







使用 Pandas 进行 Python 中的数据汇总:分析地质岩性数据
探索挪威大陆架上 Zechstein 组的岩性变化
 [外链图片转存中…(img-XDpEQvbQ-1726761704319)] Andy McDonald
[外链图片转存中…(img-XDpEQvbQ-1726761704319)] Andy McDonald
·发布于 Towards Data Science ·6 分钟阅读·2023 年 6 月 29 日
–

图片由作者使用 Midjourney(付费订阅计划)生成。
使用数据汇总技术可以帮助我们将一个庞大且几乎无法理解的数字数据集转换成易于消化且更具可读性的内容。数据汇总过程涉及将多个数据点总结为单一的度量指标,以提供数据的高层次概述。
在岩石物理学和地球科学中,我们可以应用这个过程来总结从井日志测量中解释出的地质构造的岩性组成。
在这个简短的教程中,我们将看到如何处理来自挪威大陆架的 90 多个油井的大型数据集,并提取 Zechstein 组的岩性组成。
导入库和加载数据
首先,我们需要导入 pandas 库,该库将用于从 CSV 加载数据文件并进行汇总。
import pandas as pd
一旦导入了 pandas 库,我们就可以使用 pd.read_csv() 读取 CSV 文件。
我们将使用的数据来自XEEK 和 Force 2020 机器学习竞赛,该竞赛旨在从井日志测量中预测岩性。我们使用的数据集代表了所有可用的训练数据。有关此数据集的更多详细信息,请参见文章末尾。
由于此 CSV 文件中的数据是用分号而不是逗号分隔的,我们需要在sep参数中传递一个冒号。
df = pd.read_csv('data/train.csv', sep=';')
然后我们可以运行这段代码开始加载过程。由于我们有一个大数据集(1100 万+行),这可能需要几秒钟。但一旦加载完成,我们可以通过调用df对象来查看数据框。这将返回数据框,并显示前五行和最后五行。
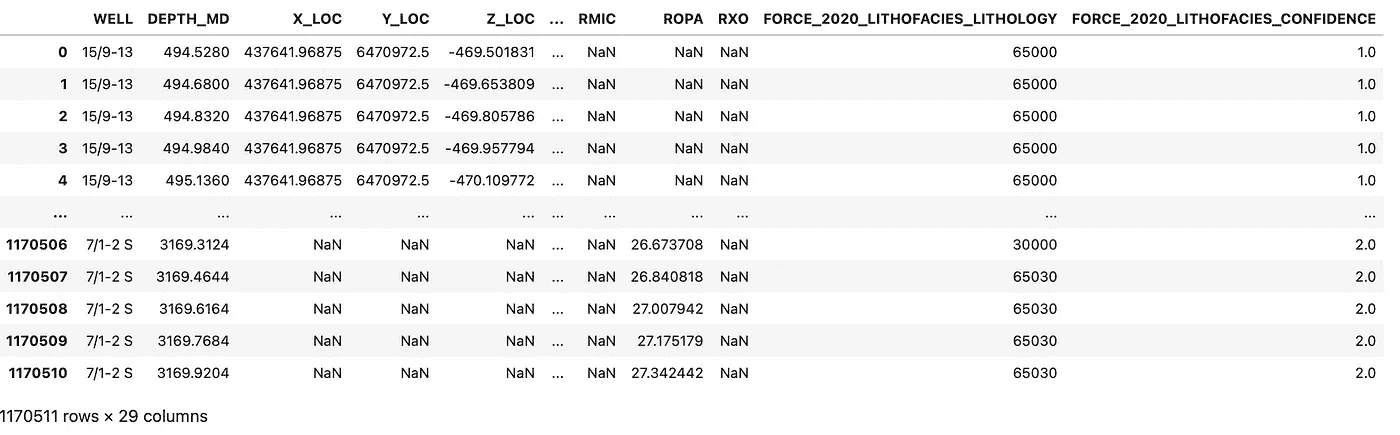
包含挪威大陆架井日志数据的数据框。图片由作者提供。
使用 pandas 的.map()将数值代码转换为岩性字符串
在这个数据集中,岩性数据存储在FORCE_2020_LITHOFACIES_LITHOLOGY列中。然而,当我们仔细查看数据时,会发现岩性值是以数字编码的。如果你不知道键,就很难解读哪个数字代表哪个岩性。
幸运的是,对于这个数据集,我们有键,可以创建一个包含键和岩性对的字典。
lithology_numbers = {30000: 'Sandstone',
65030: 'Sandstone/Shale',
65000: 'Shale',
80000: 'Marl',
74000: 'Dolomite',
70000: 'Limestone',
70032: 'Chalk',
88000: 'Halite',
86000: 'Anhydrite',
99000: 'Tuff',
90000: 'Coal',
93000: 'Basement'}
要将这应用于我们的数据集,我们可以使用 pandas 的map()函数,它将使用我们的字典进行查找,然后将正确的岩性标签分配给数值。
df['LITH'] = df['FORCE_2020_LITHOFACIES_LITHOLOGY'].map(lithology_numbers)
一旦运行完成,我们可以再次查看数据框,以确保映射成功并且数据框末尾添加了新的 LITH 列。
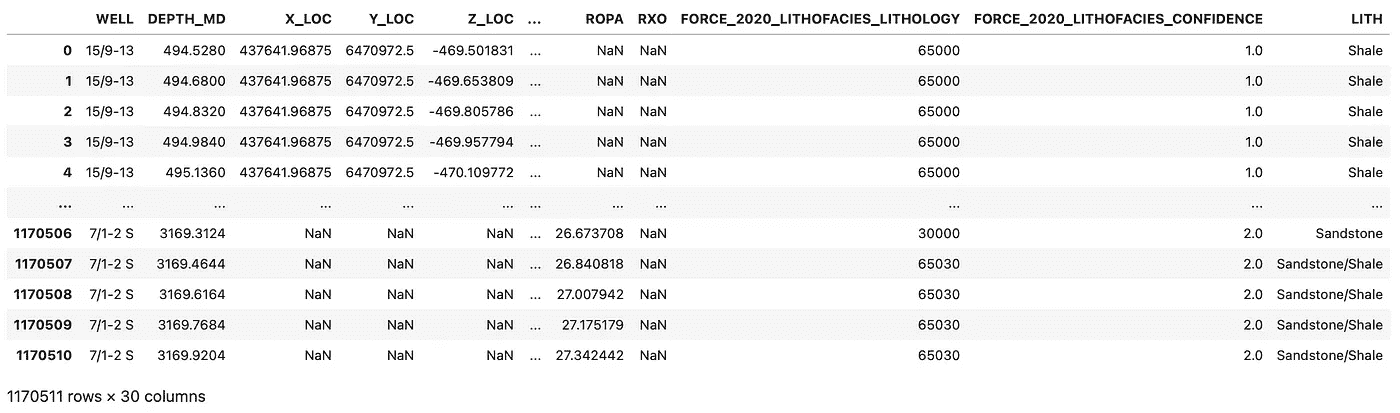
包含挪威大陆架井日志数据的数据框。图片由作者提供。
为特定地质组过滤数据框
由于我们有一个相当大的数据集,包含 11,705,511 行,因此对我们的岩性组成分析来说,关注特定的地质组会更好。
在这种情况下,我们将对子集数据进行处理,关注 Zechstein 组。
我们可以通过使用query()方法并传入一个简单的字符串来实现:GROUP == "ZECHSTEIN GP."
df_zechstein = df.query('GROUP == "ZECHSTEIN GP."')
df_zechstein.WELL.unique()
我们可以通过调用df_zechstein.WELL.unique()来检查子集中有多少个井,它返回包含 8 个井的数组。
array(['15/9-13', '16/1-2', '16/10-1', '16/11-1 ST3', '16/2-16', '16/2-6',
'16/4-1', '17/11-1'], dtype=object)
由于我们只对岩性感兴趣,我们可以简单地提取井名和岩性列。这也将使聚合过程更加便捷。
df_zechstein_liths = df_zechstein[['WELL', 'LITH']]
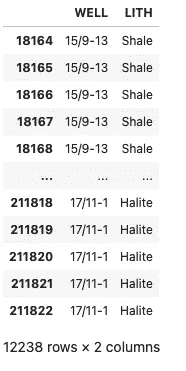
井名及相关岩性。图片由作者提供。
使用链式 Pandas 函数进行数据聚合
现在我们已经将数据整理成可以处理的格式,我们可以开始聚合过程。为此,我们将把多个 pandas 方法链在一起使用。
首先,我们将使用groupby函数按 WELL 列对数据进行分组。这实际上为 WELL 列中的每个唯一井名创建数据框的子集。
接下来,我们将计算每个组中每种岩性类型的出现次数。normalize=True部分意味着它将给出比例(介于 0 和 1 之间),而不是绝对计数。例如,如果在一个井(组)中,‘砂岩’出现了 5 次,而‘页岩’出现了 15 次,该函数将返回 0.25 给‘砂岩’和 0.75 给‘页岩’,而不是 5 和 15。
最后,我们需要重新排列结果数据框,使得行索引包含井名称,列包含岩性名称。如果某口井中没有某种岩性的实例,则用零填充,因为fill_value=0。
summary_df = df_zechstein_liths.groupby('WELL').value_counts(normalize=True).unstack(fill_value=0)
summary_df
我们得到的是以下数据框,展示了每口井中每种岩性的十进制比例。
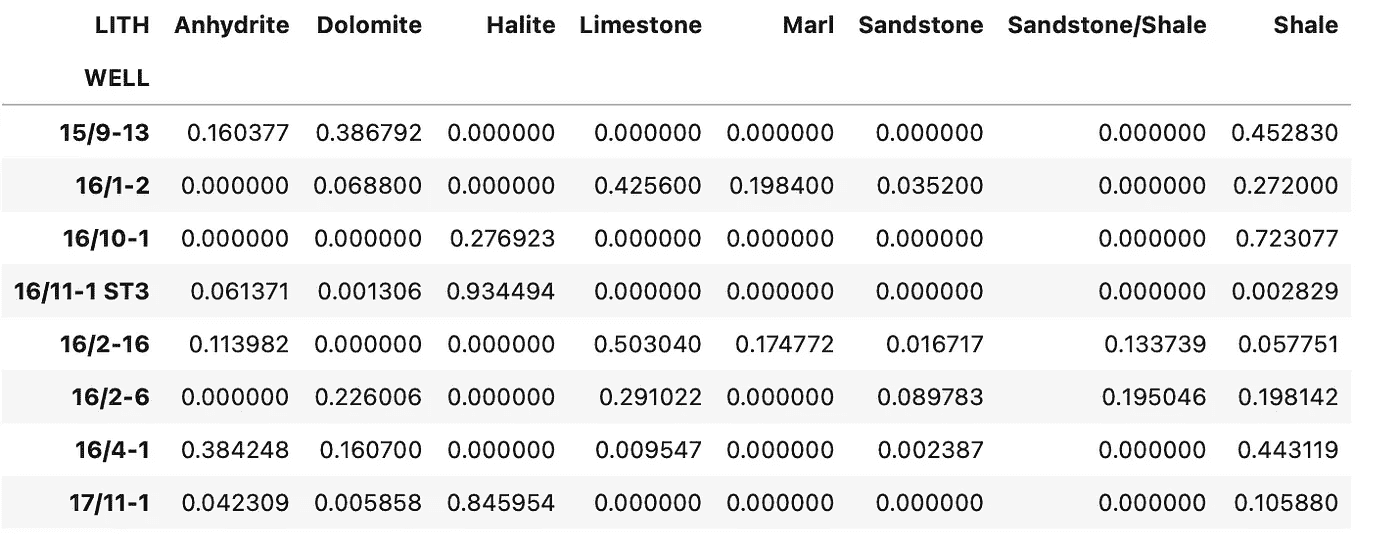
以十进制形式表示的 Zechstein 组岩性组成。图片由作者提供。
如果我们想以百分比的形式查看这些数据,我们可以使用以下代码改变它们的显示方式:
summary_df.style.format('{:.2%}')
当我们运行代码时,我们得到以下数据框,它提供了一个更易读的表格,可以纳入报告中。
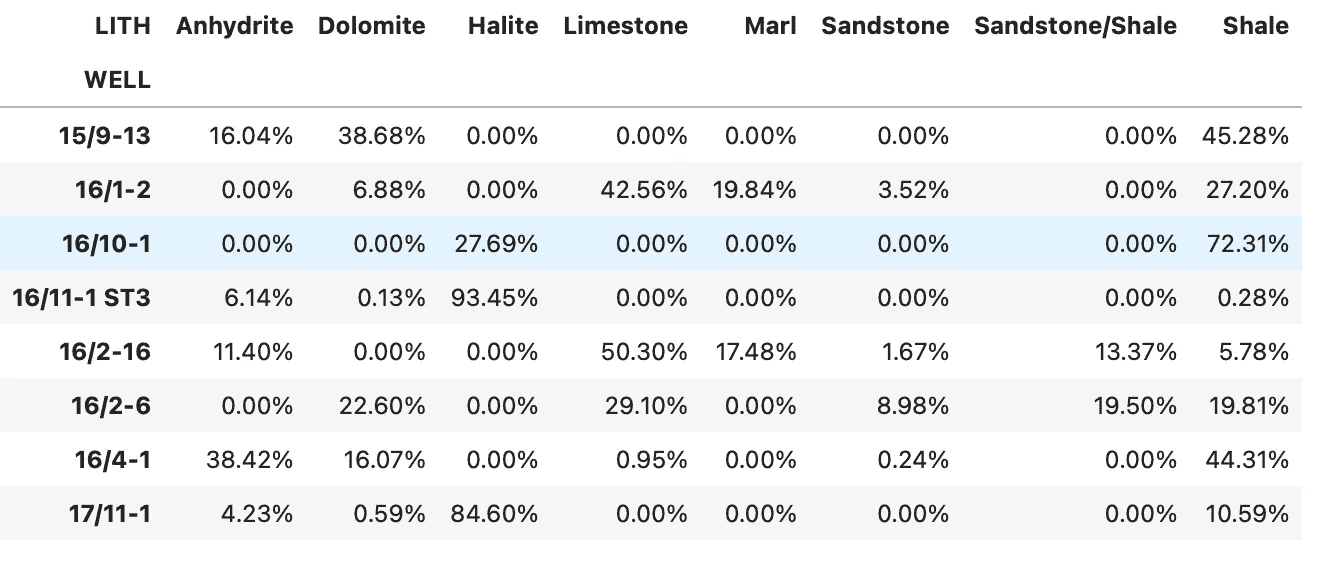
聚合后的 Zechstein 组的岩性组成,并将数字转换为百分比。图片由作者提供。
应用这种样式不会改变实际值。它们仍将以其十进制等效值存储。
如果我们确实想将值永久更改为百分比,可以通过将数据框乘以 100 来实现。
summary_df = summary_df * 100
summary_df
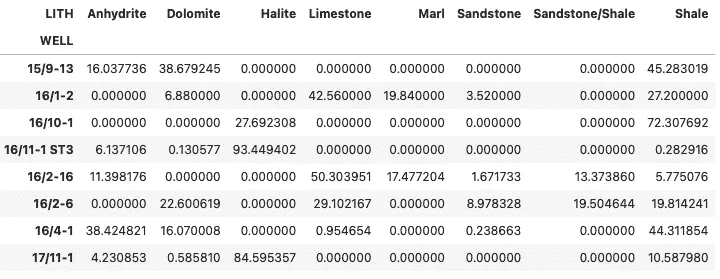
聚合后并转换为百分比的 Zechstein 组岩性组成。图片由作者提供。
一旦数据呈现此格式,我们可以用它创建类似于下方信息图的内容,该图展示了每口井的岩性百分比。
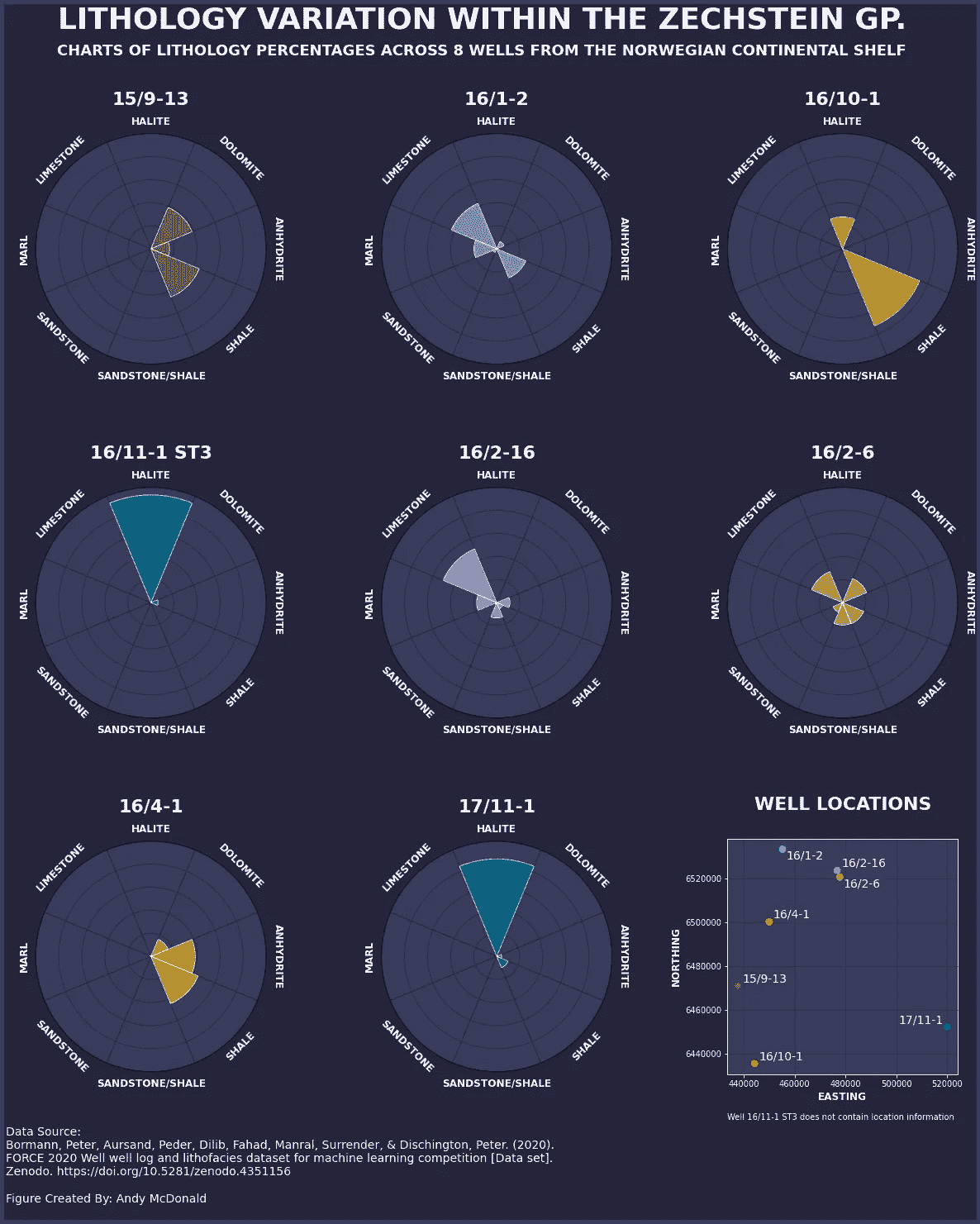
展示每口井中每种岩性的百分比变化的信息图。由作者使用 matplotlib 创建。
摘要
在这个简短的教程中,我们已经了解了如何从 90 多口井的大量测井数据中提取和总结特定的地质组。这使我们能够以易于阅读和理解的格式来了解地质组的岩性组成,并可纳入报告或演示文稿中。
本教程中使用的数据集
训练数据集用作 Xeek 和 FORCE 2020(Bormann et al., 2020)举办的机器学习竞赛的一部分。该数据集采用创作共用署名 4.0 国际许可证。
完整的数据集可以通过以下链接访问: doi.org/10.5281/zenodo.4351155。
感谢阅读。在你离开之前,你绝对应该订阅我的内容,将我的文章送到你的收件箱中。 你可以在这里订阅!
其次,你可以通过注册会员获得完整的 Medium 体验,并支持成千上万的其他作者和我。它每月只需 $5,你可以完全访问所有精彩的 Medium 文章,还可以通过写作赚取收入。
如果你通过 我的链接注册,你将直接用你的费用的一部分支持我,这不会让你多花钱。如果你这样做,非常感谢你的支持。
数据利他主义:企业引擎的数字燃料
在人工智能时代处理数据的注意事项
 [外链图片转存中…(img-1F2edxgP-1726761704322)] Tea Mustać
[外链图片转存中…(img-1F2edxgP-1726761704322)] Tea Mustać
·
关注 发表在 Towards Data Science ·10 min 阅读·2023 年 12 月 10 日
–

图片由 Gilles Lambert 提供,来源于 Unsplash
超越利润:数字时代的给予与获得
数字经济建立在平等、快速和免费的知识与信息获取的美好承诺上。这已经过去很久了。取而代之的是承诺中的平等,我们得到了由网络效应放大的权力不平衡,使用户被锁定在最受欢迎服务的提供者那里。然而,乍一看,用户似乎仍然没有付出任何费用。但这时,值得仔细观察一下,因为他们确实在付出代价。我们都在付出。我们为了访问某些服务,正在提供我们的数据(而且是大量数据)。与此同时,提供者在这不平衡的方程式的背后获得了天文数字的利润。这不仅适用于当前和成熟的社交媒体网络,也适用于不断增长的 AI 工具和服务。
在这篇文章中,我们将全面探讨这一“疯狂滑梯”,并从用户和提供者的角度进行考虑。当前现实中,大多数服务提供者依赖于黑暗模式的做法来尽可能获取数据,这只是其中一个选择。不幸的是,这正是我们所生活的现实。为了了解其他可能的情况,我们将从所谓的技术接受模型入手。这将帮助我们判断用户是否真正接受了游戏规则,或者只是无论后果如何都在追逐人工智能的炒作。一旦我们弄清楚这一点,我们将转向数据(如此慷慨地被赠予)的后续处理。最后,我们将考虑一些实用步骤和最佳实践解决方案,以便那些希望做得更好的 AI 开发者参考。
a. 技术接受还是通过滑头方式获得同意?
技术接受模型绝不是一个新概念。相反,这一理论自 1989 年 Fred D. Davis 在他的《感知有用性、感知易用性和信息技术用户接受度》中提出以来,就一直是公众讨论的话题[1]。正如标题所暗示的,这个观点的要旨在于用户对技术的有用性认知以及与技术互动时的用户体验,是决定用户是否愿意接受技术的两个关键因素。
对于许多 AI 技术而言,我们不需要考虑太久就能发现这一点。我们称许多 AI 系统为“工具”,这本身就足以表明我们确实将它们视为有用的。如果说有的话,那么至少是为了打发时间。此外,市场法则基本上要求只有最用户友好和美观的应用才能进入大规模受众。
如今,我们可以在戴维斯的方程中添加两个新因素,即网络效应和‘AI 炒作’。所以现在,不仅仅是如果你从未让 ChatGPT 纠正拼写或起草礼貌邮件你就像是一个穴居人,而且你还无法参与到四处发生的许多对话中,无法理解一半的头条新闻,而且你还显得在浪费时间,因为其他人都在利用这些工具。这对接受几乎任何呈现给你的东西的动机如何呢,尤其是当它被美丽的图形用户界面精心包装时?

