







关于有效使用 Python NumPy 数组的搭便车技巧

Tips on Effectively using NumPy Arrays
如果您正在使用 python 进行数据科学研究,那么您要么使用过 NumPy,要么肯定听说过它。大多数需要将数据存储在内存中的统计分析都使用 NumPy。
如果你是 NumPy 的新手,我强烈推荐你阅读我之前的文章python NumPy 数组的搭便车指南来了解 NumPy 的基本用法。
在这篇文章中,我将讨论一些具体的技巧、窍门和技术,它们将帮助你获得大多数 NumPy 数组
1.修改现有的 NumPy 数组
与 Python 列表不同,NumPy 没有
append(...)函数,这实际上意味着我们不能追加数据或改变 NumPy 数组的大小。为了改变大小和/或维度,我们需要通过在旧数组上应用效用函数来创建新的 NumPy 数组。
从语法上来说,NumPy 数组类似于 python 列表,我们可以使用下标操作符来插入或更改 NumPy 数组的数据。例如,对于大小为 5 的 NumPy 数组,我们可以使用像while和for这样的循环来访问/更改/更新内容
Changing individual events of NumPy array
可以理解的是,这是一种非常过时的、非功能性的访问/操作数据的方式。幸运的是,NumPy 为 same 提供了批量访问功能,它在一行中毫不费力地做了同样的事情。一个这样的功能是numpy.put(...)。
为了描述numpy.put(...)的用法,我们将创建一个 python 列表并将该列表的内容复制到 NumPy 数组中
Using numpy.put(…) function
numpy.put(...)函数获取一个范围,然后使用该范围从目的地复制源。副本将被限制在range(..)功能中提供的数量。
在上面的例子中,如果我们将np.put(...)线改为
np.put(np_arr, range(3), py_arr)
它将只改变np_arr的前三个元素,其他的都不变
np.put(...)函数的适用性不仅限于复制一维数组,还可以用于复制 n 维数组,如下面的代码所示
numpy.put(…) for multi dimensional array
使用np.put(...)函数,我们可以提供一个数字列表,但是,在某些情况下,我们希望将相同的数字复制到 NumPy 的所有元素中。这类似于调用np.zeros(...)或np.ones(...),区别在于除了 0 和 1 之外,还可以提供其他数字
这是通过调用
np.fill(...)函数实现的。
无论我们在填充中提供什么数字(…),它适用于 NumPy 数组的所有元素,而不管该数组是一维数组还是多维数组
Using numpy.fill(…) function
.fill(..)函数只接受标量值。
这里描述的是dtype=np.int的例子。它也适用于所有其他数据类型,如np.float, np.str, np.object等
2.切片 NumPy 数组
如果你有切割 python 列表的经验,在这里你会感觉像在家里一样。
切片 NumPy 数组带来了额外的功能,并且在多维数组的情况下变得有趣。然而,为了正确理解切片是如何工作的,我们需要在研究多维数组之前先研究一维数组。
:被称为分隔符,与 相容—不相容 原理一起工作,这意味着分隔符的左侧将被包含,而分隔符的右侧将被排除。
例如,np_arr[1:4]这样的语句意味着它将包括索引→ 1,但排除索引→ 4。因此这将有效地显示 Index → 1,2 & 3 中的元素
下面是一些对一维数组进行切片的例子以及它们的预期输出
Slicing 1-D arrays
切片的一个独特功能出现在 NumPy 数组中,但不能用于 python list 中,这就是用一个值就地改变数组的多个元素的能力。
老实说,这是非常有价值的功能之一,对数学和机器学习都有帮助。下面是使用该功能的方法
Slicing 1-D array
现在让我们来看一下多维数组的切片。当我们对多维数组进行切片时,分隔符左边和右边的含义保持不变(即索引),但我们通过使用两组逗号分隔的分隔符来扩展它,这两组分隔符代表行和列,即
[rows → Start_Index : End_Index, Column → Start_Index : End_Index ]
下面是一些例子,说明在 2D 阵列中切片意味着什么
Slicing a 2 — D Array
类似地,对于 3D 数组,我们必须为一个维度添加一个逗号分隔的值。这里有一些相同的例子
Slicing a 3-D Array
3.拆分 NumPy 数组
在某些时候,有必要将 n-d NumPy 数组分成行和列。拆分 numpy 数组有多种函数和方法,但是有助于按行和按列拆分 NumPy 数组的两个特定函数是split和hsplit。
split功能用于行行行行的明智拆分hsplit功能用于 列 的明智拆分
拆分 NumPy 数组的最简单方法可以在它们的维度上完成。一个 3 * 4 的数组可以很容易地分成 3 组行列表和 4 组列列表。下面是我们如何做同样的事情
NumPy Split Row and Column wise
如果多重因子允许分割,我们可以提供一个不同于分割可用维数的数。例如,我们可以将数组按列分为 2 组,如下所示
多重不均匀分裂
在上面的例子中,我们提供了一个数字来按行或列等分 NumPy 数组。
但是,通过提供需要拆分的精确索引,可以在不同的行和列上进行不均匀的拆分。
它的工作原理就像我们上面看到的切片一样。基于列表中提供的索引,这些拆分函数将相应地对行或列进行切片。
让我们假设我们有相同的 2D 数组如上所示,我想做自定义分裂。
情况 1:将 3 行分成[1]和[2,3]
在这里,我想将行分成两部分,我们提取第一行,然后将第二行和第三行合并为一行。我们将这样做
Splitting Rows
情况 2:将 4 列分为[1]、[2、3]和[4]
在这里,我想将列分成三部分,我们提取第一列,然后是第二+第三列,最后是第四列。我们将这样做
Splitting Columns
所以这是 NumPy 的一些小技巧,可以帮助你更好地使用它。
这就是这个故事的全部内容。更多关于下一组故事。
感谢阅读…!!!
达克什
探索性数据分析指南
如何用 python 调查数据集?

- “我如何在数据科学/机器学习/数据分析领域获得 kickstart?”
- “当您拥有数据集时,我应该采取哪些初始步骤来建立与数据集的连接?”
- “在探索性分析过程中,如何定义一组针对数据集的问题?”
如果你正在寻找上述任何一个问题的答案,那么这个博客系列将真正帮助你开始。
那么,什么是探索性数据分析(EDA)?
探索性数据分析(EDA)是数据科学的一个重要组成部分,它允许您开发您的数据看起来像什么以及它们可能回答什么样的问题的要点。
最终,EDA 是重要的,因为它允许研究者做出重要的决定,什么是有趣的,什么可能不值得继续,从而利用变量之间的关系建立一个假设。
一点背景知识
这是一个由两部分组成的系列,我们将查看来自 Kaggle 的电影数据集,并对数据进行一些探索性分析。
我们将在本教程中使用 python。我建议您在继续阅读之前先复习一下 python 基础知识。我将向您介绍我在数据集上执行 EDA 的步骤。
TMDB 电影数据集可以在这里找到。收集数据有不同的方法,我们将在另一篇文章中讨论。作为一名数据分析师,我的工作是能够提出一系列问题,解读字里行间的含义,并找到这些问题的答案。
我把它分成了三个部分
- **清洗:**检查收集到的数据是否有问题,比如缺失数据或测量错误、列的数据类型等。)
- 定义问题:识别特别有趣或意想不到的变量之间的关系。
- 使用有效的可视化方式来传达我的结果(将在第第二部分中介绍)
我用过 jupyter 笔记本,因为我发现它们最适合数据清理、转换、数值模拟和数据可视化。Jupyter Notebook 的另一个优势是,您可以使用用于建模和可视化数据集的 Jupyter 笔记本,并将其用作技术演示的幻灯片。
这篇文章的代码可以在我的 Github 上找到:
[## harshi codes/tmdb _ movie _ data _ analysis
探索性数据分析开始挖掘这些问题,包括剧情、演员、剧组、预算和…
github.com](https://github.com/harshitcodes/tmdb_movie_data_analysis)
第一步是创建一个虚拟环境,您将在其中安装所有的软件包。下面是使用 pip 为我们安装 4 个包的命令。
pip install numpy pandas seaborn matplotlib
- Numpy:用 Python 进行科学计算的基础包。
- Pandas :为 Python 编程语言提供高性能、易于使用的数据结构和数据分析工具的库。
- Matplotlib :一个 Python 2D 绘图库,它以多种硬拷贝格式和跨平台的交互环境生成出版物质量数字。
- Seaborn :基于 matplotlib 的 Python 数据可视化库。它提供了一个高层次的界面来绘制有吸引力的和信息丰富的统计图形。
导入你需要清理、压缩和可视化的 python 包。我已经导入了包,第二部分(作为 pd )只是为了方便,这样我就不用写“ pandas ”。命令“每次我用它的时候。
从路径加载数据:
这里,我使用了 pandas 的 read_csv 函数,该函数返回一个快速有效的 DataFrame 对象,用于集成索引的数据操作。我有两个来自 movies_df 和 credits_df 的数据帧。
movies_df.head() 将显示数据帧的前 5 行。您可以将想要查看的行数传递给 head 方法。看看我们得到的数据框架:
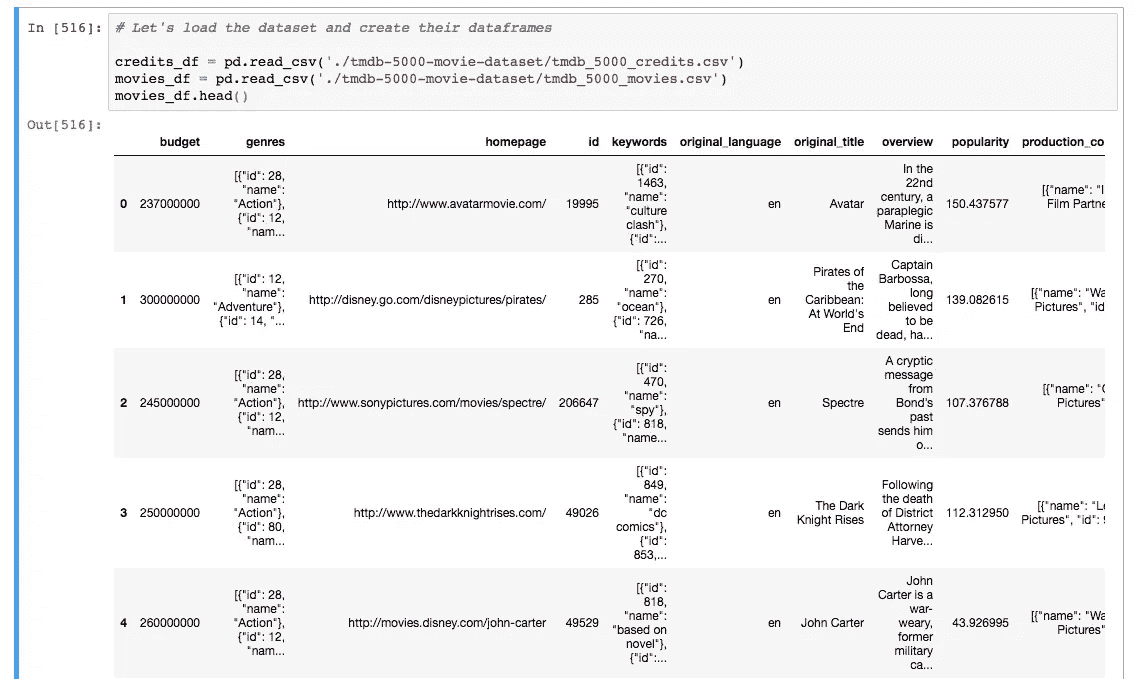
在我们开始寻找这些数据中隐藏的答案之前,我们必须清理数据,为分析做准备。
#1 数据清理过程
数据清理是整个数据准备过程的第一步,也是非常关键的一步,是对杂乱的、原始的数据进行分析、识别和修正的过程。当分析组织数据以做出战略决策时,你必须从彻底的数据清理过程开始。
- 我们需要删除未使用的列,如 id,imdb_id,vote_count,production_company,keywords,homepage 等。从实际相关且简明的数据中做出决策总是更容易。
以下是从数据帧中删除冗余列的方法:
2.移除行中的副本(如果有):
3.数据库中的一些电影具有零预算或零收入,这意味着它们的价值没有被记录或一些信息丢失。我们将从数据帧中丢弃这些条目:
4.为了方便地操作这些列,使用 python 对象是很重要的。将发布日期列转换为日期格式,并从日期中提取年份,这将有助于我们分析年度数据。
5.类似地,使用 numpy 的 int64 方法将预算和收入列的格式更改为整数。
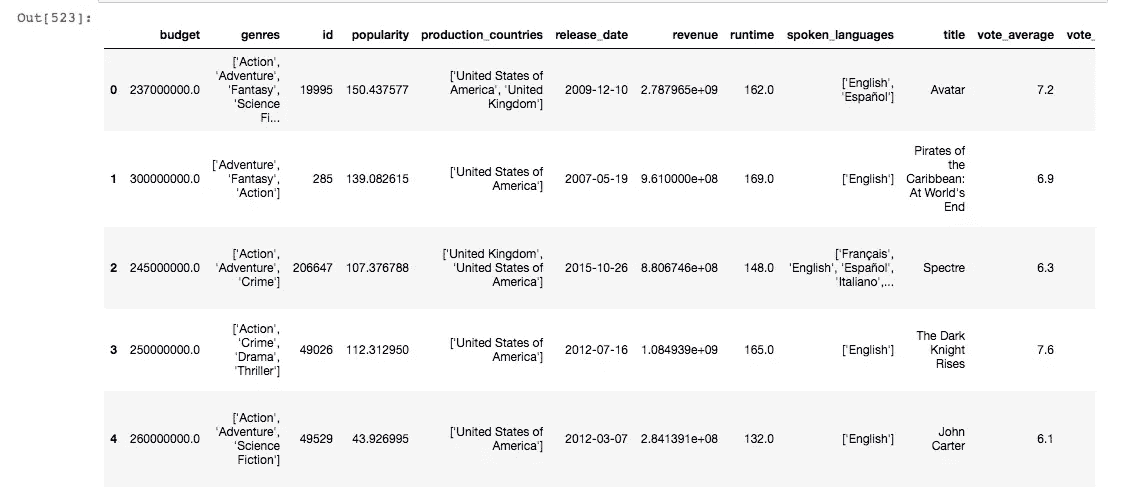
6.在检查数据集时,我们看到流派、关键词、生产公司、生产国家、口语都是 JSON 格式,这将在操作数据帧时生成。现在让我们将这些列展平成一种易于解释的格式。
我们将把它们转换成字符串,然后再转换成列表。编写一个通用函数来解析 JSON 列。
清理后,数据如下所示:
#2 确定变量/特征之间的关系
这里的主要目标是识别和建立可以帮助你建立假设的关系。我们必须定义一些能帮助我们建立一些关系的问题。
此时,我在研究这个数据集时产生了以下问题。您可能会提出一系列不同的问题,这些问题没有在下面列出:
- 哪 5 部电影最贵?两个极端之间的比较?探索最昂贵的电影,它可以告诉你,根据它们的性能和产生的收入,它们是否值得花在它们身上的钱。
2.由于我们需要比较 3 个问题中的最小值和最大值,我们可以编写一个通用函数来完成这项工作,并重用它。
2.最赚钱的 5 部电影?最小利润和最大利润的比较。这种比较有助于我们识别失败和成功的不同方法。如果我从产生的收入中减去预算,它将给出我获得的利润。
3.大多数人谈论电影。
4.电影平均播放时间?两个极端之间的比较。
5.分级在 7 级以上的电影
6.我们哪一年的电影最赚钱?
这将有助于你提出一些更深层次的问题,比如电影在哪些年份表现不佳,在哪些年份表现良好。这些都是初步的问题,这些问题引出了提供更深层次见解的问题。
让我们看看这些年来盈利电影的传播情况
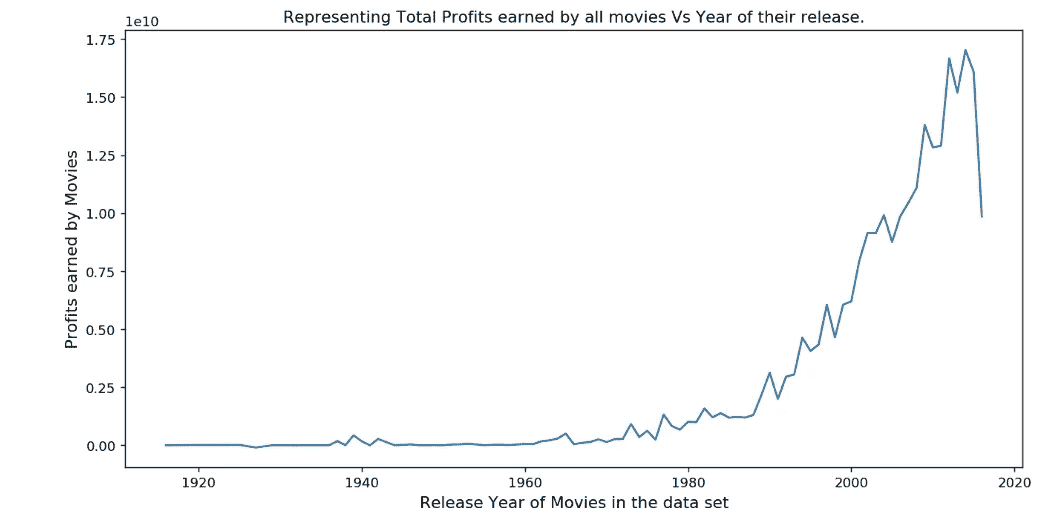
为了找出盈利电影数量最多的年份,我们使用了 idxmax 方法:
这会给我们 2014 年。你可以在 Ipython 笔记本这里查看这些代码片段的所有输出。
现在,我们已经分析了这个数据集包含的内容,是时候尝试构建一个可以根据所选的特征/变量预测电影成功率的故事了。因此,我们需要确定使电影盈利的因素。
以下是一系列问题,可以引导我们朝着理想的方向前进
- 最成功的类型——柱状图解释了每种类型电影的出现频率。
- 电影中的常见演员——显示每个演员的电影谱的图。
- 盈利电影的平均预算——分配的平均预算是多少
- 最赚钱电影的平均时长。
- 最赚钱电影的语言。
以上所有问题的答案将帮助我们建立我们的假设,即 “制作一部卖座、赚钱的电影的秘诀是什么?”
在的下一篇文章中,我将讨论如何利用 Matplotlib 和 seaborn 库**来可视化(此过程中的第三步)**上述问题的答案。
我们将在下一部分(下面的链接)用所有的发现和想象来结束调查。
如何使用 Python 调查数据集?学习如何使用可视化来回答一些重要的问题。
towardsdatascience.com](/hitchhikers-guide-to-exploratory-data-analysis-part-2-36ab72201e1d)
Harshit 的数据科学
通过 Harshit 的数据科学频道,我计划推出几个涵盖整个数据科学领域的系列。以下是你应该订阅频道的原因:
- 该系列将涵盖每个主题和副主题的所有必需/要求的高质量教程。
- 解释了为什么我们在 ML 和深度学习中做这些事情的数学和推导。
- 与谷歌、微软、亚马逊等公司的数据科学家和工程师以及大数据驱动型公司的首席执行官的播客。
- 项目和说明,以实现迄今为止所学的主题。
你可以在 LinkedIn 、 Twitter 或 Instagram 上与我联系(在那里我谈论健康和福祉。)
注意:在这些黑暗的时期,自我隔离为自我提升腾出了一些空间,我们可以利用这些空间来发展新的技能、爱好,并帮助未来的自己。
探索性数据分析指南(下)

如果您已经到达这里,我相信您已经完成了我们讨论过的第 1 部分
- 数据清理过程
- 确定变量之间的关系,并在数据集上定义探索性问题
从我们离开的地方继续,我们现在开始学习可视化如何帮助我们理解数据帧中的数字和模式。我们将使用 Matplotlib——据我和业内一些最好的数据科学家所说,这是最好的 Python 数据可视化库。
重温我们需要回答的问题,
- 最成功的流派。
- 电影中频繁的演员阵容。
- 盈利电影的平均预算。
- 最赚钱电影的平均时长。
- 所有盈利电影中使用的语言范围。
深入思考这些问题,你会发现我们需要所有盈利电影的清单。我们现在必须把研究范围缩小到赚钱的电影。这将有助于我们分析什么样的成分组合能产生一部轰动一时的电影。
我想到的下一个问题是,我们如何决定一部电影是否盈利?为此,我选择了一个随机的(但合理的)5000 万美元的利润数字,这是任何电影在盈利电影桶中占有一席之地的标准。
我是这样操纵电影的 _df:
我得到了利润数据框架,它包含了所有利润≥5000 万美元的电影。
来到问题#1
我们在利润数据帧的类型列中有类型列表,我们必须格式化这些字符串,这样我们就可以很容易地得到所有盈利电影中每个类型的数量:
流派栏现在看起来像这样
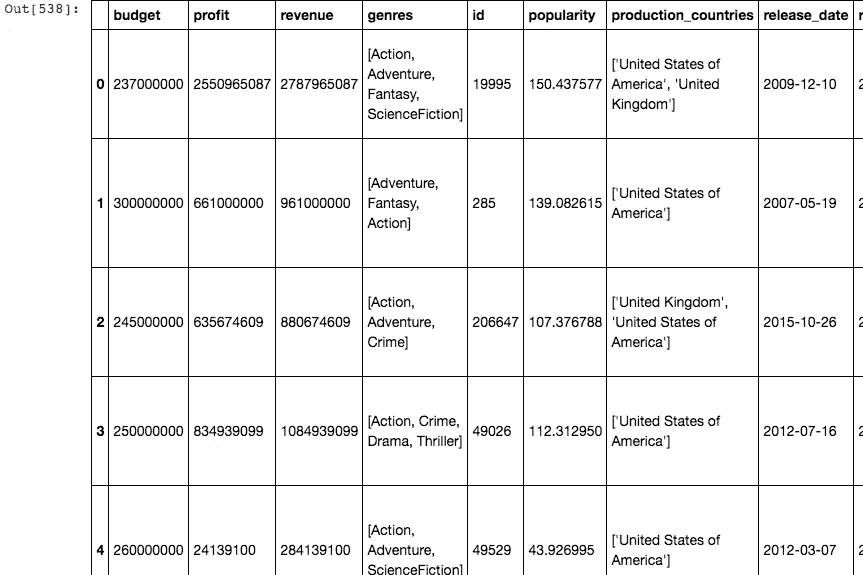
我们打算绘制一个条形图,帮助我们了解每种类型的电影在盈利电影中的成功之处,并对它们进行排名。
在我们开始绘制图表之前,我们需要了解一些事情。
Subplots: Matplotlib 有 Subplots 的概念,subplots 是一组较小的轴,它们可以一起存在于单个图形中。这些可以是插图、网格图或其他更复杂的布局。
Seaborn :基于 Matplotlib 用 python 编写的数据可视化库。重点是统计图表。该库是可视化单变量和双变量和分布图的良好资源,但 seaborn 有助于构建多图网格,让您轻松构建复杂的可视化。
我们在这里的问题是绘制出每种类型在所有盈利电影中的出现频率。我已经创建了一个熊猫系列,我可以使用 plot.barh()方法绘制它,下面是我是如何做到的:
我创建了一个列表,所有的流派都从“流派”列添加到这个特定的列表中,并扩展了列表 1。然后,我创建了一个系列,在这个系列上我使用了 value_counts()方法,该方法返回一个系列,其中包含每个流派的计数,如上面的要点所示。绘制这个数列给我们一个这样的柱状图
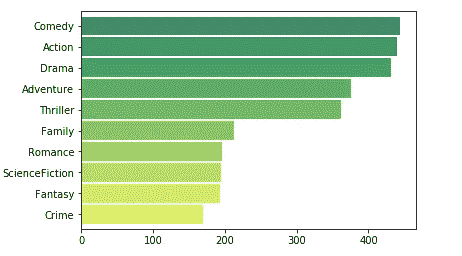
多田…!
从上面的柱状图我们可以看出,喜剧是所有盈利电影中最常见的类型。如果你想在好莱坞或其他电影行业赚点钱,这可以告诉你应该选择哪种类型。
问题 2
在类似的行中,我们能够得到盈利电影中最常见演员的类似情节,如下所示:

看看酒吧情节,塞缪尔·杰克逊是大多数电影成功背后的支柱。
问题 3
同样,我们有每种语言在盈利电影中的使用频率。
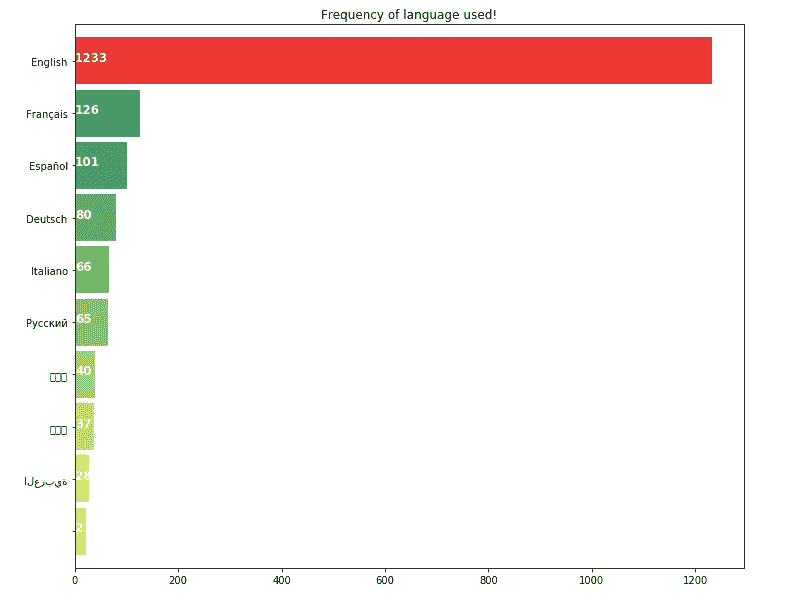
正如我们所料,英语是世界上最通用的语言。这很容易,但我们有证据。
除了这些可视化,我们还有其他非常有趣的情节要看。如果你有兴趣了解更多关于这些情节和设计模式所传达的信息,你可以浏览下面的链接。这将帮助你选择最恰当的方式来传达你的发现。
这里有一些我们想出来的帮助你考虑使用哪个图表。它的灵感来自《基因》中的表格…
extremepresentation.typepad.com](http://extremepresentation.typepad.com/blog/2006/09/choosing_a_good.html)
我们需要一些平均值(如问题 4、5 和 6 中所要求的)来总结我们的研究并阐明我们的假设。使用均值函数计算:
- 平均运行时间
- 平均收益
- 平均预算
一旦你有了这个,你就能建立你的假设,在我们的例子中如下:
这是一项非常有趣的数据分析。我们得出了一些关于电影的非常有趣的事实。经过这一分析,我们可以得出以下结论:
对于制片人来说,一部电影要想盈利:
平均预算必须在 6300 万美元左右电影平均时长必须在 114 分钟以上其中任何一位应在演员阵容:塞缪尔·杰克森,罗伯特·德·内罗,摩根·弗里曼,布鲁斯·威利斯类型必须是:动作片,冒险片,惊悚片,喜剧片,剧情片。通过这样做,这部电影可能会成为热门电影之一,因此平均收入约为 2.62 亿美元。
因此,在研究了 TMDB 数据集后,我们得出了以下结论。
PS:我希望这一系列的帖子能帮助你开始用你有的其他一些有趣的数据集进行探索性的数据分析。如果您对上述任何内容有任何问题/意见/想法,请在下面发表评论。
HMTL -解决自然语言处理任务的多任务学习
通过在任务间转移知识实现 SOTA 结果
自然语言处理领域包括许多任务,其中包括机器翻译、命名实体识别和实体检测。虽然不同的 NLP 任务通常是分别训练和评估的,但是将它们合并到一个模型中存在潜在的优势,即学习一个任务可能有助于学习另一个任务并改善其结果。
分层多任务学习模型( HMTL )提供了一种学习不同 NLP 任务的方法,首先训练“简单”的任务,然后使用这些知识训练更复杂的任务。该模型展示了几个任务的最新表现,并对模型每个部分的重要性进行了深入分析,从单词嵌入的不同方面到任务的顺序。
背景
近年来的几篇论文表明,结合多个自然语言处理任务可以产生更好和更深层次的文本表示。例如,识别句子中的实体,如地名或人名,有助于在后续句子中找到对它们的提及。然而,并非所有的 NLP 任务都是相关的,选择对其他任务有益的相关任务是很重要的。
HMTL 模型关注四个不同的任务:命名实体识别,实体提及检测,共指消解,关系抽取。
- 命名实体识别(NER) -识别文本中的实体类型(如个人、组织、位置等。)
- 实体提及检测(EMD)——NER 的扩展版本,识别任何与现实生活中的实体相关的提及,即使它不是一个名字。
- 共指消解(CR)——对同一实体的提及进行识别和分组。
- 关系提取(RE) -识别实体并对它们之间的关系类型进行分类(如果存在)。关系的类型可以在这里找到。由于 RE 和 CR 在语义上的相似性,它们都在同一层级上。
下面的文字说明了任务之间的区别(一个很棒的演示可以在这里找到):
我们在西班牙的时候,我妈妈教我如何开车。她还解释了如何给它加油

