







我在 Spotify 学到的初级数据科学家五大重要课程(第一部分)
科技领域数据科学家的前几年编年史
内幕指南,助你在科技领域的前几年迅速成长并提升你的技能。


·发表于 Towards Data Science ·阅读时间 8 分钟·2023 年 6 月 29 日
–
恭喜你,欢迎加入这段冒险!你正在成为一名数据科学家,你的旅程才刚刚开始!
你已经大学毕业,现在你进入了一个由改变游戏规则的成功人士组成的世界。虽然你可能还不是其中之一(暂时!),但你刚刚踏上了成为其中一员的旅程。你每天都在学习和成长,发现未来的角色以及如何在其中表现出色。
但是等等,几周或几个月过去了,现实是;你依然在心里是一个学生。你可能还没有意识到,因为这个开关还没有切换。
如果有一件事是我在开始科技职业生涯时学到的,那就是:
大学为我提供了良好的技术基础,但有些东西只能在不同的学校环境中学习。
如果你想节省寻找作为初学数据科学家所需核心技能的麻烦,那么你绝对来对地方了。事实上,我希望任何行业的应届毕业生都能在这里找到建议!
在这里,我不仅与你分享我的学习经验,还为你提供有用的技巧,帮助你避免在一开始就犯错。所以我真的鼓励你继续阅读!
确保订阅我的新闻通讯!
点击下面的链接,我将为你提供更多个性化内容和内幕技巧,帮助你在成为数据科学家的旅程中!
[## 加入+2k 读者 💌 关注我在科技和 Spotify 的作为数据科学家的旅程,不要错过!
加入+2k 读者 💌 关注我作为数据科学家在科技+Spotify 的旅程,别错过!通过注册,你…
medium.com](https://medium.com/@elalamik/subscribe?source=post_page-----7a040a731ecf--------------------------------)
但首先,让我给你讲个小故事!
多年来,Spotify 一直是我终极的工作场所。我知道我会在那里茁壮成长,因为它完美地结合了我在职业生涯中想要的一切:
-
拥有相似兴趣的人
-
平衡的工作与生活
-
一个创新的环境来学习和成长
-
最重要的是,作为一个小提琴演奏者,我非常重视在一个音乐是核心元素的地方工作
经过大量的努力、坚持和一点点运气,我终于进入了令人惊叹的 Spotify。

你能感受到我有多开心吗?
快进到两次实习,一篇硕士论文,和一个全职工作机会后,我终于找到了我梦想中的工作,天啊,我真是太兴奋了。
到这个阶段,我花了大量时间在项目中不断犯错,最终学到了一些非常宝贵的教训。我真希望我能更早地学到这些教训,因为这会节省我大量时间,并让我免去不断撞墙的挫败感。
错误的做事方式
所以,你做了有价值的工作,找出了一些有趣的见解,甚至可能还提出了一些好的建议!为自己感到自豪,你可以给自己一个击掌!
但如果你像我一样,你可能花了几周或几个月的时间才将你劳动的成果与关键利益相关者分享。人们第一次看到你的工作。为什么?因为你在大部分时间里消失了。
我在过程中犯的一个关键错误 是带着 学生心态 前行。

照片由 Siora Photography 提供,来源于 Unsplash
每次我接受一个大项目时,我都会陷入困境。你可能会告诉我;“K(就是我👋🏼),好吧,你犯了一次错误,但三次?拜托,你难道在课程给你当头一棒时还在打盹吗?” …… 事实上,我是清醒的,但确实花了一些时间才真正领悟到(或者说我可能半梦半醒)。
数据科学家经常独自工作
当然,他们与跨职能团队合作。但数据部分主要由一个人完成——你。所以,当你在大学期间独自工作于项目和作业时,很容易陷入这个陷阱。在现实世界中,你不能再孤立自己。
这种方法的问题在于,即使你的工作可能具有很大的价值,但如果未能及时传达给正确的人,其价值可能会减少影响力。人们可能已经开始做出决策。
所以,如果你想确保你所有的辛勤工作获得应有的重视,你需要尽快抛弃学校式的做法。怎么做? 给你两个字:
✨沟通✨ & ✨反馈✨
课程 1 — 持续沟通是关键
我的朋友,如果在你旅程的开始阶段有一项重要技能你需要迅速掌握,那就是:
沟通,沟通,沟通啊啊啊啊!
我会重复到你能理解为止。尽可能频繁地沟通你的工作!在技术领域,节奏可能很快,所以如果你想确保你未来的所有影响不会白费,那么沟通就是你的朋友。
你可以怎么做?
1. 定期向利益相关者更新你的进展,即使你还没有完成。
你可以通过与相关人员分享一些数据精华(最有趣的见解片段)来做到这一点。
你可以通过以下方式做到:
a) 消息(Slack、Teams、Hangout、电子邮件等……)
b) 每周分享
c) 1:1 会议(只要事先做好准备)
每当你发现一个值得注意的见解时,按下发送按钮。这样做可以:
-
帮助你找出故事线中的漏洞
-
识别数据不一致性
-
解决你可能对某些关键概念的误解
列表还在继续。
2. 确保找到正确的共享节奏
当然,目标不是每天分享你刚刚发现的内容,因为共享不可靠的见解可能会对决策产生负面影响。
相反,你更应该:
-
在不同的共享频率之间进行迭代,直到找到合适的频率
-
确保高举一个大横幅,上面写着**“正在进行中”**🚧
在学校里,我们可能会在自己的小圈子里辛苦工作几周。项目可能要经过很长时间才会共享,只有在完成时才会分享。在技术领域,没有人有时间等待。所以尽快加快节奏💨。
课程 2 — 向相关利益相关者请求反馈

作者提供的 GIF
大力推动反馈循环。实际上,你要紧紧拥抱这个反馈循环。你刚刚交了一个新朋友。恭喜!
定期向你的经理或与你密切合作的更有经验的人寻求反馈是至关重要的。关键是要学会何时请求反馈。记住,找到正确的平衡适用于一切。
这可以防止你花费大量时间构建错误的叙事,然后不得不再次修改它。因此,最好尽早理顺你的故事线。
请求反馈和沟通你的见解是同一枚硬币的两面。
-
沟通使你能够让你的利益相关者了解你工作的内容
-
反馈使你能够重新检查你是否提供了正确的工作内容
你怎么做?
1. 分享 你的 疑问、想法和发现,通过* 标记 相关人员在你的工作文档或演示文稿中。
我在 Spotify 学到的一个经验是,通过在文档或幻灯片上标记他们的名字来向正确的人寻求反馈,并指出我需要他们意见的部分。当然,如果他们错过了你的求助信息,别忘了通过消息跟进。
2. 定期安排会议 讨论你的工作以及你遇到的任何障碍
这里有一个小贴士:
-
安排 1:1 会议与最相关的利益相关者直接讨论你的疑问、想法和发现。
-
确保在文档中概述你的工作背景 + 仅列出你需要反馈的内容。这样,你只会处理最重要的内容,避免浪费每个人的时间。
高级职位的人都是大师,你也想被那种魔法般的光环所笼罩🪄。如果你像我一样有一位出色的经理在帮助你成长,那么一定要好好利用这个机会。你的同事们拥有你还在努力获取的领域专业知识,所以他们看待事物的角度是不同的。
他们肯定会帮助你:
-
发现情节漏洞
-
完善你的故事情节
-
给你更多的背景信息
-
教你新技能,当他们看到你在原地打转时
全局思维 在你作为数据科学家时至关重要
但你还只是个新手,你的眼界还没完全打开。所以你确实需要另一双眼镜来照亮那些黑暗的地方。

我在科技行业的第一年的快照 (Midjourney)
交流你的见解并定期寻求反馈不仅有助于你保持项目进展正常,还可以帮助你与团队和利益相关者建立信任。当他们看到你的工作并了解你在做什么时,他们会更可能支持你和你的想法。
目前就这些。
本文是两部分系列的第一篇。接下来: 第二部分
## 我在 Spotify 学到的 5 个必备课程(第二部分)
内部指南,帮助你在科技行业中顺利度过第一年并提升你的技能
[towardsdatascience.com
在这篇文章的后续部分,我将详细讲述我在 Spotify 的头几年中学到的其他经验,这些经验可以帮助你快速成功于数据科学的旅程!
我有礼物送给你🎁!
现在就注册我的通讯订阅K’s DataLadder,你将自动获得我的终极 SQL 备忘单,其中包含我在大科技公司工作中每天使用的所有查询语句,还有另一个神秘礼物!
我每周分享作为科技公司数据科学家的经历,以及实用的技巧、技能和故事,旨在帮助你提升水平——因为没有人真正了解,直到他们亲身经历!
如果你还没做过的话
期待与你很快见面!
我在 Spotify 学到的初级数据科学家 5 个重要课程(第二部分)
数据科学家的第一年纪事
内部指南,帮助你在数据科学家的前几年中取得成功,并提升你的技能


·发表于 Towards Data Science ·阅读时长 9 分钟·2023 年 6 月 29 日
–
这篇文章是“我在 Spotify 学到的初级数据科学家 5 个重要课程”系列的第二部分。确保先查看 第一部分!
## 我在 Spotify 学到的初级数据科学家 5 个重要课程(第一部分)
内部指南,帮助你在数据科学家的前几年中取得成功,并提升你的技能。
towardsdatascience.com
所以之前我们讨论了:
-
定期与利益相关者分享你的工作,即使它还未完成,这一点也很重要。
-
定期寻求反馈,确保你在正确的轨道上
这样做将帮助你与团队和利益相关者建立信任,以确保你的工作获得应有的影响。说到信任,让我们直接进入第 3 课。
第 3 课 — 开始建立信任
产生影响全在于将你的想法推向那些会 将其付诸行动的人。
这些人通常是产品经理(负责制定产品的愿景和战略)、设计师(负责设计产品)和工程师(负责评估想法的技术可行性并实现它)。你将分享的见解和提出的建议将推动整个团队(产品经理、设计师和工程师)的工作*。
因此,你需要学习如何说服别人为什么他们应该听取你的想法以及这些想法的重要性,这也就不足为奇了。
(你也可以查看我详细的帖子 ⬇️ 关于如何将你的见解转化为有影响力的行动)
来自 Spotify 的数据科学家——将你的工作转化为行动的最佳组合
towardsdatascience.com
欢迎来到第 3 课!
这可能看起来很明显,但值得信赖是数据科学家的核心角色,这是一种随着时间推移而不断磨练的技能。不过你可能会问我*‘K,我该怎么做?我还是个小菜鸟,谁会认真对待我?’*
嘘,除非公司相信你能够可靠,否则他们不会聘用你。所以人们很可能已经在信任你,现在的关键是兑现这种信任。
那么,当你刚刚起步时,如何建立信任的第一层?
我们已经讨论了如何通过沟通你的工作和寻求反馈来提升你的可信度,但让我们看看你还能做些什么!
1. 积极主动,并尽可能地提问
我天生确实有一种自然才能,那就是擅长对人们提出他们没有要求的问题。这在高中可能对我不利,但在职业世界中,尤其是我所知道的技术领域,规则则有所不同。
我发现自己屡次因能够从各个角度提出问题而受到称赞*(我本身是 ENTP,反正这就是我唯一能做的事)*。
展示你对事物如何运作以及为什么感兴趣,肯定会使你顺利成为一个可信赖的真实信息来源和决策者。
2. 保持谦虚,不要害怕承认你不知道的事情
是的,你可以再读一遍。不要像乔恩·雪诺一样。如果你不知道怎么做,没必要假装你知道。这样做可能会对你造成长远的伤害。
谦虚能产生信任,这就是为什么在你的见解中保持谦虚,并在需要时提出免责声明至关重要。
作为新手,我们常常会被诱惑去掩饰自己的无知。然而,处理数据和统计意味着结果并不是绝对的。实际上,关于你对结果的信心水平表现出脆弱可能很困难,但这是重要的。要对你的工作成果的稳健性保持透明!
你怎么做呢?
-
确保你沟通你积极尝试寻找解决方案是成长的第一步。没人会责怪你没搞对,但至少我会责怪你没有尝试。
-
显示你积极参与自己的成长,肯定会提升你在所有观察者眼中的可信度和可靠性。
解决方案喜欢高深莫测。所以我们是数据科学家也没什么坏处,因为我们确实喜欢挖掘那些隐藏的见解,对吧?
只有这样,你才能从他人那里学习并提升自己。
课程 4 — 向专家寻求帮助

图片由 Nathan Dumlao 提供,来源于 Unsplash
如果我早些时候学会了这一点,那节省的时间真是不可估量。
想象一下:
我正在做一个因果推断项目(这是一个统计学领域,旨在基于观察数据识别变量之间的因果关系)。我在大学时修过这个课程,但似乎记不太清楚(也许这次我又在睡觉了)。无论如何,我正在做这个项目,研究新颖的概念,像我喜欢的那样激发我的大脑。
我向我最亲近的同事寻求建议,回顾过去的项目,希望找到一些灵感、学习经验、技巧、上帝的话语…真的任何可以帮助我的东西。所以,是的,这也是一个你必须掌握的重要技能:
追溯 过去的资源 应该始终是开始新项目时的第一步
但我会在另一个故事中详细讨论这个问题。
所以我在做研究,调查内部和外部资源,却发现自己在因果推断上碰壁(正常,这是个棘手的问题)。我做了所有正确的事情(或者我认为如此)。我继续进行这个项目,经过一段时间…我有了一个很棒的主意,就是向其他数据科学家请教一个概念。
这样做,我显然会提供更多关于我的项目的细节。当…突然间…一个天降因果推断专家的声音照亮了我…友善地告诉我我…走错了路。我的整个方法论都偏离了轨道,因为我在比较两个不能比较的用户群体,这使整个分析变得不准确。

当我意识到自己搞砸了时——照片由 Jelleke Vanooteghem 提供,来源于 Unsplash
然而,我的朋友们,这就是几周的工作如何转瞬即逝成了垃圾桶中的一张单程票!(虽然并非完全如此,因为这将成为你脑中的核心记忆,成为生活的宝贵教训)
这让我们进入了第 4 课—— 学会如何独自克服挑战对发展你的批判性思维和解决问题的技能非常重要。但学会在需要时请求帮助也同样重要。 现在,人们直接去找 ChatGPT 寻求帮助,而不是自己尝试,这最终阻碍了他们学习正确的技能。
向合适的人寻求帮助有很大的好处
1. 从你所从事的工作领域的专家那里获得第一手指导
很明显,这只能给你带来提升:a) 对你的项目 和 b) 对你的技能。记住,你可能还是个新手,但你也在和领域中的专家同一个沙箱中玩耍,所以别忘了在需要时寻求指导*(除非你打算再当一会儿新手,那又是另一回事)*。
你怎么做呢?
-
寻找过去的项目,看看你正在从事的工作是否已被实施或研究。然后联系那些曾参与这些项目的人。他们很可能会提供有价值的信息,并帮助你识别潜在的不一致性。
-
发送消息 到专门讨论问题/技术/功能/产品领域等的 Slack/Teams 频道,例如 #causal-inference 或 #data-science(稍微宽泛一点,肯定会有人回应)!
每个人都很乐意提供帮助。毕竟,他们自己也经历过这些。
2. 免去你意识到自己做错事的挫败感
这最终也将帮助你免受由于弥补过去错误而额外工作带来的压力……因为现在,你的计划也已经落后了。
只要记得至少先尝试一下。 如果你发现自己陷入困境的时间比预期的要长,那么你知道该寻求帮助的时候到了。
最后一个建议——对自己要有耐心
照片由 sydney Rae 提供,来源于 Unsplash
如果你已经坚持到这里,那么你绝对值得再获得一块额外的饼干。谢谢你读我的文章。
做好准备,现在我将把我最终的饼干赐给你这段旅程。
没有人期望你从第 1 天或第 100 天起就成为专家。
即使在科技行业也是如此!与经验丰富的人一起工作是一个在良好的环境中成长的独特机会。然而,我确实花了一些时间才能完全接受自己在房间里最没有经验的这一点。
我仰慕我合作的那些人,但我也潜意识地与他们比较自己:
-
否则我可能需要更长时间才能交付我的工作
-
我并不总是能提出正确的问题来进行探索,因此感觉相比于我的同龄人,我的探索范围有限
-
我会在同时处理多个项目时感到挣扎,而其他人似乎能轻松地同时处理 5 个任务
是的,这可能看起来很明显,但至少对我来说并不那么明显。所以,如果你像我一样,有时对自己很苛刻,那是很正常的。追求最优秀很重要,但要知道在刚开始时不必追求最优秀。
我的意思是,来吧,你还是个小狗,没人会期望你与完全成熟的狼在同一水平线上。但你在这个群体里,群体不会抛弃自己的成员。所以别担心,总有一天你也会嚎叫,这只是时间和承诺的问题。
从一开始就做到完美实际上并不是常态。而且,冲浪者不会在静水中滑行,这有什么乐趣呢?即使是哈利·波特一开始也没有准确地施展 Wingardium LeviOsa。
那么你能做些什么呢?
-
避免通过模仿前辈来过度努力。 很可能,这样做会让你感到不自然,人们也会察觉到。相反,不要强求,问问题时保持自然,做你自己
-
联系其他初级人员。 与可以产生共鸣的其他人交流,确实帮助我在自己挣扎时获得了更多的视角。并不一定非得是其他数据科学家,任何你关系亲近的初级人员都会有帮助。知道自己并不孤单并获得支持,改变一切。
所以最后一课: 给自己一些宽容,停止对自己施加额外的压力。如果你没有这样做,那么这个教训可能不适合你,但还是值得记住,记得对自己要善良。
我为你准备了🎁!
订阅我的新闻通讯K’s DataLadder,你将自动获得我的终极 SQL 备忘单,包括我在大科技公司每天使用的所有查询 + 另一个神秘礼物!
我每周分享作为数据科学家在科技行业的经历,包括实用技巧、技能和故事,旨在帮助你提升水平——因为没人真正了解,直到他们身处其中!
如果你还没有做过这个
很快见!
5 种适用于 R 的极佳数据管道编排工具
原文:
towardsdatascience.com/5-fantastic-data-pipeline-orchestration-tools-for-r-f34ab71b1730
探索适用于 R 用户的数据管道编排的优秀选项


