




原文:
zh.annas-archive.org/md5/86EBDE91266D2750084E0C4C5C494FF7译者:飞龙
第十章:CPU 调度器 - 第一部分
在本章和下一章中,您将深入了解一个关键的操作系统主题 - 即 Linux 操作系统上的 CPU 调度。我将尝试通过提出(并回答)典型问题并执行与调度相关的常见任务来使学习更加实际。了解操作系统级别的调度工作不仅对于内核(和驱动程序)开发人员来说很重要,而且还会自动使您成为更好的系统架构师(甚至对于用户空间应用程序)。
我们将首先介绍基本背景材料;这将包括 Linux 上的内核可调度实体(KSE),以及 Linux 实现的 POSIX 调度策略。然后,我们将使用工具 - perf和其他工具 - 来可视化操作系统在 CPU 上运行任务并在它们之间切换的控制流。这对于应用程序的性能分析也很有用!之后,我们将更深入地了解 Linux 上 CPU 调度的工作原理,包括模块化调度类、完全公平调度(CFS)、核心调度函数的运行等。在此过程中,我们还将介绍如何以编程方式(动态地)查询和设置系统上任何线程的调度策略和优先级。
在本章中,我们将涵盖以下领域:
-
学习 CPU 调度内部 - 第一部分 - 基本背景
-
可视化流程
-
学习 CPU 调度内部 - 第二部分
-
线程 - 调度策略和优先级
-
学习 CPU 调度内部 - 第三部分
现在,让我们开始这个有趣的话题吧!
技术要求
我假设您已经阅读了第一章 内核工作区设置,并已经适当地准备了一个运行 Ubuntu 18.04 LTS(或更高稳定版本)的客户虚拟机(VM)并安装了所有必需的软件包。如果没有,我强烈建议您首先这样做。
为了充分利用本书,我强烈建议您首先设置工作环境,包括克隆本书的 GitHub 存储库以获取代码并进行实际操作。存储库可以在这里找到:github.com/PacktPublishing/Linux-Kernel-Programming。
学习 CPU 调度内部 - 第一部分 - 基本背景
让我们快速了解一下我们需要了解 Linux 上 CPU 调度的基本背景信息。
请注意,在本书中,我们不打算涵盖 Linux 上熟练的系统程序员应该已经非常了解的材料;这包括基础知识,如进程(或线程)状态,状态机及其转换,以及更多关于实时性、POSIX 调度策略等的信息。这些内容(以及更多内容)已经在我之前的一本书中详细介绍过:《Linux 系统编程实战》,由 Packt 于 2018 年 10 月出版。
Linux 上的 KSE 是什么?
正如您在第六章中所学到的,在内核内部要点 - 进程和线程一节中,每个进程 - 实际上是系统上存活的每个线程 - 都被赋予一个任务结构(struct task_struct)以及用户模式和内核模式堆栈。
在这里,需要问的关键问题是:在进行调度时,它作用于哪个对象,换句话说,什么是内核可调度实体,KSE?在 Linux 上,KSE 是一个线程,而不是一个进程(当然,每个进程至少包含一个线程)。因此,线程是进行调度的粒度级别。
举个例子来解释这一点:如果我们假设有一个 CPU 核心和 10 个用户空间进程,每个进程包括三个线程,再加上五个内核线程,那么我们总共有(10 x 3)+ 5,等于 35 个线程。除了五个内核线程外,每个线程都有用户和内核栈以及一个任务结构(内核线程只有内核栈和任务结构;所有这些都在第六章中得到了详细解释,内核内部要点-进程和线程,在组织进程、线程及其栈-用户空间和内核空间部分)。现在,如果所有这 35 个线程都是可运行的,那么它们将竞争单个处理器(尽管它们不太可能同时都是可运行的,但为了讨论的完整性,让我们假设它们都是可运行的),那么现在有 35 个线程竞争 CPU 资源,而不是 10 个进程和五个内核线程。
现在我们了解了 KSE 是一个线程,我们(几乎)总是在调度上下文中引用线程。既然这一点已经理解,让我们继续讨论 Linux 实现的调度策略。
POSIX 调度策略
重要的是要意识到 Linux 内核不仅实现了一个实现 CPU 调度的算法;事实上,POSIX 标准规定了一个 POSIX 兼容的操作系统必须遵循的最少三种调度策略(实际上是算法)。Linux 不仅实现了这三种,还实现了更多,采用了一种称为调度类的强大设计(稍后在本章的理解模块化调度类部分中详细介绍)。
关于 Linux 上的 POSIX 调度策略(以及更多)的信息在我早期的书籍Hands-On System Programming with Linux中有更详细的介绍,该书于 2018 年 10 月由 Packt 出版。
现在,让我们简要总结一下 POSIX 调度策略以及它们在下表中的影响:
| 调度策略 | 关键点 | 优先级范围 |
|---|---|---|
SCHED_OTHER或SCHED_NORMAL | 始终是默认值;具有此策略的线程是非实时的;在内部实现为完全公平调度(CFS)类(稍后在关于 CFS 和 vruntime 值部分中看到)。这种调度策略背后的动机是公平性和整体吞吐量。 | 实时优先级为0;非实时优先级称为 nice 值:范围从-20 到+19(较低的数字意味着更高的优先级),基数为 0 |
| SCHED_RR | 这种调度策略背后的动机是一种(软)实时策略,相对积极。具有有限时间片(通常默认为 100 毫秒)。
SCHED_RR线程将在以下情况下让出处理器(如果且仅如果):
-
它在 I/O 上阻塞(进入睡眠状态)。
-
它停止或终止。
-
更高优先级的实时线程变为可运行状态(将抢占此线程)。
-
它的时间片到期。|(软)实时:1 到 99(较高的数字
意味着更高的优先级)|
| SCHED_FIFO | 这种调度策略背后的动机是一种(软)实时策略,相对来说非常积极。SCHED_FIFO线程将在以下情况下让出处理器:
-
它在 I/O 上阻塞(进入睡眠状态)。
-
它停止或终止。
-
更高优先级的实时线程变为可运行状态(将抢占此线程)。
它实际上有无限的时间片。|(与SCHED_RR相同)|
SCHED_BATCH | 这种调度策略背后的动机是适用于非交互式批处理作业的调度策略,较少的抢占。 | Nice 值范围(-20 到+19) |
|---|---|---|
SCHED_IDLE | 特殊情况:通常 PID0内核线程(传统上称为swapper;实际上是每个 CPU 的空闲线程)使用此策略。它始终保证是系统中优先级最低的线程,并且只在没有其他线程想要 CPU 时运行。 | 所有优先级中最低的(可以认为低于 nice 值+19) |
重要的是要注意,当我们在上表中说实时时,我们实际上指的是软实时(或者最好是硬实时),而不是实时操作系统(RTOS)中的硬实时。Linux 是一个GPOS,一个通用操作系统,而不是 RTOS。话虽如此,您可以通过应用外部补丁系列(称为 RTL,由 Linux 基金会支持)将普通的 Linux 转换为真正的硬实时 RTOS;您将在以下章节将主线 Linux 转换为 RTOS中学习如何做到这一点。
请注意,SCHED_FIFO线程实际上具有无限的时间片,并且运行直到它希望停止或前面提到的条件之一成立。在这一点上,重要的是要理解我们只关注线程(KSE)调度;在诸如 Linux 的操作系统上,现实情况是硬件(和软件)中断总是优先的,并且甚至会抢占(内核或用户空间)SCHED_FIFO线程!请参考图 6.1 以了解这一点。此外,我们将在第十四章处理硬件中断中详细介绍硬件中断。在我们的讨论中,我们暂时将忽略中断。
优先级缩放很简单:
- 非实时线程(
SCHED_OTHER)具有0的实时优先级;这确保它们甚至不能与实时线程竞争。它们使用一个(旧的 UNIX 风格)称为nice value的优先级值,范围从-20 到+19(-20 是最高优先级,+19 是最差的)。
在现代 Linux 上的实现方式是,每个 nice 级别对应于 CPU 带宽的大约 10%的变化(或增量,加或减),这是一个相当大的数量。
- 实时线程(
SCHED_FIFO / SCHED_RR)具有 1 到 99 的实时优先级范围,1 是最低优先级,99 是最高优先级。可以这样理解:在一个不可抢占的 Linux 系统上,一个SCHED_FIFO优先级为 99 的线程在一个无法中断的无限循环中旋转,实际上会使机器挂起!(当然,即使这样也会被中断 - 包括硬中断和软中断;请参见图 6.1。)
调度策略和优先级(静态 nice 值和实时优先级)当然是任务结构的成员。线程所属的调度类是独占的:一个线程在特定时间点只能属于一个调度策略(不用担心,我们稍后将在CPU 调度内部 - 第二部分中详细介绍调度类)。
此外,您应该意识到在现代 Linux 内核上,还有其他调度类(stop-schedule 和 deadline),它们实际上比我们之前提到的 FIFO/RR 更优先(优先级更高)。既然您已经了解了基础知识,让我们继续看一些非常有趣的东西:我们实际上如何可视化控制流。继续阅读!
可视化流程
多核系统导致进程和线程在不同处理器上并发执行。这对于获得更高的吞吐量和性能非常有用,但也会导致共享可写数据的同步问题。因此,例如,在一个具有四个处理器核心的硬件平台上,我们可以期望进程(和线程)在它们上面并行执行。这并不是什么新鲜事;不过,有没有一种方法可以实际上看到哪些进程或线程在哪个 CPU 核心上执行 - 也就是说,有没有一种可视化处理器时间线的方法?事实证明确实有几种方法可以做到这一点。在接下来的章节中,我们将首先使用perf来看一种有趣的方法,然后再使用其他方法(使用 LTTng、Trace Compass 和 Ftrace)。
使用 perf 来可视化流程
Linux 拥有庞大的开发人员和质量保证(QA)工具库,其中perf(1)是一个非常强大的工具。简而言之,perf工具集是在 Linux 系统上执行 CPU 性能分析的现代方式。(除了一些提示外,我们在本书中不会详细介绍perf。)
类似于古老的top(1)实用程序,要详细了解正在占用 CPU 的情况(比top(1)更详细),**perf(1)**一系列实用程序非常出色。不过,请注意,与应用程序相比,perf与其运行的内核紧密耦合,这是相当不寻常的。首先,你需要安装linux-tools-$(uname -r)包。此外,自定义的 5.4 内核包将不可用;因此,在使用perf时,我建议你使用标准(或发行版)内核引导你的虚拟机,安装linux-tools-$(uname -r)包,然后尝试使用perf。(当然,你也可以在内核源代码树中的tools/perf/文件夹下手动构建perf。)
安装并运行perf后,请尝试这些perf命令:
sudo perf top
sudo perf top --sort comm,dso
sudo perf top -r 90 --sort pid,comm,dso,symbol
(顺便说一句,comm意味着命令/进程的名称,**dso**是动态共享对象的缩写)。使用alias会更容易;尝试这个(一行)以获得更详细的信息(调用堆栈也可以展开!):
alias ptopv='sudo perf top -r 80 -f 99 --sort pid,comm,dso,symbol --demangle-kernel -v --call-graph dwarf,fractal'
perf(1)的man页面提供了详细信息;使用man perf-<foo>表示法 - 例如,man perf-top - 以获取有关perf top的帮助。
使用perf的一种方法是了解在哪个 CPU 上运行了什么任务;这是通过perf中的timechart子命令完成的。你可以使用perf记录系统范围的事件,也可以记录特定进程的事件。要记录系统范围的事件,请运行以下命令:
sudo perf timechart record
通过信号(^C)终止记录会话。这将默认生成一个名为perf.data的二进制数据文件。现在可以使用以下命令进行检查:
sudo perf timechart
这个命令生成了一个可伸缩矢量图形(SVG)文件!它可以在矢量绘图工具(如 Inkscape,或通过 ImageMagick 中的display命令)中查看,或者直接在 Web 浏览器中查看。研究时间表可能会很有趣;我建议你试试。不过,请注意,矢量图像可能会很大,因此打开需要一段时间。
以下是在运行 Ubuntu 18.10 的本机 Linux x86_64 笔记本电脑上进行的系统范围采样运行:
$ sudo perf timechart record
[sudo] password for <user>:
^C[ perf record: Woken up 18 times to write data ]
[ perf record: Captured and wrote 6.899 MB perf.data (196166 samples) ]
$ ls -lh perf.data
-rw------- 1 root root 7.0M Jun 18 12:57 perf.data
$ sudo perf timechart
Written 7.1 seconds of trace to output.svg.
可以配置perf以使用非 root 访问权限。在这里,我们不这样做;我们只是通过sudo(8)以 root 身份运行perf。
perf生成的 SVG 文件的屏幕截图如下所示。要查看 SVG 文件,你可以简单地将其拖放到你的 Web 浏览器中:
[外链图片转存中…(img-wpSXadgY-1721183650946)]
图 10.1 - (部分)屏幕截图显示由 sudo perf timechart 生成的 SVG 文件
在前面的屏幕截图中,举个例子,你可以看到EMT-0线程很忙,占用了最大的 CPU 周期(不幸的是,CPU 3 这个短语不太清楚;仔细看看紫色条下面的 CPU 2)。这是有道理的;它是代表我们运行 Fedora 29 的 VirtualBox 的虚拟 CPU(VCPU)的线程(EMT代表模拟器线程)!
你可以放大和缩小这个 SVG 文件,研究perf默认记录的调度和 CPU 事件。下图是前面截图的部分屏幕截图,放大 400%至 CPU 1 区域,显示了在 CPU#1 上运行的htop(紫色条实际上显示了它执行时的时间段):

图 10.2 - 对 perf timechart 的 SVG 文件的部分屏幕截图,放大 400%至 CPU 1 区域
还有什么?通过使用-I选项切换到perf timechart record,你可以请求仅记录系统范围的磁盘 I/O(和网络,显然)事件。这可能特别有用,因为通常真正的性能瓶颈是由 I/O 活动引起的(而不是 CPU;I/O 通常是罪魁祸首!)。perf-timechart(1)的man页面详细介绍了更多有用的选项;例如,--callchain用于执行堆栈回溯记录。另一个例子是,--highlight <name>选项将突出显示所有名称为<name>的任务。
您可以使用perf data convert -- all --to-ctf将perf的二进制perf.data记录文件转换为流行的通用跟踪格式(CTF)文件格式,其中最后一个参数是存储 CTF 文件的目录。这有什么用呢?CTF 是强大的 GUI 可视化器和分析工具(例如 Trace Compass)使用的本机数据格式(稍后在第十一章中的CPU 调度程序-第二部分中可以看到)。
然而,正如 Trace Compass Perf Profiling 用户指南中所提到的那样(archive.eclipse.org/tracecompass.incubator/doc/org.eclipse.tracecompass.incubator.perf.profiling.doc.user/User-Guide.html):“并非所有 Linux 发行版都具有内置的 ctf 转换。需要使用环境变量 LIBBABELTRACE=1 和 LIBBABELTRACE_DIR=/path/to/libbabeltrace 来编译 perf(因此 linux)以启用该支持。”
不幸的是,在撰写本文时,Ubuntu 就是这种情况。
通过替代(CLI)方法来可视化流程
当然,还有其他方法可以可视化每个处理器上正在运行的内容;我们在这里提到了一些,并保存了另一个有趣的方法(LTTng),将在第十一章中的CPU 调度程序-第二部分中的使用 LTTng 和 Trace Compass 进行可视化部分中介绍。
-
再次使用
perf(1)运行sudo perf sched record命令;这将记录活动。通过使用^C信号终止它,然后使用sudo perf sched map来查看处理器上的执行情况(CLI 地图)。 -
一些简单的 Bash 脚本可以显示在给定核心上正在执行的内容(这是对
ps(1)的简单封装)。在下面的片段中,我们展示了一些示例 Bash 函数;例如,以下c0()函数显示了当前在 CPU 核心#0上正在执行的内容,而c1()则对#1核心执行相同的操作。
# Show thread(s) running on cpu core 'n' - func c'n'
function c0()
{
ps -eLF | awk '{ if($5==0) print $0}'
}
function c1()
{
ps -eLF | awk '{ if($5==1) print $0}'
}
在广泛讨论perf的话题上,Brendan Gregg 有一系列非常有用的脚本,可以在使用perf监视生产 Linux 系统时执行许多必要的工作;请在这里查看它们:github.com/brendangregg/perf-tools(一些发行版将它们作为名为perf-tools[-unstable]的软件包包含在内)。
尝试使用这些替代方案(包括perf-tools[-unstable]包)!
了解 CPU 调度内部工作原理-第二部分
本节详细介绍了内核 CPU 调度的内部工作原理,重点是现代设计的核心部分,即模块化调度类。
了解模块化调度类
内核开发人员 Ingo Molnar(以及其他人)重新设计了内核调度程序的内部结构,引入了一种称为调度类的新方法(这是在 2007 年 10 月发布 2.6.23 内核时的情况)。
顺便说一句,这里的“类”一词并非巧合;许多 Linux 内核功能本质上都是以面向对象的方式设计的。当然,C 语言不允许我们直接在代码中表达这一点(因此结构中有数据和函数指针成员的比例很高,模拟了一个类)。然而,设计往往是面向对象的(您将在Linux 内核编程第二部分书中再次看到这一点)。有关此内容的更多详细信息,请参阅本章的进一步阅读部分。
在核心调度代码下引入了一层抽象,即schedule()函数。schedule()下的这一层通常称为调度类,设计上是模块化的。这里的“模块化”意味着调度类可以从内联内核代码中添加或删除;这与可加载内核模块(LKM)框架无关。
基本思想是:当核心调度程序代码(由schedule()函数封装)被调用时,了解到它下面有各种可用的调度类别,它按照预定义的优先级顺序迭代每个类别,询问每个类别是否有一个需要调度到处理器上的线程(或进程)(我们很快就会看到具体是如何做的)。
截至 Linux 内核 5.4,这些是内核中的调度类别,按优先级顺序列出,优先级最高的排在前面:
// kernel/sched/sched.h
[ ... ]
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
这就是我们所拥有的五个调度程序类别 - 停止调度、截止时间、(软)实时、公平和空闲 - 按优先级顺序排列,从高到低。抽象这些调度类别的数据结构struct sched_class被串联在一个单链表上,核心调度代码对其进行迭代。(稍后您将了解sched_class结构是什么;现在请忽略它)。
每个线程都与其自己独特的任务结构(task_struct)相关联;在任务结构中,policy成员指定线程遵循的调度策略(通常是SCHED_FIFO、SCHED_RR或SCHED_OTHER中的一个)。它是独占的 - 一个线程在任何给定时间点只能遵循一个调度策略(尽管它可以改变)。类似地,任务结构的另一个成员struct sched_class保存线程所属的模块化调度类别(也是独占的)。调度策略和优先级都是动态的,可以通过编程查询和设置(或通过实用程序;您很快就会看到这一点)。
因此,您现在将意识到,所有遵循SCHED_FIFO或SCHED_RR调度策略的线程都映射到rt_sched_class(在其任务结构中的sched_class),所有遵循SCHED_OTHER(或SCHED_NORMAL)的线程都映射到fair_sched_class,而空闲线程(swapper/n,其中n是从0开始的 CPU 编号)始终映射到idle_sched_class调度类别。
当内核需要进行调度时,这是基本的调用顺序:
schedule() --> __schedule() --> pick_next_task()
前面的调度类别的实际迭代发生在这里;请参见pick_next_task()的(部分)代码,如下:
// kernel/sched/core.c
/*
* Pick up the highest-prio task:
*/
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
/* Optimization: [...] */
[...]
for_each_class(class) {
p = class->pick_next_task(rq, NULL, NULL);
if (p)
return p;
}
/* The idle class should always have a runnable task: */
BUG();
}
前面的for_each_class()宏设置了一个for循环,用于迭代所有调度类别。其实现如下:
// kernel/sched/sched.h
[...]
#ifdef CONFIG_SMP
#define sched_class_highest (&stop_sched_class)
#else
#define sched_class_highest (&dl_sched_class)
#endif
#define for_class_range(class, _from, _to) \
for (class = (_from); class != (_to); class = class->next)
#define for_each_class(class) \
for_class_range(class, sched_class_highest, NULL)
从前面的实现中可以看出,代码导致每个类都被要求通过pick_next_task()"方法"来安排下一个调度的任务,从sched_class_highest到NULL(意味着它们所在的链表的末尾)。现在,调度类代码确定它是否有任何想要执行的候选者。怎么做?实际上很简单;它只是查找它的runqueue数据结构。
现在,这是一个关键点:内核为每个处理器核心和每个调度类别维护一个运行队列!因此,如果我们有一个有 8 个 CPU 核心的系统,那么我们将有8 个核心 * 5 个调度类别 = 40 个运行队列!运行队列实际上是作为每个 CPU 变量实现的,这是一种有趣的无锁技术(例外情况:在单处理器(UP)系统上,stop-sched类别不存在):

图 10.3 - 每个 CPU 核心每个调度类都有一个运行队列
请注意,在前面的图中,我展示运行队列的方式可能让它们看起来像数组。这并不是本意,这只是一个概念图。实际使用的运行队列数据结构取决于调度类别(类别代码实现了运行队列)。它可以是一个链表数组(就像实时类别一样),也可以是一棵树 - 一棵红黑(rb)树 - 就像公平类别一样,等等。
为了更好地理解调度器类模型,我们将设计一个例子:假设在对称多处理器(SMP)或多核系统上,我们有 100 个线程处于活动状态(在用户空间和内核空间)。其中,有一些线程在竞争 CPU;也就是说,它们处于准备运行(run)状态,意味着它们是可运行的,因此被排队在运行队列数据结构上:
-
线程 S1:调度器类,
stop-sched(SS) -
线程 D1 和 D2:调度器类,Deadline(DL)
-
线程 RT1 和 RT2:调度器类,Real Time(RT)
-
线程 F1、F2 和 F3:调度器类,CFS(或公平)
-
线程 I1:调度器类,空闲。
想象一下,一开始,线程 F2 正在处理器核心上,愉快地执行代码。在某个时刻,内核希望在该 CPU 上切换到其他任务(是什么触发了这个?你很快就会看到)。在调度代码路径上,内核代码最终进入kernel/sched/core.c:void schedule(void)内核例程(稍后会跟进代码级细节)。现在重要的是要理解pick_next_task()例程,由schedule()调用,遍历调度器类的链表,询问每个类是否有候选者可以运行。它的代码路径(概念上,当然)看起来像这样:
-
核心调度器代码(
schedule()):“嘿,SS,你有任何想要运行的线程吗?” -
SS 类代码:遍历其运行队列并找到一个可运行的线程;因此它回答:“是的,我有,它是线程 S1”
-
核心调度器代码(
schedule()):“好的,让我们切换到 S1 上下文”
工作完成了。但是,如果在该处理器的 SS 运行队列上没有可运行的线程 S1(或者它已经进入睡眠状态,或者已经停止,或者它在另一个 CPU 的运行队列上)。那么,SS 会说“不”,然后会询问下一个最重要的调度类 DL。如果它有潜在的候选线程想要运行(在我们的例子中是 D1 和 D2),它的类代码将确定 D1 或 D2 中应该运行的线程,并且内核调度器将忠实地上下文切换到它。这个过程会继续进行 RT 和公平(CFS)调度类。(一图胜千言,对吧:参见图 10.4)。
很可能(在您典型的中度负载的 Linux 系统上),在问题 CPU 上没有 SS、DL 或 RT 候选线程想要运行,通常至少会有一个公平(CFS)线程想要运行;因此,它将被选择并进行上下文切换。如果没有想要运行的线程(没有 SS/DL/RT/CFS 类线程想要运行),这意味着系统目前处于空闲状态(懒惰的家伙)。现在,空闲类被问及是否想要运行:它总是说是!这是有道理的:毕竟,当没有其他人需要时,CPU 空闲线程的工作就是在处理器上运行。因此,在这种情况下,内核将上下文切换到空闲线程(通常标记为swapper/n,其中n是它正在执行的 CPU 编号(从0开始))。
还要注意,swapper/n(CPU 空闲)内核线程不会出现在ps(1)列表中,尽管它一直存在(回想一下我们在第六章中展示的代码,内核内部要点-进程和线程,这里:ch6/foreach/thrd_showall/thrd_showall.c。在那里,我们编写了一个disp_idle_thread()例程来显示 CPU 空闲线程的一些细节,即使我们在那里使用的内核的do_each_thread() { ... } while_each_thread()循环也不显示空闲线程)。
以下图表清楚地总结了核心调度代码如何按优先顺序调用调度类,切换到最终选择的下一个线程:

图 10.4-遍历每个调度类以选择下一个要运行的任务
在接下来的章节中,你将学习如何通过一些强大的工具来可视化内核流程。在那里,实际上可以看到对模块化调度器类进行迭代的工作。
询问调度类
核心调度器代码(pick_next_task())如何询问调度类是否有任何想要运行的线程?我们已经看到了这一点,但我觉得值得为了清晰起见重复以下代码片段(大部分从__schedule()调用,也从线程迁移代码路径调用):
// kernel/sched/core.c
[ ... ]
static inline struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
[ ... ]
for_each_class(class){
p = class->pick_next_task(rq, NULL, NULL);
if (p)
return p;
}
[ ... ]
注意在这里的面向对象的特性:class->pick_next_task()代码,实际上是调用调度类class的pick_next_task()方法!方便的返回值是选定任务的任务结构的指针,现在代码切换到该任务。
前面的段落当然意味着,有一个class结构,体现了我们对调度类的真正意思。确实如此:它包含了所有可能的操作,以及有用的挂钩,你可能在调度类中需要。它(令人惊讶地)被称为sched_class结构:
// location: kernel/sched/sched.h
[ ... ]
struct sched_class {
const struct sched_class *next;
[...]
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
[ ... ]
struct task_struct * (*pick_next_task)(struct rq *rq,
struct task_struct *prev,
struct rq_flags *rf);
[ ... ]
void (*task_tick)(struct rq *rq, struct task_struct *p, int queued);
void (*task_fork)(struct task_struct *p);
[ ... ]
};
(这个结构的成员比我们在这里展示的要多得多;在代码中查找它)。显然,每个调度类都实例化了这个结构,并适当地填充了它的方法(当然是函数指针)。核心调度代码在调度类的链接列表上进行迭代(以及内核的其他地方),根据需要调用方法和挂钩函数,只要它不是NULL。
举个例子,让我们看看公平调度类(CFS)如何实现其调度类的调度算法:
// kernel/sched/fair.c
const struct sched_class fair_sched_class = {
.next = &idle_sched_class,
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
[ ... ]
.pick_next_task = pick_next_task_fair,
[ ... ]
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.prio_changed = prio_changed_fair,
[ ... ]
};
现在你看到了:公平调度类用于选择下一个要运行的任务的代码(当核心调度器询问时)是函数pick_next_task_fair()。FYI,task_tick和task_fork成员是调度类挂钩的很好的例子;这些函数将分别在每个定时器滴答(即每个定时器中断,理论上至少每秒触发CONFIG_HZ次)和当属于这个调度类的线程 fork 时,由调度器核心调用。
也许一个有趣的深入研究的 Linux 内核项目:创建你自己的调度类,具有特定的方法和挂钩,实现其内部调度算法。根据需要链接所有的部分(插入到所需优先级的调度类链接列表中等),并进行测试!现在你可以看到为什么它们被称为模块化调度类了。
现在你了解了现代模块化 CPU 调度器工作背后的架构,让我们简要地看一下 CFS 背后的算法,也许是通用 Linux 上最常用的调度类。
关于 CFS 和 vruntime 值
自 2.6.23 版本以来,CFS 一直是常规线程的事实内核 CPU 调度代码;大多数线程都是SCHED_OTHER,由 CFS 驱动。CFS 背后的驱动力是公平性和整体吞吐量。简而言之,在其实现中,内核跟踪每个可运行的 CFS(SCHED_OTHER)线程的实际 CPU 运行时间(以纳秒为粒度);具有最小运行时间的线程最值得运行,并将在下一个调度切换时被授予处理器。相反,不断占用处理器的线程将累积大量运行时间,因此将受到惩罚(这实际上是相当具有因果报应的)!
不深入讨论 CFS 实现的内部细节,任务结构中嵌入了另一个数据结构struct sched_entity,其中包含一个名为vruntime的无符号 64 位值。在简单的层面上,这是一个单调计数器,用于跟踪线程在处理器上累积(运行)的时间,以纳秒为单位。
在实践中,这里需要大量的代码级调整、检查和平衡。例如,通常情况下,内核会将vruntime值重置为0,触发另一个调度纪元。此外,还有各种可调参数在/proc/sys/kernel/sched_*下,以帮助更好地微调 CPU 调度器的行为。
CFS 如何选择下一个要运行的任务被封装在kernel/sched/fair.c:pick_next_task_fair()函数中。从理论上讲,CFS 的工作方式非常简单:将所有可运行的任务(对于该 CPU)排队到运行队列上,这是一个 rb-tree(一种自平衡二叉搜索树),使得在树上花费最少处理器时间的任务是树上最左边的叶节点,其后的节点表示下一个要运行的任务,然后是下一个。
实际上,从左到右扫描树可以给出未来任务执行的时间表。这是如何保证的?通过使用前面提到的vruntime值作为任务排队到 rb-tree 上的关键!
当内核需要调度并询问 CFS 时,CFS 类代码 - 我们已经提到过了,pick_next_task_fair()函数 - 简单地选择树上最左边的叶节点,返回嵌入其中的任务结构的指针;根据定义,它是具有最低vruntime值的任务,实际上是运行时间最短的任务!(遍历树是一个*O(log n)时间复杂度算法,但由于一些代码优化和对最左边叶节点的巧妙缓存,实际上将其转换为一个非常理想的O(1)*算法!)当然,实际代码比这里透露的要复杂得多;它需要进行多个检查和平衡。我们不会在这里深入讨论细节。
我们建议那些对 CFS 更多了解的人参考有关该主题的内核文档,网址为www.kernel.org/doc/Documentation/scheduler/sched-design-CFS.txt。
此外,内核包含了一些在/proc/sys/kernel/sched_*下的可调参数,对调度产生直接影响。关于这些参数以及如何使用它们的说明可以在Tuning the Task Scheduler页面找到(documentation.suse.com/sles/12-SP4/html/SLES-all/cha-tuning-taskscheduler.html),而在文章www.scylladb.com/2016/06/10/read-latency-and-scylla-jmx-process/中可以找到一个出色的实际用例。
现在让我们继续学习如何查询任何给定线程的调度策略和优先级。
线程 - 调度策略和优先级
在本节中,您将学习如何查询系统上任何给定线程的调度策略和优先级。(但是关于以编程方式查询和设置相同的讨论我们推迟到下一章,在查询和设置线程的调度策略和优先级部分。)
我们了解到,在 Linux 上,线程就是 KSE;它实际上是被调度并在处理器上运行的东西。此外,Linux 有多种选择可供使用的调度策略(或算法)。策略以及分配给给定任务(进程或线程)的优先级是基于每个线程的,其中默认值始终是SCHED_OTHER策略,实时优先级为0。
在给定的 Linux 系统上,我们总是可以看到所有活动的进程(通过简单的ps -A),甚至可以看到每个活动的线程(使用 GNU ps,ps -LA)。但这并不告诉我们这些任务正在运行的调度策略和优先级;我们如何查询呢?
这其实很简单:在 shell 上,chrt(1)实用程序非常适合查询和设置给定进程的调度策略和/或优先级。使用-p选项开关发出chrt并提供 PID 作为参数,它将显示所讨论任务的调度策略以及实时优先级;例如,让我们查询init进程(或 systemd)的 PID1的情况:
$ chrt -p 1
pid 1's current scheduling policy: SCHED_OTHER
pid 1's current scheduling priority: 0
$
像往常一样,chrt(1)的man页面提供了所有选项开关及其用法;请查看一下。
在以下(部分)屏幕截图中,我们展示了一个简单的 Bash 脚本(ch10/query_task_sched.sh,本质上是chrt的包装器),它查询并显示了所有活动线程(在运行时)的调度策略和实时优先级:

图 10.5 - 我们的 ch10/query_task_sched.sh Bash 脚本的(部分)屏幕截图
一些需要注意的事项:
-
在我们的脚本中,通过使用 GNU
ps(1),使用ps -LA,我们能够捕获系统上所有活动的线程;它们的 PID 和 TID 都会显示出来。正如您在第六章中学到的,内核内部基础知识-进程和线程,PID 是内核 TGID 的用户空间等价物,而 TID 是内核 PID 的用户空间等价物。因此,我们可以得出以下结论: -
如果 PID 和 TID 匹配,那么它 - 在该行中看到的线程(第三列有它的名称) - 是该进程的主线程。
-
如果 PID 和 TID 匹配,并且 PID 只出现一次,那么它是一个单线程进程。
-
如果我们在左侧列中多次具有相同的 PID(最左侧列)和不同的 TID(第二列),那么这些是该进程的子线程(或工作线程)。我们的脚本通过将 TID 号稍微向右缩进来显示这一点。
-
请注意,在典型的 Linux 系统(甚至是嵌入式系统)上,绝大多数线程都倾向于是非实时的(
SCHED_OTHER策略)。在典型的桌面、服务器甚至嵌入式 Linux 上,大多数线程都是SCHED_OTHER(默认策略),只有少数实时线程(FIFO/RR)。Deadline(DL)和Stop-Sched(SS)线程确实非常罕见。 -
请注意以下关于前述输出中出现的实时线程的观察:
-
我们的脚本通过在极右边显示一个星号来突出显示任何实时线程(具有策略:
SCHED_FIFO或SCHED_RR)。 -
此外,任何实时优先级为 99(最大可能值)的实时线程将在极右边有三个星号(这些往往是专门的内核线程)。
-
当与调度策略进行布尔 OR 运算时,
SCHED_RESET_ON_FORK标志会禁止任何子进程(通过fork(2))继承特权调度策略(这是一项安全措施)。 -
更改线程的调度策略和/或优先级可以使用
chrt(1)来执行;但是,您应该意识到这是一个需要 root 权限的敏感操作(或者,现在应该是首选机制的能力模型,CAP_SYS_NICE能力位是相关的能力)。
我们将让您自行查看脚本(ch10/query_task_sched.sh)的代码。另外,请注意(注意!)性能和 shell 脚本实际上并不搭配(所以在性能方面不要期望太多)。想一想,shell 脚本中的每个外部命令(我们这里有几个,如awk、grep和cut)都涉及到 fork-exec-wait 语义和上下文切换。而且,这些都是在循环中执行的。
tuna(8)程序可用于查询和设置各种属性;这包括进程/线程级别的调度策略/优先级和 CPU 亲和力掩码,以及中断请求(IRQ)亲和力。
你可能会问,具有SCHED_FIFO策略和实时优先级99的(少数)线程是否总是占用系统的处理器?实际上并不是;事实是这些线程大部分时间都是睡眠的。当内核确实需要它们执行一些工作时,它会唤醒它们。由于它们的实时策略和优先级,几乎可以保证它们将获得 CPU 并执行所需的时间(工作完成后再次进入睡眠状态)。关键是:当它们需要处理器时,它们将得到(类似于实时操作系统,但没有实时操作系统提供的铁定保证和确定性)。
chrt(1)实用程序如何查询(和设置)实时调度策略/优先级?嗯,这显而易见:由于它们驻留在内核虚拟地址空间(VAS)中的任务结构中,chrt进程必须发出系统调用。有几种系统调用变体执行这些任务:chrt(1)使用的是sched_getattr(2)进行查询,sched_setattr(2)系统调用用于设置调度策略和优先级。(务必查阅sched(7)手册页,了解更多与调度程序相关的系统调用的详细信息。)对chrt进行快速的strace(1)将验证这一点!
$ strace chrt -p 1
[ ... ]
sched_getattr(1, {size=48, sched_policy=SCHED_OTHER, sched_flags=0,
sched_nice=0, sched_priority=0, sched_runtime=0, sched_deadline=0,
sched_period=0}, 48, 0) = 0
fstat(1, {st_mode=S_IFCHR|0620, st_rdev=makedev(136, 6), ...}) = 0
write(1, "pid 1's current scheduling polic"..., 47) = 47
write(1, "pid 1's current scheduling prior"..., 39) = 39
[ ... ] $
现在你已经掌握了查询(甚至设置)线程调度策略/优先级的实际知识,是时候深入一点了。在接下来的部分中,我们将进一步探讨 Linux CPU 调度程序的内部工作原理。我们将弄清楚谁运行调度程序的代码以及何时运行。好奇吗?继续阅读!
了解 CPU 调度内部 - 第三部分
在前面的部分中,你学到了核心内核调度代码嵌入了void schedule(void)函数中,并且模块化调度器类被迭代,最终选择一个线程进行上下文切换。这一切都很好;现在一个关键问题是:schedule()代码路径由谁和何时运行?
谁运行调度器代码?
关于调度工作方式的一个微妙但关键的误解不幸地被许多人持有:我们想象存在一种称为“调度程序”的内核线程(或类似实体),定期运行和调度任务。这是完全错误的;在像 Linux 这样的单内核操作系统中,调度是由进程上下文自身执行的,即在 CPU 上运行的常规线程!
实际上,调度代码总是由当前执行内核代码的进程上下文运行,换句话说,由current运行。
这也可能是一个适当的时机来提醒您 Linux 内核的一个“黄金规则”:调度代码绝对不能在任何原子或中断上下文中运行。换句话说,中断上下文代码必须保证是非阻塞的;这就是为什么你不能在中断上下文中使用GFP_KERNEL标志调用kmalloc() - 它可能会阻塞!但是使用GFP_ATOMIC标志就可以,因为这指示内核内存管理代码永远不会阻塞。此外,当调度代码运行时,内核抢占被禁用;这是有道理的。
调度程序何时运行?
操作系统调度程序的工作是在竞争使用处理器(CPU)资源的线程之间进行仲裁,共享处理器资源。但是如果系统很忙,有许多线程不断竞争和获取处理器呢?更准确地说,为了确保任务之间公平共享 CPU 资源,必须确保图片中的警察,即调度程序本身,定期在处理器上运行。听起来不错,但你究竟如何确保呢?
这是一个(看似)合乎逻辑的方法:当定时器中断触发时调用调度程序;也就是说,它每秒有CONFIG_HZ次运行的机会(通常设置为值 250)!不过,我们在第八章中学到了一个黄金法则,模块作者的内核内存分配 - 第一部分,在永远不要在中断或原子上下文中休眠部分:你不能在任何类型的原子或中断上下文中调用调度程序;因此,在定时器中断代码路径中调用它是被明确禁止的。那么,操作系统该怎么办呢?
实际上的做法是,定时器中断上下文和进程上下文代码路径都用于进行调度工作。我们将在下一节简要描述详细信息。
定时器中断部分
在定时器中断中(在kernel/sched/core.c:scheduler_tick()的代码中,其中中断被禁用),内核执行必要的元工作,以保持调度平稳运行;这涉及到适当地不断更新每个 CPU 的运行队列,负载平衡工作等。请注意,实际上从不在这里调用schedule()函数。最多,调度类钩子函数(对于被中断的进程上下文current)sched_class:task_tick(),如果非空,将被调用。例如,对于属于公平(CFS)类的任何线程,在task_tick_fair()中会在这里更新vruntime成员(虚拟运行时间,任务在处理器上花费的(优先级偏置)时间)。
更具体地说,前面段落中描述的所有工作都发生在定时器中断软中断TIMER_SOFTIRQ中。
现在,一个关键点,就是调度代码决定:我们是否需要抢占current?在定时器中断代码路径中,如果内核检测到当前任务已超过其时间量子,或者出于任何原因必须被抢占(也许现在运行队列上有另一个具有更高优先级的可运行线程),代码会设置一个名为need_resched的“全局”标志。(我们在“全局”一词中加引号的原因是它实际上并不是真正的全局内核;它实际上只是current实例的thread_info->flags位掩码中的一个位,名为TIF_NEED_RESCHED。为什么?这样访问位实际上更快!)值得强调的是,在典型(可能)情况下,不会有必要抢占current,因此thread_info.flags:TIF_NEED_RESCHED位将保持清除。如果设置,调度程序激活将很快发生;但具体何时发生?请继续阅读…
进程上下文部分
一旦刚刚描述的调度工作的定时器中断部分完成(当然,这些事情确实非常迅速地完成),控制权就会交回到进程上下文(线程current)中,它会运行我们认为是从中断中退出的路径。在这里,它会检查TIF_NEED_RESCHED位是否已设置 - need_resched()辅助例程会执行此任务。如果返回True,这表明需要立即进行重新调度:内核将调用schedule()!在这里,这样做是可以的,因为我们现在正在运行进程上下文。(请牢记:我们在这里谈论的所有代码都是由current,即相关的进程上下文运行的。)
当然,现在关键问题是代码的确切位置,该代码将识别TIF_NEED_RESCHED位是否已被设置(由先前描述的定时器中断部分)?啊,这就成了问题的关键:内核安排了内核代码基础中存在几个调度机会点。两个调度机会点如下:
-
从系统调用代码路径返回。
-
从中断代码路径返回。
所以,请考虑一下:每当运行在用户空间的任何线程发出系统调用时,该线程就会(上下文)切换到内核模式,并在内核中以内核特权运行代码。当然,系统调用是有限长度的;完成后,它们将遵循一个众所周知的返回路径,以便切换回用户模式并在那里继续执行。在这个返回路径上,引入了一个调度机会点:检查其thread_info结构中的TIF_NEED_RESCHED位是否设置。如果是,调度器就会被激活。
顺便说一句,执行此操作的代码是与体系结构相关的;在 x86 上是这里:arch/x86/entry/common.c:exit_to_usermode_loop()。在其中,与我们相关的部分是:
static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags)
{
[...]
if (cached_flags & _TIF_NEED_RESCHED)
schedule();
类似地,在处理(任何)硬件中断之后(和任何需要运行的相关软中断处理程序),在内核中的进程上下文切换回之后(内核中的一个工件——irq_exit()),但在恢复中断的上下文之前,内核检查TIF_NEED_RESCHED位:如果设置了,就调用schedule()。
让我们总结一下关于设置和识别TIF_NEED_RESCHED位的前面讨论:
-
定时器中断(软中断)在以下情况下设置
thread_info:flags TIF_NEED_RESCHED位: -
如果调度类的
scheduler_tick()钩子函数内的逻辑需要抢占;例如,在 CFS 上,如果当前任务的vruntime值超过另一个可运行线程的给定阈值(通常为 2.25 毫秒;相关的可调参数是/proc/sys/kernel/sched_min_granularity_ns)。 -
如果一个更高优先级的线程可运行(在同一个 CPU 和运行队列上;通过
try_to_wake_up())。 -
在进程上下文中,发生了这样的事情:在中断返回和系统调用返回路径上,检查
TIF_NEED_RESCHED的值: -
如果设置为(
1),则调用schedule();否则,继续处理。
顺便说一句,这些调度机会点——从硬件中断返回或系统调用——也用作信号识别点。如果current上有信号挂起,它会在恢复上下文或返回到用户空间之前得到处理。
可抢占内核
让我们来看一个假设的情况:你在一个只有一个 CPU 的系统上运行。一个模拟时钟应用程序在 GUI 上运行,还有一个 C 程序a.out,它的一行代码是(呻吟)while(1);。那么,你认为:CPU 占用者while 1进程会无限期地占用 CPU,从而导致 GUI 时钟应用程序停止滴答(它的秒针会完全停止移动吗)?
稍加思考(和实验)就会发现,尽管有一个占用 CPU 的应用程序,GUI 时钟应用程序仍在继续滴答!实际上,这才是操作系统级调度器的全部意义:它可以并且确实抢占占用 CPU 的用户空间进程。(我们之前简要讨论了 CFS 算法;CFS 将导致侵占 CPU 的进程累积一个巨大的vruntime值,从而在其 rb-tree 运行队列上向右移动更多,从而对自身进行惩罚!)所有现代操作系统都支持这种类型的抢占——它被称为用户模式抢占。
但是现在,请考虑这样一个问题:如果你在单处理器系统上编写一个执行相同while(1)无限循环的内核模块会怎样?这可能是一个问题:系统现在将会简单地挂起。操作系统如何抢占自己(因为我们知道内核模块以内核特权在内核模式下运行)?好吧,你猜怎么着:多年来,Linux 一直提供了一个构建时配置选项来使内核可抢占,CONFIG_PREEMPT。(实际上,这只是朝着减少延迟和改进内核和调度器响应的长期目标的演变。这项工作的大部分来自早期和一些持续的努力:低延迟(LowLat)补丁,(旧的)RTLinux 工作等等。我们将在下一章中更多地介绍实时(RTOS)Linux - RTL。)一旦打开了CONFIG_PREEMPT内核配置选项并构建并引导内核,我们现在运行的是一个可抢占的内核——操作系统有能力抢占自己。
要查看此选项,在make menuconfig中,导航到 General Setup | Preemption Model。
基本上有三个可用的内核配置选项,就抢占而言:
| 抢占类型 | 特点 | 适用于 |
|---|---|---|
CONFIG_PREEMPT_NONE | 传统模型,面向高整体吞吐量。 | 服务器/企业级和计算密集型系统 |
CONFIG_PREEMPT_VOLUNTARY | 可抢占内核(桌面);操作系统内更明确的抢占机会点;导致更低的延迟,更好的应用程序响应。通常是发行版的默认设置。 | 用于桌面的工作站/台式机,运行 Linux 的笔记本电脑 |
CONFIG_PREEMPT | LowLat 内核;(几乎)整个内核都是可抢占的;意味着甚至内核代码路径的非自愿抢占现在也是可能的;以稍微降低吞吐量和略微增加运行时开销为代价,产生更低的延迟(平均为几十微秒到低百微秒范围)。 | 快速多媒体系统(桌面,笔记本电脑,甚至现代嵌入式产品:智能手机,平板电脑等) |
kernel/Kconfig.preempt kbuild 配置文件包含了可抢占内核选项的相关菜单条目。(正如你将在下一章中看到的,当将 Linux 构建为 RTOS 时,内核抢占的第四个选择出现了。)
CPU 调度器入口点
在核心内核调度函数kernel/sched/core.c:__schedule()之前的详细注释非常值得一读;它们指定了内核 CPU 调度器的所有可能入口点。我们在这里直接从 5.4 内核代码库中复制了它们,所以一定要看一下。请记住:以下代码是由即将通过上下文切换到其他线程的进程上下文中运行的!这个线程是谁?当然是current!
__schedule()函数有(其他)两个本地变量,指向名为prev和next的task_struct结构体的指针。名为prev的指针设置为rq->curr,这只是current!名为next的指针将设置为即将进行上下文切换的任务,即将运行的任务!所以,你看:current运行调度器代码,执行工作,然后通过上下文切换到next将自己从处理器中踢出!这是我们提到的大评论:
// kernel/sched/core.c/*
* __schedule() is the main scheduler function.
* The main means of driving the scheduler and thus entering this function are:
* 1\. Explicit blocking: mutex, semaphore, waitqueue, etc.
*
* 2\. TIF_NEED_RESCHED flag is checked on interrupt and user space return
* paths. For example, see arch/x86/entry_64.S.
*
* To drive preemption between tasks, the scheduler sets the flag in timer
* interrupt handler scheduler_tick().
*
* 3\. Wakeups don't really cause entry into schedule(). They add a
* task to the run-queue and that's it.
*
* Now, if the new task added to the run-queue preempts the current
* task, then the wakeup sets TIF_NEED_RESCHED and schedule() gets
* called on the nearest possible occasion:
* - If the kernel is preemptible (CONFIG_PREEMPTION=y):
*
* - in syscall or exception context, at the next outmost
* preempt_enable(). (this might be as soon as the wake_up()'s
* spin_unlock()!)
*
* - in IRQ context, return from interrupt-handler to
* preemptible context
*
* - If the kernel is not preemptible (CONFIG_PREEMPTION is not set)
* then at the next:
* - cond_resched() call
* - explicit schedule() call
* - return from syscall or exception to user-space
* - return from interrupt-handler to user-space
* WARNING: must be called with preemption disabled!
*/
前面的代码是一个大评论,详细说明了内核 CPU 核心调度代码__schedule()如何被调用。__schedule()本身的一些相关片段可以在以下代码中看到,重申了我们一直在讨论的要点:
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
[...] struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr; *<< this is 'current' ! >>*
[ ... ]
next = pick_next_task(rq, prev, &rf); *<< here we 'pick' the task to run next in an 'object-
oriented' manner, as discussed earlier in detail ... >>*
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
if (likely(prev != next)) {
[ ... ]
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);
[ ... ]
}
接下来是关于实际上下文切换的简短说明。
上下文切换
最后,简要介绍一下(调度程序)上下文切换。上下文切换(在 CPU 调度程序的上下文中)的工作非常明显:在简单地切换到下一个任务之前,操作系统必须保存先前任务的状态,也就是当前正在执行的任务的状态;换句话说,current的状态。您会回忆起第六章中所述,内核内部要点-进程和线程,任务结构包含一个内联结构,用于存储/检索线程的硬件上下文;它是成员struct thread_struct thread(在 x86 上,它始终是任务结构的最后一个成员)。在 Linux 中,一个内联函数,kernel/sched/core.c:context_switch(),执行了这项工作,从prev任务(也就是从current)切换到next任务,即本次调度轮或抢占的赢家。这个切换基本上是在两个(特定于体系结构)阶段中完成的。
-
内存(MM)切换:将特定于体系结构的 CPU 寄存器切换到
next的内存描述符结构(struct mm_struct)。在 x86[_64]上,此寄存器称为CR3(控制寄存器 3);在 ARM 上,它称为TTBR0(翻译表基址寄存器0)寄存器。 -
实际的 CPU 切换:通过保存
prev的堆栈和 CPU 寄存器状态,并将next的堆栈和 CPU 寄存器状态恢复到处理器上,从prev切换到next;这是在switch_to()宏内完成的。
上下文切换的详细实现不是我们将在这里涵盖的内容;请查看进一步阅读部分以获取更多资源。
总结
在本章中,您了解了多功能 Linux 内核 CPU 调度程序的几个领域和方面。首先,您看到实际的 KSE 是一个线程而不是一个进程,然后了解了操作系统实现的可用调度策略。接下来,您了解到为了以出色的可扩展方式支持多个 CPU,内核使用了每个调度类别每个 CPU 核心一个运行队列的设计。然后介绍了如何查询任何给定线程的调度策略和优先级,以及 CPU 调度程序的内部实现的更深层细节。我们重点介绍了现代调度程序如何利用模块化调度类别设计,实际运行调度程序代码的人员以及何时运行,最后简要介绍了上下文切换。
下一章将让您继续这个旅程,更深入地了解内核级 CPU 调度程序的工作原理。我建议您首先充分消化本章的内容,解决所提出的问题,然后再继续下一章。干得好!
问题
最后,这里有一些问题供您测试对本章材料的了解:github.com/PacktPublishing/Linux-Kernel-Programming/tree/master/questions。您会发现一些问题的答案在书的 GitHub 存储库中:github.com/PacktPublishing/Linux-Kernel-Programming/tree/master/solutions_to_assgn。
进一步阅读
为了帮助您深入研究有用的材料,我们在本书的 GitHub 存储库的进一步阅读文档中提供了一个相当详细的在线参考和链接列表(有时甚至包括书籍)。进一步阅读文档在这里可用:github.com/PacktPublishing/Linux-Kernel-Programming/blob/master/Further_Reading.md。
第十一章:CPU 调度程序-第二部分
在我们的第二章中,我们继续讨论 Linux 内核 CPU 调度程序,延续了上一章的内容。在上一章中,我们涵盖了关于 Linux 操作系统 CPU 调度程序工作(和可视化)的几个关键领域。这包括关于 Linux 上的 KSE 是什么,Linux 实现的 POSIX 调度策略,使用perf来查看调度程序流程,以及现代调度程序设计是基于模块化调度类的。我们还介绍了如何查询任何线程的调度策略和优先级(使用一些命令行实用程序),并深入了解了操作系统调度程序的内部工作。
有了这些背景,我们现在准备在 Linux 上更多地探索 CPU 调度程序;在本章中,我们将涵盖以下领域:
-
使用 LTTng 和
trace-cmd可视化流程 -
理解、查询和设置 CPU 亲和性掩码
-
查询和设置线程的调度策略和优先级
-
使用 cgroups 控制 CPU 带宽
-
将主线 Linux 转换为 RTOS
-
延迟及其测量
我们期望您在阅读本章之前已经阅读过(或具有相应的知识)之前的章节。
技术要求
我假设您已经阅读了(或具有相应的知识)之前的章节第一章 内核工作空间设置,并已经适当准备了一个运行 Ubuntu 18.04 LTS(或更高版本)的客户虚拟机(VM)并安装了所有必需的软件包。如果没有,我强烈建议您首先这样做。
为了充分利用本书,我强烈建议您首先设置工作环境,包括克隆本书的 GitHub 存储库以获取代码,并进行实际操作。存储库可以在这里找到:github.com/PacktPublishing/Linux-Kernel-Programming。
使用 LTTng 和 trace-cmd 可视化流程
在上一章中,我们看到了如何使用perf(和一些替代方案)可视化线程在处理器上的流动。现在,我们将使用更强大、更直观的性能分析工具来做到这一点:使用 LTTng(和 Trace Compass GUI)以及trace-cmd(一个 Ftrace 前端和 KernelShark GUI)。
请注意,这里的意图是仅介绍您这些强大的跟踪技术;我们没有足够的范围或空间来充分涵盖这些主题。
使用 LTTng 和 Trace Compass 进行可视化
Linux Trace Toolkit Next Generation(LTTng)是一组开源工具,使您能够同时跟踪用户空间和内核空间。有点讽刺的是,跟踪内核很容易,而跟踪用户空间(应用程序、库甚至脚本)需要开发人员手动将仪器插入应用程序(所谓的 tracepoints)(内核的 tracepoint 仪器由 LTTng 作为内核模块提供)。高质量的 LTTng 文档可以在这里在线获得:lttng.org/docs/v2.12/(截至撰写本文时,覆盖版本 2.12)。
我们在这里不涵盖 LTTng 的安装;详细信息可在lttng.org/docs/v2.12/#doc-installing-lttng找到。一旦安装完成(它有点庞大-在我的本机 x86_64 Ubuntu 系统上,有超过 40 个与 LTTng 相关的内核模块加载!),使用 LTTng-就像我们在这里做的系统范围内的内核会话-是容易的,并且分为两个明显的阶段:记录,然后是数据分析;这些步骤如下。(由于本书专注于内核开发,我们不涵盖使用 LTTng 跟踪用户空间应用程序。)
使用 LTTng 记录内核跟踪会话
您可以按照以下方式记录系统范围内的内核跟踪会话(在这里,我们故意保持讨论尽可能简单):
- 创建一个新会话,并将输出目录设置为
<dir>以保存跟踪元数据:
sudo lttng create <session-name> --output=<dir>
- 只需启用所有内核事件(可能会导致生成大量跟踪元数据):
sudo lttng enable-event --kernel --all
- 开始记录“内核会话”:
sudo lttng start
允许一些时间流逝(您跟踪的时间越长,跟踪元数据使用的磁盘空间就越多)。在此期间,LTTng 正在记录所有内核活动。
- 停止记录:
sudo lttng stop
- 销毁会话;不用担心,这不会删除跟踪元数据:
sudo lttng destroy
所有前面的命令都应该以管理员权限(或等效权限)运行。
我有一些包装脚本可以进行跟踪(LTTng、Ftrace、trace-cmd),在github.com/kaiwan/L5_debug_trg/tree/master/kernel_debug/tracing中查看。
跟踪元数据文件(以通用跟踪格式(CTF)文件格式)保存到前面指定的输出目录。
使用 GUI 进行报告 - Trace Compass
数据分析可以通过两种方式进行 - 使用通常与 LTTng 捆绑在一起的基于 CLI 的系统babeltrace,或者通过一个复杂的 GUI 称为Trace Compass。GUI 更具吸引力;我们这里只展示了它的基本用法。
Trace Compass 是一个功能强大的跨平台 GUI 应用程序,并且与 Eclipse 集成得很好。实际上,我们直接引用自 Eclipse Trace Compass 网站(projects.eclipse.org/projects/tools.tracecompass):
“Eclipse Trace Compass 是一个开源应用程序,通过读取和分析系统的日志或跟踪来解决性能和可靠性问题。它的目标是提供视图、图形、指标等,以帮助从跟踪中提取有用信息,这种方式比庞大的文本转储更加用户友好和信息丰富。”
它可以从这里下载(和安装):www.eclipse.org/tracecompass/。
Trace Compass 最低需要安装Java Runtime Environment(JRE)。我在我的 Ubuntu 20.04 LTS 系统上安装了一个,使用sudo apt install openjdk-14-jre。
安装完成后,启动 Trace Compass,单击“文件”|“打开跟踪”菜单,并导航到您在前面步骤中保存跟踪会话的跟踪元数据的输出目录。Trace Compass 将读取元数据并以可视化方式显示,以及提供各种透视图和工具视图。我们的简短系统范围内的内核跟踪会话的部分屏幕截图显示在这里(图 11.1);您可以清楚地看到上下文切换(显示为sched_switch事件 - 请参阅事件类型列)从gnome-shell进程到swapper/1内核线程(在 CPU#1 上运行的空闲线程):
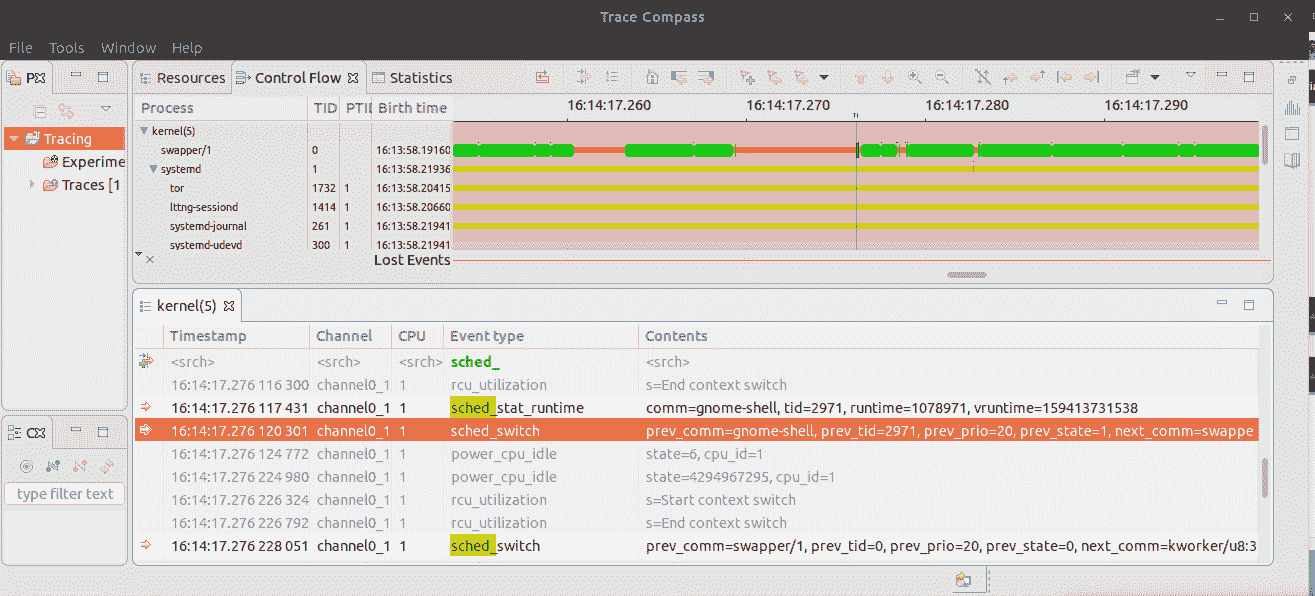
图 11.1 - Trace Compass GUI 显示通过 LTTng 获得的示例内核跟踪会话
仔细看前面的屏幕截图(图 11.1);在下方的水平窗格中,不仅可以看到执行的内核函数,还可以(在标签为内容的列下)看到每个参数在那个时间点的值!这确实非常有用。
使用 trace-cmd 进行可视化
现代 Linux 内核(从 2.6.27 开始)嵌入了一个非常强大的跟踪引擎,称为Ftrace。Ftrace 是用户空间strace(1)实用程序的粗糙内核等效物,但这样说有点贬低它了!Ftrace 允许系统管理员(或开发人员、测试人员,或任何具有 root 权限的人)直接查看内核空间中执行的每个函数,执行它的是谁(哪个线程),运行时间有多长,它调用了哪些 API,包括发生的中断(硬中断和软中断),各种类型的延迟测量等等。您可以使用 Ftrace 了解系统实用程序、应用程序和内核的实际工作原理,以及在操作系统级别执行深度跟踪。
在这本书中,我们不深入研究原始 Ftrace 的用法(因为这偏离了手头的主题);相反,使用一个用户空间包装器覆盖 Ftrace,一个更方便的接口,称为trace-cmd(1),只是更快更容易(再次强调,我们只是浅尝辄止,展示了trace-cmd的一个示例)。
对于 Ftrace 的详细信息和用法,感兴趣的读者会发现这个内核文档有用:www.kernel.org/doc/Documentation/trace/ftrace.rst。
大多数现代 Linux 发行版都允许通过其软件包管理系统安装trace-cmd;例如,在 Ubuntu 上,sudo apt install trace-cmd就足以安装它(如果需要在自定义的 Linux 上,比如 ARM,您总是可以从其 GitHub 存储库上的源代码进行交叉编译:git.kernel.org/pub/scm/linux/kernel/git/rostedt/trace-cmd.git/tree/)。
让我们进行一个简单的trace-cmd会话;首先,我们将在运行ps(1)实用程序时记录数据样本;然后,我们将通过trace-cmd report命令行界面(CLI)以及一个名为 KernelShark 的 GUI 前端来检查捕获的数据(它实际上是trace-cmd包的一部分)。
使用 trace-cmd record 记录一个示例会话
在本节中,我们使用trace-cmd(1)记录一个会话;我们使用了一些(许多可能的)选项开关来记录trace-cmd;通常,trace-cmd-foo(1)(用check-events、hist、record、report、reset等替换foo)的 man 页面非常有用,可以找到各种选项开关和用法详情。特别适用于trace-cmd record的一些有用选项开关如下:
-
-o:指定输出文件名(如果未指定,则默认为trace.dat)。 -
-p:要使用的插件之一,如function、function_graph、preemptirqsoff、irqsoff、preemptoff和wakeup;在我们的小型演示中,我们使用了function-graph插件(内核中还可以配置其他几个插件)。 -
-F:要跟踪的命令(或应用程序);这非常有用,可以让您精确指定要独占跟踪的进程(或线程)(否则,跟踪所有线程在尝试解密输出时可能会产生大量噪音);同样,您可以使用
-P选项开关来指定要跟踪的 PID。 -
-r priority:以指定的实时优先级运行trace-cmd线程(典型范围为 1 到 99;我们将很快介绍查询和设置线程的调度策略和优先级);这样可以更好地捕获所需的样本。
在这里,我们进行了一个快速演示:我们运行ps -LA;在运行时,所有内核流量都(独占地)由trace-cmd通过其record功能捕获(我们使用了function-graph插件):
$ sudo trace-cmd record -o trace_ps.dat -r 99 -p function_graph -F ps -LA
plugin 'function_graph'
PID LWP TTY TIME CMD
1 1 ? 00:01:42 systemd
2 2 ? 00:00:00 kthreadd
[ ... ]
32701 734 tty2 00:00:00 ThreadPoolForeg
CPU 2: 48176 events lost
CPU0 data recorded at offset=0x761000
[ ... ]
CPU3 data recorded at offset=0xf180000
114688 bytes in size
$ ls -lh trace_ps.dat
-rw-r--r-- 1 root root 242M Jun 25 11:23 trace_ps.dat
$
结果是一个相当大的数据文件(因为我们捕获了所有事件并且进行了ps -LA显示所有活动线程,所以花了一些时间,因此捕获的数据样本相当大。还要意识到,默认情况下,内核跟踪是在系统上的所有 CPU 上执行的;您可以通过-M cpumask选项进行更改)。
在上面的示例中,我们捕获了所有事件。-e选项开关允许您指定要跟踪的事件类别;例如,要跟踪ping(1)实用程序并仅捕获与网络和内核内存相关的事件,请运行以下命令:
sudo trace-cmd record -e kmem -e net -p function_graph -F ping -c1 packtpub.com。
使用 trace-cmd report(CLI)进行报告和解释
从前一节继续,在命令行上,我们可以得到一个(非常!)详细的报告,说明了ps进程运行时内核中发生了什么;使用trace-cmd report命令来查看这个。我们还传递了-l选项开关:它以 Ftrace 的延迟格式显示报告,显示了许多有用的细节;-i开关当然指定了要使用的输入文件:
trace-cmd report -i ./trace_ps.dat -l > report_tc_ps.txt
现在变得非常有趣!我们展示了我们用vim(1)打开的(巨大)输出文件的一些部分截图;首先我们有以下内容:

图 11.2 - 显示 trace-cmd 报告输出的部分屏幕截图
看看图 11.2;对内核 APIschedule()的调用被故意突出显示并以粗体字显示(图 11.2,在第785303行!)。为了解释这一行上的所有内容,我们必须理解每个(以空格分隔的)列;共有八列:
-
第一列:这里只是
vim显示的文件中的行号(让我们忽略它)。 -
第二列:这是调用此函数的进程上下文(函数本身在第 8 列);显然,在这里,进程是
ps-PID(其 PID 在-字符后附加)。 -
第三列:有用!一系列五个字符,显示为延迟格式(我们使用了
-l选项切换到trace-cmd record,记住!);这(在我们之前的情况下,是2.N..)非常有用,可以解释如下: -
第一个字符是它运行的 CPU 核心(所以这里是核心#2)(请注意,作为一个一般规则,除了第一个字符外,如果字符是一个句点
。,它意味着它是零或不适用)。 -
第二个字符代表硬件中断状态:
-
.意味着默认的硬件中断被启用。 -
d意味着硬件中断当前被禁用。 -
第三个字符代表了
need_resched位(我们在前一章节中解释过,在*调度程序何时运行?*部分): -
.意味着它被清除。 -
N意味着它被设置(这意味着内核需要尽快执行重新调度!)。 -
第四个字符只有在中断正在进行时才有意义,否则,它只是一个
。,意味着我们处于进程上下文中;如果中断正在进行 - 意味着我们处于中断上下文中 - 其值是以下之一: -
h意味着我们正在执行硬中断(或者顶半部中断)上下文。 -
H意味着我们正在软中断中发生的硬中断中执行。 -
s意味着我们正在软中断(或者底半部)中断上下文中执行。 -
第五个字符代表抢占计数或深度;如果是
。,它是零,意味着内核处于可抢占状态;如果不为零,会显示一个整数,意味着已经获取了那么多内核级别的锁,迫使内核进入不可抢占状态。 -
顺便说一句,输出与 Ftrace 的原始输出非常相似,只是在原始 Ftrace 的情况下,我们只会看到四个字符 - 第一个字符(CPU 核心编号)在这里不会显示;它显示为最左边的列;这是原始 Ftrace(而不是
trace-cmd)延迟格式的部分屏幕截图:

图 11.3 - 专注于原始 Ftrace 的四字符延迟格式(第四字段)的部分屏幕截图
前面的屏幕截图直接从原始 Ftrace 输出中整理出来。
-
- 因此,解释我们对
schedule()调用的例子,我们可以看到字符是2.N..,意味着进程ps的 PID 为22922在 CPU 核心#2 上执行在进程上下文中(没有中断),并且need-resched(技术上,thread_info.flags:TIF_NEED_RESCHED)位被设置(表示需要尽快重新调度!)。
- 因此,解释我们对
-
(现在回到图 11.2 中的剩余列)
第四列:以秒:微秒格式的时间戳。
-
第 5 列:发生的事件的名称(在这里,我们使用了
function_graph插件,它将是funcgraph_entry或fungraph_exit,分别表示函数的进入或退出)。 -
第 6 列[可选]:前一个函数调用的持续时间,显示了所花费的时间及其单位(us = 微秒);前缀字符用于表示函数执行时间很长(我们简单地将其视为此列的一部分);来自内核 Ftrace 文档(这里:
www.kernel.org/doc/Documentation/trace/ftrace.rst),我们有以下内容: -
+,这意味着一个函数超过了 10 微秒 -
!,这意味着一个函数超过了 100 微秒 -
#,这意味着一个函数超过了 1,000 微秒 -
*,这意味着一个函数超过了 10 毫秒 -
@,这意味着一个函数超过了 100 毫秒 -
$,这意味着一个函数超过了 1 秒 -
第 7 列:只是分隔符
|。 -
第 8 列:极右列是正在执行的内核函数的名称;右边的开括号
{表示刚刚调用了该函数;只有一个闭括号}的列表示前一个函数的结束(与开括号匹配)。
这种详细程度在排除内核(甚至用户空间)问题和深入了解内核流程方面非常有价值。
当使用trace-cmd record而没有使用-p function-graph选项开关时,我们失去了漂亮的缩进函数调用图形式的输出,但我们也得到了一些东西:现在你将看到每个函数调用右侧的所有函数参数及其运行时值!这在某些时候确实是一个非常有价值的辅助工具。
我忍不住想展示同一份报告中的另一个片段 - 另一个关于我们在现代 Linux 上学到的调度类如何工作的有趣例子(在上一章中介绍过);这实际上在trace-cmd输出中显示出来了:

图 11.4 - trace-cmd报告输出的部分截图
仔细解释前面的截图(图 11.4):第二行(右侧函数名列为粗体字体,紧随其后的两个函数也是如此)显示了pick_next_task_stop()函数被调用;这意味着发生了一次调度,内核中的核心调度代码按照优先级顺序遍历调度类的链表,询问每个类是否有要调度的线程;如果有,核心调度程序上下文切换到它(正如在前一章中详细解释的那样,在模块化调度类部分)。
在图 11.4 中,你真的看到了这种情况发生:核心调度代码询问stop-sched(SS)、deadline(DL)和real-time(RT)类是否有任何想要运行的线程,依次调用pick_next_task_stop()、pick_next_task_dl()和pick_next_task_rt()函数。显然,对于所有这些类,答案都是否定的,因为接下来要运行的函数是公平(CFS)类的函数(为什么pick_next_task_fair()函数在前面的截图中没有显示呢?啊,这又是代码优化:内核开发人员知道这是可能的情况,他们会直接调用公平类代码大部分时间)。
我们在这里介绍的强大的 Ftrace 框架和trace-cmd实用程序只是基础;我建议你查阅trace-cmd-<foo>(其中<foo>被替换为record、report等)的 man 页面,那里通常会显示很好的示例。此外,关于 Ftrace(和trace-cmd)还有一些非常好的文章 - 请参考进一步阅读部分。
使用 GUI 前端进行报告和解释
更多好消息:trace-cmd工具集包括一个 GUI 前端,用于更人性化的解释和分析,称为 KernelShark(尽管在我看来,它不像 Trace Compass 那样功能齐全)。在 Ubuntu/Debian 上安装它就像执行sudo apt install kernelshark一样简单。
下面,我们运行kernelshark,将我们之前的trace-cmd记录会话的跟踪数据文件输出作为参数传递给它(将参数调整为 KernelShark 所在位置,以引用您保存跟踪元数据的位置):
$ kernelshark ./trace_ps.dat
显示了运行前述跟踪数据的 KernelShark 的屏幕截图:
[外链图片转存中…(img-71sYSghm-1721183650948)]
图 11.5 - 显示先前捕获的数据的 kernelshark GUI 的屏幕截图
有趣的是,ps进程在 CPU#2 上运行(正如我们之前在 CLI 版本中看到的)。在这里,我们还可以看到在较低的平铺水平窗格中执行的函数;例如,我们已经突出显示了pick_next_task_fair()的条目。列是相当明显的,Latency列格式(四个字符,而不是五个)的解释如我们之前为(原始)Ftrace 解释的那样。
快速测验:在图 11.5 中看到的 Latency 格式字段dN..意味着什么?
答案:它意味着,当前,我们有以下情况:
-
第一列
d:硬件中断被禁用。 -
第二列
N:need_resched位被设置(暗示需要在下一个可用的调度机会点调用调度程序)。 -
第三列
.:内核pick_next_task_fair()函数的代码正在进程上下文中运行(任务是ps,PID 为22545;记住,Linux 是一个单内核!)。 -
第四列
.:抢占深度(计数)为零,暗示内核处于可抢占状态。
现在我们已经介绍了使用这些强大工具来帮助生成和可视化与内核执行和调度相关的数据,让我们继续下一个领域:在下一节中,我们将专注于另一个重要方面 - 线程的 CPU 亲和性掩码到底是什么,以及如何以编程方式(以及其他方式)获取/设置它。
理解、查询和设置 CPU 亲和性掩码
任务结构是一个根数据结构,包含几十个线程属性,其中有一些属性直接与调度有关:优先级(nice以及 RT 优先级值),调度类结构指针,线程所在的运行队列(如果有的话),等等。
其中一个重要成员是CPU 亲和性位掩码(实际的结构成员是cpumask_t cpus_allowed)。这也告诉你 CPU 亲和性位掩码是每个线程的数量;这是有道理的 - 在 Linux 上,KSE 是一个线程。它本质上是一个位数组,每个位代表一个 CPU 核心(在变量内有足够的位可用);如果对应于核心的位被设置(1),则允许在该核心上调度和执行线程;如果清除(0),则不允许。
默认情况下,所有 CPU 亲和性掩码位都被设置;因此,线程可以在任何核心上运行。例如,在一个有(操作系统看到的)四个 CPU 核心的盒子上,每个线程的默认 CPU 亲和性位掩码将是二进制1111(0xf)。(看一下图 11.6,看看 CPU 亲和性位掩码的概念上是什么样子。)
在运行时,调度程序决定线程实际上将在哪个核心上运行。事实上,想想看,这真的是隐含的:默认情况下,每个 CPU 核心都有一个与之关联的运行队列;每个可运行的线程将在单个 CPU 运行队列上;因此,它有资格运行,并且默认情况下在表示它的运行队列的 CPU 上运行。当然,调度程序有一个负载平衡器组件,可以根据需要将线程迁移到其他 CPU 核心(实际上是运行队列)(称为migration/n的内核线程在这个任务中协助)。
内核确实向用户空间暴露了 API(系统调用,当然,sched_{s,g}etaffinity(2)及其pthread包装库 API),这允许应用程序根据需要将线程(或多个线程)关联到特定的 CPU 核心上(按照相同的逻辑,我们也可以在内核中为任何给定的内核线程执行此操作)。例如,将 CPU 亲和性掩码设置为1010二进制,相当于十六进制的0xa,意味着该线程只能在 CPU 核心一和三上执行(从零开始计数)。
一个关键点:尽管您可以操纵 CPU 亲和性掩码,但建议避免这样做;内核调度程序详细了解 CPU 拓扑,并且可以最佳地平衡系统负载。
尽管如此,显式设置线程的 CPU 亲和性掩码可能是有益的,原因如下:
-
通过确保线程始终在同一 CPU 核心上运行,可以大大减少缓存失效(从而减少不愉快的缓存“跳动”)。
-
核心之间的线程迁移成本被有效地消除。
-
CPU 保留——一种策略,通过保证所有其他线程明确不允许在该核心上执行,将核心(或核心)专门分配给一个线程。
前两者在某些特殊情况下很有用;第三个,CPU 保留,往往是在一些时间关键的实时系统中使用的一种技术,其成本是合理的。但实际上,进行 CPU 保留是相当困难的,需要在(每个!)线程创建时进行操作;成本可能是禁止的。因此,这实际上是通过指定某个 CPU(或更多)从所有任务中隔离出来来实现的;Linux 内核提供了一个内核参数isolcpus来完成这项工作。
在这方面,我们直接引用了sched_{s,g}etaffinity(2)系统调用的 man 页面上的内容:
isolcpus 引导选项可用于在引导时隔离一个或多个 CPU,以便不会安排任何进程到这些 CPU 上运行。在使用此引导选项之后,将进程调度到被隔离的 CPU 的唯一方法是通过 sched_setaffinity()或 cpuset(7)机制。有关更多信息,请参阅内核源文件 Documentation/admin-guide/kernel-parameters.txt。如该文件中所述,isolcpus 是隔离 CPU 的首选机制(与手动设置系统上所有进程的 CPU 亲和性的替代方案相比)。
需要注意的是,先前提到的isolcpus内核参数现在被认为是不推荐使用的;最好使用 cgroups 的cpusets控制器代替(cpusets是一个 cgroup 特性或控制器;我们稍后在本章中会对 cgroups 进行一些介绍,在使用 cgroups 进行 CPU 带宽控制部分)。
我们建议您在内核参数文档中查看更多详细信息(在此处:www.kernel.org/doc/Documentation/admin-guide/kernel-parameters.txt),特别是在标记为isolcpus=的参数下。
既然你已经了解了它的理论,让我们实际编写一个用户空间 C 程序来查询和/或设置任何给定线程的 CPU 亲和性掩码。
查询和设置线程的 CPU 亲和性掩码
作为演示,我们提供了一个小型用户空间 C 程序来查询和设置用户空间进程(或线程)的 CPU 亲和性掩码。使用sched_getaffinity(2)系统调用来查询 CPU 亲和性掩码,并使用其对应的设置来设置它。
#define _GNU_SOURCE
#include <sched.h>
int sched_getaffinity(pid_t pid, size_t cpusetsize,
cpu_set_t *mask);
int sched_setaffinity(pid_t pid, size_t cpusetsize,
const cpu_set_t *mask);
一种名为cpu_set_t的专门数据类型用于表示 CPU 亲和掩码;它非常复杂:它的大小是根据系统上看到的 CPU 核心数量动态分配的。这种 CPU 掩码(类型为cpu_set_t)必须首先初始化为零;CPU_ZERO()宏可以实现这一点(还有几个类似的辅助宏;请参考CPU_SET(3)的手册页)。在前面的系统调用中的第二个参数是 CPU 集的大小(我们只需使用sizeof运算符来获取它)。
为了更好地理解这一点,值得看一下我们的代码的一个示例运行(ch11/cpu_affinity/userspc_cpuaffinity.c);我们在一个具有 12 个 CPU 核心的本机 Linux 系统上运行它:
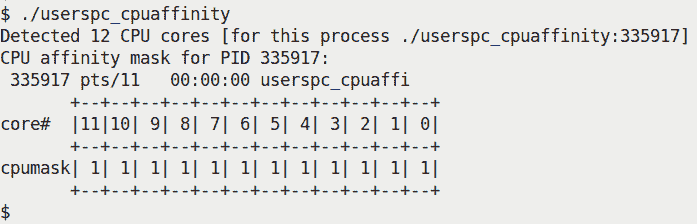
图 11.6 - 我们的演示用户空间应用程序显示 CPU 亲和掩码
在这里,我们没有使用任何参数运行应用程序。在这种模式下,它查询自身的 CPU 亲和掩码(即userspc_cpuaffinity调用进程的亲和掩码)。我们打印出位掩码的位数:正如您在前面的屏幕截图中清楚地看到的那样,它是二进制1111 1111 1111(相当于0xfff),这意味着默认情况下该进程有资格在系统上的任何 12 个 CPU 核心上运行。
该应用程序通过有用的popen(3)库 API 运行nproc(1)实用程序来检测可用的 CPU 核心数量。请注意,nproc返回的值是调用进程可用的 CPU 核心数量;它可能少于实际的 CPU 核心数量(通常是相同的);可用核心数量可以通过几种方式进行更改,正确的方式是通过 cgroup cpuset资源控制器(我们稍后在本章中介绍一些关于 cgroups 的信息)。
查询代码如下:
// ch11/cpu_affinity/userspc_cpuaffinity.c
static int query_cpu_affinity(pid_t pid)
{
cpu_set_t cpumask;
CPU_ZERO(&cpumask);
if (sched_getaffinity(pid, sizeof(cpu_set_t), &cpumask) < 0) {
perror("sched_getaffinity() failed");
return -1;
}
disp_cpumask(pid, &cpumask, numcores);
return 0;
}
我们的disp_cpumask()函数绘制位掩码(请自行查看)。
如果传递了额外的参数 - 进程(或线程)的 PID 作为第一个参数,CPU 位掩码作为第二个参数 - 那么我们将尝试设置该进程(或线程)的 CPU 亲和掩码为传递的值。当然,更改 CPU 亲和掩码需要您拥有该进程或具有 root 权限(更正确地说,需要具有CAP_SYS_NICE权限)。
一个快速演示:在图 11.7 中,nproc(1)显示了 CPU 核心的数量;然后,我们运行我们的应用程序来查询和设置我们的 shell 进程的 CPU 亲和掩码。在笔记本电脑上,假设bash的亲和掩码一开始是0xfff(二进制1111 1111 1111),如预期的那样;我们将其更改为0xdae(二进制1101 1010 1110),然后再次查询以验证更改:
[外链图片转存中…(img-8N8uw4Z3-1721183650948)]
图 11.7 - 我们的演示应用程序查询然后设置 bash 的 CPU 亲和掩码为 0xdae
好的,这很有趣:首先,该应用程序正确地检测到了可用的 CPU 核心数量为 12;然后,它查询了(默认的)bash 进程的 CPU 亲和掩码(因为我们将其 PID 作为第一个参数传递);如预期的那样,它显示为0xfff。然后,因为我们还传递了第二个参数 - 要设置的位掩码(0xdae) - 它这样做了,将 bash 的 CPU 亲和掩码设置为0xdae。现在,由于我们所在的终端窗口正是这个 bash 进程,再次运行nproc会显示值为 8,而不是 12!这是正确的:bash 进程现在只有八个 CPU 核心可用。(这是因为我们在退出时没有将 CPU 亲和掩码恢复到其原始值。)
以下是设置 CPU 亲和掩码的相关代码:
// ch11/cpu_affinity/userspc_cpuaffinity.c
static int set_cpu_affinity(pid_t pid, unsigned long bitmask)
{
cpu_set_t cpumask;
int i;
printf("\nSetting CPU affinity mask for PID %d now...\n", pid);
CPU_ZERO(&cpumask);
/* Iterate over the given bitmask, setting CPU bits as required */
for (i=0; i<sizeof(unsigned long)*8; i++) {
/* printf("bit %d: %d\n", i, (bitmask >> i) & 1); */
if ((bitmask >> i) & 1)
CPU_SET(i, &cpumask);
}
if (sched_setaffinity(pid, sizeof(cpu_set_t), &cpumask) < 0) {
perror("sched_setaffinity() failed");
return -1;
}
disp_cpumask(pid, &cpumask, numcores);
return 0;
}
在前面的代码片段中,您可以看到我们首先适当地设置了cpu_set_t位掩码(通过循环遍历每个位),然后使用sched_setaffinity(2)系统调用在给定的pid上设置新的 CPU 亲和掩码。
使用 taskset(1)执行 CPU 亲和
类似于我们在前一章中使用方便的用户空间实用程序chrt(1)来获取(或设置)进程(或线程)的调度策略和/或优先级,您可以使用用户空间taskset(1)实用程序来获取和/或设置给定进程(或线程)的 CPU 亲和性掩码。以下是一些快速示例;请注意,这些示例是在一个具有 4 个 CPU 核心的 x86_64 Linux 系统上运行的:
- 使用
taskset查询 systemd(PID 1)的 CPU 亲和性掩码:
$ taskset -p 1
pid 1's current affinity mask: f
$
- 使用
taskset确保编译器及其后代(汇编器和链接器)仅在前两个 CPU 核心上运行;taskset 的第一个参数是 CPU 亲和性位掩码(03是二进制0011):
$ taskset 03 gcc userspc_cpuaffinity.c -o userspc_cpuaffinity -Wall
查阅taskset(1)的手册页面以获取完整的使用详情。
在内核线程上设置 CPU 亲和性掩码
例如,如果我们想演示一种称为 per-CPU 变量的同步技术,我们需要创建两个内核线程,并确保它们分别在不同的 CPU 核心上运行。为此,我们必须设置每个内核线程的 CPU 亲和性掩码(第一个设置为0,第二个设置为1,以便它们只在 CPU 0和1上执行)。问题是,这不是一个干净的工作 - 老实说,相当糟糕,绝对不推荐。代码中的以下注释显示了原因:
/* ch17/6_percpuvar/6_percpuvar.c */
/* WARNING! This is considered a hack.
* As sched_setaffinity() isn't exported, we don't have access to it
* within this kernel module. So, here we resort to a hack: we use
* kallsyms_lookup_name() (which works when CONFIG_KALLSYMS is defined)
* to retrieve the function pointer, subsequently calling the function
* via it's pointer (with 'C' what you do is only limited by your
* imagination :).
*/
ptr_sched_setaffinity = (void *)kallsyms_lookup_name("sched_setaffinity");
稍后,我们调用函数指针,实际上调用sched_setaffinity代码,如下所示:
cpumask_clear(&mask);
cpumask_set_cpu(cpu, &mask); // 1st param is the CPU number, not bitmask
/* !HACK! sched_setaffinity() is NOT exported, we can't call it
* sched_setaffinity(0, &mask); // 0 => on self
* so we invoke it via it's function pointer */
ret = (*ptr_sched_setaffinity)(0, &mask); // 0 => on self
非常不寻常和有争议;它确实有效,但请在生产中避免这样的黑客行为。
现在你知道如何获取/设置线程的 CPU 亲和性掩码,让我们继续下一个逻辑步骤:如何获取/设置线程的调度策略和优先级!下一节将深入细节。
查询和设置线程的调度策略和优先级
在第十章中,CPU 调度器-第一部分,在线程-哪种调度策略和优先级部分,您学会了如何通过chrt(1)查询任何给定线程的调度策略和优先级(我们还演示了一个简单的 bash 脚本来实现)。在那里,我们提到了chrt(1)内部调用sched_getattr(2)系统调用来查询这些属性。
非常类似地,可以通过使用chrt(1)实用程序(例如在脚本中简单地这样做)或在(用户空间)C 应用程序中使用sched_setattr(2)系统调用来设置调度策略和优先级。此外,内核还公开其他 API:sched_{g,s}etscheduler(2)及其pthread库包装器 API,pthread_{g,s}etschedparam(3)(由于这些都是用户空间 API,我们让您自行查阅它们的手册页面以获取详细信息并尝试它们)。
在内核中-在内核线程上
现在你知道,内核绝对不是一个进程也不是一个线程。话虽如此,内核确实包含内核线程;与它们的用户空间对应物一样,内核线程可以根据需要创建(从核心内核、设备驱动程序、内核模块中)。它们是可调度实体(KSEs!),当然,它们每个都有一个任务结构;因此,它们的调度策略和优先级可以根据需要查询或设置。
因此,就要点而言:要设置内核线程的调度策略和/或优先级,内核通常使用kernel/sched/core.c:sched_setscheduler_nocheck()(GFP 导出)内核 API;在这里,我们展示了它的签名和典型用法的示例;随后的注释使其相当不言自明。
// kernel/sched/core.c
/**
* sched_setscheduler_nocheck - change the scheduling policy and/or RT priority of a thread from kernelspace.
* @p: the task in question.
* @policy: new policy.
* @param: structure containing the new RT priority.
*
* Just like sched_setscheduler, only don't bother checking if the
* current context has permission. For example, this is needed in
* stop_machine(): we create temporary high priority worker threads,
* but our caller might not have that capability.
*
* Return: 0 on success. An error code otherwise.
*/
int sched_setscheduler_nocheck(struct task_struct *p, int policy,
const struct sched_param *param)
{
return _sched_setscheduler(p, policy, param, false);
}
EXPORT_SYMBOL_GPL(sched_setscheduler_nocheck);
内核对内核线程的一个很好的例子是内核(相当常见地)使用线程化中断。在这里,内核必须创建一个专用的内核线程,其具有SCHED_FIFO(软)实时调度策略和实时优先级值为50(介于中间),用于处理中断。这里展示了设置内核线程调度策略和优先级的相关代码:
// kernel/irq/manage.c
static int
setup_irq_thread(struct irqaction *new, unsigned int irq, bool secondary)
{
struct task_struct *t;
struct sched_param param = {
.sched_priority = MAX_USER_RT_PRIO/2,
};
[ ... ]
sched_setscheduler_nocheck(t, SCHED_FIFO, ¶m);
[ ... ]
(这里我们不展示通过kthread_create() API 创建内核线程的代码。另外,FYI,MAX_USER_RT_PRIO的值是100。)
现在您在很大程度上了解了操作系统级别的 CPU 调度是如何工作的,我们将继续进行另一个非常引人入胜的讨论——cgroups;请继续阅读!
使用 cgroups 进行 CPU 带宽控制
在过去,内核社区曾经为一个相当棘手的问题而苦苦挣扎:尽管调度算法及其实现(早期的 2.6.0 O(1)调度器,稍后(2.6.23)的完全公平调度器(CFS))承诺了完全公平的调度,但实际上并非如此。想想这个:假设您与其他九个人一起登录到 Linux 服务器。其他一切都相等的情况下,处理器时间可能(或多或少)在所有十个人之间(相对)公平地共享;当然,您会明白,真正运行的不是人,而是代表他们运行的进程和线程。
至少目前,让我们假设它基本上是公平的。但是,如果您编写一个用户空间程序,在循环中不加选择地生成多个新线程,每个线程都执行大量的 CPU 密集型工作(也许还额外分配大量内存;例如文件(解)压缩应用程序)!那么 CPU 带宽分配在任何实际意义上都不再公平,您的账户将有效地占用 CPU(也许还占用其他系统资源,如内存)!
需要一个精确有效地分配和管理 CPU(和其他资源)带宽的解决方案;最终,谷歌工程师提供了补丁,将现代 cgroups 解决方案放入了 Linux 内核(在 2.6.24 版本)。简而言之,cgroups 是一个内核功能,允许系统管理员(或任何具有 root 访问权限的人)对系统上的各种资源(或在 cgroup 词汇中称为控制器)执行带宽分配和细粒度资源管理。请注意:使用 cgroups,不仅可以仔细分配和监视处理器(CPU 带宽),还可以根据项目或产品的需要仔细分配和监视内存、网络、块 I/O(等等)带宽。
所以,嘿,您现在感兴趣了!如何启用这个 cgroups 功能?简单——这是一个您可以通过通常的方式在内核中启用(或禁用)的内核功能:通过配置内核!相关菜单(通过方便的make menuconfig界面)是General setup / Control Group support。尝试这样做:在内核配置文件中使用grep查找CGROUP;如果需要,调整内核配置,重新构建,使用新内核重新启动并进行测试。(我们在第二章中详细介绍了内核配置,从源代码构建 5.x Linux 内核–第一部分,以及在第三章中介绍了内核构建和安装,从源代码构建 5.x Linux 内核–第二部分)。
好消息:cgroups 在运行 systemd init 框架的任何(足够新的)Linux 系统上默认启用。正如刚才提到的,您可以通过查询 cgroup 控制器来查看启用的控制器,并根据需要修改配置。
从 2.6.24 开始,与所有其他内核功能一样,cgroups 不断发展。最近,已经达到了足够改进的 cgroup 功能与旧版本不兼容的地步,导致了一个新的 cgroup 发布,即被命名为 cgroups v2(或简称为 cgroups2);这在 4.5 内核系列中被宣布为生产就绪(旧版本现在被称为 cgroups v1 或遗留 cgroups 实现)。请注意,截至目前为止,两者可以并且确实共存(有一些限制;许多应用程序和框架仍然使用旧的 cgroups v1,并且尚未迁移到 v2)。
为什么要使用 cgroups v2 而不是 cgroups v1 的详细原因可以在内核文档中找到:www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html#issues-with-v1-and-rationales-for-v2
cgroups(7)手册详细描述了接口和各种可用的(资源)控制器(有时称为子系统);对于 cgroups v1,它们是cpu、cpuacct、cpuset、memory、devices、freezer、net_cls、blkio、perf_event、net_prio、hugetlb、pids和rdma。我们建议感兴趣的读者查阅该手册以获取详细信息;例如,PIDS 控制器在防止 fork 炸弹(通常是一个愚蠢但仍然致命的 DoS 攻击,在其中fork(2)系统调用在无限循环中被发出!)方面非常有用,允许您限制可以从该 cgroup(或其后代)fork 出的进程数量。在运行 cgroups v1 的 Linux 系统上,查看/proc/cgroups的内容:它显示了可用的 v1 控制器及其当前使用情况。
控制组通过一个专门构建的合成(伪)文件系统进行公开,通常挂载在/sys/fs/cgroup下。在 cgroups v2 中,所有控制器都挂载在单个层次结构(或树)中。这与 cgroups v1 不同,cgroups v1 中可以将多个控制器挂载在多个层次结构或组下。现代 init 框架systemd同时使用 v1 和 v2 cgroups。cgroups(7)手册确实提到了systemd(1)在启动时自动挂载 cgroups v2 文件系统(在/sys/fs/cgroup/unified处)的事实。
在 cgroups v2 中,这些是支持的控制器(或资源限制器或子系统):cpu、cpuset、io、memory、pids、perf_event和rdma(前五个通常被部署)。
在本章中,重点是 CPU 调度;因此,我们不深入研究其他控制器,而是限制我们的讨论在使用 cgroups v2 cpu控制器来限制 CPU 带宽分配的示例上。有关使用其他控制器的更多信息,请参考前面提到的资源(以及本章的进一步阅读部分中找到的其他资源)。
在 Linux 系统上查找 cgroups v2
首先,让我们查找可用的 v2 控制器;要这样做,请找到 cgroups v2 挂载点;通常在这里:
$ mount | grep cgroup2
cgroup2 on /sys/fs/cgroup/unified type cgroup2
(rw,nosuid,nodev,noexec,relatime,nsdelegate)
$ sudo cat /sys/fs/cgroup/unified/cgroup.controllers
$
嘿,cgroup2中没有任何控制器吗?实际上,在存在混合 cgroups,v1 和 v2 的情况下,这是默认情况(截至目前为止)。要专门使用较新版本,并且使所有配置的控制器可见,您必须首先通过在启动时传递此内核命令行参数来禁用 cgroups v1:cgroup_no_v1=all(请注意,所有可用的内核参数可以方便地在此处查看:www.kernel.org/doc/Documentation/admin-guide/kernel-parameters.txt)。
使用上述选项重新启动系统后,您可以检查您在 GRUB(在 x86 上)或者在嵌入式系统上可能通过 U-Boot 指定的内核参数是否已被内核解析:
$ cat /proc/cmdline
BOOT_IMAGE=/boot/vmlinuz-4.15.0-118-generic root=UUID=<...> ro console=ttyS0,115200n8 console=tty0 ignore_loglevel quiet splash cgroup_no_v1=all 3
$
好的,现在让我们重试查找cgroup2控制器;您应该会发现它通常挂载在/sys/fs/cgroup/下 - unified文件夹不再存在(因为我们使用了cgroup_no_v1=all参数进行引导):
$ cat /sys/fs/cgroup/cgroup.controllers
cpu io memory pids
啊,现在我们看到它们了(您看到的确切控制器取决于内核的配置方式)。
cgroups2 的工作规则超出了本书的范围;如果您愿意,建议您阅读这里的内容:www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html#control-group-v2。此外,cgroup 中的所有cgroup.<foo>伪文件都在核心接口文件部分(www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html#core-interface-files)中有详细描述。类似的信息也以更简单的方式呈现在cgroups(7)的出色 man 页面中(在 Ubuntu 上使用man 7 cgroups查找)。
试一试 - cgroups v2 CPU 控制器
让我们尝试一些有趣的事情:我们将在系统的 cgroups v2 层次结构下创建一个新的子组。然后我们将为其设置一个 CPU 控制器,运行一些测试进程(这些进程会占用系统的 CPU 核心),并设置一个用户指定的上限,限制这些进程实际可以使用多少 CPU 带宽!
在这里,我们概述了您通常会采取的步骤(所有这些步骤都需要您以 root 访问权限运行):
- 确保您的内核支持 cgroups v2:
-
您应该在运行 4.5 或更高版本的内核。
-
在存在混合 cgroups(旧的 v1 和较新的 v2,这是写作时的默认设置)的情况下,请检查您的内核命令行是否包含
cgroup_no_v1=all字符串。在这里,我们假设 cgroup v2 层次结构得到支持并挂载在/sys/fs/cgroup下。
- 向 cgroups v2 层次结构添加
cpu控制器;这是通过以下方式实现的,作为 root 用户:
echo "+cpu" > /sys/fs/cgroup/cgroup.subtree_control
cgroups v2 的内核文档(www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html#cpu)提到了这一点:警告:cgroup2 尚不支持对实时进程的控制,cpu 控制器只能在所有 RT 进程位于根 cgroup 时启用。请注意,系统管理软件可能已经在系统引导过程中将 RT 进程放入非根 cgroup 中,这些进程可能需要移动到根 cgroup 中,然后才能启用 cpu 控制器。
- 创建一个子组:这是通过在 cgroup v2 层次结构下创建一个具有所需子组名称的目录来完成的;例如,要创建一个名为
test_group的子组,使用以下命令:
mkdir /sys/fs/cgroup/test_group
- 有趣的地方在于:设置将属于此子组的进程的最大允许 CPU 带宽;这是通过写入
<cgroups-v2-mount-point>/<sub-group>/cpu.max(伪)文件来实现的。为了清楚起见,根据内核文档(www.kernel.org/doc/html/latest/admin-guide/cgroup-v2.html#cpu-interface-files)对此文件的解释如下:
cpu.max
A read-write two value file which exists on non-root cgroups. The default is “max 100000”. The maximum bandwidth limit. It’s in the following format:
$MAX $PERIOD
which indicates that the group may consume upto $MAX in each $PERIOD duration. “max” for $MAX indicates no limit. If only one number is written, $MAX is updated.
实际上,子控制组中的所有进程将被允许在$PERIOD微秒内运行$MAX次;例如,当MAX = 300,000和PERIOD = 1,000,000时,我们实际上允许子控制组中的所有进程在 1 秒内运行 0.3 秒!
- 将一些进程插入新的子控制组;这是通过将它们的 PID 写入
<cgroups-v2-mount-point>/<sub-group>/cgroup.procs伪文件来实现的:
- 您可以通过查找每个进程的
/proc/<PID>/cgroup伪文件的内容进一步验证它们是否实际属于这个子组;如果它包含形式为0::/<sub-group>的行,则它确实属于该子组!
- 就是这样;新子组下的进程现在将在强加的 CPU 带宽约束下执行它们的工作;完成后,它们将像往常一样终止…您可以通过简单的
rmdir <cgroups-v2-mount-point>/<sub-group>来删除子组。
实际执行上述步骤的 bash 脚本在这里可用:ch11/cgroups_v2_cpu_eg/cgv2_cpu_ctrl.sh。一定要查看它!为了使其有趣,它允许您传递最大允许的 CPU 带宽-在步骤 4中讨论的$MAX值!不仅如此;我们还故意编写了一个测试脚本(simp.sh),它会在 CPU 上进行大量操作-它们会生成我们重定向到文件的整数值。因此,它们在其生命周期内生成的整数数量是它们可用的 CPU 带宽的指示…通过这种方式,我们可以测试脚本并实际看到 cgroups(v2)的运行!
这里进行几次测试运行将帮助您理解这一点:
$ sudo ./cgv2_cpu_ctrl.sh
[sudo] password for <username>:
Usage: cgv2_cpu_ctrl.sh max-to-utilize(us)
This value (microseconds) is the max amount of time the processes in the sub-control
group we create will be allowed to utilize the CPU; it's relative to the period,
which is the value 1000000;
So, f.e., passing the value 300,000 (out of 1,000,000) implies a max CPU utilization
of 0.3 seconds out of 1 second (i.e., 30% utilization).
The valid range for the $MAX value is [1000-1000000].
$
您需要以 root 身份运行它,并将$MAX值作为参数传递(之前看到的使用屏幕已经很清楚地解释了它,包括显示有效范围(微秒值))。
在下面的截图中,我们使用参数800000运行 bash 脚本,意味着 CPU 带宽为 1,000,000 中的 800,000;实际上,CPU 利用率为每秒 0.8 秒的相当高的 CPU 利用率(80%):