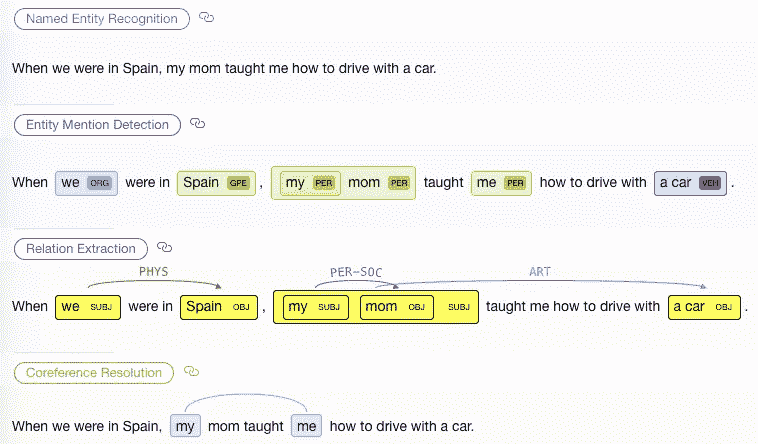
所有四项任务都与识别文本中的实体以及它们之间的关系有关,具有不同的复杂程度——而 NER 是最简单的一项,认知无线电和认知无线电需要对文本有更深的理解。因此,学习一项任务可能有助于学习其他任务。
HMTL 模式
HMTL 是一个层次模型,在这个模型中,最初简单的任务,如 NER,被学习,然后他们的结果被用来训练接下来的任务。每个任务由三个部分组成:单词嵌入、编码器和特定于任务的层。
该模型的基础是使用三种模型将输入句子中的每个单词嵌入向量的单词表示法:
- 手套 —预先训练的单词嵌入。这个模型中的单词没有上下文,给定的单词总是用相同的向量表示。
- ELMo —预训练的上下文单词嵌入。单词的矢量表示不仅取决于单词本身,还取决于句子中的其他单词。ELMo 是胶水基准中表现最好的模特之一。
- 字符级单词嵌入-一种卷积神经网络,它根据字符级特征学习表示单词。这种表示对形态特征(前缀、后缀等)更敏感,形态特征对于理解实体之间的关系很重要。
此外,每个任务都用专用的编码器进行训练——这是一个多层递归神经网络,可以生成为任务量身定制的单词嵌入。编码器使用双向 GRU 单元网络实现,其输出是前向和后向网络最后一层的级联。编码器的输入由基本单词表示和前一个任务编码器的输出(如果可用)组成。
在编码器之上,每个任务使用不同的神经网络,如下所述:
- 前两个层次(NER 和 EMD)使用一个条件随机场,根据一个词的相邻词的类型来预测该词的实体类型。该算法背后的概念是,它为句子中的所有单词 a 一起找到实体的最佳组合。很好的解释这个算法可以在这里找到。
- 在共指消解(CR)中,模型首先计算每个单词序列(“span”)成为前一个 span 的提及的可能性,例如,代词比动词更有可能成为提及。然后,它挑选前 N 个跨度,并计算每个跨度组合的得分,以形成一对。每个跨度最多可以是一个跨度的引用,通过使用 softmax 实现。在没有找到配对的情况下,添加一个伪令牌。
- 关系提取(RE)任务使用一个图层来计算每对标记匹配每种关系类型的概率(总共为 T * R_types 个概率)。该模型使用 sigmoid 函数,而不是 softmax,以允许每个令牌有多个关系。
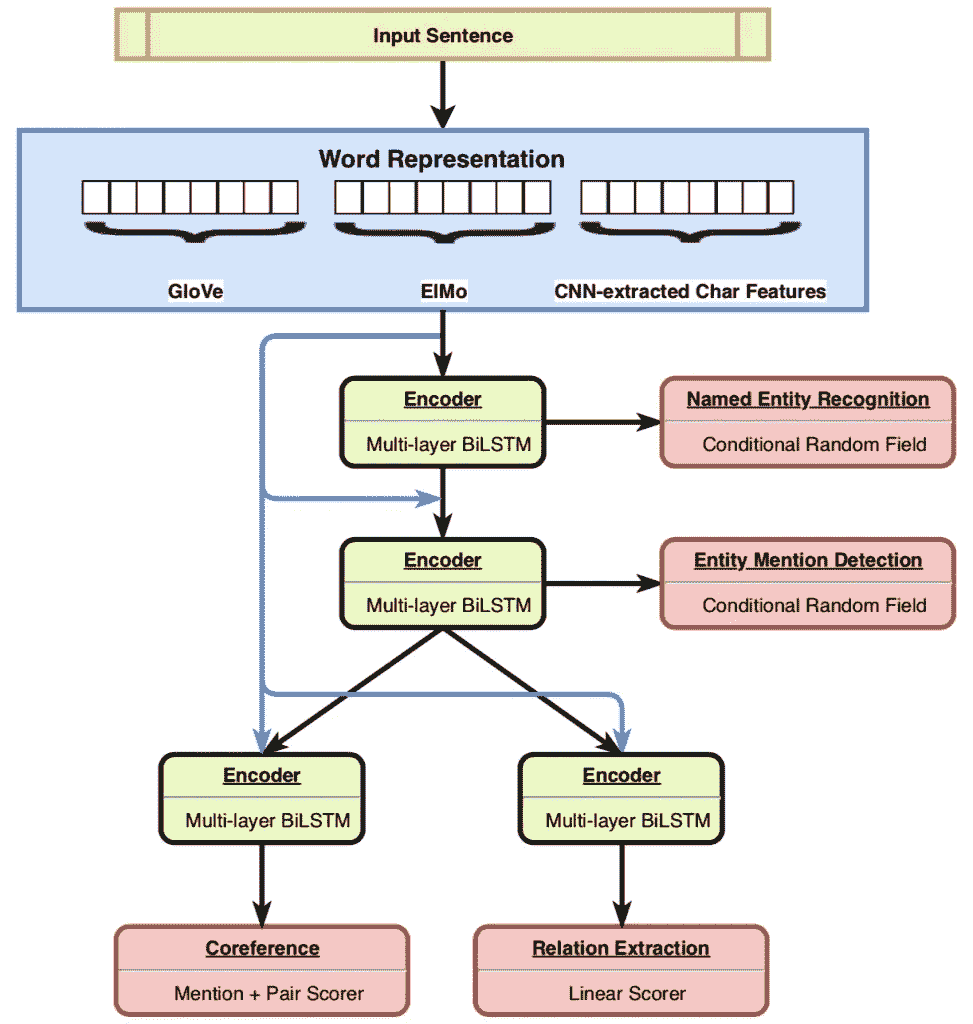
训练分层模型的挑战之一是灾难性遗忘,在这种情况下,训练新任务会导致模型“忘记”以前的任务,并对它们实现降级的性能。HMTL 通过在当前任务的训练过程中(每次参数更新后)随机选取一个先前的任务,并在随机任务数据集中的随机样本上训练模型,来处理灾难性遗忘。选择一项任务进行训练的概率并不一致,而是与其数据集的大小成比例,这是一种作者发现更有效的技术。
数据集
该模型在几个数据集上进行训练以进行比较,其中两个关键数据集是 NER 的 OntoNotes 5.0 和其余任务的 ACE05。ACE05 用于两种配置——常规和金牌提及(GM ), GM 配置由两部分组成:
- 共指消解(CR)任务的评估基于人工提取的黄金提及,而不是自动提及。这些提及的生成成本更高,并且无法用于大多数数据集。根据这篇论文,在评估中使用黄金提及可以提高 CR 的性能。
- 使用用于训练 RE 和 EMD 任务的相同数据集(ACE05)的不同分割来训练 CR 任务。使用不同的分割可以帮助模型学习更丰富的表示。
结果
该论文声称,通过使用黄金提及(GM)配置训练完整模型,在实体提及检测(EMD)和关系提取(RE)方面取得了最先进的结果。根据该论文,在训练中使用 GM 配置将 CR 任务的 F1 分数提高了 6 分,同时将 EMD 和 re 任务提高了 1-2 分。
该论文还声称在命名实体识别方面取得了最先进的结果,尽管最近的 BERT 模型似乎取得了略好的结果。然而,很难比较这两者,因为 HMTL 模型没有针对伯特使用的数据集进行微调。伯特的总结可以在这里找到。
这篇论文的另一个有趣的结果是减少了达到相同性能所需的训练时间。完整模型(含 GM)比大多数单一任务(NER (-16%)、EMD (-44%)和 CR (-28%)需要的时间少,但比 RE (+78%)需要的时间多。
关于 GM 配置的一个可能的担心是“信息泄漏”——由于不同的分割,用于训练一个任务的记录可能稍后被用作另一个任务的测试。关于这些记录的知识可能存储在一个共享层中,从而允许人工改进结果。
消融研究
任务组合多任务训练的贡献似乎是不确定的,取决于任务:
- 不同的任务通过不同的任务组合获得了最好的结果,这意味着没有一个占优势的组合。
- 在低级任务中,等级模型的好处很小(低于 0.5 F-1 分)。
- 最大的改进是在 RE 任务中实现的,超过 5 个 F-1 点。一种可能的解释是,EMD 任务在 re 任务之前被训练,并且学习识别与 RE 任务几乎相同的实体。
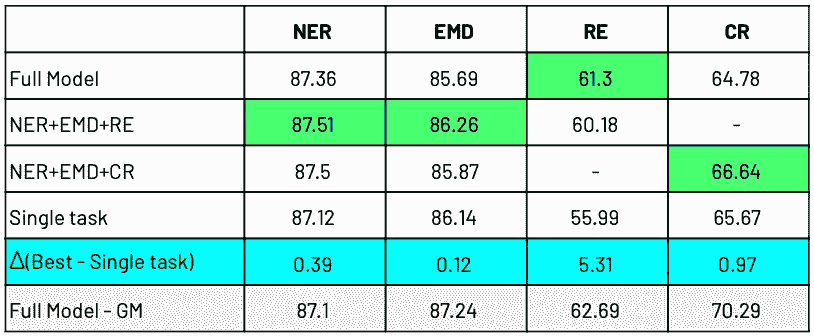
Task combinations comparison
单词表示
如前所述,该模型的基础是单词表示,它由三个模型组成——GloVe、ELMo 和字符级单词嵌入。这些模型的选择对模型性能也有很大的影响,如下表所示。Elmo 嵌入和字符级嵌入给大多数任务的 F-1 分数各增加 2-4 分。

Comparison of Word representation (Source: Sanh et al.)
结论
本文介绍了一种有趣的技术,它将看似独立的 NLP 任务和技术结合起来,以在语言分析中获得最佳结果。这些结果强调了对该领域进行进一步研究的必要性,因为目前很难理解何时特定的 NLP 任务可以有助于改善不相关的 NLP 任务的结果。
特别感谢本文作者之一 Victor Sanh,他对 HMTL 的运作提出了宝贵的见解。
与产品团队召开有效的分析会议
2015 年,我在游戏分析峰会上做了一个演讲,讲述了我在黎明游戏与不同游戏团队合作的经历。从那以后,我一直与电子艺界和 Twitch 的产品团队合作,并想为这次演讲提供一个更新。大多数科技公司现在都有分析团队,但将数据见解转化为可操作的结果通常很有挑战性。
我在 Daybreak Games 面临的挑战是,我在营销组织中领导一个中央分析团队,该团队需要与位于圣地亚哥和奥斯汀的游戏工作室合作。我们在产品团队中嵌入了分析师,但需要更多的结构来使工作室领导更加了解数据。我们努力实现这一目标的一种方式是改进分析团队与产品团队安排和举行会议的方式。
在重新设计如何安排会议时,我们会提出以下问题:
- 我们应该与产品团队共享哪些数据?
- 我们应该何时以及如何共享数据?
- 我们如何根据数据洞察采取行动?
为了确保分析团队能够与产品团队有效沟通,我们需要确定一组产品 KPI(关键性能指标),作为讨论的起点。如果没有首先决定如何跟踪产品性能,以及了解不同 KPI 之间的关系,您就有可能会因为关于跟踪什么是重要的问题而使会议偏离轨道。在《黎明游戏》中,我们提出了六个指标,在我们所有的游戏中进行跟踪,并利用这些 KPI 建立了工作室可以访问的自动化报告。我们确实担心的一个问题是,在整个公司范围内分享太多关于敏感话题的信息,比如公司财务状况。我们的方法是将所有报告和数据提供给工作室负责人,并为游戏团队的所有成员提供对特定游戏报告的访问。
一旦我们决定了如何与产品团队沟通,我们需要决定如何通过会议与团队合作。我们提出了三种方法,将在下一节详细讨论。这些不同会议的目标是确保我们能够向产品团队介绍我们的 KPI,定期检查性能,同步新功能的计划,并根据分析团队的发现提出建议。我们希望提供足够的结构,以便产品团队认为会议提供了关于产品性能的足够详细的信息,而不是默认向分析师提出特别的请求。
第三个挑战是让产品团队响应来自报告和分析的数据。我们最初的重点是让工作室领导可以访问自动报告,并让产品团队在分析会议中领导更多的讨论。这种成功因游戏团队而异,因为领导者有不同的背景和技术专长,但作为一家公司,我们在成为数据信息公司方面取得了一些进展。我们采取的另一种方法是直接与游戏团队合作,将分析团队提出的模型产品化。这包括对游戏内信息系统、营销工作和游戏内市场的改进。
在 Electronic Arts 和 Twitch,由于这些公司的规模,我在与产品团队合作时遇到了不同的问题。大多数产品团队已经确定了一组要跟踪的 KPI,但是不清楚跨团队的不同 KPI 是如何交互的。如果度量标准之间的关系不清楚,那么会议可能会因为讨论产品的分食或对归属的关注而偏离轨道。为了解决电子艺界的这一问题,我们必须更好地了解 EA Access 订阅服务和 Xbox One 游戏销售之间的关系,而在 Twitch,我们必须更深入地了解网络和移动观众之间的关系。一旦就这些不同的 KPI 如何交互达成一致,分析团队就能够召开更有效的会议。
分析会议
在修改了我们的 KPI 并在 daken Games 上报告之后,分析团队开始与产品团队召开以下类型的会议:
- 分析 101
- 数据 Scrum 会议
- 数据洞察会议
我们安排的第一类会议是与产品团队的领导一起审查我们的新报告工具,并解释我们重点跟踪的一组 KPI。然后,我们向公司的每个人开放了这些会议,并倡导更多地了解数据。这些分析 101 会议的目标是确保公司的每个人都知道我们在跟踪什么以及为什么。我们还举办了分析办公时间,产品团队的成员可以在这里学习如何获得更多的数据。
我们安排的第二组会议是每周与数据团队进行的简短的检查,称为数据 scrum 会议。我们为每个游戏都开了一次会,与会者包括来自不同学科的领导,包括设计、工程和品牌。这些会议的目标是跟踪标题的表现,并讨论更新(如促销活动)如何影响 KPI。在 Twitch,我们也利用这种类型的会议来讨论即将推出的功能,并确保我们对即将推出的新功能有跟踪规格和实验计划。数据 scrums 对于回顾分析团队在过去一周调查的特别请求,以及与更广泛的团队分享结果也很有用。
我们不想让自己的会议太多,所以我们尽量缩短 data scrum 会议,并根据需要安排 data insights 会议,当有更多实质性的结果需要讨论时。这类会议的目标是讨论分析的结果,为什么它很重要,并讨论如何根据发现做出响应。例如,我们可能希望根据对季节性商品销售的分析,对某个游戏市场进行更改。在电子艺界,我们会有类似的会议,通常可交付的是会后共享的幻灯片。Twitch 使用了一种不同的方法,分析团队会写一份长格式的报告,通过电子邮件发送给团队,然后根据产品团队的反馈召开会议。当 A/B 实验有冲突的结果时,数据洞察会议是有用的,并且产品团队需要确定是否全面推出该功能。
分析团队通常也参与每月的业务回顾会议,但通常不是与产品团队合作的好论坛。这些会议往往侧重于向高管提供细节,并往往侧重于产品路线图,而不是解释过去的业绩。
为了让分析师有效地与产品团队合作,重要的是要有足够的结构,让团队能够有效地交流产品性能,有机会在必要时分享发现,并能够跟进可操作的结果。在 Daybreak Games,我们通过标准化 KPI 和设置自动报告、安排教育会议来宣传我们的新方法、召开简短的定期会议来检查团队,以及根据需要安排会议来讨论深入分析来实现这一目标。
根据我在 Twitch 和 Electronic Arts 的经验,我对这条建议的主要改变是,鼓励通过 slack 等工具进行更频繁的沟通,而不是依赖数据 scrums 会议,并通过书面报告而不是甲板来分享结果。
一个人在家?在家用 Alexa,Echo 和 HomePod 重新定义隐私

Photo by Serge Kutuzov on Unsplash
“毫无疑问,销售这些产品的科技巨头将继续调整它们,希望避免类似的结果。然而,一个根本性的挑战依然存在:如何让那些靠便利推销自己的技术了解我们私人世界的复杂性和细微差别?”默里·古尔登,《对话》
我通常不喜欢引用别人的话来开始文章,但我认为古尔登先生很好地说明了当前个人语音命令设备上的隐私和大规模消费领域正在发生的事情。
你对家居(科技)的未来有多兴奋?人工智能驱动的虚拟助理和语音控制的设备正在权衡一场战争,看看谁将接管你的家庭命令。一个连接到你的 wifi 的设备,在云端存储数据,检查你的日常习惯,并以你的购物行为为食,这似乎是我们都在等待的完美的工程营销特洛伊木马。不是。
进入外观
虽然科技的未来似乎总是光明的,但人们似乎很容易开始怀疑反乌托邦的场景,几十年前乔治·奥威尔和雷·布雷德伯里等人就已经很好地描述了这种场景。这些设备从零售商到我们的家庭都是直接成型的,丝毫没有忽视对消费者的真正影响。进入Echo Look *,*亚马逊的新宝贝以及从纯音频到集成摄像头的交互设备的明显演变。完美的自拍杆不仅可以从 Alexa 收集音频请求,还可以拍照,以便比较你每天穿的衣服。是的,它通过使用机器学习,比较你在某一天、某一周或某个月做出的所有服装选择,学习你的购买行为并给你建议。奇特又恐怖。
变聪明:世界不是你的
可以肯定地说,对于亚马逊这样的大公司来说,数据收集是唯一重要的事情,亚马逊在说明他们在云服务器上实际存储了什么样的信息方面做得很差。虽然数据收集听起来是一项巨大的投资,但机器学习甚至更好。每个人都在这么做,所有的大品牌、社交媒体巨头和通信巨头都已经在这项技术上投入了巨资。
脸书旗下的 WhatsApp messenger 应用程序能够学习你的部分对话(音频或文本),这些对话是向你推销商品或给你推荐的基础。你提到过你和你的家人最近度假时发现的那个好地方吗?你和朋友讨论过未来去伦敦旅行的可能性吗?那么下次你登录你的脸书账户时,不要惊讶地看到你和你重要的人私下谈论的特定事情的广告或赞助内容。
开始重新定义供应商和消费者之间的关系是双方的责任。随着这些学习和识别技术的不断发展,我们必须开始要求我们的提供商在数据收集方面更加透明。从零售商的角度来看,解构和简化语言是日常消费者正确的第一步。细则应该停止微妙,让每个人都阅读所有的含义时,处理这种设备。
房屋改造分析转变为 Python 中的 Excel 数据处理

为什么清理数据是最重要的步骤
原始项目任务:寻找有趣的见解,了解改造市场的发展方向
项目任务(Twist): 如何用 Python 处理修剪良好的 excel 数据(剧透:整齐是骗人的词)
时间线:一周(我告诉你,如果你像我一样是 DS 新手,一周是不够的
针对最初目标的项目调查结果:
- 这些数字看起来很稳定,只是在优先级上有所调整
- 加州帕洛阿尔托的平均成本远高于全国平均水平
- 最大的全方位服务改造公司所在的州
**关于数据处理的发现:**熊猫(Python)有解决方案,生活还没绝望!
数据:探索不同来源的公开可用数据——哈佛大学联合住房研究中心、重塑杂志,并从 Hinkle 建筑公司的网页上获取加州帕洛阿尔托及其周边地区的平均项目成本。
方法:Python——主要使用 Pandas、Matplotlib、Seaborn 进行数据角力、基础统计和可视化。
这篇文章的顺序将是首先谈论我们从家庭改造数据中得到的结果。稍后,我们也将经历数据清理的斗争。
下图显示了不同类别的家庭装修的全国平均支出。数据显示,“客房增加”是最受欢迎的类别。在过去的 15 年中,这一类别的支出在 2005 年达到顶峰,平均支出约为 2.5 万美元。最低点是在 2011 年,支出降至 1.2 万美元以下。自那以后,市场似乎正在复苏。从 1995 年到 2005 年,房主在房屋扩建上的支出在 20 年内增长了 62%以上。另一个相对较大的变化是厨房改造,支出从 1995 年到 2015 年翻了一番,并在 2007 年达到顶峰。
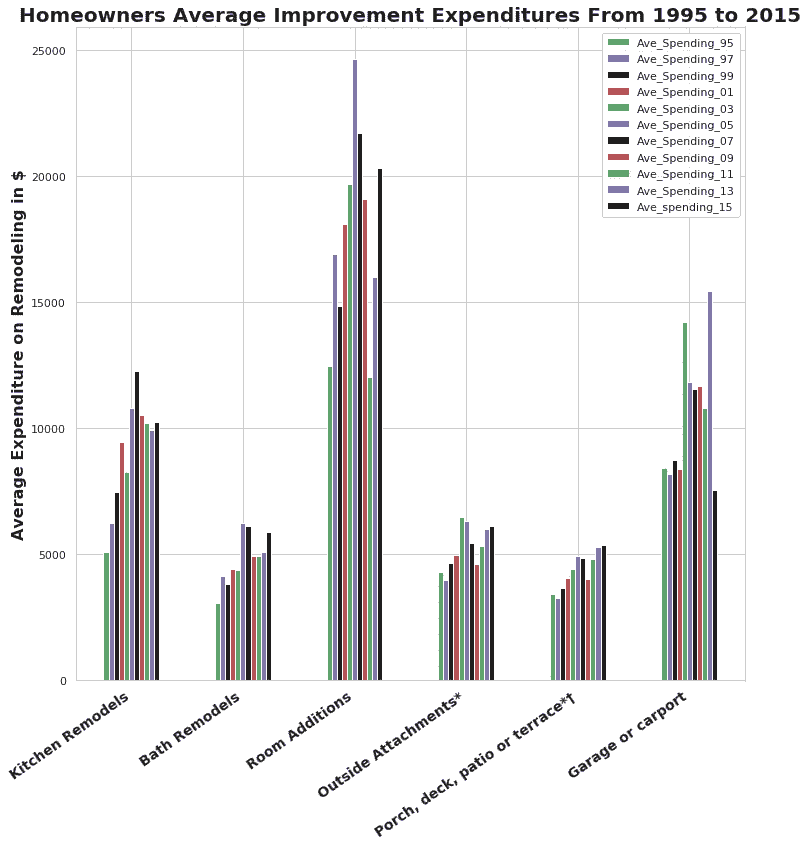
Source: Joint Center for Housing Studies at Harvard
当我得到上述结果时,我很想知道在我居住的地方,房主的平均支出。考虑到时间限制,我找不到与上图直接可比的数据,只能找到我们地区这些项目的平均值。
下面的条形图描绘了加利福尼亚州帕洛阿尔托市内及周边不同类型的房屋装修的平均成本。费用明显高于全国平均水平。增加一个 144 平方英尺的新房间,花费超过 5 万美元。主要的厨房改造也同样昂贵,为 5 万美元。

Source: Hinkle Construction Inc’ website
对于前两个图,如果感兴趣,请检查所附的 python 文件。
我不得不找出谁是装修行业最大的玩家。《重塑杂志》在这一领域进行了深入的研究。该杂志的重塑 550 部门收集数据,并根据前几年的收入宣布重塑业务的获胜者。用他们自己的话说:“2017重塑 550 有四个列表,每个列表都在下面的一个标签中显示,并显示全方位服务的重塑者、替代承包商、保险修复公司和特许经销商中的谁是谁。公司排名基于其 2016 年改造产生的收入;不按公司毛收入。
我只调查了 2017 年的全服务公司。该排名基于 2016 年的收入(2018 年的榜单要到 2019 年 5 月才会公布)。
该条形图显示了全国重塑业务中最突出的 15 家公司(总共 340 家)。
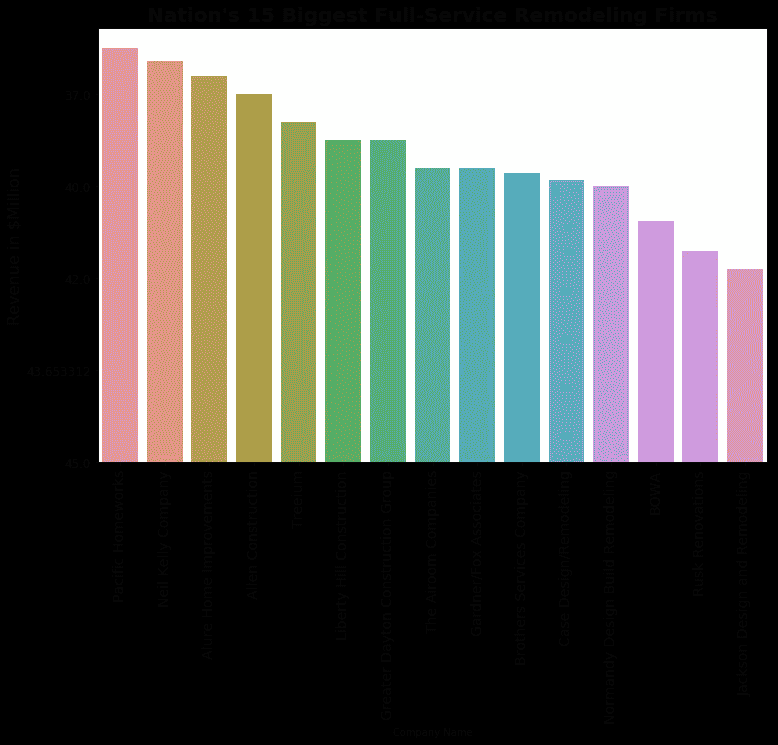
Source: Remodeling magazine
不出所料,这些公司中有相当一部分位于加州。
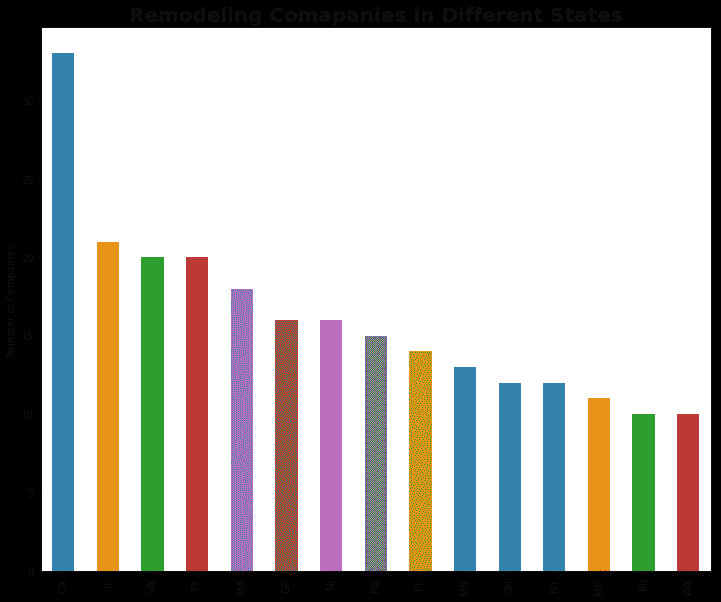
Source: Remodeling magazine
最后的情节只是为了好玩。我运行了一个相关矩阵,以了解收入、排名和其他变量之间的相互关系。阴影显示相关系数的强度。比如:排名(’ # ')和营收高度负相关。不要在这里混淆。我们都知道排名是如何工作的:数字越低,排名越好(1 是最好的)。所以,收入越高,数字越低(比如 1),意味着排名越高。
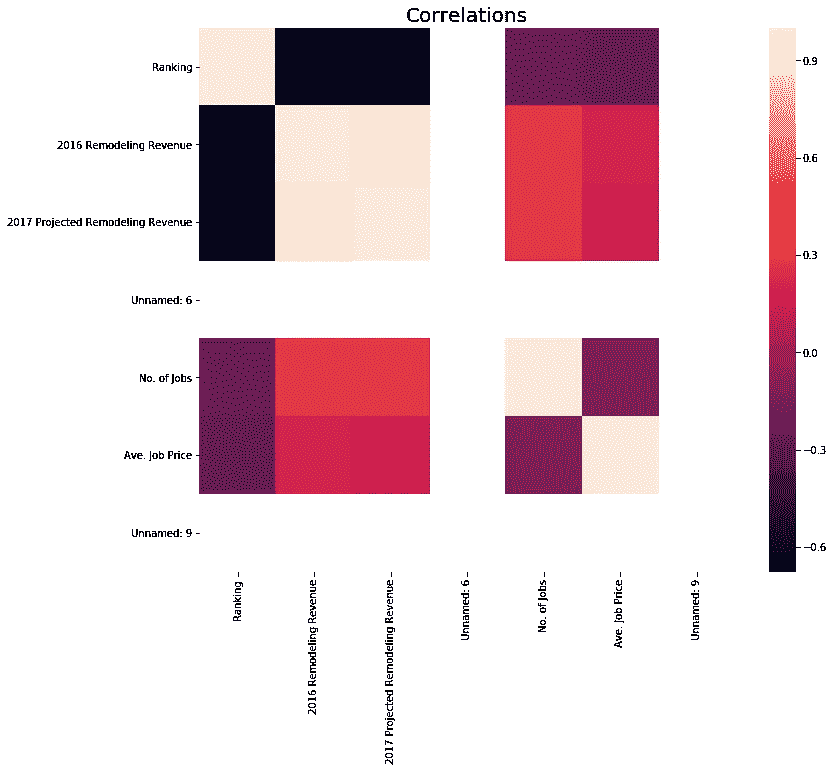
以下是我在 Jupyter 笔记本上为以上情节所做的工作。
现在,让我们像承诺的那样谈谈数据争论/清理斗争部分。我为这个项目收集的数据的一些背景:
- 我下载了比我实际需要/可以及时处理的多得多的数据
- 我认为更多的数据总是意味着更好的结果
- excel 中漂亮、整洁的数据意味着 Pandas/Python 中更少的清理。不对!第一个错误。
- 我的数据分布在 4 个不同文件的 26 个 Excel 表格中(我不是开玩笑)
**整洁的 Excel 表格中的问题:**这些是我遇到过的问题,所以要小心,可能还有更多我还没有遇到的问题。
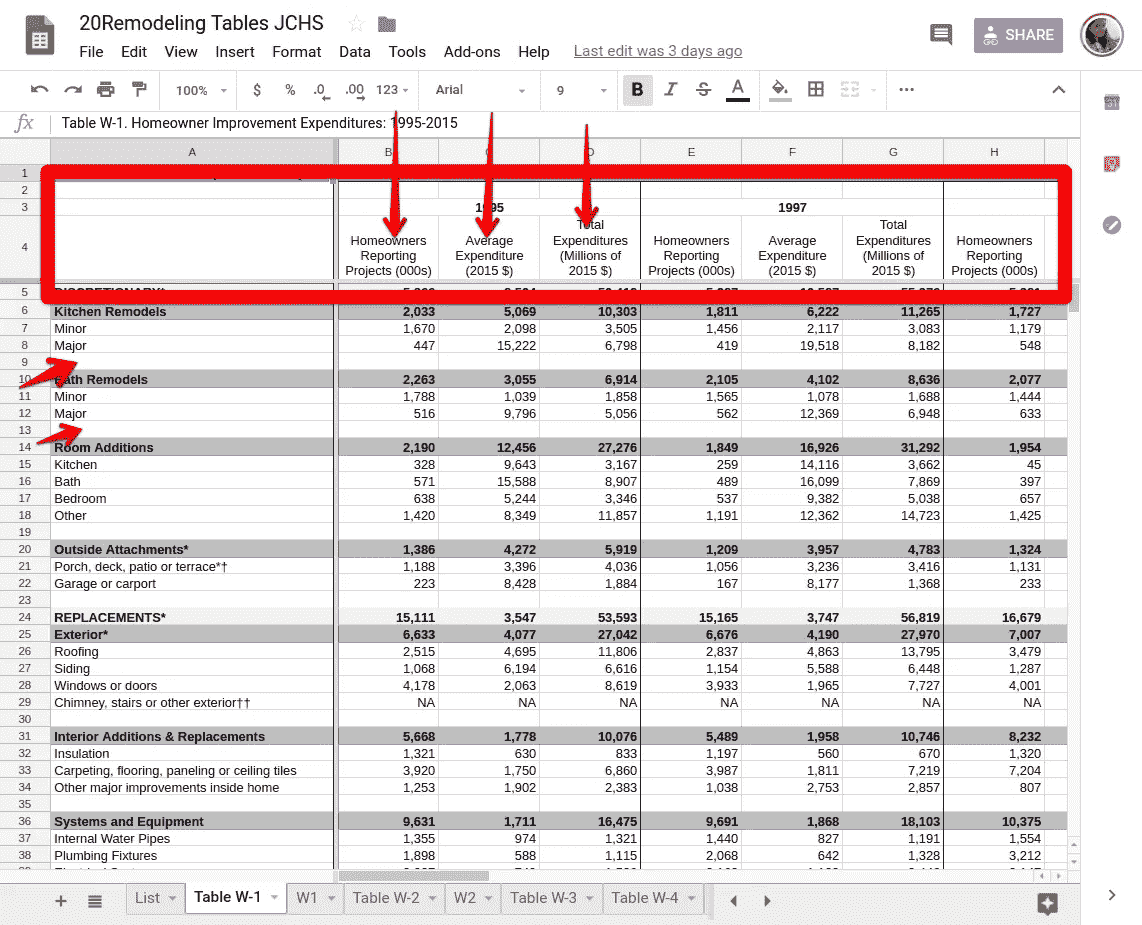
Impressively neat excel data
- 空单元格:Excel 在让单元格为空时更灵活,但你的熊猫阅读功能不会喜欢它。它在嘲笑你,就像“告诉过你,现在就去对付南方人!”
- 页眉:excel 中干净的页眉在 Pandas 中不一定意味着什么。您检查实际的列名,不要惊讶实际的列名与 excel 标题中显示的有很大不同!更改列名。列数越多,工作量越大。
- 另一个类似的问题是,当除了第一列之外的所有列都有列名时(在 excel 中,如果是分类变量列,这仍然有意义),但是在 Pandas framework 中对这样的列进行操作是一个问题。
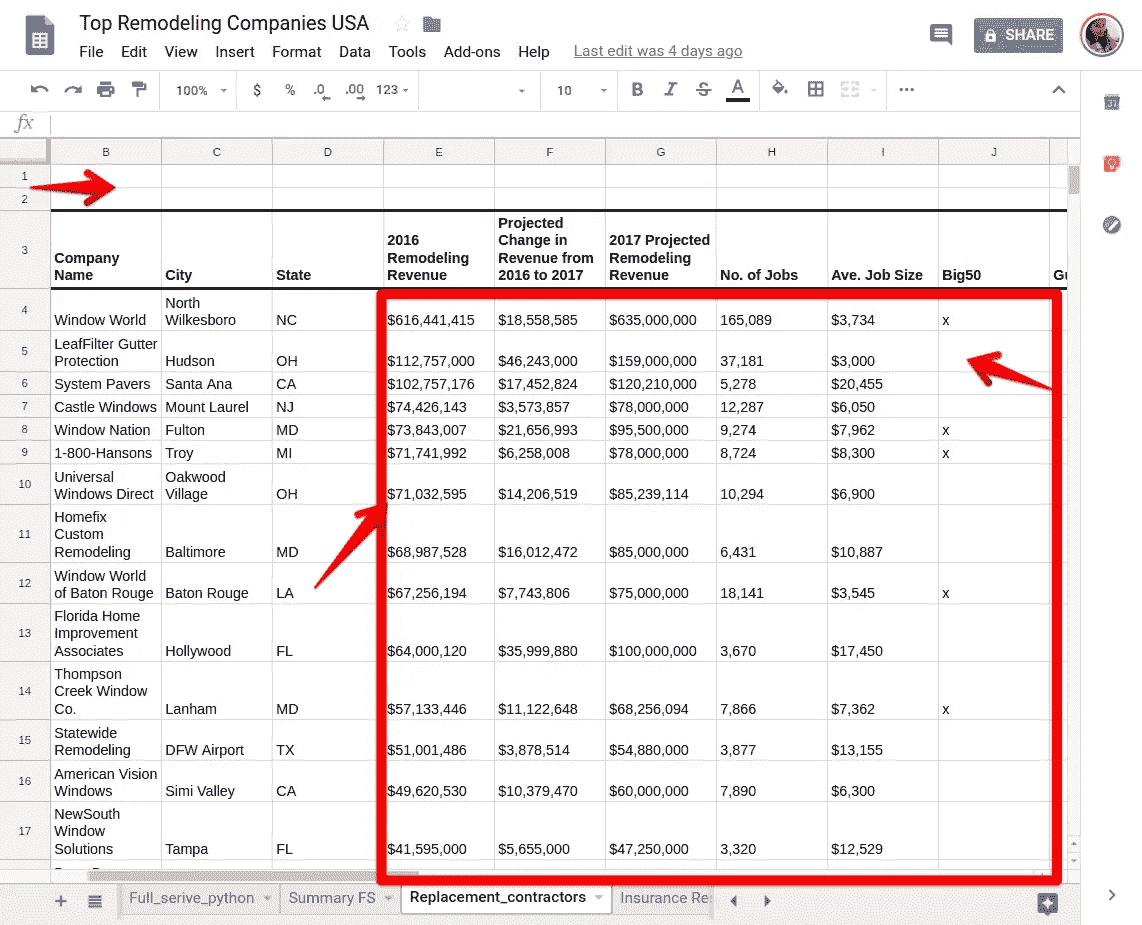
- 啊!那些看起来整洁的数值!不要被骗了。你将不得不应付每一个。单身。号外。东西。你在这两个数字之间。可以是美元符号、逗号等等。熊猫把它看做一个物体,这是一个问题。你不可能用它达到任何统计/数学目标。你必须把它转换成 int/float 才能使用。
我从这个项目中学到了什么:
- 想想时间线,不要有额外的野心。选择一个可行的数据集。与其选择多个数据集,不如选择一个,想想有多少种方法可以操纵/分析它。
- 围绕项目可交付成果对工作进行优先级排序。当你陷入我这种有很多零碎数据的情况时,重新安排你的目标的优先次序,遵循倒金字塔原则:先做最重要的工作。
- 您不必总是将 excel 文件转换为. csv。有一种更简单的方法可以直接导入所需的工作表。它只需要一个工作路径名。
- 求助。作为 Python 的初学者,我比我希望的更经常地挣扎。但是向你的同事/导师/经理寻求帮助可能会给你提供有价值的见解和针对单一问题的多种解决方案。
- 当你遇到困难时,在 excel 中解决问题比花时间在 Python 中解决问题更容易。但是,我告诉你,在熊猫身上,不付出并以正确的方式得到回报是值得的。
- 您需要知道什么样的可视化适合您的数据。Python 中有很酷的可视化库,但是没有一个很酷的图形适用于您的数据,这没关系。当看到大错误时,不要忽视它。
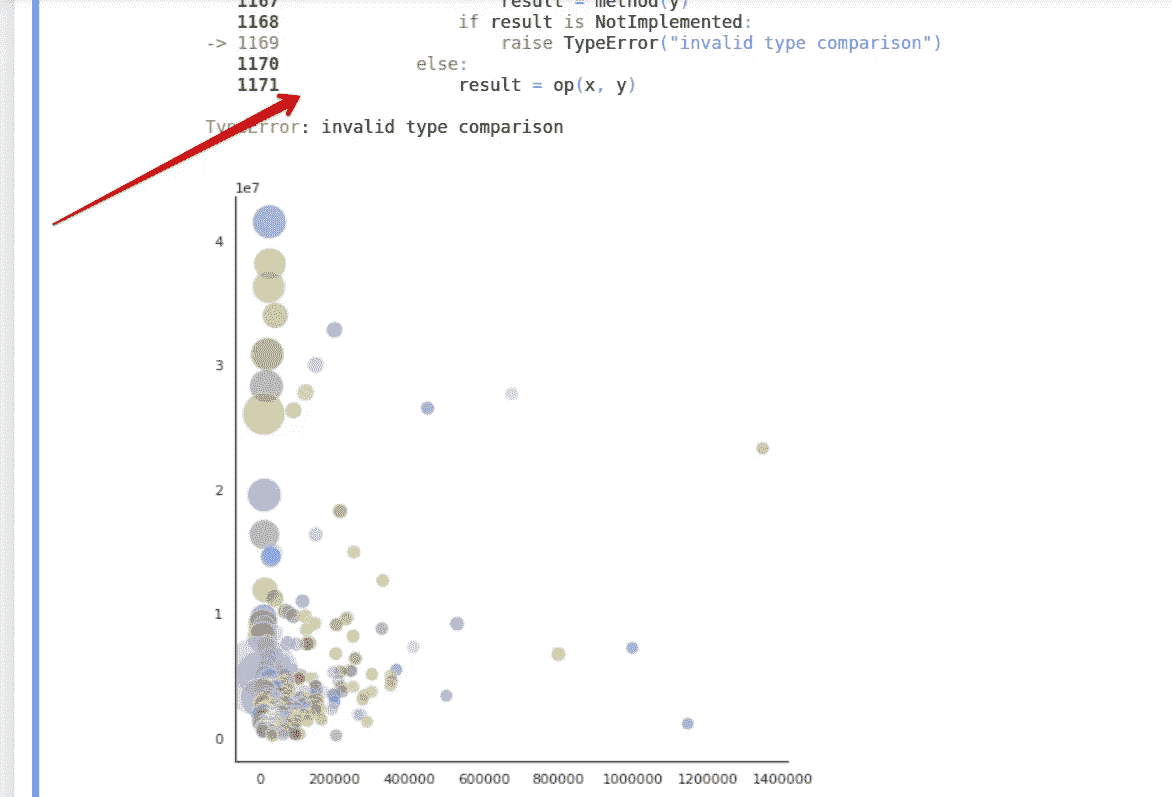
在上图中,我试图描绘出所有 340 家重塑公司,它们的收入,工作数量和平均工作价格。这是无效的比较类型。尊重错误,深入挖掘,才知道什么样的图更适合你的数据表示。简单并不意味着坏,因为花哨并不总是意味着更好(好吧,可能是葡萄酸在这种情况下,因为我不能得到一个花哨的情节,但我说的是真的)。
对我来说,第一个项目是一个很大的学习曲线。但在培训中,我成为了一名更强大、准备更充分的数据科学家,再也不会以同样的眼光看待 excel 数据表了。😃
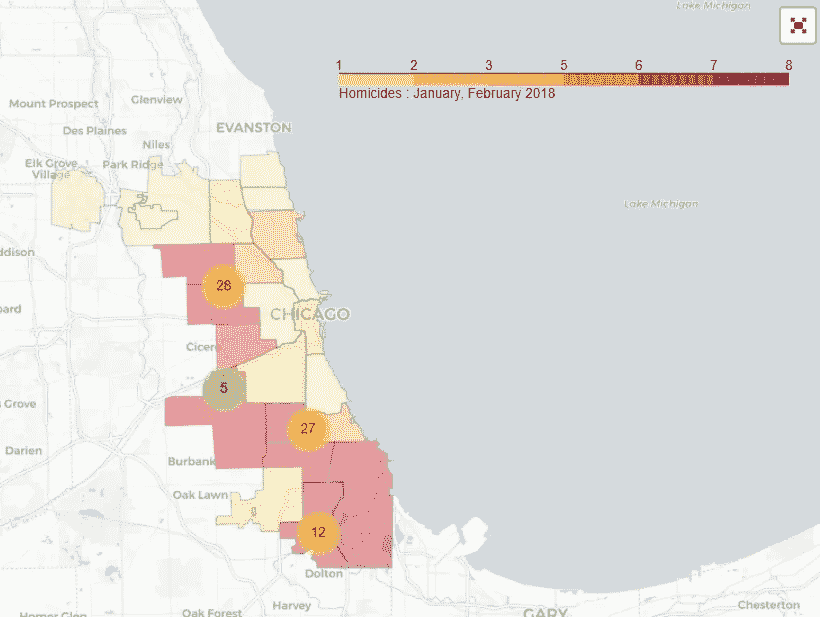
芝加哥凶杀案:数据故事第一部分

