







原文:
zh.annas-archive.org/md5/ea99677736c22d68b5818a18b5a9213a译者:飞龙
第四章:使用卷积神经网络识别图像和声音
本章内容涵盖
-
图像和其他知觉数据(例如音频)如何表示为多维张量
-
卷积神经网络是什么、如何工作以及为什么它们特别适用于涉及图像的机器学习任务
-
如何编写和训练一个 TensorFlow.js 中的卷积神经网络来解决手写数字分类的任务
-
如何在 Node.js 中训练模型以实现更快的训练速度
-
如何在音频数据上使用卷积神经网络进行口语识别
持续进行的深度学习革命始于图像识别任务的突破,比如 ImageNet 比赛。涉及图像的有许多有用且技术上有趣的问题,包括识别图像的内容、将图像分割成有意义的部分、在图像中定位对象以及合成图像。这个机器学习的子领域有时被称为计算机视觉([1])。计算机视觉技术经常被移植到与视觉或图像无关的领域(如自然语言处理),这也是为什么学习计算机视觉的深度学习至关重要的另一个原因([2])。但在深入讨论计算机视觉问题之前,我们需要讨论图像在深度学习中的表示方式。
¹
需要注意的是,计算机视觉本身是一个广泛的领域,其中一些部分使用了本书范围以外的非机器学习技术。
²
对于对计算机视觉深度学习特别感兴趣并希望深入了解该主题的读者,可以参考 Mohamed Elgendy 的《深度学习图像处理入门》,Manning 出版社,即将出版。
4.1。从向量到张量:图像的表示
在前两章中,我们讨论了涉及数值输入的机器学习任务。例如,第二章中的下载时长预测问题将单个数字(文件大小)作为输入。波士顿房价问题的输入是一个包含 12 个数字的数组(房间数量、犯罪率等)。这些问题的共同点是,每个输入示例都可以表示为一维(非嵌套)数字数组,对应于 TensorFlow.js 中的一维张量。图像在深度学习中的表示方式有所不同。
为了表示一张图片,我们使用一个三维张量。张量的前两个维度是熟悉的高度和宽度维度。第三个是颜色通道。例如,颜色通常被编码为 RGB 值。在这种情况下,三个颜色值分别是通道,导致第三个维度的大小为 3。如果我们有一张尺寸为 224 × 224 像素的 RGB 编码颜色图像,我们可以将其表示为一个尺寸为 [224, 224, 3] 的三维张量。某些计算机视觉问题中的图像是无颜色的(例如灰度图像)。在这种情况下,只有一个通道,如果将其表示为三维张量,将导致张量形状为 [height, width, 1] (参见图 4.1)。^([3])
³
另一种选择是将图像的所有像素及其关联的颜色值展开为一个一维张量(一个由数字组成的扁平数组)。但是这样做很难利用每个像素的颜色通道与像素间的二维空间关系之间的关联。
图 4.1. 在深度学习中使用张量表示一个 MNIST 图像。为了可视化,我们将 MNIST 图像从 28 × 28 缩小到 8 × 8。这张图片是一个灰度图像,它的高度-宽度-通道(HWC)形状为[8, 8, 1]。这个图示中省略了最后一维的单个颜色通道。
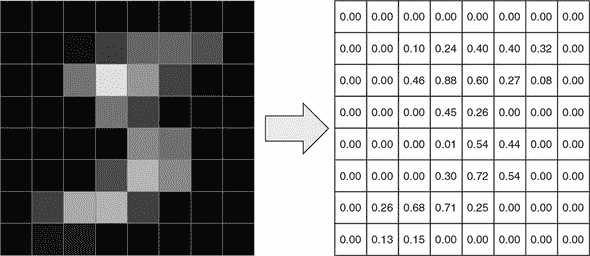
这种编码图像的方式被称为 高度-宽度-通道(HWC)。为了在图像上进行深度学习,我们经常将一组图像合并成一个批次以便进行高效的并行计算。当批量处理图像时,各个图像的维度总是第一维。这与我们在 第二章 和 第三章 中将一维张量组合成批量化的二维张量的方式类似。因此,图像的批次是一个四维张量,它的四个维度分别是图像数量(N)、高度(H)、宽度(W)和颜色通道(C)。这个格式被称为 NHWC。还有另一种格式,它由四个维度的不同排序得出。它被称为 NCHW。顾名思义,NCHW 将通道维度放在高度和宽度维度之前。TensorFlow.js 可以处理 NHWC 和 NCHW 两种格式。但是我们在本书中只使用默认的 NHWC 格式,以保持一致性。
4.1.1. MNIST 数据集
本章我们将着眼于计算机视觉问题中的 MNIST^([4])手写数字数据集。这个数据集非常重要并且频繁使用,通常被称为计算机视觉和深度学习的“Hello World”。MNIST 数据集比大多数深度学习数据集都要旧,也要小。然而熟悉它是很好的,因为它经常被用作示例并且经常用作新颖深度学习技术的第一个测试。
⁴
MNIST 代表 Modified NIST。名称中的“NIST”部分源自数据集约于 1995 年起源于美国国家标准技术研究所。名称中的“modified”部分反映了对原始 NIST 数据集所做的修改,包括 1)将图像标准化为相同的均匀 28 × 28 像素光栅,并进行抗锯齿处理,以使训练和测试子集更加均匀,以及 2)确保训练和测试子集之间的作者集是不相交的。这些修改使数据集更易于处理,并更有利于模型准确性的客观评估。
MNIST 数据集中的每个示例都是一个 28 × 28 的灰度图像(参见图 4.1 作为示例)。这些图像是从 0 到 9 的 10 个数字的真实手写转换而来的。28 × 28 的图像尺寸足以可靠地识别这些简单形状,尽管它比典型的计算机视觉问题中看到的图像尺寸要小。每个图像都附有一个明确的标签,指示图像实际上是 10 个可能数字中的哪一个。正如我们在下载时间预测和波士顿房屋数据集中看到的那样,数据被分为训练集和测试集。训练集包含 60,000 个图像,而测试集包含 10,000 个图像。MNIST 数据集^([5])大致平衡,这意味着这 10 个类别的示例大致相等(即 10 个数字)。
⁵
请参阅 Yann LeCun、Corinna Cortes 和 Christopher J.C. Burges 的《手写数字 MNIST 数据库》
yann.lecun.com/exdb/mnist/。
4.2. 您的第一个卷积网络
鉴于图像数据和标签的表示,我们知道解决 MNIST 数据集的神经网络应该采用何种输入,以及应该生成何种输出。神经网络的输入是形状为 [null, 28, 28, 1] 的 NHWC 格式张量。输出是形状为 [null, 10] 的张量,其中第二个维度对应于 10 个可能的数字。这是多类分类目标的经典一热编码。这与我们在第三章中看到的鸢尾花种类的一热编码相同。有了这些知识,我们可以深入了解卷积网络(作为提醒,卷积网络是图像分类任务(如 MNIST)的选择方法)的细节。名称中的“卷积”部分可能听起来很吓人。这只是一种数学运算,我们将详细解释它。
代码位于 tfjs-examples 的 mnist 文件夹中。与前面的示例一样,您可以按以下方式访问和运行代码:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/mnist
yarn && yarn watch
清单 4.1 是 mnist 示例中主要 index.js 代码文件的摘录。这是一个函数,用于创建我们用来解决 MNIST 问题的 convnet。此顺序模型的层数(七层)明显多于我们到目前为止看到的示例(一到三层之间)。
清单 4.1。为 MNIST 数据集定义卷积模型
function createConvModel() {
const model = tf.sequential();
model.add(tf.layers.conv2d({ ***1***
inputShape: [IMAGE_H, IMAGE_W, 1], ***1***
kernelSize: 3, ***1***
filters: 16, ***1***
activation: 'relu' ***1***
})); ***1***
model.add(tf.layers.maxPooling2d({ ***2***
poolSize: 2, ***2***
strides: 2 ***2***
})); ***2***
model.add(tf.layers.conv2d({ ***3***
kernelSize: 3, filters: 32, activation: 'relu'})); ***3***
model.add(tf.layers.maxPooling2d({poolSize: 2, strides: 2}));
model.add(tf.layers.flatten()); ***4***
model.add(tf.layers.dense({
units: 64,
activation:'relu'
}));
model.add(tf.layers.dense({units: 10, activation: 'softmax'})); ***5***
model.summary(); ***6***
return model;
}
-
1 第一个 conv2d 层
-
2 卷积后进行池化
-
3 conv2d-maxPooling2d 的重复“模式”
-
4 将张量展平以准备进行密集层
-
5 用于多类分类问题的 softmax 激活函数
-
6 打印模型的文本摘要
代码中的顺序模型由清单 4.1 中的代码构建,由add()方法调用逐个创建七个层。在我们查看每个层执行的详细操作之前,让我们先看一下模型的整体架构,如图 4.2 所示。如图所示,模型的前五层包括一组 conv2d-maxPooling2d 层的重复模式,后跟一个 flatten 层。conv2d-maxPooling2d 层组是特征提取的主力军。每个层将输入图像转换为输出图像。conv2d 层通过“卷积核”操作,该核在输入图像的高度和宽度维度上“滑动”。在每个滑动位置,它与输入像素相乘,然后将产品相加并通过非线性传递。这产生输出图像中的像素。maxPooling2d 层以类似的方式操作,但没有核。通过将输入图像数据通过连续的卷积和池化层,我们得到越来越小且在特征空间中越来越抽象的张量。最后一个池化层的输出通过展平变成一个 1D 张量。展平的 1D 张量然后进入密集层(图中未显示)。
图 4.2。简单 convnet 架构的高级概述,类似于清单 4.1 中的代码构建的模型。在此图中,图像和中间张量的大小比实际模型中定义的大小要小,以进行说明。卷积核的大小也是如此。还要注意,该图显示每个中间 4D 张量中仅有一个通道,而实际模型中的中间张量具有多个通道。

你可以将 convnet 看作是建立在卷积和池化预处理之上的 MLP。MLP 与我们在波士顿房屋和网络钓鱼问题中看到的完全相同:它仅由具有非线性激活的稠密层构成。在这里,convnet 的不同之处在于 MLP 的输入是级联 conv2d 和 maxPooling2d 层的输出。这些层专门设计用于图像输入,以从中提取有用的特征。这种架构是通过多年的神经网络研究发现的:它的准确性明显优于直接将图像的像素值馈入 MLP。
有了对 MNIST convnet 的高层次理解,现在让我们更深入地了解模型层的内部工作。
4.2.1. conv2d 层
第一层是 conv2d 层,它执行 2D 卷积。这是本书中看到的第一个卷积层。它的作用是什么?conv2d 是一个图像到图像的转换-它将一个 4D(NHWC)图像张量转换为另一个 4D 图像张量,可能具有不同的高度、宽度和通道数量。(conv2d 操作 4D 张量可能看起来有些奇怪,但请记住这里有两个额外的维度,一个是用于批处理示例,一个是用于通道。) 直观地看,它可以被理解为一组简单的“Photoshop 滤镜”^([6]),它会产生图像效果,如模糊和锐化。这些效果是通过 2D 卷积实现的,它涉及在输入图像上滑动一个小的像素块(卷积核,或简称核),并且像素与输入图像的小块重叠时,核与输入图像逐像素相乘。然后逐像素的乘积相加形成结果图像的像素。
⁶
我们将这种类比归功于 Ashi Krishnan 在 JSConf EU 2018 上的名为“JS 中的深度学习”的演讲:
mng.bz/VPa0。
与稠密层相比,conv2d 层具有更多的配置参数。kernelSize和filters是 conv2d 层的两个关键参数。为了理解它们的含义,我们需要在概念层面上描述 2D 卷积是如何工作的。
图 4.3 更详细地说明了 2D 卷积。在这里,我们假设输入图像(左上角)张量由一个简单的例子组成,以便我们可以在纸上轻松地绘制它。我们假设 conv2d 操作配置为kernelSize = 3和filters = 3。由于输入图像具有两个颜色通道(仅仅是为了图示目的而具有的相当不寻常的通道数),卷积核是一个形状为[3, 3, 2, 3]的 3D 张量。前两个数字(3 和 3)是由kernelSize确定的核的高度和宽度。第三个维度(2)是输入通道的数量。第四个维度(3)是什么?它是滤波器的数量,等于 conv2d 输出张量的最后一个维度。
图 4.3. 卷积层的工作原理,并附有一个示例。为简化起见,假设输入张量(左上角)仅包含一幅图像,因此是一个 3D 张量。其维度为高度、宽度和深度(色道)。为简单起见,批次维度被省略。输入图像张量的深度为 2。注意图像的高度和宽度(4 和 5)远小于典型真实图像的高宽。深度(2)也低于更典型的 3 或 4 的值(例如 RGB 或 RGBA)。假设 conv2D 层的 filters 属性(滤波器数量)为 3,kernelSize 为 [3, 3],strides 为 [1, 1],进行 2D 卷积的第一步是沿着高度和宽度维度滑动,并提取原始图像的小块。每个小块的高度为 3,宽度为 3,与层的 filterSize 匹配;它的深度与原始图像相同。第二步是计算每个 3 × 3 × 2 小块与卷积核(即“滤波器”)的点积。图 4.4 更详细地说明了每个点积操作。卷积核是一个 4D 张量,由三个 3D 滤波器组成。对三个滤波器分别进行图像小块与滤波器之间的点积。图像小块与滤波器逐像素相乘,然后求和,这导致输出张量中的一个像素。由于卷积核中有三个滤波器,每个图像小块被转换为一个三个像素的堆叠。这个点积操作在所有图像小块上执行,产生的三个像素堆叠被合并为输出张量,这种情况下形状为 [2, 3, 3]。
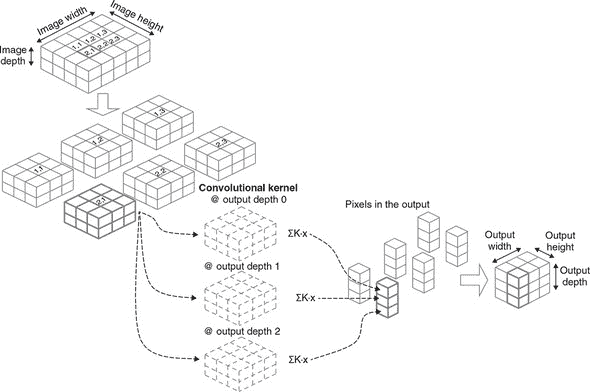
如果将输出视为图像张量(这是一个完全有效的观察方式!),那么滤波器可以理解为输出中通道的数量。与输入图像不同,输出张量中的通道实际上与颜色无关。相反,它们代表从训练数据中学到的输入图像的不同视觉特征。例如,一些滤波器可能对在特定方向上明亮和暗区域之间的直线边界敏感,而其他滤波器可能对由棕色形成的角落敏感,依此类推。稍后再详细讨论。
先前提到的“滑动”动作表示从输入图像中提取小块。每个小块的高度和宽度都等于 kernelSize(在这个例子中为 3)。由于输入图像的高度为 4,沿着高度维度只有两种可能的滑动位置,因为我们需要确保 3 × 3 窗口不会超出输入图像的边界。同样,输入图像的宽度(5)给出了三个可能的宽度维度滑动位置。因此,我们最终提取出 2 × 3 = 6 个图像小块。
在每个滑动窗口位置,都会进行一次点积操作。回想一下,卷积核的形状为[3, 3, 2, 3]。我们可以沿着最后一个维度将 4D 张量分解为三个单独的 3D 张量,每个张量的形状为[3, 3, 2],如图 4.3 中的哈希线所示。我们取图像块和三维张量之一,将它们逐像素相乘,并将所有3 * 3 * 2 = 18个值求和以获得输出张量中的一个像素。图 4.4 详细说明了点积步骤。图像块和卷积核切片具有完全相同的形状并非巧合——我们基于内核的形状提取了图像块!这个乘加操作对所有三个内核切片重复进行,得到一组三个数字。然后,该点积操作对其余的图像块重复进行,得到图中六列三个立方体。这些列最终被组合成输出,其 HWC 形状为[2, 3, 3]。
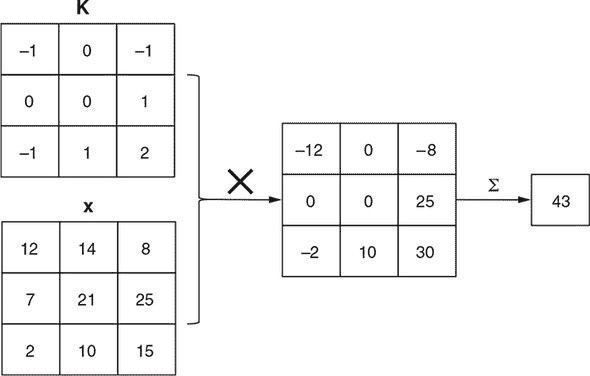
图 4.4. 在 2D 卷积操作中的点积(即乘加)操作的示意图,这是图 4.3 中概述的完整工作流程中的一步。为了说明方便,假设图像块(x)只包含一个颜色通道。图像块的形状为[3, 3, 1],与卷积核切片(K)的大小相同。第一步是逐元素相乘,产生另一个[3, 3, 1]张量。新张量的元素被加在一起(由σ表示),和即为结果。
像密集层一样,conv2d 层有一个偏置项,它被加到卷积结果中。此外,conv2d 层通常配置为具有非线性激活函数。在这个例子中,我们使用 relu。回想一下,在第三章的“避免堆叠层而不使用非线性函数的谬论”一节中,我们警告说堆叠两个没有非线性的密集层在数学上等价于使用单个密集层。类似的警告也适用于 conv2d 层:堆叠两个这样的层而没有非线性激活在数学上等价于使用一个具有更大内核的单个 conv2d 层,因此这是一种应该避免的构建卷积网络的低效方式。
哇!关于 conv2d 层如何工作的细节就是这些。让我们退后一步,看看 conv2d 实际上实现了什么。简而言之,这是一种将输入图像转换为输出图像的特殊方式。输出图像通常比输入图像具有较小的高度和宽度。尺寸的减小取决于kernelSize配置。输出图像可能具有比输入更少、更多或相同的通道数,这取决于filters配置。
conv2d 是一种图像到图像的转换。conv2d 转换的两个关键特性是局部性和参数共享:
-
局部性 指的是输出图像中给定像素的值仅受到输入图像中一个小区域的影响,而不是受到输入图像中所有像素的影响。该区域的大小为
kernelSize。这就是 conv2d 与密集层的不同之处:在密集层中,每个输出元素都受到每个输入元素的影响。换句话说,在密集层中,输入元素和输出元素在“密集连接”(因此称为密集层);而 conv2d 层是“稀疏连接”的。虽然密集层学习输入中的全局模式,但卷积层学习局部模式——卷积核的小窗口内的模式。 -
参数共享 指的是输出像素 A 受其小输入区域影响的方式与输出像素 B 受其输入区域影响的方式完全相同。这是因为每个滑动位置的点积都使用相同的卷积核(图 4.3)。
由于局部性和参数共享,conv2d 层在所需参数数量方面是高效的图像到图像变换。特别地,卷积核的大小不随输入图像的高度或宽度而变化。回到列表 4.1 中的第一个 conv2d 层,核的形状为[kernelSize, kernelSize, 1, filter](即[5, 5, 1, 8]),因此总共有 5 * 5 * 1 * 8 = 200 个参数,不管输入的 MNIST 图像是 28 × 28 还是更大。第一个 conv2d 层的输出形状为[24, 24, 8](省略批次维度)。所以,conv2d 层将由 28 * 28 * 1 = 784 个元素组成的张量转换为由 24 * 24 * 8 = 4,608 个元素组成的另一个张量。如果我们要用密集层来实现这个转换,将涉及多少参数?答案是 784 * 4,608 = 3,612,672(不包括偏差),这约是 conv2d 层的 18 千倍!这个思想实验展示了卷积层的效率。
conv2d 的局部性和参数共享之美不仅在于其效率,还在于它(以松散的方式)模拟了生物视觉系统的工作方式。考虑视网膜上的神经元。每个神经元只受到眼睛视野中的一个小区域的影响,称为感受野。位于视网膜不同位置的两个神经元对其各自感受野中的光模式的响应方式几乎相同,这类似于 conv2d 层中的参数共享。更重要的是,conv2d 层在计算机视觉问题中表现良好,正如我们将在这个 MNIST 示例中很快看到的那样。conv2d 是一个很棒的神经网络层,它集效率、准确性和与生物学相关性于一身。难怪它在深度学习中被如此广泛地使用。
4.2.2. maxPooling2d 层
在研究了 conv2d 层之后,让我们看一下顺序模型中的下一层——maxPooling2d 层。像 conv2d 一样,maxPooling2d 是一种图像到图像的转换。但与 conv2d 相比,maxPooling2d 转换更简单。正如图 4.5 所示,它简单地计算小图像块中的最大像素值,并将它们用作输出中的像素值。定义并添加 maxPooling2d 层的代码为
model.add(tf.layers.maxPooling2d({poolSize: 2, strides: 2}));
图 4.5. maxPooling2D 层的工作原理示例。此示例使用一个小的 4 × 4 图像,并假设 maxPooling2D 层配置为poolSize为[2, 2]和strides为[2, 2]。深度维度未显示,但 max-pooling 操作独立地在各维度上进行。
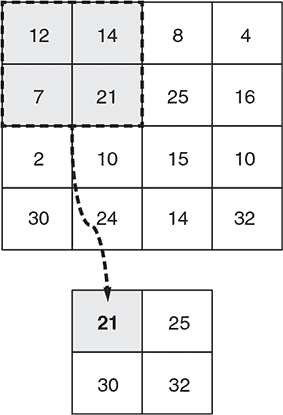
在这种特定情况下,由于指定的poolSize值为[2, 2],图像块的高度和宽度为 2 × 2。沿着两个维度,每隔两个像素提取图像块。这些图像块之间的间隔是由我们在此处使用的strides值决定的:[2, 2]。因此,输出图像的 HWC 形状为[12, 12, 8],高度和宽度是输入图像(形状为[24, 24, 8])的一半,但具有相同数量的通道。
maxPooling2d 层在卷积网络中有两个主要目的。首先,它使卷积网络对输入图像中关键特征的确切位置不那么敏感。例如,我们希望能够识别出数字“8”,无论它是否从 28 × 28 输入图像的中心向左或向右移动(或者从上到下移动),这种特性称为位置不变性。要理解 maxPooling2d 层如何增强位置不变性,需要意识到 maxPooling2d 在操作的每个图像块内部,最亮的像素位于何处并不重要,只要它落入该图像块内即可。诚然,单个 maxPooling2d 层在使卷积网络不受位移影响方面能做的事情有限,因为它的池化窗口是有限的。然而,当在同一个卷积网络中使用多个 maxPooling2d 层时,它们共同努力实现了更大程度的位置不变性。这正是我们 MNIST 模型中所做的事情——以及几乎所有实际卷积网络中所做的事情——其中包含两个 maxPooling2d 层。
作为一个思想实验,考虑当两个 conv2d 层(称为 conv2d_1 和 conv2d_2)直接叠加在一起而没有中间的 maxPooling2d 层时会发生什么。假设这两个 conv2d 层的kernelSize都为 3;那么 conv2d_2 输出张量中的每个像素都是原始输入到 conv2d_1 的 5 × 5 区域的函数。我们可以说 conv2d_2 层的每个“神经元”具有 5 × 5 的感受野。当两个 conv2d 层之间存在一个 maxPooling2d 层时会发生什么(就像我们的 MNIST 卷积网络中的情况一样)?conv2d_2 层的神经元的感受野变得更大:11 × 11。当卷积网络中存在多个 maxPooling2d 层时,较高层次的层可以具有广泛的感受野和位置不变性。简而言之,它们可以看得更广!
第二,一个 maxPooling2d 层也会使输入张量的高度和宽度尺寸缩小,大大减少了后续层次和整个卷积网络中所需的计算量。例如,第一个 conv2d 层的输出张量形状为[26, 26, 16]。经过 maxPooling2d 层后,张量形状变为[13, 13, 16],将张量元素数量减少了 4 倍。卷积网络包含另一个 maxPooling2d 层,进一步缩小了后续层次的权重尺寸和这些层次中的逐元素数学运算的数量。
4.2.3. 卷积和池化的重复模式
在审查了第一个 maxPooling2d 层后,让我们将注意力集中在卷积网络的接下来的两层上,这两层由 list 4.1 中的这些行定义:
model.add(tf.layers.conv2d(
{kernelSize: 3, filters: 32, activation: 'relu'}));
model.add(tf.layers.maxPooling2d({poolSize: 2, strides: 2}));
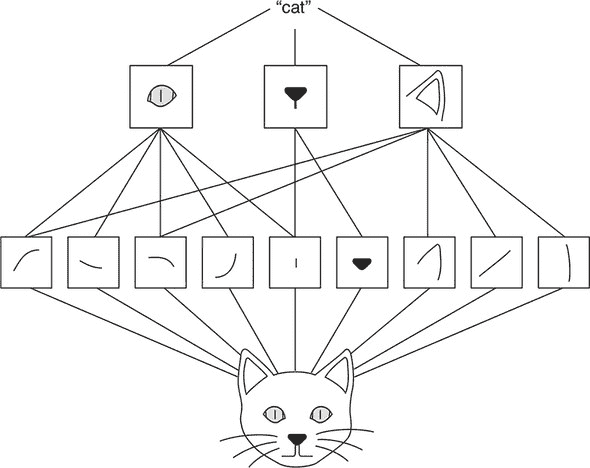
这两个层与前面的两个层完全相同(除了 conv2d 层的filters配置有一个更大的值并且没有inputShape字段)。这种几乎重复的“基本图案”由一个卷积层和一个池化层组成,在 convnets 中经常见到。它发挥了关键作用:分层特征提取。要理解这意味着什么,考虑一个用于图像中动物分类任务的 convnet。在 convnet 的早期阶段,卷积层中的滤波器(即通道)可能编码低级几何特征,如直线、曲线和角落。这些低级特征被转换成更复杂的特征,如猫的眼睛、鼻子和耳朵(见 图 4.6)。在 convnet 的顶层,一层可能具有编码整个猫的滤波器。层级越高,表示越抽象,与像素级值越远。但这些抽象特征正是在 convnet 任务上取得良好准确率所需要的特征,例如在图像中存在猫时检测出猫。此外,这些特征不是手工制作的,而是通过监督学习以自动方式从数据中提取的。这是我们在 第一章 中描述的深度学习的本质,即逐层表示变换的典型示例。
图 4.6. 通过 convnet 从输入图像中分层提取特征,以猫图像为例。请注意,在此示例中,神经网络的输入在底部,输出在顶部。
4.2.4. 压扁和稠密层
在输入张量通过两组 conv2d-maxPooling2d 变换后,它变成了一个形状为[4, 4, 16]的 HWC 形状的张量(不包括批次维度)。在 convnet 中的下一层是一个压扁层。这一层在前面的 conv2d-maxPooling2d 层和顺序模型的后续层之间形成了一个桥梁。
Flatten 层的代码很简单,因为构造函数不需要任何配置参数:
model.add(tf.layers.flatten());
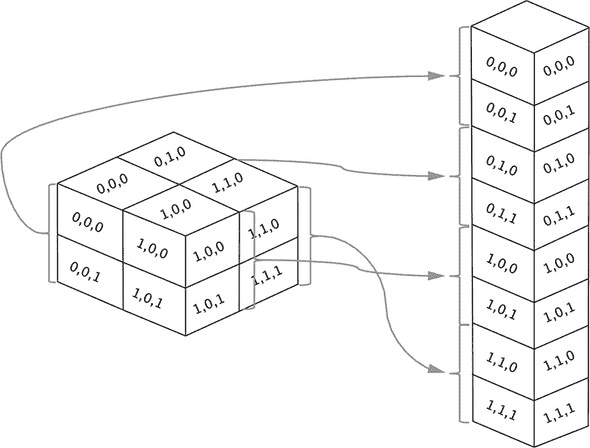
Flatten 层将多维张量“压缩”成一个一维张量,保留元素的总数。在我们的例子中,形状为[3, 3, 32]的三维张量被压扁成一个一维张量[288](不包括批次维度)。对于压扁操作一个明显的问题是如何排序元素,因为原始的三维空间没有固有的顺序。答案是,我们按照这样的顺序排列元素:当你在压扁后的一维张量中向下移动并观察它们的原始索引(来自三维张量)如何变化时,最后一个索引变化得最快,倒数第二个索引变化得次快,依此类推,而第一个索引变化得最慢。这在 图 4.7 中有所说明。
图 4.7.flatten 层的工作原理。假设输入是一个 3D 张量。为了简单起见,我们让每个维度的大小都设为 2。方块表示元素,元素的索引显示在方块的“面”上。flatten 层将 3D 张量转换成 1D 张量,同时保持元素的总数不变。在展平的 1D 张量中,元素的顺序是这样安排的:当您沿着输出 1D 张量的元素向下走,并检查它们在输入张量中的原始索引时,最后一个维度变化得最快。
flatten 层在我们的卷积网络中起到什么作用呢?它为随后的密集层做好了准备。就像我们在第二章和第三章学到的那样,由于密集层的工作原理(第 2.1.4 节),它通常需要一个 1D 张量(不包括批次维度)作为其输入。
代码中的下两行,将两个密集层添加到卷积网络中。
model.add(tf.layers.dense({units: 64, activation: 'relu'}));
model.add(tf.layers.dense({units: 10, activation: 'softmax'}));
为什么要使用两个密集层而不只是一个?与波士顿房产示例和第三章中的网络钓鱼 URL 检测示例的原因相同:添加具有非线性激活的层增加了网络的容量。实际上,您可以将卷积网络视为在此之上堆叠了两个模型:
-
包含 conv2d、maxPooling2d 和 flatten 层的模型,从输入图像中提取视觉特征
-
一个具有两个密集层的多层感知器(MLP),使用提取的特征进行数字分类预测——这本质上就是两个密集层的用途。
在深度学习中,许多模型都显示了这种特征提取层后面跟着 MLPs 进行最终预测的模式。在本书的其余部分中,我们将看到更多类似的示例,从音频信号分类器到自然语言处理的模型都会有。
4.2.5. 训练卷积网络
现在我们已经成功定义了卷积网络的拓扑结构,下一步是训练并评估训练结果。下一个清单中的代码就是用来实现这个目的的。
清单 4.2. 训练和评估 MNIST 卷积网络
const optimizer = 'rmsprop';
model.compile({
optimizer,
loss: 'categoricalCrossentropy',
metrics: ['accuracy']
});
const batchSize = 320;
const validationSplit = 0.15;
await model.fit(trainData.xs, trainData.labels, {
batchSize,
validationSplit,
epochs: trainEpochs,
callbacks: {
onBatchEnd: async (batch, logs) => { ***1***
trainBatchCount++;
ui.logStatus(
`Training... (` +
`${(trainBatchCount / totalNumBatches * 100).toFixed(1)}%` +
` complete). To stop training, refresh or close page.`);
ui.plotLoss(trainBatchCount, logs.loss, 'train');
ui.plotAccuracy(trainBatchCount, logs.acc, 'train');
},
onEpochEnd: async (epoch, logs) => {
valAcc = logs.val_acc;
ui.plotLoss(trainBatchCount, logs.val_loss, 'validation');
ui.plotAccuracy(trainBatchCount, logs.val_acc, 'validation');
}
}
});
const testResult = model.evaluate(
testData.xs, testData.labels); ***2***
-
1 使用回调函数来绘制训练期间的准确率和损失图
-
2 使用模型没有看见的数据来评估模型的准确性
很多这里的代码都是关于在训练过程中更新用户界面的,例如绘制损失和准确率值的变化。这对于监控训练过程很有用,但对于模型训练来说并不是必需的。让我们来强调一下训练所必需的部分:
-
trainData.xs(model.fit()的第一个参数)包含作为形状为[N, 28, 28, 1]的 NHWC 张量的输入 MNIST 图像表示 -
trainData.labels(model.fit()的第二个参数)。这包括作为形状为`N, -
在
model.compile()调用中使用的损失函数categoricalCrossentropy,适用于诸如 MNIST 的多类分类问题。回想一下,我们在[第三章中也使用了相同的损失函数来解决鸢尾花分类问题。 -
在
model.compile()调用中指定的度量函数:'accuracy'。该函数衡量了多大比例的示例被正确分类,假设预测是基于卷积神经网络输出的 10 个元素中最大的元素。再次强调,这与我们在新闻线问题中使用的度量标准完全相同。回想一下交叉熵损失和准确度度量之间的区别:交叉熵可微分,因此可以进行基于反向传播的训练,而准确度度量不可微分,但更容易解释。 -
在
model.fit()调用中指定的batchSize参数。一般来说,使用较大的批量大小的好处是,它会产生对模型权重的更一致和 less 变化的梯度更新,而不是较小的批量大小。但是,批量大小越大,训练过程中所需的内存就越多。您还应该记住,给定相同数量的训练数据,较大的批量大小会导致每个 epoch 中的梯度更新数量减少。因此,如果使用较大的批量大小,请务必相应地增加 epoch 的数量,以免在训练过程中意外减少权重更新的数量。因此,存在一种权衡。在这里,我们使用相对较小的批量大小 64,因为我们需要确保这个示例适用于各种硬件。与其他参数一样,您可以修改源代码并刷新页面,以便尝试使用不同批量大小的效果。 -
在
model.fit()调用中使用的validationSplit。这使得训练过程中排除了trainData.xs和trainData.labels的最后 15% 以供验证。就像你在之前的非图像模型中学到的那样,监控验证损失和准确度在训练过程中非常重要。它让你了解模型是否过拟合。什么是过拟合?简单地说,这是指模型过于关注训练过程中看到的数据的细节,以至于其在训练过程中没有看到的数据上的预测准确性受到负面影响。这是监督式机器学习中的一个关键概念。在本书的后面章节(第八章)中,我们将专门讨论如何发现和对抗过拟合。
model.fit() 是一个异步函数,因此如果后续操作依赖于 fit() 调用的完成,则需要在其上使用 await。这正是这里所做的,因为我们需要在模型训练完成后使用测试数据集对模型进行评估。评估是使用 model.evaluate() 方法进行的,该方法是同步的。传递给 model.evaluate() 的数据是 testData,其格式与前面提到的 trainData 相同,但包含较少数量的示例。这些示例在 fit() 调用期间模型从未见过,确保测试数据集不会影响评估结果,并且评估结果是对模型质量的客观评估。
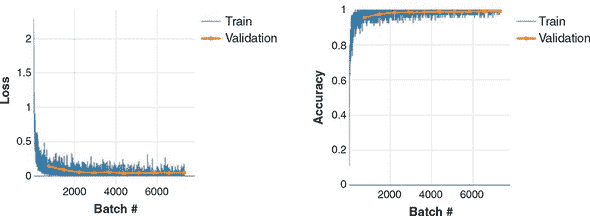
使用这段代码,我们让模型训练了 10 个 epoch(在输入框中指定),这给我们提供了 figure 4.8 中的损失和准确度曲线。如图所示,损失在训练 epochs 结束时收敛,准确度也是如此。验证集的损失和准确度值与其训练集对应值相差不大,这表明在这种情况下没有明显的过拟合。最终的 model.evaluate() 调用给出了约为 99.0% 的准确度(实际值会因权重的随机初始化和训练过程中示例的随机洗牌而略有变化)。
图 4.8. MNIST 卷积神经网络的训练曲线。进行了十个 epoch 的训练,每个 epoch 大约包含 800 个批次。左图:损失值。右图:准确度值。训练集和验证集的数值由不同颜色、线宽和标记符号表示。验证曲线的数据点比训练数据少,因为验证是在每个 epoch 结束时进行,而不像训练批次那样频繁。
99.0% 的准确度如何?从实际角度来看,这是可以接受的,但肯定不是最先进的水平。通过增加卷积层和池化层以及模型中的滤波器数量,可以达到准确率达到 99.5% 的可能性。然而,在浏览器中训练这些更大的卷积神经网络需要更长的时间,以至于最好在像 Node.js 这样资源不受限制的环境中进行训练。我们将在 section 4.3 中准确地介绍如何做到这一点。
从理论角度来看,记住 MNIST 是一个 10 类别分类问题。因此,偶然猜测的准确率是 10%;而 99.0% 远远超过了这个水平。但偶然猜测并不是一个很高的标准。我们如何展示模型中的 conv2d 和 maxPooling2d 层的价值?如果我们坚持使用传统的全连接层,我们会做得像这样吗?
