







如何为您的数据产品缩小 NumPy、SciPy、Pandas 和 Matplotlib
如果你是一名在微服务框架中部署数据产品的数据科学家或 Python 开发人员,你很有可能需要利用 NumPy、SciPy、Pandas 或 Matplotlib 的公共科学生态系统模块。微服务中的“微”,建议你应该保持组件尽可能的小。然而,当通过 PIP 安装时,这四个模块非常庞大!
让我们探索为什么 NumPy,SciPy,Pandas,Matplotlib 在通过 PIP 安装时如此庞大,并设计一个关于如何在微服务框架内优化您的数据产品的策略(使用源代码)。

Python Scientific Modules
我参与的大多数数据产品都是通过 Docker 部署的,所以本文将使用该框架。与微服务框架的“微”保持一致,第一个 Docker 最佳实践围绕着保持你的图像尺寸小。如果你对缩小 Docker 图片尺寸的最佳实践感兴趣,在 Medium 上有很多帖子。这篇文章将完全专注于减少 NumPy、SciPy、Pandas 和 Matplotlib 消耗的磁盘大小。
只使用预编译的二进制文件?
关于 NumPy、SciPy、Pandas 和 Matplotlib,你可以在互联网上读到的一般建议是通过你的 linux 包管理器(即 apt-get install -y python-numpy)来安装它们。然而,在实践中,那些包管理人员经常在官方发布的版本后面跟踪多个版本。如果您的数据产品需要这些模块的一个特定版本,这根本就行不通。

Just trust the package manager?
Anaconda 发行版用比 PIP 更少的内存完成了编译这些库的工作,那么为什么不直接使用 Python 发行版呢?根据我的经验,如果您已经处于需要特定版本的 NumPy、SciPy、Pandas 或 Matplotlib 的状态,那么您很可能还需要来自其他软件包的特定版本。不幸的消息是,那些其他的包可能不会存在于 Conda 库中。所以简单地使用 Anaconda 或 miniconda ,并引用 conda 存储库不会满足您的需求。更不用说您的 Docker 映像中不需要的 Anaconda 的额外膨胀。记住,我们想让事情尽可能的小。
码头工人历史
要查看构建 Docker 映像时运行的命令的逐层影响,历史命令非常有用:
$ docker history shrink_linalgIMAGE CREATED CREATED BY SIZE COMMENT435802ee0f42 About a minute ago /bin/sh -c buildDeps='build-essential gcc gf… 508MB
在上面的示例中,我们可以看到一个层产生了 508MB ,而我们在该层中所做的只是使用以下命令安装 NumPy、SciPy、Pandas 和 Matplotlib:
pip install numpy==1.15.1 pandas==0.23.4 scipy==1.1.0 matplotlib==3.0.0
我们还可以使用 du 命令查看映像中消耗的详细包磁盘空间:
$ docker run shrink_linalg /bin/bash -c "du -sh /usr/local/lib/python3.6/site-packages/* | sort -h"...
31M /usr/local/lib/python3.6/site-packages/matplotlib
35M /usr/local/lib/python3.6/site-packages/numpy
96M /usr/local/lib/python3.6/site-packages/pandas
134M /usr/local/lib/python3.6/site-packages/scipy
这些模块是巨大的!你可能会说这些模块的功能需要那么大的磁盘空间。但是它们不需要这么大。我们可以删除很大一部分(高达 60% )不必要的磁盘空间,而不会影响模块本身的性能!
爆破优化
NumPy 和 SciPy 的优势之一是对线性代数方法进行了优化。为此,有许多 LinAlg 优化器。在这篇文章中,我们只是使用了 OpenBLAS 。但是我们需要验证是否安装了 NumPy 和 SciPy 来利用这个库。
$ docker run shrink_linalg /bin/bash -c "python -c 'import numpy as np; np.__config__.show();'"...
openblas_info:
libraries = ['openblas', 'openblas']
library_dirs = ['/usr/lib']
language = c
define_macros = [('HAVE_CBLAS', None)]
...
这里重要的是让 OpenBLAS 被识别并映射到正确的目录。这将使 NumPy 和 SciPy 能够利用该库中的 LinAlg 优化。
PIP 安装选项
当在 Docker 容器中通过 PIP 安装时,保留缓存是没有意义的。让我们添加一些标志来指示 PIP 如何工作。
- — no-cache-dir
PIP 使用缓存来防止重复的 HTTP 请求,以便在安装到本地系统之前从存储库中提取模块。当在 Docker 映像中运行时,没有必要保留这个缓存,所以用这个标志禁用它。 - —编译
将 Python 源文件编译成字节码。在 Docker 映像中运行时,不太可能需要调试成熟的已安装模块(如 NumPy、SciPy、Pandas 或 Matplotlib)。 - — global-option=build_ext
为了通知 C 编译器我们想要在编译和链接期间添加额外的标志,我们需要设置这些额外的“全局选项”标志。
c 编译器标志
Python 有一个名为 Cython 的 C-Extension 包装器,它使开发人员能够以类似 Python 的语法编写 C 代码。这样做的好处是,它允许对 C 语言进行大量的优化,同时也便于编写 Python。NumPy,SciPy 和 Pandas 大量利用 Cython!Matplotlib 似乎也包含一些 Cython,但程度要小得多。
这些编译器标志被传递给安装在 docker 文件中的 GNU 编译器。开门见山地说,我们只打算调查其中的一小部分:
- 禁用调试语句 ( -g0 )
因为我们将数据产品粘贴到 Docker 映像中,所以我们不太可能对来自 NumPy、SciPy、Pandas 或 Matplotlib 的 Cython 代码进行任何实时调试。 - 移除符号文件 ( -Wl,— strip-all )
如果我们永远不会在 Docker 映像中调试这些包的构建,那么保留调试所需的符号文件也没有意义。 - 针对几乎所有支持的优化进行优化,这些优化不涉及空间速度权衡 ( -O2 )或针对磁盘空间的优化 ( -Os )
这些优化标志面临的挑战是,虽然它可以增加/减少磁盘大小,但它也会操纵编译后的二进制文件的运行时性能!如果没有明确测试它对我们的数据产品的影响,这些可能是有风险的(但同时,它们是非常有效的)。 - 头文件的位置(-I/usr/include:/usr/local/include)
明确告诉 GCC 在哪里可以找到编译 Cython 模块所需的头文件。 - 库文件的位置(-L/usr/lib:/usr/local/lib)
明确告诉 GCC 在哪里可以找到编译 Cython 模块所需的库文件。
但是在通过 PIP 安装期间设置这些 CFLAG 有什么影响呢?
缺少调试信息可能会使有经验的开发人员提高警惕,但是如果您以后真的需要它们,您总是可以使用标志重新构建 Docker 映像,以再现任何发生的 stacktrace 或 core dump。更大的问题是不可重现的异常…没有符号文件是无法诊断的。但是,没有人会以码头工人的形象这样做。
带 CFLAG 比较的 PIP

Disk consumption inside Docker image
采取最佳优化 CFLAG 策略,您可以将 Docker 映像的磁盘占用空间减少 60% !
对于我的数据产品,我只是删除了 debug/符号,并且不执行任何额外的优化。如果你想知道其他人是如何执行类似的 CFLAG 优化的,请查看官方的 Anaconda 食谱,包括 NumPy 、 SciPy 、 Pandas 和 Matplotlib 。这些都是针对 Python 的 Anaconda 发行版进行优化的,可能与您的特定 Docker 数据产品部署相关,也可能不相关。
单元测试
仅仅因为我们能够收缩每个模块的编译二进制文件,我们就应该进行健全性检查,以验证我们使用的 C 编译器标志没有影响这些模块的性能。
所有这些包都利用了 pytest 模块,我们没有将它安装在 Docker 映像中,因为它在生产中没有提供任何价值。我们可以安装它并从内部执行测试,尽管:
- 我们的 Docker 映像中的 NumPy 测试:
$ docker run shrink_linalg /bin/bash -c "pip install pytest; python -c \"import numpy; numpy.test('full');\""4675 passed ... in 201.90 seconds
- Docker 映像内部的 SciPy 测试:
$ docker run shrink_linalg /bin/bash -c "pip install pytest; python -c \"import scipy; scipy.test('full');\""13410 passed ... in 781.44 seconds
- 我们 Docker 图片中的熊猫测试:
$ docker run shrink_linalg /bin/bash -c "pip install pytest; python -c \"import pandas; pandas.test();\""22350 passed ... in 439.35 seconds
有相当多的测试被跳过,而被 x 失败,这取决于您的数据产品和/或安装的版本,这些都是可以预料到的,或者您可能需要进一步研究。在大多数情况下,如果不是严重的失败,很可能可以继续。
希望当您的数据产品需要 NumPy、SciPy、panases 或 Matplotlib 时,这将有助于引导您使用更小的 Docker 图像!我鼓励您尝试其他 CFLAG,并测试磁盘空间和单元测试性能。
如何解决最后一公里物流难题?
电子商务的兴起和消费者对快速送货的期望给物流公司带来了前所未有的压力,要求他们消除最后一公里物流中的摩擦和低效。“最后一英里”通常是指从运输中心(如仓库)到最终交付目的地(如您的家)的货物交付。对物流公司来说,这最后一段是最昂贵的,占运输成本的近 28%。
我们都听说过这样的轶事:送货不准时、包裹被损坏、错过送货和包裹失窃。最后一公里物流在当天送达的世界中更加重要,并给物流提供商带来越来越大的压力。巨大的挑战包括改善基础设施、确保透明度以及通过智能车辆路线将成本降至最低。在这篇文章中,我们将研究一些算法,看看它们如何应用于现实生活中的实际情况,以最小化最后一英里的成本。在一个依赖高销量和低利润的行业,优化最后一英里将直接带来高利润和满意的客户。
旅行推销员和 NP 难题
计算机科学中最著名的问题之一是旅行推销员问题。这个问题构成了物流世界中车辆路径的基础。给定一组点,我们如何找到从起点到终点的最短路径,其中我们访问每个点恰好一次?

Travelling salesman problem
求解旅行商是一个 NP-hard 问题,也就是说没有‘快速’解(快速是指多项式时间算法)。一个精确的算法将包括找到所有的路由排列和组合,并比较每一个来提取最短的路由。“Held-Karp”算法可用于求解旅行推销员问题的精确解,利用子路径并使用动态编程技术。即使这样,这样的算法也只能在合理的时间内解决少量的点。点数的任何增加都会导致计算时间的指数增长。因此,在实际应用中,我们使用近似算法的组合来逼近最佳路径,误差在最佳精确解的 1%以内。
车辆路径问题
最后一英里物流的成本最小化本质上是一个车辆路径问题。车辆路径问题概括了前面提到的旅行推销员问题,并处理寻找一组路径或路线,以最小化成本。问题域可能涉及许多车辆、数百个交货地点和一组仓库地点。车辆路线算法的目标包括但不限于以下内容:
- 为每辆车寻找最短的路径,或最短的行驶时间以节省燃料费用
- 每辆车的容量可能有限,因此目标是使用最少的车辆覆盖所有路线
- 交付需要在特定的时间窗口内发生,我们需要在特定的时间范围内安排路径
- 交货从仓库开始,必须返回仓库
克拉克·赖特储蓄算法
Clarke 和 Wright 节约算法在车辆路径问题的近似解方面非常流行。该算法的决策变量是要使用的车辆数量。该算法的基本思想是,如果两条路线可以可行地合并并产生距离节省,那么我们就选择合并的路径。该算法的工作原理如下:
- 通过将每辆车分配给客户或位置,创建一个初步可行的解决方案
- 对于所有的位置对,我们在连接它们时计算节省,并且我们将节省列表按降序排列
- 我们从节省列表的顶部选取每个子路径,如果没有超过最大车辆容量,则加入其他子路径
- 我们重复上一步,直到考虑了整个节省列表,或者容量限制不允许更多的子路径合并。
最终结果将是在不超出车辆容量的情况下,为最小车辆集分配一定数量的路径或循环,并且每个位置只被访问一次。
蚁群优化算法
蚁群算法大致基于蚂蚁寻找食物的行为。起初,一群蚂蚁会漫无目的地游荡,当一只蚂蚁找到食物时,它会走回蚁群,留下信息素或标记供其他蚂蚁跟随。随着越来越多的蚂蚁追踪这些标记,信息素的踪迹变得越来越突出。更短的路径意味着蚂蚁会更频繁地在上面行走,从而产生更强的信息素踪迹。这个原理可以用来逼近最佳路径。
谷歌或工具
我们如何构建一个软件应用程序来解决车辆路径问题,并利用广泛的优化算法?原来我们可以使用 Google 或者-tools 包来解决我们最后一英里的物流问题。
在我们的示例问题域中,我们将在悉尼市中心附近生成多个装货地点和一个仓库。然后,我们的车辆将从仓库出发,访问这些地点,并装载一些具有一定重量的货物。在我们的问题中,我们将每辆车的载重量限制在 15 公斤,我们的车队最多有 10 辆卡车。

The green marker signifies the home depot, our fleet of trucks must visit the 16 locations on this map.
这个项目将包括一个简单的 Django 后端服务器和一个用 React.js 构建的前端。第一个端点简单地生成一些地址,第二个端点在 Google 或-tools 中运行有容量限制的车辆路径算法。我们选择使用上述节约算法,该算法以其相对较快的计算时间而闻名。这种算法的输入包括使用 Google distance matrix API 计算的距离矩阵,其他参数包括每个给定位置的重量需求列表(随机生成)和许多约束条件,包括车辆的最大数量和每辆车的最大容量。
对于前端,我们只需使用谷歌地图 javascript 库来呈现位置和路线。我们只需在地图上标出送货地点,然后用彩色编码折线显示计算出的路线。我们还可以看到每辆车的路线和它们在每个位置的容量。随着我们给这个问题增加越来越多的问题,只有我们也增加车队的规模,才能产生一个解决方案。例如,如果我们将车队限制为 3 辆车,我们将无法为 20 多个地点提供载重量为 15 公斤的最佳路线。

Optimal vehicle routes plotted using Polylines using Google Maps Javascript Library
聚类增强
在上面的例子中,我们展示了我们可以使用 Google 或-tools 为我们的车队计算一组优化的路线。然而,随着递送点数量的增加,计算时间变得不合理地长。在现实世界的交付示例中,我们可能要处理数百个交付位置和多个仓库位置。在这种情况下,使用聚类算法将地理上相似的点分组在一起,然后将有容量限制的车辆路线算法应用于每个聚类是合适的。 DBSCAN 聚类算法将适合这样的任务,DBSCAN 算法是一种基于密度的聚类技术,它将紧密堆积的邻居分组在一起,这可以大大加快我们在 Google OR-tools 套件中实现算法的速度。
未来应用
正如我们所看到的,解决车辆路径问题和找到最佳路线将是任何最后一英里物流运营降低成本和增加利润的关键。几项关键的技术开发目前正在进行中,以将最后一英里物流提升到一个新的水平,并确保满足消费者对当天交付等服务的高期望。我们开始看到一些公司在测试自动地面车辆和无人驾驶送货机。这些技术有可能进一步降低运输成本,并将服务范围扩大到农村地区。
如何借助热图发现数据泄漏(在您的笔记本电脑上!)
如何确保你的模型真正学到你认为它学到的东西的指南!

Last Convolution Layer Heat Map for two training samples. (Be patient, this animated GIF could take some time to load…)
生成以下图片所需的数据集和源代码可在GitHub 资源库中找到。本文所有内容都可以在配有 1 Go 内存 GPU 的笔记本电脑上重现。
在本文中,您将了解到:
- 如何在图像分类任务中发现数据泄露,以及
- 如何修复(对于这个给定的图像分类任务)。
问题是
想象一下,玛姬·辛普森委托给你一项任务:她想让你做一个算法来区分巴特和荷马。
因为她爱她的丈夫和儿子,她给了你 66 张代表他们的照片在家庭住宅前。(上一句的粗体部分很重要。)
以下是该数据集的摘录。




Pictures Marge gave you
作为一名实验过的数据科学家,你选择使用你最喜欢的预先训练好的图像识别深度神经网络:比如说 VGG16 。
(2014 年获得大型视觉识别挑战赛。)
但是,因为感兴趣的部分(Bart 或 Homer)表示图像中的一个小区域,所以您选择用单个卷积层和一个全局平均池层替换结束的完全连接的层,如下图所示:

Model used for Bart vs. Homer classification (based on VGG16). The only trainable layer is in red.
对于那些想知道的人来说,全球平均池是一种复杂的说法……“平均”。我们稍后会更详细地解释它。
如上所述,对于我们的识别任务,您将只训练最后一个卷积层。
将给定数据集拆分为训练集和验证集后,您训练了最后一个卷积层。
学习曲线是好的:低训练和验证损失意味着你有好的表现,没有过度拟合。您甚至在训练和验证集上获得了 100%的准确率。
恭喜你!

Learning curves
现在是时候在生产中使用您的模型了!
然而,在生产中,巴特和荷马可能在世界的任何地方,包括在斯普林菲尔德核电站前,如下所示:


Ground truth: Bart — Predicted label: Bart ==> OK!


Ground truth: Homer — Predicted label: Homer ==> OK!
对于之前的这 4 张图片,您的模型 100%地预测了好标签(上面的图片预测为 Bart,下面的图片预测为 Homer)。
干得好,玛吉会高兴的!
但是现在让我们在一个稍微不同的数据集上训练您的模型:
- 因为荷马花费大量时间在工作上,所以玛吉给你的所有照片都代表了荷马在核电站前的样子。
- 因为巴特是个孩子,一直在玩,所以玛吉给你的所有照片都代表巴特在家庭住宅前。
下面是这个新数据集的摘录。




The new dataset. Notice that in this dataset, Bart is always in front of the house, and Homer is always in front of the power plant**.**
像第一次一样,在将给定的数据集分成训练集和验证集之后,您训练了模型的最后一个卷积层。
学习曲线 超级 好:你只用一个历元就达到了 100%的准确率!
提示:这好得令人难以置信。

Learning curves
与之前的训练集一样,现在是时候在生产中使用您的模型了!
让我们看看你的模型有多好,巴特在核电站前面,荷马在家庭住宅前面。
请注意,在训练集中,Bart 在房子前面,Homer 在植物前面。在“生产”中,我们测试了相反的情况:巴特在工厂前面,荷马在房子前面。


Ground truth: Bart — Predicted label: Homer ==> NOT OK at ALL!


Ground truth: Homer — Predicted label: Bart ==> NOT OK at ALL!
哎哟…你的模型总是预测错误的标签。所以我们总结一下:
- 训练集上的损失和准确性->好。
- 验证集上的损失和准确性->好。
- 生产中的模型预测->坏。
发生了什么事?
*回答:*你的模型被数据泄露感染。
为了学习,模型使用了一些本不该使用的功能。
如何发现数据泄露
首先让我们来看看你的模型的最后一部分 :

想法是在原始图片上叠加最后一个卷积层的输出。该层输出是 2 个 22×40 的矩阵。第一个矩阵表示用于 Bart 预测的激活,第二个矩阵表示用于 Homer 预测的激活。
当然,因为这些矩阵的形状都是 22x40,所以在将它们叠加到原来的 360x640 之前,您必须将它们放大。
让我们用验证集的 4 张图片来做这件事:
在左栏,你有“Bart”最后一个卷积层的输出,在右栏是“Homer”的输出。
色码:蓝色为低输出(接近 0),红色为高输出。








Extract of validation set with heat maps corresponding to the last convolution layer output
看起来你的模型根本没有使用 Bart 和 Homer 来完成分类任务,而是使用了背景来学习!
为了确定这个假设,让我们显示没有巴特和荷马的图片的最后一个卷积层的输出!




