







了解陨石
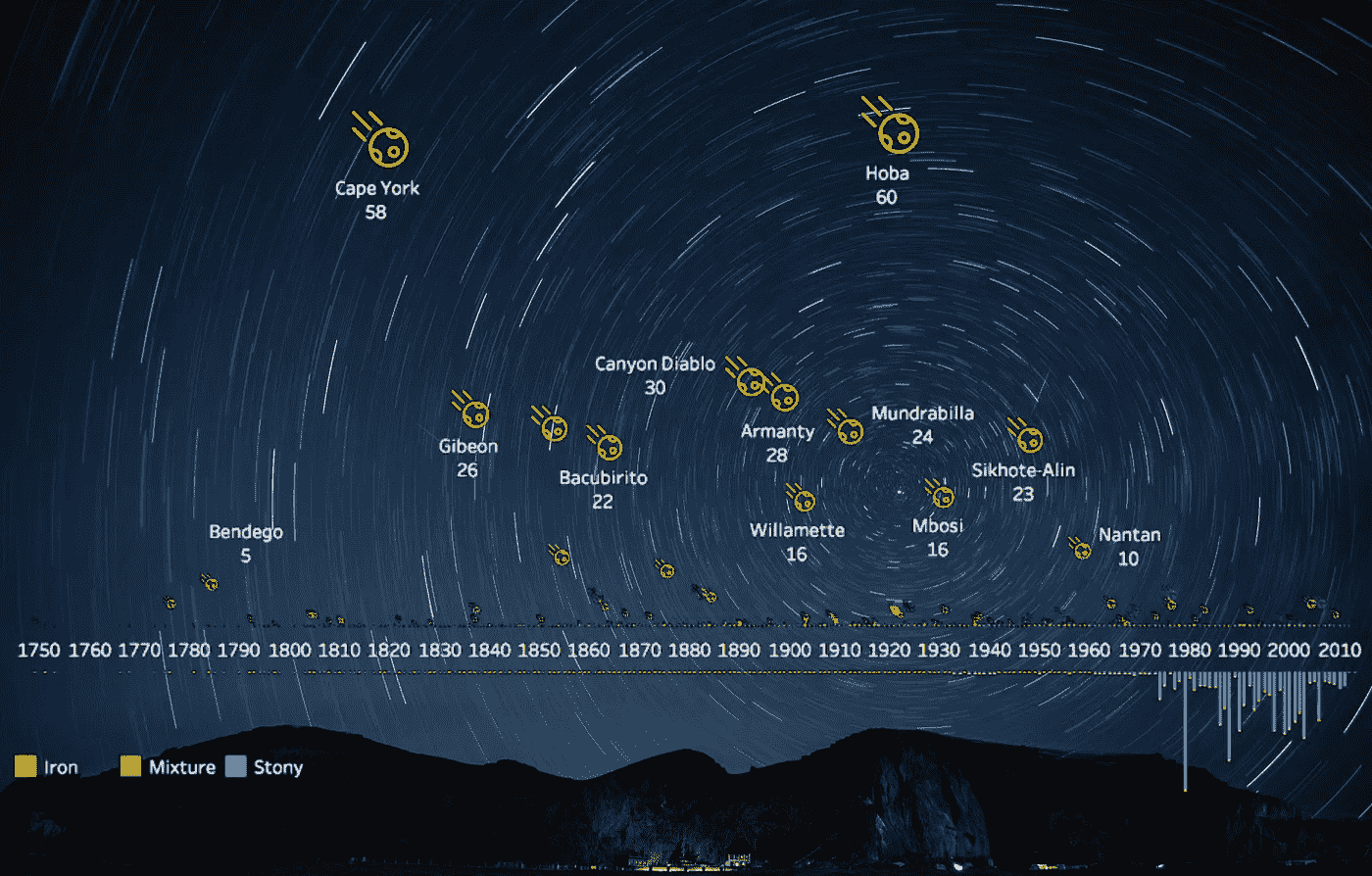
陨石是从天空坠落并降落在地球上幸存下来的流星。今天我查看了 NASA 数据库中由陨石学会收集的陨石数据。在这次探索中,我想揭示的是陨石的分类和质量,以及着陆的地理位置。
在根据分类将 386 块陨石分成 3 个桶(铁、石头或混合物)的一些预处理后,我在时间轴上画出了陨石的大小和数量,按照其质量垂直展开,并标注了名称和质量(以吨为单位)。我们可以观察到:
- 到达地球的最大陨石主要是铁
- 1920 年着陆的 60 吨重的“霍巴”是迄今为止世界上最大的火箭
- 大多数是石质的,但相对较小。直觉上,这是有道理的,因为它们在进入地球大气层时更有可能因其材料而解体
- 从 20 世纪 80 年代开始,收集了大量的陨石数据
为了放大较小的陨石,我们可以转换 y 轴来显示质量的对数标度,这揭示了近几十年来记录的从几克到几千克的更多石质陨石的数据点。这是画在纯黑色的背景上,以获得更好的可视性。
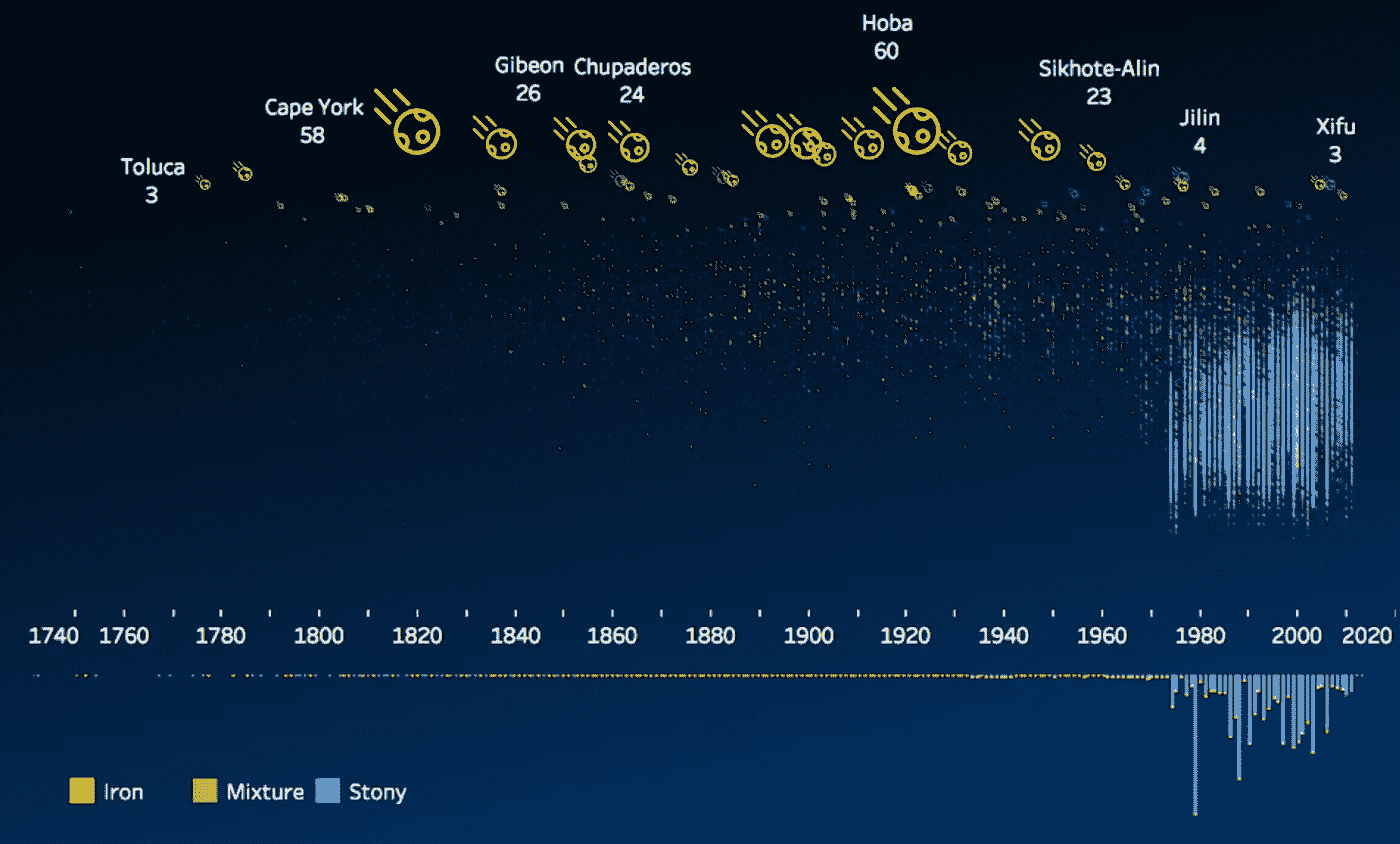
接下来,我开始绘制登陆地图。当有太多点重叠时,热图比散点图提供了更好的视图。
Meteorite landings
我们可以在南极看到陨石回收活动。如果按陨石类型划分,似乎铁陨石不太经常从南极洲收集,这可能与铁陨石沉入冰下更深有关,而在白色大陆上更容易找到小石头陨石。BBC 文章对此有更多报道。
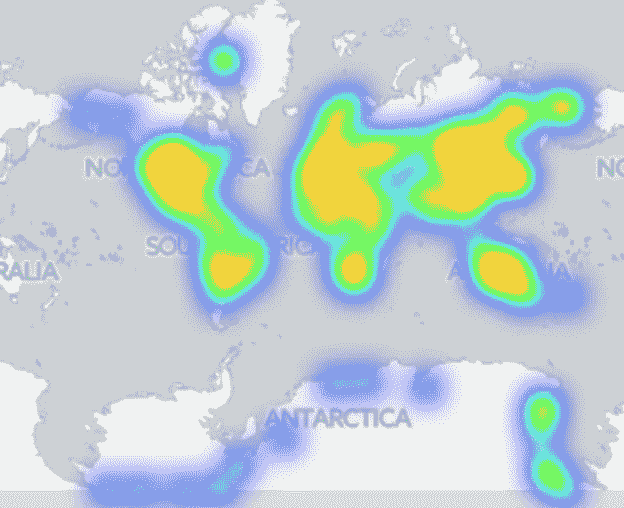
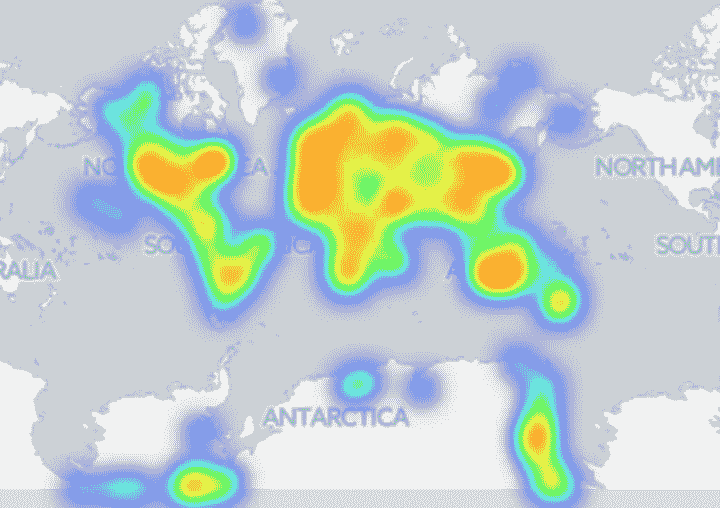
(Left) Iron meteorite landings; (Right) Stony meteorite landings
这是我关于数据科学和视觉故事的# 100 天项目的第 18 天。代码在 github 上。由于休假,我已经离开一个星期了🌠。
感谢您的阅读,欢迎您提出想法和建议。
为您的自然语言处理之旅准备好文本数据

Photo by Patrick Tomasso on Unsplash
在我们生活的各个方面,我们都被语言所包围。语言是我们存在的基础,是让我们成为我们自己的东西。语言使我们能够以如此简单的方式做事情,否则这是不可能的,比如交流思想,像指环王一样讲述巨大的故事,甚至深入了解我们的内心。
由于语言是我们生活和社会不可或缺的一部分,我们自然会被大量的文本所包围。我们可以从书籍、新闻文章、维基百科文章、推文以及许多其他形式的资源中获取文本。
这些大量的文本可能是我们所能处理的最大数量的数据。从书面文字中可以获得许多真知灼见,由此提取的信息可以产生非常有用的结果,可用于各种应用。但是,所有这些数据都有一个小缺陷,即文本是我们可用的最无结构的数据形式。这是纯粹的语言,没有任何数学含义。可悲的是,我们所有的机器学习和深度学习算法都是针对数字而不是文本的。
那么,我们该怎么办?
简单!我们需要清理这些文本,并将其转换为数学数据(向量),我们可以将这些数据提供给我们饥饿的算法,这样它们就可以为我们提供一些很好的见解。这被称为文本预处理。
文本预处理可以大致分为两个主要步骤:
- 文字清理
- 文本到矢量的转换
让我们深入了解他们的细节…
文字清理
为了避免占用我们的内存(自然语言处理是一个耗时耗内存的过程),在我们将文本转换成向量之前,文本必须尽可能的干净。以下是清理数据时可以遵循的几个步骤:
**移除 HTML 标签:**大多数可用的文本数据都是 web 废弃的,因此几乎总是包含 HTML 标签(例如:< br/ >、< p >、< h1 >等)。如果我们把它们转换成向量,它们只会占用内存空间,增加处理时间,而不会提供任何关于文本的有价值的信息。
**去掉标点:**标点没有用。与 HTML 标签相同。这些也需要清洗,原因和上面提到的一样。
**去除停用词:**像‘this’,‘there’,‘that’,‘is’等词。不能提供非常有用的信息,而且会在我们的记忆中制造一些无用的混乱。这种词被称为停用词。可以使用删除此类单词,但建议在这样做时要小心,因为像“not”这样的单词也被视为停用词(这对于情感分析等任务可能是危险的)。
**词干:**像‘有味道的’、‘有品味地’等词都是‘有味道的’这个词的变体。因此,如果我们的文本数据中有所有这些单词,当所有这些暗示(或多或少)相同的事情时,我们将最终为每个单词创建向量。为了避免这种情况,我们可以提取所有这些单词的词根,并为词根创建一个向量。提取出词根词的过程称为词干化。“雪球斯特梅尔”是最先进的词干分析器之一。
该代码片段给出了以下输出:
令人惊讶的是,tasty 的词根竟然是 tasti。
**将所有内容转换为小写:**在我们的数据中同时包含“饼干”和“饼干”是没有意义的,最好将所有内容转换为小写。此外,我们需要确保没有文字是字母数字。
实现上述所有过程的最终代码如下所示:
文本到矢量的转换
一旦我们完成了对数据的清理,就应该将清理后的文本转换为我们的机器学习/深度学习算法可以理解的向量。
有相当多的技术可供我们使用来实现这种转换。其中最简单的就是袋字。
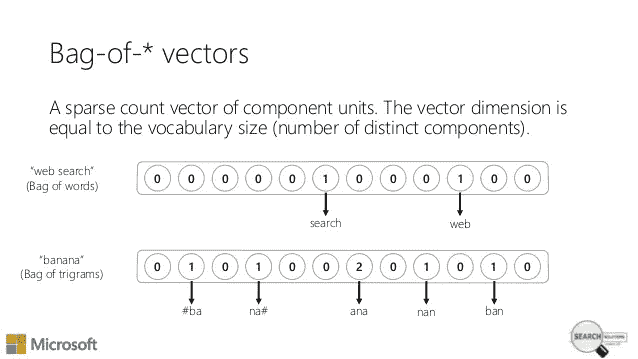
文字袋—简短介绍
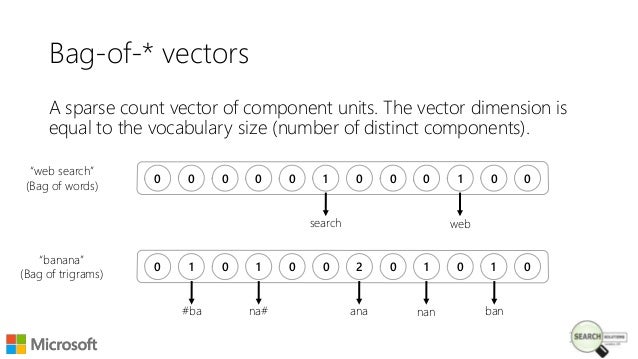
单词包基本上创建了一个*‘d’单词的字典(这不是 python 字典),其中‘d’是我们的文本语料库中唯一单词的数量。然后,它为每个文档创建‘d’*维向量(将其视为长度为‘d’的数组),每个维(单元格)的值等于相应单词在文档中出现的次数。
类似这样的-

在上面的例子中,字典有八个单词(are,cat,dog,is,on,table,the)。问题中的句子(查询)有六个单词(The,dog,is,on,the,table)。显然,每个单元格都具有相应单词在查询中出现的次数的计数值。
在非常高维的向量中,零的数量将大大超过非零值的数量,因为每个向量将具有针对数据语料库中所有唯一单词的维度。这样的向量维数可以是几千、几万甚至更多,但是单个文档不会有这么多独特的单词。这种类型的向量(其中大多数元素为零)被称为稀疏向量。
它们看起来像这样-
当这些稀疏向量相互叠加时,我们得到一个稀疏矩阵。
类似这样的-

在这个图中,可以清楚地看到大多数值是零。该稀疏矩阵将我们的整个文本语料库表示为 n*d 矩阵,其中‘n’表示文本语料库中的文档数量,而‘d’表示其中唯一单词的数量(各个向量的维数)。
下面是获取单词包的代码片段:
获得的输出是:
因此,对于我们的每个文档(总共 525814 个—‘n’),我们得到一个 70780(‘d’)维向量!这是巨大的!
我希望这个数字能说明为什么我们需要在将数据转换成向量之前清理数据,因为如果我们不清理数据,数据的维数会比我们现有的维数大得多。
文本已经被转换成向量,我们现在已经准备好建立我们的 ML/DL 模型了!
更多关于单词袋方法的信息可以在这里找到。
其他更复杂的文本到矢量转换技术包括:
这个项目的完整 Jupyter 笔记本可以在这里找到。
这里完成的预处理步骤是在 Kaggle 上可用的亚马逊美食评论数据集上执行的。执行所有步骤所依据的*“文本”*功能是指不同食品的审查(被视为文件)。
暂时就这样吧!感谢人们读到这里!

马拉松入门 v0.5.0a

Marathon Environments for Unity ML-Agents
我花了两年时间学习强化学习。我创造了马拉松环境,以帮助探索机器人和运动研究在活跃的布娃娃和虚拟代理领域的视频游戏中的适用性。
Introduction to Marathon Environments. From Hopper to Backflips
关于本教程
本教程提供了马拉松环境的入门知识。在此,您将了解到:
- 如何设置你的开发环境 (Unity,MarthonEnvs+ML-Agents+TensorflowSharp)
- 如何让每个代理使用他们预先训练好的模型。
- 如何重新培训料斗代理并遵循 Tensorboard 中的培训。
- 如何修改漏斗奖励功能训练它跳。
关于马拉松环境
Marathon Environments 使用 ML-Agents 工具包重新实现了深度强化学习文献中常见的经典连续控制基准集,即 Unity environments。
Marathon Environments 与 Unity ML- Agents v0.5 一起发布,包括四个连续控制环境。基于 DeepMind 控制套件和 OpenAI Gym 中可用环境的沃克、霍普、人形和蚂蚁。
所有的环境都有一个单一的 ML-Agent 大脑,有连续的观察和连续的行动。没有视觉观察。每个动作都与一个电动关节轴相关。使用嵌套关节策略实现多轴关节。每个环境包含 16 个同时训练的代理。
马拉松环境主页是 https://github.com/Unity-Technologies/marathon-envs——如果您有任何问题或疑问,请提出 Github 问题。
设置您的开发库
安装 Unity 2017.4 或更高版本
从 Unity 商店下载 Unity
设置存储库
转到 GitHub MarathonEnvs 0.5.0a 版本并下载QuickStart_xxx.zip。
快速入门在一个 zip 文件中包含以下内容:
- 马拉松-envs-0.5.0a
- 毫升-药剂-0.5-3.0a
- 张量流图
解压缩到您的开发文件夹。
设置 Python
跟随优秀的 ML-Agents 文档学习如何设置 python 开发环境。
运行预先训练的模型
打开 Unity 和您的项目:
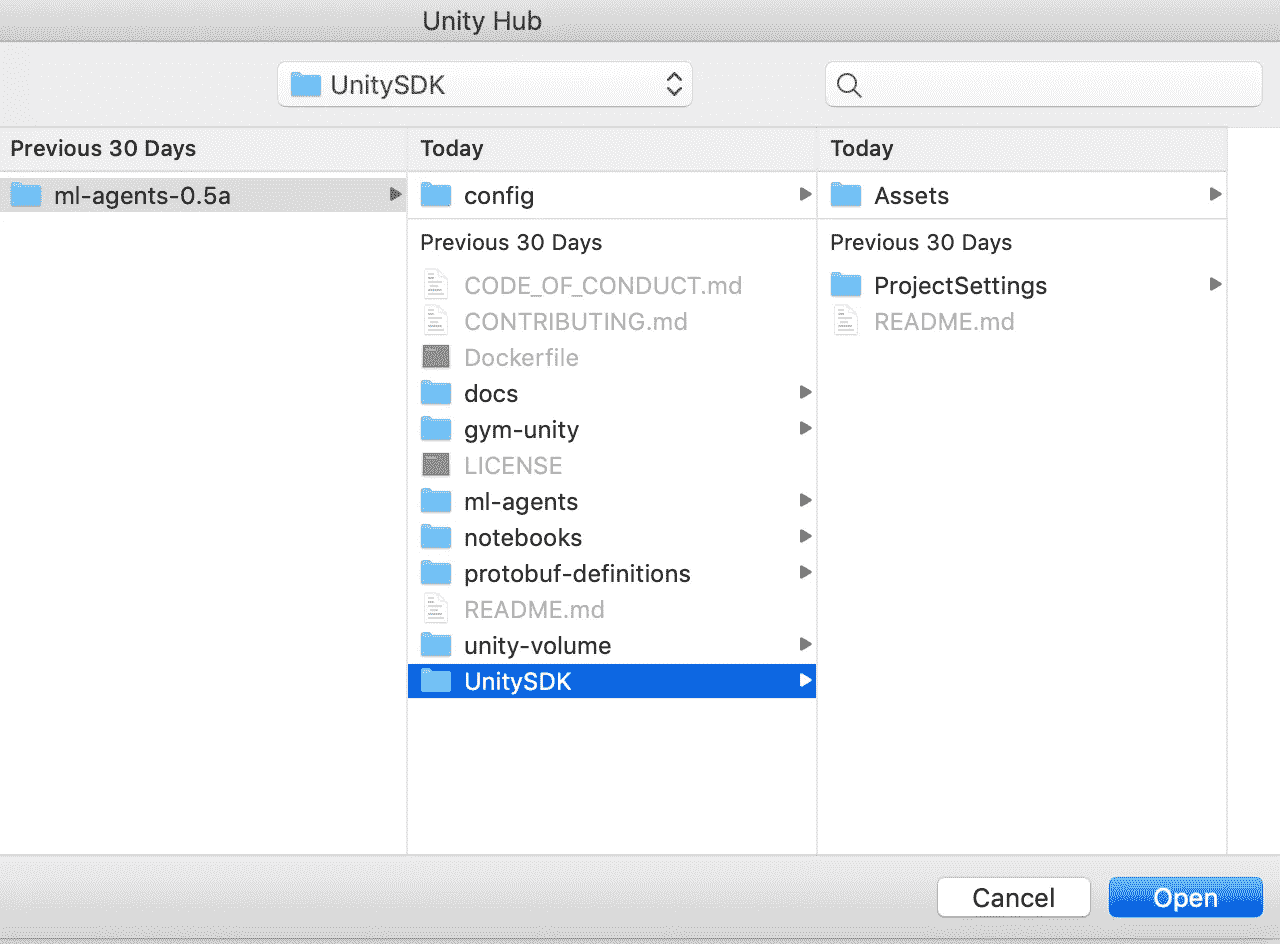
Open Unity and Your Project
打开 DeepMindWalker 场景:
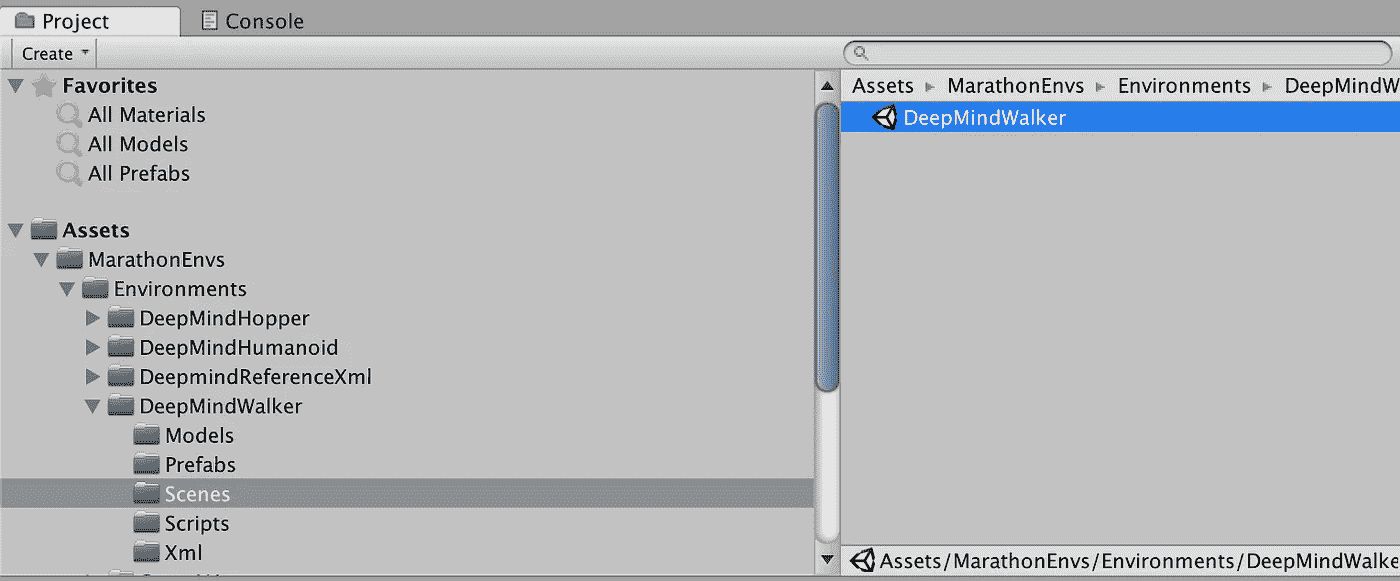
Open UnitySDK\Assets\MarathonEnvs\Environments\DeepMindWalker\Scenes\DeepMindWalker.unity
按下**播放。**这将运行预训练模型DeepMindWalker108-1m.bytes

DeepMind Walker — This model was trained using 16 agents over 1m simulation steps
步行者代理有 6 个关节/动作和 41 个观察值。奖励函数对于骨盆速度和骨盆垂直度具有正的奖励信号。对于当前动作状态的努力有一个负的奖励信号,如果身高低于 1.1 米则有一个惩罚。
人形,漏斗和蚂蚁
重复上述步骤运行其他环境:

DeepMind Humanoid
人形智能体有 21 个关节/动作,88 个观察值。奖励函数对于骨盆速度和直立度有一个正信号,对于当前动作状态的努力有一个负信号,如果身高低于 1.2m 则有一个惩罚。它还根据其腿部的相位周期增加额外的奖励。

DeepMind Hopper
料斗代理有 4 个关节/动作和 31 个观察值。奖励函数对于骨盆速度和骨盆垂直度具有正的奖励信号。同样,对于当前动作状态的努力有一个负的奖励信号,如果身高低于 1.1 米则有一个惩罚信号。

OpenAI Ant
蚂蚁智能体有 8 个关节/动作和 53 个观察值。奖励函数对于骨盆速度具有正的奖励信号,对于当前动作状态的努力具有负的奖励信号,并且如果关节处于它们的极限则具有负的信号。
培训绩效
这里是每个环境之间的训练性能比较,训练 16 个并发代理。
These results are using home PC. All environments where build and trained as executables.
训练料斗
到目前为止,我们已经运行了预训练的模型,然而,真正的乐趣开始于你自己训练和运行实验。首先,我们将重新训练料斗。稍后,我们将修改它的奖励函数来完全改变它的行为。
切换到训练模式
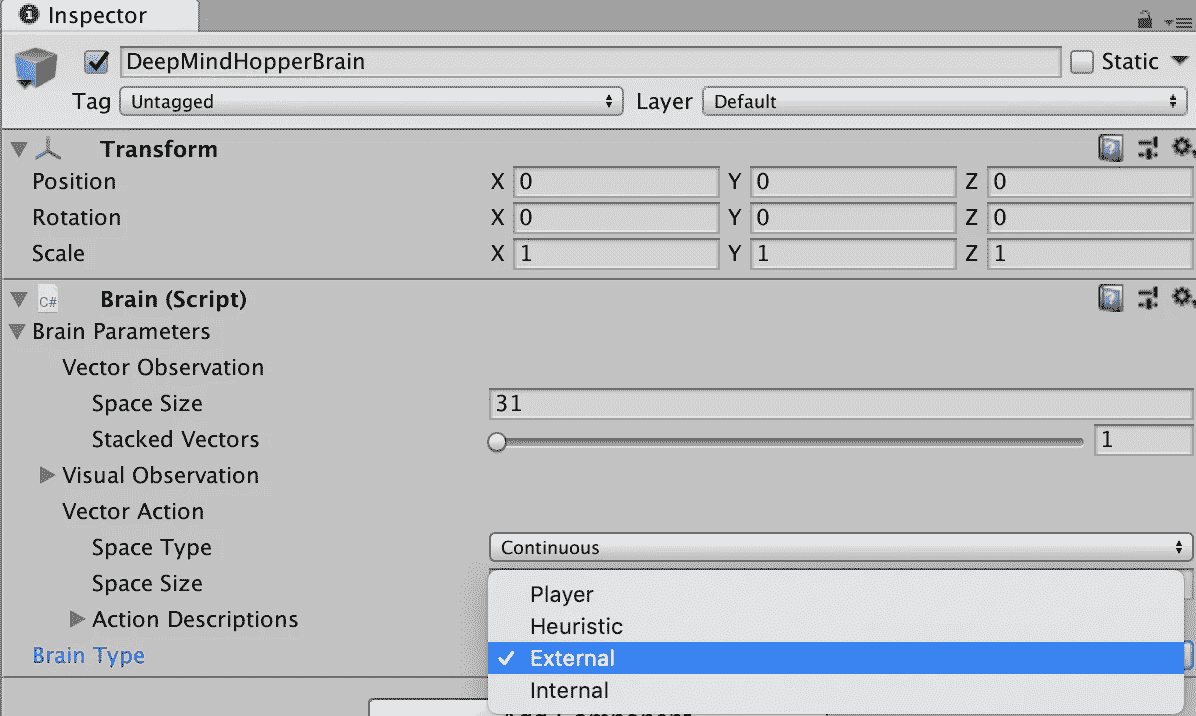
在 Unity 中,选择Academy -> DeepMindHopperBrain。然后,在检查器中,选择Brain Type下的External。顾名思义;代理现在需要外部输入。
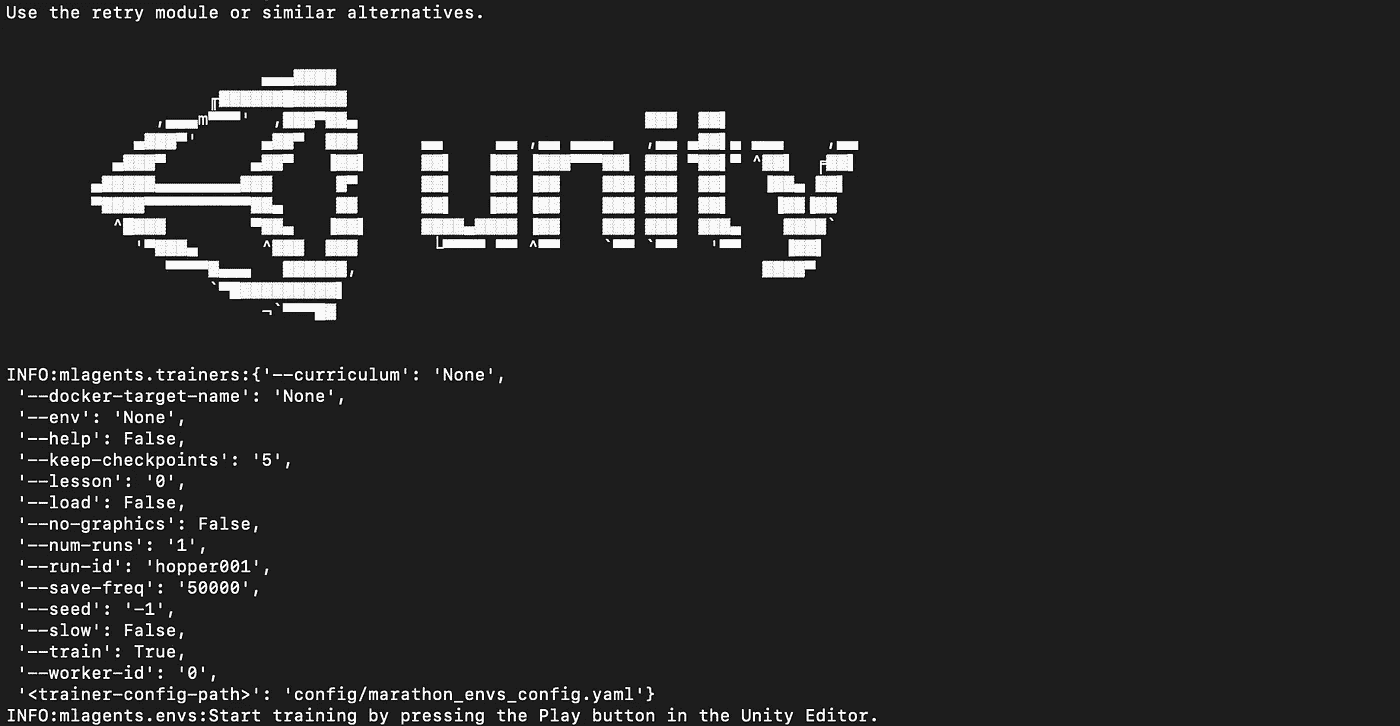
调用培训
打开终端或命令窗口,调用您的 python 环境:source activate ml-agents。转到项目cd /Development/ml-agents-0.5a/的根目录。
训练命令包含以下元素:
mlagents-learn <trainer-config-file> --train --run-id=<run-identifier>
mlagents-learn-ml-代理脚本<trainer-config-file>-路径和文件名。yaml 配置文件。我们将使用config/marathon_envs_config.yaml--train将 ml-agent 设置为训练模式--run-id=<run-identifier>设置本次训练运行的唯一标识符。(在 Tensorboard 中使用的名称和训练模型文件名)
然后调用 ml-agents python 脚本:mlagents-learn config/marathon_envs_config.yaml --train --run-id=hopper001
最后切换回 Unity,按 play 开始训练。
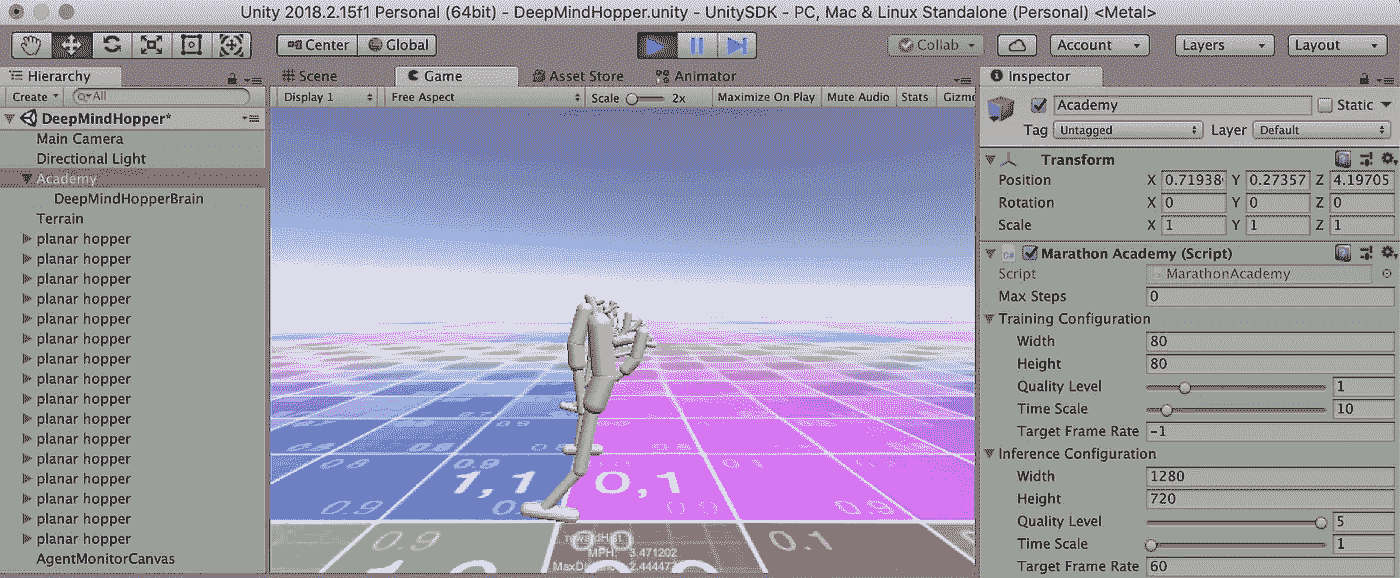
专业提示:使用可执行文件构建和训练将减少训练时间。更多信息见 ML-Agents 培训文件。
使用 Tensorboard 监控训练
打开第二个终端或命令窗口,调用您的 python 环境:source activate ml-agents.转到项目的根目录:cd /Development/ml-agents-0.5a/。使用tensorboard --logdir=summaries调用 Tensorboard。最后打开浏览器,指向 Tensorboard 输出:[http://yourPcName:6006](http://yourPcName:6006)。
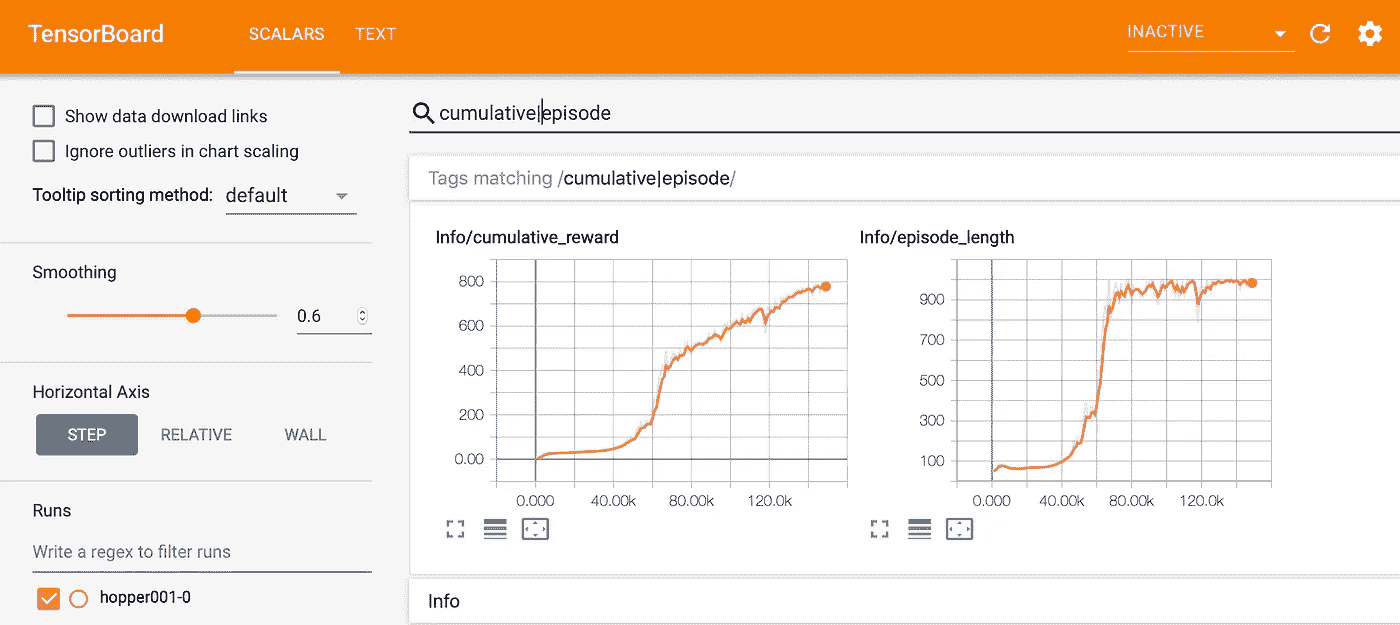
Tensorboard allows you to track training in real time
在 Unity 中运行训练好的模型
为了查看您新训练的模型,我们需要将训练好的模型文件models/hopper001-0/editor_Academy_hopper001-0.bytes复制到模型文件夹.../DeepMindHopper/Models
然后,通过选择Academy -> DeepMindHopperBrain将大脑设置回内部模式,然后在检查器中,选择Brain Type下的Internal。接下来,选择GraphModel下的editor_Academy_hopper001-0。
按“运行”查看您的训练模型:
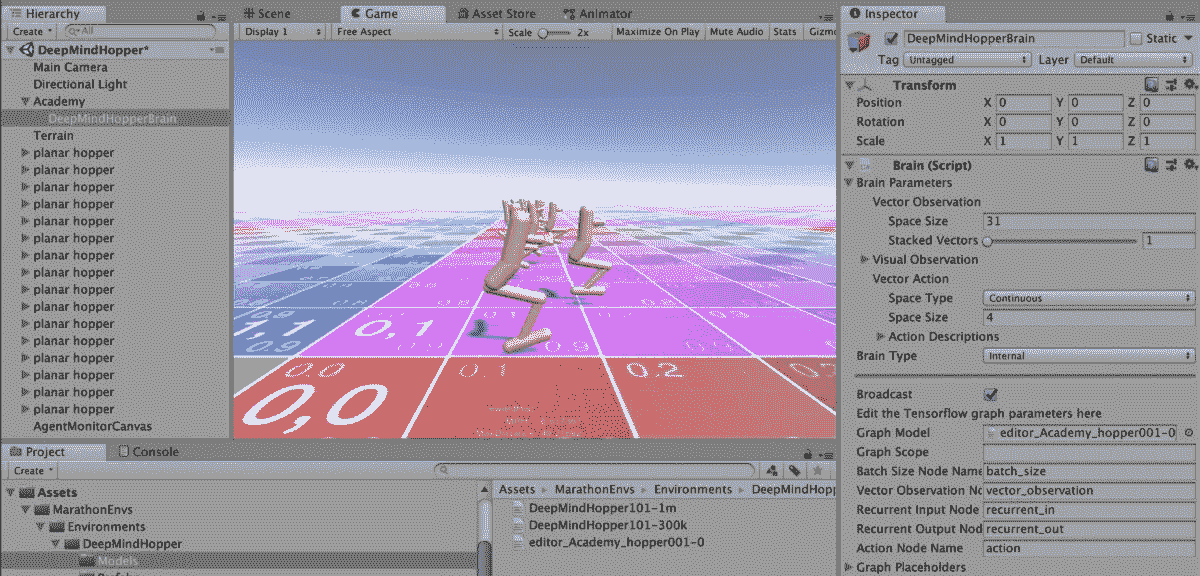
Your newly trained model running in Unity
编辑奖励函数让 hopper 跳起来。
现在你明白了基本原理,让我们来玩一玩吧!
打开DeepMindHopperAgent.cs你喜欢的代码编辑器。默认情况下,Unity 会安装 Visual Studio,但我更喜欢轻量级、响应性更好的 Visual Studio 代码。
找到StepRewardHopper101()函数并添加下面一行:
var jumpReward = SensorIsInTouch[0] == 0 ? BodyParts["foot"].transform.position.y + .5f : 0f;
这在脚不接触地面时产生一个奖励信号,并根据脚的高度而增加。
专业提示:通常我们希望所有的观察和奖励保持在-1 到 1 之间的“正常”范围内。然而,ML-Agents 可以在训练期间正常化观察和奖励值,这允许我们稍微偷懒!
通过用jumpReward替换velocity来更新reward。它应该是这样的:
var reward = jumpReward
+ uprightBonus
- effortPenality
- jointsAtLimitPenality;
确保您的 保存 DeepMindHopperAgent.cs。然后,按照之前的培训步骤,重新培训代理。结果将如下所示:

Hopper is now trained to jump!
更深入
下面是一些关于使用和扩展马拉松环境的更多技术细节。
奖励、终止和观察功能受到 DeepMind 控制套件和 OpenAI.Roboschool 的影响,一个例外是人形机器人,它在奖励中实现了一个阶段功能,以提高训练速度。
每个环境都是一个独立的 Unity 场景,每个代理类型都有一个预置,并且包含一个或多个预先训练的 Tensorflow 模型。从 MarathonAgent.cs 继承的自定义代理类用于定义该代理的行为。对于每个环境,开发人员应该实现以下内容:
AgentReset()用于初始化代理。它应该为 StepRewardFunction、TerminateFunction 和 ObservationsFunction 设置回调。开发人员应该将模型元素添加到 BodyParts 列表中,并调用SetupBodyParts()来初始化 body parts。这使得回调能够利用助手函数;例如,GetForwardBonus("pelvis")根据身体部位与前向向量的距离计算奖金。
StepReward()返回一个float,带有当前动作步骤的奖励。辅助函数包括以下:GetVelocity("pelvis")返回指定身体部位的速度;GetEffort()返回当前动作的总和(可以传递一个要忽略的身体部位列表);并且GetJointsAtLimitPenality()返回对达到其极限的动作的惩罚。
如果满足终止条件,则TerminateFunction()返回true。终止功能通过减少代理暴露于无用的观察来帮助提高训练速度。辅助终止函数包括TerminateNever(),它永远不会终止(总是返回false)和TerminateOnNonFootHitTerrain(),如果不是脚的身体部位与地形发生碰撞,它将返回true。身体部位在功能OnTerrainCollision()中定义。一些代理商要求小腿身体部位贴上"foot"标签,因为它们从足部几何形状中突出来,造成假阳性终止。
包扎
在本教程中,我们学习了如何安装马拉松环境,运行预训练的 Tensorflow 模型,我们重新训练了 hopper,然后我们学习了如何修改奖励函数来奖励 Hopper 的跳跃。
这应该给你一个很好的基础,让你用强化学习来尝试马拉松。
P ro 提示:我强烈建议您阅读 ML-Agents 培训文档以了解有关使用 Unity ML-Agents 的更多详细信息。
你可以在下面的 Github 项目中关注我的一些研究。
- github.com/Sohojoe/ActiveRagdollStyleTransfer——对活动布娃娃运动方式转移的研究(来自动作捕捉数据)
- github.com/Sohojoe/ActiveRagdollAssaultCourse—训练突击课目研究
- github.com/Sohojoe/ActiveRagdollControllers—主动布娃娃控制器的研究
- github.com/Sohojoe/MarathonEnvsBaselines—实验性—开放式健身房/基线
如果您遇到任何问题或 bug,或者有任何疑问,请在该项目的 Github 页面https://github.com/Unity-Technologies/marathon-envs提出问题
雷达上的幽灵——为什么雷达图容易被误读

Mali Akmanalp 刚刚写了一篇有趣的文章,讲述他如何使用雷达图解决一个特殊的数据问题。虽然总体来说,我仍然认为雷达图很有问题——尽管看起来很性感——我想知道这些问题到底是什么。
我的疑虑与混合类别/数字数据无关,也与人脑难以旋转和比较坐标轴无关。相反,我的问题是,雷达图经常让虚假联系变得非常容易绘制,因为它们的形式暗示着某种数据编码在起作用,即使根本没有。
与更简单的图表相比
我可以通过与更简单的非放射状图表的比较来说明这个问题。假设你有一个跨越四个范畴的价值观:
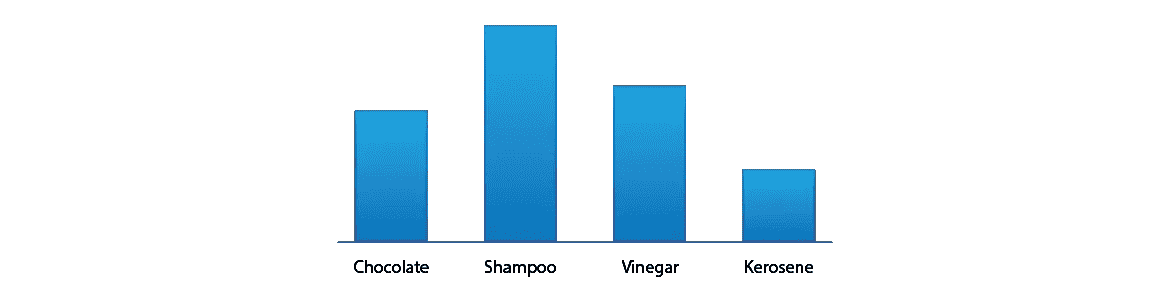
这些简单图表的唯一缺点是,我们必须为条形选择一个任意的顺序,从左到右——观众可能会误认为这个顺序是有意义的。但那不太可能,所以我们照原样接受。
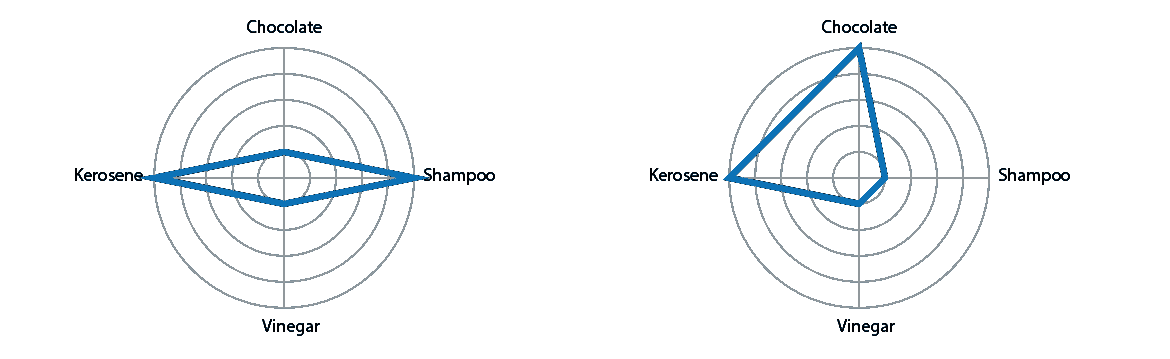
当我们用一条线将这些值连接起来时,情况就大不相同了:
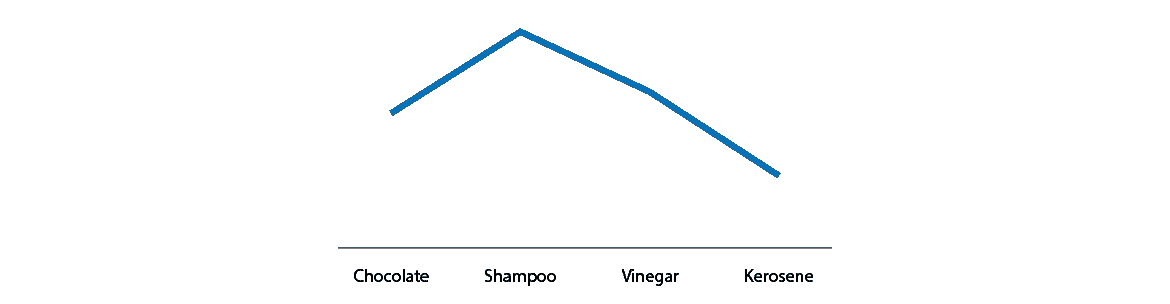
我不认为我们大多数人会认为这是合法的。这条线强烈表明,这里有一个重要的顺序——即一个无形的 x 轴编码了另一个变量,在这个变量上,煤油比巧克力“更多”,洗发水处于中间位置。(我确信我们可以找到一个合理的基础来进行事后排序,但这与我们需要用这些数据讲述的故事没有任何关系。)
这种虚假的秩序暗示正是雷达图所要做的:
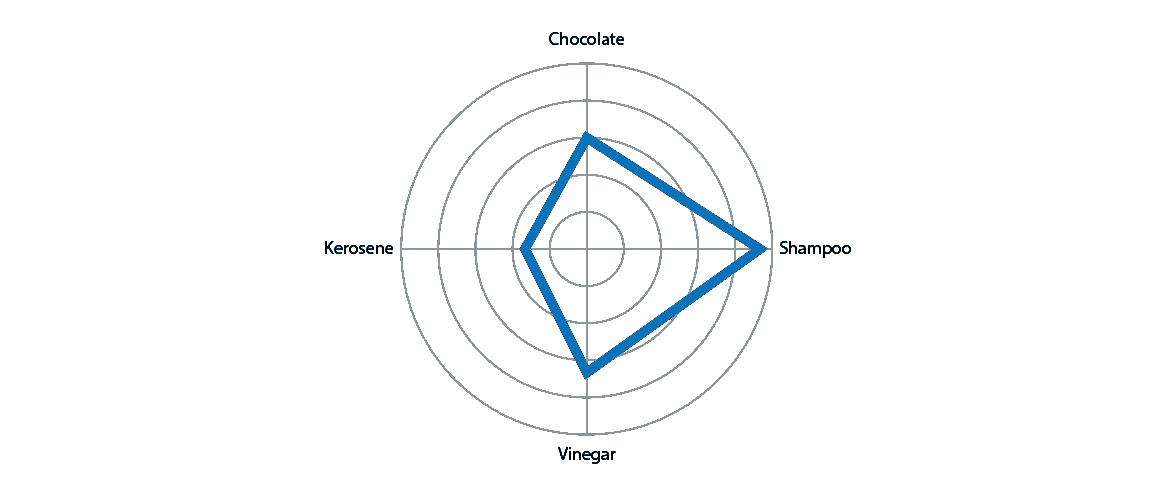
蓝色形状的突出和它在页面上的方向表明一些真实的东西正在被编码,而事实并非如此。这可能导致几种误读。
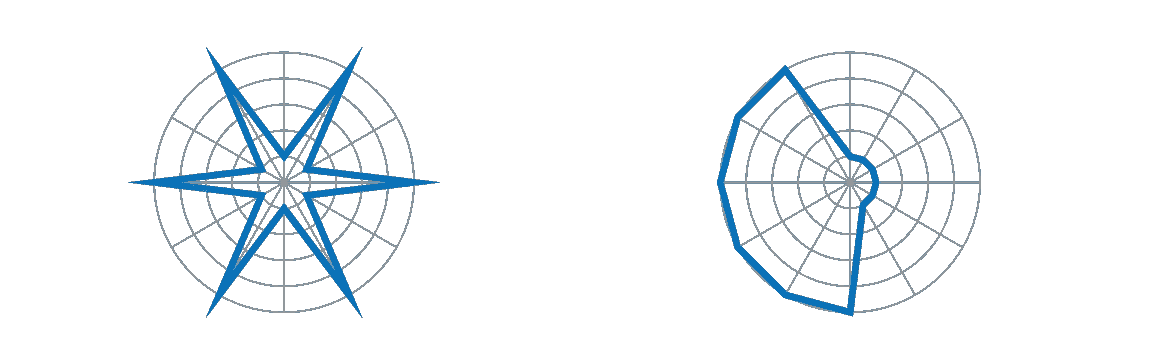
误读一:面积
通过在雷达图中绘制一个形状,我们还创建了一个区域。读者会怀疑它的重要性。但是区域的大小很大程度上取决于我们选择的排序。以下是用不同顺序绘制的完全相同的数据:
右边的数字显得更大,表明总价值更高。误读!
误读二:规律性
类似地,雷达的“尖峰”在视觉上非常突出,但可能完全取决于数据顺序。这里同样是两种排序的相同数据:
左边的图表可能看起来“不稳定”、“不稳定”或“不均衡”而正确的可能看起来只是有某些“优点和缺点”但是心理反应是我们产生的完全独立于真实数据的人工产物!这类似于 Tufte 所反对的在折线图中设置荒谬比例和起点的老把戏,让趋势看起来完全像设计师想要的那样极端。
误读三:方向性
我们不仅必须选择变量的相对顺序,还必须在页面上确定它们的方向(决定哪一个是“上”)。这可能暗示了比保证的更多的相似和对比。
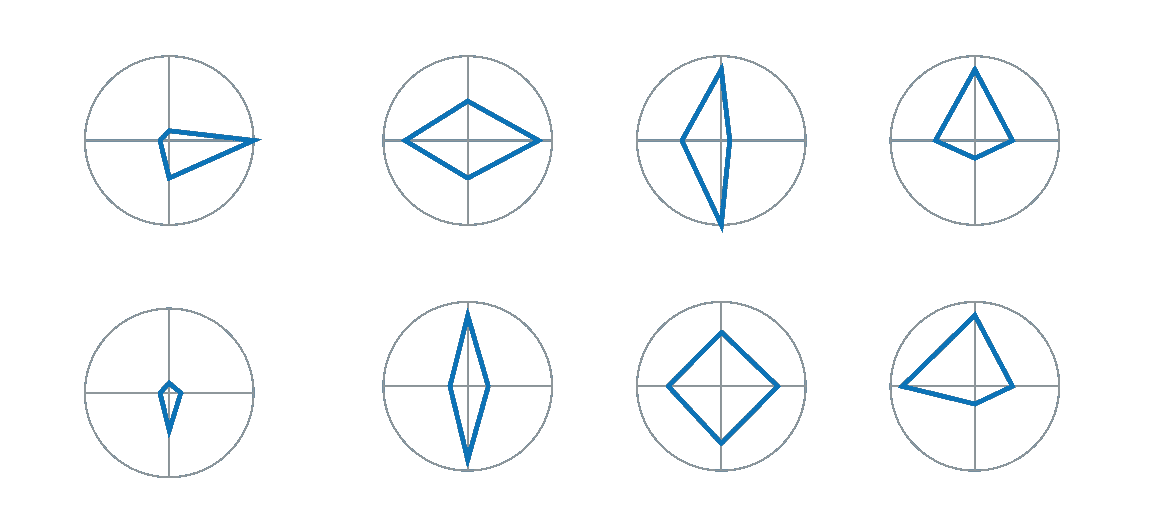
当我们查看雷达图的网格时,有一点很突出,那就是它们具有相似的整体方向:有些上下运行,有些左右运行,有些两者都没有。
这使得“垂直”项似乎在一个类别中,与“水平”项截然不同。但是如果我们把变量重新排序,一个完全不同的分组就会出现。如果我们有一个合理的故事要讲,通过强调一些可变分组而不是其他分组,那么可能是好的。但是如果这只是一个任意的选择,我们又一次误导了读者。
合法使用
就像饱受诟病的饼图一样,雷达图肯定有其用途:这就是我们讨论的额外编码——面积、规律性、方向——实际上是我们想要使用的编码。在我的书里有两个条件:
- 可变类别可以是强有序的(至少以一种方式)。
- 排序是循环:最后一项与第一项相关。
第二项是雷达图比折线图更有意义的关键:那么,它的圆形就是一个优势。例子包括:
- 真实空间中的方向性:平均风速
- 色调(色轮)频率
- 周期时间:每月销售额

我仍然不一般主张雷达图,即使你满足这些条件。是否使用雷达图将取决于你需要展示什么,展示给谁,以及你有什么样的数据。寻找大幅下跌或上涨似乎是合理的。但是,如果您需要读取特定的值,折线图可能会更好。我还对展示一大块雷达图,并要求读者在它们很小的时候发现形状的差异感到犹豫:形状的确切含义通常不明显。但是如果数据是正确的,雷达可以工作。
对我来说,最重要的是:当你有无序变量要显示时,关掉你的雷达,去寻找其他工具。
Jasper McChesney 是一名高级数据分析师,拥有自然科学和数据可视化方面的背景。他曾在非营利组织、人力资源和高等教育部门工作过。目前在麻省大学教授 R 课程,Udemy 上 。
Mac 用户的 Git 设置
Mac 用户,让我们以正确的方式设置 Git!

动机(个人,即):
几个月前,我偶然发现了 Medium——最初,我发现它的内容范围很广,材料也很注重质量——在博客和整体界面上已经有了显著的改进。有了这些,当我为实验室配置一台新的 iMac 时(例如,微笑实验室——稍后会详细介绍),我想我应该记录下安装和配置 Git 的过程。我打算把这作为我的第一篇博客;尽管如此,我认为这个简单的教程是一个“打破僵局”的好方法。我希望你喜欢它!
现在让我们转到一些不错的老式 Mac Git——我们将正确设置您的 Mac 机器。
目录
Git 安装
首先是安装。这很简单。有几种不同的方法可以做到这一点。为了安装 brew 包管理器,我推荐使用家酿。
通过自制 Git
打开终端,通过运行以下命令安装 Homebrew :
/usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)"
然后安装 git
brew install git
—或者—
Git for Mac 安装程序
在 Mac 上安装 Git 最简单的方法是通过独立的安装程序:
- 下载最新的 Git for Mac 安装程序。
- 按照提示安装 Git。
初始设置
- 打开终端,通过在终端中键入并运行以下命令来验证安装是否成功
git --version
2.使用以下命令配置您的 Git 用户名和电子邮件,用您自己的名字替换艾娃的名字。与您创建的任何提交相关联的这些详细信息:
git config --global user.name "Ava Paris"
git config --global user.email "aparis@domain.com"
3.(可选)为了在使用 HTTPS 存储库时记住您的 Git 用户名和密码,配置 git-credential-osxkeychain 助手。
终端中的 Git 样式
有许多风格可供展示。无论如何,让我们保持简单和整洁——设置 Git 配色方案和显示在终端中的分支信息。
颜色:
除非您是从单色显示器上阅读这篇文章,否则让我们利用 git 的一些彩色特性。最明确的是,Git 的特定组件最好用彩色显示,这样更容易识别不同的组件,因此阅读起来也更舒服。
从终端运行以下命令集(即,从任何文件夹):
git config --global color.status auto
git config --global color.branch auto
git config --global color.interactive auto
git config --global color.diff auto
Mac 终端可以配置为使用颜色来改善显示效果。为此,将以下内容复制并粘贴到文件~/.gitconfig中。
[color]
branch = auto
diff = auto
status = auto
[color "branch"]
current = yellow reverse
local = yellow
remote = green
[color "diff"]
meta = yellow bold
frag = magenta bold
old = red bold
new = green bold
[color "status"]
added = yellow
changed = green
untracked = cyan
回购及分行挂牌:
在我看来,Git 最好的定制之一是在终端中显示分支信息。
为此,只需将以下几行文本添加到~/.bash_profile文件中:
parse_git_branch() {git branch 2> /dev/null | sed -e '/^[^*]/d' -e 's/* \(.*\)/ (\1)/'}export PS1="$NO_COLOUR[\t] $BLUE\u$SSH_FLAG:$YELLOW\w$NO_COLOUR: \n$GREEN\$(parse_git_branch) $BLUE\\$ $NO_COLOUR"
现在,在当前的回购中,提示符看起来如下:
**[**jrobinso@blackhawk matlab **(**master**)]**$
Git 自动完成
通过 tab 键键自动完成可能是一个方便的特性。但是,MacOS 上不会自动设置自动完成功能。幸运的是,设置这个只需要几个简单的步骤。
首先,安装所需的 brew 软件包,如下所示:
brew install bash-completion
接下来,将下面的代码片段添加到~/.bash_profile文件中。
source /usr/local/etc/bash_completion.d/git-completion.bash
要么打开一个新的终端或运行source ~/.bash_profile和享受!
Git 忽略
某些文件或文件类型通常不会添加到 repo 中。因此,如果省略这些文件,“状态”显示打印输出会更清晰。为此需要做的就是创建~/.gitignore并添加。首先,让我们创建一个包含以下内容的文件:
.DS_Store
注意,~/.gitexcludes也适用于每个项目,在这种情况下,文件存在于 repo 的根目录中。尽管如此,按照上面的说明,应该全局忽略.DS_Store。
Git 别名
别名,特别是对于 Git,通常是值得的!如果没有其他的,至少将这个特性添加到您的全局 Git 配置中。请注意,我将配置称为“全局的”——~/.gitconfig是应用于系统范围的配置,而特定于项目的配置在位于存储库根的.gitconfig中处理(即<repo>/.gitconfig)。
对于别名,通常添加到全局配置中最有意义。如果以后需要,则为特定项目添加唯一的别名。也许值得注意的是,alias 或所有 Git 配置都是首先使用本地配置来设置的,如果没有在本地指定,则是全局设置。换句话说,假设您在本地和全局配置中定义了相同的别名,那么本地定义将用于该特定的回购。
不管是局部的还是全局的,但建议使用全局,将下面的*【别名】*块添加到.gitconfig:
**[**alias**]**
st **=** status -uno
ci **=** commit
br **=** branch
co **=** checkout
df **=** diff
lg **=** log -p
lgg **=** log --graph --pretty**=**format:'%Cred%h%Creset -%C(yellow)%d%Creset %s %Cgreen(%cr) %C(bold blue)<%an>%Creset' --abbrev-commit --date**=**relative
f **=** fetch
现在尝试+添加额外的别名,只要看到合适的…就这么简单。
**[**jrobinso@blackhawk matlab **(**feature_branch**)]**$ git co master
Switched to branch 'master'
**[**jrobinso@blackhawk matlab **(**master**)]**$ git st
*# On branch master*
nothing to commit **(**use -u to show untracked files**)**
**[**jrobinso@blackhawk matlab **(**master**)]**$ git f *# <fetch output>*
Git 认证
通常认证需要一个 SSH 密钥。
为此,从终端生成一个密钥:
**[**jrobinso@blackhawk ~**]**$ ssh-keygen
按几次 return 键(即,将密码留空)。
接下来,通过以下方式将 SSH 密钥复制到剪贴板
**[**jrobinso@blackhawk ~**]**$ cat ~/.ssh/id_rsa.pub | pbcopy
最后,将密钥粘贴到存储库主机上的设置页面中。
桌面(GUI)应用程序
考虑到 Git 确实有一点点的学习曲线,即使克服这一点的最好方法是熟悉它的核心(即从终端),也许一些人会更喜欢 GUI。因此,我认为有必要提一下基于 GUI 的 Git 回购工具。为此,两个选项脱颖而出: SourceTree 和 Github 桌面 App 。
Source Tree: View of local projects.
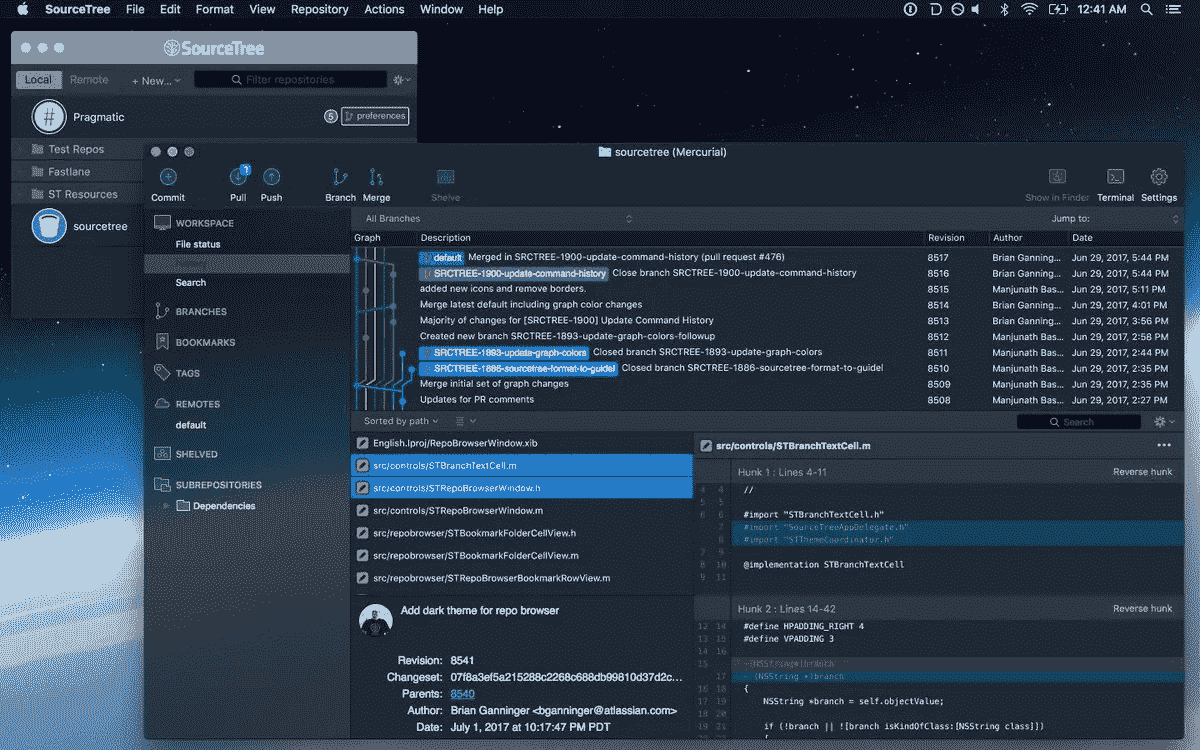
Open session, i.e., git repo
Github Desktop App
SourceTree 的优势在于可以与来自各种主机(例如 Github、Bitbucket 等)的存储库协同工作。),而 Github 桌面 App 是 Github 特有的。
结论
在大多数项目中,正确地建立开发环境是首要的。花几分钟时间完成本教程,Git 版本控制现在已经在您的机器上正确地设置好了,可以增强和优化您的吞吐量。
对于那些刚接触 git 或者不习惯使用终端的人来说,也许桌面应用程序最适合你(例如 SourceTree 或者 GitHub 桌面应用)。这些在 GUI 中提供了许多特性、工具和可视化。无论如何,终端在某些情况下是必须的。另外,如果面对从终端使用 g it 带来的学习曲线,将会获得对 Git 和版本控制的更好理解。
无论如何,无论是专家还是初学者,您的系统现在都应该可以使用 Git 了。我希望你喜欢它!
如果有什么缺失或可以改进的地方,请在下面分享——是否有一个你离不开的 Git 别名,一个简洁的特性,或者一个可以改进或过时的方面。当然,也欢迎大家提问!
感谢你阅读我的第一篇博客——希望你会喜欢,请随时提供关于如何改进未来博客的反馈。
macOS 卡特琳娜 10 . 15 . 3博客 结账版本。
GitHub 假人用底漆
使用 GitHub 托管复杂代码的简单指南
Me vs. GitHub — Source: http://devhumor.com/media/git-push
介绍
GitHub 是全球程序员的重要工具,允许用户托管和共享代码,管理项目,以及与近 3000 万开发人员一起构建软件。GitHub 通过跟踪修订和修改使代码协作变得更加容易,允许任何人对存储库做出贡献。作为一个最近才开始编程的人,GitHub 已经无数次成为真正的救星,帮助我学习新的技能、技术和库。然而,有时 GitHub 上的一个简单任务,如创建一个新的存储库或推动新的变化,比训练一个多层神经网络更令人生畏。所以,我决定创建一个指南来帮助用户(阅读:我自己)充分利用 GitHub 的力量。
创建存储库
GitHub 存储库通常被称为“repo”,是 GitHub 上的一个虚拟位置,用户可以在这里存储项目的代码、数据集和相关文件。点击主页上的new repository按钮,您将进入一个页面,在这里您可以创建一个 repo 并添加项目的名称和简要描述。有一个选项可以将您的存储库设为公共或私有,但是私有特性只对付费用户/公司可用。您还可以使用自述文件初始化存储库,该文件提供了项目的概述和描述。强烈建议将自述文件添加到您的存储库中,因为它通常是某人在查看您的存储库时看到的第一件东西,并且允许您编写有关您的项目的故事,并向查看者显示您认为最重要的内容。一份强有力的自述文件应该清楚地描述项目及其目标,展示项目的结果和成果,并展示其他人如何复制该过程。
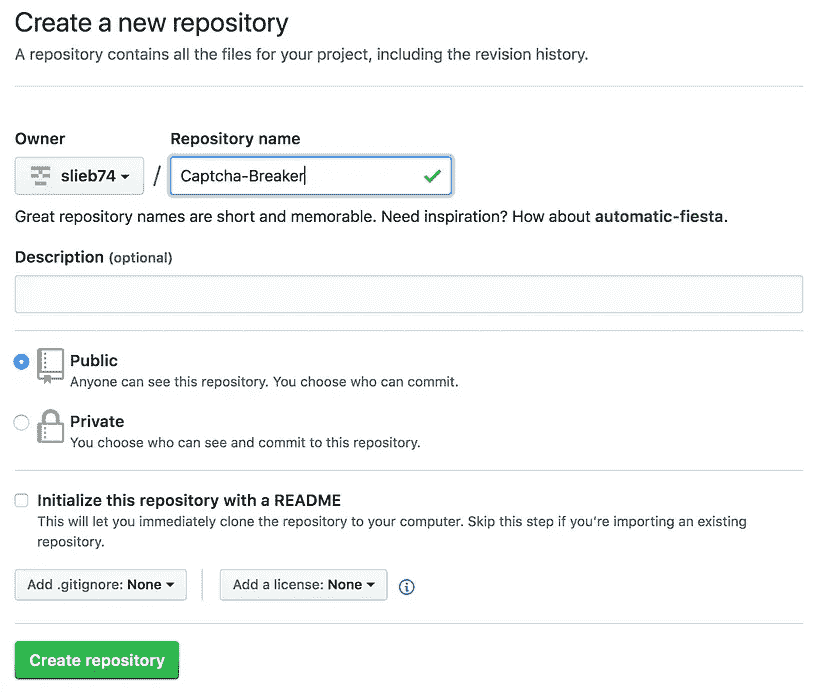

Creating a repository on GitHub
不幸的是,点击create repository只是这个过程的第一步(剧透:它实际上并没有创建你的回购)。下一步涉及到使用您的终端来初始化您的 Git 并推送您的第一次提交。Git 和 GitHub 不是一回事,虽然它们是有联系的。Git 是一个帮助管理源代码历史和编辑的修订控制系统,而 GitHub 是一个托管 Git 库的网站。通俗地说,Git 会在每次提交时为您的项目拍照,并存储一个对该状态的引用。要为您的项目初始化 Git,请使用终端输入您计算机上存储 Git 的目录,并在命令行中输入git init。键入git add FILENAME上传你的第一个文件。下一步是做你的第一次提交,或者修改。在命令行中输入git commit -m "your comment here"。注释应该提供简短的细节,说明做了什么修改,这样你可以更容易地跟踪你的修改。提交会将更改添加到本地存储库中,但不会将编辑内容推送到远程服务器。下一步是在命令行中输入git remote add origin [https://project_repo_link.git](https://project_repo_link.git),在 GitHub 上创建一个远程服务器来托管你的工作。最后,输入git push -u origin master将修改推送到远程服务器并保存您的工作。
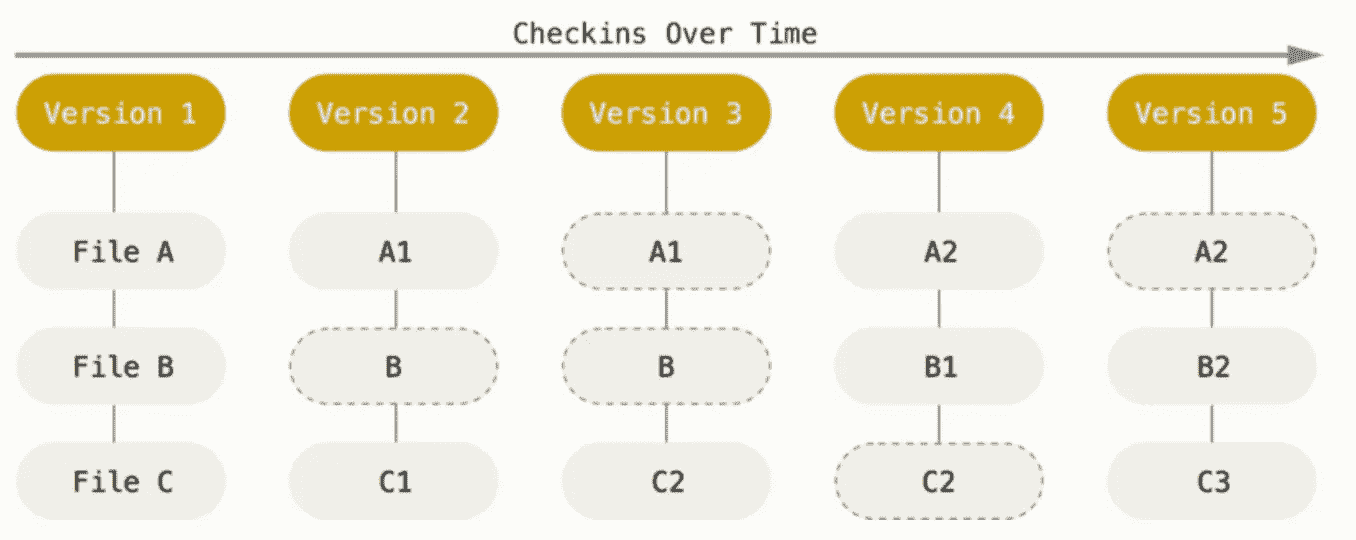
Git data stored as snapshots of the project over time — Source: https://git-scm.com/book/en/v2/Getting-Started-Git-Basics
将文件添加到存储库
向 GitHub repo 添加更改的过程类似于初始化过程。您可以选择一次性添加项目目录中的所有文件,或者在进行编辑时单独添加每个文件。由于通过反复试验发现的众多原因,我强烈建议单独推送每个文件。首先,它将保持您的存储库整洁有序,这在 LinkedIn、简历或工作申请上提供您的 GitHub 个人资料/回购的链接时非常有用。其次,这将允许您单独跟踪每个文件的更改,而不是提交一个模糊的提交描述。第三,它将防止您意外地将不打算添加到您的回购文件中。这可能是包含个人信息(如 API 密钥)的文件,如果发布到公共域,这些文件可能是有害的。它还会阻止您上传超过 100mb 的数据集,这是免费帐户的大小限制。一旦文件被添加到存储库中,即使它尚未被推送或提交,也很难移除。凭经验来说,我曾经在许多场合下,在不小心上传了一个我不想要的文件之后,不得不删除一个存储库,所以我强调仔细选择上传哪些文件的重要性。
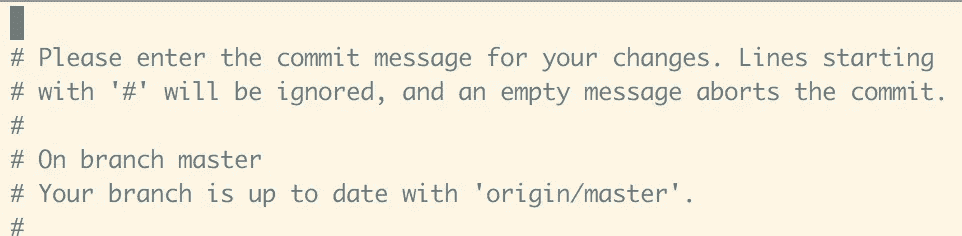
Vim interface
要添加一个新文件,通过终端进入你的项目目录,并在命令行输入git add FILENAME。要进行提交,有两种选择:您可以遵循与创建 repo 相同的过程并键入git commit -m "commit description”,或者使用 Vim,一个基于 unix 的文本编辑器来处理更改。Vim 是一个反直觉的文本编辑器,它只响应键盘(没有鼠标),但提供了多个可以重新配置的键盘快捷键,以及创建新的个性化快捷键的选项。要进入 Vim 文本编辑器,在命令行中键入git commit,然后按 enter 键。这会将您带到 Vim 编辑器;要继续编写您的提交,键入i进入 --INSERT--模式,然后键入您的提交消息。完成后,按esc退出 --INSERT--模式,然后保存并退出 Vim,输入:wq编写并退出文本编辑器。从那里,你需要做的就是在命令行中输入git push来把你的修改推送到 GitHub。
Git 忽略
要在推送到 repo 时忽略某些文件,您可以创建一个.gitignore文件,指定有意忽略未跟踪的文件。要创建该文件,请在您的存储库主页上单击new file按钮,并将该文件命名为.gitignore,或者使用提供的示例模板之一。有多种方法可以指定要忽略的文件或文件夹。第一种方法是简单地在.gitignore文件中写入文件名。例如,如果您有一个名为AWS-API-KEY-DO-NOT-STEAL.py的文件,您可以在.gitignore文件中写入该文件的名称和扩展名。
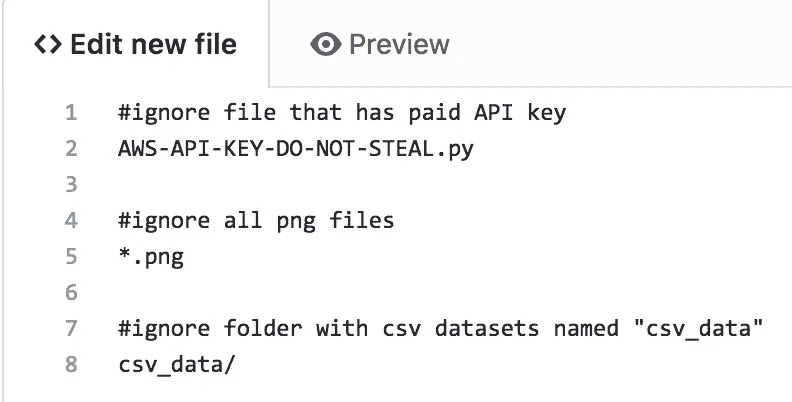
Creating a .gitignore file on GitHub
要忽略带有特定扩展名的所有文件名,比如说。txt 文件,在.gitignore文件中键入*.txt。最后,您可以通过在文件中键入folder_name/来忽略整个文件夹。一旦你添加了所有你想忽略的文件到.gitignore文件,保存它并把它放到你的项目的根文件夹中。现在,如果您尝试将这些文件添加并推送到存储库中,它们将被忽略,不会包含在存储库中。然而,如果文件在添加到.gitignore文件之前已经被添加到存储库中,那么它们在 Git 存储库中仍然是可见的。
叉子和树枝
如果你以前用过 GitHub,或者熟悉 GitHub 的行话,你可能已经见过 Fork、Branch 和 Merge 这三个术语。fork 本质上是一个克隆或存储库。派生其他人的存储库将在您的配置文件下创建一个完全独立于原始存储库的新副本。这在原始存储库被删除的情况下很有用——您的 fork 将与存储库及其所有内容一起保留。要派生存储库,只需访问 repo 页面并单击页面右上角的Fork按钮。要用更新的存储库覆盖当前的分叉,用户可以在分叉修订的 repo 之前使用分叉目录中的git stash命令。
分支提供了从存储库的主代码行中分离出来的另一种方式。对存储库进行分支会向保留原始存储库一部分的存储库添加另一个级别。分支对于长期项目或具有多个协作者的项目非常有用,这些协作者具有处于不同阶段的工作流的多个阶段。例如,如果你正在开发一个应用程序,你可能已经准备好了滑板和一个关键功能,但是还在开发另外两个功能,还没有准备好发布。您可以创建一个额外的分支,在主分支中只留下成品,而两个正在进行的特性可以在一个单独的分支中保持未部署状态。在与团队合作时,分支也很有用——每个成员都可以在不同的分支上工作,因此当他们推动更改时,不会覆盖其他团队成员正在工作的文件。这提供了一种简单的方法来保持每个人的工作是独立的,直到它准备好被合并和部署。