图片由 Possessed Photograph 在 Unsplash 提供
b. 默认设置 — 强制性的利他主义
正如已经暗示的,我们似乎对将所有数据提供给许多 AI 系统的开发者持相当开放的态度。我们在互联网上留下了痕迹,对这些痕迹没有概览或控制权,显然还必须容忍商业行为者收集这些痕迹并用它们来制作炸鸡。这个比喻可能有些牵强,但它的含义仍然适用。看来我们必须容忍某些系统可能已经用我们的数据进行训练的事实,因为如果我们甚至无法确定所有数据的去向,如何能期望提供者弄清楚所有数据的来源,并相应地通知所有数据主体。
然而,有一件事我们目前默认是利他主义的,但在隐私和 GDPR 仍有一线生机的是在与给定系统互动时收集的数据,用于改进该系统或由同一提供者开发新模型。目前我们似乎无私地提供这些数据的原因,与前一段描述的原因有所不同。这里的利他主义更多地源于我们所处的法律状况不明以及对其许多漏洞和模糊性的滥用。(此外,用户在大多数情况下也更重视他们的钱而非隐私,但这现在无关紧要。)
例如,与 OpenAI 主动寻找每一个包含在训练模型的数据集中的个人不同,它完全可以通知其活跃用户他们的聊天记录将用于改进现有模型和训练新模型。这里是免责声明
“如上所述,我们可能会使用您提供的内容来改进我们的服务,例如训练支持 ChatGPT 的模型。有关如何选择退出我们使用您的内容来训练模型的说明,请参见这里。”
由于几个原因,这种做法无法被接受。[3] 首先,用户应该能够主动决定是否希望其数据用于改进服务提供者的服务,而不仅仅是能够在事后选择退出。其次,使用如‘可能’这样的词汇可能给普通用户一种非常错误的印象。这可能暗示这是仅在偶尔和特殊情况下才会发生的事情,而实际上这是一种常见的做法和行业黄金规则。第三,“驱动 ChatGPT 的模型”对于即使是对其实践非常了解的人来说也含糊不清。他们既没有提供关于他们使用的模型和如何训练这些模型的充分信息,也没有解释这些模型如何“驱动 ChatGPT”。
最后,在阅读他们的政策时,人们会得出这样的信念:他们只使用内容(大写的 C)来训练这些未知的模型。意思是他们仅仅使用
“个人信息包括在输入、文件上传或[用户]对[OpenAI]服务的反馈中。”
然而,当我们考虑到 2023 年 3 月的丑闻时,这显然是不正确的,其中涉及一些用户的支付详情被共享给其他用户。 [4] 如果这些支付详情已经进入模型,我们可以安全地假设,随附的姓名、电子邮件地址和其他账户信息也没有被排除在外。
当然,在这种描述的背景下,数据利他主义这一术语只能带有相当大的讽刺和反讽。然而,即使是对于那些并非明显撒谎关于他们使用哪些数据,也没有故意隐瞒他们使用数据目的的提供者,我们依然会遇到问题。例如,处理操作的复杂性可能导致隐私政策的过度简化,类似于 OpenAI 的情况,或者是无人愿意查看的难以理解的政策,更不用说阅读了。这两者最终都导致相同的结果,即用户同意任何必要的条款,只为能够访问服务。
现在,对这种观察的一个非常流行的回应是,我们所泄露的大部分数据对我们来说并不重要,那么为什么对其他人来说会重要?此外,我们凭什么对那些掌控世界的大型企业如此有趣?然而,当这些数据用于建立一个完全依赖于从全球数百万个地方收集的那些微不足道的数据点的商业模型时,这个问题就会有完全不同的视角。
c. 作为商业模式的盗取数据?
要审视基于这些每天被随意抛弃的数百万个无关同意的商业模式,我们需要检查用户在放弃他们的数据时有多么利他。当然,当用户访问服务并在过程中放弃他们的数据时,他们也会以此获得服务。但这并不是他们唯一获得的东西。他们还会收到广告,或者可能得到一个二级服务,因为一级服务留给了订阅用户。更不用说这些订阅用户仍然在放弃他们的内容(以大写字母 C 表示),以及(至少在 OpenAI 的情况下)他们的账户信息。
因此,尽管用户为了使用工具或服务同意他们的数据可以被用于几乎任何用途,但他们所放弃的数据却被多次变现,以便为他们提供个性化广告和开发新的模型,这些模型可能再次采用免费增值(freemium)模式。撇开更为哲学性的问题,比如为什么银行账户上的数字比我们的生活选择和个人偏好更有价值,这似乎完全不符合逻辑,用户为了得到如此少的东西却要付出这么多。特别是因为我们讨论的数据对服务提供商至关重要,至少如果他们想保持竞争力的话。
然而,情况不必如此。我们不必等待新的具体 AI 法规来告诉我们该做什么和如何行为。至少在涉及个人数据时,GDPR 对其如何使用及其用途已经非常明确,无论上下文如何。
法律对此有何规定?
与版权问题不同,版权问题可能需要根据新技术重新解释法规,但数据保护则不能如此。数据保护在数字时代发展起来,并试图规范在线服务提供商的行为。因此,不能避免应用现有法规和遵守现有标准。是否以及如何做到这一点是另一个问题。
在这里,有几个事项需要考虑:
1. 同意是一种义务,而不是选择。
如果不在用户实际开始使用工具之前告知他们个人数据和模型输入将用于开发新模型和改进现有模型,这是一大红旗。基本上是最红的那种。类似于收集 cookie 同意的同意弹窗是一个必须,而且是一个容易编程的。
另一方面,“支付或跟踪”(或在 AI 模型背景下的“支付或收集”)的概念,即用户决定是否愿意让 AI 开发者使用他们的数据,这一想法受到激烈争议,几乎无法合法实施。主要原因是,用户仍需自由选择接受或拒绝跟踪,这意味着价格必须相对较低(服务必须非常便宜),才能证明选择是自由的。更不用说,你必须履行承诺,不收集任何订阅用户的数据。由于 Meta 最近已经转向这一模式,数据保护机构也因此收到了一些投诉[5],因此有趣的是,欧盟法院将如何裁定此事。然而,当前,依赖合法同意是最安全的方式。
2. 隐私政策需要更新
提供给数据主体的信息需要更新,以包括整个 AI 系统生命周期中的数据处理。从开发、测试到部署。为此,所有复杂的处理操作需要转化为通俗易懂的语言。这绝非易事,但这是不可避免的。虽然同意弹窗不是合适的地方来做这件事,但隐私政策可能是。只要隐私政策直接链接到同意弹窗,就可以了。
3. 发挥创造力
翻译复杂的处理操作本身就是一项复杂的任务,但对于实现 GDPR 透明度标准来说绝对必要。无论你是想使用图形、图片、测验还是视频,你都需要找到一种方式来向普通用户解释他们的数据到底发生了什么。否则,他们的同意永远无法被视为知情和合法。因此,现在是时候动动脑筋,挽起袖子,投入到规划中去了。[6]
图片由Amélie Mourichon拍摄,来源于Unsplash
[1] Fred D. Davis,《感知有用性、感知易用性与信息技术用户接受度》,MIS 季度刊,第 13 卷,第 3 期(1989 年),第 319–340 页,www.jstor.org/stable/249008?typeAccessWorkflow=login
[2] Christophe Carugati,《平台监管者面临的“支付或同意”挑战》,2023 年 11 月 6 日,www.bruegel.org/analysis/pay-or-consent-challenge-platform-regulators。
[3] OpenAI,《隐私政策》,openai.com/policies/privacy-policy
[4] OpenAI,3 月 20 日 ChatGPT 停机:发生了什么,openai.com/blog/march-20-chatgpt-outage
[5] noyb,noyb 对 Meta 提起了关于“支付或同意”的 GDPR 投诉,noyb.eu/en/noyb-files-gdpr-complaint-against-meta-over-pay-or-okay
[6] untools,六顶思考帽,untools.co/six-thinking-hats
数据分析变得简单:使用 LLMs 自动化繁琐任务
原文:
towardsdatascience.com/data-analysis-made-easy-using-llms-to-automate-tedious-tasks-bdc1fee552d5
 [外链图片转存中…(img-OEWW9dcD-1726761704323)] Jye Sawtell-Rickson
[外链图片转存中…(img-OEWW9dcD-1726761704323)] Jye Sawtell-Rickson
·发表于数据科学前沿 ·阅读时长 11 分钟·2023 年 4 月 30 日
–

一幅高质量的数字艺术作品,展示了一个能够进行技术编码、写出精彩文稿和进行战略思考的机器人(作者创作,使用 DALL-E)。
数据分析既具挑战性又有回报。从清理杂乱的数据集到构建复杂的模型,总是有做不完的工作,时间却总是不够。但如果有一种方法可以简化和自动化一些常规任务,从而腾出更多时间进行战略思考和决策呢?这就是 LLMs 的作用所在。
大型语言模型(LLMs)是可以协助处理各种自然语言处理任务的 AI 语言模型,从生成文本到回答问题。而事实证明,它们也可以成为数据分析师的宝贵工具。在本文中,我们将探讨如何在日常工作中使用 LLMs,并展示 AI 如何帮助你更聪明地工作,而不是更辛苦。
让我们直接进入正题。
注意:这些系统还不是一个完整的分析解决方案,能够取代你。但请继续关注这个领域的进展。
LLMs 如何提供帮助
LLMs 可以作为 AI 驱动的聊天机器人,帮助简化和自动化与数据分析相关的任务。凭借其先进的能力,LLMs 可以协助处理各种任务。我将这些任务分为三个大类:
-
技术:此类别包括一些最常见的应用,通常涉及编码,包括编写代码和文档、清理数据、回答编码问题、运行数据分析和数据可视化。
-
软技能:此类别涵盖了通常成为成功数据分析师所需的软技能。AI 可以帮助起草文件以传达发现结果、从合作伙伴处收集数据需求和总结会议记录。
-
战略性: 数据分析师可以提供的最有价值的部分可能是他们的战略思维,这也可以通过 AI 得到增强。这包括头脑风暴分析内容、创建广泛的理解框架、改进和迭代分析方法以及作为一般的思维伙伴。
将这些付诸实践可以在你作为数据分析师的工作中节省大量时间和精力。
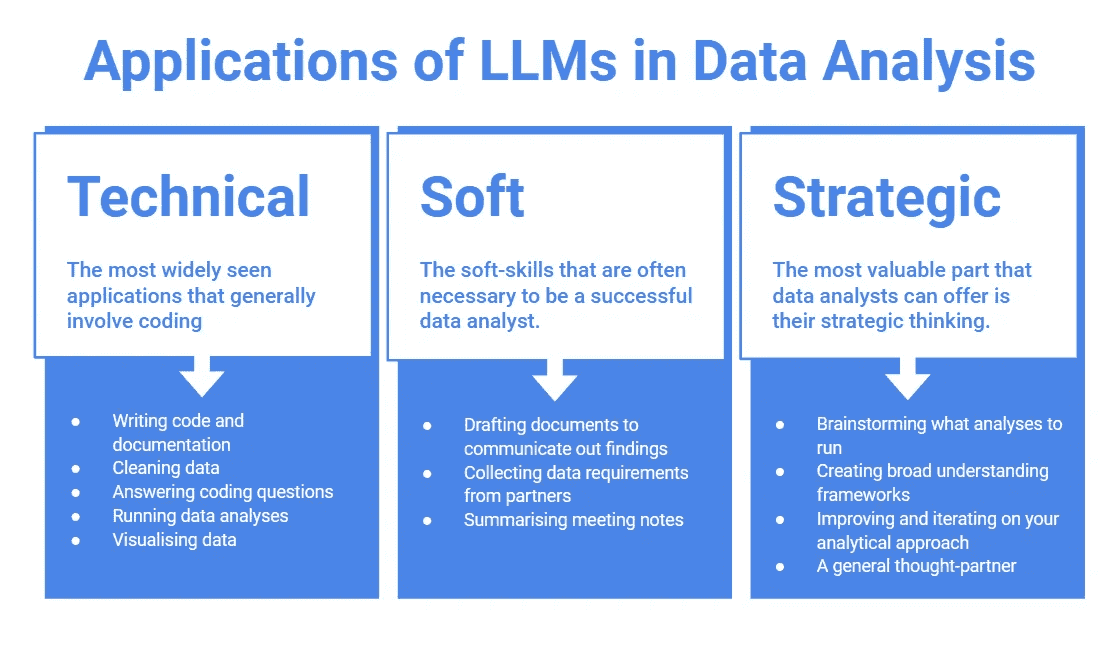
(作者创作)
让我们探索这些示例,看看今天的工具有多么强大和灵活。
使用 LLMs 的示例
本节将包含 LLMs 应用的示例。这些示例大多用不同的格式标明,以突出响应,否则你可能会将其与我的写作混淆!
在本文中,当我们提示 LLM 时,我们将使用Spotify 和 YouTube 歌曲数据集中的一个摘录,该数据集包括列信息和数据集的前 20 行。将来,LLM 可能直接访问数据集,以及执行数据集上的代码的响应,以消除如此小样本的限制。
技术高手
在这篇文章中可以看到,经过代码库训练的 LLMs 是熟练的编码人员。这意味着它们可以轻松解决常见的技术数据分析任务。它们在需要少量上下文的任务上表现出色,技术任务通常属于这一范畴。
数据分析师最基本的任务之一是执行探索性数据分析(EDA)。LLMs 能够编写 Python 代码来探索数据集,并输出相应的图像。以下引用文本包含 LLM 在提示进行 EDA 时返回的响应:
-
读取 csv 文件并显示示例: “
df = pd.read_csv("filename.csv")df.head()” -
识别感兴趣的列并进行探索: “按艺术家分组数据,检查每位艺术家的歌曲数量。
df.groupby('Artist')['song name'].count()” -
创建图表: “创建舞动值列的直方图以查看分布。
plt.hist(df['danceability'], bins=20)”
这些示例相当基础,但 LLMs 可以进一步扩展,提供其他 EDA 方法。在这种情况下,它们能够提供异常值检测和聚类等进一步探索数据的方法。
下面是给出的响应示例。通读这些内容,它们绝对可以作为初级分析师的工作,识别出一些见解,例如:
“Gorillaz 的歌曲的舞动值通常高于 Red Hot Chili Peppers 的歌曲。”
“这些数据涉及两位艺术家的歌曲,Gorillaz 和 Red Hot Chili Peppers。Gorillaz 在给定的数据中有 9 首歌曲,而 Red Hot Chili Peppers 有 4 首歌曲。”
歌曲的舞蹈性和能量值在 0.559 到 0.938 和 0.345 到 0.938 之间变化。Gorillaz 歌曲的舞蹈性值通常高于 Red Hot Chili Peppers 的歌曲。Gorillaz 歌曲的能量值也往往高于 Red Hot Chili Peppers。
歌曲的调性范围从 1.0 到 11.0,没有明显的模式或趋势。
(完整输出)
创建表格时,为列和整体表格编写良好的描述可能会有些麻烦。虽然这是好的实践,但经常被忽视。LLMs 可以通过猜测表格的上下文来完成这项工作,或者更好的是,当提供一些上下文时,LLMs 可以编写这些描述。
这张表格似乎展示了两位不同艺术家——Gorillaz 和 Red Hot Chili Peppers——的各种歌曲的信息。表格中的每一行代表一首不同的歌曲,并为每首歌曲提供了 10 列信息。以下是各列的描述:
索引:这只是一个整数索引,似乎是表中每首歌曲的唯一标识符。
艺术家:此列列出了创作歌曲的艺术家。
链接:此列提供指向艺术家在 Spotify 上页面的链接。
歌曲名称:此列列出了歌曲的名称。
专辑名称:此列列出了歌曲所属专辑的名称。
专辑:此列指示该行是否表示专辑或单曲。
来源标识符:此列似乎是每首歌曲的唯一标识符,可能是 Spotify 特有的。
舞蹈性:此列提供一个从 0 到 1 的评分,表示歌曲适合跳舞的程度。
能量:此列提供一个从 0 到 1 的评分,表示歌曲的能量水平。
调性:此列提供一个从 0 到 11 的数字,表示歌曲的音乐调性。
总体而言,这张表格似乎是一个歌曲数据的集合,包括有关艺术家、专辑和每首歌曲的各种音乐特征的信息。
这些结果的一些令人印象深刻的部分是,大型语言模型(LLM)查看了数据样本,发现“Key”列并不是行的某个关键,而是歌曲的音乐调性,“Album”列描述了它是否为专辑或单曲。典型的分析师仅凭列名无法猜测这些信息,需要花费时间进行基本的探索性数据分析(EDA)来确定数据源可以提供的值——LLMs 节省了这段时间。
今天,增强智能在数据分析中的主要应用场景是技术问题回答,例如在 Stack Overflow 上。然而,大型语言模型(LLMs)通常更具优势,它们提供特定用例和变量的正确代码,并能够给出更深入的回答或后续教程。
例如,绘制词云是一个时不时会需要的任务,但很难记住绘制词云所需的确切库和代码。你可以简单地询问 LLM,它会愉快地返回给你可用的代码。下面是关键摘录:
# 生成词云
wordcloud = WordCloud(width = 800, height = 800, background_color ='white', stopwords = set(), min_font_size = 10).generate(wordcloud_text)
我意识到这只是使用了一个单词列表,但我有单词计数,所以我很快跟进了“我可以输入加权单词吗?” LLM 重新编写了代码:
# 生成词云
wordcloud = WordCloud(width = 800, height = 800, background_color ='white', stopwords = set(), min_font_size = 10).generate_from_frequencies(weighted_words)(完整输出)
这在没有 Stack Overflow 的帮助下是不可能完成的,也节省了大量的谷歌搜索或查找旧代码的时间。
正如可以看到的那样,LLM 在技术问题上非常出色,可以节省数据分析工作流程中的时间,但它们还具备什么能力呢?
AI 的软性方法
软技能可能被忽视为数据分析的一个要求,但它们对于确保任何分析对业务有用至关重要。
任何数据分析师都知道,理解你合作伙伴实际想要的数据是最困难的部分之一。这可能会以多种方式出现问题,从合作伙伴对某事的称呼错误,到在你返回第一部分时扩展他们的需求,再到要求错误的数据来支持他们想要得出的结论。由于其对话性质,LLM 在从合作伙伴那里收集需求方面非常出色。下面是一个对话示例。
“我需要你提取最新的动画贴纸数字。”
很好,谢谢你的请求!只是为了澄清,当你说“动画贴纸数字”时,你能否提供更多关于你具体是什么意思的信息?
你是在寻找已创建的动画贴纸的数量数据吗?还是对动画贴纸的使用指标感兴趣,比如它们被查看或下载的次数?
另外,你能否指定一下你感兴趣的时间范围?你是在寻找特定日期、周或月的最新动画贴纸数字数据吗?最后,你希望我以任何方式对数据进行分段吗,比如按贴纸类别或按用户人口统计?
实际上,可能很难让你的合作伙伴先去与 LLM 聊天,但 LLM 对于确定在开始项目工作之前是否有需要进一步澄清的事项非常有用,未来也将直接集成到分析解决方案中。
一旦需求被收集并完成分析,发现必须反馈回来。LLMs 已经有帮助作者更快地生成内容并提高质量的记录。同样,LLM 可以帮助准备总结分析工作的文档或准备演示文稿。一些 LLMs 特别擅长的任务是基本的介绍和结论,以及文本摘要。
“基于这次 EDA,歌曲推荐服务可能会考虑将更多的 Gorillaz 歌曲添加到推荐算法中,并优先考虑舞曲性和能量值较高的歌曲,因为这些歌曲在用户中似乎很受欢迎。”
(完整输出)
关于使用 LLMs 进行写作的一些技巧可以在这篇文章中找到,但还有很多其他技巧,并且随着我们不断探索如何最好地使用 LLMs,还会有更多的技巧被添加。
我们已经看到 LLMs 如何解决技术任务并协助处理许多“软”任务。这对于提高分析师的工作流程已经很棒,但我们能否更进一步呢?
大命令
战略思维是分析师能够为公司提供的最高价值之一。这可以通过 LLMs 得到提升。一些实现这一目标的方法包括头脑风暴要进行哪些分析,创建广泛的理解框架,改进和迭代你的分析方法,并作为一个一般的思维伙伴。
让我们从头脑风暴开始。你可能被分配了一个通用的任务——“更多地了解你的客户”。你可以进行哪些分析?这些分析会导致什么结果?理想情况下,你会与同行进行头脑风暴,但这并不总是可能,因此你可以与 AI 进行头脑风暴。
当被问及我们应该进行什么分析以更好地了解客户时,输出的分析包括:“客户细分,RFM 分析,购物篮分析,流失分析,客户生命周期价值。” 以及一些预测结果:
“这些分析的结果将取决于你发现的具体见解。例如,你可能会发现你的最有价值的客户是年龄较大、富有且对特殊烹饪产品感兴趣的女性。这可能会导致你开发更多针对这一人群的产品,并投资于能够引起她们共鸣的营销活动。”
(完整输出)
这是一个很好的起点,可以确保你覆盖所有的空白,这在独自工作时可能很困难。LLMs 还可以提供有关框架的建议。你可能会想知道如何在接下来的几年里发展你的业务,以及如何衡量这一点,那么:
“有几种增长框架可以用来理解如何在未来三年内增加销售。以下是三种流行的框架:
AARRR:该框架代表 Acquisition、Activation、Retention、Referral 和 Revenue。它是由 Dave McClure 开发的五步框架,通常用于初创公司圈子。AARRR 框架帮助公司了解客户生命周期的不同阶段,并如何优化每个阶段以推动增长。
RACE:该框架代表 Reach、Act、Convert、Engage。它是由 Smart Insights 开发的四阶段框架,专注于数字营销。RACE 框架帮助公司了解如何优化数字营销工作以推动增长。
3HAG:该框架代表三年内高度可实现目标。它是由 Shannon Susko 开发的战略规划框架,帮助公司设定并实现雄心勃勃的增长目标。3HAG 框架包括定义一个 BHAG(宏伟目标),然后在三年的时间里将其分解为更小的、可实现的目标。
在决定使用哪个增长框架时,考虑公司独特的情况和目标非常重要。AARRR 和 RACE 是更具战术性的框架,专注于优化客户生命周期或数字营销工作的特定阶段,而 3HAG 是一个更具战略性的框架,专注于设定雄心勃勃的增长目标。
正如你所见,回应是有帮助的,完全可以代替你期待从团队分析师那里得到的回应。
使用哪个 LLM?
撰写本文时,实际上只有一个 LLM 能够很好地完成上述所有任务,那就是 OpenAI 的 ChatGPT。它是第一个普及 LLMs 的产品,仍然是市场上最强大的产品之一,并且是免费的(提供订阅选项)。
随着 AI 领域变化的步伐加快,几个月后这些信息可能就不再准确,因此值得注意的是,市场上还有许多其他竞争者。例如,Google 正在开发他们的产品 Bard,预计其表现与 ChatGPT 相似。此外,还有许多开源替代方案可以考虑。虽然这些通常不具备相同的质量,但预计会持续改进,缩小与商业运营模型之间的差距。
使用 LLMs 的有效技巧
作为数据分析师,充分利用 LLMs 有一些技巧可以遵循。首先,给 LLMs 提供清晰且具体的输入非常重要。这意味着使用恰当的语言,避免模糊,并在必要时提供上下文。此外,LLMs 可以处理结构化和非结构化数据,因此值得尝试不同的输入格式,以找出适合特定任务的最佳格式。最后,重要的是要记住 LLMs 只是工具,而不是替代人工分析的手段。虽然它可以帮助自动化一些例行任务,但仍需由数据分析师来解释结果并根据数据做出明智的决策。
现在有很多文章讨论如何使用大型语言模型(LLMs),例如这篇,这是一个不断发展的研究领域,因此要继续学习!
结论
总之,大型语言模型是提高分析工作效率的绝佳工具,甚至能帮助你成长和学习新事物。大型语言模型可以帮助解决技术问题,发展软技能,并提升你的战略思维。与人工智能合作是未来的趋势,因此现在是学习如何将其整合到工作流程中的最佳时机,以免被落在后头。
数据分析师数据清洗指南
原文:
towardsdatascience.com/data-analyst-guide-to-data-cleaning-6409159ebf3
如何处理不同类型的数据清洗
 [外链图片转存中…(img-BzyONWpX-1726761704324)] Vicky Yu
[外链图片转存中…(img-BzyONWpX-1726761704324)] Vicky Yu
·发表于 Towards Data Science ·阅读时间 6 分钟·2023 年 8 月 4 日
–

