







MGP-STR
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/mgp-str
概述
MGP-STR 模型由 Peng Wang、Cheng Da 和 Cong Yao 在多粒度预测用于场景文本识别中提出。MGP-STR 是一个概念上简单但强大的视觉场景文本识别(STR)模型,它建立在视觉 Transformer(ViT)之上。为了整合语言知识,提出了多粒度预测(MGP)策略,以隐式方式将语言模态的信息注入模型中。
论文摘要如下:
场景文本识别(STR)一直是计算机视觉中的一个活跃研究课题。为了解决这一具有挑战性的问题,已经连续提出了许多创新方法,并且将语言知识整合到 STR 模型中最近成为一个突出的趋势。在这项工作中,我们首先从视觉 Transformer(ViT)的最新进展中汲取灵感,构建了一个概念上简单但强大的视觉 STR 模型,它建立在 ViT 之上,并且在场景文本识别方面优于以前的最先进模型,包括纯视觉模型和语言增强方法。为了整合语言知识,我们进一步提出了一种多粒度预测策略,以隐式方式将语言模态的信息注入模型中,即,除了传统的字符级表示外,还引入了在 NLP 中广泛使用的子词表示(BPE 和 WordPiece)到输出空间中,而不采用独立的语言模型(LM)。由此产生的算法(称为 MGP-STR)能够将 STR 的性能推向更高的水平。具体而言,在标准基准上实现了 93.35%的平均识别准确率。
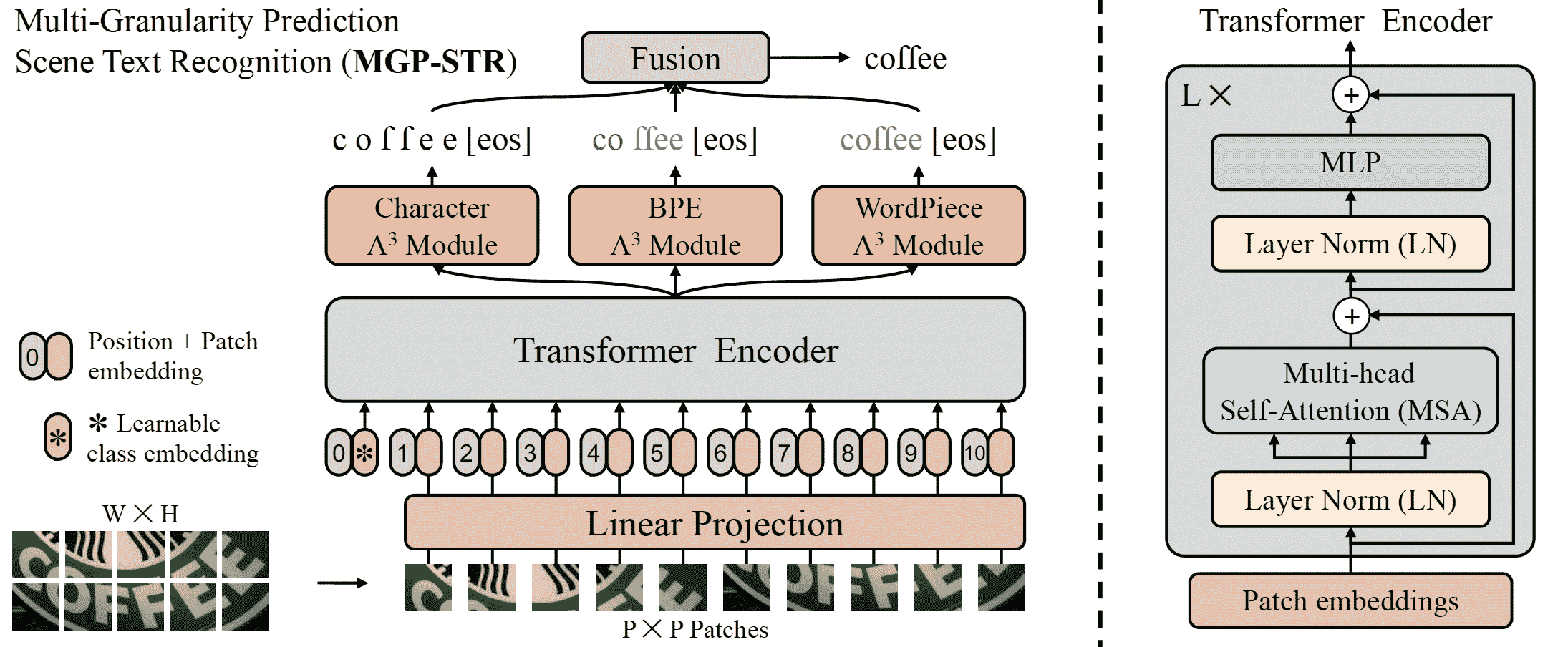 MGP-STR 架构。摘自原始论文。
MGP-STR 架构。摘自原始论文。
MGP-STR 在两个合成数据集 MJSynth)(MJ)和 SynthText(www.robots.ox.ac.uk/~vgg/data/scenetext/)(ST)上进行训练,而不在其他数据集上进行微调。它在六个标准拉丁场景文本基准上取得了最先进的结果,包括 3 个常规文本数据集(IC13、SVT、IIIT)和 3 个不规则数据集(IC15、SVTP、CUTE)。该模型由yuekun贡献。原始代码可以在这里找到。
推理示例
MgpstrModel 接受图像作为输入,并生成三种类型的预测,代表不同粒度的文本信息。这三种类型的预测被融合以给出最终的预测结果。
ViTImageProcessor 类负责预处理输入图像,MgpstrTokenizer 解码生成的字符标记为目标字符串。MgpstrProcessor 将 ViTImageProcessor 和 MgpstrTokenizer 封装成单个实例,既提取输入特征又解码预测的标记 ID。
- 逐步光学字符识别(OCR)
>>> from transformers import MgpstrProcessor, MgpstrForSceneTextRecognition
>>> import requests
>>> from PIL import Image
>>> processor = MgpstrProcessor.from_pretrained('alibaba-damo/mgp-str-base')
>>> model = MgpstrForSceneTextRecognition.from_pretrained('alibaba-damo/mgp-str-base')
>>> # load image from the IIIT-5k dataset
>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
>>> outputs = model(pixel_values)
>>> generated_text = processor.batch_decode(outputs.logits)['generated_text']
MgpstrConfig
class transformers.MgpstrConfig
( image_size = [32, 128] patch_size = 4 num_channels = 3 max_token_length = 27 num_character_labels = 38 num_bpe_labels = 50257 num_wordpiece_labels = 30522 hidden_size = 768 num_hidden_layers = 12 num_attention_heads = 12 mlp_ratio = 4.0 qkv_bias = True distilled = False layer_norm_eps = 1e-05 drop_rate = 0.0 attn_drop_rate = 0.0 drop_path_rate = 0.0 output_a3_attentions = False initializer_range = 0.02 **kwargs )
参数
-
image_size(List[int], optional, defaults to[32, 128]) — 每个图像的大小(分辨率)。 -
patch_size(int, optional, defaults to 4) — 每个补丁的大小(分辨率)。 -
num_channels(int, optional, defaults to 3) — 输入通道数。 -
max_token_length(int, optional, defaults to 27) — 输出标记的最大数量。 -
num_character_labels(int, optional, defaults to 38) — 字符头的类数。 -
num_bpe_labels(int, optional, defaults to 50257) — bpe 头的类数。 -
num_wordpiece_labels(int, optional, defaults to 30522) — wordpiece 头的类数。 -
hidden_size(int, optional, defaults to 768) — 嵌入维度。 -
num_hidden_layers(int, optional, defaults to 12) — Transformer 编码器中的隐藏层数。 -
num_attention_heads(int, optional, defaults to 12) — Transformer 编码器中每个注意力层的注意力头数。 -
mlp_ratio(float, optional, defaults to 4.0) — mlp 隐藏维度与嵌入维度的比率。 -
qkv_bias(bool, optional, defaults toTrue) — 是否为查询、键和值添加偏置。 -
distilled(bool, optional, defaults toFalse) — 模型包括蒸馏令牌和头,如 DeiT 模型。 -
layer_norm_eps(float, optional, defaults to 1e-05) — 层归一化层使用的 epsilon。 -
drop_rate(float, optional, defaults to 0.0) — 嵌入层、编码器中所有全连接层的 dropout 概率。 -
attn_drop_rate(float, optional, defaults to 0.0) — 注意力概率的 dropout 比率。 -
drop_path_rate(float, optional, defaults to 0.0) — 随机深度率。 -
output_a3_attentions(bool, optional, defaults toFalse) — 模型是否返回 A³ 模块的注意力。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。
这是一个配置类,用于存储 MgpstrModel 的配置。根据指定的参数实例化一个 MGP-STR 模型,定义模型架构。使用默认值实例化配置将产生类似于 MGP-STR alibaba-damo/mgp-str-base架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import MgpstrConfig, MgpstrForSceneTextRecognition
>>> # Initializing a Mgpstr mgp-str-base style configuration
>>> configuration = MgpstrConfig()
>>> # Initializing a model (with random weights) from the mgp-str-base style configuration
>>> model = MgpstrForSceneTextRecognition(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
MgpstrTokenizer
class transformers.MgpstrTokenizer
( vocab_file unk_token = '[GO]' bos_token = '[GO]' eos_token = '[s]' pad_token = '[GO]' **kwargs )
参数
-
vocab_file(str) — 词汇表文件路径。 -
unk_token(str, optional, defaults to"[GO]") — 未知标记。词汇表中没有的标记无法转换为 ID,而是设置为此标记。 -
bos_token(str, optional, defaults to"[GO]") — 序列开始标记。 -
eos_token(str, optional, defaults to"[s]") — 序列结束标记。 -
pad_token(strortokenizers.AddedToken, optional, defaults to"[GO]") — 用于使标记数组大小相同以进行批处理的特殊标记。然后将被注意力机制或损失计算忽略。
构建一个 MGP-STR 字符分词器。
此分词器继承自 PreTrainedTokenizer,其中包含大部分主要方法。用户应参考该超类获取有关这些方法的更多信息。
save_vocabulary
( save_directory: str filename_prefix: Optional = None )
MgpstrProcessor
class transformers.MgpstrProcessor
( image_processor = None tokenizer = None **kwargs )
参数
-
image_processor(ViTImageProcessor, 可选) — 一个ViTImageProcessor实例。图像处理器是必需的输入。 -
tokenizer(MgpstrTokenizer, 可选)— Tokenizer 是必需的输入。
构建一个 MGP-STR 处理器,将图像处理器和 MGP-STR 分词器封装成一个单独的
MgpstrProcessor 提供了所有 ViTImageProcessor 和 MgpstrTokenizer 的功能。查看 call() 和 batch_decode() 获取更多信息。
__call__
( text = None images = None return_tensors = None **kwargs )
在正常模式下使用时,此方法将所有参数转发给 ViTImageProcessor 的 call() 并返回其输出。如果 text 不是 None,此方法还将 text 和 kwargs 参数转发给 MgpstrTokenizer 的 call() 来编码文本。更多信息请参考上述方法的文档字符串。
batch_decode
( sequences ) → export const metadata = 'undefined';Dict[str, any]
参数
sequences(torch.Tensor) — 分词后输入 id 的列表。
返回
Dict[str, any]
所有解码结果的字典。 generated_text (List[str]): 融合字符、bpe 和 wp 后的最终结果。 scores (List[float]): 融合字符、bpe 和 wp 后的最终分数。 char_preds (List[str]): 字符解码句子的列表。 bpe_preds (List[str]): bpe 解码句子的列表。 wp_preds (List[str]): wp 解码句子的列表。
通过调用 decode 将 token id 的列表转换为字符串列表。
此方法将所有参数转发给 PreTrainedTokenizer 的 batch_decode()。更多信息请参考该方法的文档字符串。
MgpstrModel
class transformers.MgpstrModel
( config: MgpstrConfig )
参数
config(MgpstrConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained() 方法加载模型权重。
裸 MGP-STR 模型变压器输出原始隐藏状态,没有特定的顶部头。此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: FloatTensor output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None )
参数
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 AutoImageProcessor 获得。有关详细信息,请参阅 ViTImageProcessor.call()。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请查看返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请查看返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。
MgpstrModel 的前向方法,覆盖__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
MgpstrForSceneTextRecognition
class transformers.MgpstrForSceneTextRecognition
( config: MgpstrConfig )
参数
config(MgpstrConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
MGP-STR 模型变压器,顶部有三个分类头(三个 A³ 模块和变压器编码器输出顶部的三个线性层),用于场景文本识别(STR)。
此模型是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: FloatTensor output_attentions: Optional = None output_a3_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.mgp_str.modeling_mgp_str.MgpstrModelOutput or tuple(torch.FloatTensor)
参数
-
pixel_values(torch.FloatTensorof shape(batch_size, num_channels, height, width)) — 像素值。像素值可以使用 AutoImageProcessor 获得。有关详细信息,请参阅 ViTImageProcessor.call()。 -
output_attentions(bool, optional) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请查看返回张量下的attentions。 -
output_hidden_states(bool, optional) — 是否返回所有层的隐藏状态。有关更多详细信息,请查看返回张量下的hidden_states。 -
return_dict(bool, optional) — 是否返回 ModelOutput 而不是普通元组。 -
output_a3_attentions(bool,可选)- 是否返回 a3 模块的注意力张量。有关更多详细信息,请参阅返回张量中的a3_attentions。
返回
transformers.models.mgp_str.modeling_mgp_str.MgpstrModelOutput或tuple(torch.FloatTensor)
一个transformers.models.mgp_str.modeling_mgp_str.MgpstrModelOutput或一个torch.FloatTensor元组(如果传递了return_dict=False或当config.return_dict=False时)包括根据配置(<class 'transformers.models.mgp_str.configuration_mgp_str.MgpstrConfig'>)和输入的不同元素。
-
logits(形状为(batch_size, config.num_character_labels)的tuple(torch.FloatTensor))-torch.FloatTensor元组(一个用于字符输出的形状为(batch_size, config.max_token_length, config.num_character_labels),+ 一个用于 bpe 输出的形状为(batch_size, config.max_token_length, config.num_bpe_labels),+ 一个用于 wordpiece 输出的形状为(batch_size, config.max_token_length, config.num_wordpiece_labels))。字符、bpe 和 wordpiece 的分类分数(SoftMax 之前)。
-
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出,如果模型有一个嵌入层,+ 一个用于每一层的输出)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回)- 形状为(batch_size, config.max_token_length, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
-
a3_attentions(tuple(torch.FloatTensor),可选,当传递output_a3_attentions=True或当config.output_a3_attentions=True时返回)- 形状为(batch_size, config.max_token_length, sequence_length)的torch.FloatTensor元组(一个用于字符的注意力,+ 一个用于 bpe 的注意力,+ 一个用于 wordpiece 的注意力)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
MgpstrForSceneTextRecognition 的前向方法,覆盖__call__特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用Module实例而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import (
... MgpstrProcessor,
... MgpstrForSceneTextRecognition,
... )
>>> import requests
>>> from PIL import Image
>>> # load image from the IIIT-5k dataset
>>> url = "https://i.postimg.cc/ZKwLg2Gw/367-14.png"
>>> image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
>>> processor = MgpstrProcessor.from_pretrained("alibaba-damo/mgp-str-base")
>>> pixel_values = processor(images=image, return_tensors="pt").pixel_values
>>> model = MgpstrForSceneTextRecognition.from_pretrained("alibaba-damo/mgp-str-base")
>>> # inference
>>> outputs = model(pixel_values)
>>> out_strs = processor.batch_decode(outputs.logits)
>>> out_strs["generated_text"]
'["ticket"]'
Nougat
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/nougat
概述
Nougat 模型是由 Lukas Blecher、Guillem Cucurull、Thomas Scialom、Robert Stojnic 提出的Nougat: 用于学术文档的神经光学理解。Nougat 使用与 Donut 相同的架构,即图像 Transformer 编码器和自回归文本 Transformer 解码器,将科学 PDF 转换为标记,使其更易于访问。
论文摘要如下:
科学知识主要存储在书籍和科学期刊中,通常以 PDF 形式存在。然而,PDF 格式会导致语义信息的丢失,特别是对于数学表达式。我们提出了 Nougat(用于学术文档的神经光学理解),这是一个视觉 Transformer 模型,用于将科学文档进行光学字符识别(OCR)任务,转换为标记语言,并展示了我们的模型在新的科学文档数据集上的有效性。所提出的方法为增强数字时代科学知识的可访问性提供了一个有希望的解决方案,通过弥合人类可读文档和机器可读文本之间的差距。我们发布了模型和代码,以加速未来关于科学文本识别的工作。
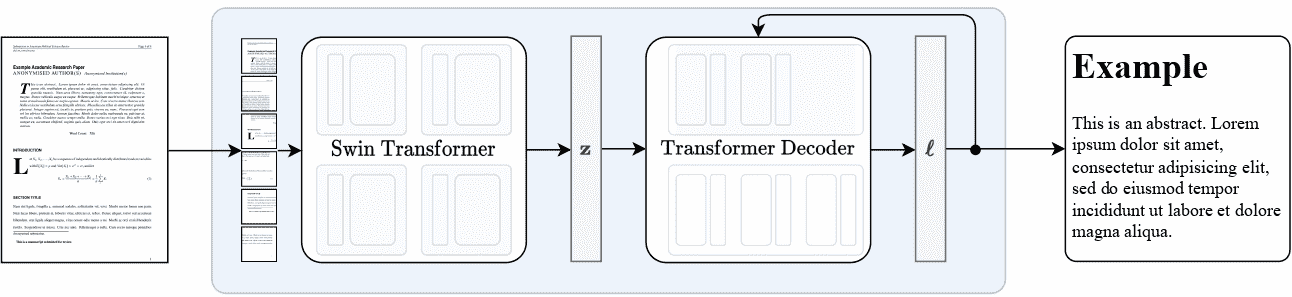 Nougat 高层概述。摘自原始论文。
Nougat 高层概述。摘自原始论文。
使用提示
-
开始使用 Nougat 的最快方法是查看教程笔记本,展示了如何在推理时使用模型以及在自定义数据上进行微调。
-
Nougat 始终在 VisionEncoderDecoder 框架内使用。该模型在架构上与 Donut 相同。
推理
Nougat 的VisionEncoderDecoder模型接受图像作为输入,并利用 generate()来自动回归生成给定输入图像的文本。
NougatImageProcessor 类负责预处理输入图像,NougatTokenizerFast 解码生成的目标标记为目标字符串。NougatProcessor 将 NougatImageProcessor 和 NougatTokenizerFast 类封装为单个实例,用于提取输入特征和解码预测的标记 ID。
- 逐步 PDF 转录
>>> from huggingface_hub import hf_hub_download
>>> import re
>>> from PIL import Image
>>> from transformers import NougatProcessor, VisionEncoderDecoderModel
>>> from datasets import load_dataset
>>> import torch
>>> processor = NougatProcessor.from_pretrained("facebook/nougat-base")
>>> model = VisionEncoderDecoderModel.from_pretrained("facebook/nougat-base")
>>> device = "cuda" if torch.cuda.is_available() else "cpu"
>>> model.to(device)
>>> # prepare PDF image for the model
>>> filepath = hf_hub_download(repo_id="hf-internal-testing/fixtures_docvqa", filename="nougat_paper.png", repo_type="dataset")
>>> image = Image.open(filepath)
>>> pixel_values = processor(image, return_tensors="pt").pixel_values
>>> # generate transcription (here we only generate 30 tokens)
>>> outputs = model.generate(
... pixel_values.to(device),
... min_length=1,
... max_new_tokens=30,
... bad_words_ids=[[processor.tokenizer.unk_token_id]],
... )
>>> sequence = processor.batch_decode(outputs, skip_special_tokens=True)[0]
>>> sequence = processor.post_process_generation(sequence, fix_markdown=False)
>>> # note: we're using repr here such for the sake of printing the \n characters, feel free to just print the sequence
>>> print(repr(sequence))
'\n\n# Nougat: Neural Optical Understanding for Academic Documents\n\n Lukas Blecher\n\nCorrespondence to: lblecher@'
请查看模型中心以查找 Nougat 检查点。
该模型在架构上与 Donut 相同。
NougatImageProcessor
class transformers.NougatImageProcessor
( do_crop_margin: bool = True do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BILINEAR: 2> do_thumbnail: bool = True do_align_long_axis: bool = False do_pad: bool = True do_rescale: bool = True rescale_factor: Union = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None **kwargs )
参数
-
do_crop_margin(bool,可选,默认为True)— 是否裁剪图像边距。 -
do_resize(bool,可选,默认为True)— 是否将图像的(高度,宽度)尺寸调整为指定的size。可以在preprocess方法中通过do_resize进行覆盖。 -
size(Dict[str, int]可选, 默认为{"height" -- 896, "width": 672}): 调整大小后的图像尺寸。可以被preprocess方法中的size覆盖。 -
resample(PILImageResampling, 可选, 默认为Resampling.BILINEAR) — 如果调整图像大小,则使用的重采样滤波器。可以被preprocess方法中的resample覆盖。 -
do_thumbnail(bool, 可选, 默认为True) — 是否使用缩略图方法调整图像大小。 -
do_align_long_axis(bool, 可选, 默认为False) — 是否通过旋转 90 度来使图像的长轴与size的长轴对齐。 -
do_pad(bool, 可选, 默认为True) — 是否将图像填充到批处理中最大的图像尺寸。 -
do_rescale(bool, 可选, 默认为True) — 是否按指定比例rescale_factor重新缩放图像。可以被preprocess方法中的do_rescale参数覆盖。 -
rescale_factor(int或float, 可选, 默认为1/255) — 如果重新缩放图像,则使用的缩放因子。可以被preprocess方法中的rescale_factor参数覆盖。 -
do_normalize(bool, 可选, 默认为True) — 是否对图像进行归一化。可以被preprocess方法中的do_normalize覆盖。 -
image_mean(float或List[float], 可选, 默认为IMAGENET_DEFAULT_MEAN) — 如果归一化图像,则使用的均值。这是一个浮点数或与图像通道数相同长度的浮点数列表。可以被preprocess方法中的image_mean参数覆盖。 -
image_std(float或List[float], 可选, 默认为IMAGENET_DEFAULT_STD) — 图像标准差。
构建 Nougat 图像处理器。
preprocess
( images: Union do_crop_margin: bool = None do_resize: bool = None size: Dict = None resample: Resampling = None do_thumbnail: bool = None do_align_long_axis: bool = None do_pad: bool = None do_rescale: bool = None rescale_factor: Union = None do_normalize: bool = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: Optional = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )
参数
-
images(ImageInput) — 要预处理的图像。期望单个图像或批处理图像,像素值范围为 0 到 255。 -
do_crop_margin(bool, 可选, 默认为self.do_crop_margin) — 是否裁剪图像边缘。 -
do_resize(bool, 可选, 默认为self.do_resize) — 是否调整图像大小。 -
size(Dict[str, int], 可选, 默认为self.size) — 调整大小后的图像尺寸。图像的最短边调整为 min(size[“height”], size[“width”]),最长边调整以保持输入的长宽比。 -
resample(int, 可选, 默认为self.resample) — 如果调整图像大小,则使用的重采样滤波器。这可以是枚举PILImageResampling中的一个。仅当do_resize设置为True时才会生效。 -
do_thumbnail(bool, 可选, 默认为self.do_thumbnail) — 是否使用缩略图方法调整图像大小。 -
do_align_long_axis(bool, 可选, 默认为self.do_align_long_axis) — 是否通过旋转 90 度来使图像的长轴与size的长轴对齐。 -
do_pad(bool, 可选, 默认为self.do_pad) — 是否将图像填充到批处理中最大的图像尺寸。 -
do_rescale(bool, 可选, 默认为self.do_rescale) — 是否按指定比例rescale_factor重新缩放图像。 -
rescale_factor(int或float, 可选, 默认为self.rescale_factor) — 如果重新缩放图像,则使用的缩放因子。 -
do_normalize(bool, 可选, 默认为self.do_normalize) — 是否对图像进行归一化。 -
image_mean(float或List[float], 可选, 默认为self.image_mean) — 用于归一化的图像均值。 -
image_std(float或List[float], 可选, 默认为self.image_std) — 用于归一化的图像标准差。 -
return_tensors(str或TensorType, 可选) — 要返回的张量类型。可以是以下之一:-
未设置: 返回
np.ndarray的列表。 -
TensorType.TENSORFLOW或'tf': 返回类型为tf.Tensor的批处理。 -
TensorType.PYTORCH或'pt': 返回类型为torch.Tensor的批处理。 -
TensorType.NUMPY或'np': 返回类型为np.ndarray的批处理。 -
TensorType.JAX或'jax': 返回类型为jax.numpy.ndarray的批处理。
-
-
data_format(ChannelDimension或str, optional, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:-
ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。 -
ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。 -
未设置:默认为输入图像的通道维度格式。
-
-
input_data_format(ChannelDimension或str, optional) — 输入图像的通道维度格式。如果未设置,将从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST: 图像格式为 (num_channels, height, width)。 -
"channels_last"或ChannelDimension.LAST: 图像格式为 (height, width, num_channels)。 -
"none"或ChannelDimension.NONE: 图像格式为 (height, width)。
-
预处理一张图片或一批图片。
NougatTokenizerFast
class transformers.NougatTokenizerFast
( vocab_file = None tokenizer_file = None clean_up_tokenization_spaces = False unk_token = '<unk>' bos_token = '<s>' eos_token = '</s>' pad_token = '<pad>' **kwargs )
参数
-
vocab_file(str, optional) — SentencePiece 文件(通常具有 .model 扩展名),其中包含实例化分词器所需的词汇表。 -
tokenizer_file(str, optional) — tokenizers 文件(通常具有 .json 扩展名),其中包含加载分词器所需的所有内容。 -
clean_up_tokenization_spaces(str, optional, 默认为False) — 解码后是否清除空格,清除包括删除额外空格等潜在瑕疵。 -
unk_token(str, optional, 默认为"<unk>") — 未知标记。词汇表中不存在的标记无法转换为 ID,而是设置为此标记。 -
bos_token(str, optional, 默认为"<s>") — 在预训练期间使用的序列开始标记。可用作序列分类器标记。 -
eos_token(str, optional, 默认为"</s>") — 序列结束标记。 -
pad_token(str, optional, 默认为"<pad>") — 用于填充的标记,例如在批处理不同长度的序列时使用。 -
model_max_length(int, optional) — 转换器模型输入的最大长度(以标记数计)。当使用 from_pretrained() 加载分词器时,将设置为存储在max_model_input_sizes中的相关模型的值(请参见上文)。如果未提供值,将默认为 VERY_LARGE_INTEGER (int(1e30))。 -
padding_side(str, optional) — 模型应用填充的侧面。应在 [‘right’, ‘left’] 中选择。默认值从同名的类属性中选择。 -
truncation_side(str, optional) — 模型应用截断的侧面。应在 [‘right’, ‘left’] 中选择。默认值从同名的类属性中选择。 -
chat_template(str, optional) — 一个 Jinja 模板字符串,用于格式化聊天消息列表。详细描述请参见huggingface.co/docs/transformers/chat_templating。 -
model_input_names(List[string], optional) — 模型前向传递接受的输入列表(如"token_type_ids"或"attention_mask")。默认值从同名的类属性中选择。 -
bos_token(str或tokenizers.AddedToken, optional) — 表示句子开头的特殊标记。将与self.bos_token和self.bos_token_id关联。 -
eos_token(str或tokenizers.AddedToken,可选)— 代表句子结束的特殊标记。将与self.eos_token和self.eos_token_id相关联。 -
unk_token(str或tokenizers.AddedToken,可选)— 代表词汇外标记的特殊标记。将与self.unk_token和self.unk_token_id相关联。 -
sep_token(str或tokenizers.AddedToken,可选)— 用于在同一输入中分隔两个不同句子的特殊标记(例如 BERT 使用)。将与self.sep_token和self.sep_token_id相关联。 -
pad_token(str或tokenizers.AddedToken,可选)— 用于使标记数组大小相同以进行批处理的特殊标记。然后将被注意机制或损失计算忽略。将与self.pad_token和self.pad_token_id相关联。 -
cls_token(str或tokenizers.AddedToken,可选)— 代表输入类别的特殊标记(例如 BERT 使用)。将与self.cls_token和self.cls_token_id相关联。 -
mask_token(str或tokenizers.AddedToken,可选)— 代表掩码标记的特殊标记(用于掩码语言建模预训练目标,如 BERT)。将与self.mask_token和self.mask_token_id相关联。 -
additional_special_tokens(元组或str或tokenizers.AddedToken,可选)— 一组额外的特殊标记。在这里添加它们以确保在将skip_special_tokens设置为 True 时解码时跳过它们。如果它们不是词汇的一部分,它们将被添加到词汇的末尾。 -
clean_up_tokenization_spaces(bool,可选,默认为True)— 模型是否应清除在标记化过程中拆分输入文本时添加的空格。 -
split_special_tokens(bool,可选,默认为False)— 是否在标记化过程中拆分特殊标记。默认行为是不拆分特殊标记。这意味着如果<s>是bos_token,那么tokenizer.tokenize("<s>") = ['<s>]。否则,如果split_special_tokens=True,那么tokenizer.tokenize(“”)将给出[‘<’, ‘s’, ‘>’]。此参数目前仅支持slow`分词器。 -
tokenizer_object(tokenizers.Tokenizer)— 来自🤗 tokenizers 的tokenizers.Tokenizer对象,用于实例化。有关更多信息,请参阅使用🤗 tokenizers 中的分词器。 -
tokenizer_file(str)— 代表以前序列化的tokenizers.Tokenizer对象的本地 JSON 文件的路径。
Nougat 的快速分词器(由 HuggingFace 分词器库支持)。
这个分词器继承自 PreTrainedTokenizerFast,其中包含大多数主要方法。用户应参考这个超类以获取有关这些方法的更多信息。这个类主要为后处理生成的文本添加了 Nougat 特定的方法。
类属性(由派生类覆盖)
-
vocab_files_names(Dict[str, str])— 一个字典,其键是模型所需的每个词汇文件的__init__关键字名称,其相关值是用于保存相关文件的文件名(字符串)。 -
pretrained_vocab_files_map(Dict[str, Dict[str, str]])— 一个字典,其中高级键是模型所需的每个词汇文件的__init__关键字名称,低级别是预训练模型的short-cut-names,作为相关值,是与相关预训练词汇文件相关联的url。 -
max_model_input_sizes(Dict[str, Optional[int]])— 一个字典,其键是预训练模型的short-cut-names,其相关值是该模型的序列输入的最大长度,如果模型没有最大输入大小,则为None。 -
pretrained_init_configuration(Dict[str, Dict[str, Any]]) — 一个字典,键为预训练模型的short-cut-names,值为传递给加载预训练模型时 tokenizer 类的__init__方法的特定参数的字典。 -
model_input_names(List[str]) — 模型前向传递中预期的输入列表。 -
padding_side(str) — 模型应该应用填充的默认值。应为'right'或'left'。 -
truncation_side(str) — 模型应该应用截断的默认值。应为'right'或'left'。
correct_tables
( generation: str ) → export const metadata = 'undefined';str
参数
generation(str) — 要进行后处理的生成文本。
返回
str
后处理的文本。
接受一个生成的字符串,并修复表格/表格,使其符合所需的 Markdown 格式。
示例:
correct_tables("\begin{table} \begin{tabular}{l l} & \ \end{tabular} \end{table}")
"\begin{table}
abular}{l l} & \ \end{tabular}
le}"
post_process_generation
( generation: Union fix_markdown: bool = True num_workers: int = None ) → export const metadata = 'undefined';Union[str, List[str]]
