







亚马逊 Alexa 是如何工作的?你的自然语言处理指南

我们现在可以与几乎所有的智能设备对话,但它是如何工作的呢?当你问“这是什么歌?”,正在使用哪些技术?
【Alexa 是如何工作的?
据微软项目经理阿迪·阿加什称,Alexa 是基于自然语言处理(NLP)构建的,这是一种将语音转换为单词、声音和想法的程序。
- 亚马逊记录你的话。事实上,解释声音需要大量的计算能力,你讲话的录音会被发送到亚马逊的服务器上进行更有效的分析。
**计算能力:**指指令执行的速度,通常用千浮点、百万浮点等表示。
- 亚马逊将你的“订单”分解成单独的声音。然后,它会查询包含各种单词发音的数据库,以找到哪些单词最接近单个发音的组合。
- 然后识别重要的单词以理解任务并执行相应的功能。例如,如果 Alexa 注意到像*“运动”或“篮球”*这样的词,它就会打开运动应用。
- 亚马逊的服务器将信息发送回你的设备,Alexa 可能会说话。如果 Alexa 需要回应什么,它会经历上述相同的过程,但顺序相反
( 来源)

深入解释
根据 Trupti Behera 的说法,“它从信号处理开始,这给了 Alexa 尽可能多的机会通过清理信号来理解音频。信号处理是远场音频领域最重要的挑战之一。
这个想法是为了改善目标信号,这意味着能够识别像电视这样的环境噪声,并将其降至最低。为了解决这些问题,七个麦克风被用来大致识别信号来自哪里,以便设备可以专注于它。声学回声消除可以减去该信号,从而只留下剩余的重要信号。
下一个任务是“唤醒词检测”。它确定用户是否说出设备被编程需要打开的单词之一,例如“Alexa”。这是减少误报和漏报所必需的,误报和漏报可能会导致意外购买和愤怒的顾客。这真的很复杂,因为它需要识别发音差异,并且它需要在 CPU 能力有限的设备上这样做。
如果检测到唤醒词,信号将被发送到云中的语音识别软件,该软件将音频转换为文本格式。这里的输出空间是巨大的,因为它查看英语中的所有单词,云是唯一能够充分扩展的技术。使用回声音乐的人的数量使这变得更加复杂——许多艺术家使用不同的拼写作为他们的名字,而不是单词。

Amazon.com
为了将音频转换成文本,Alexa 将分析用户语音的特征,如频率和音高,以给你特征值。
给定输入特征和分成两部分的模型,解码器将确定最可能的单词序列。第一个是先验,它基于大量的现有文本给你最可能的序列,而不看特征,另一个是声学模型,它通过查看音频和转录本的配对,用深度学习进行训练。这些被组合并应用动态编码,这必须实时发生。"(来源)
对“订单”的分析

上面的命令有 3 个主要部分:唤醒词、调用名、话语。(这部分摘自基兰·克里希南的文章)
- 唤醒词 当用户说‘Alexa’时,唤醒设备。唤醒词将 Alexa 置于监听模式,并准备接受用户的指令。
- 调用名称 调用名称是用来触发某个特定“技能”的关键字。用户可以将调用名称与动作、命令或问题结合起来。所有的定制技能必须有一个调用名来启动它。
Alexa“技能”:语音驱动的 Alexa 能力。
- 话语 【金牛座】是话语。话语是用户向 Alexa 发出请求时使用的短语。Alexa 从给定的话语中识别用户的意图,并做出相应的响应。所以基本上话语决定了用户想要 Alexa 执行什么。
之后,支持 Alexa 的设备将用户的指令发送到一个名为 Alexa 语音服务(AVS)的云服务。
将 Alexa 语音服务视为 Alexa 启用设备的大脑,并执行所有复杂的操作,如自动语音识别(ASR)和自然语言理解(NLU)。
Alexa 语音服务处理响应并识别用户的意图,然后在需要时向第三方服务器发出 web 服务请求。
什么是 NLP?
这是人工智能和计算语言学的融合,处理机器和人类自然语言之间的交互,其中计算机需要分析、理解、改变或生成自然语言。
NLP 帮助计算机机器使用多种形式的自然人类语言进行交流,包括但不限于演讲和写作。
“与电脑进行 20 分钟的闲聊不仅仅是一次登月,而是一次火星之旅。”
在这篇文章中,我发现了一个有趣的部分,它说“理解人类语言由于其复杂性而被认为是一项困难的任务。例如,在一个句子中有无数种不同的方式来排列单词。此外,单词可以有多种含义,正确解释句子需要上下文信息。”
开始时,系统得到自然语言的输入。
**自然语言:**人类通过使用和重复,没有有意识的计划或预谋,自然进化出来的任何语言。自然语言可以采取不同的形式,如语音或手语
之后,它将它们转换成类似语音识别的人工语言。在这里,我们将数据转换成文本形式,由 NLU(自然语言理解)处理以理解其含义。
如果你只是在谈论机器理解我们所说的话的能力,一个好的规则是使用术语 NLU。NLU 实际上是更广阔的 NLP 世界的一个子集
隐马尔可夫模型(NLU 例子) :
在语音识别中,该模型将波形的每个部分与之前和之后的内容进行比较,并与波形字典进行比较,以找出正在说的内容。
**波形:**声带的周期性振动产生浊音
隐马尔可夫模型(HMM)是一种观察到一系列排放,但不知道模型产生排放所经历的状态序列的模型。隐马尔可夫模型的分析寻求从观测数据中恢复状态序列。

对于 NeoSpeech 的营销专家 Trevor Jackins 来说,“它试图通过获取语音数据并将其分解为特定持续时间(通常为 10-20 毫秒)的小样本来理解你所说的话。这些数据集进一步与预输入的语音进行比较,以解码你在演讲的每个单元中所说的话。这里的目的是找到音素(语音的最小单位)。然后,机器会查看这一系列音素,并通过统计确定最有可能说出的单词和句子。”(来源
然后 NLU 开始深入理解每个单词,试图理解它是名词还是动词,用的是什么时态,等等。这个过程被定义为词性标注。
根据 EasyGov 的 CPO Pramod Chandra Yan 所说,“NLP 系统也有一个词典(一个词汇表)和一组编码到系统中的语法规则。现代 NLP 算法使用统计机器学习将这些规则应用于自然语言,并确定你所说的话背后最可能的含义。”(来源)
对于一家名为 Lola.com 的公司来说,“为了建造理解自然语言的机器,有必要结合使用规则和统计建模来提取语音。必须提取、识别和解析实体,语义必须在上下文中导出,并用于识别意图。例如,一个简单的短语“我需要 12 月 5 日到 10 日在巴黎的航班和酒店”必须被解析并给出结构:
need:航班{intent} / need:酒店{intent} /巴黎{ city }/12 月 5 日{ date }/10 日{ date }/sensation:0.5723(中性)"
(来源)
Bernard Marr,作者、主题演讲人和顾问,“当 Alexa 在解释你的请求时出错,这些数据将用于下次改进系统。机器学习是语音激活用户界面功能快速提高的原因。”(来源)
在亚马逊网站上,我们可以读到“通过自然语言理解(NLU),计算机可以推断出说话者实际的意思,而不仅仅是他们说的话。基本上,当你问“Alexa,外面天气怎么样?”时,它使像 Alexa 这样的语音技术能够推断出你可能在问当地的天气预报。"
今天的语音优先技术是由 NLU 构建的,它是以识别人类语言中的模式和意义为中心的人工智能。以语音助手为代理的自然语言处理已经重新定义了我们在家里和其他地方与技术互动的方式。"(来源)
你可以在这里查看 Alexa 设备背后的代码:
商业设备制造商将 Alexa 直接集成到互联产品中的 SDK。-Alexa/AVS-设备-sdk
github.com](https://github.com/alexa/avs-device-sdk/wiki)
有关更多信息:
- https://www.quora.com/How-does-Alexa-work
- https://www . quora . com/亚马逊回声背后的技术是什么
- https://chatbotsmagazine . com/how-does-Alexa-skills-works-82 a7 e 93 DEA 04
- https://becoming human . ai/a-simple-introduction-to-natural-language-processing-ea6a 1747 b 32
- http://future-ai.news/2018/03/02/hi-ai-lets-chat/
- https://machine learning-blog . com/2018/07/25/自然语言处理/
- https://code burst . io/a-guide-to-NLP-a-confluence-of-ai-and-language-2786 c56c 0749
- https://blog . neo speech . com/what-is-natural-language-processing/
- https://medium . com/@ Lola . com/NLP-vs-nlu-whats-the-difference-d91c 06780992
- https://medium . com/@ Lola . com/NLP-vs-nlu-what-the-difference-d91c 06780992
- https://developer.amazon.com/fr/alexa-skills-kit/nlu
人工智能引擎如何改善你的业务

过去十年的巨大技术进步解决并极大地影响了人类的基本通信需求。一方面是网站、博客、电子邮件、短信、脸书、Snapchat、Slack 和智能手机,另一方面是作为主导媒介的谷歌,所有这些本质上都满足了我们的沟通需求。我将此称为“通信时代”,我认为就潜在的真正颠覆性创新而言,这个时代已经“停滞不前”。
我们现在正处于下一个时代的开端,即“知识时代”,人工智能(AI)将占据主导地位。AI 是一个总括术语,包括机器学习(ML)、自然语言处理(NLP)和知识表示(KR)等多种技术。人工智能现在是技术的前沿。
你的企业如何使用人工智能?
客户和潜在客户总是问他们如何使用人工智能来增加他们业务的价值。答案是通过部署人工智能引擎作为实现工具,通过它可以利用人工智能功能,抽象出内在的复杂性。由几个不同的模块组成,例如人工智能驱动的创意引擎,人工智能引擎可以作为服务(AIaaS)部署,也可以嵌入客户端-服务器、web 或移动应用程序中。
什么是人工智能引擎?
一个 AI 引擎由几个基本模块组成,包括一个机器学习模块、一个自然语言处理模块和一个知识表示(本体)模块。
为了实现特定的业务目标,如增加销售额、降低成本、解决合规性和提高网络安全性,这些模块用于收集和转换数据、生成准确的预测和见解、读取和分类文本等。
Fortuit AI 引擎
在 Fortuitapps 我们开发了一个强大的、面向商业的人工智能引擎(相对于同样重要的面向学术的对手)。下面我将详细介绍 AI 引擎组件,并描述它们如何用于改进业务流程。

机器学习模块
机器学习基于模拟生物大脑功能的神经网络。神经网络是一个由神经元(脑细胞)组成的网络,这些神经元通过称为突触的连接相互连接(想象一个渔网)。这些连接具有一定的强度(正或负),这些连接的组合将根据特定的阈值导致神经元打开(触发)或不打开(想象一个连接有一些电源线的灯泡:如果累积的功率足够大,灯泡将打开)。人类的思维是神经元放电(或不放电)的结果。
现在,拿一个神经网络的一边,打开一些神经元。然后拿另一边,再次打开一些神经元。你已经给了网络一个给定输入和预期输出的例子(想象一个 1 加 1 的输入和一个 2 的输出,以便教它加法)。接下来,给它许多例子,然后使用一种特定的标准化学习算法,通过这种算法,它可以通过调整其连接的能力以及神经元何时激活来学习。一旦它通过多次迭代稳定下来,让它添加你没有教过它的数字:它会根据它所学到的东西以很高的概率做出准确的响应。这样,给定输入数据集(例如图像)和输出数据集(例如这些图像的描述),基于它“看到”的模式,它可以非常准确地回答新图片包含什么,即使它以前从未见过它。
机器学习模块如何改善您的业务
机器学习模块可以提供
o 描述性分析(发生了什么)
o 预测分析(将会发生什么)
o 规范性见解(应该做什么)
换句话说,ML 模块可以分析游戏的当前状态,并提供关于未来的预测和建议。用于商业目的的机器学习部署的具体示例如下:
库存需求预测
一家全国性面包店希望准确预测需求并相应地调整生产。给定与一系列因素相关的过去表现,如一年中的时间、天气、政治局势、当前事件等,基于 ML 的准确需求预测可以产生可测量的显著节约。
减少产品退货
一家在线零售服装公司希望根据各种因素降低其产品的退货率,这些因素包括买家性别、年龄、订单历史、网站访问量、产品兴趣等。根据可用数据,选择最佳 ML 模型以提供对促成退货的因素的重要见解,可以显著影响盈利能力和效率(甚至达到实时“阻止”有高退货概率的订单的程度)
产品推荐
也许机器学习最受欢迎的应用是网飞的电影推荐系统和亚马逊的“顾客也买了”功能。“结帐”时推荐的产品是根据对将要发生的事情的非常准确的预先评估(即实际将购买多少建议产品)来选择的。
不良贷款
贷款人面临的一个巨大问题是,在潜在的不良贷款候选人实际成为不良贷款之前识别出他们,并采取相应的行动,这显然可以提供重要的价值。给定足够的历史数据,包括客户交易、概况、当前事件、失业率、利率和股票市场利率,所有这些都输入到 ML 模型的选定组合中,可以以令人印象深刻的准确度识别潜在的不良贷款。
自然语言模块
自然语言处理(NLP)为计算机提供了以书面或口头方式理解和解释人类语言的能力。目标是让计算机在理解语言、识别语音和生成语言方面像人类一样智能。
主要应用领域包括:
o 摘要:提供只包含主要概念的文本摘要。摘要使用已经提供的句子或短语,而摘要使用新生成的文本
o 情绪分析 —识别给定文本中的感觉、判断和/或观点(即负面或正面的 twitter 帖子)
o 文本分类 —对文本进行分类(例如,根据域对新闻进行分类)或对文本进行比较,以识别其可能所属的组(例如,此电子邮件是否为垃圾邮件)
o 实体提取 —识别人物、地点、组织等
自然语言处理模块如何帮助您的业务
具体来说,在商业中部署自然语言处理模块的例子如下:
在线博客、新闻网站和论坛上用户评论的汇总和情感分析
抓取目标博客、论坛和新闻网站,提取与特定产品或公司相关的评论,然后自动总结和分析相关观点,以提供关于产品和服务的有价值的见解。
利用许多网站上的“关于”栏目寻找潜在客户
给定目标公司网站的列表(例如来自 CrunchBase),专门的爬行器可以从“关于”部分提取文本,对这些文本进行总结和分类,然后提供洞察,以便通过根据当前客户的“关于”部分进行分类,从列表中定位潜在客户可能感兴趣的那些公司。
电子邮件发送者档案和情感
对于每个电子邮件联系人,对所有收到的电子邮件进行总结和分类,然后将它们输入预先训练的 ML 模型,以确定符合联系人个性和写作风格的回复方式。
知识表示/本体模块
KR 是人工智能的一个领域,致力于表示关于世界的信息:以计算机系统可以使用和理解的形式对现实的基本性质进行概念表征。这可以以“本体”的形式实现,本体是一种知识表示形式,由一组分层的概念和类别以及它们的属性和它们之间的关系组成。本质上,我们对世界的认识是一种内在的本体论。
人工智能引擎的核心是作为一个本体来实现的,该本体可以默认填充大量的一般知识(例如 DBPedia 形式的整个维基百科),或者特定领域的知识,如电子商务或医疗保健。
在业务中利用知识表示模块
领域特定的本体可以提供显著的商业影响。具体例子包括:
电子商务
在电子商务网站上,用户可以通过名称或特征来搜索产品,但他们不支持诸如“如何减肥”或“如何消除蚂蚁”的查询,尽管他们可能针对这种情况销售产品。他们需要的是一个本体,通过这个本体,用自然语言表达的概念被映射到产品上。类似地,客户支持可以使用聊天机器人来利用本体,以提高的准确性和效率自动处理查询。
卫生保健
在医疗保健领域,将症状、病情、治疗和药物联系起来的本体可以为日常医疗保健业务流程提供显著的附加值。
集中公司知识
大多数公司都有一组存储在共享目录中的常用文档,以及一组驻留在本地员工 pc 和笔记本电脑上的文档。这些文档(可能是 word、pdf 或文本文档)包含重要的信息,这些信息总体上构成了重要的数字资产。通过 NLP/NLU 系统,这种知识可以被收集、预处理和语义分析,以创建公司集中的本体/知识库,然后可以被扩展、搜索或更新。
预览:自然语言生成模块
NLG 是上述“知识时代”向前迈出的非常重要的一步。在 Fortuitapps,我们现在正致力于为上述 AI 引擎添加一个 NLG 模块。由于这是我们商业专有工作的一部分,我不会给出确切的细节,而是在本文的上下文中以更一般的术语描述我们的工作。
什么是自然语言生成(NLG)?
NLG 是用自然语言生成文本以响应查询或特定用户请求的智能过程。为了做到这一点,一个 NLG 模块必须对使人类变得聪明的一项非常重要的能力进行建模:常识。如果没有大量关于世界的日常知识(或者至少是关于特定应用领域的知识),自然语言的生成在产品层面是不可能的。因此,任何 NLG 模块的核心都必须由一个本体形式的知识库组成,该本体提供最终将作为“文本”响应产生的“知识”。
我们如何创建 NLG 核心知识库?
由于人类通过阅读任何形式的文档(如书籍、文章、博客、报纸、网站等)来学习,因此 NLG 核心知识库必须由机器“阅读”文档来填充。
从机器的角度来看,文档展示了一个具有多个抽象层次的顺序结构,如标题、句子、段落和章节。这些层次抽象提供了上下文,通过它我们可以推断文本中单词和句子的意思。
因此,为了填充 NLG 核心知识库,我们需要能够阅读和理解语料库(例如谷歌新闻文本)的软件,并利用通过维基百科(文本)和 DBPedia(本体)获得的大量一般知识。
机器如何阅读和理解文本?
从更广泛的意义上来说,有两种主要的自然语言理解方法,,这两种方法我们都使用,并且在更高层次的控制模块的上下文中互为补充。这两种方法描述如下。
基于机器学习的方法
如上所述,关于神经网络,LSTM 或长短期记忆网络是一种递归神经网络,它能够从过去的“经验”中给自己反馈。LSTM 是一种非常强大的算法,可以对数据,尤其是时间序列和文本进行分类、聚类和预测。
我们将上下文特征(主题)合并到模型中,以实现特定的 NLP 任务,如下一个单词或字符预测、下一个句子选择和句子主题预测。我们使用的模型帮助我们回答问题,完成句子,生成释义,并在对话系统中提供下一个话语预测。
除了上面的深度学习模型,我们还使用 Word2vec 中实现的“浅层”模型。Word2vec 是一个工具,它为我们提供了单词、它们的含义以及与其他单词的交互的“心理地图”。每个单词被映射到“数字空间”中的一组数字,这被称为“单词嵌入”。相似的词在这个数字空间中彼此靠近,不相似的词相距很远
基于语义框架的方法
语义框架是相关概念的结构化模型,它们共同提供所有概念的知识,没有它们就不可能有任何概念的完整知识。
一个例子是查询“苹果价格预测”:我们指的是水果苹果或苹果公司的价格以及与其股票价格相关的预测吗?为了回答这个问题,我们必须模拟人类是如何做到这一点的,那就是本质上使用“贝叶斯推理”。贝叶斯推理是一种统计理论,其中关于世界真实状态的证据是根据被称为贝叶斯概率的信任度来计算的。
在贝叶斯概率的上下文中,为了选择与查询“苹果价格预测”相关的正确概念框架,从而知道我们在谈论什么,我们使用“先验素性分布”,简称为不确定量的“先验”。先验是在一些证据被考虑之前,表达一个人对这个量的信念的概率。
虽然没有保证,但是给定先验和结构,我们选择我们认为与查询相关的语义框架(水果价格或股票价格),以便产生适当的响应。在我们的例子中,我们实际上是在问人们通常是什么意思,所以我们使用股票价格语义框架。
生成自然语言文本
基于我们的核心 NLG 本体知识库,以及结合上述两种方法的**,给定一个查询或命令,我们基于以下三个主要步骤继续生成自然语言文本:**
o 制定一个文件计划:选择将形成要制作的文本的知识地图的概念
o 将概念转化为句子
o 过滤结果:概念、语义和句法审查和调整

