







SQL 中的日期和子查询
原文:
towardsdatascience.com/dates-and-subqueries-in-sql-eaf58a3c6cf9
在 SQL 中处理日期


·发布于数据科学前沿 ·阅读时长 4 分钟·2023 年 1 月 27 日
–

在处理 SQL 数据库时,通常需要处理包含日期列的表,这些日期列显示每个相关记录的日期。
然而,SQL 处理日期并从这些数据类型中提取有价值见解的能力常常不被充分理解。
天气数据示例
我们考虑以下示例。假设存在一个天气数据库,其中记录了日期和相关的天气信息。以下是数据的片段:

来源:作者使用 PostgreSQL 创建的表(及数据)。表格显示在 pgAdmin4 中。
同时,假设表中定义了一个月份变量,并从表中提取了相关值,如下所示:
update weatherdata set month=extract(month from date);
现在,为了确保我们每个月都有足够的温度记录,并且记录之间的间隔不至于过长——我们假设希望计算表中每两个连续记录之间的平均持续时间,并按月分组。
这个任务将通过以下方式完成:
-
使用 LAG()函数计算每两个连续日期之间的差异
-
使用子查询计算步骤 1 中计算的每个记录之间的平均持续时间,然后按月分组
计算日期之间的持续时间
通过使用 LAG 函数,我们可以计算每两个连续日期之间的持续时间。然而,我们还希望在新表中显示日期和月份列——我们在随后按月分组平均持续时间时需要使用月份列。
为了实现这一点,我们必须:
-
通过使用 LAG 函数,计算连续日期之间的持续时间
-
通过使用 INNER JOIN 函数将相关表与自身进行内连接
具体操作如下:
select t1.date, t1.date - lag(t1.date) over (order by t1.date) as date_difference, t1.month from weatherdata as t1 inner join weatherdata as t2 on t1.date=t2.date;
这是从上述查询生成的表格:

来源:表格(和数据)由作者使用 PostgreSQL 创建。表格在 pgAdmin4 中显示。
我们可以看到,对于上个月记录的天气数据——大多数条目的持续时间不到一天——这意味着天气模式被定期记录,我们很可能获得了该月的代表性样本!
使用带有 GROUP BY 函数的子查询
在计算了上述表格后,我们现在希望按月份计算记录日期之间的平均持续时间。
为了使用我们刚刚生成的数据——我们必须现在使用子查询。也就是说,我们将把上述查询纳入一个更广泛的聚合查询中,该查询可以使用 GROUP BY 函数。
为了按月份分组持续时间,运行以下查询:
select month, avg(date_difference) from (select t1.date as date, t1.date - lag(t1.date) over (order by t1.date) as date_difference, t1.month as month from weatherdata as t1 inner join weatherdata as t2 on t1.date=t2.date) as subquery group by month order by month;
这是生成的数据:

来源:表格(和数据)由作者使用 PostgreSQL 创建。表格在 pgAdmin4 中显示。
从上面可以看出,在第 1 个月到第 12 个月(1 月到 12 月)之间——我们计算了每个月记录日期之间的平均持续时间。
结论
在这篇文章中,你已经看到:
-
如何从日期中提取月份值
-
如何使用 LAG 函数计算连续日期之间的持续时间差
-
使用子查询以便使用诸如 GROUP BY 之类的聚合函数
非常感谢阅读,如有任何问题或反馈,欢迎提出!你还可以在这里找到原始文章,以及更多有用的 SQL 实践示例。
免责声明:本文是以“原样”基础和无担保的方式编写的。它旨在提供数据科学概念的概述,不应被解读为专业建议。本文中的发现和解释仅代表作者本人,并未得到文中提到的任何第三方的认可或关联。作者与本文提到的任何第三方没有任何关系。
如何在 Pandas 中更改日期时间格式
原文:
towardsdatascience.com/datetime-format-pandas-541c661d41c2
在 Python 和 pandas 中处理日期时间


·发表于 Towards Data Science ·4 分钟阅读·2023 年 1 月 6 日
–

图片来源:Nathan Dumlao 于 Unsplash
Pandas 是 Python 生态系统中最常用的包之一,它提供了丰富的功能,帮助开发者在内存中分析和转换数据。
在 pandas DataFrame 中,日期时间构造的表示有时可能会变得有些复杂,特别是如果你对该库如何处理这些对象不是很熟悉的话。根据你是否希望将日期时间表示为 pandas object dtype(string)还是 datetime,你可能会发现自己在处理这些列时来回切换。
在这篇文章中,我们将展示如何处理 pandas 中不同的日期时间对象表示方式,以及如何更改格式或甚至数据类型。
首先,让我们创建一个示例 DataFrame,在本教程中我们将引用它以展示一些概念。
import pandas as pd
df = pd.DataFrame(
[
(1, 'A', '12/02/1993', True),
(2, 'C', '01/01/2000', False),
(3, 'A', '10/05/2010', False),
(4, 'B', '12/03/1967', True),
(5, 'B', '19/10/2001', True),
(6, 'D', '12/03/2002', True),
(7, 'B', '04/12/2011', False),
(8, 'A', '01/06/1989', True),
(9, 'C', '30/11/1980', False),
(10, 'C', '09/09/1976', False),
],
columns=['colA', 'colB', 'colC', 'colD']
)
>>> df
colA colB colC colD
0 1 A 12/02/1993 True
1 2 C 01/01/2000 False
2 3 A 10/05/2010 False
3 4 B 12/03/1967 True
4 5 B 19/10/2001 True
5 6 D 12/03/2002 True
6 7 B 04/12/2011 False
7 8 A 01/06/1989 True
8 9 C 30/11/1980 False
9 10 C 09/09/1976 False
>>> df.dtypes
colA int64
colB object
colC object
colD bool
dtype: object
将类型为对象的列转换为日期时间
在示例数据框中,我们将日期作为字符串提供,pandas 会自动将列解析为 object dtype。为了做到这一点,我们只需调用 to_datetime() 方法,并将结果赋回到原始列。此外,我们还指定日期的格式,以确保 pandas 正确解析它们:
df['colC'] = pd.to_datetime(df.colC, format='%d/%m/%Y')
现在,如果我们打印出数据框的新 dtypes,我们应该会看到 colC 列的类型已经改变:
>>> df.dtypes
colA int64
colB object
colC datetime64[ns]
colD bool
dtype: object
如果我们也打印出数据框,我们会注意到稍有不同的格式,因为 colC 的 dtype 已经改变:
>>> df
colA colB colC colD
0 1 A 1993-02-12 True
1 2 C 2000-01-01 False
2 3 A 2010-05-10 False
3 4 B 1967-03-12 True
4 5 B 2001-10-19 True
5 6 D 2002-03-12 True
6 7 B 2011-12-04 False
7 8 A 1989-06-01 True
8 9 C 1980-11-30 False
9 10 C 1976-09-09 False
更改日期时间对象的格式
现在我们已经将colC的数据类型转换为datetime,我们可以利用strftime()方法来修改记录的日期格式。
假设我们希望日期以mm/dd/yyyy格式表示。我们需要做的就是在调用strftime()时指定这种格式。我们不覆盖colC中的值,而是创建一个新的列以新格式表示:
df['colE'] = df.colC.dt.strftime('%m/%d/%Y')
现在,新创建的列colE将遵循指定的格式:
>>> df
colA colB colC colD colE
0 1 A 1993-02-12 True 02/12/1993
1 2 C 2000-01-01 False 01/01/2000
2 3 A 2010-05-10 False 05/10/2010
3 4 B 1967-03-12 True 03/12/1967
4 5 B 2001-10-19 True 10/19/2001
5 6 D 2002-03-12 True 03/12/2002
6 7 B 2011-12-04 False 12/04/2011
7 8 A 1989-06-01 True 06/01/1989
8 9 C 1980-11-30 False 11/30/1980
9 10 C 1976-09-09 False 09/09/1976
但请注意,结果列将是object类型,因为strftime生成的输出是字符串格式:
>>> df.dtypes
colA int64
colB object
colC datetime64[ns]
colD bool
colE object
dtype: object
最终想法
在 pandas 中处理日期时间对象有时可能是一项棘手的任务。这是因为这些对象可以使用各种数据类型表示,包括object或datetime。此外,日期格式也有所不同,主要受到用户位置的影响(例如,美国人对mm/dd/yyyy格式有强烈的偏好)。
在这篇文章中,我们演示了如何处理各种不同类型,以及如何在object和datetime对象之间来回切换。我希望本教程能帮助你更有效地处理这些数据类型!
成为会员 并阅读 Medium 上的每一个故事。你的会员费用直接支持我和你阅读的其他作者。你还将获得对 Medium 上每一个故事的完全访问权限。
[## 使用我的推荐链接加入 Medium — Giorgos Myrianthous
作为 Medium 会员,你的会员费用的一部分将用于支持你阅读的作者,你还将获得对每个故事的完全访问权限……
你可能也喜欢的相关文章
## *args 和 **kwargs 在 Python 中
讨论位置参数和关键字参数之间的区别,以及如何在 Python 中使用*args 和 **kwargs
towardsdatascience.com ## Python 中的 pycache 是什么?
了解运行 Python 代码时创建的 pycache 文件夹
towardsdatascience.com
去噪声器的黎明:用于表格数据插补的多输出机器学习模型
方法概述与实际应用


