







我是如何用 Python 中的深度学习实现 iPhone X 的 FaceID 的。
逆向工程 iPhone X 的新解锁机制。
在推特上关注我的工作更新和更多:【https://twitter.com/normandipalo

新款 iPhone X 讨论最多的一个特点就是新的解锁方式,TouchID 的继任者: FaceID 。
创造了无边框手机后,苹果不得不开发一种简单快捷的解锁手机的新方法。当一些竞争对手继续使用放置在不同位置的指纹传感器时,苹果决定创新和彻底改变我们解锁手机的方式:只需看着它。由于一个先进的(非常小的)前置深度摄像头,iPhone X 能够创建用户面部的 3D 地图。此外,使用红外相机捕捉用户脸部的图片,这对于环境的光线和颜色变化更加鲁棒。使用深度学习,智能手机能够非常详细地学习用户的面部,从而在每次手机被主人拿起时识别他/她。令人惊讶的是,苹果 ha 声明这种方法甚至比 TouchID 更安全,突出错误率为 1:100 万。
我对苹果公司实现 FaceID 的技术非常感兴趣,尤其是这一切都是在设备上运行的,只需对用户的面部进行一点初始训练,然后每次拿起手机时都能顺利运行。我专注于如何使用深度学习来实现这个过程,以及如何优化每个步骤。在这篇文章中,我将展示如何使用 Keras 实现类似 FaceID 的算法。我将解释我采取的各种架构决策,并展示一些最终的实验,这些实验是使用 Kinect 完成的,这是一款非常流行的 RGB 和深度相机,其输出与 iPhone X 的前置相机非常相似(但在更大的设备上)。舒服地坐着,喝杯咖啡,让我们开始逆向工程苹果的新游戏改变功能。

了解 FaceID
“……驱动 FaceID 的神经网络不仅仅是执行分类。”

FaceID setup process.
第一步是仔细分析FaceID 如何在 iPhone X 上工作,他们的白皮书可以帮助我们了解 FaceID 的基本机制。使用 TouchID,用户最初必须通过按几次传感器来注册他/她的指纹。大约 15-20 次不同的触摸后,智能手机完成了注册,TouchID 准备就绪。类似地,使用 FaceID,用户必须注册他/她的脸。这个过程非常简单:用户只需像平常一样看着手机,然后慢慢地将头部旋转一圈,从而从不同的姿势注册面部。就这样,过程完成,手机准备解锁。这个惊人快速的注册程序可以告诉我们很多关于底层学习算法的信息。例如,驱动 FaceID 的神经网络不仅仅是执行分类,我将解释为什么。

Apple Keynote unveiling iPhone X and FaceID.
对于神经网络来说,执行分类意味着学习预测它看到的人脸是否是用户的。因此,它应该使用一些训练数据来预测“真”或“假”,基本上,但不同于许多其他深度学习用例,这里这种方法将不会工作。首先,网络应该使用从用户面部获得的新数据从头开始重新训练。这将需要大量的时间、能量消耗以及不切实际的不同面部的训练数据的可用性,以得到负面的例子(在转移学习和对已经训练好的网络进行微调的情况下变化很小)。此外,对于苹果来说,这种方法不会利用“离线”训练更复杂的网络的可能性,即在他们的实验室中,然后将已经训练好的网络运送到他们的手机中使用。相反,我认为 FaceID 是由一个暹罗状卷积神经网络驱动的,它由苹果“离线”训练,利用对比损失将人脸映射到一个低维潜在空间中,该空间的形状使不同人的人脸之间的距离最大化。发生的事情是,你得到一个能够一次性学习的架构,正如他们在主题演讲中非常简要地提到的。我知道,有些名字很多读者可能不熟悉:继续读,我会一步一步解释我的意思。

FaceID looks like it will be the new standard after TouchID. Will Apple bring it to all his new devices?
用神经网络从面孔到数字
一个连体神经网络基本上由两个相同的神经网络组成,它们也共享所有的权重。这种架构可以学习计算特定类型数据之间的距离,比如图像。其思想是,你通过暹罗网络传递几对数据(或者简单地通过同一网络分两步传递数据),网络将其映射到一个低维特征空间,就像一个 n 维数组,然后你训练网络进行这种映射,以便来自不同类的数据点尽可能远,而来自同一类的数据点尽可能近。从长远来看,网络将学会从数据中提取最有意义的特征,并将其压缩到一个数组中,从而创建一个有意义的映射。为了对此有一个直观的理解,想象一下你将如何用一个小向量来描述狗的品种,这样相似的狗就有了更接近的向量。你可能会用一个数字来编码狗的皮毛颜色,用另一个数字来表示狗的大小,用另一个数字来表示皮毛的长度,等等。这样,彼此相似的狗就会有彼此相似的向量。很聪明,对吧?嗯,一个连体神经网络可以学会为你做这件事,类似于一个 自动编码器 所做的。

A figure from the paper “Dimensionality Reduction by Learning an Invariant Mapping” by Hadsell, Chopra and LeCun. Notice how the architecture is learning similarity between digits and is automatically grouping them in 2-dimensions. A similar technique is applied to faces.
通过这种技术,可以使用大量的人脸来训练这样的架构,以识别哪些人脸最相似。有了合适的预算和计算能力(就像苹果一样),人们还可以使用越来越难的例子来使网络对诸如双胞胎、对抗性攻击(面具)等事情变得健壮。使用这种方法的最终优势是什么?你终于有了一个即插即用模型,它可以识别不同的用户,而无需任何进一步的训练,只是在初始设置期间拍摄一些照片后,简单地计算用户的面部在面部潜像图中的位置。(想象一下,就像前面说的,为一只新狗写下狗的品种向量,然后存储在某个地方)。此外,FaceID 能够适应你外貌的变化:既有突然的变化(如眼镜、帽子、化妆),也有缓慢的变化(面部毛发)。这基本上是通过在这张地图上添加参考面向量来完成的,根据你的新外观来计算。

FaceID adapts when your looks change.
现在,让我们最后看看如何使用 Keras 在 Python 中实现。
在喀拉斯实施 FaceID
至于所有的机器学习项目,我们首先需要的是数据。创建我们自己的数据集需要时间和许多人的合作,这可能是相当具有挑战性的。因此,我在网上浏览了 RGB-D 人脸数据集,我找到了一个看起来非常合适的。它由一系列面向不同方向并做出不同面部表情的 RGB-D 照片组成,就像 iPhone X 用例中发生的那样。
要看最终的实现,可以去我的 GitHub 资源库 看看,在那里可以找到 Jupyter 的笔记本。此外,我用一台 Colab 笔记本 进行了实验,你也可以试试。
我基于 SqueezeNet 架构创建了一个卷积网络。该网络将情侣脸的 RGBD 图片(即 4 通道图片)作为输入,并输出两个嵌入之间的距离。使用对比损失来训练网络,该对比损失最小化同一个人的图片之间的距离,并且最大化不同人的图片之间的距离。
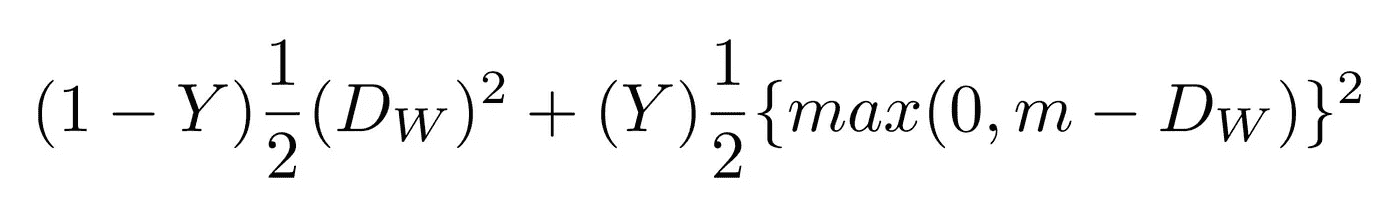
Contrastive loss.
经过一些训练后,该网络能够将人脸映射到 128 维的阵列中,这样同一个人的照片就可以分组在一起,而其他人的照片则远离。这意味着,为了解锁您的设备,网络只需计算解锁期间拍摄的图片与注册阶段存储的图片之间的距离。如果距离低于某个阈值,(距离越小,越安全)设备解锁。
我使用了 t-SNE 算法来在二维空间中可视化 128 维嵌入空间。每种颜色对应不同的人:正如你所看到的,网络已经学会了将这些图片紧密地分组。(当使用 t-SNE 算法时,聚类之间的距离是没有意义的)当使用 PCA 降维算法时,一个有趣的情节也出现了。
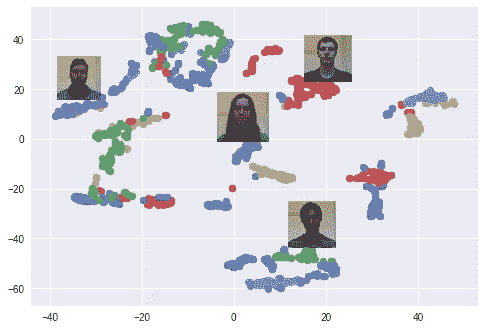
Clusters of faces in the embedding space created using t-SNE. Every color is a different face (but colors are reused).
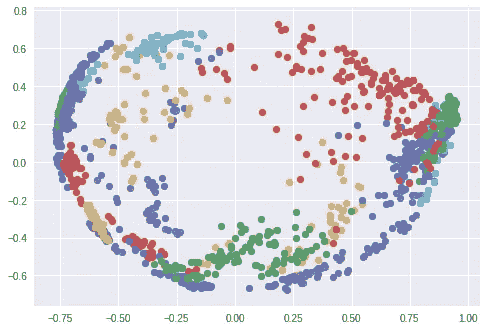
Clusters of faces in the embedding space created using PCA. Every color is a different face (but colors are reused).
实验!
我们现在可以试着看看这个模型的工作原理,模拟一个通常的 FaceID 循环:首先,注册用户的面部。然后,解锁阶段,用户(应该成功)和其他人都不能解锁设备。如前所述,差异在于网络计算的解锁手机的人脸和注册人脸之间的距离,以及该距离是否低于某个阈值。
让我们从注册开始:我从数据集中拍摄了同一个人的一系列照片,并模拟了一个注册阶段。该设备现在正在计算这些姿势中每一个的嵌入,并将它们存储在本地。

Registration phase for a new user, inspired by the FaceID process.

Registration phase as seen by the depth camera.
现在让我们看看,如果同一个用户试图解锁设备会发生什么。同一用户的不同姿势和面部表情实现了平均大约 0.30 的低距离。

Face distances in the embedding space for the same user.
另一方面,不同人的 RGBD 图片得到的平均距离为 1.1。

Face distances in the embedding space for different users.
因此,使用 0.4 左右的阈值应该足以防止陌生人解锁您的设备。
结论
在这篇文章中,我展示了如何基于面部嵌入和暹罗卷积网络实现 FaceID 解锁机制的概念验证。我希望它对你有所帮助,有任何问题你可以联系我。 你可以在这里找到所有相关的 Python 代码。
在推特上关注我的工作更新和更多:【https://twitter.com/normandipalo
我是如何战胜一个 538 预测算法的
你也可以

Photo by Fredrick Lee on Unsplash
今年,内特·西尔弗的《FiveThirtyEight》向读者发出挑战,要求预测 NFL 比赛结果比的预测算法更好。结果呢?在 20,352 名参与的读者中,不到 2%的人胜过 FiveThirtyEight 的 Elo 算法。
我是其中之一。
我是如何在锦标赛中预测股市的

在此之前,我的机器学习教程是无聊的故事和理论:),在这篇文章中,我将分享我在人工智能竞赛中的第一次代码体验。我在数字上尝试了我的基本机器学习技能。
Github 源代码:【https://github.com/andela-ysanni/numer.ai
根据他们比赛的网站,数字是一个预测股票市场的全球人工智能比赛。Numerai 有点类似于 Kaggle,但是数据集干净整洁;你下载数据,建立模型,然后上传你的预测。很难找到一个比赛,你可以应用你喜欢的任何方法,而不需要太多的数据清理和特征工程。在这场锦标赛中,你可以做到这一点。
哦,是的,我最初开始学过 Udacity 机器学习入门,并且有一些关于使用 scikit-learn 的监督机器学习算法的基础知识。一开始我很害怕;像我这样的新手如何参加有排行榜的在线比赛?我不在排行榜末尾的可能性有多大?总之,我不畏艰险。
本项目使用的包
Pandas 是一个用 Python 编写的包,用于数据结构和数据分析, numpy 用于创建大型多维数组和矩阵,您可以使用 pip install 命令简单地安装这些包。我们还将从 sklearn 库导入一些包,sklearn 库由简单高效的数据挖掘和数据分析工具组成,包括监督和非监督算法。
数据概述
对于这场比赛,我们有两个数据集,即我们的训练数据和测试数据。我建议你用数字加载你的数据集(默认情况下,它是 Mac OS 自带的),看看它看起来怎么样,否则,感谢微软 Excel。您还可以使用 Sublime 或 Atom 等文本编辑器来加载数据集。
我使用 panda 库方法“read_csv”将数据解析成 DataFrame 对象。read_csv 方法接受 file_path 和一些其他可选参数。
import pandas as pdtraining_data = pd.read_csv('numerai_training_data.csv')tournament_data = pd.read_csv('numerai_tournament_data.csv')
训练数据集有 22 列。第 21 列包括从特征 1 到特征 21 的特征,而最后一列是目标值;将用于训练我们的分类器的 1 或 0 值。我们大约有 96321 行。
锦标赛数据集是我们的测试集,它也有 22 列。列 1 是 t_id,它是来自我们训练数据的目标 id。剩下的 21 列是我们的特性值。
交叉验证
交叉验证主要是衡量统计模型对独立数据集的预测性能的一种方式(从 http://robjhyndman.com 检索)。.)衡量模型预测能力的一种方法是在一组未用于训练数据的数据上进行测试。数据挖掘者称之为“测试集”,用于估计的数据是“训练集”。
验证的主要目的是避免过度拟合。当机器学习算法(如分类器)不仅识别数据集中的信号,还识别噪声时,就会发生过拟合。噪声这里意味着模型对数据集的特征过于敏感,而这些特征实际上没有任何意义。过度拟合的实际结果是,对其训练数据表现良好的分类器可能对来自相同问题的新数据表现不佳,甚至可能非常差。
为了开发我们的分类器,我们使用 70%的数据将数据集分成两部分来训练算法。然后,我们对剩下的 30%进行分类,并记录这些结果。下面是我们自己的交叉验证版本:
from sklearn import cross_validationfeatures_train, features_test, labels_train, labels_test = cross_validation.train_test_split(training_data.iloc[:,0:21], training_data['target'], test_size=0.3, random_state=0)
我使用了 sklearn 的 cross_validation 方法,从训练数据中提取了 30%的测试集。让我解释一下参数:
train_test_split 获取我们的训练数据数组,该数组包括特征训练,但不包括我们的目标值,后跟我们的目标值数组。
test_size 是我们百分之三十的数据比例。
random_state 取用于随机采样的伪随机数发生器状态的整数值。
我们的交叉验证返回四个数组,其中包括 70%的 features_train 和 labels_train,剩余 30%的 features_test 和 labels_test。
分类器的实现和装配
在这个项目中,任务是二进制分类,输出变量也称为我们的目标预计是 1 或 0。我将使用 SVC(支持向量分类)作为分类器。一个支持向量机 ( SVM )是一个判别分类器形式上由一个分离超平面定义。换句话说,给定标记的训练数据(监督学习),算法输出一个分类新例子的最佳超平面。
支持向量机的优势在于:
- 在高维空间有效。
- 在维数大于样本数的情况下仍然有效。
- 在决策函数中使用训练点的子集(称为支持向量),因此它也是内存高效的。
- 通用:可以为决策函数指定不同的内核函数。提供了通用内核,但是也可以指定定制内核。
from sklearn.svm import SVC as svcclf = svc(C=1.0).fit(features_train, labels_train)
C 这里控制训练数据的误分类成本。大的 C 给你低偏差和高方差。低偏差是因为你对错误分类的代价进行了大量的惩罚,而小的 C 给了你更高的偏差和更低的方差。
。fit() 方法根据给定的训练数据来拟合 SVM 模型,即特征训练和标签训练。
做预测
下一步是使用 30%的数据集对我们训练的分类器进行预测。
predictions = clf.predict(features_test)
predict() 方法获取一个数组并对该数组执行分类。
精度
精确度是我们建立的模型的精确度的加权算术平均值。我将使用 sklearn 测量准确度分数。该方法返回给定测试数据和标签的平均准确度。
from sklearn.metrics import accuracy_scoreaccuracy = accuracy_score(predictions,labels_test)
accuracy_score()接受两个数组;我们之前做的预测和真实的目标测试数据。
这里得到的准确度分数是**0.51849391。**非常低,所以我决定将 C 的值提高到 100.0,以获得更好的分类和高方差。这实际上几乎花了很长时间(15 分钟)来运行分类,但给出的分数为 0.518133997785 ,比之前的分数略高。它仍然是低的,但是我很高兴知道它稍微高于平均水平。对新手来说够公平了:)
重大挑战
我使用的分类器非常慢,当 C=1.0 时需要大约 10 分钟,当 C=100.0 时需要 15 分钟才能获得更好的分数,如果我们的数据集大小增加两倍,这将是不可伸缩的。**为什么?**实现基于 libsvm。因此,拟合时间复杂度大于样本数量的平方,这使得难以扩展到具有超过 10000 个样本的数据集。
改进与结论
在我的下一篇文章中,我将谈论我如何微调我的分类器的参数,以及我如何切换到使用另一种算法来优化我的结果。我希望到目前为止你喜欢这个教程。欢迎在评论区发表评论和问题。再见
更新:这里是链接到最终教程。
禁食比你想象的要容易
我的 5 天禁食可以减少饥饿感,提高精神集中力

如果有人说你可以用一个奇怪的技巧来减肥、提高注意力、减少对食物的渴望、延长寿命,会怎么样?如果你像我一样,你可能会想:
- 这是雅虎广告吗?
- 我才不要尝试那种禁食垃圾。
- 我喜欢食物。我为什么要放弃?
狼吞虎咽地吃下一整盒 Xtra Cheddar 金鱼来平静我的神经后,我想了想,意识到我仍然很好奇。毕竟,碧昂斯做到了?
间歇性禁食的健康益处
愉快地屈服于证实偏见,我开始在谷歌上搜索证实这些说法的严肃的研究。这里有一些潜在的好处,我发现即使是核实科学类型的人也不会完全反对。
禁食有可能延缓衰老,有助于预防和治疗疾病,同时将慢性饮食干预引起的副作用降至最低。
禁食:分子机制 瓦尔特·d·隆戈和马克·p·马特森
禁食也有良好的记录。宗教和精神团体已经禁食几个世纪了。冥想和瑜伽的练习者利用禁食来提高注意力和自律。
个人对禁食的兴趣
- 癫痫症——我从 19 岁开始就患有癫痫症。在我们找到正确的药物组合后,癫痫大发作(电视节目中的身体抖动)停止了。然而,尽管尝试了不同的药物和剂量,我仍然频繁出现被称为光环的“眩晕发作”。我在哪里读到过禁食会有帮助。
- 精神专注——任何有希望让我精神振奋的事情,我都愿意尝试。还记得无限的吗?通常这相当于我在亚马逊上购买不科学的垃圾。
- 减肥——我刚刚结束为期三周的欧洲之旅。考虑到我吃了数量惊人的糕点,当我回来时,我毫不惊讶地发现自己重了几磅。我很好奇,想看看我是否能“快速启动”塑身的过程。
- 对食物的渴望——我发现自己无时无刻不在想食物,尤其是在旅行的时候。禁食似乎是一种减少食欲和减少食物依赖的合理方法。是的,我们的祖先有很好的理由去思考这个问题——食物、睡眠、击退捕食者——但今天的生活非常不同——巨无霸、懒汉、在使命召唤中击退纳粹僵尸。
结果呢
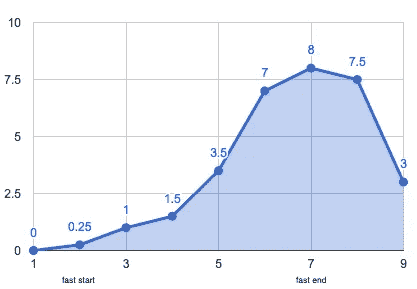
我周日晚上 9 点开始禁食,周六中午 12:30 停止。我在早上用我的 Fitbit Aria 和酮测试条进行了测量。
酮
身体通常依靠葡萄糖运转,葡萄糖来自分解碳水化合物。然而,如果你饿了,你的身体不能找到足够的葡萄糖,所以它开始分解脂肪来获取能量。酮是葡萄糖转化为脂肪的酸性副产品。
酮对追踪很重要。它们标志着你的身体从碳水化合物向脂肪的转变,如果你走得太远,它们会警告你。根据这张图,在脂肪上跑步的“好处”在 1.5-3 左右显现。空腹酮症在 4 岁开始,k 依托酸中毒(危及生命)在 9-10 岁左右开始。
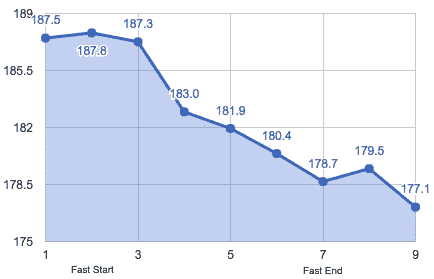
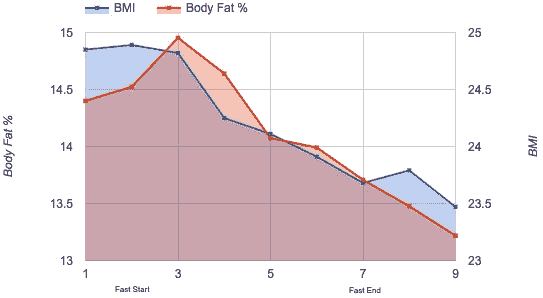
体重和体脂
我怀疑禁食是一种可持续的减肥技术,但它绝对不是一个噱头。
Weight decreased 8.8 pounds
Body fat decreased .7%. BMI decreased 1.2 lbs/in².
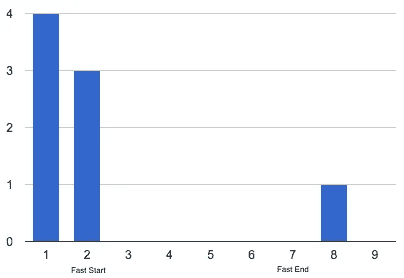
光环(眩晕)
这是整个斋戒中最令人兴奋的发现。我通常平均每天有 3 个光环,但在禁食期间,我连续 4 天没有一个光环。更好的是,禁食后光环的数量仍然很低。
精神焦点
总的来说,我感觉更加专注和坚定。白天我的能量水平保持不变,有一次我甚至发现自己熬夜阅读重构:改进现有代码的设计,它已经在我的床头柜上积了 6 个月的灰尘。
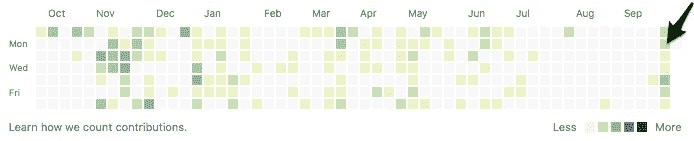
Based on GitHub contributions, I was more productive than usual during the fast
对食物的渴望
两周后,我仍然渴望某些食物,但总的来说,我对食物的关注减少了,当我不能按时吃饭时,我也不会感到压力。就像马拉松训练让跑 5000 米变得微不足道一样,禁食 5 天的经历让不吃饭,甚至禁食一整天,看起来都像是儿戏。我怀疑我新发现的超脱将会导致与食物更健康的关系。
禁食的副作用
- 身体迟缓— 这是迄今为止最明显的副作用。3 天来,我的腿感觉不稳定,下班走回家很有趣。
- 便秘 —这么说吧,那周我在卫生纸上省了钱;)
- 对寒冷的敏感——我记得不止一次问我的同事:“伙计们,这里冷吗?还是只有我冷?”显然只有我一个人。
据我的医生说,副作用是由于我血液中的电解质失衡造成的。尽管喝了大量的盐水,我还是很快脱水并缺乏关键矿物质(钾、钠、氯)。

