







使用 shard_map 的 SPMD 多设备并行性
shard_map 是一种单程序多数据(SPMD)多设备并行性 API,用于在数据分片上映射函数。映射的函数应用或实例通过显式的集合通信操作进行通信。
shard_map 是与 jit 内置的自动编译器并行化互补且可组合的。使用 jit,你编写的代码就像为单个设备编写的一样,并且编译器可以自动将计算分区到多个设备上,在幕后生成每个设备的代码和通信集合。使用 shard_map,你可以控制自己的分区代码和显式集合。或者你可以同时进行一些操作:在组设备中手动控制同时保留组内设备分区给编译器。这两种方法可以根据需要混合、匹配和组合。
如果您熟悉 pmap,可以将 shard_map 视为其演进。它更具表现力、性能和与其他 JAX API 可组合。它甚至可以急切地工作,更易于调试!(更多信息,请参阅与 pmap 的详细比较。)
通过阅读本教程,您将学习如何使用 shard_map 来完全控制您的多设备代码。您将详细了解它如何与 jax.jit 的自动并行化和 jax.grad 的自动微分结合使用。我们还将给出一些神经网络并行化策略的基本示例。
我们假设本教程在具有八个设备的环境中运行:
import os
os.environ["XLA_FLAGS"] = '--xla_force_host_platform_device_count=8' # Use 8 CPU devices
所以,让我们来看一个 shard_map 吧!
不多说了,这里是一个玩具例子:
from functools import partial
import jax
import jax.numpy as jnp
from jax.sharding import Mesh, PartitionSpec as P
from jax.experimental import mesh_utils
from jax.experimental.shard_map import shard_map
devices = mesh_utils.create_device_mesh((4, 2))
mesh = Mesh(devices, axis_names=('x', 'y'))
a = jnp.arange( 8 * 16.).reshape(8, 16)
b = jnp.arange(16 * 4.).reshape(16, 4)
@partial(shard_map, mesh=mesh, in_specs=(P('x', 'y'), P('y', None)),
out_specs=P('x', None))
def matmul_basic(a_block, b_block):
# a_block: f32[2, 8]
# b_block: f32[8, 4]
c_partialsum = jnp.dot(a_block, b_block)
c_block = jax.lax.psum(c_partialsum, 'y')
# c_block: f32[2, 4]
return c_block
c = matmul_basic(a, b) # c: f32[8, 4]
这个函数通过执行本地块矩阵乘法,然后进行集合求和操作来并行计算矩阵乘积。我们可以检查结果是否正确:
from jax.tree_util import tree_map, tree_all
def allclose(a, b):
return tree_all(tree_map(partial(jnp.allclose, atol=1e-2, rtol=1e-2), a, b))
allclose(c, jnp.dot(a, b))
True
结果沿其行被分片:
jax.debug.visualize_array_sharding(c)
CPU 0,1
CPU 2,3
CPU 4,5
CPU 6,7
在高层次上,shard_map 在某种程度上类似于 vmap 或 pmap,因为我们在数组数据的部分上映射函数,但请注意
-
shard_map将输入切片成块(输出由连接结果块形成),保持秩不变,而vmap则通过映射掉一个轴来减少秩; -
mesh参数允许我们控制计算和结果的精确设备放置; -
我们同时映射多个数据轴,并设置多个轴名称以进行集合操作(这里有
'x'和'y'); -
因为我们还没有使用
jax.jit,一切都是急切地评估的,我们甚至可以打印中间值以进行调试。
上述代码执行与此 jax.jit 自动并行化代码相同的计算:
from jax.sharding import NamedSharding
a = jax.device_put(a, NamedSharding(mesh, P('x', 'y')))
b = jax.device_put(b, NamedSharding(mesh, P('y', None)))
@jax.jit
def matmul_reference(a, b):
c = jnp.dot(a, b)
return jax.lax.with_sharding_constraint(c, NamedSharding(mesh, P('x', None)))
c_ref = matmul_reference(a, b)
allclose(c_ref, jnp.dot(a, b))
True
我们可以将 shard_map 视为根据其 mesh 和 in_specs 参数在其输入上执行 device_put 或 with_sharding_constraint,因此 matmul_basic 操作的块与 matmul_reference 中的相同:
print('a blocks:'); jax.debug.visualize_array_sharding(a)
print('b blocks:'); jax.debug.visualize_array_sharding(b)
print('c blocks:'); jax.debug.visualize_array_sharding(c)
a blocks:
b blocks:
c blocks:
CPU 0CPU 1
CPU 2CPU 3
CPU 4CPU 5
CPU 6CPU 7
CPU 0,2,4,6
CPU 1,3,5,7
CPU 0,1
CPU 2,3
CPU 4,5
CPU 6,7
放慢速度,从基础开始!
降维与保持秩的映射
我们可以将 vmap 和 pmap 看作是沿轴(例如将 2D 矩阵解包成其 1D 行)对每个数组输入应用其主体函数,然后将结果堆叠在一起,至少在不涉及集合操作时是这样的:
def check_vmap(f, xs):
ans = jax.vmap(f, in_axes=(0,), out_axes=0)(xs)
expected = jnp.stack([f(x) for x in xs]) # vmap reference semantics
print(allclose(ans, expected))
check_vmap(lambda x: x @ x, jnp.arange(12).reshape(4, 3))
True
例如,如果 xs 的形状为 f32[8,5],那么每个 x 的形状将为 f32[5],如果每个 f(x) 的形状为 f32[3,7],那么最终堆叠的结果 vmap(f)(xs) 的形状将为 f32[8,3,7]。也就是说,函数 f 的每个应用都以比 vmap(f) 对应参数少一个轴的输入作为参数。我们可以说这些是降维映射,输入/输出的解包/堆叠。
函数 f 的逻辑应用数量,或称为 f 的实例,取决于被映射输入轴的大小:例如,如果我们映射一个大小为 8 的输入轴,语义上我们得到函数的 8 个逻辑应用。
相比之下,shard_map 并没有这种降维行为。相反,我们可以将其视为沿输入轴切片(或“取消连接”)成块,应用主体函数,然后将结果再次连接在一起(同样是在不涉及集合操作时):
import numpy as np
devices = np.array(jax.devices()[:4])
mesh = Mesh(devices, ('i',)) # mesh.shape['i'] = 4
def check_shmap(f, y):
ans = shard_map(f, mesh, in_specs=P('i'), out_specs=P('i'))(y)
expected = jnp.concatenate([f(y_blk) for y_blk in jnp.split(y, mesh.shape['i'])])
print(allclose(ans, expected))
check_shmap(lambda x: x.T @ x, jnp.arange(32).reshape(8, 4))
True
回想一下,jnp.split 将其输入切片为相同大小的块,以便如果在上述示例中 y 的形状为 f32[8,5],那么每个 y_blk 的形状将为 f32[2,5],如果每个 f(y_blk) 的形状为 f32[3,7],那么最终连接的结果 shard_map(f, ...)(y) 的形状将为 f32[12,7]。因此,shard_map 对其输入进行保持秩的映射,输入/输出的取消连接/连接。
函数 f 的逻辑应用数量由网格大小决定,而不是任何输入轴的大小:例如,如果我们有总大小为 4 的网格(即在 4 个设备上),那么语义上我们得到函数的 4 个逻辑应用,对应于物理计算这些函数的 4 个设备。
控制每个输入如何分割(取消连接)并与 in_specs 平铺
每个 in_specs 通过 PartitionSpec 标识某些对应输入数组轴的网格轴名称,表示如何将该输入分割(或解串联)为应用体函数的块。该标识确定了碎片大小;当输入轴与网格轴标识为同一时,输入沿该逻辑轴分割(解串联)为数目等于相应网格轴大小的片段。(如果相应的网格轴大小不能整除输入数组轴大小,则出错。)如果输入的 pspec 未提及网格轴名称,则在该网格轴上没有分割。例如:
devices = mesh_utils.create_device_mesh((4, 2))
mesh = Mesh(devices, ('i', 'j'))
@partial(shard_map, mesh=mesh, in_specs=P('i', None), out_specs=P('i', 'j'))
def f1(x_block):
print(x_block.shape) # prints (3, 12)
return x_block
x1 = jnp.arange(12 * 12).reshape(12, 12)
y = f1(x1)
(3, 12)
在这里,因为输入 pspec 未提及网格轴名称 'j',因此没有输入数组轴沿该网格轴进行分割;类似地,因为输入数组的第二轴没有标识(因此没有沿任何网格轴分割),f1 的应用获得了沿该轴的完整视图。
当输入 pspec 中未提及网格轴时,我们可以始终重写为一个效率较低的程序,其中所有网格轴都被提及,但调用者执行 jnp.tile,例如:
@partial(shard_map, mesh=mesh, in_specs=P('i', 'j'), out_specs=P('i', 'j'))
def f2(x_block):
print(x_block.shape)
return x_block
x = jnp.arange(12 * 12).reshape(12, 12)
x_ = jnp.tile(x, (1, mesh.shape['j'])) # x_ has shape (12, 24)
y = f2(x_) # prints (3,12), and f1(x) == f2(x_)
(3, 12)
换句话说,因为每个输入 pspec 可以零次或一次提及每个网格轴名称,而不必精确一次提及每个名称,我们可以说除了其输入中内置的 jnp.split 外,shard_map 还有一个至少逻辑上内置的 jnp.tile(尽管根据参数的物理分片布局,可能不需要进行物理铺设)。要使用的铺设方式不唯一;我们也可以沿第一个轴进行铺设,并使用 pspec P(('j', 'i'), None)。
可以在输入上进行物理数据移动,因为每个设备都需要有适当数据的副本。
通过 out_specs 控制每个由连接、块转置和使用 out_specs 反铺设组装的输出。
类似于输入端,out_specs 中的每个标识符通过名称将输出数组的一些轴与网格轴相关联,表示应如何将输出块(每个体函数应用的一个,或等效地每个物理设备一个)重新组装以形成最终输出值。例如,在上述 f1 和 f2 的例子中,out_specs 表明我们应该沿两个轴连接在一起形成最终输出,结果在两种情况下都是形状为 (12, 24) 的数组 y。(如果体函数的输出形状,即输出块形状,对应的输出 pspec 描述的连接的秩过小,则出错。)
当一个网格轴名称在输出 pspec 中未被提及时,表示一个取消铺设:用户编写一个输出 pspec,其中未提及网格轴名称之一,他们保证输出块沿该网格轴是相等的,因此在输出中只使用一个沿该轴的块(而不是沿该网格轴连接所有块)。例如,使用与上述相同的网格:
x = jnp.array([[3.]])
z = shard_map(lambda: x, mesh=mesh, in_specs=(), out_specs=P('i', 'j'))()
print(z) # prints the same as jnp.tile(x, (4, 2))
z = shard_map(lambda: x, mesh=mesh, in_specs=(), out_specs=P('i', None))()
print(z) # prints the same as jnp.tile(x, (4, 1)), or just jnp.tile(x, (4,))
z = shard_map(lambda: x, mesh=mesh, in_specs=(), out_specs=P(None, None))()
print(z) # prints the same as jnp.tile(x, (1, 1)), or just x
[[3\. 3.]
[3\. 3.]
[3\. 3.]
[3\. 3.]]
[[3.]
[3.]
[3.]
[3.]]
[[3.]]
闭合在数组值上的主体函数等效于将其作为具有相应输入 pspec 的增强传递。作为另一个示例,更接近于上述其他示例:
@partial(shard_map, mesh=mesh, in_specs=P('i', 'j'), out_specs=P('i', None))
def f3(x_block):
return jax.lax.psum(x_block, 'j')
x = jnp.arange(12 * 12).reshape(12, 12)
y3 = f3(x)
print(y3.shape)
(12, 6)
结果的第二轴大小为 6,输入的第二轴大小的一半。在这种情况下,通过在输出 pspec 中未提及网格轴名称 'j' 来表达取消铺设是安全的,因为集体 psum 确保每个输出块沿相应的网格轴是相等的。以下是两个更改输出 pspec 中提及的网格轴的示例:
@partial(shard_map, mesh=mesh, in_specs=P('i', 'j'), out_specs=P(None, 'j'))
def f4(x_block):
return jax.lax.psum(x_block, 'i')
x = jnp.arange(12 * 12).reshape(12, 12)
y4 = f4(x)
print(y4.shape) # (3,12)
@partial(shard_map, mesh=mesh, in_specs=P('i', 'j'), out_specs=P(None, None))
def f5(x_block):
return jax.lax.psum(x_block, ('i', 'j'))
y5 = f5(x)
print(y5.shape) # (3,6)
(3, 12)
(3, 6)
在物理方面,在输出 pspec 中未提及网格轴名称将使用沿该网格轴复制布局从输出设备缓冲区组装 Array。
没有运行时检查,以确保输出块实际上沿网格轴是相等的,从而可以取消铺设,或者等效地说,相应的物理缓冲区具有相等的值,因此可以被解释为单个逻辑数组的复制布局。但是,我们可以提供一个静态检查机制,在所有潜在不正确的程序上引发错误。
因为 out_specs 可以零次或一次提及网格轴名称,并且可以以任何顺序提及,所以除了其输出中内置的 jnp.concatenate 外,shard_map 还包括 取消铺设 和 块转置。
输出上无论输出 pspec 如何,物理数据移动都是不可能的。相反,out_specs 只是编码如何将块输出组装成 Array,或者物理上如何解释跨设备的缓冲区作为单个逻辑 Array 的物理布局。
API 规范
from jax.sharding import Mesh
Specs = PyTree[PartitionSpec]
def shard_map(
f: Callable, mesh: Mesh, in_specs: Specs, out_specs: Specs,
auto: collections.abc.Set[AxisName] = frozenset([]),
check_rep: bool = True,
) -> Callable:
...
其中:
-
在
f的主体中,像psum这样的通信集合可以提及mesh的轴名称; -
