







原文:
annas-archive.org/md5/8831de64312a5d338410ec40c70fd171译者:飞龙
前言
这本书旨在为系统编程的基本方面提供现成的解决方案(给开发人员),尽可能使用最新的 C++标准。系统编程涉及构建与操作系统密切交互的计算机程序,并允许计算机硬件与程序员和用户进行接口。由于其高效的特性,即低级计算、数据抽象和面向对象的特性,C++是系统编程的首选语言。您将学习如何创建健壮和并发的系统,还将了解共享内存和管道的进程间通信机制。此外,您将深入研究 C++内置库和框架,以便根据您的需求设计健壮的系统。
这本书是为谁准备的
这本书适用于想要获得系统编程实际知识的 C++开发人员。虽然不需要有 Linux 系统编程的经验,但需要具备中级的 C++知识。
这本书涵盖了什么
第一章,开始系统编程,介绍了基本知识,如学习 shell、用户和组、进程 ID 和线程 ID,以便能够熟练使用 Linux 系统等等,这些是您必须了解的,以便能够阅读本书的其余部分。例如,您将学习 Linux 的设计、shell、用户和组、进程 ID 和线程 ID。此外,您还将学习如何开发一个简单的Hello World程序,编写其 makefile,执行它并进行调试。尽管这些知识很基础,但对于后面章节中将出现的更高级的主题来说是基础性的。
第二章,重温 C++,重新理解 C++17,这将贯穿整本书。它将展示为什么 C++代表了编写高质量、简洁和更具可移植性的代码的绝佳机会。本章包含了 C++11/17/20 引入的所有新特性,这些特性在本书中会很有用。
第三章,处理进程和线程,介绍了进程和线程,这是任何详细说明的基础。一个程序很少只由一个进程组成。本章揭示了处理 C++中线程和进程的技术。本章将演示如何处理线程(和任务)相对于 POSIX 来说是多么简单和方便。虽然 C++没有正式的创建进程的方式,但在极少数情况下,线程无法完成工作。
第四章,深入探讨内存管理,介绍了内存,这是处理系统开发的核心概念之一。分配、释放内存,以及了解内存管理和 C++可以提供的简化和管理内存的方法至关重要。此外,本章介绍了如何检查和分配对齐内存以及如何处理内存映射 I/O 的方法。
第五章,使用互斥锁、信号量和条件变量,向我们展示了 POSIX 机制解决方案以及 C++提供的同步线程和进程的方法。
第六章,管道、先进先出(FIFO)、消息队列和共享内存,着重于使进程之间进行通信。有不同的解决方案可用——管道、FIFO、消息队列和共享内存。对于每种进程间通信机制,都提供了一种解决方案。
第七章,网络编程,演示了通信从连接到结束的过程。不同机器上的进程之间的通信是当今互联网的基础,TCP/IP 是事实上的标准。TCP(传输控制协议)和UDP(用户数据报协议)将被详细描述,前者代表面向连接的,后者代表无连接的。这在当今是非常重要的,特别是在线视频流服务的可用性。
第八章,处理控制台 I/O 和文件,为您提供了处理文件、控制台 I/O 和字符串流的有用配方。
第九章,处理时间接口,为您提供了如何处理和测量 C++和 POSIX 提供的功能的深入理解。本章将为每种方法提供现成的配方。
第十章,管理信号,向我们介绍了软件中断信号。它们提供了一种管理异步事件的方式。例如,用户从终端键入中断键,或者另一个进程发送必须被管理的信号。每个信号都以SIG开头(例如SIGABRT)。本章将向读者展示如何编写代码来正确管理软件中断,Linux 为每个信号定义的默认操作是什么,以及如何覆盖它们。
第十一章,调度,向您展示如何使用 POSIX(C++标准不提供此功能)来设置调度程序参数、调度程序策略和调度程序优先级。系统编程是关于与底层操作系统的交互,调度程序是每个操作系统的主要组件之一,影响进程在 CPU 上的分配方式。有些情况下,开发人员需要对此进行控制,或者至少试图影响调度程序。
为了充分利用本书
以下是本书的要求列表:
-
中级 C++知识。
-
每章的技术要求部分提到了任何额外的要求。
-
免责声明:C++20 标准已经在二月底的布拉格会议上由 WG21 批准(即技术上已经最终确定)。这意味着本书使用的 GCC 编译器版本 8.3.0 不包括(或者对 C++20 的新功能支持非常有限)。因此,Docker 镜像不包括 C++20 的配方代码。
GCC 将最新功能的开发保留在分支中(您必须使用适当的标志,例如-std=c++2a);因此,鼓励您自己尝试。因此,克隆并探索 GCC 合同和模块分支,并且玩得开心。
- 一些配方(特别是第十一章,调度)需要 Docker 镜像以管理员权限运行才能正确执行。根据您的 Docker 配置,您可能需要使用
sudo来运行 Docker。为了避免这种情况,您可以创建一个 Linux 组(例如docker)并将用户添加到其中。
下载示例代码文件
您可以从www.packt.com的帐户中下载本书的示例代码文件。如果您在其他地方购买了本书,可以访问www.packtpub.com/support注册并直接将文件发送到您的邮箱。
您可以按照以下步骤下载代码文件:
-
在www.packt.com上登录或注册。
-
选择支持选项卡。
-
单击代码下载。
-
在搜索框中输入书名,然后按照屏幕上的指示操作。
下载文件后,请确保使用以下最新版本的解压缩或提取文件夹:
-
Windows 的 WinRAR/7-Zip
-
Mac 的 Zipeg/iZip/UnRarX
-
Linux 的 7-Zip/PeaZip
该书的代码包也托管在 GitHub 上,网址为github.com/PacktPublishing/C-System-Programming-Cookbook。如果代码有更新,将在现有的 GitHub 存储库上进行更新。
我们还有来自丰富书籍和视频目录的其他代码包,可在**github.com/PacktPublishing/**上找到。去看看吧!
下载彩色图片
我们还提供了一个 PDF 文件,其中包含本书中使用的屏幕截图/图表的彩色图像。您可以在这里下载:static.packt-cdn.com/downloads/9781838646554_ColorImages.pdf。
代码实战
请访问以下链接查看 CiA 视频:bit.ly/2uXftdA
使用的约定
本书中使用了许多文本约定。
CodeInText:表示文本中的代码词、数据库表名、文件夹名、文件名、文件扩展名、路径名、虚拟 URL、用户输入和 Twitter 句柄。例如:“在第二步中,我们开始开发main方法。”
代码块设置如下:
std::cout << "Start ... " << std::endl;
{
User* developer = new User();
developer->cheers();
delete developer;
}
当我们希望引起您对代码块的特定部分的注意时,相关行或项目将以粗体显示:
auto* mapPtr = static_cast<T*> (mmap(0, sizeof(T) * n,
PROT_READ | PROT_WRITE,
任何命令行输入或输出都是这样写的:
$ grep "text" filename
$ ls -l | grep filename
粗体:表示新术语、重要单词或屏幕上看到的单词。例如,菜单或对话框中的单词会在文本中出现。例如:“从管理面板中选择系统信息。”
警告或重要说明看起来像这样。
提示和技巧看起来像这样。
章节
在本书中,您会经常看到几个标题(准备工作、如何做、工作原理、还有和另请参阅)。
为了清晰地说明如何完成食谱,请使用以下各节。
准备工作
本节告诉您在食谱中可以期待什么,并描述了为食谱设置任何软件或所需的任何初步设置。
如何做…
本节包含按照食谱所需的步骤。
工作原理…
本节通常包括对前一节发生的事情的详细解释。
还有…
本节包括有关食谱的其他信息,以使您对食谱更加了解。
另请参阅
本节提供了有关食谱的其他有用信息的有用链接。
第一章:开始系统编程
在本章中,你将被介绍整本书的基础知识。你将学习(或者复习)Linux 的设计,还将学习关于 shell、用户和用户组、进程 ID 和线程 ID,以便能够熟练地使用 Linux 系统,并为接下来的章节做好准备。此外,你还将学习如何开发一个简单的hello world程序,了解它的 makefile,以及如何执行和调试它。本章的另一个重要方面是学习 Linux 如何处理错误,无论是从 shell 还是源代码的角度。这些基础知识对于理解接下来章节中的其他高级主题非常重要。如果不需要这个复习,你可以安全地跳过本章和下一章。
本章将涵盖以下内容:
-
学习 Linux 基础知识- 架构
-
学习 Linux 基础知识- shell
-
学习 Linux 基础知识- 用户
-
使用 makefile 来编译和链接程序
-
使用 GNU Project Debugger(GDB)调试程序
-
学习 Linux 基础知识- 进程和线程
-
处理 Linux bash 错误
-
处理 Linux 代码错误
技术要求
为了让你立即尝试这些程序,我们设置了一个 Docker 镜像,其中包含了整本书中需要的所有工具和库。这是基于 Ubuntu 19.04 的。
为了设置这个,按照以下步骤进行:
-
从www.docker.com下载并安装 Docker Engine。
-
从 Docker Hub 拉取镜像:
docker pull kasperondocker/system_programming_cookbook:latest。 -
镜像现在应该是可用的。输入以下命令查看镜像:
docker images。 -
现在你应该至少有这个镜像:
kasperondocker/system_programming_cookbook。 -
使用以下命令在 Docker 镜像上运行交互式 shell:
docker run -it --cap-add sys_ptrace kasperondocker/system_programming_cookbook:latest /bin/bash。 -
正在运行的容器上的 shell 现在可用。运行
root@39a5a8934370/# cd /BOOK/来获取所有按章节开发的程序。
需要--cap-add sys_ptrace参数来允许 Docker 容器中的 GDB 设置断点,默认情况下 Docker 不允许这样做。
学习 Linux 基础知识- 架构
Linux 是 Unix 操作系统的一个克隆,由 Linus Torvalds 在 90 年代初开发。它是一个多用户、多任务操作系统,可以运行在各种平台上。Linux 内核采用了单体结构的架构,出于性能原因。这意味着它是一个自包含的二进制文件,所有的服务都在内核空间运行。这在开始时是最具争议的话题之一。阿姆斯特丹自由大学的教授安迪·塔能鲍姆反对其单体系统,他说:“这是对 70 年代的巨大倒退。”他还反对其可移植性,说:“LINUX 与 80 x 86 紧密联系在一起。不是正确的方向。”在 minix 用户组中,仍然有涉及 Torvalds、Tanenbaum 和其他人的完整聊天记录。
以下图表显示了主要的 Linux 构建模块:
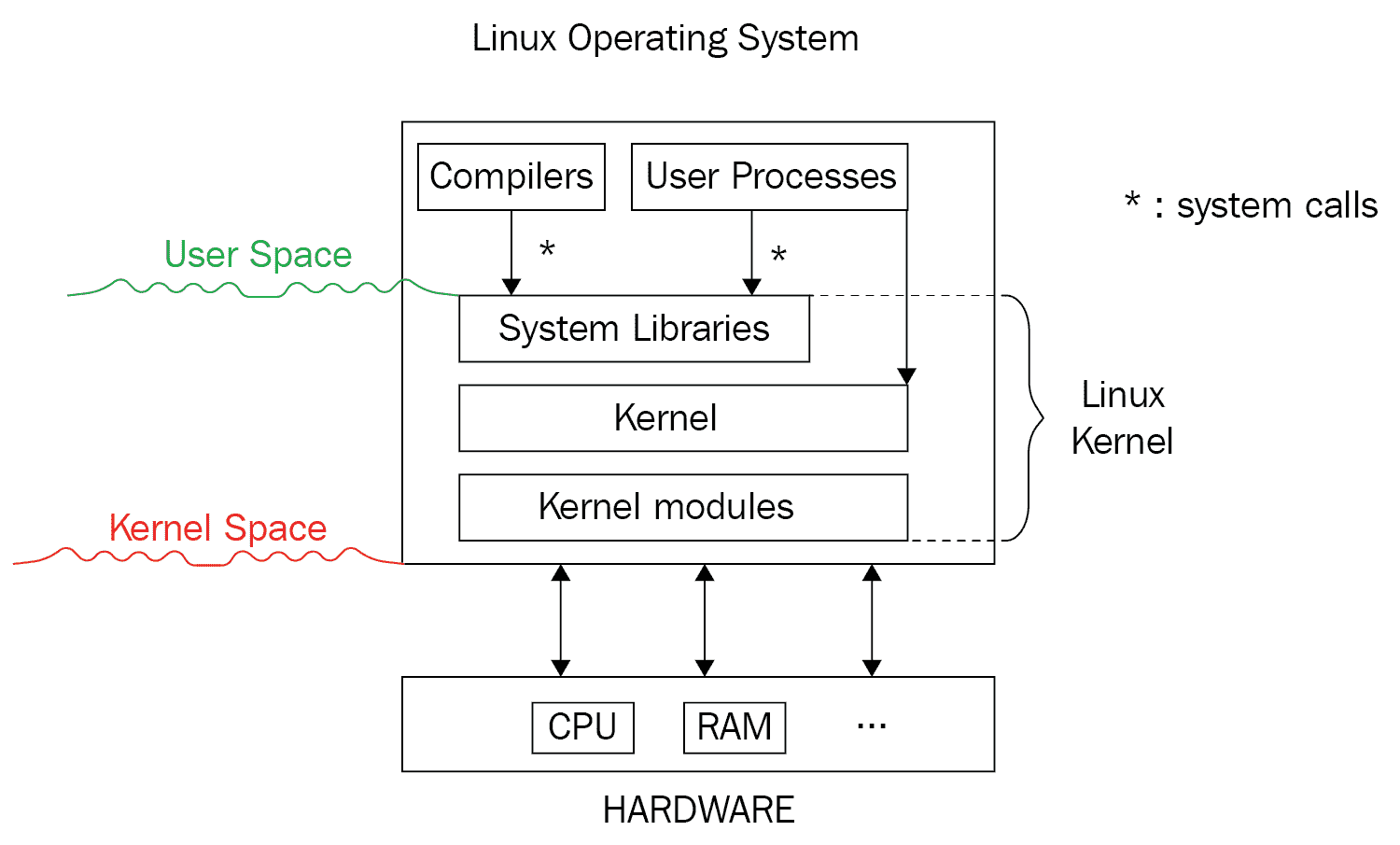
让我们描述一下图表中看到的层次:
-
在顶层,有用户应用程序、进程、编译器和工具。这一层(在用户空间运行)通过系统调用与 Linux 内核(在内核空间运行)进行通信。
-
系统库:这是一组函数,通过它应用程序可以与内核进行交互。
-
内核:这个组件包含 Linux 系统的核心。除其他功能外,它还有调度程序、网络、内存管理和文件系统。
-