My doctor ordered blood work at key times during the fast.
医生提示:用盐片代替盐水,并添加镁、钾补充剂,减轻上述症状。
副作用在很大程度上是可以控制的,但是我很高兴在尝试之前和我的医生谈过。
其他观察
- 禁食 5 天出奇不差。根据我禁食一天的经验,我假设禁食 5 天的痛苦等于禁食一天的痛苦乘以 5。事实并非如此。几天后,我的身体适应了,饥饿感慢慢演变成隐隐作痛。
- **社会含义。**没想到和朋友出去不吃东西会有多尴尬。我发现自己反复向持怀疑态度的观众解释我的推理。不要指望你的朋友会支持你或给你留下深刻印象。
- 咖啡有助。所以我作弊,每天喝大约 3 杯咖啡,一半一半(每天 120 卡路里)。咖啡是一种众所周知的食欲抑制剂,我在禁食期间肯定受益于这一事实。有趣的是,这项研究建议你应该喝不含咖啡因的咖啡。
快速发布
禁食之后,我恢复了我通常的低碳水化合物饮食,并开始四处走动。大多数症状在 48 小时内消失,但是一天早上我犯了一个错误,早餐吃了 6 个鸡蛋。还好我在卫生纸上省了钱!
减肥成功了吗?
体重仍然很低,但身体脂肪又回来了,这表明我在禁食期间也减掉了肌肉和水的重量。第 12 天,我开始尝试一种生酮饮食,这可能解释了水重量持续下降的原因。
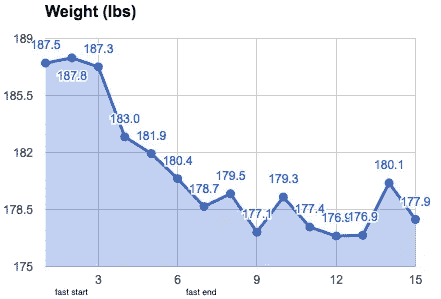
Weight decreased 9.6 pounds
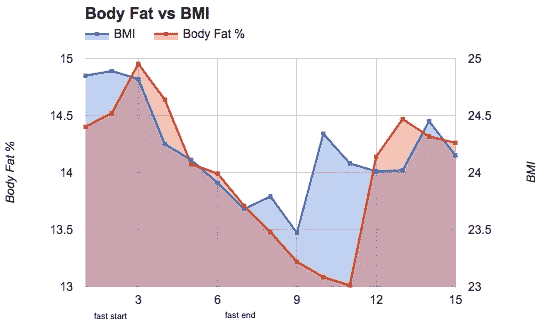
Body fat decreased .14%. BMI decreased .7 lbs/in².
光环回归,但不完全
在斋戒之前,我平均每天有 3 个光环。在禁食期间,我平均获得 0.5 光环,禁食后,我平均获得 1.6 光环。我的生酮饮食可能解释了为什么酮保持在禁食前水平以上,而光环保持在禁食前水平以下。
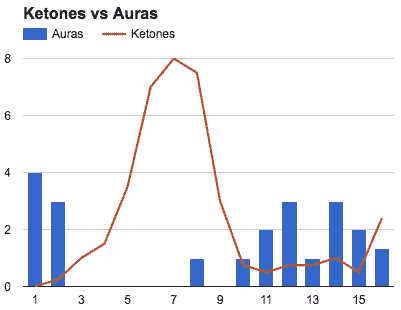
I had a hard time getting Ketones above 1, despite my new diet
下次
那么,什么是减肥、提高性生活质量、获得超人智力的一个怪异诀窍?我会留到下一篇文章来说,但是现在这里有 3 个我用来维持 5 天禁食的简单窍门:
- 喝咖啡,最好是无咖啡因的。如果再来一次,我还会加入鸡汤,这是另一种值得期待的美味高盐饮料。
- 拥抱久坐不动的生活——犒劳自己,享受所有你渴望的与食物无关的事物。用瑜伽代替慢跑,骑优步去上班,狂看第一季奇人异事,在家工作,或者更好,翘班!
- 找一个副业——找一个令人兴奋的副业,全神贯注。在哈比神工作非常有趣,我几乎忘了吃饭…;)至少,在工作中安排一些无意义的会议,这样你就没有时间在办公桌前思考食物了。
我很快肯定会再次斋戒。也许不是连续 5 天,但每季度 3 天禁食和每两周 1 天禁食的频率似乎是合理的。敬请期待!
我如何使用深度学习解决我的第一个 Kaggle 挑战——第 1 部分

Artificial Intelligence
在过去的几周里,我一直在参加免费且优秀的 fast.ai 在线课程,该课程从实用的角度教授深度学习。作为一名编程出身的人,我发现这是正确的方法。然而,我一直在用各种材料补充我的理论理解(我强烈推荐那些来自 CS231n 斯坦福课程的笔记)。
进入 Kaggle
Kaggle 是应用深度学习挑战的战场和训练场,我被其中一个特别吸引:州立农场分心司机检测挑战。在这项挑战中,我们得到了一组大约 20K 的驾驶员照片,这些驾驶员要么处于专注状态,要么处于分心状态(例如,拿着电话,化妆等)。).测试集由大约 80K 幅图像组成。目标是建立一个模型,该模型可以在一组 10 个类别中准确地对给定的驾驶员照片进行分类,同时最小化对数损失(即,每次分类器得到错误的预测时,惩罚分数都会按照对数顺序上升)。
我对 State Farm challenge 感兴趣,因为我目前正在开发一款由人工智能驱动的 dash cam 手机应用程序,它将使驾驶变得更加安全和丰富。KamCar 将做的一件事是检测司机的注意力分散/困倦,并提醒司机避免灾难。根据疾病预防控制中心的数据,司机分心是 20%车祸的原因,我相信,随着当前深度学习的进步和智能手机功能的增强,我们可以采取更多措施来解决这一问题。

Driver in different distracted states
在严格遵循杰瑞米·霍华德(fast.ai 联合创始人)的方法之前,我尝试了自己的愚蠢方法,但收效甚微。
第 1 步—获得正确的验证集
据我所知,对于有多少训练集应该放在验证集中没有明确的规则,所以我设计了一个在训练集和验证集之间 80/20 的划分。
当我开始应对州立农场挑战时,我只是在所有 10 个类中随机移动了 20%的图像,从训练集到验证集。但是当我对数据运行一个简单的线性模型时,训练集的损失是巨大的(超过 14),而验证集的准确性未能超过 17%。
我回到州立农场挑战赛页面,再次阅读其详细信息,并注意到以下内容:
训练和测试数据被分割在驱动程序上, 使得一个驱动程序只能出现在训练或测试集上。
有趣… 我想…既然我们根据验证集来验证(而不是训练)我们的模型,它应该表现出与测试集相似的属性,对吗?因此,解决方案是分割训练集和验证集,使得验证集中一定比例的驾驶员不在训练集中。 State Farm 方便地提供了一个 csv 文件,该文件将给定的驱动程序 id 映射到一个文件名,因此分割非常简单:
import pandas as pd
import randomdf = pd.read_csv(path + ‘/driver_imgs_list.csv’)
by_drivers = df.groupby(‘subject’)
unique_drivers = by_drivers.groups.keys()# Set validation set percentage with regards to training set
val_pct = 0.2
random.shuffle(unique_drivers)# These are the drivers we will be entirely moving to the validation set
to_val_drivers = unique_drivers[:int(len(unique_drivers) * val_pct)]
步骤 2 —从样品组开始
由于训练和验证集总计 20K 个图像,当您只是检查一些设置是否有效时,在这么大的数据量上训练模型仍然需要一点时间。
样本集只是训练集和验证集的子集:您的模型将根据样本训练集进行训练,以快速评估哪些有效,哪些无效。这样做让我节省了很多时间!我选择我的样本集是大约 20%的数据,其中图像被随机复制到样本集。
第三步——尝试准系统模型
下面的模型非常简单,事实上它根本没有卷积层:
def linear_model():
model = Sequential() # image size is 3 (RGB) x 224x224 (WidthxHeight)
model.add(BatchNormalization(axis=1, input_shape=(3, img_size_1D, img_size_1D)))
model.add(Flatten())
# here we have 10 classes
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
有趣的是,在没有卷积和正则化的情况下,它是如何在验证集上达到接近 40%的准确率的!
model = linear_model()
model.optimizer.lr = 10e-5model.fit_generator(sample_train_batches, samples_per_epoch=sample_train_batches.nb_sample, nb_epoch=3,
validation_data=sample_val_batches, nb_val_samples=sample_val_batches.nb_sample, verbose=1)Epoch 1/3
1803/1803 [==============================] - 29s - loss: 5.7358 - acc: 0.2806 - val_loss: 10.9750 - val_acc: 0.1741
Epoch 2/3
1803/1803 [==============================] - 24s - loss: 1.6279 - acc: 0.6339 - val_loss: 4.6160 - val_acc: 0.3304
Epoch 3/3
1803/1803 [==============================] - 24s - loss: 0.5111 - acc: 0.8358 - val_loss: 3.1399 - val_acc: 0.3951
显然,你可以看出它大大超出了训练集,因为在仅仅 3 次完整运行中,它就达到了超过 80%的准确率,而验证集的准确率是两倍。问题是我们的简单模型已经学会记忆大多数图像的正确权重,这使得它无法很好地概括以前从未遇到过的驾驶员图像(猜猜看,他们都在验证集中!).
第四步——在你的生活中增加一些回旋的余地
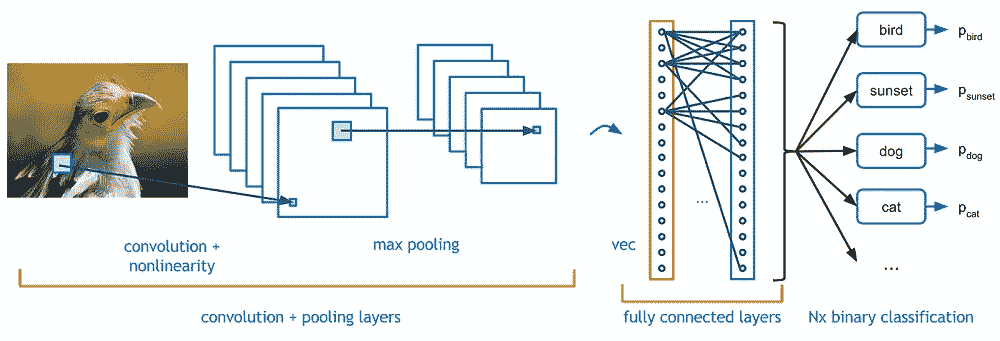
Example of a convolutional neural network — from Adit Deshpande’s blog https://adeshpande3.github.io/
好了,这才是真正有趣的地方……我创建了一个模型,用一些卷积来测试这样的架构是否会提高准确性:
def simple_convnet():
model = Sequential([
BatchNormalization(axis=1, input_shape=(3,224,224)),
Convolution2D(32,3,3, activation='relu'),
BatchNormalization(axis=1),
MaxPooling2D((3,3)),
Convolution2D(64,3,3, activation='relu'),
BatchNormalization(axis=1),
MaxPooling2D((3,3)),
Flatten(),
Dense(200, activation='relu'),
BatchNormalization(),
Dense(10, activation='softmax')
])model.compile(Adam(lr=1e-5), loss='categorical_crossentropy', metrics=['accuracy'])
return model
令人惊讶的是(至少对我来说),该模型在验证集上表现很差,但在训练集上很快达到了 100%的准确率:
Epoch 1/3
1803/1803 [==============================] - 34s - loss: 1.2825 - acc: 0.6184 - val_loss: 2.0999 - val_acc: 0.2612
Epoch 2/3
1803/1803 [==============================] - 25s - loss: 0.2360 - acc: 0.9590 - val_loss: 2.2691 - val_acc: 0.2098
Epoch 3/3
1803/1803 [==============================] - 26s - loss: 0.0809 - acc: 0.9939 - val_loss: 2.4817 - val_acc: 0.1808
Epoch 1/3
1803/1803 [==============================] - 30s - loss: 0.0289 - acc: 0.9994 - val_loss: 2.6927 - val_acc: 0.1585
Epoch 2/3
1803/1803 [==============================] - 29s - loss: 0.0160 - acc: 1.0000 - val_loss: 2.7905 - val_acc: 0.1540
Epoch 3/3
1803/1803 [==============================] - 26s - loss: 0.0128 - acc: 1.0000 - val_loss: 2.7741 - val_acc: 0.1562
第五步——有意愿,就有增加
数据扩充使我们能够对图像进行随机修改,以降低模型记忆特定图像权重的能力。一些类型的增强包括旋转、宽度/高度移动、剪切和 RGB 通道移动。我尝试了一系列参数,并确定了以下最佳结果:
gen_all = image.ImageDataGenerator(rotation_range=15, height_shift_range=0.05, shear_range=0.15, channel_shift_range=10, width_shift_range=0.1)
经过多次运行,我设法在验证集上实现了 60%的准确率,这对于接下来的事情来说是非常令人鼓舞的:
Epoch 13/15
1803/1803 [==============================] - 26s - loss: 0.4834 - acc: 0.8697 - val_loss: 1.4806 - val_acc: 0.5625
Epoch 14/15
1803/1803 [==============================] - 26s - loss: 0.4944 - acc: 0.8658 - val_loss: 1.4361 - val_acc: 0.5759
Epoch 15/15
1803/1803 [==============================] - 27s - loss: 0.4959 - acc: 0.8597 - val_loss: 1.3884 - val_acc: 0.6004
对于这样一个简单的模型来说还不错,你同意吗?

Not bad at all, according to Michelle Obama
我正在进行这个系列的第 2 部分,在那里我们将使用完整的数据集,并通过利用已经预先训练好的 VGG 网模型来执行迁移学习。代码也将很快出现在我的 github 上。
敬请期待,喜欢就分享,不要犹豫留下评论:)。
我是建筑KamCar,AI 驱动的 dash cam app,让驾驶更安全、更丰富的体验。如果你是一名移动开发者,想要开发一些令人兴奋的技术和产品,或者只是想提供一些建议,请在Twitter或这里联系我:)
第 2 部分——我如何使用深度学习解决我的第一个 Kaggle 挑战
这是我如何在 Kaggle 上擒下 国营农场分心司机检测挑战赛 的第二部分。这里的许多工作都是基于杰瑞米·霍华德和雷切尔·托马斯教授的优秀的fast . ai课程的课程和教程。
我对这个挑战特别感兴趣,因为我目前正在开发KamCar,这是一款人工智能驱动的 dash cam 移动应用程序,旨在让驾驶变得更加安全和丰富。你可以在这里 阅读一下 Part-1 。

Driver talking on the phone while driving
在对样本训练集应用了一些扩充并在验证集上达到 50%的准确度之后(即步骤 5),我们停止了第一部分-1。现在,我们正以更大的数据集作为盟友,开始我们深度学习冒险的剩余部分。
步骤 6-邀请整个数据集
在对样本集进行实验时,我也逐渐明白,如果不在更丰富的数据集上训练模型,大幅提高准确性将更具挑战性。因此,加载整个训练集和验证集并针对前者训练模型是很自然的。
第七步——减轻一些重量
我计划使用第一部分中使用的同样小的 CNN,但这次我引入了 Dropout ,它基本上使我们能够在我们的密集层中“放下”重量。我使用 Dropout,因为它迫使网络忘记它在训练集上计算的一些特征,从而减少模型对训练数据的过度拟合。如果没有退出,我们的模型将开发的特性可能不够通用,不能很好地处理新数据(即验证或测试集)。
def conv_model_with_dropout():
model = Sequential([
BatchNormalization(axis=1, input_shape=(3,img_size_1D,img_size_1D)),
Convolution2D(64,3,3, activation='relu'),
BatchNormalization(axis=1),
MaxPooling2D(),
Convolution2D(128,3,3, activation='relu'),
BatchNormalization(axis=1),
MaxPooling2D(),
Convolution2D(256,3,3, activation='relu'),
BatchNormalization(axis=1),
MaxPooling2D(),
Flatten(),
Dense(200, activation='relu'),
BatchNormalization(),
Dropout(0.5),
Dense(200, activation='relu'),
BatchNormalization(),
# Using a simple dropout of 50%
Dropout(0.5),
Dense(num_classes, activation='softmax')
])
model.compile(Adam(lr=1e-5), loss='categorical_crossentropy', metrics=['accuracy'])
return model
经过几次运行后,性能在验证集上徘徊在 60%-62%左右,没有取得太大进展:
Epoch 1/10
17990/17990 [==============================] - 521s - loss: 0.7413 - acc: 0.7560 - val_loss: 1.3689 - val_acc: 0.6087
Epoch 2/10
17990/17990 [==============================] - 520s - loss: 0.7123 - acc: 0.7665 - val_loss: 1.3105 - val_acc: 0.6238
Epoch 3/10
17990/17990 [==============================] - 520s - loss: 0.6663 - acc: 0.7815 - val_loss: 1.2932 - val_acc: 0.6283
Epoch 4/10
17990/17990 [==============================] - 520s - loss: 0.6253 - acc: 0.7973 - val_loss: 1.2504 - val_acc: 0.6245
是时候转向更强大的东西了!
第八步——不要逞英雄:让迁移学习拯救你
正如你所看到的,我之前创建的所有模型都很简单,不太深入。我当然可以创建一个更深层次的架构,但很可能需要在一个大规模数据集(比我目前拥有的大得多)上训练它很长时间,才能显著提高准确性。另外,我也负担不起两周的培训费用。
幸运的是,许多令人敬畏的研究人员通过在数百万张图像上训练深度学习模型,保存了他们模型的最终权重,并使他们的结果可用,从而使我们的生活变得更容易。该领域最活跃的研究人员之一 Andrej Karpathy 建议使用现有的技术,而不是在他的 CS231N 课程中重新发明一个昂贵的轮子:
**“不要逞英雄”😗*你应该看看 ImageNet 上目前最有效的架构,下载一个预训练模型,并根据你的数据对其进行微调,而不是推出自己的架构来解决问题。您很少需要从头开始训练或设计一个 ConvNet。
采用一个已经预先训练好的模型并用我们自己的训练数据对其进行微调被称为迁移学习。对于这个挑战,我将使用一个预先训练好的 VGG 网络,它赢得了 ImageNet ILSVRC-2014 竞赛。
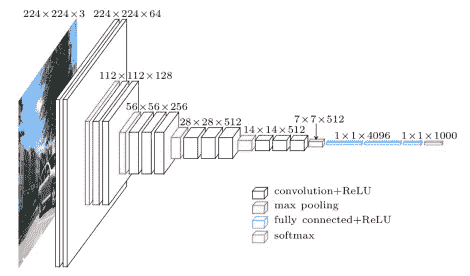
VGG Architecture — From Toronto University
第八步——保持这些卷积层紧密相连
提醒一下,以下是我决定使用预先培训过的 VGG 网络的一些原因:
- 我们只有很少的训练数据,因此无法生成一个容易通用的模型
- VGG 已经接受了数百万张图片的训练
- 从 VGG 的卷积层中提取的特征应该足够通用,可以应用于人类的图像
- VGG 比我上面的临时神经网络有更多的卷积层,我的假设是我们将获得更高的精度
神经网络最重要的组成部分是它的卷积层(马修·泽勒和罗布·弗格斯在论文可视化和理解卷积网络中写道),它学习如何识别初始层中的边缘等基本特征,以及上层中更复杂的特征。
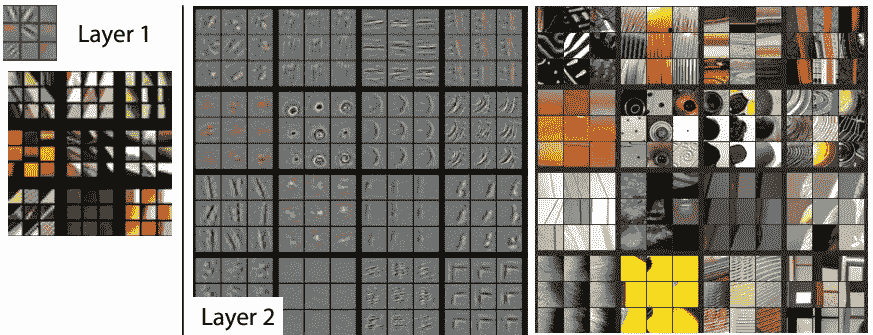
Visualisaion of early layers of a CNN — from Karpathy’s blog
因此,我们需要从预训练的 VGG 网络中提取卷积层,因为我们稍后将创建自己的密集层:
# This will import the full gcc model along with its weights
vgg = Vgg16()
model = vgg.model# identify the convolutional layers
last_conv_idx = [i for i,l in enumerate(model.layers) if type(l) is Convolution2D][-1]
conv_layers = model.layers[:last_conv_idx + 1]# Make sure those convolutional layers' weights remain fixed. We are purely using them for prediction, not training.
for layer in conv_layers: layer.trainable = False# Create a model now out of the convolutional layers
conv_model = Sequential(conv_layers)
步骤 9-预先计算卷积特征
请记住,根据 VGG 架构图,最后一个卷积层产生的输出尺寸为 512 x 14 x 14:这正是我们上面的纯卷积模型要做的。接下来需要的是在仅卷积模型上预计算我们的训练、验证和测试特征,然后在密集模型中使用它们。换句话说,我们使用仅卷积模型的输出作为仅稠密模型的输入。
# batches shuffle must be set to False when pre-computing features
train_batches = load_in_batches(train_dir, shuffle=False, batch_size=img_batch_size)# Running predictions on the conv_model only
conv_train_feat = conv_model.predict_generator(train_batches, train_batches.N)
conv_val_feat = conv_model.predict_generator(val_batches, val_batches.N)# Predict feature probabilities on test set
test_batches = load_in_batches(test_dir, shuffle=False, batch_size=img_batch_size)
conv_test_feat = conv_model.predict_generator(test_batches, test_batches.N)
我们加载我们的图像,同时确保洗牌标志设置为假,否则我们的输入特征和标签将不再匹配。
步骤 10-制作你自己的致密层
回想一下,VGG 网络产生包含 1000 个类的输出。这是因为训练它的 ImageNet 竞赛要求将图像分成 1000 个不同的类别。但是在这个 Kaggle 挑战中,我们只处理 10 个类,因此原始的 VGG 密集层不足以解决我们试图解决的问题。
因此,我们需要创建一个合适的密集层架构,该架构将使用 SoftMax 作为最后一个密集层的激活函数,最终产生我们期望的类数量的预测。此外,请记住,我们使用仅卷积模型的输出作为我们定制的密集模型的输入。我们还在这一阶段引入了辍学,以防止在训练集上过度适应。
def get_dense_layers(dropout_rate = 0.5, dense_layer_size = 256):
return [
# Here input to MaxPooling is the output of the last convolution layer (without image count): 512 x 14 x 14
MaxPooling2D(input_shape=conv_layers[-1].output_shape[1:]),
Flatten(),
Dropout(dropout_rate),
Dense(dense_layer_size, activation='relu'),
BatchNormalization(),
Dropout(dropout_rate),
Dense(dense_layer_size, activation='relu'),
BatchNormalization(),
Dropout(dropout_rate),
# num_classes is set to 10
Dense(num_classes, activation='softmax')
]
我们现在可以使用来自步骤 9 的仅卷积模型的预先计算的特征来训练我们的密集模型:
d_rate = 0.6
dense_model = Sequential(get_dense_layers(dropout_rate = d_rate))
# We will use a more aggressive learning rate right off the bat, as our model has been pre-trained
dense_model.compile(Adam(lr=0.001), loss='categorical_crossentropy', metrics=['accuracy'])# See how we call fit and not fit_generator, as our array of features has already been pre-computed
dense_model.fit(conv_train_feat, trn_labels, batch_size=img_batch_size, nb_epoch=3,
validation_data=(conv_val_feat, val_labels), verbose=1)
这使我们能够达到大约 70%的验证准确率
Train on 17990 samples, validate on 4434 samples
Epoch 1/3
17990/17990 [==============================] - 9s - loss: 0.9238 - acc: 0.7178 - val_loss: 1.0323 - val_acc: 0.6340
Epoch 2/3
17990/17990 [==============================] - 9s - loss: 0.1435 - acc: 0.9565 - val_loss: 0.8463 - val_acc: 0.7352
Epoch 3/3
17990/17990 [==============================] - 9s - loss: 0.0802 - acc: 0.9748 - val_loss: 0.9537 - val_acc: 0.7082

Doctor House’s nod of approval
虽然与我开始时相比,这是一个显著的改进,但我们实际上可以做得更好:我还没有将数据增强引入这场战斗,也没有使用一些无人监管的技术和其他技巧,我将在第 3 部分中介绍这些技巧。这将是一个非常激动人心的部分,所以不要错过!
敬请期待,喜欢就分享,不要犹豫留下评论:)。
我是建筑 KamCa r,AI 驱动的 dash cam 应用程序,让驾驶变得更安全、更丰富。如果你是一名移动开发者,想要开发一些激动人心的技术和产品,或者只是想提供一些建议,请在Twitter或这里联系我!
我如何在非 Rails 环境中测试 Ruby APIs
我用 Ruby 编程已经快 5 年了,但是(喘气)不要用 Ruby on Rails 。尽管 Sinatra 是一个很好的框架,但它可能是 Rails 拥有 Ruby 社区 90%以上的份额之后才想到的。在 Rails 之外让一个 gem 工作并被很好地记录下来,几乎就像在苏联得到一双 Levi’s。也就是说,通过一点点尝试和错误,你可以准备好任何宝石生产。

