







如何使用 PIL/Pillow
加载和操作 Python 深度学习的图像
最后更新于 2019 年 9 月 12 日
在开发图像数据的预测模型之前,您必须学习如何加载和操作图像和照片。
Python 中用于加载和处理图像数据的最流行和事实上的标准库是 Pillow。Pillow 是 Python 图像库或 PIL 的更新版本,支持一系列简单而复杂的图像处理功能。它也是其他 Python 库(如 SciPy 和 Matplotlib)中简单图像支持的基础。
在本教程中,您将了解如何使用 Pillow Python 库加载和操作图像数据。
完成本教程后,您将知道:
- 如何安装 Pillow 库并确认其工作正常。
- 如何从文件中加载图像,将加载的图像转换为 NumPy 数组,以及以新格式保存图像。
- 如何对图像数据执行基本转换,如调整大小、翻转、旋转和裁剪。
用我的新书计算机视觉深度学习启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。
- 2019 年 9 月更新:更新以反映 Pillow API 的微小变化。
教程概述
本教程分为六个部分;它们是:
- 如何安装 Pillow
- 如何加载和显示图像
- 如何将图像转换为数字阵列并返回
- 如何将图像保存到文件
- 如何调整图像大小
- 如何翻转、旋转和裁剪图像
如何安装 Pillow
Python 图像库,简称 PIL,是一个用于加载和操作图像的开源库。
它是在 25 年前开发并提供的,已经成为使用 Python 处理图像的事实上的标准应用编程接口。该库现已失效,不再更新,不支持 Python 3。
Pillow是一个支持 Python 3 的 PIL 库,是 Python 中图像操作的首选现代库。它甚至是其他 Python 科学库(如 SciPy 和 Matplotlib)中简单的图像加载和保存所必需的。
Pillow 库是作为大多数 SciPy 安装的一部分安装的;例如,如果您正在使用 Anaconda。
有关设置 SciPy 环境的帮助,请参见分步教程:
- 如何用 Anaconda 建立机器学习和深度学习的 Python 环境
如果自己为工作站管理 Python 软件包的安装,可以使用 pip 轻松安装 pipe;例如:
sudo pip install Pillow
有关手动安装 Pillow 的更多帮助,请参见:
Pillow 是建立在旧的 PIL 之上的,你可以通过打印版本号来确认图书馆安装正确;例如:
# check Pillow version number
import PIL
print('Pillow Version:', PIL.__version__)
运行该示例将打印 Pillow 的版本号;您的版本号应该相同或更高。
Pillow Version: 6.1.0
现在您的环境已经设置好了,让我们看看如何加载图像。
如何加载和显示图像
我们需要一个测试图像来演示使用 Pillow 库的一些重要功能。
在本教程中,我们将使用一张悉尼歌剧院的照片,该照片由埃德·邓恩斯拍摄,并根据知识共享许可在 Flickr 上提供,保留部分权利。

悉尼歌剧院
下载照片,保存在当前工作目录下,文件名为“ opera_house.jpg ”。
图像通常为 PNG 或 JPEG 格式,可以使用 Image 类上的 open()函数直接加载。这将返回一个 Image 对象,该对象包含图像的像素数据以及图像的详细信息。图像类是 Pillow 库的主要工具,它提供了大量关于图像的属性以及允许您操作图像的像素和格式的函数。
图像上的“格式”属性将报告图像格式(例如 JPEG),“模式将报告像素通道格式(例如 RGB 或 CMYK),“尺寸将以像素为单位报告图像尺寸(例如 640×480)。
show() 功能将使用您的操作系统默认应用程序显示图像。
下面的示例演示了如何使用 Pillow 库中的 image 类加载和显示图像。
# load and show an image with Pillow
from PIL import Image
# load the image
image = Image.open('opera_house.jpg')
# summarize some details about the image
print(image.format)
print(image.mode)
print(image.size)
# show the image
image.show()
运行该示例将首先加载图像,报告格式、模式和大小,然后在桌面上显示图像。
JPEG
RGB
(640, 360)
该图像是使用操作系统的默认图像预览应用程序显示的,例如 MacOS 上的预览。

使用默认图像预览应用程序显示悉尼歌剧院
现在您已经知道如何加载图像,让我们看看如何访问图像的像素数据。
如何将图像转换为数字阵列并返回
通常在机器学习中,我们希望将图像作为像素数据的 NumPy 数组来处理。
安装 Pillow 后,您还可以使用 Matplotlib 库加载图像,并在 Matplotlib 框架内显示它。
这可以通过使用 imread()函数和 imshow()函数来实现,前者直接将图像加载为像素阵列,后者将像素阵列显示为图像。
下面的示例使用 Matplotlib 加载和显示相同的图像,而 Matplotlib 又会在封面下使用 Pillow。
# load and display an image with Matplotlib
from matplotlib import image
from matplotlib import pyplot
# load image as pixel array
data = image.imread('opera_house.jpg')
# summarize shape of the pixel array
print(data.dtype)
print(data.shape)
# display the array of pixels as an image
pyplot.imshow(data)
pyplot.show()
运行该示例首先加载图像,然后报告数组的数据类型,在本例中为 8 位无符号整数,然后报告数组的形状,在本例中为 360 像素宽乘 640 像素高,红色、绿色和蓝色有三个通道。
uint8
(360, 640, 3)
最后,使用 Matplotlib 显示图像。
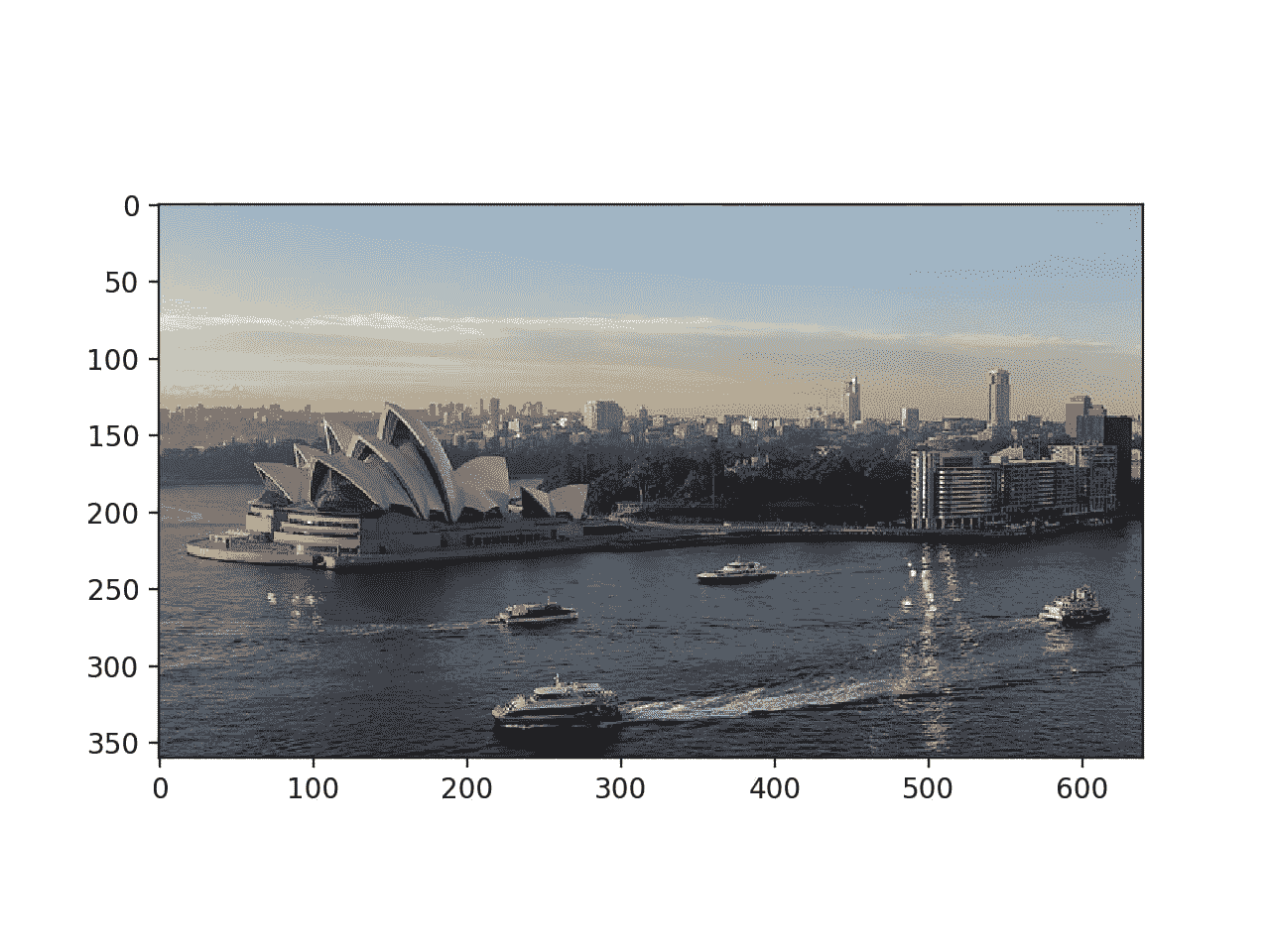
用 Matplotlib 展示悉尼歌剧院
Matplotlib 包装函数可以比直接使用 Pillow 更有效。
不过,您可以从 Pillow 图像中访问像素数据。也许最简单的方法是构造一个 NumPy 数组并传入 Image 对象。使用 Image.fromarray() 函数将给定的像素数据数组转换为枕形图像对象的过程可以颠倒过来。如果将图像数据作为 NumPy 数组进行处理,然后希望以后将其保存为 PNG 或 JPEG 文件,这将非常有用。
下面的示例将照片加载为枕形图像对象,并将其转换为 NumPy 数组,然后再次将其转换回图像对象。
# load image and convert to and from NumPy array
from PIL import Image
from numpy import asarray
# load the image
image = Image.open('opera_house.jpg')
# convert image to numpy array
data = asarray(image)
# summarize shape
print(data.shape)
# create Pillow image
image2 = Image.fromarray(data)
# summarize image details
print(image2.format)
print(image2.mode)
print(image2.size)
运行该示例首先将照片加载为 Pillow 图像,然后将其转换为 NumPy 数组并报告数组的形状。最后,阵列被转换回 Pillow 图像,并报告细节。
(360, 640, 3)
JPEG
RGB
(640, 360)
这两种方法对于将图像数据加载到 NumPy 数组中都是有效的,尽管 Matplotlib imread() 函数使用的代码行比加载和转换 Pillow 图像对象少,并且可能是首选的。
例如,您可以轻松地将目录中的所有图像加载为列表,如下所示:
# load all images in a directory
from os import listdir
from matplotlib import image
# load all images in a directory
loaded_images = list()
for filename in listdir('images'):
# load image
img_data = image.imread('images/' + filename)
# store loaded image
loaded_images.append(img_data)
print('> loaded %s %s' % (filename, img_data.shape))
现在我们知道了如何将图像加载为 NumPy 数组,让我们看看如何将图像保存到文件中。
如何将图像保存到文件
调用 save() 函数可以保存图像对象。
如果您想要以不同的格式保存图像,这将非常有用,在这种情况下,可以指定“格式参数,例如 PNG、GIF 或 PEG。
例如,下面列出的代码以 JPEG 格式加载照片,并以 PNG 格式保存。
# example of saving an image in another format
from PIL import Image
# load the image
image = Image.open('opera_house.jpg')
# save as PNG format
image.save('opera_house.png', format='PNG')
# load the image again and inspect the format
image2 = Image.open('opera_house.png')
print(image2.format)
运行示例加载 JPEG 图像,将其保存为 PNG 格式,然后再次加载新保存的图像,并确认该格式确实是 PNG。
PNG
如果在建模之前对图像进行一些数据准备,保存图像会很有用。一个例子是将彩色图像(RGB 通道)转换为灰度(1 通道)。
将图像转换为灰度有多种方法,但 Pillow 提供了 convert() 功能,模式“ L 将图像转换为灰度。
# example of saving a grayscale version of a loaded image
from PIL import Image
# load the image
image = Image.open('opera_house.jpg')
# convert the image to grayscale
gs_image = image.convert(mode='L')
# save in jpeg format
gs_image.save('opera_house_grayscale.jpg')
# load the image again and show it
image2 = Image.open('opera_house_grayscale.jpg')
# show the image
image2.show()
运行该示例加载照片,将其转换为灰度,将图像保存在新文件中,然后再次加载并显示照片,以确认照片现在是灰度而不是颜色。

照片的灰度版本示例
如何调整图像大小
能够在建模之前调整图像大小非常重要。
有时希望缩略图所有图像具有相同的宽度或高度。这可以通过 Pillow 使用*缩略图()*功能来实现。该函数采用一个具有宽度和高度的元组,并且将调整图像的大小,以使图像的宽度和高度等于或小于指定的形状。
例如,我们正在处理的测试照片的宽度和高度为(640,360)。我们可以将它的大小调整为(100,100),在这种情况下,最大的尺寸,在这种情况下,宽度,将减少到 100,高度将被缩放,以保持图像的纵横比。
下面的示例将加载照片,并创建一个宽度和高度为 100 像素的较小缩略图。
# create a thumbnail of an image
from PIL import Image
# load the image
image = Image.open('opera_house.jpg')
# report the size of the image
print(image.size)
# create a thumbnail and preserve aspect ratio
image.thumbnail((100,100))
# report the size of the thumbnail
print(image.size)
运行该示例首先加载照片并报告宽度和高度。然后调整图像的大小,在这种情况下,宽度减少到 100 像素,高度减少到 56 像素,保持原始图像的纵横比。
(640, 360)
(100, 56)
我们可能不想保留纵横比,相反,我们可能想强制像素成为新的形状。
这可以使用 resize() 功能来实现,该功能允许您以像素为单位指定宽度和高度,并且图像将被缩小或拉伸以适应新的形状。
下面的示例演示了如何调整新图像的大小并忽略原始纵横比。
# resize image and force a new shape
from PIL import Image
# load the image
image = Image.open('opera_house.jpg')
# report the size of the image
print(image.size)
# resize image and ignore original aspect ratio
img_resized = image.resize((200,200))
# report the size of the thumbnail
print(img_resized.size)
运行该示例加载图像,报告图像的形状,然后调整其大小,使其具有 200 像素的宽度和高度。
(640, 360)
(200, 200)
显示了图像的大小,我们可以看到宽照片已经被压缩成一个正方形,尽管所有的特征仍然非常明显。
标准重采样算法用于在调整大小时发明或移除像素,您可以指定一种技术,尽管默认是适合大多数一般应用的双三次重采样算法。

不保持原始纵横比的调整大小照片
如何翻转、旋转和裁剪图像
简单的图像操作可用于创建新版本的图像,进而在建模时提供更丰富的训练数据集。
通常,这被称为数据扩充,并且可能涉及创建原始图像的翻转、旋转、裁剪或其他修改版本,希望算法将学会从图像数据中提取相同的特征,而不管它们可能出现在哪里。
您可能想要实现自己的数据扩充方案,在这种情况下,您需要知道如何执行图像数据的基本操作。
翻转图像
可以通过调用 flip() 函数并传入一种方法来翻转图像,如水平翻转的 FLIP_LEFT_RIGHT 或垂直翻转的 FLIP_TOP_BOTTOM 。其他翻转也是可用的
下面的示例创建了图像的水平和垂直翻转版本。
# create flipped versions of an image
from PIL import Image
from matplotlib import pyplot
# load image
image = Image.open('opera_house.jpg')
# horizontal flip
hoz_flip = image.transpose(Image.FLIP_LEFT_RIGHT)
# vertical flip
ver_flip = image.transpose(Image.FLIP_TOP_BOTTOM)
# plot all three images using matplotlib
pyplot.subplot(311)
pyplot.imshow(image)
pyplot.subplot(312)
pyplot.imshow(hoz_flip)
pyplot.subplot(313)
pyplot.imshow(ver_flip)
pyplot.show()
运行该示例加载照片并创建照片的水平和垂直翻转版本,然后使用 Matplotlib 将所有三个版本绘制为子情节。
您会注意到 imshow() 函数可以直接绘制图像对象,而不必将其转换为 NumPy 数组。

