







支持测试覆盖(numpy.testing.overrides)
原文:
numpy.org/doc/1.26/reference/routines.testing.overrides.html
支持测试自定义数组容器实现。
实用函数
allows_array_function_override(func) | 确定一个 Numpy 函数是否可以通过*array_function*覆盖 |
|---|---|
allows_array_ufunc_override(func) | 确定一个函数是否可以通过*array_ufunc*覆盖 |
get_overridable_numpy_ufuncs() | 列出所有可以通过*array_ufunc*覆盖的 numpy ufuncs |
get_overridable_numpy_array_functions() | 列出所有可以通过*array_function*覆盖的 numpy 函数 |
实用函数
allows_array_function_override(func) | 确定一个 Numpy 函数是否可以通过*array_function*覆盖 |
|---|---|
allows_array_ufunc_override(func) | 确定一个函数是否可以通过*array_ufunc*覆盖 |
get_overridable_numpy_ufuncs() | 列出所有可以通过*array_ufunc*覆盖的 numpy ufuncs |
get_overridable_numpy_array_functions() | 列出所有可以通过*array_function*覆盖的 numpy 函数 |
numpy.testing.overrides.allows_array_function_override
原文:
numpy.org/doc/1.26/reference/generated/numpy.testing.overrides.allows_array_function_override.html
testing.overrides.allows_array_function_override(func)
确定一个 NumPy 函数是否可以通过*array_function*进行重写
参数:
funccallable
一个可能可以通过*array_function*进行重写的函数
返回:
布尔值
如果func是可以通过*array_function进行重写的 NumPy API 中的函数,则返回True*,否则返回False。
numpy.testing.overrides.allows_array_ufunc_override
原文:
numpy.org/doc/1.26/reference/generated/numpy.testing.overrides.allows_array_ufunc_override.html
testing.overrides.allows_array_ufunc_override(func)
确定一个函数是否可以通过 array_ufunc 被覆盖。
参数:
func可调用的
可能可以通过 array_ufunc 被覆盖的函数。
返回:
布尔
True 如果 func 可以通过 array_ufunc 覆盖,否则为 False。
注意
这个函数等同于 isinstance(func, np.ufunc),并且对于在 Numpy 之外定义的 ufuncs 也能够正常工作。
numpy.testing.overrides.get_overridable_numpy_ufuncs
原文:
numpy.org/doc/1.26/reference/generated/numpy.testing.overrides.get_overridable_numpy_ufuncs.html
testing.overrides.get_overridable_numpy_ufuncs()
列出所有可以通过*array_ufunc*重写的 numpy ufunc。
参数:
None
返回值:
set
包含所有可以重写的公共 numpy API 中的 ufunc 的集合。
numpy.testing.overrides.get_overridable_numpy_array_functions
testing.overrides.get_overridable_numpy_array_functions()
列出所有可以通过*array_function*进行覆盖的 numpy 函数
参数:
None
返回:
set
包含所有可以通过*array_function*进行覆盖的公共 numpy API 函数的集合。
窗口函数
各种窗口函数
bartlett(M) | 返回巴特莱特窗口。 |
|---|---|
blackman(M) | 返回布莱克曼窗口。 |
hamming(M) | 返回海明窗口。 |
hanning(M) | 返回汉宁窗口。 |
kaiser(M, beta) | 返回卡泽窗口。 |
各种窗口函数
bartlett(M) | 返回巴特莱特窗口。 |
|---|---|
blackman(M) | 返回布莱克曼窗口。 |
hamming(M) | 返回海明窗口。 |
hanning(M) | 返回汉宁窗口。 |
kaiser(M, beta) | 返回卡泽窗口。 |
numpy.bartlett
原文:
numpy.org/doc/1.26/reference/generated/numpy.bartlett.html
numpy.bartlett(M)
返回巴特勒窗口。
巴特勒窗口与三角窗口非常相似,只是端点为零。它经常在信号处理中用于锐化信号,而在频率域中不会产生太多的纹波。
参数:
M整数
输出窗口中的点数。如果小于或等于零,则返回空数组。
返回:
out数组
三角形窗口,最大值归一化为一(仅当样本数为奇数时才出现),第一个和最后一个样本等于零。
另请参阅
blackman, hamming, hanning, kaiser
注意
巴特勒窗口定义为
[w(n) = \frac{2}{M-1} \left( \frac{M-1}{2} - \left|n - \frac{M-1}{2}\right| \right)]
大多数关于巴特勒窗口的参考来源于信号处理文献,其中它被用作许多窗函数之一,用于平滑值。请注意,与此窗口的卷积会产生线性插值。它也被称为斜顶函数(即“去除足”,即平滑采样信号起止点的不连续性)或抑制函数。巴特勒窗口的傅立叶变换是两个 sinc 函数的乘积。请注意 Kanasewich [2]中的出色讨论。
参考文献
[1]
M.S. Bartlett,《周期图分析和连续谱》,Biometrika 37,1-16,1950 年。
[2]
E.R. Kanasewich,《地球物理学时间序列分析》,亚伯达大学出版社,1975 年,第 109-110 页。
[3]
A.V. Oppenheim and R.W. Schafer,《离散时间信号处理》,Prentice-Hall,1999 年,第 468-471 页。
[4]
维基百科,《窗函数》,en.wikipedia.org/wiki/Window_function
[5]
W.H. Press, B.P. Flannery, S.A. Teukolsky, and W.T. Vetterling,《数值配方》,剑桥大学出版社,1986 年,第 429 页。
示例
>>> import matplotlib.pyplot as plt
>>> np.bartlett(12)
array([ 0\. , 0.18181818, 0.36363636, 0.54545455, 0.72727273, # may vary
0.90909091, 0.90909091, 0.72727273, 0.54545455, 0.36363636,
0.18181818, 0\. ])
绘制窗口及其频率响应(需要 SciPy 和 matplotlib):
>>> from numpy.fft import fft, fftshift
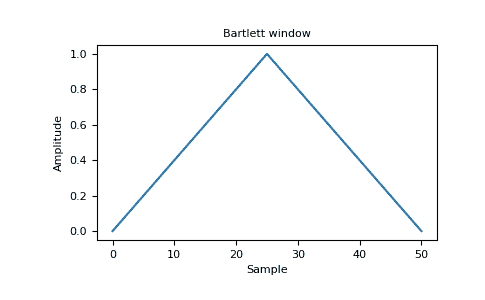
>>> window = np.bartlett(51)
>>> plt.plot(window)
[<matplotlib.lines.Line2D object at 0x...>]
>>> plt.title("Bartlett window")
Text(0.5, 1.0, 'Bartlett window')
>>> plt.ylabel("Amplitude")
Text(0, 0.5, 'Amplitude')
>>> plt.xlabel("Sample")
Text(0.5, 0, 'Sample')
>>> plt.show()
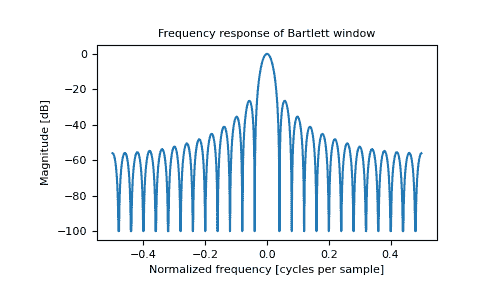
>>> plt.figure()
<Figure size 640x480 with 0 Axes>
>>> A = fft(window, 2048) / 25.5
>>> mag = np.abs(fftshift(A))
>>> freq = np.linspace(-0.5, 0.5, len(A))
>>> with np.errstate(divide='ignore', invalid='ignore'):
... response = 20 * np.log10(mag)
...
>>> response = np.clip(response, -100, 100)
>>> plt.plot(freq, response)
[<matplotlib.lines.Line2D object at 0x...>]
>>> plt.title("Frequency response of Bartlett window")
Text(0.5, 1.0, 'Frequency response of Bartlett window')
>>> plt.ylabel("Magnitude [dB]")
Text(0, 0.5, 'Magnitude [dB]')
>>> plt.xlabel("Normalized frequency [cycles per sample]")
Text(0.5, 0, 'Normalized frequency [cycles per sample]')
>>> _ = plt.axis('tight')
>>> plt.show()
numpy.blackman
原文:
numpy.org/doc/1.26/reference/generated/numpy.blackman.html
numpy.blackman(M)
返回 Blackman 窗口。
Blackman 窗口是通过使用余弦的前三项的总和形成的锥形窗口。它被设计为具有尽可能小的泄漏。它接近于最佳,只比 Kaiser 窗口略差一点。
参数:
Mint
输出窗口的点数。如果为零或小于零,则返回一个空数组。
返回:
outndarray
此窗口的最大值被标准化为 1(仅当样本数为奇数时才出现值为 1)。
另见
bartlett, hamming, hanning, kaiser
笔记
Blackman 窗口定义为
[w(n) = 0.42 - 0.5 \cos(2\pi n/M) + 0.08 \cos(4\pi n/M)]
大多数关于 Blackman 窗口的引用来自信号处理文献中,用作许多用于平滑值的窗口函数之一。它也被称为消足(即“去除脚”,即平滑采样信号开头和结尾的不连续性)函数或锥形函数。它被认为是一种“近乎最佳”的锥形函数,按某些标准几乎和 Kaiser 窗口一样好。
参考文献
Blackman, R.B. 和 Tukey, J.W., (1958) The measurement of power spectra, Dover Publications, New York.
Oppenheim, A.V., 和 R.W. Schafer. Discrete-Time Signal Processing. Upper Saddle River, NJ: Prentice-Hall, 1999, pp. 468-471.
示例
>>> import matplotlib.pyplot as plt
>>> np.blackman(12)
array([-1.38777878e-17, 3.26064346e-02, 1.59903635e-01, # may vary
4.14397981e-01, 7.36045180e-01, 9.67046769e-01,
9.67046769e-01, 7.36045180e-01, 4.14397981e-01,
1.59903635e-01, 3.26064346e-02, -1.38777878e-17])
绘制窗口和频率响应:
>>> from numpy.fft import fft, fftshift
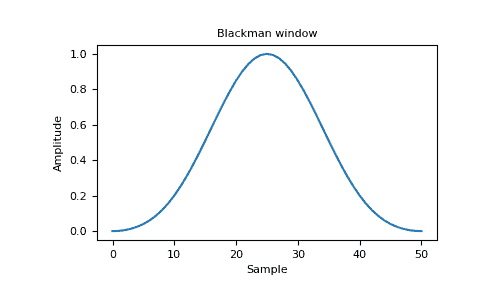
>>> window = np.blackman(51)
>>> plt.plot(window)
[<matplotlib.lines.Line2D object at 0x...>]
>>> plt.title("Blackman window")
Text(0.5, 1.0, 'Blackman window')
>>> plt.ylabel("Amplitude")
Text(0, 0.5, 'Amplitude')
>>> plt.xlabel("Sample")
Text(0.5, 0, 'Sample')
>>> plt.show()
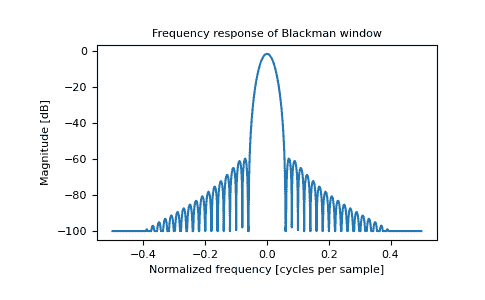
>>> plt.figure()
<Figure size 640x480 with 0 Axes>
>>> A = fft(window, 2048) / 25.5
>>> mag = np.abs(fftshift(A))
>>> freq = np.linspace(-0.5, 0.5, len(A))
>>> with np.errstate(divide='ignore', invalid='ignore'):
... response = 20 * np.log10(mag)
...
