







Fuyu
原始文本:
huggingface.co/docs/transformers/v4.37.2/en/model_doc/fuyu
概述
Fuyu 模型由ADEPT创建,作者是 Rohan Bavishi、Erich Elsen、Curtis Hawthorne、Maxwell Nye、Augustus Odena、Arushi Somani、Sağnak Taşırlar。
作者介绍了 Fuyu-8B,这是一个仅解码器的基于经典 transformers 架构的多模态模型,具有查询和键规范化。线性编码器被添加以从图像输入创建多模态嵌入。
通过将图像标记视为文本标记,并使用特殊的图像换行符,模型知道图像行何时结束。移除了图像位置嵌入。这避免了为各种图像分辨率进行不同训练阶段的需要。Fuyu-8B 具有 80 亿个参数,并在 CC-BY-NC 许可下发布,以其处理文本和图像的能力、令人印象深刻的 16K 上下文大小和整体性能而闻名。
Fuyu模型是使用bfloat16训练的,但原始推理使用float16。上传到 hub 的检查点使用torch_dtype = 'float16',AutoModel API 将使用它将检查点从torch.float32转换为torch.float16。
在线权重的dtype大多数情况下并不重要,除非在使用torch_dtype="auto"初始化模型时使用model = AutoModelForCausalLM.from_pretrained("path", torch_dtype = "auto")。原因是模型将首先被下载(使用在线检查点的dtype),然后将被转换为torch的默认dtype(变为torch.float32)。用户应该指定他们想要的torch_dtype,如果他们不这样做,它将是torch.float32。
不建议在float16中微调模型,因为已知会产生nan,因此应该在bfloat16中微调模型。
提示:
- 要转换模型,您需要使用
git clone https://github.com/persimmon-ai-labs/adept-inference克隆原始存储库,然后获取检查点:
git clone https://github.com/persimmon-ai-labs/adept-inference
wget path/to/fuyu-8b-model-weights.tar
tar -xvf fuyu-8b-model-weights.tar
python src/transformers/models/fuyu/convert_fuyu_weights_to_hf.py --input_dir /path/to/downloaded/fuyu/weights/ --output_dir /output/path \
--pt_model_path /path/to/fuyu_8b_release/iter_0001251/mp_rank_00/model_optim_rng.pt
--ada_lib_path /path/to/adept-inference
对于聊天模型:
wget https://axtkn4xl5cip.objectstorage.us-phoenix-1.oci.customer-oci.com/n/axtkn4xl5cip/b/adept-public-data/o/8b_chat_model_release.tar
tar -xvf 8b_base_model_release.tar
然后,模型可以通过以下方式加载:
from transformers import FuyuConfig, FuyuForCausalLM
model_config = FuyuConfig()
model = FuyuForCausalLM(model_config).from_pretrained('/output/path')
需要通过特定的处理器传递输入以获得正确的格式。处理器需要一个图像处理器和一个分词器。因此,输入可以通过以下方式加载:
from PIL import Image
from transformers import AutoTokenizer
from transformers.models.fuyu.processing_fuyu import FuyuProcessor
from transformers.models.fuyu.image_processing_fuyu import FuyuImageProcessor
tokenizer = AutoTokenizer.from_pretrained('adept-hf-collab/fuyu-8b')
image_processor = FuyuImageProcessor()
processor = FuyuProcessor(image_processor=image_processor, tokenizer=tokenizer)
text_prompt = "Generate a coco-style caption.\\n"
bus_image_url = "https://huggingface.co/datasets/hf-internal-testing/fixtures-captioning/resolve/main/bus.png"
bus_image_pil = Image.open(io.BytesIO(requests.get(bus_image_url).content))
inputs_to_model = processor(text=text_prompt, images=image_pil)
-
Fuyu 使用基于
sentencepiece的分词器,采用Unigram模型。它支持字节回退,仅在快速分词器的tokenizers==0.14.0中可用。LlamaTokenizer被用作它是句子片段的标准包装器。 -
作者建议为图像字幕使用以下提示:
f"生成一个 coco 风格的字幕。\\n"
FuyuConfig
class transformers.FuyuConfig
( vocab_size = 262144 hidden_size = 4096 intermediate_size = 16384 num_hidden_layers = 36 num_attention_heads = 64 hidden_act = 'relu2' max_position_embeddings = 16384 image_size = 300 patch_size = 30 num_channels = 3 initializer_range = 0.02 layer_norm_eps = 1e-05 use_cache = True tie_word_embeddings = False rope_theta = 25000.0 rope_scaling = None qk_layernorm = True hidden_dropout = 0.0 attention_dropout = 0.0 partial_rotary_factor = 0.5 pad_token_id = None bos_token_id = 1 eos_token_id = 2 text_config = None **kwargs )
参数
-
vocab_size(int, optional, 默认为 262144) — Fuyu 模型的词汇表大小。定义了在调用 FuyuForCausalLM 时可以由inputs_ids表示的不同标记数量。 -
hidden_size(int, optional, 默认为 4096) — 隐藏表示的维度。 -
intermediate_size(int, optional, 默认为 16384) — MLP 表示的维度。 -
num_hidden_layers(int, optional, 默认为 36) — Transformer 编码器中的隐藏层数量。 -
num_attention_heads(int, optional, 默认为 64) — Transformer 编码器中每个注意力层的注意力头数量。 -
hidden_act(str或function, optional, 默认为"relu2") — 解码器中的非线性激活函数(函数或字符串)。 -
max_position_embeddings(int,可选,默认为 16384)-此模型可能使用的最大序列长度。 -
image_size(int,可选,默认为 300)-输入图像大小。 -
patch_size(int,可选,默认为 30)-输入视觉变换器编码块大小。 -
num_channels(int,可选,默认为 3)-输入图像通道数。 -
initializer_range(float,可选,默认为 0.02)-用于初始化所有权重矩阵的截断正态初始化器的标准差。 -
layer_norm_eps(float,可选,默认为 1e-05)-rms 归一化层使用的 epsilon。 -
use_cache(bool,可选,默认为True)-模型是否应返回最后的键/值注意力(不是所有模型都使用)。仅在config.is_decoder=True时相关。是否绑定权重嵌入 -
tie_word_embeddings(bool,可选,默认为False)-是否绑定输入和输出嵌入。 -
rope_theta(float,可选,默认为 25000.0)-RoPE 嵌入的基本周期。 -
rope_scaling(Dict,可选)-包含 RoPE 嵌入的缩放配置的字典。当前支持两种缩放策略:线性和动态。它们的缩放因子必须是大于 1 的浮点数。预期格式为{"type":策略名称,"factor":缩放因子}。使用此标志时,不要将max_position_embeddings更新为预期的新最大值。有关这些缩放策略行为的更多信息,请参见以下线程:www.reddit.com/r/LocalFuyu/comments/14mrgpr/dynamically_scaled_rope_further_increases/。这是一个实验性功能,可能在将来的版本中会有破坏性的 API 更改。 -
qk_layernorm(bool,可选,默认为True)-在投影隐藏状态后是否规范查询和键 -
hidden_dropout(float,可选,默认为 0.0)-在将 MLP 应用于隐藏状态后的丢失比率。 -
attention_dropout(float,可选,默认为 0.0)-计算注意力分数后的丢失比率。 -
partial_rotary_factor(float,可选,默认为 0.5)-查询和键的百分比,将具有旋转嵌入。 -
pad_token_id(int,可选)- 填充 标记的 ID。 -
bos_token_id(int,可选,默认为 1)- 序列开始 标记的 ID。 -
eos_token_id(Union[int,List[int]],可选,默认为 2)- 序列结束 标记的 ID。可选择使用列表设置多个序列结束 标记。 -
text_config(dict,可选)-用于初始化language```pyAut.
This is the configuration class to store the configuration of a FuyuForCausalLM. It is used to instantiate an Fuyu model according to the specified arguments, defining the model architecture. Instantiating a configuration with the defaults will yield a similar configuration to that of the adept/fuyu-8b.
Configuration objects inherit from PretrainedConfig and can be used to control the model outputs. Read the documentation from PretrainedConfig for more information.
从转换器导入 FuyuConfig
初始化 Fuyu fuyu-7b 风格配置
配置= FuyuConfig()
```py
## FuyuForCausalLM
### `class transformers.FuyuForCausalLM`
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/fuyu/modeling_fuyu.py#L143)
```
(配置:FuyuConfig)
```py
Parameters
* `config` (FuyuConfig) — Model configuration class with all the parameters of the model. Initializing with a config file does not load the weights associated with the model, only the configuration. Check out the from_pretrained() method to load the model weights.
Fuyu Model with a language modeling head on top for causal language model conditioned on image patches and text. This model inherits from PreTrainedModel. Check the superclass documentation for the generic methods the library implements for all its model (such as downloading or saving, resizing the input embeddings, pruning heads etc.)
This model is also a PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) subclass. Use it as a regular PyTorch Module and refer to the PyTorch documentation for all matter related to general usage and behavior.
#### `forward`
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/fuyu/modeling_fuyu.py#L210)
```
(input_ids:LongTensor = None image_patches:Tensor = None image_patches_indices:Tensor = None attention_mask:Optional = None position_ids:Optional = None past_key_values:Optional = None inputs_embeds:Optional = None use_cache:Optional = None labels:Optional = None output_attentions:Optional = None output_hidden_states:Optional = None return_dict:Optional = None)→导出常量元数据='未定义';transformers.modeling_outputs.CausalLMOutputWithPast 或元组(torch.FloatTensor)
```py
Parameters
* `input_ids` (`torch.LongTensor` of shape `(batch_size, sequence_length)`) — Indices of input sequence tokens in the vocabulary. Padding will be ignored by default should you provide it.
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.`call`() for details.
What are input IDs?
* `attention_mask` (`torch.Tensor` of shape `(batch_size, sequence_length)`, *optional*) — Mask to avoid performing attention on padding token indices. Mask values selected in `[0, 1]`:
* 1 for tokens that are `not masked`,
* 0 for tokens that are `masked`.
What are attention masks?
Indices can be obtained using AutoTokenizer. See PreTrainedTokenizer.encode() and PreTrainedTokenizer.`call`() for details.
If `past_key_values` is used, optionally only the last `decoder_input_ids` have to be input (see `past_key_values`).
If you want to change padding behavior, you should read `modeling_opt._prepare_decoder_attention_mask` and modify to your needs. See diagram 1 in [the paper](https://arxiv.org/abs/1910.13461) for more information on the default strategy.
* 1 indicates the head is `not masked`,
* 0 indicates the head is `masked`.
* `image_patches` (`torch.FloatTensor` of shape `(batch_size, num_total_patches, patch_size_ x patch_size x num_channels)`, *optional*) — Image patches to be used as continuous embeddings. The patches are flattened and then projected to the hidden size of the model.
* `image_patches_indices` (`torch.LongTensor` of shape `(batch_size, num_total_patches + number_of_newline_tokens + number_of_text_tokens, patch_size_ x patch_size x num_channels )`, *optional*) — Indices indicating at which position the image_patches have to be inserted in input_embeds.
* `position_ids` (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) — Indices of positions of each input sequence tokens in the position embeddings. Selected in the range `[0, config.n_positions - 1]`.
What are position IDs?
* `past_key_values` (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`) — Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`) and 2 additional tensors of shape `(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`.
Contains pre-computed hidden-states (key and values in the self-attention blocks and in the cross-attention blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
If `past_key_values` are used, the user can optionally input only the last `decoder_input_ids` (those that don’t have their past key value states given to this model) of shape `(batch_size, 1)` instead of all `decoder_input_ids` of shape `(batch_size, sequence_length)`.
* `inputs_embeds` (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) — Optionally, instead of passing `input_ids` you can choose to directly pass an embedded representation. This is useful if you want more control over how to convert `input_ids` indices into associated vectors than the model’s internal embedding lookup matrix.
* `use_cache` (`bool`, *optional*) — If set to `True`, `past_key_values` key value states are returned and can be used to speed up decoding (see `past_key_values`).
* `output_attentions` (`bool`, *optional*) — Whether or not to return the attentions tensors of all attention layers. See `attentions` under returned tensors for more detail.
* `output_hidden_states` (`bool`, *optional*) — Whether or not to return the hidden states of all layers. See `hidden_states` under returned tensors for more detail.
* `return_dict` (`bool`, *optional*) — Whether or not to return a ModelOutput instead of a plain tuple.
* `labels` (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) — Labels for computing the masked language modeling loss. Indices should either be in `[0, ..., config.vocab_size]` or -100 (see `input_ids` docstring). Tokens with indices set to `-100` are ignored (masked), the loss is only computed for the tokens with labels in `[0, ..., config.vocab_size]`.
Returns
transformers.modeling_outputs.CausalLMOutputWithPast or `tuple(torch.FloatTensor)`
A transformers.modeling_outputs.CausalLMOutputWithPast or a tuple of `torch.FloatTensor` (if `return_dict=False` is passed or when `config.return_dict=False`) comprising various elements depending on the configuration (FuyuConfig) and inputs.
* `loss` (`torch.FloatTensor` of shape `(1,)`, *optional*, returned when `labels` is provided) — Language modeling loss (for next-token prediction).
* `logits` (`torch.FloatTensor` of shape `(batch_size, sequence_length, config.vocab_size)`) — Prediction scores of the language modeling head (scores for each vocabulary token before SoftMax).
* `past_key_values` (`tuple(tuple(torch.FloatTensor))`, *optional*, returned when `use_cache=True` is passed or when `config.use_cache=True`) — Tuple of `tuple(torch.FloatTensor)` of length `config.n_layers`, with each tuple having 2 tensors of shape `(batch_size, num_heads, sequence_length, embed_size_per_head)`)
Contains pre-computed hidden-states (key and values in the self-attention blocks) that can be used (see `past_key_values` input) to speed up sequential decoding.
* `hidden_states` (`tuple(torch.FloatTensor)`, *optional*, returned when `output_hidden_states=True` is passed or when `config.output_hidden_states=True`) — Tuple of `torch.FloatTensor` (one for the output of the embeddings, if the model has an embedding layer, + one for the output of each layer) of shape `(batch_size, sequence_length, hidden_size)`.
Hidden-states of the model at the output of each layer plus the optional initial embedding outputs.
* `attentions` (`tuple(torch.FloatTensor)`, *optional*, returned when `output_attentions=True` is passed or when `config.output_attentions=True`) — Tuple of `torch.FloatTensor` (one for each layer) of shape `(batch_size, num_heads, sequence_length, sequence_length)`.
Attentions weights after the attention softmax, used to compute the weighted average in the self-attention heads.
The FuyuForCausalLM forward method, overrides the `__call__` special method.
Although the recipe for forward pass needs to be defined within this function, one should call the `Module` instance afterwards instead of this since the former takes care of running the pre and post processing steps while the latter silently ignores them.
Examples:
```
从转换器导入 FuyuProcessor,FuyuForCausalLM
从 PIL 导入图像
导入请求
处理器= FuyuProcessor.from_pretrained(“adept/fuyu-8b”)
模型= FuyuForCausalLM.from_pretrained(“adept/fuyu-8b”)
网址=“http://images.cocodataset.org/val2017/000000039769.jpg”
图像 = Image.open(requests.get(url, stream=True).raw)
提示=“生成一个 coco 风格的标题。\n”
输入=处理器(文本= text_prompt,图像=图像,return_tensors=“pt”)
输出=模型(**输入)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=7)
>>> generation_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
>>> print(generation_text)
“停在路边的公共汽车。”
```py
## FuyuImageProcessor
### `class transformers.FuyuImageProcessor`
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/fuyu/image_processing_fuyu.py#L180)
```
(do_resize: bool=True size: Optional=None resample: Resampling=<Resampling.BILINEAR: 2> do_pad: bool=True padding_value: float=1.0 padding_mode: str='constant' do_normalize: bool=True image_mean: Union=0.5 image_std: Union=0.5 do_rescale: bool=True rescale_factor: float=0.00392156862745098 patch_size: Optional=None **kwargs)
```py
Parameters
* `do_resize` (`bool`, *optional*, defaults to `True`) — Whether to resize the image to `size`.
* `size` (`Dict[str, int]`, *optional*, defaults to `{"height" -- 1080, "width": 1920}`): Dictionary in the format `{"height": int, "width": int}` specifying the size of the output image.
* `resample` (`PILImageResampling`, *optional*, defaults to `Resampling.BILINEAR`) — `PILImageResampling` filter to use when resizing the image e.g. `PILImageResampling.BILINEAR`.
* `do_pad` (`bool`, *optional*, defaults to `True`) — Whether to pad the image to `size`.
* `padding_value` (`float`, *optional*, defaults to 1.0) — The value to pad the image with.
* `padding_mode` (`str`, *optional*, defaults to `"constant"`) — The padding mode to use when padding the image.
* `do_normalize` (`bool`, *optional*, defaults to `True`) — Whether to normalize the image.
* `image_mean` (`float`, *optional*, defaults to 0.5) — The mean to use when normalizing the image.
* `image_std` (`float`, *optional*, defaults to 0.5) — The standard deviation to use when normalizing the image.
* `do_rescale` (`bool`, *optional*, defaults to `True`) — Whether to rescale the image.
* `rescale_factor` (`float`, *optional*, defaults to `1 / 255`) — The factor to use when rescaling the image.
* `patch_size` (`Dict[str, int]`, *optional*, defaults to `{"height" -- 30, "width": 30}`): Dictionary in the format `{"height": int, "width": int}` specifying the size of the patches.