照片的原始、水平和垂直翻转版本图
旋转图像
可以使用*旋转()*功能旋转图像,并输入旋转的角度。
该功能提供了额外的控制,例如是否扩展图像的尺寸以适合旋转的像素值(默认为裁剪成相同的大小)、图像旋转的中心位置(默认为中心)以及图像外部像素的填充颜色(默认为黑色)。
下面的示例创建了图像的几个旋转版本。
# create rotated versions of an image
from PIL import Image
from matplotlib import pyplot
# load image
image = Image.open('opera_house.jpg')
# plot original image
pyplot.subplot(311)
pyplot.imshow(image)
# rotate 45 degrees
pyplot.subplot(312)
pyplot.imshow(image.rotate(45))
# rotate 90 degrees
pyplot.subplot(313)
pyplot.imshow(image.rotate(90))
pyplot.show()
运行该示例绘制原始照片,然后照片的一个版本旋转 45 度,另一个版本旋转 90 度。
您可以看到,在这两次旋转中,像素都被裁剪为图像的原始尺寸,空像素被填充为黑色。

照片的原始和旋转版本图
裁剪图像
可以裁剪图像:也就是说,可以使用*裁剪()*功能裁剪出一块来创建新图像。
裁剪函数接受一个元组参数,该参数定义了要从图像中裁剪出的框的两个 x/y 坐标。例如,如果图像是 2,000 乘 2,000 像素,我们可以通过定义一个具有(950,950,1050,1050)的左上角和右下角的元组,在图像中间裁剪出一个 100 乘 100 的框。
下面的示例演示了如何从加载的图像创建一个新的裁剪图像。
# example of cropping an image
from PIL import Image
# load image
image = Image.open('opera_house.jpg')
# create a cropped image
cropped = image.crop((100, 100, 200, 200))
# show cropped image
cropped.show()
运行该示例会创建一个从 100,100 开始,向左下方延伸到 200,200 的 100 像素的方形裁剪图像。然后显示裁剪后的正方形。
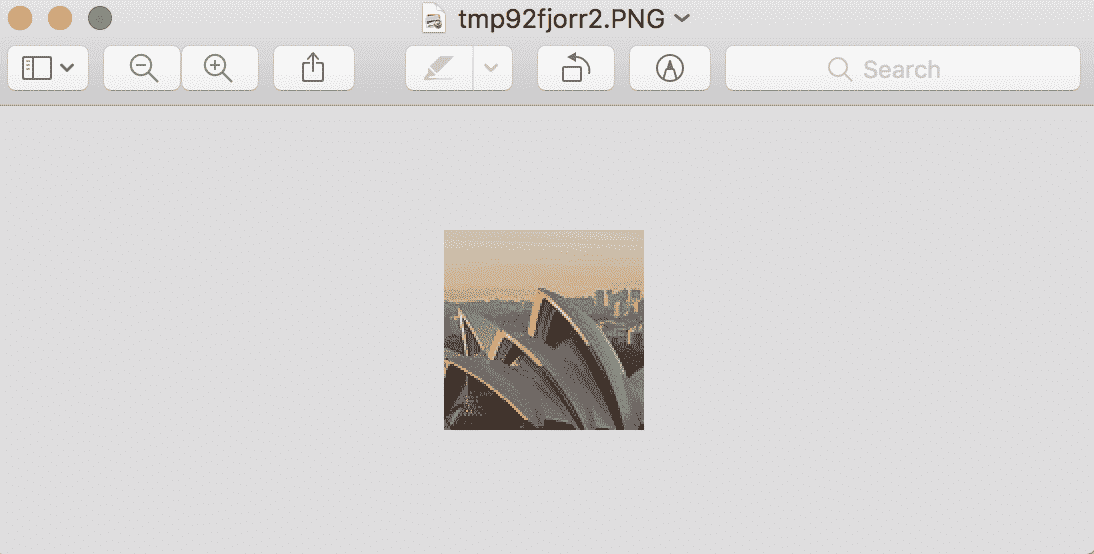
照片的裁剪版本示例
扩展ˌ扩张
本节列出了一些您可能希望探索的扩展教程的想法。
- 自己的影像。尝试 Pillow 功能,用自己的图像数据读取和处理图像。
- 更多变换。查看 Pillow 应用编程接口文档,并尝试其他图像处理功能。
- 图像预处理。编写一个函数来创建图像的增强版本,以便与深度学习神经网络一起使用。
如果你探索这些扩展,我很想知道。
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
- Pillow 主页
- Pillow 安装说明
- Pillow(PIL 叉)原料药文件
- Pillow 手册教程
- Pillow GitHub 项目
- Python 影像库(PIL)主页
- Python 影像库,维基百科。
- Matplotlib:影像教学
摘要
在本教程中,您发现了如何使用 Pillow Python 库加载和操作图像数据。
具体来说,您了解到:
- 如何安装 Pillow 库并确认其工作正常。
- 如何从文件中加载图像,将加载的图像转换为 NumPy 数组,以及以新格式保存图像。
- 如何对图像数据执行基本转换,如调整大小、翻转、旋转和裁剪。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
如何用 Keras 加载和可视化标准计算机视觉数据集
最后更新于 2019 年 7 月 5 日
开始使用计算机视觉的深度学习方法时,使用标准的计算机视觉数据集可能会很方便。
标准数据集通常很好理解,很小,易于加载。它们可以为测试技术和复制结果提供基础,以便建立对库和方法的信心。
在本教程中,您将发现 Keras 深度学习库提供的标准计算机视觉数据集。
完成本教程后,您将知道:
- 使用 Keras 下载标准计算机视觉数据集的应用编程接口和习惯用法。
- MNIST、时尚-MNIST、CIFAR-10 和 CIFAR-100 计算机视觉数据集的结构、性质和最佳结果。
- 如何使用 Keras API 加载和可视化标准计算机视觉数据集。
用我的新书计算机视觉深度学习启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。

如何用 Keras 加载和可视化标准计算机视觉数据集
图片由玛丽娜·德尔·卡斯特尔提供,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- Keras 计算机视觉数据集
- MNIST 数据集
- 时尚-MNIST 数据集
- CIFAR-10 数据集
- CIFAR-100 数据集
Keras 计算机视觉数据集
Keras 深度学习库提供对四个标准计算机视觉数据集的访问。
这特别有用,因为它允许您快速开始测试计算机视觉的模型架构和配置。
提供了四个特定的多类图像类别数据集;它们是:
- MNIST :手写数字照片分类(10 类)。
- 时尚-MNIST :服装单品照片分类(10 类)。
- CIFAR-10 :对象小照片分类(10 类)。
- CIFAR-100 :普通对象小照片分类(100 类)。
数据集可通过特定于数据集的加载函数在 keras.datasets 模块下获得。
调用加载函数后,数据集被下载到您的工作站并存储在 ~/。keras 目录下有一个“数据集”子目录。数据集以压缩格式存储,但也可能包括额外的元数据。
在第一次调用特定于数据集的加载函数并下载数据集后,不需要再次下载数据集。后续调用将立即从磁盘加载数据集。
load 函数返回两个元组,第一个包含训练数据集中样本的输入和输出元素,第二个包含测试数据集中样本的输入和输出元素。训练数据集和测试数据集之间的分割通常遵循标准分割,在对数据集进行算法基准测试时使用。
加载数据集的标准习惯用法如下:
...
# load dataset
(trainX, trainy), (testX, testy) = load_data()
每个训练和测试 X 和 y 元素分别是像素或类值的 NumPy 数组。
其中两个数据集包含灰度图像,两个数据集包含彩色图像。灰度图像的形状必须从二维阵列转换为三维阵列,以匹配 Keras 的首选通道顺序。例如:
# reshape grayscale images to have a single channel
width, height, channels = trainX.shape[1], trainX.shape[2], 1
trainX = trainX.reshape((trainX.shape[0], width, height, channels))
testX = testX.reshape((testX.shape[0], width, height, channels))
灰度和彩色图像像素数据都存储为 0 到 255 之间的无符号整数值。
在建模之前,图像数据将需要重新缩放,例如归一化到范围 0-1,并且可能进一步标准化。例如:
# normalize pixel values
trainX = trainX.astype('float32') / 255
testX = testX.astype('float32') / 255
每个样本的输出元素( y )被存储为类整数值。每个问题都是多类分类问题(两类以上);因此,通常的做法是在建模之前对类值进行热编码。这可以使用 Keras 提供的*to _ classic()*功能来实现;例如:
...
# one hot encode target values
trainy = to_categorical(trainy)
testy = to_categorical(testy)
现在我们已经熟悉了使用 Keras 提供的标准计算机视觉数据集的习惯用法,让我们依次仔细看看每个数据集。
请注意,本教程中的示例假设您可以访问互联网,并且可能会在每个示例首次在您的系统上运行时下载数据集。下载速度将取决于您的互联网连接速度,建议您从命令行运行示例。
MNIST 数据集
MNIST 数据集是一个首字母缩略词,代表修改后的国家标准和技术研究所数据集。
它是一个由 60,000 个 0 到 9 之间的手写单个数字的 28×28 像素小正方形灰度图像组成的数据集。
任务是将手写数字的给定图像分类为代表从 0 到 9 的整数值的 10 个类别之一。
它是一个被广泛使用和深入理解的数据集,大部分是“求解”表现最好的模型是深度学习卷积神经网络,其分类准确率达到 99%以上,在保持测试数据集上的错误率在 0.4%到 0.2%之间。
有关为 MNIST 开发模型的分步教程,请参见:
以下示例使用 Keras API 加载 MNIST 数据集,并创建训练数据集中前 9 幅图像的图。
# example of loading the mnist dataset
from keras.datasets import mnist
from matplotlib import pyplot
# load dataset
(trainX, trainy), (testX, testy) = mnist.load_data()
# summarize loaded dataset
print('Train: X=%s, y=%s' % (trainX.shape, trainy.shape))
print('Test: X=%s, y=%s' % (testX.shape, testy.shape))
# plot first few images
for i in range(9):
# define subplot
pyplot.subplot(330 + 1 + i)
# plot raw pixel data
pyplot.imshow(trainX[i], cmap=pyplot.get_cmap('gray'))
# show the figure
pyplot.show()
运行该示例将加载 MNIST 训练和测试数据集,并打印它们的形状。
我们可以看到训练数据集中有 6 万个例子,测试数据集中有 1 万个例子,图像确实是 28×28 像素的正方形。
Train: X=(60000, 28, 28), y=(60000,)
Test: X=(10000, 28, 28), y=(10000,)
还创建了数据集中前九幅图像的图,显示了要分类的图像的自然手写特性。

从 MNIST 数据集绘制图像子集
时尚-MNIST 数据集
时尚-MNIST 被提议作为 MNIST 数据集的更具挑战性的替代数据集。
它是一个数据集,由 60,000 个 28×28 像素的小正方形灰度图像组成,包括 10 种服装,如鞋子、t 恤、连衣裙等。
这是一个比 MNIST 更具挑战性的分类问题,通过深度学习卷积网络可以获得最佳结果,在保持测试数据集上的分类准确率约为 95%至 96%。
有关为时尚 MNIST 开发模型的分步教程,请参见:
以下示例使用 Keras API 加载时尚 MNIST 数据集,并创建训练数据集中前九幅图像的图。
# example of loading the fashion mnist dataset
from matplotlib import pyplot
from keras.datasets import fashion_mnist
# load dataset
(trainX, trainy), (testX, testy) = fashion_mnist.load_data()
# summarize loaded dataset
print('Train: X=%s, y=%s' % (trainX.shape, trainy.shape))
print('Test: X=%s, y=%s' % (testX.shape, testy.shape))
# plot first few images
for i in range(9):
# define subplot
pyplot.subplot(330 + 1 + i)
# plot raw pixel data
pyplot.imshow(trainX[i], cmap=pyplot.get_cmap('gray'))
# show the figure
pyplot.show()
运行该示例将加载时尚 MNIST 训练和测试数据集,并打印它们的形状。
我们可以看到训练数据集中有 6 万个例子,测试数据集中有 1 万个例子,图像确实是 28×28 像素的正方形。
Train: X=(60000, 28, 28), y=(60000,)
Test: X=(10000, 28, 28), y=(10000,)
还创建了数据集中前九幅图像的图,显示这些图像确实是衣物的灰度照片。

时尚 MNIST 数据集图像子集的绘图
CIFAR-10 数据集
CIFAR 是加拿大高级研究所的首字母缩略词,CIFAR-10 数据集是由 CIFAR 研究所的研究人员与 CIFAR-100 数据集(将在下一节中介绍)一起开发的。
数据集由 60,000 张 32×32 像素彩色照片组成,这些照片来自 10 个类别的对象,如青蛙、鸟类、猫、船等。
这些都是非常小的图像,比典型的照片小得多,数据集是用于计算机视觉研究的。
CIFAR-10 是一个数据集,被广泛用于机器学习领域的计算机视觉算法基准测试。问题是“解决了”通过深度学习卷积神经网络,在测试数据集上的分类准确率达到 96%或 97%以上,在该问题上取得了最佳表现。
以下示例使用 Keras API 加载 CIFAR-10 数据集,并创建训练数据集中前九幅图像的图。
# example of loading the cifar10 dataset
from matplotlib import pyplot
from keras.datasets import cifar10
# load dataset
(trainX, trainy), (testX, testy) = cifar10.load_data()
# summarize loaded dataset
print('Train: X=%s, y=%s' % (trainX.shape, trainy.shape))
print('Test: X=%s, y=%s' % (testX.shape, testy.shape))
# plot first few images
for i in range(9):
# define subplot
pyplot.subplot(330 + 1 + i)
# plot raw pixel data
pyplot.imshow(trainX[i])
# show the figure
pyplot.show()
运行该示例将加载 CIFAR-10 训练和测试数据集,并打印它们的形状。
我们可以看到训练数据集中有 50000 个例子,测试数据集中有 10000 个例子,图像确实是 32×32 像素、彩色的正方形,有三个通道。
Train: X=(50000, 32, 32, 3), y=(50000, 1)
Test: X=(10000, 32, 32, 3), y=(10000, 1)
还会创建数据集中前九幅图像的图。很明显,与现代照片相比,这些图像确实非常小;在分辨率极低的情况下,很难看清某些图像中到底表现了什么。
这种低分辨率很可能是顶级算法在数据集上所能达到的有限表现的原因。

从 CIFAR-10 数据集绘制图像子集
CIFAR-100 数据集
CIFAR-100 数据集是由加拿大高级研究所(CIFAR)的学者与 CIFAR-10 数据集一起准备的。
数据集由 60,000 张 32×32 像素的彩色照片组成,这些照片来自 100 个类别的对象,如鱼、花、昆虫等等。
像 CIFAR-10 一样,这些图像是有意制作的小而不切实际的照片,数据集旨在用于计算机视觉研究。
下面的示例使用 Keras API 加载 CIFAR-100 数据集,并创建训练数据集中前九个图像的图。
# example of loading the cifar100 dataset
from matplotlib import pyplot
from keras.datasets import cifar100
# load dataset
(trainX, trainy), (testX, testy) = cifar100.load_data()
# summarize loaded dataset
print('Train: X=%s, y=%s' % (trainX.shape, trainy.shape))
print('Test: X=%s, y=%s' % (testX.shape, testy.shape))
# plot first few images
for i in range(9):
# define subplot
pyplot.subplot(330 + 1 + i)
# plot raw pixel data
pyplot.imshow(trainX[i])
# show the figure
pyplot.show()
运行该示例将加载 CIFAR-100 训练和测试数据集,并打印它们的形状。
我们可以看到训练数据集中有 50000 个例子,测试数据集中有 10000 个例子,图像确实是 32×32 像素、彩色的正方形,有三个通道。
Train: X=(50000, 32, 32, 3), y=(50000, 1)
Test: X=(10000, 32, 32, 3), y=(10000, 1)
还创建了数据集中前九幅图像的图,像 CIFAR-10 一样,图像的低分辨率会使清晰地看到一些照片中存在的内容变得具有挑战性。