虽然有很多资源可以学习技术技能,但很少有深入讲解如何清洗数据的资源——这是数据分析师必备的技能。你可能会认为可以应用相同的规则来清洗数据,但情况并非总是如此。今天,我想分享我作为数据分析师多年来学习到的,关于如何处理不同类型的数据以进行数据分析和报告的经验。
数字值
我所说的数字值是指那些对数据分析和报告有用的值。一个好的经验法则是看平均值是否有用。例如,数字订单号字段的平均值是没有意义的。然而,平均收入金额是有用的。
作为数字字段存储的数字
对于保存在数字字段中的数字,请应用以下清洗规则:
- 计算最小值、最大值、中位数、99 百分位和平均值。如果最小值是负数,但值应该是零或更高,则在适用的情况下将其替换为零。在下面的示例销售数据中,注意第 13 行的中位数为**$800与第 12 行的平均值为$20,560**之间的巨大差异。如果中位数和平均值或最大值和 99 百分位之间差异很大,我通常会检查异常值,特别是当我不熟悉数据时。如果你报告包括第 4 行$100,000 的平均销售额,它将是$20,560,而不是$560,如果你排除了$100,000。这就是为什么检查异常值并排除它们是好的,尤其是当你计划报告平均值或使用数据来构建机器学习模型时,因为异常值可能会影响模型结果。根据最重要的字段优先安排你的时间,因为你可能有数十个字段需要检查,检查所有字段会非常耗时。
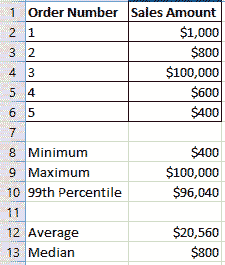
作者创建的示例数据
2. 计算缺失值和非缺失值。如果缺失值的数量超过非缺失值,那么这个数值字段在你的分析中可能不可用。例如,如果你有 1,000 条记录,但其中 900 条缺失,那么 100 条非缺失值在你的分析中可能不会有用。如果缺失值的数量少于非缺失值,则在适用的情况下将缺失值替换为零。如果缺失值意味着除零以外的值,则用你认为更合适的值替换,如中位数或平均数,前提是你已经去除了异常值。例如,我曾经遇到过一天的缺失DAU(每日活跃用户)数据。由于 DAU 根据一年中的时间有所不同,我用前 7 天的平均值来替换缺失那一天的 DAU。
作为字符串字段存储的数字
数值可以作为字符串值加载到数据库中,因为它们包含需要移除的字符,才能转换为数字。识别这些字符串字段的经验法则是问一下平均值是否有用。
这些字符串值的例子包括带有货币的销售金额,如$100.55 或包含逗号的数字,如 1,000。在这些情况下,你需要移除字符值,即删除货币符号以转换为 100.55,删除逗号以转换为 1000,然后将字符串值转换为数字。字符串值转换为数字后,应用上述数据清理规则,处理作为数值字段保存的数字。
字符串值
对于字符串值字段,应用以下清理规则:
-
按表中的 主键 检查重复项。主键通常是唯一标识符,如客户 ID 或使行在表中唯一的字段组合。在进行数据分析时,您需要确保数据源中没有重复项,因为这可能导致报告错误的数字。
-
计算 空值 和非空值的数量。确定是否可以用字符串值替换空值。有时我会将空值替换为‘N/A’或‘None’以用于报告,但这取决于您的要求。
-
计算每个唯一字符串值的行数,并按降序排列。查找具有相同含义的字符串值,并将其更改为相同的值。
在下面的示例 SQL 查询中,第 1 到第 7 行,我计算了每个item_name 值的行数,并按降序排列。由于可能有数百个唯一的字符串值,因此要集中处理行数最多的唯一值,优先清理这些,因为更改行数较少的值会花费过多时间,并且可能不会影响分析结果。
SQL 结果第 1 到第 3 行显示,item_count 为 33 的 apples,19 的 apple 和 17 的 Apples。可以将 Apples、apple 和 apples 更改为 apple。第 4 行和第 5 行中的 strawberries 和 strawberry 可以更改为 strawberry。数据清理后,第 1 行和第 2 行显示的 item_count 为 apple 69 和 strawberry 26。
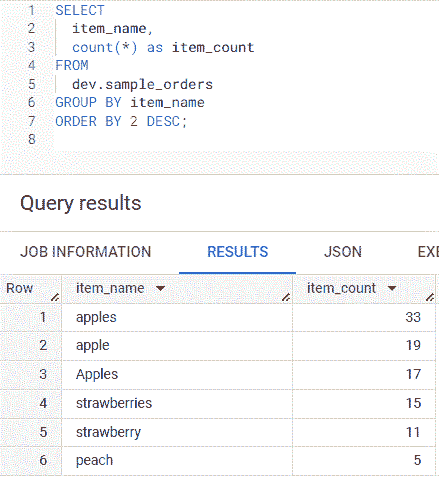
作者创建的清理前唯一 item_name 值计数的截图
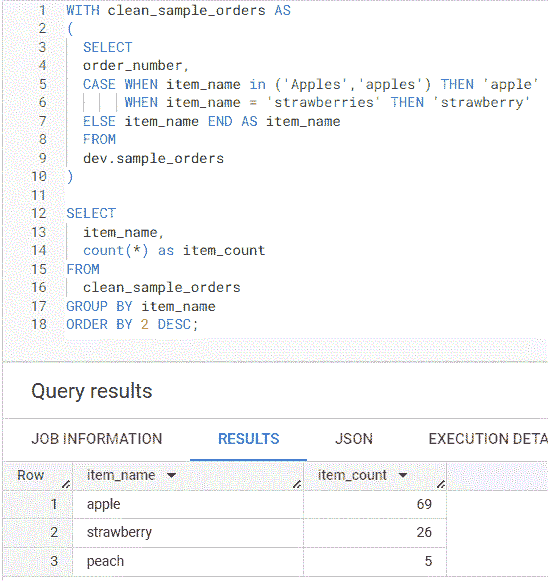
作者创建的清理后唯一 item_name 值计数的截图
搜索并根据需要移除特殊字符。这在非英语文本或自由格式文本中很常见,其中制表符和回车符可能是加载到数据库中的文本的一部分。大多数字符串字段不包含特殊字符,但如果在查询特定字符串值时没有返回任何行,则特殊字符可能是原因。
日期或日期时间值可以作为字符串值加载。确认字段中的日期值格式相同,并根据需要将其转换为日期或日期时间字段,以便可以使用日期函数。
日期和日期时间值
对具有日期或日期时间字段的表应用以下数据清理规则:
-
检查那些每个日期或日期与其他字段组合应仅有一行的表中的重复项。例如,日活跃用户(DAU)表是每日活跃用户的计数,每天应仅有一行。另一个例子是按国家的收入,其中日期和国家组合使行在收入表中唯一。我曾经继承了一个 ETL 作业,该作业没有删除更新日期相同的数据。我不小心重新运行了同一天的作业,并在收入表中引入了重复项。我只有在运行了重复检查后才意识到这一点,否则我会向利益相关者报告过多的收入。
-
在连接多个含有日期时间值的表时,请确认日期时间值处于相同的时区。我曾经需要创建一个报告,展示发送电子邮件后 24 小时内用户升级的数量。电子邮件表的日期时间是 CST(中央时间),但升级表的日期时间是 UTC(协调世界时间)。UTC 比 CST 快 5 小时。如果我仅仅检查 CST 的电子邮件发送日期时间后的 24 小时,我会错过在电子邮件发送后升级的 5 小时用户。幸运的是,大多数数据库都有一个 SQL 函数叫做 CONVERT_TIMEZONE,用于将日期时间转换到不同的时区。请查看你的数据库文档以确认。
最后思考
虽然数据清洗不是数据分析师,包括我自己,在工作中最喜欢的任务,但我希望我所介绍的方法能在你下一次需要为项目清洗数据时帮到你。祝数据清洗愉快!
注意:以上所有 SQL 查询都在 BigQuery 沙盒 上运行,该沙盒对任何拥有 Google 账户的人都是免费的。
你可能还会喜欢……
对实际案例的深入分析
towardsdatascience.com ## BigQuery SQL 函数用于数据清洗
适用的用例和函数
towardsdatascience.com ## 你在学校里学不到的数据知识
如何使用不完美的数据获得可用的结果
towardsdatascience.com
数据即产品:从概念到现实
原文:
towardsdatascience.com/data-as-a-product-from-concept-to-reality-b2a853712250
创建有效数据产品的蓝图
 [外链图片转存中…(img-l2Wzrqne-1726761704325)] Louise de Leyritz
[外链图片转存中…(img-l2Wzrqne-1726761704325)] Louise de Leyritz
·发表于Towards Data Science ·阅读时间 11 分钟·2023 年 4 月 12 日
–
数据即产品 — 图片由Castor提供
数据即产品的方法最近获得了广泛关注,因为公司希望最大化数据价值。
我坚信数据即产品的方法是我们为创造更好的数据体验所需的革命性变革,这是我心中珍视的概念。
关于数据体验的简要说明,以防你需要赶上进度:
数据曾经是技术团队的领域。但现在不再是。如今,数据驱动着公司内部的所有运营功能:销售、财务、营销、运营等。
商业用户已经成为数据用户,他们的体验即是数据体验。数据体验是这些领域专家在日常使用数据来增强工作能力时的感受。
截至今天,数据体验仍然不尽如人意。即使我们能产生高质量的数据,仍然难以找到、访问和理解。糟糕的数据体验导致业务团队对数据失去信任并失去兴趣。如果数据不能促进更好的决策,那收集数据又有什么意义呢?
数据即产品的方法简单却有效。它涉及思维方式的转变,将数据用户视为客户,突显出优先考虑其满意度的必要性。通过更好的概念化和呈现,这一方法力求提供卓越的数据体验。虽然我们会在后续详细探讨这一方法,但关键要点是将数据视为产品意味着将数据消费者放在首位。
我们如何在实践中实现这一转变?要实施数据即产品的方法,你需要改变你对生成和提供数据的方式。也就是说,你需要在生成数据和在数据生命周期内应用产品管理思维。希望将数据视为产品的公司往往会关注一个方面,而忽视另一个方面。
本文将带你了解这两个步骤:
-
在数据创建中利用产品管理思维
-
将产品管理应用于数据呈现和交付
在本文中,术语“数据产品”和“数据即产品”将交替使用,指的是数据被视为产品。
I. 在数据创建中利用产品管理思维
数据即产品的概念始于最基础的层面——你的思维方式。不仅要理解这一点,还要在整个组织中嵌入数据即产品的思维。
将数据视为产品意味着将传统产品开发中使用的相同原则和实践应用于你的数据项目。
那么,在实际生活中将数据视为产品到底意味着什么?埃里克·布罗达解释了数据产品是通过将产品思维应用于数据领域而产生的,正如下图所示。
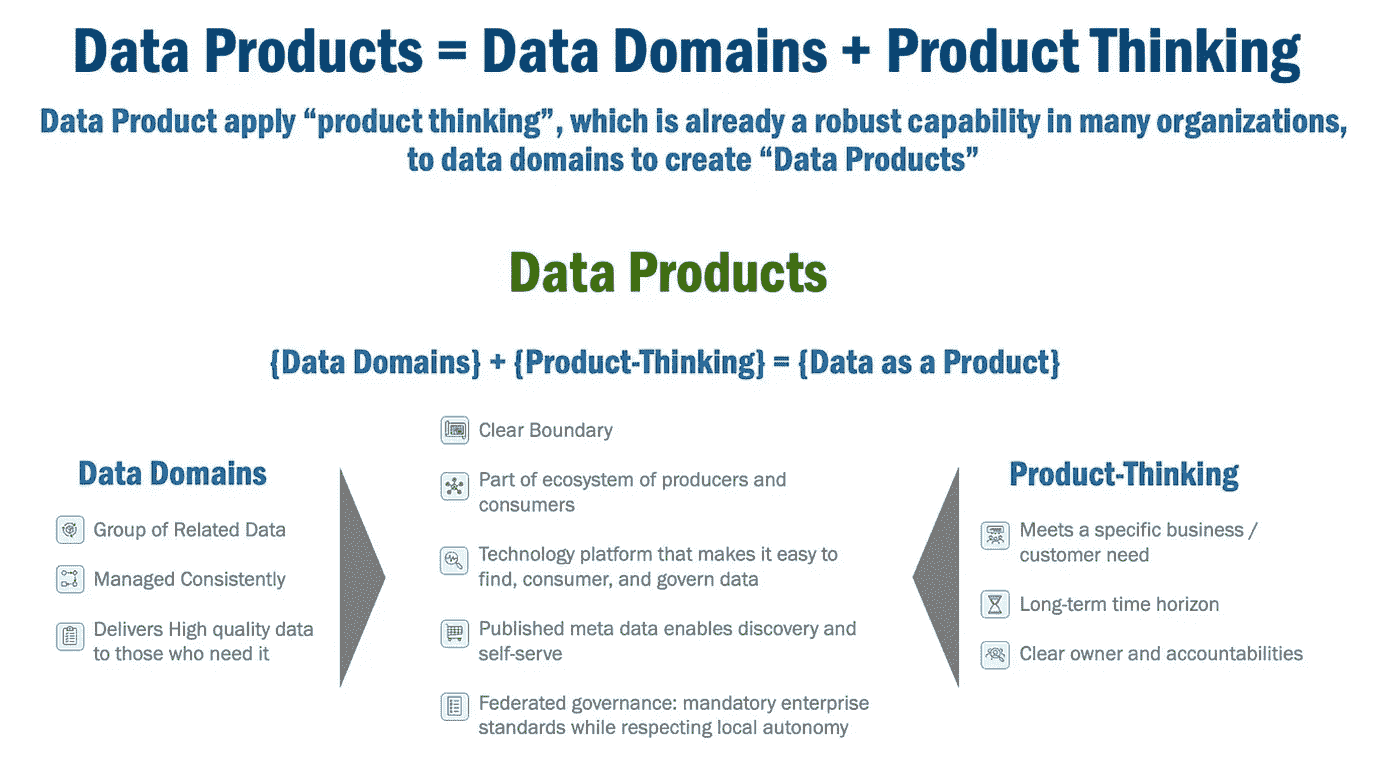
图片由埃里克·布罗达提供
现实生活中的产品:
-
分配给一个明确的负责人进行产品开发和管理。
-
遵循具体的业务和客户需求,为特定目的和目标受众量身定制。
-
以长期视角进行开发,由产品负责人制定持续改进和成功的计划。
实际操作中这意味着什么?
威廉·安吉尔,Caribou的数据工程高级技术产品经理,建议在以产品管理思维处理分析时,在数据创建阶段分配额外时间是很重要的。与其直接跳入构建仪表盘或预测模型,不如首先考虑谁将使用它,以及它将如何对他们产生价值。
“很多人认为在构建项目时这种方法是自然而然的。但很多时候,情况却是车子在马前面,我们使用模型是因为它们的准确性,而不是它们的业务影响。”威廉·安吉尔,数据工程高级技术产品经理
通过采用产品管理思维,可以确保所创建的分析对业务及其用户具有实际价值。
在数据创建之前采用产品管理思维是提供可靠数据产品的初始阶段。然而,仅此是不够的。在现实中,一旦产品创建完成,它还需要被包装和呈现给客户。这是下一节的主题。
II. 将产品管理应用于数据展示和交付
许多组织在数据生产阶段引入了产品管理思维,然后就不再关注数据。但如果你把数据当作产品来看待,你必须考虑数据的整个生命周期。
让我们考虑一下实体产品的生命周期。一个实体产品会被创建、使用,最终被丢弃。如果你要以可持续的方式创建这个产品,你需要考虑整个生命周期,并计划安全使用、存储以及产品生命周期结束时的最终处置。数据的背景下又意味着什么呢?
“当涉及到数据时,必须考虑如何存储和记录数据,以及数据将如何被利用。” 数据工程高级技术产品经理 William Angel
为确保数据产品得到有效管理和利用,应考虑一些特定的特征。这些特征来自 Zhamak Dehghani 关于数据网格的工作。我们在这里简要介绍它们,并解释如何在实践中实现这些特征。
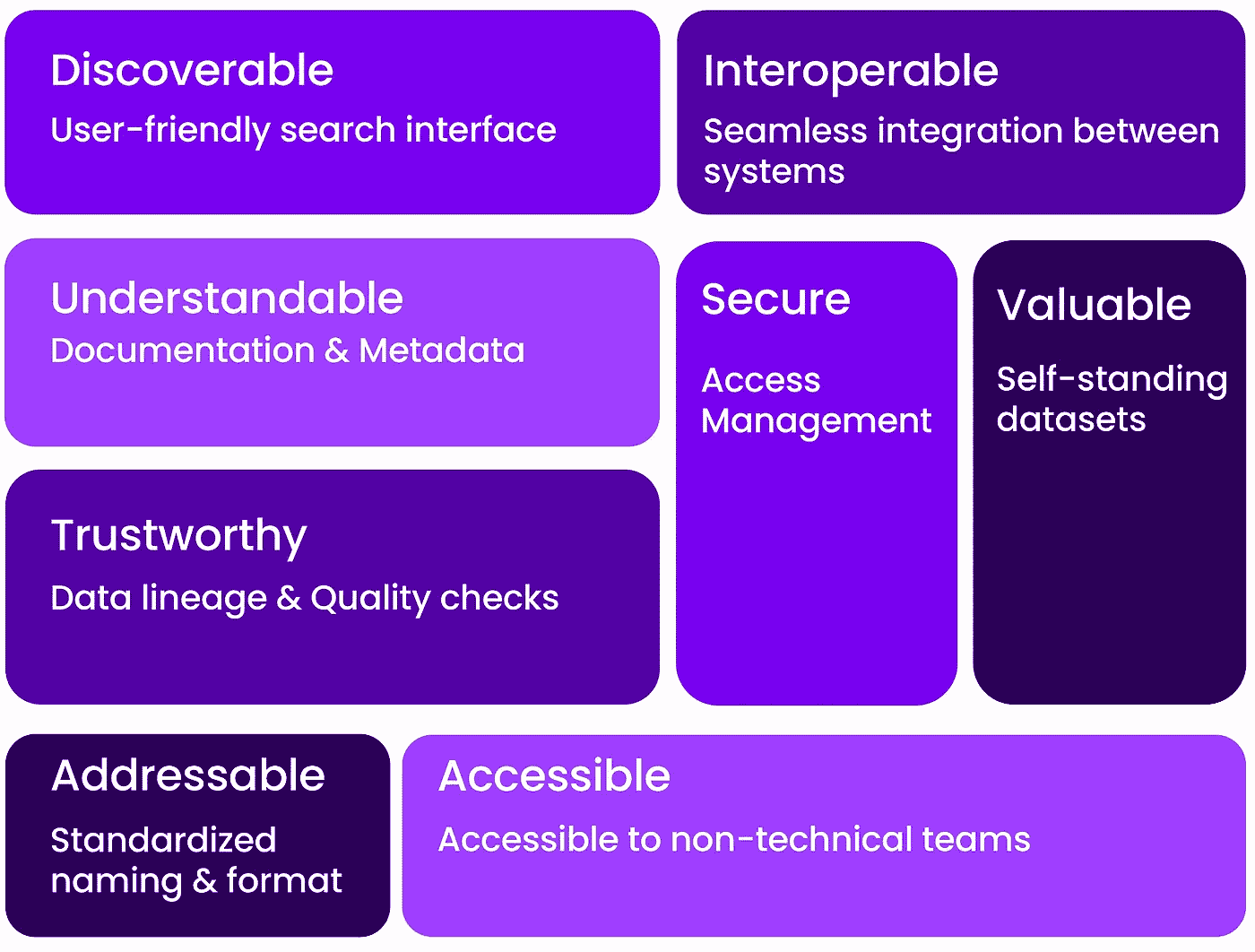
可靠数据产品的特征——图片来源于Castor
可发现性
可靠的数据产品的第一个特征是可发现性。一个很好的指标是,当数据团队不再被视作数据目录时,即数据消费者能够自主找到他们数据问题的答案。
这意味着公司里的每个人都知道在哪里以及如何找到适合他们特定项目的最佳数据。即使数据是混乱的,即使有 20 个表格具有相同的名称。
那么,“好”的标准是什么呢?当团队能够轻松浏览混乱的数据,并且毫不费力地识别出哪些是最受欢迎且最新的表格,而无需询问同事或上司时,数据就具备了可发现性。
你有两种利益相关者在寻找数据:一种是寻找特定数据集的人,另一种是浏览文档以了解数据全貌的人。数据应该对这两种人都具有可发现性。
确保这一点的最简单方法是将数据目录插件集成到你的数据堆栈上,以便于搜索和探索。如果你没有数据目录,你的数据文档可能会散布在不同的工具中:
-
用于一般知识和入职培训的 Wiki 页面
-
用于描述和标签的代码库(如果你使用代码注释)
-
用于管理问题和请求的 JIRA 或 Gitlab
-
用于部落知识的 Slack 频道
即使你还不能将这些与数据目录合并,你至少可以制作一个主页,汇集所有有用的链接。

使用 Notion 构建数据文档入口 — 图片来自于Castor
可理解的
人们理解数据集的前提是意识到这些数据将满足的需求、内容和位置。没有上下文的数据是毫无价值且危险的。一旦找到相关的数据集,你完成了 10%的工作。现在,你需要通过一系列问题的检查清单,以确保你理解你正在使用的数据。如果你不能回答以下问题,你就不理解你的数据。
-
数据来源于哪里?
-
数据流向哪里,并且流入了哪些下游表格?
-
谁拥有它/谁对它负责?
-
在我的领域中,某个字段的含义是什么?
-
为什么这很重要?
-
这个表格最后一次更新时间是什么时候?
-
这些数据的上下游依赖关系是什么?
-
这些数据是生产质量的数据吗?
当所有相关知识都与数据关联时,人们才能真正理解数据。理解是主观的。机器学习工程师会以不同于数据分析师的方式来处理数据集。这就是为什么所有的理解都需要将所有相关知识层与数据集关联起来。
应用良好的文档原则本质上意味着为数据提供正确的上下文。如上所述,传统文档帮助数据用户理解数据集的目的和字段的含义。在此基础上,你可以以显著的方式指定数据集所有者,让数据用户知道谁负责某个数据集。
最后,数据血缘是跟踪数据历史的过程,当数据经过一系列转换,如数据提取、清洗、丰富和存储时,它有助于理解数据元素的来源、转化和依赖关系。血缘功能帮助数据用户回答诸如“这些数据的上下游依赖关系是什么?”这样的问题。
可靠的
数据产品应当可靠和值得信赖。利益相关者应对其可用性感到有信心。
数据信任可以通过提供关于数据使用和数据来源的完整透明度来实现,这需要强大的血缘功能。它有助于理解数据元素的来源、转化和依赖关系。血缘功能帮助数据用户回答诸如“这些数据的上下游依赖关系是什么?”这样的问题。
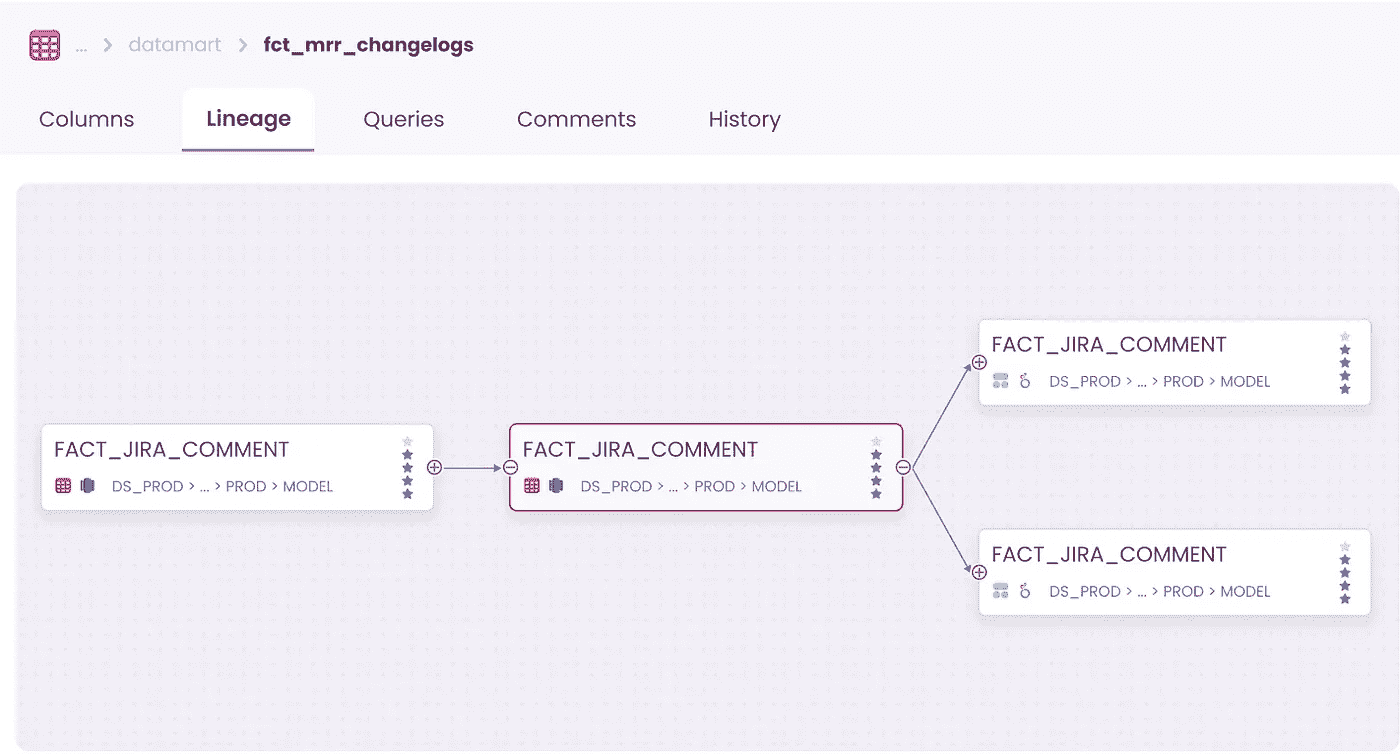
数据血缘可视化 — 图片来自于Castor
另一种建立信任的方法是围绕透明度构建你公司内人员使用数据的透明度。这使得员工可以学习专家的最佳实践。
当人们知道可信赖的同事已经查询和使用了数据时,他们可以更好地推断该数据集是可信的。获得社会验证,证明数据有价值,有助于建立数据信任。
另一种弥合信任差距的方法是遵守已批准的数据产品服务水平协议(SLA):
-
变化间隔和及时性
-
完整性
-
新鲜度、通用性和性能
这基本上指的是数据质量检查,数据必须通过这些检查。这些检查可以手动进行,也可以通过自动化工具进行,并涉及将数据与一套定义好的规则或标准进行验证,以确保其符合所需的质量标准。使这些质量检查对每个数据集都可访问,对于帮助用户理解数据非常有帮助。
可寻址性
数据产品应该有一个唯一的标识符或地址,使其可以被轻松访问和使用。
数据产品的可寻址性意味着为其提供一个独特、易于找到的位置,以便其他人可以访问它。可以把它想象成房子的街道地址。就像你需要一个具体的地址来找到房子一样,数据消费者需要一个独特的地址来访问你的数据产品。
地址应该遵循一套规则和标准,以便每个人都可以轻松找到它,并以相同的方式使用,无论他们是谁或使用什么系统。这使得人们能够轻松找到、使用和理解你的数据产品。
可访问性
当数据产品被称为“可访问”时,这意味着它们可以被用户轻松获取或到达。这可能意味着数据可以随时使用,或者获取数据的过程对于用户来说简单方便。
如果你要提供数据背景,应该通过正确的接口进行。并非所有团队成员都具有相同的技术专长,也并非所有团队都有相同的数据需求。
例如,如果你在 dbt 中记录数据,你不能指望市场团队去那里获取文档。背景信息应该在对业务团队友好的工具中提供。
安全性
数据产品必须安全以保护敏感信息这并不令人惊讶。不论数据如何处理,安全始终是一个问题。然而,对于数据产品来说,安全变得特别具有挑战性,因为它们必须既是可发现的又是可访问的。你如何在实施强安全措施的同时使其可访问呢?
管理隐私和安全风险可以通过实施一些关键策略来实现。为了保护个人信息,投资于适当的文档并建立明确的数据共享协议是很重要的。此外,实施访问控制和遵循数据最小化实践可以帮助降低安全风险,并确保敏感信息的安全。这些策略需要一整篇文章来解释。幸运的是,我们写了一篇。
确保数据共享、隐私和安全之间的兼容性 — 图片来源于Castor
可互操作
数据产品应该与其他数据产品和系统兼容,实现无缝集成。可互操作性意味着不同的数据产品可以协同工作并相互通信,而不会出现问题。
即使它们是由不同的人或组织创建的,也可以共享信息并一起使用。这使得人们更容易使用并从这些数据产品中受益。
为确保你的数据产品能够与其他产品良好配合,你需要遵循以下步骤:
-
使用常见且公认的数据格式和结构标准。
-
使用其他人可以轻松使用的开放数据格式。
-
编写清晰的说明和信息,告知他人如何正确使用你的数据产品。
-
为你的数据使用清晰的名称,以便他人可以轻松理解数据的含义。
-
测试你的数据产品与其他系统的兼容性,以确保其正常工作。
自身具有价值
数据产品应该为用户提供价值,即使在不与其他数据产品结合的情况下。
数据产品必须自身具有价值,因为如果没有价值,人们就不会使用它们。仅仅拥有数据是不够的 — 数据需要为用户提供实际价值。这种价值可以表现为洞察、知识或问题的解决方案。
为了使数据产品具有价值,数据产品经理(DPM)需要关注用户的需求和期望。在设计数据产品时,DPM 应该尝试弄清楚用户要解决什么问题,然后围绕这些问题设计解决方案。将数据生产者与业务战略对齐是确保数据能够为消费者提供洞察的最佳方式。
结论
为了创建数据即产品的方法,你需要转变思维方式,将数据视为需要生产、打包并提供给客户的产品。
这需要公司内部对数据生产方式进行新的思考。实际上,数据产品是将产品思维引入数据领域的结果。现实生活中的产品以用户为中心并具有明确的所有者。这两个来自产品管理的组件应该被引入数据领域,以构建可靠的数据产品。
但应用产品管理思维不应仅限于生产阶段。交付高质量数据产品的第二步是打包和展示数据,确保数据提供了合适的背景,使人们能够找到、理解和信任它。通过遵循这些步骤,你可以将数据转化为推动业务决策并提升整体数据体验的宝贵资产。
关于我们
我们撰写了有关利用数据资产的所有过程:包括现代数据堆栈、数据团队组成和数据治理。我们的博客涵盖了从数据中创造实际价值的技术和非技术方面。
在 Castor,我们正在为 Notion、Figma、Slack 一代构建一个数据文档工具。
想看看吗?联系我们,我们将向您展示一个演示。
最初发表于 https://www.castordoc.com.
数据一览:为数据分析创建动态仪表板
原文:
towardsdatascience.com/data-at-a-glance-creating-dynamic-dashboards-for-data-analytics-1dce62fc6638
使用 Tableau 构建互动数据可视化
 [外链图片转存中…(img-Y3n03ADp-1726761704326)] John Lenehan
[外链图片转存中…(img-Y3n03ADp-1726761704326)] John Lenehan
·发布于 Towards Data Science ·阅读时间 8 分钟·2023 年 11 月 20 日
–
图片由 Carlos Muza 在 Unsplash 提供
数据可视化是任何数据科学家工具箱中的核心技能。任何企业生成的数据量都是巨大的,及时的决策依赖于随时掌握所有相关数据和最新分析。许多组织通过使用自动化仪表板来完成这一关键的数据显示任务,例如使用 Power BI 或 Tableau。只要源数据定期更新,这些可视化工具就会自动生成所需的图表和图形,以跟踪所需的指标。
仪表板是综合叙事数据可视化方法的一个例子——用户可以自行探索数据,并为自己的目的获取洞见。这些类型的可视化允许观众自行研究数据并发现关键见解。像 Power BI 和 Tableau 这样的商业智能应用是这种叙事形式的典型例子,互动仪表板允许观众在最小的指导下深入数据。
有关叙事可视化和数据分析中不同叙事方法的更多信息,请参阅我下面关于使用数据为演示文稿创建叙事的文章:
如何使用叙事技巧来结构化你的数据展示
towardsdatascience.com
在这篇文章中,我想展示我使用 Tableau Public 创建的三个数据可视化示例。Tableau Public 是一个免费的服务,任何人都可以使用它来创建自己的交互式仪表板——但需要注意的是,所有生成的可视化都是公开可访问的(也可以购买许可证版,该版本更适合处理保密数据)。如果你想在自己的时间里探索数据,我在这里包含了我生成的所有仪表板的链接。
图片由 Luke Chesser 提供,来自 Unsplash
仪表板 1:专业薪资分析
我准备的第一个仪表板展示了不同经验水平、教育水平和工作领域的薪资指标。这些薪资数据来自 Glassdoor 的一小部分用户——原始数据集可以在 Kaggle 上找到 这里。这种类型的仪表板对于求职者和人力资源工作者特别有用,因为它快速展示了工作市场中的薪资范围和人口统计信息。要查看此仪表板中的数据,你可以访问 这里。
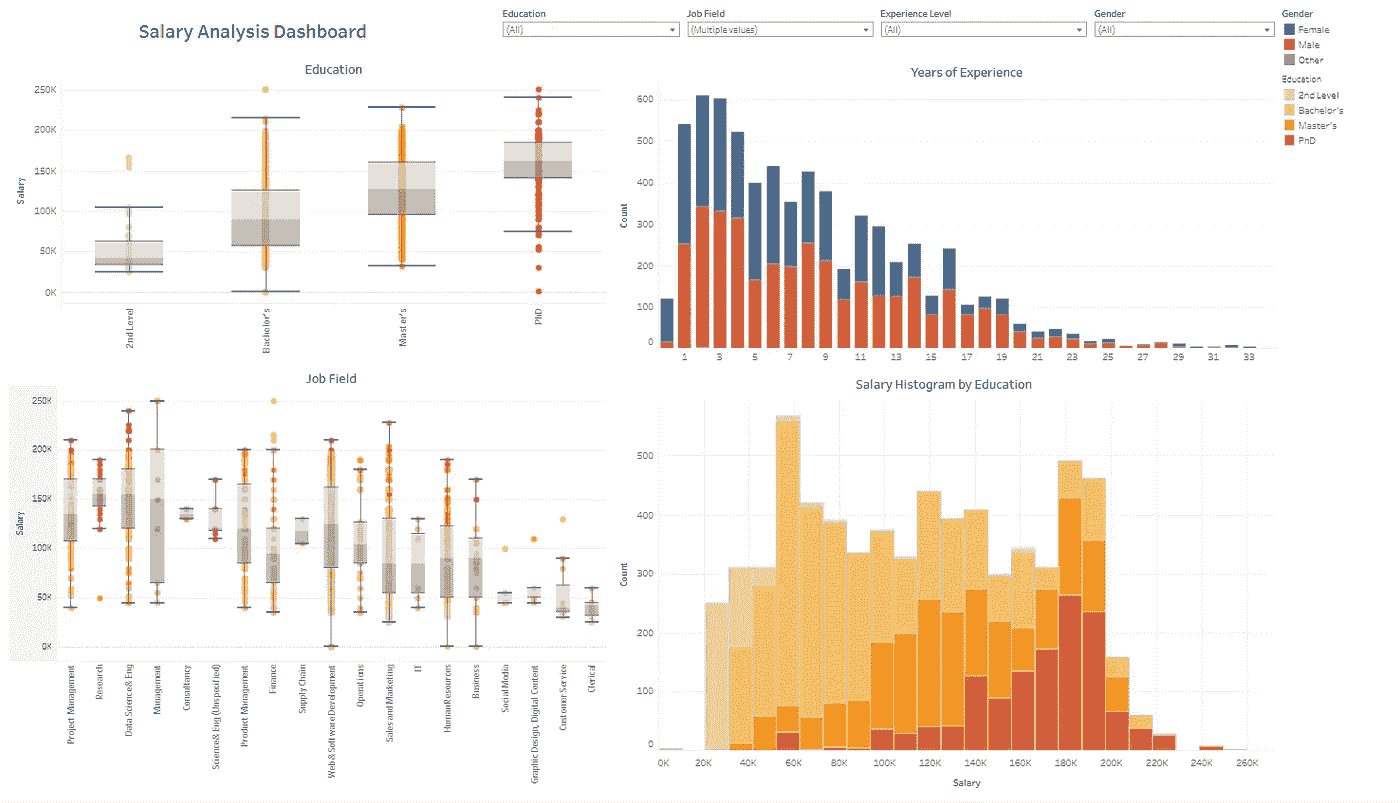
薪资分析仪表板(作者提供的图像)
我包含了教育程度和职位与薪资的箱形图,以及按经验水平(按性别分段)统计的个体直方图,还有按薪资区间和教育水平分段的个体直方图。
该仪表板可以根据所有数据特征进行过滤——例如,如果我只想查看博士学位的个体,我可以在箱形图中选择 PhD 桶,其他可视化会根据过滤后的数据进行调整。