Last convolution layer for background only
看来我们的假设是对的。添加/删除 Bart & Homer 对分类模型没有太大影响…
让我们回到我们的第一个模型上几秒钟,这个模型是用 Bart & Homer only 在房子前面的图片训练的,让我们显示一些验证示例的最后卷积层的输出:








Extract of validation set with heat maps corresponding to last convolution layer output, for the model trained with Bart only in front of the house and with Homer only in front of the power plant
在这种情况下,我们现在能够理解为什么这个模型预测了好标签:因为它实际上使用了 Bart & Homer 来预测产量!
解决方案
如何修复 Bart 总是在房子前面,Homer 总是在植物前面的训练集的数据泄露问题?我们有几个选择:
- 最常见的一种是通过使用边界框来修改模型。但是…那很无聊:你必须一个接一个地注释每个训练样本。
- 一个更简单的解决方案是将我们的 2 类分类问题(Bart & Homer)转化为 3 类分类问题(Bart、Homer 和背景)。
第一个类将包含巴特的图片(在房子前面),第二个类将包含荷马的图片(在发电厂前面),第三个类将只包含 2 张图片:一张房子的图片和一张发电厂的图片(上面没有任何人)。
还有……就这些了!
下面是这个 3 级训练模型的学习曲线。这些曲线看起来“更正常”。

Learning curves for the 3-classes trained model
下面是一些验证示例的最后一个卷积层的输出:








Extract of validation set with heat maps corresponding to the last convolution layer output, for the 3-classes trained model
您的模型现在在生产中也运行良好。
现在你知道了: 如何在一个图像分类任务上发现数据泄漏,以及如何为我们的 Bart vs. Homer 分类任务修复它。
生成上述图像所需的数据集和源代码可在GitHub 资源库中找到。
如何从 Kaldi 和语音识别开始
实现最先进的语音识别系统的最佳方式

Today Speech recognition is used mainly for Human-Computer Interactions (Photo by Headway on Unsplash)
卡尔迪是什么?
Kaldi 是一个开源工具包,用于处理语音数据。它被用于与语音相关的应用,主要用于语音识别,但也用于其他任务——如说话人识别和说话人日记化。这个工具包已经很老了(大约 7 年了),但是仍然在不断更新,并由一个相当大的社区进一步开发。Kaldi 在学术界(2015 年被引用 400 多次)和工业界都被广泛采用。
Kaldi 主要是用 C/C++编写的,但是工具包包装了 Bash 和 Python 脚本。对于基本用法,这种包装避免了深入源代码的需要。在过去的 5 个月里,我了解了这个工具包并学会了如何使用它。这篇文章的目标是引导你完成这个过程,并给你对我帮助最大的材料。把它看作一条捷径。

Kaldi simplified view (As to 2011). for basic usage you only need the Scripts.
本文将包括对 Kaldi 中语音识别模型的训练过程的一般理解,以及该过程的一些理论方面。
本文不包括代码片段和实践中做这些事情的实际方法。关于这一点,你可以阅读《卡尔迪傻瓜指南》或其他在线资料。
卡尔迪的三个部分
预处理和特征提取
如今,大多数处理音频数据的模型都使用基于像素的数据表示。当您想要提取这样的表示时,您通常会希望使用有利于以下两点的特征:
- 识别人类说话的声音
- 丢弃任何不必要的噪声。

An Example of MFCC. The Y Axis represents features and the X axis represents time.
MFCC 代表梅尔频率倒谱系数,自从戴维斯和梅尔斯坦在 80 年代发明以来,它几乎已经成为行业标准。在这篇令人惊叹的可读文章中,你可以获得关于 MFCCs 的更好的理论解释。对于基本的用法,你需要知道的是 MFCCs 只考虑我们的耳朵最容易听到的声音。**
在 Kaldi 中,我们使用了另外两个特性:
- cmvn用于更好的规范 MFCC
- I-Vectors (值得自己写一篇文章),用于更好地理解域内的方差。例如,创建依赖于说话者的表示。I 向量基于 JFA(联合因子分析)的相同思想,但是更适合于理解通道和说话者的变化。I-Vectors 背后的数学原理在这里和这里有清晰的描述。

The Process of using I-Vectors as described in Dehak, N., & Shum,S. (2011) In Practice: It’s complicated****
为了对这些概念有一个基本的了解,请记住以下几点:
- MFCC 和 CMVN 用于表示每个音频话语的内容。****
- I 向量用于表示每个音频话语或说话者的风格。****
模型
Kaldi 后面的矩阵数学是用 BLAS 和 LAPACK 实现的(用 Fortran 写的!),或者基于 CUDA 的替代 GPU 实现。由于使用了如此低级的包,Kaldi 在执行这些任务时效率很高。
Kaldi 的模型可以分为两个主要部分:
第一部分是声学模型,它曾经是一个 GMM 但现在被深度神经网络疯狂取代。该模型将把我们创建的音频特征转录成一些依赖于上下文的音素(在 Kaldi 方言中,我们称它们为“pdf-id”,并用数字表示它们)。

The Acoustic model, generalized. On top you can see IPA phoneme representation.
第二部分是解码图,它获取音素并将其转换成点阵。网格是可能用于特定音频部分的备选单词序列的表示。这通常是您希望在语音识别系统中得到的输出。解码图考虑了你的数据的语法,以及相邻特定单词的分布和概率( n-grams )。

A representation of lattice — The words and the probabilities of each word
解码图本质上是一个 WFST ,我强烈鼓励任何想要专业化的人彻底学习这个主题。最简单的方法就是通过那些视频和这篇经典文章。理解了这两点之后,你就可以更容易地理解解码图的工作方式了。这种不同 wfst 的组合在 Kaldi 项目中被命名为“HCLG.fst 文件”,它基于 open-fst 框架。

A simple representation of a WFST taken from “Springer Handbook on Speech Processing and Speech Communication”. Each connection is labeled: Input:Output/Weighted likelihood
值得注意的是:这是模型工作方式的简化。关于用决策树连接两个模型,以及你表示音素的方式,实际上有很多细节,但是这种简化可以帮助你掌握这个过程。
你可以在描述 Kaldi 的原始文章中深入了解整个架构,特别是在这个惊人的博客中了解解码图。
培训过程
一般来说,这是最棘手的部分。在 Kaldi 中,你需要按照一个真正特定的顺序排列你转录的音频数据,这个顺序在文档中有详细描述。
对数据进行排序后,您需要将每个单词表示为创建它们的音素。这种表示将被命名为“字典”,它将确定声学模型的输出。这是这种字典的一个例子:
八-> ey t
五- > f ay v
四- > f ao r
九- > n ay n
当你手头有了这两样东西,你就可以开始训练你的模型了。你可以使用的不同训练步骤在卡尔迪方言中被命名为“食谱”。最广泛使用的配方是 WSJ 配方,你可以查看 run bash 脚本来更好地理解这个配方。
在大多数食谱中,我们从用 GMM 将音素排列成声音开始。这个基本步骤(名为“比对”)帮助我们确定我们希望我们的 DNN 稍后吐出的序列是什么。

The general process of training a Kaldi model. The Input is the transcribed data and the output are the lattices.
校准后,我们将创建 DNN,它将形成声学模型,我们将训练它以匹配校准输出。创建声学模型后,我们可以训练 WFST 将 DNN 输出转换为所需的网格。
“哇,太酷了!接下来我能做什么?”
- 试试看。
- 阅读更多
如何尝试
下载这个免费口语数字数据集,试着用它来训练卡尔迪吧!你也许应该试着模糊地跟随这个。你也可以只使用上面提到的多种不同食谱中的一种。
如果你成功了,试着获取更多的数据。如果你失败了,试着在卡尔迪帮助小组中提问。
在哪里阅读更多内容
我无法强调这个 121 张幻灯片的演示对我的帮助有多大,它主要基于一系列的讲座。另一个很好的来源是约什·梅尔的网站。你可以在我的Github-Kaldi-awesome-list中找到这些链接和更多。
试着通读论坛,试着更深入地挖掘代码,试着阅读更多的文章,我很确定你会从中得到一些乐趣。😃
如果您有任何问题,请在此自由提问或通过我的电子邮件联系我,并在 Twitter 或 Linkedin 上自由关注我。
如何在没有实体数据挖掘的情况下保持在线竞争力

对零售商来说,唯一比销售更有价值的是潜在买家的信息。网上零售商可以使用大量的先进工具。然而,许多电子商务品牌已经开始了解通过店内互动收集客户数据的价值。随着亚马逊最近宣布收购全食超市(Whole Foods),以及 Fabletics 等品牌在实体店获得成功,人们越来越清楚地看到,线下品牌建设可能是成功实现在线销售的主要影响因素。
今年电子商务行业预计将在增长 10%左右,但仍仅占零售行业的 10% 多一点。鉴于近 90%的购物仍在店内进行,大型公司和品牌探索实体空间也就不足为奇了。对于凯特·哈德森的电子商务运动服装品牌 Fabletics ,最成功的市场是实体店。通过实体店中的客户交互收集的数据对于他们的店面来说是无价的信息。开一家店面是一项成本高昂的操作,但从数据的角度来看,店内收集的信息和研究是无价的。
今年早些时候,Casper 与 Target 签订了一份大合同,在店内销售他们的产品。即使有 100 天的免费试用,这个床垫品牌也看到了给予顾客触感体验的价值。此外,他们能够更好地了解他们的目标市场,以及什么类型的人在购买床垫时会考虑他们的品牌。
实体店给购物者一种品牌体验,更容易引导购买。商店员工可以提出具体问题,更准确地将个性、喜好和欲望与购买决策联系起来。StubHub 正为此在时代广场开设一家旗舰店,并计划将该空间作为路人查找该地区活动的资源。
随着所有这些大型电子商务品牌转向线下收集数据和改善客户体验,这对小卖家意味着什么? Etsy 的手工艺者、易贝的节俭者和 Bonanza 的小企业会在网上保持竞争力吗?对于行业领导者来说,挖砖是一个有价值的工具,所以小卖家必须找到独特的方法来吸引更多的顾客。
即使没有投资实体数据挖掘的资源,也有办法了解一个市场。以下是小型在线企业拓展业务的几种方式:
- 尝试跨市场销售:如果你只在一个平台上销售,尝试在其他平台上列出你的商品。亚马逊拥有最多的购物者,但你的商品也可能属于 Etsy 购物者寻找的特定商品。Bonanza 提供了一些导入工具,可以让你快捷方便地列出你的商品,此外,它们还可以让你选择在谷歌购物中为你的商品做广告。
- **使用营销工具:**通过电子邮件营销和特别优惠券吸引买家和浏览者。Bonanza 的客户营销工具让直接向过去的买家发送报价变得没有痛苦。 Shopify 为卖家提供选项,在他们的网站上创建带有 flash 销售和优惠的屏幕弹出窗口。
- **打造策划品牌体验:**在每批货中包含一点额外的东西。你能提供一个小样品吗?包括一些让买家试用的东西,鼓励他们购买不同的产品。包括品牌包装、个性化说明或特殊优惠券代码是赢得买家的另一个好方法。
- **有机会就下线:**还记得 80 年代的特百惠派对吗?谁说你不能与朋友、家人和邻居一起举办派对来展示你的物品。只要有可能,就在当地的工艺品交易会上预定一张桌子,倾听顾客的反馈,以不断提升你的品牌。
- **使用社交媒体:**像脸书和 Instagram 这样的平台是讲述你的品牌故事的有效途径。你只需花 5 美元就可以购买广告,到达特定的市场,并获得关于你在与谁打交道的详细分析。
如何构建高绩效分析团队

分析对于公司的成功和在竞争中获得竞争优势至关重要。我郑重声明,组建分析团队没有完美的方式。如今,团队的结构有多种方式,另外,如果你在谷歌上搜索,你会发现一些不同的结构正在被使用。我将在这篇文章中强调的是我认为组建团队的最佳方式。
企业可以做的最重要的事情是询问他们为什么需要分析。此外,对不同类型的分析技术有很好的理解将有助于你确定团队中需要谁。
分析学被定义为、对数据或统计的系统化计算分析。
分析是的保护伞——数据可视化(仪表盘)、EDA、机器学习、AI 等。
核心分析/数据挖掘方法
- 描述性——已经发生和正在发生什么?
- 规范性—为给定的问题找到最佳的行动方案
- 探索性—我的数据中存在哪些金块?
- 预测—未来会发生什么
谁构成了分析团队的核心?
- 数据分析师
- 数据工程师
- 数据科学家
这些角色是做什么的?
数据分析师
- 多面手,能够适应多种角色和团队,帮助他人做出数据驱动的决策
- 数据分析师通过获取数据、使用数据回答问题以及交流结果来帮助做出业务决策,从而实现价值
数据科学家
- 应用统计学和构建机器学习模型的专业知识进行预测并回答关键业务问题的专家
- 拥有数据分析师所具备的所有技能,但在这些技能方面会更有深度和专业知识
- 利用监督和非监督机器学习模型发现数据中隐藏的见解
数据工程师
- 构建并优化允许数据科学家和分析师开展工作的系统。确保数据被正确接收、转换、存储,并可供其他用户访问
- 更倾向于软件开发技能
根据您在分析之旅中所处的位置,以下是我的建议——爬之前必须先走
刚刚进入分析领域?
- 数据工程师和数据分析师
- 重要的是要有一个团队,可以建立你的数据连接,数据仓库,了解你的数据。团队中没有必要有数据科学家。您将为无法利用的技能组合买单,最终可能会让数据科学家对主要进行描述性分析感到沮丧。数据科学家是需要不断挑战的好奇生物。
已经在分析领域工作了一段时间,对您的数据有了很好的了解,想要转向高级分析吗?
- 数据工程师、数据分析师和数据科学家
- 现在是进入预测和说明性分析的正确时机,是雇用一两名数据科学家的时候了。
一旦团队扩展过了这最后一个阶段,雇佣一个项目经理来帮助推动分析团队的计划是有意义的。一旦你有一个 15 人以上的团队,这应该会发生
分析经理
谁应该管理分析团队?分析经理(也称为分析主管,或数据分析经理)如果团队只有 2 个人,这没有多大意义。然而,如果你有一个 3 人以上的团队,你需要一个经理。
分析经理的主要职责是-
- 管理数据仓库和 ETL 解决方案
- 根据最佳投资回报率对项目进行优先排序(经理必须具备丰富的领域知识,并对业务核心目标有深刻的理解)
- 保护数据分析师免受报告和可视化请求的轰炸
- 确保团队拥有完成项目所需的所有工具
- 影响业务成为数据驱动的文化
- 鼓励自助服务分析
- 为预测性和规范性分析项目提供指导
- 指导团队并为其提供持续的教育机会,以保持对其角色的掌控
分析总监
在某些情况下,根据组织的规模,可以有如下结构。
分析总监>分析经理和数据科学经理
- 分析总监管理分析和数据科学经理
- 分析经理将监督数据工程师和数据分析师,侧重于探索性和描述性分析。
- 数据科学经理将监督数据科学家,重点关注预测和说明性分析。
如果你有一个敏捷分析团队,你也可以有一个有团队领导的分析主管,但不一定是经理。我个人更喜欢敏捷团队有领导,有一个主管监督整个团队。
正如我在文章开头提到的,构建分析团队没有完美的方法,在我看来,这只是最具成本效益、最合理的解决方案。
请在评论区留下任何评论或反馈。
如何构建机器学习项目
让机器学习算法发挥作用

这篇文章不是要告诉你学习什么机器学习算法,并向你解释模型的本质。
如果你正在寻找这些材料,我强烈建议你查阅我以前的文章了解如何选择在线课程,选择哪些在线课程以及阅读哪些书籍以深入了解。
事实上,这篇文章将向您展示如何让 真正地 让机器学习算法为您的项目工作,以及如何构建它们,否则您会花费不必要的长时间在错误的方向上优化您的模型。
机器学习向往由吴恩达
不管你是数据科学的初学者还是专家,你都有可能(我是说 99%)听说过他的名字。

他在 Coursera 上最著名的课程— 机器学习对世界各地的许多学生来说都是一笔财富。我一直很着迷于他将复杂的概念分解成更简单的信息进行学习的能力,尤其是对于机器学习的初学者。
他还写了一本书——《机器学习的向往》,为那些对机器学习感兴趣的人提供了实用指南。
而且是免费的!
更新:
****如果你无法看到链接或注册邮件列表以获得草稿,请从我的 Google Drive 获得免费副本:https://Drive . Google . com/file/d/1 q 81 nayn 8 wy 8-byyxsxpziotkza 6974 x/view?usp =分享
外面有那么多机器学习的书。为什么是这本书?

举个例子,说你要建立一个图像分类不同类别的神经网络。****
然而,你的神经网络的精确度不够好,你的团队需要在一个期限内达到期望的精确度。
压力很大。因此,您和您的团队开始集思广益,寻找改进模型的方法。例如:
- 获取更多培训数据
- 收集更多样化的训练数据:不同类别的具有不同设置和背景的图像
- 增加模型的复杂性:更多的单元,隐藏的层
- 不断调整模型参数以获得最佳设置
- 降低算法的学习速度(需要更长的时间)
- 尝试将正则化添加到模型中
- …
****好消息是:如果您选择了正确的方向,您的模型将能够在时间框架内满足所需的精度(甚至更高)。
****坏消息是:如果你选择了错误的方向,你可能会浪费几个月(甚至几年)的开发时间,最终意识到你做了一个错误的决定。不太好。
有的技术 AI 课会给你一锤子;这本书教你如何使用锤子。
—吴恩达
你如何充分利用这个模型并获得最佳结果?
你看。学会如何在一开始就为你的团队制定战略决策设定方向是非常重要的,这通常需要多年的经验。
因此,这本书旨在通过优先考虑最有前途的方向、诊断复杂的机器学习系统中的错误、提高团队的生产力等等,使机器学习算法为您的项目和公司服务。
这本书的预览
1。设置开发和测试集
- 训练集——你在上面运行你的学习算法。
- Dev(开发)set —您可以使用它来调整参数、选择特性,以及做出其他关于学习算法的决定。有时也称为保留交叉验证集。
- 测试集 —用于评估算法的性能,但不决定使用什么学习算法或参数。
- 本章向读者展示了开发和测试集应该使用什么样的数据分布,要使用的开发/测试集的大小,以及要优化的指标等。
2。基本误差分析
- 在错误分析期间并行评估多个想法
- 清理贴错标签的开发和测试集示例
- 眼球和黑盒 dev 集应该有多大?
- 本章向读者展示了如何快速构建第一个简单的机器学习系统,然后通过错误分析进行迭代,以找到最佳线索,为时间投资提供最有希望的方向。
3。偏差和方差
- 偏差与方差权衡
- 减少偏差和方差的技术
- 这一章以非常清晰和简洁的方式解释了偏差和方差。它强调了识别模型欠拟合和过拟合的重要性。此外,它教读者一些有用的技术,以减少偏见和方差。
4。学习曲线
- 绘制训练误差和学习曲线
- 解释学习曲线:高偏差
- 解释学习曲线:其他案例
- 本章解释了为什么学习曲线对于理解模型的性能如此重要,以及如何使用学习曲线根据期望的性能水平做出决策。
5。对比人类水平的表现
6。不同发行版的培训和测试
7。调试推理算法
8。端到端深度学习
9。零件误差分析
最后的想法

