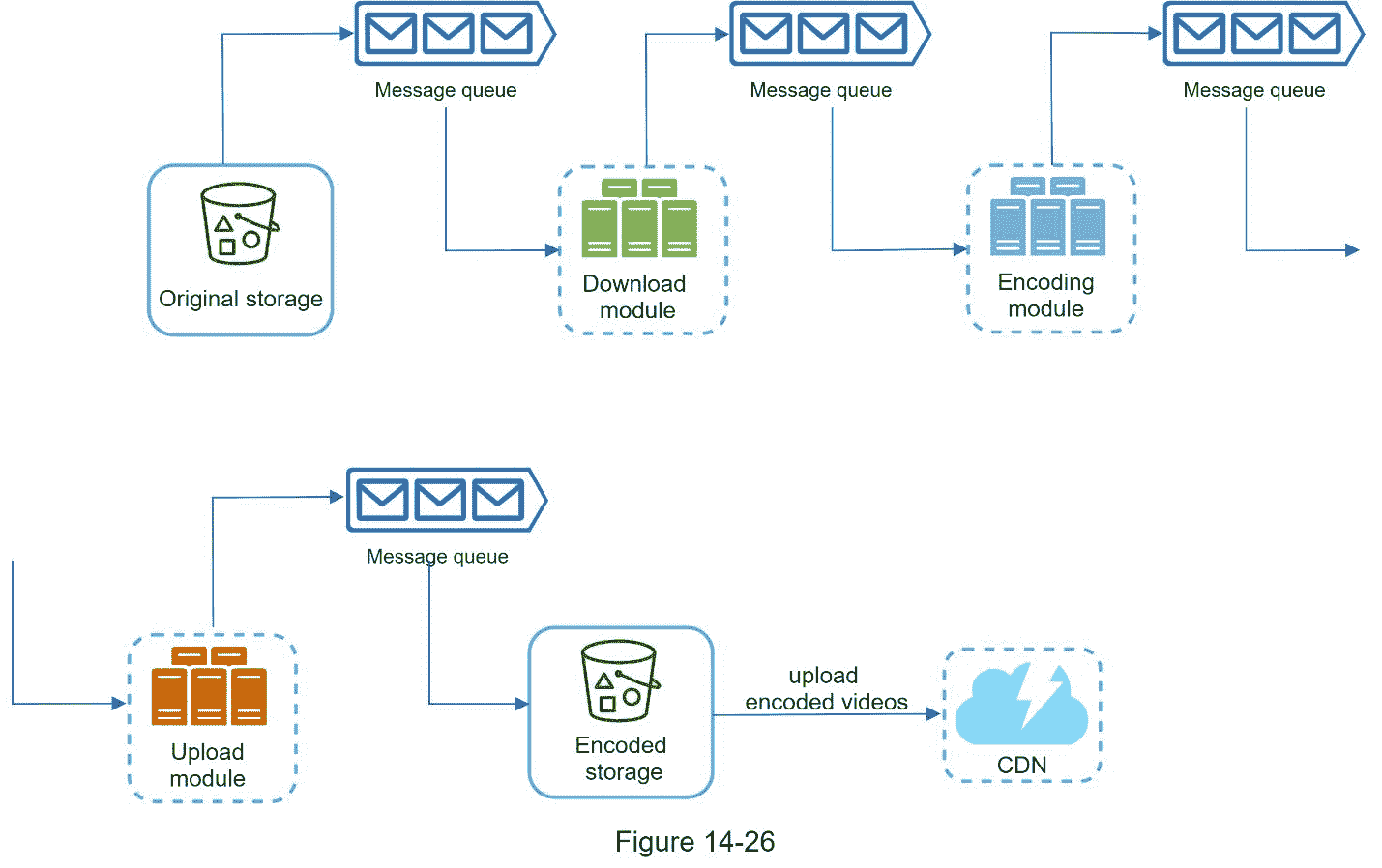
为了使系统更加松散耦合,我们引入了消息队列,如图 14-26 所示。让我们用一个例子来解释消息队列是如何使系统更加松散耦合的。
在消息队列引入之前,编码模块必须等待下载模块的输出。
引入消息队列后,编码模块不再需要等待下载模块的输出。如果消息队列中有事件,编码模块可以并行执行这些作业。
安全优化:预签名上传 URL
安全是任何产品最重要的方面之一。为了确保只有授权用户上传视频到正确的位置,我们引入了预先签名的 URL,如图 14-27 所示。

上传流程更新如下:
1。客户端向 API 服务器发出一个 HTTP 请求,以获取预先签名的 URL,这为 URL 中标识的对象提供了访问权限。术语预签名 URL 用于将文件上传到亚马逊S3。其他云服务提供商可能会使用不同的名称。例如,微软 Azure blob 存储支持相同的功能,但称之为“共享访问签名”[10]。
2。API 服务器用一个预先签名的 URL 进行响应。
3。一旦客户端收到响应,它就使用预先签名的 URL 上传视频。
安全优化:保护你的视频
许多内容制作者不愿意在网上发布视频,因为他们担心自己的原创视频会被窃取。为了保护有版权的视频,我们可以采用以下三种安全选项之一:
数字版权管理(DRM)系统:三大 DRM 系统分别是苹果 FairPlay、谷歌 Widevine、微软 PlayReady。
AES 加密:可以加密视频,配置授权策略。加密的视频将在播放时解密。这确保了只有授权用户才能观看加密视频。
视觉水印:这是覆盖在视频上的图像,包含视频的识别信息。它可以是你的公司标志或公司名称。
节约成本优化
CDN 是我们系统的重要组成部分。它确保了全球范围内的快速视频传输。然而,从信封计算的后面,我们知道 CDN 是昂贵的,尤其是当数据量很大时。怎样才能降低成本?