内核模块:这些包含仍在内核空间中运行的内核代码片段,但是完全动态(可以在运行系统中加载和卸载)。它们通常包含设备驱动程序、特定于实现协议的特定硬件模块的内核代码等。内核模块的一个巨大优势是用户可以在不重新构建内核的情况下加载它们。
GNU是一个递归缩写,代表GNU 不是 Unix。GNU 是一个自由软件的操作系统。请注意这里的术语操作系统。事实上,单独使用的 GNU 意味着代表操作系统所需的一整套工具、软件和内核部分。GNU 操作系统内核称为Hurd。由于 Hurd 尚未达到生产就绪状态,GNU 通常使用 Linux 内核,这种组合被称为GNU/Linux 操作系统。
那么,在 GNU/Linux 操作系统上的 GNU 组件是什么?例如GNU 编译器集合(GCC)、GNU C 库、GDB、GNU Bash shell 和GNU 网络对象模型环境(GNOME)桌面环境等软件包。Richard Stallman 和自由软件基金会(FSF)——Stallman 是创始人——撰写了自由软件定义,以帮助尊重用户的自由。自由软件被认为是授予用户以下四种自由(所谓的基本自由:isocpp.org/std/the-standard)的任何软件包:
-
自由按照您的意愿运行程序,无论任何目的(自由0)。
-
自由研究程序如何工作并对其进行更改,以便按照您的意愿进行计算(自由1)。访问源代码是这一自由的前提条件。
-
自由重新分发副本,以便您可以帮助他人(自由2)。
-
自由向他人分发您修改版本的副本(自由3)。通过这样做,您可以让整个社区有机会从您的更改中受益。访问源代码是这一自由的前提条件。
这些原则的具体实现在 FSF 撰写的 GNU/GPL 许可证中。所有 GNU 软件包都是根据 GNU/GPL 许可证发布的。
如何做…
Linux 在各种发行版中有一个相当标准的文件夹结构,因此了解这一点将使您能够轻松地找到程序并将其安装在正确的位置。让我们来看一下:
-
在 Docker 镜像上打开终端。
-
键入命令
ls -l /。
它是如何工作的…
命令的输出将包含以下文件夹:
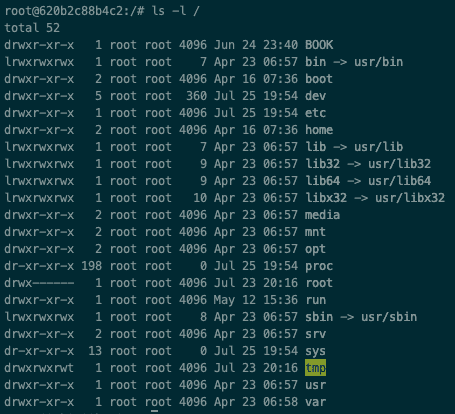
正如您所看到的,这个文件夹结构非常有组织且在所有发行版中保持一致。在 Linux 文件系统底层,它相当模块化和灵活。用户应用程序可以与 GNU C 库(提供诸如 open、read、write 和 close 等接口)或 Linux 系统调用直接交互。在这种情况下,系统调用接口与虚拟文件系统(通常称为VFS)交谈。VFS 是对具体文件系统实现(例如 ext3、日志文件系统(JFS)等)的抽象。正如我们可以想象的那样,这种架构提供了高度的灵活性。
学习 Linux 基础知识-Shell
Shell 是一个命令解释器,它接收输入中的命令,将其重定向到 GNU/Linux,并返回输出。这是用户和 GNU/Linux 之间最常见的接口。有不同的 shell 程序可用。最常用的是 Bash shell(GNU 项目的一部分)、tcsh shell、ksh shell 和 zsh shell(这基本上是一个扩展的 Bash shell)。
为什么需要 shell?如果用户需要通过命令行与操作系统进行交互,则需要 shell。在本食谱中,我们将展示一些最常见的 shell 命令。通常情况下,shell和终端这两个术语可以互换使用,尽管严格来说它们并不完全相同。
如何做……
在本节中,我们将学习在 shell 上运行的基本命令,例如查找文件、在文件中查找grep、复制和删除:
-
打开 shell:根据 GNU/Linux 发行版的不同,打开新 shell 命令有不同的快捷键。在 Ubuntu 上,按Ctrl + Alt + T,或按Alt + F2,然后输入
gnome-terminal。 -
关闭 shell:要关闭终端,只需键入
exit并按Enter。 -
find命令:用于在目录层次结构中搜索文件。在其最简单的形式中,它看起来像这样:
find . -name file
它也支持通配符:
$ find /usr/local "python*"
grep命令通过匹配模式打印行:
$ grep "text" filename
grep还支持递归搜索:
$ grep "text" -R /usr/share
- 管道命令:在 shell 上运行的命令可以连接起来,使一个命令的输出成为另一个命令的输入。连接是使用
|(管道)运算符完成的:
$ ls -l | grep filename
- 编辑文件:在 Linux 上编辑文件的最常用工具是
vi和emacs(如果您对编辑文件不感兴趣,cat filename将文件打印到标准输出)。前者是 Unix 操作系统的一部分,后者是 GNU 项目的一部分。本书将广泛使用vi:
$ vi filename
接下来,我们将看一下与文件操作相关的 shell 命令。
- 这是删除文件的命令:
$ rm filename
- 这是删除目录的命令:
$ rm -r directoryName
- 这是克隆文件的命令:
$ cp file1 file2
- 这是克隆文件夹的命令:
$ cp -r folder1 folder2
- 这是使用相对路径和绝对路径克隆文件夹的命令:
$ cp -r /usr/local/folder1 relative/folder2
下一节将描述这些命令。
它是如何工作的……
让我们详细了解*如何做……*部分中讨论的命令:
-
第一个命令从当前文件夹搜索(
.),可以包含绝对路径(例如/usr/local)或相对路径(例如tmp/binaries)。例如,在这里,-name是要搜索的文件。 -
第二个命令从
/usr/local文件夹搜索以python开头的任何文件或文件夹。find命令提供了巨大的灵活性和各种选项。有关更多信息,请通过man find命令参考man page。 -
grep命令搜索并打印包含filename文件中的text单词的任何行。 -
grep递归搜索命令搜索并打印任何包含text单词的行,从/usr/share文件夹递归搜索任何文件。 -
管道命令(
|):第一个命令的输出显示在以下截图中。所有文件和目录的列表作为输入传递给第二个命令(grep),将用于grep文件名:

现在,让我们看一下执行编辑文件、添加/删除文件和目录等操作的命令。
编辑文件:
vi命令将以编辑模式打开文件名,假设当前用户对其具有写入权限(我们将稍后更详细地讨论权限)。
以下是vi中最常用命令的简要总结:
-
Shift + :(即Shift键+冒号)切换到编辑模式。
-
Shift + :i插入。
-
Shift + :a追加。
-
*Shift + :q!*退出当前会话而不保存。
-
Shift + :wq保存并退出当前会话。
-
Shift + :set nu显示文件的行号。
-
Shift + :23(Enter)转到第 23 行。
-
按下(Esc)键切换到命令模式。
-
*.*重复上一个命令。
-
cw更改单词,或者通过将光标指向单词的开头来执行此操作。
-
dd删除当前行。
-
yy复制当前行。如果在yy命令之前选择了数字N,则将复制N行。
-
p粘贴使用yy命令复制的行。
-
u取消。
添加和删除文件和目录:
-
第一个命令删除名为
filename的文件。 -
第二个命令递归地删除
directoryName及其内容。 -
第三个命令创建了
file2,它是file1的精确副本。 -
第四个命令创建
folder2作为folder1的克隆:

在本教程中所示的命令执行中存在一个常见模式。它们列举如下:
-
用户输入命令并按Enter。
-
该命令由 Linux 解释。
-
Linux 与其不同的部分(内存管理、网络、文件系统等)进行交互以执行命令。这发生在内核空间**。**
-
结果返回给用户。
还有更多…
本教程展示了一些最常见的命令。掌握所有选项,即使只是对于最常见的 shell 命令,也是棘手的,这就是为什么创建了man pages。它们为 Linux 用户提供了坚实清晰的参考。
另请参阅
第八章,处理控制台 I/O 和文件,将更深入地介绍控制台 I/O 和文件管理。
学习 Linux 基础知识-用户
Linux 是一个多用户和多任务操作系统,因此基本的用户管理技能是必不可少的。本教程将向您展示文件和目录权限的结构,如何添加和删除用户,如何更改用户的密码以及如何将用户分配给组。
如何做…
以下一系列步骤显示了基本用户管理活动的有用命令:
- 创建用户:为每个使用 Linux 的个人配置一个用户不仅是最佳实践,而且也是推荐的。创建用户非常简单:
root@90f5b4545a54:~# adduser spacex --ingroup developers
Adding user `spacex' ...
Adding new user `spacex' (1001) with group `developers' ...
Creating home directory `/home/spacex' ...
Copying files from `/etc/skel' ...
New password:
Retype new password:
passwd: password updated successfully
Changing the user information for spacex
Enter the new value, or press ENTER for the default
Full Name []: Onorato
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] Y
spacex用户已创建并分配给现有的developers组。要切换到新创建的用户,请使用新用户的凭据登录:
root@90f5b4545a54:~# login spacex
Password:
Welcome to Ubuntu 19.04 (GNU/Linux 4.9.125-linuxkit x86_64)
* Documentation: https://help.ubuntu.com
* Management: https://landscape.canonical.com
* Support: https://ubuntu.com/advantage
This system has been minimized by removing packages and content that are
not required on a system that users do not log into.
To restore this content, you can run the 'unminimize' command.
The programs included with the Ubuntu system are free software;
the exact distribution terms for each program are described in the
individual files in /usr/share/doc/*/copyright.
Ubuntu comes with ABSOLUTELY NO WARRANTY, to the extent permitted by
applicable law.
spacex@90f5b4545a54:~$
- 更新用户密码:定期更改密码是必要的。以下是执行此操作的命令:
spacex@90f5b4545a54:~$ passwd
Changing password for spacex.