·发表于 Towards Data Science ·阅读时间 11 分钟·2023 年 1 月 30 日
–
图片由 Daria Nepriakhina 🇺🇦 提供,Unsplash
数据管道编排工具对于生成健康且可靠的数据驱动决策至关重要。R 是数据科学家常用的语言之一。凭借 R 的优秀包,R 编程语言非常适合数据处理、统计分析和可视化。
一个常见的模式是将数据科学家在 R 中编写的本地脚本重写为 Python 或 Scala(Spark),然后通过现代数据管道编排工具如 Apache Airflow 调度数据管道和模型构建。
然而,许多现代数据编排项目如 Apache Airflow、Prefect 和 Luigi 都是基于 Python 的。它们能与 R 无缝配合吗?你能用 R 编写来定义 DAG 吗?在本文中,让我们探索适用于 R 脚本的流行数据管道编排工具,并评估哪个适合你的使用场景。
成功的数据管道编排的关键组成部分
根据我的经验,数据管道编排可以分为三个主要组成部分:DAG(依赖关系)、调度程序和插件。
DAG(有向无环图)
DAG 定义了数据管道的蓝图。它为执行路径提供了方向。同时,你可以通过查看 DAG 来追踪依赖关系。
为什么 DAG 对任何数据管道的成功至关重要? 因为处理数据需要有一个顺序,以从数据中提取见解。这一顺序从业务规则的角度来看不能更改。否则,数据的输出将是无用的或出错的。
通过将有向无环图中的每个节点视为一个独立的功能,DAG 提供了一个对齐方式,使当前节点必须遵循上游节点定义的规则。例如,当前节点仅在所有上游节点成功时触发;或者当前节点在一个上游节点失败时可执行。
DAG 方便地提供了数据来源的视图。它提升了可见性,同时显著简化了在数据管道中追踪错误的能力。当数据管道在早晨值班时遇到不愉快的错误时,DAG 执行的实例可以快速指出错误发生的位置。
现如今,能够将 DAG 视为蓝图并在运行时查看其实例以检查作业运行状态的功能对于任何数据编排工具都至关重要。
调度器
调度器是执行数据管道的驱动程序。 一个调度器可以像 cron 作业一样简单。更复杂的调度器涉及构建自己的调度器,比如 Airflow 中的调度器,它管理所有任务状态并积极快照。
调度器的作用是什么? 调度器是一个守护进程,可以被视为后台进程。它应该全天候运行,并在达到某个时间或事件时进行监控。如果调用了调度的时间或事件,执行任务并等待下一个任务。
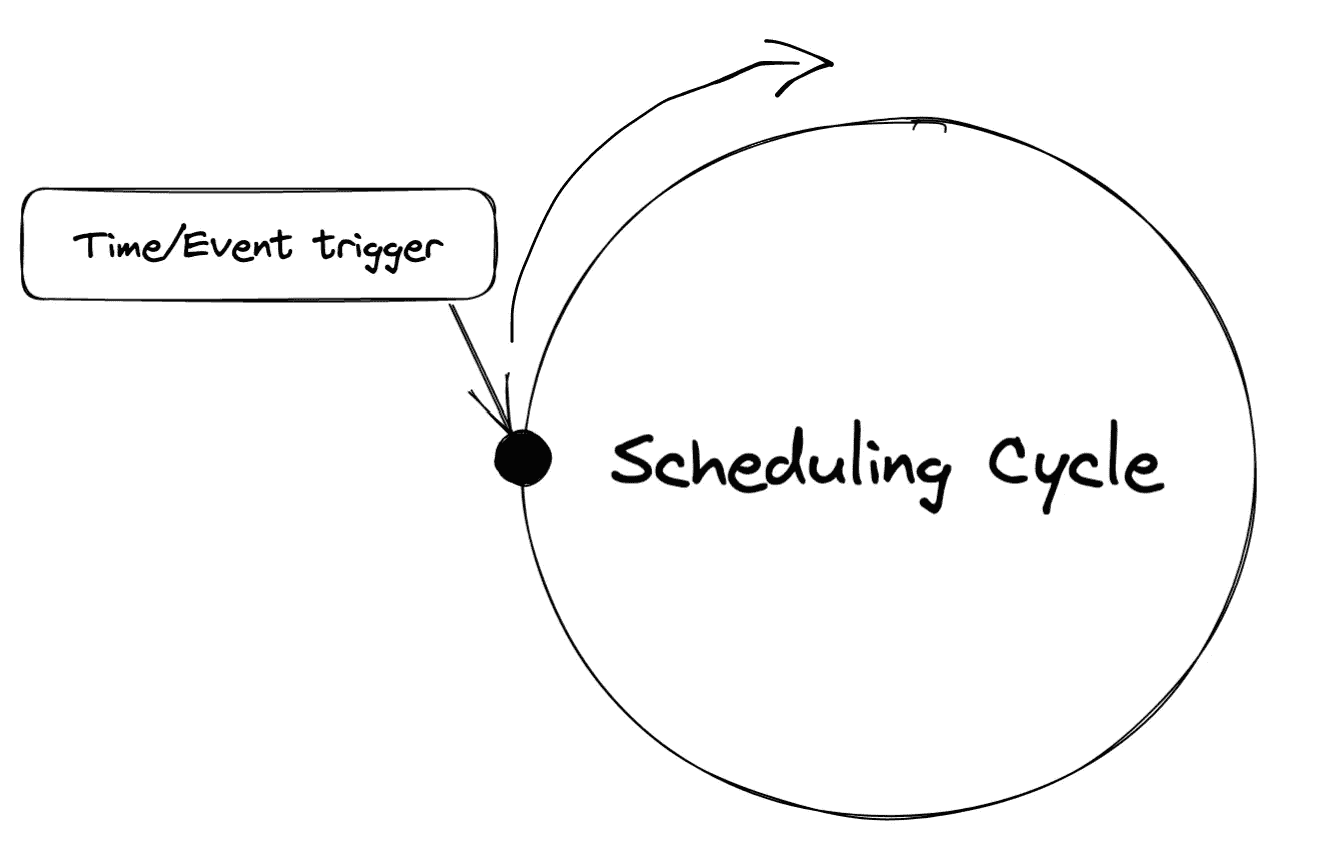
调度周期 | 图片由作者提供
插件
插件用于扩展性,被视为数据管道的潜力。 利用现有的软件包而不是重新发明轮子是很常见的。编排工具插件的丰富性可以节省你集中于业务逻辑的时间,而不是花费数天的时间搜索和编写“如何编写脚本将 Spark 作业提交到 EMR?”
如果数据编排工具不断发展,它会吸引更多的供应商和额外的社区开发者来添加更多插件,以吸引更多用户。迁移到其他数据管道编排工具也很昂贵。
不涵盖的选项
-
taskscheduleR:一个 Windows 专用的调度器,与 Windows 任务调度程序一起使用。如果你使用的是 Windows,这绝对是一个值得探索的选项。
-
github.com/kirillseva/ruigi— 这是一个令人钦佩的尝试。然而,该项目似乎处于闲置状态,自 2019 年 5 月 26 日以来没有更多活动。
探索 R 的数据管道编排工具
我们将讨论以下 5 种不同的工具,这些工具适用于不同的使用案例。
1. cronR
成功的数据管道协调的关键组成部分之一是调度。调度程序让你在无需人工干预的情况下运行数据管道更加安心。要调度 R 脚本,cronR 是你首先要探索的解决方案。
[## GitHub - bnosac/cronR: 一个简单的 R 包,用于管理你的 cron 作业。]
使用 cron 调度程序调度 R 脚本/进程。这允许在 Unix/Linux 上工作的 R 用户自动化 R 进程…
github.com](https://github.com/bnosac/cronR?source=post_page-----f34ab71b1730--------------------------------)
该包增强了一组对 crontab 的包装,使得仅使用 R 进行采纳变得更加直接。因此,你不需要担心设置 crontab,cronR 提供了一个减少复杂性的接口。
library(cronR)
f <- system.file(package = "cronR", "extdata", "helloworld.R")
cmd <- cron_rscript(f)
## schedule R script daily at 7 am
cron_add(
command = cmd,
frequency = 'daily',
at = '7AM',
id = 'my_first_cronR',
description = 'schedule R script daily at 7 am'
)
## schedule same R script every 15 mins
cron_add(cmd,
frequency = '*/15 * * * *',
id = 'my_second_cronR',
description = 'schedule same R script every 15 mins')
使用建议
如果你只想调度 R 脚本,这个选项是一个快速且轻量的解决方案。它适用于临时调度、简单依赖关系或涉及较少状态管理的用例。
限制
由于 cronR 仅提供调度程序。你需要自己构建工作流依赖关系。如果一个 R 脚本可管理,那是可行的。然而,如果脚本的规模变得巨大并且需要中间阶段,你可能希望将其拆分。这些是 cronR 不足以处理的情况,因为它仅处理调度部分而不包括 DAG 定义和插件。
2. targets
[targets](https://github.com/ropensci/targets)包是一个 Make-类似的 R 统计和数据科学管道工具包。
targets 是一个用于数据管道的 R 编程语言工具。你可以轻松定义一个 DAG 来创建依赖图。targets 的主要目标是提供可重现的工作流。它没有自带调度程序,但与我在这里提到的其他工具连接,不应该难以调度从 targets 生成的 DAG。
# functions
get_data <- function() {
print("getting data")
}
transform_data1 <- function() {
print("transforming data 1")
}
transform_data2 <- function() {
print("transforming data 2")
}
loading_data <- function() {
print("loading data")
}
# _targets.R file
library(targets)
tar_option_set(packages = c("readr", "dplyr", "ggplot2"))
list(
tar_target(extraction, get_data()),
tar_target(transform_data, transform_data1_1(extraction)),
tar_target(transform_data2, transform_data2(extraction)),
tar_target(loading_data, loading_data(transform_data, transform_data2))
)
管道和函数定义被分为两个 R 文件。你可以在 _targets.R 文件中构建依赖树,并通过 tar_visnetwork() 进行可视化,从而自动生成 DAG。
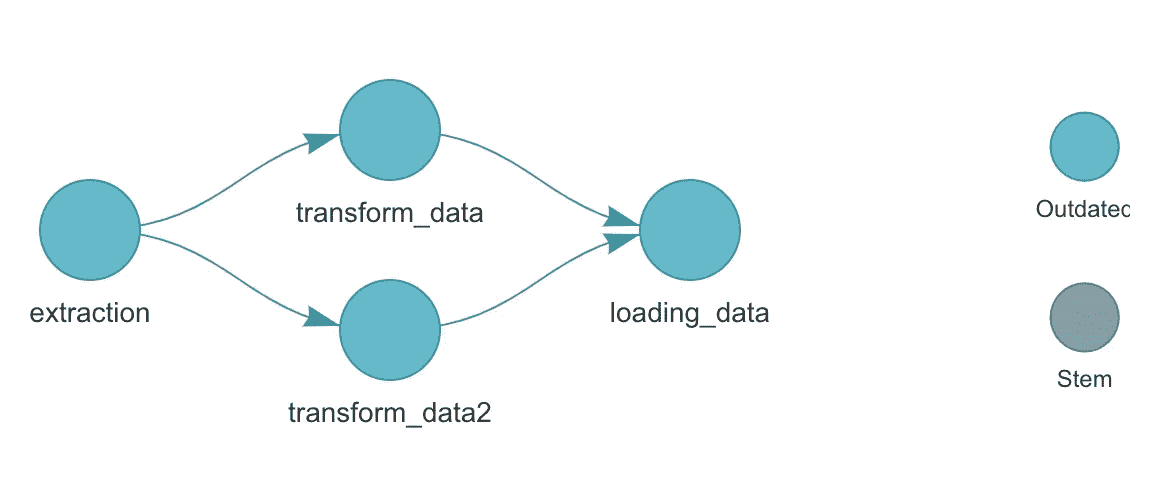
targets 可视化 DAG | 作者提供的图片
使用建议
你需要本地支持 R 来处理数据管道。targets 包可以帮助 R 用户提高日常数据分析工作的效率。它不需要后台运行额外的守护进程来获取 DAG 进行可视化和按需运行。如果你在寻找一个可以手动运行并寻找 DAG 管理解决方案的选项,targets 对于 R 用户来说是一个很好的选择。
限制
如果你决定使用 targets,你将拥有一个强大的 DAG 管理工具。然而,你需要一个调度器和额外的插件来使其成为生产中的数据管道编排工具。结合像 cronR 这样的调度器可以为你提供一个纯 R 解决方案。
3. Kestra
Kestra 是一个通用的数据管道编排工具。它目前仅支持三种类型的脚本:Bash, Node, 和 Python。
尽管 R 语言未被包含在支持的脚本中,但你仍然可以通过使用带有Rscript命令的 bash 脚本来实现 R 脚本的编排。
id: "r_script"
type: "io.kestra.core.tasks.scripts.Bash"
commands:
- 'Rscript my_awesome_R.R'
可以通过在 YAML 文件中使用 Flowable Task 来设置更复杂的 DAG。调度也在 YAML 文件中通过 Schedule 完成。
使用建议
作为 R 用户,Kestra 允许你通过 bash 命令编排 R 代码。此外,Kestra 具有在多种语言中运行数据管道的灵活性。它给你一种现代版的 Oozie 的感觉。如果你对 Oozie 比较熟悉,Kestra 应该更容易上手。
限制
运行 R 不是原生支持的。运行时检索元数据并非简单,单纯使用Rscript命令可能需要额外的学习时间来寻找合适的核心或插件以更有效地开发。
4. Apache Airflow
Airflow 迄今为止是最受欢迎的数据管道编排工具。然而,要编写 DAG,你需要使用 Python。你可以使用 Airflow 操作符来执行你的 R 脚本。然而,定义 DAG 时,R 不在实现范围内。
Airflow 社区曾提出创建ROperator的提案。该提案是利用 rpy2,它为R在 Python 进程中嵌入运行创建接口。核心思想是传递r_command,然后将 R 脚本复制到临时文件中并进行源代码处理。
有很多 R 用户对这个拉取请求感兴趣。
[## [AIRFLOW-2193] 为使用 R 添加 ROperator · briandconnelly · Pull Request #3115 · apache/airflow
确保你检查了以下所有步骤。JIRA 我的 PR 涉及以下 Airflow JIRA 问题并引用了它们……
github.com](https://github.com/apache/airflow/pull/3115?source=post_page-----f34ab71b1730--------------------------------)
然而,这项功能尚未实现。浏览了这个拉取请求后,我们注意到 R 语言的支持在当时不是 Airflow CI 的一部分,其他选项可以执行 R 脚本,因此优先级较低。如果你希望坚持使用 Airflow 生态系统,还有一些选择。
- 使用
BashOperator来运行 R 代码。如果你可以从终端运行你的 R 脚本,BashOperator满足这个要求。使用BashOperator也使得构建 DAG 关系、将参数传递到bash_command以及添加更复杂的逻辑,如重试和邮件警报,变得简单。
run_this = BashOperator(
task_id="my_first_r_task",
bash_command="Rscript my_awesome_R.R",
)
-
在 Docker 容器中运行 R(参见 rocker)并使用
DockerOperator。这个选项类似于BashOperator。使用 Docker 容器的好处是,你可以减少在与 Airflow 相同环境中执行 R 脚本的配置时间。Docker 容器每次提供一个新的 R 环境。这是一个不错且干净的解决方案。 -
[如果你仍然想要一个专用的
*ROperator*],你可以复制并粘贴上述拉取请求中的r_operator.py,并让 Airflow 基础设施团队将其添加进去。
类似的情况也出现在 Prefect。它有一个未解决的开源拉取请求,而且该 PR 被标记为低优先级。
[## 添加 RTask 到任务库 · 问题 #5449 · PrefectHQ/prefect
你目前不能执行该操作。你在另一个标签页或窗口中登录了。你在另一个标签页或窗口中注销了…
许多现代数据管道编排是使用 Python 构建的。然而,当涉及到利用另一个流行的数据相关语言如 R 时,由于其在设计时没有与其他语言一起开始,所以优先级较低。后来,项目变得过于庞大,难以进行根本性的更改,并且需要从头开始付出巨大努力。
使用建议
如果你已经有了作为数据管道编排器的 Airflow 基础设施,这个选项是好的。Airflow 提供了成功的数据管道编排平台的三个关键元素。你已经建立了基础和资源,使用上述选项运行 R 是可能的。
限制
R 并不是 Airflow 中的第一个公民。在 Airflow 中,原生不支持运行 R。虽然有多种解决方法,但 R 仍然被视为外语。无论你选择使用BashOperator还是DockerOperator,甚至是分叉那个 PR,你仍然需要额外的支持,与数据基础设施团队沟通,以帮助你使 R 脚本在 Airflow 中可运行。
另一个限制是,使用 R 时,实时拉取 Airflow 宏(Airflow 的元数据)并不简单。你仍然可以通过查询 Airflow 的后端来使用复杂的解决方案。然而,对于没有深入了解 Airflow 的 R 用户来说,这并不友好。
5. 法师
Mage 是数据管道编排领域的新玩家。我们讨论的最大收获是 Mage 默认将 R 识别为支持语言的一部分,并允许用户定义 DAG,而不论选择何种语言(目前为 python/SQL/R)。
这是 R 用户的一个里程碑。喜欢 R 的用户在定义一个将 R 脚本封装在受限支持工具中的 DAG 时,不必切换到 Python 语法。
Mage 允许用户使用 R 编写主要的 ETL(提取、转换和加载)块。Mage 通过在 YAML 文件中维护 DAG 依赖关系来构建 DAG。这成为了一种灵活的选择,绕过了编程语言的选择。你还可以在开发 DAG 时可视化 DAG 及其 R 代码块。
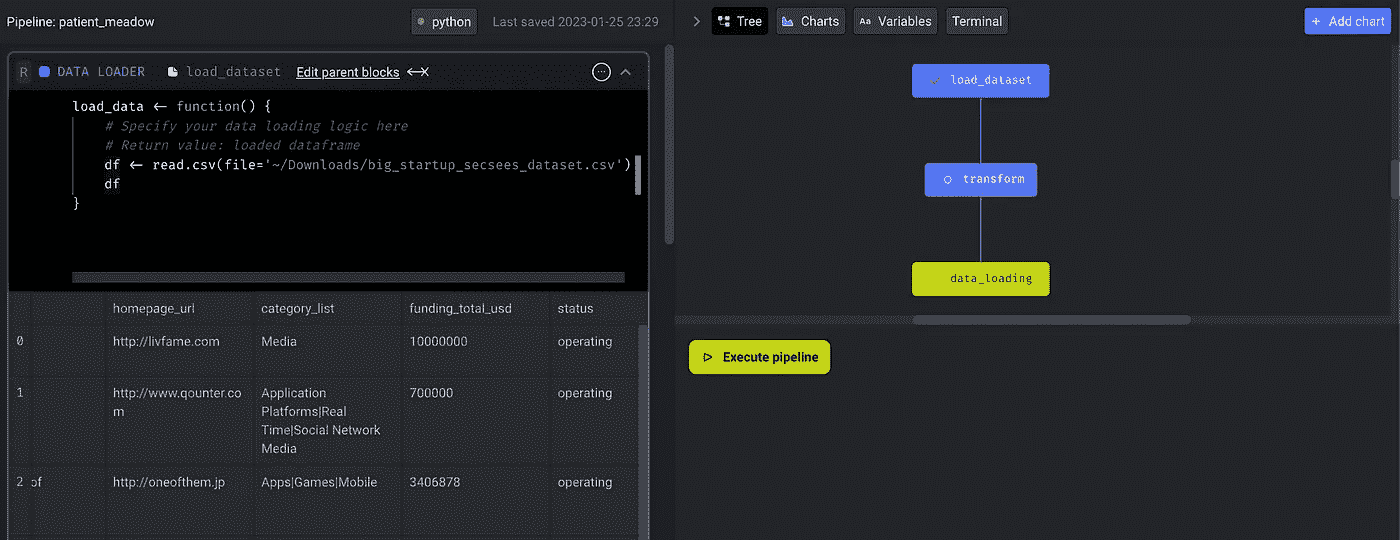
Mage 管道编辑模式使用 R | 作者提供的图像
以下是我用来演示如何使用 R 编写管道并在 Mage 中构建 DAG 的三个主要块。此外,你可以轻松地在 R 中访问调度程序元数据,如 execution_date。
## Data Loader (Extraction)
## You can download dataset here https://www.kaggle.com/datasets/yanmaksi/big-startup-secsees-fail-dataset-from-crunchbase
load_data <- function() {
df <- read.csv(file='~/Downloads/big_startup_secsees_dataset.csv')
## Access scheduler metadata or user defined variables
## This part is powerful that you can access data orchestration metadata at runtime
df['date'] <- global_vars['execution_date']
df
}
## --------------------------------------------------------------##
## Trasformation (Transformation)
library("pacman") ## install pacman before
p_load(dplyr) ## dplyr makes it easier to recognize the dataframe column
transform <- function(df_1, ...) {
## filter on USA startup
df_1 <- filter(df_1, country_code == 'USA')
df_1
}
## --------------------------------------------------------------##
## Data Exporter (Loading)
export_data <- function(df_1, ...) {
# You can write to file to locally
write.csv(df_1, "~/Downloads/usa_startup_dataset.csv")
}
一旦在 Mage 中开发了管道,你可以通过使用 crontab 调度管道来附加触发器。

Mage 管道调度 | 作者提供的图像
在内部,Mage 仍然使用 Python 作为核心,并将 R 脚本解析成 tmp 文件,然后使用该文件运行 Rscript 命令。
subprocess.run(
[
'Rscript',
'--vanilla',
file_path
],
check=True,
)
如果你想了解更多关于 Mage 作为 Apache Airflow 替代方案的内容,我写了一篇文章。
[## Apache Airflow 是否该被替代?mage-ai 的初步印象]
作为数据工程师对 Apache Airflow 的替代方案介绍 mage-ai
chengzhizhao.medium.com](https://chengzhizhao.medium.com/is-apache-airflow-due-for-replacement-the-first-impression-of-mage-ai-ade8208fb2a0?source=post_page-----f34ab71b1730--------------------------------)
使用建议
R 成为 Mage 的主要语言。你可以编写 R 块并顺利访问调度程序元数据,而无需担心如何注入或查询后台。在 Mage 中开发也具有互动性。工程师可以在开发过程中快速迭代测试;他们可以可视化结果,而不是调试一个庞大的 DAG。
限制
Mage 是一个成立于 2021 年的新项目,目前仍处于早期阶段。大量文档需要改进。此外,Mage 的插件数量无法与 Airflow 相比。
最终想法
这里没有涵盖许多数据管道编排选项。对于 R 用户来说,更好地与 R 语言集成的数据管道编排可以减少将初始数据分析转移到生产数据管道中的压力。我希望这里的选项能为 R 用户提供对各种数据管道编排工具的更好见解。
我希望这篇文章对你有所帮助。这篇文章是我关于工程与数据科学故事的系列之一,目前包括以下内容:

数据工程与数据科学故事
查看列表53 个故事!

你也可以订阅我的新文章或成为推荐的 Medium 会员,获取对 Medium 上所有故事的无限访问权限。
如有问题/意见,请随时在本文下方评论或通过Linkedin或Twitter与我直接联系。
5 个函数是管理数据所需的全部工具
原文:
towardsdatascience.com/5-functions-is-all-you-need-to-manage-your-data-with-dplyr-1630825c47b0
如何高效地使你的数据准备就绪