从 CIFAR-100 数据集绘制图像子集
虽然有组织成 100 个类的图像,但是这 100 个类被组织成 20 个超类,例如普通类的组。
默认情况下,Keras 将返回 100 个类的标签,尽管在调用 load_data() 函数时,可以通过将“ label_mode ”参数设置为“粗”(而不是默认的“精”)来检索标签。例如:
# load coarse labels
(trainX, trainy), (testX, testy) = cifar100.load_data(label_mode='coarse')
当使用*到 _ classic()*函数对标签进行一次热编码时,区别就很明显了,其中每个输出向量不是有 100 个维度,而是只有 20 个维度。下面的示例通过加载带有课程标签的数据集并对课程标签进行编码来演示这一点。
# example of loading the cifar100 dataset with coarse labels
from keras.datasets import cifar100
from keras.utils import to_categorical
# load coarse labels
(trainX, trainy), (testX, testy) = cifar100.load_data(label_mode='coarse')
# one hot encode target values
trainy = to_categorical(trainy)
testy = to_categorical(testy)
# summarize loaded dataset
print('Train: X=%s, y=%s' % (trainX.shape, trainy.shape))
print('Test: X=%s, y=%s' % (testX.shape, testy.shape))
运行该示例会像以前一样加载 CIFS ar-100 数据集,但现在图像被分类为属于二十个超类之一。
类标签是一个热编码的,我们可以看到每个标签由一个 20 个元素的向量表示,而不是我们期望的 100 个元素的向量。
Train: X=(50000, 32, 32, 3), y=(50000, 20)
Test: X=(10000, 32, 32, 3), y=(10000, 20)
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
蜜蜂
文章
摘要
在本教程中,您发现了 Keras 深度学习库提供的标准计算机视觉数据集。
具体来说,您了解到:
- 使用 Keras 下载标准计算机视觉数据集的应用编程接口和习惯用法。
- MNIST、时尚-MNIST、CIFAR-10 和 CIFAR-100 计算机视觉数据集的结构、性质和最佳结果。
- 如何使用 Keras API 加载和可视化标准计算机视觉数据集。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
如何使用 Keras API 加载、转换和保存图像
原文:https://machinelearningmastery.com/how-to-load-convert-and-save-images-with-the-keras-api/
最后更新于 2019 年 7 月 5 日
Keras 深度学习库为加载、准备和扩充图像数据提供了一个复杂的应用编程接口。
该应用编程接口还包括一些未记录的功能,允许您快速轻松地加载、转换和保存图像文件。这些功能在开始计算机视觉深度学习项目时非常方便,允许您最初使用相同的 Keras API 来检查和处理图像数据。
在本教程中,您将发现如何使用 Keras API 提供的基本图像处理功能。
完成本教程后,您将知道:
- 如何使用 Keras API 加载和显示图像。
- 如何使用 Keras API 将加载的图像转换为 NumPy 数组并转换回 PIL 格式。
- 如何使用 Keras API 将加载的图像转换为灰度并保存到新文件中。
用我的新书计算机视觉深度学习启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。
教程概述
本教程分为五个部分;它们是:
- 测试图像
- 图像处理应用编程接口
- 如何用 Keras 加载图像
- 用 Keras 转换图像
- 用 Keras 保存图像
测试图像
第一步是选择要在本教程中使用的测试图像。
我们将使用一张由伊莎贝尔·舒尔茨拍摄的悉尼邦迪海滩的照片,该照片是在许可的知识共享许可下发布的。

悉尼邦迪海滩
下载图片,放入当前工作目录,文件名为“ bondi_beach.jpg ”。
图像处理应用编程接口
Keras 深度学习库提供了处理图像数据的实用程序。
主要的应用编程接口是结合了数据加载、准备和增强的 ImageDataGenerator 类。
在本教程中,我们将不涉及 ImageDataGenerator 类。相反,我们将仔细研究一些记录较少或未记录的函数,这些函数在使用 Keras API 处理图像数据和建模时可能会很有用。
具体来说,Keras 提供了加载、转换和保存图像数据的功能。功能在 utils.py 功能中,通过 image.py 模块显示。
当开始一个新的深度学习计算机视觉项目或当您需要检查特定图像时,这些功能可能是有用的便利功能。
在应用编程接口文档的应用部分中,当使用预先训练的模型时,会演示其中的一些功能。
Keras 中的所有图像处理都需要安装枕库。如果没有安装,可以查看安装说明。
让我们依次仔细看看这些功能。
如何用 Keras 加载图像
Keras 提供了 load_img() 功能,用于将文件中的图像作为 PIL 图像对象加载。
以下示例将邦迪海滩照片从文件中加载为 PIL 图像,并报告了加载图像的详细信息。
# example of loading an image with the Keras API
from keras.preprocessing.image import load_img
# load the image
img = load_img('bondi_beach.jpg')
# report details about the image
print(type(img))
print(img.format)
print(img.mode)
print(img.size)
# show the image
img.show()
运行该示例将加载图像并报告关于加载图像的详细信息。
我们可以确认该图像是以 JPEG 格式加载的 PIL 图像,具有 RGB 通道,大小为 640×427 像素。
<class 'PIL.JpegImagePlugin.JpegImageFile'>
JPEG
RGB
(640, 427)
然后使用工作站上的默认应用程序显示加载的图像,在本例中,是 macOS 上的预览应用程序。
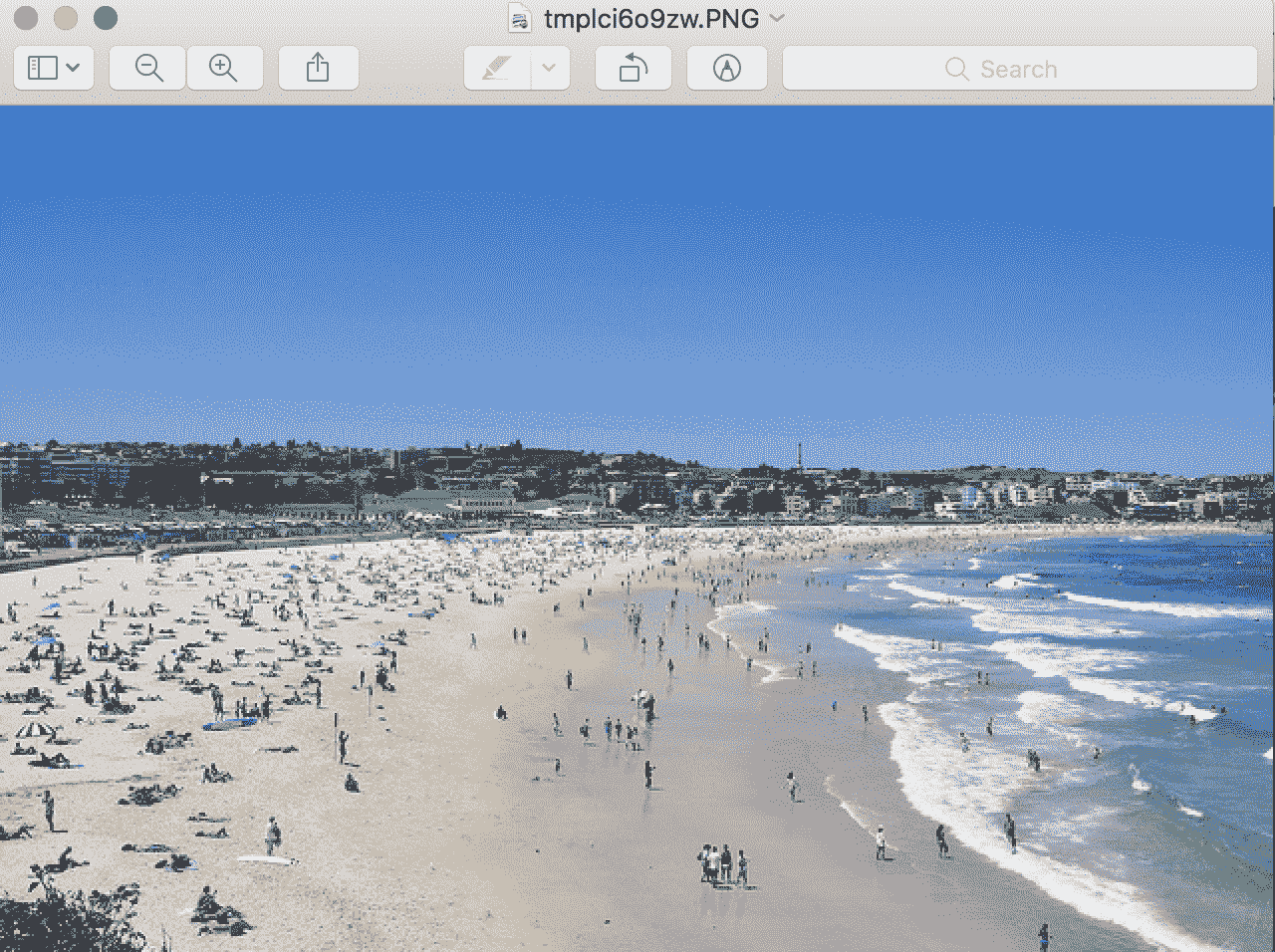
使用默认应用程序显示 PIL 图像的示例
load_img() 函数提供了加载图像时可能有用的附加参数,例如允许以灰度加载图像的“灰度”(默认为 False)、 color_mode (允许指定图像模式或通道格式)(默认为 rgb)以及允许指定元组(高度、宽度)的“ target_size ”,加载后自动调整图像大小。
如何用 Keras 转换图像
Keras 提供了 img_to_array() 功能,用于将 PIL 格式的加载图像转换为 NumPy 数组以用于深度学习模型。
该应用编程接口还提供了 array_to_img() 功能,可用于将像素数据的 NumPy 数组转换为 PIL 图像。如果在图像为阵列格式时修改了像素数据,然后可以保存或查看,这将非常有用。
下面的示例加载测试图像,将其转换为 NumPy 数组,然后将其转换回 PIL 图像。
# example of converting an image with the Keras API
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.preprocessing.image import array_to_img
# load the image
img = load_img('bondi_beach.jpg')
print(type(img))
# convert to numpy array
img_array = img_to_array(img)
print(img_array.dtype)
print(img_array.shape)
# convert back to image
img_pil = array_to_img(img_array)
print(type(img))
运行该示例首先以 PIL 格式加载照片,然后将图像转换为 NumPy 数组并报告数据类型和形状。
我们可以看到,像素值由无符号整数转换为 32 位浮点值,在这种情况下,转换为数组格式[ 高度、宽度、通道 ]。最后,图像被转换回 PIL 格式。
<class 'PIL.JpegImagePlugin.JpegImageFile'>
float32
(427, 640, 3)
<class 'PIL.JpegImagePlugin.JpegImageFile'>
如何用 Keras 保存图像
Keras API 还提供了 save_img() 功能,将图像保存到文件中。
该函数采用路径保存图像,图像数据采用 NumPy 数组格式。文件格式是从文件名推断出来的,但也可以通过“ file_format ”参数指定。
如果您已经处理了图像像素数据(如缩放),并希望保存图像以备后用,这将非常有用。
以下示例加载灰度格式的照片图像,将其转换为 NumPy 数组,并将其保存为新文件名。
# example of saving an image with the Keras API
from keras.preprocessing.image import load_img
from keras.preprocessing.image import save_img
from keras.preprocessing.image import img_to_array
# load image as as grayscale
img = load_img('bondi_beach.jpg', grayscale=True)
# convert image to a numpy array
img_array = img_to_array(img)
# save the image with a new filename
save_img('bondi_beach_grayscale.jpg', img_array)
# load the image to confirm it was saved correctly
img = load_img('bondi_beach_grayscale.jpg')
print(type(img))
print(img.format)
print(img.mode)
print(img.size)
img.show()
运行该示例首先加载图像,并强制格式为灰度。
然后将图像转换为 NumPy 数组,并保存到当前工作目录中的新文件名“”bondi _ beach _ grade . jpg。
为确认文件保存正确,它将作为 PIL 图像再次加载,并报告图像的详细信息。
<class 'PIL.Image.Image'>
None
RGB
(640, 427)
然后,使用工作站上的默认图像预览应用程序显示加载的灰度图像,该应用程序在 macOS 中是预览应用程序。

使用默认图像查看应用程序显示的已保存灰度图像示例
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
邮件
应用程序接口
摘要
在本教程中,您发现了如何使用 Keras API 提供的基本图像处理功能。
具体来说,您了解到:
- 如何使用 Keras API 加载和显示图像。
- 如何使用 Keras API 将加载的图像转换为 NumPy 数组并转换回 PIL 格式。
- 如何使用 Keras API 将加载的图像转换为灰度并保存到新文件中。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
如何为 Keras 深度学习从目录加载大数据集
最后更新于 2019 年 7 月 5 日
在磁盘上存储和构造图像数据集有一些约定,以便在训练和评估深度学习模型时快速有效地加载。
一旦结构化,您就可以使用像 Keras 深度学习库中的 ImageDataGenerator 类这样的工具来自动加载您的训练、测试和验证数据集。此外,生成器将逐步加载数据集中的图像,允许您处理包含数千或数百万个可能不适合系统内存的图像的小型和超大型数据集。
在本教程中,您将发现如何构建图像数据集,以及如何在拟合和评估深度学习模型时逐步加载它。
完成本教程后,您将知道:
- 如何将训练、测试和验证图像数据集组织成一致的目录结构。
- 如何使用 ImageDataGenerator 类逐步加载给定数据集的图像。
- 如何使用准备好的数据生成器,通过深度学习模型进行训练、评估和预测。
用我的新书计算机视觉深度学习启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。
教程概述
本教程分为三个部分;它们是:
- 数据集目录结构
- 示例数据集结构
- 如何逐步加载图像
数据集目录结构
有一种标准的方法来布局您的图像数据进行建模。
收集完图像后,必须首先按数据集(如训练、测试和验证)对它们进行排序,其次按它们的类别进行排序。
例如,想象一个图像分类问题,其中我们希望根据汽车的颜色对汽车照片进行分类,例如红色汽车、蓝色汽车等。
首先,我们有一个数据/ 目录,我们将存储所有的图像数据。
接下来,我们将有一个用于训练数据集的数据/训练/ 目录和一个用于保持测试数据集的数据/测试/ 。在训练期间,我们可能还会有一个用于验证数据集的数据/验证/ 。
到目前为止,我们已经:
data/
data/train/
data/test/
data/validation/
在每个数据集目录下,我们将有子目录,每个类别一个子目录,实际的图像文件将放在那里。
例如,如果我们有一个用于将汽车照片分类为红色汽车或蓝色汽车的二进制分类任务,我们将有两个类别,‘红色’和’蓝色’,因此每个数据集目录下有两个类别目录。
例如:
data/
data/train/
data/train/red/
data/train/blue/
data/test/
data/test/red/
data/test/blue/
data/validation/
data/validation/red/
data/validation/blue/
红色汽车的图像将被放在适当的类别目录中。
例如:
data/train/red/car01.jpg
data/train/red/car02.jpg
data/train/red/car03.jpg
...
data/train/blue/car01.jpg
data/train/blue/car02.jpg
data/train/blue/car03.jpg
...
请记住,我们不会将相同的文件放在红色/ 和蓝色/ 目录下;取而代之的是红色汽车和蓝色汽车的不同照片。
还记得我们在列车、测试和验证数据集上需要不同的照片。
用于实际图像的文件名通常并不重要,因为我们将用给定的文件扩展名加载所有图像。
如果您能够一致地重命名文件,一个好的命名约定是使用一些名称后跟一个零填充的数字,例如image0001.jpg如果您有一个类的数千个图像。
示例数据集结构
我们可以用一个例子来具体说明图像数据集的结构。
假设我们正在对汽车照片进行分类,正如我们在上一节中讨论的那样。具体来说,红色汽车和蓝色汽车的二分类问题。
我们必须创建上一节中概述的目录结构,特别是:
data/
data/train/
data/train/red/
data/train/blue/
data/test/
data/test/red/
data/test/blue/
data/validation/
data/validation/red/
data/validation/blue/
让我们实际创建这些目录。
我们也可以把一些照片放在目录里。
您可以使用创作共用图像搜索来查找一些许可的图像,您可以下载并用于本例。
我将使用两个图像:

丹尼斯·贾维斯的《红色汽车》

蓝色汽车,比尔·史密斯出品
将照片下载到当前工作目录,将红色车照片保存为“ red_car_01.jpg ”,蓝色车照片保存为“ blue_car_01.jpg ”。
我们必须为每个训练、测试和验证数据集准备不同的照片。
为了保持本教程的重点,我们将在三个数据集的每一个中重用相同的图像文件,但假设它们是不同的照片。
将“ red_car_01.jpg ”文件的副本放置在数据/列车/红色/ 、数据/测试/红色/ 和数据/验证/红色/ 目录中。
现在在数据/火车/蓝色/ 、数据/测试/蓝色/ 和数据/验证/蓝色/ 目录中放置“ blue_car_01.jpg 文件的副本。
我们现在有了一个非常基本的数据集布局,如下所示(来自树命令的输出):
data
├── test
│ ├── blue
│ │ └── blue_car_01.jpg
│ └── red
│ └── red_car_01.jpg
├── train
│ ├── blue
│ │ └── blue_car_01.jpg
│ └── red
│ └── red_car_01.jpg
└── validation
├── blue
│ └── blue_car_01.jpg
└── red
└── red_car_01.jpg
下面是目录结构的截图,取自 macOS 上的 Finder 窗口。
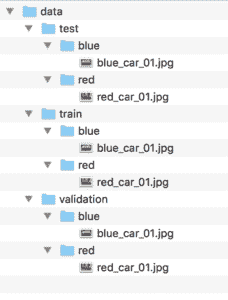
图像数据集目录和文件结构截图
现在我们有了一个基本的目录结构,让我们练习从文件中加载图像数据用于建模。
如何逐步加载图像
可以编写代码来手动加载图像数据,并返回准备建模的数据。
这将包括遍历数据集的目录结构,加载图像数据,并返回输入(像素数组)和输出(类整数)。
谢天谢地,我们不需要写这段代码。相反,我们可以使用 Keras 提供的 ImageDataGenerator 类。
使用此类加载数据的主要好处是,可以批量加载单个数据集的图像,这意味着它既可以用于加载小型数据集,也可以用于加载包含数千或数百万个图像的超大型图像数据集。
在训练和评估深度学习模型时,它不会将所有图像加载到内存中,而是将刚好足够的图像加载到内存中,用于当前以及可能的下几个小批量。我称之为渐进加载,因为数据集是从文件中渐进加载的,只检索足够的数据来满足即时需求。
使用 ImageDataGenerator 类的另外两个好处是,它还可以自动缩放图像的像素值,并且可以自动生成图像的增强版本。我们将在另一个教程中讨论这些主题,而是关注如何使用图像数据生成器类从文件中加载图像数据。
使用 ImageDataGenerator 类的模式如下:
- 构造并配置 ImageDataGenerator 类的一个实例。
- 通过调用 flow_from_directory() 函数检索迭代器。
- 在模型的训练或评估中使用迭代器。
让我们仔细看看每一步。
图像数据生成器的构造函数包含许多参数来指定如何在加载图像数据后对其进行操作,包括像素缩放和数据扩充。我们在这个阶段不需要这些特性,所以配置图像数据生成器很容易。
...
# create a data generator
datagen = ImageDataGenerator()
接下来,需要一个迭代器来逐步加载单个数据集的图像。
这需要调用 flow_from_directory() 函数并指定数据集目录,如列车、测试或验证目录。
该功能还允许您配置与图像加载相关的更多细节。值得注意的是“ target_size ”参数,它允许您将所有图像加载到特定的大小,这是建模时经常需要的。该功能默认为尺寸为 (256,256) 的方形图像。
该功能还允许您通过“ class_mode ”参数指定分类任务的类型,特别是它是“二进制还是多类分类”分类。
默认的“ batch_size ”为 32,这意味着在训练时,每一批将返回数据集内跨类随机选择的 32 幅图像。可能需要更大或更小的批次。在评估模型时,您可能还希望以确定的顺序返回批次,这可以通过将“ shuffle ”设置为“ False ”来实现
还有很多其他的选择,我鼓励大家查看 API 文档。
我们可以使用相同的 ImageDataGenerator 为单独的数据集目录准备单独的迭代器。如果我们希望将相同的像素缩放应用于多个数据集(例如 trian、test 等),这将非常有用。).
...
# load and iterate training dataset
train_it = datagen.flow_from_directory('data/train/', class_mode='binary', batch_size=64)
# load and iterate validation dataset
val_it = datagen.flow_from_directory('data/validation/', class_mode='binary', batch_size=64)
# load and iterate test dataset
test_it = datagen.flow_from_directory('data/test/', class_mode='binary', batch_size=64)
一旦迭代器准备好了,我们就可以在拟合和评估深度学习模型时使用它们。
例如,用数据生成器拟合模型可以通过调用模型上的 fit_generator() 函数并传递训练迭代器( train_it )来实现。当通过“ validation_data 参数调用该函数时,可以指定验证迭代器( val_it )。
必须为训练迭代器指定“*steps _ per _ epoch”*参数,以便定义一个 epoch 定义多少批图像。
例如,如果在训练数据集中有 1,000 个图像(跨越所有类),并且批次大小为 64,那么 steps_per_epoch 大约为 16,或者 1000/64。
同样,如果应用了验证迭代器,则还必须指定“验证 _ 步骤”参数,以指示定义一个时期的验证数据集中的批次数量。
...
# define model
model = ...
# fit model
model.fit_generator(train_it, steps_per_epoch=16, validation_data=val_it, validation_steps=8)
一旦模型合适,就可以使用 evaluate_generator() 函数在测试数据集上对其进行评估,并通过测试迭代器( test_it )。“步数参数定义了在停止前评估模型时要通过的样本批次数。
...
# evaluate model
loss = model.evaluate_generator(test_it, steps=24)
最后,如果您想使用您的拟合模型对非常大的数据集进行预测,您也可以为该数据集创建一个迭代器(例如 predict_it )并调用模型上的 predict_generator() 函数。
...
# make a prediction
yhat = model.predict_generator(predict_it, steps=24)
让我们使用上一节中定义的小数据集来演示如何定义 ImageDataGenerator 实例并准备数据集迭代器。
下面列出了一个完整的示例。
# example of progressively loading images from file
from keras.preprocessing.image import ImageDataGenerator
# create generator
datagen = ImageDataGenerator()
# prepare an iterators for each dataset
train_it = datagen.flow_from_directory('data/train/', class_mode='binary')
val_it = datagen.flow_from_directory('data/validation/', class_mode='binary')
test_it = datagen.flow_from_directory('data/test/', class_mode='binary')
# confirm the iterator works
batchX, batchy = train_it.next()
print('Batch shape=%s, min=%.3f, max=%.3f' % (batchX.shape, batchX.min(), batchX.max()))
运行该示例首先创建一个带有所有默认配置的图像数据生成器的实例。
接下来,创建三个迭代器,分别用于训练、验证和测试二进制类别数据集。在创建每个迭代器时,我们可以看到调试消息,报告发现和准备的图像和类的数量。
最后,我们测试了用于拟合模型的火车迭代器。检索第一批图像,我们可以确认该批包含两个图像,因为只有两个图像可用。我们还可以确认图像被加载并强制为 256 行和 256 列像素的正方形尺寸,并且像素数据没有被缩放并保持在范围[0,255]内。
Found 2 images belonging to 2 classes.
Found 2 images belonging to 2 classes.
Found 2 images belonging to 2 classes.
Batch shape=(2, 256, 256, 3), min=0.000, max=255.000
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
应用程序接口
文章
摘要
在本教程中,您发现了如何构建图像数据集,以及如何在拟合和评估深度学习模型时逐步加载它。
具体来说,您了解到:
- 如何将训练、测试和验证图像数据集组织成一致的目录结构。
- 如何使用 ImageDataGenerator 类逐步加载给定数据集的图像。
- 如何使用准备好的数据生成器,通过深度学习模型进行训练、评估和预测。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
如何为深度学习手动缩放图像像素数据
原文:https://machinelearningmastery.com/how-to-manually-scale-image-pixel-data-for-deep-learning/
最后更新于 2019 年 7 月 5 日
图像由像素值矩阵组成。
黑白图像是单个像素矩阵,而彩色图像对于每个颜色通道都有单独的像素值阵列,例如红色、绿色和蓝色。
像素值通常是 0 到 255 之间的无符号整数。尽管这些像素值可以以原始格式直接呈现给神经网络模型,但这会导致建模过程中的挑战,例如模型的训练速度比预期的慢。
相反,在建模之前准备图像像素值可能会有很大的好处,例如简单地将像素值缩放到 0-1 的范围,以居中甚至标准化这些值。
在本教程中,您将发现使用深度学习神经网络建模的图像数据。
完成本教程后,您将知道:
- 如何将像素值归一化到 0 到 1 之间的范围。
- 如何在全局跨通道和局部每通道中心像素值。
- 如何标准化像素值以及如何将标准化像素值转移到正域。
用我的新书计算机视觉深度学习启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。
教程概述
本教程分为四个部分;它们是:
- 样本图像
- 归一化像素值
- 中心像素值
- 标准化像素值
样本图像
在本教程中,我们需要一个用于测试的示例图像。
我们将使用“T2”伯纳德·斯拉格拍摄的悉尼海港大桥的照片。新西兰”并在许可许可下发布。

悉尼海港大桥由伯纳德·斯普拉格拍摄。NZ"
保留部分权利。
下载照片,放入当前工作目录,文件名为“ sydney_bridge.jpg ”。
下面的示例将加载图像,显示关于加载图像的一些属性,然后显示图像。
本示例和教程的其余部分假设您已经安装了 Pillow Python 库。
# load and show an image with Pillow
from PIL import Image
# load the image
image = Image.open('sydney_bridge.jpg')
# summarize some details about the image
print(image.format)
print(image.mode)
print(image.size)
# show the image
image.show()
运行该示例会报告图像的格式(即 JPEG)和模式(即三个颜色通道的 RGB)。
接下来,报告图像的大小,显示宽度为 640 像素,高度为 374 像素。
JPEG
RGB
(640, 374)
然后使用工作站上显示图像的默认应用程序预览图像。

从文件加载的悉尼海港大桥照片
归一化像素值
对于大多数图像数据,像素值是 0 到 255 之间的整数。
神经网络使用小的权值处理输入,而具有大整数值的输入会扰乱或减慢学习过程。因此,对像素值进行归一化是一种很好的做法,这样每个像素值都有一个介于 0 和 1 之间的值。
图像像素值在 0-1 范围内有效,图像可以正常观看。
这可以通过将所有像素值除以最大像素值来实现;那是 255。这是跨所有通道执行的,与图像中存在的像素值的实际范围无关。
以下示例加载图像并将其转换为 NumPy 数组。报告阵列的数据类型,然后打印所有三个通道的最小和最大像素值。接下来,在像素值被归一化并报告新的像素值范围之前,阵列被转换为浮点数据类型。
# example of pixel normalization
from numpy import asarray
from PIL import Image
# load image
image = Image.open('sydney_bridge.jpg')
pixels = asarray(image)
# confirm pixel range is 0-255
print('Data Type: %s' % pixels.dtype)
print('Min: %.3f, Max: %.3f' % (pixels.min(), pixels.max()))
# convert from integers to floats
pixels = pixels.astype('float32')
# normalize to the range 0-1
pixels /= 255.0
# confirm the normalization
print('Min: %.3f, Max: %.3f' % (pixels.min(), pixels.max()))
运行该示例打印像素值的 NumPy 数组的数据类型,我们可以看到它是一个 8 位无符号整数。
打印最小和最大像素值,分别显示预期的 0 和 255。像素值被归一化,然后报告 0.0 和 1.0 的新最小值和最大值。
Data Type: uint8
Min: 0.000, Max: 255.000
Min: 0.000, Max: 1.000
如果您对要执行的数据准备类型有疑问,规范化是一个很好的默认数据准备。
它可以针对每个图像执行,并且不需要计算整个训练数据集的统计数据,因为像素值的范围是一个域标准。
中心像素值
图像数据的一种流行的数据准备技术是从像素值中减去平均值。
这种方法称为居中,因为像素值的分布以零值为中心。
居中可以在标准化之前或之后进行。将像素居中然后归一化将意味着像素值将居中接近 0.5 并且在 0-1 的范围内。归一化后居中将意味着像素将具有正值和负值,在这种情况下,图像将无法正确显示(例如,像素的值预计在 0-255 或 0-1 的范围内)。规范化后的居中可能是首选,尽管测试这两种方法可能都是值得的。
居中要求在从像素值中减去平均像素值之前计算平均像素值。平均值有多种计算方法;例如:
- pbr 图像
- 每小批图像(在随机梯度下降下)。
- 每个训练数据集。
可以计算图像中所有像素的平均值,称为全局居中,或者可以计算彩色图像中每个通道的平均值,称为局部居中。
- 全局居中:计算并减去跨颜色通道的平均像素值。
- 局部居中:计算并减去每个颜色通道的平均像素值。
每个图像的全局居中很常见,因为实现起来很简单。同样常见的是每个小批量的全局或局部中心化,原因相同:它快速且易于实现。
在某些情况下,每个通道的平均值是在整个训练数据集中预先计算的。在这种情况下,图像手段必须在训练期间和将来对训练模型的任何推断中被存储和使用。例如,为 ImageNet 训练数据集计算的每通道像素平均值如下:
- ImageNet 训练数据集表示:【0.485,0.456,0.406】
对于使用这些方法以图像为中心训练的模型,这些方法可用于新任务的转移学习,使用相同的方法标准化新任务的图像可能是有益的,甚至是必需的。
我们来看几个例子。
全局居中
以下示例计算加载图像中所有三个颜色通道的全局平均值,然后使用全局平均值将像素值居中。
# example of global centering (subtract mean)
from numpy import asarray
from PIL import Image
# load image
image = Image.open('sydney_bridge.jpg')
pixels = asarray(image)
# convert from integers to floats
pixels = pixels.astype('float32')
# calculate global mean
mean = pixels.mean()
print('Mean: %.3f' % mean)
print('Min: %.3f, Max: %.3f' % (pixels.min(), pixels.max()))
# global centering of pixels
pixels = pixels - mean
# confirm it had the desired effect
mean = pixels.mean()
print('Mean: %.3f' % mean)
print('Min: %.3f, Max: %.3f' % (pixels.min(), pixels.max()))
运行该示例,我们可以看到平均像素值约为 152。
一旦居中,我们可以确认像素值的新平均值为 0.0,并且新的数据范围围绕该平均值为正和负。
Mean: 152.149
Min: 0.000, Max: 255.000
Mean: -0.000
Min: -152.149, Max: 102.851
局部居中
下面的示例计算加载图像中每个颜色通道的平均值,然后分别将每个通道的像素值居中。
请注意,NumPy 允许我们指定通过“轴参数计算平均值、最小值和最大值等统计量的维度。在本例中,我们将宽度和高度维度设置为(0,1),这样就剩下第三个维度或通道。结果是三个通道阵列各有一个平均值、最小值或最大值。
还要注意,当我们计算平均值时,我们将数据类型指定为’float 64’;这是必需的,因为这将导致以 64 位准确率执行均值的所有子操作,例如求和。如果没有这一点,将在较低的分辨率下执行求和,并且给定准确率损失中的累积误差,所得到的平均值将是错误的,这又意味着每个通道的中心像素值的平均值将不是零(或者非常小的接近零的数字)。
# example of per-channel centering (subtract mean)
from numpy import asarray
from PIL import Image
# load image
image = Image.open('sydney_bridge.jpg')
pixels = asarray(image)
# convert from integers to floats
pixels = pixels.astype('float32')
# calculate per-channel means and standard deviations
means = pixels.mean(axis=(0,1), dtype='float64')
print('Means: %s' % means)
print('Mins: %s, Maxs: %s' % (pixels.min(axis=(0,1)), pixels.max(axis=(0,1))))
# per-channel centering of pixels
pixels -= means
# confirm it had the desired effect
means = pixels.mean(axis=(0,1), dtype='float64')
print('Means: %s' % means)
print('Mins: %s, Maxs: %s' % (pixels.min(axis=(0,1)), pixels.max(axis=(0,1))))
运行该示例首先报告每个通道的平均像素值,以及每个通道的最小值和最大值。像素值居中,然后报告每个通道的新平均值和最小/最大像素值。
我们可以看到,新的平均像素值是非常小的接近零的数字,并且这些值是以零为中心的负值和正值。
Means: [148.61581718 150.64154412 157.18977691]
Mins: [0\. 0\. 0.], Maxs: [255\. 255\. 255.]
Means: [1.14413078e-06 1.61369515e-06 1.37722619e-06]
Mins: [-148.61581 -150.64154 -157.18977], Maxs: [106.384186 104.35846 97.81023 ]
标准化像素值
像素值的分布通常遵循正态或高斯分布,例如钟形。
这种分布可以存在于每个图像、每个小批量图像中,或者存在于整个训练数据集中以及全局或每个通道中。
因此,将像素值的分布转换为标准高斯分布可能会有好处:既可以将像素值以零为中心,又可以通过标准偏差对值进行归一化。结果是像素值的标准高斯分布,平均值为 0.0,标准偏差为 1.0。
与居中一样,操作可以在每个图像、每个小批量和整个训练数据集中执行,并且可以在通道间全局执行或在通道间局部执行。
标准化可能优于标准化和单独居中,它会导致小输入值的零居中值,大致在-3 到 3 的范围内,这取决于数据集的具体情况。
为了输入数据的一致性,如果可能的话,使用每个小批量或整个训练数据集计算的统计数据来标准化每个通道的图像可能更有意义。
我们来看一些例子。
全球标准化
以下示例计算加载图像中所有颜色通道的平均值和标准偏差,然后使用这些值来标准化像素值。
# example of global pixel standardization
from numpy import asarray
from PIL import Image
# load image
image = Image.open('sydney_bridge.jpg')
pixels = asarray(image)
# convert from integers to floats
pixels = pixels.astype('float32')
# calculate global mean and standard deviation
mean, std = pixels.mean(), pixels.std()
print('Mean: %.3f, Standard Deviation: %.3f' % (mean, std))
# global standardization of pixels
pixels = (pixels - mean) / std
# confirm it had the desired effect
mean, std = pixels.mean(), pixels.std()
print('Mean: %.3f, Standard Deviation: %.3f' % (mean, std))
运行该示例首先计算全局平均值和标准偏差像素值,标准化像素值,然后通过分别报告 0.0 和 1.0 的新全局平均值和标准偏差来确认转换。
Mean: 152.149, Standard Deviation: 70.642
Mean: -0.000, Standard Deviation: 1.000
积极的全球标准化
可能希望将像素值保持在正域中,可能是为了使图像可视化,或者可能是为了在模型中选择激活函数。
实现这一点的一种流行方式是将标准化像素值裁剪到[-1,1]的范围内,然后将值从[-1,1]重新缩放到[0,1]。
下面的示例更新了全局标准化示例,以演示这种额外的重新缩放。
# example of global pixel standardization shifted to positive domain
from numpy import asarray
from numpy import clip
from PIL import Image
# load image
image = Image.open('sydney_bridge.jpg')
pixels = asarray(image)
# convert from integers to floats
pixels = pixels.astype('float32')
# calculate global mean and standard deviation
mean, std = pixels.mean(), pixels.std()
print('Mean: %.3f, Standard Deviation: %.3f' % (mean, std))
# global standardization of pixels
pixels = (pixels - mean) / std
# clip pixel values to [-1,1]
pixels = clip(pixels, -1.0, 1.0)
# shift from [-1,1] to [0,1] with 0.5 mean
pixels = (pixels + 1.0) / 2.0
# confirm it had the desired effect
mean, std = pixels.mean(), pixels.std()
print('Mean: %.3f, Standard Deviation: %.3f' % (mean, std))
print('Min: %.3f, Max: %.3f' % (pixels.min(), pixels.max()))
运行该示例首先报告全局平均值和标准偏差像素值;像素被标准化,然后被重新缩放。
接下来,报告新的平均值和标准偏差分别约为 0.5 和 0.3,新的最小值和最大值确认为 0.0 和 1.0。
Mean: 152.149, Standard Deviation: 70.642
Mean: 0.510, Standard Deviation: 0.388
Min: 0.000, Max: 1.000
地方标准化
下面的示例计算每个通道加载图像的平均值和标准偏差,然后使用这些统计数据分别标准化每个通道中的像素。
# example of per-channel pixel standardization
from numpy import asarray
from PIL import Image
# load image
image = Image.open('sydney_bridge.jpg')
pixels = asarray(image)
# convert from integers to floats
pixels = pixels.astype('float32')
# calculate per-channel means and standard deviations
means = pixels.mean(axis=(0,1), dtype='float64')
stds = pixels.std(axis=(0,1), dtype='float64')
print('Means: %s, Stds: %s' % (means, stds))
# per-channel standardization of pixels
pixels = (pixels - means) / stds
# confirm it had the desired effect
means = pixels.mean(axis=(0,1), dtype='float64')
stds = pixels.std(axis=(0,1), dtype='float64')
print('Means: %s, Stds: %s' % (means, stds))
运行该示例首先计算并报告每个通道中像素值的平均值和标准偏差。
然后对像素值进行标准化,重新计算统计数据,确认新的零均值和单位标准偏差。
Means: [148.61581718 150.64154412 157.18977691], Stds: [70.21666738 70.6718887 70.75185228]
Means: [ 6.26286458e-14 -4.40909176e-14 -8.38046276e-13], Stds: [1\. 1\. 1.]
扩展ˌ扩张
本节列出了一些您可能希望探索的扩展教程的想法。
- 开发功能。开发一个函数来缩放提供的图像,使用参数来选择要执行的准备类型,
- 投影方法。研究并实现从像素数据中消除线性相关性的数据准备方法,如主成分分析和 ZCA。
- 数据集统计。选择并更新其中一个居中或标准化示例,以计算整个训练数据集中的统计数据,然后在准备用于训练或推理的图像数据时应用这些统计数据。
如果你探索这些扩展,我很想知道。
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
应用程序接口
文章
- 数据预处理,用于视觉识别的 CS231n 卷积神经网络
- 深度学习为什么要通过减去数据集的图像均值来归一化图像,而不是当前的图像均值?
- 在将卷积神经网络应用于图像分类任务之前,有哪些对图像进行预处理的方法?
- 对分类中的图像预处理一头雾水,Pytorch 发出。
摘要
在本教程中,您发现了如何使用深度学习神经网络为建模准备图像数据。
具体来说,您了解到:
- 如何将像素值归一化到 0 到 1 之间的范围。
- 如何在全局跨通道和局部每通道中心像素值。
- 如何标准化像素值以及如何将标准化像素值转移到正域。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
如何在 Keras 中对图像像素归一化、居中和标准化
最后更新于 2019 年 7 月 5 日
在训练或评估模型期间,在将图像作为输入提供给深度学习神经网络模型之前,必须缩放图像中的像素值。
传统上,图像必须在模型开发之前进行缩放,并以缩放后的格式存储在内存或磁盘上。
另一种方法是在训练或模型评估过程中及时使用首选的缩放技术来缩放图像。Keras 通过 ImageDataGenerator 类和 API 支持这种类型的图像数据的数据准备。
在本教程中,您将发现如何使用 ImageDataGenerator 类在拟合和评估深度学习神经网络模型时及时缩放像素数据。
完成本教程后,您将知道:
- 如何配置和使用 ImageDataGenerator 类来训练、验证和测试图像数据集。
- 在拟合和评估卷积神经网络模型时,如何使用 ImageDataGenerator 对像素值进行归一化。
- 在拟合和评估卷积神经网络模型时,如何使用 ImageDataGenerator 对像素值进行中心化和标准化。
用我的新书计算机视觉深度学习启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。