数据清理
在过去的几年里,芝加哥经常出现在新闻中,尤其是因为最近枪支暴力导致的谋杀案激增。作为芝加哥的居民,我知道这些枪击事件大多局限于该市的某些地区,但为了真正了解这种暴力的真实性质,我决定深入挖掘芝加哥市的数据。
很可能因杀人被捕的几率不到一半。如果你是住在高犯罪率地区的罪犯,这种可能性会大得多。
这篇博文分为两部分。第一部分包括数据清理,第二部分在这里找到进入数据探索和可视化。
我在 Jupyter 笔记本上使用 Python 进行了数据清理、探索和可视化,希望在这个过程中发现一些有趣的见解。我也用过下面的 python 库。完整的笔记本、支持代码和文件可以在我的 GitHub 中找到。
*# import modules*
**import** **numpy** **as** **np**
**import** **pandas** **as** **pd**
**from** **pandas** **import** *
**import** **os**
**import** **matplotlib.pyplot** **as** **plt**
**import** **seaborn** **as** **sns**
%**matplotlib** inline
**import** **datetime**
**from** **scipy** **import** stats
sns.set_style("darkgrid")
**import** **matplotlib.image** **as** **mpimg**
**from** **IPython.display** **import** IFrame
**import** **folium**
**from** **folium** **import** plugins
**from** **folium.plugins** **import** MarkerCluster, FastMarkerCluster, HeatMapWithTime
我使用了下面链接的芝加哥市数据门户网站的公开数据,来探索芝加哥从 2001 年 1 月到 2018 年 2 月的犯罪情况。
数据来源:
- https://data . city of Chicago . org/Public-Safety/Crimes-2001 年至今/ijzp-q8t2
- https://data . city of Chicago . org/Public-Safety/Boundaries-Police-Beats-current-/aerh-rz74
笔记本工作流程如下:
- 将数据集加载到 pandas 数据框架
- 数据探索和清理
- 洞察提取
- 结论
来自城市数据门户的原始数据集。CSV 格式,但对我的笔记本电脑资源来说太大了(1.5 GB)。我无法在内存中容纳整个文件,所以我使用 pandas 的 TextFileReader 函数,该函数允许我以 100,000 行的块加载大文件,然后将这些块连接回一个新的数据帧。
加载数据集后,我使用了 panda 的一些内置函数来探索数据的特征,如下所示。
*# use TextFileReader iterable with chunks of 100,000 rows.*
tp = read_csv('Crimes_-_2001_to_present.csv', iterator=**True**, chunksize=100000)
crime_data = concat(tp, ignore_index=**True**)
*# print data's shape*
crime_data.shape# Output:
(6546899, 22)
接下来,我们查看列的基本统计信息
crime_data.info()Output:<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6546899 entries, 0 to 6546898
Data columns (total 22 columns):
ID int64
Case Number object
Date object
Block object
IUCR object
Primary Type object
Description object
Location Description object
Arrest bool
Domestic bool
Beat int64
District float64
Ward float64
Community Area float64
FBI Code object
X Coordinate float64
Y Coordinate float64
Year int64
Updated On object
Latitude float64
Longitude float64
Location object
dtypes: bool(2), float64(7), int64(3), object(10)
memory usage: 1011.5+ MB
下一行代码预览数据帧的前 5 行。
crime_data.head()
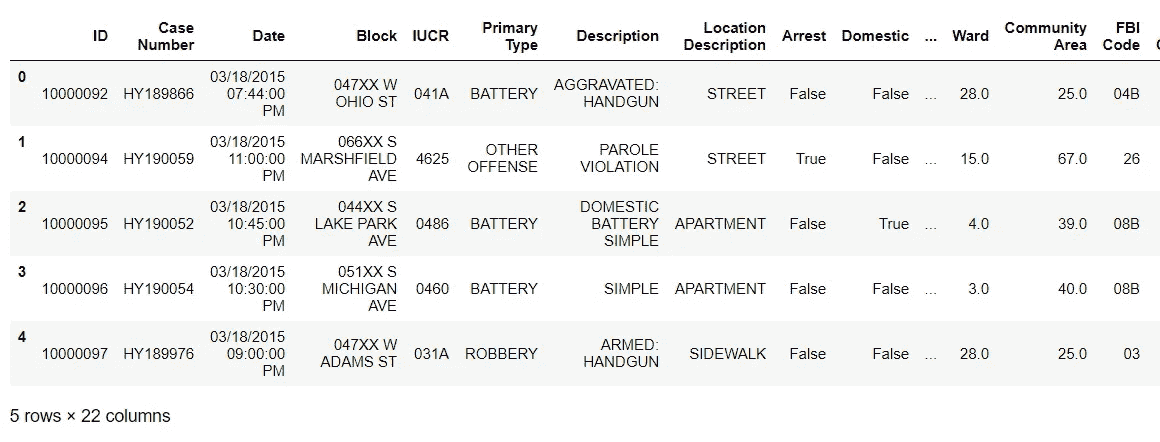
关于数据的观察。
- 从上面的单元格中,我们可以看到有 22 列和 600 多万行,但同样重要的是,我们可以看到每一列中使用的数据类型。
- 这一步很重要,有助于我们发现是否需要将数据类型更改为更适合我们特定需求的格式。例如,日期列可能需要更改为 python 的 datatime.datetime 格式,以提取月份、时间和星期几信息。
- 我们还可以从主要类型栏中看到,我们的研究主题(凶杀)与其他犯罪混合在一起,因此在某些时候我们必须将凶杀放在单独的表格中。
- 通过观察上面的输出,我们可以获得的另一条信息是,数据集中的一些列在重要性上重叠,因此在最终的 dataframe 配置中保留所有这些列是没有意义的。
- 从内存的角度来看,这也会使我们的数据帧不那么庞大。将这种臃肿的配置输入到机器学习(ML)任务中是一种糟糕的做法,因为它无助于模型对数据进行良好的概括。
*# preview all crime variables in the "Primary Type" column*
crimes = crime_data['Primary Type'].sort_values().unique()
crimes, len(crimes)

芝加哥警区地图与所有犯罪地理位置散点图
- 我对凶杀案的数字感兴趣,但我仍然想知道整个城市的总体犯罪率是如何分布的。有多种方法可以做到这一点,但我还是创建了一个散点图,绘制了数据集中所有犯罪地理位置(X 和 Y 坐标),并将其绘制在城市的地理地图上。
- 我还使用了警区作为色调,以更好地了解城市不同社区的犯罪分布情况。
- 我本可以使用社区区域或选区将城市细分为不同的区域,但这两个变量在可用时间框架(2001-2018)的持续时间内缺少大量数据点。
- 使用替代列意味着我们必须删除其他行中的大量数据,多达 600,000 多行,而这恰好是数据集的 10 %。有点太多的数据丢失,可能还有重要的信息。
*# Created a scatter plot of X and Y coordinates vs all crime data available in the dataset*
crime_data = crime_data.loc[(crime_data['X Coordinate']!=0)]
sns.lmplot('X Coordinate',
'Y Coordinate',
data=crime_data[:],
fit_reg=**False**,
hue="District",
palette='Dark2',
size=12,
ci=2,
scatter_kws={"marker": "D",
"s": 10})
ax = plt.gca()
ax.set_title("All Crime Distribution per District")
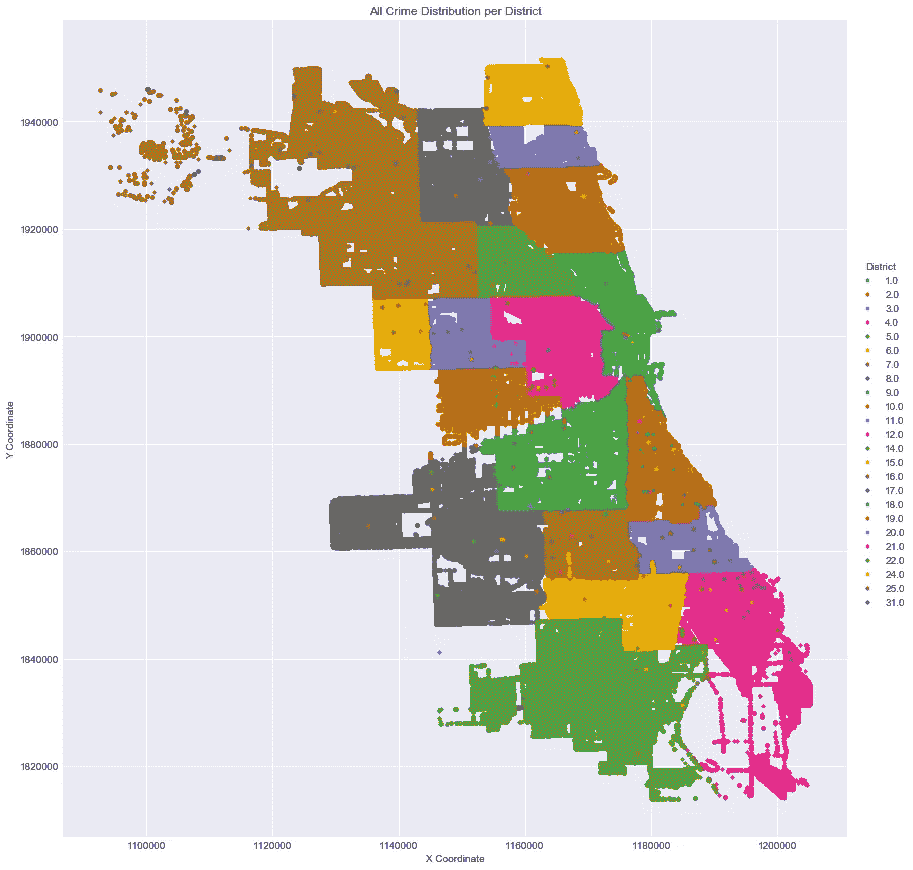
- 从上面的可视化效果中,我们可以看到来自地区网络的图像和数据集中所有犯罪数据地理位置的散点图,从而生成了芝加哥地图的副本图像。
- 散点图中有一些缺口,但这些地方没有连续的人类活动,如河流、港口和机场。
- 芝加哥警方过去将芝加哥的绝大多数凶杀案归因于帮派暴力,所以我从主要类型列中分组了 4 种通常与帮派活动有关的犯罪,并创建了散点图,以查看它们在整个城市中是否有相似的地理分布。这四种罪行是杀人罪、私藏武器罪、毒品和武器罪,其情节如下所示。
*# create and preview dataframe containing crimes associated with gang violence*
col2 = ['Date','Primary Type','Arrest','Domestic','District','X Coordinate','Y Coordinate']
multiple_crimes = crime_data[col2]
multiple_crimes = multiple_crimes[multiple_crimes['Primary Type']\
.isin(['HOMICIDE','CONCEALED CARRY LICENSE VIOLATION','NARCOTICS','WEAPONS VIOLATION'])]
*# clean some rouge (0,0) coordinates*
multiple_crimes = multiple_crimes[multiple_crimes['X Coordinate']!=0]
multiple_crimes.head()

接下来,我将该组中每起犯罪的地理分布散点图可视化,以了解这 4 起犯罪在整个城市中的分布情况。
# geographical distribution scatter plots by crime
g = sns.lmplot(x="X Coordinate",
y="Y Coordinate",
col="Primary Type",
data=multiple_crimes.dropna(),
col_wrap=2, size=6, fit_reg=**False**,
sharey=**False**,
scatter_kws={"marker": "D",
"s": 10})
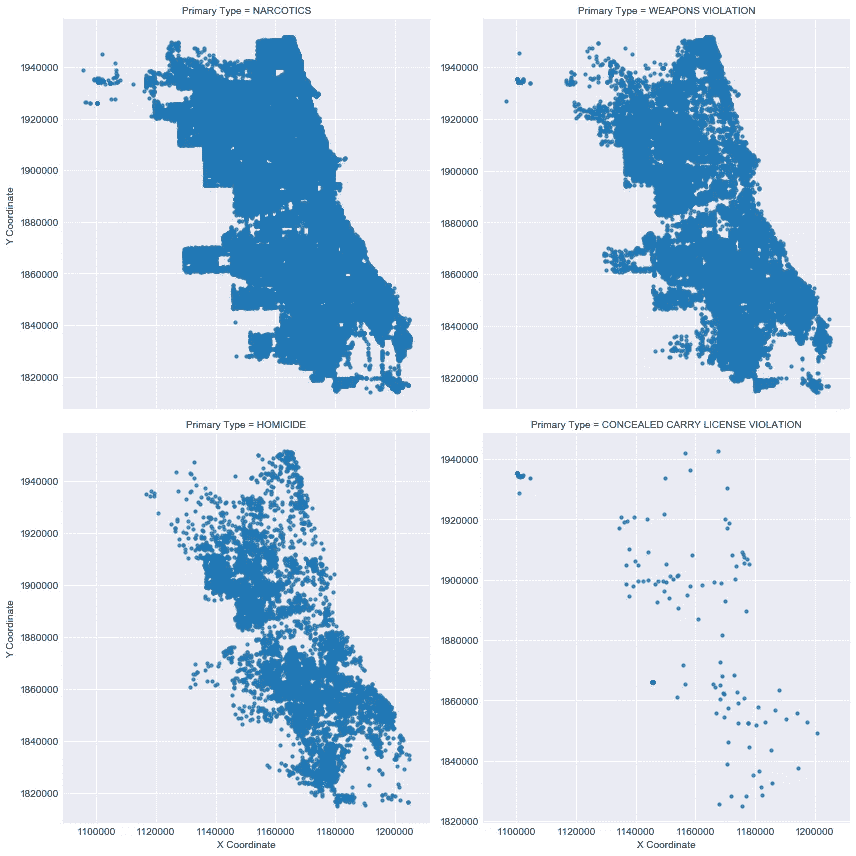
- 看起来毒品和武器违规犯罪在整个城市都很常见,但是杀人和隐蔽携带违规犯罪有一个特定的地理模式开始出现。
- 在左上角和底部有两个区域似乎发生了犯罪集群,这是一个很好的观察结果,但得出任何鼓舞人心的结论还为时过早。
- 也可能是毒品犯罪在帮派活动之外更为常见,就凶杀案而言,它并不能真正告诉我们任何事情。这将成为机器学习预测任务的一个好主题。
在进行了一些基本的观察之后,是时候检索一个包含凶杀案数据的数据框架并做一些数据清理了,然后我才能继续深入研究它。
*# create a dataframe with Homicide as the only crime*
df_homicideN = crime_data[crime_data['Primary Type']=='HOMICIDE']
df_homicideN.head()
*# print some attributes of our new homicide dataframe*
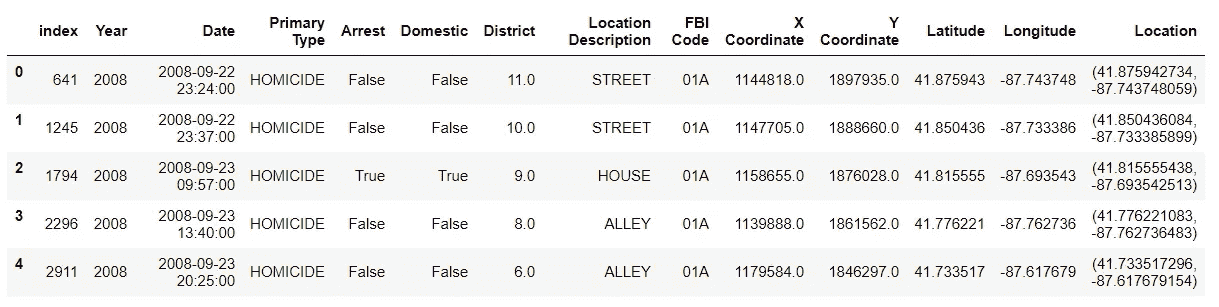
df_homicideN.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 8975 entries, 641 to 6546894
Data columns (total 22 columns):
ID 8975 non-null int64
Case Number 8975 non-null object
Date 8975 non-null object
Block 8975 non-null object
IUCR 8975 non-null object
Primary Type 8975 non-null object
Description 8975 non-null object
Location Description 8975 non-null object
Arrest 8975 non-null bool
Domestic 8975 non-null bool
Beat 8975 non-null int64
District 8975 non-null float64
Ward 8594 non-null float64
Community Area 8594 non-null float64
FBI Code 8975 non-null object
X Coordinate 8893 non-null float64
Y Coordinate 8893 non-null float64
Year 8975 non-null int64
Updated On 8975 non-null object
Latitude 8893 non-null float64
Longitude 8893 non-null float64
Location 8893 non-null object
dtypes: bool(2), float64(7), int64(3), object(10)
memory usage: 1.5+ MB
找到数据帧中的所有空值,以便进一步清理。
*# find null values in our dataframe*
df_homicideN.isnull().sum()# OUTPUTID 0
Case Number 0
Date 0
Block 0
IUCR 0
Primary Type 0
Description 0
Location Description 0
Arrest 0
Domestic 0
Beat 0
District 0
Ward 381
Community Area 381
FBI Code 0
X Coordinate 82
Y Coordinate 82
Year 0
Updated On 0
Latitude 82
Longitude 82
Location 82
dtype: int64
从上面的单元格我们可以观察到:
- 我们现在总共有 8981 行数据,7 列包含空值。
- 选区和社区区域列有 386 个空值,而区的空值为零。就绘制地理比较而言,我选择了地区列,因为它似乎更容易获得。然而,对于数据清理,人们总是必须权衡保留或丢弃数据的利弊,规则不是一成不变的,而是我们必须使用我们最好的判断和测试测试。
- 我总共有 463 行包含一个或多个空值。
- 接下来,我从数据帧中删除了所有包含空值的行,以便能够对数据集执行不同的数据转换。
*# drop null values and confirm*
df_homicide = df_homicideN.dropna()
df_homicide.isnull().sum().sum()# OUTPUT
0
接下来,我创建了一个要保存的列列表,并用新列更新了数据帧。
*# create a list of columns to keep and update the dataframe with new columns*
keep_cols = ['Year','Date','Primary Type','Arrest','Domestic','District','Location Description',
'FBI Code','X Coordinate','Y Coordinate','Latitude','Longitude','Location']
df_homicide = df_homicide[keep_cols].reset_index()
df_homicide.head()