所以你现在可能想知道:为什么上面的其余章节是空的?
答案是我还在读这本书的过程中。肯定会很快看完的!😃
老实说,在读完这本书的前四章后,我已经学到了很多,并且发现了一些有用的技巧,否则我不会意识到的!
最重要的是,这本书不是技术性的,每一节只有 1-2 页。
感谢您的阅读。我希望通过展示我从这本书里得到的东西,能让你对这本书有一个简要的概述,以及你如何能从中受益。
最终,这本书的实用性将教会你如何构建你的机器学习项目,并让你的模型为你、你的团队和公司服务。
一如既往,如果您有任何问题或意见,请随时在下面留下您的反馈,或者您可以随时通过 LinkedIn 联系我。在那之前,下一篇文章再见!😄
关于作者
Admond Lee 目前是东南亚排名第一的商业银行 API 平台Staq—的联合创始人/首席技术官。
想要获得免费的每周数据科学和创业见解吗?
加入 Admond 的电子邮件时事通讯——Hustle Hub,每周他都会在这里分享可行的数据科学职业建议、错误&以及从创建他的初创公司 Staq 中学到的东西。
你可以在 LinkedIn 、 Medium 、 Twitter 、脸书上和他联系。
让每个人都能接触到数据科学。Admond 正在通过先进的社交分析和机器学习,利用可操作的见解帮助公司和数字营销机构实现营销投资回报。
www.admondlee.com](https://www.admondlee.com/)**
如何利用人工智能:你准备好跳跃的 4 个迹象

预测营销活动是寻求获得新客户并最大化现有客户终身价值的营销人员的下一个前沿领域。为什么?人工智能驱动的活动识别最有可能购买和再次购买的客户,然后推荐有针对性的促销活动和产品。这是你每天都会遇到的技术,无论是在亚马逊购物还是浏览网飞。由于支持这些平台的机器学习技术,所有那些你离不开的个性化推荐都是可能的。现在,多亏了云计算,预测营销正在走向真正的大众化。曾经只有大型企业才能实现的昂贵提议,现在已经成为主流。在许多方面,预测营销已经从一种奢侈品变成了必需品,每个组织都需要它来生存和保持竞争力。
幸运的是,这些先进技术的准入门槛比以往任何时候都低,每个组织都应该能够利用预测分析技术。尽管如此,有些人比其他人更适合。
您如何知道自己是否准备好利用预测营销技术?以下四个指标表明,是时候迈出这一大步了:
1.**数据准备度:**你的数据比较干净;数据字典可用;组织内明确定义了数据所有权;
预测是基于机器学习的。机器是可以处理大量数据、发现隐藏模式和识别成功故事的计算机软件。为了使这些输出准确,输入必须干净。如果您已经有了一个包含干净(标准化)数据的数据仓库或某种数据存储库,那么您已经有了一个良好的开端。
明确定义团队内部的数据所有权也很重要。不可避免地,会有一些与数据相关的清理工作要做。数据所有者负责做出与数据相关的决策,并持续努力确保数据保持干净和可访问。
2.**现有基线:**你衡量你的活动表现和投资回报;你细分(或计划细分)你的客户群
衡量机器学习产生的预测的有效性的能力至关重要。你如何知道使用预测是否比当前的方法更好?如果你已经在衡量你的营销活动的表现,那太好了。否则,您应该努力建立方法来衡量您现有方法的成功。这将帮助你调整你的活动和营销方法,以确保最大的投资回报率。
3.**客户之旅:**您从客户之旅中的大多数接触点获取数据
机器学习是通过处理数据来理解因果关系。你提供给机器的数据点越多,它就越能更好地理解顾客购买或放弃购物车的原因。你应该设法捕捉所有的客户接触点和互动,从网站访问到呼叫中心互动、对外营销活动、销售历史、退货、调查等。收集这些信息将有助于您识别客户旅程中的关键差距,从而使您能够相应地修改您的活动和营销实践。
4.**数据驱动的文化:**组织文化鼓励数据驱动的决策
即使是最准确的预测,在被组织决策者接受之前也是毫无意义的。有时,预测建议可能是违反直觉的。但你总能理解为什么机器会推荐一个特定的行动方案。如果你计划实施机器学习,拥有一个鼓励数据驱动决策的数据驱动文化是绝对必要的,更不用说管理一个成功的预测营销活动了。
您的组织符合上述标准吗?如果答案是肯定的,那么是时候用人工智能驱动的方法来提高你的营销力度了。
感谢您阅读帖子。
有问题吗?我们很乐意帮忙。在 info@vectorscient.com 取得联系
作者简介 : Suresh Chaganti, VectorScient 的联合创始人&战略顾问。Suresh 专门研究大数据,并将其应用于解决现实世界的商业问题。他在跨各种行业垂直领域设计 B2B 和 B2C 应用程序方面拥有 20 年的经验。在 linkedin 上与 suresh 联系
如何利用预测分析和人工智能应对大型银行

无论您是地区银行、社区银行还是信用合作社,管理您的数据基础架构都是一项艰巨的工作。利润率很低,运行遗留系统需要时刻保持警惕。找到时间和资源来利用人工智能的进步并不容易。围绕大数据有太多的噪音,很难区分营销术语在哪里结束,现实在哪里开始,因此获得组织的认可可能是一个巨大的挑战。
但是小银行别无选择。事关生死存亡。全国性银行正在赢得下一代客户,大数据是一大优势。
“银行真的不再能够选择是否进入分析领域……现在,客户互动正在向所有人群的数字空间转移,不再需要更多的人际互动。分析是你希望个性化和影响有利结果的唯一途径。”——美国律师协会银行期刊, 大数据和预测分析:的确是一件大事
然而,对各种规模的银行来说,都有好消息。执行预测建模等高级分析项目所需的工具比以往任何时候都更加容易获得和灵活。这意味着银行可以将他们的分析预算用于最重要的地方,避免将资金投入到没有价值的系统中。他们可以独立完成,也可以在有针对性的项目中与专业顾问合作。
数据科学:参与规则
我们为参与高级分析项目的地区银行和信用合作社推荐五条原则:
- **定义明确的目标。**根据 Gartner 的调查,55%的大数据项目从未完成。问题不在于努力或数据质量。相反,最大的挑战是设定与可证明的价值相关的明确目标。
- 采取渐进的方法。没有必要在员工和软件上进行大量投资。事实上,如果你一次只关注一个机会,你会得到更好的结果。然后利用你所学到的,并在此基础上发展。
- 像科学家一样思考。假设,实验,学习,重复。一种演绎的科学方法会让你保持专注,并提供你可以依赖的结果。
- **围绕客户需求确定询问的优先顺序。**客户承诺已经让小型银行从全国性银行中脱颖而出。利用你的优势。
- 做好准备迎接惊喜。结构合理且客观的分析调查将克服确认偏差,揭示您可能没有预料到的见解。
“即使银行决定只能花很少的钱,那也比什么都不做要好。”——*美国银行家,*为什么小银行需要大数据
面向小型银行的下一级分析
社区银行已经非常了解如何使用数据,无论是用于业务分析、细分还是风险管理。人工智能的进步使另一个层面的洞察力成为可能,使个人客户层面的预测比以往任何时候都更有用。
- **预测客户需要什么。**产品交叉销售对银行来说并不新鲜。但是现在通过行为分析,预测顾客真正需要什么,并提供给顾客是可能的。
- **打造更好的在线体验。**无论是优化您的网站体验,还是最大限度地提高网上银行的效率,现在比以往任何时候都更容易收集能够产生影响的精细数据。
- **整合数据源,揭示完整的客户旅程。**连接 CRM、联络中心和 web 数据源可以让您全面了解客户体验,从而识别优势和劣势。
- **确定哪些客户可能会离开。**客户行为分析可以帮助您预测和应对潜在的客户维系挑战。
- **懂地理。**通过位置追踪互动可以告诉你很多关于你的客户在哪里做生意——以及你需要在哪里。
“国家银行现在赢得了绝大部分初级支票购买者,尤其是千禧一代。然而,国民银行的千禧一代也更愿意更换银行,这为其他银行创造了一个机会,这些银行可以了解并瞄准该细分市场的最佳部分,然后优先考虑必要的数字、营销和其他投资。”— Novantas, 2016 年全渠道购物者调查
小银行成功的关键是为使用大数据和人工智能设定明确的目标。但是要做好准备,足够灵活地去数据带你去的地方。
想了解更多关于数据科学增量方法如何在您的组织中发挥作用的信息吗?在 hello@deducive.com 给我们写封短信。
此文原载于Deducive.com。
如何与客户交谈以获得更好的结果
他们可能不懂数据科学,但他们可以教你很多东西。
本文摘自 像数据科学家一样思考 。
数据科学领域的每个项目都有一个客户。有时,客户是付钱给你或你的企业来做项目的人,例如,客户或合同代理。在学术界,客户可能是要求您分析其数据的实验室科学家。有时客户是你、你的老板或另一位同事。无论客户是谁,他们都希望从你这个负责项目的数据科学家那里得到一些东西。
通常,这些期望与以下方面有关:
- 需要回答的问题或需要解决的问题;
- 有形的最终产品,如报告或软件应用程序;或者,
- 先前研究或相关项目和产品的总结
期望可以来自任何地方。一些是希望和梦想,另一些来自类似项目的经验或知识。然而,关于期望的典型讨论可以归结为两个方面:客户想要什么,数据科学家认为什么是可能的。这可以被描述为愿望与实用主义,客户描述他们的愿望,数据科学家根据表面的可行性批准、拒绝或限定每一个。另一方面,如果你愿意把自己这个数据科学家想象成一个精灵,一个愿望的授予者,你不会是第一个这样做的人!
解决愿望和实用主义
至于客户的愿望,他们可以从完全合理到完全古怪,这是可以的。很多商业发展和硬科学都是由直觉驱动的。也就是说,首席执行官、生物学家、营销人员和物理学家都利用他们的经验和知识来发展关于世界如何运转的理论。其中一些理论有可靠的数据和分析支持,但其他更多的来自直觉,这基本上是一个人在他们的领域广泛工作时开发的概念框架。很多领域和数据科学的一个显著区别是,在数据科学中,如果一个客户有一个愿望,即使是一个有经验的数据科学家也不一定知道是否可能。软件工程师通常知道软件工具能够执行什么任务,生物学家或多或少知道实验室能做什么,但尚未看到或使用过相关数据的数据科学家面临着大量的不确定性,主要是关于哪些具体数据可用以及它能为回答任何给定问题提供多少证据。同样,不确定性是数据科学过程中的一个主要因素,在与客户谈论他们的愿望时,应该首先考虑这一点。
例如,在我与生物学家和基因表达数据打交道的几年中,我开始形成自己的概念,即 RNA 是如何从 DNA 翻译而来的,RNA 链是如何在细胞中漂浮并与其他分子相互作用的。我是一个视觉型的人,所以我经常发现自己在想象一条由数百或数千个核苷酸组成的 RNA 链,每个核苷酸看起来就像四个字母中的一个,代表一个碱基化合物(A、C、G 或 T;为了方便起见,我用“T”代替“U”),整个链看起来像一条长而柔韧的链——这个句子只对细胞内的机器有意义。由于 RNA 及其核苷酸的化学性质,互补序列喜欢彼此结合;a 喜欢与 T 结合,C 喜欢与 g 结合。因此,当两条 RNA 链包含接近互补的序列时,它们很可能会彼此粘在一起。如果一条 RNA 链足够灵活并含有互补的序列,它也可能折叠并粘在自身上。这是一个概念框架,我在很多场合下用它来猜测当一堆 RNA 在细胞中漂浮时会发生什么。
因此,当我开始处理微小 RNA 数据时,我意识到微小 RNA 大约 20 个核苷酸的短序列——可能会与遗传 mRNA 序列的一部分(即直接从对应于特定基因的 DNA 链翻译的 RNA,通常要长得多)结合,并抑制其他分子与该基因的 mRNA 相互作用,从而有效地使该基因序列变得无用。对我来说,一点 RNA 可以粘在一段遗传 RNA 上,并最终阻止另一个分子粘在同一段上,这在概念上是有意义的。这一概念得到了科学期刊文章和确凿数据的支持,这些数据表明,如果 microRNA 和基因 mRNA 具有互补序列,它们可以抑制基因 mRNA 的表达或功能。
然而,与我一起工作的一位生物学教授有一个更加微妙的概念框架,描述了他如何看待这个基因、微小 RNA 和 mRNA 的系统。特别是,他几十年来一直在研究普通小鼠小家鼠的生物学,可以列出任何数量的显著基因、它们的功能、相关基因以及物理系统和特征,如果开始做“敲除”这些基因的实验,这些基因就会受到明显的影响。因为教授比我更了解老鼠的遗传学,而且因为他不可能和我分享他所有的知识,所以在花太多时间研究一个项目的任何方面之前,讨论这个项目的目标和期望对我们来说是非常重要的。没有他的投入,我基本上只能猜测生物学相关的目标是什么。如果我错了(这很有可能),工作就白费了。例如,某些特定的微小 RNA 已经得到了很好的研究,并且已知它们在细胞内完成非常基本的功能,甚至更多。如果该项目的目标之一是发现很少研究的微小 RNA 的新功能,我们可能会想从分析中排除某些微小 RNA 家族。如果我们不把它们排除在外,它们很可能只会给细胞内已经非常嘈杂的基因对话增添噪音。这仅仅是教授知道的许多重要事情中的一件,而我却不知道。因此,在认真开始任何项目之前,对目标、期望和注意事项进行冗长的讨论是必要的。
从广义(如果简单的话)来说,当且仅当客户对结果满意时,项目才被认为是成功的。当然,这一准则也有例外,但无论如何,在数据科学项目的每一步中始终牢记期望和目标是非常重要的。不幸的是,根据我自己的经验,在项目的开始阶段,期望通常是不清楚或者不明显的,或者不容易简明地表达出来。因此,我决定采用一些实践来帮助我找出合理的目标,这些目标可以指导我完成涉及数据科学的项目的每一步。
客户很可能不是数据科学家
关于客户期望的一件有趣的事情是,他们可能不合适。这并不总是——甚至通常也不是——客户的错,因为数据科学解决的问题本质上是复杂的,如果客户完全了解他们自己的问题,他们可能就不需要数据科学家来帮助他们了。因此,当客户的语言或理解不清楚时,我总是放他们一马,我认为设定期望和目标的过程是一个联合练习,可以说类似于冲突解决或关系治疗。
您,数据科学家,和客户都有成功完成项目的共同兴趣,但是你们两个可能有不同的具体动机,不同的技能,最重要的是,不同的观点。即使你自己是客户,你也可以把自己想象成分成两半,一部分(数据科学家)专注于获得结果,另一部分(客户)专注于使用这些结果做一些“真正的”事情,或者项目本身之外的事情。通过这种方式,数据科学的项目从寻找两种性格、两种观点之间的一致开始,如果它们不冲突,至少是完全不同的。
虽然严格来说,您和客户之间没有冲突,但有时看起来是这样的,因为你们都在朝着一组既可实现(对数据科学家而言)又有帮助(对客户而言)的目标混日子。而且,就像在解决冲突和关系治疗中一样,也涉及到感情。这些感觉可能是意识形态的,受个人经历、偏好或观点的驱使,对另一方来说可能没有意义。因此,一点耐心和理解,而不需要太多的判断,对你们双方都非常有益,更重要的是,对项目也非常有益。
问非常具体的问题来揭露事实,而不是发表意见
当客户描述关于您要研究的系统的理论或假设时,他们几乎肯定会表达事实和观点的混合,区分这两者通常很重要。例如,在一项关于小鼠癌症发展的研究中,前述生物学教授告诉我,“众所周知,哪些基因与癌症有关,而这项研究只关注那些基因,以及抑制它们的微小 RNA。”人们可能会试图从表面上接受这种说法,并只分析癌症相关基因的数据,但这可能是一个错误,因为这种说法有些模糊。原则上,还不清楚是否其他可能与癌症无关的基因在实验引发的复杂反应中起辅助作用,或者是否众所周知并证明癌症相关基因的表达完全独立于其他基因。在前一种情况下,忽略与非癌症相关基因相对应的数据不是一个好主意,而在后一种情况下,这可能是一个好主意。不解决这个问题,就不清楚哪一个是合适的选择。所以,问很重要。
同样重要的是,问题本身要以客户能够理解的方式表述。例如,问“我应该忽略来自与癌症无关的基因的数据吗?”是不明智的这是一个关于数据科学实践的问题,属于你的领域,而不是生物学家的。相反,你应该问类似于“你有任何证据证明癌症相关基因的表达是独立于其他基因的吗?”这是一个关于生物学的问题,希望生物学教授能够理解。
在他的回答中,区分他所想的和他所知的是很重要的。如果教授只是认为这些基因的表达是独立于其他基因的,那么在整个项目过程中,这肯定是要记住的事情,但你不应该根据它做出任何非常重要的决定——比如忽略某些数据。另一方面,如果教授可以引用科学研究来支持他的观点,那么利用这个事实来做决定是绝对明智的。
在任何项目中,作为数据科学家,你是统计学和软件工具方面的专家,但是主要的主题专家通常是其他人,就像涉及生物学教授的情况一样。在向这位主题专家学习的过程中,你应该提出一些问题,这些问题不仅能让你对所研究的系统是如何工作的有一些直观的感觉,还能试图将事实与观点和直觉分开。基于事实的实际决策总是一个好主意,但是基于观点的决策可能是危险的。“信任,但要确认”这句格言在这里很合适。如果我忽略了数据集中的任何基因,我很可能错过了癌症实验中各种类型的 RNA 之间发生的复杂相互作用的一个关键方面。事实证明,癌症是一种非常复杂的疾病,不仅在医学层面,在基因层面也是如此。
提示交付物:猜测并检查
您的客户可能不了解数据科学及其用途。问他们,“你希望在最终报告中出现什么?”或者“这个分析应用程序应该做什么?”很容易导致“我不知道”,或者更糟,一个没有实际意义的建议。数据科学不是他们的专业领域,他们可能没有完全意识到软件和数据的可能性和局限性。因此,通常最好用一系列建议来解决最终产品的问题,然后注意顾客的反应。
我最喜欢问客户的一个问题是,“你能给我一个你可能希望在最终报告中看到的句子的例子吗?”我可能会得到这样的回答,“我想看看:‘微小 RNA-X 似乎能显著抑制 Y 基因’;”或者“基因 Y 和基因 Z 似乎在所有测试样本中表达水平相同。”诸如此类的回答为构思最终产品的格式提供了一个很好的起点。如果客户能给你这样的种子想法,你可以扩展它们,提出最终产品的建议。你可能会问,“如果我给你一张特定微 RNA 和基因 mRNAs 之间最强相互作用的表格会怎么样?”客户可能会说这很有价值,也可能不会。
然而,最有可能的是,客户会做出不太明确的陈述,例如,“我想知道哪些微小 RNA 在癌症发展中是重要的。”当然,如果我们希望成功地完成这个项目,我们需要澄清这一点。生物学意义上的“重要”是什么意思?这种重要性如何体现在现有的数据中?在继续之前得到这些问题的答案是很重要的;如果你不知道微小 RNA 的重要性如何在数据中体现出来,你怎么知道你什么时候找到了它?
我和许多其他人犯的一个错误是将相关性和重要性混为一谈。一些人谈到了相关性和因果性的混淆,一个例子是:戴头盔的骑车人比不戴头盔的骑车人卷入事故的比例更高;头盔引发事故的结论可能很诱人,但这可能是错误的。头盔与事故的相关性并不意味着头盔导致事故;也不是说事故[直接]导致头盔。事实上,在更繁忙、更危险的道路上骑自行车的人更有可能戴头盔,也更有可能发生事故。本质上,在更危险的道路上骑车会导致这两种情况。在头盔和事故的问题上,尽管存在相关性,但没有直接的因果关系。反过来,因果关系仅仅是相关性可能很重要的一个例子。如果你正在对头盔的使用和事故率进行研究,那么这种相关性可能是显著的,即使它并不意味着因果关系。应该强调的是,重要性,正如我所使用的术语,是由项目的目标决定的。头盔-事故相关性的知识可以导致考虑(和建模)作为项目一部分的每条道路上的交通和危险水平。相关性也不能保证显著性。我相当肯定更多的骑自行车事故发生在晴天,但这是因为更多的骑自行车的人在晴天上路,而不是因为任何其他重要的关系(当然,除非下雨)。我现在还不清楚如何利用这些信息来实现我的目标,所以我不会花太多时间去探索它。在这种特殊情况下,这种相关性似乎没有任何意义。
在基因/RNA 表达实验中,通常在 10-20 个生物样品中测量了数千个 RNA 序列。这种变量(每个 RNA 序列的表达水平)远多于数据点(样本)的分析被称为“高维”或通常“欠确定”,因为变量太多,其中一些只是随机相关,如果说它们在真正的生物学意义上是真正相关的,那将是荒谬的。如果你向生物学教授提交一份强相关性的列表,他会立即发现你报告的一些相关性不重要,或者更糟的是,与已有的研究相反,你将不得不回去做更多的分析。
基于知识而不是愿望来重复你的想法
正如在你所掌握的领域知识中,把事实和观点分开是重要的一样,避免让过度乐观使你对障碍和困难视而不见也是重要的。我早就说过,优秀数据科学家的一项无价技能是预见潜在困难并为其开路的能力。
在当今的软件行业中,在分析能力还处于开发阶段时就对其进行断言是很流行的。我了解到,这是一种推销策略,似乎经常是必要的,尤其是对于年轻的初创企业,以便在竞争激烈的行业中取得成功。当有人积极销售一款分析软件时,我总是感到紧张,我说我认为我可以开发这款软件,但考虑到我们现有数据的一些限制,我不能 100%肯定它会按计划工作。因此,当我做出如此大胆的声明时,我会尽可能地将它们保持在我几乎肯定能做到的事情范围内,如果我做不到,我会尝试制定一个备用计划,不涉及原计划中最棘手的部分。
假设您想要开发一个总结新闻文章的应用程序。你需要创建一个算法,可以解析文章中的句子和段落,并提取主要思想。有可能编写一个算法来做到这一点,但尚不清楚它的性能如何。对于大多数文章来说,摘要在某种意义上可能是成功的,但 51%的成功和 99%的成功之间有很大的区别,至少在你建立了第一个版本之前,你不会知道你的特定算法属于那个范围。盲目销售和狂热开发这种算法可能看起来是最好的主意;努力就会有回报,对吧?也许吧。这项任务很难。完全有可能的是,尽管你尽了最大努力,但你永远不会获得超过 75%的成功,从商业角度来看,这可能还不够好。那你会怎么做?你会放弃并关闭商店吗?只有在这次失败后,你才开始寻找替代方案吗?
一个优秀的数据科学家甚至在开始之前就知道任务有多难。句子和段落是复杂的随机变量,通常看起来是专门设计来挫败你可能扔给它的任何算法的。在失败的情况下,我总是回到“首要原则”,在某种意义上:我试图解决什么问题?除了总结,最终目标是什么?
如果最终目标是建立一个让阅读新闻更有效率的产品,也许有另一种方法来解决新闻读者效率低下的问题。或许把相似的文章聚合在一起呈现给读者更容易。或许可以通过更友好的设计或整合社交媒体来设计更好的新闻阅读器。
没有人想宣布失败,但数据科学是一个有风险的行业,假装失败从来没有发生本身就是一个失败。解决问题总是有多种方法,制定一个承认障碍和失败可能性的计划可以让你在前进的道路上从微小的成功中获得价值,即使主要目标没有实现。
一个更大的错误是忽略失败的可能性以及测试和评估应用程序性能的需要。如果你认为产品工作得近乎完美,但事实并非如此,那么将产品交付给客户可能是一个巨大的错误。你能想象如果你开始销售一个未经测试的应用程序,该应用程序本应该对新闻文章进行摘要,但是很快你的用户就开始抱怨摘要完全错误吗?不仅应用程序会失败,而且你和你的公司可能会因为软件不工作而名声大噪。
要了解更多信息,请下载免费的第一章 像数据科学家 一样思考,并查看此 幻灯片演示 获取折扣代码。
Brian Godsey 博士,是一位数学家、企业家、投资人和数据科学家,他的著作 像数据科学家一样思考 现已面世。——【briangodsey.com】
如果你喜欢这个,请点击💚下面。
*[## (我喜欢你)叫我大数据
恶名昭彰的 IDE 人群的滑稽嘻哈联合
medium.com](https://medium.com/@briangodsey/i-love-it-when-you-call-me-big-data-2e4b89e84740)* *[## 不确定性意识:数据科学的一个优点
脸书最近在趋势分析上的失态再次表明,好的数据科学取决于承认你不知道
medium.com](https://medium.com/@briangodsey/awareness-of-uncertainty-a-virtue-in-data-science-c6751e7f5a00)*
如何用卷积神经网络教计算机看东西
在过去的几年里,计算机视觉领域取得了巨大的进步。卷积神经网络极大地提高了图像识别模型的准确性,并在现实世界中有大量的应用。在本文中,我将介绍它们是如何工作的,一些真实世界的应用程序,以及如何用 Python 和 Keras 编写一个应用程序。

