







scipy.stats.skew
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.skew.html#scipy.stats.skew
scipy.stats.skew(a, axis=0, bias=True, nan_policy='propagate', *, keepdims=False)
计算数据集的样本偏度。
对于正态分布的数据,偏度应该大约为零。对于单峰连续分布,偏度值大于零意味着分布的右尾部分权重更大。函数skewtest可用于确定偏度值是否足够接近零,从统计学角度讲。
参数:
andarray
输入数组。
axis整数或 None,默认值:0
如果是整数,则是要沿其计算统计量的输入轴。输入的每个轴切片(例如行)的统计量将出现在输出的相应元素中。如果为None,则在计算统计量之前将对输入进行拉平。
bias布尔值,可选
如果为 False,则校正统计偏差。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN。
-
propagate:如果轴切片(例如行)中存在 NaN,则计算统计量的相应条目将是 NaN。 -
omit:在执行计算时将省略 NaN。如果沿着计算统计量的轴切片中剩余的数据不足,输出的相应条目将是 NaN。 -
raise:如果存在 NaN,则引发ValueError。
keepdims布尔值,默认值:False
如果设置为 True,则减少的轴将作为具有大小为一的维度保留在结果中。使用此选项,结果将正确广播到输入数组。
返回:
skewnessndarray
沿轴线的值的偏斜度,在所有值相等时返回 NaN。
注意
样本偏斜度被计算为费舍尔-皮尔逊偏斜度系数,即。
[g_1=\frac{m_3}{m_2^{3/2}}]
where
[m_i=\frac{1}{N}\sum_{n=1}N(x[n]-\bar{x})i]
是偏样本(i\texttt{th})中心矩,(\bar{x})是样本均值。如果bias为 False,则校正了偏差并计算出调整后的费舍尔-皮尔逊标准化矩系数,即。
[G_1=\frac{k_3}{k_2^{3/2}}= \frac{\sqrt{N(N-1)}}{N-2}\frac{m_3}{m_2^{3/2}}.]
从 SciPy 1.9 开始,np.matrix输入(不建议用于新代码)在执行计算之前会转换为np.ndarray。在这种情况下,输出将是一个适当形状的标量或np.ndarray,而不是 2D np.matrix。类似地,虽然忽略掩码数组的掩码元素,但输出将是一个标量或np.ndarray,而不是具有mask=False的掩码数组。
参考文献
[1]
Zwillinger, D. 和 Kokoska, S. (2000). CRC 标准概率和统计表和公式。Chapman & Hall: 纽约。2000 年。第 2.2.24.1 节
示例
>>> from scipy.stats import skew
>>> skew([1, 2, 3, 4, 5])
0.0
>>> skew([2, 8, 0, 4, 1, 9, 9, 0])
0.2650554122698573
scipy.stats.kstat
原文:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.kstat.html#scipy.stats.kstat
scipy.stats.kstat(data, n=2, *, axis=None, nan_policy='propagate', keepdims=False)
返回第 n 个 k-统计量(目前 1<=n<=4)。
第 n 个 k-统计量 k_n 是第 n 个累积量(\kappa_n)的唯一对称无偏估计量。
参数:
dataarray_like
输入数组。注意,n 维输入被展平。
n整数,{1, 2, 3, 4},可选
默认值为 2。
axis整数或 None,默认值:None
如果是整数,则为计算统计量的输入轴。输入的每个轴切片(例如行)的统计量将出现在输出的相应元素中。如果为None,则在计算统计量之前将对输入进行拉平。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN。
-
propagate:如果在计算统计量的轴切片(例如行)中存在 NaN,则输出的相应条目将是 NaN。 -
omit:在执行计算时将省略 NaN。如果沿着计算统计量的轴切片中剩余的数据不足,输出的相应条目将是 NaN。 -
raise:如果存在 NaN,则会引发ValueError。
keepdims布尔值,默认值:False
如果设置为 True,则被减少的轴将作为大小为一的维度保留在结果中。通过此选项,结果将正确地广播到输入数组。
返回:
kstat浮点数
第 n 个 k-统计量。
另见
kstatvar
返回第 n 个 k-统计量的无偏估计方差
moment
返回样本关于均值的第 n 个中心矩。
注:
对于样本大小 n,前几个 k-统计量为:
[k_{1} = \mu k_{2} = \frac{n}{n-1} m_{2} k_{3} = \frac{ n^{2} } {(n-1) (n-2)} m_{3} k_{4} = \frac{ n^{2} [(n + 1)m_{4} - 3(n - 1) m²_{2}]} {(n-1) (n-2) (n-3)}]
其中(\mu)是样本均值,(m_2)是样本方差,(m_i)是第 i 个样本中心矩。
从 SciPy 1.9 开始,np.matrix输入(不推荐新代码使用)在执行计算之前会转换为np.ndarray。在这种情况下,输出将是合适形状的标量或np.ndarray,而不是 2D 的np.matrix。类似地,虽然忽略掩码数组的掩码元素,输出将是标量或np.ndarray,而不是带有mask=False的掩码数组。
参考文献
mathworld.wolfram.com/k-Statistic.html
mathworld.wolfram.com/Cumulant.html
示例
>>> from scipy import stats
>>> from numpy.random import default_rng
>>> rng = default_rng()
随着样本大小的增加,第 n 个矩和第 n 个 k-统计量收敛到相同的数值(尽管它们不完全相同)。在正态分布的情况下,它们收敛到零。
>>> for n in [2, 3, 4, 5, 6, 7]:
... x = rng.normal(size=10**n)
... m, k = stats.moment(x, 3), stats.kstat(x, 3)
... print("%.3g %.3g %.3g" % (m, k, m-k))
-0.631 -0.651 0.0194 # random
0.0282 0.0283 -8.49e-05
-0.0454 -0.0454 1.36e-05
7.53e-05 7.53e-05 -2.26e-09
0.00166 0.00166 -4.99e-09
-2.88e-06 -2.88e-06 8.63e-13
scipy.stats.kstatvar
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.kstatvar.html#scipy.stats.kstatvar
scipy.stats.kstatvar(data, n=2, *, axis=None, nan_policy='propagate', keepdims=False)
返回 k-统计量方差的无偏估计器。
查看kstat以获取 k-统计量的更多详细信息。
参数:
dataarray_like
输入数组。请注意,n 维输入会被展平。
nint,{1, 2},可选
默认为 2。
axisint 或 None,默认值:None
如果是整数,则是计算统计量的输入轴。输入的每个轴切片(例如行)的统计量将出现在输出的相应元素中。如果是None,则在计算统计量之前将对输入进行拉平。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN 值。
-
propagate:如果在计算统计量的轴片段(例如行)中存在 NaN,则输出的相应条目将为 NaN。 -
omit:在执行计算时将省略 NaN 值。如果沿着计算统计量的轴片段的数据不足,输出的相应条目将为 NaN。 -
raise:如果存在 NaN,则会引发ValueError。
keepdimsbool,默认值:False
如果设置为 True,则缩减的轴将作为大小为一的维度保留在结果中。使用此选项,结果将正确地对输入数组进行广播。
返回:
kstatvarfloat
第 n 个 k-统计量的方差。
另请参阅
返回第 n 个 k-统计量。
返回样本关于均值的第 n 个中心矩。
注意事项
前几个 k-统计量的方差为:
[var(k_{1}) = \frac{\kappa²}{n} var(k_{2}) = \frac{\kappa⁴}{n} + \frac{2\kappa²_{2}}{n - 1} var(k_{3}) = \frac{\kappa⁶}{n} + \frac{9 \kappa_2 \kappa_4}{n - 1} + \frac{9 \kappa²_{3}}{n - 1} + \frac{6 n \kappa³_{2}}{(n-1) (n-2)} var(k_{4}) = \frac{\kappa⁸}{n} + \frac{16 \kappa_2 \kappa_6}{n - 1} + \frac{48 \kappa_{3} \kappa_5}{n - 1} + \frac{34 \kappa²_{4}}{n-1} + \frac{72 n \kappa²_{2} \kappa_4}{(n - 1) (n - 2)} + \frac{144 n \kappa_{2} \kappa²_{3}}{(n - 1) (n - 2)} + \frac{24 (n + 1) n \kappa⁴_{2}}{(n - 1) (n - 2) (n - 3)}]
