







使用深度学习创建混合内容协作电影推荐器

编剧:亚当·莱恩贝里和 T2 克莱尔·朗格
介绍
在这篇文章中,我们将描述我们如何使用深度学习模型来创建一个利用内容和协作数据的混合推荐系统。这种方法首先分别处理内容和协作数据,然后将两者结合起来产生一个两全其美的系统。
使用 MovieLens 20M 数据集,我们开发了一个项目到项目(电影到电影)推荐系统,它可以推荐与给定输入电影相似的电影。为了创建混合模型,我们将从标签数据中学习基于内容的电影嵌入的自动编码器和从收视率数据中学习基于协作的电影嵌入的深度实体嵌入神经网络的结果进行了集成。
我们提供了内容和协作推荐系统的简要总结,并讨论了混合模型的好处。我们将跟踪不同系统在我们最喜欢的电影之一中的表现:指环王:指环王联盟。
使用 PyTorch 0.4.1 在 Paperspace GPU 机器上执行深度学习工作。这个项目的代码可以在这个 GitHub 库中找到。
协作与内容推荐系统
协作推荐器依赖于用户在与项目交互时生成的数据。这方面的例子包括:
- 用户对电影的评分范围为 1-5
- 用户在在线零售网站上购买甚至查看商品
- 用户对在线音乐流媒体服务上的歌曲表示“赞成”或“反对”
- 在约会网站上向左或向右滑动
在电影推荐器的上下文中,协作过滤器基于评级简档发现相似用户如何对电影进行评级的趋势。可以使用各种技术来分解或处理评级数据,以最终找到用户和电影在共享潜在空间中的嵌入。电影嵌入描述了它们在潜在空间中的位置,然后可以用于进行电影到电影的推荐。
协作数据的一个好处是它总是“自我生成”——用户在与项目交互时自然地为您创建数据。这可能是一个有价值的数据源,尤其是在高质量项目特征不可用或难以获得的情况下。协作过滤器的另一个好处是,它帮助用户发现他们的历史档案所定义的子空间之外的新项目。
然而,协作过滤器也有一些缺点,例如众所周知的冷启动问题。协作过滤器也很难准确地推荐新颖或合适的项目,因为这些项目通常没有足够的用户-项目交互数据。
内容推荐器依靠项目特征来进行推荐。这方面的例子包括:
- 电影上用户生成的标签
- 项目颜色
- 项目的文本描述或用户评论
内容过滤器往往对流行性偏差和冷启动问题更具鲁棒性。他们可以根据小众口味轻松推荐新的或新奇的商品。然而,在项目到项目推荐器中,内容过滤器只能推荐与原始项目具有相似特征的项目。这限制了推荐的范围,也可能导致出现评分较低的项目。
在电影到电影推荐器的环境中,一个协作过滤器回答了这个问题:“什么电影有相似的用户评级简档?”,一个内容过滤器回答这个问题:“什么电影有相似的特征?”。通过创建一个混合推荐器,我们试图创建一个系统来推荐其他用户以类似方式评价的电影,同时仍然基于该电影的特征进行主题推荐。
什么是嵌入?
嵌入是机器学习的几个领域中的一个热门话题,例如自然语言处理、具有分类特征的预测模型和推荐系统。计算嵌入有许多方法,但最终目标是将“事物”映射到一个具有复杂和有意义维度的潜在空间。在电影推荐中,你可以想象潜在的维度来衡量诸如“科幻”和“浪漫”等类型以及诸如“对话驱动与动作包装”等其他概念。用户和电影通过它们与每个维度的关联程度被映射到这个空间。
在著名的 word2vec 例子中,习得的单词嵌入能够完成“男人对女人就像国王对 ___”的类比如下图所示,单词已经被映射到一个共享的潜在空间中,单词的意思以几何形式呈现。

Visualize Word Vectors (https://www.tensorflow.org/images/linear-relationships.png)
在机器学习和深度学习的情况下,人们可以选择使用一键编码(OHE)或学习嵌入来执行特定的任务。数据的 OHE 表示法有一个潜在的不良特性,即每一项都与所有其他项正交(因此在数量上完全不同)。当以单词为例时,这可能是数据的弱表示,因为类似单词如“alien”和“外星人”的相似性/可交换性由于正交性而完全丧失。因此,使用单词嵌入可以扩展某些模型的功能。
余弦相似性
我们使用余弦相似度来量化电影之间的相似性。余弦相似度的范围从-1 到 1,计算方法是两个向量之间的点积除以它们的大小。

Equation for calculating cosine similarity between two vectors
简而言之,指向相同方向的电影嵌入向量将获得高余弦相似性分数。这个想法是,通过潜在的概念空间的方向抓住了电影的本质。一个简单的例子来帮助形象化这一点:如果“科幻”和“浪漫”是潜在空间中的维度,那么科幻与浪漫比例相似的电影将指向相同的方向,从而获得高余弦相似性分数。

2D Visualization of vectors arranged in different ways and the resulting cosine similarities
这段代码从电影嵌入中构造余弦相似矩阵,并输出给定输入电影的前 n 个最相似的电影。
从内容数据中寻找电影嵌入
MovieLens 数据中包括一组大约 50 万个用户生成的电影标签。根据 MovieLens 的自述文件:“每个标签通常是一个单词或短语。特定标签的含义、价值和用途由每个用户决定。”
这些数据按电影分组,标签连接在一起,产生一个文档集。在这个语料库中,文档是特定电影的所有标签的组合。下面是“指环王:指环王联盟”标签文档的摘录。正如你所看到的,像“冒险”、“幻想”和“根据一本书”这样的词/短语频繁出现。这些数据还包括演员和作者的名字。
adventure characters epic fantasy world fighting photography Action adventure atmospheric based on a book based on book beautifully filmed ensemble cast fantasy fantasy world high fantasy imdb top 250 magic music nature nothing at all Oscar (Best Cinematography) Oscar (Best Effects - Visual Effects) scenic stylized Tolkien wizards adventure atmospheric ensemble cast fantasy fantasy world magic stylized wizards Watched adapted from:book author:J. R. R. Tolkein based on book epic fantasy middle earth faithful to book fantasy good versus evil high fantasy joseph campbell's study of mythology influenced magic atmospheric boring high fantasy Action adventure atmospheric based on a book beautifully filmed fantasy high fantasy magic music mythology romance stylized time travel Viggo Mortensen wizards Peter Jackson Peter Jackson music must see Tolkien high fantasy Myth Tolkien wizards Ian McKellen bast background universe
接下来,我们将标记文档转换为词频——逆文档频率(TF-IDF)表示。TF-IDF 将非结构化文本数据标记为数字特征,这些数字特征更容易被机器学习算法处理。粗略地说,文档中每个术语的出现频率取决于包含该术语的文档数量。结果,区分电影的词(例如,“外星人”、“幻想”)将比用于描述所有电影的词(例如,“电影”、“演员”)具有更高的权重。
sci-kit learn 中的 TF-IDF 矢量器允许您选择要考虑的 ngrams 范围。对于这个项目,我们发现 unigrams 是足够的,同时仍然保持我们的一些功能是可管理的。
在 TF-IDF 空间中,每个维度都代表了某个词对一部电影有多重要。这种表示不太理想,因为单个概念(例如,外星人/外星人)的编码是碎片化的,并且分散在多个维度上。我们希望将 TF-IDF 数据压缩到一个低维空间中,在这里概念被整合到共享维度中。在压缩的空间中,希望每个维度将代表复杂和健壮的概念。
为了执行压缩,我们选择使用自动编码器。自动编码器是输出与输入相同的神经网络。在我们的架构中(如下图所示),高维的 TF-IDF 输入被逐渐压缩成 100 维的中央隐层。网络的前半部分是“编码器”。网络的另一半,即“解码器”,试图重建原始输入。通过设置均方误差损失函数并执行反向传播,网络(尤其是编码器)学习一个函数,该函数将数据映射到较低维度的空间中,从而保留大部分信息。

Autoencoder Architecture
让我们从定义编码器和解码器网络开始。它们是单独定义的,以便在网络训练完成后易于对数据进行编码。
接下来,让我们定义一个 PyTorch 数据集类。注意在__getitem__方法中x和y是等价的——这是自动编码器的基本概念。
有了这些构建块,让我们定义一个包装器类,它实例化一切,处理训练循环,并执行数据编码。
从这里开始,训练自动编码器和编码/压缩数据就很简单了:
下面是训练和验证损失随时间变化的曲线图。如您所见,该模型没有过度拟合或拟合不足,最终损耗收敛到一个非常低的值(大约 1e-4)。

使用自动编码器学习的基于内容的电影嵌入,按照余弦相似性的定义,与“指环王:指环王”最相似的前 20 部电影如下所示。
从协作数据中发现电影嵌入
完全连接的神经网络用于寻找电影和用户嵌入。在该架构中,大小为(n_users, n_factors)的用户嵌入矩阵和大小为(n_movies, n_factors)的电影嵌入矩阵被随机初始化,随后通过梯度下降学习。每个训练数据点都是一个用户索引、电影索引和一个评级(等级为 1-5)。用户和电影索引用于查找嵌入向量(嵌入矩阵的行)。这些向量然后被连接并作为输入传递给神经网络。