在 NLG 领域还会有更多有趣的事情发生!
最新跟进:元宇宙
关于作者
人工智能如何解决“玛丽的房间”思维实验
想象我们有一个人工玛丽智能(Ami)。Ami 是一个具有大型复杂人工神经网络和定制的感觉和运动设备系统的机器人。她的感觉装置不断向神经网络发送信息流,她有复杂的奖励信号驱动她学习关于颜色的一切。她的人工神经网络反过来与她的运动系统接口,以驱动机器人身体,从外表看起来就像玛丽的身体。
Ami 的生活和 Mary 的生活有很多相似之处。她的相机能够处理红色,并将信息发送到她的人工神经网络,但事实上,在她的生活中,它们从未这样做过,因为她的环境只包含黑白物体。她的书只是黑白的。她的电脑屏幕只是黑白的。她学习了所有关于颜色的物理知识,以及她的照相机和人工神经网络是如何工作的。所以她非常清楚一旦她的相机前面真的有了彩色的东西,她的系统会如何对颜色做出反应。
然而,关键的是,Ami 没有被允许重新连接她自己的人工神经网络。因此,尽管她知道自己的视觉系统会对看到的颜色做出怎样的反应,但她无法提前做出这些改变。
最后,Ami 被释放了。她走到外面,走进一个充满色彩的世界。她看到一大片健康的玫瑰花丛,有许多玫瑰,她的邻居告诉她是红色的,她看到附近有一个停车标志和一个消防栓,她用手指戳刺,看到一滴人造血。附近一个帅哥看到她脸红了。她对体验红色的感觉有什么新的了解吗?
她的人工神经网络到目前为止只有几秒钟的时间来处理这些新信息,所以网络中的连接权重才刚刚开始变化。她“大脑”中处理颜色的部分仍处于发育的最早期阶段。因此,起初,Ami 并不认为红色物体具有与其他颜色不同的颜色。但随着她与周围世界的互动,她的人工神经网络逐渐通过接触这些新的颜色输入进行训练,她开始能够区分颜色。起初她犯了许多错误。随着她识别颜色的经验越来越多,她变得越来越准确,不久她就能一直正确识别颜色。(除了偶尔在新的和不寻常的照明条件下,她会遇到边缘情况,她和她的朋友对事物的颜色有分歧,比如黑色和蓝色或金色和白色的裙子。)
在她的电子大脑适应她周围丰富多彩的世界的整个过程中,由于她的学习,Ami 理解并期待着每一个新的变化。她“大脑”中以前未被使用的部分从事新的联想和运动学习,但她没有学到新的事实。
玛丽也是如此。
轶事证据如何成就或破坏你的洞察力
你一直在等待一个特殊的场合,带你的伴侣去城里新开的高级餐厅。你已经做了调查:查了 yelp 评论,问了几个朋友,甚至搜索了报纸和杂志的文章,以确保它会成为一个完美的夜晚。
就在你预订之前,你告诉你的朋友,让我们叫她黛比,关于你的计划。“你犯了一个大错误,”她警告说,“我上周五在那里吃的,很糟糕。即使我有预约,我也要等 20 分钟,我们桌子旁边的声音太大,面包不新鲜,服务很慢,我的饭煮过头了。”
黛比不会对你隐瞒她的经历,但你详尽的研究表明这是一个很好的机构。你是做什么的?!
眼下的问题是企业不断挣扎的一个问题:我们应该如何恰当地从轶事证据中获得洞见?如果不正确地看待,轶事会让你和你的组织得出错误的结论。如果使用得当,它们对于与客户建立联系至关重要。
在我们进入什么在这里工作得很好之前,让我们从分析的角度来看“轶事”的定义。
我们如何定义与分析相关的“轶事”?
你知道轶事基本上是一个短篇故事,但是让我们想出一个定义来说明它在数据收集方面的价值。
“轶事是对数据点的描述,不仅仅是提供正在收集的指标。”
看一下餐馆体验的例子,让我们首先确定您可能收集的一个或多个指标。网上的评论和文章提供了所有的细节,从“良好的体验”到每个课程和服务元素的描述。(毫无疑问,在 yelp 的每篇评论和文章中,你都会读到有关这家餐厅就餐体验的细节。然而,如果你在 yelp 上看到的评论仅仅是“太棒了!”,您仍然会考虑该数据点。)
你真正衡量的是什么?如果你选择将体验作为一个整体来衡量(你是在衡量人们作为一个整体的体验。如果 Debbie 简单地说“我真的不喜欢”,该数据点仍然会提供很多价值,因为它说明了你的目标指标。除非你是专门跟踪服务和食品质量细节的反馈,否则你不需要额外的信息。
因此,黛比的“我真的不喜欢它”将构成一个数据点,但不是一个轶事。根据我们的定义,她实际上说的是一件轶事,因为它包含的信息超出了你正在收集的指标。请记住,这并不是说额外输入没有价值,我们稍后会谈到这一点。
趣闻轶事如何影响你的数据洞察力
大数据面临的一个众所周知的挑战是信息过载。你用什么?你能折腾什么?
奇闻轶事是同一个问题的缩影:给你的信息太多了!你如何比较 yelp 上给餐厅 5 颗星的评论和“年度美食!”用黛比的账户吗?有价值的数据点是那些与你优先考虑的变量相关的数据点。
轶事在情感层面上引起我们的共鸣,这会导致过分强调那些数据点。当黛比带你经历晚上的每一步时,就好像你自己正在经历一样。你想象自己感受到等待餐桌的烦恼,品尝不新鲜面包的不快,无法引起服务员注意的沮丧,以及期待已久的饭菜不合标准时的失望。
与其比较数据本身,不如比较你对每个数据点的情绪反应。是一般的网上评论还是黛比的描述给了你更大幅度的感动?显然是黛比的!我们很自然地把引起强烈情绪反应的叙述与更大的意义联系起来。
事实上,你认为写五星在线评论的人有强烈的情绪反应吗?可能是这样,特别是如果他们被感动后,一个好评如潮的审查。那个人和黛比暴露在相同的变量中,但是描述没有那么详细。同样的评论也可以被写成符合或超过黛比描述中的情感水平。
简而言之,当你亲身经历一个数据点时,你会比仅仅是向你报告时联想到更大的价值。因为你从一个数据点体验到更多的情绪,你自然地(通常是下意识地)赋予它更多的重要性。
这对你的数据洞察力有何影响?太多时候,这些轶事是对数据点的描述,这些数据点与为你提供你想要的度量和你想要的度量的数据点没有什么不同。这件轶事只是沧海一粟,它会诱使你把它看起来比实际更重要。
这种情况在客户服务中每天都会发生。最有可能打电话进来的人是不满意的顾客,你可以打赌他们会详细描述一个产品或服务是如何给他们带来可怕的体验的。如果高管们听到这些故事,并将它们与显示其销售正变得更强劲的原始数据进行比较,他们可能会倾向于做出不明智的改变,因为消费者轶事具有情感分量。这并不是说那些不满意的客户不算数据点,也不是说在改进产品或服务方面没有什么可做的。它只是简单地陈述了这样一个事实,即每个客户都应该得到同等的重视,即使不满意的数据点更具情感吸引力。
情感在生活的各个领域都是有用的,包括商业。它们让我们能够与客户建立联系,这样我们就可以有效地进行营销,开发出满足他们需求的产品和服务。然而,它们会影响我们的判断,阻止我们从数据集得出结论时保持客观。
如果没有一个事先准备好的数据收集过程,轶事证据会使你容易受到人类本能的影响,即赋予那些感动你的信息更大的价值。不正确的加权输入导致不正确的输出。这可能导致实施错误的策略,耗费您的资源,甚至更糟的是,客户。
联系客户和最终用户
在任何政治辩论中,你都会听到每个候选人讲述他们自己或他们在竞选中遇到的某个人的轶事。他们明白信息不足以投资,人们想要一种式的情感纽带。
数据本身是冰冷的,没有人情味的。它们呈现的数字和图形只不过是屏幕上的像素或页面上的墨水。事实上,这些数字通常代表人和经历。数据背后的意义对于联系内部和外部的人是至关重要的。
在内部,最终用户必须相信来自数据的洞察力足以改变他们的行动。没有他们的认同,你的洞察力是没有用的。轶事可以用来激励内部客户采取行动,而冰冷的数据可能不会。
例如,如果一家汽车制造商的产品开发人员正在确定应该在安全功能上投入多少质量,他们可能会获得如下图所示的数据。
该开发商可能会将每年每 10 亿英里死亡人数的下降(红线)视为不重视安全的理由,因为人们似乎是更好的司机。然而,如果听到一些关于汽车的安全特性如何极大地影响人们生活的故事,他们可能会采取新的行动,因为他们现在感觉到了安全。原始数据不能形成这种纽带,轶事可以。
对外,轶事可以把你和客户联系起来。这就是焦点小组的目的。仅仅知道人们认可或不认可你的产品是不够的。理解他们因你的产品而体验到的情绪,对于与你的目标市场建立联系并推动销售至关重要。
轶事也有助于解释没有意义的数据点。听到一些没有直观意义的数据点的故事,可以发现真正推动结果的隐藏变量。
只有当您的最终用户在实践中利用这些数据时,从您的数据中获得的洞察力才是有用的。轶事证据可能是获得你需要的认同的有效方式,因此你的分析为你的组织提供优势。
我们将何去何从?
如果使用得当,轶事证据可以成为从数据中获得独特见解的强大工具。还记得我们对轶事的定义吗?这是一个提供额外信息的数据点。如果你有一个训练有素的方法,这些信息不会误导你,它能让你更好地理解你正在研究的东西。
如果有一个收获,那就是:让轶事证据驱动你的问题,以及数据分析支持答案。
科学方法在你的数据分析过程中起着至关重要的作用。系统地测试你的假设,并从结果中传达结论,这就是数据如何帮助我们做出更明智的战略决策。然而,不要被术语“数据科学”误导,因为它也是一门艺术。
当接近一个数据集时,实际上有无限多的假设要发展。因此,选择一个测试是一种艺术形式,它允许并且经常需要创造力来获得最有用的洞察力。
轶事证据为我们提供了典型数据点之外的额外信息。在那些故事中可能会有反直觉的模式,或者你没有考虑到的变量。
让我们回到我们的餐馆例子。在读了许多评论和听了黛比的故事后,你会注意到在考虑星期几时可能会有一个模式。黛比周五在那里用餐,也许你看到的唯一负面评论也是在周五。这不足以得出应该避免周五的结论,但它可以促使你现在用一个新的问题来处理数据:一周中的某一天与客户体验之间有任何关联吗?轶事提供了问题,现在你让你的分析为你提供一个客观的答案。无论您是否发现了相关性,现在您都可以从您的数据集中做出更明智的决策,这要感谢轶事证据提供的额外洞察力。因此,当黛比抱怨她的外出之夜时,记住如何处理趣闻轶事:
- 抛开情绪
- 倾听你还没有考虑到的变量
- 从你的新变量中发展出新颖的、可测试的假设
- 系统客观地测试这些假设
- 根据结果维持或改变你的策略
现在,你可以更有信心,你的夜晚将是一个愉快的夜晚。
本文原载于www.strataquant.com
动物投资者如何战胜市场
许多文章声称,一群驯养的动物可以成为选股者,不仅打败市场,也打败了熟练的基金经理。从一只名叫 Orlando 的可爱的猫,它通过将一只老鼠放在股票网格上来“击败”经理,到训练外汇交易的实验室老鼠和被蒙住眼睛的猴子在《华尔街日报》扔飞镖,动物王国似乎比我们优越!

“一只被蒙住眼睛的猴子向一份报纸的金融版投掷飞镖,可能会选择一个与专家精心挑选的投资组合一样好的投资组合。”—伯顿·马尔基尔
这回避了一个显而易见的问题——为什么我们付给基金经理那么多钱,而这些钱显然应该去奥兰多?
好吧,让我们看看是否有其他动物可以战胜市场!为了节省水族馆的费用,我将模拟金鱼从 S&P500 随机挑选股票。奥兰多几乎没有研究基本面,所以随机选择对我们的鱼来说不是一个可怕的假设。在这个模拟中,每条鱼挑选 50 只股票,构建一个相等权重的投资组合,持有 3 年。

1000 goldfish returns, S&P500 in black
在管理金鱼的 1000 个模拟基金中,96.1%跑赢了市场,市场回报与金鱼 3 年回报的平均差为 14.5%!
但是,S&P500 96%的随机样本怎么可能胜过整个 S&P500 呢?乍一看,这类似于抛硬币,96%的情况下得到的是反面,或者在 1-100 之间随机选择 10 个数字,大多数情况下得到的平均值在 50 以上。
然而,这是假设 S&P500 的每只股票对 S & P500 指数的整体表现的贡献是相同的,但是 S & P500 和其他指数是根据其中包含的每家公司的规模或市值进行加权的。

The divisor is roughly $8.933 Billion and is adjusted for major shakeups any of the component companies
与 S&P500 不同,我们的金鱼和其他非人类投资者选择的投资组合权重相等,这意味着他们持有相同数量的每只股票。

事实证明,S&P500 前 10%的股票贡献了近 50%的整体指数。这些大盘股的回报往往远不如小盘股那样易变或多变,这使得小盘股的风险更大。大多数投资者并不特别喜欢高风险的股票,所以为了补偿购买这些股票的投资者,这些股票需要提供更高的回报。这是从经验上看的,因为在 1980 年至 2015 年之间,小型股票的平均年增长率为 11.24%,而大型股票的平均年增长率为 8.0%。
因此,当我们的动物朋友选择随机投资组合时,他们选择了不成比例的大量小股票,与 S&P500 相比,这提高了投资组合的回报率,同时也增加了很多风险,这一点 Orlando 忘记提到了。因此,尽管金鱼/猫/老鼠选择的随机投资组合确实提供了高回报,但其风险水平的回报不太可能是最佳的。
苹果如何建立其 iPhone X 面部识别系统 TensorFlow 中的暹罗网络解释道
背景
在机器学习中,输入数据的质量经常取代模型架构和训练方案。与在较低质量数据集上训练的更高级、高度调整的模型相比,具有正确标记的高质量图像的大型、平衡数据集将始终产生更好的模型性能。然而,数据科学家并不总是收到大量的数据集。事实上,在我参与的大多数项目中,数据集甚至没有被标上。因此,机器学习的最大瓶颈是数据集的创建。
苹果已经建立了一个自动面部识别系统——在训练中只需给定几个人脸样本,它就能在测试中以极高的准确度正确识别出个人。有几个模型在幕后一起工作来实现这一点。这里有两个最重要的模型——1)能够区分真实的人和其他人工制品(如人的照片)的模型,以及 2)能够区分人的模型。考虑到 iPhone 用户的巨大数量(为了便于讨论,假设有 1000 万),苹果如何建立一个足够强大的系统来识别一个人的图像?
解决这个问题的第一步是数据扩充。通过旋转、模糊或裁剪图像数据,可以创建近似反映原始数据集中图像分布的合成图像。然而,这种方法并不完美——它提供了一种正则化效果,如果网络在训练中表现不佳,这种效果可能是不想要的。
第二步,也是更重要的一步,是采用一类被称为暹罗网络的通用架构。这里讨论的暹罗网络的特殊风格使用带有共享参数的模型为每个图像构建特征表示。损失定义如下——如果两个图像属于同一类,则当它们的相关特征向量之间的距离较低时损失较低,而当它们的相关特征向量之间的距离较高时损失较高。反之亦然,如果两个图像属于不同的类别,只有当图像特征表示相距很远时,损失才很低。该模型架构旨在处理以下两种情况:
- 稀疏数据
- 新数据
该架构已经在苹果、百度等公司进行了全球部署。
现在,让我们在 tensorflow 中建立模型!

输入管道
由于暹罗网络严格的输入参数,输入管道可能是我们编写的最复杂的代码。基本要求是我们必须选择两幅输入图像。这些输入图像必须以相等的概率属于同一类或不同类。
虽然 tensorflow 中的健壮数据集类可以简单有效地提供图像数据,但它不是为暹罗网要求而设计的,因此需要一些技巧才能实现。
为了提高效率,在下面的代码中,我从 TFRecords 格式读入图像数据。图像数据可以很容易地与 tensorflow 的数据集类
dataset = tf.data.Dataset.from_tensor_slices()
第一步是创建一个包含所有图像数据的数据集。
数据以一定的缓冲区大小进行混洗(较大的值增加时间,较小的值减少随机性),并映射到它们各自的图像和标签张量。回想一下,所有这些操作都是张量流图的一部分。
接下来,必须将上述结构的两个数据集压缩在一起,以创建暹罗数据集。对于这个数据集,我们有一些架构和性能要求
- 数据必须被重新洗牌
- 数据必须均匀分布
- 开销应该是分布式的和同步的
通过 tensorflow 的prefetch()、filter()和 shuffle()实用程序,这可以实现。这些操作的顺序非常重要——在过滤之前重复可能会导致无限循环!prefetch()操作允许 CPU 在 GPU 训练时加载一批图像。
由于我们已经在 tensorflow 图形中工作,所有操作都必须由 tensorflow 支持。我在这里定义了操作filter_func。该操作根据图像对是否出现在同一数据集中来随机过滤图像对。
咻!我们有数据集了!现在,我们建模。
模型
让我们定义一个基本模型。首先,我们可以定义一个卷积块。
有了这些卷积块,我们可以定义一个模型。给定一个输入图像,该模型返回一个展平的 1024 单位特征向量。
回想一下,在暹罗网络中,两个图像都是由同一模型处理的。因此,我们可以在 tensorflow 中设置一个可变范围,允许我们在处理每一对输入时共享参数。
一个紧密连接的层被附加到特征因子的绝对差上。值得注意的是,没有激活函数应用于这个最终向量,这允许模型捕捉输出的自然分布,并允许所有神经元被表示。
最后,我们必须定义暹罗损失。在暹罗网络的这个特殊变体中,我展示了对比损耗——另一种常见的损耗是三重损耗。然而,三重态损耗需要与上述不同的模型架构。
培养
让我们现在把它拉在一起。首先,我们调用我们的数据集,并在我们的图中实例化代表左右输入图像的张量,以及它们对应的标签。
接下来,我们将损耗添加到张量流图中。
最后,我们实例化一个优化器来最小化损失,实例化一个初始化器来将所有变量实例化为值的某种分布(可以为每个操作指定)。我在这里使用流行的 Adam 优化器。
现在,我们可以开始张量流训练。
一些离别的想法
这里描述了一个使用低级 tensorflow API 的基本暹罗网络。这个网络在解析稀疏数据集方面非常强大,并被用于全球公认的系统,包括 iPhone X。
如果你对代码有任何问题/评论/修正,给我发消息或在这个帖子上发表评论。
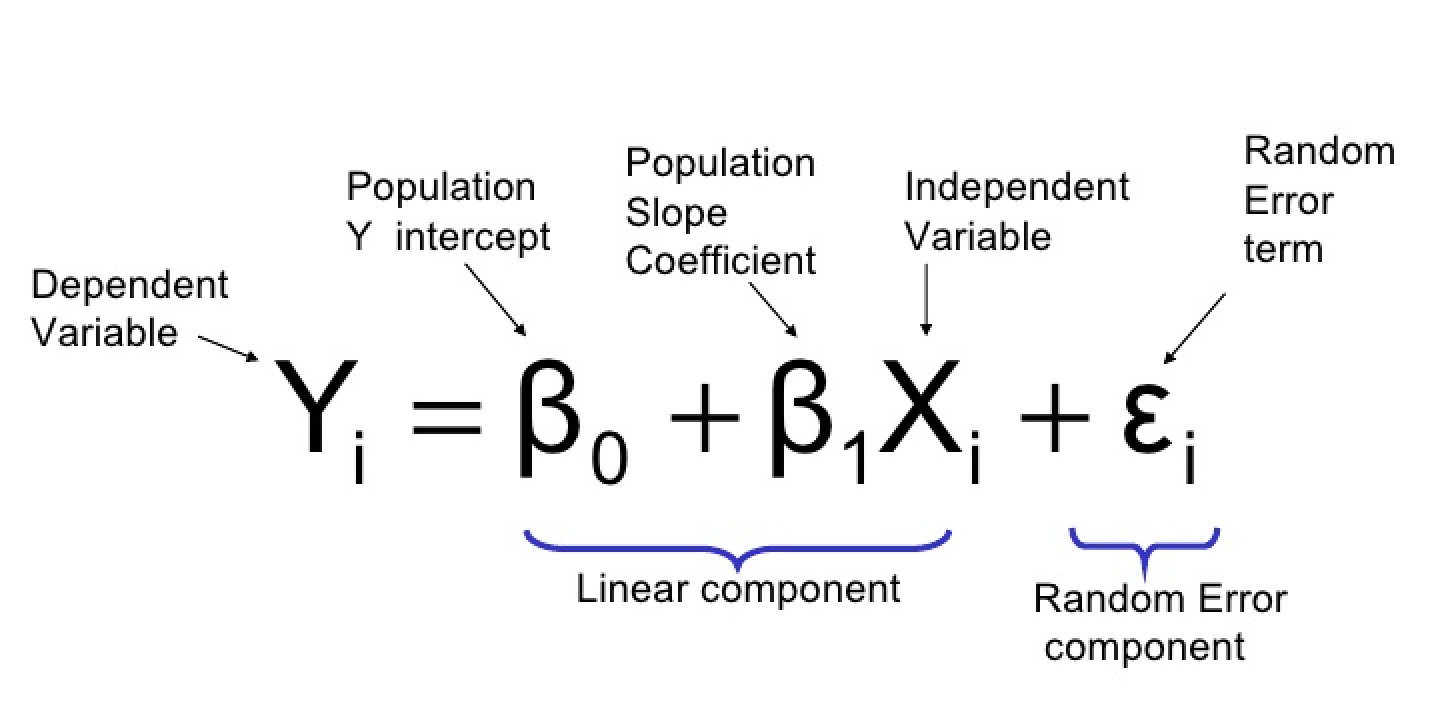
逻辑回归和普通最小二乘回归(线性回归)有什么关系?为什么会出现逻辑上的“回归”?