This class should handle the image processing part before the main FuyuForCausalLM. In particular, it should handle:
* Processing Images: Taking a batch of images as input. If the images are variable-sized, it resizes them based on the desired patch dimensions. The image output is always img_h, img_w of (1080, 1920)
Then, it patches up these images using the patchify_image function.
* Creating Image Input IDs: For each patch, a placeholder ID is given to identify where these patches belong in a token sequence. For variable-sized images, each line of patches is terminated with a newline ID.
* Image Patch Indices: For each image patch, the code maintains an index where these patches should be inserted in a token stream.
#### `__call__`
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/image_processing_utils.py#L550)
```
(images **kwargs)
```py
Preprocess an image or a batch of images.
## FuyuProcessor
### `class transformers.FuyuProcessor`
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/fuyu/processing_fuyu.py#L309)
```
(图像处理器 标记器)
```py
Parameters
* `image_processor` (FuyuImageProcessor) — The image processor is a required input.
* `tokenizer` (LlamaTokenizerFast) — The tokenizer is a required input.
Constructs a Fuyu processor which wraps a Fuyu image processor and a Llama tokenizer into a single processor.
FuyuProcessor offers all the functionalities of FuyuImageProcessor and LlamaTokenizerFast. See the **call**() and `decode()` for more information.
#### `__call__`
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/fuyu/processing_fuyu.py#L451)
```
(text=None images=None add_special_tokens: bool=True return_attention_mask: bool=True padding: Union=False truncation: Union=None max_length: Optional=None stride: int=0 pad_to_multiple_of: Optional=None return_overflowing_tokens: bool=False return_special_tokens_mask: bool=False return_offsets_mapping: bool=False return_token_type_ids: bool=False return_length: bool=False verbose: bool=True return_tensors: Union=None **kwargs)→ export const metadata = 'undefined';FuyuBatchEncoding
```
参数
+ `text`(`str`,`List[str]`)— 要编码的序列或序列批次。每个序列可以是字符串或字符串列表(预标记化字符串)。如果将序列提供为字符串列表(预标记化),则必须设置`is_split_into_words=True`(以消除与序列批次的歧义)。
+ `images`(`PIL.Image.Image`,`List[PIL.Image.Image]`)— 要准备的图像或图像批次。每个图像可以是 PIL 图像、NumPy 数组或 PyTorch 张量。对于 NumPy 数组/PyTorch 张量,每个图像的形状应为(C,H,W),其中 C 是通道数,H 和 W 是图像的高度和宽度。
返回
`FuyuBatchEncoding`
一个具有以下字段的`FuyuBatchEncoding`:
+ `input_ids` — 要提供给模型的标记 id 张量。当`text`不是`None`时返回。
+ `image_patches` — 图像补丁张量列表。当`images`不是`None`时返回。
+ `image_patches_indices` — 指示模型应插入补丁嵌入的索引张量。
+ `attention_mask` — 指定模型在`return_attention_mask=True`时应关注哪些标记的索引列表。
准备模型一个或多个序列和图像的主要方法。如果`text`不是`None`,此方法将`text`和`kwargs`参数转发给 LlamaTokenizerFast 的**call**()以对文本进行编码。要准备图像,如果`images`不是`None`,此方法将`images`和`kwargs`参数转发给 FuyuImageProcessor 的**call**()。有关更多信息,请参考上述两种方法的文档。
# OpenAI GPT
> 原始文本:[`huggingface.co/docs/transformers/v4.37.2/en/model_doc/openai-gpt`](https://huggingface.co/docs/transformers/v4.37.2/en/model_doc/openai-gpt)
 
## 概述
OpenAI GPT 模型是由 Alec Radford、Karthik Narasimhan、Tim Salimans 和 Ilya Sutskever 在[通过生成预训练改进语言理解](https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf)中提出的。它是一个使用语言建模在大型语料库上进行预训练的因果(单向)变压器,具有长距离依赖性,多伦多图书语料库。
论文摘要如下:
*自然语言理解包括各种不同的任务,如文本蕴涵、问题回答、语义相似性评估和文档分类。尽管大量未标记的文本语料库丰富,但用于学习这些特定任务的标记数据稀缺,这使得经过区分训练的模型难以表现出色。我们证明,通过在多样化的未标记文本语料库上对语言模型进行生成预训练,然后在每个特定任务上进行区分微调,可以实现这些任务的大幅提升。与以往方法相反,我们在微调过程中利用任务感知的输入转换,实现有效的迁移,同时对模型架构进行最小的更改。我们在自然语言理解的广泛基准上展示了我们方法的有效性。我们的通用任务不可知模型在 9 个研究的 12 个任务中优于使用专门为每个任务精心设计的架构的经过区分训练的模型,显著改进了技术水平。*
[使用 Transformer 写作](https://transformer.huggingface.co/doc/gpt)是由 Hugging Face 创建和托管的网络应用程序,展示了几种模型的生成能力。GPT 是其中之一。
此模型由[thomwolf](https://huggingface.co/thomwolf)贡献。原始代码可以在[此处](https://github.com/openai/finetune-transformer-lm)找到。
## 使用提示
+ GPT 是一个具有绝对位置嵌入的模型,因此通常建议在右侧而不是左侧填充输入。
+ GPT 是通过因果语言建模(CLM)目标进行训练的,因此在预测序列中的下一个标记时非常强大。利用这一特性使 GPT-2 能够生成句法连贯的文本,可以在*run_generation.py*示例脚本中观察到。
注意:
如果您想复制*OpenAI GPT*论文的原始标记化过程,您需要安装`ftfy`和`SpaCy`:
```py
pip install spacy ftfy==4.4.3
python -m spacy download en
```
如果您没有安装`ftfy`和`SpaCy`,OpenAIGPTTokenizer 将默认使用 BERT 的`BasicTokenizer`进行标记化,然后是字节对编码(对于大多数用途来说应该没问题,不用担心)。
## 资源
官方 Hugging Face 和社区(由🌎表示)资源列表,可帮助您开始使用 OpenAI GPT。如果您有兴趣提交资源以包含在此处,请随时打开 Pull Request,我们将进行审查!资源应该理想地展示一些新东西,而不是重复现有资源。
文本分类
+ 一篇关于[使用 SetFit 在文本分类中胜过 OpenAI GPT-3 的博客文章](https://www.philschmid.de/getting-started-setfit)。
+ 另请参阅:文本分类任务指南
文本生成
+ 关于如何[使用 Hugging Face 对非英语 GPT-2 模型进行微调](https://www.philschmid.de/fine-tune-a-non-english-gpt-2-model-with-huggingface)的博客。
+ 一篇关于如何使用 GPT-2 进行文本生成的博客:[使用不同解码方法进行语言生成与 Transformers](https://huggingface.co/blog/how-to-generate)。
+ 一篇关于从头开始训练 [CodeParrot 🦜 的博客](https://huggingface.co/blog/codeparrot),一个大型的 GPT-2 模型。
+ 一篇关于如何使用 GPT-2 进行 [更快的文本生成与 TensorFlow 和 XLA](https://huggingface.co/blog/tf-xla-generate) 的博客。
+ 一篇关于如何使用 GPT-2 模型 [训练语言模型与 Megatron-LM](https://huggingface.co/blog/megatron-training) 的博客。
+ 一篇关于如何 [微调 GPT2 以生成您最喜爱艺术家风格的歌词](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb) 的笔记本。🌎
+ 一篇关于如何 [微调 GPT2 以生成您最喜爱 Twitter 用户风格的推文](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb) 的笔记本。🌎
+ 🤗 Hugging Face 课程的 [因果语言建模](https://huggingface.co/course/en/chapter7/6?fw=pt#training-a-causal-language-model-from-scratch) 章节。
+ OpenAIGPTLMHeadModel 在这个 [因果语言建模示例脚本](https://github.com/huggingface/transformers/tree/main/examples/pytorch/language-modeling#gpt-2gpt-and-causal-language-modeling)、[文本生成示例脚本](https://github.com/huggingface/transformers/blob/main/examples/pytorch/text-generation/run_generation.py) 和 [笔记本](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling.ipynb) 中得到支持。
+ TFOpenAIGPTLMHeadModel 在这个 [因果语言建模示例脚本](https://github.com/huggingface/transformers/tree/main/examples/tensorflow/language-modeling#run_clmpy) 和 [笔记本](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/language_modeling-tf.ipynb) 中得到支持。
+ 另请参阅:因果语言建模任务指南
标记分类
+ 有关 [字节对编码标记化](https://huggingface.co/course/en/chapter6/5) 的课程材料。
## OpenAIGPTConfig
### `class transformers.OpenAIGPTConfig`
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/configuration_openai.py#L27)
```py
( vocab_size = 40478 n_positions = 512 n_embd = 768 n_layer = 12 n_head = 12 afn = 'gelu' resid_pdrop = 0.1 embd_pdrop = 0.1 attn_pdrop = 0.1 layer_norm_epsilon = 1e-05 initializer_range = 0.02 summary_type = 'cls_index' summary_use_proj = True summary_activation = None summary_proj_to_labels = True summary_first_dropout = 0.1 **kwargs )
```
参数
+ `vocab_size` (`int`, *可选*, 默认为 40478) — GPT-2 模型的词汇大小。定义了在调用 OpenAIGPTModel 或 TFOpenAIGPTModel 时可以表示的不同标记数量。
+ `n_positions` (`int`, *可选*, 默认为 512) — 此模型可能会使用的最大序列长度。通常设置为较大的值以防万一(例如,512、1024 或 2048)。
+ `n_embd` (`int`, *可选*, 默认为 768) — 嵌入和隐藏状态的维度。
+ `n_layer` (`int`, *可选*, 默认为 12) — Transformer 编码器中的隐藏层数。
+ `n_head` (`int`, *可选*, 默认为 12) — Transformer 编码器中每个注意力层的注意力头数。
+ `afn` (`str` 或 `Callable`, *可选*, 默认为 `"gelu"`) — 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持 `"gelu"`, `"relu"`, `"silu"` 和 `"gelu_new"`。
+ `resid_pdrop` (`float`, *可选*, 默认为 0.1) — 嵌入、编码器和池化器中所有全连接层的丢弃概率。
+ `embd_pdrop` (`int`, *可选*, 默认为 0.1) — 嵌入的丢弃比率。
+ `attn_pdrop` (`float`, *可选*, 默认为 0.1) — 注意力的丢弃比率。
+ `layer_norm_epsilon` (`float`, *可选*, 默认为 1e-05) — 在层归一化层中使用的 epsilon
+ `initializer_range` (`float`, *可选*, 默认为 0.02) — 用于初始化所有权重矩阵的截断正态初始化器的标准差。
+ `summary_type` (`str`, *可选*, 默认为 `"cls_index"`) — 在进行序列摘要时使用的参数,在模型 OpenAIGPTDoubleHeadsModel 和 OpenAIGPTDoubleHeadsModel 中使用。
必须是以下选项之一:
+ `"last"`: 获取最后一个标记的隐藏状态(类似于 XLNet)。
+ `"first"`: 获取第一个标记的隐藏状态(类似于 BERT)。
+ `"mean"`: 获取所有标记的隐藏状态的平均值。
+ `"cls_index"`: 提供一个分类标记位置的张量(类似于 GPT/GPT-2)。
+ `"attn"`: 目前未实现,使用多头注意力。
+ `summary_use_proj` (`bool`, *可选*, 默认为 `True`) — 在进行序列摘要时使用的参数,在模型 OpenAIGPTDoubleHeadsModel 和 OpenAIGPTDoubleHeadsModel 中使用。
是否在向量提取后添加投影。
+ `summary_activation` (`str`, *可选*) — 在进行序列摘要时使用的参数,在模型 OpenAIGPTDoubleHeadsModel 和 OpenAIGPTDoubleHeadsModel 中使用。
将 `"tanh"` 传递给输出以获得双曲正切激活,其他任何值都将导致无激活。
+ `summary_proj_to_labels` (`bool`, *可选*, 默认为 `True`) — 在进行序列摘要时使用的参数,在模型 OpenAIGPTDoubleHeadsModel 和 OpenAIGPTDoubleHeadsModel 中使用。
投影输出应具有 `config.num_labels` 或 `config.hidden_size` 类。
+ `summary_first_dropout` (`float`, *可选*, 默认为 0.1) — 在进行序列摘要时使用的参数,在模型 OpenAIGPTDoubleHeadsModel 和 OpenAIGPTDoubleHeadsModel 中使用。
在投影和激活之后使用的辍学比例。
这是用于存储 OpenAIGPTModel 或 TFOpenAIGPTModel 配置的配置类。它用于根据指定的参数实例化一个 GPT 模型,定义模型架构。使用默认值实例化配置将产生类似于 OpenAI 的 GPT [openai-gpt](https://huggingface.co/openai-gpt)架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
```py
>>> from transformers import OpenAIGPTConfig, OpenAIGPTModel
>>> # Initializing a GPT configuration
>>> configuration = OpenAIGPTConfig()
>>> # Initializing a model (with random weights) from the configuration
>>> model = OpenAIGPTModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
## OpenAIGPTTokenizer
### `class transformers.OpenAIGPTTokenizer`
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/tokenization_openai.py#L245)
```py
( vocab_file merges_file unk_token = '<unk>' **kwargs )
```
参数
+ `vocab_file` (`str`) — 词汇文件的路径。
+ `merges_file` (`str`) — 合并文件的路径。
+ `unk_token`(`str`,*可选*,默认为`"<unk>"`)- 未知标记。词汇表中不存在的标记无法转换为 ID,而是设置为此标记。
构建一个 GPT 分词器。基于字节对编码,具有以下特点:
+ 将所有输入转换为小写,
+ 如果安装了`SpaCy`分词器和`ftfy`,则使用它们进行 BPE 标记化,否则回退到 BERT 的`BasicTokenizer`。
此分词器继承自 PreTrainedTokenizer,其中包含大多数主要方法。用户应参考此超类以获取有关这些方法的更多信息。
#### `save_vocabulary`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/tokenization_openai.py#L378)
```py
( save_directory: str filename_prefix: Optional = None )
```
## OpenAIGPTTokenizerFast
### `class transformers.OpenAIGPTTokenizerFast`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/tokenization_openai_fast.py#L40)
```py
( vocab_file = None merges_file = None tokenizer_file = None unk_token = '<unk>' **kwargs )
```
参数
+ `vocab_file`(`str`)- 词汇表文件的路径。
+ `merges_file`(`str`)- 合并文件的路径。
+ `unk_token`(`str`,*可选*,默认为`"<unk>"`)- 未知标记。词汇表中不存在的标记无法转换为 ID,而是设置为此标记。
构建一个“快速”GPT 分词器(由 HuggingFace 的*tokenizers*库支持)。基于字节对编码,具有以下特点:
+ 将所有输入转换为小写
+ 使用 BERT 的 BasicTokenizer 进行 BPE 标记化
此分词器继承自 PreTrainedTokenizerFast,其中包含大多数主要方法。用户应参考此超类以获取有关这些方法的更多信息。
## OpenAI 特定输出
### `class transformers.models.openai.modeling_openai.OpenAIGPTDoubleHeadsModelOutput`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_openai.py#L297)
```py
( loss: Optional = None mc_loss: Optional = None logits: FloatTensor = None mc_logits: FloatTensor = None hidden_states: Optional = None attentions: Optional = None )
```
参数
+ `loss`(形状为`(1,)`的`torch.FloatTensor`,*可选*,在提供`labels`时返回)- 语言建模损失。
+ `mc_loss`(形状为`(1,)`的`torch.FloatTensor`,*可选*,在提供`mc_labels`时返回)- 多项选择分类损失。
+ `logits`(形状为`(batch_size, num_choices, sequence_length, config.vocab_size)`的`torch.FloatTensor`)- 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。
+ `mc_logits`(形状为`(batch_size, num_choices)`的`torch.FloatTensor`)- 多项选择分类头的预测分数(SoftMax 之前每个选择的分数)。
+ `hidden_states`(`tuple(torch.FloatTensor)`,*可选*,当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回)- 形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`元组(一个用于嵌入的输出 + 一个用于每一层的输出)。
模型在每一层输出的隐藏状态加上初始嵌入输出。
+ `attentions`(`tuple(torch.FloatTensor)`,*可选*,当传递`output_attentions=True`或`config.output_attentions=True`时返回)- 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每层一个)。
注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
用于预测两个句子是否连续的模型输出的基类。
### `class transformers.models.openai.modeling_tf_openai.TFOpenAIGPTDoubleHeadsModelOutput`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_tf_openai.py#L413)
```py
( logits: tf.Tensor = None mc_logits: tf.Tensor = None hidden_states: Tuple[tf.Tensor] | None = None attentions: Tuple[tf.Tensor] | None = None )
```
参数
+ `logits`(形状为`(batch_size, num_choices, sequence_length, config.vocab_size)`的`tf.Tensor`)- 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。
+ `mc_logits` (`tf.Tensor`,形状为 `(batch_size, num_choices)`) — 多项选择分类头的预测分数(SoftMax 之前每个选择的分数)。
+ `hidden_states` (`tuple(tf.Tensor)`,*可选*,当传递 `output_hidden_states=True` 或 `config.output_hidden_states=True` 时返回) — 形状为 `(batch_size, sequence_length, hidden_size)` 的 `tf.Tensor` 元组(一个用于嵌入的输出 + 一个用于每一层的输出)。
模型在每一层输出的隐藏状态加上初始嵌入输出。
+ `attentions` (`tuple(tf.Tensor)`,*可选*,当传递 `output_attentions=True` 或 `config.output_attentions=True` 时返回) — 形状为 `(batch_size, num_heads, sequence_length, sequence_length)` 的 `tf.Tensor` 元组(每层一个)。
注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
模型输出的基类,用于预测两个句子是否连续。
PytorchHide Pytorch 内容
## OpenAIGPTModel
### `class transformers.OpenAIGPTModel`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_openai.py#L398)
```py
( config )
```
参数
+ `config` (OpenAIGPTConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
裸的 OpenAI GPT 变压器模型输出原始隐藏状态,没有特定的头部。
此模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型也是 PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module) 的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以了解一般用法和行为相关的所有事项。
#### `forward`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_openai.py#L428)
```py
( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutput or tuple(torch.FloatTensor)
```
参数
+ `input_ids` (`torch.LongTensor`,形状为 `(batch_size, sequence_length)`) — 词汇表中输入序列标记的索引。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `attention_mask` (`torch.FloatTensor`,形状为 `(batch_size, sequence_length)`,*可选*) — 避免在填充标记索引上执行注意力的掩码。掩码值在 `[0, 1]` 中选择:
+ 对于未被 `masked` 的标记为 1,
+ 对于被 `masked` 的标记为 0。
什么是注意力掩码?