>>> response = np.clip(response, -100, 100)
>>> plt.plot(freq, response)
[<matplotlib.lines.Line2D object at 0x...>]
>>> plt.title("Frequency response of Blackman window")
Text(0.5, 1.0, 'Frequency response of Blackman window')
>>> plt.ylabel("Magnitude [dB]")
Text(0, 0.5, 'Magnitude [dB]')
>>> plt.xlabel("Normalized frequency [cycles per sample]")
Text(0.5, 0, 'Normalized frequency [cycles per sample]')
>>> _ = plt.axis('tight')
>>> plt.show()
numpy.hamming
原文:
numpy.org/doc/1.26/reference/generated/numpy.hamming.html
numpy.hamming(M)
返回 Hamming 窗口。
Hamming 窗口是通过使用加权余弦形成的锥形。
参数:
Mint
输出窗口中的点数。如果为零或小于零,则返回一个空数组。
返回:
out数组
窗口,其最大值归一化为一(仅当样本数量为奇数时才出现值为一)。
另请参阅
bartlett, blackman, hanning, kaiser
注意事项
Hamming 窗口定义为
[w(n) = 0.54 - 0.46\cos\left(\frac{2\pi{n}}{M-1}\right) \qquad 0 \leq n \leq M-1]
Hamming 窗口是以 R. W. Hamming 的名字命名的,他是 J. W. Tukey 的合作者,并在 Blackman 和 Tukey 的著作中有描述。建议用于平滑时域中截断自相关函数。对 Hamming 窗口的大多数引用来自信号处理文献,其中它被用作众多窗函数之一,用于平滑数值。它也被称为 apodization(意思是“去除脚部”,即平滑采样信号开头和结尾的不连续性)或锥形函数。
参考文献
[1]
Blackman, R.B. 和 Tukey, J.W., (1958)《功率谱的测量》,多佛出版社,纽约。
[2]
E.R. Kanasewich,“地球物理中的时间序列分析”,阿尔伯塔大学出版社,1975 年,第 109-110 页。
[3]
维基百科,“窗函数”,zh.wikipedia.org/wiki/窗函数
[4]
W.H. Press, B.P. Flannery, S.A. Teukolsky 和 W.T. Vetterling,“数值计算方法”,剑桥大学出版社,1986 年,第 425 页。
示例
>>> np.hamming(12)
array([ 0.08 , 0.15302337, 0.34890909, 0.60546483, 0.84123594, # may vary
0.98136677, 0.98136677, 0.84123594, 0.60546483, 0.34890909,
0.15302337, 0.08 ])
绘制窗口和频率响应:
>>> import matplotlib.pyplot as plt
>>> from numpy.fft import fft, fftshift
>>> window = np.hamming(51)
>>> plt.plot(window)
[<matplotlib.lines.Line2D object at 0x...>]
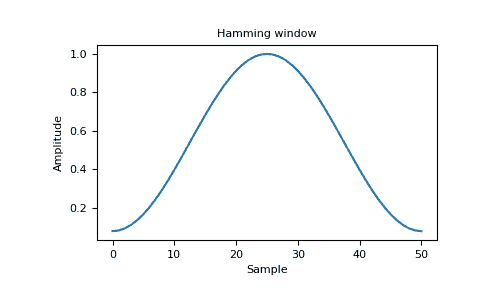
>>> plt.title("Hamming window")
Text(0.5, 1.0, 'Hamming window')
>>> plt.ylabel("Amplitude")
Text(0, 0.5, 'Amplitude')
>>> plt.xlabel("Sample")
Text(0.5, 0, 'Sample')
>>> plt.show()
>>> plt.figure()
<Figure size 640x480 with 0 Axes>
>>> A = fft(window, 2048) / 25.5
>>> mag = np.abs(fftshift(A))
>>> freq = np.linspace(-0.5, 0.5, len(A))
>>> response = 20 * np.log10(mag)
>>> response = np.clip(response, -100, 100)
>>> plt.plot(freq, response)
[<matplotlib.lines.Line2D object at 0x...>]
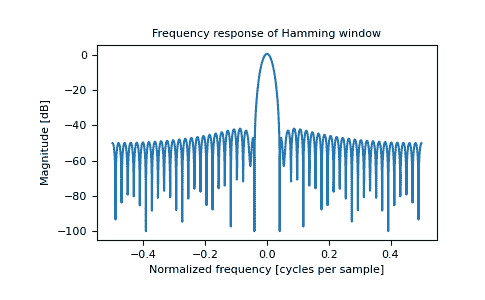
>>> plt.title("Frequency response of Hamming window")
Text(0.5, 1.0, 'Frequency response of Hamming window')
>>> plt.ylabel("Magnitude [dB]")
Text(0, 0.5, 'Magnitude [dB]')
>>> plt.xlabel("Normalized frequency [cycles per sample]")
Text(0.5, 0, 'Normalized frequency [cycles per sample]')
>>> plt.axis('tight')
...
>>> plt.show()
numpy.hanning
原文:
numpy.org/doc/1.26/reference/generated/numpy.hanning.html
numpy.hanning(M)
返回汉宁窗口。
汉宁窗口是通过使用加权余弦形成的锥形。
参数:
M整型
输出窗口中的点数。如果为零或更少,则返回一个空数组。
返回值:
out数组,形状(M,)
窗口,最大值归一化为一(仅当 M 为奇数时出现值一)。
也请参阅
bartlett,blackman,hamming,kaiser
注释
汉宁窗口的定义为
[w(n) = 0.5 - 0.5\cos\left(\frac{2\pi{n}}{M-1}\right) \qquad 0 \leq n \leq M-1]
汉宁窗是以奥地利气象学家尤利乌斯·汉尼(Julius von Hann)的名字命名的。它也被称为余弦钟。一些作者更喜欢将其称为汉宁窗口,以避免与非常相似的哈明窗口混淆。
汉宁窗口的大多数参考文献来自信号处理文献,它被用作许多平滑数值的窗口函数之一。它也被称为加权削波(即“去除基座”,即使采样信号的开始和结束处的不连续性平滑)或锥形函数。
参考文献
[1]
Blackman,R.B.和 Tukey,J.W.,(1958)功率谱的测量,多佛出版社,纽约。
[2]
E.R. Kanasewich,“地球物理学中的时间序列分析”,阿尔伯塔大学出版社,1975 年,第 106-108 页。
[3]
维基百科,“窗口函数”,en.wikipedia.org/wiki/Window_function
[4]
W.H. Press, B.P. Flannery, S.A. Teukolsky, and W.T. Vetterling,“数值算法”,剑桥大学出版社,1986 年,第 425 页。
示例
>>> np.hanning(12)
array([0\. , 0.07937323, 0.29229249, 0.57115742, 0.82743037,
0.97974649, 0.97974649, 0.82743037, 0.57115742, 0.29229249,
0.07937323, 0\. ])
绘制窗口及其频率响应:
>>> import matplotlib.pyplot as plt
>>> from numpy.fft import fft, fftshift
>>> window = np.hanning(51)
>>> plt.plot(window)
[<matplotlib.lines.Line2D object at 0x...>]
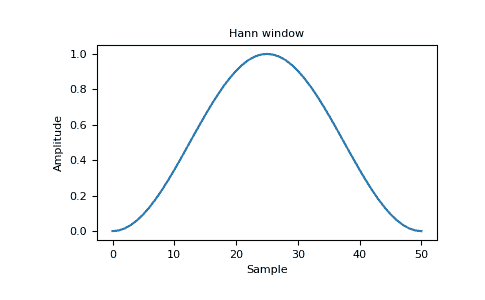
>>> plt.title("Hann window")
Text(0.5, 1.0, 'Hann window')
>>> plt.ylabel("Amplitude")
Text(0, 0.5, 'Amplitude')
>>> plt.xlabel("Sample")
Text(0.5, 0, 'Sample')
>>> plt.show()
>>> plt.figure()
<Figure size 640x480 with 0 Axes>
>>> A = fft(window, 2048) / 25.5
>>> mag = np.abs(fftshift(A))
>>> freq = np.linspace(-0.5, 0.5, len(A))
>>> with np.errstate(divide='ignore', invalid='ignore'):
... response = 20 * np.log10(mag)
...
>>> response = np.clip(response, -100, 100)
>>> plt.plot(freq, response)
[<matplotlib.lines.Line2D object at 0x...>]
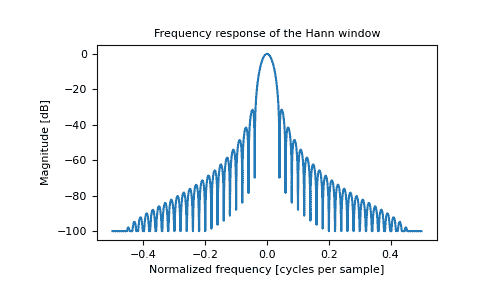
>>> plt.title("Frequency response of the Hann window")
Text(0.5, 1.0, 'Frequency response of the Hann window')
>>> plt.ylabel("Magnitude [dB]")
Text(0, 0.5, 'Magnitude [dB]')
>>> plt.xlabel("Normalized frequency [cycles per sample]")
Text(0.5, 0, 'Normalized frequency [cycles per sample]')
>>> plt.axis('tight')
...
