







原文:
zh.annas-archive.org/md5/E8BAF3E098756D223B5C9821072F71B1译者:飞龙
前言
Apache Storm 是一个强大的框架,用于创建摄取和处理大量数据的复杂工作流。借助其 spouts 和 bolts 的通用概念,以及简单的部署和监控工具,它允许开发人员专注于其工作流的具体内容,而无需重新发明轮子。
然而,Storm 是用 Java 编写的。虽然它支持除 Java 以外的其他编程语言,但工具不完整,文档和示例很少。
本书的作者之一创建了 Petrel,这是第一个支持使用 100% Python 创建 Storm 拓扑的框架。他亲身经历了在 Java 工具集上构建 Python Storm 拓扑的困难。本书填补了这一空白,为所有经验水平的 Python 开发人员提供了一个资源,帮助他们构建自己的应用程序使用 Storm。
本书涵盖的内容
第一章,熟悉 Storm,提供了有关 Storm 用例、不同的安装模式和 Storm 配置的详细信息。
第二章,Storm 解剖,告诉您有关 Storm 特定术语、流程、Storm 中的容错性、调整 Storm 中的并行性和保证元组处理的详细解释。
第三章,介绍 Petrel,介绍了一个名为 Petrel 的框架,用于在 Python 中构建 Storm 拓扑。本章介绍了 Petrel 的安装,并包括一个简单的示例。
第四章,示例拓扑-推特,提供了一个关于实时计算推特数据统计的拓扑的深入示例。该示例介绍了 tick tuples 的使用,这对于需要按计划计算统计信息或执行其他操作的拓扑非常有用。在本章中,您还将看到拓扑如何访问配置数据。
第五章,使用 Redis 和 MongoDB 进行持久化,更新了示例推特拓扑,用于使用 Redis,一种流行的键值存储。它向您展示如何使用内置的 Redis 操作简化复杂的 Python 计算逻辑。本章还介绍了将推特数据存储在 MongoDB 中的示例,MongoDB 是一种流行的 NoSQL 数据库,并使用其聚合功能生成报告。
第六章,实践中的 Petrel,教授实际技能,将使开发人员在使用 Storm 时更加高效。您将学习如何使用 Petrel 为您的 spout 和 bolt 组件创建在 Storm 之外运行的自动化测试。您还将看到如何使用图形调试器来调试在 Storm 内运行的拓扑结构。
【附录】,使用 Supervisord 管理 Storm,是使用监督者在集群上监控和控制 Storm 的实际演示。
本书所需内容
您需要一台安装有 Python 2.7、Java 7 JDK 和 Apache Storm 0.9.3 的计算机。推荐使用 Ubuntu,但不是必需的。
本书适合对象
本书适用于初学者和高级 Python 开发人员,他们希望使用 Storm 实时处理大数据。虽然熟悉 Java 运行时环境有助于安装和配置 Storm,但本书中的所有代码示例都是用 Python 编写的。
约定
在本书中,您将找到许多文本样式,用于区分不同类型的信息。以下是一些这些样式的示例,以及它们的含义解释。
文本中的代码词、数据库表名、文件夹名、文件名、文件扩展名、路径名、虚拟 URL、用户输入和 Twitter 句柄显示如下:“可以使用storm.yaml在conf文件夹中进行 Storm 配置”。
代码块设置如下:
import nltk.corpus
from petrel import storm
from petrel.emitter import BasicBolt
class SplitSentenceBolt(BasicBolt):
def __init__(self):
super(SplitSentenceBolt, self).__init__(script=__file__)
self.stop = set(nltk.corpus.stopwords.words('english'))
self.stop.update(['http', 'https', 'rt'])
当我们希望引起您对代码块的特定部分的注意时,相关行或项目将以粗体显示:
import logging
from collections import defaultdict
from petrel import storm
from petrel.emitter import BasicBolt
任何命令行输入或输出都以以下方式编写:
tail -f petrel24748_totalrankings.log
新术语和重要单词以粗体显示。例如,屏幕上看到的单词,如菜单或对话框中的单词,会以这样的方式出现在文本中:“最后,点击创建您的 Twitter 应用程序”。
注意
警告或重要说明会以这样的方式出现在框中。
提示
提示和技巧会以这样的方式出现。
第一章:熟悉 Storm
在本章中,您将熟悉以下主题:
-
Storm 概述
-
“风暴”之前的时代和风暴的关键特性
-
风暴集群模式
-
Storm 安装
-
启动各种守护程序
-
玩转 Storm 配置
在整个本章课程中,您将了解为什么 Storm 在行业中引起轰动,以及为什么它在当今的场景中很重要。这是什么实时计算?我们还将解释 Storm 的不同类型的集群模式,安装和配置方法。
Storm 概述
Storm 是一个分布式,容错和高度可扩展的平台,可实时处理流数据。它于 2014 年 9 月成为 Apache 顶级项目,并且自 2013 年 9 月以来一直是 Apache 孵化器项目。
实时处理大规模数据已成为企业的需求。Apache Storm 提供了在分布式计算选项中以实时方式处理数据(也称为元组或流)的能力。向 Storm 集群添加更多机器使 Storm 具有可伸缩性。然后,随风暴而来的第三个最重要的事情是容错性。如果风暴程序(也称为拓扑)配备了可靠的喷口,它可以重新处理由于机器故障而丢失的失败元组,并且还具有容错性。它基于 XOR 魔术,将在第二章 风暴解剖中进行解释。
Storm 最初是由 Nathan Marz 及其 BackType 团队创建的。该项目在被 Twitter 收购后成为开源项目。有趣的是,Storm 被称为实时 Hadoop。
Storm 非常适合许多实时用例。这里解释了一些有趣的用例:
-
ETL 管道:ETL 代表提取,转换和加载。这是 Storm 的一个非常常见的用例。数据可以从任何来源提取或读取。这里的数据可以是复杂的 XML,JDBC 结果集行,或者只是一些键值记录。数据(在 Storm 中也称为元组)可以在飞行中用更多信息进行丰富,转换为所需的存储格式,并存储在 NoSQL/RDBMS 数据存储中。所有这些都可以以实时方式通过简单的风暴程序以非常高的吞吐量实现。使用 Storm ETL 管道,您可以以高速将数据摄入到大数据仓库中。
-
趋势话题分析:Twitter 使用这样的用例来了解给定时间范围内或当前的趋势话题。有许多用例,实时查找热门趋势是必需的。Storm 可以很好地适应这样的用例。您还可以借助任何数据库执行值的运行聚合。
-
监管检查引擎:实时事件数据可以通过特定于业务的监管算法,以实时方式进行合规性检查。银行在实时进行交易数据检查时使用这些。
风暴可以理想地适应任何需要以快速可靠的方式处理数据的用例,每秒处理超过 10,000 条消息,一旦数据到达。实际上,10,000+是一个很小的数字。Twitter 能够在大型集群上每秒处理数百万条推文。这取决于 Storm 拓扑结构的编写情况,调优情况以及集群大小。
Storm 程序(也称为拓扑)旨在全天候运行,并且除非有人明确停止它们,否则不会停止。
Storm 使用 Clojure 和 Java 编写。Clojure 是一种 Lisp,运行在 JVM 上的函数式编程语言,最适合并发和并行编程。Storm 利用了成熟的 Java 库,该库在过去 10 年中构建。所有这些都可以在storm/lib文件夹中找到。
风暴时代之前
在 Storm 变得流行之前,实时或准实时处理问题是使用中间代理和消息队列解决的。监听器或工作进程使用 Python 或 Java 语言运行。对于并行处理,代码依赖于编程语言本身提供的线程模型。许多时候,旧的工作方式并没有很好地利用 CPU 和内存。在某些情况下,还使用了大型机,但随着时间的推移,它们也变得过时了。分布式计算并不那么容易。在这种旧的工作方式中,要么有许多中间输出或跳跃。没有办法自动执行故障重放。Storm 很好地解决了所有这些痛点。它是目前可用的最好的实时计算框架之一。
Storm 的关键特性
以下是 Storm 的关键特性;它们解决了前面提到的问题:
-
编程简单:学习 Storm 框架很容易。您可以使用自己选择的编程语言编写代码,也可以使用该编程语言的现有库。没有妥协。
-
Storm 已经支持大多数编程语言:但即使某些语言不受支持,也可以通过使用 Storm 数据规范语言 (DSL)中定义的 JSON 协议提供代码和配置来实现。
-
水平扩展性或分布式计算是可能的:通过向 Storm 集群添加更多机器,可以增加计算而无需停止运行的程序,也称为拓扑。
-
容错性:Storm 管理工作进程和机器级别的故障。跟踪每个进程的心跳以管理不同类型的故障,例如一台机器上的任务故障或整个机器的故障。
-
消息处理保证:Storm 进程可以在消息(元组)上执行自动和显式的 ACK。如果未收到 ACK,Storm 可以重发消息。
-
免费、开源,以及大量的开源社区支持:作为 Apache 项目,Storm 具有免费分发和修改权,无需担心法律方面的问题。Storm 受到开源社区的高度关注,并吸引了大量优秀的开发人员为其贡献代码。
Storm 集群模式
根据需求,Storm 集群可以设置为四种不同的类型。如果您想要设置一个大型集群,可以选择分布式安装。如果您想学习 Storm,那么选择单机安装。如果您想连接到现有的 Storm 集群,则使用客户端模式。最后,如果您想在 IDE 上进行开发,只需解压storm TAR 并指向storm库的所有依赖项。在最初的学习阶段,单机器 Storm 安装实际上是您需要的。
开发者模式
开发人员可以从分发站点下载 Storm,在$HOME的某个位置解压缩,并简单地以本地模式提交 Storm 拓扑。一旦拓扑在本地成功测试,就可以提交以在集群上运行。
单机器 Storm 集群
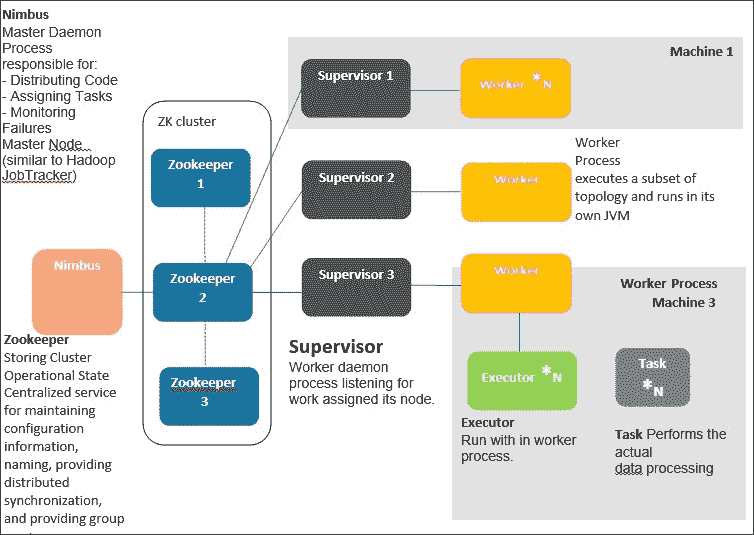
这种类型最适合学生和中等规模的计算。在这里,包括Zookeeper,Nimbus和Supervisor在内的所有内容都在一台机器上运行。Storm/bin用于运行所有命令。也不需要额外的 Storm 客户端。您可以在同一台机器上完成所有操作。这种情况在下图中有很好的演示:

多机器 Storm 集群
当您有大规模计算需求时,需要选择此选项。这是一个水平扩展选项。下图详细解释了这种情况。在这个图中,我们有五台物理机器,为了增加系统的容错性,我们在两台机器上运行 Zookeeper。如图所示,Machine 1和Machine 2是一组 Zookeeper 机器;它们中的一个在任何时候都是领导者,当它死掉时,另一个就成为领导者。Nimbus是一个轻量级进程,所以它可以在机器 1 或 2 上运行。我们还有Machine 3、Machine 4和Machine 5专门用于执行实际处理。这三台机器(3、4 和 5)中的每一台都需要运行一个监督守护进程。机器 3、4 和 5 应该知道 Nimbus/Zookeeper 守护进程运行的位置,并且该条目应该存在于它们的storm.yaml中。
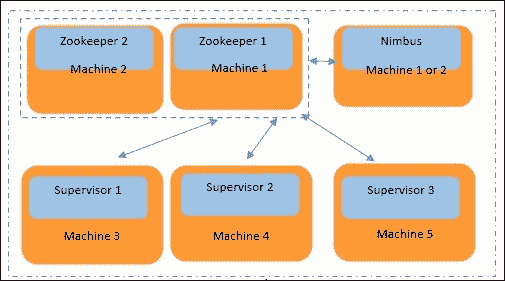
因此,每台物理机器(3、4 和 5)运行一个监督守护进程,并且每台机器的storm.yaml指向 Nimbus 运行的机器的 IP 地址(可以是 1 或 2)。所有监督守护进程机器都必须将 Zookeeper 的 IP 地址(1 和 2)添加到storm.yaml中。Storm UI 守护进程应该在 Nimbus 机器上运行(可以是 1 或 2)。
Storm 客户端
只有当您有多台机器的 Storm 集群时才需要 Storm 客户端。要启动客户端,解压 Storm 分发包,并将 Nimbus IP 地址添加到storm.yaml文件中。Storm 客户端可用于从命令行选项提交 Storm 拓扑和检查正在运行的拓扑的状态。Storm 版本早于 0.9 的版本应该将yaml文件放在$STORM_HOME/.storm/storm.yaml中(新版本不需要)。
注意
jps命令是一个非常有用的 Unix 命令,用于查看 Zookeeper、Nimbus 和 Supervisor 的 Java 进程 ID。kill -9 <pid>选项可以停止正在运行的进程。jps命令只有在PATH环境变量中设置了JAVA_HOME时才能工作。
Storm 安装的先决条件
安装 Java 和 Python 很容易。让我们假设我们的 Linux 机器已经准备好了 Java 和 Python:
-
一个 Linux 机器(Storm 版本 0.9 及更高版本也可以在 Windows 机器上运行)
-
Java 6 (
set export PATH=$PATH:$JAVA_HOME/bin) -
Python 2.6(用于运行 Storm 守护进程和管理命令)
我们将在 storm 配置文件(即storm.yaml)中进行许多更改,实际上该文件位于$STORM_HOME/config下。首先,我们启动 Zookeeper 进程,它在 Nimbus 和 Supervisors 之间进行协调。然后,我们启动 Nimbus 主守护进程,它在 Storm 集群中分发代码。接下来,Supervisor 守护进程监听由 Nimbus 分配给其所在节点的工作,并根据需要启动和停止工作进程。
ZeroMQ/JZMQ 和 Netty 是允许两台机器或两个 JVM 之间发送和接收进程数据(元组)的 JVM 间通信库。JZMQ 是 ZeroMQ 的 Java 绑定。最新版本的 Storm(0.9+)现在已经转移到 Netty。如果您下载的是旧版本的 Storm,则需要安装 ZeroMQ 和 JZMQ。在本书中,我们只考虑最新版本的 Storm,因此您实际上不需要 ZeroMQ/JZMQ。
Zookeeper installation
Zookeeper 是 Storm 集群的协调器。Nimbus 和工作节点之间的交互是通过 Zookeeper 完成的。Zookeeper 的安装在官方网站zookeeper.apache.org/doc/trunk/zookeeperStarted.html#sc_InstallingSingleMode上有很好的解释。
可以从以下位置下载设置:
archive.apache.org/dist/zookeeper/zookeeper-3.3.5/zookeeper-3.3.5.tar.gz。下载后,编辑zoo.cfg文件。
以下是使用的 Zookeeper 命令:
- 启动
zookeeper进程:
../zookeeper/bin/./zkServer.sh start
- 检查
zookeeper服务的运行状态:
../zookeeper/bin/./zkServer.sh status
- 停止
zookeeper服务:
../zookeeper/bin/./zkServer.sh stop
或者,使用jps查找<pid>,然后使用kill -9 <pid>来终止进程。
Storm 安装
Storm 可以通过以下两种方式安装:
- 使用 Git 从此位置获取 Storm 版本:
- 直接从以下链接下载:
storm.apache.org/downloads.html
可以使用conf文件夹中的storm.yaml进行 Storm 配置。
以下是单机 Storm 集群安装的配置。
端口#2181是 Zookeeper 的默认端口。要添加多个zookeeper,请保持条目之间的分隔:
storm.zookeeper.servers:
- "localhost"
# you must change 2181 to another value if zookeeper running on another port.
storm.zookeeper.port: 2181
# In single machine mode nimbus run locally so we are keeping it localhost.
# In distributed mode change localhost to machine name where nimbus daemon is running.
nimbus.host: "localhost"
# Here storm will generate logs of workers, nimbus and supervisor.
storm.local.dir: "/var/stormtmp"
java.library.path: "/usr/local/lib"
# Allocating 4 ports for workers. More numbers can also be added.
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
# Memory is allocated to each worker. In below case we are allocating 768 mb per worker.worker.childopts: "-Xmx768m"
# Memory to nimbus daemon- Here we are giving 512 mb to nimbus.
nimbus.childopts: "-Xmx512m"
# Memory to supervisor daemon- Here we are giving 256 mb to supervisor.
注意
注意supervisor.childopts: "-Xmx256m"。在此设置中,我们保留了四个 supervisor 端口,这意味着最多可以在此机器上运行四个 worker 进程。
storm.local.dir:如果启动 Nimbus 和 Supervisor 时出现问题,应清理此目录位置。在 Windows 机器上的本地 IDE 上运行拓扑的情况下,应清理C:\Users\<User-Name>\AppData\Local\Temp。
启用本地(仅 Netty)依赖项
Netty 使得 JVM 之间的通信变得非常简单。
Netty 配置
您实际上不需要安装任何额外的内容来使用 Netty。这是因为它是一个纯 Java-based 通信库。所有新版本的 Storm 都支持 Netty。
将以下行添加到您的storm.yaml文件中。配置和调整值以最适合您的用例:
storm.messaging.transport: "backtype.storm.messaging.netty.Context"
storm.messaging.netty.server_worker_threads: 1
storm.messaging.netty.client_worker_threads: 1
storm.messaging.netty.buffer_size: 5242880
storm.messaging.netty.max_retries: 100
storm.messaging.netty.max_wait_ms: 1000
storm.messaging.netty.min_wait_ms: 100
启动守护程序
Storm 守护程序是在将程序提交到集群之前需要预先运行的进程。当您在本地 IDE 上运行拓扑程序时,这些守护程序会在预定义端口上自动启动,但在集群上,它们必须始终运行:
- 启动主守护程序
nimbus。转到 Storm 安装的bin目录并执行以下命令(假设zookeeper正在运行):
./storm nimbus
Alternatively, to run in the background, use the same command with nohup, like this:
Run in background
nohup ./storm nimbus &
- 现在我们必须启动
supervisor守护程序。转到 Storm 安装的bin目录并执行此命令:
./storm supervisor
要在后台运行,请使用以下命令:
nohup ./storm supervisor &
注意
如果 Nimbus 或 Supervisors 重新启动,则运行中的拓扑不受影响,因为两者都是无状态的。
- 让我们启动
stormUI。 Storm UI 是一个可选进程。它帮助我们查看运行拓扑的 Storm 统计信息。您可以看到为特定拓扑分配了多少执行器和工作进程。运行 storm UI 所需的命令如下:
./storm ui
另外,要在后台运行,请使用以下命令与nohup一起使用:
nohup ./storm ui &
要访问 Storm UI,请访问http://localhost:8080。
- 我们现在将启动
storm logviewer。 Storm UI 是另一个可选的进程,用于从浏览器查看日志。您还可以使用$STORM_HOME/logs文件夹中的命令行选项查看storm日志。要启动 logviewer,请使用此命令:
./storm logviewer
要在后台运行,请使用以下命令与nohup一起使用:
nohup ./storm logviewer &
注意
要访问 Storm 的日志,请访问http://localhost:8000log viewer守护程序应在每台机器上运行。另一种访问<machine name>的 worker 端口6700日志的方法在这里给出:
<Machine name>:8000/log?file=worker-6700.log
- DRPC 守护程序:DRPC 是另一个可选服务。DRPC代表分布式远程过程调用。如果您想通过 DRPC 客户端从外部提供参数给 storm 拓扑,您将需要 DRPC 守护程序。请注意,参数只能提供一次,DRPC 客户端可能会长时间等待,直到 storm 拓扑进行处理并返回。DRPC 不是项目中常用的选项,首先它对客户端是阻塞的,其次您一次只能提供一个参数。DRPC 不受 Python 和 Petrel 支持。
总结一下,启动进程的步骤如下:
-
首先是所有 Zookeeper 守护程序。
-
Nimbus 守护程序。
-
一个或多个机器上的 Supervisor 守护程序。
-
UI 守护程序,Nimbus 正在运行的地方(可选)。
-
Logviewer 守护程序(可选)。
-
提交拓扑。
您可以随时重新启动nimbus守护程序,而不会对现有进程或拓扑产生影响。您可以重新启动监督程序守护程序,并随时向 Storm 集群添加更多监督程序机器。
要向 Storm 集群提交jar,请转到 Storm 安装的bin目录并执行以下命令:
./storm jar <path-to-topology-jar> <class-with-the-main> <arg1> … <argN>
玩弄可选配置
启动集群需要之前的所有设置,但还有许多其他可选设置可以根据拓扑的要求进行调整。前缀可以帮助找到配置的性质。默认的yaml配置的完整列表可在github.com/apache/storm/blob/master/conf/defaults.yaml上找到。
配置可以通过前缀的起始方式进行识别。例如,所有 UI 配置都以ui*开头。
| 配置的性质 | 要查找的前缀 |
|---|---|
| 一般 | storm.* |
| Nimbus | nimbus.* |
| UI | ui.* |
| 日志查看器 | logviewer.* |
| DRPC | drpc.* |
| Supervisor | supervisor.* |
| 拓扑 | topology.* |
除默认值以外,所有这些可选配置都可以添加到STORM_HOME/conf/storm.yaml中。所有以topology.*开头的设置可以从拓扑或storm.yaml中以编程方式设置。所有其他设置只能从storm.yaml文件中设置。例如,以下表格显示了玩弄这些参数的三种不同方式。然而,这三种方式都是做同样的事情:
| /conf/storm.yaml | 拓扑构建器 | 自定义 yaml |
|---|---|---|
更改storm.yaml(影响集群的所有拓扑) | 在编写代码时更改拓扑构建器(仅影响当前拓扑) | 作为命令行选项提供topology.yaml(仅影响当前拓扑) |
topology.workers: 1 | conf.setNumberOfWorker(1);这是通过 Python 代码提供的 | 创建topology.yaml,其中包含类似于storm.yaml的条目,并在运行拓扑时提供 Python:petrel submit --config topology.yaml |
在storm.yaml中进行任何配置更改都会影响所有正在运行的拓扑,但在代码中使用conf.setXXX选项时,不同的拓扑可以覆盖该选项,以适应它们各自的最佳选择。
摘要
第一章的结论就要来了。本章概述了 Storm 出现之前应用程序是如何开发的。随着我们阅读本章并接近结论,我们还获得了实时计算的简要知识以及 Storm 作为编程框架如何变得如此受欢迎。本章教会了你执行 Storm 配置。它还为你提供了有关 Storm 的守护程序、Storm 集群及其设置的详细信息。在下一章中,我们将探索 Storm 解剖的细节。
第二章:风暴解剖
本章详细介绍了风暴技术的内部结构和流程。本章将涵盖以下主题:
-
风暴流程
-
风暴拓扑特定术语
-
进程间通信
-
风暴中的容错
-
保证元组处理
-
风暴中的并行性-扩展分布式计算
随着我们在本章中的深入,您将详细了解 Storm 的流程及其作用。在本章中,将解释各种特定于 Storm 的术语。您将了解 Storm 如何实现不同类型故障的容错。我们将看到什么是消息处理的保证,最重要的是如何配置 Storm 中的并行性以实现快速可靠的处理。
风暴流程
我们将首先从 Nimbus 开始,实际上 Nimbus 是 Storm 中的入口守护程序。仅仅与 Hadoop 相比,Nimbus 实际上是 Storm 的作业跟踪器。Nimbus 的工作是将代码分发到集群的所有监督守护程序。因此,当拓扑代码被提交时,它实际上会到达集群中的所有物理机器。Nimbus 还监视监督守护程序的故障。如果监督守护程序继续失败,那么 Nimbus 会将这些工作重新分配给集群中不同物理机器的其他工作程序。当前版本的 Storm 只允许运行一个 Nimbus 守护程序实例。Nimbus 还负责将任务分配给监督节点。如果丢失 Nimbus,工作程序仍将继续计算。监督守护程序将在工作程序死亡时继续重新启动工作程序。没有 Nimbus,工作程序的任务将不会重新分配到集群中的另一台机器上的工作程序。
如果 Nimbus 死亡,没有替代的风暴流程会接管,也没有进程会尝试重新启动它。然而,不用担心,因为它可以随时重新启动。在生产环境中,当 Nimbus 死亡时也可以设置警报。在未来,我们可能会看到高可用的 Nimbus。
监督守护程序
监督守护程序管理各自机器的所有工作程序。由于在您的集群中每台机器上都有一个监督守护程序,因此风暴中的分布式计算是可能的。监督守护程序监听 Nimbus 分配给其运行的机器的工作,并将其分配给工作程序。由于任何运行时异常,工作程序随时可能会死亡,当没有来自死亡工作程序的心跳时,监督守护程序会重新启动它们。每个工作程序进程执行拓扑的一部分。与 Hadoop 生态系统类似,监督守护程序是风暴的任务跟踪器。它跟踪同一台机器上的工作程序的任务。可能的工作程序的最大数量取决于storm.yaml中定义的端口数量。
动物园管理员
除了自己的组件外,风暴还依赖于一个动物园管理员集群(一个或多个动物园管理员服务器)来在 Nimbus 和监督守护程序之间执行协调工作。除了用于协调目的,Nimbus 和监督守护程序还将它们所有的状态存储在动物园管理员中,并且动物园管理员将它们存储在其运行的本地磁盘上。拥有多个动物园管理员守护程序可以增加系统的可靠性,因为如果一个守护程序崩溃,另一个守护程序将成为领导者。
风暴 UI
风暴还配备了基于 Web 的用户界面。它应该在运行 Nimbus 的机器上启动。风暴 UI 提供了整个集群的报告,例如所有活动监督机器的总和,可用的工作程序总数,分配给每个拓扑的工作程序数量以及剩余的数量,以及拓扑级诊断,例如元组统计(发射了多少元组,spout 到 bolt 或 bolt 到 bolt 之间的 ACK)。风暴 UI 还显示了工作程序的总数,实际上是所有监督机器的所有可用工作程序的总和。
以下截图显示了风暴 UI 的示例屏幕:
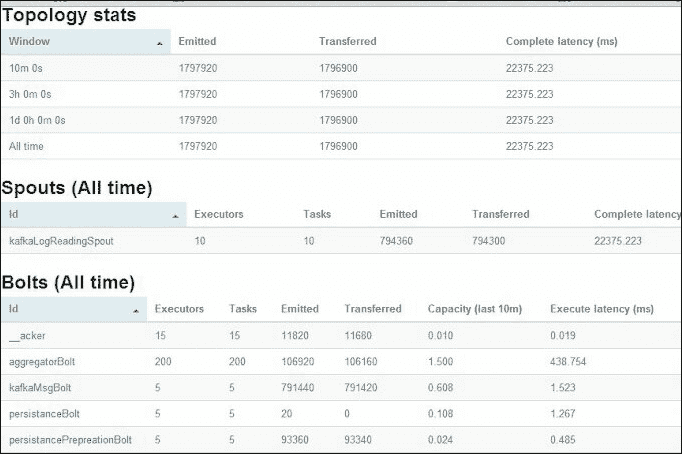
以下是风暴 UI 的解释:
-
拓扑统计:在拓扑统计下,您可以点击并查看最近 10 分钟、3 小时或所有时间的统计信息。
-
喷口(所有时间):显示了为此喷口分配的执行者和任务数量,以及发射的元组和其他延迟统计信息的状态。
-
螺栓(所有时间):显示了所有螺栓的列表,以及分配的执行者/任务。在进行性能调优时,保持容量列接近
1。在前面的aggregatorBolt示例中,它是1.500,所以我们可以使用300而不是200个执行者/任务。容量列帮助我们决定正确的并行度。这个想法非常简单;如果容量列读数超过1,尝试以相同比例增加执行者和任务。如果执行者/任务的值很高,而容量列接近零,尝试减少执行者/任务的数量。您可以一直这样做,直到获得最佳配置。
风暴拓扑特定术语
拓扑是将编程工作逻辑上分成许多小规模处理单元的分离,称为喷口和螺栓,类似于 Hadoop 中的 MapReduce。拓扑可以用许多语言编写,包括 Java、Python 和更多支持的语言。在视觉描述中,拓扑显示为连接喷口和螺栓的图形。喷口和螺栓在集群中执行任务。Storm 有两种操作模式,称为本地模式和分布式模式:
-
在本地模式下,Storm 和工作者的所有进程都在您的代码开发环境中运行。这对于拓扑的测试和开发很有用。
-
在分布式模式下,Storm 作为一组机器的集群运行。当您将拓扑代码提交给 Nimbus 时,Nimbus 负责分发代码并根据您的配置分配工作者来运行您的拓扑。
在下图中,我们有紫色的螺栓;这些从它们上面的喷口接收元组或记录。元组支持拓扑代码所使用的编程语言中的大多数数据类型。它作为一个独立单元从喷口流向螺栓或从一个螺栓流向另一个螺栓。无限的元组流称为流。在一个元组中,您可以有许多键值对一起传递。
下图更详细地说明了流。喷口连接到元组的源并为拓扑生成连续的元组流。从喷口发出的键值对可以被螺栓使用相同的键接收。