有时候,让一个专注于 rails 的 gem 在 Rails 之外工作需要更长的时间。例如,我的团队在弄清楚如何让 ActiveRecord 与多种模式一起工作之前,使用了将近一年的数据映射器。ActiveRecord 是 Rails 核心的一部分,除了自动重新连接失败之外,我们很喜欢它。我们的测试也有类似的问题,这导致我们放弃了测试覆盖率。直到我们的暑期实习生 Parker McGowan 整个夏天都在这个项目上,我们才最终得到了一个好的 Sinatra 测试套件。它看起来是这样的:
我们如何运行我们的测试
我们的团队使用非常传统的 web 开发设置。我们选择在前端(Angular)和后端(Ruby)之间进行硬分离。我们使用 Sinatra 框架运行微服务(小型 REST APIs ),并将数据存储在 MySQL 中。我们偶尔会用 Redis,Beanstalk 进行排队,联系 Twitter 之类的公共 API。为了测试,我们选择了 MiniTest 而不是 Rspec,因为很像 Tenderlove ,我们更喜欢它的语法。它使用普通的老 ruby 代替 DSL,库现在在 core Ruby 中。
我们使用 SQLite 作为我们的测试数据库。不要使用 MySQL,因为您的测试会在每次运行时清除您的本地数据库。我们的数据库也遇到了一个有趣的问题。我的团队使用 SQL 已经有 10-15 年了,所以我们更喜欢手工创建表,而不是使用迁移来构建表。它给了我们更多的控制,但是超出了 Rails 的约定,使得用 ActiveRecord 测试变得很痛苦。我们手工创建我们的表,然后使用独立迁移 gem 来生成迁移,然后我们可以使用它来动态生成我们的数据库以供测试。
注意:如果您使用独立迁移,您将使用 。standalone _ migrations文件而不是 Rakefile。看起来是这样的:
# .standalone_migrationsconfig:
database: config/development.yml
db:
schema: test/db/schema.rb
我们用bundle exec rake test从命令行运行我们的测试
我们的每个测试都需要测试助手文件:
# /test/helper.rb**# Setup our test environment**
ENV[‘RACK_ENV’] = ‘test’
require ‘minitest/autorun’
require ‘mocha/mini_test’
require ‘rack/test’**# Include our application**
$LOAD_PATH.unshift ‘lib’
$LOAD_PATH.unshift ‘routes’
require File.expand_path ‘../../app.rb’, __FILE__ **# Sinatra App****# Setup database (and tear it down afterwards)**
test_db = SQLite3::Database.new(‘test/db/test.db’)Minitest.after_run do
test_db.close
File.delete(‘test/db/test.db’)
endActiveRecord::Base.establish_connection adapter: ‘sqlite3’, database: ‘test/db/test.db’
load ‘test/db/schema.rb’
这设置了我们的测试环境,包括我们的测试框架(rack 和 minitest)和 mocha 我们的模拟库。然后,在启动数据库和运行迁移之前,我们包括我们的应用程序特定的文件。由于 ActiveRecord 连接的运行方式,我们只运行一次迁移来构建我们的结构。为了保持测试的整洁,我们在每次测试后都清除数据库(截断表而不是删除它)。
试验
我们的自动化测试分为两类: 单元 和 集成 。我为库和助手编写单元测试,为路由编写集成测试。单元测试范围很小,但是很全面。他们也跑得非常快。集成测试可以覆盖很多动作,有时会测试多个 API 调用。状态被大量修改,所以从一个干净的石板开始每个单独的测试是必要的。此外,您必须假设集成测试中的单元正在工作。稍后我们将讨论当我们测试特定于业务的代码时,如何使用模拟来忽略经过良好测试的库。
自动化测试基于一个简单的度量: 断言 。你要么通过你的断言,要么失败。尽管有大量的断言(和反驳)可用,我倾向于只使用这些:
**assert** # is it truthy?**assert_nil** # is it nil?**assert_equal** # do the 2 parameters match?**assert_match** # test string against a pattern
单元测试
那么应该如何选择用单元测试测试什么,用集成测试测试什么呢?我建议为副作用少、代码使用频繁的库编写单元测试。我认为为您的数据库模型编写它们是很忙的,因为您的 ORM 应该经过良好的测试。对于包装类(例如,包装对另一个 API 的调用的方法),我也会忽略它们。话又说回来,我倾向于只写集成测试,除非一个库几乎没有副作用(错误不太可能发生在那些方法中看不到的代码中)并且经常被使用:
- 人物计数器——我的公司为社交媒体编写工具。我们必须在用户发送/安排消息之前验证文本的长度。
- Url shorter 的哈希生成器 —我们运行自己定制的 Url shorter。一个常见的函数是将整数(数据库表 ID)转换为 base 62 字符串,反之亦然。
以下是 Url Shortener 的一些测试:
require ‘./test/test_helper’class BaseConversionTest < MiniTest::Testdef setup
[@logger](http://twitter.com/logger) = Logger.new(STDOUT)
end# Encodedef test_convert_b10_to_b62_zero
assert_equal(‘0’, Leadify::LinkShortener::Math.to_base(0, base=62))
enddef test_convert_b10_to_b62_one_digit
assert_equal(‘5’, Leadify::LinkShortener::Math.to_base(5, base=62))
enddef test_convert_b10_to_b62_two_digit
assert_equal(‘A’, Leadify::LinkShortener::Math.to_base(36, base=62))
enddef test_convert_b10_to_b62_two_digit_b62
assert_equal(‘10’, Leadify::LinkShortener::Math.to_base(62, base=62))
enddef test_convert_b10_to_b62_two_char_b62
assert_equal(‘1A’, Leadify::LinkShortener::Math.to_base(98, base=62))
enddef test_convert_b10_to_b62_max_two_char_b62
assert_equal(‘ZZ’, Leadify::LinkShortener::Math.to_base(3_843, base=62))
end# ...
如你所见,这变得非常乏味。代码覆盖率不够。您必须涵盖代码中可能遇到的所有变化。我们测试 0、5、36、62、98 和 3843。这给了我们一组广泛的数据,让我们可以专注于失败。我们知道,如果我们在新的基本系统中处理一位数、两位数、带进位的两位数,等等。
在为函数编写了这样的测试之后,我们仍然有可能错过一些东西。由于我们有编码和解码功能,我们可以使用我们的代码来测试自己。我们可以做一个蒙特卡罗模拟,并使用函数x = decode(encode(x))测试一组随机输入。
# Reversibility Sampler
def test_monte_carlo_b10_to_b62_to_b10
1000.times do |i|
seed = rand(1_073_741_823) # Max 32 bit Fixnum
b62 = Leadify::LinkShortener::Math.to_base(seed, base=62)
assert_equal(seed, Leadify::LinkShortener::Math.from_base(b62, base=62))
end
end
但即使这样也不能囊括一切。你的编码器和解码器都可能损坏,但损坏的方式通过了x = decode(encode(x))测试。你的单元测试应该是健壮的,但是你不能抓住所有的东西。只要尽可能多的测试,当你看到一个失败时,添加一个测试。一旦你修改了你的代码,你就可以解决这个问题了。
如果你想看一套好的单元测试,看看热门 库。您还可以使用它们来理解文档记录不良的特性,或者找到有用的未记录的方法。通过阅读其他人的代码,你也可以学习编码风格。
集成测试
如果单元测试是树,那么集成测试就是森林。我们不再测试小而独特的组件。在我们的 Sinatra 集成测试中,我们通常测试单个 API 调用,然后测试一系列 API 调用。
创建、读取、更新、删除(CRUD) 路由大量使用我们的永久数据存储,我们使用 ActiveRecord 来访问它。正如我前面提到的,我们在生产中使用 MySQL,在测试中使用 sqlite。除了删除之外,我们所有的路由都返回 JSON 数据。因此,我们可以通过返回的 http 状态代码和输出 JSON 来验证 API 调用的正确性。这里有一个例子:
**def test_post_messages_with_message**
post '/messages', text: '[@ash_ketchum_all](http://twitter.com/ash_ketchum_all), check out this pikachu I found digging through the dumpster behind the #Pokestop!'
assert last_response.ok? response = Oj.load(last_response.body)
assert(response.key?('message'))
message = response['message']
assert_equal '[@ash_ketchum_all](http://twitter.com/ash_ketchum_all), check out this pikachu I found digging through the dumpster behind the #Pokestop!', message['text']
**end**
由于有了 Rack::Test 库,我们可以进行这些 CRUD 调用。它提供了 http 方法,get、post、put、patch和delete。您可以用一种非常简单的方式来调用它们:
<http method> <route name>, <parameters>, <headers># Examples
get '/messages'
post '/messages', text: "Gotta catch 'em all"
post '/shares', { facebook_post_id: '1337' }, 'rack.session' => { visit_id: 1 }
这些 Rack::Test 方法允许我们导航我们的 API,MiniTest 允许我们断言应用程序的状态是我们所期望的。
我们的 CRUD 路线整合测试涵盖以下模式:
1)验证
路由是否按照我们期望的方式处理不存在或无效的参数?每次验证失败时,它应该停止执行并返回一个错误代码,有时还会返回一条错误消息(例如,“name 是必填字段”)。
2)输出
首先,我们检查 http 状态是成功还是失败。如果它失败了,我们可以就此打住,我们必须找出它出错的原因。
接下来,我们检查 JSON 输出是什么。它是否返回了一个格式正确的对象?数据是我们预期的吗?如果我们有问题,具体是哪里的问题?
3)持久数据
当我们发布、上传或删除数据时,我们希望修改我们的数据。我们可以验证我们的 API 调用返回了正确的输出,但这并不意味着我们的应用程序永久地存储了数据。因为我们使用 ActiveRecord,所以我们可以在测试和生产中使用完全不同的数据库引擎。由于 ActiveRecord 经过了很好的测试,我们简单地假设,如果它在测试中有效,它将在生产中有效。为了验证永久存储中的数据是否被修改,我们只需要在 API 调用后检查我们的数据存储。
4)业务逻辑
API 中总是会有业务逻辑。如果它很小并且容易测试,那么我们可以把它移到库中,为它编写单元测试。那是首选。但是隔离这种行为通常很困难或者很费时间。对于这些情况,我们可以使用集成测试。例如,我们在新用户的注册过程中使用了大量的业务逻辑。我们首先创建一个登录名和一个帐户,然后为用户创建一个订阅,并将其连接到他们的 Stripe 订阅。然后,我们的一些用户在完成注册过程并登录我们的 web 应用程序之前授权他们的 twitter 帐户。
由于我们依赖于一些外部依赖(Stripe 和 Twitter),我们不能通过在测试模式下调用我们的 API 来模拟这一点。我们必须启动一个真正的网络浏览器,通过模拟用户界面上的点击来进行端到端的测试。我们的 UI 超出了 API 测试的范围。此外,我们将依赖这些网站的可用性和速度。出于这些原因,模拟您的数据和模拟您的外部依赖性要好得多。
嘲弄
当我说 mocks 时,我实际上是指 stubs 。实际上,您可能会听到 Mock 既用于 Mock 又用于 stubs。FWIW,我们用摩卡(懂了吗?)宝石写我们的存根。存根通常用于覆盖类方法。他们的名字来源于他们的长相。下面是一个覆盖 Stripe 类方法的模拟示例:
**# Mock for a class method**
Stripe::Plan.stubs(:create).returns(
stripe_uuid: 'vindaloo',
name: 'Red Dwarf',
subtitle: 'Spaceship',
statement_descriptor: 'EDGETHEORY SB VIP',
amount: 9999,
currency: 'usd',
interval: 'month',
interval_count: 1,
is_active: false
)
模拟实例方法需要更多技巧。您必须首先创建一个模拟对象,然后用一个存根来扩展该模拟对象。下面是一个示例存根,它覆盖了他们的计划类的条带实例上的删除方法:
**# Mock for an instance method**
object = mock('object')
Stripe::Plan.stubs(:retrieve).returns(object)
object.stubs(:delete).returns(true)
这些模拟允许我们消除外部 api 的不可预测性和缓慢性。我们在 MiniTest 应用程序的 setup 块中运行这两个代码片段,这样当我们创建或删除一个计划时,我们可以得到一个可预测的结果。当我们创建一个计划时,我们总是返回相同的散列,我们也可以干净地删除一个。
例子
我在下面包含了一个完整的集成测试的例子,所以你可以看到一些相关的样板文件。我们包含了测试助手,并且必须使用 app 方法,这样 Rack::Test 就可以访问我们的 Sinatra app 并调用我们的内部 API routes。我还有设置(在测试用例运行之前)和拆卸(在测试用例完成之后)的方法。
require File.expand_path '../helper.rb', __FILE__class ShareTest < MiniTest::Test
include Rack::Test::Methodsdef app
EdgeTheory::Loyalty::ApplicationController # Require our Sinatra app
end**# Called before each individual test case is run**
def setup
@account = EdgeTheory::DB::Loyalty::Account.create!(name: 'Your Cash Now', key: 'yourcashnow', is_active: true)
@style = EdgeTheory::DB::Loyalty::Style.create!(
account_id: [@account](http://twitter.com/account).id,
logo: '[http://rs278.pbsrc.com/albums/kk110/joker8851/PIKACHU.jpg~c200'](http://rs278.pbsrc.com/albums/kk110/joker8851/PIKACHU.jpg~c200')
)
@promotion = EdgeTheory::DB::Loyalty::Promotion.create!(account_id: @account.id)@reward = EdgeTheory::DB::Loyalty::Reward.create!(reward_type: 'instant',
name: 'Your Cash Now',
title: 'Fast cash, Money Now.',
instruction: 'Give us your social security number?')
[@promotion](http://twitter.com/promotion).instant_reward_id = [@reward](http://twitter.com/reward).id
[@promotion](http://twitter.com/promotion).save
[@message](http://twitter.com/message) = EdgeTheory::DB::Loyalty::Message.create!(account_id: [@account](http://twitter.com/account).id, text: 'They gave me money')[@visit](http://twitter.com/visit) = EdgeTheory::DB::Loyalty::Visit.create!(promotion_id: [@promotion](http://twitter.com/promotion).id)
end**# Called after each individual test case is completed**
def teardown
ActiveRecord::Base.connection.tables.each do |table|
ActiveRecord::Base.connection.execute("DELETE FROM #{table}")
ActiveRecord::Base.connection.execute("DELETE FROM sqlite_sequence where name='#{table}'")
end
ActiveRecord::Base.connection.execute('VACUUM')
enddef test_requires_visit
err = assert_raises(EdgeTheory::Loyalty::SessionError) { post '/shares' }
assert_match('Session has no visit_id', err.message)
enddef test_share
post '/shares', {}, 'rack.session' => { visit_id: [@visit](http://twitter.com/visit).id }
assert last_response.ok?
enddef test_create_share
post '/shares', {}, 'rack.session' => { visit_id: [@visit](http://twitter.com/visit).id }
assert last_response.ok?shares = EdgeTheory::DB::Loyalty::Share.all
assert_equal(1, shares.length)
assert_equal(1, shares[0].id)
assert_equal(1, shares[0].visit_id)
enddef test_create_share_with_facebook_post_id
post '/shares', { facebook_post_id: '1337' }, 'rack.session' => { visit_id: [@visit](http://twitter.com/visit).id }
assert last_response.ok?shares = EdgeTheory::DB::Loyalty::Share.all
assert_equal('1337', shares[0].facebook_post_id)
enddef test_create_share_with_message
post '/shares', { message_id: 1 }, 'rack.session' => { visit_id: [@visit](http://twitter.com/visit).id }
assert last_response.ok?shares = EdgeTheory::DB::Loyalty::Share.all
assert_equal(1, shares[0].message_id)
enddef test_create_share_with_invalid_message
post '/shares', { message_id: 1_337 }, 'rack.session' => { visit_id: [@visit](http://twitter.com/visit).id }
assert last_response.ok?shares = EdgeTheory::DB::Loyalty::Share.all
assert_equal(1, shares.length)
assert_equal(1, shares[0].id)
assert_equal(1_337, shares[0].message_id)
enddef test_create_share_with_message_and_facebook_post_id
post '/shares', { message_id: 1, facebook_post_id: '1337' }, 'rack.session' => { visit_id: [@visit](http://twitter.com/visit).id }
assert last_response.ok?shares = EdgeTheory::DB::Loyalty::Share.all
assert_equal(1, shares[0].message_id)
assert_equal('1337', shares[0].facebook_post_id)
end
end
进一步阅读
我希望你觉得这很有用。我不想写一个正式的教程,而是想把几个月的学习成果传递给大家,我绞尽脑汁,直到最终在 Ruby 中完成测试。
[## 隔离测试 active record-Iain . nl
不加载 Rails 测试 ActiveRecord 并不困难。让我告诉你如何开始。
www.iain.nl](http://www.iain.nl/testing-activerecord-in-isolation) [## 马特·西尔斯|迷你测试快速参考
给出了所有 MiniTest 断言的示例
www.mattsears.com](http://www.mattsears.com/articles/2011/12/10/minitest-quick-reference/) [## 使用 Rack 测试 Sinatra::Test
以下各节中的所有示例都假定正在使用,以尽可能做到通用。请参见…
www.sinatrarb.com](http://www.sinatrarb.com/testing.html) [## 模仿不是树桩
几年前,我在极限编程(XP)社区第一次接触到“模拟对象”这个术语。从那以后我就…
martinfowler.com](https://martinfowler.com/articles/mocksArentStubs.html)
我如何在 20 分钟内训练一个语言检测人工智能,准确率达到 97%

Weird — I actually kind of look like that guy
这个故事一步一步地指导我如何在 20 分钟内使用机器学习建立一个语言检测模型(最终准确率为 97%)。
语言检测是机器学习的一个很好的用例,更具体地说,是文本分类。给定来自电子邮件、新闻文章、语音到文本功能的输出或任何其他地方的一些文本,语言检测模型将告诉您它是什么语言。
这是快速对信息进行分类和排序,以及应用特定于语言的工作流的附加层的好方法。例如,如果您想对 Word 文档应用拼写检查,您首先必须为正在使用的词典选择正确的语言。否则你会发现拼写检查是完全错误的。
其他用例可能包括将电子邮件路由到地理位置正确的客户服务部门,对视频应用正确的字幕或隐藏式字幕,或者对正在分析的文本应用一些其他语言特定的文本分类。
好了,你明白了,语言检测真的很有用,让我们继续我是如何这么快做到的。
我从这个数据集开始。https://cloud.google.com/prediction/docs/language_id.txt
它基本上是一个. csv 格式的文件,带有英语、法语和西班牙语的样本。我的目标是看看我是否可以训练一个机器学习模型来理解这些语言之间的差异,然后,给定一些新文本,预测它是哪种语言。
所以我做的第一件事是启动分类框,一个运行在 Docker 容器中的机器学习模型生成器,有一个简单的 API。这用了不到一分钟。
The output of the terminal
然后我下载了这个方便的工具,它可以让你在电脑上用文本文件训练分类框变得非常容易。这又花了一分钟左右。
下一步是将 CSV 转换成文本文件,这样我就可以很容易地训练 Classificationbox。
一个合格的开发人员会跳过这一步,直接解析 CSV 文件并从那里对 Classificationbox 进行 API 调用。
这里是我写的一些不太好的 Go 代码,以防你感兴趣,如果不感兴趣,请跳到下一步。
运行这个脚本后,我的硬盘上有了以不同语言命名的文件夹。每个文件夹里都有语言样本的文本文件。我花了大约 10 分钟编写脚本并运行它。
现在有趣的部分来了。我确保分类框已经启动并运行,然后我在语言文件夹的父目录上运行textclass。大约花了 3 秒钟:
- 处理所有样本
- 将 20%的样本分成一个验证集
- 用训练集训练分类框
- 使用验证集进行验证
这些是我的结果:

97% !对于只花 20 分钟训练语言检测机器学习模型来说,这已经很不错了。
需要注意的一件重要事情是,我的班级并不是平衡的。我对每一个类都有不同数量的样本,这不符合训练模型的最佳实践。理想情况下,我会在每节课中有相同数量的例子。
关键是,机器学习最受益于实验。我强烈鼓励每个人尝试使用机器盒或任何其他工具。我希望我能够展示给定一个好的数据集,创建自己的机器学习/分类模型是多么容易。
什么是机器盒子?
Machine Box 将最先进的机器学习功能放入 Docker 容器中,这样像您这样的开发人员就可以轻松地将自然语言处理、面部检测、对象识别等融入其中。到您自己的应用程序中。
盒子是为扩展而建造的,所以当你的应用真正起飞时,只需水平地添加更多的盒子,直到无限甚至更远。哦,它比任何云服务都要便宜得多(而且可能更好)……而且你的数据不会离开你的基础设施。
我如何训练一个人工智能在一小时内发现讽刺

source: https://www.theonion.com/nasa-announces-plans-to-place-giant-pair-of-shades-on-s-1825413851
我决定给自己一个挑战,看看我能否教会一个机器学习模型在不到一个小时的时间内检测洋葱文章(和其他讽刺文章)和真实新闻文章之间的差异。这些是我的结果:
解决这个问题的第一步是收集训练数据。这是迄今为止最困难的部分。有很多方法可以实现这一点。一种方法是尝试抓取网站。如果你正在寻找合适的工具,你当然可以尝试“https://scrapy.org/或https://scrapinghub.com/open-source,或者简单地构建你自己的工具(如果你愿意的话)。
我不太擅长计算机,不知道如何抓取网站,所以我决定手动收集数据(畏缩)。**这个过程占用了大半个小时。**我访问了www.theonion.com,开始将文章内容复制粘贴到单独的文本文件中,我简单地按顺序命名为(“0.txt”、“1.txt”等……)。我把这些文本文件保存在一个名为“讽刺”的文件夹里。(前 10 个之后,我开始用 Command-C 变得非常快,打开一个新的文本编辑窗口,Command-V sequence。)
我当然不建议手动这么做。做一个比我更好的程序员,做适当的网页抓取。
Screenshot of my Finder
一旦我有了大约 300 篇洋葱文章,我就转向路透社和美联社,作为非讽刺新闻的来源。我开始手动将这些文章复制粘贴到文本文件中,并保存到一个新文件夹中,我称之为“notsatire”。
再说一次,一开始进展很慢,但是一旦我掌握了窍门,事情就变快了。在这一点上,我做了大约 45 分钟,已经非常累了。我决定每个类 300 个就足够了,看看我是否可以训练一个分类器来检测两者之间的差异。
Classificationbox
自然,我的计划是使用分类框,因为它使得构建和部署分类器变得极其容易。而且,为了让事情变得更简单,我很快从 GitHub 克隆了 Mat Ryer 的便利的 textclass 工具,这样我就可以直接从我的计算机上的文件中运行这个小东西(而不是试图用正文中的文本构建 API 查询)。
首先,我启动了分类箱。
然后,我发出了这个命令:
go run main.go -teachratio 0.8 -src ./testdata/fakenews/
坐下来看结果出来。