Current password:
New password:
Retype new password:
passwd: password updated successfully
spacex@90f5b4545a54:~$
- 将用户分配给组:如图所示,可以在创建用户时将用户分配给组。或者,可以随时通过运行以下命令将用户分配给组:
root@90f5b4545a54:~# usermod -a -G testers spacex
here spacex is added to the testers group
- 删除用户:同样,删除用户非常简单:
root@90f5b4545a54:~# userdel -r spacex
userdel: spacex mail spool (/var/mail/spacex) not found
root@90f5b4545a54:~#
-r 选项表示删除 spacex 主目录和邮件邮箱。
- 现在,让我们看看最后一个命令,它显示当前用户(
spacex)所属的组的列表:
spacex@90f5b4545a54:~$ groups
developers testers
spacex@90f5b4545a54:~$
如您所见,spacex用户属于developers和testers组。
工作原理…
在步骤 1中,我们使用adduser命令添加了spacex用户,并在上下文中将用户添加到developers组。
步骤 2显示了如何更改当前用户的密码。要更改密码,必须提供先前的密码。定期更改密码是一个好习惯。
如果我们想将用户分配给组,可以使用usermod命令。在步骤 3中,我们已将spacex用户添加到testers组。-a和-G参数只是指示新组(-G)将被附加到用户的当前组(-a)上。也就是说,spacex用户将被分配到testers组,该组将在上下文中创建。在同一步骤中,groups命令显示当前用户属于哪些组。如果您只想创建一个组,那么groupadd group-name就是您需要的命令。
步骤 4显示了如何使用userdel命令删除用户,传递-r参数。此参数确保将删除要删除的用户的所有文件。
还有更多…
在 Linux 文件系统中,每个文件和目录都有一组信息,定义了谁可以做什么。这个机制既简单又强大。文件(或目录)上允许的操作有读取、写入和执行(r、w和x)。这些操作可以由文件或目录的所有者、一组用户或所有用户执行。Linux 用 Owner: rwx;Group: rwx;All Users: rwx来表示这些信息;或者更简单地表示为rwx-rwx-rwx(总共 9 个)。实际上,Linux 在这些标志之上还有一个表示文件类型的标志。它可以是一个文件夹(d)、一个符号链接到另一个文件(l)、一个常规文件(-)、一个命名管道(p)、一个套接字(s)、一个字符设备文件(c)和一个块设备(b)。文件的典型权限看起来像这样:
root@90f5b4545a54:/# ls -l
-rwxr-xr-x 1 root root 13 May 8 20:11 conf.json
让我们详细看一下:
-
从左边开始阅读,第一个字符
-告诉我们conf.json是一个常规文件。 -
接下来的三个字符是关于当前用户的,
rwx。用户对文件有完全的读取(r)、写入(w)和执行(x)权限。 -
接下来的三个字符是关于用户所属的组,
r-x。所有属于该组的用户都可以读取和执行文件,但不能修改它(w未被选择,标记为-)。 -
最后的三个字符是关于所有其他用户,
r-x。所有其他用户只能读取和执行文件(r和x被标记,但w没有)。
所有者(或 root 用户)可以更改文件的权限。实现这一点的最简单方法是通过chmod命令:
$ chmod g+w conf.json
在这里,我们要求 Linux 内核向组用户类型(g)添加写权限(w)。用户类型有:u(用户)、o(其他人)、a(所有人)和g(组),权限标志可以是x、w和r,如前所述。chmod也可以接受一个整数:
$ chmod 751 conf.json
对于每种组类型的权限标志,有一个二进制到十进制的转换,例如:
wxr:111 = 7
w-r:101 = 5
--r:001 = 1
一开始可能有点神秘,但对于日常使用来说非常实用和方便。
另请参阅
man页面是一个无限的信息资源,应该是你查看的第一件事。像man groups、man userdel或man adduser这样的命令会对此有所帮助。
使用makefile来编译和链接程序
makefile是描述程序源文件之间关系的文件,由make实用程序用于构建(编译和链接)目标目标(可执行文件、共享对象等)。makefile非常重要,因为它有助于保持源文件的组织和易于维护。要使程序可执行,必须将其编译并链接到其他库中。GCC 是最广泛使用的编译器集合。C 和 C++世界中使用的两个编译器是 GCC 和 g++(分别用于 C 和 C++程序)。本书将使用 g++。
如何做…
这一部分将展示如何编写一个makefile,来编译和运行一个简单的 C++程序。我们将开发一个简单的程序,并创建它的makefile来学习它的规则:
- 让我们从打开
hello.cpp文件开始开发程序:
$vi hello.cpp
- 输入以下代码(参考学习 Linux 基础知识- shell中的
vi命令):
#include <iostream>
int main()
{
std::cout << "Hello World!" << std::endl;
return 0;
}
-
保存并退出:在
vi中,从命令模式下,输入:wq,表示写入并退出。:x命令具有相同的效果。 -
从 shell 中,创建一个名为
Makefile的新文件:
$ vi Makefile
- 输入以下代码:
CC = g++
all: hello
hello: hello.o
${CC} -o hello hello.o
hello.o: hello.cpp
${CC} -c hello.cpp
clean:
rm hello.o hello
尽管这是一个典型的Hello World!程序,但它很有用,可以展示一个makefile的结构。
它是如何工作的…
简单地说,makefile由一组规则组成。规则由一个目标、一组先决条件和一个命令组成。
在第一步中,我们打开了文件(hello.cpp)并输入了步骤 2中列出的程序。同样,我们打开了另一个文件Makefile,在hello.cpp程序的相同文件夹中,并输入了特定的 makefile 命令。现在让我们深入了解 makefile 的内部。典型的 makefile 具有以下内容:
-
第一个规则包括一个名为
all的目标和一个名为hello的先决条件。这个规则没有命令。 -
第二个规则包括一个名为
hello的目标。它有一个对hello.o的先决条件和一个链接命令:g++。 -
第三个规则有一个名为
hello.o的目标,一个对hello.cpp的先决条件和一个编译命令:g++ -c hello.cpp。 -
最后一个规则有一个
clean目标,带有一个命令来删除所有hello和hello.o可执行文件。这会强制重新编译文件。 -
对于任何规则,如果任何源文件发生更改,则执行定义的命令。
现在我们可以使用我们创建的 makefile 来编译程序:
$ make
我们还可以执行程序,其输出如下:

从源文件生成二进制可执行文件的过程包括编译和链接阶段,这里压缩在一个单独的命令中;在大多数情况下都是这样。一般来说,大型系统代码库依赖于更复杂的机制,但步骤仍然是相同的:源文件编辑、编译和链接。
还有更多…
这个简单的例子只是向我们展示了 makefile 及其make命令的基本概念。它比这更多。以下是一些例子:
- 宏的使用:makefile 允许使用宏,它们可以被视为变量。这些可以用于组织 makefile 以使其更加模块化,例如:
-
程序中使用的所有动态库的宏:
LIBS = -lxyz -labc。 -
编译器本身的宏(如果要更改为其他编译器):
COMPILER = GCC。 -
在整个 makefile 中引用这些宏:
$(CC)。这使我们可以在一个地方进行更改。
- 只需在 shell 上输入
make,就会运行 makefile 中定义的第一个规则。在我们的情况下,第一个规则是all。如果我们通过将**clean**作为第一个规则来更改 makefile,运行不带参数的make将执行clean规则。通常,您总是会传递一些参数,例如make clean。
使用 GDB 调试程序
调试是从软件系统中识别和消除错误的过程。GNU/Linux 操作系统有一个标准 事实上的工具(即不是任何标准的一部分,但几乎在 Linux 世界中被任何人使用)称为 GDB。安装在本书的 Docker 上的 GDB 版本是 8.2.91。当然,有一些可以在 GDB 下使用的图形工具,但在 Linux 上,GDB 是可靠、简单和快速的选择。在这个示例中,我们将调试我们在上一个示例中编写的软件。
如何做…
为了使用一些 GDB 命令,我们需要修改之前的程序并在其中添加一些变量:
- 打开一个 shell,并通过输入以下代码修改
hello.cpp文件:
#include <iostream>
int main()
{
int x = 10;
x += 2;
std::cout << "Hello World! x = " << x << std::endl;
return 0;
}
这是一个非常简单的程序:取一个变量,加上2,然后打印结果。
- 通过输入以下命令,确保程序已编译:
root@bffd758254f8:~/Chapter1# make
g++ -c hello.cpp
g++ -o hello hello.o
- 现在我们有了可执行文件,我们将对其进行调试。从命令行输入
gdb hello:
root@bffd758254f8:~/Chapter1# gdb hello
GNU gdb (Ubuntu 8.2.91.20190405-0ubuntu3) 8.2.91.20190405-git
Copyright (C) 2019 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from hello...
(No debugging symbols found in hello)
(gdb)
- 正如您所看到的,最后一行说(
hello中未找到调试符号)。GDB 不需要调试符号来调试程序,因此我们必须告诉编译器在编译过程中包含调试符号。我们必须退出当前会话;要做到这一点,输入q(Enter)。然后,编辑 makefile,并在g++编译器部分的hello.o目标中添加-g选项:
CC = g++
all: hello
hello: hello.o
${CC} -o hello hello.o
hello.o: hello.cpp
$(CC) -c -g hello.cpp
clean:
rm hello.o hello
- 让我们再次运行它,但首先,我们必须用
make命令重新构建应用程序:
root@bcec6ff72b3c:/BOOK/chapter1# gdb hello
GNU gdb (Ubuntu 8.2.91.20190405-0ubuntu3) 8.2.91.20190405-git
Copyright (C) 2019 Free Software Foundation, Inc.
License GPLv3+: GNU GPL version 3 or later <http://gnu.org/licenses/gpl.html>
This is free software: you are free to change and redistribute it.
There is NO WARRANTY, to the extent permitted by law.
Type "show copying" and "show warranty" for details.
This GDB was configured as "x86_64-linux-gnu".
Type "show configuration" for configuration details.
For bug reporting instructions, please see:
<http://www.gnu.org/software/gdb/bugs/>.
Find the GDB manual and other documentation resources online at:
<http://www.gnu.org/software/gdb/documentation/>.
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from hello...
(No debugging symbols found in hello)
(gdb)
我们已经准备好调试了。调试会话通常包括设置断点,观察变量的内容,设置监视点等。下一节将展示最常见的调试命令。
它是如何工作的…
在前一节中,我们已经看到了创建程序和 makefile 所需的步骤。在本节中,我们将学习如何调试我们开发的Hello World!程序。
让我们从可视化我们要调试的代码开始。我们通过运行l命令(缩写)来做到这一点:
(gdb) l
1 #include <iostream>
2 int main()
3 {
4 int x = 10;
5 x += 2;
6 std::cout << "Hello World! x = " << x << std::endl;
7 return 0;
8 }
我们必须设置一个断点。要设置断点,我们运行b 5命令。这将在当前模块的代码行号5处设置一个断点:
(gdb) b 5
Breakpoint 1 at 0x1169: file hello.cpp, line 5.
(gdb)
现在是运行程序的时候了。要运行程序,我们输入r命令。这将运行我们用 GDB 启动的hello程序:
(gdb) r
Starting program: /root/Chapter1/hello
一旦启动,GDB 将自动停在进程流程命中的任何断点处。在这种情况下,进程运行,然后停在hello.cpp文件的第5行:
Breakpoint 1, main () at hello.cpp:5
5 x += 2;
为了逐步进行,我们在 GDB 上运行n命令(即,跳过)。这会执行当前可视化的代码行。类似的命令是s(跳入)。如果当前命令是一个函数,它会跳入函数:
(gdb) n
6 std::cout << "Hello World! x = " << x << std::endl;
the 'n' command (short for next) execute one line. Now we may want to check the content of the variable x after the increment:
如果我们需要知道变量的内容,我们运行p命令(缩写),它会打印变量的内容。在这种情况下,预期地,x = 12被打印出来:
(gdb) p x
$1 = 12
现在,让我们运行程序直到结束(或者直到下一个断点,如果设置了)。这是用c命令(继续的缩写)完成的:
(gdb) c
Continuing.