筛选博士学位的仪表板(作者提供的图像)
通过查看以上这些可视化,我们可以获得一些有趣的见解:
-
中位薪资随着教育水平的提高而增加,在所有相关领域中,持有博士学位的人在薪资直方图中位于最高薪资区间。
-
整体调查在经验水平上存在明显偏斜,大多数受访者具有 2-3 年的经验。这可能会在任何基于此仪表板的决策中引入偏差——理想情况下,应进行一个更具代表性的调查以获得更好的分析(值得庆幸的是,一旦在源文件中收集了额外的回应,所有可视化都会立即更新)。
-
不出所料,研究职位由博士学位持有者主导——尽管我们也看到大量博士在网络/软件开发以及销售/市场营销领域工作。博士受访者中性别比例严重失衡,女性远少于男性。
这些只是对薪资数据集的一些分析示例——额外的分析可能会揭示薪资数据中更多的趋势。
仪表板 2: 纽约市驱逐趋势,2017 年至今
我创建的下一个可视化是一个显示纽约市范围内驱逐趋势的仪表板,涵盖了城市的五个区。原始数据集来自纽约市开放数据门户,可以在这里找到。这个仪表板对于那些在市政政府或非营利组织中工作的人尤其有用,例如想要减少全市驱逐趋势的人——你可以通过链接这里探索该仪表板中的可视化内容。
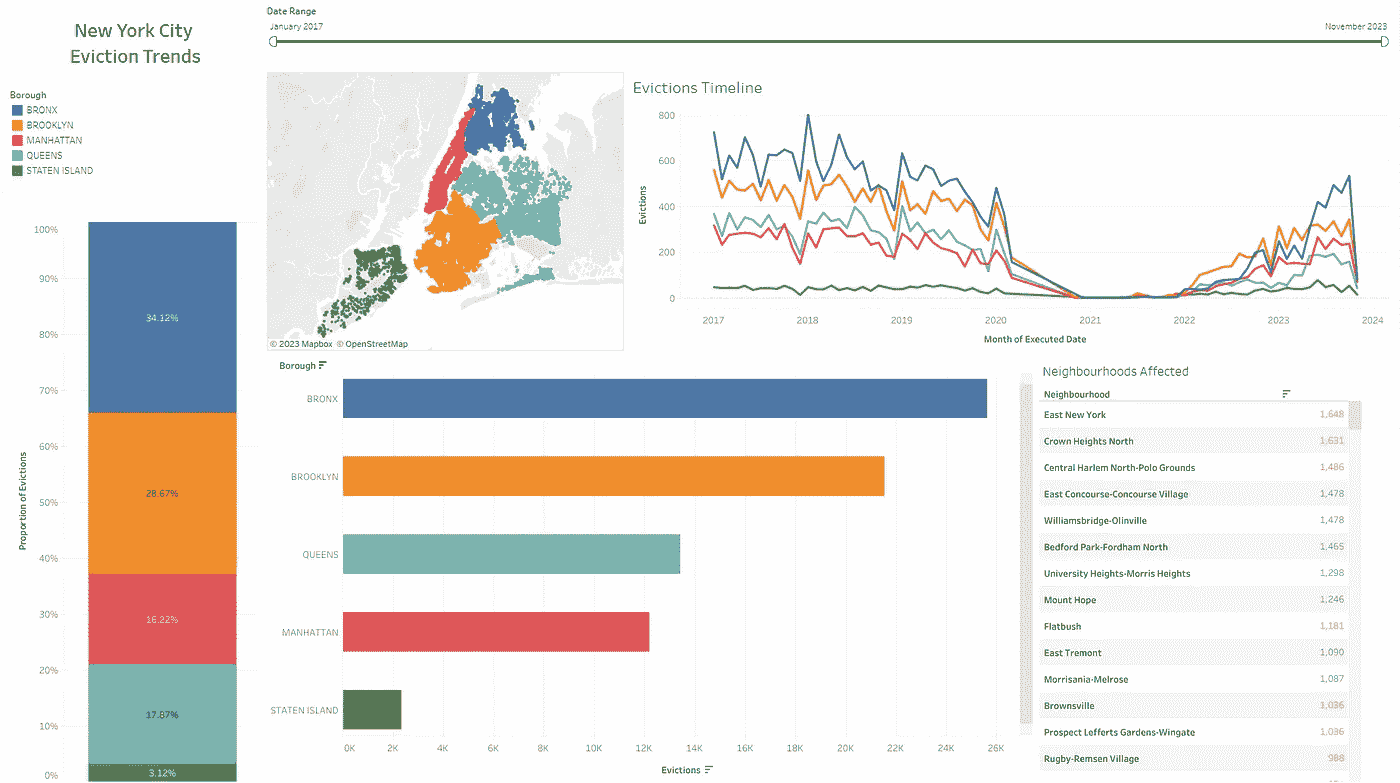
纽约市驱逐趋势,2017 年至今(图片由作者提供)
对于这个仪表板,我包含了过去 6 年内纽约市记录的所有驱逐地点的地图、每个区的驱逐条形图(还可以扩展到显示区或街区级别的驱逐情况)、按区显示历史驱逐趋势的折线图,以及按受影响程度排序的街区列表。仪表板顶部的滑块使得选择分析日期范围成为可能。
数据和可视化可以按时间和地点进行筛选——在下方的截图中,我已筛选出 2019 年布朗克斯的驱逐情况。与我之前的示例类似,所有其他可视化都会调整以适应筛选的数据——例如,请注意地图现在仅包括布朗克斯区。
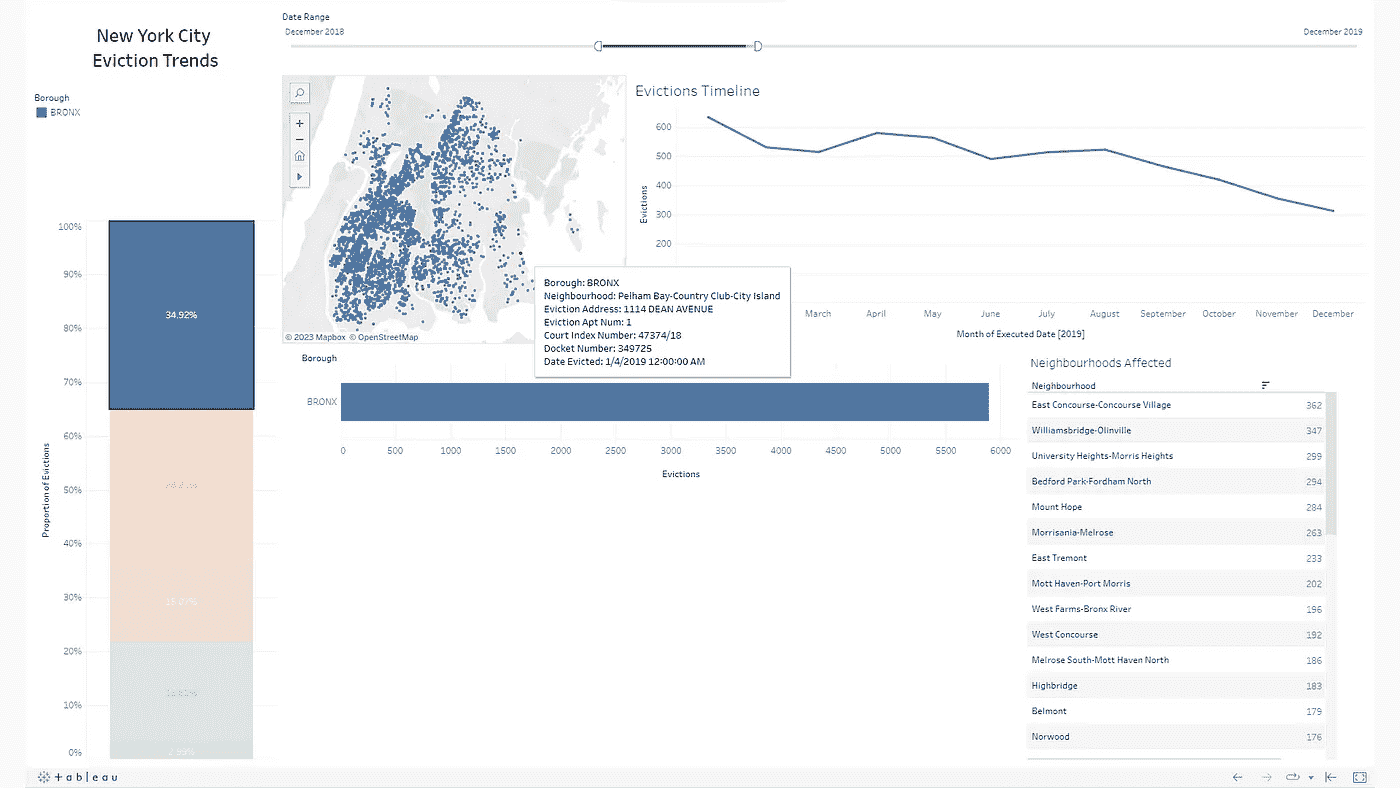
筛选 2019 年布朗克斯区驱逐情况,显示在驱逐实例上的提示框(图片由作者提供)
列举一下从上述可视化中获得的一些观察结果:
-
布朗克斯区在本报告所涵盖的整个时间段内的驱逐趋势最高,其次是布鲁克林和皇后区。
-
2021 年至 2022 年间,驱逐情况明显下降,这显然是由于 Covid-19 大流行期间对驱逐的禁令。
-
2019 年布朗克斯的驱逐率似乎随着时间的推移稳定下降,这与该时期其他区的趋势一致。
再次强调,这些示例仅代表了从驱逐情况仪表板中提取的可能观察结果的一小部分。深入分析仪表板可能会揭示更多见解,这将最终支持围绕驱逐资源做出更明智的决策。
仪表板 3: 西班牙旅游趋势,2018–2021
我想讨论的最后一个仪表板是 2018 年至 2021 年西班牙旅游趋势的仪表板。这些可视化的数据来源于西班牙政府的开放数据门户,网址是这里(不幸的是,西班牙政府尚未公布 2022 年或 2023 年的数据)。这有明显的商业和政府应用——例如,西班牙旅游部门的人可能会使用这些数据决定在哪里花钱发展区域旅游。同样,企业也可以利用这些数据预测某一年哪个地区的旅游量最大。任何想探索数据的人可以在链接这里找到仪表板。
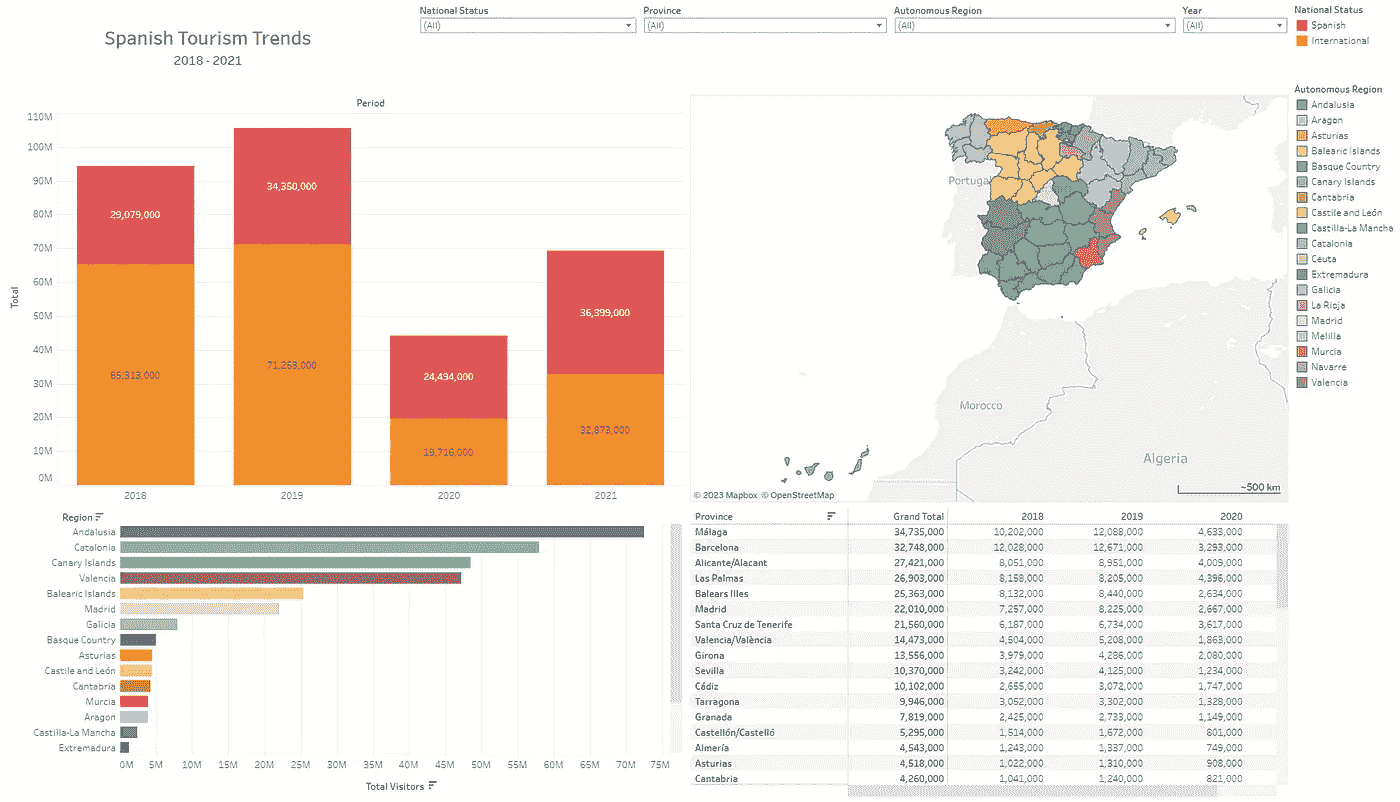
西班牙旅游趋势,2018–2021(作者提供的图片)
在这个可视化中,我包含了一个堆积柱状图,显示了按年分的旅游情况(按游客的国籍状态细分),一个按区域的旅游条形图(可以扩展以显示按省份的旅游情况),一个显示按省份和年份的旅游矩阵,以及西班牙所有省份的地图。
再次,这个仪表板可以按位置进行调整——下面我已经筛选了加泰罗尼亚地区,并突出显示了巴塞罗那省。地图工具提示显示了该省的旅游详情,条形图显示了这一期间西班牙国民与国际游客的比例。
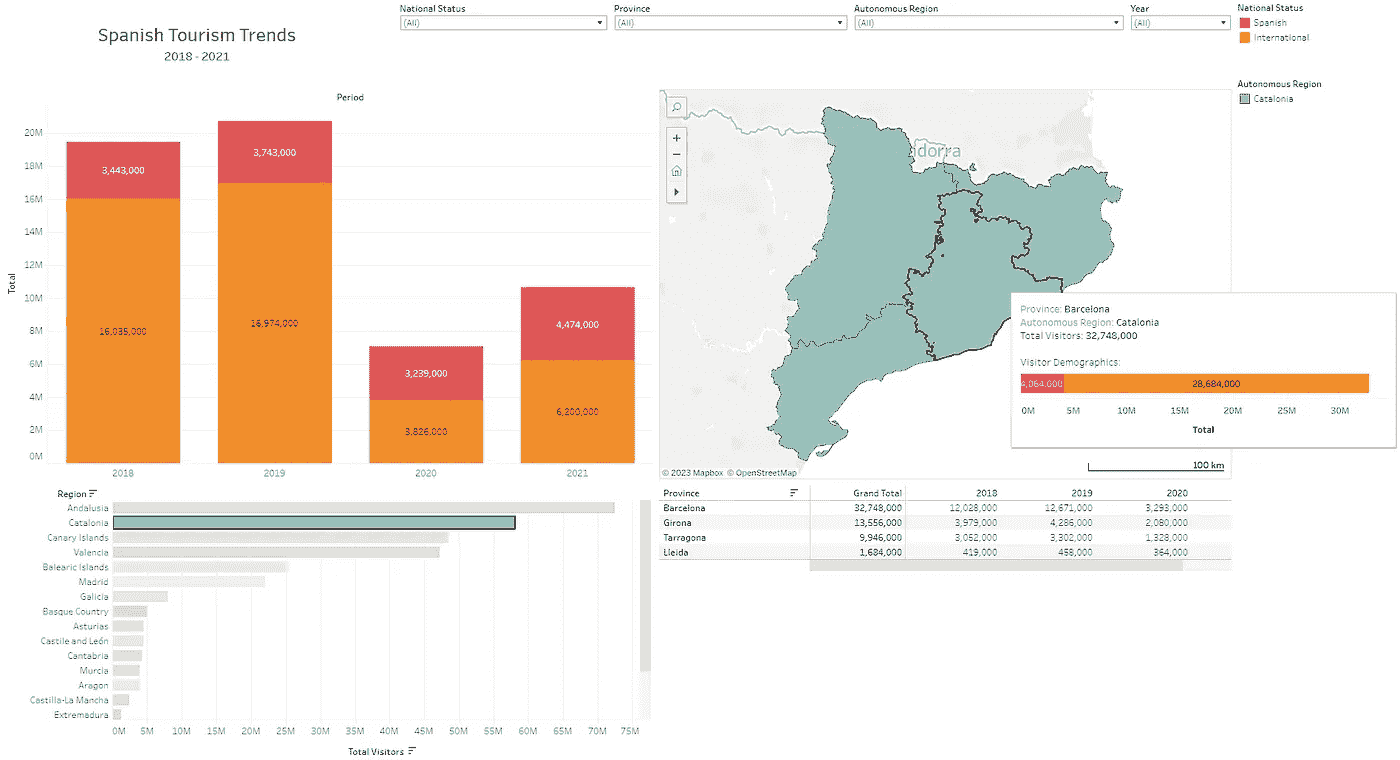
为加泰罗尼亚筛选并显示巴塞罗那的工具提示(作者提供的图片)
从查看这个仪表板的图表中,有几个要点值得注意:
-
安达卢西亚、加泰罗尼亚、加纳利群岛和瓦伦西亚是西班牙最受欢迎的自治区,差距非常大。
-
国际旅游在 2018 年和 2019 年远远超过了国内旅游——2020 年和 2021 年的比例大致相等,这很可能是由于 Covid-19 疫情导致的旅行限制。
-
巴塞罗那省的旅游人数占加泰罗尼亚省整体旅游人数的一半以上,几乎是该地区第二大受欢迎省份(赫罗纳)的 2.5 倍。这很可能主要归因于巴塞罗那市。
对西班牙其他地区和省份进行类似的分析和观察,可以更好地了解这些地区的旅游预期。
总结
总结来说,Tableau 是一个强大的数据可视化工具,使用户能够在各种数据集中创建简洁而有影响力的可视化。我在本文中介绍了最近创建的三个相对简单的可视化示例,但在 Tableau Public 上可以找到许多其他示例。在 Tableau 上可以找到的许多视觉效果都是对极其复杂主题的高度直观的表现,这显示了这些仪表盘在数据可视化中的强大能力。这些分析工具的价值不仅在于它们能够快速生成及时的图表和视觉效果,还在于它们可以以清晰且智能的格式呈现数据,从而加快分析和决策过程。
参考文献
[1] Mohith Sai Ram Reddy 等人. (2023). Salary_Data. Kaggle。可用网址: www.kaggle.com/datasets/mohithsairamreddy/salary-data (访问日期:2023 年 11 月 6 日)。
[2] (DOI), D.of I. (2023) 驱逐:纽约市开放数据,驱逐 | 纽约市开放数据。可用网址: data.cityofnewyork.us/City-Government/Evictions/6z8x-wfk4 (访问日期:2023 年 11 月 7 日)。
[3] Diaz, J. (2020 年 12 月 29 日). 纽约批准驱逐禁令至 5 月。NPR。 [在线] 可用网址: www.npr.org/sections/coronavirus-live-updates/2020/12/29/951042050/new-york-approves-eviction-moratorium-until-may (访问日期:2023 年 11 月 7 日)。
[3] Instituto Nacional de Estadística (经济事务与数字化转型部). (2022). 根据旅行者居住地的过夜住宿情况。各省。OAT(API 标识符:48427)。可用网址: datos.gob.es/en/catalogo/ea0010587-pernoctaciones-por-residencia-del-viajero-provincias-oat-identificador-api-48427 (访问日期:2023 年 11 月 10 日)。
Python 中的音频数据增强技术
原文:
towardsdatascience.com/data-augmentation-techniques-for-audio-data-in-python-15505483c63c
如何使用 librosa、numpy 和 PyTorch 在波形(时域)和频谱图(频域)中增强音频
 [外链图片转存中…(img-g1boverd-1726761704328)] Leonie Monigatti
[外链图片转存中…(img-g1boverd-1726761704328)] Leonie Monigatti
·发布于 Towards Data Science ·7 分钟阅读·2023 年 3 月 28 日
–