图 11.8-运行我们的 cgroups v2 CPU 控制器演示 bash 脚本,有效的最大 CPU 带宽为 80%
研究我们脚本的图 11.8输出;您可以看到它完成了它的工作:在验证 cgroup v2 支持后,它添加了一个cpu控制器并创建了一个子组(称为test_group)。然后继续启动两个名为j1和j2的测试进程(实际上,它们只是指向我们的simp.sh脚本的符号链接)。一旦启动,它们当然会运行。然后脚本查询并将它们的 PID 添加到子控制组(如步骤 5所示)。我们给这两个进程 5 秒钟来运行;然后脚本显示它们写入的文件的内容。它被设计成作业j1从1开始写入整数,作业j2从900开始写入整数。在前面的截图中,您可以清楚地看到,在其生命周期内,并在有效的 80% CPU 带宽下,作业j1从 1 到 68 输出数字;同样(在相同的约束下),作业j2从900到965输出数字(实际上是相似数量的工作)。然后脚本清理,终止作业并删除子组。
然而,为了真正欣赏效果,我们再次运行我们的脚本(研究以下输出),但这次最大 CPU 带宽只有 1,000($MAX值)-实际上,最大 CPU 利用率只有 0.1%!:
$ sudo ./cgv2_cpu_ctrl.sh 1000 [+] Checking for cgroup v2 kernel support
[+] Adding a 'cpu' controller to the cgroups v2 hierarchy
[+] Create a sub-group under it (here: /sys/fs/cgroup/test_group)
***
Now allowing 1000 out of a period of 1000000 by all processes (j1,j2) in this
sub-control group, i.e., .100% !
***
[+] Launch processes j1 and j2 (slinks to /home/llkd/Learn-Linux-Kernel-Development/ch11/cgroups_v2_cpu_eg/simp.sh) now ...
[+] Insert processes j1 and j2 into our new CPU ctrl sub-group
Verifying their presence...
0::/test_group
Job j1 is in our new cgroup v2 test_group
0::/test_group
Job j2 is in our new cgroup v2 test_group
............... sleep for 5 s ................
[+] killing processes j1, j2 ...
./cgv2_cpu_ctrl.sh: line 185: 10322 Killed ./j1 1 > ${OUT1}
cat 1stjob.txt
1 2 3
cat 2ndjob.txt
900 901
[+] Removing our cpu sub-group controller
rmdir: failed to remove '/sys/fs/cgroup/test_group': Device or resource busy
./cgv2_cpu_ctrl.sh: line 27: 10343 Killed ./j2 900 > ${OUT2}
$
有何不同!这次我们的作业j1和j2实际上只能输出两到三个整数(如前面输出中看到的作业 j1 的值为1 2 3,作业 j2 的值为900 901),清楚地证明了 cgroups v2 CPU 控制器的有效性。
容器,本质上是轻量级的虚拟机(在某种程度上),目前是一个炙手可热的商品。今天使用的大多数容器技术(Docker、LXC、Kubernetes 等)在本质上都是两种内置的 Linux 内核技术,即命名空间和 cgroups 的结合。
通过这样,我们完成了对一个非常强大和有用的内核特性:cgroups 的简要介绍。让我们继续本章的最后一部分:学习如何将常规 Linux 转换为实时操作系统!
将主线 Linux 转换为 RTOS
主线或原始的 Linux(从kernel.org下载的内核)明显不是一个实时操作系统(RTOS);它是一个通用操作系统(GPOS;就像 Windows,macOS,Unix 一样)。在 RTOS 中,当硬实时特性发挥作用时,软件不仅必须获得正确的结果,还有与此相关的截止日期;它必须保证每次都满足这些截止日期。尽管主线 Linux 操作系统不是 RTOS,但它的表现非常出色:它很容易符合软实时操作系统的标准(在大多数情况下都能满足截止日期)。然而,真正的硬实时领域(例如军事行动,许多类型的交通,机器人技术,电信,工厂自动化,股票交易,医疗电子设备等)需要 RTOS。
在这种情况下的另一个关键点是确定性:关于实时的一个经常被忽视的点是,软件响应时间并不总是需要非常快(比如说在几微秒内响应);它可能会慢得多(在几十毫秒的范围内);这本身并不是 RTOS 中真正重要的事情。真正重要的是系统是可靠的,以相同一致的方式工作,并始终保证截止日期得到满足。
例如,对调度请求的响应时间应该是一致的,而不是一直在变化。与所需时间(或基线)的差异通常被称为抖动;RTOS 致力于保持抖动微小,甚至可以忽略不计。在 GPOS 中,这通常是不可能的,抖动可能会变化得非常大 - 一会儿很低,下一刻很高。总的来说,能够在极端工作负荷的情况下保持稳定的响应和最小的抖动的能力被称为确定性,并且是 RTOS 的标志。为了提供这样的确定性响应,算法必须尽可能地设计为*O(1)*时间复杂度。
Thomas Gleixner 和社区支持已经为此目标努力了很长时间;事实上,自 2.6.18 内核以来,已经有了将 Linux 内核转换为 RTOS 的离线补丁。这些补丁可以在许多内核版本中找到,网址是:mirrors.edge.kernel.org/pub/linux/kernel/projects/rt/。这个项目的旧名称是PREEMPT_RT;后来(2015 年 10 月起),Linux 基金会(LF)接管了这个项目 - 这是一个非常积极的举措! - 并将其命名为实时 Linux(RTL)协作项目(wiki.linuxfoundation.org/realtime/rtl/start#the_rtl_collaborative_project),或 RTL(不要将这个项目与 Xenomai 或 RTAI 等共核方法,或者旧的、现在已经废弃的尝试称为 RTLinux 混淆)。
当然,一个常见的问题是“为什么这些补丁不直接合并到主线中呢?”事实证明:
-
很多 RTL 工作确实已经合并到了主线内核中;这包括重要领域,如调度子系统,互斥锁,lockdep,线程中断,PI,跟踪等。事实上,RTL 的一个持续的主要目标是尽可能多地合并它(我们在主线和 RTL - 技术差异总结部分展示了一个总结表)。
-
Linus Torvalds 认为,Linux 作为一个主要设计和架构为 GPOS,不应该具有只有 RTOS 真正需要的高度侵入性功能;因此,尽管补丁确实被合并了,但这是一个缓慢的审慎过程。
在本章的进一步阅读部分,我们包括了一些有趣的文章和有关 RTL(和硬实时)的参考资料;请阅读一下。
接下来您将要做的事情确实很有趣:您将学习如何使用 RTL 补丁对主线 5.4 LTS 内核进行打补丁、配置、构建和引导;因此,您最终将运行一个 RTOS - 实时 Linux 或 RTL!我们将在我们的 x86_64 Linux VM(或本机系统)上执行此操作。
我们不会止步于此;然后您将学习更多内容 - 常规 Linux 和 RTL 之间的技术差异,系统延迟是什么,以及如何实际测量它。为此,我们将首先在树莓派设备的内核源上应用 RTL 补丁,配置和构建它,并将其用作使用cyclictest应用程序进行系统延迟测量的测试平台(您还将学习使用现代 BPF 工具来测量调度程序延迟)。让我们首先在 x86_64 上为我们的 5.4 内核构建一个 RTL 内核!
为主线 5.x 内核(在 x86_64 上)构建 RTL
在本节中,您将逐步学习如何以实际操作的方式打补丁、配置和构建 Linux 作为 RTOS。如前一节所述,这些实时补丁已经存在很长时间了;现在是时候利用它们了。
获取 RTL 补丁
导航至mirrors.edge.kernel.org/pub/linux/kernel/projects/rt/5.4/(或者,如果您使用的是另一个内核,转到此目录的上一级目录并选择所需的内核版本):
图 11.9 - 5.4 LTS Linux 内核的 RTL 补丁的截图
您很快会注意到 RTL 补丁仅适用于所讨论的内核的某些版本(在这里是 5.4.y);接下来会有更多内容。在前面的截图中,您可以看到两种类型的补丁文件 - 解释如下:
-
patch-<kver>rt[nn].patch.[gz|xz]:前缀是patch-;这是补丁的完整集合,用于在一个统一的(压缩的)文件中打补丁到主线内核(版本<kver>)。 -
patches-<kver>-rt[nn].patch.[gz|xz]:前缀是patches-;这个压缩文件包含了用于这个版本的 RTL 的每个单独的补丁(作为单独的文件)。
(还有,正如您应该知道的,<fname>.patch.gz和<fname>.patch.xz是相同的存档;只是压缩器不同 - .sign文件是 PGP 签名文件。)
我们将使用第一种类型;通过单击链接(或通过wget(1))将patch-<kver>rt[nn].patch.xz文件下载到目标系统。
请注意,对于 5.4.x 内核(截至撰写时),RTL 补丁似乎只存在于 5.4.54 和 5.4.69 版本(而不是 5.4.0,我们一直在使用的内核)。
实际上,RTL 补丁适用的特定内核版本可能与我在撰写本文时提到的不同。这是预期的 - 只需按照这里提到的步骤用您正在使用的发布号替换即可。
别担心 - 我们马上就会向您展示一个解决方法。这确实是事实;社区不可能针对每个单独的内核发布构建补丁 - 这些实在太多了。这确实有一个重要的含义:要么我们将我们的 5.4.0 内核打补丁到 5.4.69,要么我们只需下载 5.4.69 内核并对其应用 RTL 补丁。
第一种方法可行,但工作量更大(特别是在没有 git/ketchup/quilt 等补丁工具的情况下;在这里,我们选择不使用 git 来应用补丁,而是直接在稳定的内核树上工作)。由于 Linux 内核补丁是增量的,我们将不得不下载从 5.4.0 到 5.4.69 的每个补丁(总共 69 个补丁!),并依次按顺序应用它们:首先是 5.4.1,然后是 5.4.2,然后是 5.4.3,依此类推,直到最后一个!在这里,为了简化事情,我们知道要打补丁的内核是 5.4.69,所以最好直接下载并提取它。因此,前往www.kernel.org/并这样做。因此,我们最终下载了两个文件:
-
主线 5.4.69 的压缩内核源代码:
mirrors.edge.kernel.org/pub/linux/kernel/v5.x/linux-5.4.69.tar.xz -
5.4.69 的 RTL 补丁:
mirrors.edge.kernel.org/pub/linux/kernel/projects/rt/5.4/patches-5.4.69-rt39.tar.xz
(如第三章 从源代码构建 5.x Linux 内核-第二部分中详细解释的那样,如果您打算为另一个目标交叉编译内核,通常的做法是在功能强大的工作站上构建它,然后在那里下载。)
接下来,提取 RTL 补丁文件以及内核代码基础tar.xz文件,以获取内核源代码树(这里是版本 5.4.69;当然,这些细节在第二章 从源代码构建 5.x Linux 内核-第一部分中已经详细介绍过)。到目前为止,您的工作目录内容应该类似于这样:
$ ls -lh
total 106M
drwxrwxr-x 24 kaiwan kaiwan 4.0K Oct 1 16:49 linux-5.4.69/
-rw-rw-r-- 1 kaiwan kaiwan 105M Oct 13 16:35 linux-5.4.69.tar.xz
-rw-rw-r-- 1 kaiwan kaiwan 836K Oct 13 16:33 patch-5.4.69-rt39.patch
$
(FYI,unxz(1)实用程序可用于提取.xz压缩的补丁文件。)对于好奇的读者:看一下补丁(文件patch-5.4.69-rt39.patch),看看为实现硬实时内核所做的所有代码级更改;当然不是简单的!技术更改的概述将在即将到来的主线和 RTL-技术差异摘要部分中看到。既然我们已经准备就绪,让我们开始将补丁应用到稳定的 5.4.69 内核树上;接下来的部分只涵盖这一点。
应用 RTL 补丁
确保将提取的补丁文件patch-5.4.69-rt39.patch放在 5.4.69 内核源代码树的上一级目录中(如前所示)。现在,让我们应用补丁。小心-(显然)不要尝试将压缩文件应用为补丁;提取并使用未压缩的补丁文件。为了确保补丁正确应用,我们首先使用--dry-run(虚拟运行)选项来使用patch(1):
$ cd linux-5.4.69
$ patch -p1 --dry-run < ../patch-5.4.69-rt39.patch
checking file Documentation/RCU/Design/Expedited-Grace-Periods/Expedited-Grace-Periods.html
checking file Documentation/RCU/Design/Requirements/Requirements.html
[ ... ]
checking file virt/kvm/arm/arm.c
$ echo $?
0
一切顺利,现在让我们实际应用它:
$ patch -p1 < ../patch-5.4.69-rt39.patch patching file Documentation/RCU/Design/Expedited-Grace-Periods/Expedited-Grace-Periods.html
patching file Documentation/RCU/Design/Requirements/Requirements.html
[ ... ]
太好了-我们现在已经准备好了 RTL 补丁内核!
当然,有多种方法和各种快捷方式可以使用;例如,您还可以通过xzcat ../patch-5.4.69-rt39.patch.xz | patch -p1命令(或类似命令)来实现前面的操作。
配置和构建 RTL 内核
我们在第二章 从源代码构建 5.x Linux 内核-第一部分和第三章 从源代码构建 5.x Linux 内核-第二部分中详细介绍了内核配置和构建步骤,因此我们不会在这里重复。几乎所有内容都保持不变;唯一的显著区别是我们必须配置此内核以利用 RTL(这在新的 RTL 维基网站上有解释,网址为:wiki.linuxfoundation.org/realtime/documentation/howto/applications/preemptrt_setup)。
为了将要构建的内核特性减少到大约匹配当前系统配置,我们首先在内核源树目录(linux-5.4.69)中执行以下操作(我们也在第二章中介绍过,从源代码构建 5.x Linux 内核 - 第一部分,在通过 localmodconfig 方法调整内核配置部分):
$ lsmod > /tmp/mylsmod
$ make LSMOD=/tmp/mylsmod localmodconfig
接下来,使用make menuconfig启动内核配置:
- 导航到
通用设置子菜单:

图 11.10 - 进行 menuconfig / 通用设置:配置 RTL 补丁内核
-
一旦到达那里,向下滚动到
抢占模型子菜单;我们在前面的截图中看到它被突出显示,以及当前(默认)选择的抢占模型是自愿内核抢占(桌面)。 -
在这里按Enter会进入
抢占模型子菜单:
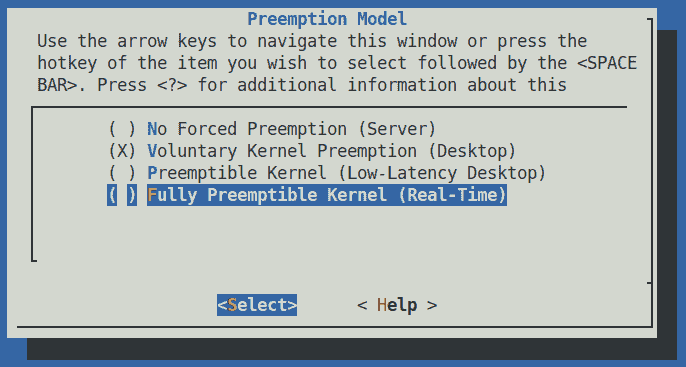
图 11.11 - 进行 menuconfig / 通用设置 / 抢占模型的配置 RTL 补丁内核
就是这样!回想一下前一章,在可抢占内核部分,我们描述了这个内核配置菜单实际上有三个项目(在图 11.11 中看到的前三个)。现在有四个。第四个项目 - 完全可抢占内核(实时)选项 - 是由于我们刚刚应用的 RTL 补丁而添加的!
- 因此,要为 RTL 配置内核,请向下滚动并选择
完全可抢占内核(实时)菜单选项(参见图 11.1)。这对应于内核CONFIG_PREEMPT_RT配置宏,其<帮助>非常描述性(确实要看一看);事实上,它以这样的陈述结束:如果您正在构建需要实时保证的系统内核,请选择此选项。
在较早版本的内核(包括 5.0.x)中,抢占模型子菜单显示了五个选择项;其中两个是用于 RT:一个称为基本 RT,另一个是我们在这里看到的第四个选择 - 现在(5.4.x)它们已经被简单地合并为一个真正的实时选项。
- 一旦选择了第四个选项并保存并退出
menuconfigUI,(重新)检查已选择完全可抢占内核 - 实际上是 RTL:
$ grep PREEMPT_RT .config
CONFIG_PREEMPT_RT=y
好的,看起来不错!(当然,在构建之前,您可以根据产品的需要调整其他内核配置选项。)
- 现在让我们构建 RTL 内核:
make -j4 && sudo make modules_install install
- 一旦成功构建和安装,重新启动系统;在启动时,按下一个键以显示 GRUB 引导加载程序菜单(按住其中一个Shift键可以确保在启动时显示 GRUB 菜单);在 GRUB 菜单中,选择新构建的
5.4.69-rtlRTL 内核(实际上,刚刚安装的内核通常是默认选择的)。现在应该可以启动了;一旦登录并进入 shell,让我们验证内核版本:
$ uname -r
5.4.69-rt39-rtl-llkd1
注意CONFIG_LOCALVERSION设置为值-rtl-llkd1。(还可以通过uname -a看到PREEMPT RT字符串。)现在我们 - 如承诺的那样 - 运行 Linux,RTL,作为硬实时操作系统,即 RTOS!
然而,非常重要的是要理解,对于真正的硬实时,仅仅拥有一个硬实时内核是不够的;你必须非常小心地设计和编写你的用户空间(应用程序、库和工具)以及你的内核模块/驱动程序,以符合实时性。例如,频繁的页面错误可能会使确定性成为过去式,并导致高延迟(和高抖动)。 (回想一下你在第九章中学到的,模块作者的内核内存分配 - 第二部分,在内存分配和需求分页的简短说明*部分。页面错误是生活的一部分,经常发生;小的页面错误通常不会引起太多担忧。但在硬实时的情况下呢?无论如何,“主要错误”都会妨碍性能。)诸如使用mlockall(2)来锁定实时应用程序进程的所有页面可能是必需的。这里提供了编写实时代码的几种其他技术和建议:rt.wiki.kernel.org/index.php/HOWTO:_Build_an_ RT-application。(同样,关于 CPU 亲和性和屏蔽、cpuset管理、中断请求(IRQ)优先级等主题可以在先前提到的旧 RT 维基站点上找到;rt.wiki.kernel.org/index.php/Main_Page。)
所以,很好 - 现在你知道如何配置和构建 Linux 作为 RTOS!我鼓励你自己尝试一下。接下来,我们将总结标准和 RTL 内核之间的关键差异。
主线和 RTL - 技术差异总结
为了让你更深入地了解这个有趣的主题领域,在本节中,我们将进一步深入探讨:我们总结了标准(或主线)和 RTL 内核之间的关键差异。
在下表中,我们总结了标准(或主线)和 RTL 内核之间的一些关键差异。RTL 项目的主要目标是最终完全整合到常规主线内核树中。由于这个过程是渐进的,从 RTL 合并到主线的补丁是缓慢但稳定的;有趣的是,正如你可以从下表的最右列看到的那样,在撰写本文时,大部分(约 80%)的 RTL 工作实际上已经合并到了主线内核中,并且它还在继续:
| 组件/特性 | 标准或主线(原始)Linux | RTL(完全可抢占/硬实时 Linux) | RT 工作合并到主线? |
|---|---|---|---|
| 自旋锁 | 自旋锁关键部分是不可抢占的内核代码 | 尽可能可抢占;称为“睡眠自旋锁”!实际上,自旋锁已转换为互斥锁。 | 否 |
| 中断处理 | 传统上通过顶半部分和底半部分(hardirq/tasklet/softirq)机制完成 | 线程中断:大多数中断处理在内核线程内完成(2.6.30,2009 年 6 月)。 | 是 |
| HRTs(高分辨率定时器) | 由于从 RTL 合并而可用 | 具有纳秒分辨率的定时器(2.6.16,2006 年 3 月)。 | 是 |
| RW 锁 | 无界;写者可能会挨饿 | 具有有界写入延迟的公平 RW 锁。 | 否 |
| lockdep | 由于从 RTL 合并而可用 | 非常强大(内核空间)的工具,用于检测和证明锁的正确性或缺乏正确性。 | 是 |
| 跟踪 | 由于从 RTL 合并而可用的一些跟踪技术 | Ftrace 的起源(在某种程度上也包括 perf)是 RT 开发人员试图找到延迟问题。 | 是 |
| 调度器 | 由于从 RTL 合并而可用的许多调度器功能 | 首先在这里进行了实时调度的工作以及截止时间调度类(SCHED_DEADLINE)(3.14,2014 年 3 月);此外,完全无滴答操作(3.10,2013 年 6 月)。 | 是 |
不要担心-我们一定会在书的后续章节中涵盖许多前面的细节。
当然,一个众所周知的(至少应该是)经验法则就是:没有银弹。这当然意味着,没有一个解决方案适用于所有需求。
如果你还没有这样做,请务必读一读弗雷德里克·P·布鲁克斯的《神话般的程序员:软件工程论文》这本仍然相关的书。
如第十章中所述,《CPU 调度器-第一部分》,在可抢占内核部分,Linux 内核可以配置为使用CONFIG_PREEMPT选项;这通常被称为低延迟(或LowLat)内核,并提供接近实时的性能。在许多领域(虚拟化、电信等),使用 LowLat 内核可能比使用硬实时 RTL 内核更好,主要是由于 RTL 的开销。通常情况下,使用硬实时,用户空间应用程序可能会受到吞吐量的影响,CPU 可用性降低,因此延迟更高。(请参阅进一步阅读部分,了解 Ubuntu 的一份白皮书,其中对比了原始发行版内核、低延迟可抢占内核和完全可抢占内核-实际上是 RTL 内核。)
考虑到延迟,接下来的部分将帮助您了解系统延迟的确切含义;然后,您将学习一些在实时系统上测量它的方法。继续!
延迟及其测量
我们经常遇到术语延迟;在内核的上下文中,它到底是什么意思呢?延迟的同义词是延迟,这是一个很好的提示。延迟(或延迟)是反应所需的时间 - 在我们这里的上下文中,内核调度程序唤醒用户空间线程(或进程)的时间,使其可运行,以及它实际在处理器上运行的时间是调度延迟。(不过,请注意,调度延迟这个术语也在另一个上下文中使用,指的是每个可运行任务保证至少运行一次的时间间隔;在这里的可调整项是:/proc/sys/kernel/sched_latency_ns,至少在最近的 x86_64 Linux 上,默认值为 24 毫秒)。类似地,从硬件中断发生(比如网络中断)到它实际由其处理程序例程服务的经过的时间是中断延迟。
cyclictest用户空间程序是由 Thomas Gleixner 编写的;它的目的是测量内核延迟。其输出值以微秒为单位。平均延迟和最大延迟通常是感兴趣的值-如果它们在系统的可接受范围内,那么一切都很好;如果不在范围内,这可能指向产品特定的重新设计和/或内核配置调整,检查其他时间关键的代码路径(包括用户空间)等。
让我们以 cyclictest 进程本身作为一个例子,来清楚地理解调度延迟。cyclictest 进程被运行;在内部,它发出nanosleep(2)(或者,如果传递了-n选项开关,则是clock_nanosleep(2)系统调用),将自己置于指定的时间间隔的睡眠状态。由于这些*sleep()系统调用显然是阻塞的,内核在内部将 cyclictest(为简单起见,我们在下图中将其称为ct)进程排入等待队列,这只是一个保存睡眠任务的内核数据结构。
等待队列与事件相关联;当事件发生时,内核唤醒所有在该事件上休眠的任务。在这里,所讨论的事件是定时器的到期;这是由定时器硬件发出的硬件中断(或 IRQ)来传达的;这开始了必须发生的事件链,以使 cyclictest 进程唤醒并在处理器上运行。当然,关键点在于,说起来容易做起来难:在进程实际在处理器核心上运行的路径上可能发生许多潜在的延迟!以下图表试图传达的就是潜在的延迟来源:
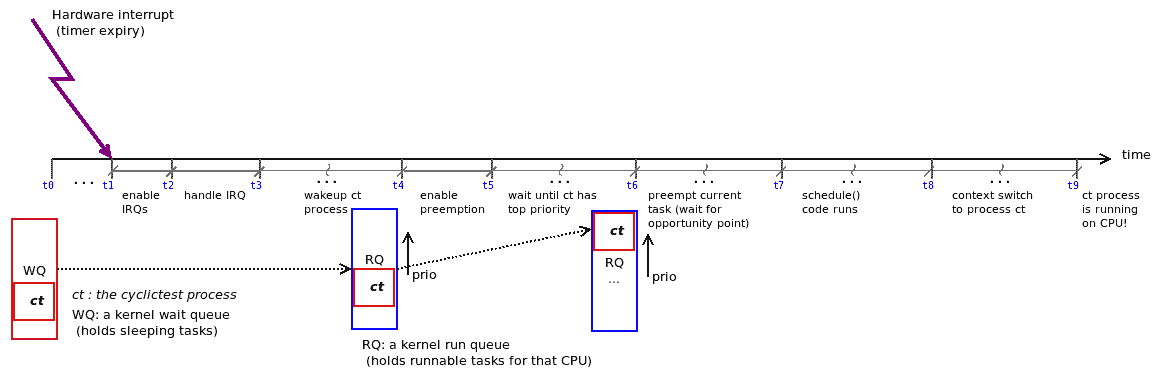
图 11.12 - 唤醒、上下文切换和运行 cyclictest(ct)进程的路径;可能发生多个延迟
(部分前述输入来自于优秀的演示使用和理解实时 Cyclictest 基准测试,Rowand,2013 年 10 月。)仔细研究图 11.12;它显示了从硬件中断由于定时器到期的断言(在时间t0,因为 cyclictest 进程通过nanosleep() API 发出的休眠在时间t1完成),通过 IRQ 处理(t1到t3),以及 ct 进程唤醒的时间线 - 作为其结果,它被排入将来运行的核心的运行队列(在t3和t4之间)。
从那里,它最终将成为调度类别的最高优先级,或者最好或最值得的任务(在时间t6;我们在前一章中介绍了这些细节),因此,它将抢占当前正在运行的线程(t6)。schedule()代码将执行(时间t7到t8),上下文切换将发生在schedule()的尾端,最后(!),cyclictest 进程将实际在处理器核心上执行(时间t9)。虽然乍看起来可能很复杂,但实际情况是这是一个简化的图表,因为其他潜在的延迟源已被省略(例如,由于 IPI、SMI、缓存迁移、前述事件的多次发生、额外中断在不合适的时刻触发导致更多延迟等)。
确定具有实时优先级的用户空间任务的最大延迟值的经验法则如下:
max_latency = CLK_WAVELENGTH x 105 s
例如,树莓派 3 型号的 CPU 时钟运行频率为 1 GHz;其波长(一个时钟周期到下一个时钟周期之间的时间)是频率的倒数,即 10^(-9)或 1 纳秒。因此,根据前述方程,理论最大延迟应该是(在)10^(-7)秒,约为 10 纳秒。正如您很快会发现的,这仅仅是理论上的。
使用 cyclictest 测量调度延迟
为了使这更有趣(以及在受限系统上运行延迟测试),我们将使用众所周知的 cyclictest 应用程序进行延迟测量,同时系统处于一定负载(通过stress(1)实用程序)下运行,使用同样著名的树莓派设备。本节分为四个逻辑部分:
-
首先,在树莓派设备上设置工作环境。
-
其次,在内核源上下载和应用 RT 补丁,进行配置和构建。
-
第三,安装 cyclictest 应用程序,以及设备上的其他一些必需的软件包(包括
stress)。 -
第四,运行测试用例并分析结果(甚至绘制图表来帮助分析)。
第一步和第二步的大部分内容已经在第三章中详细介绍过,从源代码构建 5.x Linux 内核-第二部分,在树莓派的内核构建部分。这包括下载树莓派特定的内核源树,配置内核和安装适当的工具链;我们不会在这里重复这些信息。唯一的显著差异是,我们首先必须将 RT 补丁应用到内核源树中,并配置为硬实时;我们将在下一节中介绍这一点。
让我们开始吧!
获取并应用 RTL 补丁集
检查运行在您的树莓派设备上的主线或发行版内核版本(用任何其他设备替换树莓派,您可能在其上运行 Linux);例如,在我使用的树莓派 3B+上,它正在运行带有 5.4.51-v7+内核的标准 Raspbian(或树莓派 OS)GNU/Linux 10(buster)。
我们希望为树莓派构建一个 RTL 内核,使其与当前运行的标准内核尽可能匹配;对于我们的情况,它正在运行 5.4.51[-v7+],最接近的可用 RTL 补丁是内核版本 5.4.y-rt[nn](mirrors.edge.kernel.org/pub/linux/kernel/projects/rt/5.4/);我们马上就会回到这一点…
让我们一步一步来:
-
下载树莓派特定的内核源树到您的主机系统磁盘的步骤已经在第三章中详细介绍过,从源代码构建 5.x Linux 内核-第二部分,在树莓派的内核构建部分;请参考并获取源树。
-
完成此步骤后,您应该会看到一个名为
linux的目录;它保存了树莓派内核源代码,截至撰写本文的时间,内核版本为 5.4.y。y的值是多少?这很容易;只需执行以下操作:
$ head -n4 linux/Makefile
# SPDX-License-Identifier: GPL-2.0
VERSION = 5
PATCHLEVEL = 4
SUBLEVEL = 70
这里的SUBLEVEL变量是y的值;显然,它是 70,使得内核版本为 5.4.70。
- 接下来,让我们下载适当的实时(RTL)补丁:最好是一个精确匹配,也就是说,补丁的名称应该类似于
patch-5.4.70-rt[nn].tar.xz。幸运的是,它确实存在于服务器上;让我们获取它(请注意,我们下载patch-<kver>-rt[nn]文件;因为它是统一的补丁,所以更容易处理):
wget https://mirrors.edge.kernel.org/pub/linux/kernel/projects/rt/5.4/patch-5.4.70-rt40.patch.xz。
这确实引发了一个问题:如果可用的 RTL 补丁的版本与设备的内核版本不完全匹配会怎么样?很不幸,这确实会发生。在这种情况下,为了最有可能将其应用于设备内核,选择最接近的匹配并尝试应用它;通常会成功,也许会有轻微的警告… 如果不行,您将不得不手动调整代码库以适应补丁集,或者切换到存在 RTL 补丁的内核版本(推荐)。
不要忘记解压补丁文件!
- 现在应用补丁(如前面所示,在应用 RTL 补丁部分):
cd linux
patch -p1 < ../patch-5.4.70-rt40.patch
-
配置打补丁的内核,打开
CONFIG_PREEMPT_RT内核配置选项(如前面所述): -
不过,正如我们在第三章中学到的,从源代码构建 5.x Linux 内核-第二部分,对于目标,设置初始内核配置是至关重要的;在这里,由于目标设备是树莓派 3[B+],请执行以下操作:
make ARCH=arm bcm2709_defconfig
-
- 使用
make ARCH=arm menuconfig命令自定义您的内核配置。在这里,当然,您应该转到General setup / Preemption Model,并选择第四个选项,CONFIG_PREEMPT_RT,以打开硬实时抢占特性。
- 使用
-
我还假设您已经为树莓派安装了适当的 x86_64 到 ARM32 的工具链:
make -j4 ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- zImage modules dtbs
提示:安装适当的工具链(用于 x86_64 到 ARM32)可以像这样简单地进行:sudo apt install crossbuild-essential-armhf。现在构建内核(与我们之前描述的配置和构建 RTL 内核部分相同),不同之处在于我们进行交叉编译(使用之前安装的 x86_64 到 ARM32 交叉编译器)。
- 安装刚构建的内核模块;确保你使用
INSTALL_MOD_PATH环境变量指定了 SD 卡的根文件系统的位置(否则它可能会覆盖你主机上的模块,这将是灾难性的!)。假设 microSD 卡的第二个分区(包含根文件系统)挂载在/media/${USER}/rootfs下,然后执行以下操作(一行命令):
sudo env PATH=$PATH make ARCH=arm CROSS_COMPILE=arm-linux-gnueabihf- INSTALL_MOD_PATH=/media/${USER}/rootfs modules_install
-
将图像文件(引导加载程序文件,内核
zImage文件,设备树块(DTB),内核模块)复制到树莓派 SD 卡上(这些细节在官方树莓派文档中有介绍:www.raspberrypi.org/documentation/linux/kernel/building.md;我们也在第三章中(轻微地)介绍了这一点,从源代码构建 5.x Linux 内核-第二部分)。 -
测试:使用 SD 卡中的新内核映像引导树莓派。你应该能够登录到一个 shell(通常是通过
ssh)。验证内核版本和配置:
rpi ~ $ uname -a
Linux raspberrypi 5.4.70-rt40-v7-llkd-rtl+ #1 SMP PREEMPT_RT Thu Oct 15 07:58:13 IST 2020 armv7l GNU/Linux
rpi ~ $ zcat /proc/config.gz |grep PREEMPT_RT
CONFIG_PREEMPT_RT=y
我们确实在设备上运行了一个硬实时内核!所以,很好 - 这解决了“准备”部分;现在你可以继续下一步了。
在设备上安装 cyclictest(和其他所需的软件包)
我们打算通过 cyclictest 应用程序对标准和新创建的 RTL 内核运行测试用例。这意味着,当然,我们必须首先获取 cyclictest 的源代码并在设备上构建它(请注意,这里的工作是在树莓派上进行的)。
这里有一篇文章介绍了这个过程:树莓派 3 在标准和实时 Linux 4.9 内核上的延迟:metebalci.com/blog/latency-of-raspberry-pi-3-on-standard-and-real-time-linux-4.9-kernel/。
它提到了在树莓派 3 上运行 RTL 内核时遇到的问题以及一个解决方法(重要!):(除了通常的参数之外)还要传递这两个内核参数:dwc_otg.fiq_enable=0和dwc_otg.fiq_fsm_enable=0。你可以将这些参数放在设备上的/boot/cmdline.txt文件中。
首先,确保所有所需的软件包都已安装到你的树莓派上:
sudo apt install coreutils build-essential stress gnuplot libnuma-dev
libnuma-dev软件包是可选的,可能在树莓派 OS 上不可用(即使没有也可以继续)。
现在让我们获取 cyclictest 的源代码:
git clone git://git.kernel.org/pub/scm/utils/rt-tests/rt-tests.git
有点奇怪的是,最初只会存在一个文件,README。阅读它(惊喜,惊喜)。它告诉你如何获取和构建稳定版本;很简单,只需按照以下步骤进行:
git checkout -b stable/v1.0 origin/stable/v1.0
make
对我们来说很幸运,开源自动化开发实验室(OSADL)有一个非常有用的 bash 脚本包装器,可以运行 cyclictest 甚至绘制延迟图。从这里获取脚本:www.osadl.org/uploads/media/mklatencyplot.bash(关于它的说明:https://www.osadl.org/Create-a-latency-plot-from-cyclictest-hi.bash-script-for-latency-plot.0.html?&no_cache=1&sword_list[0]=cyclictest)。我已经对它进行了轻微修改以适应我们的目的;它在本书的 GitHub 存储库中:ch11/latency_test/latency_test.sh。
运行测试用例
为了对系统(调度)延迟有一个好的概念,我们将运行三个测试用例;在所有三个测试中,cyclictest 应用程序将在 stress(1) 实用程序将系统置于负载下时对系统延迟进行采样:
-
树莓派 3 型 B+(4 个 CPU 核心)运行 5.4 32 位 RTL 补丁内核
-
树莓派 3 型 B+(4 个 CPU 核心)运行标准 5.4 32 位树莓派 OS 内核
-
x86_64(4 个 CPU 核心)Ubuntu 20.04 LTS 运行标准的 5.4(主线)64 位内核
我们使用一个名为 runtest 的小包装脚本覆盖 latency_test.sh 脚本以方便起见。它运行 latency_test.sh 脚本来测量系统延迟,同时运行 stress(1) 实用程序;它使用以下参数调用 stress,对系统施加 CPU、I/O 和内存负载:
stress --cpu 6 --io 2 --hdd 4 --hdd-bytes 1MB --vm 2 --vm-bytes 128M --timeout 1h
(顺便说一句,还有一个名为 stress-ng 的后续版本可用。)当 stress 应用程序执行加载系统时,cyclictest(8) 应用程序对系统延迟进行采样,并将其 stdout 写入文件:
sudo cyclictest --duration=1h -m -Sp90 -i200 -h400 -q >output
(请参考stress(1)和cyclictest(8)的 man 页面以了解参数。)它将运行一个小时(为了更准确的结果,建议您将测试运行更长时间 - 也许 12 小时)。我们的 runtest 脚本(以及底层脚本)在内部使用适当的参数运行 cyclictest;它捕获并显示最小、平均和最大延迟的挂钟时间(通过time(1)),并生成直方图图表。请注意,这里我们运行 cyclictest 的最长持续时间为一小时。
默认情况下,我们的 runtest 包装脚本具有一个名为 LAT 的变量,其中包含以下设置的 latency_tests 目录的路径名:LAT=~/booksrc/ch11/latency_tests。确保您首先更新它以反映系统上 latency_tests 目录的位置。
我们在树莓派 3B+上运行 RTL 内核的测试用例#1 的脚本截图如下:
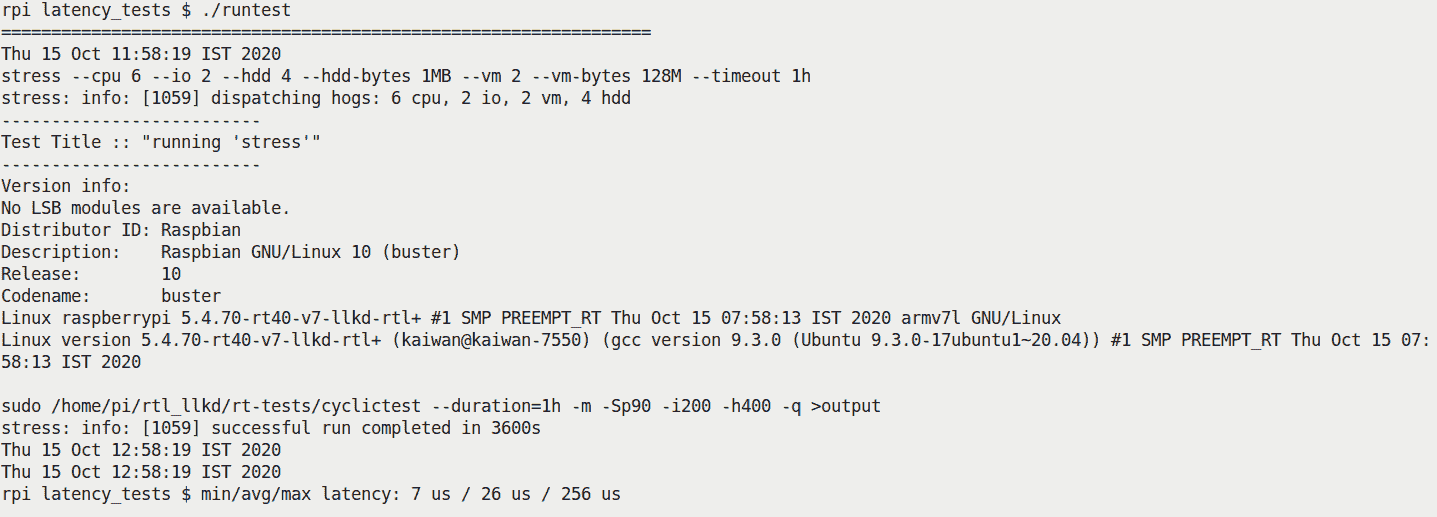
图 11.13 - 在受压力的 RTL 内核上运行树莓派 3B+的 cyclictest 的第一个测试用例
研究前面的截图;您可以清楚地看到系统详细信息,内核版本(请注意,这是 RTL 补丁的PREEMPT_RT内核!),以及 cyclictest 的最小、平均和最大(调度)延迟测量结果。
查看结果
我们对剩下的两个测试用例进行类似的过程,并在图 11.14 中总结所有三个的结果:
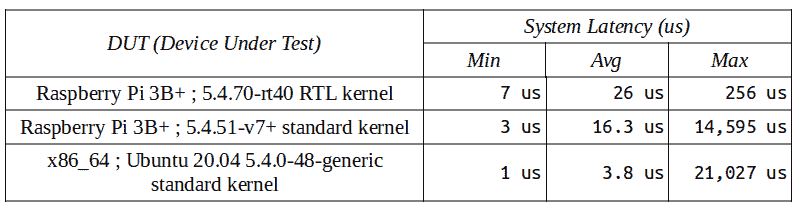
图 11.14 - 我们运行的(简单的)测试用例结果,显示了在一些压力下不同内核和系统的最小/平均/最大延迟
有趣的是,尽管 RTL 内核的最大延迟远低于其他标准内核,但最小延迟,更重要的是平均延迟,对于标准内核来说更好。这最终导致标准内核的整体吞吐量更高(这个观点之前也强调过)。
latency_test.sh bash 脚本调用 gnuplot(1) 实用程序生成图表,标题行显示最小/平均/最大延迟值(以微秒为单位)和运行测试的内核。请记住,测试用例#1 和#2 在树莓派 3B+设备上运行,而测试用例#3 在通用(更强大)的 x86_64 系统上运行。这里是所有三个测试用例的 gnuplot 图表:
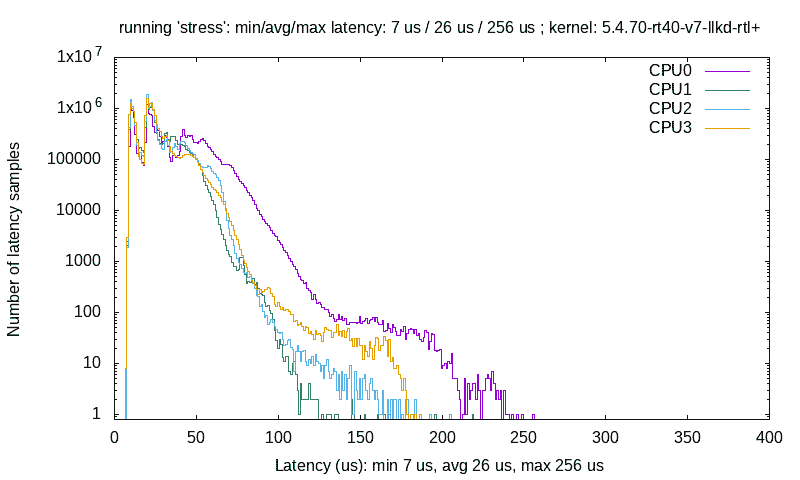
图 11.15 - 测试用例#1 绘图:树莓派 3B+运行 5.4 RTL 内核的 cyclictest 延迟测量
图 11.15 显示了由gnuplot(1)(从我们的ch11/latency_test/latency_test.sh脚本中调用)绘制的测试用例#1 的图表。被测试设备(DUT),Raspberry Pi 3B+,有四个 CPU 核心(由操作系统看到)。注意图表如何告诉我们故事 - 绝大多数样本位于左上角,意味着大部分时间延迟非常小(100,000 到 1,000,000 延迟样本(y 轴)落在几微秒到 50 微秒(x 轴)之间!)。这真的很好!当然,在另一个极端会有离群值 - 所有 CPU 核心的样本具有更高的延迟(在 100 到 256 微秒之间),尽管样本数量要小得多。cyclictest 应用程序给出了最小、平均和最大系统延迟值。使用 RTL 补丁内核,虽然最大延迟实际上非常好(非常低),但平均延迟可能相当高:
[外链图片转存中…(img-HX3pkXsi-1721183650950)]
图 11.16 - 测试用例#2 图:在运行标准(主线)5.4 内核的 Raspberry Pi 3B+上进行的 cyclictest 延迟测量
图 11.16 显示了测试用例#2 的图表。与先前的测试用例一样,实际上,在这里甚至更加明显,系统延迟样本的绝大多数表现出非常低的延迟!标准内核因此做得非常好;即使平均延迟也是一个“不错”的值。然而,最坏情况(最大)延迟值确实可能非常大 - 这正是为什么它不是一个 RTOS。对于大多数工作负载,延迟往往是“通常”很好的,但是一些特殊情况往往会出现。换句话说,它是不确定的 - 这是 RTOS 的关键特征:
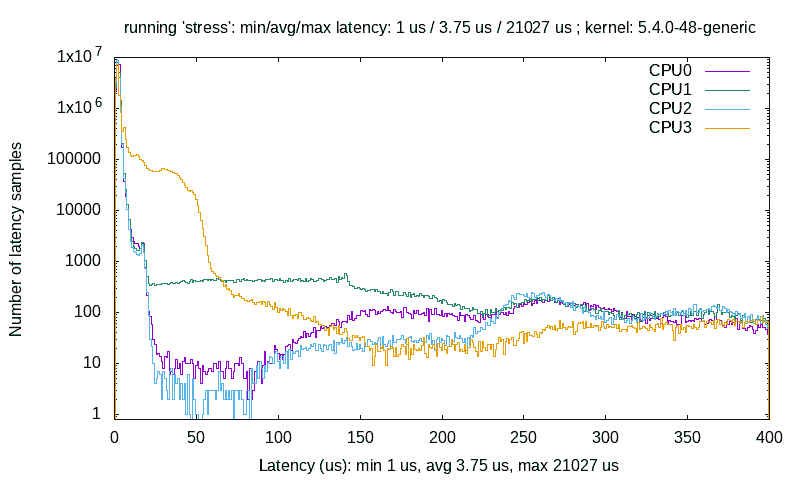
图 11.17 - 测试用例#3 图:在运行标准(主线)5.4 内核的 x86_64 Ubuntu 20.04 LTS 上进行的 cyclictest 延迟测量
图 11.17 显示了测试用例#3 的图表。这里的方差 - 或抖动 - 更加明显(再次,非确定性!),尽管最小和平均系统延迟值确实非常好。当然,它是在一个远比前两个测试用例更强大的系统上运行的 - 一个桌面级的 x86_64 - 最大延迟值 - 尽管这里有更多的特殊情况,但往往相当高。再次强调,这不是一个 RTOS - 它不是确定性的。
你是否注意到图表清楚地展示了抖动:测试用例#1 具有最少的抖动(图表往往很快下降到 x 轴 - 这意味着很少数量的延迟样本,如果不是零,表现出较高的延迟),而测试用例#3 具有最多的抖动(图表大部分仍然远高于x轴!)。
再次强调这一点:结果清楚地表明,它是确定性的(非常少的抖动)与 RTOS,而与 GPOS 则是高度非确定性的!(作为一个经验法则,标准 Linux 在中断处理方面会产生大约+/- 10 微秒的抖动,而在运行 RTOS 的微控制器上,抖动会小得多,大约+/- 10 纳秒!)
进行这个实验,你会意识到基准测试是一件棘手的事情;你不应该对少数测试运行读太多(长时间运行测试,有一个大样本集是重要的)。使用您期望在系统上体验的真实工作负载进行测试,将是查看哪个内核配置产生更优越性能的更好方法;它确实会随着工作负载的变化而变化!
(Canonical 的一个有趣案例研究显示了某些工作负载的常规、低延迟和实时内核的统计数据;在本章的进一步阅读部分查找)。如前所述,通常情况下,RTL 内核的最大延迟特性往往会导致整体吞吐量较低(用户空间可能因为 RTL 的相当无情的优先级而遭受降低的 CPU)。
通过现代 BPF 工具测量调度器延迟
不详细介绍,但我们不得不提及最近和强大的[e]BPF Linux 内核功能及其相关前端;有一些专门用于测量调度器和运行队列相关系统延迟的工具。 (我们在第一章中介绍了[e]BPF 工具的安装,现代跟踪和性能分析与[e]BPF部分)。
以下表格总结了一些这些工具(BPF 前端);所有这些工具都需要以 root 身份运行(与任何 BPF 工具一样);它们将它们的输出显示为直方图(默认为微秒):
| BPF 工具 | 它测量什么 |
|---|---|
runqlat-bpfcc | 计算任务在运行队列上等待的时间,等待在处理器上运行 |
runqslower-bpfcc | (读作 runqueue slower);计算任务在运行队列上等待的时间,显示只有超过给定阈值的线程,默认为 10 毫秒(可以通过传递微秒为单位的时间阈值来调整);实际上,您可以看到哪些任务面临(相对)较长的调度延迟。 |
runqlen-bpfcc | 显示调度器运行队列长度+占用(当前排队等待运行的线程数) |
这些工具还可以根据每个进程的任务基础提供这些指标,或者甚至可以根据 PID 命名空间(用于容器分析;当然,这些选项取决于具体的工具)。请查阅这些工具的 man 页面(第八部分),了解更多细节(甚至包括示例用法!)。
甚至还有更多与调度相关的[e]BPF 前端:cpudist- cpudist-bpfcc、cpuunclaimed-bpfcc、offcputime-bpfcc、wakeuptime-bpfcc等等。请参阅进一步阅读部分获取资源。
所以,到目前为止,您不仅能够理解,甚至可以测量系统的延迟(通过cyclictest应用程序和一些现代 BPF 工具)。
我们在本章中结束时列出了一些杂项但有用的小(内核空间)例程供查看:
-
rt_prio(): 给定优先级作为参数,返回一个布尔值,指示它是否是实时任务。 -
rt_task(): 基于任务的优先级值,给定任务结构指针作为参数,返回一个布尔值,指示它是否是实时任务(是rt_prio()的包装)。 -
task_is_realtime(): 类似,但基于任务的调度策略。给定任务结构指针作为参数,返回一个布尔值,指示它是否是实时任务。
总结
在这本关于 Linux 操作系统上 CPU 调度的第二章中,您学到了一些关键内容。其中,您学会了如何使用强大的工具(如 LTTng 和 Trace Compass GUI)来可视化内核流,以及使用trace-cmd(1)实用程序,这是内核强大的 Ftrace 框架的便捷前端。然后,您了解了如何以编程方式查询和设置任何线程的 CPU 亲和力掩码。这自然而然地引出了如何以编程方式查询和设置任何线程的调度策略和优先级的讨论。整个“完全公平”的概念(通过 CFS 实现)被质疑,并且对称为 cgroups 的优雅解决方案进行了一些阐述。您甚至学会了如何利用 cgroups v2 CPU 控制器为子组中的进程分配所需的 CPU 带宽。然后我们了解到,尽管 Linux 是一个 GPOS,但 RTL 补丁集确实存在,一旦应用并且内核配置和构建完成,您就可以将 Linux 运行为真正的硬实时系统,即 RTOS。
最后,您学会了如何通过 cyclictest 应用程序以及一些现代 BPF 工具来测量系统的延迟。我们甚至在 Raspberry Pi 3 设备上使用 cyclictest 进行了测试,并在 RTL 和标准内核上进行了对比。
这是相当多的内容!一定要花时间透彻理解材料,并且以实际操作的方式进行工作。
问题
在我们结束时,这里有一些问题列表,供您测试对本章材料的了解:github.com/PacktPublishing/Linux-Kernel-Programming/tree/master/questions。您会发现一些问题的答案在书的 GitHub 存储库中:github.com/PacktPublishing/Linux-Kernel-Programming/tree/master/solutions_to_assgn。
进一步阅读
为了帮助您深入了解这个主题并提供有用的材料,我们在本书的 GitHub 存储库中提供了一个相当详细的在线参考和链接列表(有时甚至包括书籍)的《进一步阅读》文档。进一步阅读文档在这里可用:github.com/PacktPublishing/Linux-Kernel-Programming/blob/master/Further_Reading.md。
第三部分:深入探讨
在这里,您将了解一个高级和关键的主题:内核同步技术和 API 背后的概念、需求和用法。
本节包括以下章节:
-
第十二章,内核同步-第一部分
-
第十三章,内核同步-第二部分
第十二章:内核同步 - 第一部分
任何熟悉在多线程环境中编程的开发人员(甚至在单线程环境中,多个进程在共享内存上工作,或者中断是可能的情况下)都知道,当两个或多个线程(一般的代码路径)可能会竞争时,需要进行同步。也就是说,它们的结果是无法预测的。纯粹的代码本身从来不是问题,因为它的权限是读/执行(r-x);在多个 CPU 核心上同时读取和执行代码不仅完全正常和安全,而且是受鼓励的(它会提高吞吐量,这就是为什么多线程是个好主意)。然而,当你开始处理共享可写数据时,你就需要开始非常小心了!
围绕并发及其控制 - 同步 - 的讨论是多样的,特别是在像 Linux 内核(其子系统和相关区域,如设备驱动程序)这样的复杂软件环境中。因此,为了方便起见,我们将把这个大主题分成两章,本章和下一章。
在本章中,我们将涵盖以下主题:
-
关键部分,独占执行和原子性
-
Linux 内核中的并发问题
-
互斥锁还是自旋锁?何时使用
-
使用互斥锁
-
使用自旋锁
-
锁定和中断
让我们开始吧!
关键部分,独占执行和原子性
想象一下,你正在为一个多核系统编写软件(嗯,现在,通常情况下,你会在多核系统上工作,甚至在大多数嵌入式项目中)。正如我们在介绍中提到的,同时运行多个代码路径不仅是安全的,而且是可取的(否则,为什么要花那些钱呢,对吧?)。另一方面,在并发(并行和同时)代码路径中,其中共享可写数据(也称为共享状态)以任何方式被访问的地方,你需要保证在任何给定的时间点,只有一个线程可以同时处理该数据!这真的很关键;为什么?想想看:如果你允许多个并发代码路径同时在共享可写数据上工作,你实际上是在自找麻烦:数据损坏(“竞争”)可能会发生。
什么是关键部分?
可以并行执行并且可以处理(读取和/或写入)共享可写数据(共享状态)的代码路径称为关键部分。它们需要保护免受并行性的影响。识别和保护关键部分免受同时执行是你作为设计师/架构师/开发人员必须处理的隐含要求。
关键部分是一段代码,必须要么独占地运行;也就是说,单独运行(序列化),要么是原子的;也就是说,不可分割地完成,没有中断。
通过独占执行,我们暗示在任何给定的时间点,只有一个线程在运行关键部分的代码;这显然是出于数据安全的原因而必需的。
这个概念也提出了原子性的重要概念:单个原子操作是不可分割的。在任何现代处理器上,两个操作被认为总是原子的;也就是说,它们不能被中断,并且会运行到完成:
-
单个机器语言指令的执行。
-
对齐的原始数据类型的读取或写入,该类型在处理器的字长内(通常为 32 位或 64 位);例如,在 64 位系统上读取或写入 64 位整数保证是原子的。读取该变量的线程永远不会看到中间、断裂或脏的结果;它们要么看到旧值,要么看到新值。
因此,如果您有一些处理共享(全局或静态)可写数据的代码行,在没有任何显式同步机制的情况下,不能保证独占运行。请注意,有时需要原子地运行临界区的代码,以及独占地运行,但并非始终如此。
当临界区的代码在安全睡眠的进程上下文中运行时(例如通过用户应用程序对驱动程序进行典型文件操作(打开、读取、写入、ioctl、mmap 等),或者内核线程或工作队列的执行路径),也许不需要临界区真正是原子的。但是,当其代码在非阻塞原子上下文中运行时(例如硬中断、tasklet 或 softirq),它必须像独占地运行一样原子地运行(我们将在使用互斥锁还是自旋锁?何时使用部分中更详细地讨论这些问题)。
一个概念性的例子将有助于澄清事情。假设三个线程(来自用户空间应用程序)在多核系统上几乎同时尝试打开和读取您的驱动程序。在没有任何干预的情况下,它们可能会同时运行临界区的代码,从而并行地处理共享可写数据,从而很可能破坏它!现在,让我们看一个概念性的图表,看看临界区代码路径内的非独占执行是错误的(我们甚至不会在这里谈论原子性):