如何使用 Keras 中的 ImageDataGenerator 对图像进行规范化、居中和标准化萨加尔拍摄的照片,保留部分权利。
教程概述
本教程分为五个部分;它们是:
- MNIST 手写图像类别数据集
- 用于像素缩放的图像数据生成器类
- 如何使用图像数据生成器规范化图像
- 如何使用图像数据生成器将图像居中
- 如何使用图像数据生成器标准化图像
MNIST 手写图像类别数据集
在我们深入研究 ImageDataGenerator 类用于准备图像数据之前,我们必须选择一个图像数据集来测试生成器。
MNIST 问题,是一个由 70,000 幅手写数字图像组成的图像分类问题。
该问题的目标是将手写数字的给定图像分类为从 0 到 9 的整数。因此,这是一个多类图像分类问题。
该数据集作为 Keras 库的一部分提供,可以通过调用Keras . datasets . mnist . load _ data()函数自动下载(如果需要)并加载到内存中。
该函数返回两个元组:一个用于训练输入和输出,一个用于测试输入和输出。例如:
# example of loading the MNIST dataset
from keras.datasets import mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
我们可以加载 MNIST 数据集并汇总数据集。下面列出了完整的示例。
# load and summarize the MNIST dataset
from keras.datasets import mnist
# load dataset
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
# summarize dataset shape
print('Train', train_images.shape, train_labels.shape)
print('Test', (test_images.shape, test_labels.shape))
# summarize pixel values
print('Train', train_images.min(), train_images.max(), train_images.mean(), train_images.std())
print('Test', test_images.min(), test_images.max(), test_images.mean(), test_images.std())
运行该示例首先将数据集加载到内存中。然后报告训练和测试数据集的形状。
我们可以看到,所有图像都是 28×28 像素,黑白图像只有一个通道。训练数据集有 60,000 幅图像,测试数据集有 10,000 幅图像。
我们还可以看到,像素值是介于 0 和 255 之间的整数值,并且两个数据集之间像素值的平均值和标准差相似。
Train (60000, 28, 28) (60000,)
Test ((10000, 28, 28), (10000,))
Train 0 255 33.318421449829934 78.56748998339798
Test 0 255 33.791224489795916 79.17246322228644
我们将使用这个数据集来探索使用 Keras 中的 ImageDataGenerator 类的不同像素缩放方法。
用于像素缩放的图像数据生成器类
Keras 中的 ImageDataGenerator 类提供了一套在建模之前缩放图像数据集中像素值的技术。
该类将包装您的图像数据集,然后在需要时,它将在训练、验证或评估期间分批将图像返回给算法,并及时应用缩放操作。这为使用神经网络建模时缩放图像数据提供了一种高效便捷的方法。
ImageDataGenerator 类的用法如下。
- 1.加载数据集。
- 2.配置 ImageDataGenerator(例如,构建一个实例)。
- 3.计算图像统计(如调用 fit() 函数)。
- 4.使用生成器来拟合模型(例如,将实例传递给 fit_generator() 函数)。
- 5.使用生成器评估模型(例如,将实例传递给 evaluate_generator() 函数)。
ImageDataGenerator 类支持多种像素缩放方法,以及一系列数据扩充技术。我们将集中讨论像素缩放技术,并将数据扩充方法留给后面的讨论。
ImageDataGenerator 类支持的三种主要像素缩放技术如下:
- 像素归一化:将像素值缩放到 0-1 的范围。
- 像素居中:缩放像素值至零平均值。
- 像素标准化:缩放像素值,使其平均值和单位方差为零。
像素标准化在两个层次上得到支持:每图像(称为样本方式)或每数据集(称为特征方式)。具体而言,标准化像素值所需的均值和/或均值和标准偏差统计量可以仅从每个图像中的像素值(样本方式)或跨整个训练数据集(特征方式)来计算。
支持其他像素缩放方法,如 ZCA、增亮等,但我们将重点关注这三种最常见的方法。
通过在构造实例时为 ImageDataGenerator 指定参数来选择像素缩放;例如:
# create and configure the data generator
datagen = ImageDataGenerator(...)
接下来,如果所选的缩放方法要求跨训练数据集计算统计数据,则可以通过调用 fit() 函数来计算和存储这些统计数据。
评估和选择模型时,通常会在训练数据集上计算这些统计数据,然后将它们应用于验证和测试数据集。
# calculate scaling statistics on the training dataset
datagen.fit(trainX)
数据生成器一旦准备好,就可以用来拟合神经网络模型,方法是调用 flow() 函数来检索返回成批样本的迭代器,并将其传递给 fit_generator() 函数。
# get batch iterator
train_iterator = datagen.flow(trainX, trainy)
# fit model
model.fit_generator(train_iterator, ...)
如果需要验证数据集,可以从相同的数据生成器创建单独的批处理迭代器,该迭代器将执行相同的像素缩放操作,并使用在训练数据集上计算的任何所需统计信息。
# get batch iterator for training
train_iterator = datagen.flow(trainX, trainy)
# get batch iterator for validation
val_iterator = datagen.flow(valX, valy)
# fit model
model.fit_generator(train_iterator, validation_data=val_iterator, ...)
一旦适合,就可以通过为测试数据集创建批处理迭代器并在模型上调用 evaluate_generator() 函数来评估模型。
同样,将执行相同的像素缩放操作,并且如果需要,将使用在训练数据集上计算的任何统计数据。
# get batch iterator for testing
test_iterator = datagen.flow(testX, testy)
# evaluate model loss on test dataset
loss = model.evaluate_generator(test_iterator, ...)
现在我们已经熟悉了如何使用 ImageDataGenerator 类来缩放像素值,让我们看一些具体的例子。
如何使用图像数据生成器规范化图像
ImageDataGenerator 类可用于将像素值从 0-255 范围重新缩放到神经网络模型首选的 0-1 范围。
将数据缩放到 0-1 的范围通常被称为归一化。
这可以通过将重新缩放参数设置为一个比率来实现,通过该比率可以将每个像素相乘以获得所需的范围。
在这种情况下,比率是 1/255 或大约 0.0039。例如:
# create generator (1.0/255.0 = 0.003921568627451)
datagen = ImageDataGenerator(rescale=1.0/255.0)
在这种情况下,不需要安装 ImageDataGenerator,因为没有需要计算的全局统计信息。
接下来,可以使用生成器为训练和测试数据集创建迭代器。我们将使用 64 的批量。这意味着图像的每个训练和测试数据集被分成 64 个图像组,当从迭代器返回时,这些图像组将被缩放。
通过打印每个迭代器的长度,我们可以看到一个纪元中有多少批次,例如一次通过训练数据集。
# prepare an iterators to scale images
train_iterator = datagen.flow(trainX, trainY, batch_size=64)
test_iterator = datagen.flow(testX, testY, batch_size=64)
print('Batches train=%d, test=%d' % (len(train_iterator), len(test_iterator)))
然后,我们可以通过检索第一批缩放图像并检查最小和最大像素值来确认像素归一化是否已按预期执行。
# confirm the scaling works
batchX, batchy = train_iterator.next()
print('Batch shape=%s, min=%.3f, max=%.3f' % (batchX.shape, batchX.min(), batchX.max()))
接下来,我们可以使用数据生成器来拟合和评估模型。我们将定义一个简单的卷积神经网络模型,并将其拟合到 5 个时期的 train_iterator 上,其中 60,000 个样本除以每批 64 个样本,即每时期约 938 个批次。
# fit model with generator
model.fit_generator(train_iterator, steps_per_epoch=len(train_iterator), epochs=5)
一旦拟合,我们将在测试数据集上评估模型,大约 10,000 幅图像除以每批 64 个样本,或者在单个时期内大约 157 个步骤。
_, acc = model.evaluate_generator(test_iterator, steps=len(test_iterator), verbose=0)
print('Test Accuracy: %.3f' % (acc * 100))
我们可以把这一切联系在一起;下面列出了完整的示例。
# example of using ImageDataGenerator to normalize images
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.preprocessing.image import ImageDataGenerator
# load dataset
(trainX, trainY), (testX, testY) = mnist.load_data()
# reshape dataset to have a single channel
width, height, channels = trainX.shape[1], trainX.shape[2], 1
trainX = trainX.reshape((trainX.shape[0], width, height, channels))
testX = testX.reshape((testX.shape[0], width, height, channels))
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
# confirm scale of pixels
print('Train min=%.3f, max=%.3f' % (trainX.min(), trainX.max()))
print('Test min=%.3f, max=%.3f' % (testX.min(), testX.max()))
# create generator (1.0/255.0 = 0.003921568627451)
datagen = ImageDataGenerator(rescale=1.0/255.0)
# prepare an iterators to scale images
train_iterator = datagen.flow(trainX, trainY, batch_size=64)
test_iterator = datagen.flow(testX, testY, batch_size=64)
print('Batches train=%d, test=%d' % (len(train_iterator), len(test_iterator)))
# confirm the scaling works
batchX, batchy = train_iterator.next()
print('Batch shape=%s, min=%.3f, max=%.3f' % (batchX.shape, batchX.min(), batchX.max()))
# define model
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(width, height, channels)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
# compile model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# fit model with generator
model.fit_generator(train_iterator, steps_per_epoch=len(train_iterator), epochs=5)
# evaluate model
_, acc = model.evaluate_generator(test_iterator, steps=len(test_iterator), verbose=0)
print('Test Accuracy: %.3f' % (acc * 100))
运行该示例首先报告训练集和测试集上的最小和最大像素值。这证实了原始数据确实具有 0-255 范围内的像素值。
接下来,创建数据生成器并准备迭代器。我们可以看到,训练数据集每个时期有 938 个批次,测试数据集每个时期有 157 个批次。
我们从数据集中检索第一批,并确认它包含 64 幅图像,高度和宽度(行和列)为 28 个像素和 1 个通道,新的最小和最大像素值分别为 0 和 1。这证实了正常化取得了预期的效果。
Train min=0.000, max=255.000
Test min=0.000, max=255.000
Batches train=938, test=157
Batch shape=(64, 28, 28, 1), min=0.000, max=1.000
然后将该模型拟合到归一化的图像数据上。在 CPU 上训练不需要很长时间。最后,在测试数据集中评估模型,应用相同的规范化。
Epoch 1/5
938/938 [==============================] - 12s 13ms/step - loss: 0.1841 - acc: 0.9448
Epoch 2/5
938/938 [==============================] - 12s 13ms/step - loss: 0.0573 - acc: 0.9826
Epoch 3/5
938/938 [==============================] - 12s 13ms/step - loss: 0.0407 - acc: 0.9870
Epoch 4/5
938/938 [==============================] - 12s 13ms/step - loss: 0.0299 - acc: 0.9904
Epoch 5/5
938/938 [==============================] - 12s 13ms/step - loss: 0.0238 - acc: 0.9928
Test Accuracy: 99.050
既然我们已经熟悉了如何使用 ImageDataGenerator 进行图像规范化,那么让我们来看看像素居中和标准化的例子。
如何使用图像数据生成器将图像居中
另一种流行的像素缩放方法是计算整个训练数据集的平均像素值,然后从每个图像中减去它。
这被称为居中,并且具有将像素值的分布居中为零的效果:也就是说,居中图像的平均像素值将为零。
ImageDataGenerator 类指的是定心,它使用在训练数据集上计算的平均值作为特征定心。它要求在缩放之前对训练数据集计算统计数据。
# create generator that centers pixel values
datagen = ImageDataGenerator(featurewise_center=True)
# calculate the mean on the training dataset
datagen.fit(trainX)
它不同于计算每个图像的平均像素值,Keras 称之为样本中心化,不需要在训练数据集上计算任何统计数据。
# create generator that centers pixel values
datagen = ImageDataGenerator(samplewise_center=True)
在本节中,我们将演示按特征居中。一旦在训练数据集上计算出统计量,我们就可以通过访问和打印来确认该值;例如:
# print the mean calculated on the training dataset.
print(datagen.mean)
我们还可以通过计算批处理迭代器返回的一批图像的平均值来确认缩放过程已经达到了预期的效果。我们希望平均值是一个接近于零的小值,但不是零,因为批次中的图像数量很少。
# get a batch
batchX, batchy = iterator.next()
# mean pixel value in the batch
print(batchX.shape, batchX.mean())
更好的检查是将批次大小设置为训练数据集的大小(例如 60,000 个样本),检索一个批次,然后计算平均值。它应该是一个非常小的接近于零的值。
# try to flow the entire training dataset
iterator = datagen.flow(trainX, trainy, batch_size=len(trainX), shuffle=False)
# get a batch
batchX, batchy = iterator.next()
# mean pixel value in the batch
print(batchX.shape, batchX.mean())
下面列出了完整的示例。
# example of centering a image dataset
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
# load dataset
(trainX, trainy), (testX, testy) = mnist.load_data()
# reshape dataset to have a single channel
width, height, channels = trainX.shape[1], trainX.shape[2], 1
trainX = trainX.reshape((trainX.shape[0], width, height, channels))
testX = testX.reshape((testX.shape[0], width, height, channels))
# report per-image mean
print('Means train=%.3f, test=%.3f' % (trainX.mean(), testX.mean()))
# create generator that centers pixel values
datagen = ImageDataGenerator(featurewise_center=True)
# calculate the mean on the training dataset
datagen.fit(trainX)
print('Data Generator Mean: %.3f' % datagen.mean)
# demonstrate effect on a single batch of samples
iterator = datagen.flow(trainX, trainy, batch_size=64)
# get a batch
batchX, batchy = iterator.next()
# mean pixel value in the batch
print(batchX.shape, batchX.mean())
# demonstrate effect on entire training dataset
iterator = datagen.flow(trainX, trainy, batch_size=len(trainX), shuffle=False)
# get a batch
batchX, batchy = iterator.next()
# mean pixel value in the batch
print(batchX.shape, batchX.mean())
运行该示例首先报告训练和测试数据集的平均像素值。
MNIST 数据集只有一个通道,因为图像是黑白的(灰度),但是如果图像是彩色的,则训练数据集中所有图像的所有通道的平均像素值将被计算,即每个通道没有单独的平均值。
图像数据生成器适合训练数据集,我们可以确认平均像素值与我们自己的手动计算相匹配。
检索单批居中的图像,我们可以确认平均像素值是接近于零的小值。使用整个训练数据集作为批次大小来重复测试,在这种情况下,缩放数据集的平均像素值是非常接近于零的数字,这证实了居中具有期望的效果。
Means train=33.318, test=33.791
Data Generator Mean: 33.318
(64, 28, 28, 1) 0.09971977
(60000, 28, 28, 1) -1.9512918e-05
我们可以用上一节开发的卷积神经网络来演示居中。
下面列出了按特征对中的完整示例。
# example of using ImageDataGenerator to center images
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.preprocessing.image import ImageDataGenerator
# load dataset
(trainX, trainY), (testX, testY) = mnist.load_data()
# reshape dataset to have a single channel
width, height, channels = trainX.shape[1], trainX.shape[2], 1
trainX = trainX.reshape((trainX.shape[0], width, height, channels))
testX = testX.reshape((testX.shape[0], width, height, channels))
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
# create generator to center images
datagen = ImageDataGenerator(featurewise_center=True)
# calculate mean on training dataset
datagen.fit(trainX)
# prepare an iterators to scale images
train_iterator = datagen.flow(trainX, trainY, batch_size=64)
test_iterator = datagen.flow(testX, testY, batch_size=64)
print('Batches train=%d, test=%d' % (len(train_iterator), len(test_iterator)))
# define model
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(width, height, channels)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
# compile model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# fit model with generator
model.fit_generator(train_iterator, steps_per_epoch=len(train_iterator), epochs=5)
# evaluate model
_, acc = model.evaluate_generator(test_iterator, steps=len(test_iterator), verbose=0)
print('Test Accuracy: %.3f' % (acc * 100))
运行该示例将准备 ImageDataGenerator,使用在训练数据集上计算的统计信息对图像进行居中。
我们可以看到,表现开始很差,但确实有所提高。居中的像素值将具有大约-227 到 227 的范围,并且神经网络通常使用小输入来更有效地训练。在实践中,正常化之后是居中将是更好的方法。
重要的是,在测试数据集上评估模型,其中使用在训练数据集上计算的平均值将测试数据集中的图像居中。这是为了避免任何数据泄露。
Batches train=938, test=157
Epoch 1/5
938/938 [==============================] - 12s 13ms/step - loss: 12.8824 - acc: 0.2001
Epoch 2/5
938/938 [==============================] - 12s 13ms/step - loss: 6.1425 - acc: 0.5958
Epoch 3/5
938/938 [==============================] - 12s 13ms/step - loss: 0.0678 - acc: 0.9796
Epoch 4/5
938/938 [==============================] - 12s 13ms/step - loss: 0.0464 - acc: 0.9857
Epoch 5/5
938/938 [==============================] - 12s 13ms/step - loss: 0.0373 - acc: 0.9880
Test Accuracy: 98.540
如何使用图像数据生成器标准化图像
标准化是一种数据缩放技术,它假设数据的分布是高斯分布,并将数据的分布转换为平均值为零,标准偏差为 1。
具有这种分布的数据称为标准高斯分布。当训练神经网络时,这可能是有益的,因为数据集和为零,并且输入是大约-3.0 到 3.0 的粗略范围内的小值(例如, 99.7 的值将落在平均值的三个标准偏差内)。
图像的标准化是通过减去平均像素值并将结果除以像素值的标准偏差来实现的。
均值和标准差统计可以在训练数据集上计算,正如上一节所讨论的,Keras 将其称为特征统计。
# feature-wise generator
datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True)
# calculate mean and standard deviation on the training dataset
datagen.fit(trainX)
还可以计算统计数据,然后分别用于标准化每个图像,Keras 称之为采样标准化。
# sample-wise standardization
datagen = ImageDataGenerator(samplewise_center=True, samplewise_std_normalization=True)
在本节中,我们将演示图像标准化的前一种方法或特征方法。效果将是一批批图像,其近似平均值为零,标准偏差为一。
与前一部分一样,我们可以通过一些简单的实验来证实这一点。下面列出了完整的示例。
# example of standardizing a image dataset
from keras.datasets import mnist
from keras.preprocessing.image import ImageDataGenerator
# load dataset
(trainX, trainy), (testX, testy) = mnist.load_data()
# reshape dataset to have a single channel
width, height, channels = trainX.shape[1], trainX.shape[2], 1
trainX = trainX.reshape((trainX.shape[0], width, height, channels))
testX = testX.reshape((testX.shape[0], width, height, channels))
# report pixel means and standard deviations
print('Statistics train=%.3f (%.3f), test=%.3f (%.3f)' % (trainX.mean(), trainX.std(), testX.mean(), testX.std()))
# create generator that centers pixel values
datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True)
# calculate the mean on the training dataset
datagen.fit(trainX)
print('Data Generator mean=%.3f, std=%.3f' % (datagen.mean, datagen.std))
# demonstrate effect on a single batch of samples
iterator = datagen.flow(trainX, trainy, batch_size=64)
# get a batch
batchX, batchy = iterator.next()
# pixel stats in the batch
print(batchX.shape, batchX.mean(), batchX.std())
# demonstrate effect on entire training dataset
iterator = datagen.flow(trainX, trainy, batch_size=len(trainX), shuffle=False)
# get a batch
batchX, batchy = iterator.next()
# pixel stats in the batch
print(batchX.shape, batchX.mean(), batchX.std())
运行该示例首先报告训练和测试数据集中像素值的平均值和标准偏差。
然后将数据生成器配置为基于特征的标准化,并在训练数据集上计算统计数据,这与我们手动计算统计数据时的预期相匹配。
然后检索单批 64 幅标准化图像,我们可以确认这个小样本的均值和标准差接近预期的标准高斯。
然后在整个训练数据集上重复测试,我们可以确认平均值确实是一个非常小的接近 0.0 的值,标准偏差是一个非常接近 1.0 的值。
Statistics train=33.318 (78.567), test=33.791 (79.172)
Data Generator mean=33.318, std=78.567
(64, 28, 28, 1) 0.010656365 1.0107679
(60000, 28, 28, 1) -3.4560264e-07 0.9999998
现在,我们已经确认,像素值的标准化正在按照我们的预期进行,我们可以在拟合和评估卷积神经网络模型的同时应用像素缩放。
下面列出了完整的示例。
# example of using ImageDataGenerator to standardize images
from keras.datasets import mnist
from keras.utils import to_categorical
from keras.models import Sequential
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
from keras.layers import Dense
from keras.layers import Flatten
from keras.preprocessing.image import ImageDataGenerator
# load dataset
(trainX, trainY), (testX, testY) = mnist.load_data()
# reshape dataset to have a single channel
width, height, channels = trainX.shape[1], trainX.shape[2], 1
trainX = trainX.reshape((trainX.shape[0], width, height, channels))
testX = testX.reshape((testX.shape[0], width, height, channels))
# one hot encode target values
trainY = to_categorical(trainY)
testY = to_categorical(testY)
# create generator to standardize images
datagen = ImageDataGenerator(featurewise_center=True, featurewise_std_normalization=True)
# calculate mean on training dataset
datagen.fit(trainX)
# prepare an iterators to scale images
train_iterator = datagen.flow(trainX, trainY, batch_size=64)
test_iterator = datagen.flow(testX, testY, batch_size=64)
print('Batches train=%d, test=%d' % (len(train_iterator), len(test_iterator)))
# define model
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(width, height, channels)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(10, activation='softmax'))
# compile model
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# fit model with generator
model.fit_generator(train_iterator, steps_per_epoch=len(train_iterator), epochs=5)
# evaluate model
_, acc = model.evaluate_generator(test_iterator, steps=len(test_iterator), verbose=0)
print('Test Accuracy: %.3f' % (acc * 100))
运行该示例将 ImageDataGenerator 类配置为标准化图像,仅计算训练集所需的统计信息,然后分别准备训练和测试迭代器来拟合和评估模型。
Epoch 1/5
938/938 [==============================] - 12s 13ms/step - loss: 0.1342 - acc: 0.9592
Epoch 2/5
938/938 [==============================] - 12s 13ms/step - loss: 0.0451 - acc: 0.9859
Epoch 3/5
938/938 [==============================] - 12s 13ms/step - loss: 0.0309 - acc: 0.9906
Epoch 4/5
938/938 [==============================] - 13s 13ms/step - loss: 0.0230 - acc: 0.9924
Epoch 5/5
938/938 [==============================] - 13s 14ms/step - loss: 0.0182 - acc: 0.9941
Test Accuracy: 99.120
扩展ˌ扩张
本节列出了一些您可能希望探索的扩展教程的想法。
- 颜色。更新一个示例,将图像数据集用于彩色图像,并确认缩放是在整个图像上执行的,而不是按通道执行的。
- 采样。演示像素图像的样本式居中或标准化示例。
- ZCA 美白。演示使用 ZCA 方法准备图像数据的示例。
如果你探索这些扩展,我很想知道。
在下面的评论中发表你的发现。
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
应用程序接口
文章
摘要
在本教程中,您发现了如何使用 ImageDataGenerator 类在拟合和评估深度学习神经网络模型时及时缩放像素数据。
具体来说,您了解到:
- 如何配置和使用 ImageDataGenerator 类来训练、验证和测试图像数据集。
- 在拟合和评估卷积神经网络模型时,如何使用 ImageDataGenerator 对像素值进行归一化。
- 在拟合和评估卷积神经网络模型时,如何使用 ImageDataGenerator 对像素值进行中心化和标准化。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。
如何将深度学习用于人脸检测
最后更新于 2020 年 8 月 24 日
人脸检测是一个计算机视觉问题,涉及到在照片中寻找人脸。
对于人类来说,这是一个微不足道的问题,并且已经通过经典的基于特征的技术(例如级联分类器)得到了相当好的解决。最近,深度学习方法在标准基准人脸检测数据集上取得了最先进的结果。一个例子是多任务级联卷积神经网络,简称 MTCNN。
在本教程中,您将发现如何使用经典和深度学习模型在 Python 中执行人脸检测。
完成本教程后,您将知道:
- 人脸检测是一个非常重要的计算机视觉问题,用于识别和定位图像中的人脸。
- 人脸检测可以使用经典的基于特征的级联分类器使用 OpenCV 库来执行。
- 最先进的人脸检测可以通过有线电视新闻网库使用多任务级联有线电视新闻网实现。
用我的新书计算机视觉深度学习启动你的项目,包括分步教程和所有示例的 Python 源代码文件。
我们开始吧。
- **2019 年 11 月更新:**针对 TensorFlow v2.0 和 MTCNN v0.1.0 进行了更新。