+ `token_type_ids` (`torch.LongTensor`,形状为 `(batch_size, sequence_length)`,*可选*) — 指示输入的第一部分和第二部分的段标记索引。索引在 `[0, 1]` 中选择:
+ 0 对应于一个 *句子 A* 标记,
+ 1 对应于一个 *句子 B* 标记。
什么是标记类型 ID?
+ `position_ids` (`torch.LongTensor`,形状为 `(batch_size, sequence_length)`,*可选*) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为 `[0, config.max_position_embeddings - 1]`。
什么是位置 ID?
+ `head_mask` (`torch.FloatTensor`,形状为`(num_heads,)`或`(num_layers, num_heads)`,*可选*) — 用于使自注意力模块中的选定头部失效的掩码。掩码值选定在`[0, 1]`之间:
+ 1 表示头部未被`masked`,
+ 0 表示头部被`masked`。
+ `inputs_embeds` (`torch.FloatTensor`,形状为`(batch_size, sequence_length, hidden_size)`,*可选*) — 可选地,您可以直接传递嵌入表示而不是传递`input_ids`。如果您想要更多控制如何将`input_ids`索引转换为关联向量,而不是使用模型的内部嵌入查找矩阵,这将很有用。
+ `output_attentions` (`bool`, *可选*) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请查看返回张量下的`attentions`。
+ `output_hidden_states` (`bool`, *可选*) — 是否返回所有层的隐藏状态。有关更多详细信息,请查看返回张量下的`hidden_states`。
+ `return_dict` (`bool`, *可选*) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutput 或`tuple(torch.FloatTensor)`
transformers.modeling_outputs.BaseModelOutput 或一个`torch.FloatTensor`元组(如果传递`return_dict=False`或当`config.return_dict=False`时)包含各种元素,取决于配置(OpenAIGPTConfig)和输入。
+ `last_hidden_state` (`torch.FloatTensor`,形状为`(batch_size, sequence_length, hidden_size)`) — 模型最后一层输出的隐藏状态序列。
+ `hidden_states` (`tuple(torch.FloatTensor)`,*可选*,当传递`output_hidden_states=True`或当`config.output_hidden_states=True`时返回) — 形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)。
每层输出的模型的隐藏状态加上可选的初始嵌入输出。
+ `attentions` (`tuple(torch.FloatTensor)`,*可选*,当传递`output_attentions=True`或当`config.output_attentions=True`时返回) — 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每层一个)。
在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
OpenAIGPTModel 的前向方法,覆盖了`__call__`特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用`Module`实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
```py
>>> from transformers import AutoTokenizer, OpenAIGPTModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("openai-gpt")
>>> model = OpenAIGPTModel.from_pretrained("openai-gpt")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
## OpenAIGPTLMHeadModel
### `class transformers.OpenAIGPTLMHeadModel`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_openai.py#L526)
```py
( config )
```
参数
+ `config` (OpenAIGPTConfig) — 模型的所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
OpenAI GPT 模型变压器,顶部带有语言建模头(线性层,其权重与输入嵌入绑定)。
此模型继承自 PreTrainedModel。检查超类文档以获取库实现的所有模型的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
此模型还是 PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
#### `forward`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_openai.py#L550)
```py
( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.CausalLMOutput or tuple(torch.FloatTensor)
```
参数
+ `input_ids` (`torch.LongTensor`,形状为`(batch_size, sequence_length)`) — 词汇表中输入序列令牌的索引。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `attention_mask` (`torch.FloatTensor`,形状为`(batch_size, sequence_length)`,*可选*) — 用于避免在填充令牌索引上执行注意力的掩码。掩码值在`[0, 1]`中选择:
+ 1 表示未被`masked`的令牌,
+ 0 表示被`masked`的令牌。
什么是注意力掩码?
+ `token_type_ids` (`torch.LongTensor`,形状为`(batch_size, sequence_length)`,*可选*) — 段令牌索引,指示输入的第一部分和第二部分。索引在`[0, 1]`中选择:
+ 0 对应于*句子 A*令牌,
+ 1 对应于*句子 B*令牌。
什么是令牌类型 ID?
+ `position_ids` (`torch.LongTensor`,形状为`(batch_size, sequence_length)`,*可选*) — 每个输入序列令牌在位置嵌入中的位置索引。选择范围为`[0, config.max_position_embeddings - 1]`。
什么是位置 ID?
+ `head_mask` (`torch.FloatTensor`,形状为`(num_heads,)`或`(num_layers, num_heads)`,*可选*) — 用于使自注意力模块中选择的头部失效的掩码。掩码值在`[0, 1]`中选择:
+ 1 表示头部未被`masked`,
+ 0 表示头部被`masked`。
+ `inputs_embeds` (`torch.FloatTensor`,形状为`(batch_size, sequence_length, hidden_size)`,*可选*) — 可选地,您可以选择直接传递嵌入表示,而不是传递`input_ids`。如果您想要更多控制如何将`input_ids`索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。
+ `output_attentions` (`bool`,*可选*) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的`attentions`。
+ `output_hidden_states` (`bool`,*可选*) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的`hidden_states`。
+ `return_dict` (`bool`,*可选*) — 是否返回一个 ModelOutput 而不是一个普通的元组。
+ `labels` (`torch.LongTensor`,形状为`(batch_size, sequence_length)`,*可选*) — 用于语言建模的标签。请注意,模型内部的标签**已经被移位**,即您可以设置`labels = input_ids`。索引在`[-100, 0, ..., config.vocab_size]`中选择。所有设置为`-100`的标签都被忽略(掩码),损失仅计算在`[0, ..., config.vocab_size]`中的标签。
返回
transformers.modeling_outputs.CausalLMOutput 或`tuple(torch.FloatTensor)`
一个 transformers.modeling_outputs.CausalLMOutput 或一个`torch.FloatTensor`元组(如果传递`return_dict=False`或`config.return_dict=False`)包含根据配置(OpenAIGPTConfig)和输入的各种元素。
+ `loss`(形状为`(1,)`的`torch.FloatTensor`,*可选*,当提供`labels`时返回)— 语言建模损失(用于下一个标记预测)。
+ `logits`(形状为`(batch_size, sequence_length, config.vocab_size)`的`torch.FloatTensor`)— 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。
+ `hidden_states`(`tuple(torch.FloatTensor)`,*可选*,当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回)— 形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)。
每层模型的隐藏状态加上可选的初始嵌入输出。
+ `attentions`(`tuple(torch.FloatTensor)`,*可选*,当传递`output_attentions=True`或`config.output_attentions=True`时返回)— 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每层一个)。
在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
OpenAIGPTLMHeadModel 的前向方法,覆盖了`__call__`特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用`Module`实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
```py
>>> import torch
>>> from transformers import AutoTokenizer, OpenAIGPTLMHeadModel
>>> tokenizer = AutoTokenizer.from_pretrained("openai-gpt")
>>> model = OpenAIGPTLMHeadModel.from_pretrained("openai-gpt")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs, labels=inputs["input_ids"])
>>> loss = outputs.loss
>>> logits = outputs.logits
```
## OpenAIGPTDoubleHeadsModel
### `class transformers.OpenAIGPTDoubleHeadsModel`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_openai.py#L615)
```py
( config )
```
参数
+ `config`(OpenAIGPTConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
OpenAI GPT 模型变压器,顶部带有语言建模和多选分类头,例如用于 RocStories/SWAG 任务。这两个头是两个线性层。语言建模头的权重与输入嵌入绑定,分类头以指定的分类标记索引的输入作为输入序列的输入)。
这个模型继承自 PreTrainedModel。检查超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个 PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有内容。
#### `forward`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_openai.py#L644)
```py
( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None mc_token_ids: Optional = None labels: Optional = None mc_labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.models.openai.modeling_openai.OpenAIGPTDoubleHeadsModelOutput or tuple(torch.FloatTensor)
```
参数
+ `input_ids`(形状为`(batch_size, sequence_length)`的`torch.LongTensor`)— 词汇表中输入序列标记的索引。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参见 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `attention_mask` (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) — 避免在填充标记索引上执行注意力的掩码。掩码值选择在`[0, 1]`之间:
+ 1 表示未被掩盖的标记,
+ 0 表示被掩盖的标记。
什么是注意力掩码?
+ `token_type_ids` (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) — 指示输入的第一部分和第二部分的段标记索引。索引选择在`[0, 1]`中:
+ 0 对应于*句子 A*标记,
+ 1 对应于*句子 B*标记。
什么是标记类型 ID?
+ `position_ids` (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为`[0, config.max_position_embeddings - 1]`。
什么是位置 ID?
+ `head_mask` (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*) — 用于使自注意力模块的选定头部无效的掩码。掩码值选择在`[0, 1]`中:
+ 1 表示头部未被掩盖,
+ 0 表示头部被掩盖。
+ `inputs_embeds` (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) — 可选地,可以直接传递嵌入表示,而不是传递`input_ids`。如果您想要更多控制如何将`input_ids`索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。
+ `output_attentions` (`bool`, *optional*) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的`attentions`。
+ `output_hidden_states` (`bool`, *optional*) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的`hidden_states`。
+ `return_dict` (`bool`, *optional*) — 是否返回 ModelOutput 而不是普通元组。
+ `mc_token_ids` (`torch.LongTensor` of shape `(batch_size, num_choices)`, *optional*, 默认为输入的最后一个标记的索引) — 每个输入序列中分类标记的索引。选择范围为`[0, input_ids.size(-1) - 1]`。
+ `labels` (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) — 用于语言建模的标签。请注意,模型内部的标签**已经移位**,即您可以设置`labels = input_ids`。索引选择在`[-1, 0, ..., config.vocab_size]`中。所有设置为`-100`的标签都被忽略(掩盖),损失仅计算在`[0, ..., config.vocab_size]`中的标签。
+ `mc_labels` (`torch.LongTensor` of shape `(batch_size)`, *optional*) — 用于计算多项选择分类损失的标签。索引应在`[0, ..., num_choices]`中,其中*num_choices*是输入张量第二维的大小。(参见上面的*input_ids*)
返回
transformers.models.openai.modeling_openai.OpenAIGPTDoubleHeadsModelOutput 或 `tuple(torch.FloatTensor)`
一个 transformers.models.openai.modeling_openai.OpenAIGPTDoubleHeadsModelOutput 或一个`torch.FloatTensor`元组(如果传递了`return_dict=False`或`config.return_dict=False`时)包含根据配置(OpenAIGPTConfig)和输入不同元素。
+ `loss`(`torch.FloatTensor`,形状为`(1,)`,*可选*,在提供`labels`时返回)— 语言建模损失。
+ `mc_loss`(`torch.FloatTensor`,形状为`(1,)`,*可选*,在提供`mc_labels`时返回)— 多项选择分类损失。
+ `logits`(`torch.FloatTensor`,形状为`(batch_size, num_choices, sequence_length, config.vocab_size)`)— 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。
+ `mc_logits`(`torch.FloatTensor`,形状为`(batch_size, num_choices)`)— 多项选择分类头的预测分数(SoftMax 之前每个选择的分数)。
+ `hidden_states`(`tuple(torch.FloatTensor)`,*可选*,在传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回)— 形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`元组(一个用于嵌入的输出 + 一个用于每个层的输出)。
模型在每个层的输出的隐藏状态以及初始嵌入输出。
+ `attentions`(`tuple(torch.FloatTensor)`,*可选*,在传递`output_attentions=True`或`config.output_attentions=True`时返回)— 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每个层一个)。
在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
OpenAIGPTDoubleHeadsModel 的前向方法,覆盖了`__call__`特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用`Module`实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
```py
>>> from transformers import AutoTokenizer, OpenAIGPTDoubleHeadsModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("openai-gpt")
>>> model = OpenAIGPTDoubleHeadsModel.from_pretrained("openai-gpt")
>>> tokenizer.add_special_tokens(
... {"cls_token": "[CLS]"}
... ) # Add a [CLS] to the vocabulary (we should train it also!)
>>> model.resize_token_embeddings(len(tokenizer))
>>> choices = ["Hello, my dog is cute [CLS]", "Hello, my cat is cute [CLS]"]
>>> input_ids = torch.tensor([tokenizer.encode(s) for s in choices]).unsqueeze(0) # Batch size 1, 2 choices
>>> mc_token_ids = torch.tensor([input_ids.size(-1) - 1, input_ids.size(-1) - 1]).unsqueeze(0) # Batch size 1
>>> outputs = model(input_ids, mc_token_ids=mc_token_ids)
>>> lm_logits = outputs.logits
>>> mc_logits = outputs.mc_logits
```
## OpenAIGPTForSequenceClassification
### `class transformers.OpenAIGPTForSequenceClassification`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_openai.py#L740)
```py
( config )
```
参数
+ `config`(OpenAIGPTConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
原始的 OpenAI GPT 模型变压器,顶部带有序列分类头(线性层)。OpenAIGPTForSequenceClassification 使用最后一个标记进行分类,就像其他因果模型(例如 GPT-2)一样。由于它在最后一个标记上进行分类,因此需要知道最后一个标记的位置。如果在配置中定义了`pad_token_id`,则找到每行中不是填充标记的最后一个标记。如果未定义`pad_token_id`,则简单地取批次中每行的最后一个值。由于在传递`inputs_embeds`而不是`input_ids`时无法猜测填充标记,因此它执行相同操作(取批次中每行的最后一个值)。
此模型继承自 PreTrainedModel。检查超类文档,了解库为其所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
此模型还是 PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取与一般用法和行为相关的所有事项。
#### `forward`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_openai.py#L762)
```py
( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.SequenceClassifierOutput or tuple(torch.FloatTensor)
```
参数
+ `input_ids`(形状为`(batch_size, sequence_length)`的`torch.LongTensor`) — 词汇表中输入序列标记的索引。
可以使用 AutoTokenizer 来获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `attention_mask`(形状为`(batch_size, sequence_length)`的`torch.FloatTensor`,*可选*) — 用于避免在填充标记索引上执行注意力的掩码。掩码值在`[0, 1]`中选择:
+ 1 表示“未被掩盖”的标记,
+ 0 表示“被掩盖”的标记。
什么是注意力掩码?
+ `token_type_ids`(形状为`(batch_size, sequence_length)`的`torch.LongTensor`,*可选*) — 段标记索引,用于指示输入的第一部分和第二部分。索引在`[0, 1]`中选择:
+ 0 对应于*句子 A*标记。
+ 1 对应于*句子 B*标记。
什么是标记类型 ID?
+ `position_ids`(形状为`(batch_size, sequence_length)`的`torch.LongTensor`,*可选*) — 每个输入序列标记在位置嵌入中的位置索引。在范围`[0, config.max_position_embeddings - 1]`中选择。
什么是位置 ID?