删除空列后,我用我认为最有助于理解芝加哥凶杀案的列更新了数据框架。
- 我应该提到,新的见解可能会导致我们回去重新检查我们放弃的列,但现在我们应该没问题。
- 下面我使用 pandas datetime 函数从 Date 列中提取一些时间变量。这些新列给了我额外的维度来可视化数据,也许还有新的见解。
*# change string Date to datetime.datetime format*
df_homicide['Date'] = df_homicide['Date'].apply(**lambda** x: datetime.datetime.strptime(x,"%m/**%d**/%Y %I:%M:%S %p"))
df_homicide.head()
*# create new columns from date column -- Year, Month, Day, Hour, Minutes, DayOfWeek*
df_homicide['Year'] = df_homicide['Date'].dt.year
df_homicide['Month'] = df_homicide['Date'].dt.month
df_homicide['Day'] = df_homicide['Date'].dt.day
df_homicide['Weekday'] = df_homicide['Date'].dt.dayofweek
df_homicide['HourOfDay'] = df_homicide['Date'].dt.hour
df_homicide = df_homicide.sort_values('Date')
*# print columns list and info*
df_homicide.info()
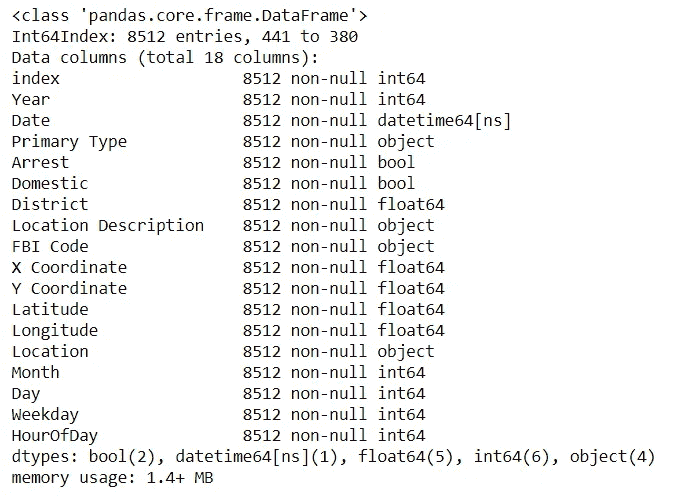
到目前为止,我已经创建了一个更精简的熊猫数据框架,只包含原始犯罪数据框架中的相关数据。在下一节中,我们将尝试探索和可视化新的凶杀数据框架。
泡菜数据
现在,我们已经执行了一些数据清理,我们可以开始将其可视化,以获得芝加哥犯罪的更大图片。为了能够从我们停止的地方继续,我以 pickle 形式存储了新数据,这是 Python 中一种将对象保存到文件中供以后检索的方法。Pickling 通过将对象写成一个长字节流来实现这一点。
*# save cleaned data to pickle file*
df_homicide.to_pickle('df_homicide.pkl')
print('pickle size:', os.stat('df_homicide.pkl').st_size)# load pickled data
df_homicide = pd.read_pickle('df_homicide.pkl')
这个芝加哥犯罪数据集的数据探索和可视化将在本帖的第二部分继续。
芝加哥凶杀案:数据故事第二部分
Image via Wikipedia
数据探索和可视化
这是关于芝加哥凶杀案的数据故事的第二部分,这是最近的一个热门话题,包括特朗普总统在 2017 年竞选时提到的。作为芝加哥人,每次我遇到来自其他州的人,他们都会情不自禁地和我谈论这个城市的谋杀率,但很少有人从数据意识的角度提起这个话题。
在本系列的第一部分中,我清理了犯罪数据,但现在我将尝试从这些数据中提取一些见解。在这一节中,我将使用前一节中新创建的熊猫数据帧来描绘芝加哥市的凶杀案。
芝加哥最危险的地方是街道上,在夏天,周末,晚上 11 点到凌晨 2 点。
整个城市的犯罪分布
我们首先想看到的是按警区分组的整个城市的凶杀犯罪分布。
为此,我们将使用 Seaborn 。我们将从第一部分中早期的散点图中获得灵感,按地区可视化 2001 年至 2018 年 2 月的所有凶杀案。下面是代码和结果图。
*# plot all homicides in dataset by location per District*df_homicide = df_homicide.loc[(df_homicide['X Coordinate']!=0)]sns.lmplot('X Coordinate',
'Y Coordinate',
data=df_homicide[:],
fit_reg=**False**,
hue="District",
palette='Dark2',
size=12,
ci=2,
scatter_kws={"marker": "D",
"s": 10})
ax = plt.gca()
ax.set_title("All Homicides (2001-2018) per District")
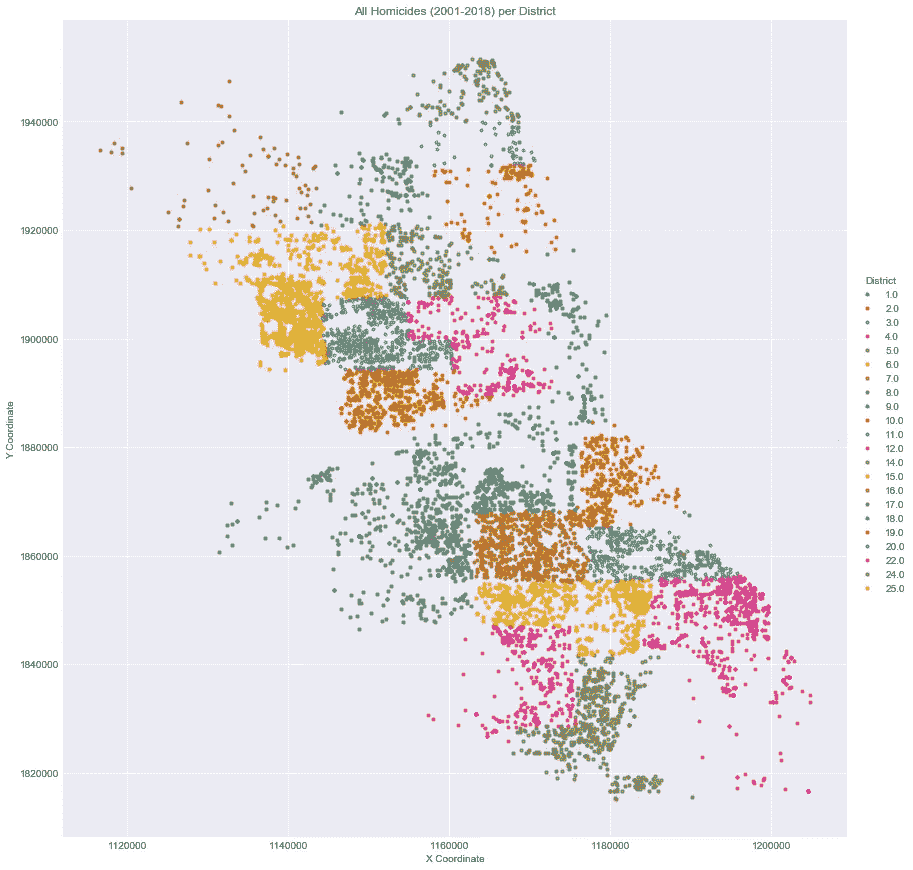
从上图中,我们可以观察到以下情况:
- 高凶杀率聚集在散点图的左上方和中下方。
- 右上角和中间一些区域的凶杀率更为分散。
由于每个区都是不同的颜色,我们可以从这张图表中获得的重要见解是,有很多点聚集在一起的区比没有聚集在一起的区有更多的凶杀率。所以现在,在某种程度上,我们对空间维度的凶杀有了一个概念,但我也想从时间维度了解这些凶杀率。
下面我创建了一些凶杀案与时间的可视化,并对之后的观察做了笔记。
年度凶杀率:
*# plot bar chart of homicide rates for all years*plt.figure(figsize=(12,6))
sns.barplot(x='Year',
y='HOMICIDE',
data=df_homicide.groupby(['Year'])['Primary Type'].value_counts().\
unstack().reset_index(),
color='steelblue').\
set_title("CHICAGO MURDER RATES: 2001 - 2018")
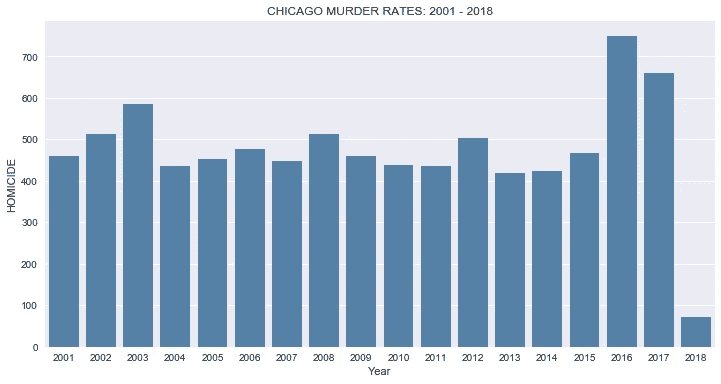
从上面的柱状图可视化中,我们可以得出以下结论:
- 在现有的数据范围内,芝加哥的凶杀案从 2001 年到 2003 年有一个短暂的上升趋势,从 460 起上升到 586 起。
- 接下来是一个良好的下降到 400 的范围,并保持了四年,直到 2008 年。
- 在 2016 年之前的七年里,凶杀率立即回落到 400。
- 然而,谋杀率在 2016 年急剧上升,从 2015 年的 467 起上升到 749,282 起,创历史新高。
- 2017 年也出现了持续的高凶杀率,尽管下降了 90 至 659 起。
- 我们可以说,2016 年和 2017 年芝加哥的凶杀率显著上升。
- 我想我们可以开始理解为什么有那么多关于风城谋杀案的新闻了。
- 根据我们对数据集中过去两年的观察,我想记住这一点,并在探索其余数据的过程中进行更深入的研究。
每月凶杀率:
*# plot homicides sorted by month*fig, ax = plt.subplots(figsize=(14,6))
month_nms = ['January','February','March','April','May','June','July','August'\
,'September','October','November','December']
fig = sns.barplot(x='Month',
y='HOMICIDE',
data=df_homicide.groupby(['Year','Month'])['Primary Type'].\
value_counts().unstack().reset_index(),
color='#808080')
ax.set_xticklabels(month_nms)
plt.title("CHICAGO MURDER RATES by MONTH -- All Years")*# -------------------------------------------**# plot average monthly temps in Chicago*
*# source of data: ncdc.noaa.gov*mntemp = [26.5,31,39.5,49.5,59.5,70,76,75.5,68,56,44,32]
df_temps = pd.DataFrame(list(zip(month_nms,mntemp)),
columns=['Month','AVERAGE TEMPERATURE'])
fig, ax = plt.subplots(figsize=(14,6))
sns.barplot(x='Month', y='AVERAGE TEMPERATURE', data=df_temps,color='steelblue')
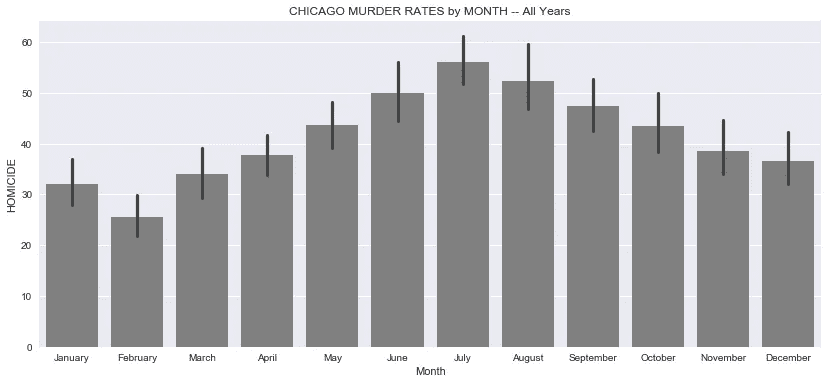
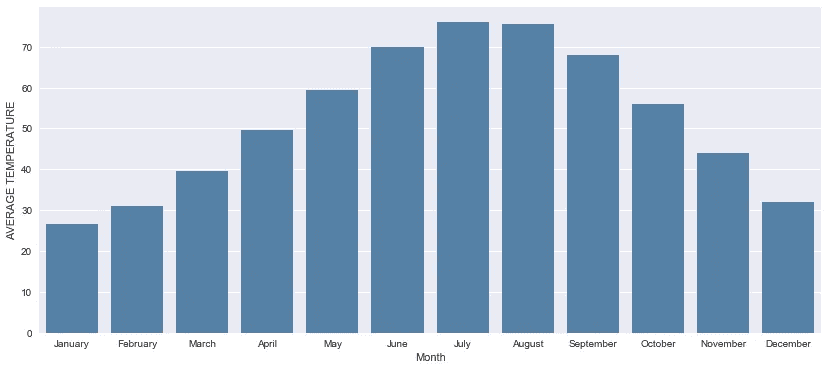
- 从逐月凶杀率来看,我们看到平均凶杀案在 3 月份开始稳步上升,在 7 月份达到高峰。
- 一月份略高于二月份,但这似乎是十二月份的延续。
- 这种周期性趋势有很多原因,但最好的解释似乎与月平均气温和总体天气有关。
- 芝加哥的冬天往往很冷,这使得大多数人不到万不得已不出门。
- 这种周期性趋势的另一个可能原因是,学校在夏季放假,因此更多的年轻人有时间去惹更多的麻烦。考虑到风险最大的年龄组在 15 至 30 岁之间。(来源:芝加哥论坛报)
一周中的凶杀率:
*# plot homicide rates vs. day of the week*fig, ax = plt.subplots(figsize=(14,6))
week_days = ['Sunday','Monday','Tuesday','Wednesday','Thursday','Friday','Saturday']
fig = sns.barplot(x='Weekday',
y='HOMICIDE',
data=df_homicide.groupby(['Year','Weekday'])['Primary Type'].\
value_counts().unstack().reset_index(),
color='steelblue')
ax.set_xticklabels(week_days)
plt.title('HOMICIDE BY DAY OF THE WEEK -- All Years')
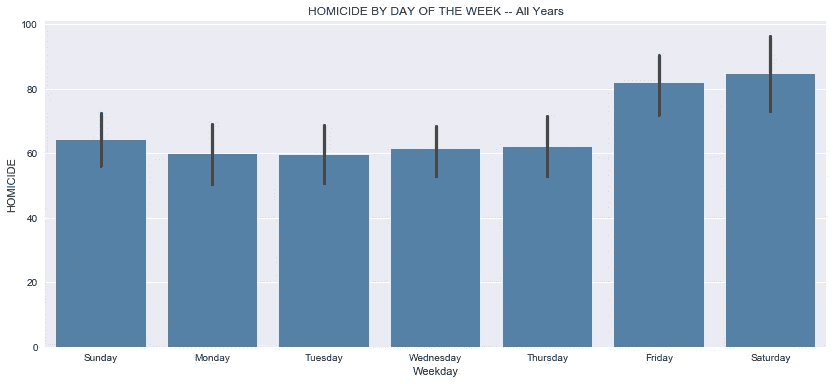
接下来,我们深入挖掘从每月到每周的时间框架,以获得更精细的外观。
- 在这个水平上,周一和周二的谋杀率最低,平均每天约 60 起。
- 周三略有上升,周四又略有上升。这种微小的变化几乎不明显,但考虑到这是 18 年的平均值,我们可以假设这种上升在某些周比其他周更明显。
- 本周早些时候出现的这种小幅上升趋势从平均每天 61 起凶杀案跃升至每天 81 起凶杀案,增幅达 25%。我们必须记住,这些平均值并没有根据这些杀戮的季节性进行调整。所以实际上,在温暖的月份,这个数字要高得多,而在寒冷的月份,这个数字要低得多。
- 周六出现了持续的高利率,但仅比周五略有上升。
- 周日的谋杀率确实从 80 年代下降到 60 年代,并持续下降到周一,并在每周循环再次重复之前稳定在 50 年代以上。
- 我们不知道是什么导致了这种循环,但我们可以假设,它们与离开学校或工作的时间有关,更多的人倾向于在这段时间参与毒品和帮派活动以及其他犯罪。
一天中的小时凶杀率:
*# use seaborn barplot to plot homicides vs. hour of the day* fig, ax = plt.subplots(figsize=(14,6))
fig = sns.barplot(x='HourOfDay',
y='HOMICIDE',
data=df_homicide.groupby(['Year','HourOfDay'])['Primary Type'].\
value_counts().unstack().reset_index(),
color='steelblue',
alpha=.75)
plt.title('HOMICIDE BY HOUR OF THE DAY -- All Years')
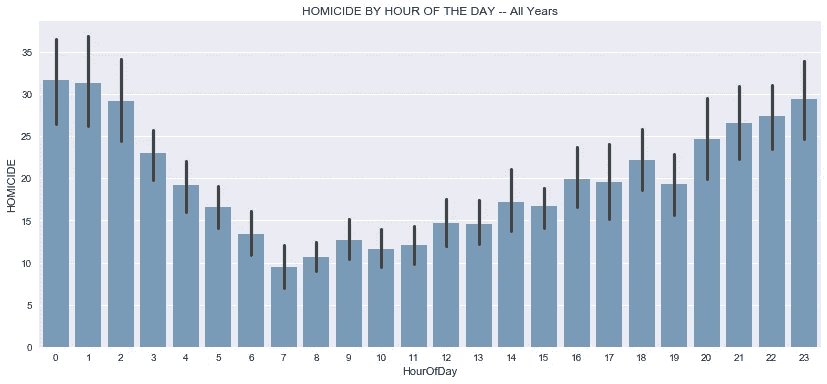
继续时间框架分析,从一天中的某个时间来看芝加哥的凶杀率是有意义的。我认为很容易假设谋杀发生在晚上比白天多,但这充其量只是一种猜测,所以不管我们认为结论有多明显,看看这些数字是明智的。
看待上述情节的一种方式是从一个正常的工作日或学校日的角度。
- 上午 7 点的凶杀案数量最少,约为 9 起,但随着时间的推移,我们看到凶杀案的数量稳步上升。
- 下午 2 点,我们穿过 15 关口,这为另一个稳定的上涨让路,有一点波动,其中下午 6 点飙升,下午 7 点下降,但不足以抹去之前的利率收益。
- 晚上 9 点是事情开始变得令人担忧的时候。平均值有时可能无法给出清晰的图像,但它们确实报告了一个简单的指标,即所有观察值的总和除以观察值的数量。考虑到这一点,每小时 25 起谋杀案是相当高的。
- 从晚上 9 点到凌晨 12 点的高峰,我们看到这些数字持续上升。凌晨 12 点和 1 点的谋杀率保持在每小时 30 起以上,只有在凌晨 2 点我们才看到低于 30 起,然后迅速下降,直到早上 7 点回到低于 10 起。
- 下降的一个可能原因可能是因为每个人都倾向于在深夜睡觉。即使是毒贩子和黑帮成员也有睡着的时候。
- 我想从上面的图表中得出的最后一个观察结果是,通过每个小时的误差棒线,夜间的时间比白天的时间有更多的变化,这表明夜间的凶杀活动更加活跃。
按家庭成员分列的年度凶杀率:
*# plot domestic variable vs. homicide variable*fig, ax = plt.subplots(figsize=(14,6))
df_arrest = df_homicide[['Year','Domestic']]
ax = sns.countplot(x="Year",
hue='Domestic',
data=df_arrest,
palette="Blues_d")
plt.title('HOMICIDE - DOMESTIC STATS BY YEAR')
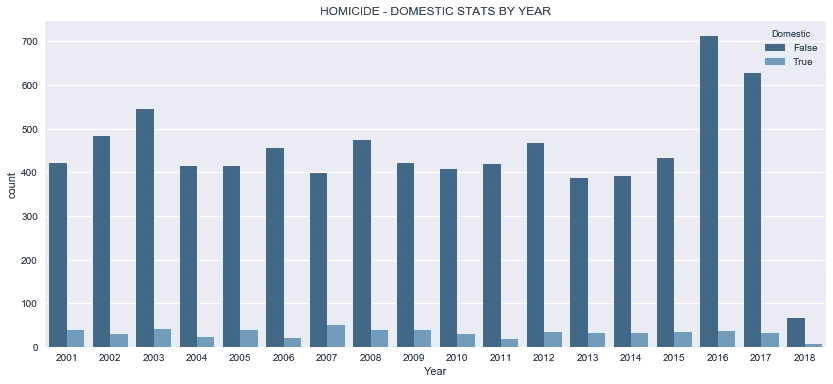
- 在整个数据范围内,家庭参与的程度似乎对凶杀率没有任何明显的影响。2016 年至 2017 年谋杀案的激增与国内数字没有任何明显的相关性。
- 考虑到原始数据集包含 40 多种犯罪类型,包括纵火、性侵犯、家庭暴力、跟踪等,因此将该变量包含在数据集中是有意义的,但它对我们涉及杀人的特定案例没有用处,尽管它在家庭暴力中肯定有权重。
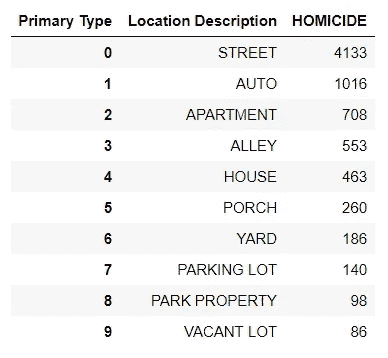
按犯罪现场分列的凶杀率:
*# visualize the "scene of the crime" vs. number of occurences at such scene*crime_scene = df_homicide['Primary Type'].\
groupby(df_homicide['Location Description']).\
value_counts().\
unstack().\
sort_values('HOMICIDE',ascending=**False**).\
reset_index()
*# Top Homicide Crime Scene Locations*
crime_scene.head(10)
*# create a count plot for all crime scene locations*g = sns.factorplot(x='Location Description',
y='HOMICIDE',
data=crime_scene,
kind='bar',
size=10,
color='steelblue',
saturation=10)g.fig.set_size_inches(15,5)
g.set_xticklabels(rotation=90)
plt.title('CRIME SCENE BY LOCATION FREQUENCY')
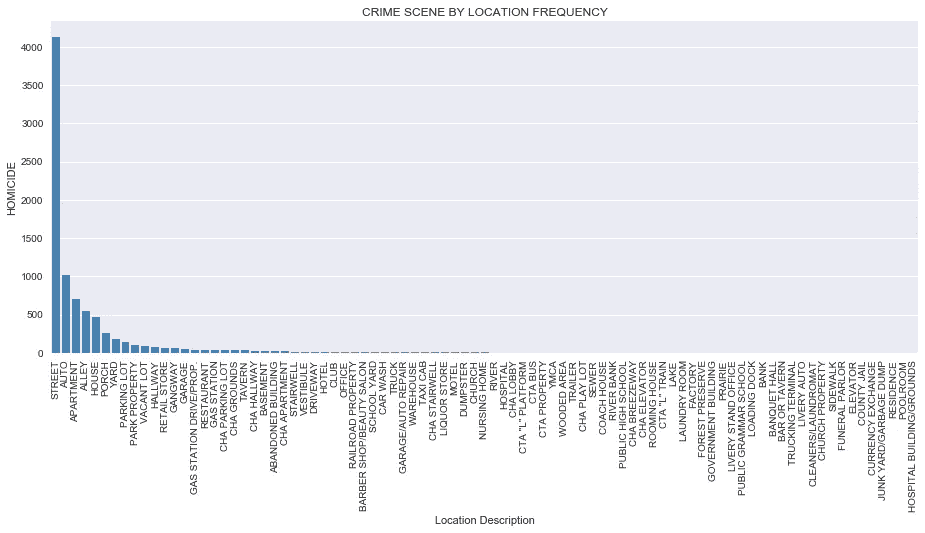
- 从上面的 Seaborn FactorPlot,我们可以观察到大多数谋杀(超过 60%)发生在街上。
- 第二个最常见的地方是汽车,然后依次是公寓、小巷、房子、门廊、院子和停车场。
- 其余位置的含量非常低,具有显著的统计影响。然而,更深入地研究数据采集方法是值得的,因为其他一些位置(尽管标注可能很专业)可能会在更大的一般化标注(如街道)之后进行标注。
- 到目前为止,从所有上述观察到目前为止,我们可以开始看到一个画面出现;芝加哥最危险的地方是街道上,在夏天,周末,晚上 11 点到凌晨 2 点。
- 然而,我们想知道这是否适用于芝加哥的所有地区。我经常被外地的朋友问住在芝加哥是否安全,我告诉他们,只要你不去错误的地方,这是安全的。接下来,我将展示我的探索,看看这是否是真的。
热图—每个警区的凶杀率:
*# create a heatmap showing crime by district by year*corr = df_homicide.groupby(['District','Year']).count().Date.unstack()
fig, ax = plt.subplots(figsize=(15,13))
sns.set(font_scale=1.0)
sns.heatmap(corr.dropna(axis=1),
annot=**True**,
linewidths=0.2,
cmap='Blues',
robust=**True**,
cbar_kws={'label': 'HOMICIDES'})
plt.title('HOMICIDE vs DISTRICT vs YEAR')
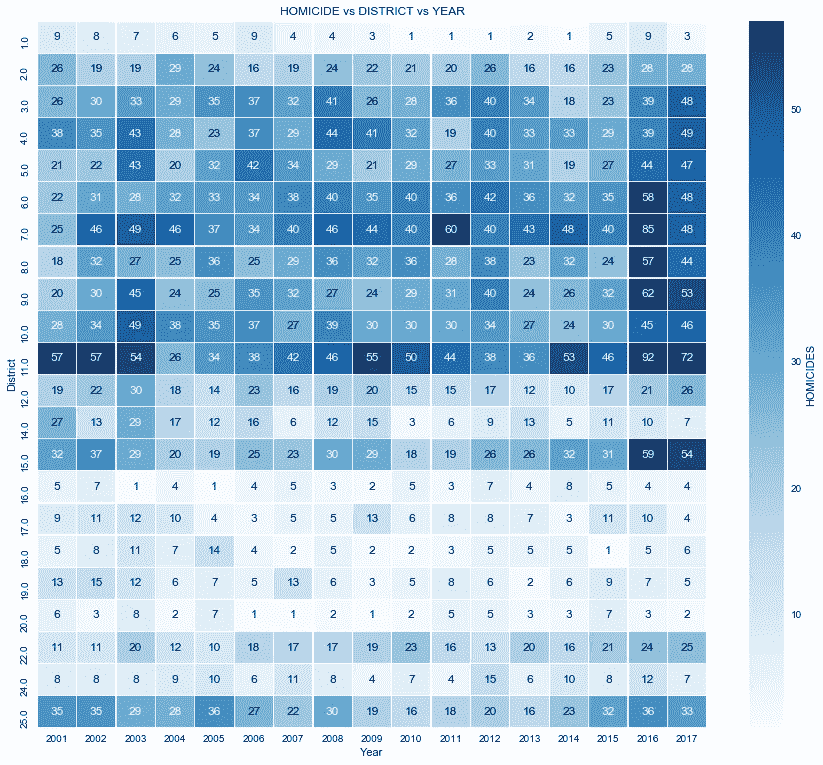
上面我创建了一个热图,比较了 2001 年至 2017 年芝加哥所有警区与每个警区的凶杀案数量。
- 正如热图所示,谋杀案在各地区的分布并不均匀。较暗区域对应较高的谋杀率。
- 热图上的区域越暗,该地区相应年份的谋杀案就越多。
- 在数据集中的所有年份中,第 1、16 和 20 区的凶杀率较低,每年为 10 起或更少。
- 第 17、18、19 和 24 区的谋杀率都在每年 20 起或更少(T3)的水平,尽管有些年份低于 10 起。
- 第 2、12、14 和 22 区每年有 30 起或更少的谋杀案发生在 T4。
- 其余的地区每年有超过 30 起谋杀案,有些地区的谋杀率甚至超过了 50 起。
- 第 7 区和第 11 区在 17 年的数据集中一直保持较高的数字。我们甚至可以宣布它们为芝加哥凶杀案最致命的警区。
- 整个数据集的最高谋杀率是在 2016 年的第 11 区,有 92 起谋杀案。
- 2016 年是数据集中凶杀案最糟糕的一年**,有 6 个区的凶杀案超过 50 起。**
- 热图使这些数据变得生动,是我们数据探索工具包中的一个非常好的工具。
最危险和最不危险的警区
**with** sns.plotting_context('notebook',font_scale=1.5):
sorted_homicides = df_homicide[df_homicide['Year']>=2016].groupby(['District']).count()\
.Arrest.reset_index().sort_values('Arrest',ascending=**False**)
fig, ax = plt.subplots(figsize=(14,6))
sns.barplot(x='District',
y='Arrest',
data=sorted_homicides,
color='steelblue',
order = list(sorted_homicides['District']),
label='big')
plt.title('HOMICIDES PER DISTRICT (2016-2017) - Highest to Lowest')
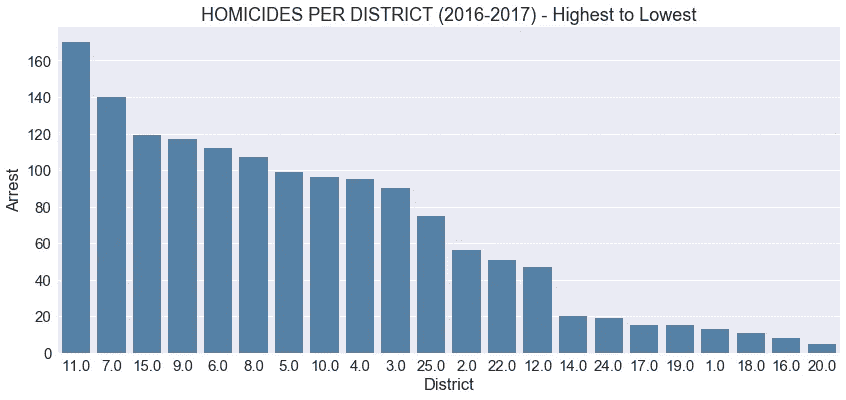
正如我们之前从热图中观察到的,有些地区比其他地区更危险,但现在我们可以更仔细地观察这一现象。从我们创造的各种可视化来看,我们至少可以得出结论,2016 年和 2017 年是芝加哥凶杀案最活跃的年份。
- 在上面的柱状图中,我将每个地区在这两年中最多和最少的谋杀案可视化,以了解它们之间的关系。
- 在这两年中,排名前 10 的地区都发生了 90 起以上的凶杀案。
- 11 区比名单上的下一组多了 30 起谋杀案。
- 22 个群体中的前 5 个群体占了该市所有凶杀案的 50%以上。
- 前 10 个群体占芝加哥所有凶杀案的 80%以上。
- 25 个区中有 8 个区的凶杀率非常低或相对较低。
杀人罪的逮捕与不逮捕:
接下来,我通过绘制下面的一些关系来看逮捕和杀人之间的关系。
看起来你可以在芝加哥逃脱谋杀。
*# create seaborn countplots for whole dataset*fig, ax = plt.subplots(figsize=(14,6))
df_arrest = df_homicide[['Year','Arrest']]
ax = sns.countplot(x="Year",
hue='Arrest',
data=df_arrest,
palette="PuBuGn_d")
plt.title('HOMICIDE - ARRESTS STATS BY YEAR')
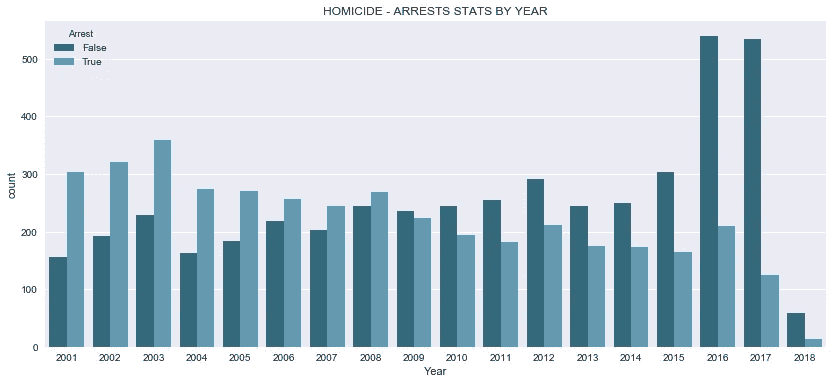
上图比较了 17 年来数据集中所有凶杀案的逮捕与不逮捕情况。
- 在 21 世纪初,警方逮捕的人比没有逮捕的人多。
- 从 2001 年到 2008 年,警方逮捕了超过一半的凶杀案。
- 从 2009 年至今,警方逮捕了不到一半的人。
- 事实上,这种趋势看起来像是警察逮捕人数的下降趋势,可能始于 2004 年左右。
- 2016 年和 2017 年,逮捕率不到 30%。
*# create seaborn countplots for 2016 and 2017 -- high crime rate spike years*fig, ax = plt.subplots(figsize=(14,6))
ax = sns.countplot(x="Month",
hue='Arrest',
data=df_homicide[df_homicide['Year']>=2016][['Month','Arrest']],
palette="PuBuGn_d")
month_nms = ['January','February','March','April','May','June','July',\
'August','September','October','November','December']
ax.set_xticklabels(month_nms)
plt.title('HOMICIDE - ARRESTS STATS BY MONTH -- (2016-2018)')
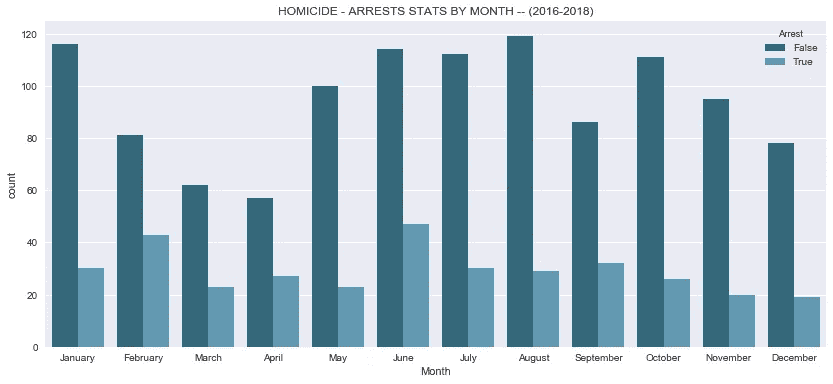
- 真正让我惊讶的是,即使在 2016 年和 2107 年犯罪激增后,警方逮捕的谋杀事件仍在继续下降。上图试图观察月份特征,但只是证实了我们之前的观察。
- 我还没有发现这种下降的好原因,但经过一点点挖掘,我发现媒体报道了芝加哥警察局的政策变化,减少了对逮捕低级别罪犯的关注,更多地关注犯罪规模方面的大鱼。这就引出了一个问题,谋杀难道不是一种高调的犯罪吗?
- 2016 年发生的另一件有趣的事情是公众关注警察对有色人种的枪击事件,这让我想知道这是否在警察逮捕时不太积极方面发挥了重要作用。大多数高犯罪率地区都是以少数族裔为主的社区,2016 年,一名法官下令发布一段视频,显示芝加哥警察枪杀了一名黑人社区成员。
*# create seaborn lmplot to compare arrest rates for different districts*dfx = df_homicide[df_homicide['District'].\
isin(list(sorted_homicides.head(10)['District']))].\
groupby(['District','Year','Month','Arrest'])['Primary Type'].\
value_counts().unstack().reset_index()**with** sns.plotting_context('notebook',font_scale=1.25):
sns.set_context("notebook", font_scale=1.15) g = sns.lmplot('Year','HOMICIDE',
col='District',
col_wrap=5,
size=5,
aspect=0.5,
sharex=**False**,
data=dfx[:],
fit_reg=**True**,
hue="Arrest",
palette=sns.color_palette("seismic_r", 2),
scatter_kws={"marker": "o",
"s": 7},
line_kws={"lw":0.7})
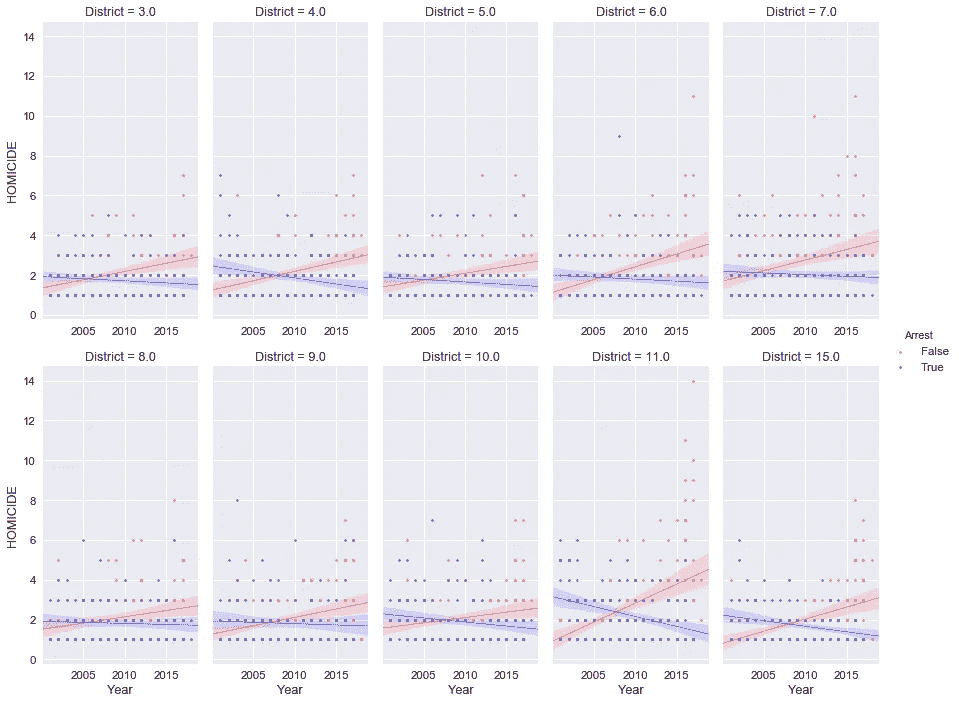
进一步细分地区一级的逮捕与不逮捕,仅是高凶杀率地区,为我之前观察到的数据集中逮捕数量逐年下降提供了更多依据。上图显示了前 10 个最危险地区在同一轴上的逮捕和未逮捕回归线。
2006 年以前,警察逮捕的人数就开始比前一年少,到 2010 年,所有地区逮捕的杀人案不到一半。
很可能因杀人被捕的几率不到一半。如果你是住在高犯罪率地区的罪犯,这种可能性会大得多。
接下来,我用 python 可视化相册“叶子”创建了一些地图,展示了我的一些发现,并在下面做了笔记。原始代码上的地图是用户响应的,所以你可以放大、缩小和移动它们。
凶杀案与地区的对比图
(2001–2017)
*# plot chloropleth maps 2001 - 2017* **def** toString(x):
**return** str(int(x))df_homicide_allyears = df_homicide.groupby(['District']).count().Arrest.reset_index()
df_homicide_allyears['District'] = df_homicide_allyears['District'].apply(toString)*# ______________________________________________________#*chicago = location=[41.85, -87.68]
m = folium.Map(chicago,
zoom_start=10)plugins.Fullscreen(
position='topright',
title='Expand me',
title_cancel='Exit me',
force_separate_button=**True**).add_to(m)m.choropleth(
geo_data='chicago_police_districts.geojson',
name='choropleth',
data=df_homicide_allyears,
columns=['District', 'Arrest'],
key_on='feature.properties.dist_num',
fill_color='YlOrRd',
fill_opacity=0.4,
line_opacity=0.2,
legend_name='Choropleth of Homicide per Police District : 2001-2017',
highlight=**True**
)
folium.TileLayer('openstreetmap').add_to(m)
folium.TileLayer('cartodbpositron').add_to(m)
folium.LayerControl().add_to(m)
m.save("map1.html")
IFrame('map1.html', width=990, height=700)*# plot 2016-2018 chloropleth map*# code for *second map* is available on github
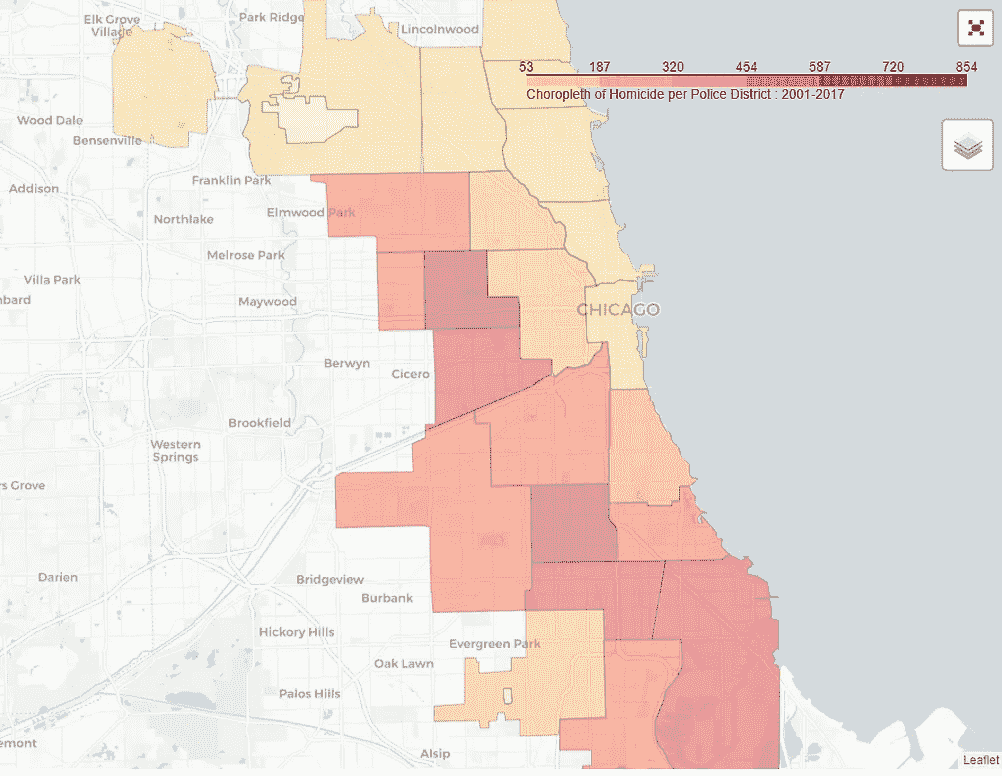
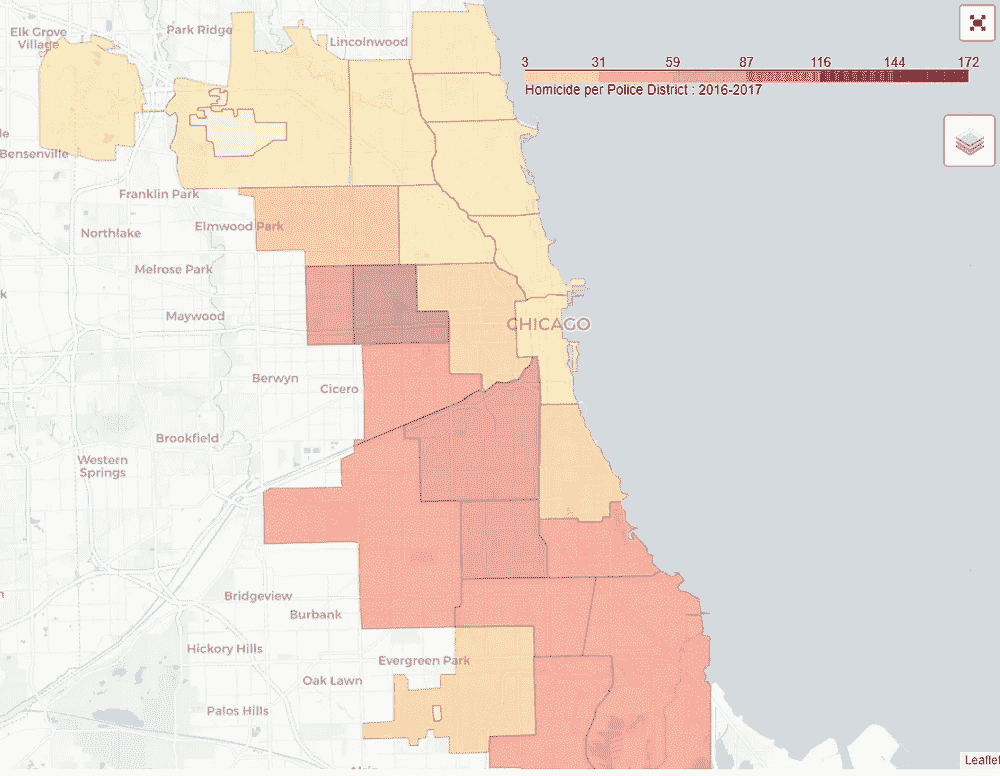
2001–2017 vs 2018
- 我为两个不同的时间段制作了两张 choropleth 地图。一个针对整个数据集,另一个针对 2016-2017 年期间,我们看到了谋杀案的激增。
- 这些地图很好地展示了不同警区的凶杀犯罪情况。
- 从这两张地图上,我们可以看到犯罪集中在城市西边和南边的警区周围。
- 有两个地区特别突出。这是 11 区和 7 区。
- 此外,犯罪率较高的地区在地理上是相连的/会传染的。
凶杀案 vs 地区热图—(2016–2017)
*# plot heatmap all districts -- (2016-2018)*after_2015_geo = []
**for** index, row **in** df_homicide[df_homicide['Year']>=2016][['Latitude','Longitude','District']].dropna().iterrows():
after_2015_geo.append([row["Latitude"], row["Longitude"],row['District']])
*# ___________________________________________________________________*
chicago = location=[41.85, -87.68]
m = folium.Map(chicago, zoom_start=9.5,control_scale = **False**)plugins.Fullscreen(
position='topright',
title='Expand me',
title_cancel='Exit me',
force_separate_button=**True**).add_to(m)m.choropleth(
geo_data='chicago_police_districts.geojson',
name='choropleth',
data=df_homicide_after_2015,
columns=['District', 'Arrest'],
key_on='feature.properties.dist_num',
fill_color='YlOrRd',
fill_opacity=0.4,
line_opacity=0.2,
legend_name='HeatMap Homicides : 2016-2017',
highlight=**True**
)
m.add_child(plugins.HeatMap(after_2015_geo,
name='all_homicides_2016_to_2017',
radius=5,
max_zoom=1,
blur=10,
max_val=3.0))
folium.TileLayer('openstreetmap').add_to(m)
folium.TileLayer('cartodbpositron').add_to(m)
folium.LayerControl().add_to(m)
m.save("map3.html")
IFrame('map3.html', width=990, height=700)
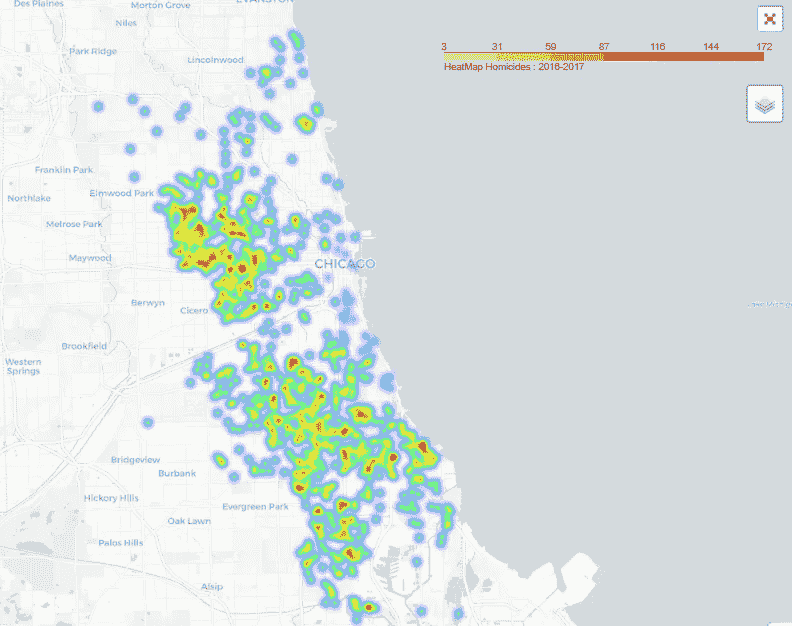
Chicago Homicide Heat Map
- 上面的热图可视化是用 pythonfollow可视化库创建的,它可以很好地控制在笔记本上绘制动态地图。
- 该热图适用于 2016-2017 年时间框架。这个时间段的各个犯罪现场位置被绘制在城市的画布上,并用颜色表示。
- 热图可以帮助我们在地图上直观地显示犯罪发生频率高或低的大致位置。深橙色代表犯罪率高的区域,断开的浅黄色/绿色阴影显示地图上犯罪率低的位置。
- 给人的第一印象是芝加哥西区和南区的凶杀率较高。我们可以放大每个区域的更多细节,每次放大都会显示该子区域中的更多集群。
注:我还创建了更具交互性的时移热图和聚类图,可以在这里 和在github上**查看。
最后,我创建了显示谋杀地点的聚类地图。在 nbviewer 上渲染的现场互动笔记本就位于这里。
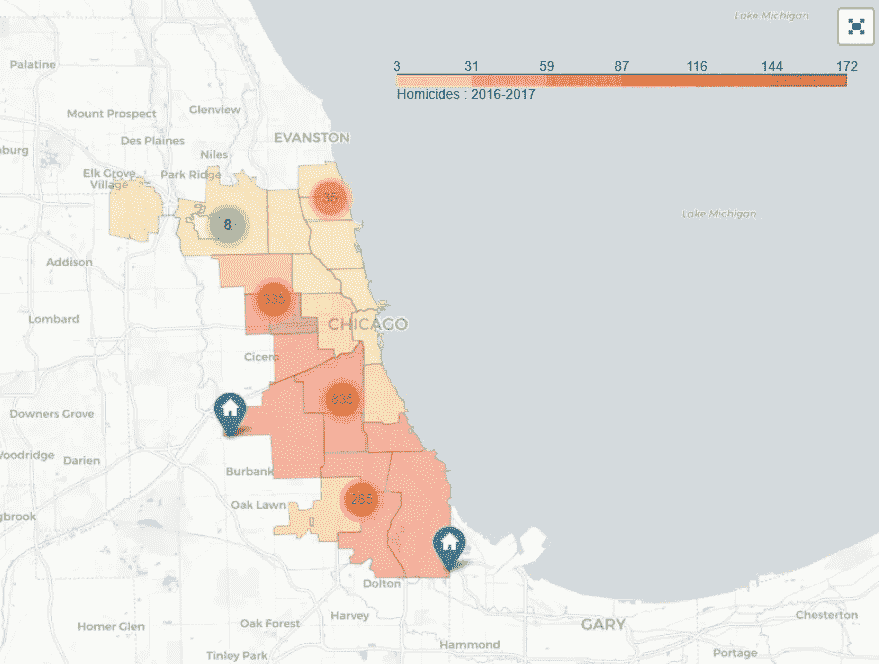
(2001–2017) vs 2018
这些地图描绘了各个犯罪现场,这或多或少类似于热图,只是没有给这些地理位置添加颜色。其中一张地图是 2016-2017 年期间的,另一张地图是 2018 年的两个月数据(1 月和 2 月)。
1 月和 2 月的地图特别有趣,因为它显示了 2018 年初犯罪已经开始大量出现的地方。可悲的是,凶杀案遵循与前几年相同的模式,绝大多数犯罪发生在同一地区。
对于在正确领域中试图确定哪些问题点需要更多资源的任何人来说,该地图将是一个很好的工具。这些地图也是一个很好的工具,可以直观地检查社区中的个人犯罪地点,结合他们对该地区的了解,可以带来新的见解,可以探索并采取行动,使社区更加安全。例如,社区成员可以确定问题点,并为儿童建立安全的上下学通道。这张地图将有助于他们识别不太危险的街区。
结论
在这本笔记本中,我使用了芝加哥警察局收集的数据,从中提取了一些关于芝加哥凶杀案的见解。虽然这里进行的数据分析缺乏国家视角,但我的主要发现可以归纳为以下几个要点:
- 各警区的凶杀犯罪数量差异很大。数字高的地区似乎年复一年都有高的数字,反之亦然。
- 从 2004 年到 2015 年,凶杀案数量基本未变,每年分别为 400 起和 500 起。这些数字在 2016 年突然跃升至每年 700 起凶杀案。
- 这个新数字一直保持到 2017 年,每年超过 650 起凶杀案。
- 天气温度和每月凶杀案数量之间有关联。越是温暖的月份,杀人犯罪就越多。
- 一周中的某一天也会影响谋杀案的数量,周末的谋杀案数量会更多。
- 一天中的时间也会影响杀人案件的数量,晚上 9 点到凌晨 2 点最危险,早上 7 点到下午 1 点最安全。
- 第 11 区、第 7 区和第 15 区在 2016-2017 年期间发生的凶杀案最多,同一时期各发生了 120 多起凶杀案。
- 绝大多数凶杀案发生在街头,占所有凶杀犯罪现场的 60%以上。
- 2016-2017 年期间,第 20、16、18、1、19、17、24 和 14 区的凶杀案都不到 20 起,这使它们成为芝加哥最安全的警区。
- 自 2003 年以来,因杀人罪而被逮捕的人数一直在下降,2008 年,谋杀案的数量超过了因谋杀而被逮捕的人数。截至 2018 年,每 10 起凶杀案中有不到 3 起被逮捕。
虽然这些观察结果很有启发性,但我应该指出,它们并没有描绘出全貌,应该与国家或其他可比数据进行比较,以提供更多的视角。例如,虽然每年的凶杀案数量看起来很高,但我们不知道这是在全国平均水平以内还是太高了。这种比较将有助于我们在讲述数据故事时建立更有说服力的论据,用它们来支持我们的本地发现。
话虽如此,我们的发现仍然与当地决策者密切相关,因为他们非常清楚何时何地,但不是为什么。
抓住你的下一条鱼——如何撰写完美的数据科学白皮书