先前的研究表明,YouTube 视频流遵循长尾分布[11] [12]。这意味着一些受欢迎的视频被频繁访问,但许多其他视频很少或没有观众。基于这个观察,我们实现了一些优化:
1。仅提供来自 CDN 的最受欢迎的视频和来自我们高容量存储视频服务器的其他视频(图 14-28)。
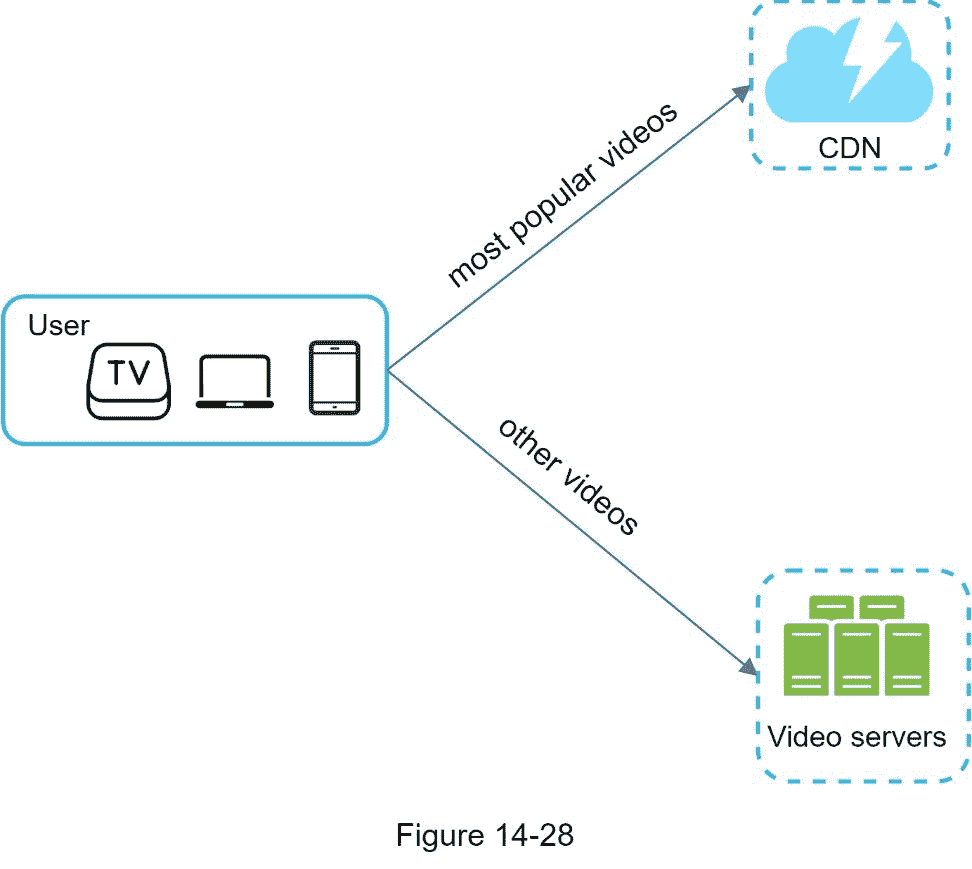
2。对于不太受欢迎的内容,我们可能不需要存储许多编码视频版本。短视频可以按需编码。
3。有些视频只在某些地区受欢迎。没有必要将这些视频分发到其他地区。
4。像网飞一样建立自己的 CDN,并与互联网服务提供商(ISP)合作。建设你的 CDN 是一个巨大的工程;然而,这对大型流媒体公司来说可能是有意义的。ISP 可以是康卡斯特、威瑞森 T2 电信公司或其他互联网提供商。ISP 遍布世界各地,离用户很近。通过与 ISP 合作,您可以改善观看体验并降低带宽费用。
所有这些优化都基于内容受欢迎程度、用户访问模式、视频大小等。在进行任何优化之前,分析历史观看模式是很重要的。以下是一些关于这个话题的有趣文章:[12] [13]。
错误处理
对于一个大型系统来说,系统误差是不可避免的。为了建立一个高度容错的 - 系统,我们必须优雅地处理错误并快速恢复。存在两种类型的错误:
可恢复的错误。对于可恢复的错误,如视频片段无法转码,一般的想法是重试几次操作。如果任务继续失败,并且系统认为它是不可恢复的,它将向客户端返回一个适当的错误代码。
不可恢复的错误。对于不可恢复的错误,如格式错误的视频格式,系统会停止运行与视频相关的任务,并将正确的错误代码返回给客户端。
每个系统组件的典型错误包含在以下行动手册中:
上传错误:重试几次。
分割视频错误:如果旧版本的客户端不能通过 GOP 对齐来分割视频,则整个视频被传递到服务器。分割视频的工作是在服务器端完成的。
转码错误:重试。
预处理器错误:重新生成 DAG 图。
DAG 调度程序错误:重新调度任务。
资源管理器排队:使用副本。
任务工作线程关闭:在新的工作线程上重试任务。
API 服务器关闭:API 服务器是无状态的,因此请求将被定向到不同的 API 服务器。
元数据缓存服务器宕机:数据被 多次复制。如果一个节点出现故障,您仍然可以访问其他节点来获取数据。我们可以启用一个新的缓存服务器来替换失效的服务器。
元数据数据库服务器关闭:
主人被打倒了。如果主服务器关闭,提升其中一个从服务器作为新的主服务器。
建奴被打倒了。如果一个从属服务器关闭,您可以使用另一个从属服务器进行读取,并启动另一个数据库服务器来替换关闭的服务器。
第四步——总结
在本章中,我们介绍了 YouTube 等视频流服务的架构设计。如果面试结束还有额外的时间,这里补充几点:
伸缩 API 层:因为 API 服务器是无状态的,所以很容易横向伸缩 API 层。
伸缩数据库:可以说说数据库复制和分片。
流媒体直播:指视频如何实时录制和播放的过程。虽然我们的系统不是专门为直播设计的,但直播和非直播有一些相似之处:都需要上传、编码和流式传输。显著的区别是:
直播流媒体的延迟要求更高,因此可能需要不同的流媒体协议。
直播对并行性的要求较低,因为小块数据已经被实时处理。
直播需要不同的错误处理集合。任何花费太多时间的错误处理都是不可接受的。