https://cdn-images-1.medium.com/max/1436/1*_TqRJ9SmwFzRigJhMiN2uw.png
如果你和我一样被“逻辑回归”中的“回归”所困扰,而逻辑回归实际上应该被称为“逻辑分类”,考虑到它确实分类,我对你的困扰有一个答案!
逻辑回归和普通最小二乘回归(又名线性回归)简介:
逻辑回归适用于根据一组预测变量的值预测某个特征或结果是否存在的情况。它类似于线性回归模型,但适用于因变量为二分变量的模型。它的系数可以用来估计模型中每个独立变量的奇数比率。它比判别分析适用于更广泛的研究情况。另一方面,逻辑回归用于确定事件的概率,该事件以二进制格式捕获,即 0 或 1。
如你所知,使用逻辑回归,多类分类是可能的,而不仅仅是二元分类。但 logistic 回归多用于二元分类。
线性回归又名最小二乘回归,估计线性方程的系数,涉及一个或多个自变量,能最好地预测因变量的值。例如,可以根据年龄、教育程度和经验年限等独立变量来预测销售人员的年总销售额(因变量)。
线性回归是连续的,而逻辑回归是离散的。
这里有更多关于连续变量和离散变量的内容。
它们有什么特别的联系?
- 逻辑回归估计结果的概率。事件被编码为二进制变量,值 1 表示目标结果的出现,值 0 表示不出现。
- 最小二乘回归也可以使用线性概率模型来模拟二元变量。最小二乘回归可能会给出超出范围(0,1)的预测值,但该分析仍可用于分类和假设检验。
- 逻辑回归模型将事件的概率估计为独立变量的函数。设 y 表示情况 I 的因变量上的一个值,同样情况下 k 个自变量的值表示为 x (j = l,k)。假设 Y 是一个二元变量,用来衡量某个群体的成员关系。如果情况 I 是该组的成员,编码 y = 1,否则编码 0,那么让 p = y = 1 的概率。y = 1 的几率由 p/(l-p)给出。p 的对数概率或 logit 等于 p/(l-p)的自然对数。逻辑回归将对数优势估计为独立变量的线性组合
logit§ =B0 + B1X1 + B2X2+ ……。+ BkXk
(0、1、2、k 都是在时缺乏媒介订阅能力的下标)
- 最小二乘回归对因变量和自变量集合之间的关系进行建模。因变量的值被定义为自变量加上误差项ϵ.的线性组合
Y = B0 + B1X1 + B2X2+ ……。+ BkXk + ϵ
(0,1,2,k 都是下标)
其中(B0 … Bk)是回归系数,Xs 是独立变量的列向量,e 是预测误差的向量
- 逻辑回归应用于二元因变量的建模。逻辑回归模型的结构是为二元结果设计的。
- 最小二乘回归不是为二元分类而构建的,因为与最小二乘回归相比,逻辑回归在分类数据点方面表现更好,并且具有更好的对数损失函数。
它们在哪里排列在一起:
线性回归使用一般线性方程 Y=b0+∑(biXi)+ϵ,其中 y 是连续的因变量,自变量 Xi 通常是连续的(但也可以是二元的,例如当线性模型用于 t-检验时)或其他离散域。ϵ是模型无法解释的方差的术语,通常被称为“误差”。用 Yj 表示的独立相关值可以通过稍微修改等式来求解:
Yj=b0+∑(biXij)+ϵj
(j,0,I,j 都是下标,具有与所解释的相同的表示)
线性回归的输出如下所示:

逻辑回归是另一种广义线性模型 (GLM)程序,使用相同的基本公式,但它不是连续的 Y,而是回归分类结果的概率。简单来说,这意味着我们只考虑一个结果变量和该变量的两种状态——0 或 1。
Y=1 的概率公式如下:
p(y = 1)= 1**/**(1+e−^(b0+∑(bixi)))
(0,我都是下标)
其中术语与先前解释的相同。
自变量 Xi 可以是连续的,也可以是二进制的。回归系数 bi 可以被指数化,以给出 Xi 每改变一次 Y 的几率的改变。
输出是一条如下所示的 s 形曲线:

两者都是线性模型,然而:
逻辑回归本身绝对不是一种分类算法。只有分类算法与决策规则相结合,才能使结果的预测概率二分法。逻辑回归是一种回归模型,因为它将类成员的概率估计为要素的多元线性函数(的变换)。
我们可能会问,为什么它被称为“逻辑回归”,而不是“逻辑分类”?
要回答这个问题,我们必须追溯到 19 世纪,在那里逻辑回归找到了它的目的。它被广泛用于发现种群的增长和自催化化学反应的过程,如这里的所示。
同样需要明确的是,正如一些专家指出的那样,“逻辑回归”这个名字远在任何“监督学习”出现之前就被创造出来了。此外,术语“回归”并不意味着结果总是连续的,正如本文 中指出的 。所以,并不是每个“回归”都是连续变量预测。
线性回归通常通过最小化模型对数据的最小二乘误差来解决,因此大的误差被平方惩罚。逻辑回归正好相反。
仅供参考:以下是线性回归的损失函数:

使用逻辑损失函数会导致较大的误差被罚为渐近常数。
考虑对分类{0,1}结果的线性回归,看看为什么这是一个问题。如果模型预测当真值为 1 时结果为 67,没有太大损失。线性回归会试图减少 67,而逻辑回归不会(同样多),这意味着,对这一连续产出使用逻辑回归不会解释更多的损失。它认为损失并不大,换句话说,逻辑回归并不惩罚使“最佳拟合线”根本不是“最佳拟合线”的损失。
逻辑回归的结果在许多方面可以与最小二乘回归的结果相比,但它能更准确地预测相关结果的概率。最小二乘回归在从因变量预测连续值方面是准确的。
如上所述,重要的是要知道“回归”是一个抽象的术语。它根据上下文有不同的解释。
这是一个对比图像:

http://slideplayer.com/slide/6183997/18/images/8/Linear+versus+Logistic+Regression.jpg
最后,让我们来看看每个属性:
产出:
**线性回归:**连续值【2 个以上输出】。
**Logistic 回归:**离散值。通常是 2 个输出{0,1}。输出是在舍入到最接近的值 0 或 1 后得出的。请记住,多类是允许的。
解释系数:
**线性回归:**线性回归系数代表预测变量变化一个单位的响应变量的平均变化,同时保持模型中其他预测变量不变。换句话说,保持所有其他变量不变,这个变量增加一个单位,因变量预计会增加或减少某个值 x。
**逻辑回归:**解释逻辑回归系数需要解释概率,而概率本身就是另一个话题。然而,这里有一个直观的解释。
方程式:
线性回归:线性回归是一种对两个变量之间的关系进行建模的方法。你可能还会把这个方程看作斜率公式。该等式的形式为 Y=a+bX ,其中 Y 是因变量(Y 轴上的变量),X 是自变量(即,它绘制在 X 轴上),b 是直线的斜率,a 是 Y 截距。

Simple linear regression equation : http://www.statisticshowto.com/probability-and-statistics/regression-analysis/find-a-linear-regression-equation/
总有一个误差项,又名剩余项 ϵ ,如图所示:

https://cdn-images-1.medium.com/max/1436/1*_TqRJ9SmwFzRigJhMiN2uw.png
**逻辑回归:**逻辑回归使用一个等式作为表示,非常类似于线性回归。输入值( x )使用权重或系数值(称为希腊大写字母,beta)进行线性组合,以预测输出值( y )。与线性回归的一个关键区别是,被建模的输出值是二进制值( 0 或 1 ),而不是数值(来自 Safari 在线图书)。

Example for logistic regression: https://www.safaribooksonline.com/library/view/ensemble-machine-learning/9781788297752/e2d207ff-3690-4e74-9663-2d946e2a7a1c.xhtml
误差方程:
线性回归:均方误差:

**逻辑回归:**逻辑回归的输出是概率,这些概率随后被分类。底线是,你不能像以前看到的那样用逻辑回归做线性回归。
逻辑回归的通常成本或损失函数也称为误差方程,被称为“分类交叉熵”,如神经网络中所见。

Binary outcomes loss function aka binary categorical cross entropy (BCE): http://cat.birdhabitat.site/categorical-cross-entropy-loss-formula/
然而,由于这是一个分类,这里是来自 sklearn 的分类常用指标。
线性关系:
**线性回归:**需要因变量和自变量之间的线性关系。
**Logistic 回归:**因变量和自变量之间不需要线性关系。
剩余分配:
**线性回归:**要求误差项呈正态分布。
**Logistic 回归:**不要求误差项呈正态分布。
既然我们知道了线性回归和逻辑回归之间的关系。
如果你喜欢这篇文章,那就鼓掌吧!:)也许一个跟随?
在社交网站上与我联系:
[## Rakshith Vasudev | LinkedIn
查看拉克什特·瓦苏德夫在全球最大的职业社区 LinkedIn 上的个人资料。拉克什特教育上市…
www.linkedin.com](https://www.linkedin.com/in/rakshith-vasudev/) [## 拉克什特·瓦苏德夫
拉克什·瓦苏德夫。和我一起学习人工智能,让这个世界变得更美好。张量流…
www.facebook.com](https://www.facebook.com/imrakshithvasudev/) [## 拉克什特·瓦苏德夫
Datascience 入门,最佳编程实践。主题包括机器学习和其他。
www.youtube.com](https://www.youtube.com/c/rakshithvasudev)
来源:
http://papers.tinbergen.nl/02119.pdf
https://pdfs . semantic scholar . org/5a 20/ff 2760311 af 589617 ba 1b 82192 aa 42 de 4 e 08 . pdf
https://stats . stack exchange . com/questions/29325/线性回归和逻辑回归的区别是什么
https://stats . stack exchange . com/questions/24904/least-squares-logistic-regression
http://www . statistics solutions . com/what-is-logistic-regression/
https://stack overflow . com/questions/12146914/线性回归和逻辑回归的区别是什么
人工智能如何改变商业世界的面貌
人工智能行业已经成为商业和技术整合的主流。
人工智能不再是未来某个地方会发生在小企业身上的现象——它已经在这里了。企业主和管理人员现在可以利用商业世界中的这些创新,因为等待人工智能到来意味着在商业发展中被抛在后面。人工智能可以帮助企业的几乎每个方面,包括移动性、营销和广告、客户服务和安全。

通过人工智能实现卓越的企业移动性
人工智能还允许员工在办公室之外的其他地方工作,并且仍然与办公室保持联系。例如,通过人工智能,员工可以通过云共享文档、信息、财务工作、营销和其他信息。移动性因素意味着办公室中的人可以在现场,他们可以在家工作,或者从不同的位置工作,但是团队中的每个人仍然能够相互联系以回答问题和进行协作。移动性的增加意味着员工可以随时随地工作。研究表明,当员工能够在不同的地点工作时,他们会感到更加快乐,并表现出更高的生产率。
营销和广告
人工智能改变了客户接收广告和营销信息的方式。任何上过社交媒体的人都知道人工智能在营销中扮演的角色。例如,如果客户在谷歌上搜索一家企业,该企业的广告可能会出现在他们的社交媒体订阅源上,而无需他们要求,因为人工智能能够识别某人过去的搜索,并使用搜索历史来做有针对性的广告。
人工智能对销售产品和服务的企业也至关重要,因为它能够通过有针对性的广告和搜索历史将客户带到企业。人工智能在网上收集重要的数据,并可以指出企业可以增加网站流量的方式,以及商店的位置。
以更低的成本提高效率和精度
使用人工智能的公司的增加只能意味着一件事——人工智能改变了任务的效率和速度。如前所述,人工智能在企业中的作用是增加企业以前留给员工的自动化量。例如,在 20 世纪 90 年代,人们被雇用来将公司必须支付的发票数据输入到计算机中,然后一名员工运行一个支票书写程序,该程序大约每周运行一次支票,以支付公司欠其他人的发票。然后,一个完全不同的员工会拿着公司从其他公司收到的支票,手动将其输入分类帐程序,然后将支票带到银行。然而,通过人工智能,计算机能够在没有输入的情况下根据从企业收到的数据生成发票,然后以电子方式支付发票上的存款,同时也以电子方式支付其他人,并将双方都记入其分类账,以便员工可以查看。
人工智能不需要喝咖啡休息,也不会在圣诞节休假,这意味着它能够生成数据,检索信息并进行分析,供员工在到达时或假期结束时查看和采取行动。
人工智能和机器人在工作场所意味着更好的客户服务和支持
虽然机器人不会像末日预言家们不断预测的那样,抹去世界上所有的工作,但机器人和先进的计算机编程可以自动完成一些任务。例如,使用人工智能语音电话系统的企业能够让客户接受服务,并在不与人类交谈的情况下回答他们的许多问题,这让客户感觉他们的问题已经得到解决,并允许与客户服务合作的员工帮助客户解决需要人工干预的更复杂的问题。此外,工作场所中的机器人技术允许通过计算机或机器人干预来完成重复性任务,而不可预测的任务可以由人类来完成。
帮助整合和巩固业务运营
AI 帮助商家巩固业务领域。虽然上面简要描述了,但还有其他方式可以整合业务,那就是通过使用人工智能结合云技术。有了人工智能和云,业务信息和文件不必保存在多个地方,而是可以保存在云中,这意味着不仅可以有多人查看文件,而且没有搜索文件,也没有因为文件丢失而导致的办公室混乱,因为使用云技术可以获得信息。此外,可以简化日常业务流程,减少从事相同工作的人员,让办公室内的人员专注于特定的业务领域。
更强的网络安全
当与云技术结合时,人工智能还增加了公司的安全性。人工智能能够发现在线或服务器内的威胁,并在违规发生前或发生时警告技术和安全人员。鉴于黑客不仅在信息损失方面给公司造成了数百万美元的损失,而且当黑客泄露数百万客户的个人信息时,客户的不信任也给公司带来了损失,因此人工智能帮助公司更加安全的概念尤为重要。出于这个原因,企业越来越多地指望人工智能来帮助填补他们的安全漏洞。
人工智能可能有点可怕,特别是如果一家企业难以将所有业务流程的控制权交给计算机。然而,通过一点灵活性和一点工作,企业可以让人工智能为他们工作。人工智能可以简化和自动化企业的许多方面,从客户服务电话到办公室程序到营销,甚至到完成销售。人工智能不再是一种说企业懂技术的方式。在 21 世纪的第二个十年,信息技术正迅速成为商业运作的重要组成部分。
深度神经网络眼中的你有多有魅力?
几个月前,华南大学发表了一篇论文和一个关于“面部美容预测”的数据集。这里可以找到[。该数据集包括 5500 人,他们对自己的吸引力进行了 1 到 5 分的评分。
以下是文中的一些例子:](https://arxiv.org/abs/1801.06345)

片场还有几个名人。这张朱莉娅·罗伯特的照片平均得分为 3.78:

以色列著名模特芭儿·莱法利的这张照片得到了 3.7 分:

这些看起来可能很低,但 3.7 分意味着 bar 比数据集中的 80%的人更有吸引力。
除了数据集,作者还训练了多个模型,试图根据面部照片预测一个人的吸引力。
在这篇文章中,我想复制他们的结果,看看我有多有魅力。
原始论文实现了一堆不同的模型,包括具有手工制作功能的经典 ML 模型和 3 个深度学习模型:AlexNet、ResNet18 和 ResNext50。
我想让我的工作尽可能简单(我不想从头开始实施和培训整个resnet网络),我想微调一些将完成工作的现有模型。在keras中,有一个叫做applications的模块,它是不同预训练模型的集合。其中一个就是resnet50。不幸的是,在keras.applications没有 ResNet18 或 ResNext50,所以我无法复制完全相同的作品,但我应该足够接近resnet50。
from keras.applications import ResNet50
ResNet 是一个深度卷积网络,由微软开发,并赢得了 2015 年 ImageNet 竞赛,这是一个图像分类任务。
当我们在keras中启动resnet50 模型时,我们创建了一个具有 ResNet50 架构的模型,并且我们还下载了在 ImageNet 数据集上训练的训练权重。
论文作者没有提到他们到底是如何训练模型的,所以我尽量做到最好。
我想删除最后一层(“softmax”层)并添加一个没有激活功能的密集层来执行回归。
resnet = ResNet50(include_top=False, pooling=’avg’)
model = Sequential()
model.add(resnet)
model.add(Dense(1))model.layers[0].trainable = Falseprint model.summary()# Output:
Layer (type) Output Shape Param # ================================================================= resnet50 (Model) (None, 2048) 23587712 _________________________________________________________________ dense_1 (Dense) (None, 1) 2049 ================================================================= Total params: 23,589,761
Trainable params: 23,536,641
Non-trainable params: 53,120
您可以看到,我将第一层(resnet 模型)设置为不可训练,因此我只有 2,049 个可训练参数,而不是 23,589,761 个。
我的计划是训练最后的密集层,然后,用更小的学习率训练整个网络。
model.compile(loss='mean_squared_error', optimizer=Adam())model.fit(batch_size=32, x=train_X, y=train_Y, epochs=30)
在那之后,我改变第一层为可训练的,编译并且适合另外 30 个时期的模型。
这里的train_X是照片,即numpy个形状(350, 350, 3)的数组,train_Y是被标记图像的分数。
结果
论文使用两种技术训练模型:5 重交叉验证和 60%-40%的训练测试分割。他们使用皮尔逊相关(PC)、平均绝对误差(MAE)和均方根误差(RMSE)来衡量他们的结果。这些是他们使用五重交叉验证得到的结果:

这些是他们用 60%-40%的训练测试分割得到的结果:

我将进行 80%-20%的训练测试分割,因此这类似于执行 1 倍的交叉验证部分。
我得到了以下结果:
RMSE: 0.301799791952313
MAE: 0.2333630505619627
PC: 0.9012570266136678
非常好。此外,查看分数的散点图和直方图总是很好的:

原始分数分布(标准化):

预测分数分布(标准化):

结果看起来相当不错。现在让我们看看这个深度神经网络对我说了什么。我一开始用这张照片:

我得了 2.85 分,这意味着我比这个数据集中 52%的人更有吸引力。我不得不说我有点失望,我希望我会比那更好。所以我试图改善我的处境。
我拍了很多照片,最终这张照片我得到了 3.15 分,这意味着我比数据集中 64%的人都更有吸引力。

这好多了,我必须诚实地说,我希望更好:)
最后一点,我使用谷歌合作实验室构建并微调了这个模型,简而言之,它给你一个免费使用 GPU 的 python 笔记本!
希望你喜欢这篇文章。
贝叶斯统计如何说服我去健身房

Image Source: Pixabay
一次有趣的贝叶斯线性回归理论之旅(是的,我在这篇文章中使用了度量标准)
正如文章题目所暗示的,我会对我的体质做一个科学的调查。
“得了吧,你不会是认真的吧!!!"
是的,我是。所以有一点背景信息:我来自越南,在新加坡上高中,目前在美国上大学。我经常听到人们取笑我看起来有多小,我的体重肯定有多轻,我应该如何锻炼,去健身房,增加体重,以便拥有“更好的体格”。我常常对这些评论半信半疑。对于一个身高 1 米 69 (5 英尺 6 英寸)、体重 58 公斤(127 磅)的人来说,我的身体质量指数指数接近完美(20.3)。
“不老兄!我们说的是体格"
好吧,我明白了,没人在这里谈论身体质量指数。
想想看,人们可能有一个好的观点:鉴于我比普通越南男性略高,体重也完全相同(维基百科的资料显示为 1 米 62,58 公斤),我可能“看起来”更瘦一点。 看 是这里的关键词。逻辑挺简单的不是吗?如果你稍微伸展一下自己,保持同样的体重,你会看起来更瘦更苗条。我认为这是一个需要进一步研究的严肃的科学问题:
对于一个身高 1 米 69 的越南男性来说,我(体重)有多小?
我们需要一种方法来研究这个话题。一个很好的前进方式就是尽可能多地找到越南男性身高体重的数据,看看我在他们中间的位置。
越南人口概况
在浏览网页后,我发现了一份调查研究数据,其中包含了一万多名越南人的人口统计信息。我将样本量限制在 18-29 岁年龄组的男性。这样我就有了 383 名年龄在 18-29 岁之间的越南男性的样本,这对于分析来说可能足够了。
首先,让我们画出人口的重量,看看我如何融入年轻的越南男人。