Terminal view of imgclass running
大约 1 秒钟,分类框就训练好了!然后又花了 2 或 3 秒钟来确定,然后进行验证。
结果显示准确率为 83%。这告诉我,很有可能建立一个分类器来检测讽刺和真实新闻之间的差异,我可能只需要添加更多的例子来增加准确性。
为了确保万无一失,我花了 5 分钟时间,每篇文章又增加了 20 篇,然后重新进行测试。这次我考了 86 分。
这表明,在没有大量训练数据的情况下,你可以开始构建一个机器学习驱动的分类器。甚至像检测讽刺或真实新闻这样复杂的事情也能在一个小时内完成!
我强烈建议你亲自尝试一下。
什么是机器盒子?
Machine Box 将最先进的机器学习功能放入 Docker 容器中,以便像您这样的开发人员可以轻松整合自然语言处理、面部检测、对象识别等功能。到您自己的应用程序中。
这些盒子是为扩展而建造的,所以当你的应用真正起飞时,只需水平地添加更多的盒子,直到无限甚至更远。哦,它比任何云服务都便宜**(它们可能更好)……而且你的数据不会离开你的基础设施。**
我如何使用机器学习来节省时间
事情已经变了。某些类型的问题曾经非常困难,或者需要大量重复的工作才能解决。我相信我们都有过这样的经历,面对一些我们知道需要很长时间才能完成的事情,不是因为它具有挑战性,而是因为它重复且耗时。
像苹果公司的 Automator 这样的东西可以用来使某些与计算机相关的任务变得更可行,尤其是如果你不擅长脚本语言的话。这些工具可用于解决需要重命名文件夹中的数千个文件或删除重复文件等问题。但是有些事情是它解决不了的。
许多年前,我制作了一个网络系列,有相当广泛的演员阵容。我需要完成的一项任务是为这个节目制作一个网站。我记得我很喜欢这部作品,直到我看到演员名单。我突然意识到,我需要裁剪和放置大量不同大小和形状的头像,以便在网站上看起来统一(这是在我知道网格布局之前)。这个过程花了我几天时间来完成。自从我手动完成所有工作后,我从来没有觉得自己做得很对。
今天,这个问题可以通过机器学习很容易地解决。以下是我的方法:
- 从机器盒子(我帮忙创立的一家初创公司)下载并安装 Facebox。
- 编写一个脚本,将您想要裁剪的每张照片发布到 Facebox,并获取人脸的位置。
- 使用 Facebox 返回的尺寸在脸部周围裁剪照片(带有一些填充)。
我已经在这里开源了一些这样做的代码: profilecropper

profilecropper powered by Machine Box
你可以用这种方式创建和自动裁剪数以百万计的个人资料图片,而不必做任何手工劳动。只需要知道人脸在哪里,这是机器学习可以解决的问题。
让我们再举一个例子。比方说,你已经有了一个过去 50 年扫描的照片库。扫描每张照片是一种痛苦,但至少现在它们都是数字文件。但问题是,你无法搜索它们。幸运的是,机器学习可以再次拯救我们。以下是我的方法:
- 从机器盒下载并安装 Tagbox
- 编写一个脚本,将你拥有的每张照片发布到 Tagbox,并获取标签列表。
- 您可以根据结果决定是否过滤掉低可信度的标签。
- 将标签与文件名一起存储在一个文本文件中,您的操作系统稍后将对其进行索引。或者,将数据写入简单的数据库,如 excel 电子表格或 SQL 表。
- 现在,您可以通过照片中的内容来搜索照片。
为了让你开始,这里也有一些解决这个问题的开源代码: tagroll
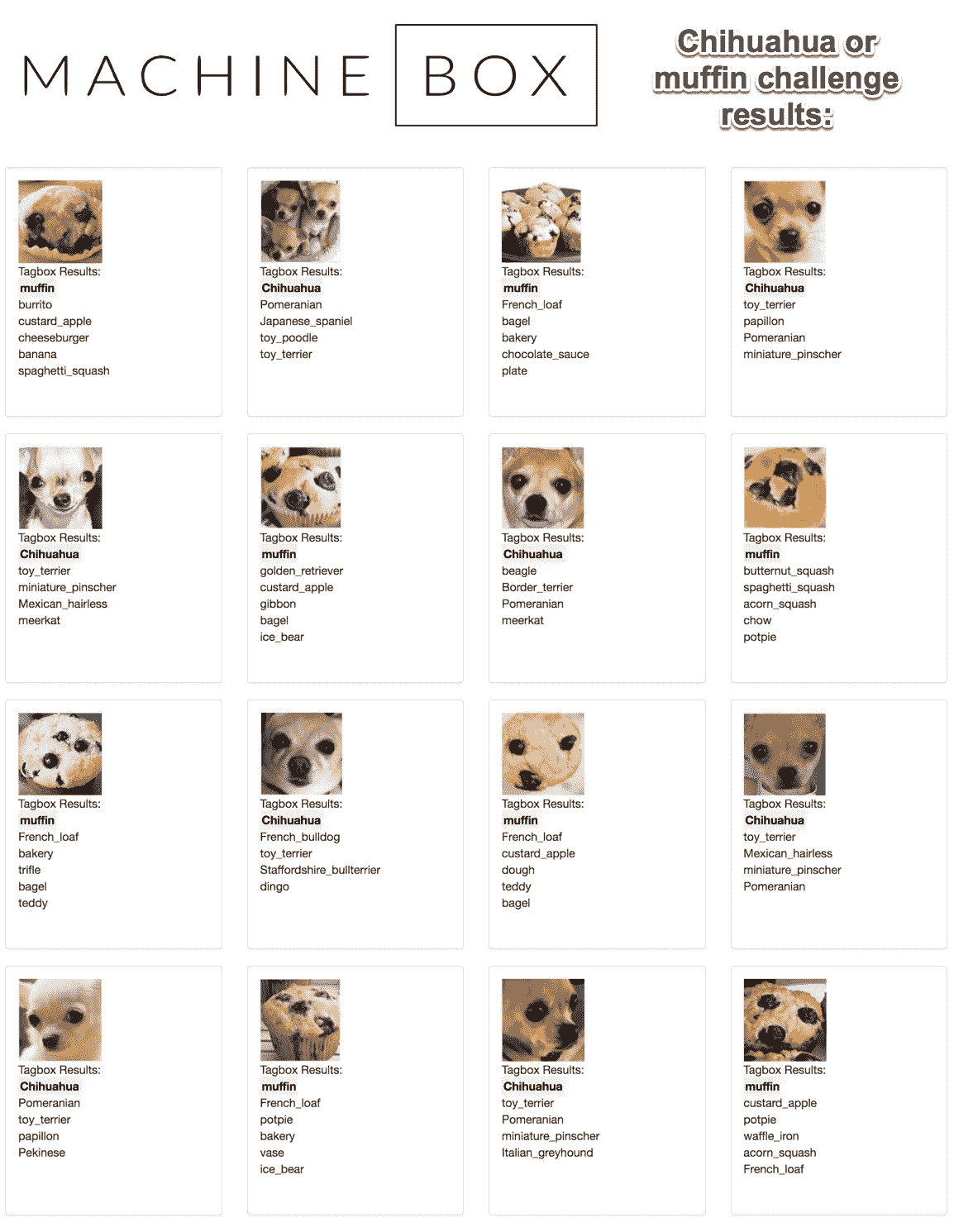
Solving the chihuahua/muffin problem with Tagbox
好玩的小旁注;假设你有特定类型的想要搜索的对象,比如一辆特殊类型的汽车或房子。你可以用一两张样本照片来教 Tagbox 这些东西,然后它会从那时起标记它看到的每张照片。点击阅读更多关于如何做的。
你还可以做一些非常聪明的事情,比如对你所有的照片进行视觉相似性搜索。上传某样东西的照片,并使用 Tagbox 向您显示您收藏的其他类似照片。
可以想象,这些解决方案几乎无处不在。例如,您的电子商务网站可以为客户提供强大的工具,根据他们喜欢的东西的视觉相似性来找到他们更有可能购买的衣服。
在这个时代,我们都在处理大量的数据。无论是个人照片还是产品目录,我们都需要开始定期考虑将机器学习作为一种强大的方法,来解决因拥有如此多的数据而产生的问题。
我如何使用 200 名专家和 Reddit 的评论排名算法来赢得我的办公室 NFL Pick’em 池
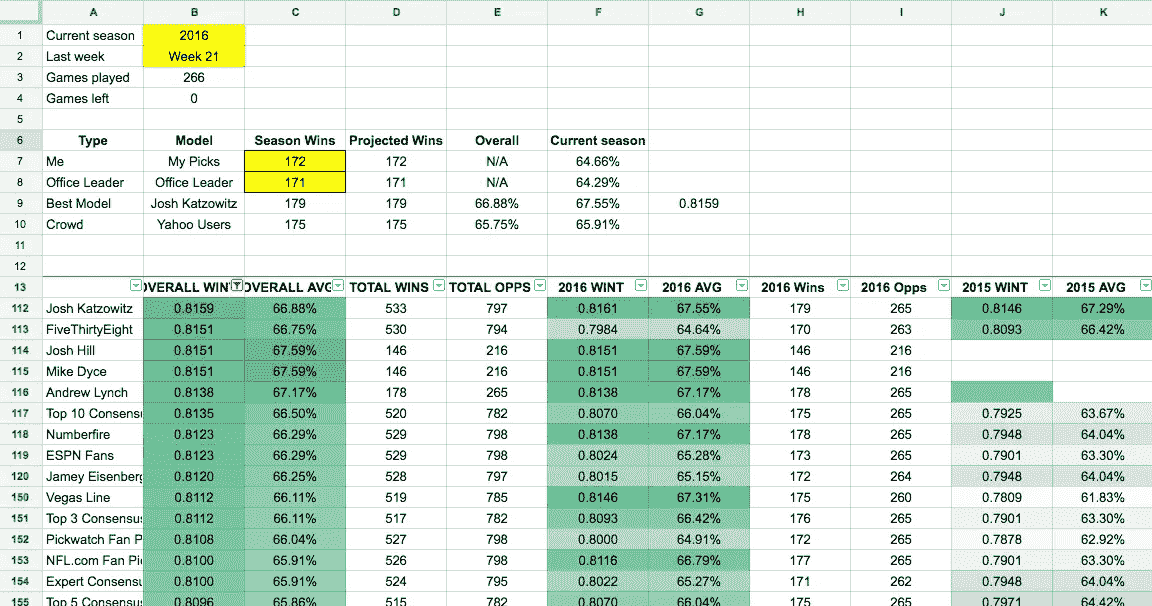
The spreadsheet that won me my NFL pick’em office pool: https://docs.google.com/spreadsheets/d/1caV-Uv7f4OsVuioSU3iPWn8cMkYjG0S9XgU9pgKwlPU/edit?usp=sharing
我发现,每年参加我办公室的 NFL 扑克比赛都是一种极大的快乐。去年(2015-2016 NFL 赛季),在没有任何连贯策略的情况下,我在 24 场比赛中排名第 18,并在赛季结束时排名并列第 4。今年,我想如果我采用一致的策略,我可能真的会赢。
我赢了。
新英格兰队昨天在超级碗比赛中令人难以置信地战胜了亚特兰大队,使我在 19 名同事中排名第一,在 265 次正确选择中取得了 172 次的成绩。
我是怎么做到的?我创建了一个系统,使用来自 200 多名“专家”的数据和 Reddit 评论排名算法的变体,有条不紊地产生超越我同事的优势。
我的主要论点是:每周,我都会听从记录最好的专家的建议,将他或她预先宣布的选择作为自己下周的选择。
随着这些专家证明了他们在挑选赢家方面的熟练程度,我也跟着他们走向了成功。随着他们争夺和交换最高神谕的位置,我也相应地改变了我的忠诚。
我的逻辑虽然在理论上容易出错,但在实践中是成功的:过去在某些专家中的成功确实保证了我未来的表现。
结果呢?一个将数以千计的专家预测变成办公室吹嘘资本的系统。
收集“专家”预测
如果我要追随最可靠的专家,我首先需要数据来告诉我,这些所谓的“专家”中的哪一个实际上每周都在挑选赢家。
我在 NFL Pickwatch 找到了我所需要的。
NFL Pickwatch 跟踪 NFL“专家”在 NFL 赛季期间每周的选择和预测。大多数专家是 NFL 媒体分析师(因此他们的“专家”身份),但 NFL Pickwatch 也跟踪 Vegas line、ESPN 用户共识、微软的人工智能机器人 Cortana 和算法,如 FiveThirtyEight 的 Elo 预测。NFL Pickwatch 背后的家伙,用他们自己的话说,“跟踪、观察和跟踪(象征性地)每个网络和网站上的每个 NFL 专家”。
NFL Pickwatch 每周都有专家预测,可以追溯到 2014 赛季。8 月,我从 NFL Pickwatch 手动复制并粘贴了 2014 和 2015 赛季每周选秀权数据到一个谷歌电子表格。每周的数据如下所示:
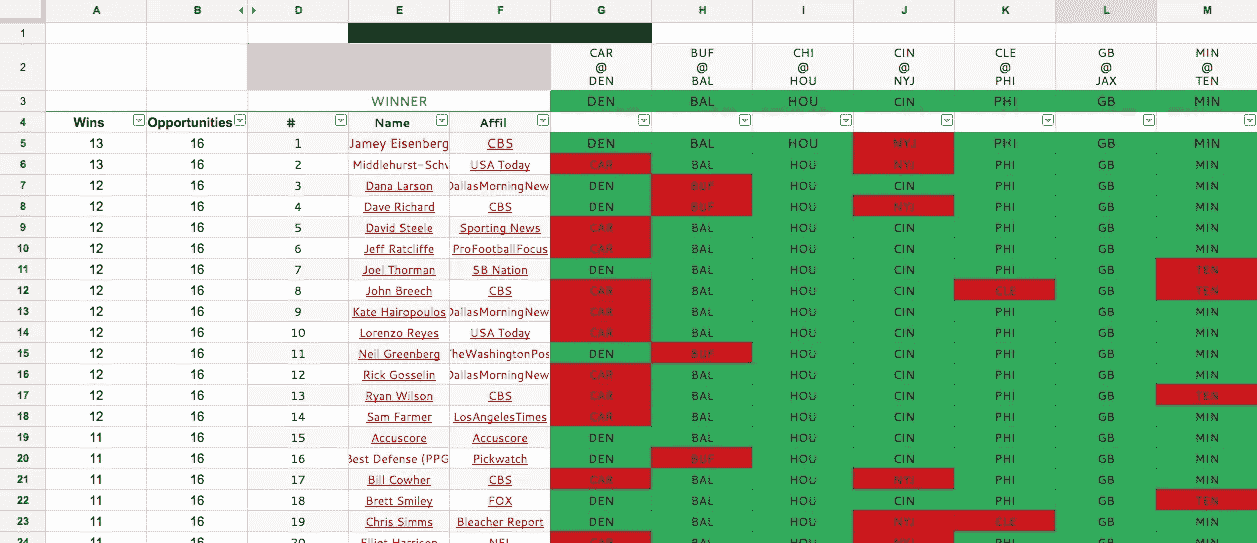
第 3 行包含每场比赛的获胜者,我会每周手动发布。左边的一个公式计算了所有选秀权中的获胜次数。
该公式只惩罚错误选择的专家,而不是不完整的选择。这是我自己计算的,而不是依靠 NFL Pickwatch 的计算,因为他们只是在 2016 赛季开始时停止了对不完整选秀权的处罚。
寻找最好的专家
NFL Pickwatch 的数据面临的一个挑战是,他们只能跟踪专家公开提供的预测。多年来,NFL Pickwatch 已经扩大了他们追踪的专家数量。这意味着一些专家拥有 2014 年的数据,而其他人则是 2016 赛季开始时的新手。这使得比较专家成为一个挑战。
胜率的问题
比较专家的一个自然的起点是比较他们的胜率,即所有预测中正确预测的数量。例如,如果我做了 100 个预测,并在其中的 60 个中选择了正确的赢家,我的胜率将是 60%。
这种方法的问题是,在 500 场比赛中表现稳定的专家不容易与第一周运气好的新手相比。
例如,在 2014、2015 和 2016 赛季,要被认为是所有专家中第 90 百分位的顶级专家,专家必须在至少 66.25%的时间里正确选择获胜者。同一时期的几个基准供参考:
- 拉斯维加斯线:66.11%
- ESPN 粉丝共识度:66.29%
- 主队赢了 56.4%的时间
使用获胜百分比对专家进行排名将导致一位公认的专家预测 600 场游戏中的 400 名获胜者(66.67%的获胜百分比),排名在之后,一位新参与者在第一周运气不错,在 16 名获胜者中正确选择了 13 名(81.25%的获胜百分比)。
我希望我的系统能够平衡新加入者(他们可能发现了一种创新的预测方式)和专家(他们在多个季节里一直表现良好)之间的优势。
输入 Reddit 的评论排名算法
几年前,我偶然看到阿米尔·萨利哈芬迪克的一篇文章,详细介绍了Reddit 如何对评论进行排名。
Reddit 允许评论被投票赞成和投票反对,以根据其众包质量对评论进行排名。为了对它们进行排名,Reddit 必须将一条有 1 张赞成票和 0 张反对票的评论与另一条有 50 张赞成票和 0 张反对票的评论进行比较。两者都有 100%的“正面”评价,但 Reddit 的算法将第二条评论的排名高于第一条。
Reddit 通过执行“置信度排序”来做到这一点。它平衡了评论的质量和信心,即从长远来看,当前的赞成票和反对票的分配将是准确的。参见“如何不按平均评分排序”,了解为什么这种方法比城市字典和亚马逊等其他网站的排名计算更准确。
为了进行置信度排序,Reddit 使用了一个威尔逊评分区间:
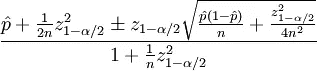
Source: https://medium.com/hacking-and-gonzo/how-reddit-ranking-algorithms-work-ef111e33d0d9#.ar9spcw5k
Salihefendic 解释:
"在上述公式中,参数定义如下:
- p 是正面评级的观察分数
- n 是评级总数
- zα/2 是标准正态分布 的(1-α/2) 分位数
下面我们总结一下:
- 信心排序将计票视为每个人的假想全票的统计抽样
我们可以使用相同的参数为我们的专家计算威尔逊评分区间。在我们的例子中,
- p 是正确预测的数量
- n 是预测的总数
- zα/2 仍然是标准正态分布的理想分位数,或者我们希望对专家预测的准确性有多有信心
下面是公式在 Excel 公式中的表示方式:= sqrt((p/n)+z * z/(2 * n)-z (p/n)(1-(p/n))+z * z/(4 * n))/n)/(1+z * z/n)
根据 Salihefendic 的说法, Reddit 的评论排名算法使用的置信区间(上面 z 的值)为 1.281551565545。他声称这相当于 85%的置信区间,这意味着:
- “置信度排序给一个评论一个临时排序,它有 85%的把握它会到达
- 投票越多,85%的置信度得分越接近实际得分”
我认为他弄错了,基于维基百科上的这个分位数函数表显示 1.28 是 80%置信区间的值,而不是 85%。
不管怎样,总的想法是一样的。我们应该根据我们对专家预测质量的信心程度来选择 z 的值。
在试验不同的 z 值时,我选择使用 1.6,从代表 90%置信区间的 1.644853626951 取整。我选择了 90%超过 95%和 98%的置信区间( z = 2.0, z = 2.3 分别)。我觉得 90%给了我最好的平衡,既尊重久经考验的专家,又有足够的进取心,在短短几周持续的优秀选择后识别出“冉冉升起的新星”。
结合数据和算法
使用 NFL Pickwatch 的两个赛季的数据,我根据他们的威尔逊得分区间对 177 名专家进行了排名。前 5 名专家:
- 538—0.8205(531 个中的 360 个,占 67.8%)
- ESPN 球迷—0.8144(533 人中的 356 人,占 66.8%)
- 杰米·艾森伯格—0.8144(533 人中的 356 人,占 66.8%)
- 拨片风扇拨片—0.8133(533 个中的 355 个,占 66.6%)
- 乔希·卡佐维茨—0.8129(532 人中的 354 人,占 66.5%)
于是,在 2016 赛季的第一周,我把 FiveThirtyEight 的选秀权据为己有。
我每周都重复这个方法。我从 NFL Pickwatch 导出了前一周的结果,重新计算了每位专家的威尔逊得分区间,并相应地更改了我的选择。在 2016 赛季,NFL Pickwatch 增加了 30 多名专家,使专家总数超过 200 人。我还添加了一些我自己的专家,我可能会在以后的帖子中写一些。
这是显示我的系统的完整电子表格,其中有从 2014 赛季第一周到昨天超级碗 51 的数据。
正如你在上面看到的, FiveThirtyEight 的 Elo 模型在整个 2014 和 2015 赛季占据主导地位,在 2016 赛季开始时,比排名第二的“专家”ESPN 粉丝高出近一个百分点。正因为如此,FiveThirtyEight 在整个 2016 赛季都保持领先!
尽管要花费数小时复制和粘贴数据,并创建一个复杂的自动生成公式的电子表格,但我的系统一直告诉我只需遵循 FiveThirtyEight 的建议。
FiveThirtyEight 在整个常规赛中都将是顶级专家,只是在 2016 年季后赛第一周之后被踢下了宝座。
到本赛季结束时,使用 2014 年、2015 年和 2016 年(包括每个赛季的季后赛和超级碗)的数据,目前排名前 5 的专家是:
- 乔希·卡佐维茨—0.8159(797 人中的 533 人,占 66.9%)
- 538—0.8151(794 个中的 530 个,占 66.8%)
- 迈克·戴斯—0.8151(216 人中的 146 人,占 67.6%)
- 乔希·希尔—0.8151(216 人中的 146 人,占 67.6%)
- 安德鲁·林奇—0.8138(265 个中的 178 个,7.2%)
以下是这五位专家从 2014 年第一周开始每周的排名:
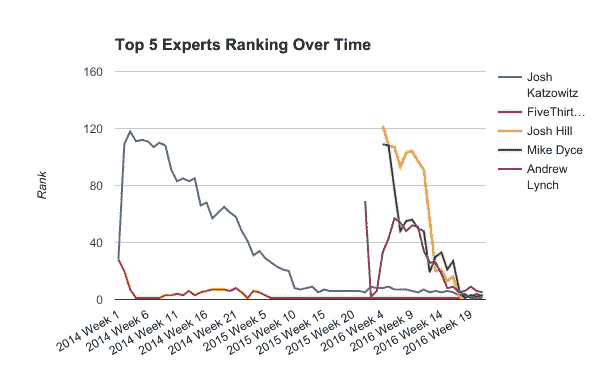
正如你所知,FiveThirtyEight 在过去的三年中占据了主导地位,在 63 周中有 39 周高居榜首,只是在 2016 年季后赛的最后几周输给了 Josh Katzowitz。
赢得办公室赌注
使用这个系统,实际上相当于整个赛季都在复制 FiveThirtyEight 的选秀权,我在 265 场比赛中选对了 172 场,最终胜率为 64.66%。我排名第二的同事做了 171 次正确的选择,几乎赢得了所有的选择,直到她的超级碗 51 次选择,亚特兰大猎鹰队,在第四季度崩溃。
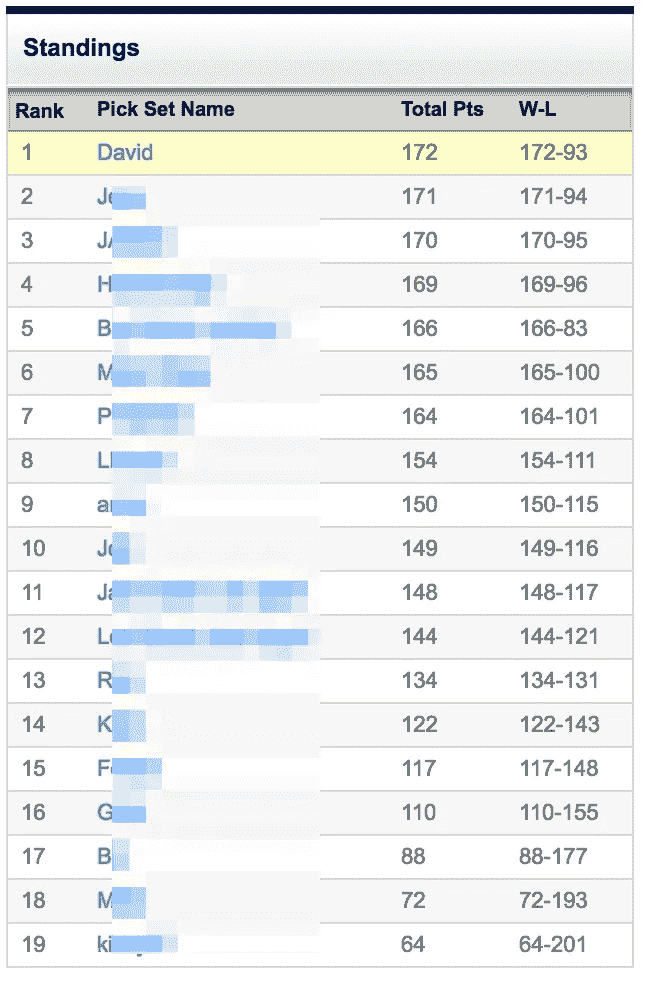
现在,我很乐意承认我们的办公室并不特别热衷于运动。此外,游泳池显然很小。这个系统可能不会在另一个更大的办公室里工作。尽管如此,我花了无数个小时把这个系统组装在一起,这是一个巨大的乐趣,只是碰巧最后胜出了。
可悲的是。如果我们中的任何人只是随大流,选择了雅虎用户的最爱,我们会以 174 个正确的选择排名第一。如果我们选择拉斯维加斯线的最爱,我们会有 175 个正确的选择。这显示了大众和市场的力量,以及为什么在试图击败它们时要小心谨慎。
但至少今年,办公室的荣耀——以及几块钱——是我的。
请在下面的评论中告诉我你对我的方法的看法。我没有花时间详细指出它的各种缺陷,但是如果你读到这里,我相信你已经有了自己的一些聪明的批评和建议。
我如何使用深度学习来优化 Keras 的电子商务业务流程
问题介绍
在进入问题细节之前,我想先介绍一下业务工作流程, Avito.ma 是摩洛哥领先的电子商务广告平台,用户在这里发布广告,销售二手或新产品,如手机、笔记本电脑、汽车、摩托车等。
现在让我们进入问题的细节,为了发布你的广告来销售产品,你必须填写一个表格,在表格中描述你的产品,设定价格,并上传相应的照片。成功填写这些字段后,您需要等待大约 60 分钟,以便您的广告在版主验证这些图像后发布。
如今,在深度学习和计算机视觉的时代,手动检查网页内容被认为是一种缺陷,非常耗时,此外,它可能会导致许多错误,如下面的这个错误,其中版主接受了电话类别中的笔记本电脑广告,这是错误的,并影响搜索引擎质量,而这项工作可以通过深度学习模型在一秒钟内完成。

Laptop ad published on phones category — link
在这篇博文中,我将介绍我如何通过使用 Keras 框架构建一个简单的卷积神经网络来优化这一过程,该网络可以分类上传的图像是用于手机还是笔记本电脑,并告诉我们图像是否与广告类别匹配。

这篇博客将分为 5 个具体步骤。
- 数据收集
- 数据预处理
- 数据建模
- 用张量板分析模型
- 模型部署和评估
1.数据收集
像任何数据科学项目一样,我们应该寻找的第一个组成部分是数据,在这种情况下,我们将处理的数据是从同一网站 Avito.ma 废弃的一组图像。对于笔记本电脑和手机两类,结果文件夹将包含两个子目录,分别名为“笔记本电脑和“手机”,其中下载图像的形状在 120 x 90 和 67 x 90 之间变化,每个图像有 3 个通道的 RGB。这里是执行这项任务的代码的快照,而完整的代码在笔记本中提供。
一旦这个过程很好地完成,我们得到了 2097 张笔记本和 2180 张**手机的图像。**为了使分类更加准确且没有偏差,我们需要验证两个类别具有几乎相同数量的观察值,因为我们可以从下图中看到两个类别大致相当平衡。
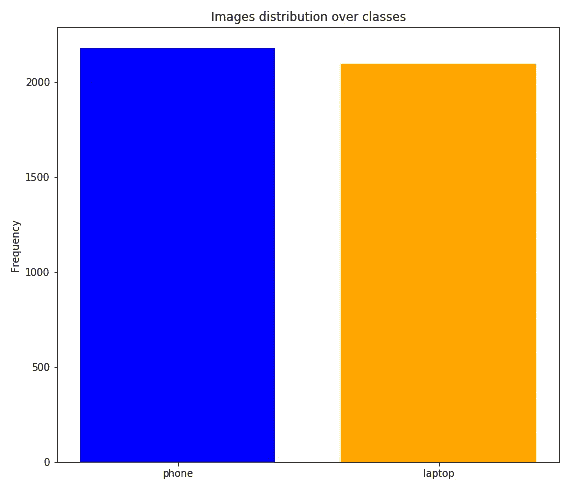
Images distribution over classes
2.数据预处理
对于预处理任务,我们将它分成如下三个子任务:
2.1 去除噪声数据
当手动检查下载的图像时,我注意到存在一些与相关类别无关的噪声图像,例如,在手机文件夹中观察到以下图像(手机充电器、手机包、虚拟现实眼镜):