Peter Sellars as Dr Strangelove, emphasing the importance of publicising a successful project.
如果你保守秘密,这个项目就失去了意义。“你为什么不告诉全世界,嗯?”——奇爱博士,1964 年。
做令人兴奋的工作的最大好处之一就是告诉别人这件事。除了自我满足的热情之外,当你用过去的工作给别人留下深刻印象时,你很有可能会有更令人兴奋的工作。
做到这一点的一个关键方法是写一份白皮书。白皮书是一份营销文件,旨在展示作者在特定领域的专业知识。通常,作者会试图解释他们是如何用自己的专业知识解决问题的,或者教授他们领域的一些基本知识,目的是帮助读者理解什么时候该给专家打电话。因此,一个商人可能会分享一些关于一些非常小的工作的提示,导致读者应该打电话给专业人士。
互联网上有很多写白皮书的指南,比如这里的,通常包括结构指南。然而,在数据科学的情况下,有一个转折,即作者通常使用他们的数据科学专业知识来解决读者是专家的领域中的问题。这对文档的组织方式以及如何接近观众有一个微小但明显的影响。
第一项任务是在读者的问题领域建立凭证,因为你在该领域不太可能比读者有更高的资格或经验,直接提供你自己的凭证不太可能成功。相反,最好的方法可能是“展示不说”法,这种方法在创意写作课上很常见。在这种情况下,它指的是让读者看到你的角色在行动和他们的故事展开,而不是写出他们的特点或概述情节。在这种情况下,它意味着以一种不怀疑其对该领域的重要性的方式解释你所处理的领域问题。如果一个解决方案没有价值,你就不会去做它,所以解释价值在哪里——很多时候它会以这个问题成为更大目标的障碍的形式出现。总的来说,通过展示你了解问题如何影响他们的业务,你可以赢得听众。
一旦你确定了问题,故事的下一步将是你如何解决它。在数据科学的背景下,通常需要两种工具来获得解决方案——足够的数据集(“足够”是因为大多数数据集与我们的“理想数据集”相差甚远)和合适的分析工具。
鉴于如此多的数据科学工具都是开源的,数据集(如果不是处于原始状态,通常是在您对其进行清理和预处理之后)有可能比竞争对手更具优势。因此,提及数据获取或清理的方式可能有助于进一步建立可信度。如果您使用主题专家的建议来改进预处理流程,情况尤其如此,例如,如果存在与收集流程相关的丢失数据的原因,而收集流程决定了如何处理这些丢失的数据。
当讨论所使用的算法时,这不仅仅是一个为非技术观众正确定制讨论的问题,还是一个节奏的问题。为了保持读者的注意力,白皮书需要有一个正在展开的故事的感觉和节奏;太多关于算法如何工作和你是如何做的细节会减慢速度,让读者失去兴趣。至关重要的是,读者没有必要完全理解用来传达你的信息的算法。几乎可以说,对算法的任何描述都比它对算法如何工作的真实解释更有色彩和趣味。
将您的算法应用于数据代表了您的三幕故事中的第二幕。在这里,解决方案本身并不是卖点,尽管它很重要。当您实施类似于预测模型的东西时,卖点通常是您在此过程中观察到的数据——关于变量相互作用方式的额外经验,或者关于哪些变量最有影响力或关系形状的惊喜。如果有必要的话,将你的分析扩展为一个完整的推理分析(无论如何你都要这么做,但那是改天的话题)。
如果你的白皮书框架正确,它会让人们记住你,并在他们的领域中想到你。接受数据科学解决方案的最大障碍之一是认为数据科学正在篡夺专家知识——白皮书提供了一个绝佳的机会来证明数据科学不是篡夺者,而是对专家知识的补充。
这一块源自 这一块 和 这一块 ,它们与数据科学销售周期的早期阶段相关。这篇文章如何与预期的未来文章相适应的纲要可以在我的博客 这里 找到。
人工智能研究的热点

如果你正在阅读这篇文章,你已经被人工智能驱动的技术包围了,超出你的想象。从你面前的网站到阅读 CT 扫描,AI 应用是不可避免的。
一般来说,当人们听到人工智能时,他们往往会将其等同于机器学习和深度学习,但它们只是人工智能研究中的许多子主题中的两个。这两个主题可以说是当今人工智能世界中最有效的主题,但还有许多其他子主题因其应用和未来潜力而在人工智能社区中获得了巨大的吸引力。在本文中,我们将讨论人工智能研究中的一些热门子主题,其中许多主题是相互关联的,并属于人工智能的大范围:
大规模机器学习
机器学习(ML)关注的是开发能够通过经验提高性能的系统。在过去的十年里,人工智能的进步可以很容易地归因于人工智能的进步。ML 太受欢迎了,已经成了 AI 的代名词。研究人员现在专注于将最先进的 ML 算法扩展到大型数据集。想了解更多关于 ML 的信息,请阅读这篇介绍性博客。
深度学习
深度学习(DL)是 ML 的一个子集,是神经网络的重新品牌化——一类受我们大脑中生物神经元启发的模型。DL 一直是人工智能中许多应用的驱动力,如对象识别、语音、语言翻译、玩计算机游戏和控制无人驾驶汽车。欲了解更多关于 DL 的信息,请阅读这篇介绍性博客。
强化学习
强化学习是人类学习方式的封闭形式。它由一个智能代理组成,智能代理与环境智能地相互作用,以获得一定数量的回报。代理的目标是学习顺序动作,以便最大化长期回报。就像一个从现实世界中学习经验的人一样,不断探索新事物,更新自己的价值观和信念,RL 代理人以类似的原则工作,以从长远角度最大化自己的回报。2017 年,谷歌的 AlphaGo 计算机程序在围棋比赛中使用 RL 击败了世界冠军。想了解更多关于 RL 的信息,请阅读这个博客。
机器人技术
从技术上讲,机器人技术是一个独立的分支,但它确实与人工智能有一些重叠。人工智能使机器人在动态环境中导航成为可能。你如何确保一辆自动驾驶汽车在最短的时间内从 A 点到 B 点,而不伤害自己和其他任何人?DL,RL 的进展可能有机器人学中此类问题的答案。想了解更多关于机器人技术的信息,请阅读这篇关于人工智能机器人技术的博客,并观看这些演示视频: 1 、 2 、 3 。
计算机视觉
如果我们想让机器思考,我们需要教它们看。费-李非,斯坦福人工智能实验室主任计算机视觉(CV)关注的是计算机如何视觉感知周围的世界。具有讽刺意味的是,计算机擅长做庞大的任务,如寻找一个 100 位数的 10 次方根,但在识别和区分物体等简单的任务中却举步维艰。最近在 DL 和标记数据集的可用性以及高计算能力方面的进展使得 CV 系统有可能在一些狭窄定义的任务(如视觉对象分类)中胜过它们的人类对应物。想了解更多关于简历的信息,请阅读这个博客。
自然语言处理
自然语言处理(NLP)涉及能够感知和理解人类口语的系统。它由语音识别、自然语言理解、生成和翻译等子任务组成。随着全球使用多种语言,NLP 系统可能成为真正的变革者。目前的 NLP 研究包括开发可以与人类动态交互的聊天机器人。想了解更多关于 NLP 的信息,请阅读这篇介绍性博客。
推荐系统
从读什么,买什么,到和谁约会,推荐系统无处不在,已经完全取代了虚拟世界中烦人的推销员。像网飞和亚马逊重工这样的公司依赖 RS。智能推荐系统会考虑用户过去的偏好、同伴的偏好和趋势,从而做出有效的推荐。要了解更多关于 RS 的信息,请阅读以下文章: 1 , 2 。
算法博弈论与计算机制设计
算法博弈论从经济学和社会科学的角度考虑多主体系统。它看到这些代理人如何在基于激励的环境中做出选择。这些多智能体系统可以包括自私的人类成员以及在有限资源环境中一起竞争的智能体。关于这个话题的更多信息,你可以关注大卫·巴夏礼教授的文章。这个环节也是很好的资源。
物联网
物联网(IoT)是一个概念,日常使用的物理设备连接到互联网,并可以通过交换数据相互通信。收集到的数据可以进行智能处理,使设备更加智能。这篇文章解释了人工智能如何被用来建造更智能的建筑。
神经形态计算
随着依赖于基于神经元的模型的深度学习的兴起,研究人员一直在开发可以直接实现神经网络架构的硬件芯片。这些芯片被设计成在硬件层面模仿大脑。在普通芯片中,数据需要在中央处理器和存储块之间传输,这导致了时间开销和能量消耗。在神经形态芯片中,数据以模拟方式在芯片中进行处理和存储,并可以在需要时生成突触,从而节省时间和能量。更多关于这些智能芯片开发的信息,请阅读这两篇文章: 1 、 2 。
其他详细介绍 AI 研究动态的文章: 0 、 1 、 2 、 3 。
注:该文章于 2018 年 5 月 7 日在 medium 上的出版物 AI Tale 中首次发表为“AI 研究中的热点子主题”。
参考文献:
斯通、彼得等《2030 年的人工智能与生活》。人工智能百年研究:2015–2016 研究小组报告 (2016)
房价和回归
本着我正在进行的系列活动的精神,如泰坦尼克号游戏竞赛,这里是另一个机器学习游戏竞赛。这次是为了用回归法计算出缺失的房价。
一如既往这里是我提交的捷径这里
数据
你从来不知道你想去爱荷华州的埃姆斯,但最终你会从迪安·德·科克收集的一组数据中获得超乎你想象的知识。有许多城市都有公开的住房数据集,比如我所在的佛蒙特州伯灵顿镇,但是在这次卡格尔竞赛中,我们希望探索销售价格与房子所有其他特征之间的可能关系。
房子的许多特征,但不是所有特征,都与销售价格有线性关系。通过填补缺失值,一些决定销售价格的功能工程和功能选择应该不会太远。在这种情况下,我尝试应用随机森林回归、套索和山脊回归来得出我的最终答案。
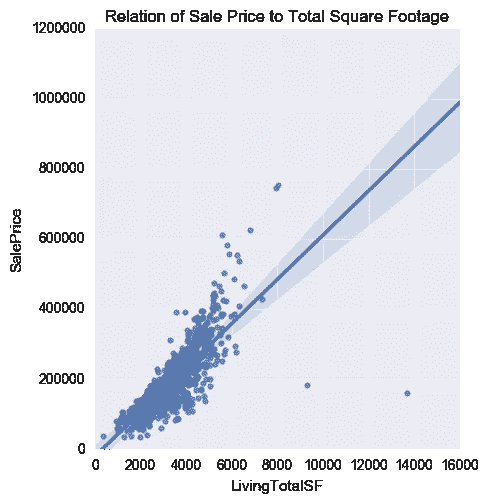
快速看一下地面以上平方英尺与销售价格的线性回归,就可以看出这种方法的优势。
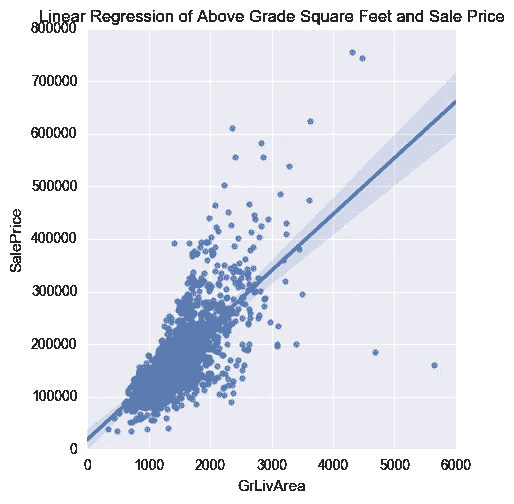
方法
该数据集中有大量的特征,为了创建良好的预测,必须提前做大量的工作。组合训练集和测试集将意味着只需要在两个数据集之间进行一次更改。我们将探索以下步骤:
- 相互关系
- 特征探索
- 缺少值
- 数据标准化
- 特征工程
- 组装数据集
- 预言;预测;预告
销售价格应该有几个良好的指标,挑战将是数据和特征工程的标准化。
数据
该数据具有广泛的整数、浮点和分类信息。最终,它们将以数字的形式结束,但还不完全是。有几组不同类型的测量,了解它们的差异将有助于确定可以创建哪些新特征。
街区— 关于街区、分区和地段的信息。
- 示例:MSSubClass、LandContour、Neighborhood、BldgType
日期— 关于何时建造、改造或出售的基于时间的数据。
- 示例:YearBuilt、YearRemodAdd、GarageYrBlt、YrSold
质量/条件— 对房屋的各种特征进行分类评估,很可能是由房产评估员进行的。
- 示例:PoolQC、SaleCondition、GarageQual、HeatingQC
物业特征— 建筑附加特征和属性的分类集合
- 示例:基础、外部 1st、BsmtFinType1、实用程序
平方英尺— 建筑截面的面积测量以及门廊和地块面积等特征(单位为英亩)
- 示例:TotalBsmtSF、GrLivArea、GarageArea、PoolArea、LotArea
房间/特征计数— 特征(相对于分类)的定量计数,如房间,特征工程的主要候选
- 例如:全浴室、卧室、壁炉、车库
定价— 货币值,其中之一是我们试图确定的销售价格
- 示例:SalePrice、MiscVal
相互关系
快速相关性检查是了解数据集核心的最佳方式。销售价格与几个变量有很大的相关性:
- 总质量— 0.790982
- GrLivArea — 0.708624
- 车库汽车-0.640409
- 车库面积-0.623431
- TotalBsmtSF — 0.613581
- 1stFlrSF — 0.605852
- 全浴— 0.560664
- TotRmsAbvGrd — 0.533723
- 年份-0.522897
- YearRemodAdd — 0.507101
热图显示了整个数据集与其自身的相关性。记住红色越深(正相关)或蓝色越深(负相关)越好。
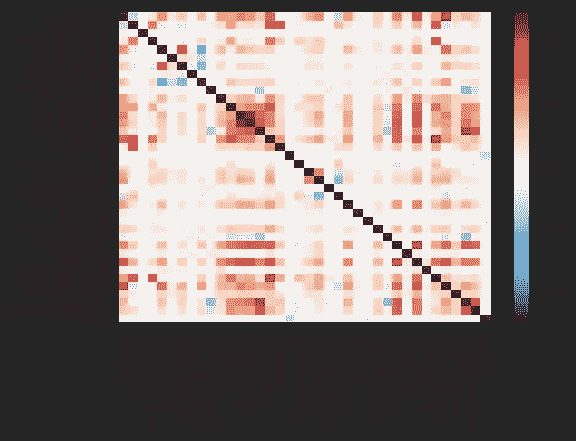
缺少值
缺失值的选择范围很广。首先,有意义的是先击中低垂的果实,处理那些缺少一两个值的,然后处理剩下的。其中一些看起来缺少值,不是因为他们没有数据,而是因为建筑物缺少该特征,如车库。使用熊猫获取。傻瓜会把那个问题分成真/假值。
替换丢失的数据
对于缺少单个值的分类信息,快速检查会显示哪些值占主导地位,并手动替换缺少的值。对大多数人来说,这是一个快速的过程。
推断缺失值
某些缺失值可以从该给定属性的其他值中推断出来。车库的建造时间最早应该是房子建造的那一年。同样,TotalBasementSQFeet 必须等于一楼的平方英尺。
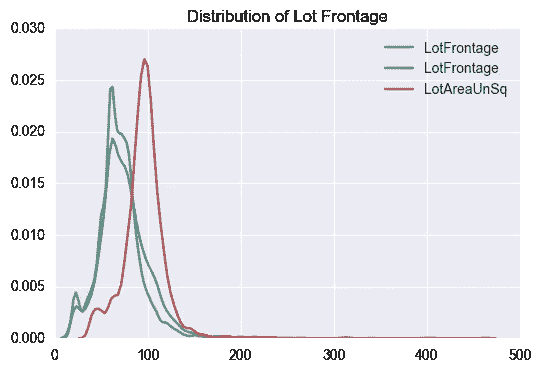
地段临街
很多正面有点棘手。有 486 个缺失值(占总值的 17%),但快速检查相关性后发现,在地块区域之外具有高相关性的要素少得惊人。
逻辑表明,地块面积应与地块正面成线性关系。通过对地块正面和地块面积的平方根(如果是方形地块,则为有效的一边)之间的关系进行线性回归,快速检查表明我们处于大致范围内。
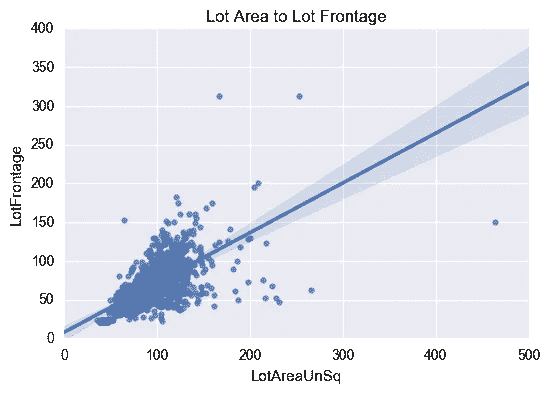
一旦缺失的值被填充,就可以很好地确认分布没有超出 wack 的范围。蓝色是原始分布,绿色是推断出缺失值的新分布,红色是地块面积的平方根曲线。不出所料,这些地产中的大部分看起来都没有完美的正方形地块,但就我们的目的而言,一切看起来都很好。
特征工程
现在是时候创建一些新的功能,看看它们如何帮助模型的准确性。首先是几个宏观的创造,比如把所有的内部和外部面积加在一起,得到包括楼层、车库和外部空间在内的总居住空间。有趣的是,这里有一个与整体条件评级相关的新功能的可视化