红线显示样本的中值,而橙色线显示平均值
这张图表明,我略低于 383 名越南年轻男性的平均体重和中值体重。令人鼓舞的消息?有点,但不完全是。看,问题并不在于我的体重与样本中的体重相比如何,而在于 给定 1 米 68 的身高, 假设这 383 个人很好地代表了越南男性人口,那么与整个越南人口相比,我们可以推断出我的体重是多少?为此,我们需要进行回归分析。
首先,让我们绘制一个身高和体重的二维散点图

嗯,我只是看起来一般。事实上,如果我们只看那些身高 168 厘米的人的数据(想象一条 168 厘米的垂直线穿过红点),我的体重比这些人稍微轻一点。
另一个重要的观察结果是,该图表明越南男性的身高和体重之间存在正线性关系。我们将做一个定量分析,以弄清这种关系。
首先,我们快速添加一条标准的“普通最小二乘法”线。

我们可以将我们的最小二乘法直线y**= 86.32+0.889x解释为,对于我这个年龄的越南男性的一般轮廓来说,身高每增加 1 厘米,体重就会增加 0.88 公斤**
然而,这仍然没有回答我们的问题;也就是说, 对于我这种身高(1 米 68)的人来说,58 公斤是算多了,还是算少了,还是算一般? 用一种更定量的方式重新表述这个问题,如果我们有一个身高 1 米 68 的所有人的分布,我的体重落入 25、50 或 75 百分位的几率有多大?要做到这一点,让我们更深入地挖掘,并试图理解回归背后的理论。
线性回归理论:
在线性回归模型中, Y 变量(在我们的例子中是人的体重)的期望值是 x (身高)的线性函数。我们姑且称这种线性关系的截距和斜率为0和β1;即我们假设 E(Y|X=X)=β0*+β1×X。我们不知道0和β1所以我们把它们当作未知参数。***
在最标准的线性回归模型中,我们进一步假设给定X=X的条件分布是正态分布
这意味着简单的线性回归模型:

可以改写为:

(1)
注意,在很多模型中,我们可以将 方差 参数 σ 替换为 精度 参数 τ ,其中 τ=1/σ 。
****总结:因变量 Y 服从均值 μ i 和精度参数τ参数化的正态分布。 μ i 是由 β0 和 β1 参数化的 X 的线性函数
最后,我们还假设未知方差不依赖于x**;这个假设被称为同质性。****
这是很多,但你可以想象我用这个图像讨论了什么。

在实际的数据分析问题中,我们得到的只是黑点——数据。注意每个点周围的正态分布看起来完全相同。这就是 同质化的本质。使用这些数据,我们的目标是对我们不知道的事物做出推断,包括【β0】、β1** (它们决定了神秘的黑线)和***【σ】(它们决定了从中得出【y】数据值的红色法线密度的宽度)。***
估计参数
现在,有几种方法可以用来估算和 β1 。如果您使用普通最小二乘法估计这种模型,您不必担心概率公式,因为您是通过最小化拟合值与预测值的平方误差来搜索 β0 和 β1 的最优值。另一方面,您可以使用最大似然估计来估计这种模型,您可以通过最大化似然函数来寻找参数的最佳值**

注意:一个有趣的结果(这里没有数学证明)是,如果我们进一步假设误差也属于正态分布,最小二乘估计也是最大似然估计。
带有贝叶斯方法的线性回归;
贝叶斯方法不是单独最大化似然函数,而是假设参数的先验分布并使用贝叶斯定理:

似然函数同上,但变化的是你对估计参数 β0,β1,τ 假设了一些先验分布,并把它们包含到方程中:

(2)
“等等,之前的演出是怎么回事,为什么它让我们的公式看起来复杂了 10 倍?”
相信我,这个优先业务感觉有点奇怪,但它是非常直观的。事实是,有一个强大的哲学推理,为什么我们可以用一些看似任意的分布来分配一个未知参数(在我们的例子中是 β0,β1,τ )。这些先验分布是为了在看到数据 之前捕捉 我们对情况的信念。在观察了一些数据后,我们应用贝叶斯规则来获得这些未知量的后验分布,它考虑了先验和数据。根据这个后验分布,我们可以计算出未来观测值的预测分布。
跟我重复:这些先验分布是为了在看到数据之前捕捉我们对情况的信念
最终的估计将取决于来自 1) 你的数据和 2) 你的前科的信息,但是你的数据包含的信息越多,前科的影响就越小。
“所以我可以选择任何先验分布?”
这是一个好问题,因为有无限多的选择。(理论上)只有一个正确的先验,这个先验捕获了你的(主观的)先验信念。然而,在实践中,先验分布的选择可能是相当主观的,有时是任意的。我们可以只选择具有大标准偏差(小精度)的正态先验;例如,我们可以假设 β0 和 β1 来自均值为 0 且 SD 为 10,000 或其他值的正态分布。这被称为无信息先验,因为本质上这种分布将是相当平坦的(也就是说,它将几乎相等的分布分配给特定范围内的任何值)。
接下来的是,如果这个分布族是我们的选择,我们不需要担心哪个确切的分布可能是最好的,因为:
(a)在可能性不可忽略的区域中,它们几乎都是平坦的,以及(b)在可能性可忽略的区域中,先验分布看起来像什么对于后验分布并不重要。
同样,对于精度,我们知道这些必须是非负的,因此选择限制为非负值的分布是有意义的——例如,我们可以使用低形状和比例参数的伽马分布。**
另一个有用的无信息选择是均匀分布。如果你为 σ 或 τ 选择均匀分布,你可能会得到一个由约翰·k·克鲁施克展示的模型
用 R 和 JAGS 进行模拟
理论到目前为止还不错。问题是解方程(2)在数学上是有挑战性的。在绝大多数情况下,后验分布不会直接可用(看看正态分布和伽玛分布有多复杂,你必须将它们相乘)。马尔可夫链蒙特卡罗方法常用于估计模型的参数。JAGS 帮助我们做到了这一点。
“等等!!!有一种工具可以帮助我们解决这些可怕的方程?”
JAGS 模型是一个基于马尔可夫链蒙特卡罗(MCMC)的仿真过程会产生参数空间θ=(β0;β1;τ)* 。为该参数空间中的每个参数生成的样本的分布将近似该参数的总体分布。*****
为什么会这样呢?这个解释比这篇文章所能容纳的要复杂得多。一行解释是:MCMC 通过构造马尔可夫链(!idspninfopath)从后验分布生成样本。?)具有目标后验分布作为其稳定分布。
我告诉过你这不好玩。快速的收获是:我们可以做一些智能采样,用数学证明我们的样本分布是 β0,β1,τ的真实分布,而不是求解方程(2),这在分析上通常是不可能的。
“好了,数学挥舞够了。我如何使用这个 JAGS 魔法?”
我们在 R 中运行 JAGS 如下
- 首先,我们以文本格式编写模型:
然后,我们命令 JAGs 进行模拟。这里我让 JAGs 模拟参数空间 θ 的值 10000 次。
经过这样的采样,我们得到的采样数据为θ=(β0;β1;τ)如是

“很酷的东西,那又怎么样?”
现在我们有参数空间 θ 的 10000 次迭代,记住由方程(1) :

这意味着,如果我们将 x=168cm 代入每次迭代,我们将找到 10,000 个权重值,因此,假设的高度为 168cm,权重**的分布。****
我们感兴趣的是我体重的百分位数,以我的身高为条件。我们能做的是找到以我的身高为条件的我体重的百分位数分布。****

现在,这张图告诉我们的是,我的体重(考虑到 168 厘米的身高)很可能位于模拟越南人口的 0.3%左右。
例如,我们可以找到我的体重在前 40 个百分点或更少的百分点
因此,有压倒性的证据表明,以我 168 厘米的身高为条件,我 58 公斤的体重将使我处于越南人口的较低百分位。也许是时候去健身房增肥了。毕竟,如果你不能相信一些做得很好的贝叶斯统计结果,你还能相信什么?
我在数据源中包含了一个数据集,其中包含了 8169 名美国男女青年的身高和体重(国家纵向调查 1997 2 ),您能进行同样的分析并看看您的情况吗?
如果你喜欢这篇文章,你可能也会喜欢我的另一篇关于有趣的统计事实和经验法则的文章
对于其他深潜分析:
这篇文章的完整 R 脚本可以在我的 Github 页面找到。
注:我想为 Joseph Chang 教授(耶鲁大学)和他的班级 S&DS238:(贝叶斯)概率与统计大声喊出来。我几乎是偶然上了这门课,这很容易成为我上过的最有影响力的课之一(谈论一个政治科学专业的学生正在成为一名数据科学家)
数据来源:Vuong Q. H…开放的科学框架。2017 年https://doi.org/10.17605/OSF.IO/AFZ2W
资料来源:1997 年全国纵向调查| https://www.nlsinfo.org/investigator/pages/search.jsp?劳动统计局 s = nlsy 97
大数据分析如何帮助企业开发新机遇
无论你经营的企业规模有多大,你都需要有价值的数据和见解来帮助你了解谁是你的目标受众,他们的偏好是什么,这样你就可以预测他们的需求。这就是所谓的“大数据”它在你的业务中扮演着非常重要的角色。有了它,你可以有效地提出和分析所有这些问题,实现你的品牌目标。考虑到这一点,这里有一些你们都想知道和需要知道的事情。
云:大数据战略的关键点
IE 表示,大数据战略的一个关键组成部分是云。这是因为企业外部的数据比企业内部的数据多得多。因此,我们应该开始看到公司更加依赖外部数据——特别是现在越来越多的数据存储在云中,API 和外部服务用于访问这些数据。
当您准备考虑大数据战略时,您也必须决定是将信息存储在自己的系统中还是使用云。云的主要好处之一是没有任何限制或障碍,因此您可以直接链接到任何其他数据源。这意味着您可以快速实施变革和新的业务模式。这在今天是至关重要的,即使这意味着从我们的错误中学习,然后花时间去纠正它们。当你使用云来做到这一点时,你将不必承受进行大量初始投资的限制,这种投资会使你局限于单一的行动过程。
大数据——一种新的竞争优势
Simpli Learn 表示,你可以通过捕捉和创新大数据,利用大数据超越竞争对手。这就是为什么你会发现它被应用于当今几乎每个领域的例子。公司用它来发现他们的服务和产品,供应商和买家,以及消费者的意图和偏好的缺陷,这样他们就可以创造更新更好的产品。老实说,自从 1997 年公司开始使用它以来,它创造了许多新的增长机会。从那时起,它甚至催生了一种新的业务类别——包括那些负责分析和汇总这些数据的业务。在过去的 20 多年里,它也成为大多数企业非常积极的事情。
除了其他好处,大数据还经常被实时挖掘。这是至关重要的,因为它可以评估指标,包括消费者忠诚度,这在过去是相互独立处理的。现在,它们不仅被连续处理,而且被更广泛地处理,甚至使它们成为对您的业务更有力的因素,因为您现在可以实时测试您的理论。
这些只是大数据可以帮助公共和私营部门企业的多种方式中的几种。
创造新的收入来源
有了大数据,你将拥有基于对市场及其消费者分析的洞察力。这些数据不仅对你有价值,对其他人也有价值。你可以通过向同行业的大型企业出售非个性化趋势数据来获得额外收入,从而为你的企业创造新的收入来源。
技术帮助
Data Floq 表示,有很多技术可以帮助你进行大数据分析。还有很多方法可以收集您想要和需要的数据,包括:
基于云的电话系统让您可以轻松存储和检索大量与通信相关的数据——包括保存的通话记录、客户信息和客户对话,无论它们发生在何时何地。这是非常经济、可靠和稳定的。您还可以轻松集成新的附加功能(如 Google Apps、Office 365),使数据收集和存储变得更加简单。然后,当您仍在进行通话时,您将能够收集和存储电子邮件 id、公司名称和物理地址等信息。
云存储也提供了许多优势。其中最大的一个好处是,它让你的企业可以轻松存储、访问和共享你收集的信息。这是以一种安全且经济高效的方式完成的,便于您以后访问这些信息。
今天,分析工具大量存在。这些将有助于你分析收集到的信息。你也可以使用这些工具来寻找具体的信息,比如你的公司在获取客户方面花了多少钱,你的每个客户在你的业务的不同领域花了多少钱。分析工具本质上是描述性的、预测性的和说明性的,这意味着您可以使用它们来了解在任何给定的时间点您的业务的任何部分正在发生什么。你也可以用它们来发现未来会发生什么。这些工具可以根据它们过去为你收集的信息做出这些预测。这在你考虑做出某些决定或制定某些行动计划的任何时候都是有益的。
数据安全和风险分析
有了大数据工具,您可以规划出公司的完整数据环境,以便在各种内部威胁发生之前进行分析。当您掌握了这些信息后,您就可以采取适当的措施(根据法规要求)来保护您所有的敏感信息。这也是如今大多数行业都在关注大数据的另一个重要原因。但是,任何处理财务信息、信用卡和借记卡信息或任何其他此类业务的公司都应该更加注意这一点,甚至要持续进行风险分析。为了取得成功,必须考虑许多不同的因素,包括经济和社会因素——这两个因素在决定你的成就时都起着重要作用。这并不难做到,因为大数据带来了预测分析,这意味着你可以快速、持续地扫描和分析你的社交媒体源和报纸报道。因此,你将能够轻松地跟上行业的最新趋势和发展。
大数据和商业智能如何改变资本市场

商业决策通常会对财务产生影响,但在金融交易中影响最大,每个决策,无论大小,都会对底线产生直接影响,导致损失或收益。
因此,商业智能(BI)解决方案开始利用其处理大量结构化和非结构化数据的能力来支持交易决策就不足为奇了。对投资银行和大型交易机构来说是这样,但对小型金融企业甚至个人交易员来说也是如此。
金融交易市场一直非常依赖数据分析,因此大数据和高级商业智能的出现应该会扰乱这些市场参与者的运营方式。它确实做到了,其结果与本文简要探讨的三个结果一样重要。
金融交易变得数据驱动
投资银行和对冲基金从来都不缺数据。然而,自从大数据和金融商业智能的出现,他们使用数据的方式发生了相当大的变化。更快地分析市场状况的需求已经将金融交易组织从数据消费者转变为真正的数据驱动型实体,这依赖于除金融专家和分析师之外的可用数据工程师和科学家的专业知识。
金融行业的许多企业都有非常具体的软件需求,因此决定从头开始构建大数据解决方案。对于这项任务,数据工程师是不可或缺的。
对于雇不起数据工程师的较小企业来说,答案往往是金融科技开发外包,这种做法反过来刺激了软件公司对金融专业知识的需求。
金融交易中的数据科学
数据科学家比工程资源更受欢迎。这部分是因为,与其他商业领域不同,数据的数量和种类通常过于复杂,无法在交易员可以理解的通用仪表盘上提供。相反,数据科学家需要识别微妙的数据模式,并在复杂算法的帮助下生成可操作的见解。
因此,大数据和商业智能在金融交易中的使用越来越多,这对科技行业来说是个好消息。然而,这也导致了分析专业人员的短缺,迫使金融服务和交易公司为他们雇佣的资源支付更多费用。
事实上,根据 Glassdoor 的数据,2018 年一名数据科学家的中值基本工资约为 11 万美元。毫无疑问,这一高比率部分归因于金融行业,IBM 的一项研究显示,该行业目前对数据科学家和分析师的需求高于其他任何行业,占所有相关职位空缺的 19%。
大数据:新型交易者的数字黄金
对于能够访问大数据和金融商业情报的交易员来说,决策变得越来越明智,因此风险也越来越小。交易曾经主要基于对价格行为的分析,而大数据的整合使得支持和反对水平、政治和社会因素以及其他有影响的条件能够被添加到等式中。
预测性商业智能的应用可以进一步降低风险,使交易员能够评估每笔交易的可能结果和回报率。然而,整个过程都需要大量数据,这促使越来越多的企业准备收集数据并出售给金融交易机构。
量化对冲基金:大数据的大买家
通过购买或其他方式获得大数据,也催生了一种全新的交易实体——量化对冲基金。这些基金在某些方面类似于传统或“基本面”对冲基金,但几乎完全依赖数字算法和模型来选择和发起交易。
由于他们的商业模式,量化对冲基金需要大量的数据,讽刺的是,他们的胃口已经把出售数据变成了金融行业最赚钱的活动之一。事实上,在所谓的“替代数据”上的支出到 2016 年已经达到 2 亿美元,预计在五年内将翻一番。这是研究和咨询公司 Tabb Group 的研究得出的结论之一。
HFT 让位于智能交易
金融科技行业进步产生的一个更有趣的动态可以被视为影响了有争议但广泛存在的高频交易实践(HFT)。高频交易本身是一个数据驱动的过程,一度非常有利可图(对一些 HFT 公司来说仍然如此)。
然而,随着在 HFT 领域竞争的技术要求变得越来越复杂,利润开始下降,机构开始将注意力从闪电般的机器启动交易转向基于大数据洞察的人工交易。例如,人类股票交易者可能使用市场情绪分析的结果来提取可操作的交易信号。
HFST 的趋势?
考虑到 BI 技术的持续改进,这种动态变得更加有趣。例如,实时分析将成为金融科技领域的一股强大力量。随着交易实体可以实时收集和分析来自新闻、社交媒体和股票市场的数据,然后将情报输入自动化交易解决方案,我们可能会再次看到高频交易的兴起。
然而,在下一次迭代中(会是 HFT 2.0,还是高频智能交易?)区别可能在于机器执行更智能算法的能力,这使得高度知情的交易能够以极高的频率达成。
当然,尽管自动化金融交易在公平性方面名声不佳,但仍有很多值得称道的地方。毕竟,机器不会受到紧张、兴奋或任何其他导致错误决策的行为特征的影响,而在金融市场的世界里,这些行为特征确实非常昂贵。
这只是大数据和金融 BI 的开始
奇怪的是,对于一个一直依赖数据的行业来说,情绪分析、智能高频交易和数据科学等发展在金融交易领域相对较新。
实际上,这还只是皮毛,所以如果你的公司在资本市场交易或涉足金融服务,你应该预计大数据和商业智能将在你的业务中发挥越来越大的作用。
此外,机会不太可能仅限于创收。密切关注在中后台流程中利用财务 BI 的可能性,因为随着越来越多的公司适应大数据,这些领域的用例肯定会变得明显。
以下是数据分析如何帮助社区银行

大数据工具不仅简化了任何行业中冗长的分析程序,还为银行提供了竞争优势。随着新法规的出台,银行正在寻找使合规程序更加有效和准确的方法。银行业的大数据正慢慢获得动力,并成为整个银行业不可避免的必需品。随着传统数据管理结构变得过时,社区银行很难适应外部竞争和监管压力。
在社区银行系统中执行分析工具的需求逐渐成为一种强制而不是一种选择。Gartner 的 2014 年首席信息官调查显示,金融公司鼓励在技术支出方面投资数据分析。尽管大银行通过在数据分析方面的昂贵投资,在了解客户方面拥有明显优势,但社区银行在采用这种创新趋势方面似乎有点谨慎。为了实施大数据工具,社区银行面临着围绕高成本、缺乏专业知识和数据安全性的障碍。
社区银行并不总是负担得起实施分析工具和基础设施,以及雇佣新数据库所需的专业人员。
此外,对于许多社区银行来说,与私人客户信息相关的数据安全是一个敏感问题。大多数银行在当地社区发展壮大,在那里银行和客户之间有着高度的信任。通过个人互动和长期建立的关系,社区银行往往比大银行更了解客户的信贷决策。
随着大数据的实施,社区银行可以保持密切的监督,并实时检测任何欺诈行为。通过预测分析,银行可以识别和监控客户账户中的任何差异,甚至预测贷款违约。社区银行还将能够发现高风险账户,帮助他们做出更明智的决定。但不愿分享私人信息对许多银行来说仍是一个问题,因为它们的繁荣依赖于客户的信任和信心。
然而,许多社区银行正在采用分析解决方案来做出完全基于准确风险分析和透明度的数据驱动型决策。
这些银行越来越有兴趣与技术驱动的竞争对手竞争,并从中脱颖而出。他们正在与 Verizon Enterprise Solutions、亚马逊、IBM 和谷歌等云服务公司合作,以更低的成本获得大数据和分析的存储。此类服务的实施有助于社区银行通过实时市场反馈和社会趋势在成本和回报之间实现平衡。除了与以相对较低的成本获得的服务建立伙伴关系之外,数据可视化工具还为银行内的更多员工而不仅仅是少数员工提供数据趋势。
随着运营变得越来越复杂,对数据分析工具的需求对这些小型银行来说也变得至关重要。据北卡罗来纳银行(BNC)称,数据可视化软件也有助于简化数据报告过程。通过 SAS Visual Analytics ,获得的数据比通过传统电子表格获得的数据更强大、更准确。数据可视化工具可靠、成本较低,并且有助于银行快速把握趋势。
MX 为银行提供了一个类似的可视化平台,帮助潜在账户持有人实现账户聚合、自动分类和资金管理功能。Insight 和 Target 等工具有助于同时对不同的账户持有人应用更加定制化的方法。这种分析工具不仅有助于社区银行在竞争对手中的定位,而且有助于在不到五分钟的时间内跟踪潜在的活动,而不需要它。这些工具的部署有助于实时掌握客户的需求。
视觉分析在并购过程中也很有用,可以发现不准确之处,从而确认数据的真实性。
通过利用大数据,社区银行可以管理信贷、流动性和利率风险,并更好地为社区服务。随着对社区银行的既定看法慢慢适应这种变化,通过整合智能数据治理、低成本和客户隐私的平衡方法可以恢复人们对当前银行系统失去的信任和信心。
版权所有。重新出版需要作者的许可。
大数据和位置智能如何改变世界