要回答这些问题,我们可以进行一个实验。index.js 中的代码包含了另一个用于模型创建的函数,名为 createDenseModel()。与我们在 列表 4.1 中看到的 createConvModel() 函数不同,createDenseModel() 创建的是仅由展平和密集层组成的顺序模型,即不使用本章学习的新层类型。createDenseModel() 确保它所创建的密集模型和我们刚刚训练的卷积网络之间的总参数数量大约相等 —— 约为 33,000,因此这将是一个更公平的比较。
列表 4.3. 用于与卷积网络进行比较的 MNIST 的展平-仅密集模型
function createDenseModel() {
const model = tf.sequential();
model.add(tf.layers.flatten({inputShape: [IMAGE_H, IMAGE_W, 1]}));
model.add(tf.layers.dense({units: 42, activation: 'relu'}));
model.add(tf.layers.dense({units: 10, activation: 'softmax'}));
model.summary();
return model;
}
列表 4.3 中定义的模型概述如下:
_________________________________________________________________
Layer (type) Output shape Param #
=================================================================
flatten_Flatten1 (Flatten) [null,784] 0
_________________________________________________________________
dense_Dense1 (Dense) [null,42] 32970
_________________________________________________________________
dense_Dense2 (Dense) [null,10] 430
=================================================================
Total params: 33400
Trainable params: 33400
Non-trainable params: 0
_________________________________________________________________
使用相同的训练配置,我们从非卷积模型中获得的训练结果如 图 4.9 所示。经过 10 次训练周期后,我们获得的最终评估准确率约为 97.0%。两个百分点的差异可能看起来很小,但就误差率而言,非卷积模型比卷积网络差三倍。作为一项动手练习,尝试通过增加 createDenseModel() 函数中的隐藏(第一个)密集层的 units 参数来增加非卷积模型的大小。你会发现,即使增加了更大的尺寸,仅有密集层的模型也无法达到与卷积网络相当的准确性。这向你展示了卷积网络的强大之处:通过参数共享和利用视觉特征的局部性,卷积网络可以在计算机视觉任务中实现优越的准确性,其参数数量相等或更少于非卷积神经网络。
图 4.9. 与 图 4.8 相同,但用于 MNIST 问题的非卷积模型,由 列表 4.3 中的 createDenseModel() 函数创建

4.2.6. 使用卷积网络进行预测
现在我们有了一个训练好的卷积网络。我们如何使用它来实际分类手写数字的图像呢?首先,你需要获得图像数据。有许多方法可以将图像数据提供给 TensorFlow.js 模型。我们将列出它们并描述它们何时适用。
从 TypedArrays 创建图像张量
在某些情况下,您想要的图像数据已经存储为 JavaScript 的 TypedArray。这就是我们专注于的 tfjs-example/mnist 示例中的情况。详细信息请参见 data.js 文件,我们不会详细说明其中的机制。假设有一个表示正确长度的 MNIST 的 Float32Array(例如,一个名为 imageDataArray 的变量),我们可以将其转换为我们的模型所期望的形状的 4D 张量,如下所示^([7]):
⁷
参见附录 B 了解如何使用 TensorFlow.js 中的低级 API 创建张量的更全面教程。
let x = tf.tensor4d(imageDataArray, [1, 28, 28, 1]);
tf.tensor4d() 调用中的第二个参数指定要创建的张量的形状。这是必需的,因为 Float32Array(或一般的 TypedArray)是一个没有关于图像尺寸信息的平坦结构。第一个维度的大小为 1,因为我们正在处理 imageDataArray 中的单个图像。与之前的示例一样,在训练、评估和推断期间,模型始终期望有一个批次维度,无论是一个图像还是多个图像。如果 Float32Array 包含多个图像的批次,则还可以将其转换为单个张量,其中第一个维度的大小等于图像数量:
let x = tf.tensor4d(imageDataArray, [numImages, 28, 28, 1]);
tf.browser.fromPixels:从 HTML img、canvas 或 video 元素获取图像张量
浏览器中获取图像张量的第二种方法是在包含图像数据的 HTML 元素上使用 TensorFlow.js 函数 tf.browser.fromPixels() ——这包括 img、canvas 和 video 元素。
例如,假设网页包含一个如下定义的 img 元素
<img id="my-image" src="foo.jpg"></img>
你可以用一行代码获取显示在 img 元素中的图像数据:
let x = tf.browser.fromPixels(
document.getElementById('my-image')).asType('float32');
这将生成形状为 [height, width, 3] 的张量,其中三个通道用于 RGB 颜色编码。末尾的 asType0 调用是必需的,因为 tf.browser.fromPixels() 返回一个 int32 类型的张量,但 convnet 期望输入为 float32 类型的张量。高度和宽度由 img 元素的大小确定。如果它与模型期望的高度和宽度不匹配,您可以通过使用 TensorFlow.js 提供的两种图像调整方法之一 tf.image.resizeBilinear() 或 tf.image.resizeNearestNeigbor() 来改变 tf.browser.fromPixels() 返回的张量大小:
x = tf.image.resizeBilinear(x, [newHeight, newWidth]);
tf.image.resizeBilinear() 和 tf.image.resizeNearestNeighbor() 具有相同的语法,但它们使用两种不同的算法进行图像调整。前者使用双线性插值来生成新张量中的像素值,而后者执行最近邻采样,通常比双线性插值计算量小。
请注意,tf.browser.fromPixels() 创建的张量不包括批次维度。因此,如果张量要被馈送到 TensorFlow.js 模型中,必须首先进行维度扩展;例如,
x = x.expandDims();
expandDims() 通常需要一个维度参数。但在这种情况下,可以省略该参数,因为我们正在扩展默认为该参数的第一个维度。
除了 img 元素外,tf.browser.fromPixels() 也适用于 canvas 和 video 元素。在 canvas 元素上应用 tf.browser.fromPixels() 对于用户可以交互地改变 canvas 内容然后使用 TensorFlow.js 模型的情况非常有用。例如,想象一下在线手写识别应用或在线手绘形状识别应用。除了静态图像外,在 video 元素上应用 tf.browser.fromPixels() 对于从网络摄像头获取逐帧图像数据非常有用。这正是在 Nikhil Thorat 和 Daniel Smilkov 在最初的 TensorFlow.js 发布中展示的 Pac-Man 演示中所做的(参见 mng.bz/xl0e),PoseNet 演示,^([8]) 以及许多其他使用网络摄像头的基于 TensorFlow.js 的网络应用程序。你可以在 GitHub 上查看源代码 mng.bz/ANYK。
⁸
Dan Oved,“使用 TensorFlow.js 在浏览器中进行实时人体姿势估计”,Medium,2018 年 5 月 7 日,
mng.bz/ZeOO。
正如我们在前面的章节中所看到的,应该非常小心避免训练数据和推断数据之间的 偏差(即不匹配)。在这种情况下,我们的 MNIST 卷积网络是使用范围在 0 到 1 之间的图像张量进行训练的。因此,如果 x 张量中的数据范围不同,比如常见的 HTML 图像数据范围是 0 到 255,那么我们应该对数据进行归一化:
x = x.div(255);
有了手头的数据,我们现在准备调用 model.predict() 来获取预测结果。请参见下面的清单。
清单 4.4。使用训练好的卷积网络进行推断
const testExamples = 100;
const examples = data.getTestData(testExamples);
tf.tidy(() => { ***1***
const output = model.predict(examples.xs);
const axis = 1;
const labels = Array.from(examples.labels.argMax(axis).dataSync());
const predictions = Array.from(
output.argMax(axis).dataSync()); ***2***
ui.showTestResults(examples, predictions, labels);
});
-
1 使用 tf.tidy() 避免 WebGL 内存泄漏
-
2 调用 argMax() 函数获取概率最大的类别
该代码假设用于预测的图像批已经以一个单一张量的形式可用,即 examples.xs。它的形状是 [100, 28, 28, 1](包括批处理维度),其中第一个维度反映了我们要运行预测的 100 张图像。model.predict() 返回一个形状为 [100, 10] 的输出二维张量。输出的第一个维度对应于示例,而第二个维度对应于 10 个可能的数字。输出张量的每一行包含为给定图像输入分配的 10 个数字的概率值。为了确定预测结果,我们需要逐个图像找出最大概率值的索引。这是通过以下代码完成的
const axis = 1;
const labels = Array.from(examples.labels.argMax(axis).dataSync());
argMax() 函数返回沿指定轴的最大值的索引。在这种情况下,这个轴是第二维,const axis = 1。argMax() 的返回值是一个形状为 [100, 1] 的张量。通过调用 dataSync(),我们将 [100, 1] 形状的张量转换为长度为 100 的 Float32Array。然后 Array.from() 将 Float32Array 转换为由 100 个介于 0 和 9 之间的整数组成的普通 JavaScript 数组。这个预测数组有一个非常直观的含义:它是模型对这 100 个输入图像的分类结果。在 MNIST 数据集中,目标标签恰好与输出索引完全匹配。因此,我们甚至不需要将数组转换为字符串标签。下一行消耗了预测数组,调用了一个 UI 函数,该函数将分类结果与测试图像一起呈现(见 图 4.10)。
图 4.10. 训练后模型进行预测的几个示例,显示在输入的 MNIST 图像旁边

4.3. 超越浏览器:使用 Node.js 更快地训练模型
在前一节中,我们在浏览器中训练了一个卷积网络,测试准确率达到了 99.0%。在本节中,我们将创建一个更强大的卷积网络,它将给我们更高的测试准确率:大约 99.5%。然而,提高的准确性也伴随着代价:模型在训练和推断期间消耗的内存和计算量更多。成本的增加在训练期间更为显著,因为训练涉及反向传播,这与推断涉及的前向运行相比,需要更多的计算资源。较大的卷积网络将过重且速度过慢,在大多数 web 浏览器环境下训练。
4.3.1. 使用 tfjs-node 的依赖项和导入
进入 TensorFlow.js 的 Node.js 版本!它在后端环境中运行,不受像浏览器标签那样的任何资源限制。TensorFlow.js 的 CPU 版本(此处简称 tfjs-node)直接使用了在 C++ 中编写的多线程数学运算,这些数学运算也被 TensorFlow 的主 Python 版本使用。如果您的计算机安装了支持 CUDA 的 GPU,tfjs-node 还可以使用 CUDA 编写的 GPU 加速数学核心,实现更大的速度提升。
我们增强的 MNIST 卷积神经网络的代码位于 tfjs-examples 的 mnist-node 目录中。与我们所见的示例一样,您可以使用以下命令访问代码:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/mnist-node
与之前的示例不同之处在于,mnist-node 示例将在终端而不是 web 浏览器中运行。要下载依赖项,请使用 yarn 命令。
如果你检查 package.json 文件,你会看到依赖项 @tensorflow/tfjs-node。通过将 @tensorflow/tfjs-node 声明为依赖项,yarn 将自动下载 C++ 共享库(在 Linux、Mac 或 Windows 系统上分别命名为 libtensorflow.so、libtensorflw .dylib 或 libtensorflow.dll)到你的 node_modules 目录,以供 TensorFlow.js 使用。
一旦 yarn 命令运行完毕,你就可以开始模型训练了
node main.js
我们假设你的路径上已经有了节点二进制文件,因为你已经安装了 yarn(如果你需要更多关于这个的信息,请参见附录 A)。
刚刚描述的工作流将允许你在 CPU 上训练增强的 convnet。如果你的工作站和笔记本电脑内置了 CUDA 启用的 GPU,你也可以在 GPU 上训练模型。所涉及的步骤如下:
-
安装正确版本的 NVIDIA 驱动程序以适配你的 GPU。
-
安装 NVIDIA CUDA 工具包。这是一个库,可以在 NVIDIA 的 GPU 系列上实现通用并行计算。
-
安装 CuDNN,这是基于 CUDA 构建的高性能深度学习算法的 NVIDIA 库(有关步骤 1-3 的更多详细信息,请参见附录 A)。
-
在 package.json 中,将
@tensorflow/tfjs-node依赖项替换为@-tensor-flow/tfjs-node-gpu,但保持相同的版本号,因为这两个软件包的发布是同步的。 -
再次运行
yarn,这将下载包含 TensorFlow.js 用于 CUDA 数学运算的共享库。 -
在 main.js 中,将该行替换为
require('@tensorflow/tfjs-node');使用
require('@tensorflow/tfjs-node-gpu'); -
再次开始训练
node main.js
如果步骤正确完成,你的模型将在 CUDA GPU 上迅猛地训练,在速度上通常是 CPU 版本(tfjs-node)的五倍。与在浏览器中训练相同模型相比,使用 tfjs-node 的 CPU 或 GPU 版本训练速度都显著提高。
在 tfjs-node 中为 MNIST 训练增强的 convnet
一旦在 20 个周期内完成训练,模型应该显示出约 99.6% 的最终测试(或评估)准确度,这超过了我们在 section 4.2 中取得的 99.0% 的先前结果。那么,导致准确度提高的是这个基于节点的模型和基于浏览器的模型之间的区别是什么呢?毕竟,如果你使用训练数据在 tfjs-node 和 TensorFlow.js 的浏览器版本中训练相同的模型,你应该得到相同的结果(除了随机权重初始化的影响)。为了回答这个问题,让我们来看看基于节点的模型的定义。模型是在文件 model.js 中构建的,这个文件由 main.js 导入。
列表 4.5. 在 Node.js 中定义一个更大的 MNIST convnet
const model = tf.sequential();
model.add(tf.layers.conv2d({
inputShape: [28, 28, 1],
filters: 32,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.conv2d({
filters: 32,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2]}));
model.add(tf.layers.conv2d({
filters: 64,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.conv2d({
filters: 64,
kernelSize: 3,
activation: 'relu',
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2]}));
model.add(tf.layers.flatten());
model.add(tf.layers.dropout({rate: 0.25})); ***1***
model.add(tf.layers.dense({units: 512, activation: 'relu'}));
model.add(tf.layers.dropout({rate: 0.5}));
model.add(tf.layers.dense({units: 10, activation: 'softmax'}));
model.summary();
model.compile({
optimizer: 'rmsprop',
loss: 'categoricalCrossentropy',
metrics: ['accuracy'],
});
- 1 添加了 dropout 层以减少过拟合
模型的摘要如下:
_________________________________________________________________
Layer (type) Output shape Param #
=================================================================
conv2d_Conv2D1 (Conv2D) [null,26,26,32] 320
_________________________________________________________________
conv2d_Conv2D2 (Conv2D) [null,24,24,32] 9248
_________________________________________________________________
max_pooling2d_MaxPooling2D1 [null,12,12,32] 0
_________________________________________________________________
conv2d_Conv2D3 (Conv2D) [null,10,10,64] 18496
_________________________________________________________________
conv2d_Conv2D4 (Conv2D) [null,8,8,64] 36928
_________________________________________________________________
max_pooling2d_MaxPooling2D2 [null,4,4,64] 0
_________________________________________________________________
flatten_Flatten1 (Flatten) [null,1024] 0
_________________________________________________________________
dropout_Dropout1 (Dropout) [null,1024] 0
_________________________________________________________________
dense_Dense1 (Dense) [null,512] 524800
_________________________________________________________________
dropout_Dropout2 (Dropout) [null,512] 0
_________________________________________________________________
dense_Dense2 (Dense) [null,10] 5130
=================================================================
Total params: 594922
Trainable params: 594922
Non-trainable params: 0
_________________________________________________________________
这些是我们的 tfjs-node 模型和基于浏览器的模型之间的关键区别:
-
基于节点的模型具有四个 conv2d 层,比基于浏览器的模型多一个。
-
基于节点的模型的 hidden dense 层比基于浏览器的模型的对应层单元更多(512 与 100)。
-
总体而言,基于节点的模型的权重参数约为基于浏览器的模型的 18 倍。
-
基于节点的模型在 flatten 层和 dense 层之间插入了两个dropout层。
列表中的前三个差异使基于节点的模型具有比基于浏览器的模型更高的容量。这也是使基于节点的模型在浏览器中训练速度无法接受的原因。正如我们在第三章中学到的那样,更大的模型容量意味着更大的过拟合风险。第四个差异增加了过拟合风险的减轻,即包括 dropout 层。
使用 dropout 层来减少过拟合。
Dropout 是你在本章中遇到的另一个新的 TensorFlow.js 层类型之一。它是减少深层神经网络过拟合最有效和广泛使用的方式之一。它的功能可以简单地描述为:
-
在训练阶段(在
Model.fit()调用期间),它随机将输入张量的一部分作为零(或“丢失”),并且其输出张量是 dropout 层的输出张量。对于本示例来说,dropout 层只有一个配置参数:dropout 比例(例如,如列表 4.5 所示的两个rate字段)。例如,假设一个 dropout 层被配置为有一个 0.25 的 dropout 比例,并且输入张量是值为[0.7, -0.3, 0.8, -0.4]的 1D 张量,则输出张量可以是[0.7, -0.3, 0.0, 0.4],其中 25%的输入张量元素随机选择并设置为值 0。在反向传播期间,dropout 层的梯度张量也会受到类似的归 0 影响。 -
在推理期间(在
Model.predict()和Model.evaluate()调用期间),dropout 层不会随机将输入张量中的元素置零。相反,输入会简单地作为输出传递,不会发生任何改变(即,一个恒等映射)。
图 4.11 展示了一个带有二维输入张量的 dropout 层在训练和测试时的工作示例。
图 4.11. dropout 层的一个示例。在这个示例中,输入张量是 2D 的,形状为[4, 2]。dropout 层的比例被配置为 0.25,导致在训练阶段随机选择输入张量中 25%(即 8 个中的两个)的元素并将它们设置为零。在推理阶段,该层充当一个简单的传递层。

这种简单算法是对抗过拟合最有效的方法之一似乎很奇怪。为什么它有效呢?Geoff Hinton,是 dropout 算法的发明者(神经网络中的许多其他内容也是他的创造),他说他受到了一些银行用于防止员工欺诈的机制的启发。用他自己的话说,
我去了我的银行。出纳员不停地换,我问其中一个为什么。他说他不知道,但他们经常被调动。我想这一定是因为需要员工之间的合作才能成功欺诈银行。这让我意识到,随机移除每个示例上的不同子集神经元将防止共谋,从而减少过拟合。
将这种深度学习的术语引入,向层的输出值引入噪声会破坏不重要的偶然模式,这些模式与数据中的真实模式不相关(Hinton 称之为“共谋”)。在本章末尾的练习 3 中,您应该尝试从 model.js 中的基于节点的卷积网络中移除两个 dropout 层,然后再次训练模型,并查看由此导致的训练、验证和评估准确度的变化。
清单 4.6 显示了我们用于训练和评估增强型卷积网络的关键代码。如果您将此处的代码与 清单 4.2 中的代码进行比较,您就会欣赏到这两个代码块之间的相似之处。两者都围绕着 Model.fit() 和 Model.evaluate() 调用。语法和样式相同,只是在如何呈现或显示损失值、准确度值和训练进度上有所不同(终端与浏览器)。
这展示了 TensorFlow.js 的一个重要特性,这是一个跨越前端和后端的 JavaScript 深度学习框架:
就创建和训练模型而言,在 TensorFlow.js 中编写的代码与您是在 web 浏览器还是在 Node.js 中工作无关。
列表 4.6. 在 tfjs-node 中训练和评估增强型卷积网络
await model.fit(trainImages, trainLabels, {
epochs,
batchSize,
validationSplit
});
const {images: testImages, labels: testLabels} = data.getTestData();
const evalOutput = model.evaluate ***1***
testImages, testLabels);
console.log('\nEvaluation result:');
console.log(
` Loss = ${evalOutput[0].dataSync()[0].toFixed(3)}; `+
`Accuracy = ${evalOutput[1].dataSync()[0].toFixed(3)}`);
- 1 使用模型未见过的数据评估模型
4.3.2. 从 Node.js 保存模型并在浏览器中加载
训练模型会消耗 CPU 和 GPU 资源,并需要一些时间。您不希望浪费训练的成果。如果不保存模型,下次运行 main.js 时,您将不得不从头开始。本节展示了如何在训练后保存模型,并将保存的模型导出为磁盘上的文件(称为 检查点 或 工件)。我们还将向您展示如何在浏览器中导入检查点,将其重新构建为模型,并用于推断。main.js 中 main() 函数的最后一部分是以下清单中的保存模型代码。
列表 4.7. 在 tfjs-node 中将训练好的模型保存到文件系统中
if (modelSavePath != null) {
await model.save(`file://${modelSavePath}`);
console.log(`Saved model to path: ${modelSavePath}`);
}
model对象的save()方法用于将模型保存到文件系统上的目录中。该方法接受一个参数,即以 file://开头的 URL 字符串。请注意,由于我们使用的是 tfjs-node,所以可以将模型保存在文件系统上。TensorFlow.js 的浏览器版本也提供了model.save()API,但不能直接访问机器的本地文件系统,因为浏览器出于安全原因禁止了这样做。如果我们在浏览器中使用 TensorFlow.js,则必须使用非文件系统保存目标(例如浏览器的本地存储和 IndexedDB)。这些对应于 file://以外的 URL 方案。
model.save()是一个异步函数,因为它通常涉及文件或网络输入输出。因此,在save()调用上使用await。假设modelSavePath的值为/tmp/tfjs-node-mnist;在model.save()调用完成后,您可以检查目录的内容,
ls -lh /tmp/tfjs-node-mnist
这可能打印出类似以下的文件列表:
-rw-r--r-- 1 user group 4.6K Aug 14 10:38 model.json
-rw-r--r-- 1 user group 2.3M Aug 14 10:38 weights.bin
在那里,你可以看到两个文件:
-
model.json 是一个包含模型保存拓扑的 JSON 文件。这里所说的“拓扑”包括形成模型的层类型、它们各自的配置参数(例如卷积层的
filters和 dropout 层的rate),以及层之间的连接方式。对于 MNIST 卷积网络来说,连接是简单的,因为它是一个顺序模型。我们将看到连接模式不太平凡的模型,这些模型也可以使用model.save()保存到磁盘上。 -
除了模型拓扑,model.json 还包含模型权重的清单。该部分列出了所有模型权重的名称、形状和数据类型,以及权重值存储的位置。这将我们带到第二个文件:weights.bin。正如其名称所示,weights.bin 是一个存储所有模型权重值的二进制文件。它是一个没有标记的平面二进制流,没有标明个体权重的起点和终点。这些“元信息”在 model.json 中的权重清单部分中可用于。
要使用 tfjs-node 加载模型,您可以使用tf.loadLayersModel()方法,指向 model.json 文件的位置(未在示例代码中显示):
const loadedModel = await tf.loadLayersModel('file:///tmp/tfjs-node-mnist');
tf.loadLayersModel()通过反序列化model.json中保存的拓扑数据来重建模型。然后,tf.loadLayersModel()使用model.json中的清单读取weights.bin中的二进制权重值,并将模型的权重强制设置为这些值。与model.save()一样,tf.loadLayersModel()是异步的,所以我们在这里调用它时使用await。一旦调用返回,loadedModel对象在所有意图和目的上等同于使用 listings 4.5 和 4.6 中的 JavaScript 代码创建和训练的模型。你可以通过调用其summary()方法打印模型的摘要,通过调用其predict()方法执行推理,通过使用evaluate()方法评估其准确性,甚至通过使用fit()方法重新训练它。如果需要,也可以再次保存模型。重新训练和重新保存加载的模型的工作流程将在我们讨论第五章的迁移学习时相关。
上一段中所说的内容同样适用于浏览器环境。你保存的文件可以用来在网页中重建模型。重建后的模型支持完整的tf.LayersModel()工作流程,但有一个警告,如果你重新训练整个模型,由于增强卷积网络的尺寸较大,速度会特别慢且效率低下。在 tfjs-node 和浏览器中加载模型唯一根本不同的是,你在浏览器中应该使用除file://之外的其他 URL 方案。通常,你可以将model.json和weights.bin文件作为静态资产文件放在 HTTP 服务器上。假设你的主机名是localhost,你的文件在服务器路径my/models/下可见;你可以使用以下行在浏览器中加载模型:
const loadedModel =
await tf.loadLayersModel('http:///localhost/my/models/model.json');
在浏览器中处理基于 HTTP 的模型加载时,tf.loadLayersModel()在底层调用浏览器内置的 fetch 函数。因此,它具有以下特性和属性:
-
支持
http://和https://。 -
支持相对服务器路径。事实上,如果使用相对路径,则可以省略 URL 的
http://或https://部分。例如,如果你的网页位于服务器路径my/index.html,你的模型的 JSON 文件位于my/models/model.json,你可以使用相对路径model/model.json:const loadedModel = await tf.loadLayersModel('models/model.json'); -
若要为 HTTP/HTTPS 请求指定额外选项,应该使用
tf.io.browserHTTPRequest()方法代替字符串参数。例如,在模型加载过程中包含凭据和标头,你可以这样做:const loadedModel = await tf.loadLayersModel(tf.io.browserHTTPRequest( 'http://foo.bar/path/to/model.json', {credentials: 'include', headers: {'key_1': 'value_1'}}));
4.4. 语音识别:在音频数据上应用卷积网络
到目前为止,我们已经向您展示了如何使用卷积网络执行计算机视觉任务。但是人类的感知不仅仅是视觉。音频是感知数据的一个重要模态,并且可以通过浏览器 API 进行访问。如何识别语音和其他类型声音的内容和意义?值得注意的是,卷积网络不仅适用于计算机视觉,而且在音频相关的机器学习中也以显著的方式发挥作用。
在本节中,您将看到我们如何使用类似于我们为 MNIST 构建的卷积网络来解决一个相对简单的音频任务。该任务是将短语音片段分类到 20 多个单词类别中。这个任务比您可能在亚马逊 Echo 和 Google Home 等设备中看到的语音识别要简单。特别是,这些语音识别系统涉及比本示例中使用的词汇量更大的词汇。此外,它们处理由多个词连续发音组成的连续语音,而我们的示例处理逐个单词发音。因此,我们的示例不符合“语音识别器”的条件;相反,更准确地描述它为“单词识别器”或“语音命令识别器”。然而,我们的示例仍然具有实际用途(如无需手动操作的用户界面和可访问性功能)。此外,本示例中体现的深度学习技术实际上是更高级语音识别系统的基础。^([9])
⁹
Ronan Collobert、Christian Puhrsch 和 Gabriel Synnaeve,“Wav2Letter: 一种基于端到端卷积网络的语音识别系统”,2016 年 9 月 13 日提交,
arxiv.org/abs/1609.03193。
4.4.1. 声谱图:将声音表示为图像
与任何深度学习应用一样,如果您想要理解模型的工作原理,首先需要了解数据。要理解音频卷积网络的工作原理,我们需要首先查看声音是如何表示为张量的。请回忆高中物理课上的知识,声音是空气压力变化的模式。麦克风捕捉到空气压力变化并将其转换为电信号,然后计算机的声卡可以将其数字化。现代 Web 浏览器提供了WebAudio API,它与声卡通信并提供对数字化音频信号的实时访问(在用户授权的情况下)。因此,从 JavaScript 程序员的角度来看,声音就是一组实值数字的数组。在深度学习中,这种数字数组通常表示为 1D 张量。
你可能会想,迄今为止我们见过的这种卷积网络是如何在 1D 张量上工作的?它们不是应该操作至少是 2D 的张量吗?卷积网络的关键层,包括 conv2d 和 maxPooling2d,利用了 2D 空间中的空间关系。事实证明声音可以被表示为称为声谱图的特殊类型的图像。声谱图不仅使得可以在声音上应用卷积网络,而且在深度学习之外还具有理论上的解释。
如 图 4.12 所示,频谱图是一个二维数组,可以以与 MNIST 图像基本相同的方式显示为灰度图像。水平维度是时间,垂直维度是频率。频谱图的每个垂直切片是一个短时间窗口内的声音的频谱。频谱是将声音分解为不同频率分量的过程,可以粗略地理解为不同的“音高”。就像光可以通过棱镜分解成多种颜色一样,声音可以通过称为傅里叶变换的数学操作分解为多个频率。简而言之,频谱图描述了声音的频率内容如何在一系列连续的短时间窗口(通常约为 20 毫秒)内变化。
图 4.12. “zero” 和 “yes” 这两个孤立口语单词的示例频谱图。频谱图是声音的联合时间-频率表示。你可以将频谱图视为声音的图像表示。沿着时间轴的每个切片(图像的一列)都是时间的短时刻(帧);沿着频率轴的每个切片(图像的一行)对应于特定的窄频率范围(音调)。图像的每个像素的值表示给定时间点上给定频率区段的声音相对能量。本图中的频谱图被渲染为较暗的灰色,对应着较高的能量。不同的语音有不同的特征。例如,类似于“z”和“s”这样的咝音辅音以在 2–3 kHz 以上频率处集中的准稳态能量为特征;像“e”和“o”这样的元音以频谱的低端(< 3 kHz)中的水平条纹(能量峰值)为特征。在声学中,这些能量峰值被称为共振峰。不同的元音具有不同的共振峰频率。所有这些不同语音的独特特征都可以被深度卷积神经网络用于识别单词。
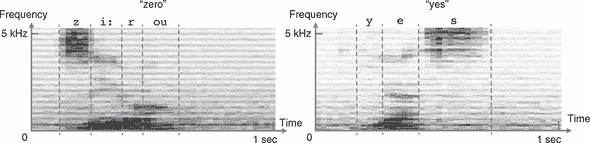
谱图对于以下原因是声音的合适表示。首先,它们节省空间:谱图中的浮点数通常比原始波形中的浮点值少几倍。其次,在宽泛的意义上,谱图对应于生物学中的听力工作原理。内耳内部的一种名为耳蜗的解剖结构实质上执行了傅里叶变换的生物版本。它将声音分解成不同的频率,然后被不同组听觉神经元接收。第三,谱图表示可以更容易地区分不同类型的语音。这在 图 4.12 的示例语音谱图中可以看到:元音和辅音在谱图中都有不同的特征模式。几十年前,在机器学习被广泛应用之前,从谱图中检测不同的元音和辅音的人们实际上尝试手工制作规则。深度学习为我们节省了这种手工制作的麻烦和泪水。
让我们停下来思考一下。看一看 图 4.1 中的 MNIST 图片和 图 4.12 中的声音谱图,你应该能够理解这两个数据集之间的相似之处。两个数据集都包含在二维特征空间中的模式,一双经过训练的眼睛应该能够区分出来。两个数据集都在特征的具体位置、大小和细节上呈现一定的随机性。最后,两个数据集都是多类别分类任务。虽然 MNIST 有 10 个可能的类别,我们的声音命令数据集有 20 个类别(从 0 到 9 的 10 个数字,“上”,“下”,“左”,“右”,“前进”,“停止”,“是”,“否”,以及“未知”词和背景噪音的类别)。正是这些数据集本质上的相似性使得卷积神经网络非常适用于声音命令识别任务。
但是这两个数据集也有一些显著的区别。首先,声音命令数据集中的音频录音有些噪音,可以从 图 4.12 中的示例谱图中看到不属于语音声音的黑色像素点。其次,声音命令数据集中的每个谱图的尺寸为 43×232,与单个 MNIST 图像的 28×28 大小相比显著较大。谱图的尺寸在时间和频率维度之间是不对称的。这些差异将体现在我们将在音频数据集上使用的卷积神经网络中。
定义和训练声音命令卷积神经网络的代码位于 tfjs-models 存储库中。您可以使用以下命令访问代码:
git clone https://github.com/tensorflow/tfjs-models.git
cd speech-commands/training/browser-fft
模型的创建和编译封装在 model.ts 中的createModel()函数中。
4.8 章节的声音命令谱图分类的卷积神经网络
function createModel(inputShape: tf.Shape, numClasses: number) {
const model = tf.sequential();
model.add(tf.layers.conv2d({ ***1***
filters: 8,
kernelSize: [2, 8],
activation: 'relu',
inputShape
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
model.add( tf.layers.conv2d({
filters: 32,
kernelSize: [2, 4],
activation: 'relu'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
model.add(
tf.layers.conv2d({
filters: 32,
kernelSize: [2, 4],
activation: 'relu'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [2, 2]}));
model.add(
tf.layers.conv2d({
filters: 32,
kernelSize: [2, 4],
activation: 'relu'
}));
model.add(tf.layers.maxPooling2d({poolSize: [2, 2], strides: [1, 2]}));
model.add(tf.layers.flatten()); ***2***
model.add(tf.layers.dropout({rate: 0.25})); ***3***
model.add(tf.layers.dense({units: 2000, activation: 'relu'}));
model.add(tf.layers.dropout({rate: 0.5}));
model.add(tf.layers.dense({units: numClasses, activation: 'softmax'}));
model.compile({ ***4***
loss: 'categoricalCrossentropy',
optimizer: tf.train.sgd(0.01),
metrics: ['accuracy']
});
model.summary();
return model;
}
-
1 conv2d+maxPooling2d 的重复模式
-
2 多层感知器开始
-
3 使用 dropout 减少过拟合
-
4 配置多类别分类的损失和指标
我们的音频卷积网络的拓扑结构看起来很像 MNIST 卷积网络。顺序模型以多个重复的 conv2d 层与 maxPooling2d 层组合开始。模型的卷积 - 池化部分在一个展平层结束,在其上添加了 MLP。MLP 有两个密集层。隐藏的密集层具有 relu 激活,最终(输出)层具有适合分类任务的 softmax 激活。模型编译为在训练和评估期间使用 categoricalCrossentropy 作为损失函数并发出准确度指标。这与 MNIST 卷积网络完全相同,因为两个数据集都涉及多类别分类。音频卷积网络还显示出与 MNIST 不同的一些有趣之处。特别是,conv2d 层的 kernelSize 属性是矩形的(例如,[2, 8])而不是方形的。这些值被选择为与频谱图的非方形形状匹配,该频谱图的频率维度比时间维度大。
要训练模型,首先需要下载语音命令数据集。该数据集源自谷歌 Brain 团队工程师 Pete Warden 收集的语音命令数据集(请参阅 www.tensorflow.org/tutorials/sequences/audio_recognition)。它已经转换为浏览器特定的频谱图格式:
curl -fSsL https://storage.googleapis.com/learnjs-data/speech-
commands/speech-commands-data- v0.02-browser.tar.gz -o speech-commands-
data-v0.02-browser.tar.gz &&
tar xzvf speech-commands-data-v0.02-browser.tar.gz
这些命令将下载并提取语音命令数据集的浏览器版本。一旦数据被提取,您就可以使用以下命令启动训练过程:
yarn
yarn train \
speech-commands-data-browser/ \
/tmp/speech-commands-model/
yarn train 命令的第一个参数指向训练数据的位置。以下参数指定了模型的 JSON 文件将保存的路径,以及权重文件和元数据 JSON 文件的路径。就像我们训练增强的 MNIST 卷积网络时一样,音频卷积网络的训练也发生在 tfjs-node 中,有可能利用 GPU。由于数据集和模型的大小都比 MNIST 卷积网络大,训练时间会更长(大约几个小时)。如果您有 CUDA GPU 并且稍微更改命令以使用 tfjs-node-gpu 而不是默认的 tfjs-node(仅在 CPU 上运行),您可以显著加快训练速度。要做到这一点,只需在上一个命令中添加标志 --gpu:
yarn train \
--gpu \
speech-commands-data-browser/ \
/tmp/speech-commands-model/
当训练结束时,模型应该达到约 94% 的最终评估(测试)准确率。
训练过的模型保存在上一个命令中指定的路径中。与我们用 tfjs-node 训练的 MNIST 卷积网络一样,保存的模型可以在浏览器中加载以提供服务。然而,您需要熟悉 WebAudio API,以便能够从麦克风获取数据并将其预处理为模型可用的格式。为了方便起见,我们编写了一个封装类,不仅可以加载经过训练的音频卷积网络,还可以处理数据输入和预处理。如果您对音频数据输入流水线的机制感兴趣,可以在 tfjs-model Git 仓库中的 speech-commands/src 文件夹中研究底层代码。这个封装类可以通过 npm 的 @tensorflow-models/speech-commands 名称使用。Listing 4.9 展示了如何使用封装类在浏览器中进行在线语音命令识别的最小示例。
在 tfjs-models 仓库的 speech-commands/demo 文件夹中,您可以找到一个相对完整的示例,该示例展示了如何使用该软件包。要克隆并运行该演示,请在 speech-commands 目录下运行以下命令:
git clone https://github.com/tensorflow/tfjs-models.git
cd tfjs-models/speech-commands
yarn && yarn publish-local
cd demo
yarn && yarn link-local && yarn watch
yarn watch 命令将自动在默认的网页浏览器中打开一个新的标签页。要看到语音命令识别器的实际效果,请确保您的计算机已准备好麦克风(大多数笔记本电脑都有)。每次识别到词汇表中的一个单词时,屏幕上将显示该单词以及包含该单词的一秒钟的频谱图。所以,这是基于浏览器的单词识别,由 WebAudio API 和深度卷积网络驱动。当然,它没有能力识别带有语法的连接语音?这将需要其他类型的能够处理序列信息的神经网络模块的帮助。我们将在第八章中介绍这些模块。
Listing 4.9. @tensorflow-models/speech-commands 模块的示例用法
import * as SpeechCommands from
'@tensorflow-models/speech-commands'; ***1***
const recognizer =
SpeechCommands.create('BROWSER_FFT'); ***2***
console.log(recognizer.wordLabels()); ***3***
recognizer.listen(result => { ***4***
let maxIndex;
let maxScore = -Infinity;
result.scores.forEach((score, i) => { ***5***
if (score > maxScore) { ***6***
maxIndex = i;
maxScore = score;
}
});
console.log(`Detected word ${recognizer.wordLabels()[maxIndex]}`);
}, {
probabilityThreshold: 0.75
});
setTimeout(() => recognizer.stopStreaming(), 10e3); ***7***
-
1 导入 speech-commands 模块。确保它在 package.json 中列为依赖项。
-
2 创建一个使用浏览器内置快速傅里叶变换(FFT)的语音命令识别器实例
-
3 您可以查看模型能够识别的单词标签(包括“background-noise”和“unknown”标签)。
-
4 启动在线流式识别。第一个参数是一个回调函数,每当识别到概率超过阈值(本例为 0.75)的非背景噪声、非未知单词时,都会调用该函数。
-
5 result.scores 包含与 recognizer.wordLabels() 对应的概率得分。
-
6 找到具有最高得分的单词的索引
-
7 在 10 秒内停止在线流式识别
练习
-
用于在浏览器中对 MNIST 图像进行分类的卷积网络(listing 4.1)有两组 conv2d 和 maxPooling2d 层。修改代码,将该数量减少到只有一组。回答以下问题:
-
这会影响卷积网络可训练参数的总数吗?