·
关注 发表在 Towards Data Science · 11 分钟阅读 · 2023 年 6 月 28 日
–

处理表格数据中的缺失值是数据科学中的一个基本问题。如果由于某种原因不能忽略或省略缺失值,那么我们可以尝试填补它们,即用其他值替代缺失值。填补有几种简单(但过于简单)的方式和几种先进的(更准确但复杂且可能需要大量资源)方式。本文介绍了一种表格数据填补的新方法,旨在实现简洁性和实用性之间的平衡。
具体来说,我们将看到如何利用去噪的概念(通常与非结构化数据相关联)来迅速将几乎任何多输出机器学习算法转变为适用于实际的表格数据填补器。我们将首先介绍一些关于去噪、填补和多输出算法的基本概念,然后深入探讨如何使用去噪将多输出算法转变为填补器。接着,我们将简要地看一下这种新颖的方法如何在实际中应用,并以行业中的一个例子为例。最后,我们将讨论在生成式人工智能和基础模型时代,基于去噪的表格数据填补的未来相关性。为了便于解释,代码示例仅以 Python 语言展示,尽管概念方法本身是不依赖于语言的。
从去噪到填补
去噪是关于从数据中去除噪声的。去噪算法将含有噪声的数据作为输入,进行一些巧妙的处理以尽可能减少噪声,然后返回去噪后的数据。去噪的典型应用包括去除音频数据中的噪声和锐化模糊的图像。去噪算法可以通过多种方法来构建,从高斯和中值滤波器到自编码器。
尽管去噪的概念主要与涉及非结构化数据(例如,音频、图像)的应用场景相关,但对结构化表格数据的填补是一个密切相关的概念。有许多方法可以替代(或填补)表格数据中的缺失值。例如,数据可以简单地用零(或在特定上下文中等效的值)替代,或用相关行或列的一些统计数据(例如,均值、中位数、众数、最小值、最大值)替代——但这样做可能会扭曲数据,如果作为机器学习训练工作流程中的预处理步骤使用,这种简单的填补可能会对预测性能产生不利影响。其他方法如 K 近邻(KNN)或关联规则挖掘可能表现更好,但由于它们没有训练的概念,并直接在测试数据上工作,当测试数据量很大时,它们的速度可能会受到影响;这在需要快速在线推理的应用场景中尤其成问题。
现在,可以简单地训练一个 ML 模型,将具有缺失值的特征设置为输出,并使用其余特征作为预测器(或输入)。如果我们有多个具有缺失值的特征,构建每个特征的单输出模型可能既繁琐又昂贵,因此我们可以尝试构建一个多输出模型,一次性预测所有受影响特征的缺失值。至关重要的是,如果缺失值可以被视为噪声,那么我们可能能够应用去噪概念来填补表格数据——这是我们将在以下部分中深入探讨的关键见解。
多输出 ML 算法
正如其名所示,多输出(或多目标)算法可用于训练模型以同时预测多个输出/目标特征。Scikit-learn 网站提供了关于分类和回归的多输出算法的出色概述(参见 这里)。
虽然一些 ML 算法允许开箱即用的多输出建模,但其他算法可能仅原生支持单输出建模。像 Scikit-learn 这样的库提供了利用单输出算法进行多输出建模的方法,通过提供实现通常功能(如fit 和 predict)的包装器,并在后台独立应用这些包装器到单输出模型。以下示例代码展示了如何将原生仅支持单输出建模的 Scikit-learn 中的线性支持向量回归(Linear SVR)封装成一个多输出回归器,使用 MultiOutputRegressor 包装器。
from sklearn.datasets import make_regression
from sklearn.svm import LinearSVR
from sklearn.multioutput import MultiOutputRegressor
# Construct a toy dataset
RANDOM_STATE = 100
xs, ys = make_regression(
n_samples=2000, n_features=7, n_informative=5,
n_targets=3, random_state=RANDOM_STATE, noise=0.2
)
# Wrap the Linear SVR to enable multi-output modeling
wrapped_model = MultiOutputRegressor(
LinearSVR(random_state=RANDOM_STATE)
).fit(xs, ys)
虽然这种封装策略至少让我们在多输出用例中使用单输出算法,但它可能无法考虑输出特征之间的相关性或依赖性(即预测的输出特征集合是否整体上有意义)。相比之下,一些原生支持多输出建模的 ML 算法似乎确实考虑了输出间的关系。例如,当使用 Scikit-learn 中的决策树根据一些输入数据建模 n 个输出时,所有 n 个输出值都存储在叶子节点中,并使用考虑所有 n 个输出值作为一个集合的拆分标准,例如,通过对它们进行平均(参见 这里)。以下示例代码展示了如何构建一个多输出决策树回归器——你会注意到,在表面上,这些步骤与之前训练带有包装器的线性支持向量回归(Linear SVR)时的步骤非常相似。
from sklearn.datasets import make_regression
from sklearn.tree import DecisionTreeRegressor
# Construct a toy dataset
RANDOM_STATE = 100
xs, ys = make_regression(
n_samples=2000, n_features=7, n_informative=5,
n_targets=3, random_state=RANDOM_STATE, noise=0.2
)
# Train a multi-output model directly using a decision tree
model = DecisionTreeRegressor(random_state=RANDOM_STATE).fit(xs, ys)
将多输出 ML 模型训练为表格数据插补的去噪器
现在我们已经涵盖了去噪、插补和多输出机器学习算法的基础知识,我们准备将所有这些构建块结合起来。通常,训练多输出机器学习模型以使用去噪插补表格数据包括以下步骤。请注意,与前一节中的代码示例不同,在接下来的步骤中我们不会明确区分预测变量和目标变量——这是因为,在表格数据插补的上下文中,如果特征在数据中存在,它们可以作为预测变量,如果缺失,它们可以作为目标变量。
第 1 步:创建训练和验证数据集
将数据拆分为训练集和验证集,例如,使用 80:20 的拆分比例。我们将这些数据集称为df_training和df_validation。
第 2 步:创建训练和验证数据集的噪声/掩盖副本
复制df_training和df_validation,并在这些副本的数据中添加噪声,例如,通过随机掩盖值。我们将这些掩盖后的副本称为df_training_masked和df_validation_masked。掩盖函数的选择可能会影响最终训练的插补器的预测准确性,因此我们将在下一节中讨论一些掩盖策略。此外,如果df_training的大小较小,可以考虑将行数上采样到某个因子k,这样如果df_training有n行和m列,则上采样后的df_training_masked数据集将有nk行(列数m*保持不变)。
第 3 步:训练一个基于去噪的多输出模型作为插补器
选择一个你喜欢的多输出算法,并训练一个使用噪声/掩盖副本来预测原始训练数据的模型。从概念上讲,你可以进行类似*model.fit(predictors = df_training_masked, targets = df_training)*的操作。
第 4 步:将插补器应用于被掩盖的验证数据集
将df_validation_masked传递给训练好的模型以预测df_validation。从概念上讲,这将类似于df_validation_imputed = model.predict(df_validation_masked)。注意,某些拟合函数可能会直接将验证数据集作为参数来计算拟合过程中的验证误差(例如,在 TensorFlow 中的神经网络)——如果是这样,那么记得在计算验证误差时,使用噪声/掩盖验证集(df_validation_masked)作为预测变量,使用原始验证集(df_validation)作为目标变量。
第 5 步:评估验证数据集的插补准确性
通过将df_validation_imputed(模型预测的结果)与df_validation(真实值)进行比较来评估填补准确性。评估可以按列(以确定每个特征的填补准确性)或按行(以检查预测实例的准确性)进行。为了避免每列得到夸大的准确性结果,可以在计算准确性之前,过滤掉在df_validation_masked中未掩盖的待预测列值的行。
最后,尝试上述步骤来优化模型(例如,使用另一种掩码策略或选择不同的多输出机器学习算法)。
以下代码展示了如何实现步骤 1–5 的一个示例。
import pandas as pd
import numpy as np
from sklearn.datasets import make_classification
from sklearn.tree import DecisionTreeClassifier
# Construct a toy dataset
RANDOM_STATE = 100
data = make_classification(n_samples=2000, n_features=7, n_classes=1, random_state=RANDOM_STATE, class_sep=2, n_informative=3)
df = pd.DataFrame(data[0]).applymap(lambda x: int(abs(x)))
#####
# Step 1: Create training and validation datasets
#####
TRAIN_TEST_SPLIT_FRAC = 0.8
n = int(df.shape[0]*TRAIN_TEST_SPLIT_FRAC)
df_training, df_validation = df.iloc[:n, :], df.iloc[n:, :].reset_index(drop=True)
#####
# Step 2: Create noisy/masked copies of training and validation datasets
#####
# Example of random masking where each decision to mask a value is framed as a coin toss (Bernoulli event)
def random_masking(value): return -1 if np.random.binomial(n=1, p=0.5) else value
df_training_masked = df_training.applymap(random_masking)
df_validation_masked = df_validation.applymap(random_masking)
#####
# Step 3: Train a multi-output model to be used as a denoising-based imputer
#####
# Notice that the masked data is used to model the original data
model = DecisionTreeClassifier(random_state=RANDOM_STATE).fit(X=df_training_masked, y=df_training)
#####
# Step 4: Apply imputer to masked validation dataset
#####
df_validation_imputed = pd.DataFrame(model.predict(df_validation_masked))
#####
# Step 5: Evaluate imputation accuracy on validation dataset
#####
# Check basic top-1 accuracy metric, accounting for inflated results
feature_accuracy_dict = {}
for i in range(df_validation_masked.shape[1]):
# Get list of row indexes where feature i was masked, i.e., needed to be imputed
masked_indexes = df_validation_masked.index[df_validation_masked[i] == -1]
# Compute imputation accuracy only for those rows for feature i
feature_accuracy_dict[i] = (df_validation_imputed.iloc[masked_indexes, i] == df_validation.iloc[masked_indexes, i]).mean()
print(feature_accuracy_dict)
数据掩码策略
通常,可以采用几种策略来掩盖训练和验证数据。从高层次来看,我们可以区分三种掩码策略:穷举、随机和领域驱动。
穷举掩码
该策略涉及为数据集中每一行生成所有可能的掩码组合。假设我们有一个包含n行和m列的数据集。那么穷举掩码将把每一行扩展到最多 2*m*行,每种掩码组合对应一行;该行的最大组合总数等于帕斯卡三角形中行*m*的和,尽管我们可能选择忽略一些对特定用例不有用的组合(例如,所有值都被掩盖的组合)。因此,最终掩盖的数据集将最多包含*n**(2m)行和m列。虽然穷举策略具有相当全面的优点,但在m较大的情况下可能不太实际,因为生成的掩盖数据集可能过大,以至于大多数计算机难以处理。例如,如果原始数据集仅有 1000 行和 50 列,则穷举掩盖的数据集将大约有 10¹⁸行(即一千亿亿行)。
随机掩码
正如其名称所示,该策略通过使用某种随机函数来掩盖值。例如,在一个简单的实现中,决定掩盖数据集中的每个值可以被视为独立的伯努利事件,掩盖的概率为p。随机掩码策略的明显优点是,与穷举掩码不同,掩盖数据的大小是可以管理的。然而,特别是在小数据集的情况下,为了达到足够高的填补准确性,可能需要在应用随机掩码之前对训练数据集进行上采样,以便在生成的掩盖数据集中反映更多的掩码组合。
领域驱动掩码
该策略旨在以一种接近现实生活中缺失值模式的方式应用掩码,即在填补器将被使用的领域或用例中。为了发现这些模式,分析定量的观察数据以及结合领域专家的见解可能会很有用。
实际应用
本文讨论的基于去噪的填补器可以在实践中提供一种务实的“中间路径”,其中其他方法可能过于简单或过于复杂且资源密集。除了在更大的 ML 工作流中作为数据清洗的预处理步骤外,基于去噪的表格数据填补还可能用于推动某些实际用例中的核心产品功能。
AI 辅助完成在线表单是行业中的一个例子。随着各种业务流程的数字化,纸质表单正被数字在线版本所取代。提交工作申请、创建采购申请、企业旅行预订和注册活动等流程通常涉及填写某种在线表单。手动完成这样的表单可能会很繁琐、耗时且可能容易出错,尤其是当表单有多个需要填写的字段时。然而,在 AI 助手的帮助下,通过根据可用的上下文信息向用户提供输入建议,完成这样的在线表单可以变得更加轻松、快捷和准确。例如,当用户开始填写表单上的某些字段时,AI 助手可以推断剩余字段最可能的值,并实时向用户建议这些值。这样的用例可以被自然地框架为基于去噪的多输出填补问题,其中噪声/掩码数据由表单的当前状态(有些字段填写了,其他字段为空/缺失)给出,目标是预测缺失的字段。可以根据需要调整模型以满足各种用例要求,包括预测准确性和端到端响应时间(用户感知的)。
在生成性人工智能和基础模型时代的相关性
随着生成性人工智能和基础模型的最新进展,以及即使在非技术观众中也越来越意识到它们的潜力,自从 ChatGPT 于 2022 年末亮相以来,探讨基于去噪的填补器在未来的相关性是合理的。例如,大型语言模型(LLMs)可以在理论上处理表格数据的填补任务。毕竟,预测句子中的缺失标记是用于训练像**双向编码器表示(BERT)**这样的 LLMs 的典型学习目标。
然而,基于去噪的插补方法——或现今存在的其他更简单的表格数据插补方法——在生成式 AI 和基础模型的时代,不太可能很快变得过时。了解这一点的原因可以通过考虑 2010 年代末期的情况来感受,那时神经网络已成为在几个以前依赖简单算法(如逻辑回归、决策树和随机森林)的用例中,技术上更可行且经济上更具吸引力的选项。虽然神经网络确实在某些需要大规模训练数据且训练和维护成本被认为是合理的高端用例中取代了这些其他算法,但许多其他用例仍未受到影响。实际上,神经网络的普及得益于存储和计算资源成本的降低,而这种降低也使得其他简单算法受益。从这个角度来看,成本、复杂性、解释性需求、实时用例的快速响应时间以及对可能出现的寡头垄断外部预训练模型提供商的锁定威胁等因素,都似乎指向一个未来,在这个未来中,像基于去噪的表格数据插补这样的务实创新有可能与生成式 AI 和基础模型有意义地共存,而不是被它们取代。
dbt CLI 模型选择
原文:
towardsdatascience.com/dbt-cli-model-selection-52ddd038d8b2
一个完整的选择特定模型的备忘单,当运行 dbt 命令时
 [外链图片转存中…(img-tIRW0qYR-1726761744745)] Giorgos Myrianthous
[外链图片转存中…(img-tIRW0qYR-1726761744745)] Giorgos Myrianthous
·发表于 Towards Data Science ·7 分钟阅读·2023 年 1 月 25 日
–

照片由 Yulia Matvienko 提供,来源于 Unsplash
在处理 dbt 项目时,你需要确保用于运行或测试模型、种子和快照的 CLI 命令只包含感兴趣的资源(或其子集)。换句话说,你需要能够针对特定的模型、测试、种子或快照,以避免浪费资源和金钱。当你处理处理大量数据的大型模型时,这一点尤其重要。
默认情况下,dbt run|test|seed|snapshot 会在依赖图中执行所有相应的节点(即 dbt run 将运行所有模型,dbt test 将运行所有模型测试,依此类推)。在本文中,我们将介绍你在通过 dbt 命令行界面(CLI)运行或测试模型、种子或快照时可以利用的所有可能的模型选择简写。
如果你希望尝试我们在接下来的几个部分中介绍的命令,可以随时在本地创建一个示例 dbt 项目。你可以通过 这个逐步指南创建(可能不到两分钟)本地 dbt 环境。
运行 dbt 项目中的所有资源
为了选择 dbt 项目中的所有资源,你只需选择项目名称:
# Runs all models in project my_dbt_project
dbt run --select my_dbt_project
# Runs all tests in project my_dbt_project
dbt test --select my_dbt_project
# Runs all snapshots in project my_dbt_project
dbt snapshot --select my_dbt_project
# Runs all seeds in project my_dbt_project
dbt seed --select my_dbt_project
选择特定资源
为了执行 run、test、snapshot 或 seed 命令以针对特定模型,你只需在 --select 选项中指定模型名称:
# Run model with name `my_model`
dbt run --select my_model
# Run test with id `not_null_orders_order_id`
dbt test --select not_null_orders_order_id
# Run snapshot with name `my_snapshot`
dbt snapshot --select my_snapshot
# Run seed with name `my_seed`
dbt seed --select my_seed
你甚至可以通过指向定义模型的 SQL 文件的特定路径来运行特定的模型、种子或快照:
# Run model my_model
dbt run --select path/to/my_model.sql
# Run snapshot my_snapshot
dbt snapshot --select path/to/my_snapshot.sql
# Run seed my_seed
dbt seed --select path/to/my_seed.sql
选择多个模型
--select接受多个参数,这意味着它能够同时运行多个模型(或测试、快照和种子)。要做到这一点,只需在运行命令时提供所有模式、测试、快照或种子名称:
# Run multiple models
dbt run --select my_model another_model
# Run multiple tests
dbr test --select not_null_orders_order_id unique_orders_order_id
# Run multiple snapshots
dbt snapshot --select my_snapshot another_snapshot
# Run multiple seeds
dbt seed --select my_seed another_seed
选择节点和下游依赖
为了运行一个 dbt 节点及其下游依赖,您需要在资源名称后指定+操作符。
# Run the model with name `my_model` as well as its downstream dependencies
dbt run --select my_model+
# Run my_model tests and the tests of its downstream dependencies
dbt test --select my_model+
# Run seed my_seed and its downstream dependencies
dbt seed --select my_seed+
选择模型和上游依赖
同样地,要选择一个节点及其上游依赖,需要在节点名称之前指定+操作符:
# Run the upstream dependencies of model `my_model` and the model itself
dbt run --select +my_model
# Run the tests of my_model and the tests of its upstream dependencies
dbt test --select +my_model
# Run the upstream dependencies of snapshot my_snapshot and the snapshot itself
dbt snapshot --select +my_snapshot
# Run the upstream dependencies of seed my_seed and the seed itself
dbt seed --select +my_seed
选择具有下游和上游依赖的模型
现在,为了运行一个模型及其所有下游和上游依赖,您只需在两个+操作符之间指定模型名称:
# Run the model `my_model` including its parents and children nodes
dbt run --select +my_model+
# Run the tests for model `my_model` including the tests of its parents and children
dbt test --select +my_model+
# Run the snapshot `my_snapshot` and all downstream and upstream dependencies
dbt snapshot --select +my_snapshot+
# Run the seed `my_seed` and all of the downstream and upstream depdencies
dbt seed --select +my_seed+
选择模型和 N 个下游依赖
有可能您需要运行的不是模型的所有下游(子级)依赖,而是仅需遍历一定数量的边。这可以通过再次使用+操作符来实现,但这次需要指定要执行的父级模型的度数/级别。
# Run model my_model and its first-degree children
dbt run --select my_model+1
# Run tests for `my_model` model and the tests of its first-degree children
dbt test --select my_model+1
# Run `my_snapshot` snapshot and its first-degree children
dbt snapshot --select my_snapshot+1
# Run seed `my_seed` and its first-degree children
dbt seed --select my_seed+1
选择模型和 N 个上游依赖
以相同的方式,您可以指定在上游(或父级)依赖中要遍历的边数
# Run my_model and its first and second degree parent nodes
dbt run --select 2+my_model
# Run tests of my_model and the tests of its first and second degree parents
dbt test --select 2+my_model
# Run snapshot my_snapshot and its first and second degree parent nodes
dbt snapshot --select 2+my_snapshot
# Run seed my_seed and its first and second degree parent nodes
dbt seed --select 2+my_seed
选择模型和 N 个上游以及 M 个下游依赖
最后,要选择一个模型以及 N 个父节点和 M 个子节点,您可以在上游和下游依赖的边数之间指定模型:
# Run model `my_model`, its parents up to the 4th level and its downstreams up to the 5th level
dbt run --select 4+my_model+5
# Run tests of model `my_model` and the tests of its parents up to the 4th level and its downstreams up to the 5th level
dbt test --select 4+my_model+5
# Run snapshot `my_snapshot`, its parents up to the 4th level and its downstreams up to the 5th level
dbt snapshot --select 4+my_snapshot+5
# Run seed `my_seed`, its parents up to the 4th level and its downstreams up to the 5th level
dbt seed --select 4+my_seed+5
排除一个模型
除了--select之外,dbt CLI 还提供了--exclude标志(其语义与--select相同)。在--exclude参数中指定的任何模型将从用--select选择的模型集合中移除。
以下命令将运行除名为my_model的模型之外的所有模型:
dbt run --exclude my_model
--exclude参数也适用于其他 dbt 命令:
# Run all tests except the one with id `not_null_orders_order_id`
dbt test --exclude not_null_orders_order_id
# Run all tests except the tests of customers model
dbt test --exclude customers
# Run all snapshots except `my_snapshot`
dbt snapshot --exclude my_snapshot
# Run all seeds except `my_seed`
dbt seed --exclude my_seed
请注意,--select和--exclude参数可以在单个 dbt 命令中组合使用。
例如,以下命令将运行my_package包中的所有模型,但排除user_base_model及其下游依赖。
dbt run --select my_package --exclude my_package.user_base_model+
运行特定包中的模型
要运行属于特定 dbt 包的模型、测试、快照或种子,您需要遵循点表示法,如下命令所示:
# Runs model my_model in package mypackage
dbt run --select mypackage.my_model
# Runs tests of my_model model in package mypackage
dbt test --select mypackage.my_model
# Runs snapshot my_snapshot in package mypackage
dbt snapshot --select mypackage.my_snapshot
# Runs seed my_seed in package mypackage
dbt seed --select mypackage.my_seed
运行特定路径中的所有模型
为了运行位于特定目录下的模型、测试、快照或种子,您可以使用以下选择器表示法:
# Runs all models under path.to.my.models directory
dbt run --select path.to.my.models
# Runs all tests under path.to.my.models directory
dbt test --select path.to.my.models
# Runs all snapshots under path.to.my.snapshots directory
dbt snapshot --select path.to.my.snapshots
# Runs all seeds under path.to.my.seeds directory
dbt seed --select path.to.my.seeds
除了点表示法,您还可以如下面所示在特定路径中运行模型:
# Runs all models under path/to/my/models directory
dbt run --select path/to/my/models
# Runs all tests under path/to/my/models directory
dbt test --select path/to/my/models
# Runs all snapshots under path/to/my/snapshots directory
dbt snapshot --select path/to/my/snapshots
# Runs all seeds under path/to/my/seeds directory
dbt seed --select path/to/my/seeds
选择具有特定标签的模型
如果您有标记的资源并且希望执行所有这些资源,您可以提供tag选择器并跟上标签名称,如下命令所示:
# Run all models with "finance" tag
dbt run --select tag:finance
组合多个选择器
注意,你实际上可以将教程中描述的几乎任何选择器组合在一个命令中。例如,以下命令将运行每一个标记为 finance 标签的资源,单个模型 my_model 以及路径 path.to.my.marketing.models 中的所有模型:
dbt run --select tag:finance my_model path.to.my.marketing.models
像往常一样,这可以应用于几乎所有的资源,包括测试、种子和快照:
# Tests
dbt test --select tag:finance not_null_orders_order_id path.to.my.marketing.models
# Seeds
dbt seed --select tag:finance my_seed path.to.my.marketing.seeds
# Snapshots
dbt snapshot --select tag:finance my_snapshot path.to.my.marketing.snapshots
最终思考
总结来说,在处理 dbt 项目时,能够针对特定的模型、测试、种子或快照进行操作是很重要的,以避免浪费资源和金钱。 dbt 命令行界面(CLI)提供了多种简写方式,允许你选择特定的资源进行运行、测试、种子或快照。这些包括在运行任何 dbt 命令时包含或排除这些模型的能力。
成为会员 并阅读 Medium 上的每一个故事。你的会员费直接支持我和其他你阅读的作者。你还将获得 Medium 上每一个故事的完全访问权限。
[## 通过我的推荐链接加入 Medium — Giorgos Myrianthous
作为 Medium 的会员,你的一部分会员费会支付给你阅读的作者,同时你可以完全访问每一个故事…
相关的文章你可能也会喜欢
数据工程中的 ETL 和 ELT 的比较
[towardsdatascience.com ## dbt 中的分阶段 vs 中间 vs mart 模型
理解在数据构建工具(dbt)背景下,分阶段、中间和 mart 模型的目的
[towardsdatascience.com ## 如何构建你的 dbt 项目和数据模型
强化 dbt 数据模型的有效结构
[towardsdatascience.com
dbt Core、Snowflake 和 GitHub Actions:数据工程师的个人项目
数据/分析工程师的个人项目:探索现代数据堆栈工具——dbt Core、Snowflake、Fivetran 和 GitHub Actions。