从 SciPy 1.9 开始,np.matrix输入(不建议新代码使用)在执行计算之前会转换为np.ndarray。在这种情况下,输出将是适当形状的标量或np.ndarray,而不是二维np.matrix。同样地,忽略掩码数组的掩码元素,输出将是标量或np.ndarray,而不是具有mask=False的掩码数组。
scipy.stats.tmean
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.tmean.html#scipy.stats.tmean
scipy.stats.tmean(a, limits=None, inclusive=(True, True), axis=None, *, nan_policy='propagate', keepdims=False)
计算修剪均值。
此函数找到给定值的算术平均值,忽略limits外的值。
参数:
a类似数组
数组的值。
limitsNone 或(下限,上限),可选
输入数组中小于下限或大于上限的值将被忽略。当 limits 为 None(默认值)时,使用所有值。元组中的任一限值也可以是 None,表示半开区间。
inclusive(布尔值,布尔值),可选
元组包含(下限标志,上限标志)。这些标志确定是否包括等于下限或上限的值。默认值为(True,True)。
axis整数或 None,默认为:None
如果是整数,则为计算统计量的输入轴(例如行)。输入的每个轴切片的统计量将显示在输出的相应元素中。如果为None,则在计算统计量之前会展平输入。
nan_policy{‘propagate’,‘omit’,‘raise’}
定义如何处理输入的 NaN 值。
-
propagate:如果在计算统计量的轴切片(例如行)中存在 NaN,则输出的相应条目将为 NaN。 -
omit:执行计算时将省略 NaN。如果在计算统计量的轴切片中剩余的数据不足,则输出的相应条目将为 NaN。 -
raise:如果存在 NaN,则会引发ValueError。
keepdims布尔值,默认为:False
如果设置为 True,则减少的轴将作为尺寸为一的维度保留在结果中。使用此选项,结果将正确广播到输入数组。
返回:
tmeanndarray
修剪均值。
另请参见
返回修剪了两侧比例后的均值。
注释
从 SciPy 1.9 开始,np.matrix输入(不推荐用于新代码)在执行计算之前会转换为np.ndarray。在这种情况下,输出将是标量或适当形状的np.ndarray,而不是二维np.matrix。类似地,尽管被屏蔽数组的屏蔽元素被忽略,输出将是标量或np.ndarray,而不是带有mask=False的屏蔽数组。
示例
>>> import numpy as np
>>> from scipy import stats
>>> x = np.arange(20)
>>> stats.tmean(x)
9.5
>>> stats.tmean(x, (3,17))
10.0
scipy.stats.tvar
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.tvar.html#scipy.stats.tvar
scipy.stats.tvar(a, limits=None, inclusive=(True, True), axis=0, ddof=1, *, nan_policy='propagate', keepdims=False)
计算修剪的方差。
此函数计算值数组的样本方差,同时忽略超出给定限制的值。
参数:
aarray_like
值数组。
limitsNone 或(下限, 上限),可选
输入数组中小于下限或大于上限的值将被忽略。当 limits 为 None 时,所有值都被使用。元组中的任一限制值也可以为 None,表示半开区间。默认值为 None。
inclusive(bool, bool),可选
一个由(下限标志,上限标志)组成的元组。这些标志确定是否包括等于下限或上限的值。默认值为(True, True)。
axisint 或 None,默认值:0
如果是 int,则计算统计量的输入轴。输入的每个轴切片(例如行)的统计量将出现在输出的相应元素中。如果为None,则在计算统计量之前将输入展平。
ddofint,可选
自由度的增量。默认值为 1。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN。
-
propagate: 如果在计算统计量的轴切片(例如行)中存在 NaN,则输出的相应条目将为 NaN。 -
omit: 在执行计算时将省略 NaN。如果沿着计算统计量的轴切片中剩余的数据不足,则输出的相应条目将为 NaN。 -
raise: 如果存在 NaN,将引发ValueError。
keepdimsbool,默认值:False
如果设置为 True,则减少的轴将保留在结果中作为大小为一的维度。使用此选项,结果将正确地针对输入数组进行广播。
返回:
tvarfloat
修剪方差。
注意
tvar计算无偏样本方差,即使用修正因子n / (n - 1)。
从 SciPy 1.9 开始,np.matrix输入(不建议在新代码中使用)在执行计算之前将被转换为np.ndarray。在这种情况下,输出将是适当形状的标量或np.ndarray,而不是 2D 的np.matrix。类似地,忽略掩码数组的掩码元素,输出将是适当形状的标量或np.ndarray,而不是带有mask=False的掩码数组。
示例
>>> import numpy as np
>>> from scipy import stats
>>> x = np.arange(20)
>>> stats.tvar(x)
35.0
>>> stats.tvar(x, (3,17))
20.0
scipy.stats.tmin
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.tmin.html#scipy.stats.tmin
scipy.stats.tmin(a, lowerlimit=None, axis=0, inclusive=True, nan_policy='propagate', *, keepdims=False)
计算修剪后的最小值。
此函数沿指定轴找到数组a的最小值,但仅考虑大于指定下限的值。
参数:
aarray_like
值数组。
lowerlimitNone 或浮点数,可选
输入数组中小于给定限制的值将被忽略。当 lowerlimit 为 None 时,将使用所有值。默认值为 None。
axis整数或 None,默认值:0
如果是整数,则沿着计算统计量的输入轴(例如行)的轴切片中的每个统计量将出现在输出的相应元素中。如果None,则在计算统计量之前将展平输入。
inclusive{True, False},可选
此标志确定是否包括与下限完全相等的值。默认值为 True。
nan_policy{‘传播’, ‘省略’, ‘提升’}
定义如何处理输入 NaN。
-
传播:如果轴切片(例如行)中存在 NaN,则计算统计量的相应输出条目将是 NaN。 -
省略:在执行计算时将省略 NaN。如果轴切片中的数据不足,计算统计量时,相应的输出条目将是 NaN。 -
提升:如果存在 NaN,则会引发ValueError。
keepdimsbool,默认值:False
如果设置为 True,则减少的轴将作为具有大小为一的维度保留在结果中。使用此选项,结果将正确广播到输入数组。
返回:
tmin浮点数、整数或 ndarray
修剪后的最小值。
注意事项
从 SciPy 1.9 开始,np.matrix输入(不建议用于新代码)在执行计算之前会转换为np.ndarray。在这种情况下,输出将是适当形状的标量或np.ndarray,而不是 2D 的np.matrix。类似地,虽然忽略掩码数组的掩码元素,但输出将是标量或np.ndarray,而不是具有mask=False的掩码数组。
示例
>>> import numpy as np
>>> from scipy import stats
>>> x = np.arange(20)
>>> stats.tmin(x)
0
>>> stats.tmin(x, 13)
13
>>> stats.tmin(x, 13, inclusive=False)
14
scipy.stats.tmax
原文:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.tmax.html#scipy.stats.tmax
scipy.stats.tmax(a, upperlimit=None, axis=0, inclusive=True, nan_policy='propagate', *, keepdims=False)
计算被修剪的最大值。
此函数计算沿给定轴的数组的最大值,同时忽略大于指定上限的值。
参数:
aarray_like
值的数组。
upperlimitNone 或 float,可选
输入数组中大于给定限制的值将被忽略。当 upperlimit 为 None 时,将使用所有值。默认值为 None。
axisint 或 None,默认:0
如果是 int,则是输入沿其计算统计量的轴。输入的每个轴切片(例如行)的统计量将显示在输出的相应元素中。如果为 None,则在计算统计量之前将展平输入。
inclusive{True, False},可选
此标志确定是否包括等于上限的值。默认值为 True。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN 值。
-
propagate:如果在计算统计量的轴切片(例如行)中存在 NaN,则输出的相应条目将为 NaN。 -
omit:在执行计算时将省略 NaN。如果在计算统计量的轴切片中剩余的数据不足,则输出的相应条目将为 NaN。 -
raise:如果存在 NaN,则会引发ValueError。
keepdimsbool,默认值:False
如果设置为 True,则被减少的轴作为大小为一的维度留在结果中。使用此选项,结果将正确地对输入数组进行广播。
返回:
tmaxfloat、int 或 ndarray
被修剪的最大值。
注:
从 SciPy 1.9 开始,np.matrix 输入(不建议用于新代码)在执行计算之前会转换为 np.ndarray。在这种情况下,输出将是适当形状的标量或 np.ndarray,而不是二维 np.matrix。类似地,虽然忽略了掩码数组的掩码元素,但输出将是标量或 np.ndarray,而不是带有 mask=False 的掩码数组。
示例
>>> import numpy as np
>>> from scipy import stats
>>> x = np.arange(20)
>>> stats.tmax(x)
19
>>> stats.tmax(x, 13)
13
>>> stats.tmax(x, 13, inclusive=False)
12
scipy.stats.tstd
原始文档:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.tstd.html#scipy.stats.tstd
scipy.stats.tstd(a, limits=None, inclusive=(True, True), axis=0, ddof=1, *, nan_policy='propagate', keepdims=False)
计算修剪样本标准差。
此函数找到给定值的样本标准差,忽略给定 limits 外的值。
参数:
a array_like
值数组。
limits None 或(下限,上限),可选
输入数组中小于下限或大于上限的值将被忽略。当限制为 None 时,所有值都被使用。元组中的任一限制值也可以为 None,表示半开区间。默认值为 None。
inclusive(布尔值,布尔值),可选
由(较低标志,较高标志)组成的元组。这些标志确定是否包含值等于下限或上限。默认值为(True,True)。
axis整数或 None,默认值:0
如果是整数,则是计算统计量的输入轴。输入的每个轴切片(例如行)的统计量将出现在输出的相应元素中。如果为 None,则在计算统计量之前将展平输入。
ddof整数,可选
自由度的 Delta。默认为 1。
nan_policy{‘propagate’,‘omit’,‘raise’}
定义如何处理输入的 NaN。
-
propagate:如果在计算统计量的轴切片(例如行)中存在 NaN,则输出的相应条目将是 NaN。 -
omit:在执行计算时将忽略 NaN。如果沿着计算统计量的轴切片的数据不足,输出的相应条目将为 NaN。 -
raise:如果存在 NaN,则会引发ValueError。
keepdims 布尔值,默认值:False
如果设置为 True,则减少的轴将作为尺寸为一的维度保留在结果中。使用此选项,结果将正确广播到输入数组。
返回:
tstd 浮点数
修剪样本标准差。
注意
tstd计算无偏样本标准差,即使用校正因子 n / (n - 1)。
从 SciPy 1.9 开始,np.matrix 输入(不建议新代码使用)在执行计算之前将转换为 np.ndarray。在这种情况下,输出将是适当形状的标量或 np.ndarray,而不是二维 np.matrix。同样,虽然忽略掩码数组的掩码元素,输出将是标量或 np.ndarray,而不是具有 mask=False 的掩码数组。
示例
>>> import numpy as np
>>> from scipy import stats
>>> x = np.arange(20)
>>> stats.tstd(x)
5.9160797830996161
>>> stats.tstd(x, (3,17))
4.4721359549995796
scipy.stats.tsem
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.tsem.html#scipy.stats.tsem
scipy.stats.tsem(a, limits=None, inclusive=(True, True), axis=0, ddof=1, *, nan_policy='propagate', keepdims=False)
计算剪裁后的平均标准误差。
此函数找到给定值的平均标准误差,忽略超出给定limits的值。
参数:
aarray_like
值数组。
limitsNone 或者 (下限, 上限),可选项
输入数组中小于下限或大于上限的值将被忽略。当 limits 为 None 时,将使用所有值。元组中的任何一个限制值也可以是 None,表示半开区间。默认值为 None。
inclusive(布尔值,布尔值),可选项
一个元组,包含(下限标志,上限标志)。这些标志确定是否包括与下限或上限完全相等的值。默认值为(True,True)。
axis整数或 None,默认为 0
如果是整数,则计算统计量的输入轴。输入的每个轴切片(例如行)的统计量将显示在输出的相应元素中。如果为None,则在计算统计量之前将展开输入。
ddof整数,可选项
自由度增量。默认值为 1。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN 值。
-
propagate: 如果轴切片(例如行)中存在 NaN,则输出的相应条目将是 NaN。 -
omit: 在执行计算时将省略 NaN 值。如果沿着计算统计量的轴切片中的数据不足,则输出的相应条目将是 NaN。 -
raise: 如果存在 NaN,则会引发ValueError。
keepdims布尔值,默认为 False
如果设置为 True,则减少的轴将作为大小为一的维度留在结果中。使用此选项,结果将正确地广播到输入数组。
返回:
tsemfloat
剪裁后的平均标准误差。
注释
tsem 使用无偏样本标准差,即使用校正因子 n / (n - 1)。
从 SciPy 1.9 开始,np.matrix 输入(不建议用于新代码)在执行计算之前将转换为 np.ndarray。在这种情况下,输出将是适当形状的标量或 np.ndarray,而不是 2D 的 np.matrix。类似地,忽略掩码数组的屏蔽元素,输出将是标量或 np.ndarray,而不是具有 mask=False 的掩码数组。
示例
>>> import numpy as np
>>> from scipy import stats
>>> x = np.arange(20)
>>> stats.tsem(x)
1.3228756555322954
>>> stats.tsem(x, (3,17))
1.1547005383792515
scipy.stats.variation
原文:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.variation.html#scipy.stats.variation
scipy.stats.variation(a, axis=0, nan_policy='propagate', ddof=0, *, keepdims=False)
计算变异系数。
变异系数是标准偏差除以均值。此函数等效于:
np.std(x, axis=axis, ddof=ddof) / np.mean(x)
ddof的默认值为 0,但是许多变异系数的定义使用样本标准偏差的无偏样本方差的平方根,对应于ddof=1。
函数不取数据均值的绝对值,因此如果均值为负,则返回值为负。
参数:
aarray_like
输入数组。
axisint 或 None,默认值:0
如果是整数,则输入沿其计算统计量的轴。输入的每个轴切片(例如行)的统计量将出现在输出的相应元素中。如果为None,则在计算统计量之前将对输入进行展平。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN。
-
propagate:如果在计算统计量的轴切片(例如行)中存在 NaN,则输出的相应条目将为 NaN。 -
omit: 在执行计算时将省略 NaN。如果沿着计算统计量的轴切片中剩余的数据不足,则输出的相应条目将为 NaN。 -
raise:如果存在 NaN,则会引发ValueError。
ddofint,可选
提供了在计算标准偏差时使用的“Delta Degrees Of Freedom”(自由度)。在计算标准偏差时使用的除数是N - ddof,其中N是元素的数量。ddof必须小于N;如果不是,则结果将是nan或inf,这取决于N和数组中的值。默认情况下,ddof为零以确保向后兼容性,但建议使用ddof=1以确保计算样本标准偏差作为无偏样本方差的平方根。
keepdimsbool,默认值:False
如果设置为 True,则减少的轴将保留在结果中作为大小为一的维度。使用此选项,结果将正确地对输入数组进行广播。
返回:
variationndarray
请求轴上计算的计算变异。
注意事项
处理多种边缘情况而不生成警告:
-
如果均值和标准偏差都为零,则返回
nan。 -
如果均值为零且标准偏差不为零,则返回
inf。 -
如果输入长度为零(因为数组长度为零,或所有输入值都是
nan且nan_policy为'omit'),则返回nan。 -
如果输入包含
inf,则返回nan。
从 SciPy 1.9 开始,不推荐使用np.matrix输入,在执行计算之前会转换为np.ndarray。在这种情况下,输出将是一个适当形状的标量或np.ndarray,而不是二维的np.matrix。类似地,虽然忽略掩码数组的掩码元素,但输出将是一个适当形状的标量或np.ndarray,而不是具有mask=False的掩码数组。
参考资料
[1]
Zwillinger, D. 和 Kokoska, S.(2000)。CRC 标准概率和统计表格与公式。Chapman & Hall:纽约。2000 年。
示例
>>> import numpy as np
>>> from scipy.stats import variation
>>> variation([1, 2, 3, 4, 5], ddof=1)
0.5270462766947299
计算包含少量nan值的数组沿给定维度的变化:
>>> x = np.array([[ 10.0, np.nan, 11.0, 19.0, 23.0, 29.0, 98.0],
... [ 29.0, 30.0, 32.0, 33.0, 35.0, 56.0, 57.0],