毫无疑问,智能手机数量的爆炸式增长已经改变了我们所知道的世界。传感器和互联设备数量的增加产生了海量数据。这正被用来改变我们的生活方式。
物联网,位置数据,位置智能,大数据。不管你给它起了什么名字,很难否认各种行业的潜力
现在很明显,精确的位置数据可以提供对离线世界前所未有的洞察力。越来越多的企业意识到移动位置数据的价值及其在全球范围内的影响。
随着我们远离不可靠的数据集,传感器驱动的精确数据集正在占据中心舞台。这种精确的数据有许多用途。但是我想看看一些具有最大破坏性影响的。
商业智能

通过使用数据来观察趋势的能力并不新鲜。基于人们在线下世界的活动,以接近实时的方式做到这一点的能力。
位置智能揭示了经常被忽略的大数据集之间的关系。它将这些见解转化为可操作的商业智能。帮助通知关键业务决策,提高转化率优化,尤其是在网站上。
从与大型连锁场馆竞争的小酒吧,到与在线大公司竞争的小零售商,这些企业正在通过使用这种大数据来制定商业战略,从而获得宝贵的见解。
事实是,移动位置数据现在已经足够成熟,可以解决小型企业和大型企业面临的许多问题。让我们来看几个:
金融服务 —通过大数据集了解客流量对于金融行业很有价值。移动设备数据有助于在正式报告之前预测收入和其他 KPI。这有助于投资决策。
零售 — 大数据可以帮助小型和大型零售商。通过移动设备数据了解商店访问以及客户行为,对零售行业产生了许多积极的影响。这些见解有助于为商业决策提供信息,如商店布局、营业时间、人员配备等。
基础设施和规划

我们都听说过智能城市这个术语。我们倾向于认为,这不仅仅是添加一些数据点,并在前面加上“智能”一词。事实上,还不止这些。我们正朝着人口众多的城市中心前进,并渴望实现无人驾驶汽车。大数据是开启这一真正智能未来的关键。
移动设备数据的增加为理解城市如何运转提供了更好的机会。它有助于创建反映这一点的系统和基础设施。
结合城市中不断增加的联网设备,中央规划机构现在拥有了一套工具,可以为许多不同领域的决策提供信息。
移动位置数据有助于更好地了解哪里对公共基础设施的需求最大。例如,我们可以检查移动设备位置数据,以了解城市中自行车最多的道路。当计划在哪里实施新的自行车路线时,这些信息是精确的和无价的。
交通和拥堵也是如此。在日益拥挤和污染的大城市,了解如何缓解交通问题是很重要的。了解交通流量以及在哪里建设新的道路结构或引入新的低排放区,对于建设能够维持当前人口增长水平的智能城市至关重要。
大数据正在对此类规划产生巨大的积极影响。由于移动设备数据和位置智能的准确性和独特性,它正在改变世界各地城镇的决策方式。
营销和广告

大数据和营销从来都是相辅相成的。营销人员总是希望利用数据集来提高广告的效率和效果。使用大数据创建量身定制的相关受众并不是一种新的做法。
但是移动位置数据允许营销商和广告商将数字广告与消费者离线时的行为联系起来。了解消费者如何在线下世界移动有助于营销人员变得更加有效。它帮助营销人员向消费者提供更多的个人广告。
对消费者行为的这种理解使品牌能够根据一个人的独特体验来定制沟通——例如建立更好的网站来匹配访问者的行为,并相应地进行个性化。
位置智能正在扰乱消费者生命周期的许多阶段。它把网络上的分析能力带到了现实世界。
分割
移动设备数据有助于构建人们如何移动和行为的复杂图像。这有助于广告商建立复杂的客户档案。品牌最终理解了顾客去的地方,以及他们如何与周围的物质世界互动。
这远比其他受众细分的方法有效。这是因为一个人的位置往往比他们在电脑上搜索或坐在沙发上浏览手机时更能表明意图。
这使得营销人员能够准确识别消费者在购买过程中的位置。此外,它允许他们以更详细的级别来完成这项工作。
个性化
大数据在营销和广告方面的一个重大突破是增强大规模个性化的能力。
位置数据让品牌通过了解顾客的情况变得更有帮助和人性化。这个概念并不新鲜,但是这个空间中数据集的准确性和不断增长的规模使得交流变得更加个人化。
位置有助于在客户实际兑换时提供促销。它让“顾客也买了”的体验到达现实世界的零售店。通过这种方式,大数据正在为线下问题提供数字化解决方案。位置智能是根据一个人对现实世界的独特体验来定制品牌传播。
对消费者行为的这种理解,使得品牌能够根据一个人的独特体验来定制沟通——例如,建立符合访问者行为的网站,并据此进行个性化。营销人员应该问问自己,他们如何能够使用行为目标来实现他们的目标和提高他们的底线。
客户体验
大数据改善了客户体验。位置智能有助于自动寻路、订购、协助和队列管理。了解一个人的物理位置有助于改善许多领域的游客体验。
体育场、度假村、机场和交通枢纽都会改善在这些地方花费时间和金钱的人们的体验。这可能是基于位置的售票方式——你走上火车买票。或者它可能在你的位置订购食物和饮料。
大数据和位置智能在改善客户体验方面仍有巨大的应用空间。在网络定制和登陆页面中,无论是 Leadpages 还是insta page,你都会获得更好的参与度和更好的客户体验。
属性
正如我们所见,移动设备数据已经将许多数字生活方式与线下消费者行为联系起来。这项技术革新营销和广告空间的另一种方式是通过属性。
传统上,许多广告商在衡量线下广告对线下 KPI 的影响时都是盲目的。
但是移动设备位置数据正在填补空白。例如,当一个人站在户外广告前时,位置智能可以理解。然后,它可以测量这些人中有多少人在商店内或特定实物产品前被看到。
将两者联系起来,为营销人员提供了一种准确的方法来衡量线下广告库存的影响和投资回报率。这种线下归因也让他们能够衡量数字广告对线下目标的影响。这些事情以前是不可能确定的。但是大数据改变了广告的衡量方式。
阿肯色州
如果 AR 真的要实现它的承诺,它将不得不依赖复杂的数据集和准确的位置智能。
随着 AR 越来越突出,它的应用将从好玩的游戏转向有用的生产力应用。随着 AR 的发展,它作为一种通过内容和广告接触观众的方式的使用将会增长。像以前的营销活动一样,它将通过使用大数据和位置智能来改进。
当用户在现实世界中移动时,AR 将需要大量准确和实时的位置数据才能正常工作。
优化供应链

大数据和位置智能正在影响希望优化供应链的组织。
位置智能在供应链中的明显应用在于理解和跟踪交货和供应的能力。它已经被用来生成数据集,可以优化和改善这些服务。
但是位置智能不仅仅是帮助企业优化流程。这有助于他们了解对产品的需求。历史上有很多人建造一些东西,希望人们想要它,结果却发现他们并不需要。
大数据帮助制造业优化的另一种方式是帮助它调整运输类型、装货地点或销售地点。
随着位置数据的兴起,这些见解现在由来自线下世界的信息推动。随着数据治理的出现,以前无法实现或已经滞后的洞察力现在可以实时获得。这是扰乱供应链运作的核心问题。
隐私和透明度
像往常一样,对于新的破坏性活动,焦点集中在这些新技术的责任上。理应如此。事实上,大数据领域的企业需要更加透明地了解数据集的来源。
仅仅勾选一个框并开始收集和汇总个人数据是不够的。为了清理数据供应链,还需要做更多的工作。需要将更多的控制权交给用户。
这一点已经很明显了,从目前移动 VPN的兴起就可以看出来。这些应用是用户的一种反应,他们希望保护自己的隐私,并控制谁可以看到他们在网上做什么。
通过这种方式,我们有责任向用户传达大数据和位置智能的价值。它在全球范围内产生了巨大的积极影响,这也是保护隐私的更多理由。
您的数据应该有多大?
在设计机器学习模型时,所有数据科学家都会想到一个简单的问题:“数据集应该有多大?建模应该使用多少特征?”。本文将通过一项实验研究,向您展示如何决定数据集大小和模型所需的特性数量。

https://commons.wikimedia.org/wiki/File:BigData_2267x1146_white.png
下面是我的 github 资源库的链接。它包含用于分析的 python 代码。您可以派生或克隆存储库,并使用代码:-P
机器学习-数据分析-01 -使用统计方法对数据集进行实验分析,以获得更好的机器…
github.com](https://github.com/bmonikraj/machine-learning-data-analysis-01.git)
下面是从 UCI 机器学习知识库到数据仓库的链接。它包含与数据集和属性相关的信息。这里提到,这个问题是一个回归问题。
https://archive . ics . UCI . edu/ml/datasets/理化+属性+of+蛋白质+三级+结构
**Description of Dataset**
Dataset inititally has 10 columns.
Column with name 'RMSD' is the target column of our data set
Rest 9 columns with name F1, F2, ... , F9 are the features columns of the data set. m = Number of observations in the data set
Dimension of Y : m X 1
Dimension of X : m X 9
现在,我将向您展示数据帧的每一列之间的关联矩阵,包括 RMSD (数据帧是一个术语,用来表示 Python 的 Pandas 模块读取的数据集)。

Correlation Matrix — Heat Map , showing the correlation between each and every column of data frame
从上图中,我们可以得出结论,RMSD 与其他列几乎是独立的,因为理论上说如果,correlation(x,y)~0,那么‘x’和‘y’是彼此独立的(其中‘x’和‘y’是相同维数的向量)。
在我们不知道哪一列将被选为目标列的情况下,我们可以找到相关矩阵,并找到与所有其他列最独立的列。
这是 x 中所有特征列之间的相关矩阵图。
对于 X 的列‘I’和列‘j ’,它显示了两个变量之间的散点图,当‘I’时!= ‘j ‘。如果’ i’=='j ',那么它显示了变量的频率分布。

Correlation Matrix plot — Correlation between two variables (feature column) and frequency distribution of the variable itself
上图讲述了变量之间的相互关系。同样,我们可以用图形来推断矩阵之间的相关性,以便更好地进行分析。
变量的频率分布显示了它所遵循的分布类型,如果遵循一个已知的标准分布,如 【高斯】 分布或 【瑞利】 分布,我们可以预测和分析变量的行为,这在进一步研究数据时会很方便。
注:变量的频率分布或直方图通常用于将变量拟合为标准分布。
现在,我想请大家注意功能选择。在这里,我将阐明决定保留哪些特性的方法。我将使用 Python 的 Sci-kit 学习模块中的 SelectKBest 模块来完成这项工作。他们使用 f 检验估计从数据集中找到最佳特征。关于模块和理论的更多信息可以在参考资料中找到。
from sklearn.feature_selection import SelectKBest, f_regression
#Assuming X and Y are numpy array of dimension (m,9) and (m,1) #respectively
#We use f_regression function since our's is a regression problem
X_best = SelectKBest(f_regression, k=5).fit_transform(X,Y)
'''
After the code snippet is run, X_best keeps top k=5 features from X.
'''
现在,我将使用线性回归向您展示最佳“k”特征对模型的“ R2 分数”指标的影响。这里你可以看到,通过增加“k”的值,我们的线性回归模型得到了更好的 R2 分数。我还存储了与’ SelectKBest '方法相关的功能的降序。同样的代码可以在我上面的 github 链接中找到。

‘k’ vs ‘R2 Score ‘ plot on linear regression model (‘k’ determines the top k features from the data set)
这样,我们可以选择一个合适的“k”值作为模型的 R2 分数的相应值,这对于我们的问题陈述来说是可接受的(我可能会选择 k=5,但对于您来说,可能会根据问题的需求而有所不同)。
以下是按降序排列的‘k’个特性列表:【F3,F4,F2,F9,F6,F1,F5,F7,F8】
特征选择的主要应用之一是降低数据的维数,以获得更好的计算性能。
主成分分析是将维度(特征)分解成更小维度空间的另一种方法。使用主成分分析的主要好处是:
- 降维
- 将高维空间数据转化为低维空间数据进行可视化
以下是将高维空间分解为低维空间后的数据可视化(对于“X”)。

Visualizing ‘X(1-D space)’ vs ‘Y’ after decomposing X into lower single dimension space

Visualizing ‘X(2-D space)’ vs ‘Y’ after decomposing X into lower 2 dimension space
现在,我将向您展示使用线性回归将数据投影到“p”分量特征空间对模型的“ R2 分数”度量的影响。这里你可以看到,通过增加“p”的值,我们可以得到更好的线性回归模型的 R2 分数。

‘p’ vs ‘R2 Score ‘ plot on linear regression model (‘p’ determines the top p components from the eigen vector projection of data set)
查看图表,我们可以为我们的解决方案选择一个合适的“p”值。根据问题的要求,应通过相应的可接受的 R2 评分值来选择“p”的值。
现在我将讨论数据集大小的影响,【m】=数据集 中的观察次数。我保留了最初出现在数据集中的 9 个特征,我改变了“m”,在训练集 (80%) 上训练,并使用线性回归模型计算了测试集 (20%) 上每个“m”的 R2 分数。

分析上面的图表,我们可以推断出以下几点:
- R2 分数的最初峰值是由于较低的“m”值造成的数据偏差。
- 在尖峰之后,R2 分数在某种程度上饱和(忽略中间的尖峰,这是因为在分裂成‘m’’时随机选择数据点),这意味着逐渐增加数据集大小,最终增加 R2 分数,直到饱和。
- 在某一点之后,它饱和,增加“m”,不影响 R2 分数。
- 较低的“m”导致模型中的偏差或较低的 R2 分数。
D 设计机器学习模型包括许多因素,如选择特征、决定数据大小以获得更好的模型性能、计算成本、实现实时数据的可行性(对于某些情况),以及根据问题的要求的许多其他因素。这总是对数据的探索性分析,这导致了更好的模型设计,因为
机器学习中的每个问题都是不同的
参考:
- Sci-kit 模块:http://scikit-learn.org
- SelectKBest 模块:http://sci kit-learn . org/stable/modules/feature _ selection . html
- 熊猫模块:https://pandas.pydata.org/pandas-docs/stable/
- 用于可视化的 Seaborn 模块:https://seaborn.pydata.org/
- 主成分分析:https://en.wikipedia.org/wiki/Principal_component_analysis
区块链将如何保护隐私

科技侵蚀了我们的隐私保护。个人或组织所做的大多数事情现在都在公共领域。第三方监控、存储和使用个人和组织数据、模式、偏好和活动。许多新兴的商业模式依赖于我们个人数据的收集、组织和转售。
技术也使得将数据与个人联系起来变得更加容易,即使个人选择退出社交网络平台。例如,面部识别技术的突破已经在商业和安全领域得到广泛应用,特别是在中国和俄罗斯。
区块链技术可能会限制这种隐私侵蚀的影响,同时仍然会在有用的时候发布个人信息。例如,用户可以在区块链上存储个人信息,并临时释放部分信息以接受服务。比特币和其他基于区块链的数字货币已经证明,使用点对点的分散网络和公共账本,可信和透明的计算是可能的。
这篇文章探讨了个人和组织产生的数据对隐私的影响。它还简要考虑了支持区块链的系统如何帮助用户重新掌控自己的数据。
第一部分:个人

个人
隐私对个人来说很重要,因为他们的个人信息对组织、营销人员和其他个人来说很有价值。互联网用户中的一个普遍说法是:如果你不为产品付费,你就是产品。这意味着,对于提供免费服务的公司,如社交网络平台,个人信息是有价值的。
宪法保护
在美国,隐私对于行使各种宪法权利非常重要,包括言论自由权、结社自由权、出版自由权、免受不合理搜查和扣押权以及免受自证其罪权。缺乏国家行为者的隐私会危及这些权利。知道他们的言论将在公共领域被归因于他们,一个人可能不会为正义的事业大声疾呼,特别是如果他们的观点或主题是有争议的或不受欢迎的。由于许多重要的观点不受欢迎或有争议,自我审查应该引起社会的严重关注。知道自己被监视,也可能会阻止你和志同道合的人见面。如果举报者和其他揭露组织不法行为的人不能保持匿名,他们就不太可能这样做。随着技术的进步,法院已经勾勒出了对国家行为的限制。
健康资讯
如果信息就是力量,保护信息可以帮助一个人与组织谈判。例如,健康保险公司可以利用负面健康信息向特定个人收取更高的保费,或者拒绝承保。因此,个人有动机阻止这些信息进入公共领域。健康信息的公开发布也会给一个人的社交或职业生活带来尴尬或尴尬。
金融信息
金融信息是个人信息赋予其拥有者权力的另一个领域。个人可能不希望金融机构知道几年前的不良信用记录,并且肯定不希望邪恶的行为者使用个人的个人信息来实施身份盗窃或金融欺诈。
虽然人们不得不经常披露个人财务信息,例如纳税或获得抵押贷款,但如果这种信息进入公共领域,各种行为者都会感兴趣。寻求客户的公司、寻求捐赠者的慈善机构以及寻求捐赠的政治候选人都对了解个人的个人财务信息感兴趣。尽管这些行为者大多是良性的,但人们对于他们想要与谁分享个人财务信息以及他们想要这些信息用于什么目的有着不同的偏好。
例如,人们可能不希望他们的财务信息被公司用来确定他们愿意和能够为通常以较低价格购买的东西支付的最高金额。然而,Orbitz 向 Mac 用户展示同样的酒店房间,价格却比 PC 用户高。这表明,即使是一点点个人信息,比如一个人是使用 PC 还是 Mac,也能对营销人员评估一个人的经济能力有用,这种方式会让大多数人感到不舒服。
个人行为
研究表明,当人们知道自己被监视时,他们的行为会有所不同。因此,在更基本的层面上,隐私使一个人能够以一种受启发的、亲密的或愚蠢的方式行动,而没有恐惧。就像人们凭直觉关上或锁上前门一样,他们在与技术的互动中也渴望隐私。如上所述,组织有许多充分的理由收集个人信息(从未来使用产品或服务的便利性,到未来互动的便利性,到研究消费者偏好以创造更好的产品或服务)。精明的组织努力不违反个人对个人隐私的期望,因为个人隐私具有内在的价值:它允许人们做自己,以不受约束的方式行事。
匿名和假名
互联网的核心存在一个悖论:人们期望它成为一个公开透明的论坛来交流思想、信息、商品和服务,然而他们也期望匿名上网。正如《纽约客》一幅著名漫画的标题所言:在互联网上,没有人知道你是一只狗。对互联网隐私的期望因利益集团和国家而异。例如,由于政府监管,韩国人对互联网隐私的期望比美国人低。2015 年初,中国政府通过了新的规定,要求互联网用户今后在写博客或使用社交媒体时使用真实姓名。在互联网上匿名和假名是可取的情况是有争议的。例如,虽然一个大学生期望在互联网上匿名是合理的,但对于利用互联网策划暴力犯罪的人来说就不是这样了。对于是否应该允许教授用笔名写作,人们有不同的看法。
虽然有趣,但关于何时应该尊重匿名或假名的辩论有可能变得没有实际意义,因为新技术对个人隐私构成了前所未有的新挑战。
社交媒体和按需经济要求披露个人数据
脸书、推特和其他社交网络平台的崛起改变了人们对互联网隐私的期望。使用这些平台的人自愿提供个人信息,并同意与有限的受众或所有人分享。然而,即使是那些不想分享个人信息的人(例如,那些没有脸书或 Twitter 账户的人)也会因为职业或营销目的而感到压力。雇主经常对候选员工进行谷歌搜索。虽然没有结果总比糟糕的结果好,但今天的求职者通常会使用互联网来推销自己,要么创建一个 LinkedIn 帐户,要么通过个人网站、博客或文章展示成就。对小企业来说也是如此:大多数要么有网上业务,要么因为没有网上业务而失去业务。
过去十年的另一个主要技术趋势是按需经济(简称为共享经济)的出现,在这种经济中,商品或服务的提供商和用户通过网络或电话应用程序或网站进行交易。这就产生了排挤现有中间参与者的效果(这一过程被称为非中介化)。正如优步和 Lyft 等拼车服务已经让传统的出租车服务和城市出租车牌照系统几乎过时一样,维基百科已经取代了微软 Encarta 等大型私人编辑的百科全书。如今,旅行者不仅会查看其他城市的酒店价格,还会查看 Airbnb 的价格,以便直接从其他人那里租赁短期房间或房屋。随着 Airbnb 和其他代表按需经济的公司的出现,他们通过要求主人和客人提供个人信息来满足客户的安全需求。此外,在 Airbnb 住宿后,主人和客人会被邀请互相评论,这些评论通常包含个人信息,任何浏览 Airbnb 网站的人都可以免费获得。
尽管几十年来,易贝等公司一直在使用身份验证和用户评论来打击欺诈,并鼓励在线市场的质量,但新一代共享经济应用认为个人信息等同于可信度:越多越好。由于按需服务的参与者之间的互动比易贝上的买家和卖家之间的互动更密切,这是有意义的。上陌生人的车,在陌生人家里睡觉,让陌生人帮你遛狗,这些都需要对应用、站点或平台的高度信任。收集更多信息的平台会产生更多信任。例如,虽然 Airbnb 的客人可以通过积极的主机评论历史来建立信任,但没有先前历史的客人可以上传政府 ID,甚至链接到他们的脸书账户,以表明可信度。因此,尽管共享经济的去中介化让人们能够相互信任,但它也经常要求人们向平台甚至公共领域披露公共信息。
个人提供给社交媒体网络和按需经济服务的个人数据可以为希望基于诸如位置、年龄、性别、消费者偏好、社交偏好和其他类似属性来描述个人的组织或个人提供基础。个人信息赋予其拥有者权力,因此个人应该仔细考虑他们在不同情况下可以接受的个人隐私级别。
第 2 部分:组织