Noisy images found with phones images
不幸的是,没有自动的方法来处理这个问题,所以我们必须手动检查它们,并开始删除它们,以便只保留那些与适当的类相关的图像。
2.2 图像大小调整
这一步完全取决于所采用的深度学习架构,例如当使用 Alexnet 模型对图像进行分类时,输入形状应该是 227 x 227,而对于 VGG-19 来说,输入形状是 224 x 224。
由于我们不打算采用任何预先构建的架构,我们将构建自己的卷积神经网络模型,其中输入大小为 64 x 64,如下面的代码快照所示。
为了执行这个任务,我们在两个子目录**phone** 和**laptop** **,**中创建了另一个名为preprocessed_data 的目录,然后我们对raw_data的原始文件夹中的每个图像进行循环,以调整其大小并将其保存在新创建的目录中。
因此,我们最终在 64 x 64 的适当形状内得到两个类的新生成数据集。

2.3 数据拆分
在调整数据集的大小后,我们将其分成 80%用于训练集,剩下的用于验证。为了执行这个任务,我们创建了一个名为data **、**的新目录,其中我们设置了另外两个新目录train 和validation 、,我们将在其中为**phones**和**laptops**设置两个类图像。
更明确地说,我们定义当前目录和目标目录,然后我们将训练集的比率固定为 0.8,将验证的比率固定为 0.2,以测量我们将有多少图像从原始路径移动到目标路径。
Snapshot of code doing the data splitting
为了更好地显示文件夹层次结构,下面是项目树视图:
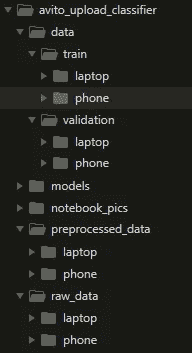
Global project structure
3.数据建模
现在,我们来到了所有这些管道中的主要步骤,即数据建模,为此,我们将建立一个卷积神经网络,该网络将在我们之前处理过的几千张手机和笔记本电脑图像上进行训练。
在计算机视觉中,卷积运算是卷积神经网络的基本构建模块之一,它需要 4 个强制组件:

Major components of a convolutional neural networks
对于该模型,我们将讨论每个组件是如何使用 Keras 及其自身参数实现的,从卷积到全连接层,但首先,让我们了解内置模型的完整架构。

CNN model architecture
卷积层
model.add(Conv2D(filters=32, kernel_size=(3, 3), input_shape=(64, 64, 3), activation=‘relu’))
在将一个顺序对象实例化为model后,我们使用add方法添加一个名为Conv2D的卷积层,其中第一个参数是filters,它是输出体积的维度,就像模型摘要上显示的那样,第一层输出的形状是(None, 62, 62, **32**)。
因为第二个参数kernel_size是指定 1D 卷积窗口的长度,这里我们选择 3×3 的窗口大小来卷积输入体积。
第三个参数代表input_shape,它是分别与image_width x image_height x color channels (RGB)相关的64 x 64 x 3的量,最后但并非最不重要的是activation_function,它负责向网络添加非线性变换,在这种情况下,我们选择relu激活函数。
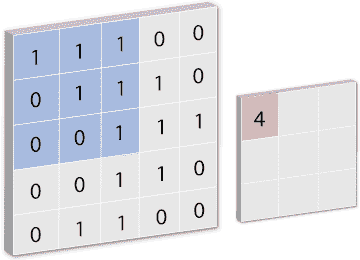
Illustration of a convolution operation with kernel_size = (3, 3)
最大池层
在卷积后添加最大池图层的原因是为了减少我们之前应用的卷积图层提取的要素数量,换句话说,我们对这些要素的位置感兴趣。
为了给网络一个高度概括,如果我们有一个从 x 到 y 的垂直边,这并不重要,但是有一个近似垂直的边,距离左边缘大约 1/3,大约图像的 2/3 高度。
所有这些过程都在 Keras 的一行代码中恢复:
model.add(MaxPooling2D(pool_size = (2, 2)))
简单地说,这里我们使用add方法注入另一个最大池层MaxPooling2D,其中 pool_size 是(2,2)的窗口,默认情况下是strides=None 和padding='valid'。
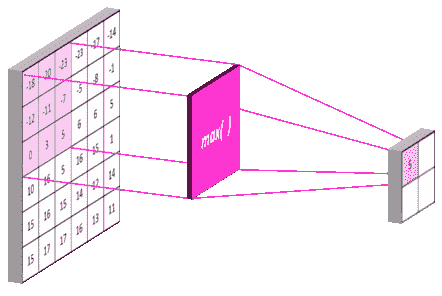
Illustration of Maximum pooling with pool_size = (2, 2)
拉平输出
在结束 CNN 模型时,将最大池输出展平为连续的一维向量是一个强制步骤。
model.add(Flatten())
Keras 在这里所做的,只是简单地在网络中添加了一个Flatten层,它简单地等同于带有‘C’排序的numpy中的reshape功能。
全连接层
最后,我们将最后一层注入到网络中,这是一个完全连接的层,您可以将其视为一种廉价的方式来学习从以前的卷积中提取的特征的非线性组合。
model.add(Dense(units = 128, activation = 'relu'))
model.add(Dense(units = 2, activation = 'sigmoid'))
Keras 通过在网络中添加Dense函数很容易做到这一点,它只需要两个参数units和activation,这两个参数分别代表我们将拥有的输出单元的数量,因为我们正在进行二元分类,所以它将值 2 和激活函数作为要使用的值。
编译网络
最后,我们必须通过调用compile函数来编译我们刚刚构建的网络,这是使用 Keras 构建的每个模型的强制步骤。
model.compile(optimizer = 'adam', loss = 'binary_crossentropy', metrics = ['accuracy'])
loss参数,因为我们有一个二进制分类,其中类的数量 M 等于 2,交叉熵可以计算为:
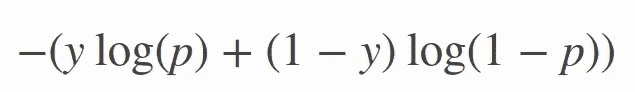
Objective function of binary cross entropy
其中p是预测概率,y是二进制指示器(0 或 1)。
为了最小化这个目标函数,我们需要调用一个优化器,比如adam是Adaptive Moment Estimation的缩写,默认情况下它的学习率被设置为 0.001,但是这并没有关闭超参数调整窗口。总结我们所做的,下面是内置模型的完整代码。
加载图像和数据转换
为了将图像馈送到我们编译的模型,我们调用ImageDataGenerator函数,它将帮助我们生成批量的张量图像数据,并进行实时数据扩充。数据将(分批)循环。
现在我们已经创建了两个ImageDataGenerator实例,我们需要用一个categorical类模式为它们提供训练和验证数据集的正确路径。
一旦train和validation集合准备好提供给网络,我们调用fit_generator方法将它们提供给模型。
通常,除了评估最终训练模型的验证之外,我们还准备了另一个测试数据集,但我们将保持它的简单性,只在验证集上评估它。
模型评估
训练结束后,准确率达到了 87.7%,仍然有 0.352 的较高损失,但高准确率并不一定意味着我们拥有好的模型质量。我们需要跟踪并可视化模型在这段时间内的行为,为此,我们使用了 TensorBoard,它提供了 Keras 作为与 TensorFlow 后端一起运行的回调函数。
4.用 TensorBoard 分析模型
在这一步中,我们将看到如何使用 TensorBoard 来分析我们的模型行为。TensorBoard 是一个工具,用于与 TensorFlow 后端一起构建模型,帮助我们可视化基本上我们的模型随时间的训练,以及
观察准确性与验证准确性或损失与验证损失。
使用 Keras,这个步骤可以通过调用TensorBoard函数,在仅仅一行代码中重新开始,并在拟合数据时注入它作为回调。
from keras.callbacks import TensorBoardtensorboard = TensorBoard(log_dir='./tf-log', histogram_freq=0,
write_graph=True, write_images=False)
失败
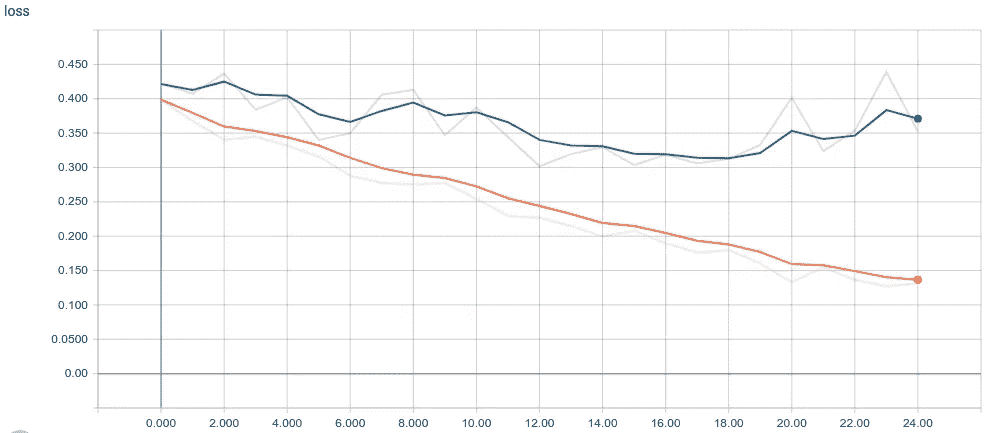
Loss histogram for both training and validation set
从上面的图中,我们可以清楚地看到,对于从 0.39 开始到 0.13 的训练线,损失严格地减小,而对于从 0.42 开始并且花费 25 个历元来达到 0.35 的验证线,损失缓慢地减小。
就我个人而言,每当我要评估一个模型时,我会观察验证损失,这里我们可以想象的是,在第 19 个纪元之后,验证损失开始增加一点,这可能会导致模型记住许多输入样本,为了验证这个假设,我们最好检查准确性直方图。
准确(性)
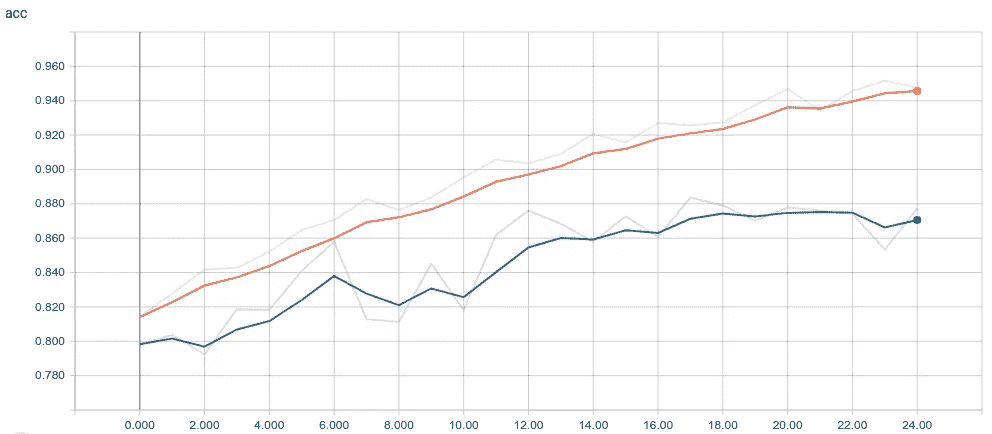
Evolution of Accuracy histogram for both training and validation set
如我们所见,验证准确度一直在增加,直到第 19 个纪元,此时验证准确度趋于稳定,出现了预期的下降和上升,这可以用从同一纪元开始增加验证准确度时的验证损失行为来解释。
为了保持良好的模型质量,建议在这种情况下使用提前停止回调,这将迫使模型在验证损失开始增加或准确度以一定容差下降时停止训练。
5.使用 Flask 进行模型部署
在转到部署细节之前,我们首先需要保存之前已经训练好的模型,为此我们调用save方法如下图所示:
# save models weights on hdf5 extension
models_dir = 'models/'
model.save(models_dir+'avito_model.h5')
一旦我们的模型被保存,我们以后就可以使用它来预测新的图像类。
为什么是 Flask?
Flask 是 Python 的一个微型框架,它的灵感来自于一句名言“做一件事,把它做好”,这就是我选择 Flask 作为 REST API 的原因。
flask 应用程序由两个主要组件组成:python 应用程序(app.py)和 HTML 模板,对于app.py,它将包含进行预测的逻辑代码,并作为 HTTP 响应发送。该文件包含三个主要组成部分,可呈现如下:
- 载入储存的模型。
- 变换上传的图像。
- 使用加载的模型预测其适当的类。
在下一节中,我们将讨论其中最重要的组成部分。
回到主要问题。
当用户选择笔记本电脑作为广告类别时,预计他必须为笔记本电脑上传图像,但发生的事情是不同的。正如我们之前看到的,许多广告中的图片都包含手机类别中的笔记本电脑。
运行应用程序后,假设模型成功加载,用户可能上传不同大小的图像,而我们的模型只能预测 64 x 64 x 3 的图像,因此我们需要将它们转换为正确的大小,以便我们的模型可以很好地预测它。
Snapshot of code processing uploaded images
一旦上传的图像被转换,我们就将它作为参数发送给加载的模型,以便进行预测,并以 JSON 对象的形式返回 HTTP 响应,模式如下:
{"class" : "laptop/phone", "categories_matched": True/False}
第一个属性是图像预测类别,第二个属性是布尔值,指示从用户选择的类别是否与上传的图像匹配。下面我展示了完成这项工作的代码逻辑的快照。
应用程序演示
要运行应用程序,我们只需切换到创建app.py的文件夹,并运行以下命令:
$ python3 app.py
然后,我们浏览控制台上显示的以下 URL:[http://127.0.0.1:5000/](http://127.0.0.1:5000/),一旦显示索引页面,选择广告类别并上传其相关照片,在后台会向路由/upload发送一个请求,该路由会将照片保存在一个目录中,以预测其适当的类别。
这是一个现场演示,展示了我们在这个项目结束时能够建造的东西。
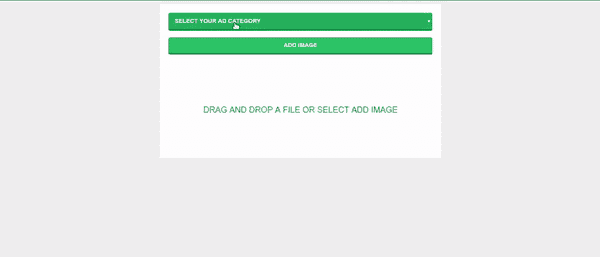
Web application demo
如果选择的类和预测的类都匹配,那么你会得到一个成功的消息,表明一切正常,否则你会得到一个警告消息,并且select box会自动改变到适当的预测类。
结论
最后,这篇博文通过建立一个深度学习模型,展示了一个完整的计算机视觉管道,该模型可以预测应用于电子商务环境的上传图像的类别,从数据收集到数据建模,最后通过模型部署为 web 应用程序来完成。
改进方法
- 通过废弃两个类别的更多图像并移除有噪声的图像来增加数据大小。
- 学习率和 beta 值的超参数调整。
- 尝试其他架构,如 Lenet-5 。
- 在完全连接的(密集)层上使用 Dropout。
有用的链接
完整项目+笔记本+数据集:https://github.com/PaacMaan/avito_upload_classifier
Flask Web 应用:https://github . com/PaacMaan/avito _ upload _ classifier/tree/master/flask _ app
我如何使用机器学习对电子邮件进行分类,并将其转化为见解(第 1 部分)。
今天,我想知道如果我抓起一堆没有标签的电子邮件,把它们放在一个黑盒子里,然后让一台机器来处理它们,会发生什么。知道会发生什么吗?我没有。
我做的第一件事是寻找一个包含各种电子邮件的数据集。在查看了几个数据集之后,我想出了安然语料库。这个数据集有超过 500,000 封电子邮件是由安然公司的员工生成的,如果你问我的话,这足够了。
作为编程语言,我使用了 Python 及其强大的库:scikit-learn、pandas、numpy 和 matplotlib。
无监督机器学习
为了对未标记的邮件进行聚类,我使用了**无监督机器学习。**什么,怎么?是的,无监督的,因为我的训练数据只有输入,也称为特征,不包含结果。在有监督的机器学习中,我们处理输入及其已知的结果。在这种情况下,我想根据邮件正文对邮件进行分类,这绝对是一项无人监管的机器学习任务。
载入数据
我没有加载所有+500k 的电子邮件,而是将数据集分成几个文件,每个文件包含 10k 的电子邮件。相信我,你不会想在内存中加载完整的安然数据集并用它进行复杂的计算。
import pandas as pdemails = pd.read_csv('split_emails_1.csv')
print emails.shape # (10000, 3)
现在,我的数据集中有 10k 封电子邮件,分为 3 列(索引、message_id 和原始邮件)。在处理这些数据之前,我将原始消息解析成键值对。
这是一个原始电子邮件的例子。
消息-id:❤0965995.1075863688265.javamail.evans@thyme>
日期:2000 年 8 月 31 日星期四 04:17:00 -0700 (PDT)
发件人:phillip.allen@enron.com 收件人:greg.piper@enron.com 主题:回复:你好
mime-版本:1.0
内容-类型:文本/普通;charset = us-ascii
Content-Transfer-Encoding:7 bit
X-From:Phillip K Allen
X-To:Greg Piper
X-cc:
X-bcc:
X-Folder:\ Phillip _ Allen _ de c2000 \ Notes Folders \ ’ sent mail
X-Origin:Allen-P
X-FileName:pallen . NSF格雷格,
下周二或周四怎么样?
菲利普
为了只处理发件人、收件人和邮件正文数据,我创建了一个函数,将这些数据提取到键值对中。
def parse_raw_message(raw_message):
lines = raw_message.split('\n')
email = {}
message = ''
keys_to_extract = ['from', 'to']
for line in lines:
if ':' not in line:
message += line.strip()
email['body'] = message
else:
pairs = line.split(':')
key = pairs[0].lower()
val = pairs[1].strip()
if key in keys_to_extract:
email[key] = val
return emaildef parse_into_emails(messages):
emails = [parse_raw_message(message) for message in messages]
return {
'body': map_to_list(emails, 'body'),
'to': map_to_list(emails, 'to'),
'from_': map_to_list(emails, 'from')
}
运行该函数后,我创建了一个新的数据帧,如下所示:
email_df = pd.DataFrame(parse_into_emails(emails.message))index body from_ to
0 After some... [phillip.allen@](mailto:phillip.allen@enron.com).. [tim.belden@](mailto:tim.belden@enron.com)..
要 100%确定没有空列:
mail_df.drop(email_df.query(
"body == '' | to == '' | from_ == ''"
).index, inplace=True)
使用 TF-IDF 分析文本
是术语 频率的简称——逆文档频率 和是一种数字统计,旨在反映一个词对集合或语料库中的文档有多重要。我需要给机器输入一些它能理解的东西,机器不擅长处理文本,但它们会处理数字。这就是为什么我把邮件正文转换成一个文档术语矩阵:
vect = TfidfVectorizer(stop_words='english', max_df=0.50, min_df=2)
X = vect.fit_transform(email_df.body)
我做了一个快速的图表来显示这个矩阵。为此,我首先需要制作一个 DTM 的 2d 表示(文档术语矩阵)。
X_dense = X.todense()
coords = PCA(n_components=2).fit_transform(X_dense)plt.scatter(coords[:, 0], coords[:, 1], c='m')
plt.show()
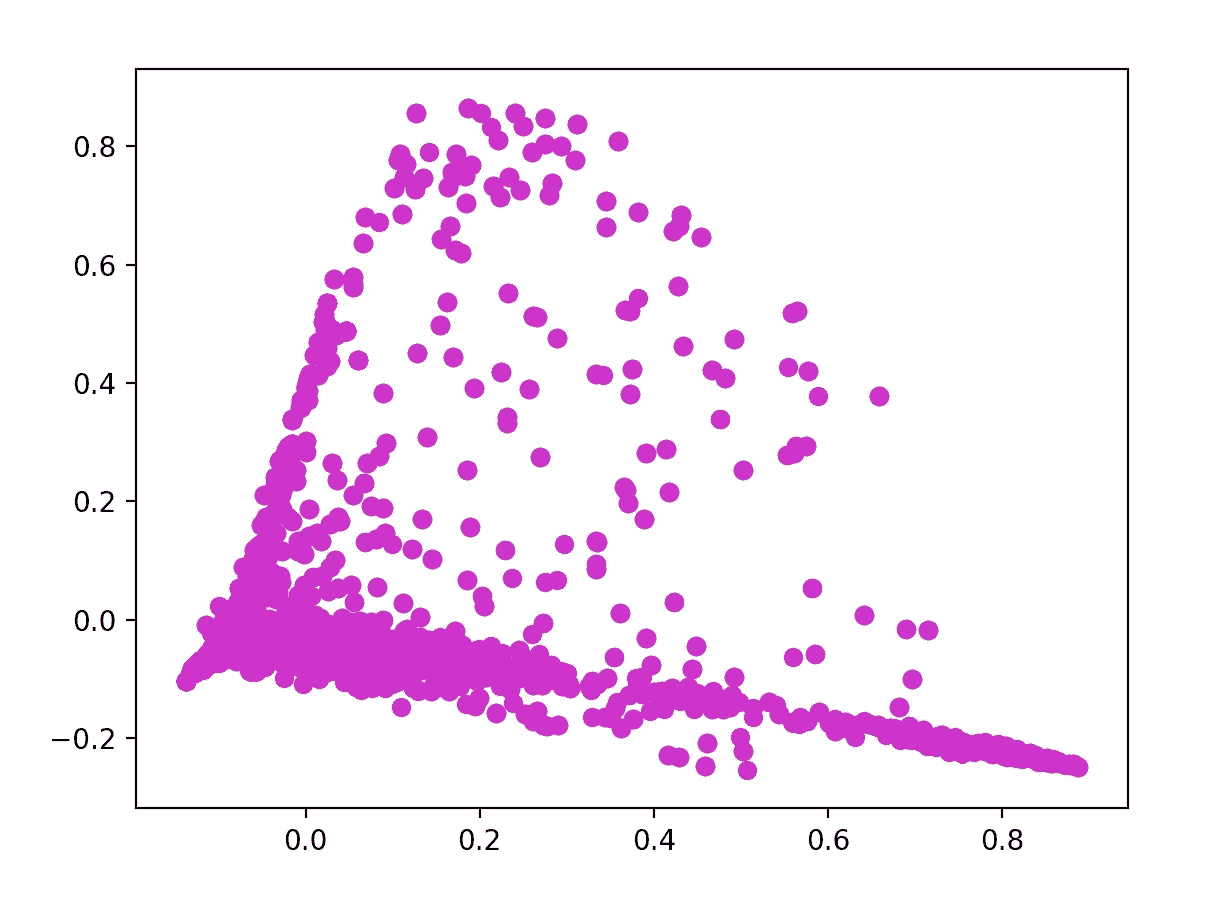
做完这些后,我想找出那些邮件中最热门的关键词是什么。我创建这个函数的目的就是:
def top_tfidf_feats(row, features, top_n=20):
topn_ids = np.argsort(row)[::-1][:top_n]
top_feats = [(features[i], row[i]) for i in topn_ids]
df = pd.DataFrame(top_feats, columns=['features', 'score'])
return dfdef top_feats_in_doc(X, features, row_id, top_n=25):
row = np.squeeze(X[row_id].toarray())
return top_tfidf_feats(row, features, top_n)
在对一个文档运行这个函数之后,它得到了下面的结果。
features = vect.get_feature_names()
print top_feats_in_doc(X, features, 1, 10) features score
0 meetings 0.383128
1 trip 0.324351
2 ski 0.280451
3 business 0.276205
4 takes 0.204126
5 try 0.161225
6 presenter 0.158455
7 stimulate 0.155878
8 quiet 0.148051
9 speaks 0.148051
10 productive 0.145076
11 honest 0.140225
12 flying 0.139182
13 desired 0.133885
14 boat 0.130366
15 golf 0.126318
16 traveling 0.125302
17 jet 0.124813
18 suggestion 0.124336
19 holding 0.120896
20 opinions 0.116045
21 prepare 0.112680
22 suggest 0.111434
23 round 0.108736
24 formal 0.106745
如果你查看相应的电子邮件,这一切都说得通。
出差去参加商务会议会让旅行变得无趣。尤其是如果你要准备一个演示的话。我建议在这里举行商务计划会议然后进行旅行没有任何正式的商务会议。我甚至会试着获得一些诚实的意见,看看是否需要或有必要进行一次旅行。就商业会议而言,我认为在不同的小组中尝试和激发讨论什么是可行的,什么是不可行的会更有成效。主持人发言,其他人安静地等着轮到自己,这种情况太常见了。如果以圆桌讨论的形式举行,会议可能会更好。我建议去奥斯汀。打高尔夫球,租一艘滑雪船和水上摩托。飞到某个地方太花时间了。
下一步是编写一个函数来获取所有电子邮件中的热门词汇。
def top_mean_feats(X, features,
grp_ids=None, min_tfidf=0.1, top_n=25):
if grp_ids:
D = X[grp_ids].toarray()
else:
D = X.toarray()D[D < min_tfidf] = 0
tfidf_means = np.mean(D, axis=0)
return top_tfidf_feats(tfidf_means, features, top_n)
返回所有电子邮件中的热门词汇。
print top_mean_feats(X, features, top_n=10) features score
0 enron 0.044036
1 com 0.033229
2 ect 0.027058
3 hou 0.017350
4 message 0.016722
5 original 0.014824
6 phillip 0.012118
7 image 0.009894
8 gas 0.009022
9 john 0.008551
到目前为止,我得到的很有趣,但我想看到更多,并找出机器还能从这组数据中学习到什么。
使用 k 均值聚类
KMeans 是机器学习中使用的一种流行的聚类算法,其中 K 代表聚类的数量。我创建了一个具有 3 个聚类和 100 次迭代的 KMeans 分类器。
n_clusters = 3
clf = KMeans(n_clusters=n_clusters, max_iter=100, init='k-means++', n_init=1)
labels = clf.fit_predict(X)
在训练分类器之后,它出现了以下 3 个集群。
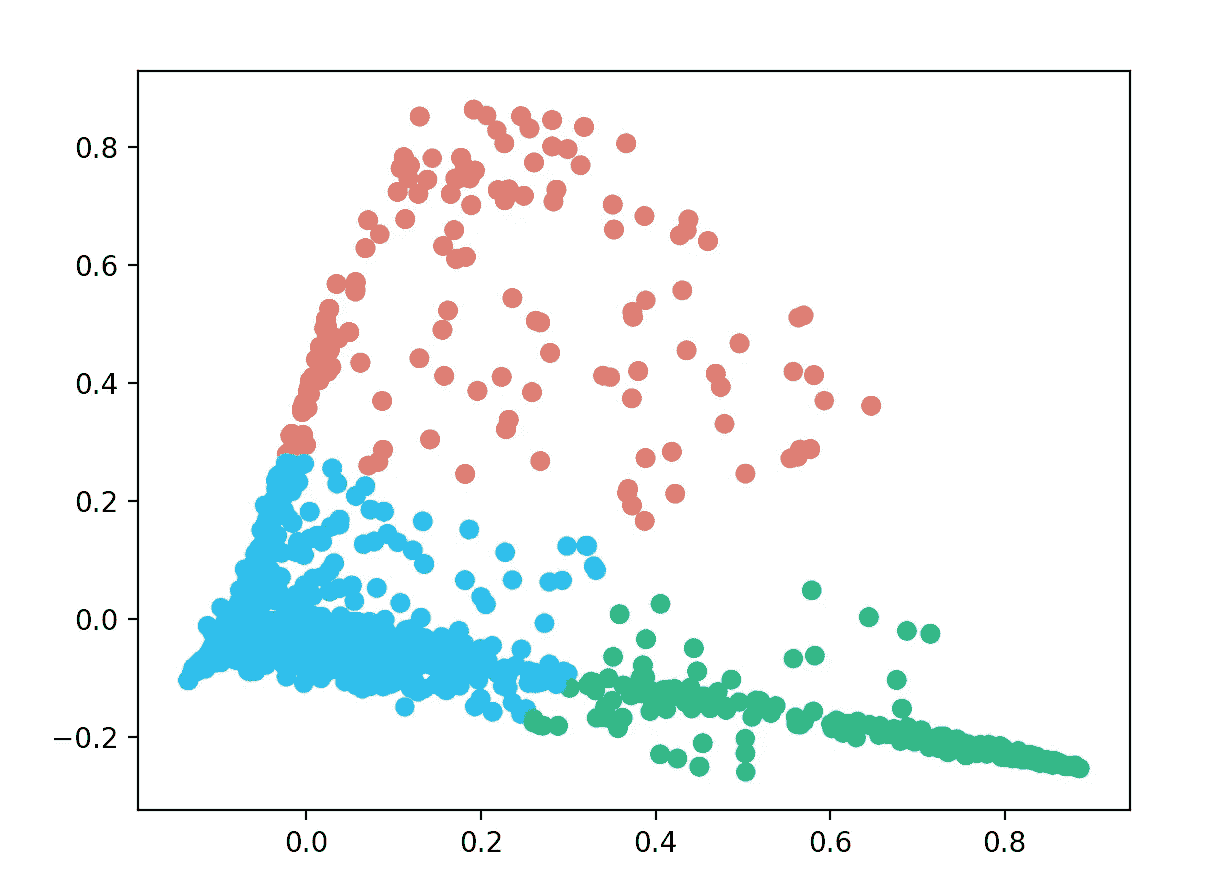
因为我现在知道了机器将哪些电子邮件分配给了每个聚类,所以我能够编写一个函数来提取每个聚类的最高术语。
def top_feats_per_cluster(X, y, features, min_tfidf=0.1, top_n=25):
dfs = [] labels = np.unique(y)
for label in labels:
ids = np.where(y==label)
feats_df = top_mean_feats(X, features, ids, min_tfidf=min_tfidf, top_n=top_n)
feats_df.label = label
dfs.append(feats_df)
return dfs
我没有打印出这些术语,而是找到了一个关于如何用 matlibplot 绘制这个图形的很好的例子。所以我复制了函数,做了一些调整,想出了这个情节:
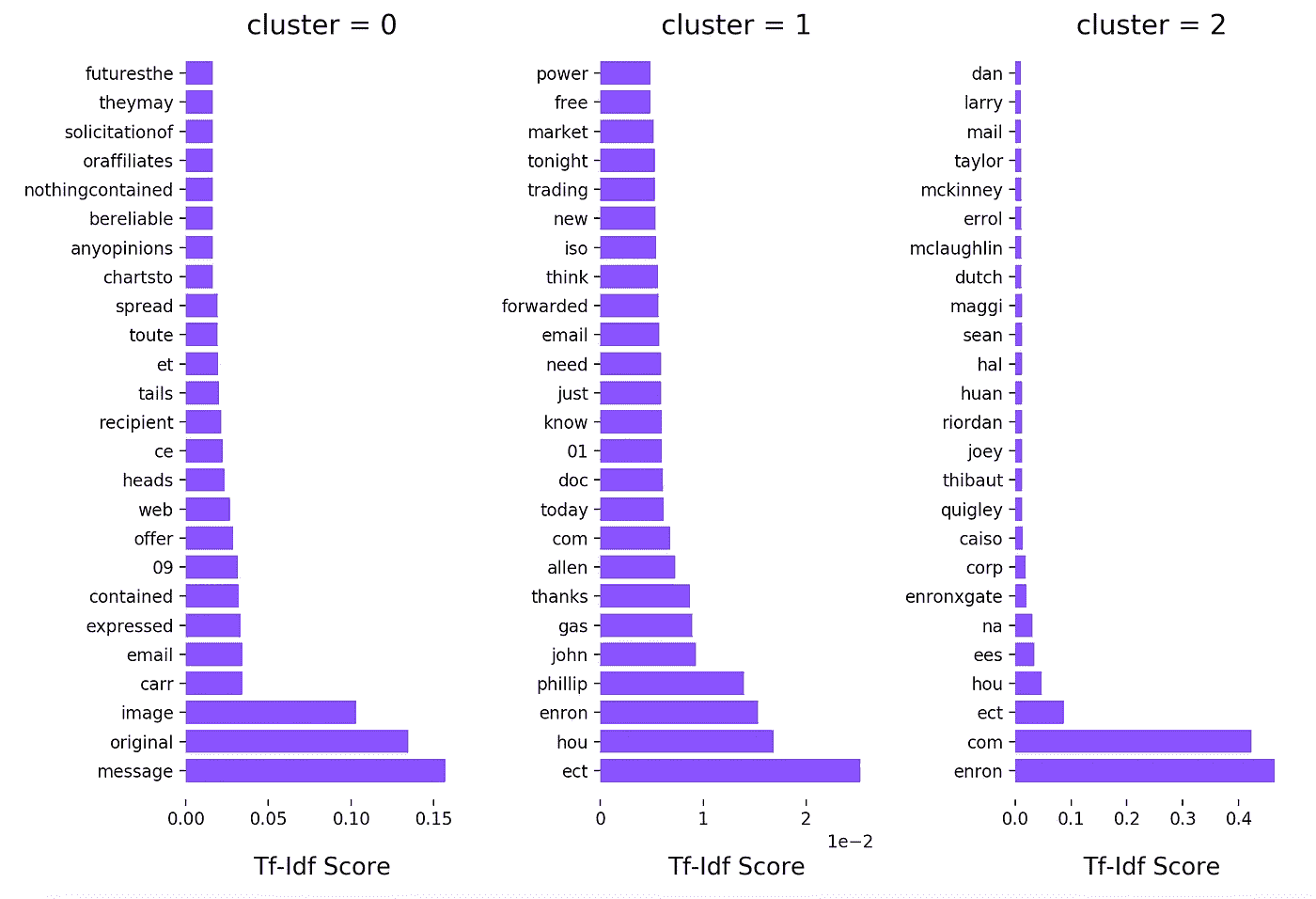
我立刻注意到集群 1 ,有奇怪的术语,如“后”和“等”。为了获得更多关于为什么像“后”和“等”这样的术语如此受欢迎的见解,我基本上需要获得整个数据集的更多见解,这意味着一种不同的方法…
要知道我是如何想出这种不同的方法以及我是如何发现新的有趣见解的,可以在 第二部分 中阅读。
我如何使用机器学习对电子邮件进行分类,并将其转化为见解(第二部分)。