参数
-
generation(Union[str, List[str]]) — 生成的文本或生成的文本列表。 -
fix_markdown(bool, 可选, 默认为True) — 是否执行 Markdown 格式修复。 -
num_workers(int, 可选) — 传递给利用多进程的工作人员数量(并行后处理多个文本)。
返回
Union[str, List[str]]
后处理的文本或后处理文本列表。
后处理生成的文本或生成的文本列表。
此函数可用于对生成的文本执行后处理,例如修复 Markdown 格式。
后处理速度较慢,建议使用多进程加快处理速度。
post_process_single
( generation: str fix_markdown: bool = True ) → export const metadata = 'undefined';str
参数
-
generation(str) — 要进行后处理的生成文本。 -
fix_markdown(bool, optional) — 是否执行 Markdown 格式修复。默认为 True。
返回
str
后处理的文本。
后处理单个生成的文本。此处使用的正则表达式直接来自 Nougat 文章作者。这些表达式已经过注释以确保清晰,并在大多数情况下进行了端到端测试。
remove_hallucinated_references
( text: str ) → export const metadata = 'undefined';str
参数
text(str) — 包含引用的输入文本。
返回
str
删除虚构引用的文本。
从文本中删除虚构或缺失的引用。
此函数识别并删除输入文本中标记为缺失或虚构的引用。
NougatProcessor
class transformers.NougatProcessor
( image_processor tokenizer )
参数
-
image_processor(NougatImageProcessor) — 一个 NougatImageProcessor 的实例。图像处理器是必需的输入。 -
tokenizer(NougatTokenizerFast) — 一个 NougatTokenizerFast 的实例。分词器是必需的输入。
构建一个 Nougat 处理器,将 Nougat 图像处理器和 Nougat tokenizer 包装成一个单一处理器。
NougatProcessor 提供了 NougatImageProcessor 和 NougatTokenizerFast 的所有功能。有关更多信息,请参考 call() 和 decode()。
__call__
( images = None text = None do_crop_margin: bool = None do_resize: bool = None size: Dict = None resample: PILImageResampling = None do_thumbnail: bool = None do_align_long_axis: bool = None do_pad: bool = None do_rescale: bool = None rescale_factor: Union = None do_normalize: bool = None image_mean: Union = None image_std: Union = None data_format: Optional = 'channels_first' input_data_format: Union = None text_pair: Union = None text_target: Union = None text_pair_target: Union = None add_special_tokens: bool = True padding: Union = False truncation: Union = None max_length: Optional = None stride: int = 0 is_split_into_words: bool = False pad_to_multiple_of: Optional = None return_tensors: Union = None return_token_type_ids: Optional = None return_attention_mask: Optional = None return_overflowing_tokens: bool = False return_special_tokens_mask: bool = False return_offsets_mapping: bool = False return_length: bool = False verbose: bool = True )
from_pretrained
( pretrained_model_name_or_path: Union cache_dir: Union = None force_download: bool = False local_files_only: bool = False token: Union = None revision: str = 'main' **kwargs )
参数
-
pretrained_model_name_or_path(stroros.PathLike) — 这可以是:-
一个字符串,预训练特征提取器的 模型 id,托管在 huggingface.co 上的模型存储库中。有效的模型 id 可以位于根级别,如
bert-base-uncased,或者在用户或组织名称下命名空间化,如dbmdz/bert-base-german-cased。 -
一个包含使用 save_pretrained() 方法保存的特征提取器文件的 目录 路径,例如
./my_model_directory/。 -
已保存的特征提取器 JSON 文件 的路径或 URL,例如
./my_model_directory/preprocessor_config.json。**kwargs — 传递给 from_pretrained() 和~tokenization_utils_base.PreTrainedTokenizer.from_pretrained的额外关键字参数。
-
实例化与预训练模型相关联的处理器。
这个类方法只是调用特征提取器 from_pretrained()、图像处理器 ImageProcessingMixin 和分词器 ~tokenization_utils_base.PreTrainedTokenizer.from_pretrained 方法。有关更多信息,请参考上述方法的文档字符串。
save_pretrained
( save_directory push_to_hub: bool = False **kwargs )
参数
-
save_directory(stroros.PathLike) — 将保存特征提取器 JSON 文件和分词器文件的目录(如果目录不存在,则将创建)。 -
push_to_hub(bool, optional, defaults toFalse) — 是否在保存模型后将其推送到 Hugging Face 模型中心。您可以使用repo_id指定要推送到的存储库(将默认为您的命名空间中的save_directory名称)。 -
kwargs(Dict[str, Any], optional) — 传递给 push_to_hub() 方法的额外关键字参数。
将此处理器的属性(特征提取器、分词器等)保存在指定的目录中,以便可以使用 from_pretrained() 方法重新加载。
这个类方法只是调用 save_pretrained() 和 save_pretrained()。有关更多信息,请参考上述方法的文档字符串。
batch_decode
( *args **kwargs )
这个方法将所有参数转发给 NougatTokenizer 的 batch_decode()。请参考此方法的文档字符串以获取更多信息。
解码
( *args **kwargs )
这个方法将所有参数转发给 NougatTokenizer 的 decode()。请参考此方法的文档字符串以获取更多信息。
后处理生成
( *args **kwargs )
这个方法将所有参数转发给 NougatTokenizer 的~PreTrainedTokenizer.post_process_generation。请参考此方法的文档字符串以获取更多信息。
OneFormer
原文链接:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/oneformer
概述
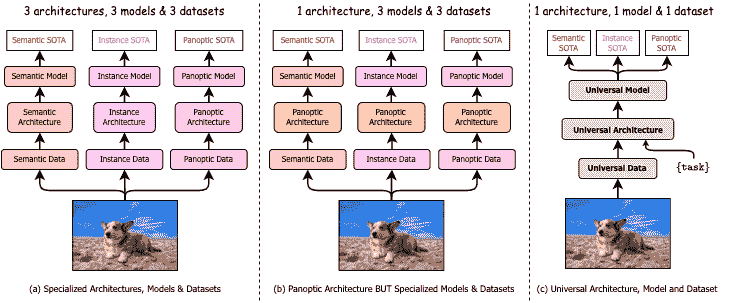
OneFormer 模型是由 Jitesh Jain、Jiachen Li、MangTik Chiu、Ali Hassani、Nikita Orlov、Humphrey Shi 在OneFormer: One Transformer to Rule Universal Image Segmentation中提出的。OneFormer 是一个通用的图像分割框架,可以在单个全景数据集上进行训练,执行语义、实例和全景分割任务。OneFormer 使用任务标记来使模型在关注的任务上进行条件化,使架构在训练时受任务引导,在推断时动态适应任务。
该论文的摘要如下:
通用图像分割并不是一个新概念。过去几十年来统一图像分割的尝试包括场景解析、全景分割,以及最近的新全景架构。然而,这些全景架构并不能真正统一图像分割,因为它们需要分别在语义、实例或全景分割上进行训练,才能达到最佳性能。理想情况下,一个真正通用的框架应该只需要训练一次,并在所有三个图像分割任务上实现 SOTA 性能。为此,我们提出了 OneFormer,一个通用图像分割框架,通过多任务一次训练的设计统一了分割。我们首先提出了一个任务条件联合训练策略,使得可以在单个多任务训练过程中训练每个领域(语义、实例和全景分割)的地面真相。其次,我们引入了一个任务标记,使我们的模型在手头的任务上进行条件化,使我们的模型支持多任务训练和推断。第三,我们提出在训练期间使用查询文本对比损失,以建立更好的任务间和类间区别。值得注意的是,我们的单个 OneFormer 模型在 ADE20k、CityScapes 和 COCO 上的所有三个分割任务中均优于专门的 Mask2Former 模型,尽管后者在每个任务上分别使用了三倍的资源进行训练。通过新的 ConvNeXt 和 DiNAT 骨干,我们观察到更多的性能改进。我们相信 OneFormer 是使图像分割更加通用和可访问的重要一步。
下图展示了 OneFormer 的架构。摘自原始论文。
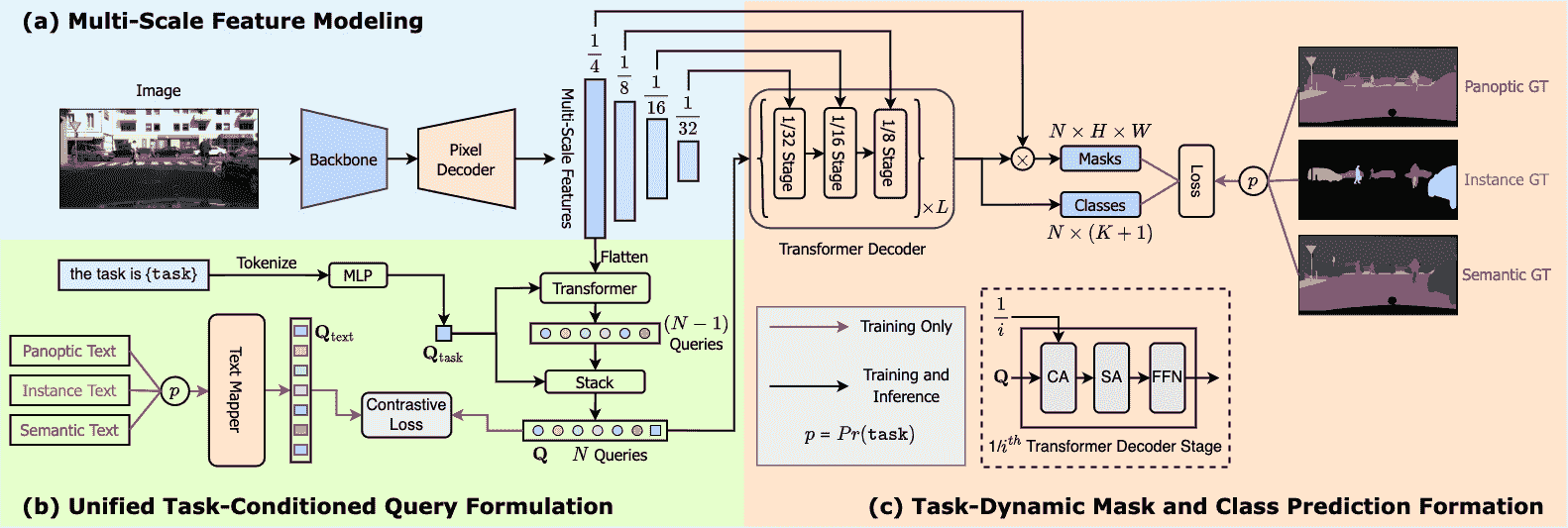
这个模型是由Jitesh Jain贡献的。原始代码可以在这里找到。
使用提示
-
在推断期间,OneFormer 需要两个输入:图像和任务标记。
-
在训练期间,OneFormer 只使用全景注释。
-
如果要在多个节点上的分布式环境中训练模型,则应该在
modeling_oneformer.py的OneFormerLoss类中更新get_num_masks函数。在多节点训练时,这应该设置为所有节点上目标掩码的平均数量,可以在原始实现中看到这里。 -
可以使用 OneFormerProcessor 来准备输入图像和模型的任务输入,以及可选的模型目标。
OneformerProcessor将 OneFormerImageProcessor 和 CLIPTokenizer 封装成一个单一实例,既可以准备图像又可以编码任务输入。 -
要获得最终的分割结果,可以调用 post_process_semantic_segmentation()或 post_process_instance_segmentation()或 post_process_panoptic_segmentation()。这三个任务都可以使用 OneFormerForUniversalSegmentation 的输出来解决,全景分割接受一个可选的
label_ids_to_fuse参数,用于将目标对象(例如天空)的实例融合在一起。
资源
一份官方 Hugging Face 和社区(由🌎表示)资源列表,可帮助您开始使用 OneFormer。
- 关于推断+在自定义数据上进行微调的演示笔记本可以在这里找到。
如果您有兴趣提交资源以包含在此处,请随时提交拉取请求,我们将对其进行审查。资源应该展示一些新的东西,而不是重复现有资源。
OneFormer 特定输出
class transformers.models.oneformer.modeling_oneformer.OneFormerModelOutput
( encoder_hidden_states: Optional = None pixel_decoder_hidden_states: Optional = None transformer_decoder_hidden_states: Optional = None transformer_decoder_object_queries: FloatTensor = None transformer_decoder_contrastive_queries: Optional = None transformer_decoder_mask_predictions: FloatTensor = None transformer_decoder_class_predictions: FloatTensor = None transformer_decoder_auxiliary_predictions: Optional = None text_queries: Optional = None task_token: FloatTensor = None attentions: Optional = None )
参数
-
encoder_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个阶段的输出),形状为(batch_size, num_channels, height, width)。编码器模型在每个阶段输出的隐藏状态(也称为特征图)。 -
pixel_decoder_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个阶段的输出),形状为(batch_size, num_channels, height, width)。像素解码器模型在每个阶段输出的隐藏状态(也称为特征图)。 -
transformer_decoder_hidden_states(tuple(torch.FloatTensor), optional, 当传递output_hidden_states=True或config.output_hidden_states=True时返回) —torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个阶段的输出),形状为(batch_size, sequence_length, hidden_size)。transformer 解码器在每个阶段输出的隐藏状态(也称为特征图)。 -
transformer_decoder_object_queries(torch.FloatTensor,形状为(batch_size, num_queries, hidden_dim)) — 来自 transformer 解码器最后一层的输出对象查询。 -
transformer_decoder_contrastive_queries(torch.FloatTensor,形状为(batch_size, num_queries, hidden_dim)) — 来自 transformer 解码器的对比查询。 -
transformer_decoder_mask_predictions(torch.FloatTensor,形状为(batch_size, num_queries, height, width)) — 来自 transformer 解码器最后一层的掩码预测。 -
transformer_decoder_class_predictions(torch.FloatTensor,形状为(batch_size, num_queries, num_classes+1)) — 来自 transformer 解码器最后一层的类别预测。 -
transformer_decoder_auxiliary_predictions(str, torch.FloatTensor字典的元组,可选) — 来自 transformer 解码器每一层的类别和掩码预测的元组。 -
text_queries(torch.FloatTensor,可选,形状为(batch_size, num_queries, hidden_dim)) — 从用于计算对比损失的输入文本列表派生的文本查询。 -
task_token(形状为(batch_size, hidden_dim)的torch.FloatTensor)—用于条件查询的一维任务令牌。 -
attentions(tuple(tuple(torch.FloatTensor)),可选,当传递output_attentions=True或当config.output_attentions=True时返回)—形状为(batch_size, num_heads, sequence_length, sequence_length)的tuple(torch.FloatTensor)元组(每层一个)。transformer 解码器的自注意力和交叉注意力权重。
用于 OneFormerModel 输出的类。此类返回计算 logits 所需的所有隐藏状态。
class transformers.models.oneformer.modeling_oneformer.OneFormerForUniversalSegmentationOutput
( loss: Optional = None class_queries_logits: FloatTensor = None masks_queries_logits: FloatTensor = None auxiliary_predictions: List = None encoder_hidden_states: Optional = None pixel_decoder_hidden_states: Optional = None transformer_decoder_hidden_states: Optional = None transformer_decoder_object_queries: FloatTensor = None transformer_decoder_contrastive_queries: Optional = None transformer_decoder_mask_predictions: FloatTensor = None transformer_decoder_class_predictions: FloatTensor = None transformer_decoder_auxiliary_predictions: Optional = None text_queries: Optional = None task_token: FloatTensor = None attentions: Optional = None )
参数
-
loss(torch.Tensor,可选)—当存在标签时返回计算的损失。 -
class_queries_logits(torch.FloatTensor)—形状为(batch_size, num_queries, num_labels + 1)的张量,表示每个查询的建议类别。请注意,需要+ 1,因为我们包含了空类。 -
masks_queries_logits(torch.FloatTensor)—形状为(batch_size, num_queries, height, width)的张量,表示每个查询的建议掩码。 -
auxiliary_predictions(str,torch.FloatTensor字典列表,可选)—来自 transformer 解码器每一层的类别和掩码预测的列表。 -
encoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)—形状为(batch_size, num_channels, height, width)的torch.FloatTensor元组(一个用于嵌入的输出+一个用于每个阶段的输出)。编码器模型在每个阶段输出的隐藏状态(也称为特征图)。 -
pixel_decoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)—形状为(batch_size, num_channels, height, width)的torch.FloatTensor元组(一个用于嵌入的输出+一个用于每个阶段的输出)。像素解码器模型在每个阶段输出的隐藏状态(也称为特征图)。 -
transformer_decoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)—形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出+一个用于每个阶段的输出)。transformer 解码器在每个阶段输出的隐藏状态(也称为特征图)。 -
transformer_decoder_object_queries(形状为(batch_size, num_queries, hidden_dim)的torch.FloatTensor)—来自 transformer 解码器中最后一层的输出对象查询。 -