·发布于 Towards Data Science ·8 分钟阅读·2023 年 3 月 10 日
–

照片由 Kelly Sikkema 提供,来源于 Unsplash
那些处理过真实数据的任务的人知道,大部分的工作都集中在数据整理上。
我所说的数据整理包括将数据准备好以供其他利益相关者或下游过程使用的操作。
无论你是数据分析师、数据科学家,还是数据工程师,你都需要在日常工作中执行以下一种或多种操作:
-
过滤(例如,给我德克萨斯州的销售数据)
-
排序(例如,我想查看上周的前 10 名畅销产品)
-
更新(例如,更改这些产品的类别)
-
总结(例如,我想查看每个类别的平均收入)
数据分析和操作工具存在于数据科学生态系统中,以提供高效的操作方式,从而在生态系统中保持其存在。
在这篇文章中,我们将学习如何使用数据科学中主要工具之一:dplyr 来处理这些任务。
这是一个针对 R 编程语言的包,被描述为“数据操作的语法”。
我们可以单独安装 dplyr,也可以使用 tidyverse,这是一个用于数据科学的 R 包集合。我更喜欢后者,因为它允许我使用 tidyverse 中其他包的一些函数(例如 read_csv 来自 readr)。
让我们从导入库和读取数据集开始。我们将使用我准备的模拟数据的样本数据集。你可以从我的 datasets 仓库下载它。
library(tidyverse)
sales <- read_csv("sales_data_with_stores.csv")
# display the first 6 rows
head(sales)
# A tibble: 6 x 8
store product_group product_code stock_qty cost price last_week_sales last_month_sales
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Violet PG2 4187 498 421\. 570\. 13 58
2 Rose PG2 4195 473 546\. 712\. 16 58
3 Violet PG2 4204 968 640\. 855\. 22 88
4 Daisy PG2 4219 241 870\. 1035\. 14 45
5 Daisy PG2 4718 1401 12.5 26.6 50 285
6 Violet PG4 5630 287 5.85 7.59 24 116
结果对象是一个 tibble,类似于 DataFrame 或表格。
所有数据处理挑战都可以归结为使用以下 5 个函数中的一个或多个:
-
select
-
mutate
-
filter
-
arrange
-
summarise
1. 选择
select 函数可用于选择列。它允许我们通过保留或删除列来进行选择,依据列的名称和类型。
让我们通过几个示例来了解 select 的工作方式。以下示例展示了如何选择特定的列。
# select product_code and price columns
select(sales, product_code, price)
# A tibble: 1,000 x 2
product_code price
<dbl> <dbl>
1 4187 570\.
2 4195 712\.
3 4204 855\.
4 4219 1035\.
5 4718 26.6
# the following does the same
select(sales, c(product_code, price))
我们也可以通过排除(删除)一个或多个列来进行选择,方法是使用“!”:
# select all but product_group column
select(sales, !product_group)
# A tibble: 1,000 x 7
store product_code stock_qty cost price last_week_sales last_month_sales
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Violet 4187 498 421\. 570\. 13 58
2 Rose 4195 473 546\. 712\. 16 58
3 Violet 4204 968 640\. 855\. 22 88
4 Daisy 4219 241 870\. 1035\. 14 45
5 Daisy 4718 1401 12.5 26.6 50 285
如果我们选择多个连续的列,使用“:”定义范围会更方便。
# select all columns from store to cost
select(sales, store:cost)
# A tibble: 1,000 x 5
store product_group product_code stock_qty cost
<chr> <chr> <dbl> <dbl> <dbl>
1 Violet PG2 4187 498 421\.
2 Rose PG2 4195 473 546\.
3 Violet PG2 4204 968 640\.
4 Daisy PG2 4219 241 870\.
5 Daisy PG2 4718 1401 12.5
我们还可以使用列索引,因此以下操作与上述操作相同:
# select all columns from store to cost
select(sales, 1:5)
我们还可以根据列的数据类型选择列。例如,以下示例选择了数值列。
# select all numeric columns
select(sales, where(is.numeric))
# A tibble: 1,000 x 6
product_code stock_qty cost price last_week_sales last_month_sales
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 4187 498 421\. 570\. 13 58
2 4195 473 546\. 712\. 16 58
3 4204 968 640\. 855\. 22 88
4 4219 241 870\. 1035\. 14 45
5 4718 1401 12.5 26.6 50 285
通过使用相同的谓词函数(即 where),我们可以选择非数字列,如下所示:
# select all non-numeric columns
select(sales, !where(is.numeric))
# A tibble: 1,000 x 2
store product_group
<chr> <chr>
1 Violet PG2
2 Rose PG2
3 Violet PG2
4 Daisy PG2
5 Daisy PG2
2. mutate
mutate 函数顾名思义,通过更新现有列或创建新列来修改 tibble。
例如,我们可以将价格值增加 10%:
# increase price by 10 percent
mutate(sales, price = price * 1.1)
# A tibble: 1,000 x 8
store product_group product_code stock_qty cost price last_week_sales last_month_sales
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Violet PG2 4187 498 421\. 627\. 13 58
2 Rose PG2 4195 473 546\. 784\. 16 58
3 Violet PG2 4204 968 640\. 940\. 22 88
4 Daisy PG2 4219 241 870\. 1138\. 14 45
5 Daisy PG2 4718 1401 12.5 29.2 50 285
我们还可以创建新列:
# create price_updated column by increasing price by 10 percent
mutate(sales, price_updated = price * 1.1)
# A tibble: 1,000 x 9
store product_group product_code stock_qty cost price last_week_sales last_month_sales price_updated
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Violet PG2 4187 498 421\. 570\. 13 58 627\.
2 Rose PG2 4195 473 546\. 712\. 16 58 784\.
3 Violet PG2 4204 968 640\. 855\. 22 88 940\.
4 Daisy PG2 4219 241 870\. 1035\. 14 45 1138\.
5 Daisy PG2 4718 1401 12.5 26.6 50 285 29.2
多次更新可以在一次操作中完成。在做一个示例演示这种情况之前,我们先提到两个非常有用的功能:
-
我们可以使用“%>%”运算符将不同类型的操作组合在一起,以创建管道并解决涉及多个步骤的复杂任务。
-
新列会立即可用,因此我们可以在同一个 mutate 函数中使用它们。
这里是一个示例,展示了上述两个功能:
> sales %>%
+ select(cost, price) %>%
+ mutate(
+ price_updated = price * 1.1,
+ profit_updated = price_updated - cost)
# A tibble: 1,000 x 4
cost price price_updated profit_updated
<dbl> <dbl> <dbl> <dbl>
1 421\. 570\. 627\. 206\.
2 546\. 712\. 784\. 238\.
3 640\. 855\. 940\. 300\.
4 870\. 1035\. 1138\. 268\.
5 12.5 26.6 29.2 16.7
在上述示例中,我们首先从 sales 中选择价格和成本列,并从价格列创建 price_updated 列,然后使用这个新列创建 profit_updated 列。
3. 筛选
filter 函数允许我们根据条件或条件集筛选观察值(即行)。
以下示例筛选出价格超过 1000 的行。
filter(sales, price > 1000)
# A tibble: 5 x 8
store product_group product_code stock_qty cost price last_week_sales last_month_sales
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Daisy PG2 4219 241 870\. 1035\. 14 45
2 Violet PG1 9692 68 1243 1500\. 26 94
3 Violet PG1 7773 602 976\. 1325\. 19 60
4 Daisy PG1 1941 213 847 1177\. 18 72
5 Daisy PG1 4140 92 803 1202\. 12 24
让我们使用一个更复杂的筛选条件:
# rows with a price of more than 1000 and store is Daisy
filter(sales, price > 1000 & store == "Daisy")
# A tibble: 3 x 8
store product_group product_code stock_qty cost price last_week_sales last_month_sales
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Daisy PG2 4219 241 870\. 1035\. 14 45
2 Daisy PG1 1941 213 847 1177\. 18 72
3 Daisy PG1 4140 92 803 1202\. 12 24
如果我们有一个包含多个值的条件,可以使用“%in%”运算符。
# rows with product group of PG3, PG4, or PG5 and store is Daisy
filter(sales, product_group %in% c("PG3", "PG4", "PG5") & store == "Daisy")
# A tibble: 302 x 8
store product_group product_code stock_qty cost price last_week_sales last_month_sales
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Daisy PG4 5634 205 14.2 18.0 14 53
2 Daisy PG4 2650 239 59.4 111\. 15 38
3 Daisy PG4 5647 352 5.85 13.3 37 108
4 Daisy PG4 5693 260 7.62 13.3 19 74
5 Daisy PG4 5696 260 7.62 13.3 29 98
4. 排序
arrange 函数根据列中的值对行进行排序。它类似于 SQL 的 order by 和 Pandas 的 sort_values 函数。
# order rows by price
arrange(sales, price)
# A tibble: 1,000 x 8
store product_group product_code stock_qty cost price last_week_sales last_month_sales
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Violet PG4 5454 -22 0.570 0.66 31 28
2 Violet PG5 5621 -123 1.32 0.76 49 100
3 Daisy PG4 2279 525 1.34 1.23 14 18
4 Rose PG2 9372 350 1.41 1.42 16 40
5 Rose PG4 2138 482 1.63 1.61 13 23
默认情况下,排序是按升序进行的。我们可以通过在列名之前添加“ -”来将其更改为降序。
# order rows by price descending
arrange(sales, -price)
# A tibble: 1,000 x 8
store product_group product_code stock_qty cost price last_week_sales last_month_sales
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Violet PG1 9692 68 1243 1500\. 26 94
2 Violet PG1 7773 602 976\. 1325\. 19 60
3 Daisy PG1 4140 92 803 1202\. 12 24
4 Daisy PG1 1941 213 847 1177\. 18 72
5 Daisy PG2 4219 241 870\. 1035\. 14 45
要按多个列排序,我们可以用逗号分隔列名。以下示例按商店名称排序,然后按 last_week_sales(降序)排序。
arrange(sales, store, -last_week_sales)
# A tibble: 1,000 x 8
store product_group product_code stock_qty cost price last_week_sales last_month_sales
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Daisy PG6 856 52748 31.4 38.0 1883 6880
2 Daisy PG3 2481 10543 8.25 14.2 947 4100
3 Daisy PG6 3957 10090 26.9 31.3 867 2355
4 Daisy PG6 889 21569 13.0 16.1 808 2990
5 Daisy PG6 9635 26576 8.53 11.4 673 2484
5. 总结
它将组汇总为一行。结合 group_by 函数,我们可以使用它来计算组的聚合值。这一操作类似于 SQL 的 group by 和 Pandas 的 groupby 函数。
# group by rows in sales by store
by_store <- group_by(sales, store)
# calculate the avg price for each store
summarise(by_store, avg_price = mean(price))
# A tibble: 3 x 2
store avg_price
* <chr> <dbl>
1 Daisy 69.3
2 Rose 60.5
3 Violet 67.8
有几个聚合函数可以从数据中提取见解并进行深入分析。
这是来自官方文档的列表:
-
中心:
[mean()](https://rdrr.io/r/base/mean.html)、[median()](https://rdrr.io/r/stats/median.html) -
分布:
[sd()](https://rdrr.io/r/stats/sd.html)、[IQR()](https://rdrr.io/r/stats/IQR.html)、[mad()](https://rdrr.io/r/stats/mad.html) -
范围:
[min()](https://rdrr.io/r/base/Extremes.html)、[max()](https://rdrr.io/r/base/Extremes.html), -
位置:
[first()](https://dplyr.tidyverse.org/reference/nth.html)、[last()](https://dplyr.tidyverse.org/reference/nth.html)、[nth()](https://dplyr.tidyverse.org/reference/nth.html), -
计数:
[n()](https://dplyr.tidyverse.org/reference/context.html)、[n_distinct()](https://dplyr.tidyverse.org/reference/n_distinct.html) -
逻辑:
[any()](https://rdrr.io/r/base/any.html)、[all()](https://rdrr.io/r/base/all.html)
本文中涵盖的函数可以帮助你完成几乎所有的数据处理和分析工作。将它们一起使用在管道中提供了更大的灵活性。
你可以成为 Medium 会员 来解锁我写作的全部内容,以及 Medium 的其他内容。如果你已经是会员,请不要忘记 订阅 ,这样你会在我发布新文章时收到电子邮件。
感谢你的阅读。请告诉我你的反馈意见。
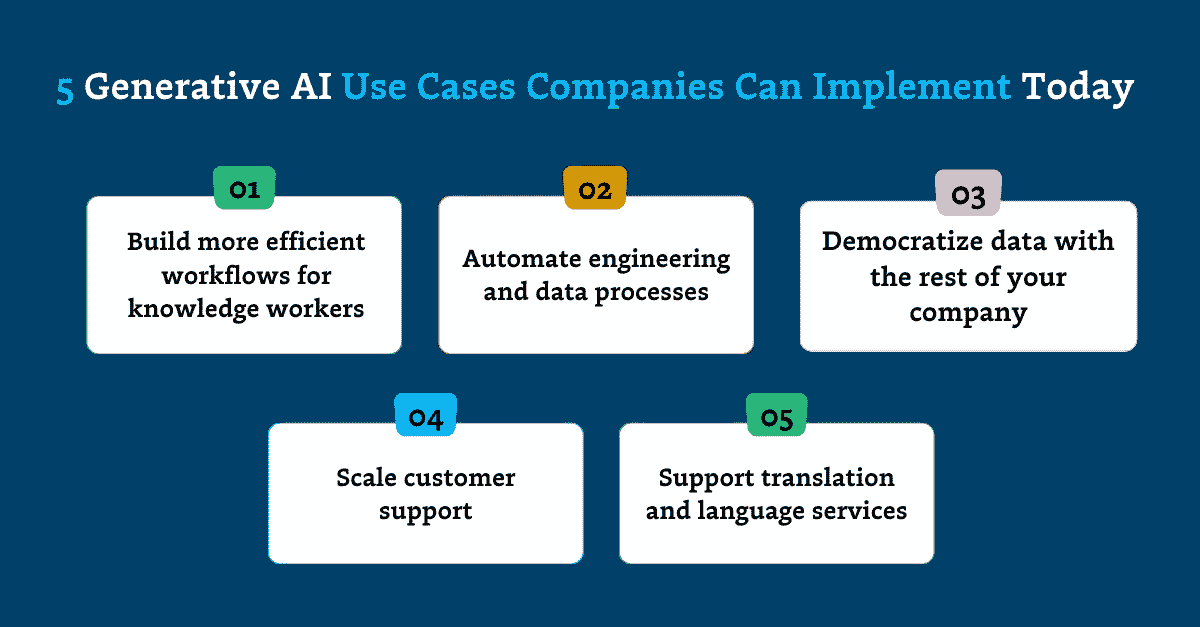
5 种公司可以立即实施的生成 AI 应用场景
刚开始接触大语言模型(LLM)?以下是 OpenAI、Vimeo 和其他公司数据团队目前正在实践的 5 种热门应用。


·
关注 发表在 Towards Data Science ·10 分钟阅读·2023 年 10 月 7 日
–
图片由作者提供。
生成 AI 的炒作是真实的,数据和机器学习团队正在感受到压力。
各行各业的高管们正推动他们的数据负责人 开发能够节省时间、推动收入或带来竞争优势的 AI 驱动产品。
科技巨头如 OpenAI、Google、Amazon 和 Microsoft 一直在充斥市场 推出由大型语言模型(LLM)和图像生成扩散模型驱动的功能。他们承诺帮助公司大规模分析数据,总结和综合信息,生成内容,并以其他方式转变业务。
但大多数公司在开始融入生成性 AI 时实际上从哪里开始?哪些生成性 AI 应用案例是现实的、可实现的,且真正值得投资回报的?
我们深入探讨了早期采用者的策略,以了解公司如何今天将这项技术付诸实践——以及数据团队需要什么才能大规模实施生成性 AI。
为知识工作者构建更高效的工作流程
各行业的公司正在通过自动化和简化知识工作者的耗时过程来推动早期的生成性 AI 应用案例。
鉴于 LLM 理解和提取非结构化数据洞察的能力,企业发现总结、分析、搜索和挖掘大量内部信息的价值。让我们探索一下几个关键行业如何利用生成 AI。
法律事务所
在法律行业中,AI 驱动的系统通过以下方式帮助公司:
-
自动化监管监测以确保客户遵守合规要求
-
起草和审查标准文档,如遗嘱和合同
-
通过审查大量文档以识别潜在风险和问题来协助尽职调查
-
分析合同以标记可能的问题或建议修订
-
通过识别、分析和总结案例法、法规、期刊、规定和其他相关出版物中的相关信息来协助法律研究
技术解决方案: 法律团队正在采用具有定制模型或针对法律系统进行微调的 LLM 的专门解决方案,包括CoCounsel(由 GPT-4 驱动)、Harvey和Thomson Reuters的全套软件。
实际案例: 伦敦律师事务所Macfarlanes 使用 Harvey 来支持研究、分析和总结文件,并创建电子邮件和备忘录的初稿,包括客户工作——由人工律师审查其工作成果。
金融服务
早在 2023 年初,像高盛和花旗这样的华尔街机构由于数据隐私问题,著名地禁止使用 ChatGPT。尽管有这些“反 AI”头条新闻,金融行业已经使用机器学习算法多年——用于驱动欺诈检测算法和即时信用决策。而且金融产品和公司充满了生成式 AI 的潜在应用案例。
目前,Databricks 估计在金融服务中,80% 的生成式 AI 应用案例专注于简化流程以节省时间和资源。这包括:
-
使用内部文档作为知识库的对话金融聊天机器人
-
自动化基本会计功能,如发票捕获和处理
-
分析、总结和提取年度报告、保险合同和财报电话记录等文档的洞见
此外,业内领导者认为,AI 检测和阻止金融犯罪和欺诈的能力 是一个极具吸引力的应用。
技术解决方案: 定制解决方案开始出现,包括 BloombergGPT,这是一个专门为金融服务开发的 50 亿参数的 LLM。
现实生活中的案例: 在 2023 年 9 月,摩根士丹利推出了一个 AI 驱动的助手,通过提供对其内部研究报告和文档数据库的便捷访问来支持金融顾问。员工可以使用该工具询问市场、内部流程和建议。
销售团队
销售和营销团队正在大量采用生成式 AI,应用案例包括:
-
编写电子邮件、着陆页、博客文章和其他内容的初稿
-
根据 CRM 数据为个人推广内容进行个性化
-
分析销售互动以指导代表
-
基于人口统计、公司数据和数字行为自动化潜在客户评分
-
总结通话和视频会议的互动
技术解决方案: 销售平台如 Gong 使用专有模型 来生成通话摘要并推荐下一步,以帮助推动潜在客户的购买旅程,而 Salesforce 的 Einstein Copilot 基于客户的具体背景自动生成电子邮件回复和账户更新。
现实生活中的应用案例: 帐户互动平台 6sense 使用支持 AI 的对话式电子邮件解决方案 来进行潜在客户沟通——这为营销互动账户带来了 10% 的新业务管道生成。
自动化工程和数据流程
通过自动化编码和数据工程中的重复或单调工作,生成 AI 正在简化工作流程并提高软件和数据工程师的生产力。
例如,团队可以使用生成 AI 来:
-
自动生成代码块并检查代码中的错误
-
自动调试和修正小错误,或预测可能出现的错误
-
生成大量与现实世界信息相符的合成数据,以便工程师在不担心隐私问题的情况下测试模型
-
自动生成关于代码和项目的详细文档
-
更方便地将遗留软件从如 COBOL 这样的语言(在金融领域中常见,并且 成本显著)更新为现代语言
LLMs 也直接集成到开发者解决方案中。例如,在 Monte Carlo 平台内,我们利用 OpenAI API 支持两个功能——Fix with AI 和 Generate with AI——这些功能帮助团队更好地操作数据可观察性。Fix with AI 使用 LLMs 来识别数据质量检查中的错误,而 Generate with AI 使用 LLMs 来生成新的数据质量检查建议。
即使在 OpenAI 自身,LLM 也被用于支持 DevOps 和内部功能。正如Yaniv Markovsi,AI 专家负责人,所说,他们的团队使用 GPT 模型来聚合和翻译操作信号,如服务器日志或社交媒体事件,以了解客户在使用他们的产品时的体验。这比传统的 Site Reliability Engineering 团队手动调查和分类事件的方法更为简化。
技术解决方案: 工程团队正在采用像GitHub Copilot和Amazon 的 CodeWhisperer这样的工具来支持他们的日常工作流。开发人员可以提供自然语言提示,并获得像 Python、JavaScript、Ruby 等语言的代码片段和建议。
现实生活中的使用案例: 一家全球媒体公司的数据工程团队正在使用 LLMs 将拉取请求分类为其 dbt 工作流中不同级别的需要处理的请求。根据更改的分类,模型触发不同的构建命令。这有助于显著简化开发工作流——因为团队的另一种选择是硬编码一些复杂的解析来确定哪个命令适合测试更改。
与公司其他部门一起民主化数据
在数据领域,公司利用生成 AI 的最佳机会可能是增加非技术用户对数据的访问。LLMs 提供了一种途径,使组织内的团队成员可以输入自然语言提示,从而生成 SQL 查询以检索特定数据点或回答复杂问题。
这正是 Adam Conway,Databricks 产品高级副总裁,最近强调的公司最明确的第一步。
“我见过一些行业拥有大量文档,他们希望使内部团队能够从成千上万页记录中检索答案,”Adam 说道。“这才是正确的方法,因为风险很低——它让你亲自参与,提供了很多价值,并且没有太多风险。在 Databricks,我们有一个内部聊天机器人,帮助员工解决问题并查看数据。我们在这里看到了很多价值。”
技术解决方案: 像 Databricks 这样的平台正在研发嵌入式功能——他们最近宣布了 LakehouseIQ,该功能承诺使团队能够用普通语言查询数据。
尽管这些技术仍在发展中,数据团队可以根据内部文档或知识库微调模型,以为其组织构建定制能力——或者利用生成式 AI 帮助员工更快捷地进行自助查询,正如我们的实际例子所描述的那样。
实际案例: 直播购物平台Whatnot 强烈鼓励每位员工掌握 SQL,以便他们能够查询自己的数据、创建自己的仪表盘以及编写自己的 dbt 模型——即使在市场营销、财务和运营等非技术部门也是如此。生成式 AI 在员工培训中发挥了作用。
正如工程总监 Emmanuel Fuentes 最近告诉我们的,“这正在帮助人们启动。如果他们没有 SQL 背景,它能帮助他们迅速上手,这真的很棒。如果有人不知道怎么做窗口函数,比如,他们可以描述自己想做什么,得到一段 SQL 代码,然后将我们的数据表替换进去。这就像是给那些完全不了解高级分析的人一个导师。”
扩展客户支持
客户支持团队应当获得特别的赞誉,因为他们是 LLM 赋能工作流的特别理想受众。通过将语义搜索融入基本的聊天机器人和工作流中,数据团队可以使客户服务团队更快地访问信息、创建响应并解决请求。
技术解决方案: 一些 CX 解决方案已经在其平台中包含了生成式 AI 功能。例如,Oracle 的 Fusion Cloud CX 使用一个参考内部数据的 LLM,帮助代理根据客户的互动历史生成即时响应,并建议新的知识库内容以应对新出现的服务问题。
实际案例: Vimeo 工程师 使用生成式 AI 构建了一个帮助台聊天原型。该工具在一个向量存储中索引公司的 Zendesk 托管帮助文章(关于向量数据库的更多内容见下文),并将该存储与 LLM 提供商连接。当客户与现有前端聊天机器人进行的对话不成功时,记录会发送到 LLM 寻求进一步帮助。LLM 会将问题重新表述成一个单一的问题,查询向量存储中相关内容的文章,并接收相关文档。然后,LLM 会为客户生成一个最终的总结回答。
支持翻译和语言服务
最后,生成性人工智能使得在组织内部实现近乎即时的翻译和语言支持成为可能,这些组织每年在语言服务上的支出接近$60 billion——但仅翻译了它们生产内容的一小部分。像 GPT-4 这样的 LLM 有可能帮助团队提供多语言客户服务互动、进行全球情感分析,并大规模本地化内容。
技术解决方案: 目前,大多数模型可能缺乏足够的训练数据来熟练掌握不常用的语言——或理解俚语或行业特定术语——因此团队可能需要微调模型以获得良好结果。尽管如此,Google正在开发一种训练了 400 多种语言的通用语音模型,目标是构建一个通用翻译器。
真实使用案例: 在对传统翻译模型进行独特的改进时,健康科技公司Vital推出了一款由人工智能驱动的医生到患者翻译器,能够即时将高度专业的医学术语转换为通俗语言。
开始使用生成性人工智能时的三个关键考虑因素
当你的团队进入不断变化的生成性人工智能领域时,有几个关键因素需要记住。
补充你的技术栈
拥有适当的技术栈来支持生成性人工智能将帮助你的团队更快地扩展和创造价值。除了现代数据栈的常见组件外,你还需要考虑添加:
向量数据库
向量数据库目前是团队利用 OpenAI 的 LLM 构建可扩展应用程序的最有效方式之一。这些数据库支持向量嵌入,携带语义信息,有助于 AI 理解数据中的关系和模式。
团队可以使用像Pinecone或Zilliz这样的独立向量数据库,或在现有的数据存储解决方案中使用向量嵌入功能,例如Databricks和Snowflake。
微调模型
对于有更多定制需求的团队,微调模型——在针对你需求的数据集上训练预训练模型——将可能是超越向量嵌入的下一步。像Tensorflow和HuggingFace这样的工具是微调模型的好选择。
非结构化或流数据处理
生成式 AI 倾向于通过从大量非结构化数据中提取洞见来提供最大价值。如果你尚未将非结构化数据处理纳入你的技术栈,你可能需要实现一个类似于Spark的工具——或者Kafka,如果你正在涉足流数据的话。
确保拥有合适的团队和资源
创建 AI 试点项目需要时间和资源。虽然你可能有一个不惜成本将生成 AI 引入你的产品或业务的热情 CEO,但仍然需要对所需时间和成本有一个现实的了解。
组建你的团队
你很可能会将现有员工重新分配到原型开发或概念验证上,而不是一开始就聘请经验丰富的生成 AI 开发人员(部分原因是这是一个全新的领域,经验丰富的生成 AI 开发人员还不太存在)。这些先锋团队通常由具有一定 ML 背景的数据工程师组成。
换句话说,你的一些宝贵成员将需要从即时的创收工作中抽离出来,参与你的 AI 试点项目。考虑固有的机会成本,并将其纳入你的整体规划——同时为你的团队配备一位业务赞助人,能够为这种资源转变提供支持,同时保持团队与业务价值的紧密联系。
考虑你的硬件成本
如果你计划对你的模型进行微调,并且你对 ML Ops 不熟悉,预测并关注你将会产生的计算成本。那些 GPU 时数可能会累积起来。
优先考虑数据质量
无论你的技术栈、选择的模型或用例是什么,有一点真理始终不变:你需要确保数据输入和数据输出的质量。否则,你将冒着将糟糕数据暴露给更多内部团队的风险,无论是通过自然语言提示直接暴露,还是通过生成 AI 驱动的产品间接暴露。
生成性人工智能有可能彻底改变每个企业,但它也并非没有风险和潜在陷阱。数据测试、数据监控、AI 治理 和 数据可观测性 有助于确保生成性人工智能为您的组织创造巨大的价值——而不是尴尬的数据灾难。
特别感谢 Naren Venkatraman、Yaniv Markovski 和 Emmanuel Fuentes 花时间与我们聊这篇文章。
5 个有用的提取与加载实践,帮助获得高质量原始数据
不可变的原始区域,未经过变换、平展或去重,直到完成你的挖掘工作


·
关注 发表在 Towards Data Science ·8 分钟阅读·2023 年 4 月 4 日
–

挖掘机 - 图片由 Dmitriy Zub 提供,来源于 Unsplash。
这篇文章是对 Meltano 博客的更新版。
ELT 正成为数据架构的默认选择,但许多最佳实践主要关注“变换(T)”。
但数据质量在提取和加载阶段之后的转换中决定。正如谚语所说,“垃圾进,垃圾出。”
强大的 EL 管道为提供准确、及时和无误的数据奠定了基础。
幸运的是,我们有一个充满数据专家的社区,他们使用过 Meltano、Stitch、Airbyte、Fivetran 和市场上所有的大型提取和加载工具。因此,我们请他们提供他们最关键的提取和加载实践!
我们提炼了 5 个数据实践 被社区使用和喜爱,这些实践将提升所有数据集的质量,无论你使用什么工具。
但等等,这些不是“最佳实践”吗?因为我们认为它们是可以选择的。如果你正在处理一个新项目或在提取和加载过程中还没有很多实践,你可以全部实施。如果你已经有了一些,补充那些有意义的实践。
设置舞台:我们需要提取和加载实践,因为“复制原始数据”比听起来复杂得多。
ELT 作为一种模式的概念听起来很简单,“只需首先复制源数据,然后在自己的空间中对原始数据进行转换。”然而,“复制”和“原始数据”这两个词有隐藏的障碍。
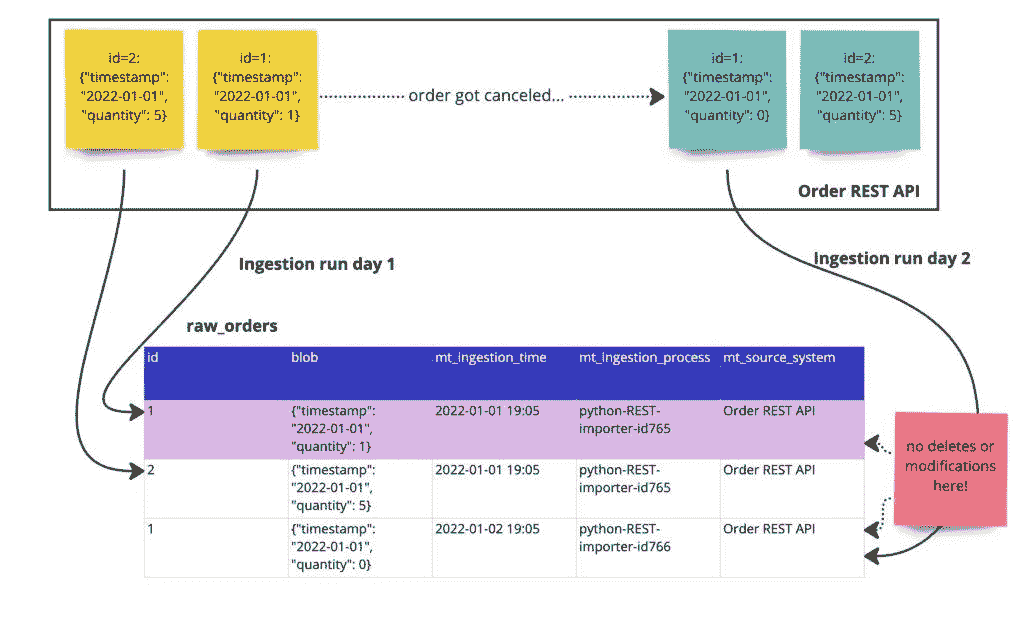
“复制”听起来很简单。但源数据会变化,除非你知道发生了什么变化,否则“复制”比你想象的要复杂。想象一下一个包含 1.5 亿个“订单”的生产表,它有一个“时间戳”,但没有“修改”数据。是的,这样的表随处可见。那么,你怎么知道订单是否被修改了?如果是,哪些订单被修改了?例如,你怎么知道哪些订单被“取消”,这种操作通常发生在同一数据记录中并在原地“修改”它?
“原始数据”听起来很清晰。然而,提取和加载的概念隐含着通常你在两个不同的技术系统 A 和 B 之间复制数据,其中你需要调整数据以匹配系统 B。你从 REST API 中获取数据并将其放入 Snowflake,或从 Oracle 数据库中提取数据并放入 Redshift。每次更换系统时,你都需要修改“原始数据”以遵循新系统的规则。你需要进行类型转换;你需要考虑是否要“展平 JSON”或是否要向数据中添加额外的元数据。
单纯“复制原始数据”每次添加新数据源或目标时都会提出新问题。即使只是来自同一生产数据库的新表,你一直在复制的数据。
这些实践将在你使用新数据源将数据导入数据系统时为你提供指导。
1. 使每次 EL 运行具有唯一标识——时间戳所有内容
我们从可能最重要的最佳实践开始:使你加载到数据系统中的每一位数据都能被识别并追溯到获取它的过程。
典型的方法是包含捕获的元数据值:
-
摄取时间:表示加载过程开始的时间戳。
-
摄取过程:表示加载过程及其实例的唯一标识符。
-
源系统:关于数据来源的元数据。