Photo by Amanda Dalbjörn on Unsplash
对我们大多数人来说,看是我们日常生活的一部分。我们用眼睛来寻找我们周围世界的道路。我们用它们来交流和理解。大概不用我说,视力超级重要。这是我们一天中如此重要的一部分。我是说,你能想象,看不见吗?
但是如果我让你解释视觉是如何工作的呢?我们如何理解眼睛解读的东西?嗯,首先你看一些东西,然后…什么?大脑就像一台经过数百万年自然发展的超级复杂的计算机。我们已经非常擅长识别各种模式和物体。
**许多技术都是基于自然机制。**以相机为例。快门控制光量,类似于我们的瞳孔。相机和眼睛中的镜头聚焦并反转图像。相机和眼睛都有某种方式来感知光线,并将其转换为可以理解的信号。

Photo by Alfonso Reyes on Unsplash
但显然,我们不只是用胳膊和腿移动摄像机。我们目前拥有的相机显然不能完全理解他们在拍什么。如果他们这样做了,那就有点可怕了。对照相机和电脑来说,一张照片只是一串排列的数字。

Digit 8 from MNIST dataset represented as an array. Source.
那么,我们究竟怎样才能创造出能够告诉我们狗是狗还是猫的程序呢?这是我们试图用计算机视觉解决的问题。
这就是神经网络如何帮助我们的!
神经网络如何工作
人工神经网络(ANN)是基于人脑的松散程序。**神经网络由许多相连的神经元组成。**这些神经网络中的一些可以有数百万个节点和数十亿个连接!
神经元基本上是一种接受输入并返回输出的功能。

Artificial neurons are modeled off biological neurons. Source.
一个神经元本身做不了多少事。但是当你有大量的神经元连接在一起时,乐趣就开始了。不同层次/结构的神经网络让你做很多很酷的事情。

You can get something like this!
每个神经元通常与某种权重相关联。基本上,当一个连接比另一个更重要时。假设我们有一个网络想告诉你图片是不是一个热狗。那么我们会希望包含热狗特征的神经元比普通狗的特征更重要。
神经网络的权重是通过对数据集进行训练来学习的。它将运行许多次,通过关于损失函数的反向传播来改变它的权重。神经网络基本上通过测试数据,做出预测,然后看到它有多错。然后它得到这个分数,让自己变得稍微准确一点。通过这个过程,神经网络可以学习提高其预测的准确性。
我不会在这篇文章中讨论反向传播或损失函数,但是有很多很棒的资源,比如 this 涵盖了这些主题!
卷积神经网络(CNN)是一种特殊的神经网络。当应用于图像数据集时,它们表现得非常好。
卷积神经网络

A diagram of Convolutional Neural Networks. Source.
正如我之前提到的,计算机将图片视为一组数组中的数字。CNN 的不同层将函数应用于这些阵列,以从图像中提取各种特征,并降低图像的复杂性。
让我们来看看在热狗检测器上训练 CNN 的一些步骤。
首先,我们用随机权重初始化 CNN。这基本上意味着网络完全是在猜测。一旦它做出预测,它将检查使用损失函数的错误程度,然后更新其权重,以便下次做出更好的预测。
CNN 包含称为卷积层和池层的层。你可以这样想象卷积层会发生什么。
假设你有一张照片和一个放大镜。把你的放大镜放在图片的左上角,寻找一个特定的特征。记下它是否在那里。慢慢地在图像中移动,重复这个过程。

Visualizing feature extraction in a convolutional layer. Source.
卷积层创建一堆特征图。
对于一个用来描述不同图像如动物或面孔的 CNN 来说。第一卷积层寻找的特征可以是对象的不同边缘。这就像是把图片中不同的边列了一个清单。这个列表然后被传递到另一个卷积层,它做类似的事情,除了它在图像中寻找更大的形状。这可能是动物的一条腿,也可能是脸上的一只眼睛。最终,这些特征被一个全连接的层所接受,该层对图像进行分类。
汇集层也用于卷积层。这需要另一个放大镜,但它不会寻找特征。而是取一个区域的最大值来降低图像的复杂度。

Pooling in a CNN. Source.
这很有用,因为大多数图像都很大。它们有大量的像素,这使得处理器很难处理它们。共享让我们在保留大部分重要信息的同时缩小图像的尺寸。池化还用于防止过度拟合,即当模型变得过于擅长识别我们对其进行训练的数据,而对我们给出的其他示例不太适用时。

An example of overfitting on a linear dataset. [Source.](http://By Ghiles - Own work, CC BY-SA 4.0, https://commons.wikimedia.org/w/index.php?curid=47471056)
如图所示,该图中的数据可以用一条直线来表示。蓝色的模型显然击中了所有的数据点,但如果我们试图让它预测其他东西,它将无法做到。就我们的 CNN 而言,这可能意味着它将对我们训练它的图像超级准确,但无法在其他图像上给我们正确的预测。
最后,我们把 CNN 的结构扁平化成一个超长的特写。我们基本上只是把所有的数据放在一起,这样我们就可以把它传递给一个完全连接的层来进行预测。
为什么神经网络更好?
假设我们没有使用神经网络。我们将如何处理这个问题?假设我们正在尝试编写一个识别猫的程序。我们可以通过寻找特定的形状来表现猫。

Cat shapes from Computer Vision Expert Fei-Fei Li’s TED Talk.
看起来很简单,对吧?但是等一下。不是所有的猫都长这样。如果你有一只伸展开的猫呢?我们需要添加更多的形状。

More cat shapes from Computer Vision Expert Fei-Fei Li’s TED Talk.
至此,应该很清楚告诉计算机寻找某些形状是行不通的。猫有各种形状和大小。这是假设我们只在找猫。如果我们想要一个可以对各种图片进行分类的程序呢?
这就是为什么使用神经网络要好得多。你可以让电脑设定自己的规则。**通过使用高度先进的算法,神经网络可以以极高的准确度对图像进行分类。**一些模型已经在这项任务中击败了人类!
我们应用计算机视觉的一些很酷的方式
随着算法变得更高效,硬件变得更强大,我们可能能够用更接近科幻小说领域的神经网络来完成任务。但这并不意味着我们现在没有用这项技术做很多很酷的事情!
零售
你可能在新闻里听说过。 亚马逊 Go ,电商巨头的无收银员杂货店。你走进去,拿起一些东西,然后走出来。系统会自动向你收取费用。**覆盖在天花板上的摄像头会记录下你拿起的物品。**虽然该系统并不完善,而且可能容易受到入店行窃的影响。看到这个想法在未来几年内如何发展将会非常有趣。
自动驾驶汽车
在我看来,自动驾驶汽车是目前正在开发的最酷的东西之一。 Waymo **,**最初是谷歌的自动驾驶汽车项目,优步和特斯拉是一些公司目前正在开发可以自行导航道路的车辆。
Waymo 的自动驾驶汽车车队已经行驶了超过 1000 万英里的道路!平均每年旅行约 12000 英里。总共有 800 多年的驾驶经验!

One of Waymo’s self-driving cars. Source.
卫生保健
在医疗保健中,CNN 被用于识别许多不同种类的疾病。通过对癌症或其他医疗状况的某些数据集进行训练,神经网络可以以很高的准确率找出是否有问题!通过让神经网络提取特征并在数据中找到模式,它可以利用我们从未想到过的图片信息!
微软正在开发其InnerEye项目,该项目帮助临床医生使用深度学习和 CNN 分析 3D 放射图像。这有助于医疗从业者提取定量测量值,并有效地计划手术。
用 Keras 创建卷积神经网络
既然我们理解了 CNN 应该如何工作背后的一些直觉。我们可以用 Python 编写的高级 APIKeras在 Python 中创建一个。Keras 将帮助我们编写易于理解和超级可读的代码。
你可以从安装 Anaconda 开始,在命令界面运行conda install keras。然后你可以使用 Jupyter 笔记本开始用 Python 编程。如果你想在云端运行一切,你也可以使用谷歌的合作实验室。
**我们将使用属于 Keras 库的 MNIST 数据集。包含 6 万个训练样本和 1 万个手写数字测试样本。我们开始吧!

The first few training examples in the MNIST dataset.
首先,我们要从 Keras 库中导入我们需要的所有东西。这包括顺序模型,这意味着我们可以通过添加层来轻松构建模型。接下来我们将导入 Conv2D (Convolution2D),MaxPooling2D,Flatten 和 Dense 层。前 3 个是不言自明的,密集层帮助我们建立完全连接的层。
我们将需要 Keras Utils 来帮助我们编码数据以确保它与我们模型的其余部分兼容。这使得数字 9 不会被视为比 1 更好。最后,我们将导入用于训练模型的 MNIST 数据集。
导入数据集后,我们需要将它分成训练数据和测试数据。训练数据就是我们要教给神经网络的东西。测试数据是我们用来衡量准确性的。我们将重塑数据,以匹配 TensorFlow 后端所需的格式。接下来我们将归一化数据,以保持数值范围在 0 到 1 之间。并且对MNIST 标签进行分类编码。
太好了!现在我们可以开始构建我们的模型了。我们将从创建一个序列模型开始,这是一个层的线性堆栈。正如你在下面的代码中看到的,这使得我们向模型中添加更多的层变得非常容易。
在我们建立完模型后,我们将编译它。该模型使用 Adam 优化器,这是一种用于调整权重的梯度下降算法。我们的模型使用的损失函数是分类交叉熵,它告诉我们的模型我们离结果有多远。指标参数用于定义如何评估绩效。它类似于损失函数,但在实际训练过程中不会用到。
我们将在训练台上调整或训练我们的模型。批量大小决定了我们在每次迭代中要考虑多少张图像。历元的数量决定了模型在整个集合中迭代的次数。在一定数量的时代之后,模型将基本上停止改进。
详细值决定了模型是否会告诉我们模型的进度,而验证数据决定了模型如何在每个时期后评估其损失。**
最后,我们将打印出我们的模型有多精确。最终结果应该在 98%到 99%之间
你可以在 my GitHub 上找到完整的代码,或者你可以在 Google Colaboratory 上运行它。
关键要点
- 神经网络松散地基于我们大脑解释信息的方式。
- 卷积神经网络特别适合处理图像。
- 计算机视觉在现实世界中有很多应用。
感谢阅读!如果您喜欢,请:
- 在 LinkedIn上添加我并关注我的媒体,了解我的旅程
- 留下一些反馈或给我发电子邮件(alexjy@yahoo.com)
- 与你的网络分享这篇文章
如何教 AI 玩游戏:深度强化学习

如果你对机器学习感兴趣,并且对它如何应用于游戏或优化感兴趣,那么这篇文章就是为你准备的。我们将看到强化学习和深度强化学习(神经网络+ Q 学习)的基础知识应用于游戏 Snake。让我们开始吧!
与普遍的看法相反,人工智能和游戏并不能和谐相处。这是一个有争议的观点吗?是的,它是,但是我将解释它。人工智能和人工行为是有区别的。我们不希望我们游戏中的代理比玩家更聪明。我们希望他们足够聪明,能够提供乐趣和参与。我们不想挑战我们 ML bot 的极限,就像我们通常在不同行业所做的那样。对手需要是不完美的,模仿一个类似人类的行为。
然而,游戏不仅仅是娱乐。训练一个虚拟代理人超越人类玩家可以教会我们如何在各种不同和令人兴奋的子领域中优化不同的过程。这就是谷歌 DeepMind 用其广受欢迎的 AlphaGo 所做的事情,它击败了历史上最强的围棋选手,打进了一个在当时被认为不可能的进球。在本文中,我们将开发一个人工智能代理,它能够从头开始学习如何玩热门游戏《贪吃蛇》。为了做到这一点,我们在 Tensorflow 和 PyTorch(两个版本都可用,您可以选择您喜欢的一个)之上使用两个 Keras 实现了一个深度强化学习算法。这种方法包括两个组件之间的交互:环境(游戏本身)和代理(Snake)。代理收集关于其当前状态的信息(我们将在后面看到这意味着什么)并相应地执行动作。环境基于执行的动作奖励或惩罚代理。随着时间的推移,代理学会了什么样的行为能使回报最大化(在我们的例子中,什么样的行为会导致吃掉苹果和避开墙壁)。没有给出关于游戏的规则。最初,Snake 不知道该做什么,并且执行随机的动作。目标是制定一个策略(技术上称为“政策”)来最大化分数——或回报。
我们将看到一个深度 Q 学习算法如何学习玩蛇,在短短 5 分钟的训练中,得分高达 50 分,显示出扎实的策略。可选地,代码显示如何使用贝叶斯优化来优化人工神经网络。这个过程不是必须的,但是我想为高级读者提一下。
关于完整代码**,请参考 GitHub 库。下面我将展示学习模块的实现。**
游戏

On the left, the AI does not know anything about the game. On the right, the AI is trained and learnt how to play.
这个游戏是用 Pygame 用 python 编写的,Pygame 是一个允许开发相当简单的游戏的库。在左边,代理没有经过训练,也不知道该做什么。右边的游戏指的是训练后的特工(5 分钟左右)。
它是如何工作的?
强化学习是一系列用于控制的算法和技术(如机器人技术、自动驾驶等)…)和决策。这些方法解决了需要表达为马尔可夫决策过程(MDP)的问题。这是什么意思?这意味着我们需要通过一组状态 S(例如,基于蛇的位置的索引)、一组动作 A(例如,上、下、右、左)、一个奖励函数 R(例如,当蛇吃苹果时+10,当蛇碰壁时-10)和可选的描述状态之间转换的转换函数 T 来描述我们的游戏。为了使用强化学习,我们需要使用这四个部分来形式化我们的问题。如果这是令人困惑的,怕不是,几分钟后一切都会明朗。
在我的实现中,我使用了深度 Q 学习**,而不是传统的监督机器学习方法。有什么区别?传统的 ML 算法需要用一个输入和一个叫做 target 的“正确答案”来训练。然后,系统将尝试学习如何根据看不见的输入来预测目标。在这个例子中,我们不知道在游戏的每个状态下应该采取的最佳行动(这实际上是我们正在努力学习的!),所以传统的方法不会有效。
在强化学习中,我们有两个主要组件:环境*(我们的游戏)和代理*(我们的蛇…或者正确的说,驱动我们蛇行动的深层神经网络)。每当代理执行一个动作,环境就给代理一个奖励,奖励可以是正的也可以是负的,这取决于该动作在特定状态下有多好。代理的目标是在给定每一种可能状态的情况下,学习什么样的行为能使奖励最大化。状态状态是代理在每次迭代中从环境中接收到的观察结果。一个状态可以是它的位置,它的速度,或者任何描述环境的变量数组。更严格地说,使用强化学习符号,代理用来做决策的策略被称为策略。在理论层面上,策略是从状态空间(代理可以接收的所有可能观察的空间)到动作空间(代理可以采取的所有动作的空间,比如上、下、左和右)的映射。最优智能体可以在整个状态空间中进行归纳,从而总是预测最佳的可能行动…甚至对于那些代理人从来没有见过的情况!如果这还不清楚,下一个例子会澄清你的疑惑。为了理解代理如何做决定,我们需要知道什么是 Q 表。Q 表是一个矩阵,它将代理的状态与代理可能采取的行动相关联。表中的值是行动成功的概率(从技术上来说,是对预期累积奖励的一种衡量),根据代理在培训期间获得的奖励进行更新。贪婪策略的一个例子是代理查找表格并选择导致最高分数的动作的策略。****