Microsoft rolls out automated GitHub support chatbot
只要本地保存了存储库的克隆版本,就可以从您的终端本地创建分支。要查看 repo 中的所有分支,请在项目目录中的命令行中键入git branch。如果没有创建分支,输出应该是*master,星号表示该分支当前是活动的。要创建一个新的分支,输入git branch <new_branch_name>,然后输入git checkout <new_branch_name>切换到新的分支,这样您就可以从它开始工作了。git checkout命令允许用户在存储库的不同分支之间导航。将变更提交到分支的过程与提交到主分支的过程相同,只是要确保知道您正在哪个分支中工作。
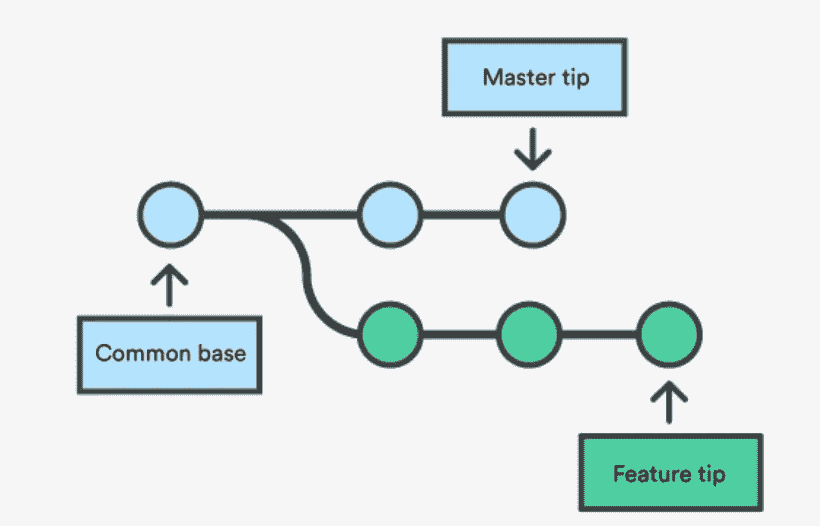
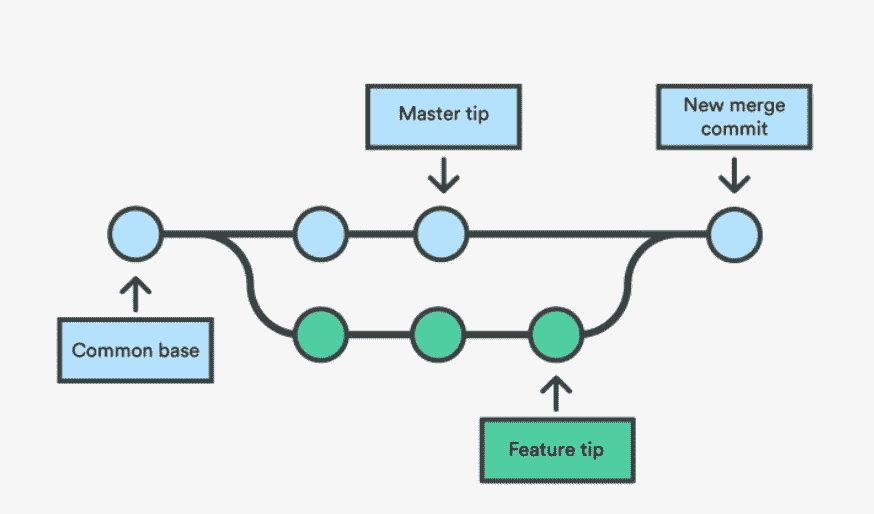
Merging two branches — Source: Atlassian GitHub Docs
要将多个分支合并成一个统一的历史,您可以使用git merge <branch_name>命令。一种类型的合并被称为三路合并,它包括将两个分叉的分支合并为一个。三向合并的名称来源于生成合并所需的提交次数——两个分支顶端和它们共同的祖先节点。调用 merge 命令将通过找到公共基础提交,然后创建将两个提交历史合并为一个的新的合并提交,来将当前分支与指定分支合并。如果每个分支中有一部分数据被更改,git 合并将会失败,需要用户干预。
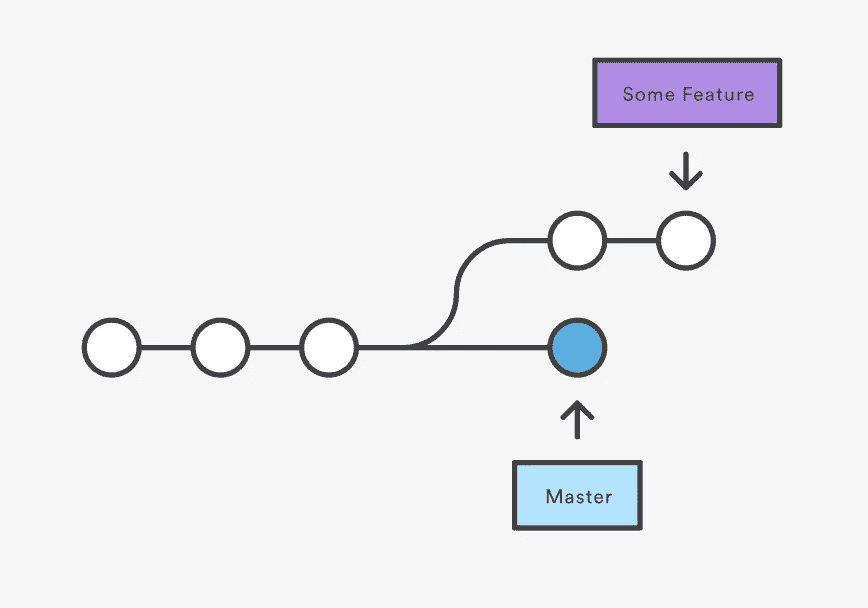
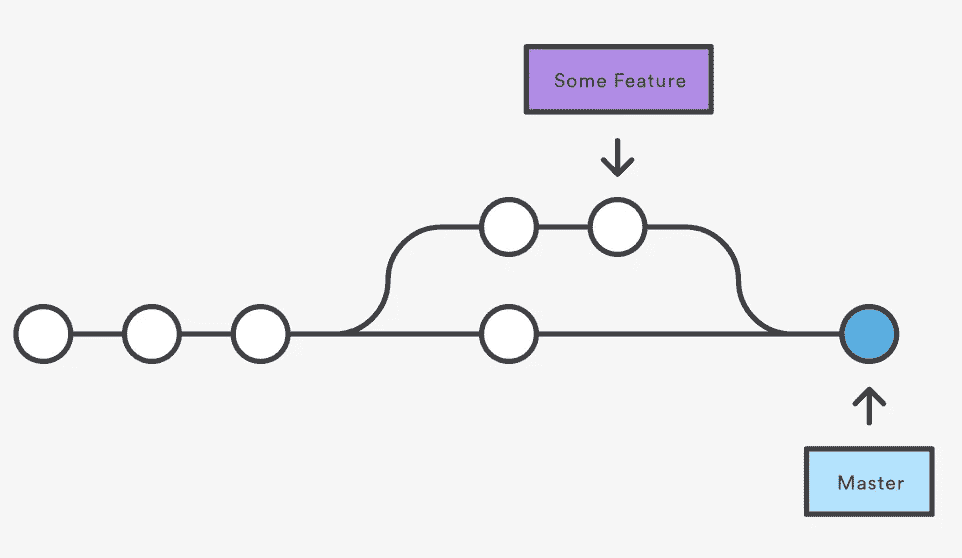
3-way Merge — Source: Atlassian GitHub Docs
另一种类型的合并是快速前进合并,在目标分支和当前分支之间有线性路径的情况下使用。在这种情况下,merge 将当前分支顶端向前移动,直到它到达目标分支顶端,有效地将两个历史合并为一个。一般来说,开发人员更喜欢使用快速合并来修复 bug 或添加小的功能,从而节省了三路合并来集成运行时间更长的功能。
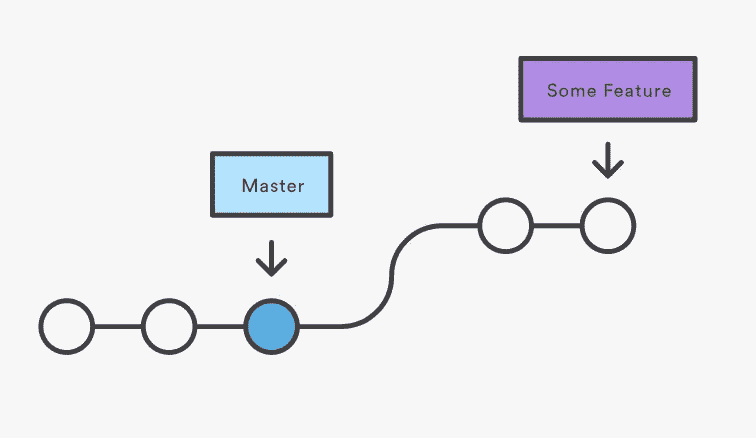
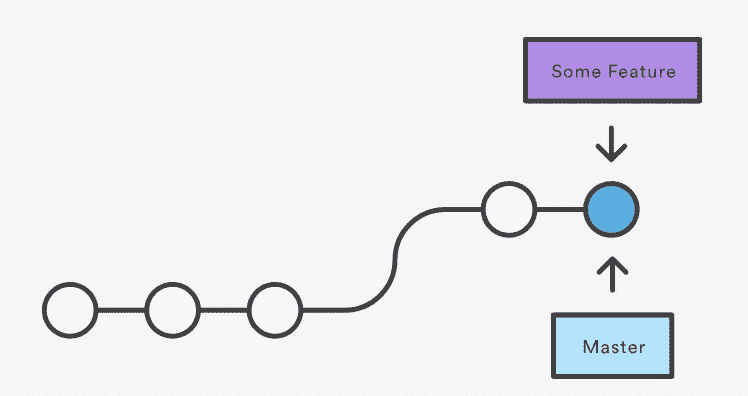
Fast Forward Merge — Source: Atlassian GitHub Docs
提示和技巧
这些都是成功使用 GitHub 的基本要素;然而,我想分享一些我认为有用的提示。:
- **固定存储库:**一个免费帐户最多可以固定六个存储库,这些存储库将始终显示在用户资料的顶部。这是一个展示你所做的最重要的项目的好方法,而不需要有人去筛选杂乱的旧提交。
- **添加协作者:**当与一组人一起工作时,最好让每个用户都成为存储库的协作者,这样他们就可以从他们的工作中获得荣誉。要添加一个协作者,单击存储库主页上的
settings选项卡,并从左侧菜单中选择collaborator。在那里,输入其他用户的 GitHub 名称或电子邮件来添加他们。 - 推送后从历史中删除敏感数据:
git filter-branch — force — index-filter ‘git rm — cached — ignore-unmatch <path-to-your-file>’ — prune-empty — tag-name-filter cat — — all && git push origin — force — all - 显示所有保存的仓库列表:
- 查看作者和最后编辑时间,这样你就可以责怪他们搞砸了:
git blame <file-name> - 缩短 GitHub 分享网址:https://git.io/
- 【https://pages.github.com/】GitHub Pages:你可以通过几个简单的终端命令很容易地把你的回购变成 GitHub 托管的网站
额外资源
[## 学习如何 Git:使用 GitIgnore 忽略文件和文件夹
有时,我们的项目不仅仅包含我们创建的代码。有一些文件是由我们的 IDE 生成的…
medium.com](https://medium.com/@haydar_ai/learning-how-to-git-ignoring-files-and-folders-using-gitignore-177556afdbe3) [## Git - Git 基础知识
Git 中的所有内容在存储之前都要进行校验和检查,然后通过该校验和进行引用。这意味着它是…
git-scm.com](https://git-scm.com/book/en/v2/Getting-Started-Git-Basics) [## Git - gitignore 文档
底层的 Git 管道工具,比如 git ls-files 和 git read-tree,读取 gitignore 指定的模式…
git-scm.com](https://git-scm.com/docs/gitignore) [## Git 分支|亚特兰大 Git 教程
Git 分支简介。用 git branch 创建,列出,重命名,删除分支。git checkout:选择哪一行…
www.atlassian.com](https://www.atlassian.com/git/tutorials/using-branches) [## 分支或分叉您的存储库- Atlassian 文档
随着 DVCS 主机的发展,术语 fork 也在发展。Bitbucket 软件增加了对 forks 的管理;派生存储库…
confluence.atlassian.com](https://confluence.atlassian.com/bitbucket/branch-or-fork-your-repository-221450630.html) [## 了解 GitHub 流程
当你在做一个项目时,在任何给定的时间,你都会有一堆不同的功能或想法在进行中…
guides.github.com](https://guides.github.com/introduction/flow/) [## git-提示/技巧
最常用的 git 技巧和窍门。在 GitHub 上创建一个帐户,为 git-tips/tips 开发做贡献。
github.com](https://github.com/git-tips/tips) [## 哦,妈的,饭桶!
Git 很难:搞砸很容易,弄清楚如何修复你的错误他妈的是不可能的。Git 文档…
ohshitgit.com](http://ohshitgit.com/)
给你的顾客一件东西,他们永远不会流失
如何利用嵌入式分析从您的数据中获得更多价值

数据是当今组织对话的核心。组织渴望数据并受数据驱动。毕竟,现在是信息时代!
能够掌握、解锁、理解和利用其数据来支持自身、员工和产品的组织已经走上了成功之路。
对于这些组织来说,分析是关键,尤其是嵌入式分析。
充分利用数据
公司总是积累数据。即使以最古老的形式,他们也收集和贮藏它。社交媒体的繁荣给已经蓬勃发展的数据增加了混乱的真实世界数据集。大约十年的这种活动已经帮助将这些土堆扩展成不断增加的数据山。
在这些山上行走和导航是一项艰巨的任务。信息流不透明,部分原因是组织的数据架构不清晰。数据是孤立的、不完整的、非结构化的和不可访问的。数据支离破碎,分散在各个口袋里。而且,数据是不可验证的,不可靠的。

了解更多>
对于一个试图将所有数据点联系在一起以创建一个有凝聚力的故事情节的组织来说,数据需要分析的帮助——筛选数字以准确预测未来,报告、预测和开出路径,收集见解,以及解开数字中根深蒂固的故事和模式。
这是有分析的!
商业智能和分析诞生于组织对解密其数据告诉他们的信息的需求。自助毕走上舞台,吸引了所有人的目光。
这是每个组织都在经历转型和分析实现之旅的时期。IT 部门开始着手复杂(而且通常昂贵)的数据仓库集成和 BI 部署。每个人都在实现解决业务问题的单一观点的道路上。
这些商业智能工具的庞然大物很快就被交给了未经培训的员工。虽然分析的承诺仍然存在——使用户能够做出明智的决策,而不管他们的技术方向、资质或技能组合如何,但事实上,分析需要大量的支持。仪表盘和报告也只是显示了冻结数据的快照,而不是探索真实世界的数据。具有独立界面的 BI 应用程序迫使用户离开他们熟悉的应用程序,在屏幕、视图和仪表板之间切换,以便获得洞察力。
当然,扶持人民过去是,现在也是最重要的。但是单独的分析也许并不合适。事实上,能引起用户共鸣的解决方案被紧密集成到他们使用的系统中。
为他们执行的非常具体的任务带来额外的背景、意识和分析能力。
嵌入式分析如何真正有所帮助
嵌入式分析,或捆绑到商业应用中的分析功能,正在进行一次戏剧性的进军。将传统的探索性数据分析和移动可视化功能引入核心应用,如 CRM、HRMS、ERP 和 SCM 等。
需求是巨大的,越来越多的来自销售人员、招聘人员、人力资源经理、物流经理、供应商、库存管理员、医药代表等等。需要对他们在各自的业务部门中处理的数据进行及时、可视化和交互式的访问。人们期望分析能够无缝集成到核心应用套件中。
一般来说,这些集成分析功能不是内部开发的(尽管它们可以内部开发)。相反,Sisense 等 BI 供应商为业务应用程序供应商开发它们,然后这些供应商将分析打包到产品中。因此得名嵌入式分析。
很明显,嵌入式分析可以为组织带来诸多好处,从与传统 BI 部署相比降低总拥有成本,到使您的最终产品变得强大和可用。现有应用程序中的嵌入式报告和仪表板可以使其高度用户友好。给它一个竞争优势。该产品满足了您的客户的需求,他们无缝地接受了它。
Gartner 有话说 *:
“在选择新的业务应用程序时,公司应该将搜索重点放在提供嵌入式分析的解决方案上,或者在不久的将来提供嵌入式分析的清晰路线图上。从寻找补充您的 ERP 和 BI 平台投资的特定分析应用程序开始。从长远来看,审查供应商在面向服务的架构环境中支持可重用分析构件(即服务)的能力。”
( Gartner 客户可获得完整报告)*
未来:人工智能和嵌入式分析
人工智能正在增强嵌入式商业智能来分析企业范围内的数据。机器学习正在实现更快、更有效的数据挖掘、管理和分析。结合深度学习,公司正在建立分析更复杂、丰富和多样的数据的能力,以及处理更大数量的数据的能力。
自然语言处理的使用使得细节更加连贯。社交媒体评论可读性强;视频、图片和图像是可解释的;情绪是可以理解的。突然间,我们之前谈到的堆积如山的数据变得很容易克服。
所有这些都在您的数据环境中,集成在熟悉的应用程序中,简化了您的日常任务。
原载于 2018 年 5 月 23 日 www.sisense.com。
全球恐怖和 EDA 可视化兔子洞
数据科学家面临的最大挑战之一是知道何时继续前进。它可能会进行更多的探索性数据分析(EDA),它可能会调整您的模型参数以获得更好的分数,或者只是试图让您的笔记本看起来尽可能专业。无论主题是什么,都很容易忘记时间,陷入分析的兔子洞,但随着最后期限的临近,你必须面对现实,你必须跳出整体,确保项目的其他部分不会被忽略,因为如果你的项目只有一部分看起来很棒,而其他部分充其量看起来很平庸,那么你的客户会想“为什么他/她的其他分析和演示不如[插入兔子洞项目]。”从而降低你所做工作的价值和评价。
我最近经历了一个最好的例子,当我在 ed a 可视化中迷失时,我从一开始就提供了一个全球恐怖主义数据库。全球恐怖主义数据库(GTD)是一个关于 1970 年至 2016 年世界各地恐怖袭击的数据库,包含超过 150,000 条观察数据。国家联盟的研究人员维护着恐怖主义研究和应对恐怖主义数据库,总部设在马里兰大学。
我之前在大学学习过全球和世界历史,显然对这个主题有着浓厚的兴趣,因此很容易被诱惑去钻研 EDA。随着项目的完成,我现在可以给你我的可视化的全部范围,以及它们所呈现和不呈现的所有信息。这个项目的主要目的之一是深入研究围绕时间和它们所展示的东西生成可视化。它专注于 1970 年至 2016 年间的全球爆炸事件,其原因你将在下面看到为什么它是焦点的明确选择。
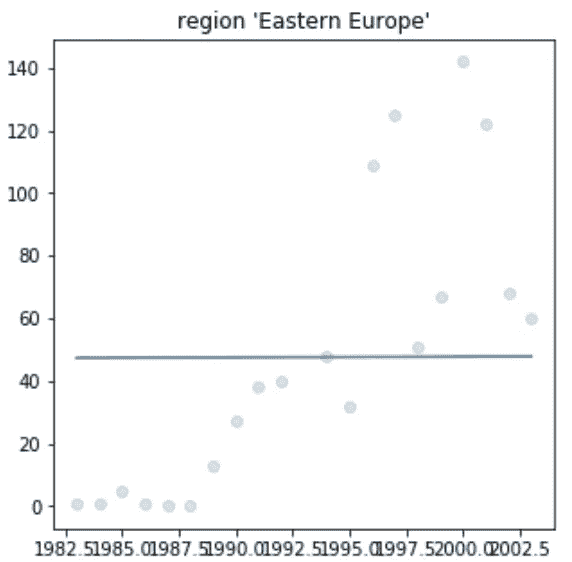
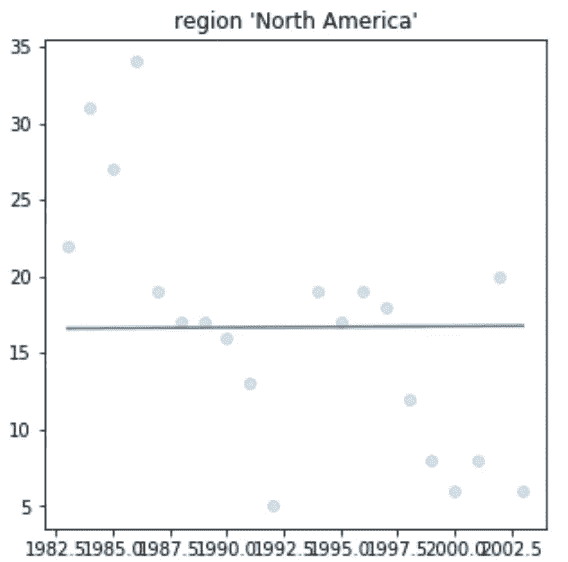
当最初查看数据时,你想回答的一个非常直接的问题是,在我们的数据集时间线内发生了多少事件,在这种情况下是恐怖袭击。第二,如果你关注一个地区,在我们的例子中是爆炸事件,你想看到事件数量随时间的变化,看看这两种趋势之间是否有任何明显的差异。
我们可以看到,从 1970 年到大约 1993 年,恐怖袭击开始缓慢增加,尽管发生了 2001 年 9 月 11 日这样的事件,但直到 2003 年,我们看到全球恐怖事件呈下降趋势。我们还可以在第二张图中看到,爆炸案的数量大致遵循相同的趋势,但在 90 年代初,爆炸案的数量急剧下降。
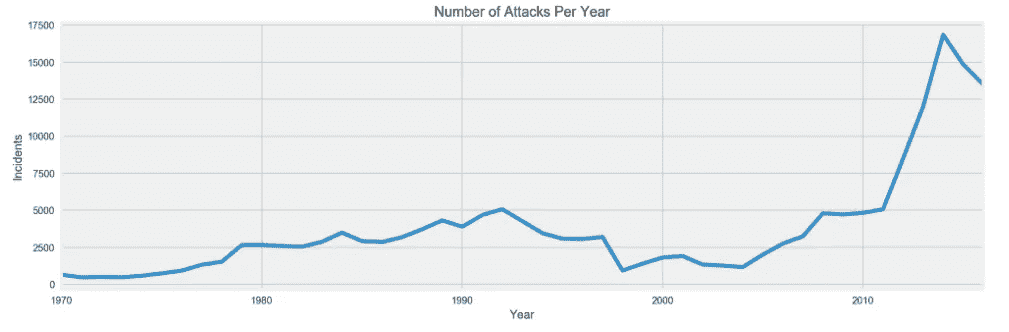
Global Terrorist Attack Incidents 1970–2016
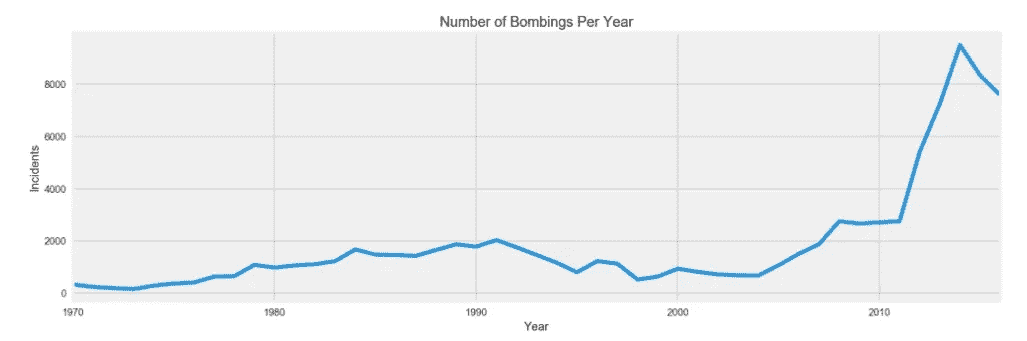
Global Bombing Numbers 1970–2016
在这里,我们可以清楚地看到全球不同地区的总体攻击趋势是如何变化的。在 20 世纪 70 年代,我们可以看到大多数恐怖袭击发生在西欧,其次是 20 世纪 80 年代的拉丁美洲和南美洲,但在 20 世纪 90 年代中期至 2003 年期间,袭击次数总体下降。我们也可以看到,我们经历了同样的人数激增,并看到中东和北非以及南亚是受恐怖袭击最严重的地区。然而,同样重要的是要注意到,尽管总体趋势有所增加,但似乎无论在哪个地区,恐怖袭击的发生率都有所上升。
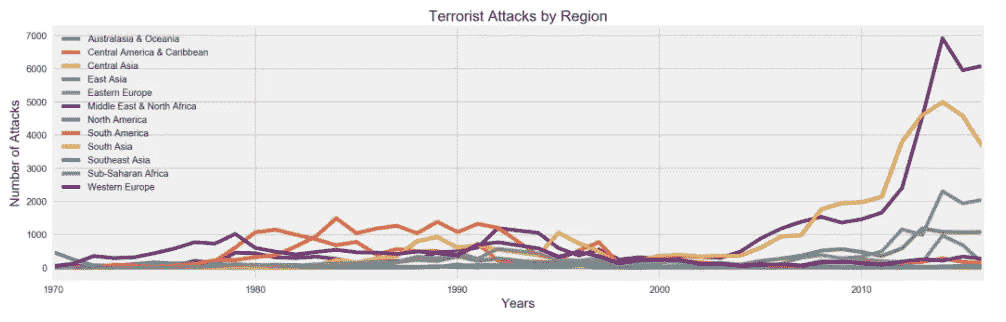
Terrorist Attacks by Region 1970–2016
在这里我们可以看到,在过去的 47 年里,恐怖分子最喜欢的袭击方式是爆炸,是武装袭击的两倍多。然而,应该指出的是,如果这两个事件单独或一起发生时有区别,我无法找到这样的数据澄清,所以这些数字可能是扭曲的,因为像孟买酒店和巴塔克兰袭击事件都涉及炸弹和武装袭击。有趣的是,尽管劫机在上世纪七八十年代盛行,但它却排在了最后。
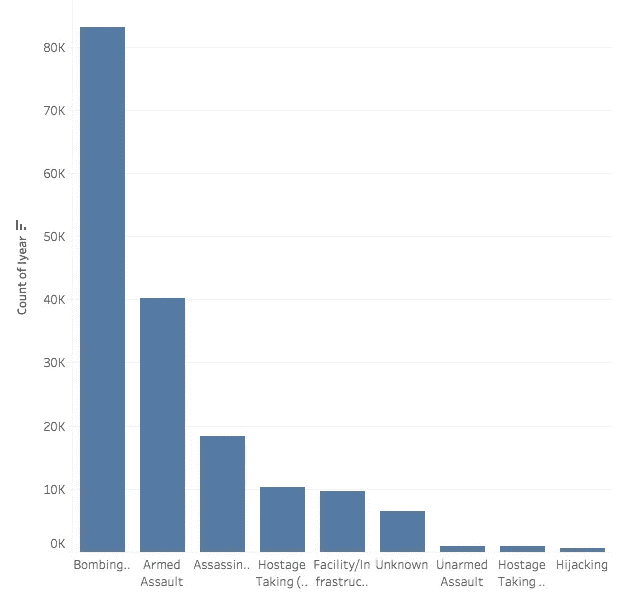
Type of Terror Attacks
下面,我们看到一个 tableau 生成的图表,显示了“受打击最严重”的目标类型,按受伤人数和死亡人数排列,圆圈的大小表示发生的次数。我们可以看到,绝大多数情况下,最常见的目标是平民,因此他们在恐怖分子手中遭受的痛苦也最大。然而,这个图表可能会产生误导,因为像 9/11、1993 年 WTC 爆炸案和 Bishopsgate 这样的单一事件可能会扭曲这个数字,因为这三个事件要么记录了大量的死亡人数,要么记录了大量的受伤人数,或者两者都记录了。还应该注意的是,这是您应该更好地组织数据的一个主要示例,因为图中有几个点可以合并。例如平民可以包括村庄、市场、车辆、公共汽车,当然还有平民,而单个军事类别可以包括军事单位、士兵、检查站、巡逻队、车队、军官、单位和警察局。
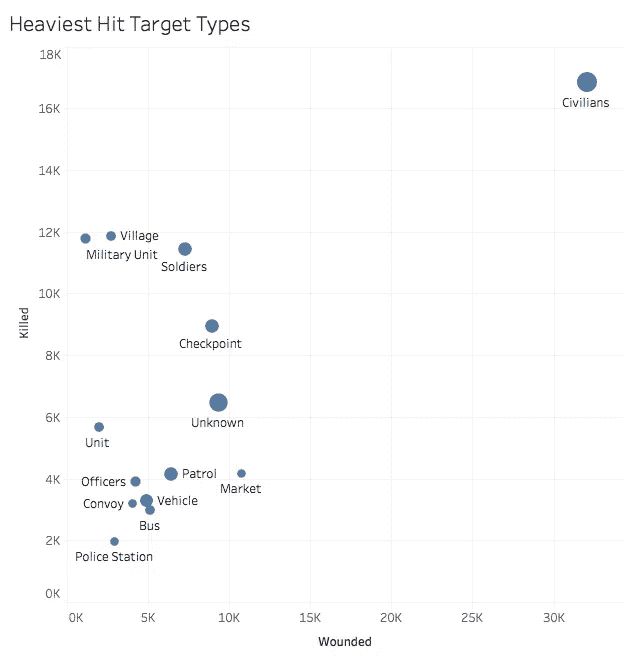
由于恐怖行动通常是对目标政府或国家采取的行动的反应,我接下来想看看历史上相处不好的国家(说得好听点)之间的事件数量趋势是否有任何相似之处。
第一个比较是英国和爱尔兰,从下面的图表中我们可以看到,英国在所有的暴力事件中首当其冲。与这两个国家之间的冲突主要相关的高峰是 1970 年至 20 世纪 90 年代末,这包括了被称为“动乱的整个时期,在此期间有 3500 多人死亡,47500 多人受伤。这里需要注意的是,虽然很大一部分攻击似乎发生在英国,但大多数事件并没有发生在英国本土,而是发生在北爱尔兰,所以如果你要显示整个爱尔兰(爱尔兰和北爱尔兰)与英国的对比,我想数字会有所不同。
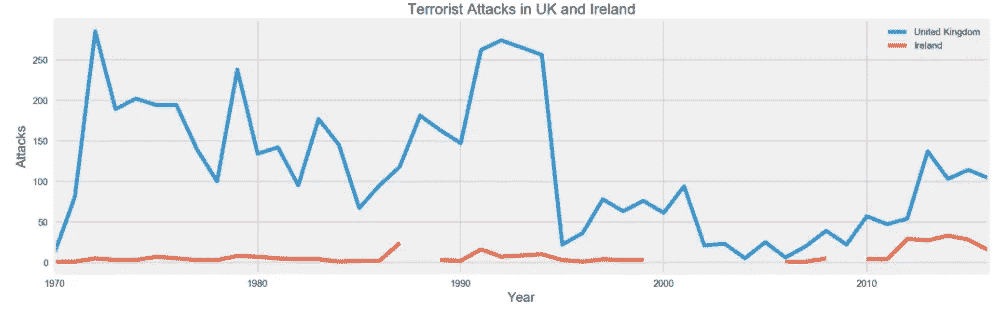
UK vs Ireland Incidents
接下来,我们看到两个国家自脱离英国独立以来经历了动荡的历史。然而,我们可以看到,除了 20 世纪 90 年代中期的一次激增之外,恐怖事件的数量每年都保持在 500 起以下,而且大多数发生在印度。然而,随着 2008 年孟买恐怖袭击,这一切开始改变。从那时起,巴基斯坦已经压倒性地比印度发生了更多的恐怖事件,但是在过去的一两年里,这个数字似乎已经开始急剧下降。然而,自 2008 年袭击以来,印度的数字急剧上升,自那以后,似乎是一个缓慢,但稳定的攻击增加。事实上,如果你放大图表的最末端,你可以看到印度在事故数量上超过了巴基斯坦。
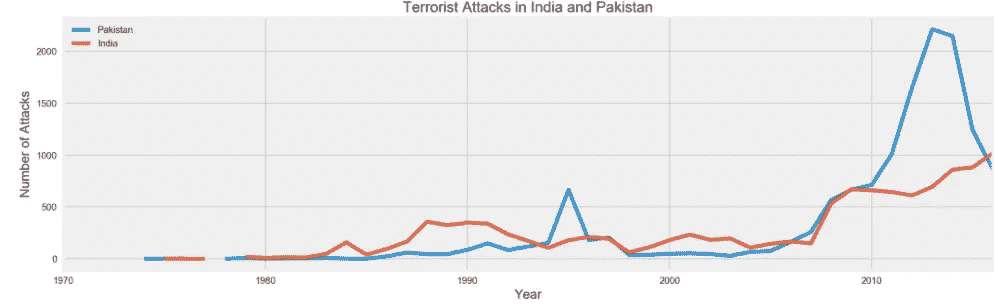
India vs Pakistan
在过去的 46 年里,我们见过的另外两个锁头国家当然是美国和俄罗斯。而他们之间的战争要么是代理方式,要么是冷战(即制裁、间谍等。)它从未发展成一场可能会席卷全球的全面战争。然而,我们在这里可以看到,虽然美国经历了一些高调的恐怖袭击,如地下天气组织、蒂莫西·麦克维、尤那邦摩、基地组织、ISIS 和萨纳耶夫兄弟,但它经历的袭击次数远远少于俄罗斯。这在很大程度上是因为美国不像俄罗斯和前苏联的某些地区那样动荡,如达吉斯坦、车臣、乌克兰/俄罗斯边境以及俄罗斯与格鲁吉亚的冲突。这两个国家都遭受了损失,但是很明显,由于俄罗斯的国土面积和它与邻国之间的暴力冲突,它在恐怖分子手中遭受的损失最大。
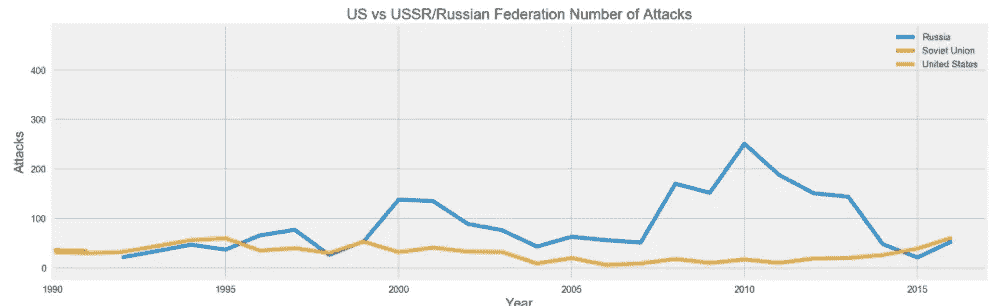
United States vs Russian Federation/USSR
更令人高兴的是,也是我关注的这个个人项目的一大部分,自 1994 年以来,随着该国首次自由选举任命纳尔逊·曼德拉为总统,并非正式地结束了种族隔离,南非的局势有了显著改善。然而,随着曼德拉从监狱中被释放,种族隔离制度在 1991 年正式结束,选举直到三年后才举行。事实上,我们可以从下图中看到,1991 年至 1994 年是南非最暴力的时期之一,因为阿非利卡民族主义者采取了更暴力的手段来阻止 1994 年的选举,但没有成功,这当然会激起南非黑人的反击行动。幸运的是,我们可以看到,这些年来,我们有数据显示,在选举之后,事故数量大幅下降。可悲的是,这些数据似乎在 2000 年后开始消失,对于任何了解南非历史和政治的人来说,包括姆贝基总统和祖马总统,他们对国家的状况都不太透明。
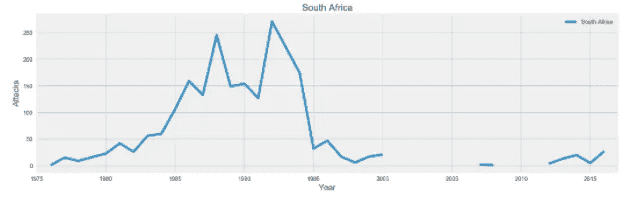
虽然自 1994 年以来,这些数字确实出现了显著下降,但该图向我们展示了个人在处理所有数据时必须尽最大努力获得和/或管理的两件事。也就是获得尽可能多的关于数据的知识,以获得一些背景知识,并能够从数据中理解或推断出你必须为我们不知道的数据生成可能的数字。
基于贝叶斯推理的全球恐怖主义数据库
在大会的数据科学沉浸式课程中,我的一个项目是使用全球恐怖主义数据库,利用贝叶斯技术进行分析。该项目由三部分组成。第一部分是做一些 EDA(探索性数据分析)和可视化,这将帮助你更好地理解数据。第二部分是对我们选择的一部分数据进行贝叶斯推断。最后一部分是对 1993 年“爆炸/爆炸”类袭击的数量进行预测。
数据
全球恐怖主义数据库由国家研究恐怖主义和应对恐怖主义联合会创建和维护
(START)。它是在 2006 年编制的。它不包括 1993 年,因为缺乏该年的数据收集。全球恐怖主义数据库顾问委员会估计,他们只收集了那一年大约 15%的攻击数据。一些比较突出的栏目包括:日期栏,地区,县,攻击类型,目标类型和杀死的数量。你可以在http://start.umd.edu/gtd/downloads/Codebook.pdf的密码本上阅读更多关于数据收集过程和数据集的更详细信息。
第一部分
这个项目的第一部分是做一些 EDA 和熟悉数据集,以完成第二部分和第三部分。我首先浏览代码本,并尝试了解数据集中一些列的含义的背景信息。我看的第一个是“attacktype”。该数据集中有九种不同类型的攻击。我关注的一些类型还有爆炸、暗杀和武装袭击。这些特别重要,因为爆炸对第三部分很重要,在这个项目中,我想尝试用暗杀或武装袭击作为第二部分的推理主题。
有了所有的时间序列信息和地理信息,我知道理解这些数据的最好和最有趣的方法是使用可视化。我首先想看看数据集中包含的历年攻击类型。使用 Tableau,我能够创建一个信息丰富的图表,能够将每种攻击类型分开,以查看每年每种攻击的数量。然后,我可以给图表中的每个区域赋予自己的颜色,以给出一些地理背景。下面是爆炸/爆炸的截图但是请到我的 Tableau 公众号和图互动。
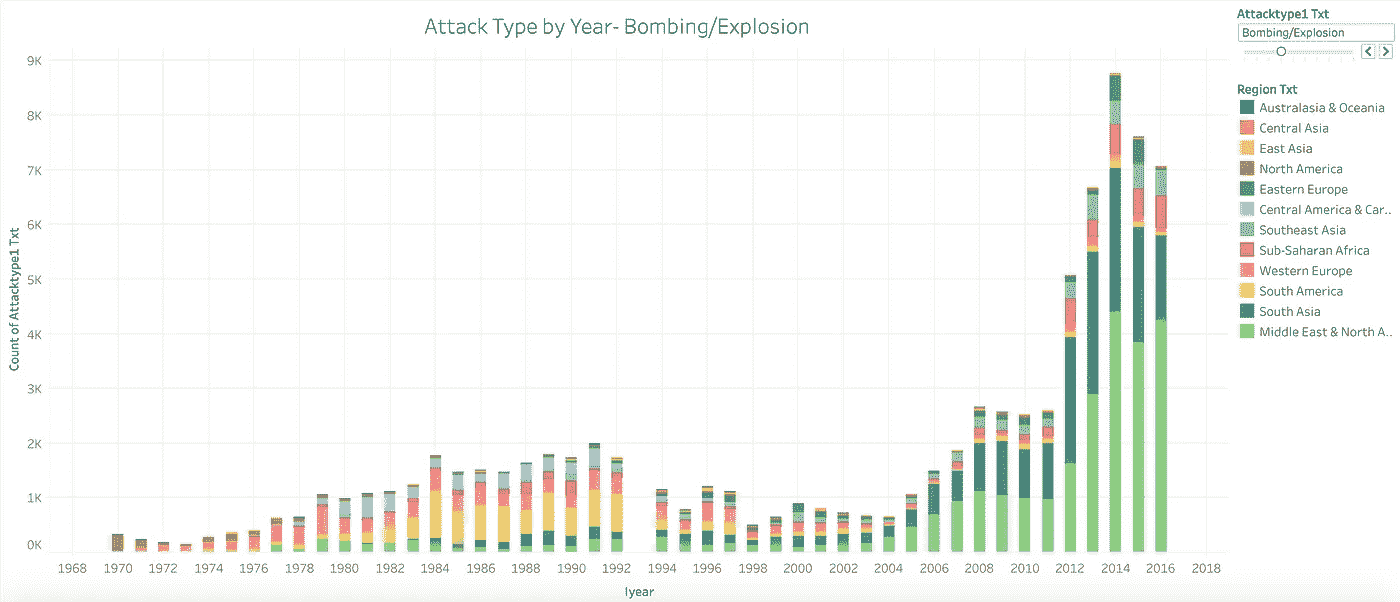
https://public.tableau.com/profile/cbjohnson30#!/vizhome/WorldTerror-T_S/Sheet2
我从这个图表中得到的一个重要信息是,当我试图预测 1993 年发生的爆炸事件的数量时,这个信息对这个项目的第三部分是有用的。只看这个图表,我就能猜出我要找的数字在 1000 到 1500 之间。
我创建的下一个可视化是关注数据集中多年来每次攻击的地理信息。再次使用 tableau,我能够在世界地图上按年份标出每次袭击的位置。下面是 1980 年的可视化设置的截图。
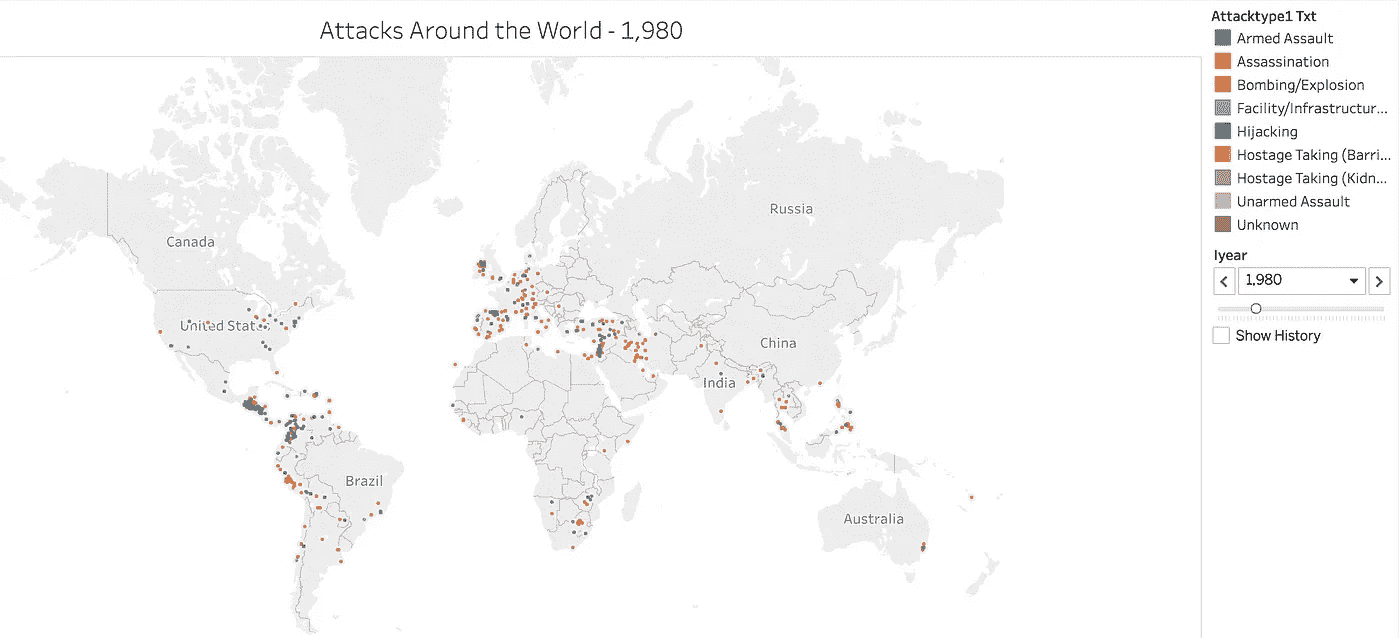
https://public.tableau.com/profile/cbjohnson30#!/vizhome/WorldTerror-T_S/Sheet1
通过在 Tableau 公众帐户上查看,您可以与可视化交互以更改显示的攻击年份。在 Tableau Desktop 上创建时,年份之间的过渡更加平滑,让您可以更清楚地看到世界各地的攻击活动。
第二部分
这个项目的第二部分是在这个数据集上创建一个贝叶斯推理。我问的问题是,美国和西欧“成功的”武装袭击造成的死亡人数是否有显著差异。要使一次袭击“成功”,必须至少有一人死亡。随着枪支暴力成为全世界的热门话题,我想深入探讨一下这类袭击。所有的贝叶斯推理都包括一个先验信念和一个后验信念。对于我的先验,我使用了西欧和北美袭击中的死亡人数,我比较的两个后验是西欧的死亡人数和美国的武装袭击死亡人数。第一步是找到先验的均值和标准差。西欧和北美袭击死亡人数的均值和标准差分别为 1.94 和 4.3。接下来,我绘制了 95%置信水平下两个后验概率的均值和标准差。以下是每一项的图表:
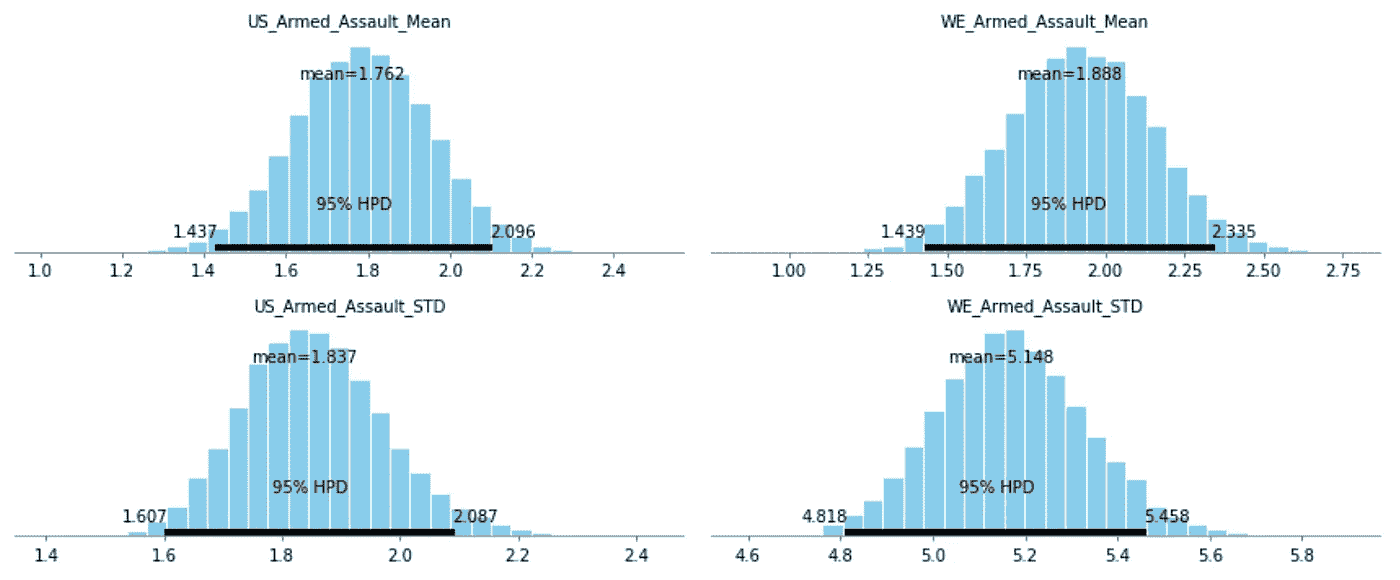
美国的真实平均值在 1.44 和 2.1 之间,在 95%的置信水平下,其标准偏差在 1.61 和 2.87 之间。西欧的真实平均值在 1.44 和 2.34 之间,其标准偏差在 4.81 和 5.46 之间,两者的置信度均为 95%。最后一步是绘制两个相互对立的后验概率。这可以从下面看出:
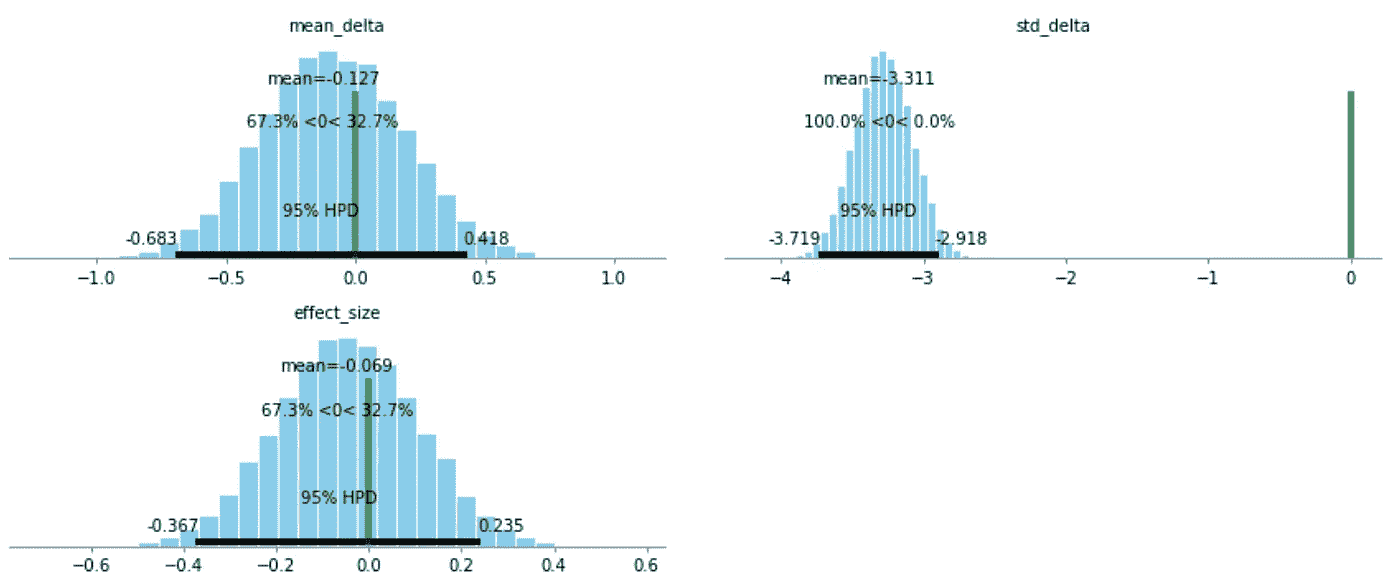
在这些图表中,绿线代表我正在查看的每个统计数据的西欧基线数字。Delta-mean 相对接近,意味着这些数字相当相似。Delta-STD 则相反,绿线并不靠近条形图。这是因为西欧的标准差比美国高得多。这意味着西欧在他们的袭击中有更大范围的死亡。鉴于这一数据的性质,这意味着西欧的武装袭击死亡人数高于美国。
第三部分
该项目的最后一部分是试图预测 1993 年爆炸袭击的数量。由于这个项目的性质,我想留在贝叶斯分析领域做这件事。在我的 EDA(第 1 部分)中,我找到了我所寻找的攻击数量的目标范围。我的目标数字在 1000 到 1500 之间。我的目标是创建一个爆炸袭击数量的散点图,并在图上画一条最佳拟合线。然后我会用 1993 年的那个时间点,作为我对攻击次数的估计。建议该课程在预测攻击数量之前将数据分成几个部分。我决定按地区来划分,因为我认为这是对世界和这个时间范围内可能发生的趋势的合理划分。为了得到更准确的数字,我还决定使用 1993 年前后 10 年的数据。我想这也能帮助我更好地了解每个地区的情况。一个很好的例子就是看看中东和北非的爆炸袭击数量。大约在 2004 年,由于该地区冲突和战争的增加,爆炸事件的数量开始急剧上升。我不希望这一攻击高峰影响我的预测。在对每个地区做出预测后,我将它们相加,得到 1993 年所有爆炸袭击的数字。结果这个数字是 1250。这是我刚开始写这一部分时正在寻找的产品系列的中间位置。
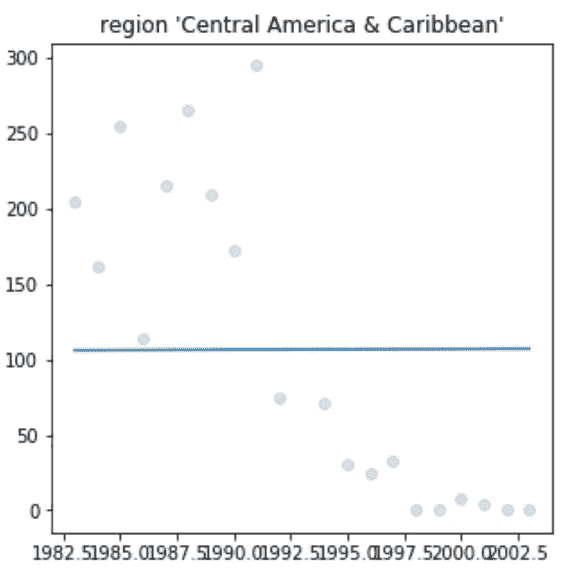
正如你在上面的图表中看到的,我的最佳拟合线确实有问题。对于每一个图,我的线实际上是水平的,即使它们应该有更多的斜率,只看标绘的点。每张图都估计了一个非极端的数字,总的估计值在我期望的范围内。我不知道为什么我对视觉化有这个问题。我的作品可以在我的 GitHub 上看到,(文章底部的链接)如果有人知道为什么会这样,请随时联系我。
我所有的代码都可以在我的 GitHub 上找到:https://github.com/CBJohnson30/Global-Terrorism
手套+有趣-无聊
GloVe,源自GlobalVectors的首字母缩写,是一种将单词表示为向量的无监督学习方法。它对语料库的单词共现统计进行训练,目标函数是专门选择来编码单词向量之间有意义的差异。一个比较著名的例子是,“国王”+“女人”-“男人”的结果与“女王”的向量最为相似。学习者设法量化皇室和性别的概念,以便它们可以被分解和重新组合,从而得到与 king 类似的单词。