Embedding Net Architecture
这类似于杰瑞米·霍华德在 fast.ai MOOC 中教授的技术,我们也使用了 fastai 库。让我们读入数据,创建一个验证集,并构造一个 fastai ColumnarModelData 对象,它本质上是 PyTorch 的 Dataset 和 DataLoader 类的一个方便的包装器。
接下来,我们来定义一下神经网络。由于网络的输出被限制在 1–5 范围内,因此在输出层使用了一个缩放的 sigmoid 激活函数。通过 sigmoid 传递线性激活给了模型更多的灵活性,从而使其更容易训练。例如,如果模型试图输出一个 5,而不是强迫它从线性计算中输出一个非常接近 5 的值,使用 sigmoid 允许它输出任何高值(因为输入~6 或更大值都被 sigmoid 函数映射到~1.0)。另一种方法是在没有达到 sigmoid 时停止,让模型学习直接从线性输出中输出正确的评级。
fastai 库使得拟合模型变得非常简单。这里使用的fit函数负责训练循环,并提供一个漂亮的动画状态栏,显示每个迷你批次的剩余时间和损失值。
由于训练数据的规模很大(2000 万),该模型需要一段时间来训练。在整个训练的不同阶段,我们调整了辍学水平,以应对过度或不足。学习率也可以使用 fastai 库中的学习率查找工具中的信息进行定期调整:
在学习率查找程序中,学习率最初被设置为非常小的值(1e-5),并且在一个时期的过程中被迭代地增加,直到高的上限值(10)。在每个阶段,损失都被记录下来,这样就可以绘制出如下图。解释这个图是一个启发式的过程,在 fastai 课程中有更详细的解释,但要点是:选择一个学习率,在这个学习率上,损失仍在快速减少,尚未稳定下来。在这种情况下,选择 1e-2 将是合理的选择。

对于这种规模的数据集(以及相关的长训练时间),您可能需要保持和依赖已训练模型的能力,以便可以在以后继续训练。完成后,您还需要将学习到的嵌入保存到磁盘,以便进行后期处理。下面的代码将处理这些项目。
一旦网络得到了令人满意的训练,你将拥有健壮的电影和用户嵌入,随时可以用于各种实际任务。使用由该神经网络学习的基于协作的电影嵌入,由余弦相似性定义的与“指环王:指环王”最相似的前 20 部电影如下所示。
将这一切结合在一起
如上所述,《指环王》的合作推荐似乎主要是受欢迎和高度评价的大片,具有强烈的动作和冒险主题。内容推荐似乎受受欢迎程度的影响较小,可能包括一些奇幻类的隐藏宝石。
为了集成来自内容和协作模型的结果,我们简单地对余弦相似性进行平均。通过集合协作和基于内容的结果,我们能够提出有希望从两种方法的优势中吸取的建议。以下是《指环王》的合集推荐。
结论
在这篇文章中,我们开发了一个电影到电影的混合内容协作推荐系统。我们讨论并举例说明了基于内容和协作的方法的优缺点。我们还展示了如何使用深度学习而不是传统的矩阵分解方法来开发推荐系统。
在我们的观察中,协作过滤器擅长跨越不同类型的差距,并持续推荐高评级的电影。内容过滤器善于识别非常相似的风格(例如,以中世纪为背景的魔法王国)和较少观看的、潜在隐藏的宝石电影。混合方法的目的是结合两种系统的优势。
我们还找到了一些我们想看的电影!如果你想看你选择的特定电影的推荐,请随时在 Twitter、LinkedIn 或电子邮件上联系。


Adam 是丹佛的一名数据科学家,对深度学习、大数据、一级方程式赛车和滑雪感兴趣。
Claire 是丹佛的一名数据科学家,在时尚行业工作。她的研究兴趣是推荐系统。
使用卷积神经网络创建电影推荐器
在网飞上看完你最喜欢的电视剧或 YouTube 上的视频后,你必须做出一个重要的决定,接下来我该看什么?很多时候你都是从自己喜欢的视频点播平台的推荐系统得到一些帮助。这些平台花费大量的时间和精力(参见:网飞推荐系统:算法、商业价值和创新 & 用于 YouTube 推荐的深度神经网络)让你的用户体验尽可能愉快,增加你在平台上的总观看时间。但是即使有这些帮助,你如何选择呢?我通常会选择最吸引我的视频缩略图/海报。考虑到这一点,我构建了一个电影推荐器,它只接受电影缩略图/海报作为输入。让我们看看那是什么样子。
主旨
主要思想是创建电影海报图像数据集,并从在 ImageNet 上训练的预训练卷积神经网络 (ConvNet)中提取特征。我将使用提取的特征来推荐给定目标电影海报的 5 个最相似的电影海报。为了验证这种方法,我将使用鞋子图像数据集做同样的事情。
第一步:网络抓取电影海报
首先我需要一些电影海报,我决定使用 Kaggle 上的 TMDB 5000 电影数据集。有了数据集中提供的信息,我使用 web scraping 通过 Python 库 BeautifulSoup 从 IMDB 下载海报图像。我将海报 id 添加到每张图片的名称中,并将所有 4911 张成功下载的图片存储在一个文件夹中。

Image from: https://www.kaggle.com/tmdb/tmdb-movie-metadata/data
这就是完整的 WebScraping.ipynb 笔记本。
第二步:推荐人
我对基于海报图像的视觉方面寻找类似的电影海报感兴趣,因此我将使用 ConvNets。就视觉识别而言,ConvNets 目前是首选型号。对于我的推荐者,我不会从零开始训练一个 ConvNet。但是在 ImageNet 上使用预先训练好的模型。从而节省时间并具有开箱即用的最新模型。这就叫“迁移学习”。推荐者我会用 Inception-v3 模型。选择这种型号的原因之一是与 VGG16 或 VGG19 型号相比,输出阵列相对较小。使得处理内存中的所有内容变得更加容易。我感兴趣的是模型学习的特征,而不是类别概率。识别形状、图案等的预学习层。希望能提出有意义的建议。出于这个原因,我删除了输出层,并将 ConvNet 的其余部分作为电影海报的特征提取器。请参见此处的示例,了解每个图层或节点基于面部图像数据集可以了解的内容。

Image from: https://cdn.edureka.co/blog/wp-content/uploads/2017/05/Deep-Neural-Network-What-is-Deep-Learning-Edureka.png
对于推荐器的实现,我使用带有 TensorFlow 的 Keras 作为后端。对于数据集中的每个图像,我保存模型最后一个隐藏层的展平输出数组。有了这个新的特征数组,我可以根据数组之间的欧氏距离来计算目标图像/海报的 x 个最近邻。为了将结果与基线进行比较,我还将使用给定目标海报的原始展平图像数组显示 x 个最近邻。我不会分享我所有的代码,但会在这个博客中分享一些代码片段。
选择模型特征图层:
from keras.models import Model
from keras.applications.inception_v3 import InceptionV3
from keras.models import Modelselectedlayer = "..."
base_modelv3 = InceptionV3(weights='imagenet', include_top=False)
model= Model(inputs=base_modelv3.input, outputs=base_modelv3.get_layer(selectedlayer).output)
从图像中提取特征:
from os import listdir
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_arraydef preprocess_input(x):
x /= 255.
x -= 0.5
x *= 2.
return xdef load_photos_predict(directory):
images = []
for name in listdir(directory):
# load an image from file
filename = directory + '/' + name
image = load_img(filename, target_size=(299, 299))
# convert the image pixels to a numpy array
image = img_to_array(image)
# reshape data for the model
image = np.expand_dims(image, axis=0)
# prepare the image for the model
image = preprocess_input(image)
# get image id
image_id = name.split('.')[0]
feature = model.predict(image).ravel()
images.append((image_id, image, feature))
return images
查找最近邻居:
from sklearn.neighbors import NearestNeighbors
import pandas as pd
import numpynn_num = 6
X = list(results[“modelfeatures”])nbrs = NearestNeighbors(n_neighbors=nn_num, algorithm=’ball_tree’, metric=”euclidean”, n_jobs = -1).fit(X)
第三步:结果
让我们来看看基于詹姆斯·邦德电影《幽灵》的推荐。我将展示基于原始展平图像阵列的 5 个推荐,以及基于 Inception-v3 模型的提取特征阵列的 5 个推荐。

Recommender based on raw image array vs ConvNet features for James Bond — Specter
尽管我没有定义明确的评估标准,也没有利用 A/B 测试来确定哪种推荐方法是最好的,但直觉上,模型结果似乎稍好一些。该模型甚至推荐了一部额外的邦德电影《永不说永不》作为它的第四个推荐。让我们再看一部电影,印第安纳琼斯和水晶头骨王国。

Recommender based on raw image array vs ConvNet features for Indiana Jones and the Kingdom of the Crystal Skull
该模型推荐印第安纳琼斯和最后的十字军东征作为其第一推荐,这看起来很好。其他的就不太合适了,但是 ConvNet 特性的表现似乎又比只使用原始图像数组作为输入要好。
显示结果功能:
import matplotlib.pyplot as pltdef udfsimular(indices, table):
neighbours = []
for i in range(len(indices)):
t = indices[i]
idv = table[(table.index == t)].iloc[0][‘ID’]
neighbours.append(idv)
return neighboursdef udfidfpathh(ids,directory):
paths = []
for i in range(len(ids)):
t = ids[i]
filename = wdir + directory + t + “.jpg”
paths.append(filename)
return pathsdef show5recommendations(name, table, NearestN, idnr, directory, columnfeature):
key = table[(table.ID == idnr)].iloc[0][columnfeature]
distances, indices = NearestN.kneighbors(key)
listindices = pd.DataFrame(indices).values.tolist()
listindices2 = listindices[0]
ids = udfsimular(listindices2, table)
paths2 = udfidfpathh(ids,directory)
fig, ((ax1, ax2, ax3, ax4, ax5, ax6)) = plt.subplots(nrows=1, ncols=6, sharex=True, sharey=True, figsize=(14,3))
# Doing each of these manually (ugh)
ax1.imshow(mpimg.imread(paths2[0]))
ax1.set_title(r"$\bf{" + str(name) + "}$"+"\n Targer:\n"+ ids[0])
ax1.set_yticklabels([])
ax2.imshow(mpimg.imread(paths2[1]))
ax2.set_title("Rec 1:\n"+ ids[1])
ax3.imshow(mpimg.imread(paths2[2]))
ax3.set_title("Rec 2:\n"+ ids[2])
ax4.imshow(mpimg.imread(paths2[3]))
ax4.set_title("Rec 3:\n"+ ids[3])
ax5.imshow(mpimg.imread(paths2[4]))
ax5.set_title("Rec 4:\n"+ ids[4])
ax6.imshow(mpimg.imread(paths2[5]))
ax6.set_title("Rec 5:\n"+ ids[5])
步骤 4:使用鞋子图像验证推荐器
既然我们已经看到了它对电影海报的效果,让我们使用一个不同的数据集。像亚马逊、Zalando 和其他网上商店这样的网站使用类似的技术向你推荐产品。例如,你要找的商品缺货,他们想向你推荐类似的产品。所以让我们用鞋的图像。我使用的数据集是从 Zappos50K 的收集的目录图像的 UT Zappos50K 。我用了 1882 张鞋子图片。
因此,让我们在这个数据集上重复同样的方法,看看“黑色开口高跟鞋”的结果是什么:

Recommender based on raw image array vs ConvNet features for a black open high heel shoe
基于提取的特征,模型显然学会了区分鞋子的不同图案。而正常阵列的建议显然不知道什么是开鞋。运动鞋怎么样:

Recommender based on raw image array vs ConvNet features for a sneaker shoe
再次推荐。
那么,为什么这些结果比电影海报的结果要好呢?
Inception-v3 模型在 ImageNet 上进行训练,以区分 1000 个类预测。模型被训练的图像每个图像有一个对象/类。它接受训练的 1000 个班级中有一个甚至被称为“跑鞋”。预测每个图像的一个对象是模型被训练的目的,也应该是模型做得最好的。而电影海报在对象、文本等的数量上要复杂得多。因此,使用在不同图像数据集上训练的模型可以为电影海报产生更好的结果。
最后备注
正如我们所看到的,仅使用电影海报结合预先训练的 ConvNets 来创建电影推荐器确实会产生一些不错的推荐。结果略好于仅使用原始图像阵列。对于鞋子,这种方法已经显示了一些非常好的建议。看到 ConvNets 的纯视觉识别功能已经可以做什么是很有趣的。根据推荐器创建的预期目的或行业,这似乎是一个很好的附加功能,可以添加到用于开发最先进的推荐系统的功能集中。
在 Python 中使用 Tinn(C 语言中的微型神经网络)
使用 Python 和 ctypes 调用 Tinn(一个 200 行 c 语言的微型神经网络)的指南

Image by Author
在 SensiML 我们专注于构建机器学习工具,使开发人员能够轻松创建训练有素的模型并将其部署到嵌入式物联网设备上。在这篇文章中,我将向您展示如何将 Tinn(一个用标准 C 编写的微型神经网络)转换成一个共享库,然后从 Python 中调用它,就像它是一个原生 Python 函数一样。我们在 SensiML 使用这种方法来试验和构建面向嵌入式设备的 C 库,同时仍然在本地使用我们的 Python 数据科学工具包。
第一步。去下载 Tinn
如果你要完成这个教程,你需要 Tinn。可以从 GitHub 下载 Tinn。
如果您安装了 git,
git clone [https://github.com/glouw/tinn.git](https://github.com/glouw/tinn.git)
或者,访问该网站并通过单击克隆或下载它,然后选择下载 zip 文件来下载它。
第二步。将 Tinn 编译成共享库
为了调用 Tinn 函数,我们必须创建一个共享库。我已经创建了一个 makefile 来将 Tinn 库编译成一个共享库,你可以在这里找到它。用提供的文件替换 Tinn 文件夹中的 make 文件,将 cd 放入终端中的 Tinn 文件夹,然后运行 make。
cd tinnmake>>cc -std=c99 -fPIC -fno-builtin -Werror -I../include -I. -c -o >>Tinn.o Tinn.c
>>making lib
>>ar rcs /Users/chrisknorowski/Software/tinn/libtinn.so Tinn.o
>>cc -shared -Wl,-o libtinn.so *.o
(注意:这是为 Linux/OSX 写的,如果你在 windows 上使用 ubuntu bash shell 来编译)
如果一切正常,目录中应该已经创建了一个名为 libtinn.so 的共享库文件。我们将在下一步中链接到这个共享库,以便直接调用这些函数。
第三步。使用 cTypes 创建 Python 接口
让我们首先看看 Tinn.h 文件,看看我们需要从 python 调用哪些函数。
我们将创建的第一个 python 接口是 Tinn 结构。我们可以使用 ctypes 做到这一点。结构类。该结构有两个属性需要填写, slots 和 fields 。slots 让我们将属性分配给 struct_tinn 类。fields 让我们描述每个变量使用哪种类型。
下面你可以看到 python Tinn struct 类,我称之为 struct_tinn 。使用 ctypes,我们可以指定 struct_tinn 中的所有变量类型,在本例中,是整数和指向浮点数组的指针。
既然我们已经创建了 Tinn 结构的 python 表示,我们需要导入并创建我们想要调用的 c 函数的 python 表示。对于本教程,它们是
有了这三个函数,我们将能够使用 Tinn 库进行初始化、训练和预测。接下来,我们使用 ctyles。CDLL 来导入我们在本教程的步骤 2 中创建的共享库。
对于我们想要调用的每个函数,我们必须将函数的输入和输出类型指定为 python ctypes。我们通过设置 cf_lib 函数的 argtypes 和 restype 属性来实现这一点。
第四步。使用 Python 训练 Tinn NN 识别数字
至此,我们已经创建了能够从 python 调用 Tinn 所需的所有 python 包装器对象。为了使用神经网络,我们仍然需要为 python 编写初始化、训练和预测方法。
让我们从用一组参数初始化 Tinn 对象的函数开始。我们将调用这个 init_tinn 并在我们的 nn 中传递我们想要的输入数、输出数和隐藏层数。
在这里你可以看到,在将所有的输入传递给 xtbuild 函数之前,我们将它们转换为 ctypes。现在可以通过调用我们的 python 函数来初始化 Tinn 对象。
Tinn = init_tinn(64,10,128)
因为它是一个 python 对象,所以我们可以动态地索引所有的 Tinn 属性。
Tinn.weights[0]
>> 0.15275835990905762
Tinn.biases[0]
>> -0.30305397510528564
接下来,让我们构建训练和预测函数。我们的 train 函数将接受 Tinn 对象、X 数字的数组、y 目标以及训练步长α。
预测函数将接受已定型的 Tinn 对象和要识别的输入向量,从 nn 返回具有最高可信度的预测值。
最后,让我们在标准的数据科学工作流中使用 python Tinn 函数来识别手写数字。我们将从 sklearn 导入数字数据,然后创建一个 80/20 分割的标准训练测试数据集。为了好玩,我们还循环学习率,看看什么样的学习率最适合这个数据集。最后,做一些预测来检验模型的准确性。
alpha: 0.1
precision recall f1-score support
0 1.00 0.94 0.97 17
1 0.80 0.73 0.76 11
2 0.88 0.88 0.88 17
3 0.71 0.71 0.71 17
4 0.84 0.84 0.84 25
5 1.00 0.95 0.98 22
6 0.95 1.00 0.97 19
7 0.94 0.84 0.89 19
8 0.55 0.75 0.63 8
9 0.81 0.84 0.82 25
avg / total 0.87 0.86 0.86 180

Image by author
总结
这篇博文到此结束。我们已经讨论了如何创建一个共享的 c 库,如何使用 ctypes 在 python 中实例化 c 结构和 c 函数。然后,我们使用 python shell 中的调用来初始化和训练 Tinn NN 模型。我希望你喜欢这个教程,如果你有任何问题,请随时给我留言或评论。如果您有兴趣为物联网设备构建智能传感器算法,并希望在传感器本地运行推理,请联系我们或访问我们的网站了解更多信息。
使用 TensorFlow 创建拼写检查