·
关注 发表在 Towards Data Science ·6 分钟阅读·2023 年 12 月 1 日
–

图片由 Gaining Visuals 提供,来源于 Unsplash
这是一个简单且快速的宠物项目,适合希望尝试现代数据栈工具的 Data/Analytics 工程师,包括 dbt Core、Snowflake、Fivetran 和 GitHub Actions。通过这个实践经验,你可以开发一个端到端的数据生命周期,从从你的 Google Calendar 提取数据到在 Snowflake 分析仪表板中展示数据。在本文中,我将带你了解这个项目,并分享一些见解和技巧。查看 GitHub 仓库
技术概述
项目架构如下所示:
Google Calendar -> Fivetran -> Snowflake -> dbt -> Snowflake Dashboard,由GitHub Actions协调部署。

架构
参考 Joe Reis 的《数据工程基础》,让我们根据数据生命周期的定义阶段来审视我们的项目:

数据工程生命周期 [1]
-
数据生成 — Google Calendar, Fivetran 如果你是 Google Calendar 用户,你可能已经积累了大量的数据。现在,你可以通过利用 Fivetran 这样的“数据移动平台”轻松从你的账户中检索这些数据。该工具自动化了 ELT(提取、加载、转换)过程,将数据从 Google Calendar 源系统集成到我们的 Snowflake 数据仓库中。
目前,Fivetran 提供 14 天的免费试用 — 链接。注册非常简单。
-
存储 — Snowflake Snowflake 是一个针对分析需求的云数据仓库,将作为我们的数据存储解决方案。我们处理的数据量较小,因此不会过度使用数据分区、时间旅行、Snowpark 和其他 Snowflake 高级功能。然而,我们会特别关注访问控制(这将用于 dbt 访问)。你需要 设置试用账户,这将为你提供 30 天的免费使用和 400$ 的企业版额度。
-
数据摄取 — Fivetran 数据摄取可以通过 Fivetran 和 Snowflake 的 Partner Connect 功能进行配置。选择你喜欢的方法并设置 Google Calendar 连接器。初始同步后,你可以通过 Snowflake UI 访问你的数据。你可以访问连接器网页查看模式图 这里。
将专门为 Fivetran 同步创建一个新数据库,以及相应的仓库以运行 SQL 工作负载。你应该知道,Snowflake 采用了解耦的存储和计算,因此费用也是分开的。作为最佳实践,你应该为不同的工作负载(如临时、同步、BI 分析)或不同的环境(如开发、生产)使用不同的仓库。

转到 Partner Connect 以连接 Fivetran。

在 Fivetran 中设置 Google Calendar 连接器。

同步的数据会出现在 Snowflake 中。
-
Transformation — dbt Core 数据存储在 Snowflake 中(默认每 6 小时自动同步),我们使用 dbt Core 进入变换阶段。dbt(数据构建工具)有助于 SQL 查询的模块化,使 SQL 工作流能够重用和版本控制,就像软件代码通常被管理一样。有两种方式可以访问 dbt:dbt Cloud 和 dbt Core。dbt Cloud 是一个付费的云版本服务,而 dbt Core 是一个提供所有功能的 Python 包,你可以免费使用。
在你的机器上安装 dbt Core,通过 CLI 使用**“dbt init”**命令初始化项目,并设置 Snowflake 连接。请查看我的 profiles.yml 文件。
为了能够连接到 Snowflake,我们还需要运行一系列 DCL(数据控制语言)SQL 命令,详细信息请见 这里。遵循最小权限原则,我们将为 dbt 创建一个单独的用户,并仅授予其对源数据库(Fivetran 同步数据的位置)、开发数据库和生产数据库的访问权限(我们将在这些数据库中接收转换后的数据)。
-
按照 最佳实践结构化方法,你需要创建三个文件夹,代表数据转换的 staging、intermediate 和 marts 层。在这里你可以试验你的模型,也可以复制我的 示例 来处理 Google Calendar 数据。
在仓库中,你会找到列出 Google Calendar 架构中所有表的 “sources.yml” 文件。创建了 3 个 staging 模型(event.sql,
包括 1 个变换模型(utc_event.sql)和 1 个数据集市模型(event_attendee_summary.sql)在内的 attendee.sql 和 recurrence.sql。
dbt 的重要功能是 Jinja 和宏,你可以将其编织到 SQL 中,从而增强其影响力和可重用性。

选择不同类型的模型物化。
-
使用 dbt 中的通用或单一测试设置数据期望,以确保数据质量。一些数据质量规则位于 “source.yml” 文件中,
以及 “/tests” 文件夹中。在**“dbt build”**命令期间,这些数据质量检查将与模型构建一起运行,以防止数据损坏。

你可以使用 “dbt test” 运行测试。
- 探索 dbt 的快照功能,用于变更数据捕获和类型 2 缓慢变化维度。在我们的示例中,我们捕获了“recurrence”表中的变化。

将快照存储在单独的模式中
-
使用**“dbt docs generate”**命令生成 dbt 文档可能需要一些时间。你将看到从项目中自动创建的数据血缘图和元数据。你可以通过在你的 .yml 文件中添加对数据实体的描述来进一步增强它。
良好的文档提供了更好的数据发现性和治理。
运行 dbt docs serve 以在浏览器中打开它。
- 服务 — Snowflake 仪表板 最后,使用 Snowflake 仪表板可视化你的转换数据。在 Snowflake UI 中创建一个仪表板,并根据你的 SQL 查询尝试使用图块(绘图)。

仪表板示例
-
部署 — GitHub Actions 虽然 dbt Cloud 提供了一个简单的部署选项,但我们将使用 GitHub Actions 工作流来进行我们的 dbt Core 项目。你需要创建一个workflow .yml 文件,该文件将在对 GitHub dbt repo 进行更改时触发,运行指定的操作。在我的示例工作流中,你可以看到一个两步的部署过程:dbt build用于开发环境,成功后还会执行**dbt
用于生产环境的 build。
注意:将 Snowflake 账户和密码等机密替换为 GitHub 机密。为此,请在你的 repo 网页上,转到 Settings -> Secrets and Variables -> Actions。
每次“master”分支更新时,你可以在 repo 的 Actions 标签中看到工作流的启动情况:

查看 Actions 结果
在这个项目中,我们仅仅触及了现代数据工程栈中各种技术的表面。这不仅是一个实际的成就,也是深入探索的绝佳起点。感谢阅读,祝编程愉快!
如果你读到了文章的末尾,也许你觉得它很有价值,并且可能想通过 LinkedIn与我联系。我对机会持开放态度!
除非另有说明,否则所有图片均为作者提供。
参考文献:
[1] Reis, J. (2022). 《数据工程基础:计划和构建强大的数据系统》。O’Reilly Media。
dbt 增量模型——正确的方式
从全面加载的痛苦到增量收益(以及途中一些错误)


·
关注 发表在Towards Data Science ·9 分钟阅读·2023 年 7 月 21 日
–

图片来源:Lukas Tennie在Unsplash
当我在 GlamCorner 的团队开始从传统的 MySQL 数据库过渡到使用 dbt 作为转换和建模层的 Postgres 数据库的 ELT 时,我们感到非常高兴。我们设置了 dbt 项目和配置文件,为我们的模型专门编写了宏,并构建了更多的数据集市以满足下游需求。我们以为一切都完成了——我以为一切都完成了,直到我们遇到第一个障碍:模型运行时间。在这篇文章中,我解释了如何通过采用 dbt 增量模型来克服当时最艰难的性能挑战,犯错(谁没有呢?)并在过程中学到宝贵的经验教训。
进化中的怪物
在 GlamCorner,我们玩的是循环时尚游戏。我们的“后端”团队在仓库里使用 RFID 扫描器,像专业人士一样扫描进出商品。我们还使用像 Zendesk 和 Google Analytics 这样的高级平台,让我们的客户感觉特别棒。更棒的是,我们有自己内部的库存系统——多亏了我们出色的软件工程师——将所有前端和后端系统连接在一起。这就像是天作之合。但随着我们的成长和运营年限的增加,我们的数据库越来越大。可以说,传统的全表加载开始感觉有点像是个麻烦。
痛苦
你要么理解“我希望数据在早上 9 点前准备好”的痛苦,要么不理解。

图片来自作者
团队付出了努力来创建无瑕的**(E)xtract 和(L)oad,我们一起庆祝。然后有一天,(T)**ransformation 就像“哎,这里不是这样运作的”一样,把总运行时间从 10 分钟提高到 90 分钟。我可能夸张了 10 分钟到 90 分钟的部分,因为是的,一切都有其原因,但当你还没喝第一杯咖啡,早上 8:55 商务团队就敲门问:“最新数据在哪里?”这种感觉真的是每天上班的地狱。这就像把所有的辛勤工作扔进垃圾桶,我自己无法接受这个现实。
回到我说的事情:每件事都有它的理由,而曾经只需要 10 分钟的童话故事现在却变成了 90 分钟的红角魔鬼。为了说明这一点,我们以fct_booking数据表为例。这个表包含了每天从网站上获取的所有预订信息。每个**booking_id**代表一个在网站上预订的订单。

图片来自作者
每天,大约有 4 个订单被添加到预订表中,而该表已经包含 80 个订单。当使用 dbt 运行这个模型时,它会删除前一天的整个表,用 84 条记录(包括旧订单和新订单)替换所有记录(80 个历史累计订单+最新一天增加的 4 个新订单)。另外,每新增 4 条记录,查询时间会增加约 0.5 秒。

图片来自作者
现在,想象一下 4 个订单等于每天 4000 条记录,而 80 个订单实际上代表 80 万条记录。你能猜到转换 fct_bookings 表需要多长时间吗?例如,三个月后我们会在哪里?
好吧, 我会把数学留给你。
金蛋
所以,在无目的地浏览 dbt 社区线程并半心半意地浏览 dbt 文档之后(我意思是,谁没这样做过?),我发现了 dbt 增量的圣杯。这就像在稻草堆中找针,只不过那根针是金色的,而稻草堆是由代码组成的。
用通俗的话说,dbt 增量意味着你不必从头开始处理所有数据。你只需处理新数据和修改过的数据,从而节省时间和资源。这就像一个实际有效的快捷方式,不会让你在老板面前出丑。