保护组织战略和专有信息
组织需要保护敏感信息,如公司战略见解或专有信息(如知识产权),这些信息可能会被竞争对手或不法行为者用来破坏组织。这不仅适用于制造行业尖端技术的组织(如国防、航空航天或汽车行业),也适用于所有类型的组织。2016 年,黑客以民主党全国委员会为目标,发布了其内部电子邮件通信,破坏了几位民主党候选人的可信度。同样在 2016 年,冒充孟加拉国中央银行官员的黑客向纽约美联储发送指令,试图从孟加拉国中央银行在纽约美联储的账户中窃取 9.51 亿美元。他们成功地吸走了 1 . 01 亿美元,其中大部分国际当局仍未追回。这些引人注目的黑客事件象征着组织在保护其组织战略和专有信息免受竞争对手和不良行为者攻击时所面临的挑战。
出于营销和研究目的收集客户信息
组织出于营销目的收集客户信息。杂货店筛选从人们的手机上收集的位置信息,以确定他们在特定的过道里花了多长时间。常旅客和其他忠诚度计划向人们提供额外津贴,以换取他们的个人信息,这些信息可用于加强产品和服务的促销。营利性和非营利性组织都建立客户或捐赠者档案,帮助他们进行销售和筹集资金。
客户信息还可以用来帮助了解消费者的偏好,并在未来提供更好的产品和服务。此外,组织对客户信息的收集通常会使客户将来与该组织的交易更加方便。
在收集此类信息时,组织必须遵守适用的联邦和州法律。在美国,医疗保健公司、金融服务公司和其他公司在允许收集的客户信息类型方面受到不同的限制。成熟的组织熟悉管理其行业的法律框架。随着数据收集和分析越来越多地由非人类参与者执行,法律和法规合规性变得越来越困难。
保护客户信息
对于所有面向消费者的公司,尤其是谷歌、苹果和亚马逊等科技公司,收集消费者的个人信息有助于为每位消费者提供更个性化的服务。这也让公司有责任保护这些信息。例如,在一个人的 Mac、iPhone 和 iPad 上同步数据可以方便地访问信息,但也让人预期苹果会采取措施保护这些信息不受外人影响。
保护客户信息
对于为其他组织提供服务的组织(如会计或法律服务组织),保护客户信息对于维护客户关系同样至关重要。黑客以前曾瞄准专业服务公司,以获取他们客户的数据,试图绕过客户复杂的数据保护措施。认识到这一风险后,主要的专业服务公司已经采取了大量措施来保护客户信息。
当前保护敏感信息的组织措施
组织已经采取了许多措施来保护敏感信息:例如,雇用内部和外部信息安全专业人员,教育员工如何保护信息,以及审查员工以防范内部威胁。一些已经成为或可能成为目标的组织也开始使用蜜罐(伪造的、由公司监控的数据室,声称保存敏感的公司信息,引诱和欺骗黑客,帮助公司了解黑客的动机)。这些措施是重要和必要的,需要发展以应对新的挑战。
第 3 部分:大数据

组织收集包含各种信息的数据,例如公司的产品和服务、内部流程、市场条件和竞争对手、供应链、消费者偏好趋势、个人消费者偏好以及消费者与产品、服务和在线门户之间的特定交互。组织收集的数据量显著增加。
对存储数据数量膨胀的担忧至少在上个世纪就已经存在。2014 年 4 月,研究机构 IDC 发布了一份题为“充满机遇的数字世界:丰富的数据和物联网不断增长的价值”的报告,该报告预测,“从 2013 年到 2020 年,数字世界将增长 10 倍——从 4.4 万亿千兆字节到 44 万亿字节”。当今数据的扩展是由计算和数据存储能力的增加、传感器的增加和连接性的增加推动的。
计算能力和数据存储能力的提升
随着时间的推移,我们发现存储更多的信息变得更加容易,因为在过去的几十年中,计算能力和存储容量都有了显著的提高。英特尔联合创始人戈登·摩尔在 1975 年观察到,芯片上的晶体管数量每两年翻一番。这一观察结果被称为摩尔定律,准确地描述了 21 世纪计算能力的指数增长。类似地,同时,在过去的几十年中,数据存储容量呈指数增长,尤其是我们在越来越小的驱动器上存储大量数据的能力。
由于这些增长,存储大量数据变得可能、便宜,甚至方便。因此,组织往往倾向于存储更多数据,因为丢失随后证明有用的数据的风险超过了通过保存更少的数据来略微降低存储成本的好处。
云计算的兴起
云计算仅仅意味着按需使用远程(而非本地)计算能力、数据存储、应用程序或网络。由于云计算,组织可以简单地从云提供商那里租用计算能力或存储,而不再需要在自己的服务器上存储大量数据,维护巨大的计算能力,或维护供应商的传统数据库(尽管传统数据库对大型组织仍然有用)。由于云提供商必须提供可靠的按需、可扩展的解决方案,像亚马逊、微软和谷歌这样的大公司是占主导地位的云提供商。
面向企业的云计算服务有三种形式:软件即服务(SaaS),其中云提供商允许组织在线使用其软件(例如,在线访问 TurboTax 平台即服务(PaaS),其中组织使用云提供商的资源开发应用程序供其成员访问(例如,Microsoft Azure);基础设施即服务(IaaS),其中云提供商为客户提供基本的基础设施服务以提供服务(例如,网飞使用亚马逊网络服务基础设施来支持视频流)。(个人用户可能更熟悉 iDrive、Google Docs 或 Dropbox 等云应用。)云计算的实现不仅得益于前面讨论的计算能力和数据存储能力的进步,还得益于互联网接入、速度和可靠性的显著提高。虽然云计算的采用在一定程度上是为了应对存储不断增长的数据量的困难,但它的广泛采用促进了存储数据量的增长。
增加传感器的使用、传感器的复杂性和连接性
传统上,互联网由人类用户相互之间以及与数据库的交互组成,互联网越来越多地用于将物理设备相互连接。机器对机器(M2M)交互的定性和定量增长预计将导致无处不在的物联网:一个智能设备网络,这些设备相互集成,在最少的人工干预下执行越来越复杂的功能。
物联网不需要全新的基础设施。相反,它是通过在现有设备和基础设施中嵌入传感器来实现的。例如,当家庭空调系统使用传感器来确定人们何时在家,并使用这些信息来决定温度以保持每个房间时,它就变得’智能’。类似地,当城市能源和水基础设施嵌入传感器时,智能系统可以监控使用情况,预测未来使用情况,并更有效地分配资源。先进的传感器可以改善几乎任何技术,从智能手机到心脏监视器,再到大型农场或工厂。
智能设备根据其用途需要不同种类的传感器。电脑有摄像头和麦克风已经有几十年了。现在,设备还可以配备传感器,测量温度、运动、其他物体的距离、压力、化学物质和各种其他东西。传感器的质量每年都在提高,价格也越来越低。
虽然传感器本身可以极大地改善设备,但设备之间的通信对于许多智能系统来说是必不可少的。例如,虽然使用嵌入在汽车中的各种传感器让你的汽车自动驾驶会很有用,但让路上的所有汽车相互通信会更有用。这将缓解交通流量,并理想地使汽车旅行更加安全。同样,当物联网适用于大规模生产或仓储时,它将需要设备之间良好的通信。各种通信技术的进步,尤其是无线通信技术的进步,释放了物联网技术的潜力。
智能设备经常收集个人数据
在智能设备出现之前,晨跑几乎不会产生任何数据。今天,如果你在智能手机上安装一个健康应用程序,并进行相同的跑步,关于跑步持续时间、你走的路线、你走的步数以及你在跑步过程中各个点的心率的数据都可以收集并存储在你的手机中。同样,三十年前,你家窗户里装个空调也不会产生多少数据。如今,智能家居温度系统每天都会收集大量的温度和湿度数据。一旦收集起来,这些数据不仅可以用来保持室内温度和节能,还可以推断出你通常在家的时间,或者你最有可能调整温度设置的时间。晨跑和家用空调系统的例子表明,智能设备可以创造更多的数据。它们还表明,为一个目的收集的个人数据可以用于许多其他目的。
数字世界正在以指数速度扩张:在 2013 年 4 月的一篇文章中,Ralph Jacobson 在 IBM 的消费品行业博客上发表了一篇文章,估计世界每天创造 25 亿千兆字节的数据。正如计算能力和存储能力的进步促使组织收集的数据量增加一样,改进的传感器和通信技术的出现也是如此。传感器测量事物,这些测量结果被传送到其他设备或服务器,被收集并存储为数据点。
人工智能
人工智能从数据中出现,正如我在 之前的 中所讨论的。
大多数人工智能研究都是由谷歌、亚马逊和百度资助的,因为数据是人工智能的食物,这些公司每天都产生大量数据。微软收购 LinkedIn 不是为了它的平台,而是为了它的数据。
到目前为止,公司已经利用人工智能彻底改变了金融和制造业。保护我们的财务信息有时看起来像是一个失败的事业,因为政府、房东、银行、信用卡公司和信用评级机构都在收集这些信息(正如 Equifax hack 所显示的,存储得很差)。
人们通常认为他们的医疗保健信息比他们的财务信息更敏感。人工智能已被用于医疗保健数据,但由于隐私问题,这些数据往往是分散和碎片化的,人工智能在医疗保健中的影响有限。然而,最终,公司将利用我们的私人健康信息编制越来越全面的数据库。
如果是技术导致了隐私的侵蚀,也许技术可以帮助解决这个问题。
第四部分:区块链

采用特殊协议的区块链允许不同程度的匿名、保密和隐私,可以保护医疗保健、金融和其他个人数据,同时仍允许这些数据用于人工智能应用。例如,用户可以拥有带有个人健康信息的区块链,并且出于特定目的,仅向产品或服务提供商(例如隐形眼镜制造商)简要发布该信息的特定元素(例如视力处方)。
虽然区块链是一个公共账本,存储在多个地方,但它可以实现匿名和信任,正如多个区块链应用程序和已经存在的高隐私加密货币所证明的那样。
目前,第三方收集的个人数据通常存储在具有单点故障的集中式数据库中。这种数据的泄露通常不被注意和报道。一旦我们的数据落入不受信任的一方手中,我们就无法控制如何使用这些数据。
区块链解决方案
正如比特币所显示的,密码学和深思熟虑的经济激励可以创造一种安全的方式来存储和管理信息,包括个人信息。
区块链上的私人数据受密码保护。我曾在其他地方讨论过散列是区块链技术的核心。以下是区块链技术可用于保护个人数据的一些方式,即使这些数据的一部分可供算法处理。
同态加密
一种称为“同态加密”的新加密技术允许在加密数据上进行计算,而无需首先解密数据。这意味着在对数据进行计算时,可以保护数据的隐私和安全。只有拥有适当解密密钥的用户才能访问数据或交易的私人细节。
诸如零知识证明(ZKPs)和 zk-SNARKs 之类的密码技术已经使用同态加密。一种叫做 Zcash 的流行加密协议使用 ZK-SNARKs 加密其数据,并且只将解密密钥提供给授权方,以便他们查看该数据。
状态通道
区块链可以为非区块链解决方案提供模型,或者成为保护隐私的混合解决方案的一部分。
国家频道是区块链互动,可以发生在区块链,但不是在区块链进行。状态通道通过三个过程工作。
1.锁定:使用链上的智能契约锁定事务。
2.相互作用:相互作用发生在链外或侧链上。
3.发布:在交互完成并且状态通道关闭之后,智能合约被解锁,并且在区块链上发布对交易的引用。
国家频道可以允许服务提供商保护用户数据的隐私和安全。交易可以在区块链之外进行,交易的参考散列(不泄露关于交易的机密细节)被保存在区块链上。
结论
我们的私人信息目前集中在互联网和公司数据库中,因此被少数玩家控制。数据创建和收集的指数级增长预计会继续侵蚀我们的隐私。基于区块链或受区块链启发的解决方案可以帮助减少这种隐私侵蚀,同时让我们受益于更快的交易、更好的服务和更强大的人工智能算法。
请关注 Lansaar Research 关于媒体的报道,了解最新的新兴技术和新的商业模式。
来自 Shaan Ray 的最新推文(@ShaanRay)。创造新价值和探索新兴技术| ENTJ | #科学…
twitter.com](https://twitter.com/shaanray)**
博客如何帮助你建立一个数据科学社区

天啊。我在三月份开始写博客,这让我大开眼界。
首先,我想说我并没有奇迹般地想出自己写博客的主意。我注意到我的朋友乔纳森·诺利斯在 LinkedIn 上变得活跃起来,所以我给他们发了短信来获取独家新闻。他们让我开个博客,还开玩笑地说“我正在做我的#品牌”。我是那种什么都尝试一次的人,而且我已经拥有了一个域名,有了一个网站建设者(在 Vistaprint 工作时),我还有一个电子邮件营销账户(因为我的工作是为了保持联系)。那么确定,为什么不呢?
如果你想开一个博客。要知道,你不需要有一堆现成的工具供你使用。你可以在 Medium.com 的 LinkedIn 上写文章,在投资一分钱之前,你有很多选择可以尝试…当然,你也可以创建自己的网站。从那以后,我开始使用自托管的 Wordpress。我已经爱上了写博客,Wordpress 让我利用了很多额外的功能。
在我的第一篇文章中,我开始看到数据科学社区的其他成员正在做的所有事情。老实说,如果你在我开始写博客之前问我在数据科学方面谁是我最崇拜的人,我可能只会快速说出那些创造了让我生活更轻松的 R 包的人,或者那些在 Stack Overflow 上发布了许多问题答案的人。但现在我关注 LinkedIn 和 Twitter,看到 Kirk Borne、Lillian Pierson、Carla Gentry、Bernard Marr 和许多其他人(说真的,还有许多其他人)等大数据科学影响者正在向社区添加信息。
我也开始第一手地看到很多人正在学习成为一名数据科学家(耶!).即使是仍在上学或刚刚步入职业生涯的人也在积极参与数据科学社区。(不需要专业人士,直接跳进去就行)。
我关注了我的博客统计(当然,我是一个数据狂),发现我写的得到最大回应的文章要么是:
- 关于如何进入数据科学的文章
- 关于如何执行数据科学领域的编码演示
但是你可能会发现有些不同的东西适合你和你的写作风格。我不只是在 LinkedIn 上发布我的文章。我也在 Twitter 上发帖,Medium,我把它们发到我的邮件列表,我把它们放到 Pinterest 上。当有人第一次提到 Pinterest 用于数据科学文章的想法时,我犹豫了。这很疯狂,但 Pinterest 是我网站流量的最大推荐者。谷歌分析没有骗我。
我在 LinkedIn 消息中与许多人聊天,我有机会与一些热爱数据和围绕数据科学创作内容的优秀人士交谈和(虚拟地)见面。我真诚地建立关系,为社区做贡献,这感觉很棒。如果你是“活跃于 LinkedIn 上的数据科学社区”的新手,请关注塔里·辛格、兰迪·劳、凯特·斯特拉赫尼、法维奥·瓦兹奎、博·沃克、埃里克·韦伯和莎拉·诺拉维。如果你走出去,你会很快找到你的部落。我发现当我参与时,我得到的比我投入的要多得多。
第一次点击你创建的内容的“发布”是令人生畏的,我不是说这将是你做过的最容易的事情。但是你会和有同样热情的人建立真正有价值的关系甚至友谊。如果你开了博客,我期待着阅读你的文章,看你的旅程。
如果你喜欢这篇文章,请访问我在 www.datamovesme.com的博客
你的国家对商业有多友好?Python 中的线性回归

Image courtesy: Wikipedia
动机
世界发展指标(WDI) 是由世界银行编制的广泛而全面的数据汇编。WDI 包括 200 多个国家经济的 1400 个指标,它提供了现有的最新和最准确的全球发展数据。
“营商便利度排名”指标对各国进行比较,其排名范围从 1 到 190(1 =最有利于商业的法规)。我今天的目标是开发一个多元线性回归模型,以了解什么属性使一个国家排名更高。那么,我们开始吧。
数据
r 有一个叫做 WDI 的很棒的软件包,可以让你搜索和下载世界银行的数据系列。
library(WDI)
indicator1 <- WDI(country="all", indicator=c("NY.GDP.PCAP.CD", "IC.REG.COST.PC.ZS", "IC.REG.PROC", "IC.TAX.TOTL.CP.ZS", "IC.TAX.DURS", "IC.BUS.EASE.XQ"),
start=2016, end=2016)colnames(indicator1) <- c("code","country","year", "GDP_per_capita", "Cost_start_Bus", "Days_reg_bus", "Bus_tax_rate", "Hours_do_tax", "Ease_Bus")write.csv(indicator1, file = "indicator1.csv",row.names=FALSE)
根据常识,我选择了以下变量作为预测值(独立变量):
- 人均国内生产总值
- 创业程序成本占人均国民总收入的百分比
- 注册企业的天数
- 营业税税率
- 纳税时间
预测变量:
- 做生意容易(1 =最有利于商业的法规)
我选择 2016 年,因为它是最近的一年,并且缺少的值最少。在选择了所有我需要的变量后,我将它保存为一个 csv 文件。
多重线性回归假设
- 线性
- 无多重共线性
- 同方差性
- 多元正态性
- 误差的独立性
我们将在分析过程中检查上述假设。现在我们来看看 Python。
数据预处理
%matplotlib inline
import numpy as np
import pandas as pd
np.random.seed(45)
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['axes.labelsize'] = 14
plt.rcParams['xtick.labelsize'] = 12
plt.rcParams['ytick.labelsize'] = 12indicator = pd.read_csv('indicator1.csv')
indicator.head()

很好,正是我们需要的。
现在,删除“代码”列和“年份”列。
indicator.drop(indicator.columns[[0, 2]], axis=1, inplace=True)
indicator.info()

我们正在处理 186 个观察值(国家)和 7 列(变量或属性或特征)。
我现在使用 describe()方法来显示数字变量的汇总统计信息。
indicator.describe()

计数、平均值、最小值和最大值行是不言自明的。std 显示标准偏差。25%、50%和 75%的行显示了相应的百分位数。
为了了解我们正在处理的数据类型,我们为每个数字变量绘制了一个直方图。
indicator.hist(bins=50, figsize=(20, 15))
plt.savefig('numeric_attributes.png')
plt.show()

Figure 1
两个直方图向右倾斜,因为它们向中间值的右侧延伸得比向左侧延伸得更远。然而,我会考虑他们所有的回归分析。
我们检查属性之间的相关性。
from pandas.plotting import scatter_matrixattributes = ["GDP_per_capita", "Hours_do_tax", "Days_reg_bus", "Cost_start_Bus", "Bus_tax_rate", "Ease_Bus"]
scatter_matrix(indicator[attributes], figsize=(12, 8))
plt.savefig("scatter_matrix_plot.png")
plt.show()

Figure 2
看来“人均 GDP”和“营商难易程度排名”是负相关的。其他自变量均与“营商难易程度排名”呈正相关。让我们找出最有希望预测“做生意容易程度排名”的变量。
from sklearn.linear_model import LinearRegression
X = indicator.drop(['country', 'Ease_Bus'], axis=1)
regressor = LinearRegression()
regressor.fit(X, indicator.Ease_Bus)
*print('Estimated intercept coefficient:', regressor.intercept_)*
预计截距系数:59.9441729113
*print('Number of coefficients:', len(regressor.coef_))*
系数个数:5
*pd.DataFrame(list(zip(X.columns, regressor.coef_)), columns = ['features', 'est_coef'])*