条件评级增加到平方英尺,这并不奇怪。然而,当对销售价格进行线性回归时,一个更明显的模式出现了。
这是一个很好的添加特性,但是它确实向您展示了特性的选择非常依赖于您想要预测的内容。
房间总数
相反,如果你对房间感兴趣,房间和浴室的数量有明显的关系。这是浴室的平均值,这条线是方差(大多数值偏离平均值的程度)。
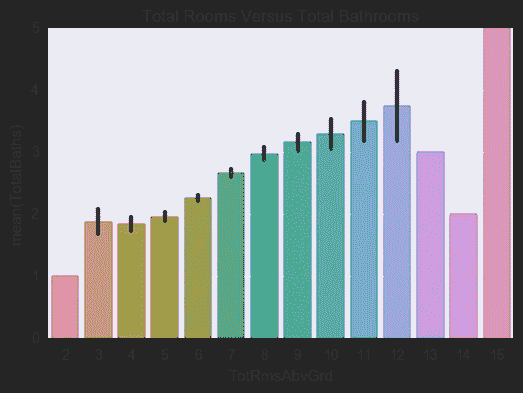
楼上的房间越多,浴室之间的关系也越紧密。对于 13 个房间及以上的房间,房屋数量要少得多,因此数据的可靠性和可预测性较差。
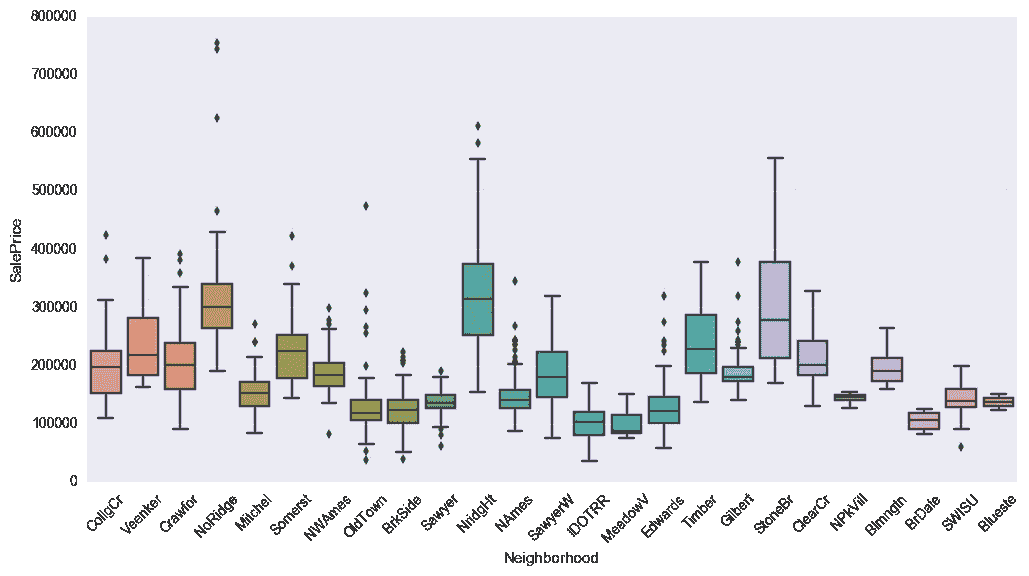
地区
我们都知道社区有各种各样的特点。在某种程度上,它与销售价格有关系,但它更难定义,在预测中也不太有用。
销售月
在结束之前,最后一次彩色图表。我想知道佛蒙特州的房地产市场,因为天气会对许多活动产生很大的影响,包括看我想象中的房子。
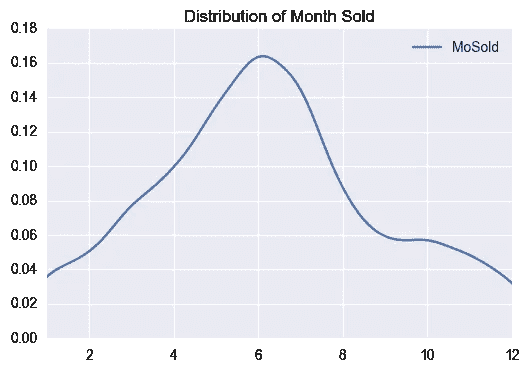
这两个图表向我们展示了,虽然价格没有明显的月与月之间的变化,但有几个月的房屋销售量比其他月份多得多。如果我想预测房子什么时候会被卖掉,那会很有用。因为我看到的是实际价格,所以实际价格要低得多。
特征选择
选择正确的功能至关重要。低相关性的不良特征只会使噪声比信号更强,遗漏太多会导致数据丢失。因为有这么多,我不打算在这里列出来,但它在笔记本上。
模型和结论
有几个模型试过了。随机森林回归、LassoLarsCV 和 Ridge 都是选项,经过试验,我最终选择 Ridge 作为更好的选项。令人着迷和沮丧的是,每次我运行它时,准确性都有很大的变化。这些模型似乎都有一些波动。最后,我有了大约 82%-90%的准确率。在尝试将同样的过程应用于伯灵顿的住房数据时,我遇到了更奇怪的不一致和巨大的过度拟合问题。
回归的应用是复杂的,因为你试图预测一个特定的值,而不是像泰坦尼克号一样的是/否答案。我的提交可以进一步完善,但我的目标是在我拥有的 Burlington 数据集上做,而不是在这里。
3 个行业如何利用人工智能和物联网个性化在 CX 竞争

Photo by Daniil Vnoutchkov on Unsplash
在全球品牌家喻户晓之前,本土品牌和较小的市场允许在直呼其名的基础上进行面对面的交流——想想安迪·格里菲斯吧。随着品牌变得地区性甚至全球性,奢侈品个性化通过客户关系管理软件来实现——例如,酒店员工记住客人的首选房间。但是曾经的奢侈待遇现在变成了现状,消费者需要更多来保持忠诚。
数字化通过消费者喜爱的数据建议帮助品牌保持竞争力——想想亚马逊和网飞。但是,顾客期望的改变意味着,没有新的个性化举措将是不够的。Gartner 报告称,不断投资新技术以提供完全个性化的客户体验(CX)的品牌——从品牌认知到购买等——将比那些不投资的品牌获得高 30%的销售率。
品牌转向全方位个性化,以保持消费者的忠诚度。
因此,品牌必须始终准备采用新技术来提高他们的个性化能力。而且,如果他们善于观察,他们知道物联网(IoT)和人工智能(AI)将在客户旅程的所有阶段塑造我们与产品和服务的交互方式。事实上,来自不同行业的许多品牌已经在利用人工智能和物联网的强大伙伴关系来实现全方位的 CX 个性化。
医疗保健品牌创建个性化护理的完整健康视图。
一名 58 岁男性因内出血被紧急送往急诊室。在找到并止住了出血后,一位医生提出了一个看似难以忍受的诊断:正在恶化的肝癌。
鉴于潜在的肝脏疾病,他可以接受治愈性肝脏移植,但肿瘤必须很小,以符合从负担过重的器官池中获得肝脏的资格。进一步的测试显示,在漫长的器官等待期内,他的肿瘤不太可能保持在标准范围内。病人和他的妻子都希望他们能早点发现肝癌。但是肝癌是无症状的,直到进行治疗时往往已经太晚了。
为了防止更多家庭遭受类似的创伤,IBM Research 正在开发一种纳米技术设备,它实际上是一个芯片上的 T2 实验室。这种手持设备可以分离出直径小至 20 纳米的生物颗粒,如病毒、外来体,甚至 DNA,这比人类头发的直径小 1000 倍。这样,即使患者没有任何症状,它也能在体液中检测出癌症等疾病。
但这还不是全部。IBM Research 的转化系统生物学和纳米生物技术项目主任 Gustavo Stolovitzky 说“我们的目标是,在未来 5 年内,我们将能够将这一技术和其他纳米技术与人工智能相结合,以克服当前的挑战,并在最早的可能阶段检测出癌症等疾病。”
患者可以像进行家庭怀孕测试一样轻松地使用纳米技术设备。然后,诊断数据将被发送到云中,并与其他物联网健康设备数据相结合,如智能手表或睡眠监测数据。总之,这些数据显示了完整的患者健康视图,通过人工智能分析实现了个性化的实时计划。
酒店品牌提供每时每刻的个性化服务来取悦每一位客人。
商务旅行时,你登记入住万豪酒店,然后去你的房间。在里面,每台电视机都叫着你的名字迎接你。时间不早了,你还有一个早会,所以你决定马上去睡觉。
夜里,你醒来需要去洗手间。当你起床时,红色的落地灯照亮了黑暗中的道路。当你回到床上时,你深吸一口气,注意到房间里的氧气水平会根据房间里的人数自动调节,所以不会感到闷热。
早上,蓝色的灯光让你进入清醒状态。你走向房间的智能镜子,它会指导你进行晨练,同时监控你的心率。天亮了,你环顾四周墙上的个性化艺术作品。
你开了一整天的会,然后回到你的房间,渴望进行一次缓解压力的锻炼。当您喜欢的健身器闲置并可供您使用时,您的手机会提醒您。锻炼后,您可以享受智能淋浴,水龙头会自动将水调节到完美的温度,带来舒缓的体验。
这就像一个包裹在商务旅行中的假期。万豪酒店已经准备好了。该品牌与三星和罗格朗合作,创建了一个原型智能房间,可以提供这种和其他个性化体验,包括家庭度假体验。
“这个想法是,如果我是万豪奖励会员,我的个人资料中有我的属性和不喜欢/喜欢,它可以根据我和我的旅行类型来做事情,更加个性化,”Legrand 需求挖掘高级副总裁 Ken Freeman 解释说。客人只需加入品牌的奖励计划,创建个人资料,然后进入他们的个性化人工智能/物联网体验。

Photo by Denys Nevozhai on Unsplash
汽车品牌与 autotech 公司合作,在旅途中实现实时个性化。
莎拉开着她新买的车在高速公路上行驶时,听到汽车仪表板发出叮的一声。因此,她的一天变得很紧张。仪表板显示屏上出现一盏小小的发动机灯。由于几乎没有指向原因的信息,她的想象力变得天马行空。她想象自己在高速公路边,汽车冒着热气。她驶离高速公路,开始给经销商打电话。与此同时,她担心会迟到或完全错过工作。
好消息是,这种情况很快就会成为一种濒临灭绝的物种。这是因为,到 2020 年,将有 2.5 亿辆联网汽车上路。此外,联网汽车带来了大数据,为实时诊断当前和潜在问题提供了潜力。即使没有连接的物联网汽车也存储数据,一旦连接,这些数据可以用于创建个性化的驾驶体验。
例如, CarForce 与 AT & T 合作,将断开连接的汽车重新连接到汽车服务中心,从而将人们从可怕的仪表盘叮当声中解救出来。经许可,经销商服务中心可以在客户汽车上安装小型设备,然后从所有当前连接的传感器收集数据。利用这些数据,CarForce 依靠人工智能来诊断和提醒经销商潜在的车辆问题。
反过来,经销商通过预防性维护警报和驾驶员可以采取的主动措施来解决现有问题,帮助驾驶员在可怕的高速公路场景中保持领先。更好的是,通过将物联网和人工智能结合起来,汽车经销商在 CX 有了一种新的竞争方式:他们不再简单地出售汽车,而是成为值得信赖的维护来源,提供全方位的个性化汽车拥有体验。
品牌可以采取小步骤为消费者未来的个性化期望做准备。
《商业内幕》报道称,如果不能在 CX 很好地竞争,T2 40%的品牌将在七年后不复存在。一些品牌显然致力于提供前沿的个性化服务,从而提高了所有行业的标准。这意味着,鉴于预计到 2020 年将有 204 亿台联网设备,品牌必须知道如何利用它们来获得个性化体验。
三个步骤帮助品牌开始实现个性化技术的现代化,以尖端的客户体验取代现状:
1.**确定哪种技术将提供行业特定的 CX 个性化,且几乎没有陷阱。**虽然 HIPPA 可能会为医疗保健公司的大规模物联网和人工智能个性化战略设置障碍,但物联网和人工智能 it 仍然可以通过个人设备数据分析来帮助个性化与患者的一对一关系。
2.通过循序渐进的方式为新兴技术做准备。万豪不是从创造智能房间开始的。相反,他们首先试验了 Alexa 为客人提供更个性化 CXs 的能力。与此同时,他们计划下一步的发展。
3.与提供特定行业个性化功能的科技公司建立合作伙伴关系。CarForce 就是这样一家科技公司。合作的代理商和维修中心不需要建立内部能力。通过战略合作伙伴关系,他们将物联网和人工智能满足目标市场的个性化需求,为消费者和品牌创造双赢。
通过三个小步骤,品牌可以大步迈向未来最重要的个性化体验的竞争。
一个高中生如何制造一辆自动驾驶汽车
与这个库相关的问题是我收到的最多的问题之一,这个库来自我三年前创建的一个项目。这个存储库本身并没有什么特别的,只是一年前发布的 Nvidia 论文的一个实现。一名研究生后来设法在一辆实际大小的汽车上实现了我的代码,这真的很酷。我的代码创建背后的故事是有趣的部分。
我对机器学习的迷恋始于 2015 年初,那时我偶然发现了遗传算法和神经网络。YouTube 上的热门视频显示,虚拟生物似乎在没有任何人类输入的情况下神奇地进化出复杂的行为。视频解释说,算法就像我在生物课上学到的交叉和随机突变一样简单,但我仍然不相信这样的计算机模拟是可能的。所以很自然的,我写了我自己的模拟来验证这是可能的。在它实际上起作用后,我被迷住了,我深入研究了麻省理工学院关于人工智能的开放课件系列。我花了大约两个星期的时间,每天看一到两个讲座,基本上是吃了整整一学期的人工智能入门材料。
现在,真正有趣的事情开始了——数学。老实说,在我真正理解 backprop 之前,我与它斗争了几个星期。我找到的所有论文、指南和博客都没有以我能真正理解的方式解释它,我花了很长时间试图实现它,但几乎没有成功。最后,我找到了一个我点击的博客,我在 YouTube 上制作了一个视频浓缩了我所了解到的信息,以便处于我这个位置的困惑的人可以像我一样学习*。最后,我用 C++从头开始编写了一个神经网络库,以确保我理解了我所学的内容,并且(很)后来将其改进为一个小型知识库,旨在帮助初学者理解神经网络如何工作。*
我对自动驾驶汽车的迷恋几乎完全是受特斯拉(该公司,而不是天才)的启发,特斯拉最近发布了他们的自动驾驶仪“驾驶”他们汽车的疯狂视频。带着我新发现的天真和对机器学习的浅薄知识,我开始制作我自己的。
第一个(也许是最明显的)挑战是数据收集。我需要记录视频和相应的方向盘角度。视频很简单:我只是草率地在挡风玻璃上贴了一个摄像头。另一方面,方向盘角度是一个完全不同的挑战。我的第一个方法是将加速度计和 Arduino 连接到方向盘上,并将时间数据与视频同步。对于任何一个曾经在糟糕的司机急转弯时被甩到车边的人来说,你会立刻明白为什么这种方法会彻底失败。首先,加速度计从汽车的任何微小运动中获得加速度。其次,精确同步来自不同设备的加速度计数据和视频数据是一个巨大的挑战,我不想应对。
我的第二种方法是直接与汽车接口,使用每辆现代汽车都配备的 OBD-II 端口访问 CAN 总线。这给带来了许多挑战,但回报(超精确的方向盘测量)绝对值得。
*挑战 1: *我如何从 OBD-II 端口读取 CAN 总线?解码和处理 CAN 总线信号是一个复杂的过程,需要花费大量时间来编写和调试。幸运的是,已经有人做到了。使用这段代码和相对便宜的 Arduino shield,我能够轻松地从汽车中提取和读取 CAN 总线数据。

*挑战 2: *我如何将大量的 CAN 总线数据转化为方向盘读数?下面是我收到的仅 10 行(不到一秒)CAN 总线数据的图像。
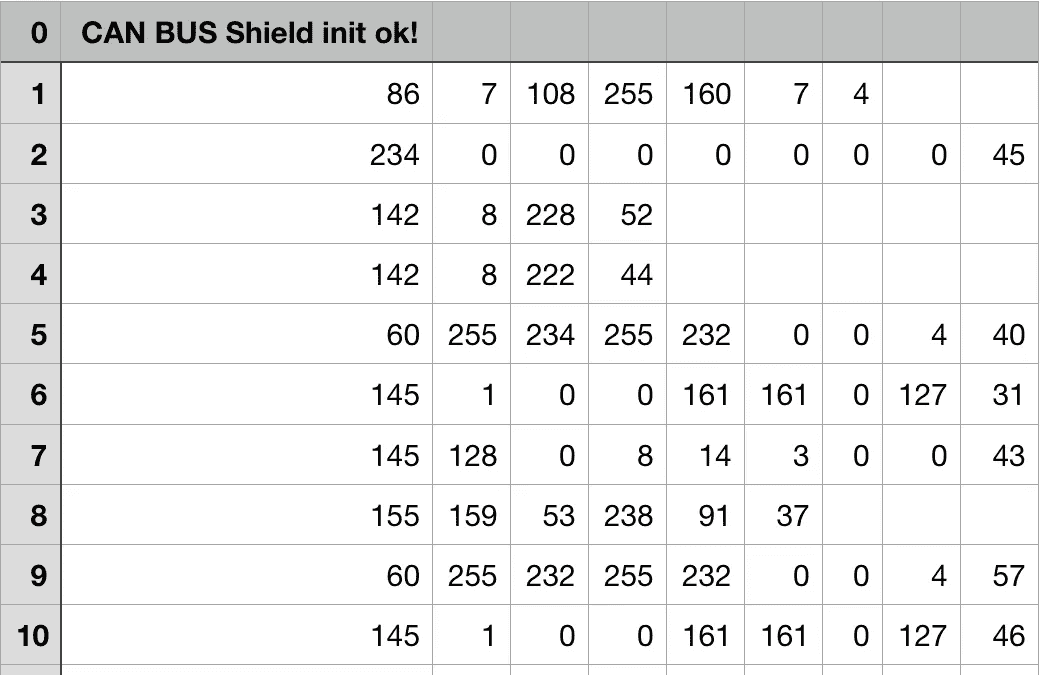
所有这些数据都包含了与 CAN 总线相连的汽车中每个系统的信息,从挡风玻璃雨刷到方向盘上的扭矩传感器。在数据的最左列是对应于接收到的数据包的地址(右列)。例如,在第 1 行,我们从地址 86 接收[7,108,255,160,7,4]。汽车公司真的不喜欢公开发布哪些地址对应于汽车的哪些部件,他们尤其不喜欢有人摆弄他们汽车的硬件。因此,我必须设计一些方法来解析数百个 CAN 总线通道,并找到提供方向盘角度信息的单个通道。**
我基本上是通过手动单独监控每个通道来做到这一点的,同时我慢慢转动方向盘,寻找接收到的数据的平滑变化。经过大量的实验,我设法找出了哪个通道对应于方向盘,以及汽车的其他几个部件(油门、刹车、速度等)。).
挑战三: 我有了数据和渠道,现在怎么办?来自 CAN 总线的数据格式不佳。你不会收到类似“64 频道发送信息:43.5 度”的信息相反,你得到的是一堆杂乱的数据,这些杂乱的数据在某种程度上对应着一个角度。我需要确定几个字节的数据和方向盘角度之间的某种“转换函数”。为此,我将方向盘移动到不同的位置,并记录与该位置相关的相应字节。例如,如果我将方向盘移动到 90 度并接收到[0,128,0,0],然后将其移动到 135 度并接收到[0,192,0,0],我可以粗略估计第二个数据点对应于大约:(192–128)/(135–90)度的倍数。我非常幸运地得到数据是转向角的简单线性变换。使用这种方法,我最终通过实验确定了一个可以应用于数据的线性变换,以获得方向盘角度。
这里有一个视频展示了这一过程,三个挑战都得到了解决。后来我出去了,在我的镇上开了几个小时的车,收集有标签的数据,我的 2015 Macbook Air 放在副驾驶座上。我拿到驾照还不到一年,所以这真的不是个好主意。另一个有趣的事实是:我有几次逃学出去收集数据,所以为我错过的所有课程向 S 先生和 N 女士道歉!
现在有趣的部分:将机器学习应用于任务。
我的第一次尝试是用 Caffe 在 AlexNet 上训练一个分类模型。我把我的数据分成大小为 10 度的箱,得到一组方向盘角度在 0-9 度、10-19 度、20-29 度之间的图像。最后,我对分类输出进行线性组合,以获得最终预测。动机大致是这样的:“如果模型预测 20 度和 30 度的角度有相同的可能性,那么真实的角度可能在 25 度左右。”快速声明:这是而不是处理事情的好方法。感谢当时我并不真正理解的统计学的魔力,这实际上并没有变成可怕的,我后来把它变成了一个仓库的垃圾箱火灾。知识库中嵌入了许多糟糕的编码实践,我将它作为我成功和失败的提醒,将它作为我从那时起学到的许多东西的时间胶囊。
我的第二次尝试是复制最近出来的 Nvidia 论文,稍加修改。Nvidia 型号使用以下架构:
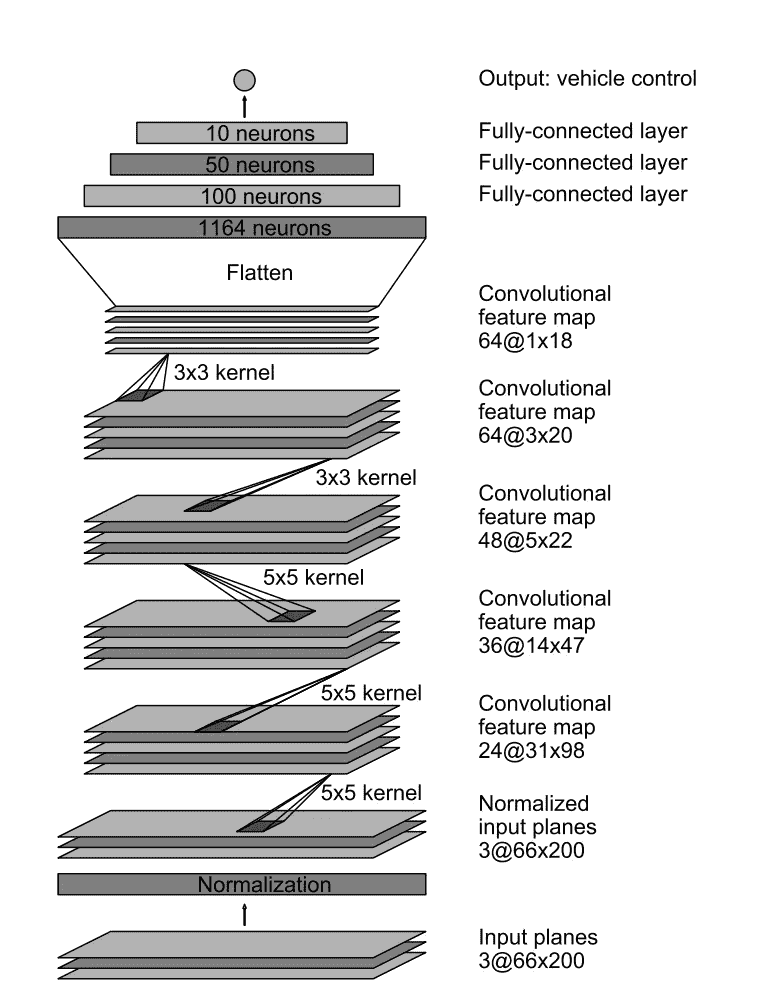
最后的输出是前面十个神经元的简单线性组合,我觉得还可以改进。我通过对线性组合应用反正切函数来改变这一点,我认为这样更直观。反正切为网络提供了一种从可视数据中“恢复”曲率角度的工具,而不必重新学习将斜率或切线转换为弧度的方法。在实践中,它真的没有什么不同,但我保留它只是为了好玩。
我在 TensorFlow 中花了大约一个晚上编写了代码,并在我当时拥有的廉价 750ti GPU 上对它进行了训练。Nvidia 的论文并没有详细说明他们的训练过程,总体来说,论文没有给出太多关于他们如何完成他们所做事情的信息。我使用亚当优化连同 L2-正常化和辍学的训练。最后,我取得了不错的成绩!
总的来说,这个庞大的项目教会了我大量的信息、技术和编码实践。它也引起了很多关注,并为我带来了一些面试和一些工作机会!Nvidia 甚至让我飞到他们的自动驾驶实验室,参观他们的技术,这真的很酷!他们给了我一个相当优厚的条件,让我在接下来的一年里和他们一起实习,但我不情愿地拒绝了继续读本科。在我发布了我的作品后,我在网上遇到了很多了不起的人,这可能是整个经历中最有收获的部分。
有什么问题尽管问!
一个简单的算法如何以中等精度对文本进行分类
涵盖的内容:数据探索、文本分类、不平衡数据、各种度量