作者提供的图片
如果你想了解更多关于 dbt 增量的细节,可以查看这个博客和文档:
在 BigQuery 上的实验
towardsdatascience.com [## 增量模型 | dbt 开发者中心
阅读此教程,了解如何在构建 dbt 时使用增量模型。
docs.getdbt.com](https://docs.getdbt.com/docs/build/incremental-models?source=post_page-----63f931263f4a--------------------------------)
要在你的 dbt 模型中设置这个模型,你需要在模型脚本的开头添加一个配置块,同时考虑这两个组件:
- Materialized(物化视图): 默认情况下,dbt 模型的物化视图等于 ‘table’,当没有配置时。要设置增量模式,请将物化视图设置为 ‘incremental’。有关其他 dbt 物化视图的信息,请访问:
阅读此教程,了解如何在构建 dbt 时使用物化视图。
docs.getdbt.com](https://docs.getdbt.com/docs/build/materializations?source=post_page-----63f931263f4a--------------------------------)
-
Unique_key(唯一键): 尽管根据 dbt 文档设置唯一键是可选的,但合理考虑如何设置这一点是极其重要的。实际上,唯一键将是主要驱动因素,帮助 dbt 确定记录是否应添加或更改。需要考虑的一些问题包括:
-
唯一键真的唯一吗?
-
这是两个或更多列的组合吗?
未设置唯一键可能导致数据丢失和模糊值,所以要小心!
这是一个如何为单个唯一键设置配置块的示例:
如果唯一键是多个列的组合,你可以调整配置为:
注意: 如果你使用 BigQuery 或 Snowflake 存储数据,你可能可以调整更多的配置,如设置 sync_mode。但由于我们公司的数据库基于 Redshift,具体来说是 Postgres,我们没有这些高级配置。
一旦解决了这个问题,我们还需要在 dbt 增量模型的脚本中添加一个重要步骤:为 **is_incremental()** 宏添加一个条件块。
is_incremental() 宏在满足以下条件时返回 True:
-
目标表已经存在于数据库中。
-
dbt 没有以
**full-refresh**模式运行。 -
运行的模型配置为
**materialized=’incremental’**
请注意,无论 **is_incremental()** 计算结果是 True 还是 False,你的模型中的 SQL 需要是有效的。
回到 fct_booking 的例子,以下是原始查询:
在应用上述增量设置后,我们有一个模型,其中包括唯一键、模型标签和 **is_incremental()** 宏的条件块,如下所示:
如代码中所示,unique_key 已设置为 **booking_id**,因为一个 booking_id 对应一个订单。
为了使其更高端,我还为任何其他与增量物化集成的模型添加了一个模型标签 incremental_model。主要原因是,通常当 dbt 模型增量出现问题时,它们往往会成批出现问题。因此,为了刷新这些模型而不影响其他模型,并且不需要记住每个启用了增量模式的模型,我可以运行上述代码,而不是单独指定每个模型名称。
dbt run — select tag:incremental_model --full-fresh
还要注意,如果增量模型设置不正确并且在生产表中更新了错误的数据,我需要使用 --full-refresh 命令重新运行模型。然而,你应该记住,以全量加载刷新而不是增量模式运行会更慢,因此记得选择合适的时间进行此操作 (提示:不要在早上 9 点进行)。
反击
到目前为止,生活再次美好!我完美地设置了表,性能查询显著提高。终于,我可以安然入睡。我的手可以触摸草地,dbt 增量模型也没有错过小 Leah —— 这是一个梦想成真。然而,不久之后,财务团队的一名员工急匆匆地跑到我的桌前,手里拿着一份报告,激动地声称:“你给了我错误的数据!”
结果是增量模型在一天中意外跳过了许多订单,然后进入了第二天。“这怎么可能发生?我按照专家教程操作——这不可能错!”我在心里低语。除非上游发生了一些我可能遗漏的事情。经过一番挖掘,问题浮出水面。
每天,在午夜进行数据提取和加载过程,以同步直到那一刻的所有数据。同步通常发生在午夜,但其时间可能会受到启动时间和包缓存等因素的影响。需要注意的是,提取过程可能会在午夜之后稍微开始。
考虑一种情况:提取在凌晨 12:02 开始,而某人决定在凌晨 12:01 进行预订。在这种情况下,数据也将包括当天的一小部分订单,这在更技术性的术语中被称为“迟到数据”。
然而,当前 WHERE 筛选器的逻辑存在一个缺点。筛选器的效率受到影响,因为它仅从 **created_at** 的最新日期值中追加新记录。这意味着它不会捕捉到整天的数据。
为了修复这个问题,我们将稍微调整这个逻辑:
新的筛选器涉及同步过去 7 天的所有数据。任何新数据将被添加到现有数据集中,而任何旧数据的更新字段值将被替换。
权衡
既然你已经跟随到了这里,你可能会想:“我应该使用 is_incremental 筛选器回溯多少天?为什么我选择了 7 天?如果我需要过去 30 天的数据怎么办?”答案并不简单——这取决于你的具体情况。
在我的情况中,我确保每天至少有一个订单。由于过去 7 天的数据可能会发生内部变化,我将筛选器设置为在该时间范围内追加新数据和更新现有数据。然而,如果你对你的查询性能有信心并且想要回溯更长的时间,比如过去 365 天,你可以自由选择!只需注意需要考虑的权衡。
使用增量模型的主要原因是降低模型运行性能的成本。然而,根据数据的大小和公司具体的使用案例,扫描过去 7 天的大数据集可能会降低性能。根据你的需求,找到合适的平衡是至关重要的。
对于更通用的方法,我建议将 7 天作为标准规则。你可以设置每周或每年进行一次完整刷新,以更新 dbt 增量模型。这种方法允许你考虑到意外问题,因为无论你的设置多么完善,仍然可能会有偶尔的停机时间。
在我的使用案例中,我通常会在周末安排增量运行的完整刷新,因为那时操作任务较少。然而,这个时间表可以根据你的团队要求进行自定义。
请记住,关键是找到数据新鲜度和查询性能之间的最佳平衡,确保数据保持准确和最新,同时优化模型的效率。
解码:用简单英语解释 Transformers
无需代码、数学或提及 Keys、Queries 和 Values


·
关注 发表于 Towards Data Science ·15 分钟阅读·2023 年 10 月 9 日
–
自从2017 年引入以来,transformers 已成为机器学习领域的显著力量,彻底改变了主要翻译和自动补全服务的能力。
最近,随着大型语言模型如 OpenAI 的ChatGPT、GPT-4和 Meta 的LLama的出现,变换器的受欢迎程度更高了。这些模型获得了极大的关注和兴奋,都建立在变换器架构的基础上。通过利用变换器的力量,这些模型在自然语言理解和生成方面取得了显著突破,向公众展示了这些成就。
尽管有很多优质资源详细讲解了变换器的工作原理,但我发现自己在理解其数学机制的同时,很难直观地解释变换器是如何工作的。在进行许多访谈、与同事讨论以及在相关主题上做简短讲座之后,似乎很多人都面临这个问题!
在这篇博客文章中,我将旨在提供一个高级解释,讲解变换器是如何工作的,而不依赖于代码或数学。我的目标是避免令人困惑的技术术语和与以前架构的比较。虽然我会尽量保持简单,但由于变换器相当复杂,这不会很容易,但我希望它能提供更好的直观理解,了解它们的作用及其工作方式。
什么是变换器?
变换器是一种神经网络架构,特别适用于处理序列输入的任务。在这个上下文中,最常见的序列例子可能是句子,我们可以把它看作是一个有序的单词集合。
这些模型的目标是为序列中的每个元素创建一个数值表示;封装关于元素及其邻近上下文的关键信息。生成的数值表示可以传递给下游网络,这些网络可以利用这些信息来执行各种任务,包括生成和分类。
通过创建如此丰富的表示,这些模型使下游网络能够更好地理解输入序列中的潜在模式和关系,从而增强它们生成连贯且具有上下文相关性的输出的能力。
变换器的主要优势在于其处理序列中的长距离依赖的能力,以及高度的效率;能够并行处理序列。这对于机器翻译、情感分析和文本生成等任务尤其有用。

图片由 Azure OpenAI Service DALL-E model 生成,提示为:“绿色和黑色的矩阵代码,形状像 Optimus Prime”
Transformer 中包含什么?
要将输入传递给 transformer,我们必须首先将其转换为一系列标记;一组整数表示我们的输入。
由于 transformers 最初应用于 NLP 领域,我们首先考虑这一场景。将句子转换为一系列标记的最简单方法是定义一个 词汇表,它充当查找表,将单词映射到整数;我们可以保留特定的数字来表示词汇表中未包含的任何单词,以便始终分配一个整数值。
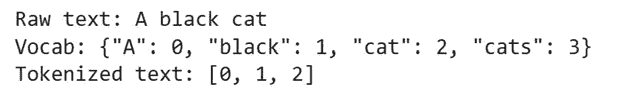
实际上,这是一种简单的文本编码方式,因为像 cat 和 cats 这样的单词被视为完全不同的标记,尽管它们是相同动物的单数和复数描述!为了克服这一点,已经制定了不同的标记化策略——如 byte-pair encoding——它们在索引单词之前会将其拆分成更小的块。此外,通常还需要添加特殊标记,以表示句子的开始和结束,从而为模型提供额外的上下文。
让我们考虑以下示例,以更好地理解标记化过程。
“你好,今天在 Drosval 的天气不错吗?”
Drosval 是 GPT-4 使用以下提示生成的名称:“你能创建一个虚构的地名,它听起来像是属于 David Gemmell 的 Drenai 宇宙吗?”;这个名字被故意选择,因为它不应该出现在任何训练模型的词汇中。
使用来自 transformers library 的 [bert-base-uncased](https://huggingface.co/bert-base-uncased) 标记化器,这被转换为以下标记序列:

代表每个单词的整数将根据特定的模型训练和标记化策略而变化。解码后,我们可以看到每个标记代表的单词:

有趣的是,我们可以看到这与我们的输入并不相同。添加了特殊标记,我们的缩写被拆分为多个标记,我们的虚构地名由不同的“块”表示。由于我们使用了‘uncased’模型,我们也丢失了所有的大写上下文。
然而,尽管我们用句子作为例子,变压器模型并不限于文本输入;这种架构在视觉任务上也展示了良好的结果。为了将图像转换为序列,ViT 的作者将图像切割成不重叠的 16x16 像素块,并将这些块串联成一个长向量,然后输入到模型中。如果我们在推荐系统中使用变压器,一种方法可能是将用户浏览过的最后n个项目的 ID 作为输入传递到我们的网络中。如果我们能够为我们的领域创建有意义的输入标记表示,我们可以将其输入到变压器网络中。
嵌入我们的标记
一旦我们得到一个表示输入的整数序列,我们可以将它们转换为词嵌入。词嵌入是一种表示信息的方式,能够被机器学习算法轻松处理;其目的是通过将信息表示为数字序列,以压缩的格式捕捉编码的标记的意义。最初,词嵌入被初始化为随机数字序列,有意义的表示在训练过程中被学习。然而,这些词嵌入有一个固有的限制:它们不考虑标记出现的上下文。这有两个方面。
根据任务的不同,当我们嵌入标记时,我们可能还希望保留标记的顺序;这在 NLP 等领域尤为重要,否则我们基本上会得到一个词袋模型方法。为了解决这个问题,我们对词嵌入应用位置编码。虽然有多种创建位置嵌入的方法,但主要思想是我们有另一组嵌入,表示输入序列中每个标记的位置,这些位置嵌入与我们的标记嵌入结合。

另一个问题是标记的含义可以根据周围的标记而变化。考虑以下句子:
天黑了,谁关掉了灯?
哇,这个包裹真的很轻!
在这里,light 这个词在两个不同的上下文中使用,其含义完全不同!然而,根据分词策略的不同,词嵌入可能是相同的。在变压器模型中,这由其注意力机制处理。
从概念上讲,什么是注意力机制?
也许变换器架构中最重要的机制被称为注意力,它使网络能够理解输入序列中哪些部分对于给定任务最为相关。对于序列中的每个标记,注意力机制确定哪些其他标记在给定上下文中对理解当前标记是重要的。在我们探讨变换器中如何实现这一机制之前,让我们从简单开始,试图从概念上理解注意力机制的目标,以建立我们的直觉。
理解注意力的一种方式是将其视为一种方法,用来将每个标记嵌入替换为包含其邻近标记信息的嵌入;而不是在不考虑上下文的情况下对每个标记使用相同的嵌入。如果我们知道哪些标记与当前标记相关,那么捕捉这种上下文的一种方式是创建一个加权平均——或者更一般地说,是一个线性组合——这些嵌入。

让我们考虑一个简单的例子,看看这对于我们之前看到的一个句子会是什么样子。在应用注意力之前,序列中的嵌入没有邻居的上下文。因此,我们可以将light一词的嵌入可视化为以下线性组合。

在这里,我们可以看到我们的权重只是单位矩阵。应用我们的注意力机制后,我们希望学习一个权重矩阵,以便我们能够以类似于以下的方式表达我们的light嵌入。

这次,较大的权重被赋予对应于我们选择的标记最相关部分的嵌入;这应该确保最重要的上下文被捕捉到新的嵌入向量中。
含有当前上下文信息的嵌入有时被称为上下文化嵌入,这就是我们最终试图创建的东西。
现在我们对注意力机制的目标有了一个高层次的理解,让我们探讨一下它在下一部分是如何实际实现的。
注意力是如何计算的?
注意力有多种类型,主要区别在于用于执行线性组合的权重计算方式。这里,我们将考虑缩放点积注意力,如在原始论文中介绍的,这是最常见的方法。在这一部分中,假设我们所有的嵌入都已经进行位置编码。
记住,我们的目标是通过对原始嵌入的线性组合来创建上下文化嵌入,让我们从简单开始,假设我们可以将所有必要的信息编码到学习到的嵌入向量中,我们只需要计算权重。
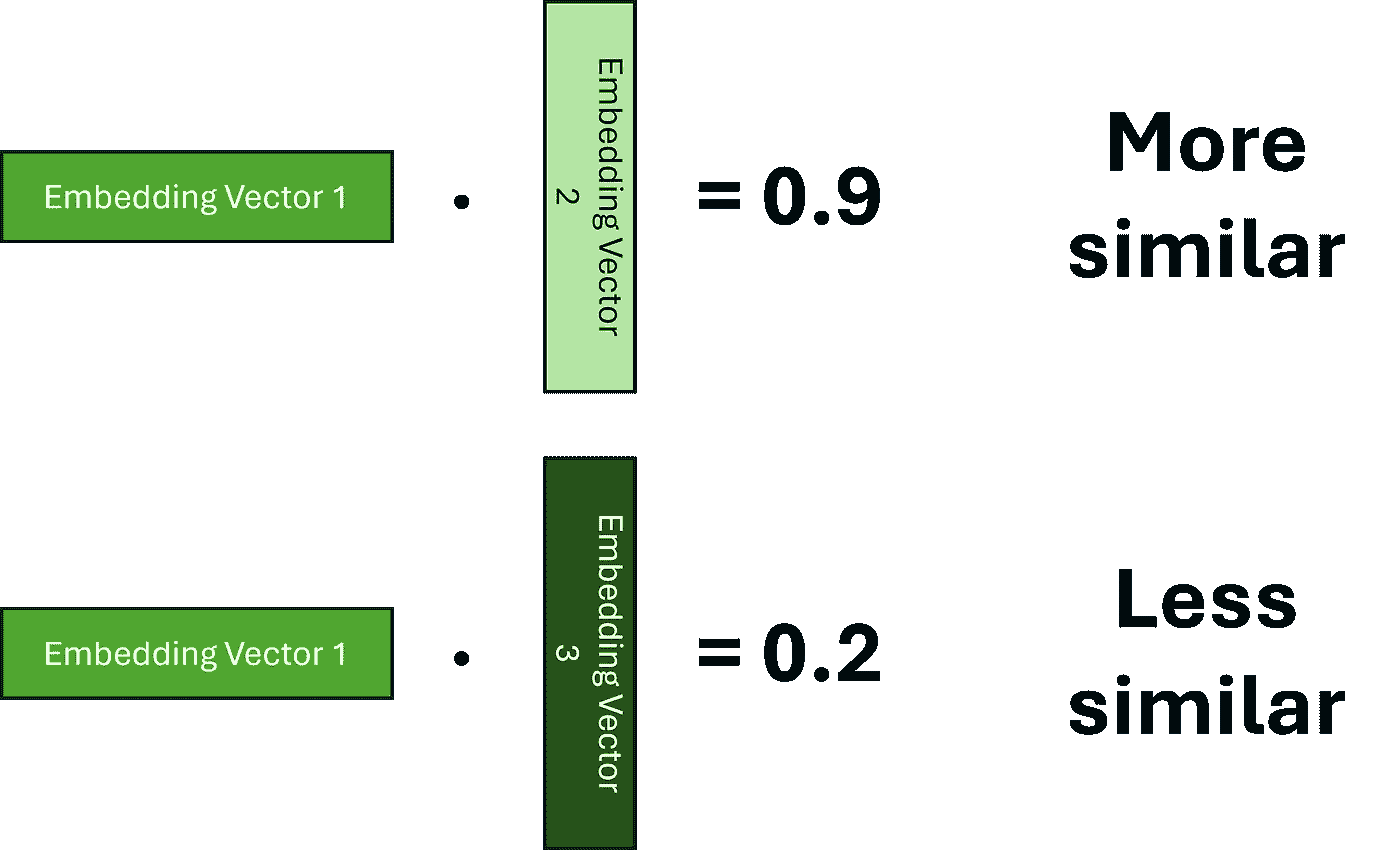
为了计算权重,我们必须首先确定哪些 tokens 彼此相关。为此,我们需要建立两个嵌入之间相似性的概念。表示这种相似性的一种方法是使用点积,我们希望学习嵌入,使得较高的分数表示两个词更相似。
由于我们需要计算每个 token 与序列中其他每个 token 的相关性,我们可以将其概括为矩阵乘法,这为我们提供了权重矩阵,这些矩阵通常被称为注意力分数。为了确保我们的权重总和为 1,我们还应用了 SoftMax 函数。然而,由于矩阵乘法可能产生任意大的数字,这可能导致 SoftMax 函数对较大的注意力分数返回非常小的梯度,这可能在训练过程中导致 梯度消失问题。为了应对这一问题,在应用 SoftMax 之前,注意力分数会乘以一个缩放因子。