Hello World! x = 12
[Inferior 1 (process 101) exited normally]
(gdb)
GDB 实际上充当解释器,让程序员逐行步进程序。这有助于开发人员解决问题,查看运行时变量的内容,更改变量的状态等。
还有更多…
GDB 有很多非常有用的命令。在接下来的章节中,将更多地探索 GDB。这里有四个更多的命令要展示:
-
s:跳入的缩写。如果在一个方法上调用,它会跳入其中。 -
bt:回溯的缩写。打印调用堆栈。 -
q:退出的缩写。用于退出 GDB。 -
d:删除的缩写。它删除一个断点。例如,d 1删除第一个设置的断点。
GNU GDB 项目的主页可以在这里找到:www.gnu.org/software/gdb。更详细的信息可以在man dbg的man pages和在线上找到。您也可以参考Using GDB: A Guide to the GNU Source-Level Debugger, by Richard M. Stallman and Roland H. Pesch*.*
学习 Linux 基础知识 - 进程和线程
进程和线程是任何操作系统的执行单元。在这个教程中,您将学习如何在 GNU/Linux 命令行上处理进程和线程。
在 Linux 中,进程由sched.h头文件中定义的task_struct结构定义。另一方面,线程由thread_info.h头文件中的thread_info结构定义。线程是主进程的一个可能的执行流。一个进程至少有一个线程(主线程)。进程的所有线程在系统上并发运行。
在 Linux 上需要记住的一点是,它不区分进程和线程。线程就像一个与其他一些进程共享一些资源的进程。因此,在 Linux 中,线程经常被称为轻量级进程(LWP)。
如何做…
在本节中,我们将逐步学习在 GNU/Linux 发行版上控制进程和线程的所有最常见命令:
ps命令显示当前系统中的进程、属性和其他参数。
root@5fd725701f0f:/# ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 4184 3396 pts/0 Ss 17:20 0:00 bash
root 18 0.0 0.1 5832 2856 pts/0 R+ 17:22 0:00 ps u
- 获取有关进程(及其线程)的信息的另一种方法是查看
/process/PID文件夹。该文件夹包含所有进程信息,进程的线程(以进程标识符(PID)的形式的子文件夹),内存等等:
root@e9ebbdbe3899:/# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 4184 3344 pts/0 Ss 16:24 0:00 bash
root 149 0.0 0.1 4184 3348 pts/1 Ss 17:40 0:00 bash
root 172 85.0 0.0 5832 1708 pts/0 R+ 18:02 0:04 ./hello
root 173 0.0 0.1 5832 2804 pts/1 R+ 18:02 0:00 ps aux
root@e9ebbdbe3899:/# ll /proc/172/
total 0
dr-xr-xr-x 9 root root 0 May 12 18:02 ./
dr-xr-xr-x 200 root root 0 May 12 16:24 ../
dr-xr-xr-x 2 root root 0 May 12 18:02 attr/
-rw-r--r-- 1 root root 0 May 12 18:02 autogroup
-r-------- 1 root root 0 May 12 18:02 auxv
-r--r--r-- 1 root root 0 May 12 18:02 cgroup
--w------- 1 root root 0 May 12 18:02 clear_refs
-r--r--r-- 1 root root 0 May 12 18:02 cmdline
-rw-r--r-- 1 root root 0 May 12 18:02 comm
-rw-r--r-- 1 root root 0 May 12 18:02 coredump_filter
-r--r--r-- 1 root root 0 May 12 18:02 cpuset
lrwxrwxrwx 1 root root 0 May 12 18:02 cwd -> /root/Chapter1/
-r-------- 1 root root 0 May 12 18:02 environ
lrwxrwxrwx 1 root root 0 May 12 18:02 exe -> /root/Chapter1/hello*
dr-x------ 2 root root 0 May 12 18:02 fd/
dr-x------ 2 root root 0 May 12 18:02 fdinfo/
-rw-r--r-- 1 root root 0 May 12 18:02 gid_map
-r-------- 1 root root 0 May 12 18:02 io
-r--r--r-- 1 root root 0 May 12 18:02 limits
...
- 进程也可以被终止。从技术上讲,终止一个进程意味着停止它的执行:
root@5fd725701f0f:/# kill -9 PID
该命令向具有 PID 的进程发送kill信号(9)。其他信号也可以发送给进程,例如HUP(挂起)和INT(中断)。
它是如何工作的…
在步骤 1中,对于每个进程,我们可以看到以下内容:
-
进程所属的用户
-
PID
-
特定时刻的 CPU 和内存百分比
-
当进程启动和运行时间
-
用于运行进程的命令
通过ps aux命令,我们可以获取hello进程的 PID,即172。现在我们可以查看/proc/172文件夹。
进程和线程是操作系统的构建模块。在本教程中,我们已经看到如何通过命令行与内核交互,以获取有关进程的信息(例如ps),并通过查看 Linux 在进程运行时更新的特定文件夹来获取信息。同样,每次我们调用命令(在这种情况下是为了获取有关进程的信息),命令必须进入内核空间以获取有效和更新的信息。
还有更多…
ps命令有比本教程中所见更多的参数。完整列表可在其 Linux man 页面man ps上找到。
作为ps的替代方案,一个更高级和交互式的命令是top命令,man top。
处理 Linux bash 错误
我们已经看到,通过 shell 是与 Linux 内核交互的一种方式,通过调用命令。命令可能会失败,正如我们可以想象的那样,而传达失败的一种方式是返回一个非负整数值。在大多数情况下,0 表示成功。本教程将向您展示如何处理 shell 上的错误处理。
如何做…
本节将向您展示如何直接从 shell 和通过脚本获取错误,这是脚本开发的一个基本方面:
- 首先,运行以下命令:
root@e9ebbdbe3899:/# cp file file2
cp: cannot stat 'file': No such file or directory
root@e9ebbdbe3899:/# echo $?
1
- 创建一个名为
first_script.sh的新文件,并输入以下代码:
#!/bin/bash
cat does_not_exists.txt
if [ $? -eq 0 ]
then
echo "All good, does_not_exist.txt exists!"
exit 0
else
echo "does_not_exist.txt really DOES NOT exists!!" >&2
exit 11
fi
-
保存文件并退出(
:wq或:x)。 -
为
first_script.sh文件为当前用户授予执行权限(x标志):
root@e9ebbdbe3899:~# chmod u+x first_script.sh
这些步骤在下一节中详细介绍。
它是如何工作的…
在步骤 1中,cp命令失败了,因为file和file2不存在。通过查询echo $?,我们得到了错误代码;在这种情况下,它是1。这在编写 bash 脚本时特别有用,因为我们可能需要检查特定条件。
在步骤 2中,脚本只是列出了does_not_exist.txt文件,并读取返回的错误代码。如果一切顺利,它会打印一个确认消息并返回0。否则,它会返回错误代码11。
通过运行脚本,我们得到以下输出:

在这里,我们注意到了一些事情:
-
我们记录了我们的错误字符串。
-
错误代码是我们在脚本中设置的。
在幕后,每次调用命令时,它都会进入内核空间。命令被执行,并以整数的形式将返回状态发送回用户。考虑这个返回状态非常重要,因为我们可能有一个命令,表面上成功了(没有输出),但最终失败了(返回的代码与0不同)。
还有更多…
命令的返回状态的一个重要方面是它可以用于(有条件地)运行下一个命令。为此目的使用了两个重要的运算符:&&(AND)和||(OR)。
在这两个命令中,第二个命令只有在第一个成功时才会运行(&&运算符)。如果file.txt被复制到项目文件夹中,它将被删除:
cp file.txt ~/projects && rm -f file.txt
让我们看一个第二个例子:
cp file.txt ~/projects || echo 'copy failed!'
在前面的示例中,第二个命令仅在第一个失败时运行(||运算符)。如果复制失败,则打印copy failed!。
在这个示例中,我们只是展示了如何在 shell 脚本中组合命令以创建更复杂的命令,并通过控制错误代码,我们可以控制执行流程。man 页面是一个很好的资源,因为它包含了所有的命令和错误代码(例如,man cp和man cat)。
处理 Linux 代码错误
这个示例代表了错误处理主题中的另一面:源代码级别的错误处理。Linux 通过命令以及编程 API 公开其内核特性。在这个示例中,我们将看到如何通过 C 程序处理错误代码和errno,以打开一个文件。
如何做…
在本节中,我们将看到如何在 C 程序中从系统调用中获取错误。为此,我们将创建一个程序来打开一个不存在的文件,并显示 Linux 返回的错误的详细信息:
-
创建一个新文件:
open_file.c。 -
编辑新创建的文件中的以下代码:
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
int main(int argc, char *argv[])
{
int fileDesc = open("myFile.txt", O_RDONLY);
if (fileDesc == -1)
{
fprintf(stderr, "Cannot open myFile.txt .. error: %d\n",
fileDesc);
fprintf(stderr, "errno code = %d\n", errno);
fprintf(stderr, "errno meaningn = %s\n", strerror(errno));
exit(1);
}
}
-
保存文件并退出(
:x)。 -
编译代码:
gcc open_file.c。 -
前面的编译(不带参数)将产生一个名为
a.out的二进制文件(这是 Linux 和 Unix 操作系统上的默认名称)。
工作原理…
列出的程序尝试以读取模式打开文件。错误将通过fprintf命令打印在标准错误上。运行后,输出如下:
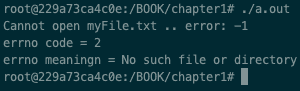
有一些要点需要强调。该程序是通过严格遵循 open 系统调用的 man 页面(man 2 open)开发的:
RETURN VALUES
If successful, open() returns a non-negative integer, termed a
file descriptor. It
returns -1 on failure, and sets errno to indicate the error
开发人员(在这种情况下是我们)检查了文件描述符是否为-1(通过fprintf确认),以打印errno(代码为2)。errno 2是什么意思?strerror对于这个目的非常有用,它可以将errno(这是晦涩的)翻译成程序员(或用户)能理解的内容。
还有更多…
在第二章中,重新审视 C++,我们将看到 C++如何通过提供更高级的机制、易于编写和更简洁的代码来帮助程序员。即使我们试图最小化直接与内核 API 的交互,而更倾向于使用 C++11-14-17 更高级的机制,也会有需要检查错误状态的情况。在这些情况下,您被邀请注意错误管理。
第二章:重温 C++
本章作为 C++ 11-20 的复习,将贯穿本书。我们将解释为什么 C++代表了一个绝佳的机会,不容错过,当涉及编写比以往更简洁和更具可移植性的高质量代码时。
本章不包含 C++(11 到 20)引入的所有新功能,只包括本书其余部分将使用的功能。具体来说,您将复习(如果您已经知道)或学习(如果您是新手)编写现代代码所需的最基本的新 C++技能。您将亲自动手使用 lambda 表达式、原子操作和移动语义等。
本章将涵盖以下示例:
-
理解 C++原始类型
-
Lambda 表达式
-
自动类型推断和
decltype -
学习原子操作的工作原理
-
学习
nullptr的工作原理 -
智能指针 -
unique_ptr和shared_ptr -
学习语义的工作原理
-
理解并发性
-
理解文件系统
-
C++核心指南
-
将 GSL 添加到您的 makefile
-
理解概念
-
使用 span
-
学习范围如何工作
-
学习模块的工作原理
技术要求
为了让您立即尝试本章中的程序,我们设置了一个 Docker 镜像,其中包含本书中将需要的所有工具和库。它基于 Ubuntu 19.04。
为了设置它,请按照以下步骤进行:
-
从www.docker.com下载并安装 Docker Engine。
-
从 Docker Hub 拉取镜像:
docker pull kasperondocker/system_programming_cookbook:latest。 -
现在应该可以使用该镜像。输入以下命令查看镜像:
docker images。 -
现在,您应该有以下镜像:
kasperondocker/system_programming_cookbook。 -
使用以下命令运行 Docker 镜像并打开交互式 shell:
docker run -it --cap-add sys_ptrace kasperondocker/system_programming_cookbook:latest /bin/bash。 -
正在运行的容器上的 shell 现在可用。使用
root@39a5a8934370/# cd /BOOK/获取为本书章节开发的所有程序。
需要--cap-add sys_ptrace参数以允许 GDB 在 Docker 容器中设置断点,默认情况下 Docker 不允许。
免责声明:C++20 标准已经在二月底的布拉格会议上得到批准(即技术上已经最终确定)。这意味着本书使用的 GCC 编译器版本 8.3.0 不包括(或者对 C++20 的新功能支持非常有限)。因此,Docker 镜像不包括 C++20 示例代码。GCC 将最新功能的开发保留在分支中(您必须使用适当的标志,例如-std=c++2a);因此,鼓励您自己尝试。因此,请克隆并探索 GCC 合同和模块分支,并尽情玩耍。
理解 C++原始类型
这个示例将展示 C++标准定义的所有原始数据类型,以及它们的大小。
如何做…
在本节中,我们将更仔细地查看 C++标准定义的原始类型以及其他重要信息。我们还将了解到,尽管标准没有为每个类型定义大小,但它定义了另一个重要参数:
- 首先,打开一个新的终端并输入以下程序:
#include <iostream>
#include <limits>
int main ()
{
// integral types section
std::cout << "char " << int(std::numeric_limits<char>::min())
<< "-" << int(std::numeric_limits<char>::max())
<< " size (Byte) =" << sizeof (char) << std::endl;
std::cout << "wchar_t " << std::numeric_limits<wchar_t>::min()