>>> plt.show()
numpy.kaiser
numpy.kaiser(M, beta)
返回 Kaiser 窗口。
Kaiser 窗口是通过使用贝塞尔函数形成的锥形。
参数:
Mint
输出窗口中的点数。如果为零或更少,则返回一个空数组。
betafloat
窗口的形状参数。
返回:
outarray
窗口,最大值归一化为一(仅当样本数为奇数时才出现值为一)。
参见
bartlett, blackman, hamming, hanning
注释
Kaiser 窗口定义为
[w(n) = I_0\left( \beta \sqrt{1-\frac{4n²}{(M-1)²}} \right)/I_0(\beta)]
具有
[\quad -\frac{M-1}{2} \leq n \leq \frac{M-1}{2},]
其中 (I_0) 是修改后的零阶贝塞尔函数。
Kaiser 窗口以 Jim Kaiser 命名,他发现了基于贝塞尔函数的 DPSS 窗口的简单近似。Kaiser 窗口是对数字椭球序列(Digital Prolate Spheroidal Sequence,或 Slepian 窗口)的一个非常好的近似,该序列最大化了窗口主瓣中的能量相对于总能量。
Kaiser 可通过改变 beta 参数来近似许多其他窗口。
| beta | 窗口形状 |
|---|---|
| 0 | 矩形 |
| 5 | 类似于 Hamming |
| 6 | 类似于 Hanning |
| 8.6 | 类似于 Blackman |
beta 值为 14 可能是一个很好的起点。请注意,随着 beta 值变大,窗口变窄,因此样本数量需要足够大以对越来越窄的尖峰进行采样,否则会返回 NaN。
大多数关于 Kaiser 窗口的参考资料来自信号处理文献,它被用作许多窗口函数之一,用于平滑值。它也被称为消足(即“去除脚部”,即平滑采样信号开头和结尾的不连续性)或锥形函数。
参考文献
[1]
J. F. Kaiser,“数字滤波器” - “数字计算机系统分析”第七章,编辑:F.F. Kuo 和 J.F. Kaiser,第 218-285 页。约翰·威利和儿子,纽约,(1966)。
[2]
E.R. Kanasewich,“地球物理中的时间序列分析”,阿尔伯塔大学出版社,1975 年,第 177-178 页。
[3]
维基百科,“窗口函数”,en.wikipedia.org/wiki/Window_function
示例
>>> import matplotlib.pyplot as plt
>>> np.kaiser(12, 14)
array([7.72686684e-06, 3.46009194e-03, 4.65200189e-02, # may vary
2.29737120e-01, 5.99885316e-01, 9.45674898e-01,
9.45674898e-01, 5.99885316e-01, 2.29737120e-01,
4.65200189e-02, 3.46009194e-03, 7.72686684e-06])
绘制窗口和频率响应:
>>> from numpy.fft import fft, fftshift
>>> window = np.kaiser(51, 14)
>>> plt.plot(window)
[<matplotlib.lines.Line2D object at 0x...>]
>>> plt.title("Kaiser window")
Text(0.5, 1.0, 'Kaiser window')
>>> plt.ylabel("Amplitude")
Text(0, 0.5, 'Amplitude')
>>> plt.xlabel("Sample")
Text(0.5, 0, 'Sample')
>>> plt.show()
>>> plt.figure()
<Figure size 640x480 with 0 Axes>
>>> A = fft(window, 2048) / 25.5
>>> mag = np.abs(fftshift(A))
>>> freq = np.linspace(-0.5, 0.5, len(A))
>>> response = 20 * np.log10(mag)
>>> response = np.clip(response, -100, 100)
>>> plt.plot(freq, response)
[<matplotlib.lines.Line2D object at 0x...>]
>>> plt.title("Frequency response of Kaiser window")
Text(0.5, 1.0, 'Frequency response of Kaiser window')
>>> plt.ylabel("Magnitude [dB]")
Text(0, 0.5, 'Magnitude [dB]')
>>> plt.xlabel("Normalized frequency [cycles per sample]")
Text(0.5, 0, 'Normalized frequency [cycles per sample]')
>>> plt.axis('tight')
(-0.5, 0.5, -100.0, ...) # may vary
>>> plt.show()
类型(numpy.typing)
1.20 版本中的新功能。
NumPy API 的大部分内容采用了PEP 484风格的类型注解。此外,用户还可以使用一些类型别名,其中两个最重要的如下:
-
ArrayLike:可以转换为数组的对象 -
DTypeLike:可以转换为数据类型的对象
Mypy 插件
1.21 版本中的新功能。
一个mypy插件,用于管理一系列特定于平台的注解。它的功能可以分为三个不同的部分:
-
分配某些
number子类的(依赖于平台)精度,包括int_、intp和longlong等。查看标量类型的文档,了解受影响类的全面概述。如果没有插件,所有相关类的精度将被推断为Any。 -
移除在特定平台上不可用的所有扩展精度
number子类。其中最显著的包括float128和complex256等。如果没有插件,则在 mypy 的视角下,所有扩展精度类型都将对所有平台可用。 -
分配
c_intp的(依赖于平台)精度。如果没有插件,类型将默认为ctypes.c_int64。1.22 版本中的新功能。
示例
要启用插件,必须将其添加到自己的 mypy 配置文件中:
[mypy]
plugins = numpy.typing.mypy_plugin
与运行时 NumPy API 的差异
NumPy 非常灵活。试图静态描述所有可能性将导致类型不太有用。因此,有时候,有类型的 NumPy API 通常比运行时 NumPy API 更严格。本节描述了一些显著差异。
ArrayLike
ArrayLike类型试图避免创建对象数组。例如,
>>> np.array(x**2 for x in range(10))
array(<generator object <genexpr> at ...>, dtype=object)
是有效的 NumPy 代码,将创建一个零维对象数组。然而,如果使用 NumPy 类型,类型检查器将会对上述示例提出异议。如果您确实打算执行上述操作,那么可以使用# type: ignore注释:
>>> np.array(x**2 for x in range(10)) # type: ignore
或者明确将类似数组对象类型定义为Any:
>>> from typing import Any
>>> array_like: Any = (x**2 for x in range(10))
>>> np.array(array_like)
array(<generator object <genexpr> at ...>, dtype=object)
ndarray
可以在运行时改变数组的数据类型。例如,以下代码是有效的:
>>> x = np.array([1, 2])
>>> x.dtype = np.bool_
类型检查器不允许此类变异。想要编写静态类型代码的用户应该使用numpy.ndarray.view方法,用不同的 dtype 创建数组的视图。
DTypeLike
DTypeLike 类型试图避免使用字段字典创建 dtype 对象,如下所示:
>>> x = np.dtype({"field1": (float, 1), "field2": (int, 3)})
尽管这是有效的 NumPy 代码,但类型检查器会对此提出抱怨,因为不鼓励使用它。请参见:数据类型对象
数字精度
numpy.number子类的精度被视为协变泛型参数(见NBitBase),简化了涉及基于精度的转换的注释过程。
>>> from typing import TypeVar
>>> import numpy as np
>>> import numpy.typing as npt
>>> T = TypeVar("T", bound=npt.NBitBase)
>>> def func(a: "np.floating[T]", b: "np.floating[T]") -> "np.floating[T]":
... ...
因此,float16、float32和float64仍然是floating的子类型,但与运行时相反,它们未必被视为子类。
Timedelta64
timedelta64 类在静态类型检查时不被视为signedinteger的子类,它只从generic继承。
0 维数组
在运行时,numpy 会将任何传递进来的 0 维数组积极地转换为相应的generic实例。在引入形状类型(参见PEP 646)之前,很遗憾目前无法进行必要的区分 0D 和> 0D 数组。因此,尽管不严格正确,所有可能执行 0 维数组->标量转换的操作都目前被标注为只返回ndarray。
如果事先知道某个操作将执行 0 维数组->标量的转换,那么可以考虑使用typing.cast或# type: ignore注释手动解决该问题。
记录数组数据类型
numpy.recarray的数据类型,以及一般情况下的numpy.rec函数,可以通过以下两种方式之一指定:
-
通过
dtype参数直接指定。 -
具有通过
numpy.format_parser操作的最多五个辅助参数:formats、names、titles、aligned和byteorder。
目前这两种方法被标记为互斥,即 如果指定了 dtype,则不能指定 formats。虽然这种互斥性在运行时不是(严格)强制执行的,但结合两种 dtype 指定符可能会导致意外或甚至明显错误的行为。
API
numpy.typing.ArrayLike = typing.Union[...]
代表可以强制转换为 ndarray 的对象的 Union。
其中包括但不限于:
-
标量。
-
(嵌套的)序列。
-
实现 array 协议的对象。
新版本 1.20 中新增。
参见
array_like:
任何可解释为 ndarray 的标量或序列。
示例
>>> import numpy as np
>>> import numpy.typing as npt
>>> def as_array(a: npt.ArrayLike) -> np.ndarray:
... return np.array(a)
numpy.typing.DTypeLike = typing.Union[...]
代表可以强制转换为 dtype 的对象的 Union。
其中包括但不限于:
新版本 1.20 中新增。
参见
指定和构造数据类型
所有可以强制转换为数据类型的对象的全面概述。
示例
>>> import numpy as np
>>> import numpy.typing as npt
>>> def as_dtype(d: npt.DTypeLike) -> np.dtype:
... return np.dtype(d)
numpy.typing.NDArray = numpy.ndarray[typing.Any, numpy.dtype[+_ScalarType_co]]
np.ndarray[Any, np.dtype[+ScalarType]] 的通用 版本。
可在运行时用于为具有给定 dtype 和未指定形状的数组进行类型标注。
新版本 1.21 中新增。
示例
>>> import numpy as np
>>> import numpy.typing as npt
>>> print(npt.NDArray)
numpy.ndarray[typing.Any, numpy.dtype[+ScalarType]]
>>> print(npt.NDArray[np.float64])
numpy.ndarray[typing.Any, numpy.dtype[numpy.float64]]
>>> NDArrayInt = npt.NDArray[np.int_]
>>> a: NDArrayInt = np.arange(10)
>>> def func(a: npt.ArrayLike) -> npt.NDArray[Any]:
... return np.array(a)
class numpy.typing.NBitBase
代表 numpy.number 精度的类型在静态类型检查期间。
专门用于静态类型检查目的,NBitBase 代表一个层次化子类集合的基类。每个后续子类用于表示更低级别的精度,例如 64Bit > 32Bit > 16Bit。
新版本 1.20 中新增。
示例
下面是一个典型的使用示例:NBitBase 用于为接受任意精度的浮点数和整数作为参数并返回精度较大的新浮点数的函数进行注释(例如 np.float16 + np.int64 -> np.float64)。
>>> from __future__ import annotations
>>> from typing import TypeVar, TYPE_CHECKING
>>> import numpy as np
>>> import numpy.typing as npt
>>> T1 = TypeVar("T1", bound=npt.NBitBase)
>>> T2 = TypeVar("T2", bound=npt.NBitBase)
>>> def add(a: np.floating[T1], b: np.integer[T2]) -> np.floating[T1 | T2]:
... return a + b
>>> a = np.float16()
>>> b = np.int64()
>>> out = add(a, b)
>>> if TYPE_CHECKING:
... reveal_locals()
... # note: Revealed local types are:
... # note: a: numpy.floating[numpy.typing._16Bit*]
... # note: b: numpy.signedinteger[numpy.typing._64Bit*]
... # note: out: numpy.floating[numpy.typing._64Bit*]
Mypy 插件
新版本 1.21 中新增。
用于管理一些特定平台注释的 mypy 插件。其功能可以分为三个明确的部分:
-
分配了某些
number子类的(平台相关)精度,包括int_、intp和longlong的精度。有关受影响类的综合概述,请参阅标量类型的文档。没有使用插件,所有相关类的精度将被推断为Any。 -
删除在特定平台上不可用的所有扩展精度的
number子类。最显著的包括float128和complex256。如果不使用插件,所有扩展精度类型在 mypy 看来都对所有平台可用。 -
分配
c_intp的(平台相关)精度。没有使用插件,类型将默认为ctypes.c_int64。版本 1.22 中的新功能。
示例
要启用该插件,必须将其添加到 mypy 的配置文件中:
[mypy]
plugins = numpy.typing.mypy_plugin
示例
要启用该插件,必须将其添加到 mypy 的配置文件中:
[mypy]
plugins = numpy.typing.mypy_plugin
与运行时 NumPy API 的差异
NumPy 非常灵活。试图静态描述所有可能性将导致不太有帮助的类型。因此,类型化 NumPy API 往往比运行时 NumPy API 严格。本节描述了一些值得注意的差异。
ArrayLike
ArrayLike类型尝试避免创建对象数组。例如,
>>> np.array(x**2 for x in range(10))
array(<generator object <genexpr> at ...>, dtype=object)
这是有效的 NumPy 代码,将创建一个 0 维对象数组。然而,当使用 NumPy 类型时,类型检查器会对上述示例提出抱怨。如果您真的打算执行上述操作,那么您可以使用# type: ignore注释:
>>> np.array(x**2 for x in range(10)) # type: ignore
或者将数组对象明确类型为Any:
>>> from typing import Any
>>> array_like: Any = (x**2 for x in range(10))
>>> np.array(array_like)
array(<generator object <genexpr> at ...>, dtype=object)
ndarray
数组的数据类型可以在运行时进行变异。例如,以下代码是有效的:
>>> x = np.array([1, 2])
>>> x.dtype = np.bool_
类型不允许此类变异。希望编写静态类型代码的用户应该使用numpy.ndarray.view方法,以创建具有不同数据类型的数组视图。
DTypeLike
DTypeLike 类型试图避免像下面这样使用字段字典创建 dtype 对象:
>>> x = np.dtype({"field1": (float, 1), "field2": (int, 3)})
尽管这是有效的 NumPy 代码,类型检查器会对其提出异议,因为不鼓励使用。请参见:数据类型对象
数字精度
numpy.number子类的精度被视为协变通用参数(参见NBitBase),简化了涉及基于精度的转换的注释过程。
>>> from typing import TypeVar
>>> import numpy as np
>>> import numpy.typing as npt
>>> T = TypeVar("T", bound=npt.NBitBase)
>>> def func(a: "np.floating[T]", b: "np.floating[T]") -> "np.floating[T]":
... ...