(图片由作者绘制)
深度学习模型需要大量数据。如果你没有足够的数据,生成合成数据可以帮助提高深度学习模型的泛化能力。尽管你可能已经熟悉图像的数据增强技术(例如,水平翻转图像),但音频数据的数据增强技术往往鲜为人知。
微调图像模型以应对领域转移和类别不平衡,使用 PyTorch 和 torchaudio 处理音频数据
towardsdatascience.com
本文将回顾流行的音频数据增强技术。你可以在波形和频谱图中应用音频数据增强:
-
音频数据增强(波形,时域)
∘ 噪声注入
∘ 时间偏移
∘ 改变速度
∘ 改变音调
∘ 改变音量(不推荐)
-
频谱图的音频数据增强(频域)
∘ 混合数据
∘ SpecAugment
对于数据增强,我们将使用[librosa](https://librosa.org/doc/main/index.html),这是一个流行的音频处理库,以及numpy。
import numpy as np
import librosa
如果你已经在使用 PyTorch,你还可以使用torchaudio作为替代方案。
音频数据增强(波形,时域)
本节将讨论可以应用于波形音频数据的流行数据增强技术。你可以使用[librosa](https://librosa.org/doc/main/index.html)库中的load()方法将音频文件加载为波形。
PATH = "audio_example.wav" # Replace with your file here
original_audio, sample_rate = librosa.load(PATH)
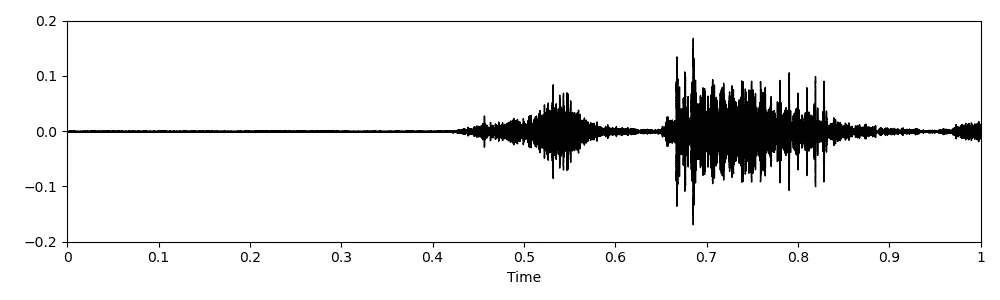
“Speech Commands”数据集中单词“stop”的原始音频数据(图片来源:作者)
以下代码实现参考自 Kaggle 笔记本,作者为kaerururu [7]和CVxTz [5]。
噪音注入
一种流行的数据增强技术是将某种噪音注入到原始音频数据中。
你可以选择多种不同类型的噪音:
- 白噪音
# Code copied and edited from https://www.kaggle.com/code/kaerunantoka/birdclef2022-use-2nd-label-f0
noise_factor = 0.005
white_noise = np.random.randn(len(original_audio)) * noise_factor
- 彩色噪音(例如粉色噪音、棕色噪音等)
# Code copied and edited from https://www.kaggle.com/code/kaerunantoka/birdclef2022-use-2nd-label-f0
import colorednoise as cn
pink_noise = cn.powerlaw_psd_gaussian(1, len(original_audio))
- 背景噪音
# Load background noise from another audio file
background_noise, sample_rate = librosa.load("background_noise.wav")
一旦定义了你想注入的噪音类型,你可以将噪音添加到原始波形音频中。当然,你可以使用各种不同类型的噪音进行数据增强。下方可以看到白噪音注入的示例。
augmented_audio = original_audio + noise
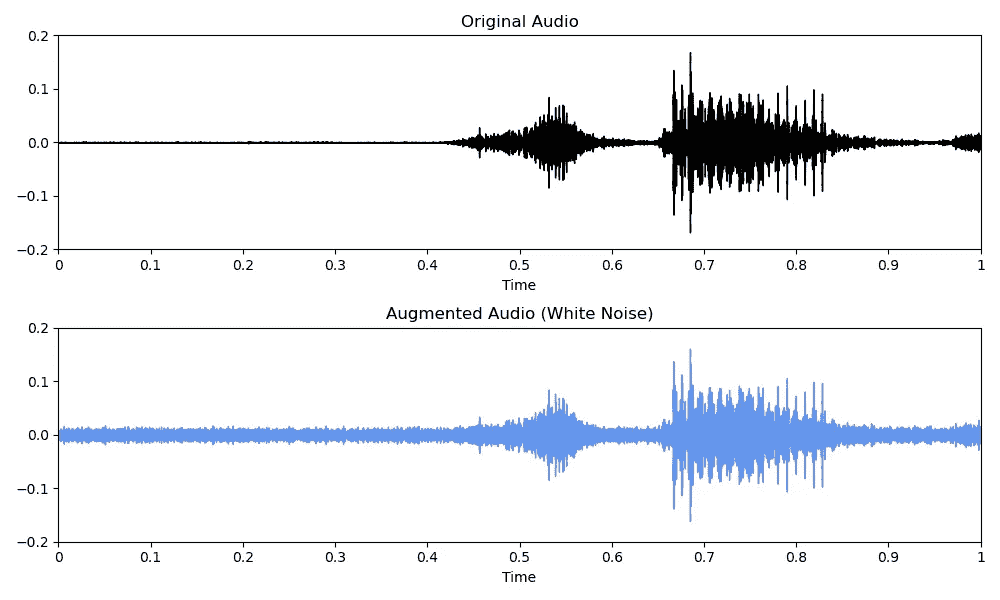
音频数据增强:白噪音(图片来源:作者)
时间平移
使用numpy库中的roll()函数,你可以在时间上平移音频。
# Code copied and edited from https://www.kaggle.com/code/CVxTz/audio-data-augmentation/notebook
augmented_audio = np.roll(original_audio, 3000)
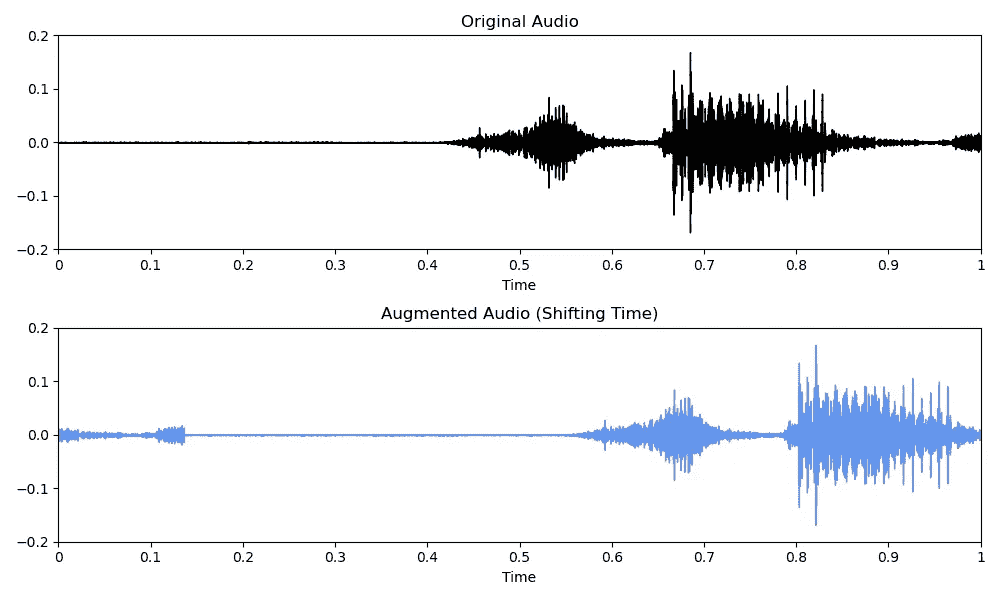
音频数据增强:时间平移(图片来源:作者)
请注意,如果没有足够的尾部静音,音频将会环绕。根据你的声音类型,这种数据增强在某些情况下(例如人声)可能不推荐使用。
改变速度
你还可以使用[librosa](https://librosa.org/doc/main/index.html)库中的time_stretch()方法来增加(rate>1)或减少(rate<1)音频的速度。
# Code copied and edited from https://www.kaggle.com/code/CVxTz/audio-data-augmentation/notebook
rate = 0.9
augmented_audio = librosa.effects.time_stretch(original_audio, rate = rate)
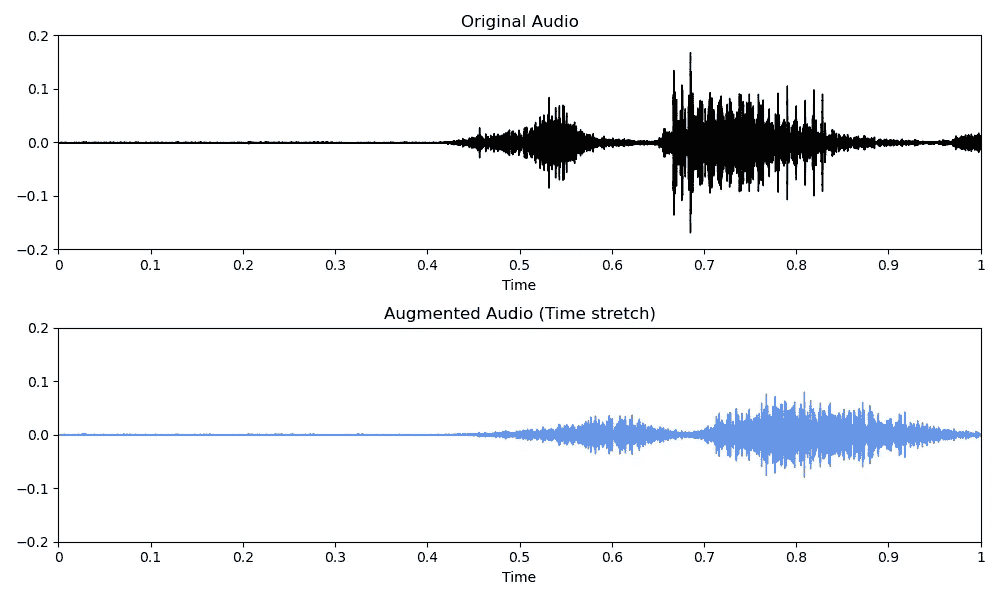
音频数据增强:时间拉伸/改变速度(图片来源:作者)
改变音高
或者你可以使用[librosa](https://librosa.org/doc/main/index.html)库中的pitch_shift()方法来修改音频的音高。
# Code copied and edited from https://www.kaggle.com/code/CVxTz/audio-data-augmentation/notebook
augmented_audio = librosa.effects.pitch_shift(original_audio, sampling_rate, pitch_factor)
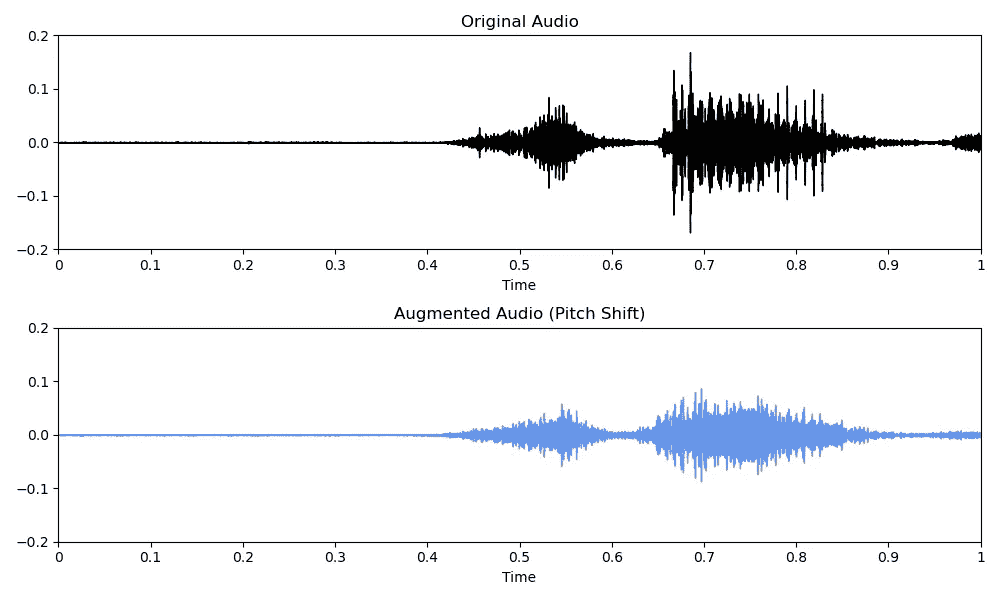
音频数据增强:音高变换(图片来源:作者)
改变音量(不推荐)
你也可以在音量方面增强波形。然而,如果你打算将波形转换为谱图,音量增强将无效,因为幅度在频域中不被考虑。
# Increase volume by 5 dB
augmented_audio = original_audio + 5
# Decrease volume by 5 dB
augmented_audio = original_audio - 5
频域的音频数据增强(谱图)
在用深度学习模型建模音频数据时,将音频分类问题转化为图像分类问题是一种流行的方法。为此,波形音频数据被转换为 Mel 谱图。如果你需要对 Mel 谱图有进一步了解,推荐阅读以下文章:
[## 音频深度学习简明教程(第二部分):为何 Mel 频谱图表现更佳]
《Python 音频处理指南》:用简单的英语解释什么是 Mel 频谱图以及如何生成它们。
towardsdatascience.com
你可以使用melspectrogram()和power_to_db()方法从[librosa](https://librosa.org/doc/main/index.html)库将波形音频转换为 Mel 频谱图。
original_melspec = librosa.feature.melspectrogram(y = original_audio,
sr = sample_rate,
n_fft = 512,
hop_length = 256,
n_mels = 40).T
original_melspec = librosa.power_to_db(original_melspec)
“Speech Commands” 数据集中“stop”一词的原始音频数据(波形) [1](图像作者提供)
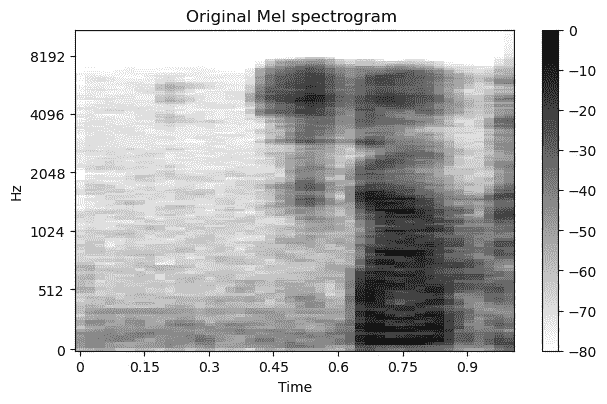
“Speech Commands” 数据集中“stop”一词的原始音频数据作为 Mel 频谱图 [1](图像作者提供)
尽管你现在面临的是图像分类问题,但在选择频谱图的图像增强技术时,你必须小心。例如,水平翻转频谱图会实质性改变频谱图中包含的信息,因此不推荐这样做。
本节将讨论你可以应用于 Mel 频谱图的流行数据增强技术。
以下代码实现参考自 Kaggle Notebooks,由 kaerururu [7] 和 DavidS [6] 提供。
Mixup
简单来说,Mixup [4] 通过叠加两个样本并给新样本两个标签来实现样本的合成。
# Code copied and edited from https://www.kaggle.com/code/kaerunantoka/birdclef2022-use-2nd-label-f0
def mixup(original_melspecs, original_labels, alpha=1.0):
indices = torch.randperm(original_melspecs.size(0))
lam = np.random.beta(alpha, alpha)
augmented_melspecs = original_melspecs * lam + original_melspecs[indices] * (1 - lam)
augmented_labels = [(original_labels * lam), (original_labels[indices] * (1 - lam))]
return augmented_melspec, augmented_labels

频谱图的数据增强:Mixup [4](图像作者提供)
另外,你也可以尝试计算机视觉中使用的其他数据增强技术,比如 cutmix [3]。
SpecAugment
SpecAugment [2] 对频谱图的作用类似于 cutout 对常规图像的作用。虽然 cutout 会遮挡图像中的随机区域,SpecAugment [2] 会遮罩随机频率和时间段。
# Code copied and edited from https://www.kaggle.com/code/davids1992/specaugment-quick-implementation
def spec_augment(original_melspec,
freq_masking_max_percentage = 0.15,
time_masking_max_percentage = 0.3):
augmented_melspec = original_melspec.copy()
all_frames_num, all_freqs_num = augmented_melspec.shape
# Frequency masking
freq_percentage = random.uniform(0.0, freq_masking_max_percentage)
num_freqs_to_mask = int(freq_percentage * all_freqs_num)
f0 = int(np.random.uniform(low = 0.0, high = (all_freqs_num - num_freqs_to_mask)))
augmented_melspec[:, f0:(f0 + num_freqs_to_mask)] = 0
# Time masking
time_percentage = random.uniform(0.0, time_masking_max_percentage)
num_frames_to_mask = int(time_percentage * all_frames_num)
t0 = int(np.random.uniform(low = 0.0, high = (all_frames_num - num_frames_to_mask)))
augmented_melspec[t0:(t0 + num_frames_to_mask), :] = 0
return augmented_melspec
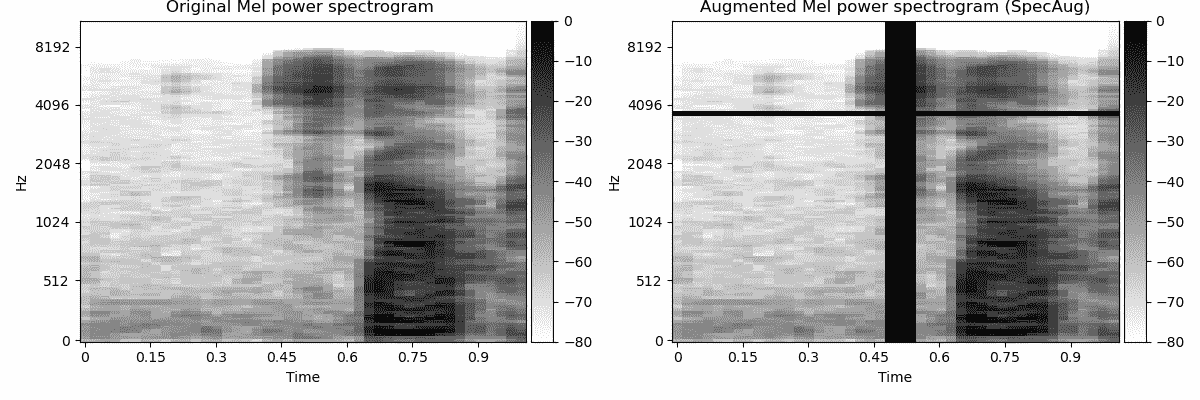
频谱图的数据增强:SpecAugment [2](图像作者提供)
另外,如果你使用的是 Pytorch,你还可以使用 torchaudio 中的 TimeMasking 和 FrequencyMasking 增强方法:
import torch
import torchaudio
import torchaudio.transforms as T
time_masking = T.TimeMasking(time_mask_param = 80)
freq_masking = T.FrequencyMasking(freq_mask_param=80)
augmented_melspec = time_masking(original_melspec)
augmented_melspec = freq_masking(augmented_melspec)
总结
音频数据的增强可以应用于时间域(波形)以及频率域(Mel 频谱图)。为了在深度学习环境中成功应用数据增强,你需要考虑以下处理步骤:
-
将音频文件加载为波形(时间域)
-
将数据增强应用于波形
-
将音频从波形转换为频谱图(频率域)
-
将数据增强应用于频谱图
本文介绍了波形数据的不同数据增强技术。需要注意的是,某些数据增强技术,如增强音量,在将波形转换为谱图时效果不佳,因为频域中不考虑振幅。
虽然理论上你可以将所有图像增强技术应用于谱图,但并非所有技术都是合理的。例如,垂直或水平翻转会改变谱图的意义。此外,一种专为谱图量身定制的流行 cutout 图像增强变体会遮蔽整个时间戳和频率。
喜欢这个故事吗?
免费订阅 以便在我发布新故事时收到通知。
[## 每当 Leonie Monigatti 发布新内容时获取电子邮件。
每当 Leonie Monigatti 发布新内容时获取电子邮件。通过注册,如果你还没有,你将创建一个 Medium 账户……
medium.com](https://medium.com/@iamleonie/subscribe?source=post_page-----15505483c63c--------------------------------)
在 LinkedIn、Twitter和 Kaggle上找到我!
参考文献
数据集
[1] Warden P. Speech Commands: 用于单词语音识别的公开数据集,2017 年。可从 download.tensorflow.org/data/speech_commands_v0.01.tar.gz 获得
许可:CC-BY-4.0
文献
[2] Park, D. S., Chan, W., Zhang, Y., Chiu, C. C., Zoph, B., Cubuk, E. D., & Le, Q. V. (2019). Specaugment: 一种用于自动语音识别的简单数据增强方法。 arXiv 预印本 arXiv:1904.08779。
[3] Yun, S., Han, D., Oh, S. J., Chun, S., Choe, J., & Yoo, Y. (2019). Cutmix: 正则化策略以训练具有可定位特征的强分类器。 IEEE/CVF 国际计算机视觉会议论文集(第 6023–6032 页)。
[4] Zhang, H., Cisse, M., Dauphin, Y. N., & Lopez-Paz, D. (2017) mixup: 超越经验风险最小化。arXiv 预印本 arXiv:1710.09412。
代码
[5] CVxTz (2018). 音频数据增强 在 Kaggle 笔记本中(访问日期:2023 年 3 月 24 日)。
[6] DavidS (2019). SpecAugment 快速实现 在 Kaggle 笔记本中(访问日期:2023 年 3 月 24 日)。
[7] kaerururu (2022). BirdCLEF2022:使用第二标签 f0 在 Kaggle 笔记本中(访问日期:2023 年 3 月 24 日)。
2023 年你需要知道的数据热词 — 第二部分
原文:
towardsdatascience.com/data-buzzwords-you-need-to-know-in-2023-part-ii-42057a87814a
你今年可能会遇到的数据术语及其含义
 [外链图片转存中…(img-pa2iM4Jo-1726761704331)] Rashi Desai
[外链图片转存中…(img-pa2iM4Jo-1726761704331)] Rashi Desai
·发表于Towards Data Science ·7 分钟阅读·2023 年 2 月 27 日
–

照片由Sienna Wall提供,来自Unsplash
早在 1 月初,我写过一篇关于 2023 年你需要知道的 13 个数据热词的文章,与TDS 编辑一起。我当时不愿意写一篇 15 分钟的长文来包括 23 个 2023 年的热词,但我知道我必须很快写关于那 10 个热词的内容!通过对那篇博客的评论、Twitter 私信和 LinkedIn 消息,我听到了一些我应该涵盖的 10 个词汇和一些新的词汇。因此,这里是关于 2023 年你应该知道的数据热词的第二部分,来赶上数据词汇吧!
1. 数据可扩展性
在 2023 年,公司的生存或死亡将取决于他们的数据策略。
随着数据源、获取渠道和企业消费的洞察数量的增加,组织必须具备扩展和应对变化需求的能力,方法是添加/移除数据资源。
数据可扩展性是指数据、数据库或任何数据系统在响应处理需求变化时,能够增加或减少处理能力,而不会对性能和成本产生重大影响。今天,可扩展性至关重要,因为它允许企业增长和盈利,而不会因数据结构或容量和资源的不足而受到限制。
2. 数据网格
组织在消费数据时面临的一个挑战是数据管理和治理的去中心化,这导致人们在 2023 年讨论数据网格。
数据网格采取了为去中心化的数据构建去中心化数据架构的方法。它本质上将分散在多个数据孤岛(云、本地数据、应用程序数据库、BI 仪表板、分析应用程序等)中的数据连接起来。
数据网格和数据织物之间经常进行比较——哪种选择更适合组织,让我告诉你,它们之间的差异很大。数据织物通过一个单一的、集中的系统来管理和治理多个数据源,而数据网格则完全相反。最终目标保持一致——连接分布在不同地点和组织中的数据。
3. 数据湖屋
数据湖屋在过去几年中成为一个新兴概念,我认为 2023 年是湖屋展示其功能和能力的年份(它们存在的巅峰)。
我相信每个阅读这篇博客的人都至少听说过或读过Databricks。Databricks 是一个数据湖屋,它的功能是结合运营卓越性、可靠性、安全性、合规性、性能效率、成本优化和组织数据规模,以实现商业智能(BI)和机器学习(ML)。
我不知道你怎样,但我有一个问题——数据湖与数据仓库有什么不同?
两者都被广泛接受并用于存储大数据,但我理解的区别是——数据湖是一个巨大的原始数据池,在数据进入时没有定义明确的目的,而数据仓库则是一个结构化的存储库,用于托管经过筛选、处理的数据,以达到特定的目的。
4. 黑暗数据
数据是今天科技世界中任何对话的核心,如果我们讨论每天产生的数据量,2023 年的最新估计是每天 1.145 万亿 MB。
我们为“常规业务活动”收集、处理和存储数据,一旦项目完成,通常会失败地将这些数据用于其他目的。我们将黑暗数据定义为通过各种来源获取但未用于分析或提取决策见解的数据。
存储和保护数据对企业来说不仅花费更高,有时甚至带来更大的风险。一些组织的黑暗数据示例可能包括日志文件、账户信息、财务档案、前员工的数据等,这些数据不再有用,仍在占用空间。
5. Web3
我在 2022 年中期的一个播客中听到过 Web3 这个词,那时一位单口喜剧演员谈到了他除了喜剧之外的兴趣,并谈到了 Web3、Web3 带来的机会以及其兴起所涉及的财务。
我对这意味着什么很感兴趣,谷歌了一下了解到 Web3 是万维网的第三代,它引入了由区块链技术和基于代币的经济学支持的去中心化互联网。我们在 2022 年开始看到 Web3 友好的方法,2023 年,越来越多的国家正在制定和通过立法,将自己定位为“Web3 友好”区域。
Web3 将彻底改变数据的存储和使用方式。数据将不再由一个中央实体在一个庞大的服务器中存储和控制,而是由通过一个网络(去中心化)链接在一起的数百万用户设备拥有——提升个人数据所有权。Web3 采用基于机器的数据理解来为用户开发更智能、更互联的网络体验。
6. 数据同步
2023 年是数据分析师的年头。任何数据分析师面临的一个痛点是保持所有报告工作的一致性。因此,如果我们希望 2023 年对分析师来说是一个好年头,我们就要转向同步。
数据同步正如其字面意思——确保你的数据在所有应用程序中保持一致、相同和准确,无论它们的位置如何(基本上,每个数据分析师的噩梦)。
我在一个博客中读到一个示例,以更好地理解数据同步,这里是我的见解——假设我们在音乐流媒体平台的一个服务器上添加了一个包含五首歌曲的新专辑,那么,通过数据同步,所有其他音乐流媒体平台的服务器(在协议下)将获得相同的专辑数据。数据同步在数据库管理中扮演着重要角色。数据同步还带来数据治理和安全访问控制。
7. 分布式云
全球云计算市场预计在 2023 年将 增长 42%,我预期今年组织和行业将大规模转向优化云成本和支出。
组织正在转向云计算,讨论是继续使用本地部署还是采用混合模式,在所有这些有益的讨论中,分布式云作为一种选项出现,其中一个组织使用多个云来满足性能期望、合规需求和支持计算需求,同时由公共云提供商集中管理。
当我第一次了解分布式云时,我将其与混合云混淆了,并想为我的工作场所制定建议,这里是它们的区别——混合云由多个公共云服务和本地基础设施组成,而分布式云由一个中央公共云提供商管理。
8. 超自动化
日常工作的自动化在 2023 年成为许多组织的优先事项(我的团队也是如此),而超自动化旨在自动化组织中可以自动化的一切。
超自动化旨在通过人工智能(AI)工作、机器人过程自动化(RPA)和其他技术来简化数据过程,使其能够在没有任何人工干预的情况下自主运行。超自动化从确定要自动化的项目开始,选择合适的自动化工具,通过多个自动化过程推动快速性,并使用各种数据形式扩展其能力。
9. 以人为本的数据科学
“以人为本的人工智能”这一术语已经流行了一段时间。我们今天所做的一切和创造的东西并不是在真空中运作的,它们会在某个交互点涉及到人类。我一直好奇实际应用的以人为本的数据科学会是什么样的,2023 年出现了一些项目,其中人类与产品的互动主导了业务决策。
我喜欢将以人为本的数据科学定义为一种概念,旨在理解人们如何互动以及如何理解社会情境,从而使人类能够探索和获取洞察,并以最终用户为中心(不仅仅是业务)设计数据模型。
我们可以这样看待——数据不过是人类互动的数字痕迹。以人为本的方法可以通过使过程更透明、提出问题和考虑数据的社会背景,来增强数据科学家每天做出的选择。
10. 决策智能
决策智能是新时代的智能决策处理方法。
观察 > 调查 > 建模 > 上下文化 > 执行
我第一次了解决策智能(DI)是在 2021 年,期间我在百事公司的实习项目中接触到了这一概念,其中一个项目是使用决策智能预测百事食品产品在超级碗前后的各个人群中的销售情况。决策智能提供了一个干净而简洁的数据驱动决策结构。
你使用描述性、诊断性和预测性分析,每种分析都有其自身的特点作为核心力量。借助决策智能,你可以创建三种不同类型的模型:基于人类的决策、基于机器的决策以及混合决策。这个过程涉及一个重度减少算法,它将数据科学与社会科学、决策理论和管理科学相结合。
我注意到越来越多的职位描述面向对分析感兴趣的心理学专业人士,日益关注决策智能。
这就是我在这篇长博客中的全部内容。感谢阅读!希望你觉得这篇文章有趣。请在评论中告诉我你在讲故事方面的经验、你在数据领域的旅程,以及你在 2023 年期望获得什么!
如果你喜欢阅读这样的故事,考虑通过这个链接成为 Medium 会员。
祝数据分析愉快!
拉希是来自芝加哥的数据专家,她热衷于可视化数据并创造有洞察力的故事以传达见解。她是全职的医疗数据分析师,周末时会边喝一杯热巧克力边写数据博客…
HuggingFace 中的数据整理器
原文:
towardsdatascience.com/data-collators-in-huggingface-a0c76db798d2
它们是什么以及它们的功能
 [外链图片转存中…(img-xf8zasam-1726761704332)] Mina Ghashami
[外链图片转存中…(img-xf8zasam-1726761704332)] Mina Ghashami
·发表于 数据科学前沿 ·9 分钟阅读·2023 年 11 月 8 日
–