+ `head_mask`(形状为`(num_heads,)`或`(num_layers, num_heads)`的`torch.FloatTensor`,*可选*) — 用于使自注意力模块中选择的头部失效的掩码。掩码值在`[0, 1]`中选择:
+ 1 表示头部“未被掩盖”,
+ 0 表示头部“被掩盖”。
+ `inputs_embeds`(形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`,*可选*) — 可选地,您可以选择直接传递嵌入表示,而不是传递`input_ids`。如果您想要更多控制权来将`input_ids`索引转换为相关向量,这将非常有用,而不是使用模型的内部嵌入查找矩阵。
+ `output_attentions`(`bool`,*可选*) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的`attentions`。
+ `output_hidden_states`(`bool`,*可选*) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的`hidden_states`。
+ `return_dict`(`bool`,*可选*) — 是否返回 ModelOutput 而不是普通元组。
+ `labels`(形状为`(batch_size,)`的`torch.LongTensor`,*可选*) — 用于计算序列分类/回归损失的标签。索引应在`[0, ..., config.num_labels - 1]`中。如果`config.num_labels == 1`,则计算回归损失(均方损失),如果`config.num_labels > 1`,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.SequenceClassifierOutput 或`tuple(torch.FloatTensor)`
一个 transformers.modeling_outputs.SequenceClassifierOutput 或一个`torch.FloatTensor`元组(如果传递`return_dict=False`或`config.return_dict=False`时)包含各种元素,取决于配置(OpenAIGPTConfig)和输入。
+ `loss` (`torch.FloatTensor`,形状为`(1,)`, *可选的*, 当提供`labels`时返回) — 分类(如果 config.num_labels==1 则为回归)损失。
+ `logits` (`torch.FloatTensor`,形状为`(batch_size, config.num_labels)`) — 分类(如果 config.num_labels==1 则为回归)得分(SoftMax 之前)。
+ `hidden_states` (`tuple(torch.FloatTensor)`, *可选的*, 当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回) — 形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`元组(如果模型有嵌入层,则为嵌入输出的输出+每层的输出)。
模型在每一层输出的隐藏状态加上可选的初始嵌入输出。
+ `attentions` (`tuple(torch.FloatTensor)`, *可选的*, 当传递`output_attentions=True`或`config.output_attentions=True`时返回) — 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每层一个)。
注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
OpenAIGPTForSequenceClassification 的前向方法,覆盖了`__call__`特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用`Module`实例,而不是在此处调用,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
单标签分类示例:
```py
>>> import torch
>>> from transformers import AutoTokenizer, OpenAIGPTForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("openai-gpt")
>>> model = OpenAIGPTForSequenceClassification.from_pretrained("openai-gpt")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = OpenAIGPTForSequenceClassification.from_pretrained("openai-gpt", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss
```
多标签分类示例:
```py
>>> import torch
>>> from transformers import AutoTokenizer, OpenAIGPTForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("openai-gpt")
>>> model = OpenAIGPTForSequenceClassification.from_pretrained("openai-gpt", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = OpenAIGPTForSequenceClassification.from_pretrained(
... "openai-gpt", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).loss
```
TensorFlow 隐藏 TensorFlow 内容
## TFOpenAIGPTModel
### `class transformers.TFOpenAIGPTModel`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_tf_openai.py#L540)
```py
( config *inputs **kwargs )
```
参数
+ `config` (OpenAIGPTConfig) — 模型的所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法来加载模型权重。
裸的 OpenAI GPT 变换器模型输出原始隐藏状态,没有特定的顶部头。
此模型继承自 TFPreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型也是[tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)的子类。将其用作常规的 TF 2.0 Keras 模型,并参考 TF 2.0 文档以获取有关一般用法和行为的所有相关信息。
`transformers`中的 TensorFlow 模型和层接受两种格式的输入:
+ 将所有输入作为关键字参数(类似于 PyTorch 模型),或
+ 将所有输入作为列表、元组或字典放在第一个位置参数中。
第二种格式得到支持的原因是,当将输入传递给模型和层时,Keras 方法更喜欢这种格式。由于这种支持,在使用诸如`model.fit()`之类的方法时,应该对您“只需工作” - 只需以`model.fit()`支持的任何格式传递您的输入和标签!但是,如果您想在 Keras 方法之外使用第二种格式,例如在使用 Keras`Functional` API 创建自己的层或模型时,有三种可能性可以用来收集所有输入张量在第一个位置参数中:
+ 只有一个包含`input_ids`的张量,没有其他内容:`model(input_ids)`
+ 一个长度可变的列表,其中包含一个或多个输入张量,按照文档字符串中给定的顺序:`model([input_ids, attention_mask])`或`model([input_ids, attention_mask, token_type_ids])`
+ 一个字典,其中包含与文档字符串中给定的输入名称相关联的一个或多个输入张量:`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
请注意,当使用[子类化](https://keras.io/guides/making_new_layers_and_models_via_subclassing/)创建模型和层时,您无需担心任何这些,因为您可以像将输入传递给任何其他 Python 函数一样传递输入!
#### `call`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_tf_openai.py#L549)
```py
( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False ) → export const metadata = 'undefined';transformers.modeling_tf_outputs.TFBaseModelOutput or tuple(tf.Tensor)
```
参数
+ `input_ids`(形状为`(batch_size, sequence_length)`的`Numpy array`或`tf.Tensor`) - 词汇表中输入序列令牌的索引。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.`call`()和 PreTrainedTokenizer.encode()。
什么是输入 ID?
+ `attention_mask`(形状为`(batch_size, sequence_length)`的`tf.Tensor`或`Numpy array`,*可选*) - 用于避免在填充令牌索引上执行注意力的掩码。掩码值在`[0, 1]`中选择:
+ 1 表示未被`masked`的令牌,
+ 0 表示被`masked`的令牌。
什么是注意力掩码?
+ `token_type_ids`(形状为`(batch_size, sequence_length)`的`tf.Tensor`或`Numpy array`,*可选*) - 段标记索引,指示输入的第一部分和第二部分。索引在`[0, 1]`中选择:
+ 0 对应于*句子 A*令牌,
+ 1 对应于*句子 B*令牌。
什么是令牌类型 ID?
+ `position_ids`(形状为`(batch_size, sequence_length)`的`tf.Tensor`或`Numpy array`,*可选*) - 每个输入序列令牌在位置嵌入中的位置索引。在范围`[0, config.max_position_embeddings - 1]`中选择。
什么是位置 ID?
+ `head_mask`(形状为`(num_heads,)`或`(num_layers, num_heads)`的`tf.Tensor`或`Numpy array`,*可选*) - 用于使自注意力模块的选定头部无效的掩码。掩码值在`[0, 1]`中选择:
+ 1 表示头部未被`masked`,
+ 0 表示头部是`masked`。
+ `inputs_embeds`(形状为`(batch_size, sequence_length, hidden_size)`的`tf.Tensor`或`Numpy array`,*可选*) - 可选地,您可以选择直接传递嵌入表示,而不是传递`input_ids`。如果您想要更多控制权,以便将`input_ids`索引转换为相关向量,而不是模型的内部嵌入查找矩阵。
+ `output_attentions`(`bool`,*可选*) - 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的`attentions`。此参数仅在急切模式下使用,在图模式下将使用配置中的值。
+ `output_hidden_states` (`bool`,*可选*) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的 `hidden_states`。此参数仅在 eager 模式下使用,在图模式下将使用配置中的值。
+ `return_dict` (`bool`,*可选*) — 是否返回一个 ModelOutput 而不是一个普通元组。这个参数可以在 eager 模式下使用,在图模式下该值将始终设置为 True。
+ `training` (`bool`, *可选*,默认为 `False`) — 是否在训练模式下使用模型(一些模块如 dropout 模块在训练和评估之间有不同的行为)。
返回
transformers.modeling_tf_outputs.TFBaseModelOutput 或 `tuple(tf.Tensor)`
一个 transformers.modeling_tf_outputs.TFBaseModelOutput 或一个 `tf.Tensor` 元组(如果传入 `return_dict=False` 或当 `config.return_dict=False` 时)包含根据配置(OpenAIGPTConfig)和输入的各种元素。
+ `last_hidden_state` (`tf.Tensor`,形状为 `(batch_size, sequence_length, hidden_size)`) — 模型最后一层输出的隐藏状态序列。
+ `hidden_states` (`tuple(tf.FloatTensor)`,*可选*,当传入 `output_hidden_states=True` 或当 `config.output_hidden_states=True` 时返回)— 形状为 `(batch_size, sequence_length, hidden_size)` 的 `tf.Tensor` 元组。
模型在每一层输出的隐藏状态以及初始嵌入输出。
+ `attentions` (`tuple(tf.Tensor)`,*可选*,当传入 `output_attentions=True` 或当 `config.output_attentions=True` 时返回)— 形状为 `(batch_size, num_heads, sequence_length, sequence_length)` 的 `tf.Tensor` 元组。
注意力权重在注意力 softmax 之后,用于计算自注意力头中的加权平均值。
TFOpenAIGPTModel 的前向方法,覆盖了 `__call__` 特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用 `Module` 实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
```py
>>> from transformers import AutoTokenizer, TFOpenAIGPTModel
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("openai-gpt")
>>> model = TFOpenAIGPTModel.from_pretrained("openai-gpt")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
## TFOpenAIGPTLMHeadModel
`transformers.TFOpenAIGPTLMHeadModel` 类
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_tf_openai.py#L592)
```py
( config *inputs **kwargs )
```
参数
+ `config` (OpenAIGPTConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只加载配置。查看 from_pretrained() 方法以加载模型权重。
带有语言建模头的 OpenAI GPT 模型变换器(线性层,其权重与输入嵌入相关联)。
此模型继承自 TFPreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型也是一个[tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)子类。将其用作常规的 TF 2.0 Keras 模型,并参考 TF 2.0 文档以获取与一般用法和行为相关的所有事项。
`transformers`中的 TensorFlow 模型和层接受两种输入格式:
+ 将所有输入作为关键字参数(类似于 PyTorch 模型),或
+ 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是 Keras 方法在将输入传递给模型和层时更喜欢这种格式。由于这种支持,当使用`model.fit()`等方法时,应该可以“正常工作” - 只需以`model.fit()`支持的任何格式传递输入和标签即可!但是,如果您想在 Keras 方法之外使用第二种格式,例如在使用 Keras `Functional` API 创建自己的层或模型时,有三种可能性可以用来收集第一个位置参数中的所有输入 Tensor:
+ 仅具有`input_ids`的单个 Tensor,没有其他内容:`model(input_ids)`
+ 一个具有不同长度的列表,其中包含一个或多个按照文档字符串中给定的顺序的输入 Tensor:`model([input_ids, attention_mask])`或`model([input_ids, attention_mask, token_type_ids])`
+ 一个字典,其中包含一个或多个与文档字符串中给定的输入名称相关联的输入 Tensor:`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
请注意,当使用[子类化](https://keras.io/guides/making_new_layers_and_models_via_subclassing/)创建模型和层时,您无需担心任何这些,因为您可以像对待任何其他 Python 函数一样传递输入!
#### `call`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_tf_openai.py#L612)
```py
( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None labels: np.ndarray | tf.Tensor | None = None training: Optional[bool] = False ) → export const metadata = 'undefined';transformers.modeling_tf_outputs.TFCausalLMOutput or tuple(tf.Tensor)
```
参数
+ `input_ids`(形状为`(batch_size, sequence_length)`的`Numpy`数组或`tf.Tensor`)- 词汇表中输入序列标记的索引。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.`call`()和 PreTrainedTokenizer.encode()。
什么是输入 ID?
+ `attention_mask`(形状为`(batch_size, sequence_length)`的`tf.Tensor`或`Numpy`数组,*可选*)- 避免在填充标记索引上执行注意力的掩码。选择的掩码值在`[0, 1]`中:
+ 1 表示`not masked`的标记,
+ 0 表示`masked`的标记。
什么是注意力掩码?
+ `token_type_ids`(形状为`(batch_size, sequence_length)`的`tf.Tensor`或`Numpy`数组,*可选*)- 指示输入的第一部分和第二部分的段标记索引。索引在`[0, 1]`中选择:
+ 0 对应于*句子 A*的标记,
+ 1 对应于*句子 B*的标记。
什么是标记类型 ID?
+ `position_ids`(`tf.Tensor`或形状为`(batch_size, sequence_length)`的`Numpy`数组,*可选*)- 每个输入序列标记在位置嵌入中的位置的索引。在范围`[0, config.max_position_embeddings - 1]`中选择。
什么是位置 ID?
+ `head_mask`(形状为`(num_heads,)`或`(num_layers, num_heads)`的`tf.Tensor`或`Numpy`数组,*可选*)- 用于使自注意力模块的选定头部无效的掩码。选择的掩码值在`[0, 1]`中:
+ 1 表示头部是`not masked`,
+ 0 表示头部是`masked`。
+ `inputs_embeds`(形状为`(batch_size, sequence_length, hidden_size)`的`tf.Tensor`或`Numpy array`,*可选*)— 可选地,可以直接传递嵌入表示,而不是传递`input_ids`。如果您想要更多控制如何将`input_ids`索引转换为关联向量,而不是模型的内部嵌入查找矩阵,则这很有用。
+ `output_attentions`(`bool`,*可选*)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的`attentions`。此参数仅在急切模式下使用,在图模式下将使用配置中的值。
+ `output_hidden_states`(`bool`,*可选*)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的`hidden_states`。此参数仅在急切模式下使用,在图模式下将使用配置中的值。
+ `return_dict`(`bool`,*可选*)— 是否返回 ModelOutput 而不是普通元组。此参数可在急切模式下使用,在图模式下该值将始终设置为 True。
+ `training`(`bool`,*可选*,默认为`False`)— 是否在训练模式中使用模型(一些模块如 dropout 模块在训练和评估之间有不同的行为)。
+ `labels`(形状为`(batch_size, sequence_length)`的`tf.Tensor`,*可选*)— 用于计算交叉熵分类损失的标签。索引应在`[0, ..., config.vocab_size - 1]`范围内。
返回
transformers.modeling_tf_outputs.TFCausalLMOutput 或`tuple(tf.Tensor)`
一个 transformers.modeling_tf_outputs.TFCausalLMOutput 或一个`tf.Tensor`元组(如果传递`return_dict=False`或`config.return_dict=False`,则根据配置(OpenAIGPTConfig)和输入包含各种元素。
+ `loss`(形状为`(n,)`的`tf.Tensor`,*可选*,当提供`labels`时返回,其中 n 是未屏蔽标签的数量)— 语言建模损失(用于下一个标记预测)。
+ `logits`(形状为`(batch_size, sequence_length, config.vocab_size)`的`tf.Tensor`)— 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。
+ `hidden_states`(`tuple(tf.Tensor)`,*可选*,当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回)— 形状为`(batch_size, sequence_length, hidden_size)`的`tf.Tensor`元组(一个用于嵌入的输出 + 一个用于每个层的输出)。
模型在每个层的输出处的隐藏状态以及初始嵌入输出。
+ `attentions`(`tuple(tf.Tensor)`,*可选*,当传递`output_attentions=True`或`config.output_attentions=True`时返回)— 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`tf.Tensor`元组(每个层一个)。
注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
TFOpenAIGPTLMHeadModel 的前向方法,覆盖了`__call__`特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用`Module`实例,而不是这个,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
示例:
```py
>>> from transformers import AutoTokenizer, TFOpenAIGPTLMHeadModel
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("openai-gpt")
>>> model = TFOpenAIGPTLMHeadModel.from_pretrained("openai-gpt")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> outputs = model(inputs)
>>> logits = outputs.logits
```
## TFOpenAIGPTDoubleHeadsModel
### `class transformers.TFOpenAIGPTDoubleHeadsModel`
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_tf_openai.py#L685)
```py
( config *inputs **kwargs )
```
参数
+ `config`(OpenAIGPTConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
OpenAI GPT 模型变压器,具有语言建模和顶部的多选分类头,例如用于 RocStories/SWAG 任务。这两个头是两个线性层。语言建模头的权重与输入嵌入绑定,分类头以输入序列中指定分类标记索引的输入为输入)。
此模型继承自 TFPreTrainedModel。查看超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个[tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)的子类。将其用作常规的 TF 2.0 Keras 模型,并参考 TF 2.0 文档以获取与一般用法和行为相关的所有内容。
`transformers`中的 TensorFlow 模型和层接受两种格式的输入:
+ 将所有输入作为关键字参数(类似于 PyTorch 模型),或
+ 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,当将输入传递给模型和层时,Keras 方法更喜欢这种格式。由于这种支持,当使用`model.fit()`等方法时,应该“只需工作” - 只需以`model.fit()`支持的任何格式传递您的输入和标签!但是,如果您想在 Keras 方法之外使用第二种格式,比如在使用 Keras `Functional` API 创建自己的层或模型时,有三种可能性可以用来收集第一个位置参数中的所有输入张量:
+ 一个仅包含`input_ids`的单个张量,没有其他内容:`model(input_ids)`
+ 一个长度不同的列表,其中包含一个或多个输入张量,按照文档字符串中给定的顺序:`model([input_ids, attention_mask])`或`model([input_ids, attention_mask, token_type_ids])`
+ 一个字典,其中包含一个或多个与文档字符串中给定的输入名称相关联的输入张量:`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
请注意,当使用[子类化](https://keras.io/guides/making_new_layers_and_models_via_subclassing/)创建模型和层时,您无需担心这些问题,因为您可以像将输入传递给任何其他 Python 函数一样传递输入!
#### `call`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_tf_openai.py#L703)
```py
( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None mc_token_ids: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None training: Optional[bool] = False ) → export const metadata = 'undefined';transformers.models.openai.modeling_tf_openai.TFOpenAIGPTDoubleHeadsModelOutput or tuple(tf.Tensor)
```
参数
+ `input_ids`(形状为`(batch_size, sequence_length)`的`Numpy array`或`tf.Tensor`)— 词汇表中输入序列标记的索引。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.`call`()和 PreTrainedTokenizer.encode()。
什么是输入 ID?
+ `attention_mask`(`tf.Tensor`或形状为`(batch_size, sequence_length)`的`Numpy array`,*可选*)— 用于避免在填充标记索引上执行注意力的掩码。选择在`[0, 1]`中的掩码值:
+ 1 表示未被`masked`的标记,
+ 0 表示被`masked`的标记。
什么是注意力掩码?
+ `token_type_ids` (`tf.Tensor`或`Numpy array`,形状为`(batch_size, sequence_length)`,*optional*) — 段标记索引,指示输入的第一部分和第二部分。索引在`[0, 1]`中选择:
+ 0 对应于 *sentence A* 标记,
+ 1 对应于 *sentence B* 标记。
什么是 token type IDs?
+ `position_ids` (`tf.Tensor`或`Numpy array`,形状为`(batch_size, sequence_length)`,*optional*) — 每个输入序列标记在位置嵌入中的位置索引。在范围`[0, config.max_position_embeddings - 1]`中选择。
什么是 position IDs?