我想看看这些单词向量是否有助于创建一个更智能的词库。如今,如果你在搜索一个和另一个单词“x”意思相似的单词,你可以用谷歌搜索“x 的同义词”。更有效且有助于缩小搜索空间的方法是给出所需同义词的特定方向。例如,如果你在寻找一个表示“缺乏经验”但没有负面含义的词,你可能会更喜欢“新鲜的”或“新的”而不是“无能的”。为此,我下载了词向量,这些词向量在由 2014 年维基百科文章和 Gigaword 5 组成的数据集上进行了预训练。我发现单词与其他向量相加和相减得到的向量最相似(由余弦相似度定义)。以下是一些沿好坏轴的类比。如表所示,“方案”+“好”–“坏”≘“计划”,反其道而行之,“方案”–“好”+“坏”≘“骗局”,沿着好的光谱正确捕捉语义。
** + good - bad - good + bad**
scheme plan scam
intelligence knowledge spy
naive idealistic stupid
possibility potential consequences
dream wish nightmare
notion concept stereotype
bold courageous risky
有趣无聊轴上的一些类比很有趣。
**+ fun - boring - fun + boring**
presentation showcase powerpoint
woman girl housewife
acquaintance friend coworker
music pop orchestral
test challenge exam
premiere festival opera
这里有一些优雅-笨拙轴心的例子。
**+ elegant - clumsy - elegant + clumsy**
persuade convince pressuring
walked strolled stumbled
threw tossed hurled
placed adorned mishandled
stylish sleek uninspired
根据 Richard Socher 的讲座,没有数学证明可以保证这些类比脱离模型。实际上,有时类比似乎是正确的,但很多时候却不是。一个更智能的词库已经初露端倪,但它可能需要一种未来的方法来更好地捕捉语义关系。
数据解释中的萤火虫、热手和其他(所谓的)谬误。
很久以前,当我第一次学习认知心理学时,我被分配到了关于所谓“热手谬误”的著名论文。要点很简单:人们不擅长评估概率。他们认为罕见的事件更有可能发生,并倾向于将一些基本原理归因于没有任何特殊情况下出现的所谓随机序列(这一点在 Tversky 和 Kahneman 的整个职业生涯中不断出现)。
这是一个微妙的论点,具有潜在的广泛应用——如果人们仔细考虑小样本分布的性质的移动部分。你可能会注意到,这与我之前关于城市与农村的区别的推测有着直接的相似之处:在足够高的聚集水平上,城市地区通常比农村地区的单位面积人口密度更高(有明显的例外,例如在恒河流域),它们的特点是相邻“块”之间的密度存在高度的局部差异——非常密集的块紧挨着非常稀疏的块(与米勒和桑十郎的论点中代表冷热手的块数据不同)。)农村地区可能平均密度较低,聚集程度较高,但它们的密度变化也较小,分布均匀,与萤火虫没有什么不同。人们可以很容易地想到利用置换测试来解决这个问题的分析方法:假设样本量为 100,其中 60 个是 A 型,40 个是 B 型,如果序列是随机的,那么您找到一个具有相同类型邻居的元素的概率分布是什么,您在真实数据中找到的实际“邻居”是什么?当然,诀窍在于这是两个极端都不自然的情况:太多的睦邻友好表明存在某种形式的“吸引力”,以子集为条件,而太少的睦邻友好表明某种形式的“排斥力”,而这反过来又可以量化。
这引发了一些额外的问题:这些“排斥”和“吸引”力量出现的“自然分析单位”是什么?从某种意义上说,这是吉洛维奇似乎犯了一个错误:先验地假设没有“自然”子集可以找到这些聚集的“倾向”。由于“冷”条纹会消除“热”条纹,因此只在更高的聚合级别检查数据时,它们的结果为零也就不足为奇了。但同样诱人的是,假设数据中存在的所有簇,也许通过聚类分析识别,实际上是有意义的——这正是 Gilovich 等人首先指出的谬误。我们可以将简单的模式识别转化为实际的科学,Miller 和 Sanjuro 指出了前进的方向,即一旦问题得到充分考虑,我们就可以在纯粹随机机会的假设下构建和模拟反事实,并将其作为基线来估计/量化数据中的“聚集”在多大程度上是“不自然的”。
保罗·克鲁格曼(Paul Krugman)在一篇关于理论和经验的旧文章(在发展经济学的背景下)中指出,数据分析的伟大之处在于它迫使我们精确地知道我们知道什么和不知道什么。这是有代价的,有时代价很高:在许多不精确的真理中,隐藏着许多事实上是真实的东西,我们只是在给定现有数据(和模型)的情况下,无法足够精确地知道这些东西。因此,我们扔掉了乞力马扎罗山的雪,就像我们扔掉了热带的雪一样,不是因为它们“不真实”,而是因为我们对它们了解不够。这意味着,一旦我们有必要的手段在足够精细的分析水平上更精确地检验数据,我们可能不得不收回以前的“荒谬的废话”,如乞力马扎罗的雪,篮球中的热手,或者,事实上,甚至艾丁斯(如果需要的话)是“暂时真实的”,如果重新检验的数据表明它们可能事实上存在的可能性。
使用 Firebase 实现无服务器化
关于无服务器什么,为什么和如何?
什么是无服务器架构?

Firebase Cloud Function
简而言之,无服务器架构是一种编程范式,专注于直接为 web 端点编写函数,而不是经历设置服务器、路由请求、定义 REST 资源,然后创建 GET、POST 和 PUT 方法的整个过程。还在迷茫?用程序员的术语来说,我们只需要编写方法体,其他的都是由服务提供商现成提供的。
最常见的无服务器服务提供商是亚马逊,他们有的 AWS Lambda 服务。这是一种高度可扩展的解决方案,广泛用于企业级应用。这些服务大部分要么与亚马逊发电机一起使用,要么与 MongoDB Atlas 一起使用。从 AWS 开始并构建一个应用程序是相当麻烦的,尽管它有如此多的功能和酷的集成。所以让我们用 Firebase 做同样的事情吧!!😃
为什么选择无服务器架构?
除了简单性,无服务器架构几乎没有其他优势。由于您只对 web 服务的逻辑进行编程,可伸缩性将不再是一个问题。您将只为执行次数付费,这意味着未使用的功能不会收费。Firebase 通过其身份验证平台简化了身份验证方式。毕竟,这也有不好的一面。您可能不了解底层硬件,因此在某些情况下,您必须遵循它们提供的标准硬件 API。但是对于存储,谷歌提供谷歌存储,AWS 为此提供 S3 存储桶。
怎么会?
我觉得这是最有意思的事情。让我们使用 firebase 云函数制作一个简单的应用程序,这是他们对无服务器架构的称呼。
第一步
- 转到https://firebase.google.com/
- 转到控制台
- 添加项目,给一个名字,然后按下创建
- 选择“确定”后,您将被定向到 firebase 控制台
- 在开发部分,转到功能
第二步
现在您已经创建了一个应用程序,您将有一些 NPM 软件包要安装。
安装 Firebase CLI 工具
$ npm install -g firebase-tools
现在使用工具登录
$ firebase login
您将被要求通过打开浏览器登录。相应地登录。现在使用下面的命令启动项目。
$ firebase init
选择云函数并按回车键,然后选择创建的项目并按回车键。在同一个项目文件夹中,创建一个名为 functions 的文件夹,转到该文件夹并启动一个节点项目,如下所示。
$ npm init
$ npm install firebase-functions@latest firebase-admin@latest --save
现在创建一个 index.js 文件并创建函数,假设它是一个普通的节点 js 服务器端代码。示例代码如下。
如果您熟悉 Node JS,很明显这个函数会将查询参数和主体参数返回给用户。
第三步
您现在可以部署应用程序了。为此,我们可以使用以下命令。
$ firebase deploy --only functions
一旦部署结束,您将获得函数 URL。您可以将其粘贴到浏览器上并发送 GET 请求,或者通过 REST API 测试工具发送请求。

Firebase
工作量很大吗?一旦你将这些步骤分类,你就可以专注于编写函数了,上面的代码是我唯一需要自己编写的代码;-).您可以轻松地与 Firebase 数据库、存储或身份验证连接,构建一个完整的应用程序。另外,你可以用免费的配额做很多事情。
我希望你喜欢读这篇文章。启动你的下一个项目,干杯!!
文件:https://firebase.google.com/docs/functions/get-started
视频系列:https://www.youtube.com/watch?v=EvV9Vk9iOCQ
上帝不玩骰子,但我们玩
或者说,我们是如何学会爱上多种武器的土匪行为的
如今个性化无处不在。从网飞电影推荐到优化行动号召的字体大小,在有记载的历史中,从来没有像福克纳的小说那样投入如此多的存在主义的悲伤和精神能量,让人们点击闪烁的图标。每个人现在都在做 A/B 测试,从他们的电子商务前端到他们的电子邮件营销活动;你(或者你的 UX 设计师)可能也不例外。真正的问题是,你真的需要知道“家庭错误率”是什么(你应该知道),或者有其他方法吗?
有!如果传统的 A/B 测试可以描述为掷硬币,两组有不同的转换概率,那么多臂强盗(MAB)就像掷骰子。更重要的是,如果我们真的是为了乐趣和利润而玩,我们可以把正常的骰子换成有负荷或有偏见的骰子,某些方面比其他方面更有可能被掷出

We’re about to go from ashy to classy
在这种情况下,就像我们这些四处游荡的恶棍一样,我们在任何给定的时刻都在赌该选择哪个选项;就像我们这些聪明的流浪儿一样,随着时间的推移,我们试图通过选择期望值较高的选项来最大化我们的收益,而不是选择期望值较低的选项,并试图在我们学习新信息时调整相对频率。
MAB 的好处在于,它旨在平衡收集信息的需求和收集信息的成本。感兴趣的 KPI(例如点击率)可以在开始时直接优化。但是我们需要确定如何给骰子的每一面分配权重。有许多方法可以实现这一点,如ε贪婪或置信上限,但 Thompson 采样是一个特别优雅的解决方案(顺便提一下,这也是 WeWork 的首选 MAB 策略)。简而言之,这是一种基于某个选项是最佳选项的概率来选择选项的有效方法。
假设我们有三种类型的登录页面,每个页面都有不同的副本和千年美学,因此有不同但未知的引发转换事件的概率。我们需要在每个页面的可能转换率上定义一个概率分布(通常是一个 Beta 分布)。预期的转换以及我们估计的不确定性将被很好地编码到与其登录页面相关的每个发行版中。
通过汤普森抽样,我们将从每个登录页面的相关概率分布中随机抽取。然后,我们获取具有最大采样值的登录页面,简单地将其提供给用户,并记录结果。重复这个过程,直到你的产品经理满意或者宇宙的热寂,无论哪个更快。


Left: A state of maximum entropy. Right: Also a state of maximum entropy.
这一过程隐含地优化了登录页面,使其具有最大的预期转换率和最少的估计不确定性(在文献中称为“利用”),同时仍然允许选择具有较低预期转换率和较高不确定性的选项(“探索”)。随着时间的推移,每个页面被选择的频率将与该选项是最佳选项的概率一致。随着时间的推移,我们可以最大限度地提高转化的数量,从而最大限度地提高贵组织最终销售的产品数量(在我们的案例中,是桌子和潮人的产品)。
这里真正强大的是这些分布不是静态的。当我们观察用户如何响应登录页面时,我们可以获取这些信息并更新每个选项的底层分布,以反映新数据中的信息,如下所示。
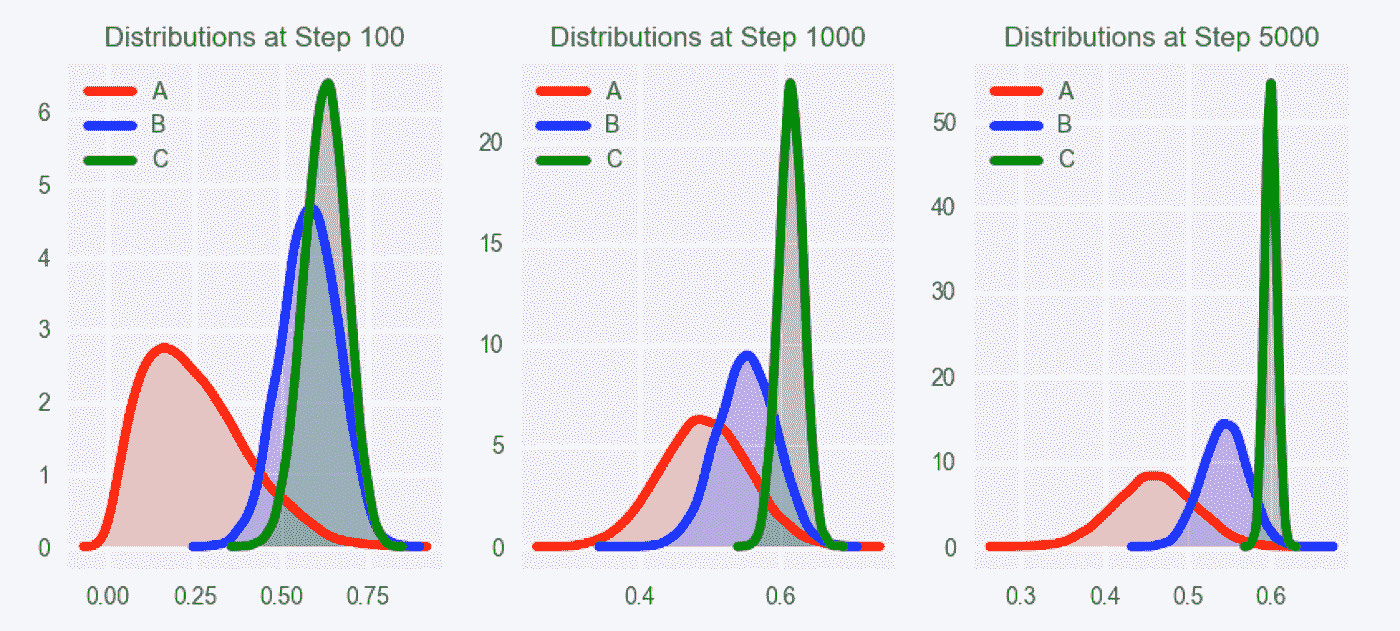
事实上,如果您对每个登录页面的预期转换没有先入为主的概念,您可以从每个页面的相同分布开始,简单地“让数据自己说话”开始时,选择是随机的,然后随着收集到更多的数据来更新分布,开始倾向于最高性能的选项。在这个例子中,登录页面“C”逐渐成为明显的赢家。
Bandits 允许从探索到利用的平稳过渡,并且可以更快更有效,因为它们实时地将流量转移到获胜的变化,而不是强迫你等到测试期结束。如果自动化和持续优化是你的目标,它们是有用的工具。
也就是说,A/B 测试仍然有一席之地,特别是如果统计的严格性和不确定性估计很重要的话。真正的诀窍是在给定的情况下找到合适的工具,并理解其中的利弊。
临别赠言:我们建议你拿出一小部分流量,用于随机选择。这个调整对抗了数据收集过程中的偏见,并确保您有一个无偏见的随机基线来评估您的 bandit 的功效。它还可以抵御不可预见的外部或季节性变化的影响,这些变化可能会彻底改变分布的参数。
超越敏捷数据科学工作流
超越我的眼睛所看到的,是我应用于生活中每一个方面的东西。在本文中,我将展示敏捷数据科学工作流如何在这方面帮助我。

我们生活在一个复杂的世界,我们生活在一个文化的世界。这意味着我们不能选择成为没有文化的生物。我们出生了,就是这样,你已经在那里了。你无法选择你的身份,父母,城市等等。然后我们学习,从生活和学校,我们的朋友,我们的家庭。
这个过程创造了一种看待事物的方式,一种思考世界、思考我们自己和我们周围事物的方式。我们的感官向世界敞开我们的大门,我们听到,我们感觉到,我们品尝到,我们看到。当我提到“超越”或类似的东西时,我指的是我们所有感官的结合,即我们从各个角度所感知的东西。
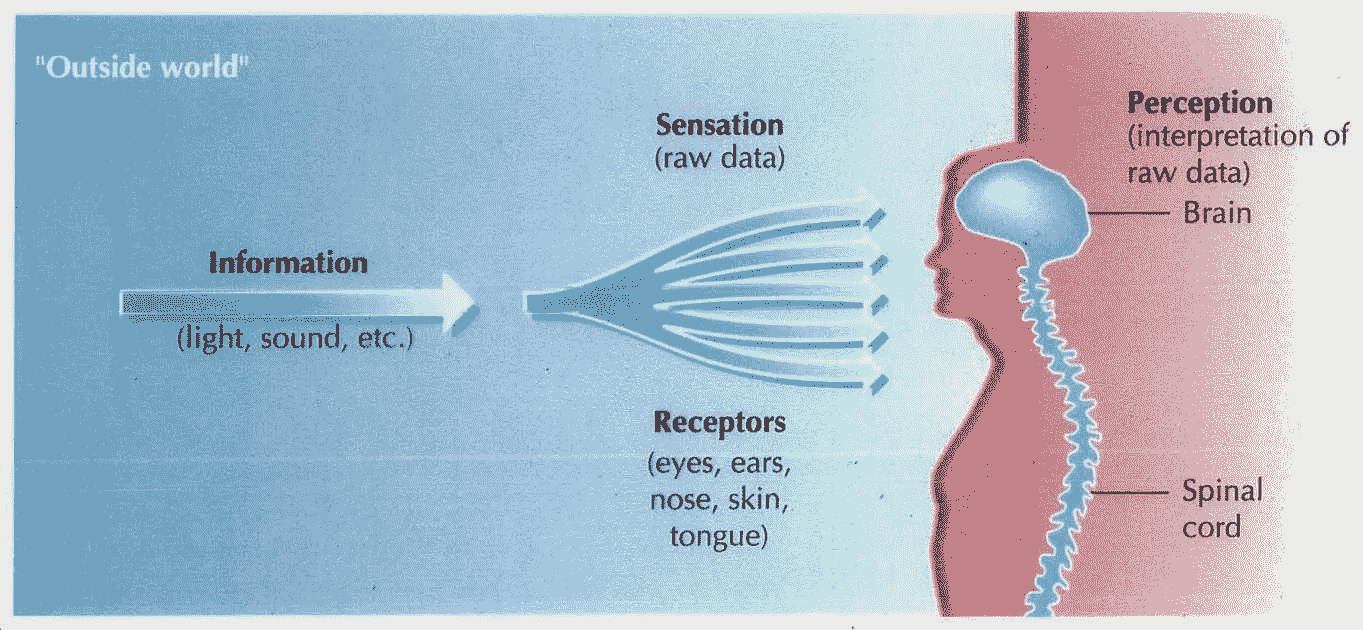
我们从“外部世界”获得数据,我们的身体和大脑分析我们获得的原始数据,然后我们“解释”事物。
建模世界

这是什么“解读”?只是我们从所获得的信息中学到了如何反应、思考、感受和理解。当我们理解时,我们正在解码形成这个复杂事物的各个部分,并将我们一开始获得的原始数据转化为有用和简单的东西。
我们通过建模来做到这一点。这是理解“现实”,我们周围的世界,但创造一个更高层次的原型来描述我们所看到的,听到的和感觉到的东西的过程,但这是一个代表性的东西,而不是“实际”或“真实”的东西。
更进一步
我们不呆在那里。我们的世界模型,或者说过程,有另一部分。我们认为特定的事物意味着什么,以及我们对它的感受。
ME JUMPING TO CONCLUSIONS
当我年轻的时候,我对很多很多事情有很多偏见。在见到人和事之前就对他们下结论。我不认为我是一个人。
我们习惯于很快下结论,而不是分析事情的每一面。我们习惯于看到我们眼睛所看到的,并“相信我们的直觉”。
遗憾的是,在我们的文化中占主导地位的常识是亚里士多德式的和中世纪式的。这意味着直觉在试图理解世界时会失败很多次,而且这种“常识”有时会伴随着判断,这种判断会在我们看待事物的方式上产生偏见。
在这种情况下,向前看意味着向前迈一步,把你的判断、常识和直觉放在一边,真正分析一种情况。我们应该为我们周围发生的每一件事都这样做,问问我们自己你正在做的、思考的和感知的事情是否真的正确。这是非常接近笛卡尔的的东西。
为什么要超越数据科学?
在一个难以预测未来的世界里,商业成功构建系统的能力离不开能力。
那么数据科学和这些有什么关系呢?实际上,超越我们的常识和直觉是解决复杂商业问题的唯一途径。
在一个充满直观模型的世界里,颠覆和进步来自超越,用数据去理解肉眼或“专家的眼光”看不到的东西。
由 Russell Jurney 提出的敏捷数据科学工作流程是理解数据科学和敏捷如何以及为什么帮助我们以创造性的方式超越、看到更多和解决问题的一种令人惊讶的方式。

https://www.oreilly.com/ideas/a-manifesto-for-agile-data-science
敏捷数据科学宣言(我们应该把敏捷数据科学工作流程放在这里)引领我们走向这一点。一次又一次地重复,重新思考业务流程和需求,尝试很多,倾听数据要说什么,理解并鼓励业务部门理解数据的意见必须始终包含在产品讨论中,找到解决问题的关键路径然后组织团队完成问题,走得更远,让模型解决问题,当然使用我们的专业知识来帮助他们,但不要偏袒他们
从了解业务及其需求到部署解决方案,我们需要从上、下、侧面看更大的画面。清空我们头脑中的直觉,每个人都可以加入到解决方案中,相信我们的模型所说的过程,并理解它是如何解决问题的。
最后,我想记住并声明,每个模型都假设一些事情,在这里,模型可以表示一种理解世界如何工作的方式,以随机森林分类器来判断交易是否是欺诈性的。我们需要理解这些假设,它们可能在开始时并不清晰,但它们确实存在。在机器学习和深度学习中,更容易看到这些假设是什么,它们在提出算法的论文中,也在代码中,所以在使用 ML 或 DL 库导入模型之前,理解它从数据和过程中假设什么,这将使“调试”变得容易得多。
感谢你阅读这篇文章。希望你在这里发现了一些有趣的东西:)
如果你有问题,就在推特上加我
Favio Vázquez 的最新推文(@FavioVaz)。数据科学家。物理学家和计算工程师。我有一个…
twitter.com](https://twitter.com/faviovaz)
还有 LinkedIn。
[## Favio Vázquez -首席数据科学家- OXXO | LinkedIn
查看 Favio Vázquez 在世界上最大的职业社区 LinkedIn 上的个人资料。Favio 有 15 个工作职位列在…
linkedin.com](http://linkedin.com/in/faviovazquez/)
那里见:)**
深入到对象检测
随着基于深度学习的计算机视觉模型的最新进展,对象检测应用程序比以往任何时候都更容易开发。除了显著的性能改进,这些技术还利用了大量的图像数据集来减少对大型数据集的需求。此外,由于目前的方法侧重于完整的端到端管道,性能也有了显著提高,实现了实时用例。
类似于我写的关于不同图像分类架构的博客文章,我将介绍两种对象检测架构。我将讨论 SSD 和更快的 RCNN,它们目前都可以在 Tensorflow 检测 API 中使用。
首先,我将介绍对象检测中的一些关键概念,然后举例说明如何在 SSD 和更快的 RCNN 中实现这些概念。
图像分类与目标检测
人们经常混淆图像分类和对象检测场景。一般来说,如果你想把一幅图像归入某个类别,你就使用图像分类。另一方面,如果您的目标是识别图像中对象的位置,例如计算对象实例的数量,则可以使用对象检测。

Illustrating the difference between classification and object detection.
然而,这两种情况之间有一些重叠。如果您想要将图像分类到某个类别中,可能会出现执行分类所需的对象或特征相对于整个图像来说太小的情况。在这种情况下,即使您对对象的确切位置或数量不感兴趣,您也可以通过对象检测而不是图像分类获得更好的性能。
想象一下,你需要检查电路板,并将其分为缺陷或正确。虽然这本质上是一个分类问题,但缺陷可能太小,用图像分类模型无法察觉。构建对象检测数据集将花费更多的时间,但它很可能会产生更好的模型。

An example of an IC board with defects.
使用图像分类模型,您可以生成完整图像的图像特征(通过传统或深度学习方法)。这些特征是图像的集合。使用对象检测,您可以在更细粒度、更精细的图像区域级别上完成这项工作。在前一种情况下,您可能会失去对分类信号的跟踪,而在后一种情况下,信号可能会以更适合用例的方式保存下来。
数据要求
为了训练自定义模型,您需要带标签的数据。对象检测环境中的标记数据是具有相应边界框坐标和标记的图像,即左下和右上(x,y)坐标+类别。

The normalised bounding box coordinates for the dogs in the image are e.g. [0.1, 0.44, 0.34, 0.56] and [0.72, 0.57, 0.87, 0.77]
一个经常被问到的问题是这样的:为了在问题 X 上做物体检测,我需要多少张图片?相反,更重要的是正确理解模型将在哪些场景中部署。每个类别有大量(例如> 100 个,可能> 1000 个)代表性图像是至关重要的。在这种情况下,代表性意味着它们应该与模型将被使用的场景范围相对应。如果您正在构建一个将在汽车上运行的交通标志检测模型,您必须使用在不同天气、照明和相机条件下拍摄的图像。对象检测模型并不神奇,实际上相当愚蠢。如果模型没有足够的数据来学习一般模式,它在生产中就不会有很好的表现。

While the image on the left is clear and easy to detect, ultimately, you should train on data which better reflects the use case.
通用对象检测框架
通常,在对象检测框架中有三个步骤。
1。首先,使用模型或算法来生成感兴趣的区域或区域提议。这些区域提议是跨越整个图像的一大组边界框(即,对象定位组件)。
2。在第二步中,为每个边界框提取视觉特征,对它们进行评估,并基于视觉特征确定提议中是否存在以及存在哪些对象(即,对象分类组件)。
3。在最后的后处理步骤中,重叠的框被组合成单个边界框(即,非最大抑制)。
区域提议
有几种不同的方法可以生成区域建议。最初,“选择性搜索”算法用于生成对象建议。莉莉艾·翁在她的博客文章中对这个算法做了详尽的解释。简而言之,选择性搜索是一种基于聚类的方法,它试图对像素进行分组,并基于生成的聚类生成建议。

An example of selective search applied to an image. A threshold can be tuned in the SS algorithm to generate more or fewer proposals.
其他方法使用从图像中提取的更复杂的视觉特征来生成区域(例如,基于来自深度学习模型的特征)或者采用强力方法来生成区域。这些强力方法类似于应用于图像的滑动窗口,具有多种比率和比例。这些区域是自动生成的,不考虑图像特征。

An example of the sliding window approach. Each of the bounding boxes will be used as a region of interest (ROI).
区域提议生成的一个重要权衡是区域的数量与计算复杂度。生成的区域越多,找到该对象的可能性就越大。另一方面,如果您详尽地生成所有可能的建议,则不可能实时运行对象检测器。在某些情况下,可以使用问题特定信息来减少 ROI 的数量(例如,行人的比率通常约为 1.5,因此生成比率为 0.25 的 ROI 是没有用的)。
特征抽出
特征提取的目标是将可变尺寸的图像缩减为一组固定的视觉特征。图像分类模型通常使用强视觉特征提取方法来构建。它们是否基于传统的计算机视觉方法(例如,基于滤波器的方法、直方图方法等)。)或深度学习方法,它们都具有完全相同的目标:从输入图像中提取代表手头任务的特征,并使用这些特征来确定图像的类别。在对象检测框架中,人们通常使用预训练的图像分类模型来提取视觉特征,因为这些模型往往能够相当好地概括(例如,在 MS CoCo 数据集上训练的模型能够提取相当一般的特征)。然而,为了改进模型,建议试验不同的方法。我在博客上发表的关于迁移学习的文章清楚地区分了不同类型的迁移学习以及它们的优缺点(一般和应用)。
非最大抑制
非最大值抑制的一般思想是将一帧中的检测数量减少到存在的对象的实际数量。如果框架中的对象相当大,并且已经生成了 2000 个以上的对象提议,则很可能其中一些提议彼此之间以及与对象之间会有显著的重叠。观看 Coursera 上的这个视频,了解更多关于 NMS 的信息。NMS 技术通常是不同检测框架的标准,但这是一个重要的步骤,可能需要根据场景调整超参数。