图片由作者提供。
将这些元数据中的任何一个或全部添加到你摄取的数据的每一行/条目中。我们建议使用摄取器的开始时间作为“摄取时间”,因为这简化了过程。“摄取实例的标识符”应该明确。不要仅仅提供“Airflow-OracleDB-Ingester”作为过程,而是提供“Airflow-OracleDB-Ingester-ID1244”,其中 ID1244 标识特定的摄取运行。
将源系统作为元数据的一个好处是,你可以快速调试下游仪表板中的问题并识别其来源。这也是其他用例中有用的元数据。
假设你有一个遗留系统和一个新的客户注册组件。在这种情况下,你可以在仪表板中将源系统作为过滤选项,让用户仅过滤来自一个系统的客户。
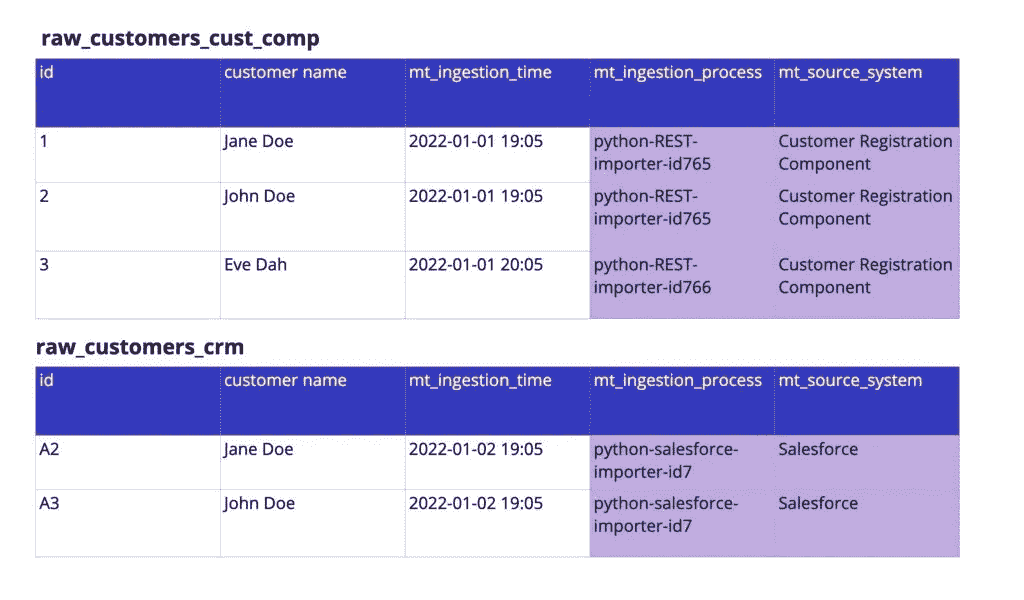
图片由作者提供。
2. 在原始层级之外的层级去重数据
通常,你会遇到三种数据重复情况需要“去重”。但无论是哪种情况,都不要在原始/落地层进行去重!
第一种情况是有意的重复数据,其中源系统包含你和终端用户认为重复的内容。例如,你的 CRM 系统可能有两个相同客户的条目,该客户取消后重新注册。如果你在原始层级去重,这意味着要么合并两个条目,要么删除一个。这两者都会删除源系统中存在的数据。
第二种情况是无意间产生的重复数据,其中源系统可能会删除你在数据仓库中仍然存在的记录,或者源系统无意中生成了未来可能会删除的重复数据。尽管这是一个“错误”,我不建议在原始摄取区域删除这些数据,而是应该在后续阶段进一步过滤,例如在建模的下一阶段。否则,你会在摄取中添加难以跟踪的逻辑。
第三种情况是由于技术限制导致的重复。可能是你的摄取工具倾向于“至少一次交付”策略,或者可能是摄取过程中的一个 bug。使用“至少一次交付”增量加载策略,你确保获取所有数据行,但可能会产生一些重复数据。再次建议在原始层级保留重复数据,并在后续阶段进行过滤。

图片由作者提供。
无论情况如何,都不要在加载时去重。加载所有数据,并保持原样。稍后在下一阶段进行去重。
3. 在 EL 期间不要展平,推迟到一个阶段后进行
许多源系统在摄取时会返回数组、JSON 或其他具有某些层级的嵌套对象,你希望将其拆解以进行进一步处理。但不是在摄取层面。将原始数据按原样导入你的数据系统,然后让一个过程进行“扁平化”。
一个很典型的例子是 JSON 对象。你的源数据可能包含一个大的 JSON 对象,而你希望将其处理成 Snowflake 数据库中的单独列。这种做法建议首先创建一个仅包含元数据列和一个“JSON_blob”列的原始表,其中包含 JSON 对象。在第二步,你可以将这些数据处理成列。
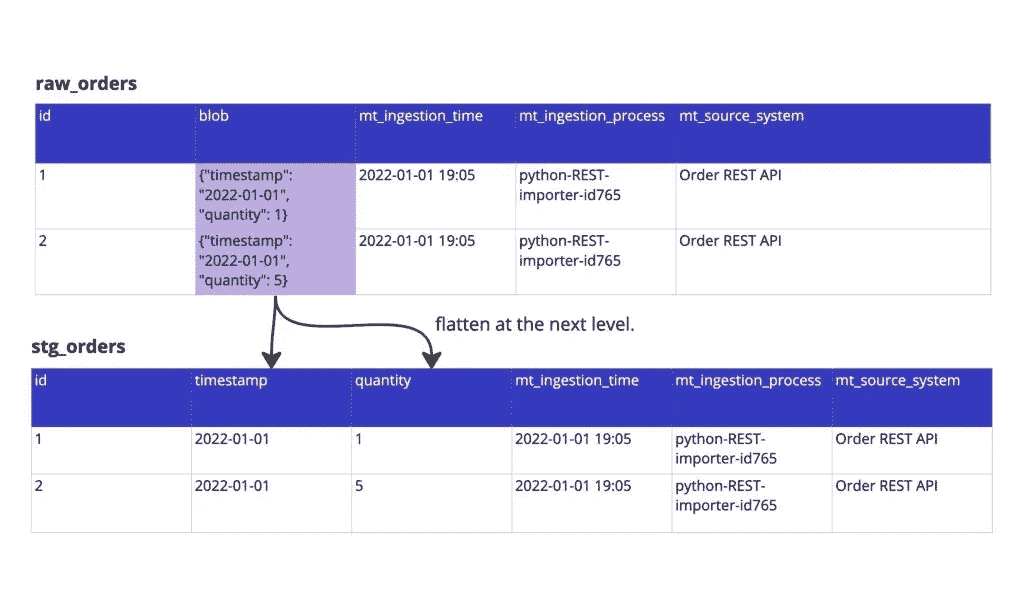
图片由作者提供。
这样做的原因是,扁平化涉及业务逻辑。它涉及到你知道哪些属性是“始终存在的”。如果你在摄取时进行扁平化,你的摄取过程可能会因为一个 JSON 对象为空,或者一个 JSON 对象没有一个预期的值而中断。处理已经摄取的数据并重新运行扁平化工具总是比运行摄取和扁平化过程更容易。
附加提示:相同的实践可以避免在摄取时进行类型转换(如果可能的话)。我们建议在摄取之后再进行类型转换。
4. 拥有一个不可变的原始层
在某个时候,你将切换到数据的增量更新。此时要记住创建一个“不可变原始层”,这是一个你绝对不要修改或删除数据的区域。
“不可变原始层”:一个你绝对不要修改或删除数据的区域。
不去重复数据是其中的一部分(见规则 2),但还有更多:在你的不可变原始层中,你不会删除上游移除的记录或修改上游修改的数据。你只是加载新数据,仅此而已。
一个我仍然痛苦记忆的例子是北极星指标仪表板。它展示了我基于过去几个月客户行为所工作的北极星指标的当前发展情况。仪表板和数字看起来都很好,呈上升趋势。产品和管理决策基于此做出。北极星指标的新记录每周广播一次。
然后突然有一天,仪表板看起来不同了。我们的北极星指标减少了 10%的值,并在某个特定细分市场中减少了 30%。
一位大客户离开了,记录被完全删除。
由于我们在修改原始数据,我们彻底搞砸了北极星指标,无法恢复。
从那天起,我们使用了可能会变动的所有原始数据的快照。
图片由作者提供。
为自己做个好事,让你的原始层不可变。
注意:不可变的暂存区域实际上就是你在进行全表同步时创建的,如果你不删除数据的话。此外,出于 GDPR 和隐私问题,你应该在这里做一个例外。
5. 在数据摄取时不要进行任何形式的转换,即使是轻微的,除非确实必要
在摄取时即时转换数据有充分的理由,但几乎所有你能想到的案例也可以在不转换的情况下运作。法律和安全是即时转换数据的两个好理由。对于其他所有理由,你应该首先摄取数据,然后对摄取的数据进行小规模的转换。
如果你选择在摄取数据时进行“即时”转换,确保你使其防故障。尽量只添加数据或删除数据,而不是修改数据。
如果你默认要进行转换,最好先进行数据摄取。然后,你可以,例如,创建一个映射表并在那里进行连接。

图片由作者提供。
你可以通过使用像“dbt seeds”这样的机制或摄取由外部贡献者维护的 Google Sheets 来实现。
总结
我们都知道“垃圾进,垃圾出”,但我们往往未能在提取和加载的世界中认识到这一点。
这些做法侧重于在我们流程的最开始阶段减少垃圾数据。它们将帮助你更快地解决问题,并从长远来看提高数据质量。
如果你想了解所有实践的简短版本,请查看下面的图示。

5 个有用的提取和加载实践,图片由作者提供。
5 个促进数据科学家/分析师参与的想法,而不至于在会议中窒息
作者分享了他们成功实现这一平衡的策略


·发表于 Towards Data Science ·阅读时间 8 分钟·2023 年 10 月 21 日
–

图片由 Aziz Acharki 拍摄,来源于 Unsplash
在管理数据科学或数据分析团队时,找到为团队成员提供不受干扰的专注时间与促进参与、合作和团队精神之间的良好平衡可能是一项挑战。在我的团队领导经历中,我尝试了许多迭代和方法来实现这一平衡。在这篇文章中,我将概述我当前拥有的五个有效的关键点。
无论你是寻求灵感的分析团队领导,还是渴望摆脱“过多会议”的数据科学家,我希望这些见解能够激励你自己的职业旅程。
1 — 早晨站会
-
节奏:每日
-
时长:15 分钟
早晨站会直接来源于 敏捷方法论,这是一个简短但至关重要的每日聚会,每天早晨的第一个环节(在固定时间)。尽管有些人可能会更早开始他们的一天,但站会作为整个团队的统一起点。在这个会议中,每个人,包括经理,轮流提供简洁的更新,内容包括:
-
他们昨天完成的工作,
-
他们今天计划达成的目标,
-
需要与相关方进行线下讨论的任何障碍或问题
为什么要进行早晨站会?
→ 促进专注与承诺:它培养了对团队日常目标的目的感和承诺感。
→ 提升意识和协作:它让团队成员了解彼此的项目和进展,促进联系和合作。
→ 早期识别阻碍因素:在早期识别障碍可以防止浪费精力,确保顺利进展。
→ 让经理及时了解:会议使经理充分了解团队的进展,从而有效监督。
除非涉及整个团队,否则更深入的讨论应与相关方离线进行。
这个简短的会议也是经理进行小型公告或提醒以完成行政任务的机会。(有关早晨站会的更多细节 请点击这里)。
关于替代方法的反思:
在完全敏捷模式下,使用 冲刺 节奏:
这种方法已被 证明 对于专注于单一产品或项目的开发团队非常有效。然而,它在分析/数据科学实践中的应用却面临挑战。根本问题在于团队成员通常参与各种项目或分析,许多项目无法与标准的冲刺周期对接——数据科学项目往往超出典型的 2 到 3 周的冲刺周期。
项目时间表和范围的这种差异也意味着,只有一小部分敏捷仪式(规划和待办事项整理会议)与个别数据科学家的具体需求对接。显而易见,将各种复杂的数据科学任务强行融入传统敏捷冲刺的严格结构中存在显著低效。

Mimi Thian 的照片,来源于 Unsplash
2 — 周五“进行中的工作”展示
-
节奏:每周
-
持续时间:15 分钟+
我们最近实施了这种方法,以促进合作,而不需要在日历上预订额外的时间槽。这个举措取代了标准的每周五每日站会,具有迷你 braintrust 的本质。会议定为 15 分钟,但由于周五早晨通常较少会议,如果需要,讨论可以延长。
这是一个志愿者可以非正式地展示一个正在进行的工作,并寻求团队集体智慧的空间,例如:
-
“我正在做这个模型,想听听你的想法。”
-
“我在考虑两种解决方案,哪个选项最好?”
-
“这是我即将向利益相关者展示的内容,我如何才能使其更好?”
为什么要有“进行中的工作”展示?
→ 沟通技巧:这个环节提供了一个定期的平台来磨练总结和沟通技巧。
→ 更深入的洞察:它为团队提供了一个了解正在进行的项目和任务技术复杂性的窗口
→ 协作解决问题:它鼓励团队成员互相交流和碰撞想法
这种格式取得了良好的平衡,促进了积极参与和协作,同时为那些对主题有更深兴趣的人提供了进一步探索的灵活性。
替代方法的反思:
起初,我将这些智囊会议作为单独的 1 小时会议进行,这种格式本可以允许更深入的技术讨论。然而,事实证明,参与者往往选择跳过这些会议,以完成任务或项目,从而导致出席率不尽如人意。此外,1 小时的时间有时也成为志愿者主动分享他们正在进行的工作的障碍。

图片由Estée Janssens拍摄,来源于Unsplash
3 — 数据科学团队会议
-
节奏:每月一次
-
时间:1 小时
这种更正式的聚会每月举行一次(请参见下文关于节奏选择的说明),是从日常任务/项目中退后一步,反思团队的工作方式和未来机会的机会。我们还尝试邀请来自不同职能领域的人介绍他们的工作,并讨论潜在的协同效应。我们的会议结构遵循以下框架:
-
5 分钟:快速更新行政事务和必要的提醒。
-
25 分钟:A) 回顾,提供了反思我们过去经验的机会
或
B) 战略/路线图更新和项目规划,使我们能够展望未来
-
30 分钟:来自组织的嘉宾
为什么要召开数据科学团队会议?
→ 反思与规划:这次会议提供了一个机会,让我们退后一步,反思过去,展望未来
→ 工作方式的责任:它赋予我们的数据科学家掌控权,分析哪些做法有效,哪些无效,并致力于改进
→ 项目可见性:它使团队了解即将开展的项目,并有机会与那些符合他们兴趣和专长的项目对接。
→ 拓宽视野:它拓宽了我们团队对组织的理解,培养了与不同业务职能的联系和合作关系
替代方法的反思:
这些会议最初是每两个月一次,专注于回顾,因为我们通过其他接触点处理其他元素。然而,随着我们团队表达了对项目分配和战略的更多见解的需求,我们合并了一些其他接触点,从而允许独立的每月团队会议。
在没有早晨站会和不太定期的一对一会议的不同环境下,我发现每周的团队会议节奏是有效的。这种格式包括了行政更新、看板审查以及团队成员每周项目或技术见解的展示。

4 — 个人一对一
-
节奏:每周
-
时长:30 分钟
这是每周日程中专门为数据科学家或数据分析师留出的时间。这里 是一个关于如何设立和进行成功的一对一会议的极好资源。我已将其调整为以下结构:
-
JIRA/看板审查和更新(5 分钟或更少)
-
讨论的重点不是谈论具体的项目或任务,而是提供机会让个人提出他们想要讨论的内容。
-
反馈、辅导、职业发展
-
季度目标检查和规划
-
如果时间允许,可以进行项目或任务的讨论
为何进行个人一对一会议?
→ 关系建设:它建立并培养了数据科学家/分析师与其经理之间的关系,建立了信任
→ 成长与发展:它通过个性化反馈和辅导促进数据科学家/分析师的成长与发展,同时通过互惠反馈来培养管理能力。有关不同级别的数据科学家/分析师期望的详细信息,请参见 这篇文章 。
每季度末,我们的关注点转向评估我们的年度目标,包括组织/项目目标和个人职业发展目标,并检查我们实现这些目标的进展。
替代方法的反思:
我们探讨了每两周一次 45 分钟的对话选项,但对于我们来说效果不佳。我们的对话通常在 30 分钟内结束,两周一次的间隔似乎过长,难以保持强烈的联系。
看板板块回顾:我们最初为看板回顾安排了单独的会议。后来我们将其并入了稍长的早间站立会议。由于数据科学家/分析师任务和项目的个体性质,两个选项都未能达到与完全敏捷运营相同的效果:会议的有限部分对每个人而言相关。因此,将这种个性化的接触点与单对单会议结合,作为进入核心讨论之前的快速管理事项,显得更为合理。

Chris Montgomery 的照片,来自 Unsplash
5 — 部门团队会议
-
频率:每月
-
持续时间:1 小时-1.5 小时
促进数据科学家/分析师参与和团队精神的最后一件事,我自己不做——就是更广泛的团队每月会议。它通常包括以下几个元素:
-
介绍新团队成员
-
认可成功的项目或团队成员
-
来自部门主任或副总裁的更新
-
商业更新
-
趣味活动
-
项目分享
-
组织文化活动
为什么要进行部门团队会议?
它让数据科学家/分析师接触到更广泛的部门,并建立归属感
→ 它让个人理解他们的工作如何融入部门中
→ 它帮助识别部门中的专业知识和用于当前或未来障碍的资源
结论:
这就是我认为的必要接触点——它们不会过度增加工作负担,但能促进参与感和团队精神。当然,它仍然需要不断的完善和调整!
你认为这 5 项中哪些是多余或不必要的?你和你的团队有哪些不同的方法效果良好?请在下面的评论中告诉我!
参考文献
[1],[3]K Schwaber & J Sutherland,《Scrum 指南》(2020)。 链接。
[2]M. Oster,《什么是每日站立会议以及如何有效地进行》(2023)。 链接。
[4]M. Mah,《哥伦布发现敏捷》(2012)。 链接。
[5]E. Catmull,《皮克斯智囊团内部揭秘》(2014)。 链接。
[6] Scrum.org,《什么是冲刺回顾》。 链接。
[7] S. Rogelberg,《充分利用你的单对单会议》(2022)。 链接。
5 个激励人心的学习资源,帮助我保持在数据分析的前沿
5 个激励人心的学习资源,推动你的技能和专业知识


·发表于 Towards Data Science ·阅读时间 5 分钟·2023 年 7 月 18 日
–
最近,我和一组同事举行了一次早餐会议。
我们详细讨论了职业历程、品牌价值、所犯的错误和所学到的经验。有人问我推荐哪些学习资源,以跟上行业变化,同时也提供一般的职业和管理建议。
这里是我经常参考的 5 个信息资源。
让我们开始吧!
关注这些人以获取数据管理、工程、分析以及对立观点的最新信息
1. Prukalpa
Prukalpa 是元数据方面的权威。
我通过她的一篇文章发现了 Prukalpa,数据治理品牌问题。当时我正处于最复杂的治理实施过程中,这篇文章的内容安抚了我,令我感到并不孤单。
由于 Prukalpa 是 Atlan 的联合创始人,她可以写关于她的公司的文章;然而,她选择将文章的重点放在数据管理行业上,这有助于提供更多的背景信息。她还有一个名为 Metadata Weekly 的 Substack 新闻通讯。
2. Barr Moses
Barr 是另一位行业思想领袖和联合创始人(Monte Carlo),我跟随了他一段时间。
在实施治理解决方案时,我总是很难让客户理解数据质量(DQ)及其高昂的成本。组织喜欢战术性地修复问题,积累技术债务,并在为时已晚时抱怨数据质量。
Barr 广泛撰写了数据质量、可靠性和停机问题,而这些都是数据团队每天面临的挑战。
我还推荐其他思想领袖,如 Chad Sanderson (数据合同),Ben Rogojan (咨询和工程) 和 Teresa Tung (GenAI)。
数据团队的关键收获与经验教训(第一部分)
越来越多的技术创始人曾经是数据团队的一部分,并继续撰写他们面临的挑战,这也与普通的数据工程师/分析师产生共鸣。这建立了个人和商业品牌的飞轮效应。
-
在 Medium/Twitter 上撰写你每日的技术挑战;这有助于与志同道合的人建立联系并澄清你的想法。
-
新趋势不是由 Gartner 创造的,而是由数据背后的人创造的,因此要在 Medium/Twitter/Reddit 上阅读和消费与你的领域相关的内容。
-
没有人能掌握所有答案,所以要阅读对立的观点和看法。Chad Sanderson写了关于数据合同的文章。Ben Rogojan则讨论了辞职 FAANG 后独立工作。这些概念可能不太常见,但它们存在,并有助于塑造你的观点。
-
个人品牌至关重要——爬升企业阶梯可能是无意的,但选择并遵循特定的路径更具回报。围绕你的领域建立个人品牌可以帮助你在同行中脱颖而出。
关于职业管理、激励、生产力与哲学的书籍
3. 经理的养成
我的第一年作为经理是我职业生涯中最令人不知所措的一年。
期望突然从个人贡献转变为激励团队共同贡献。一旦华丽的头衔消失,现实就会显现:这是一项艰巨的工作。我转向了 Julie Zhou 的这本书,它帮助我理解了我并不孤单。
伟大的经理是培养出来的,而非天生的!
我学会了如何举办高效的会议,提供反馈,委派任务,并成为一个领导者而不是老板。虽然仍有很多改进的地方,但这让我获得了优势!
4. 如此出色他们无法忽视你
跟随你的热情是个糟糕的建议!
我最初对此持怀疑态度;我们都学过“享受你做的工作,你的一生都不会工作一天。”然而,这本书改变了我的观点,我能够与之产生共鸣。它提倡,当你磨练你的技艺时,你将积累足够的职业资本,以便你能够掌控你的工作和生活。
我小时候并没有想过要成为数据与分析领域的领导者;事实上,我甚至不知道这样的职位存在。多年来在这个领域的不断进步,我获得了更多的自主权、能力和关联感,这三样东西是幸福的必要条件。
5. Naval Ravikant 年鉴
与长期合作的人一起玩长期游戏!
我不知道怎么评价 Naval,但他的哲学推文和这本书都是那些推文的总结,非常了不起。Naval 提倡“特定知识”,这是无法通过培训获得的。如果可以培训,那么其他人也可以。
在早餐会上,我向一些技术团队成员提到,你可以通过课程和视频学习许多技术技能,但软技能只有通过应用才能获得。如果你能将这两者结合起来,你将变得不可阻挡。
数据团队的关键要点和教训(第二部分)
-
当 Naval 在数据领域提到“特定知识”时,它意味着将软技能和硬技能结合起来。与不同的受众进行量身定制的沟通,无论是技术还是商业,都可以构成“特定知识”。你无法通过培训来获得这种知识;你必须应用、迭代并学习它。
-
管理就是理解每个人擅长某些事情,并利用他们来完成这些任务。例如,使用工程师来修复数据管道,而不是创建高层次的状态更新。
-
在你的专业领域建立职业资本;即花时间提高你的技能,建立你独有的特定知识,围绕这一特定知识建立你的品牌,然后请求更多的自主权。你所做的项目、你合作的团队、你服务的客户等方面的自由。
-
当 Naval 提到“长期”合作伙伴时,他指的是数据分析师的工程、业务、基础设施和治理团队。你今天合作的人将在 10 年内晋升职业阶梯。现在利用你的特定知识来为他们提供服务,将使你能与他们建立长期关系。
-
你的网络应该充满你曾工作过的所有公司和客户的人;无论项目好坏,每个人在过程中都教会了你一两课。
结论
所以——这篇文章比我预期的要长,但希望从这些资源中你能获得很多收获。如果你认为还有其他很棒的人我没有提到,请在下方评论中留下他们的名字。
如果你渴望提高你的数据技能,请查看这篇文章:
通过掌握这 4 项技能来提升你的数据游戏
towardsdatascience.com
如果你还没有订阅 Medium,可以考虑使用我的推荐链接订阅。比 Netflix 便宜,且客观上更值得你的时间。 如果你使用我的链接,我会赚取少量佣金,而你可以访问 Medium 上的无限故事。
所有观点均为我个人意见
你从未知道的 5 个 Jupyter 小技巧
原文:
towardsdatascience.com/5-jupyter-hacks-that-you-never-knew-even-existed-9dc0a08fd90a
提供一个额外的小贴士