<< "-" << std::numeric_limits<wchar_t>::max()
<< " size (Byte) ="
<< sizeof (wchar_t) << std::endl;
std::cout << "int " << std::numeric_limits<int>::min() << "-"
<< std::numeric_limits<int>::max() << " size
(Byte) ="
<< sizeof (int) << std::endl;
std::cout << "bool " << std::numeric_limits<bool>::min() << "-"
<< std::numeric_limits<bool>::max() << "
size (Byte) ="
<< sizeof (bool) << std::endl;
// floating point types
std::cout << "float " << std::numeric_limits<float>::min() <<
"-"
<< std::numeric_limits<float>::max() << " size
(Byte) ="
<< sizeof (float) << std::endl;
std::cout << "double " << std::numeric_limits<double>::min()
<< "-"
<< std::numeric_limits<double>::max() << " size
(Byte) ="
<< sizeof (double) << std::endl;
return 0;
}
-
接下来,构建(编译和链接)
g++ primitives.cpp。 -
这将生成一个可执行文件,名称为
a.out(默认)。
它是如何工作的…
前面程序的输出将类似于这样:
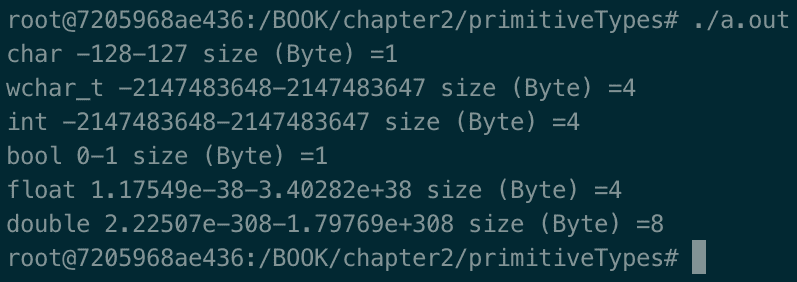
这代表了类型可以表示的最小和最大值,以及当前平台的字节大小。
C++标准不定义每种类型的大小,但它定义了最小宽度:
-
char: 最小宽度= 8 -
short int: 最小宽度= 16 -
int: 最小宽度= 16 -
long int: 最小宽度= 32 -
long int int: 最小宽度= 64
这一点有着巨大的影响,因为不同的平台可能有不同的大小,程序员应该应对这一点。为了帮助我们获得关于数据类型的一些指导,有一个数据模型的概念。数据模型是每个实现(编译器和操作系统遵循的体系结构的 psABI)所做的一组选择(每种类型的特定大小)来定义所有原始数据类型。以下表格显示了存在的各种类型和数据模型的子集:
| 数据类型 | LP32 | ILP32 | LLP64 | LP64 |
|---|---|---|---|---|
char | 8 | 8 | 8 | 8 |
short int | 16 | 16 | 16 | 16 |
int | 16 | 32 | 32 | 32 |
long | 32 | 32 | 32 | 64 |
指针 | 32 | 32 | 64 | 64 |
Linux 内核对 64 位体系结构(x86_64)使用 LP64 数据模型。
我们简要地提到了 psABI 主题(特定于平台的应用程序二进制接口(ABIs)的缩写)。每个体系结构(例如 x86_64)都有一个 psABI 规范,操作系统遵循这个规范。GNU 编译器集合(GCC)必须知道这些细节,因为它必须知道它编译的原始类型的大小。i386.h GCC 头文件包含了该体系结构的原始数据类型的大小:
root@453eb8a8d60a:~# uname -a
Linux 453eb8a8d60a 4.9.125-linuxkit #1 SMP Fri Sep 7 08:20:28 UTC 2018 x86_64 x86_64 x86_64 GNU/Linux
程序输出显示,当前操作系统(实际上是我们正在运行的 Ubuntu 镜像)使用了 LP64 数据模型,这是预期的,并且机器的体系结构是 x86_64。
还有更多…
正如我们所见,C++标准定义了以下原始数据类型:
-
整数:
int -
字符:
char -
布尔值:
bool -
浮点数:
float -
双精度浮点数:
double -
空:
void -
宽字符:
wchar_t -
空指针:
nullptr_t
数据类型可以包含其他信息,以便定义它们的类型:
-
修饰符:
signed、unsigned、long和short -
限定词:
const和restrict -
存储类型:
auto、static、extern和mutable
显然,并非所有这些附加属性都可以应用于所有类型;例如,unsigned不能应用于float和double类型(它们各自的 IEEE 标准不允许这样做)。
另请参阅
特别是对于 Linux,Linux 内核文档通常是深入研究这个问题的好地方:www.kernel.org/doc/html/latest。GCC 源代码显示了每个支持的体系结构的原始数据类型的大小。请参考以下链接以了解更多信息:github.com/gcc-mirror/gcc。
Lambda 表达式
lambda 表达式(或lambda 函数)是一种方便的方式,用于定义一个匿名的、小型的、一次性使用的函数,以便在需要的地方使用。Lambda 在标准模板库(STL)中特别有用,我们将会看到。
如何做…
在本节中,我们将编写一些代码,以便熟悉 lambda 表达式。尽管机制很重要,但要特别注意 lambda 的代码可读性,特别是与 STL 结合使用。按照以下步骤:
- 在这个程序中,lambda 函数获取一个整数并将其打印到标准输出。让我们打开一个名为
lambda_01.cpp的文件,并在其中写入以下代码:
#include <iostream>
#include <vector>
#include <algorithm>
int main ()
{
std::vector<int> v {1, 2, 3, 4, 5, 6};
for_each (begin(v), end(v), [](int x) {std::cout << x
<< std::endl;});
return 0;
}
- 在这第二个程序中,lambda 函数通过引用捕获一个前缀,并将其添加到标准输出的整数前面。让我们在一个名为
lambda_02.cpp的文件中写入以下代码:
#include <iostream>
#include <vector>
#include <algorithm>
int main ()
{
std::vector<int> v {1, 2, 3, 4, 5, 6};
std::string prefix ("0");
for_each (begin(v), end(v), &prefix {std::cout
<< prefix << x << std::endl;});
return 0;
}
- 最后,我们用
g++ lambda_02.cpp编译它。
它是如何工作的…
在第一个例子中,lambda 函数只是获取一个整数作为输入并打印它。请注意,代码简洁且可读。Lambda 可以通过引用&或值=捕获作用域中的变量。
第二个程序的输出如下:

在第二个例子中,lambda 通过引用捕获了变量前缀,使其对 lambda 可见。在这里,我们通过引用捕获了prefix变量,但我们也可以捕获以下任何一个:
-
所有变量按引用
[&] -
所有变量按值
[=] -
指定要捕获的变量和如何捕获它们
[&var1, =var2]
有些情况下,我们必须明确指定要返回的类型,就像这种情况:
[](int x) -> std::vector<int>{
if (x%2)
return {1, 2};
else
return {3, 4};
});
-> std::vector<int>运算符,称为尾返回类型,告诉编译器这个 lambda 将返回一个整数向量。
还有更多…
Lambda 可以分解为六个部分:
-
捕获子句:
[] -
参数列表:
() -
可变规范:
mutable -
异常规范:
noexcept -
尾返回类型:
-> type -
主体:
{}
在这里,1、2和6是强制性的。
虽然可选,但可变规范和异常规范值得一提,因为它们在某些情况下可能很方便。可变规范允许通过 lambda 主体修改按值传递的参数。参数列表中的变量通常是以const-by-value方式捕获的,因此mutable规范只是去除了这个限制。第二种情况是异常规范,我们可以用它来指定 lambda 可能抛出的异常。
另请参阅
Scott Meyers 的《Effective Modern C++》和 Bjarne Stroustrup 的《C++程序设计语言》详细介绍了这些主题。
自动类型推断和 decltype
C++提供了两种从表达式中推断类型的机制:auto和decltype()。auto用于从其初始化程序推断类型,而decltype()用于更复杂的情况推断类型。本文将展示如何使用这两种机制的示例。
如何做…
避免明确指定将使用的变量类型可能很方便(实际上确实如此),特别是当它特别长并且在本地使用时:
- 让我们从一个典型的例子开始:
std::map<int, std::string> payslips;
// ...
for (std::map<int,
std::string>::const_iterator iter = payslips.begin();
iter !=payslips.end(); ++iter)
{
// ...
}
- 现在,让我们用
auto来重写它:
std::map<int, std::string> payslips;
// ...
for (auto iter = payslips.begin(); iter !=payslips.end(); ++iter)
{
// ...
}
- 让我们看另一个例子:
auto speed = 123; // speed is an int
auto height = calculate (); // height will be of the
// type returned by calculate()
decltype()是 C++提供的另一种机制,可以在表达式比auto更复杂的情况下推断表达式的类型。
- 让我们用一个例子来看看:
decltype(a) y = x + 1; // deducing the type of a
decltype(str->x) y; // deducing the type of str->x, where str is
// a struct and x
// an int element of that struct
在这两个例子中,我们能否使用auto代替decltype()?我们将在下一节中看一看。
它是如何工作的…
第一个使用auto的例子显示,类型是在编译时从右侧参数推断出来的。auto用于简单的情况。
decltype()推断表达式的类型。在这个例子中,它定义了y变量,使其与a的类型相同。正如你可以想象的那样,这是不可能用auto来实现的。为什么?这很简单:decltype()告诉编译器定义一个特定类型的变量;在第一个例子中,y是一个与a相同类型的变量。而使用auto,类型会自动推断。
我们应该在不必显式指定变量类型的情况下使用auto和decltype();例如,当我们需要double类型(而不是float)时。值得一提的是,auto和decltype()都推断编译器已知的表达式的类型,因此它们不是运行时机制。
还有更多…
有一个特殊情况必须提到。当auto使用{}(统一初始化程序)进行类型推断时,它可能会引起一些麻烦(或者至少是我们不会预期的行为)。让我们看一个例子:
auto fuelLevel {0, 1, 2, 3, 4, 5};
在这种情况下,被推断的类型是initializer_list<T>,而不是我们可能期望的整数数组。
另请参阅
Scott Meyers 的《Effective Modern C++》和 Bjarne Stroustrup 的《C++程序设计语言》详细介绍了这些主题。
学习原子操作的工作原理
传统上,C 和 C++在系统编程中有着悠久的可移植代码传统。C++11 标准引入的atomic特性通过本地添加了操作被其他线程视为原子的保证,进一步加强了这一点。原子是一个模板,例如template <class T> struct atomic;或template <class T> struct atomic<T*>;。C++20 已经将shared_ptr和weak_ptr添加到了T和T*。现在对atomic变量执行的任何操作都受到其他线程的保护。
如何做…
std::atomic是现代 C++处理并发的重要方面。让我们编写一些代码来掌握这个概念:
- 第一段代码片段展示了原子操作的基础知识。现在让我们写下这个:
std::atomic<int> speed (0); // Other threads have access to the speed variable
auto currentSpeed = speed.load(); // default memory order: memory_order_seq_cst
- 在第二个程序中,我们可以看到
is_lock_free()方法在实现是无锁的或者使用锁实现时返回true。让我们编写这段代码:
#include <iostream>
#include <utility>
#include <atomic>
struct MyArray { int z[50]; };
struct MyStr { int a, b; };
int main()
{
std::atomic<MyArray> myArray;
std::atomic<MyStr> myStr;
std::cout << std::boolalpha
<< "std::atomic<myArray> is lock free? "
<< std::atomic_is_lock_free(&myArray) << std::endl
<< "std::atomic<myStr> is lock free? "
<< std::atomic_is_lock_free(&myStr) << std::endl;
}
- 让我们编译程序。在这样做时,您可能需要向 g++添加
atomic库(由于 GCC 的一个错误):g++ atomic.cpp -latomic。
它是如何工作的…
std::atomic<int> speed (0);将speed变量定义为原子整数。尽管变量是原子的,但这种初始化不是原子的!相反,以下代码:speed +=10;原子地增加了10的速度。这意味着不会发生竞争条件。根据定义,当访问变量的线程中至少有 1 个是写入者时,就会发生竞争条件。
std::cout << "current speed is: " << speed;指令自动读取当前速度的值。请注意,从速度中读取值是原子的,但接下来发生的事情不是原子的(也就是说,通过cout打印它)。规则是读取和写入是原子的,但周围的操作不是,正如我们所见。
第二个程序的输出如下:
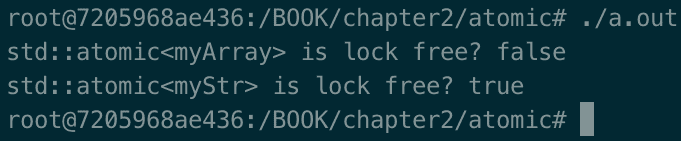
原子的基本操作是load、store、swap和cas(compare and swap的缩写),适用于所有类型的原子。根据类型,还有其他操作可用(例如fetch_add)。
然而,还有一个问题没有解决。为什么myArray使用锁而myStr是无锁的?原因很简单:C++为所有原始类型提供了无锁实现,而MyStr内部的变量是原始类型。用户将设置myStr.a和myStr.b。另一方面,MyArray不是基本类型,因此底层实现将使用锁。
标准保证是对于每个原子操作,每个线程都会取得进展。需要牢记的一个重要方面是,编译器经常进行代码优化。使用原子会对编译器施加关于代码如何重新排序的限制。一个限制的例子是,不能将写入atomic变量之前的任何代码移动到之后的原子写入。
还有更多…
在这个示例中,我们使用了名为memory_order_seq_cst的默认内存模型。其他可用的内存模型包括:
-
memory_order_relaxed:只保证当前操作的原子性。也就是说,没有保证不同线程中的内存访问与原子操作的顺序有关。 -
memory_order_consume:操作被排序在释放线程上所有对释放操作有依赖的内存访问发生后。 -
