








 超级会员免费看
超级会员免费看

主要内容
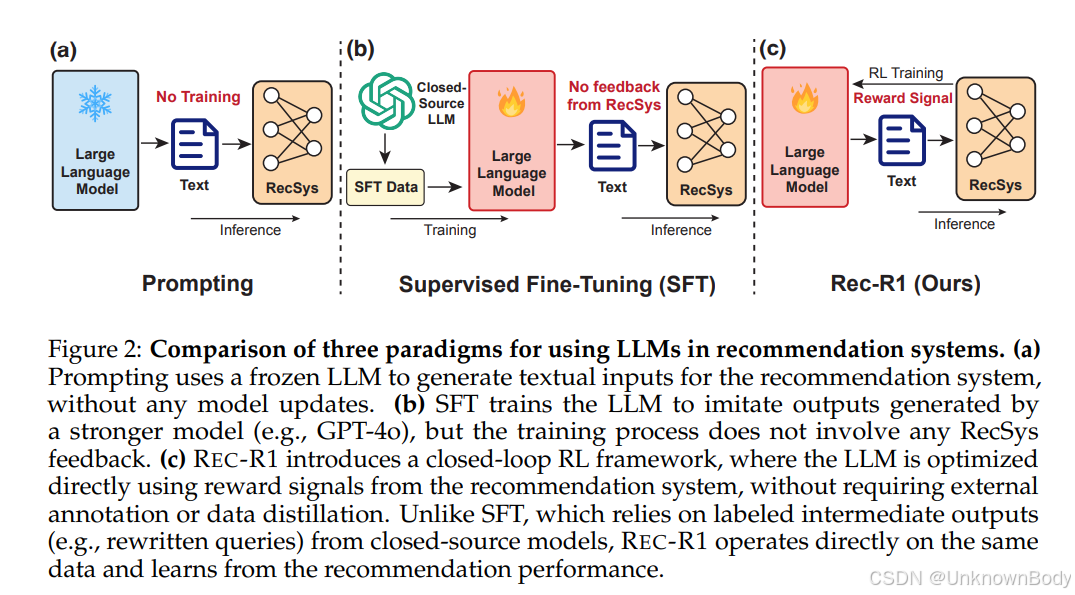
本文提出了REC-R1框架,通过强化学习(RL)将大型语言模型(LLM)与推荐系统相结合,解决传统推荐系统缺乏开放域知识和用户意图理解的问题。REC-R1直接利用推荐系统的反馈信号(如NDCG、Recall)优化LLM的生成策略,无需依赖监督微调(SFT)或外部标注数据。实验表明,REC-R1在商品搜索和序列推荐任务中均显著优于基于提示或SFT的方法,同时保留了LLM的通用能力。
创新点
- 闭环优化框架:首次将LLM与推荐系统通过强化学习闭环连接,使LLM直接学习最大化推荐性能的生成策略。
- 避免监督微调局限性:无需依赖如GPT-4o生成的合成数据,消除数据蒸馏的高成本,且突破SFT性能受限于数据生成模型的天花板。
- 任务灵活性与模型无关性:适用于多种推荐架构(如BM25、BLAIR),支持不同生成任务(查询改写、用户画像生成等),无需修改推荐系统内部结

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1621
1621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