图片来自 unsplash.com
当我开始学习 HuggingFace 时,数据整理器是我最不直观的组件之一。我很难理解它们,而且没有找到足够好的资源来直观地解释它们。
在这篇文章中,我们将探讨数据整理器是什么,它们有何不同,以及如何编写自定义的数据整理器。
数据整理器:高级
数据整理器是 HuggingFace 中数据处理的关键部分。我们在对数据进行标记化后,都会使用它们,然后将数据传递给 Trainer 对象来训练模型。
简而言之,它们将样本列表整理成一个小型训练批次。它们的功能取决于它们所定义的任务,但至少会对输入样本进行填充或截断,以确保小批次中的所有样本长度相同。典型的小批量大小范围从 16 到 256 个样本,具体取决于模型大小、数据和硬件限制。
数据整理器是任务特定的。每个以下任务都有一个数据整理器:
-
因果语言建模(CLM)
-
掩码语言建模(MLM)
-
序列分类
-
Seq2Seq
-
标记分类
一些数据整理器很简单。例如,对于“序列分类”任务,数据整理器只需填充小批量中的所有序列以确保它们长度相同。然后将它们连接成一个张量。
一些数据整理器非常复杂,因为它们需要处理该任务的数据处理。
基本数据整理器
最基本的两个数据整理器如下:
1)DefaultDataCollator: 这不进行任何填充或截断。它假设所有输入样本的长度相同。如果你的输入样本长度不一致,这会引发错误。
import torch
from transformers import DefaultDataCollator
texts = ["Hello world", "How are you?"]
# Tokenize
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
tokens = [tokenizer(t) for t in texts]
# Default collate function
collate_fn = DefaultDataCollator()
# Pass it to dataloader
dataloader = torch.utils.data.DataLoader(dataset=tokens, collate_fn=collate_fn, batch_size=2)
# this will end in error
for batch in dataloader:
print(batch)
break
令牌化后的输出是:
[{'input_ids': [101, 7592, 2088, 102], 'token_type_ids': [0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1]},
{'input_ids': [101, 2129, 2024, 2017, 1029, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1]}]
如你所见,两个序列的长度不同。第一个序列有 4 个标记,第二个序列有 6 个标记。这是在调用数据加载器时出现错误的原因!
现在如果我们将输入更改为两个相同长度的序列,例如:
texts = ["Hello world", "How are"]
然后代码运行正常,输出将是:
{'input_ids': tensor([[ 101, 7592, 2088, 102],
[ 101, 2129, 2024, 102]]),
'token_type_ids': tensor([[0, 0, 0, 0],
[0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1],
[1, 1, 1, 1]])}
请注意,它不返回labels。
2) DataCollatorWithPadding: 这个整理器填充输入样本,使它们都具有相同长度。对于填充,
-
它要么填充到提供的
max_length参数。 -
或者它填充到批次中最长的序列。
查看 文档 获取更多详细信息。
此外,这个整理器接受tokenizer,因为许多标记器有不同的填充标记,因此DataCollatorWithPadding接受标记器来确定填充序列时的填充标记。
import torch
from transformers import DataCollatorWithPadding
texts = ["Hello world", "How are you?"]
# Tokenize
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
tokens = [tokenizer(t) for t in texts]
# Default collate function
collate_fn = DataCollatorWithPadding(tokenizer, padding=True) #padding=True, 'max_length'
dataloader = torch.utils.data.DataLoader(dataset=tokens, collate_fn=collate_fn, batch_size=2)
for batch in dataloader:
print(batch)
break
上述代码的输出是:
{'input_ids': tensor([[ 101, 7592, 2088, 102, 0, 0],
[ 101, 2129, 2024, 2017, 1029, 102]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1]])}
注意第一个序列的 4 个标记现在填充为 6 个标记。在bert-base-uncase标记器中,填充标记的 ID 是 0。让我们在代码中查看:
print(tokenizer.special_tokens_map)
print()
这段代码输出:
{'unk_token': '[UNK]', 'sep_token': '[SEP]', 'pad_token': '[PAD]', 'cls_token': '[CLS]', 'mask_token': '[MASK]'}
pad_token = [PAD] 是用于填充的标记。让我们检查它的 token_id。
print(tokenizer.convert_tokens_to_ids('[PAD]'))
这输出为0。
请注意,与 DefaultDataCollator 类似,DataCollatorWithPadding 不创建labels。如果你的数据中已经有标签,它们会返回,但否则不会创建!!
简而言之,如果你的标签简单明了,且数据在喂给模型进行训练之前不需要任何特殊处理,则使用这两个整理器。
语言建模数据整理器
语言建模数据整理器有两种模式:
-
MLM 数据整理器:这是用于掩码语言建模的,我们掩盖 15%的标记,模型进行预测。
-
CLM 数据整理器:这是用于因果语言建模的,我们掩盖当前标记右侧的所有标记,并期望模型在每一步预测下一个标记。
在代码中,MLM 整理器是:
collate_fn = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
CLM 整理器是:
collate_fn = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
让我们看看 MLM 整理器的例子:
from transformers import DataCollatorForLanguageModeling
from transformers import AutoTokenizer
import torch
## input text
texts = [
"The quick brown fox jumps over the lazy dog.",
"I am learning about NLP and AI today"
]
## tokenize
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
data = [tokenizer(t) for t in texts]
## MLM collator
collate_fn = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=True, mlm_probability=0.15)
## pass collator to dataloader
dataloader = torch.utils.data.DataLoader(data, collate_fn=collate_fn, batch_size=2)
## let's look at one sample
for batch in dataloader:
print(batch)
break
它输出如下内容:
{'input_ids': tensor([[ 101, 1996, 4248, 2829, 4419, 14523, 2058, 1996, 13971, 3899,
1012, 102],
[ 101, 1045, 2572, 103, 2055, 17953, 2361, 1998, 9932, 2651,
102, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]),
'labels': tensor([[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100],
[-100, -100, -100, 4083, -100, -100, -100, -100, -100, -100, -100, -100]])}
注意几点:
1) 两个示例的input_ids都以101开头,以102结尾。在第二个示例中,102之后有一个0,我们已经知道这是填充标记。让我们看看101和102是什么?
print( tokenizer.decode(101), tokenizer.decode(102))
## prints [CLS] and [SEP]
它分别打印[CLS]和[SEP]标记。
2) 它返回labels,不同于基本的数据整理器。我们看到标签中有很多-100。请注意,每个样本的labels长度与input_ids的长度相同!标签为-100的地方意味着对应的标记没有被屏蔽,因此在计算损失时我们需要忽略这些位置。MLM 使用交叉熵损失函数,如果你查看文档,默认的ignore_index=-100;这意味着如果标签设置为-100则忽略。
第三点需要注意的是,对于第一个示例,标签是[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100],这意味着没有任何标记被屏蔽。然而,对于第二个输入,标签是[-100, -100, -100, 4083, -100, -100, -100, -100, -100, -100, -100, -100],我们看到有一个标记被屏蔽,其对应的标签是4083。input_ids中的对应标记是103,这是[MASK]标记的 token_id。
CLM 数据整理器要简单得多,因为它用于因果语言建模,即预测下一个标记。我们来看一个示例:
from transformers import DataCollatorForLanguageModeling
from transformers import AutoTokenizer
texts = [
"The quick brown fox jumps over the lazy dog.",
"I am learning about NLP and AI today"
]
# Tokenize
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-uncased')
tokens = [tokenizer(t) for t in texts]
collate_fn = DataCollatorForLanguageModeling(tokenizer=tokenizer, mlm=False)
dataloader = torch.utils.data.DataLoader(data, collate_fn=collate_fn, batch_size=2)
for batch in dataloader:
print(batch)
输出如下:
{'input_ids': tensor([[ 101, 1996, 4248, 2829, 4419, 14523, 2058, 1996, 13971, 3899,
1012, 102],
[ 101, 1045, 2572, 4083, 2055, 17953, 2361, 1998, 9932, 2651,
102, 0]]),
'token_type_ids': tensor([[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),
'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0]]),
'labels': tensor([[ 101, 1996, 4248, 2829, 4419, 14523, 2058, 1996, 13971, 3899,
1012, 102],
[ 101, 1045, 2572, 4083, 2055, 17953, 2361, 1998, 9932, 2651,
102, -100]])}
你会看到在这两个示例中,标签是input_ids的副本。这是因为在因果语言建模中,任务是预测给定所有先前标记的下一个标记,而某个位置的标签就是该标记本身。
自定义数据整理器
假设你有一个数据集,包含两列:指令和响应。

作者提供的图像
你想对一个预训练模型进行指令调优。不深入细节,我们注意到我们需要一个自定义数据整理器来仅屏蔽响应而不是指令。
假设我们写一个函数,将两列合并成以下格式:
下面是一个描述任务的指令。写一个适当完成请求的响应。 ### 指令: {instruction} ### 响应: {response} ### 结束
数据现在看起来是这样的:

作者提供的图像
我们看到有特殊标记:
那么让我们开始编写自定义数据整理器。我们希望有一个仅屏蔽响应而不屏蔽指令的数据整理器。为什么?因为我们希望模型生成响应而不是指令。
from typing import Any, Dict, List, Tuple, Union
import numpy as np
from transformers import AutoModelForCausalLM
from transformers import AutoTokenizer
from transformers import TextDataset, DataCollatorForLanguageModeling
from transformers import Pipeline, PreTrainedTokenizer
RESPONSE_KEY = f"### Response:\n"
class DataCollatorForCompletionLM(DataCollatorForLanguageModeling):
def torch_call(self, examples: List[Union[List[int], Any, Dict[str, Any]]]) -> Dict[str, Any]:
# The torch_call method overrides the same method in the base class and
# takes a list of examples as input.
batch = super().torch_call(examples)
labels = batch["labels"].clone()
# The code then encodes a special token, RESPONSE_KEY_NL,
# representing the end of the prompt followed by a newline.
# It searches for this token in the sequence of tokens (labels)
# and finds its index.
response_token_ids = self.tokenizer.encode(RESPONSE_KEY)
for i in range(len(examples)):
response_token_ids_start_idx = None
for idx in np.where(batch["labels"][i] == response_token_ids[0])[0]:
response_token_ids_start_idx = idx
break
if response_token_ids_start_idx is None:
# If the response token is not found in the sequence, it raises a RuntimeError.
# Otherwise, it determines the end index of the response token.
raise RuntimeError(
f'Could not find response key {response_token_ids} in token IDs \
{batch["labels"][i]}'
)
response_token_ids_end_idx = response_token_ids_start_idx + 1
# To train the model to predict only the response and ignore the prompt tokens,
# it sets the label values before the response token to -100\.
# This ensures that those tokens are ignored by the PyTorch loss function during training.
labels[i, :response_token_ids_end_idx] = -100
batch["labels"] = labels
return batch
这个数据整理器找到###Response: \n的位置,并将该位置之前的任何标记的标签更改为-100。这样,损失函数将忽略这些标记。
当我们调用数据整理器时,我们使用它如下:
data_collator = DataCollatorForCompletionLM(
tokenizer=tokenizer, mlm=False, return_tensors="pt"
)
像往常一样,我们在进行模型训练之前,在训练对象中使用这个数据整理器。
结论
在这篇文章中,我们深入探讨了 HuggingFace 中的数据收集器。我们了解到数据收集器负责填充序列,使得批次中的所有样本长度相同。我们还看到了四种不同的数据收集器示例。其中一个重要的数据收集器是 DataCollatorForLanguageModeling,它用于 MLM 和 CLM 训练。我们还看到了如何修改数据收集器以进行指令调优的示例。
如果你有任何问题或建议,请随时联系我:
电子邮件: mina.ghashami@gmail.com
LinkedIn: www.linkedin.com/in/minaghashami/
计算机视觉数据整理指南
原文:
towardsdatascience.com/data-curation-guide-for-computer-vision-acc525f4cd7
计算机视觉中的数据整理缺乏标准化,导致许多从业者不确定如何正确进行。我们总结了一些最常见的方法。
 [外链图片转存中…(img-WGUtofJU-1726761704333)] 伊戈尔·苏斯梅尔
[外链图片转存中…(img-WGUtofJU-1726761704333)] 伊戈尔·苏斯梅尔
·发表于Towards Data Science ·阅读时间 10 分钟·2023 年 3 月 9 日
–

从哪里开始数据整理?瓦伦丁·安东努奇的图片:www.pexels.com/de-de/foto/person-die-kompass-halt-691637/
本文是以计算机视觉中的数据整理为背景编写的。然而,一些概念可以应用于其他数据领域,如自然语言处理、音频或表格数据。
什么是数据整理?
数据整理是一个广泛使用的术语,特别是在数据驱动的人工智能领域。理解数据整理在机器学习中的组成部分非常重要。我们理解数据整理包括以下几个组成部分:
-
数据清理和归一化 — 删除“损坏”样本或尝试纠正它们的过程
-
数据选择 — 根据特定任务的重要性对数据进行排序的过程
机器学习中的数据清理
理解结构化数据的数据清理最简单的方法是考虑表格数据。假设你在一家银行从事一个项目,想要根据客户的来源分析他们的支出。你的数据在一个 CSV 文件中,你发现位置信息缺失。一些条目存在拼写错误,例如城市拼写错误或完全缺失的条目。你现在可以选择通过删除所有“损坏”的条目来清理数据,或者根据其他可用数据尝试纠正缺失的条目。像fancyimpute和autoimpute这样的开源库可以对表格数据中的缺失示例进行插补。
当处理非结构化数据如图像时,可以检查相机故障的图像。硬件问题可能导致视频帧损坏,或者记录的数据可能质量更好(光线不足,图像模糊)。
对于非结构化数据,你通常依赖于监督学习。你也应该考虑清理“损坏”的标签,或至少尝试纠正它们。
数据选择(与主动学习相关)
正如你可能之前听说过的,并非所有数据对你的机器学习模型都同等重要。你不想在不需要的数据上浪费资源。
在训练机器学习模型时,你必须确保用于训练的数据与系统运行时预期的数据匹配。这听起来简单,但实际上是一个巨大的问题。考虑开发一个自动送货机器人感知系统。你有一个原型机器人从你有研发的城市中选择数据。你的模型将基于单一城市的数据进行训练,但最终需要在全球各种城市中工作。不同的城市可能有不同的建筑结构、环境条件、交通标志等。
可以进行逐步推出,按城市部署机器人,并持续收集更多数据以改进感知系统。但是,这样一来,初始城市的数据贡献显著高于最后的城市。如何跟踪哪些是新的、有效的,或者哪些是“冗余”的?
什么是良好整理的数据集?
首先,实际上没有通用的完美数据集。数据集的价值取决于你想要解决的任务以及模型架构、训练过程和可用计算能力等其他变量。尽管如此,一个良好整理的数据集可以帮助防止遇到本指南中概述的任何问题。
理想情况下,你的数据集是良好平衡的。你的测试集代表了模型的部署领域,并且独立于训练数据。因此,你了解模型的泛化能力。你的数据集涵盖了你关心的边缘情况,标签也是正确的。
数据整理入门指南
我创建了一个入门指南来帮助你识别机器学习管道中的问题。将其作为参考以了解最常见的数据整理工作流程。
请注意,这份备忘单并没有涵盖所有可能的问题,应作为你不知从何开始时的帮助工具。
如何使用数据整理入门指南:
-
识别你面临的模型问题,位于左侧
-
跟随箭头查找潜在的数据问题
-
选择解决问题的数据整理工作流程

数据整理入门指南。[图片由作者提供]
常见模型问题及其解决方案
最常见的数据问题概述及解决建议。
1: 我的模型在训练集上准确率很高,但在测试集上准确率很低
发生这种情况有不同的原因。首先,你应该排除可能导致模型过拟合训练数据的常见训练过程错误。添加更多的数据增强或正则化方法,如 L2 或权重范数,可以帮助减少过拟合的风险,正如 Andre Ng 在这个视频中所述。
也可能存在其他过拟合的原因。
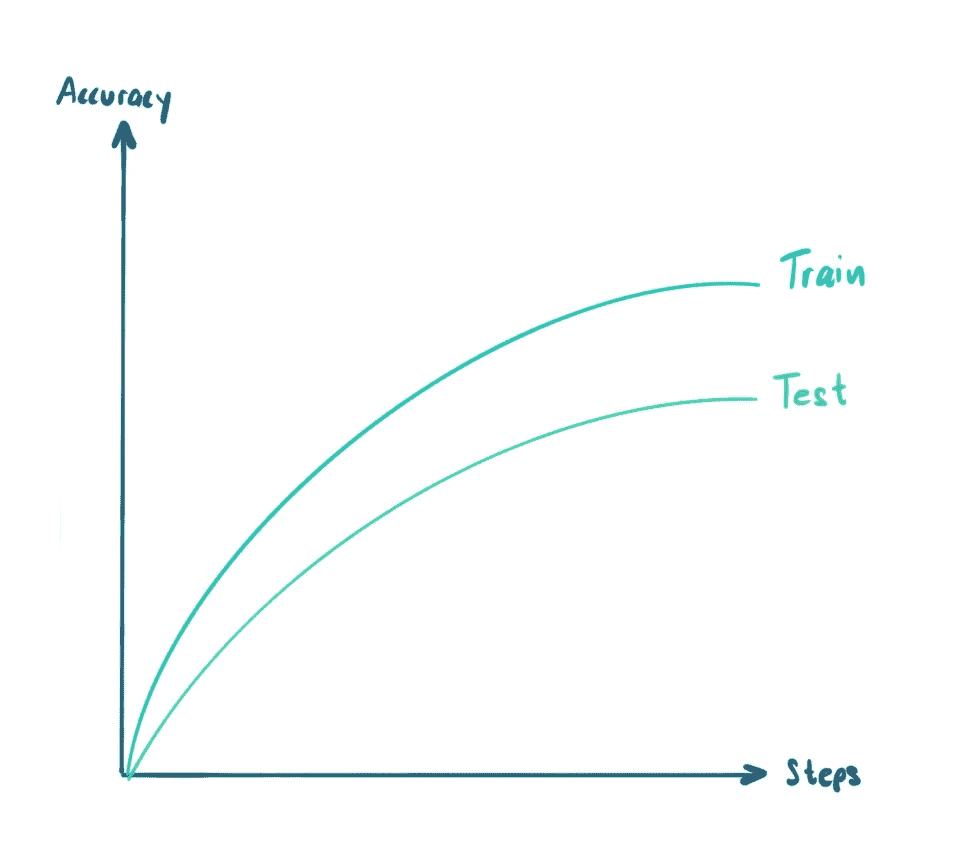
最常见的情况之一是你的模型在训练数据上表现良好,但在测试集上表现较差。这很可能是你的模型过拟合了。简单的训练方法,如添加正则化方法,可以减少这个问题。但在某个时候,你需要改进数据本身。[image by author]
一旦你知道这不再是模型训练问题而是数据问题,你应该查看你用于训练和测试集的数据。另一个可能的原因是你的训练数据代表性不够。可能是一些示例出现频率很低,模型无法从中学习。在这种情况下,一个潜在的解决方案是收集更多关于模型难以处理的稀有事件的数据。像主动学习这样的方案已经被提出,以自动化和可扩展的方式解决这个问题。BAAL[1] 是 2020 年的一个主动学习算法。
2: 模型在不常见/稀有情况下失败
通常情况下,你的模型只在某些类别和情况中表现良好。例如,稀有类别通常被常见的学习过程忽略。在特定的应用场景中,例如医学影像中,稀有类别可能比其他类别更重要。在这种情况下,存在几种解决方案。
首先,如果你的模型在某个特定类别上的表现不佳,也要检查一下该类别是否在你的数据集中代表性不足。如果这是一个少数类别,你应该尝试使用加权损失函数来解决这种不平衡。这是一个简单的技巧,通常会产生很有希望的结果。
如果问题仍然存在,你可以开始从数据的角度思考如何解决这个问题。有两个选项。我们可以改善类别平衡或尝试找到更多边缘情况。
改进类别平衡 你需要改变训练数据集中类别的比例,使其更加均衡。有几种方法可以处理不同的情况。如果你处理大量数据,可以开始丢弃多数类的样本(欠采样)以平衡类别。
如果你处理小型数据集或无法负担删除训练数据,你可以尝试收集更多数据,并优先考虑之前代表性不足的类别。但是如何实现后者呢?你可以使用模型在未标记数据上的预测来了解数据分布。每当我们发现主要类别时,我们就会降低对它们的优先级。我们会增加对稀有类别潜在预测的优先级。有一个处理不平衡数据的开源库叫做 imbalanced-learn。
通过主动学习发现更多边界情况 如果你确切知道你在寻找什么(例如,模型在检测警车方面表现不佳),你可以依靠相似性搜索方法,如SEALS[2]。你可以使用这些稀有物体的参考图像,并利用它们的嵌入作为搜索向量,在未标记数据中寻找相似的图像或物体。使用相似性搜索时要小心。如果你只使用某种特定类型的警车或某个角度的图像,那么你可能会发现更多相似的警车图像,这些图像不会增强你的数据集,反而增加了附近的重复项。这会产生类似于仅仅扩充初始数据集的效果。相反,你希望找到与现有警车略有不同的相似警车!
另一种更通用的方法是使用主动学习的模型预测和嵌入组合[3]。你可以通过找到难以分类或在语义上与现有训练数据非常不同的未标记数据来将新图像添加到训练集中。在 Lightly,我们在这种方法中取得了很大的成功,因为它可以自动化并扩展到大规模数据集。
3: 模型随着时间变差
你可能会发现失败率增加,并且有一种直觉认为你在几周前部署的模型没有按预期工作。这可能是“数据漂移”问题。模型需要用新的训练数据进行更新。首先,你应该分析模型在生产中看到的数据,并将其与用于训练模型的数据进行比较。可能会有明显的分布差异。