An example of NMS in the context of face detection.
评估指标
在对象识别任务中使用的最常见的评估度量是“mAP”,它代表“平均精度”。它是一个从 0 到 100 的数字,通常值越高越好,但是它的值不同于分类中的精度度量。
每个边界框将有一个相关的分数(该框包含对象的可能性)。基于预测,通过改变分数阈值来计算每个类别的精确召回曲线(PR 曲线)。平均精度(AP)是 PR 曲线下的面积。首先计算每个类别的 AP,然后对不同类别进行平均。最终结果是地图。
注意,如果检测具有大于某个阈值(通常为 0.5)的与地面实况框的联合’ (IoU 或重叠)的’交集,则该检测为真阳性。我们通常不使用 mAP,而是使用 mAP@0.5 或 mAP@0.25 来指代所使用的 IoU。
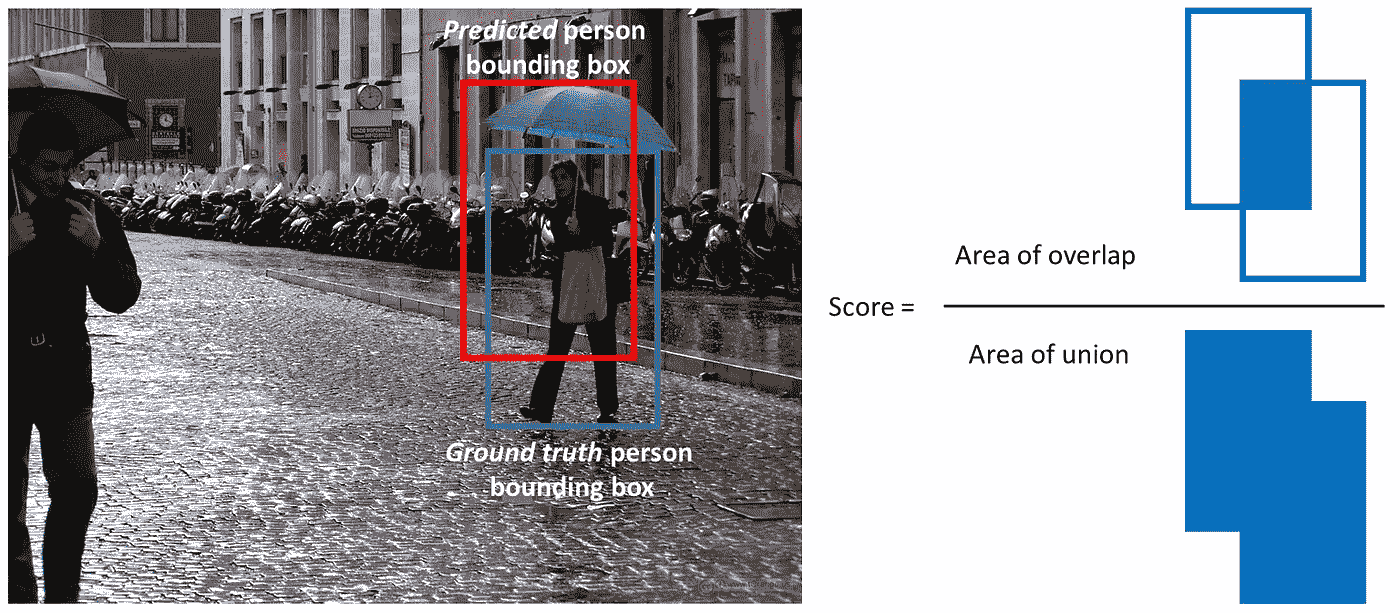
A visualisation of the definition of IoU.
张量流检测 API
Tensorflow 检测 API 在一个包中汇集了许多上述想法,允许您使用 Tensorflow 后端快速迭代不同的配置。通过 API,您可以使用配置文件定义对象检测模型,Tensorflow 检测 API 负责将所有必要的元素组织在一起。
普罗托斯
为了更好地理解不同的支持组件是什么,请看一下包含功能定义的’ protos 文件夹。特别是,在微调模型时,train、eval、ssd、faster_rcnn 和预处理原型非常重要。
单次多盒探测器
概述
SSD 架构由谷歌的研究人员于 2016 年发布。它提出了一个目标检测模型使用单一的深度神经网络结合区域建议和特征提取。
使用不同纵横比和比例的一组默认框,并将其应用于特征地图。由于这些特征图是通过将图像通过图像分类网络来计算的,因此可以在单个步骤中提取边界框的特征提取。为每个默认边界框中的每个对象类别生成分数。为了更好地适应地面真值框,为每个框计算调整偏移量。
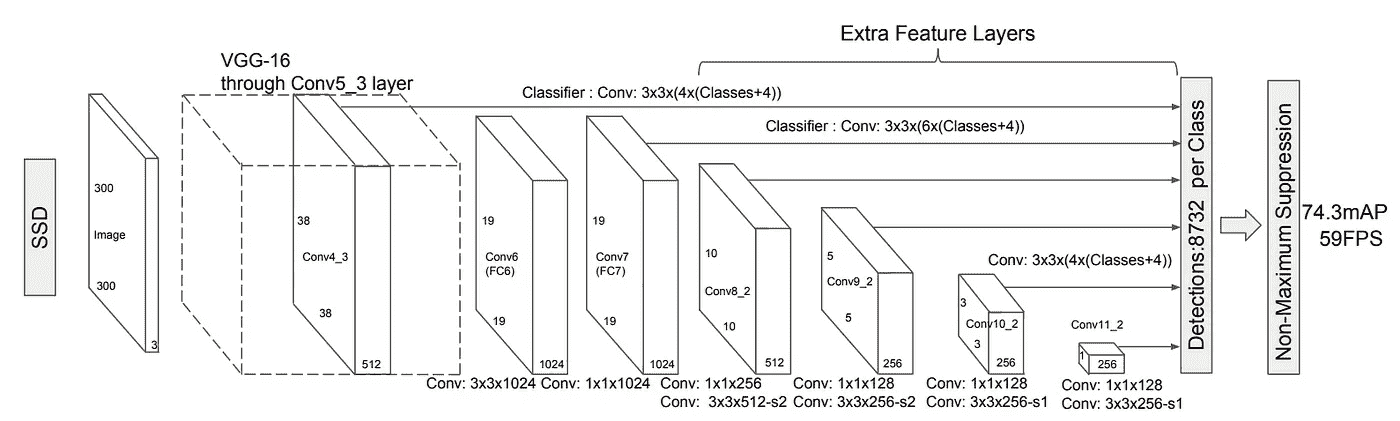
The SSD network leveraging feature maps from VGG-16
卷积网络中不同的特征图对应不同的感受野,用于自然处理不同尺度的对象。因为所有计算都封装在单个网络中,并且实现了相当高的计算速度(例如,对于 300 × 300 输入 59 FPS)。
用法 关于用法,我们将研究 SSD 的不同示例配置文件。在利用 SSD 架构时,有几个参数非常重要,我们将逐一介绍。
首先,不同的分类网络有不同的优势和劣势(见这篇博文的概述)。例如,Inceptionv3 网络经过训练,可以很好地检测不同尺度的物体,而 ResNet 架构总体上实现了非常高的精度。另一方面,Mobilenet 是一种经过训练的网络,可以最大限度地减少所需的计算资源。ImageNet 上的特征提取网络的性能、参数的数量以及对其进行训练的原始数据集是性能/速度折衷的良好代表。特征提取器在‘feature _ extractor’部分定义。
第二组明显的参数是默认框和纵横比的设置。根据问题的类型,分析标记数据的边界框的各种纵横比和比例是值得的。设置纵横比和比例将确保网络不会进行不必要的计算。您可以在“ssd_anchor_generator”部分对这些进行调整。请注意,增加更多的比例和纵横比会带来更好的性能,但通常回报会减少。
第三,在训练模型时,在“数据增强选项”和“图像大小调整”部分设置图像大小和数据增强选项是很重要的。较大图像尺寸将执行得更好,因为小的对象通常难以检测,但是它将具有显著的计算成本。数据扩充在 SSD 的环境中尤其重要,以便能够检测不同尺度的对象(甚至在训练数据中可能不存在的尺度)。
最后,调整“train_config ”,设置学习率和批量大小对于减少过度拟合是很重要的,并且将高度依赖于您拥有的数据集的大小。
更快的 R-CNN
概述
更快的 R-CNN 是由微软的研究人员开发的。它基于 R-CNN,使用多阶段方法进行目标检测。R-CNN 使用选择性搜索来确定地区建议,将这些建议通过分类网络,然后使用 SVM 对不同地区进行分类。
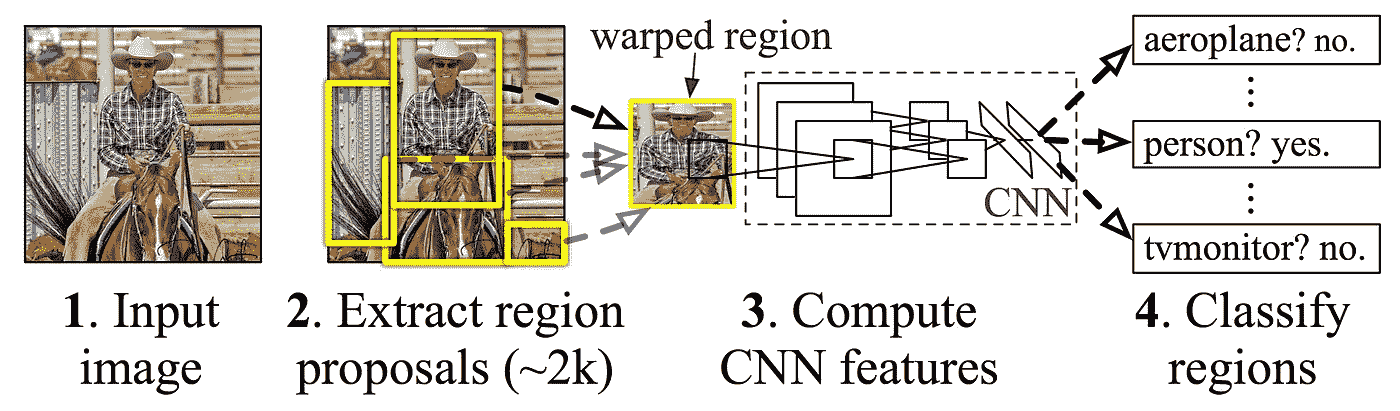
An overview of the R-CNN architecture. The NMS phase is not shown.
更快的 R-CNN,类似 SSD,是一种端到端的方式。更快的 R-CNN 没有使用默认的边界框,而是使用区域提议网络(RPN)来生成一组固定的区域。RPN 使用来自图像分类网络的卷积特征,实现几乎无成本的区域提议。RPN 被实现为预测每个位置的对象边界和对象性分数的完全卷积网络。
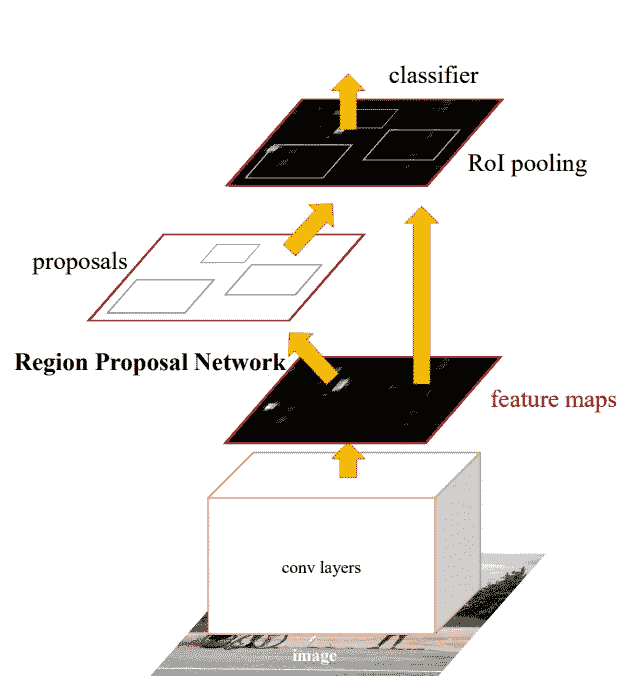
An overview of Faster-RCNN
请注意,RPN 的设置与 SSD 网络类似(即,它不会凭空预测边界框)。RPN 网络与跨特征地图的滑动窗口一起工作。在每个滑动窗口位置或锚,一组建议被计算出不同的比例和长宽比。与 SSD 类似,RPN 的结果是基于锚点的“调整”边界框。
不同的组件被组合在单个设置中,并且被端到端或分多个阶段训练(以提高稳定性)。对 RPN 的另一种解释是,它引导网络“关注”感兴趣的区域。
用法 更快的 R-CNN 的大部分使用细节与 SSD 的类似。在 raw mAP 方面,更快的 R-CNN 通常优于 SSD,但它需要更高的计算能力。
Fast-RCNN 检测器的一个重要部分是“第一阶段锚生成器”,它定义了由 RPN 生成的锚。本节中的步幅定义了滑动窗口的步幅。请注意,尤其是在尝试检测小物体时(如果步幅过大,您可能会错过它们)。
尽管 fast-RCNN 论文的作者没有使用广泛的数据扩充,但仍然建议在处理较小的数据集时使用它。
结论
还有几个对象检测架构,我还没有提到。尤其是在查看实时应用程序时,Yolov2 经常被杜撰为一种重要的架构(相当类似于 SSD)。每当这篇博文被添加到 Tensorflow 检测 API 时,我都会更新。
问题
如果你有任何问题,我很乐意在评论中阅读。如果你想收到我博客上的更新,请在 Medium 或 Twitter 上关注我!
各付各的:我如何利用数据科学和机器学习在阿姆斯特丹找到一间公寓——第一部分

阿姆斯特丹的房地产市场正在经历一场难以置信的危机,自 2013 年以来,阿姆斯特丹的房价每年以两位数的速度飙升。虽然房主有很多理由笑,但对那些想买房或租房的人来说就不一样了。
作为一名前往旧大陆的数据科学家,这对我来说是一个有趣的话题。在阿姆斯特丹,据说房产租赁市场和房产购买市场一样疯狂。我决定利用一些工具( Python、Pandas、Matplotlib、leav、plot . ly和 SciKit-Learn )来仔细研究一下这个城市的租赁市场格局,以便尝试回答以下问题:
- 一般租赁价格分布是什么样的?
- 哪些是最热门的地区?
- 哪个地区开始狩猎会更有趣?
最后,但同样重要的是,蛋糕上的樱桃:
- 我们能够预测公寓租金价格吗?
我的方法分为以下几个步骤:
- 获取数据:使用 Python,我能够从一些网站上收集出租公寓的数据。
- 数据清理:这通常是任何数据分析过程中最长的部分。在这种情况下,为了正确处理数据格式、删除异常值等,清理数据是很重要的。
- EDA: 一些探索性的数据分析为了可视化,更好的理解我们的数据。
- 预测分析:在这一步,我创建了一个机器学习模型,用我得到的数据集对它进行了训练和测试,以预测阿姆斯特丹公寓的租金价格。
- 特征工程:通过调整我们的数据和添加地理特征,概念化一个更健壮的模型
所以…我们各付各的吧

“各付各的”可以理解为在餐馆或其他场合分摊账单。根据城市词典,荷兰人在金钱上有点吝啬是出了名的——这并非巧合,我完全认同这一点。这个表达来自几个世纪前;英国与荷兰的竞争,尤其是在英荷战争期间,催生了包括荷兰语在内的一些词汇,这些词汇宣扬了某些负面的刻板印象。
回到我们的分析,我们将各付各的,以便找到一些便宜货。
由于我们管道中的“获取我们的数据”步骤,我们能够以 CSV 格式获得包含截至 2018 年 2 月阿姆斯特丹 1182 套出租公寓的数据集。
我们首先从这些数据中创建一个熊猫数据框架。
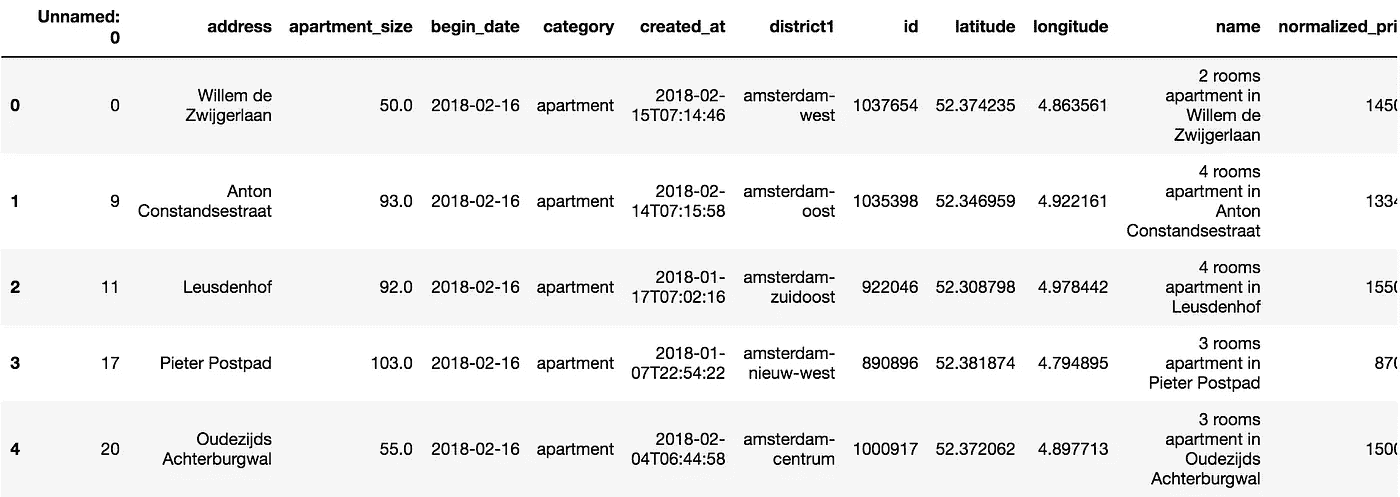
我们已经知道我们正在处理一个包含 1182 个观察值的数据集。现在让我们来看看什么是我们的变量和它们的数据类型。

现在来看一些统计数据——让我们来看一些汇总和分散测量。
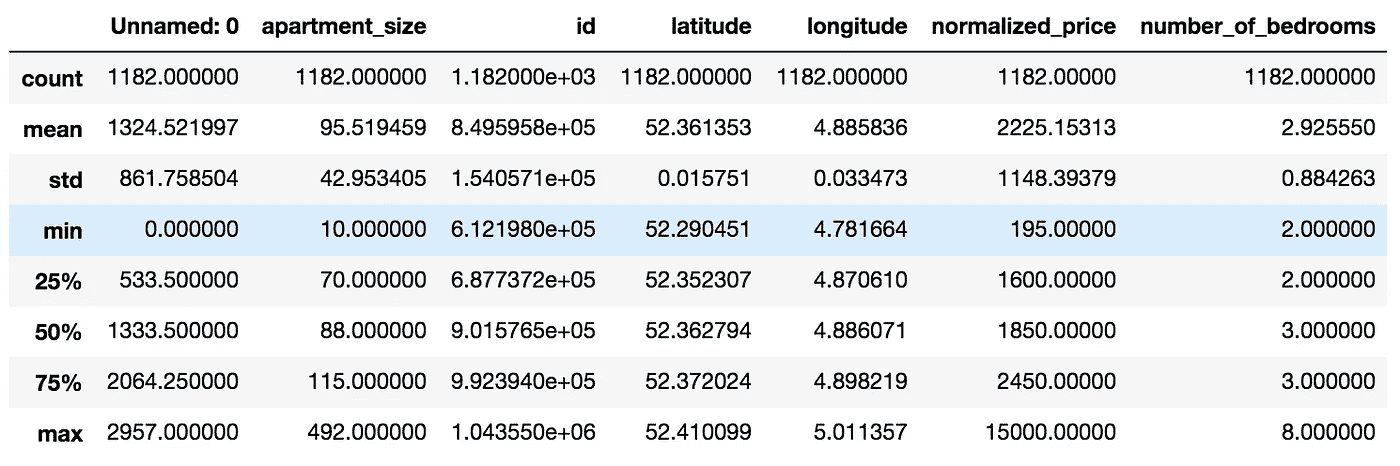
此时,我们能够在数据集上得出一些观察结果:
- 有一个*“未命名:0”*列,似乎没有保存重要信息。我们会放弃的。
- 我们有一些数据类型为*“object”*的变量。如果我们需要分析数字或字符串数据,这可能是一个问题。我们将把它转换成适当的数据类型。
- “卧室数量”的最小值是 2。同时,“公寓大小”的最小值是 10。把两间卧室放在 10 平方米的空间里听起来有点挑战,不是吗?事实证明,在荷兰,公寓的评估是基于房间的数量,而不是卧室的数量。因此,对于我们的数据集,当我们说卧室的最小数量是 2 时,我们实际上是指房间的最小数量是 2(一个卧室和一个客厅)。
- 一些列,如名称、提供商代码、开始日期和城市代码似乎没有为我们的分析增加多少价值,所以我们将删除它们。
- 我们有一些日期时间字段。但是,无法使用包含此数据类型的数据集创建预测模型。然后我们将这些字段转换成整数, Unix Epoch 编码。
- 平均公寓租金价格约为。【2225.13 欧元。公寓租金价格的标准偏差约为。【1148.40 欧元。因此,关于 normalized_price,我们的数据是过度分散的,因为分散指数(均值方差)约为 592.68。
一些基本的 EDA —探索性数据分析
除了做一些清理工作,作为数据科学家,我们的工作是向我们的数据提出一些问题。
我们已经看到了大多数变量的四分位数、最小值、最大值和平均值的一些信息。然而,我更喜欢视觉。所以让我们跳进去,生成一个 Plot.ly **box plot,**这样我们就可以看到我们数据的快照了。
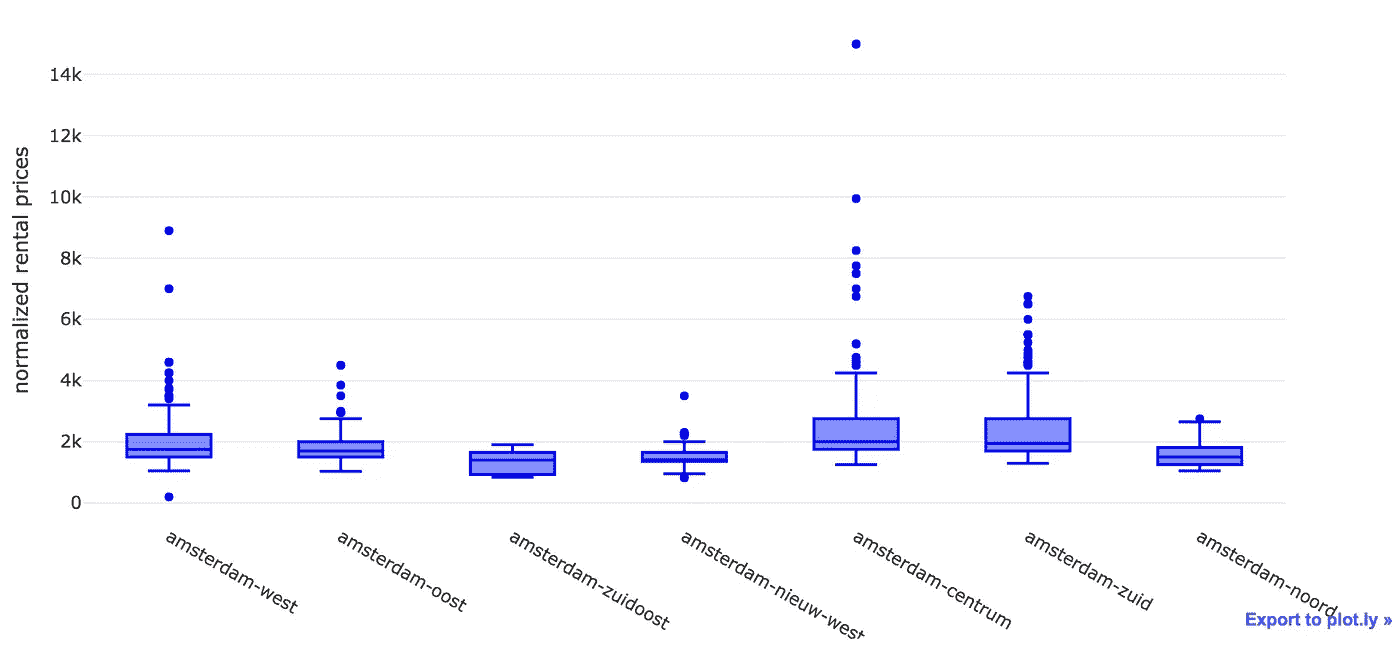
看起来我们有很多异常值——特别是阿姆斯特丹市中心的公寓。我猜有很多人想住在运河和博物馆附近——这不能怪他们。
让我们通过创建我们的数据子集来减少离群值的数量——也许对 normalized_price 的一个好的限制是欧元 3K。
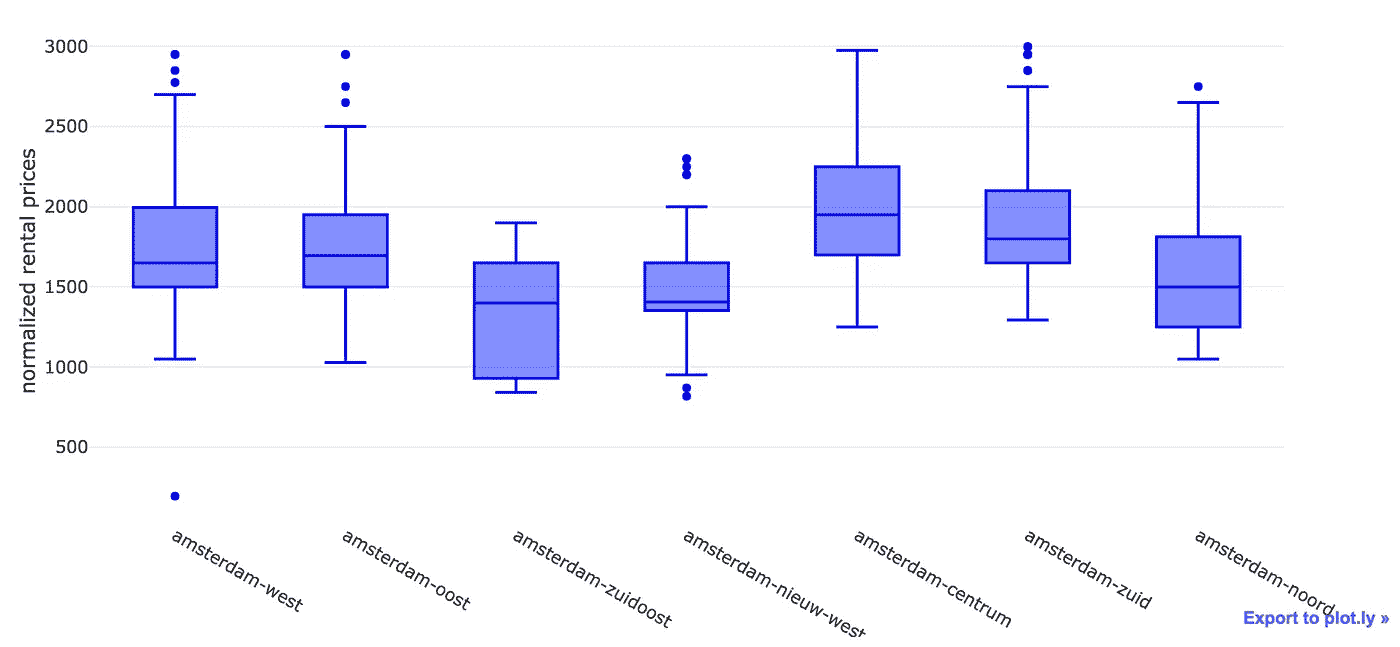
我们能够去除大部分异常值。初步分析来看,阿姆斯特丹 Zuidoost(T21)和阿姆斯特丹 Nieuw West(T23)看起来很适合我们找房子。
现在让我们看看数据的分布。
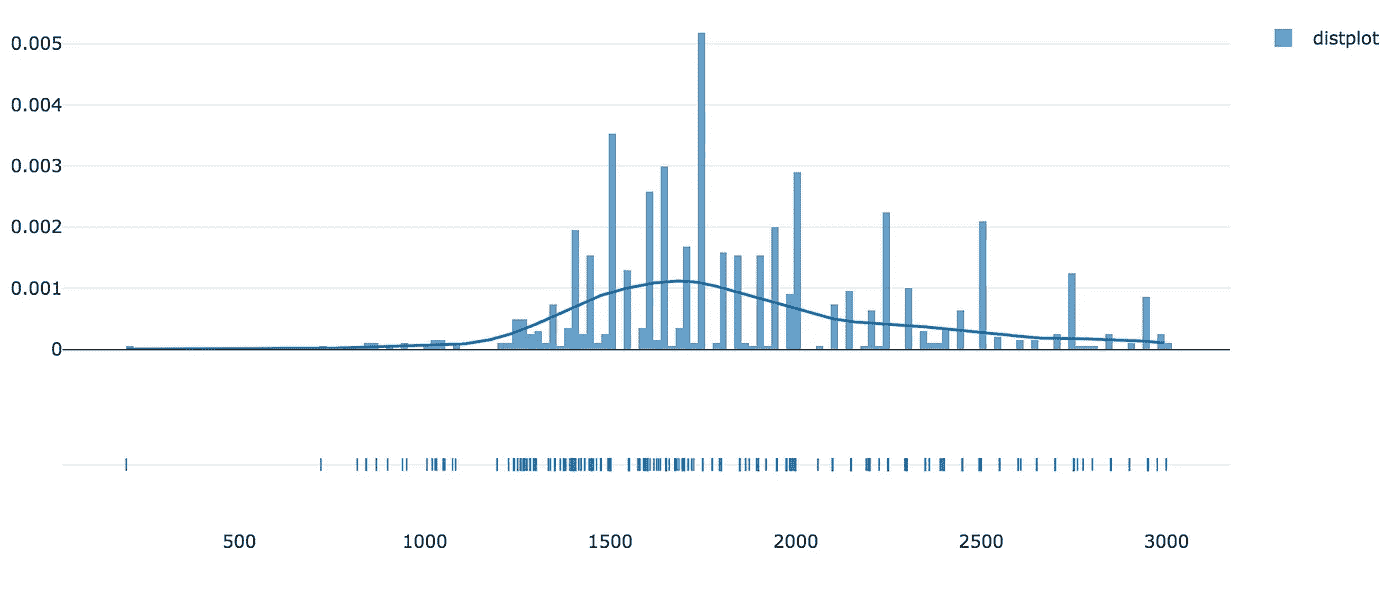
通过目测我们的分布,我们可以注意到它偏离了正态分布。
但不是偏态 ( 偏态约为 0.5915)也不是峰态 ( 峰度约为 0.2774)。
高偏度和峰值通常表示创建预测模型的问题,因为一些算法对具有(几乎)正态分布的训练数据做出一些假设。峰值可能会影响算法计算误差的方式,从而增加预测的偏差。
作为一名数据科学家,人们应该意识到这些可能的警告。幸运的是,我们没有这个问题。所以我们继续分析。我们将利用 seaborn 来生成一个 pairplot。配对图非常有用,因为它们为数据科学家提供了一种简单的方法来可视化特定数据集中变量之间的关系。
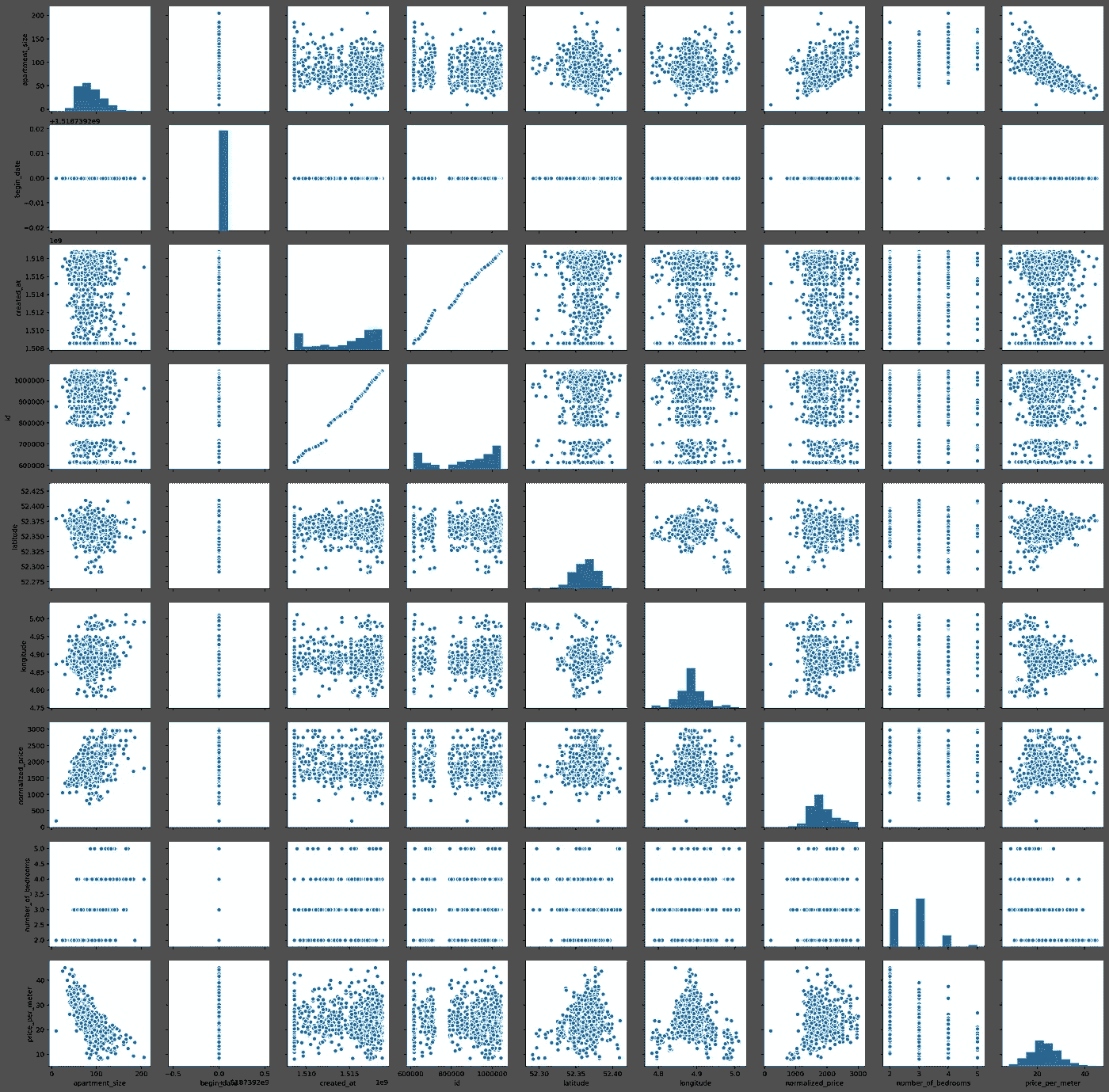
有趣的是,我们有一些近乎线性的关系。诚然,它们中的大多数一开始都有点琐碎,例如 normalized_price 对 apartment_size 。但我们也可以看到一些其他有趣的关系——例如,公寓大小与每米价格,这似乎是一种几乎线性的负相关关系。
让我们继续,借助 Seaborn 的 热图绘制每个变量之间的皮尔逊相关值。热图(或热图)是数据的图形矩阵表示,其中各个值用颜色表示。除了是一个新术语之外,“热图的概念已经存在了几个世纪,只是有不同的名称(例如阴影矩阵)。
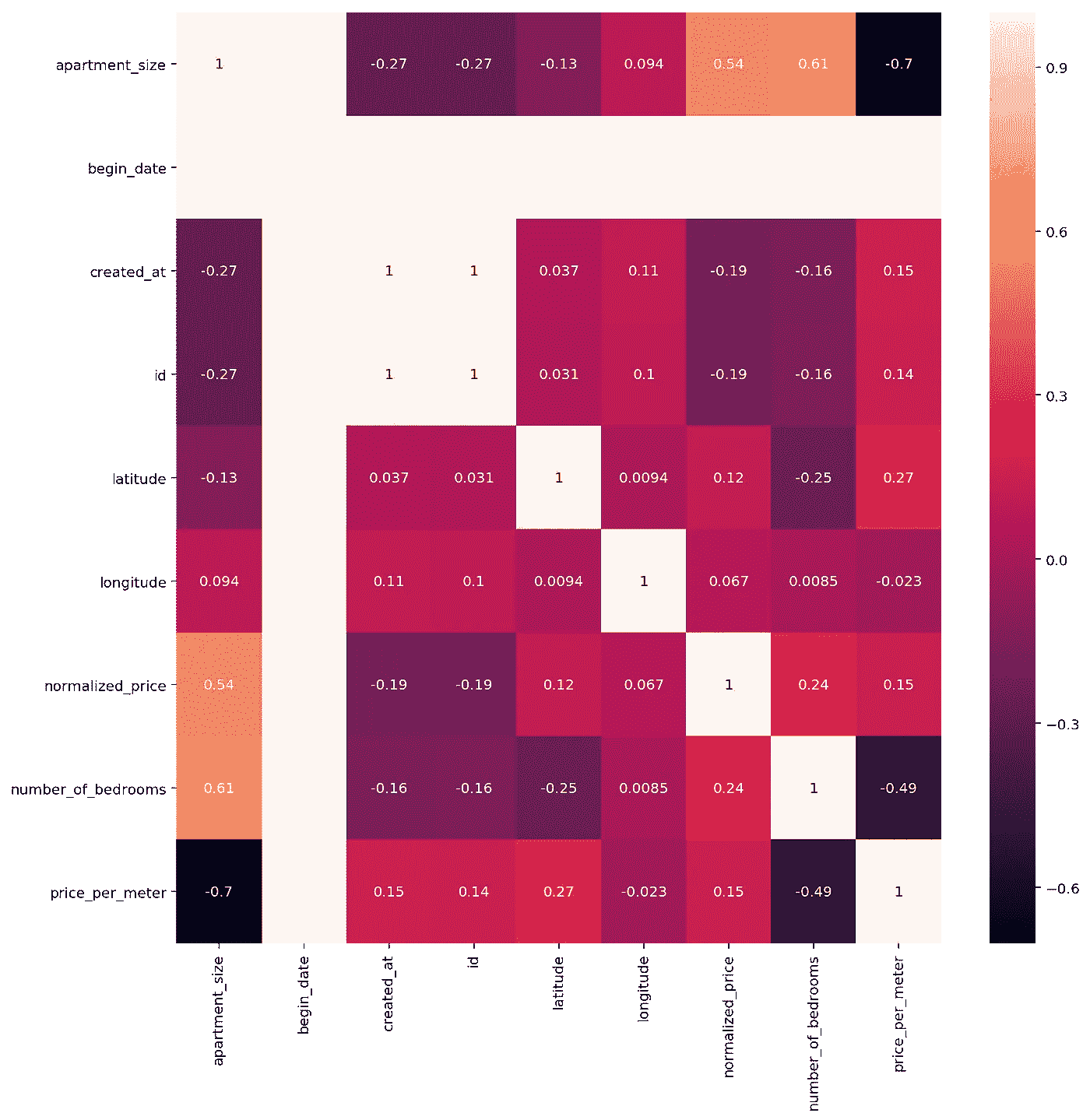
一些有趣的发现:
- 正如最初从我们的配对图中注意到的,每平方米价格和公寓面积确实有相当大的负皮尔逊相关指数(-0.7)。也就是说,粗略地说,公寓越小,每平方米的价格越高——每平方米价格上涨的 70%左右可以由公寓面积的减少来解释。这可能是由很多因素造成的,但我个人的猜测是对小公寓的需求更高。阿姆斯特丹正在巩固自己作为来自欧盟和世界各地的年轻人的目的地的地位,这些年轻人通常是单身,或者已婚但没有孩子。此外,即使在有孩子的家庭中,每个家庭的孩子数量在过去几年也快速下降。最后,较小的地方对这类公众来说更实惠。这些言论既没有科学依据,也没有统计依据——只是单纯的观察和猜测。
- 标准化价格和公寓面积的皮尔逊相关指数为 0.54。这意味着它们是相关的,但没那么相关。这是意料之中的,因为租赁价格可能包含其他因素,如位置、公寓条件等。
- 有两条白线与 begin_date 变量相关。结果,对于每一次观察,这个变量的值等于 16/02/2018 。所以很明显,在开始日期和我们数据集中的其他变量之间没有线性关系。因此,我们将放弃这个变量。
- 经度和 normalized_price 的相关性可以忽略不计,几乎为零。对于经度和每米价格之间的相关性也可以这样说。
近距离观察
由于我们的 pairplot 和 heatmap,我们已经看到了一些变量之间的相关性。让我们放大这些关系,首先是规模与奖金,然后是规模与价格(对数标度)。我们还将调查价格和纬度(对数标度)之间的关系,因为我们有兴趣知道哪些是最热门的狩猎地区。此外,尽管在上一步中获得了相关性,我们还将调查大小和纬度(对数标度)之间的关系。难道古老的&黄金地产咒语T21【地段、地段、地段 对阿姆斯特丹适用吗?这句口头禅也会决定公寓的大小吗?
我们会找到答案的。
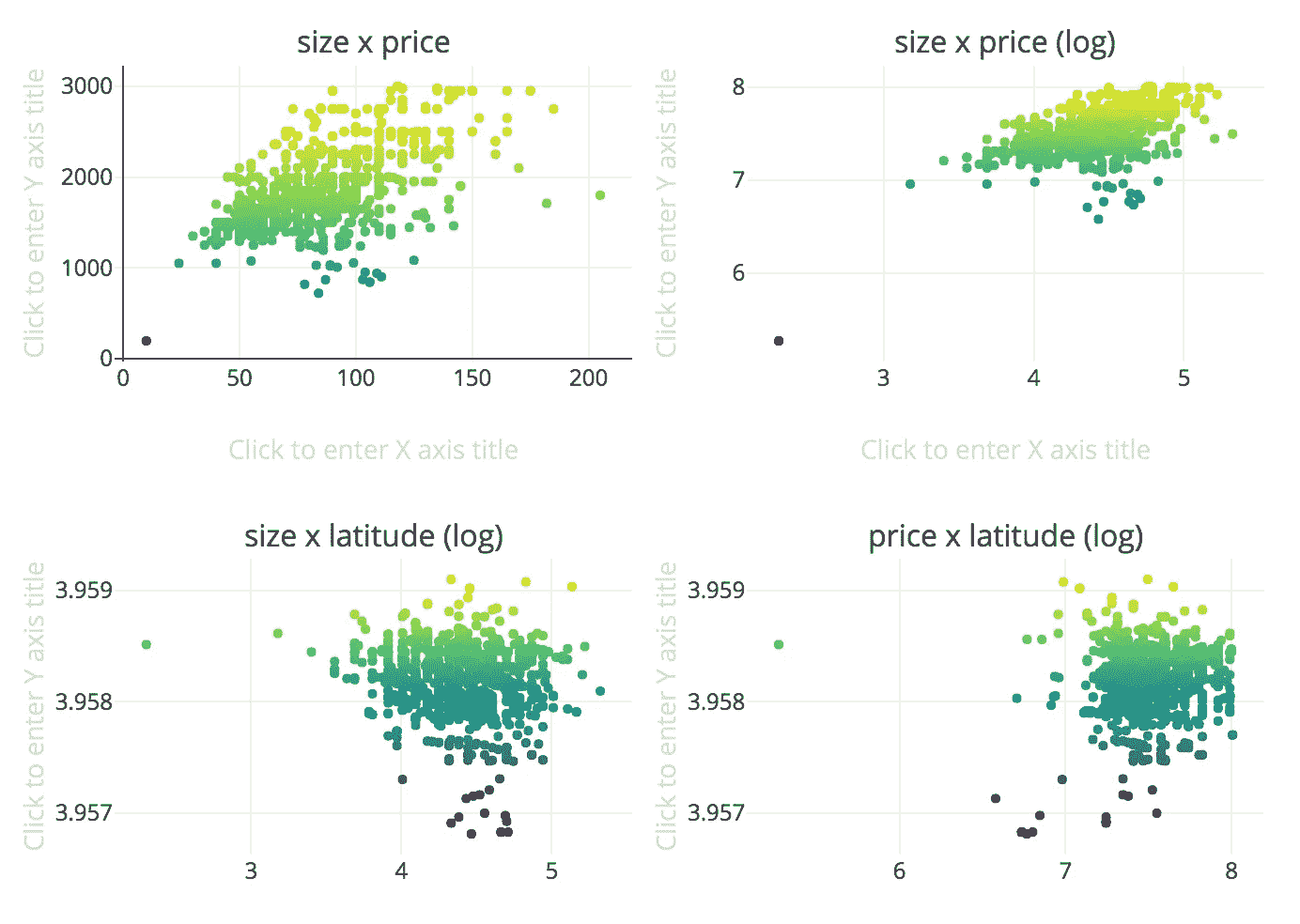
嗯,我们不能真的说这些变量之间有线性关系,至少目前没有。请注意,我们对一些图使用了对数标度,以尝试消除由于标度之间的差异而可能产生的失真。
这是这条线的终点吗?
尽头
我们对模型中变量之间的一些关系做了一些检查。我们无法想象标准化价格或每米价格与纬度、经度和经度之间的任何关系。
然而,我想对这些价格在地理上的表现有一个更直观的看法。如果我们能看到阿姆斯特丹的地图,描绘出哪些地区更贵/更便宜,会怎么样?
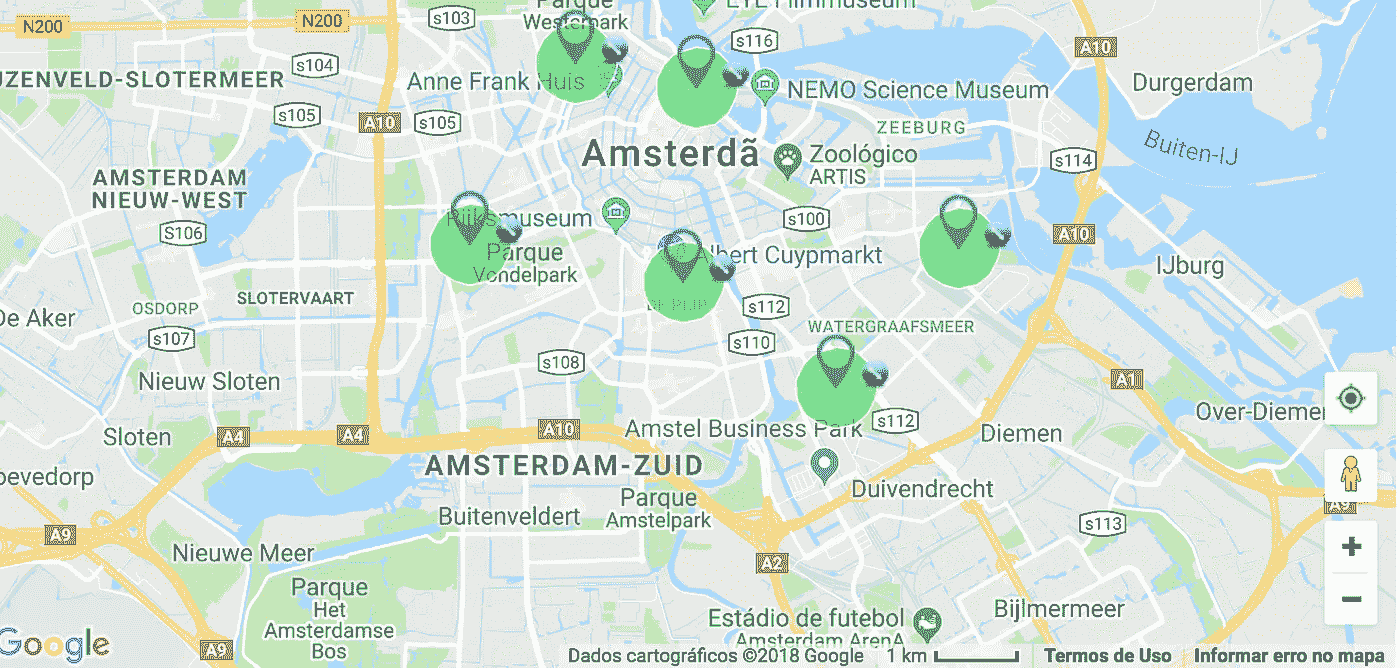
使用叶子,我能够创建下面的可视化。
- 圆圈尺寸根据公寓尺寸定义,使用 0-1 的标度,其中 1 =最大公寓尺寸,0 =最小公寓尺寸。
- 红圈代表高 价格与面积比的公寓
- 绿色圆圈代表相反的情况——价格与面积比低的公寓
- 每个圆圈在被点击时会显示一个文本框,其中包含以欧元为单位的月租金,以及以平方米为单位的公寓面积。
在视频的前几秒钟,我们可以看到运河之间的一些红点,靠近阿姆斯特丹中心。当我们离开这一地区,走近其他地区,如阿姆斯特丹祖伊德、阿姆斯特丹祖伊杜斯特、阿姆斯特丹西和阿姆斯特丹北时,我们能够看到这种模式的变化——大部分是由大绿圈组成的绿点。也许这些地方提供一些不错的交易。使用我们创建的地图,可以定义一条路径来开始寻找一个地方。
所以也许价格和位置终究是有关系的?
也许这就是线的终点了。也许这些变量之间没有线性关系。
走向绿色:随机森林
随机森林或随机决策森林是一种用于分类、回归等任务的集成学习方法,通过在训练时构建大量决策树并输出类(分类)或单个树的均值预测(回归)的模式的类来操作。随机决策树纠正了决策树的习惯,即过度适应到它们的训练集,并且在检测数据中的非线性关系时非常有用。
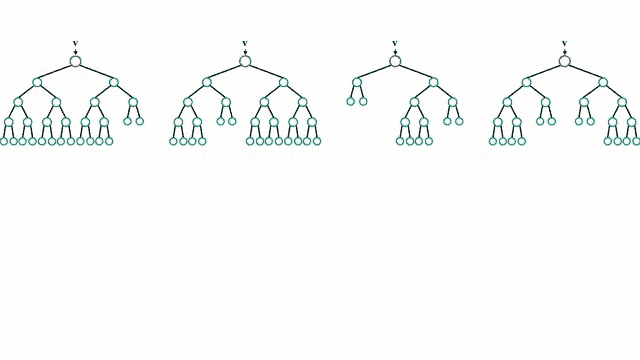
This.
随机森林是我最喜欢的机器学习算法之一,由于一些特征:
- 随机森林几乎不需要数据准备。由于它们的逻辑,随机森林不需要对数据进行缩放。这消除了清理和/或扩展数据的部分负担
- 随机森林可以训练的非常快。旨在使单个树多样化的随机特征子集同时也是一个很好的性能优化
- 随机森林很难出错。例如,与神经网络相反,它们对超参数不那么敏感。
这样的例子不胜枚举。我们将利用这种力量,尝试用我们目前掌握的数据来预测公寓租赁价格。我们的目标变量为我们的 R **随机森林回归变量,**即我们将尝试预测的变量,将是 normalized_price 。
但在此之前,我们需要做一些功能工程。我们将使用 Scikit-learn 的随机森林实现,这需要我们对分类变量进行一些编码。在我们的例子中是地区 1 和地址。其次,我们还会去掉一些不重要的功能。最后,我们需要删除 **price_per_meter,**我们创建的一个变量,它是 normalized_price 的代理——否则我们将会有数据泄漏,因为我们的模型将能够“欺骗”并轻松猜测公寓价格。
培训和测试
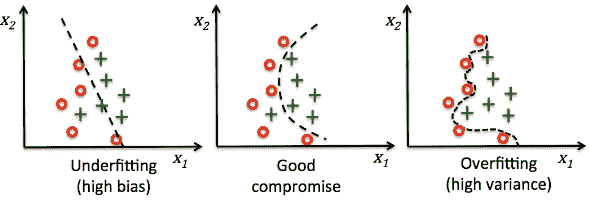
How overfitting usually looks like.
过度拟合发生在模型捕捉到数据中的噪声和异常值以及潜在模式时。这些模型通常具有高方差和低偏差。这些模型通常很复杂,像决策树、SVM 或神经网络,容易过度拟合。这就像一个足球运动员,除了是一个非常好的前锋,他在其他位置上表现很差,比如中场或者防守。他太擅长达成目标了,然而在其他事情上却做得极其糟糕。
测试过度配合的一种常见方法是设置单独的训练和测试。在我们的例子中,我们将使用由数据集的 70%组成的训练集,使用剩余的 30%作为我们的测试集。如果在预测训练集的目标变量时,我们的模型得到了很高的分数,但在预测测试集时却得到了很低的分数,那么我们可能会过度拟合。
摊牌
在训练和测试我们的模型之后,我们能够得到下面的结果。
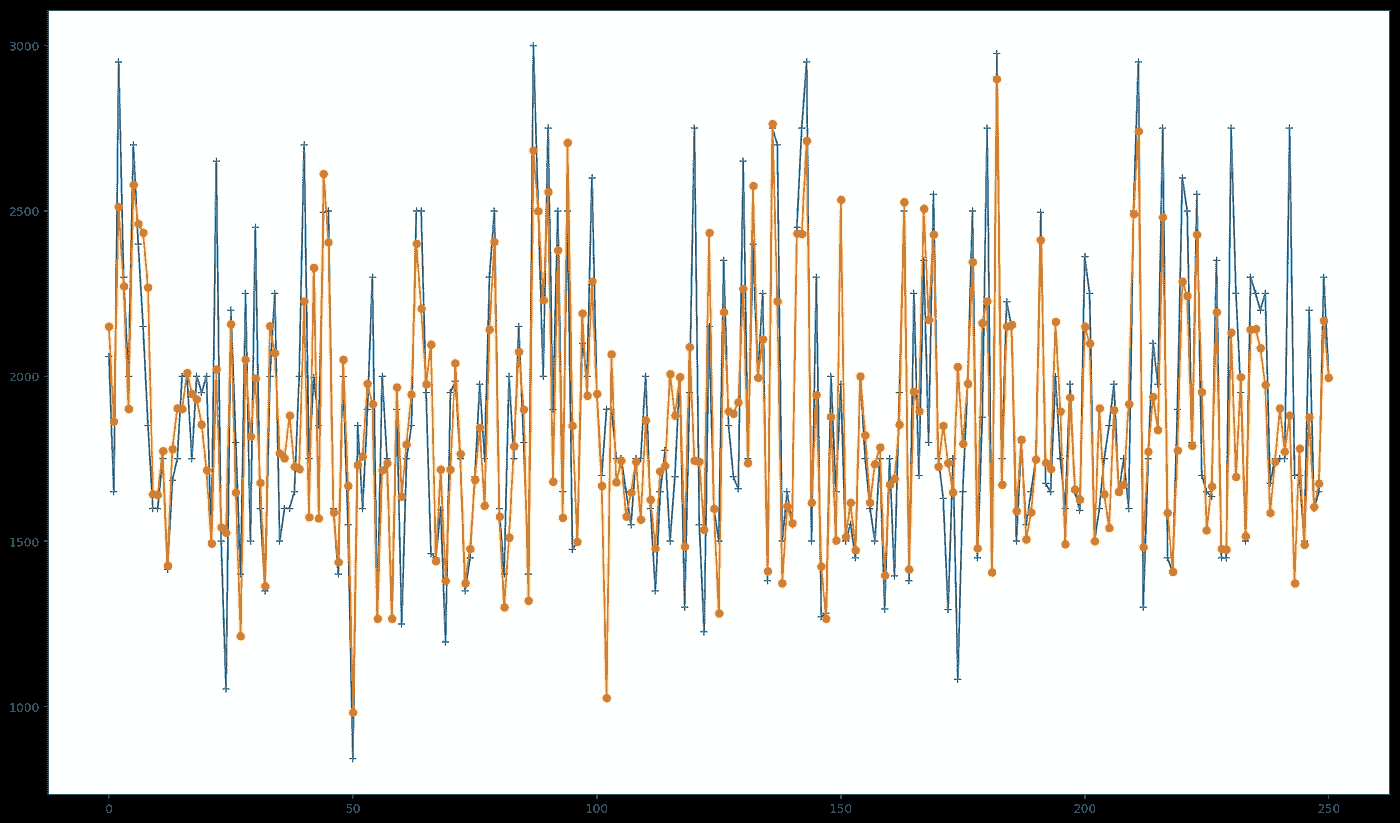
Predicted Values in Orange; Actual Values in Blue.
从图中我们可以看到,我们的模型在预测公寓租金价格方面做得不错。使用我们的模型,我们能够获得 0.70的分数,其中 1 代表可能的最佳分数,而-1 代表可能的最差分数。
请注意,这是我们的基线模型。在本系列的第二篇文章中,我将事情扩展了一点,以便在模型分数上获得大约 10%的提高。
你可能也会喜欢
**** [## 保持机器学习模型在正确的轨道上:MLflow 入门,第 1 部分
了解为什么模型跟踪和 MLflow 对于成功的机器学习项目至关重要
mlopshowto.com](https://mlopshowto.com/keeping-your-machine-learning-models-on-the-right-track-getting-started-with-mlflow-part-1-f8ca857b5971) [## 各付各的,第 2 部分:使用地理数据改进机器学习模型
一切开始的地方
towardsdatascience.com](/going-dutch-part-2-improving-a-machine-learning-model-using-geographical-data-a8492b67b885)****
各付各的,第 2 部分:使用地理数据改进机器学习模型