transformer_decoder_contrastive_queries(形状为(batch_size, num_queries, hidden_dim)的torch.FloatTensor)—来自 transformer 解码器的对比查询。 -
transformer_decoder_mask_predictions(形状为(batch_size, num_queries, height, width)的torch.FloatTensor)—来自 transformer 解码器中最后一层的掩码预测。 -
transformer_decoder_class_predictions(形状为(batch_size, num_queries, num_classes+1)的torch.FloatTensor)—来自 transformer 解码器中最后一层的类别预测。 -
transformer_decoder_auxiliary_predictions(str,torch.FloatTensor字典列表,可选)—来自 transformer 解码器每一层的类别和掩码预测的列表。 -
text_queries(torch.FloatTensor,可选,形状为(batch_size, num_queries, hidden_dim))—从用于训练期间计算对比损失的输入文本列表派生的文本查询。 -
task_token(形状为(batch_size, hidden_dim)的torch.FloatTensor)—用于条件查询的一维任务令牌。 -
attentions(tuple(tuple(torch.FloatTensor)), optional, 当传递output_attentions=True或config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tuple(torch.FloatTensor)元组。来自 transformer 解码器的自注意力和交叉注意力权重。
用于OneFormerForUniversalSegmentationOutput的输出类。
此输出可以直接传递给 post_process_semantic_segmentation()或 post_process_instance_segmentation()或 post_process_panoptic_segmentation(),具体取决于任务。请参阅[`~OneFormerImageProcessor]以获取有关用法的详细信息。
OneFormerConfig
class transformers.OneFormerConfig
( backbone_config: Optional = None ignore_value: int = 255 num_queries: int = 150 no_object_weight: int = 0.1 class_weight: float = 2.0 mask_weight: float = 5.0 dice_weight: float = 5.0 contrastive_weight: float = 0.5 contrastive_temperature: float = 0.07 train_num_points: int = 12544 oversample_ratio: float = 3.0 importance_sample_ratio: float = 0.75 init_std: float = 0.02 init_xavier_std: float = 1.0 layer_norm_eps: float = 1e-05 is_training: bool = False use_auxiliary_loss: bool = True output_auxiliary_logits: bool = True strides: Optional = [4, 8, 16, 32] task_seq_len: int = 77 text_encoder_width: int = 256 text_encoder_context_length: int = 77 text_encoder_num_layers: int = 6 text_encoder_vocab_size: int = 49408 text_encoder_proj_layers: int = 2 text_encoder_n_ctx: int = 16 conv_dim: int = 256 mask_dim: int = 256 hidden_dim: int = 256 encoder_feedforward_dim: int = 1024 norm: str = 'GN' encoder_layers: int = 6 decoder_layers: int = 10 use_task_norm: bool = True num_attention_heads: int = 8 dropout: float = 0.1 dim_feedforward: int = 2048 pre_norm: bool = False enforce_input_proj: bool = False query_dec_layers: int = 2 common_stride: int = 4 **kwargs )
参数
-
backbone_config(PretrainedConfig, optional, defaults toSwinConfig) — 主干模型的配置。 -
ignore_value(int, optional, defaults to 255) — 在计算损失时要忽略的 GT 标签中的值。 -
num_queries(int, optional, defaults to 150) — 对象查询的数量。 -
no_object_weight(float, optional, defaults to 0.1) — 无对象类预测的权重。 -
class_weight(float, optional, defaults to 2.0) — 分类 CE 损失的权重。 -
mask_weight(float, optional, defaults to 5.0) — 二元 CE 损失的权重。 -
dice_weight(float, optional, defaults to 5.0) — Dice 损失的权重。 -
contrastive_weight(float, optional, defaults to 0.5) — 对比损失的权重。 -
contrastive_temperature(float, optional, defaults to 0.07) — 用于缩放对比对数的初始值。 -
train_num_points(int, optional, defaults to 12544) — 在计算掩码预测损失时要采样的点数。 -
oversample_ratio(float, optional, defaults to 3.0) — 决定过采样多少点的比率。 -
importance_sample_ratio(float, optional, defaults to 0.75) — 通过重要性采样抽样的点的比率。 -
init_std(float, optional, defaults to 0.02) — 正态初始化的标准差。 -
init_xavier_std(float, optional, defaults to 1.0) — 用于 xavier 均匀初始化的标准差。 -
layer_norm_eps(float, optional, defaults to 1e-05) — 层归一化的 epsilon。 -
is_training(bool, optional, defaults toFalse) — 是否在训练或推理模式下运行。 -
use_auxiliary_loss(bool, optional, defaults toTrue) — 是否使用 transformer 解码器的中间预测计算损失。 -
output_auxiliary_logits(bool, optional, defaults toTrue) — 是否从 transformer 解码器返回中间预测。 -
strides(list, optional, defaults to[4, 8, 16, 32]) — 包含编码器中特征图的步幅的列表。 -
task_seq_len(int, optional, defaults to 77) — 用于对文本列表输入进行分词的序列长度。 -
text_encoder_width(int, optional, defaults to 256) — 文本编码器的隐藏大小。 -
text_encoder_context_length(int, optional, defaults to 77) — 文本编码器的输入序列长度。 -
text_encoder_num_layers(int, optional, defaults to 6) — 文本编码器中 transformer 的层数。 -
text_encoder_vocab_size(int, optional, defaults to 49408) — 分词器的词汇量。 -
text_encoder_proj_layers(int, optional, defaults to 2) — 用于项目文本查询的 MLP 中的层数。 -
text_encoder_n_ctx(int, optional, 默认为 16) — 可学习文本上下文查询的数量。 -
conv_dim(int, optional, 默认为 256) — 从骨干网络映射输出的特征图维度。 -
mask_dim(int, optional, 默认为 256) — 像素解码器中特征图的维度。 -
hidden_dim(int, optional, 默认为 256) — 变压器解码器中隐藏状态的维度。 -
encoder_feedforward_dim(int, optional, 默认为 1024) — 像素解码器中 FFN 层的维度。 -
norm(str, optional, 默认为"GN") — 归一化类型。 -
encoder_layers(int, optional, 默认为 6) — 像素解码器中的层数。 -
decoder_layers(int, optional, 默认为 10) — 变压器解码器中的层数。 -
use_task_norm(bool, optional, 默认为True) — 是否对任务令牌进行归一化。 -
num_attention_heads(int, optional, 默认为 8) — 像素和变压器解码器中的注意力头数。 -
dropout(float, optional, 默认为 0.1) — 像素和变压器解码器的丢失概率。 -
dim_feedforward(int, optional, 默认为 2048) — 变压器解码器中 FFN 层的维度。 -
pre_norm(bool, optional, 默认为False) — 是否在变压器解码器中的注意力层之前对隐藏状态进行归一化。 -
enforce_input_proj(bool, optional, 默认为False) — 是否在变压器解码器中投影隐藏状态。 -
query_dec_layers(int, optional, 默认为 2) — 查询变压器中的层数。 -
common_stride(int, optional, 默认为 4) — 用于像素解码器中特征的常用步幅。
这是用于存储 OneFormerModel 配置的配置类。它用于根据指定的参数实例化一个 OneFormer 模型,定义模型架构。使用默认值实例化配置将产生类似于在 ADE20k-150 上训练的 OneFormer shi-labs/oneformer_ade20k_swin_tiny 架构的配置。
配置对象继承自 PretrainedConfig 并可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import OneFormerConfig, OneFormerModel
>>> # Initializing a OneFormer shi-labs/oneformer_ade20k_swin_tiny configuration
>>> configuration = OneFormerConfig()
>>> # Initializing a model (with random weights) from the shi-labs/oneformer_ade20k_swin_tiny style configuration
>>> model = OneFormerModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
OneFormerImageProcessor
class transformers.OneFormerImageProcessor
( do_resize: bool = True size: Dict = None resample: Resampling = <Resampling.BILINEAR: 2> do_rescale: bool = True rescale_factor: float = 0.00392156862745098 do_normalize: bool = True image_mean: Union = None image_std: Union = None ignore_index: Optional = None do_reduce_labels: bool = False repo_path: Optional = 'shi-labs/oneformer_demo' class_info_file: str = None num_text: Optional = None **kwargs )
参数
-
do_resize(bool, optional, 默认为True) — 是否将输入调整大小到特定的size。 -
size(int, optional, 默认为 800) — 将输入调整大小到给定大小。仅在do_resize设置为True时有效。如果 size 是一个类似(width, height)的序列,则输出大小将匹配到这个。如果 size 是一个整数,图像的较小边将匹配到这个数字。即,如果height > width,则图像将重新缩放为(size * height / width, size)。 -
resample(int, optional, 默认为Resampling.BILINEAR) — 可选的重采样滤波器。可以是PIL.Image.Resampling.NEAREST,PIL.Image.Resampling.BOX,PIL.Image.Resampling.BILINEAR,PIL.Image.Resampling.HAMMING,PIL.Image.Resampling.BICUBIC或PIL.Image.Resampling.LANCZOS中的一个。仅在do_resize设置为True时有效。 -
do_rescale(bool, optional, 默认为True) — 是否将输入重新缩放到特定的scale。 -
rescale_factor(float, optional, 默认为1/ 255) — 通过给定因子重新缩放输入。仅在do_rescale设置为True时有效。 -
do_normalize(bool,可选,默认为True)— 是否对输入进行均值和标准差归一化。 -
image_mean(int,可选,默认为[0.485, 0.456, 0.406])— 每个通道的均值序列,在规范化图像时使用。默认为 ImageNet 均值。 -
image_std(int,可选,默认为[0.229, 0.224, 0.225])— 每个通道的标准差序列,在规范化图像时使用。默认为 ImageNet 标准差。 -
ignore_index(int,可选)— 分割地图中要分配给背景像素的标签。如果提供,用 0(背景)表示的分割地图像素将被替换为ignore_index。 -
do_reduce_labels(bool,可选,默认为False)— 是否将所有分割地图的标签值减 1。通常用于数据集中使用 0 表示背景,并且背景本身不包含在数据集的所有类中的情况(例如 ADE20k)。背景标签将被替换为ignore_index。 -
repo_path(str,可选,默认为"shi-labs/oneformer_demo")— 包含数据集类信息的 JSON 文件的 hub 存储库或本地目录的路径。如果未设置,将在当前工作目录中查找class_info_file。 -
class_info_file(str,可选)— 包含数据集类信息的 JSON 文件。查看shi-labs/oneformer_demo/cityscapes_panoptic.json以获取示例。 -
num_text(int,可选)— 文本输入列表中的文本条目数。
构建一个 OneFormer 图像处理器。该图像处理器可用于为模型准备图像、任务输入以及可选的文本输入和目标。
这个图像处理器继承自BaseImageProcessor,其中包含大部分主要方法。用户应参考这个超类以获取有关这些方法的更多信息。
preprocess
( images: Union task_inputs: Optional = None segmentation_maps: Union = None instance_id_to_semantic_id: Optional = None do_resize: Optional = None size: Optional = None resample: Resampling = None do_rescale: Optional = None rescale_factor: Optional = None do_normalize: Optional = None image_mean: Union = None image_std: Union = None ignore_index: Optional = None do_reduce_labels: Optional = None return_tensors: Union = None data_format: Union = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )
encode_inputs
( pixel_values_list: List task_inputs: List segmentation_maps: Union = None instance_id_to_semantic_id: Union = None ignore_index: Optional = None reduce_labels: bool = False return_tensors: Union = None input_data_format: Union = None ) → export const metadata = 'undefined';BatchFeature
参数
-
pixel_values_list(List[ImageInput])— 要填充的图像(像素值)列表。每个图像应该是形状为(channels, height, width)的张量。 -
task_inputs(List[str])— 任务值列表。 -
segmentation_maps(ImageInput,可选)— 具有像素级注释的相应语义分割地图。(
bool,可选,默认为True):是否将图像填充到批次中最大的图像并创建像素掩码。如果保持默认设置,将返回一个像素掩码,即:
-
对于真实像素(即
未掩码)为 1, -
对于填充像素(即
掩码)为 0。
-
-
instance_id_to_semantic_id(List[Dict[int, int]]或Dict[int, int],可选)— 对象实例 ID 和类 ID 之间的映射。如果传递,segmentation_maps将被视为实例分割地图,其中每个像素表示一个实例 ID。可以提供为单个字典,其中包含全局/数据集级别的映射,或作为字典列表(每个图像一个),以分别映射每个图像中的实例 ID。 -
return_tensors(str或 TensorType,可选)— 如果设置,将返回张量而不是 NumPy 数组。如果设置为'pt',则返回 PyTorchtorch.Tensor对象。 -
input_data_format(str或ChannelDimension,可选)— 输入图像的通道维度格式。如果未提供,将从输入图像中推断。
返回
BatchFeature
一个具有以下字段的 BatchFeature:
-
pixel_values— 要馈送给模型的像素值。 -
pixel_mask— 要馈送给模型的像素掩模(当=True或pixel_mask在self.model_input_names中时)。 -
mask_labels— 形状为(labels, height, width)的可选掩模标签列表,要馈送给模型(当提供annotations时)。 -
class_labels— 形状为(labels)的可选类标签列表,要馈送给模型(当提供annotations时)。它们标识mask_labels的标签,例如,如果class_labels[i][j]的标签为mask_labels[i][j]。 -
text_inputs— 要馈送给模型的可选文本字符串条目列表(当提供annotations时)。它们标识图像中存在的二进制掩模。
将图像填充到批处理中最大的图像,并创建相应的 pixel_mask。