-
这会影响训练速度吗?
-
这会影响训练后卷积网络获得的最终准确率吗?
-
-
这个练习与练习 1 相似。但是,与其调整 conv2d-maxPooling2d 层组的数量,不如在卷积网络的 MLP 部分中尝试调整密集层的数量。如果去除第一个密集层,只保留第二个(输出)层,总参数数量、训练速度和最终准确率会发生什么变化,见列表 4.1。
-
从 mnist-node 中的卷积网络(列表 4.5)中移除 dropout,并观察训练过程和最终测试准确率的变化。为什么会发生这种情况?这说明了什么?
-
使用
tf.browser.fromPixels()方法练习从网页中图像和视频相关元素中提取图像数据,尝试以下操作:-
使用
tf.browser.fromPixels()通过img标签获取表示彩色 JPG 图像的张量。-
tf.browser.fromPixels()返回的图像张量的高度和宽度是多少?是什么决定了高度和宽度? -
使用
tf.image.resizeBilinear()将图像调整为固定尺寸 100 × 100(高 × 宽)。 -
重复上一步,但使用替代的调整大小函数
tf.image.resizeNearestNeighbor()。你能发现这两种调整大小函数的结果之间有什么区别吗?
-
-
创建一个 HTML 画布并在其中绘制一些任意形状,例如使用
rect()函数。或者,如果愿意,也可以使用更先进的库,如 d3.js 或 three.js,在其中绘制更复杂的 2D 和 3D 形状。然后,使用tf.browser.fromPixels()从画布获取图像张量数据。
-
摘要
-
卷积网络通过堆叠的 conv2d 和 maxPooling2d 层的层次结构从输入图像中提取 2D 空间特征。
-
conv2d 层是多通道、可调节的空间滤波器。它们具有局部性和参数共享的特性,使它们成为强大的特征提取器和高效的表示转换器。
-
maxPooling2d 层通过在固定大小的窗口内计算最大值来减小输入图像张量的大小,从而实现更好的位置不变性。
-
卷积网络的 conv2d-maxPooling2d“塔”通常以一个 flatten 层结束,其后是由密集层组成的 MLP,用于分类或回归任务。
-
受限于其资源,浏览器只适用于训练小型模型。要训练更大的模型,建议使用 tfjs-node,即 TensorFlow.js 的 Node.js 版本;tfjs-node 可以使用与 Python 版本的 TensorFlow 相同的 CPU 和 GPU 并行化内核。
-
模型容量增加会增加过拟合的风险。通过在卷积网络中添加 dropout 层可以缓解过拟合。在训练期间,dropout 层会随机将给定比例的输入元素归零。
-
Convnets 不仅对计算机视觉任务有用。当音频信号被表示为频谱图时,卷积神经网络也可以应用于它们,以实现良好的分类准确性。
第五章:转移学习:重用预训练的神经网络
本章涵盖
-
什么是转移学习,为什么它对许多类型的问题而言比从头开始训练模型更好
-
如何通过将其从 Keras 转换为 TensorFlow.js 来利用最先进的预训练卷积神经网络的特征提取能力
-
转移学习技术的详细机制,包括层冻结、创建新的转移头和微调
-
如何使用转移学习在 TensorFlow.js 中训练简单的目标检测模型
在第四章中,我们看到了如何训练卷积神经网络来对图像进行分类。现在考虑以下情景。我们用于分类手写数字的卷积神经网络对某位用户表现不佳,因为他们的手写与原始训练数据非常不同。我们能否通过使用我们可以从他们那里收集到的少量数据(比如,50 个样本)来改进模型,从而更好地为用户提供服务?再考虑另一种情况:一个电子商务网站希望自动分类用户上传的商品图片。但是公开可用的卷积神经网络(例如 MobileNet^([1]))都没有针对这种特定领域的图像进行训练。在给定少量标记图片(比如,几百张)的情况下,是否可以使用公开可用的图像模型来解决定制分类问题?
¹
Andrew G. Howard 等人,“MobileNets: 面向移动视觉应用的高效卷积神经网络”,2017 年 4 月 17 日提交,
arxiv.org/abs/1704.04861。
幸运的是,本章的主要焦点——一种称为转移学习的技术,可以帮助解决这类任务。
5.1. 转移学习简介:重用预训练模型
本质上,转移学习是通过重用先前学习结果来加速新的学习任务。它涉及使用已经在数据集上训练过的模型来执行不同但相关的机器学习任务。已经训练好的模型被称为基础模型。转移学习有时涉及重新训练基础模型,有时涉及在基础模型的顶部创建一个新模型。我们将新模型称为转移模型。正如图 5.1 所示,用于这个重新训练过程的数据量通常比用于训练基础模型的数据量要小得多(就像本章开头给出的两个例子一样)。因此,与基础模型的训练过程相比,转移学习通常需要的时间和资源要少得多。这使得在像浏览器这样的资源受限环境中使用 TensorFlow.js 进行转移学习成为可能。因此,对于 TensorFlow.js 学习者来说,转移学习是一个重要的主题。
图 5.1. 迁移学习的一般工作流程。大型数据集用于基础模型的训练。这个初始训练过程通常很长且计算量大。然后重新训练基础模型,可能成为新模型的一部分。重新训练过程通常涉及比原始数据集小得多的数据集。重新训练所涉及的计算量远远小于初始训练,并且可以在边缘设备上进行,例如运行 TensorFlow.js 的笔记本电脑或手机。

描述迁移学习中的关键短语“不同但相关”在不同情况下可能意味着不同的事情:
-
本章开头提到的第一个场景涉及将模型调整为特定用户的数据。尽管数据与原始训练集不同,但任务完全相同——将图像分类为 10 个数字。这种类型的迁移学习被称为模型适应。
-
其他迁移学习问题涉及与原始标签不同的目标。本章开头提到的商品图像分类场景属于这一类别。
与从头开始训练新模型相比,迁移学习的优势是什么?答案有两个方面:
-
从数据量和计算量两个方面来看,迁移学习更加高效。
-
它借助基础模型的特征提取能力,建立在先前训练成果的基础上。
这些观点适用于各种类型的问题(例如分类和回归)。在第一个观点上,迁移学习使用来自基础模型(或其子集)的训练权重。因此,与从头开始训练新模型相比,它需要更少的训练数据和训练时间才能收敛到给定精度水平。在这方面,迁移学习类似于人类学习新任务的方式:一旦你掌握了一个任务(例如玩纸牌游戏),学习类似的任务(例如玩类似的纸牌游戏)在将来会变得更容易和更快。对于我们为 MNIST 构建的 convnet 这样的神经网络来说,节省的训练时间成本可能相对较小。然而,对于在大型数据集上训练的较大模型(例如在 TB 级图像数据上训练的工业规模 convnet),节省可以是相当可观的。
关于第二点,迁移学习的核心思想是重用之前的训练结果。通过从一个非常大的数据集中学习,原始神经网络已经非常擅长从原始输入数据中提取有用的特征。只要迁移学习任务中的新数据与原始数据不相差太大,这些特征对于新任务将是有用的。研究人员已经为常见的机器学习领域组装了非常大的数据集。在计算机视觉领域,有 ImageNet^([2]),其中包含大约一千个类别的数百万张带标签的图像。深度学习研究人员已经使用 ImageNet 数据集训练了深度卷积神经网络,包括 ResNet、Inception 和 MobileNet(我们将很快接触到的最后一个)。由于 ImageNet 中图像的数量和多样性,训练在其上的卷积神经网络是一般类型图像的良好特征提取器。这些特征提取器对于处理像前述情景中的小数据集这样的小数据集将是有用的,但是使用小数据集训练这样有效的特征提取器是不可能的。迁移学习的机会也存在于其他领域。例如,在自然语言处理领域,人们已经在包含数十亿个单词的大型文本语料库上训练了词嵌入(即语言中所有常见单词的向量表示)。这些嵌入对于可用的远小于大文本数据集的语言理解任务是有用的。话不多说,让我们通过一个例子来看看迁移学习是如何在实践中工作的。
²
不要被名字所迷惑。“ImageNet”指的是一个数据集,而不是一个神经网络。
5.1.1. 基于兼容输出形状的迁移学习:冻结层
让我们从一个相对简单的例子开始。我们将在 MNIST 数据集的前五个数字(0 到 4)上训练一个卷积神经网络。然后,我们将使用得到的模型来识别剩余的五个数字(5 到 9),这些数字在原始训练中模型从未见过。虽然这个例子有些人为,但它展示了迁移学习的基本工作流程。你可以通过以下命令查看并运行这个例子:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/mnist-transfer-cnn
yarn && yarn watch
在打开的演示网页中,通过点击“重新训练”按钮来开始迁移学习过程。你可以看到这个过程在新的五个数字(5 到 9)上达到了约 96%的准确率,这需要在一台性能较强的笔记本电脑上大约 30 秒。正如我们将要展示的,这比不使用迁移学习的替代方案(即从头开始训练一个新模型)要快得多。让我们逐步看看这是如何实现的。
我们的例子从 HTTP 服务器加载预训练的基础模型,而不是从头开始训练,以免混淆工作流程的关键部分。回想一下第 4.3.3 节,TensorFlow.js 提供了tf.loadLayersModel()方法来加载预训练模型。这在 loader.js 文件中调用:
const model = await tf.loadLayersModel(url);
model.summary();
模型的打印摘要看起来像 图 5.2。正如你所见,该模型由 12 层组成。^([3]) 其中的大约 600,000 个权重参数都是可训练的,就像迄今为止我们见过的所有 TensorFlow.js 模型一样。请注意,loadLayersModel() 不仅加载模型的拓扑结构,还加载所有权重值。因此,加载的模型已经准备好预测数字 0 到 4 的类别。但是,这不是我们将使用模型的方式。相反,我们将训练模型来识别新的数字(5 到 9)。
³
在这个模型中,你可能没有看到激活层类型。激活层是仅对输入执行激活函数(如 relu 和 softmax)的简单层。假设你有一个具有默认(线性)激活的稠密层;在其上叠加一个激活层等同于使用具有非默认激活的稠密层。这就是我们在 第四章 中的例子所做的。但是有时也会看到前一种风格。在 TensorFlow.js 中,你可以通过以下代码获取这样的模型拓扑:
constmodel=tf.sequential();model.add(tf.layers.dense({untis:5,`inputShape})); model.add(tf.layers.activation({activation: ‘relu’}))。
图 5.2. MNIST 图像识别和迁移学习卷积神经网络的打印摘要
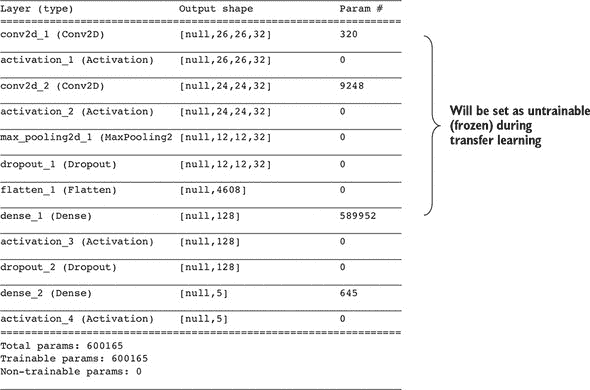
查看回调函数以重新训练按钮(在 index.js 的 retrainModel() 函数中)时,如果选择了冻结特征层选项(默认情况下选择了),你会注意到一些代码行将模型的前七层的 trainable 属性设置为 false。
那是做什么用的?默认情况下,模型加载后通过 loadLayersModel() 方法或从头创建后,模型的每个层的 trainable 属性都是 true。 trainable 属性在训练期间(即调用 fit() 或 fitDataset() 方法)中使用。它告诉优化器是否应该更新层的权重。默认情况下,模型的所有层的权重都在训练期间更新。但是,如果你将某些模型层的属性设置为 false,那么这些层的权重在训练期间将不会更新。在 TensorFlow.js 的术语中,这些层变为不可训练或冻结。列表 5.1 中的代码冻结了模型的前七层,从输入 conv2d 层到 flatten 层,同时保持最后几层(稠密层)可训练。
列表 5.1. 冻结卷积网络的前几层以进行迁移学习
const trainingMode = ui.getTrainingMode();
if (trainingMode === 'freeze-feature-layers') {
console.log('Freezing feature layers of the model.');
for (let i = 0; i < 7; ++i) {
this.model.layers[i].trainable = false; ***1***
}
} else if (trainingMode === 'reinitialize-weights') {
const returnString = false ;
this.model = await tf.models.modelFromJSON({ ***2***
modelTopology: this.model.toJSON(null, returnString) ***2***
}); ***2***
}
this.model.compile({ ***3***
loss: 'categoricalCrossentropy',
optimizer: tf.train.adam(0.01),
metrics: ['acc'],
});
this.model.summary(); ***4***
-
1 冻结层
-
2 创建一个与旧模型具有相同拓扑结构但重新初始化权重值的新模型
-
3 冻结将不会在调用 fit() 时生效,除非你首先编译模型。
-
4 在 compile() 后再次打印模型摘要。您应该看到模型的一些权重已变为不可训练。
然而,仅设置层的 trainable 属性是不够的:如果您只修改 trainable 属性并立即调用模型的 fit() 方法,您将看到这些层的权重在 fit() 调用期间仍然会被更新。在调用 Model.fit() 之前,您需要调用 Model.compile() 以使 trainable 属性更改生效,就像在 列表 5.1 中所做的那样。我们之前提到 compile() 调用配置了优化器、损失函数和指标。但是,该方法还允许模型在这些调用期间刷新要更新的权重变量列表。在 compile() 调用之后,我们再次调用 summary() 来打印模型的新摘要。通过将新摘要与 图 5.2 中的旧摘要进行比较,您会发现一些模型的权重已变为不可训练:
Total params: 600165
Trainable params: 590597
Non-trainable params: 9568
您可以验证非可训练参数的数量,即 9,568,是两个冻结层中的权重参数之和(两个 conv2d 层的权重)。请注意,我们已冻结的一些层不包含权重(例如 maxPooling2d 层和 flatten 层),因此当它们被冻结时不会对非可训练参数的计数产生贡献。
实际的迁移学习代码显示在 列表 5.2 中。在这里,我们使用了与从头开始训练模型相同的 fit() 方法。在此调用中,我们使用 validationData 字段来衡量模型在训练期间未见过的数据上的准确性。此外,我们将两个回调连接到 fit() 调用,一个用于在用户界面中更新进度条,另一个用于使用 tfjs-vis 模块绘制损失和准确率曲线(更多细节请参见 第七章)。这显示了 fit() API 的一个方面,我们之前没有提到过:您可以给 fit() 调用一个回调或一个包含多个回调的数组。在后一种情况下,所有回调将在训练期间被调用(按照数组中指定的顺序)。
列表 5.2 使用 Model.fit() 进行迁移学习
await this.model.fit(this.gte5TrainData.x, this.gte5TrainData.y, {
batchSize: batchSize,
epochs: epochs,
validationData: [this.gte5TestData.x, this.gte5TestData.y],
callbacks: [ ***1***
ui.getProgressBarCallbackConfig(epochs),
tfVis.show.fitCallbacks(surfaceInfo, ['val_loss', 'val_acc'], { ***2***
zoomToFit: true, ***2***
zoomToFitAccuracy: true, ***2***
height: 200, ***2***
callbacks: ['onEpochEnd'], ***2***
}), ***2***
]
});
-
1 给
fit()调用添加多个回调是允许的。 -
2 使用 tfjs-vis 绘制迁移学习过程中的验证损失和准确率
迁移学习的结果如何?正如您在图 5.3 的 A 面板中所看到的,经过 10 个 epoch 的训练后,准确率达到约 0.968,大约需要在一台相对更新的笔记本电脑上花费约 15 秒,还算不错。但与从头开始训练模型相比如何呢?我们可以通过一个实验演示从预训练模型开始相对于从头开始的价值,即在调用 fit() 前随机重新初始化预训练模型的权重。在点击重新训练按钮之前,在训练模式下拉菜单中选择重新初始化权重选项即可。结果显示在同一图表的 B 面板中。
图 5.3. 在 MNIST 卷积网络上的迁移学习的损失和验证曲线。面板 A:使用预训练模型的前七层冻结得到的曲线。面板 B:使用模型的所有权重随机重新初始化得到的曲线。面板 C:不冻结任何预训练模型层获得的曲线。请注意三个面板之间的 y 轴有所不同。面板 D:一个多系列图,显示了面板 A–C 中的损失和准确度曲线在相同轴上以便进行比较。
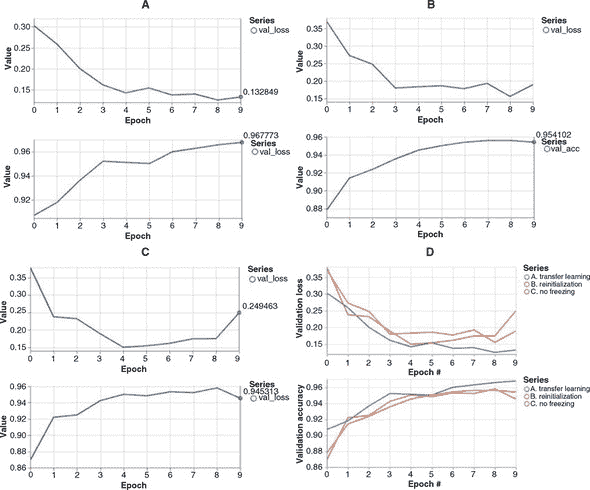
通过比较 B 面板和 A 面板,可以看出模型权重的随机重新初始化导致损失从一个显著更高的值开始(0.36 对比 0.30),准确度则从一个显著更低的值开始(0.88 对比 0.91)。重新初始化的模型最终的验证准确率也比重复使用从基本模型中的权重的模型低(约 0.954 对比 ~0.968)。这些差异反映了迁移学习的优势:通过重复使用模型的初始层(特征提取层)中的权重,相对于从头开始学习,模型获得了一个良好的起步。这是因为迁移学习任务中遇到的数据与用于训练原始模型的数据相似。数字 5 到 9 的图像与数字 0 到 4 的图像有很多共同点:它们都是带有黑色背景的灰度图像;它们有类似的视觉模式(相似宽度和曲率的笔画)。因此,模型从数字 0 到 4 中学习提取的特征对学习分类新数字(5 到 9)也很有用。
如果我们不冻结特征层的权重会怎样?在训练模式下拉菜单中选择不冻结特征层选项可以进行此实验。结果显示在图 5.3 的 C 面板中。与 A 面板的结果相比,有几个值得注意的差异:
-
没有特征层冻结时,损失值开始较高(例如,在第一个时期之后:0.37 对比 0.27);准确率开始较低(0.87 对比 0.91)。为什么会这样?当预训练模型首次开始在新数据集上进行训练时,预测结果将包含大量错误,因为预训练权重为五个新数字生成基本上是随机的预测。因此,损失函数将具有非常高的值和陡峭的斜率。这导致在训练的早期阶段计算的梯度非常大,进而导致所有模型的权重出现大幅波动。因此,所有层的权重都将经历一个大幅波动的时期,这导致面板 C 中看到的初始损失较高。在正常的迁移学习方法(面板 A)中,模型的前几层被冻结,因此免受这些大的初始权重扰动的影响。
-
由于这些大的初始扰动,采用无冻结方法达到的最终准确率(约为 0.945,面板 C)与采用正常的迁移学习方法相比(约为 0.968,面板 A)并没有明显提高。
-
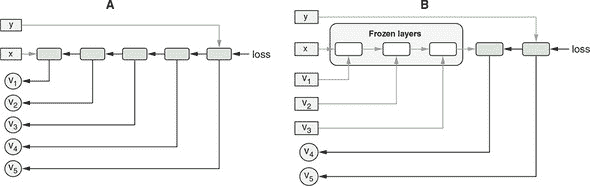
当模型的任何一层都没有被冻结时,训练时间会更长。例如,在我们使用的其中一台笔记本电脑上,使用冻结特征层训练模型大约需要 30 秒,而没有任何层冻结的模型训练大约需要两倍长(60 秒)。图 5.4 以示意的方式说明了其中的原因。在反向传播期间,冻结的层被从方程中排除,这导致每个
fit()调用的批次速度大大加快。
图 5.4. 模型冻结某些层加快训练速度的示意图。在该图中,通过指向左边的黑色箭头显示了反向传播路径。面板 A:当没有任何层被冻结时,所有模型的权重(v[1]–v[5])在每个训练步骤(每个批次)中都需要更新,因此将参与反向传播,由黑色箭头表示。请注意,特征(x)和目标(y)永远不会包括在反向传播中,因为它们的值不需要更新。面板 B:通过冻结模型的前几层,一部分权重(v[1]–v[3])不再是反向传播的一部分。相反,它们变成了类似于 x 和 y 的常数,只是作为影响损失计算的因素。因此,执行反向传播所需的计算量减少,训练速度提高。
这些观点为迁移学习的层冻结方法提供了理由:它利用了基础模型的特征提取层,并在新训练的早期阶段保护它们免受大的权重扰动,从而在较短的训练周期内实现更高的准确性。
在我们继续下一节之前,有两点需要注意。首先,模型适应——重新训练模型以使其在特定用户的输入数据上更有效的过程——使用的技术与此处展示的技术非常相似,即冻结基础层,同时让顶层的权重通过对用户特定数据的训练而发生变化。尽管本节解决的问题并不涉及来自不同用户的数据,而是涉及具有不同标签的数据。其次,你可能想知道如何验证冻结层(在这种情况下是 conv2d 层)的权重在fit()调用之前和之后是否确实相同。这个验证并不是很难做到的。我们把它留给你作为一个练习(参见本章末尾的练习 2)。
5.1.2. 不兼容输出形状上的迁移学习:使用基础模型的输出创建一个新的 m 模型
在前一节中看到的迁移学习示例中,基础模型的输出形状与新输出形状相同。这种属性在许多其他迁移学习案例中并不成立(参见图 5.5)。例如,如果你想要使用最初在五个数字上进行训练的基础模型来对四个新数字进行分类,先前描述的方法将不起作用。更常见的情况是:给定一个已经在包含 1,000 个输出类别的 ImageNet 分类数据集上训练过的深度卷积网络,你手头有一个涉及更少输出类别的图像分类任务(图 5.5 中的 B 案例)。也许这是一个二元分类问题——图像是否包含人脸——或者这是一个具有少数类别的多类分类问题——图片中包含什么类型的商品(回想一下本章开头的例子)。在这种情况下,基础模型的输出形状对于新问题不起作用。
图 5.5. 根据新模型的输出形状和激活方式是否与原模型相同,迁移学习可分为三种类型。情况 A:新模型的输出形状和激活函数与基础模型相匹配。将 MNIST 模型迁移到 5.1.1 节中的新数字就是这种类型的迁移学习示例。情况 B:新模型具有与基础模型相同的激活类型,因为原任务和新任务是相同类型的(例如,都是多类分类)。然而,输出形状不同(例如,新任务涉及不同数量的类)。这种类型的迁移学习示例可在 5.1.2 节(通过网络摄像头控制类似于 Pac-Man^(TM 4) 的视频游戏)和 5.1.3(识别一组新的口语单词)中找到。情况 C:新任务与原始任务的类型不同(例如,回归与分类)。基于 MobileNet 的目标检测模型就是这种类型的示例。
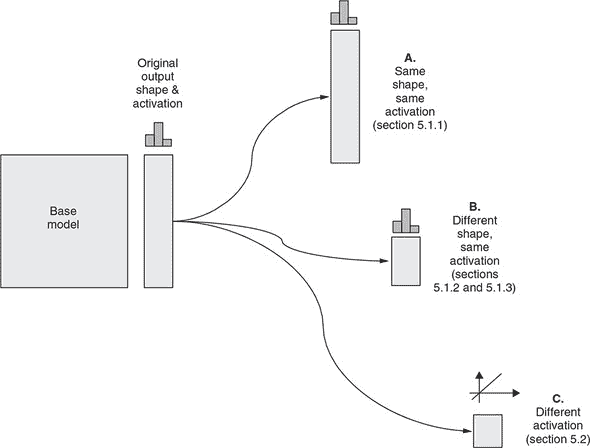
在某些情况下,甚至机器学习任务的类型也与基础模型训练的类型不同。例如,您可以通过对分类任务训练的基础模型应用迁移学习来执行回归任务(预测一个数字,如图 5.5 中的情况 C)5.2 节中,您将看到迁移学习的更加有趣的用途——预测一系列数字,而不是单个数字,用于在图像中检测和定位对象。
这些情况都涉及期望的输出形状与基础模型不同。这使得需要构建一个新模型。但因为我们正在进行迁移学习,所以新模型不会从头开始创建。相反,它将使用基础模型。我们将在 tfjs-examples 存储库中的 webcam-transfer-learning 示例中说明如何做到这一点。
要查看此示例的实际操作,请确保您的设备具有前置摄像头——示例将从摄像头收集用于迁移学习的数据。现在大多数笔记本电脑和平板电脑都配备了内置的前置摄像头。但是,如果您使用的是台式电脑,可能需要找到一个网络摄像头并将其连接到设备上。与之前的示例类似,您可以使用以下命令来查看和运行演示:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/webcam-transfer-learning
这个有趣的演示将您的网络摄像头转换为游戏控制器,通过对 MobileNet 的 TensorFlow.js 实现进行迁移学习,让您可以用它玩 Pac-Man 游戏。让我们走过运行演示所需的三个步骤:数据收集、模型迁移学习和游戏进行^([4])。
⁴
Pac-Man 是万代南梦宫娱乐公司的商标。
迁移学习的数据来自于您的网络摄像头。一旦演示在您的浏览器中运行,您将在页面右下角看到四个黑色方块。它们的排列方式类似于任天堂家庭电脑控制器上的四个方向按钮。它们对应着模型将实时识别的四个类别。这四个类别对应着 Pac-Man 将要移动的四个方向。当您点击并按住其中一个时,图像将以每秒 20–30 帧的速度通过网络摄像头收集。方块下面的数字告诉您目前已经为此控制器方向收集了多少图像。
为了获得最佳的迁移学习质量,请确保您:1)每个类别至少收集 50 张图像;2)在数据收集过程中稍微移动和摆动您的头部和面部,以使训练图像包含更多的多样性,这有利于您从迁移学习中获得的模型的稳健性。在这个演示中,大多数人会在四个方向(上、下、左、右;参见图 5.6)转动头部,以指示 Pac-Man 应该朝哪个方向移动。但您可以使用任何您想要的头部位置、面部表情甚至手势作为输入图像,只要输入图像在各个类别之间足够视觉上有区别即可。
图 5.6. 网络摄像头迁移学习示例的用户界面^([5])
⁵
这个网络摄像头迁移学习示例的用户界面是由吉姆博·威尔逊(Jimbo Wilson)和山姆·卡特(Shan Carter)完成的。您可以在
youtu.be/YB-kfeNIPCE?t=941查看这个有趣示例的视频录制。

收集完训练图像后,点击“训练模型”按钮,这将开始迁移学习过程。迁移学习应该只需要几秒钟。随着进展,您应该看到屏幕上显示的损失值变得越来越小,直到达到一个非常小的正值(例如 0.00010),然后停止变化。此时,迁移学习模型已经被训练好了,您可以用它来玩游戏了。要开始游戏,只需点击“播放”按钮,等待游戏状态稳定下来。然后,模型将开始对来自网络摄像头的图像流进行实时推理。在每个视频帧中,赢得的类别(由迁移学习模型分配的概率分数最高的类别)将在用户界面的右下角用明亮的黄色突出显示。此外,它会导致 Pac-Man 沿着相应的方向移动(除非被墙壁挡住)。
对于那些对机器学习不熟悉的人来说,这个演示可能看起来像魔术一样,但它基于的只是一个使用 MobileNet 执行四类分类任务的迁移学习算法。该算法使用通过网络摄像头收集的少量图像数据。这些图像通过您收集图像时执行的点击和按住操作方便地标记。由于迁移学习的力量,这个过程不需要太多数据或太多的训练时间(它甚至可以在智能手机上运行)。这就是这个演示的工作原理的简要概述。如果您希望了解技术细节,请在下一节中与我们一起深入研究底层的 TensorFlow.js 代码。
深入研究网络摄像头迁移学习
列表 5.3 中的代码(来自 webcam-transfer-learning/index.js)负责加载基础模型。特别地,我们加载了一个可以在 TensorFlow.js 中高效运行的 MobileNet 版本。信息框 5.1 描述了这个模型是如何从 Python 的 Keras 深度学习库转换而来的。一旦模型加载完成,我们使用 getLayer() 方法来获取其中一个层。getLayer() 允许您通过名称(在本例中为 'conv_pw_13_relu')指定一个层。您可能还记得另一种从 第 2.4.2 节 访问模型层的方法——即通过索引到模型的 layers 属性,该属性将所有模型的层作为 JavaScript 数组保存。当模型由少量层组成时,这种方法很容易使用。我们正在处理的 MobileNet 模型有 93 层,这使得这种方法变得脆弱(例如,如果将来向模型添加更多层会发生什么?)。因此,基于名称的 getLayer() 方法更可靠,如果我们假设 MobileNet 的作者在发布新版本模型时会保持关键层的名称不变的话。
列表 5.3. 加载 MobileNet 并从中创建一个“截断”模型
async function loadTruncatedMobileNet() {
const mobilenet = await tf.loadLayersModel( ***1***
'https://storage.googleapis.com/' + ***1***
'tfjs-models/tfjs/mobilenet_v1_0.25_224/model.json'); ***1***
const layer = mobilenet.getLayer( ***2***
'conv_pw_13_relu'); ***2***
return tf.model({ ***3***
inputs: mobilenet.inputs, ***3***
outputs: layer.output ***3***
}); ***3***
}
-
1 storage.google.com/tfjs-models 下的 URL 设计为永久和稳定的。
-
2 获取 MobileNet 的一个中间层。这个层包含对于自定义图像分类任务有用的特征。
-
3 创建一个新模型,它与 MobileNet 相同,只是它在 ‘conv_pw_13_relu’ 层结束,也就是说,最后几层(称为“头部”)被截断
将 Python Keras 模型转换为 TensorFlow .js 格式
TensorFlow.js 具有与 Keras 高度兼容和互操作的特性,Keras 是最受欢迎的 Python 深度学习库之一。从这种兼容性中获益的其中一个好处是,你可以利用 Keras 中的许多所谓的“应用程序”。这些应用程序是一组在大型数据集(如 ImageNet)上预训练的深度卷积神经网络(详见 keras.io/applications/)。Keras 的作者们已经在库中辛苦地对这些卷积神经网络进行了训练,并使它们可通过库随时重用,包括推理和迁移学习,就像我们在这里所做的那样。对于在 Python 中使用 Keras 的人来说,导入一个应用程序只需一行代码。由于前面提到的互操作性,一个 TensorFlow.js 用户也很容易使用这些应用程序。以下是所需步骤:
-
确保已安装名为
tensorflowjs的 Python 包。最简单的安装方法是通过pip命令:pip install tensorflowjs -
通过 Python 源文件或者像 ipython 这样的交互式 Python REPL 运行以下代码:
import keras import tensorflowjs as tfjs model = keras.applications.mobilenet.MobileNet(alpha=0.25) tfjs.converters.save_keras_model(model, '/tmp/mobilnet_0.25')
前两行导入了所需的keras和tensorflowjs模块。第三行将 MobileNet 加载到一个 Python 对象(model)中。实际上,你可以以几乎与打印 TensorFlow.js 模型摘要相同的方式打印模型的摘要:即model.summary()。你可以看到模型的最后一层(模型的输出)确实具有形状(None, 1000)(在 JavaScript 中相当于[null, 1000]),反映了 MobileNet 模型在 ImageNet 分类任务上训练的 1000 类。我们为这个构造函数调用指定的alpha=0.25关键字参数选择了一个更小的 MobileNet 版本。你可以选择更大的alpha值(如0.75, 1),同样的转换代码仍将继续工作。
前一代码片段中的最后一行使用了tensorflowjs模块中的一个方法,将模型保存到指定目录中。在该行运行结束后,将在磁盘上的/tmp/mobilenet_0.25 路径下创建一个新目录,其内容如下所示:
group1-shard1of6
group1-shard2of6
...