... [np.nan, np.nan, 12.0, 13.0, 16.0, 16.0, 17.0]])
>>> variation(x, axis=1, ddof=1, nan_policy='omit')
array([1.05109361, 0.31428986, 0.146483 ])
scipy.stats.find_repeats
scipy.stats.find_repeats(arr)
查找重复项和重复计数。
参数:
arrarray_like
输入数组。此数组被转换为 float64 类型。
返回:
valuesndarray
来自(扁平化的)输入的唯一值,它们是重复的。
countsndarray
相应的“value”重复的次数。
笔记
在 numpy >= 1.9 中,numpy.unique 提供类似的功能。主要区别在于 find_repeats 只返回重复的值。
示例
>>> from scipy import stats
>>> stats.find_repeats([2, 1, 2, 3, 2, 2, 5])
RepeatedResults(values=array([2.]), counts=array([4]))
>>> stats.find_repeats([[10, 20, 1, 2], [5, 5, 4, 4]])
RepeatedResults(values=array([4., 5.]), counts=array([2, 2]))
scipy.stats.rankdata
原文:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.rankdata.html#scipy.stats.rankdata
scipy.stats.rankdata(a, method='average', *, axis=None, nan_policy='propagate')
分配排名给数据,适当处理并列值。
默认情况下(axis=None),数据数组首先被展平,返回一个平坦的排名数组。如果需要,可以单独将排名数组重塑为数据数组的形状(请参见示例)。
排名从 1 开始。method参数控制如何对等值分配排名。详细讨论排名方法,请参见[1]。
参数:
aarray_like
要排名的值数组。
method{‘average’, ‘min’, ‘max’, ‘dense’, ‘ordinal’},可选
用于对并列元素分配排名的方法。提供以下方法(默认为‘average’):
- ‘average’:将所有并列值分配的排名的平均值分配给每个值。
- ‘min’:将所有并列值分配的排名的最小值分配给每个值。(这也称为“竞争”排名。)
- ‘max’:将所有并列值分配的排名的最大值分配给每个值。
- ‘dense’:类似于‘min’,但是将下一个最高元素的排名分配给紧接在并列元素之后的排名。
- ‘ordinal’:所有值都被赋予不同的排名,对应于它们在a中出现的顺序。
axis{None, int},可选
执行排名的轴。如果为None,则首先展平数据数组。
nan_policy{‘propagate’, ‘omit’, ‘raise’},可选
定义输入包含 nan 时的处理方式。提供以下选项(默认为‘propagate’):
- ‘propagate’:通过排名计算传播 nan
- ‘omit’:在执行排名时忽略 nan 值
- ‘raise’:引发错误
注意
当nan_policy为‘propagate’时,输出是所有 nan 的数组,因为输入中 nan 的排名是未定义的。当nan_policy为‘omit’时,排名其他值时会忽略a中的 nan,并且输出的对应位置是 nan。
版本 1.10 中的新增功能。
返回:
ranksndarray
一个大小与a相同的数组,包含排名分数。
参考文献
[1]
“排名”,en.wikipedia.org/wiki/Ranking
示例
>>> import numpy as np
>>> from scipy.stats import rankdata
>>> rankdata([0, 2, 3, 2])
array([ 1\. , 2.5, 4\. , 2.5])
>>> rankdata([0, 2, 3, 2], method='min')
array([ 1, 2, 4, 2])
>>> rankdata([0, 2, 3, 2], method='max')
array([ 1, 3, 4, 3])
>>> rankdata([0, 2, 3, 2], method='dense')
array([ 1, 2, 3, 2])
>>> rankdata([0, 2, 3, 2], method='ordinal')
array([ 1, 2, 4, 3])
>>> rankdata([[0, 2], [3, 2]]).reshape(2,2)
array([[1\. , 2.5],
[4\. , 2.5]])
>>> rankdata([[0, 2, 2], [3, 2, 5]], axis=1)
array([[1\. , 2.5, 2.5],
[2\. , 1\. , 3\. ]])
>>> rankdata([0, 2, 3, np.nan, -2, np.nan], nan_policy="propagate")
array([nan, nan, nan, nan, nan, nan])
>>> rankdata([0, 2, 3, np.nan, -2, np.nan], nan_policy="omit")
array([ 2., 3., 4., nan, 1., nan])
scipy.stats.tiecorrect
scipy.stats.tiecorrect(rankvals)
Mann-Whitney U 和 Kruskal-Wallis H 检验的校正系数。
参数:
rankvalsarray_like
一个一维排名序列。通常这将是由rankdata返回的数组。
返回:
factorfloat
U 或 H 的校正因子。
另请参阅
为数据分配排名
Mann-Whitney 秩和检验
Kruskal-Wallis H 检验
参考文献
[1]
Siegel, S. (1956)《行为科学的非参数统计》。纽约:麦格劳-希尔。
示例
>>> from scipy.stats import tiecorrect, rankdata
>>> tiecorrect([1, 2.5, 2.5, 4])
0.9
>>> ranks = rankdata([1, 3, 2, 4, 5, 7, 2, 8, 4])
>>> ranks
array([ 1\. , 4\. , 2.5, 5.5, 7\. , 8\. , 2.5, 9\. , 5.5])
>>> tiecorrect(ranks)
0.9833333333333333
scipy.stats.trim_mean
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.trim_mean.html#scipy.stats.trim_mean
scipy.stats.trim_mean(a, proportiontocut, axis=0)
返回修剪了分布两端后数组的均值。
如果proportiontocut = 0.1,则切掉分数的‘最左端’和‘最右端’各 10%。切片前对输入进行排序。如果比例导致非整数切片索引,则保守地切掉proportiontocut 。
参数:
aarray_like
输入数组。
proportiontocutfloat
分布两端要切掉的分数比例。
axisint 或 None,可选
计算修剪均值的轴。默认为 0。如果为 None,则在整个数组a上计算。
返回:
trim_meanndarray
修剪后数组的均值。
参见
trimboth
tmean
计算在给定limits外忽略的修剪均值。
示例
>>> import numpy as np
>>> from scipy import stats
>>> x = np.arange(20)
>>> stats.trim_mean(x, 0.1)
9.5
>>> x2 = x.reshape(5, 4)
>>> x2
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])
>>> stats.trim_mean(x2, 0.25)
array([ 8., 9., 10., 11.])
>>> stats.trim_mean(x2, 0.25, axis=1)
array([ 1.5, 5.5, 9.5, 13.5, 17.5])
scipy.stats.gstd
原文:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.gstd.html#scipy.stats.gstd
scipy.stats.gstd(a, axis=0, ddof=1)
计算数组的几何标准偏差。
几何标准偏差描述了首选几何平均值的一组数字的扩展。它是一个乘法因子,因此是一个无量纲的量。
定义为log(a)的标准偏差的指数。数学上,人口几何标准偏差可以计算为:
gstd = exp(std(log(a)))
新版本 1.3.0 中。
参数:
aarray_like
一个类似数组的对象,包含样本数据。
axisint、元组或无,可选
沿其操作的轴。默认为 0。如果为 None,则在整个数组a上计算。
ddofint,可选
在计算几何标准偏差时需要使用自由度修正。默认值为 1。
返回:
gstdndarray 或浮点数
一个几何标准偏差的数组。如果axis为 None 或a是 1 维数组,则返回一个浮点数。
参见
几何平均数
标准偏差
几何标准分数
注释
由于计算需要使用对数,几何标准偏差仅支持严格正值。任何非正或无限值都会引发ValueError。几何标准偏差有时会与标准偏差的指数exp(std(a))混淆。实际上,几何标准偏差是exp(std(log(a)))。ddof的默认值与其他包含 ddof 函数的默认值(0)不同,如np.std和np.nanstd。
参考文献
[1]
“几何标准偏差”,维基百科,en.wikipedia.org/wiki/Geometric_standard_deviation.