工作者进程、执行者和任务
Storm 区分以下三个主要实体,用于在 Storm 集群中实际运行拓扑:
-
工作者
-
执行者
-
任务
假设我们决定保留两个工作者,一个喷口执行者,三个Bolt1执行者和两个Bolt2执行者。假设执行者和任务数量的比例相同。喷口和螺栓的总执行者数为六。在六个执行者中,一些将在工作者 1 的范围内运行,一些将由工作者 2 控制;这个决定由监督者负责。这在下图中有解释。
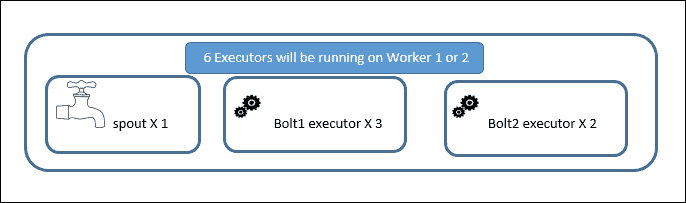
下图解释了在运行在一台机器上的监督者范围内工作者和执行者的位置:
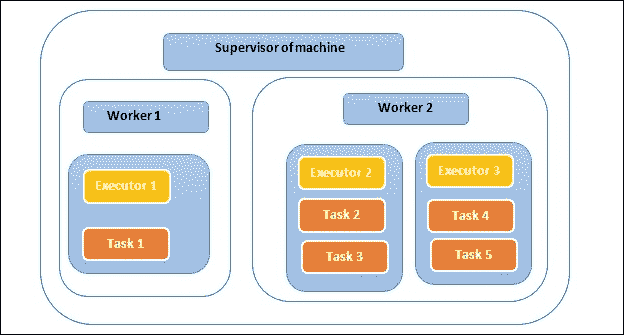
在构建拓扑代码时设置执行器和任务的数量。在上图中,我们有两个工作进程(1 和 2),由该机器的监督者运行和管理。假设执行器 1正在运行一个任务,因为执行器与任务的比例相同(例如,10 个执行器意味着 10 个任务,这使得比例为 1:1)。但是执行器 2正在顺序运行两个任务,因此任务与执行器的比例为 2:1(例如,10 个执行器意味着 20 个任务,这使得比例为 2:1)。拥有更多的任务并不意味着更高的处理速度,但对于更多的执行器来说是正确的,因为任务是顺序运行的。
工作进程
单个工作进程执行拓扑的一部分,并在自己的 JVM 上运行。工作进程在拓扑提交期间分配。工作进程与特定的拓扑相关联,并且可以为该拓扑的一个或多个 spout 或螺栓运行一个或多个执行器。运行中的拓扑由许多这样的工作进程组成,这些工作进程在 Storm 集群中的许多机器上运行。
执行器
执行器是在工作进程的 JVM 范围内运行的线程。执行器可以顺序运行一个或多个 spout 或螺栓的任务。
执行器始终在一个线程上运行其所有任务,这意味着任务在执行器上顺序运行。在拓扑启动后,可以使用rebalance命令更改执行器的数量而无需关闭。
storm rebalance <topology name> -n <number of workers> -e <spout>=<number of executors> -e <bolt1 name>=<number of executors> -e <bolt2 name>=<number of executors>
任务
任务执行数据处理,并在其父执行器的执行线程中运行。任务数量的默认值与执行器的数量相同。在构建拓扑时,我们也可以保留更多的任务数量。这有助于在未来增加执行器的数量,从而保持扩展的范围。最初,我们可以有 10 个执行器和 20 个任务,因此比例为 2:1。这意味着每个执行器有两个任务。未来的重新平衡操作可以使 20 个执行器和 20 个任务,这将使比例为 1:1。
进程间通信
以下图示了 Storm 提交者(客户端)、Nimbus thrift 服务器、Zookeeper、监督者、监督者的工作进程、执行器和任务之间的通信。每个工作进程都作为一个单独的 JVM 运行。

Storm 集群的物理视图
下图解释了每个进程的物理位置。只能有一个 Nimbus。但是,有多个 Zookeeper 来支持故障转移,并且每台机器上都有一个监督者。
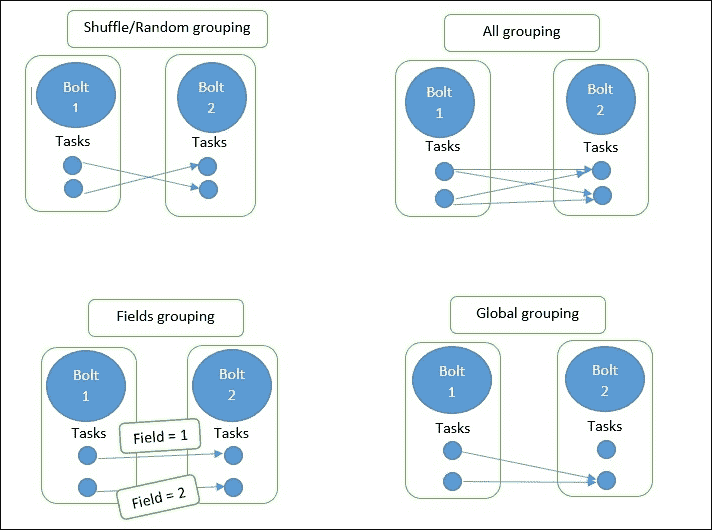
流分组
流分组控制元组在 spout 和螺栓之间或螺栓之间的流动。在 Storm 中,我们有四种类型的分组。Shuffle 和字段分组是最常用的:
-
Shuffle 分组:此分组中两个随机任务之间的元组流
-
字段分组:具有特定字段键的元组始终传递到下游螺栓的相同任务
-
所有分组:将相同的元组发送到下游螺栓的所有任务
-
全局分组:所有任务的元组都到达一个任务
下图解释了所有四种分组类型的图解说明:
Storm 中的容错
监督者运行同步线程,从 Zookeeper 获取分配信息(我应该运行拓扑的哪一部分)并写入本地磁盘。这个本地文件系统信息有助于保持工作进程的最新状态:
-
情况 1:这在大多数情况下都是理想的情况。当集群正常工作时,工作节点的心跳通过 Zookeeper 返回给监督者和 Nimbus。

-
案例 2:如果监督员死亡,处理仍将继续,但任务将永远不会同步。Nimbus 将重新分配工作给另一台不同机器的监督员。这些工人将在运行,但不会接收任何新的元组。确保设置警报以重新启动监督员或使用可以重新启动监督员的 Unix 工具。
-
案例 3:如果 Nimbus 死亡,拓扑将继续正常运行。处理仍将继续,但拓扑生命周期操作和重新分配到另一台机器将不可能。
-
案例 4:如果工作人员死亡(因为心跳停止到达),监督员将尝试重新启动工作进程并继续处理。如果工作人员反复死亡,Nimbus 将重新分配工作给集群中的其他节点。
Storm 中的元组处理保证
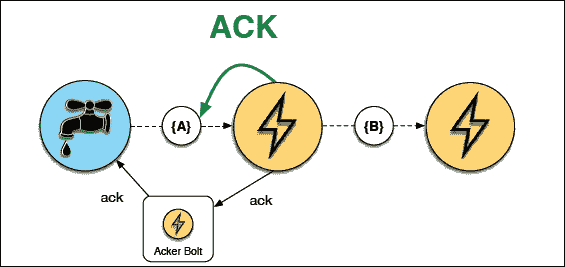
由于 Storm 已经配备了处理各种进程级故障的能力,另一个重要特性是处理工作人员死亡时发生的元组失败的能力。这只是为了给出按位 XOR 的概念:相同位的两组的 XOR 为 0。这被称为 XOR 魔术,它可以帮助我们知道元组传递到下一个螺栓是否成功。Storm 使用 64 位来跟踪元组。每个元组都有一个 64 位的元组 ID。此 64 位 ID 连同任务 ID 一起保存在 ACKer 中。
在下一个图中,解释了 ACKing 和重播案例:
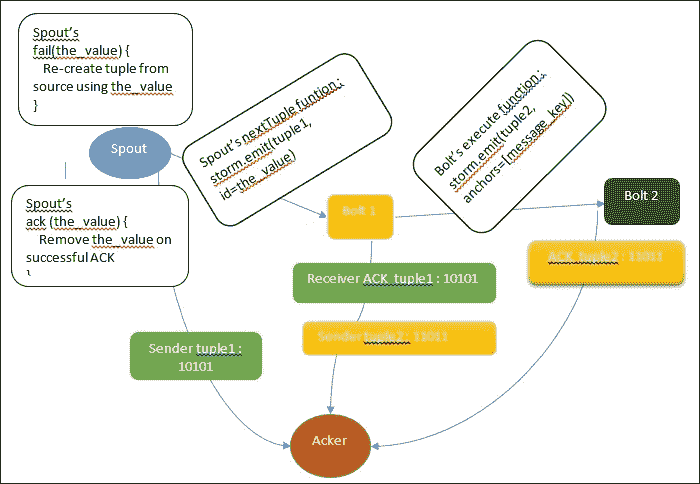
ACKing 中的 XOR 魔术
在链接的元组树中的所有元组完成之前,喷口元组不会被完全处理。如果在配置的超时时间内未完成元组树(默认值为topology.message.timeout.secs: 30),则会重播喷口元组。
在前面的图中,第一个 acker 从喷口获得了10101(为了简单起见,我们保留了 5 位)的元组 1。一旦Bolt 1接收到相同的元组,它也会向 acker 发送 ACK。从两个来源,acker 都获得了10101。这意味着10101 XOR 10101 = 0。元组 1 已成功被Bolt 1接收。同样的过程在螺栓 1 和 2 之间重复。最后,Bolt 2向 acker 发送 ACK,元组树完成。这会创建一个信号来调用喷口的success函数。元组处理中的任何失败都可以触发喷口的fail函数调用,这表明需要将元组发送回进行再次处理。
Storm 的 acker 通过对发送者的元组和接收者的元组执行 XOR 来跟踪元组树的完成。每次发送元组时,它的值都会被 XOR 到 acker 维护的校验和中,每次确认元组时,它的值都会再次 XOR 到 acker 中。
如果所有元组都已成功确认,校验和将为零。Ackers 是系统级执行者。
在喷口中,我们可以选择两个发射函数。
-
emit([tuple]):这是一个简单的发射 -
storm.emit([tuple], id=the_value):这将创建一个可靠的喷口,但只有在您可以使用the_value重新发射元组时才能实现
在喷口中,我们还有两个 ACK 函数:
-
fail(the_value):当发生超时或元组失败时调用此函数 -
ack(the_value):当拓扑的最后一个螺栓确认元组树时调用此函数
此 ID 字段应该是一个随机且唯一的值,以便从喷口的fail函数中重播。使用此 ID,我们可以从fail函数中重新发射它。如果成功,将调用success函数,并且可以从全局列表中删除成功的元组或从源中重新创建。
如果拓扑中有一个可靠的喷口,您将能够重新创建相同的元组。要创建可靠的喷口,请从喷口的下一个元组函数中发射一个唯一的消息 ID(the_value)以及元组:
storm.emit([tuple], id=the_value)
如果元组在配置的时间段内未被确认,或者编程代码由于某些错误条件而失败了元组,这两种情况都是重播的有效情况。
当调用fail函数时,代码可以使用相同的消息 ID 从喷口的源中读取,并且当调用success函数时,可以执行诸如从队列中删除消息之类的操作。
消息 ID 是一个特定于应用程序的键,可以帮助您重新创建一个元组并从喷口重新发出。消息 ID 的一个示例可以是队列消息 ID,或者是表的主键。如果发生超时或由于其他原因,元组被视为失败。
Storm 具有容错机制,可以保证所有仅从可靠喷口发出的元组至少处理一次。
一旦有了可靠的喷口,就可以让螺栓在输入和输出元组之间进行链接,从而创建一个元组树。一旦建立了元组树,确认者就知道了链接树中的任何故障,并且使用原始消息 ID 再次创建整个元组树。
在螺栓中,有两个函数:
-
emit([tuple]): 没有元组树链接。我们无法追踪使用了哪个原始消息 ID。 -
storm.emit([tuple], anchors=[message_key]): 有了链接,现在可以重放原始元组。
下图解释了元组 B 是如何从元组 A 生成的:

下图说明了执行ACK的螺栓:

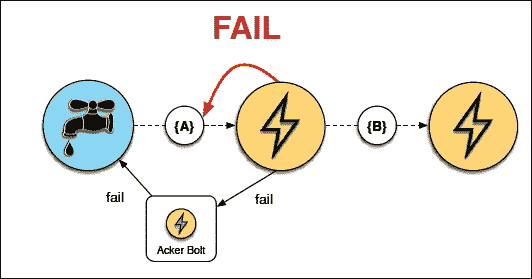
下图说明了故障情况,信号在故障时到达喷口:
成功的ACK演示如下:
下图说明了没有螺栓的大元组树的情况,也没有失败:

下图演示了元组树中的故障示例 - 在元组树的中间:

Storm 中的并行性调优 - 扩展分布式计算
为了解释 Storm 的并行性,我们将配置三个参数:
-
工作人员的数量
-
执行者的数量
-
任务的数量
下图给出了一个拓扑结构的示例,其中只有一个喷口和一个螺栓。在这种情况下,我们将为喷口和螺栓级别的工作人员、执行者和任务设置不同的值,并看看在每种情况下并行性是如何工作的:
// assume we have two workers in total for topology.
topology.workers: 2
// just one executor of spout.
builder.setSpout("spout-sentence", TwitterStreamSpout(),1)
// two executors of bolt.
builder.setBolt("bolt-split", SplitSentenceBolt(),2)
// four tasks for bolts.
.setNumTasks(4)
.shuffleGrouping("spout-sentence");
对于这个配置,我们将有两个工作人员,它们将在单独的 JVM 中运行(工作人员 1 和工作人员 2)。
对于喷口,有一个执行者,任务的默认数量是一个,这使得比例为 1:1(每个执行者一个任务)。
对于螺栓,有两个执行者和四个任务,这使得 4/2 = 每个执行者两个任务。这两个执行者在工作人员 2 下运行,每个执行者有两个任务,而工作人员 1 的执行者只有一个任务。
这可以用下图很好地说明:

让我们将螺栓的配置更改为两个执行者和两个任务:
builder.setBolt("bolt-split", SplitSentenceBolt(),2)
// 2 tasks for bolts.
.setNumTasks(2)
.shuffleGrouping("spout-sentence");
这在这里可以很好地说明:

工作人员的数量再次是两个。由于螺栓有两个执行者和两个任务,这使得它成为 2/2,或者每个执行者一个任务。现在您可以看到,两个执行者都分别获得一个任务。在性能方面,两种情况完全相同,因为任务在执行者线程内顺序运行。更多的执行者意味着更高的并行性,更多的工作人员意味着更有效地使用 CPU 和 RAM 等资源。内存分配是在工作人员级别使用worker.childopts设置完成的。我们还应该监视特定工作人员进程所持有的最大内存量。这在决定工作人员的总数时起着重要作用。可以使用ps -ef选项来查看。始终保持任务和执行者的比例相同,并使用 Storm UI 的容量列推导出执行者数量的正确值。作为一个重要的注意事项,我们应该将较短的持续时间事务保留在螺栓中,并尝试通过将代码拆分为更多的螺栓或减少批处理大小元组来调整它。批处理大小是螺栓在单个元组传递中接收的记录数量。此外,不要因为较长的持续时间事务而阻塞喷口的nextTuple方法。
总结
随着本章接近尾声,您一定对 Nimbus、supervisor、UI 和 Zookeeper 进程有了一个简要的了解。本章还教会了您如何通过调整 Storm 中的并行性来玩弄工作人员、执行者和任务的数量。您熟悉了分布式计算的重要问题,即系统中可用的不同类型的容错机制来克服故障和故障。最重要的是,您学会了如何编写一个“可靠”的喷口,以实现消息处理和在螺栓中的链接的保证。
下一章将为您提供有关如何使用名为 Petrel 的 Python 库构建简单拓扑的信息。Petrel 解决了 Storm 内置 Python 支持的一些限制,提供了更简单、更流畅的开发。
第三章:介绍 Petrel
如第一章中所讨论的,熟悉 Storm,Storm 是一个用于实时处理大量数据的平台。Storm 应用通常用 Java 编写,但 Storm 也支持其他语言,包括 Python。虽然各种语言的概念相似,但细节因语言而异。在本章中,我们将首次使用 Python 与 Storm 进行实际操作。首先,您将了解一个名为 Petrel 的 Python 库,这对于在 Python 中创建拓扑是必要的。接下来,我们将设置 Python/Storm 开发环境。然后,我们将仔细研究一个用 Python 编写的工作中的 Storm 拓扑。最后,我们将运行拓扑,您将学习一些关键技术,以便简化开发和调试拓扑的过程。完成本章后,您将对开发基本 Storm 拓扑有一个很好的高层理解。在本章中,我们将涵盖以下主题:
-
什么是 Petrel?
-
安装 Petrel
-
创建您的第一个拓扑
-
运行拓扑
-
使用 Petrel 的生产力技巧
什么是 Petrel?
本书中所有的 Python 拓扑都依赖于一个名为 Petrel 的开源 Python 库。如果您之前有 Storm 的经验,您可能会记得有一个名为storm-starter的 GitHub 项目,其中包括了使用各种语言与 Storm 的示例(您可以在github.com/apache/storm/tree/master/examples/storm-starter找到storm-starter的最新版本)。storm-starter项目包括一个名为storm.py的模块,它允许您在 Python 中实现 Storm 拓扑。鉴于storm.py的可用性,真的有必要使用另一个库吗?虽然使用storm.py构建拓扑是完全可能的,但它缺少一些重要的功能。为了解决这些差距,开发者必须使用对大多数 Python 开发者来说并不熟悉的语言和工具。如果您已经熟悉这些工具,并且在使用 Storm 时不介意同时使用多种技术栈,您可能会满意于storm.py。但大多数对 Storm 不熟悉的开发者发现storm.py的方法过于复杂,甚至令人不知所措。让我们更详细地讨论一下storm.py的弱点。
构建拓扑
为了运行一个拓扑,Storm 需要其中 spouts、bolts 和 streams 的描述。这个描述是用一种叫做Thrift的格式编码的。storm.py模块不支持创建这个描述;开发者必须使用另一种编程语言(通常是 Java 或 Clojure)来创建它。
打包拓扑
拓扑以 Java.jar文件的形式提交给 Storm(类似于 Python.egg或.tar.gz文件)。除了拓扑描述,Python 拓扑.jar还必须包括拓扑的 Python 代码。创建一个 JAR 文件通常涉及使用 Java 开发工具,如 Ant 或 Maven。
记录事件和错误
如果拓扑包括记录消息以跟踪流经其中的数据,那么调试和监视拓扑将更加容易。如果 Python 拓扑出现问题并且代码崩溃,查看错误和发生错误的位置是非常宝贵的。storm.py模块在这些方面提供不了任何帮助。如果一个组件崩溃,它会简单地退出而不捕获任何信息。根据我的经验,这是使用storm.py最令人沮丧的方面。
管理第三方依赖
现实世界的 Python 应用程序经常使用第三方库。如果一个集群需要运行多个拓扑,每个拓扑可能具有不同甚至冲突的这些库的版本。Python 虚拟环境是管理这一切的好工具。然而,storm.py不会帮助您在 Python 虚拟环境中创建、激活或安装第三方库。Petrel 解决了 Storm 内置 Python 支持的所有这些限制,提供了更简单、更流畅的开发体验。Petrel 的主要特点包括以下内容:
-
用于构建拓扑的 Python API
-
将拓扑打包以提交到 Storm
-
记录事件和错误
-
在工作节点上,使用
setup.sh设置特定于拓扑的 Python 运行时环境
在本章中,我们将讨论前三点。我们将在第四章中看到第四点的示例,示例拓扑 - Twitter。
安装 Petrel
让我们设置我们的 Python 开发环境。我们在这里假设您已经按照第一章中的说明安装了 Storm 0.9.3:
- 首先,我们需要安装
virtualenv,这是一个管理 Python 库的工具。在 Ubuntu 上,只需运行此命令:
sudo apt-get install python-virtualenv
- 接下来,我们创建一个 Python 虚拟环境。这提供了一种安装 Python 库的方式,而无需对机器进行根访问,也不会干扰系统的 Python 包:
virtualenv petrel
您将看到类似以下的输出:
New python executable in petrel/bin/python
Installing distribute.............................................................................................................................................................................................done
- 接下来,运行此命令以激活虚拟环境。您的 shell 提示符将更改以包括
virtualenv名称,表示虚拟环境处于活动状态:
source petrel/bin/activate
(petrel)barry@Dell660s:~$
注意
您需要再次运行此命令 - 每次打开新终端时。
- 最后,安装 Petrel:
easy_install petrel==0.9.3.0.3
注意
Petrel 版本号的前三位数字必须与您使用的 Storm 版本号匹配。如果您使用的 Storm 版本没有相应的 Petrel 发布,您可以从源代码安装 Petrel。查看github.com/AirSage/Petrel#installing-petrel-from-source获取说明。
提示
下载示例代码
您可以从您在www.packtpub.com的帐户中下载您购买的所有 Packt 图书的示例代码文件。如果您在其他地方购买了这本书,您可以访问www.packtpub.com/support并注册,以便将文件直接通过电子邮件发送给您
创建您的第一个拓扑
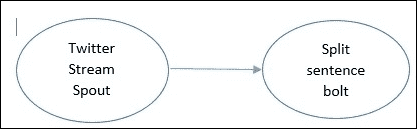
现在,我们将创建一个 Storm 拓扑,将句子分解为单词,然后计算每个单词的出现次数。在 Storm 中实现这个拓扑需要以下组件:
-
句子喷口(
randomsentence.py):拓扑始终以喷口开始;这就是数据进入 Storm 的方式。句子喷口将发出无限流的句子。 -
分割器螺栓(
splitsentence.py):接收句子并将其分割成单词。 -
单词计数螺栓(
wordcount.py):接收单词并计算出现次数。对于每个处理的单词,输出该单词以及出现次数。
以下图显示了数据如何通过拓扑流动:

单词计数拓扑
现在我们已经看到了基本的数据流动,让我们实现拓扑并看看它是如何工作的。
句子喷口
在本节中,我们实现了一个生成随机句子的喷口。在名为randomsentence.py的文件中输入此代码:
import time
import random
from petrel import storm
from petrel.emitter import Spout
class RandomSentenceSpout(Spout):
def __init__(self):
super(RandomSentenceSpout, self).__init__(script=__file__)
@classmethod
def declareOutputFields(cls):
return ['sentence']
sentences = [
"the cow jumped over the moon",
"an apple a day keeps the doctor away",
]
def nextTuple(self):
time.sleep(0.25)
sentence = self.sentences[
random.randint(0, len(self.sentences) - 1)]
storm.emit([sentence])
def run():
RandomSentenceSpout().run()
喷口继承自 Petrel 的Spout类。
Petrel 要求每个喷口和螺栓类都要实现__init__()并将其文件名传递给(script=__file__)基类。script参数告诉 Petrel 在启动组件实例时运行哪个 Python 脚本。
declareOutputFields()函数告诉 Storm 关于这个分流器发出的元组的结构。每个元组由一个名为sentence的单个字段组成。
Storm 每次准备从分流器获取更多数据时都会调用nextTuple()。在真实的分流器中,您可能会从外部数据源(如 Kafka 或 Twitter)读取数据。这个分流器只是一个例子,所以它生成自己的数据。它只是在两个句子之间随机选择一个。
您可能已经注意到,分流器在每次调用nextTuple()时都会休眠 0.25 秒。为什么会这样?这在技术上并不是必要的,但它会减慢速度,并且在本地模式下运行拓扑时,使输出更容易阅读。
run()函数的作用是什么?这是 Petrel 需要的一点粘合代码。当一个分流器或螺栓脚本被加载到 Storm 中时,Petrel 调用run()函数来创建组件并开始处理消息。如果您的分流器或螺栓需要进行额外的初始化,这是一个很好的地方。
分割器螺栓
本节提供了分割器螺栓,它从分流器中获取句子并将其分割成单词。将以下代码输入名为splitsentence.py的文件中:
from petrel import storm
from petrel.emitter import BasicBolt
class SplitSentenceBolt(BasicBolt):
def __init__(self):
super(SplitSentenceBolt, self).__init__(script=__file__)
def declareOutputFields(self):
return ['word']
def process(self, tup):
words = tup.values[0].split("")
for word in words:
storm.emit([word])
def run():
SplitSentenceBolt().run()
SplitSentenceBolt继承自BasicBolt Petrel 类。这个类用于大多数简单的螺栓。您可能还记得 Storm 有一个特性,可以确保每条消息都被处理,如果它们没有被完全处理,就会“重放”之前的元组。BasicBolt简化了使用这个特性。它通过在每个元组被处理时自动向 Storm 确认来实现。更灵活的Bolt类允许程序员直接确认元组,但这超出了本书的范围。
分割句子螺栓具有运行函数,类似于分流器。
process()函数接收来自分流器的句子并将其分割成单词。每个单词都作为一个单独的元组发出。
单词计数螺栓
本节实现了单词计数螺栓,它从分流器中获取单词并对其进行计数。将以下代码输入名为wordcount.py的文件中:
from collections import defaultdict
from petrel import storm
from petrel.emitter import BasicBolt
class WordCountBolt(BasicBolt):
def __init__(self):
super(WordCountBolt, self).__init__(script=__file__)
self._count = defaultdict(int)
@classmethod
def declareOutputFields(cls):
return ['word', 'count']
def process(self, tup):
word = tup.values[0]
self._count[word] += 1
storm.emit([word, self._count[word]])
def run():
WordCountBolt().run()
单词计数螺栓有一个新的变化;与句子螺栓不同,它需要存储从一个元组到下一个元组的信息——单词计数。__init__()函数设置了一个_count字段来处理这个问题。
单词计数螺栓使用 Python 方便的defaultdict类,它通过在访问不存在的键时自动提供0条目来简化计数。
定义拓扑
前面的章节提供了单词计数拓扑的分流器和螺栓。现在,我们需要告诉 Storm 如何将组件组合成拓扑。在 Petrel 中,可以通过create.py脚本来完成这个任务。该脚本提供以下信息:
-
组成拓扑的分流器和螺栓
-
每个螺栓的输入数据来自哪里
-
元组如何在螺栓的实例之间分区
以下是create.py脚本:
from randomsentence import RandomSentenceSpout
from splitsentence import SplitSentenceBolt
from wordcount import WordCountBolt
def create(builder):
builder.setSpout("spout", RandomSentenceSpout(), 1)
builder.setBolt(
"split", SplitSentenceBolt(), 1).shuffleGrouping("spout")
builder.setBolt(
"count", WordCountBolt(), 1).fieldsGrouping(
"split", ["word"])
单词计数螺栓必须使用 Storm 的fieldsGrouping行为(如第二章Storm 解剖中的流分组部分所述)。这个螺栓的设置可以让您在数据流中根据一个或多个字段对元组进行分组。对于单词计数拓扑,fieldsGrouping确保所有单词的实例都将由同一个 Storm 工作进程计数。
当拓扑部署在集群上时,单词计数螺栓可能会有很多个独立运行的实例。如果我们没有在"word"字段上配置fieldsGrouping,那么通过处理句子“the cow jumped over the moon”,我们可能会得到以下结果:
Word count instance 1: { "the": 1, "cow": 1, "jumped": 1 }
Word count instance 2: { "over": 1, "the": 1, "moon": 1 }
有两个"the"的条目,因此计数是错误的!我们希望得到这样的结果:
Word count instance 1: { "the": 2, "cow": 1, "jumped": 1 }
Word count instance 2: { "over": 1, "moon": 1 }
运行拓扑
只需再提供一些细节,我们就可以运行拓扑了:
- 创建一个
topology.yaml文件。这是 Storm 的配置文件。这本书的范围超出了对该文件的完整解释,但您可以在github.com/apache/storm/blob/master/conf/defaults.yaml上看到所有可用选项的完整集合:
nimbus.host: "localhost"
topology.workers: 1
-
创建一个空的
manifest.txt文件。您可以使用编辑器来做这个或者简单地运行touch manifest.txt。这是一个特定于 Petrel 的文件,告诉 Petrel 应该在提交给 Storm 的.jar文件中包含哪些附加文件(如果有的话)。在第四章中,示例拓扑 - Twitter我们将看到一个真正使用这个文件的示例。 -
在运行拓扑之前,让我们回顾一下我们创建的文件列表。确保您已正确创建这些文件:
-
randomsentence.py -
splitsentence.py -
wordcount.py -
create.py -
topology.yaml -
manifest.txt
- 使用以下命令运行拓扑:
petrel submit --config topology.yaml --logdir `pwd`
恭喜!您已经创建并运行了您的第一个拓扑!
Petrel 运行create.py脚本来发现拓扑的结构,然后使用该信息加上manifest.txt文件来构建topology.jar文件并将其提交给 Storm。接下来,Storm 解压topology.jar文件并准备工作进程。使用 Petrel,这需要创建一个 Python 虚拟环境并从互联网安装 Petrel。大约 30 秒后,拓扑将在 Storm 中运行起来。
您将看到无休止的输出流,其中夹杂着类似以下的消息:
25057 [Thread-20] INFO backtype.storm.daemon.task - Emitting: split default ["the"]
25058 [Thread-20] INFO backtype.storm.daemon.task - Emitting: split default ["moon"]
25059 [Thread-22] INFO backtype.storm.daemon.task - Emitting: count default ["cow",3]
25059 [Thread-9-count] INFO backtype.storm.daemon.executor - Processing received message source: split:3, stream: default, id: {}, ["over"]
25059 [Thread-9-count] INFO backtype.storm.daemon.executor - Processing received message source: split:3, stream: default, id: {}, ["the"]
25059 [Thread-9-count] INFO backtype.storm.daemon.executor - Processing received message source: split:3, stream: default, id: {}, ["moon"]
25060 [Thread-22] INFO backtype.storm.daemon.task - Emitting: count default ["jumped",3]
25060 [Thread-22] INFO backtype.storm.daemon.task - Emitting: count default ["over",3]
25060 [Thread-22] INFO backtype.storm.daemon.task - Emitting: count default ["the",9]
25060 [Thread-22] INFO backtype.storm.daemon.task - Emitting: count default ["moon",3]
-
当您看够了,请按Ctrl + C 杀死 Storm。有时它不会干净地退出。如果不行,通常以下步骤会清理问题:多按几次Ctrl + C,然后按Ctrl + Z 暂停 Storm。
-
键入
ps以获取processes列表,查找 Java 进程并获取其进程idType "kill -9 processid",将processid替换为 Java 进程的 ID。
故障排除
如果拓扑不能正确运行,请查看在当前目录中创建的日志文件。错误通常是由于使用与 PyPI 网站上的 Petrel 对应版本的 Storm 版本不匹配(pypi.python.org/pypi/petrel)。在撰写本书时,有两个 Storm 版本得到支持:
-
0.9.3
-
0.9.4
如果您使用的是不受支持的 Storm 版本,可能会看到类似以下错误之一:
File "/home/barry/.virtualenvs/petrel2/lib/python2.7/site-packages/petrel-0.9.3.0.3-py2.7.egg/petrel/cmdline.py", line 19, in get_storm_version
return m.group(2)
AttributeError: 'NoneType' object has no attribute 'group'
IOError: [Errno 2] No such file or directory: '/home/barry/.virtualenvs/petrel2/lib/python2.7/site-packages/petrel-0.9.3.0.3-py2.7.egg/petrel/generated/storm-petrel-0.10.0-SNAPSHOT.jar'
使用 Petrel 的生产力技巧
在本章中,我们已经涵盖了很多内容。虽然我们不知道 Storm 的每一个细节,但我们已经看到了如何构建一个具有多个组件的拓扑,并在它们之间发送数据。
拓扑的 Python 代码非常简短——总共只有大约 75 行。这是一个很好的例子,但实际上,它只是稍微有点短。当您开始编写自己的拓扑时,事情可能不会一开始就完美。新代码通常会有错误,有时甚至会崩溃。要正确地使事情运行,您需要知道拓扑中发生了什么,特别是在出现问题时。当您努力解决问题时,您将一遍又一遍地运行相同的拓扑,而拓扑的 30 秒启动时间可能会显得很漫长。
改进启动性能
首先让我们解决启动性能问题。默认情况下,当 Petrel 拓扑启动时,它会创建一个新的 Python virtualenv 并在其中安装 Petrel 和其他依赖项。虽然这种行为在部署拓扑到集群上时非常有用,但在开发过程中,当您可能会多次启动拓扑时,这种行为非常低效。要跳过virtualenv创建步骤,只需将submit命令更改为 Petrel 重用现有的 Python 虚拟环境:
petrel submit --config topology.yaml --venv self
这将将启动时间从 30 秒减少到约 10 秒。
启用和使用日志记录
像许多语言一样,Python 有一个日志框架,提供了一种捕获运行应用程序内部发生的情况的方法。本节描述了如何在 Storm 中使用日志记录:
- 在与单词计数拓扑相同的目录中,创建一个名为
logconfig.ini的新文件:
[loggers]
keys=root,storm
[handlers]
keys=hand01
[formatters]
keys=form01
[logger_root]
level=INFO
handlers=hand01
[logger_storm]
qualname=storm
level=DEBUG
handlers=hand01
propagate=0
[handler_hand01]
class=FileHandler
level=DEBUG
formatter=form01
args=(os.getenv('PETREL_LOG_PATH') or 'petrel.log', 'a')
[formatter_form01]
format=[%(asctime)s][%(name)s][%(levelname)s]%(message)s
datefmt=
class=logging.Formatter
注意
您刚刚看到的是一个用于演示目的的简单日志配置。有关 Python 日志记录的更多信息,请参阅www.python.org/上的日志模块文档。
- 更新
wordcount.py以记录其输入和输出。新增加的行已经标出:
import logging
from collections import defaultdict
from petrel import storm
from petrel.emitter import BasicBolt
log = logging.getLogger('wordcount')
class WordCountBolt(BasicBolt):
def __init__(self):
super(WordCountBolt, self).__init__(script=__file__)
self._count = defaultdict(int)
@classmethod
def declareOutputFields(cls):
return ['word', 'count']
def process(self, tup):
log.debug('WordCountBolt.process() called with: %s',
tup)
word = tup.values[0]
self._count[word] += 1
log.debug('WordCountBolt.process() emitting: %s',
[word, self._count[word]])
storm.emit([word, self._count[word]])
def run():
WordCountBolt().run()
- 现在启动更新后的拓扑:
petrel submit --config topology.yaml --venv self --logdir `pwd`
当拓扑运行时,单词计数组件的日志文件将被写入当前目录,捕获正在发生的事情。文件名因运行而异,但类似于petrel22011_wordcount.log:
WordCountBolt.process() called with: <Tuple component='split' id='5891744987683180633' stream='default' task=3 values=['moon']>
WordCountBolt.process() emitting: ['moon', 2]
WordCountBolt.process() called with: <Tuple component='split' id='-8615076722768870443' stream='default' task=3 values=['the']>
WordCountBolt.process() emitting: ['the', 7]
自动记录致命错误
如果一个喷口或螺栓因运行时错误而崩溃,您需要知道发生了什么才能修复它。为了帮助解决这个问题,Petrel 会自动将致命的运行时错误写入日志:
- 在单词计数螺栓的
process()函数开头添加一行,使其崩溃:
def process(self, tup):
raise ValueError('abc')
log.debug('WordCountBolt.process() called with: %s', tup)
word = tup.values[0]
self._count[word] += 1
log.debug('WordCountBolt.process() emitting: %s',
[word, self._count[word]])
storm.emit([word, self._count[word]])
- 再次运行拓扑,并检查单词计数日志文件。它将包含失败的回溯:
[2015-02-08 22:28:42,383][storm][INFO]Caught exception
[2015-02-08 22:28:42,383][storm][ERROR]Sent failure message ("E_BOLTFAILED__wordcount__Dell660s__pid__21794__port__-1__taskindex__-1__ValueError") to Storm
[2015-02-08 22:28:47,385][storm][ERROR]Caught exception in BasicBolt.run
Traceback (most recent call last):
File "/home/barry/dev/Petrel/petrel/petrel/storm.py", line 381, in run
self.process(tup)
File "/tmp/b46e3137-1956-4abf-80c8-acaa7d3626d1/supervisor/stormdist/test+topology-1-1423452516/resources/wordcount.py", line 19, in process
raise ValueError('abc')
ValueError: abc
[2015-02-08 22:28:47,386][storm][ERROR]The error occurred while processing this tuple: ['an']
Worker wordcount exiting normally.
总结
在本章中,您学习了 Petrel 如何使得在纯 Python 中开发 Storm 拓扑成为可能。我们创建并运行了一个简单的拓扑,您也学会了它是如何工作的。您还学会了如何使用 Petrel 的--venv self选项和 Python 日志记录来简化您的开发和调试过程。
在下一章中,我们将看到一些更复杂的拓扑结构,包括一个从真实数据源(Twitter)读取而不是随机生成数据的喷口。
第四章:示例拓扑 - Twitter
本章建立在第三章 介绍 Petrel的材料基础上。在本章中,我们将构建一个演示许多新功能和技术的拓扑。特别是,我们将看到如何:
-
实现一个从 Twitter 读取的喷头
-
基于第三方 Python 库构建拓扑组件
-
计算滚动时间段内的统计数据和排名
-
从
topology.yaml中读取自定义配置设置 -
使用“tick tuples”按计划执行逻辑
Twitter 分析
你们大多数人都听说过 Twitter,但如果你没有,看看维基百科是如何描述 Twitter 的:
“一种在线社交网络服务,使用户能够发送和阅读称为“推文”的短 140 字符消息。”
2013 年,用户在 Twitter 上每天发布了 4 亿条消息。Twitter 提供了一个 API,让开发人员实时访问推文流。在上面,消息默认是公开的。消息的数量、API 的可用性以及推文的公开性结合在一起,使 Twitter 成为对当前事件、感兴趣的话题、公众情绪等进行洞察的宝贵来源。
Storm 最初是在 BackType 开发的,用于处理推文,Twitter 分析仍然是 Storm 的一个受欢迎的用例。您可以在 Storm 网站上看到一些示例,网址为storm.apache.org/documentation/Powered-By.html。
本章的拓扑演示了如何从 Twitter 的实时流 API 中读取数据,计算最受欢迎的单词的排名。这是 Storm 网站上“滚动热门词”示例的 Python 版本(github.com/apache/storm/blob/master/examples/storm-starter/src/jvm/storm/starter/RollingTopWords.java),由以下组件组成:
-
Twitter 流喷头(
twitterstream.py):这从 Twitter 样本流中读取推文。 -
分割器螺栓(
splitsentence.py):这个接收推文并将它们分割成单词。这是第三章 介绍 Petrel中分割器螺栓的改进版本。 -
滚动词计数螺栓(
rollingcount.py):这接收单词并计算出现次数。它类似于第三章 介绍 Petrel中的单词计数螺栓,但实现了滚动计数(这意味着螺栓定期丢弃旧数据,因此单词计数仅考虑最近的消息)。 -
中间排名螺栓(
intermediaterankings.py):这消耗单词计数,并定期发出* n *最常见的单词。 -
总排名螺栓(
totalrankings.py):这类似于中间排名螺栓。它将中间排名组合起来,产生一个总体排名。
Twitter 的流 API
Twitter 的公共 API 既强大又灵活。它有许多功能,用于发布和消费推文。我们的应用程序需要实时接收和处理推文。Twitter 的流 API 旨在解决这个问题。在计算机科学中,流是随时间提供的数据元素(在本例中是推文)的序列。
流 API 在dev.twitter.com/streaming/overview中有详细说明。要使用它,应用程序首先创建到 Twitter 的连接。连接保持打开状态以无限期接收推文。
流 API 提供了几种选择应用程序接收哪些 tweets 的方法。我们的拓扑使用所谓的示例流,它由 Twitter 任意选择的所有 tweets 的一个小子集。示例流用于演示和测试。生产应用程序通常使用其他流类型之一。有关可用流的更多信息,请参阅dev.twitter.com/streaming/public。
创建 Twitter 应用程序以使用流 API
在我们可以使用 Twitter 的流 API 之前,Twitter 要求我们创建一个应用程序。这听起来很复杂,但是设置起来非常容易;基本上,我们只需要在网站上填写一个表格:
-
如果您没有 Twitter 帐户,请在
twitter.com/上创建一个。 -
一旦您拥有一个帐户,请登录并转到
apps.twitter.com/。单击创建新应用程序。填写创建应用程序的表格。将回调 URL字段留空。默认访问级别是只读,这意味着此应用程序只能读取 tweets;它不能发布或进行其他更改。只读访问对于此示例来说是可以的。最后,单击创建您的 Twitter 应用程序。您将被重定向到您的应用程序页面。 -
单击密钥和访问令牌选项卡,然后单击创建我的访问令牌。Twitter 将生成由两部分组成的访问令牌:访问令牌和访问令牌密钥。连接到 Twitter 时,您的应用程序将使用此令牌以及消费者密钥和消费者密钥。
生成访问令牌后,下面的屏幕截图显示了密钥和访问令牌选项卡:

拓扑配置文件
现在我们已经设置了具有 API 访问权限的 Twitter 帐户,我们准备创建拓扑。首先,创建topology.yaml。我们在第三章中首次看到了一个基本的topology.yaml文件,介绍 Petrel。在这里,topology.yaml还将保存 Twitter 的连接参数。输入以下文本,用您从apps.twitter.com/获取的四个oauth值替换:
nimbus.host: "localhost"
topology.workers: 1
oauth.consumer_key: "blahblahblah"
oauth.consumer_secret: "blahblahblah"
oauth.access_token: "blahblahblah"
oauth.access_token_secret: "blahblahblah"
Twitter 流 spout
现在,让我们看看 Twitter spout。在twitterstream.py中输入以下代码:
import json
import Queue
import threading
from petrel import storm
from petrel.emitter import Spout
from tweepy.streaming import StreamListener
from tweepy import OAuthHandler, Stream
class QueueListener(StreamListener):
def __init__(self, queue):
self.queue = queue
def on_data(self, data):
tweet = json.loads(data)
if 'text' in tweet:
self.queue.put(tweet['text'])
return True
class TwitterStreamSpout(Spout):
def __init__(self):
super(TwitterStreamSpout, self).__init__(script=__file__)
self.queue = Queue.Queue(1000)
def initialize(self, conf, context):
self.conf = conf
thread = threading.Thread(target=self._get_tweets)
thread.daemon = True
thread.start()
@classmethod
def declareOutputFields(cls):
return ['sentence']
def _get_tweets(self):
auth = OAuthHandler(
self.conf['oauth.consumer_key'],
self.conf['oauth.consumer_secret'])
auth.set_access_token(
self.conf['oauth.access_token'],
self.conf['oauth.access_token_secret'])
stream = Stream(auth, QueueListener(self.queue))
stream.sample(languages=['en'])
def nextTuple(self):
tweet = self.queue.get()
storm.emit([tweet])
self.queue.task_done()
def run():
TwitterStreamSpout().run()
spout 如何与 Twitter 通信?Twitter API 对 API 客户端施加了一些要求:
-
连接必须使用安全套接字层(SSL)进行加密
-
API 客户端必须使用 OAuth 进行身份验证,这是一种用于与安全网络服务进行交互的流行身份验证协议
-
由于它涉及长时间的连接,流 API 涉及的不仅仅是一个简单的 HTTP 请求。
幸运的是,有一个名为Tweepy(www.tweepy.org/)的库,它以简单易用的 Python API 实现了这些要求。Tweepy 提供了一个Stream类来连接到流 API。它在_get_tweets()中使用。
创建 Tweepy 流需要前面列出的四个 Twitter 连接参数。我们可以直接在我们的 spout 中硬编码这些参数,但是如果连接参数发生更改,我们就必须更改代码。相反,我们将这些信息放在topology.yaml配置文件中。我们的 spout 在initialize()函数中读取这些设置。Storm 在此组件的任务启动时调用此函数,向其传递有关环境和配置的信息。在这里,initialize()函数捕获了self.conf中的拓扑配置。这个字典包括oauth值。
下面的序列图显示了 spout 如何与 Twitter 通信,接收 tweets 并发出它们。您可能已经注意到 spout 创建了一个后台线程。该线程从 Tweepy 接收 tweets,并使用 Python 队列将它们传递给主 spout 线程。
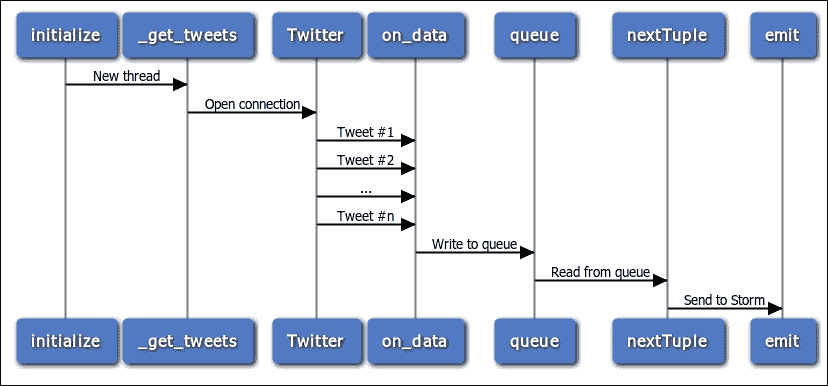
为什么 spout 使用线程?通常,线程用于支持并发处理。但这里并非如此。相反,Tweepy 的行为与 Petrel spout API 之间存在不匹配。
当从 Twitter 流中读取时,Tweepy 会阻止执行,并为接收到的每条推文调用一个由应用程序提供的事件处理程序函数。
在 Petrel 中,spout 上的nextTuple()函数必须在每个元组后从函数返回。
在后台线程中运行 Tweepy 并写入队列为这些冲突的要求提供了一个简单而优雅的解决方案。
分割器螺栓
这里的分割器螺栓在结构上类似于第三章中的一个,介绍 Petrel。这个版本有两个改进,使它更有用和更现实。
提示
忽略那些非常常见以至于在“热门单词”列表中不感兴趣或有用的单词。这包括英语单词,如“the”,以及在推文中频繁出现的类似单词的术语,如“http”,“https”和“rt”。
在将推文拆分为单词时省略标点符号。
一个名为自然语言工具包(NLTK)的 Python 库使得实现这两者变得容易。NLTK 还有许多其他引人入胜的、强大的语言处理功能,但这些超出了本书的范围。
在splitsentence.py中输入以下代码:
import nltk.corpus
from petrel import storm
from petrel.emitter import BasicBolt
class SplitSentenceBolt(BasicBolt):
def __init__(self):
super(SplitSentenceBolt, self).__init__(script=__file__)
self.stop = set(nltk.corpus.stopwords.words('english'))
self.stop.update(['http', 'https', 'rt'])
def declareOutputFields(self):
return ['word']
def process(self, tup):
for word in self._get_words(tup.values[0]):
storm.emit([word])
def _get_words(self, sentence):
for w in nltk.word_tokenize(sentence):
w = w.lower()
if w.isalpha() and w not in self.stop:
yield w
def run():
SplitSentenceBolt().run()
滚动字数螺栓
滚动字数螺栓类似于第三章中的字数螺栓,介绍 Petrel。早期章节中的螺栓只是无限累积单词计数。这对于分析 Twitter 上的热门话题并不好,因为热门话题可能在下一刻就会改变。相反,我们希望计数反映最新信息。为此,滚动字数螺栓将数据存储在基于时间的存储桶中。然后,定期丢弃超过 5 分钟的存储桶。因此,此螺栓的字数仅考虑最近 5 分钟的数据。
在rollingcount.py中输入以下代码:
from collections import defaultdict
from petrel import storm
from petrel.emitter import BasicBolt
class SlotBasedCounter(object):
def __init__(self, numSlots):
self.numSlots = numSlots
self.objToCounts = defaultdict(lambda: [0] * numSlots)
def incrementCount(self, obj, slot):
self.objToCounts[obj][slot] += 1
def getCount(self, obj, slot):
return self.objToCounts[obj][slot]
def getCounts(self):
return dict((k, sum(v)) for k, v in self.objToCounts.iteritems())
def wipeSlot(self, slot):
for obj in self.objToCounts.iterkeys():
self.objToCounts[obj][slot] = 0
def shouldBeRemovedFromCounter(self, obj):
return sum(self.objToCounts[obj]) == 0
def wipeZeros(self):
objToBeRemoved = set()
for obj in self.objToCounts.iterkeys():
if sum(self.objToCounts[obj]) == 0:
objToBeRemoved.add(obj)
for obj in objToBeRemoved:
del self.objToCounts[obj]
class SlidingWindowCounter(object):
def __init__(self, windowLengthInSlots):
self.windowLengthInSlots = windowLengthInSlots
self.objCounter = /
SlotBasedCounter(
self.windowLengthInSlots)
self.headSlot = 0
self.tailSlot = self.slotAfter(self.headSlot)
def incrementCount(self, obj):
self.objCounter.incrementCount(obj, self.headSlot)
def getCountsThenAdvanceWindow(self):
counts = self.objCounter.getCounts()
self.objCounter.wipeZeros()
self.objCounter.wipeSlot(self.tailSlot)
self.headSlot = self.tailSlot
self.tailSlot = self.slotAfter(self.tailSlot)
return counts
def slotAfter(self, slot):
return (slot + 1) % self.windowLengthInSlots
class RollingCountBolt(BasicBolt):
numWindowChunks = 5
emitFrequencyInSeconds = 60
windowLengthInSeconds = numWindowChunks * \
emitFrequencyInSeconds
def __init__(self):
super(RollingCountBolt, self).__init__(script=__file__)
self.counter = SlidingWindowCounter(
self.windowLengthInSeconds /
self.emitFrequencyInSeconds
@classmethod
def declareOutputFields(cls):
return ['word', 'count']
def process(self, tup):
if tup.is_tick_tuple():
self.emitCurrentWindowCounts()
else:
self.counter.incrementCount(tup.values[0])
def emitCurrentWindowCounts(self):
counts = self.counter.getCountsThenAdvanceWindow()
for k, v in counts.iteritems():
storm.emit([k, v])
def getComponentConfiguration(self):
return {"topology.tick.tuple.freq.secs":
self.emitFrequencyInSeconds}
def run():
RollingCountBolt().run()
SlotBasedCounter为每个单词存储了一个numSlots(五)个计数值的列表。每个槽存储emitFrequencyInSeconds(60)秒的数据。超过 5 分钟的计数值将被丢弃。
螺栓如何知道已经过去了 60 秒?Storm 通过提供称为tick tuples的功能使这变得容易。当您需要按计划在螺栓中执行一些逻辑时,此功能非常有用。要使用此功能,请执行以下步骤:
-
在
getComponentConfiguration()中,返回一个包含topology.tick.tuple.freq.secs键的字典。该值是期望的 tick 之间的秒数。 -
在
process()中,检查元组是正常元组还是 tick 元组。当接收到 tick 元组时,螺栓应运行其计划的处理。
中间排名螺栓
中间排名螺栓维护一个由发生计数排名的前maxSize(10)个项目组成的字典,并且每隔emitFrequencyInSeconds(15)秒发出这些项目。在生产中,拓扑将运行许多此类螺栓的实例,每个实例维护整体单词的子集的顶部单词。拥有同一组件的多个实例允许拓扑处理大量推文,并且即使不同单词的数量相当大,也可以轻松地将所有计数保存在内存中。
在intermediaterankings.py中输入此代码:
from petrel import storm
from petrel.emitter import BasicBolt
def tup_sort_key(tup):
return tup.values[1]
class IntermediateRankingsBolt(BasicBolt):
emitFrequencyInSeconds = 15
maxSize = 10
def __init__(self):
super(IntermediateRankingsBolt, self).__init__(script=__file__)
self.rankedItems = {}
def declareOutputFields(self):
return ['word', 'count']
def process(self, tup):
if tup.is_tick_tuple():
for t in self.rankedItems.itervalues():
storm.emit(t.values)
else:
self.rankedItems[tup.values[0]] = tup
if len(self.rankedItems) > self.maxSize:
for t in sorted(
self.rankedItems.itervalues(), key=tup_sort_key):
del self.rankedItems[t.values[0]]
break
def getComponentConfiguration(self):
return {"topology.tick.tuple.freq.secs":
self.emitFrequencyInSeconds}