如何用经典和深度学习方法进行人脸检测
图片由米盖尔·迪斯卡特提供,版权所有。
教程概述
本教程分为四个部分;它们是:
- 人脸检测
- 测试照片
- 基于 OpenCV 的人脸检测
- 深度学习的人脸检测
人脸检测
人脸检测是计算机视觉中定位和定位照片中一个或多个人脸的问题。
在照片中定位人脸是指在图像中找到人脸的坐标,而定位是指通常通过人脸周围的边界框来标定人脸的范围。
这个问题的一般描述可以定义如下:给定一个静止或视频图像,检测并定位未知数量(如果有的话)的人脸
——人脸检测:一项调查,2001。
检测照片中的人脸很容易被人类解决,尽管考虑到人脸的动态特性,这对计算机来说一直是一个挑战。例如,无论人脸面对的方向或角度、光线水平、服装、配饰、头发颜色、面部毛发、妆容、年龄等,都必须检测人脸。
人脸是一个动态的对象,其外观具有高度的可变性,这使得人脸检测成为计算机视觉中的一个难题。
——人脸检测:一项调查,2001。
给定一张照片,人脸检测系统将输出零个或多个包含人脸的边界框。然后,检测到的面部可以作为输入提供给后续系统,例如面部识别系统。
人脸检测是人脸识别系统中必不可少的第一步,目的是从背景中定位和提取人脸区域。
——人脸检测:一项调查,2001。
人脸识别可能有两种主要方法:基于特征的方法,使用手工制作的过滤器来搜索和检测人脸,以及基于图像的方法,整体学习如何从整个图像中提取人脸。
测试照片
在本教程中,我们需要用于人脸检测的测试图像。
为了简单起见,我们将使用两个测试图像:一个有两张脸,另一个有多张脸。我们并不是试图突破人脸检测的极限,只是演示如何用正常的正面人脸照片进行人脸检测。
第一张图片是两个大学生的照片,由colleged grees 360拍摄,并在许可许可下提供。
下载图像,并将其放入当前工作目录,文件名为“test1.jpg”。