[2]
Kirkwood,T.B.,“几何平均数和离散度度量”,生物统计学,第 35 卷,第 908-909 页,1979 年
示例
找到对数正态分布样本的几何标准偏差。注意,分布的标准偏差为 1,在对数尺度上大约为exp(1)。
>>> import numpy as np
>>> from scipy.stats import gstd
>>> rng = np.random.default_rng()
>>> sample = rng.lognormal(mean=0, sigma=1, size=1000)
>>> gstd(sample)
2.810010162475324
计算多维数组和给定轴的几何标准偏差。
>>> a = np.arange(1, 25).reshape(2, 3, 4)
>>> gstd(a, axis=None)
2.2944076136018947
>>> gstd(a, axis=2)
array([[1.82424757, 1.22436866, 1.13183117],
[1.09348306, 1.07244798, 1.05914985]])
>>> gstd(a, axis=(1,2))
array([2.12939215, 1.22120169])
几何标准偏差进一步处理了掩码数组。
>>> a = np.arange(1, 25).reshape(2, 3, 4)
>>> ma = np.ma.masked_where(a > 16, a)
>>> ma
masked_array(
data=[[[1, 2, 3, 4],
[5, 6, 7, 8],
[9, 10, 11, 12]],
[[13, 14, 15, 16],
[--, --, --, --],
[--, --, --, --]]],
mask=[[[False, False, False, False],
[False, False, False, False],
[False, False, False, False]],
[[False, False, False, False],
[ True, True, True, True],
[ True, True, True, True]]],
fill_value=999999)
>>> gstd(ma, axis=2)
masked_array(
data=[[1.8242475707663655, 1.2243686572447428, 1.1318311657788478],
[1.0934830582350938, --, --]],
mask=[[False, False, False],
[False, True, True]],
fill_value=999999)
scipy.stats.iqr
原文:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.iqr.html#scipy.stats.iqr
scipy.stats.iqr(x, axis=None, rng=(25, 75), scale=1.0, nan_policy='propagate', interpolation='linear', keepdims=False)
计算沿指定轴的数据的四分位距。
**四分位距(IQR)**是数据的第 75 百分位数和第 25 百分位数之间的差异。它是一种类似于标准差或方差的离散度量,但对异常值更为稳健 [2]。
参数rng允许此函数计算除了实际 IQR 之外的其他百分位范围。例如,设置rng=(0, 100)等效于numpy.ptp。
空数组的 IQR 为 np.nan。
从版本 0.18.0 开始。
参数:
xarray_like
输入数组或可转换为数组的对象。
axisint 或 None,默认值:None
如果是整数,则是要计算统计量的输入轴。输入的每个轴切片(例如行)的统计量将显示在输出的相应元素中。如果为None,则在计算统计量之前将对输入进行拉平。
rng两个浮点数的序列,范围在[0,100]之间,可选
要计算范围的百分位数。每个必须在 0 到 100 之间,包括 0 和 100。默认为真实 IQR:(25, 75)。元素的顺序不重要。
scale标量或字符串或实数组成的 array_like,可选
scale 的数值将除以最终结果。也识别以下字符串值:
- ‘normal’:按(2 \sqrt{2} erf^{-1}(\frac{1}{2}) \approx 1.349)缩放。
默认为 1.0。也允许具有实数 dtype 的 array-like scale,只要它正确广播到输出,使得out / scale是有效的操作。输出的维度取决于输入数组 x、axis 参数和 keepdims 标志。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN 值。
-
propagate: 如果在计算统计量的轴切片(例如行)中存在 NaN,则输出的相应条目将为 NaN。 -
omit: 在执行计算时将省略 NaN 值。如果沿着计算统计量的轴切片中的数据不足,则输出的相应条目将为 NaN。 -
raise: 如果存在 NaN,则会引发ValueError。
interpolation字符串,可选
指定在百分位边界位于两个数据点i和j之间时要使用的插值方法。可用以下选项(默认为‘linear’):
- ‘linear’:
i + (j - i)*fraction,其中fraction是由i和j包围的索引的分数部分。- ‘lower’:
i.- ‘higher’:
j.- ‘nearest’:
i或j中最近的一个。- ‘midpoint’:
(i + j)/2.
对于 NumPy >= 1.22.0,numpy.percentile 的 method 关键字提供的附加选项也是有效的。
keepdims 布尔值,默认值:False
如果设置为 True,则减少的轴将作为大小为一的维度保留在结果中。使用此选项,结果将正确地对输入数组进行广播。
返回:
iqr 标量或 ndarray
如果 axis=None,则返回标量。如果输入包含小于 np.float64 的整数或浮点数,则输出数据类型为 np.float64。否则,输出数据类型与输入相同。
另请参阅
注意事项
从 SciPy 1.9 开始,np.matrix 输入(不建议新代码使用)在执行计算之前会转换为 np.ndarray。在这种情况下,输出将是合适形状的标量或 np.ndarray,而不是二维的 np.matrix。类似地,忽略掩码数组的掩码元素,输出将是合适形状的标量或 np.ndarray 而不是带有 mask=False 的掩码数组。
参考资料
[1]
“四分位距” zh.wikipedia.org/wiki/%E5%9B%9B%E5%88%86%E4%BD%8D%E8%B7%9D
[2]
“尺度的稳健测度” zh.wikipedia.org/wiki/%E5%B0%BA%E5%BA%A6%E7%9A%84%E7%A8%B3%E5%81%A5%E6%B5%8B%E5%BA%A6
[3]
“分位数” zh.wikipedia.org/wiki/%E5%88%86%E4%BD%8D%E6%95%B0
示例
>>> import numpy as np
>>> from scipy.stats import iqr
>>> x = np.array([[10, 7, 4], [3, 2, 1]])
>>> x
array([[10, 7, 4],
[ 3, 2, 1]])
>>> iqr(x)
4.0
>>> iqr(x, axis=0)
array([ 3.5, 2.5, 1.5])
>>> iqr(x, axis=1)
array([ 3., 1.])
>>> iqr(x, axis=1, keepdims=True)
array([[ 3.],
[ 1.]])
scipy.stats.sem
原文:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.sem.html#scipy.stats.sem
scipy.stats.sem(a, axis=0, ddof=1, nan_policy='propagate', *, keepdims=False)
计算均值的标准误差。
计算输入数组中值的均值标准误差(或测量标准误差)。
参数:
aarray_like
包含标准误差值的数组。
axisint 或 None,默认值:0
如果是整数,则为计算统计量的输入轴。输入的每个轴切片(例如行)的统计量将出现在输出的相应元素中。如果为 None,则在计算统计量之前会展平输入。
ddofint, optional
Delta 自由度。在有限样本中相对于总体方差估计进行偏差调整的自由度数量。默认为 1。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN。
-
propagate:如果轴切片(例如行)中存在 NaN,则计算统计量的相应输出条目将是 NaN。 -
omit:在执行计算时将忽略 NaN。如果沿计算统计量的轴切片中剩余的数据不足,则输出的相应条目将是 NaN。 -
raise:如果存在 NaN,则会引发ValueError。
keepdimsbool,默认值:False
如果设置为 True,则减少的轴将作为大小为一的维度保留在结果中。使用此选项,结果将正确传播到输入数组。
返回:
sndarray 或 float
样本中的均值标准误差,沿着输入轴。
注释
ddof 的默认值与其他包含 ddof 的例程(例如 np.std 和 np.nanstd)使用的默认值(0)不同。
从 SciPy 1.9 开始,将 np.matrix 输入(不建议新代码使用)转换为 np.ndarray 后执行计算。在这种情况下,输出将是适当形状的标量或 np.ndarray,而不是 2D np.matrix。类似地,尽管忽略了掩码数组的掩码元素,输出将是标量或 np.ndarray,而不是具有 mask=False 的掩码数组。
示例
沿第一个轴找到标准误差:
>>> import numpy as np
>>> from scipy import stats
>>> a = np.arange(20).reshape(5,4)
>>> stats.sem(a)
array([ 2.8284, 2.8284, 2.8284, 2.8284])
在整个数组中找到标准误差,使用 n 自由度:
>>> stats.sem(a, axis=None, ddof=0)
1.2893796958227628
scipy.stats.bayes_mvs
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.bayes_mvs.html#scipy.stats.bayes_mvs
scipy.stats.bayes_mvs(data, alpha=0.9)
均值、方差和标准差的贝叶斯置信区间。
参数:
dataarray_like
输入数据,如果是多维的,则通过bayes_mvs将其展平为 1-D。需要至少 2 个数据点。
alpha浮点数,可选
返回置信区间包含真实参数的概率。
返回:
mean_cntr, var_cntr, std_cntr元组
这三个结果分别是均值、方差和标准差的元组形式:
(center, (lower, upper))
对于center,是给定数据的条件概率密度函数均值,对于*(lower, upper)*,是以中位数为中心的置信区间,包含到概率alpha的估计。
另见
mvsdist
注意事项
每个均值、方差和标准差估计的元组表示为(center, (lower, upper)),其中 center 是给定数据的条件概率密度函数均值,(lower, upper)是以中位数为中心的置信区间,包含到概率alpha的估计。
转换数据为 1-D,假设所有数据具有相同的均值和方差。使用杰弗里先验法进行方差和标准差估计。
等效于tuple((x.mean(), x.interval(alpha)) for x in mvsdist(dat))
参考文献
T.E. Oliphant, “从数据中估计均值、方差和标准差的贝叶斯视角”,scholarsarchive.byu.edu/facpub/278,2006 年。
示例
首先是一个基本示例,用于展示输出:
>>> from scipy import stats
>>> data = [6, 9, 12, 7, 8, 8, 13]
>>> mean, var, std = stats.bayes_mvs(data)
>>> mean
Mean(statistic=9.0, minmax=(7.103650222612533, 10.896349777387467))
>>> var
Variance(statistic=10.0, minmax=(3.176724206..., 24.45910382...))