·发表于 Towards Data Science ·阅读时长 6 分钟·2023 年 3 月 1 日
–

Jupyter Notebook 是几乎所有与 Python 相关的编程任务(如数据科学、机器学习、科学计算等)中最受欢迎的 IDE 之一。
它的交互式编码功能使其成为初学者和专家的首选工具。
尽管其广泛使用,但许多用户并没有充分利用它的全部潜力。
结果是,他们往往使用 Jupyter 的默认界面/功能,而在我看来,这些功能可以显著改进,以提供更丰富的体验。
因此,在本文中,我将介绍 5 个你可能从未知道的酷炫 Jupyter 小技巧。
这些将允许你在这个强大的工具上解锁新的生产力和创造力水平。
让我们开始吧 🚀!
#1 停止预览原始 DataFrame
当我们在 Jupyter 中加载 DataFrame 时,通常通过打印来预览。这如下所示:
然而,这几乎没有告诉我们数据内部的情况。
因此,你必须通过分析来深入挖掘,这涉及简单但重复的代码。
相反,使用 Jupyter-DataTables。你可以按如下方式安装:
要使用它,请在 Jupyter 中运行以下代码:
它通过许多有用的功能极大增强了 DataFrame 的默认预览。
结果是,每当你打印 DataFrame 时,它将显得更加优雅,如下所示。

这种更丰富的预览提供了排序、过滤、导出和分页操作,同时显示列分布和数据类型。
#2 一键标记你的数据
不是所有的数据都是预先标记的。
因此,通常对于未标记的数据,可能需要花费一些时间进行注释/标记。
不必在外部预览文件并标记它们或构建复杂的注释管道,你可以使用ipyannotate仅用几行代码进行注释。
它提供了一个专门用于数据注释的 Jupyter 小部件。
运行以下命令来安装它:
通过点击按钮,数据注释变得更容易。因此,ipyannotate 允许你将数据标签附加到按钮上。
假设我们有一些猫和狗的图片(未标记)。我们可以创建如下的注释管道:
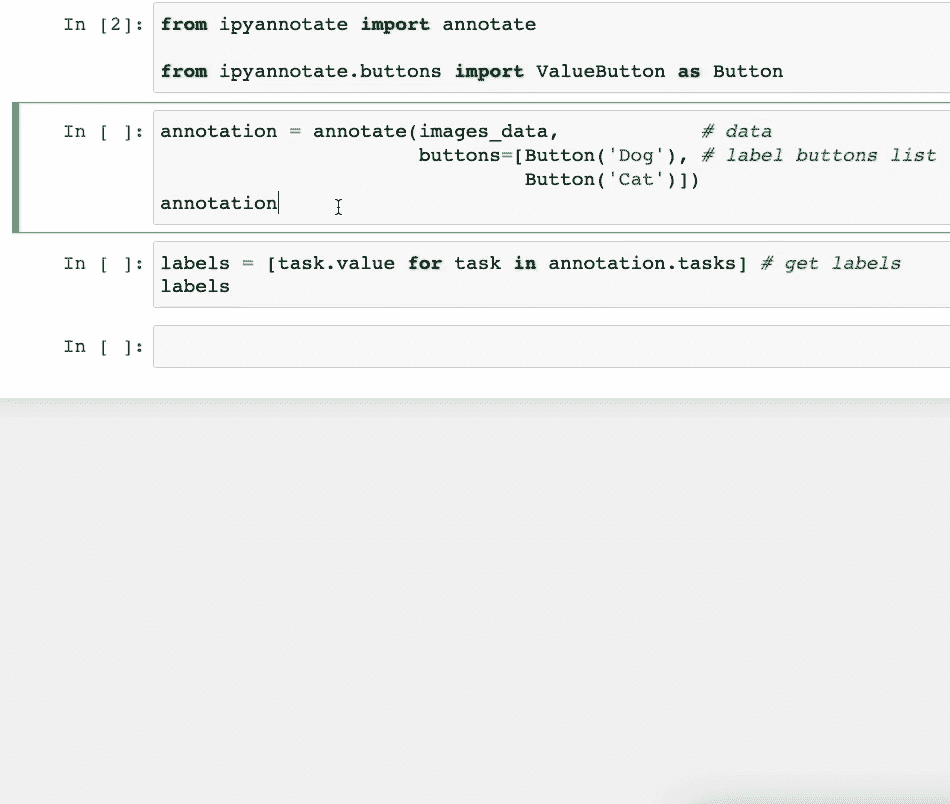
如上所示,你可以通过简单地点击相应的按钮来注释数据。
更重要的是,你还可以检索标签并根据需要将它们用于你的数据管道。
#3 在 Jupyter 中查看文档
在 Jupyter 中工作时,忘记函数的参数并访问官方文档(或 StackOverflow)是很常见的。
然而,你可以在笔记本中查看文档。
按下Shift-Tab会打开文档面板。这非常有用,可以节省时间,因为你不必每次都打开官方文档。
下面展示了一个演示:
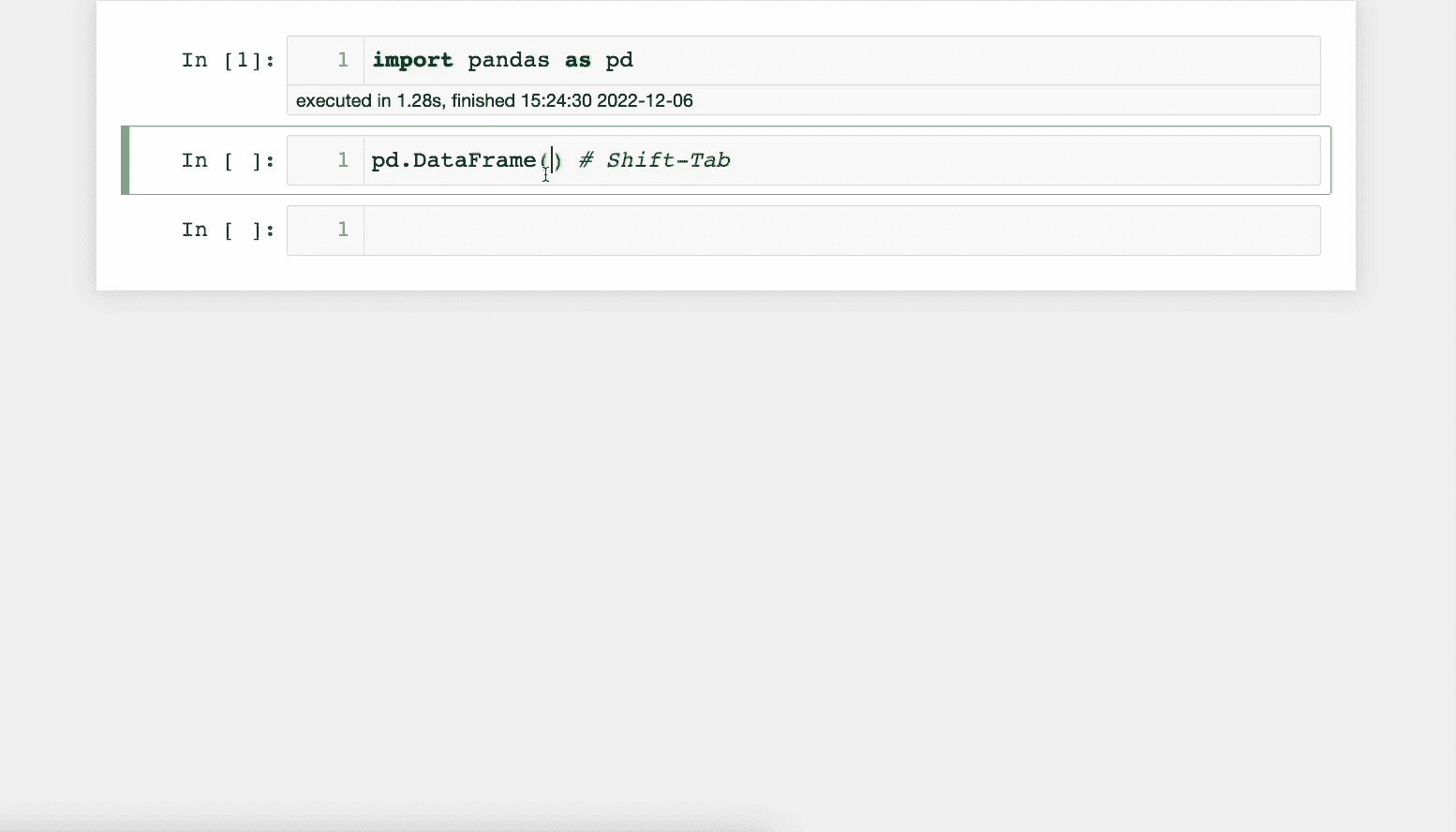
此功能也适用于你的自定义函数。
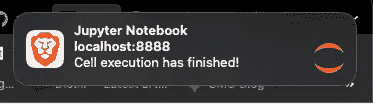
#4 Jupyter 单元格执行完成时接收通知
在 Jupyter 单元格中运行一些代码后,我们经常会离开去做其他工作。
在这里,你需要反复返回到 Jupyter 标签页来检查单元格是否已执行。
为了避免这种情况,你可以使用来自jupyternotify扩展的%%notify魔法命令。
正如名称所示,它会在 Jupyter 单元格完成(无论成功还是失败)时通过浏览器通知用户。
要安装它,运行以下命令:
接下来,加载扩展:
完成了!
现在,每当你想要接收通知时,在单元格顶部输入以下魔法命令:
每当单元格完成执行时,你将收到以下通知:
点击通知将带你回到 Jupyter 标签页。
#5 在 Jupyter Notebook 运行时清除单元格输出
在使用 Jupyter 时,我们通常会打印很多细节来跟踪代码的进展。
然而,当输出面板积累了一堆细节,而我们只对最新的输出感兴趣时,可能会感到沮丧。
此外,每次滚动到输出的底部也可能很烦人。
要清除单元格的输出,你可以使用来自IPython包的clear_output方法。
IPython 已预装在 Python 中,因此无需安装。
你可以按如下方式导入该方法:
当调用时,它会移除单元格当前的输出,然后你可以打印最新的细节。
下面展示了一个演示:
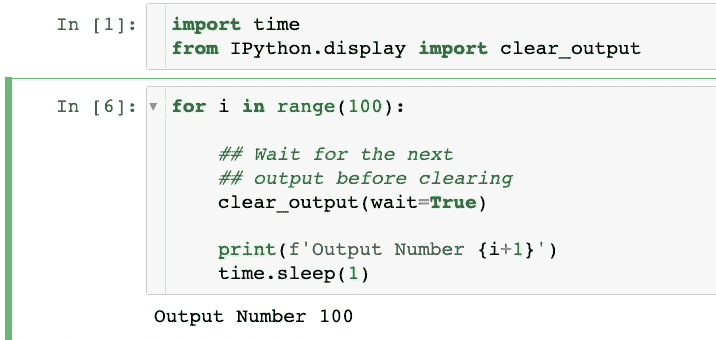
如上所示,我们只能看到单元格中的最新输出。之前的输出被删除了。
额外提示
尽管上述提示会显著丰富你的 Jupyter 体验,但我仍然面临许多在 Jupyter 上难以解决的问题。
比如说,Jupyter 在协作方面表现糟糕。由于它在本地运行,因此无法嵌入实时协作功能,让团队可以一起工作、添加评论、跟踪进展等。
更有甚者,分享同样令人痛苦。如果我需要与他人分享我的 notebook,唯一的方式就是通过电子邮件发送或在 GitHub 等网站上托管并分享链接。
最后,许多数据科学任务不仅仅局限于 Python。它们同样涉及 SQL,SQL 在与组织数据库交互时被广泛使用。
然而,在 Jupyter 中集成 SQL 是可行的,但过程繁琐。
解决方案
对这些限制感到沮丧,我开始寻找替代方案,并且很高兴我发现了 Deepnote。
在无需学习任何新知识的情况下,它迅速解决了 Jupyter 的所有限制,并始终为我提供了丰富的类似 Jupyter 的体验。
分享、协作、使用 SQL、无需代码创建图表、连接数据库等,所有这些都在 Deepnote 中无缝集成。
虽然我理解 Jupyter 旨在为所有 Python 用户提供一个通用的体验,但它在解决数据科学家的所有痛点方面做得非常糟糕,尤其是对团队工作的那些用户。
在我看来,Deepnote 是 Jupyter 的增强版,适用于所有数据驱动的项目,你一定要去试试。
结论
这篇博客到此结束。
恭喜你学会了一些 Jupyter notebook 的绝妙技巧。我相信这些提示会提升你的 Python 编程生产力。
此外,我很想知道你在使用 Jupyter notebook 时喜欢哪些技巧。
一如既往,感谢阅读!
5 个我在数据科学生涯中仅发现了 2 年的 Jupyter Notebook 技巧
自定义键盘快捷键、高亮文本等


·发表于 Towards Data Science ·阅读时间 7 分钟·2023 年 7 月 17 日
–

图片来源于 Lukas Bato 在 Unsplash
尽管 R、Python 和 Julia 的用户都很喜欢使用它们,Jupyter Notebook 的潜力却很少被充分利用。
大多数用户知道基本命令(执行代码、注释、保存等),但很少有人利用 Jupyter 的隐藏技巧 — 尽管这些技巧可以节省大量时间和精力。
自 2019 年(我开始使用 Jupyter)以来,我发现了很多节省时间的技巧和窍门,这些是大多数初学者不知晓的。在本文中,我将展示我最喜欢的 5 个技巧:
-
键盘快捷键 — “现成的”命令,例如插入/删除/移动单元格和文本
-
自定义 键盘快捷键 — 可以从键盘直接添加自己的高级命令,例如上下移动单元格、重启内核以及运行到当前单元格
-
Markdown 格式 — 创建表格、格式化文本和创建复选框
-
HTML 格式 — 突出显示文本并使评论更引人注目
-
“启用输出滚动” — 抑制冗长的单元格结果(在调整超参数时,这是一笔巨大的财富)
提示 1:键盘快捷键
键盘快捷键提供了一种方便的方法来导航 Jupyter Notebook 并执行命令。以下是我常用的主要快捷键:
运行单元格
-
Shift + Enter— 运行当前单元格并选择下一个单元格 -
Ctrl/Cmd + Enter— 运行当前单元格 -
Option/Alt + Enter— 运行当前单元格并在下方插入另一个单元格
保存进度
Ctrl/Cmd + s— 保存笔记本
插入/删除单元格
首先,点击单元格内,然后确保你在command模式下,按Esc键。如果不按Esc,你将处于edit模式,只能对单元格内容进行操作(而不是单元格本身)。一旦你进入command模式,单元格中的光标将停止闪烁。然后,按以下任意一个键:
-
a— 在当前单元格上方插入一个新单元格 -
dd(按d键两次) — 删除当前单元格 -
b— 在当前单元格下方插入一个新单元格
更改单元格类型
Jupyter Notebooks 的一个乐趣在于它们允许你将评论和代码并排放置。要设置单元格的类型并确定其应将文本视为“评论”还是“代码”,首先通过选择一个单元格并按Esc键进入command模式。然后,按以下任意一个键:
-
m— markdown 模式(用于编写评论和标题) -
y— 代码模式(用于编写代码)
选择多个单元格
再次确保你在command模式下,然后按住Shift键,使用Up或Down箭头扩展选择范围,选择任意数量的单元格。
作者提供的图片
选定所有想要操作的单元格后,你可以一次性删除或移动它们,而不是逐个进行。
提示 2:自定义键盘快捷键
这对我来说是一个改变游戏规则的功能。
除了安装 Jupyter 时为你预定义的标准键盘快捷键外,你还可以创建你自己的自定义快捷键来执行高级命令。
例如,假设我想定义两个新的键盘快捷键:一个用于将单元格向上移动,另一个用于将单元格向下移动。默认情况下,可以通过使用鼠标“拖放”单元格来完成,但也可以创建一个自定义键盘快捷键,一键即可完成这个操作。
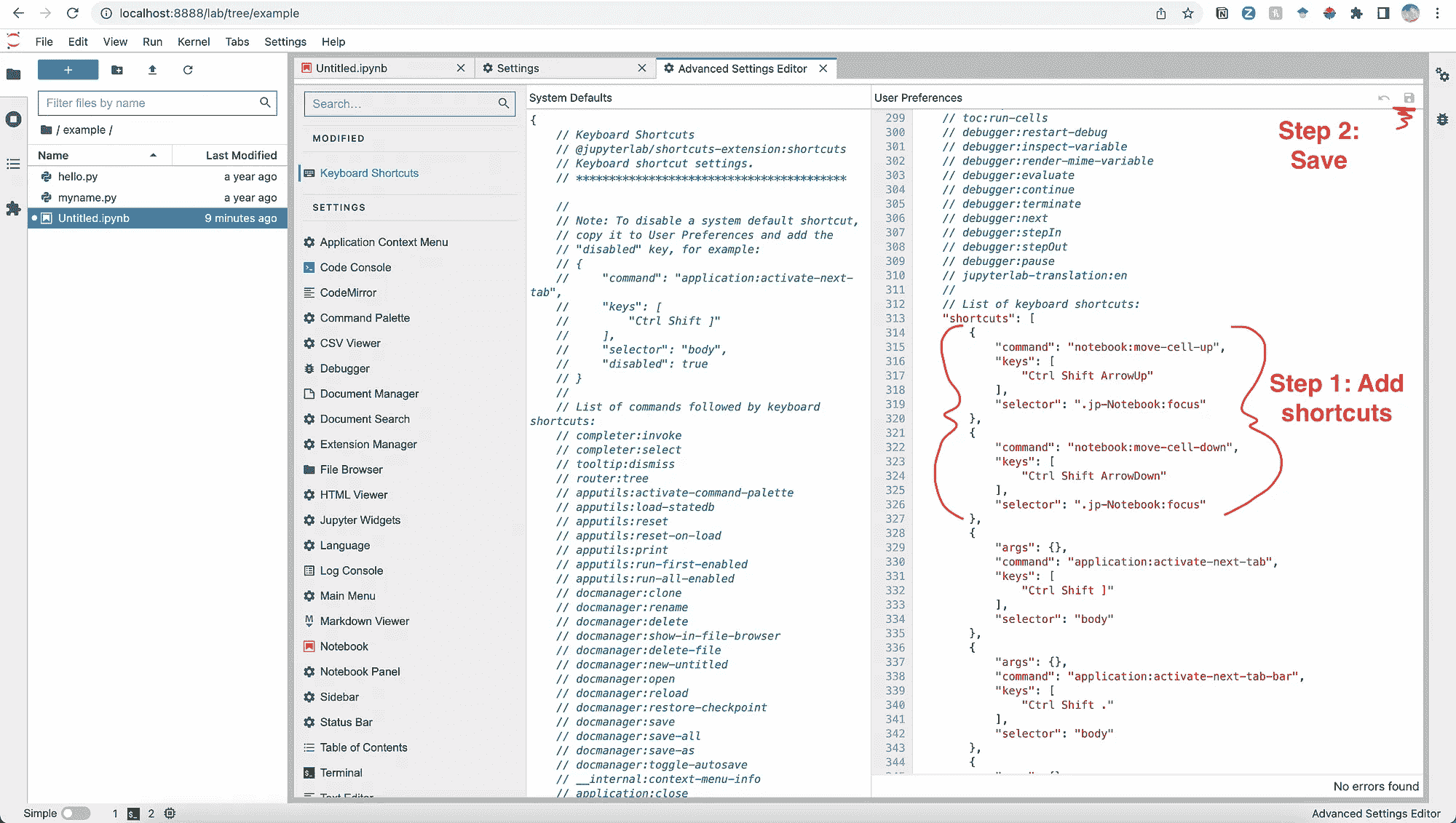
首先,点击 JupyterLab 窗口中的‘设置’,然后点击‘高级设置编辑器’,你将能够看到所有现有的键盘快捷键。