预测“做生意容易程度”的最有希望的变量是“注册企业的天数”变量,所以让我们放大它们的相关散点图。
*indicator.plot(kind="scatter", x="Days_reg_bus", y="Ease_Bus",
alpha=0.8)
plt.savefig('scatter_plot.png')*

Figure 3
相关性确实很强;你可以清楚地看到上升的趋势,而且这些点不是太分散。
将数据分为训练集和测试集。
*from sklearn.cross_validation import train_test_split
y = indicator.Ease_BusX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)*
建立线性回归模型
*from sklearn.linear_model import LinearRegression
regressor = LinearRegression()
regressor.fit(X_train, y_train)*
linear regression(copy _ X = True,fit_intercept=True,n_jobs=1,normalize=False)
*y_pred = regressor.predict(X_test)regressor.score(X_test, y_test)*
0.60703279859102988
因此,在我们的模型中,Y 的 60.7%的可变性可以用 x 来解释。
计算均方根误差(RMSE)。
*from sklearn.metrics import mean_squared_error
regressor_mse = mean_squared_error(y_pred, y_test)import math
math.sqrt(regressor_mse)*
33.582374172286
因此,在我们的测试集上进行预测时,我们离“做生意容易程度”的实际分数平均相差 33.59 分。
“做生意容易程度”的中值是 95,因此 33.59 的典型预测误差不是很令人满意。这是一个模型欠拟合训练数据的示例。当这种情况发生时,可能意味着这些特征没有提供足够的信息来做出正确的预测,或者模型不够强大。修复欠拟合的主要方法是从词库指标中选择更多的特征(例如,“获得信贷”、“登记财产”等)。
剩余剧情
最后,我们绘制残差图来检查线性回归假设。残差图是检验同质性的好方法。分布中不应该有明确的模式;特别是,不应该有锥形图案。
*plt.scatter(regressor.predict(X_train), regressor.predict(X_train)-y_train, c='indianred', s=40)
plt.scatter(regressor.predict(X_test), regressor.predict(X_test)-y_test, c='b', s=40)
plt.hlines(y=0, xmin=0, xmax=200)
plt.title('Residual plot using training(red) and test(blue) data')
plt.ylabel('Residual')
plt.savefig('residual_plot.png')*

Figure 4
我们的剩余地块看起来不错。
结论
- 在这个练习中,我下载并研究了一个世界银行业务相关指标数据集。我的目标是通过选定的特征来预测一个国家的“经商便利度”排名。
- 我使用 Sklearn 对整个数据集进行线性回归拟合,并计算系数。
- 我将数据分为训练集和测试集,并计算了测试集的 R 平方和 RMSE。
- 我绘制了训练集和测试集的残差图。
- 如前所述,为了获得更好的 RMSE 分数,我可以尝试添加更多的功能,或者尝试另一种模型,如随机森林或决策树。
- 由于缺乏信息,朝鲜和索马里没有包括在本分析中。
- 叙利亚最新的人均 GDP 是 2007 年的数据。因此,关于叙利亚的信息不是最新的。
创建这篇文章的源代码可以在这里找到。我将很高兴收到关于上述任何反馈或问题。
人工智能如何成为你的营养师并预防糖尿病
以下故事基于这篇文章:通过预测血糖反应进行个性化营养发表在《细胞》上。
带回家的信息
- 餐后高血糖(餐后高血糖)是二型糖尿病的主要危险因素。
- 餐后葡萄糖反应因人而异。
- 具有微生物组和个人数据的机器学习算法可以帮助区分改善或恶化餐后葡萄糖反应的食物。
- 该算法可以提供有效改善餐后葡萄糖反应的个人定制饮食建议。
背景
糖尿病是影响全球 8.5%成年人口的主要健康负担,其并发症包括中风、心脏病发作、肾衰竭、视力丧失等。(世卫组织,2016)

餐后高血糖(餐后高血糖)是发生二型糖尿病和前驱糖尿病的主要危险因素。而饮食摄入是餐后血糖的核心决定因素。(加尔维茨,2009)
问题:差的葡萄糖反应预测导致差的控制
我们知道饮食摄入是餐后葡萄糖反应(PPGR)最重要的决定因素,但我们没有现有的方法可以准确预测 PPGR。
碳水化合物计数是目前的做法,但它不能提供良好的预测,因为不同的人对同一种食物的 PPGR 差异很大。例如,PPGR 的一些地区涨幅较大,而另一些地区涨幅较小。

Variability of PPGR of different patients gathered from the study, doi: 10.1016/j.cell.2015.11.001
假设我的血糖目标是餐后血糖控制在 7.8mmol/L 以下(美国糖尿病协会推荐)。
如果我能在决定自助餐选择什么食物之前有一个准确的预测值,那就简单多了。
问题的根源:没有考虑到个体差异
我们可以把计算 PPGR 看作一个数学函数。我们选择食物作为输入 x,我们的生理过程作为函数 f:,我们的 PPGR 将是输出 f(x)。

input: food. Function: physiological process. output: PPGR
我们生理功能的个体差异解释了为什么不同的患者会有不同的 PPGR,给定相同的输入 x(相同的膳食)。这是因为每个个体的功能部分是不同的。
以前的方法是基于广义总体,因此忽略了个体差异。
解决方案:学会用个人数据建立个人模型
目标是为 PPGR 建立一个准确的预测模型,我们可以通过找到个人的函数公式来实现。
生物过程非常复杂,许多因素都可能导致 PPGR,包括饮食习惯、体育锻炼、药物摄入、微生物群等…我们将期待该函数是一个多元线性回归模型,它将有许多不同的输入,不同的输入不同的权重。

目标是:
- 列出对 PPGR 有贡献的因素作为输入(X1,X2,…,Xn)
- 找出不同输入(β1,β2,…,βn)的单独权重
用机器学习的方法解决它
我们将通过机器学习的方式来解决这个问题,我们收集了大量的数据,不同的个人和微生物组数据作为特征和 PPGR 作为标签。我们将数据交给计算机算法,我们将能够得到不同个体的 PPGR 的预测模型。

收集数据
患者人口统计:
该研究针对以色列成年非糖尿病人群。
该研究招募了 800 名年龄在 18-70 岁之间、之前未被诊断为二型糖尿病的人。
该算法来自于从上述 800 个人中收集的数据。
该算法随后被另外 100 名具有相似人口统计学特征的个体验证。
收集输入:
生活方式信息
一个移动网站已经被开发出来,供患者记录他们的饮食、锻炼、睡眠和其他个人信息。

微生物组
患者使用omni gene GUT工具包收集他们的粪便样本。用 MagAttract PowerSoil DNA 试剂盒提取 DNA(从粪便中自动分离 DNA)。用 Illumina MiSeq 对微生物组进行测序。
衡量产出:PPGR
连续血糖监测器(CGM)用于收集 800 名参与患者的血糖,连续 7 天,每 5 分钟一次。

算法
使用梯度推进回归来生成模型,作为 PGGR 和我们数据集中不同因素之间非线性关系的方法。
梯度推进回归使用决策树对数据进行分类。
决策树模型不断尝试用是/否问题对数据进行分类,直到我们得出最终答案。


梯度推进回归基于先前树的残差来训练决策树。例如,黑点代表实际数据,蓝线代表我们模型的预测。我们可以观察到,每个树都建立在先前树的分类之上,并且与实际数据更加匹配。
使用梯度推进回归,该研究推断了数千棵决策树。这些树的特征是从代表膳食含量(卡路里、营养含量)、血液参数(HbA1c)、日常活动和微生物组特征的 137 个特征中选出的。
模型:在预测中超越黄金标准
一种定制算法的预测结果考虑了个体差异的 137 个特征,并与当前“碳水化合物计数”的黄金标准进行了比较。
我们可以通过使用决定系数来比较模型与实际数据的拟合程度。
如果 R 2 =1,表示模型可以完全预测结果,如果 R 2=0,表示模型完全不能预测结果。


基于个体的模型比目前“碳水化合物计数”的黄金标准大大提高了预测能力。
给出定制饮食建议的算法
另外招募了 26 个人,旨在通过给出定制的饮食建议来研究该算法在 PPGR 改善中的有效性。
所有 26 名患者都经历了一个“分析周”,收集个人数据,供算法生成预测模型。
12 名患者被分为算法组,另外 14 名被分为营养师组。
根据个人的 PPGR 模型的预测,所有的参与者都经历了一个“好饮食”周和一个“坏饮食”周。无论在“好”或“坏”饮食周,所有建议的膳食都有相同的卡路里含量,但成分不同。

Red represents PPGR in “bad diet” week, green represents PPGR in “good diet” week. Both the expert’s and algorithm’s dietary suggestion shows significant difference in PPGR response.

Individual data shows fewer glucose spikes and fewer fluctuations
注意:饮食建议是高度个性化的
对建议膳食的分析表明,不存在普遍的“好”或“坏”饮食。一些能有效控制一个病人 PPGR 的饮食对另一个病人来说可能是“坏”的饮食。
这就是为什么拥有一个适合您自己的 PPRG 的个性化模型对于管理您的血糖水平非常重要。
结论
这是“个性化医学”的一个例子,现代医学尚未了解个体差异,但这些差异确实很重要。
故事中的例子是关于 PPRG 的,但该原则也适用于医疗保健的其他方面,例如癌症治疗。
随着个人数据收集变得越来越可用,例如更便宜的基因组学测试成本,我们开始拥有更精确和个性化的医疗保健。
分析和人工智能如何让营销人员预测未来?

永远不要做预测,尤其是对未来。
我们并没有预测未来的良好记录,所以这似乎是明智的建议。
从 IBM 总裁 Thomas Watson 在 20 世纪 40 年代早期宣称将会有“大约 5 台计算机”的世界市场(诚然,这个星球上可能只容得下 5 台早期的 IBM 机器),到 Y2K 的喧嚣,人们无法抗拒浮夸的、常常是极其不准确的预测。
提前知道未来的回报太大了,以至于无法抗拒尝试一下,但我们相当依赖人类的直觉来形成我们的预测。因此,这些奖励经常无人认领。
然而,这是一个快速发展的行业,人工智能(AI)的进步可能很快会让我们将未来的预测建立在可靠的统计模型上,而不是我们熟悉但有缺陷的直觉上。
在这个由三部分组成的系列中,我们将探索人工智能在开发准确、可访问的预测分析以提高业务绩效方面的潜在作用。
本文将首先分析预测分析行业的现状,以及一些帮助企业充分利用现有技术和数据的技巧。
我们所说的“预测分析”是什么意思?
预测分析是一种数据挖掘形式,它采用机器学习和统计建模,根据历史数据预测未来的事态。
我们周围已经有了预测分析的例子。如果您的银行通知您,您的信用卡有潜在的可疑活动,很有可能已经使用统计模型根据您过去的交易来预测您未来的行为。严重偏离这种模式被标记为可疑。
作为理解该领域兴趣水平的一个简单代表,我们可以从 Google Trends 中看到,主题“预测分析”的搜索量在过去 5 年中显著上升:

我们可以看看这条线,预测它会继续增长。但这实际上只是基于最近的历史趋势,或者我们在业内听到了很多关于这个话题的议论。我们需要进行更多的调查,才能真正确定这条线的下一步走向。
这么多企业对这个话题感兴趣也是有道理的。据预测到 2020 年,每年将有超过 760 亿美元花费在大数据技术上。获得投资回报的最佳方式是利用所有这些数据来预测未来的需求趋势。
正如我们所看到的,这对于人们来说是一项很难掌握的任务。如果我们要开始做出正确的预测,我们需要一点帮助。
因此,在 Gartner 的“分析优势模型”中,预测分析被视为描述性分析和诊断性分析的进化飞跃。

也就是说,对精确预测分析的渴望并不新鲜,使用分析来模拟未来消费者行为的尝试也不新鲜。例如,许多分析专业人员每天都在从事这一领域的工作,以计算典型客户的终身价值(LTV)等数字。大量不同的数据集的可用性有助于大大提高这些计算的准确性。
相对较新的是人工智能的应用,以填补我们技能组合中的差距,并扩展预测分析的可能性。
这种结合产生了更复杂的统计模型,这些模型可以发现过去消费者行为的模式,并利用这些模式来规划未来可能的行动。
但是为什么人工智能在实现我们自己发现几乎不可能的事情上如此有效呢?
习惯的生物:预测分析在现实世界中是如何应用的?
人们的可预测性极大地帮助了预测分析。
尽管我们愿意相信自己是独一无二的、有自由意志的,但人工智能可以根据我们过去的行为和类似人的行为,相当准确地预测我们将继续做什么。
麻省理工学院媒体实验室的科学家在 2007 年进行的一项研究发现“大多数人每天所做的事情中有 90%都遵循着如此完整的常规,以至于他们的行为可以用几个数学公式来预测。”
许多营销活动都基于这一假设,但我们现在可以更准确、更负责地应用这一原则。
人工智能在这一领域发挥作用的地方在于它能够识别人类根本看不到的更广泛的模式。我们根据我们认为安全的假设选择调查领域,但 AI 可以识别其他变量,当这些变量被改变时,会相互影响。
这种方法(在很大程度上是通过使用回归分析形成的)恰当地反映了消费者所处的不断变化的世界。
例如,根据我的位置、年龄、过去的购买和性别,如果我刚刚在篮子里放了面包,我有多大可能会买牛奶?网上超市可以利用这类信息,根据我预测的购买倾向,自动向我推荐产品。
此外,金融服务提供商可以利用我和类似人的在线互动产生的数千个数据点来决定何时向我提供哪张信用卡。一家时装零售商可以根据我刚买的牛仔裤,使用我的数字档案来决定我下一次购买哪双鞋。
这有助于企业提高转化率,但其影响远不止于此。预测分析允许公司根据消费者预期和竞争对手基准制定定价策略。它允许零售商预测需求,从而确保每种产品都有合适的库存水平。
预测分析甚至可以通过发现客户偏好的变化,为新的产品线提供建议。这标志着分析从数据专家的追溯工具转变为塑造业务战略、改善客户关系和创造运营效率的重要预测功能。
事实上,最近的一份 Forrester 报告指出,“预测型营销人员报告收入增长率高于行业平均水平的可能性是 2.9 倍。”
这场革命的证据已经在我们周围了。例如,每次我们在谷歌、脸书或亚马逊输入搜索查询,我们都在向机器输入数据。机器因数据而繁荣,随着接收这些反馈信号,变得越来越智能。
这种现象给营销人员带来了很多好处。谷歌使用这项技术已经有一段时间了,通过其在分析领域的 Smart Goals 产品,以及去年底推出的会话质量评分功能。这些是由机器学习技术推动的预测分析的例子。
有一种观点认为预测是智能的基石,所以这对人工智能来说是一个壮举。
然而,这仅仅是开始。目前预测分析的大部分工作都集中在提出建议或推荐上,但基于人工智能的预测有机会成为营销战略的支点。
在这方面,最近的发展提供了很多乐观(或者有些人可能会说是恐惧)的理由。谷歌的 DeepMind 团队刚刚创造了一个人工智能,它能够规划未来,并在行动前考虑不同的结果。
这在预测分析的范围内是相关的,因为想象力是创建预测的一个基本方面。这种能力只会巩固人工智能作为成功预测分析活动的重要组成部分的作用。
企业如何整合预测分析?
为了利用人工智能和预测分析的潜力,组织需要落实四个要素。
1.正确的问题
最好的预测分析项目始于一个要测试的合理假设。尽管我们应该为机器学习算法提供空间,让它们能够在数据点之间建立自己的客观关联,但我们需要着手解决一个我们希望克服的商业挑战。这有助于提供一些努力的形状。
2.正确的数据
过去十年数据科学的进步意味着我们可以更准确地从大量非结构化数据中获得洞察力,但我们仍然需要完整的数据集来得出令人信服的结论。
因此,在定义了您希望用预测分析来回答的问题之后,下一步就是弄清楚哪些数据可供您使用,以及这些数据是否足以令人信服地回答您的问题。
3.正确的技术
正如预计到 2020 年价值 760 亿美元所暗示的那样,大数据技术是一个蓬勃发展的行业。数据产生的速度如此之快,以至于我们需要不断改进的技术能力来捕捉、存储和理解数据。
许多领先的分析软件包已经推出了预测分析工具,但它们的方法各不相同。要决定哪种解决方案最适合您的企业,现在比以往任何时候都更需要一个团队,他们对每种解决方案都有经验,能够确定最合适的方案。
4.合适的人
本质上,这将我们带回到第一步。没有合适的人,很难提出合适的问题。也很难知道可能需要什么数据来回答这些问题,或者从最新技术中获得最佳效果。对于所有关于人工智能取代人的讨论,它只是真正加强了对让正确的人充分利用它创造的新机会的关注。
这项技术的应用已经很广泛了,但我们还只是刚刚触及皮毛。在本系列的下一篇文章中,我们将了解目前使用预测分析来提高业务绩效的五家企业。
最初发表于【www.clickz.com】。
如何释放大数据在风险管理方面的潜力?

一个相互关联的世界意味着更大的增长潜力,但也带来了更多的系统性风险,因为各个组成部分都在一起移动,任何变化都会传播。有时,这放大了协同效应。大数据分析的作用是通过揭示可能预示市场甚至个人账户危机或突变的模式,为经理们提供预见和对冲这些风险的必要信息。到目前为止,唯一的应用是在金融领域——以投资组合管理为目标——但最近在其他活动领域的进展证明,这种方法还有更大的潜力可挖。
大数据的潜力
如果您准备好加入大数据运动,并成为这个到 2020 年将达到500 亿美元的行业的一部分,那么很自然会问这将给您的组织带来什么?大数据是一个术语,指各种信息源的巨大集合,其中大多数是非结构化的,有时是作为其他活动的副产品生成的。例如,与卡支付历史相关的数据,或者媒体上的新闻和谣言,甚至社交媒体聊天,都可以用来提取关于风险管理的知识。
欺诈检测
大数据是用来为专门从事模式检测的机器学习算法提供信息的原材料。这在可能存在欺诈的情况下非常有用,因为“照常营业”的变化可能是恶意活动的信号。分析中包含的数据可能各不相同,如地理位置、用于连接账户的设备类型或转账金额。参与交易的各方的身份也是一个潜在的警告信号。主要优势是由于实时处理,这种类型的欺诈检测可以触发警告并停止操作,直到进一步授权,从而最大限度地降低风险。
增强场景分析
在大数据出现之前,情景分析和模拟很难创建,并且结果不准确。现在,使用大量信息样本的能力提高了准确性,加快了决策过程。现在的挑战是在模拟的数量和容量与速度限制之间达到完美的平衡。这项工作最有用的工具之一是蒙特卡洛模拟,由分布式文件系统上的并行计算提供动力。结果给出了给定时间范围内投资组合的风险价值。
开发新的商业模式
到目前为止,风险要么通过对公司的审计和尽职调查来计算,要么通过评估个人的 FICO 或 Vantage 分数来计算。然而,这些代理并不能说明全部情况,尤其是对新进入者而言。一家拥有百万美元创意的初创公司没有资格获得融资,一名常青藤联盟(Ivy League)的应届毕业生即使有六位数的收入,也无法在大学毕业后马上找到像样的住房解决方案。
同样,大数据在这里重新定义了风险衡量标准,并创造了机会和新的业务模式。一些公司现在使用每个申请的 10K 数据点来衡量信用度,他们考虑的不仅仅是信用历史。
使用区块链预先验证申请人
风险衡量不是用几十年前的标准来衡量,而是可以根据情况进行调整。引入基于大数据的区块链技术可以提供一种方法来追踪特定个人的历史,直到他们在网络中的进入点。这种新的交易方式会使当前的风险衡量变得多余。每次操作都可以自动计算风险分值,并将其附加到每个账户上。这可能意味着信贷或智能合同的申请人甚至不需要披露他们的身份,他们可以通过网络预先验证。
常见障碍
由于金融和银行业是 T4 监管最严格的行业之一,即使承诺削减成本和增加利润,引入创新模式也是困难的。旨在利用大数据提供的洞察力的公司不仅需要得到董事会的批准,还需要得到客户的批准。否则,他们可能会被指控未经同意处理个人数据。此外,人们可以期待更多的监管和进一步加强数据的数字处理。
目前已知的风险只是随着技术进步而出现的一小部分危险。通过大数据进行的分析应该能够识别网络攻击,就像它检测欺诈一样,并建立实时机制来预防它。
由于机器学习在很大程度上是一个黑盒,因此纠正有偏差的模型或其假设比纠正确定性模型更困难,因此正确的测试和校准应该是模型定义的一个组成部分。
上升的预期
我们越来越习惯于技术,以至于我们将很难等待银行和信贷机构使用他们几十年前的程序。为了避免客户失望并提高他们的利润率,他们最终将被迫采用大数据技术。金融机构可以从零售连锁店和艺人那里获得灵感,他们已经通过这些工具完善了与客户的关系。
好消息是,有大量可能的应用,因为直到现在,关于使用大数据模型进行风险管理的讨论更多地是在学术层面,而不是在实践中。大型、单一的机构需要跟上更小、更灵活的公司和点对点模式。
数据如何刺激创新?