自从我写了 第一部分 已经有一段时间了,在过去一年的许多项目中,我找不到时间和精力来继续我离开的地方。在我写第 2 部分的时候,圣诞节越来越近了,这给了我一些空闲时间来继续我的研究。
在第 1 部分的最后一节中,我讨论了每个集群的热门术语,以及为什么这些奇怪的术语(例如,HOU 等,…)如此频繁地出现。为了找到答案,我检查了数据集中的一些电子邮件,看能否找到其中的一些。
Richard Burchfield
10/06/2000 06:59 AM
To: Phillip K Allen/HOU/ECT@ECT
cc: Beth Perlman/HOU/ECT@ECT
Subject: Consolidated positions: Issues & To Do list
在浏览了数据集中的一些电子邮件后,很明显为什么这些词是热门词汇。它们几乎出现在每个“收件人”、“抄送”或“密件抄送”规则中。为了解决这个问题,我在 tfidf 矢量器中添加了一些自定义的停用词。因为停用词是一个冻结列表,所以我复制了一份,并将其传递给矢量器。
添加停用词后的聚类图。
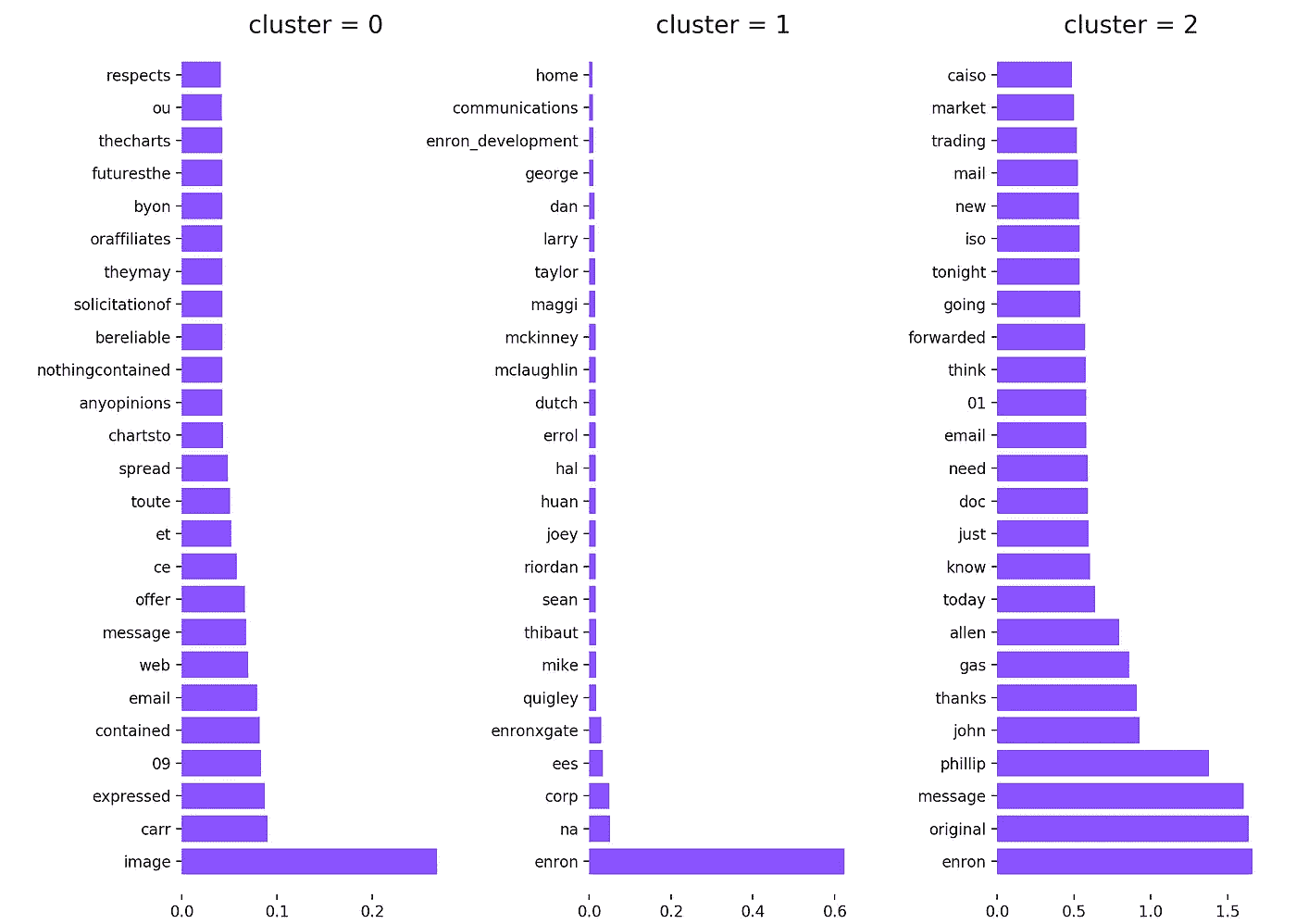
当我看这个情节时,三件事很快浮现在我的脑海里。
1。第一个群集不包含令人兴奋的术语。
2。第二群集几乎单独由人名组成。
3。最后一组看起来非常有趣,绝对值得进一步研究
我对安然公司一无所知,但在看了最后一组之后,不可否认的是“菲利普”和“约翰”与该公司有一些重要的关系。
现在我对这些邮件是如何聚集在一起的有了一些了解,是时候让我的研究更进一步了。
查找相关电子邮件
在通过聚类算法发现了最流行的术语和最令人兴奋的电子邮件后,我正在寻找一种方式来进一步将与特定关键字相关的电子邮件分组。比如找到所有和工资或费用有关的邮件,安然因为某种原因卷入了丑闻,对吗?
首先想到要实现这一点的是余弦相似度。在数据挖掘领域中,一种用于测量聚类内聚力的常用技术。
余弦相似性是内积空间的两个非零向量之间的相似性的度量,它度量它们之间角度的余弦。0 的余弦为 1,其他任何角度都小于 1。
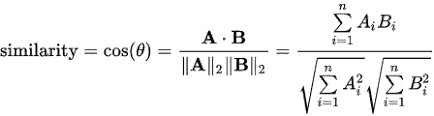
为了找到一封邮件和所有其他邮件的余弦距离,我只需要计算第一个向量与所有其他向量的点积,因为 tfidf 向量已经行规范化。为了得到第一个向量,我需要按行分割矩阵,得到一个只有一行的子矩阵。
# The vector of the first email.
vec_train[0:1]
幸运的是,scikit-learn 已经提供了成对度量(机器学习术语中的内核),既适用于向量集合的密集表示,也适用于向量集合的稀疏表示。在这种情况下,我需要一个点积,也就是线性核。
[ 1\. 0\. 0\. ..., 0\. 0\. 0.]
输出显示,数据集中第一个向量和第一封电子邮件之间的余弦相似度为 1,这很明显,因为这是完全相同的电子邮件。
我希望看到与我可以指定的“查询”(例如,特定的关键字或术语)相关的电子邮件,而不是查找彼此相关的电子邮件。
假设我想找到与最后一个集群中的一个顶级术语“Phillip”相关的所有电子邮件,例如,在这种情况下,我需要从查询(Phillip)中创建一个单独的向量,该向量将适合原始向量。
因此,为了找到匹配我的查询的前 10 封电子邮件,我使用了 argsort 和一些负数组切片(大多数相关的电子邮件具有较高的余弦相似值)
related_email_indices = cosine_sim.argsort()[:-10:-1]
print(related_email_indices)
要查看电子邮件,我只需通过返回的索引来查找它们。
# Print out the first result
first_email_index = related_email_indices[0]
print(email_df.body.as_matrix()[first_email_index])
哪些输出:
约翰,你这个星期还想聚一聚吗?菲利普
为了提高代码的可重用性,我创建了一个类,它可以快速查找我想要的任何术语或查询。
在那之后,我忍不住用更令人兴奋的关键词搜索邮件,比如工资或费用。我做了一个新的查询,找到 50 封与关键字薪水最相关的邮件。
ds = EmailDataset()
results = ds.query('salary', 100)# print out the first result.
print(ds.find_email_by_index(results[0]))
兰迪,你能给我发一份调度组每个人的工资和级别的明细表吗?加上你对任何需要改变的想法。(举帕蒂的例子)菲利普
对**费用的另一个查询,**显示第一个结果:
yesIna RangelJohn,您认为我们是否需要在周五为您和 Maggi 派遣一名 IT 技术人员,以确保一切正常运行?如果我们这样做,我们将不得不支付他们的旅行费用。这将是有益的,而不是你必须在电话上与它的任何问题。让我知道。表示女名
摘要
在第一部分中,我使用了一种无监督聚类算法,让机器为我对电子邮件进行分组。在检查这些集群并发现一些有趣的见解后,我使用了一种更受监督的方法来对与特定关键字相关的电子邮件进行分组。
我可以使用很多更先进的技术来获得更深入的见解,但我在摆弄我所使用的那些技术时获得了很好的体验。
对于有兴趣对安然数据集进行更深入研究的人来说,这篇论文值得一看。
如果你和我一样喜欢这个系列,别忘了鼓掌。源代码可以在我的 Github 页面上找到。欢迎在下面留下评论或在 Twitter 上联系我。
我如何使用自然语言处理从新闻标题中提取上下文
最近,我在 ka ggle(https://www.kaggle.com/therohk/india-headlines-news-dataset)偶然发现了一个非常惊人的数据集。这是一个难得的机会,你可以看到印度背景下的数据。这个数据是在一份名为《印度时报》的印度全国性日报上发表的大约 250 万条新闻标题。我想,如果我能分析这些数据并从这些数据中提取一些见解,那就太好了。因此,在一个晴朗的夜晚,我决定通宵从超过 250 万条新闻标题中搜集任何有趣的东西

Searching for insights!!!
第 1 部分:了解数据
所以,我开始探索这个数据集。如果你有大量的文本,你想知道数据中存在什么样的趋势,你会怎么做?你从简单的词频开始!!!最后,我计算了最常见的单字母词、双字母词和三字母词,发现了一些真知灼见。下面是一个非常简单的记号频率的例子
第二部:碰壁
从这个图像中,我可以很容易地看出沙鲁克·汗吸引了大量的头条新闻,而 BJP 作为一个政治团体设法与宝莱坞明星一起保持其显著的地位!!!!!到目前为止一切顺利。这是我的分析将要撞上砖墙的时候。

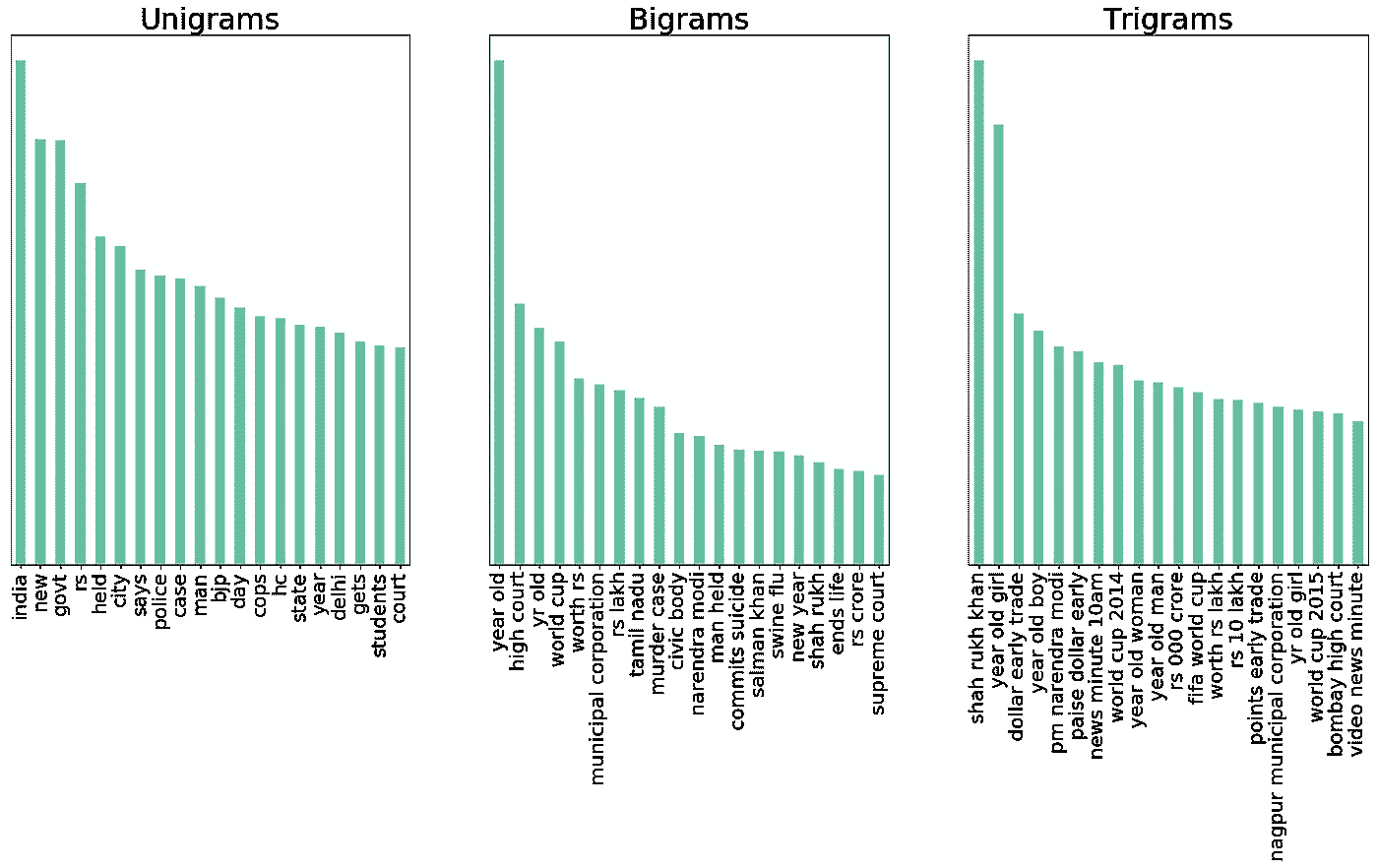
所以,我想,为什么不继续从不同的角度来创造频率图呢?因此,我认为,如果我能绘制出多年来常见二元符号的频率图,那将是一个好主意?本质上,我想找出 2001 年(这是有数据的第一年)最频繁的二元模型标记,然后找出 2002 年最频繁的二元模型标记,最后找出 2001 年和 2002 年常见的频繁标记。并继续累积这些代币。这是我结尾的情节:
Problem Plot !!!
这里可以看到历年来最频繁最常见的重名是***‘岁’。但这意味着什么呢?它是在什么背景下使用的?可悲的是,频率图只能带我们到这里。他们大多没有告知关于的上下文。这是我的砖墙!有一会儿,我想,现在是凌晨 2 点,让我去睡觉吧!!!!*