现在,为了得到我们的上下文化嵌入矩阵,我们可以将注意力分数与原始嵌入矩阵相乘;这相当于对我们的嵌入进行线性组合。
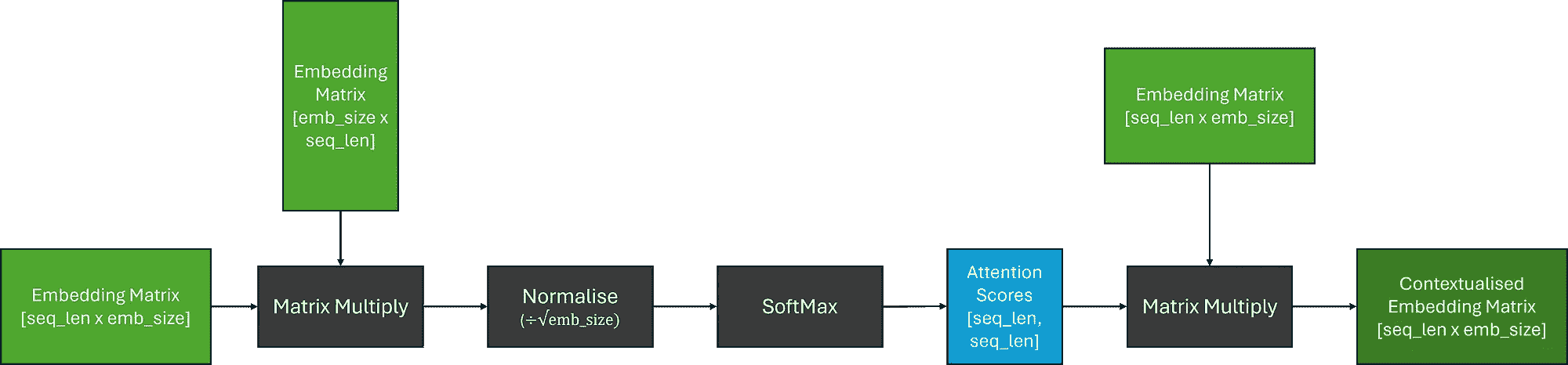
简化的注意力计算:假设嵌入是位置编码的
虽然模型可能能够学习到足够复杂的嵌入来生成注意力分数和后续的上下文化嵌入,但我们试图将大量信息压缩到通常非常小的嵌入维度中。
因此,为了让模型学习任务稍微简单一些,我们引入一些可学习的参数!我们不直接使用嵌入矩阵,而是通过三个独立的线性层(矩阵乘法)来处理它;这应该使模型能够“关注”嵌入的不同部分。如下图所示:

缩放的点积自注意力:假设嵌入是位置编码的
从图像中,我们可以看到线性投影被标记为 Q、K 和 V。在原始论文中,这些投影被称为 查询、键和值,显然受到信息检索的启发。就个人而言,我发现这个类比并没有帮助我理解,因此我通常不会关注这一点;我在这里遵循文献中的术语,以保持一致,并明确这些线性层是不同的。
现在我们了解了这个过程如何运作,我们可以把注意力计算视作一个有三个输入的单一块,这些输入将被传递到 Q、K 和 V。

当我们将相同的嵌入矩阵传递给 Q、K 和 V 时,这被称为 自注意力。
什么是多头注意力?
在实践中,我们通常并行使用多个自注意力块,以使变换器能够同时关注输入序列的不同部分——这被称为 多头注意力。
多头注意力的想法相当简单,多个独立的自注意力块的输出被连接在一起,然后通过一个线性层。这个线性层使模型能够学习如何结合来自每个注意力头的上下文信息。
在实践中,每个自注意力块中使用的隐藏维度大小通常选择为原始嵌入大小除以注意力头的数量;以保持嵌入矩阵的形状。

变换器还包含什么?
尽管引入变换器的论文(现在臭名昭著)被命名为Attention is all you need,但这有些令人困惑,因为变换器的组件不仅仅是注意力!
一个变换器块还包含以下内容:
-
前馈神经网络(FFN):一个两层神经网络,独立应用于批次和序列中的每个令牌嵌入。FFN 块的目的是将额外的可学习参数引入变换器,这些参数是确保上下文嵌入是独特且分散的。原始论文使用了一个GeLU 激活函数,但 FFN 的组件可以根据架构的不同而有所变化。
-
层归一化:有助于稳定深度神经网络的训练,包括变换器。它对每个序列的激活进行归一化,防止它们在训练过程中变得过大或过小,这可能导致梯度相关问题,如梯度消失或梯度爆炸。这种稳定性对于有效训练非常深的变换器模型至关重要。
-
跳跃连接:如在ResNet 架构中,残差连接用于缓解梯度消失问题并提高训练稳定性。
尽管自引入以来,转换器架构保持了相当稳定,但层归一化块的位置可能会根据转换器架构而有所不同。原始架构,现在称为后层归一化,如下所示:

在最近的架构中,如下图所示,最常见的放置位置是预层归一化,它将归一化块放在自注意力和 FFN 块之前,位于跳跃连接中。

不同类型的 Transformer 有哪些?
虽然现在有许多不同的转换器架构,但大多数可以归纳为三种主要类型。
编码器架构
编码器模型旨在生成可以用于下游任务(如分类或命名实体识别)的上下文嵌入,因为注意力机制能够覆盖整个输入序列;这就是本文迄今为止探索的架构类型。最受欢迎的编码器-only 转换器家族是BERT及其变体。
在通过一个或多个转换器块处理数据后,我们得到了一个复杂的上下文化嵌入矩阵,表示序列中每个标记的嵌入。然而,为了用于下游任务,如分类,我们只需要做一个预测。传统上,取第一个标记,并通过分类头;分类头通常包含 Dropout 和线性层。这些层的输出可以通过 SoftMax 函数转换为类别概率。下面展示了这可能的样子。

解码器架构
几乎与编码器架构相同,关键区别在于解码器架构使用了掩蔽(或因果) 自注意力层,使得注意力机制只能关注输入序列的当前和先前元素;这意味着生成的上下文嵌入仅考虑先前的上下文。流行的解码器-only 模型包括GPT 家族。

这通常是通过用二进制下三角矩阵掩蔽注意力分数,并用负无穷替换未掩蔽的元素来实现的;当通过以下 SoftMax 操作时,这将确保这些位置的注意力分数为零。我们可以更新之前的自注意力图以包括如下内容。

掩码自注意力计算:假设位置编码嵌入
由于它们只能从当前位置及之前的位置进行注意力计算,解码器架构通常用于自回归任务,如序列生成。然而,在使用上下文嵌入生成序列时,与使用编码器相比,有一些额外的考虑因素。下方展示了一个例子。

我们可以注意到,尽管解码器为输入序列中的每个 token 生成了一个上下文嵌入,但我们通常使用与最终 token 对应的嵌入作为生成序列时输入到后续层的内容。
此外,在对 logits 应用 SoftMax 函数后,如果没有进行过滤,我们将会得到模型词汇表中每个 token 的概率分布;这可能非常庞大!通常,我们希望使用各种过滤策略减少潜在选项的数量,一些常见的方法包括:
-
温度调整: 温度是一个在 SoftMax 操作中应用的参数,影响生成文本的随机性。它通过改变输出单词的概率分布来决定模型输出的创造性或专注性。较高的温度会使分布变平,生成的输出更具多样性。
-
Top-P 采样: 这种方法根据给定的概率阈值筛选下一个 token 的潜在候选数量,并基于超过该阈值的候选重新分配概率分布。
-
Top-K 采样: 这种方法将潜在候选数量限制为基于其 logit 或概率评分(取决于实现)的 K 个最可能的 token。
这些方法的更多细节 可以在这里找到。
一旦我们调整或减少了对下一个 token 潜在候选的概率分布,我们可以从中进行采样以获得预测结果——这只是从一个 多项分布 进行采样。预测的 token 然后附加到输入序列中,并反馈到模型中,直到生成所需数量的 tokens,或模型生成一个 停止 token;一个特殊的 token,用于标记序列的结束。
编码器-解码器架构
最初,变换器被提出作为一种机器翻译架构,使用了编码器和解码器来实现这一目标;先使用编码器创建中间表示,再使用解码器翻译成所需的输出格式。虽然编码器-解码器变换器已经变得不那么常见,诸如 T5 的架构展示了如何将任务如问答、摘要和分类框架化为序列到序列的问题,并利用这种方法进行解决。
编码器-解码器架构的关键区别在于,解码器使用编码器-解码器注意力,在其注意力计算过程中使用编码器的输出(作为 K 和 V)和解码器块的输入(作为 Q)。这与自注意力形成对比,在自注意力中,相同的输入嵌入矩阵用于所有输入。除此之外,总体生成过程与仅使用解码器架构非常相似。
我们可以通过下图来可视化编码器-解码器架构。在这里,为了简化图示,我选择了描绘原始论文中所见的后层归一化变种,其中层归一化层位于注意力块之后。

结论
希望这提供了对变换器工作原理的直观了解,帮助将一些细节以某种易于消化的方式分解,并且作为解开现代变换器架构神秘面纱的良好起点!
Chris Hughes 在 LinkedIn 上
除非另有说明,所有图像均由作者创建。
参考文献
处理转化指标?考虑使用 Beta-二项式模型
原文:
towardsdatascience.com/dealing-with-conversion-metrics-consider-beta-binomial-model-29733906ff38

图片由 Karim MANJRA 提供,来源于 Unsplash
学习一种特征工程技术,使基于转化的指标如 CTR/CVR 更具代表性和稳定性


·发布于 Towards Data Science ·10 分钟阅读·2023 年 7 月 26 日
–
行业内有大量的转化指标。而且我们经常希望将它们用作我们机器学习模型中的一个特征。例如,产品在搜索页面上展示的印象到点击的产品详情点击率(CTR)可能是一个相关特征,用于建模产品是否会在电子商务平台上被购买。
在这篇博客中,我们将学习一种针对这些转化指标的特征工程技术。为了实现这一目标,博客的其余部分将按以下结构进行。
-
解释为什么我们需要谨慎处理转化特征(即,我们不应使用这些特征的原始形式)。
-
解决方案:使用 Beta-二项式模型将原始转化值转换为更稳定/更具代表性的版本
-
Beta-二项式模型的理论基础
-
调整模型 Beta-prior 分布参数的指南
-
用于进行 Beta-二项式转换的 Python 代码(提示:非常简单!)
让我们开始吧!
使用原始转化值的缺点
假设我们正在构建一个分类模型,以预测产品是否会在电子商务平台上被购买。作为数据预处理的一部分,我们提取与每个产品相关的两列数据:获得的印象数和点击数。因为我们是具有强大领域知识的优秀数据科学家,所以我们衍生出一个名为“印象到点击转化”的新特征。
这一特征工程的原理是我们相信更高的印象到点击转换率表示更好的产品质量。逻辑是,如果一个产品在展示次数(印象)中获得了更高的点击百分比,这表明用户觉得这个产品有吸引力,从而增加了购买的可能性。
现在考虑以下三个产品场景。

原始转换值(图片来源于作者)
在表格中,产品 A 和产品 B 的印象到点击转换率都是 70%。这是否意味着产品 A 和 B 的质量相同?注意产品 A 在经过大量展示(1000 次印象)后达到了 70% 的转换率,表明测试和稳定性较高。另一方面,产品 B 从更少的展示次数(仅 10 次印象)中获得了相同的转换率,使其不那么可靠,更容易受到波动的影响。
鉴于这种测试和稳定性的差异,我认为将较高的转换评分分配给产品 A 比产品 B 更合适。
当我们考虑产品 C 时,使用原始转换值的问题变得更加明显。产品 C 在仅被展示 1 次后就达到了 100% 的印象到点击转换率。使用原始转换值暗示产品 C 比其他产品显著更好——但这不一定是真的。因为产品 C 可能只是“初学者运气”而已。产品 C 的真实/稳定转换率很可能低于 100%,随着用户的印象增加而变化。
Beta-Binomial 模型来救援!
有没有比使用原始转换值更好的方法?
确实有更好的方法!我们可以使用 Beta-Binomial 模型来获得更稳定的转换值,这可能更好地代表特征。我们可以通过以下转换,使用 Beta-Binomial 模型计算产品的点击倾向(我们用来指代印象到点击转换的更好/更稳定版本)。

Beta-binomial 转换公式(图片来源于作者)
α 和 β 是一些指定的值。
例如,使用 α = β = 10,我们可以得到之前考虑过的产品 A、B 和 C 的以下结果。

Beta-Binomial 转换(图片来源于作者)
比使用原始转换值更好,对吧?现在产品 A 在三者中得分最高,这似乎更公平,因为它已经经过了最多的用户测试(大量印象)。此外,产品 C 现在得分最低,因为我们对它看似完美的转换结果不确定(即需要更多的测试来证明其价值)。
Beta-Binomial 模型的理论基础
尽管其简单,但上述变换有着坚实的理论基础,这将在本节中讨论。
实用的读者可以直接跳过这个更技术性的部分,继续阅读“如何选择 α 和 β”部分。
二项分布
第一个相关概念是二项分布。回忆一下,它是一种概率分布,用于建模从一组独立的二项试验(n)中获得的成功次数(y),每次试验的成功概率为 pi(π)。
在我们的案例中,我们可以使用二项分布来建模产品获得的点击次数(y),这些点击是产品展示给用户的次数(n),假设产品的点击倾向是 pi(π)。
二项分布的概率质量函数如下所示。

二项分布 PMF(作者图像)
使用上述公式,我们可以计算(给定 n 和 π)成功次数等于 y 的概率。结果,我们可以确定哪个 y 值的发生概率高于其他值。
然而,在我们的案例中,我们不感兴趣于学习 y 的最佳值(即,获得最高概率的点击次数)。这是因为我们有点击和展示数据作为输入(也就是说,我们可以查询产品 A 从我们的跟踪数据库中获得了多少展示次数(n)和点击次数(y))。
相反,我们想要推断产品的点击倾向。也就是说,给定 n 和 y,π 应该是什么值?
回答这个问题需要将概率质量函数翻转过来,如下所示。