Representation of a Q-Table
在这个例子中,如果我们处于状态 2,我们可能会选择右,如果我们处于状态 4,我们可能会选择上。Q 表中的值代表从状态 s. 采取行动 a 的累积 预期报酬,换句话说,这些值给我们一个指示,即如果代理从该状态 s 采取行动 a 时它获得的平均报酬。 这个表就是我们之前提到的代理人的策略: 它决定了从每个状态应该采取什么行动来最大化期望报酬。这有什么问题?策略是一个表,因此它只能处理有限的状态空间。换句话说,我们不能有一个无限大的表,有无限个状态。对于我们有很多可能状态的情况,这可能是个问题。
深度 Q 学习通过将表格转换成深度神经网络来增加 Q 学习的潜力,深度神经网络是参数化函数的强大表示。Q 值根据贝尔曼方程更新:

一般来说,该算法工作如下:
- 游戏开始,Q 值随机初始化。
- 代理收集当前状态 s (观察)。
- 代理基于收集的状态执行动作。动作可以是随机的,也可以由神经网络返回。在训练的第一阶段,系统通常选择随机动作来最大化探索。后来,系统越来越依赖它的神经网络。****
- 当人工智能选择并执行动作时,环境给智能体一个奖励。然后,代理到达新状态state’,并根据上述贝尔曼方程更新其 Q 值。此外,对于每一步棋,它存储原始状态、动作、执行该动作后达到的状态、获得的奖励以及游戏是否结束。该数据稍后被采样以训练神经网络。这个操作被称为重放存储器。
- 这最后两个操作重复进行,直到满足某个条件(例如:游戏结束)。
状态
状态是代理发现自己所处的情况的表示。状态也代表神经网络的输入。在我们的例子中,状态是一个包含 11 个布尔变量的数组。它考虑到:
-如果蛇的接近(右,左,直)有立即的危险。
-蛇是否上下左右移动。
-如果食物在上面、下面、左边或右边。
失败
深度神经网络将输出(行动)优化为特定的输入(状态),试图最大化预期的回报。损失函数给出了表示预测与事实相比有多好的值。神经网络的工作是最小化损失,减少真实目标和预测目标之间的差异。在我们的例子中,损失表示为:

报酬
如前所述,人工智能试图最大化预期回报。在我们的例子中,只有当代理吃了食物目标(+10)时,才会给予它积极的奖励。如果蛇撞到墙或者撞到自己,奖励为负(-10)。此外,我们可以对蛇每走一步而不死给予积极的奖励。在这种情况下,Snake 可能会利用这种情况,跑一圈而不是去够食物,因为它每走一步都会得到积极的回报,同时避免撞到墙上的风险。有时,强化学习代理比我们聪明,在我们的策略中呈现出我们没有预料到的缺陷。
深度神经网络
人工智能代理的大脑使用深度学习。在我们的例子中,它由 120 个神经元的 3 个隐藏层组成。学习率不固定,从 0.0005 开始,递减到 0.000005。不同的架构和不同的超参数有助于更快地收敛到最优,以及可能的最高分数。
网络接收状态作为输入,并返回与三个动作相关的三个值作为输出:向左移动、向右移动、直线移动。最后一层使用 Softmax 函数。

学习模块的实施
该计划最重要的部分是深度 Q 学习迭代。在上一节中,解释了高级步骤。在这里你可以看到它是如何实现的(要查看完整代码,请访问 GitHub 库)。编辑:由于我正在扩展这个项目,Github repo 中的实际实现可能会略有不同。概念与下面的实现相同)。
**while not game.crash:
#agent.epsilon is set to give randomness to actions
agent.epsilon = 80 - counter_games
#get old state
state_old = agent.get_state(game, player1, food1)
#perform random actions based on agent.epsilon, or choose the action
if randint(0, 1) < agent.epsilon:
final_move = to_categorical(randint(0, 2), num_classes=3)
else:
# predict action based on the old state
prediction = agent.model.predict(state_old.reshape((1,11)))
final_move = to_categorical(np.argmax(prediction[0]), num_classes=3)[0]
#perform new move and get new state
player1.do_move(final_move, player1.x, player1.y, game, food1, agent)
state_new = agent.get_state(game, player1, food1)
#set treward for the new state
reward = agent.set_reward(player1, game.crash)
#train short memory base on the new action and state
agent.train_short_memory(state_old, final_move, reward, state_new, game.crash)
# store the new data into a long term memory
agent.remember(state_old, final_move, reward, state_new, game.crash)
record = get_record(game.score, record)**
决赛成绩
在实施结束时,人工智能在 20x20 的游戏棋盘上平均得分为 40 分(每吃一个水果奖励一分)。记录是 83 分。
为了可视化学习过程以及深度强化学习方法的有效性,我绘制了分数和玩游戏的数量。正如我们在下图中看到的,在前 50 场比赛中,人工智能得分很低:平均不到 10 分。这是意料之中的:在这一阶段,代理人经常采取随机行动探索棋盘,并在其记忆中存储许多不同的状态、行动和奖励。在过去的 50 场比赛中,代理不再采取随机的行动,而是根据它的神经网络(它的策略)来选择做什么。
在仅仅 150 场比赛中——不到 5 分钟——代理学会了一个可靠的策略,并获得了 45 分!

结论
这个例子展示了一个简单的代理如何在几分钟内用几行代码学会一个进程的机制,在这个例子中是游戏 Snake。我强烈建议深入研究代码并尝试改进结果。一个有趣的升级可能会在每次迭代时通过当前游戏的截图获得。在这种情况下,状态可以是每个像素的 RGB 信息。深度 Q 学习模型可以用双深度 Q 学习算法来代替,以实现更精确的收敛。
如果您有任何问题或建议,请随时留言,我将非常乐意回答。
要引用这篇文章,请参考这个快速 BibTex 推荐:
****@article**{comi2018,
title = "How to Teach an AI to Play Games using Deep Q-Learning",
author = "Comi, Mauro",
journal = "Towards Data Science",
year = "2018",
url = "https://towardsdatascience.com/how-to-teach-an-ai-toplay-games-deep-reinforcement-learning-28f9b920440a"
}**
如果你喜欢这篇文章,我希望你能点击鼓掌按钮👏这样别人可能会偶然发现它。对于任何意见或建议,不要犹豫留下评论!
我是一名研究工程师,热爱机器学习及其无尽的应用。你可以在 maurocomi.com找到更多关于我和我的项目的信息。你也可以在 Linkedin ,在 Twitter 上找到我,或者直接给我发邮件。我总是乐于聊天,或者合作新的令人敬畏的项目。
如果你对这篇文章感兴趣,你可能会喜欢我的其他文章:
如何讲故事,用数据编织有凝聚力的叙事

讲故事是人类最重要的进化优势之一。这是一个大胆的说法,但我相信这是真的。
当古代人围坐在村庄的篝火旁讲故事时,他们正在教其他村民去哪里寻找食物,如何成功捕获猎物,什么草药可以治愈疾病,哪些动物应该避开(以及如何避开!)等必备的生存技能。
这些信息没有在村里的时事通讯或洞壁上的安全海报中分享(嗯…我猜它们有点像早期的海报…但你知道我的意思)。这些课程主要以故事的形式出现。

所以几万年来,这是人类相互学习最重要的东西的方式,因此,这也是我们期望相互学习的方式。
数字让人害怕

每个人都知道如何讲故事。我们都到处编故事。我们知道如何讲笑话,制造悬念,围绕一个奇怪的假期轶事或关于我们孩子的芭蕾课讲一个流畅的故事。
然而,出于某种原因,一旦大多数人不得不交流数字,他们吓坏了。“我讨厌数学!我不知道数字!我有数据要分享…我该怎么办?!?我知道,我会把所有的数字放在一张幻灯片上,然后期待最好的结果。其他人都会想通的……”
这感觉熟悉吗?你并不孤单。在我们的文化中,我们有一种严重的数字恐惧症,这种恐惧症让许多人——尤其是专业沟通者——神经紧张。
但是正如认知行为疗法可以通过直面恐惧来帮助解决各种恐惧症的问题一样,我相信每个人都可以学会以类似的方式交流数据——通过这样做。仅仅是尝试和练习的行为,就能使任何沟通者成为数据沟通者。
最重要的策略之一是从讲故事的角度来看待数据通信。不仅因为讲故事是如此强大,是在许多主题上与许多观众联系的最佳方式,而且因为我们都知道如何做,所以它有助于将令人生畏的数字转化为故事的简单成分。
用数字编织一个故事

将数字转化为叙事的最重要的步骤之一是,像你讲述其他故事一样,概述或讲述你的故事,忽略数据本身,专注于论点的流动。例如,假设你有公司的销售数据,你需要为你的 CEO 做一份报告。你是做什么的?
首先,你要弄清楚 KWYRWTS——我的首字母缩略词,这是有史以来最糟糕的首字母缩略词,但它代表了一个非常重要的思想:知道你真正想说什么。
假设你这个季度的销售数字大幅下降。但你知道主要原因是因为围绕英国退出欧盟公投的争论和随后的通过,你的欧洲办公室的销售额大幅下降。显然这将是你故事的焦点。那是你的 KWYRWTS。也许有两个要点,或者三个要点,但是你必须知道它们到底是什么!
所以你创建一个故事板,并像这样决定叙事流程:

这五个“面板”故事建立了一个流程和逻辑,你可以很容易地围绕它编织一个故事。你知道你以“销售额下降”开始,这可能包括公司销售的概述。你正在建立一些预期,激活你的 CEO 的情绪(希望不是针对你的愤怒——也许他有些焦虑!).
然后,你会通过显示地区数字,暗示一些好消息,将故事转移到缓解焦虑上?或者至少一些可能有助于支持解决方案的信息。接下来,你得到你对问题的假设,这是从地区故事的逻辑构建。然后你进入预测未来阶段,关注近期(下个季度)和长期(明年),这让你以一个快乐的音符结束——对你的数据故事来说,这是一个好莱坞式的结局!
只有当你对自己的故事非常有信心时,你才会担心获得实际的数据,并考虑要展示什么图表,以及如何展示。换句话说,我需要理解数据的要点,以知道要讲什么故事,但我不需要一点实际数据来概述一个令人信服的故事,解释需要解释的内容,并以最大化我对首席执行官的影响的方式呈现信息。
这是一个非常简单的过程,根据大量的内容简单地勾勒出一个基本的线性故事,这是从一堆数字中挤出一个故事的非常有效和非常简单的方法。
对了,隐藏在这里面的,是我观众非常清晰的认识。我知道我虚构的 CEO 不会因为一点坏消息就大发雷霆——我肯定她已经知道了。我也知道她很好奇销售额下降的原因,以及我们是否能对未来做出任何预测。
因此,我将这个故事编织成一种方式,可以很快找到原因,然后进行预测。我也知道她希望坦诚,所以清楚地知道下一季度可能没那么好是很重要的,同时也在最后提供一缕阳光。
如果是另一位老板,我可能会以不同的方式讲述这个故事:

只是不要害怕

你已经知道如何讲故事了。知道你想说什么,尽可能在你的叙述中注入情感、悬念和兴趣,概述你的故事流程,忽略数据直到过程的最后,然后才担心具体包括什么以及如何可视化你的数据。最好的建议?你在用数字讲故事。不要害怕。你在讲一个故事…用数字——它们只是成分!
要了解更多关于数据叙事的信息,只需在 Udemy 上查看课程即可(使用此链接可节省 50%的费用)。
如何像数据科学家一样思考组合学
牢固掌握这些基本概念,以改善您的决策过程并推动您的公司向前发展。
我们最近讨论了决策树、 博弈论和客户角色。对于每个主题,我们都使用了具有少量案例的示例,这样我们就可以向您展示一些有趣但大小可控的内容。上周,我们讨论了如何使用集群来减少您试图解决的问题的规模。本周,我们将更进一步,讨论如何计算你必须开始的案例数。
为此,我们将讨论组合学的数学领域,特别是排列和组合。排列计算结果的数量,而你计算的顺序很重要。另一方面,组合计算结果的数量,而你计算的顺序并不重要。排列和组合都被进一步细分,以考虑您正在选择的选项是否允许重复,即在每次选择后在可用选项集中替换,或者不允许(您将看到这个概念被称为“重复”和“替换”——本周我将使用“替换”)。本周我们将讨论每个场景:
开始数数吧!
离群值 **监控您的业务数据,并在发生意外变化时通知您。**我们帮助营销/发展&产品团队从他们的业务数据中获取更多价值。
- Outlier 是 Strata+Hadoop World 2017 观众奖得主。
置换置换
回到我们讨论博弈论的时候,我们讨论的一个场景是,你的公司(例如,道格的甜点)需要决定是提高价格、降低价格还是保持价格不变。假设你有另外 3 个竞争者(让我们称他们为 A、B 和 C ),他们和你卖同样的产品,他们面临同样的三个决定。此外,根据您过去的经验,您知道您的公司是该领域的领导者,然后其他公司总是以相同的顺序对您的定价决策做出反应,A,B,c。
排列计算结果的数量,而你计算的顺序很重要。另一方面,组合计算结果的数量,而你计算的顺序并不重要。
那么会发生多少种不同的情况呢?我们当然可以用手数出来…

…但随着选项数量的增加,这变得越来越难。这个问题是置换排列的一个例子。让我们从头开始思考结果的数量。道格的甜点首先在 3 个选项中做出选择,然后 A 公司在同样的 3 个选项中做出选择。换句话说,对于道格的甜点可以选择的 3 个选项中的每一个,公司 A 可以选择相同的 3 个选项中的任何一个,这意味着有 3 * 3 = 9 种可能的结果。接下来,B 公司在同样的 3 个选项中做出选择。换句话说,对于我们为道格的甜点和 A 公司计算的 9 个结果中的每一个,B 公司可以选择 3 个选项,这意味着有 9 * 3 = 27 个结果。最后,C 公司在同样的 3 个选项中做出选择。换句话说,对于我们为道格甜点计算的 27 个结果中的每一个,公司 A、公司 B、公司 C 可以选择 3 个选项,这意味着有 27 * 3 = 81 个结果。
你现在可以看到这个模式了——每次做出一个新的选择,我们都要把之前的结果乘以选项的数量。让我们将 n 表示为选项的数量,在本例中 n = 3,k 表示做出选择的次数,在本例中 k = 4。然后,我们可以概括置换的概念:当有 n 个选项被选择 k 次,每次替换选项,有 n^k 不同的结果。在这个例子中,这意味着,3⁴ = 3 * 3 * 3 * 3 = 81。
接下来,我将讨论不允许替换选项的排列场景。
没有替换的排列
这就是当在过程的每一步都有相同的选项时,如何计算排列的方法。现在我来讲讲每个选择只允许做一次的情况下,如何统计结果。
假设你准备推出一款新产品,并试图找出向公众发布的最佳策略。你已经确定了四种不同的营销策略,并正在考虑实施:
- 发送新闻稿并安排新闻媒体的采访
- 开展在线营销活动
- 开展电视/广播营销活动
- 在行业会议上发起并发言
根据您的营销经验,您认为采取这些措施的顺序很重要。换句话说,你认为在发起行业会议并在会议上发言之前进行在线营销活动的结果会与在线营销活动之前举行会议的结果不同。
那么你要考虑多少种不同的结果呢?这是一个没有替换的排列的例子。有四种不同的策略可以考虑,我们将它们表示为 n。当考虑先做什么时,您有四种选择。当考虑下一步做什么时,你只剩下三个选择(因为我们不会做两次同样的营销策略)。当你选择第三步做什么的时候,你还有两个策略。最后,最后做的策略是由你之前的选择决定的,因为只剩下一个选项了。综上所述,你有 4 * 3 * 2 * 1 = 24 种不同的结果需要考虑。
我们刚刚做的整数乘积的计算发生得如此频繁,以至于它有自己特殊的名字和数学符号。它被称为阶乘,用“!”表示在一个数字之后。它的简写意思是,取每个小于或等于该数的整数的乘积。比如 4!= 4 * 3 * 2 * 1 = 24,正是我们上面计算的结果。更一般地说,如果我们要采取所有 n 个营销策略,那么我们必须考虑 n 个!不同的结果。
但是,如果你因为没有时间或预算而无法完成所有的营销策略,该怎么办呢?而是只能选择 4 个选项中的 2 个。让我们把你要做的选择数记为 k,在这个例子中 k = 2。你可以从第一步的 4 个策略和第二步的 3 个策略中选择,但是你就此打住。所以你有 4 * 3 = 12 个结果要考虑。请注意,这个结果与之前的唯一不同之处是 2 * 1 不再出现在公式中。我们可以将公式改写为 4 * 3 * 2 * 1 / 2 * 1 = 4 * 3 = 12(很快就会明白为什么了)。换句话说,我们总共有 n 个!结果,但需要将该值减去我们能够做出的选择数,即(n — k)!
把这两个例子,我们可以写一个,一般公式如何计算置换:n!/ (n — k)!,通常表示为 P(n,k)。在我们讲的第一个例子中,有 4 个选项(n = 4)和 4 个选择(k = 4),所以 4!/ (4–4)!= 4!/ 0!= 24 [1].在第二个例子中,有 4 个选项(n = 4)和 2 个选择(k = 2),所以 4!/ (4–2)!= 4!/ 2!= 12.
既然我们已经知道了如何在顺序很重要的情况下计数,明天,我将讨论顺序无关紧要的组合。
没有替换的组合
当你想到密码时,首先想到的可能是“密码锁”。不幸的是,这实际上是一个非常糟糕的组合的例子!正如我们在过去的几天里谈到的,在排列中,顺序很重要,但在组合中,顺序并不重要。正如你所知道的,你在密码锁中输入数字的顺序非常重要,所以如果我们想要更准确(至少从数学家的角度来看),我们应该将“密码锁”重命名为“排列锁”!
让我们重新考虑一下昨天的例子,您有四个不同的营销活动策略,您正在考虑即将到来的产品发布。在排列的情况下,这些决定的顺序很重要。但是今天,让我们假设你要进行一次大的营销宣传,同时实施所有这些策略。那有多少种不同的结果?简单,一——你同时做所有的事情!
现在让我们假设你想大出风头,但没有预算或时间同时实施这四个策略。相反,你只能做两个。考虑没有替换的组合的最简单的方法是首先计算没有替换的排列的数量,然后用选项可以排序的方式的数量来减少该值。昨天我们计算出,当我有四个选项和两个选择时,有 12 种不同的没有替换的排列。那么,有多少种方法可以让我们做出两种选择,并进行替换呢?我们从昨天就已经知道答案了,是 P(2,2) = 2!/ (2–2)!= 2!= 2 * 1 / 1 = 2.这意味着没有替换的组合数是 12 / 2 = 6。
我们可以把所有这些放在一起形成一个通用的形式,再次表示 n 为选项的数量,k 为选择的数量。我们将今天的结果计算为 P(n,k) / P(k,k)。因为 P(k,k)和 k 是一样的!,我们可以把这个写成 P(n,k) / k!= n!/ (n — k)!* k!,通常表示为 C(n,k)。在我们今天讲的第一个例子中,有 4 个选项(n = 4)和 4 个选择(k = 4),所以 4!/ (4–4)!* 4!= 4!/ 0!* 4!= 1.在第二个例子中,有 4 个选项(n = 4)和 2 个选择(k = 4),所以 4!/ (4–2)!* 2!= 4!/ 2!* 2!= 6.
接下来,我将通过讨论替换组合来结束我们关于组合学的讨论。
替换组合
我们要讨论的最后一种组合是替换组合。这类计数问题的一个例子是在商店购买产品。举个例子,你站在我假设的面包店 Doug 's Desserts 的柜台前,想买四个甜甜圈(即你做出选择的数量,这里 k = 4)。我的面包店出售三种甜甜圈:香草霜甜甜圈、糖衣甜甜圈和果冻馅甜甜圈(即你拥有的选择数量,其中 n = 3)。现在的问题是,考虑到你可以随心所欲地购买每种甜甜圈,你有多少种方法可以从三种选择中购买四种甜甜圈?
类似的逻辑也适用于我在讨论置换时讨论的例子——四家公司各自选择三种产品价格处理方案。在排列的背景下,我们假设选择的顺序很重要。不过,对于组合来说,让我们假设顺序无关紧要。现在的问题是,假设这四家公司都在同一时间定价,他们有多少种不同的定价方式?
在这两个例子中,有 n = 3 个选项可供选择,并且做出 k = 4 次决策,其中每次做出决策时所有选项都可用。
让我们用甜甜圈的例子来思考如何解决这个问题,因为它更容易形象化。想象你在面包店,每种类型的甜甜圈都在自己的托盘上。因此,一个托盘上有一打香草冰淇淋(在表格中用“O”表示),旁边的托盘上有一打果冻,还有一打糖浆放在自己的托盘上。