OneFormer 使用掩模分类范式来处理语义分割,因此输入分割地图将被转换为二进制掩模列表及其相应的标签。让我们看一个例子,假设 segmentation_maps = [[2,6,7,9]],输出将包含 mask_labels = [[1,0,0,0],[0,1,0,0],[0,0,1,0],[0,0,0,1]](四个二进制掩模)和 class_labels = [2,6,7,9],每个掩模的标签。
post_process_semantic_segmentation
( outputs target_sizes: Optional = None ) → export const metadata = 'undefined';List[torch.Tensor]
参数
-
outputs(MaskFormerForInstanceSegmentation) — 模型的原始输出。 -
target_sizes(List[Tuple[int, int]], 可选) — 长度为 (batch_size) 的列表,其中每个列表项 (Tuple[int, int]]) 对应于每个预测的请求最终大小(高度、宽度)。如果保持为 None,则不会调整预测大小。
返回
List[torch.Tensor]
一个长度为 batch_size 的列表,每个项是一个形状为 (height, width) 的语义分割地图,对应于目标大小条目(如果指定了 target_sizes)。每个 torch.Tensor 的每个条目对应于一个语义类别 id。
将 MaskFormerForInstanceSegmentation 的输出转换为语义分割地图。仅支持 PyTorch。
post_process_instance_segmentation
( outputs task_type: str = 'instance' is_demo: bool = True threshold: float = 0.5 mask_threshold: float = 0.5 overlap_mask_area_threshold: float = 0.8 target_sizes: Optional = None return_coco_annotation: Optional = False ) → export const metadata = 'undefined';List[Dict]
参数
-
outputs(OneFormerForUniversalSegmentationOutput) — 从OneFormerForUniversalSegmentationOutput得到的输出。 -
task_type(str, 可选),默认为“instance”) — 后处理取决于任务令牌输入。如果task_type是“panoptic”,我们需要忽略杂项预测。 -
is_demo(bool, 可选),默认为True) — 模型是否处于演示模式。如果为真,则使用阈值预测最终掩模。 -
threshold(float, 可选, 默认为 0.5) — 保留预测实例掩模的概率分数阈值。 -
mask_threshold(float, 可选, 默认为 0.5) — 在将预测的掩模转换为二进制值时使用的阈值。 -
overlap_mask_area_threshold(float, 可选, 默认为 0.8) — 合并或丢弃每个二进制实例掩模中的小断开部分的重叠掩模区域阈值。 -
target_sizes(List[Tuple], 可选) — 长度为 (batch_size) 的列表,其中每个列表项 (Tuple[int, int]]) 对应于批处理中每个预测的请求最终大小(高度、宽度)。如果保持为 None,则不会调整预测大小。 -
return_coco_annotation(bool, 可选),默认为False) — 是否以 COCO 格式返回预测。
返回
List[Dict]
一个字典列表,每个图像一个字典,每个字典包含两个键:
-
segmentation— 形状为(height, width)的张量,其中每个像素代表一个segment_id,如果未找到高于threshold的掩模,则设置为None。如果指定了target_sizes,则将分割调整为相应的target_sizes条目。 -
segments_info— 包含每个段的其他信息的字典。-
id— 代表segment_id的整数。 -
label_id— 代表与segment_id对应的标签/语义类别 ID 的整数。 -
was_fused— 一个布尔值,如果label_id在label_ids_to_fuse中,则为True,否则为False。相同类别/标签的多个实例被融合并分配一个单独的segment_id。 -
score— 具有segment_id的段的预测分数。
-
将OneFormerForUniversalSegmentationOutput的输出转换为图像实例分割预测。仅支持 PyTorch。
post_process_panoptic_segmentation
( outputs threshold: float = 0.5 mask_threshold: float = 0.5 overlap_mask_area_threshold: float = 0.8 label_ids_to_fuse: Optional = None target_sizes: Optional = None ) → export const metadata = 'undefined';List[Dict]
参数
-
outputs(MaskFormerForInstanceSegmentationOutput)— 来自 MaskFormerForInstanceSegmentation 的输出。 -
threshold(float,可选,默认为 0.5)— 保留预测实例掩模的概率分数阈值。 -
mask_threshold(float,可选,默认为 0.5)— 在将预测的掩模转换为二进制值时使用的阈值。 -
overlap_mask_area_threshold(float,可选,默认为 0.8)— 用于合并或丢弃每个二进制实例掩模中的小断开部分的重叠掩模区域阈值。 -
label_ids_to_fuse(Set[int],可选)— 此状态中的标签将使其所有实例被融合在一起。例如,我们可以说图像中只能有一个天空,但可以有几个人,因此天空的标签 ID 将在该集合中,但人的标签 ID 不在其中。 -
target_sizes(List[Tuple],可选)— 长度为(batch_size)的列表,其中每个列表项(Tuple[int, int])对应于批处理中每个预测的请求的最终大小(高度,宽度)。如果保持为 None,则不会调整预测大小。
返回值
List[Dict]
一个字典列表,每个图像一个,每个字典包含两个键:
-
segmentation— 形状为(height, width)的张量,其中每个像素代表一个segment_id,如果未找到高于threshold的掩模,则设置为None。如果指定了target_sizes,则将分割调整为相应的target_sizes条目。 -
segments_info— 包含每个段的其他信息的字典。-
id— 代表segment_id的整数。 -
label_id— 代表与segment_id对应的标签/语义类别 ID 的整数。 -
was_fused— 一个布尔值,如果label_id在label_ids_to_fuse中,则为True,否则为False。相同类别/标签的多个实例被融合并分配一个单独的segment_id。 -
score— 具有segment_id的段的预测分数。
-
将MaskFormerForInstanceSegmentationOutput的输出转换为图像全景分割预测。仅支持 PyTorch。
OneFormerProcessor
class transformers.OneFormerProcessor
( image_processor = None tokenizer = None max_seq_length: int = 77 task_seq_length: int = 77 **kwargs )
参数
-
image_processor(OneFormerImageProcessor)— 图像处理器是必需的输入。 -
tokenizer([CLIPTokenizer,CLIPTokenizerFast])— 分词器是必需的输入。 -
max_seq_len(int,可选,默认为 77)— 输入文本列表的序列长度。 -
task_seq_len(int,可选,默认为 77)— 输入任务令牌的序列长度。
构建一个 OneFormer 处理器,将 OneFormerImageProcessor 和 CLIPTokenizer/CLIPTokenizerFast 包装成一个单一处理器,继承了图像处理器和标记化器的功能。
encode_inputs
( images = None task_inputs = None segmentation_maps = None **kwargs )
此方法将其所有参数转发到 OneFormerImageProcessor.encode_inputs(),然后对任务输入进行标记化。有关更多信息,请参阅此方法的文档字符串。
post_process_instance_segmentation
( *args **kwargs )
此方法将其所有参数转发到 OneFormerImageProcessor.post_process_instance_segmentation()。有关更多信息,请参阅此方法的文档字符串。
post_process_panoptic_segmentation
( *args **kwargs )
此方法将其所有参数转发到 OneFormerImageProcessor.post_process_panoptic_segmentation()。有关更多信息,请参阅此方法的文档字符串。
post_process_semantic_segmentation
( *args **kwargs )
此方法将其所有参数转发到 OneFormerImageProcessor.post_process_semantic_segmentation()。有关更多信息,请参阅此方法的文档字符串。
OneFormerModel
class transformers.OneFormerModel
( config: OneFormerConfig )
参数
config(OneFormerConfig)- 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
裸的 OneFormer 模型,在顶部没有任何特定的头部输出原始隐藏状态。此模型是 PyTorch nn.Module子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: Tensor task_inputs: Tensor text_inputs: Optional = None pixel_mask: Optional = None output_hidden_states: Optional = None output_attentions: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.oneformer.modeling_oneformer.OneFormerModelOutput or tuple(torch.FloatTensor)
参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)- 像素值。像素值可以使用 OneFormerProcessor 获得。有关详细信息,请参阅OneFormerProcessor.__call__()。 -
task_inputs(形状为(batch_size, sequence_length)的torch.FloatTensor)- 任务输入。任务输入可以使用 AutoImageProcessor 获得。有关详细信息,请参阅OneFormerProcessor.__call__()。 -
pixel_mask(形状为(batch_size, height, width)的torch.LongTensor,可选)- 用于避免在填充像素值上执行注意力的掩码。在[0, 1]中选择的掩码值:-
对于真实像素为 1(即
not masked), -
对于填充的像素为 0(即
masked)。
什么是注意力掩码?
-
-
output_hidden_states(bool,可选)- 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
output_attentions(bool,可选)- 是否返回 Detr 解码器注意力层的注意力张量。 -
return_dict(bool,可选)- 是否返回~OneFormerModelOutput而不是普通元组。
返回
transformers.models.oneformer.modeling_oneformer.OneFormerModelOutput 或tuple(torch.FloatTensor)
transformers.models.oneformer.modeling_oneformer.OneFormerModelOutput 或torch.FloatTensor元组(如果传递return_dict=False或当config.return_dict=False时)包括根据配置(OneFormerConfig)和输入的各种元素。
-
encoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)- 形状为(batch_size, num_channels, height, width)的torch.FloatTensor元组(一个用于嵌入的输出+一个用于每个阶段的输出)。编码器模型在每个阶段输出的隐藏状态(也称为特征图)。 -
pixel_decoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)- 形状为(batch_size, num_channels, height, width)的torch.FloatTensor元组(一个用于嵌入的输出+一个用于每个阶段的输出)。像素解码器模型在每个阶段输出的隐藏状态(也称为特征图)。 -
transformer_decoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)- 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出+一个用于每个阶段的输出)。transformer 解码器在每个阶段输出的隐藏状态(也称为特征图)。 -
transformer_decoder_object_queries(形状为(batch_size, num_queries, hidden_dim)的torch.FloatTensor)- transformer 解码器中最后一层的输出对象查询。 -
transformer_decoder_contrastive_queries(形状为(batch_size, num_queries, hidden_dim)的torch.FloatTensor)- 来自 transformer 解码器的对比查询。 -
transformer_decoder_mask_predictions(形状为(batch_size, num_queries, height, width)的torch.FloatTensor)- transformer 解码器中最后一层的掩码预测。 -
transformer_decoder_class_predictions(形状为(batch_size, num_queries, num_classes+1)的torch.FloatTensor)- transformer 解码器中最后一层的类别预测。 -
transformer_decoder_auxiliary_predictions(str,torch.FloatTensor字典的元组,可选)- 来自 transformer 解码器每一层的类别和掩码预测的元组。 -
text_queries(torch.FloatTensor,可选,形状为(batch_size, num_queries, hidden_dim))- 从用于训练期间计算对比损失的输入文本列表派生的文本查询。 -
task_token(形状为(batch_size, hidden_dim)的torch.FloatTensor)- 用于条件查询的一维任务令牌。 -
attentions(tuple(tuple(torch.FloatTensor)),可选,当传递output_attentions=True或当config.output_attentions=True时返回)— 形状为(batch_size, num_heads, sequence_length, sequence_length)的tuple(torch.FloatTensor)元组。来自变压器解码器的自注意力和交叉注意力权重。
OneFormerModelOutput
OneFormerModel 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> import torch
>>> from PIL import Image
>>> import requests
>>> from transformers import OneFormerProcessor, OneFormerModel
>>> # download texting image
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # load processor for preprocessing the inputs
>>> processor = OneFormerProcessor.from_pretrained("shi-labs/oneformer_ade20k_swin_tiny")
>>> model = OneFormerModel.from_pretrained("shi-labs/oneformer_ade20k_swin_tiny")
>>> inputs = processor(image, ["semantic"], return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> mask_predictions = outputs.transformer_decoder_mask_predictions
>>> class_predictions = outputs.transformer_decoder_class_predictions
>>> f"👉 Mask Predictions Shape: {list(mask_predictions.shape)}, Class Predictions Shape: {list(class_predictions.shape)}"
'👉 Mask Predictions Shape: [1, 150, 128, 171], Class Predictions Shape: [1, 150, 151]'
OneFormerForUniversalSegmentation
class transformers.OneFormerForUniversalSegmentation
( config: OneFormerConfig )
参数
config(OneFormerConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
OneFormer 模型例如,语义和全景图像分割。此模型是 PyTorch nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
forward
( pixel_values: Tensor task_inputs: Tensor text_inputs: Optional = None mask_labels: Optional = None class_labels: Optional = None pixel_mask: Optional = None output_auxiliary_logits: Optional = None output_hidden_states: Optional = None output_attentions: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.oneformer.modeling_oneformer.OneFormerForUniversalSegmentationOutput or tuple(torch.FloatTensor)
参数
-
pixel_values(形状为(batch_size, num_channels, height, width)的torch.FloatTensor)— 像素值。像素值可以使用 OneFormerProcessor 获取。有关详细信息,请参阅OneFormerProcessor.__call__()。 -
task_inputs(形状为(batch_size, sequence_length)的torch.FloatTensor)— 任务输入。任务输入可以使用 AutoImageProcessor 获取。有关详细信息,请参阅OneFormerProcessor.__call__()。 -
pixel_mask(形状为(batch_size, height, width)的torch.LongTensor,可选)— 用于避免在填充像素值上执行注意力的掩码。掩码值选在[0, 1]中:-
对于真实像素(即
not masked)的像素为 1, -
对于填充像素(即
masked)的像素为 0。
注意力掩码是什么?