图 12.1-一个概念性图表,显示了多个线程同时在临界区代码路径内运行,违反了临界区代码路径。
如前图所示,在您的设备驱动程序中,在其(比如)读取方法中,您正在运行一些代码以执行其工作(从硬件中读取一些数据)。让我们更深入地看一下这个图表在不同时间点进行数据访问:
-
从时间
t0到t1:没有或只有本地变量数据被访问。这是并发安全的,不需要保护,可以并行运行(因为每个线程都有自己的私有堆栈)。 -
从时间
t1到t2:访问全局/静态共享可写数据。这是不并发安全的;这是一个临界区,因此必须受到保护,以防并发访问。它应该只包含独占运行的代码(独自,一次只有一个线程,串行运行),可能是原子的。 -
从时间
t2到t3:没有或只有本地变量数据被访问。这是并发安全的,不需要保护,可以并行运行(因为每个线程都有自己的私有堆栈)。
在本书中,我们假设您已经意识到需要同步临界区;我们将不再讨论这个特定的主题。有兴趣的人可以参考我的早期著作,《Linux 系统编程实战》(Packt 出版社,2018 年 10 月),其中详细介绍了这些问题(特别是第十五章,使用 Pthreads 进行多线程编程第二部分-同步)。
因此,了解这一点,我们现在可以重新阐述临界区的概念,同时提到情况何时出现(在项目符号和斜体中显示在项目符号中)。临界区是必须按以下方式运行的代码:
-
(始终) 独占地:独自(串行)
-
(在原子上下文中) 原子地:不可分割地,完整地,没有中断
在下一节中,我们将看一个经典场景-全局整数的增量。
一个经典案例-全局 i++
想想这个经典的例子:在一个并发的代码路径中,一个全局的i整数正在被增加,其中多个执行线程可以同时执行。对计算机硬件和软件的天真理解会让你相信这个操作显然是原子的。然而,现代硬件和软件(编译器和操作系统)实际上比你想象的要复杂得多,因此会引起各种看不见的(对应用程序开发者来说)性能驱动的优化。
我们不打算在这里深入讨论太多细节,但现实情况是现代处理器非常复杂:它们采用了许多技术来提高性能,其中一些是超标量和超流水线执行,以便并行执行多个独立指令和各种指令的几个部分(分别),进行即时指令和/或内存重排序,在复杂的层次结构的 CPU 缓存中缓存内存,虚假共享等等!我们将在第十三章中的内核同步 - 第二部分中的缓存效应 - 虚假共享和内存屏障部分中深入探讨其中的一些细节。
Matt Kline 在 2020 年 4 月发表的论文《每个系统程序员都应该了解并发性》(assets.bitbashing.io/papers/concurrency-primer.pdf)非常出色,是这个主题上必读的内容;一定要阅读!
所有这些使得情况比乍一看复杂得多。让我们继续讨论经典的i ++:
static int i = 5;
[ ... ]
foo()
{
[ ... ]
i ++; // is this safe? yes, if truly atomic... but is it truly atomic??
}
这个增量操作本身安全吗?简短的答案是否定的,你必须保护它。为什么?这是一个关键部分 - 我们正在访问共享的可写数据进行读取和/或写入操作。更长的答案是,这实际上取决于增量操作是否真正是原子的(不可分割的);如果是,那么i ++在并行性的情况下不会造成危险 - 如果不是,就会有危险!那么,我们如何知道i ++是否真正是原子的呢?有两件事决定了这一点:
-
处理器的指令集架构(ISA),它确定了(在处理器的低级别上)在运行时执行的机器指令。
-
编译器。
如果 ISA 有能力使用单个机器指令执行整数增量,并且编译器有智能使用它,那么它是真正原子的 - 它是安全的,不需要锁定。否则,它是不安全的,需要锁定!
试一试:将浏览器导航到这个精彩的编译器资源网站:godbolt.org/。选择 C 作为编程语言,然后在左侧窗格中声明全局的i整数并在一个函数中进行增量。在右侧窗格中使用适当的编译器和编译器选项进行编译。你将看到为 C 高级i ++;语句生成的实际机器代码。如果它确实是一个单一的机器指令,那么它将是安全的;如果不是,你将需要锁定。总的来说,你会发现你真的无法判断:实际上,你不能假设事情是安全的 - 你必须假设它默认是不安全的并加以保护!这可以在以下截图中看到:
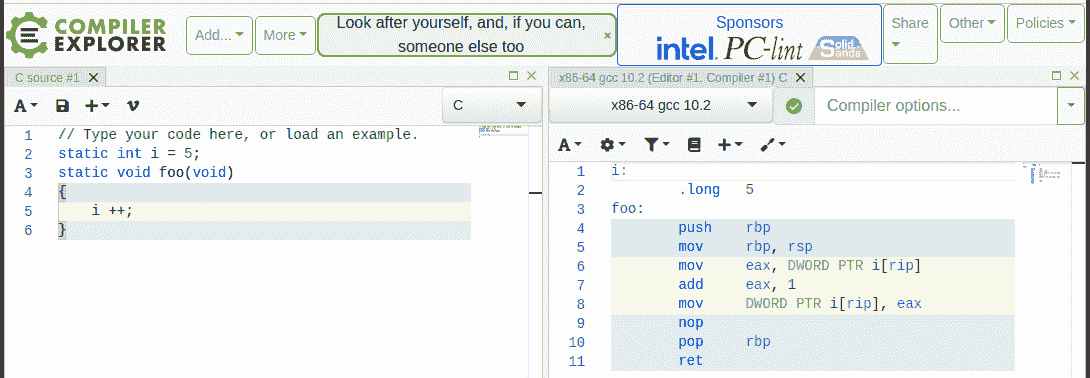
图 12.2 - 即使是最新的稳定 gcc 版本,但没有优化,x86_64 gcc 对 i ++产生了多个指令
前面的截图清楚地显示了这一点:左右两个窗格中的黄色背景区域分别是 C 源代码和编译器生成的相应汇编代码(基于 x86_64 ISA 和编译器的优化级别)。默认情况下,没有优化,i ++会变成三条机器指令。这正是我们所期望的:它对应于获取(内存到寄存器)、增量和存储(寄存器到内存)!现在,这不是原子的;完全有可能,在其中一条机器指令执行后,控制单元干扰并将指令流切换到不同的位置。这甚至可能导致另一个进程或线程被上下文切换!
好消息是,通过在“编译器选项…”窗口中快速添加-O2,i ++只变成了一条机器指令-真正的原子操作!然而,我们无法预测这些事情;有一天,您的代码可能在一个相当低端的 ARM(RISC)系统上执行,增加了需要多条机器指令来执行i ++的机会。(不用担心-我们将在使用原子整数操作符部分介绍专门针对整数的优化锁技术)。
现代语言提供本地原子操作符;对于 C/C++来说,这是相当近期的(从 2011 年起);ISO C++11 和 ISO C11 标准为此提供了现成的和内置的原子变量。稍微搜索一下就可以快速找到它们。现代 glibc 也在使用它们。例如,如果您在用户空间中使用信号处理,您将知道要使用volatile sig_atomic_t数据类型来安全地访问和/或更新信号处理程序中的原子整数。那么内核呢?在下一章中,您将了解 Linux 内核对这一关键问题的解决方案。我们将在使用原子整数操作符和使用原子位操作符部分进行介绍。
Linux 内核当然是一个并发环境:多个执行线程在多个 CPU 核心上并行运行。不仅如此,即使在单处理器(UP/单 CPU)系统上,硬件中断、陷阱、故障、异常和软件信号也可能导致数据完整性问题。毋庸置疑,保护代码路径中所需的并发性比说起来要容易;识别和保护关键部分使用诸如锁等技术的同步原语和技术是绝对必要的,这也是为什么这是本章和下一章的核心主题。
概念-锁
我们需要同步,因为事实上,如果没有任何干预,线程可以同时执行关键部分,其中共享可写数据(共享状态)正在被处理。为了消除并发性,我们需要摆脱并行性,我们需要序列化关键部分内的代码-共享数据正在被处理的地方(用于读取和/或写入)。
强制使代码路径变得序列化的常见技术是使用锁。基本上,锁通过保证在任何给定时间点上只有一个执行线程可以“获取”或拥有锁来工作。因此,在代码中使用锁来保护关键部分将给您我们所追求的东西-独占地运行关键部分的代码(也许是原子的;关于这一点将在后面详细介绍)。

图 12.3-一个概念图,显示了如何使用锁来保护关键部分代码路径,确保独占性
前面的图表显示了解决前面提到的情况的一种方法:使用锁来保护关键部分!锁(和解锁)在概念上是如何工作的呢?
锁的基本前提是每当有争用时 - 也就是说,当多个竞争的线程(比如,n个线程)尝试获取锁(LOCK操作)时 - 恰好只有一个线程会成功。这被称为锁的“赢家”或“所有者”。它将lock API 视为非阻塞调用,因此在执行临界区代码时会继续运行 - 并且是独占的(临界区实际上是lock和unlock操作之间的代码!)。那么剩下的n-1个“失败者”线程会发生什么呢?它们(也许)将锁 API 视为阻塞调用;它们实际上在等待。等待什么?当然是由锁的所有者(“赢家”线程)执行的unlock操作!一旦解锁,剩下的n-1个线程现在竞争下一个“赢家”位置;当然,其中一个将“赢”并继续前进;在此期间,n-2个失败者现在将等待(新的)赢家的unlock;这一过程重复,直到所有n个线程(最终和顺序地)获取锁。
现在,锁当然有效,但 - 这应该是相当直观的 - 它会导致(相当大的!)开销,因为它破坏了并行性并使执行流程串行化!为了帮助您可视化这种情况,想象一个漏斗,狭窄的茎是临界区,一次只能容纳一个线程。所有其他线程都被堵住;锁创建了瓶颈:
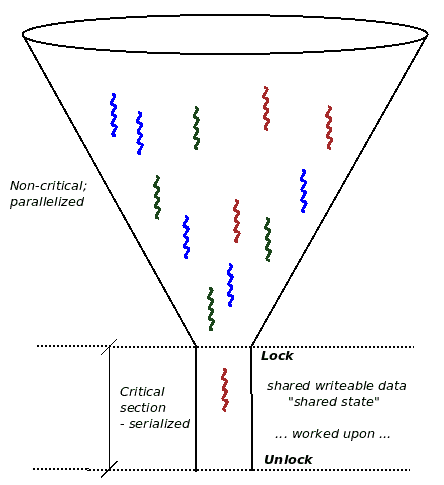
图 12.4 - 锁创建了一个瓶颈,类似于物理漏斗
另一个经常提到的物理类比是一条高速公路,有几条车道汇入一条非常繁忙 - 交通拥堵的车道(也许是一个设计不佳的收费站)。再次,并行性 - 车辆(线程)在不同车道(CPU)中与其他车辆并行行驶 - 被丢失,需要串行行为 - 车辆被迫排队排队。
因此,作为软件架构师,我们必须尽量设计我们的产品/项目,以便最小化锁的需求。虽然在大多数现实世界的项目中完全消除全局变量是不切实际的,但优化和最小化它们的使用是必要的。我们将在以后介绍更多相关内容,包括一些非常有趣的无锁编程技术。
另一个非常关键的点是,一个新手程序员可能天真地认为对可写数据对象进行读取是完全安全的,因此不需要显式保护(除了在处理器总线大小内的对齐原始数据类型之外);这是不正确的。这种情况可能导致所谓的脏读或破碎读,即在另一个写入线程同时写入时,可能读取到过时的数据,而你 - 在没有锁的情况下 - 正在读取同一个数据项。
由于我们正在讨论原子性,正如我们刚刚了解的那样,在典型的现代微处理器上,唯一保证是原子的是单个机器语言指令或对处理器总线宽度内的对齐原始数据类型的读/写。那么,如何标记几行“C”代码,使其真正原子化?在用户空间,这甚至是不可能的(我们可以接近,但无法保证原子性)。
在用户空间应用程序中如何“接近”原子性?您可以始终构建一个用户线程来使用SCHED_FIFO策略和99的实时优先级。这样,当它想要运行时,除了硬件中断/异常之外,几乎没有其他东西可以抢占它。(旧的音频子系统实现就大量依赖于此。)
在内核空间,我们可以编写真正原子化的代码。具体来说,我们可以使用自旋锁!我们将很快更详细地了解自旋锁。
关键点摘要
让我们总结一些关于关键部分的关键点。仔细审查这些内容非常重要,保持这些内容方便,并确保您在实践中使用它们:
-
关键部分是可以并行执行并且可以处理(读取和/或写入)共享可写数据(也称为“共享状态”)的代码路径。
-
因为它在共享可写数据上工作,关键部分需要保护免受以下方面的影响:
-
并行性(也就是说,它必须独立/串行/以互斥的方式运行)
-
在原子(中断)非阻塞上下文中运行时 - 原子地:不可分割地,完整地,没有中断。一旦受保护,您可以安全地访问共享状态,直到“解锁”。
-
代码库中的每个关键部分都必须被识别和保护:
-
识别关键部分至关重要!仔细审查您的代码,并确保您没有错过它们。
-
可以通过各种技术来保护它们;一个非常常见的技术是锁定(还有无锁编程,我们将在下一章节中看到)。
-
一个常见的错误是只保护写入全局可写数据的关键部分;您还必须保护读取全局可写数据的关键部分;否则,您会面临**撕裂或脏读!**为了帮助澄清这一关键点,想象一下在 32 位系统上读取和写入无符号 64 位数据项;在这种情况下,操作无法是原子的(需要两次加载/存储操作)。因此,如果在一个线程中读取数据项的值的同时,另一个线程正在同时写入数据项,会发生什么?写入线程会以某种方式“锁定”,但是因为您认为读取是安全的,读取线程不会获取锁;由于不幸的时间巧合,您最终可能会执行部分/撕裂/脏读!我们将在接下来的章节和下一章节中学习如何通过使用各种技术来克服这些问题。
-
另一个致命的错误是不使用相同的锁来保护给定的数据项。
-
未能保护关键部分会导致数据竞争,即结果 - 被读/写的数据的实际值 - 是“竞争的”,这意味着它会根据运行时情况和时间而变化。这被称为一个错误。(一旦在“现场”中,这种错误非常难以看到,重现,确定其根本原因并修复。我们将在下一章节中介绍一些非常有用的内容,以帮助您解决这个问题,在内核中的锁调试部分;一定要阅读!)
-
异常:在以下情况下,您是安全的(隐式地,无需显式保护):
-
当您处理局部变量时。它们分配在线程的私有堆栈上(或者,在中断上下文中,分配在本地 IRQ 堆栈上),因此,根据定义,是安全的。
-
当您在代码中处理共享可写数据时,这些代码不可能在另一个上下文中运行;也就是说,它是串行化的。在我们的上下文中,LKM 的init和cleanup方法符合条件(它们仅在
insmod和rmmod上运行一次,串行地运行)。 -
当您处理真正的常量和只读共享数据时(不过不要让 C 的
const关键字愚弄您!)。 -
锁定本质上是复杂的;您必须仔细思考,设计和实现以避免死锁。我们将在锁定指南和死锁部分中更详细地介绍这一点。
Linux 内核中的并发关注点
在内核代码中识别关键部分至关重要;如果您甚至看不到它,您如何保护它?以下是一些建议,可以帮助您作为新兴的内核/驱动程序开发人员识别并发关注点 - 因此关键部分可能出现的地方:
-
对称多处理器(SMP)系统的存在(
CONFIG_SMP) -
可抢占内核的存在
-
阻塞 I/O
-
硬件中断(在 SMP 或 UP 系统上)
这些是需要理解的关键点,我们将在本节中讨论每一个。
多核 SMP 系统和数据竞争
第一点是非常明显的;请看以下截图中显示的伪代码:

图 12.5 - 伪代码 - 在(虚构的)驱动程序读取方法中的临界区;由于没有锁定,这是错误的
这与我们在图 12.1和12.3中展示的情况类似;只是这里,我们用伪代码来展示并发性。显然,从时间t2到时间t3,驱动程序正在处理一些全局共享的可写数据,因此这是一个临界区。
现在,想象一个具有四个 CPU 核心(SMP 系统)的系统;两个用户空间进程,P1(在 CPU 0 上运行)和 P2(在 CPU 2 上运行),可以同时打开设备文件并同时发出read(2)系统调用。现在,两个进程将同时执行驱动程序读取“方法”,因此同时处理共享可写数据!这(在t2和t3之间的代码)是一个临界区,由于我们违反了基本的排他规则 - 临界区必须由单个线程在任何时间点执行 - 我们很可能最终损坏数据、应用程序,甚至更糟。
换句话说,现在这是一个数据竞争;取决于微妙的时间巧合,我们可能会或可能不会生成错误(错误)。这种不确定性 - 微妙的时间巧合 - 正是发现和修复这种错误极其困难的原因(它可能逃脱了您的测试工作)。
这句格言非常不幸地是真的:*测试可以检测到错误的存在,但不能检测到它们的缺失。*更重要的是,如果您的测试未能捕捉到竞争(和错误),允许它们在现场自由发挥,那么情况会更糟。
您可能会觉得,由于您的产品是在单个 CPU 核心(UP)上运行的小型嵌入式系统,因此关于控制并发性(通常通过锁定)的讨论不适用于您。我们不这么认为:几乎所有现代产品,如果尚未这样做,都将转向多核(也许是在它们的下一代阶段)。更重要的是,即使是 UP 系统也存在并发性问题,我们将在下文中探讨。
可抢占内核,阻塞 I/O 和数据竞争
想象一下,您正在在已配置为可抢占的 Linux 内核上运行您的内核模块或驱动程序(即CONFIG_PREEMPT已打开;我们在第十章中涵盖了这个主题,CPU 调度器 - 第一部分)。考虑一个进程 P1,在进程上下文中运行驱动程序的读取方法代码,处理全局数组。现在,在临界区内(在时间t2和t3之间),如果内核抢占了进程 P1 并切换到另一个进程 P2,后者正好在等待执行这条代码路径?这是危险的,同样是数据竞争。这甚至可能发生在 UP 系统上!
另一个有些类似的情景(同样可能发生在单核(UP)或多核系统上):进程 P1 正在通过驱动程序方法的临界区运行(在时间t2和t3之间;再次参见图 12.5)。这一次,在临界区内,如果遇到阻塞调用会怎么样呢?
阻塞调用是一个导致调用进程上下文进入休眠状态,等待事件发生的函数;当事件发生时,内核将“唤醒”该任务,并且它将从中断的地方恢复执行。这也被称为 I/O 阻塞,非常常见;许多 API(包括几个用户空间库和系统调用,以及几个内核 API)本质上是阻塞的。在这种情况下,进程 P1 实际上从 CPU 上的上下文切换并进入休眠状态,这意味着schedule()的代码运行并将其排队到等待队列。在此期间,在 P1 被切换回之前,如果另一个进程 P2 被调度运行会怎么样?如果该进程也在运行这个特定的代码路径怎么办?想一想 - 当 P1 回来时,共享数据可能已经在其“下面”发生了变化,导致各种错误;再次,数据竞争,一个 bug!
硬件中断和数据竞争
最后,设想这样的情景:进程 P1 再次无辜地运行驱动程序的读取方法代码;它进入临界区(在时间t2和t3之间;再次参见图 12.5)。它取得了一些进展,但然后,哎呀,硬件中断触发了(在同一个 CPU 上)!(你将在*Linux 内核编程(第二部分)*中详细了解。)在 Linux 操作系统上,硬件(外围)中断具有最高的优先级;它们默认情况下会抢占任何代码(包括内核代码)。因此,进程(或线程)P1 至少会被暂时搁置,从而失去处理器;中断处理代码将抢占它并运行。
好吧,你可能会想,那又怎样?的确,这是一个非常普遍的现象!硬件中断在现代系统上非常频繁地触发,有效地(字面上)中断了各种任务上下文(在你的 shell 上快速执行vmstat 3命令;system标签下的列in显示了你的系统在最近 1 秒内触发的硬件中断数量!)。要问的关键问题是:中断处理代码(无论是硬中断的顶半部分还是所谓的任务或软中断的底半部分,无论哪个发生了),是否共享并处理了它刚刚中断的进程上下文的相同可写数据?
如果是这样,那么,休斯顿,我们有问题 - 数据竞争!如果不是,那么你中断的代码对于中断代码路径来说不是一个临界区,这很好。事实是,大多数设备驱动程序确实处理中断;因此,驱动程序的作者(你!)有责任确保没有全局或静态数据 - 实际上,没有临界区 - 在进程上下文和中断代码路径之间共享。如果它们是(这确实会发生),你必须以某种方式保护这些数据,以防数据竞争和可能的损坏。
这些情景可能让你觉得防范这些并发问题是一个非常艰巨的任务;在各种可能的并发问题存在的情况下,如何确保数据的安全?有趣的是,实际的 API 并不难学习使用;我们再次强调,识别临界区是关键。
再次,关于锁(概念上)如何工作,锁定指南(非常重要;我们很快会回顾它们),以及如何防止死锁的类型,都在我早期的书籍*《Linux 系统编程实战》(Packt,2018 年 10 月)中有详细介绍。这本书在第十五章* 使用 Pthreads 进行多线程编程第 II 部分 - 同步中详细介绍了这些内容。
话不多说,让我们深入探讨将保护我们的临界区的主要同步技术 - 锁定。
锁定指南和死锁
锁定,本质上是一个复杂的问题;它往往会产生复杂的交织情况。不充分理解它可能会导致性能问题和错误-死锁、循环依赖、中断不安全的锁定等。以下锁定指南对确保正确编写代码至关重要:
-
锁定粒度:锁定和解锁之间的“距离”(实际上是关键部分的长度)不应该是粗粒度的(关键部分太长),它应该是“足够细”; 这是什么意思?下面的几点解释了这一点:
-
在这里你需要小心。在大型项目中,保持太少的锁是一个问题,保持太多的锁也是一个问题!太少的锁可能会导致性能问题(因为相同的锁会被重复使用,因此往往会受到高度争用)。
-
拥有很多锁实际上对性能有好处,但对复杂性控制不利。这也导致另一个关键点的理解:在代码库中有很多锁的情况下,你应该非常清楚哪个锁保护哪个共享数据对象。如果你使用,比如,
lockA来保护mystructX,但在一个遥远的代码路径(也许是一个中断处理程序)中你忘记了这一点,并尝试使用另一个锁,lockB,来保护同一个结构!现在这些事情可能听起来很明显,但(有经验的开发人员知道),在足够的压力下,即使显而易见的事情也并非总是显而易见! -
尝试平衡事物。在大型项目中,使用一个锁来保护一个全局(共享)数据结构是典型的。 (为锁变量命名可能本身就会成为一个大问题!这就是为什么我们将保护数据结构的锁放在其中作为成员。)
-
锁的顺序至关重要;锁必须始终以相同的顺序获取,并且他们的顺序应该由所有在项目上工作的开发人员记录和遵循(注释锁也很有用;在下一章关于lockdep的部分中会更多介绍)。不正确的锁顺序经常导致死锁。
-
尽量避免递归锁定。
-
注意防止饥饿;验证一旦获取锁,确实“足够快”释放锁。
-
简单是关键:尽量避免复杂性或过度设计,特别是涉及锁的复杂情况。
在锁定的话题上,(危险的)死锁问题出现了。死锁是无法取得任何进展;换句话说,应用程序和/或内核组件似乎无限期地挂起。虽然我们不打算在这里深入研究死锁的可怕细节,但我会快速提到一些可能发生的常见死锁场景:
-
简单情况,单锁,进程上下文:
-
我们尝试两次获取相同的锁;这会导致自死锁。
-
简单情况,多个(两个或更多)锁,进程上下文-一个例子:
-
在 CPU
0上,线程 A 获取锁 A,然后想要获取锁 B。 -
同时,在 CPU
1上,线程 B 获取锁 B,然后想要获取锁 A。 -
结果是死锁,通常称为AB-BA 死锁。
-
它可以被扩展;例如,AB-BC-CA 循环依赖(A-B-C 锁链)导致死锁。
-
复杂情况,单锁,进程和中断上下文:
-
锁 A 在中断上下文中获取。
-
如果中断发生(在另一个核心上),处理程序尝试获取锁 A 会发生什么?死锁是结果!因此,在中断上下文中获取的锁必须始终与中断禁用一起使用。(如何?我们将在涵盖自旋锁时更详细地讨论这个问题。)
-
更复杂的情况,多个锁,进程和中断(硬中断和软中断)上下文
在更简单的情况下,始终遵循锁定顺序指南就足够了:始终按照有文档记录的顺序获取和释放锁(我们将在使用互斥锁部分的内核代码中提供一个示例)。然而,这可能会变得非常复杂;复杂的死锁情况甚至会使经验丰富的开发人员感到困惑。幸运的是,lockdep - Linux 内核的运行时锁依赖验证器 - 可以捕捉到每一个死锁情况!(不用担心 - 我们会到那里的:我们将在下一章中详细介绍 lockdep)。当我们涵盖自旋锁(使用自旋锁部分)时,我们将遇到类似于之前提到的进程和/或中断上下文场景;在那里清楚地说明了要使用的自旋锁类型。
关于死锁,Steve Rostedt 在 2011 年的 Linux Plumber’s Conference 上做了一个关于 lockdep 的非常详细的介绍;相关幻灯片内容丰富,探讨了简单和复杂的死锁场景,以及 lockdep 如何检测它们(blog.linuxplumbersconf.org/2011/ocw/sessions/153)。
另外,现实情况是,不仅是死锁,甚至活锁情况也可能同样致命!活锁本质上是一种类似于死锁的情况;只是参与任务的状态是运行而不是等待。例如,中断“风暴”可能导致活锁;现代网络驱动程序通过关闭中断(在中断负载下)并采用称为新 API;切换中断(NAPI)的轮询技术来减轻这种效应(在适当时重新打开中断;好吧,这比较复杂,但我们就到这里吧)。
对于那些一直生活在石头下的人来说,你会知道 Linux 内核有两种主要类型的锁:互斥锁和自旋锁。实际上,还有其他几种类型,包括其他同步(和“无锁”编程)技术,所有这些都将在本章和下一章中涵盖。
互斥锁还是自旋锁?在何时使用
学习使用互斥锁和自旋锁的确切语义非常简单(在内核 API 集中进行适当的抽象,使得对于典型的驱动程序开发人员或模块作者来说更容易)。在这种情况下的关键问题是一个概念性的问题:两种锁之间的真正区别是什么?更重要的是,在什么情况下应该使用哪种锁?您将在本节中找到这些问题的答案。
以前的驱动程序读取方法的伪代码(图 12.5)作为基本示例,假设有三个线程 - tA,tB和tC - 在并行运行(在 SMP 系统上)通过此代码。我们将通过在临界区开始之前(时间t2)获取锁来解决这个并发问题,同时避免任何数据竞争,并在临界区代码路径结束后(时间t3)释放锁(解锁)。让我们再次看一下伪代码,这次使用锁定以确保它是正确的:

图 12.6 - 伪代码 - 在(虚构的)驱动程序读取方法中的临界区;正确,带锁定
当三个线程尝试同时获取锁时,系统保证只有一个线程会获得。假设tB(线程 B)获得了锁:现在它是“赢家”或“所有者”线程。这意味着线程tA和tC是“输家”;他们会等待解锁!“赢家”(tB)完成临界区并解锁锁时,之前的输家之间的竞争重新开始;其中一个将成为下一个赢家,过程重复。
两种锁类型 - 互斥锁和自旋锁 - 的关键区别在于失败者等待解锁的方式。使用互斥锁时,失败的线程会进入睡眠状态;也就是说,它们会通过睡眠来等待。当获胜者执行解锁时,内核会唤醒失败者(所有失败者),它们会再次运行,争夺锁。(事实上,互斥锁和信号量有时被称为睡眠锁。)
然而,使用自旋锁,没有睡眠的问题;失败者会在锁上旋转等待,直到它被解锁。从概念上看,情况如下:
while (locked) ;
请注意,这仅仅是概念上的。好好想一想 - 这实际上是轮询。然而,作为一个好的程序员,你会明白,轮询通常被认为是一个坏主意。那么,为什么自旋锁会这样工作呢?其实并不是这样;它只是以这种方式呈现出来是为了概念上的目的。很快你就会明白,自旋锁只在多核(SMP)系统上才有意义。在这样的系统中,当获胜的线程离开并运行临界区代码时,失败者会在其他 CPU 核心上旋转等待!实际上,在实现级别上,用于实现现代自旋锁的代码是高度优化的(并且与体系结构相关),并不是通过简单地“旋转”来工作(例如,许多 ARM 的自旋锁实现使用等待事件(WFE)机器语言指令,该指令使 CPU 在低功耗状态下等待;请参阅进一步阅读部分,了解有关自旋锁内部实现的几个资源)。
理论上确定使用哪种锁
自旋锁的实现方式并不是我们关心的重点;自旋锁的开销比互斥锁低这一事实对我们很有兴趣。为什么呢?其实很简单:对于互斥锁来说,失败的线程必须进入睡眠状态。为了做到这一点,内部会调用schedule()函数,这意味着失败者将把互斥锁 API 视为一个阻塞调用!调用调度程序最终会导致处理器被切换上下文。相反,当拥有者线程解锁锁时,失败的线程必须被唤醒;同样,它将被切换回处理器。因此,互斥锁/解锁操作的最小“成本”是在给定机器上执行两次上下文切换所需的时间。(请参阅下一节中的信息框。)通过再次查看前面的屏幕截图,我们可以确定一些事情,包括在临界区(“锁定”代码路径)中花费的时间;也就是说,t_locked = t3 - t2。
假设t_ctxsw代表上下文切换的时间。正如我们所了解的,互斥锁/解锁操作的最小成本是2 * t_ctxsw。现在,假设以下表达式为真:
t_locked < 2 * t_ctxsw
换句话说,如果在临界区内花费的时间少于两次上下文切换所需的时间,那么使用互斥锁就是错误的,因为这样的开销太大;执行元工作的时间比实际工作的时间更多 - 这种现象被称为抖动。这种情况 - 非常短的临界区存在的情况 - 在现代操作系统(如 Linux)中经常出现。因此,总之,对于短的非阻塞临界区,使用自旋锁(远远)优于使用互斥锁。
实际上确定使用哪种锁
因此,根据t_locked < 2 * t_ctxsw的“规则”进行操作在理论上可能很好,但等等:你真的期望精确测量每种情况中临界区内的上下文切换时间和花费的时间吗?当然不是 - 那太不现实和过分了。
从实际角度来看,可以这样理解:互斥锁通过让失败的线程在解锁时睡眠来工作;自旋锁不会(失败的线程“自旋”)。让我们回顾一下 Linux 内核的一个黄金规则:内核不能在任何类型的原子上下文中睡眠(调用schedule())。因此,我们永远不能在中断上下文中使用互斥锁,或者在任何不安全睡眠的上下文中使用;然而,使用自旋锁是可以的。(记住,一个阻塞的 API 是通过调用schedule()来使调用上下文进入睡眠状态的。)让我们总结一下:
-
关键部分是否在原子(中断)上下文中运行,或者在进程上下文中运行,其中它不能睡眠?使用自旋锁。
-
关键部分是否在进程上下文中运行,并且在关键部分需要睡眠吗?使用互斥锁。
当然,使用自旋锁的开销比使用互斥锁要低;因此,你甚至可以在进程上下文中使用自旋锁(比如我们虚构的驱动程序的读方法),只要关键部分不阻塞(睡眠)。
[1] 上下文切换所需的时间是不同的;它在很大程度上取决于硬件和操作系统的质量。最近(2018 年 9 月)的测量结果显示,在固定的 CPU 上,上下文切换时间大约为 1.2 到 1.5 微秒,在没有固定的情况下大约为 2.2 微秒(https://eli.thegreenplace.net/2018/measuring-context-switching-and-memory-overheads-for-linux-threads/)。
硬件和 Linux 操作系统都有了巨大的改进,因此平均上下文切换时间也有了显著提高。一篇 1998 年 12 月的 Linux Journal 文章确定,在 x86 类系统上,平均上下文切换时间为 19 微秒,最坏情况下为 30 微秒。
这带来了一个问题,我们如何知道代码当前是在进程上下文还是中断上下文中运行的?很简单:我们的PRINT_CTX()宏(在我们的convenient.h头文件中)可以告诉我们这一点:
if (in_task())
/* we're in process context (usually safe to sleep / block) */
else
/* we're in an atomic or interrupt context (cannot sleep / block) */
(我们的PRINT_CTX()宏的实现细节在《Linux 内核编程(第二部分)》中有介绍)。
现在你明白了在什么情况下使用互斥锁或自旋锁,让我们进入实际用法。我们将从如何使用互斥锁开始!
使用互斥锁
互斥锁也被称为可睡眠或阻塞互斥锁。正如你所学到的,如果关键部分可以睡眠(阻塞),则它们在进程上下文中使用。它们不能在任何类型的原子或中断上下文(顶半部、底半部,如 tasklets 或 softirqs 等)、内核定时器,甚至不允许阻塞的进程上下文中使用。
初始化互斥锁
在内核中,互斥锁“对象”表示为struct mutex数据结构。考虑以下代码:
#include <linux/mutex.h>
struct mutex mymtx;
要使用互斥锁,必须显式地将其初始化为解锁状态。初始化可以通过DEFINE_MUTEX()宏进行静态执行(声明和初始化对象),也可以通过mutex_init()函数进行动态执行(实际上是对__mutex_init()函数的宏包装)。
例如,要声明和初始化一个名为mymtx的互斥锁对象,我们可以使用DEFINE_MUTEX(mymtx);。
我们也可以动态地做这个。为什么是动态的?通常,互斥锁是它所保护的(全局)数据结构的成员(聪明!)。例如,假设我们在驱动程序代码中有以下全局上下文结构(请注意,这段代码是虚构的):
struct mydrv_priv {
<member 1>;
<member 2>;
[...]
struct mutex mymtx; /* protects access to mydrv_priv */
[...]
};
然后,在你的驱动程序(或 LKM)的init方法中,执行以下操作:
static int init_mydrv(struct mydrv_priv *drvctx)
{
[...]
mutex_init(drvctx->mymtx);
[...]
}
将锁变量作为(父)数据结构的成员保护起来是 Linux 中常见(而巧妙)的模式;这种方法的附加好处是避免了命名空间污染,并且清楚地表明了哪个互斥锁保护了哪个共享数据项(这在庞大的项目中可能比看起来更为严重,尤其是在 Linux 内核等庞大项目中!)。
将保护全局或共享数据结构的锁作为该数据结构的成员。
正确使用互斥锁
通常情况下,你可以在内核源代码树中找到非常有见地的注释。这里有一个很好的总结了你必须遵循以正确使用互斥锁的规则的注释;请仔细阅读:
// include/linux/mutex.h
/*
* Simple, straightforward mutexes with strict semantics:
*
* - only one task can hold the mutex at a time
* - only the owner can unlock the mutex
* - multiple unlocks are not permitted
* - recursive locking is not permitted
* - a mutex object must be initialized via the API
* - a mutex object must not be initialized via memset or copying
* - task may not exit with mutex held
* - memory areas where held locks reside must not be freed
* - held mutexes must not be reinitialized
* - mutexes may not be used in hardware or software interrupt
* contexts such as tasklets and timers
*
* These semantics are fully enforced when DEBUG_MUTEXES is
* enabled. Furthermore, besides enforcing the above rules, the mutex
* [ ... ]
作为内核开发人员,你必须理解以下内容:
-
关键部分会导致代码路径被序列化,破坏了并行性。因此,至关重要的是将关键部分保持尽可能短。与此相关的是锁定数据,而不是代码。
-
尝试重新获取已经获取(锁定)的互斥锁——实际上是递归锁定——不受支持,并且会导致自我死锁。
-
锁定顺序:这是防止危险死锁情况的一个非常重要的经验法则。在存在多个线程和多个锁的情况下,关键的是锁定的顺序被记录并且所有在项目上工作的开发人员都严格遵循。实际的锁定顺序本身并不是不可侵犯的,但一旦决定了,就必须遵循。在浏览内核源代码树时,你会发现许多地方,内核开发人员确保这样做,并且(通常)为其他开发人员写下了一条注释以便他们看到并遵循。这里有一个来自 slab 分配器代码(
mm/slub.c)的示例注释:
/*
* Lock order:
* 1\. slab_mutex (Global Mutex)
* 2\. node->list_lock
* 3\. slab_lock(page) (Only on some arches and for debugging)
现在我们从概念上理解了互斥锁的工作原理(并且理解了它们的初始化),让我们学习如何使用锁定/解锁 API。
互斥锁和解锁 API 及其用法
互斥锁的实际锁定和解锁 API 如下。以下代码分别显示了如何锁定和解锁互斥锁:
void __sched mutex_lock(struct mutex *lock);
void __sched mutex_unlock(struct mutex *lock);
(这里忽略__sched;这只是一个编译器属性,使得这个函数在WCHAN输出中消失,在 procfs 中出现,并且在ps(1)的某些选项开关下显示出来。)
再次强调,在kernel/locking/mutex.c源代码中的注释非常详细和描述性;我鼓励你更详细地查看这个文件。我们在这里只展示了其中的一些代码,这些代码直接取自 5.4 版 Linux 内核源代码树:
// kernel/locking/mutex.c
[ ... ]
/**
* mutex_lock - acquire the mutex
* @lock: the mutex to be acquired
*
* Lock the mutex exclusively for this task. If the mutex is not
* available right now, it will sleep until it can get it.
*
* The mutex must later on be released by the same task that
* acquired it. Recursive locking is not allowed. The task
* may not exit without first unlocking the mutex. Also, kernel
* memory where the mutex resides must not be freed with
* the mutex still locked. The mutex must first be initialized
* (or statically defined) before it can be locked. memset()-ing
* the mutex to 0 is not allowed.
*
* (The CONFIG_DEBUG_MUTEXES .config option turns on debugging
* checks that will enforce the restrictions and will also do
* deadlock debugging)
*
* This function is similar to (but not equivalent to) down().
*/
void __sched mutex_lock(struct mutex *lock)
{
might_sleep();
if (!__mutex_trylock_fast(lock))
__mutex_lock_slowpath(lock);
}
EXPORT_SYMBOL(mutex_lock);
might_sleep()是一个具有有趣调试属性的宏;它捕捉到了应该在原子上下文中执行但实际上没有执行的代码!(关于might_sleep()的解释可以在*Linux 内核编程(第二部分)*书中找到)。因此,请考虑:might_sleep()是mutex_lock()中的第一行代码,这意味着这段代码路径不应该被任何处于原子上下文中的东西执行,因为它可能会休眠。这意味着只有在进程上下文中安全休眠时才应该使用互斥锁!
一个快速而重要的提醒:Linux 内核可以配置大量的调试选项;在这种情况下,CONFIG_DEBUG_MUTEXES配置选项将帮助你捕捉可能的与互斥锁相关的错误,包括死锁。同样,在 Kernel Hacking 菜单下,你会找到大量与调试相关的内核配置选项。我们在第五章中讨论过这一点,编写你的第一个内核模块——LKMs 第二部分。关于锁调试,有几个非常有用的内核配置;我们将在下一章中介绍这些内容,在内核中的锁调试部分。
互斥锁——通过[不]可中断的睡眠?
和我们迄今为止看到的互斥锁一样,还有更多。你已经知道 Linux 进程(或线程)会在状态机的各种状态之间循环。在 Linux 上,睡眠有两种离散状态-可中断睡眠和不可中断睡眠。处于可中断睡眠状态的进程(或线程)是敏感的,这意味着它会响应用户空间信号,而处于不可中断睡眠状态的任务对用户信号不敏感。
在一个具有人机交互的应用程序中,根据一个经验法则,你通常应该将一个进程置于可中断睡眠状态(当它在锁上阻塞时),这样就由最终用户决定是否通过按下Ctrl + C(或某种涉及信号的机制)来中止应用程序。在类 Unix 系统上通常遵循的设计规则是:提供机制,而不是策略。话虽如此,在非交互式代码路径上,通常情况下你必须等待锁来无限期地等待,这意味着已经传递给任务的信号不应该中止阻塞等待。在 Linux 上,不可中断的情况是最常见的。
所以,问题来了:mutex_lock() API 总是将调用任务置于不可中断的睡眠状态。如果这不是你想要的,可以使用mutex_lock_interruptible() API 将调用任务置于可中断的睡眠状态。在语法上有一个不同之处;后者在成功时返回整数值0,在失败时返回-EINTR(记住0/-E返回约定)(由于信号中断)。
一般来说,使用mutex_lock()比使用mutex_lock_interruptible()更快;当临界区很短时(因此几乎可以保证锁只持有很短的时间,这是一个非常理想的特性)使用它。
内核 5.4.0 包含超过 18,500 个mutex_lock()和 800 多个mutex_lock_interruptible() API 的调用实例;你可以通过内核源树上强大的cscope(1)实用程序来检查这一点。
理论上,内核也提供了mutex_destroy() API。这是mutex_init()的相反操作;它的工作是将互斥锁标记为不可用。它只能在互斥锁处于未锁定状态时调用一次,并且一旦调用,就不能再使用互斥锁。这有点理论性,因为在常规系统上,它只是一个空函数;只有在启用了CONFIG_DEBUG_MUTEXES的内核上,它才变成实际的(简单的)代码。因此,当使用互斥锁时,我们应该使用这种模式,如下面的伪代码所示:
DEFINE_MUTEX(...); // init: initialize the mutex object
/* or */ mutex_init();
[ ... ]
/* critical section: perform the (mutex) locking, unlocking */
mutex_lock[_interruptible]();
<< ... critical section ... >>
mutex_unlock();
mutex_destroy(); // cleanup: destroy the mutex object
现在你已经学会了如何使用互斥锁 API,让我们把这些知识付诸实践。在下一节中,我们将在我们早期的一个(编写不良-没有保护!)“misc”驱动程序的基础上,通过使用互斥对象来锁定必要的临界区。
互斥锁示例驱动程序
我们在《Linux 内核编程(第二部分)》一书中的编写简单的杂项字符设备驱动程序章节中创建了一个简单的设备驱动程序代码示例,即miscdrv_rdwr。在那里,我们编写了一个简单的misc类字符设备驱动程序,并使用了一个用户空间实用程序(miscdrv_rdwr/rdwr_drv_secret.c)来从设备驱动程序的内存中读取和写入(所谓的)秘密。
然而,在那段代码中我们明显(这里应该用“惊人地”才对!)没有保护共享(全局)可写数据!这在现实世界中会让我们付出昂贵的代价。我敦促你花一些时间思考这个问题:两个(或三个或更多)用户模式进程打开这个驱动程序的设备文件,然后同时发出各种 I/O 读写操作是不可行的。在这里,全局共享可写数据(在这种特殊情况下,两个全局整数和驱动程序上下文数据结构)很容易被破坏。
因此,让我们通过复制这个驱动程序并更正我们的错误来学习(我们现在将其称为ch12/1_miscdrv_rdwr_mutexlock/1_miscdrv_rdwr_mutexlock.c),并重新编写其中的一些部分。关键是我们必须使用互斥锁来保护所有关键部分。而不是在这里显示代码(毕竟,它在本书的 GitHub 存储库中github.com/PacktPublishing/Linux-Kernel-Programming,请使用git clone!),让我们做一些有趣的事情:让我们看一下旧的未受保护版本和新的受保护代码版本之间的“差异”(diff(1)生成的差异-增量)。这里的输出已经被截断:
$ pwd
<...>/ch12/1_miscdrv_rdwr_mutexlock
$ diff -u ../../ch12/miscdrv_rdwr/miscdrv_rdwr.c miscdrv_rdwr_mutexlock.c > miscdrv_rdwr.patch
$ cat miscdrv_rdwr.patch
[ ... ]
+#include <linux/mutex.h> // mutex lock, unlock, etc
#include "../../convenient.h"
[ ... ]
-#define OURMODNAME "miscdrv_rdwr"
+#define OURMODNAME "miscdrv_rdwr_mutexlock"
+DEFINE_MUTEX(lock1); // this mutex lock is meant to protect the integers ga and gb
[ ... ]
+ struct mutex lock; // this mutex protects this data structure
};
[ ... ]
在这里,我们可以看到在驱动程序的更新安全版本中,我们声明并初始化了一个名为lock1的互斥变量;我们将使用它来保护(仅用于演示目的)驱动程序中的两个全局整数ga和gb。接下来,重要的是,在“驱动程序上下文”数据结构drv_ctx中声明了一个名为lock的互斥锁;这将用于保护对该数据结构成员的任何和所有访问。它在init代码中初始化:
+ mutex_init(&ctx->lock);
+
+ /* Initialize the "secret" value :-) */
strscpy(ctx->oursecret, "initmsg", 8);
- dev_dbg(ctx->dev, "A sample print via the dev_dbg(): driver initialized\n");
+ /* Why don't we protect the above strscpy() with the mutex lock?
+ * It's working on shared writable data, yes?
+ * Yes, BUT this is the init code; it's guaranteed to run in exactly
+ * one context (typically the insmod(8) process), thus there is
+ * no concurrency possible here. The same goes for the cleanup
+ * code path.
+ */
这个详细的注释清楚地解释了为什么我们不需要在strscpy()周围进行锁定/解锁。再次强调,这应该是显而易见的,但是局部变量隐式地对每个进程上下文是私有的(因为它们驻留在该进程或线程的内核模式堆栈中),因此不需要保护(每个线程/进程都有一个变量的单独实例,所以没有人会干涉别人的工作!)。在我们忘记之前,清理代码路径(通过rmmod(8)进程上下文调用)必须销毁互斥锁:
-static void __exit miscdrv_rdwr_exit(void)
+static void __exit miscdrv_exit_mutexlock(void)
{
+ mutex_destroy(&lock1);
+ mutex_destroy(&ctx->lock);
misc_deregister(&llkd_miscdev);
}
现在,让我们看一下驱动程序的打开方法的差异:
+
+ mutex_lock(&lock1);
+ ga++; gb--;
+ mutex_unlock(&lock1);
+
+ dev_info(dev, " filename: \"%s\"\n"
[ ... ]
这就是我们操纵全局整数的地方,使其成为一个关键部分;与此程序的先前版本(在Linux 内核编程(第二部分)中)不同,在这里,我们确实保护了这个关键部分,使用了lock1互斥体。所以,关键部分在这里是代码ga++; gb--;:在(互斥体)锁定和解锁操作之间的代码。
但是(总会有但是,不是吗?),一切并不顺利!看一下mutex_unlock()代码行后面的printk函数(dev_info()):
+ dev_info(dev, " filename: \"%s\"\n"
+ " wrt open file: f_flags = 0x%x\n"
+ " ga = %d, gb = %d\n",
+ filp->f_path.dentry->d_iname, filp->f_flags, ga, gb);
这看起来对你来说没问题吗?不,仔细看:我们读取全局整数ga和gb的值。回想一下基本原理:在并发存在的情况下(在这个驱动程序的open方法中肯定是可能的),即使没有锁定,读取共享可写数据也可能是不安全的。如果这对你来说没有意义,请想一想:如果一个线程正在读取整数,另一个线程同时正在更新(写入)它们;那么呢?这种情况被称为脏读(或断裂读);我们可能会读取过时的数据,必须加以保护。(事实上,这并不是一个脏读的很好的例子,因为在大多数处理器上,读取和写入单个整数项目确实是一个原子操作。然而,我们不应该假设这样的事情-我们只需要做好我们的工作并保护它。)
实际上,还有另一个类似的等待中的错误:我们已经从打开文件结构(filp指针)中读取数据,而没有费心保护它(实际上,打开文件结构有一个锁;我们应该使用它!我们稍后会这样做)。
诸如脏读之类的事物发生的具体语义通常非常依赖于体系结构(机器);然而,我们作为模块或驱动程序的作者的工作是明确的:我们必须确保保护所有关键部分。这包括对共享可写数据的读取。
目前,我们将这些标记为潜在错误(错误)。我们将在使用原子整数操作符部分以更加性能友好的方式处理这个问题。查看驱动程序读取方法的差异会发现一些有趣的东西(忽略这里显示的行号;它们可能会改变):

图 12.7 - 驱动程序读取()方法的差异;查看新版本中互斥锁的使用
我们现在已经使用了驱动程序上下文结构的互斥锁来保护关键部分。对于设备驱动程序的写和关闭(释放)方法都是一样的(生成补丁并查看)。
请注意,用户模式应用程序保持不变,这意味着为了测试新的更安全的版本,我们必须继续使用ch12/miscdrv_rdwr/rdwr_drv_secret.c中的用户模式应用程序。在调试内核上运行和测试此驱动程序代码,该内核包含各种锁定错误和死锁检测功能,这是至关重要的(我们将在下一章中返回这些“调试”功能,在内核中的锁调试部分)。
在前面的代码中,我们在copy_to_user()例程之前刚好取得了互斥锁;这很好。然而,我们只在dev_info()之后释放它。为什么不在这个printk之前释放它,从而缩短关键部分的时间?
仔细观察dev_info()会发现为什么它在关键部分内部。我们在这里打印了三个变量的值:secret_len读取的字节数以及ctx->tx和ctx->rx分别"传输"和"接收"的字节数。secret_len是一个局部变量,不需要保护,但另外两个变量在全局驱动程序上下文结构中,因此需要保护,即使是(可能是脏的)读取也需要保护。
互斥锁 - 一些剩余的要点
在本节中,我们将介绍有关互斥锁的一些其他要点。
互斥锁 API 变体
首先,让我们看一下互斥锁 API 的一些变体;除了可中断变体(在互斥锁 - 通过[不]可中断睡眠?部分中描述),我们还有trylock,可杀死和io变体。
互斥 trylock 变体
如果您想要实现忙等待语义,即测试(互斥)锁的可用性,如果可用(表示当前未锁定),则获取/锁定它并继续关键部分代码路径?如果不可用(当前处于锁定状态),则不等待锁;而是执行其他工作并重试。实际上,这是一种非阻塞的互斥锁变体,称为 trylock;以下流程图显示了它的工作原理:
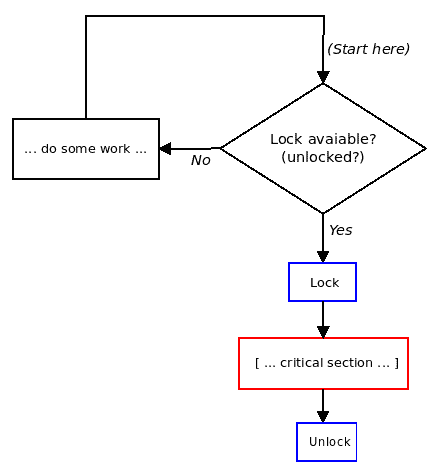
图 12.8 - "忙等待"语义,非阻塞 trylock 操作
互斥锁的此 trylock 变体的 API 如下所示:
int mutex_trylock(struct mutex *lock);
此 API 的返回值表示运行时发生了什么:
-
返回值
1表示成功获取了锁。 -
返回值
0表示锁当前被争用(已锁定)。
虽然尝试使用mutex_trylock() API 来确定互斥锁的锁定状态或解锁状态听起来很诱人,但这本质上是"竞态"。接下来,请注意,在高度争用的锁路径中使用此 trylock 变体可能会降低您获得锁的机会。trylock 变体传统上用于死锁预防代码,该代码可能需要退出某个锁定顺序序列,并通过另一个序列进行重试(排序)。
另外,关于 trylock 变体,尽管文献使用术语尝试原子地获取互斥锁,但它在原子或中断上下文中不起作用 - 它仅在进程上下文中起作用(与任何类型的互斥锁一样)。通常情况下,锁必须由所有者上下文调用的mutex_unlock()释放。
我建议你尝试使用 trylock 互斥锁变体作为练习。在本章末尾的问题部分查看作业!
互斥锁可中断和可杀死变体
正如您已经了解的那样,当驱动程序(或模块)愿意接受任何(用户空间)信号中断时,将使用mutex_lock_interruptible()API(并返回-ERESTARTSYS以告知内核 VFS 层执行信号处理;用户空间系统调用将以errno设置为EINTR失败)。一个例子可以在内核中的模块处理代码中找到,在delete_module(2)系统调用中(rmmod(8)调用):
// kernel/module.c
[ ... ]
SYSCALL_DEFINE2(delete_module, const char __user *, name_user,
unsigned int, flags)
{
struct module *mod;
[ ... ]
if (!capable(CAP_SYS_MODULE) || modules_disabled)
return -EPERM;
[ ... ]
if (mutex_lock_interruptible(&module_mutex) != 0)
return -EINTR;
mod = find_module(name);
[ ... ]
out:
mutex_unlock(&module_mutex);
return ret;
}
请注意 API 在失败时返回-EINTR。(SYSCALL_DEFINEn()宏成为系统调用签名;n表示此特定系统调用接受的参数数量。还要注意权限检查-除非您以 root 身份运行或具有CAP_SYS_MODULE权限(或者模块加载完全被禁用),否则系统调用将返回失败(-EPERM)。)
然而,如果您的驱动程序只愿意被致命信号(将杀死用户空间上下文的信号)中断,那么请使用mutex_lock_killable()API(签名与可中断变体相同)。
互斥锁 io 变体
mutex_lock_io()API 在语法上与mutex_lock()API 相同;唯一的区别是内核认为失败线程的等待时间与等待 I/O 相同(kernel/locking/mutex.c:mutex_lock_io()中的代码注释清楚地记录了这一点;看一看)。这在会计方面很重要。
您可以在内核中找到诸如mutex_lock[_interruptible]_nested()之类的相当奇特的 API,这里重点是nested后缀。但是,请注意,Linux 内核不建议开发人员使用嵌套(或递归)锁定(正如我们在正确使用互斥锁部分中提到的)。此外,这些 API 仅在存在CONFIG_DEBUG_LOCK_ALLOC配置选项时才会被编译;实际上,嵌套 API 是为了支持内核锁验证器机制而添加的。它们只应在特殊情况下使用(在同一类型的锁定实例之间必须包含嵌套级别的情况)。
在下一节中,我们将回答一个典型的常见问题:互斥锁和信号量对象之间有什么区别?Linux 是否甚至有信号量对象?继续阅读以了解更多!
信号量和互斥锁
Linux 内核确实提供了信号量对象,以及您可以对(二进制)信号量执行的常规操作:
-
通过
down[_interruptible]()(和变体)API 获取信号量锁 -
通过
up()API 释放信号量。
一般来说,信号量是一个较旧的实现,因此建议您使用互斥锁来替代它。
值得一看的常见问题是:*互斥锁和信号量之间有什么区别?*它们在概念上似乎相似,但实际上是非常不同的:
-
信号量是互斥锁的一种更通用的形式;互斥锁可以被获取(随后释放或解锁)一次,而信号量可以被获取(随后释放)多次。
-
互斥锁用于保护临界区免受同时访问,而信号量应该用作向另一个等待任务发出信号的机制,表明已经达到了某个里程碑(通常,生产者任务通过信号量对象发布信号,等待接收的消费者任务继续进行进一步工作)。
-
互斥锁具有锁的所有权概念,只有所有者上下文才能执行解锁;二进制信号量没有所有权。
优先级反转和 RT 互斥锁
使用任何类型的锁时需要注意的一点是,您应该仔细设计和编码,以防止可能出现的可怕的死锁情况(关于这一点,我们将在下一章的锁验证器 lockdep - 及早捕捉锁定问题部分详细介绍)。
除了死锁,使用互斥时还会出现另一种风险情景:优先级反转(在本书中我们不会深入讨论细节)。可以说,无限的优先级反转情况可能是致命的;最终结果是产品的高(最高)优先级线程被长时间挡在 CPU 之外。
正如我在早期的书Hands-on System Programming with Linux中详细介绍的那样,正是这个优先级反转问题在 1997 年 7 月击中了 NASA 的火星探路者机器人,就在火星表面!请参阅本章的进一步阅读部分,了解有关这一问题的有趣资源,这是每个软件开发人员都应该知道的事情!
用户空间 Pthreads 互斥实现当然具有优先级继承(PI)语义。但是 Linux 内核内部呢?对此,Ingo Molnar 提供了基于 PI-futex 的 RT-mutex(实时互斥;实际上是扩展为具有 PI 功能的互斥。futex(2)是一个复杂的系统调用,提供快速的用户空间互斥)。当启用CONFIG_RT_MUTEXES配置选项时,这些功能就可用了。与“常规”互斥语义非常相似,RT-mutex API 用于初始化、(解)锁定和销毁 RT-mutex 对象。(此代码已从 Ingo Molnar 的-rt树合并到主线内核中)。就实际使用而言,RT-mutex 用于内部实现 PI futex(futex(2)系统调用本身在内部实现了用户空间 Pthreads 互斥)。除此之外,内核锁定自测代码和 I2C 子系统直接使用 RT-mutex。
因此,对于典型的模块(或驱动程序)作者来说,这些 API 并不经常使用。内核确实提供了一些关于 RT-mutex 内部设计的文档,涵盖了优先级反转、优先级继承等等。
内部设计
关于内核中互斥锁的内部实现的现实情况:Linux 在可能的情况下尝试实现快速路径方法。
快速路径是最优化的高性能代码路径;例如,没有锁定和阻塞的路径。其目的是让代码尽可能地遵循这条快速路径。只有在真的不可能的情况下,内核才会退回到(可能的)“中间路径”,然后是“慢路径”方法;它仍然有效,但速度较慢。
在没有锁定争用的情况下(即,锁定状态一开始就是未锁定状态),会采用这种快速路径。因此,锁定时会立即完成,没有麻烦。然而,如果互斥已经被锁定,那么内核通常会使用中间路径的乐观自旋实现,使其更像是混合(互斥/自旋锁)锁类型。如果这也不可能,就会采用“慢路径”——试图获取锁的进程上下文可能会进入睡眠状态。如果您对其内部实现感兴趣,可以在官方内核文档中找到更多详细信息:www.kernel.org/doc/Documentation/locking/mutex-design.rst。
LDV(Linux Driver Verification)项目:在第一章中,内核工作空间设置部分的LDV - Linux Driver Verification - 项目中,我们提到该项目对 Linux 模块(主要是驱动程序)以及核心内核的各种编程方面有有用的“规则”。
关于我们当前的主题,这里有一个规则:两次锁定互斥锁或在先前未锁定的情况下解锁(linuxtesting.org/ldv/online?action=show_rule&rule_id=0032)。它提到了您不能使用互斥锁做的事情的类型(我们已经在正确使用互斥锁部分中涵盖了这一点)。有趣的是:您可以看到一个实际的 bug 示例 - 一个互斥锁双重获取尝试,导致(自身)死锁 - 在内核驱动程序中(以及随后的修复)。
现在您已经了解了如何使用互斥锁,让我们继续看看内核中另一个非常常见的锁 - 自旋锁。
使用自旋锁
在互斥锁还是自旋锁?何时使用部分,您学会了何时使用自旋锁而不是互斥锁,反之亦然。为了方便起见,我们在此重复了我们之前提供的关键陈述:
-
临界区是否在原子(中断)上下文中运行,或者在进程上下文中无法睡眠的情况下? 使用自旋锁。
-
临界区是否在进程上下文中运行,且在临界区中需要睡眠? 使用互斥锁。
在这一部分,我们假设您现在决定使用自旋锁。
自旋锁 - 简单用法
对于所有自旋锁 API,您必须包含相关的头文件;即include <linux/spinlock.h>。
与互斥锁类似,必须在使用之前声明和初始化自旋锁为未锁定状态。自旋锁是通过名为spinlock_t的typedef数据类型声明的“对象”(在include/linux/spinlock_types.h中定义的结构)。它可以通过spin_lock_init()宏进行动态初始化:
spinlock_t lock;
spin_lock_init(&lock);
或者,可以使用DEFINE_SPINLOCK(lock);进行静态执行(声明和初始化)。
与互斥锁一样,在(全局/静态)数据结构中声明自旋锁旨在防止并发访问,并且通常是一个非常好的主意。正如我们之前提到的,这个想法在内核中经常被使用;例如,Linux 内核上表示打开文件的数据结构称为struct file:
// include/linux/fs.h
struct file {
[...]
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
/*
* Protects f_ep_links, f_flags.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock;
[...]
struct mutex f_pos_lock;
loff_t f_pos;
[...]
看看这个:对于file结构,名为f_lock的自旋锁变量是保护file数据结构的f_ep_links和f_flags成员的自旋锁(它还有一个互斥锁来保护另一个成员;即文件的当前寻位位置f_pos)。
您如何实际上锁定和解锁自旋锁?内核向我们模块/驱动程序作者公开了许多 API 的变体;自旋锁的最简单形式的(解)锁 API 如下:
void spin_lock(spinlock_t *lock);
<< ... critical section ... >>
void spin_unlock(spinlock_t *lock);
请注意,自旋锁没有mutex_destroy()API 的等效物。
现在,让我们看看自旋锁 API 的运行情况!
自旋锁 - 一个示例驱动程序
与我们之前使用互斥锁示例驱动程序(互斥锁 - 一个示例驱动程序部分)类似,为了说明自旋锁的简单用法,我们将把之前的ch12/1_miscdrv_rdwr_mutexlock驱动程序复制为起始模板,然后放置在一个新的内核驱动程序中;即ch12/2_miscdrv_rdwr_spinlock。同样,在这里,我们只会展示差异的小部分(diff(1)生成的差异,我们不会展示每一行的差异,只展示相关部分):
// location: ch12/2_miscdrv_rdwr_spinlock/
+#include <linux/spinlock.h>
[ ... ]
-#define OURMODNAME "miscdrv_rdwr_mutexlock"
+#define OURMODNAME "miscdrv_rdwr_spinlock"
[ ... ]
static int ga, gb = 1;
-DEFINE_MUTEX(lock1); // this mutex lock is meant to protect the integers ga and gb
+DEFINE_SPINLOCK(lock1); // this spinlock protects the global integers ga and gb
[ ... ]
+/* The driver 'context' data structure;
+ * all relevant 'state info' reg the driver is here.
*/
struct drv_ctx {
struct device *dev;
@@ -63,10 +66,22 @@
u64 config3;
#define MAXBYTES 128
char oursecret[MAXBYTES];
- struct mutex lock; // this mutex protects this data structure
+ struct mutex mutex; // this mutex protects this data structure
+ spinlock_t spinlock; // ...so does this spinlock
};
static struct drv_ctx *ctx;
这一次,为了保护我们的drv_ctx全局数据结构的成员,我们既有原始的互斥锁,也有一个新的自旋锁。这是非常常见的;互斥锁保护了临界区中可能发生阻塞的成员使用,而自旋锁用于保护在临界区中可能发生阻塞(睡眠 - 记住它可能会睡眠)的成员。
当然,我们必须确保初始化所有的锁,使它们处于未锁定状态。我们可以在驱动程序的init代码中执行这个操作(继续输出补丁):
- mutex_init(&ctx->lock);
+ mutex_init(&ctx->mutex);
+ spin_lock_init(&ctx->spinlock);
在驱动程序的open方法中,我们用自旋锁替换了互斥锁,以保护全局整数的增量和减量:
* open_miscdrv_rdwr()
@@ -82,14 +97,15 @@
PRINT_CTX(); // displays process (or intr) context info
- mutex_lock(&lock1);
+ spin_lock(&lock1);
ga++; gb--;
- mutex_unlock(&lock1);
+ spin_unlock(&lock1);
现在,在驱动程序的read方法中,我们使用自旋锁而不是互斥锁来保护一些关键部分:
static ssize_t read_miscdrv_rdwr(struct file *filp, char __user *ubuf, size_t count, loff_t *off)
{
- int ret = count, secret_len;
+ int ret = count, secret_len, err_path = 0;
struct device *dev = ctx->dev;
- mutex_lock(&ctx->lock);
+ spin_lock(&ctx->spinlock);
secret_len = strlen(ctx->oursecret);
- mutex_unlock(&ctx->lock);
+ spin_unlock(&ctx->spinlock);
但这还不是全部!继续进行驱动程序的read方法,仔细看一下以下代码和注释:
[ ... ]
@@ -139,20 +157,28 @@
* member to userspace.
*/
ret = -EFAULT;
- mutex_lock(&ctx->lock);
+ mutex_lock(&ctx->mutex);
+ /* Why don't we just use the spinlock??
+ * Because - VERY IMP! - remember that the spinlock can only be used when
+ * the critical section will not sleep or block in any manner; here,
+ * the critical section invokes the copy_to_user(); it very much can
+ * cause a 'sleep' (a schedule()) to occur.
+ */
if (copy_to_user(ubuf, ctx->oursecret, secret_len)) {
[ ... ]
在保护可能有阻塞 API 的关键部分数据时——比如在copy_to_user()中——我们必须只使用互斥锁!(由于空间有限,我们没有在这里显示更多的代码差异;我们希望您能阅读自旋锁示例驱动程序代码并自行尝试。)
测试——在原子上下文中睡眠
您已经学到了我们不应该在任何原子或中断上下文中睡觉(阻塞)。让我们来测试一下。一如既往,经验主义方法——即自己测试而不是依赖他人的经验——是关键!
我们如何测试这个问题呢?很简单:我们将使用一个简单的整数模块参数buggy,当设置为1时(默认值为0),会执行违反这一规则的自旋锁关键部分内的代码路径。我们将调用schedule_timeout() API(正如您在第十五章“定时器、内核线程和更多”中学到的,在“理解如何使用sleep()阻塞 API”部分内部调用schedule();这是我们在内核空间中睡眠的方式)。以下是相关代码:
// ch12/2_miscdrv_rdwr_spinlock/2_miscdrv_rdwr_spinlock.c
[ ... ]
static int buggy;
module_param(buggy, int, 0600);
MODULE_PARM_DESC(buggy,
"If 1, cause an error by issuing a blocking call within a spinlock critical section");
[ ... ]
static ssize_t write_miscdrv_rdwr(struct file *filp, const char __user *ubuf,
size_t count, loff_t *off)
{
int ret, err_path = 0;
[ ... ]
spin_lock(&ctx->spinlock);
strscpy(ctx->oursecret, kbuf, (count > MAXBYTES ? MAXBYTES : count));
[ ... ]
if (1 == buggy) {
/* We're still holding the spinlock! */
set_current_state(TASK_INTERRUPTIBLE);
schedule_timeout(1*HZ); /* ... and this is a blocking call!
* Congratulations! you've just engineered a bug */
}
spin_unlock(&ctx->spinlock);
[ ... ]
}
现在,让我们来测试一下这个(错误的)代码路径,分别在两个内核中进行:首先是我们定制的 5.4“调试”内核(我们在这个内核中启用了几个内核调试配置选项(主要是从make menuconfig中的Kernel Hacking菜单),如第五章中所解释的,“编写您的第一个内核模块——LKMs 第二部分”),其次是一个没有启用任何相关内核调试选项的通用发行版(我们通常在 Ubuntu 上运行)5.4 内核。
在 5.4 调试内核上进行测试
首先确保您已经构建了定制的 5.4 内核,并且所有必需的内核调试配置选项都已启用(如果需要,请回顾第五章,“编写您的第一个内核模块——LKMs 第二部分”,“配置调试内核”部分)。然后,启动调试内核(这里命名为5.4.0-llkd-dbg)。现在,在此调试内核上构建驱动程序(在ch12/2_miscdrv_rdwr_spinlock/中进行通常的make应该可以完成这一步;您可能会发现,在调试内核上,构建速度明显较慢!):
$ lsb_release -a 2>/dev/null | grep "^Description" ; uname -r
Description: Ubuntu 20.04.1 LTS
5.4.0-llkd-dbg $ make
[ ... ]
$ modinfo ./miscdrv_rdwr_spinlock.ko
filename: /home/llkd/llkd_src/ch12/2_miscdrv_rdwr_spinlock/./miscdrv_rdwr_spinlock.ko
[ ... ]
description: LLKD book:ch12/2_miscdrv_rdwr_spinlock: simple misc char driver rewritten with spinlocks
[ ... ]
parm: buggy:If 1, cause an error by issuing a blocking call within a spinlock critical section (int)
$ sudo virt-what
virtualbox
kvm
$
如您所见,我们在 x86_64 Ubuntu 20.04 虚拟机上运行我们定制的 5.4.0“debug”内核。
您如何知道自己是在虚拟机(VM)上运行还是在“裸机”(本机)系统上运行?virt-what(1)是一个有用的小脚本,可以显示这一点(您可以在 Ubuntu 上使用sudo apt install virt-what进行安装)。
要运行我们的测试用例,将驱动程序插入内核,并将buggy模块参数设置为1。通过我们的用户空间应用程序调用驱动程序的read方法(即ch12/miscdrv_rdwr/rdwr_test_secret)不是问题,如下所示:
$ sudo dmesg -C
$ sudo insmod ./miscdrv_rdwr_spinlock.ko buggy=1
$ ../../ch12/miscdrv_rdwr/rdwr_test_secret
Usage: ../../ch12/miscdrv_rdwr/rdwr_test_secret opt=read/write device_file ["secret-msg"]
opt = 'r' => we shall issue the read(2), retrieving the 'secret' form the driver
opt = 'w' => we shall issue the write(2), writing the secret message <secret-msg>
(max 128 bytes)
$
$ ../../ch12/miscdrv_rdwr/rdwr_test_secret r /dev/llkd_miscdrv_rdwr_spinlock
Device file /dev/llkd_miscdrv_rdwr_spinlock opened (in read-only mode): fd=3
../../ch12/miscdrv_rdwr/rdwr_test_secret: read 7 bytes from /dev/llkd_miscdrv_rdwr_spinlock
The 'secret' is:
"initmsg"
$
接下来,我们通过用户模式应用程序向驱动程序发出write(2);这一次,我们的错误代码路径被执行。正如您所看到的,我们在自旋锁关键部分内(即在锁定和解锁之间)调用了schedule_timeout()。调试内核将此检测为错误,并在内核日志中生成(令人印象深刻的大量)调试诊断信息(请注意,这样的错误很可能会导致系统挂起,因此请先在虚拟机上进行测试):