大学生(test1.jpg)
图片由大学生提供 360,保留部分权利。
第二张照片是一个游泳队的一些人的照片,由鲍勃·n·雷尼拍摄,并在许可的情况下发布。
下载图像,并将其放入当前工作目录,文件名为“test2.jpg”。
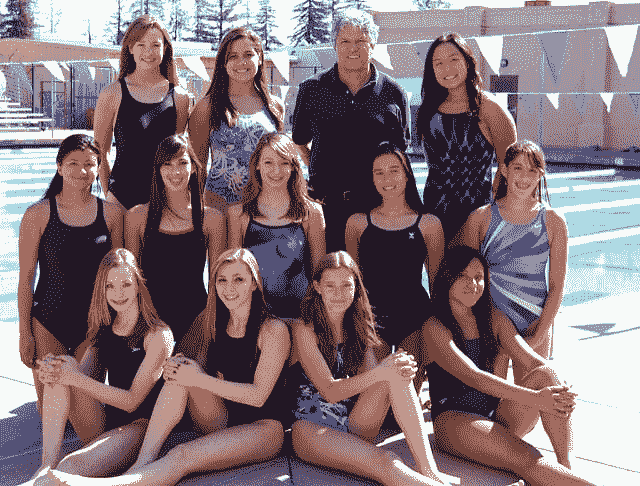
游泳队(test2.jpg)
鲍勃·n·雷尼摄,版权所有。
基于 OpenCV 的人脸检测
基于特征的人脸检测算法快速有效,已经成功应用了几十年。
也许最成功的例子是一种称为级联分类器的技术,首先由保罗·维奥拉和迈克尔·琼斯描述,他们在 2001 年发表了题为“使用简单特征的增强级联快速对象检测”的论文
在本文中,使用 AdaBoost 算法来学习有效的特征,尽管重要的是,多个模型被组织成层次结构或级联
在本文中,AdaBoost 模型用于学习每个人脸中的一系列非常简单或弱的特征,这些特征共同提供了一个健壮的分类器。
……特征选择是通过对 AdaBoost 过程的简单修改来实现的:弱学习器受到约束,因此返回的每个弱分类器只能依赖于单个特征。结果,选择新的弱分类器的增强过程的每个阶段可以被视为特征选择过程。
——使用简单特征的增强级联快速对象检测,2001 年。
然后,这些模型被组织成一个越来越复杂的层次结构,称为“级联”。
简单的分类器直接对候选人脸区域进行操作,就像一个粗过滤器,而复杂的分类器只对那些最有希望作为人脸的候选区域进行操作。
…一种在级联结构中连续组合更复杂的分类器的方法,通过将注意力集中在图像中有希望的区域,显著提高了检测器的速度。
——使用简单特征的增强级联快速对象检测,2001 年。
其结果是非常快速和有效的人脸检测算法,该算法已经成为消费产品(如相机)中人脸检测的基础。
他们的检测器被称为检测器级联,由一系列简单到复杂的人脸分类器组成,吸引了广泛的研究。此外,探测器级联已被部署在许多商业产品中,如智能手机和数码相机。
——使用深度卷积神经网络的多视角人脸检测,2015。
这是一个稍微复杂的分类器,在过去近 20 年里也进行了调整和完善。
OpenCV 库中提供了分类器级联人脸检测算法的现代实现。这是一个提供 python 接口的 C++计算机视觉库。这种实现的好处是它提供了预先训练好的人脸检测模型,并提供了一个在自己的数据集上训练模型的接口。
OpenCV 可以由你的平台上的包管理器系统安装,或者通过 pip 例如:
sudo pip install opencv-python
安装过程完成后,确认库安装正确非常重要。
这可以通过导入库并检查版本号来实现;例如:
# check opencv version
import cv2
# print version number
print(cv2.__version__)
运行该示例将导入库并打印版本。在这种情况下,我们使用的是库的版本 4。
4.1.1
OpenCV 提供了级联分类器类,可以用来创建人脸检测的级联分类器。构造函数可以将文件名作为参数,为预先训练的模型指定 XML 文件。
作为安装的一部分,OpenCV 提供了许多预先训练好的模型。这些都可以在你的系统上获得,也可以在 OpenCV GitHub 项目上获得。
从 OpenCV GitHub 项目中下载一个用于正面人脸检测的预训练模型,并将其放入当前工作目录中,文件名为“haarcscade _ frontal face _ default . XML”。
下载后,我们可以按如下方式加载模型:
# load the pre-trained model
classifier = CascadeClassifier('haarcascade_frontalface_default.xml')
加载后,通过调用detectmulticale()函数,该模型可用于对照片进行人脸检测。
该功能将返回照片中检测到的所有人脸的边界框列表。
# perform face detection
bboxes = classifier.detectMultiScale(pixels)
# print bounding box for each detected face
for box in bboxes:
print(box)
我们可以用大学生照片(test.jpg)来举例说明。
可以通过 imread() 功能使用 OpenCV 加载照片。
# load the photograph
pixels = imread('test1.jpg')
下面列出了在 OpenCV 中用预先训练好的级联分类器对大学生照片进行人脸检测的完整例子。
# example of face detection with opencv cascade classifier
from cv2 import imread
from cv2 import CascadeClassifier
# load the photograph
pixels = imread('test1.jpg')
# load the pre-trained model
classifier = CascadeClassifier('haarcascade_frontalface_default.xml')
# perform face detection
bboxes = classifier.detectMultiScale(pixels)
# print bounding box for each detected face
for box in bboxes:
print(box)
运行该示例首先加载照片,然后加载和配置级联分类器;检测面并打印每个边界框。
每个框列出了边界框左下角的 x 和 y 坐标,以及宽度和高度。结果表明检测到两个边界框。
[174 75 107 107]
[360 102 101 101]
我们可以更新示例来绘制照片并绘制每个边界框。
这可以通过使用取两点的*矩形()*函数在加载图像的像素正上方为每个框绘制一个矩形来实现。
# extract
x, y, width, height = box
x2, y2 = x + width, y + height
# draw a rectangle over the pixels
rectangle(pixels, (x, y), (x2, y2), (0,0,255), 1)
然后,我们可以绘制照片,并保持窗口打开,直到我们按下一个键关闭它。
# show the image
imshow('face detection', pixels)
# keep the window open until we press a key
waitKey(0)
# close the window
destroyAllWindows()
下面列出了完整的示例。
# plot photo with detected faces using opencv cascade classifier
from cv2 import imread
from cv2 import imshow
from cv2 import waitKey
from cv2 import destroyAllWindows
from cv2 import CascadeClassifier
from cv2 import rectangle
# load the photograph
pixels = imread('test1.jpg')
# load the pre-trained model
classifier = CascadeClassifier('haarcascade_frontalface_default.xml')
# perform face detection
bboxes = classifier.detectMultiScale(pixels)
# print bounding box for each detected face
for box in bboxes:
# extract
x, y, width, height = box
x2, y2 = x + width, y + height
# draw a rectangle over the pixels
rectangle(pixels, (x, y), (x2, y2), (0,0,255), 1)
# show the image
imshow('face detection', pixels)
# keep the window open until we press a key
waitKey(0)
# close the window
destroyAllWindows()
运行该示例,我们可以看到照片绘制正确,并且每个面部都被正确检测到。

利用 OpenCV 级联分类器检测人脸的大学生照片
我们可以在游泳队的第二张照片上尝试相同的代码,特别是“test2.jpg”。
# load the photograph
pixels = imread('test2.jpg')
运行该示例,我们可以看到许多人脸被正确检测到,但结果并不完美。
注:考虑到算法或评估程序的随机性,或数值准确率的差异,您的结果可能会有所不同。考虑运行该示例几次,并比较平均结果。
我们可以看到,第一排或最下面一排人的一张脸被检测了两次,中间一排人的一张脸没有被检测到,第三排或最上面一排的背景被检测为人脸。
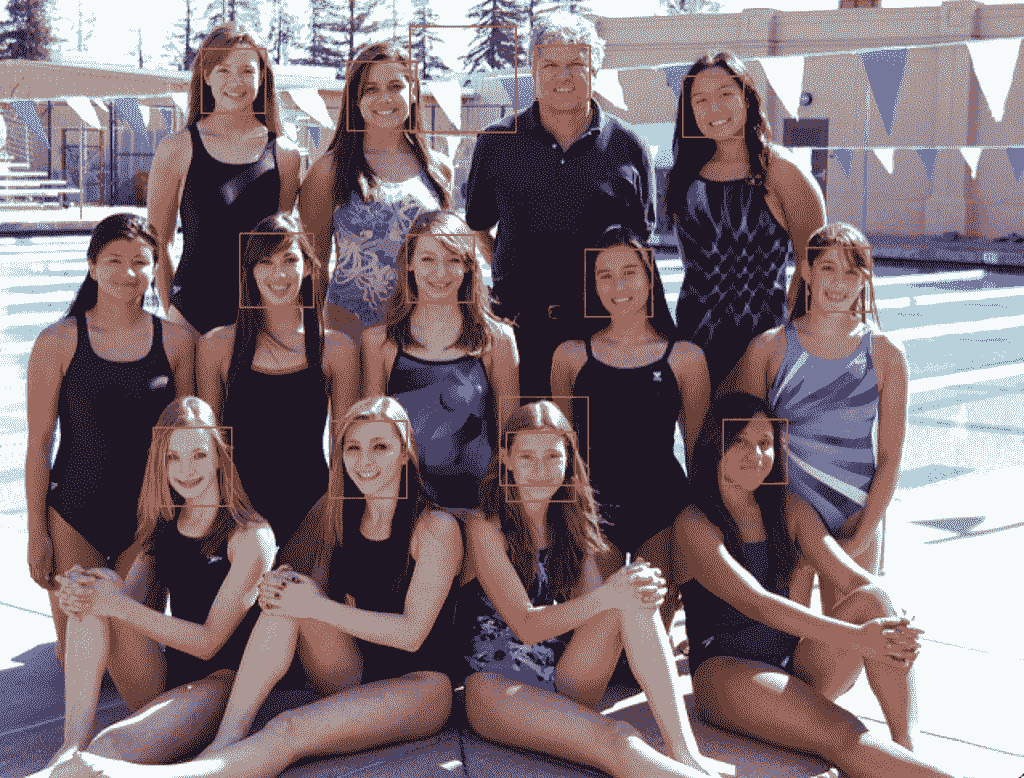
使用 OpenCV 级联分类器检测人脸的游泳队照片
检测多尺度()函数提供了一些参数来帮助调整分类器的使用。值得注意的两个参数是比例因子和明尼阿波利斯;例如:
# perform face detection
bboxes = classifier.detectMultiScale(pixels, 1.1, 3)
缩放因子控制检测前如何缩放输入图像,例如是放大还是缩小,这有助于更好地找到图像中的人脸。默认值为 1.1(增加 10%),但也可以降低到 1.05(增加 5%)或提高到 1.4(增加 40%)等值。
minNeighbors 确定每个检测必须有多稳健才能被报告,例如找到面部的候选矩形的数量。默认值为 3,但可以降低到 1,以检测更多的人脸,这可能会增加误报,或者增加到 6 或更多,以在检测到人脸之前需要更多的信心。
比例因子和 minNeighbors 通常需要针对给定的图像或数据集进行调整,以便最好地检测人脸。在一个数值网格上进行灵敏度分析,看看在一张或多张照片上什么效果好或最好,可能会有所帮助。
快速策略可能是降低(或提高小照片的比例因子)直到检测到所有人脸,然后增加 minNeighbors 直到所有假阳性消失,或接近它。
经过一些调优,我发现 1.05 的 scaleFactor 成功检测到了所有的人脸,但是检测为人脸的背景直到 8 的 minNeighbors 才消失,之后中间一排的三张人脸不再被检测到。
# perform face detection
bboxes = classifier.detectMultiScale(pixels, 1.05, 8)
结果并不完美,也许可以通过进一步的调整和边界框的后处理来获得更好的结果。
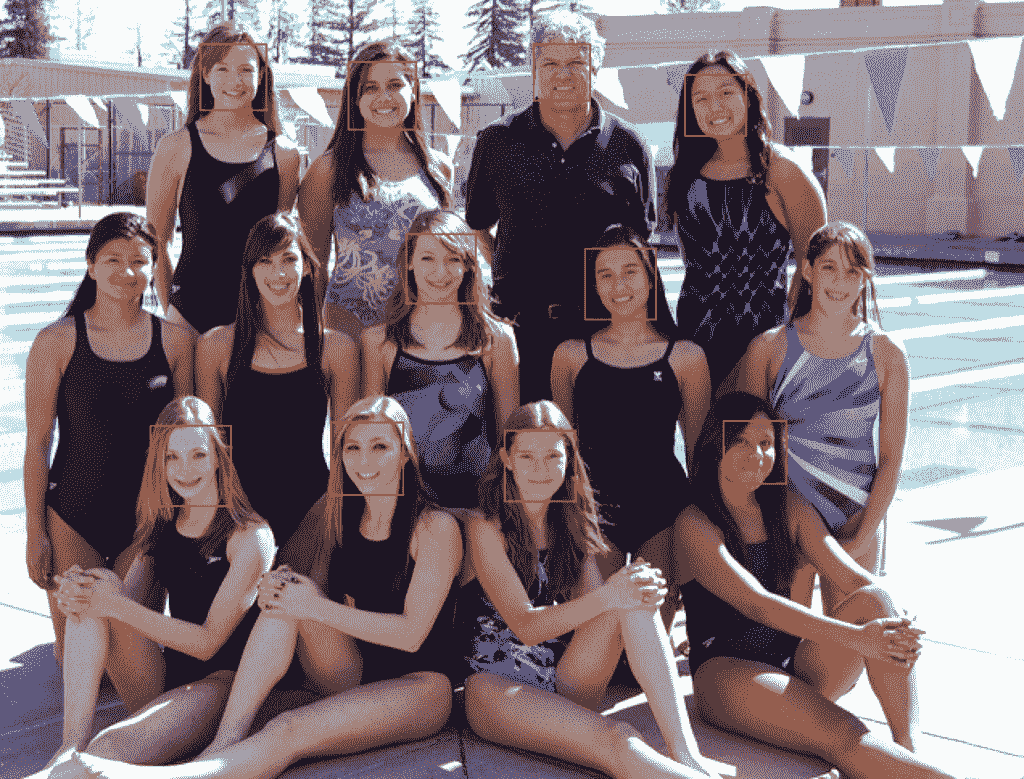
经过一些调整后,使用 OpenCV 级联分类器检测人脸的游泳队照片
深度学习的人脸检测
已经开发并演示了许多深度学习方法用于人脸检测。
也许其中一种更流行的方法被称为“多任务级联卷积神经网络,简称 MTCNN,由张等人在 2016 年发表的论文《使用多任务级联卷积网络的联合人脸检测和对齐》中描述
MTCNN 之所以受欢迎,是因为它在一系列基准数据集上取得了当时最先进的结果,还因为它能够识别眼睛和嘴巴等其他面部特征,称为地标检测。
该网络采用三个网络的级联结构;首先将图像重新缩放到不同大小的范围(称为图像金字塔),然后第一个模型(proposition Network 或 P-Net)提出候选面部区域,第二个模型(Refine Network 或 R-Net)过滤边界框,第三个模型(Output Network 或 O-Net)提出面部界标。
拟议的氯化萘包括三个阶段。在第一阶段,它通过一个浅 CNN 快速产生候选窗口。然后,它通过更复杂的 CNN 对窗口进行细化,以拒绝大量非人脸窗口。最后,它使用更强大的 CNN 来细化结果并输出面部地标位置。
——使用多任务级联卷积网络的联合人脸检测和对齐,2016。
下图取自论文,对从上到下的三个阶段以及每个阶段从左到右的输出进行了有益的总结。