-
-
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
output_attentions(bool,可选)— 是否返回 Detr 解码器注意力层的注意力张量。 -
return_dict(bool,可选)— 是否返回~OneFormerModelOutput而不是普通元组。 -
text_inputs(List[torch.Tensor],可选)— 形状为(num_queries, sequence_length)的张量,将被馈送到模型 -
mask_labels(List[torch.Tensor],可选)— 形状为(num_labels, height, width)的掩码标签列表,将被馈送到模型 -
class_labels(List[torch.LongTensor],可选)— 形状为(num_labels, height, width)的目标类标签列表,将被馈送到模型。它们标识mask_labels的标签,例如,如果class_labels[i][j]的标签是mask_labels[i][j]。
返回
transformers.models.oneformer.modeling_oneformer.OneFormerForUniversalSegmentationOutput 或tuple(torch.FloatTensor)
transformers.models.oneformer.modeling_oneformer.OneFormerForUniversalSegmentationOutput 或一个torch.FloatTensor元组(如果传递return_dict=False或当config.return_dict=False时)包含根据配置(OneFormerConfig)和输入的各种元素。
-
loss(torch.Tensor,可选)—计算得到的损失,在存在标签时返回。 -
class_queries_logits(torch.FloatTensor)—形状为(batch_size, num_queries, num_labels + 1)的张量,表示每个查询的提议类别。请注意,需要+ 1,因为我们包含了空类。 -
masks_queries_logits(torch.FloatTensor)—形状为(batch_size, num_queries, height, width)的张量,表示每个查询的提议掩码。 -
auxiliary_predictions(str,torch.FloatTensor字典的列表,可选)—来自 transformer 解码器每一层的类别和掩码预测的列表。 -
encoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)—形状为(batch_size, num_channels, height, width)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个阶段的输出)。编码器模型在每个阶段输出的隐藏状态(也称为特征图)。 -
pixel_decoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)—形状为(batch_size, num_channels, height, width)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个阶段的输出)。像素解码器模型在每个阶段输出的隐藏状态(也称为特征图)。 -
transformer_decoder_hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回)—形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(一个用于嵌入的输出 + 一个用于每个阶段的输出)。transformer 解码器在每个阶段输出的隐藏状态(也称为特征图)。 -
transformer_decoder_object_queries(torch.FloatTensor,形状为(batch_size, num_queries, hidden_dim))—transformer 解码器中最后一层的输出对象查询。 -
transformer_decoder_contrastive_queries(torch.FloatTensor,形状为(batch_size, num_queries, hidden_dim))—transformer 解码器中的对比查询。 -
transformer_decoder_mask_predictions(torch.FloatTensor,形状为(batch_size, num_queries, height, width))—transformer 解码器中最后一层的掩码预测。 -
transformer_decoder_class_predictions(torch.FloatTensor,形状为(batch_size, num_queries, num_classes+1))—transformer 解码器中最后一层的类别预测。 -
transformer_decoder_auxiliary_predictions(str,torch.FloatTensor字典的列表,可选)—来自 transformer 解码器每一层的类别和掩码预测的列表。 -
text_queries(torch.FloatTensor,可选,形状为(batch_size, num_queries, hidden_dim))—从用于训练期间计算对比损失的输入文本列表派生的文本查询。 -
task_token(torch.FloatTensor,形状为(batch_size, hidden_dim))—用于条件查询的一维任务令牌。 -
attentions(tuple(tuple(torch.FloatTensor)), 可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的tuple(torch.FloatTensor)元组(每层一个)。来自变压器解码器的自注意力和交叉注意力权重。
OneFormerUniversalSegmentationOutput
OneFormerForUniversalSegmentation 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
通用分割示例:
>>> from transformers import OneFormerProcessor, OneFormerForUniversalSegmentation
>>> from PIL import Image
>>> import requests
>>> import torch
>>> # load OneFormer fine-tuned on ADE20k for universal segmentation
>>> processor = OneFormerProcessor.from_pretrained("shi-labs/oneformer_ade20k_swin_tiny")
>>> model = OneFormerForUniversalSegmentation.from_pretrained("shi-labs/oneformer_ade20k_swin_tiny")
>>> url = (
... "https://huggingface.co/datasets/hf-internal-testing/fixtures_ade20k/resolve/main/ADE_val_00000001.jpg"
... )
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> # Semantic Segmentation
>>> inputs = processor(image, ["semantic"], return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # model predicts class_queries_logits of shape `(batch_size, num_queries)`
>>> # and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
>>> class_queries_logits = outputs.class_queries_logits
>>> masks_queries_logits = outputs.masks_queries_logits
>>> # you can pass them to processor for semantic postprocessing
>>> predicted_semantic_map = processor.post_process_semantic_segmentation(
... outputs, target_sizes=[image.size[::-1]]
... )[0]
>>> f"👉 Semantic Predictions Shape: {list(predicted_semantic_map.shape)}"
'👉 Semantic Predictions Shape: [512, 683]'
>>> # Instance Segmentation
>>> inputs = processor(image, ["instance"], return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # model predicts class_queries_logits of shape `(batch_size, num_queries)`
>>> # and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
>>> class_queries_logits = outputs.class_queries_logits
>>> masks_queries_logits = outputs.masks_queries_logits
>>> # you can pass them to processor for instance postprocessing
>>> predicted_instance_map = processor.post_process_instance_segmentation(
... outputs, target_sizes=[image.size[::-1]]
... )[0]["segmentation"]
>>> f"👉 Instance Predictions Shape: {list(predicted_instance_map.shape)}"
'👉 Instance Predictions Shape: [512, 683]'
>>> # Panoptic Segmentation
>>> inputs = processor(image, ["panoptic"], return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> # model predicts class_queries_logits of shape `(batch_size, num_queries)`
>>> # and masks_queries_logits of shape `(batch_size, num_queries, height, width)`
>>> class_queries_logits = outputs.class_queries_logits
>>> masks_queries_logits = outputs.masks_queries_logits
>>> # you can pass them to processor for panoptic postprocessing
>>> predicted_panoptic_map = processor.post_process_panoptic_segmentation(
... outputs, target_sizes=[image.size[::-1]]
... )[0]["segmentation"]
>>> f"👉 Panoptic Predictions Shape: {list(predicted_panoptic_map.shape)}"
'👉 Panoptic Predictions Shape: [512, 683]'
OWL-ViT
原文:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/owlvit
概述
OWL-ViT(Vision Transformer for Open-World Localization)是由 Matthias Minderer、Alexey Gritsenko、Austin Stone、Maxim Neumann、Dirk Weissenborn、Alexey Dosovitskiy、Aravindh Mahendran、Anurag Arnab、Mostafa Dehghani、Zhuoran Shen、Xiao Wang、Xiaohua Zhai、Thomas Kipf 和 Neil Houlsby 在Simple Open-Vocabulary Object Detection with Vision Transformers中提出的。OWL-ViT 是一个在各种(图像,文本)对上训练的开放词汇目标检测网络。它可以用于使用一个或多个文本查询查询图像,以搜索和检测文本中描述的目标对象。
来自论文的摘要如下:
将简单的架构与大规模预训练相结合,已经在图像分类方面取得了巨大的改进。对于目标检测,预训练和扩展方法尚未建立良好的基础,特别是在长尾和开放词汇设置中,训练数据相对稀缺的情况下。在本文中,我们提出了一个强大的配方,将图像文本模型转移到开放词汇的目标检测中。我们使用标准的 Vision Transformer 架构进行最小修改,对比图像文本预训练,并进行端到端的检测微调。我们对这一设置的扩展属性进行了分析,结果表明增加图像级别的预训练和模型大小可以在下游检测任务中获得一致的改进。我们提供了适应策略和规范化,以实现零样本文本条件和一次样本图像条件的目标检测的非常强大的性能。代码和模型可在 GitHub 上获得。
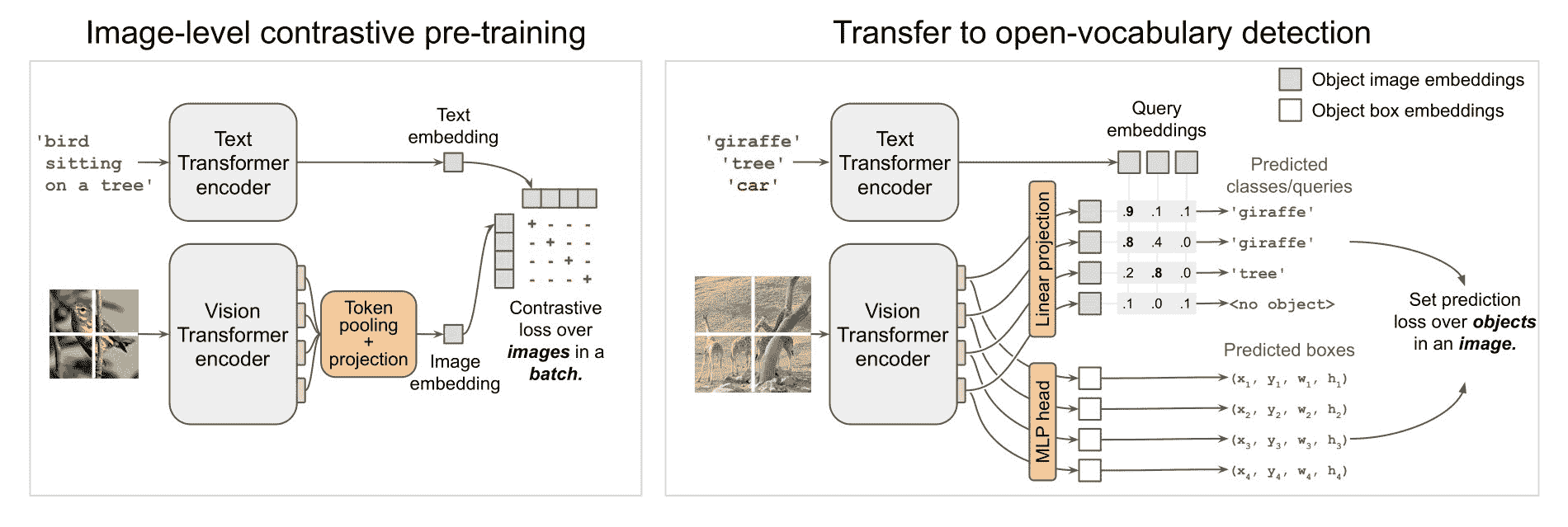 OWL-ViT 架构。摘自原始论文。
OWL-ViT 架构。摘自原始论文。
使用提示
OWL-ViT 是一个零样本文本条件的目标检测模型。OWL-ViT 使用 CLIP 作为其多模态骨干,具有类似 ViT 的 Transformer 来获取视觉特征和因果语言模型来获取文本特征。为了使用 CLIP 进行检测,OWL-ViT 移除了视觉模型的最终令牌池化层,并将轻量级分类和框头附加到每个 Transformer 输出令牌上。通过用从文本模型获得的类名嵌入替换固定的分类层权重,实现了开放词汇分类。作者首先从头开始训练 CLIP,然后在标准检测数据集上使用二部匹配损失对其进行端到端的微调,包括分类和框头。可以使用一个或多个文本查询来执行零样本文本条件的目标检测。
OwlViTImageProcessor 可用于调整(或重新缩放)和规范化模型的图像,而 CLIPTokenizer 用于对文本进行编码。OwlViTProcessor 将 OwlViTImageProcessor 和 CLIPTokenizer 包装成一个单一实例,用于同时对文本进行编码和准备图像。以下示例展示了如何使用 OwlViTProcessor 和 OwlViTForObjectDetection 执行目标检测。
>>> import requests
>>> from PIL import Image
>>> import torch
>>> from transformers import OwlViTProcessor, OwlViTForObjectDetection
>>> processor = OwlViTProcessor.from_pretrained("google/owlvit-base-patch32")
>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = [["a photo of a cat", "a photo of a dog"]]
>>> inputs = processor(text=texts, images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
>>> target_sizes = torch.Tensor([image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
>>> results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=0.1)
>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
>>> text = texts[i]
>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
>>> for box, score, label in zip(boxes, scores, labels):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.58, 373.29]
Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
资源
可以在这里找到使用 OWL-ViT 进行零样本和一样本(图像引导)目标检测的演示笔记本。
OwlViTConfig
class transformers.OwlViTConfig
( text_config = None vision_config = None projection_dim = 512 logit_scale_init_value = 2.6592 return_dict = True **kwargs )
参数
-
text_config(dict, optional) — 用于初始化 OwlViTTextConfig 的配置选项字典。 -
vision_config(dict, optional) — 用于初始化 OwlViTVisionConfig 的配置选项字典。 -
projection_dim(int, optional, 默认为 512) — 文本和视觉投影层的维度。 -
logit_scale_init_value(float, optional, 默认为 2.6592) — logit_scale 参数的初始值。默认值根据原始的 OWL-ViT 实现而定。 -
return_dict(bool, optional, 默认为True) — 模型是否应返回一个字典。如果为False,则返回一个元组。 -
kwargs(optional) — 关键字参数的字典。
OwlViTConfig 是用于存储 OwlViTModel 配置的配置类。根据指定的参数实例化 OWL-ViT 模型,定义文本模型和视觉模型配置。使用默认值实例化配置将产生类似于 OWL-ViT google/owlvit-base-patch32 架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读来自 PretrainedConfig 的文档以获取更多信息。
from_text_vision_configs
( text_config: Dict vision_config: Dict **kwargs ) → export const metadata = 'undefined';OwlViTConfig
返回
OwlViTConfig
配置对象的一个实例
从 owlvit 文本模型配置和 owlvit 视觉模型配置实例化一个 OwlViTConfig(或派生类)。
OwlViTTextConfig
class transformers.OwlViTTextConfig
( vocab_size = 49408 hidden_size = 512 intermediate_size = 2048 num_hidden_layers = 12 num_attention_heads = 8 max_position_embeddings = 16 hidden_act = 'quick_gelu' layer_norm_eps = 1e-05 attention_dropout = 0.0 initializer_range = 0.02 initializer_factor = 1.0 pad_token_id = 0 bos_token_id = 49406 eos_token_id = 49407 **kwargs )
参数
-
vocab_size(int, optional, 默认为 49408) — OWL-ViT 文本模型的词汇量。定义了在调用 OwlViTTextModel 时可以表示的不同标记数量。 -
hidden_size(int, optional, 默认为 512) — 编码器层和池化层的维度。 -
intermediate_size(int, optional, 默认为 2048) — Transformer 编码器中“中间”(即前馈)层的维度。 -
num_hidden_layers(int, optional, 默认为 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, 默认为 8) — Transformer 编码器中每个注意力层的注意力头数。 -
max_position_embeddings(int, optional, 默认为 16) — 该模型可能使用的最大序列长度。通常设置为一个较大的值(例如 512、1024 或 2048)以防万一。 -
hidden_act(strorfunction, optional, defaults to"quick_gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,则支持"gelu"、"relu"、"selu"和"gelu_new"以及"quick_gelu"。 -
layer_norm_eps(float, optional, defaults to 1e-05) — 层归一化层使用的 epsilon。 -
attention_dropout(float, optional, defaults to 0.0) — 注意力概率的丢失比率。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
initializer_factor(float, optional, defaults to 1.0) — 用于初始化所有权重矩阵的因子(应保持为 1,用于内部初始化测试)。 -
pad_token_id(int, optional, defaults to 0) — 输入序列中填充标记的 id。 -
bos_token_id(int, optional, defaults to 49406) — 输入序列中起始标记的 id。 -
eos_token_id(int, optional, defaults to 49407) — 输入序列中终止标记的 id。
这是用于存储 OwlViTTextModel 配置的配置类。根据指定的参数实例化一个 OwlViT 文本编码器,定义模型架构。使用默认值实例化配置将产生与 OwlViT google/owlvit-base-patch32架构类似的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import OwlViTTextConfig, OwlViTTextModel
>>> # Initializing a OwlViTTextModel with google/owlvit-base-patch32 style configuration
>>> configuration = OwlViTTextConfig()
>>> # Initializing a OwlViTTextConfig from the google/owlvit-base-patch32 style configuration
>>> model = OwlViTTextModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
OwlViTVisionConfig
class transformers.OwlViTVisionConfig
( hidden_size = 768 intermediate_size = 3072 num_hidden_layers = 12 num_attention_heads = 12 num_channels = 3 image_size = 768 patch_size = 32 hidden_act = 'quick_gelu' layer_norm_eps = 1e-05 attention_dropout = 0.0 initializer_range = 0.02 initializer_factor = 1.0 **kwargs )
参数
-
hidden_size(int, optional, defaults to 768) — 编码器层和池化器层的维度。 -
intermediate_size(int, optional, defaults to 3072) — Transformer 编码器中“中间”(即前馈)层的维度。 -
num_hidden_layers(int, optional, defaults to 12) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, defaults to 12) — Transformer 编码器中每个注意力层的注意力头数量。 -
num_channels(int, optional, defaults to 3) — 输入图像中的通道数。 -
image_size(int, optional, defaults to 768) — 每个图像的大小(分辨率)。 -
patch_size(int, optional, defaults to 32) — 每个补丁的大小(分辨率)。 -
hidden_act(strorfunction, optional, defaults to"quick_gelu") — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,则支持"gelu"、"relu"、"selu"和"gelu_new"以及"quick_gelu"。 -
layer_norm_eps(float, optional, defaults to 1e-05) — 层归一化层使用的 epsilon。 -
attention_dropout(float, optional, defaults to 0.0) — 注意力概率的丢失比率。 -
initializer_range(float, optional, defaults to 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
initializer_factor(float, optional, defaults to 1.0) — 用于初始化所有权重矩阵的因子(应保持为 1,用于内部初始化测试)。
这是一个配置类,用于存储 OwlViTVisionModel 的配置。它用于根据指定的参数实例化一个 OWL-ViT 图像编码器,定义模型架构。使用默认值实例化配置将产生与 OWL-ViT google/owlvit-base-patch32架构类似的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