>>> std
Std_dev(statistic=2.9724954732045084,
minmax=(1.7823367265645143, 4.945614605014631))
现在我们生成一些正态分布的随机数据,并使用 95%置信区间对均值和标准差的估计进行如下操作:
>>> n_samples = 100000
>>> data = stats.norm.rvs(size=n_samples)
>>> res_mean, res_var, res_std = stats.bayes_mvs(data, alpha=0.95)
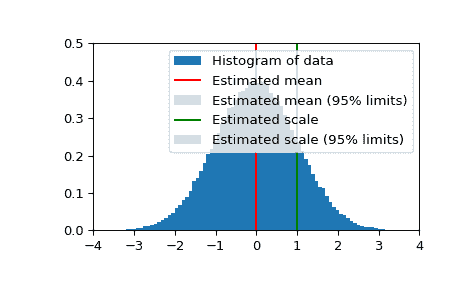
>>> import matplotlib.pyplot as plt
>>> fig = plt.figure()
>>> ax = fig.add_subplot(111)
>>> ax.hist(data, bins=100, density=True, label='Histogram of data')
>>> ax.vlines(res_mean.statistic, 0, 0.5, colors='r', label='Estimated mean')
>>> ax.axvspan(res_mean.minmax[0],res_mean.minmax[1], facecolor='r',
... alpha=0.2, label=r'Estimated mean (95% limits)')
>>> ax.vlines(res_std.statistic, 0, 0.5, colors='g', label='Estimated scale')
>>> ax.axvspan(res_std.minmax[0],res_std.minmax[1], facecolor='g', alpha=0.2,
... label=r'Estimated scale (95% limits)')
>>> ax.legend(fontsize=10)
>>> ax.set_xlim([-4, 4])
>>> ax.set_ylim([0, 0.5])
>>> plt.show()
scipy.stats.mvsdist
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.mvsdist.html#scipy.stats.mvsdist
scipy.stats.mvsdist(data)
数据的“冻结”分布,包括均值、方差和标准差。
参数:
dataarray_like
输入数组。使用 ravel 转换为 1-D。需要 2 个或更多数据点。
返回:
mdist“冻结”分布对象
表示数据均值的分布对象。
vdist“冻结”分布对象
表示数据方差的分布对象。
sdist“冻结”分布对象
表示数据标准差的分布对象。
参见
bayes_mvs
注意
bayes_mvs(data) 的返回值等同于 tuple((x.mean(), x.interval(0.90)) for x in mvsdist(data))。
换句话说,在从此函数返回的三个分布对象上调用 <dist>.mean() 和 <dist>.interval(0.90) 将返回与 bayes_mvs 返回的相同结果。
参考文献
T.E. Oliphant,“从数据中估计均值、方差和标准差的贝叶斯视角”,scholarsarchive.byu.edu/facpub/278,2006 年。
示例
>>> from scipy import stats
>>> data = [6, 9, 12, 7, 8, 8, 13]
>>> mean, var, std = stats.mvsdist(data)
现在我们有了冻结的分布对象“mean”、“var”和“std”,我们可以进行检查:
>>> mean.mean()
9.0
>>> mean.interval(0.95)
(6.6120585482655692, 11.387941451734431)
>>> mean.std()
1.1952286093343936
scipy.stats.entropy
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.entropy.html#scipy.stats.entropy
scipy.stats.entropy(pk, qk=None, base=None, axis=0, *, nan_policy='propagate', keepdims=False)
计算给定分布的 Shannon 熵/相对熵。
如果仅提供了概率pk,则香农熵计算为H = -sum(pk * log(pk))。
如果qk不为 None,则计算相对熵D = sum(pk * log(pk / qk))。这个量也被称为 Kullback-Leibler 散度。
如果pk和qk的和不为 1,则此例程将对它们进行标准化。
参数:
pkarray_like
定义(离散)分布。对于pk的每个轴切片,元素i是事件i的(可能未标准化的)概率。
qkarray_like,可选
用于计算相对熵的序列。应与pk具有相同的格式。
basefloat,可选
要使用的对数基数,默认为e(自然对数)。
axisint 或 None,默认值:0
如果是整数,则是计算统计量的输入轴。输入的每个轴切片(例如行)的统计量将出现在输出的相应元素中。如果为None,则在计算统计量之前将对输入进行展平。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN 值。
-
propagate:如果在计算统计量的轴切片(例如行)中存在 NaN 值,则输出的相应条目将为 NaN。 -
omit:在执行计算时将忽略 NaN 值。如果沿着计算统计量的轴切片中剩余的数据不足,输出的相应条目将为 NaN。 -
raise:如果存在 NaN 值,则会引发ValueError。
keepdimsbool,默认值:False
如果设置为 True,则减少的轴将作为大小为 1 的维度保留在结果中。选择此选项后,结果将正确地与输入数组进行广播。
返回值:
S{float, array_like}
计算得到的熵。
注意事项
通俗地讲,香农熵量化了离散随机变量可能结果的预期不确定性。例如,如果要对由一组符号序列组成的消息进行编码并通过无噪声信道传输,则香农熵H(pk)给出了每个符号所需的信息单位数的平均下界,如果符号的发生频率由离散分布pk控制[1]。基数的选择确定了单位的选择;例如,自然对数e用于 nats,2用于 bits,等等。
相对熵 D(pk|qk) 量化了如果编码针对概率分布 qk 而不是真实分布 pk 进行了优化,则每个符号所需的平均信息单位数的增加量。非正式地,相对熵量化了在真实分布实际为 pk 时,但人们认为其为 qk 时所经历的预期惊讶的过量。
相关量,交叉熵 CE(pk, qk),满足方程 CE(pk, qk) = H(pk) + D(pk|qk),也可以用公式 CE = -sum(pk * log(qk)) 计算。如果编码针对概率分布 qk 进行了优化,当真实分布为 pk 时,它给出每个符号所需的平均信息单位数。它不是直接由 entropy 计算的,但可以通过两次调用函数来计算(见示例)。
更多信息请参见 [2]。
从 SciPy 1.9 开始,np.matrix 输入(不建议在新代码中使用)在进行计算之前会转换为 np.ndarray。在这种情况下,输出将是一个标量或适当形状的 np.ndarray,而不是二维的 np.matrix。类似地,虽然忽略了掩码数组的掩码元素,但输出将是一个标量或 np.ndarray,而不是带有 mask=False 的掩码数组。
参考文献
[1]
Shannon, C.E. (1948),A Mathematical Theory of Communication. Bell System Technical Journal, 27: 379-423. doi.org/10.1002/j.1538-7305.1948.tb01338.x
[2]
Thomas M. Cover 和 Joy A. Thomas. 2006. Elements of Information Theory (Wiley Series in Telecommunications and Signal Processing). Wiley-Interscience, USA.