def run():
IntermediateRankingsBolt().run()
总排名螺栓
总排名螺栓与中间排名螺栓非常相似。拓扑中只有一个此类螺栓的实例。它接收来自该螺栓每个实例的顶部单词,并选择整体的前maxSize(10)个项目。
在totalrankings.py中输入以下代码:
import logging
from petrel import storm
from petrel.emitter import BasicBolt
log = logging.getLogger('totalrankings')
def tup_sort_key(tup):
return tup.values[1]
class TotalRankingsBolt(BasicBolt):
emitFrequencyInSeconds = 15
maxSize = 10
def __init__(self):
super(TotalRankingsBolt, self).__init__(script=__file__)
self.rankedItems = {}
def declareOutputFields(self):
return ['word', 'count']
def process(self, tup):
if tup.is_tick_tuple():
for t in sorted(
self.rankedItems.itervalues(),
key=tup_sort_key,
reverse=True):
log.info('Emitting: %s', repr(t.values))
storm.emit(t.values)
else:
self.rankedItems[tup.values[0]] = tup
if len(self.rankedItems) > self.maxSize:
for t in sorted(
self.rankedItems.itervalues(),
key=tup_sort_key):
del self.rankedItems[t.values[0]]
break
zero_keys = set(
k for k, v in self.rankedItems.iteritems()
if v.values[1] == 0)
for k in zero_keys:
del self.rankedItems[k]
def getComponentConfiguration(self):
return {"topology.tick.tuple.freq.secs": self.emitFrequencyInSeconds}
def run():
TotalRankingsBolt().run()
定义拓扑
这是定义拓扑结构的create.py脚本:
from twitterstream import TwitterStreamSpout
from splitsentence import SplitSentenceBolt
from rollingcount import RollingCountBolt
from intermediaterankings import IntermediateRankingsBolt
from totalrankings import TotalRankingsBolt
def create(builder):
spoutId = "spout"
splitterId = "splitter"
counterId = "counter"
intermediateRankerId = "intermediateRanker"
totalRankerId = "finalRanker"
builder.setSpout(spoutId, TwitterStreamSpout(), 1)
builder.setBolt(
splitterId, SplitSentenceBolt(), 1).shuffleGrouping("spout")
builder.setBolt(
counterId, RollingCountBolt(), 4).fieldsGrouping(
splitterId, ["word"])
builder.setBolt(
intermediateRankerId,
IntermediateRankingsBolt(), 4).fieldsGrouping(
counterId, ["word"])
builder.setBolt(
totalRankerId, TotalRankingsBolt()).globalGrouping(
intermediateRankerId)
这个拓扑的结构类似于第三章中的单词计数拓扑,Introducing Petrel。TotalRankingsBolt有一个新的变化。如前所述,这个螺栓只有一个实例,并且它使用globalGrouping(),所以所有来自IntermediateRankingsBolt的元组都会被发送到它。
你可能想知道为什么拓扑需要中间排名和总排名的螺栓。为了让我们知道最常见的单词,需要有一个单一的螺栓实例(总排名),可以跨越整个推文流。但是在高数据速率下,一个单一的螺栓不可能跟得上流量。中间排名螺栓实例“保护”总排名螺栓免受这种流量的影响,计算其推文流片段的热门词汇。这使得最终排名螺栓能够计算整体最常见的单词,同时只消耗整体单词计数的一小部分。优雅!
运行拓扑
在运行拓扑之前,我们还有一些小事情要处理:
-
从第三章中的第二个例子中复制
logconfig.ini文件,Introducing Petrel,到这个拓扑的目录中。 -
创建一个名为
setup.sh的文件。Petrel 将把这个脚本与拓扑打包并在启动时运行。这个脚本安装了拓扑使用的第三方 Python 库。文件看起来像这样:
pip install -U pip
pip install nltk==3.0.1 oauthlib==0.7.2 tweepy==3.2.0
- 创建一个名为
manifest.txt的文件,包含以下两行:
logconfig.ini
setup.sh
- 在运行拓扑之前,让我们回顾一下我们创建的文件列表。确保你已经正确创建了这些文件:
-
topology.yaml -
twitterstream.py -
splitsentence.py -
rollingcount.py -
intermediaterankings.py -
totalrankings.py -
manifest.txt -
setup.sh
- 使用以下命令运行拓扑:
petrel submit --config topology.yaml --logdir `pwd`
一旦拓扑开始运行,打开topology目录中的另一个终端。输入以下命令以查看总排名螺栓的log文件,按从最旧到最新的顺序排序:
ls -ltr petrel*totalrankings.log
如果这是你第一次运行拓扑,那么只会列出一个日志文件。每次运行都会创建一个新文件。如果列出了几个文件,请选择最近的一个。输入此命令以监视日志文件的内容(在你的系统上确切的文件名将不同):
tail -f petrel24748_totalrankings.log
大约每 15 秒,你会看到按热门程度降序排列的前 10 个单词的日志消息,就像这样:
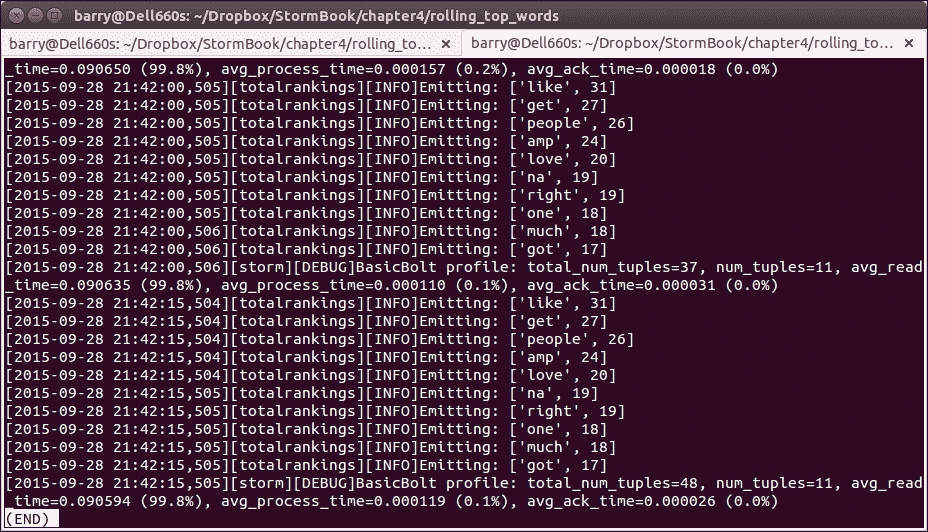
摘要
在本章中,我们使用了许多新技术和库来开发一个复杂的拓扑。阅读完这个例子后,你应该准备好开始应用 Petrel 和 Storm 来解决实际问题。
在即将到来的章节中,我们将更仔细地研究一些 Storm 的内置功能,这些功能在操作集群时非常有用,比如日志记录和监控。
第五章:使用 Redis 和 MongoDB 进行持久化
通常需要将元组存储在持久性数据存储中,例如 NoSQL 数据库或快速键值缓存,以进行额外的分析。在本章中,我们将借助两种流行的持久性媒体 Redis 和 MongoDB,重新访问来自第四章的 Twitter 趋势分析拓扑,示例拓扑-推特。
Redis(redis.io/)是一个开源的 BSD 许可高级键值缓存和存储。MongoDB 是一个跨平台的面向文档的数据库(www.mongodb.org/)。
在本章中,我们将解决以下两个问题:
-
使用 Redis 查找热门推文话题
-
使用 MongoDB 计算城市提及的每小时聚合
使用 Redis 查找排名前 n 的话题
拓扑将计算过去 5 分钟内最受欢迎的单词的滚动排名。单词计数存储在长度为 60 秒的各个窗口中。它包括以下组件:
-
Twitter 流喷口(
twitterstream.py):这从 Twitter 样本流中读取推文。这个喷口与第四章中的相同,示例拓扑-推特。 -
分割器螺栓(
splitsentence.py):这接收推文并将它们分割成单词。这也与第四章中的相同,示例拓扑-推特。 -
滚动字数计数螺栓(
rollingcount.py):这接收单词并计算出现次数。 Redis 键看起来像twitter_word_count:<当前窗口开始时间(以秒为单位)>,值存储在哈希中,格式如下:
{
"word1": 5,
"word2", 3,
}
这个螺栓使用 Redis 的expireat命令在 5 分钟后丢弃旧数据。这些代码行执行关键工作:
self.conn.zincrby(name, word)
self.conn.expireat(name, expires)
Total rankings bolt (totalrankings.py)
在这个螺栓中,以下代码完成了最重要的工作:
self.conn.zunionstore(
'twitter_word_count',
['twitter_word_count:%s' % t for t in xrange(
first_window, now_floor)])
for t in self.conn.zrevrange('twitter_word_count', 0, self.maxSize, withscores=True):
log.info('Emitting: %s', repr(t))
storm.emit(t)
这个螺栓计算了在过去的 num_windows 周期内的前maxSize个单词。zunionstore()组合了各个时期的单词计数。zrevrange()对组合计数进行排序,返回前maxSize个单词。
在原始的 Twitter 示例中,rollingcount.py,intermediaterankings.py和totalrankings.py中实现了大致相同的逻辑。使用 Redis,我们可以用几行代码实现相同的计算。设计将大部分工作委托给了 Redis。根据您的数据量,这可能不如前一章中的拓扑那样具有规模。但是,这表明了 Redis 的能力远远不止于简单存储数据。
拓扑配置文件-Redis 案例
接下来是拓扑配置文件。根据您的 Redis 安装,您可能需要更改redis_url的值。
在topology.yaml中输入以下代码:
nimbus.host: "localhost"
topology.workers: 1
oauth.consumer_key: "your-key-for-oauth-blah"
oauth.consumer_secret: "your-secret-for-oauth-blah"
oauth.access_token: "your-access-token-blah"
oauth.access_token_secret: "your-access-secret-blah"
twitter_word_count.redis_url: "redis://localhost:6379"
twitter_word_count.num_windows: 5
twitter_word_count.window_duration: 60
滚动字数计数螺栓-Redis 案例
滚动字数计数螺栓类似于第三章中的字数计数螺栓,介绍 Petrel。早期章节中的螺栓只是无限累积了单词计数。这对于分析 Twitter 上的热门话题并不好,因为热门话题可能在下一刻就会改变。相反,我们希望计数反映最新的信息。如前所述,滚动字数计数螺栓将数据存储在基于时间的存储桶中。然后,定期丢弃超过 5 分钟的存储桶。因此,这个螺栓的单词计数只考虑最近 5 分钟的数据。
在rollingcount.py中输入以下代码:
import math
import time
from collections import defaultdict
import redis
from petrel import storm
from petrel.emitter import BasicBolt
class RollingCountBolt(BasicBolt):
def __init__(self):
super(RollingCountBolt, self).__init__(script=__file__)
def initialize(self, conf, context):
self.conf = conf
self.num_windows = self.conf['twitter_word_count.num_windows']
self.window_duration = self.conf['twitter_word_count.window_duration']
self.conn = redis.from_url(conf['twitter_word_count.redis_url'])
@classmethod
def declareOutputFields(cls):
return ['word', 'count']
def process(self, tup):
word = tup.values[0]
now = time.time()
now_floor = int(math.floor(now / self.window_duration) * self.window_duration)
expires = int(now_floor + self.num_windows * self.window_duration)
name = 'twitter_word_count:%s' % now_floor
self.conn.zincrby(name, word)
self.conn.expireat(name, expires)
def run():
RollingCountBolt().run()
总排名螺栓-Redis 案例
在totalrankings.py中输入以下代码:
import logging
import math
import time
import redis
from petrel import storm
from petrel.emitter import BasicBolt
log = logging.getLogger('totalrankings')
class TotalRankingsBolt(BasicBolt):
emitFrequencyInSeconds = 15
maxSize = 10
def __init__(self):
super(TotalRankingsBolt, self).__init__(script=__file__)
self.rankedItems = {}
def initialize(self, conf, context):
self.conf = conf
self.num_windows = \
self.conf['twitter_word_count.num_windows']
self.window_duration = \
self.conf['twitter_word_count.window_duration']
self.conn = redis.from_url(
conf['twitter_word_count.redis_url'])
def declareOutputFields(self):
return ['word', 'count']
def process(self, tup):
if tup.is_tick_tuple():
now = time.time()
now_floor = int(math.floor(now / self.window_duration) *
self.window_duration)