因此,float16、float32和float64等类型仍然是floating的子类型,但与运行时相反,它们不一定被视为子类。
Timedelta64
timedelta64 类不被视为signedinteger的子类,前者仅在静态类型检查中继承自generic。
零维数组
在运行时,NumPy 会将任何传递的 0 维数组强制转换为相应的generic实例。在引入形状类型编制(参见PEP 646)之前,不幸的是目前无法区分 0 维和>0 维数组。因此,所有可能进行 0 维数组 -> 标量转换的操作当前都被注释地专门返回一个ndarray,虽然这不严格正确。
如果预先知道一个操作将执行 0 维数组 -> 标量转换,那么可以考虑使用typing.cast或# type: ignore注释手动处理情况。
记录数组 dtypes
numpy.recarray的 dtype,以及一般的numpy.rec函数,可以通过两种方式指定:
-
直接通过
dtype参数。 -
通过
numpy.format_parser提供的最多五个帮助参数进行操作:formats、names、titles、aligned和byteorder。
目前,这两种方法被彼此排斥化为互斥,即如果指定了dtype,则不能指定formats。尽管这种互斥在运行时并没有(严格)执行,但结合两种 dtype 说明符可能会导致意外或严重错误行为。
ArrayLike
ArrayLike类型尝试避免创建对象数组。例如,
>>> np.array(x**2 for x in range(10))
array(<generator object <genexpr> at ...>, dtype=object)
是有效的 NumPy 代码,它将创建一个 0 维对象数组。然而,当使用 NumPy 类型时,类型检查器会对上述示例报错。如果您真的打算执行上述操作,那么您可以使用# type: ignore注释:
>>> np.array(x**2 for x in range(10)) # type: ignore
或者将类似数组的对象明确类型为Any:
>>> from typing import Any
>>> array_like: Any = (x**2 for x in range(10))
>>> np.array(array_like)
array(<generator object <genexpr> at ...>, dtype=object)
ndarray
可以在运行时更改数组的 dtype。例如,以下代码是有效的:
>>> x = np.array([1, 2])
>>> x.dtype = np.bool_
类型不允许进行此类变异。希望编写静态类型代码的用户应该使用 numpy.ndarray.view 方法以不同的 dtype 创建数组的视图。
DTypeLike
DTypeLike类型尝试避免使用以下格式的字段字典创建 dtype 对象:
>>> x = np.dtype({"field1": (float, 1), "field2": (int, 3)})
尽管这是有效的 NumPy 代码,但类型检查器会对其报错,因为它的使用是不鼓励的。请参阅:数据类型对象
数值精度
numpy.number子类的精度被视为协变通用参数(参见NBitBase
def func(a: “np.floating[T]”, b: “np.floating[T]”) -> “np.floating[T]”:
… …
因此,`float16`、`float32`和`float64`仍然是`floating`的子类型,但与运行时相反,它们不一定被视为子类。
### Timedelta64
在静态类型检查中,`timedelta64`类不被视为`signedinteger`的子类,前者仅继承自 `generic`。
### 0D 数组
运行时,numpy 会将任何传入的 0D 数组强制转换为相应的`generic`实例。在引入 shape typing(参见[**PEP 646**](https://peps.python.org/pep-0646/)) 之前,不幸的是无法对 0D 和>0D 数组进行必要的区分。因此,虽然不严格正确,但目前将所有可能执行 0D-array -> scalar 转换的操作都注释为仅返回*ndarray*。
如果预先知道一个操作 _will_ 执行 0D-array -> 标量转换,则可以考虑使用[`typing.cast`](https://docs.python.org/3/library/typing.html#typing.cast "(在 Python v3.11)")或者`# type: ignore`注释手动解决这种情况。
### 记录数组 dtypes
`numpy.recarray`的 dtype,以及通用的`numpy.rec`函数,可以通过两种方式指定:
+ 通过`dtype`参数直接指定。
+ 通过`numpy.format_parser`操作的最多五个辅助参数: `formats`、`names`、`titles`、`aligned`和`byteorder`。
目前这两种方法的类型被定义为互斥的,*即*如果指定了`dtype`,则不允许指定`formats`。虽然这种互斥性在运行时并没有(严格)强制执行,但结合两种 dtype 指定器可能会导致意外或甚至严重的错误行为。
## API
```py
numpy.typing.ArrayLike = typing.Union[...]
代表可以强制转换为ndarray的Union。
其中包括:
-
标量。
-
(嵌套) 序列。
-
实现*array*协议的对象。
1.20 版中的新功能。
参见
array_like:
任何可以解释为 ndarray 的标量或序列。
例子
>>> import numpy as np
>>> import numpy.typing as npt
>>> def as_array(a: npt.ArrayLike) -> np.ndarray:
... return np.array(a)
numpy.typing.DTypeLike = typing.Union[...]
代表可以被强制转换为dtype的对象的Union。
其中包括:
1.20 版中的新功能。
参见
指定和构造数据类型
所有可强制转换为数据类型的对象的全面概述。
例子
>>> import numpy as np
>>> import numpy.typing as npt
>>> def as_dtype(d: npt.DTypeLike) -> np.dtype:
... return np.dtype(d)
numpy.typing.NDArray = numpy.ndarray[typing.Any, numpy.dtype[+_ScalarType_co]]
np.ndarray[Any, np.dtype[+ScalarType]]的通用版本。
可以在运行时用于对具有给定 dtype 和未指定形状的数组进行类型标记。
1.21 版中的新功能。
例子
>>> import numpy as np
>>> import numpy.typing as npt
>>> print(npt.NDArray)
numpy.ndarray[typing.Any, numpy.dtype[+ScalarType]]
>>> print(npt.NDArray[np.float64])
numpy.ndarray[typing.Any, numpy.dtype[numpy.float64]]
>>> NDArrayInt = npt.NDArray[np.int_]
>>> a: NDArrayInt = np.arange(10)
>>> def func(a: npt.ArrayLike) -> npt.NDArray[Any]:
... return np.array(a)
class numpy.typing.NBitBase
用于静态类型检查期间的numpy.number精度类型。
仅供静态类型检查目的使用,NBitBase 表示一组子类的基类。每个后续子类在此用于表示更低级的精度,e.g. 64Bit > 32Bit > 16Bit。
1.20 版中的新功能。
例子
下面是一个典型的使用示例:NBitBase 在这里用于注释一个接受任意精度的浮点数和整数作为参数,并返回具有最大精度的新浮点数的函数(例如 np.float16 + np.int64 -> np.float64)。
>>> from __future__ import annotations
>>> from typing import TypeVar, TYPE_CHECKING
>>> import numpy as np
>>> import numpy.typing as npt
>>> T1 = TypeVar("T1", bound=npt.NBitBase)
>>> T2 = TypeVar("T2", bound=npt.NBitBase)
>>> def add(a: np.floating[T1], b: np.integer[T2]) -> np.floating[T1 | T2]:
... return a + b
>>> a = np.float16()
>>> b = np.int64()
>>> out = add(a, b)
>>> if TYPE_CHECKING:
... reveal_locals()
... # note: Revealed local types are:
... # note: a: numpy.floating[numpy.typing._16Bit*]
... # note: b: numpy.signedinteger[numpy.typing._64Bit*]
... # note: out: numpy.floating[numpy.typing._64Bit*]
全局状态
NumPy 具有一些导入时、编译时或运行时选项,可以更改全局行为。其中大多数与性能或调试目的有关,对绝大多数用户来说不会有太大兴趣。
与性能相关的选项
用于线性代数的线程数
NumPy 本身通常在函数调用期间有意限制为单个线程,但它确实支持同时运行多个 Python 线程。请注意,对于性能良好的线性代数,NumPy 使用 OpenBLAS 或 MKL 等 BLAS 后端,这可能使用多个线程,这些线程可以通过环境变量(如OMP_NUM_THREADS)进行控制,具体取决于使用了什么。控制线程数的一种方法是使用 threadpoolctl 包。
Linux 上的 Madvise Hugepage
在现代 Linux 内核上操作非常大的数组时,当使用透明大页时,您会体验到显着的加速。可以通过以下方式查看透明大页的当前系统策略:
cat /sys/kernel/mm/transparent_hugepage/enabled
将其设置为madvise时,NumPy 通常会使用 hugepages 来提高性能。通过设置环境变量可以修改此行为:
NUMPY_MADVISE_HUGEPAGE=0
或将其设置为1 以始终启用它。未设置时,默认值是在内核 4.6 及更高版本上使用 madvise。这些内核应该通过 hugepage 支持实现大幅加速。此标志在导入时进行检查。
SIMD 特性选择
设置NPY_DISABLE_CPU_FEATURES将在运行时排除 simd 特性。详见运行时分发。
与调试相关的选项
松散的步幅检查
编译时环境变量:
NPY_RELAXED_STRIDES_DEBUG=0
可以设置以帮助调试通过 C 编写的代码,手动遍历数组。当数组是连续的并以连续的方式遍历时,不应查询其strides。此选项可帮助找到错误,其中strides被错误使用。有关详细信息,请参见内存布局文档。
在释放数据时,如果没有内存分配策略则发出警告
某些用户可能通过设置OWNDATA标志将数据指针的所有权传递给ndarray。如果他们这样做而没有(手动)设置内存分配策略,则默认值将调用free。如果NUMPY_WARN_IF_NO_MEM_POLICY设置为"1",则会发出RuntimeWarning。更好的替代方法是使用带有解除分配器的PyCapsule并设置ndarray.base。
测试计划未来的行为
NumPy 有一些代码路径,计划在将来激活,但目前不是默认行为。您可以尝试测试其中一些可能会与新的“主要”发布(NumPy 2.0)一起提供的功能,方法是在导入 NumPy 之前设置环境:
NPY_NUMPY_2_BEHAVIOR=1
默认情况下,这也会激活NEP 50相关的设置NPY_PROMOTION_STATE(请参阅 NEP 以获取详细信息)。
在 1.25.2 版本中更改:此变量仅在首次导入时被检查。
与性能相关的选项
用于线性代数的线程数
NumPy 本身通常在函数调用期间有意限制为单个线程,但支持同时运行多个 Python 线程。请注意,为了进行高性能的线性代数运算,NumPy 使用类似 OpenBLAS 或 MKL 的 BLAS 后端,该后端可能使用多个线程,这些线程可能受环境变量(如OMP_NUM_THREADS)的控制。控制线程数的一种方法是使用包threadpoolctl
Linux 上的 Madvise Hugepage
在现代 Linux 内核上操作非常大的数组时,启用透明大页 可以获得显着的加速。当前透明大页的系统策略可以通过以下方式查看:
cat /sys/kernel/mm/transparent_hugepage/enabled
当设置为madvise时,NumPy 通常会使用大页来提升性能。可以通过设置环境变量来修改此行为:
NUMPY_MADVISE_HUGEPAGE=0
或将其设置为1以始终启用。如果未设置,默认情况下在内核 4.6 及更新版本上使用 madvise。据称这些内核在支持大页的情况下会获得大幅加速。此标志在导入时会被检查。
SIMD 特性选择
设置NPY_DISABLE_CPU_FEATURES将在运行时排除 simd 特性。请参阅运行时调度。
用于线性代数的线程数
NumPy 本身通常在函数调用期间有意限制为单个线程,但支持同时运行多个 Python 线程。请注意,为了进行高性能的线性代数运算,NumPy 使用类似 OpenBLAS 或 MKL 的 BLAS 后端,该后端可能使用多个线程,这些线程可能受环境变量(如OMP_NUM_THREADS)的控制。控制线程数的一种方法是使用包threadpoolctl
Linux 上的 Madvise Hugepage
在现代 Linux 内核上操作非常大的数组时,启用透明大页 可以获得显着的加速。当前透明大页的系统策略可以通过以下方式查看:
cat /sys/kernel/mm/transparent_hugepage/enabled
当设置为madvise时,NumPy 通常会使用大页来提升性能。可以通过设置环境变量来修改此行为:
NUMPY_MADVISE_HUGEPAGE=0
或将其设置为1以始终启用。如果未设置,默认情况下在内核 4.6 及更新版本上使用 madvise。据称这些内核在支持大页的情况下会获得大幅加速。此标志在导入时会被检查。
SIMD 特性选择
设置 NPY_DISABLE_CPU_FEATURES 将在运行时排除 simd 功能。请参阅 运行时调度。
与调试相关的选项
放松的strides检查
编译时环境变量:
NPY_RELAXED_STRIDES_DEBUG=0
可以设置以帮助调试用 C 编写的代码,该代码手动遍历数组。当数组连续并以连续方式迭代时,不应查询其strides。此选项可帮助找出错误,其中strides被错误使用。有关详细信息,请参阅 内存布局 文档。
在释放数据时,如果没有内存分配策略,则发出警告
一些用户可能会通过设置ndarray的OWNDATA标志来将数据指针的所有权传递给ndarray。如果他们这样做而没有设置(手动设置)内存分配策略,则默认将调用free。如果将NUMPY_WARN_IF_NO_MEM_POLICY设置为"1",则会发出RuntimeWarning。更好的替代方法是使用具有解除分配器的PyCapsule并设置ndarray.base。
放松的strides检查
编译时环境变量:
NPY_RELAXED_STRIDES_DEBUG=0
可以设置以帮助调试用 C 编写的代码,该代码手动遍历数组。当数组连续并以连续方式迭代时,不应查询其strides。此选项可帮助找出错误,其中strides被错误使用。有关详细信息,请参阅 内存布局 文档。
在释放数据时,如果没有内存分配策略,则发出警告
一些用户可能会通过设置ndarray的OWNDATA标志来将数据指针的所有权传递给ndarray。如果他们这样做而没有设置(手动设置)内存分配策略,则默认将调用free。如果将NUMPY_WARN_IF_NO_MEM_POLICY设置为"1",则会发出RuntimeWarning。更好的替代方法是使用具有解除分配器的PyCapsule并设置ndarray.base。