如果模型性能随着时间的推移而下降,你可能面临数据漂移问题。简单来说,模型在部署中看到的数据开始与训练中看到的数据逐渐偏离。如果不使用新数据重新训练模型并重新部署,准确率的损失可能会增加,直到系统不再可靠。[图片由作者提供]
作为一个简单的实验,你也可以训练一个简单的分类器模型,来分类给定的图像是否属于现有的训练数据或新的生产数据。如果数据分布完全匹配,你的分类器不会比随机猜测表现更好。然而,如果分类器表现良好,说明两个领域有所不同。分析领域差距后,你应该更新训练数据。例如,你可以选择一部分生产数据,使用基于多样性的采样,然后进行新的训练/测试拆分。然后,将相应的训练/测试拆分添加到你用来训练已部署模型的现有拆分中。
现在模型将使用以下内容进行训练和评估:
-
训练(初始)+ 训练(新生产数据)
-
测试(初始),测试(新生产数据)
注意,我们建议分别评估两个测试集,以确保你可以衡量不同分布的指标。这也将帮助你发现测试(初始)集的准确率是否发生了变化。
4: 我的模型在训练集和测试集上的准确率很高,但在部署后表现很差
这是每个机器学习模型都会面临的普遍问题。当你开始训练和评估模型时,你假设可用的训练集和测试集的分布与模型在部署时面对的情况相似。如果情况不是这样,你就不知道模型的表现如何。例如,一个专门在加州数据上训练和评估的交通标志检测模型,在部署到欧洲时可能会因为交通标志样式不同而表现很差。
确保模型在与其部署环境尽可能匹配的数据上进行训练和评估是至关重要的。避免这个问题的一种方法是持续收集数据,并仔细考虑数据收集策略,以减少任何领域差距。
为了更早发现模型泛化的潜在问题,你可以使用不同的训练测试拆分,例如基于城市而不是随机地划分训练和测试数据。
5: 训练准确率低,测试准确率低
如果训练和测试的准确率都很低,说明你的模型没有学到很多东西。模型没有改善的原因可能有多种:
-
任务过于困难 — 根据现有的训练数据和模型的能力,解决这个问题太困难了。
-
标签错误 — 即使数据本身非常有价值。没有正确的标签,模型无法学到任何东西。
我的模型任务是否过于困难?
在计算机视觉中,一个简单而有效的方法来确定任务是否最终太难解决,就是做“我能自己做吗”测试。给定几张带标签的训练图像和任务,你能否正确分类测试集中的图像?
如果是,你知道你可以解决它,并且数据可能足够好。检查模型是否有足够的训练数据来捕捉正确的信号。
注意:这在计算机视觉中效果特别好,因为人类在模式匹配方面非常出色。如果你处理其他数据类型,这个简单的测试可能不适用。
处理坏标签
在监督学习中,训练数据由样本(例如图像)及其对应的标签组成。即使数据集中的样本具有代表性和均衡性,不良标签仍然可能导致模型学习不到有用的东西。这就像在学校教一个孩子做数学,但使用的公式和例子是随机排列的。今天你学到 1+1=3,明天你学到 1+1=5。如果没有一致的教学模式,因为数据标注错误,我们就会遇到问题。
如果你有标签问题,可以做以下操作。从训练集中随机挑选一小部分(例如 100)样本,并手动检查潜在的标签错误。你可以对测试集做相同的操作。
拥有一些错误标签是不幸的非常常见。一些学术数据集,如 ImageNet 和 CIFAR10 的标签错误率约为 5%[4]。如果错误不是系统性的且错误率不是很高,它不应该有显著的影响。但如果你遇到系统性错误(例如,所有猫都标记为狗),你必须纠正它们。
如果你在处理大型数据集时,可能不想重新标注整个训练集/验证集和测试集。一种更直接的方法可能是纠正验证集和测试集的标签。拥有好的评估数据集是非常关键的。对于训练集,你可以使用诸如共教学[5]之类的方法来训练你的模型,即便是有噪声的标签。如今,许多模型还通过不需要标签的自监督学习方法进行预训练。因此,这些模型不会拾取训练数据中的系统性错误。但你仍然需要对这些模型进行适当评估,因此需要好的验证集和测试集。
希望你喜欢这篇文章。如果你有任何关于如何进一步改进本指南的建议,请随时联系我们或留下评论!
Igor Susmelj,
联合创始人 Lightly
[1] Atighehchian 等(2020),“用于生产的贝叶斯主动学习:系统研究和可重用库”
[2] Coleman 等(2020),“高效主动学习和稀有概念搜索的相似性搜索”
[3] Haussmann 等(2020),“面向目标检测的可扩展主动学习”
[4] Northcutt 等人 (2021), “测试集中的普遍标签错误使机器学习基准不稳定”
[5] Han 等人 (2018), “共同教学:在极度噪声标签下对深度神经网络的鲁棒训练”
数据民主化:大型公司采纳的 5 种“人人数据”策略
这关乎数据、技能、工具……特别是文化!
 [外链图片转存中…(img-aPzzTq1u-1726761704334)] Col Jung
[外链图片转存中…(img-aPzzTq1u-1726761704334)] Col Jung
·发表于 Towards Data Science ·15 分钟阅读·2023 年 7 月 19 日
–

图片由Windows(Unsplash)提供
2006 年,《哈佛商业评论》发表了一篇题为“竞争于分析”的文章。
由学者托马斯·达文波特和珍妮·哈里斯撰写的这篇具有影响力的文章引发了关于如何利用分析作为商业竞争优势的广泛讨论。
公司开始投资于 BI 软件、大数据平台、数据科学团队和尖端的AI 和机器学习工具,希望成为数据驱动型公司。
结果令人失望。
一项德勤调查显示,14 年后只有 10%的公司在分析洞察方面具有竞争力。大多数公司只能声称拥有孤立的分析卓越领域。而最受欢迎的分析工具是,鼓声……
……微软 Excel。
事实是,转型为数据驱动型组织比看起来要困难得多。
请关注我的分析和数据 YouTube 频道 这里。
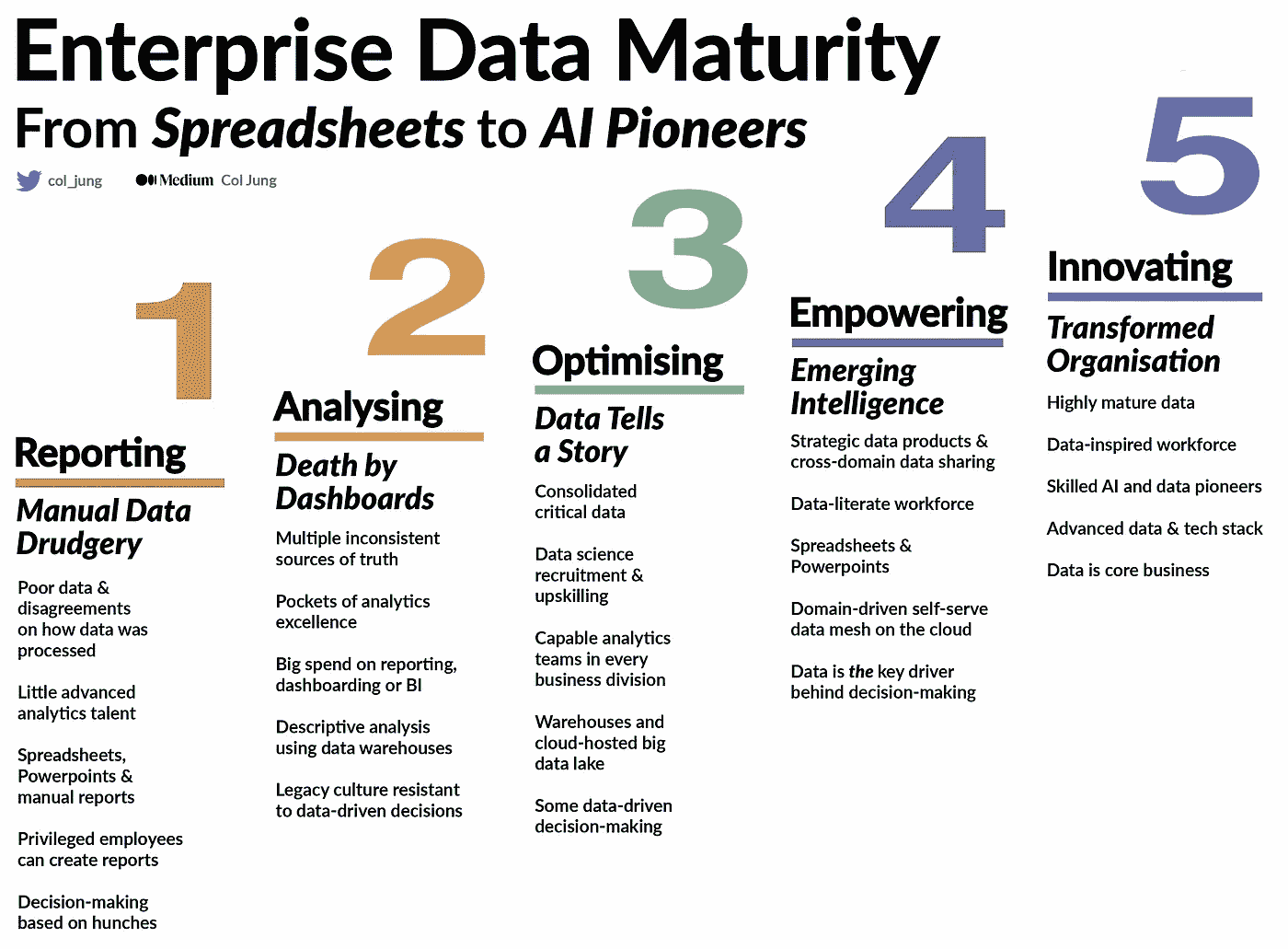
你们公司处于什么位置?图片由作者提供
能够大规模地利用数据驱动的洞察,并将其融入到日常决策中,需要在多个领域达到较高水平的企业数据成熟度:
-
数据: 如果你没有优质数据,AI 就无从谈起。
-
技能: 你的员工整体上是否具备数据素养?
-
工具: 你的基础设施是否为大规模分析做好了准备?
-
文化: 这是最大的障碍。你的公司是否存在对数据驱动洞察抗拒的传统文化?这是一个严重的问题。
我所在的公司,一家‘四大’银行我在这里工作的过去五年作为工程师和数据科学家,是数据成熟度量表上的 2.5 分。我们正在努力达到数据驱动的 4 分,将我们置于行业领先的‘数字原生’公司边缘。(加油团队!)
全球范围内,平均公司数据成熟度大约为 2.2,参考国际高级分析研究所。
这意味着只有少数员工具备超越电子表格的分析技能。

数据民主化弥合了数据素养的差距。图片由作者提供
解决方案似乎很明确。
为了铺垫迈向数据驱动的步伐,企业需要推动数据成熟度。
那么,如何推动数据成熟度呢?
向数据民主化问好,这是一种被全球公司采纳的方式。
数据民主化是一种数据为所有人的全员参与精神,旨在提升公司各个角落的数据成熟度。
例如,我的银行并没有扶持只能由少数特权且高度专业化的数据科学团队使用的专门工具,而是投资于提升数据、技能、工具和文化,以赋能所有 40,000 名同事……
-
自助获取可靠的数据;
-
自动化掉他们日常工作中的繁琐事务;
-
拥抱数据驱动的洞察和决策,而不是‘直觉’。
如果每个人仅通过自动化一个简单的流程每周节省一个小时,我的银行每年将节省 200 万小时,相当于大约 1.5 亿美元,这些钱可以用于其他地方。
这其中蕴含着一个重要的教训。
数据民主化认识到繁琐事务与大胆创新分析项目同样重要。
我们最优秀的数据科学家(公司 1%)的尖端 AI 和机器学习项目值得庆祝。
同样值得庆祝的是我们日常知识工作者和公民分析师的快速胜利。
通过为企业分析和数据科学建立一个坚实的大规模基础,数据民主化有望解决大多数公司迄今为止失败成为数据驱动的根本原因。
那么,数据民主化在实践中究竟是什么样的呢?
我会讲到五种策略,并结合我自己的经验。
前三种代表了工具的进步,而最后两种则关注数据、技能和文化领域的进展。
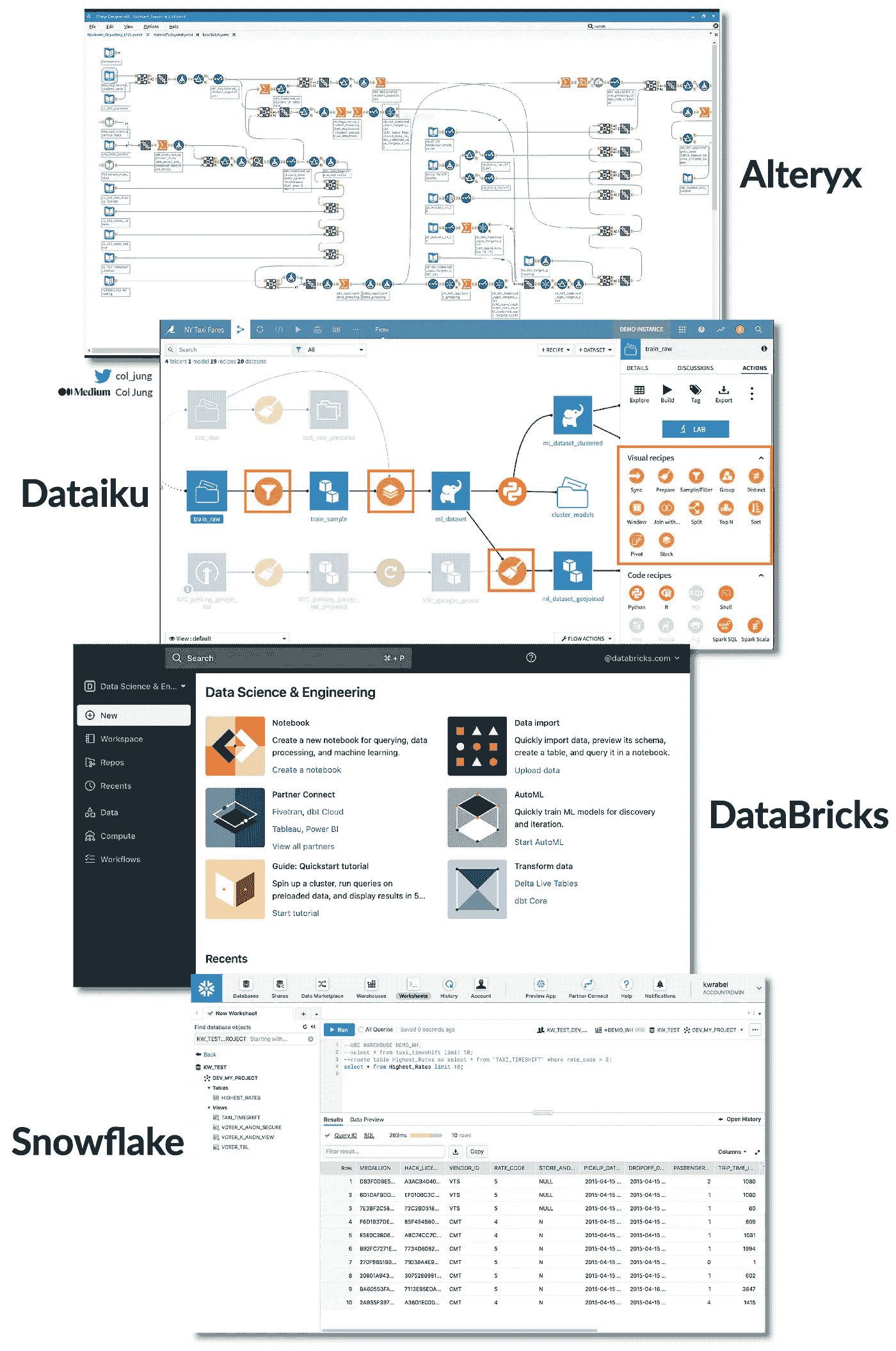
1. 全能分析与自动机器学习平台
2020 年代见证了低代码一站式分析与机器学习平台的兴起,它们将三种主要的企业问题解决方法整合在一个平台下:
-
可视化;
-
分析;
-
自动化。
最受欢迎的平台包括:
-
Alteryx,被全球最大 2000 家公司中的一半使用;
-
Dataiku,一家由谷歌投资部门支持的法国独角兽;
-
DataBricks,它将大数据计算和机器学习统一在一个平台下;
-
Snowflake,一个快速的云数据仓库颠覆者。
这是他们的用户界面:
流行的全能分析和机器学习平台。图片由作者提供
我的银行目前使用Alteryx和Dataiku。
这些平台使我们的财务团队能够在几分钟内建立审计管道。只需将一些数据源拖放到屏幕上,使用几次点击按钮将它们连接起来,然后设置自动化,当出现红旗时通过电子邮件通知你。
不需要电子表格、SQL 或 Python。
不需要在不同程序之间跳转。
不需要对自动化管道进行繁琐的测试以查看它们是否按预期工作。
一切正常运作。
在一个全能平台上拥有所有这些功能可以产生额外的协同效应。
假设我的经理让我深入探讨**客户或员工流失——**这是一个经典的商业问题。在这些现代平台中,我可以……
-
从一些可视化开始,尝试发现有趣的趋势。很好。如果我没有太大运气怎么办?
-
不用担心,该进行一些分析。我可以原型化预测模型,以揭示数据中流失的潜在驱动因素。结果显示每周工作超过 48 小时的人辞职的几率显著增加。很好的洞察,现在我们有一个商业决策——招聘更多的人分担工作,或者识别出有辞职风险的人并及时阻止。
-
我可以非常迅速地设置一个自动化,当数据显示有人工作过度时,通过电子邮件通知我(或人力资源部)。
在企业问题解决中,你永远不知道哪种方法——可视化、分析或自动化——效果最好。
在这里,自动化实际上是最有影响力的,因为它标记出风险员工,使得立即采取行动成为可能,从而节省了大量的后续开支。人力资源部会告诉你,替换失去的员工花费很多钱。
但确实,达到目标之前需要一些探索。分析通常不是线性的。能够在一个地方完成所有工作,并推动数据和结果——通常无需编码——让生活变得轻松许多。
对于公民分析师和数据科学家来说,这无疑是一个极具赋能性的提议。
2. 综合生产力与分析生态系统
该策略审视了一组联合的应用程序和平台,它们在一个生态系统下紧密而协同地集成在一起。
最好的例子是微软。
对于企业生产力,业界标准已经是Windows和Office 365一代:
-
Outlook 用于日历和邮件;
-
Teams 和 Yammer 用于聊天和社区;
-
OneDrive 和 SharePoint 用于文件存储;
-
Word和Excel用于日常工作。
这些基础工具现在是更广泛的Microsoft 365生态系统的一部分,反映了微软提供统一生产力 和 分析平台的战略。
公式中的分析部分是微软Power Platform,这是一个低代码应用程序家族,包括……
-
Power BI — 创建数据模型和惊艳的可视化,无需编码。
-
Power Apps — 创建桌面和移动应用,几乎无需编码。
-
Power Automate — 自动化工作流和任务,几乎无需编码。
-
Power Virtual Agent — 构建自己的聊天机器人,几乎无需编码。
他们用户界面的预览:
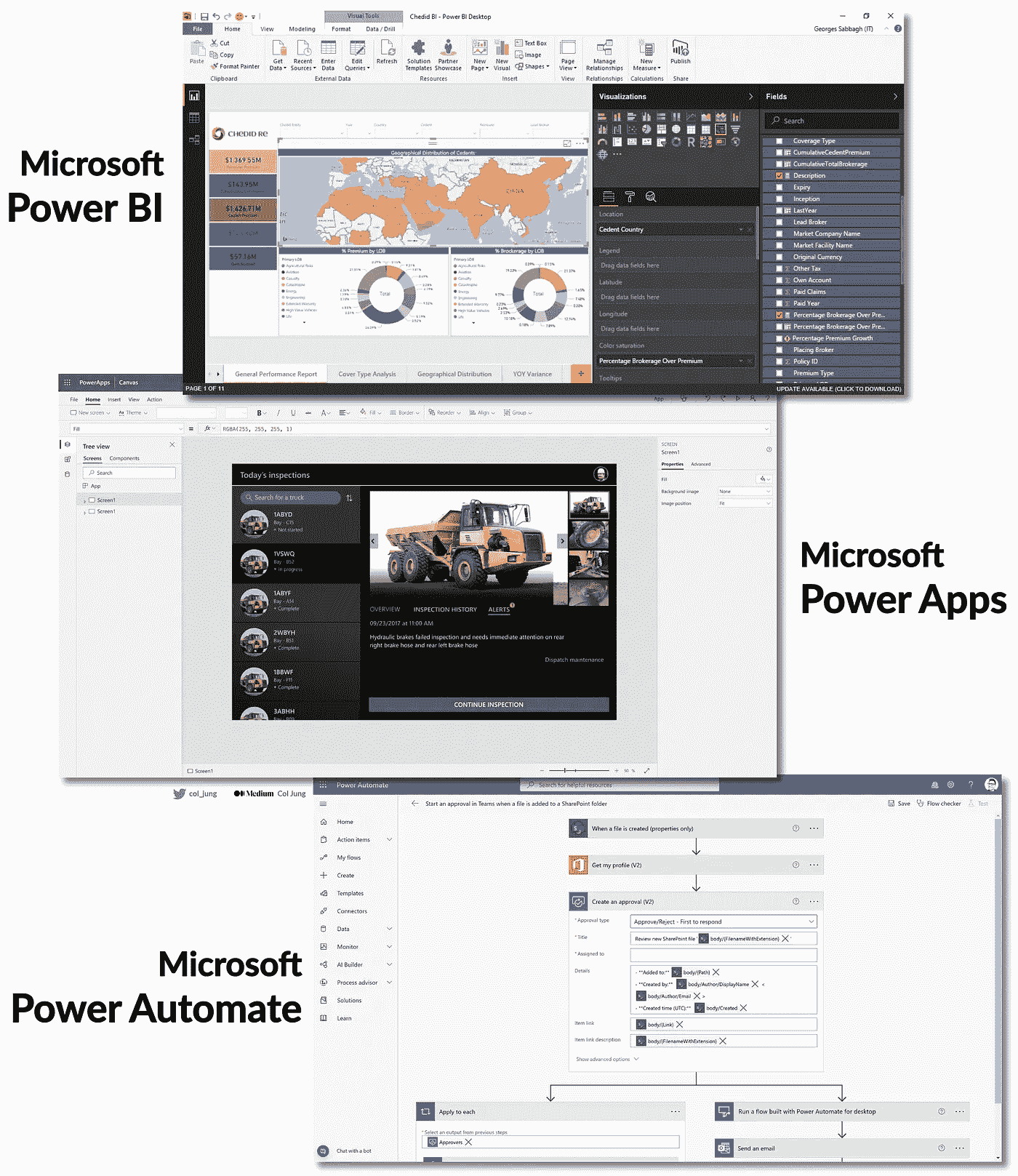
制作可视化,构建应用程序和自动化工作流。图片由作者提供
‘民主化’来自两个方面。
首先,这些工具易于使用,并且每个月变得越来越容易。易用意味着采用,正如任何商界人士、企业家和 UX 设计师会告诉你的那样。
其次,这些 Power Platform 应用程序的集成与彼此 以及微软更广泛的核心生产力应用程序,如 Outlook 和 Teams,至关重要,以使每位员工能够为自己和组织创造价值。
比如说,审查和批准请求的繁琐过程,通常通过无尽的来回邮件和手动流程处理。这是大多数组织中的主要问题源。
够了!厌倦了每次都花几个小时审查,比如数据请求?
拥有数据的公民分析师可以构建一个Power BI报告,提供有关他们拥有的数据资产的信息,并确定这些数据是否可以与同事共享。
他们可以将这些数据驱动的洞察直接嵌入到Power Apps中构建的应用程序中,该应用程序作为同事申请访问的前端。(此外,由于微软与大型企业基础设施的成熟集成,这个应用程序会立即投入生产——数据治理人员的喘息!)
现在,当同事通过应用提交他们的数据请求时,数据所有者将通过Outlook 收到自动请求的电子邮件,甚至通过 Microsoft 的Approvals 应用在Teams上直接收到通知,因为这些自动化设置在Power Automate中完成,几乎无需编码。
我们谦虚的公民分析师将一个每周占用 5 小时的繁琐任务转变为一个现在只需几分钟的自动化管道,从而释放出宝贵的时间用于更具生产力的工作。
(或者也许早下班……!)
3. 成熟的大数据工具
过去五年中,全球企业对大数据和数据湖的接受在很大程度上未能兑现其炒作的承诺。
由于粗糙的工具、数据质量问题、夸大的承诺和可扩展性挑战,解锁数据湖中所有数据潜在价值的必要手段和员工面临的现实之间的差距实在太大。
在我的银行,我们最初的 Apache Zeppelin 笔记本难以使用。Apache Atlas 上的元数据对于非数据工程师来说难以导航。数据通常是按项目基础摄取的,并且经常不完整,需要与我们的数据仓库资产集成——这对喜欢使用未处理数据进行处理和建模的数据科学家来说是一个不理想的情况。
由于许多数据资产未被使用,数据质量问题堆积如山。
数据湖中的水变得陈旧。
我们后来将更好的工具,如Power BI和管理机器学习的平台如Dataiku,接入到我们的数据湖基础设施中,但奇怪和低效的问题仍然存在,就像 PC 制造商必须将来自不同供应商的硬件和软件拼凑在一起所遇到的挑战一样。
如果有一种提供“苹果般”体验的大数据解决方案就好了:硬件和软件完美同步,数据天作之合。
那个时候就是现在。
我们的数据湖现在托管在Microsoft Azure的云端,为我们提供了弹性计算和超大规模能力。此外,鉴于许多组织在 2015 年至 2020 年间开始了大数据之旅,我们正在逐步放弃 Apache Hadoop 技术栈,转而使用完全原生的 Azure 解决方案。
全程 Azure。
这包括Azure Synapse,用于无缝的数据集成和分析,将数据仓库和大数据整合在一个平台下。此外,我们还使用Azure Purview以确保全面和简化的数据治理体验。
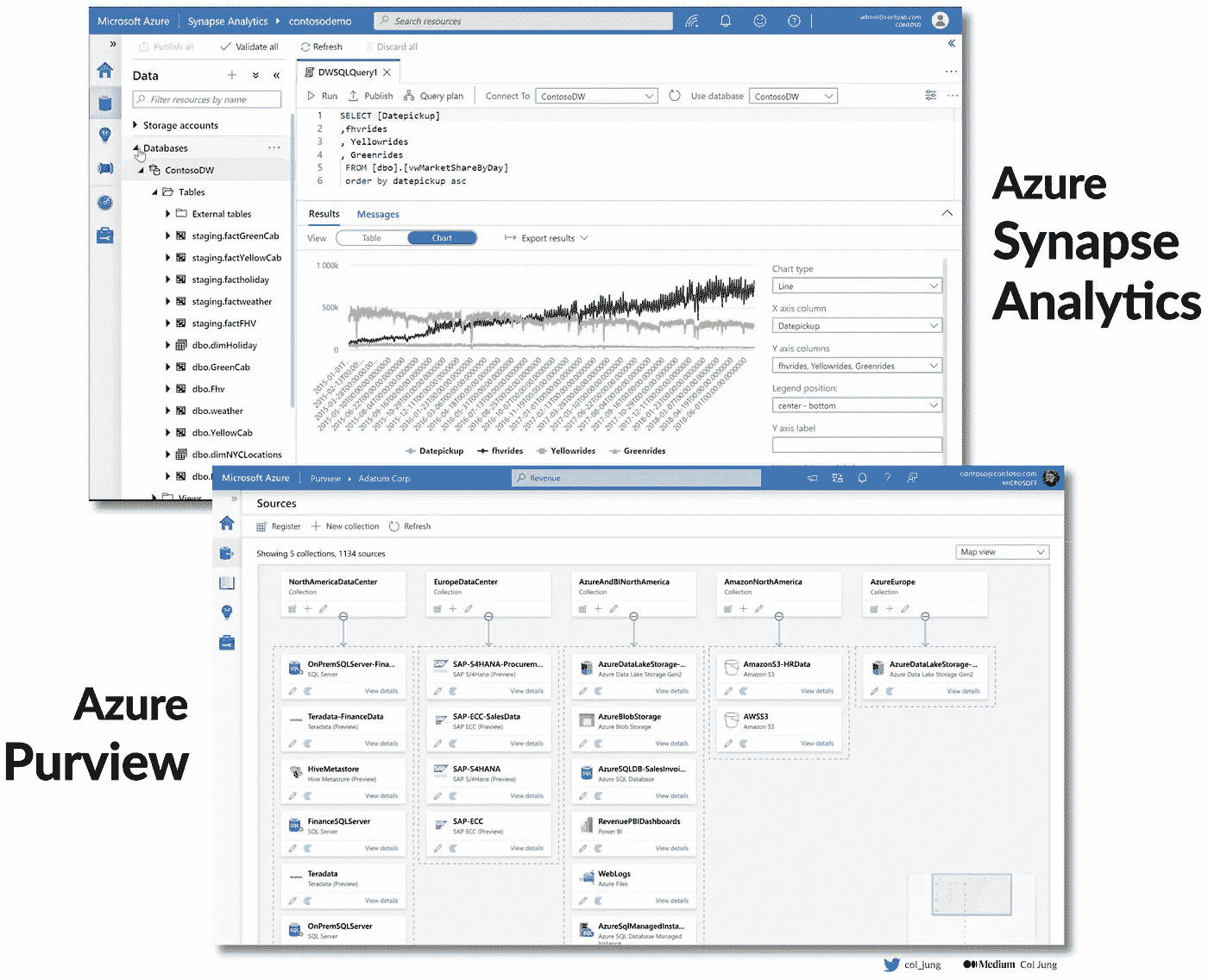
Azure 原生的数据分析、集成和治理工具。图片由作者提供
当然,微软只是主要的云供应商之一。其他包括:
-
亚马逊网络服务(AWS);
-
谷歌云平台(GCP);
-
阿里巴巴云。
所有这些巨头每年投入数十亿美元来改善他们的云基础设施、产品和服务。
简而言之——将数据、分析工具来处理数据、集成工具来结合数据和治理工具来管理数据——都集中在一个平台上,创造了 2023 年尽可能无缝的大数据体验。
4. 文化与教育……文化与教育……
我们刚刚看到三种专注于工具技术进步的策略。
我有一些可能让人有点惊讶的消息:
成为数据驱动的最大挑战不是技术。
关键在于人、流程和 文化。
你可以拥有世界上最好的技术栈,但一个抵触数据驱动洞察的传统文化将阻碍你的数据成熟之路。这是致命的。
生活的现实是人们抗拒变化。
这就是为什么通过提供充足的机会来提升技能和建立数据驱动的社区至关重要。
我的银行刚刚推出了一项企业范围的数据与数字赋能计划,提供给所有 40,000 名员工学习各种主题的机会,从数据流畅性到数据领导力,通过为期 8 周的课程,包括讲座、大师班、播客和由内部专家和行业人物主讲的视频。
我们还举办了一年一度的TechX大会,展示新兴技术,以及一个数据周活动,包含一整周令人兴奋的数据相关演讲。
而且猜猜看?今年的数据周主题是数据为所有人。
每一个演讲都融入了数据民主化的元素。我们不惜一切代价邀请了来自数据领导者如亚马逊、Alteryx、Dataiku、微软、谷歌等的高管与我们的员工交流。
听着,我们自己的数据架构主管装扮成不可思议的“数据英雄”,强调数据是每个人的。