Soon typos will be a thing of the past!
机器学习最重要的一个方面是处理好干净的数据。自然语言进展项目存在使用人类书写的文本的问题,不幸的是,我们不擅长书写。想想在 Reddit 的帖子和评论数据集中会有多少拼写错误。出于这个原因,我认为一个非常有价值的项目是做一个拼写检查器,这将有助于缓解这些问题。
我们将在这个项目中使用的模型非常类似于我在我的文章“使用亚马逊评论的文本摘要”(两者都是 seq2seq 模型)中所写的模型,但是我添加了一些额外的代码行,以便可以使用网格搜索来调整架构和超参数,并且可以使用 TensorBoard 来分析结果。如果你想更详细地了解如何将 TensorBoard 添加到你的代码中,那么看看“用 TensorFlow 和 TensorBoard 预测电影评论情绪”。
本文的主要焦点将是如何为模型准备数据,我还将讨论模型的其他一些特性。我们将在这个项目中使用 Python 3 和 TensorFlow 1.1。数据由来自古腾堡计划的二十本流行书籍组成。如果你有兴趣扩大这个项目,使它更加准确,有数百本书可以在古腾堡项目上下载。另外,看看用这个模型可以做多好的拼写检查也是很有趣的。
查看完整代码,这里是其 GitHub 页面 。
为了让您预览这种模式的能力,这里有一些精选的示例:
- 拼写 比较难,whch就是wyh你需要每天学习。
- 拼写难,哪个是为什么你需要每天学习。
- 她在thcountryvrey为多莉卖命。
- 对多莉来说,她在 T4 这个国家的最初几天非常艰难。
- Thi 真是了不起impression ivthaat我们应该马上调查一下!**
- 这个确实是令人印象深刻的我们应该马上调查一下**!
为了让事情更有条理,我把所有我们会用到的书都放在他们自己的文件夹里,叫做“书”。下面是我们将用来加载所有书籍的函数:
***def load_book(path):
input_file = os.path.join(path)
with open(input_file) as f:
book = f.read()
return book***
我们还需要每本书的唯一文件名。
***path = './books/'
book_files = [f for f in listdir(path) if isfile(join(path, f))]
book_files = book_files[1:]***
当我们将这两个代码块放在一起时,我们将能够将所有书籍中的文本加载到一个列表中。
***books = []
for book in book_files:
books.append(load_book(path+book))***
如果您想知道每本书有多少单词,您可以使用以下代码行:
***for i in range(len(books)):
print("There are {} words in {}.".format(len(books[i].split()), book_files[i]))***
注:如果不包含 .split() ,则返回每本书的人物数量。
清理这些书的正文相当简单。因为我们将使用字符而不是单词作为模型的输入,所以我们不需要担心删除停用的单词,或者将单词缩短到它们的词干。我们只需要删除不想包含的字符和多余的空格。
***def clean_text(text):
'''Remove unwanted characters and extra spaces from the text'''
text = re.sub(r'\n', ' ', text)
text = re.sub(r'[{}[@_](http://twitter.com/_)*>()\\#%+=\[\]]','', text)
text = re.sub('a0','', text)
text = re.sub('\'92t','\'t', text)
text = re.sub('\'92s','\'s', text)
text = re.sub('\'92m','\'m', text)
text = re.sub('\'92ll','\'ll', text)
text = re.sub('\'91','', text)
text = re.sub('\'92','', text)
text = re.sub('\'93','', text)
text = re.sub('\'94','', text)
text = re.sub('\.','. ', text)
text = re.sub('\!','! ', text)
text = re.sub('\?','? ', text)
text = re.sub(' +',' ', text) # Removes extra spaces
return text***
我将跳过如何制作vocab_to_int和int_to_vocab字典,因为这是非常标准的东西,你可以在这个项目的 GitHub 页面上找到。但是,我认为有必要向您展示输入数据中包含的字符:
***The vocabulary contains 78 characters.
[' ', '!', '"', '$', '&', "'", ',', '-', '.', '/', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', ':', ';', '<EOS>', '<GO>', '<PAD>', '?', 'A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u', 'v', 'w', 'x', 'y', 'z']***
我们可以删除更多的特殊字符,或者让文本全部小写,但是我想让这个拼写检查器尽可能有用。
数据在输入模型之前会被组织成句子。我们将拆分每个时间段的数据,每个时间段后面跟一个空格(“.”).其中一个问题是,有些句子以问号或感叹号结尾,但我们没有考虑到这一点。幸运的是,我们的模型仍然能够学习问号和感叹号的用法,只要这两个句子加起来没有最大句子长度长。
仅举一个例子:
- 今天是美好的一天。我想去海滩。(这将被分成两个输入句子)**
- 今天天气好吗?我想去海滩。(这将是一个长输入句子)**
***sentences = []
for book in clean_books:
for sentence in book.split('. '):
sentences.append(sentence + '.')***
我在 loydhub.com 的 T2 使用 GPU 来训练我的模型(我强烈推荐他们的服务),这为我节省了几个小时的训练时间。尽管如此,为了正确地调优这个模型,仍然需要 30-60 分钟来运行一次迭代,这就是为什么我限制了数据,以便它不需要更长的时间。这当然会降低我们模型的准确性,但由于这只是个人项目,所以我不介意权衡。
***max_length = 92
min_length = 10good_sentences = []for sentence in int_sentences:
if len(sentence) <= max_length and len(sentence) >= min_length:
good_sentences.append(sentence)***
为了跟踪这个模型的性能,我将把数据分成训练集和测试集。测试集将由 15%的数据组成。
***training, testing = train_test_split(good_sentences,
test_size = 0.15,
random_state = 2)***
就像我最近的一些项目一样,我将按长度对数据进行排序。这导致一批句子的长度相似,因此使用较少的填充,并且模型将训练得更快。
***training_sorted = []
testing_sorted = []for i in range(min_length, max_length+1):
for sentence in training:
if len(sentence) == i:
training_sorted.append(sentence)
for sentence in testing:
if len(sentence) == i:
testing_sorted.append(sentence)***
也许这个项目最有趣/最重要的部分是将句子转换成有错误的句子的功能,这些句子将被用作输入数据。在这个函数中,错误以三种方式之一产生:
- 两个字符的顺序将被交换(hlelo ~hello)
- 会多加一个字母(heljlo ~ hello)
- 一个字符不会打(helo ~hello)
三个错误中任何一个发生的可能性都是相等的,任何一个错误发生的可能性都是 5%。因此,平均每 20 个字符中就有一个包含错误。
***letters = ['a','b','c','d','e','f','g','h','i','j','k','l','m',
'n','o','p','q','r','s','t','u','v','w','x','y','z',]def noise_maker(sentence, threshold):
noisy_sentence = []
i = 0
while i < len(sentence):
random = np.random.uniform(0,1,1)
if random < threshold:
noisy_sentence.append(sentence[i])
else:
new_random = np.random.uniform(0,1,1)
if new_random > 0.67:
if i == (len(sentence) - 1):
continue
else:
noisy_sentence.append(sentence[i+1])
noisy_sentence.append(sentence[i])
i += 1
elif new_random < 0.33:
random_letter = np.random.choice(letters, 1)[0]
noisy_sentence.append(vocab_to_int[random_letter])
noisy_sentence.append(sentence[i])
else:
pass
i += 1
return noisy_sentence***
本文中我想向您展示的最后一件事是如何创建批处理。通常,人们会在训练他们的模型之前创建他们的输入数据,这意味着他们有固定数量的训练数据。然而,我们将在训练模型时创建新的输入数据,将noise_maker应用于每一批数据。这意味着对于每个时期,目标(正确的)句子将通过noise_maker被反馈,并且应该接收新的输入句子。使用这种方法,从某种稍微夸张的意义上来说,我们拥有无限量的训练数据。
***def get_batches(sentences, batch_size, threshold):
for batch_i in range(0, len(sentences)//batch_size):
start_i = batch_i * batch_size
sentences_batch = sentences[start_i:start_i + batch_size]
sentences_batch_noisy = []
for sentence in sentences_batch:
sentences_batch_noisy.append(
noise_maker(sentence, threshold))
sentences_batch_eos = []
for sentence in sentences_batch:
sentence.append(vocab_to_int['<EOS>'])
sentences_batch_eos.append(sentence)
pad_sentences_batch = np.array(
pad_sentence_batch(sentences_batch_eos))
pad_sentences_noisy_batch = np.array(
pad_sentence_batch(sentences_batch_noisy))
pad_sentences_lengths = []
for sentence in pad_sentences_batch:
pad_sentences_lengths.append(len(sentence))
pad_sentences_noisy_lengths = []
for sentence in pad_sentences_noisy_batch:
pad_sentences_noisy_lengths.append(len(sentence))
yield (pad_sentences_noisy_batch,
pad_sentences_batch,
pad_sentences_noisy_lengths,
pad_sentences_lengths)***
这个项目到此为止!尽管结果令人鼓舞,但这一模式仍有局限性。如果有人能按比例放大这个模型或改进它的设计,我将不胜感激!如果你有,请在评论中发表。新设计的一个想法是应用博览会的新 CNN 模式(它实现了最先进的翻译效果)。
感谢阅读,我希望你学到了新的东西!
从头开始用 Core ML 创建一个 IOS 应用程序!
这个世界需要选择和决断*——Re 创作者动漫。*
在机器学习中,一切都始于模型,即进行预测或识别的系统。教计算机学习涉及一种机器学习算法,该算法具有要学习的训练数据。训练产生的输出通常被称为机器学习模型。有不同类型的机器学习模型解决相同的问题(例如物体识别),但使用不同的算法。神经网络、树集成、支持向量机就是这些机器学习算法中的一些。
机器学习就像一个迭代过程
首先,我们用公共模型进行实验,但是为了带来独特的市场价值和优势,我们希望我们的模型胜过其他模型。我们正在寻找的叫做 ML 反馈回路。Google 对 ML 特性的处理遵循以下模式:
- 获取初始化数据(一次)
- — — — — —
- 标签数据
- 火车模型
- 试验模型
- 在生产中运行模型
- 获取新数据(并重复)
现在,对于一个移动应用程序,这个过程看起来像:

在上图中,移动应用程序似乎使用了 ML 创建的模型,但它是如何工作的呢?是的,这就是核心 ML 发挥作用的地方。
CoreML 怎么用?
核心 ML 是苹果公司的新机器学习框架。它为苹果设备带来了机器学习模型,并使开发人员能够轻松利用 ML。我们可以使用苹果或 c 准备的十几个模型转换来自流行的 ML 框架的开源模型,如 Keras 、 Caffe 或 scikit-learn 。
使用 CoreML 创建 IOS 应用程序的工作流程如下:

1-你需要使用一些 ML 框架创建一个数据模型,比如 Caffe,turi,Keras 等等。
2-为了安装名为 Core ML Tools 的 Python 框架,它将数据模型转换为 Core ML 格式。转换的结果是一个扩展名为 mlmodel 的文件。
3-就是这样,你用核心 ML 工具创建的模型,在你的移动应用程序中使用它。
软件要求
为了训练模型,我们需要一个 ML 框架。最流行的是谷歌开发的 Tensorflow 。它拥有来自社区、教程和大量开发者关注的最好支持。然而,当你更深入一点时,你可能会在 G ithub issue page 或处理一些数学问题或未记录代码的堆栈溢出中结束。与 web 应用程序或移动开发相比,ML 仍然是一个小婴儿,作为开发人员,你需要依赖它。安排一些额外的时间迷失在神秘的 ML 中。从像 Keras 这样的高级库开始也更容易。你可以在文章末尾查看一些培训教程的链接。