然后我想起了兰迪·波许

所以,我继续努力…最终我明白了…
第三部分:爬砖墙
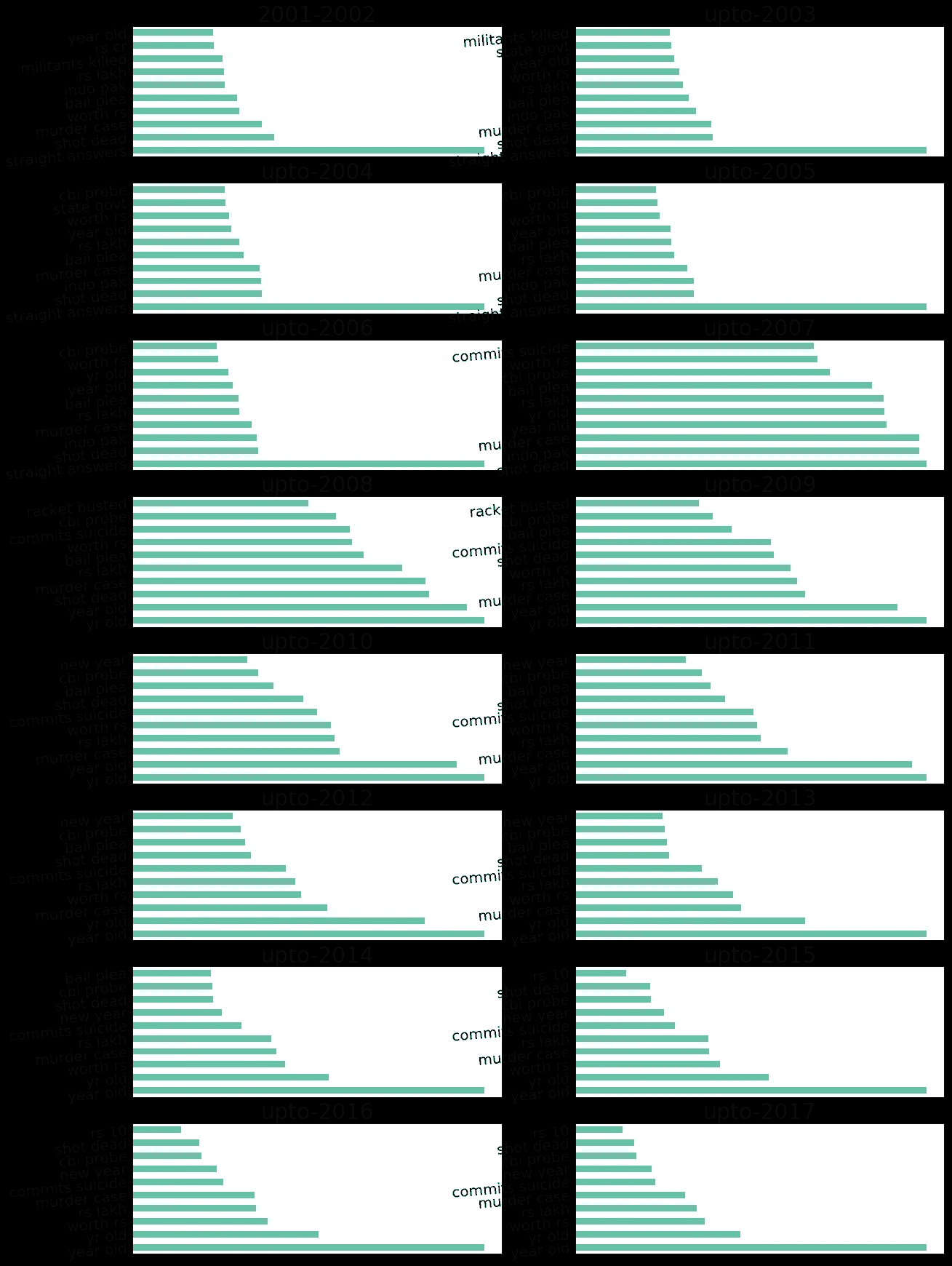
我不会撒谎,我想我睡了一会儿,梦见了我在高中的语法课。在给定的句子中,名词、动词或形容词传达了什么样的信息?报纸标题不是句子吗?
我接下来需要做的就是过滤掉所有出现单词“ 岁 ”的标题,然后找出哪些名词和动词与这个单词同时出现。但是你是怎么做到的呢?实现这一点的方法是为每个句子创建一个词性树。词性标注是一种标准的自然语言处理技术。所有的 NLP 实现都有这个特性。我选择了 spacy,这是我必须写的一小段代码:
index=data['headline_text'].str.match(r'(?=.*\byear\b)(?=.*\bold\b).*$')
texts=data['headline_text'].loc[index].tolist()
noun=[]
verb=[]
for doc **in** nlp.pipe(texts,n_threads=16,batch_size=10000):
try:
for c **in** doc:
if c.pos_=="NOUN":
noun.append(c.text)
elif c.pos_=="VERB":
verb.append(c.text)
except:
noun.append("")
verb.append("")
plt.subplot(1,2,1)
pd.Series(noun).value_counts().head(10).plot(kind="bar",figsize=(20,5))
plt.title("Top 10 Nouns in context of 'Year Old'",fontsize=30)
plt.xticks(size=20,rotation=80)
plt.yticks([])
plt.subplot(1,2,2)
pd.Series(verb).value_counts().head(10).plot(kind="bar",figsize=(20,5))
plt.title("Top 10 Verbs in context of 'Year Old'",fontsize=30)
plt.xticks(size=20,rotation=80)
plt.yticks([]
要创建此图:
看哪!!!我有与 token“岁”相关联的上下文。这个符号被用在报道暴力行为/犯罪的新闻标题中,这些暴力行为/犯罪也大多是针对妇女的。
为了确保我的结论是正确的,我查看了实际的新闻标题,其中提到了“岁”,这是我看到的-
['10-year-old girl missing',
'Relative kills 9-year-old',
'59-year-old widow murdered',
'Spunky 60-year-old woman prevents burglary',
"75-year-old woman done to death in B'lore",
'Encroachments threaten 900-year-old temple',
'3 nabbed for 5-year-old robbery',
'25-year-old man electrocuted',
'5-year-old boy run over',
'Killers of 88-year-old woman arrested',
'21-year-old held in theft case',
"60-year-old gets two years' RI for rape attempt",
'STRAIGHT ANSWERSBRSwati Aneja 13 year old schoolgirl on what I Day means to her',
'Robbers stab 9-year-old',
"Eight year old's brush with 'commissions'",
'By Ganesha; what 81-year-old Deryck does BEST',
'Six-year-old girl raped; murdered',
'FBI woos 16-year-old indian author',
'Six-year old raped murdered in Patiala cantonment',
'FBI woos 16-year-old Indian author']
唷!!!那是一些工作。我继续研究这个数据集,寻找更多这样的故事。你可以在这个 Kaggle 内核https://www . ka ggle . com/gunvant/what-India-talks-about-a-visual-essay上查看我正在进行的工作
如果你喜欢这篇文章,别忘了鼓掌。另外,如果你在 Kaggle 上,如果你能投票支持我的内核就太好了
我如何使用文本挖掘来决定观看哪个 Ted 演讲
我喜欢 ted 演讲,谁不喜欢呢?当我第一次看这个数据集的时候,我突然想到了一些事情。首先,由于这个数据集包含了许多 ted 演讲的文字记录,默认情况下,我们有一个非常丰富的语料库,并且在语言学上有很好的结构。第二,由于这个语料库有很好的语言学属性,它可能是一个和路透社 20 新闻组或任何版本的古滕贝格语料库一样好的数据集。这让我想到:

我有许多 ted 演讲的所有记录的数据,我能试着想出一种方法来根据它们的相似性推荐 ted 演讲吗,就像官方 Ted 页面所做的那样?
当然,官方 ted 页面所使用的推荐引擎将会比我在这里演示的更加复杂,并且还会涉及到使用某种历史用户-项目交互数据。
这里的想法是演示如何仅仅使用内容就能产生推荐。当你没有任何用户-项目交互数据时,这变得非常重要,尤其是当你开始一个新的项目,并且仍然想要为你的内容的消费者提供相关的上下文推荐时。
满足数据
数据以表格文件的形式输入,每次谈话的文字记录存储在名为 文字记录 的一行中。下面是该文件的样子
**import** **pandas** **as** **pd**
transcripts=pd.read_csv("E:**\\**Kaggle**\\**ted-data**\\**transcripts.csv")
transcripts.head()
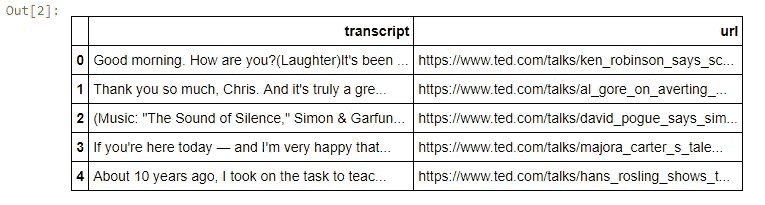
在检查了数据的样子之后,我发现我可以很容易地从 url 中提取演讲的标题。我的最终目标是使用抄本栏中的文本来创建一个相似性度量。然后为一个演讲推荐 4 个最相似的标题。使用简单的字符串分割操作将标题从 url 中分离出来非常简单,如下所示
transcripts['title']=transcripts['url'].map(**lambda** x:x.split("/")[-1])
transcripts.head()

在这一点上,我准备开始拼凑将帮助我建立一个谈话推荐器的组件。为了实现这一目标,我必须:
- 创建每个转录本的向量表示
- 为上面创建的向量表示创建相似性矩阵
- 对于每个演讲,基于一些相似性度量,选择 4 个最相似的演讲
使用 Tf-Idf 创建单词向量:
因为我们的最终目标是基于内容的相似性来推荐演讲,所以我们要做的第一件事是,创建一个可以比较的文字记录的表示。一种方法是为每个转录本创建一个 tfidf 载体。但是这个 tfidf 到底是什么东西?让我们先讨论一下。
语料库、文档和计数矩阵
为了表示文本,我们将把每个抄本看作一个“文档”,把所有文档的集合看作一个“语料库”。然后,我们将创建一个向量,表示每个文档中出现的字数,如下所示:
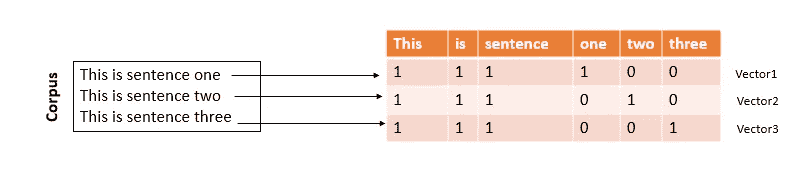
如您所见,对于每个文档,我们都创建了一个向量来计算每个单词出现的次数。所以向量(1,1,1,1,0,0)表示文档 1 中单词“This”、“is”、“sentence”、“one”、“two”、“three”的计数。这就是所谓的计数矩阵。这种文本表示有一个问题,它没有考虑到文档中单词的重要性。例如,单词“one”在文档 1 中只出现一次,但在其他文档中却没有出现,因此从其重要性的角度来看,“one”是文档 1 的一个重要单词,因为它表征了文档 1,但是如果我们查看文档 1 的计数向量,我们可以看到“one”的权重为 1,像“This”、“is”等单词也是如此。关于文档中单词重要性的问题可以使用所谓的 Tf-Idf 来处理。
术语频率-逆文档频率(Tf-Idf):
为了理解 Tf-Idf 如何帮助识别单词的重要性,让我们做一个思维实验,问我们自己几个问题,什么决定一个单词是否重要?
- 如果这个词在文档中出现很多?
- 如果这个词在语料库中很少出现?
- 1 和 2 都是?
如果一个单词在文档中出现很多,但在语料库中的其他文档中很少出现,则该单词在文档中是重要的。术语频率衡量该词在给定文档中出现的频率,而逆文档频率衡量该词在语料库中出现的频率。这两个量的乘积,衡量这个词的重要性,被称为 Tf-Idf 。创建 tf-idf 表示相当简单,如果您正在使用机器学习框架,比如 scikit-learn,那么创建文本数据的矩阵表示也相当简单
**from** **sklearn.feature_extraction** **import** text
Text=transcripts['transcript'].tolist()
tfidf=text.TfidfVectorizer(input=Text,stop_words="english")
matrix=tfidf.fit_transform(Text)
*#print(matrix.shape)*
因此,一旦我们通过考虑单词的重要性来解决表示单词向量的问题,我们就可以开始处理下一个问题了,如何找出哪些文档(在我们的例子中是 Ted talk 抄本)与给定的文档相似?
查找相似文档
为了在不同的文档中找出相似的文档,我们需要计算相似性的度量。通常在处理 Tf-Idf 向量时,我们使用余弦相似度。可以把余弦相似性看作是衡量一个 TF-Idf 向量与另一个向量的接近程度。如果你还记得之前的讨论,我们能够把每个抄本表示为一个向量,所以余弦相似度将成为我们发现一个 Ted 演讲的抄本和另一个有多相似的一种方法。
所以本质上,我从 Tf-Idf 向量创建了一个余弦矩阵来表示每个文档与另一个文档的相似程度,大致如下:
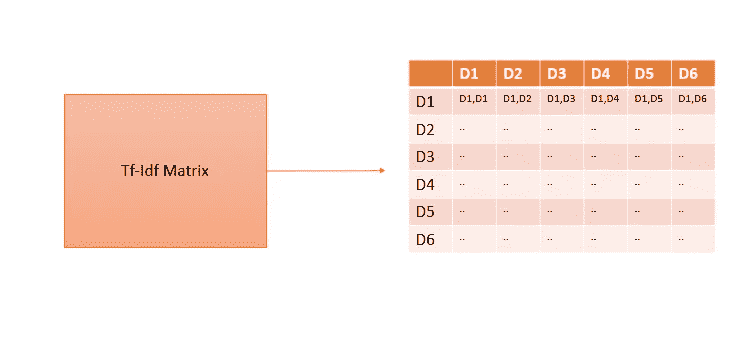
再一次,使用 sklearn,这样做是非常直接的
*### Get Similarity Scores using cosine similarity*
**from** **sklearn.metrics.pairwise** **import** cosine_similarity
sim_unigram=cosine_similarity(matrix)
我现在要做的就是,根据余弦相似度,找出每份抄本中最相似的 4 份。从算法上来说,这相当于为上面构建的余弦矩阵中的每一行找出五列的索引,这五列与对应于相应行号的文档(在我们的情况下是抄本)最相似。这是使用几行代码完成的
**def** get_similar_articles(x):
**return** ",".join(transcripts['title'].loc[x.argsort()[-5:-1]])
transcripts['similar_articles_unigram']=[get_similar_articles(x) **for** x **in** sim_unigram]
让我们通过检查建议来检查我们是如何公平的。让我们从列表中选择任何一个 Ted 演讲题目,比如说我们选择:
transcripts['title'].str.replace("_"," ").str.upper().str.strip()[1]'AL GORE ON AVERTING CLIMATE CRISIS'
然后,根据我们的分析,四个最相似的标题是
transcripts['similar_articles_unigram'].str.replace("_"," ").str.upper().str.strip().str.split("**\n**")[1]['RORY BREMNER S ONE MAN WORLD SUMMIT',
',ALICE BOWS LARKIN WE RE TOO LATE TO PREVENT CLIMATE CHANGE HERE S HOW WE ADAPT',
',TED HALSTEAD A CLIMATE SOLUTION WHERE ALL SIDES CAN WIN',
',AL GORE S NEW THINKING ON THE CLIMATE CRISIS']
你可以清楚地看到,通过使用 Tf-Idf 向量来比较会谈的记录,我们能够挑选出,主题相似的会谈。
我还在这里创建了一个 kaggle 内核,别忘了向上投票:https://www . ka ggle . com/gunvant/building-content-recommender-tutorial
你可以在这里找到完整的代码https://github . com/gun vant/ted _ talks/blob/master/blog March 18 . ipynb
我如何从阅读保罗·兰德到做回归分析影响了 DJ Mix
这里有一个灵感的故事,有一些不寻常的转折。有时你不明白你在一条路上,直到你发现隐藏的线索。
在软件开发领域工作了 10 年,并且在过去的 5 年里作为一名 UX 设计师,我发现自己对下一个项目不那么感兴趣了。我觉得我对设计和开发软件有相当多的了解,但是我对我为什么要做这个有一些疑问。
但是在这开始之前,我的日历上还有一些时间,所以我想我应该利用这段时间去探索一个不同的方向。我住在纽约,经常去 The Strand,但去年秋天的某一天,我有一个小时的额外空闲,在设计区寻找,碰巧发现了这本书:

buy it here or view on slide share
保罗·兰德是二十世纪最有影响力的平面设计师之一。就像副标题所说的,这是一本与学生对话的书,他不是在谈论自己或他的工作,他在回答关于设计本质的问题,并通过他的回答重新构建这些问题。你可以看到他的答案真的挑战了学生,他没有让他们摆脱困境。更重要的是,你可以看到他真的在这个他认为是大师的主题上推行他自己的观点,这是一个超级有趣的阅读。
然后,在第 19 页,他说:

…就这样,我明白他不仅仅指“页面上”的对象,还指人与人甚至组织之间的复杂关系。
让我产生共鸣的想法是,我可以通过使用我的能力,超越绘制软件图片的界限,来帮助“设计”一个组织。当然,实用性植根于技术,但真正的工作是理解做出了什么业务决策,需要做出什么决策,并通过向我们的同事提供证明组织实际正在做什么的数据来帮助他们提升思维。这是解放!
正如我在这篇文章的开头所说,我在专业上有点害怕,这三个小词帮助我离开了产品设计,走向了分析设计。那天晚上,我开始研究机器学习,这让我找到了维基百科的条目:
"回归分析广泛用于预测和预报,其使用与机器学习领域有大量重叠。回归分析也用于了解哪些自变量与因变量相关,并探究这些关系的形式。”—维基百科
哦——你也看到了,对吗?
因此,如果… 设计是关系… 而统计回归是揭示这些关系的技术… 那么…理解回归分析…就是设计的工具!
哇,好吧!我知道我现在在正确的道路上!那么我接下来做了什么?
…我做了一个 DJ 混音!
观察力敏锐的读者可能已经在我的简历中注意到我是一名音乐家。我发现我倾向于以多种方式处理我所学到的东西;有时候我会直接在日常实践中插入新的概念,但有时候我需要从抽象的角度思考,让东西渗透进来。作为一名务实的 UX 设计师,我戴上了“同理心帽子”,试图思考我那些有统计学头脑的同事是如何从不同的角度解决问题的。
但是不要让我欺骗你——当我坐下来做混音的时候,这些我都没想到。我只是有一种想做点什么的冲动。当你制作 DJ 混音时,你可能知道你想要播放的歌曲,但你通常不知道它们是如何组合在一起的。这就像一个谜题,很难理解歌曲之间的关系,但当它起作用时,你就知道了。
对于这个特殊的组合,我给了自己一堆约束。我想在混音中使用每个艺术家两次,我想把它分成两个“侧面”,我想用环境声音以及某种丛林节拍来演奏,但不要过度索引任何一个流派。我喜欢有内在逻辑的混音,尤其是当你不知道它要去哪里的时候。
看,在我之前的帖子中,我解释了我刚刚作为他们的 UX 设计师过渡到一个人员分析团队。自从我开始与我的新团队合作以来,我一直在思考我们如何衡量事物,由于我的角色很大一部分将是数据可视化,我一直在绘制尺子、网格、线条和圆形以获取灵感。
作为一名平面设计师,我还继续探索我认为是设计“基础”的东西——圆、线、网格等等。因此,我以类似的方式为我的组合做了一个设计,作为探索一些创造性想法的练习,并没有真正考虑数据科学。这是我想到的:

当我完成混音后,我知道这与我在分析设计方面的新工作有关。我明白,我在视觉上摆弄的设计元素与为我的业务同事创建的图表是一样的。“测量”当然已经渗透到我的潜意识里了。
所以现在我们在时间线的尽头,我正在做机器学习的研究,我已经完成了我的混音,设计有点不完整,我受到了兰德的话的启发。像许多人一样,我的浏览器中有许多打开的标签,我去关闭它们——它就在那里。回归分析作为一种在嘈杂世界中寻找逻辑线索的方法。
这是一个灵感的故事。这篇文章试图通过三个层次的灵感。当然,(翻白眼),我不得不把它画成图表:
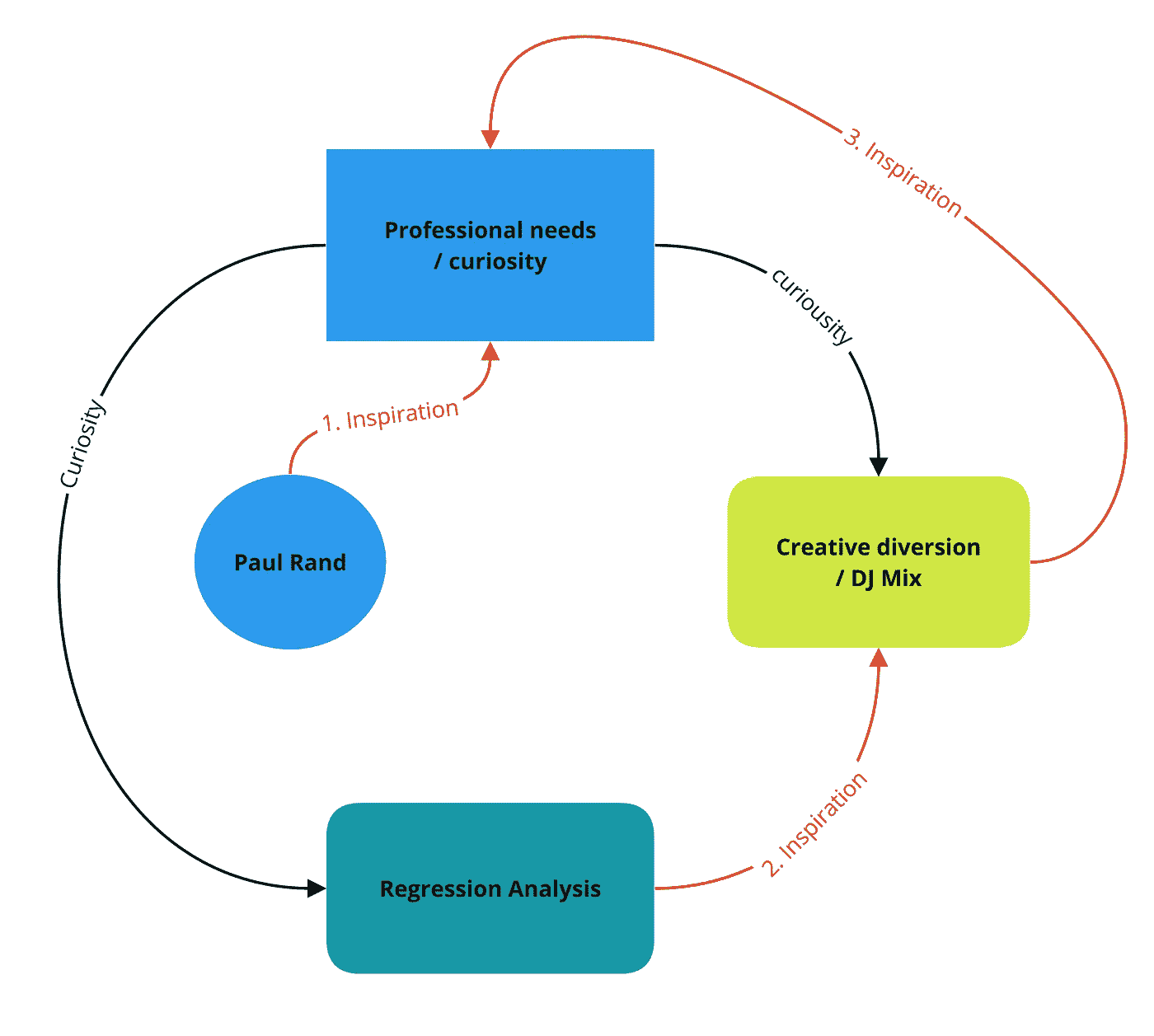
- 兰德的话激发了学习和应用新技能的欲望
- 回归分析成为 DJing 的意外隐喻
- 由此产生的组合激发了设计和数据科学概念在持续学习和激活方面的应用
最终很难理解我们的想法到底从何而来,但思考它们如何演变以及它们可能对未来决策产生什么影响是很有趣的。谁知道呢——你拿起或浏览的最后一本书可能会激发你做出一个有所作为的创造性决定。
我如何学习深度学习—第一部分
通过构建深度学习模型学习编程