mesh编码排列成数组并带有关联轴名称的设备,就像sharding.NamedSharding一样; -
in_specs和out_specs是PartitionSpec,可以用来从mesh中仿射地提及轴名称,以表达输入和输出的切片/未连接和连接,分别对应于未提及名称的复制和取消铺设(断言-复制-因此-给我-一个-副本); -
auto是对应于mesh名称子集的可选轴名称,在主体中自动处理,如在调用者中,而不是手动处理; -
check_rep是一个可选布尔值,指示静态检查out_specs中是否存在任何复制错误,并且是否启用相关的自动微分优化(参见JEP)。
传递给f的参数的形状与传递给shard_map-of-f的参数的形状具有相同的秩,f的参数的形状从相应的shard_map-of-f的形状shape和相应的PartitionSpec spec中粗略计算为tuple(sz // (1 if n is None else mesh.shape[n]) for sz, n in zip(shape, spec))。
集合教程
shard_map不必是纯映射:函数应用可以通过集合与彼此通信,使用在mesh参数中定义的轴名称。
请记住,shard_map将函数映射到输入数据的分片或块,因此这样:
mesh = Mesh(jax.devices(), ('i',))
x = jnp.arange(16.)
f_shmapped = shard_map(f, mesh, in_specs=P('i'), out_specs=P('i'))
y = f_shmapped(x)
计算相同的值,评估对相同参数值的f的应用,如此参考函数:
def f_shmapped_ref(x):
x_blocks = jnp.array_split(x, mesh.shape[0])
y_blocks = [f(x_blk) for x_blk in x_blocks]
return jnp.concatenate(y_blocks)
我们将这些对不同参数分片的f的应用称为函数实例。每个函数实例在不同的设备(或设备子集)上执行。
这些引用语义在f中没有通信集合时有效。但是如果我们希望函数实例进行通信,即进行跨设备通信,该怎么办?也就是说,当f包含一个集合时,引用语义是什么?假设f只有一个集合,并且形式如下:
def f(x_blk):
z_blk = f_part1(x_blk)
u_blk = collective(z_blk, axis_name)
v_blk = f_part2(x_blk, z_blk, u_blk)
return v_blk
假设我们映射的唯一网格轴只有一个,并且axis_name是其对应的名称。然后引用语义看起来更像是:
def f_shmapped_ref(x):
x_blocks = jnp.array_split(x, mesh.shape[0])
z_blocks = [f_part1(x_blk) for x_blk in x_blocks]
u_blocks = [collective_ref(i, z_blocks) for i in range(len(z_blocks))]
v_blocks = [f_part2(x_blk, z_blk, u_blk) for x_blk, z_blk, u_blk
in zip(x_blocks, z_blocks, u_blocks)]
return jnp.concatenate(v_blocks)
注意,collective_ref可能依赖于所有的z_blocks。也就是说,虽然f_part1和f_part2独立地映射到块上,但是集合引入了跨块依赖。在物理上,这意味着跨设备的通信。确切地说,通信发生了什么,以及计算了什么值,取决于集合。
psum
最简单的集合可能是jax.lax.psum,它沿着设备网格轴(或多个轴)计算全归约和。这里是一个玩具示例:
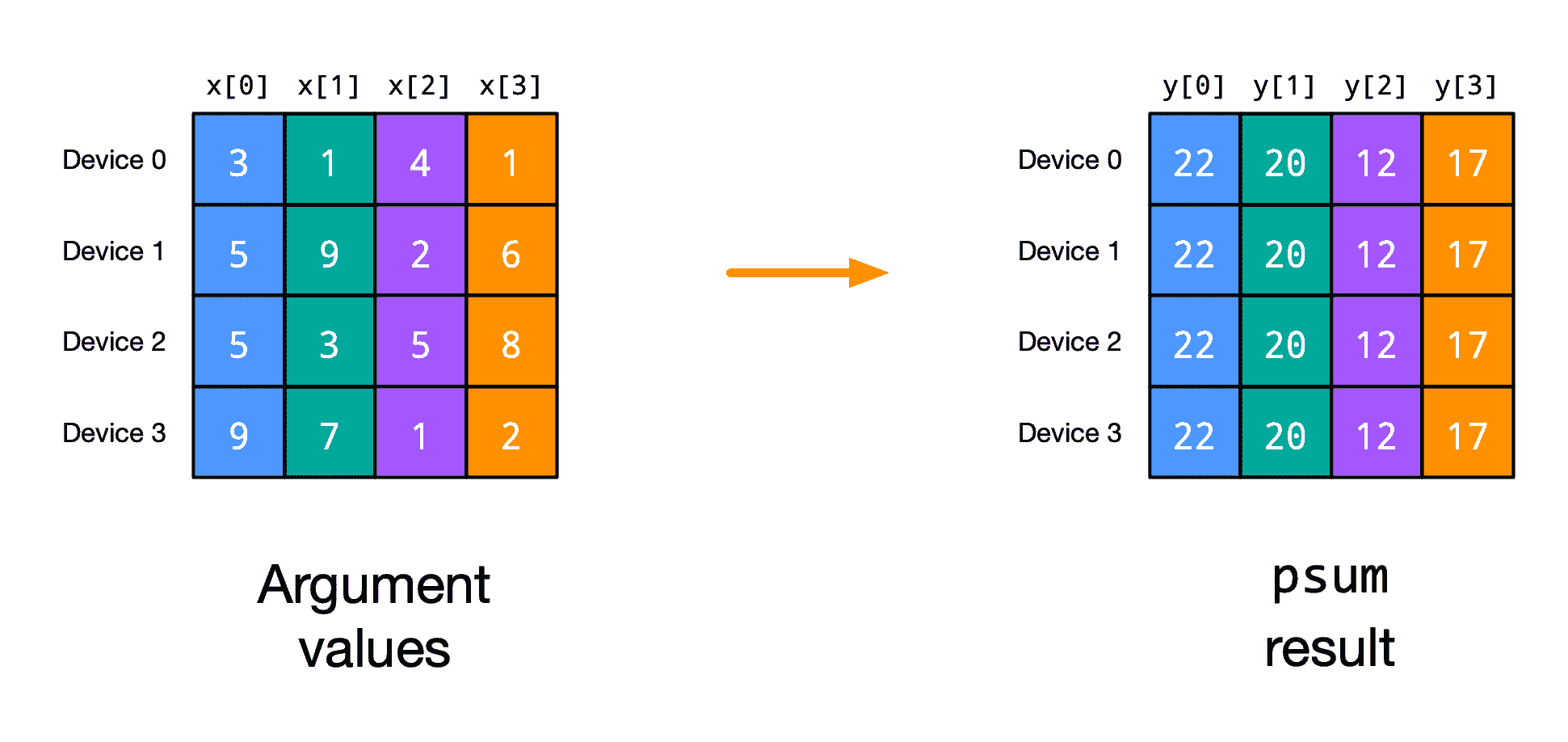
import jax
import jax.numpy as jnp
from jax import lax
from jax.sharding import Mesh, NamedSharding, PartitionSpec as P
from jax.experimental.shard_map import shard_map
mesh1d = Mesh(jax.devices()[:4], ('i',))
@partial(shard_map, mesh=mesh1d, in_specs=P('i'), out_specs=P(None))
def f1(x_block):
print('BEFORE:\n', x_block)
y_block = jax.lax.psum(x_block, 'i')
print('AFTER:\n', y_block)
return y_block
x = jnp.array([3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8, 9, 7, 1, 2])
y = f1(x)
print('FINAL RESULT:\n', y)
BEFORE:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[3 1 4 1]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[5 9 2 6]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[5 3 5 8]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[9 7 1 2]
AFTER:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[22 20 12 17]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[22 20 12 17]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[22 20 12 17]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[22 20 12 17]
FINAL RESULT:
[22 20 12 17]
打印显示,每个函数应用都从其自己的参数值块x_block开始。在psum之后,每个函数应用都有相同的y_block值,通过将应用的x_block值求和而得到。
在计算中存在单个轴名称的情况下,我们可以说collective_ref对于psum的引用实现是:
def psum_ref(_, x_blocks):
tot = sum(x_blocks)
return [tot] * len(x_blocks)
还要注意,因为f1返回y_block,对'i'进行psum的结果,我们可以使用out_specs=P(),这样调用者就可以得到单个逻辑副本的结果值,而不是平铺的结果。
当存在多个网格轴时,我们可以分别对每个轴执行psum,或者同时对多个轴执行:
mesh2d = Mesh(np.array(jax.devices()[:4]).reshape(2, 2), ('i', 'j'))
@partial(shard_map, mesh=mesh2d, in_specs=P('i', 'j'), out_specs=P(None, 'j'))
def f2(x_block):
print('BEFORE:\n', x_block)
y_block = jax.lax.psum(x_block, 'i')
print('AFTER:\n', y_block)
return y_block
y = f2(jnp.arange(16).reshape(4, 4))
print('FINAL RESULT:\n', y)
BEFORE:
On TFRT_CPU_0 at mesh coordinates (i, j,) = (0, 0):
[[0 1]
[4 5]]
On TFRT_CPU_1 at mesh coordinates (i, j,) = (0, 1):
[[2 3]
[6 7]]
On TFRT_CPU_2 at mesh coordinates (i, j,) = (1, 0):
[[ 8 9]
[12 13]]
On TFRT_CPU_3 at mesh coordinates (i, j,) = (1, 1):
[[10 11]
[14 15]]
AFTER:
On TFRT_CPU_0 at mesh coordinates (i, j,) = (0, 0):
[[ 8 10]
[16 18]]
On TFRT_CPU_1 at mesh coordinates (i, j,) = (0, 1):
[[12 14]
[20 22]]
On TFRT_CPU_2 at mesh coordinates (i, j,) = (1, 0):
[[ 8 10]
[16 18]]
On TFRT_CPU_3 at mesh coordinates (i, j,) = (1, 1):
[[12 14]
[20 22]]
FINAL RESULT:
[[ 8 10 12 14]
[16 18 20 22]]
通过在网格轴 'i' 上应用 psum,我们得到沿 'i' 轴相等的 y_block 值,但不沿 'j' 轴相等。(因此,我们可以使用 out_specs=P(None, 'j') 来获取沿该轴的单一逻辑结果。)
如果我们在两个轴上应用 psum,则 y_block 值沿两个轴相等:
@partial(shard_map, mesh=mesh2d, in_specs=P('i', 'j'), out_specs=P(None, None))
def f3(x_block):
print('BEFORE:\n', x_block)
y_block = jax.lax.psum(x_block, ('i', 'j'))
print('AFTER:\n', y_block)
return y_block
y = f3(jnp.arange(16).reshape(4, 4))
print('FINAL RESULT:\n', y)
BEFORE:
On TFRT_CPU_0 at mesh coordinates (i, j,) = (0, 0):
[[0 1]
[4 5]]
On TFRT_CPU_1 at mesh coordinates (i, j,) = (0, 1):
[[2 3]
[6 7]]
On TFRT_CPU_2 at mesh coordinates (i, j,) = (1, 0):
[[ 8 9]
[12 13]]
On TFRT_CPU_3 at mesh coordinates (i, j,) = (1, 1):
[[10 11]
[14 15]]
AFTER:
On TFRT_CPU_0 at mesh coordinates (i, j,) = (0, 0):
[[20 24]
[36 40]]
On TFRT_CPU_1 at mesh coordinates (i, j,) = (0, 1):
[[20 24]
[36 40]]
On TFRT_CPU_2 at mesh coordinates (i, j,) = (1, 0):
[[20 24]
[36 40]]
On TFRT_CPU_3 at mesh coordinates (i, j,) = (1, 1):
[[20 24]
[36 40]]
FINAL RESULT:
[[20 24]
[36 40]]
在机器学习中,我们经常使用 psum 来计算总损失,或者当我们在 shard_map 函数体内有一个 grad 时,计算总梯度。
接下来,我们将看到如何用其他基元实现 psum,这些基元能够对其通信成本提供一些直观的理解。
all_gather
另一个基本操作是沿轴收集数组片段,以便每个函数应用程序在该轴上都有数据的完整副本:
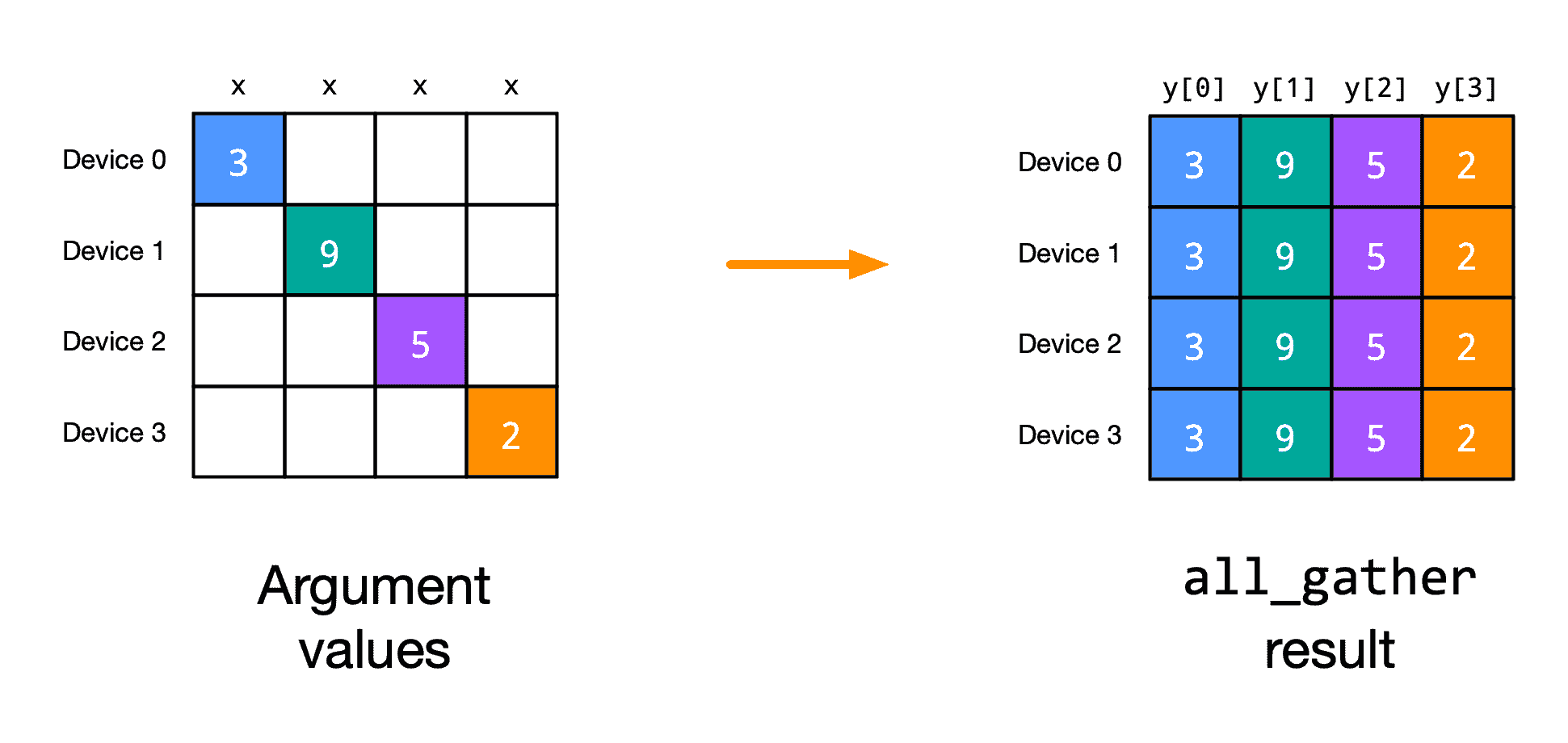
@partial(shard_map, mesh=mesh1d, in_specs=P('i'), out_specs=P('i'))
def f4(x_block):
print('BEFORE:\n', x_block)
y_block = jax.lax.all_gather(x_block, 'i', tiled=True)
print('AFTER:\n', y_block)
return y_block
x = jnp.array([3, 9, 5, 2])
y = f4(x)
print('FINAL RESULT:\n', y)
BEFORE:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[3]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[9]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[5]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[2]
AFTER:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[3 9 5 2]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[3 9 5 2]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[3 9 5 2]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[3 9 5 2]
FINAL RESULT:
[3 9 5 2 3 9 5 2 3 9 5 2 3 9 5 2]
打印显示,每个函数应用程序再次以其自己的 x_block 参数值块的一个片段开始。在 all_gather 后,它们具有一个通过连接 x_block 值计算得到的共同值。
(请注意,我们实际上不能在此处设置 out_specs=P()。由于与自动微分相关的技术原因,我们认为 all_gather 的输出不保证在不同设备上不变。如果我们希望它保证不变,我们可以使用 jax.lax.all_gather_invariant,或者在这种情况下,我们可以避免在函数体中执行 all_gather,而是只使用 out_specs=P('i') 来执行连接。)
当 tiled=False(默认情况下)时,结果沿新轴堆叠而不是连接:
@partial(shard_map, mesh=mesh1d, in_specs=P('i'), out_specs=P('i'))
def f5(x_block):
print('BEFORE:\n', x_block)
y_block = jax.lax.all_gather(x_block, 'i', tiled=False)
print('AFTER:\n', y_block)
return y_block
y = f5(x)
print('FINAL RESULT:\n', y)
BEFORE:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[3]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[9]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[5]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[2]
AFTER:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[[3]
[9]
[5]
[2]]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[[3]
[9]
[5]
[2]]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[[3]
[9]
[5]
[2]]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[[3]
[9]
[5]
[2]]
FINAL RESULT:
[[3]
[9]
[5]
[2]
[3]
[9]
[5]
[2]
[3]
[9]
[5]
[2]
[3]
[9]
[5]
[2]]
我们可以为 all_gather 编写 collective_ref 引用语义函数:
def all_gather_ref(_, x_blocks, *, tiled=False):
combine = jnp.concatenate if tiled else jnp.stack
return [combine(x_blocks)] * len(x_blocks)
在深度学习中,我们可以在完全分片数据并行性(FSDP)中对参数使用 all_gather。
psum_scatter
jax.lax.psum_scatter 集合操作有点不那么直观。它类似于 psum,但每个函数实例只获得结果的一个分片:

@partial(shard_map, mesh=mesh1d, in_specs=P('i'), out_specs=P('i'))
def f6(x_block):
print('BEFORE:\n', x_block)
y_block = jax.lax.psum_scatter(x_block, 'i', tiled=True)
print('AFTER:\n', y_block)
return y_block
x = jnp.array([3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8, 9, 7, 1, 2])
y = f6(x)
print('FINAL RESULT:\n', y)
BEFORE:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[3 1 4 1]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[5 9 2 6]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[5 3 5 8]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[9 7 1 2]
AFTER:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[22]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[20]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[12]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[17]
FINAL RESULT:
[22 20 12 17]
如打印所示,每个结果的 y_block 比参数 x_block 的大小要小,与 psum 不同。此外,与 psum 相比,这里每个 y_block 只表示函数实例的 x_block 总和的一个片段。 (尽管每个函数实例只获得总和的一个分片,但最终输出 y 与 psum 示例中的相同,因为我们在这里使用 out_specs=P('i') 来连接每个函数实例的输出。)
在计算的值方面,collective_ref 参考实现可能如下所示:
def psum_scatter_ref(i, x_blocks, *, tiled=False):
axis_size = len(x_blocks)
tot = sum(x_blocks)
if tiled:
tot = tot.reshape(axis_size, -1, *tot.shape[1:]) # split leading axis
return [tot[i] for i in range(tot.shape[0])]
语义参考实现中未捕获,但 psum_scatter 很有用,因为这些结果可以比完整的 psum 更高效地计算,通信量更少。事实上,可以将 psum_scatter 看作是 psum 的“前半部分,即 all_gather”的一种方式。也就是说,实现 psum 的一种方式是:
def psum(x, axis_name):
summed_chunk = jax.lax.psum_scatter(x, axis_name)
return jax.lax.all_gather(summed_chunk, axis_name)
实际上,这种实现经常在 TPU 和 GPU 上使用!
psum_scatter需要约一半通信量的原因在ppermute部分有所体现。
另一个直觉是,我们可以使用psum_scatter来实现分布式矩阵乘法,其中输入和输出在相同的轴上分片。在机器学习中,psum_scatter可以用于张量并行矩阵乘法或完全分片数据并行梯度累积,如下例所示。
ppermute
jax.lax.ppermute集合提供了实例函数相互发送数据的最直接方式。给定一个网格轴和一个表示沿着该网格轴的索引的(source_index, destination_index)对列表,ppermute将其参数值从每个源函数实例发送到每个目标:
@partial(shard_map, mesh=mesh1d, in_specs=P('i'), out_specs=P('i'))
def f7(x_block):
sz = jax.lax.psum(1, 'i')
print('BEFORE:\n', x_block)
y_block = jax.lax.ppermute(x_block, 'i', [(i, (i + 1) % sz) for i in range(sz)])
print('AFTER:\n', y_block)
return y_block
y = f7(jnp.arange(8))
print('FINAL RESULT:\n', y)
BEFORE:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[0 1]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[2 3]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[4 5]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[6 7]
AFTER:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[6 7]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[0 1]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[2 3]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[4 5]
FINAL RESULT:
[6 7 0 1 2 3 4 5]
在这种情况下,仅有两个函数实例,每个实例的y_block值是另一个实例的x_block值。
源索引和目标索引不能重复。如果一个索引未出现为目标,则相应函数实例结果的值为零数组。
一个collective_ref的参考实现可能是这样的:
def ppermute_ref(i, x_blocks, perm):
results = [jnp.zeros_like(x_blocks[0])] * len(x_blocks)
for src, dst in perm:
results[dst] = x_blocks[src]
return results
其他集合操作可以通过使用ppermute来实现,其中每个函数只向其邻居传递数据,从而在总通信量方面实现高效。例如,我们可以用这种方式实现psum_scatter,通过一系列ppermute和本地加法:
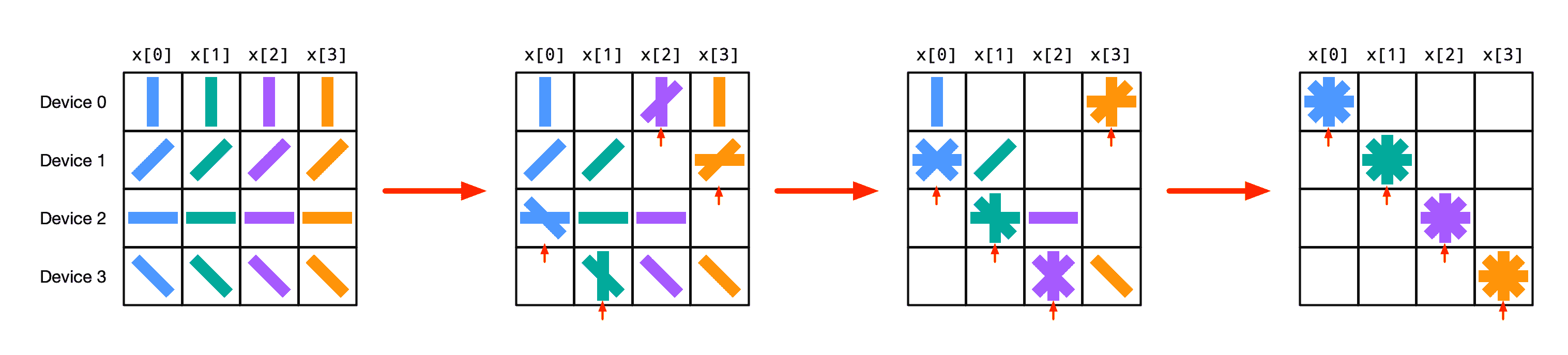
或者,举个数值示例:
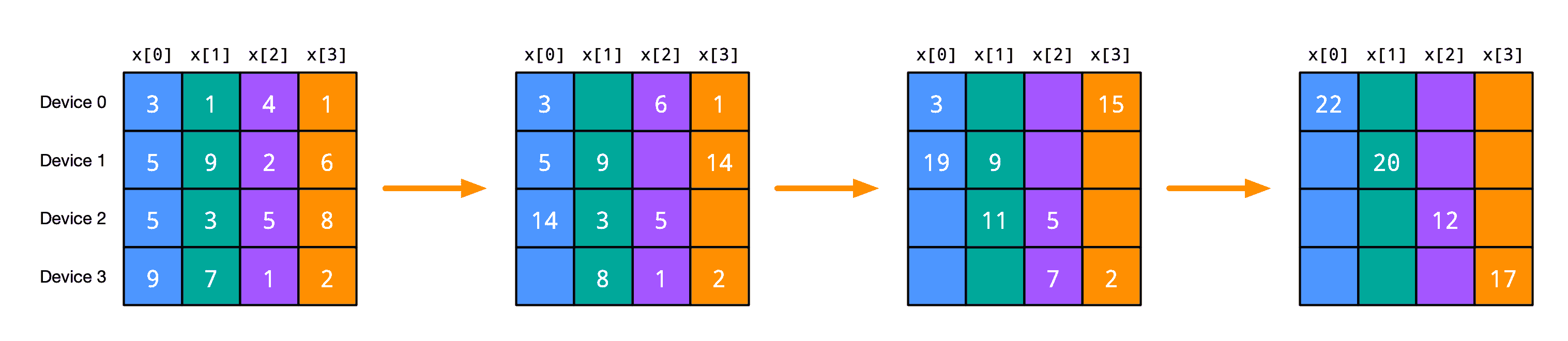
直观地说,每次迭代时,每个函数实例都将前一次迭代接收到的值“上送”,并在本次迭代中减少(添加)它接收到的值。在代码中,可能看起来像这样:
def psum_scatter(x, axis_name, *, tiled=False):
size = jax.lax.psum(1, axis_name)
idx = jax.lax.axis_index(axis_name) # function instance index along axis_name
if tiled:
x = x.reshape(size, -1, *x.shape[1:]) # split leading axis
shift = partial(jax.lax.ppermute, axis_name=axis_name,
perm=[(i, (i - 1) % size) for i in range(size)])
for i in range(1, size):
update = shift(x[(idx + i) % size])
x = x.at[(idx + i + 1) % size].add(update)
return x[idx]
@partial(shard_map, mesh=mesh1d, in_specs=P('i'), out_specs=P('i'))
def f8(x_block):
print('BEFORE:\n', x_block)
y_block = psum_scatter(x_block, 'i', tiled=True)
print('AFTER:\n', y_block)
return y_block
x = jnp.array([3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8, 9, 7, 1, 2])
y = f8(x)
print('FINAL RESULT:\n', y)
BEFORE:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[3 1 4 1]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[5 9 2 6]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[5 3 5 8]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[9 7 1 2]
AFTER:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[22]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[20]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[12]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[17]
FINAL RESULT:
[22 20 12 17]
在 TPU 上,有更高维度的算法变体来利用多向双向物理网格轴。
注意,psum_scatter是all_gather的转置。事实上,实现all_gather的一种方式是使用ppermute的逆过程:
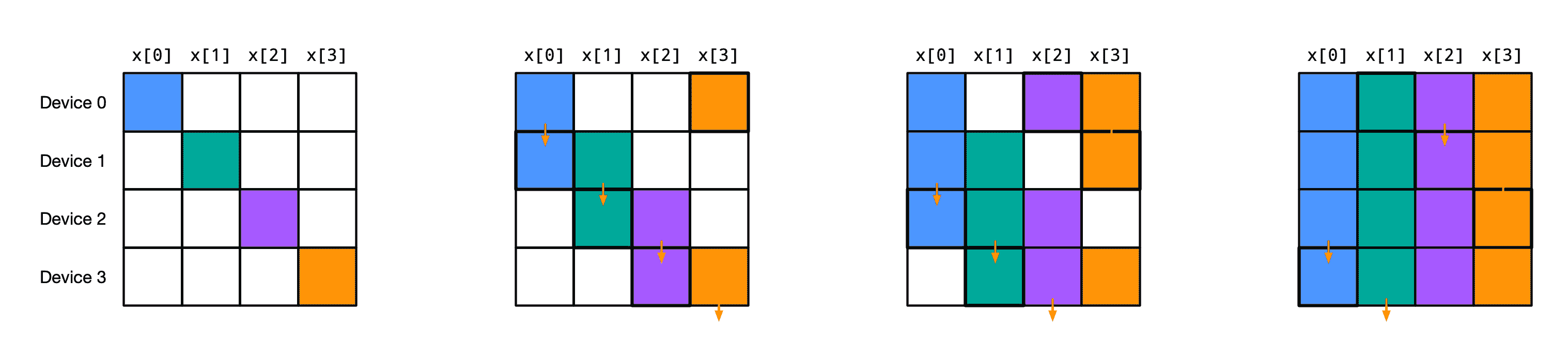
在深度学习中,当实现 SPMD 管道并行时,我们可能会使用ppermute,其中我们沿着深度将网络分割成阶段并并行评估阶段的应用。或者,当并行化卷积层的评估时,我们可能会使用ppermute,其中我们在空间轴上分片,因此设备必须相互通信“halos”。或者在张量并行矩阵乘法的幕后使用它。
all_to_all
最后一个集合操作是all_to_all,它本质上是沿一个位置轴和一个跨设备轴进行的块矩阵转置操作:
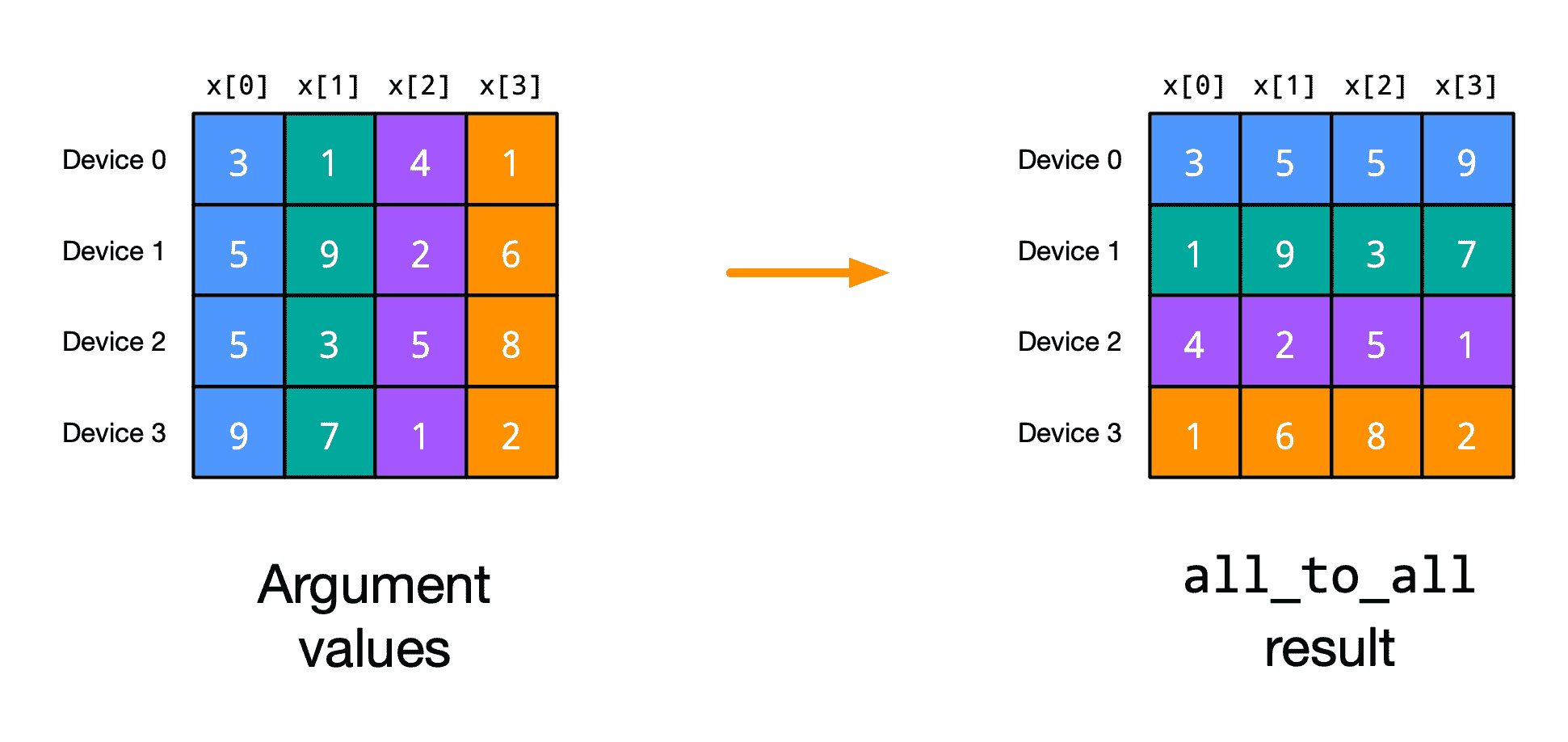
@partial(shard_map, mesh=mesh1d, in_specs=P('i'), out_specs=P('i'))
def f9(x_block):
print('BEFORE:\n', x_block)
y_block = jax.lax.all_to_all(x_block, 'i', split_axis=0, concat_axis=0,
tiled=True)
print('AFTER:\n', y_block)
return y_block
x = jnp.array([3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8, 9, 7, 1, 2])
y = f9(x)
print('FINAL RESULT:\n', y)
BEFORE:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[3 1 4 1]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[5 9 2 6]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[5 3 5 8]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[9 7 1 2]
AFTER:
On TFRT_CPU_0 at mesh coordinates (i,) = (0,):
[3 5 5 9]
On TFRT_CPU_1 at mesh coordinates (i,) = (1,):
[1 9 3 7]
On TFRT_CPU_2 at mesh coordinates (i,) = (2,):
[4 2 5 1]
On TFRT_CPU_3 at mesh coordinates (i,) = (3,):
[1 6 8 2]
FINAL RESULT:
[3 5 5 9 1 9 3 7 4 2 5 1 1 6 8 2]
split_axis 参数指示应该在网格轴上分片和分区的位置轴。concat_axis 参数指示应该在通信结果应该被连接或堆叠的轴。
当 tiled=False(默认情况下),split_axis 轴的大小必须等于命名为 axis_name 的网格轴的大小,并且在位置 concat_axis 创建一个新的该大小的轴用于堆叠结果。当 tiled=True 时,split_axis 轴的大小只需可以被网格轴的大小整除,结果沿现有轴 concat_axis 连接。
当 split_axis=0 和 concat_axis=0 时,collective_ref 引用语义可能如下:
def all_to_all_ref(_, x_blocks, *, tiled=False):
axis_size = len(x_blocks)
if tiled:
splits = [jnp.array_split(x, axis_size) for x in x_blocks]
return [jnp.concatenate(s) for s in zip(*splits)]
else:
splits = [list(x) for x in x_blocks]
return [jnp.stack(s) for s in zip(*splits)]
在深度学习中,我们可能在专家混合路由中使用 all_to_all,我们首先根据它们应该去的专家对我们的本地批次的示例进行排序,然后应用 all_to_all 重新分发示例到专家。
玩具示例
我们如何在实践中使用 shard_map 和集体通信?这些例子虽然简单,但提供了一些思路。
矩阵乘法
并行化矩阵乘法对于扩展深度学习模型至关重要,无论是用于训练还是推断。当 jax.jit 自动并行化矩阵乘法时,它可以使用几种不同的策略,这取决于矩阵大小、硬件细节和其他因素。我们如何更明确地编写一些使用 shard_map 并行化的例程?如何优化它们以获得更好的计算/通信重叠,从而提高 FLOP 利用率?
import jax
import jax.numpy as jnp
from jax.sharding import Mesh, NamedSharding, PartitionSpec as P
from jax.experimental.shard_map import shard_map
mesh = Mesh(jax.devices()[:4], ('i',))
def device_put(x, pspec):
return jax.device_put(x, NamedSharding(mesh, pspec))
示例 1:all-gather 在一侧
考虑执行一个矩阵乘法,在这个过程中我们在其主(非收缩)维度上分片左侧参数(可以考虑:参数):
lhs_spec = P('i', None)
lhs = device_put(jax.random.normal(jax.random.key(0), (8, 8)), lhs_spec)
并且我们在其收缩维度上分片右侧参数(可以考虑:激活),输出也类似分片:
rhs_spec = P('i', None)
rhs = device_put(jax.random.normal(jax.random.key(1), (8, 4)), rhs_spec)
为了执行这个矩阵乘法,我们可以首先全收集右侧,然后对分片左侧进行本地矩阵乘法:
@jax.jit
@partial(shard_map, mesh=mesh, in_specs=(lhs_spec, rhs_spec),
out_specs=rhs_spec)
def matmul_allgather(lhs_block, rhs_block):
rhs = jax.lax.all_gather(rhs_block, 'i', tiled=True)
return lhs_block @ rhs
out = matmul_allgather(lhs, rhs)
print(jnp.allclose(out, lhs @ rhs, atol=1e-3, rtol=1e-3))
True
这很棒,但我们这里没有计算/通信重叠:在我们可以开始矩阵乘法之前,我们需要 all_gather 完成。这里是使用相同代码的性能分析,但在更大的示例形状上 (lhs 为 (8192, 8192),rhs 为 (8192, 1024)):