计划的未来行为测试
NumPy 有一些代码路径,计划在将来激活,但目前不是默认行为。您可以通过在导入 NumPy 之前设置环境来尝试测试其中一些可能随新的“主要”版本(NumPy 2.0)一起发布的功能:
NPY_NUMPY_2_BEHAVIOR=1
默认情况下,这也会激活与 NEP 50 相关的设置 NPY_PROMOTION_STATE(请参阅 NEP 了解详情)。
从版本 1.25.2 开始更改:此变量仅在首次导入时进行检查。
打包(numpy.distutils)
警告
numpy.distutils 已被弃用,并将在 Python >= 3.12 版本中移除。更多详情,请参阅 Status of numpy.distutils and migration advice。
警告
请注意,setuptools经常进行重大发布,可能包含破坏numpy.distutils的更改,而numpy.distutils将不再针对新的setuptools版本进行更新。因此,建议在您的构建配置中设置一个上限版本,以确保最后已知可与您的构建配合使用的setuptools版本。
NumPy 提供了增强的 distutils 功能,使构建和安装子包、自动生成代码以及使用 Fortran 编译库的扩展模块更容易。要使用 NumPy distutils 的功能,请使用numpy.distutils.core中的 setup 命令。同时,numpy.distutils.misc_util 还提供了一个有用的 Configuration 类,可以更轻松地构建传递给 setup 函数的关键字参数(通过传递从该类的 todict() 方法获得的字典)。更多信息请参阅 NumPy distutils - 用户指南。
选择和链接库的位置,例如 BLAS 和 LAPACK,以及包含路径等其他构建选项可以在 NumPy 根仓库中的 site.cfg 文件或者位于用户主目录中的 .numpy-site.cfg 文件中指定。参见在 NumPy 仓库或者 sdist 中附带的 site.cfg.example 示例文件获取文档。
numpy.distutils 中的模块
-
distutils.misc_util
-
all_strings -
allpath -
appendpath -
as_list -
blue_text -
cyan_text -
cyg2win32 -
default_config_dict -
dict_append -
dot_join -
exec_mod_from_location -
filter_sources -
generate_config_py -
get_build_architecture -
get_cmd -
get_data_files -
get_dependencies -
get_ext_source_files -
get_frame -
get_info -
get_language -
get_lib_source_files -
get_mathlibs -
get_num_build_jobs -
get_numpy_include_dirs -
get_pkg_info -
get_script_files -
gpaths -
green_text -
has_cxx_sources -
has_f_sources -
is_local_src_dir -
is_sequence -
is_string -
mingw32 -
minrelpath -
njoin -
red_text -
sanitize_cxx_flags -
terminal_has_colors -
yellow_text
-
ccompiler | |
|---|---|
ccompiler_opt | 提供CCompilerOpt类,用于处理 CPU/硬件优化,从解析命令参数开始,到管理 CPU 基线和可调度特性之间的关系,还生成所需的 C 标头,并以合适的编译器标志编译源代码。 |
cpuinfo.cpu | |
core.Extension(name, sources[, …]) |
参数:
|
exec_command | exec_command |
|---|---|
log.set_verbosity(v[, force]) | |
system_info.get_info(name[, notfound_action]) | notfound_action: |
system_info.get_standard_file(fname) | 从 1)系统范围的目录(这个模块的目录位置)2)用户 HOME 目录(os.environ[‘HOME’])3)本地目录返回一个名为“fname”的文件列表 |
配置类
class numpy.distutils.misc_util.Configuration(package_name=None, parent_name=None, top_path=None, package_path=None, **attrs)
为给定的包名称构造一个配置实例。如果parent_name不为 None,则构造包作为parent_name包的子包。如果top_path和package_path为 None,则它们被假定为与创建此实例的文件的路径相等。numpy 分配中的 setup.py 文件是如何使用Configuration实例的很好的例子。
todict()
返回一个与 distutils setup 函数的关键字参数兼容的字典。
例子
>>> setup(**config.todict())
get_distribution()
返回 self 的 distutils 分发对象。
get_subpackage(subpackage_name, subpackage_path=None, parent_name=None, caller_level=1)
返回子包配置列表。
参数:
subpackage_namestr 或 None
获取配置的子包的名称。在 subpackage_name 中的‘*’被视为通配符。
subpackage_pathstr
如果为 None,则假定路径为本地路径加上 subpackage_name。如果在 subpackage_path 中找不到 setup.py 文件,则使用默认配置。
parent_namestr
父名称。
add_subpackage(subpackage_name, subpackage_path=None, standalone=False)
向当前 Configuration 实例添加一个子包。
在 setup.py 脚本中,这对于向包添加子包非常有用。
参数:
subpackage_namestr
子包的名称
subpackage_pathstr
如果提供,则子包路径例如子包位于子包路径/子包名称。如果为 None,则假定子包位于本地路径/子包名称。
standalonebool
add_data_files(*files)
将数据文件添加到配置数据文件中。
参数:
files序列
参数可以是
- 2-序列(<数据目录前缀>,<数据文件路径>)
- 数据文件的路径,其中 python 数据目录前缀默认为包目录。
注意事项
文件序列的每个元素的形式非常灵活,允许从包中获取文件的多种组合以及它们应最终安装到系统的位置。最基本的用法是让文件参数序列的一个元素成为一个简单的文件名。这将导致将该文件从本地路径安装到 self.name 包的安装路径(包路径)。文件参数还可以是相对路径,此时整个相对路径将安装到包目录中。最后,文件可以是绝对路径名,此时文件将在绝对路径名处找到,但安装到包路径。
通过将 2 元组作为文件参数传递来增强此基本行为。元组的第一个元素应指定应将其余文件序列安装到的相对路径(在包安装目录下)(它与源分发中的文件名无关)。元组的第二个元素是应安装的文件序列。此序列中的文件可以是文件名、相对路径或绝对路径。对于绝对路径,文件将安装在顶级包安装目录中(不管第一个参数如何)。文件名和相对路径名将安装在给定为元组第一个元素的路径名下的包安装目录中。
安装路径规则:
- file.txt -> (., file.txt)-> parent/file.txt
- foo/file.txt -> (foo, foo/file.txt) -> parent/foo/file.txt
- /foo/bar/file.txt -> (., /foo/bar/file.txt) -> parent/file.txt
*.txt -> parent/a.txt, parent/b.txt- foo/
*.txt`` -> parent/foo/a.txt, parent/foo/b.txt*/*.txt-> (*,*/*.txt) -> parent/c/a.txt, parent/d/b.txt- (sun, file.txt) -> parent/sun/file.txt
- (sun, bar/file.txt) -> parent/sun/file.txt
- (sun, /foo/bar/file.txt) -> parent/sun/file.txt
- (sun,
*.txt) -> parent/sun/a.txt, parent/sun/b.txt- (sun, bar/
*.txt) -> parent/sun/a.txt, parent/sun/b.txt- (sun/
*,*/*.txt) -> parent/sun/c/a.txt, parent/d/b.txt
另一个特性是数据文件的路径实际上可以是一个不带参数且返回数据文件实际路径的函数。这在构建包时生成数据文件时非常有用。
示例
将文件添加到要随包一起包含的数据文件列表中。
>>> self.add_data_files('foo.dat',
... ('fun', ['gun.dat', 'nun/pun.dat', '/tmp/sun.dat']),
... 'bar/cat.dat',
... '/full/path/to/can.dat')
将这些数据文件安装到:
<package install directory>/
foo.dat
fun/
gun.dat
nun/
pun.dat
sun.dat
bar/
car.dat
can.dat
其中是包(或子包)目录,例如‘/usr/lib/python2.4/site-packages/mypackage’(‘C: Python2.4 Lib site-packages mypackage’)或‘/usr/lib/python2.4/site- packages/mypackage/mysubpackage’(‘C: Python2.4 Lib site-packages mypackage mysubpackage’)。
add_data_dir(data_path)
递归地将 data_path 下的文件添加到 data_files 列表中。
递归地将 data_path 下的文件添加到要安装(和分发)的 data_files 列表中。data_path 可以是相对路径名、绝对路径名,或者是一个 2 元组,第一个参数指示数据目录应安装到安装目录的何处。
参数:
data_pathseq 或 str
参数可以是
- 2 序列(<datadir 后缀>,<数据目录路径>)
- 数据目录的路径,其中 python datadir 后缀默认为包目录。
注
安装路径规则:
foo/bar -> (foo/bar, foo/bar) -> parent/foo/bar
(gun, foo/bar) -> parent/gun
foo/* -> (foo/a, foo/a), (foo/b, foo/b) -> parent/foo/a, parent/foo/b
(gun, foo/*) -> (gun, foo/a), (gun, foo/b) -> gun
(gun/*, foo/*) -> parent/gun/a, parent/gun/b
/foo/bar -> (bar, /foo/bar) -> parent/bar
(gun, /foo/bar) -> parent/gun
(fun/*/gun/*, sun/foo/bar) -> parent/fun/foo/gun/bar
示例
例如,假设源目录包含 fun/foo.dat 和 fun/bar/car.dat:
>>> self.add_data_dir('fun')
>>> self.add_data_dir(('sun', 'fun'))
>>> self.add_data_dir(('gun', '/full/path/to/fun'))
将数据文件安装到以下位置:
<package install directory>/
fun/
foo.dat
bar/
car.dat
sun/
foo.dat
bar/
car.dat
gun/
foo.dat
car.dat
add_include_dirs(*paths)
将路径添加到配置的包含目录中。
将给定的路径序列添加到 include_dirs 列表的开头。这个列表将���当前包的所有扩展模块可见。
add_headers(*files)
将可安装的头文件添加到配置中。
将给定的文件序列添加到头文件列表的开头。默认情况下,头文件将安装在/<self.name.replace(‘.’,’/’)>/目录下。如果 files 的项是元组,则其第一个参数指定相对于路径的实际安装位置。
参数:
filesstr 或 seq
参数可以是:
- 2 序列(<includedir 后缀>,<头文件路径>)
- 头文件路径,其中 python 包含目录后缀将默认为包名称。
add_extension(name, sources, **kw)
将扩展添加到配置中。
创建并将一个 Extension 实例添加到 ext_modules 列表中。此方法还接受以下可选关键字参数,这些参数传递给 Extension 构造函数。
参数:
namestr
扩展名
sourcesseq
源文件列表。源文件列表可能包含函数(称为源文件生成器),它们必须将扩展实例和构建目录作为输入,并返回一个源文件或源文件列表或 None。如果返回 None,则不生成任何源文件。如果处理完所有源文件生成器后 Extension 实例没有源文件,则不会构建扩展模块。
include_dirs
define_macros
undef_macros
library_dirs
libraries
runtime_library_dirs
extra_objects
extra_compile_args
extra_link_args
extra_f77_compile_args
extra_f90_compile_args
export_symbols
swig_opts
depends
依赖列表包含扩展模块源文件所依赖的文件或目录的路径。如果依赖列表中的任何路径比扩展模块更新,那么将重新构建该模块。
language
f2py_options
module_dirs
extra_infodict 或 list
要附加到关键字的关键字的字典或关键字的列表。
注释
对可能包含路径的所有列表应用 self.paths(…) 方法。
add_library(name, sources, **build_info)
将库添加到配置中。
参数:
namestr
扩展的名称。
sources序列
源列表。源列表可能包含函数(称为源生成器),这些函数必须接受扩展实例和构建目录作为输入,并返回一个源文件或源文件列表或 None。如果返回 None,则不生成任何源。如果 Extension 实例在处理所有源生成器后没有源,则不会构建扩展模块。
build_info字典,可选
允许以下键:
- 依赖项
- 宏
- include_dirs
- extra_compiler_args
- extra_f77_compile_args
- extra_f90_compile_args
- f2py_options
- 语言
add_scripts(*files)
将脚本添加到配置中。
将文件序列添加到脚本列表的开头。脚本将安装在 /bin/ 目录下。
add_installed_library(name, sources, install_dir, build_info=None)
类似于 add_library,但安装指定的库。
大多数与 distutils 一起使用的 C 库仅用于构建 Python 扩展,但通过此方法构建的库将被安装,以便它们可以被第三方包重用。
参数:
namestr
安装的库的名称。
sources序列
库的源文件列表。有关详细信息,请参见 add_library。
install_dirstr
库的安装路径,相对于当前子包。