二项分布的似然函数(作者图像)
上述函数被称为似然函数。值得注意的是,在这个函数中,π 现在被视为关注的变量。而 n 和 y 被认为是常数(它们的值是预先给定的)。
Beta 分布
Beta 分布是一种概率分布,用于建模一个取值范围在 0 和 1 之间的随机变量。因此,我们可以用它来建模我们之前感兴趣的点击倾向 π。
Beta 分布的概率密度函数如下所示。

Beta 分布 PDF(作者图像)
其中Γ是伽玛函数,α 和 β 是分布参数。更多细节,请参见 Beta 分布的维基页面。
随机变量 Beta(α, β) 的期望值(均值)是。

Beta 分布均值(作者图像)
这个量对于我们的建模工作至关重要,因为我们将用它来定义我们所寻找的最佳 π 值。
贝叶斯统计
贝叶斯统计是一种统计思维方式,我们不仅检查观察到的数据,还考虑我们的先验知识,以便从数据中得出结论。我们通过在看到数据之前权衡观察到的数据(证据)与我们的初始假设来做到这一点。
在贝叶斯统计中,我们从一个初始信念开始,这个信念由一个先验概率分布表示,并将其与观察到的数据的可能性结合,以获得一个后验概率分布。这个后验分布反映了我们对研究现象的更新理解,结合了可用的数据和我们最初的假设。

后验公式(图片作者提供)
在我们的背景下,我们对找到最佳值以代表给定产品的点击倾向 π 感兴趣。为此,我们可以在未看到任何数据的情况下,使用 Beta 分布作为我们点击倾向 π 的先验分布。然后将该先验与给定观察数据(印象数 n 和点击数 y)的二项分布的可能性结合。

Beta-Binomial 后验推导(图片作者提供)
通过进行一些代数运算(这里略过,感兴趣的读者可以查看完整推导 这里),结果表明 π 的后验分布将等于 Beta(α+y, β+n-y)。请记住,n 和 y 分别是印象数和点击数。
因此,这个 π 的后验分布的均值如下。

转换公式推导(图片作者提供)
这正是我们之前示例中使用的转换公式。
如何选择 α 和 β?
让我们总结一下我们所做的工作。我们使用 Beta(α=10, β=10) 作为我们点击倾向 π 的先验分布。这导致了 Beta(α+点击数, β+印象数-点击数) 的后验分布。该后验分布的均值为 (点击数+α/印象数+α+β),我们用来转换原始的转化值。
这些 α 和 β 的值来自哪里?
为了明确,后验分布(因此 Beta 后验均值公式)仅仅是所选先验分布的一个结果。因此,选择 α 和 β 实际上是选择先验分布的问题。具体来说,我们希望在未观察任何数据的情况下(即尚无印象的产品)得到什么样的点击倾向 π 分布?
这里的关键思想是理解 α 和 β 对 Beta 分布 PDF(概率密度函数)形状的影响。为了对这个主题有一些直观认识,下面展示了几个具有不同 α 和 β 值的 Beta PDFs。

α 和 β 对 Beta 分布形状的影响(图片作者提供)
从图表中可以看到,使用 Beta(α=10, β=10)作为我们的先验(橙色曲线)意味着在没有数据的情况下,我们倾向于认为点击倾向π集中在 0.5 左右,且对称变化范围在 0.2 和 0.8 之间。
如果我们认为默认的点击倾向可能在 0.7 左右,我们可以使用 Beta(α=7, β=3)作为我们的先验(棕色曲线)。另一个例子是:如果我们对默认点击倾向没有偏好(即任何比例值都是一样可能的),我们可以使用 Beta(α=1, β=1)作为我们的先验(蓝色线),因为它类似于均匀分布。
现在,敏锐的读者可能会说:“我知道 Beta(α=10, β=10)和 Beta(α=2, β=2)都导致一个以 0.5 为中心的对称分布。那么,我们为什么选择前者而不是后者呢?”
回答这个问题需要理解α和β对 Beta 分布方差的影响。下面的图片清晰地展示了这个问题。

α和β对变异性的影响(图片来源:作者)
从图表中可以看到,更高的α和β值导致分布的变异性降低。Beta(α=10, β=10)的 PDF 比 Beta(α=2, β=2)更陡峭。而 Beta(α=50, β=50)的变异性低于 Beta(α=10, β=10),依此类推。
实际上,如果我们使用更大的α和β值,这意味着我们在先验上施加更大的权重以影响后验(回顾:后验是从先验和观察数据之间的平衡作用中得出的)。
为了更好地理解,让我们看看我们的产品 A、B 和 C 如何响应不同的α和β值(假设 Beta 先验均值/默认转换在 0.5 处相同)。

α和β大小的不同效果(图片来源:作者)
让我们关注产品 B。当α=2,β=2 时,Beta 后验均值为 64%(比先验均值偏移了近 15%)。当我们增加α=10,β=10 时,偏移缩小到不到 7%。而当我们使用α和β都大于 100 时,Beta 后验均值实际上没有从默认转换的 50%移动。
粗略地说,使用更大的α和β意味着我们对模型设置了更高的“固执程度”。也就是说,我们要求更多的数据(证据)才能使后验从我们的默认信念中有意义地移动。
Python 代码
最后,你可以在下面找到导出 beta-binomial 转换的代码。
总结
呼。那是一篇冗长的阅读。所以,恭喜你读到这里!🎉
在这篇博客中,我们学习了一种简单的特征工程技术,可以用来提高转换度量的代表性和稳定性。尽管它很简单,但该技术基于贝叶斯统计中的 Beta-Binomial 模型,具有优雅的基础。
在文章后面,我们学习了如何调整α和β以选择适当的先验分布。简而言之,更高的α和β实际上意味着我们需要更多的数据来使结果转化分数远离我们初始/默认的转化分数。
希望这篇文章对你遇到类似情况时有所帮助!总之,感谢阅读,欢迎在LinkedIn上与我联系!👋
参考文献
约翰逊, 艾丽西亚·A., 奥特, 迈尔斯·Q., 多古楚, 米娜. (2021). 贝叶斯规则!应用贝叶斯建模简介. CRC Press.
处理 Python 数据框中的日期,第一部分 — 日期系列创建
Python 数据处理
Pandas 日期系列创建方法


·发布于 Towards Data Science ·阅读时间 10 分钟·2023 年 1 月 4 日
–

大多数情况下,DateTime 对象是从数据中获取洞察的重要元素。我们可以通过日期理解数据中的趋势、周期和季节模式。基于这些模式,我们可以准备报告,并进一步研究和分析数据。
DateTime 对象在分析中的重要性激励我进一步研究在 pandas 模块中可以用 DateTime 对象做什么。然后,我记录下了我经常使用的方法和属性,以及我可能需要使用的一些方法。此外,我根据自己的理解将其分成了两个部分,具体如下:

图片来源于作者。
为了更好的阅读体验,我决定将这一组内容拆分为 2 篇文章。这是第一篇,你可以在这里找到 第二篇文章。
让我们从第一部分开始,处理 DateTime 系列的基础知识。
第一部分 — 处理 DateTime 系列的基础知识
DateTime 系列创建
-
pandas.date_range
-
pandas.bdate_range
-
pandas.period_range
-
pandas.timedelta_range
DateTime 系列创建
当你想创建一个示例数据集以测试你正在编写的几个新功能时,创建 DateTime 系列是很实用的。以下是 pandas 模块中四种 DateTime 系列创建方法。
-
pandas.date_range — 返回固定频率的 DatetimeIndex。
-
pandas.bdate_range — 返回固定频率的 DatetimeIndex,默认频率为工作日。
-
pandas.period_range — 返回固定频率的 PeriodIndex。默认频率为天(历法)。
-
pandas.timedelta_range — 返回固定频率的 TimedeltaIndex,默认频率为天。
上述频率指的是生成日期之间的间隔,可能是每小时、每日、每月、每季度、每年等。你可以了解更多关于频率字符串别名的内容 [1]。
让我们一个一个看吧!
1. pandas.date_range
pandas.date_range()方法根据以下四个参数中的三种组合返回 DateTime 序列:
-
start— 生成的日期范围的开始日期 -
end— 生成的日期范围的结束日期 -
periods— 生成的日期数量 -
freq— 默认为“D”,日期之间的间隔,可能是每小时、每月或每年
注意: freq = “D” 表示每日频率。
要生成 DateTime 序列,以上 4 个参数中的至少三个必须指定。由于freq默认为“D”,如果你使用freq=D,只需指定其他两个参数。如果省略freq,即只指定start、end和period参数,则生成的日期将具有从开始日期到结束日期的线性间隔元素。在该方法中还有其他参数,但本文将重点关注这 4 个主要参数。
对于第一个示例,通过指定开始日期和周期生成日期。如上所述,默认情况下频率设置为每日。因此,将生成 10 个日期,频率为每日。
import pandas as pd
df = pd.DataFrame()
df["date_range"] = pd.date_range(start="2022/1/1", periods=10)
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片由作者提供。
对于第二个示例,指定了开始日期、周期和频率。以下示例创建了一个从 2020/1/1 开始的日期序列,共 10 个日期,每个日期之间间隔 3 个月。
import pandas as pd
df = pd.DataFrame()
df["date_range"] = pd.date_range(start="2022/1/1", periods=10, freq="3M")
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片由作者提供。
为什么日期从月末开始?🤨
其实这是因为“M”频率指的是月末频率,而“MS”指的是月初频率 [1]。
对于第三个示例,提供了开始日期和结束日期,以及频率。如前所述,当你省略频率时,生成的日期将是线性间隔的。如果省略了周期,生成的日期将是开始日期和结束日期之间按指定频率间隔的日期。
import pandas as pd
df = pd.DataFrame()
df["date_range"] = pd.date_range(start="2022/1/1", end="2022-12-31", freq="3M")
print(df.head(10))
print("Data Type: ", df.dtypes)

图片来自作者。

图片来自作者。创建于 Excalidraw。
由于下一个周期将是 2023 年 1 月 31 日,因此在第三个示例中只生成了 4 个日期 😉。
这里是一个简单指南:
当你确定要生成的日期数量时,使用 period 参数。
当你不确定确切的日期数量但知道结束时间或不应超过时,使用 end 参数。
2. pandas.bdate_range
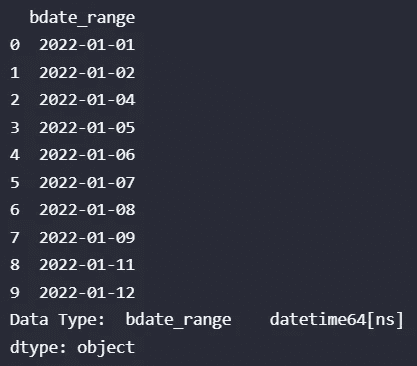
与 pandas.date_range() 方法类似,pandas.bdate_range() 也有 4 个主要参数,即 start、end、periods 和 freq,但 pandas.bdate_range() 中 freq 默认为 “B”。“B” 指的是工作日频率,即跳过周末如星期六和星期天。
让我们看看第一个示例!在以下示例中,指定了开始日期和周期,并且如前所述,频率默认为 “B”。
import pandas as pd
df = pd.DataFrame()
# frequency is default to B, the weekend will be skipped
df["bdate_range"] = pd.bdate_range(start="2022/1/1", periods=10)
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片来自作者。
被跳过的两个日期,“2022–01–08”和“2022–01–09”分别是星期六和星期天。
你可能会注意到,pandas.date_range() 方法在设置 freq= “B” 时也可以只返回工作日,那么我们为什么还需要使用 pandas.bdate_range() 呢?🤷♀️
这是因为 pandas.bdate_range() 默认返回工作日,并且 pandas.bdate_range() 有 weekmask 和 holidays 参数。
注意: 要使用 holidays 或 weekmask 参数,必须使用自定义工作日频率,其中 freq= “C”。[2]
现在,让我们深入了解 holidays 参数。Holidays 指的是要从有效工作日集合中排除的日期列表。
对于第二个示例,指定了开始日期、周期、频率和假期参数。
import pandas as pd
df = pd.DataFrame()
# frequency is set to C, the weekend and holidays will be skipped
# only can set holiday when freq is set to "C"
holidays = [pd.datetime(2022,1,7)]
df["bdate_range"] = pd.bdate_range(start="2022/1/1", periods=10, freq="C", holidays=holidays)
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片来自作者。
指定的假期日期不在生成的日期列表中,由于 “C” 指的是自定义工作日频率,因此创建的日期范围中周末仍会被跳过。
注意: Holidays 参数仅接受 datetime 对象的列表。
现在,让我们看看 weekmask 参数。Weekmask 指的是对于不遵循传统工作日(如周一至周五)的企业有效的工作日。此外,weekmask 的默认值相当于 ‘Mon Tue Wed Thu Fri’。
对于第三个示例,我们指定了开始日期和自定义的工作日,weekmask = “Tue Wed Thu Fri Sat Sun”。
import pandas as pd
df = pd.DataFrame()
df["bdate_range"] = pd.bdate_range(start="2022/1/1", periods=10, freq="C", weekmask="Tue Wed Thu Fri Sat Sun")
print(df.head(10))
print("Data Type: ", df.dtypes)
图片来源:作者。
星期一的日期(2022–01–10)将不会包含在生成的日期中。这个参数在业务不按正常工作日运行时非常有用。
结合这两个参数,你可以根据业务操作日生成 DateTime 系列,如下面的示例所示。
import pandas as pd
df = pd.DataFrame()
df["bdate_range"] = pd.bdate_range(start="2022/1/1", periods=10, freq="C", weekmask="Tue Wed Thu Fri Sat Sun", holidays=[pd.datetime(2022,1,7)])
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片来源:作者。
从输出中可以看出,星期一的日期(2022–01–10)和节假日的日期(2022–01–07)没有包含在生成的列表中。
3. pandas.period_range
pandas.period_range() 方法与之前的两个方法,即 pandas.date_range() 和 pandas.bdate_range(),之间存在一些相似之处和不同之处。
类似于之前的两种方法,pandas.period_range() 可以通过指定四个主要参数中的三个,即 start、end、periods 和 freq,来生成日期系列。同时,频率仍默认为每日。
一个需要注意的不同点是,pandas.period_range() 生成的是周期对象,而不是 DateTime 对象。
对于第一个示例,我们生成了一系列按日频率的 5 个周期,默认从 2022–01–01 开始。
import pandas as pd
df = pd.DataFrame()
df["period_range"] = pd.period_range(start="2022/1/1", periods=5)
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片来源:作者。
对于第二个示例,我们生成了一系列的 5 个周期,频率为每月一次,从 2022–01–01 开始。
import pandas as pd
df = pd.DataFrame()
df["period_range"] = pd.period_range(start="2022/1/1", periods=5, freq="M")
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片来源:作者。
对于第三个示例,我们生成了一系列按年频率的 5 个周期,从 2022–01–01 开始。
import pandas as pd
df = pd.DataFrame()
df["period_range"] = pd.period_range(start="2022/1/1", periods=5, freq="Y")
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片来源:作者。
对于最后一个示例,我们生成了一系列按年为频率的周期,从 2022–01–01 到 2027–01–01。
import pandas as pd
df = pd.DataFrame()
df["period_range"] = pd.period_range(start="2022/1/1", end="2027/1/1", freq="Y")
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片来源:作者。
period_range 方法的工作方式与 pandas.date_range() 相同,只是它返回的是周期而不是日期。因此,如果省略 periods 参数,则创建的周期将是指定频率间隔的开始和结束日期之间的周期。
4. pandas.timedelta_range
类似于上述三种方法,pandas.timedelta_range() 方法根据四个主要参数中的三个参数组合返回日期系列,即 start、end、periods 和 frequency。频率仍默认为每日。与之前的三个示例方法不同的一点可以通过下面的例子进行解释。
以下示例来自我在运行脚本时犯的一个错误,以及随后发生的错误。
import pandas as pd
df = pd.DataFrame()
df["timedelta_range"] = pd.timedelta_range(start="2022/1/1", periods=5, freq="Y")
print(df.head(10))
print("Data Type: ", df.dtypes)
上面的脚本返回了如下的键错误和数值错误。