memory_order_acquire:操作被排序在释放线程上所有对内存的访问发生后。 -
memory_order_release:操作被排序在发生在消费或获取操作之前。 -
memory_order_seq_cst:操作是顺序一致的。
另请参阅
Scott Meyers 的《Effective Modern C++》和 Bjarne Stroustrup 的《C++程序设计语言》详细介绍了这些主题。此外,Herb Sutter 的原子武器演讲在 YouTube 上免费提供(www.youtube.com/watch?v=A8eCGOqgvH4),是一个很好的介绍。
学习nullptr的工作原理
在 C++11 之前,NULL标识符是用于指针的。在这个示例中,我们将看到为什么这是一个问题,以及 C++11 是如何解决它的。
如何做…
要理解为什么nullptr很重要,让我们看看NULL的问题:
- 让我们写下以下代码:
bool speedUp (int speed);
bool speedUp (char* speed);
int main()
{
bool ok = speedUp (NULL);
}
- 现在,让我们使用
nullptr重写前面的代码:
bool speedUp (int speed);
bool speedUp (char* speed);
int main()
{
bool ok = speedUp (nullptr);
}
它是如何工作的…
第一个程序可能无法编译,或者(如果可以)调用错误的方法。我们希望它调用bool speedUp (char* speed);。NULL的问题正是这样:NULL被定义为0,这是一个整数类型,并且被预处理器使用(替换所有NULL的出现)。这是一个巨大的区别,因为nullptr现在是 C++原始类型之一,并由编译器管理。
对于第二个程序,使用char*指针调用了speedUp(重载)方法。这里没有歧义 - 我们调用了char*类型的版本。
还有更多…
nullptr代表不指向任何对象的指针:
int* p = nullptr;
由于这个,就没有歧义,这意味着可读性得到了提高。另一个提高可读性的例子如下:
if (x == nullptr)
{
// ...\
}
这使得代码更易读,并清楚地表明我们正在比较一个指针。
另请参阅
Scott Meyers 的《Effective Modern C++》和 Bjarne Stroustrup 的《C++程序设计语言》详细介绍了这些主题。
智能指针 - unique_ptr 和 shared_ptr
这个示例将展示unique_ptr和shared_ptr的基本用法。这些智能指针是程序员的主要帮手,他们不想手动处理内存释放。一旦你学会了如何正确使用它们,这将节省头痛和夜间调试会话。
如何做…
在本节中,我们将看一下两个智能指针std::unique_ptr和std::shared_ptr的基本用法:
- 让我们通过开发以下类来开发一个
unique_ptr示例:
#include <iostream>
#include <memory>
class CruiseControl
{
public:
CruiseControl()
{
std::cout << "CruiseControl object created" << std::endl;
};
~CruiseControl()
{
std::cout << "CruiseControl object destroyed" << std::endl;
}
void increaseSpeedTo(int speed)
{
std::cout << "Speed at " << speed << std::endl;
};
};
- 现在,让我们通过调用前面的类来开发一个
main类:
int main ()
{
std::cout << "unique_ptr test started" << std::endl;
std::unique_ptr<CruiseControl> cruiseControl =
std::make_unique<CruiseControl>();
cruiseControl->increaseSpeedTo(12);
std::cout << "unique_ptr test finished" << std::endl;
}
-
让我们编译
g++ unique_ptr_01.cpp。 -
另一个
unique_ptr的例子展示了它在数组中的行为。让我们重用相同的类(CruiseControl):
int main ()
{
std::cout << "unique_ptr test started" << std::endl;
std::unique_ptr<CruiseControl[]> cruiseControl =
std::make_unique<CruiseControl[]>(3);
cruiseControl[1].increaseSpeedTo(12);
std::cout << "unique_ptr test finished" << std::endl;
}
- 让我们看看一个小程序中
std::shared_ptr的实际应用:
#include <iostream>
#include <memory>
class CruiseControl
{
public:
CruiseControl()
{
std::cout << "CruiseControl object created" << std::endl;
};
~CruiseControl()
{
std::cout << "CruiseControl object destroyed" << std::endl;
}
void increaseSpeedTo(int speed)
{
std::cout << "Speed at " << speed << std::endl;
};
};
main看起来像这样:
int main ()
{
std::cout << "shared_ptr test started" << std::endl;
std::shared_ptr<CruiseControl> cruiseControlMaster(nullptr);
{
std::shared_ptr<CruiseControl> cruiseControlSlave =
std::make_shared<CruiseControl>();
cruiseControlMaster = cruiseControlSlave;
}
std::cout << "shared_ptr test finished" << std::endl;
}
*它是如何工作的…*部分将详细描述这三个程序。
它是如何工作的…
通过运行第一个unique_ptr程序,即./a.out,我们得到以下输出:
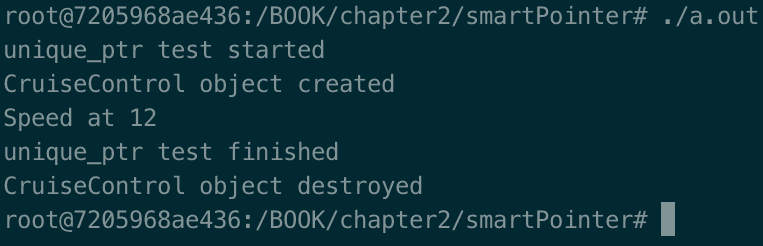
unique_ptr是一个智能指针,体现了独特所有权的概念。独特所有权简单来说意味着只有一个变量可以拥有一个指针。这个概念的第一个结果是不允许在两个独特指针变量上使用复制运算符。只允许move,其中所有权从一个变量转移到另一个变量。运行的可执行文件显示,对象在当前作用域结束时被释放(在这种情况下是main函数):CruiseControl object destroyed。开发人员不需要记得在需要时调用delete,但仍然可以控制内存,这是 C++相对于基于垃圾收集器的语言的主要优势之一。
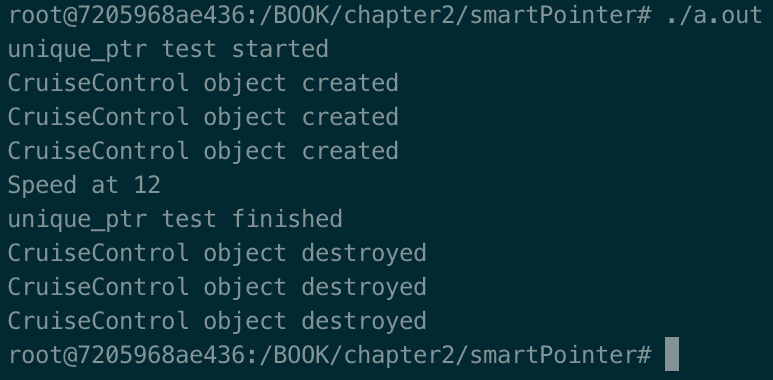
在第二个unique_ptr示例中,使用数组,有三个CruiseControl类型的对象被分配然后释放。因此,输出如下:
第三个例子展示了shared_ptr的用法。程序的输出如下:
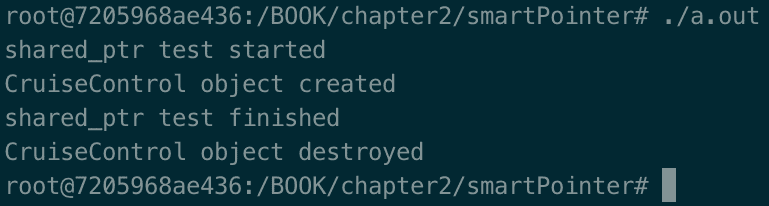
shared_ptr智能指针代表一个对象被多个变量指向的概念(即,由所有者指向)。在这种情况下,我们谈论的是共享所有权。很明显,规则与unique_ptr的情况不同。一个对象不能被释放,直到至少有一个变量在使用它。在这个例子中,我们定义了一个指向nullptr的cruiseControlMaster变量。然后,我们定义了一个块,在该块中,我们定义了另一个变量:cruiseControlSlave。到目前为止一切顺利!然后,在块内部,我们将cruiseControlSlave指针分配给cruiseControlMaster。此时,分配的对象有两个指针:cruiseControlMaster和cruiseControlSlave。当此块关闭时,cruiseControlSlave析构函数被调用,但对象没有被释放,因为它仍然被另一个对象使用:cruiseControlMaster!当程序结束时,我们看到shared_ptr test finished日志,紧接着是cruiseControlMaster,因为它是唯一指向CruiseControl对象释放的对象,然后调用构造函数,如CruiseControl object destroyed日志所述。
显然,shared_ptr数据类型具有引用计数的概念来跟踪指针的数量。这些引用在构造函数(并非总是;move构造函数不是)和复制赋值运算符中增加,并在析构函数中减少。
引用计数变量是否可以安全地增加和减少?指向同一对象的指针可能在不同的线程中,因此操纵这个变量可能会有问题。这不是问题,因为引用计数变量是原子管理的(即,它是原子变量)。
关于大小的最后一点。unique_ptr的大小与原始指针一样大,而shared_ptr的大小通常是unique_ptr的两倍,因为有引用计数变量。
还有更多…
我强烈建议始终使用std::make_unique和std::make_shared。它们的使用消除了代码重复,并提高了异常安全性。想要更多细节吗?shared_ptr.h(github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/bits/shared_ptr.h)和shared_ptr_base.h(github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/bits/shared_ptr_base.h)包含了 GCC shared_ptr的实现,这样我们就可以看到引用计数是如何被操纵的。
另请参阅
Scott Meyers 的《Effective Modern C++》和 Bjarne Stroustrup 的《C++程序设计语言》详细介绍了这些主题。
学习移动语义的工作原理
我们知道复制是昂贵的,特别是对于重型对象。C++11 引入的移动语义帮助我们避免昂贵的复制。std::move和std::forward背后的基本概念是右值引用。这个示例将向您展示如何使用std::move。
如何做…
让我们开发三个程序来学习std::move及其通用引用:
- 让我们从开发一个简单的程序开始:
#include <iostream>
#include <vector>
int main ()
{
std::vector<int> a = {1, 2, 3, 4, 5};
auto b = std::move(a);
std::cout << "a: " << a.size() << std::endl;
std::cout << "b: " << b.size() << std::endl;
}
- 让我们开发第二个例子:
#include <iostream>
#include <vector>
void print (std::string &&s)
{
std::cout << "print (std::string &&s)" << std::endl;
std::string str (std::move(s));
std::cout << "universal reference ==> str = " << str
<< std::endl;
std::cout << "universal reference ==> s = " << s << std::endl;
}
void print (std::string &s)
{
std::cout << "print (std::string &s)" << std::endl;
}
int main()
{
std::string str ("this is a string");
print (str);
std::cout << "==> str = " << str << std::endl;
return 0;
}
- 让我们看一个通用引用的例子:
#include <iostream>
void print (std::string &&s)
{
std::cout << "print (std::string &&s)" << std::endl;
std::string str (std::move(s));
std::cout << "universal reference ==> str = " << str
<< std::endl;
std::cout << "universal reference ==> s = " << s << std::endl;
}
void print (std::string &s)
{
std::cout << "print (std::string &s)" << std::endl;
}
int main()
{
print ("this is a string");
return 0;
}
下一节将详细描述这三个程序。
工作原理…
第一个程序的输出如下(g++ move_01.cpp和./a.out):
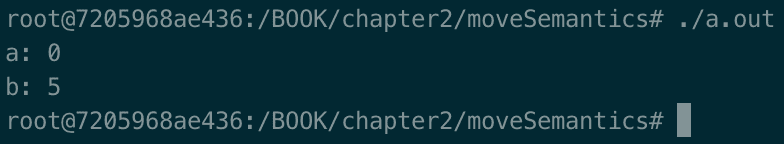
在这个程序中,auto b = std::move(a);做了一些事情:
-
它将向量
a转换为右值引用。 -
由于它是右值引用,所以调用了向量的移动构造函数,将
a向量的内容移动到b向量中。 -
a不再具有原始数据,b有。
第二个程序的输出如下(g++ moveSemantics2.cpp和./a.out):

在第二个例子中,我们传递给print方法的str字符串是一个左值引用(也就是说,我们可以取该变量的地址),因此它是通过引用传递的。
第三个程序的输出如下(g++ moveSemantics3.cpp和./a.out):

在第三个例子中,被调用的方法是带有通用引用作为参数的方法:print (std::string &&s)。这是因为我们无法取this is a string的地址,这意味着它是一个右值引用。
现在应该清楚了,std::move并没有实际移动任何东西-它是一个函数模板,执行无条件转换为右值,正如我们在第一个例子中看到的那样。这使我们能够将数据移动(而不是复制)到目标并使源无效。std::move的好处是巨大的,特别是每当我们看到一个方法(T&&)的右值引用参数,在语言的以前版本(C++98 及以前)中可能*是一个复制。
*可能:这取决于编译器的优化。
还有更多…
std::forward有些类似(但目的不同)。它是对右值引用的条件转换。您可以通过阅读下一节中引用的书籍来了解更多关于std::forward、右值和左值的知识。
另请参阅
Scott Meyers 的Effective Modern C++和 Bjarne Stroustrup 的The C++ Programming Language详细介绍了这些主题。
理解并发
过去,C++开发人员通常使用线程库或本地线程机制(例如pthread、Windows 线程)编写程序。自 C++11 以来,这已经发生了巨大的变化,并发是另一个重要的功能,它朝着一个自洽的语言方向发展。我们将在这个配方中看到的两个新特性是std::thread和std::async。
如何做…
在本节中,我们将学习如何在基本场景(创建和加入)中使用std::thread,以及如何向其传递和接收参数:
std::thread:通过使用基本的线程方法,create和join,编写以下代码:
#include <iostream>
#include <thread>
void threadFunction1 ();
int main()
{
std::thread t1 {threadFunction1};
t1.join();
return 0;