build_info字典,可选
允许以下键:
- 依赖项
- 宏
- include_dirs
- extra_compiler_args
- extra_f77_compile_args
- extra_f90_compile_args
- f2py_options
- 语言
返回:
None
参见
add_library,add_npy_pkg_config,get_info
注释
链接到指定的 C 库所需选项的最佳方法是使用“libname.ini”文件,并使用 get_info 检索所需的选项(有关更多信息,请参见 add_npy_pkg_config)。
add_npy_pkg_config(template, install_dir, subst_dict=None)
从模板生成并安装一个 npy-pkg 配置文件。
从 template 生成的配置文件将使用 subst_dict 进行变量替换,并安装在给定的安装目录中。
参数:
templatestr
模板的路径,相对于当前包路径。
install_dirstr
安装 npy-pkg 配置文件的位置,相对于当前软件包路径而言。
subst_dictdict,可选
如果提供了任何形式为 @key@ 的字符串,将在模板文件安装时将其替换为 subst_dict[key]。安装前缀始终可以通过变量 @prefix@ 获得,因为从 setup.py 可靠地获取安装前缀并不容易。
另请参见
add_installed_library,get_info
注
这适用于标准安装和就地编译,即 @prefix@ 指的是就地编译的源目录。
示例
config.add_npy_pkg_config('foo.ini.in', 'lib', {'foo': bar})
假设 foo.ini.in 文件具有以下内容:
[meta]
Name=@foo@
Version=1.0
Description=dummy description
[default]
Cflags=-I@prefix@/include
Libs=
生成的文件将具有以下内容:
[meta]
Name=bar
Version=1.0
Description=dummy description
[default]
Cflags=-Iprefix_dir/include
Libs=
并将安装为 lib 子路径下的 foo.ini 文件。
当使用 numpy distutils 进行交叉编译时,可能需要使用修改后的 npy-pkg-config 文件。使用默认生成的文件将链接到主机库(即 libnpymath.a)。而在交叉编译时,必须链接到目标库,同时使用主机 Python 安装。
您可以拷贝 numpy/core/lib/npy-pkg-config 目录,向 .ini 文件中添加 pkgdir 值,并将 NPY_PKG_CONFIG_PATH 环境变量设置为指向修改后的 npy-pkg-config 文件所在的目录。
修改的 npymath.ini 示例用于交叉编译:
[meta]
Name=npymath
Description=Portable, core math library implementing C99 standard
Version=0.1
[variables]
pkgname=numpy.core
pkgdir=/build/arm-linux-gnueabi/sysroot/usr/lib/python3.7/site-packages/numpy/core
prefix=${pkgdir}
libdir=${prefix}/lib
includedir=${prefix}/include
[default]
Libs=-L${libdir} -lnpymath
Cflags=-I${includedir}
Requires=mlib
[msvc]
Libs=/LIBPATH:${libdir} npymath.lib
Cflags=/INCLUDE:${includedir}
Requires=mlib
paths(*paths, **kws)
对路径应用 glob 并根据需要添加 local_path。
对序列中的每个路径应用 glob.glob(…)(如果需要),并根据需要添加 local_path。因为此方法在所有源列表上调用,所以可以在扩展模块、库、脚本的源列表中指定通配符和相对于源目录的路径名。
get_config_cmd()
返回 numpy.distutils 配置命令的实例。
get_build_temp_dir()
返回应放置临时文件的临时目录的路径。
have_f77c()
检查 Fortran 77 编译器的可用性。
在源代码生成函数中使用它,以确保设置的发行实例已被初始化。
注
如果存在 Fortran 77 编译器(因为简单的 Fortran 77 代码能够成功编译),则为真。
have_f90c()
检查 Fortran 90 编译器的可用性。
在源代码生成函数中使用它,以确保设置的发行实例已被初始化。
注
如果存在 Fortran 90 编译器(因为简单的 Fortran 90 代码能够成功编译),则为真。
get_version(version_file=None, version_variable=None)
尝试获取软件包的版本字符串。
返回当前软件包的版本字符串,如果无法检测到版本信息,则返回 None。
注
该方法扫描名为 version.py、_version.py、version.py 和 svn_version.py 的文件,以查找字符串变量 version、version 和 _version,直到找到版本号。
make_svn_version_py(delete=True)
向 data_files 列表附加一个数据函数,用于在当前包目录中生成 svn_version.py 文件。
从 SVN 版本号生成包 svn_version.py 文件,它在 python 退出后将被删除,但在执行 sdist 等命令时可用。
注意
如果 svn_version.py 在之前存在,则不执行任何操作。
这适用于在 SVN 存储库中的源目录中的工作。
make_config_py(name='__config__')
生成包含在构建软件包期间使用的 system_info 信息的包 config.py 文件。
此文件将被安装到包安装目录中。
get_info(*names)
获取资源信息。
以单个字典的形式返回参数列表中所有名称的信息(来自 system_info.get_info)。
构建可安装的 C 库
传统的 C 库(通过add_library安装)不会被安装,仅在构建过程中使用(它们是静态链接的)。可安装的 C 库是一个纯 C 库,不依赖于 python C 运行时,并且被安装以便它可以被第三方软件包使用。要构建和安装 C 库,只需使用方法add_installed_library,而不是add_library,它除了额外的install_dir参数外,其他参数和add_library相同:
.. hidden in a comment so as to be included in refguide but not rendered documentation
>>> import numpy.distutils.misc_util
>>> config = np.distutils.misc_util.Configuration(None, '', '.')
>>> with open('foo.c', 'w') as f: pass
>>> config.add_installed_library('foo', sources=['foo.c'], install_dir='lib')
npy-pkg-config 文件
为了使必要的构建选项对第三方可用,您可以使用numpy.distutils中实现的npy-pkg-config机制。该机制基于包含所有选项的.ini 文件。.ini 文件与 pkg-config UNIX 实用程序使用的.pc 文件非常相似:
[meta]
Name: foo
Version: 1.0
Description: foo library
[variables]
prefix = /home/user/local
libdir = ${prefix}/lib
includedir = ${prefix}/include
[default]
cflags = -I${includedir}
libs = -L${libdir} -lfoo
通常在构建时需要生成该文件,因为它仅需要在构建时才能获得一些已知信息(例如前缀)。如果使用Configuration方法add_npy_pkg_config,则大部分情况下会自动生成。假设我们有一个模板文件 foo.ini.in 如下所示:
[meta]
Name: foo
Version: @version@
Description: foo library
[variables]
prefix = @prefix@
libdir = ${prefix}/lib
includedir = ${prefix}/include
[default]
cflags = -I${includedir}
libs = -L${libdir} -lfoo
以及 setup.py 中的以下代码:
>>> config.add_installed_library('foo', sources=['foo.c'], install_dir='lib')
>>> subst = {'version': '1.0'}
>>> config.add_npy_pkg_config('foo.ini.in', 'lib', subst_dict=subst)
这将把文件 foo.ini 安装到目录 package_dir/lib 中,并且 foo.ini 文件将从 foo.ini.in 生成,其中每个@version@都将被替换为subst_dict['version']。字典还自动添加了一个额外的前缀替换规则,其中包含安装前缀(因为这不容易从 setup.py 中获取)。npy-pkg-config 文件也可以安装在与 numpy 使用的相同位置,使用从get_npy_pkg_dir函数返回的路径。
重用另一个软件包中的 C 库
信息可以很容易地从get_info函数中获取,该函数位于numpy.distutils.misc_util中:
>>> info = np.distutils.misc_util.get_info('npymath')
>>> config.add_extension('foo', sources=['foo.c'], extra_info=info)
<numpy.distutils.extension.Extension('foo') at 0x...>
可以提供一个附加的 .ini 文件路径列表给 get_info。
.src 文件的转换
NumPy distutils 支持自动转换命名为 .src 的源文件。此功能可用于维护非常相似的代码块,只需在块之间进行简单的更改。在设置的构建阶段中,如果遇到名为 .src 的模板文件,则会从模板构造一个名为 的新文件,并将其放置在生成目录中以供使用。支持两种模板转换形式。第一种形式用于命名为 .ext.src 的文件,其中 ext 是已识别的 Fortran 扩展名(f、f90、f95、f77、for、ftn、pyf)。第二种形式用于所有其他情况。请参阅 使用模板转换 .src 文件。
Modules in numpy.distutils
-
distutils.misc_util
-
all_strings -
allpath -
appendpath -
as_list -
blue_text -
cyan_text -
cyg2win32 -
default_config_dict -
dict_append -
dot_join -
exec_mod_from_location -
filter_sources -
generate_config_py -
get_build_architecture -
get_cmd -
get_data_files -
get_dependencies -
get_ext_source_files -
get_frame -
get_info -
get_language -
get_lib_source_files -
get_mathlibs -
get_num_build_jobs -
get_numpy_include_dirs -
get_pkg_info -
get_script_files -
gpaths -
green_text -
has_cxx_sources -
has_f_sources -
is_local_src_dir -
is_sequence -
is_string -
mingw32 -
minrelpath -
njoin -
red_text -
sanitize_cxx_flags -
terminal_has_colors -
yellow_text
-
ccompiler | |
|---|---|
ccompiler_opt | 提供CCompilerOpt类,用于处理 CPU/硬件优化,从解析命令参数开始,管理 CPU 基线和可调度功能之间的关系,还生成所需的 C 头文件,最后以正确的编译器标志编译源代码。 |
cpuinfo.cpu | |
core.Extension(name, sources[, …]) |
Parameters:
|
exec_command | exec_command |
|---|---|
log.set_verbosity(v[, force]) | |
system_info.get_info(name[, notfound_action]) | notfound_action: |
system_info.get_standard_file(fname) | 从以下位置之一返回名为 ‘fname’ 的文件列表:1) 系统范围的目录(该模块的目录位置) 2) 用户主目录(os.environ[‘HOME’]) 3) 本地目录 |
配置类
class numpy.distutils.misc_util.Configuration(package_name=None, parent_name=None, top_path=None, package_path=None, **attrs)
为给定的包名称构造一个配置实例。如果 parent_name 不为 None,则将包构造为 parent_name 包的子包。如果 top_path 和 package_path 为 None,则它们被假定为与创建此实例的文件的路径相等。numpy 分发中的 setup.py 文件是如何使用Configuration实例的好例子。
todict()
返回一个与 distutils 安装函数的关键字参数兼容的字典。
示例
>>> setup(**config.todict())
get_distribution()
返回 self 的 distutils 分发对象。
get_subpackage(subpackage_name, subpackage_path=None, parent_name=None, caller_level=1)
返回子包配置的列表。
参数:
subpackage_namestr 或 None
获取配置的子包名称。子包名称中的‘*’将被视为通配符处理。
subpackage_pathstr
如果为 None,则路径假定为本地路径加上 subpackage_name。如果在 subpackage_path 中找不到 setup.py 文件,则使用默认配置。
parent_namestr
父级名称。
add_subpackage(subpackage_name, subpackage_path=None, standalone=False)
将子包添加到当前 Configuration 实例中。
这在 setup.py 脚本中对包添加子包时非常有用。
参数:
subpackage_namestr
子包的名称。
subpackage_pathstr
如果提供了该参数,则子包的路径为 subpackage_path / subpackage_name。如果为 None,则假定子包位于本地路径 / subpackage_name。
standalonebool
add_data_files(*files)
将数据文件添加到配置数据文件中。
参数:
filessequence
参数可以是以下内容之一
- 2-sequence(<datadir 前缀>,<数据文件的路径>)
- 数据文件的路径,默认为包目录。
注意事项