图 12.9——由我们故意触发的“在原子上下文中调度”错误引发的内核诊断
前面的截图显示了发生的部分情况(在查看ch12/2_miscdrv_rdwr_spinlock/2_miscdrv_rdwr_spinlock.c中的驱动程序代码时跟随):
- 首先,我们有我们的用户模式应用程序的进程上下文(
rdwr_test_secre;请注意名称被截断为前 16 个字符,包括NULL字节),它进入了驱动程序的写入方法;也就是write_miscdrv_rdwr()。这可以在我们有用的PRINT_CTX()宏的输出中看到(我们在这里重现了这一行):
miscdrv_rdwr_spinlock:write_miscdrv_rdwr(): 004) rdwr_test_secre :23578 | ...0 /* write_miscdrv_rdwr() */
-
它从用户空间写入进程中复制新的“秘密”并写入了 24 个字节。
-
然后它“获取”自旋锁,进入临界区,并将这些数据复制到我们驱动程序上下文结构的
oursecret成员中。 -
之后,
if (1 == buggy) {评估为真。 -
然后,它调用
schedule_timeout(),这是一个阻塞 API(因为它内部调用schedule()),触发了错误,这在红色下面有明显标出:
BUG: scheduling while atomic: rdwr_test_secre/23578/0x00000002
- 内核现在转储了大量的诊断输出。首先要转储的是调用堆栈。
进程的调用堆栈或堆栈回溯(或“调用跟踪”)的内核模式堆栈 - 在这里,是我们的用户空间应用程序rdwr_drv_secret,它在进程上下文中运行我们(有错误的)驱动程序的代码 - 可以在图 12.9中清楚地看到。Call Trace:标题之后的每一行本质上都是内核堆栈上的一个调用帧。
作为提示,忽略以?符号开头的堆栈帧;它们实际上是可疑的调用帧,很可能是在相同内存区域中以前的堆栈使用中留下的“剩余物”。这里值得进行一次与内存相关的小的偏离:这就是堆栈分配的真正工作原理;堆栈内存不是按照每个调用帧的基础分配和释放的,因为那将是非常昂贵的。只有当堆栈内存页耗尽时,才会自动故障新的内存页!(回想一下我们在第九章中的讨论,模块作者的内核内存分配 - 第二部分,关于内存分配和需求分页的简短说明部分。)因此,事实是,当代码调用和从函数返回时,相同的堆栈内存页往往会不断被重用。
不仅如此,出于性能原因,内存不是每次都擦除,导致以前的帧留下的残留物经常出现。(它们实际上可以“破坏”图像。然而,幸运的是,现代堆栈调用帧跟踪算法通常能够出色地找出正确的堆栈跟踪。)
按照堆栈跟踪自下而上(总是自下而上阅读),我们可以看到,正如预期的那样,我们的用户空间write(2)系统调用(它经常显示为(类似于)SyS_write或者在 x86 上显示为__x64_sys_write,尽管在图 12.9中不可见)调用了内核的 VFS 层代码(你可以在这里看到vfs_write(),它调用了__vfs_write()),进一步调用了我们的驱动程序的写入方法;也就是write_miscdrv_rdwr()!正如我们所知,这段代码调用了有错误的代码路径,我们在其中调用了schedule_timeout(),这又调用了schedule()(和__schedule()),导致整个**BUG: scheduling while atomic**错误触发。
调度时原子代码路径的格式是从以下代码行中检索的,可以在kernel/sched/core.c中找到:
printk(KERN_ERR "BUG: scheduling while atomic: %s/%d/0x%08x\n", prev->comm, prev->pid, preempt_count());
有趣!在这里,你可以看到它打印了以下字符串:
BUG: scheduling while atomic: rdwr_test_secre/23578/0x00000002
在atomic:之后,它打印进程名称 - PID - 然后调用preempt_count()内联函数,打印抢占深度;抢占深度是一个计数器,每次获取锁时递增,每次解锁时递减。因此,如果它是正数,这意味着代码在临界区或原子区域内;在这里,它显示为值2。
请注意,这个错误在这次测试运行中得到了很好的解决,因为CONFIG_DEBUG_ATOMIC_SLEEP调试内核配置选项已经打开。这是因为我们正在运行一个自定义的“调试内核”(内核版本 5.4.0)!配置选项的详细信息(你可以在make menuconfig中交互式地找到并设置这个选项,在Kernel Hacking菜单下)如下:
// lib/Kconfig.debug
[ ... ]
config DEBUG_ATOMIC_SLEEP
bool "Sleep inside atomic section checking"
select PREEMPT_COUNT
depends on DEBUG_KERNEL
depends on !ARCH_NO_PREEMPT
help
If you say Y here, various routines which may sleep will become very
noisy if they are called inside atomic sections: when a spinlock is
held, inside an rcu read side critical section, inside preempt disabled
sections, inside an interrupt, etc...
在一个 5.4 非调试发行版内核上进行测试
作为对比的测试,我们现在将在我们的 Ubuntu 20.04 LTS VM 上执行完全相同的操作,我们将通过其默认的通用“发行版”5.4 Linux 内核进行引导,通常情况下不配置为“调试”内核(这里,CONFIG_DEBUG_ATOMIC_SLEEP内核配置选项未设置)。
首先,我们插入我们的(有错误的)驱动程序。然后,当我们运行我们的rdwr_drv_secret进程以将新的秘密写入驱动程序时,错误的代码路径被执行。然而,这一次,内核没有崩溃,也没有报告任何问题(查看dmesg(1)输出可以验证这一点):
$ uname -r
5.4.0-56-generic
$ sudo insmod ./miscdrv_rdwr_spinlock.ko buggy=1
$ ../../ch12/miscdrv_rdwr/rdwr_test_secret w /dev/llkd_miscdrv_rdwr_spinlock "passwdcosts500bucksdude"
Device file /dev/llkd_miscdrv_rdwr_spinlock opened (in write-only mode): fd=3
../../ch12/miscdrv_rdwr/rdwr_test_secret: wrote 24 bytes to /dev/llkd_miscdrv_rdwr_spinlock
$ dmesg
[ ... ]
[ 65.420017] miscdrv_rdwr_spinlock:miscdrv_init_spinlock(): LLKD misc driver (major # 10) registered, minor# = 56, dev node is /dev/llkd_miscdrv_rdwr
[ 81.665077] miscdrv_rdwr_spinlock:miscdrv_exit_spinlock(): miscdrv_rdwr_spinlock: LLKD misc driver deregistered, bye
[ 86.798720] miscdrv_rdwr_spinlock:miscdrv_init_spinlock(): VERMAGIC_STRING = 5.4.0-56-generic SMP mod_unload
[ 86.799890] miscdrv_rdwr_spinlock:miscdrv_init_spinlock(): LLKD misc driver (major # 10) registered, minor# = 56, dev node is /dev/llkd_miscdrv_rdwr
[ 130.214238] misc llkd_miscdrv_rdwr_spinlock: filename: "llkd_miscdrv_rdwr_spinlock"
wrt open file: f_flags = 0x8001
ga = 1, gb = 0
[ 130.219233] misc llkd_miscdrv_rdwr_spinlock: stats: tx=0, rx=0
[ 130.219680] misc llkd_miscdrv_rdwr_spinlock: rdwr_test_secre wants to write 24 bytes
[ 130.220329] misc llkd_miscdrv_rdwr_spinlock: 24 bytes written, returning... (stats: tx=0, rx=24)
[ 131.249639] misc llkd_miscdrv_rdwr_spinlock: filename: "llkd_miscdrv_rdwr_spinlock"
ga = 0, gb = 1
[ 131.253511] misc llkd_miscdrv_rdwr_spinlock: stats: tx=0, rx=24
$
我们知道我们的写入方法有一个致命的错误,但它似乎没有以任何方式失败!这真的很糟糕;这种情况可能会让你错误地得出结论,认为你的代码没有问题,而实际上一个难以察觉的错误悄悄地等待着某一天突然袭击!
为了帮助我们调查底层发生了什么,让我们再次运行我们的测试应用程序(rdwr_drv_secret进程),但这次通过强大的trace-cmd(1)工具(它是 Ftrace 内核基础设施的一个非常有用的包装器;以下是它的截断输出:
Linux 内核的Ftrace基础设施是内核的主要跟踪基础设施;它提供了几乎每个在内核空间执行的函数的详细跟踪。在这里,我们通过一个方便的前端利用 Ftrace:trace-cmd(1)实用程序。这些确实是非常强大和有用的调试工具;我们在第一章中提到了几个其他工具,但不幸的是,细节超出了本书的范围。查看手册页以了解更多信息。
$ sudo trace-cmd record -p function_graph -F ../../ch12/miscdrv_rdwr/rdwr_test_secret w /dev/llkd_miscdrv_rdwr_spinlock "passwdcosts500bucks"
$ sudo trace-cmd report -I -S -l > report.txt
$ sudo less report.txt
[ ... ]
输出可以在以下截图中看到:

图 12.10-trace-cmd(1)报告输出的部分截图
正如你所看到的,我们的用户模式应用程序中的write(2)系统调用变成了预期的vfs_write(),它本身(经过安全检查后)调用__vfs_write(),然后调用我们的驱动程序的写入方法-write_miscdrv_rdwr()函数!
在(大量的)Ftrace 输出流中,我们可以看到schedule_timeout()函数确实被调用了:

图 12.11-trace-cmd(1)报告输出的部分截图,显示了(错误的!)调用schedule_timeout()和schedule()在原子上下文中
在schedule_timeout()之后的几行输出中,我们可以清楚地看到schedule()被调用!所以,我们得到了答案:我们的驱动程序(当然是故意的)执行了一些错误的操作-在原子上下文中调用schedule()。但这里的关键点再次是,在这个 Ubuntu 系统上,我们没有运行“调试”内核,这就是为什么我们有以下情况:
$ grep DEBUG_ATOMIC_SLEEP /boot/config-5.4.0-56-generic
# CONFIG_DEBUG_ATOMIC_SLEEP is not set
$
这就是为什么这个错误没有被报告!这证明了在“调试”内核上运行测试用例的有用性-确实进行内核开发-一个启用了许多调试功能的内核。(作为练习,如果你还没有这样做,准备一个“调试”内核并在其上运行这个测试用例。)
LDV(Linux Driver Verification)项目:在第一章中,内核工作空间设置,在LDV-Linux 驱动程序验证项目一节中,我们提到这个项目对 Linux 模块(主要是驱动程序)以及核心内核的各种编程方面有有用的“规则”。
关于我们当前的话题,这里有一个规则:使用自旋锁和解锁函数 (linuxtesting.org/ldv/online?action=show_rule&rule_id=0039)。它提到了关于正确使用自旋锁的关键点;有趣的是,这里展示了一个实际的驱动程序中的 bug 实例,其中尝试两次释放自旋锁 - 这是对锁定规则的明显违反,导致系统不稳定。
锁定和中断
到目前为止,我们已经学会了如何使用互斥锁,以及对于自旋锁,基本的spin_[un]lock() API。自旋锁还有一些其他 API 变体,我们将在这里检查更常见的一些。
要确切理解为什么可能需要其他自旋锁 API,让我们来看一个场景:作为驱动程序作者,你发现你正在处理的设备断言了硬件中断;因此,你为其编写了中断处理程序(你可以在*Linux Kernel Programming (Part 2)*书中详细了解)。现在,在为驱动程序实现read方法时,你发现在其中有一个非阻塞的临界区。这很容易处理:正如你已经学到的,你应该使用自旋锁来保护它。但是,如果在read方法的临界区中,设备的硬件中断触发了怎么办?正如你所知,硬件中断会抢占任何事情;因此,控制权将转移到中断处理程序代码,抢占驱动程序的read方法。
关键问题是:这是一个问题吗?这个答案取决于你的中断处理程序和你的read方法在做什么以及它们是如何实现的。让我们想象一些情景:
-
中断处理程序(理想情况下)只使用本地变量,因此即使
read方法在临界区中,它实际上并不重要;中断处理将非常快速地完成,并且控制将被交还给被中断的内容(同样,这还有更多内容;正如你所知,任何现有的底半部分,如 tasklet 或 softirq,也可能需要执行)。换句话说,在这种情况下实际上并没有竞争。 -
中断处理程序正在处理(全局)共享可写数据,但不是你的读取方法正在使用的数据项。因此,再次,这里没有冲突,也没有与读取代码的竞争。当然,你应该意识到,中断代码确实有一个临界区,必须受到保护(也许需要另一个自旋锁)。
-
中断处理程序正在处理与你的
read方法使用的相同的全局共享可写数据。在这种情况下,我们可以看到确实存在竞争的潜力,因此我们需要锁定!
让我们专注于第三种情况。显然,我们应该使用自旋锁来保护中断处理代码中的临界区(请记住,在任何类型的中断上下文中使用互斥锁是不允许的)。此外,除非我们在read方法和中断处理程序的代码路径中都使用完全相同的自旋锁,否则它们将根本不受保护!(在处理锁时要小心;花时间仔细思考你的设计和代码。)
让我们试着更加实际一些(暂时使用伪代码):假设我们有一个名为gCtx的全局(共享)数据结构;我们在驱动程序中的read方法以及中断处理程序(硬中断处理程序)中对其进行操作。由于它是共享的,它是一个临界区,因此需要保护;由于我们在原子(中断)上下文中运行,不能使用互斥锁,因此必须使用自旋锁(这里,自旋锁变量称为slock)。以下伪代码显示了这种情况的一些时间戳(t1, t2, ...):
// Driver read method ; WRONG ! driver_read(...) << time t0 >>
{
[ ... ]
spin_lock(&slock);
<<--- time t1 : start of critical section >>
... << operating on global data object gCtx >> ...
spin_unlock(&slock);
<<--- time t2 : end of critical section >>
[ ... ]
} << time t3 >>
以下伪代码是设备驱动程序的中断处理程序:
handle_interrupt(...) << time t4; hardware interrupt fires! >>
{
[ ... ]
spin_lock(&slock);
<<--- time t5: start of critical section >>
... << operating on global data object gCtx >> ...
spin_unlock(&slock);
<<--- time t6 : end of critical section >>
[ ... ]
} << time t7 >>
这可以用以下图表总结:
[外链图片转存中…(img-08Ps7z98-1721183650952)]
图 12.12 - 时间线 - 驱动程序的读方法和硬中断处理程序在处理全局数据时按顺序运行;这里没有问题
幸运的是,一切都进行得很顺利——“幸运”是因为硬件中断是在read函数的关键部分完成之后才触发的。当然,我们不能指望运气成为我们产品的唯一安全标志!硬件中断是异步的;如果它在一个不太合适的时间(对我们来说)触发了——比如,在read方法的关键部分在时间 t1 和 t2 之间运行时会怎么样?好吧,自旋锁会执行它的工作并保护我们的数据吗?
在这一点上,中断处理程序的代码将尝试获取相同的自旋锁(&slock)。等一下——它无法“获取”它,因为它当前被锁定了!在这种情况下,它会“自旋”,实际上是在等待解锁。但是它如何解锁呢?它无法解锁,这就是我们所面临的一个**(自我)死锁**。
有趣的是,自旋锁在 SMP(多核)系统上更直观并且更有意义。假设read方法在 CPU 核心 1 上运行;中断可以在另一个 CPU 核心,比如核心 2 上被传递。中断代码路径将在 CPU 核心 2 上的锁上“自旋”,而read方法在核心 1 上完成关键部分,然后解锁自旋锁,从而解除中断处理程序的阻塞。但是在UP(单处理器,只有一个 CPU 核心)上呢?那么它会如何工作呢?啊,所以这是解决这个难题的方法:当与中断“竞争”时,无论是单处理器还是 SMP,都简单地使用自旋锁 API 的*_irq变体:
#include <linux/spinlock.h>
void spin_lock_irq(spinlock_t *lock);
spin_lock_irq() API 在运行它的处理器核心上(即本地核心)内部禁用中断;因此,在我们的read方法中使用这个 API,将会在本地核心上禁用中断,从而通过中断使任何可能的“竞争”变得不可能。(如果中断确实在另一个 CPU 核心上触发,自旋锁技术将像之前讨论的那样正常工作!)
spin_lock_irq()的实现是相当嵌套的(就像大多数自旋锁功能一样),但是很快;在下一行,它最终会调用local_irq_disable()和preempt_disable()宏,从而在它正在运行的本地处理器核心上禁用中断和内核抢占。(禁用硬件中断也会有(可取的)副作用,即禁用内核抢占。)
spin_lock_irq()与相应的spin_unlock_irq() API 配对使用。因此,对于这种情况的自旋锁的正确使用(与我们之前看到的相反)如下:
// Driver read method ; CORRECT ! driver_read(...) << time t0 >>
{
[ ... ]
spin_lock_irq(&slock);
<<--- time t1 : start of critical section >>
*[now all interrupts + preemption on local CPU core are masked (disabled)]*
... << operating on global data object gCtx >> ...
spin_unlock_irq(&slock);
<<--- time t2 : end of critical section >>
[ ... ]
} << time t3 >>
在我们自满地拍拍自己的后背并休息一天之前,让我们考虑另一种情况。这一次,在一个更复杂的产品(或项目)上,有可能在代码库上工作的几个开发人员中,有人故意将中断屏蔽设置为某个值,从而阻止一些中断而允许其他中断。为了举例说明,让我们假设这在之前的某个时间点 t0 发生了。现在,正如我们之前描述的,另一个开发人员(就是你!)过来了,并且为了保护驱动程序的read方法中的关键部分,使用了spin_lock_irq() API。听起来正确,是吗?是的,但是这个 API 有权利关闭(屏蔽)所有硬件中断(和内核抢占,我们暂时忽略)。它通过在本地 CPU 核心上低级地操作(非常特定于架构的)硬件中断屏蔽寄存器来实现。假设将对应于中断的位设置为1会启用该中断,而清除该位(为0)会禁用或屏蔽它。由于这个原因,我们可能会得到以下情况:
- 时间 t0:中断屏蔽被设置为某个值,比如
0x8e (10001110b),启用了一些中断并禁用了一些中断。这对项目很重要(在这里,为了简单起见,我们假设有一个 8 位的屏蔽寄存器)
[…时间流逝…].
- 时间
t1:在进入驱动程序read方法的临界区之前调用
spin_lock_irq(&slock);。这个 API 将内部效果是将注册的中断屏蔽位清零,从而禁用所有中断(正如我们认为所需的)。
- 时间
t2:现在,硬件中断无法在这个 CPU 核心上触发,所以我们继续完成临界区。完成后,我们调用
spin_unlock_irq(&slock);。这个 API 将内部效果是将注册的中断屏蔽位设置为1,重新启用所有中断。
然而,中断屏蔽寄存器现在被错误地“恢复”为值0xff (11111111b),而不是原始开发者想要、需要和假设的值0x8e!这可能会(并且可能会)在项目中造成一些问题。
解决方案非常简单:不要假设任何东西,只需保存和恢复中断屏蔽。可以通过以下 API 对实现这一点:
#include <linux/spinlock.h>
unsigned long spin_lock_irqsave(spinlock_t *lock, unsigned long flags);
void spin_unlock_irqrestore(spinlock_t *lock, unsigned long flags);
锁定和解锁函数的第一个参数都是要使用的自旋锁变量。第二个参数flags必须是unsigned long类型的本地变量。这将用于保存和恢复中断屏蔽:
spinlock_t slock;
spin_lock_init(&slock);
[ ... ]
driver_read(...)
{
[ ... ]
spin_lock_irqsave(&slock, flags);
<< ... critical section ... >>
spin_unlock_irqrestore(&slock, flags);
[ ... ]
}
要严谨一点,spin_lock_irqsave()不是一个 API,而是一个宏;我们将其显示为 API 是为了可读性。此宏的返回值虽然不是 void,但这是一个内部细节(这里更新了flags参数变量)。
如果任务或软中断(底半部中断机制)有一个与您的进程上下文代码路径“竞争”的临界区,那么在这种情况下,使用spin_lock_bh()例程可能是所需的,因为它可以在本地处理器上禁用底半部,然后获取自旋锁,从而保护临界区(类似于spin_lock_irq[save]()在进程上下文中通过禁用本地核心上的硬件中断来保护临界区的方式):
void spin_lock_bh(spinlock_t *lock);
当然,在高性能敏感代码路径中,开销确实很重要(网络堆栈就是一个很好的例子)。因此,使用最简单形式的自旋锁将有助于处理更复杂的变体。尽管如此,肯定会有需要使用更强形式的自旋锁 API 的情况。例如,在 Linux 内核 5.4.0 上,这是我们看到的不同形式自旋锁 API 的使用实例数量的近似值:spin_lock():超过 9,400 个使用实例;spin_lock_irq():超过 3,600 个使用实例;spin_lock_irqsave():超过 15,000 个使用实例;和spin_lock_bh():超过 3,700 个使用实例。(我们不从中得出任何重大推论;只是我们希望指出,在 Linux 内核中广泛使用更强形式的自旋锁 API)。
最后,让我们简要说明一下自旋锁的内部实现:在底层内部方面,实现往往是非常特定于架构的代码,通常由在微处理器上执行非常快的原子机器语言指令组成。例如,在流行的 x86[_64]架构中,自旋锁最终归结为自旋锁结构成员上的原子测试和设置机器指令(通常通过cmpxchg机器语言指令实现)。在 ARM 机器上,正如我们之前提到的,实现的核心往往是wfe(等待事件,以及SetEvent(SEV))机器指令。(您将在进一步阅读部分找到关于其内部实现的资源)。无论如何,作为内核或驱动程序的作者,您在使用自旋锁时应该只使用公开的 API(和宏)。
使用自旋锁-快速总结
让我们快速总结一下自旋锁:
-
最简单,开销最低:在进程上下文中保护关键部分时,使用非中断自旋锁原语
spin_lock()/spin_unlock()(要么没有中断需要处理,要么有中断,但我们根本不与它们竞争;实际上,当中断不起作用或不重要时使用这个)。 -
中等开销:当中断起作用并且很重要时(进程和中断上下文可以“竞争”;也就是说,它们共享全局数据)使用禁用中断(以及内核抢占禁用)版本,
spin_lock_irq() / spin_unlock_irq()。 -
最强(相对而言),开销最高:这是使用自旋锁的最安全方式。它与中等开销相同,只是通过
spin_lock_irqsave()/spin_unlock_irqrestore()对中断掩码执行保存和恢复,以确保以前的中断掩码设置不会被意外覆盖,这可能会发生在前一种情况下。
正如我们之前所看到的,自旋锁在等待锁时在其运行的处理器上“自旋”是不可能的(在另一个线程同时在同一处理器上运行时,你怎么能在一个可用的 CPU 上自旋呢?)。事实上,在 UP 系统上,自旋锁 API 的唯一真正效果是它可以禁用处理器上的硬件中断和内核抢占!然而,在 SMP(多核)系统上,自旋逻辑实际上会起作用,因此锁定语义会按预期工作。但是等一下——这不应该让你感到压力,新手内核/驱动程序开发人员;事实上,整个重点是你应该简单地按照描述使用自旋锁 API,你将永远不必担心 UP 与 SMP;做什么和不做什么的细节都被内部实现隐藏起来。
尽管这本书是基于 5.4 LTS 内核的,但 5.8 内核从实时 Linux(RTL,之前称为 PREEMPT_RT)项目中添加了一个新功能,值得在这里快速提一下:“本地锁”。虽然本地锁的主要用例是(硬)实时内核,但它们也对非实时内核有所帮助,主要是通过静态分析进行锁调试,以及通过 lockdep 进行运行时调试(我们将在下一章中介绍 lockdep)。这是有关该主题的 LWN 文章:lwn.net/Articles/828477/。
通过这一点,我们完成了关于自旋锁的部分,这是 Linux 内核中几乎所有子系统(包括驱动程序)都使用的一种极其常见和关键的锁。
总结
祝贺你完成了这一章节!
理解并发及其相关问题对于任何软件专业人员来说绝对至关重要。在本章中,您学习了关于关键部分、其中独占执行的需求以及原子性含义的关键概念。然后,您了解了在为 Linux 操作系统编写代码时为什么需要关注并发。之后,我们详细介绍了实际的锁技术——互斥锁和自旋锁。您还学会了在何时使用哪种锁。最后,我们讨论了在硬件中断(以及可能的底半部分)起作用时如何处理并发问题。
但我们还没有完成!我们还需要学习更多概念和技术,这正是我们将在下一章,也是最后一章中做的。我建议你先浏览本章的内容,以及进一步阅读部分和提供的练习,然后再深入研究最后一章!
问题
最后,这里有一些问题供您测试对本章材料的了解:github.com/PacktPublishing/Linux-Kernel-Programming/tree/master/questions。您会在本书的 GitHub 存储库中找到一些问题的答案:github.com/PacktPublishing/Linux-Kernel-Programming/tree/master/solutions_to_assgn。
进一步阅读
为了帮助您深入了解这个主题并提供有用的材料,我们在本书的 GitHub 存储库中提供了一个相当详细的在线参考和链接列表(有时甚至包括书籍)的《进一步阅读》文档。进一步阅读文档在这里可用:github.com/PacktPublishing/Linux-Kernel-Programming/blob/master/Further_Reading.md。

















 1455
1455

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