示例
公平硬币的结果是最不确定的:
>>> import numpy as np
>>> from scipy.stats import entropy
>>> base = 2 # work in units of bits
>>> pk = np.array([1/2, 1/2]) # fair coin
>>> H = entropy(pk, base=base)
>>> H
1.0
>>> H == -np.sum(pk * np.log(pk)) / np.log(base)
True
有偏硬币的结果不那么不确定:
>>> qk = np.array([9/10, 1/10]) # biased coin
>>> entropy(qk, base=base)
0.46899559358928117
公平硬币和有偏硬币之间的相对熵计算如下:
>>> D = entropy(pk, qk, base=base)
>>> D
0.7369655941662062
>>> D == np.sum(pk * np.log(pk/qk)) / np.log(base)
True
交叉熵可以计算为熵和相对熵的总和`:
>>> CE = entropy(pk, base=base) + entropy(pk, qk, base=base)
>>> CE
1.736965594166206
>>> CE == -np.sum(pk * np.log(qk)) / np.log(base)
True
scipy.stats.differential_entropy
scipy.stats.differential_entropy(values, *, window_length=None, base=None, axis=0, method='auto', nan_policy='propagate', keepdims=False)
给定分布的样本,估计微分熵。
根据样本大小选择默认的方法,可使用method参数选择多种估计方法。
参数:
values序列
从连续分布中抽取样本。
window_length整数,可选
用于计算 Vasicek 估计的窗口长度。必须是 1 到样本大小的一半之间的整数。如果为None(默认值),则使用启发式值
[\left \lfloor \sqrt{n} + 0.5 \right \rfloor]
其中 (n) 是样本大小。这一启发式方法最初是在文献中提出的[2],现在在文献中很常见。
base浮点数,可选
使用的对数基数,默认为e(自然对数)。
axisint 或 None,默认值为:0
如果为整数,则是计算统计量的输入轴。输入的每个轴切片(例如行)的统计量将出现在输出的相应元素中。如果为None,则在计算统计量之前将对输入进行展平。
method{‘vasicek’, ‘van es’, ‘ebrahimi’, ‘correa’, ‘auto’},可选
从样本中估计微分熵的方法。默认为'auto'。更多信息请参阅注意事项。
nan_policy{‘propagate’, ‘omit’, ‘raise’}
定义如何处理输入的 NaN 值。
-
propagate: 如果在进行统计计算的轴切片(例如行)中存在 NaN,则输出的相应条目将为 NaN。 -
omit: 在执行计算时将省略 NaN 值。如果沿着进行统计计算的轴切片中剩余的数据不足,则输出的相应条目将为 NaN。 -
raise: 如果存在 NaN 值,则会引发ValueError。
keepdimsbool,默认值为:False
如果设置为 True,则被减少的轴将作为大小为一的维度保留在结果中。使用此选项,结果将正确地与输入数组进行广播。
返回:
entropy浮点数
计算得到的微分熵。
注意事项
该函数在极限情况下将收敛到真实的微分熵
[n \to \infty, \quad m \to \infty, \quad \frac{m}{n} \to 0]
对于给定的样本大小,window_length的最佳选择取决于(未知的)分布。通常,分布的密度越平滑,window_length的最佳值就越大[1]。
method参数有以下选项可供选择。
-
'vasicek'使用[1]中提出的估计器。这是微分熵的最早和最有影响力的估计器之一。 -
'van es'使用在[3]中提出的修正偏差估计器,不仅是一致的,而且在某些条件下渐近正态。 -
'ebrahimi'使用在[4]中提出的估计器,在模拟中显示比 Vasicek 估计器具有更小的偏差和均方误差。 -
'correa'使用在[5]中基于局部线性回归提出的估计器。在模拟研究中,其均方误差始终比 Vasiceck 估计器小,但计算成本更高。 -
'auto'自动选择方法(默认)。目前,这为非常小的样本(<10)选择'van es',对于中等样本大小(11-1000)选择'ebrahimi',对于较大样本选择'vasicek',但此行为可能在未来版本中更改。
所有估计器均按照[6]中描述的方式实现。
从 SciPy 1.9 开始,不推荐新代码使用np.matrix输入,在进行计算之前将其转换为np.ndarray。在这种情况下,输出将是适当形状的标量或np.ndarray,而不是 2D 的np.matrix。类似地,尽管忽略了掩码数组的掩码元素,输出将是标量或np.ndarray,而不是带有mask=False的掩码数组。
参考文献
[1] (1,2)
Vasicek, O. (1976). 基于样本熵的正态性检验. 《皇家统计学会杂志:B 系列(方法学)》,38(1),54-59。
[2]
Crzcgorzewski, P., & Wirczorkowski, R. (1999). 基于熵的指数分布适合性检验. 《统计学通信-理论与方法》,28(5),1183-1202。
[3]
Van Es, B. (1992). 通过基于间隔的统计量类估计密度相关的函数. 《斯堪的纳维亚统计学杂志》,61-72。
[4]
Ebrahimi, N., Pflughoeft, K., & Soofi, E. S. (1994). 两种样本熵测量. 《统计与概率信函》,20(3),225-234。
[5]
Correa, J. C. (1995). 新的熵估计器. 《统计学通信-理论与方法》,24(10),2439-2449。
[6]
Noughabi, H. A. (2015). 使用数值方法进行熵估计. 《数据科学年鉴》,2(2),231-241。link.springer.com/article/10.1007/s40745-015-0045-9
示例
>>> import numpy as np
>>> from scipy.stats import differential_entropy, norm
标准正态分布的熵:
>>> rng = np.random.default_rng()
>>> values = rng.standard_normal(100)
>>> differential_entropy(values)
1.3407817436640392
与真实熵比较:
>>> float(norm.entropy())
1.4189385332046727
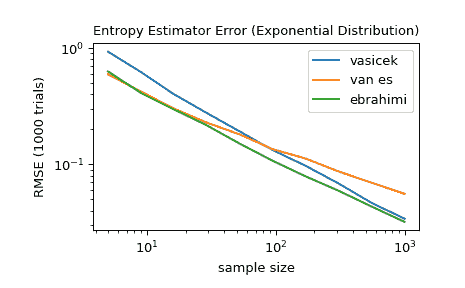
对于在 5 到 1000 之间的多个样本大小,比较'vasicek','van es'和'ebrahimi'方法的准确性。具体比较(1000 次试验中)估计与分布真实差分熵之间的均方根误差。
>>> from scipy import stats
>>> import matplotlib.pyplot as plt
>>>
>>>
>>> def rmse(res, expected):
... '''Root mean squared error'''
... return np.sqrt(np.mean((res - expected)**2))
>>>
>>>
>>> a, b = np.log10(5), np.log10(1000)
>>> ns = np.round(np.logspace(a, b, 10)).astype(int)
>>> reps = 1000 # number of repetitions for each sample size
>>> expected = stats.expon.entropy()
>>>
>>> method_errors = {'vasicek': [], 'van es': [], 'ebrahimi': []}
>>> for method in method_errors:
... for n in ns:
... rvs = stats.expon.rvs(size=(reps, n), random_state=rng)
... res = stats.differential_entropy(rvs, method=method, axis=-1)
... error = rmse(res, expected)
... method_errors[method].append(error)
>>>
>>> for method, errors in method_errors.items():
... plt.loglog(ns, errors, label=method)
>>>
>>> plt.legend()
>>> plt.xlabel('sample size')
>>> plt.ylabel('RMSE (1000 trials)')
>>> plt.title('Entropy Estimator Error (Exponential Distribution)')
scipy.stats.median_abs_deviation
scipy.stats.median_abs_deviation(x, axis=0, center=<function median>, scale=1.0, nan_policy='propagate')
计算给定轴上数据的中位绝对偏差。
中位数绝对偏差(MAD,[1])计算从中位数到绝对偏差的中位数。这是一种与标准偏差类似但更鲁棒于异常值的离散度测量方法[2]。
空数组的 MAD 是 np.nan。
新版本 1.5.0 中新增。
参数:
x类似数组
可转换为数组的输入数组或对象。
axisint 或 None,可选
计算范围的轴。默认为 0。如果为 None,则在整个数组上计算 MAD。
中心可调用,可选
将返回中心值的函数。默认使用 np.median。任何用户定义的函数都需要具有 func(arr, axis) 的函数签名。
尺度标量或字符串,可选
尺度的数值将从最终结果中除去。默认为 1.0。还接受字符串“normal”,这将导致 scale 成为标准正态分位函数在 0.75 处的倒数,约为 0.67449。还允许类似数组的尺度,只要它正确广播到输出,使得 out / scale 是有效操作即可。输出维度取决于输入数组 x 和 axis 参数。