文件序列的每个元素的形式非常灵活,允许从包中获取文件的许多组合,以及它们应该最终安装在系统上的位置。最基本的用法是将 files 参数序列的一个元素设置为简单的文件名。这将导致将本地路径的该文件安装到 self.name 包的安装路径(包路径)中。文件参数还可以是相对路径,这样将整个相对路径安装到包目录中。最后,文件可以是绝对路径名,在这种情况下,文件将在绝对路径名处找到,但安装到包路径中。
该基本行为可以通过将 2 元组作为文件参数传递进行增强。元组的第一个元素应指定应安装剩余一系列文件的相对路径(在包安装目录下)(与源分发中的文件名无关)。元组的第二个元素是应安装的文件序列。该序列中的文件可以是文件名,相对路径或绝对路径。对于绝对路径,该文件将安装在顶层包安装目录中(而不管第一个参数)。文件名和相对路径名将安装在作为元组第一个元素给出的路径名下的包安装目录中。
安装路径规则:
- file.txt -> (., file.txt)-> parent/file.txt
- foo/file.txt -> (foo, foo/file.txt) -> parent/foo/file.txt
- /foo/bar/file.txt -> (., /foo/bar/file.txt) -> parent/file.txt
*.txt -> parent/a.txt,parent/b.txt- foo/
*.txt`` -> parent/foo/a.txt, parent/foo/b.txt*/*.txt-> (*,*/*.txt) -> parent/c/a.txt, parent/d/b.txt- (sun, file.txt) -> parent/sun/file.txt
- (sun, bar/file.txt) -> parent/sun/file.txt
- (sun, /foo/bar/file.txt) -> parent/sun/file.txt
- (sun,
*.txt) -> parent/sun/a.txt, parent/sun/b.txt- (sun, bar/
*.txt) -> parent/sun/a.txt, parent/sun/b.txt- (sun/
*,*/*.txt) -> parent/sun/c/a.txt, parent/d/b.txt
一个附加特性是数据文件的路径实际上可以是一个不带参数并返回数据文件实际路径的函数。当数据文件在构建软件包时生成时,这将非常有用。
示例
将文件添加到要与该软件包一起包含的 data_files 列表中。
>>> self.add_data_files('foo.dat',
... ('fun', ['gun.dat', 'nun/pun.dat', '/tmp/sun.dat']),
... 'bar/cat.dat',
... '/full/path/to/can.dat')
将这些数据文件安装到:
<package install directory>/
foo.dat
fun/
gun.dat
nun/
pun.dat
sun.dat
bar/
car.dat
can.dat
其中<包安装目录>是包(或子包)目录,例如’/usr/lib/python2.4/site-packages/mypackage’(‘C:Python2.4 Lib site-packages mypackage’)或’/usr/lib/python2.4/site-packages/mypackage/mysubpackage’(‘C:Python2.4 Lib site-packages mypackage mysubpackage’)。
add_data_dir(data_path)
递归地将 data_path 下的文件添加到 data_files 列表中。
递归地将 data_path 下的文件添加到要安装(和分发)的 data_files 列表中。data_path 可以是相对路径名,也可以是绝对路径名,还可以是一个 2 元组,其中第一个参数显示数据文件夹应安装到安装目录中的位置。
参数:
data_pathseq 或 str
参数可以是
- 2 元组(<datadir 后缀>,<数据目录路径>)
- 数据目录路径,其中 python datadir 后缀默认为包目录。
注意
安装路径规则:
foo/bar -> (foo/bar, foo/bar) -> parent/foo/bar
(gun, foo/bar) -> parent/gun
foo/* -> (foo/a, foo/a), (foo/b, foo/b) -> parent/foo/a, parent/foo/b
(gun, foo/*) -> (gun, foo/a), (gun, foo/b) -> gun
(gun/*, foo/*) -> parent/gun/a, parent/gun/b
/foo/bar -> (bar, /foo/bar) -> parent/bar
(gun, /foo/bar) -> parent/gun
(fun/*/gun/*, sun/foo/bar) -> parent/fun/foo/gun/bar
示例
例如,假设源目录包含 fun/foo.dat 和 fun/bar/car.dat:
>>> self.add_data_dir('fun')
>>> self.add_data_dir(('sun', 'fun'))
>>> self.add_data_dir(('gun', '/full/path/to/fun'))
将数据文件安装到以下位置:
<package install directory>/
fun/
foo.dat
bar/
car.dat
sun/
foo.dat
bar/
car.dat
gun/
foo.dat
car.dat
add_include_dirs(*paths)
添加到配置包含目录的路径。
将给定的路径序列添加到 include_dirs 列表的开头。这个列表将对当前包的所有扩展模块可见。
add_headers(*files)
将可安装的头文件添加到配置中。
将给定的文件序列添加到头文件列表的开头。默认情况下,头文件将安装在/<self.name.replace(‘.’,‘/’)>/目录下。如果 files 的项目是元组,则其第一个参数指定相对于路径的实际安装位置。
参数:
files字符串或序列
参数可以是:
- 2 元组(<includedir 后缀>,<头文件路径>)
- 头文件的路径,其中 python include 目录后缀默认为包名称。
add_extension(name, sources, **kw)
添加扩展到配置。
创建并将一个 Extension 实例添加到 ext_modules 列表。此方法还接受以下可选关键字参数,这些参数传递给 Extension 构造函数。
参数:
name字符串
扩展的名称
sources序列
源文件列表。源文件列表可能包含函数(称为源代码生成器),其必须以扩展实例和构建目录为输入,并返回源文件或源文件列表或 None。如果返回 None,则不会生成任何源文件。如果扩展实例在处理所有源代码生成器后没有源文件,则不会构建任何扩展模块。
include_dirs
define_macros
undef_macros
library_dirs
libraries
runtime_library_dirs
extra_objects
extra_compile_args
extra_link_args
extra_f77_compile_args
extra_f90_compile_args
export_symbols
swig_opts
depends
depends 列表包含扩展模块的来源依赖的文件或目录路径。如果 depends 列表中的任何路径比扩展模块更新,那么模块将被重建。
language
f2py_options
module_dirs
extra_info字典或列表
字典或关键字列表以附加到关键字。
注意
对所有可能包含路径的列表应用 self.paths(…)方法。
add_library(name, sources, **build_info)
将库添加到配置。
参数:
name字符串
扩展的名称。
sources序列
源文件列表。源文件列表可能包含函数(称为源代码生成器),其必须以扩展实例和构建目录为输入,并返回源文件或源文件列表或 None。如果返回 None,则不会生成任何源文件。如果扩展实例在处理所有源代码生成器后没有源文件,则不会构建任何扩展模块。
build_info字典,可选
允许以下键:
- depends
- 宏
- include_dirs
- extra_compiler_args
- extra_f77_compile_args
- extra_f90_compile_args
- f2py_options
- 语言
add_scripts(*files)
添加脚本到配置。
将文件序列添加到脚本列表的开头。脚本将安装在/bin/目录下。
add_installed_library(name, sources, install_dir, build_info=None)
类似于 add_library,但指定的库已安装。
大多数与distutils一起使用的 C 库仅用于构建 Python 扩展,但通过此方法构建的库将被安装,以便它们可以被第三方包重复使用。
参数:
namestr
安装库的名称。
sourcessequence
库的源文件列表。有关详情,请参见add_library。
install_dirstr
库的安装路径,相对于当前子包。
build_infodict,可选
允许以下键:
- 依赖
- 宏
- include_dirs
- extra_compiler_args
- extra_f77_compile_args
- extra_f90_compile_args
- f2py_options
- 语言
返回:
无
另请参阅
add_library,add_npy_pkg_config,get_info
注释
链接到指定的 C 库所需选项的最佳方法是使用“libname.ini”文件,并使用get_info检索所需选项(有关更多信息,请参见add_npy_pkg_config)。
add_npy_pkg_config(template, install_dir, subst_dict=None)
从模板生成并安装一个 npy-pkg 配置文件。
从template生成的配置文件使用subst_dict进行变量替换,并安装在给定的安装目录中。
参数:
templatestr
模板的路径,相对于当前包路径。
install_dirstr
安装 npy-pkg 配置文件的位置,相对于当前包路径。
subst_dictdict,可选
如果给定,任何形式为@key@的字符串在安装时都将在模板文件中被subst_dict[key]替换。由于从 setup.py 中可靠地获取安装前缀并不容易,所以安装前缀始终可通过变量@prefix@获得。
另请参阅
add_installed_library,get_info
注释
这适用于标准安装和原地构建,即对于原地构建,@prefix@指的是源目录。
示例
config.add_npy_pkg_config('foo.ini.in', 'lib', {'foo': bar})
假设 foo.ini.in 文件具有以下内容:
[meta]
Name=@foo@
Version=1.0
Description=dummy description
[default]
Cflags=-I@prefix@/include
Libs=
生成的文件将具有以下内容:
[meta]
Name=bar
Version=1.0
Description=dummy description
[default]
Cflags=-Iprefix_dir/include
Libs=
并将安装为‘lib’子路径中的 foo.ini。
在使用 numpy distutils 进行交叉编译时,可能需要使用修改过的 npy-pkg-config 文件。使用默认/生成的文件将链接到宿主库(即 libnpymath.a)。在交叉编译时,你当然需要链接到目标库,同时使用宿主 Python 安装。
您可以将 numpy/core/lib/npy-pkg-config 目录复制出来,向 .ini 文件添加 pkgdir 值,并将 NPY_PKG_CONFIG_PATH 环境变量设置为指向修改后的 npy-pkg-config 文件的目录。
修改了用于交叉编译的 npymath.ini 示例:
[meta]
Name=npymath
Description=Portable, core math library implementing C99 standard
Version=0.1
[variables]
pkgname=numpy.core
pkgdir=/build/arm-linux-gnueabi/sysroot/usr/lib/python3.7/site-packages/numpy/core
prefix=${pkgdir}
libdir=${prefix}/lib
includedir=${prefix}/include
[default]
Libs=-L${libdir} -lnpymath
Cflags=-I${includedir}
Requires=mlib
[msvc]
Libs=/LIBPATH:${libdir} npymath.lib
Cflags=/INCLUDE:${includedir}
Requires=mlib
paths(*paths, **kws)
对路径应用 glob 并在需要时在路径前加上 local_path。
对序列中的每个路径(如果需要)应用 glob.glob(…)并在需要时在路径前加上 local_path。因为这在所有源列表上都会被调用,这允许在扩展模块、库和脚本的源列表中指定通配符字符,同时也允许路径名相对于源目录。
get_config_cmd()
返回 numpy.distutils 配置命令实例。
get_build_temp_dir()
返回一个临时目录的路径,用于存放临时文件。
have_f77c()
检查是否可用 Fortran 77 编译器。
在源生成函数内部使用,以确保设置分发实例已被初始化。
注意
如果可用(因为能够成功编译简单的 Fortran 77 代码),则返回 True。
have_f90c()
检查是否可用 Fortran 90 编译器。
在源生成函数内部使用,以确保设置分发实例已被初始化。
注意
如果可用(因为能够成功编译简单的 Fortran 90 代码),则返回 True。
get_version(version_file=None, version_variable=None)
尝试获取包的版本字符串。
返回当前包的版本字符串,如果无法检测到版本信息,则返回 None。
注意
此方法扫描名为 version.py、_version.py、version.py 和 svn_version.py 的文件,查找字符串变量 version、version 和 _version,直到找到版本号为止。
make_svn_version_py(delete=True)
向 data_files 列表添加一个生成 svn_version.py 文件的数据函数,将其生成到当前包目录。
从 SVN 修订号生成包 svn_version.py 文件,它将在 Python 退出时被移除,但在执行 sdist 等命令时仍然可用。
注意
如果 svn_version.py 存在,则不进行任何操作。
这是为了处理处于 SVN 代码库中的源目录而设计的。
make_config_py(name='__config__')
生成包含在构建包期间使用的 system_info 信息的包 config.py 文件。
此文件将安装到包安装目录中。
get_info(*names)
获取资源信息。
以单个字典的形式返回参数列表中所有名称的信息(来自 system_info.get_info)。
构建可安装的 C 库
传统的 C 库(通过 add_library 安装)不会被安装,而只是在构建期间使用(它们是静态链接的)。可安装的 C 库是一个纯 C 库,不依赖于 python C 运行时,并且被安装以便第三方包可以使用。要构建和安装 C 库,只需使用方法 add_installed_library 而不是 add_library,它接受相同的参数,除了额外的 install_dir 参数:
.. hidden in a comment so as to be included in refguide but not rendered documentation
>>> import numpy.distutils.misc_util
>>> config = np.distutils.misc_util.Configuration(None, '', '.')