一切开始的地方
在我之前的帖子中,我描述了使用数据科学和机器学习在阿姆斯特丹寻找公寓的过程。使用从互联网上获得的公寓租金数据,我能够探索和可视化这些数据。作为可视化部分的一部分,我可以创建下面的地图:
最终,我能够使用这些数据来构建、训练和测试一个使用随机森林的预测模型。有可能达到 R2 得分 **0.70,**这对于基线模型来说是一个很好的衡量标准。测试集的预测值与实际值的对比结果如下图所示:
从这些数据中创建一个预测模型的想法是为了有一个好的参数,以便知道租赁列表是否有一个公平价格。这将允许我们找到一些便宜的或者扭曲的东西。这背后的推理是,如果我遇到任何一套公寓的租赁价格比我们的模型预测的低得多,这可能意味着一笔好交易。最终,这被证明是在阿姆斯特丹找房子的一种有效方式,因为我能够专注于特定的区域,发现一些好的交易,并在我来到这座城市的第一天找到一套公寓。****

After finding an apartment in AMS
现在回到我们的模型。作为一个基线模型,在预测质量方面有潜在的改进空间。下面的管道已经成为我最喜欢的处理数据问题的方法:
- 从基线模型开始
- 检查结果
- 改进模型
- 重复直到结果令人满意
所以我们现在到了第三步。我们需要改进我们的模型。在上一篇文章中,我列出了我如此喜欢随机森林的原因,其中之一是你不需要花很多时间调优超参数(例如神经网络就是这种情况)。虽然这是一件好事,但另一方面,为了改进我们的模型,它给我们施加了一些限制。我们几乎只剩下工作和改进我们的数据,而不是试图通过调整参数来改进我们的预测模型。
这就是数据科学的妙处之一。有时候这感觉像是一项调查工作:你需要寻找线索并把这些点联系起来。就好像真相就在那里。

Look! An empty apartment in Amsterdam!
所以现在我们知道,我们需要处理我们的数据,并使它变得更好。但是怎么做呢?
在我们的原始数据集中,我们能够应用一些特征工程来创建一些与公寓位置相关的变量。我们为一些分类特征创建了虚拟变量,例如地址和地区。这样,我们最终为每个地址和地区类别创建了一个变量,它们的值可以是 0 或 1。但是我们在分析中忽略了一个方面。
北方的威尼斯

阿姆斯特丹有一百多公里长的grachten(canals),大约 90 个岛屿和 1500 座桥梁。沿着主要运河有 1550 座纪念性建筑。17 世纪的运河圈地区,包括 Prinsengracht、Keizersgracht、Herengracht 和 Jordaan,在 2010 年被联合国教科文组织列为世界遗产T21,为阿姆斯特丹赢得了“北方威尼斯”的美誉。

阿姆斯特丹的地址通常包含一些信息,可以让人们知道一个地方是否坐落在运河前面——所谓的“运河房屋”。位于 Leidsegracht 的公寓最有可能看到运河的景色,而位于 Leidsestraat、的公寓就不一样了。也有建筑物位于广场内的情况,例如广场上的一些建筑物。
不用说,运河房子有额外的吸引力,因为它们提供了美丽的景色。在脸书群体中,可以看到运河房屋在挂牌后几个小时内就被出租。

Who wants to live in a Canal House?
我们将从公寓地址中提取这些信息,以创建另外三个变量: gracht 、 straat 和 plein ,可能的值为 0 和 1。为这些变量创建单独的变量,而不是仅创建一个具有不同可能值(如 1、2、3)的变量的原因是,在这种情况下,我们会将其视为一个连续变量,诱使我们的模型考虑这一重要性尺度。我们将有希望发现运河房屋是否真的如此受欢迎。
位置,位置,位置
通过观察我们的模型的特征重要性排名中的前 15 个最重要的特征,我们能够注意到,除了纬度和经度之外,许多与地址和地区相关的虚拟变量对于我们的模型是有价值的,以便正确地进行预测。所以我们可以说,位置数据肯定大有可为。
我们将详细阐述这一点。但问题是,怎么做?

Restaurants, bars and cafes near Leidseplein, Amsterdam.
走向社交
阿姆斯特丹除了拥有大约 80 万居民(对于西欧国家的首都来说,这个数字很小)之外,还遍布酒吧、咖啡馆和餐馆,拥有欧洲最好的公共交通系统之一。但是,重要的是要想清楚我们的目标主体:人。我们在这里的主要目的是了解人们在寻找公寓时的行为。我们需要将我们的目标分成不同的群体,这样我们就可以了解他们在住房和位置方面的需求。有人可能会说,靠近酒吧、咖啡馆和餐馆对某些人来说是有吸引力的。其他人可能愿意住在离公园和学校更近的地方,比如有小孩的夫妇。这两类人也可能对住在公共交通附近感兴趣,比如电车和公共汽车站。

Amsterdam Centraal Station
这给了我们一些建立假设的提示。靠近这些类型的地方会影响公寓租金价格吗?
为了测试这个假设,我们需要将这些数据输入到我们的模型中。
Yelp 是一个社交平台,它宣传自己的宗旨是“将人们与当地伟大的企业联系起来”。它列出了诸如酒吧、餐馆、学校和许多其他类型的兴趣点——世界各地的兴趣点,允许用户对这些地方写评论。2018 年,在 Q1,Yelp 每月平均有 3000 万独立访客通过 Yelp 应用程序访问 Yelp,7000 万独立访客通过移动网络访问 Yelp。通过 Yelp 的融合 API 可以很容易地提取 POI 信息,将纬度和经度作为参数。
Yelp 在其数据库中列出了一些地点类别(不幸的是,没有关于咖啡店的类别)。我们对以下内容感兴趣:
活跃的生活:公园、健身房、网球场、篮球场
酒吧:酒吧和酒馆
咖啡馆:不言自明
教育:幼儿园、高中和大学
酒店/旅游:酒店、汽车租赁店、旅游信息点
交通:电车/公共汽车站和地铁站
对于这些类别中的每一个,Yelp 都列出了包含其纬度和经度的 POI。
我们的方法是:
- 查询Yelp Fusion API以获取阿姆斯特丹上述类别的兴趣点数据
- 计算每个公寓和每个 POI 之间的米距离。
- 计算每个类别中有多少个 poi位于每个公寓的 250 米半径内。这些数字将成为我们数据集中的变量。
通过使用 Yelp 的 Fusion API,我们已经能够获取目标范围内每个类别的 50 个兴趣点的地理数据。
在我们开始计算每个 POI 和每个公寓之间的距离之前,请记住:纬度和经度是角度的度量。
纬度是指赤道以北或以南的度数。经度被测量为本初子午线线以东或以西的度数。这两个角度的组合可用于精确定位地球表面的确切位置。
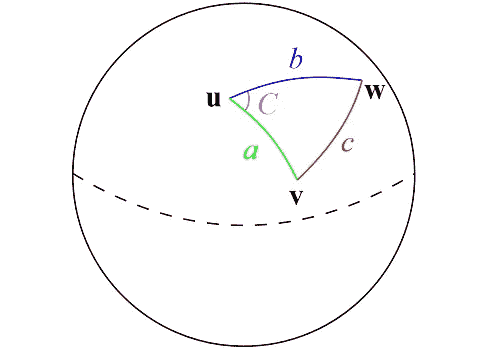
如上图所示,地球表面两点之间最快的路径是"大圆路径",换句话说,这条路径包含了你可以在地球上画出的与两点相交的最长圆的一部分。并且,由于这是使用以角度表示的坐标的球体上的圆形路径,距离的所有属性将由三角公式给出。
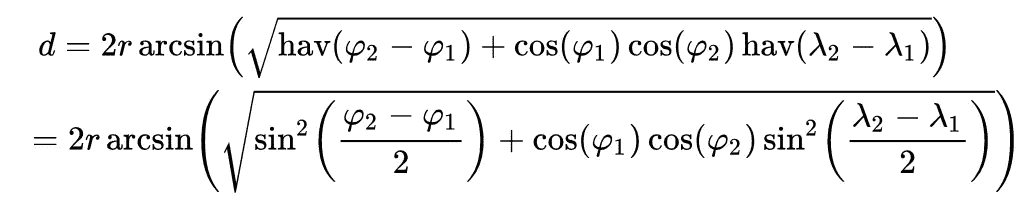
Haversine Formula.
地球上两点之间的最短距离可以用哈弗辛公式计算出来。在 Python 中,它看起来像这样:
from math import sin, cos, sqrt, atan2, radians
# approximate radius of earth in km
R = 6373.0
lat1 = radians(52.2296756)
lon1 = radians(21.0122287)
lat2 = radians(52.406374)
lon2 = radians(16.9251681)
dlon = lon2 - lon1
dlat = lat2 - lat1
a = sin(dlat / 2)**2 + cos(lat1) * cos(lat2) * sin(dlon / 2)**2
c = 2 * atan2(sqrt(a), sqrt(1 - a))
distance = R * c
现在我们知道了如何计算两点之间的距离,对于每个公寓,我们将计算每个类别中有多少个 POI 位于 250 米半径范围内。
将这些数据连接到我们之前的数据集中后,让我们看一下它的样子——注意右侧的最后几列:
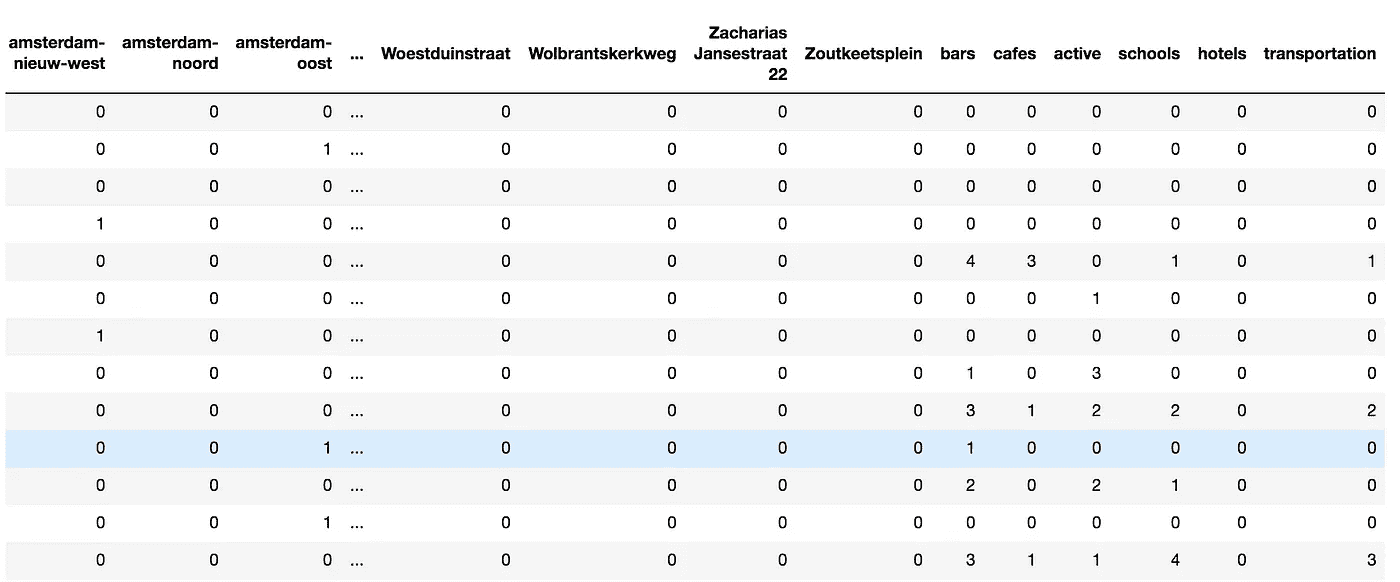
把所有的放在一起
让我们看看添加这些变量后的数据集。
我们将从获得描述性统计的一些度量开始:
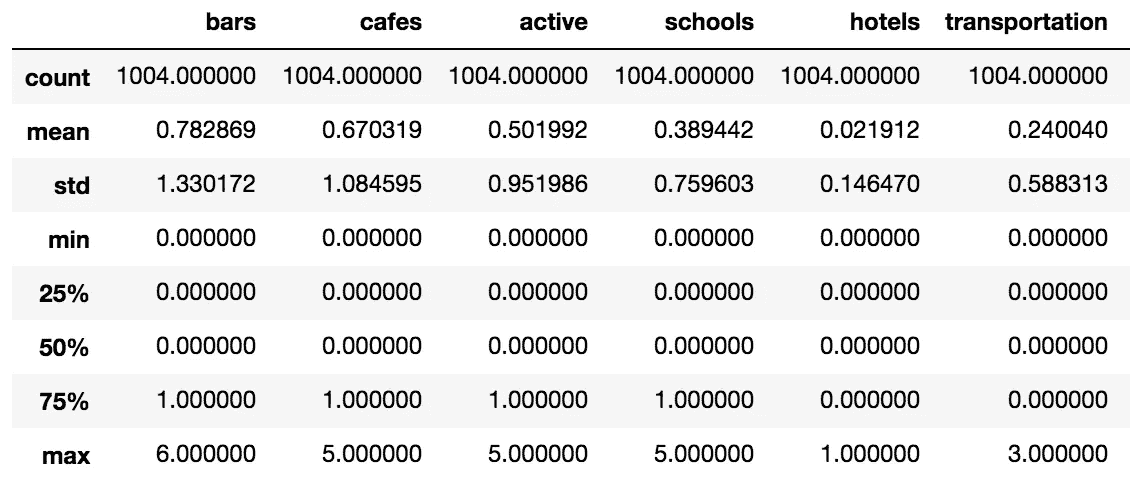
- 公寓在 250 米半径范围内平均有 0.7828 个酒吧。对于那些喜欢去喝一杯啤酒而不需要走太多路的人来说,这是个好消息。
- 咖啡馆似乎也遍布整个城市,平均每个公寓步行距离内有 0.6703 个 POI。
- 公寓 250 米内交通 POI 平均数量接近于零。
我们现在将为这些变量生成一些箱线图,看看它们如何影响 normalized_price 。
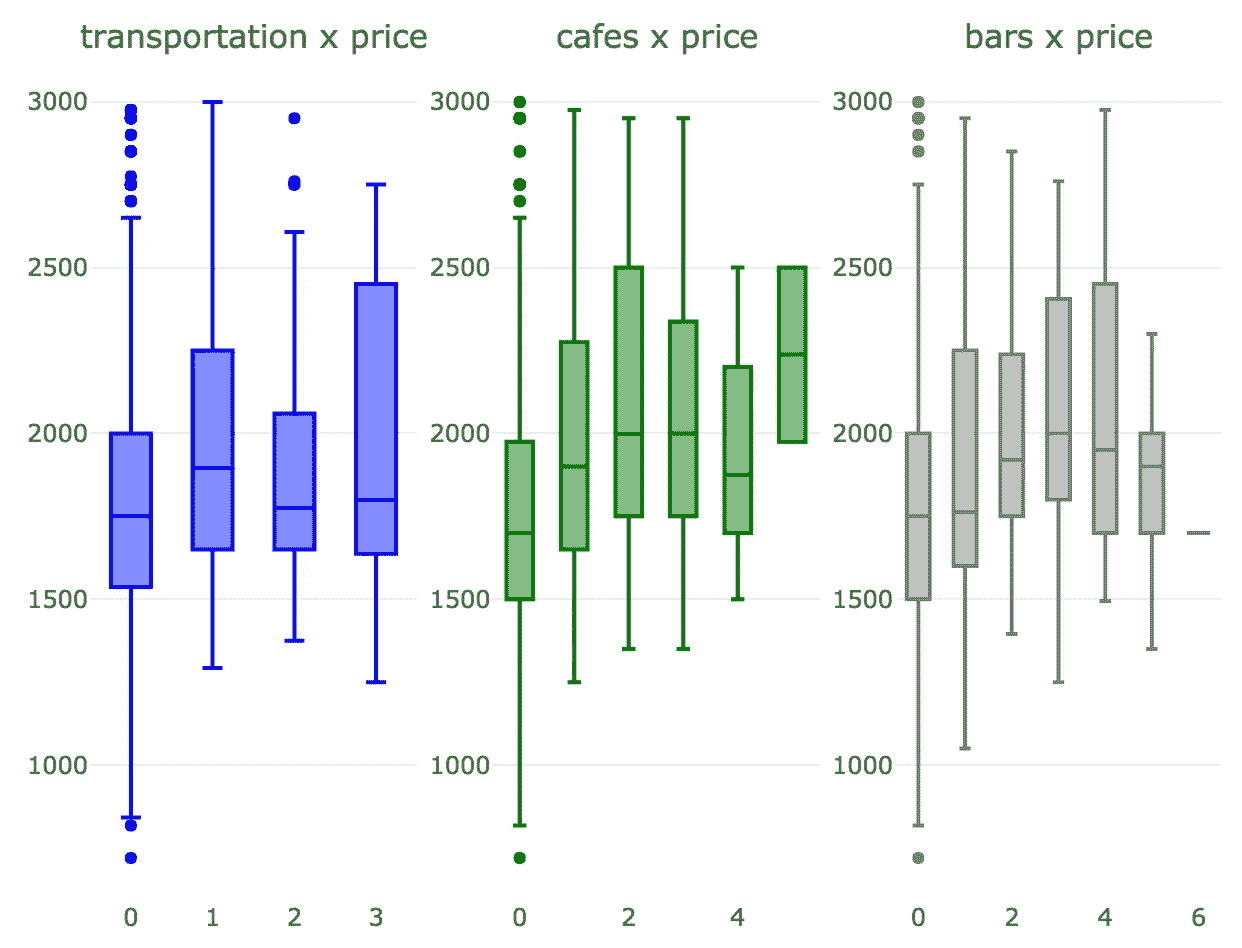
看起来这三个变量确实对 normalized_price 有重大影响。
那么 gracht 、 straat 和 plein 呢?
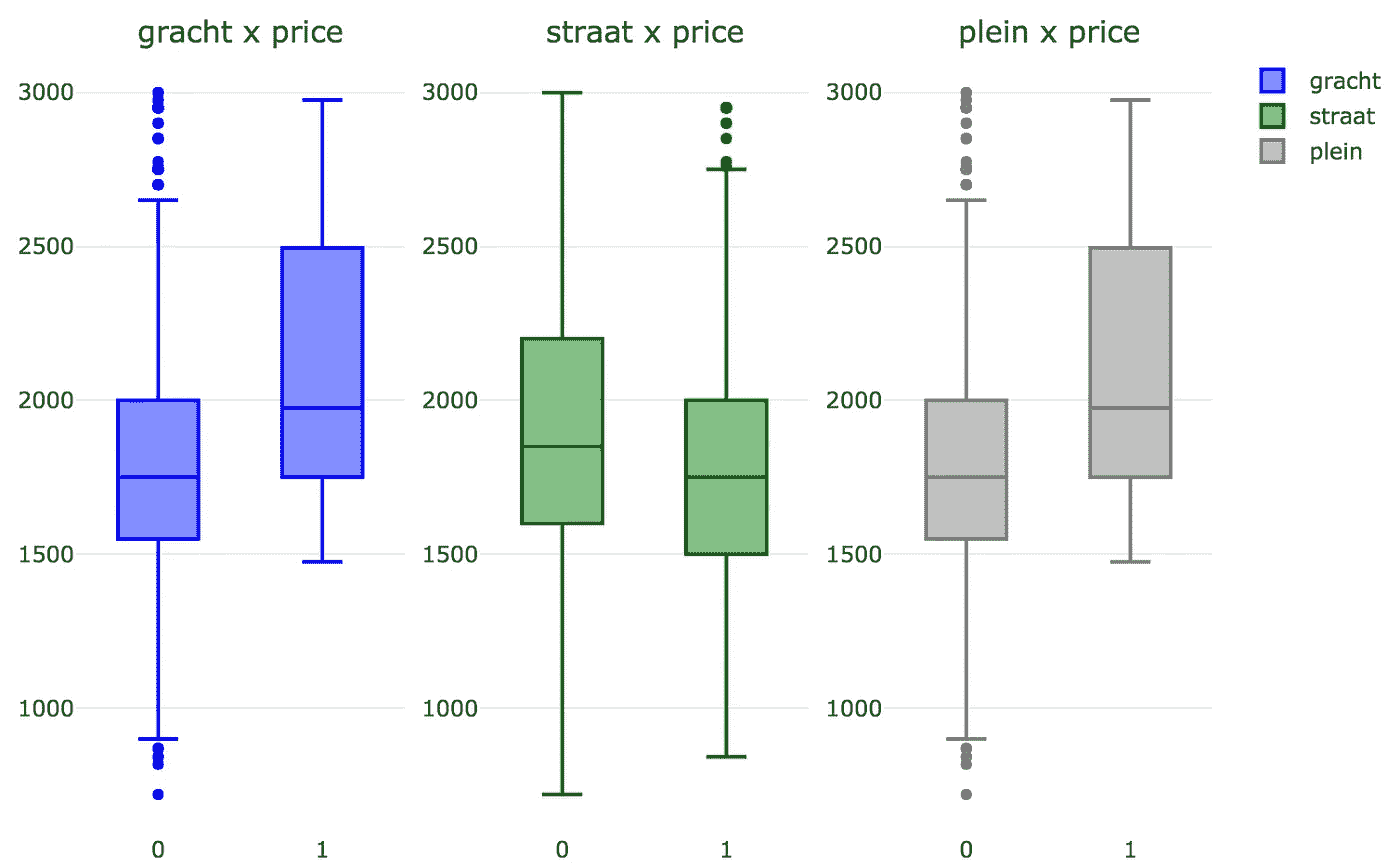
不出所料,运河别墅和广场公寓的价格都略高。对于位于普通街道的公寓,价格略低。
现在,我们将总结所有内容,并通过模型中引入的新变量和我们的目标变量 normalized_price 之间的 Pearson Correlation 矩阵生成热图。
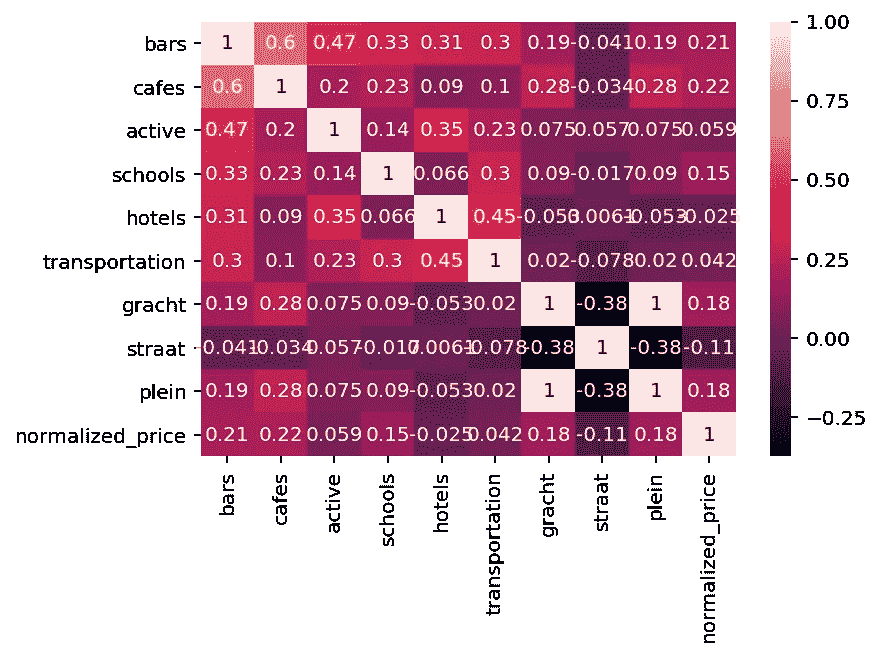
不幸的是,我们的热图没有提供我们的新变量和 normalized_price 之间显著相关性的任何迹象。但是,这并不意味着它们之间没有任何关系,只是意味着没有显著的线性关系。
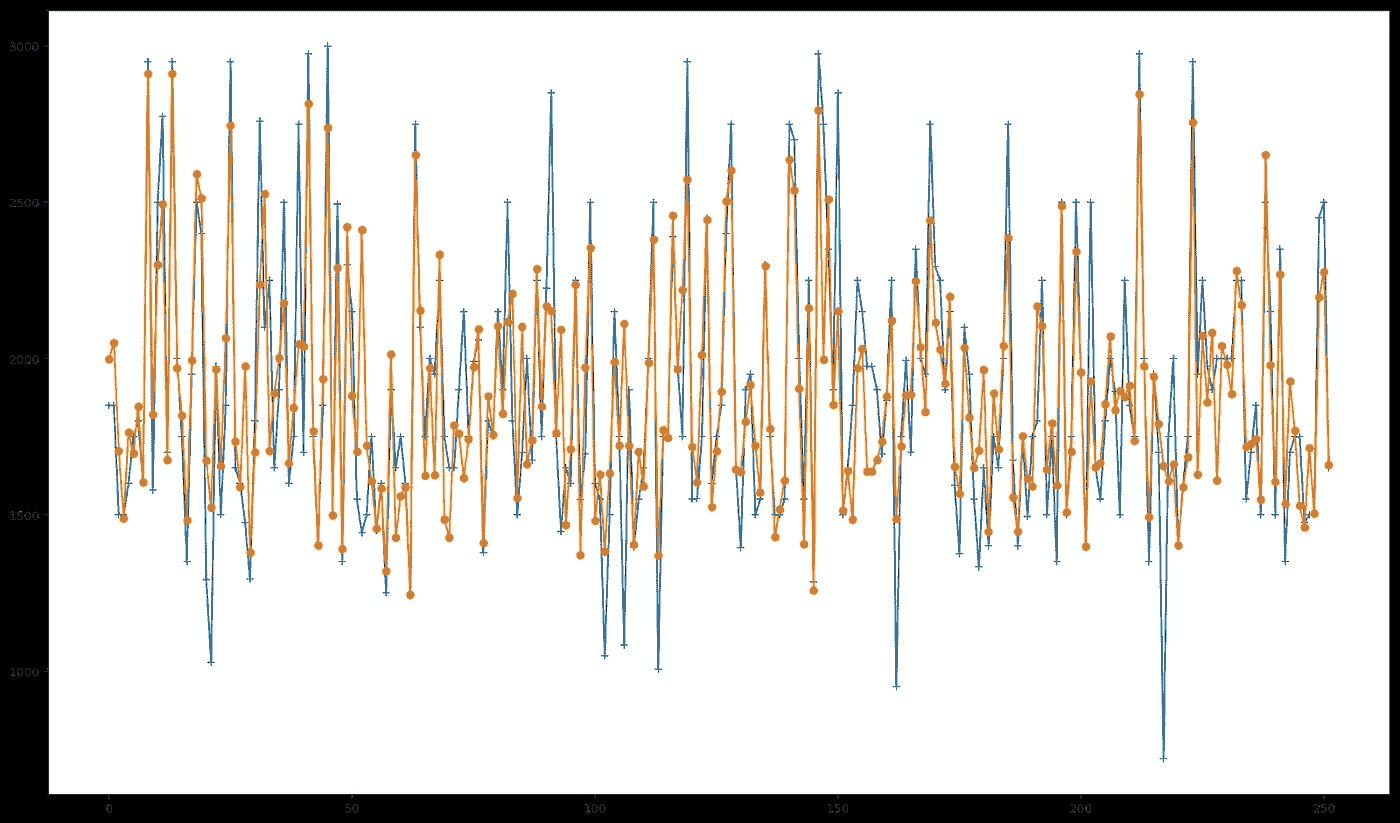
走向绿色,第 2 部分
既然我们丰富了我们的数据集,现在是时候用新数据训练我们的模型,看看它的表现如何。
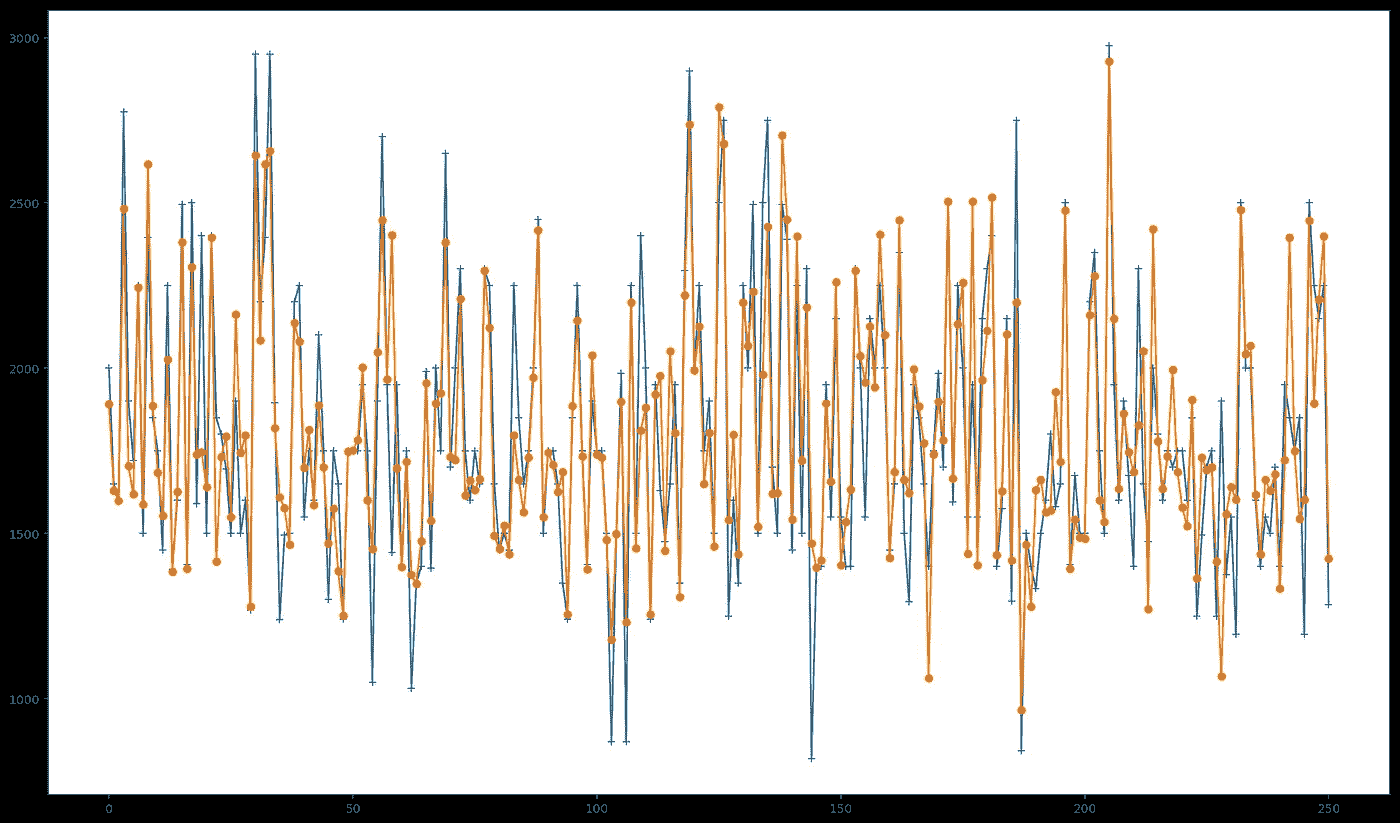
How our new predictions perform. Predicted values in orange, actual values in blue.
考虑到我们的基准模型,我们能够将我们的 R2 得分从 0.70 提高到 0.75 — 大约 7.14% 。
上面的图描绘了我们获得的新预测值与实际值的比较。特别是在预测接近最高和最低价格的值时,可能会看到一个小的改进。
就特性的重要性而言,发生了一些有趣的事情。我们引入的一些新变量变得非常重要,从而降低了其他变量的重要性。注意由地址生成的虚拟变量变量是如何失去重要性的。就区变量而言,它们甚至不再是前 15 个最重要变量的一部分。如果我们想把这些变量从模型中去掉,我们的结果可能不会有太大的不同。
有趣的是,250 米半径范围内的交通 POI 数量不如该距离内的咖啡馆数量重要。一种可能的猜测是,交通更加均匀地分散在整个城市——大多数公寓靠近电车、公共汽车或地铁站,而咖啡馆可能集中在更中心的地区。
我们研究了大量可用的地理数据。也许让我们的模型变得更好的一个方法是获取诸如建筑建造日期、公寓条件和其他特征的信息。我们甚至可以利用地理数据,将变量建立在 POI 半径大于 250 米的范围内。也可以探索 Yelp 的其他类别,如商店、杂货店等,看看它们如何影响租赁价格。
关键要点
- 提高一个模型的预测能力不是一件小事,可能需要一点创造力来找到使我们的数据更丰富、更全面的方法
- 有时一个小的模型改进需要相当多的工作
- 在预测分析管道中,获取、理解、清理和丰富您的数据是一个关键步骤,但有时会被忽视;这也是最耗时的任务——在这种情况下,这也是最有趣的部分
这是两部分系列的第二部分。点击这里查看《T2》第一部:
[## 各付各的:我如何使用数据科学和机器学习在阿姆斯特丹找到一间公寓——部分…
阿姆斯特丹的房地产市场正在经历一场令人难以置信的危机,房地产价格以两位数的速度飙升…
towardsdatascience.com](/going-dutch-how-i-used-data-science-and-machine-learning-to-find-an-apartment-in-amsterdam-part-def30d6799e4)
如果你喜欢这篇文章,你可能也会喜欢:
[## 保持机器学习模型在正确的轨道上:MLflow 入门,第 1 部分
了解为什么模型跟踪和 MLflow 对于成功的机器学习项目至关重要
mlopshowto.com](https://mlopshowto.com/keeping-your-machine-learning-models-on-the-right-track-getting-started-with-mlflow-part-1-f8ca857b5971) [## 使用机器学习检测金融欺诈:赢得对不平衡数据的战争
机器学习和人工智能会在这场战斗中成为伟大的盟友吗?
towardsdatascience.com](/detecting-financial-fraud-using-machine-learning-three-ways-of-winning-the-war-against-imbalanced-a03f8815cce9)
走向规范——数据科学的真正超级力量