如果我们不是调用 all_gather,而是基本上在我们的 ppermute 实现中内联我们上面的 all_gather,那么我们可以获得计算/通信重叠,然后交错进行收集排列步骤与本地矩阵乘法的步骤:
@jax.jit
@partial(shard_map, mesh=mesh, in_specs=(lhs_spec, rhs_spec),
out_specs=rhs_spec)
def matmul_allgather_overlapped(lhs_block, rhs_block):
size = jax.lax.psum(1, 'i')
idx = jax.lax.axis_index('i')
shift = partial(jax.lax.ppermute, axis_name='i',
perm=[(i, (i + 1) % size) for i in range(size)])
B = lhs_block.shape[1] // size
lhs_blocks = lambda i: lax.dynamic_slice_in_dim(lhs_block, i * B, B, 1)
out_block = lhs_blocks(idx) @ rhs_block
for i in range(1, size):
rhs_block = shift(rhs_block)
out_block += lhs_blocks((idx - i) % size) @ rhs_block
return out_block
out = matmul_allgather_overlapped(lhs, rhs)
print(jnp.allclose(out, lhs @ rhs, atol=1e-3, rtol=1e-3))
True
此实现允许在通信和计算之间重叠,并且还避免在每个设备上聚合大量中间数据。但在 TPU 上,通过沿环的一个方向仅置换,仅使用一半的互连带宽。要双向置换,我们只需将块分成两半,并将每半分别发送到每个方向:
@jax.jit
@partial(shard_map, mesh=mesh, in_specs=(lhs_spec, rhs_spec),
out_specs=rhs_spec)
def matmul_allgather_overlapped_bidi(lhs_block, rhs_block):
size = jax.lax.psum(1, 'i')
idx = jax.lax.axis_index('i')
shift_up = partial(jax.lax.ppermute, axis_name='i',
perm=[(i, (i + 1) % size) for i in range(size)])
shift_dn = partial(jax.lax.ppermute, axis_name='i',
perm=[(i, (i - 1) % size) for i in range(size)])
B = lhs_block.shape[1] // size // 2 # half-size blocks
lhs_blocks = lambda i, hi: lax.dynamic_slice_in_dim(lhs_block, (2*i+hi) * B, B, 1)
rhs_block_lo, rhs_block_hi = jnp.split(rhs_block, 2, axis=0)
out_block = lhs_blocks(idx, 0) @ rhs_block_lo
out_block += lhs_blocks(idx, 1) @ rhs_block_hi
for i in range(1, size):
rhs_block_lo = shift_up(rhs_block_lo)
rhs_block_hi = shift_dn(rhs_block_hi)
out_block += lhs_blocks((idx - i) % size, 0) @ rhs_block_lo
out_block += lhs_blocks((idx + i) % size, 1) @ rhs_block_hi
return out_block
out = matmul_allgather_overlapped_bidi(lhs, rhs)
print(jnp.allclose(out, lhs @ rhs, atol=1e-3, rtol=1e-3))
True
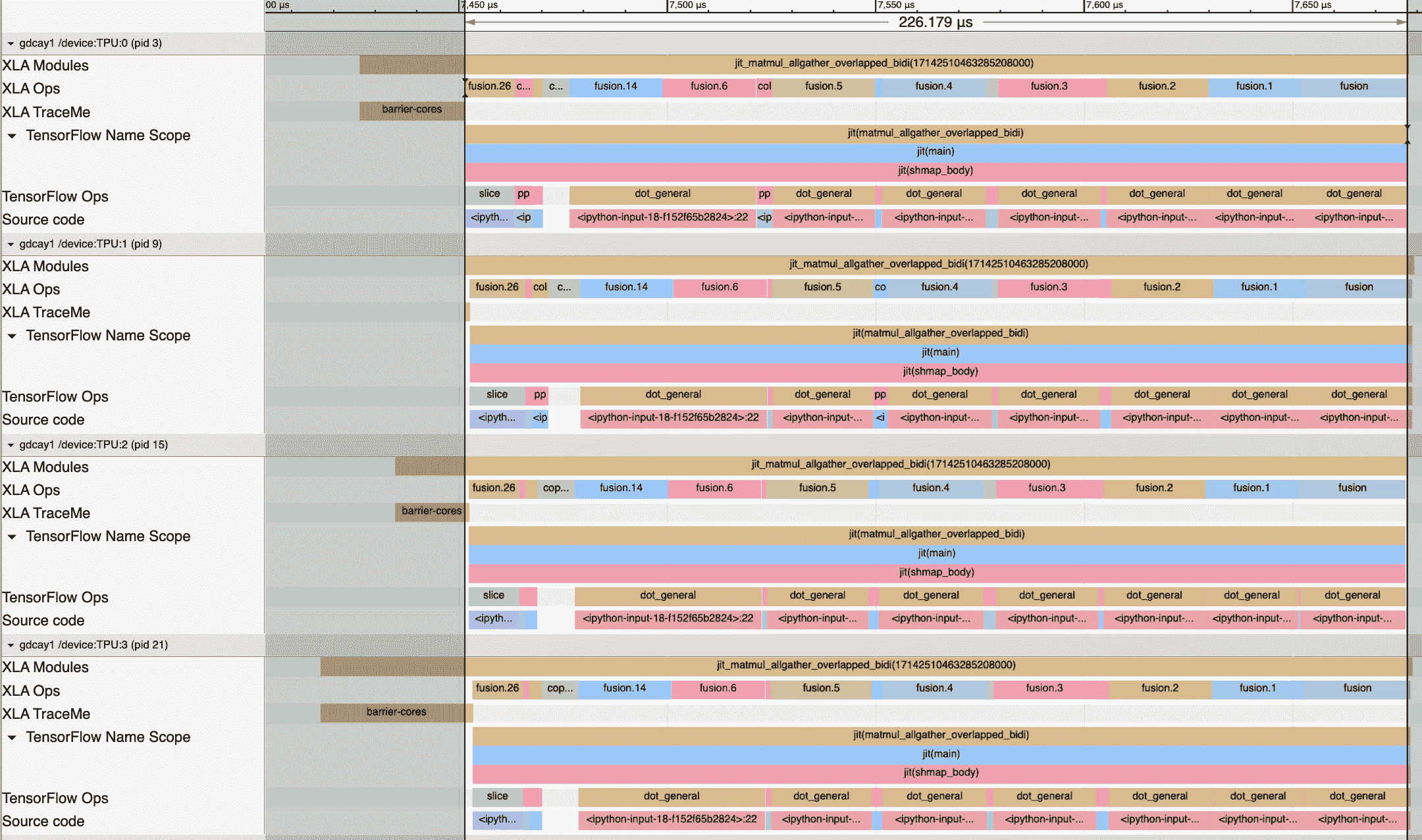
在实践中,为了减少编译时间,我们可能会将这些内容合并到jax.lax.fori_loop中。我们可能还涉及额外的轴并行化。
示例 2:psum_scatter结果
另一个我们可以开始的分片方法是,将lhs和rhs沿其收缩维度进行分片,输出再次像rhs一样进行分片:
lhs_spec = P(None, 'i')
lhs = device_put(lhs, lhs_spec)
rhs_spec = P('i', None)
rhs = device_put(rhs, rhs_spec)
在这里,我们可以使用reduce_scatter来执行分片上的收缩求和:
@partial(shard_map, mesh=mesh, in_specs=(lhs_spec, rhs_spec),
out_specs=rhs_spec)
def matmul_psumscatter(lhs_block, rhs_block):
out_summand = lhs_block @ rhs_block
return jax.lax.psum_scatter(out_summand, 'i', tiled=True)
out = matmul_psumscatter(lhs, rhs)
print(jnp.allclose(out, lhs @ rhs, atol=1e-3, rtol=1e-3))
True
但散射通信必须等待整个本地矩阵乘法完成后才能开始。为了实现通信/计算重叠,我们可以内联psum_scatter的ppermute实现,然后将通信步骤与本地矩阵乘法交错进行:
@partial(shard_map, mesh=mesh, in_specs=(lhs_spec, rhs_spec),
out_specs=rhs_spec)
def matmul_psumscatter_overlapped(lhs_block, rhs_block):
size = jax.lax.psum(1, 'i')
idx = jax.lax.axis_index('i')
shift = partial(jax.lax.ppermute, axis_name='i',
perm=[(i, (i - 1) % size) for i in range(size)])
lhs_block = lhs_block.reshape(size, -1, lhs_block.shape[1]) # split 1st axis
out_summand = lhs_block[(idx + 1) % size] @ rhs_block
for i in range(1, size):
out_summand = shift(out_summand)
out_summand += lhs_block[(idx + i + 1) % size] @ rhs_block
return out_summand
out = matmul_psumscatter_overlapped(lhs, rhs)
print(jnp.allclose(out, lhs @ rhs, atol=1e-3, rtol=1e-3))
True
如前例所示,为了充分利用 TPU 上的互连,我们将运行一个双向版本:
@partial(shard_map, mesh=mesh, in_specs=(lhs_spec, rhs_spec),
out_specs=rhs_spec)
def matmul_psumscatter_overlapped_bidi(lhs_block, rhs_block):
size = jax.lax.psum(1, 'i')
idx = jax.lax.axis_index('i')
shift_up = partial(jax.lax.ppermute, axis_name='i',
perm=[(i, (i + 1) % size) for i in range(size)])
shift_dn = partial(jax.lax.ppermute, axis_name='i',
perm=[(i, (i - 1) % size) for i in range(size)])
B = lhs_block.shape[0] // size // 2 # half-size blocks
lhs_blocks = lambda i, hi: lax.dynamic_slice_in_dim(lhs_block, (2*i+hi) * B, B, 0)
out_summand_lo = lhs_blocks((idx - 1) % size, 0) @ rhs_block
out_summand_hi = lhs_blocks((idx + 1) % size, 1) @ rhs_block
for i in range(1, size):
out_summand_lo = shift_up(out_summand_lo)
out_summand_hi = shift_dn(out_summand_hi)
out_summand_lo += lhs_blocks((idx - i - 1) % size, 0) @ rhs_block
out_summand_hi += lhs_blocks((idx + i + 1) % size, 1) @ rhs_block
return jnp.concatenate([out_summand_lo, out_summand_hi])
out = matmul_psumscatter_overlapped_bidi(lhs, rhs)
print(jnp.allclose(out, lhs @ rhs, atol=1e-3, rtol=1e-3))
True
神经网络
我们可以使用shard_map来并行计算神经网络中的计算,可以单独使用,也可以与jax.jit中的自动分区组合使用。本节基于此玩具神经网络和随机数据提供了一些示例:
import jax
import jax.numpy as jnp
def predict(params, inputs):
for W, b in params:
outputs = jnp.dot(inputs, W) + b
inputs = jax.nn.relu(outputs)
return outputs
def loss(params, batch):
inputs, targets = batch
predictions = predict(params, inputs)
return jnp.mean(jnp.sum((predictions - targets)**2, axis=-1))
def init_layer(key, n_in, n_out):
k1, k2 = jax.random.split(key)
W = jax.random.normal(k1, (n_in, n_out)) / jnp.sqrt(n_in)
b = jax.random.normal(k2, (n_out,))
return W, b
def init(key, layer_sizes, batch_size):
key, *keys = jax.random.split(key, len(layer_sizes))
params = list(map(init_layer, keys, layer_sizes[:-1], layer_sizes[1:]))
key, *keys = jax.random.split(key, 3)
inputs = jax.random.normal(keys[0], (batch_size, layer_sizes[0]))
targets = jax.random.normal(keys[1], (batch_size, layer_sizes[-1]))
return params, (inputs, targets)
layer_sizes = [784, 128, 128, 128, 128, 128, 8]
batch_size = 32
params, batch = init(jax.random.PRNGKey(0), layer_sizes, batch_size)
将这些示例与纯粹的“分布式数组和自动分区”文档中的自动分区示例进行比较。在这些自动分区示例中,我们无需编辑模型函数即可使用不同的并行化策略,而在shard_map中,我们经常需要这样做。
8 路批次数据并行
最简单的多设备并行策略是将输入和目标的批次在多个设备上进行分片,将参数复制到这些设备上,并并行应用模型于数据的这些分片。为了评估总损失,设备只需在末尾进行标量大小的全约和求和。(为了评估损失的梯度,设备必须在后向传播中执行参数梯度的全约和求和。)
from functools import partial
from jax.sharding import NamedSharding, Mesh, PartitionSpec as P
from jax.experimental.shard_map import shard_map
from jax.experimental import mesh_utils
devices = mesh_utils.create_device_mesh((8,))
# replicate initial params on all devices, shard data batch over devices
mesh = Mesh(devices, ('batch',))
batch = jax.device_put(batch, NamedSharding(mesh, P('batch')))
params = jax.device_put(params, NamedSharding(mesh, P()))
# adapt the loss function to sum the losses across devices
def loss_dp(params, batch):
@partial(shard_map, mesh=mesh, in_specs=P('batch', None), out_specs=P())
def loss_spmd(local_batch):
inputs, targets = local_batch
predictions = predict(params, inputs) # use reference 'predict`
local_loss = jnp.mean(jnp.sum((predictions - targets)**2, axis=-1))
return jax.lax.pmean(local_loss, 'batch')
return loss_spmd(batch)
我们可以检查损失及其梯度是否与参考(基础)模型匹配:
print(jax.jit(loss)(params, batch))
print(jax.jit(loss_dp)(params, batch))
22.779888
22.779888
def allclose(a, b):
return tree_all(tree_map(partial(jnp.allclose, atol=1e-2, rtol=1e-2), a, b))
print(allclose(jax.jit(jax.grad(loss))(params, batch),
jax.jit(jax.grad(loss_dp))(params, batch)))
True
我们可以打印编译器 IR 以检查梯度计算,并验证在预期位置进行的集体全约和求和操作:在前向传播的末尾计算损失值时,以及在后向传播中计算总参数梯度时。
8 路完全分片数据并行(FSDP)
另一种策略是在设备上额外对参数进行分片,在需要完整值进行jnp.dot或偏置添加时进行全部聚集。由于我们每次只在本地设备内存中保留一个完整的参数,而不像前面的 DP 示例中在所有设备内存中保留所有参数,这样我们可以释放出大量内存,用于更大的模型或更大的批处理大小。并且由于 XLA 会重叠计算和设备间通信,所以墙钟时间不会受影响。
因此,现在我们需要在两个地方进行集体操作:模型预测函数predict需要在使用参数之前对其进行全部聚集,而与 DP 情况一样,损失函数需要对本地损失进行求和以计算总损失。
还有一项我们需要的内容:我们不希望在反向传播中存储从前向传播中完全聚集的参数。相反,我们希望在反向传播时再次聚集它们。我们可以通过使用jax.remat与自定义策略(或custom_vjp)来表达这一点,尽管 XLA 通常会自动进行该重现操作。
这种通用的FSDP 方法类似于权重更新分片(WUS)和ZeRO-3。
# shard data batch *and params* over devices
mesh = Mesh(devices, ('batch',))
batch = jax.device_put(batch, NamedSharding(mesh, P('batch')))
params = jax.device_put(params, NamedSharding(mesh, P('batch')))
# adapt the prediction function to gather weights just before their use,
# and to re-gather them on the backward pass (rather than saving them)
@partial(jax.remat, policy=lambda op, *_, **__: str(op) != 'all_gather')
def predict_fsdp(params_frag, inputs):