+ `head_mask` (`tf.Tensor`或`Numpy array`,形状为`(num_heads,)`或`(num_layers, num_heads)`,*optional*) — 用于使自注意力模块的选定头部无效的掩码。选择的掩码值在`[0, 1]`中:
+ 1 表示头部未被`masked`,
+ 0 表示头部被`masked`。
+ `inputs_embeds` (`tf.Tensor`或`Numpy array`,形状为`(batch_size, sequence_length, hidden_size)`,*optional*) — 可选地,可以直接传递嵌入表示,而不是传递`input_ids`。如果您想要更多控制如何将`input_ids`索引转换为相关向量,这很有用,而不是使用模型的内部嵌入查找矩阵。
+ `output_attentions` (`bool`,*optional*) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的`attentions`。此参数仅在急切模式下使用,在图模式下将使用配置中的值。
+ `output_hidden_states` (`bool`,*optional*) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的`hidden_states`。此参数仅在急切模式下使用,在图模式下将使用配置中的值。
+ `return_dict` (`bool`,*optional*) — 是否返回 ModelOutput 而不是普通元组。此参数可在急切模式下使用,在图模式下该值将始终设置为 True。
+ `training` (`bool`, *optional*, defaults to `False`) — 是否在训练模式下使用模型(一些模块如 dropout 模块在训练和评估之间有不同的行为)。
+ `mc_token_ids` (`tf.Tensor`或`Numpy array`,形状为`(batch_size, num_choices)`,*optional*,默认为输入序列的最后一个标记的索引) — 每个输入序列中分类标记的索引。在范围`[0, input_ids.size(-1) - 1]`中选择。
返回
transformers.models.openai.modeling_tf_openai.TFOpenAIGPTDoubleHeadsModelOutput 或 `tuple(tf.Tensor)`
一个 transformers.models.openai.modeling_tf_openai.TFOpenAIGPTDoubleHeadsModelOutput 或一个`tf.Tensor`元组(如果传递`return_dict=False`或当`config.return_dict=False`时)包含根据配置(OpenAIGPTConfig)和输入的不同元素。
+ `logits` (`tf.Tensor`,形状为`(batch_size, num_choices, sequence_length, config.vocab_size)`) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。
+ `mc_logits` (`tf.Tensor`,形状为`(batch_size, num_choices)`) — 多项选择分类头的预测分数(SoftMax 之前每个选择的分数)。
+ `hidden_states` (`tuple(tf.Tensor)`, *optional*, 当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回) — 形状为`(batch_size, sequence_length, hidden_size)`的`tf.Tensor`元组(一个用于嵌入的输出 + 一个用于每个层的输出)。
模型在每一层输出的隐藏状态以及初始嵌入输出。
+ `attentions`(`tuple(tf.Tensor)`,*可选*,当传递`output_attentions=True`或`config.output_attentions=True`时返回)- 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`tf.Tensor`元组(每层一个)。
在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
TFOpenAIGPTDoubleHeadsModel 的前向方法,覆盖`__call__`特殊方法。
尽管前向传递的配方需要在这个函数内定义,但应该在此之后调用`Module`实例,而不是这个函数,因为前者负责运行前处理和后处理步骤,而后者则默默地忽略它们。
示例:
```py
>>> import tensorflow as tf
>>> from transformers import AutoTokenizer, TFOpenAIGPTDoubleHeadsModel
>>> tokenizer = AutoTokenizer.from_pretrained("openai-gpt")
>>> model = TFOpenAIGPTDoubleHeadsModel.from_pretrained("openai-gpt")
>>> # Add a [CLS] to the vocabulary (we should train it also!)
>>> tokenizer.add_special_tokens({"cls_token": "[CLS]"})
>>> model.resize_token_embeddings(len(tokenizer)) # Update the model embeddings with the new vocabulary size
>>> print(tokenizer.cls_token_id, len(tokenizer)) # The newly token the last token of the vocabulary
>>> choices = ["Hello, my dog is cute [CLS]", "Hello, my cat is cute [CLS]"]
>>> encoding = tokenizer(choices, return_tensors="tf")
>>> inputs = {k: tf.expand_dims(v, 0) for k, v in encoding.items()}
>>> inputs["mc_token_ids"] = tf.constant(
... [inputs["input_ids"].shape[-1] - 1, inputs["input_ids"].shape[-1] - 1]
... )[
... None, :
... ] # Batch size 1
>>> outputs = model(inputs)
>>> lm_prediction_scores, mc_prediction_scores = outputs[:2]
```
## TFOpenAIGPTForSequenceClassification
### `class transformers.TFOpenAIGPTForSequenceClassification`
[< source >](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_tf_openai.py#L817)
```py
( config *inputs **kwargs )
```
参数
+ `config`(OpenAIGPTConfig)- 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
在顶部带有序列分类头的 OpenAI GPT 模型变压器(线性层)。
TFOpenAIGPTForSequenceClassification 使用最后一个令牌来进行分类,就像其他因果模型(例如 GPT-2)一样。
由于它对最后一个令牌进行分类,因此需要知道最后一个令牌的位置。如果在配置中定义了`pad_token_id`,则它会找到每行中不是填充令牌的最后一个令牌。如果没有定义`pad_token_id`,则它会简单地取每行批次中的最后一个值。由于在传递`inputs_embeds`而不是`input_ids`时无法猜测填充令牌,因此它会执行相同的操作(取每行批次中的最后一个值)。
这个模型继承自 TFPreTrainedModel。查看超类文档,了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是一个[tf.keras.Model](https://www.tensorflow.org/api_docs/python/tf/keras/Model)子类。将其用作常规的 TF 2.0 Keras 模型,并参考 TF 2.0 文档以获取与一般用法和行为相关的所有信息。
`transformers`中的 TensorFlow 模型和层接受两种格式的输入:
+ 将所有输入作为关键字参数(类似于 PyTorch 模型),或
+ 将所有输入作为列表、元组或字典放在第一个位置参数中。
支持第二种格式的原因是,当将输入传递给模型和层时,Keras 方法更喜欢这种格式。由于这种支持,当使用`model.fit()`等方法时,您应该可以“只需传递”您的输入和标签,以任何`model.fit()`支持的格式!但是,如果您想在 Keras 方法之外使用第二种格式,比如在使用 Keras`Functional`API 创建自己的层或模型时,有三种可能性可以用来收集第一个位置参数中的所有输入张量:
+ 只有`input_ids`的单个张量,没有其他内容:`model(input_ids)`
+ 一个长度可变的列表,其中包含按照文档字符串中给定的顺序的一个或多个输入张量:`model([input_ids, attention_mask])` 或 `model([input_ids, attention_mask, token_type_ids])`
+ 一个字典,其中包含与文档字符串中给定的输入名称相关联的一个或多个输入张量:`model({"input_ids": input_ids, "token_type_ids": token_type_ids})`
请注意,当使用 [子类化](https://keras.io/guides/making_new_layers_and_models_via_subclassing/) 创建模型和层时,您无需担心这些内容,因为您可以像对待其他 Python 函数一样传递输入!
#### `call`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/openai/modeling_tf_openai.py#L845)
```py
( input_ids: TFModelInputType | None = None attention_mask: np.ndarray | tf.Tensor | None = None token_type_ids: np.ndarray | tf.Tensor | None = None position_ids: np.ndarray | tf.Tensor | None = None head_mask: np.ndarray | tf.Tensor | None = None inputs_embeds: np.ndarray | tf.Tensor | None = None output_attentions: Optional[bool] = None output_hidden_states: Optional[bool] = None return_dict: Optional[bool] = None labels: np.ndarray | tf.Tensor | None = None training: Optional[bool] = False ) → export const metadata = 'undefined';transformers.modeling_tf_outputs.TFSequenceClassifierOutput or tuple(tf.Tensor)
```
参数
+ `input_ids` (`Numpy array` 或 `tf.Tensor`,形状为 `(batch_size, sequence_length)`) — 词汇表中输入序列标记的索引。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.`call`() 和 PreTrainedTokenizer.encode()。
什么是输入 ID?
+ `attention_mask` (`tf.Tensor` 或 `Numpy array`,形状为 `(batch_size, sequence_length)`,*可选*) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选定在 `[0, 1]`:
+ 1 表示未被 `masked` 的标记,
+ 0 表示被 `masked` 的标记。
什么是注意力掩码?
+ `token_type_ids` (`tf.Tensor` 或 `Numpy array`,形状为 `(batch_size, sequence_length)`,*可选*) — 段标记索引,指示输入的第一部分和第二部分。索引选定在 `[0, 1]`:
+ 0 对应于 *句子 A* 标记,
+ 1 对应于 *句子 B* 标记。
什么是标记类型 ID?
+ `position_ids` (`tf.Tensor` 或 `Numpy array`,形状为 `(batch_size, sequence_length)`,*可选*) — 每个输入序列标记在位置嵌入中的位置索引。选定范围为 `[0, config.max_position_embeddings - 1]`。
什么是位置 ID?
+ `head_mask` (`tf.Tensor` 或 `Numpy array`,形状为 `(num_heads,)` 或 `(num_layers, num_heads)`,*可选*) — 用于使自注意力模块中的选定头部失效的掩码。掩码值选定在 `[0, 1]`:
+ 1 表示头部未被 `masked`,
+ 0 表示头部被 `masked`。
+ `inputs_embeds` (`tf.Tensor` 或 `Numpy array`,形状为 `(batch_size, sequence_length, hidden_size)`,*可选*) — 可选地,您可以选择直接传递嵌入表示,而不是传递 `input_ids`。如果您想要更多控制权,以便将 `input_ids` 索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,则这很有用。
+ `output_attentions` (`bool`,*可选*) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量中的 `attentions`。此参数仅可在急切模式下使用,在图模式中将使用配置中的值。
+ `output_hidden_states` (`bool`,*可选*) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量中的 `hidden_states`。此参数仅可在急切模式下使用,在图模式中将使用配置中的值。
+ `return_dict` (`bool`,*可选*) — 是否返回 ModelOutput 而不是普通元组。此参数可在急切模式下使用,在图模式中该值将始终设置为 True。
+ `training` (`bool`,*可选*,默认为 `False`) — 是否在训练模式下使用模型(一些模块,如 dropout 模块,在训练和评估之间有不同的行为)。
+ `labels` (`tf.Tensor`,形状为`(batch_size, sequence_length)`,*可选*) — 用于计算交叉熵分类损失的标签。索引应在`[0, ..., config.vocab_size - 1]`范围内。
返回
`transformers.modeling_tf_outputs.TFSequenceClassifierOutput` 或 `tuple(tf.Tensor)`
一个 transformers.modeling_tf_outputs.TFSequenceClassifierOutput 或一个`tf.Tensor`元组(如果传递`return_dict=False`或`config.return_dict=False`时)包含根据配置(OpenAIGPTConfig)和输入而异的各种元素。
+ `loss` (`tf.Tensor`,形状为`(batch_size, )`,*可选*,当提供`labels`时返回) — 分类(如果`config.num_labels==1`则为回归)损失。
+ `logits` (`tf.Tensor`,形状为`(batch_size, config.num_labels)`) — 分类(如果`config.num_labels==1`则为回归)得分(SoftMax 之前)。
+ `hidden_states` (`tuple(tf.Tensor)`,*可选*,当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回) — 形状为`(batch_size, sequence_length, hidden_size)`的`tf.Tensor`元组(一个用于嵌入的输出 + 一个用于每个层的输出)。
模型在每个层的输出以及初始嵌入输出的隐藏状态。
+ `attentions` (`tuple(tf.Tensor)`,*可选*,当传递`output_attentions=True`或`config.output_attentions=True`时返回) — 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`tf.Tensor`元组(每个层一个)。
在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
TFOpenAIGPTForSequenceClassification 的前向方法,覆盖了`__call__`特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用`Module`实例,而不是这个,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
示例:
```py
>>> from transformers import AutoTokenizer, TFOpenAIGPTForSequenceClassification
>>> import tensorflow as tf
>>> tokenizer = AutoTokenizer.from_pretrained("openai-gpt")
>>> model = TFOpenAIGPTForSequenceClassification.from_pretrained("openai-gpt")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="tf")
>>> logits = model(**inputs).logits
>>> predicted_class_id = int(tf.math.argmax(logits, axis=-1)[0])
```
```py
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = TFOpenAIGPTForSequenceClassification.from_pretrained("openai-gpt", num_labels=num_labels)
>>> labels = tf.constant(1)
>>> loss = model(**inputs, labels=labels).loss
```
# GPT Neo
> 原始文本:[`huggingface.co/docs/transformers/v4.37.2/en/model_doc/gpt_neo`](https://huggingface.co/docs/transformers/v4.37.2/en/model_doc/gpt_neo)
## 概述
GPTNeo 模型是由 Sid Black、Stella Biderman、Leo Gao、Phil Wang 和 Connor Leahy 在[EleutherAI/gpt-neo](https://github.com/EleutherAI/gpt-neo)存储库中发布的。它是一个类似于 GPT2 的因果语言模型,训练于[Pile](https://pile.eleuther.ai/)数据集。
该架构类似于 GPT2,只是 GPT Neo 在每个其他层中使用窗口大小为 256 的本地注意力。
此模型由[valhalla](https://huggingface.co/valhalla)贡献。
## 使用示例
`generate()`方法可用于使用 GPT Neo 模型生成文本。
```py
>>> from transformers import GPTNeoForCausalLM, GPT2Tokenizer
>>> model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> tokenizer = GPT2Tokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> prompt = (
... "In a shocking finding, scientists discovered a herd of unicorns living in a remote, "
... "previously unexplored valley, in the Andes Mountains. Even more surprising to the "
... "researchers was the fact that the unicorns spoke perfect English."