>>> from transformers import OwlViTVisionConfig, OwlViTVisionModel
>>> # Initializing a OwlViTVisionModel with google/owlvit-base-patch32 style configuration
>>> configuration = OwlViTVisionConfig()
>>> # Initializing a OwlViTVisionModel model from the google/owlvit-base-patch32 style configuration
>>> model = OwlViTVisionModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
OwlViTImageProcessor
class transformers.OwlViTImageProcessor
( do_resize = True size = None resample = <Resampling.BICUBIC: 3> do_center_crop = False crop_size = None do_rescale = True rescale_factor = 0.00392156862745098 do_normalize = True image_mean = None image_std = None **kwargs )
参数
-
do_resize(bool,可选,默认为True) — 是否将输入的较短边调整为特定的size。 -
size(Dict[str, int],可选,默认为{“height” — 768, “width”: 768}):用于调整图像大小的大小。仅在do_resize设置为True时有效。如果size是一个类似(h, w)的序列,输出大小将与之匹配。如果size是一个整数,则图像将被调整为(size, size)。 -
resample(int,可选,默认为Resampling.BICUBIC) — 可选的重采样滤波器。可以是PIL.Image.Resampling.NEAREST、PIL.Image.Resampling.BOX、PIL.Image.Resampling.BILINEAR、PIL.Image.Resampling.HAMMING、PIL.Image.Resampling.BICUBIC或PIL.Image.Resampling.LANCZOS之一。仅在do_resize设置为True时有效。 -
do_center_crop(bool,可选,默认为False) — 是否在中心裁剪输入。如果输入大小在任何边缘上小于crop_size,则图像将填充 0,然后进行中心裁剪。 -
crop_size(int,可选,默认为{“height” — 768, “width”: 768}):用于中心裁剪图像的大小。仅在do_center_crop设置为True时有效。 -
do_rescale(bool,可选,默认为True) — 是否按一定因子重新缩放输入。 -
rescale_factor(float,可选,默认为1/255) — 用于重新缩放图像的因子。仅在do_rescale设置为True时有效。 -
do_normalize(bool,可选,默认为True) — 是否使用image_mean和image_std对输入进行归一化。在应用中心裁剪时的期望输出大小。仅在do_center_crop设置为True时有效。 -
image_mean(List[int],可选,默认为[0.48145466, 0.4578275, 0.40821073]) — 每个通道的均值序列,用于归一化图像时使用。 -
image_std(List[int],可选,默认为[0.26862954, 0.26130258, 0.27577711]) — 每个通道的标准差序列,用于归一化图像时使用。
构建一个 OWL-ViT 图像处理器。
这个图像处理器继承自 ImageProcessingMixin,其中包含大部分主要方法。用户应参考这个超类以获取有关这些方法的更多信息。
preprocess
( images: Union do_resize: Optional = None size: Optional = None resample: Resampling = None do_center_crop: Optional = None crop_size: Optional = None do_rescale: Optional = None rescale_factor: Optional = None do_normalize: Optional = None image_mean: Union = None image_std: Union = None return_tensors: Union = None data_format: Union = <ChannelDimension.FIRST: 'channels_first'> input_data_format: Union = None **kwargs )
参数
-
images(ImageInput) — 要准备的图像或图像批次。期望单个或批量像素值范围为 0 到 255。如果传入像素值在 0 到 1 之间的图像,请设置do_rescale=False。 -
do_resize(bool,可选,默认为self.do_resize) — 是否调整输入大小。如果为True,将输入调整为size指定的大小。 -
size(Dict[str, int], 可选, 默认为self.size) — 调整输入大小的大小。仅在do_resize设置为True时有效。 -
resample(PILImageResampling, 可选, 默认为self.resample) — 调整输入大小时使用的重采样滤波器。仅在do_resize设置为True时有效。 -
do_center_crop(bool, 可选, 默认为self.do_center_crop) — 是否对输入进行中心裁剪。如果为True,将对输入进行中心裁剪,裁剪到由crop_size指定的大小。 -
crop_size(Dict[str, int], 可选, 默认为self.crop_size) — 中心裁剪输入的大小。仅在do_center_crop设置为True时有效。 -
do_rescale(bool, 可选, 默认为self.do_rescale) — 是否对输入进行重新缩放。如果为True,将通过除以rescale_factor对输入进行重新缩放。 -
rescale_factor(float, 可选, 默认为self.rescale_factor) — 重新缩放输入的因子。仅在do_rescale设置为True时有效。 -
do_normalize(bool, 可选, 默认为self.do_normalize) — 是否对输入进行归一化。如果为True,将通过减去image_mean并除以image_std对输入进行归一化。 -
image_mean(Union[float, List[float]], 可选, 默认为self.image_mean) — 在归一化时从输入中减去的均值。仅在do_normalize设置为True时有效。 -
image_std(Union[float, List[float]], 可选, 默认为self.image_std) — 在归一化时除以输入的标准差。仅在do_normalize设置为True时有效。 -
return_tensors(str或TensorType, 可选) — 要返回的张量类型。可以是以下之一:-
未设置:返回一个
np.ndarray列表。 -
TensorType.TENSORFLOW或'tf':返回类型为tf.Tensor的批处理。 -
TensorType.PYTORCH或'pt':返回类型为torch.Tensor的批处理。 -
TensorType.NUMPY或'np':返回类型为np.ndarray的批处理。 -
TensorType.JAX或'jax':返回类型为jax.numpy.ndarray的批处理。
-
-
data_format(ChannelDimension或str, 可选, 默认为ChannelDimension.FIRST) — 输出图像的通道维度格式。可以是以下之一:-
ChannelDimension.FIRST:图像以 (通道数, 高度, 宽度) 格式。 -
ChannelDimension.LAST:图像以 (高度, 宽度, 通道数) 格式。 -
未设置:默认为输入图像的通道维度格式。
-
-
input_data_format(ChannelDimension或str, 可选) — 输入图像的通道维度格式。如果未设置,则从输入图像中推断通道维度格式。可以是以下之一:-
"channels_first"或ChannelDimension.FIRST:图像以 (通道数, 高度, 宽度) 格式。 -
"channels_last"或ChannelDimension.LAST:图像以 (高度, 宽度, 通道数) 格式。 -
"none"或ChannelDimension.NONE:图像以 (高度, 宽度) 格式。
-
为模型准备一张图像或一批图像。
post_process_object_detection
( outputs threshold: float = 0.1 target_sizes: Union = None ) → export const metadata = 'undefined';List[Dict]
参数
-
outputs(OwlViTObjectDetectionOutput) — 模型的原始输出。 -
threshold(float, 可选) — 保留对象检测预测的分数阈值。 -
target_sizes(torch.Tensor或List[Tuple[int, int]], 可选) — 形状为(batch_size, 2)的张量或包含每个图像批次中目标大小(高度, 宽度)的元组列表 (Tuple[int, int])。如果未设置,预测将不会被调整大小。
返回
List[Dict]
一个字典列表,每个字典包含模型预测的图像批次中每个图像的分数、标签和框。
将 OwlViTForObjectDetection 的原始输出转换为最终边界框,格式为 (左上角 x 坐标, 左上角 y 坐标, 右下角 x 坐标, 右下角 y 坐标)。
post_process_image_guided_detection
( outputs threshold = 0.0 nms_threshold = 0.3 target_sizes = None ) → export const metadata = 'undefined';List[Dict]
参数
-
outputs(OwlViTImageGuidedObjectDetectionOutput) — 模型的原始输出。 -
threshold(float, 可选, 默认为 0.0) — 用于过滤预测框的最小置信度阈值。 -
nms_threshold(float, 可选, 默认为 0.3) — 用于非极大值抑制重叠框的 IoU 阈值。 -
target_sizes(torch.Tensor, 可选) — 形状为(batch_size, 2)的张量,其中每个条目是批次中相应图像的(高度,宽度)。如果设置,预测的归一化边界框将重新缩放为目标大小。如果保持为 None,则预测不会被取消归一化。
返回
List[Dict]
一个字典列表,每个字典包含模型预测的批次中每张图像的分数、标签和框。所有标签都设置为 None,因为OwlViTForObjectDetection.image_guided_detection执行一次性目标检测。
将 OwlViTForObjectDetection.image_guided_detection()的输出转换为 COCO api 所期望的格式。
OwlViTFeatureExtractor
class transformers.OwlViTFeatureExtractor
( *args **kwargs )
__call__
( images **kwargs )
预处理一张图像或一批图像。
post_process
( outputs target_sizes ) → export const metadata = 'undefined';List[Dict]
参数
-
outputs(OwlViTObjectDetectionOutput) — 模型的原始输出。 -
target_sizes(torch.Tensor的形状为(batch_size, 2)) — 包含批次中每个图像的大小(h, w)的张量。对于评估,这必须是原始图像大小(在任何数据增强之前)。对于可视化,这应该是数据增强后的图像大小,但在填充之前。
返回
List[Dict]
一个字典列表,每个字典包含模型预测的批次中每张图像的分数、标签和框。
将 OwlViTForObjectDetection 的原始输出转换为最终的边界框格式为(top_left_x, top_left_y, bottom_right_x, bottom_right_y)。
post_process_image_guided_detection
( outputs threshold = 0.0 nms_threshold = 0.3 target_sizes = None ) → export const metadata = 'undefined';List[Dict]
参数
-
outputs(OwlViTImageGuidedObjectDetectionOutput) — 模型的原始输出。 -
threshold(float, 可选, 默认为 0.0) — 用于过滤预测框的最小置信度阈值。 -
nms_threshold(float, 可选, 默认为 0.3) — 用于非极大值抑制重叠框的 IoU 阈值。 -
target_sizes(torch.Tensor, 可选) — 形状为(batch_size, 2)的张量,其中每个条目是批次中相应图像的(高度,宽度)。如果设置,预测的归一化边界框将重新缩放为目标大小。如果保持为 None,则预测不会被取消归一化。
返回
List[Dict]
一个字典列表,每个字典包含模型预测的批次中每张图像的分数、标签和框。所有标签都设置为 None,因为OwlViTForObjectDetection.image_guided_detection执行一次性目标检测。
将 OwlViTForObjectDetection.image_guided_detection()的输出转换为 COCO api 所期望的格式。
OwlViTProcessor
class transformers.OwlViTProcessor
( image_processor = None tokenizer = None **kwargs )
参数
-
image_processor(OwlViTImageProcessor,可选)— 图像处理器是必需的输入。 -
tokenizer([CLIPTokenizer,CLIPTokenizerFast],可选)— 分词器是必需的输入。
构建一个 OWL-ViT 处理器,将 OwlViTImageProcessor 和 CLIPTokenizer/CLIPTokenizerFast 包装成一个单一处理器,继承了图像处理器和分词器的功能。查看__call__()和 decode()以获取更多信息。
batch_decode
( *args **kwargs )
该方法将其所有参数转发到 CLIPTokenizerFast 的 batch_decode()。有关更多信息,请参考此方法的文档字符串。
decode
( *args **kwargs )
该方法将其所有参数转发到 CLIPTokenizerFast 的 decode()。有关更多信息,请参考此方法的文档字符串。
post_process
( *args **kwargs )
该方法将其所有参数转发到 OwlViTImageProcessor.post_process()。有关更多信息,请参考此方法的文档字符串。
post_process_image_guided_detection
( *args **kwargs )
该方法将其所有参数转发到OwlViTImageProcessor.post_process_one_shot_object_detection。有关更多信息,请参考此方法的文档字符串。
post_process_object_detection
( *args **kwargs )
该方法将其所有参数转发到 OwlViTImageProcessor.post_process_object_detection()。有关更多信息,请参考此方法的文档字符串。
OwlViTModel
class transformers.OwlViTModel
( config: OwlViTConfig )
参数
config(OwlViTConfig)— 模型配置类,包含模型的所有参数。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
该模型继承自 PreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型也是 PyTorch torch.nn.Module子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
forward
( input_ids: Optional = None pixel_values: Optional = None attention_mask: Optional = None return_loss: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_base_image_embeds: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.owlvit.modeling_owlvit.OwlViTOutput or tuple(torch.FloatTensor)
参数
-
input_ids(torch.LongTensor,形状为(batch_size, sequence_length)) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。什么是输入 ID? -
attention_mask(torch.Tensor,形状为(batch_size, sequence_length),可选) — 用于避免在填充标记索引上执行注意力的掩码。选择在[0, 1]中的掩码值:-
1 表示
未被 masked的标记, -
0 表示被
masked的标记。什么是注意力掩码?
-
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。 -
return_loss(bool,可选) — 是否返回对比损失。 -
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.owlvit.modeling_owlvit.OwlViTOutput或tuple(torch.FloatTensor)
一个transformers.models.owlvit.modeling_owlvit.OwlViTOutput或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含各种元素,这取决于配置(<class 'transformers.models.owlvit.configuration_owlvit.OwlViTConfig'>)和输入。
-
loss(torch.FloatTensor,形状为(1,),可选,当return_loss为True时返回) — 图像-文本相似性的对比损失。 -
logits_per_image(torch.FloatTensor,形状为(image_batch_size, text_batch_size)) —image_embeds和text_embeds之间的缩放点积分数。这代表图像-文本相似性分数。 -
logits_per_text(torch.FloatTensor,形状为(text_batch_size, image_batch_size)) —text_embeds和image_embeds之间的缩放点积分数。这代表文本-图像相似性分数。 -
text_embeds(torch.FloatTensor,形状为(batch_size * num_max_text_queries, output_dim) — 通过将投影层应用于 OwlViTTextModel 的汇聚输出获得的文本嵌入。 -
image_embeds(torch.FloatTensor,形状为(batch_size, output_dim) — 通过将投影层应用于 OwlViTVisionModel 的汇聚输出获得的图像嵌入。 -
text_model_output(TupleBaseModelOutputWithPooling) — OwlViTTextModel 的输出。 -
vision_model_output(BaseModelOutputWithPooling) — OwlViTVisionModel 的输出。
OwlViTModel 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, OwlViTModel
>>> model = OwlViTModel.from_pretrained("google/owlvit-base-patch32")
>>> processor = AutoProcessor.from_pretrained("google/owlvit-base-patch32")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(text=[["a photo of a cat", "a photo of a dog"]], images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> logits_per_image = outputs.logits_per_image # this is the image-text similarity score
>>> probs = logits_per_image.softmax(dim=1) # we can take the softmax to get the label probabilities
get_text_features
( input_ids: Optional = None attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';text_features (torch.FloatTensor of shape (batch_size, output_dim)
参数
-
input_ids(torch.LongTensor,形状为(batch_size * num_max_text_queries, sequence_length)) — 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参见 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。什么是输入 ID? -
attention_mask(torch.Tensor,形状为(batch_size, num_max_text_queries, sequence_length),可选) — 避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]之间:-
对于未被
masked的标记为 1, -
对于被
masked的标记为 0。什么是注意力掩码?
-
-
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通元组。
返回
text_features (torch.FloatTensor,形状为(batch_size, output_dim))
通过将投影层应用于 OwlViTTextModel 的池化输出获得的文本嵌入。
OwlViTModel 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, OwlViTModel
>>> model = OwlViTModel.from_pretrained("google/owlvit-base-patch32")
>>> processor = AutoProcessor.from_pretrained("google/owlvit-base-patch32")
>>> inputs = processor(
... text=[["a photo of a cat", "a photo of a dog"], ["photo of a astranaut"]], return_tensors="pt"
... )
>>> text_features = model.get_text_features(**inputs)
get_image_features
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';image_features (torch.FloatTensor of shape (batch_size, output_dim)
参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。 -
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool, 可选) — 是否返回 ModelOutput 而不是普通元组。
返回
image_features (torch.FloatTensor,形状为(batch_size, output_dim))
通过将投影层应用于 OwlViTVisionModel 的池化输出获得的图像嵌入。
OwlViTModel 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行前处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, OwlViTModel
>>> model = OwlViTModel.from_pretrained("google/owlvit-base-patch32")
>>> processor = AutoProcessor.from_pretrained("google/owlvit-base-patch32")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> image_features = model.get_image_features(**inputs)
OwlViTTextModel
class transformers.OwlViTTextModel
( config: OwlViTTextConfig )
forward
( input_ids: Tensor attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
参数
-
input_ids(形状为(batch_size * num_max_text_queries, sequence_length)的torch.LongTensor)— 词汇表中输入序列标记的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。什么是输入 ID? -
attention_mask(形状为(batch_size, num_max_text_queries, sequence_length)的torch.Tensor,可选)— 用于避免在填充标记索引上执行注意力的掩码。掩码值选在[0, 1]之间:-
对于未被
masked的标记为 1, -
对于被
masked的标记为 0。什么是注意力掩码?