视频删除:侵犯版权、色情或其他非法行为的视频将被删除。有些可以在上传过程中被系统发现,而有些则可能通过用户标记被发现。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
[1] YouTube by the numbers: https://www.omnicoreagency.com/youtube-statistics/
[2] 2019 YouTube Demographics:
https://blog.hubspot.com/marketing/youtube-demographics
[3] Cloudfront Pricing: https://aws.amazon.com/cloudfront/pricing/
[4] Netflix on AWS: https://aws.amazon.com/solutions/case-studies/netflix/
[5] Akamai homepage: https://www.akamai.com/
[6] Binary large object: https://en.wikipedia.org/wiki/Binary_large_object
[7] Here’s What You Need to Know About Streaming Protocols:
https://www.dacast.com/blog/streaming-protocols/
[8] SVE: Distributed Video Processing at Facebook Scale: https://www.cs.princeton.edu/~wlloyd/papers/sve-sosp17.pdf
[9] Weibo video processing architecture (in Chinese): https://www.upyun.com/opentalk/399.html
[10] Delegate access with a shared access signature:
https://docs.microsoft.com/en-us/rest/api/storageservices/delegate-access-with-shared-access-signature
[11] YouTube scalability talk by early YouTube employee: https://www.youtube.com/watch?v=w5WVu624fY8
[12] Understanding the characteristics of internet short video sharing: A youtube-based measurement study. https://arxiv.org/pdf/0707.3670.pdf
[13] Content Popularity for Open Connect:
https://netflixtechblog.com/content-popularity-for-open-connect-b86d56f613b


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