你喜欢香草霜,也确实喜欢果冻馅的,但是不喜欢蜜饯的,所以你的方案是选一个香草霜,三个果冻馅的。您可以想象购买过程如下。
首先,你站在香草霜甜甜圈托盘前(你看到的托盘是蓝色的)…

然后要一个甜甜圈放在你的包里。然后你移到下一盘甜甜圈,浇上糖浆。

既然你不想要这些甜甜圈,就不要从托盘里拿走。你移动到最后一盘油炸圈饼,果冻填充…

三次要一个甜甜圈。
如果一个旁观者记录了你购买甜甜圈的步骤,它应该是这样的:(1)甜甜圈(2)移到下一个托盘(3)移到下一个托盘(4)甜甜圈(5)甜甜圈(6)甜甜圈。实际选择的甜甜圈并不重要,因为这是一个组合,选择的顺序并不重要。
以这种方式来看购买,无论你选择哪种甜甜圈,你总是会有 4(即,k)“甜甜圈”步骤和 2(即,n-1)“移动到下一个托盘”步骤。这就像说,我们有 k + (n -1),在我们的例子中是 6,选择甜甜圈或移动到下一个托盘的不同选项,我们想选择 k,在我们的例子中是 4,甜甜圈。换句话说,这与没有替换的组合是一样的,但是对我们昨天讨论的公式的输入稍作修改!结果总数为 C(k + (n — 1),k) = (k + (n — 1))!/ (k + (n — 1) — k)!* k!=(k+(n-1))!/ (n — 1)!* k!。从示例中插入我们的值,有 6 个!/ 2!* 4!=你如何选择甜甜圈的 15 个结果(或者公司可以做出定价决定)。
好了,这就是排列和组合。我希望你已经享受了这一周的计算结果,你可能会面临你的业务!
离群值 **监控您的业务数据,并在发生意外变化时通知您。**我们帮助营销/发展&产品团队从他们的业务数据中获取更多价值。 今天安排试玩。
- Outlier 是 Strata+Hadoop World 2017 观众奖得主。
这是 30 秒后的异常值。
[1] 0!= 1,按照惯例。
[2]一打油炸圈饼并不重要,只要每个托盘上至少有四个——因为这是你要做的选择,我们假设每个选择都有所有选项——逻辑是一样的。
如何在 5 分钟内训练一个机器学习模型
关于 Mateverse :我们在 Mate Labs 已经建立了 Mateverse,使每个人都能够建立和训练机器学习模型,而无需编写一行代码。在 Mateverse 上培训模型只需 5 个步骤。如果你想要的只是一个智能解决方案,甚至不需要学习编码技能,更不用说机器学习的概念了。
看看它是如何工作的:

1。 模型命名 —给你的模型起个名字:先给你的模型起个名字,描述你的模型,给你的模型贴上标签。标签是为了让你的模型可以被搜索。

Step 1— Naming your model
2。 数据类型选择 —选择数据类型(Images/Text/CSV):是时候告诉我们你想要训练你的模型的数据类型了。我们支持**图片、文字和*。**CSV(分类数据)数据类型。选择适当的数据类型,然后单击“下一步”继续下一步。我们还公开了一些数据集,供大家开始使用。 公开数据集 是为了让你知道在 Mateverse 上训练你的模型需要什么类型的数据。

Step 2— Data Type Selection
3。 数据上传 —上传您的数据或从公共数据集中选择:从公共数据集中选择,如珠宝数据集(图像)、性别数据集(图像)、问题或句子数据集(文本)、数字数据集(CSV)或上传您的数据。上传您的数据是一个简单的过程,只需选择您的文件并键入所选文件的标签。
我们举一个图像数据集的例子。图像可以直接上传,也可以压缩成压缩文件上传(不同的标签/类别有不同的压缩文件)。属于一个唯一类别的所有图像都应该在这个压缩文件中。
附:建议:不要压缩文件夹,压缩文件夹的话就不行了。选择文件并直接压缩。

Sample compressed file with images — This is how your compressed file’s data should look like
文本—同样,您可以上传文本(*。txt)文件。下面是一个示例文本文件。每个独特的句子应该是文本文件中的不同行。

Sample Text(.txt) file
CSV——如果你想训练一个模型,不管是分类还是回归(预测),只需上传一个 csv 文件就可以了。一旦你上传了文件,你必须做两件事:
a) 按下“跳过”按钮,跳过您发现对训练所需模型来说多余/不重要的列。
b)在模型训练完成后,选择一个要进行预测的列。
您甚至可以更改列名以供参考。

CSV fIle Upload Preview
附注:尽量避免在文本和 CSV 文件中使用不支持的字符。
4。 为您上传的文件(图像/文本文件)键入类别(标签),点击提交开始上传。等待一段时间,直到我们的 web 应用程序上传所有文件。您可以上传尽可能多类别的图像。您需要至少 2 个标签(类别)来对图像/文本进行分类。我们支持带“*”的文本文件。txt "扩展名。
5。 **开始训练:**按下按钮,开始训练。现在,Mateverse 的智能后端将开始处理你上传的数据,并为训练做准备。与此同时,它还将开始选择最佳的机器学习/深度学习算法,以最高的精度训练最佳模型。

Step 4: Push the Button to Start Training
6。 **开始测试:**你的模型训练好了,可以开始测试你刚训练好的模型了。您可以通过 UI 使用它,或者通过 API 集成它(参考文档)。

关于我们的更多信息
在让 Mateverse 成为一个更好的平台方面,我们已经走了很长的路。借助 Mateverse V1.0,我们利用专有技术、复杂管道、大数据支持、自动化数据预处理(使用 ML 模型的缺失值插补、异常值检测和格式化)、自动化超参数优化以及更多功能,让分析师和数据科学家的工作变得更加轻松。
如果你也想在 5 分钟内训练出一个 ML 模型,请在这里填写 。
为了帮助您的企业采用机器学习,而不会浪费您的团队在数据清理和创建有效数据模型方面的时间,您也可以通过电子邮件与我们联系,我们将与您联系。
让我们携起手来。
告诉我们你第一次在 Mateverse 中训练模型的经历。而且我们会分享给所有我们认识的对 AI 和机器学习着迷的人。共建共享。查看 LinkedIn ,了解更多。
如果你有新的建议,请告诉我们。我们的耳朵和眼睛总是为真正令人兴奋的事情而张开。
之前我们分享过。
- 公共数据集:用这些在 Mateverse 上训练机器学习模型。
- Mateverse 公测公告。
- 为什么我们需要机器学习的民主化?
- 一个非常清晰的解释全有线电视新闻网的实施。这些研究人员如何尝试一些非常规的东西,以实现更小但更好的图像识别。
- 我们的愿景。关于人工智能大家都没告诉你的事情
如何训练一个 Tensorflow 人脸对象检测模型
人工智能使得分析图像成为可能。在这篇博文中,我将着重于用定制的类来训练一个对象检测器。你要做的第一件事是设置。在 Tensorflow 文档中写了如何在本地机器上设置。我们将使用 Tensorflow 对象检测来训练实时对象识别应用程序。训练好的模型在这个库中可用
这是一个翻译的’Train een tensor flow gezi cht object detectie model和Objectherkenning meet de 计算机视觉库 Tensorflow

MS COCO Tensorflow Nürburgring example (own picture)
OpenCV
你可以在 Ubuntu 上的 */usr/local 中自动安装 OpenCV。*用下面的脚本。该脚本安装 OpenCV 3.2 并与 Ubuntu 16.04 一起工作。
$ curl -L [https://raw.githubusercontent.com/qdraw/tensorflow-object-detection-tutorial/master/install.opencv.ubuntu.sh](https://raw.githubusercontent.com/qdraw/tensorflow-object-detection-tutorial/master/install.opencv.ubuntu.sh) | bash
在我的 Mac 上,我使用 OpenCV 3.3.0 en Python 2.7.13。我在 OpenCV 3.2 和 3.3 中试过,但是在 Python 3.6 中失败了。然而,在 Ubuntu Linux 上,这种组合确实有效。
$ brew install homebrew/science/opencv
“超薄”和对象检测模块的设置
第一步是克隆 Tensorflow-models 存储库。在本教程中,我们只使用了 slim 和 object_detection 模块。
$ nano .profileexport PYTHONPATH=$PYTHONPATH:/home/dion/models/research:/home/dion/models/research/slim
您还需要编译 protobuf 库
$ protoc object_detection/protos/*.proto --python_out=.
克隆教程存储库并安装依赖项
示例代码可在tensor flow-face-object-detector-tutorial资源库中找到。你可以克隆这个回购。
$ git clone [https://github.com/qdraw/tensorflow-face-object-detector-tutorial.git](https://github.com/qdraw/tensorflow-face-object-detector-tutorial.git)
转到子文件夹:
$ cd tensorflow-face-object-detector-tutorial/
使用 PIP 安装依赖项:我使用 Python 3.6,OpenCV 使用 Python 绑定安装。
$ pip install -r requirements.txt
下载培训和验证数据
香港中文大学有一个庞大的标签图像数据集。较宽的人脸数据集是人脸检测基准数据集。我已经使用了标签来显示边界框。所选文本是面标注。

WIDER example using labelImg (credits: http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/))
脚本 001_down_data.py 将用于下载 WIDERFace 和SSD _ mobilenet _ v1 _ coco _ 11 _ 06 _ 2017。我将使用预训练模型来加快训练时间。
$ python 001_down_data.py
将 WIDERFace 转换为 Pascal XML
首先,我们需要将数据集转换成 Pascal XML。Tensorflow 和 labelImg 使用不同的格式。图像被下载到 WIDER_train 文件夹中。使用002 _ data-to-Pascal-XML . py我们转换宽面数据并将其复制到不同的子文件夹。我的电脑处理 9263 张图片需要 5 分钟。
$ python 002_data-to-pascal-xml.py

From the dataset WIDERFace and the film Marching Band (2009) with XML and LabelImg interface.
Pascal XML 到 Tensorflow CSV 索引
当数据被转换成 Pascal XML 时,就会创建一个索引。通过训练和验证数据集,我们使用这些文件作为输入来生成 TFRecords。但是,也可以使用 labelImg 之类的工具手动标记图像,并使用此步骤在此创建索引。
$ python 003_xml-to-csv.py

Excel and OS X Finder with list of files
创建 TFRecord 文件
TFRecords 文件是一个很大的二进制文件,可以读取它来训练机器学习模型。在下一步中,Tensorflow 将顺序读取该文件。训练和验证数据将被转换为二进制文件。
训练数据到 TFRecord (847.6 MB)
$ python 004_generate_tfrecord.py --images_path=data/tf_wider_train/images --csv_input=data/tf_wider_train/train.csv --output_path=data/train.record
验证数据到 TFRecord (213.1MB)
$ python 004_generate_tfrecord.py --images_path=data/tf_wider_val/images --csv_input=data/tf_wider_val/val.csv --output_path=data/val.record
设置配置文件
在储存库中,SSD _ mobilenet _ v1 _ face . config是用于训练人工神经网络的配置文件。这个文件基于一个 pet 探测器。
在这种情况下, num_classes 的数量保持为 1,因为只有面部会被识别。
变量 fine_tune_checkpoint 用于指示获取学习的前一模型的路径。这个位置将适合你在这个文件。微调检查点文件用于应用迁移学习。迁移学习是机器学习中的一种方法,专注于将从一个问题获得的知识应用到另一个问题。
在类 train_input_reader 中,与用于训练模型的 TFRecord 文件建立链接。在配置文件中,您需要将其定制到正确的位置。
变量 label_map_path 包含索引 id 和名称。在这个文件中,零被用作占位符,所以我们从 1 开始。
item {
id: 1
name: 'face'
}
对于验证,两个变量很重要。类 eval_config 中的变量 num_examples 用于设置示例的数量。
T5eval _ input _ reader类描述了验证数据的位置。这个位置也有一条小路。
此外,还可以更改学习率、批量和其他设置。目前,我保留了默认设置。
让我们训练;)
现在要开始真正的工作了。计算机将从数据集中学习,并在这里建立一个神经网络。由于我在 CPU 上模拟火车,这将需要几天才能得到一个好的结果。有了强大的 Nvidia 显卡,这是有可能缩短到几个小时。
$ python ~/tensorflow_models/object_detection/train.py --logtostderr --pipeline_config_path=ssd_mobilenet_v1_face.config --train_dir=model_output
Tensorboard 让我们深入了解学习过程。该工具是 Tensorflow 的一部分,是自动安装的。
$ tensorboard --logdir= model_output

Tensorflow Tensorboard TotalLoss
将检查点转换为 protobuf
通过计算机视觉库 Tensorflow 在对象识别中使用该模型。下面的命令提供了模型库和最后一个检查点的位置。文件夹 folder 将包含 freezed _ inference _ graph . Pb。
$ python ~/tensorflow_models/object_detection/export_inference_graph.py \
--input_type image_tensor \
--pipeline_config_path ssd_mobilenet_v1_face.config \
--trained_checkpoint_prefix model_output/model.ckpt-12262 \
--output_directory model/
TL;DR;
中的*模型/冻结 _ 推理 _ 图形。*github 知识库上的 pb 文件夹是一个人工神经网络的冻结模型。香港中文大学拥有广泛的研究面,该数据集已被用于训练模型。
估价
除了用于训练的数据之外,还有一个评估数据集。基于该评估数据集,可以计算准确度。对于我的模型,我计算了精度(平均精度)。我在 14337 步(epochs)时得到了 83.80%的分数。对于这个过程,Tensorflow 有一个脚本,可以在 Tensorboard 中看到分数。除了培训之外,建议您运行评估流程。
python ~/tensorflow_models/object_detection/eval.py --logtostderr --pipeline_config_path=ssd_mobilenet_v1_face.config --checkpoint_dir=model_output --eval_dir=eval
然后你可以用 Tensorboard 监控这个过程。
tensorboard --logdir=eval --port=6010
冻结模型的结论和使用
训练人脸识别模型已经成为可能。冻结模型model/frozen _ inference _ graph . Pb可以部署在例如具有计算机视觉库 Tensorflow 的对象识别中。
计算机视觉的世界应该让你感兴趣,但是你仍然不知道如何应用它,并且有必要的问题吗?给我发一封电子邮件,然后我们可以一起喝杯咖啡。

Me and a cup of coffee

In this example, 43 faces are recognized. Source image: Ricardo Lago https://www.flickr.com/photos/kruzul/4763629720/
如何在 PyTorch 中训练一个图像分类器,并使用它对单幅图像进行基本推理
使用自己的图像训练 ResNet 的教程
如果你刚刚开始使用 PyTorch,并且想学习如何做一些基本的图像分类,你可以遵循这个教程。它将介绍如何组织您的训练数据,使用预训练的神经网络来训练您的模型,然后预测其他图像。
为此,我将使用一个由 Google Maps 地图切片组成的数据集,并根据它们包含的地形特征对它们进行分类。我将写另一个关于我如何使用它的故事(简而言之:为了识别无人机飞越或着陆的安全区域)。但是现在,我只想使用一些训练数据来对这些地图分块进行分类。
下面的代码片段来自 Jupyter 笔记本。你可以将它们组合在一起构建你自己的 Python 脚本,或者从 GitHub 下载笔记本。这些笔记本最初是基于 Udacity 的 PyTorch 课程。如果你使用云虚拟机进行深度学习开发,并且不知道如何远程打开笔记本,请查看我的教程。
组织你的训练数据集
PyTorch 希望数据按文件夹组织,每个类一个文件夹。大多数其他 PyTorch 教程和示例希望您进一步组织它,在顶部有一个 training and validation 文件夹,然后在其中有 class 文件夹。但我认为这非常麻烦,必须从每个类中挑选一定数量的图像,并将它们从训练文件夹移动到验证文件夹。因为大多数人会选择一组连续的文件,所以在选择时可能会有很多偏差。
因此,有一种更好的方法可以将数据集动态拆分为训练集和测试集,就像 Python 开发人员习惯的 SKLearn 一样。但是首先,让我们导入模块:
%matplotlib inline
%config InlineBackend.figure_format = 'retina'
import matplotlib.pyplot as pltimport numpy as np
import torch
from torch import nn
from torch import optim
import torch.nn.functional as F
from torchvision import datasets, transforms, models
接下来,我们将定义训练/验证数据集加载器,使用 SubsetRandomSampler 进行拆分:
data_dir = '/data/train'def load_split_train_test(datadir, valid_size = .2):
train_transforms = transforms.Compose([transforms.Resize(224),
transforms.ToTensor(),
]) test_transforms = transforms.Compose([transforms.Resize(224),
transforms.ToTensor(),
]) train_data = datasets.ImageFolder(datadir,
transform=train_transforms)
test_data = datasets.ImageFolder(datadir,
transform=test_transforms) num_train = len(train_data)
indices = list(range(num_train))
split = int(np.floor(valid_size * num_train))
np.random.shuffle(indices)
from torch.utils.data.sampler import SubsetRandomSampler
train_idx, test_idx = indices[split:], indices[:split]
train_sampler = SubsetRandomSampler(train_idx)
test_sampler = SubsetRandomSampler(test_idx)
trainloader = torch.utils.data.DataLoader(train_data,
sampler=train_sampler, batch_size=64)
testloader = torch.utils.data.DataLoader(test_data,
sampler=test_sampler, batch_size=64)
return trainloader, testloadertrainloader, testloader = load_split_train_test(data_dir, .2)
print(trainloader.dataset.classes)
接下来我们来确定我们有没有 GPU。我假设如果你这样做,你有一个 GPU 驱动的机器,否则代码将至少慢 10 倍。但是概括和检查 GPU 的可用性是一个好主意。
我们还将加载一个预训练模型。对于这个例子,我选择了 ResNet 50:
device = torch.device("cuda" if torch.cuda.is_available()
else "cpu")
model = models.resnet50(pretrained=True)
print(model)
打印模型将向您展示 ResNet 模型的层架构。这可能超出了你我的理解范围,但看看这些深藏的层里面是什么仍然很有趣。
选择哪种模型取决于您,并且可能会根据您的特定数据集而有所不同。这里列出了所有的 PyTorch 型号 。
现在我们进入了深层神经网络的有趣部分。首先,我们必须冻结预训练的层,这样我们就不会在训练过程中反向穿透它们。然后,我们重新定义最终的完全连接的层,我们将使用我们的图像进行训练。我们还创建了标准(损失函数)并选择了优化器(在这种情况下是 Adam)和学习率。
for param in model.parameters():
param.requires_grad = False
model.fc = nn.Sequential(nn.Linear(2048, 512),
nn.ReLU(),
nn.Dropout(0.2),
nn.Linear(512, 10),
nn.LogSoftmax(dim=1))
criterion = nn.NLLLoss()
optimizer = optim.Adam(model.fc.parameters(), lr=0.003)
model.to(device)
现在最后,让我们训练我们的模型!在这个例子中只有一个纪元,但是在大多数情况下你需要更多。从代码来看,基本过程非常直观:加载成批图像并进行前馈循环。然后计算损失函数,并使用优化器在反向传播中应用梯度下降。
PyTorch 就是这么简单。下面的大部分代码用于显示每 10 个批次的损失和计算准确度,因此您可以在训练过程中获得更新。在验证过程中,不要忘记将模型设置为 eval()模式,完成后再返回到 train()。
epochs = 1
steps = 0
running_loss = 0
print_every = 10
train_losses, test_losses = [], []for epoch in range(epochs):
for inputs, labels in trainloader:
steps += 1
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
logps = model.forward(inputs)
loss = criterion(logps, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
if steps % print_every == 0:
test_loss = 0
accuracy = 0
model.eval()
with torch.no_grad():
for inputs, labels in testloader:
inputs, labels = inputs.to(device),
labels.to(device)
logps = model.forward(inputs)
batch_loss = criterion(logps, labels)
test_loss += batch_loss.item()
ps = torch.exp(logps)
top_p, top_class = ps.topk(1, dim=1)
equals =
top_class == labels.view(*top_class.shape)
accuracy +=
torch.mean(equals.type(torch.FloatTensor)).item()
train_losses.append(running_loss/len(trainloader))
test_losses.append(test_loss/len(testloader))
print(f"Epoch {epoch+1}/{epochs}.. "
f"Train loss: {running_loss/print_every:.3f}.. "
f"Test loss: {test_loss/len(testloader):.3f}.. "
f"Test accuracy: {accuracy/len(testloader):.3f}")
running_loss = 0
model.train()
torch.save(model, 'aerialmodel.pth')
然后…在您等待几分钟(或更长时间,取决于数据集的大小和历元数)后,训练完成,模型被保存以供以后的预测使用!
现在还有一件事你可以做,那就是绘制训练和验证损失图:
plt.plot(train_losses, label='Training loss')
plt.plot(test_losses, label='Validation loss')
plt.legend(frameon=False)
plt.show()