Tensorflow and Keras are the most common ML libraries
五金器具
很多人说我们需要一个 GPU 来训练一个模型。对于需要高精度或一些网络架构调整的项目来说,这是事实。如果我们需要 10 个类别的图像分类器,那么我们可以利用迁移学习,在标准 CPU 上在 10 分钟内微调我们的模型。然而,对于真正的生产应用程序,我们通常需要 GPU 的性能。我们已经尝试了几家云提供商,亚马逊 AWS g 2.2x 大型实例是一个不错的选择
开始吧!!
至此,您已经知道了使用机器学习创建 IOS 应用程序所需的必备工具,让我们开始吧!
管道设置:
要使用核心 ML 工具,第一步是在 Mac 上安装 Python。首先,下载 Anaconda (选择 Python 2.7 版本)。Anaconda 是一种在 Mac 上运行 Python 的超级简单的方法,不会引起任何问题。一旦安装了 Anaconda,就进入终端并键入以下内容:
conda install python=2.7.13conda update python
下一步是创建一个虚拟环境。在虚拟环境中,你可以用不同版本的 Python 或者其中的包来编写程序。要创建新的虚拟环境,请键入以下代码行。
conda create --name handwriting
当终端提示您时,
proceed ([y]/n)?
键入“y”表示是。恭喜你。现在,您有了一个名为手写的虚拟环境!
要激活该环境,请使用:source activate handwriting
最后,键入以下命令来安装核心 ML 工具和 Kera 的依赖项:
conda install pandas matplotlib jupyter notebook scipy opencvpip install -U scikit-learn==0.15
pip install -U coremltools
pip install tensorflow==1.1
pip install keras==2.0.6
pip install h5py
设计和培训网络
在这篇文章中,正如你注意到的,我将使用 Kera,就像我们例子中的 ML 框架一样。
好了,你应该创建一个名为train.py的 python 文件。在train.py内插入以下代码:
- 首先让我们导入一些必要的库,并确保 TensorFlow 中的 keras 后端:
**import** numpy as np**import** keras**from** keras.datasets **import** mnist**from** keras.models **import** Sequential**from** keras.layers **import** Dense, Dropout, Flatten**from** keras.layers.convolutional **import** Conv2D, MaxPooling2D**from** keras.utils **import** np_utils# (Making sure) Set backend as tensorflow**from** keras **import** backend as KK.set_image_dim_ordering('tf')
- 现在让我们为训练和测试准备数据集。
# Define some variablesnum_rows **=** 28num_cols **=** 28num_channels **=** 1num_classes **=** 10# Import data(X_train, y_train), (X_test, y_test) **=** mnist.load_data()X_train **=** X_train.reshape(X_train.shape[0], num_rows, num_cols, num_channels).astype(np.float32) **/** 255X_test **=** X_test.reshape(X_test.shape[0], num_rows, num_cols, num_channels).astype(np.float32) **/** 255y_train **=** np_utils.to_categorical(y_train)y_test **=** np_utils.to_categorical(y_test)
- 设计培训模型。
# Modelmodel **=** Sequential()model.add(Conv2D(32, (5, 5), input_shape**=**(28, 28, 1), activation**=**'relu'))model.add(MaxPooling2D(pool_size**=**(2, 2)))model.add(Dropout(0.5))model.add(Conv2D(64, (3, 3), activation**=**'relu'))model.add(MaxPooling2D(pool_size**=**(2, 2)))model.add(Dropout(0.2))model.add(Conv2D(128, (1, 1), activation**=**'relu'))model.add(MaxPooling2D(pool_size**=**(2, 2)))model.add(Dropout(0.2))model.add(Flatten())model.add(Dense(128, activation**=**'relu'))model.add(Dense(num_classes, activation**=**'softmax'))model.compile(loss**=**'categorical_crossentropy', optimizer**=**'adam', metrics**=**['accuracy'])
- 训练模型。
# Trainingmodel.fit(X_train, y_train, validation_data**=**(X_test, y_test), epochs**=**10, batch_size**=**200, verbose**=**2)
- 通过移除缺失层为推理准备模型。
# Prepare model for inference**for** k **in** model.layers:**if** type(k) **is** keras.layers.Dropout:model.layers.remove(k)
- 最后保存模型。
model.save('handWritten.h5')
然后,转到您之前打开的终端,键入以下内容:
python train.py
它将创建一个名为 手写的数据模型。
Keras 到 CoreML
要将您的模型从 Keras 转换到 CoreML,我们需要做一些额外的步骤。我们的深度学习模型期望 28×28 归一化灰度图像,并给出类别预测的概率作为输出。此外,让我们添加更多的信息到我们的模型,如许可证,作者等。让我们创建一个名为convert.py的文件,并插入以下代码:
import coremltoolsoutput_labels = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']scale = 1/255.coreml_model = coremltools.converters.keras.convert('./handWritten.h5',input_names='image',image_input_names='image',output_names='output',class_labels= output_labels,image_scale=scale)coreml_model.author = 'Gerardo Lopez Falcon'coreml_model.license = 'MIT'coreml_model.short_description = 'Model to classify hand written digit'coreml_model.input_description['image'] = 'Grayscale image of hand written digit'coreml_model.output_description['output'] = 'Predicted digit' coreml_model.save('handWritten.mlmodel')
回到终端,键入以下内容:python convert.py。它为我们创建了一个名为 handled . ml model 的文件(现在,我们可以在 IOS 应用程序中使用这个文件)。
将模型集成到 Xcode 中
现在我们到了最后一步,将刚刚转换的模型集成到 Xcode 项目中。打开 starter 项目,根据您目前所学,我要求您将核心 ML 模型集成到应用程序中。
第一步是将handWritten.mlmodel 拖放到我们的 Xcode 项目中。确保选中了目标成员资格框。

现在,转到下面实例化 IBOutlet 的 ViewController,并从手写类型创建一个对象:
let model = handWritten()
之后,进入let pixelBuffer = .....插件下方的 tappedDetect 功能:
let output = try? model.prediction(image: pixelBuffer!)
我们刚刚定义了常数预测等于模型预测的数据。
仅此而已!构建并运行应用程序。这些是应用程序在 iPhone 7 上测试的结果。


结论
既然您已经知道了如何转换数据模型,那么您可能想知道在哪里可以找到数据模型。一个简单的谷歌搜索会给你大量的结果。您可以找到几乎任何类别的数据模型,例如不同类型的汽车、植物、动物,甚至还有一个模型可以告诉您最像哪个名人。这里有几个地方可以让你开始!
如果您找不到支持您需求的模型,您可能想知道是否可以创建自己的数据模型。这是可以做到的,但很难做到。如果你觉得自己已经准备好迎接挑战,我建议你从 Scikit-Learn 或 TensorFlow 的主页开始。
谢谢分享,如果你能把这篇文章分享给其他人,我会很感激的。我希望你的掌声:D
用 MCMC 创建动画

马尔可夫链蒙特卡罗(MCMC)是贝叶斯统计中一种广泛流行的技术。它用于后验分布抽样,因为分析形式通常是不可跟踪的。然而,在本帖中,我们将使用它从静态图像/徽标中生成动画。顺便说一句,这可能是对 MCMC 和拒绝采样的介绍。这个想法是基于一个伟大的开源包 imcmc ,它是建立在 PyMC3 之上的。
预赛
虽然 MCMC 适用于任何维度,但我们将集中讨论 2D 分布。为什么?好吧,看看下面的图表。

我们从一个 RGB 图像(最好是一个简单的标志)开始,将其转换为灰度,并根据强度为每个像素分配一个概率。在我们的例子中,像素越暗,概率越高。这导致了离散 2D 分布。
一旦我们有了这个分布,我们就可以从中抽取样本(像素)。一般来说,我们寻找以下两个属性:
- 样本确实来自目标分布
- 样品的连续及其可视化在美学上是令人愉悦的
虽然第二个属性总是在旁观者的眼中,但第一个属性可以通过使用适当的采样算法来实现。具体来说,让我们仔细看看 3 种非常适合当前问题的采样算法:拒绝、Gibbs 和 Metropolis-Hastings 采样。
拒绝抽样
第一种方法属于 IID ( 独立同分布)抽样方法。这实质上意味着当前样本对下一个样本没有影响。该算法假设我们能够从所谓的建议分布中进行采样。可以使用许多不同的建议分布,但最常见的是均匀(有限支持)和正态(无限支持)分布。

为了最大限度地降低拒绝样本的可能性,我们必须选择与我们的目标尽可能相似的建议分布。此外,我们希望比例常数 M 尽可能低。见下图(1D)方案。

在我们的设置中,我们可以采用 2D 均匀分布作为建议。
在较低的维度中,拒绝采样表现得非常好。然而,随着维数的增加,它遭受了臭名昭著的维数灾难。幸运的是,2D 没有被诅咒,因此拒绝采样是一个很好的选择。
吉布斯采样
吉布斯采样属于第二类采样器,它们通过构建马尔可夫链来生成样本。因此,这些样本不是独立的。事实上,在链达到稳定分布之前,它们甚至不是同分布的。因此,通常的做法是丢弃前 x 个样本,以确保链“忘记”初始化(老化)。

算法本身假设我们能够沿着目标的每个维度从条件分布中抽取样本。每当我们从这些单变量分布中取样时,我们都以剩余成分的最新值为条件。
大都会-黑斯廷斯抽样
与 Gibbs 类似,Metropolis-Hastings 采样也创建了马尔可夫链。但是,它更一般(Gibbs 是特例),更灵活。