first_window = int(now_floor - self.num_windows *
self.window_duration)
self.conn.zunionstore(
'twitter_word_count',
['twitter_word_count:%s' % t for t in xrange(first_window, now_floor)])
for t in self.conn.zrevrange('
'twitter_word_count', 0,
self.maxSize, withScores=True):
log.info('Emitting: %s', repr(t))
storm.emit(t)
def getComponentConfiguration(self):
return {"topology.tick.tuple.freq.secs":
self.emitFrequencyInSeconds}
def run():
TotalRankingsBolt().run()
定义拓扑-Redis 案例
这是定义拓扑结构的create.py脚本:
from twitterstream import TwitterStreamSpout
from splitsentence import SplitSentenceBolt
from rollingcount import RollingCountBolt
from totalrankings import TotalRankingsBolt
def create(builder):
spoutId = "spout"
splitterId = "splitter"
counterId = "counter"
totalRankerId = "finalRanker"
builder.setSpout(spoutId, TwitterStreamSpout(), 1)
builder.setBolt(
splitterId, SplitSentenceBolt(), 1).shuffleGrouping("spout")
builder.setBolt(
counterId, RollingCountBolt(), 4).fieldsGrouping(
splitterId, ["word"])
builder.setBolt(
totalRankerId, TotalRankingsBolt()).globalGrouping(
counterId)
运行拓扑-Redis 案例
在运行拓扑之前,我们还有一些小事情要处理:
-
从第三章的第二个例子中复制
logconfig.ini文件,Petrel 介绍到这个拓扑的目录。 -
创建一个名为
setup.sh的文件。Petrel 将会把这个脚本和拓扑一起打包,并在启动时运行它。这个脚本安装了拓扑使用的第三方 Python 库。文件看起来是这样的:
pip install -U pip
pip install nltk==3.0.1 oauthlib==0.7.2
tweepy==3.2.0
- 创建一个名为
manifest.txt的文件,包含以下两行:
logconfig.ini
setup.sh
- 在一个已知的节点上安装 Redis 服务器。所有的工作节点都会在这里存储状态:
sudo apt-get install redis-server
- 在所有 Storm 工作节点上安装 Python Redis 客户端:
sudo apt-get install python-redis
- 在运行拓扑之前,让我们回顾一下我们创建的文件列表。确保你已经正确创建了这些文件:
-
topology.yaml -
twitterstream.py -
splitsentence.py -
rollingcount.py -
totalrankings.py -
manifest.txt -
setup.sh
- 使用以下命令运行拓扑:
petrel submit --config topology.yaml --logdir `pwd`
拓扑运行后,在拓扑目录中打开另一个终端。输入以下命令来查看总排名 bolt 的日志文件,从最旧到最新排序:
ls -ltr petrel*totalrankings.log
如果这是你第一次运行这个拓扑,那么只会列出一个日志文件。每次运行都会创建一个新文件。如果列出了几个文件,选择最近的一个。输入以下命令来监视日志文件的内容(确切的文件名在你的系统上会有所不同):
tail -f petrel24748_totalrankings.log
定期地,你会看到类似以下的输出,按照流行度降序列出前 5 个单词:
totalrankings的示例输出:
[2015-08-10 21:30:01,691][totalrankings][INFO]Emitting: ('love', 74.0)
[2015-08-10 21:30:01,691][totalrankings][INFO]Emitting: ('amp', 68.0)
[2015-08-10 21:30:01,691][totalrankings][INFO]Emitting: ('like', 67.0)
[2015-08-10 21:30:01,692][totalrankings][INFO]Emitting: ('zaynmalik', 61.0)
[2015-08-10 21:30:01,692][totalrankings][INFO]Emitting: ('mtvhottest', 61.0)
[2015-08-10 21:30:01,692][totalrankings][INFO]Emitting: ('get', 58.0)
[2015-08-10 21:30:01,692][totalrankings][INFO]Emitting: ('one', 49.0)
[2015-08-10 21:30:01,692][totalrankings][INFO]Emitting: ('follow', 46.0)
[2015-08-10 21:30:01,692][totalrankings][INFO]Emitting: ('u', 44.0)
[2015-08-10 21:30:01,692][totalrankings][INFO]Emitting: ('new', 38.0)
[2015-08-10 21:30:01,692][totalrankings][INFO]Emitting: ('much', 37.0)
使用 MongoDB 按城市名称查找每小时推文数量
MongoDB 是一个用于存储大量数据的流行数据库。它被设计为在许多节点之间轻松扩展。
要运行这个拓扑,首先需要安装 MongoDB 并配置一些特定于数据库的设置。这个例子使用一个名为cities的 MongoDB 数据库,其中包含一个名为minute的集合。为了计算每个城市和分钟的计数,我们必须在cities.minute集合上创建一个唯一索引。为此,启动 MongoDB 命令行客户端:
mongo
在cities.minute集合上创建一个唯一索引:
use cities
db.minute.createIndex( { minute: 1, city: 1 }, { unique: true } )
这个索引在 MongoDB 中存储了每分钟城市计数的时间序列。在运行示例拓扑捕获一些数据后,我们将运行一个独立的命令行脚本(city_report.py)来按小时和城市汇总每分钟的城市计数。
这是之前 Twitter 拓扑的一个变种。这个例子使用了 Python 的 geotext 库(pypi.python.org/pypi/geotext)来查找推文中的城市名称。
以下是拓扑的概述:
-
阅读推文。
-
将它们拆分成单词并找到城市名称。
-
在 MongoDB 中,计算每分钟提到一个城市的次数。
-
Twitter 流 spout(
twitterstream.py):从 Twitter 样本流中读取推文。 -
城市计数 bolt(
citycount.py):这个模块找到城市名称并写入 MongoDB。它类似于 Twitter 样本中的SplitSentenceBolt,但在拆分单词后,它会寻找城市名称。
这里的_get_words()函数与之前的例子略有不同。这是因为 geotext 不会将小写字符串识别为城市名称。
它创建或更新 MongoDB 记录,利用了分钟和城市的唯一索引来累积每分钟的计数。
这是在 MongoDB 中表示时间序列数据的常见模式。每条记录还包括一个hour字段。city_report.py脚本使用这个字段来计算每小时的计数。
在citycount.py中输入以下代码:
Import datetime
import logging
import geotext
import nltk.corpus
import pymongo
from petrel import storm
from petrel.emitter import BasicBolt
log = logging.getLogger('citycount')
class CityCountBolt(BasicBolt):
def __init__(self):
super(CityCountBolt, self).__init__(script=__file__)
self.stop_words = set(nltk.corpus.stopwords.words('english'))
self.stop_words.update(['http', 'https', 'rt'])
self.stop_cities = set([
'bay', 'best', 'deal', 'man', 'metro', 'of', 'un'])
def initialize(self, conf, context):
self.db = pymongo.MongoClient()
def declareOutputFields(self):
return []
def process(self, tup):
clean_text = ' '.join(w for w in self._get_words(tup.values[0]))
places = geotext.GeoText(clean_text)
now_minute = self._get_minute()
now_hour = now_minute.replace(minute=0)
for city in places.cities:
city = city.lower()
if city in self.stop_cities:
continue
log.info('Updating count: %s, %s, %s', now_hour, now_minute, city)
self.db.cities.minute.update(
{
'hour': now_hour,
'minute': now_minute,
'city': city
},
{'$inc': { 'count' : 1 } },
upsert=True)
@staticmethod
def _get_minute():
return datetime.datetime.now().replace(second=0, microsecond=0)
def _get_words(self, sentence):
for w in nltk.word_tokenize(sentence):
wl = w.lower()
if wl.isalpha() and wl not in self.stop_words:
yield w
def run():
CityCountBolt().run()
定义拓扑 - MongoDB 案例
在create.py中输入以下代码:
from twitterstream import TwitterStreamSpout
from citycount import CityCountBolt
def create(builder):
spoutId = "spout"
cityCountId = "citycount"
builder.setSpout(spoutId, TwitterStreamSpout(), 1)
builder.setBolt(cityCountId, CityCountBolt(), 1).shuffleGrouping("spout")
运行拓扑 - MongoDB 案例
在我们运行拓扑之前,我们还有一些小事情要处理:
-
从第三章的第二个例子中复制
logconfig.ini文件,Petrel 介绍到这个拓扑的目录。 -
创建一个名为
setup.sh的文件:
pip install -U pip
pip install nltk==3.0.1 oauthlib==0.7.2 tweepy==3.2.0 geotext==0.1.0 pymongo==3.0.3
- 接下来,创建一个名为
manifest.txt的文件。这与 Redis 示例相同。
安装 MongoDB 服务器。在 Ubuntu 上,您可以使用docs.mongodb.org/manual/tutorial/install-mongodb-on-ubuntu/中提供的说明。
- 在所有 Storm 工作机器上安装 Python MongoDB 客户端:
pip install pymongo==3.0.3
- 要验证
pymongo是否已安装并且索引已正确创建,请运行python启动交互式 Python 会话,然后使用此代码:
import pymongo
from pymongo import MongoClient
db = MongoClient()
for index in db.cities.minute.list_indexes():
print index
您应该看到以下输出。第二行是我们添加的索引:
SON([(u'v', 1), (u'key', SON([(u'_id', 1)])), (u'name', u'_id_'), (u'ns', u'cities.minute')])
SON([(u'v', 1), (u'unique', True), (u'key', SON([(u'minute', 1.0), (u'city', 1.0)])), (u'name', u'minute_1_city_1'), (u'ns', u'cities.minute')])
- 接下来,安装
geotext:
pip install geotext==0.1.0
- 在运行拓扑之前,让我们回顾一下我们创建的文件列表。确保您已正确创建这些文件:
-
topology.yaml -
twitterstream.py -
citycount.py -
manifest.txt -
setup.sh
- 使用以下命令运行拓扑:
petrel submit --config topology.yaml --logdir `pwd`
city_report.py文件是一个独立的脚本,它从拓扑插入的数据中生成一个简单的每小时报告。此脚本使用 MongoDB 聚合来计算每小时的总数。正如前面所述,报告取决于是否存在hour字段。
在city_report.py中输入此代码:
import pymongo
def main():
db = pymongo.MongoClient()
pipeline = [{
'$group': {
'_id': { 'hour': '$hour', 'city': '$city' },
'count': { '$sum': '$count' }
}
}]
for r in db.cities.command('aggregate', 'minute', pipeline=pipeline)['result']:
print '%s,%s,%s' % (r['_id']['city'], r['_id']['hour'], r['count'])
if __name__ == '__main__':
main()
摘要
在本章中,我们看到如何将两种流行的 NoSQL 存储引擎(Redis 和 MongoDB)与 Storm 一起使用。我们还向您展示了如何在拓扑中创建数据并从其他应用程序访问它,证明了 Storm 可以成为 ETL 管道的有效部分。

















 441
441

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