作者提供的图片
要添加自定义键盘快捷键,你需要点击高级设置编辑器窗口右上角的‘JSON 设置编辑器’(如上图所示)。
然后,在右侧的‘用户首选项’标签页中,向下滚动到键盘快捷键列表,并添加所需的快捷键。我添加了这两个,是 David 在 StackOverflow 上建议的。
{
"command": "notebook:move-cell-up",
"keys": [
"Ctrl Shift ArrowUp"
],
"selector": ".jp-Notebook:focus"
},
{
"command": "notebook:move-cell-down",
"keys": [
"Ctrl Shift ArrowDown"
],
"selector": ".jp-Notebook:focus"
},
作者提供的图片
完成快捷键添加后,点击‘保存’(在右上角),然后你就可以开始使用了!
很酷吧?
如果你喜欢这个故事,点击我的‘关注’按钮对我来说意义重大——只有 1% 的读者会这样做!感谢阅读。
提示 3:Markdown 格式
当你在所谓的“注释”单元格中写文本时,你实际上是在使用 markdown,所以,惊喜惊喜,你可以使用 markdown 格式进行书写。
这可能看起来显而易见或微不足道,但根据我的经验,很少有 Jupyter 用户充分利用他们笔记本中的 markdown 功能。
使用 markdown,你可以书写文本、标题、列表、表格,甚至代码片段。这是为你的笔记本带来更多动态和结构化的好方法。
例如,这里是我最常使用的一些格式。我特别喜欢‘表格’格式(因为这是展示某些预处理代码结果的好方法),并且我推荐使用这个Markdown Tables Generator来快速生成正确格式的表格。
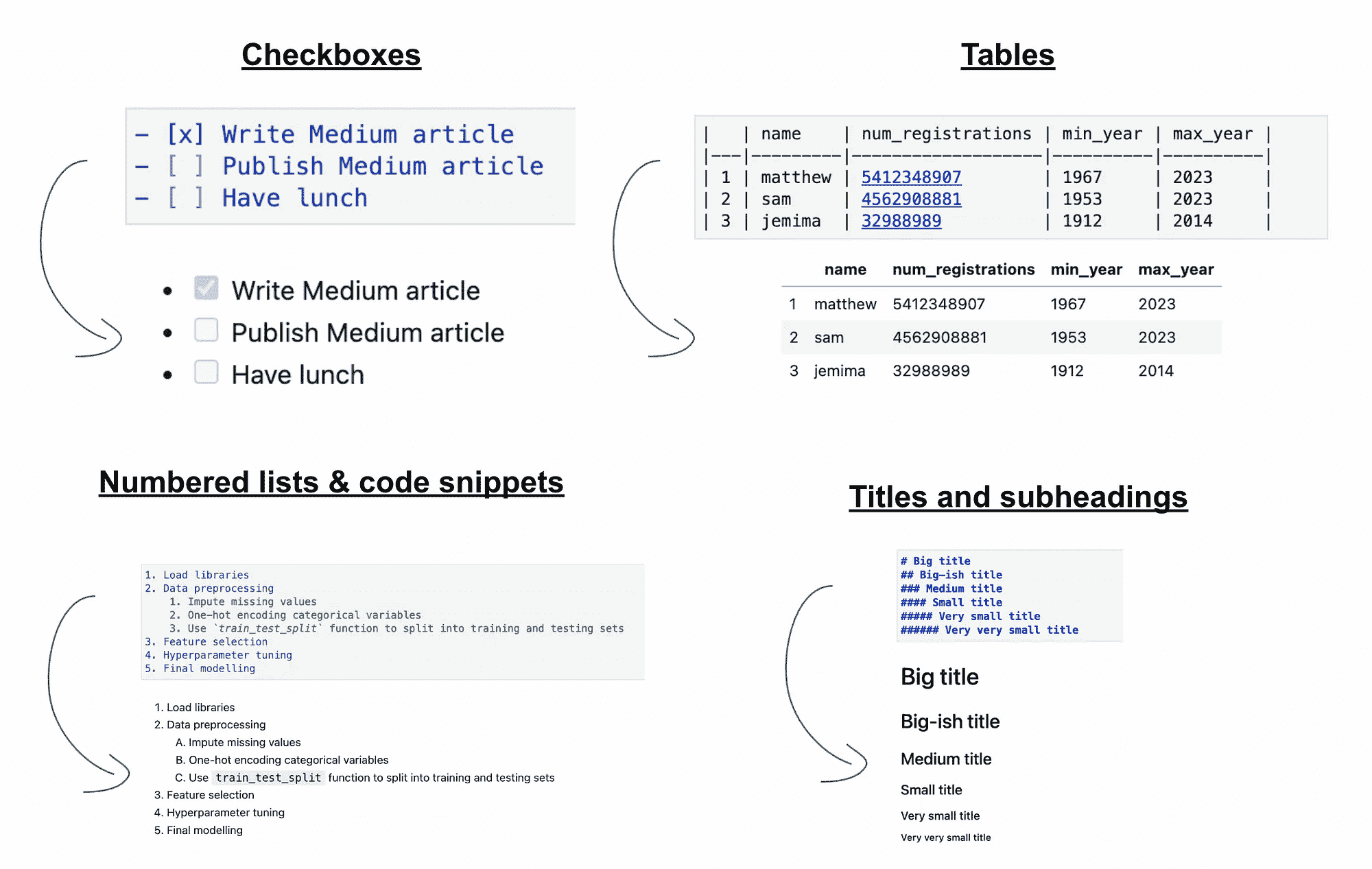
使用 markdown 格式你可以做的一些事情。作者提供的图片
提示 4: HTML 格式化
这个提示有点像上面的扩展,但使用频率更低。
当你在 markdown 单元格中写文本时,你可以使用 HTML 标签来格式化文本,实现非常自定义的格式,比如高亮文本和在切换中隐藏文本。

作者提供的图片
就个人而言,我发现高亮功能在我审查他人笔记本时非常有用,尤其是当我想做评论或标记一些稍后需要回顾的内容时。这是一种很好的方式来突出我留下的注释,而不至于让笔记本显得杂乱。
提示 5: “启用输出的滚动”
默认情况下,Jupyter Notebooks 中的‘output’单元格会根据输出的高度进行调整——即当你运行一些代码时,Jupyter 会打印你代码指示的所有内容。我是说所有内容。
通常这非常有用,但在你运行打印大量输出的代码时,笔记本单元格可能会迅速增长到荒谬的长度,使得在笔记本中导航变得困难。
例如,下图展示了一个简单的代码片段,它将打印从 1 到 1001 的每一个整数。正如你所见,输出是很长的。
为了在不丢失有价值的打印信息的情况下压缩输出,右键点击输出单元格并选择‘启用输出的滚动’。这将输出保留在一个可滚动的输出单元格中,但避免了笔记本的杂乱。
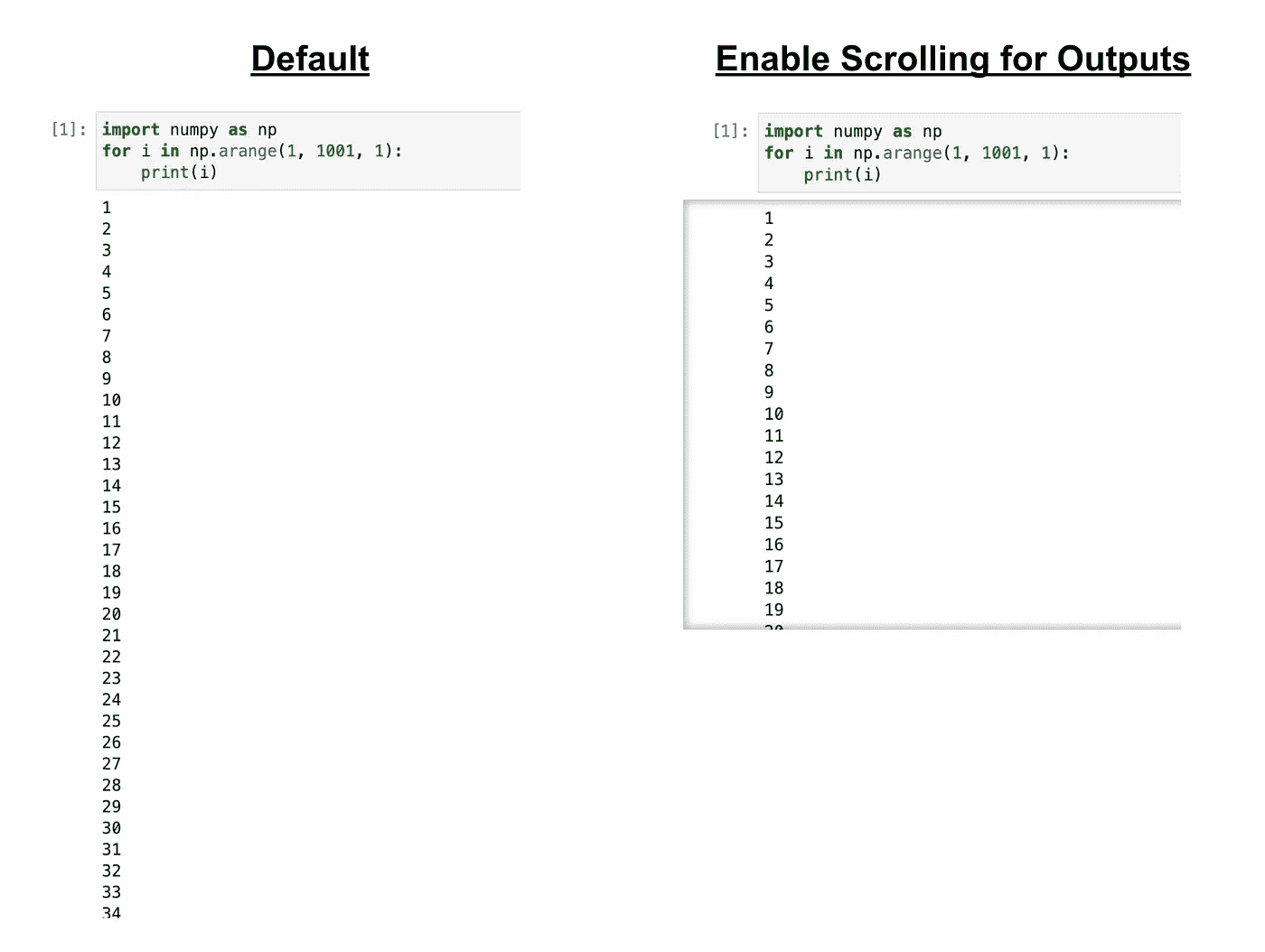
作者提供的图片
在实际应用中,我发现这非常有用,比如(a)打印出表中所有列的名称,或者(b)使用optuna这样的库来调整模型的超参数。在这两种情况下,看到所有输出(所有列名或每轮训练的结果)都很有价值,我很少想要完全抑制这些输出,因为它们对调试非常有帮助。通过选择‘启用输出滚动’,我可以保留输出但将其最小化,使其不会占据整个笔记本。
还有一件事 —
我开设了一个名为AI in Five的免费新闻通讯,每周分享 5 个要点,涵盖最新的 AI 新闻、编码技巧以及数据科学家/分析师的职业故事。没有炒作,没有“数据是新的石油”的废话,也没有埃隆的推文——只有实用的技巧和见解,帮助你在职业上有所发展。
在这里订阅 如果你对此感兴趣!
[## AI in Five | Matt Chapman | Substack
最新的新闻、职业故事和来自数据科学与 AI 领域的编码技巧,概括为 5 个要点…
aiinfive.substack.com](https://aiinfive.substack.com/?source=post_page-----99bbe482a45f--------------------------------)
5 个从测试 Databricks SQL Serverless + DBT 中获得的经验教训
我们进行了一项$12K 的实验,以测试 Serverless 仓库和 dbt 并发线程的成本和性能,并获得了意外的结果。


·
关注 发表在Towards Data Science · 9 分钟阅读 · 2023 年 10 月 17 日
–
作者:Jeff Chou, Stewart Bryson

图片来自Los Muertos Crew
Databricks 的 SQL 仓库产品对于希望简化生产 SQL 查询和仓库的公司具有很大的吸引力。然而,随着使用的扩展,这些系统的成本和性能变得至关重要。
在本文中,我们通过利用行业标准的 TPC-DI 基准测试,对他们的 Serverless SQL 数据仓库产品的成本和性能进行了技术深入分析。我们希望数据工程师和数据平台管理者能够利用这里呈现的结果,在选择数据基础设施时做出更好的决策。
Databricks 的 SQL 数据仓库提供了什么?
在我们深入探讨特定产品之前,让我们退后一步,看看今天提供的不同选项。Databricks 目前提供3 种不同的仓库选项。
-
SQL Classic —— 最基本的仓库,运行在客户的云环境内。
-
SQL Pro —— 提升的性能,适合探索性数据科学,运行在客户的云环境内。
-
SQL Serverless —— 最佳性能,计算完全由 Databricks 管理。
从成本的角度来看,经典版和专业版都在用户的云环境内运行。这意味着您将为您的 Databricks 使用获得两个账单 —— 一个是纯粹的 Databricks 成本(DBU),另一个来自您的云提供商(例如 AWS EC2 账单)。
为了真正了解成本比较,让我们看一个在 Small 数据仓库上运行的示例成本细分的示例费用分解。
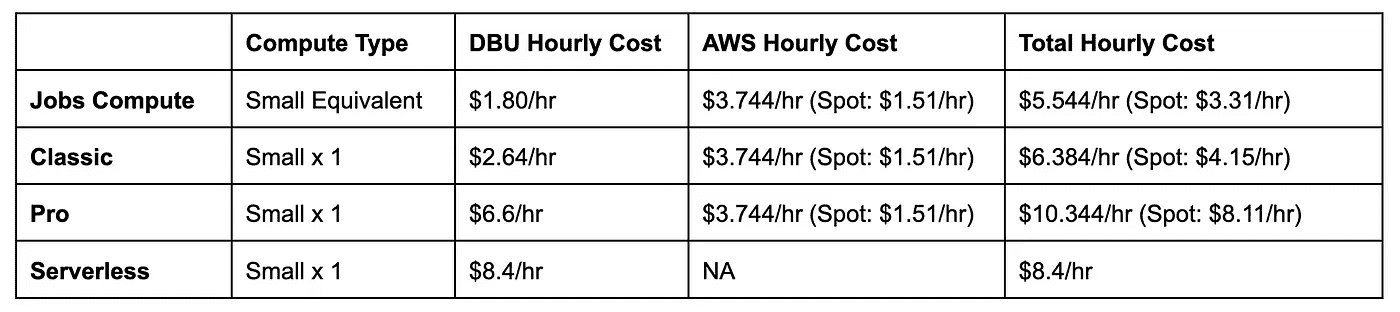
作业计算成本比较,以及各种 SQL Serverless 选项。所显示的价格基于按需列表价格。Spot prices will vary,并且是根据本出版物时的价格选择的。作者提供的图像。
在上表中,我们也看到了按需与 spot 成本的成本比较。您可以从表中看出,Serverless 选项没有云组件,因为所有管理工作都由 Databricks 处理。
Serverless 相比于专业版来说可能更具成本效益,如果您使用所有按需实例的话。但如果有廉价的 spot 节点可用,那么专业版可能会更便宜。总体来说,我认为 Serverless 的定价相当合理,因为它还包括云成本,尽管它仍然是一个“高端”价格。
我们还包括了等效的作业计算集群,这是全面管理的选择中最便宜的选项。如果成本是您关注的问题,您也可以在作业计算中运行 SQL 查询!
Serverless 的优缺点
Databricks 的 Serverless 选项是一个完全管理的计算平台。这基本上与 Snowflake 的运行方式相同,其中所有计算细节对用户隐藏。在高层次上,这种方法有其利弊:
优点:
-
您不必考虑实例或配置。
-
启动时间比从头开始启动集群要少得多(根据我们的观察为 5-10 秒)。
缺点:
-
企业可能会对所有计算都在 Databricks 内部运行存在安全问题。
-
企业可能无法利用其云合同中对特定实例的特殊折扣
-
无法优化集群,因此你不知道 Databricks 选择的实例和配置是否实际上适合你的作业
-
计算是一个黑箱——用户不知道发生了什么或 Databricks 在幕后实施了哪些更改,这可能导致稳定性问题。
由于无服务器的固有黑箱特性,我们对人们仍然可以调整的各种参数及其对性能的影响感到好奇。因此,让我们深入探讨一下我们探索的内容:
实验设置
我们尝试采用“实用”方法来进行这项研究,并模拟当一家真实公司希望运行 SQL 仓库时可能采取的措施。由于DBT在现代数据堆栈中非常流行,我们决定检查两个参数进行扫描和评估:
-
仓库大小 — [‘2X-Small’, ‘X-Small’, ‘Small’, ‘Medium’, ‘Large’, ‘X-Large’, ‘2X-Large’, ‘3X-Large’, ‘4X-Large’]
-
DBT 线程 — [‘4’, ‘8’, ‘16’, ‘24’, ‘32’, ‘40’, ‘48’]
我们选择这两个参数的原因是它们都是任何工作负载的“通用”调优参数,并且它们都影响作业的计算方面。DBT 线程特别有效地调整作业在 DAG 中运行时的并行性。
我们选择的工作负载是流行的TPC-DI基准测试,规模因子为 1000。这个工作负载特别有趣,因为它实际上是一个完整的管道,模拟了更真实的数据工作负载。例如,下面是我们的 DBT DAG 的屏幕截图,你可以看到它相当复杂,改变 DBT 线程的数量可能会对其产生影响。

来自我们 TPC-DI 基准测试的 DBT DAG,作者图片
顺便提一下,Databricks 有一个出色的开源库,可以帮助快速在 Databricks 中设置 TPC-DI 基准测试。(我们没有使用这个库,因为我们是使用 DBT 进行的)
要深入了解我们如何运行实验,我们使用了Databricks Workflows并将 dbt 作为 dbt CLI 的“运行器”,所有作业都并行执行;由于 Databricks 方面的环境条件未知,不应存在变异。
每个作业启动一个新的 SQL 仓库,然后在同一 Unity Catalog 中的独特模式中运行并随后拆除。我们使用了Elementary dbt 包来收集执行结果,并在每次运行结束时运行 Python 笔记本,将这些指标收集到集中式模式中。
成本通过 Databricks 系统表提取,特别是那些用于计费使用的表。
自己尝试这个实验并克隆Github 仓库
结果
下面是成本和运行时间与仓库大小的图表。我们可以看到,运行时间在达到中等规模的仓库时停止扩展。比中等大一点的仓库对运行时间几乎没有影响(或许更糟)。这是一个典型的扩展趋势,显示了扩展集群规模不是无限的,它们总有一个点,增加更多计算资源的回报会递减。
对于计算机科学爱好者来说,这只是基本的计算机科学原理——阿姆达尔定律
一个不寻常的观察是,中等仓库的表现优于接下来的三个尺寸(大到 2xlarge)。我们重复了这个特定的数据点几次,并得到了一致的结果,所以这不是一个奇怪的偶然现象。由于无服务器的黑箱特性,我们不幸地不知道背后的情况,也无法给出解释。
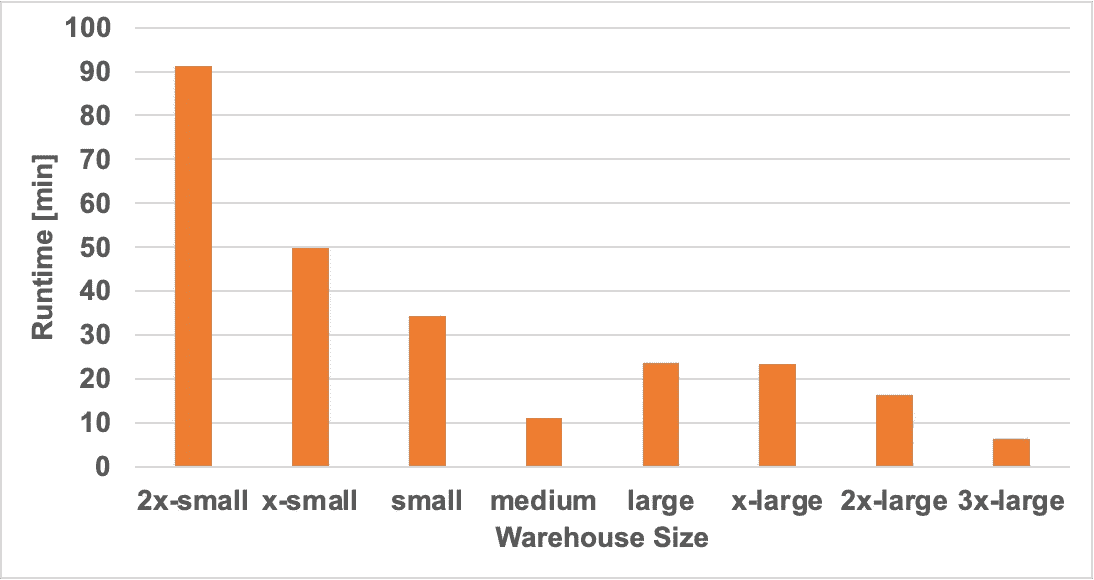
各仓库大小的运行时间(分钟)。图片由作者提供
由于扩展在中等规模处停止,我们可以在下面的成本图中看到,成本在中等仓库大小后开始急剧上升,因为基本上你投入了更昂贵的机器,而运行时间保持不变。因此,你是在为额外的计算能力支付费用,但没有获得任何好处。
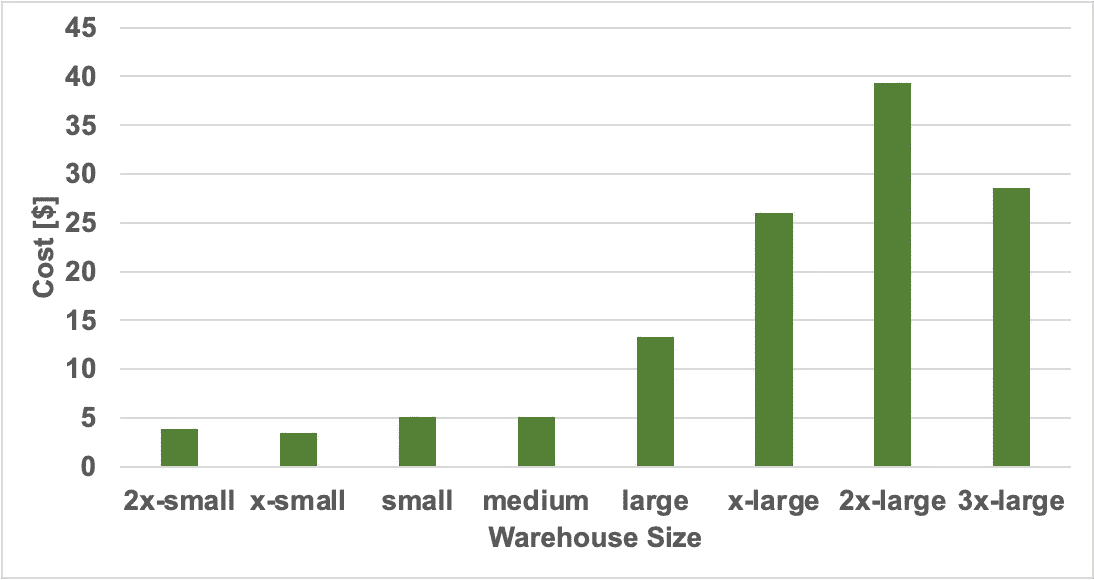
各仓库大小的成本(美元)。图片由作者提供
下面的图表显示了我们改变线程数和仓库大小时运行时间的相对变化。对于横轴零线以上的值,运行时间增加(这是不好的)。
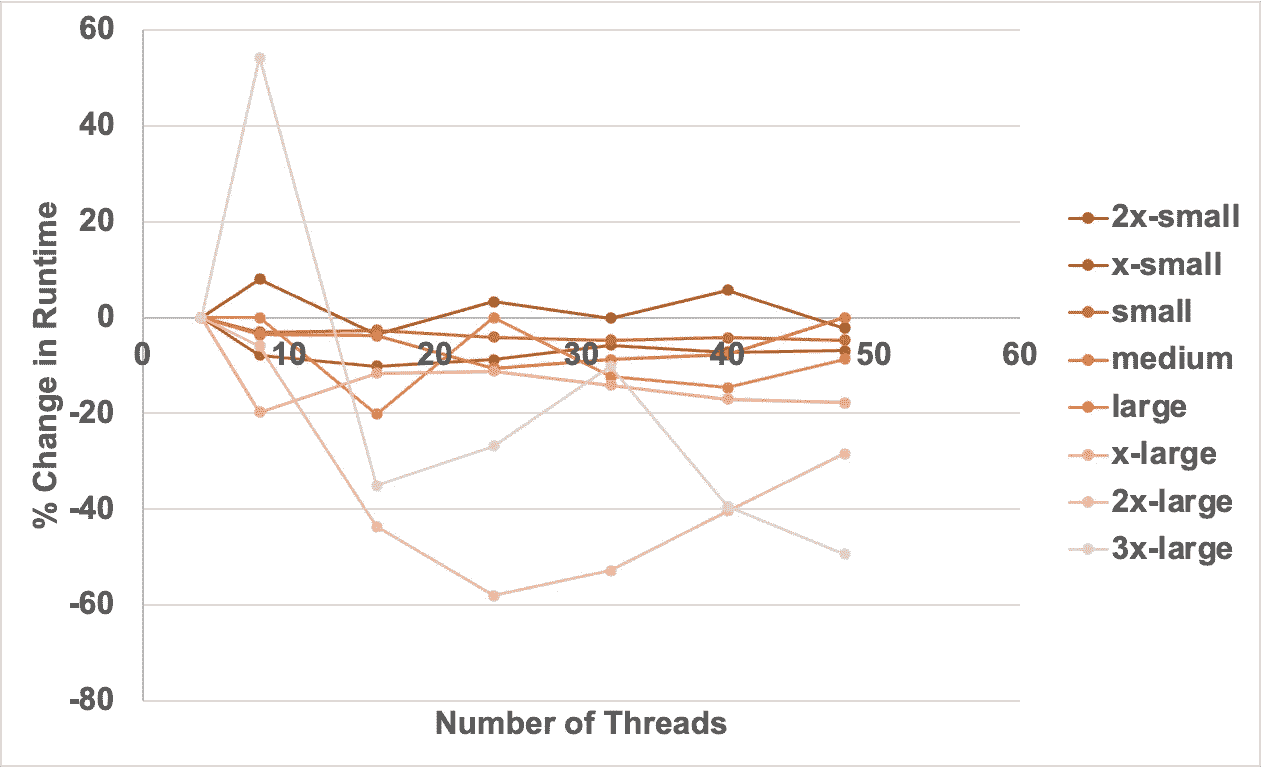
线程增加时运行时间的百分比变化。图片由作者提供
这里的数据有些噪声,但根据仓库的大小有一些有趣的见解:
-
2x-small — 增加线程数通常会使任务运行时间更长。
-
X-small to large — 增加线程数通常能使任务运行速度提高约 10%,尽管增益相对平稳,所以继续增加线程数没有价值。
-
2x-large — 实际上存在一个最佳线程数,即 24,从清晰的抛物线可以看出。
-
3x-large — 在线程数为 8 时运行时间出现了非常不寻常的峰值,为什么?不清楚。
为了将所有内容整合到一个综合图中,我们可以看到下面的图表,绘制了成本与总任务时长的关系。不同的颜色代表不同的仓库大小,气泡的大小表示 DBT 线程的数量。
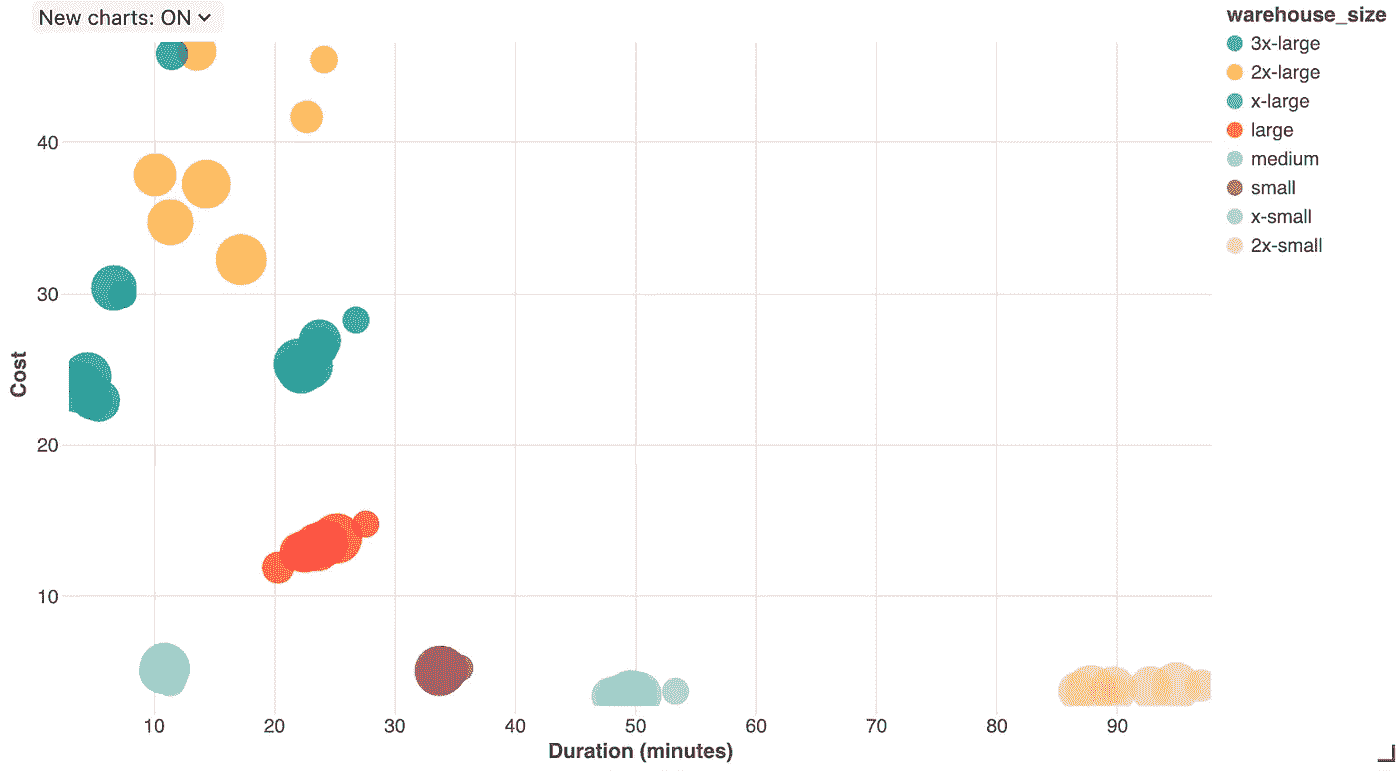
成本与任务时长的关系。气泡的大小表示线程数量。图片由作者提供
在上图中,我们看到较大的仓库通常会导致较短的持续时间,但成本更高。然而,我们确实发现了一些不寻常的点:
-
中型是最佳的——从纯成本和运行时间的角度来看,中型是最好的仓库选择
-
DBT 线程的影响——对于较小的仓库,线程数量的变化似乎使持续时间变化了大约+/- 10%,但成本变化不大。对于较大的仓库,线程数量显著影响了成本和运行时间。
结论
总结一下,我们关于 Databricks SQL 无服务器 + DBT 产品的前五个教训是:
-
经验法则是错误的——我们不能仅仅依赖关于仓库大小或 DBT 线程数量的“经验法则”。虽然确实存在一些预期的趋势,但它们并不一致或可预测,完全依赖于你的工作负载和数据。
-
**巨大差异——**对于完全相同的工作负载,成本范围从$5 到$45,运行时间从 2 分钟到 90 分钟,所有这些都由于线程数量和仓库大小的不同组合。
-
**无服务器扩展有极限——**无服务器仓库不会无限扩展,最终较大的仓库将无法提供任何加速,只会导致成本增加而没有任何好处。
-
中型很棒?——我们发现中型无服务器 SQL 仓库在 TPC-DI 基准测试中在成本和作业持续时间方面超越了许多较大的仓库。我们不知道原因。
-
作业集群可能是最便宜的——如果成本是一个问题,切换到仅使用标准作业计算和笔记本可能会便宜很多
这里报告的结果揭示了“无服务器”黑箱系统的性能可能会出现一些不寻常的异常。由于这一切都在 Databrick 的墙后,我们不知道发生了什么。也许所有这些都运行在巨大的 Spark on Kubernetes 集群上,也许他们在某些实例上与亚马逊有特殊的交易?无论如何,不可预测的性质使得控制成本和性能变得棘手。
因为每个工作负载在很多维度上都是独特的,我们不能依赖“经验法则”,或仅适用于当前状态的高成本实验。无服务器系统的混乱性质确实引发了这样一个问题:这些系统是否需要一个闭环控制系统来加以控制?
作为一种反思——无服务器的商业模式确实引人注目。假设 Databricks 是一个理性的企业,并且不希望降低他们的收入,同时他们也希望降低成本,那么必须提出一个问题:“Databricks 是否有动力去改善底层的计算?”
问题是这样的——如果他们让无服务器速度提高 2 倍,那么他们的无服务器收入会突然下降 50%——这对 Databricks 来说是非常糟糕的一天。如果他们能使其速度提高 2 倍,然后将 DBU 成本提高 2 倍以抵消速度提升,那么他们的收入将保持不变(实际上,这就是他们为 Photon 所做的)。
因此,Databricks 确实有动力在保持客户运行时间大致不变的情况下降低内部成本。虽然这对 Databricks 来说是好事,但很难将任何无服务器加速技术传递给用户,从而减少成本。
想了解如何改善你的 Databricks 管道?请联系 Jeff Chou 和 Sync 团队 的其他成员。
资源
相关内容
5 个 MLOps 成熟度级别
原文:
towardsdatascience.com/5-levels-of-mlops-maturity-9c85adf09fe2