Photo by Damiano Lingauri on Unsplash
尽管最近围绕 NLP 的深度学习取得了令人兴奋的进展,但我想展示简单的分类器如何能够达到中等精度。这是一件好事,因为训练这些分类器不需要大量的数据和计算,这是训练深度神经网络的情况。
在这篇博文中,我选择了一个叫做逻辑回归的分类器。我将在亚马逊美食评论上训练它,以预测给定的文本被归类为正面评论或负面评论。
1。数据描述
数据形状(行,列):(568454,10)
列名:描述
- Id:分配给每行的唯一编号
2.产品 Id:产品 id 号
3.用户标识:用户标识号
4.ProfileName:用户名
5.HelpfulnessNumerator:认为评论有帮助的用户数量
6.HelpfulnessDenominator:投票总数(认为评论有帮助的用户数和认为没有帮助的用户数)
7.得分:评分在 1 到 5 之间(1 =最不喜欢,5 =最喜欢)
8.时间:审核的时间戳
9.总结:产品的简短回顾
10.文本:产品评论的文本
我将只使用两个特征:7:分数和 10:文本作为预测器或自变量。
2.数据探索
import panda as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns; sns.set();data = '../../datasets/amazon_review/Reviews.csv'
data = pd.read_csv(data) *# Take proportion of each review score* score_pct = np.bincount(data['Score']) **/** data.shape[0]
scores = pd.DataFrame(np.random.rand(1, 5),
index=['scores'],
columns=pd.Index([1, 2, 3, 4, 5], name='Score'))
scores.iloc[0] = score_pct[1:]
scores.plot.bar()
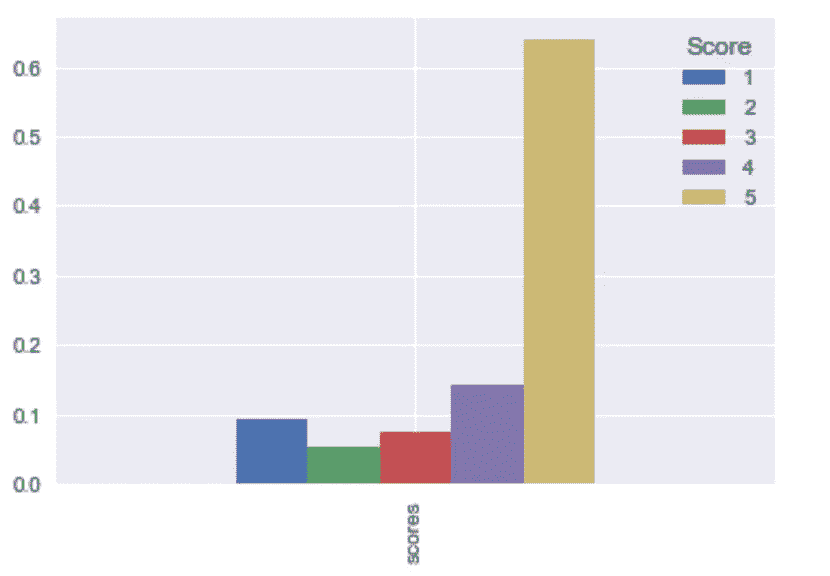
Proportion of review from 1 to 5
超过 60%的评论是最受欢迎的评论(得分 5),其次是中等受欢迎的评论(得分 4)。总评论的 70%由这两个评论分数组成。
来看一些评分 3 和评分 4 的评论。
10 条评分为 3 的评论:
这些评论包括正面评论和负面评论。我将评分为 3 的评论归类为负面,原因如下:第一、第三和第十条评论不包含任何正面评论,即使有些评论有正面评论,但在同一食品的评论中包含负面评论可能会阻止其他人购买食品。
print(data[data['Score'] == 3]['Text'].values[:10])[ "This seems a little more wholesome than some of the supermarket brands, but it is somewhat mushy and doesn't have quite as much flavor either. It didn't pass muster with my kids, so I probably won't buy it again."
'The flavors are good. However, I do not see any differce between this and Oaker Oats brand - they are both mushy.'
'This is the same stuff you can buy at the big box stores. There is nothing healthy about it. It is just carbs and sugars. Save your money and get something that at least has some taste.'
"we're used to spicy foods down here in south texas and these are not at all spicy. doubt very much habanero is used at all. could take it up a notch or two."
'Watch your prices with this. While the assortment was good, and I did get this on a gold box purchase, the price for this was<br />$3-4 less at Target.'
"If you're impulsive like me, then $6 is ok. Don't get me wrong, the quality of these babies is very good and I have no complaints. But in retrospect, the price is a little ridiculous (esp. when you add on the shipping)."
'The taste was great, but the berries had melted. May order again in winter. If you order in cold weather you should enjoy flavor.'
'While my dogs like all of the flavors that we have tried of this dog food, for some reason their itching increased when I tried the lamb and rice. I have some very itchy dogs and am giving them a limited ingredient dog food to try to help. The duck and sweet potato cut down on the itching significantly, but when we tried lamb and rice they started itching more once again. I like Natural Balance for the quality ingredients.'
'Awesome dog food. However, when given to my "Boston", who has severe reactions to some food ingredients; his itching increased to violent jumping out of bed at night, scratching. As soon as I changed to a different formula, the scratching stopped. So glad Natural Balance has other choices. I guess you have to try each, until you find what\'s best for your pet.'
"not what I was expecting in terms of the company's reputation for excellent home delivery products"]
5 条评分为 4 的评论:
得分为 4 的评论总体上是正面的,并且包括诸如“高度推荐”、“我很高兴”之类的词语。
print(data[data['Score'] == 4]['Text'].values[:10])[ 'This is a confection that has been around a few centuries. It is a light, pillowy citrus gelatin with nuts - in this case Filberts. And it is cut into tiny squares and then liberally coated with powdered sugar. And it is a tiny mouthful of heaven. Not too chewy, and very flavorful. I highly recommend this yummy treat. If you are familiar with the story of C.S. Lewis\' "The Lion, The Witch, and The Wardrobe" - this is the treat that seduces Edmund into selling out his Brother and Sisters to the Witch.'
'I got a wild hair for taffy and ordered this five pound bag. The taffy was all very enjoyable with many flavors: watermelon, root beer, melon, peppermint, grape, etc. My only complaint is there was a bit too much red/black licorice-flavored pieces (just not my particular favorites). Between me, my kids, and my husband, this lasted only two weeks! I would recommend this brand of taffy -- it was a delightful treat.'
'good flavor! these came securely packed... they were fresh and delicious! i love these Twizzlers!'
'I was so glad Amazon carried these batteries. I have a hard time finding them elsewhere because they are such a unique size. I need them for my garage door opener.<br />Great deal for the price.'
"McCann's Instant Oatmeal is great if you must have your oatmeal but can only scrape together two or three minutes to prepare it. There is no escaping the fact, however, that even the best instant oatmeal is nowhere near as good as even a store brand of oatmeal requiring stovetop preparation. Still, the McCann's is as good as it gets for instant oatmeal. It's even better than the organic, all-natural brands I have tried. All the varieties in the McCann's variety pack taste good. It can be prepared in the microwave or by adding boiling water so it is convenient in the extreme when time is an issue.<br /><br />McCann's use of actual cane sugar instead of high fructose corn syrup helped me decide to buy this product. Real sugar tastes better and is not as harmful as the other stuff. One thing I do not like, though, is McCann's use of thickeners. Oats plus water plus heat should make a creamy, tasty oatmeal without the need for guar gum. But this is a convenience product. Maybe the guar gum is why, after sitting in the bowl a while, the instant McCann's becomes too thick and gluey."]
2。训练分类器和预测
我会将每一篇评论分为正面或负面,并训练一个分类器来预测这两个值。正如我们在上面看到的,分数为 3 的评论可以被视为负面的,所以如果分数超过 3,我会将每个评论分为正面的,如果分数低于 3,则分为负面的。由于数据量很大,我将使用 4%的数据。
*# We shuffle the rows and extract 10% of the rows* df_reduced = data.sample(frac=0.04, random_state=7)
reduced_data_size = df_reduced.shape[0]# Encode positive as 1 and negative as 0
reduced_labels = np.array([df_reduced['Score'] >= 4])[0][:].astype(int)
reduced_texts = df_reduced['Text'].values
样本数量从 568454 减少到 22738
reduced_sentiment_pct = np.bincount(reduced_labels) / reduced_data_size # percentage value of each sentiment
sentiment = pd.DataFrame(np.random.rand(1, 2),
index=[‘count’],
columns=pd.Index([“negative”, “positive”], name=’sentiment’))
sentiment.iloc[0] = reduced_sentiment_pct
sentiment
sentiment.plot.bar(title="Ratio of each sentiment")
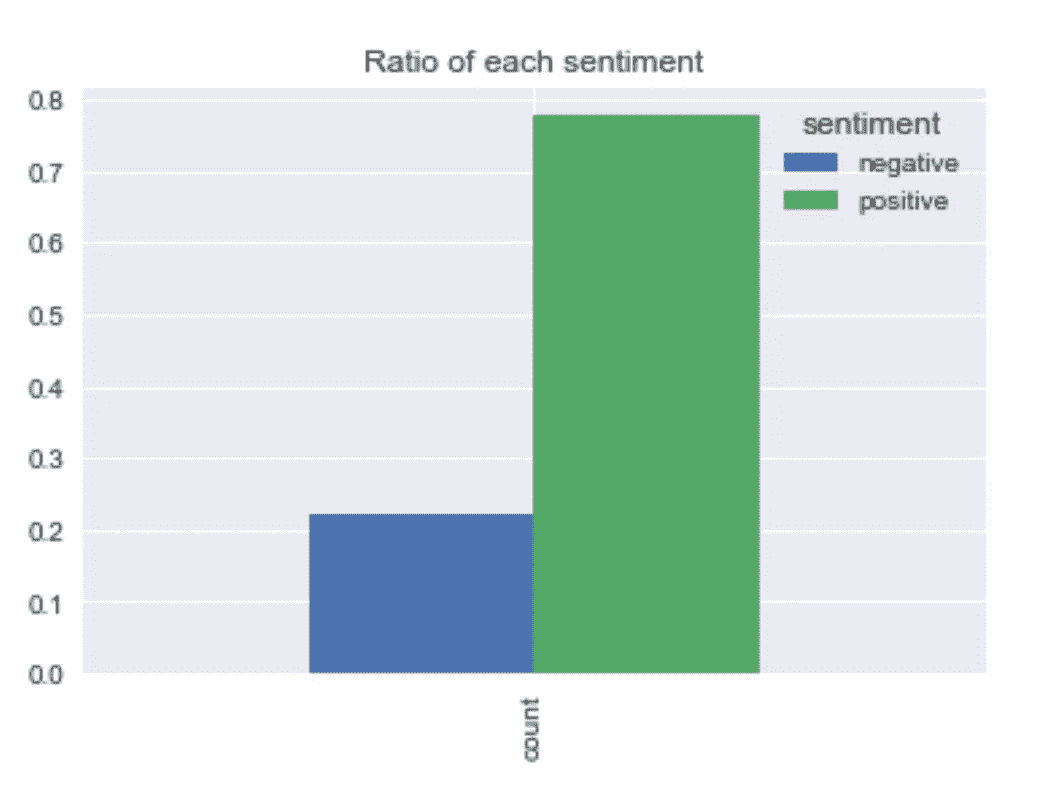
Proportion of each sentiment value
正如我们在上面的柱状图中看到的,78%的评论是正面的。所以这是不平衡的数据,这意味着,**“如果我们只是手动将每个样本(或每个样本)分类为“阳性”,我们将获得大约 78%的分类准确率。”**因此,78%的准确率是我们的基准之一。
我将使用 80%的数据作为训练集,20%作为测试集。
*# we will use 80% of data as training set, 20% as test set*train_size = int(reduced_data_size ***** .8)text_train = reduced_texts[:train_size]y_train = reduced_labels[:train_size]text_test = reduced_texts[train_size:]y_test = reduced_labels[train_size:]
训练集:18190 个样本
测试集:4548 个样本
我会将文本转换成适当的格式(由数值组成),以便可以对它们进行分类训练。我将使用两种方法:A:单词袋和 B.TFIDF
答:一堆废话
单词包使用标记化将文本转换成数字表示。
使用下面的单词包处理两个文档的示例:
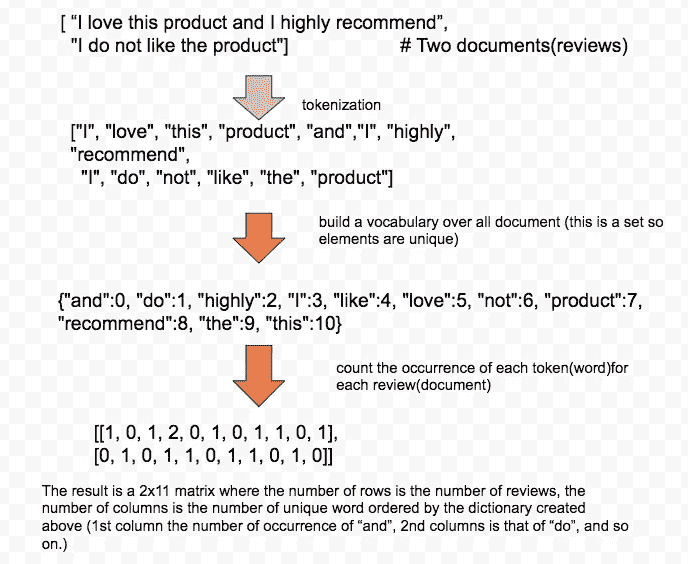
Process of bag-of-words. Inspired by [Introduction to Machine Learning with Python](http://Process of bag-of-words. Inspired by Introduction to Machine Learning with Python)
上述过程的代码
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer().fit(text_train)
X_train = vect.transform(text_train)
print(repr(X_train))X_test = vect.transform(text_test)
print(repr(X_test))
X_train 是:8190x26817 稀疏矩阵
X_test 为:4548x26817 稀疏矩阵
#稀疏矩阵是只包含非零元素的矩阵
拟合逻辑回归
注意:
- 我在下面的实例化中使用了 class_weigtht=“balanced”。这具有惩罚少数类(该数据集中的负类)上的错误的效果。
- 我用的 GridSearchCV 是带“roc_auc”的,不是“分类精度”。这方面的理由写在下面一节。
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import confusion_matrix
from sklearn.linear_model import LogisticRegressionlogreg = LogisticRegression(class_weight=”balanced”, random_state=0)
param_grid = {‘C’: [0.01, 0.1, 1, 10, 100]}grid = GridSearchCV(logreg, param_grid, scoring=”roc_auc”, cv=5)
logreg_train = grid.fit(X_train, y_train)pred_logreg = logreg_train.predict(X_test)
confusion = confusion_matrix(y_test, pred_logreg)
print(confusion)
print("Classification accuracy is: ", (confusion[0][0] + confusion[1][1]) / np.sum(confusion))
混乱矩阵:
[[ 826 206]
[ 468 3048]]
分类精度为:0.851802990325
我打印了一个混淆矩阵,下面画出了它的一个概念。总的来说,我们希望增加真阴性和真阳性的数量。(这两个是矩阵的主对角线)同时最小化假阴性和假阳性的数量(这两个是非对角线)。在上面的混淆矩阵中,假阴性比假阳性多。这可能是由于给定的类权重的惩罚。分类精度计算为:(TN+TP) / (TN+TP+FP + FN)。
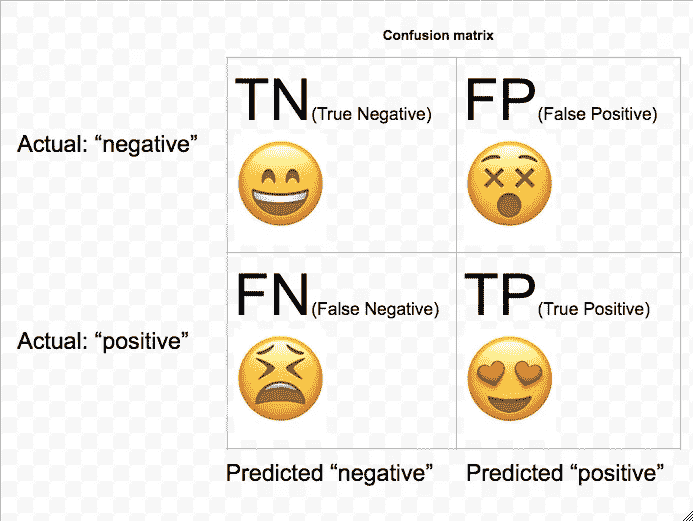
Concept of confusion matrix
from sklearn.metrics import roc_curvefpr, tpr, thresholds = roc_curve(y_test, grid.decision_function(X_test))
# find threshold closest to zero:
close_zero = np.argmin(np.abs(thresholds))
plt.plot(fpr[close_zero], tpr[close_zero], ‘o’, markersize=10,
label=”threshold zero(default)”, fillstyle=”none”, c=’k’, mew=2)
plt.plot([0,1], linestyle=’ — ‘, lw=2, color=’r’, label=’random’, alpha=0.8)
plt.legend(loc=4)
plt.plot(fpr, tpr, label=”ROC Curve”)
plt.xlabel(“False Positive Rate”)
plt.ylabel(“True Positive Rate (recall)”)
plt.title(“roc_curve”);
from sklearn.metrics import auc
print(“AUC score is: “, auc(fpr, tpr));
AUC 分数是:0.901340273919
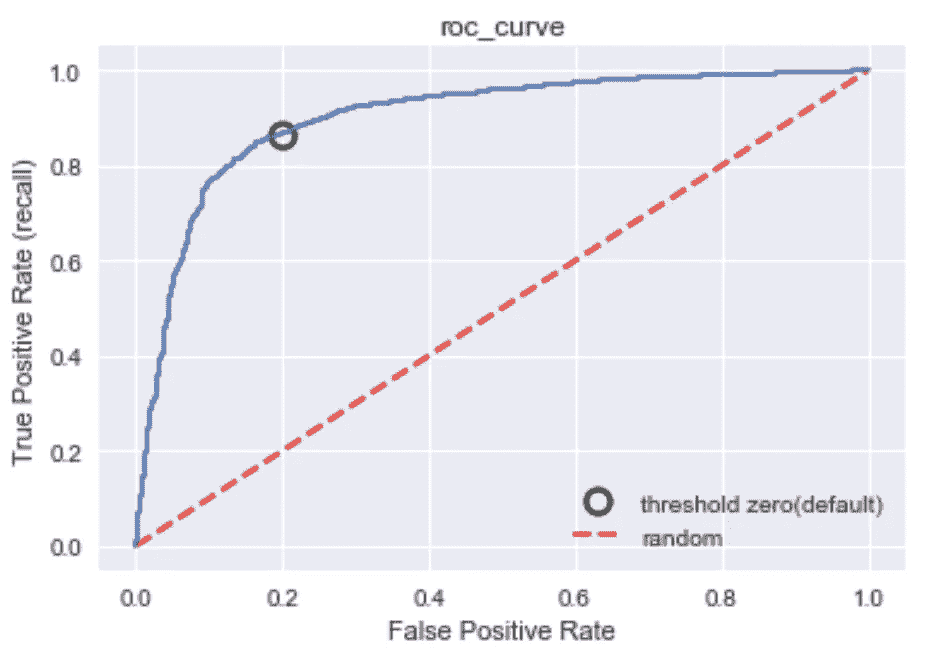
ROC curve
ROC & AUC
ROC:针对假阳性率和真阳性率绘制的曲线,它考虑了分类器的所有阈值。真阳性率也叫召回率。最佳点是左上角,在这里可以实现最低的 FPR 和最高的 TPR。
AUC:ROC 曲线下的面积。此 AUC 的范围(可能值)介于 0(最差)和 1(最佳)之间。随机预测总是产生 0.5 的 AUC 分数。 AUC 是从阳性类别中随机选择的样本比从阴性类别中随机选择的样本给出更高分数的概率或阳性类别中的置信度。因此,AUC 给出了关于预测的附加信息,即关于模型比较(例如,一些模型可能是随机分类器)和可以产生更高分类率的适当阈值的信息。这就是我在 GridSearch 中使用 AUC 作为度量标准的原因。
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds = precision_recall_curve(\
y_test, logreg_train.decision_function(X_test))
close_zero = np.argmin(np.abs(thresholds))
plt.plot(precision[close_zero], recall[close_zero], 'o', markersize=10,
label="threhold zero", fillstyle="none", c="k", mew=2)
plt.plot(precision, recall, label="precision recall curve")
plt.xlabel("precision")
plt.ylabel("recall")
plt.title("Precision Recall Curve")
plt.legend(loc="best");
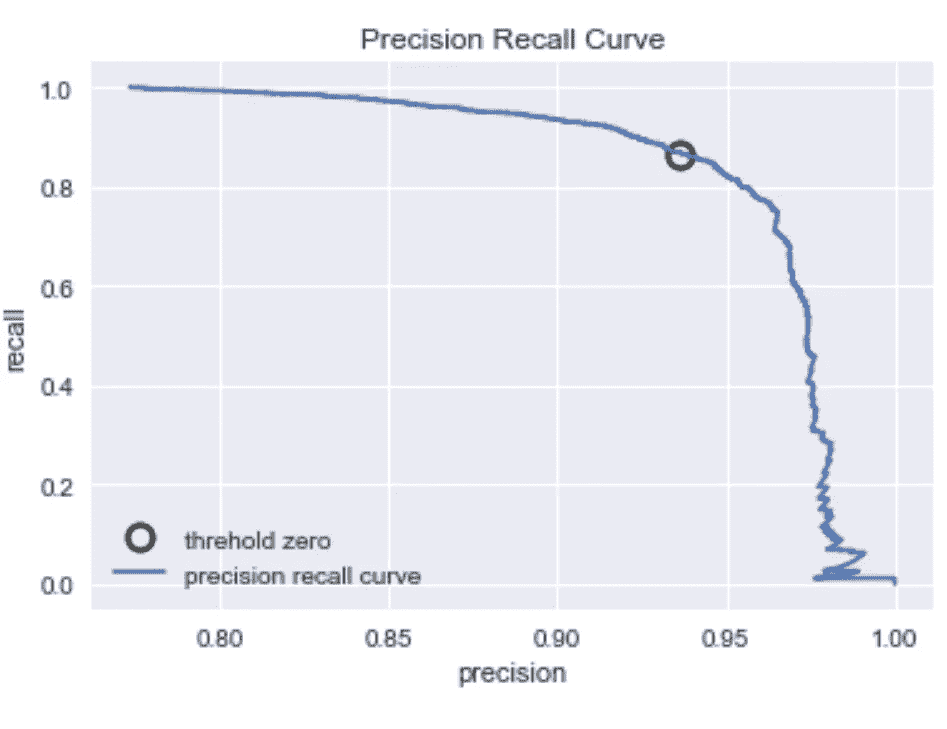
Precision Recall Curve
精确和召回
精确度和召回率由下面的公式决定。这两种价值观之间是有取舍的。当目标是减少假阳性的数量时,使用精度。在该数据中,目标可以是减少被预测为正面的负面评论的数量。设定这一目标的理由是,如果预测是肯定的,一些食品公司可能会出售大量不喜欢或不受欢迎的食品。因此,更高的假阳性率将导致不必要的更高的食品生产成本。另一方面,当目标是减少假阴性的数量时,使用召回。在这些数据中,这意味着目标是减少被错误分类为负面评价的正面评价的数量。我们可能需要更高的召回率,因为销售更多的大众食品会增加利润。因此,我们可以将精确度和召回率的权衡视为该数据集中成本最小化和利润最大化的权衡。

Formulas of precision and recall and tradeoff
B: TFIDF(频率-逆文档频率)
TFIDF 对在特定评论(文档)中频繁出现但在作为整体的评论(语料库)中不频繁出现的词给予高权重。具有高权重的单词是每个评论的代表,而具有低权重的单词出现在许多评论(例如,吃、食物)中,并且不与特定评论相关联。


A process of tf-idf
logreg = LogisticRegression(class_weight="balanced", random_state=0)
pipe = make_pipeline(TfidfVectorizer(norm=None, stop_words='english'), logreg)
param_grid = {'logisticregression__C': [0.001, 0.01, 0.1, 1, 10]}grid = GridSearchCV(pipe, param_grid, scoring="roc_auc", cv=5)
logreg_train = grid.fit(text_train, y_train)fpr, tpr, thresholds = roc_curve(y_test, grid.decision_function(text_test))
pred_logreg = logreg_train.predict(text_test)
confusion = confusion_matrix(y_test, pred_logreg)
print(confusion)
print("Classification accuracy is: ", (confusion[0][0] + confusion[1][1]) / np.sum(confusion))
print("Test AUC score is: ", auc(fpr, tpr));
混淆矩阵
[[806 226]
【454 3062]]
分类准确率为:0.850483729112
AUC 得分为:0.899483666
让我们想象一下哪 25 个单词对预测的影响最大。(点击下图放大)
mglearn.tools.visualize_coefficients(grid.best_estimator_.named_steps['logisticregression'].coef_,
feature_names, n_top_features=25)
plt.title("tfidf-cofficient")
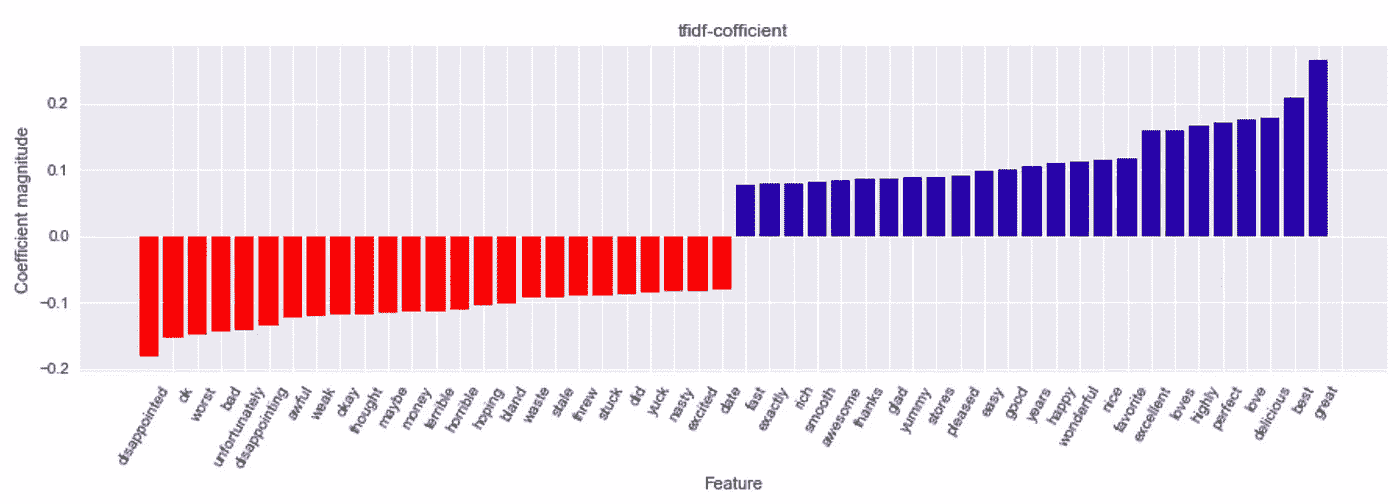
Blue for word which has huge influence on making prediction on positive review and red for negative.
对于负面评论(红色部分),会出现“失望”、“最差”等词语。对于正面评论(蓝色部分),会出现“很好”、“最好”等词语。奇怪的是,还有一些红色的单词,如“ok”、“excited”,这些应该是正面的评论。这将在下面讨论。
N-gram
对单词或每个单词进行训练是很棘手的,因为一些单词组合在一起表示非常不同的意思。
例如,“这不是一个好产品”,如果你用 1-gram(unigram)来标记这个句子,你会得到 6 个不同的单词,其中包括“好”。如果你用 3-gram,那么你会得到 3 个单词的所有组合,其中一个是“不好”。很明显,对“不是一个好”的训练可能导致更好的准确性,因为“不是一个好”更好地抓住了这句话的负面含义。
3-gram(三元模型)用于训练下面的分类器。
pipe = make_pipeline(TfidfVectorizer(min_df=5), LogisticRegression(class_weight="balanced", random_state=0))
param_grid = {'logisticregression__C': [0.001, 0.01, 0.1, 10, 100],
'tfidfvectorizer__ngram_range': [(1,1), (1,2), (1,3)]}grid = GridSearchCV(pipe, param_grid, scoring="roc_auc", cv=5)
logreg_train = grid.fit(text_train, y_train)
pred_logreg = logreg_train.predict(text_test)
confusion = confusion_matrix(y_test, pred_logreg)
print("confusion matrix \n", confusionprint("Classification accuracy is: ", (confusion[0][0] + confusion[1][1]) / np.sum(confusion))
print("AUC score is: ", auc(fpr, tpr));
混淆矩阵
[[810 222]
【261 3255】]
分类准确率为:0.893799472296
AUC 评分为:0.932426383
AUC 增加了约 3%
feature_names = np.array(grid.best_estimator_.named_steps["tfidfvectorizer"].get_feature_names())
coef = grid.best_estimator_.named_steps["logisticregression"].coef_
mask = np.array([len(feature.split(" ")) for feature in feature_names]) == 3
mglearn.tools.visualize_coefficients(coef.ravel()[mask],
feature_names[mask], n_top_features=40)
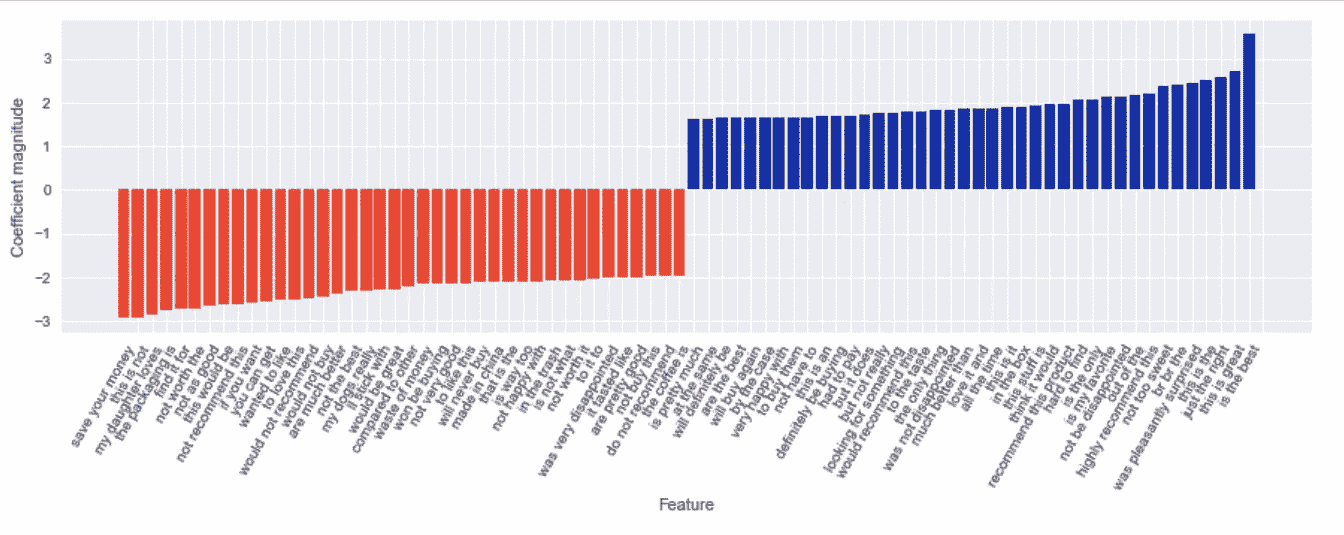
Trigram gram visualization
对于负面评论,会出现“不值得”、“不如”这样的词。对于这些单词,每个单词不传达任何意思(例如,the,as)或相反的意思(例如,值得,不值得)。对于正面评价,有一个连词,“喜出望外”。“惊讶”只能被认为是消极或积极的,副词,“愉快地”确保这有一个积极的意义。
总结:
对于少量数据和少量计算资源,您可以使用分类器,如逻辑回归,并根据如何转换数据来达到中等精度。考虑到数据大小和有限的硬件,在某些情况下,您可能不需要使用像 RNN、LSTM 这样的模型。
完整代码在此
主动学习如何帮助您用更少的数据训练模型
即使有大量的计算资源,在大型数据集上训练一个机器学习模型也可能需要几个小时、几天甚至几周的时间,这是昂贵的,并且是你生产力的负担。但是,在大多数情况下,您不需要所有可用的数据来训练您的模型。在本文中,我们将比较数据子集化策略以及它们对模型性能的影响(训练时间和准确性)。我们将在对 MNIST 数据集子集的 SVM 分类器的训练中实现它们。
通过主动学习构建子集
我们将使用主动学习来构建我们的数据子集。
主动学习是机器学习的一种特殊情况,在这种情况下,学习算法能够交互式地询问用户,以在新的数据点获得所需的输出。
子集化数据的过程是由一个主动学习者完成的,该学习者将基于一个策略进行学习,该策略的训练子集适合于最大化我们的模型的准确性。我们将考虑 4 种不同的策略来从原始训练集中构建这些数据子集:
- 随机采样:随机采样数据点
- 不确定性采样:我们选择我们最不确定其类别的点。
- 熵采样:选择类概率熵最大的点
- 边缘采样:我们选择最有可能和第二有可能类别之间的差异最小的点。
这些策略中的概率与 SVM 分类器的预测相关联。
对于这项研究,我们将构建 5000 个子集(8%的数据);原始训练集 60,000 点中的 10,000 点(数据的 17%)和 15,000 点(数据的 25%)。
结果
为了测量我们在子集上训练的性能,我们将测量 训练准确度 和 训练时间比率计算如下:
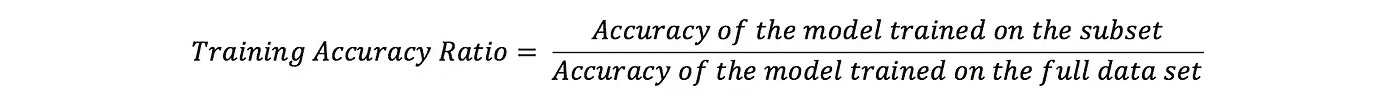

我们可以为测试数据集计算相同的比率。结果总结在下图中。每个策略的 3 个数据点对应于子集的大小(5,000;一万和一万五)。
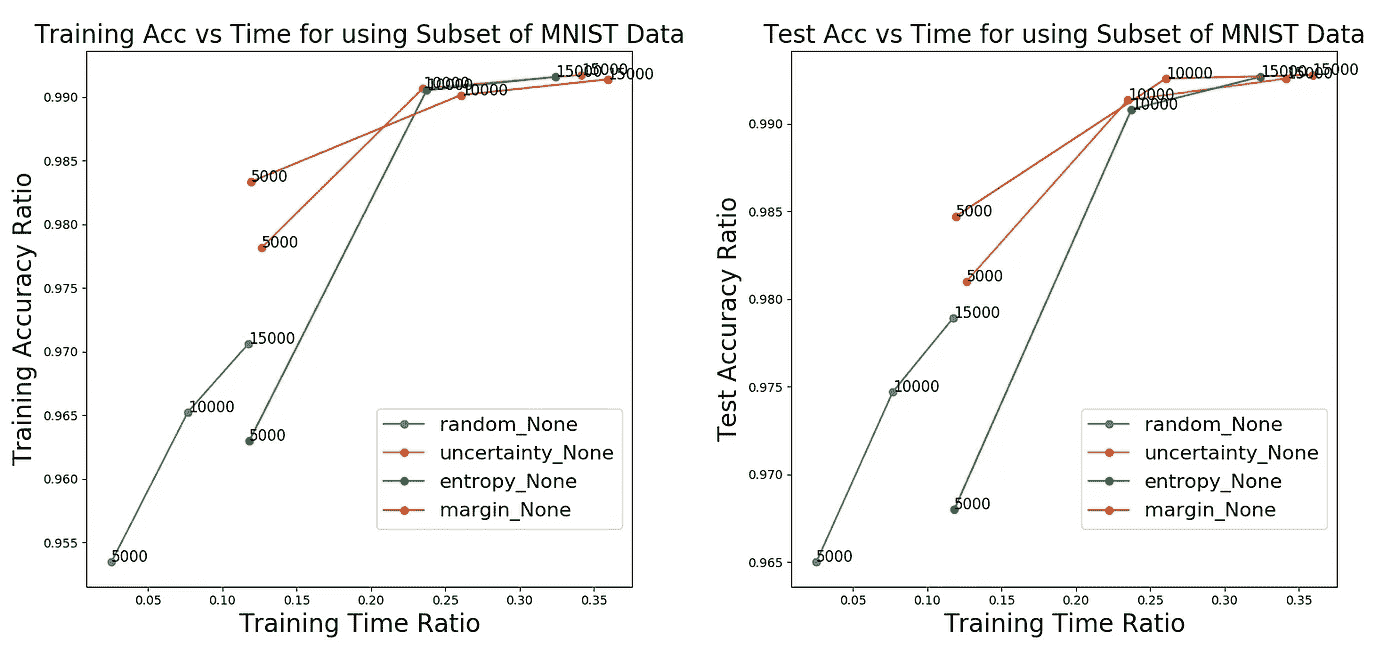
正如我们所看到的,使用不确定性采样策略,我们可以在 15,000 个点的子集上实现 99%以上的性能,而在完整数据集上训练 SVM 所需的时间仅为 35%。这清楚地表明,我们可以获得与使用完整数据集相当的结果,但只需要 25%的数据和 35%的时间。随机抽样是所有策略中最快的,但就准确率而言也是最差的。
因此,对数据子集进行处理是一种合理的方法,可以用更少的计算量显著减少训练时间,并且不会影响准确性。子集化数据适用于大多数分类数据集,但需要扩展以适用于时间序列数据和您正在训练的模型。
我们需要多少数据?
既然我们已经证明了在数据子集上训练模型的价值和可行性,我们如何知道最佳的子集大小应该是多少呢?一种叫做 FABOLAS [Klein et al.]的方法在这里实现可以推荐你应该使用的子集的大小。它通过学习上下文变量(要使用的数据集的大小)和最终得分的可靠性之间的关系来做到这一点。这意味着,通过在子集上训练模型,它可以推断模型在完整数据集上的性能。
贝叶斯优化扩展
如果我们想更进一步,我们可以通过使用贝叶斯优化来更有效地优化子集上的超参数的训练。我在以前的帖子中已经写了很多关于它的内容:
在某些应用中,目标函数是昂贵的或难以评估的。在这些情况下,一般…
towardsdatascience.com](/the-intuitions-behind-bayesian-optimization-with-gaussian-processes-7e00fcc898a0) [## 揭开超参数调谐的神秘面纱
它是什么,为什么是自然的
towardsdatascience.com](/demystifying-hyper-parameter-tuning-acb83af0258f)
在 Mind Foundry,我们正在努力通过贝叶斯优化和主动学习来实现最优和高效的机器学习。如果您有任何问题或想尝试我们的产品,请随时给发电子邮件给我!
【更新:我开了一家科技公司。你可以在这里找到更多的
1:https://en . Wikipedia . org/wiki/Active _ learning _(machine _ learning)
2: 亚伦·克莱因,斯特凡·福克纳,西蒙·巴特尔,菲利普·亨宁,弗兰克·赫特,大型数据集上机器学习超参数的快速贝叶斯优化,arXiv:1605.07079【cs。LG]
人工智能和人类如何优化空气污染监测
空气污染监测
众包空气质量监测案例