如您所见,在我的一个时期的特定示例中,验证损失(这是我们感兴趣的)在第一个时期结束时趋于平缓,甚至开始上升趋势,因此 1 个时期可能就足够了。培训损失,正如预期的那样,非常低。
现在进入第二部分。因此,您训练了您的模型,保存了它,并需要在应用程序中使用它。为此,您需要能够对图像进行简单的推断。您也可以在我们的资源库中找到这款演示笔记本。我们导入与培训笔记本中相同的模块,然后再次定义转换。我只再次声明图像文件夹,这样我就可以使用其中的一些示例:
data_dir = '/datadrive/FastAI/data/aerial_photos/train'test_transforms = transforms.Compose([transforms.Resize(224),
transforms.ToTensor(),
])
然后,我们再次检查 GPU 可用性,加载模型并将其置于评估模式(因此参数不会改变):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model=torch.load('aerialmodel.pth')
model.eval()
预测特定图像的类别的函数非常简单。注意,它需要一个枕头图像,而不是一个文件路径。
def predict_image(image):
image_tensor = test_transforms(image).float()
image_tensor = image_tensor.unsqueeze_(0)
input = Variable(image_tensor)
input = input.to(device)
output = model(input)
index = output.data.cpu().numpy().argmax()
return index
现在为了更容易测试,我还创建了一个函数,它将从数据集文件夹中随机选取一些图像:
def get_random_images(num):
data = datasets.ImageFolder(data_dir, transform=test_transforms)
classes = data.classes
indices = list(range(len(data)))
np.random.shuffle(indices)
idx = indices[:num]
from torch.utils.data.sampler import SubsetRandomSampler
sampler = SubsetRandomSampler(idx)
loader = torch.utils.data.DataLoader(data,
sampler=sampler, batch_size=num)
dataiter = iter(loader)
images, labels = dataiter.next()
return images, labels
最后,为了演示预测功能,我获取随机图像样本,预测它们并显示结果:
to_pil = transforms.ToPILImage()
images, labels = get_random_images(5)
fig=plt.figure(figsize=(10,10))
for ii in range(len(images)):
image = to_pil(images[ii])
index = predict_image(image)
sub = fig.add_subplot(1, len(images), ii+1)
res = int(labels[ii]) == index
sub.set_title(str(classes[index]) + ":" + str(res))
plt.axis('off')
plt.imshow(image)
plt.show()
这里有一个在谷歌地图上预测的例子。标签是预测的类,我也显示它是否是一个正确的预测。

差不多就是这样了。继续在您的数据集上尝试。只要您正确地组织了您的图像,这段代码应该可以正常工作。很快我会有更多关于你可以用神经网络和 PyTorch 做的其他酷事情的故事。
克里斯·福塔什(Chris Fotache)是一名人工智能研究员,他在新泽西的 CYNET.ai 工作。他涵盖了与我们生活中的人工智能、Python 编程、机器学习、计算机视觉、自然语言处理等相关的主题。
如何仅使用 SQL 来训练和预测回归和分类 ML 模型—使用 BigQuery ML
在我的书(Google 云平台上的数据科学)中,我讲述了一个航班延误预测问题,并展示了如何使用包括 Spark Mlib 和 TensorFlow 在内的各种工具来解决这个问题。既然已经宣布了 BigQuery ML,我想我应该展示如何使用 BQ ML 预测航班延误。

Predict whether this flight will arrive late. Using only SQL.
毫无疑问,您仍然需要收集数据、探索数据、清理数据并丰富数据。基本上所有我在第 1-9 章做的事情。在第十章,我用了 TensorFlow。在本文中,我将使用 BQML。
创建回归模型
下面是一个创建模型的 BigQuery 查询:
#standardsql
CREATE OR REPLACE MODEL flights.arrdelayOPTIONS
(model_type='linear_reg', input_label_cols=['arr_delay']) ASSELECT
arr_delay,
carrier,
origin,
dest,
dep_delay,
taxi_out,
distance
FROM
`cloud-training-demos.flights.tzcorr`
WHERE
arr_delay IS NOT NULL
请注意:
- 它从创建模型开始,模型的名称看起来就像一个表名。注意:“flights”是用于存储结果模型的数据集的名称,因此,您需要在运行查询之前创建一个空数据集。
- 这些选项指定了算法,在本例中是线性回归算法,标签为 arr_delay
- 本质上,我在 SELECT 中引入了预测变量和标签变量
大约 10 分钟后,模型被训练,并且评估结果已经为每个迭代填充:

这里的损失是均方误差,因此模型收敛于迭代#6,RMSE 约为 sqrt(97) = 10 分钟。
使用模型预测
训练模型的目的是用它来预测。您可以使用 SQL 语句进行模型预测:
#standardsql
SELECT * FROM ML.PREDICT(MODEL flights.arrdelay,
(
SELECT
carrier,
origin,
dest,
dep_delay,
taxi_out,
distance,
arr_delay AS actual_arr_delay
FROM
`cloud-training-demos.flights.tzcorr`
WHERE
arr_delay IS NOT NULL
LIMIT 10))
这导致:

如你所见,因为我们训练了模型来预测一个叫做“arr_delay”的变量,ML。PREDICT 创建一个名为 predicted_arr_delay 的结果列。在本例中,我从原始表中提取 10 行,并预测这些航班的到达延迟。
创建分类模型
在书中,我实际上并没有试图预测到达延迟。相反,我预测航班晚点超过 15 分钟的概率。这是一个分类问题,您可以通过稍微更改训练查询来做到这一点:
#standardsql
CREATE OR REPLACE MODEL flights.ontime
OPTIONS
(model_type='logistic_reg', input_label_cols=['on_time']) ASSELECT
IF(arr_delay < 15, 1, 0) AS on_time,
carrier,
origin,
dest,
dep_delay,
taxi_out,
distance
FROM
`cloud-training-demos.flights.tzcorr`
WHERE
arr_delay IS NOT NULL
下面是评测结果:

预测的一个例子是:

评估模型
可以在独立的数据集上评估模型。我手边没有,所以我将只向您展示如何在模型训练的同一数据集上运行评估:
#standardsql
SELECT * FROM ML.EVALUATE(MODEL flights.ontime,
(
SELECT
IF(arr_delay < 15, 1, 0) AS on_time,
carrier,
origin,
dest,
dep_delay,
taxi_out,
distance
FROM
`cloud-training-demos.flights.tzcorr`
WHERE
arr_delay IS NOT NULL
))
结果是:

BQML 真的很简单,真的很强大。尽情享受吧!
如何在 5 分钟内训练自定义图像分类器
使用 Vize 分类器 API 识别图像
今天我将展示如何使用 Vize.ai —自定义图像分类 API 来设置和测试自定义图像分类引擎。我们将准备数据集,上传图像,训练分类器,并在 web 界面中测试我们的分类器。我们不需要编码经验,除非我们想在我们的项目中建立 API。让我们现在开始。
准备数据集
我们希望分类器识别人的性别。首先,我们需要每只雄性和雌性的 20 张图片。让我们用谷歌搜索“男人”和“女人”,并分别保存 20 张照片。在这里你可以下载我的数据集。我尽量避免时尚图片和模特,所以我的数据集是普通人图片。我还搜索了不同的文化类型和肤色,因此我的数据集尽可能多样化。我只用了正面图像。

Male and female images in dataset
将数据集上传到 Vize



Homepage, signup page, task dashboard
我们点击**“新任务”按钮,填写我们的分类器名称“男性或女性分类器”。我们要增加两类【男】****【女】。我们可以随时添加和删除类别。点击“创建”**进入图像上传。

Name your task and create categories to sort
现在,我们将点击**“直接上传”将图片上传到我们的两个类别中。我们可以在下面的图片上看到上传的 22 和 21 张图片。我们可以使用“编辑”按钮来显示图像,并将它们从一个类别移动到另一个类别。要删除一些图像,将它们移动到新的“删除”类别,并删除该类别。我们现在不需要这些。让我们点击右上角的“复习训练”**。

Images uploaded into categories
训练分类器
在这一步,我们可以回顾我们的类别。我们准备点击**【开始训练】**按钮。

Start custom classifier training
一项任务正在训练中。根据图像的数量,可能需要一至五个小时。Vize 使用迁移学习和一组微调的模型架构,以在每项任务上达到尽可能最佳的准确性。现在是喝咖啡的时候了,等待训练结束。

Classifier training finished
测试分类器
我们的模型准备好了!我们在 43 张图像数据集上达到了 93%的准确率。我们现在可以使用预览来测试它。我们将点击**“部署和预览”,然后点击“预览我的任务”。** 在我们的数据集“test”文件夹中,我们可以找到一些测试图像来测试我们的分类器。

Preview trained task — test classification
摘要
我们使用 Vize web 界面训练和测试了我们的分类器。这是构建图像分类引擎最简单的方法。我们达到了 93%的准确率,随着上传更多的图像,我们可以将准确率提高到 100%。是时候尝试图像分类带来的巨大可能性了。在开发者文档中,我们还可以找到将 REST API 实现到我们的应用中的示例代码。
使用视觉 AI 可以构建什么样的应用?在评论中让我知道你的想法。
如何在 AWS 上使用 GPU 训练自定义单词嵌入
语言很重要。人类用文字交流,文字承载着意义。我们能训练机器也学习意义吗?这篇博客的主题是我们如何训练机器使用单词嵌入来学习单词的意思。在我浏览堆栈溢出、EC2 文档和博客的过程中,我将记下某人在 AWS 的 GPU 上使用 TensorFlow 训练单词嵌入的步骤。但是在介绍这些步骤之前,让我们先简要了解一下为什么我们需要单词嵌入。

Language is all around us — can we make a machine learn meaning?
通常,在大多数自然语言处理任务中,单词被转换成一键向量,其中每个单词在向量中获得唯一的索引。因此,在苹果、桔子和果汁这三个单词的词汇表中,我们可以用[1 0 0]、[0 1 0]和[0 0 1]来表示这三个单词。对于小型语言任务,这些向量非常有用。然而,其中有两个主要缺点:
a)对于具有 n 个字的训练数据,我们将需要 n 个维度向量。所以你可以想象 1000000 维向量非常大,并且非常稀疏。
b)one-hot vectors 中没有上下文的意义——每个单词都是完全唯一的。因此,如果一个模特已经学会了“苹果汁”,它就不能转移对填充“桔子 __”的学习。单词嵌入遵循的原则是“你将一个单词由它所保持的公司”,因此我们在单词嵌入向量中的每个维度都可以表示一个“特征”,如食物或性别或资本等等——如下所示:

Visualizing Word Embeddings (from a class by Andrew Ng)
训练有素的单词嵌入可以用于翻译、文本摘要、情感分析和类比任务,例如男人>女人、国王>王后。word 2 vec和 Glove 是两个流行的预训练单词嵌入,可以作为开源软件获得——它们对于开始一般的语言任务非常强大。但是,在本教程中,我们将学习如何在特定领域为我们自己的自定义数据构建 word 嵌入。我正致力于为电子数据,如微处理器、电容器、ram、电源等构建字嵌入。
因此,让我们开始制作单词嵌入的旅程,我们将在 AWS GPU 上进行训练!
- ****选择 P2 或 P3 实例类型T3 首先,您需要选择一个 EC2 实例类型。最近 AWS 在 EC2 上发布了 p3 实例,但是它们的价格大约是每小时 3 美元,这是一笔不小的数目。所以我将继续使用 p2 实例,它可能没有那么快,但是更便宜(大约每小时 1 美元)。这篇博客进行了更详细的比较。一旦你选择了 p2 实例,你可能需要在你的帐户上请求一个限制增加来得到使用他们。
- **建立深度学习 AMI 和安全组 如果您正在构建自己的 GPU 硬件,您需要自己设置 CUDA 驱动程序,但是在 AWS 上使用 EC2 实例为我们提供了使用预构建 AMI 或 Amazon 机器映像的优势。我选择了**深度学习 AMI,带源代码(CUDA 8,Ubuntu)。
更新(2018 年 6 月):最新的 TensorFlow 库与 CUDA 8 不太兼容,请使用支持 CUDA 9 的 AMI 比如这个这个。

如果我们想在 EC2 实例中使用 Jupyter notebook,我们需要更改安全组,以允许从端口 8888 访问 EC2。这可以通过创建一个新的安全组和使用自定义 TCP 规则和端口范围作为 8888** 和在源选择**任何地方来完成。现在您可以启动实例了。接下来,创建一个新的密钥对,并将其保存在本地计算机上。当我丢失这个的时候,我不得不再次做这些步骤。pem 文件,所以请确保它在一个安全的地方!使用chmod 400 YourPEMFile.pem将读写权限更改为只读。接下来,通过右键单击实例实例状态> Start 来启动您的 GPU。****
3.登录并在 EC2 实例上设置 Conda 环境 您可以通过ssh -i path/YourPEMFile.pem ubuntu@X.X.X.X登录到您的 GPU,其中X.X.X.X代表您的 GPU 的公共 IP,path/YourPEMFile.pem是您在上一步中创建的.pem文件的路径。一旦您登录到 EC2 实例,您就可以设置自己的 Conda 环境。你为什么需要它?我们来看看这个的回答,它讨论了康达如何优于 virtualenv。键入conda -V会导致一个错误,因为路径变量还没有设置好。我们需要转到.bash_profile并添加路径。
下面是让 **conda** 在新 EC2 实例
上工作的步骤 a .通过vim ~/.bash_profile和
创建或编辑文件 b .添加export PATH=”/home/ubuntu/src/anaconda2/bin:$PATH”路径指定包含可执行程序的目录,无需知道命令行上的完整路径即可启动这些程序。运行source ~/.bash_profile来获取这个文件。你现在可以运行conda -V并且不会看到错误。
e .通过conda create -n embeddings python=3创建一个新环境这将使用最新版本的 Python 3 创建一个新的 conda 环境。
f .运行source activate embeddings启动 conda 环境。****
4.安装 Tensorflow-GPU、Jupyter notebook 等软件包 设置并激活 conda 环境后,现在可以安装 Tensorflow 等软件包了。
a)我们可以使用pip install tensorflow-gpu jupyter notebook nltk scikit-learn pandas来安装所有必要的包来完成 word 嵌入的工作。我们需要使用tensorflow-gpu而不是tensorflow,因为前者已经过优化,适合在 GPU 中使用。所有这些要求都可以用pip freeze > requirements.txt保存到一个文件中
b)我们现在可以使用jupyter notebook --ip=0.0.0.0 --no-browser转到X.X.X.X:8888/?token=<TOKEN>来启动 jupyter 笔记本,其中X.X.X.X是 EC2 机器的 IP 地址,<TOKEN>是我们运行上面的命令时出现的令牌。
c)运行以下代码检查 TensorFlow 版本,并查看 TensorFlow 是否在 GPU 上正确运行。
import tensorflow as tf
print('TensorFlow Version: {}'.format(tf.__version__))
print('Default GPU Device: {}'.format(tf.test.gpu_device_name()))
我得到的输出是:
TensorFlow Version: 1.3.0 Default GPU Device: /gpu:0
为了绝对确定 GPU 确实被使用,运行
sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)),你应该会看到以/gpu:0结尾的东西,这也是官方文档所建议的。这帮助我最近在设置实际使用 GPU。
5.建立用于训练单词嵌入的文本语料库 你可以使用 IMDB 或维基百科数据集,但由于本博客的目标是通过自定义单词嵌入,我们将建立自己的语料库。如果你有很多文本文件,那么你可以一个一个地阅读它们,并建立语料库。在这里,我假设你有 PDF 文件,这是有点难以处理。为此,我使用了库PyPDF2。我使用的代码是:
import PyPDF2def read_pdf(fname):
pdfFileObj = open(fname, 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
print("TOTAL PAGES in file", pdfReader.numPages)
pageObj = pdfReader.getPage(0)
text = pageObj.extractText()
return ' '.join(text.split())
我在本地存储的一堆 PDF 文件上运行了上面的代码。我将上述函数返回的字符串连接起来,并写入一个文本文件。我们的文本语料库准备好了!
6。预处理文本并创建查找表 现在,让我们预处理文本,为训练单词嵌入做好准备。在自然语言处理中,在运行分类器或算法之前,通常的做法是将所有单词小写,并进行一些停用词移除。我们将使用库re(Python 中的正则表达式库)来执行其中的一些任务。
text = text.lower()
text = text.replace('.', ' __PERIOD__ ')
text = text.replace('-', ' ')
# Remove ' and full stops and brackets
text = re.sub(r'[{}()\']', '', text)
# Replace commas, dashes, colons and @ with spaces
text = re.sub(r'[;,:-@#]', ' ', text)
我们可以根据需要做更多的预处理,比如把缩写改成全称,用__NUMBER__ token 代替数字等等。上图中,我把句号改成了一个__PERIOD__,它可以作为训练的标志。理解句子中单词上下文的动态变化是很重要的,而__PERIOD__将帮助我们做到这一点。
接下来,让我们创建两个散列表,我们可以使用它们从索引>词汇以及词汇>索引中查找词汇。
下面的代码可以做到这一点:
word_counts = Counter(words)
sorted_vocab = sorted(word_counts, key=word_counts.get, reverse=True)
int_to_vocab = {ii: word for ii, word in enumerate(sorted_vocab)}
vocab_to_int = {word: ii for ii, word in int_to_vocab.items()}
7.执行二次采样 经常出现的单词,如“the”、“is”等,对于为附近的单词提供上下文来说不是很有用。如果我们删除所有这些信息,我们就有效地删除了他们提供的任何信息。Mikolov 等人提出的一种更好的方法是删除一些单词,以消除数据中的一些噪声。对于训练集中的每个单词,我们以概率丢弃它:

Probability to discard words to reduce noise
其中 t 是阈值参数,f(w)是单词 w 的频率。
8.创建张量流图
我总是很难想象单词嵌入和数学是如何工作的。我发现吴恩达的解释在理解数学方面非常有用,下面是我们试图用 TensorFlow 做的工作流程(假设一个单词向量有 300 个维度,词汇表有 100,000 个独特的单词):

The 3 steps in training word embeddings — we only care about embedding matrix
输入的单词作为一个热点向量传递到一个隐藏的线性单元层。这些然后被连接到用于预测上下文单词的软最大层。换句话说,给定每个单词,我们将尝试最小化预测邻居或上下文单词的损失。我们最终可以扔掉 soft-max 层权重,只使用我们构建的单词向量的嵌入矩阵——这些单词向量是单词的低维表示,同时保留了上下文!
Chris McCormick 的博客是下图的灵感来源,该图是上图的另一个视图:

Visualizing the neural network of word embeddings
TensorFlow 使用数据流图来计算深度学习操作,我们需要首先定义图,然后在一个会话中在这个图上运行我们的数据。
让我们浏览一下这段代码:
import tensorflow as tf
train_graph = tf.Graph() # Placeholders for our training data
with train_graph.as_default():
inputs = tf.placeholder(tf.int32, [None], name='inputs')
labels = tf.placeholder(tf.int32, [None, None], name='labels')n_vocab = len(int_to_vocab)
n_embedding = 300 # Number of embedding features# Embedding matrix that we care about
with train_graph.as_default():
embedding = tf.Variable(tf.random_uniform((n_vocab, n_embedding), -1, 1))
word_vector = tf.nn.embedding_lookup(embedding, inputs)
首先我们定义图中的placeholders的inputs和labels。接下来,我们使用Variable来定义我们想要训练的内容。这个讨论对他们的区别很好。我们使用一个feed_dict将值输入到占位符中。我们的total vocabulary size x number of embedding dimensions给出了我们需要训练的总重量。
接下来,我们可以定义 softmax 权重和偏差:
# Softmax layer that we use for training but don't care about
with train_graph.as_default():
softmax_w = tf.Variable(tf.truncated_normal((n_vocab, n_embedding), stddev=0.1))
softmax_b = tf.Variable(tf.zeros(n_vocab))
9。负采样和损失函数 我们准备了一组单词和上下文单词,它们是正示例。但是我们也会添加一些单词和非上下文单词。这些将作为反面的例子。所以orange juice是正面例子,但orange book和orange king也是反面例子。这使得向量的学习更好。对于每个正面的例子,我们可以选择 2 到 20 个反面的例子。这被称为负采样,TensorFlow 为此提供了一个函数[tf.nn.sampled_softmax_loss](https://www.tensorflow.org/api_docs/python/tf/nn/sampled_softmax_loss)!
我们已经写好了整个图表,我们需要写损失函数是什么,以及如何优化权重。
with train_graph.as_default():
loss = tf.nn.sampled_softmax_loss(softmax_w, softmax_b,
labels, word_vector,
n_sampled, n_vocab)
cost = tf.reduce_mean(loss)
optimizer = tf.train.AdamOptimizer().minimize(cost)
10。运行 TensorFlow 会话来训练单词嵌入 写出图形和损失函数以及优化器后,我们可以编写 TensorFlow 会话来训练单词嵌入。
**with** tf.Session(graph=train_graph) **as** sess:
loss = 0
sess.run(tf.global_variables_initializer())
**for** e **in** range(1, 11): # Run for 10 epochs
batches = get_batches(train_words, batch_size, window_size)
**for** x, y **in** batches:
train_loss, _ = sess.run([cost, optimizer], feed_dict= {inputs: x, labels: np.array(y)[:, **None**]})
loss += train_loss
get_batches此处未显示函数,但它在笔记本中(在参考文献中)——它批量返回特征和类的生成器。上述步骤在 CPU 上可能需要很长时间,但在 p2.x 实例上运行起来相当快。我能够在几分钟内运行 10 个纪元来训练 100k 单词的单词大小。我们可以使用我们学过的embedding来绘制 T-SNE 图,以形象化地展示上下文是如何被学习的。请注意,T-SNE 图将把我们的 300D 数据缩减到 2D,因此一些上下文将会丢失,但是它保留了许多关于上下文的信息。
from sklearn.manifold import TSNE
tsne = TSNE()
embed_tsne = tsne.fit_transform(embedding[:viz_words, :])
fig, ax = plt.subplots(figsize=(14, 14))
**for** idx **in** range(viz_words):
plt.scatter(*embed_tsne[idx, :], color='steelblue')
plt.annotate(int_to_vocab[idx], (embed_tsne[idx, 0], embed_tsne[idx, 1]), alpha=0.7)
我们还可以使用主成分分析来可视化单词之间的关系,我们预计会发现如下关系:

Visualizing word vectors using PCA from the original Mikolov paper
这使得单词嵌入非常有趣!如果你在一家电子商务公司工作,如果你能开始识别battery size和battery capacity是否是同一件事,这可能会对用户产生巨大的影响,或者如果你在一个酒店预订网站,发现hotel和motel相似可能会产生巨大的影响!因此,在涉及语言的情况下,单词嵌入在改善用户体验方面非常有效。
我也觉得这个话题挺有意思的。我喜欢写作和语言,也喜欢数学和机器学习。词向量在某种程度上是这两个世界之间的桥梁。我刚刚完成了一个关于文本分类的大项目,接下来我会更多地研究这些与单词向量相关的想法!
祝你好运~
我正在创建一个类似主题的新课程,名为
“查询理解技术概述”。
本课程将涵盖信息检索技术、文本挖掘、查询理解技巧和诀窍、提高精确度、召回率和用户点击量的方法。有兴趣的请在这里报名!这种兴趣展示将允许我优先考虑和建立课程。

My new course: Overview of Query Understanding Techniques
如果你有任何问题,给我的 LinkedIn 个人资料留言或者给我发电子邮件到 sanket@omnilence.com。感谢阅读!
参考文献:
a) 吴恩达关于单词嵌入的课程。斯坦福大学 CS224n 曼宁教授的讲座。c)uda city 的深度学习纳米度。
d)我在 Github 上的字矢量笔记本。
如何使用 Spotty 在 AWS Spot 实例上训练深度学习模型?

Spotty 是一个工具,它极大地简化了 AWS 上深度学习模型的训练。
你为什么会❤️这个工具?
- 它使得在 AWS GPU 实例上的培训就像在本地计算机上的培训一样简单
- 它自动管理所有必要的 AWS 资源,包括 ami、卷、快照和 SSH 密钥
- 它使得每个人都可以通过几个命令在 AWS 上训练你的模型
- 它使用 tmux 轻松地将远程进程从 SSH 会话中分离出来
- 通过使用 AWS Spot 实例,它可以为您节省高达 70%的成本
为了展示它是如何工作的,让我们采用一些非平凡的模型,并尝试训练它。我选择了 Tacotron 2 的一个实现。这是谷歌的语音合成系统。
将 Tacotron 2 的存储库克隆到您的计算机上:
git clone https://github.com/Rayhane-mamah/Tacotron-2.git
Docker 图像
码头集装箱内参差不齐的火车模型。因此,我们需要找到一个满足模型需求的公开可用的 Docker 映像,或者用适当的环境创建一个新的 Docker 文件。
Tacotron 的这个实现使用 Python 3 和 TensorFlow,所以我们可以使用 Docker Hub 的官方 Tensorflow 图像。但是这个图像并不满足“requirements.txt”文件中的所有要求。所以我们需要扩展映像,并在其上安装所有必要的库。
将“requirements.txt”文件复制到“docker/requirements-spotty.txt”文件中,并创建包含以下内容的docker/Dockerfile.spotty文件:
这里我们扩展了原始的 TensorFlow 映像,并安装了所有其他需求。当您启动实例时,将自动构建此映像。
参差不齐的配置文件
一旦我们有了 docker 文件,我们就可以编写一个参差不齐的配置文件了。在项目的根目录下创建一个spotty.yaml文件。
在这里你可以找到这个文件的全部内容。它由 4 个部分组成:项目、容器、实例、和脚本。我们一个一个来看。
第一部分:项目
此部分包含以下参数:
**name**: 项目名称。该名称将用于 Spotty 为此项目创建的所有 AWS 资源的名称中。例如,它将用作 EBS 卷的前缀,或者用在帮助将项目代码与实例同步的 S3 存储桶的名称中。**syncFilters**: 同步过滤器。这些过滤器将用于在将项目代码与正在运行的实例同步时跳过一些目录或文件。在上面的例子中,我们忽略了 PyCharm 配置、Git 文件、Python 缓存文件和训练数据。在幕后,Spotty 通过“aws s3 sync”命令使用这些过滤器,因此您可以在这里获得更多关于它们的信息:使用排除和包含过滤器。
第二部分:集装箱
本节描述了项目的 Docker 容器:
**projectDir**: 容器内的一个目录,一旦实例启动,本地项目将被同步到这个目录。确保它是卷装载路径的子目录(见下文)或者与卷装载路径完全匹配,否则,一旦实例停止,对项目代码的所有远程更改都将丢失。**volumeMounts**: 定义 EBS 卷应该挂载到的容器内的目录。EBS 卷本身将在配置文件的instances部分描述。该列表的每个元素描述一个挂载点,其中name参数应该与来自instance部分的相应 EBS 卷相匹配(见下文),而mountPath参数指定一个卷在容器中的目录。**file**:我们之前创建的 Dockerfile 文件的路径。一旦实例启动,Docker 映像将自动构建。作为一种替代方法,您可以在本地构建映像,并将其推送到 Docker Hub ,然后您可以使用**image**参数而不是**file**参数直接指定映像的名称。**ports**:实例应该公开的端口。在上面的例子中,我们打开了 2 个端口:6006 用于 TensorBoard,8888 用于 Jupyter Notebook。
在文档中阅读更多关于其他容器参数的信息。
第 3 节:实例
本节描述了实例及其参数的列表。每个实例包含以下参数:
**name**:实例名称。该名称将用于专门为此实例创建的 AWS 资源的名称中。例如,EBS 卷和 EC2 实例本身。此外,如果在配置文件中有多个实例,这个名称也可以用在 Spotty 命令中。例如,spotty start i1。**provider**:实例的云提供商。目前,Spotty 只支持“ aws ”提供商(亚马逊网络服务),但在不久的将来也会支持谷歌云平台。**parameters**:实例的参数。它们特定于云提供商。请参见下面的 AWS 实例参数。
AWS 实例参数:
**region**:应该启动 Spot 实例的 AWS 区域。**instanceType**:EC2 实例的类型。点击阅读更多关于 AWS GPU 实例的信息。**volumes**:应该附加到实例的 EBS 卷列表。要将一个卷附加到容器的文件系统,参数name应该匹配来自container部分的一个volumeMounts名称。请参见下面对 EBS 卷参数的描述。**dockerDataRoot**:使用此参数,我们可以更改 Docker 存储所有图像(包括我们构建的图像)的目录。在上面的示例中,我们确保它是连接的 EBS 卷上的一个目录。所以下一次不会再重建图像,而只是从 Docker 缓存中加载。
EBS 音量参数:
**size**:卷的大小,以 GB 为单位。**deletionPolicy**:使用spotty stop命令停止实例后,如何处理卷。可能的值包括:" create_snapshot " (默认), update_snapshot ", retain , delete "。在文档中阅读更多信息:卷和删除策略。**mountDir**:将在实例上安装卷的目录。默认情况下,它将被装载到“/mnt/ < ebs_volume_name >”目录中。在上面的例子中,我们需要为“docker”卷显式指定这个目录,因为我们在dockerDataRoot参数中重用了这个值。
在文档中阅读更多关于其他 AWS 实例参数的信息。
第 4 部分:脚本
脚本是可选的,但是非常有用。可以使用以下命令在实例上运行它们:
spotty run <SCRIPT_NAME>
对于这个项目,我们创建了 4 个脚本:
- 预处理:下载数据集并为训练做准备。
- 训练:开始训练,
- tensorboard :在 6006 端口运行 tensorboard,
- jupyter :启动端口 8888 上的 jupyter 笔记本服务器。
就是这样!该模型已准备好在 AWS 上接受训练。
参差不齐的安装
要求
- Python ≥3.5
- 安装和配置 AWS CLI(参见安装 AWS 命令行界面)
装置
使用 pip 安装 Spotty:
pip install -U spotty
模特培训
1。使用 Docker 容器启动 Spot 实例:
spotty start

一旦实例启动并运行,您将看到它的 IP 地址。以后用它打开 TensorBoard 和 Jupyter 笔记本。
2。下载并预处理 Tacotron 模型的数据。我们在配置文件中已经有了一个自定义脚本来完成这个任务,只需运行:
spotty run preprocess

数据处理完毕后,使用**Ctrl + b**,然后使用**x**组合键关闭 tmux 面板。
3。预处理完成后,训练模型。运行“训练”脚本:
spotty run train

您可以使用**Ctrl + b**,然后使用**d**组合键来分离这个 SSH 会话。训练过程不会中断。要重新连接该会话,只需再次运行spotty run train命令。
张量板
使用“TensorBoard”脚本启动 tensorboard:
spotty run tensorboard
TensorBoard 将在端口 6006 上运行。您可以使用**Ctrl + b**键和**d**组合键分离 SSH 会话,TensorBoard 仍将运行。
Jupyter 笔记本
您也可以使用“Jupyter”脚本启动 Jupyter Notebook:
spotty run jupyter
Jupyter 笔记本将在 8888 端口上运行。使用将在命令输出中看到的实例 IP 地址和令牌打开它。
下载检查点
如果您需要将检查点或任何其他文件从正在运行的实例下载到您的本地机器,只需使用download命令:
spotty download -f 'logs-Tacotron-2/taco_pretrained/*'
SSH 连接
要通过 SSH 连接到正在运行的 Docker 容器,请使用以下命令:
spotty ssh
它使用一个 tmux 会话,因此您可以使用**Ctrl + b**然后使用**d**组合键来分离它,并在以后再次使用spotty ssh命令来附加该会话。
**完成后,不要忘记停止实例!**使用以下命令:
spotty stop

在上面的示例中,我们对卷使用了“保留”删除策略,因此 Spotty 将只终止实例,而不会触及卷。但是,如果我们使用“创建快照”或“更新快照”删除策略,它可以自动创建快照。
结论
使用 Spotty 是在 AWS Spot 实例上训练深度学习模型的一种便捷方式。它不仅可以为您节省高达 70%的成本,还可以节省大量为您的型号和笔记本电脑设置环境的时间。一旦你的模型有了一个参差不齐的配置,每个人都可以用几个命令来训练它。
如果你喜欢这篇文章,请在 GitHub 上启动 项目,点击👏按钮,并与您的朋友分享这篇文章。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
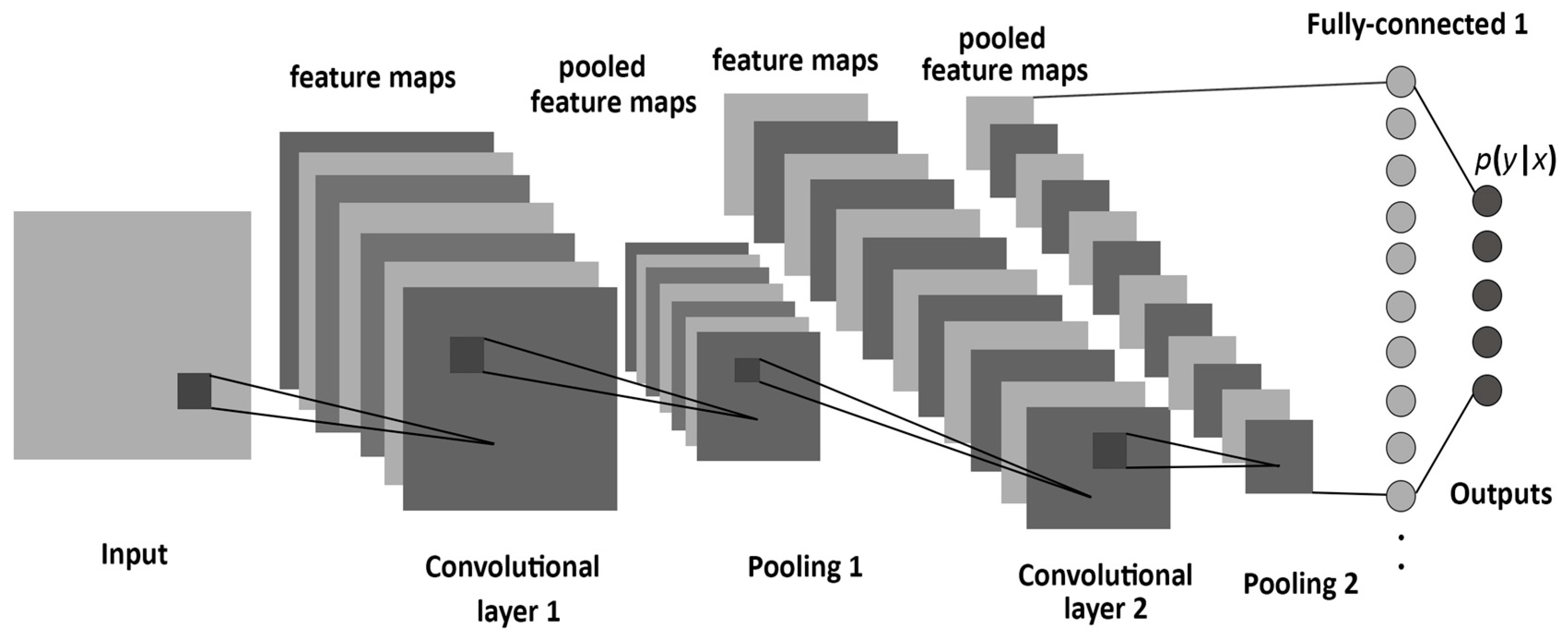{kind=link}
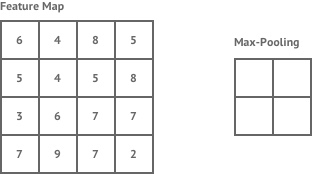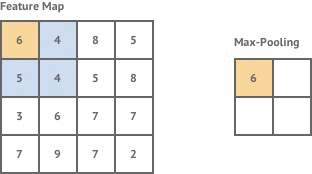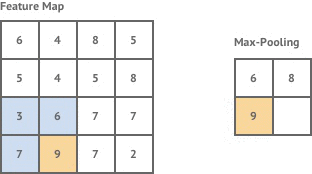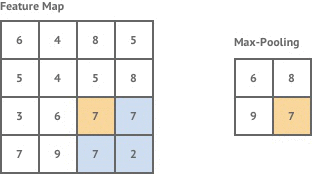{kind=link}