·发表于 Towards Data Science ·10 分钟阅读·2023 年 6 月 15 日
–
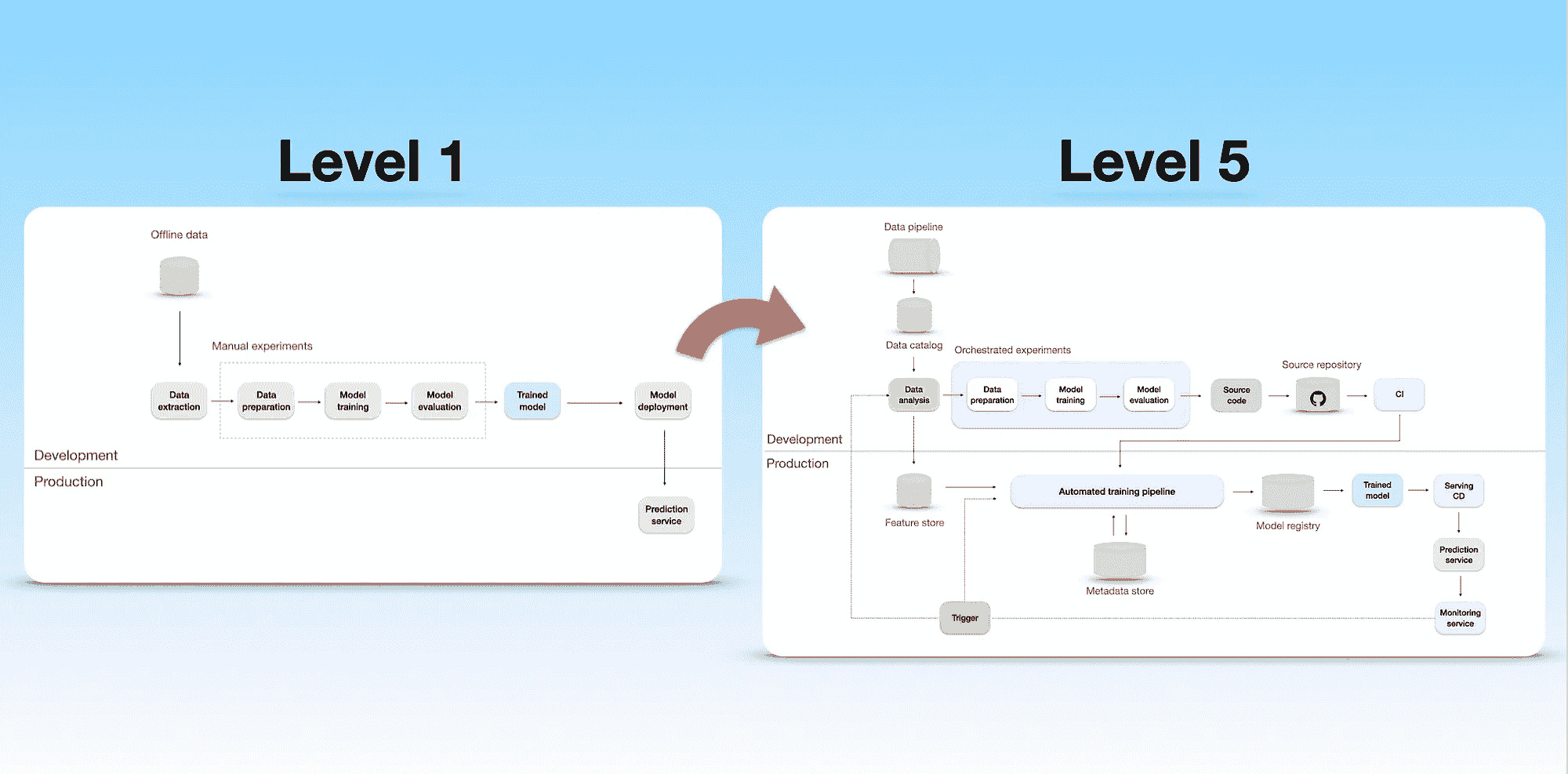
ML 基础设施从 1 级成熟度到 5 级的进展。图片由作者提供。
介绍
构建稳固的 ML 系统基础设施至关重要。它需要确保 ML 应用程序的开发和部署是有序且可靠的。但问题在于——每个公司的基础设施需求不同。这取决于他们有多少 ML 应用程序、需要多快部署,或者需要处理多少请求。
例如,如果一家公司只有一个生产模型,那么部署过程可以手动处理。在光谱的另一端,如 Netflix 或 Uber 这样有数百个生产模型的公司,需要高度专业化的基础设施来支持它们。
现在你可能会问自己一个问题:你的公司在这个光谱中处于什么位置?
Google 和 Microsoft 分享的 MLOps 成熟度级别旨在提供帮助。它们描述了基于行业最佳实践的 ML 基础设施的发展和复杂性。
本博客文章旨在综合并提取两个框架中的最佳实践。首先,我们将分析五个成熟度级别,并展示从手动流程到高级自动化基础设施的进展。然后,在最后一部分,我们将论证 Microsoft 和 Google 提出的某些观点不应盲目遵循,而应根据你的需求进行调整。这将帮助你在了解自己的基础设施现状和发现潜在改进领域时更加自觉。
好的,让我们深入探讨吧!
什么是 MLOps?
MLOps 是一组实践,用于建立一个标准化和可重复的流程,管理整个机器学习生命周期,从数据准备、模型训练、部署到监控。它借鉴了在软件工程中广泛采用的 DevOps 实践,后者关注于为团队提供快速和持续迭代的软件应用交付方法。
然而,DevOps 工具对机器学习世界来说是不够的,并且在几个方面有所不同:
-
MLOps 需要一个具有多学科技能的团队。这个团队包括负责数据收集和存储的数据工程师,开发模型的数据科学家,部署模型的机器学习工程师(MLE),以及将其与产品集成的软件工程师。
-
数据科学本质上是实验性的,通过探索不同的模型、数据分析、训练技术和超参数配置来持续改进。支持 MLOps 的基础设施应包括跟踪和评估成功和失败的方法。
-
即使模型在生产中正常运行,它仍可能由于输入数据的变化而失败。这被称为静默模型失败,由数据和概念漂移引起。因此,机器学习基础设施需要一个监控系统来不断检查模型的性能和数据,以防止这个问题。
现在让我们探索 MLOps 基础设施的不同成熟度级别。
级别 1 — 手动