根据世界卫生组织(世卫组织)的数据,空气污染每年导致 420 万人死亡。难怪我们应该投入资源来了解和监测城市和社区的空气质量。这应该有助于城市规划当局,因为他们可以决定在哪里种树,建设绿地和管理交通。此外,它可以让我们所有人意识到空气污染对我们日常生活的影响,这对我们的健康至关重要。
在这篇文章中,我们从不同的角度探讨空气污染。我们想介绍和讨论众包空气质量监测的概念。对于那些不熟悉众包概念的人来说,它是关于让公众参与进来以实现一个共同的目标。我们可以通过将参与者的工作分成小任务来实现这一点;在这种情况下,收集空气质量测量值。我们的目标是以一种聪明的方式使用众包,通过使用人工智能(AI)来建立一个准确的空气污染热图。
我们认为,与目前放置在城市中的静态空气质量传感器相比,众包可能是一种更好的方法。首先,不是每个城市或城镇都有一个,当他们有一个时,他们通常被放置在一个捕捉该地区平均空气质量的方式。这意味着它们不一定反映我们在市中心行走时吸入的污染物。此外,我们需要考虑获取、维护和使用静态空气质量传感器的成本。
相反,众包提案依赖于我们参与的意愿。然而,这也需要使用低成本的移动空气质量设备来读取我们的行踪。
重要的是,我们不希望在任何时候任何地方都进行测量。这既有实际原因,也有数据隐私原因。首先,传感器必须连续工作。它还必须跟踪我们的位置,并采取时间戳空气质量测量。即使我们在室内,或者它在我们的包里或口袋里。因此,电池寿命很容易耗尽。最重要的是,这个小小的传感器比你的另一半更了解你的行动。不太好。
因此,挑战在于
确定何时何地应该进行空气质量测量,以便有效地监测我们的城市。
希望现在这里的优化问题开始变得更加清晰。考虑到我们实际愿意贡献的频率和设备可用的电池量,我们希望确定进行测量的最佳位置,以便这些测量对促进有效的环境探索最有用,从而提高我们对环境的了解。
要解决问题,首先需要回答一些关键问题。具体来说,我们的环境是如何表现的?每个测量对整体情况的贡献有多大?不同的测量方法如何影响我们对空气质量的理解?
本质上,我们需要一个环境模型。这将有助于我们量化每次阅读中包含的信息。它还可以帮助我们了解每个测量如何影响随时间收集的整体信息。
一个很好的候选方法是使用高斯过程。对于更专业的读者来说,高斯过程是一种回归技术,它自然地提供了估计值的预测均值和方差。在实践中,这意味着我们可以使用这种技术来插值随着时间推移的环境空气质量,只要进行一些测量。换句话说,我们可以预测未被观察到的位置(没有进行测量的位置)的空气质量,以及预测未来的环境状态。然而,重要的是,高斯过程也可用于提供我们对每个位置的空气质量有多确定(通过利用预测方差)。
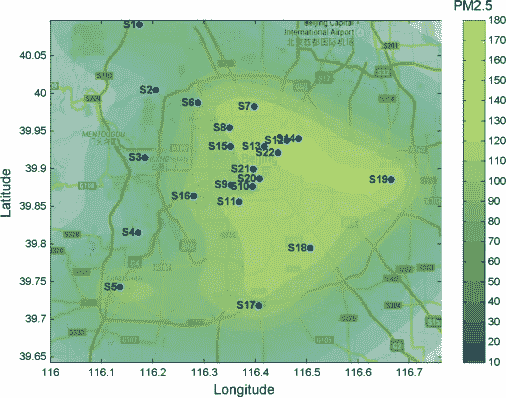
Average air pollution over Beijing in terms of particulate matter (PM2.5) — Image by Author
在统计学和信息论中,*方差是不确定性的度量。*我们的目标是消除热图中的不确定性。我们想知道我们地区的空气质量。为了帮助我们直观地理解插值的含义,请看上图。在该图中,我们可以看到高斯过程作为回归技术的应用。具体来说,它插值了北京市的空气质量。
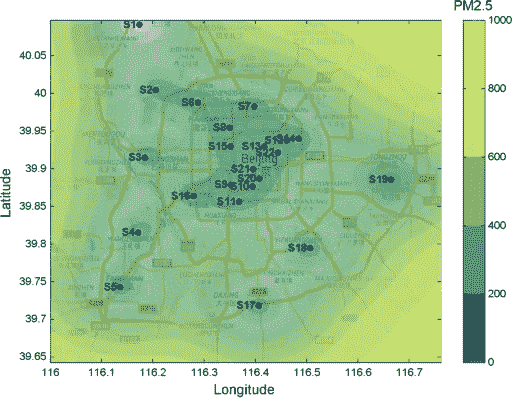
Variance/Uncertainty of air quality over Beijing — Image by Author
然而,正如我们所声称的,重要的是,高斯过程为你提供了对不确定性领域的理解。上图显示,静态传感器周围的不确定性较低,而其间的不确定性开始上升。离传感器越远,不确定性就越高。
现在,回到我们的众包方法。这种建模方法对我们有什么帮助呢?
让我们考虑一下。等效的数字看起来像什么,而不是静态传感器,我们正在模拟志愿者进行的测量。正如我们所说的,一直进行测量是很困难的。当我们在户外或者只是想测量时,我们更有可能进行测量。然而,从概率上来说,更多的人聚集在市中心,也许靠近受欢迎的景点。这部分不用想太多。下面是一个设置示例。确实有些人在市中心,有些人在颐和园附近。
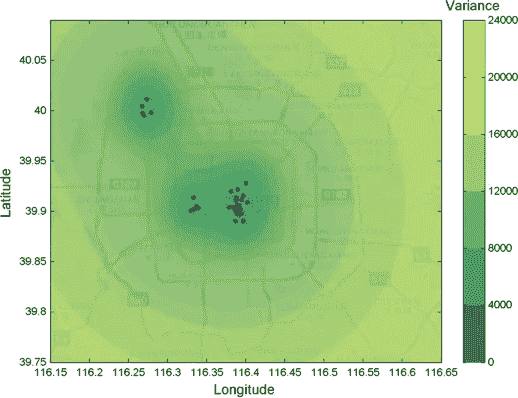
Variance/Uncertainty of air quality over Beijing — Image by Author
然而,从该图中我们可以看出,静态传感器设置可能并没有那么糟糕。这是因为环境的变化或不确定性在所有区域都很高(如图中黄色部分所示)。从好的方面来看,市中心或热门景点的人们可以确信,他们知道他们所在地区的空气质量如何。但这对于城市规划来说用处不大。
我们可以做得更好。我们还没有真正解决这个问题,因为我们还没有指导或提醒人们何时何地获取读数。考虑到人们如何移动或者他们更可能愿意在哪里进行测量,这仅仅是一个可能的默认设置。
然而,我们设法发展了我们的理解。我们现在可以用我们的建模方法来描述这个问题。具体来说,我们需要进行一组测量,以使通过使用高斯过程测量的信息最大化。
这个问题的解决方案需要使用广泛的人工智能领域的算法。具体来说,我们需要一个智能系统来决定何时何地进行测量,以最大限度地获取有关空气质量的信息,同时最大限度地减少所需的读数数量。该系统可以采用与元启发式算法相结合的贪婪搜索技术,例如随机局部搜索、无监督学习(聚类)和随机模拟。这些只是一些潜在技术的例子,我不打算进一步展开,而是给出一个算法的大概情况。
主要想法是随着时间的推移模拟环境,问一些假设的问题。如果我现在进行测量,而不是晚上。哪一个会给我最好的结果?两者都有必要吗?如果我在市区测量或者在我家附近测量会怎么样?
想想我们可以问的所有可能的假设问题。这是每个人每时每刻的假设。即使对于最强大的计算机,这个问题也很难解决。这将需要运行数百万次模拟来涵盖我们每个志愿者的所有可能场景。幸运的是,如上所述,我们有更多的算法方法。例如,聚类可用于将同一地点的人分组,并从本质上将其视为一个实体。因此,智能系统不需要为每个志愿者考虑不同的模拟,而是为每个实体考虑不同的模拟。我们不仅能在空间上,而且能在时间上把人们分组。在相似的时间在相似的地点进行测量的人也可以被看作是一个单一的实体。
既然我们减少了所需的模拟,我们可以使用元启发式方法,基本上是按顺序评估每个组合,以便我们逐渐接近更好的配置,但不一定是最好的配置。一个比上述更好的可能对参与者和城市规划都有用。例如,贪婪算法将首先随时间迭代所有可能的实体,并评估如果这些实体中的任何一个进行单次测量,所收集的信息如何变化。以同样的方式,该算法可以逐步选择最佳位置,而实际上不必评估所有可能的设置。
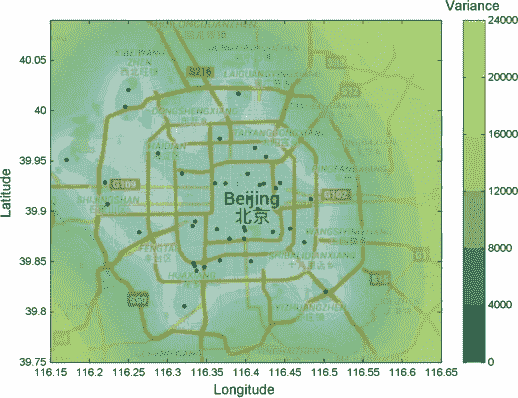
Variance/Uncertainty of air quality over Beijing — Image by Author
最后,给定上述算法过程,智能系统给了我们一个很好的可能的解决方案。这意味着我们有一组推荐的位置来获取空气质量读数。正如我们在上图中看到的,这是一个比我们以前的设置好得多的设置。此外,它与我们之前讨论的静态传感器放置相当。想象一下有更多的志愿者。这只会变得更好,使上面的地图更绿。总体而言,随着人工智能算法和众包的使用,空气质量监测可以变得更容易和更有效。
这篇文章和数字是基于一个出版的期刊:泽诺诺斯,亚历山大,塞巴斯蒂安斯坦,和尼古拉斯詹宁斯。"在不确定的参与式传感环境中协调测量."人工智能研究杂志61(2018):433–474。
人工智能咨询如何损害您的数字化转型

Image by Edu Lauton, CC0
你对人工智能如何提升你的业务有很好的想法?你有预算,有支持,只是想让它动起来。现在你聘请外部顾问来做这项工作。他是一个完美的模型建造者——但是尽管他很善良,他却在摧毁你的生意,因为他在做模型和跑步!
伟大的机器学习顾问会被推进一项工作,并做得很好。然后他们消失了;留下一个模型。以下是为什么模型和运行对你的业务伤害大于帮助的原因。
失去了知识
在项目开始之前,顾问需要做很多事情。首先,他需要从统计学的角度定义你的问题。他需要抓住潜在的问题并找到正确的数据。这个过程很耗时间,需要大量的沟通。当顾问离开项目时,他最终的继任者面临两个主要问题。
他为什么要这样做?理想情况下,这应该可以从代码和注释中得到解答。现实告诉我,事实往往并非如此。另一个人工智能顾问进入这个项目的问题是,他需要从用例的角度理解派生的价值。虽然乍一看这听起来微不足道,但人们可能会碰到从物理方程推导出来的东西。
更难的问题是:他为什么不这么做?或他试过这个吗?。失败的尝试有时和成功的尝试一样重要。如果你想再次接触模型,你不想做徒劳的重复,只是因为你不知道这已经被尝试过了。失败通常没有记录。你可能会说这没关系,因为模型是静态的;但通常情况下这是不正确的。
型号维护
人工智能模型和其他机器一样需要维护。这是因为世界在变化。机器可能会更新,或者你的客户行为可能会改变。你需要发现这些概念的变化并采取行动。这可能像简单的再培训一样简单,但可能涉及建模技术或数据模型的重大变化。失去你的顾问对任何新的人工智能专家来说都是一项艰巨的任务。
另一个密切相关的点是,你经常想要在相同的数据上建立一个模型,但是有不同的目标。你建立了一个客户流失模型?也许你想在相同的数据上建立一个销售线索评分模型或客户生命周期模型。如果有相同的人参与,许多工作流程可以重复使用,许多讨论可以缩短。
运行不驱动变化
许多企业正处于转型阶段。他们需要采用新技术,并将数字化作为竞争优势。对于“非数字原生”企业来说,这带来了一个复杂的问题:*我如何利用我员工的现有技能来实现这一点?*拥抱数字化需要一个自下而上的组成部分。
团队中的每个人都需要看到用例,看到为什么要用 AI 来解决的原因。复杂的任务是让预测文化和思维进入公司。新的潜在的改变游戏规则的想法需要专家可以给出反馈的明确点。实际上,这个任务就是从推动式文化中走出来——做这个项目吧! —对于拉动式文化:——嘿,我们有这种数据,我想我们可以对此建模,你觉得呢?
让人工智能顾问运行意味着你移除了一个关键的结晶点。有多少午餐讨论比一小时的会议更有成效?
解决方案:辅导
永远拥有一个人工智能顾问通常是不可能的,因为预算原因或者因为他想继续前进。你可以做的是转换到教练型的参与。与其在地下室的小衣柜里做模型,不如让其他人尽早参与进来。
最极端的情况是,顾问不是自己做工作,而是和别人一起做。这些人接受以数据科学的方式思考的训练。他们可以添加有价值的反馈和运输信息。
这方面最大的挑战是数据科学的两个最苛刻的技能:统计和编码。但是两者都可以通过正确的工具训练或减少到最低的必要水平。RapidMiner 等无代码数据科学解决方案与编码解决方案一样强大,并为每个人提供了参与旅程的选项。
人工智能如何改变公关

如今,人工智能正在被广泛讨论,因为它有可能自动完成需要重复手工操作的任务。分析人工智能是否会在未来取代人类,这不是本文的范围,而是我在这里提出人工智能如何真正帮助公关专业人员的日常工作。
如果你有一个满是客户的机构,你可能已经意识到在社交媒体上与公众接触是多么令人疲惫,喜欢、回复、关注、搜索你每天管理的每个账户。如果每一项任务都可以自动化该有多好,这样可以节省公关专业人员的时间,让他们去做一些重要的工作,比如创造性的工作和决策活动。
如果你认为有足够的软件可以帮助营销人员,那你就大错特错了。大多数情况下,这些机构不得不依靠多种解决方案,因为没有一个软件能够满足公关机构的大部分需求。
因此,我越来越相信,公关专业人士将不得不掌握人工智能和机器学习的良好命令,以自动化上述重复性的手工工作。不要害怕,人的因素将始终与建立公众参与的机器人相关,因为算法必须不断受到监控,也由公共关系和营销专家设计。
总之,人工智能将塑造未来的公共关系,人们必须准备好充分利用它。
我在这里结束这个话题,但我建议你快速阅读关于人工智能和机器学习的文章,以了解它们如何帮助你推动你的活动。
想取得联系?请在下方留言或通过LinkedIn**😃**联系我
人工智能如何改变信任和安全
信任是人类互动的基础。这是贸易、政治和社会纽带所必需的。对于互联网来说是必不可少的。在过去的 20 年里,我们经历了三次不同的互联网活动爆炸,每一次都有自己的信任问题。
- 从 2000 年到 2005 年,我们见证了电子商务在 Ebay、亚马逊和 Paypal 等平台上的发展。这些公司饱受洗钱和欺诈问题的困扰。
- 从 2005 年到 2010 年,像脸书、Linkedin 和 Twitter 这样的社交网络发展迅速。这些公司面临着网络辱骂、仇恨言论、虚假账户以及最近的虚假内容等问题。
- 自 2010 年以来,像优步和 Airbnb 这样促进同伴互动的公司越来越多。这些公司面临着上述一些问题,以及游客破坏、卖淫、性骚扰和杀人案件中的新问题。
网上信任的主要目的是安全。随着在线互动变得越来越个人化,这种互动带来的危险也越来越大。去年最致命的枪击事件之一是密歇根州卡拉马祖市的一名优步司机所为。归咎于拼车公司的事故清单在这里汇总。
大多数领先公司已经采取措施解决信任和安全问题。这些步骤包括制定保护保险等政策、要求背景调查和对交易进行人工审查。但这些工具中最强的可以说是机器学习,因为不可能人工审查任何给定平台上的所有交易。
在我看来,机器学习的兴起导致了三个主要变化。**首先,企业在信任和安全方面变得更加积极主动。**在点对点经济的早期阶段,大多数公司只是在用户犯了一个不好的行为后才封禁用户。然而,当欺诈、损害和潜在诉讼造成的损失开始增加时,许多公司都出台了更严格的政策,甚至禁止用户进行可疑活动。例如,一家公司可能禁止 IP 地址来自尼日利亚的所有用户。这种新的警戒级别可能会导致大量的误报或假警报。在对个人或公司可能存在风险的情况下,人们可以调整算法以接受更多的误报。在其他情况下,风险只是很小的财务损失(促销滥用等)。),公司可能愿意接受假阴性。机器学习允许我们根据场景做出正确的权衡。
**其次,在信任和安全领域,已经出现了建立行业模型的初创公司。**以前,公司仅依靠自己的数据来做出决策。现在,他们可以用外部数据来补充。 Sift Science 和 Onfido 就是这类创业公司的两个例子。这些公司与不同行业的各种客户合作过,并能够调整自己的模型来检测许多模式。
例如,在处理电子邮件地址时,提供信任解决方案的初创公司会查看诸如首字母大写、电子邮件中数字的存在以及一次性电子邮件域的使用等特征。根据他们的研究,存在上述特征的用户更有可能是欺诈用户的 6 倍、4 倍和 9 倍。Sift Science 在支付欺诈、账户接管和内容、推广和账户滥用方面提供解决方案;Onfido 在身份验证和背景调查方面提供解决方案。通过使用这些外部解决方案,引领 P2P 经济的公司已经能够减少良好用户的摩擦,减少欺诈造成的损失,提高转化率,同时节省欺诈团队的时间和金钱。
**最后,人工智能最积极的影响是减少了偏见。**研究人员表明人类基于认知、社会和个人偏见做出决定。例如,众所周知,Airbnb 的客人会歧视名字很黑的客人、亚裔和甚至是残疾人。这些偏见甚至已经蔓延到了我们的机器学习模型中。
微软研究院的研究表明,当你在谷歌新闻的文章上应用一种名为 word2vec 的神经网络技术时,它会对基于性别的刻板印象进行编码,如“父亲:医生::母亲:护士”和“男人:计算机程序员::女人:家庭主妇”。这些偏见往往对少数民族和有色人种影响最大。然而,一旦识别出这种偏差,修复人工智能或消除算法偏差就容易多了。公司现在正在采取积极的措施来减少他们平台上的偏见和歧视。最突出的例子是 Airbnb,该公司已采取重大措施促进包容性 。
如今,有大量的公开数据,以网站、社交媒体、观察名单、犯罪名单等形式存在。然而,从这些数据中提取洞察力是一个巨大的挑战。我一直致力于使用公开可用的数据来增强身份验证、滥用检测、背景调查和就业筛选解决方案。这很有挑战性,因为每个平台都是不同的,每个平台都有自己的问题。我认为,随着我们在线互动的增长,我们需要投资于信任层,以减少并有望在某一天消除不良事件。机器学习将在构建这一层中发挥巨大的作用。
Chirag Mahapatra 在 Trooly 工作,这是一家使用机器学习的初创公司,根据网站、社交媒体和犯罪记录等公共来源的数据提供信任评级。所有观点仅代表其个人观点,不代表其雇主的观点。
人工智能如何改变金融行业?

风险评估
因为人工智能的基础是从过去的数据中学习;很自然地, AI 应该在金融服务领域取得成功,在这个领域,记账和记录是业务的第二天性。让我们以信用卡为例。今天,我们用信用评分来决定谁有资格申请信用卡,谁没有。然而,将人们分为“富人”和“穷人”并不总是对企业有效。取而代之的是关于每个人的贷款偿还习惯、当前活跃的贷款数量、现有信用卡数量等数据。可用于自定义卡上的利率,使其对提供卡的金融机构更有意义。现在,花一分钟思考一下,哪个系统有能力检查成千上万的个人财务记录并提出解决方案——当然是一台有学问的机器!这就是人工智能的用武之地。由于它是数据驱动和数据依赖的,扫描这些记录也使人工智能能够提出具有历史意义的贷款和信贷建议。
人工智能和人工智能正在很快取代人类分析师,因为人类选择中涉及的不准确性可能会花费数百万美元。人工智能建立在机器学习的基础上,它随着时间的推移学习,减少出错的可能性,并分析大量的数据;人工智能在需要智能分析和清晰思维的领域建立了自动化。聊天机器人确实证明了自己是提高客户满意度的强大工具,也是帮助企业节省大量时间和金钱的无与伦比的资源。现在,回到脸书在设计和开发机器人以像人类一样进行谈判方面的努力,让我们分析一下这项研究成功的机会。这项新技术不仅会改变我们做生意的方式,也会改变非商业活动。非商业活动的例子可以包括固定会议时间。机器人可以安排会议,记住参与会议的每个人的可用性。
欺诈检测和管理
每个企业都旨在降低其周围的风险条件。对于一个金融机构来说更是如此。银行给你的贷款基本上是别人的钱,这就是为什么你还可以获得存款利息和投资红利。这也是银行和金融机构非常、非常严肃对待欺诈的原因。在安全和欺诈识别方面,人工智能处于领先地位。它可以利用过去在不同交易工具上的消费行为来指出奇怪的行为,例如在其他地方使用过一张来自另一个国家的卡几个小时后就使用这张卡,或者试图提取一笔对相关账户来说不寻常的钱。使用 AI 的欺诈检测的另一个优秀特性是,系统对学习没有疑虑。如果它对常规交易发出了危险信号,而人类纠正了这一点,系统可以从经验中学习,并做出更复杂的决定,确定哪些可以被视为欺诈,哪些不可以。
金融咨询服务
贸易
投资公司一直依赖计算机和数据科学家来确定市场的未来模式。作为一个领域,交易和投资依赖于准确预测未来的能力。机器在这方面很棒,因为它们可以在短时间内处理大量数据。也可以教会机器观察过去数据中的模式,并预测这些模式在未来如何重复。虽然数据中确实存在 2008 年金融危机这样的异常,但可以教会机器研究数据,以找到这些异常的“触发器”,并在未来预测中为它们做好计划。更重要的是,根据个人的风险偏好,人工智能可以建议投资组合解决方案,以满足每个人的需求。因此,一个有高风险偏好的人可以依靠人工智能来决定何时购买、持有和出售股票。风险偏好较低的人可以在市场预期下跌时收到警报,从而决定是继续投资还是退出市场。
管理财务
在这个联系紧密、物质至上的世界里管理财务对我们许多人来说都是一项具有挑战性的任务,当我们进一步展望未来时,我们可以看到 AI 正在帮助我们管理财务。PFM(个人财务管理)是人工智能钱包的最新发展之一。 Wallet 由旧金山的一家初创公司创立,使用人工智能来构建算法,以帮助消费者在花钱时做出明智的决定。钱包背后的想法非常简单,它只是从你的网络足迹中积累所有数据,并创建你的消费图表。主张在互联网上侵犯隐私的人可能会觉得这很无礼,但也许这是未来的事情。因此,为了节省制作冗长的电子表格或写在纸上的时间,它必须是首选的个人财务管理。从小规模投资到大规模投资,AI 承诺做未来理财的看门狗。
毫无疑问,人工智能是金融业的未来。由于它在使客户的财务流程变得更容易方面的进步速度,它很快就会取代人类,提供更快、更有效的解决方案。随着人工智能领域的创新,机器人正在逐步发展。这些公司正在进行大规模投资,他们认为这是一项长期的成本削减投资。这有助于公司节省雇人的费用,也避免了这个过程中的人为错误。
虽然它仍处于萌芽阶段,但以其发展金融业的速度,可以预期其前景将导致轻微亏损、更智能的交易,当然还有一流的客户体验。
到 2020 年,人工智能、虚拟现实和大数据将如何改变房地产行业

Photo credit: Shutterstock
对虚拟现实和人工智能的大肆宣传让我很长一段时间没有写这篇文章。在某一点上,似乎每个能够把单词放在一起的人都至少写了一篇关于这个话题的帖子。我不想追随潮流。我也不知道一些关于人工智能或虚拟现实的独特和有趣的东西,我可能会与他人分享。
然而,事情发生了变化。生活中所有美好的事情都发生在午餐时间(我是一个美食家,对此我很抱歉)。我坐在餐厅里,听到我的两个同事在谈论我们公司即将推出的新功能。我听了几分钟,这足以让我大吃一惊。“天哪,太大了,”我只能这么说。他们所描述的在我听来像是 2050 年。只不过这是我们团队当时正在开发的功能。那是 2017 年。现在依然如此。
如果我告诉你这是什么机密信息,希望没有人会责备我泄露了它。毕竟,已经上了新闻了。我的同事们谈论的是一些完全不寻常的事情。我惊讶地意识到,我工作的公司(和我一起工作的人)创造了由人工智能驱动的下一代租赁平台。我花了几个小时消化这些信息,花了几天时间才意识到我需要了解细节。这就是为什么我让我的同事告诉我他们所知道的一切。
长话短说,我听到的比我预料的要多。我不仅了解了 Rentberry 计划推出的新功能,还发现了整个房地产行业的未来。
长话短说,整个房地产世界将会翻天覆地。更具体地说,即将到来的将改变人们租房和出租的方式。告诉你最好的部分,最新的技术进步将带来优质的租赁体验,并节省我们的时间,金钱和精力。
对于对所有这些未来事物都不是特别满意的我(我就是那个害怕机器人有一天征服世界的人),它给未来带来了一些希望。我准备承认,人工智能实际上可以服务于像你我这样的人的需求。但是我们先把空话放在一边,深入挖掘话题。我等不及要透露细节了。
租户智能搜索工具
想象一下搬到你从未去过的城市。你不知道哪些社区是安全舒适的,哪些是最好不要去的。你不熟悉当地的交通模式,这使得很难对可能的上下班通勤做出估计。更不用说你无法确定某个特定的街区是否符合你对餐饮和购物设施的期望。
在不久的将来,人工智能算法将能够分析你的习惯和偏好,并告诉你特定城市的哪个部分最适合你。很难相信,但有算法能够分析你的日常工作,并根据它们的位置、设施等为你建议最佳的租赁单元。
对你有什么好处?
正如我之前所说,由人工智能驱动的租赁平台将能够搜索成千上万的房源,并预测你最有可能喜欢的房源。该算法将根据你的工作地点、你满意的价格范围、你最可能喜欢的活动等等做出假设。该系统将不断研究你的偏好,并随着时间的推移使其假设更加准确。你能想象一个租赁平台知道你在找什么,并向你展示完全符合你需求的房产列表吗?
VR 和 AR vs. Open House
我几乎可以听到保守的房东尖叫说,没有什么可以取代传统的开放房屋。我几乎可以听到他们说,无论是高质量的照片还是 3D 旅行都不会挤掉对未来家园的真正访问。嘘,老学生。我明白你的意思。你说得对。但是没有人说新技术会取代所有传统的东西。不要想替代,要想补充。
看房仍然是了解某个房产是否符合你的需求的最佳方式。然而,如果手头有更多合适的选择,参加开放日有时可能太昂贵、太耗时,而且完全不合理。你未来的房产可能离你现在的住处有几英里远,或者你的日程安排可能被会议和紧急事情排得满满的。如果这描述了你的经历,开放参观选择可能是天赐之物。
你有什么好处?
假设你正计划搬迁到另一个城市,而你在那里没有地方住。你在网上搜索租房信息并找到几个你喜欢的房源。在旧世界(没有 VR 和 AR 的世界),你的下一步将是花费时间和金钱去新城市旅行,以便参加开放参观。然而,在当今世界,这只是选择之一。让我告诉你这不是最好的。
多亏了新技术,你所要做的就是戴上虚拟现实耳机,让自己沉浸在另一个现实中。不需要去参观就能享受到开放日的所有好处。听起来很酷?确实如此。房地产公司看到了 VR 和 AR 的巨大潜力。虽然虚拟现实可以作为开放门户的替代方案,但增强现实可能有助于潜在客户想象他们现在空无一人的家中的家具和装饰。
由大数据驱动的列表
任何精通房地产的人都会证实,经过计算的风险才是王道。不要相信那些告诉你他们投资成功是靠运气的人。质疑那些向你保证他们在为房产定价时不分析市场的人的话。在房地产行业,一切都归结于分析。数据越多,预测就越准确。
这就是大数据在房地产领域如此强大的原因。由于大数据服务越来越受欢迎,在购买出租、设定合适的租赁价格或出售房产时,可以消除所有猜测并依赖统计假设。
在 Rentberry,我们现在正在开发一个功能,该功能将使用大数据资产来帮助房东和房主定义他们房产的真实价值,并确保他们的价格符合当前的市场趋势。
你有什么好处?
让我们假设你有一处房产出租。你需要找出什么是你的财产的正确价格。但是,你以前没有租出去的经验。你也没有时间和欲望去研究市场。
如果没有大数据分析,您将需要手动搜索类似的租赁单元,确保它们位于与您相同的城市/社区,并计算所有单元的平均价格。显然,要做到这一切需要时间、努力和耐心。多亏了 AI,系统会帮你跑腿。它将搜索相同大小、相同设施和相似位置的房产。最终,它会告诉你像你这样的财产最合理的价格是多少。
遇见未来
他们说我们永远不知道未来会发生什么。听起来不错,但对于本文的主题并不成立。作为一个在 IT 和租赁业务之间取得平衡的公司工作的人,我可以清楚地看到现在的情况和未来的情况。房地产的未来是关于改善和进步的。它是关于在更短的时间内获得更好的结果。而是让智能算法在很短的时间内解决我们的问题。而是变得更好,做得更多。
这是未来,孩子。你会喜欢的。
AI 将如何影响不同的技术领域!
人工智能是一个在一些人的头脑中激发奇迹,但在另一些人的心中引发恐惧的术语。事实是,人工智能正在以惊人的速度改变我们的生活。从无人驾驶汽车到专用机器人,人工智能旨在提高人类生活质量。

由人工智能和机器学习驱动的技术已经开始改变工业格局,为组织提供了巨大的利益,并为其业务增加了巨大的价值。
在人工智能的影响下,交通运输、医疗保健、物流、金融和工业制造等行业将经历巨大的变革,它们将变得更具生产力、更便宜,更重要的是,提供更好的服务。
在它的所有应用中,我最兴奋的是人工智能在以下领域产生的结果:
卫生保健
在人工智能专家系统和自主机器人外科医生的帮助下,与所有类型手术相关的风险可以大幅降低,因为即使是小手术也可以以惊人的精度和效率完成。
由于人工智能系统可以作为一个整体不断学习和进化,与只能从自己的经验中学习的人类医生相反,它们将在利用现有的大量医疗数据诊断和治疗疾病方面变得更加优越。
研究已经表明,通过从医疗保健系统收集的数百万患者扫描档案中进行训练,可以训练深度神经网络产生高度可靠的基本放射学结果。许多巨头已经进入了医疗保健机器人领域。
例如,在 2000 年,Intuitive Surgical 推出了达芬奇系统,这是一种新颖的技术,最初上市是为了支持微创心脏搭桥手术,然后在前列腺癌治疗方面获得了巨大的市场牵引力,并在 2003 年与它唯一的主要竞争对手 Computer Motion 合并。
目前处于第四代的达芬奇,在一个符合人体工程学的平台上提供了 3D 可视化(与 2D 单眼腹腔镜相反)和腕式仪器。许多研究人员正在研究类似的医疗设备,这些进展有可能增加和提高人类的平均寿命。
个人护理
我们已经有几个聊天机器人和个人代理,如 Google home、Alexa 和 Siri,它们可以帮助我们进行简单的查询。
在不久的将来,我们可能会有能替我们做日常家务的人形机器人。国家劳工统计局预测,家庭健康助理在未来十年将增长 38%。
这说明了市场的需求。像亚马逊机器人和优步这样的公司正在研究能够提供基本家庭援助服务的类人机器人。

由深度学习实现的自然语言处理和图像处理的巨大进步将增强机器人在家中与人的互动。人工智能真正有用的另一个领域是老年人护理。
尽管目前市场上已经有了一些设备,但一种帮助老年人的可持续人形机器人仍在研发中。人工智能将成为我们生活中不可或缺的一部分,因为我们的家庭将充满智能技术,带来更高的效率和更高的舒适度,为我们节省时间、金钱和能源,同时为我们提供优质服务。
最新的例子是 Amazon Go stores,它使用人工智能和计算机视觉来消除百货商店的长队账单,节省了我们的时间和精力。
自治系统
不管技术变得多么智能,它们永远不能被认为是人类生活的替代品。
在一段时间内,所有危及人类生命但很重要的工作都可以由 AI 赋能的机器人来完成;这包括修理电线,在最深的海沟中寻找石油,以及充当打击犯罪的警察力量。

机器人保护人类免受伤害的最好例子之一是机器人焊接。手工焊接是危险的,会对相关人员造成很大伤害。 RobotWorx ,一家机器人初创公司已经开发出机器人来完成这种任务,只需要几个人来帮助机器人焊接。
另一个这样的例子是下水道勘测;目前,遥控设备可以爬下沙井,导航下水道,调查堵塞的下水道管道,很快它们就会有足够的智能来自行操作和自主行动。
这样,每年可以从这些地区发生的不幸事故中挽救许多生命。
太空旅行
人工智能最伟大的应用之一是在太空旅行和探索中。人工智能可以帮助我们到达未知的行星和恒星,而不必冒生命危险。
在不久的将来,人工智能驱动的人形机器人将足够聪明,能够独立执行太空任务,为人类的繁荣发展寻找新的资源。
正如你在这里看到的,美国宇航局喷气推进实验室的钱志军和奇莉·瓦格斯塔夫预测,在未来,太空探测器的行为将由人工智能而不是来自地球的人类提示来控制。

In future AI empowered robots will govern space programs autonomously
许多组织已经努力设计专门用于探索目的的人工智能技术,他们取得的进步继续模糊了虚构和现实之间的界限。
例如,2003 年发射的勇气号和机遇号火星车都有一个名为 Autonav 的人工智能驾驶系统,允许他们探索火星表面。鉴于人工智能行业的快速发展,我们将拥有完全自主的系统,这将很快改变太空探索领域。
这些只是人工智能应用的一小部分,尽管毫无疑问,人类将从这些应用中大大受益,但不可否认的是,将会有重大的后果。
根据一份报告,到 2021 年**,智能代理人和相关机器人将会减少 6%的工作岗位**。
也就是到 2021 年。因此,最重要的是密切监测人工智能的发展,并采取措施确保社会最终不会受害。
现在和人工智能驱动的未来之间的平稳过渡需要实施。
一个良好的开端是谷歌的“人人都有人工智能”项目,该项目试图向人们展示如何利用人工智能的力量。因此,人工智能可以被认为是一种工具,如果使用得当,它可以在无数方面造福人类。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}