}
void threadFunction1 ()
{
std::cout << "starting thread 1 ... " << std::endl;
std::cout << "end thread 1 ... " << std::endl;
}
- 使用
g++ concurrency_01.cpp -lpthread进行编译。
第二个例子与前一个例子类似,但在这种情况下,我们传递和获取参数:
std::thread:创建和加入一个线程,传递一个参数并获取结果。编写以下代码:
#include <iostream>
#include <thread>
#include <vector>
#include <algorithm>
void threadFunction (std::vector<int> &speeds, int& res);
int main()
{
std::vector<int> speeds = {1, 2, 3, 4, 5};
int result = 0;
std::thread t1 (threadFunction, std::ref(speeds),
std::ref(result));
t1.join();
std::cout << "Result = " << result << std::endl;
return 0;
}
void threadFunction (std::vector<int> &speeds, int& res)
{
std::cout << "starting thread 1 ... " << std::endl;
for_each(begin(speeds), end(speeds), [](int speed)
{
std::cout << "speed is " << speed << std::endl;
});
res = 10;
std::cout << "end thread 1 ... " << std::endl;
}
- 使用
g++ concurrency_02.cpp -lpthread进行编译。
第三个例子使用async来创建一个任务,执行它,并获取结果,如下所示:
std::async:在这里,我们可以看到为什么 async 被称为基于任务的线程。编写以下代码:
root@b6e74d5cf049:/Chapter2# cat concurrency_03.cpp
#include <iostream>
#include <future>
int asyncFunction ();
int main()
{
std::future<int> fut = std::async(asyncFunction);
std::cout << "max = " << fut.get() << std::endl;
return 0;
}
int asyncFunction()
{
std::cout << "starting asyncFunction ... " << std::endl;
int max = 0;
for (int i = 0; i < 100000; ++i)
{
max += i;
}
std::cout << " Finished asyncFunction ..." << std::endl;
return max;
}
- 现在,我们需要编译程序。这里有一个问题。由于我们使用了线程机制,编译器依赖于本地实现,而在我们的情况下,结果是
pthread。为了编译和链接而不出现错误(我们会得到一个未定义的引用),我们需要包含-lpthread:
g++ concurrency_03.cpp -lpthread
在第四个例子中,std::async与std::promise和std::future结合使用是使两个任务相互通信的一种好而简单的方法。让我们来看一下:
std::async:这是另一个std::async示例,展示了基本的通信机制。让我们编写它:
#include <iostream>
#include <future>
void asyncProducer(std::promise<int> &prom);
void asyncConsumer(std::future<int> &fut);
int main()
{
std::promise<int> prom;
std::future<int> fut = prom.get_future();
std::async(asyncProducer, std::ref(prom));
std::async(asyncConsumer, std::ref(fut));
std::cout << "Async Producer-Consumer ended!" << std::endl;
return 0;
}
void asyncConsumer(std::future<int> &fut)
{
std::cout << "Got " << fut.get() << " from the producer ... "
<< std::endl;
}
void asyncProducer(std::promise<int> &prom)
{
std::cout << " sending 5 to the consumer ... " << std::endl;
prom.set_value (5);
}
- 最后,编译它:
g++ concurrency_04.cpp -lpthread
它是如何工作的…
让我们分析前面的四个程序:
std::thread:下面的程序展示了基本的线程使用方法,用于创建和加入:

在这个第一个测试中并没有什么复杂的。std::thread通过统一初始化用函数初始化,并加入(等待线程完成)。线程将接受一个函数对象:
struct threadFunction
{
int speed;
void operator ()();
}
std::thread t(threadFunction);
std::thread:创建和加入一个线程,传递一个参数并获取结果:

这第二个测试展示了如何通过std::vector<int>& speeds将参数传递给线程,并获取返回参数int& ret。这个测试展示了如何向线程传递参数,并且不是多线程代码(也就是说,如果至少有一个线程将对它们进行写入,那么向其他线程传递相同的参数将导致竞争条件)!
std::async:在这里,我们可以看到为什么async被称为基于任务的线程:

请注意,当我们调用std::async(asyncFunction);时,我们可以使用auto fut = std::async(asyncFunction);在编译时推断出std::async的返回类型。
std::async:这是另一个std::async示例,展示了一种基本的通信机制:

消费者void asyncConsumer(std::future<int> &fut)调用get()方法来获取由生产者通过promise的set_value()方法设置的值。fut.get()等待值的计算,如果需要的话(也就是说,这是一个阻塞调用)。
还有更多…
C++并发库不仅包括本示例中显示的功能,尽管这些是基础功能。您可以通过查看 Bjarne Stroustrup 的《C++程序设计语言》第五章第三段来探索可用的完整并发工具集。
另请参阅
Scott Meyers 的《Effective Modern C++》和 Bjarne Stroustrup 的《C++程序设计语言》详细介绍了这些主题。
理解文件系统
C++17 标志着另一个新功能方面的重大里程碑。filesystem库提供了一种更简单的与文件系统交互的方式。它受到了自 2003 年以来就可用的Boost.Filesystem的启发。本示例将展示其基本功能。
如何做到的…
在本节中,我们将通过使用directory_iterator和create_directories来展示filesystem库的两个示例。尽管在这个命名空间下肯定还有更多内容,但这两个片段的目标是突出它们的简单性:
std::filesystem::directory_iterator:让我们编写以下代码:
#include <iostream>
#include <filesystem>
int main()
{
for(auto& p: std::filesystem::directory_iterator("/"))
std::cout << p << std::endl;
}
- 现在,使用
g++ filesystem_01.cpp -std=c++17 -lstdc++fs进行编译,其中**-std=c++17**告诉编译器使用 C++17 标准,-lstdc++fs告诉编译器使用filesystem库。
第二个示例是关于创建目录和文件:
std::filesystem::create_directories:编写以下代码:
#include <iostream>
#include <filesystem>
#include <fstream>
int main()
{
std::filesystem::create_directories("test/src/config");
std::ofstream("test/src/file.txt") << "This is an example!"
<< std::endl;
}
- 编译与前面的示例相同:
g++ filesystem_02.cpp -std=c++17 -lstdc++fs。
只需两行代码,我们就创建了一个文件夹结构、一个文件,并且还对其进行了写入!就是这么简单(而且可移植)。
它是如何工作的…
filesystem库位于std::filesystem命名空间下的<filesystem>头文件中。尽管这两个测试非常简单,但它们需要展示filesystem库的强大之处。第一个程序的输出如下:

可以在这里找到std::filesystem方法的完整列表:en.cppreference.com/w/cpp/header/filesystem。
std::filesystem::create_directories在当前文件夹中创建一个目录(如果test/src不存在,则递归创建),在这种情况下。当然,绝对路径也是可以的,当前行也是完全有效的,即std::filesystem::create_directories("/usr/local/test/config");。
源代码的第二行使用ofstream来创建一个名为test/src/file.txt的输出文件流,并将<<附加到字符串:This is an example!.
还有更多…
filesystem库受Boost.Filesystem的启发,自 2003 年以来一直可用。如果你想要尝试和调试一下,只需在编译器中添加-g选项(将调试符号添加到二进制文件):g++ **-g** fs.cpp -std=c++17 -lstdc++fs。
另请参阅
Scott Meyers 的书Effective Modern C++和 Bjarne Stroustrup 的书The C++ Programming Language详细介绍了这些主题。
C++核心指南
C++核心指南是由 Bjarne Stroustrup 领导的协作努力,就像 C++语言本身一样。它们是多年来在许多组织中进行讨论和设计的结果。它们的设计鼓励普遍适用性和广泛采用,但可以自由复制和修改以满足您组织的需求。更准确地说,这些指南是指 C++14 标准。
准备就绪
前往 GitHub 并转到 C++核心指南文档(isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines),以及 GitHub 项目页面:github.com/isocpp/CppCoreGuidelines。
如何做…
C++核心指南分为易于浏览的各个部分。这些部分包括类和类层次结构、资源管理、性能和错误处理。C++核心指南是由 Bjarne Stroustrup 和 Herb Sutter 领导的协作努力,但总共涉及 200 多名贡献者(要了解更多信息,请访问github.com/isocpp/CppCoreGuidelines/graphs/contributors)。他们提出的质量、建议和最佳实践令人难以置信。
它是如何工作的…
使用 C++核心指南的最常见方法是在 GitHub 页面上保持一个浏览器标签,并持续查阅它以完成日常任务。
还有更多…
如果您想为已提供的问题做出贡献,GitHub 页面包含许多可供选择的项目。有关更多信息,请访问github.com/isocpp/CppCoreGuidelines/issues。
另请参阅
本章的在 makefile 中添加 GSL配方将非常有帮助。
在 makefile 中添加 GSL
“GSL 是这些指南中指定的一小组类型和别名。在撰写本文时,它们的规范还不够详细;我们计划添加一个 WG21 风格的接口规范,以确保不同的实现达成一致,并提议作为可能标准化的贡献,通常受委员会决定接受/改进/更改/拒绝的影响。” - C++核心指南的 FAQ.50。
准备就绪
前往 GitHub 并转到 C++核心指南文档:isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines。
如何做…
在本节中,我们将通过修改 makefile 将指南支持库(gsl)集成到程序中:
-
下载并复制
gsl实现(例如github.com/microsoft/GSL)。 -
将
gsl文件夹复制到您的项目中。 -
在 makefile 中添加包含:
-I$HOME/dev/GSL/include。 -
在您的源文件中,包含
#include <gsl/gsl>。
gsl目前提供以下内容:
-
GSL.view -
GSL.owner -
GSL.assert: Assertions -
GSL.util: Utilities -
GSL.concept: Concepts
它是如何工作的…
您可能已经注意到,要使gsl工作,只需在 makefile 中指定头文件夹路径,即-I$HOME/dev/GSL/include。还要注意的一点是,在 makefile 中没有指定任何库。
这是因为整个实现都是在gsl文件夹下的头文件中提供的内联。
还有更多…
Microsoft GSL (isocpp.github.io/CppCoreGuidelines/CppCoreGuidelines) 只是由 Microsoft 维护的一个实现。您可以在这里找到另一个实现:github.com/martinmoene/gsl-lite。这两个实现都是以 MIT 许可类型发布的。
另请参阅
本章的《C++核心指南》示例。
理解概念
概念是与模板一起使用的编译时谓词。C++20 标准通过提供更多的编译时机会,使开发人员能够更多地传达其意图,从而明显提升了通用编程。我们可以将概念视为模板使用者必须遵守的要求(或约束)。我们为什么需要概念?您需要自己定义概念吗?这个示例将回答这些问题以及更多问题。
如何做…
在本节中,我们将使用概念开发一个具体的模板示例:
- 我们想要创建自己版本的 C++标准库中的
std::sort模板函数。让我们从在.cpp文件中编写以下代码开始:
#include <algorithm>
#include <concepts>
namespace sp
{
template<typename T>
requires Sortable<T>
void sort(T& container)
{
std::sort (begin(container), end(container));
};
}
- 现在,让我们使用我们的新模板类,并约束我们传递的类型,即
std::vector必须是可排序的;否则,编译器会通知我们:
int main()
{
std::vector<int> myVec {2,1,4,3};
sp::sort(vec);
return 0;
}
我们将在下一节中详细讨论。
它是如何工作的…
我坚信概念是缺失的特性。在它们之前,模板没有明确定义的要求集,也没有在编译错误的情况下对其进行简单和简要的描述。这些是驱动概念特性设计的两个支柱。
步骤 1包括std::sort方法的algorithms include和concepts头文件。为了不让编译器和我们自己感到困惑,我们将新模板封装在一个命名空间sp中。正如您所看到的,与我们过去使用的经典模板相比,几乎没有什么区别,唯一的区别是使用了requires关键字。