给定当前样本,建议分布为我们提供了一个新样本的建议。然后,我们通过检查它比当前样本的可能性大(小)多少来评估其合格性,并考虑建议分布对该样本的可能偏差。综合所有因素,我们计算接受新样本的概率,然后让随机性做出决定。
不言而喻,建议分配的作用是至关重要的,并将影响性能和收敛性。一个更常见的选择是使用当前状态中心的法线。
动画片
最后来看一些结果。对于每个徽标,运行 Rejection 和 Metropolis-Hastings(使用 PyMC3)并创建可视化(gif)。最重要的超参数:
- 老化样品:500 个
- 样品:10000 个








对于多模态分布,Metropolis-Hastings 可能会陷入某些区域。这是一个非常常见的问题,可以通过改变方案或增加/加长样品链来解决。自然,我们也可以冒险到野外使用一些其他的采样器。
如果你想更深入地挖掘并查看源代码,请查看本 笔记本 。
参考
1.imcmc:https://github.com/ColCarroll/imcmc)
2。pymc 3:https://github.com/pymc-devs/pymc3)3。凯文·p·墨菲。2012.机器学习:概率观点。麻省理工学院出版社。
原载于 2018 年 7 月 11 日jank repl . github . io。
用 Conv 神经网络创作艺术
在这篇文章中,我正在使用卷积神经网络来制作一些精美的艺术品!
迄今为止,艺术一直是最好留给创意者的想象作品。艺术家有一种独特的方式来表达自己和他们生活的时代,通过独特的镜头,具体到他们看待周围世界的方式。无论是达芬奇和他令人惊叹的作品,还是梵高和他扭曲的世界观,艺术总是激励着一代又一代的人。
技术总是激励艺术家去突破界限,探索已经完成的事情之外的可能性。第一部电影摄影机不是作为辅助艺术的技术而发明的,而仅仅是捕捉现实的工具。显然,艺术家们对它的看法不同,它催生了整个电影和动画产业。对于我们创造的每一项主要技术来说都是如此,艺术家们总能找到创造性地使用这一新颖工具的方法。
随着机器学习的最新进展,我们可以在几分钟内创作出令人难以置信的艺术作品,而这在大约一个世纪前可能需要专业艺术家数年才能完成。机器学习创造了一种可能性,即在让媒体与艺术家合作的同时,以至少 100 倍的速度制作艺术作品的原型。这里的美妙之处在于,这一新的技术进步浪潮将通过升级手边的工具来增强艺术的创作和观赏方式。
介绍
在这里,我将使用 python 来获取任何图像,并将其转换为我选择的任何艺术家的风格。谷歌在 2015 年发布了一款名为“深度梦想”的类似产品,互联网对它产生了强烈的热情。他们本质上训练了一个卷积神经网络,该网络对图像进行分类,然后使用一种优化技术来增强输入图像中的模式,而不是基于网络所学的自身权重。此后不久,“Deepart”网站出现了,它允许用户点击鼠标将任何图像转换成他们选择的绘画风格!
那么这是如何工作的呢?
为了理解这个被称为样式转换过程的“魔法”是如何工作的,我们将使用 TensorFlow 后端在 Keras 中编写我们自己的脚本。我将使用一个基础图像(我最喜欢的动物的照片)和一个风格参考图像。我的剧本将使用文森特·梵高的《星夜》作为参考,并将其应用于基础图像。这里,我们首先导入必要的依赖项:
**from** **__future__** **import** print_function
**import** **time**
**from** **PIL** **import** Image
**import** **numpy** **as** **np**
**from** **keras** **import** backend
**from** **keras.models** **import** Model
**from** **keras.applications.vgg16** **import** VGG16
**from** **scipy.optimize** **import** fmin_l_bfgs_b
**from** **scipy.misc** **import** imsave
所以我们将这些图像输入神经网络,首先将它们转换成所有神经网络的实际格式,张量。Keras backend Tensorflow 中的变量函数相当于 tf.variable。它的参数将是转换为数组的图像,然后我们对样式图像做同样的事情。然后,我们创建一个组合图像,通过使用占位符将它初始化为给定的宽度和高度,可以在以后存储我们的最终结果。
以下是内容图片:
height = 512
width = 512
content_image_path = 'images/elephant.jpg'
content_image = Image.open(content_image_path)
content_image = content_image.resize((height, width))
content_image

Content Image (Elephants are cool)
在这里,我加载了样式图像:
style_image_path = '/Users/vivek/Desktop/VanGogh.jpg'
style_image = Image.open (style_image_path)
style_image = style_image.resize((height, width))
style_image

Style Image (gotta pull out the classic)
接下来,我们转换这两个图像,使它们具有适合数字处理的形式。我们添加了另一个维度(除了高度、宽度和正常的 3 个维度之外),这样我们以后可以将两个图像的表示连接成一个公共的数据结构:
content_array = np.asarray(content_image, dtype='float32')
content_array = np.expand_dims(content_array, axis=0)
print(content_array.shape)
style_array = np.asarray(style_image, dtype='float32')
style_array = np.expand_dims(style_array, axis=0)
print(style_array.shape)
我们将继续使用 VGG 网络。Keras 已经很好地包装了这个模型,以便我们在前进的过程中可以轻松使用。VGG16 是一个 16 层卷积网,由牛津大学的视觉几何小组创建,在 2014 年赢得了 ImageNet 竞赛。这里的想法是,对于成千上万不同图像的图像分类,预先训练的 CNN 已经知道如何在容器图像中编码信息。我已经了解了每一层的特征,这些特征可以检测某些一般化的特征。这些是我们将用来执行风格转移的功能。我们不需要这个网络顶部的卷积块,因为它的全连接层和 softmax 函数通过挤压维度特征图和输出概率来帮助分类图像。我们不仅仅是对转移进行分类。这本质上是一种优化,我们有一些损失函数来衡量我们将试图最小化的误差值。在这种情况下,我们的损失函数可以分解为两部分:
1)内容损失我们将总损失初始化为零,并将这些中的每一个加到其上。首先是内容损失。图像总是有一个内容组件和一个样式组件。我们知道 CNN 学习的特征是按照越来越抽象的成分的顺序排列的。由于更高层的特征更抽象,比如检测人脸,我们可以把它们和内容联系起来。当我们通过网络运行我们的输出图像和我们的参考图像时,我们从我们选择的隐藏层获得两者的一组特征表示。然后我们测量它们之间的欧几里德距离来计算我们的损失。
2)风格损失这也是我们的网络的隐藏层输出的函数,但是稍微复杂一些。我们仍然通过网络传递两幅图像来观察它们的激活,但是我们没有直接比较原始激活的内容,而是增加了一个额外的步骤来测量激活之间的相关性。对于网络中给定层的两个活化图像,我们采用所谓的格拉姆矩阵。这将测量哪些功能倾向于一起激活。这基本上代表了不同特征在图像的不同部分同时出现的概率。一旦有了这些,我们就可以将这种风格损失定义为参考图像和输出图像之间的 gram 矩阵之间的欧几里德距离,并将总风格损失计算为我们选择的每一层的风格损失的加权和。
既然我们有了损失,我们需要定义输出图像相对于损失的梯度,然后使用这些梯度迭代地最小化损失。
我们现在需要对输入数据进行处理,以匹配在 Simonyan 和 Zisserman (2015) 介绍 VGG 网络模型的论文中所做的工作。
为此,我们需要执行两个转换:
- 从每个像素中减去平均 RGB 值(之前在 ImageNet 训练集上计算的,并且很容易从谷歌搜索中获得)。
- 将多维数组的排序从 RGB 翻转到 BGR (文中使用的排序)。
content_array[:,:,:,0] -= 103.99
content_array[:, :, :, 1] -= 116.779
content_array[:, :, :, 2] -= 123.68
content_array = content_array[:, :, :, ::-1]
style_array[:, :, :, 0] -= 103.939
style_array[:, :, :, 1] -= 116.779
style_array[:, :, :, 2] -= 123.68
style_array = style_array[:, :, :, ::-1]
现在我们准备使用这些数组来定义 Keras 后端(TensorFlow 图)中的变量。我们还引入了一个占位符变量来存储组合图像,它保留了内容图像的内容,同时合并了样式图像的样式。
content_image = backend.variable(content_array)
style_image = backend.variable(style_array)
combination_image = backend.placeholder((1, height, width, 3))
现在,我们将所有这些图像数据连接成一个张量,用于处理 Kera 的 VGG16 模型。
input_tensor = backend.concatenate([content_image,
style_image,
combination_image], axis = 0)
如前所述,由于我们对分类问题不感兴趣,我们不需要完全连接的层或最终的 softmax 分类器。我们只需要下表中用绿色标记的模型部分。