我们公司的年度数据周大会
一个数据驱动的组织需要持续地提升和赋能其员工,这需要强大的文化、强大的社区和高层领导的强力倡导。
没有绕过的办法。
5. 数据市场
最后,让我们谈谈支持分析的数据本身。
寻求数据驱动洞察的讽刺在于,数据在大多数公司中处于糟糕的状态,主要表现为三个问题:
-
缺乏可见性。这些数据到底在哪里?
-
缺乏信任。不可靠的数据意味着不可靠的洞察。
-
缺乏时效性。需要一些数据迅速得到?太遗憾了。
数据在不断流动,但就像一个谜团——没有人能可靠地确定具体内容:它包含了什么,去向何处,源头在哪里,或者谁拥有这些数据。更别提数据质量以及它如何与其他数据连接了。在尝试执行数据战略以成为数据驱动型公司时,这些痛点从一开始就成为严重的障碍。
正如我在这篇文章中所写的企业数据架构:
“几十年的数据仓库让组织淹没在一片由混乱的数据管道连接的数据系统的海洋中。魔法般的解决方案本意是将数据集中到一个中央库中。不幸的是,数据湖的梦想在许多组织中变成了数据湖的沼泽。”
企业长期以来以项目为导向来处理数据,这导致业务团队在需要解决某些问题时创建孤立的数据管道。将数据管道整合到一个集中化的数据团队中,在一个大型数据湖中迅速遇到了瓶颈,导致数据海洋泛滥,难以访问、理解,并且充满了持久的数据问题。
这对全球首席数据和分析官(CDAO)来说是令人沮丧的事情。
在 2020 年代,已经取得了显著的进展来克服这些挑战。
公司正在投资于一种去中心化的数据网格架构,这种架构使各个业务单元能够自豪地打造可重用且可信赖的 数据产品,这些数据产品可以在整个数据网格中无缝共享。
这些数据产品——就像任何从货架上取下的骄傲产品一样——可以由知识工作者进行选购和自助服务,促进了所有战略企业数据资产的最高可见性。
在我的银行中,正在构建一个Netflix或YouTube 风格的数据市场,使员工能够自助服务精选的数据产品和其他数据资产……并且发布他们自己的资产。

将数据视为一种产品,使数据成为一级公民。图片由作者提供
凭借一个经过精心打磨的用户界面,该界面整合了社交元素,并快速提供元数据、数据来源和所有权信息等关键信息,我们正在见证一个集中化且精致的一站式数据商店的兴起,使组织中的每个人都能够轻松地获取和发布数据。
就像伊斯坦布尔的 16 世纪大巴扎,被视为当时的亚马逊市场,吸引了来自世界各地的商人,企业数据市场使数据民主化,面向所有人开放。
突然间,数据资产变得可发现、快速且易于访问,且值得信赖。这大大降低了推动数据洞察、智能决策和先进分析能力(如机器学习和人工智能)的成本。
很棒的东西。
未来会怎样?一些结束语
最具影响力的分析历史上通常来自具备一点分析技能的领域专家。
在 1850 年代,约翰·斯诺 使用地理空间地图来分析数据,并说服科学家和政策制定者霍乱的传播与污水源有关。
Snow 不是‘分析师’或‘数据科学家’。他是医生。
在同一时期,弗洛伦斯·南丁格尔 运用了类似现代 A/B 测试的技术,并利用饼图等可视化手段揭示影响战地死亡率的潜在因素。
今天被公认为统计学的先驱,她开创性的工作奠定了我们今天遵循的众多卫生实践的基础,例如洗手和戴口罩。
南丁格尔不是统计学家。她是护士。
170 多年后,现代企业正在被提醒,数据和分析的民主化对于实现数据驱动的成功是一个前提条件。
这种胜利的心态间接解决了许多问题。
例如,识别和解决大规模数据质量问题的最佳方法是对这些数据进行运用。通过将数据访问的民主化超越少数特权者,企业正在创造出一个提升自身数据质量的绝佳配方。
换句话说,赋予公民数据分析师在公司数据湖中畅游的能力,他们清理的垃圾越多,就会激励更多同事参与其中。
数据民主化启动了一个成功的良性循环。
随着时间的推移,多方面的数据成熟度——数据、技能、工具和文化的同步提升,将最终使企业更接近于成为 4 级或 5 级分析驱动的强大企业的梦想。
未来会怎样?
技术领域正被生成性人工智能剧烈震动。
我预计大型语言模型将在当前工具之上添加一个抽象层,进一步简化各行各业人士利用分析和数据驱动洞察的用户体验。
历史上,技术进步一直关注于抽象层。
在过去,计算机先驱们深陷于汇编代码中。你必须编写这些代码来计算 1 + 1:
section .data
result db 0 ; Variable to store the result
section .text
global _start
_start:
mov al, 1 ; Move 1 into AL register
add al, 1 ; Add 1 to AL
mov [result], al ; Store the result in the 'result' variable
; Exit the program
mov eax, 1 ; System call number for exit
xor ebx, ebx ; Exit status 0
int 0x80 ; Invoke the kernel
C++、Java 和 Python 等高级编程语言在 1980 年代之后出现,使我们的生活轻松了很多。到 2012 年,统计学家现在可以在‘笔记本’中原型制作常用的机器学习模型,而无需太多编程经验:
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
iris = load_iris()
X = iris.data
y = iris.target
# Train a logistic regression model
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
# Make some predictions and evaluate
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
在 2023 年,像Power BI和Tableau这样的企业工具,以及像Alteryx、Databricks和Dataiku这样的托管机器学习平台,可以通过点击几下按钮生成强大的分析。
微软推出了Fabric,一个统一了数据仓储、大数据、数据工程和管理的SaaS 云分析平台。
生成式 AI 会革新分析吗?图像作者提供
几十年后,专用分析平台可能会成为历史遗迹。
只需简单地提示你想要什么,然后看奇迹发生:
“在我的数据集中寻找相关性。”
“运行压力测试以模拟 5 个基点的利率上升。”
“预测未来 5 年的当前销售预测。”
“分析数据质量并给我展示报告。”
我能说什么——现在正是分析和 AI 领域的激动人心的时刻。
在 Twitter 和 YouTube 这里、这里 和 这里 找到我。
我的热门 AI、ML 和数据科学文章
-
AI 与机器学习:快速入门 — 这里
-
机器学习与机制建模 — 这里
-
数据科学:现代数据科学家的新时代技能 — 这里
-
生成式 AI:大型公司如何争先恐后地采用 — 这里
-
ChatGPT & GPT-4: OpenAI 如何赢得 NLU 战争 — 这里
-
GenAI 艺术:DALL-E、Midjourney 和 Stable Diffusion 解析 — 这里
-
超越 ChatGPT: 寻找真正智能的机器 — 这里
-
现代企业数据策略解析 — 这里
-
从数据仓库与数据湖到数据网格 — 这里
-
从数据湖到数据网格:最新架构指南 — 这里
-
Azure Synapse Analytics 实战:7 种用例解析 — 这里
-
云计算基础:利用云计算为您的业务服务 — 这里
-
数据仓库与数据建模 — 快速入门课程 — 这里
-
数据产品:为分析建立坚实的基础 — 这里
-
数据民主化:5 种“数据普及”策略 — 这里
-
数据治理:分析师的 5 个常见痛点 — 这里
-
数据讲故事的力量 — 销售故事,而非数据 — 这里
-
数据分析入门:谷歌方法 — 这里
-
Power BI — 从数据建模到惊艳报告 — 这里
-
回归分析:使用 Python 预测房价 — 这里
-
分类:使用 Python 预测员工流失 — 这里
-
Python Jupyter Notebooks 与 Dataiku DSS — 这里
-
常见机器学习性能指标解析 — 这里
-
在 AWS 上构建 GenAI — 我的初次体验 — 这里
-
数学建模与机器学习在 COVID-19 中的应用 — 这里
-
工作的未来:在 AI 时代您的职业安全吗 — 这里
数据文档 101:为何?如何?为谁?
原文:
towardsdatascience.com/data-documentation-101-why-how-for-whom-927311354a92
数据管理
在你的组织内部建立完整且可靠的数据文档的最佳实践
 [外链图片转存中…(img-wO95T19Q-1726761704337)] Marie Lefevre
[外链图片转存中…(img-wO95T19Q-1726761704337)] Marie Lefevre
·发表于 Towards Data Science ·6 分钟阅读·2023 年 6 月 13 日
–

摄影师 Maksym Kaharlytskyi 的照片,来源于 Unsplash
我记得每次作为数据团队成员进入新公司时,我的主要关注点之一是:
我会找到完整且可靠的数据文档吗?如果找到的话,在哪里呢?
在与其他公司的同行以及不属于数据团队的同事交谈时,我发现许多利益相关者依赖某种数据文档,并希望找到一个可以提供公司所有数据相关知识的地方。
在这个如梦似幻的愿景中,数据文档将是完整且可靠的,并且可以在适当的地点提供给合适的人。想象一下那种感觉会是怎样的!
作为我当前雇主的数据策略师,我的优先事项之一是使数据对所有部门可用。这意味着不仅要沟通数据团队在公司所取得的工作,还要让我的每一位同事(以及可能的外部利益相关者)了解我们作为一个组织拥有的数据资产。
为此,我建立了一个中央数据文档页面,同时为每类利益相关者提供了相应的衍生文档。为了让你了解它的样子,以下是我向所有人开放的中央数据文档页面的前几行:

中央数据文档页面(作者提供的图像)
你在以前或当前的公司是否遇到过类似的问题?你想开始或继续构建你公司的数据文档吗? 在本文中,我想与大家分享我从创建数据文档的想法到其具体实施所遵循的主要步骤。我希望你能觉得这些内容有用且适用。
现在让我们深入探讨一下你应该采取的必要步骤,以为自己和你的利益相关者创建完整可靠的数据文档。
什么是数据文档?
这是一组关于公司数据资产的相关信息。 它包含了一系列元素,例如指标定义、数据源描述、数据模式、数据模型解释、数据工具的访问权限映射等。
没有通用的模板来创建数据文档。最重要的是数据文档服务于你的组织。把它想象成一本全面的手册,能够帮助利益相关者自信且清晰地浏览数据环境。
为什么数据文档至关重要?
就像任何类型的文档一样,数据文档为你的公司提供了一种关于过去事件的记忆。书面文档不仅仅告诉你当前的情况。它还允许任何成员掌握数据管理的历史,无论他们在组织中待了多久。通过记录逐步建立的定义、规则和流程,你为任何有意使用数据的人员带来了清晰和背景。
目前,建立和维护最新的数据文档可以将概念层面上决定的内容和技术实施的内容确立下来。将所有这些元素集中在一个文档中,无疑将利益相关者聚集在一起:在他们就数据管理达成一致后,记录下来能增加其可靠性。
那么,你应该从哪里开始?
正如我们稍后将看到的,你的数据文档的格式可能会根据你的目标受众而有所不同。最初不要专注于文档的形式,而是关注其意图。然后,你将根据构建数据文档的意图来衍生文档的内容和形式。
你可以从问自己以下问题开始:
-
我的受众是谁?他们的技术背景是什么?
-
他们对数据文档有什么期望?
-
我希望我的受众了解关于数据的哪些信息?
-
我的受众在深入细节之前应该知道哪些基本知识?
-
在深入细节时,我应该深入到什么程度,以便让我的受众能够很好地理解而不会迷失?
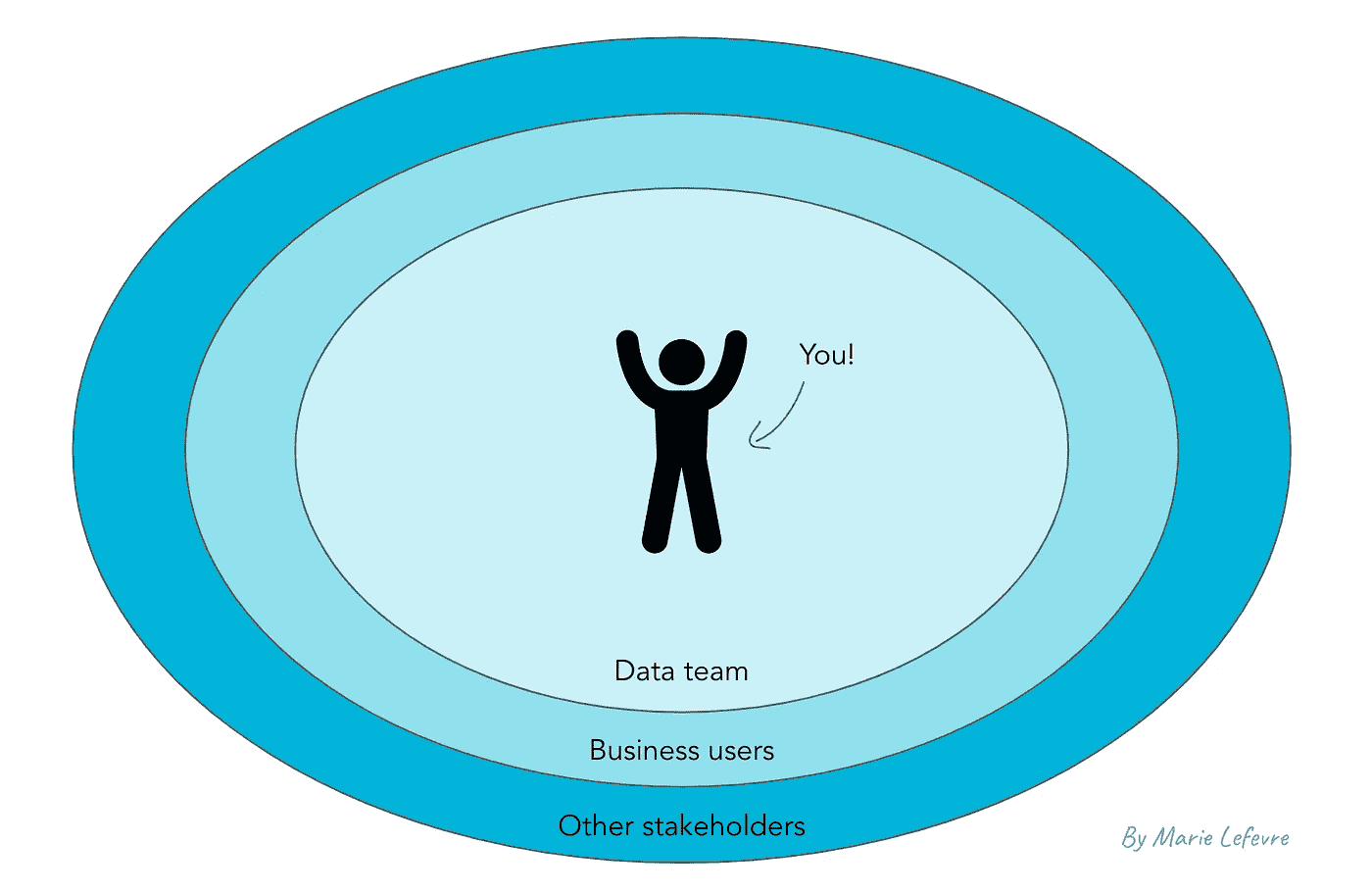
谁是你的目标受众?
一般来说,我识别出三种类型的受众,你应该针对这些受众来编写数据文档。
首要受众是最接近你作为数据领导者的位置的人:即你的数据团队。在这个可能具有异质性的团队中,我们可以区分新成员和初级员工,以及更多的高级成员。因此,你的文档应包括基本概念和更高级的元素,如指标的详细计算方法。
排在第二的位置是业务用户。首先你要服务于那些日常使用数据的用户。他们的需求可能与另一个群体的需求略有不同:业务用户可能偶尔会有数据相关的问题,而且他们与你的工作关系不紧密。你的文档应对这两种类型的业务用户都要提供便利。
最后,其他利益相关者可能需要与公司数据资产相关的特定文档。在这一类别中,我包括了管理委员会、与其他部门的同事(你不一定与他们有互动),以及外部利益相关者。他们对数据文档的需求可能较小,但需要简洁和准确。
不同受众类型的地图(图像由作者提供)
数据文档应包括(或不包括)什么?
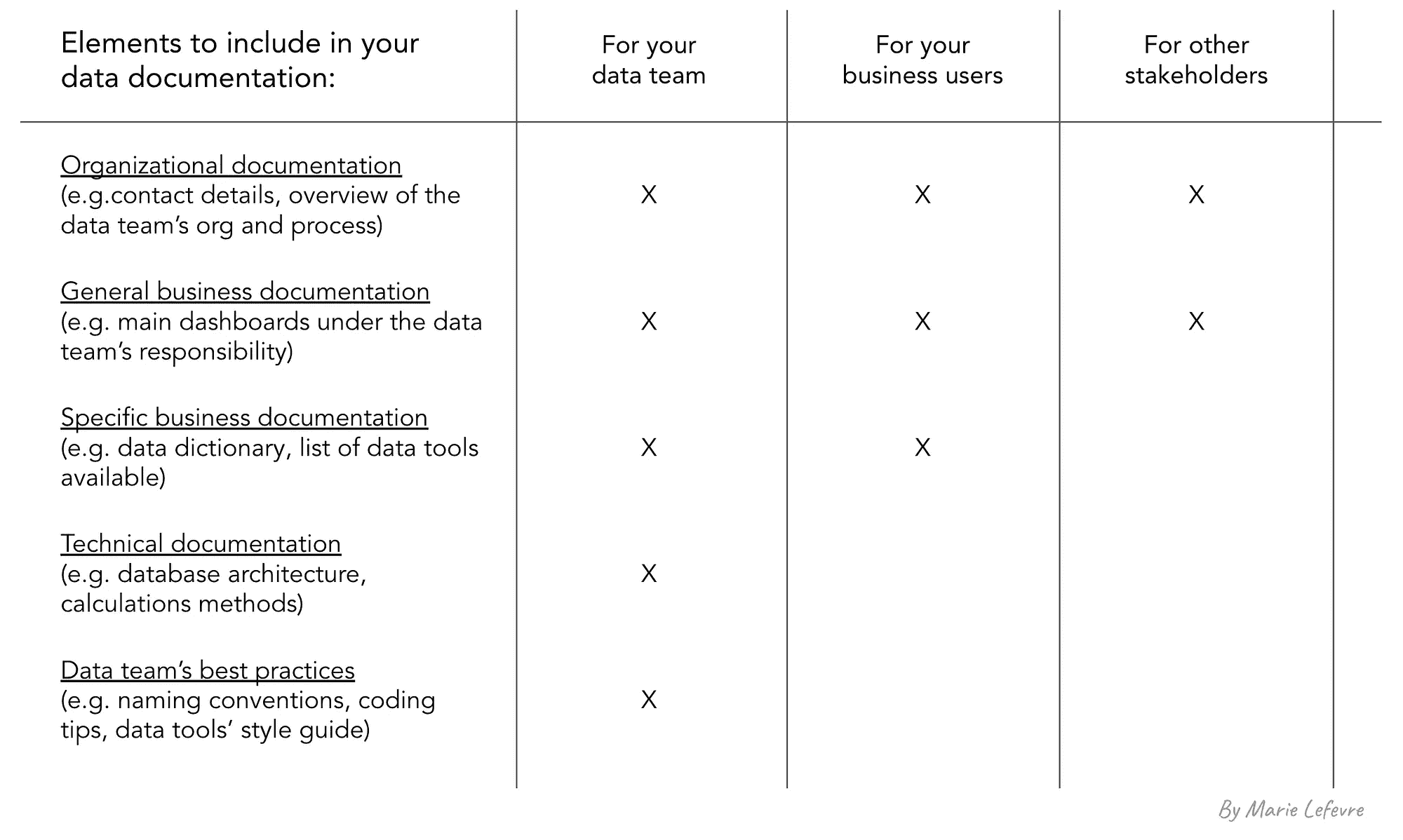
数据文档的内容将根据目标受众的不同而有所变化。
向所有类型的受众提供的共同元素包括关于数据团队的一般知识,如:
-
数据团队的联系方式
-
数据团队概述以及它如何与组织其他部分互动
-
数据团队负责的数据资产
除了这些元素,业务用户需要与他们自己职责范围相关的文档,以及数据如何支持他们的日常活动。这些元素包括:
-
常用术语的词汇表
-
包含指标定义和计算方法的数据字典(可能简化)
-
数据来源的列表以及它们在数据中心的利用方式
-
可用的数据工具列表以及谁应该有权限使用它们
-
最常用的仪表板列表、其内容、拥有者
-
如何使用数据工具的教程(如相关)
最后,数据团队成员需要更加具体的文档,包括技术元素,例如:
-
数据架构和数据模型的架构图
-
包含指标定义和计算方法的数据字典
-
所有数据工具中使用的命名规范
-
数据工具的风格指南
-
你的仪表板设计系统(颜色、字体等)
-
任何成员都应使用的模板(例如用于分享数据分析结果、向听众展示关键数据等)
-
编码语言的最佳实践(SQL、Python、R 等)
简而言之,最好是只包含与每种受众相关的元素,以便他们能全面了解可用文档,而不会被不必要的文档元素淹没。
根据目标受众回顾数据文档的内容(图像由作者提供)
你应该如何以及在哪里提供数据文档?
至于形式,你应该适应目标受众使用的工具。他们是否将知识库集中在像 Notion 或 Confluence 这样的工具中?那么,你的数据文档就应该放在这里。他们是否更倾向于使用共享在 Google Drive 或 Sharepoint 服务器上的幻灯片?那么,你应该在这里展示数据文档的元素。
除了根据受众的习惯调整文档的形式和位置外,你还可以将一些关于数据的信息直接包含在你的数据工具中(例如,在数据仓库或数据转换工具中)。像数据目录和支持(元)数据管理的软件等新兴工具可以帮助你实现这一点。
总结
要建立完整且可靠的数据文档,请记住遵循以下步骤:
-
确保你了解数据文档为何至关重要
-
问问自己你的目标受众是谁——可能有多个受众群体,需求各不相同
-
决定你想在数据文档中包含哪些元素
-
选择合适的工具和合适的地方来创建和维护你的数据文档
这样你就准备好了!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