requires向编译器(以及模板使用者)传达,这个模板只有在T Sortable类型(Sortable<T>)有效时才有效。好的;Sortable是什么?这是一个只有在评估为 true 时才满足的谓词。还有其他指定约束的方法,如下所示:
- 使用尾随
requires:
template<typename T>
void sort(T& container) requires Sortable<T>;
- 作为
模板参数:
template<Sortable T>
void sort(T& container)
我个人更喜欢*如何做…*部分的风格,因为它更符合惯用法,更重要的是,它允许我们将所有的requires放在一起,就像这样:
template<typename T>
requires Sortable<T> && Integral<T>
void sort(T& container)
{
std::sort (begin(container), end(container));
};
在这个示例中,我们想要传达我们的sp::sort方法对类型T有效,这个类型是Sortable和Integral,出于任何原因。
步骤 2只是使用我们的新定制版本的 sort。为此,我们实例化了一个(Sortable!)向sp::sort方法传入输入的向量。
还有更多…
可能有情况需要创建自己的概念。标准库包含了大量的概念,因此您可能不需要自己创建概念。正如我们在前一节中学到的,概念只有在评估为 true 时才是谓词。将概念定义为两个现有概念的组合可能如下所示:
template <typename T>
concept bool SignedSwappable()
{
return SignedIntegral<T>() && Swappable<T>();
}
在这里,我们可以使用sort方法:
template<typename T>
requires SignedSwappable<T>
void sort(T& container)
{
std::sort (begin(container), end(container));
};
为什么这很酷?有几个原因:
-
它让我们立即知道模板期望什么,而不会迷失在实现细节中(也就是说,要求或约束是明确的)。
-
在编译时,编译器将评估约束是否已满足。
另请参阅
-
《C++之旅,第二版》,B. Stroustrup:第 7.2 章和第 12.7 章,列出了标准库中定义的概念的完整列表。
-
gcc.gnu.org/projects/cxx-status.html以获取与 GCC 版本和状态映射的 C++20 功能列表。
使用 span
我们可能会遇到这样的情况,我们需要编写一个方法,但我们希望能够接受普通数组或 STL 容器作为输入。std::span解决了这个问题。它为用户提供了对连续元素序列的视图。这个食谱将教会你如何使用它。
如何做…
在这个食谱中,我们将编写一个带有一个参数(std::span)的方法,可以在不同的上下文中使用。然后,我们将强调它提供的灵活性:
- 让我们首先添加我们需要的包含文件。然后,我们需要通过传递
std::span类型的container变量来定义print方法:
#include <iostream>
#include <vector>
#include <array>
#include <span>
void print(std::span<int> container)
{
for(const auto &c : container)
std::cout << c << "-";
}
- 在
main中,我们想通过调用print方法打印我们的数组:
int main()
{
int elems[]{4, 2, 43, 12};
print(elems);
std::vector vElems{4, 2, 43, 12};
print(vElems);
}
让我们看看这是如何工作的。
它是如何工作的…
std::span描述了一个引用连续元素序列的对象。C++标准将数组定义为具有连续内存部分。这绝对简化了std::span的实现,因为典型的实现包括指向序列第一个元素的指针和大小。
步骤 1定义了通过std::span传递的print方法,我们可以将其视为整数序列。任何具有连续内存的数组类型都将从该方法中看到为序列。
步骤 2使用print方法与两个不同的数组,一个是 C 风格的,另一个是 STL 库的std::vector。由于这两个数组都在连续的内存部分中定义,std::span能够无缝地管理它们。
还有更多…
我们的方法考虑了带有int类型的std::span。您可能需要使该方法通用。在这种情况下,您需要编写类似于以下内容:
template <typename T>
void print(std::span<T> container)
{
for(const auto &c : container)
std::cout << c << "-";
}
正如我们在理解概念食谱中所学到的,为这个模板指定一些要求是明智的。因此,我们可能会写成以下内容:
template <typename T>
requires Integral<T>
void print(std::span<T> container)
{
for(const auto &c : container)
std::cout << c << "-";
}
requires Integral<T>将明确指出模板需要Integral类型。
另请参阅
-
理解概念食谱回顾如何使用模板编写概念并将其应用于
std::span。 -
gcc.gnu.org/projects/cxx-status.html列出了与 GCC 版本及其状态映射的 C++20 功能列表。
学习 Ranges 的工作原理
C++20 标准添加了 Ranges,它们是对容器的抽象,允许程序统一地操作容器的元素。此外,Ranges 代表了一种非常现代和简洁的编写表达性代码的方式。我们将了解到,这种表达性在使用管道和适配器时甚至更加强大。
如何做…
在本节中,我们将编写一个程序,帮助我们学习 Ranges 与管道和适配器结合的主要用例。给定一个温度数组,我们想要过滤掉负数,并将正数(温暖的温度)转换为华氏度:
- 在一个新的源文件中,输入以下代码。正如你所看到的,两个 lambda 函数和一个
for循环完成了工作:
#include <vector>
#include <iostream>
#include <ranges>
int main()
{
auto temperatures{28, 25, -8, -3, 15, 21, -1};
auto minus = [](int i){ return i <= 0; };
auto toFahrenheit = [](int i) { return (i*(9/5)) + 32; };
for (int t : temperatures | std::views::filter(minus)
| std::views::transform(toFahrenheit))
std::cout << t << ' '; // 82.4 77 59 69.8
}
我们将在下一节分析 Ranges 的背后是什么。我们还将了解到 Ranges 是concepts的第一个用户。
它是如何工作的…
std::ranges代表了一种非常现代的方式来以可读的格式描述容器上的一系列操作。这是一种语言提高可读性的情况之一。
步骤 1定义了包含一些数据的temperatures向量。然后,我们定义了一个 lambda 函数,如果输入i大于或等于零,则返回 true。我们定义的第二个 lambda 将i转换为华氏度。然后,我们循环遍历temperatures(viewable_range),并将其传递给filter(在 Ranges 范围内称为adaptor),它根据minus lambda 函数删除了负温度。输出被传递给另一个适配器,它转换容器的每个单个项目,以便最终循环可以进行并打印到标准输出。
C++20 提供了另一个层次,用于迭代容器元素的层次更现代和成语化。通过将viewable_range与适配器结合使用,代码更加简洁、紧凑和可读。
C++20 标准库提供了许多遵循相同逻辑的适配器,包括std::views::all、std::views::take和std::views::split。
还有更多…
所有这些适配器都是使用概念来定义特定适配器需要的要求的模板。一个例子如下:
template<ranges::input_range V, std::indirect_unary_predicate<ranges::iterator_t<V>> Pred >
requires ranges::view<V> && std::is_object_v<Pred>
class filter_view : public ranges::view_interface<filter_view<V, Pred>>
这个模板是我们在这个配方中使用的std::views::filter。这个模板需要两种类型:第一种是V,输入范围(即容器),而第二种是Pred(在我们的情况下是 lambda 函数)。我们为这个模板指定了两个约束:
-
V必须是一个视图 -
谓词必须是对象类型:函数、lambda 等等
另请参阅
-
理解概念配方来审查概念。
-
访问
github.com/ericniebler/range-v3以查看 C++20 库提案作者(Eric Niebler)的range实现。 -
在第一章的学习 Linux 基础知识-Shell配方中,注意 C++20 范围管道与我们在 shell 上看到的管道概念非常相似。
-
要了解有关
std::is_object的更多信息,请访问以下链接:en.cppreference.com/w/cpp/types/is_object。
学习模块如何工作
在 C++20 之前,构建程序的唯一方法是通过#include指令(由预编译器解析)。最新标准添加了另一种更现代的方法来实现相同的结果,称为模块。这个配方将向您展示如何使用模块编写代码以及#include和模块之间的区别。
如何做…
在本节中,我们将编写一个由两个模块组成的程序。这个程序是我们在学习范围如何工作配方中开发的程序的改进。我们将把温度代码封装在一个模块中,并在客户端模块中使用它。让我们开始吧:
- 让我们创建一个名为
temperature.cpp的新.cpp源文件,并键入以下代码:
export module temperature_engine;
import std.core
#include <ranges>
export
std::vector<int> toFahrenheitFromCelsius(std::vector<int>& celsius)
{
std::vector<int> fahrenheit;
auto toFahrenheit = [](int i) { return (i*(9/5)) + 32; };
for (int t : celsius | std::views::transform(toFahrenheit))
fahrenheit.push_back(t);
return fahrenheit;
}
- 现在,我们必须使用它。创建一个新文件(例如
temperature_client.cpp)并包含以下代码:
import temperature_engine;
import std.core; // instead of iostream, containers
// (vector, etc) and algorithm
int main()
{
auto celsius = {28, 25, -8, -3, 15, 21, -1};
auto fahrenheit = toFahrenheitFromCelsius(celsius);
std::for_each(begin(fahrenheit), end(fahrenheit),
&fahrenheit
{
std::cout << i << ";";
});
}
下一节将解释模块如何工作,它们与命名空间的关系以及它们相对于#include预编译指令的优势。
工作原理…
模块是 C++20 对(可能)#include指令的解决方案。这里可能是强制性的,因为数百万行的遗留代码不可能一夜之间转换为使用模块。
步骤 1的主要目标是定义我们的temperature_engine模块。第一行export module temperature_engine;定义了我们要导出的模块。接下来,我们有import std.core。这是 C++20 引入的最大区别之一:不再需要使用#include。具体来说,import std.core等同于#include <iostream>。我们还#include了范围。在这种情况下,我们以旧方式做到了这一点,以向您展示可以混合旧和新解决方案的代码。这一点很重要,因为它将使我们更好地了解如何管理到模块的过渡。每当我们想要从我们的模块中导出东西时,我们只需要用export关键字作为前缀,就像我们对toFahrenheitFromCelsius方法所做的那样。方法的实现不受影响,因此它的逻辑不会改变。
步骤 2包含使用temperature_engine的模块客户端的代码。与上一步一样,我们只需要使用import temperature_engine并使用导出的对象。我们还使用import std.core来替换#include <iostream>。现在,我们可以像通常一样使用导出的方法,调用toFahrenheitFromCelsius并传递预期的输入参数。toFahrenheitFromCelsius方法返回一个整数向量,表示转换后的华氏温度,这意味着我们只需要使用for_each模板方法通过**import std.core**打印值,而我们通常会使用#include <algorithm>。
此时的主要问题是:为什么我们应该使用模块而不是#include?模块不仅代表了一种语法上的差异 - 它比那更深刻:
-
模块只编译一次,而
#include不会。要使#include只编译一次,我们需要使用#ifdef#define和#endif预编译器。 -
模块可以以任何顺序导入,而不会影响含义。这对
#include来说并非如此。 -
如果一个符号没有从模块中导出,客户端代码将无法使用它,如果用户这样做,编译器将通知错误。
-
与包含不同,模块不是传递的。将模块
A导入模块B,当模块C使用模块B时,并不意味着它自动获得对模块A的访问权限。
这对可维护性、代码结构和编译时间有很大影响。
还有更多…
一个经常出现的问题是,模块与命名空间是否冲突(或重叠)?这是一个很好的问题,答案是否定的。命名空间和模块解决了两个不同的问题。命名空间是另一种表达意图将一些声明分组在一起的机制。将声明分组在一起的其他机制包括函数和类。如果两个类冲突怎么办?我们可以将其中一个封装到命名空间中。您可以在理解概念配方中看到一个例子,我们在那里创建了我们自己的版本的 sort,称为sp::sort。另一方面,模块是一组逻辑功能。这两个概念是正交的,这意味着我可以将我的命名空间分布在更多的模块上。一个具体的例子是std::vector和std::list容器,它们位于两个不同的模块中,但在相同的namespace:std。
值得强调的另一件事是,模块允许我们将模块的一部分设置为private,使其对其他翻译单元(TUs)不可访问。如果要将符号导出为不完整类型,这将非常有用。
export module temperature_engine;
import std.core
#include <ranges>
export struct ConversionFactors; //exported as incomplete type
export
void myMethod(ConversionFactors& factors)
{
// ...
}
module: private;
struct ConversionFactors
{
int toFahrenheit;
int toCelsius;
};
另请参阅
-
转到
gcc.gnu.org/projects/cxx-status.html检查模块(以及其他 C++20 功能)支持时间表。 -
有关 lambda 表达式的刷新,请参阅Lambda 表达式配方。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