键错误。图片来源:作者。

值错误。图片由作者提供。
从错误脚本中,我们可以看到错误来源于我们为“start”参数提供的值。由于我们正在生成时间增量对象,因此为“start”参数提供的值也应该是 timedelta 格式。
因此,正确的示例应如下所示,其中起始时间以 timedelta 格式指定,周期数被指定,并使用默认的每日频率。
import pandas as pd
df = pd.DataFrame()
df["timedelta_range"] = pd.timedelta_range(start="1 days", periods=5)
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片由作者提供。
对于第二个示例,指定了起始时间增量、周期和频率。
import pandas as pd
df = pd.DataFrame()
df["timedelta_range"] = pd.timedelta_range(start="1 day", periods=5, freq="6H")
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片由作者提供。
对于第三个示例,指定了起始时间增量、结束时间增量和频率。
import pandas as pd
df = pd.DataFrame()
df["timedelta_range"] = pd.timedelta_range(start="1 day", end="5days", freq="8H")
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片由作者提供。
对于第四个示例,指定了起始时间增量、结束时间增量和周期。当没有设置频率时,生成的时间增量系列将会是线性分布的。
import pandas as pd
df = pd.DataFrame()
df["timedelta_range"] = pd.timedelta_range(start="1 day", end="5days", periods=3)
print(df.head(10))
print("Data Type: ", df.dtypes)
输出:

图片由作者提供。
注意:对于pandas.timedelta_range()方法,“start”参数仅接受时间增量对象,而对于其他三种方法,“start”参数则接受 DateTime 对象作为输入。
5. 使用时间戳创建 DateTime
在 pandas 模块中,我们还可以使用时间戳方法创建 datetime 对象。
创建 DateTime 对象有两种方法,第一种是使用如下的 datetime 参数。
# https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.Timestamp.html
import pandas as pd
timestampsample = pd.Timestamp(year=2022,month=12,day=13,hour=21,minute=48, second=23, microsecond=35, nanosecond=58)
timestampsample
输出:

图片由作者提供。
第二种方法是从 DateTime 字符串创建时间戳。
import pandas as pd
str_timestamp = '2022-12-13 21:48:23.000035058'
timestampsample2 = pd.Timestamp(str_timestamp)
timestampsample2

图片由作者提供。
好的,上述内容演示了如何使用时间戳方法来创建一个 DateTime 对象。
结论
总之,我们已经看到与 DateTime 系列创建相关的 4 种方法,包括标准日期创建、工作日日期创建、周期创建和时间增量创建。此外,还演示了使用时间戳的日期创建方法。
关于 Python 中的 DateTime 系列创建就是这些了。希望你喜欢阅读这篇文章,并希望它能帮助你更好地理解 DataFrame 中的 DateTime 系列创建。谢谢!😊
保持联系
订阅 YouTube
附注
本文第二部分,处理 Python DataFrame 中的日期(第二部分)——基础知识。
我在处理 Python 中的日期中解释了你可以对 DateTime 变量进行的可能操作。
在使用 Python 进行报告自动化技巧中,我解释了一些关于报告自动化的技巧。查看一下吧!
参考
[1] 时间序列/数据功能 — 偏移别名。pandas:有用的常见时间序列频率的字符串别名
[2] pandas-指定自定义假期:在pandas.bdate_range()方法中指定自定义假期
感谢你阅读到最后 😊!

照片由 JOSHUA COLEMAN 拍摄,来源于 Unsplash
处理 Python DataFrame 中的日期 第二部分——基础知识
原文:
towardsdatascience.com/dealing-with-dates-in-pythons-dataframe-part-2-the-basics-9ad5edacd2f8
数据处理在 Python 中
本文解释了处理数据框中 DateTime 系列的基本 pandas 方法和属性。


·发表于 Towards Data Science ·8 分钟阅读·2023 年 1 月 4 日
–

图片由 Lukas Blazek 提供,来自 Unsplash
正如标题所述,这篇文章是我处理 Python DataFrame 中日期系列的第二部分。以下展示了处理 Python DataFrame 中日期系列的每一部分内容。

图片来自作者。
在 我之前的文章 中,我展示了 DateTime 系列的创建方法。接下来,在这篇文章中,我将展示处理数据框中 DateTime 系列的基本属性和方法。
有了这些,这篇文章将按如下结构安排:
-
将数据类型转换为 DateTime
-
通用 DateTime 信息提取
-
检查日期是否为周期的开始或结束
-
检查日期是否属于闰年
-
检查月份中的天数
让我们开始吧!
将数据类型转换为 DateTime
在我之前的文章中展示的日期创建方法中,系列被创建为 DateTime 对象。当你从 Excel 或其他数据源读取数据时,如果没有将其解析为日期,DateTime 列将作为字符串对象读取。要从 DateTime 系列中提取 DateTime 信息,列需要先转换为 DateTime 数据类型。
有两种方法可以将数据类型转换为 DateTime。
-
pandas.Series.astype(“DateTime”) -
pandas.datetime(pandas.SeriesSeries)
我用下面的脚本创建了一个 demo.csv 文件,以演示本节的方法和属性。
import pandas as pd
import datetime as dt
df = pd.DataFrame()
initial_date = pd.Timestamp("2023-01-04 21:55:00")
df["timedelta_range"] = pd.timedelta_range(start="1 day", end="5days", freq="4H")
df.insert(loc=0, column="initial_date",value=initial_date)
df.insert(loc=2, column="next_date",value=df["initial_date"] + df["timedelta_range"])
print(df.head(10))
print("Data Type: ", df.dtypes)
df.to_csv("demo.csv")
输出的数据框如下截图所示。

图像来源于作者。
现在,我们将读取生成的文件。
import pandas as pd
df = pd.read_csv(r"demo.csv", usecols=["next_date"])
print(df.info())
df.head()
为演示目的,仅读取 next_date 列。

图像来源于作者。
如你所见,当直接导入列而未将其解析为 DateTime 时,该列将是一个字符串列,其中 Dtype 为对象。以下是两种将列转换为 DateTime 数据类型的常用方法。
- pandas.to_datetime(pandas.Series)
df["next_date"] = pd.to_datetime(df["next_date"])
df.info()
- pandas.Series.astype(“datetime64”)
df["next_date"] = df["next_date"].astype("datetime64")
df.info()
上述两个脚本的输出结果:

图像来源于作者。
另外,你可以在导入数据时使用 parse_dates 参数将列解析为 DateTime 对象。
import pandas as pd
df = pd.read_csv(r"demo.csv", usecols=["next_date"], parse_dates=["next_date"])
print(df.info())
df.head()

图像来源于作者。
一般的日期时间信息提取
从日期时间系列中可以获得大量信息。
-
时间戳
-
周
-
年中的天数
-
季度
-
ISO 日历
提取时间戳信息
以下是返回时间戳信息的属性和方法列表。
-
pandas.Series.dt.date — 返回时间戳的日期部分,不包括时间和时区信息。
-
pandas.Series.dt.time — 返回时间戳的时间部分。
-
pandas.Series.dt.year — 返回日期时间的年份。
-
pandas.Series.dt.month — 返回月份,1 月为 1,12 月为 12。
-
pandas.Series.dt.month_name() — 返回指定语言环境的 Series 或 DatetimeIndex 的月份名称。
-
pandas.Series.dt.day — 返回日期时间的天数。
-
pandas.Series.dt.hour — 返回日期时间的小时数。
-
pandas.Series.dt.minute — 返回日期时间的分钟数。
-
pandas.Series.dt.second — 返回日期时间的秒数。
-
pandas.Series.dt.microsecond — 返回日期时间的微秒数。
-
pandas.Series.dt.nanosecond — 返回日期时间的纳秒。
import datetime as dt
在使用 series.dt 下的方法或属性之前,需要导入 datetime 模块。以下是提取时间戳信息的示例。
df.insert(loc=1, column="Date_",value=df["next_date"].dt.date)
df.insert(loc=2, column="Time",value=df["next_date"].dt.time)
df.insert(loc=3, column="year",value=df["next_date"].dt.year)
df.insert(loc=4, column="month",value=df["next_date"].dt.month)
# note that the month_name is a method instead of properties
df.insert(loc=5, column="month_name",value=df["next_date"].dt.month_name())
df.insert(loc=6, column="day",value=df["next_date"].dt.day)
df.insert(loc=7, column="hour",value=df["next_date"].dt.hour)
df.insert(loc=8, column="minute",value=df["next_date"].dt.minute)
df.head()
输出:

图片来自作者。
需要注意的一点是创建的列不是 DateTime 对象,即使是“Date_”列也是如此。

图片来自作者。
你可能会注意到,第二、微秒和纳秒的示例没有展示。这是因为它们不适用于数据集。此外,应用的方式是相同的。列类型需要在使用属性或方法返回相应的值之前转换为 datetime。
提取周信息/年中的天数/季度/ISO 日历
以下是返回周数、年中的天数、季度和基于 ISO 日历的信息的属性和方法列表,用于 DateTime 系列。
周信息
-
pandas.Series.dt.dayofweek — 星期几,星期一=0,星期日=6。
-
pandas.Series.dt.day_of_week — 星期几,星期一=0,星期日=6。
-
pandas.Series.dt.weekday — 星期几,星期一=0,星期日=6。
-
pandas.Series.dt.day_name() — 返回指定地区的 Series 或 DatetimeIndex 的日期名称。
一年中的天数
-
pandas.Series.dt.dayofyear — 一年的序数天。
-
pandas.Series.dt.day_of_year — 一年的序数天。
季度
- pandas.Series.dt.quarter — 日期的季度。
ISO 日历
- pandas.Series.dt.isocalendar() — 根据 ISO 8601 标准计算年、周和日。(返回年、周和日列)
为了展示我们可以用上述方法/属性做的有趣的事情,我创建了一个日期列表,其中包含分布在全年中的随机日期,如下所示。
import pandas as pd
import datetime as dt
date_list = ["2022-10-03", "2022-11-17", "2022-12-14", "2023-01-23", "2023-02-14", "2023-03-23", "2023-04-11", "2023-05-28", "2023-06-24", "2023-07-04", "2023-08-06", "2023-09-08"]
df = pd.DataFrame(date_list, columns=["Date"])
df["Date"] = pd.to_datetime(df["Date"])
df.head(12)
由于我们不是从文件中读取,因此没有 parse_dates 函数可用。因此,必须手动将列转换为 datetime。

图片由作者提供。
以下是提取周、年中的天数、季度和 ISO 日历的示例。为了更好地理解,列名基于属性或方法名称。
df.insert(loc=1, column="Day of Week",value=df["Date"].dt.day_of_week)
df.insert(loc=2, column="Weekday",value=df["Date"].dt.weekday)
# note that the month_name is a method instead of properties
df.insert(loc=3, column="Day Name",value=df["Date"].dt.day_name())
# day of the year
df.insert(loc=4, column="Day of Year",value=df["Date"].dt.day_of_year)
# quarter
df.insert(loc=5, column="Quarter",value=df["Date"].dt.quarter)
# iso calendar
df.insert(loc=6, column="ISO Year",value=df["Date"].dt.isocalendar().year)
df.insert(loc=7, column="ISO Week",value=df["Date"].dt.isocalendar().week)
df.insert(loc=8, column="ISO Day",value=df["Date"].dt.isocalendar().day)
df[["Date", "Day of Week", "Weekday", "Day Name", "Day of Year", "Quarter", "ISO Year", "ISO Week", "ISO Day"]].head(12)
输出:

图片由作者提供。
以下是上述表格的总结:
-
对于
day_of_week和weekday属性,它们返回从 0 开始计数的星期几。 -
对于
day_of_year、quarter属性和isocalendar()方法,它们的返回值以从 1 开始的索引计数。
isocalendar()方法中,计算星期几的索引从 1 开始,而weekday从 0 开始。它们都以星期一为星期的起点。换句话说,第一个索引指的是星期一。
检查日期是否为周期的开始或结束
对于这一部分,将创建一个不同的日期列表,以更好地展示下面的属性。
-
pandas.Series.dt.is_month_start — 指示日期是否为月份的第一天。
-
pandas.Series.dt.is_month_end — 指示日期是否为月份的最后一天。
-
pandas.Series.dt.is_quarter_start — 指示日期是否为季度的第一天。
-
pandas.Series.dt.is_quarter_end — 指示日期是否为季度的最后一天。
-
pandas.Series.dt.is_year_start — 指示日期是否为年的第一天。
-
pandas.Series.dt.is_year_end — 指示日期是否为年的最后一天。
示例:
date_list = ["2023-01-01", "2023-01-23", "2023-01-31", "2023-02-01", "2023-02-28", "2023-04-01", "2023-06-30", "2023-09-30", "2023-11-30", "2023-12-31"]
df = pd.DataFrame(date_list, columns=["Date"])
df["Date"] = pd.to_datetime(df["Date"])
df.insert(loc=1, column="Month Start",value=df["Date"].dt.is_month_start)
df.insert(loc=2, column="Month End",value=df["Date"].dt.is_month_end)
df.insert(loc=3, column="Quarter Start",value=df["Date"].dt.is_quarter_start)
df.insert(loc=4, column="Quarter End",value=df["Date"].dt.is_quarter_end)
df.insert(loc=5, column="Year Start",value=df["Date"].dt.is_year_start)
df.insert(loc=6, column="Year End",value=df["Date"].dt.is_year_end)
df.head(12)
输出:

图片由作者提供。
思考: 我认为这些属性对于需要每月、每季度或每年准备新报告的人来说是最有用的。
这些属性将帮助他们基于创建的自动化逻辑来刷新报告。除此之外,上述属性在需要定期重新开始的计算中也可能很有用。
检查日期是否属于闰年
- pandas.Series.dt.is_leap_year — 布尔值指示日期是否属于闰年。
闰年是指一年有 366 天(而不是 365 天),包括 2 月 29 日作为闰日。闰年是四的倍数的年份,但除去能被 100 整除但不能被 400 整除的年份。
我们可以通过创建的周期范围的日期来演示这个函数。
df = pd.DataFrame()
df["Year"] = pd.period_range(start="2022/1/1", periods=10, freq="Y")
df.insert(loc=1, column="Leap Year",value=df["Year"].dt.is_leap_year)
print(df.head(10))
输出:

图片由作者提供。
检查一个月中的天数
以下这两个属性都可以返回一个月中的天数。
-
pandas.Series.dt.daysinmonth — 一个月中的天数。
-
pandas.Series.dt.days_in_month — 一个月中的天数。
df = pd.DataFrame()
df["Month"] = pd.period_range(start="2022/1/1", periods=12, freq="M")
df.insert(loc=1, column="Days in Month",value=df["Month"].dt.days_in_month)
df.head(12)
输出:

图片由作者提供。
结论
总结来说,解释了一些处理 DateTime 系列的基本属性和方法。展示了将包含日期时间对象的列的数据类型转换为日期时间的方法。然后,演示了提取或返回日期时间信息的基本属性和方法。日期时间信息如星期几在不同的方法中有不同的索引。
此外,还展示了一些检查日期属性的方法,例如日期是否为一个时期的开始或结束,或者日期是否属于闰年。最后,还介绍了检查一个月中日期的数量的方法。这些方法和属性可能对报告用途很有帮助。
这就是处理 Python 中日期的基础内容。希望你喜欢这篇文章,并且希望它能帮助你更好地理解如何处理 DataFrame 中的 DateTime 系列。谢谢! 😊
保持联系
订阅 YouTube
旁注
本文的第一部分,在 Python 的 DataFrame 中处理日期的第一部分 — 日期系列创建。
我在在 Python 中处理日期中解释了你可以对 DateTime 变量执行的操作。
在 使用 Python 进行报告自动化技巧 中,我解释了一些报告自动化的技巧。快去看看吧!
感谢你阅读到最后 😊!
祝你 2023 年快乐!