for W_frag, b_frag in params_frag:
W = jax.lax.all_gather(W_frag, 'batch', tiled=True)
b = jax.lax.all_gather(b_frag, 'batch', tiled=True)
outputs = jnp.dot(inputs, W) + b
inputs = jax.nn.relu(outputs)
return outputs
def loss_fsdp(params, batch):
@partial(shard_map, mesh=mesh, in_specs=P('batch'), out_specs=P())
def loss_spmd(local_params, local_batch):
inputs, targets = local_batch
predictions = predict_fsdp(local_params, inputs)
local_loss = jnp.mean(jnp.sum((predictions - targets)**2, axis=-1))
return jax.lax.pmean(local_loss, 'batch')
return loss_spmd(params, batch)
再次,我们可以检查损失及其梯度是否与参考模型匹配:
print(jax.jit(loss)(params, batch))
print(jax.jit(loss_fsdp)(params, batch))
print(allclose(jax.jit(jax.grad(loss))(params, batch),
jax.jit(jax.grad(loss_fsdp))(params, batch)))
22.779888
22.779888
True
8 路张量并行性(TP)
通常我们不单独使用张量模型并行性,但单独看它可以作为并行矩阵乘法的一个良好热身。这也是在库函数中使用shard_map的一个良好示例,被调用于基于jit的大型计算中。
并行化的理念是我们将保持数据/激活沿其特征轴分片(而不是批处理轴),并且我们将类似地在输入特征轴上分片权重矩阵(和在其特征轴上的偏置)。然后,为了执行并行矩阵乘法,我们将执行本地矩阵乘法,然后进行psum_scatter以对本地结果求和并高效地分散结果的分片。
devices = mesh_utils.create_device_mesh((8,))
mesh = Mesh(devices, ('feats',))
batch = jax.device_put(batch, NamedSharding(mesh, P(None, 'feats')))
params = jax.device_put(params, NamedSharding(mesh, P('feats')))
def predict_tp(params, inputs):
for W, b in params:
outputs = gemm_tp(inputs, W, b)
inputs = jax.nn.relu(outputs)
return outputs
@partial(shard_map, mesh=mesh,
in_specs=(P(None, 'feats'), P('feats', None), P('feats')),
out_specs=P(None, 'feats'))
def gemm_tp(inputs, W, b):
block_result = jnp.dot(inputs, W)
return jax.lax.psum_scatter(block_result, 'feats',
scatter_dimension=1, tiled=True) + b
def loss_tp(params, batch):
inputs, targets = batch
predictions = predict_tp(params, inputs)
return jnp.mean(jnp.sum((predictions - targets) ** 2, axis=-1)) # NOTE psum!
FSDP + TP,在顶层使用shard_map
我们可以将这些策略组合在一起,使用多轴并行性。
devices = mesh_utils.create_device_mesh((4, 2))
mesh = Mesh(devices, ('batch', 'feats'))
batch_ = jax.device_put(batch, NamedSharding(mesh, P('batch', 'feats')))
params_ = jax.device_put(params, NamedSharding(mesh, P(('batch', 'feats'))))
# mostly same as previous predict_fsdp definition, except we call gemm_tp
@partial(jax.remat, policy=lambda op, *_, **__: str(op) != 'all_gather')
def predict_fsdp_tp(params_frag, inputs):
for W_frag, b_frag in params_frag:
W = jax.lax.all_gather(W_frag, 'batch', tiled=True)
b = jax.lax.all_gather(b_frag, 'batch', tiled=True)
block_result = jnp.dot(inputs, W)
outputs = jax.lax.psum_scatter(block_result, 'feats',
scatter_dimension=1, tiled=True) + b
inputs = jax.nn.relu(outputs)
return outputs
@partial(shard_map, mesh=mesh,
in_specs=(P(('feats', 'batch')), P('batch', 'feats')),
out_specs=P())
def loss_fsdp_tp(local_params, local_batch):
inputs, targets = local_batch
predictions = predict_fsdp_tp(local_params, inputs)
sq_err = jax.lax.psum(jnp.sum((predictions - targets)**2, axis=-1), 'feats')
return jax.lax.pmean(jnp.mean(sq_err), 'batch')
注意我们必须进行两次集体归约的方式:一次是在'feats'上,另一次是在'batch'上。在纯 TP 示例中,我们没有显式写出'feats'归约,因为我们仅在gemm_tp内部使用了shard_map;在调用loss_tp时,编译器会自动将我们对jnp.sum的使用转换为根据predict_tp返回的分片结果执行所需的psum。
print(jax.jit(loss)(params, batch))
print(jax.jit(loss_fsdp_tp)(params_, batch_))
print(allclose(jax.jit(jax.grad(loss))(params, batch),
jax.jit(jax.grad(loss_fsdp_tp))(params, batch)))
22.779886
22.779886
True
SPMD 管道并行性(PP)
通过流水线并行,我们的目标是并行评估网络中不同深度层的层。例如,一个设备可能计算第一层的应用,而另一个设备计算第二层的应用;当它们完成时,第一个设备将其结果传递给第二个设备,而第二个设备将其结果传递给负责第三层的设备,这个过程重复进行。一般来说,流水线阶段的数量可能与层的数量不同,因为每个阶段可能负责多个层。
使用 SPMD 流水线,我们利用网络中大多数层应用计算的事实,只是参数值不同。特别是,我们可以堆叠除了第一层和最后一层之外的所有参数,然后使用shard_map将这些层参数块映射到管道阶段。然后我们使用jax.lax.ppermute集合来沿并行管道向下移动数据。
这种特定的流水线策略本质上是GPipe 策略。有几种变体以及相当不同的策略,哪一种适合取决于各阶段之间的网络速度和批量大小。但是在本教程中,我们将专注于只有一种策略。
首先,我们选择一些流水线参数:
L = len(params) - 2 # num layers, excluding first and last
N = batch_size # batch size
F = params[0][0].shape[1] # num features
# choose some pipeline parameters
S = 2 # number of stages
B = 8 # size of each microbatch
assert L % S == 0, "S (number of stages) must divide L (number of inner layers)"
# compute some useful quantities
M, ragged = divmod(N, B) # M is number of microbatches
assert not ragged, "B (size of each microbatch) must divide total batch size"
K, ragged = divmod(M, S) # K is microbatches per stage
assert not ragged, "S (number of stages) must divide number of microbatches"
print(f'{S} stages, {L // S} layer(s) per stage, {L} pipelined layers total')
print(f'{B} examples per microbatch, {M} microbatches total')
2 stages, 2 layer(s) per stage, 4 pipelined layers total
8 examples per microbatch, 4 microbatches total
mesh = Mesh(jax.devices()[:S], ('stages',))
def predict_pp(params, inputs):
(W_first, b_first), inner_params, (W_last, b_last) = params
inputs = jax.nn.relu(jnp.dot(inputs, W_first) + b_first)
inputs = spmd_pipeline(lambda Wb, x: jax.nn.relu(x @ Wb[0] + Wb[1]),
inner_params, inputs)
outputs = jnp.dot(inputs, W_last) + b_last
return outputs
@partial(shard_map, mesh=mesh, in_specs=((P(), P('stages'), P()), P('stages')),
out_specs=P())
def loss_pp(params, batch):
inputs, targets = batch
predictions = predict_pp(params, inputs.reshape(K, B, -1)).reshape(K * B, -1)
local_loss = jnp.mean(jnp.sum((predictions - targets)**2, axis=-1))
return jax.lax.pmean(local_loss, 'stages')
def spmd_pipeline(fn, stage_params, inputs):
stage = jax.lax.axis_index('stages')
outputs = jnp.zeros_like(inputs) * jnp.nan
state = jnp.zeros((L // S, B, F)) * jnp.nan
for i in range(M+L-1):
state = state.at[0].set(jnp.where(stage == 0, inputs[i % K], state[0]))
state = jax.vmap(fn)(stage_params, state)
outputs = outputs.at[(i-L+1) % K].set(jnp.where(stage == S-1, state[-1], outputs[(i-L+1) % K]))
state, inputs, outputs = shift(i, state, inputs, outputs)
outputs = jax.lax.ppermute(outputs, 'stages', [(i, (i+1) % S) for i in range(S)])
return outputs
def shift(i, state, inputs, outputs):
sh = lambda x, d: jax.lax.ppermute(x, 'stages', [(i, (i+d) % S) for i in range(S)])
state = jnp.roll(state, +1, axis=0).at[0].set(sh(state[-1], +1))
if (i % K) == (-1 % K):
inputs = sh(inputs, +1)
if ((i-L+1) % K) == (-1 % K):
outputs = sh(outputs, +1)
return state, inputs, outputs
first_params, *inner_params, last_params = params
Ws, bs = zip(*inner_params)
params_stacked = jnp.stack(Ws), jnp.stack(bs)
first_params = jax.device_put(first_params, NamedSharding(mesh, P()))
params_stacked = jax.device_put(params_stacked, NamedSharding(mesh, P('stages')))
last_params = jax.device_put(last_params, NamedSharding(mesh, P()))
params_ = first_params, params_stacked, last_params
batch_ = jax.device_put(batch, NamedSharding(mesh, P('stages')))
print(jax.jit(loss)(params, batch))
print(jax.jit(loss_pp)(params_, batch_))
22.779886
22.779884
_ = jax.jit(jax.grad(loss_pp))(params_, batch_) # don't crash
分布式数据加载在多主机/多进程环境中
原文:
jax.readthedocs.io/en/latest/distributed_data_loading.html
这个高级指南演示了如何执行分布式数据加载——当你在多主机或多进程环境中运行 JAX 时,用于 JAX 计算的数据被分布在多个进程中。本文档涵盖了分布式数据加载的整体方法,以及如何将其应用于数据并行(更简单)和模型并行(更复杂)的工作负载。
分布式数据加载通常比起其它方法更高效(数据分割在各个进程之间),但同时也更复杂。例如:1)在单一进程中加载整个全局数据,将其分割并通过 RPC 发送到其它进程需要的部分;和 2)在所有进程中加载整个全局数据,然后在每个进程中只使用需要的部分。加载整个全局数据通常更简单但更昂贵。例如,在机器学习中,训练循环可能会因等待数据而阻塞,并且每个进程会使用额外的网络带宽。
注意
当使用分布式数据加载时,每个设备(例如每个 GPU 或 TPU)必须访问其需要运行计算的输入数据分片。这通常使得分布式数据加载比前述的替代方案更复杂和具有挑战性。如果错误的数据分片最终出现在错误的设备上,计算仍然可以正常运行,因为计算无法知道输入数据“应该”是什么。然而,最终结果通常是不正确的,因为输入数据与预期不同。
加载jax.Array的一般方法
考虑一个情况,从未由 JAX 生成的原始数据创建单个jax.Array。这些概念适用于不仅限于加载批量数据记录,例如任何未直接由 JAX 计算产生的多进程jax.Array。例如:1)从检查点加载模型权重;或者 2)加载大型空间分片图像。
每个jax.Array都有一个相关的Sharding,描述了每个全局设备所需的全局数据的哪个分片。当你从头创建一个jax.Array时,你还需要创建其Sharding。这是 JAX 理解数据在各个设备上布局的方式。你可以创建任何你想要的Sharding。在实践中,通常根据你正在实现的并行策略选择一个Sharding(稍后在本指南中将更详细地了解数据和模型并行)。你也可以根据原始数据在每个进程中如何生成来选择一个Sharding。
一旦定义了Sharding,你可以使用addressable_devices()为当前进程需要加载数据的设备提供一个设备列表。(注:术语“可寻址设备”是“本地设备”的更一般版本。目标是确保每个进程的数据加载器为其所有本地设备提供正确的数据。)
示例
例如,考虑一个(64, 128)的jax.Array,你需要将其分片到 4 个进程,每个进程有 2 个设备(总共 8 个设备)。这将导致 8 个唯一的数据分片,每个设备一个。有许多分片jax.Array的方法。你可以沿着jax.Array的第二维进行 1D 分片,每个设备得到一个(64, 16)的分片,如下所示:

在上图中,每个数据分片都有自己的颜色,表示哪个进程需要加载该分片。例如,假设进程0的 2 个设备包含分片A和B,对应于全局数据的第一个(64, 32)部分。
你可以选择不同的分片到设备的分布方式。例如:

这里是另一个示例——二维分片:

但是,无论jax.Array如何分片,你都必须确保每个进程的数据加载器提供/加载全局数据所需的分片。有几种高级方法可以实现这一点:1)在每个进程中加载全局数据;2)使用每设备数据流水线;3)使用合并的每进程数据流水线;4)以某种方便的方式加载数据,然后在计算中重新分片。
选项 1:在每个进程中加载全局数据

使用此选项,每个进程:
-
加载所需的完整值;并且
-
仅将所需的分片传输到该进程的本地设备。
这并不是一个高效的分布式数据加载方法,因为每个进程都会丢弃其本地设备不需要的数据,并且总体加载的数据量可能会比必要的要多。但这个选项可以运行,并且相对简单实现,对于某些工作负载的性能开销可能是可以接受的(例如,如果全局数据量较小)。
选项 2:使用每设备数据流水线

在此选项中,每个进程为其每个本地设备设置一个数据加载器(即,每个设备仅为其所需的数据分片设置自己的数据加载器)。
这在加载数据方面非常高效。有时,独立考虑每个设备可能比一次性考虑所有进程的本地设备更简单(参见下面的选项 3:使用合并的每进程数据流水线)。然而,多个并发数据加载器有时会导致性能问题。
选项 3:使用集中的每个进程数据管道

如果选择此选项,每个过程:
-
设置一个单一的数据加载器,加载所有本地设备所需的数据;然后
-
在传输到每个本地设备之前对本地数据进行分片。
这是最有效的分布式加载方式。然而,这也是最复杂的,因为需要逻辑来确定每个设备所需的数据,以及创建一个单一的数据加载,仅加载所有这些数据(理想情况下,没有其他额外的数据)。
选项 4:以某种便捷方式加载数据,在计算中重新分片

这个选项比前述选项(从 1 到 3)更难解释,但通常比它们更容易实现。
想象一个场景,设置数据加载器以精确加载您需要的数据,无论是为每个设备还是每个进程加载器,这可能很困难或几乎不可能。然而,仍然可以为每个进程设置一个数据加载器,加载数据的1 / num_processes,只是没有正确的分片。
然后,继续使用您之前的 2D 示例分片,假设每个过程更容易加载数据的单个列:
然后,您可以创建一个带有表示每列数据的Sharding的jax.Array,直接将其传递到计算中,并使用jax.lax.with_sharding_constraint()立即将列分片输入重新分片为所需的分片。由于数据在计算中重新分片,它将通过加速器通信链路(例如 TPU ICI 或 NVLink)进行重新分片。
选项 4 与选项 3(使用集中的每个进程数据管道)具有类似的优点:
-
每个过程仍然具有单个数据加载器;和
-
全局数据在所有过程中仅加载一次;和
-
全局数据的额外好处在于提供如何加载数据的更大灵活性。
然而,这种方法使用加速器互连带宽执行重新分片,可能会降低某些工作负载的速度。选项 4 还要求将输入数据表示为单独的Sharding,除了目标Sharding。
复制
复制描述了多个设备具有相同数据分片的过程。上述提到的一般选项(选项 1 到 4)仍然适用于复制。唯一的区别是某些过程可能会加载相同的数据分片。本节描述了完全复制和部分复制。
全部复制
完全复制是所有设备都具有数据的完整副本的过程(即,“分片”是整个数组值)。
在下面的示例中,由于总共有 8 个设备(每个进程 2 个),您将得到完整数据的 8 个副本。数据的每个副本都未分片,即副本存在于单个设备上:

部分复制
部分复制描述了一个过程,其中数据有多个副本,并且每个副本分片到多个设备上。对于给定的数组值,通常有许多执行部分复制的可能方法(注意:对于给定的数组形状,总是存在单一完全复制的Sharding)。
下面是两个可能的示例。
在下面的第一个示例中,每个副本都分片到进程的两个本地设备上,总共有 4 个副本。这意味着每个进程都需要加载完整的全局数据,因为其本地设备将具有数据的完整副本。

在下面的第二个示例中,每个副本仍然分片到两个设备上,但每个设备对是分布在两个不同的进程中。进程 0(粉色)和进程 1(黄色)都只需要加载数据的第一行,而进程 2(绿色)和进程 3(蓝色)都只需要加载数据的第二行:

现在您已经了解了创建 jax.Array 的高级选项,让我们将它们应用于机器学习应用程序的数据加载。
数据并行性
在纯数据并行性(无模型并行性)中:
-
您在每个设备上复制模型;和
-
每个模型副本(即每个设备)接收不同的副本批次数据。

将输入数据表示为单个 jax.Array 时,该数组包含此步骤所有副本的数据(称为全局批处理),其中 jax.Array 的每个分片包含单个副本批处理。您可以将其表示为跨所有设备的 1D 分片(请查看下面的示例)——换句话说,全局批处理由所有副本批处理沿批处理轴连接在一起组成。

应用此框架,您可以得出结论,进程 0 应该获取全局批处理的第一个季度(8 的 2 分之一),而进程 1 应该获取第二个季度,依此类推。
但是,您如何知道第一个季度是什么?您如何确保进程 0 获得第一个季度?幸运的是,数据并行性有一个非常重要的技巧,这意味着您不必回答这些问题,并使整个设置更简单。
关于数据并行性的重要技巧
诀窍在于您不需要关心哪个每副本批次会落到哪个副本上。因此,不管哪个进程加载了一个批次都无所谓。原因在于每个设备都对应执行相同操作的模型副本,每个设备获取全局批次中的每个每副本批次都无关紧要。
这意味着您可以自由重新排列全局批次中的每副本批次。换句话说,您可以随机化每个设备获取哪个数据分片。
例如:

通常,重新排列jax.Array的数据分片并不是一个好主意 —— 事实上,您是在对jax.Array的值进行置换!然而,对于数据并行处理来说,全局批次顺序并不重要,您可以自由重新排列全局批次中的每个每副本批次,正如前面已经提到的那样。
这简化了数据加载,因为这意味着每个设备只需要独立的每副本批次流,大多数数据加载器可以通过为每个进程创建一个独立的流水线并将结果分割为每副本批次来轻松实现。

这是选项 2: 合并每进程数据流水线的一个实例。您也可以使用其他选项(如 0、1 和 3,在本文档的早期部分有介绍),但这个选项相对简单和高效。
这是一个如何使用 tf.data 实现此设置的示例:
import jax
import tensorflow as tf
import numpy as np
################################################################################
# Step 1: setup the Dataset for pure data parallelism (do once)
################################################################################
# Fake example data (replace with your Dataset)
ds = tf.data.Dataset.from_tensor_slices(
[np.ones((16, 3)) * i for i in range(100)])
ds = ds.shard(num_shards=jax.process_count(), index=jax.process_index())
################################################################################
# Step 2: create a jax.Array of per-replica batches from the per-process batch
# produced from the Dataset (repeat every step). This can be used with batches
# produced by different data loaders as well!
################################################################################
# Grab just the first batch from the Dataset for this example
per_process_batch = ds.as_numpy_iterator().next()
per_process_batch_size = per_process_batch.shape[0] # adjust if your batch dim
# isn't 0
per_replica_batch_size = per_process_batch_size // jax.local_device_count()
assert per_process_batch_size % per_replica_batch_size == 0, \
"This example doesn't implement padding."
per_replica_batches = np.split(per_process_batch, jax.local_device_count())
# Thanks to the very important trick about data parallelism, no need to care what
# order the devices appear in the sharding.
sharding = jax.sharding.PositionalSharding(jax.devices())
# PositionalSharding must have same rank as data being sharded.
sharding = sharding.reshape((jax.device_count(),) +
(1,) * (per_process_batch.ndim - 1))
global_batch_size = per_replica_batch_size * jax.device_count()
global_batch_shape = ((global_batch_size,) + per_process_batch.shape[1:])
global_batch_array = jax.make_array_from_single_device_arrays(
global_batch_shape, sharding,
# Thanks again to the very important trick, no need to care which device gets
# which per-replica batch.
arrays=[jax.device_put(batch, device)
for batch, device
in zip(per_replica_batches, sharding.addressable_devices)])
assert global_batch_array.shape == global_batch_shape
assert (global_batch_array.addressable_shards[0].data.shape ==
per_replica_batches[0].shape)
数据 + 模型并行处理
在模型并行处理中,您将每个模型副本分片到多个设备上。如果您使用纯模型并行处理(不使用数据并行处理):
-
只有一个模型副本分片在所有设备上;并且
-
数据通常在所有设备上完全复制。
本指南考虑了同时使用数据和模型并行处理的情况:
-
您将多个模型副本中的每一个分片到多个设备上;并且
-
您可以部分复制数据到每个模型副本 —— 每个模型副本中的设备得到相同的每副本批次,不同模型副本之间的设备得到不同的每副本批次。
进程内的模型并行处理
对于数据加载,最简单的方法可以是在单个进程的本地设备中将每个模型副本分片。
举个例子,让我们切换到每个有 4 个设备的 2 个进程(而不是每个有 2 个设备的 4 个进程)。考虑一个情况,每个模型副本都分片在单个进程的 2 个本地设备上。这导致每个进程有 2 个模型副本,总共 4 个模型副本,如下所示:

在这里,再次强调,输入数据表示为单个jax.Array,其中每个分片是一个每副本批次的 1D 分片,有一个例外:
-
不同于纯数据并行情况,你引入了部分复制,并制作了 1D 分片全局批次的 2 个副本。
-
这是因为每个模型副本由两个设备组成,每个设备都需要一个副本批次的拷贝。

将每个模型副本保持在单个进程内可以使事情变得更简单,因为你可以重用上述纯数据并行设置,除非你还需要复制每个副本的批次:

注意
同样重要的是要将每个副本批次复制到正确的设备上! 虽然数据并行性的一个非常重要的技巧意味着你不在乎哪个批次最终落到哪个副本上,但你确实关心单个副本只得到一个批次。
例如,这是可以的:

但是,如果你在加载每批数据到本地设备时不小心,可能会意外地创建未复制的数据,即使分片(和并行策略)表明数据已经复制:

如果你意外地创建了应该在单个进程内复制的未复制数据的jax.Array,JAX 将会报错(不过对于跨进程的模型并行性,情况并非总是如此;请参阅下一节)。
下面是使用tf.data实现每个进程模型并行性和数据并行性的示例:
import jax
import tensorflow as tf
import numpy as np
################################################################################
# Step 1: Set up the Dataset with a different data shard per-process (do once)
# (same as for pure data parallelism)
################################################################################
# Fake example data (replace with your Dataset)
per_process_batches = [np.ones((16, 3)) * i for i in range(100)]
ds = tf.data.Dataset.from_tensor_slices(per_process_batches)
ds = ds.shard(num_shards=jax.process_count(), index=jax.process_index())
################################################################################
# Step 2: Create a jax.Array of per-replica batches from the per-process batch
# produced from the Dataset (repeat every step)
################################################################################
# Grab just the first batch from the Dataset for this example
per_process_batch = ds.as_numpy_iterator().next()
num_model_replicas_per_process = 2 # set according to your parallelism strategy
num_model_replicas_total = num_model_replicas_per_process * jax.process_count()
per_process_batch_size = per_process_batch.shape[0] # adjust if your batch dim
# isn't 0
per_replica_batch_size = (per_process_batch_size //
num_model_replicas_per_process)
assert per_process_batch_size % per_replica_batch_size == 0, \
"This example doesn't implement padding."
per_replica_batches = np.split(per_process_batch,
num_model_replicas_per_process)
# Create an example `Mesh` for per-process data parallelism. Make sure all devices
# are grouped by process, and then resize so each row is a model replica.
mesh_devices = np.array([jax.local_devices(process_idx)
for process_idx in range(jax.process_count())])
mesh_devices = mesh_devices.reshape(num_model_replicas_total, -1)
# Double check that each replica's devices are on a single process.
for replica_devices in mesh_devices:
num_processes = len(set(d.process_index for d in replica_devices))
assert num_processes == 1
mesh = jax.sharding.Mesh(mesh_devices, ["model_replicas", "data_parallelism"])
# Shard the data across model replicas. You don't shard across the
# data_parallelism mesh axis, meaning each per-replica shard will be replicated
# across that axis.
sharding = jax.sharding.NamedSharding(
mesh, jax.sharding.PartitionSpec("model_replicas"))
global_batch_size = per_replica_batch_size * num_model_replicas_total
global_batch_shape = ((global_batch_size,) + per_process_batch.shape[1:])
# Create the final jax.Array using jax.make_array_from_callback. The callback
# will be called for each local device, and passed the N-D numpy-style index
# that describes what shard of the global data that device should receive.
#
# You don't need care exactly which index is passed in due to the very important data
# parallelism, but you do use the index argument to make sure you replicate each
# per-replica batch correctly -- the `index` argument will be the same for
# devices in the same model replica, and different for devices in different
# model replicas.
index_to_batch = {}
def callback(index: tuple[slice, ...]) -> np.ndarray:
# Python `slice` objects aren't hashable, so manually create dict key.
index_key = tuple((slice_.start, slice_.stop) for slice_ in index)
if index_key not in index_to_batch:
# You don't care which per-replica batch goes to which replica, just take the
# next unused one.
index_to_batch[index_key] = per_replica_batches[len(index_to_batch)]
return index_to_batch[index_key]
global_batch_array = jax.make_array_from_callback(
global_batch_shape, sharding, callback)
assert global_batch_array.shape == global_batch_shape
assert (global_batch_array.addressable_shards[0].data.shape ==
per_replica_batches[0].shape)
跨进程的模型并行性
当模型副本分布在不同进程中时,可能会变得更加有趣,无论是:
-
因为单个副本无法适应一个进程;或者
-
因为设备分配并不是按照这种方式设置的。
例如,回到之前的设置,4 个每个有 2 个设备的进程,如果你像这样为副本分配设备:

这与之前的每个进程模型并行性示例相同的并行策略 - 4 个模型副本,每个副本分布在 2 个设备上。唯一的区别在于设备分配 - 每个副本的两个设备分布在不同的进程中,每个进程只负责每个副本批次的一份拷贝(但是对于两个副本)。
像这样跨进程分割模型副本可能看起来是一种随意且不必要的做法(在这个例子中,这可能是这样),但实际的部署可能会采用这种设备分配方式,以最大程度地利用设备之间的通信链路。
数据加载现在变得更加复杂,因为跨进程需要一些额外的协调。在纯数据并行和每个进程模型并行的情况下,每个进程只需加载唯一的数据流即可。现在某些进程必须加载相同的数据,而另一些进程必须加载不同的数据。在上述示例中,进程0和2(分别显示为粉色和绿色)必须加载相同的 2 个每个副本的批次,并且进程1和3(分别显示为黄色和蓝色)也必须加载相同的 2 个每个副本的批次(但不同于进程0和2的批次)。
此外,每个进程不混淆它的 2 个每个副本的批次是非常重要的。虽然您不关心哪个批次落在哪个副本(这是关于数据并行的一个非常重要的技巧),但您需要确保同一个副本中的所有设备获取相同的批次。例如,以下情况是不好的:

注意
截至 2023 年 8 月,JAX 无法检测到如果jax.Array在进程之间的分片应该复制但实际没有复制,则在运行计算时会产生错误结果。因此,请务必注意避免这种情况!
要在每个设备上获取正确的每个副本批次,您需要将全局输入数据表示为以下的jax.Array:

命名轴和 xmap 轻松修改并行处理策略
原文:
jax.readthedocs.io/en/latest/notebooks/xmap_tutorial.html
更新: xmap 已弃用,并将在未来版本中删除。在 JAX 中执行多设备编程的推荐方法是使用:1) jit(计算自动分区和 jax.Array 分片); 和/或 2) shard_map(手动数据分片)。详细了解请参阅shard_map JEP 文档中的“为什么 pmap 或 xmap 不能解决此问题?”。
本教程介绍了 JAX xmap (jax.experimental.maps.xmap) 和随附的命名轴编程模型。通过阅读本教程,您将学习如何使用命名轴编写避免错误、自描述的函数,然后控制它们在从笔记本电脑 CPU 到最大 TPU 超级计算机的任何规模的硬件上执行的方式。
我们从一个玩具神经网络的例子开始。
从玩具神经网络中的位置到名称
JAX 的演示通常从纯 NumPy 编写的简单神经网络预测函数和损失开始。这是一个具有一个隐藏层的简单网络:
import os
os.environ["XLA_FLAGS"] = '--xla_force_host_platform_device_count=8' # Use 8 CPU devices
import jax.numpy as jnp
from jax import lax
from jax.nn import one_hot, relu
from jax.scipy.special import logsumexp
def predict(w1, w2, images):
hiddens = relu(jnp.dot(images, w1))
logits = jnp.dot(hiddens, w2)
return logits - logsumexp(logits, axis=1, keepdims=True)
def loss(w1, w2, images, labels):
predictions = predict(w1, w2, images)
targets = one_hot(labels, predictions.shape[-1])
losses = jnp.sum(targets * predictions, axis=1)
return -jnp.mean(losses, axis=0)
然后我们可以用正确的形状初始化输入并计算损失值:
w1 = jnp.zeros((784, 512))
w2 = jnp.zeros((512, 10))
images = jnp.zeros((128, 784))
labels = jnp.zeros(128, dtype=jnp.int32)
print(loss(w1, w2, images, labels))
这是我们如何使用命名轴写相同函数的方式。如果您无法理解 API 的细节,请不要担心。现在这些不重要,我们将逐步解释一切。这只是为了展示在学习之前您可以使用 xmap 做些什么!
def named_predict(w1, w2, image):
hidden = relu(lax.pdot(image, w1, 'inputs'))
logits = lax.pdot(hidden, w2, 'hidden')
return logits - logsumexp(logits, 'classes')
def named_loss(w1, w2, images, labels):
predictions = named_predict(w1, w2, images)
num_classes = lax.psum(1, 'classes')
targets = one_hot(labels, num_classes, axis='classes')
losses = lax.psum(targets * predictions, 'classes')
return -lax.pmean(losses, 'batch')
这段代码更简单:我们在调用 jnp.dot 等函数时不需要担心轴的顺序,也不需要记住使用 logsumexp、jnp.sum 或 jnp.mean 时要减少哪个轴位置。
但真正的优势在于,名称使我们可以使用 xmap 控制函数的执行。最简单的情况下,xmap 将仅在所有命名轴上向量化,使函数的执行方式与其位置轴的对应方式相同:
from jax.experimental.maps import xmap
in_axes = [['inputs', 'hidden', ...],
['hidden', 'classes', ...],
['batch', 'inputs', ...],
['batch', ...]]
loss = xmap(named_loss, in_axes=in_axes, out_axes=[...])
print(loss(w1, w2, images, labels))
但我们可以随心所欲地决定在批处理轴上进行并行处理:
import jax
import numpy as np
from jax.sharding import Mesh
loss = xmap(named_loss, in_axes=in_axes, out_axes=[...],
axis_resources={'batch': 'x'})
devices = np.array(jax.local_devices())
with Mesh(devices, ('x',)):
print(loss(w1, w2, images, labels))
或者我们可能希望在隐藏轴上执行模型并行处理:
loss = xmap(named_loss, in_axes=in_axes, out_axes=[...],
axis_resources={'hidden': 'x'})
devices = np.array(jax.local_devices())
with Mesh(devices, ('x',)):
print(loss(w1, w2, images, labels))
或者我们可能希望同时进行模型和批处理数据的并行处理:
loss = xmap(named_loss, in_axes=in_axes, out_axes=[...],
axis_resources={'batch': 'x', 'hidden': 'y'})
devices = np.array(jax.local_devices()).reshape((4, 2))
with Mesh(devices, ('x', 'y')):
print(loss(w1, w2, images, labels))
使用 xmap,我们可以随时修改我们的并行处理策略,而无需重写我们的神经网络函数。
准备工作
import jax.numpy as jnp
from jax import lax
from functools import partial
import jax
import numpy as np
为了更好地说明新的编程模型,我们在本笔记本中广泛使用自定义类型注释。这些注释不会影响代码的评估方式,并且现在将不会进行检查。
from typing import Any, Callable
class ArrayType:
def __getitem__(self, idx):
return Any
f32 = ArrayType()
i32 = ArrayType()
具有命名轴的张量
NumPy 编程模型是围绕 nd-arrays 构建的。每个 nd-array 可以与两部分类型相关联:
-
元素类型(通过
.dtype属性访问) -
形状(由
.shape给出的整数元组)。
使用我们的小型类型注释语言,我们将这些类型写成dtype[shape_tuple]。
例如,一个由 32 位浮点数构成的 5x7x4 数组将被表示为
f32[(5, 7, 4)]。
这里有一个小例子,展示了注释如何演示形状在简单 NumPy 程序中传播的方式:
x: f32[(2, 3)] = np.ones((2, 3), dtype=np.float32)
y: f32[(3, 5)] = np.ones((3, 5), dtype=np.float32)
z: f32[(2, 5)] = x.dot(y) # matrix multiplication
w: f32[(7, 1, 5)] = np.ones((7, 1, 5), dtype=np.float32)
q: f32[(7, 2, 5)] = z + w # broadcasting
我们建议的扩展是添加另一个数组类型的组成部分:一个named_shape,将轴名称(任意可散列对象,字符串是常见选择)映射到整数大小。最重要的是,因为每个轴都有一个名称,它们的顺序没有意义。也就是说,{'a': 2, 'b': 5}的命名形状与{'b': 5, 'a': 2}的命名形状是无法区分的。
这并不是一个全新的想法。过去提出使用命名轴的一些好例子包括:Mesh TensorFlow、Tensor Considered Harmful宣言,以及xarray和einops包。请记住,这些中许多在于它们在 JAX 中无序,尽管它们会为命名轴分配顺序。
从现在开始,我们将允许类型注释具有两个组件,第一个仍然是值的.shape,而第二个将是.named_shape。
e: f32[(5, 7), {'batch': 20, 'sequence': 30}]
# e.shape == (5, 7)
# e.named_shape == {'batch': 20, 'sequence': 30} == {'sequence': 30, 'batch': 20}
虽然我们不修改.ndim的含义(始终等于len(shape))和.size的含义(等于shape的乘积),但我们仅出于向后兼容性的原因而这样做。具有非空命名轴的数组的真实秩为len(shape) + len(named_shape)。存储在这种数组中的元素的真实数量等于所有维度的大小的乘积,包括位置和命名维度。
引入和消除命名轴
但是,如果所有顶级 JAX 操作都使用纯位置轴的 NumPy 模型,那么如何创建这样的数组呢?尽管在某些时候可以解除此约束,但目前引入命名轴的唯一方式是使用xmap。
xmap可以被视为一种适配器,接受具有位置轴的数组,将其中一些命名(由in_axes指定),并调用其包装的函数。一旦包装函数返回数组,所有出现在其中的命名轴都会转换回位置轴(由out_axes指定)。
in_axes的结构应该与xmap函数参数的签名匹配,但所有数组参数的位置都应被轴映射替换。有两种指定轴映射的方式:
-
作为将位置轴映射到轴名称的字典(例如
{0: 'x', 2: 'y'});以及 -
作为以省略号对象结尾的轴名称列表(例如
['a', 'b', ...]),指示要将一组位置维度映射到给定名称。
out_axes类似,但其结构必须与xmap函数的返回签名匹配(但再次,所有数组都用轴映射替换)。
对于每个数组参数,其各自的in_axes轴映射中提到的所有位置轴都会转换为命名轴。对于每个数组结果,所有命名轴都插入到其各自out_axes指示的位置中。
from jax.experimental.maps import xmap
def my_func(x: f32[(5,), {'batch': 20}]) -> f32[(5,), {'batch': 20}]:
assert x.shape == (5,)
# assert x.named_shape == {'batch': 20} # TODO: Implement named_shape
return x
x: f32[(20, 5)] = jnp.zeros((20, 5), dtype=np.float32)
f = xmap(my_func,
in_axes={0: 'batch'}, # Name the first axis of the only argument 'batch'
out_axes={1: 'batch'}) # Place the 'batch' named axis of the output as the second positional axis
y: f32[(5, 20)] = f(x)
assert (y == x.T).all() # The first dimension was removed from x and then re-inserted as the last dim
虽然起初可能会有些困难,但如果您见过使用jnp.einsum的代码,您已经熟悉这种方法。 einsum函数解释表达式如nk,km->nm,为位置轴分配名称(每个字母被视为单独的名称),执行必要的广播和约简,最后根据->分隔符右侧给定的顺序将结果放回位置轴。虽然einsum从不让您直接与命名轴交互,但它们在其实现中自然出现。 xmap是广义的 einsum,因为现在命名轴是一流的,您可以实现可以操作它们的函数。
继续这个类比,上述示例中的xmap(my_func, ...)等同于jnp.einsum('bx->xb')。但当然,并非每个xmap的函数都有等效的einsum。
还有一个与einsum相似的地方是,每当一个名称被多个轴重用时,它们必须具有相同的大小:
x = jnp.arange(5)
y = jnp.arange(7)
try:
jnp.einsum('i,i->i', x, y)
except Exception as e:
print('einsum:', e)
try:
xmap(lambda x, y: x * y,
in_axes=(['i', ...], ['i', ...]),
out_axes=['i', ...])(x, y)
except Exception as e:
print('xmap:', e)
命名轴传播
我们现在知道了命名轴是如何引入和消除的,但它们有什么好处?它们如何在整个程序中传播?让我们来探讨几个例子。
与位置轴的交互
第一条规则:命名轴从不隐式与位置轴交互。任何未考虑命名轴的函数总是可以使用具有命名尺寸的输入调用。结果与应用vmap到每个命名轴基础上时的结果相同。
from jax.scipy.linalg import expm_frechet
# Any other function that does not assume existence of any named axes would do too,
# at least as long as it matches this type signature:
expm_frechet: Callable[[f32[(3, 3)], f32[(3, 3)]], f32[(3, 3)]]
f = partial(expm_frechet, compute_expm=False)
# Each A with each E
batch_A = jnp.ones((5, 3, 3), dtype=np.float32)
batch_E = jnp.ones((5, 3, 3), dtype=np.float32)
batch_AE = xmap(f,
in_axes=(['b', ...], ['b', ...]), # Map first axes of both inputs to 'b'
out_axes=['b', ...])(batch_A, batch_E) # Place 'b' as the first positional axis in the result
for i in range(5):
np.testing.assert_allclose(batch_AE[i], f(batch_A[i], batch_E[i]))
# All-pairs of As and Es
batch_A = jnp.ones((7, 3, 3), dtype=np.float32)
batch_E = jnp.ones((5, 3, 3), dtype=np.float32)
batch_AE = xmap(f,
in_axes=(['ba', ...], ['be', ...]), # Map first axes of inputs to 'ba' and 'be' respectively
out_axes=['ba', 'be', ...])(batch_A, batch_E) # Prefix all positional dimensions of output with 'ba' and 'be'
for i in range(7):
for j in range(5):
np.testing.assert_allclose(batch_AE[i,j], f(batch_A[i], batch_E[j]))
广播
其次,命名轴通过名称进行广播,几乎每个现有的 NumPy(以及几乎每个 JAX)运算符都会隐式地广播命名维度。每当使用具有命名轴的数组调用标准 NumPy 函数时,NumPy 函数确定结果数组的位置形状,而命名形状成为其输入所有命名形状的并集。分析以下示例以了解轴如何传播:
def named_broadcasting(
x: f32[(2, 1, 1), {'a': 2}],
y: f32[(1, 3, 1), {'b': 3}],
z: f32[(1, 1, 5), {'c': 5}]) \
-> f32[(2, 3, 5), {'a': 2, 'b': 3, 'c': 5}]:
i: f32[(2, 3, 1), {'a': 2, 'b': 3}] = x + y
j: f32[(1, 3, 5), {'b': 3, 'c': 5}] = y + z
k: f32[(2, 3, 5), {'a': 2, 'b': 3, 'c': 5}] = i + j
return k
x = jnp.ones((2, 2, 1, 1), dtype=np.float32)
y = jnp.ones((3, 1, 3, 1), dtype=np.float32)
z = jnp.ones((5, 1, 1, 5), dtype=np.float32)
k = xmap(named_broadcasting,
in_axes=(['a', ...], ['b', ...], ['c', ...]),
out_axes=['a', 'b', 'c', ...])(x, y, z)
assert k.shape == (2, 3, 5, 2, 3, 5)
总结一下,例如表达式i + j的结果的命名形状,其中i的命名形状为{'a': 2, 'b': 3},j为{'b': 3, 'c': 5},则为{'a': 2, 'b': 3, 'c': 5}。 'b'轴存在于两个输入中,因此不需要广播,而'a'和'c'仅出现在两个输入中的一个中,导致另一个沿其命名形状中缺少的轴进行广播。
操作命名轴时不会出现形状错误,因为xmap强制其体内的单个名称与单个大小关联。
尽管广播命名轴的规则可能看起来像 NumPy 模型的任意扩展,但实际上与其一致。
广播首先查找它认为在两个操作数中等效的维度对。对于所有匹配的维度对,它断言两个尺寸要么相等,要么其中一个为 1。所有未配对的维度都传递到结果中。
现在,在位置世界中,NumPy 广播选择形成对的方式是通过右对齐形状。但是我们的轴是有名称的,因此找到等效轴的方法非常直接:只需检查它们的名称是否相等!
缩减
但是,命名轴不仅对批处理有益!实际上,我们的目标是,命名轴应等同于位置轴。特别是,每个将位置轴作为参数的 NumPy 函数也应接受命名轴。
上面的段落是雄心勃勃的,接受具有命名轴的 NumPy 函数的集合相对有限。目前,仅支持具有命名轴的:
jnp.sum、jnp.max、jnp.min
缩减是一个很好的例子:
def named_broadcast_and_reduce(
x: f32[(), {'x': 2}],
y: f32[(5,), {'y': 4}]) \
-> f32[()]:
z: f32[(5,), {'x': 2, 'y': 4}] = x + y
w: f32[()] = jnp.sum(z, axis=(0, 'x', 'y'))
# We could also reduce in steps:
# w0 : f32[(), {'x': 2, 'y': 4}] = jnp.sum(z, 0) # eliminate the positional axis
# w0x: f32[(), {'y': 4}] = jnp.sum(w0, 'x') # eliminate the `x` axis
# w : f32[()] = jnp.sum(w0x, 'y') # eliminate the `y` axis
return w
positional_broadcast_and_reduce: Callable[[f32[(2,)], f32[(5, 4)]], f32[()]]
positional_broadcast_and_reduce = \
xmap(named_broadcast_and_reduce,
in_axes=({0: 'x'}, {1: 'y'}),
out_axes={})
positional_broadcast_and_reduce(jnp.arange(2, dtype=np.float32),
jnp.arange(20, dtype=np.float32).reshape((5, 4)))
einsum
类似于我们如何扩展支持命名轴的缩减,我们还使得可以使用jnp.einsum在命名轴上进行收缩成为可能。
操作数和结果仍然使用每个位置轴的一个字母的约定,但现在也可以在花括号中提到命名轴。例如,n{b,k}表示一个值将具有单个位置维度n和命名维度b和k(它们的顺序不重要)。按照通常的 einsum 语义,任何出现在输入中但不出现在输出中的命名轴都将被收缩(在执行所有乘法后求和)。
可以接受从所有参数和结果中省略一个命名维度,此时它将根据通常的广播语义处理。但是,在一个参数中提到具有命名形状的命名轴并跳过另一个参数中也具有它的命名形状是不可接受的。当然,在没有它的参数中跳过它是必需的。
注意:目前未经检查(仍在进行中)。这种跳过轴将导致未定义的行为。
目前,
jnp.einsum仅支持两个输入和单个结果的命名轴。
def named_batch_matrix_single_matrix(
x: f32[(5,), {'b': 20, 'k': 7}],
y: f32[(), {'k': 7, 'm': 11}]) \
-> f32[(5,), {'b': 20, 'm': 11}]:
return jnp.einsum('n{b,k},{k,m}->n{b,m}', x, y)
x = jnp.ones((20, 5, 7))
y = jnp.ones((7, 11))
z = jnp.einsum('bnk,km->bnm', x, y)
zx = xmap(named_batch_matrix_single_matrix,
in_axes=[{0: 'b', 2: 'k'}, ['k', 'm', ...]],
out_axes={0: 'b', 2: 'm'})(x, y)
np.testing.assert_allclose(z, zx)
上面的示例毫不意外地比直接使用jnp.einsum更清晰。但是,对命名轴的收缩是更大应用(如 Transformer 模型)的关键组成部分,这只是一个演示如何传播名称的练习。
集合
最后,所有可能用于pmap函数的集合在命名轴上也有效。正如我们稍后将展示的,xmap可以作为pmap的替代方案,使多维硬件网格的编程变得更加容易。
x = jnp.arange(8)
xmap(lambda x: lax.pshuffle(x, 'i', list(reversed(range(8)))),
in_axes=['i', ...], out_axes=['i', ...])(x)
并行支持
尽管新的编程范式有时可能很好,但 xmap 的杀手级特性在于其能够在超级计算机规模的硬件网格上并行化代码!
命名轴是使所有这一切成为可能的秘密武器,多亏了精心调整的规则来描述它们的传播方式。在纯位置编程模型中支持分区通常非常困难。位置轴通常是一次性的,很难跟踪轴分区传播方式。正如您将在下文中看到的,命名轴使我们能够定义它们的名称与硬件资源之间直接的对应关系,从而使我们能够轻松推断不同值的分区方式。
在所有先前的示例中,我们还没有提到并行性,有其原因。默认情况下,xmap 不执行任何并行化,而是像 vmap 一样向量化计算(即仍然在单个设备上执行)。要在多个加速器上分区计算,我们必须引入一个概念:资源轴。
基本思想是逻辑轴(出现在命名形状中的轴)假设我们拥有充足的硬件和内存,但在程序执行之前,它们必须放置在某个位置。默认的(类似 vmap 的)评估风格在默认的 JAX 设备上付出了高昂的内存成本。通过通过 axis_resources 参数将逻辑轴映射到(一个或多个)资源轴,我们可以控制 xmap 如何评估计算。
x = jnp.ones((2048, 2048))
local_matmul = xmap(jnp.vdot,
in_axes=({0: 'left'}, {1: 'right'}),
out_axes=['left', 'right', ...])
distr_matmul = xmap(jnp.vdot,
in_axes=({0: 'left'}, {1: 'right'}),
out_axes=['left', 'right', ...],
axis_resources={'left': 'x', 'right': 'y'})
local_matmul 和 distr_matmul 都实现了矩阵乘法,但 distr_matmul 会额外将 left 和 right 逻辑轴分割到 x 和 y 资源轴上。
但是… 这些资源名称是从哪里来的呢?
嗯,这取决于情况,但一个很好的选择是… 硬件网格!
对于我们的目的,网格是一个带有命名轴的设备 nd-数组。但由于 NumPy 不支持命名轴(这是我们的扩展!),网格由 JAX 设备对象的 nd-数组对(如从 jax.devices() 或 jax.local_devices() 获得的对象)和长度与数组秩匹配的资源轴名称元组表示。