group1-shard6of6
model.json
这与我们在第 4.3.3 节中看到的格式完全相同,当时我们展示了如何在 Node.js 版本的 TensorFlow.js 中使用其save()方法将训练好的 TensorFlow.js 模型保存到磁盘上。因此,对于从磁盘加载此转换模型的 TensorFlow.js 程序而言,保存的格式与在 TensorFlow.js 中创建和训练模型的格式是相同的:它可以简单地调用tf.loadLayersModel()方法并指向模型.json 文件的路径(无论是在浏览器中还是在 Node.js 中),这正是 listing 5.3 中发生的事情。
载入的 MobileNet 模型已经准备好执行模型最初训练的机器学习任务——将输入图像分类为 ImageNet 数据集的 1,000 个类别。请注意,该特定数据集非常强调动物,特别是各种品种的猫和狗(这可能与互联网上此类图像的丰富性有关!)。对于对此特定用法感兴趣的人,tfjs-example 仓库中的 MobileNet 示例展示了如何做到这一点(github.com/tensorflow/tfjs-examples/tree/master/mobilenet)。然而,在本章中,我们不专注于直接使用 MobileNet;相反,我们探讨如何使用载入的 MobileNet 进行迁移学习。
先前展示的 tfjs.converters.save_keras_model() 方法能够转换和保存不仅是 MobileNet 还有其他 Keras 应用,例如 DenseNet 和 NasNet。在本章末尾的练习 3 中,您将练习将另一个 Keras 应用(MobileNetV2)转换为 TensorFlow.js 格式并在浏览器中加载它。此外,应指出 tfjs.converters.save_keras_model() 通常适用于您在 Keras 中创建或训练的任何模型对象,而不仅仅是来自 keras.applications 的模型。
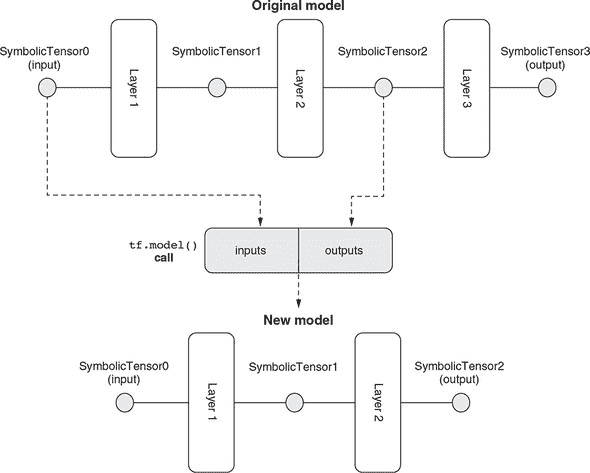
一旦获得 conv_pw_13_relu 层,我们该怎么做?我们创建一个包含原始 MobiletNet 模型层的新模型,从其第一(输入)层到 conv_pw_13_relu 层。这是本书中首次看到这种模型构建方式,因此需要一些仔细的解释。为此,我们首先需要介绍符号张量的概念。
创建符号张量模型
到目前为止,您已经看到了张量。Tensor 是 TensorFlow.js 中的基本数据类型(也缩写为 dtype)。一个张量对象携带着给定形状和 dtype 的具体数值,支持由 WebGL 纹理(如果在启用 WebGL 的浏览器中)或 CPU/GPU 内存(如果在 Node.js 中)支持的存储。然而,SymbolicTensor 是 TensorFlow.js 中另一个重要的类。与携带具体值不同,符号张量仅指定形状和 dtype。可以将符号张量视为“槽”或“占位符”,可以稍后插入一个实际张量值,前提是张量值具有兼容的形状和 dtype。在 TensorFlow.js 中,层或模型对象接受一个或多个输入(到目前为止,您只看到了一个输入的情况),这些输入被表示为一个或多个符号张量。
让我们使用一个类比来帮助你理解符号张量。想象一下编程语言(比如 Java 或 TypeScript,或者其他你熟悉的静态类型语言)中的函数。函数接受一个或多个输入参数。函数的每个参数都有一个类型,规定了可以作为参数传递的变量类型。然而,参数本身并不包含任何具体的值。参数本身只是一个占位符。符号张量类似于函数的参数:它指定了可以在该位置使用的张量的种类(形状和 dtype 的组合)。类似地,静态类型语言中的函数有一个返回类型。这与模型或层对象的输出符号张量相似。它是模型或层对象输出的实际张量值形状和 dtype 的“蓝图”。
⁶
张量形状和符号张量形状之间的区别在于前者始终具有完全指定的维度(比如
[8, 32, 20]),而后者可能具有未确定的维度(比如[null, null, 20])。你已经在模型摘要的“输出形状”列中见过这一点。
在 TensorFlow.js 中,模型对象的两个重要属性是其输入和输出。这两者都是符号张量的数组。对于具有一个输入和一个输出的模型,这两个数组的长度都为 1。类似地,层对象具有两个属性:输入和输出,每个都是一个符号张量。符号张量可以用于创建新模型。这是 TensorFlow.js 中创建模型的新方法,与你之前见过的方法有所不同:即使用 tf.sequential() 创建顺序模型,然后调用 add() 方法。在新方法中,我们使用 tf.model() 函数,它接受一个包含两个必填字段 inputs 和 outputs 的配置对象。inputs 字段需要是一个符号张量(或者是一个符号张量数组),outputs 亦然。因此,我们可以从原始 MobileNet 模型中获取符号张量,并将它们提供给 tf.model() 调用。结果是一个由原始 MobileNet 的一部分组成的新模型。
这个过程在 图 5.7 中以示意图形式说明。(请注意,为了简单的图示,该图将实际 MobileNet 模型的层数减少了。)重要的是要意识到,从原始模型中提取的符号张量并不是孤立的对象。相反,它们携带关于它们属于哪些层以及层如何相互连接的信息。对于熟悉数据结构中图的读者来说,原始模型是一个符号张量的图,连接边是层。通过在原始模型中指定新模型的输入和输出为符号张量,我们正在提取原始 MobileNet 图的一个子图。这个子图成为新模型,包含 MobileNet 的前几层(特别是前 87 层),而最后 6 层则被略过。深度卷积网络的最后几层有时被称为头部。我们在 tf.model() 调用中所做的可以称为截断模型。截断的 MobileNet 保留了提取特征的层,同时丢弃了头部。为什么头部包含六层?这是因为这些层是 MobileNet 最初训练的 1,000 类分类任务所特有的。这些层对我们面对的四类分类任务没有用处。
图 5.7. 示意图解释了如何从 MobileNet 创建新的(“截断的”)模型。在 代码清单 5.3 中的 tf.model() 调用中查看相应的代码。每一层都有一个输入和一个输出,都是 SymbolicTensor 实例。在原始模型中,SymbolicTensor0 是第一层的输入,也是整个模型的输入。它被用作新模型的输入符号张量。此外,我们将中间层的输出符号张量(相当于 conv_pw_13_relu)作为新模型的输出张量。因此,我们得到一个由原始模型的前两层组成的模型,如图的底部所示。原始模型的最后一层,即输出层,有时被称为模型的头部,被丢弃。这就是为什么有时会将这样的方法称为截断模型的原因。请注意,这个图示了具有少量层的模型,以便清楚地表达。实际上,在 代码清单 5.3 中的代码涉及一个比这个图示的层多得多(93 层)的模型。
基于嵌入的迁移学习
截断的 MobileNet 的输出是原始 MobileNet 的中间层激活。但是 MobileNet 的中间层激活对我们有何用呢?答案可以在处理每个四个黑色方块的点击和保持事件的函数中看到(列表 5.4)每当摄像头可用的时候(通过 capture() 方法),我们调用截断的 MobileNet 的 predict() 方法,并将输出保存在一个名为 controllerDataset 的对象中,稍后将用于迁移学习。
⁷
有关 TensorFlow.js 模型的常见问题是如何获取中间层的激活。我们展示的方法就是答案。
但是如何解释截断的 MobileNet 的输出?对于每个图像输入,它都是一个形状为 [1, 7, 7, 256] 的张量。它不是任何分类问题的概率,也不是任何回归问题的预测值。它是输入图像在某个高维空间中的表示。该空间具有 7 * 7 * 256,约为 12.5k,维度。尽管空间具有很多维度,但与原始图像相比,它是低维的,原始图像由于具有 224 × 224 的图像尺寸和三个颜色通道,有 224 * 224 * 3 ≈ 150k 个维度。因此,截断的 MobileNet 的输出可以被视为图像的有效表示。这种输入的低维表示通常称为嵌入。我们的迁移学习将基于从网络摄像头收集到的四组图像的嵌入。
列表 5.4. 使用截断的 MobileNet 获取图像嵌入
ui.setExampleHandler(label => {
tf.tidy(() => { ***1***
const img = webcam.capture();
controllerDataset.addExample(
truncatedMobileNet.predict(img), ***2***
label);
ui.drawThumb(img, label);
});
});
-
1 使用 tf.tidy() 来清理中间张量,比如 img。有关在浏览器中使用 TensorFlow.js 内存管理的教程,请参见附录 B,第 B.3 节。
-
2 获取 MobileNet 的输入图像的内部激活
现在我们有了获取网络摄像头图像嵌入的方法,我们如何使用它们来预测给定图像对应的方向呢?为此,我们需要一个新模型,该模型以嵌入作为其输入,并输出四个方向类的概率值。以下代码(来自 index.js)创建了这样一个模型。
列表 5.5. 使用图像嵌入预测控制器方向
model = tf.sequential({
layers: [
tf.layers.flatten({ ***1***
inputShape: truncatedMobileNet.outputs[0].shape.slice(1) ***1***
}), ***1***
tf.layers.dense({ ***2***
units: ui.getDenseUnits(), ***2***
activation: 'relu', ***2***
kernelInitializer: 'varianceScaling', ***2***
useBias: true ***2***
}), ***2***
tf.layers.dense({ ***3***
units: NUM_CLASSES, ***3***
kernelInitializer: 'varianceScaling', ***3***
useBias: false, ***3***
activation: 'softmax' ***3***
}) ***3***
]
});
-
1 将截断的 MobileNet 的[7, 7, 256]嵌入层展平。slice(1) 操作丢弃了第一个(批次)维度,该维度存在于输出形状中,但是不需要在层的工厂方法的 inputShape 属性中,因此它可以与密集层一起使用。
-
2 一个具有非线性(relu)激活的第一个(隐藏的)密集层
-
3 最后一层的单元数应该与我们想要预测的类的数量相对应。
与 MobileNet 截断版相比,清单 5.5 中创建的新模型具有更小的尺寸。它仅由三层组成:
-
输入层是一个展平层。它将来自截断模型的 3D 嵌入转换为 1D 张量,以便后续的密集层可以采用。我们在
inputShape中设置其与截断的 MobileNet 的输出形状匹配(不包括批处理维度),因为新模型将接收来自截断的 MobileNet 的嵌入。 -
第二层是隐藏层。它是隐藏的,因为它既不是模型的输入层也不是输出层。相反,它被夹在其他两层之间,以增强模型的能力。这与第三章中遇到的 MLP 非常相似。它是一个带有 relu 激活的密集的隐藏层。回想一下,在第三章的“避免堆叠没有非线性的层的谬论”一节中,我们讨论了使用类似这样的隐藏层的非线性激活的重要性。
-
第三层是新模型的最终(输出)层。它具有适合我们面临的多类分类问题的 softmax 激活(即,四个类别:每个 Pac-Man 方向一个)。
因此,我们可以将 MLP 建立在 MobileNet 的特征提取层的顶部。即使在这种情况下,特征提取器(截断的 MobileNet)和 MLP 都是两个分离的模型(见图 5.8)。由于这种两个模型的设置,不可能直接使用图像张量(形状为[numExamples,224,224,3])来训练新的 MLP。相反,新的 MLP 必须在图像的嵌入上进行训练——即截断的 MobileNet 的输出。幸运的是,我们已经收集了那些嵌入张量(清单 5.4)。我们只需要在嵌入张量上调用其 fit() 方法即可训练新的 MLP。在 index.js 的 train() 函数中执行此操作的代码十分简单,我们不再详细介绍。
图 5.8. Webcam-transfer-learning 示例背后的迁移学习算法的概要

一旦迁移学习完成,截断模型和新头将一起用于从网络摄像头的输入图像获取概率分数。您可以在 index.js 的 predict() 函数中找到代码,显示在 列表 5.6 中。特别是,涉及两个 predict() 调用。第一个调用将图像张量转换为其嵌入,使用截断的 MobileNet;第二个使用与迁移学习训练的新头将嵌入转换为四个方向的概率分数。列表 5.6 中的随后代码获取获胜索引(在四个方向的最大概率分数中对应的索引)并使用它来控制 Pac-Man 并更新 UI 状态。与之前的示例一样,我们不涵盖示例的 UI 部分,因为它不是机器学习算法的核心。您可以使用下一个列表中的代码自行研究和玩耍 UI 代码。
列表 5.6. 在迁移学习后从网络摄像头输入图像获取预测
async function predict() {
ui.isPredicting();
while (isPredicting) {
const predictedClass = tf.tidy(() => {
const img = webcam.capture(); ***1***
const embedding = truncatedMobileNet.predict( ***2***
img); ***2***
const predictions = model.predict(activation); ***3***
return predictions.as1D().argMax(); ***4***
});
const classId = (await predictedClass.data())[0]; ***5***
predictedClass.dispose();
ui.predictClass(classId); ***6***
await tf.nextFrame();
}
ui.donePredicting();
}
-
1 从网络摄像头捕获一帧
-
2 从截断的 MobileNet 获取嵌入
-
3 使用新头模型将嵌入转换为四个方向的概率分数
-
4 获取最大概率分数的索引
-
5 将索引从 GPU 下载到 CPU
-
6 根据获胜方向更新 UI:控制 Pac-Man 并更新其他 UI 状态,如控制器上相应“按钮”的突出显示
这结束了我们讨论与迁移学习算法相关的 webcam-transfer-learning 示例的部分。这个示例中我们使用的方法的一个有趣之处是训练和推断过程涉及两个独立的模型对象。这对我们的教育目的来说是有好处的,因为它说明了如何从预训练模型的中间层获取嵌入。这种方法的另一个优点是它暴露了嵌入,并且使得应用直接使用这些嵌入的机器学习技术更容易。这种技术的一个例子是k 最近邻(kNN,在信息框 5.2 中讨论)。然而,直接暴露嵌入也可能被视为以下原因的缺点:
-
这导致稍微复杂一些的代码。例如,推断需要两个
predict()调用才能对单个图像执行推断。 -
假设我们希望保存模型以供以后会话使用或转换为非 TensorFlow.js 库。那么截断模型和新的头模型需要分别保存,作为两个单独的构件。
-
在一些特殊情况下,迁移学习将涉及基础模型的某些部分的反向传播(例如截断的 MobileNet 的前几层)。当基础和头部是两个分开的对象时,这是不可能的。
在接下来的部分中,我们将展示一种通过形成单个模型对象来克服这些限制的方法进行迁移学习。这将是一个端到端模型,因为它可以将原始格式的输入数据转换为最终的期望输出。
基于嵌入的 k 最近邻分类
在机器学习中,解决分类问题的非神经网络方法有很多。其中最著名的之一就是 k 最近邻(kNN)算法。与神经网络不同,kNN 算法不涉及训练步骤,更容易理解。
我们可以用几句话来描述 kNN 分类的工作原理:
-
你选择一个正整数k(例如,3)。
-
你收集一些带有真实类别标签的参考示例。通常收集的参考示例数量至少是k的几倍。每个示例都被表示为一系列实值数字,或者一个向量。这一步类似于神经网络方法中的训练示例的收集。
-
为了预测新输入的类别,你计算新输入的向量表示与所有参考示例的距离。然后对距离进行排序。通过这样做,你可以找到在向量空间中距离输入最近的k个参考示例。这些被称为输入的“k个最近邻居”(算法的名字来源)。
-
你观察k个最近邻居的类别,并使用它们中最常见的类别作为输入的预测。换句话说,你让k个最近的邻居“投票”来预测类别。
这个算法的一个示例如下图所示。
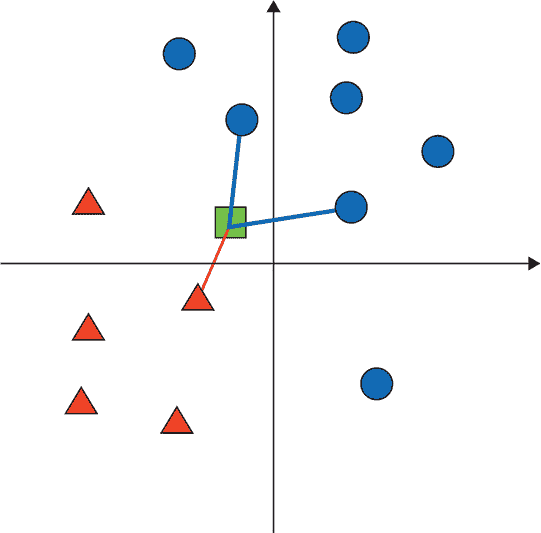
在二维嵌入空间中的 kNN 分类示例。在这种情况下,k=3,有两个类别(三角形和圆形)。三角形类别有五个参考示例,圆形类别有七个。输入示例表示为一个正方形。与输入相连的三个最近邻居由连线表示。因为三个最近邻居中有两个是圆形,所以输入示例的预测类别将是圆形。
正如您从前面的描述中可以看到的,kNN 算法的一个关键要求是,每个输入示例都表示为一个向量。像我们从截断的 MobileNet 获取的那样的嵌入是这样的向量表示的良好候选者,原因有两个。首先,与原始输入相比,它们通常具有较低的维度,因此减少了距离计算所需的存储和计算量。其次,由于它们已经在大型分类数据集上进行了训练,所以这些嵌入通常捕捉到输入中的更重要的特征(例如图像中的重要几何特征;参见图 4.5),并忽略了不太重要的特征(例如亮度和大小)。在某些情况下,嵌入给我们提供了原本不以数字形式表示的事物的向量表示(例如第九章中的单词嵌入)。
与神经网络方法相比,kNN 不需要任何训练。在参考样本数量不太多且输入维度不太高的情况下,使用 kNN 可以比训练神经网络并对其进行推断的计算效率更高。
然而,kNN 推断不随数据量的增加而扩展。特别是,给定 N 个参考示例,kNN 分类器必须计算 N 个距离,以便为每个输入进行预测。当 N 变大时,计算量可能变得难以处理。相比之下,神经网络的推断不随训练数据的量而变化。一旦网络被训练,训练数据的数量就不重要了。网络正向传播所需的计算量仅取决于网络的拓扑结构。
^a
但是,请查看研究努力设计近似 kNN 算法但运行速度更快且规模比 kNN 更好的算法:Gal Yona,“利用局部敏感哈希进行快速近似重复图像搜索”,Towards Data Science,2018 年 5 月 5 日,
mng.bz/1wm1。
如果您有兴趣在您的应用程序中使用 kNN,请查看基于 TensorFlow.js 构建的 WebGL 加速 kNN 库:mng.bz/2Jp8。
5.1.3. 通过微调充分利用迁移学习:音频示例
在前几节中,迁移学习的示例处理了视觉输入。在这个例子中,我们将展示迁移学习也适用于表示为频谱图像的音频数据。回想一下,我们在第 4.4 节中介绍了用于识别语音命令(孤立的、短的口头单词)的卷积网络。我们构建的语音命令识别器只能识别 18 个不同的单词(如“one”、“two”、“up” 和 “down”)。如果你想为其他单词训练一个识别器呢?也许你的特定应用程序需要用户说特定的单词,比如“red” 或 “blue”,甚至是用户自己选的单词;或者你的应用程序面向的是讲英语以外语言的用户。这是迁移学习的一个经典例子:在手头数据量很少的情况下,你可以尝试从头开始训练一个模型,但使用预训练模型作为基础可以在更短的时间内和更少的计算资源下获得更高的准确度。
如何在语音命令示例应用中进行迁移学习
在我们描述如何在这个示例中进行迁移学习之前,最好让你熟悉如何通过 UI 使用迁移学习功能。要使用 UI,请确保您的计算机连接了音频输入设备(麦克风),并且在系统设置中将音频输入音量设置为非零值。要下载演示代码并运行它,请执行以下操作(与第 4.4.1 节相同的过程):
git clone https://github.com/tensorflow/tfjs-models.git
cd tfjs-models/speech-commands
yarn && yarn publish-local
cd demo
yarn && yarn link-local && yarn watch
当 UI 启动时,请允许浏览器访问麦克风的请求。图 5.9 显示了演示的示例截图。当演示页面启动时,将自动从互联网上加载预训练的语音命令模型,使用指向 HTTPS URL 的 tf.loadLayersModel() 方法。模型加载完成后,“开始” 和 “输入转移词” 按钮将被启用。如果点击 “开始” 按钮,演示将进入推理模式,连续检测屏幕上显示的 18 个基本单词。每次检测到一个单词时,屏幕上相应的单词框将点亮。但是,如果点击 “输入转移词” 按钮,屏幕上将会出现一些额外的按钮。这些按钮是从右侧的文本输入框中的逗号分隔的单词创建的。默认单词是 “noise”、“red” 和 “green”。这些是转移学习模型将被训练识别的单词。但是,如果你想为其他单词训练转移模型,可以自由修改输入框的内容,只要保留 “noise” 项即可。“noise” 项是特殊的一个,你应该收集背景噪声样本,即没有任何语音声音的样本。这允许转移模型区分语音和静音(背景噪声)的时刻。当你点击这些按钮时,演示将从麦克风记录 1 秒的音频片段,并在按钮旁边显示其频谱图。单词按钮中的数字跟踪到目前为止已经收集到的特定单词的示例数量。
图 5.9. 语音命令示例的转移学习功能的示例截图。在这里,用户已经为转移学习输入了一组自定义单词:“feel”、“seal”、“veal” 和 “zeal”,以及始终需要的 “noise” 项。此外,用户已经收集了每个单词和噪声类别的 20 个示例。
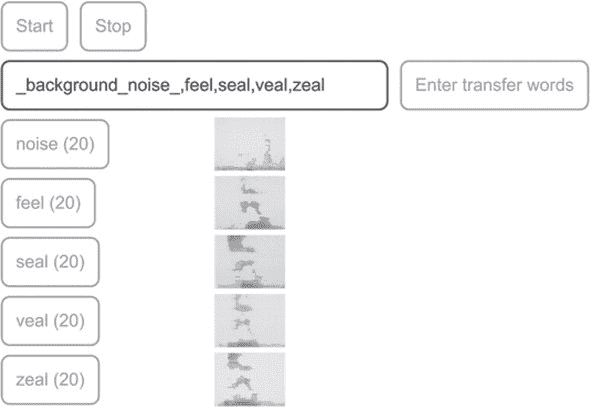
如同机器学习问题中的一般情况,你能够收集的数据越多(在可用时间和资源允许的范围内),训练出的模型就会越好。示例应用程序至少需要每个单词的八个示例。如果你不想或无法自己收集声音样本,可以从mng.bz/POGY(文件大小:9 MB)下载预先收集好的数据集,并在 UI 的数据集 IO 部分使用上传按钮上传。
数据集准备好后,通过文件上传或你自己的样本收集,“开始迁移学习” 按钮将变为可用状态。你可以点击该按钮启动迁移模型的训练。该应用在你收集的音频频谱图上执行 3:1 的分割,随机选择其中 75%用于训练,剩余的 25%用于验证。应用程序在迁移学习过程中显示训练集损失和准确度值以及验证集值。一旦训练完成,可以点击 “开始” 按钮,让演示程序连续识别迁移词,此时你可以经验性地评估迁移模型的准确度。
⁸
这也是为什么演示要求你每个单词至少收集八个样本的原因。如果单词更少,在验证集中每个单词的样本数量将很少,可能会导致不可靠的损失和准确度估计。
你应该尝试不同的词汇组合,观察它们在经过迁移学习后对精确度的影响。默认集合中,“red”和“green”这两个词在音位内容方面非常不同。例如,它们的起始辅音是两个非常不同的声音,“r”和“g”。它们的元音也听起来非常不同(“e”和“ee”);结尾辅音也很不同(“d”和“n”)。因此,只要每个单词收集的样本数量不太小(例如>=8),使用的时代数不太小(这会导致欠拟合)或太大(这会导致过拟合;请参阅第八章),你就能够在迁移训练结束时获得几乎完美的验证精度。
为使模型的迁移学习任务更具挑战性,使用由 1)更具混淆性的单词和 2)更大的词汇组成的集合。这就是我们在图 5.9 的屏幕截图中所做的。在该截图中,使用了四个听起来相似的单词:“feel”、“seal”、“veal”和“zeal”。这些单词的元音和结尾辅音相同,开头的辅音也相似。它们甚至可能会让一个不注意或在坏电话线路上听的人听起来混淆。从图的右下角的准确度曲线可以看出,模型要达到 90%以上的准确度并不是一件容易的事,必须通过额外的“微调”阶段来补充初始的迁移学习 - 这是一种迁移学习技巧。
深入了解迁移学习中的微调
微调是一种技术,它可以帮助您达到仅通过训练迁移模型的新头部无法达到的准确度水平。如果您希望了解微调的工作原理,本节将更详细地解释。您需要消化一些技术细节。但通过它,您将深入理解迁移学习及其相关的 TensorFlow.js 实现,这将是值得的努力。
构建单个迁移学习模型
首先,我们需要了解语音迁移学习应用程序如何为迁移学习创建模型。列表 5.7(来自 speech-commands/src/browser_ fft_recognizer.ts 的代码)中的代码从基础语音命令模型(您在 第 4.4.1 节中学到的模型)创建一个模型。它首先找到模型的倒数第二个(倒数第二个)密集层,并获取其输出符号张量(代码中的truncatedBaseOutput)。然后,它创建一个仅包含一个密集层的新头模型。这个新头的输入形状与truncatedBaseOutput符号张量的形状匹配,其输出形状与迁移数据集中的单词数匹配(在图 5.9 的情况下为五个)。密集层配置为使用 softmax 激活,适用于多类别分类任务。(请注意,与书中大多数其他代码清单不同,以下代码是用 TypeScript 编写的。如果您不熟悉 TypeScript,可以简单地忽略类型标记,例如void和tf.SymbolicTensor`。)
列表 5.7. 将迁移学习模型创建为单个tf.Model对象^([9])
⁹
关于此代码列表的两点说明:1)代码是用 TypeScript 编写的,因为它是可重用的 @tensorflow-models/speech-commands 库的一部分。2)出于简化的目的,此代码中删除了一些错误检查代码。
private createTransferModelFromBaseModel(): void {
const layers = this.baseModel.layers;
let layerIndex = layers.length - 2;
while (layerIndex >= 0) { ***1***
if (layers[layerIndex].getClassName().toLowerCase() === 'dense') { ***1***
break; ***1***
} ***1***
layerIndex--; ***1***
} ***1***
if (layerIndex < 0) {
throw new Error('Cannot find a hidden dense layer in the base model.');
}
this.secondLastBaseDenseLayer = ***2***
layers[layerIndex]; ***2***
const truncatedBaseOutput = layers[layerIndex].output as ***3***
tf.SymbolicTensor; ***3***
this.transferHead = tf.layers.dense({ ***4***
units: this.words.length, ***4***
activation: 'softmax', ***4***
inputShape: truncatedBaseOutput.shape.slice(1) ***4***
})); ***4***
const transferOutput = ***5***
this.transferHead.apply(truncatedBaseOutput) as tf.SymbolicTensor; ***5***
this.model = ***6***
tf.model({inputs: this.baseModel.inputs, outputs: transferOutput});***6***
}
-
1 找到基础模型的倒数第二个密集层
-
2 获取稍后在微调过程中将解冻的层(请参阅列表 5.8)
-
3 找到符号张量
-
4 创建模型的新头
-
5 在截断的基础模型输出上“应用”新的头部,以获取新模型的最终输出作为符号张量。
-
6 使用
tf.model()API 创建一个新的用于迁移学习的模型,指定原始模型的输入作为其输入,新的符号张量作为输出。
新的头部以一种新颖的方式使用:其apply()方法使用截断的基础输出符号张量作为输入参数进行调用。apply()是 TensorFlow.js 中每个层和模型对象上都可用的方法。apply()方法的作用是什么?顾名思义,它“应用”新的头模型于输入,并给出输出。要认识到的重要事项如下:
-
输入和输出都是符号化的——它们是具体张量值的占位符。
-
图 5.10 给出了一个图形示例:符号输入(
truncatedBaseOutput)不是一个孤立的实体;而是基模型倒数第二个密集层的输出。该密集层从另一层接收输入,该层又从其上游层接收输入,依此类推。因此,truncatedBaseOutput携带着基模型的一个子图,即基模型的输入到倒数第二个密集层的输出之间的子图。换句话说,它是基模型的整个图,减去倒数第二个密集层之后的部分。因此,apply()调用的输出包含该子图以及新的密集层。输出和原始输入在调用tf.model()函数时共同使用,得到一个新模型。这个新模型与基模型相同,只是其头部被新的密集层替换了(参见图 5.10 的底部部分)。
图 5.10. 示出了创建迁移学习的新端到端模型的方式的示意图。在阅读此图时,请参考 list 5.7。与 list 5.7 中的变量对应的图的某些部分用固定宽度字体标记。步骤 1:获取原始模型倒数第二个密集层的输出符号张量(由粗箭头指示)。它将在步骤 3 中被使用。步骤 2:创建新的头模型,包含一个单输出的密集层(标记为“dense 3”)。步骤 3:使用步骤 1 中的符号张量作为输入参数调用新头模型的apply()方法。此调用将该输入与步骤 1 中的截断的基模型连接起来。步骤 4:将apply()调用的返回值与原始模型的输入符号张量一起在调用tf.model()函数时使用。此调用返回一个新模型,其中包含了原始模型的所有层,从第一层到倒数第二个密集层,以及新头的密集层。实际上,这将原始模型的旧头和新头交换,为后续在迁移数据上训练做准备。请注意,为了简化可视化效果,图中省略了实际语音命令模型的一些(七个)层。在此图中,有颜色的层是可训练的,而白色的层是不可训练的。
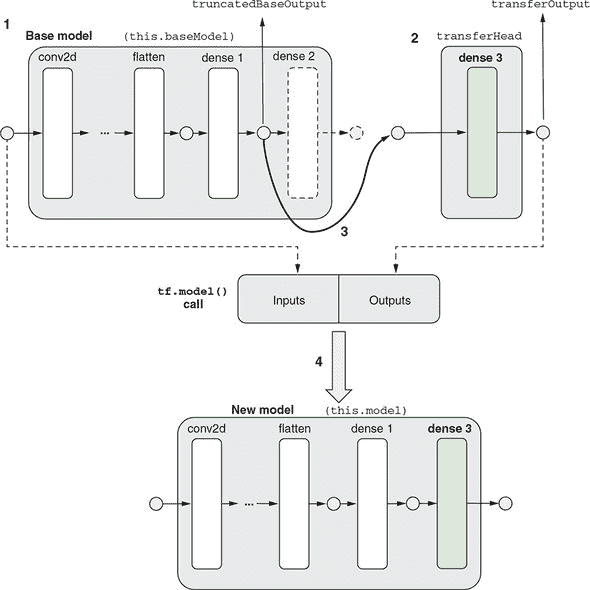
请注意,这里的方法与我们在 5.1.2 节 中如何融合模型的方法不同。在那里,我们创建了一个被截断的基础模型和一个新的头模型作为两个独立的模型实例。因此,对每个输入示例进行推断涉及两个 predict() 调用。在这里,新模型期望的输入与基础模型期望的音频频谱张量相同。同时,新模型直接输出新单词的概率分数。每次推断仅需一个 predict() 调用,因此是一个更加流畅的过程。通过将所有层封装在单个模型中,我们的新方法在我们的应用中具有一个额外的重要优势:它允许我们通过参与识别新单词的任何层执行反向传播。这使我们能够执行微调技巧。这是我们将在下一节中探讨的内容。
通过解冻层进行微调
微调是转移学习的可选步骤,紧随模型训练的初始阶段。在初始阶段,来自基础模型的所有层都被冻结(它们的trainable属性设置为false),权重更新仅发生在头部层。我们在本章前面的 mnist-transfer-cnn 和 webcam-transfer-learning 示例中已经看到了这种初始训练类型。在微调期间,基础模型的一些层被解冻(它们的trainable属性设置为true),然后模型再次在转移数据上进行训练。这种层解冻在 图 5.11 中以示意图显示。代码在 TensorFlow.js 中显示了如何为语音命令示例执行此操作,详见 清单 5.8(来自 speech-commands/src/browser_fft_recognizer.ts)。
图 5.11。展示了转移学习初始阶段(面板 A)和微调阶段(面板 B)期间冻结和未冻结(即可训练)层的示意图,代码见 清单 5.8。注意 dense1 紧随 dense3 之后的原因是,dense2(基础模型的原始输出)已被截断为转移学习的第一步(参见 图 5.10)。

清单 5.8。初始转移学习,然后进行微调^([10])
¹⁰
一些错误检查代码已被删除,以便集中关注算法的关键部分。
async train(config?: TransferLearnConfig):
Promise<tf.History|[tf.History, tf.History]> {
if (config == null) {
config = {};
}
if (this.model == null) {
this.createTransferModelFromBaseModel();
}
this.secondLastBaseDenseLayer.trainable = false; ***1***
this.model.compile({ ***2***
loss: 'categoricalCrossentropy', ***2***
optimizer: config.optimizer || 'sgd', ***2***
metrics: ['acc'] ***2***