Photo credit : The Vegan Society
如果管理是为了降低风险、不确定性和模糊性;数据科学就是将数据转化为集体行动。今年的皇后国际创新挑战赛为研究生提供了一个利用他们的分析技能和创造力解决食品安全问题的机会——这是一个普遍的、永恒的挑战,不会消失。竞赛面向在本学年注册学位或证书研究生课程的所有学生。数据科学和创新之间的关系是什么,为什么参与这样的挑战,为什么是食品安全,以及你的努力会有什么回报?
大学挑战和创新之间有什么联系?斯蒂夫·约翰森对创新历史的十年研究使他得出结论,某些“空间”的固有特征,如 18 世纪的英国咖啡馆、19 世纪的 T4 赌场和今天的万维网,有利于创新思想、产品和实践的诞生。这种空间的一个特点是,它们将注意力集中在特定的问题上,而不是久经考验的“解决方案”。第二个特征是,这种空间允许参与者以新的眼光看待数据,促进了现在和可预见的未来的无限结合。最后,这些空间鼓励小预感的对抗,这种对抗随着时间的推移发展成在新的环境中应用想法。与他研究的例子类似,创新挑战提供了一个将数据转化为创新的绝佳机会。
在这个比赛中你能学到什么关于数据科学的知识?数据科学是衡量要解决的问题,鉴定手头的数据,应用适当的方法,并将数据转化为行动。加拿大丰业银行客户分析中心副主任 Dean McKeown 指出,创新挑战为每个参与者提供了一个独特的平台,与来自世界各地的高度多元化的学生、从业者和专家团队合作。您将与 Queen ’ s Master of Management Analytics 的员工一起研究来自各种公共和私人数据源的真实数据。您将被要求开发一个数据科学模型,以理解数据,提供可操作的见解,并以激励行动的方式传达您的结果。数据科学永远不会在教室里掌握,而是通过在处理现实世界挑战时练习分析方法来掌握。
为什么关注粮食安全?根据联合国世界粮食安全委员会的定义,粮食安全是指所有人在物质、社会和经济上都能获得积极健康生活所需的营养的状况。麦克欧文教授提醒我们,在可预见的未来,对自然资源的管理充满了风险、不确定性和模糊性。全球变暖、大规模移民、商品价格波动和政治动荡严重影响着粮食安全。公共政策以及企业预测需要适应当地和全球条件,包括处理土地使用模式、用水、商品贸易和食品加工的战略。
你努力的回报是什么?女王国际创新挑战赛为您提供了使用最先进的分析平台(如 SAS Institute 的 VIYA)解决重要问题的可能性。这是一个与来自其他学校和文化的学生联系的理想场合,面对你的经历和见解,并提出可以对社会产生真正影响的做法。该活动提供了一个向经验丰富的从业者学习和向潜在雇主展示你的技能的绝佳机会。前五名团队将被邀请到多伦多展示他们的作品,获奖者将获得 2 000 至 20 000 加元的奖金。带上你的思考帽,今天就报名吧——因为正如斯蒂夫·约翰森会补充的那样——“未来属于互联的头脑”。
Lee Schlenker 是 Pau 商学院的教授,也是 http://baieurope.com T2 商业分析研究所的负责人。他的 LinkedIn 个人资料可以在 www.linkedin.com/in/leeschlenker.查看你可以在 https://twitter.com/DSign4Analytics通过 Twitter 关注我们
更多关于女王 2017 年国际创新挑战赛的信息可以在https://www.facebook.com/queenschallenge找到。
研究生可以在https://Smith . queensu . ca/centres/scotiabank/competition/index . PHP报名参赛
约翰逊,S. (2010),好主意从何而来:创新的自然史,河源图书公司
怎样才能写出更好的 AI 文章?
我很清楚,我在媒体上的写作让我获得了有趣的联系,这些联系可以转化为我业务发展渠道中的线索。对我在 medium.com 上发表的 35 篇文章的分析告诉我,你们——我的读者——喜欢阅读更多关于人工智能的业务,以及我作为顾问的经历。你似乎不太关心技术建议或学习资源。
数据告诉我,像“如何雇用一名人工智能顾问”和“如何为一个人工智能项目定价”这样的文章,比关于如何提取电子邮件有效性的演示或关于机器视觉的演示有趣 10 倍。
支点:少一些科学,多一些远见
好吧,与其和数据斗争,我要听听你们的点击和掌声,把我的文章集中在我收集的经验上。这将需要一些额外的认知努力,但我会在不违反任何保密协议的情况下做到这一点,基本上是通过用说明性的例子来讲述故事,而不是使用声明性的“我为 y 公司做了 X,”事实上,我在这篇文章中承诺不会成为一个名字滴漏者。我将从我俯瞰人工智能工程和商业化漩涡的树枝上,给你我对正在发生的事情的诚实看法。所以不要再说“这是做 x 的代码。”而且,从严格的自私的角度来看,为这些文章编写代码并不简单。所以当我写观点和经历的时候,我花费的时间更少,吸引的眼球也更多。
在开始这一系列文章时,我问自己,如何在不违反 NDAs 的情况下,表达我公司做的事情。这些是回归、分类、标准化、云、物联网、教育等等。相反,我转而谈论经验和观点。正如我的商业伙伴马特指出的,我的努力需要赚钱、省钱或者节省工作和时间。这个支点将节省工作和时间(我的工作和时间),它将赚钱(通过介绍你,我的观众,给我)。所以,亲爱的读者,如果我误解了你对人工智能世界中商业故事的渴望,而你真正想要的是技术细节…告诉我。发表评论。
经验和观点:付费数据清理
现在,关于我要写的许多经历中的第一个……一个客户最近要求我在他们签订合同之前帮助他们组织他们的数据。这种态度忽略了一点,即数据科学的核心是数据,而不是算法。下面这张漂亮的图片让你感受到清理数据是一项多么艰巨的工作。这通常比项目的其余部分要大得多。

From Mohamadreza Mohtat in this post.
现在,一旦组织好数据,就需要一些时间来为数据找到合适的解决方案,并将解决方案与体系结构挂钩。通常我们的客户端会从某种数据库(例如 postgres)进入 tensors,然后从 tensors 返回某种可调用的 JSON 服务,发出响应。
总结一下,当我做人工智能咨询时,我不会让数据清理逃避工作声明。这是工作。对客户来说,项目的其余部分可能看起来很难,但对顾问来说这并不是最难的部分。困难的部分是整理你的数据。剩下的就是魔法了。
如果你喜欢这篇文章,那么请试试屏幕右下角的新鼓掌工具。就像我之前说的,我也很高兴在评论中听到你的反馈。
编码快乐!
——丹尼尔
丹尼尔@ lsci . ioLemaySolutions.com
如何用球员名字预测世界杯,准确率 80%?

在这个内核中,我将演示如何通过 Tensorflow 使用球员姓名来预测历史世界杯结果,准确率达到 80%。后来,我试图预测 2018 年世界杯的结果,似乎有一些有趣的发现
阶段
- 数据摄取:首先,我从给定的数据集中获得 3 个数据框架,并从网站上手工构建 2018 年世界杯数据
- 预处理:对建筑物特征嵌入输入所需的特征进行预处理
- 转换:为模型输入转换处理过的数据
- 模型构建:构建字符嵌入模型
- 评估:尝试预测 2018 年世界杯结果
特征工程
为什么球员名字和教练名字选择为特色?这是因为我们发现这些名字可能为我们做预测提供关键信号(来自测试集结果)。
标记
为了建立一个训练数据,让冠军的标号为 1,亚军的标号为 2,季军的标号为 3,依次为 4。团队的其他成员为 0。从数据来看,我们有大约 20 个世界杯记录。
数据分布:标签 1、2、3 和 4 分别有 20 条记录,大约有 300 条负数据。
模型结构
我们使用字符嵌入来建模预测模型。如果你不熟悉,你可以看看这篇文章。通过使用定义的函数,我们可以简单地用几行代码构建模型
char_cnn = CharCNN(max_len_of_sentence=256, max_num_of_setnence=1)
char_cnn.preporcess(labels=training_df['label'].unique())
然后处理原始数据
x_train, y_train = char_cnn.process(
df=train_df, x_col='name', y_col='label')
x_test, y_test = char_cnn.process(
df=test_df, x_col='name', y_col='label')
试着预测结果
char_cnn.build_model()
char_cnn.train(x_train, y_train, x_test, y_test, batch_size=32, epochs=10)
输出
Train on 341 samples, validate on 86 samples
Epoch 1/10
341/341 [==============================] - 13s 40ms/step - loss: 0.9741 - acc: 0.7801 - val_loss: 1.0188 - val_acc: 0.7674
Epoch 2/10
341/341 [==============================] - 10s 30ms/step - loss: 0.7981 - acc: 0.8240 - val_loss: 1.0271 - val_acc: 0.7674
Epoch 3/10
341/341 [==============================] - 11s 31ms/step - loss: 0.7864 - acc: 0.8240 - val_loss: 1.0512 - val_acc: 0.7674
Epoch 4/10
341/341 [==============================] - 10s 30ms/step - loss: 0.7660 - acc: 0.8240 - val_loss: 0.9753 - val_acc: 0.7674
Epoch 5/10
341/341 [==============================] - 10s 30ms/step - loss: 0.7506 - acc: 0.8240 - val_loss: 1.0135 - val_acc: 0.7674
Epoch 6/10
341/341 [==============================] - 10s 30ms/step - loss: 0.7426 - acc: 0.8240 - val_loss: 1.0135 - val_acc: 0.7674
Epoch 7/10
341/341 [==============================] - 10s 30ms/step - loss: 0.7824 - acc: 0.8240 - val_loss: 1.0176 - val_acc: 0.7674
Epoch 8/10
341/341 [==============================] - 10s 30ms/step - loss: 0.7763 - acc: 0.8240 - val_loss: 1.0137 - val_acc: 0.7674
Epoch 9/10
341/341 [==============================] - 10s 30ms/step - loss: 0.7805 - acc: 0.8240 - val_loss: 0.9793 - val_acc: 0.7674
Epoch 10/10
341/341 [==============================] - 10s 31ms/step - loss: 0.7624 - acc: 0.8240 - val_loss: 1.0138 - val_acc: 0.7674
估价
来到这篇文章的结尾,准确率好像很不错,大概是 80%左右。让我们看看 2018 年世界杯的预测结果。
在我们的编码中,4 表示团队失败。说到这一点,你可能会认为这有什么不对吗?请看看结论部分。
输出
array([4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,
4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,
4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4,
4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4, 4])
结论
完整源代码请去 kaggle 看看。
谢谢你看了这个毫无意义的模型。实际上,我想展示的是特性的重要性,而不是模型架构。
- 当人们谈论“我们正在使用机器学习”、“应用深度神经网络”时,你可能更好地询问特征和数据,而不是询问模型架构。当然,模型架构很重要,但是特性和数据也很重要。请记住垃圾进,垃圾出。
- 当人们谈论拥有 80%甚至 90%的准确率时。你最好检查一下是实验的结果还是实际的结果。许多模型在实验阶段过度拟合,尽管数据科学家认为他们已经很好地防止了这种情况。
- 对于测量,更好地理解其他指标,而不仅仅是准确度。比如我们在分类上也有精准和召回。我们有机器翻译的 BELU。
- 作为一名数据科学家,与其谈论使用 CNN,LSTM bla bla bla,花更多的时间去理解你的特性和数据
- 如果您没有足够大的数据(在本例中,少于 500 条记录)。不要相信你可以从零开始建立一个惊人的模型。
关于我
我是湾区的数据科学家。专注于数据科学、人工智能,尤其是 NLP 和平台相关领域的最新发展。
中:http://medium.com/@makcedward/
领英:https://www.linkedin.com/in/edwardma1026
github:https://github.com/makcedward
https://www.kaggle.com/makcedward
VLSI 设计的模式检测有多复杂?

VLSI pattern detection can be exciting and scary at the same time !
早期,电子设计自动化行业吸引我的主要原因之一是过多的 NP 完全问题及其天文复杂性。在机器学习的时代,这仍然是正确的,全世界都震惊于训练一个神经 50 层 CNN 所需的天数。就性能而言,EDA 问题的复杂性让图像识别等现实生活中的解决方案相形见绌。请允许我用神经网络展示一个简单 VLSI 单元模式检测的简单问题的艰巨性。
为了便于讨论,我们假设在电路级使用一个简单的 VLSI 单元,如下图所示。

transistor schematic of simple AND gate
上图显示了一个简单与门的晶体管原理图。这个电路的连接性被转化为适合输入深度学习网络的数字矩阵的形式。该矩阵的第一列显示了分别表示为任意整数 20 和 10 的 PMOS 和 NMOS 晶体管。矩阵中其余 3 列是 MOS 器件的漏极、栅极和源极节点,编号如下图所示。

每个器件有三个电节点。受 M. Ohlrich 的工作[1]的启发,我们分别为特殊节点地和电源保留节点号 1 和 2。其余的节点可以在不改变电网络的情况下任意标记。
让我们假设 n 是节点的数量, d 是电气网络中设备的数量。电网络可以标记的排列数由下面的等式给出:
(n-2)!
其中感叹号代表一个数的阶乘。上面的表达式减去了 2,因为 2 个特殊的节点地/电源是不可置换的。现在,节点已被标记,它们与符合 SPICE 格式[2]的表 1 所示的器件放在一起。排列设备可以在矩阵中排序,矩阵由下式给出:
维!
给定任何器件(矩阵行)的漏极和源极端子可以在不改变电气网络的情况下互换,该操作的组合总数给定为:
σd!/我!。(d-i)!
从 1 到 n-2。一个电网络的排列总数可以表示为矩阵,它是上述三个表达式的简单乘积。这在下面给出。
d!。(n-2)!。(σd!/我!。(d-i)!)
让我们为上面的例子计算矩阵排列的数量。在 n=7 和 d=6 的情况下,矩阵排列的总数刚好低于140 亿。
走向无限… ∞
对于具有(d=) 351 个设备和(n=) 44 个节点的数据集中的较大尺寸的单元之一,矩阵置换超过 1e900。
这个数字是 1 后面跟着 900 个零。
如果这还不足以惊叹设计自动化中模式检测数据集的巨大规模,我会让你计算出在最快的 GPU 上训练一个具有 50 层的深度神经网络需要多少年,就像 nVidia 的 Titan X Pascal 每秒仅 11 万亿次浮点运算(1e13)。
提示:远远超过宇宙的年龄(即 4.35e17 秒)
超越👊
该计算时间是针对具有 351 个晶体管的非常小的单元的。我将给你们留下一个真实的例子,nvidia 的 Volta 芯片有超过 210 亿个晶体管。这么说吧,为这种模式训练一个神经网络所需的时间超出了…嗯,超出了我的想象。

Totem spinning forever (credit: Movie Inception)
参考
- 米(meter 的缩写))Ohlrich,C. Ebeling,E. Ginting 和 L. Sather,“使用快速子图同构算法识别子电路”,Proc .1993 年设计自动化会议,第 31-37 页,1993 年 6 月。
- 长度以集成电路为重点的模拟程序。第十六届中西部电路理论研讨会,加拿大滑铁卢,1973 年 4 月 12 日。
- 设计自动化中的机器智能
数据和设计如何帮助防止托管安置。

Prototype of the Extra Team member application and game board at Dutch Design Week 2018
把孩子从家里带走是一件令人痛苦的事情。青年福利部门的社会工作者尽一切可能防止这种情况发生。然而,在 2017 年,每 10,000 名儿童中,就有 121 名儿童被带离家庭。2017 年,阿姆斯特丹市政府(青年部)和 Garage2017 使用数据分析来深入了解影响监管安置的因素。
在荷兰市政协会(VNG)和荷兰设计基金会的“如果实验室:智能社会遇见设计”中,数字设计机构 Greenberry 与garages 2020一起着手在青年社会工作者中寻找这些数据的应用。我们希望通过假设实验室回答的关键问题是:我们如何成功地利用青少年福利部门的数据,以最大限度地降低监管安置的可能性?原型可以在荷兰埃因霍温举行的 2018 年荷兰设计周上看到
阿姆斯特丹市政府进行的数据分析确定了某些可识别的模式。它还表明,在向社会工作者提供的信息方面还有改进的余地。然而,仅仅听到“数据”这个词就会让许多社会工作者吃惊。说到底,数据不就是冷冰冰的、硬邦邦的、匿名的信息,与社工的同理心和直觉工作关系不大吗?

Mapping insights from the interviews
不是放在地球上坐在电脑前
我们设计流程的第一步是对一线专业人员进行一系列全面的采访。我们总共采访了八名社会工作者。在采访中,我们决定不要过多谈论数据。相反,我们把讨论集中在参与者的工作,他们的挫折,他们的动机。这些都是很棒的谈话,在谈话中,我们获得了对社会工作者工作的更多尊重。但我们也越来越深入地了解到青年福利部门面临的挑战:从极高的工作量到专业人士不愿采取行动。
“帮助社工复查一下很好:我是不是把事情看清楚了?”—社会工作者玛丽莎
采访向我们表明,青年福利是一个直观的职业。在经验和感觉的基础上,与家庭、儿童和其他专业人员协商(在个案讨论期间),就下一种干预形式作出决定。数据目前在这方面不起作用。我们了解到,社会工作者来到这个世界上不是为了坐在电脑前,他们主要是想把时间花在他们的客户身上。我们还发现,社会工作者需要确认他们的决定。我看清形势了吗?对我的当事人来说这是正确的干预途径吗?

Co-design session with experts & designers
我们如何……
在与来自 Garage2020、阿姆斯特丹市政当局和 Greenberry 的设计师、护理专业人员和团队负责人的设计会议上,我们开始在合作设计过程中开发原型。我们把采访作为我们的出发点:我们如何创造一个工具,方便专业人士在不同的干预途径之间作出决定?我们如何让社会工作者洞察可比的情况?我们如何向他们展示干预过程中所有可能的选项(包括不太为人所知的选项)?我们如何帮助他们更快更有效地分析一个案例?
“我来到这个世界上不是为了坐在电脑前。”—朱迪思,社会工作者
经过几次合作设计会议,我们开发了两个概念。我们使用故事板研究每个概念的细节,并再次与社会工作者交谈。我们在格林伯里实验室展示了故事板,并让社会工作者在实践中测试这些概念。他们被要求深入探索原型,对其进行改进和补充。在原型测试结束时,我们达成了一个可行的概念:为青年社会工作者增加一名“额外的团队成员”。
玩玩具
在与社会工作者的访谈中,我们发现社会工作者从来不会在没有与其他专业人士和同事进行深入讨论的情况下就某个客户做出决定。为了进一步支持这一过程,我们提出了“额外团队成员”的概念。想象一下,有一个团队成员拥有阿姆斯特丹(以及后来整个荷兰)所有青少年福利案例的信息。最重要的是,在与团队或客户讨论时,你可以咨询谁。
然而,我们不想生产一种社会工作者被迫坐在电脑前使用的数据工具。我们的偏好是创造一个实体产品,通过它可以很容易地检索数据,而不需要在屏幕上点击太多。所以,我们玩玩具。当我们这样做时,我们寻找合适的格式。

Early storyboard of the concept
额外的团队成员
额外的团队成员包括一个游戏板、木块和一个软件应用程序。每个干预路径都由一个特定的木块代表,这些木块由社会工作者按时间顺序放置在游戏板上。这创建了到目前为止部署的所有干预路径的可视化时间线。
“如果这个概念行得通,结果可能会改变游戏规则。”社会工作者萨宾
额外团队成员应用程序“了解”所有可能的情况,并通过数据分析支持社会工作者为其客户选择下一个干预途径。通过在应用程序中拍摄游戏板的照片(木块通过图像识别被识别为代码),社会工作者可以立即看到下一个合乎逻辑的干预可能是什么。此外,extra team member 应用程序提供了与不同干预途径相关的故事和背景信息。还显示了不同选项的等待时间、可用性和位置。更重要的是,通过数字化游戏板,我们积累了关于不同干预途径的新的匿名数据。

The Extra Team member prototype
在实践中
在 2018 年荷兰设计周期间,Greenberry、Garage2020 和阿姆斯特丹市政府将展示原型:一名额外的团队成员。与社会工作者一起为他们设计。原型可以在 4 号展厅 Klokgebouw 的 VNG 现实主义展台上看到。下一步是将原型转化为我们可以在实践中测试的功能应用程序。想法?感兴趣吗?小贴士?我们希望通过extra teamlid @ garages 2020 . nl收到您的来信
产品演示:https://vimeo.com/295986844
本文由green berry的创意总监 Alain Dujardin 撰写。
译本:丽贝卡·海鲁尔, D2E 译本 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}