>>> with open('foo.c', 'w') as f: pass
>>> config.add_installed_library('foo', sources=['foo.c'], install_dir='lib')
npy-pkg-config 文件
要使必要的构建选项对第三方可用,可以使用 npy-pkg-config 机制,该机制在 numpy.distutils 中实现。该机制基于一个 .ini 文件,其中包含所有选项。一个 .ini 文件与 pkg-config unix 实用程序使用的 .pc 文件非常相似:
[meta]
Name: foo
Version: 1.0
Description: foo library
[variables]
prefix = /home/user/local
libdir = ${prefix}/lib
includedir = ${prefix}/include
[default]
cflags = -I${includedir}
libs = -L${libdir} -lfoo
通常,文件需要在构建期间生成,因为它只在构建时需要一些仅在构建时已知的信息(例如前缀)。如果使用了 Configuration 方法 add_npy_pkg_config,那么这主要是自动的。假设我们有一个模板文件 foo.ini.in,如下所示:
[meta]
Name: foo
Version: @version@
Description: foo library
[variables]
prefix = @prefix@
libdir = ${prefix}/lib
includedir = ${prefix}/include
[default]
cflags = -I${includedir}
libs = -L${libdir} -lfoo
以及在 setup.py 中的以下代码:
>>> config.add_installed_library('foo', sources=['foo.c'], install_dir='lib')
>>> subst = {'version': '1.0'}
>>> config.add_npy_pkg_config('foo.ini.in', 'lib', subst_dict=subst)
这将把文件 foo.ini 安装到目录 package_dir/lib 中,并且 foo.ini 文件将从 foo.ini.in 生成,其中每个 @version@ 将被 subst_dict['version'] 替换。字典还自动添加了一个额外的前缀替换规则,其中包含安装前缀(因为这在 setup.py 中不容易获取)。npy-pkg-config 文件也可以安装到与 numpy 使用的相同位置,使用从 get_npy_pkg_dir 函数返回的路径。
从另一个包中重用 C 库
信息可以轻松地从 numpy.distutils.misc_util 中的 get_info 函数中检索到:
>>> info = np.distutils.misc_util.get_info('npymath')
>>> config.add_extension('foo', sources=['foo.c'], extra_info=info)
<numpy.distutils.extension.Extension('foo') at 0x...>
额外的 .ini 文件搜索路径列表可以提供给 get_info。
npy-pkg-config 文件
要使必要的构建选项对第三方可用,可以使用 npy-pkg-config 机制,该机制在 numpy.distutils 中实现。该机制基于一个 .ini 文件,其中包含所有选项。一个 .ini 文件与 pkg-config unix 实用程序使用的 .pc 文件非常相似:
[meta]
Name: foo
Version: 1.0
Description: foo library
[variables]
prefix = /home/user/local
libdir = ${prefix}/lib
includedir = ${prefix}/include
[default]
cflags = -I${includedir}
libs = -L${libdir} -lfoo
通常,文件需要在构建期间生成,因为它只在构建时需要一些仅在构建时已知的信息(例如前缀)。如果使用了 Configuration 方法 add_npy_pkg_config,那么这主要是自动的。假设我们有一个模板文件 foo.ini.in,如下所示:
[meta]
Name: foo
Version: @version@
Description: foo library
[variables]
prefix = @prefix@
libdir = ${prefix}/lib
includedir = ${prefix}/include
[default]
cflags = -I${includedir}
libs = -L${libdir} -lfoo
以及在 setup.py 中的以下代码:
>>> config.add_installed_library('foo', sources=['foo.c'], install_dir='lib')
>>> subst = {'version': '1.0'}
>>> config.add_npy_pkg_config('foo.ini.in', 'lib', subst_dict=subst)
这将把文件 foo.ini 安装到目录 package_dir/lib 中,并且 foo.ini 文件将从 foo.ini.in 生成,其中每个 @version@ 将被 subst_dict['version'] 替换。字典还会自动添加一个额外的前缀替换规则,其中包含安装前缀(因为这在 setup.py 中不容易获取)。npy-pkg-config 文件也可以安装到与 numpy 使用的相同位置,使用从 get_npy_pkg_dir 函数返回的路径。
重用另一个软件包中的 C 库
信息可以轻松从 numpy.distutils.misc_util 中的 get_info 函数中检索:
>>> info = np.distutils.misc_util.get_info('npymath')
>>> config.add_extension('foo', sources=['foo.c'], extra_info=info)
<numpy.distutils.extension.Extension('foo') at 0x...>
可以向 get_info 函数提供一个额外的路径列表,用于查找 .ini 文件。
.src 文件的转换
NumPy distutils 支持自动转换命名为 .src 的源文件。这个功能可以用来维护非常相似的代码块,只需要在块之间进行简单的更改。在设置的构建阶段中,如果遇到名为 .src 的模板文件,则会从模板构建一个新文件命名为 并放置在构建目录中以供使用。支持两种形式的模板转换。第一种形式适用于以已识别的 Fortran 扩展名(f、f90、f95、f77、for、ftn、pyf)命名的文件。第二种形式适用于所有其他情况。请参阅使用模板转换 .src 文件。
-lfoo
通常,文件需要在构建期间生成,因为它只在构建时需要一些仅在构建时已知的信息(例如前缀)。如果使用了 `Configuration` 方法 *add_npy_pkg_config*,那么这主要是自动的。假设我们有一个模板文件 foo.ini.in,如下所示:
```py
[meta]
Name: foo
Version: @version@
Description: foo library
[variables]
prefix = @prefix@
libdir = ${prefix}/lib
includedir = ${prefix}/include
[default]
cflags = -I${includedir}
libs = -L${libdir} -lfoo
以及在 setup.py 中的以下代码:
>>> config.add_installed_library('foo', sources=['foo.c'], install_dir='lib')
>>> subst = {'version': '1.0'}
>>> config.add_npy_pkg_config('foo.ini.in', 'lib', subst_dict=subst)
这将把文件 foo.ini 安装到目录 package_dir/lib 中,并且 foo.ini 文件将从 foo.ini.in 生成,其中每个 @version@ 将被 subst_dict['version'] 替换。字典还自动添加了一个额外的前缀替换规则,其中包含安装前缀(因为这在 setup.py 中不容易获取)。npy-pkg-config 文件也可以安装到与 numpy 使用的相同位置,使用从 get_npy_pkg_dir 函数返回的路径。
从另一个包中重用 C 库
信息可以轻松地从 numpy.distutils.misc_util 中的 get_info 函数中检索到:
>>> info = np.distutils.misc_util.get_info('npymath')
>>> config.add_extension('foo', sources=['foo.c'], extra_info=info)
<numpy.distutils.extension.Extension('foo') at 0x...>
额外的 .ini 文件搜索路径列表可以提供给 get_info。
npy-pkg-config 文件
要使必要的构建选项对第三方可用,可以使用 npy-pkg-config 机制,该机制在 numpy.distutils 中实现。该机制基于一个 .ini 文件,其中包含所有选项。一个 .ini 文件与 pkg-config unix 实用程序使用的 .pc 文件非常相似:
[meta]
Name: foo
Version: 1.0
Description: foo library
[variables]
prefix = /home/user/local
libdir = ${prefix}/lib
includedir = ${prefix}/include
[default]
cflags = -I${includedir}
libs = -L${libdir} -lfoo
通常,文件需要在构建期间生成,因为它只在构建时需要一些仅在构建时已知的信息(例如前缀)。如果使用了 Configuration 方法 add_npy_pkg_config,那么这主要是自动的。假设我们有一个模板文件 foo.ini.in,如下所示:
[meta]
Name: foo
Version: @version@
Description: foo library
[variables]
prefix = @prefix@
libdir = ${prefix}/lib
includedir = ${prefix}/include
[default]
cflags = -I${includedir}
libs = -L${libdir} -lfoo
以及在 setup.py 中的以下代码:
>>> config.add_installed_library('foo', sources=['foo.c'], install_dir='lib')
>>> subst = {'version': '1.0'}
>>> config.add_npy_pkg_config('foo.ini.in', 'lib', subst_dict=subst)
这将把文件 foo.ini 安装到目录 package_dir/lib 中,并且 foo.ini 文件将从 foo.ini.in 生成,其中每个 @version@ 将被 subst_dict['version'] 替换。字典还会自动添加一个额外的前缀替换规则,其中包含安装前缀(因为这在 setup.py 中不容易获取)。npy-pkg-config 文件也可以安装到与 numpy 使用的相同位置,使用从 get_npy_pkg_dir 函数返回的路径。
重用另一个软件包中的 C 库
信息可以轻松从 numpy.distutils.misc_util 中的 get_info 函数中检索:
>>> info = np.distutils.misc_util.get_info('npymath')
>>> config.add_extension('foo', sources=['foo.c'], extra_info=info)
<numpy.distutils.extension.Extension('foo') at 0x...>
可以向 get_info 函数提供一个额外的路径列表,用于查找 .ini 文件。
.src 文件的转换
NumPy distutils 支持自动转换命名为 .src 的源文件。这个功能可以用来维护非常相似的代码块,只需要在块之间进行简单的更改。在设置的构建阶段中,如果遇到名为 .src 的模板文件,则会从模板构建一个新文件命名为 并放置在构建目录中以供使用。支持两种形式的模板转换。第一种形式适用于以已识别的 Fortran 扩展名(f、f90、f95、f77、for、ftn、pyf)命名的文件。第二种形式适用于所有其他情况。请参阅使用模板转换 .src 文件。

















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