对我们来说,访问这个截断的模型是微不足道的,因为 Keras 附带了一组预训练的模型,包括我们感兴趣的 VGG16 模型。注意,通过在下面的代码中设置include_top=False,我们不包括任何完全连接的层。
**import** **h5py**
model = VGG16(input_tensor=input_tensor, weights='imagenet',
include_top=**False**)
从上表可以清楚地看出,我们正在使用的模型有很多层。Keras 对这些层有自己的名字。让我们把这些名字列一个表,这样我们以后可以很容易地引用各个层。
layers = dict([(layer.name, layer.output) **for** layer **in** model.layers])
layers
我们现在选择重量,可以这样做:
content_weight = 0.025
style_weight = 5.0
total_variation_weight = 1.0
我们现在将使用由我们的模型的特定层提供的特征空间来定义这三个损失函数。我们首先将总损耗初始化为 0,然后分阶段增加。
loss = backend.variable(0.)
现在内容丢失:
**def** content_loss(content, combination):
**return** backend.sum(backend.square(combination - content))
layer_features = layers['block2_conv2']
content_image_features = layer_features[0, :, :, :]
combination_features = layer_features[2, :, :, :]
loss += content_weight * content_loss(content_image_features,
combination_features)
和风格损失:
**def** gram_matrix(x):
features = backend.batch_flatten(backend.permute_dimensions(x, (2, 0, 1)))
gram = backend.dot(features, backend.transpose(features))
**return** gram**def** style_loss(style, combination):
S = gram_matrix(style)
C = gram_matrix(combination)
channels = 3
size = height * width
**return** backend.sum(backend.square(S - C)) / (4\. * (channels ** 2) * (size ** 2))
feature_layers = ['block1_conv2', 'block2_conv2',
'block3_conv3', 'block4_conv3',
'block5_conv3']
**for** layer_name **in** feature_layers:
layer_features = layers[layer_name]
style_features = layer_features[1, :, :, :]
combination_features = layer_features[2, :, :, :]
sl = style_loss(style_features, combination_features)
loss += (style_weight / len(feature_layers)) * sl
最后是总变异损失:
**def** total_variation_loss(x):
a = backend.square(x[:, :height-1, :width-1, :] - x[:, 1:, :width-1, :])
b = backend.square(x[:, :height-1, :width-1, :] - x[:, :height-1, 1:, :])
**return** backend.sum(backend.pow(a + b, 1.25))
loss += total_variation_weight * total_variation_loss(combination_image)
现在,我们继续定义解决优化问题所需的梯度:
grads = backend.gradients(loss, combination_image)
然后,我们引入一个赋值器类,它在一次运算中计算损失和梯度,同时通过两个独立的函数 loss 和 grads 检索它们。这样做是因为 scipy.optimize 需要单独的损失和梯度函数,但是单独计算它们是低效的。
outputs = [loss]
outputs += grads
f_outputs = backend.function([combination_image], outputs)
**def** eval_loss_and_grads(x):
x = x.reshape((1, height, width, 3))
outs = f_outputs([x])
loss_value = outs[0]
grad_values = outs[1].flatten().astype('float64')
**return** loss_value, grad_values
**class** **Evaluator**(object):
**def** __init__(self):
self.loss_value = **None**
self.grads_values = **None**
**def** loss(self, x):
**assert** self.loss_value **is** **None**
loss_value, grad_values = eval_loss_and_grads(x)
self.loss_value = loss_value
self.grad_values = grad_values
**return** self.loss_value
**def** grads(self, x):
**assert** self.loss_value **is** **not** **None**
grad_values = np.copy(self.grad_values)
self.loss_value = **None**
self.grad_values = **None**
**return** grad_values
evaluator = Evaluator()
现在我们终于准备好解决我们的优化问题。这个组合图像从(有效)像素的随机集合开始,我们使用 L-BFGS 算法(一种比标准梯度下降收敛快得多的拟牛顿算法)对其进行迭代改进。我们在 8 次迭代后停止,因为输出对我来说看起来很好,损失停止显著减少。
x = np.random.uniform(0, 255, (1, height, width, 3)) - 128.
iterations = 8
**for** i **in** range(iterations):
print('Start of iteration', i)
start_time = time.time()
x, min_val, info = fmin_l_bfgs_b(evaluator.loss, x.flatten(),
fprime=evaluator.grads, maxfun=20)
print('Current loss value:', min_val)
end_time = time.time()
print('Iteration **%d** completed in **%d**s' % (i, end_time - start_time))
如果你像我一样在笔记本电脑上工作,那就去吃顿大餐吧,因为这需要一段时间。这是上一次迭代的输出!
x = x.reshape((height, width, 3))
x = x[:, :, ::-1]
x[:, :, 0] += 103.939
x[:, :, 1] += 116.779
x[:, :, 2] += 123.68
x = np.clip(x, 0, 255).astype('uint8')
Image.fromarray(x)

Merger!
整洁!我们可以通过改变两幅图像、它们的大小、我们的损失函数的权重等等来继续玩这个游戏。重要的是要记住,我的 MacBook air 仅运行了 8 次迭代就花了大约 4 个小时。这是一个非常 CPU 密集型的过程,因此在扩展时,这是一个相对昂贵的问题。
感谢阅读!
用 Python 创建漂亮的 Twitter 图表
想学两个有用的 Python 包?想在一张痛苦而可悲的图表中想象出所有没有在 Twitter 上关注你的人吗?请继续阅读。

Follows between players on all 30 NBA teams
编程意义上的图是顶点和边的集合,而不是条形图或散点图——但是你已经知道了。图表是强大的工具,有可能直观地交流复杂的关系。此外,他们可以很漂亮。为什么不看看我们能从推特上推断出什么关系呢?
数据收集
Twitter 已经有一个 Python API,python-twitter,所以我们不必自己发出 HTTP 请求和解析响应。为了使用它,我们必须通过 Twitter 创建一些应用程序凭证。我发现这是一个相当轻松的过程,所以我会简单地让你参考 python-twitter 的优秀指南来了解如何做到这一点。你只需要一个 Twitter 账户,不需要任何特权。
有了凭证,我们就可以创建 Twitter API 的一个实例并开始工作。
Add your tokens to get an api instance
我是一名 NBA 球迷,所以在这次演示中,我将在 Twitter 上绘制球员之间的联系。这是一个有趣的数据集,因为联盟有一个非常活跃的社交媒体存在,每个球员都很容易获得属性,如合同大小,球队和位置。你可以对任何你感兴趣的 Twitter 用户遵循同样的步骤,无论是名厨、音乐艺术家还是#QAnon 海报。
NBA 有 30 支球队,每支球队大约有 15 名球员。我并不热衷于手动查找 450 个 Twitter 句柄来将它们输入 API,尤其是如果我可以通过编程来完成的话。Basketball-reference.com 来救我了。下面我找到了 2018-19 赛季所有签约球员的表格。
[## 2018-19 赛季 NBA 球员合同| Basketball-Reference.com
当前 NBA 球员合同概要
www.basketball-reference.com](https://www.basketball-reference.com/contracts/players.html#player-contracts::none)
有了这个玩家名字的列表,我使用 API 来搜索相应的 Twitter-id,并将每个玩家的所有属性捆绑在一个顶点列表中,称为 V. 如果你已经有了一个屏幕名称或 Twitter-id 的列表,这可能是多余的,但如果你没有,下面是代码:
毕竟, V 将是一个列表列表,我将其作为一个. csv 文件转储,其中包含| TWITTER ID |用户名|昵称|团队列。
nba_verts.csv42562446,Stephen Curry,StephenCurry30, GSW
53853197,Chris Paul,CP3, HOU
23083404,LeBron James,KingJames, LAL
...
我知道我在寻找知名度高的运动员,所以我只在搜索中包括经过验证的用户,并假设搜索的第一个结果是正确的——事实证明并不总是如此。最后,我迭代了 V ,并使用 GetFriendIDs() API 调用来查找每个 Twitter-id 的好友。朋友是用户正在关注的人。如果朋友处于 V 状态,这是我用字典检查过的一个条件,我将这个边输出给另一个。csv 文件。
nba_edges.csv42562446,53643297
42562446,59297233
42562446,28066436
42562446,46704247
42562446,34430522
...
图是顶点和边的集合,现在我们两者都有了;我们准备好尽我们的职责了。
用 igraph 可视化
此时,你可以简单地将你的顶点和边列表加载到你最喜欢的图形绘制软件中(我的是 cytoscape )。但那一点都不好玩。让我们看看在严格遵守 Python 的情况下我们能做些什么。
Python-igraph 是我选择的包。它有相当多的依赖项,安装起来可能不像它的 R 实现那样流畅,但是一旦你掌握了它的语法,它会得到很好的维护并且非常强大。我发现用 Python 2.7 安装是最容易的,在一个 Jupyter 笔记本中使用也是最容易的。
让我们用我们的边和顶点做一个图。出于演示的目的,我将只包括前 10 名收入最高的球员。
from igraph import *#this info read in from our .csv files
E = [("42562446","53643297"), ("42562446","59297233"),...]
V = ["42562446", "53853197", "23083404",...]
user_names = ["Stephen Curry", "Chris Paul", "LeBron James",...]
scrn_names = ["StephenCurry30", "CP3", "KingJames",...]g = Graph(directed=True)
g.add_vertices(V)
g.add_edges(E)
plot(g)
那**剧情()**会产生这种美:

The graph, no styling
我的天啊。到底发生了什么事?什么顶点是什么 Twitter 用户?还有为什么这么多毛?
别担心,我们将应用一些样式来解决所有这些问题。
首先,让我们添加一些标签。然后,我们可以通过移除弯曲的边缘来拉直毛团,并添加一个边距来保护标签不会漂移到边界框之外。我们将把我们的样式决定保存在一个名为 style 的字典中,这样我们可以在以后重用它。
#add vertex attributes
g.vs["screen_name"] = scrn_names
g.vs["user_name"] = user_namesstyle = {}
style["edge_curved"] = False
style["margin"] = 100
style["vertex_label"] = g.vs["user_name"]
plot(g, **style)
我们使用**。vs** 图的成员,用于将属性与顶点相关联,每个顶点的属性值按照添加顶点的顺序进行映射。因为我们的用户名和 scrn_name 数组是与 **V、**并行的,所以这是一个非常简单的过程。

The graph with some more sane styling
这看起来还不错,但是我的 viz 目标之一是有效地交流什么是追随,什么是追随和追随回来。使用 igraph 很容易迭代边缘,检测这些情况,并相应地改变边缘样式。
for e in g.es:
src, targ = e.tuple
if g.are_connected(targ, src):
e["color"] = "green" #follow + followback
e["arrow_size"] = 0
else:
e["color"] = "blue" #follow
e["arrow_size"] = 1
plot(g, **style)