nan_policy{‘propagate’, ‘raise’, ‘omit’},可选
定义当输入包含 nan 时如何处理。可用以下选项(默认为 ‘propagate’):
-
‘propagate’: 返回 nan。
-
‘raise’: 抛出错误
-
‘omit’: 在计算时忽略 nan 值。
返回:
mad标量或 ndarray
如果 axis=None,则返回一个标量。如果输入包含小于 np.float64 的整数或浮点数,则输出数据类型为 np.float64。否则,输出数据类型与输入相同。
另请参见
numpy.std, numpy.var, numpy.median, scipy.stats.iqr, scipy.stats.tmean
scipy.stats.tstd, scipy.stats.tvar
注释
center参数仅影响计算 MAD 时计算的中心值。也就是说,传入center=np.mean将计算围绕平均值的 MAD - 而不是计算平均绝对偏差。
输入数组可能包含inf,但如果center返回inf,则该数据对应的 MAD 将为nan。
参考文献
[1]
“中位数绝对偏差”,en.wikipedia.org/wiki/Median_absolute_deviation
[2]
“尺度鲁棒性测量”,en.wikipedia.org/wiki/Robust_measures_of_scale
示例
当比较median_abs_deviation与np.std的行为时,后者在我们将数组的单个值更改为异常值时受影响,而 MAD 几乎没有变化:
>>> import numpy as np
>>> from scipy import stats
>>> x = stats.norm.rvs(size=100, scale=1, random_state=123456)
>>> x.std()
0.9973906394005013
>>> stats.median_abs_deviation(x)
0.82832610097857
>>> x[0] = 345.6
>>> x.std()
34.42304872314415
>>> stats.median_abs_deviation(x)
0.8323442311590675
轴处理示例:
>>> x = np.array([[10, 7, 4], [3, 2, 1]])
>>> x
array([[10, 7, 4],
[ 3, 2, 1]])
>>> stats.median_abs_deviation(x)
array([3.5, 2.5, 1.5])
>>> stats.median_abs_deviation(x, axis=None)
2.0
标准化尺度示例:
>>> x = stats.norm.rvs(size=1000000, scale=2, random_state=123456)
>>> stats.median_abs_deviation(x)
1.3487398527041636
>>> stats.median_abs_deviation(x, scale='normal')
1.9996446978061115
scipy.stats.cumfreq
原文链接:
docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.cumfreq.html#scipy.stats.cumfreq
scipy.stats.cumfreq(a, numbins=10, defaultreallimits=None, weights=None)
返回一个累积频率直方图,使用直方图函数。
累积直方图是一种映射,它计算了到指定箱子的所有箱子中的观测累积数。
参数:
aarray_like
输入数组。
numbinsint,可选
用于直方图的箱子数。默认为 10。
defaultreallimitstuple (lower, upper),可选
直方图的范围的下限和上限值。如果未指定值,则使用稍大于 a 值范围的范围。具体而言,(a.min() - s, a.max() + s),其中 s = (1/2)(a.max() - a.min()) / (numbins - 1)。
weightsarray_like,可选
a 中每个值的权重。默认为 None,即每个值的权重为 1.0。
返回:
cumcountndarray
累积频率的分箱值。
lowerlimitfloat
较低的实际限制
binsizefloat
每个箱子的宽度。
extrapointsint
额外点。
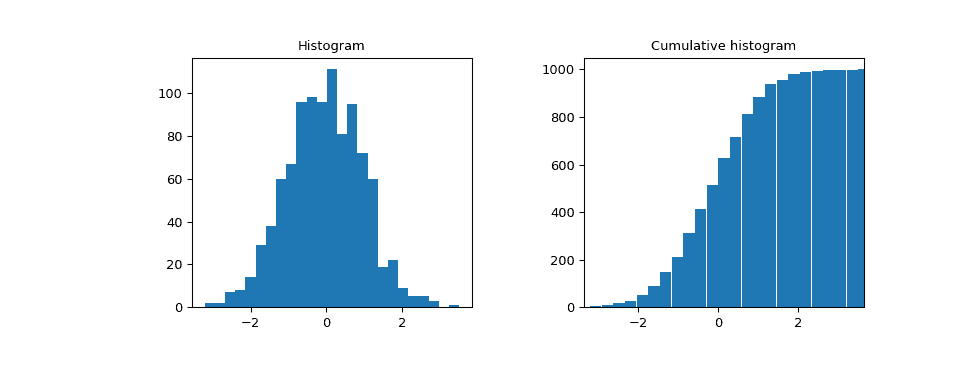
示例
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> from scipy import stats
>>> rng = np.random.default_rng()
>>> x = [1, 4, 2, 1, 3, 1]
>>> res = stats.cumfreq(x, numbins=4, defaultreallimits=(1.5, 5))
>>> res.cumcount
array([ 1., 2., 3., 3.])
>>> res.extrapoints
3
创建具有 1000 个随机值的正态分布
>>> samples = stats.norm.rvs(size=1000, random_state=rng)
计算累积频率
>>> res = stats.cumfreq(samples, numbins=25)
计算 x 的值的空间
>>> x = res.lowerlimit + np.linspace(0, res.binsize*res.cumcount.size,
... res.cumcount.size)
绘制直方图和累积直方图
>>> fig = plt.figure(figsize=(10, 4))
>>> ax1 = fig.add_subplot(1, 2, 1)
>>> ax2 = fig.add_subplot(1, 2, 2)
>>> ax1.hist(samples, bins=25)
>>> ax1.set_title('Histogram')
>>> ax2.bar(x, res.cumcount, width=res.binsize)
>>> ax2.set_title('Cumulative histogram')
>>> ax2.set_xlim([x.min(), x.max()])
>>> plt.show()
_abs_deviation(x)
1.3487398527041636
stats.median_abs_deviation(x, scale=‘normal’)
1.9996446978061115
# `scipy.stats.cumfreq`
> 原文链接:[`docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.cumfreq.html#scipy.stats.cumfreq`](https://docs.scipy.org/doc/scipy-1.12.0/reference/generated/scipy.stats.cumfreq.html#scipy.stats.cumfreq)
```py
scipy.stats.cumfreq(a, numbins=10, defaultreallimits=None, weights=None)
返回一个累积频率直方图,使用直方图函数。
累积直方图是一种映射,它计算了到指定箱子的所有箱子中的观测累积数。
参数:
aarray_like
输入数组。
numbinsint,可选
用于直方图的箱子数。默认为 10。
defaultreallimitstuple (lower, upper),可选
直方图的范围的下限和上限值。如果未指定值,则使用稍大于 a 值范围的范围。具体而言,(a.min() - s, a.max() + s),其中 s = (1/2)(a.max() - a.min()) / (numbins - 1)。
weightsarray_like,可选
a 中每个值的权重。默认为 None,即每个值的权重为 1.0。
返回:
cumcountndarray
累积频率的分箱值。
lowerlimitfloat
较低的实际限制
binsizefloat
每个箱子的宽度。
extrapointsint
额外点。
示例
>>> import numpy as np
>>> import matplotlib.pyplot as plt
>>> from scipy import stats
>>> rng = np.random.default_rng()
>>> x = [1, 4, 2, 1, 3, 1]
>>> res = stats.cumfreq(x, numbins=4, defaultreallimits=(1.5, 5))
>>> res.cumcount
array([ 1., 2., 3., 3.])
>>> res.extrapoints
3
创建具有 1000 个随机值的正态分布
>>> samples = stats.norm.rvs(size=1000, random_state=rng)
计算累积频率
>>> res = stats.cumfreq(samples, numbins=25)
计算 x 的值的空间
>>> x = res.lowerlimit + np.linspace(0, res.binsize*res.cumcount.size,
... res.cumcount.size)
绘制直方图和累积直方图
>>> fig = plt.figure(figsize=(10, 4))
>>> ax1 = fig.add_subplot(1, 2, 1)
>>> ax2 = fig.add_subplot(1, 2, 2)
>>> ax1.hist(samples, bins=25)
>>> ax1.set_title('Histogram')
>>> ax2.bar(x, res.cumcount, width=res.binsize)
>>> ax2.set_title('Cumulative histogram')
>>> ax2.set_xlim([x.min(), x.max()])
>>> plt.show()
[外链图片转存中…(img-UBqnxMDu-1719632632912)]

















 6492
6492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