... )
>>> input_ids = tokenizer(prompt, return_tensors="pt").input_ids
>>> gen_tokens = model.generate(
... input_ids,
... do_sample=True,
... temperature=0.9,
... max_length=100,
... )
>>> gen_text = tokenizer.batch_decode(gen_tokens)[0]
```
## 结合 GPT-Neo 和 Flash Attention 2
首先,请确保安装最新版本的 Flash Attention 2,以包括滑动窗口注意力特性,并确保您的硬件与 Flash-Attention 2 兼容。有关安装的更多详细信息,请参见[此处](https://huggingface.co/docs/transformers/perf_infer_gpu_one#flashattention-2)。
还要确保将模型加载为半精度(例如`torch.float16`)。
要加载和运行使用 Flash Attention 2 的模型,请参考下面的代码片段:
```py
>>> import torch
>>> from transformers import AutoModelForCausalLM, AutoTokenizer
>>> device = "cuda" # the device to load the model onto
>>> model = AutoModelForCausalLM.from_pretrained("EleutherAI/gpt-neo-2.7B", torch_dtype=torch.float16, attn_implementation="flash_attention_2")
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-2.7B")
>>> prompt = "def hello_world():"
>>> model_inputs = tokenizer([prompt], return_tensors="pt").to(device)
>>> model.to(device)
>>> generated_ids = model.generate(**model_inputs, max_new_tokens=100, do_sample=True)
>>> tokenizer.batch_decode(generated_ids)[0]
"def hello_world():\n >>> run_script("hello.py")\n >>> exit(0)\n<|endoftext|>"
```
### 预期加速
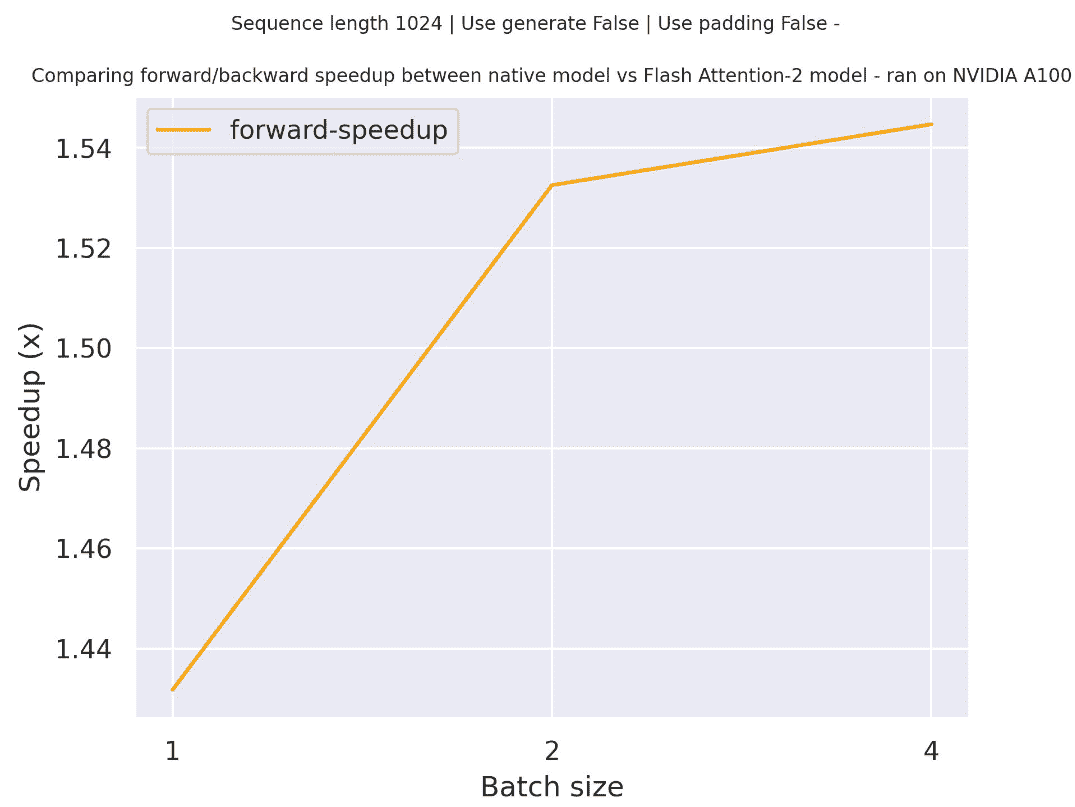
下面是一个预期加速图表,比较了 transformers 中的原生实现和使用`EleutherAI/gpt-neo-2.7B`检查点以及模型的 Flash Attention 2 版本之间的纯推理时间。请注意,对于 GPT-Neo,不可能在非常长的上下文中进行训练/运行,因为最大[位置嵌入](https://huggingface.co/EleutherAI/gpt-neo-2.7B/blob/main/config.json#L58)限制为 2048 - 但这适用于所有 gpt-neo 模型,而不仅仅是 FA-2
## 资源
+ 文本分类任务指南
+ 因果语言建模任务指南
## GPTNeoConfig
### `class transformers.GPTNeoConfig`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/configuration_gpt_neo.py#L34)
```py
( vocab_size = 50257 max_position_embeddings = 2048 hidden_size = 2048 num_layers = 24 attention_types = [[['global', 'local'], 12]] num_heads = 16 intermediate_size = None window_size = 256 activation_function = 'gelu_new' resid_dropout = 0.0 embed_dropout = 0.0 attention_dropout = 0.0 classifier_dropout = 0.1 layer_norm_epsilon = 1e-05 initializer_range = 0.02 use_cache = True bos_token_id = 50256 eos_token_id = 50256 **kwargs )
```
参数
+ `vocab_size`(`int`,*可选*,默认为 50257)— GPT Neo 模型的词汇量。定义了在调用 GPTNeoModel 时可以表示的不同令牌数量。模型的词汇量。定义了在调用 GPTNeoModel 的 forward 方法时可以表示的不同令牌。
+ `max_position_embeddings`(`int`,*可选*,默认为 2048)— 此模型可能被使用的最大序列长度。通常将其设置为较大的值以防万一(例如,512 或 1024 或 2048)。
+ `hidden_size`(`int`,*可选*,默认为 2048)— 编码器层和池化器层的维度。
+ `num_layers`(`int`,*可选*,默认为 24)— Transformer 编码器中的隐藏层数量。
+ `attention_types`(`List`,*可选*,默认为`[[['global', 'local'], 12]]`)— 每个层中的注意力类型在`List`中的格式为`[[["attention_type"], num_layerss]]`,例如对于一个 24 层模型`[[["global"], 24]]`或`[[["global", "local"], 12]]`从`["global", "local"]`中选择`attention_type`的值
+ `num_heads`(`int`,*可选*,默认为 16)— Transformer 编码器中每个注意力层的注意力头数。
+ `intermediate_size`(`int`,*可选*,默认为 8192)— Transformer 编码器中“中间”(即前馈)层的维度。
+ `window_size`(`int`,*可选*,默认为 256)— 本地注意力的滑动窗口大小。
+ `activation_function`(`str`或`function`,*可选*,默认为`"gelu_new"`)— 编码器和池化器中的非线性激活函数(函数或字符串)。如果是字符串,支持`"gelu"`,`"relu"`,`"selu"`和`"gelu_new"`。
+ `resid_dropout`(`float`,*可选*,默认为 0.0)— 用于注意力模式中的残差丢失。
+ `embed_dropout`(`float`,*可选*,默认为 0.0)— 嵌入层、编码器和池化器中所有全连接层的丢失概率。
+ `attention_dropout`(`float`,*可选*,默认为 0.0)— 注意力概率的丢失比率。
+ `classifier_dropout`(`float`,*可选*,默认为 0.1)— 在进行标记分类时使用的参数,用于模型 GPTNeoForTokenClassification。隐藏层的丢失比率。
+ `layer_norm_epsilon`(`float`,*可选*,默认为 1e-05)— 层归一化层使用的 epsilon。
+ `initializer_range`(`float`,*可选*,默认为 0.02)— 用于初始化所有权重矩阵的截断正态初始化器的标准差。
+ `use_cache`(`bool`,*可选*,默认为`True`)— 模型是否应返回最后的键/值注意力(不是所有模型都使用)。仅在`config.is_decoder=True`时相关。
+ `bos_token_id`(`int`,*可选*,默认为 50256)— 词汇表中句子开头标记的 ID。
+ `eos_token_id`(`int`,*可选*,默认为 50256)— 词汇表中句子结束标记的 ID。
这是用于存储 GPTNeoModel 配置的配置类。它用于根据指定的参数实例化一个 GPT Neo 模型,定义模型架构。使用默认值实例化配置将产生类似于 GPTNeo [EleutherAI/gpt-neo-1.3B](https://huggingface.co/EleutherAI/gpt-neo-1.3B)架构的配置。
配置对象继承自 PretrainedConfig,可用于控制模型输出。阅读 PretrainedConfig 的文档以获取更多信息。
示例:
```py
>>> from transformers import GPTNeoConfig, GPTNeoModel
>>> # Initializing a GPTNeo EleutherAI/gpt-neo-1.3B style configuration
>>> configuration = GPTNeoConfig()
>>> # Initializing a model (with random weights) from the EleutherAI/gpt-neo-1.3B style configuration
>>> model = GPTNeoModel(configuration)
>>> # Accessing the model configuration
>>> configuration = model.config
```
PytorchHide Pytorch 内容
## GPTNeoModel
### `class transformers.GPTNeoModel`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L712)
```py
( config )
```
参数
+ `config`(GPTNeoConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
裸的 GPT Neo 模型变压器输出原始隐藏状态,没有特定的头部。
这个模型继承自 PreTrainedModel。查看超类文档以了解库实现的通用方法(如下载或保存,调整输入嵌入大小,修剪头等)。
这个模型也是一个 PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
#### `forward`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L738)
```py
( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions or tuple(torch.FloatTensor)
```
参数
+ `input_ids` (`torch.LongTensor`,形状为 `(batch_size, input_ids_length)`) — `input_ids_length` = `sequence_length`,如果 `past_key_values` 是 `None`,否则为 `past_key_values[0][0].shape[-2]`(输入过去键值状态的序列长度)。词汇表中输入序列标记的索引。
如果使用了 `past_key_values`,则只需传递尚未计算其过去的 `input_ids` 作为 `input_ids`。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode() 和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `past_key_values` (`Tuple[Tuple[torch.Tensor]]`,长度为 `config.num_layers`) — 包含由模型计算的预计算隐藏状态(注意力块中的键和值)(请参见下面的 `past_key_values` 输出)。可用于加速顺序解码。已经计算过其过去的 `input_ids` 不应作为 `input_ids` 传递。
+ `attention_mask` (`torch.FloatTensor`,形状为 `(batch_size, sequence_length)`,*可选*) — 避免在填充标记索引上执行注意力的掩码。掩码值选择在 `[0, 1]` 中:
+ 1 对于 `未被掩盖` 的标记,
+ 0 对于 `被掩盖` 的标记。
什么是注意力掩码?
+ `token_type_ids` (`torch.LongTensor`,形状为 `(batch_size, input_ids_length)`,*可选*) — 段标记索引,指示输入的第一部分和第二部分。索引选择在 `[0, 1]` 中:
+ 0 对应于 *句子 A* 的标记,
+ 1 对应于 *句子 B* 的标记。
什么是标记类型 ID?
+ `position_ids` (`torch.LongTensor`,形状为 `(batch_size, sequence_length)`,*可选*) — 每个输入序列标记在位置嵌入中的位置索引。在范围 `[0, config.max_position_embeddings - 1]` 中选择。
什么是位置 ID?
+ `head_mask` (`torch.FloatTensor`,形状为 `(num_heads,)` 或 `(num_layers, num_heads)`,*可选*) — 用于使自注意力模块的选定头部失效的掩码。掩码值选择在 `[0, 1]` 中:
+ 1 表示头部未被 `掩盖`,
+ 0 表示头部被 `掩盖`。
+ `inputs_embeds` (`torch.FloatTensor`,形状为 `(batch_size, sequence_length, hidden_size)`,*可选*) — 可选地,您可以选择直接传递嵌入表示,而不是传递 `input_ids`。如果您想要更多控制如何将 `input_ids` 索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,则这很有用。
如果使用了 `past_key_values`,则只需输入最后的 `inputs_embeds`(参见 `past_key_values`)。
+ `use_cache` (`bool`,*可选*) — 如果设置为 `True`,则返回 `past_key_values` 键值状态,并可用于加速解码(参见 `past_key_values`)。
+ `output_attentions` (`bool`,*可选*) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回的张量中的 `attentions`。
+ `output_hidden_states` (`bool`,*可选*) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回的张量中的 `hidden_states`。
+ `return_dict` (`bool`,*可选*) — 是否返回 ModelOutput 而不是普通元组。
返回
transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或 `tuple(torch.FloatTensor)`
一个 transformers.modeling_outputs.BaseModelOutputWithPastAndCrossAttentions 或一个`torch.FloatTensor`元组(如果传递`return_dict=False`或者`config.return_dict=False`)包含根据配置(GPTNeoConfig)和输入不同的元素。
+ `last_hidden_state`(形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`) — 模型最后一层的隐藏状态序列。
如果使用`past_key_values`,则仅输出形状为`(batch_size, 1, hidden_size)`的序列的最后一个隐藏状态。
+ `past_key_values`(`tuple(tuple(torch.FloatTensor))`,*可选*,当传递`use_cache=True`或者`config.use_cache=True`时返回) — 长度为`config.n_layers`的`tuple(torch.FloatTensor)`元组,每个元组有 2 个形状为`(batch_size, num_heads, sequence_length, embed_size_per_head)`的张量,如果`config.is_encoder_decoder=True`还有 2 个额外的形状为`(batch_size, num_heads, encoder_sequence_length, embed_size_per_head)`的张量。
包含预先计算的隐藏状态(自注意力块中的键和值,以及可选的如果`config.is_encoder_decoder=True`在交叉注意力块中)可用于(见`past_key_values`输入)加速顺序解码。
+ `hidden_states`(`tuple(torch.FloatTensor)`,*可选*,当传递`output_hidden_states=True`或者`config.output_hidden_states=True`时返回) — 形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`元组(如果模型有嵌入层,则为嵌入输出的输出+每层的输出)。
模型每一层输出的隐藏状态以及可选的初始嵌入输出。
+ `attentions`(`tuple(torch.FloatTensor)`,*可选*,当传递`output_attentions=True`或者`config.output_attentions=True`时返回) — 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每层一个)。
自注意力头中的注意力权重经过注意力 softmax 后,用于计算自注意力头中的加权平均值。
+ `cross_attentions`(`tuple(torch.FloatTensor)`,*可选*,当传递`output_attentions=True`和`config.add_cross_attention=True`或者`config.output_attentions=True`时返回) — 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每层一个)。
解码器的交叉注意力层的注意力权重,在注意力 softmax 后使用,用于计算交叉注意力头中的加权平均值。
GPTNeoModel 的前向方法,覆盖了`__call__`特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用`Module`实例,而不是这个,因为前者会负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
```py
>>> from transformers import AutoTokenizer, GPTNeoModel
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> model = GPTNeoModel.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
## GPTNeoForCausalLM
### `class transformers.GPTNeoForCausalLM`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L877)
```py
( config )
```
参数
+ `config`(GPTNeoConfig) — 包含模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
GPT Neo 模型变压器,顶部带有语言建模头(线性层,其权重与输入嵌入绑定)。
这个模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
这个模型也是 PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)的子类。将其用作常规的 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
#### `forward`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L946)
```py
( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.CausalLMOutputWithCrossAttentions or tuple(torch.FloatTensor)
```
参数
+ `input_ids` (`torch.LongTensor` of shape `(batch_size, input_ids_length)`) — `input_ids_length` = `sequence_length`,如果`past_key_values`为`None`,否则为`past_key_values[0][0].shape[-2]`(输入过去键值状态的序列长度)。词汇表中输入序列标记的索引。
如果使用了`past_key_values`,则只有那些没有计算过其过去的`input_ids`应该作为`input_ids`传递。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `past_key_values` (`Tuple[Tuple[torch.Tensor]]` of length `config.num_layers`) — 包含由模型计算的预计算隐藏状态(注意力块中的键和值,如下面的`past_key_values`输出所示)。可用于加速顺序解码。将其过去给予该模型的`input_ids`不应作为`input_ids`传递,因为它们已经被计算过了。
+ `attention_mask` (`torch.FloatTensor` of shape `(batch_size, sequence_length)`, *optional*) — 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在`[0, 1]`之间:
+ 1 表示未被屏蔽的标记,
+ 0 表示被屏蔽的标记。
什么是注意力掩码?
+ `token_type_ids` (`torch.LongTensor` of shape `(batch_size, input_ids_length)`, *optional*) — 段标记索引,用于指示输入的第一部分和第二部分。索引选择在`[0, 1]`之间:
+ 0 对应于*句子 A*标记,
+ 1 对应于*句子 B*标记。
什么是标记类型 ID?
+ `position_ids` (`torch.LongTensor` of shape `(batch_size, sequence_length)`, *optional*) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为`[0, config.max_position_embeddings - 1]`。
什么是位置 ID?
+ `head_mask` (`torch.FloatTensor` of shape `(num_heads,)` or `(num_layers, num_heads)`, *optional*) — 用于使自注意力模块中的选定头部失效的掩码。掩码值选择在`[0, 1]`之间:
+ 1 表示头部未被屏蔽,
+ 0 表示头部被屏蔽。
+ `inputs_embeds` (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) — 可选地,可以直接传递嵌入表示,而不是传递`input_ids`。如果您想要更多控制权,以便将`input_ids`索引转换为相关向量,而不是模型的内部嵌入查找矩阵。
如果使用了`past_key_values`,则只需输入最后的`inputs_embeds`(参见`past_key_values`)。
+ `use_cache` (`bool`, *optional*) — 如果设置为`True`,则返回`past_key_values`键值状态,并可用于加速解码(参见`past_key_values`)。
+ `output_attentions` (`bool`, *optional*) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回的张量下的`attentions`。
+ `output_hidden_states` (`bool`, *optional*) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的`hidden_states`。
+ `return_dict` (`bool`, *optional*) — 是否返回 ModelOutput 而不是普通元组。
+ `labels` (`torch.LongTensor`,形状为`(batch_size, sequence_length)`,*optional*) — 用于语言建模的标签。请注意,模型内部**移动**了标签,即您可以设置`labels = input_ids`。在`[-100, 0, ..., config.vocab_size]`中选择索引。所有设置为`-100`的标签都被忽略(掩码),损失仅计算`[0, ..., config.vocab_size]`中的标签。
返回
transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或`tuple(torch.FloatTensor)`
一个 transformers.modeling_outputs.CausalLMOutputWithCrossAttentions 或一个`torch.FloatTensor`元组(如果传递`return_dict=False`或`config.return_dict=False`)包含各种元素,取决于配置(GPTNeoConfig)和输入。
+ `loss` (`torch.FloatTensor`,形状为`(1,)`,*optional*, 当提供`labels`时返回) — 语言建模损失(用于下一个标记预测)。
+ `logits` (`torch.FloatTensor`,形状为`(batch_size, sequence_length, config.vocab_size)`) — 语言建模头的预测分数(SoftMax 之前每个词汇标记的分数)。
+ `hidden_states` (`tuple(torch.FloatTensor)`, *optional*, 当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回) — 形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`元组(如果模型有嵌入层,则为嵌入的输出+每层的输出)。
模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
+ `attentions` (`tuple(torch.FloatTensor)`, *optional*, 当传递`output_attentions=True`或`config.output_attentions=True`时返回) — 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每层一个)。
在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
+ `cross_attentions` (`tuple(torch.FloatTensor)`, *optional*, 当传递`output_attentions=True`或`config.output_attentions=True`时返回) — 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每层一个)。
在注意力 softmax 之后的交叉注意力权重,用于计算交叉注意力头中的加权平均值。
+ `past_key_values` (`tuple(tuple(torch.FloatTensor))`, *optional*, 当传递`use_cache=True`或`config.use_cache=True`时返回) — 长度为`config.n_layers`的`torch.FloatTensor`元组,每个元组包含自注意力和交叉注意力层的缓存键、值状态,如果模型用于编码器-解码器设置,则相关。仅在`config.is_decoder = True`时相关。
包含预先计算的隐藏状态(注意力块中的键和值),可用于加速顺序解码。
GPTNeoForCausalLM 的前向方法,覆盖了`__call__`特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用`Module`实例,而不是在此处调用,因为前者会处理运行前后的处理步骤,而后者会默默地忽略它们。
示例:
```py
>>> import torch
>>> from transformers import AutoTokenizer, GPTNeoForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> model = GPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> outputs = model(**inputs, labels=inputs["input_ids"])
>>> loss = outputs.loss
>>> logits = outputs.logits
```
## GPTNeoForQuestionAnswering
### `class transformers.GPTNeoForQuestionAnswering`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L1251)
```py
( config )
```
参数
+ `config`(GPTNeoConfig)— 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
GPT-Neo 模型变压器在顶部具有一个用于提取式问答任务(如 SQuAD)的跨度分类头(在隐藏状态输出顶部的线性层,用于计算`span start logits`和`span end logits`)。
这个模型继承自 PreTrainedModel。检查超类文档以获取库为所有模型实现的通用方法(例如下载或保存,调整输入嵌入大小,修剪头等)。
这个模型也是 PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
#### `forward`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L1268)
```py
( input_ids: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None start_positions: Optional = None end_positions: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.QuestionAnsweringModelOutput or tuple(torch.FloatTensor)
```
参数
+ `input_ids`(形状为`(batch_size, input_ids_length)`的`torch.LongTensor`)— `input_ids_length` = `sequence_length`,如果`past_key_values`为`None`,则为`past_key_values[0][0].shape[-2]`(输入过去键值状态的序列长度)。词汇表中输入序列标记的索引。
如果使用了`past_key_values`,则只应将未计算其过去的`input_ids`作为`input_ids`传递。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `past_key_values`(长度为`config.num_layers`的`Tuple[Tuple[torch.Tensor]]`)— 包含由模型计算的预计算隐藏状态(注意力块中的键和值)(请参见下面的`past_key_values`输出)。可用于加速顺序解码。将其过去给定给此模型的`input_ids`不应作为`input_ids`传递,因为它们已经计算过。
+ `attention_mask`(形状为`(batch_size, sequence_length)`的`torch.FloatTensor`,*可选*)— 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在`[0, 1]`范围内:
+ 1 表示未被屏蔽的标记,
+ 0 表示被屏蔽的标记。
什么是注意力掩码?