Adnan Mistry 在 Unsplash 上的照片
使用 Python 处理 MRI 和深度学习
使用 PyTorch 的深度学习模型进行 MRI 分析的综合指南


·
关注 发表在 Towards Data Science ·13 分钟阅读·2023 年 12 月 20 日
–

图片来源:Olga Rai 于 Adobe Stock。
介绍
首先,我想介绍一下自己。我叫 Carla Pitarch,是一名人工智能(AI)博士候选人。我的研究重点是通过使用深度学习(DL)模型,特别是卷积神经网络(CNNs),从磁共振图像(MRI)中提取信息,以开发自动化的脑肿瘤分级分类系统。
在我的博士研究之初,深入研究 MRI 数据和 DL 是一个全新的领域。在这个领域中运行模型的初步步骤并不像预期的那样简单。尽管花了一些时间在这个领域进行研究,我发现缺乏全面的资源来指导 MRI 和 DL 的入门。因此,我决定分享一些我在这一期间获得的知识,希望它能让你的旅程更加顺利。
通过 DL 进行计算机视觉(CV)任务通常涉及使用标准公共图像数据集,如[ImageNe](https://image-net.org/about.php)t,这些数据集以 3 通道 RGB 自然图像为特征。PyTorch 模型为这些规格做好了准备,期望输入图像为这种格式。然而,当我们的图像数据来自不同的领域,如医疗领域,与这些自然图像数据集在格式和特征上都有所不同时,就会带来挑战。本文深入探讨了这个问题,强调了在模型实施之前的两个关键准备步骤:使数据与模型的要求对齐,并准备模型以有效处理我们的数据。
背景
让我们首先简要概述一下 CNNs 和 MRI 的基本方面。
卷积神经网络
在本节中,我们将深入探讨 CNNs 领域,假设读者对深度学习(DL)有基本的理解。CNNs 作为计算机视觉(CV)中的黄金标准架构,专注于处理 2D 和 3D 输入图像数据。我们在这篇文章中的重点将集中在 2D 图像数据的处理上。
图像分类,将输出类别或标签与输入图像关联,是卷积神经网络(CNNs)的核心任务。由 LeCun 等人于 1989 年提出的开创性 LeNet5 架构为 CNNs 奠定了基础。该架构可以总结如下:

CNN 架构包含两个卷积层、两个池化层,以及一个位于输出层之前的全连接层。
2D CNN 架构通过接收图像像素作为输入来操作,期望图像是一个形状为Height x Width x Channels的张量。彩色图像通常包含 3 个通道:红色、绿色和蓝色(RGB),而灰度图像则包含一个通道。
CNNs 中的一个基本操作是卷积,通过在输入数据的所有区域应用一组滤波器或内核来执行。下图展示了卷积在 2D 上下文中的工作原理。

一个对 5x5 图像进行 3x3 滤波器卷积的示例,生成一个 3x3 卷积特征。
这个过程涉及将滤波器滑过图像并计算加权和,以获得一个卷积特征图。输出将表示输入图像的该位置是否识别到特定的视觉模式,例如边缘。每个卷积层后,激活函数会引入非线性。常见的选择包括:ReLU(修正线性单元)、Leaky ReLU、Sigmoid、Tanh 和 Softmax。有关每个激活函数的更多详细信息,本文提供了清晰的解释 Activation Functions in Neural Networks | by SAGAR SHARMA | Towards Data Science。
不同类型的层对 CNNs 的构建做出贡献,每一层在定义网络功能方面扮演着独特的角色。除了卷积层,CNNs 中还包括几种其他显著的层:
-
池化层,如最大池化或平均池化,有效地减少特征图维度,同时保留关键信息。
-
Dropout 层 通过在训练期间随机停用部分神经元来防止过拟合,从而增强网络的泛化能力。
-
批量归一化层 关注对每层的输入进行标准化,从而加快网络训练速度。
-
全连接(FC)层 在一个层中的所有神经元和前一层中的所有激活之间建立连接,整合学到的特征以促进最终分类。
CNNs 通过层次化的方式学习识别模式。初始层关注低级特征,逐渐移动到更深层次的高度抽象特征。当到达全连接(FC)层时,Softmax 激活函数会估计图像输入的类别概率。
除了 LeNet 的创始之外,像 AlexNet²、GoogLeNet³、VGGNet⁴、ResNet⁵ 和更新的 Transformer⁶ 等著名 CNN 架构也显著推动了深度学习领域的发展。
自然图像概述
探索自然 2D 图片可以提供对图像数据的基础理解。我们将从一些示例开始,深入探讨。
在我们的第一个示例中,我们将从广泛使用的MNIST数据集中选择一张图片。

这个图像的形状是 [28,28],表示一个具有单一通道的灰度图像。然后,神经网络的图像输入将是 (28*28*1)。
现在,让我们探索来自ImageNet数据集的一张图片。你可以直接从 ImageNet 的网站 ImageNet (image-net.org) 访问该数据集,或者在 Kaggle 上探索一个可用的子集 ImageNet Object Localization Challenge | Kaggle。

我们可以将这张图片分解为其 RGB 通道:

由于该图像的形状是 [500, 402, 3],神经网络的图像输入将表示为 (500*402*3)。
磁共振成像
MRI 扫描是神经学和神经外科中使用最广泛的检查方法,提供了一种非侵入性的方法,能提供良好的软组织对比度⁷。除了可视化结构细节外,MR 成像还深入提供了对大脑结构和功能方面的宝贵见解。
MRI 是由 3D 体积组成的,能够在三个解剖平面:轴向、冠状面和矢状面上进行可视化。这些体积由称为 体素 的 3D 立方体组成,与标准的 2D 图像相比,后者由称为 像素 的 2D 方块构成。虽然 3D 体积提供了全面的数据,但也可以被分解为 2D 切片。
各种 MRI 模态或序列,如 T1、T1 磁性增强(T1ce)、T2 和 FLAIR(液体衰减反转恢复),通常用于诊断。这些序列通过提供对应于特定区域或组织的不同信号强度,使肿瘤区分成为可能。以下插图展示了来自一个被诊断为胶质母细胞瘤的病人的这四种序列,胶质母细胞瘤是胶质瘤中最具侵袭性的类型,也是最常见的原发性脑肿瘤。

脑肿瘤分割数据
脑肿瘤分割(BraTS)挑战赛 提供了一个最广泛的多模态脑 MRI 扫描数据集,涵盖了 2012 到 2023 年的胶质瘤病人。BraTS 比赛的主要目标是评估最先进的方法在多模态 MRI 扫描中分割脑肿瘤的效果,尽管随着时间的推移还添加了额外的任务。
BraTS 数据集提供了关于肿瘤的临床信息,包括一个二进制标签,指示肿瘤级别(低级别或高级别)。BraTS 扫描以 NIfTI 文件形式提供,描述了 T1、T1ce、T2 和 Flair 模态。这些扫描在经过一些预处理步骤后提供,包括共配准到相同的解剖模板、插值到均匀的各向同性分辨率(1mm³)和去颅骨处理。
在这篇文章中,我们将使用 Kaggle 的 2020 数据集 BraTS2020 数据集 (训练 + 验证) 来将胶质瘤 MRI 分类为低级别或高级别。
以下图片展示了低级别和高级别胶质瘤的例子:

MRI 模态和 BraTS 病人 287 的分割掩膜。

MRI 模态和 BraTS 病人 006 的分割掩膜。
Kaggle 存储库包含 369 个目录,每个目录代表一个患者并包含相应的图像数据。此外,它还包含两个 .csv 文件:name_mapping.csv 和 survival_info.csv。为了我们的目的,我们将使用 name_mapping.csv,它将 BraTS 患者姓名与 TCGA-LGG 和 TCGA-GBM 来自 Cancer Imaging Archive 的公开数据集相关联。这个文件不仅便于姓名映射,还提供了肿瘤等级标签(LGG-HGG)。

让我们探索每个患者文件夹的内容,以 Patient 006 为例。在 BraTS20_Training_006 文件夹中,我们可以找到 5 个文件,每个文件对应一种 MRI 模态和分割掩模:
-
BraTS20_Training_006_flair.nii
-
BraTS20_Training_006_t1.nii
-
BraTS20_Training_006_t1ce.nii
-
BraTS20_Training_006_t2.nii
-
BraTS20_Training_006_seg.nii
这些文件是 .nii 格式,代表 NIfTI 格式——神经成像中最流行的格式之一。
MRI 数据准备
为了在 Python 中处理 NIfTI 图像,我们可以使用 NiBabel 包。以下是数据加载的示例。通过使用 get_fdata() 方法,我们可以将图像解释为 numpy 数组。
数组形状 [240, 240, 155] 表示一个 3D 体积,由 240 个 x 和 y 维度的 2D 切片和 155 个 z 维度的切片组成。这些维度对应不同的解剖视角:轴向视图(x-y 平面)、冠状视图(x-z 平面)和矢状视图(y-z 平面)。

为了简化,我们将仅使用轴向平面的 2D 切片,生成的图像将具有 [240, 240] 的形状。
为了符合 PyTorch 模型的规格,输入张量必须具有 [batch_size, num_channels, height, width] 的形状。在我们的 MRI 数据中,四种模态(FLAIR、T1ce、T1、T2)各自强调图像中的不同特征,类似于图像中的通道。为了使数据格式符合 PyTorch 的要求,我们将这些序列堆叠为通道,从而实现 [4, 240, 240] 张量。
PyTorch 提供了两个数据工具,torch.utils.data.Dataset 和 torch.utils.data.DataLoader,旨在迭代数据集和批量加载数据。Dataset 包含各种标准数据集的子类,如 MNIST、CIFAR 或 ImageNet。导入这些数据集涉及加载相应的类并初始化 DataLoader。
考虑一个 MNIST 数据集的示例:
这使我们能够获得最终的张量,其维度为 [batch_size=32, num_channels=1, H=28, W=28] 张量。
由于我们有一个非平凡的数据集,在使用 DataLoader 之前需要创建一个自定义的 Dataset class。虽然本文未详细介绍创建此自定义数据集的步骤,但读者可以参考 PyTorch 关于 Datasets & DataLoaders 的教程以获取全面的指导。
PyTorch 模型准备
PyTorch 是由 Facebook AI 研究人员在 2017 年开发的深度学习框架。torchvision 包含流行的数据集、图像变换和模型架构。在 [torchvision.models](https://pytorch.org/vision/0.8/models.html) 中,我们可以找到用于不同任务的深度学习架构实现,例如分类、分割或目标检测。
对于我们的应用程序,我们将加载 ResNet18 架构。
ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=1000, bias=True)
)
在神经网络中,输入层和输出层与具体问题密切相关。PyTorch 深度学习模型通常期望输入为 3 通道 RGB 图像,正如我们在初始卷积层配置中所观察到的 Conv2d(in_channels = 3, out_channels = 64, kernel_size=(7,7), stride=(2,2), padding=(3,3), bias=False)。此外,最终层 Linear(in_features = 512, out_features = 1000, bias = True) 默认输出大小为 1000,代表 ImageNet 数据集中的类别数量。
在训练分类模型之前,调整 in_channels 和 out_features 以与我们的特定数据集对齐是至关重要的。我们可以通过 resnet.conv1 访问第一个卷积层并更新 in_channels。类似地,我们可以通过 resnet.fc 访问最后一个全连接层并修改 out_features。
ResNet(
(conv1): Conv2d(4, 64, kernel_size=(7, 7), stride=(1, 1))
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(1): BasicBlock(
(conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): BasicBlock(
(conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): BasicBlock(
(conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): BasicBlock(
(conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): BasicBlock(
(conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=512, out_features=2, bias=True)
)
图像分类
准备好模型和数据后,我们可以继续进行实际应用。
以下示例展示了如何有效地利用我们的 ResNet18 将图像分类为低等级或高等级。为了管理我们张量中的批量尺寸维度,我们将简单地添加一个单位维度(注意,这通常由数据加载器处理)。
tensor(0.5465, device='cuda:0', grad_fn=<NllLossBackward0>)
这篇文章到此结束。希望这对那些进入 MRI 和深度学习交叉领域的人有所帮助。感谢你抽出时间阅读。欲了解我研究的深入见解,请随时查阅我的最新论文! 😃
Pitarch, C.; Ribas, V.; Vellido, A. 基于 AI 的胶质瘤分级以获得可信诊断:提高可靠性的分析管道。Cancers 2023,15,3369。 doi.org/10.3390/cancers15133369。
除非另有说明,所有图片均由作者提供。
[1] Y. LeCun 等人。“反向传播应用于手写邮政编码
识别”。刊载于《Neural Computation》1(1989 年 12 月 4 日),第 541–551 页。
ISSN: 0899–7667。DOI: 10.1162/NECO.1989.1.4.541。
[2] Alex Krizhevsky, Ilya Sutskever 和 Geoffrey E. Hinton. “ImageNet 分类与深度卷积神经网络”。
深度卷积神经网络的分类”。出现在:进展。
在神经信息处理系统第 25 卷(2012)。
[3] Christian Szegedy 等. “通过卷积进一步深入”。出现在:论文集。
IEEE 计算机学会计算机视觉会议论文集。
计算机视觉与模式识别 07–12-2015 年 6 月(2014 年 9 月),第 1–9 页。
ISSN: 10636919。DOI: 10.1109/CVPR.2015.7298594。
[4] Karen Simonyan 和 Andrew Zisserman. “非常深的卷积网络”。
大规模图像识别的网络”。出现在:第三届国际。
学习表示大会,ICLR 2015 — 大会追踪。
论文集(2014 年 9 月)。
[5] Kaiming He 等. “用于图像识别的深度残差学习”。
出现在:IEEE 计算机学会计算机视觉会议论文集。
计算机视觉与模式识别 2016 年 12 月(2015 年 12 月),第 770–778 页。
778。ISSN: 10636919。DOI: 10.1109/CVPR.2016.90。
[6] Ashish Vaswani 等. “注意力机制”。出现在:进展。
神经信息处理系统 2017 年 12 月(2017 年 6 月),第 5999–6009 页。ISSN: 10495258。DOI: 10.48550/arxiv.1706.03762。
[7] Lisa M. DeAngelis. “脑肿瘤”。出现在:新英格兰医学杂志 344 卷(2001 年 8 月 2 日),第 114–123 页。ISSN: 0028–4793。DOI: 10.1056/NEJM200101113440207

















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