By Luca Bravo
整个人工智能革命令我着迷。我想参与进来。我的搜索把我带到了 Udacity 。一个漂亮的在线学习平台。我真的很喜欢网站的布局和颜色。我对此很感兴趣。
我注册了新课程通知,并发现了深度学习基金会纳米学位。
先决条件是基本的 Python 语法和一些微积分知识。当我第一次读这封邮件时,我从高中起就没有什么 python 经验(最少的整体编程经验)和少量微积分知识。
建设
我对涉足编程领域非常感兴趣。看了那么多 Medium、博客和互联网其他地方的文章,机器学习和深度学习最让我感兴趣。我决定开始准备这门课程。我在最后期限前有三个星期。
我开始通过多种方式学习 python,主要是通过我之前在 Udemy 上购买的 Python Bootcamp 课程。
最后期限很快就要到了。在我有 24 个小时来决定之前,我几乎没有通过 Python 中的方法和函数。
充满了对自己是否准备好的焦虑,我输入了我的信用卡信息并在 Udacity 上注册了 Nanodegree。我怀疑自己,我甚至发邮件给支持人员,说明我的担忧以及退款窗口何时结束。
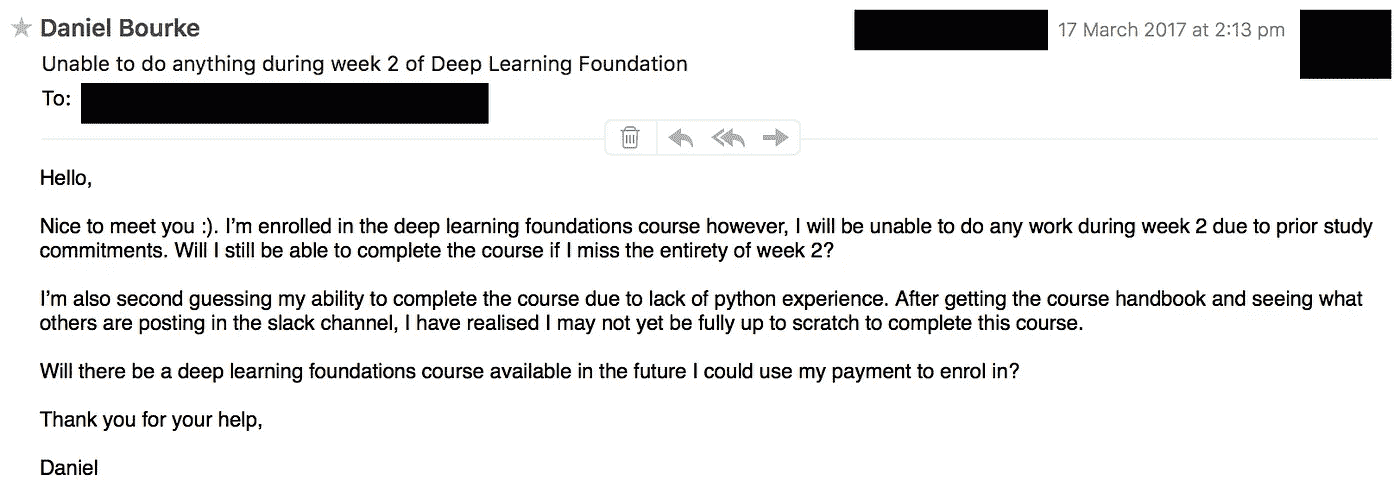
The anxious email I sent to the Udacity support team.
我在怀疑自己。
我决定不选择退款。我想测试一下自己。我想,“最坏的情况会是什么?”。
学习 Python 很有趣。在我见过的所有语言中,Python 最快地征服了我。
除了 Udemy 课程,我还开设了 Udacity 的免费的 Python 编程基础课程。这两个人合作得很好。
课程开始日期的迅速临近是每天学习 Python 的巨大动力。在三周时间里,我从对 Python 一无所知到能够画出花朵,检查一段文字中的脏话,当然,还完成了经典的 FizzBuzz 算法挑战。
我甚至制作了一个 YouTube 视频,我试图解释我是如何使用 Python 来画花的。这确实有助于巩固我的学习。
所以经过三周的 Python 准备,我成功地从 mega noob 变成了 super noob。
课程结束两天了,我没有学任何数学。我从高中(7 年前)就有很强的数学背景,但从那以后就没怎么做过。我对数字很在行,所以比起编程,我对数学部分更有信心。
在课程开始前的一些公告中,我听到几次提到矩阵操作。Udacity 团队推荐使用可汗学院来温习矩阵和向量。所以我开始看一些视频,练习矩阵乘法,重新发现什么是向量。
第一天
我加入了深度学习基金会的 Slack 频道。介绍频道挤满了未读的信息。我开始滚动频道。
“大家好,我是来自 SF 的 John,X 的软件工程师”*
“大家好,我是来自伦敦的 Paul,X 的数据分析师”*
*这两个都是杜撰的名字。频道里的每个人都非常友好,乐于助人。
焦虑程度上升。
我让自己陷入了什么?
我意识到,这不是我和其他同学之间的竞争。我们上这门课都是有原因的,最有可能是为了提高自己的技能,互相帮助,改变世界,而不是竞争。
有趣的是,我们很快就会把自己和他人进行比较。我是唯一这样做的人吗?
即使是比赛,Udacity 团队也竭尽全力警告我课程会很难,并给出了详细的先决条件。如果我因为不知所措而对开课感到焦虑,那是我的选择。
另一种认识。我身边有一些世界上最聪明的人。我现在有机会向这个领域的佼佼者学习,我怎么能不兴奋呢?
第一周
到第一周结束时,我已经学到了相当多的知识。我被介绍给了一些令人惊叹的 Udacity 深度学习团队。
我了解了深度学习的真正含义。是的,我在实际上不知道深度学习的正确定义的情况下,创办了深度学习基金会 Nanodegree。跟机器学习有关吧?
我知道了深度学习可以应用在哪里,我甚至利用一些预先制作的算法为我的狗设计了一张照片,就像毕加索的 La Muse 。

My dog Bella, recreated by my computer in the style of Picasso’s La Muse.
我用这种技术为朋友们设计了一系列不同的照片,他们都很喜欢。
My friends and I in a human pyramid, La Muse style.
我了解了线性和逻辑回归模型,以及它们如何作为神经网络的构建模块在机器学习中使用。
通过几个编程例子,我了解了 NumPy 和矩阵数学。在本周之前,我从未使用过 NumPy。关于 NumPy 的文档非常广泛,结合 Udacity 的课程,非常有用。
最后,我深入研究了逻辑回归和神经网络背后的思想。对我来说,这是一周中最困难的部分。有时我感到沮丧,因为我不明白发生了什么。为了克服这一点,我会把课文内容复习一遍。然后我会走开几分钟,只是想一想。然后,我会回来写下(在纸上)所有我不理解的部分,并在尝试挑战之前修改它们。
这种技术似乎很有效。
第二周
我错过了第二周的所有内容,因为我在家乡参加了麻省理工学院的训练营。
在线课程的美妙之处在于所有的信息在任何时候都是可以获取的。
下一步是什么?
第三周是本周。
在开始第三周之前,我将继续完成第一周和第二周的剩余内容,然后最终开始我的第一个项目。
我正在用特雷罗追踪我的进度,随时跟进,如果我松懈了就告诉我。
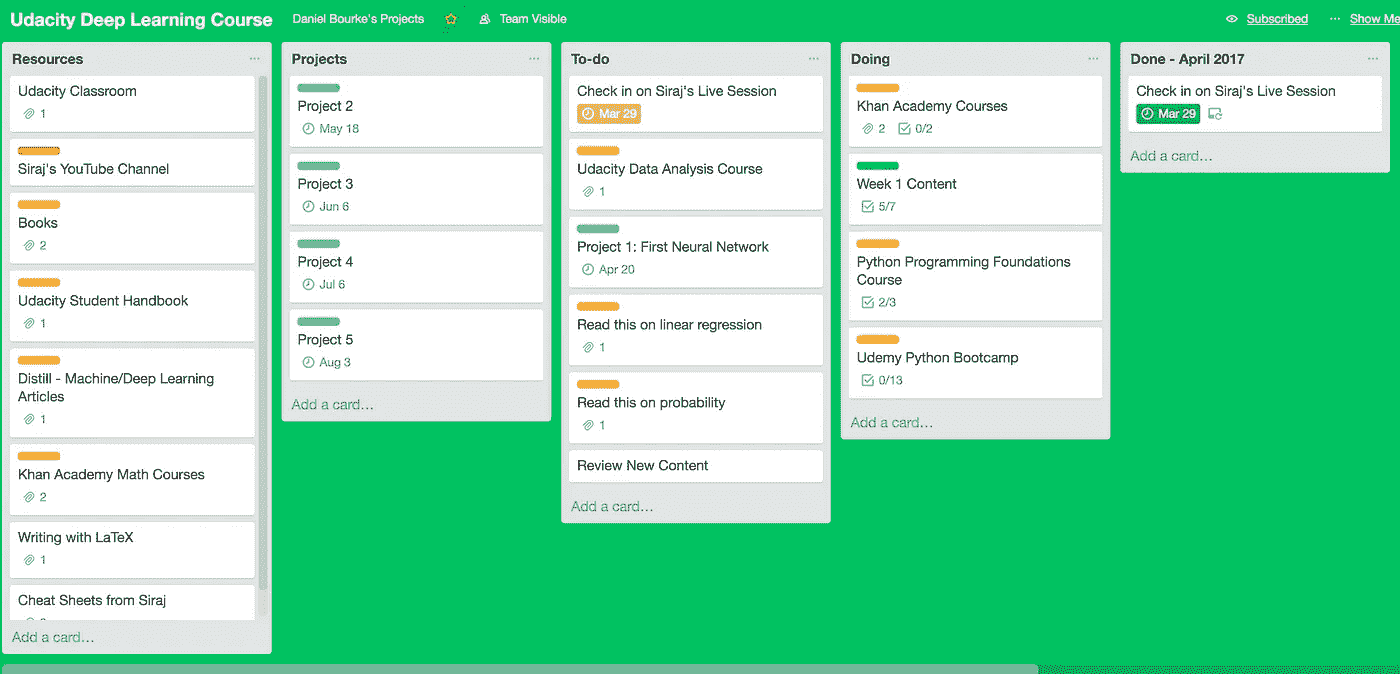
I’m using a modified Kanban technique to stay on top of things.
到这个月底,我将从零开始建立和训练我自己的神经网络。
我有许多工作要做。
我很害怕,但也很兴奋。
开始学习这门课程是我做过的最好的事情之一。我在学习如何编程的过程中获得了乐趣,同时也成为了我经常从外部观察的社区的一部分。
我已经学到了很多,但最重要的事情之一就是开始。很久以来,我一直想学习编程,我终于做到了。
如果你想开始学习如何编程,那就试试吧。网上有很多免费资源,都试试吧。找到最适合自己的。
我仍然不知道这是否最适合我,但目前为止我很喜欢它。
这篇文章是一个系列的一部分,这里是其余的。
- 第一部分:新的开始。
- 第二部分:动态学习 Python。
- 第三部分:广度太多,深度不够。
- 第四部分: AI(营养)对 AI(智能)。
- 第五部分:回归基础。
- 额外:我自创的 AI 硕士学位
我如何学习深度学习—第二部分
动态学习 Python
TL;速度三角形定位法(dead reckoning)
- 提交了我的第一个深度学习项目,我通过了!
- 开始学习卷积神经网络
- 了解了 TensorFlow 和情绪分析
- 回到基础,开始在树屋学习 Python,在可汗学院学习基础微积分
- 下个月:项目 2 和循环神经网络
第 1 部分 从我开始 Udacity 深度学习基础
Nanodegree ,以及通过 Udacity 的 Python 编程入门开始学习 Python 开始。
那篇文章在第三周结束。我现在在第六周。
我是如何追踪的
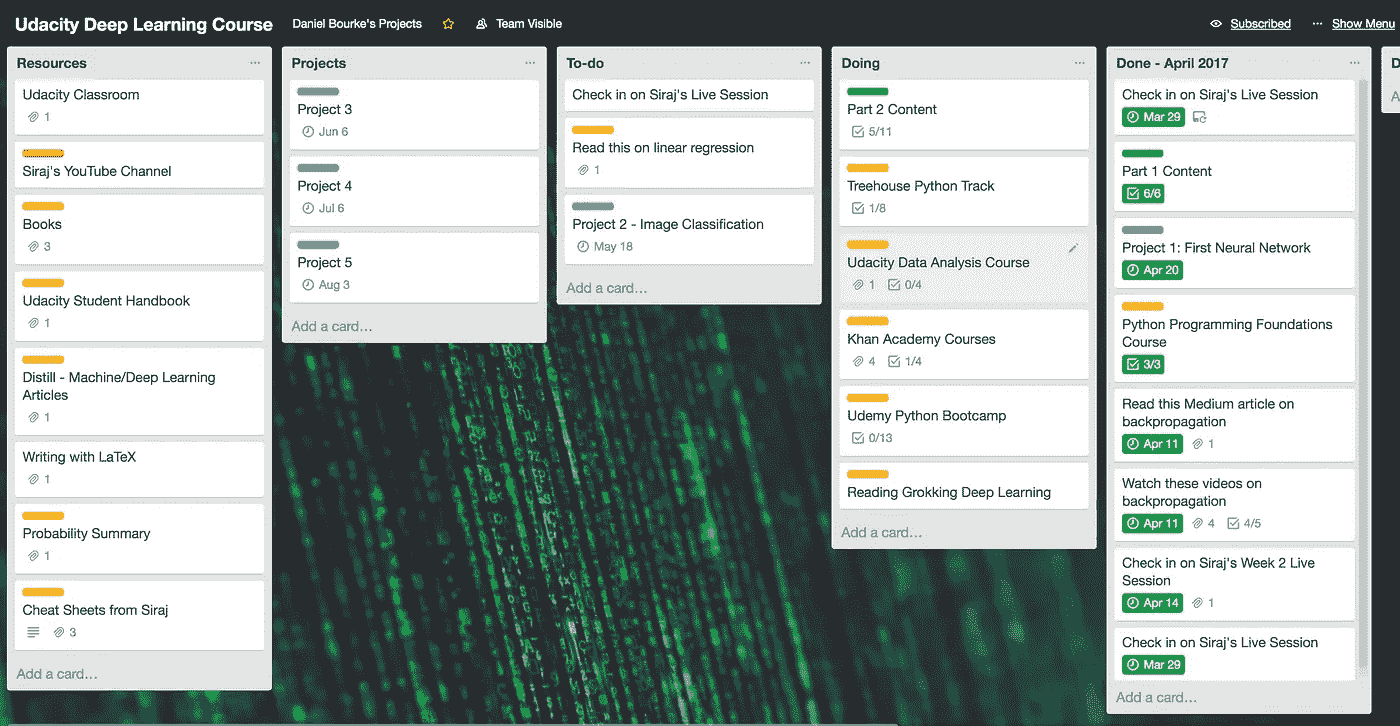
How I’m using Trello to stay on top of things.
到目前为止,它一直具有挑战性,但惊人的支持渠道已经令人难以置信。
我遇到的大多数麻烦都是我自己造成的。这主要是因为我在编程和统计方面的背景知识很少。
我喜欢挑战。在 8 号球后面意味着我的学习已经是指数级的。我从对 Python 和微积分知识几乎一窍不通,到能在六周内写出部分神经网络。
这一切都来之不易。我每周至少花 20-30 个小时在这些技能上,但我还有很长的路要走。这么长时间是因为我在开始课程前缺乏必要的知识。
第三周
在 Udacity Slack 频道的大力帮助下,我成功完成了我的第一个项目。该项目包括训练我自己的神经网络来预测某一天的自行车共享用户数量。
看到模型在调整诸如迭代次数(模型尝试映射数据的次数)、学习速率(模型从训练数据中学习的速度)和隐藏节点的数量(输入数据在成为输出数据之前流经的算法数量)等参数时得到改善,真的很有趣。
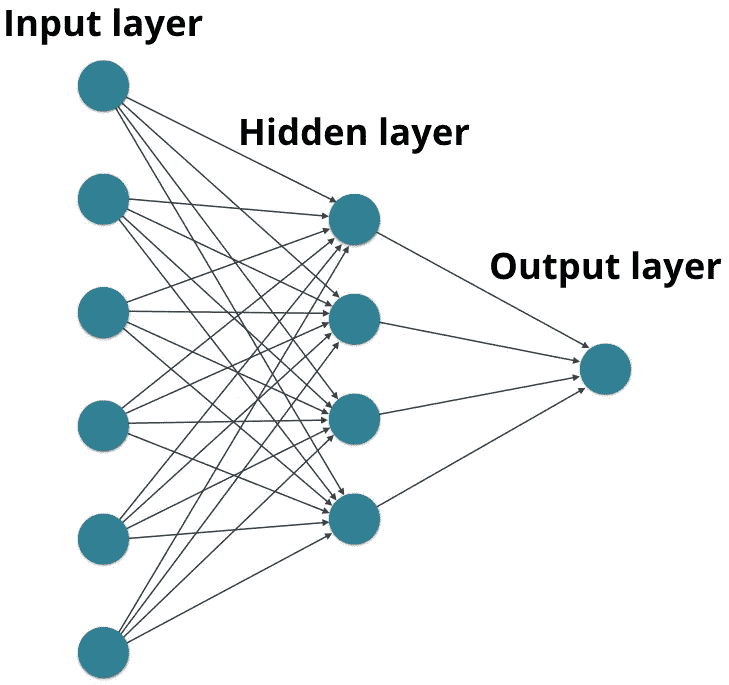
Source: Udacity
上图显示了一个神经网络的示例。隐藏层也称为隐藏节点。在深度学习中,输入和输出之间可能有数百个,如果不是数千个这样的隐藏层,反过来创建了一个深度神经网络(深度学习由此得名)。
在等待我的项目被评分和继续深度学习基础 Nanodegree 的过程中,我决定继续学习 Udacity 提供的其他一些课程。
我完成了 Python 编程入门课程,开始了数据分析入门课程。我在数据分析课程上没有取得多大进展,但这是我下个月的目标之一。
提交项目三天后,我收到了反馈。我通过了!我无法向你解释这有多令人满意。
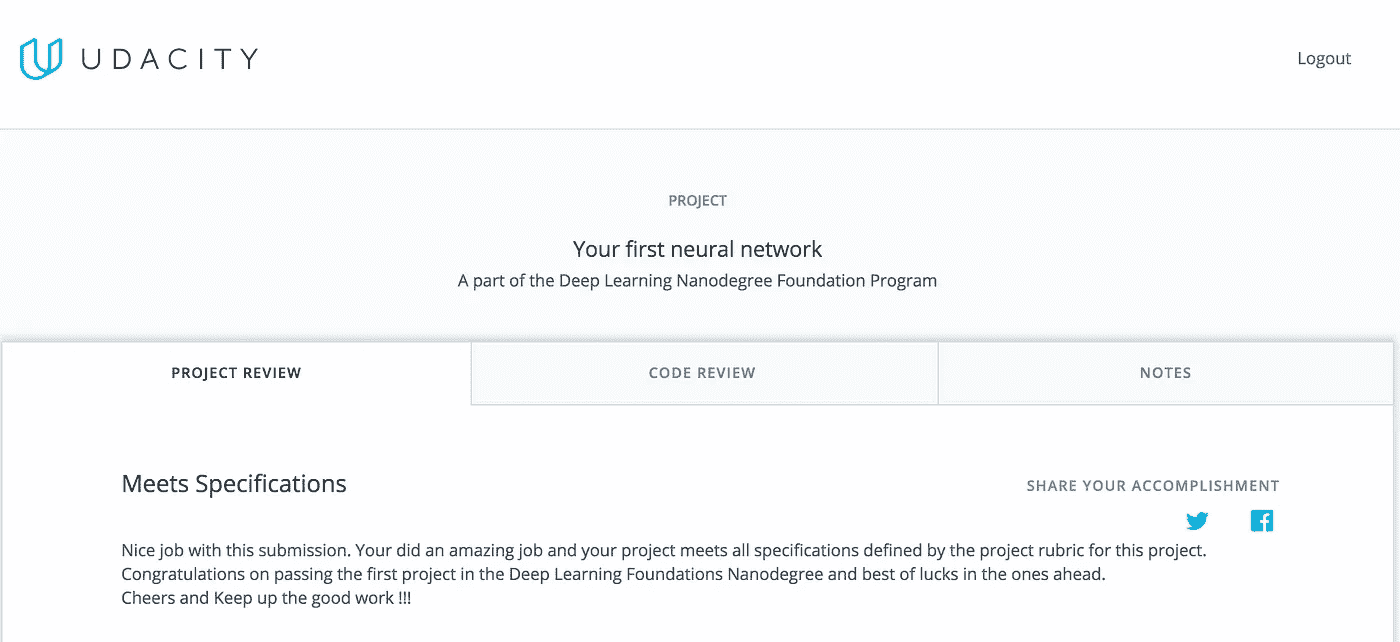
Passing my first Deep Learning project! 😄
在询问了课程的退款流程(见 第一部分 )三周后,我已经完成了课程的第一个重要里程碑。
我做出了正确的选择,留下来。
向 Slack 频道大声呼喊,感谢他们所有的惊人帮助!
卷积神经网络
在收到我的第一个项目的反馈后的几天,我开始了纳米级卷积神经网络的第二部分。
卷积神经网络能够识别图像中的对象。它们是强大的功能,例如脸书的照片自动标记功能。
为了更深入地了解卷积神经网络,我强烈推荐你阅读 Adam Geitgey 的文章。事实上,当你在的时候,看看他的整个系列。
第 2 部分从 Siraj Raval 的一段视频开始,讲述如何为神经网络准备最好的数据。
Siraj 可能是我在 YouTube 上见过的最有趣的教练。即使你不喜欢 DL、ML 或 AI(你应该喜欢),看他的视频也很有趣。
就像人类一样,当信号从噪音中被破译出来时,机器工作得最好。为神经网络准备数据包括移除数据边缘的所有绒毛,以便神经网络可以更有效地处理数据。
请记住,机器学习只能在数据中找到人类最终能够找到的模式,只是这样做要快得多。
(非常)简单的例子:
您想要了解特定学校中特定九年级班级的考试成绩趋势。
您的初始数据集包含全国每所高中的结果。
使用这个数据集来寻找特定类的趋势是不明智的。
因此,为了准备数据,除了您想要测试的特定的 9 年级班级之外,您要删除每个班级和年级。
关于数据准备的更多信息,我推荐 Siraj 的这个视频:
第四周
本周我开始构建和学习 Miniflow,这是我自己的 TensorFlow 版本(稍后我将介绍 TensorFlow)。本课的目标是学习可微分图和反向传播。
这两个词都是行话,上课前对我来说毫无意义。
当我用最简单的术语定义它们时,我发现事情变得更容易了。
可微图:(从函数中)可以求出导数的图。用这个导数可以更容易的计算未来的事情。
**反向传播:**通过神经网络前后移动,计算每次输出和期望输出之间的误差。该误差然后被用于相应地调整网络,以更精确地计算期望的输出。
我在这门课的某些部分遇到了困难。我越来越沮丧。我休息了一下,决定吞下我的自我,我必须回到基础。
回归基础
如果你对一个概念有困难,回到基础,而不是试图推进。如果你继续让沉没成本谬误得逞,你最终可能会成功,但它可能弊大于利。我对在许多紧张的时间里努力完成目标感到内疚。我不想让这种事情在这门课上发生。
课堂上的数学是最困扰我的。不过,不要把我的麻烦当成害怕的理由,没多久我就被可汗学院可爱的人们带着熟悉起来。
我看了关于偏导数、梯度和链式法则的整个系列。在这之后,迷你流课程中的一切开始变得更有意义了。
在完成可汗学院的课程后,我不仅获得了更好的理解,学习过程也远没有那么令人沮丧。
本着返璞归真的精神,我买了几本关于 DL 的书。第一个是安德鲁·特拉斯克的探索深度学习。安德鲁是这门课程的讲师,也是牛津大学的博士生。
这本书的前半部分我已经看了大约 50%(后半部分还没有发行),它已经开始巩固我已经学到的知识了。在稍微深入地挖掘神经网络的整体概念之前,它从 DL 的大概述开始。
我向任何希望开始学习深度学习的人推荐这一点。Trask 指出,如果你通过了高中数学考试,并且可以用 Python 编程,你就可以学习深度学习。我几乎没有勾选任何一个选项,这绝对对我有帮助。
在 Slack 频道的一次推荐后,我最近还购买了自制神经网络。我还没有开始做这件事,但是我会在下个月的某个时候开始做。
计算机编程语言
当课程开始时,它说初级到中级 Python 知识是先决条件。我知道这个。问题是,除了 Udacity 上的 Python 基础课程,我什么都没有。
为了解决这个问题,我注册了 Treehouse 上的 Python Track。除了没有要求退款之外,这是迄今为止我在课程中做出的最好的决定。
突然间,我有了另一个知识来源。由于基础课程,我有一个小的基础,但现在知识正在复合。
树屋的社区就像 Udacity 一样,非常有帮助。事实上,我已经开始在树屋论坛上分享我自己对人们关于 Python 的问题的回答。
5 周从学生到老师??
在 Treehouse 上学习更多关于 Python 的知识让我进一步了解了深度学习纳米学位基金会正在发生的事情。
我发现混合知识是一件非常强大的事情。在过去,我总是坚持不懈地学习新的东西,而不是复习已经学过的东西。
如果你太快地尝试一些超出你舒适区的事情,你会很快达到筋疲力尽的地步。
回归基础不仅提高了我的知识,更重要的是,给了我继续学习的信心。
第五周
接下来是情感分析。我看了特拉斯克和西拉杰的课。
情感分析包括使用神经网络来决定电影评论是正面还是负面。
我无法相信我正在编写代码来分析一篇文章中的单词,然后用这些代码来判断它的意思。
想到在你真正做一件事之前,你永远也做不了这件事,这很有趣。
Siraj 有另一个关于情感分析的很棒的视频,我会看它只是为了看看迷因。
接下来是张量流。我很努力地研究 TensorFlow。连 logo 看起来都很酷。
TensorFlow 是 Google Brain 开发的开源 DL 库。它几乎被用于所有的谷歌产品。它最初是为 ML 和 DL 研究设计的,但后来被用于各种其他用途。
TensorFlow 让我兴奋的是它是开源的。这意味着任何有想法和足够计算能力的人都可以像谷歌一样有效地使用同一个库来实现他们的想法。
我真的很激动,以后能更多的了解 TensorFlow。
第六周
这就是我现在的处境!
我玩得很开心。这些课程有时很难,但我不会有别的办法。
通常,最困难的任务也是最令人满意的。每当我完成一门课或一个我已经工作了几个小时的项目时,我都会有一种巨大的满足感。
我下个月的计划是什么?
我想花更多的时间在复习模式上。我学到了很多。
因为很多东西对我来说都是新的,我的直觉告诉我应该复习一下我所学的。
我将尝试使用抽认卡(通过 Anki )来帮助记忆 Python 语法和各种其他项目。
在我写第 3 部分的时候,我将已经完成了另一个项目,读了几本书,完成了更多的在线课程。
你可以通过查看我的 Trello 板来观察我在做什么。我会尽可能保持更新。
回到学习上来。
这篇文章是一个系列的一部分,这里是其余的。
- 第一部分:新的开始。
- 第二部分:快速学习 Python。
- 第三部分:广度太多,深度不够。
- 第四部分: AI(营养)对 AI(智能)。
- 第五部分:返璞归真。
- 号外:我自创的 AI 硕士学位


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}