Superhero Girl Speed by alan9187— CC0
在其核心,数据科学依赖于机器学习的方法。但是数据科学也不仅仅是预测谁会购买,谁会点击或者什么会坏掉。数据科学使用 ML 方法,并将其与其他方法相结合。在本文中,我们将讨论规范分析,这是一种将机器学习与优化相结合的技术。
说明性分析——做什么,不做什么
关于如何解释,我最喜欢的例子来自 Ingo Mierswa。假设你有一个预测明天会下雨的机器学习模型。不错——但这对你来说意味着什么呢?你开车去上班还是骑自行车去?在这种情况下,你不可能是唯一一个喜欢开车的人。结果可能是,你被堵在路上一个小时。尽管下雨,还是骑自行车会不会更好?
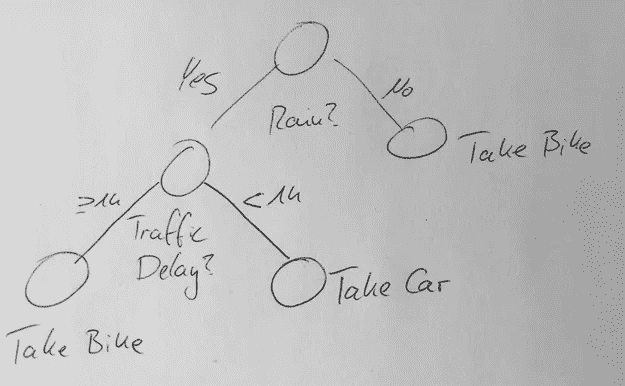
Depending on your forecasts for weather and traffic you might either take the car or the bike
对此的解决方案是定义一个定制的适应度函数。在给定天气预报、预期交通和个人偏好的情况下,你可以最大化这种适应性。这是说明性分析!这个想法不仅仅是预测将会发生什么,也是建议做什么。
在这个简单的例子中,我们有一个非常小的可操作选项的超空间:要不要骑自行车。这使得我们的优化很容易:评估两者并取其精华。在即将到来的现实世界的例子中,你可以看到这个超空间可能是巨大的,优化问题相当棘手。
预测定价
您可能会尝试使用直接预测模型进行价格计算。假设您有一个带有正确价格的数据集。你可以把这当作一个回归问题,用你最喜欢的 ML 方法来解决。由此产生的模型可以直接用于生产,以预测价格。
这里的大问题是有一个标签的奇迹。你从哪里得到的价格?在实践中,您使用人为生成的价格。你怎么知道这些是好的?实际上,这些标签的质量限制了建模的最高质量。当然,您可以通过使用 A/B 测试来引导自己摆脱这个问题。你有时会提供比人为价格更低或更高的价格来衡量成功。但是这是昂贵的并且不总是可行的。
指令性定价
解决这一问题的另一种方法是指令性定价。与 rain 示例类似,我们需要定义一个适应度函数来反映业务案例。在零售的例子中,你可以从需求价格关系开始。一个简单的健身功能看起来像这样:
fitness = gain = (Price — Cost)*demand
其中需求是机器学习模型的结果,该模型取决于日期、价格甚至其他因素。
如果你与保险公司合作,你的健康状况将会是这样的:
fitness = profitability = f(Premium,DefaultRisk,..)
在本例中,我们希望优化保费,以获得最大收益。其他因素也是从依赖于客户属性的机器学习模型中得出的。
在 RapidMiner 中实现
让我们看看如何实现这样一个系统。我受雇于 RapidMiner,因此我的首选工具当然是 RapidMiner 。当然,如果你愿意,你可以用 Python 或者 R 来构建类似的东西。
在我们的实现中,我们希望对客户是否会接受给定的报价进行评分。结果是取决于价格和其他元数据的接受置信度。这里需要注意的是,置信度不等于概率,即使在[0,1]中归一化。
在规定部分,我们将使用这个模型来定义我们的价格。我们会以这样的方式改变价格,每个客户有 0.75 的信心接受我们的报价。0.75 可能源自样本约束。例如,我们希望每个月至少有 1000 个被接受的报价。我们由此得出的适应度函数是:
fitness = price-if([confidence(accept)]<0.75,(0.75-[confidence(accept)])*1e6,0)
这意味着每当我们的信心下降到阈值以下时,我们就增加一个惩罚因子。
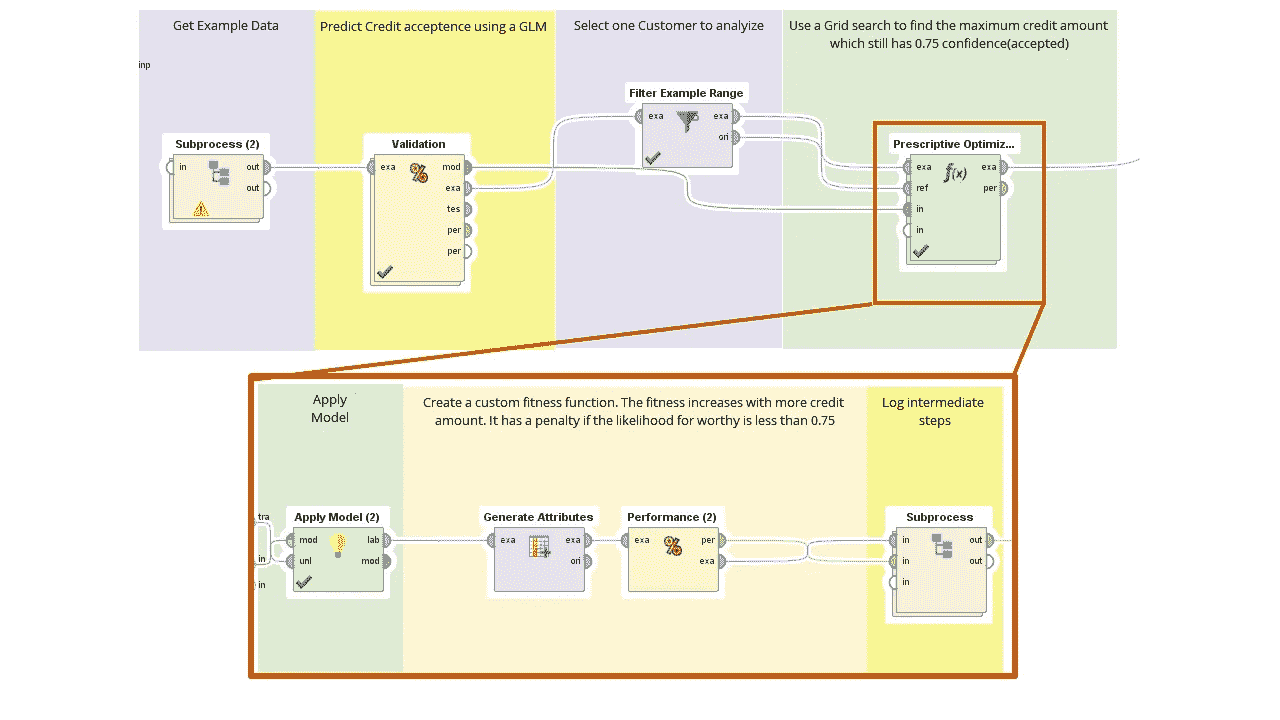
Example Implementation in RapidMiner. This trains a model and optimized the price for acceptance of offer. The fitness function is defined within Prescriptive Optimization
上面描述的示例过程首先是导出一个模型来预测。接下来,我们进入优化。优化采用我们想要优化的输入示例、设置默认边界的参考集和模型。在优化循环中,我们计算上面的适应度。由于优化是单变量的,我们可以使用网格。我们可以使用 CMA-ES、BYOBA 或进化优化。结果是这样的健身
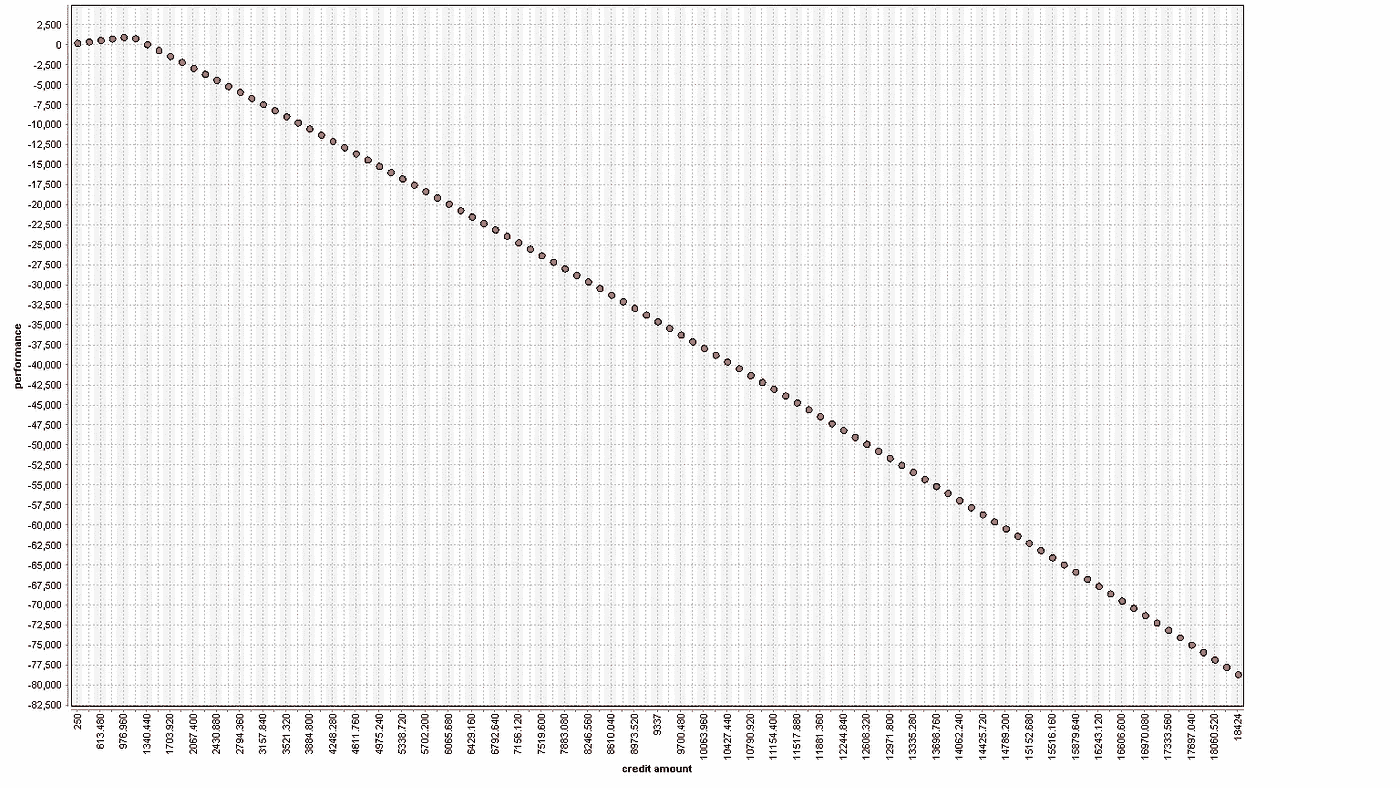
Performance evaluation for one customer. The fitness gets better for higher prices until it hit the spot where confidence(accepted) < 0.75.
我们可以看到,适应度随着价格的增加而上升,然后下降,因为置信度低于 0.75。衍生价格为:976 欧元。
这里描述的过程可以在我的 github 档案中找到。
在神经网络中走向侧面
神经网络有几个致命的问题。其中最主要的是过度拟合——给定足够的训练时间,神经网络将准确预测训练数据,同时失去理解新数据的能力。它完全不能概括它所学到的东西。例如,一个图像分类器最终可以完美地预测它是否正在看一只猫的照片,在你已经手动分类的图像中*。然而,这种特殊性使得对所有不完全像它所学习的图像的分类成为一场掷硬币的游戏。图像分类器已经学会记忆答案。*
研究人员通过提前停止来避免过度适应。他们根据一组不存在于训练数据中的输入测试网络,这组输入被称为“保持”组。网络在保留集上的精确度是对网络在新数据上表现如何的估计。一旦这个坚持组的准确性变得更差,研究人员就停止训练网络。网络已经学习了足够的知识来进行归纳,任何额外的训练都会导致记忆(即过拟合训练数据)。**
从根本上说,我们不想要一个与我们的训练数据完全匹配的网络。提前停止是一种组装,一种补偿研究人员优化错误事物的方式。我们想要一个能够归纳的网络,这样它就可以预测不完全像它以前看到的事情。然而,我们优化了网络的成本函数,该网络仅准确预测了它所看到的。我们有错误的成本函数。
出路
想象成本函数的最小值是碗的中心。优化类似于把球滚下碗,直到它停在中间。然而,通过提前停止,我们希望我们的球滚到靠近中心的点,而不是正好在中心的点。当球滚下碗边时,它提高了预测的准确性。在接近底部的某个地方,网络对陌生输入的准确性开始恶化。网络开始记忆,而不是归纳。我们在某一点上停止了球,这就是提前停止。**
重要的是要认识到,如果我们多次滚动球,并找到我们提前停止的位置(没有记忆就概括的位置),所有这些提前停止的点形成一个围绕碗中心的连续环*。我们甚至可以把碗切割成这个更小的环!每一个“好的概括”网络都将是碗唇上的**,而任何进一步进入碗中的都将是一个“记忆陷阱”网络。对于这个更小的碗,我们不想再滚下——我们应该而不是顺着斜坡的方向;我们不应该使用梯度下降!***
相反,我们希望沿着这个碗的边缘迁移,停留在“良好概括”网络的边缘,永远不要偏离到所有“记忆陷阱”所在的碗的中心。重要的一点是,碗的某些面可能会很早就开始记忆,因为他们从一个糟糕的概括开始。我们想在碗的边缘走来走去,尝试不同的‘好的概括’,因为其中一些概括可能比其他的更好!沿着边缘行进是找到更好的概括的最好方法——远胜于将球滚向不同的方向数百次,摆弄初始化!****
横着走
从数学上来说,我们如何像那样沿着边缘滚动?
简单—我们垂直于梯度移动。梯度向量是我们碗中最陡下降的方向;碗的一些区域凸起或起皱,最陡的方向并不总是朝着中心。然而,无论最陡的方向是什么,边缘总是垂直于它!在更高维度中,那个边缘仍然是垂直的,尽管有许多垂直的方向。轮圈为子空间。并且,通过测量网络在保留输入上的准确性,我们有了在这个子空间中进行优化的度量。
因此,当你第一次训练网络并在泛化时提前停止时,你然后运行新的优化:最小化子空间边缘上的损失函数,该损失函数与梯度正交,其中损失是网络在保持集上的不准确性。在每一步,你都要测量训练集的倾斜度,就像常规的 SGD 一样,但是你要移动垂直于那个倾斜度。高维空间中有许多垂直方向,因此您为保持输入 选择梯度最大的方向!你实际上是在说“我不想记住我的训练数据;我只想改进这个新数据。”******
那不会导致对隐藏数据的记忆吗?没错。该子空间边缘遭受相同的过度配合问题。沿篮筐移动,你保证不会记住旧的训练数据,但你沿篮筐的移动可以记住保持数据 。轮辋需要自己的早停,创造自己的碗轮辋!你的新的边缘是一个更小的子空间,它被约束为与训练数据的梯度和与保持数据的梯度正交。有了许多坚持的设定,这可能会永远继续下去…这实际上是计划!
抵制的层次
假设你有一百万张图片,一半是猫,一半是其他的东西,都有正确的标签。你可以给你的神经网络 80 万张这样的图片用于训练,保留 10 万张作为确定提前停止的保留集,另外 10 万张作为测量预期真实世界准确度的验证集。那是正常的做事方式。
然而,有了对碗状边缘和提前停止的这种认识,一种不同的方法出现了:将图像分块到箱中,每个箱有 100k 张图像;在第一个 100k 图像上训练您的网络,使用第二个 100k 作为确定提前停止的保留;当撑出精度开始下降时,及早停止;将*垂直于训练数据的坡度,并在保持数据的坡度的方向上移动,从而移动轮辋;使用第三个 100k 作为支撑,以确定这一新梯度的早期停止。*****
重复这一过程,仔细消化 10 万批新数据,而不去记忆旧数据。通过沿着每个连续箱的边缘移动,我们正在搜索一个越来越小的子空间。每个箱子都有自己的限制,说“不要沿着我的梯度移动——那只会导致记忆”。结合所有这些限制,我们沿着碗的边缘缩小了可用的方向,使得搜索更容易。(但是,当我们沿着边缘移动一步时,我们仍然需要检查我们的新位置是否对应于一个提前停止点。这意味着我们检查训练数据的梯度,并查看在该方向上的移动是否会导致保持精度下降。)
一切都是坚持
在具有一百万个图像的示例中,我们形成了 100k 个图像的连续箱,并且迭代梯度下降、提前停止和正交子空间。如果我们把这些箱子做得更小,每个箱子只有 100 张图片,会怎么样?或者,如果每个图像都是自己的 bin,并且可以随时添加新的图像,会怎么样?这就是在线学习——当每个新图像到达时,网络执行额外的训练,而不牺牲先前的归纳!传统的网络是在实验室中训练出来的,不能从新的经验中学习。通过迭代正交梯度技巧,我们的“rim”网络可以在操作期间继续学习。(DARPA 正在资助对人工智能的研究,这种研究可以边进行边学习,所以这可能很重要。)**
这可能有助于拟人化这个正交的把戏,它在“滚下碗”和“沿着边缘滚”之间摆动。网络在碗的梯度方向(最陡的方向)上滚动一小段距离,询问“如果我以这种方式改变一点,我对新信息的准确性会不会降低?”如果精度提高,网络向那个方向移动,这是普通的梯度下降。然而,如果新信息的准确性下降,网络会对自己说“如果我从碗的最陡部分往下走,我会失去一般性,并开始记忆;沿着边缘的哪个方向,垂直于最陡方向,反而会提高拒绝数据的准确性?”在每一步之后,该过程重复进行。****
因此,每个输入都是一个拒绝集合,我们将向下移动到拒绝的梯度的分量,该分量与所有先前输入的梯度正交,遍历碗的边缘。一旦我们沿着那个边缘走了一步,我们也检查沿着的一步是否所有先前输入的梯度会降低保持精度(这决定我们是否已经‘远离边缘’了)。如果保持精度会增加,那么网络不在“边缘上”,所以我们沿着所有先前输入的梯度移动一步;如果精度会降低,我们将搜索限制在该梯度的正交子空间,而不是沿着保持的梯度移动。每一个新的输入都会触发这一过程,学习新的数据而不失一般性。**
我希望这有助于我们寻找一种真正的可以终生学习的普遍智能。有诱人的证据表明,我们的大脑使用一种学习技术,这种技术相当于梯度下降的反向传播(在 19:30 这里是)——如果我们自己的大脑也使用类似于我上面描述的“边缘”搜索的方法来避免过度拟合,我不会感到惊讶。
足够好的数据科学
围绕数据科学的炒作的一个症状是,我们作为从业者需要实践它。归咎于营销、销售、博客作者甚至投资者很容易,但我们同样有责任让我们所做的事情变得不必要的复杂。
如果你在一个标题为“数据科学”、“机器学习”或(上帝保佑你)“人工智能”的部门工作了 1 周以上,你就会感受到这种压力,并完全明白我的意思。如果你没有听过,这里有一些你可能听过的问题和短语——按照恐慌发作的递增顺序排列。
- “这个新功能利用了机器学习吗?”
- “我们为什么不用更多的人工智能?”
- “我邀请了 IBM 的销售代表。沃森毕竟有助于治疗疾病,他们肯定能帮助你建立一个更好的推荐系统。”
并不是说机器学习,AI 或者沃森都是不好的东西。而是我们已经到了一个地步,数据科学/AI/ML 的炒作已经把解决方案放在了问题之前。假设是,如果你没有使用最复杂或最前沿的方法,你就不是真正的数据科学家。
现在回头看看这三个引起恐慌的短语。你自己团队中的某个人可以像销售副总裁一样轻松地说出这些话。相信我,我有时也有罪。我们的理由不同,但最终的结果是一样的。销售想要告诉客户驱动产品的复杂人工智能。高管团队想要吹嘘公司的数据科学能力。当然,数据科学团队希望学习如何使用最酷的工具,创建真正改变游戏规则的功能或产品。
改变叙述——一个例子
与其从解决方案开始,不如回到问题本身。假设您的公司以高于预期的速度带来新客户,客户支持团队不堪重负。电子邮件是主要的客户支持渠道,团队的平均响应时间从 4 小时缩短到了 3 天。客户不满意,团队精疲力竭,有人说简单地雇佣更多的人不是一个可扩展的解决方案。
值得庆幸的是,你是一个有能力的数据科学团队的一员,你随时准备提供帮助。现在是做两件事的时候了:
- 设定期望值
- 从简单的方法开始
首先,要积极主动,对任何可能向客户推销你未来解决方案的人设定期望值。不要让它变成“我们正在开发一个先进的人工智能解决方案来自动化客户支持”。您仍然不知道要部署什么,而且考虑到产生影响的迫切需要,您的初始解决方案根本不可能非常先进。在您的团队内部以及客户支持团队中设定相同的期望。你怎么能现在就想出一个简单的第一个版本来帮助他们,而不是 6 个月后?
现在是时候开始了。忘记你最近阅读的深度学习论文,想想你可以获得增量收益的方法。与其构建一个“智能”机器人来响应客户请求,不如对电子邮件进行优先排序和分类,这样团队就可以更有效率?
您与客户支持团队坐下来,发现如果他们知道哪些电子邮件最重要,他们可以将这些邮件分配给高级团队成员,让他们集中精力。此外,如果他们知道其余电子邮件*的一般类别,他们可以将它们批量分配给销售代表,这样他们就可以通过避免在工具和任务之间切换来节省时间。
你可能会问为什么不直接向顾客询问这些名称和类别。首先,你可以但不要期望一致性。其次,许多客户反对通过网络提交请求,而不是发送到电子邮件地址。
所以我们的目标是:
- 将电子邮件分为“关键”和“非关键”
- 将“非关键”桶中的电子邮件进一步分类,以便客户支持团队能够更有效地处理它们。
如果您能确保他们及时处理最关键的问题,并对其余问题进行分类,以便销售代表能够批量处理,您将会让很多人感到满意。更重要的是,这是一个你可以卖给越来越不耐烦的顾客的故事。

Serve your customer, not yourself
开始
您的第一项任务是浏览之前已经解决的电子邮件,并根据问题类型和严重性对其进行标记。大多数客户支持系统要求代表标记这样的属性,但您可能需要做一些清理工作,并与支持团队坐在一起,了解他们如何对这些东西进行分类。众所周知,花在数据准备上的时间在以后会有很大的回报,但这通常很无聊。无论如何都要做。
现在,将数据集分成训练/测试/验证集,并开始使用一些简单的分类器。试试线性回归,随机森林,甚至老朋友朴素贝叶斯。回去获取更多的数据,清理干净,必要时继续调整。注意你所花费的时间。
事情是这样的。你不需要一个完美的解决方案,你只需要让事情变得更好。这个例子的关键是知道在哪个方向上你错了会更好。在将电子邮件标记为“关键”时,你能忍受一些误报吗?当然可以!销售代表会给它贴上这样的标签,你和你的模型下次会变得更好。总比错过一个关键的好。
非关键电子邮件类别也是如此。尽你所能,但是如果负责登录问题的代表偶尔收到关于其他事情的电子邮件,你也可以忍受。让这成为期望设定的一部分。确保他们在收到邮件时正确标记邮件,您将利用这一点来改进您的模型。
部署
既然您已经有了一个足够好的模型(基于构建它的时间和减少支持团队的痛苦之间的权衡),那么就把它拿出来。在这里,您可以进行一些进一步的权衡,这可能会让数据科学宣传机器尖叫起来。在您的笔记本电脑甚至是开发服务器上构建和运行模型是一回事。投产是另一个。
你使用的库对于一个处理邮件的系统来说可能太慢了。你让他们建立和批量处理吗?设计实时运行的模型?如果它崩溃了,你停止了所有的电子邮件支持,会发生什么?
在这个阶段,您有几个选择。
- 简化您的模型,并与一些习惯于生产级软件的工程师合作,以实现批处理作业。请记住,处理过程中的任何延迟都将影响对客户的响应时间。
- (喘息!)利用您从模型中学到的知识,在生产中实施基于规则的实时方法。
- 回过头来改进模型的运行时。
这些都不是完美的,但请记住这种情况。上市时间至关重要,因此第三点已经过时。选项 2 并不总是可行的,但我确实看到过这样的例子,您从分类器中学到了足够多的东西来构建和部署基于规则的作业,并转移到选项 3,同时让支持团队松一口气。
然而,选项 1 非常常见。代价是一个缓慢的模型,不能实时处理电子邮件。您可能不得不每 15 分钟运行一次,这样会消耗您的响应时间。尽管如此,还是不要把它算在内。这个模型并不完美,但是你可以在生产工程师的一点帮助下部署它,然后回到实验室研究 V2。它也比基于规则的选项更容易更新。
当然,您的选择将取决于许多因素,但关键是等待您在会议上自豪地展示的模型很少是最适合业务的。如果你得到了“足够好”的结果,你可以为自己赢得更多的时间来改进模型,但即使这样,也要小心优化是否超过了有价值的增量值。会不会有优雅的模特走到一起的时候?当然,这些是你最想与其他数据科学家谈论的话题。然而,我敢打赌“足够好”的模型是拯救世界的模型。
感谢阅读!你可以联系我或者在我的网站上阅读我的其他博客文章。
好的统计数据是坏的,或者更糟的是误导。
托尔斯泰有句名言:所有幸福的家庭都是相似的,但不幸的家庭却各不相同。当然,大多数家庭都相当幸福,这可能是真的。因此,一个预测不幸福的看似“好”的算法,如果事实上是真的,可能只是非常可靠地预测一个家庭是否幸福,并报告说不幸福的家庭只是奇怪的,无法准确预测,但这并不重要,因为它们并不多。
这可能看起来很傻,但这是在各种环境中使用统计数据时的一个常见问题。举个(修辞)例子,考虑谷歌翻译。它运行的前提是,翻译算法实际上不需要“理解”语言如何工作的机制,只需要识别模式。为了学习这些模式,它从翻译的文档中吸收大量数据——这些文档必然会包括更大比例的旨在高度可靠和忠实地翻译的文档(例如,来自欧盟或联合国等国际组织的内部文档),并将它“学习”的模式应用于其他情况。这至少有点粗糙,但这始终击败了以前在计算机化翻译算法方面的尝试,因为人类语言整体上对于完全“理性”的翻译方案来说太怪异和不规则了,但奇怪的不规则往往出现得太不频繁,不会对普通文档的熟练翻译造成严重问题。如果你愿意的话,以前的翻译尝试由于过于关注少数不幸福的家庭而使事情变得复杂,而谷歌翻译发现大多数家庭都是幸福的,如果你的工作是为大多数家庭服务,无论幸福还是不幸福,那么最好关注那些既相似又非常多的家庭——只是将不幸福的家庭视为可以被视为(统计)错误的罕见异常。众所周知,尤金·奥涅金是很难翻译的,至少我是这么听说的,但是诗歌在要翻译的文件中只占很小一部分,而且它们提供的许多不规则之处,大概会被归入(总体上很小的)一组错误中。
问题是,在许多情况下,我们对那些为我们提供大量数据的幸福家庭不感兴趣。他们是可预测的,你不需要特别的专业知识就能看出他们快乐,以及是什么让他们快乐。对我们来说,有趣的问题来自相对较少的不快乐的案例,而来自快乐家庭的数据,尽管可能很丰富,却只是污染了这个问题的样本。政治为我们提供了大量这方面的例子:DW-Nominate 引起了轰动,因为它表明绝大多数国会投票可以根据一维预测器进行预测,我认为这已经被贴上了非常误导的标签,即“意识形态”,但这一切都令人震惊吗?国会议员有时可能会投票支持钢铁、糖或玉米,而不是意识形态,但钢铁核心小组的成员不会一直投票支持钢铁——这不是一个经常出现的问题。另外,反正钢铁核心小组的成员也不多。因此,只有相对较小比例的国会议员出人意料地在很小的一部分选票上投票。因为他们都是各自政党的成员,所以他们会在其他时间——也就是绝大多数时间——投票给民主党或共和党。所以这就是托尔斯泰式的幸福家庭,他们可能构成了绝大部分的数据,但对于我们可能感兴趣的问题完全没用——如果我们对这样的问题感兴趣的话。这个问题变得更加复杂,因为尽管 DW-Nominate 算法可能很简单(因为第一维的重要性),但与一个更简单的算法相比,它相当复杂:假设国会成员投票给政党。随着时间的推移,如果你比较简单的“投票党”算法与一维 DW-Nominate 算法的预测准确性,就会出现一个有趣的问题:DW-Nominate 相对于“投票党”算法的(预测)附加值在过去几十年中一直在急剧下降,当时它的倡导者一直在吹嘘它在预测国会投票方面有多好。与“投票党”算法相比,DW-Nominate 的潜在附加值在于,它可以预测,在国会议员不投票党的情况下——这是一个相对罕见的事件——谁将倒戈。按照这种有条件的衡量标准,情况从来就没那么好,而且变得更糟了,尽管部分原因是叛逃并不经常发生。
可能不幸福的人,除了人数少,也没那么有趣,不值得研究?如果样本中没有不快乐的人(也就是说,没有人超越党派界限),也许研究不快乐或检查相关数据是没有意义的。这似乎是我们已经走了一段时间的趋势。但 2016 年选举应该提醒我们,这可能会严重误导我们。像国会议员一样,大多数人投票给政党,但有一小部分人不投。在这样一个选民群体中,党派选民(根据各州的分布情况进行调整)大致势均力敌,只要有百分之几的“不开心”的人就能让一切变得不同。当数据收集和分析工作被鼓励专注于容易产生良好预测能力的“可靠”数据时,这变得越来越严重——换句话说,就是“快乐的人”。不快乐的人从一开始就很少,但他们最终被更精确地欠采样(在技术上正确和不正确的意义上),因为检查他们不会产生太多的回报。当然,试图对“不快乐”的人进行过度采样可能会导致意外情况被过度重视的错误——当 DW-Nominate 首次出现时,它让国会专家如此惊讶的原因是,人们普遍认为国会政治中不成比例的份额是在钢铁、玉米和糖上,而且如此压倒性的投票比例可以简单地通过政党投票来解释(这就是 DW-Nominate 真正所说的一切——它在很大程度上并不是真正的“意识形态”)是出乎意料的。
我认为,分析学的未来在于认识到它在抽样过程中的局限性,其中很大一部分是它在提供大量数据的“简单”问题上做得非常好(当然,这正是 Landon 被期望以压倒性优势击败 FDR 的原因)。这并不是贬低它的潜在贡献:大多数问题都是常规问题,只需要“显而易见”的解决方案。但是“重要的”问题往往不是那么常规的——毕竟,这将是相当重要且相当罕见的投票,因为钢铁党团的人被收买去反对他们的党派关系。这些不寻常的例子什么时候会出现,根据这些例子(假设这是一个该法案的支持者购买钢铁而不是糖的例子——需要能够区分它们)中非常少的数据点将是可用的,你可以获得多少统计杠杆?
谷歌人工智能的新物体探测竞赛

我为学习者写了一份名为《强大的知识》的时事通讯。每一期都包含链接和最佳内容的关键课程,包括引文、书籍、文章、播客和视频。每一个人都是为了学习如何过上更明智、更快乐、更充实的生活而被挑选出来的。 在这里报名 。
就在几天前,谷歌人工智能在 Kaggle 上发起了一项名为开放图像挑战的物体检测比赛。很高兴看到计算机视觉社区已经有一段时间没有这么大规模的竞争了。
几年来,ImageNet 一直是计算机视觉领域的“黄金标准”竞赛。许多团队每年都在竞争 ImageNet 数据集上的最低错误率。由于深度学习,我们最近看到了图像识别任务的巨大进步,甚至超过了人类水平的准确性。在下面的图表中,我们可以看到像 ImageNet 这样大规模的竞争如何帮助加速该领域的研究,特别是在 2012 年开始的最初几年。
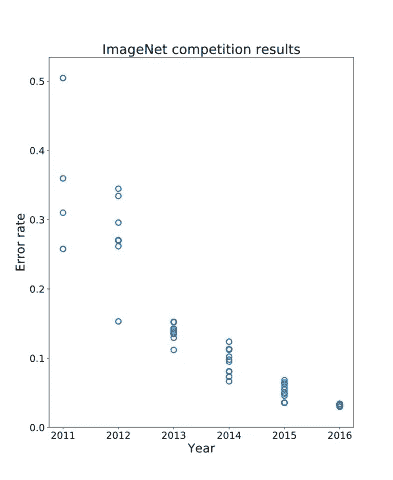
Error rate history on ImageNet (showing best result per team and up to 10 entries per year)
ImageNet 是一个巨大的竞争,有 1000 个不同的类和 120 万个训练图像!庞大的数据规模是 ImageNet 如此具有挑战性的真正原因。我们从如此大规模的竞赛中获得的一个非常重要的东西(当然除了学习如何很好地对图像进行分类)是我们可以用于其他任务的特征提取器。在 ImageNet 上预先训练的特征提取网络用于许多其他计算机视觉任务,包括对象检测、分割和跟踪。此外,网络的一般风格或设计通常用于这些其他任务。例如,快捷连接最初用于 2015 年获奖的 ImageNet 条目,此后一直用于计算机视觉中的绝大多数 CNN!这是一件很棒的事情,当我们可以在一个简单的任务上工作时,它会对更复杂但相关的任务产生巨大的影响。
谷歌人工智能在 Kaggle 上举办的新物体检测比赛是朝着这个积极方向迈出的一步。到目前为止,COCO 检测一直是物体检测的最大挑战。但是,与 ImageNet 相比,它非常小。COCO 只有 80 个类别,330K 图片。它远没有你在现实世界中看到的那么复杂。许多从业者经常发现在野外进行物体检测极具挑战性。至少 ImageNet 有足够大的数据集和足够多的类,这对于预训练和使用网络进行迁移学习非常有用。也许有了足够大的数据集,我们的物体检测器就能同样适用于迁移学习。
这就是新的竞争的由来! Google AI 已经公开发布了开放图像数据集。Open Images 沿袭了 PASCAL VOC、ImageNet 和 COCO 的传统,如今规模空前。
开放图像挑战赛基于开放图像数据集。挑战赛的训练集包含:
- 1.7 米训练图像上 500 个对象类别的 12 米包围盒注释
- 具有多个对象的复杂场景的图像–平均每幅图像 7 个盒子
- 各种各样的图像,包含全新的对象,如“软呢帽”和“雪人”
- 反映打开图像类之间关系的类层次结构
除了对象检测轨迹,比赛还包括视觉关系检测轨迹,以检测特定关系中的对象对,例如“弹吉他的女人”、“桌子上的啤酒”、“车内的狗”、“拿咖啡的男人”等。你可以在这里找到更多关于数据集的信息。这个数据集令人惊叹的地方在于它的多样性。数据集中的所有 600 个类在这里有一个很好的可视化,在这里你可以看到类的分解和层次结构;真的挺多样化的。我们还可以观察到有一个非常宽的类频率范围。这意味着我们不能天真地平等对待所有的职业;我们被迫考虑职业分布,更真实的风格!这个数据集的健壮性无疑让我们更接近于创建对野外部署更有用的模型。
如果你喜欢奖品,还有 30,000 美元的奖金池!此外,挑战的结果将在 2018 年欧洲计算机视觉会议的研讨会上公布。它正在德国慕尼黑举行,这肯定会是一次不错的旅行!
也很高兴看到比赛在 Kaggle 上举行。挑战的核心往往是通过看到竞争对手的许多不同方法而获得的巨大知识来源。如此大规模和复杂的挑战将有望带来最好的研究和新的想法,可以应用于整个计算机视觉领域,就像 ImageNet 所做的那样!
Google 联合实验室—简化数据科学工作流程
谷歌最近公开了其数据科学和机器学习工作流的内部工具,名为合作实验室。虽然它非常类似于 Jupyter Notebook,但真正的价值来自这项服务目前提供的免费计算能力。协作功能,类似于 Google Docs,允许小团队紧密合作,快速构建小型原型。总的来说,这个工具与谷歌成为“人工智能第一”公司的愿景紧密相连。
Example Notebook (Source)
这个工具对于初学者来说也是非常强大的,因为它附带了 Python 2.7 环境和所有主要的 Python 库。他们不再需要首先经历各种安装过程,而是可以立即开始编写代码。
例如,我使用 OpenCV 创建了一个简短的关于人脸识别的公共合作笔记本,这是以机器学习为核心的计算机视觉的主题之一。为了运行笔记本,建议用户将笔记本复制到他们自己的实验室,从那里他们将能够运行代码。
要开始使用笔记本,运行所有现有的单元以加载库和底层数据是很重要的。然后,您可以在新的代码单元格中执行新版本的findfaces('<---IMAGE_URL--->')函数,将<---IMAGE_URL--->替换为网络上任何图像的 URL,例如http://epilepsyu.com/wp-content/uploads/2014/01/happy-people-1050x600.jpg。这将使用新的 URL 获取图像,并在代码单元格下生成已识别图像的输出。如果照片包含由 OpenCV 算法拾取的人脸,那么将提供这些人脸的总数以及显示图像上识别的人脸位置的方块。

Example Output (Source)
我相信,对于那些刚刚开始编码的人来说,使用 Google 协作工具可以真正改变游戏规则。它允许我们快速开始执行脚本,而不用担心底层架构。上面提到的笔记本就是一个很好的例子,因为它的用户只需要插入一个新的功能。如果他或她对底层代码感兴趣,他们也可以看一看,并按照他们感兴趣的方式进行调整。
因此,最近引入的脚本更改的影响可以被快速识别,从而缩短开发反馈周期。笔记本也非常容易共享,并支持评论,允许从社区的不同成员那里收集反馈。
你还在等什么?试试看这里。
[谷歌]连续可微分指数线性单位与互动代码[手动反推与 TF ]

Image from this website
Jonathan T. Barron 是谷歌的一名研究人员,他提出了 CELU(),意为“ ”连续可微的指数线性单位 ”。简言之,这个新的激活函数在任何地方都是可微的。(对于一般的 ELU,当α值不为 1 时,它不是处处可微的。)
由于我最近报道了“ 【通过指数线性单元(ELUs) ”快速准确的深度网络学习”(请单击此处阅读博文),接下来报道这篇文章自然是有意义的。最后,为了好玩,让我们用不同的优化方法来训练我们的网络。
情况 a)用 ADAM 优化器自动微分(【MNIST】数据集)
情况 b)用 ADAM 优化器自动微分(cifar 10数据集)
情况 c)用AMSGrad 优化器膨胀背 Pro p 带AMSGrad 优化器(cifar 10数据集
连续可微的指数线性单位
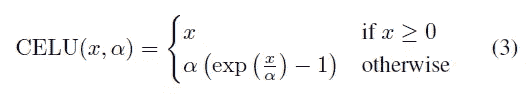
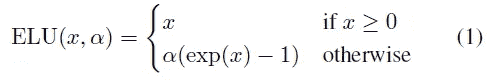
左图→CELU 方程式()
右图→ELU 方程式()
以上是 CELU()的方程式,我们已经可以看出它与 ELU()的原始方程式并无多大不同。只有一个区别,当 x 小于零时,用α除 x 值。现在让我们看看这个激活函数是怎样的。
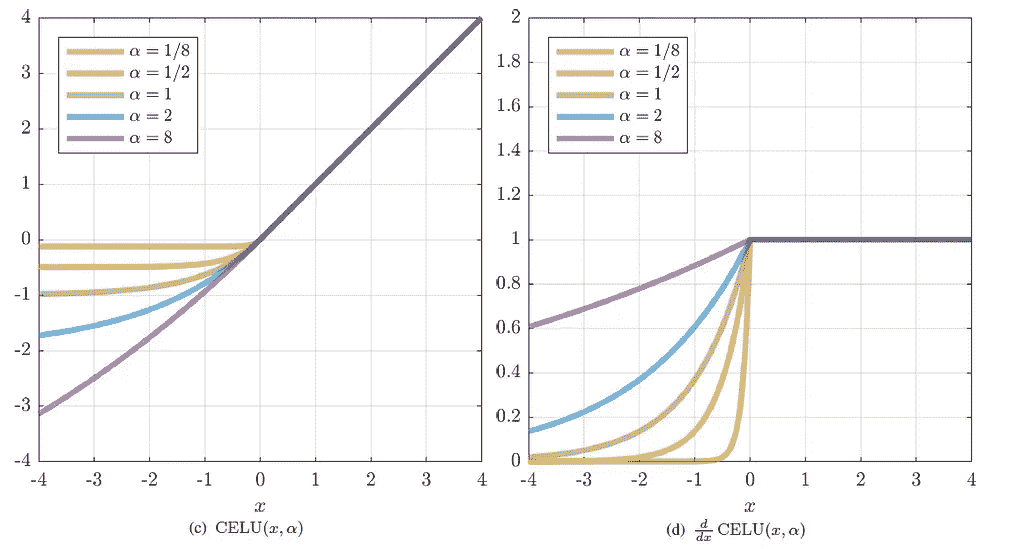

左图→CELU()和它的导数绘制时的样子
右图→ELU()和它的导数绘制时的样子
在最右边的图像(ELU()的导数)上,我们可以观察到函数不是连续的,然而对于 CELU()的导数,我们可以观察到函数在任何地方都是连续的。现在让我们看看如何实现 CELU()及其衍生物。
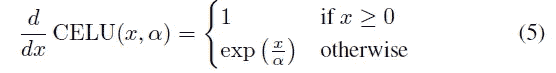
首先让我们看看 CELU()对输入 x 的导数
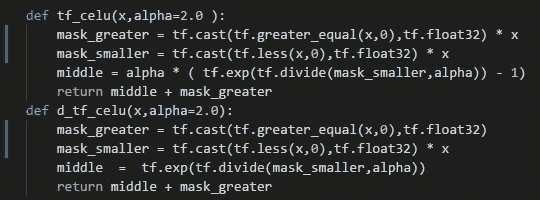
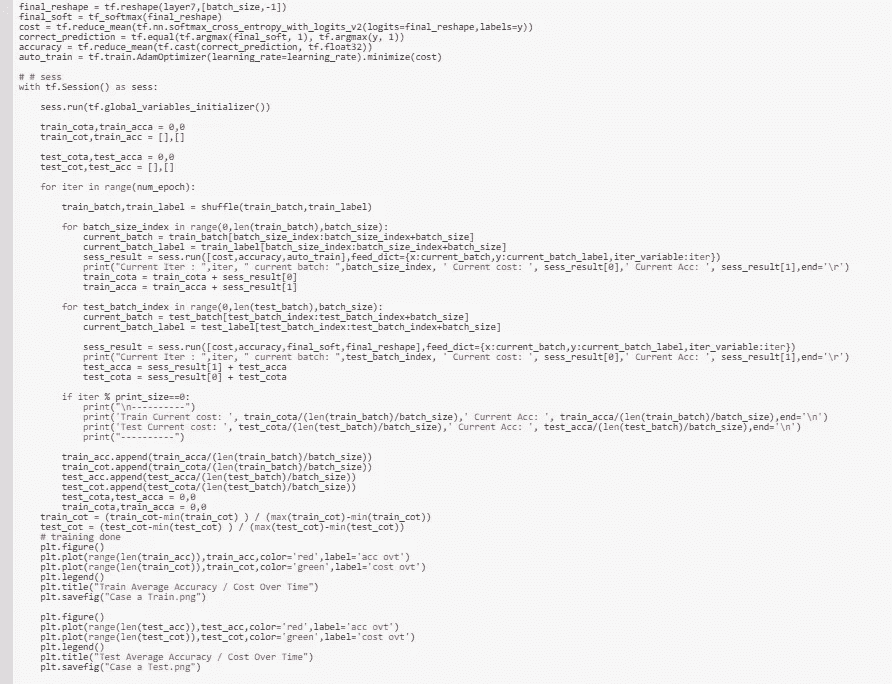
当用 python ( Tensorflow )实现时,它看起来像上面的东西,请注意我已经将 alpha 值设置为 2。
网络架构
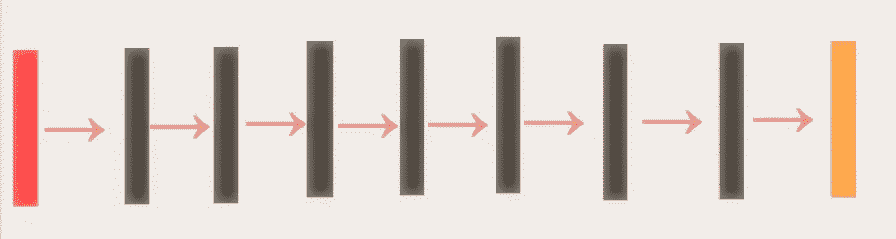