}); ***2***
const {xs, ys} = this.collectTransferDataAsTensors();
let trainXs: tf.Tensor;
let trainYs: tf.Tensor;
let valData: [tf.Tensor, tf.Tensor];
try {
if (config.validationSplit != null) {
const splits = balancedTrainValSplit( ***3***
xs, ys, config.validationSplit); ***3***
trainXs = splits.trainXs;
trainYs = splits.trainYs;
valData = [splits.valXs, splits.valYs];
} else {
trainXs = xs;
trainYs = ys;
}
const history = await this.model.fit(trainXs, trainYs, { ***4***
epochs: config.epochs == null ? 20 : config.epochs, ***4***
validationData: valData, ***4***
batchSize: config.batchSize, ***4***
callbacks: config.callback == null ? null : [config.callback] ***4***
}); ***4***
if (config.fineTuningEpochs != null && config.fineTuningEpochs > 0) {***5***
this.secondLastBaseDenseLayer.trainable = ***5***
true;
const fineTuningOptimizer: string|tf.Optimizer =
config.fineTuningOptimizer == null ? 'sgd' :
config.fineTuningOptimizer;
this.model.compile({ ***6***
loss: 'categoricalCrossentropy', ***6***
optimizer: fineTuningOptimizer, ***6***
metrics: ['acc'] ***6***
}); ***6***
const fineTuningHistory = await this.model.fit(trainXs, trainYs, { ***7***
epochs: config.fineTuningEpochs, ***7***
validationData: valData, ***7***
batchSize: config.batchSize, ***7***
callbacks: config.fineTuningCallback == null ? ***7***
null : ***7***
[config.fineTuningCallback] ***7***
}); ***7***
return [history, fineTuningHistory];
} else {
return history;
}
} finally {
tf.dispose([xs, ys, trainXs, trainYs, valData]);
}
}
-
1 确保所有截断基础模型的层,包括稍后将进行微调的层,在转移训练的初始阶段都被冻结
-
2 为初始转移训练编译模型
-
3 如果需要 validationSplit,则以平衡的方式将转移数据分割为训练集和验证集
-
4 调用 Model.fit() 进行初始转移训练
-
5 对于微调,解冻基础模型的倒数第二个密集层(截断基础模型的最后一层)
-
6 在解冻层之后重新编译模型(否则解冻不会生效)
-
7 调用 Model.fit() 进行微调
有几个关于 列表 5.8 中代码需要指出的重要事项:
-
每次您通过更改它们的
trainable属性来冻结或解冻任何层时,都需要再次调用模型的compile()方法,以使更改生效。我们已经在 第 5.1.1 节 中讨论了这一点,当我们谈到 MNIST 迁移学习示例时。 -
我们保留了训练数据的一部分用于验证。这样做可以确保我们观察的损失和准确率反映了模型在反向传播期间没有见过的输入上的表现。然而,我们为验证而从收集的数据中拆分出一部分的方式与以前不同,并且值得注意。在 MNIST 卷积网络示例(列表 4.2 在 第四章)中,我们使用了
validationSplit参数,让Model.fit()保留最后的 15–20% 的数据用于验证。但是,在这里使用相同的方法效果不佳。为什么?因为与早期示例中的数据量相比,我们这里的训练集要小得多。因此,盲目地将最后几个示例拆分为验证可能会导致一些词在验证子集中表示不足。例如,假设您为“feel”、“seal”、“veal” 和 “zeal” 中的每个词收集了八个示例,并选择最后的 32 个样本(8 个示例)的 25% 作为验证。那么,平均而言,验证子集中每个单词只有两个示例。由于随机性,一些单词可能最终只在验证子集中有一个示例,而其他单词可能根本没有示例!显然,如果验证集缺少某些单词,它将不是用于测量模型准确性的很好的集合。这就是为什么我们使用一个自定义函数(balancedTrainValSplit在 列表 5.8)。此函数考虑了示例的真实单词标签,并确保所有不同的单词在训练和验证子集中都得到公平的表示。如果您有一个涉及类似小数据集的迁移学习应用程序,那么做同样的事情是个好主意。
那么,微调为我们做了什么呢?在迁移学习的初始阶段之上,微调提供了什么附加价值?为了说明这一点,我们将面板 A 中初始阶段和微调阶段的损失和准确率曲线连续绘制在一起,如图 5.12 所示。这里涉及的迁移数据集包含了我们在图 5.9 中看到的相同的四个单词。每条曲线的前 100 个纪元对应于初始阶段,而最后的 300 个纪元对应于微调。你可以看到,在初始训练的前 100 个纪元结束时,损失和准确率曲线开始变平并开始进入递减回报的区域。在验证子集的准确率在约 84% 时达到平稳状态。(请注意,仅查看 训练子集 的准确率曲线是多么具有误导性,因为它很容易接近 100%。)然而,解冻基础模型中的密集层,重新编译模型,并开始微调训练阶段,验证准确率就不再停滞,可以提高到 90–92%,这是一个非常可观的准确率增加 6–8 个百分点。验证损失曲线也可以看到类似的效果。
图 5.12. 面板 A:迁移学习和随后微调(图例中标为 FT)的示例损失和准确率曲线。注意曲线初始部分和微调部分之间的拐点。微调加速了损失的减少和准确率的提高,这是由于基础模型的顶部几层解冻以及模型容量的增加,以及向迁移学习数据中的独特特征的调整所致。面板 B:在不进行微调的情况下训练迁移模型相同数量的纪元(400 纪元)的损失和准确率曲线。注意,没有微调时,验证损失收敛到较高值,验证准确率收敛到比面板 A 低的值。请注意,虽然进行了微调(面板 A)的最终准确率达到约 0.9,但在没有进行微调但总纪元数相同的情况下(面板 B),准确率停留在约 0.85。

为了说明微调相对于不进行微调的迁移学习的价值,我们在图 5.12 的面板 B 中展示了如果不微调基础模型的顶部几层,而将迁移模型训练相同数量(400)的纪元时会发生什么。在面板 A 中发生的在第 100 纪元时进行微调的损失或准确率曲线上没有“拐点”。相反,损失和准确率曲线趋于平稳,并收敛到较差的值。
那么为什么微调有帮助呢?可以理解为增加了模型的容量。通过解冻基本模型的一些最顶层,我们允许转移模型在比初始阶段更高维的参数空间中最小化损失函数。这类似于向神经网络添加隐藏层。解冻的密集层的权重参数已经针对原始数据集进行了优化(由诸如“one”、“two”、“yes”和“no”之类的单词组成的数据集),这可能对转移单词不是最优的。这是因为帮助模型区分这些原始单词的内部表示可能不是使转移单词最容易区分的表示。通过允许进一步优化(即微调)这些参数以用于转移单词,我们允许表示被优化用于转移单词。因此,我们在转移单词上获得验证准确性的提升。请注意,当转移学习任务很难时(如四个易混淆的单词:“feel”、“seal”、“veal”和“zeal”),更容易看到这种提升。对于更容易的任务(更不同的单词,如“red”和“green”),验证准确性可能仅仅通过初始的转移学习就可以达到 100%。
你可能想问的一个问题是,在这里我们只解冻了基本模型的一层,但是解冻更多的层会有帮助吗?简短的答案是,这取决于情况,因为解冻更多的层会使模型的容量更高。但正如我们在第四章中提到的,并且将在第八章中更详细地讨论,更高的容量会导致过拟合的风险增加,特别是当我们面对像这里收集到的音频示例这样的小数据集时。更不用说训练更多层所需的额外计算负载了。鼓励你作为本章末尾的一部分来进行自己的实验。
让我们结束 TensorFlow.js 中关于迁移学习的这一部分。我们介绍了三种在新任务上重用预训练模型的不同方法。为了帮助你决定在将来的迁移学习项目中使用哪种方法,我们在 table 5.1 中总结了这三种方法及其相对优缺点。
表 5.1. TensorFlow.js 中三种迁移学习方法及其相对优势和缺点的总结
| 方法 | 优势 | 缺点 |
|---|---|---|
| 使用原始模型并冻结其前几层(特征提取层)(section 5.1.1)。 |
- 简单而方便
|
- 仅当迁移学习所需的输出形状和激活与基本模型的形状和激活匹配时才起作用
|
| 从原始模型中获取内部激活作为输入示例的嵌入,并创建一个以该嵌入作为输入的新模型(section 5.1.2)。 |
|---|
-
适用于需要与原始输出形状不同的迁移学习情况
-
嵌入张量是直接可访问的,使得 k 最近邻(kNN,见信息框 5.2)分类器等方法成为可能
|
-
需要管理两个独立的模型实例
-
很难微调原始模型的层
|
| 创建一个包含原始模型的特征提取层和新头部层的新模型(请参见第 5.1.3 节)。 |
|---|
-
适用于需要与原始输出形状不同的迁移学习情况
-
只需要管理一个模型实例
-
允许对特征提取层进行微调
|
- 无法直接访问内部激活(嵌入)张量
|
5.2. 通过卷积神经网络进行目标检测的迁移学习
到目前为止,你在本章中所看到的迁移学习示例都有一个共同点:在迁移后机器学习任务的性质保持不变。特别是,它们采用了一个在多类分类任务上训练的计算机视觉模型,并将其应用于另一个多类分类任务。在本节中,我们将展示这并不一定是这样的。基础模型可以用于非常不同于原始任务的任务,例如当你想使用在分类任务上训练的基础模型来执行回归(拟合数字)时。这种跨领域迁移是深度学习的多功能性和可重复使用性的良好例证,是该领域成功的主要原因之一。
为了说明这一点,我们将使用新的任务——目标检测,这是本书中第一个非分类计算机视觉问题类型。目标检测涉及在图像中检测特定类别的物体。它与分类有何不同?在目标检测中,检测到的物体不仅会以类别(它是什么类型的物体)的形式报告,还会包括有关物体在图像中内部位置的一些附加信息(物体在哪里)。后者是一个普通分类器无法提供的信息。例如,自动驾驶汽车使用的典型目标检测系统会分析输入图像的一个框架,以便该系统不仅输出图像中存在的有趣对象的类型(如车辆和行人),还输出这些对象在图像坐标系内的位置、表面积和姿态等信息。
示例代码位于 tfjs-examples 仓库的 simple-object-detection 目录中。请注意,此示例与您迄今为止看到的示例不同,因为它将在 Node.js 中的模型训练与浏览器中的推理结合起来。具体来说,模型训练使用 tfjs-node(或 tfjs-node-gpu)进行,训练好的模型将保存到磁盘上。然后使用 parcel 服务器来提供保存的模型文件,以及静态的 index.html 和 index.js,以展示浏览器中模型的推理。
您可以使用的运行示例的命令序列如下(其中包含一些您在输入命令时不需要包含的注释字符串):
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/simple-object-detection
yarn
# Optional step for training your own model using Node.js:
yarn train \
--numExamples 20000 \
--initialTransferEpochs 100 \
--fineTuningEpochs 200
yarn watch # Run object-detection inference in the browser.
yarn train命令会在您的机器上进行模型训练,并在完成后将模型保存到./dist文件夹中。请注意,这是一个长时间运行的训练任务,如果您有 CUDA 启用的 GPU,则最好处理,因为这可以将训练速度提高 3 到 4 倍。为此,您只需要向yarn train命令添加--gpu标志:
yarn train --gpu \
--numExamples 20000 \
--initialTransferEpochs 100 \
--fineTuningEpochs 200
如果您没有时间或资源在自己的机器上对模型进行训练,不用担心:您可以直接跳过yarn train命令,直接执行yarn watch。在浏览器中运行的推理页面将允许您通过 HTTP 从集中位置加载我们已经为您训练好的模型。
5.2.1. 基于合成场景的简单目标检测问题
最先进的目标检测技术涉及许多技巧,这些技巧不适合用于初学者教程。我们在这里的目标是展示目标检测的本质,而不受太多技术细节的困扰。为此,我们设计了一个涉及合成图像场景的简单目标检测问题(见图 5.13)。这些合成图像的尺寸为 224 × 224,色深为 3(RGB 通道),因此与将成为我们模型基础的 MobileNet 模型的输入规范匹配。正如图 5.13 中的示例所示,每个场景都有一个白色背景。要检测的对象可以是等边三角形或矩形。如果对象是三角形,则其大小和方向是随机的;如果对象是矩形,则其高度和宽度是随机变化的。如果场景仅由白色背景和感兴趣的对象组成,则任务将太容易,无法展示我们技术的强大之处。为了增加任务的难度,在场景中随机分布了一些“噪声对象”。这些对象包括每个图像中的 10 个圆和 10 条线段。圆的位置和大小以随机方式生成,线段的位置和长度也是如此。一些噪声对象可能位于目标对象的顶部,部分遮挡它。所有目标和噪声对象都具有随机生成的颜色。
图 5.13. 简单物体检测使用的合成场景示例。面板 A:一个旋转的等边三角形作为目标对象。面板 B:一个矩形作为目标对象。标记为“true”的框是感兴趣对象的真实边界框。请注意,感兴趣对象有时可能会被一些噪声对象(线段和圆)部分遮挡。
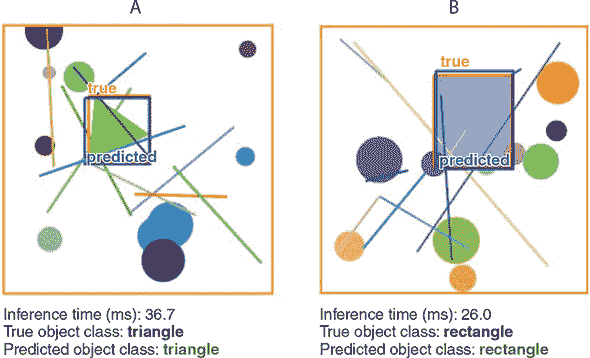
随着输入数据被完全描述,我们现在可以为我们即将创建和训练的模型定义任务。该模型将输出五个数字,这些数字被组织成两组:
-
第一组包含一个数字,指示检测到的对象是三角形还是矩形(不考虑其位置、大小、方向和颜色)。
-
剩下的四个数字组成了第二组。它们是检测到的物体周围边界框的坐标。具体来说,它们分别是边界框的左 x 坐标、右 x 坐标、顶部 y 坐标和底部 y 坐标。参见图 5.13 作为示例。
使用合成数据的好处是 1)真实标签值会自动知道,2)我们可以生成任意数量的数据。每次生成场景图像时,对象的类型和其边界框都会自动从生成过程中对我们可用。因此,不需要对训练图像进行任何劳动密集型的标记。这种输入特征和标签一起合成的非常高效的过程在许多深度学习模型的测试和原型环境中使用,并且这是一种你应该熟悉的技术。然而,用于真实图像输入的训练物体检测模型需要手动标记的真实场景。幸运的是,有这样的标记数据集可用。通用物体和背景(COCO)数据集就是其中之一(参见cocodataset.org)。
训练完成后,模型应能够以相当高的准确性定位和分类目标对象(如图 5.13 中所示的示例所示)。要了解模型如何学习这个物体检测任务,请跟随我们进入下一节中的代码。
5.2.2. 深入了解简单物体检测
现在让我们构建神经网络来解决合成对象检测问题。与以前一样,我们在预训练的 MobileNet 模型上构建我们的模型,以使用模型的卷积层中的强大的通用视觉特征提取器。这是 列表 5.9 中的 loadTruncatedBase() 方法所做的。然而,我们的新模型面临的一个新挑战是如何同时预测两个东西:确定目标对象的形状以及在图像中找到其坐标。我们以前没有见过这种“双任务预测”类型。我们在这里使用的技巧是让模型输出一个张量,该张量封装了两个预测,并且我们将设计一个新的损失函数,该函数同时衡量模型在两个任务中的表现如何。我们可以训练两个单独的模型,一个用于分类形状,另一个用于预测边界框。但是与使用单个模型执行两个任务相比,运行两个模型将涉及更多的计算和更多的内存使用,并且不利用特征提取层可以在两个任务之间共享的事实。(以下代码来自 simple-object-detection/train.js。)
列表 5.9. 基于截断 MobileNet 定义简单对象学习模型^([11])
¹¹
为了清晰起见,一些用于检查错误条件的代码已被删除。
const topLayerGroupNames = [ ***1***
'conv_pw_9', 'conv_pw_10', 'conv_pw_11']; ***1***
const topLayerName =
`${topLayerGroupNames[topLayerGroupNames.length - 1]}_relu`;
async function loadTruncatedBase() {
const mobilenet = await tf.loadLayersModel(
'https://storage.googleapis.com/' +
'tfjs-models/tfjs/mobilenet_v1_0.25_224/model.json');
const fineTuningLayers = [];
const layer = mobilenet.getLayer(topLayerName); ***2***
const truncatedBase = ***3***
tf.model({ ***3***
inputs: mobilenet.inputs, ***3***
outputs: layer.output ***3***
}); ***3***
for (const layer of truncatedBase.layers) {
layer.trainable = false; ***4***
for (const groupName of topLayerGroupNames) {
if (layer.name.indexOf(groupName) === 0) { ***5***
fineTuningLayers.push(layer);
break;
}
}
}
return {truncatedBase, fineTuningLayers};
}
function buildNewHead(inputShape) { ***6***
const newHead = tf.sequential(); ***6***
newHead.add(tf.layers.flatten({inputShape})); ***6***
newHead.add(tf.layers.dense({units: 200, activation: 'relu'})); ***6***
newHead.add(tf.layers.dense({units: 5})); ***6*** ***7***
return newHead; ***6***
} ***6***
async function buildObjectDetectionModel() { ***8***
const {truncatedBase, fineTuningLayers} = await loadTruncatedBase(); ***8***
const newHead = buildNewHead(truncatedBase.outputs[0].shape.slice(1));***8***
const newOutput = newHead.apply(truncatedBase.outputs[0]); ***8***
const model = tf.model({ ***8***
inputs: truncatedBase.inputs, ***8***
outputs: newOutput ***8***
}); ***8***
return {model, fineTuningLayers};
}
-
1 设置要解冻以进行微调的层
-
2 获取中间层:最后一个特征提取层
-
3 形成截断的 MobileNet
-
4 冻结所有特征提取层以进行迁移学习的初始阶段
-
5 跟踪在微调期间将解冻的层
-
6 为简单对象检测任务构建新头模型
-
7 长度为 5 的输出包括长度为 1 的形状指示器和长度为 4 的边界框(请参见 图 5.14)。
-
8 将新的头模型放在截断的 MobileNet 顶部,形成整个对象检测模型
“双任务”模型的关键部分由 列表 5.9 中的 buildNewHead() 方法构建。模型的示意图显示在 图 5.14 的左侧。新头部由三层组成。一个展平层将截断的 MobileNet 基础的最后一个卷积层的输出形状为后续可以添加的密集层。第一个密集层是具有 relu 非线性的隐藏层。第二个密集层是头部的最终输出,因此也是整个对象检测模型的最终输出。该层具有默认的线性激活。这是理解该模型如何工作的关键,因此需要仔细查看。
图 5.14. 对象检测模型及其基于的自定义损失函数。请参见 列表 5.9,了解模型(左侧部分)的构建方式。请参见 列表 5.10,了解自定义损失函数的编写方式。

正如你从代码中看到的那样,最终的稠密层输出单元数为 5。这五个数字代表什么?它们结合了形状预测和边界框预测。有趣的是,决定它们含义的不是模型本身,而是将用于模型的损失函数。之前,你看到过各种类型的损失函数,可以直接使用字符串名称,如"meanSquaredError",并适用于各自的机器学习任务(例如,请参阅第三章表 3.6)。然而,这只是在 TensorFlow.js 中指定损失函数的两种方法之一。另一种方法,也是我们在这里使用的方法,涉及定义一个满足某个特定签名的自定义 JavaScript 函数。该签名如下:
-
有两个输入参数:1)输入示例的真实标签和 2)模型的对应预测。它们都表示为 2D 张量。这两个张量的形状应该是相同的,每个张量的第一个维度都是批处理大小。
-
返回值是一个标量张量(形状为
[]的张量),其值是批处理中示例的平均损失。
我们根据这个签名编写的自定义损失函数在列表 5.10 中显示,并在图 5.14 的右侧进行了图形化说明。customLossFunction的第一个输入(yTrue)是真实标签张量,其形状为[batchSize, 5]。
第二个输入(yPred)是模型的输出预测,其形状与yTrue完全相同。在yTrue的第二轴上的五个维度(如果我们将其视为矩阵,则为五列)中,第一个维度是目标对象形状的 0-1 指示器(三角形为 0,矩形为 1)。这是由数据合成方式确定的(请参阅 simple-object-detection/synthetic_images.js)。其余四列是目标对象的边界框,即其左、右、上和下值,每个值范围从 0 到 CANVAS_SIZE(224)。数字 224 是输入图像的高度和宽度,来自于 MobileNet 的输入图像大小,我们的模型基于此。
列表 5.10。为对象检测任务定义自定义损失函数
const labelMultiplier = tf.tensor1d([CANVAS_SIZE, 1, 1, 1, 1]);
function customLossFunction(yTrue, yPred) {
return tf.tidy(() => {
return tf.metrics.meanSquaredError(
yTrue.mul(labelMultiplier), yPred); ***1***
});
}
- 1
yTrue的形状指示器列通过 CANVAS_SIZE(224)缩放,以确保形状预测和边界框预测对损失的贡献大致相等。
自定义损失函数接收yTrue并将其第一列(0-1 形状指示器)按CANVAS_SIZE进行缩放,同时保持其他列不变。然后它计算yPred和缩放后的yTrue之间的均方误差。为什么我们要缩放yTrue中的 0-1 形状标签?我们希望模型输出一个代表它预测形状是三角形还是矩形的数字。具体地说,它输出一个接近于 0 的数字表示三角形,一个接近于CANVAS_SIZE(224)的数字表示矩形。因此,在推理时,我们只需将模型输出的第一个值与CANVAS_SIZE/2(112)进行比较,以获取模型对形状更像是三角形还是矩形的预测。那么如何衡量这种形状预测的准确性以得出损失函数呢?我们的答案是计算这个数字与 0-1 指示器之间的差值,乘以CANVAS_SIZE。
为什么我们这样做而不像在第三章中钓鱼检测示例中使用二进制交叉熵呢?我们需要在这里结合两个准确度指标:一个是形状预测,另一个是边界框预测。后者任务涉及预测连续值,可以视为回归任务。因此,均方误差是边界框的自然度量标准。为了结合这些度量标准,我们只需“假装”形状预测也是一个回归任务。这个技巧使我们能够使用单个度量函数(列表 5.10 中的tf.metric.meanSquaredError()调用)来封装两种预测的损失。
但是为什么我们要将 0-1 指示器按CANVAS_SIZE进行缩放呢?如果我们不进行这种缩放,我们的模型最终会生成一个接近于 0-1 的数字,作为它预测形状是三角形(接近于 0)还是矩形(接近于 1)的指示器。在[0, 1]区间内的数字之间的差异显然要比我们从比较真实边界框和预测边界框得到的差异要小得多,后者在 0-224 的范围内。因此,来自形状预测的误差信号将完全被来自边界框预测的误差信号所掩盖,这对于我们得到准确的形状预测没有帮助。通过缩放 0-1 形状指示器,我们确保形状预测和边界框预测对最终损失值(customLossFunction()的返回值)的贡献大致相等,因此当模型被训练时,它将同时优化两种类型的预测。在本章末尾的练习 4 中,我们鼓励你自己尝试使用这种缩放。
¹²
这里的一个替代方法是采用基于缩放和
meanSquaredError的方法,将yPred的第一列作为形状概率分数,并与yTrue的第一列计算二元交叉熵。然后,将二元交叉熵值与在yTrue和yPred的其余列上计算的 MSE 相加。但在这种替代方法中,需要适当缩放交叉熵,以确保与边界框损失的平衡,就像我们当前的方法一样。缩放涉及一个自由参数,其值需要仔细选择。在实践中,它成为模型的一个额外超参数,并且需要时间和计算资源来调整,这是该方法的一个缺点。为了简单起见,我们选择了当前方法,而不采用该方法。
数据准备就绪,模型和损失函数已定义,我们准备好训练我们的模型!模型训练代码的关键部分显示在 清单 5.11(来自 simple-object-detection/train.js)。与我们之前见过的微调(第 5.1.3 节)类似,训练分为两个阶段:初始阶段,在此阶段仅训练新的头部层;微调阶段,在此阶段将新的头部层与截断的 MobileNet 基础的顶部几层一起训练。需要注意的是,在微调的 fit() 调用之前,必须(再次)调用 compile() 方法,以便更改层的 trainable 属性生效。如果在您自己的机器上运行训练,很容易观察到损失值在微调阶段开始时出现显着下降,这反映了模型容量的增加以及解冻特征提取层对目标检测数据中的唯一特征的适应能力。在微调期间解冻的层的列表由 fineTuningLayers 数组确定,在截断 MobileNet 时填充(参见 清单 5.9 中的 loadTruncatedBase() 函数)。这些是截断的 MobileNet 的顶部九层。在本章末尾的练习 3 中,您可以尝试解冻更少或更多的基础顶部层,并观察它们如何改变训练过程产生的模型的准确性。
清单 5.11. 训练目标检测模型的第二阶段
const {model, fineTuningLayers} = await buildObjectDetectionModel();
model.compile({ ***1***
loss: customLossFunction, ***1***
optimizer: tf.train.rmsprop(5e-3) ***1***
}); ***1***
await model.fit(images, targets, { ***2***
epochs: args.initialTransferEpochs, ***2***
batchSize: args.batchSize, ***2***
validationSplit: args.validationSplit ***2***
}); ***2***
// Fine-tuning phase of transfer learning.
for (const layer of fineTuningLayers) { ***3***
layer.trainable = true; ***4***
}
model.compile({ ***5***
loss: customLossFunction, ***5***
optimizer: tf.train.rmsprop(2e-3) ***5***
}); ***5***
await model.fit(images, targets, {
epochs: args.fineTuningEpochs,
batchSize: args.batchSize / 2, ***6***
validationSplit: args.validationSplit
}); ***7***
-
1 在初始阶段使用相对较高的学习率
-
2 执行迁移学习的初始阶段
-
3 开始微调阶段
-
4 解冻一些层进行微调
-
5 在微调阶段使用稍低的学习率
-
6 在微调阶段,我们将 batchSize 减少以避免由于反向传播涉及更多权重并消耗更多内存而引起的内存不足问题。
-
7 执行微调阶段
微调结束后,模型将保存到磁盘,并在浏览器内推断步骤期间加载(通过yarn watch命令启动)。如果加载托管模型,或者您已经花费了时间和计算资源在自己的计算机上训练了一个相当不错的模型,那么您在推断页面上看到的形状和边界框预测应该是相当不错的(在初始训练的 100 个周期和微调的 200 个周期后,验证损失在<100)。推断结果是好的但并非完美(请参阅 图 5.13 中的示例)。当您检查结果时,请记住,在浏览器内评估是公平的,并且反映了模型的真实泛化能力,因为训练模型在浏览器中要解决的示例与迁移学习过程中它所见到的训练和验证示例不同。
结束本节时,我们展示了如何将之前在图像分类上训练的模型成功地应用于不同的任务:对象检测。在此过程中,我们演示了如何定义一个自定义损失函数来适应对象检测问题的“双重任务”(形状分类 + 边界框回归)的特性,以及如何在模型训练过程中使用自定义损失。该示例不仅说明了对象检测背后的基本原理,还突显了迁移学习的灵活性以及它可能用于的问题范围。在生产应用中使用的对象检测模型当然比我们在这里使用合成数据集构建的玩具示例更复杂,并且涉及更多技巧。信息框 5.3 简要介绍了一些有关高级对象检测模型的有趣事实,并描述了它们与您刚刚看到的简单示例的区别以及您如何通过 TensorFlow.js 使用其中之一。
生产对象检测模型

TensorFlow.js 版本的 Single-Shot Detection (SSD) 模型的一个示例对象检测结果。注意多个边界框及其关联的对象类和置信度分数。
对象检测是许多类型应用的重要任务,例如图像理解、工业自动化和自动驾驶汽车。最著名的最新对象检测模型包括 Single-Shot Detection^([a])(SSD,示例推断结果如图所示)和 You Only Look Once (YOLO)^([b])。这些模型在以下方面与我们在简单对象检测示例中看到的模型类似:
^a
Wei Liu 等人,“SSD: Single Shot MultiBox Detector,” 计算机科学讲义 9905,2016,
mng.bz/G4qD。^b
Joseph Redmon 等人,“You Only Look Once: Unified, Real-Time Object Detection,” IEEE 计算机视觉与模式识别会议论文集 (CVPR), 2016, pp. 779–788,
mng.bz/zlp1.
-
它们预测对象的类别和位置。
-
它们是建立在 MobileNet 和 VGG16 等预训练图像分类模型上的,并通过迁移学习进行训练。
^c
Karen Simonyan 和 Andrew Zisserman,“Very Deep Convolutional Networks for Large-Scale Image Recognition,” 2014 年 9 月 4 日提交,
arxiv.org/abs/1409.1556.