axis_names = ('x', 'y')
mesh_devices = np.array(jax.devices()).reshape((2, 4))
assert len(axis_names) == mesh_devices.ndim
mesh_def = (mesh_devices, axis_names)
mesh_def
网格轴名称正是可以将命名轴映射到的资源名称。但仅创建网格定义并不会使资源名称对 distr_matmul 可见:
try:
distr_matmul(x, x)
except Exception as e:
print(e)
要在范围内引入资源,请使用 with Mesh 上下文管理器:
from jax.sharding import Mesh
local = local_matmul(x, x) # The local function doesn't require the mesh definition
with Mesh(*mesh_def): # Makes the mesh axis names available as resources
distr = distr_matmul(x, x)
np.testing.assert_allclose(local, distr)
不过,最好的部分在于,指定axis_resources从不改变程序语义。您可以自由尝试不同的计算分区方式(只需更改资源分配到命名轴的分配!),甚至可以更改网格中物理设备的组织方式(通过更改设备的 NumPy 数组构造)。这些变化不应对您获得的结果产生重大影响(例如浮点精度不准确性),尽管当然其中一些方法的性能显著优于其他方法。
xmap目前不提供任何自动调度选项,因为最佳调度通常必须与您的程序相匹配。我们正在考虑在未来添加对此的支持,但这需要时间。
一旦您将逻辑轴映射到网格维度,该逻辑轴的大小必须可被网格维度大小整除。
我的数据是复制的吗?还是分区的?它在哪里?
命名轴还为我们提供了一种关于分区和复制的简洁方式。如果一个值在网格轴上分区,则该值的命名轴已在其形状中映射到该网格轴。否则,它将在该轴上的所有切片中复制。
例如,假设我们在具有axis_resources={'a': 'x', 'b': 'y'}的xmap中(即在具有分别大小为 2 和 3 的x和y轴上运行计算)。那么:
-
类型为
f32[(5, 5), {}]的数组在整个网格上完全复制。所有设备存储该值的本地副本。 -
类型为
f32[(6,), {'a': 8}]的数组在网格轴x上进行分区,因为其命名形状中含有'a',且'a'被映射到x。它在网格轴y上复制。换句话说,网格切片中具有相同x坐标的所有设备将存储该数组的一块本地副本。而具有不同x坐标的网格切片将存储数据的不同块。 -
类型为
f32[(), {'a': 8, 'c': 7}]的数组与前一情况完全相同:在x网格轴上分割,在y轴上复制。未指定资源的命名维度在考虑分区时与位置维度没有任何不同,因此'c'对其没有影响。 -
类型为
f32[(), {'a': 8, 'b': 12}]的数组完全分区在整个网格上。每个设备持有数据的不同块。
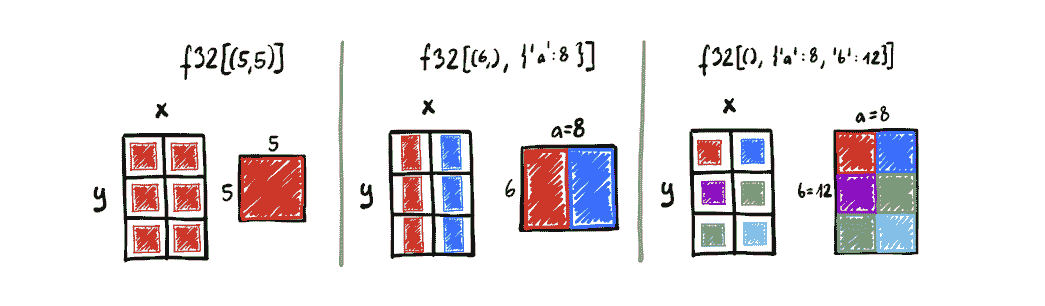
这也突显了一个限制:如果您指定axis_resources={'a': 'x', 'b': 'x'},xmap不会发出投诉,但请考虑f32[(2, 8), {'a': 4, 'b': 12}]类型的数组如何分区。如果x网格轴的大小为 2,则我们只有 2 个设备,但我们有 4 个要放置的块(2 个沿着'a'和 2 个沿着'b')!现在我们可以完整陈述:映射到相同资源的命名轴永远不能同时出现在单个数组的命名形状中。但它们可以出现在两个不同数组的命名形状中,例如在这个程序中:
def sum_two_args(x: f32[(), {'a': 4}], y: f32[(), {'b': 12}]) -> f32[()]:
return jnp.sum(x, axis='a') + jnp.sum(y, axis='b')
q = jnp.ones((4,), dtype=np.float32)
u = jnp.ones((12,), dtype=np.float32)
with Mesh(np.array(jax.devices()[:4]), ('x',)):
v = xmap(sum_two_args,
in_axes=(['a', ...], ['b', ...]),
out_axes=[...],
axis_resources={'a': 'x', 'b': 'x'})(q, u)
print(v)
这个程序是有效的,因为jnp.sum在值相加之前消除了不能同时出现的轴。
尽管最终版本的
xmap将确保您不会意外地这样做,但当前实现并不验证它。违反此限制将导致未定义的行为。
为什么选择axis_resources而不是更直接地映射到硬件?
此时您可能会想为什么要引入混合中的另一个资源轴的绕道。只要您对在硬件上分区您的计算感兴趣,就没有好的理由,但这种思维框架比那更灵活!
例如,我们都在处理一个额外的资源:时间!就像计算可以分区到多个硬件设备上,例如降低其内存使用,同样的事情可以通过一个单一的加速器实现,该加速器在多个步骤中评估计算的一个块。
因此,虽然硬件网格目前是 JAX 程序中资源轴的唯一来源,但我们计划扩展整个系统以涵盖其他来源。
将位置代码移植到命名代码
在本节中,我们将举几个实际例子,展示xmap如何帮助您实现和分发各种模型。
本节内容正在完善
可见:
try:
distr_matmul(x, x)
except Exception as e:
print(e)
要在范围内引入资源,请使用 with Mesh 上下文管理器:
from jax.sharding import Mesh
local = local_matmul(x, x) # The local function doesn't require the mesh definition
with Mesh(*mesh_def): # Makes the mesh axis names available as resources
distr = distr_matmul(x, x)
np.testing.assert_allclose(local, distr)
不过,最好的部分在于,指定axis_resources从不改变程序语义。您可以自由尝试不同的计算分区方式(只需更改资源分配到命名轴的分配!),甚至可以更改网格中物理设备的组织方式(通过更改设备的 NumPy 数组构造)。这些变化不应对您获得的结果产生重大影响(例如浮点精度不准确性),尽管当然其中一些方法的性能显著优于其他方法。
xmap目前不提供任何自动调度选项,因为最佳调度通常必须与您的程序相匹配。我们正在考虑在未来添加对此的支持,但这需要时间。
一旦您将逻辑轴映射到网格维度,该逻辑轴的大小必须可被网格维度大小整除。
我的数据是复制的吗?还是分区的?它在哪里?
命名轴还为我们提供了一种关于分区和复制的简洁方式。如果一个值在网格轴上分区,则该值的命名轴已在其形状中映射到该网格轴。否则,它将在该轴上的所有切片中复制。
例如,假设我们在具有axis_resources={'a': 'x', 'b': 'y'}的xmap中(即在具有分别大小为 2 和 3 的x和y轴上运行计算)。那么:
-
类型为
f32[(5, 5), {}]的数组在整个网格上完全复制。所有设备存储该值的本地副本。 -
类型为
f32[(6,), {'a': 8}]的数组在网格轴x上进行分区,因为其命名形状中含有'a',且'a'被映射到x。它在网格轴y上复制。换句话说,网格切片中具有相同x坐标的所有设备将存储该数组的一块本地副本。而具有不同x坐标的网格切片将存储数据的不同块。 -
类型为
f32[(), {'a': 8, 'c': 7}]的数组与前一情况完全相同:在x网格轴上分割,在y轴上复制。未指定资源的命名维度在考虑分区时与位置维度没有任何不同,因此'c'对其没有影响。 -
类型为
f32[(), {'a': 8, 'b': 12}]的数组完全分区在整个网格上。每个设备持有数据的不同块。
[外链图片转存中…(img-GYRD8s9p-1718950586040)]
这也突显了一个限制:如果您指定axis_resources={'a': 'x', 'b': 'x'},xmap不会发出投诉,但请考虑f32[(2, 8), {'a': 4, 'b': 12}]类型的数组如何分区。如果x网格轴的大小为 2,则我们只有 2 个设备,但我们有 4 个要放置的块(2 个沿着'a'和 2 个沿着'b')!现在我们可以完整陈述:映射到相同资源的命名轴永远不能同时出现在单个数组的命名形状中。但它们可以出现在两个不同数组的命名形状中,例如在这个程序中:
def sum_two_args(x: f32[(), {'a': 4}], y: f32[(), {'b': 12}]) -> f32[()]:
return jnp.sum(x, axis='a') + jnp.sum(y, axis='b')
q = jnp.ones((4,), dtype=np.float32)
u = jnp.ones((12,), dtype=np.float32)
with Mesh(np.array(jax.devices()[:4]), ('x',)):
v = xmap(sum_two_args,
in_axes=(['a', ...], ['b', ...]),
out_axes=[...],
axis_resources={'a': 'x', 'b': 'x'})(q, u)
print(v)
这个程序是有效的,因为jnp.sum在值相加之前消除了不能同时出现的轴。
尽管最终版本的
xmap将确保您不会意外地这样做,但当前实现并不验证它。违反此限制将导致未定义的行为。
为什么选择axis_resources而不是更直接地映射到硬件?
此时您可能会想为什么要引入混合中的另一个资源轴的绕道。只要您对在硬件上分区您的计算感兴趣,就没有好的理由,但这种思维框架比那更灵活!
例如,我们都在处理一个额外的资源:时间!就像计算可以分区到多个硬件设备上,例如降低其内存使用,同样的事情可以通过一个单一的加速器实现,该加速器在多个步骤中评估计算的一个块。
因此,虽然硬件网格目前是 JAX 程序中资源轴的唯一来源,但我们计划扩展整个系统以涵盖其他来源。
将位置代码移植到命名代码
在本节中,我们将举几个实际例子,展示xmap如何帮助您实现和分发各种模型。
本节内容正在完善















 179
179











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