+ `token_type_ids`(形状为`(batch_size, input_ids_length)`的`torch.LongTensor`,*可选*)— 段标记索引,指示输入的第一部分和第二部分。索引在`[0, 1]`中选择:
+ 0 对应于*句子 A*标记,
+ 1 对应于*句子 B*标记。
什么是标记类型 ID?
+ `position_ids`(形状为`(batch_size, sequence_length)`的`torch.LongTensor`,*可选*)— 每个输入序列标记在位置嵌入中的位置索引。在范围`[0, config.max_position_embeddings - 1]`中选择。
什么是位置 ID?
+ `head_mask`(形状为`(num_heads,)`或`(num_layers, num_heads)`的`torch.FloatTensor`,*可选*)— 用于使自注意力模块的选定头部失效的掩码。掩码值选择在`[0, 1]`范围内:
+ 1 表示头部未被屏蔽,
+ 0 表示头部被`masked`。
+ `inputs_embeds` (`torch.FloatTensor` of shape `(batch_size, sequence_length, hidden_size)`, *optional*) — 可选地,您可以选择直接传递嵌入表示而不是传递`input_ids`。如果您想要更多控制如何将`input_ids`索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,这将非常有用。
如果使用`past_key_values`,则可选择仅输入最后的`inputs_embeds`(参见`past_key_values`)。
+ `use_cache` (`bool`, *optional*) — 如果设置为`True`,则返回`past_key_values`键值状态,可用于加速解码(参见`past_key_values`)。
+ `output_attentions` (`bool`, *optional*) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回张量下的`attentions`。
+ `output_hidden_states` (`bool`, *optional*) — 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的`hidden_states`。
+ `return_dict` (`bool`, *optional*) — 是否返回一个 ModelOutput 而不是一个普通的元组。
+ `start_positions` (`torch.LongTensor` of shape `(batch_size,)`, *optional*) — 用于计算标记分类损失的标记跨度起始位置的标签。位置被夹在序列的长度(`sequence_length`)内。序列外的位置不会被考虑在内计算损失。
+ `end_positions` (`torch.LongTensor` of shape `(batch_size,)`, *optional*) — 用于计算标记分类损失的标记跨度结束位置的标签。位置被夹在序列的长度(`sequence_length`)内。序列外的位置不会被考虑在内计算损失。
返回
transformers.modeling_outputs.QuestionAnsweringModelOutput 或`tuple(torch.FloatTensor)`
一个 transformers.modeling_outputs.QuestionAnsweringModelOutput 或一个`torch.FloatTensor`元组(如果传递`return_dict=False`或`config.return_dict=False`)包含根据配置(GPTNeoConfig)和输入的各种元素。
+ `loss` (`torch.FloatTensor` of shape `(1,)`, *optional*, 当提供`labels`时返回) — 总跨度提取损失是起始位置和结束位置的交叉熵之和。
+ `start_logits` (`torch.FloatTensor` of shape `(batch_size, sequence_length)`) — 跨度起始分数(SoftMax 之前)。
+ `end_logits` (`torch.FloatTensor` of shape `(batch_size, sequence_length)`) — 跨度结束分数(SoftMax 之前)。
+ `hidden_states` (`tuple(torch.FloatTensor)`, *optional*, 当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回) — 形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`元组(如果模型有嵌入层,则为嵌入的输出和每一层的输出)。
模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
+ `attentions` (`tuple(torch.FloatTensor)`, *optional*, 当传递`output_attentions=True`或`config.output_attentions=True`时返回) — 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每层一个)。
注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
GPTNeoForQuestionAnswering 的前向方法,覆盖`__call__`特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在此之后调用`Module`实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者则默默地忽略它们。
此示例使用随机模型,因为真实模型都非常庞大。为了获得正确的结果,您应该使用 EleutherAI/gpt-neo-1.3B,而不是 EleutherAI/gpt-neo-1.3B。如果在加载该检查点时出现内存不足的情况,可以尝试在`from_pretrained`调用中添加`device_map="auto"`。
示例:
```py
>>> from transformers import AutoTokenizer, GPTNeoForQuestionAnswering
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> model = GPTNeoForQuestionAnswering.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> question, text = "Who was Jim Henson?", "Jim Henson was a nice puppet"
>>> inputs = tokenizer(question, text, return_tensors="pt")
>>> with torch.no_grad():
... outputs = model(**inputs)
>>> answer_start_index = outputs.start_logits.argmax()
>>> answer_end_index = outputs.end_logits.argmax()
>>> predict_answer_tokens = inputs.input_ids[0, answer_start_index : answer_end_index + 1]
>>> # target is "nice puppet"
>>> target_start_index = torch.tensor([14])
>>> target_end_index = torch.tensor([15])
>>> outputs = model(**inputs, start_positions=target_start_index, end_positions=target_end_index)
>>> loss = outputs.loss
```
## GPTNeoForSequenceClassification
### `class transformers.GPTNeoForSequenceClassification`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L1037)
```py
( config )
```
参数
+ `config`(GPTNeoConfig)- 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
GPTNeo 模型变压器,顶部带有序列分类头(线性层)。
GPTNeoForSequenceClassification 使用最后一个标记来进行分类,就像其他因果模型(例如 GPT-1)一样。
由于它对最后一个标记进行分类,因此需要知道最后一个标记的位置。如果在配置中定义了`pad_token_id`,则会找到每行中不是填充标记的最后一个标记。如果未定义`pad_token_id`,则会简单地取批处理中每行的最后一个值。当传递`inputs_embeds`而不是`input_ids`时,它无法猜测填充标记,因此会执行相同操作(取批处理中每行的最后一个值)。
此模型继承自 PreTrainedModel。检查超类文档,了解库为其所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
此模型还是 PyTorch [torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
#### `forward`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L1062)
```py
( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.SequenceClassifierOutputWithPast or tuple(torch.FloatTensor)
```
参数
+ `input_ids`(形状为`(batch_size, input_ids_length)`的`torch.LongTensor`)- `input_ids_length` = `sequence_length`(如果`past_key_values`为`None`)否则为`past_key_values[0][0].shape[-2]`(输入过去键值状态的序列长度)。词汇表中输入序列标记的索引。
如果使用`past_key_values`,则只应将未计算其过去的`input_ids`作为`input_ids`传递。
可以使用 AutoTokenizer 来获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `past_key_values`(长度为`config.num_layers`的`Tuple[Tuple[torch.Tensor]]`)- 包含由模型计算的预计算隐藏状态(注意力块中的键和值)(请参见下面的`past_key_values`输出)。可用于加速顺序解码。已将其过去给定给此模型的`input_ids`不应作为`input_ids`传递,因为它们已经计算过。
+ `attention_mask`(形状为`(batch_size, sequence_length)`的`torch.FloatTensor`,*可选*)— 用于避免在填充令牌索引上执行注意力的掩码。选择的掩码值在`[0, 1]`中选择:
+ 对于未被`masked`的令牌为 1,
+ 对于被`masked`的令牌为 0。
什么是注意力掩码?
+ `token_type_ids`(形状为`(batch_size, input_ids_length)`的`torch.LongTensor`,*可选*)— 段令牌索引,指示输入的第一部分和第二部分。索引在`[0, 1]`中选择:
+ 0 对应于*句子 A*令牌,
+ 1 对应于*句子 B*令牌。
什么是令牌类型 ID?
+ `position_ids`(形状为`(batch_size, sequence_length)`的`torch.LongTensor`,*可选*)— 每个输入序列令牌的位置在位置嵌入中的索引。在范围`[0, config.max_position_embeddings - 1]`中选择。
什么是位置 ID?
+ `head_mask`(形状为`(num_heads,)`或`(num_layers, num_heads)`的`torch.FloatTensor`,*可选*)— 用于使自注意力模块的选定头部失效的掩码。选择的掩码值在`[0, 1]`中选择:
+ 1 表示头部未被`masked`,
+ 0 表示头部被`masked`。
+ `inputs_embeds`(形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`,*可选*)— 可选择直接传递嵌入表示,而不是传递`input_ids`。如果您想要更多控制权来将`input_ids`索引转换为相关向量,而不是使用模型的内部嵌入查找矩阵,则这很有用。
如果使用`past_key_values`,可选择仅输入最后的`inputs_embeds`(请参见`past_key_values`)。
+ `use_cache`(`bool`,*可选*)— 如果设置为`True`,则返回`past_key_values`键值状态,可用于加速解码(请参见`past_key_values`)。
+ `output_attentions`(`bool`,*可选*)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参见返回的张量下的`attentions`。
+ `output_hidden_states`(`bool`,*可选*)— 是否返回所有层的隐藏状态。有关更多详细信息,请参见返回张量下的`hidden_states`。
+ `return_dict`(`bool`,*可选*)— 是否返回 ModelOutput 而不是普通元组。
+ `labels`(形状为`(batch_size,)`的`torch.LongTensor`,*可选*)— 用于计算序列分类/回归损失的标签。索引应在`[0, ..., config.num_labels - 1]`中。如果`config.num_labels == 1`,则计算回归损失(均方损失),如果`config.num_labels > 1`,则计算分类损失(交叉熵)。
返回
`transformers.modeling_outputs.SequenceClassifierOutputWithPast`或`tuple(torch.FloatTensor)`
一个`transformers.modeling_outputs.SequenceClassifierOutputWithPast`或一个包含各种元素的`torch.FloatTensor`元组(如果传递了`return_dict=False`或`config.return_dict=False`时)取决于配置(GPTNeoConfig)和输入。
+ `loss`(形状为`(1,)`的`torch.FloatTensor`,*可选*,当提供`labels`时返回)— 分类(如果`config.num_labels==1`则为回归)损失。
+ `logits`(形状为`(batch_size, config.num_labels)`的`torch.FloatTensor`)— 分类(如果`config.num_labels==1`则为回归)得分(SoftMax 之前)。
+ `past_key_values`(`tuple(tuple(torch.FloatTensor))`,*可选*,当传递`use_cache=True`或`config.use_cache=True`时返回)— 长度为`config.n_layers`的`tuple(torch.FloatTensor)`元组,每个元组有 2 个形状为`(batch_size, num_heads, sequence_length, embed_size_per_head)`的张量)
包含预先计算的隐藏状态(自注意力块中的键和值),可用于加速顺序解码。
+ `hidden_states`(`tuple(torch.FloatTensor)`,*可选*,当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回) — 形状为`(batch_size, sequence_length, hidden_size)`的`torch.FloatTensor`元组(如果模型有嵌入层,则为嵌入的输出和每层的输出)。
每层模型的输出的隐藏状态以及可选的初始嵌入输出。
+ `attentions`(`tuple(torch.FloatTensor)`,*可选*,当传递`output_attentions=True`或`config.output_attentions=True`时返回) — 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`torch.FloatTensor`元组(每层一个)。
在自注意力头中用于计算加权平均值的注意力权重之后的注意力 softmax。
GPTNeoForSequenceClassification 的前向方法,覆盖了`__call__`特殊方法。
虽然前向传递的步骤需要在此函数内定义,但应该在之后调用`Module`实例,而不是这个,因为前者会处理运行前后处理步骤,而后者会默默地忽略它们。
单标签分类示例:
```py
>>> import torch
>>> from transformers import AutoTokenizer, GPTNeoForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> model = GPTNeoForSequenceClassification.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_id = logits.argmax().item()
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = GPTNeoForSequenceClassification.from_pretrained("EleutherAI/gpt-neo-1.3B", num_labels=num_labels)
>>> labels = torch.tensor([1])
>>> loss = model(**inputs, labels=labels).loss
```
多标签分类示例:
```py
>>> import torch
>>> from transformers import AutoTokenizer, GPTNeoForSequenceClassification
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> model = GPTNeoForSequenceClassification.from_pretrained("EleutherAI/gpt-neo-1.3B", problem_type="multi_label_classification")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_class_ids = torch.arange(0, logits.shape[-1])[torch.sigmoid(logits).squeeze(dim=0) > 0.5]
>>> # To train a model on `num_labels` classes, you can pass `num_labels=num_labels` to `.from_pretrained(...)`
>>> num_labels = len(model.config.id2label)
>>> model = GPTNeoForSequenceClassification.from_pretrained(
... "EleutherAI/gpt-neo-1.3B", num_labels=num_labels, problem_type="multi_label_classification"
... )
>>> labels = torch.sum(
... torch.nn.functional.one_hot(predicted_class_ids[None, :].clone(), num_classes=num_labels), dim=1
... ).to(torch.float)
>>> loss = model(**inputs, labels=labels).loss
```
## GPTNeoForTokenClassification
### `class transformers.GPTNeoForTokenClassification`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L1166)
```py
( config )
```
参数
+ `config`(GPTNeoConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
GPT Neo 模型,顶部带有一个标记分类头(隐藏状态输出的线性层),例如用于命名实体识别(NER)任务。
此模型继承自 PreTrainedModel。查看超类文档以了解库为所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
此模型也是 PyTorch 的[torch.nn.Module](https://pytorch.org/docs/stable/nn.html#torch.nn.Module)子类。将其用作常规 PyTorch 模块,并参考 PyTorch 文档以获取有关一般用法和行为的所有相关信息。
#### `forward`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_gpt_neo.py#L1185)
```py
( input_ids: Optional = None past_key_values: Optional = None attention_mask: Optional = None token_type_ids: Optional = None position_ids: Optional = None head_mask: Optional = None inputs_embeds: Optional = None labels: Optional = None use_cache: Optional = None output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_outputs.TokenClassifierOutput or tuple(torch.FloatTensor)
```
参数
+ `input_ids`(形状为`(batch_size, input_ids_length)`的`torch.LongTensor`) — 如果`past_key_values`为`None`,则`input_ids_length`=`sequence_length`,否则`input_ids_length`=`past_key_values[0][0].shape[-2]`(输入过去关键值状态的序列长度)。词汇表中输入序列标记的索引。
如果使用`past_key_values`,则只应将未计算其过去的`input_ids`作为`input_ids`传递。
可以使用 AutoTokenizer 来获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `past_key_values`(长度为`config.num_layers`的`Tuple[Tuple[torch.Tensor]]`)— 包含由模型计算的预计算隐藏状态(注意力块中的键和值),如下面的`past_key_values`输出所示。可用于加速顺序解码。已将其过去给予此模型的`input_ids`不应作为`input_ids`传递,因为它们已经计算过。
+ `attention_mask`(`torch.FloatTensor`,形状为`(batch_size, sequence_length)`,*可选*)— 用于避免在填充标记索引上执行注意力的掩码。掩码值选择在`[0, 1]`中:
+ 1 表示未被“掩盖”的标记,
+ 0 表示被“掩盖”的标记。
什么是注意力掩码?
+ `token_type_ids`(`torch.LongTensor`,形状为`(batch_size, input_ids_length)`,*可选*)— 段标记索引,指示输入的第一部分和第二部分。索引选择在`[0, 1]`中:
+ 0 对应于*句子 A*标记。
+ 1 对应于*句子 B*标记。
什么是标记类型 ID?
+ `position_ids`(`torch.LongTensor`,形状为`(batch_size, sequence_length)`,*可选*)— 每个输入序列标记在位置嵌入中的位置索引。在范围`[0, config.max_position_embeddings - 1]`中选择。
什么是位置 ID?