多任务级联卷积神经网络的流水线来自:使用多任务级联卷积网络的联合人脸检测和对准。
该模型被称为多任务网络,因为级联中的三个模型(P-Net、R-Net 和 O-Net)中的每一个都在三个任务上进行训练,例如进行三种类型的预测;它们是:人脸分类、包围盒回归和面部标志定位。
三个型号没有直接连接;相反,前一级的输出作为输入被馈送到下一级。这允许在阶段之间执行额外的处理;例如,在将第一阶段 P-Net 提出的候选包围盒提供给第二阶段 R-Net 模型之前,使用非最大抑制(NMS)来过滤它们。
MTCNN 架构实现起来相当复杂。令人欣慰的是,该架构有开源的实现,可以在新的数据集上进行训练,还有预训练的模型,可以直接用于人脸检测。值得注意的是正式发布,其中包含本文使用的代码和模型,实现在 Caffe 深度学习框架中提供。
也许最好的基于 Python 的第三方 MTCNN 项目被称为“T0”MTCNN,由ivn de Paz Centeno或 ipazc 提供,在一个许可的麻省理工学院开源许可下提供。作为一个第三方开源项目,是会有变化的,所以我在写的时候有一个项目的岔口,这里有。
MTCNN 项目,我们将称之为 ipazc/MTCNN 以区别于网络名称,提供了一个使用 TensorFlow 和 OpenCV 的 MTCNN 架构的实现。这个项目主要有两个好处;首先,它提供了一个表现最佳的预训练模型,其次,它可以作为一个库安装,准备在您自己的代码中使用。
可以通过 pip 安装库;例如:
sudo pip install mtcnn
成功安装后,您应该会看到如下消息:
Successfully installed mtcnn-0.1.0
然后,您可以通过 pip 确认库安装正确;例如:
sudo pip show mtcnn
您应该会看到如下所示的输出。在这种情况下,您可以看到我们使用的是 0.0.8 版本的库。
Name: mtcnn
Version: 0.1.0
Summary: Multi-task Cascaded Convolutional Neural Networks for Face Detection, based on TensorFlow
Home-page: http://github.com/ipazc/mtcnn
Author: Iván de Paz Centeno
Author-email: ipazc@unileon.es
License: MIT
Location: ...
Requires: opencv-python, keras
Required-by:
您还可以通过 Python 确认库安装正确,如下所示:
# confirm mtcnn was installed correctly
import mtcnn
# print version
print(mtcnn.__version__)
运行该示例将加载库,确认它安装正确;并打印版本。
0.1.0
现在我们有信心库安装正确,我们可以使用它进行人脸检测。
通过调用 MTCNN() 构造函数,可以创建网络的一个实例。
默认情况下,库将使用预训练的模型,尽管您可以通过“权重 _ 文件”参数指定自己的模型,并指定路径或网址,例如:
model = MTCNN(weights_file='filename.npy')
检测人脸的最小框大小可以通过“ min_face_size 参数指定,默认为 20 像素。构造函数还提供了一个“比例因子参数来指定输入图像的比例因子,默认为 0.709。
模型配置加载后,通过调用 detect_faces() 功能,可以直接用于检测照片中的人脸。
这将返回一个 dict 对象列表,每个对象为检测到的每个人脸的详细信息提供多个键,包括:
- 框:提供边框左下方的 x 、 y ,以及框的宽和高。
- 置信度’:预测的概率置信度。
- 要点:为“左眼”、“右眼”、“鼻子”、“嘴 _ 左”和“嘴 _ 右”提供带点的字典。
例如,我们可以对大学生照片执行人脸检测,如下所示:
# face detection with mtcnn on a photograph
from matplotlib import pyplot
from mtcnn.mtcnn import MTCNN
# load image from file
filename = 'test1.jpg'
pixels = pyplot.imread(filename)
# create the detector, using default weights
detector = MTCNN()
# detect faces in the image
faces = detector.detect_faces(pixels)
for face in faces:
print(face)
运行该示例加载照片、加载模型、执行人脸检测,并打印检测到的每个人脸的列表。
{'box': [186, 71, 87, 115], 'confidence': 0.9994562268257141, 'keypoints': {'left_eye': (207, 110), 'right_eye': (252, 119), 'nose': (220, 143), 'mouth_left': (200, 148), 'mouth_right': (244, 159)}}
{'box': [368, 75, 108, 138], 'confidence': 0.998593270778656, 'keypoints': {'left_eye': (392, 133), 'right_eye': (441, 140), 'nose': (407, 170), 'mouth_left': (388, 180), 'mouth_right': (438, 185)}}
我们可以先用 matplotlib 绘制图像,然后使用给定边界框的 x 、 y 和宽度和高度创建矩形对象来绘制图像上的框;例如:
# get coordinates
x, y, width, height = result['box']
# create the shape
rect = Rectangle((x, y), width, height, fill=False, color='red')
下面是一个名为*draw _ image _ with _ box()*的函数,它显示照片,然后为每个检测到的边界框绘制一个框。
# draw an image with detected objects
def draw_image_with_boxes(filename, result_list):
# load the image
data = pyplot.imread(filename)
# plot the image
pyplot.imshow(data)
# get the context for drawing boxes
ax = pyplot.gca()
# plot each box
for result in result_list:
# get coordinates
x, y, width, height = result['box']
# create the shape
rect = Rectangle((x, y), width, height, fill=False, color='red')
# draw the box
ax.add_patch(rect)
# show the plot
pyplot.show()
下面列出了使用该函数的完整示例。
# face detection with mtcnn on a photograph
from matplotlib import pyplot
from matplotlib.patches import Rectangle
from mtcnn.mtcnn import MTCNN
# draw an image with detected objects
def draw_image_with_boxes(filename, result_list):
# load the image
data = pyplot.imread(filename)
# plot the image
pyplot.imshow(data)
# get the context for drawing boxes
ax = pyplot.gca()
# plot each box
for result in result_list:
# get coordinates
x, y, width, height = result['box']
# create the shape
rect = Rectangle((x, y), width, height, fill=False, color='red')
# draw the box
ax.add_patch(rect)
# show the plot
pyplot.show()
filename = 'test1.jpg'
# load image from file
pixels = pyplot.imread(filename)
# create the detector, using default weights
detector = MTCNN()
# detect faces in the image
faces = detector.detect_faces(pixels)
# display faces on the original image
draw_image_with_boxes(filename, faces)
运行示例绘制照片,然后为每个检测到的面部绘制一个边界框。
我们可以看到两张脸都被正确检测到了。

大学生用移动电视新闻网为每个检测到的人脸绘制边界框
我们可以通过圆类为眼睛、鼻子和嘴巴画一个圆;例如
# draw the dots
for key, value in result['keypoints'].items():
# create and draw dot
dot = Circle(value, radius=2, color='red')
ax.add_patch(dot)
下面列出了添加到*draw _ image _ with _ box()*功能的完整示例。
# face detection with mtcnn on a photograph
from matplotlib import pyplot
from matplotlib.patches import Rectangle
from matplotlib.patches import Circle
from mtcnn.mtcnn import MTCNN
# draw an image with detected objects
def draw_image_with_boxes(filename, result_list):
# load the image
data = pyplot.imread(filename)
# plot the image
pyplot.imshow(data)
# get the context for drawing boxes
ax = pyplot.gca()
# plot each box
for result in result_list:
# get coordinates
x, y, width, height = result['box']
# create the shape
rect = Rectangle((x, y), width, height, fill=False, color='red')
# draw the box
ax.add_patch(rect)
# draw the dots
for key, value in result['keypoints'].items():
# create and draw dot
dot = Circle(value, radius=2, color='red')
ax.add_patch(dot)
# show the plot
pyplot.show()
filename = 'test1.jpg'
# load image from file
pixels = pyplot.imread(filename)
# create the detector, using default weights
detector = MTCNN()
# detect faces in the image
faces = detector.detect_faces(pixels)
# display faces on the original image
draw_image_with_boxes(filename, faces)
该示例使用边界框和面部关键点再次绘制照片。
我们可以看到,眼睛、鼻子和嘴巴在每张脸上都能很好地被检测到,尽管右脸上的嘴巴可能更好地被检测到,这些点看起来比嘴角低一点。

大学生用边界框和为每个检测到的面部绘制的面部关键点拍摄
我们现在可以在游泳队的照片上尝试人脸检测,例如 test2.jpg 的照片。
运行该示例,我们可以看到所有 13 个面部都被正确检测到,并且看起来大致上所有面部关键点也都是正确的。
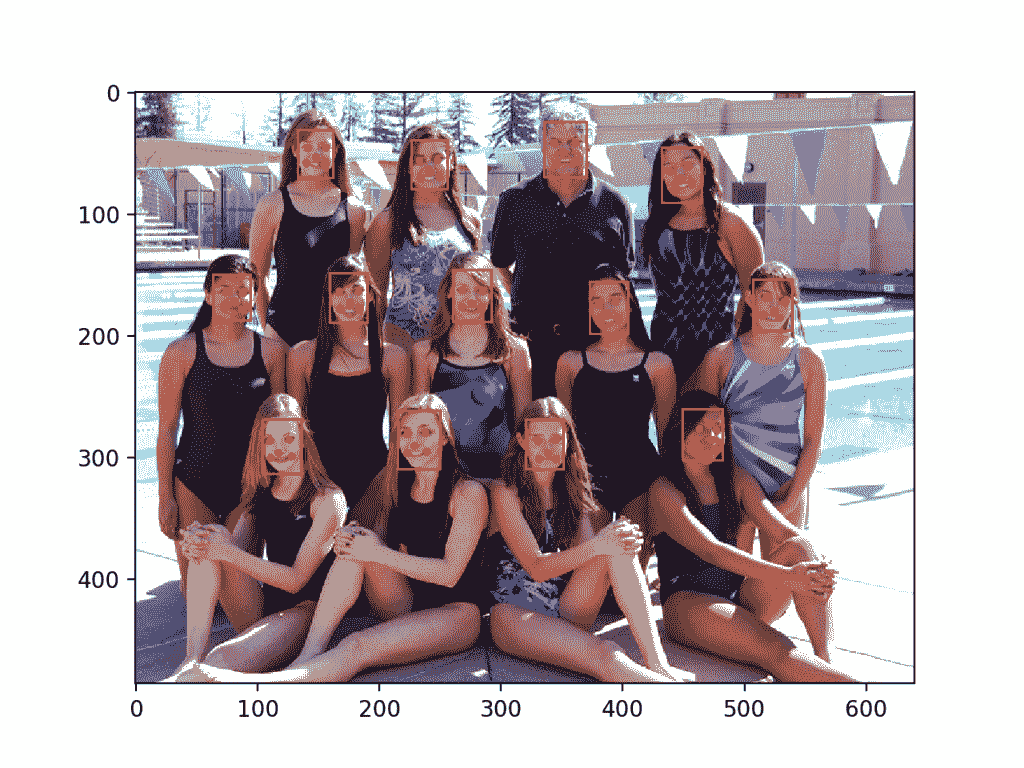
游泳队照片与边界框和面部关键点绘制每个检测到的脸使用 MTCNN
我们可能希望提取检测到的人脸,并将它们作为输入传递给另一个系统。
这可以通过直接从照片中提取像素数据来实现;例如:
# get coordinates
x1, y1, width, height = result['box']
x2, y2 = x1 + width, y1 + height
# extract face
face = data[y1:y2, x1:x2]
我们可以通过提取每个人脸并将其绘制为单独的子情节来演示这一点。你可以很容易地将它们保存到文件中。下面的*draw _ face()*提取并绘制照片中每个检测到的人脸。
# draw each face separately
def draw_faces(filename, result_list):
# load the image
data = pyplot.imread(filename)
# plot each face as a subplot
for i in range(len(result_list)):
# get coordinates
x1, y1, width, height = result_list[i]['box']
x2, y2 = x1 + width, y1 + height
# define subplot
pyplot.subplot(1, len(result_list), i+1)
pyplot.axis('off')
# plot face
pyplot.imshow(data[y1:y2, x1:x2])
# show the plot
pyplot.show()
下面列出了为游泳队照片演示该功能的完整示例。
# extract and plot each detected face in a photograph
from matplotlib import pyplot
from matplotlib.patches import Rectangle
from matplotlib.patches import Circle
from mtcnn.mtcnn import MTCNN
# draw each face separately
def draw_faces(filename, result_list):
# load the image
data = pyplot.imread(filename)
# plot each face as a subplot
for i in range(len(result_list)):
# get coordinates
x1, y1, width, height = result_list[i]['box']
x2, y2 = x1 + width, y1 + height
# define subplot
pyplot.subplot(1, len(result_list), i+1)
pyplot.axis('off')
# plot face
pyplot.imshow(data[y1:y2, x1:x2])
# show the plot
pyplot.show()
filename = 'test2.jpg'
# load image from file
pixels = pyplot.imread(filename)
# create the detector, using default weights
detector = MTCNN()
# detect faces in the image
faces = detector.detect_faces(pixels)
# display faces on the original image
draw_faces(filename, faces)
运行该示例会创建一个图表,显示在游泳队照片中检测到的每个单独的面部。

游泳队照片中检测到的每个单独面部的图
进一步阅读
如果您想更深入地了解这个主题,本节将提供更多资源。
报纸
- 人脸检测:一项调查,2001。
- 使用简单特征的增强级联的快速对象检测,2001。
- 使用深度卷积神经网络的多视角人脸检测,2015。
- 使用多任务级联卷积网络的联合人脸检测和对准,2016。
书
- 第十一章人脸检测,人脸识别手册,第二版,2011。
应用程序接口
- OpenCV 主页
- OpenCV GitHub 项目
- 使用哈尔级联的人脸检测,OpenCV 。
- 级联分类器训练,OpenCV 。
- 级联分类器,OpenCV 。
- 【MTCNN 官方项目
- Python MTCNN 项目
- matplotlib . patches . rectangle API
- matplot lib . patches . circle API
文章
摘要
在本教程中,您发现了如何使用经典和深度学习模型在 Python 中执行人脸检测。
具体来说,您了解到:
- 人脸检测是用于识别和定位图像中人脸的计算机视觉问题。
- 人脸检测可以使用经典的基于特征的级联分类器使用 OpenCV 库来执行。
- 最先进的人脸检测可以通过有线电视新闻网库使用多任务级联有线电视新闻网实现。
你有什么问题吗?
在下面的评论中提问,我会尽力回答。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
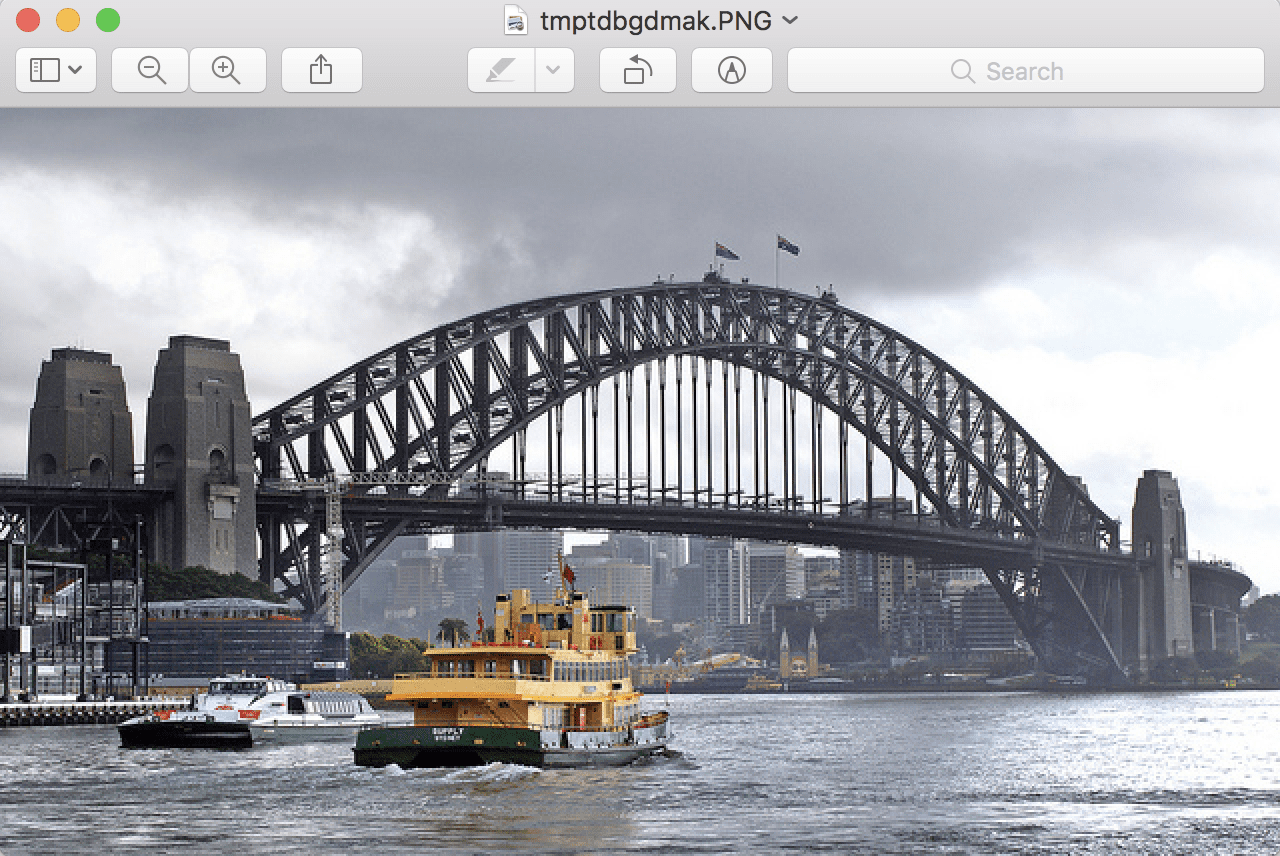{kind=link}
{kind=link}
{kind=link}