然而,它们在很多方面也与我们的玩具模型不同:
-
真实的目标检测模型预测的对象类别比我们的简单模型多得多(例如,COCO 数据集有 80 个对象类别;参见
cocodataset.org/#home)。 -
它们能够在同一图像中检测多个对象(请参见示例图)。
-
它们的模型架构比我们简单模型中的更复杂。例如,SSD 模型在截断的预训练图像模型顶部添加了多个新头部,以便预测输入图像中多个对象的类别置信度分数和边界框。
-
与使用单个
meanSquaredError度量作为损失函数不同,真实目标检测模型的损失函数是两种类型损失的加权和:1)对于对象类别预测的类似 softmax 交叉熵的损失和 2)对于边界框的meanSquaredError或meanAbsoluteError-like 损失。两种类型损失值之间的相对权重被精心调整以确保来自两种错误来源的平衡贡献。 -
真实的目标检测模型会为每个输入图像产生大量的候选边界框。这些边界框被“修剪”以便保留具有最高对象类别概率分数的边界框作为最终输出。
-
一些真实的目标检测模型融合了关于对象边界框位置的“先验知识”。这些是关于边界框在图像中位置的教育猜测,基于对更多标记的真实图像的分析。这些先验知识通过从一个合理的初始状态开始而不是完全随机的猜测(就像我们简单的目标检测示例中一样)来加快模型的训练速度。
一些真实的目标检测模型已被移植到 TensorFlow.js 中。例如,你可以玩的最好的模型之一位于 tfjs-models 存储库的 coco-ssd 目录中。要看它的运行情况,执行以下操作:
git clone https://github.com/tensorflow/tfjs-models.git
cd tfjs-models/coco-ssd/demo
yarn && yarn watch
如果你对了解更多真实目标检测模型感兴趣,你可以阅读以下博文。它们分别是关于 SSD 模型和 YOLO 模型的,它们使用不同的模型架构和后处理技术:
-
“理解 SSD MultiBox——深度学习中的实时目标检测” by Eddie Forson:
mng.bz/07dJ。 -
“使用 YOLO、YOLOv2 和现在的 YOLOv3 进行实时目标检测” by Jonathan Hui:
mng.bz/KEqX。
到目前为止,在本书中,我们处理的是交给我们并准备好探索的机器学习数据集。它们格式良好,已经通过我们之前的数据科学家和机器学习研究人员的辛勤工作进行了清理,以至于我们可以专注于建模,而不用太担心如何摄取数据以及数据是否正确。这对本章中使用的 MNIST 和音频数据集是真实的;对于我们在第三章中使用的网络钓和鸢尾花数据集也是如此。
我们可以肯定地说,这永远不是您将遇到的真实世界机器学习问题的情况。事实上,大多数机器学习从业者的时间都花在获取、预处理、清理、验证和格式化数据上。在下一章中,我们将教您在 TensorFlow.js 中可用的工具,使这些数据整理和摄取工作流更容易。
¹³
Gil Press,“清理大数据:调查显示,最耗时、最不受欢迎的数据科学任务”,《福布斯》,2016 年 3 月 23 日,
mng.bz/9wqj。
练习
-
当我们在第 5.1.1 节中访问 mnist-transfer-cnn 示例时,我们指出设置模型层的
trainable属性在训练期间不会生效,除非在训练之前调用模型的compile()方法。通过对示例的 index.js 文件中的retrainModel()方法进行一些更改来验证这一点。具体来说,-
在带有
this.model .compile()行之前添加一个this.model.summary()调用,并观察可训练和不可训练参数的数量。它们显示了什么?它们与在compile()调用之后获得的数字有何不同? -
独立于前一项,将
this.model.compile()调用移到特征层的trainable属性设置之前。换句话说,在compile()调用之后设置这些层的属性。这样做会如何改变训练速度?速度是否与仅更新模型的最后几层一致?你能找到其他确认,在这种情况下,模型的前几层的权重在训练期间是否被更新的方法吗?
-
-
在第 5.1.1 节的迁移学习中(列表 5.1),我们通过将其
trainable属性设置为false来冻结了前两个 conv2d 层,然后开始了fit()调用。你能在 mnist-transfer-cnn 示例的 index.js 中添加一些代码来验证 conv2d 层的权重确实没有被fit()调用改变吗?我们在同一节中尝试的另一种方法是在不冻结层的情况下调用fit()。你能验证在这种情况下层的权重值确实被fit()调用改变了吗?(提示:回想一下在第 2.4.2 节的第二章中,我们使用了模型对象的layers属性和其getWeights()方法来访问权重的值。) -
将 Keras MobileNetV2^([14])(不是 MobileNetV1!—我们已经完成了)应用转换为 TensorFlow.js 格式,并将其加载到浏览器的 TensorFlow.js 中。详细步骤请参阅信息框 5.1。你能使用
summary()方法来检查 MobileNetV2 的拓扑结构,并确定其与 MobileNetV1 的主要区别吗?¹⁴
Mark Sandler 等人,“MobileNetV2: Inverted Residuals and Linear Bottlenecks”,2019 年 3 月 21 日修订,
arxiv.org/abs/1801.04381。 -
列表 5.8 中微调代码的一个重要方面是在基础模型中解冻密集层后再次调用
compile()方法。你能做到以下几点吗?-
使用与练习 2 相同的方法来验证密集层的权重(核心和偏置)确实没有被第一次
fit()调用(用于迁移学习的初始阶段)所改变,并且确实被第二次fit()调用(用于微调阶段)所改变。 -
尝试在解冻行之后(更改 trainable 属性值的行)注释掉
compile()调用,看看这如何影响你刚刚观察到的权重值变化。确信compile()调用确实是让模型的冻结/解冻状态变化生效的必要步骤。 -
更改代码,尝试解冻基础 speech-command 模型的更多承载权重的层(例如,倒数第二个密集层之前的 conv2d 层),看看这对微调的结果有何影响。
-
-
在我们为简单对象检测任务定义的自定义损失函数中,我们对 0-1 形状标签进行了缩放,以便来自形状预测的误差信号与来自边界框预测的误差信号匹配(参见 listing 5.10 中的代码)。试验一下,如果在代码中删除
mul()调用会发生什么。说服自己这种缩放对于确保相当准确的形状预测是必要的。这也可以通过在compile()调用中简单地将customLossFunction的实例替换为meanSquaredError来完成(参见 listing 5.11)。还要注意,训练期间移除缩放需要伴随着对推断时的阈值调整:将推断逻辑中的阈值从CANVAS_SIZE/2更改为1/2(在 simple-object-detection/index.js 中)。 -
在简单对象检测示例中的微调阶段,涉及到解冻截断的 MobileNet 基础的前九个顶层(参见 listing 5.9 中的
fineTuningLayers如何填充)。一个自然的问题是,为什么是九个?在这个练习中,通过在fineTuningLayers数组中包含更少或更多的层来改变解冻层的数量。当你在微调期间解冻更少的层时,你期望在以下情况下会看到什么:1) 最终损失值和 2) 每个纪元在微调阶段花费的时间?实验结果是否符合你的期望?解冻更多的层在微调期间会怎样?
摘要
-
迁移学习是在与模型最初训练的任务相关但不同的学习任务上重新使用预训练模型或其一部分的过程。这种重用加快了新的学习任务的速度。
-
在迁移学习的实际应用中,人们经常会重用已经在非常大的分类数据集上训练过的卷积网络,比如在 ImageNet 数据集上训练过的 MobileNet。由于原始数据集的规模庞大以及包含的示例的多样性,这些预训练模型带来了强大的、通用的特征提取器卷积层,适用于各种计算机视觉问题。这样的层对于在典型的迁移学习问题中可用的少量数据来说很难,如果不是不可能的话,进行训练。
-
我们在 TensorFlow.js 中讨论了几种通用的迁移学习方法,它们在以下方面有所不同:1) 新层是否被创建为迁移学习的“新头部”,以及 2) 是否使用一个模型实例或两个模型实例进行迁移学习。每种方法都有其优缺点,并适用于不同的用例(参见 table 5.1)。
-
通过设置模型层的
trainable属性,我们可以防止在训练(Model.fit()函数调用)期间更新其权重。这被称为冻结,并用于在迁移学习中“保护”基础模型的特征提取层。 -
在一些迁移学习问题中,我们可以在初始训练阶段之后解冻一些基础模型的顶层,从而提升新模型的性能。这反映了解冻层对新数据集中独特特征的适应性。
-
迁移学习是一种多用途、灵活的技术。基础模型可以帮助我们解决与其初始训练内容不同的问题。我们通过展示如何基于 MobileNet 训练目标检测模型来阐明这一点。
-
TensorFlow.js 中的损失函数可以定义为在张量输入和输出上操作的自定义 JavaScript 函数。正如我们在简单目标检测示例中展示的,为了解决实际的机器学习问题,通常需要自定义损失函数。
第三部分:TensorFlow.js 的高级深度学习。
阅读完第一部分和第二部分,您现在应该熟悉在 TensorFlow.js 中进行基本深度学习的方法。第三部分旨在为想要更牢固掌握技术和对深度学习有更广泛理解的用户提供帮助。第六章介绍了如何处理、转换和使用机器学习数据的技巧。第七章介绍了用于可视化数据和模型的工具。第八章关注欠拟合和过拟合等重要现象以及如何有效应对。在这个讨论的基础上,我们介绍了机器学习的通用工作流程。第九章至第十一章是三个高级领域的实践之旅:序列导向模型、生成模型和强化学习。它们将使您熟悉深度学习最激动人心的前沿技术。
第六章:处理数据
本章涵盖内容
-
如何使用
tf.dataAPI 来使用大型数据集训练模型 -
探索您的数据以查找和解决潜在问题
-
如何使用数据增强来创建新的“伪样本”以提高模型质量
大量高质量数据的广泛可用是导致当今机器学习革命的主要因素。如果没有轻松获取大量高质量数据,机器学习的急剧上升就不会发生。现在数据集可以在互联网上随处可得——在 Kaggle 和 OpenML 等网站上免费共享——同样可以找到最先进性能的基准。整个机器学习领域都是通过可用的“挑战”数据集前进的,这些数据集设定了一个标准和一个共同的基准用于社区。如果说机器学习是我们这一代的太空竞赛,那么数据显然就是我们的火箭燃料;它是强大的,它是有价值的,它是不稳定的,它对于一个正常工作的机器学习系统绝对至关重要。更不用说污染的数据,就像污染的燃料一样,很快就会导致系统性失败。这一章是关于数据的。我们将介绍组织数据的最佳实践,如何检测和清除问题,以及如何高效使用数据。
¹
看看 ImageNet 如何推动目标识别领域,或者 Netflix 挑战对协同过滤做出了什么贡献。
²
感谢 Edd Dumbill 将这个类比归功于“大数据是火箭燃料”,大数据,卷 1,号 2,第 71-72 页。
“但我们不是一直在处理数据吗?”你可能会抗议。没错,在之前的章节中,我们处理过各种数据源。我们使用合成和网络摄像头图像数据集来训练图像模型。我们使用迁移学习从音频样本数据集构建了一个口语识别器,并访问了表格数据集以预测价格。那么还有什么需要讨论的呢?我们不是已经能够熟练处理数据了吗?
在我们之前的例子中回顾我们对数据使用的模式。我们通常需要首先从远程源下载数据。然后我们(通常)对数据应用一些转换,将数据转换为正确的格式,例如将字符串转换为独热词汇向量,或者规范化表格源的均值和方差。然后我们总是需要对数据进行分批处理,并将其转换为表示为张量的标准数字块,然后再连接到我们的模型。这一切都是在我们运行第一个训练步骤之前完成的。
下载 - 转换 - 批处理的模式非常常见,TensorFlow.js 提供了工具,使这些类型的操作更加简单、模块化和不容易出错。本章将介绍 tf.data 命名空间中的工具,最重要的是 tf.data.Dataset,它可以用于惰性地流式传输数据。惰性流式传输的方法允许按需下载、转换和访问数据,而不是将数据源完全下载并在访问时将其保存在内存中。惰性流式传输使得更容易处理数据源,这些数据源太大,无法放入单个浏览器标签页甚至单台机器的 RAM 中。
我们首先介绍 tf.data.Dataset API,并演示如何配置它并与模型连接起来。然后,我们将介绍一些理论和工具,帮助你审查和探索数据,并解决可能发现的问题。本章还介绍了数据增强,这是一种通过创建合成伪示例来扩展数据集,提高模型质量的方法。
6.1. 使用 tf.data 管理数据
如果你的电子邮件数据库有数百 GB 的容量,并且需要特殊凭据才能访问,你该如何训练垃圾邮件过滤器?如果训练图像数据库的规模太大,无法放入单台机器上,你该如何构建图像分类器?
访问和操作大量数据是机器学习工程师的关键技能,但到目前为止,我们所处理的应用程序都可以在可用内存中容纳得下数据。许多应用程序需要处理大型、笨重且可能涉及隐私的数据源,此技术就不适用了。大型应用程序需要一种技术,能够按需逐块从远程数据源中访问数据。
TensorFlow.js 附带了一个集成库,专门用于这种类型的数据管理。它的构建目标是以简洁易读的方式,让用户能够快速地摄取、预处理和路由数据,灵感来自于 TensorFlow Python 版本中的 tf.data API。假设你的代码使用类似于 import 语句来导入 TensorFlow.js,像这样:
import * as tf from '@tensorflow/tfjs';
这个功能在 tf.data 命名空间下可用。
6.1.1. tf.data.Dataset 对象
与tfjs-data的大多数交互都通过一种称为Dataset的单一对象类型进行。tf.data.Dataset对象提供了一种简单、可配置和高性能的方式来迭代和处理大型(可能是无限的)数据元素列表^([3])。在最粗略的抽象中,你可以将数据集想象成任意元素的可迭代集合,不太不同于 Node.js 中的Stream。每当需要从数据集中请求下一个元素时,内部实现将根据需要下载、访问或执行函数来创建它。这种抽象使得模型能够在内存中一次性存储的数据量比可以想象的要多。它还使得在有多个要跟踪的数据集时,将数据集作为一流对象进行共享和组织变得更加方便。Dataset通过仅流式传输所需的数据位而不是一次性访问整个数据来提供内存优势。Dataset API 还通过预取即将需要的值来提供性能优化。
³
在本章中,我们将经常使用术语元素来指代
Dataset中的项。在大多数情况下,元素与示例或数据点是同义词——也就是说,在训练数据集中,每个元素都是一个(x, y)对。当从 CSV 源中读取数据时,每个元素都是文件的一行。Dataset足够灵活,可以处理异构类型的元素,但不建议这样做。
6.1.2. 创建tf.data.Dataset
截至 TensorFlow.js 版本 1.2.7,有三种方法可以将tf.data.Dataset连接到某个数据提供程序。我们将对每种方法进行详细介绍,但 table 6.1 中包含了简要摘要。
表 6.1. 从数据源创建一个tf.data.Dataset对象
| 如何获得新的 tf.data.Dataset | API | 如何使用它构建数据集 |
|---|---|---|
| 从 JavaScript 数组中获取元素;也适用于像 Float32Array 这样的类型化数组 | tf.data.array(items) | const dataset = tf.data.array([1,2,3,4,5]); 有关更多信息,请参见 listing 6.1。 |
| 从(可能是远程)CSV 文件中获取,其中每一行都是一个元素 | tf.data.csv( source,
csvConfig) | const dataset = tf.data.csv(“https://path/to/my.csv”); 有关更多信息,请参见 listing 6.2。唯一必需的参数是从中读取数据的 URL。此外,csvConfig 接受一个带有键的对象来帮助指导 CSV 文件的解析。例如,
-
columnNames—可以提供一个字符串数组来手动设置列的名称,如果它们在标题中不存在或需要被覆盖。
-
delimiter—可以使用单字符字符串来覆盖默认的逗号分隔符。
-
columnConfigs—可以提供一个从字符串列名到 columnConfig 对象的映射,以指导数据集的解析和返回类型。columnConfig 将通知解析器元素的类型(字符串或整数),或者如果列应被视为数据集标签。
-
configuredColumnsOnly—是否仅返回 CSV 中包含的列或仅返回列配置对象中包含的列的数据。
更多详细信息请查阅js.tensorflow.org上的 API 文档。 |
| 从生成元素的通用生成函数 | tf.data.generator(generatorFunction) | function* countDownFrom10() { for (let i=10; i>0; i–) {
yield(i);
}
}
const dataset =
tf.data.generator(countDownFrom10); 详见清单 6.3。请注意,在没有参数的情况下调用 tf.data.generator()时传递给 tf.data.generator()的参数将返回一个 Generator 对象。 |
从数组创建 tf.data.Dataset
创建新的tf.data.Dataset最简单的方法是从一个 JavaScript 数组中构建。假设已经存在一个内存中的数组,您可以使用tf.data.array()函数创建一个由该数组支持的数据集。当然,这不会比直接使用数组带来任何训练速度或内存使用上的好处,但通过数据集访问数组提供了其他重要的好处。例如,使用数据集更容易设置预处理,并通过简单的model.fitDataset()和model.evaluateDataset()API 使我们的训练和评估更加简单,就像我们将在第 6.2 节中看到的那样。与model.fit(x, y)相比,model.fitDataset(myDataset)不会立即将所有数据移入 GPU 内存,这意味着可以处理比 GPU 能够容纳的更大的数据集。请注意,V8 JavaScript 引擎的内存限制(64 位系统上为 1.4 GB)通常比 TensorFlow.js 一次可以在 WebGL 内存中容纳的内存要大。使用tf.data API 也是良好的软件工程实践,因为它使得以模块化的方式轻松地切换到另一种类型的数据而无需改变太多代码。如果没有数据集抽象,很容易让数据集源的实现细节泄漏到模型训练中的使用中,这种纠缠将需要在使用不同实现时解开。
要从现有数组构建数据集,请使用tf.data.array(itemsAsArray),如下面的示例所示。
清单 6.1. 从数组构建tf.data.Dataset
const myArray = [{xs: [1, 0, 9], ys: 10},
{xs: [5, 1, 3], ys: 11},
{xs: [1, 1, 9], ys: 12}];
const myFirstDataset = tf.data.array(myArray); ***1***
await myFirstDataset.forEachAsync(
e => console.log(e)); ***2***
// Yields output like
// {xs: Array(3), ys: 10}
// {xs: Array(3), ys: 11}
// {xs: Array(3), ys: 12}
-
1 创建由数组支持的 tfjs-data 数据集。请注意,这不会克隆数组或其元素。
-
2 使用
forEachAsync()方法迭代数据集提供的所有值。请注意,forEachAsync()是一个异步函数,因此应该在其前面使用 await。
我们使用forEachAsync()函数迭代数据集的元素,该函数依次生成每个元素。有关Dataset.forEachAsync函数的更多详细信息,请参见第 6.1.3 节。
数据集的元素可能包含 JavaScript 基元^([4])(如数字和字符串),以及元组、数组和这些结构的嵌套对象,除了张量。在这个小例子中,数据集的三个元素都具有相同的结构。它们都是具有相同键和相同类型值的对象。tf.data.Dataset通常支持各种类型的元素,但常见的用例是数据集元素是具有相同类型的有意义的语义单位。通常,它们应该表示同一类型的示例。因此,除非在非常不寻常的用例中,每个元素都应具有相同的类型和结构。
⁴
如果您熟悉 Python TensorFlow 中
tf.data的实现,您可能会对tf.data.Dataset可以包含 JavaScript 基元以及张量感到惊讶。
从 CSV 文件创建 tf.data.Dataset
一种非常常见的数据集元素类型是表示表的一行的键值对象,例如 CSV 文件的一行。下一个列表显示了一个非常简单的程序,该程序将连接并列出波士顿房屋数据集,我们首先在 chapter 2 中使用过的数据集。
列表 6.2. 从 CSV 文件构建 tf.data.Dataset
const myURL =
"https://storage.googleapis.com/tfjs-examples/" +
"multivariate-linear-regression/data/train-data.csv";
const myCSVDataset = tf.data.csv(myURL); ***1***
await myCSVDataset.forEachAsync(e => console.log(e)); ***2***
// Yields output of 333 rows like
// {crim: 0.327, zn: 0, indus: 2.18, chas: 0, nox: 0.458, rm: 6.998,
// age: 45.8, tax: 222}
// ...
-
1 创建由远程 CSV 文件支持的 tfjs-data 数据集
-
2 使用 forEachAsync() 方法在数据集提供的所有值上进行迭代。请注意,forEachAsync() 是一个异步函数。
这里我们使用 tf.data.csv() 而不是 tf.data.array(),并指向 CSV 文件的 URL。这将创建一个由 CSV 文件支持的数据集,并且在数据集上进行迭代将遍历 CSV 行。在 Node.js 中,我们可以通过使用以 file:// 为前缀的 URL 句柄连接到本地 CSV 文件,如下所示:
> const data = tf.data.csv(
'file://./relative/fs/path/to/boston-housing-train.csv');
在迭代时,我们看到每个 CSV 行都被转换为 JavaScript 对象。从数据集返回的元素是具有 CSV 的每列的一个属性的对象,并且属性根据 CSV 文件中的列名命名。这对于与元素交互非常方便,因为不再需要记住字段的顺序。Section 6.3.1 将详细描述如何处理 CSV 并通过一个例子进行说明。
从生成器函数创建 tf.data.Dataset
创建tf.data.Dataset的第三种最灵活的方式是使用生成器函数构建。这是使用tf.data.generator()方法完成的。tf.data.generator()接受一个 JavaScript 生成器函数(或function*)^([5])作为参数。如果您对生成器函数不熟悉,它们是相对较新的 JavaScript 功能,您可能希望花一点时间阅读它们的文档。生成器函数的目的是在需要时“产出”一系列值,可以是永远或直到序列用尽为止。从生成器函数产生的值将流经并成为数据集的值。一个非常简单的生成器函数可以产生随机数,或者从连接的硬件中提取数据的快照。一个复杂的生成器函数可以与视频游戏集成,产生屏幕截图、得分和控制输入输出。在下面的示例中,非常简单的生成器函数产生骰子掷得的样本。
⁵
了解有关 ECMAscript 生成器函数的更多信息,请访问
mng.bz/Q0rj。
清单 6.3。构建用于随机掷骰子的tf.data.Dataset
let numPlaysSoFar = 0; ***1***
function rollTwoDice() {
numPlaysSoFar++;
return [Math.ceil(Math.random() * 6), Math.ceil(Math.random() * 6)];
}
function* rollTwoDiceGeneratorFn() { ***2***
while(true) { ***2***
yield rollTwoDice(); ***2***
}
}
const myGeneratorDataset = tf.data.generator( ***3***
rollTwoDiceGeneratorFn); ***3***
await myGeneratorDataset.take(1).forEachAsync( ***4***
e => console.log(e)); ***4***
// Prints to the console a value like
// [4, 2]
-
1 numPlaysSoFar 被 rollTwoDice()闭合,这使我们可以计算数据集执行该函数的次数。
-
2定义了一个生成器函数(使用 function*语法),可以无限次调用 rollTwoDice()并产生结果。
-
3数据集在此处创建。
-
4获取数据集中仅一个元素的样本。
take()方法将在第 6.1.4 节中描述。
关于在清单 6.3 中创建的游戏模拟数据集,有一些有趣的要点。首先,请注意,这里创建的数据集myGeneratorDataset是无限的。由于生成器函数永远不会返回,我们可以从数据集中无限次取样。如果我们在此数据集上执行forEachAsync()或toArray()(参见第 6.1.3 节),它将永远不会结束,并且可能会使我们的服务器或浏览器崩溃,所以要小心。为了使用这样的对象,我们需要创建一些其他数据集,它是无限数据集的有限样本,使用take(n)。稍后会详细介绍。
其次,请注意,数据集会关闭局部变量。这对于记录和调试,以确定生成器函数执行了多少次非常有帮助。
此外,请注意数据直到被请求才存在。在这种情况下,我们只能访问数据集的一项样本,并且这会反映在numPlaysSoFar的值中。
生成器数据集非常强大且非常灵活,允许开发人员将模型连接到各种提供数据的 API,例如来自数据库查询、通过网络逐段下载的数据,或者来自一些连接的硬件。有关tf.data.generator() API 的更多详细信息请参见信息框 6.1。
tf.data.generator()参数规范
tf.data.generator()API 是灵活且强大的,允许用户将模型连接到许多类型的数据提供者。传递给tf.data.generator()的参数必须符合以下规范:
-
它必须可调用且不带参数。
-
在不带参数的情况下调用时,它必须返回符合迭代器和可迭代协议的对象。这意味着返回的对象必须具有一个
next()方法。当调用next()而没有参数时,它应该返回 JavaScript 对象{value: ELEMENT, done: false},以便将值ELEMENT传递给下一步。当没有更多值可返回时,它应该返回{value: undefined, done: true}。
JavaScript 的生成器函数返回Generator对象,符合此规范,因此是使用tf.data.generator()的最简单方法。该函数可能闭包于局部变量,访问本地硬件,连接到网络资源等。
表 6.1 包含以下代码,说明如何使用tf.data.generator():
function* countDownFrom10() {
for (let i = 10; i > 0; i--) {
yield(i);
}
}
const dataset = tf.data.generator(countDownFrom10);
如果出于某种原因希望避免使用生成器函数,而更愿意直接实现可迭代协议,还可以以以下等效方式编写前面的代码:
function countDownFrom10Func() {
let i = 10;
return {
next: () => {
if (i > 0) {
return {value: i--, done: false};
} else {
return {done: true};
}
}
}
}
const dataset = tf.data.generator(countDownFrom10Func);
6.1.3. 访问数据集中的数据
一旦将数据作为数据集,您必然会想要访问其中的数据。创建但从不读取数据结构实际上并不实用。有两种 API 可以访问数据集中的数据,但tf.data用户应该只需要偶尔使用这些 API。更典型的情况是,高级 API 将为您访问数据集中的数据。例如,在训练模型时,我们使用model.fitDataset()API,如第 6.2 节所述,它会为我们访问数据集中的数据,而我们,用户,从不需要直接访问数据。然而,在调试、测试和理解Dataset对象工作原理时,了解如何查看内容很重要。
从数据集中访问数据的第一种方法是使用Dataset.toArray()将其全部流出到数组中。这个函数的作用正是它的名字听起来的样子。它遍历整个数据集,将所有元素推入数组中,并将该数组返回给用户。用户在执行此函数时应小心,以免无意中生成一个对 JavaScript 运行时来说太大的数组。如果,例如,数据集连接到一个大型远程数据源或是从传感器读取的无限数据集,则很容易犯这个错误。
从数据集中访问数据的第二种方法是使用dataset.forEachAsync(f)在数据集的每个示例上执行函数。提供给forEachAsync()的参数将逐个应用于每个元素,类似于 JavaScript 数组和集合中的forEach()构造——即本地的Array.forEach()和Set.forEach()。
需要注意的是,Dataset.forEachAsync() 和 Dataset.toArray() 都是异步函数。这与 Array.forEach() 相反,后者是同步的,因此在这里可能很容易犯错。Dataset.toArray() 返回一个 Promise,并且通常需要使用 await 或 .then() 来获取同步行为。要小心,如果忘记使用 await,则 Promise 可能不会按照您期望的顺序解析,从而导致错误。一个典型的错误是数据集看起来为空,因为在 Promise 解析之前已经迭代了其内容。
Dataset.forEachAsync() 是异步的而 Array.forEach() 不是的原因是,数据集正在访问的数据通常需要创建、计算或从远程源获取。异步性使我们能够在等待期间有效地利用可用的计算资源。这些方法在 table 6.2 中进行了总结。
表 6.2. 迭代数据集的方法
tf.data.Dataset 对象的实例方法 | 功能 | 示例 |
|---|
| .toArray() | 异步地迭代整个数据集,并将每个元素推送到一个数组中,然后返回该数组 | const a = tf.data.array([1, 2, 3, 4, 5, 6]); const arr = await a.toArray();
console.log(arr);
// 1,2,3,4,5,6 |
| .forEachAsync(f) | 异步地迭代数据集的所有元素,并对每个元素执行 f | const a = tf.data.array([1, 2, 3]); await a.forEachAsync(e => console.log("hi " + e));
// hi 1
// hi 2
// hi 3 |
6.1.4. 操作 tfjs-data 数据集
当我们可以直接使用数据而不需要任何清理或处理时,这当然是非常好的。但在作者的经验中,除了用于教育或基准测试目的构建的示例外,这几乎从未发生。在更常见的情况下,数据必须在某种程度上进行转换,然后才能进行分析或用于机器学习任务。例如,源代码通常包含必须进行过滤的额外元素;或者需要解析、反序列化或重命名某些键的数据;或者数据已按排序顺序存储,因此在使用它来训练或评估模型之前,需要对其进行随机洗牌。也许数据集必须分割成用于训练和测试的非重叠集。预处理几乎是不可避免的。如果你遇到了一个干净且可直接使用的数据集,很有可能是有人已经为你清理和预处理了!
tf.data.Dataset 提供了可链式 API 的方法来执行这些操作,如表 6.3 中所述。每一个这些方法都返回一个新的 Dataset 对象,但不要被误导以为所有数据集元素都被复制或每个方法调用都迭代所有数据集元素!tf.data.Dataset API 只会懒惰地加载和转换元素。通过将这些方法串联在一起创建的数据集可以看作是一个小程序,它只会在从链的末端请求元素时执行。只有在这个时候,Dataset 实例才会爬回操作链,可能一直爬回到请求来自远程源的数据。
表 6.3. tf.data.Dataset 对象上的可链式方法
| tf.data.Dataset 对象的实例方法 | 它的作用 | 示例 |
|---|---|---|
| .filter(谓词) | 返回一个仅包含谓词为真的元素的数据集 | myDataset.filter(x => x < 10); 返回一个数据集,仅包含 myDataset 中小于 10 的值。 |
| .map(转换) | 将提供的函数应用于数据集中的每个元素,并返回一个新数据集,其中包含映射后的元素 | myDataset.map(x => x * x); 返回一个数据集,包含原始数据集的平方值。 |
| .mapAsync(异步转换) | 类似 map,但提供的函数必须是异步的 | myDataset.mapAsync(fetchAsync); 假设 fetchAsync 是一个异步函数,可以从提供的 URL 获取数据,将返回一个包含每个 URL 数据的新数据集。 |
| .batch(批次大小,
smallLastBatch?) | 将连续的元素跨度捆绑成单一元素组,并将原始元素转换为张量 | const a = tf.data.array([1, 2, 3, 4, 5, 6, 7, 8])
.batch(4);
await a.forEach(e => e.print());
// 输出:
// 张量 [1, 2, 3, 4]
// 张量 [5, 6, 7, 8] |
| .concatenate(数据集) | 将两个数据集的元素连接在一起形成一个新的数据集 | myDataset1.concatenate(myDataset2) 返回一个数据集,首先迭代 myDataset1 中的所有值,然后迭代 myDataset2 中的所有值。 |
|---|---|---|
| .repeat(次数) | 返回一个将多次(可能无限次)迭代原始数据集的 dataset | myDataset.repeat(NUM_EPOCHS) 返回一个 dataset,将迭代 myDataset 中所有的值 NUM_EPOCHS 次。如果 NUM_EPOCHS 为负数或未定义,则结果将无限次迭代。 |
| .take(数量) | 返回一个仅包含前数量个示例的数据集 | myDataset.take(10); 返回一个仅包含 myDataset 的前 10 个元素的数据集。如果 myDataset 中的元素少于 10 个,则没有变化。 |
| .skip(count) | 返回一个跳过前 count 个示例的数据集 | myDataset.skip(10); 返回一个包含 myDataset 中除了前 10 个元素之外所有元素的数据集。如果 myDataset 包含 10 个或更少的元素,则返回一个空数据集。 |
| .shuffle( bufferSize,
种子?
) | 生成原始数据集元素的随机洗牌数据集 注意:此洗牌是通过在大小为 bufferSize 的窗口内随机选择来完成的;因此,超出窗口大小的排序被保留。| const a = tf.data.array( [1, 2, 3, 4, 5, 6]).shuffle(3);
await a.forEach(e => console.log(e));
// 输出,例如,2, 4, 1, 3, 6, 5 以随机洗牌顺序输出 1 到 6 的值。洗牌是部分的,因为不是所有的顺序都是可能的,因为窗口比总数据量小。例如,最后一个元素 6 现在成为新顺序中的第一个元素是不可能的,因为 6 需要向后移动超过 bufferSize(3)个空间。|
这些操作可以链接在一起创建简单但强大的处理管道。例如,要将数据集随机分割为训练和测试数据集,可以按照以下列表中的步骤操作(参见 tfjs-examples/iris-fitDataset/data.js)。
列表 6.4. 使用 tf.data.Dataset 创建训练/测试分割
const seed = Math.floor(
Math.random() * 10000); ***1***
const trainData = tf.data.array(IRIS_RAW_DATA)
.shuffle(IRIS_RAW_DATA.length, seed); ***1***
.take(N); ***2***
.map(preprocessFn);
const testData = tf.data.array(IRIS_RAW_DATA)
.shuffle(IRIS_RAW_DATA.length, seed); ***1***
.skip(N); ***3***
.map(preprocessFn);
-
1 我们在训练和测试数据中使用相同的洗牌种子;否则它们将独立洗牌,并且一些样本将同时出现在训练和测试中。
-
2 获取训练数据的前 N 个样本
-
3 跳过测试数据的前 N 个样本
在这个列表中有一些重要的考虑事项需要注意。我们希望将样本随机分配到训练和测试集中,因此我们首先对数据进行洗牌。我们取前 N 个样本作为训练数据。对于测试数据,我们跳过这些样本,取剩下的样本。当我们取样本时,数据以 相同的方式 进行洗牌非常重要,这样我们就不会在两个集合中都有相同的示例;因此当同时采样两个管道时,我们使用相同的随机种子。
还要注意,我们在跳过操作之后应用 map() 函数。也可以在跳过之前调用 .map(preprocessFn),但是那样 preprocessFn 就会对我们丢弃的示例执行——这是一种计算浪费。可以使用以下列表来验证这种行为。
列表 6.5. 说明 Dataset.forEach skip() 和 map() 交互
let count = 0;
// Identity function which also increments count.
function identityFn(x) {
count += 1;
return x;
}
console.log('skip before map');
await tf.data.array([1, 2, 3, 4, 5, 6])
.skip(6) ***1***
.map(identityFn)
.forEachAsync(x => undefined);
console.log(`count is ${count}`);
console.log('map before skip');
await tf.data.array([1, 2, 3, 4, 5, 6])
.map(identityFn) ***2***
.skip(6)
.forEachAsync(x => undefined);
console.log(`count is ${count}`);
// Prints:
// skip before map
// count is 0
// map before skip
// count is 6
-
1 先跳过再映射
-
2 先映射再跳过
dataset.map() 的另一个常见用法是对输入数据进行归一化。我们可以想象一种情况,我们希望将输入归一化为零均值,但我们有无限数量的输入样本。为了减去均值,我们需要先计算分布的均值,但是计算无限集合的均值是不可行的。我们还可以考虑取一个代表性的样本,并计算该样本的均值,但如果我们不知道正确的样本大小,就可能犯错误。考虑一个分布,几乎所有的值都是 0,但每一千万个示例的值为 1e9。这个分布的均值是 100,但如果你在前 100 万个示例上计算均值,你就会相当偏离。
我们可以使用数据集 API 进行流式归一化,方法如下(示例 6.6)。在此示例中,我们将跟踪我们已经看到的样本数量以及这些样本的总和。通过这种方式,我们可以进行流式归一化。此示例操作标量(不是张量),但是针对张量设计的版本具有类似的结构。
示例 6.6. 使用 tf.data.map() 进行流式归一化
function newStreamingZeroMeanFn() { ***1***
let samplesSoFar = 0;
let sumSoFar = 0;
return (x) => {
samplesSoFar += 1;
sumSoFar += x;
const estimatedMean = sumSoFar / samplesSoFar;
return x - estimatedMean;
}
}
const normalizedDataset1 =
unNormalizedDataset1.map(newStreamingZeroMeanFn());
const normalizedDataset2 =
unNormalizedDataset2.map(newStreamingZeroMeanFn());
- 1 返回一个一元函数,它将返回输入减去迄今为止其所有输入的均值。
请注意,我们生成了一个新的映射函数,它在自己的样本计数器和累加器上关闭。这是为了允许多个数据集独立归一化。否则,两个数据集将使用相同的变量来计数调用和求和。这种解决方案并不是没有限制,特别是在 sumSoFar 或 samplesSoFar 中可能发生数值溢出的情况下,需要谨慎处理。
6.2. 使用 model.fitDataset 训练模型
流式数据集 API 不错,我们已经看到它可以让我们进行一些优雅的数据操作,但是 tf.data API 的主要目的是简化将数据连接到模型进行训练和评估的过程。那么 tf.data 如何帮助我们呢?