-
-
output_attentions(bool,可选)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的attentions。 -
output_hidden_states(bool,可选)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的hidden_states。 -
return_dict(bool,可选)— 是否返回一个 ModelOutput 而不是一个普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个torch.FloatTensor元组(如果传递return_dict=False或config.return_dict=False时)包含根据配置(<class 'transformers.models.owlvit.configuration_owlvit.OwlViTTextConfig'>)和输入的不同元素。
-
last_hidden_state(形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor)— 模型最后一层的隐藏状态序列输出。 -
pooler_output(形状为(batch_size, hidden_size)的torch.FloatTensor)— 经过用于辅助预训练任务的层进一步处理后的序列第一个标记(分类标记)的最后一层隐藏状态。例如,对于 BERT 系列模型,这返回经过线性层和 tanh 激活函数处理后的分类标记。线性层权重是在预训练期间从下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或config.output_hidden_states=True时返回)— 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层的输出,则为一个+每个层的输出)。模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor),可选,当传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
OwlViTTextModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from transformers import AutoProcessor, OwlViTTextModel
>>> model = OwlViTTextModel.from_pretrained("google/owlvit-base-patch32")
>>> processor = AutoProcessor.from_pretrained("google/owlvit-base-patch32")
>>> inputs = processor(
... text=[["a photo of a cat", "a photo of a dog"], ["photo of a astranaut"]], return_tensors="pt"
... )
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled (EOS token) states
OwlViTVisionModel
class transformers.OwlViTVisionModel
( config: OwlViTVisionConfig )
forward
( pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPooling or tuple(torch.FloatTensor)
参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。 -
output_attentions(bool, 可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的attentions。 -
output_hidden_states(bool, 可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的hidden_states。 -
return_dict(bool,可选) — 是否返回一个 ModelOutput 而不是一个普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPooling 或 tuple(torch.FloatTensor)
一个 transformers.modeling_outputs.BaseModelOutputWithPooling 或一个torch.FloatTensor元组(如果传递return_dict=False或当config.return_dict=False时)包含根据配置(<class 'transformers.models.owlvit.configuration_owlvit.OwlViTVisionConfig'>)和输入的不同元素。
-
last_hidden_state(torch.FloatTensor,形状为(batch_size, sequence_length, hidden_size)) — 模型最后一层的隐藏状态序列。 -
pooler_output(torch.FloatTensor,形状为(batch_size, hidden_size)) — 序列中第一个标记(分类标记)的最后一层隐藏状态,在通过用于辅助预训练任务的层进一步处理后。例如,对于 BERT 系列模型,这返回经过线性层和 tanh 激活函数处理后的分类标记。线性层的权重是在预训练期间从下一个句子预测(分类)目标中训练的。 -
hidden_states(tuple(torch.FloatTensor),可选,当传递output_hidden_states=True或当config.output_hidden_states=True时返回) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)。模型在每一层输出处的隐藏状态加上可选的初始嵌入输出。
-
attentions(tuple(torch.FloatTensor), 可选, 当传递output_attentions=True或当config.output_attentions=True时返回) — 形状为(batch_size, num_heads, sequence_length, sequence_length)的torch.FloatTensor元组(每层一个)。注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
OwlViTVisionModel 的前向方法,覆盖了__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
>>> from PIL import Image
>>> import requests
>>> from transformers import AutoProcessor, OwlViTVisionModel
>>> model = OwlViTVisionModel.from_pretrained("google/owlvit-base-patch32")
>>> processor = AutoProcessor.from_pretrained("google/owlvit-base-patch32")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> inputs = processor(images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_state = outputs.last_hidden_state
>>> pooled_output = outputs.pooler_output # pooled CLS states
OwlViT 目标检测
class transformers.OwlViTForObjectDetection
( config: OwlViTConfig )
forward
( input_ids: Tensor pixel_values: FloatTensor attention_mask: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.owlvit.modeling_owlvit.OwlViTObjectDetectionOutput or tuple(torch.FloatTensor)
参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width))— 像素值。 -
input_ids(torch.LongTensor,形状为(batch_size * num_max_text_queries, sequence_length),可选)— 输入序列标记在词汇表中的索引。可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.call()。什么是输入 ID?。 -
attention_mask(torch.Tensor,形状为(batch_size, num_max_text_queries, sequence_length),可选)— 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在[0, 1]之间:-
对于未被
masked的标记为 1, -
对于被
masked的标记为 0。什么是注意力掩码?
-
-
output_hidden_states(bool,可选)— 是否返回最后一个隐藏状态。有关更多详细信息,请参阅返回的张量中的text_model_last_hidden_state和vision_model_last_hidden_state。 -
return_dict(bool,可选)— 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.models.owlvit.modeling_owlvit.OwlViTObjectDetectionOutput或tuple(torch.FloatTensor)
一个transformers.models.owlvit.modeling_owlvit.OwlViTObjectDetectionOutput或一个torch.FloatTensor元组(如果传递了return_dict=False或当config.return_dict=False时),包括根据配置(<class 'transformers.models.owlvit.configuration_owlvit.OwlViTConfig'>)和输入的不同元素。
-
loss(torch.FloatTensor,形状为(1,),可选,在提供labels时返回)— 总损失作为类别预测的负对数似然(交叉熵)和边界框损失的线性组合。后者被定义为 L1 损失和广义尺度不变 IoU 损失的线性组合。 -
loss_dict(Dict,可选)— 包含各个损失的字典。用于记录日志。 -
logits(torch.FloatTensor,形状为(batch_size, num_patches, num_queries))— 所有查询的分类 logits(包括无对象)。 -
pred_boxes(torch.FloatTensor,形状为(batch_size, num_patches, 4))— 所有查询的标准化框坐标,表示为(中心 _x,中心 _y,宽度,高度)。这些值在[0, 1]范围内标准化,相对于批处理中每个单独图像的大小(忽略可能的填充)。您可以使用 post_process_object_detection()来检索未标准化的边界框。 -
text_embeds(torch.FloatTensor,形状为(batch_size, num_max_text_queries, output_dim) — 通过将池化输出应用于 OwlViTTextModel 的文本嵌入。 -
image_embeds(torch.FloatTensor,形状为(batch_size, patch_size, patch_size, output_dim) — OwlViTVisionModel 的池化输出。OWL-ViT 将图像表示为一组图像补丁,并为每个补丁计算图像嵌入。 -
class_embeds(torch.FloatTensor,形状为(batch_size, num_patches, hidden_size)) — 所有图像补丁的类嵌入。OWL-ViT 将图像表示为一组图像补丁,其中总补丁数为(图像大小/补丁大小)**2。 -
text_model_output(TupleBaseModelOutputWithPooling) — OwlViTTextModel 的输出。 -
vision_model_output(BaseModelOutputWithPooling) — OwlViTVisionModel 的输出。
OwlViTForObjectDetection 的前向方法,覆盖__call__特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用Module实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> import requests
>>> from PIL import Image
>>> import torch
>>> from transformers import AutoProcessor, OwlViTForObjectDetection
>>> processor = AutoProcessor.from_pretrained("google/owlvit-base-patch32")
>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch32")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> texts = [["a photo of a cat", "a photo of a dog"]]
>>> inputs = processor(text=texts, images=image, return_tensors="pt")
>>> outputs = model(**inputs)
>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
>>> target_sizes = torch.Tensor([image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to final bounding boxes and scores
>>> results = processor.post_process_object_detection(
... outputs=outputs, threshold=0.1, target_sizes=target_sizes
... )
>>> i = 0 # Retrieve predictions for the first image for the corresponding text queries
>>> text = texts[i]
>>> boxes, scores, labels = results[i]["boxes"], results[i]["scores"], results[i]["labels"]
>>> for box, score, label in zip(boxes, scores, labels):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected {text[label]} with confidence {round(score.item(), 3)} at location {box}")
Detected a photo of a cat with confidence 0.707 at location [324.97, 20.44, 640.58, 373.29]
Detected a photo of a cat with confidence 0.717 at location [1.46, 55.26, 315.55, 472.17]
image_guided_detection
( pixel_values: FloatTensor query_pixel_values: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.owlvit.modeling_owlvit.OwlViTImageGuidedObjectDetectionOutput or tuple(torch.FloatTensor)
参数
-
pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 像素值。 -
query_pixel_values(torch.FloatTensor,形状为(batch_size, num_channels, height, width)) — 要检测的查询图像的像素值。每个目标图像传入一个查询图像。 -
output_attentions(bool,可选) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的attentions。 -
output_hidden_states(bool,可选) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的hidden_states。 -
return_dict(bool,可选) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.models.owlvit.modeling_owlvit.OwlViTImageGuidedObjectDetectionOutput或tuple(torch.FloatTensor)
一个transformers.models.owlvit.modeling_owlvit.OwlViTImageGuidedObjectDetectionOutput或一个torch.FloatTensor元组(如果传递了return_dict=False或config.return_dict=False时)包含各种元素,具体取决于配置(<class 'transformers.models.owlvit.configuration_owlvit.OwlViTConfig'>)和输入。
-
logits(torch.FloatTensor,形状为(batch_size, num_patches, num_queries)) — 所有查询的分类 logits(包括无对象)。 -
target_pred_boxes(torch.FloatTensor,形状为(batch_size, num_patches, 4)) — 所有查询的标准化框坐标,表示为(中心 _x,中心 _y,宽度,高度)。这些值在[0, 1]范围内标准化,相对于批处理中每个单独目标图像的大小(忽略可能的填充)。您可以使用 post_process_object_detection()来检索未标准化的边界框。 -
query_pred_boxes(torch.FloatTensorof shape(batch_size, num_patches, 4)) — 所有查询的归一化框坐标,表示为(中心 _x,中心 _y,宽度,高度)。这些值在[0, 1]范围内归一化,相对于批处理中每个单独查询图像的大小(忽略可能的填充)。您可以使用 post_process_object_detection()来检索未归一化的边界框。 -
image_embeds(torch.FloatTensorof shape(batch_size, patch_size, patch_size, output_dim) — OwlViTVisionModel 的汇集输出。OWL-ViT 将图像表示为一组图像补丁,并为每个补丁计算图像嵌入。 -
query_image_embeds(torch.FloatTensorof shape(batch_size, patch_size, patch_size, output_dim) — OwlViTVisionModel 的汇集输出。OWL-ViT 将图像表示为一组图像补丁,并为每个补丁计算图像嵌入。 -
class_embeds(torch.FloatTensorof shape(batch_size, num_patches, hidden_size)) — 所有图像补丁的类嵌入。OWL-ViT 将图像表示为一组图像补丁,其中补丁的总数为(图像大小/补丁大小)**2。 -
text_model_output(TupleBaseModelOutputWithPooling) — OwlViTTextModel 的输出。 -
vision_model_output(BaseModelOutputWithPooling) — OwlViTVisionModel 的输出。
OwlViTForObjectDetection 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此之后调用,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> import requests
>>> from PIL import Image
>>> import torch
>>> from transformers import AutoProcessor, OwlViTForObjectDetection
>>> processor = AutoProcessor.from_pretrained("google/owlvit-base-patch16")
>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch16")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> query_url = "http://images.cocodataset.org/val2017/000000001675.jpg"
>>> query_image = Image.open(requests.get(query_url, stream=True).raw)
>>> inputs = processor(images=image, query_images=query_image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model.image_guided_detection(**inputs)
>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
>>> target_sizes = torch.Tensor([image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
>>> results = processor.post_process_image_guided_detection(
... outputs=outputs, threshold=0.6, nms_threshold=0.3, target_sizes=target_sizes
... )
>>> i = 0 # Retrieve predictions for the first image
>>> boxes, scores = results[i]["boxes"], results[i]["scores"]
>>> for box, score in zip(boxes, scores):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected similar object with confidence {round(score.item(), 3)} at location {box}")
Detected similar object with confidence 0.856 at location [10.94, 50.4, 315.8, 471.39]
Detected similar object with confidence 1.0 at location [334.84, 25.33, 636.16, 374.71]
度,高度)。这些值在[0, 1]范围内归一化,相对于批处理中每个单独查询图像的大小(忽略可能的填充)。您可以使用 post_process_object_detection()来检索未归一化的边界框。
-
image_embeds(torch.FloatTensorof shape(batch_size, patch_size, patch_size, output_dim) — OwlViTVisionModel 的汇集输出。OWL-ViT 将图像表示为一组图像补丁,并为每个补丁计算图像嵌入。 -
query_image_embeds(torch.FloatTensorof shape(batch_size, patch_size, patch_size, output_dim) — OwlViTVisionModel 的汇集输出。OWL-ViT 将图像表示为一组图像补丁,并为每个补丁计算图像嵌入。 -
class_embeds(torch.FloatTensorof shape(batch_size, num_patches, hidden_size)) — 所有图像补丁的类嵌入。OWL-ViT 将图像表示为一组图像补丁,其中补丁的总数为(图像大小/补丁大小)**2。 -
text_model_output(TupleBaseModelOutputWithPooling) — OwlViTTextModel 的输出。 -
vision_model_output(BaseModelOutputWithPooling) — OwlViTVisionModel 的输出。
OwlViTForObjectDetection 的前向方法,覆盖了__call__特殊方法。
尽管前向传递的步骤需要在此函数内定义,但应该在此之后调用Module实例,而不是在此之后调用,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
>>> import requests
>>> from PIL import Image
>>> import torch
>>> from transformers import AutoProcessor, OwlViTForObjectDetection
>>> processor = AutoProcessor.from_pretrained("google/owlvit-base-patch16")
>>> model = OwlViTForObjectDetection.from_pretrained("google/owlvit-base-patch16")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg"
>>> image = Image.open(requests.get(url, stream=True).raw)
>>> query_url = "http://images.cocodataset.org/val2017/000000001675.jpg"
>>> query_image = Image.open(requests.get(query_url, stream=True).raw)
>>> inputs = processor(images=image, query_images=query_image, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model.image_guided_detection(**inputs)
>>> # Target image sizes (height, width) to rescale box predictions [batch_size, 2]
>>> target_sizes = torch.Tensor([image.size[::-1]])
>>> # Convert outputs (bounding boxes and class logits) to Pascal VOC format (xmin, ymin, xmax, ymax)
>>> results = processor.post_process_image_guided_detection(
... outputs=outputs, threshold=0.6, nms_threshold=0.3, target_sizes=target_sizes
... )
>>> i = 0 # Retrieve predictions for the first image
>>> boxes, scores = results[i]["boxes"], results[i]["scores"]
>>> for box, score in zip(boxes, scores):
... box = [round(i, 2) for i in box.tolist()]
... print(f"Detected similar object with confidence {round(score.item(), 3)} at location {box}")
Detected similar object with confidence 0.856 at location [10.94, 50.4, 315.8, 471.39]
Detected similar object with confidence 1.0 at location [334.84, 25.33, 636.16, 374.71]

















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