红色矩形 →输入图像(32323)
黑色矩形 →与 CELU 卷积()有/无均值合并
橙色矩形 → Softmax 进行分类
我要使用的网络是七层网络,采用平均池操作。由于我们将使用 MNIST 数据集以及 CIFAR 10 数据集,因此对平均池的数量进行了相应的调整,以适应图像尺寸。
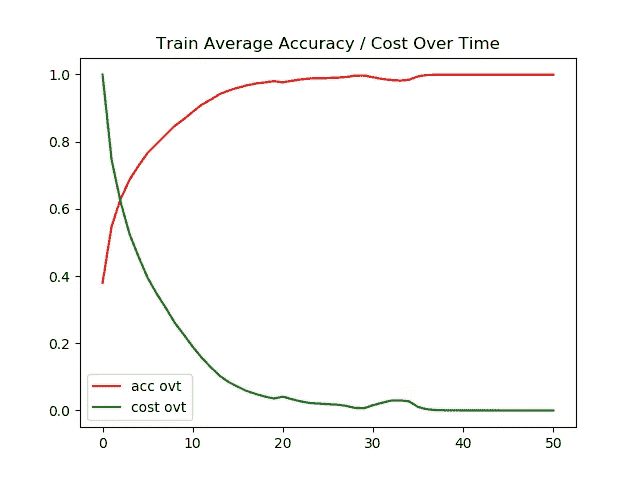
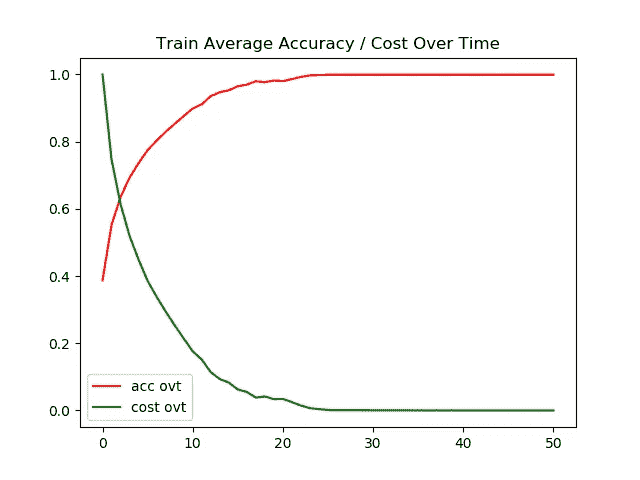
案例 1)结果:用 ADAM 优化器自动微分(MNIST 数据集)
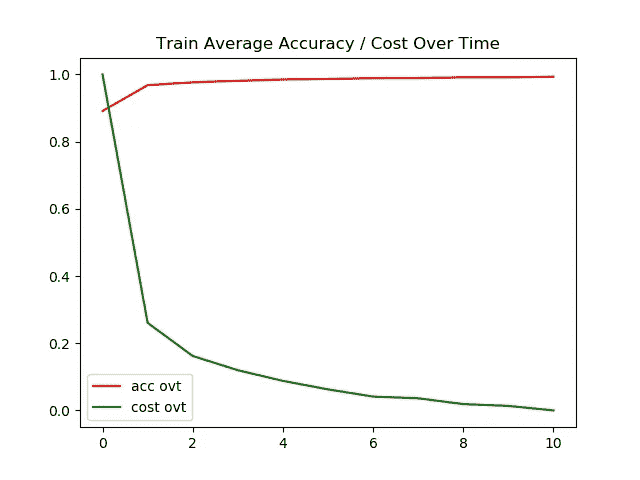
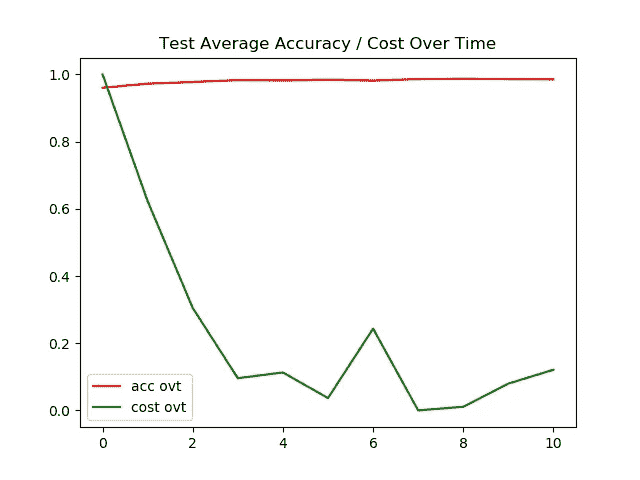
左图 →一段时间内的训练精度/成本
右图 →一段时间内的测试精度/成本
对于 MNIST 数据集,测试图像和训练图像的准确率都达到了 95%以上。我对训练/测试图像的超时成本进行了标准化,以使图形看起来更漂亮。

测试和训练图像的最终准确度都是 98+%。
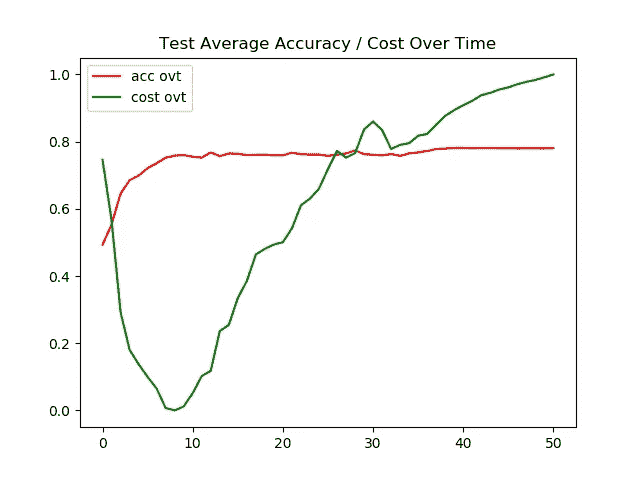
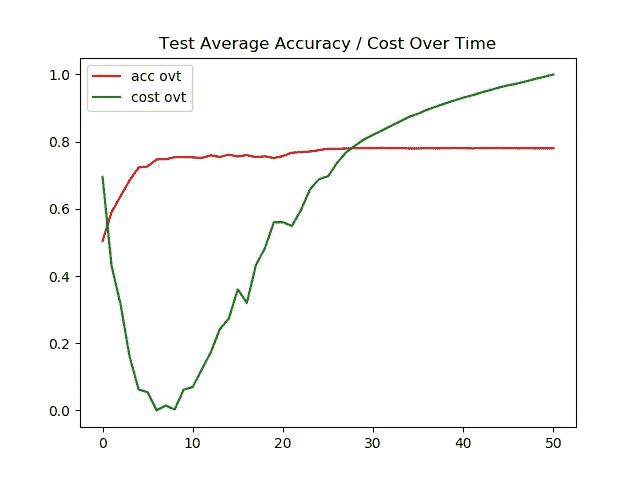
情况 2)结果:用 ADAM 优化器自动微分(cifar 10数据集)
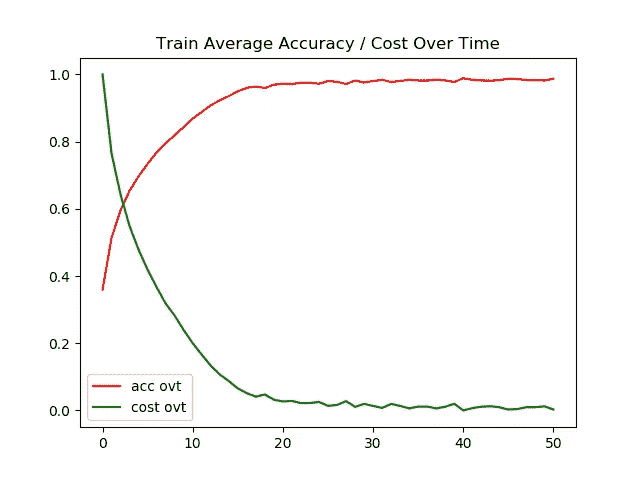
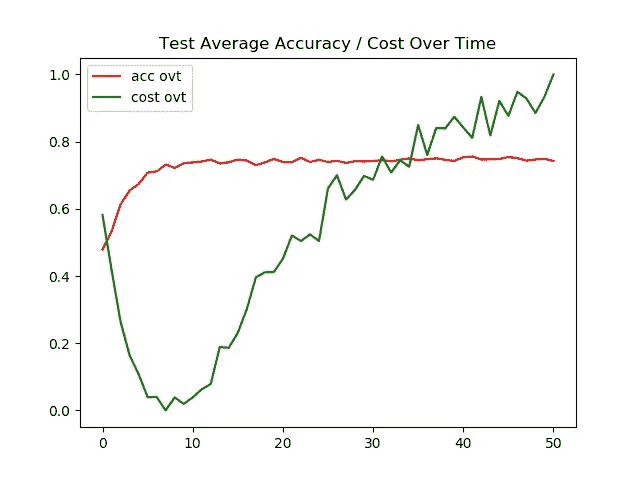
左图 →一段时间内的训练精度/成本
右图 →一段时间内的测试精度/成本
现在我们可以观察到模型开始遭受过度拟合。特别是使用 Adam optimizer,测试图像的准确率停滞在 74%。

测试图像的最终准确率为 74%,而训练图像的最终准确率为 99%,这表明我们的模型过度拟合。
案例 3)结果:手动回柱带 AMSGrad 优化器(cifar 10数据集)
左图 →一段时间内的训练精度/成本
右图 →一段时间内的测试精度/成本
对于这个实验,AMSGrad 比常规的 Adam 优化器做得更好。尽管测试图像的准确性不能超过 80%,并且模型仍然存在过度拟合的问题,但给出的结果比 Adam 好 4%。

测试图像的最终精度为 78%,表明该模型仍然过拟合,但比使用没有任何正则化技术的常规 Adam 的结果好 4%,还不错。
案例 4)结果: 扩背 Pro p 带 AMSGrad 优化器(cifar 10数据集)
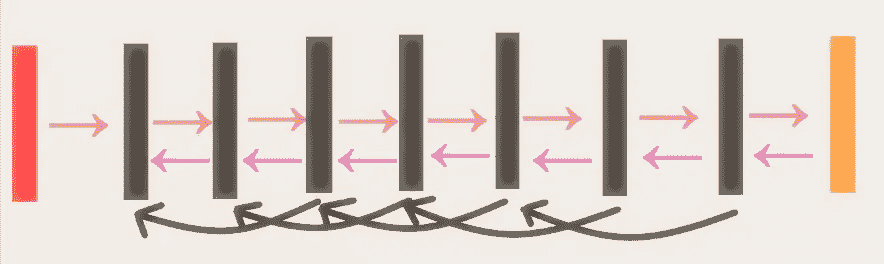
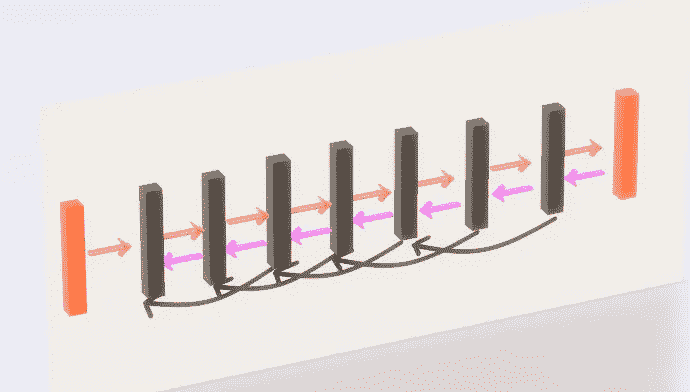
紫色箭头 →反向传播的常规梯度流
黑色弯箭头 →增大梯度流的扩张后支柱
记住这个架构,让我们看看我们的网络在测试图像上的表现。
左图 →一段时间内的训练精度/成本
右图 →一段时间内的测试精度/成本
同样,它比常规的 Adam 优化器做得更好,但是它不能在测试图像上达到 80%的准确率。(仍然)

测试图像的最终准确率为 77%,比 AMSGrad 的常规反向传播低 1%,但比常规 Adam 好 3%。
交互代码
对于 Google Colab,你需要一个 Google 帐户来查看代码,而且你不能在 Google Colab 中运行只读脚本,所以在你的操场上做一个副本。最后,我永远不会请求允许访问你在 Google Drive 上的文件,仅供参考。编码快乐!同样为了透明,我在训练期间上传了所有的日志。
要访问案例 a 的代码,请点击这里,要访问日志,请点击这里。
访问案例 b 的代码请点击此处,访问日志请点击此处。
访问案例 c 的代码请点击此处,访问日志请点击此处。
要访问案例 d 的代码,请点击此处,要访问日志,请点击此处。
最后的话
有趣的是,根据训练方式的不同,每个网络的表现也各不相同。CELU()似乎比 ELU()的激活函数表现得更好(至少对我来说是这样)。
如果发现任何错误,请发电子邮件到 jae.duk.seo@gmail.com 给我,如果你希望看到我所有写作的列表,请在这里查看我的网站。
与此同时,在我的 twitter 上关注我这里,访问我的网站,或者我的 Youtube 频道了解更多内容。我还实现了广残网,请点击这里查看博文 pos t。
参考
- 乔恩·巴伦。(2018).Jon Barron . info . 2018 年 5 月 8 日检索,来自https://jonbarron.info/
- j . t . Barron(2017 年)。连续可微指数线性单位。arXiv 预印本 arXiv:1704.07483。
- [ICLR 2016]通过指数线性单元(ELUs)进行快速准确的深度网络学习,具有…(2018).走向数据科学。2018 年 5 月 8 日检索,来自https://towards data science . com/iclr-2016-fast-and-accurate-deep-networks-learning-by-index-linear-units-elus-with-c 0 cdbb 71 bb 02
- 克利夫特博士、安特辛纳、t .和霍克雷特博士(2015 年)。通过指数线性单元(ELUs)进行快速准确的深度网络学习。Arxiv.org。检索于 2018 年 5 月 8 日,来自 https://arxiv.org/abs/1511.07289
- 张量流。(2018).张量流。检索于 2018 年 5 月 9 日,来自 https://www.tensorflow.org/
- CIFAR-10 和 CIFAR-100 数据集。(2018).Cs.toronto.edu。检索于 2018 年 5 月 9 日,来自https://www.cs.toronto.edu/~kriz/cifar.html
- MNIST 手写数字数据库,Yann LeCun,Corinna Cortes 和 Chris Burges。(2018).Yann.lecun.com。检索于 2018 年 5 月 9 日,来自http://yann.lecun.com/exdb/mnist/
[ Google DeepMind ] —利用交互式代码进行医学图像分割的深度学习

Gif from this website
Matthew Lai 是 Deep Mind 的研究工程师,也是“ 长颈鹿,利用深度强化学习下棋 的创造者。但是他的硕士 Msc 项目是在 MRI 图像上,也就是“ 医学图像分割的深度学习 ”,所以我想深入看看他的项目。
因为这不是一篇传统的会议论文,而是一个主要项目,我会用不同的方式来处理这个问题。我会做一个论文总结(对我不知道的东西做笔记)和实施。
请注意,在原始论文中,Matthew 使用了 ADNI 老年痴呆症 MRI 数据集,不幸的是,我无法获得这些数据,所以我将使用“ 驱动:用于血管提取的数字视网膜图像 ”数据集。还请注意,由于使用了不同的数据集,以及硬件限制,网络架构与原始论文的差异很小,但是我试图保持总体结构相似。
2.2 网络节点和激活功能

在这里我了解到激活功能必须满足三个标准。(我只认识其中两个。)并且它们是差分的、非线性的和单调的。(我不知道单调。)
微分 →执行反向传播
非线性 →赋予模型计算非线性函数的能力
单调 →防止产生更多的局部最小值
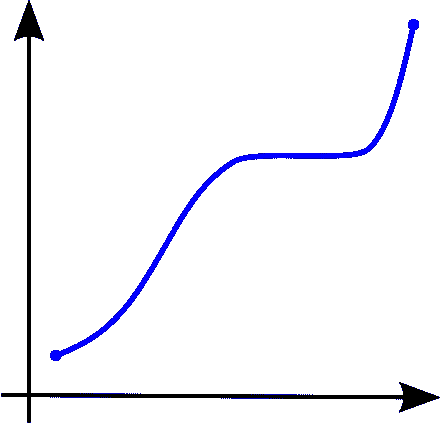
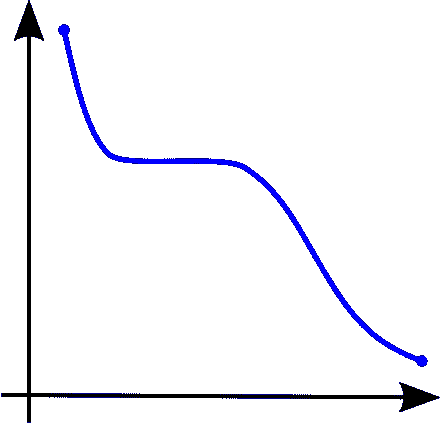
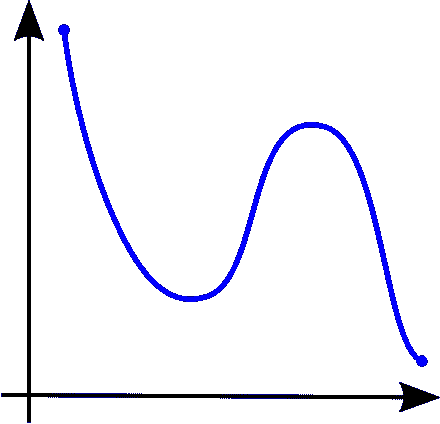
Image from Wiki
左图 →单调递增的函数
中图 →单调递减的函数
右图 →非单调的函数
2.3 训练神经网络

在这里,我了解到 Rprop 反向传播的存在,这种反向传播方法只考虑偏导数的符号,而不考虑大小。如果您想了解更多信息,请点击此处。
3.1 为什么要建立深度网络?

在这里,我了解到我们需要使用深度神经网络的确切原因。我学到了几件事…
- 从理论上讲,用两层模型来模拟任何功能都是可能的,这意味着我们真的不需要一个比两层更深的模型。
- 但是使用深度神经网络的好处其实是节点效率。当我们有一个更小但更深的神经网络时,用更高的精度逼近复杂函数是可能的。

本质上,更小更深的神经网络更有效,因为(每个节点)完成的冗余工作量减少了。
3.2 消失渐变

在这里,我学到了三种解决消失梯度问题的方法。我已经知道了辍学和 ReLU,但我从来不知道 ReLU 激活功能是用来克服消失梯度。我也不知道分层预训练。
3.2.1 方案一:分层预训练

这个想法非常有趣,因为我们将首先以无人监督的方式训练每一层,然后一起使用它。
3.2.2 解决方案 2:整流线性激活单元

虽然 ReLU()激活可能在两个方面存在问题,因为
a.0 处没有导数。
b .正区域内没有边界。
然而,它仍然可以使用,因为它们在进行反向传播时不会降低梯度(导数为 1)。我不知道 ReLU()激活层是用来克服渐变消失问题的。
3.3 辍学

通过丢弃某些节点的值,我们可以使每个节点独立地从另一个节点进化,这使得网络更加健壮。
3.5 使深网变浅

在这里,我学到了一种提高网络性能的方法,这种方法非常有趣。来自论文“ 深网真的需要深吗? “我们可以看到一个深度 NN 被训练来指导一个较浅网络的情况。并且这种引导的浅层网络比用给定数据直接训练的浅层网络表现得更好。

网络架构(描述形式)

红框 →网络架构描述
因为其他两个网络与这个非常相似,所以我们只实现第一个。我从未真正使用全连接网络进行过分段,但我认为这会非常有趣。此外,请注意,由于使用不同的数据集,我将增加一个层,只是为了适应我们的数据。然而,网络的一般结构是相似的。
网络架构(图形形式)
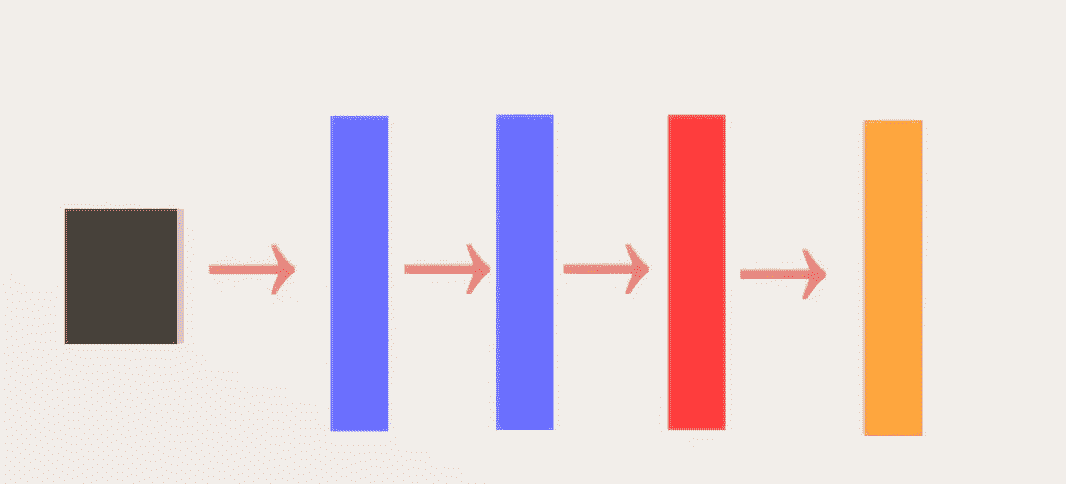

黑色矩形 →输入图像
蓝色矩形 →卷积层
红色矩形 →全连通层(输入图像矢量化)
橙色矩形 →软 max 层
网络本身很简单,现在让我们来看看 OOP 的形式。此外,为了克服消失梯度,让我们使用 ReLU()激活功能,并 tanh()激活在完全连接的层。
注意由于硬件限制,我不得不将两个卷积层的滤波器大小减半,以及批量大小(2)。
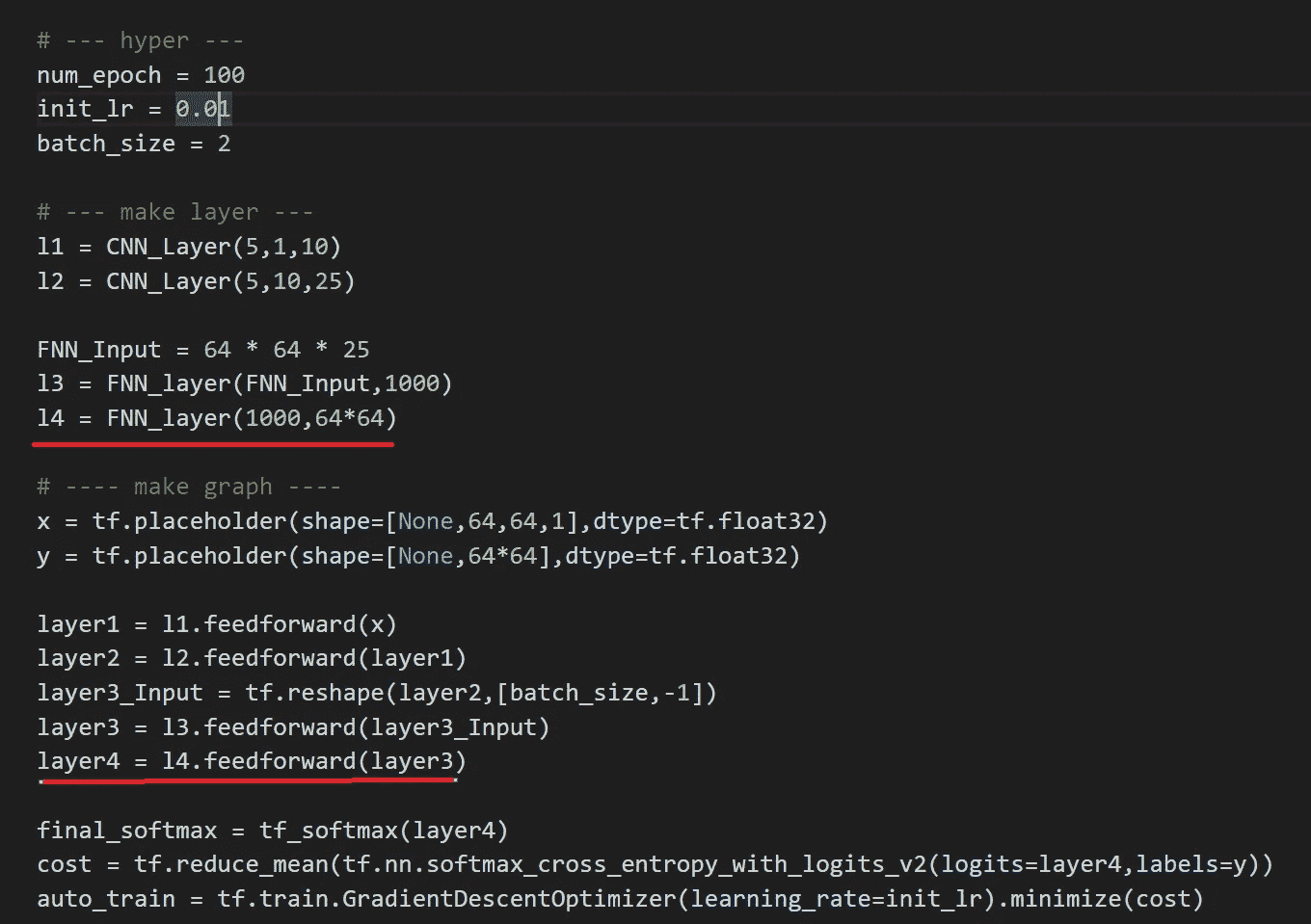
红线 →添加图层
整个网络(由于其深度)可以在一个屏幕截图中查看。最后,我们将使用随机梯度下降优化器。
结果


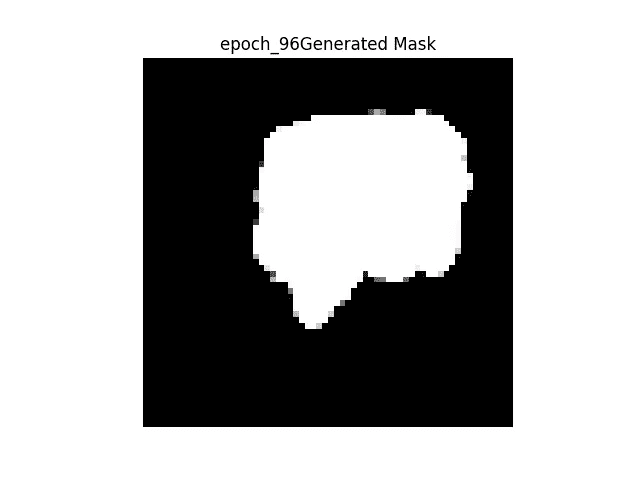
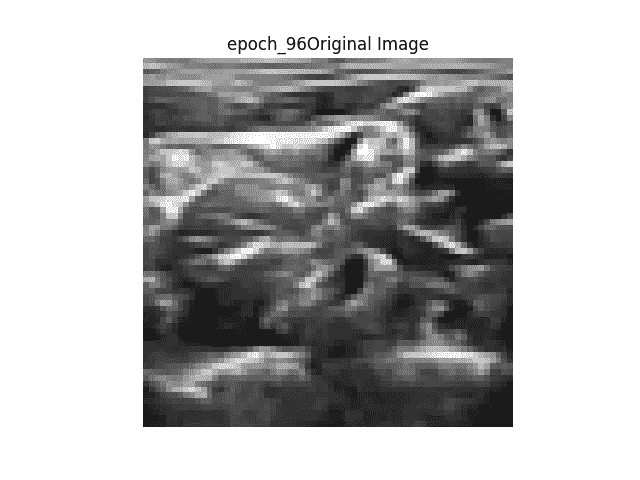

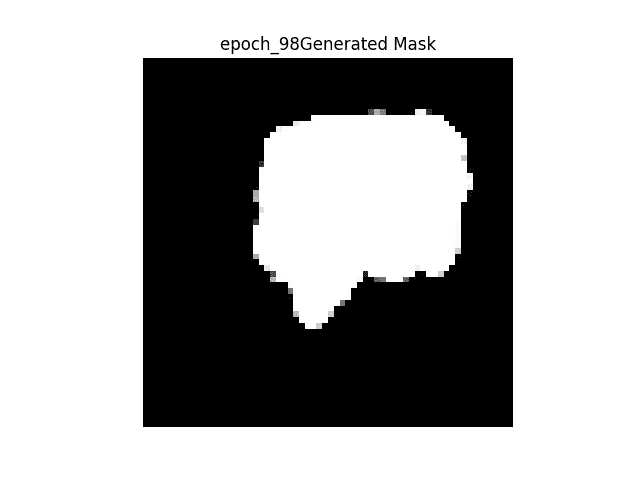
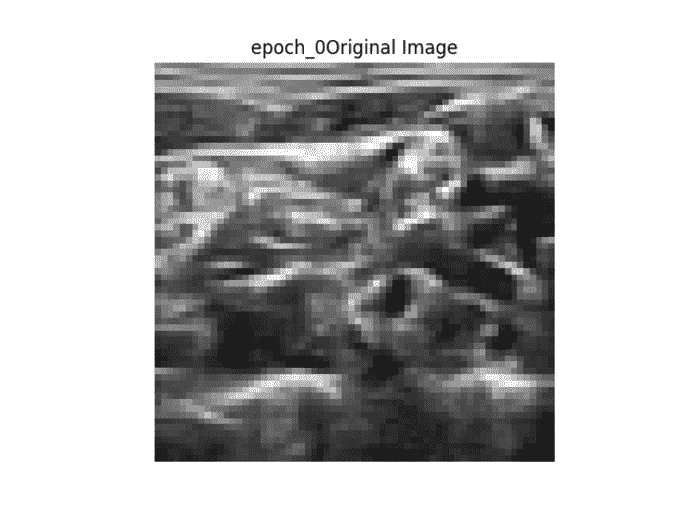
右图 →原图
中图 →二值掩码
地面真相左图 →从网络生成二值掩码
网络给出的结果很差,但是我相信这是由于我使用了不同的数据集。我没有 ADNI 老年痴呆症的核磁共振数据集,但我相信网络的最终输出不是图像的矢量化版本。可能是海马体所在位置的坐标等等…
GIF 格式的结果
显示图像的顺序 → 1。原图→ 2。地面真实二进制掩码→ 3。生成的二进制掩码→ 4。原始图像上的地面真实遮罩叠加→ 5。原始图像上生成的蒙版覆盖。
如上所述,随着训练的继续,我们可以看到所生成的滤波器变得更加清晰,但是所生成的掩模不会从一幅图像改变到另一幅图像,并且在正确分割图像方面表现不佳。
互动代码/透明度
对于 Google Colab,你需要一个 Google 帐户来查看代码,而且你不能在 Google Colab 中运行只读脚本,所以在你的操场上复制一份。最后,我永远不会请求允许访问你在 Google Drive 上的文件,仅供参考。编码快乐!
要访问 Google Colab 上的代码,请点击这里。
- 注*:我不想在 github 上存放私人医疗数据,因为我可能会违反他们的数据使用政策。所以这段代码不能直接在线运行。
- 为了让这个实验更加透明,我上传了我所有的命令输出到我的 Github,如果你想看,请点击这里。
最后的话
这篇硕士论文在英语和内容方面都写得非常好,我希望在我做硕士论文时能写出类似的内容。
如果发现任何错误,请发电子邮件到 jae.duk.seo@gmail.com 给我,如果你想看我所有写作的列表,请点击这里查看我的网站。
同时,在我的推特这里关注我,访问我的网站,或者我的 Youtube 频道了解更多内容。如果你感兴趣,我还在这里做了解耦神经网络的比较。
参考
- 赖,男(2015)。长颈鹿:利用深度强化学习下棋。Arxiv.org。检索于 2018 年 4 月 8 日,来自https://arxiv.org/abs/1509.01549
- 赖,男(2015)。用于医学图像分割的深度学习。Arxiv.org。检索于 2018 年 4 月 8 日,来自https://arxiv.org/abs/1505.02000
- 单调函数。(2018).En.wikipedia.org。检索于 2018 年 4 月 8 日,来自https://en.wikipedia.org/wiki/Monotonic_function
- Rprop。(2018).En.wikipedia.org。检索于 2018 年 4 月 8 日,来自https://en.wikipedia.org/wiki/Rprop
- 驱动:用于血管提取的数字视网膜图像。(2018).isi . uu . nl . 2018 年 4 月 8 日检索,来自https://www.isi.uu.nl/Research/Databases/DRIVE/
- ADNI |阿尔茨海默病神经影像倡议。(2018).Adni.loni.usc.edu。检索于 2018 年 4 月 8 日,来自http://adni.loni.usc.edu/
- 导数双曲线。(2018).Math.com。2018 年 4 月 8 日检索,来自http://www.math.com/tables/derivatives/more/hyperbolics.htm
- j . brown lee(2017 年)。深度学习的 Adam 优化算法的温和介绍-机器学习掌握。机器学习精通。检索于 2018 年 4 月 8 日,来自https://machine learning mastery . com/Adam-optimization-algorithm-for-deep-learning/
【谷歌/ ICLR 2017 /论文摘要】反事实的梯度
GIF from this website
Mukund Sundararajan ,是论文“神经元有多重要?”的作者之一(我也做了论文总结这里)。但是今天我想看看他之前的论文“反事实的梯度”。
请注意,这篇帖子是为了我未来的自己复习这篇论文上的材料,而不是从头再看一遍。
Paper from this website
摘要

执行分类时,梯度可用于识别哪些要素对网络很重要。然而,在深度神经网络中,不仅神经元,而且整个网络都可能遭受饱和。且导致给出小梯度值,即使对于非常重要的特征也是如此。
在这项工作中,作者提出了内部梯度,这是反事实输入的梯度。(缩小原始输入)。该方法不仅易于实现,而且能更好地捕捉特征的重要性。
简介

同样,梯度可以用来确定哪些特征是重要的。然而,由于网络内的饱和,重要特征可能具有非常小的梯度。以前有过克服这个问题的工作,但是它们需要开发者做大量的工作。相比之下,内部渐变非常容易实现,只需要最小的变化。(仅输入值)
我们(作者)的手法

作者首先从调查梯度如何用于测量特征重要性开始,他们决定使用 GoogleNet。如上所述,当我们直接可视化与原始图像重叠的归一化梯度时,我们不能准确地说出为什么网络将该图像分类为相机。
凭直觉,我们应该期望镜头区域和相机整体的渐变比左上区域更亮。因此,作者从原始图像中裁剪掉了左边部分,然而,即使这样做了,我们也可以观察到图像中最奇怪的部分梯度最强。
饱和度

从上面的实验中,我们已经知道,由于网络中的饱和,梯度有可能表现出奇怪的行为。为了捕捉网络中饱和度的分布范围,作者提出了反事实输入。并且这些输入可以通过将α值乘以原始图像来获得。
通过大量的实验,作者发现饱和度在谷歌网络中广泛分布。(更具体地说,甚至在中间层以及最终软最大层和预软最大层中。)此外,作者还注意到,当输入值乘以低 alpha 值时,网络中会有更多的活动。(如 0.02)。
最后,众所周知的事实是,梯度的饱和会阻止模型收敛到高质量的最小值,如果发生这种情况,网络的性能会受到严重影响。然而,当网络中仍然存在饱和时,GoogleNet 具有很好的性能测量,因此作者做出了以下假设。
我们的假设是,重要特征的梯度在训练过程的早期没有饱和。梯度仅在特征已经被充分学习之后饱和,即,输入远离决策边界。
内部梯度

在本节中,作者描述了如何创建反事实输入,并指出这样一个事实,即我们可以通过在颜色维度上对它们求和来聚合所有的最终渐变。当我们在每个比例因子α下可视化这些梯度时,我们得到如下结果。
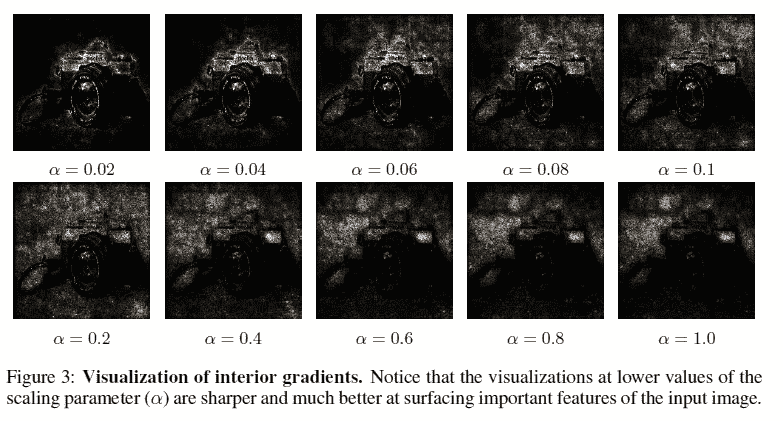
我们可以观察到,随着比例因子的降低,网络将该图像归类为相机的原因变得更有意义。当我们绘制最终梯度的绝对幅度时,我们得到如下图。
这表明随着α值的增加,最终梯度的值由于饱和而减小。
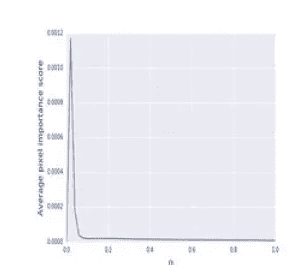
累积内部渐变

在本节中,作者通过将不同 alpha 值的所有梯度值相加来扩展内部梯度。他们用一种非常聪明的方式做到了这一点,他们不是有多个α值,比如说 100,而是取α从 0 到 1 的所有可能值的积分。最后,他们用黎曼和来逼近积分梯度。
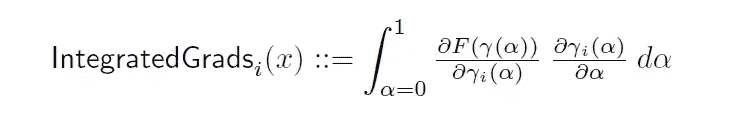
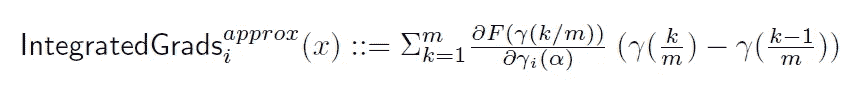
左图 →积分梯度的原始方程
右图 →用黎曼和近似积分
这个方法最好的部分就是简单地说,我们只是一遍又一遍地计算梯度。但是使用了缩小版本的输入,所以实现起来非常简单和自然。当我们将得到的积分梯度可视化时,我们会得到如下结果。

评估/调试网络/讨论

总之,在本节中,作者进行了额外的实验来评估积分梯度。(例如像素烧蚀或比较最高有效梯度的边界框)并且当与纯梯度相比时,积分梯度给出了更好的结果。(如果您希望查看更多示例,请点击此处。)
在精度要求较高的环境中,例如医疗诊断,了解网络中的情况非常重要。并且更准确地知道哪些特征贡献给哪些类,积分梯度可以用作获得更多洞察的工具。
最后,作者讨论了这种方法的局限性。
a .无法捕获特征交互 →模型可以执行一些操作,将某些特征组合在一起。重要的分数没有办法代表这些组合。
b .特征相关性→ 如果相似的特征出现多次,模型可以为其中任何一个分配权重。(或者两者都有)。但是这些重量可能不是人类能够理解的。
相关工作

在本节中,作者讨论了不同研究人员提出的其他方法,希望揭开神经网络内部工作的神秘面纱。
基于梯度的方法 →使用纯梯度或内部/整体梯度
基于分数反向传播的方法 → 深度提升、逐层相关传播、反卷积网络、导向反向传播
基于模型近似的方法 → 我为什么要相信你?
应用于其他网络
我不会深入每个实验的细节,但简而言之作者已经进行了两次实验。(一个与药物有关,另一个与语言建模有关。)通过使用积分梯度,他们能够确定哪些特征对模型做出预测起着最重要的作用。让他们更深入地了解模型在做什么。
结论

总之,作者提供了一种新的和简单的方法来衡量特征的重要性。并提供了广泛的实验,表明内部/积分梯度如何优于传统的梯度方法。
遗言
我真的相信这篇论文打开了研究神经网络的大门。总的来说,这是一篇相当长的论文,所以我没有包括很多内容和细节,如果你有时间,我强烈推荐你阅读这篇论文。
如果发现任何错误,请发电子邮件到 jae.duk.seo@gmail.com 给我,如果你希望看到我所有写作的列表,请在这里查看我的网站。
同时,在我的推特这里关注我,并访问我的网站,或我的 Youtube 频道了解更多内容。我也实现了广残网,请点击这里查看博文 pos t。
参考
- Sundararajan,m .,Taly,a .,和 Yan,Q. (2016 年)。反事实的梯度。Arxiv.org。检索于 2018 年 6 月 15 日,来自https://arxiv.org/abs/1611.02639
- Dhamdhere,m . Sundararajan 和 q . Yan(2018 年)。一个神经元有多重要?。Arxiv.org。检索于 2018 年 6 月 15 日,来自https://arxiv.org/abs/1805.12233
- 【NIPS2018/ Google /论文摘要】一个神经元有多重要?。(2018).走向数据科学。检索于 2018 年 6 月 15 日,来自https://towards data science . com/nips 2018-Google-paper-summary-how-importance-is-a-neuron-3d E4 b 085 EB 03
- ankurtaly/集成渐变。(2018).GitHub。检索于 2018 年 6 月 15 日,来自https://github.com/ankurtaly/Integrated-Gradients
- 斯普林根贝格,j .,多索维茨基,a .,布罗克斯,t .,&里德米勒,M. (2014)。追求简单:全卷积网。Arxiv.org。检索于 2018 年 6 月 15 日,来自https://arxiv.org/abs/1412.6806
- m .泽勒和 r .弗格斯(2013 年)。可视化和理解卷积网络。Arxiv.org。检索于 2018 年 6 月 15 日,来自https://arxiv.org/abs/1311.2901
- 宾德,a .,蒙塔冯,g .,巴赫,s .,M:ller,k .,& Samek,W. (2016 年)。具有局部重正化层的神经网络的逐层相关性传播。Arxiv.org。检索于 2018 年 6 月 15 日,来自 https://arxiv.org/abs/1604.00825
- Shrikumar,a .,Greenside,p .,和 Kundaje,A. (2017 年)。通过传播激活差异学习重要特征。Arxiv.org。检索于 2018 年 6 月 15 日,来自 https://arxiv.org/abs/1704.02685
- (2018).Kdd.org。检索于 2018 年 6 月 15 日,来自http://www . KDD . org/KDD 2016/papers/files/RFP 0573-ribeiroa . pdf

Photo by Dollar Gill on Unsplash


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}