手动机器学习基础设施。设计灵感来自谷歌的博客文章。图片由作者提供。
在这个级别,数据处理、实验和模型部署过程完全是手动的。微软将这一级别称为‘没有 MLOps’,因为机器学习生命周期难以重复和自动化。
整个工作流程高度依赖于熟练的数据科学家,并且在需要时,数据工程师协助准备数据,软件工程师协助将模型与产品/业务流程集成。
这种方法在以下情况中效果很好:
-
早期阶段的初创公司和概念验证项目——在这些情况下,重点是实验,资源有限。在扩大运营规模之前,开发和部署机器学习模型是主要关注点。
-
小规模的机器学习应用——对于范围有限或用户基础较小的机器学习应用(如小型在线时尚商店),手动方法可能是足够的。数据科学家可以手动处理数据处理、实验和部署过程,因数据依赖性较小且实时要求不高。
-
临时机器学习任务——在特定场景如营销活动中,一次性的机器学习任务或分析可能不需要全面的 MLOps 实施。
根据谷歌和微软的说法,这种方法也面临一些局限性,包括:
-
缺乏监控系统——没有关于模型性能的可视性。如果性能下降,将会对业务产生负面影响。此外,还需要在部署后进行数据科学分析,以了解模型在生产中的表现。
-
生产模型没有频繁的重训练——模型没有适应最新的趋势或模式。
-
发布过程痛苦且不频繁——由于是手动完成,模型发布每年只有几次。
-
缺乏对模型性能的集中跟踪,使得比较不同模型的性能、重复结果或更新变得困难。
-
有限的文档和缺乏版本控制——带来了一些挑战,比如引入意外代码更改的风险、有限的回滚到工作版本的能力和缺乏可重复性。
级别 2——可重复
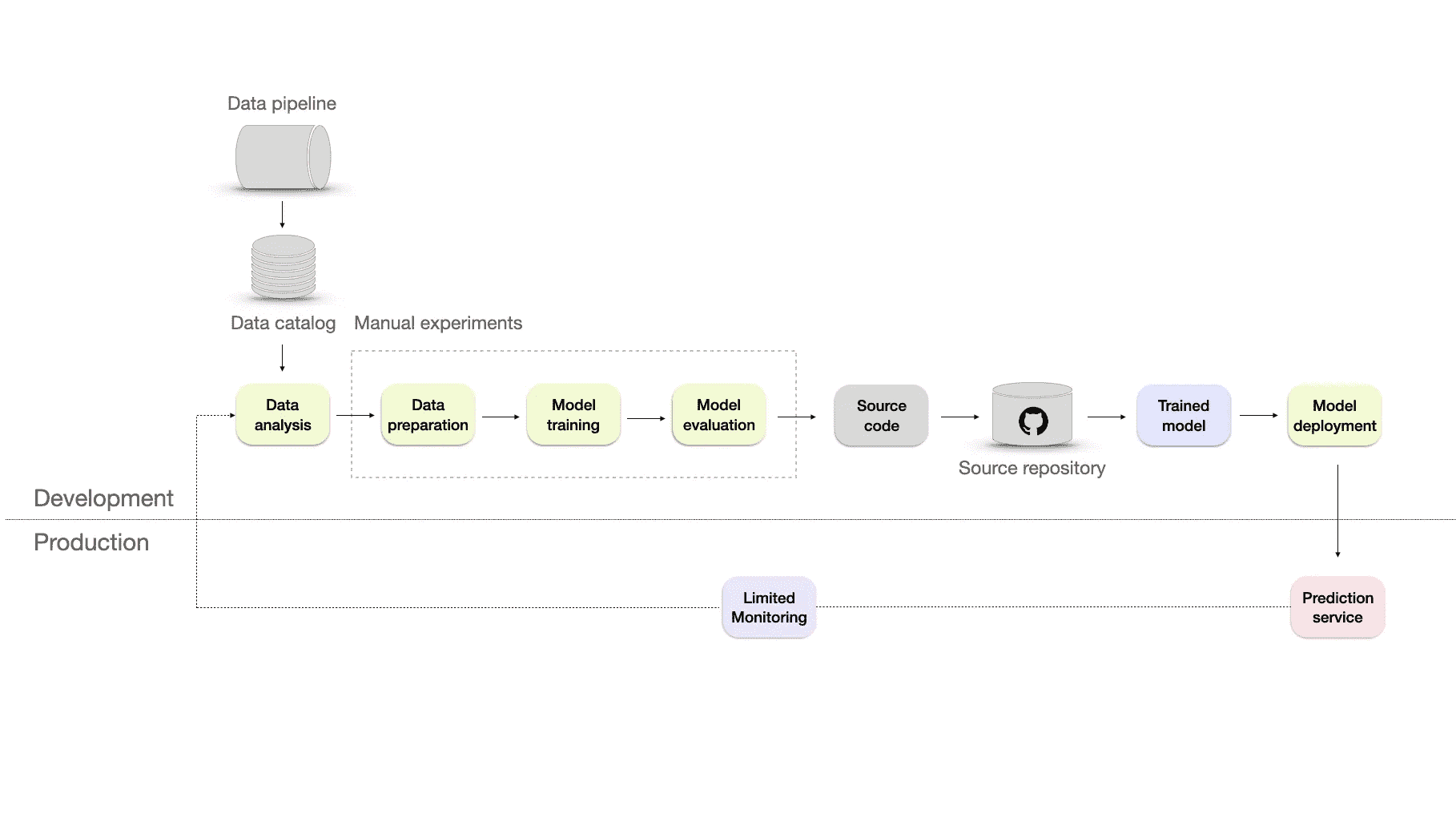
可重复的机器学习基础设施,配有额外的源代码仓库和监控。图片来源于作者。
接下来,我们通过将实验转换为源代码并使用像 Git 这样的版本控制系统将其存储在源代码仓库中,引入 DevOps 方面的内容。
微软建议通过添加以下内容来修改数据收集过程:
-
数据管道——允许从不同来源提取数据并将其合并。然后,通过清理、汇总或过滤操作对数据进行转换。它使基础设施比手动处理更具可扩展性、效率和准确性。
-
数据目录——一个集中存储的数据仓库,包含数据源、数据类型、数据格式、所有者、使用情况和数据源流等信息。它有助于以可扩展和高效的方式组织、管理和维护大量数据。
为了提升基础设施,我们必须引入一些自动化测试以及版本控制。这意味着使用单元测试、集成测试或回归测试等实践。这些将帮助我们更快地部署,并通过确保代码更改不会引起错误或漏洞来提高可靠性。
在这些变化到位后,我们可以重复数据收集和部署过程。然而,我们仍然需要一个适当的监控系统。微软简单提到这一点,称“关于模型在生产中表现如何的反馈有限”,但他们没有详细说明。
级别 3——可重复
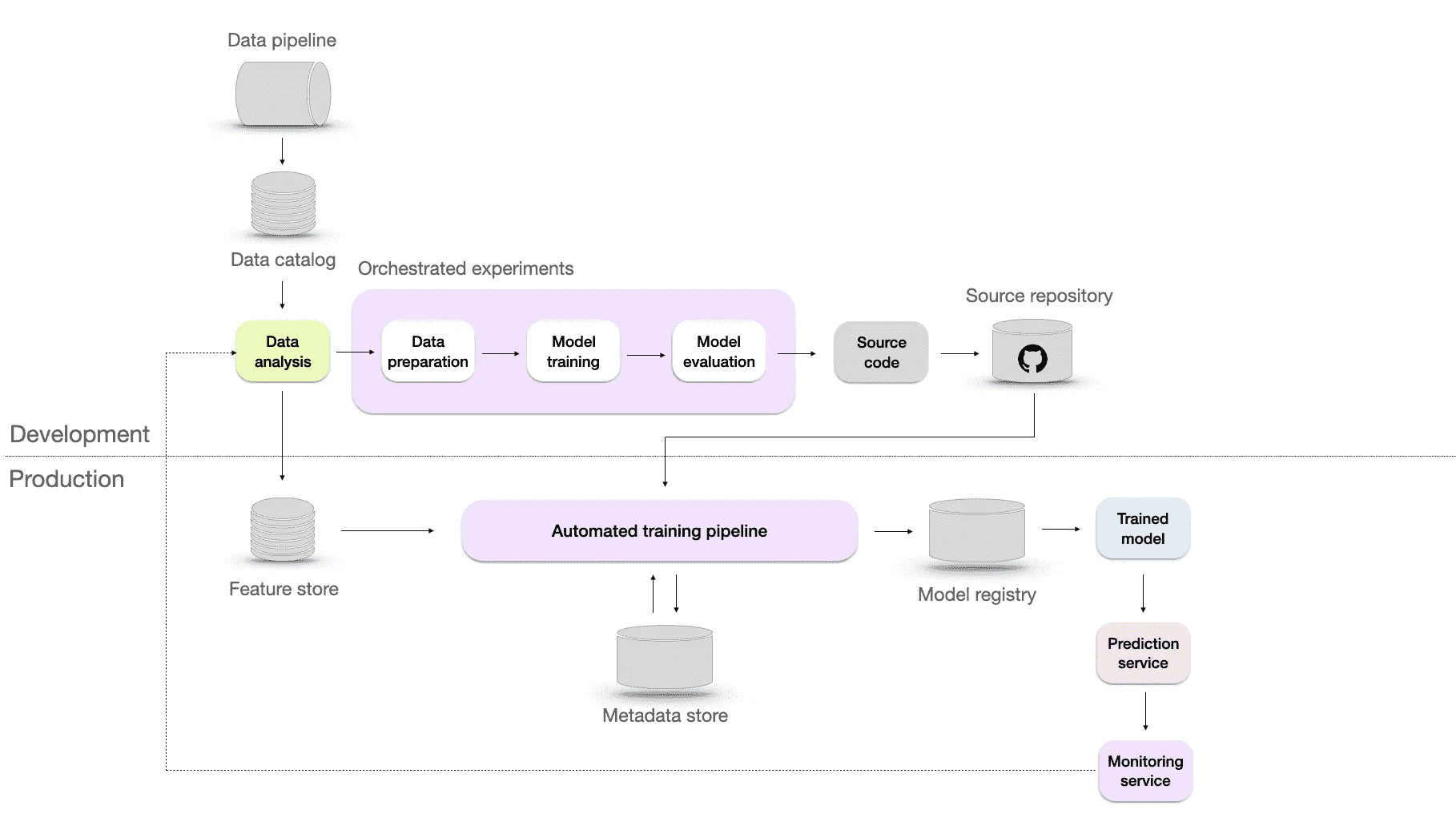
可重复的机器学习基础设施,配有自动化训练和协调实验。图片来源于作者。
可重复性至关重要的两个关键原因是:故障排除和协作。设想一种情况,你最近部署的模型性能下降,导致预测不准确。在这种情况下,你需要保留数据和模型的先前版本,以便在找到根本问题之前回滚到其他版本的模型。
此外,可重复性使不同团队成员更容易理解他人的工作并在彼此的工作基础上进行改进。这种协作方式和知识共享可以带来更快的创新和更好的模型。
为了实现可重复性,我们可能需要通过四种方式提升架构:
-
自动化训练管道 — 处理从数据准备到模型评估的端到端训练过程。
-
元数据存储库 — 一个数据库,用于跟踪和管理元数据,包括数据源、模型配置、超参数、训练运行、评估指标及所有实验数据。
-
模型注册表 — 是一个存储机器学习模型、其版本及其部署所需工件的仓库,这有助于在需要时检索到确切的版本。
-
特征存储 — 旨在帮助数据科学家和机器学习工程师通过提供集中存储、管理和服务特征的地点,更高效地开发、测试和部署机器学习模型。它还可以用于跟踪特征随时间的演变,并根据需要对特征进行预处理和转换。
在这一阶段,提供了监控服务,实时反馈模型的性能。然而,除了确认存在外,微软和谷歌均未提供更多信息。
Level 4 — 自动化
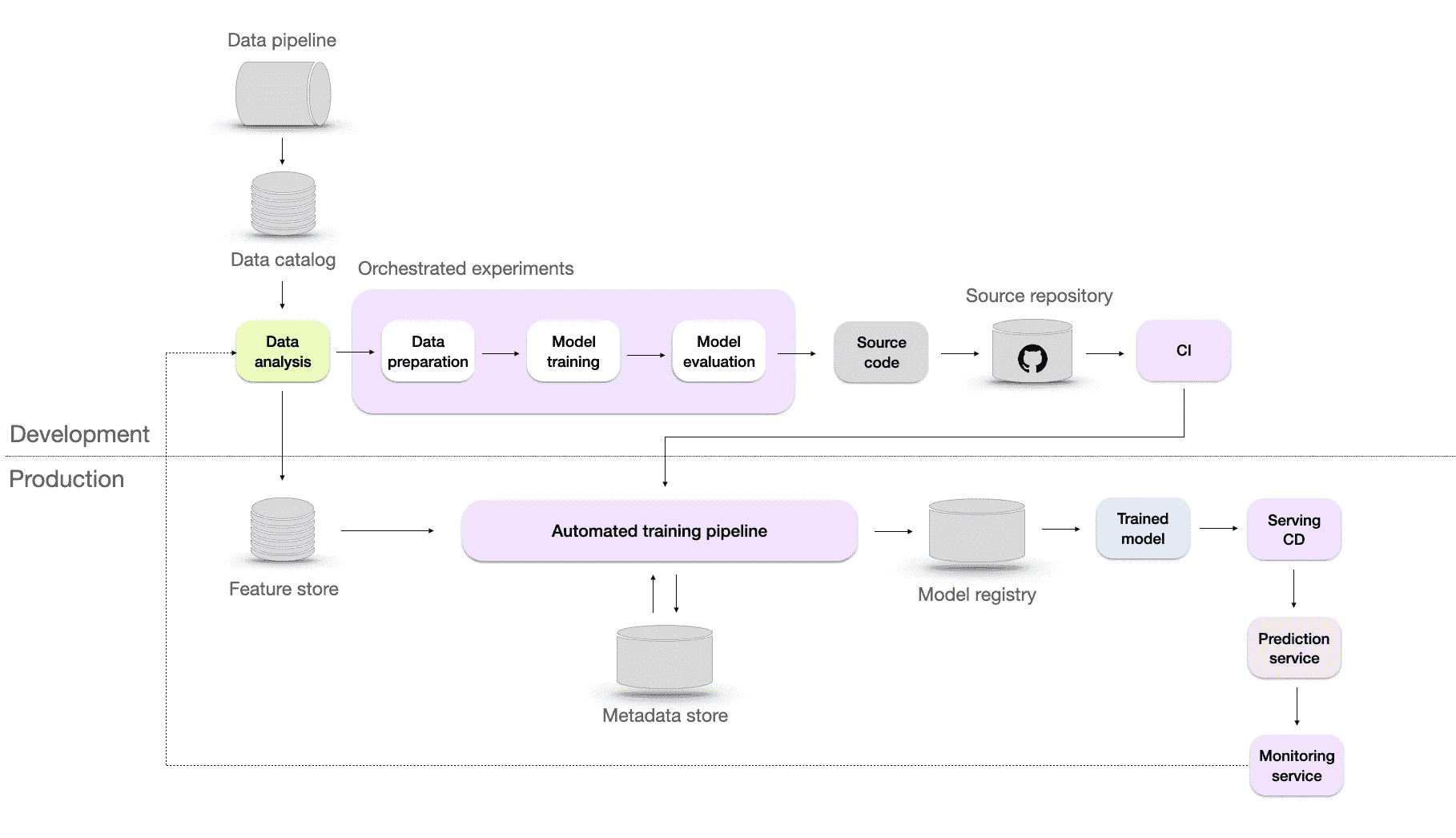
自动化机器学习基础设施与 CI/CD。图片来自作者。
这一自动化水平帮助数据科学家高效探索特征工程、模型架构和超参数的新想法,通过自动化机器学习管道(包括构建、测试和部署)。为实现这一点,微软建议加入两个额外的组件:
-
CI/CD — 在持续集成(CI)中,确保来自不同团队成员的代码变更集成到共享的代码库中,而持续部署(CD)则自动化将经过验证的代码部署到生产环境中。这允许快速部署模型更新、改进和修复漏洞。
-
模型的 A/B 测试 — 这种模型验证方法涉及比较现有模型和候选模型之间的预测和用户反馈,以确定更好的模型。
Level 5 — 持续改进
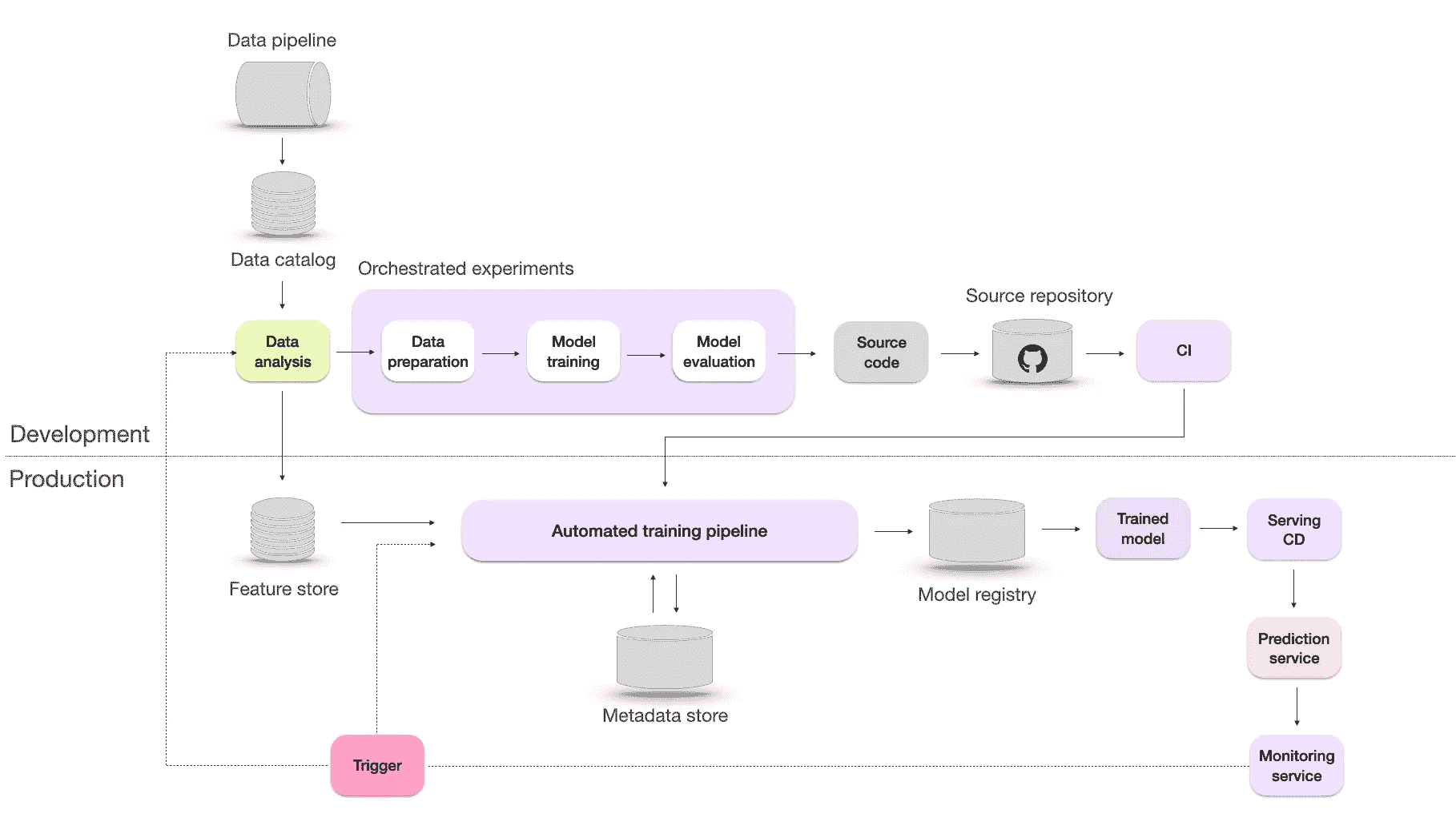
通过自动重新训练持续改进的机器学习基础设施。图片来自作者。
在这一阶段,模型会根据监控系统的触发器自动重新训练。这个重新训练的过程也称为持续学习。持续学习的目标包括:
-
应对可能出现的突发数据漂移,确保模型在面对数据的意外变化时仍然有效。
-
适应诸如黑色星期五等稀有事件,在这些事件中,数据中的模式和趋势可能会显著偏离常规。
-
克服冷启动问题,即模型需要为缺乏历史数据的新用户做出预测
推动自动化
微软和谷歌是云计算市场的主要参与者,Azure 占据了 22% 的市场份额,而谷歌为 10%。 他们提供了广泛的服务,包括计算、存储和开发工具,这些都是构建先进的机器学习基础设施的重要组成部分。
像任何业务一样,他们的主要目标是通过销售这些服务来创造收入。这也是他们的博客强调进步和自动化的部分原因。然而,更高的成熟度水平并不保证你的业务会有更好的结果。最优的解决方案是与公司特定需求和适当的技术栈相一致的方案。
尽管成熟度级别可以帮助你确定当前的进展,但不应盲目遵循,因为微软和谷歌的主要动机是销售他们的服务。一个具体的例子是他们推动自动再培训的过程。这个过程需要大量的计算,但通常是不必要的或有害的。再培训应在需要时进行。对于你的基础设施来说,更重要的是拥有一个可靠的监控系统和一个有效的根本原因分析过程。
监控应该从手动级别开始
在描述的成熟度级别中,第 2 级出现了一个有限的监控系统。实际上,一旦基于模型的输出做出业务决策,你就应该对模型进行监控,无论成熟度级别如何。这可以帮助你降低失败的风险,并查看模型在实现业务目标方面的表现。
监控的初步步骤可以简单到仅仅比较模型的预测值与实际值。这种基本的比较是对模型性能的基线评估,也是进一步分析模型失败时的良好起点。此外,还需要考虑数据科学工作的评估,包括投资回报率(ROI)的衡量。这意味着评估数据科学技术和算法带来的价值。理解这些努力在生成业务价值方面的有效性至关重要。
评估投资回报率可以为你提供洞察和信息,帮助你更好地做出资源分配和未来投资的决策。随着基础设施的发展,监控系统可能会变得更加复杂,具有更多的功能和能力。然而,你仍然应该关注在成熟度的第一个级别上应用基本监控设置的重要性。
再培训的风险
在第 5 级的描述中,我们列出了生产中自动再培训的好处。然而,在将其添加到基础设施之前,你应该考虑与之相关的风险:
- 延迟数据上的再培训
在一些现实场景中,例如贷款违约预测,标签可能会延迟数月甚至数年。实际情况仍在变化,但你却在用旧数据重新训练模型,这可能无法很好地代表当前的现实。
2. 无法确定问题的根本原因
如果模型的性能下降,并不总是意味着需要更多的数据。模型失败的原因可能有多种,例如下游业务流程的变化、训练-服务偏差或数据泄露。你应该首先调查以找到潜在的问题,然后在必要时重新训练模型。
3. 更高的失败风险
重新训练增加了模型失败的风险。除了它增加了基础设施的复杂性之外,更新的频率越高,模型失败的机会就越多。数据收集或预处理中的任何未检测到的问题都会传递到模型中,导致在缺陷数据上重新训练的模型。
4. 更高的成本
重新训练不是一个无需成本的过程。它涉及到与以下方面相关的费用:
-
存储和验证重新训练的数据
-
重新训练模型所需的计算资源
-
测试一个新模型,以确定它是否比当前模型表现更好
总结
机器学习系统非常复杂。以可重复和可持续的方式构建和部署模型是很有挑战性的。在这篇博客文章中,我们探讨了基于谷歌和微软行业最佳实践的五个 MLOps 成熟度水平。我们讨论了从手动部署到自动化基础设施的演变,强调了每个水平带来的好处。然而,理解这些实践不应盲目跟随至关重要。相反,它们的适应应基于公司特定的需求和要求。
庆祝地球月的 5 个机器学习项目作为开发者
环保项目的深入概述


·发表于 Towards Data Science ·阅读时长 10 分钟·2023 年 4 月 19 日
–

Luca Bravo 在 Unsplash 上传的照片
现在世界上数据的数量难以夸大。我们淹没在从数十亿互联网用户生成的点击流数据到工业设备和科学实验产生的千兆字节数据中。数据正变得越来越像互联网时代的流通货币。
数据也代表了巨大的机会;通过分析和理解数据,我们可以获得以前不可能得到的洞察,并利用这些洞察来解决一些人类最紧迫的问题。
无论是开发机器学习模型预测自然灾害,还是构建数据驱动的工具优化能源使用,我们都有无数机会可以利用我们的数据科学知识来促进可持续发展和保护环境。
数据科学的潜力确实令人惊叹,很难不对其可能性和成果感到兴奋。通过使用先进的分析技术和机器学习从海量数据集中提取洞察,我们可以在为自己和下一代创造一个更加可持续和公平的未来方面产生真正的影响。我们正生活在一个激动人心的时代,我迫不及待地想看看未来会带来什么。
在本文中,我将分享 5 个动手数据科学/机器学习项目,这些项目将为我们提供如何利用技术解决现实世界问题的一些见解。我认为这将是庆祝地球月的一个很好的方式,并挑战自己并开展这些项目。我尽量使列表在项目主题和编程技能方面都保持多样化。这些项目也是很好的作品集项目。
让我们开始吧!
下面是本文将讨论的项目列表:
-
熊类保护项目
-
LANL — 地震预测
-
EDSA — 气候变化信念分析
-
基于机器学习技术的太阳能预测
-
开放足迹
-
结论
1. 熊类保护项目
机器学习、无服务器和公民科学中的熊类保护

照片由Hans-Jurgen Mager在Unsplash上提供
让我们从可爱而巨大的生物——熊开始吧。
熊类保护项目解决了在偏远地区监控和跟踪熊类种群的挑战。这对保护工作至关重要,因为它可以帮助研究人员了解熊类的行为和分布,并识别可能威胁其生存的因素。
该项目结合了多种机器学习技术与计算机视觉技术,以分析由志愿者收集的公民科学数据。具体而言,它使用目标检测和人脸识别算法来识别图像和视频中的熊。这些算法使用标记数据进行训练,如ImageNet,以识别熊的特定特征,如其形状、大小和颜色。
一旦熊的图像和视频被处理,这些数据会存储在 Amazon S3(简单存储服务)桶中,并使用 Amazon SageMaker 进行分析。这使得研究人员和保护工作者能够对数据进行更深入的分析,包括识别熊类行为和种群分布的模式和趋势。
该项目还采用了无服务器架构,通过使用 AWS Lambda 和 Amazon DynamoDB 服务来处理和存储数据。无服务器计算方法允许系统根据需求的变化自动扩展或缩减,从而降低成本并提高效率。
总体而言,该项目展示了机器学习和无服务器计算技术在解决复杂环境挑战和促进保护工作中的强大能力。是AWS(亚马逊网络服务)在改善世界方面的一个极佳应用案例。
了解更多关于该项目的信息:BearResearch.org。
视频演示由 Ed Miller 提供。
2. LANL — 地震预测
我们可以通过机器学习预测即将发生的地震吗?

照片由 Mohammed Ibrahim 提供,来源于 Unsplash
今年早些时候,2 月 6 日,土耳其南部发生了 7.8 级地震,靠近叙利亚北部边界。约九小时后,这次地震后又发生了另一场7.5 级地震。根据联合国新闻简报的报道,截至 3 月 23 日,死亡人数已经超过 56000 人。我们的心与受影响者同在,祝他们耐心和恢复。
也许确切预测地震灾害的时间很困难,但借助我们今天已有的先进技术,我相信我们可以减少破坏的影响,从而让更多生命免受影响。
最近发生的事件是我希望将地震预测项目纳入此列表的主要原因。
洛斯阿拉莫斯国家实验室 (LANL) 地震预测项目仅仅是一个开发机器学习模型来预测地震的研究项目。该项目基于这样一个前提,即地震通常会伴随着地壳中可检测的变化,如地震活动或其他地球物理变量的变化。
LANL 地震预测项目已经进行多年,涉及了来自地震学、地质学和计算机科学等多个学科的研究人员合作。
这个地震预测项目的动机在于地震可能带来的毁灭性后果,会对基础设施造成广泛的损坏和生命损失。如果地震能够更准确地预测,将使社区能够采取主动措施来减轻其影响。
该项目专注于开发和测试各种机器学习模型,包括神经网络、决策树和支持向量机。这些模型使用大量的地震数据进行训练,包括地震仪、GPS 传感器和卫星影像,以及其他地球物理变量如地面运动、应变和倾斜。
该项目还涉及开发和创建用于可视化和解释结果的软件工具。最终目标是识别可以用于更准确地预测地震的模式和相关性。
尽管取得了显著进展,但在实现准确可靠的地震预测之前,还必须克服许多挑战。以下是该项目面临的一些挑战:
最大的挑战之一是地壳的复杂性,它可能受到包括构造活动、火山喷发以及矿业和压裂等人类活动在内的多种因素的影响。此外,地震本质上是不可预测的,任何预测都存在一定程度的不确定性。
尽管面临这些挑战,LANL Earthquake Prediction 项目代表了在开发用于预测自然灾害的机器学习模型方面的重要进展。这些模型最终可以挽救无数生命,减少地震对全球社区的影响。
了解更多关于该项目的信息:LANL Earthquake Prediction。
数据集可在Kaggle上公开获取。
3. EDSA — 气候变化信念分析 2022
我们能否基于个人的历史推文数据预测其对气候变化的信念?

图片由Matt Palmer拍摄,来源于Unsplash。
该项目是一个数据科学项目,旨在使用机器学习技术分析南非公众对气候变化的态度。
该项目由 Explore Data Science Academy(EDSA)进行,该组织位于南非,提供数据科学及相关领域的培训。该项目是他们社会影响数据科学项目的一部分,该项目旨在应用数据科学技术解决社会和环境问题。他们的项目也得到了 AWS 的支持。
该项目涉及通过在线调查收集数据,调查分发给了南非代表性样本的居民。调查包含了开放式和封闭式问题,以捕捉受访者对气候变化的信念、人口统计信息以及其他相关因素。
数据收集完成后,项目团队使用各种数据清洗技术对其进行了处理,以确保数据适合分析。然后,他们采用了一系列算法来探索数据,并对公众对气候变化的态度进行洞察。
团队使用的一个重要技术是自然语言处理(NLP),它涉及使用计算方法来分析人类语言。团队对调查中的开放式回答应用 NLP,以识别受访者的常见主题和情感。这使他们能够更好地了解影响南非公众对气候变化态度的因素。
团队还应用了分类算法,根据受访者的 demographics 和其他因素预测其对气候变化的信仰。这涉及到训练机器学习模型,将受访者分类为“相信者”或“非相信者”。他们还创建了可视化工具,以帮助向更广泛的受众传达他们的发现,包括创建互动仪表板和数据可视化。
总体而言,这个项目是一个重要的举措,利用数据科学技术洞察南非公众对气候变化的态度。数据是公开的,欢迎挑战自己并运用你的数据科学技能。
了解更多关于项目的信息:EDSA — 气候变化。
了解他们如何在 Explore Data Science Academy 使用 AWS:视频。
数据集可以在 Kaggle 上公开获取。
4. 太阳能发电预测与机器学习技术
EMIL ISAKSSON 和 MIKAEL KARPE CONDE 的研究论文。

这篇论文聚焦于太阳能发电预测问题,这对在电网中整合和管理太阳能至关重要。准确的太阳能发电预测可以帮助电网操作员做出与电网管理相关的明智决策,并减少在电力市场中平衡供应和需求的成本。
作者使用了一个历史天气和太阳能发电数据集,该数据集包括八年来测量的太阳辐射的每日能源输出。该数据集通过应用特征提取和归一化技术进行了预处理,以便与机器学习算法配合使用。
使用该数据集训练和评估了几个机器学习模型,包括支持向量回归(SVR)、随机森林回归(RFR)和人工神经网络(ANN)。这些模型使用平均绝对误差(MAE)和均方根误差(RMSE)等指标进行评估。
快速洞察:研究发现 ANN 模型在准确性和鲁棒性方面优于其他模型。ANN 模型可以捕捉输入特征与太阳能发电输出之间复杂的非线性关系,使其成为更有效的预测工具。
论文还讨论了所开发的预测模型的潜在实际应用,例如帮助电网运营商做出与电网管理相关的决策,并减少电力市场上平衡供需的成本。
研究得出结论,机器学习技术,特别是 ANN 模型,可以作为准确太阳能预测的实用工具,最终有助于在电网中集成和管理太阳能。
了解更多关于该项目的信息:太阳能预测。
5. Open Footprint
个人、组织、产品和社区的环境档案

图片由JuniperPhoton拍摄,发布在Unsplash。
气候变化是我们今天面临的最紧迫的问题之一。大气中的二氧化碳及其他温室气体增加导致气温上升、冰川融化和极端天气事件频发。作为个人、组织和社区,我们每个人都在减少碳足迹和缓解气候变化影响方面发挥作用。
为了解决这一问题,一组开发人员和环保主义者创建了 Open Footprint——一个开源碳足迹项目,旨在为个人、组织、产品和社区提供环境档案。
该项目设计为模块化和可定制的,允许用户选择与其需求最相关的指标和计算。项目托管在 GitHub 上,代码对任何人开放下载、使用和贡献。
项目包含了各种功能,如数据可视化和报告工具,使用户更容易理解和传达他们的碳足迹数据。该项目根据GNU 通用公共许可证授权,确保软件保持开源并对所有人免费提供。
总体而言,Open Footprint 项目是一个重要的倡议,促进了碳足迹和其他环境影响指标的透明度和问责制。通过提供一个开放且易于访问的平台来测量和跟踪生态数据,该项目旨在赋予个人、组织和社区更多的信息,以便做出更明智的环境影响决策,并采取行动减少碳足迹。
该项目的目标是创建一个免费的、开放的、可访问的平台,用于测量和跟踪碳足迹以及其他环境影响指标。该项目的模块化和可定制设计也确保它具有足够的灵活性,以满足各种用户的需求,使其成为任何有兴趣减少环境影响的人的有价值工具。
了解更多关于该项目的信息:Open Footprint。
示例用例:EPA 的碳足迹计算器。
结论

总结来说,作为当今的开发者和数据科学家,我们有能力真正改变世界。无论是预测自然灾害还是优化能源使用,数据科学和机器学习为我们提供了强大的工具,帮助我们为自己和下一代创造一个更好、更可持续的未来。
所以,让我们撸起袖子,开始工作吧!
进行实际的编程项目是提升我们技能的最佳方式。如果你对这些项目有任何问题或反馈,请随时联系我或回应这篇文章。
我是Behic Guven,我喜欢分享有关编程、技术和教育的故事。如果你喜欢阅读这些故事并想支持我的旅程,可以考虑成为Medium 会员。谢谢,
如果你想知道我写了什么样的文章,这里有一些:
-
用 Python 构建面部识别器。
-
逐步指南——用 Python 构建预测模型。
-
用 Python 构建语音情感识别器。

















 510
510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}