+ `head_mask`(`torch.FloatTensor`,形状为`(num_heads,)`或`(num_layers, num_heads)`,*可选*)— 用于使自注意力模块的选定头部失效的掩码。掩码值选择在`[0, 1]`中:
+ 1 表示头部未被“掩盖”,
+ 0 表示头部被“掩盖”。
+ `inputs_embeds`(`torch.FloatTensor`,形状为`(batch_size, sequence_length, hidden_size)`,*可选*)— 可选地,您可以选择直接传递嵌入表示,而不是传递`input_ids`。如果您想要更多控制权,以便将`input_ids`索引转换为相关向量,而不是模型的内部嵌入查找矩阵,则这很有用。
如果使用了`past_key_values`,则可以选择仅输入最后的`inputs_embeds`(请参阅`past_key_values`)。
+ `use_cache`(`bool`,*可选*)— 如果设置为`True`,则返回`past_key_values`键值状态,并可用于加速解码(请参阅`past_key_values`)。
+ `output_attentions`(`bool`,*可选*)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的`attentions`。
+ `output_hidden_states`(`bool`,*可选*)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的`hidden_states`。
+ `return_dict`(`bool`,*可选*)— 是否返回一个 ModelOutput 而不是一个普通元组。
+ `labels`(`torch.LongTensor`,形状为`(batch_size, sequence_length)`,*可选*)— 用于计算序列分类/回归损失的标签。索引应在`[0, ..., config.num_labels - 1]`中。如果`config.num_labels == 1`,则计算回归损失(均方损失),如果`config.num_labels > 1`,则计算分类损失(交叉熵)。
返回
transformers.modeling_outputs.TokenClassifierOutput 或`tuple(torch.FloatTensor)`
一个 transformers.modeling_outputs.TokenClassifierOutput 或一个`torch.FloatTensor`元组(如果传递了`return_dict=False`或当`config.return_dict=False`时)包括根据配置(GPTNeoConfig)和输入不同元素。
+ `loss`(`torch.FloatTensor`,形状为`(1,)`,*可选*,在提供`labels`时返回)— 分类损失。
+ `logits`(`torch.FloatTensor`,形状为`(batch_size, sequence_length, config.num_labels)`)— 分类分数(SoftMax 之前)。
+ `hidden_states` (`tuple(torch.FloatTensor)`, *可选*,当传递 `output_hidden_states=True` 或当 `config.output_hidden_states=True` 时返回) — 形状为 `(batch_size, sequence_length, hidden_size)` 的 `torch.FloatTensor` 元组(如果模型有嵌入层,则为嵌入输出的一个 + 每层的输出的一个)。
模型在每一层输出的隐藏状态以及可选的初始嵌入输出。
+ `attentions` (`tuple(torch.FloatTensor)`, *可选*,当传递 `output_attentions=True` 或当 `config.output_attentions=True` 时返回) — 形状为 `(batch_size, num_heads, sequence_length, sequence_length)` 的 `torch.FloatTensor` 元组(每层一个)。
在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
GPTNeoForTokenClassification 的前向方法,覆盖了`__call__`特殊方法。
虽然前向传递的配方需要在此函数内定义,但应该在此之后调用 `Module` 实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默忽略它们。
示例:
```py
>>> from transformers import AutoTokenizer, GPTNeoForTokenClassification
>>> import torch
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-125m")
>>> model = GPTNeoForTokenClassification.from_pretrained("EleutherAI/gpt-neo-125m")
>>> inputs = tokenizer(
... "HuggingFace is a company based in Paris and New York", add_special_tokens=False, return_tensors="pt"
... )
>>> with torch.no_grad():
... logits = model(**inputs).logits
>>> predicted_token_class_ids = logits.argmax(-1)
>>> # Note that tokens are classified rather then input words which means that
>>> # there might be more predicted token classes than words.
>>> # Multiple token classes might account for the same word
>>> predicted_tokens_classes = [model.config.id2label[t.item()] for t in predicted_token_class_ids[0]]
>>> labels = predicted_token_class_ids
>>> loss = model(**inputs, labels=labels).loss
>>> round(loss.item(), 2)
0.25
```
JAX 隐藏 JAX 内容
## FlaxGPTNeoModel
### `class transformers.FlaxGPTNeoModel`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_flax_gpt_neo.py#L587)
```py
( config: GPTNeoConfig input_shape: Tuple = (1, 1) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
```
参数
+ `config`(GPTNeoConfig) — 具有模型所有参数的模型配置类。使用配置文件初始化不会加载与模型关联的权重,只加载配置。查看 from_pretrained()方法以加载模型权重。
+ `dtype` (`jax.numpy.dtype`, *可选*,默认为 `jax.numpy.float32`) — 计算的数据类型。可以是 `jax.numpy.float32`、`jax.numpy.float16`(在 GPU 上)和 `jax.numpy.bfloat16`(在 TPU 上)之一。
这可以用于在 GPU 或 TPU 上启用混合精度训练或半精度推断。如果指定了,所有计算将使用给定的 `dtype` 执行。
请注意,这仅指定了计算的数据类型,不会影响模型参数的数据类型。
如果您希望更改模型参数的数据类型,请参阅 to_fp16()和 to_bf16()。
裸的 GPTNeo 模型变换器输出原始隐藏状态,没有特定的头部在顶部。
此模型继承自 FlaxPreTrainedModel。检查超类文档以获取库为所有模型实现的通用方法(如下载或保存、调整输入嵌入、修剪头等)。
此模型还是一个 Flax Linen [flax.nn.Module](https://flax.readthedocs.io/en/latest/_autosummary/flax.nn.module.html) 子类。将其用作常规 Flax 模块,并参考 Flax 文档以获取与一般用法和行为相关的所有事项。
最后,此模型支持 JAX 的固有特性,例如:
+ [即时编译(JIT)](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
+ [自动微分](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
+ [矢量化](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
+ [并行化](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
#### `__call__`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_flax_gpt_neo.py#L401)
```py
( input_ids attention_mask = None position_ids = None params: dict = None past_key_values: dict = None dropout_rng: PRNGKey = None train: bool = False output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_flax_outputs.FlaxBaseModelOutput or tuple(torch.FloatTensor)
```
参数
+ `input_ids` (`numpy.ndarray` of shape `(batch_size, input_ids_length)`) — `input_ids_length` = `sequence_length`。词汇表中输入序列标记的索引。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `attention_mask` (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*) — 避免在填充标记索引上执行注意力的掩码。掩码值选择在`[0, 1]`之间:
+ 对于`未掩码`的标记,值为 1,
+ 对于`被掩码`的标记,值为 0。
什么是注意力掩码?
+ `position_ids` (`numpy.ndarray` of shape `(batch_size, sequence_length)`, *optional*) — 每个输入序列标记在位置嵌入中的位置索引。选择范围为`[0, config.max_position_embeddings - 1]`。
+ `past_key_values` (`Dict[str, np.ndarray]`, *optional*, 由`init_cache`返回或传递先前的`past_key_values`时返回) — 预先计算的隐藏状态字典(注意力块中的键和值),可用于快速自回归解码。预先计算的键和值隐藏状态的形状为*[batch_size, max_length]*。
+ `output_attentions` (`bool`, *optional*) — 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的`attentions`。
+ `output_hidden_states` (`bool`, *optional*) — 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的`hidden_states`。
+ `return_dict` (`bool`, *optional*) — 是否返回一个 ModelOutput 而不是一个普通元组。
返回
transformers.modeling_flax_outputs.FlaxBaseModelOutput 或`tuple(torch.FloatTensor)`
一个 transformers.modeling_flax_outputs.FlaxBaseModelOutput 或一个`torch.FloatTensor`元组(如果传递了`return_dict=False`或`config.return_dict=False`)包含各种元素,具体取决于配置(GPTNeoConfig)和输入。
+ `last_hidden_state` (`jnp.ndarray` of shape `(batch_size, sequence_length, hidden_size)`) — 模型最后一层输出的隐藏状态序列。
+ `hidden_states` (`tuple(jnp.ndarray)`, *optional*, 当传递`output_hidden_states=True`或`config.output_hidden_states=True`时返回) — 形状为`(batch_size, sequence_length, hidden_size)`的`jnp.ndarray`元组(一个用于嵌入的输出 + 一个用于每个层的输出)。
模型在每一层输出的隐藏状态加上初始嵌入输出。
+ `attentions` (`tuple(jnp.ndarray)`, *optional*, 当传递`output_attentions=True`或`config.output_attentions=True`时返回) — 形状为`(batch_size, num_heads, sequence_length, sequence_length)`的`jnp.ndarray`元组(每个层一个)。
在注意力 softmax 之后的注意力权重,用于计算自注意力头中的加权平均值。
`FlaxGPTNeoPreTrainedModel`的前向方法,覆盖了`__call__`特殊方法。
尽管前向传递的配方需要在此函数内定义,但应该在此之后调用`Module`实例,而不是在此处调用,因为前者负责运行预处理和后处理步骤,而后者会默默地忽略它们。
示例:
```py
>>> from transformers import AutoTokenizer, FlaxGPTNeoModel
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> model = FlaxGPTNeoModel.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="jax")
>>> outputs = model(**inputs)
>>> last_hidden_states = outputs.last_hidden_state
```
## FlaxGPTNeoForCausalLM
### `class transformers.FlaxGPTNeoForCausalLM`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_flax_gpt_neo.py#L647)
```py
( config: GPTNeoConfig input_shape: Tuple = (1, 1) seed: int = 0 dtype: dtype = <class 'jax.numpy.float32'> _do_init: bool = True **kwargs )
```
参数
+ `config`(GPTNeoConfig)- 模型的所有参数的配置类。使用配置文件初始化不会加载与模型相关的权重,只会加载配置。查看 from_pretrained()方法以加载模型权重。
+ `dtype`(`jax.numpy.dtype`,*可选*,默认为`jax.numpy.float32`)- 计算的数据类型。可以是`jax.numpy.float32`、`jax.numpy.float16`(在 GPU 上)和`jax.numpy.bfloat16`(在 TPU 上)之一。
这可用于在 GPU 或 TPU 上启用混合精度训练或半精度推断。如果指定了`dtype`,则所有计算将使用给定的数据类型执行。
请注意,这仅指定了计算的数据类型,不会影响模型参数的数据类型。
如果要更改模型参数的数据类型,请参阅 to_fp16()和 to_bf16()。
GPTNeo 模型变压器,顶部带有语言建模头(线性层,其权重与输入嵌入相关联)。
此模型继承自 FlaxPreTrainedModel。检查超类文档以获取库为其所有模型实现的通用方法(例如下载或保存、调整输入嵌入、修剪头等)。
该模型还是一个 Flax Linen [flax.nn.Module](https://flax.readthedocs.io/en/latest/_autosummary/flax.nn.module.html)子类。将其用作常规 Flax 模块,并参考 Flax 文档以获取有关一般用法和行为的所有相关信息。
最后,此模型支持 JAX 的固有功能,例如:
+ [即时(JIT)编译](https://jax.readthedocs.io/en/latest/jax.html#just-in-time-compilation-jit)
+ [自动微分](https://jax.readthedocs.io/en/latest/jax.html#automatic-differentiation)
+ [矢量化](https://jax.readthedocs.io/en/latest/jax.html#vectorization-vmap)
+ [并行化](https://jax.readthedocs.io/en/latest/jax.html#parallelization-pmap)
#### `__call__`
[<来源>](https://github.com/huggingface/transformers/blob/v4.37.2/src/transformers/models/gpt_neo/modeling_flax_gpt_neo.py#L401)
```py
( input_ids attention_mask = None position_ids = None params: dict = None past_key_values: dict = None dropout_rng: PRNGKey = None train: bool = False output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_flax_outputs.FlaxMaskedLMOutput or tuple(torch.FloatTensor)
```
参数
+ `input_ids`(形状为`(batch_size, input_ids_length)`的`numpy.ndarray`)- `input_ids_length` = `sequence_length`。词汇表中输入序列标记的索引。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `attention_mask`(形状为`(batch_size, sequence_length)`的`numpy.ndarray`,*可选*)- 用于避免在填充标记索引上执行注意力的掩码。选择的掩码值为`[0, 1]`:
+ 1 表示“未屏蔽”的标记,
+ 0 表示“屏蔽”的标记。
什么是注意力掩码?
+ `position_ids`(形状为`(batch_size, sequence_length)`的`numpy.ndarray`,*可选*)- 每个输入序列标记在位置嵌入中的位置索引。在范围`[0, config.max_position_embeddings - 1]`中选择。
+ `past_key_values` (`Dict[str, np.ndarray]`,*可选*,由 `init_cache` 返回或传递先前的 `past_key_values` 时返回)— 预先计算的隐藏状态字典(注意力块中的键和值),可用于快速自回归解码。预先计算的键和值隐藏状态的形状为 *[batch_size, max_length]*。
+ `output_attentions` (`bool`,*可选*)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的 `attentions`。
+ `output_hidden_states` (`bool`,*可选*)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的 `hidden_states`。
+ `return_dict` (`bool`,*可选*)— 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_flax_outputs.FlaxMaskedLMOutput 或 `tuple(torch.FloatTensor)`
一个 transformers.modeling_flax_outputs.FlaxMaskedLMOutput 或一个 `torch.FloatTensor` 元组(如果传递 `return_dict=False` 或 `config.return_dict=False` 时)包含各种元素,取决于配置(GPTNeoConfig)和输入。
+ `logits` (`jnp.ndarray`,形状为 `(batch_size, sequence_length, config.vocab_size)`)— 语言建模头的预测分数(SoftMax 前每个词汇标记的分数)。
+ `hidden_states` (`tuple(jnp.ndarray)`,*可选*,当传递 `output_hidden_states=True` 或 `config.output_hidden_states=True` 时返回)— 形状为 `(batch_size, sequence_length, hidden_size)` 的 `jnp.ndarray` 元组(一个用于嵌入的输出 + 一个用于每个层的输出)。
模型在每个层输出处的隐藏状态加上初始嵌入输出。
+ `attentions` (`tuple(jnp.ndarray)`,*可选*,当传递 `output_attentions=True` 或 `config.output_attentions=True` 时返回)— 形状为 `(batch_size, num_heads, sequence_length, sequence_length)` 的 `jnp.ndarray` 元组(每个层一个)。
注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
`FlaxGPTNeoPreTrainedModel` 的前向方法,覆盖了 `__call__` 特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用 `Module` 实例,而不是这个,因为前者负责运行前后处理步骤,而后者会默默地忽略它们。
示例:
```py
>>> from transformers import AutoTokenizer, FlaxGPTNeoForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> model = FlaxGPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="np")
>>> outputs = model(**inputs)
>>> # retrieve logts for next token
>>> next_token_logits = outputs.logits[:, -1]
```
output_attentions: Optional = None output_hidden_states: Optional = None return_dict: Optional = None ) → export const metadata = 'undefined';transformers.modeling_flax_outputs.FlaxMaskedLMOutput or tuple(torch.FloatTensor)
```
参数
+ `input_ids`(形状为`(batch_size, input_ids_length)`的`numpy.ndarray`)- `input_ids_length` = `sequence_length`。词汇表中输入序列标记的索引。
可以使用 AutoTokenizer 获取索引。有关详细信息,请参阅 PreTrainedTokenizer.encode()和 PreTrainedTokenizer.`call`()。
什么是输入 ID?
+ `attention_mask`(形状为`(batch_size, sequence_length)`的`numpy.ndarray`,*可选*)- 用于避免在填充标记索引上执行注意力的掩码。选择的掩码值为`[0, 1]`:
+ 1 表示“未屏蔽”的标记,
+ 0 表示“屏蔽”的标记。
什么是注意力掩码?
+ `position_ids`(形状为`(batch_size, sequence_length)`的`numpy.ndarray`,*可选*)- 每个输入序列标记在位置嵌入中的位置索引。在范围`[0, config.max_position_embeddings - 1]`中选择。
+ `past_key_values` (`Dict[str, np.ndarray]`,*可选*,由 `init_cache` 返回或传递先前的 `past_key_values` 时返回)— 预先计算的隐藏状态字典(注意力块中的键和值),可用于快速自回归解码。预先计算的键和值隐藏状态的形状为 *[batch_size, max_length]*。
+ `output_attentions` (`bool`,*可选*)— 是否返回所有注意力层的注意力张量。有关更多详细信息,请参阅返回张量下的 `attentions`。
+ `output_hidden_states` (`bool`,*可选*)— 是否返回所有层的隐藏状态。有关更多详细信息,请参阅返回张量下的 `hidden_states`。
+ `return_dict` (`bool`,*可选*)— 是否返回一个 ModelOutput 而不是一个普通的元组。
返回
transformers.modeling_flax_outputs.FlaxMaskedLMOutput 或 `tuple(torch.FloatTensor)`
一个 transformers.modeling_flax_outputs.FlaxMaskedLMOutput 或一个 `torch.FloatTensor` 元组(如果传递 `return_dict=False` 或 `config.return_dict=False` 时)包含各种元素,取决于配置(GPTNeoConfig)和输入。
+ `logits` (`jnp.ndarray`,形状为 `(batch_size, sequence_length, config.vocab_size)`)— 语言建模头的预测分数(SoftMax 前每个词汇标记的分数)。
+ `hidden_states` (`tuple(jnp.ndarray)`,*可选*,当传递 `output_hidden_states=True` 或 `config.output_hidden_states=True` 时返回)— 形状为 `(batch_size, sequence_length, hidden_size)` 的 `jnp.ndarray` 元组(一个用于嵌入的输出 + 一个用于每个层的输出)。
模型在每个层输出处的隐藏状态加上初始嵌入输出。
+ `attentions` (`tuple(jnp.ndarray)`,*可选*,当传递 `output_attentions=True` 或 `config.output_attentions=True` 时返回)— 形状为 `(batch_size, num_heads, sequence_length, sequence_length)` 的 `jnp.ndarray` 元组(每个层一个)。
注意力 softmax 后的注意力权重,用于计算自注意力头中的加权平均值。
`FlaxGPTNeoPreTrainedModel` 的前向方法,覆盖了 `__call__` 特殊方法。
虽然前向传递的方法需要在此函数内定义,但应该在此之后调用 `Module` 实例,而不是这个,因为前者负责运行前后处理步骤,而后者会默默地忽略它们。
示例:
```py
>>> from transformers import AutoTokenizer, FlaxGPTNeoForCausalLM
>>> tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> model = FlaxGPTNeoForCausalLM.from_pretrained("EleutherAI/gpt-neo-1.3B")
>>> inputs = tokenizer("Hello, my dog is cute", return_tensors="np")
>>> outputs = model(**inputs)
>>> # retrieve logts for next token
>>> next_token_logits = outputs.logits[:, -1]
```


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