自第二章以来,每当我们想要训练一个模型时,我们都会使用 model.fit() API。回想一下,model.fit()至少需要两个必要参数 - xs 和 ys。作为提醒,xs 变量必须是一个表示一系列输入示例的张量。ys 变量必须绑定到表示相应输出目标集合的张量。例如,在上一章的 示例 5.11 中,我们使用类似的调用对我们的合成目标检测模型进行训练和微调。
model.fit(images, targets, modelFitArgs)
其中images默认情况下是一个形状为[2000, 224, 224, 3]的秩为 4 的张量,表示一组 2000 张图像。modelFitArgs配置对象指定了优化器的批处理大小,默认为 128。回顾一下,我们可以看到 TensorFlow.js 被提供了一个内存中^([6])的包含 2000 个示例的集合,表示整个数据集,然后循环遍历该数据,每次以 128 个示例为一批完成每个时期的训练。
⁶
在GPU内存中,通常比系统 RAM 有限!
如果这些数据不足,我们想要用更大的数据集进行训练怎么办?在这种情况下,我们面临着一对不太理想的选择。选项 1 是加载一个更大的数组,然后看看它是否起作用。然而,到某个时候,TensorFlow.js 会耗尽内存,并发出一条有用的错误消息,指示它无法为训练数据分配存储空间。选项 2 是我们将数据上传到 GPU 中的不同块中,并在每个块上调用model.fit()。我们需要执行自己的model.fit()协调,每当准备好时,就对我们的训练数据的部分进行迭代训练我们的模型。如果我们想要执行多个时期,我们需要回到一开始,以某种(可能是打乱的)顺序重新下载我们的块。这种协调不仅繁琐且容易出错,而且还干扰了 TensorFlow 自己的时期计数器和报告的指标,我们将被迫自己将它们拼接在一起。
Tensorflow.js 为我们提供了一个更方便的工具,使用model.fitDataset()API:
model.fitDataset(dataset, modelFitDatasetArgs)
model.fitDataset() 的第一个参数接受一个数据集,但数据集必须符合特定的模式才能工作。具体来说,数据集必须产生具有两个属性的对象。第一个属性名为xs,其值为Tensor类型,表示一批示例的特征;这类似于model.fit()中的xs参数,但数据集一次产生一个批次的元素,而不是一次产生整个数组。第二个必需的属性名为ys,包含相应的目标张量。^([7]) 与model.fit()相比,model.fitDataset()提供了许多优点。首先,我们不需要编写代码来管理和协调数据集的下载——这在需要时以一种高效、按需流式处理的方式为我们处理。内置的缓存结构允许预取预期需要的数据,有效利用我们的计算资源。这个 API 调用也更强大,允许我们在比 GPU 容量更大得多的数据集上进行训练。事实上,我们可以训练的数据集大小现在只受到我们拥有多少时间的限制,因为只要我们能够获得新的训练样本,我们就可以继续训练。这种行为在 tfjs-examples 存储库中的数据生成器示例中有所体现。
⁷
对于具有多个输入的模型,期望的是张量数组而不是单独的特征张量。对于拟合多个目标的模型,模式类似。
在此示例中,我们将训练一个模型来学习如何估计获胜的可能性,一个简单的游戏机会。和往常一样,您可以使用以下命令来查看和运行演示:
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/data-generator
yarn
yarn watch
此处使用的游戏是一个简化的纸牌游戏,有点像扑克牌。每个玩家都会被分发 N 张牌,其中 N 是一个正整数,并且每张牌由 1 到 13 之间的随机整数表示。游戏规则如下:
-
拥有相同数值牌最多的玩家获胜。例如,如果玩家 1 有三张相同的牌,而玩家 2 只有一对,玩家 1 获胜。
-
如果两名玩家拥有相同大小的最大组,则拥有最大面值组的玩家获胜。例如,一对 5 比一对 4 更大。
-
如果两名玩家甚至都没有一对牌,那么拥有最高单张牌的玩家获胜。
-
平局将随机解决,50/50。
要说服自己,每个玩家都有平等的获胜机会应该很容易。因此,如果我们对自己的牌一无所知,我们应该只能猜测我们是否会赢得比赛的时间一半。我们将构建和训练一个模型,该模型以玩家 1 的牌作为输入,并预测该玩家是否会获胜。在图 6.1 的屏幕截图中,您应该看到我们在大约 250,000 个示例(50 个周期 * 每周期 50 个批次 * 每个批次 100 个样本)训练后,在这个问题上达到了约 75% 的准确率。在这个模拟中,每手使用五张牌,但对于其他数量也可以达到类似的准确率。通过使用更大的批次和更多的周期,可以实现更高的准确率,但是即使在 75% 的情况下,我们的智能玩家也比天真的玩家在估计他们将获胜的可能性时具有显著的优势。
图 6.1. 数据生成器示例的用户界面。游戏规则的描述和运行模拟的按钮位于左上方。在此下方是生成的特征和数据管道。Dataset-to-Array 按钮运行链接数据集操作,模拟游戏,生成特征,将样本批次化,取 N 个这样的批次,将它们转换为数组,并将数组打印出来。右上角有用于使用此数据管道训练模型的功能。当用户点击 Train-Model-Using-Fit-Dataset 按钮时,model.fitDataset() 操作接管并从管道中提取样本。下方打印了损失和准确率曲线。在右下方,用户可以输入玩家 1 的手牌值,并按下按钮从模型中进行预测。更大的预测表明模型认为该手牌更有可能获胜。值是有替换地抽取的,因此可能会出现五张相同的牌。
如果我们使用 model.fit() 执行此操作,那么我们需要创建和存储一个包含 250,000 个示例的张量,以表示输入特征。这个例子中的数据相当小——每个实例只有几十个浮点数——但是对于上一章中的目标检测任务,250,000 个示例将需要 150 GB 的 GPU 内存,^([8]) 远远超出了 2019 年大多数浏览器的可用范围。
⁸
numExamples × width × height × colorDepth × sizeOfInt32 = 250,000 × 224 × 224 × 3 × 4 bytes 。
让我们深入了解此示例的相关部分。首先,让我们看一下如何生成我们的数据集。下面清单中的代码(从 tfjs-examples/data-generator/index.js 简化而来)与 清单 6.3 中的掷骰子生成器数据集类似,但更复杂一些,因为我们存储了更多信息。
清单 6.7. 为我们的卡片游戏构建 tf.data.Dataset
import * as game from './game'; ***1***
let numSimulationsSoFar = 0;
function runOneGamePlay() {
const player1Hand = game.randomHand(); ***2***
const player2Hand = game.randomHand(); ***2***
const player1Win = game.compareHands( ***3***
player1Hand, player2Hand); ***3***
numSimulationsSoFar++;
return {player1Hand, player2Hand, player1Win}; ***4***
}
function* gameGeneratorFunction() {
while (true) {
yield runOneGamePlay();
}
}
export const GAME_GENERATOR_DATASET =
tf.data.generator(gameGeneratorFunction);
await GAME_GENERATOR_DATASET.take(1).forEach(
e => console.log(e));
// Prints
// {player1Hand: [11, 9, 7, 8],
// player2Hand: [10, 9, 5, 1],
// player1Win: 1}
-
1 游戏库提供了
randomHand()和compareHands()函数,用于从简化的类似扑克牌的卡片游戏生成手牌,以及比较两个这样的手牌以确定哪位玩家赢了。 -
2 模拟简单的类似扑克牌的卡片游戏中的两名玩家
-
3 计算游戏的赢家
-
4 返回两名玩家的手牌以及谁赢了
一旦我们将基本生成器数据集连接到游戏逻辑,我们希望以对我们的学习任务有意义的方式格式化数据。具体来说,我们的任务是尝试从 player1Hand 预测 player1Win 位。为了做到这一点,我们需要使我们的数据集返回形式为 [batchOf-Features, batchOfTargets] 的元素,其中特征是从玩家 1 的手中计算出来的。下面的代码简化自 tfjs-examples/data-generator/index.js。
清单 6.8. 构建玩家特征的数据集
function gameToFeaturesAndLabel(gameState) { ***1***
return tf.tidy(() => {
const player1Hand = tf.tensor1d(gameState.player1Hand, 'int32');
const handOneHot = tf.oneHot(
tf.sub(player1Hand, tf.scalar(1, 'int32')),
game.GAME_STATE.max_card_value);
const features = tf.sum(handOneHot, 0); ***2***
const label = tf.tensor1d([gameState.player1Win]);
return {xs: features, ys: label};
});
}
let BATCH_SIZE = 50;
export const TRAINING_DATASET =
GAME_GENERATOR_DATASET.map(gameToFeaturesAndLabel) ***3***
.batch(BATCH_SIZE); ***4***
await TRAINING_DATASET.take(1).forEach(
e => console.log([e.shape, e.shape]));
// Prints the shape of the tensors:
// [[50, 13], [50, 1]]
-
1 获取一局完整游戏的状态,并返回玩家 1 手牌的特征表示和获胜状态
-
2
handOneHot的形状为[numCards, max_value_card]。此操作对每种类型的卡片进行求和,结果是形状为[max_value_card]的张量。 -
3 将游戏输出对象格式的每个元素转换为两个张量的数组:一个用于特征,一个用于目标
-
4 将 BATCH_SIZE 个连续元素分组成单个元素。如果它们尚未是张量,则还会将数据从 JavaScript 数组转换为张量。
现在我们有了一个符合规范的数据集,我们可以使用 model.fitDataset() 将其连接到我们的模型上,如下清单所示(简化自 tfjs-examples/data-generator/index.js)。
清单 6.9. 构建并训练数据集的模型
// Construct model.
model = tf.sequential();
model.add(tf.layers.dense({
inputShape: [game.GAME_STATE.max_card_value],
units: 20,
activation: 'relu'
}));
model.add(tf.layers.dense({units: 20, activation: 'relu'}));
model.add(tf.layers.dense({units: 1, activation: 'sigmoid'}));
// Train model
await model.fitDataset(TRAINING_DATASET, { ***1***
batchesPerEpoch: ui.getBatchesPerEpoch(), ***2***
epochs: ui.getEpochsToTrain(),
validationData: TRAINING_DATASET, ***3***
validationBatches: 10, ***4***
callbacks: {
onEpochEnd: async (epoch, logs) => {
tfvis.show.history(
ui.lossContainerElement, trainLogs, ['loss', 'val_loss'])
tfvis.show.history( ***5***
ui.accuracyContainerElement, trainLogs, ['acc', 'val_acc'],
{zoomToFitAccuracy: true})
},
}
}
-
1 此调用启动训练。
-
2 一个 epoch 包含多少批次。由于我们的数据集是无限的,因此需要定义此参数,以告知 TensorFlow.js 何时执行 epoch 结束回调。
-
3 我们将训练数据用作验证数据。通常这是不好的,因为我们会对我们的表现有偏见。但在这种情况下,由于训练数据和验证数据是由生成器保证独立的,所以这不是问题。
-
4 我们需要告诉 TensorFlow.js 从验证数据集中取多少样本来构成一个评估。
-
5 model.fitDataset() 创建与 tfvis 兼容的历史记录,就像 model.fit() 一样。
正如我们在前面的清单中看到的,将模型拟合到数据集与将模型拟合到一对 x、y 张量一样简单。只要我们的数据集以正确的格式产生张量值,一切都能正常工作,我们能从可能是远程来源的流数据中获益,而且我们不需要自己管理编排。除了传入数据集而不是张量对之外,在配置对象中还有一些差异值得讨论:
-
batchesPerEpoch—正如我们在 清单 6.9 中看到的,model.fitDataset()的配置接受一个可选字段来指定构成一个周期的批次数。当我们把整个数据交给model.fit()时,计算整个数据集中有多少示例很容易。它就是data.shape[0]!当使用fitDataset()时,我们可以告诉 TensorFlow.js 一个周期何时结束有两种方法。第一种方法是使用这个配置字段,fitDataset()将在那么多批次之后执行onEpochEnd和onEpochStart回调。第二种方法是让数据集本身结束作为信号,表明数据集已经耗尽。在 清单 6.7 中,我们可以改变while (true) { ... }到
for (let i = 0; i<ui.getBatchesPerEpoch(); i++) { ... }模仿这种行为。
-
validationData—当使用fitDataset()时,validationData也可以是一个数据集。但不是必须的。如果你想要的话,你可以继续使用张量作为validationData。验证数据集需要符合返回元素格式的相同规范,就像训练数据集一样。 -
validationBatches—如果你的验证数据来自一个数据集,你需要告诉 TensorFlow.js 从数据集中取多少样本来构成一个完整的评估。如果没有指定值,那么 TensorFlow.js 将继续从数据集中提取,直到返回一个完成信号。因为 清单 6.7 中的代码使用一个永不结束的生成器来生成数据集,这永远不会发生,程序会挂起。
其余配置与 model.fit() API 完全相同,因此不需要进行任何更改。
6.3. 访问数据的常见模式
所有开发人员都需要一些解决方案,将其数据连接到其模型中。这些连接范围从常见的股票连接,到众所周知的实验数据集,如 MNIST,到完全自定义连接,到企业内的专有数据格式。在本节中,我们将回顾 tf.data 如何帮助简化和可维护这些连接。
6.3.1. 处理 CSV 格式数据
除了使用常见的股票数据集之外,访问数据的最常见方式涉及加载存储在某种文件格式中的准备好的数据。由于其简单性、易读性和广泛支持,数据文件通常存储在 CSV(逗号分隔值)格式^([9]) 中。其他格式在存储效率和访问速度方面具有其他优势,但 CSV 可能被认为是数据集的共通语言。在 JavaScript 社区中,我们通常希望能够方便地从某个 HTTP 终端流式传输数据。这就是为什么 TensorFlow.js 提供了对从 CSV 文件中流式传输和操作数据的本机支持。在 section 6.1.2 中,我们简要描述了如何构建由 CSV 文件支持的 tf.data.Dataset。在本节中,我们将深入介绍 CSV API,以展示 tf.data 如何使与这些数据源的工作变得非常容易。我们将描述一个示例应用程序,该应用程序连接到远程 CSV 数据集,打印其模式,计算数据集的元素数量,并为用户提供选择和打印单个示例的便利。查看使用熟悉的命令的示例:
⁹
截至 2019 年 1 月,数据科学和机器学习挑战网站 kaggle.com/datasets 拥有 13,971 个公共数据集,其中超过三分之二以 CSV 格式托管。
git clone https://github.com/tensorflow/tfjs-examples.git
cd tfjs-examples/data-csv
yarn && yarn watch
这将弹出一个网站,指导我们输入托管的 CSV 文件的 URL,或通过点击建议的四个 URL 之一,例如波士顿房屋 CSV。请参见 figure 6.2 进行说明。在 URL 输入框下方,提供了三个按钮来执行三个操作:1) 计算数据集中的行数,2) 检索 CSV 的列名(如果存在),以及 3) 访问并打印数据集的指定样本行。让我们看看这些是如何工作的,以及 tf.data API 如何使它们变得非常容易。
图 6.2. 我们的 tfjs-data CSV 示例的 Web UI。点击顶部的预设 CSV 按钮之一或输入您自己托管的 CSV 的路径(如果有)。如果您选择自己托管的文件,请确保为您的 CSV 启用 CORS 访问。
我们之前看到,使用类似以下命令从远程 CSV 创建一个 tfjs-data 数据集非常简单:
const myData = tf.data.csv(url);
其中 url 可以是使用 http://、https:// 或 file:// 协议的字符串标识符,或者是 RequestInfo。此调用实际上并不会向 URL 发出任何请求,以检查文件是否存在或是否可访问,这是由于惰性迭代。在 列表 6.10 中,CSV 首先在异步 myData.forEach() 调用处获取。我们在 forEach() 中调用的函数将简单地将数据集中的元素转换为字符串并打印,但我们可以想象对此迭代器执行其他操作,比如为集合中的每个元素生成 UI 元素或计算报告的统计信息。
列表 6.10. 打印远程 CSV 文件中的前 10 条记录
const url = document.getElementById('queryURL').value;
const myData = tf.data.csv(url); ***1***
await myData.take(10).forEach(
x => console.log(JSON.stringify(x)))); ***2***
// Output is like
// {"crim":0.26169,"zn":0,"indus":9.9,"chas":0,"nox":0.544,"rm":6.023, ...
// ,"medv":19.4}
// {"crim":5.70818,"zn":0,"indus":18.1,"chas":0,"nox":0.532,"rm":6.75, ...
// ,"medv":23.7}
// ...
-
1 通过提供 URL 到
tf.data.csv()创建 tfjs-data 数据集。 -
2 创建由 CSV 数据集的前 10 行组成的数据集。然后,使用 forEach() 方法迭代数据集提供的所有值。请注意,forEach() 是一个异步函数。
CSV 数据集通常使用第一行作为包含每列名称的元数据标题。默认情况下,tf.data.csv() 假定是这种情况,但可以使用作为第二个参数传递的 csvConfig 对象进行控制。如果 CSV 文件本身未提供列名,则可以像这样手动提供:
const myData = tf.data.csv(url, {
hasHeader: false,
columnNames: ["firstName", "lastName", "id"]
});
如果为 CSV 数据集提供了手动的 columnNames 配置,则它将优先于从数据文件读取的标题行。默认情况下,数据集将假定第一行是标题行。如果第一行不是标题行,则必须配置缺少的部分并手动提供 columnNames。
一旦 CSVDataset 对象存在,就可以使用 dataset.columnNames() 查询其列名,该方法返回列名的有序字符串列表。columnNames() 方法是特定于 CSVDataset 子类的,不是通常从其他来源构建的数据集中可用的。示例中的 Get Column Names 按钮连接到使用此 API 的处理程序。请求列名将导致 Dataset 对象向提供的 URL 发送获取调用以访问和解析第一行;因此,下面列表中的异步调用(从 tfjs-examples/csv-data/index.js 简化而来)。
列表 6.11. 从 CSV 中访问列名
const url = document.getElementById('queryURL').value;
const myData = tf.data.csv(url);
const columnNames = await myData.columnNames(); ***1***
console.log(columnNames);
// Outputs something like [
// "crim", "zn", "indus", ..., "tax",
// "ptratio", "lstat"] for Boston Housing
- 1 联系远程 CSV 文件以收集和解析列标题。
现在我们有了列名,让我们从数据集中获取一行。在清单 6.12 中,我们展示了 Web 应用程序如何打印 CSV 文件的单个选择的行,用户通过输入元素选择行。为了满足这个请求,我们首先使用Dataset.skip()方法创建一个新的数据集,与原始数据集相同,但跳过前n - 1个元素。然后,我们将使用Dataset.take()方法创建一个在一个元素后结束的数据集。最后,我们将使用Dataset.toArray()将数据提取到标准的 JavaScript 数组中。如果一切顺利,我们的请求将产生一个包含指定位置的一个元素的数组。该序列在下面的清单中组合在一起(从 tfjs-examples/csv-data/index.js 中精简)。
清单 6.12. 访问远程 CSV 中的选择行
const url = document.getElementById('queryURL').value;
const sampleIndex = document.getElementById( ***1***
'whichSampleInput').valueAsNumber; ***1***
const myData = tf.data.csv(url); ***2***
const sample = await myData
.skip(sampleIndex) ***3***
.take(1) ***4***
.toArray(); ***5***
console.log(sample);
// Outputs something like: [{crim: 0.3237, zn: 0, indus: 2.18, ..., tax:
// 222, ptratio: 18.7, lstat: 2.94}]
// for Boston Housing.
-
1 sampleIndex 是由 UI 元素返回的一个数字。
-
2 创建名为 myData 的数据集,配置为从 url 读取,但实际上还没有连接
-
3 创建一个新的数据集,但跳过前 sampleIndex 个值
-
4 创建一个新的数据集,但只保留第一个元素。
-
5 这是实际上导致 Dataset 对象联系 URL 并执行获取的调用。请注意,返回类型是一个对象数组,本例中仅包含一个对象,键对应于标题名称和与那些列关联的值。
现在我们可以取得行的输出,正如你从清单 6.12 中的console.log输出中所看到的(在评论中重复),它以将列名映射到值的对象形式呈现,并对其进行样式化以插入到我们的文档中。需要注意的是:如果我们请求一个不存在的行,例如 300 个元素数据集的第 400 个元素,我们将得到一个空数组。
在连接远程数据集时,常常会犯错,使用错误的 URL 或不当的凭证。在这些情况下,最好捕获错误并向用户提供一个合理的错误消息。由于Dataset对象实际上直到需要数据时才联系远程资源,因此重要的是要注意将错误处理写在正确的位置。下面的清单显示了我们 CSV 示例 Web 应用程序中如何处理错误的一个简短片段(从 tfjs-examples/csv-data/index.js 中精简)。有关如何连接受身份验证保护的 CSV 文件的更多详细信息,请参见信息框 6.2。
清单 6.13. 处理由于连接失败引起的错误
const url = 'http://some.bad.url';
const sampleIndex = document.getElementById(
'whichSampleInput').valueAsNumber;
const myData = tf.data.csv(url); ***1***
let columnNames;
try {
columnNames = await myData.columnNames(); ***2***
} catch (e) {
ui.updateColumnNamesMessage(`Could not connect to ${url}`);
}
-
1 将这行代码放在 try 块中也没有帮助,因为坏的 URL 在这里并没有被获取。
-
2 从坏连接引起的错误将在此步骤抛出。
在 6.2 节 中,我们学习了如何使用 model.fitDataset()。我们看到该方法需要一个以非常特定形式产生元素的数据集。回想一下,形式是一个具有两个属性 {xs, ys} 的对象,其中 xs 是表示输入批次的张量,ys 是表示相关目标批次的张量。默认情况下,CSV 数据集将返回 JavaScript 对象形式的元素,但我们可以配置数据集以返回更接近我们训练所需的元素。为此,我们将需要使用 tf.data.csv() 的 csvConfig.columnConfigs 字段。考虑一个关于高尔夫的 CSV 文件,其中有三列:“club”、“strength” 和 “distance”。如果我们希望从俱乐部和力量预测距离,我们可以在原始输出上应用映射函数,将字段排列成 xs 和 ys;或者,更容易的是,我们可以配置 CSV 读取器来为我们执行此操作。表 6.4 显示了如何配置 CSV 数据集以分离特征和标签属性,并执行批处理,以便输出适合输入到 model.fitDataset() 中。
表 6.4. 配置 CSV 数据集以与 model.fitDataset() 一起使用
| 数据集的构建和配置方式 | 构建数据集的代码 | dataset.take(1).toArray()[0] 的结果(从数据集返回的第一个元素) |
|---|---|---|
| 默认的原始 CSV | dataset = tf.data.csv(csvURL) | {club: 1, strength: 45, distance: 200} |
| 在 columnConfigs 中配置标签的 CSV | columnConfigs = {distance: {isLabel: true}};
dataset = tf.data.csv(csvURL,
{columnConfigs}); | {xs: {club: 1, strength: 45}, ys: {distance: 200}} |
| 在 columnConfigs 中配置后进行批处理的 CSV | columnConfigs = {distance: {isLabel: true}};
dataset = tf.data
.csv(csvURL,
{columnConfigs})
.batch(128); | [xs: {club: Tensor, strength: Tensor},
ys: {distance:Tensor}] 这三个张量中的每一个的形状都是 [128]。 |
| 在 columnConfigs 中配置后进行批处理和从对象映射到数组的 CSV | columnConfigs = {distance: {isLabel: true}}。
dataset = tf.data
.csv(csvURL,
{columnConfigs})
.map(({xs, ys}) =>
{
return
{xs:Object.values(xs),
ys:Object.values(ys)};
})
.batch(128); | {xs: Tensor, ys: Tensor} 请注意,映射函数返回的项目形式为 {xs: [number, number], ys: [number]}。批处理操作会自动将数值数组转换为张量。因此,第一个张量 (xs) 的形状为 [128,2]。第二个张量 (ys) 的形状为 [128, 1]。 |
通过认证获取 CSV 数据
在之前的示例中,我们通过简单提供 URL 来连接到远程文件中的数据。这在 Node.js 和浏览器中都很好用,而且非常容易,但有时我们的数据是受保护的,我们需要提供 Request 参数。tf.data.csv() API 允许我们在原始字符串 URL 的位置提供 RequestInfo,如下面的代码所示。除了额外的授权参数之外,数据集没有任何变化:
> const url = 'http://path/to/your/private.csv'
> const requestInfo = new Request(url);
> const API_KEY = 'abcdef123456789'
> requestInfo.headers.append('Authorization', API_KEY);
> const myDataset = tf.data.csv(requestInfo);
6.3.2. 使用 tf.data.webcam() 访问视频数据
TensorFlow.js 项目最令人兴奋的应用之一是直接训练和应用机器学习模型到移动设备上直接可用的传感器。使用移动设备上的内置加速计进行运动识别?使用内置麦克风进行声音或语音理解?使用内置摄像头进行视觉辅助?有很多好主意,而我们才刚刚开始。
在第五章 中,我们探讨了在转移学习的背景下使用网络摄像头和麦克风的工作。我们看到了如何使用摄像头来控制一款“吃豆人”游戏,并使用麦克风来微调语音理解系统。虽然并非每种模态都可以通过方便的 API 调用来使用,但 tf.data 对于使用网络摄像头有一个简单易用的 API。让我们来看看它是如何工作以及如何使用它来预测训练好的模型。
使用 tf.data API,从网络摄像头获取图像流并创建数据集迭代器非常简单。列表 6.14 展示了来自文档的一个基本示例。我们注意到的第一件事是调用 tf.data.webcam()。这个构造函数通过接受一个可选的 HTML 元素作为其输入参数来返回一个网络摄像头迭代器。该构造函数仅在浏览器环境中有效。如果在 Node.js 环境中调用 API,或者没有可用的网络摄像头,则构造函数将抛出一个指示错误来源的异常。此外,浏览器会在打开网络摄像头之前向用户请求权限。如果权限被拒绝,构造函数将抛出一个异常。负责任的开发应该用用户友好的消息来处理这些情况。
列表 6.14. 使用 tf.data.webcam() 和 HTML 元素创建数据集
const videoElement = document.createElement('video'); ***1***
videoElement.width = 100;
videoElement.height = 100;
onst webcam = await tf.data.webcam(videoElement); ***2***
const img = await webcam.capture(); ***3***
img.print();
webcam.stop(); ***4***
-
1 元素显示网络摄像头视频并确定张量大小
-
2 视频数据集对象的构造函数。该元素将显示来自网络摄像头的内容。该元素还配置了创建的张量的大小。
-
3 从视频流中获取一帧并将其作为张量提供
-
4 停止视频流并暂停网络摄像头迭代器
创建网络摄像头迭代器时,重要的是迭代器知道要生成的张量的形状。有两种方法可以控制这个。第一种方法,如 列表 6.14 所示,使用提供的 HTML 元素的形状。如果形状需要不同,或者视频根本不需要显示,可以通过一个配置对象提供所需的形状,如 列表 6.15 所示。请注意,提供的 HTML 元素参数是未定义的,这意味着 API 将创建一个隐藏的元素在 DOM 中作为视频的句柄。
列表 6.15. 使用配置对象创建基本网络摄像头数据集
const videoElement = undefined;
const webcamConfig = {
facingMode: 'user',
resizeWidth: 100,
resizeHeight: 100};
const webcam = await tf.data.webcam(
videoElement, webcamConfig); ***1***
- 1 使用配置对象构建网络摄像头数据集迭代器,而不是使用 HTML 元素。在这里,我们还指定了设备上要使用的摄像头,对于具有多个摄像头的设备,“user” 指的是面向用户的摄像头;作为“user”的替代,“environment” 指的是后置摄像头。
也可以使用配置对象裁剪和调整视频流的部分。使用 HTML 元素和配置对象并行,API 允许调用者指定要从中裁剪的位置和期望的输出大小。输出张量将插值到所需的大小。请参阅下一个清单,以查看选择方形视频的矩形部分并缩小尺寸以适应小模型的示例。
清单 6.16。从网络摄像头裁剪和调整数据
const videoElement = document.createElement('video');
videoElement.width = 300;
videoElement.height = 300; ***1***
const webcamConfig = {
resizeWidth: 150,
resizeHeight: 100, ***2***
centerCrop: true ***3***
};
const webcam = await tf.data.webcam(
videoElement, webcamConfig); ***4***
-
1 没有显式配置,videoElement 将控制输出大小,这里是 300 × 300。
-
2 用户请求从视频中提取 150 × 100 的内容。
-
3 提取的数据将来自原始视频的中心。
-
4 从此网络摄像头迭代器中捕获的数据取决于 HTML 元素和 webcamConfig。
强调一些这种类型的数据集与我们迄今为止使用的数据集之间的一些明显区别是很重要的。例如,从网络摄像头中产生的值取决于您何时提取它们。与以 CSV 数据集不同,不管它们是以多快或慢的速度绘制的,它们都会按顺序产生行。此外,可以根据用户需要从网络摄像头中提取样本。API 调用者在完成后必须明确告知流结束。
使用 capture() 方法从网络摄像头迭代器中访问数据,该方法返回表示最新帧的张量。API 用户应该将这个张量用于他们的机器学习工作,但必须记住使其释放,以防止内存泄漏。由于涉及网络摄像头数据的异步处理的复杂性,最好直接将必要的预处理函数应用于捕获的帧,而不是使用由 tf.data 提供的延迟 map() 功能。
换句话说,不要使用 data.map() 处理数据,
// No:
let webcam = await tfd.webcam(myElement)
webcam = webcam.map(myProcessingFunction);
const imgTensor = webcam.capture();
// use imgTensor here.
tf.dispose(imgTensor)
将函数直接应用于图像:
// Yes:
let webcam = await tfd.webcam(myElement);
const imgTensor = myPreprocessingFunction(webcam.capture());
// use imgTensor here.
tf.dispose(imgTensor)
不应在网络摄像头迭代器上使用 forEach() 和 toArray() 方法。为了从设备中处理长序列的帧,tf.data.webcam() API 的用户应该自己定义循环,例如使用 tf.nextFrame() 并以合理的帧率调用 capture()。原因是,如果您在网络摄像头上调用 forEach(),那么框架会以浏览器的 JavaScript 引擎可能要求它们从设备获取的速度绘制帧。这通常会比设备的帧速率更快地创建张量,导致重复的帧和浪费的计算。出于类似的原因,不应将网络摄像头迭代器作为 model.fit() 方法的参数传递。
示例 6.17 展示了来自我们在第五章中看到的网络摄像头迁移学习(Pac-Man)示例中的简化预测循环。请注意,外部循环将持续到 isPredicting 为 true 为止,这由 UI 元素控制。内部上循环的速率由调用 tf.nextFrame() 控制,该调用与 UI 的刷新率固定。以下代码来自 tfjs-examples/webcam-transfer-learning/index.js。
示例 6.17. 在预测循环中使用 tf.data.webcam()
async function getImage() { ***1***
return (await webcam.capture()) ***2***
.expandDims(0)
.toFloat()
.div(tf.scalar(127))
.sub(tf.scalar(1));
while (isPredicting) {
const img = await getImage(); ***3***
const predictedClass = tf.tidy(() => {
// Capture the frame from the webcam.
// Process the image and make predictions...
...
await tf.nextFrame(); ***4***
}
-
1 从网络摄像头捕获一帧图像,并将其标准化为 -1 到 1 之间。返回形状为 [1, w, h, c] 的批处理图像(1 个元素的批处理)。
-
2 这里的网络摄像头指的是从 tfd.webcam 返回的迭代器;请参见 示例 6.18 中的 init()。
-
3 从网络摄像头迭代器绘制下一帧
-
4 在执行下一个预测之前等待下一个动画帧
最后需要注意的是:在使用网络摄像头时,通常最好在进行预测之前绘制、处理并丢弃一张图像。这样做有两个好处。首先,通过模型传递图像可以确保相关的模型权重已经加载到 GPU 上,防止启动时出现任何卡顿或缓慢。其次,这会给网络摄像头硬件时间来热身并开始发送实际的帧。根据硬件不同,有时在设备启动时,网络摄像头会发送空白帧。在下一节中,您将看到一个片段,展示了如何在网络摄像头迁移学习示例(来自 webcam-transfer-learning/index.js)中完成这个操作。
示例 6.18. 从 tf.data.webcam() 创建视频数据集
async function init() {
try {
webcam = await tfd.webcam(
document.getElementById('webcam')); ***1***
} catch (e) {
console.log(e);
document.getElementById('no-webcam').style.display = 'block';
}
truncatedMobileNet = await loadTruncatedMobileNet();
ui.init();
// Warm up the model. This uploads weights to the GPU and compiles the
// WebGL programs so the first time we collect data from the webcam it
// will be quick.
const screenShot = await webcam.capture();
truncatedMobileNet.predict(screenShot.expandDims(0)); ***2***
screenShot.dispose(); ***3***
}
-
1 视频数据集对象的构造函数。‘webcam’ 元素是 HTML 文档中的视频元素。
-
2 对从网络摄像头返回的第一帧进行预测,以确保模型完全加载到硬件上
-
3 从
webcam.capture()返回的值是一个张量。必须将其销毁以防止内存泄漏。
6.3.3. 使用 tf.data.microphone() 访问音频数据
除了图像数据外,tf.data 还包括专门处理从设备麦克风收集音频数据的功能。与网络摄像头 API 类似,麦克风 API 创建了一个惰性迭代器,允许调用者根据需要请求帧,这些帧被整齐地打包成适合直接输入模型的张量。这里的典型用例是收集用于预测的帧。虽然技术上可以使用此 API 生成训练数据流,但与标签一起压缩它将是具有挑战性的。
示例 6.19 展示了使用 tf.data.microphone() API 收集一秒钟音频数据的示例。请注意,执行此代码将触发浏览器请求用户授权访问麦克风。
示例 6.19. 使用 tf.data.microphone() API 收集一秒钟的音频数据
const mic = await tf.data.microphone({ ***1***
fftSize: 1024,
columnTruncateLength: 232,
numFramesPerSpectrogram: 43,
sampleRateHz: 44100,
smoothingTimeConstant: 0,
includeSpectrogram: true,
includeWaveform: true
});
const audioData = await mic.capture(); ***2***
const spectrogramTensor = audioData.spectrogram; ***3***
const waveformTensor = audioData.waveform; ***4***
mic.stop(); ***5***
-
1 麦克风配置允许用户控制一些常见的音频参数。我们在正文中详细说明了其中的一些。
-
2 执行从麦克风捕获音频。
-
3 音频频谱数据以形状 [43, 232, 1] 的张量返回。
-
4 除了频谱图数据之外,还可以直接检索波形数据。此数据的形状将为 [fftSize * numFramesPerSpectrogram, 1] = [44032, 1]。
-
5 用户应该调用 stop() 来结束音频流并关闭麦克风。
麦克风包括一些可配置参数,以使用户对如何将快速傅里叶变换(FFT)应用于音频数据有精细控制。用户可能希望每个频域音频数据的频谱图有更多或更少的帧,或者他们可能只对音频频谱的某个特定频率范围感兴趣,例如对可听到的语音所必需的那些频率。列表 6.19 中的字段具有以下含义:
-
sampleRateHz:44100- 麦克风波形的采样率。这必须是精确的 44,100 或 48,000,并且必须与设备本身指定的速率匹配。如果指定的值与设备提供的值不匹配,将会抛出错误。
-
fftSize: 1024-
控制用于计算每个不重叠的音频“帧”的样本数。每个帧都经过 FFT 处理,较大的帧具有更高的频率敏感性,但时间分辨率较低,因为帧内的时间信息 丢失了。
-
必须是介于 16 和 8,192 之间的 2 的幂次方,包括 16 和 8,192。在这里,
1024意味着在约 1,024 个样本的范围内计算频率带内的能量。 -
请注意,最高可测频率等于采样率的一半,即约为 22 kHz。
-
-
columnTruncateLength: 232-
控制保留多少频率信息。默认情况下,每个音频帧包含
fftSize点,或者在我们的情况下是 1,024,覆盖从 0 到最大值(22 kHz)的整个频谱。然而,我们通常只关心较低的频率。人类语音通常只有高达 5 kHz,因此我们只保留表示零到 5 kHz 的数据部分。 -
这里,232 = (5 kHz/22 kHz) * 1024。
-
-
numFramesPerSpectrogram: 43-
FFT 是在音频样本的一系列不重叠窗口(或帧)上计算的,以创建频谱图。此参数控制每个返回的频谱图中包含多少个窗口。返回的频谱图将具有形状
[numFramesPerSpectrogram, fftSize, 1],在我们的情况下为[43, 232, 1]。 -
每个帧的持续时间等于
sampleRate/fftSize。在我们的情况下,44 kHz * 1,024 约为 0.023 秒。 -
帧之间没有延迟,因此整个频谱图的持续时间约为 43 * 0.023 = 0.98,或者约为 1 秒。
-
-
smoothingTimeConstant: 0- 要将前一帧的数据与本帧混合多少。它必须介于 0 和 1 之间。
-
includeSpectogram: True- 如果为真,则会计算并提供声谱图作为张量。如果应用程序实际上不需要计算声谱图,则将其设置为 false。这只有在需要波形时才会发生。
-
includeWaveform: True- 如果为真,则保留波形并将其作为张量提供。如果调用者不需要波形,则可以将其设置为 false。请注意,
includeSpectrogram和includeWaveform中至少一个必须为 true。如果它们都为 false,则会报错。在这里,我们将它们都设置为 true,以显示这是一个有效的选项,但在典型应用中,两者中只需要一个。
- 如果为真,则保留波形并将其作为张量提供。如果调用者不需要波形,则可以将其设置为 false。请注意,
与视频流类似,音频流有时需要一些时间才能启动,设备的数据可能一开始就是无意义的。常见的是遇到零和无穷大,但实际值和持续时间是依赖于平台的。最佳解决方案是通过丢弃前几个样本来“预热”麦克风一小段时间,直到数据不再损坏为止。通常,200 毫秒的数据足以开始获得干净的样本。
6.4. 您的数据可能存在缺陷:处理数据中的问题
几乎可以保证您的原始数据存在问题。如果您使用自己的数据源,并且您还没有花费数小时与专家一起研究各个特征、它们的分布和它们的相关性,那么很有可能存在会削弱或破坏您的机器学习模型的缺陷。我们,本书的作者,可以自信地说这一点,因为我们在指导多个领域的许多机器学习系统的构建以及构建一些自己的系统方面具有丰富的经验。最常见的症状是某些模型没有收敛,或者收敛到远低于预期精度的水平。另一个相关但更为阴险和难以调试的模式是模型在验证和测试数据上收敛并表现良好,但在生产中未能达到预期。有时确实存在建模问题、糟糕的超参数或只是倒霉,但到目前为止,这些错误的最常见根本原因是数据存在缺陷。
在幕后,我们使用的所有数据集(如 MNIST、鸢尾花和语音命令)都经过了手动检查、剪裁错误示例、格式化为标准和合适的格式以及其他我们没有讨论的数据科学操作。数据问题可以以多种形式出现,包括缺失字段、相关样本和偏斜分布。在处理数据时存在如此丰富和多样的复杂性,以至于有人可以写一本书来讲述。事实上,请参阅 Ashley Davis 的用 JavaScript 进行数据整理,以获取更详尽的阐述!^([10])
¹⁰
由 Manning Publications 出版,www.manning.com/books/data-wrangling-with-javascript。
数据科学家和数据管理人员在许多公司已经成为全职专业角色。这些专业人员使用的工具和他们遵循的最佳实践是多样的,并且通常取决于正在审查的具体领域。在本节中,我们将介绍基础知识,并指出一些工具,帮助你避免长时间模型调试会话的痛苦,只是发现数据本身存在缺陷。对于更全面的数据科学处理,我们将提供你可以进一步学习的参考资料。
6.4.1. 数据理论
为了知道如何检测和修复不好的数据,我们必须首先知道好的数据是什么样子。机器学习领域的许多理论基础在于我们的数据来自概率分布的假设。在这种表述中,我们的训练数据包含一系列独立的样本。每个样本都描述为一个(x, y)对,其中y是我们希望从x部分预测出的部分。继续这个假设,我们的推断数据包含一系列来自与我们的训练数据完全相同分布的样本。训练数据和推断数据之间唯一重要的区别是在推断时,我们无法看到y。我们应该使用从训练数据中学到的统计关系来估计样本的y部分。
我们的真实数据有许多方面可能与这种理想情况不符。例如,如果我们的训练数据和推断数据来自不同的分布,我们称之为数据集偏斜。举个简单例子,如果你正在根据天气和时间等特征来估计道路交通情况,而你所有的训练数据都来自周一和周二,而你的测试数据来自周六和周日,你可以预期模型的准确性将不如最佳。工作日的汽车交通分布与周末的不同。另一个例子,想象一下我们正在构建一个人脸识别系统,我们训练系统来识别基于我们本国的一组标记数据。我们不应该感到惊讶的是,当我们在具有不同人口统计数据的地点使用时,系统会遇到困难和失败。你在真实机器学习环境中遇到的大多数数据偏差问题会比这两个例子更微妙。
数据中偏斜的另一种可能性是在数据收集过程中出现了某种变化。例如,如果我们正在采集音频样本来学习语音信号,然后在构建训练集的过程中,我们的麦克风损坏了一半,所以我们购买了升级版,我们可以预期我们训练集的后半部分会与前半部分具有不同的噪声和音频分布。据推测,在推断时,我们将仅使用新麦克风进行测试,因此训练集和测试集之间也存在偏差。
在某个层面上,数据集的偏斜是无法避免的。对于许多应用程序,我们的训练数据必然来自过去,我们传递给应用程序的数据必然来自现在。产生这些样本的潜在分布必然会随着时间的变化而改变,如文化、兴趣、时尚和其他混淆因素的变化。在这种情况下,我们所能做的就是理解偏斜并尽量减少其影响。因此,生产环境中的许多机器学习模型都会不断使用最新可用的训练数据进行重新训练,以尝试跟上不断变化的分布。
我们的数据样本无法达到理想状态的另一种方式是缺乏独立性。我们的理想状态是样本是独立同分布(IID)的。但在某些数据集中,一个样本会提供下一个样本的可能值的线索。这些数据集的样本不是独立的。样本与样本的依赖关系最常见的方式是通过排序现象引入到数据集中。为了访问速度和其他各种很好的理由,我们作为计算机科学家已经接受了对数据进行组织的训练。事实上,数据库系统通常会在我们不经意的情况下为我们组织数据。因此,当你从某个源流式传输数据时,必须非常谨慎,确保结果的顺序没有某种模式。
考虑以下假设。我们希望为房地产应用程序建立一个对加利福尼亚州住房成本的估计。我们获得了一个来自全州各地的住房价格的 CSV 数据集^([11]),以及相关特征,如房间数、开发年龄等。我们可能会考虑立即开始从特征到价格的训练函数,因为我们有数据,而且我们知道如何操作。但是知道数据经常有缺陷,我们决定先看看数据。我们首先使用数据集和 Plotly.js 绘制一些特征与数组中的索引的图。请参考图 6.3 中的插图^([12])和下面的清单(摘自codepen.io/tfjs-book/pen/MLQOem)了解如何制作这些插图。
¹¹
关于在这里使用的加利福尼亚住房数据集的描述可在机器学习速成课程的网址
mng.bz/Xpm6中找到。¹²
图 6.3 中的插图是使用 CodePen 制作的,网址是
codepen.io/tfjs-book/pen/MLQOem。
图 6.3. 四个数据集特征与样本索引的图。理想情况下,在一个干净的 IID 数据集中,我们预期样本索引对特征值没有任何信息。我们可以看到,对于某些特征,y 值的分布显然取决于 x。尤其令人震惊的是,“经度”特征似乎是按照样本索引排序的。
列表 6.20. 使用 tfjs-data 构建特征与索引的绘图
const plottingData = {
x: [],
y: [],
mode: 'markers',
type: 'scatter',
marker: {symbol: 'circle', size: 8}
};
const filename = 'https://storage.googleapis.com/learnjs-data/csv-
datasets/california_housing_train.csv';
const dataset = tf.data.csv(filename);
await dataset.take(1000).forEachAsync(row => { ***1***
plottingData.x.push(i++);
plottingData.y.push(row['longitude']);
});
Plotly.newPlot('plot', [plottingData], {
width: 700,
title: 'Longitude feature vs sample index',
xaxis: {title: 'sample index'},
yaxis: {title: 'longitude'}
});
- 1 获取前 1,000 个样本并收集它们的值和它们的索引。别忘了等待,否则你的图表可能会是空的!
想象一下,如果我们使用这个数据集构建了一个训练-测试分割,其中我们取前 500 个样本进行训练,剩余的用于测试。会发生什么?从这个分析中可以看出,我们将用来自一个地理区域的数据进行训练,而用来自另一个地理区域的数据进行测试。图 6.3 中的经度面板显示了问题的关键所在:第一个样本来自一个经度更高(更向西)的地方。特征中可能仍然有大量信号,模型会“工作”一定程度,但准确性或质量不如如果我们的数据真正是 IID。如果我们不知道更好的话,我们可能会花费几天甚至几周时间尝试不同的模型和超参数,直到找出问题所在并查看我们的数据!
我们可以做些什么来清理这个问题?修复这个特定问题非常简单。为了消除数据和索引之间的关系,我们可以将数据随机洗牌成随机顺序。然而,这里有一些需要注意的地方。TensorFlow.js 数据集有一个内置的洗牌例程,但它是一个流式窗口洗牌例程。这意味着样本在固定大小的窗口内随机洗牌,但没有更进一步。这是因为 TensorFlow.js 数据集流式传输数据,它们可能传输无限数量的样本。为了完全打乱一个永无止境的数据源,你首先需要等待直到它完成。
那么,我们能否使用这个经度特征的流式窗口洗牌?当然,如果我们知道数据集的大小(在这种情况下是 17,000),我们可以指定窗口大小大于整个数据集,然后一切都搞定了。在非常大的窗口大小极限下,窗口化洗牌和我们的常规穷举洗牌是相同的。如果我们不知道我们的数据集有多大,或者大小是不可行的大(即,我们无法一次性在内存缓存中保存整个数据集),我们可能不得不凑合一下。
图 6.4,使用 codepen.io/tfjs-book/pen/JxpMrj 创建,说明了使用 tf.data 的 .Dataset 的 shuffle() 方法进行四种不同窗口大小的数据洗牌时会发生什么:
for (let windowSize of [10, 50, 250, 6000]) {
shuffledDataset = dataset.shuffle(windowSize);
myPlot(shuffledDataset, windowSize)
}
图 6.4. 四个不同的洗牌数据集的经度与样本索引的四个图。每个洗牌窗口大小不同,从 10 增加到 6,000 个样本。我们可以看到,即使在窗口大小为 250 时,索引和特征值之间仍然存在强烈的关系。在开始附近有更多的大值。直到我们使用的洗牌窗口大小几乎与数据集一样大时,数据的 IID 特性才几乎恢复。
我们看到,即使对于相对较大的窗口大小,索引与特征值之间的结构关系仍然很明显。直到窗口大小达到 6,000 时,我们才能用肉眼看到数据现在可以视为 IID。那么,6,000 是正确的窗口大小吗?在 250 和 6,000 之间是否有一个数字可以起作用?6,000 仍然不足以捕捉我们在这些示例中没有看到的分布问题吗?在这里的正确方法是使用一个windowSize >= 数据集中的样本数量来对整个数据集进行洗牌。对于由于内存限制、时间限制或可能是无限数据集而无法进行此操作的数据集,您必须戴上数据科学家的帽子并检查分布以确定适当的窗口大小。
6.4.2. 检测和清理数据问题
在前一节中,我们已经讨论了如何检测和修复一种类型的数据问题:样本间的依赖关系。当然,这只是数据可能出现的许多问题类型之一。由于出现数据问题的种类和代码出错的种类一样多,因此对所有可能出错的事情进行全面处理远远超出了本书的范围。不过,我们还是要在这里介绍一些问题,这样当你遇到问题时就能识别出它们,并且知道要搜索哪些术语以获取更多信息。
离群值
离群值是我们数据集中非常不寻常的样本,而且在某种程度上不符合基础分布。例如,如果我们正在处理健康统计数据集,我们可能会期望典型成年人的体重在大约 40 至 130 公斤之间。如果我们的数据集中有 99.9%的样本在这个范围内,但偶尔我们遇到了一些荒谬的样本报告,如 145,000 公斤,或者 0 公斤,或者更糟糕的 NaN,我们会将这些样本视为离群值。快速的在线搜索显示,关于处理离群值的正确方式有很多不同的观点。理想情况下,我们的训练数据中应该只有很少的离群值,并且我们应该知道如何找到它们。如果我们能编写一个程序来拒绝离群值,我们就可以将它们从我们的数据集中移除,然后继续训练而不受它们的影响。当然,我们也希望在推断时触发相同的逻辑;否则,我们会引入偏差。在这种情况下,我们可以使用相同的逻辑通知用户,他们的样本构成了系统的离群值,并且他们必须尝试其他方法。
¹³
在我们的输入特征中摄取 NaN 值将在我们的模型中传播该 NaN 值。
在特征级别处理离群值的另一种常见方法是通过提供合理的最小值和最大值来夹紧数值。在我们的案例中,我们可能会用以下方式替换体重
weight = Math.min(MAX_WEIGHT, Math.max(weight, MIN_WEIGHT));
在这种情况下,还有一个好主意是添加一个新的特征,指示异常值已被替换。这样,原始值 40 公斤就可以与被夹为 40 公斤的值-5 公斤区分开来,给网络提供了学习异常状态与目标之间关系的机会,如果这样的关系存在的话:
isOutlierWeight = weight > MAX_WEIGHT | weight < MIN_WEIGHT;
缺失数据
经常,我们面临一些样本缺少某些特征的情况。这可能发生在任何数量的原因。有时数据来自手工录入的表单,有些字段被跳过了。有时传感器在数据收集时损坏或失效。对于一些样本,也许一些特征根本没有意义。例如,从未出售过的房屋的最近销售价格是多少?或者没有电话的人的电话号码是多少?
与异常值一样,有许多方法可以解决缺失数据的问题,数据科学家对于在哪些情况下使用哪些技术有不同的意见。哪种技术最好取决于一些考虑因素,包括特征缺失的可能性是否取决于特征本身的值,或者“缺失”是否可以从样本中的其他特征预测出来。信息框 6.3 概述了缺失数据类别的术语表。
缺失数据的类别
随机缺失(MAR):
-
特征缺失的可能性并不取决于隐藏的缺失值,但它可能取决于其他一些观察到的值。
-
示例:如果我们有一个自动化的视觉系统记录汽车交通,它可能记录,除其他外,车牌号码和时间。有时,如果天黑了,我们就无法读取车牌。车牌的存在与车牌值无关,但可能取决于(观察到的)时间特征。
完全随机缺失(MCAR)
-
特征缺失的可能性不取决于隐藏的缺失值或任何观察到的值。
-
示例:宇宙射线干扰我们的设备,有时会破坏我们数据集中的值。破坏的可能性不取决于存储的值或数据集中的其他值。
非随机缺失(MNAR)
-
特征缺失的可能性取决于给定观察数据的隐藏值。
-
示例:个人气象站跟踪各种统计数据,如气压、降雨量和太阳辐射。然而,下雪时,太阳辐射计不会发出信号。
当数据在我们的训练集中缺失时,我们必须应用一些修正才能将数据转换为固定形状的张量,这需要每个单元格中都有一个值。处理缺失数据的四种重要技术。
最简单的技术是,如果训练数据丰富且缺失字段很少,就丢弃具有缺失数据的训练样本。但是,请注意,这可能会在您的训练模型中引入偏差。为了明显地看到这一点,请想象一个问题,其中从正类缺失数据的情况远比从负类缺失数据的情况要常见得多。您最终会学习到错误的类别可能性。只有当您的缺失数据是 MCAR 时,您才完全可以放心地丢弃样本。
第 6.21 列表。通过删除数据处理缺失的特征
const filteredDataset =
tf.data.csv(csvFilename)
.filter(e => e['featureName']); ***1***
- 1 仅保留值为’truthy’的元素:即不为 0、null、未定义、NaN 或空字符串时
处理缺失数据的另一种技术是用某个值填充缺失数据,也称为插补。常见的插补技术包括用该特征的均值、中位数或众数替换缺失的数值特征值。缺失的分类特征可以用该特征的最常见值(也是众数)替换。更复杂的技术包括从可用特征构建缺失特征的预测器,并使用它们。事实上,使用神经网络是处理缺失数据的“复杂技术”之一。使用插补的缺点是学习器不知道特征缺失了。如果缺失信息与目标变量有关,则在插补中将丢失该信息。
第 6.22 列表。使用插补处理缺失的特征
async function calculateMeanOfNonMissing( ***1***
dataset, featureName) { ***1***
let samplesSoFar = 0;
let sumSoFar = 0;
await dataset.forEachAsync(row => {
const x = row[featureName];
if (x != null) { ***2***
samplesSoFar += 1;
sumSoFar += x;
}
});
return sumSoFar / samplesSoFar; ***3***
}
function replaceMissingWithImputed( ***4***
row, featureName, imputedValue)) { ***4***
const x = row[featureName];
if (x == null) {
return {...row, [featureName]: imputedValue};
} else {
return row;
}
}
const rawDataset tf.data.csv(csvFilename);
const imputedValue = await calculateMeanOfNonMissing(
rawDataset, 'myFeature');
const imputedDataset = rawDataset.map( ***5***
row => replaceMissingWithImputed( ***5***
row, 'myFeature', imputedValue)); ***5***
-
1 用于计算用于插补的值的函数。在计算均值时,请记住只包括有效值。
-
2 这里将未定义和 null 值都视为缺失。一些数据集可能使用哨兵值,如 -1 或 0 来表示缺失。请务必查看您的数据!
-
3 请注意,当所有数据都丢失时,这将返回 NaN。
-
4 如果 featureName 处的值缺失,则有条件地更新行的函数
-
5 使用 tf.data.Dataset map()方法将替换映射到所有元素上
有时缺失值会被替换为哨兵值。例如,缺失的体重值可能会被替换为 -1,表示未称重。如果您的数据看起来是这种情况,请注意在将其视为异常值之前先处理哨兵值(例如,根据我们先前的示例,用 40 kg 替换这个 -1)。
可以想象,如果缺失特征与要预测的目标之间存在关系,模型可能能够使用哨兵值。实际上,模型将花费部分计算资源来学习区分特征何时用作值,何时用作指示器。
管理缺失数据可能最稳健的方法是既使用插补来填补一个值,又添加一个第二个指示特征,以便在该特征缺失时通知模型。在这种情况下,我们将缺失的体重替换为一个猜测值,同时添加一个新特征weight_missing,当体重缺失时为 1,提供时为 0。这使得模型可以利用缺失情况,如果有价值的话,并且不会将其与体重的实际值混淆。
列表 6.23. 添加一个特征来指示缺失
function addMissingness(row, featureName)) { ***1***
const x = row[featureName];
const isMissing = (x == null) ? 1 : 0;
return {...row, [featureName + '_isMissing']: isMissing};
}
const rawDataset tf.data.csv(csvFilename);
const datasetWithIndicator = rawDataset.map(
(row) => addMissingness(row, featureName); ***2***
-
1 将一个新特征添加到每一行的函数,如果特征缺失则为 1,否则为 0
-
2 使用 tf.data.Dataset map() 方法将附加特征映射到每一行
偏斜
在本章的前面,我们描述了偏斜的概念,即一个数据集与另一个数据集之间的分布差异。当将训练好的模型部署到生产中时,这是机器学习实践者面临的主要问题之一。检测偏斜涉及对数据集的分布进行建模并比较它们是否匹配。快速查看数据集统计信息的简单方法是使用像 Facets(pair-code.github.io/facets/)这样的工具。参见图 6.5 以查看截图。Facets 将分析和总结您的数据集,以便您查看每个特征的分布,这将帮助您快速发现数据集之间的不同分布问题。
图 6.5. Facets 的截图显示了 UC Irvine Census Income 数据集的训练集和测试集的每个特征值分布情况(参见archive.ics.uci.edu/ml/datasets/Census+Income)。该数据集是默认加载在pair-code.github.io/facets/上的,但您可以导航到该网站并上传自己的 CSV 文件进行比较。这个视图被称为 Facets 概览。

一个简单、基础的偏斜检测算法可能会计算每个特征的均值、中位数和方差,并检查数据集之间的任何差异是否在可接受范围内。更复杂的方法可能会尝试根据样本预测它们来自哪个数据集。理想情况下,这应该是不可能的,因为它们来自相同的分布。如果能够预测数据点是来自训练还是测试,这是偏斜的迹象。
错误字符串
非常常见的情况是,分类数据是以字符串形式提供的特征。例如,当用户访问您的网页时,您可能会记录使用的浏览器,值为FIREFOX、SAFARI和CHROME。通常,在将这些值送入深度学习模型之前,这些值会被转换为整数(通过已知词汇表或哈希),然后映射到一个n维向量空间(见 9.2.3 节关于词嵌入)。一个常见的问题是,一个数据集中的字符串与另一个数据集中字符串的格式不同。例如,训练数据可能有FIREFOX,而在服务时间,模型收到FIREFOX\n,包括换行符,或者"FIREFOX",包括引号。这是一个特别阴险的形式的偏差,应该像处理偏差一样处理。
其他需要注意的数据内容。
除了前面提到的问题之外,在将数据提供给机器学习系统时,还有一些需要注意的事项:
-
过度不平衡的数据——如果有一些特征在你的数据集中几乎每个样本都取相同的值,你可以考虑将它们去掉。这种类型的信号很容易过拟合,而深度学习方法对非常稀疏的数据不能很好地处理。
-
数值/分类区别——一些数据集将使用整数表示列举集合的元素,而当这些整数的等级顺序没有意义时,这可能会导致问题。例如,如果我们有一个音乐类型的列举集合,比如
ROCK,CLASSICAL等,和一个将这些值映射到整数的词汇表,很重要的是,当我们把这些值传递到模型中时,我们要像处理列举值一样处理这些值。这意味着使用 one-hot 或嵌入(见第九章)对值进行编码。否则,这些数字将被解释为浮点数值,根据它们的编码之间的数字距离,可能会提示虚假的术语之间的关系。 -
规模巨大的差异——这是之前提到过的,但在这一节中重申,可以出现数据错误的情况。要注意具有大量差异的数值特征。它们可能导致训练不稳定。通常情况下,在训练之前最好对数据进行 z 标准化(规范化均值和标准差)。只需要确保在服务时间中使用与训练期间相同的预处理即可。你可以在 tensorflow/tfjs-examples iris example 中看到一个例子,我们在第三章中探讨过。
-
偏见、安全和隐私——显然,在负责任的机器学习开发中,有很多内容远远超出了一本书章的范围。如果你正在开发机器学习解决方案,花时间了解至少管理偏见、安全和隐私的基本最佳实践至关重要。一个好的起点是谷歌在
ai.google/education/responsible-ai-practices上的负责任 AI 实践页面。遵循这些实践只是做一个好人和一个负责任的工程师的正确选择——显然是重要的目标本身。此外,仔细关注这些问题也是一个明智的选择,因为即使是偏见、安全或隐私的小失误也可能导致令人尴尬的系统性故障,迅速导致客户寻找更可靠的解决方案。
一般来说,你应该花时间确信你的数据符合你的预期。有许多工具可以帮助你做到这一点,从像 Observable、Jupyter、Kaggle Kernel 和 Colab 这样的笔记本,到图形界面工具如 Facets。在 Facets 中,看 图 6.6 ,还有另一种探索数据的方式。在这里,我们使用 Facets 的绘图功能,也就是 Facets Dive,来查看纽约州立大学(SUNY)数据集中的点。Facets Dive 允许用户从数据中选择列,并以自定义的方式直观地表达每个字段。在这里,我们使用下拉菜单将 Longitude1 字段用作点的 x 位置,将 Latitude1 字段用作点的 y 位置,将 City 字符串字段用作点的名称,并将 Undergraduate Enrollment 用作点的颜色。我们期望在二维平面上绘制的纬度和经度能揭示出纽约州的地图,而确实是我们所看到的。地图的正确性可以通过将其与 SUNY 的网页 www.suny.edu/attend/visit-us/campus-map/ 进行比较来验证。
图 6.6. Facets 的另一张截图,这次探索的是数据-csv 示例中的纽约州校园数据集。在这里,我们看到 Facets Dive 视图,它允许您探索数据集的不同特征之间的关系。每个显示的点都是数据集中的一个数据点,这里我们将点的 x 位置设置为 Latitude1 特征,y 位置是 Longitude1 特征,颜色与 Undergraduate Enrollment 特征相关,前面的字是设置为 City 特征的,其中包含每个数据点所在的城市的名称。从这个可视化中,我们可以看到纽约州的大致轮廓,西边是布法罗,东南边是纽约。显然,Selden 市包含了一个根据本科生注册人数计算的最大校园之一。
6.5. 数据增强
所以,我们已经收集了我们的数据,我们将其连接到一个tf.data.Dataset以便进行简单操作,我们仔细检查并清理了其中的问题。还有什么其他方法可以帮助我们的模型成功呢?
有时,你拥有的数据不足,希望通过程序化地扩展数据集,通过对现有数据进行微小更改来创建新的示例。例如,回顾一下第四章中的 MNIST 手写数字分类问题。MNIST 包含 60,000 个训练图像,共 10 个手写数字,每个数字 6,000 个。这足以学习我们想要为我们的数字分类器提供的所有类型的灵活性吗?如果有人画了一个太大或太小的数字会发生什么?或者稍微旋转了一下?或者有偏斜?或者用笔写得粗或细了?我们的模型还会理解吗?
如果我们拿一个 MNIST 样本数字,并将图像向左移动一个像素,那么数字的语义标签不会改变。向左移动的 9 仍然是一个 9,但我们有了一个新的训练示例。这种从实际示例变异生成的程序化示例称为伪示例,将伪示例添加到数据的过程称为数据增强。
数据增强采取的方法是从现有的训练样本中生成更多的训练数据。对于图像数据,各种变换如旋转、裁剪和缩放通常会产生看起来可信的图像。其目的是增加训练数据的多样性,以增加训练模型的泛化能力(换句话说,减轻过拟合),这在训练数据集大小较小时特别有用。
图 6.7 展示了应用于由猫图像组成的输入示例的数据增强,来自带标签的图像数据集。通过应用旋转和偏斜等方式增强数据,使得示例的标签即“CAT”不变,但输入示例发生了显著变化。
图 6.7。通过随机数据增强生成猫图片。单个标记示例可以通过提供随机旋转、反射、平移和偏斜来产生整个训练样本族。喵。
如果你使用这个数据增强配置来训练一个新的网络,那么这个网络永远不会看到相同的输入两次。但它所看到的输入仍然存在很强的相互关联性,因为它们来自少量原始图像——你无法产生新的信息,只能重新混合现有信息。因此,这可能不足以完全消除过拟合。使用数据增强的另一个风险是,训练数据现在不太可能与推断数据的分布匹配,引入了偏差。额外训练伪例的好处是否超过偏差成本取决于应用程序,并且这可能只是需要测试和实验的内容。
代码清单 6.24 展示了如何将数据增强作为dataset.map()函数包括在内,将允许的变换注入到数据集中。请注意,增强应逐个样本应用。还需要注意的是,不应将增强应用于验证或测试集。如果在增强数据上进行测试,则在推断时不会应用增强,因此会对模型的能力产生偏见。
6. 在使用数据增强对数据集进行训练的示例中的代码清单。
function augmentFn(sample) { ***1***
const img = sample.image;
const augmentedImg = randomRotate(
randomSkew(randomMirror(img)))); ***2***
return {image: augmentedImg, label: sample.label};
}
const (trainingDataset, validationDataset} = ***3***
getDatsetsFromSource(); ***3***
augmentedDataset = trainingDataset ***4***
.repeat().map(augmentFn).batch(BATCH_SIZE); ***4***
// Train model
await model.fitDataset(augmentedDataset, { ***5***
batchesPerEpoch: ui.getBatchesPerEpoch(),
epochs: ui.getEpochsToTrain(),
validationData: validationDataset.repeat(), ***6***
validationBatches: 10,
callbacks: { ... },
}
}
-
1 数据增强函数以{图像,标签}格式的样本作为输入,并返回相同格式下的新样本。
-
2 假设随机旋转、随机扭曲和随机镜像在其他地方由某个库定义。旋转、扭曲等的数量在每次调用时随机生成。数据增强只应依赖于特征,而不是样本的标签。
-
3 该函数返回两个 tf.data.Datasets,每个元素类型为{image, label}。
-
4 增强应用于单个元素的批处理之前。
-
5 我们在增强的数据集上拟合模型。
-
6 重要!不要对验证集应用数据增强。在这里对验证数据进行重复操作,因为数据不会自动循环。每次验证测量只会取 10 批数据,根据配置。
希望本章能让你深刻理解在将机器学习模型应用于数据之前了解数据的重要性。我们介绍了 Facets 等开箱即用的工具,您可以使用它们来检查数据集并深入了解它们。然而,当您需要更灵活和自定义的数据可视化时,需要编写一些代码来完成这项工作。在下一章中,我们将教您 tfjs-vis 的基础知识,这是由 TensorFlow.js 的作者维护的可支持此类数据可视化用例的可视化模块。
练习
-
将第五章的简单物体检测示例扩展,使用
tf.data .generator()和model.fitDataset()代替提前生成完整数据集。此结构有何优势?如果为模型提供更大的图像数据集进行训练,性能会有明显提升吗? -
通过对示例中的 MNIST 示例添加小偏移、缩放和旋转来添加数据增强。这是否有助于性能?在使用数据流进行验证和测试时,是否对数据流进行增强更合适,还是只在“真实”的自然样本上测试?
-
使用第 6.4.1 节中的技术绘制其他章节中使用的一些数据集的一些特征。数据符合独立性的预期吗?有异常值吗?还有缺失值吗?
-
将我们在这里讨论过的一些 CSV 数据集导入 Facets 工具中。哪些特征看起来可能会引起问题?有什么意外情况吗?
-
考虑一些我们在早期章节中使用的数据集。哪些数据增强技术适用于那些数据?
概要
-
数据是推动深度学习革命的关键力量。没有大型、组织良好的数据集,大多数深度学习应用都无法实现。
-
TensorFlow.js 内置了
tf.dataAPI,使得流式传输大型数据集、以各种方式转换数据,并将其连接到模型进行训练和预测变得简单。 -
有几种方法可以构建
tf.data.Dataset对象:从 JavaScript 数组、从 CSV 文件,或者从数据生成函数。从远程 CSV 文件流式传输数据集可以在一行 JavaScript 代码中完成。 -
tf.data.Dataset对象具有可链接的 API,使得在机器学习应用中常见的洗牌、过滤、批处理、映射和执行其他操作变得简单而方便。 -
tf.data.Dataset以延迟流式传输的方式访问数据。这使得处理大型远程数据集变得简单高效,但付出的代价是处理异步操作。 -
tf.Model对象可以直接使用其fitDataset()方法从tf.data.Dataset进行训练。 -
审计和清理数据需要时间和关注,但这是任何你打算投入实际应用的机器学习系统都必不可少的一步。在数据处理阶段检测和管理偏差、缺失数据和异常值等问题,最终会节省建模阶段的调试时间。
-
数据增强可以用于扩展数据集,包括程序生成的伪示例。这可以帮助模型覆盖原始数据集中未充分表示的已知不变性。

















 1168
1168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