Green for a mutual follow, blue for an unreturned follow
好了,伙计们,勒布朗已经离开了猛龙队的凯尔·洛瑞和凯尔特人队的戈登·海沃德。加油勒布朗!
在这里,您可以设置顶点的样式,使它们不会与标签发生太多冲突,调整标签与顶点的距离,尝试不同的布局(图表的结构),等等。我建议把你的情节保存为。svg 文件,这样你就可以用像 Inkscape 这样的编辑器准确地排列你的标签或顶点。
本文开头显示的 30 支 NBA 球队的图形使用了圆形图形布局,颜色来自每支球队的官方调色板( igraph 支持十六进制代码着色)。这是我最喜欢的球队金州勇士队的特写:

Dubs on Twitter
这不仅赏心悦目,而且也让我们对玩家之间的关系有了一些了解。库里和格林看起来整体联系最紧密,跟在后面也很大方。汤普森、杜兰特和利文斯顿稍微有点冷漠,有更多未回归的追随者。德马库斯·考辛斯,一个新来的球员,已经努力跟随他的新队友了(…或者已经跟随他们了)。
你可以更进一步,利用 igraph 内置的大量图形算法来回答如下问题:
- NBA 哪个球员最中锋?
- 谁有最好的跟随者-跟随者差异?
- NBA 存在哪些派系?
- 哪个团队的(边缘)密度最高,哪个团队的密度最低?
我会在 GitHub 上偶尔重构和更新我的代码,但我所展示的要点已经在那里了,还有完整的 NBA 图表。
我焦急地等待着你从 Twitter 上创建的漂亮的图表!如果你能和我分享,我会很高兴的。
在 Twitter-kublasean/NBA-Twitter-analysis 上制作球员-球员关系图
github.com](https://github.com/kublasean/nba-twitter-analysis)
利用网络摄像头和深度学习创建定制的堡垒之夜舞蹈
使用姿势估计和条件敌对网络创建和可视化新堡垒之夜舞蹈。

Recreating a Fortnite character’s dance moves using poses from my webcam video.
如果你知道游戏堡垒之夜,你可能也知道围绕着游戏中的庆祝/表情/舞蹈的狂热。游戏玩家已经花费了数百万美元通过应用内购买来购买舞蹈动作,这使得一些简单而愚蠢的事情成为游戏开发者的一大收入来源。这让我想到,如果开发者允许用户在游戏中创作这些舞蹈并收取额外费用,他们可能会赚更多的钱。对于用户来说,如果我们可以在网络摄像头上记录自己,并在游戏中创造自己的庆祝舞蹈,那将会非常酷。
目前这样做需要一个类似微软 Kinect 的设备,它有专用的硬件来感知我们的身体运动。然而,并不是每个人都想为此购买单独的设备。我认为随着深度学习的进步,很快就有可能只用一个很好的旧网络摄像头来实现类似的功能。让我们看看如何在深度学习算法的帮助下,在未来实现这样的事情。
从网络摄像头到堡垒之夜
为了验证这一点,我在这个项目中使用了两种深度学习技术。首先,我们将使用姿势估计算法从我们的网络摄像头记录中提取简笔画表示(姿势)。对于一个游戏开发人员来说,这种姿势表示足以使游戏中的角色产生动画效果,但是因为我不是开发人员,所以我只能简单地想象使用这种姿势创建的堡垒之夜舞是什么样子。为此,我使用了名为 pix2pix 的条件对抗网络来生成给定姿势的角色。

Pipeline to go from webcam to Fortnite involves two steps: (1) getting pose from webcam image, followed by (2) synthesizing Fortnite character in that particular pose.
从网络摄像头进行姿态估计
为了估计输入图像姿态,我已经使用了来自论文 [的算法,实时多人 2D 姿态估计使用部分亲和场](http://The image shown here is the output of a net trained to detect the right arm of the body shown as the highlighted area in this heatmap.) 由曹等人【CVPR 17】。该算法使用多个尺度的卷积神经网络来识别身体的不同部分,如左臂、右臂、躯干等。这些检测到的部分代表单个节点。

This image shows the detection results of a Convolutional Neural Net trained to detect the right arm of a human body. The detection is shown by the hot region of this heatmap at multiple scales.

一旦检测到所有这样的身体部分,它就使用贪婪的解析算法来连接附近的节点,以形成一个连通图,给我们一个简笔画,这是姿势的表示。它实时运行,也可以与图像中出现的多人一起工作。
从姿态合成图像
一旦我们得到了这个姿势,我们想把它转换成堡垒之夜的角色。为此,我们将使用相同的姿态估计算法来生成我们的训练数据。我们用这个获得带标签的训练数据,其中姿势图是我们的输入,堡垒之夜角色是我们的目标标签。

Training data contains collection of paired images of the pose (input) and the targeted dance move (output).
然后,训练一个 pix2pix 网络将输入转换为输出。它使用一个生成的对抗网络来产生目标图像,条件是输入图像而不是随机噪声,因此我们可以实际生成堡垒之夜角色的图像,这些图像遵循作为输入给定的姿势。

在训练期间,输入图像和目标图像都可用于发生器和鉴别器网络。pix2pix 中的生成器网络显式地产生真实和虚假图像,以便鉴别器可以更快地学会区分这两者。
结果
发生器和鉴频器损耗收敛后,网络产生相当不错的结果。通过将堡垒之夜角色的每个身体部位与简笔画相关联,它已经学会很好地跟随输入姿势。不幸的是,产生的图像非常模糊,没有高层次的细节。如果你知道我可以如何改善 pix2pix 网络的结果,请在下面的评论区告诉我。

更多这样的结果可以在我的 YouTube 频道和下面嵌入的视频中找到。如果你喜欢它,请随意订阅到我的频道来关注我更多的作品。
用于姿态估计的代码可以在这里找到,用于图像合成的代码可以在这里找到。
感谢您的阅读!如果你喜欢这篇文章,请在媒体、 GitHub 上关注我,或者订阅我的 YouTube 频道。
用数据科学创造智能
在这篇文章中,我将展示数据科学如何让我们通过人工智能创造智能。

什么是智能?

这个问题不容易回答。不久前我还在努力定义它是什么,但我在莱克斯·弗里德曼的课程中找到了一个我喜欢的简单短语。
所以让我们把智能定义为:
完成复杂目标的能力。
但是什么是复杂的呢?我们如何定义复杂的事物?如果你在互联网上查找,你会发现几个不同的定义,但我认为“主要的”一个接近我认为智力的定义是什么。
如果我们认为复杂的事物是由许多部分以难以理解的方式相互联系在一起的事物,那么我们可以说复杂的事物是事物或部分的混合,它们共同形成一个更大的事物,而这些部分的联系方式是不容易理解的。
例如,一辆汽车是一个复杂的东西,它有许多部件以一种不容易理解的方式协同工作。

但是!如果我们看一看,个别部分并不难理解。我并不是说它们很容易构建或者很容易看到它们到底在做什么,而是说更容易掌握它们在做什么。
所以我们现在可以说智能是:
通过理解构成主要目标的部分来完成困难目标的能力。
这些目标将在我们希望的背景下定义,但现在我们希望专注于人工智能(AI)领域。因此,当人工智能想要使用机器和计算来建立智能,试图模仿我们人类看、听、学习等方式时,这些目标将是看、学习、 听、移动、理解等。
什么是理解?
我们将从 Lex 的课上学到的另一个重要概念是理解。到目前为止,我们已经多次使用这个词,所以让我们来定义它:
理解是将复杂的信息转化为简单的、有用的信息的能力。

我们需要这个,看到车的零件的时候就谈过了。当我们理解时,我们正在解码形成这个复杂事物的各个部分,并将我们一开始获得的原始数据转化为有用的、简单易懂的东西。
我们通过建模来做到这一点。这是理解“现实”,我们周围的世界,但创造一个更高层次的原型来描述我们所看到的,听到的和感觉到的东西的过程,但这是一个代表性的东西,而不是“实际”或“真实”的东西。
那么我们人类是如何创造智慧的呢?通过模拟我们周围的世界,了解它的组成部分,将我们得到的原始数据转化为有用和简单的信息,然后看看这些部分如何形成更复杂的东西,最终实现目标,“困难”的目标。
我们还要多久才能变得聪明?
这花了大约 380 万年的时间。我们希望这能在未来五年内实现:

即使我们用人工智能完成复杂的目标不会花那么长时间,也不会像我们想象的那么快。我们是一个正在成熟的领域,每天都在进步。但是 AI along 并不能解决所有的问题。
用 AI 创造智能我们需要什么?
我认为创造智慧的秘诀在高层次上并不难。这就是我提议我们需要做的事情:
大数据+ AI +数据科学=人工通用智能
我所说的人工通用智能(AGI)是这场革命的主要目标。AGI 是通用系统,其智能堪比人类思维(或者可能超越人类)。
我们需要大数据作为到达 AGI 的催化剂,因为有了更多的数据,加上分析数据的新方法,加上更好的软件和硬件,我们可以创建更好的模型和更好的理解。我们需要 AI 的当前状态,非常接近深度学习、深度强化学习及其周围环境(更多关于深度学习这里),然后我们需要数据科学作为这场革命背后的控制器和科学。
什么是数据科学?

这个定义可能会引起一些人的争议,但我认为这非常接近领导者(理论上和业务上)现在所说的。所以,
数据科学是通过数学、编程和科学方法来解决业务/组织问题,其中涉及通过分析数据和生成预测模型来创建假设**、实验和测试。它负责将这些问题转化为适定问题,这些适定问题也能以创造性的方式对初始假设做出回应。还必须包括对所获结果的有效沟通,以及解决方案如何为企业/组织增加价值。**
有了这个定义,我们可以定义谁是数据科学家:
数据科学家是一个人(或者系统?)负责分析业务/组织问题并给出结构化解决方案首先由将该问题转化为有效且完整的问题,然后使用编程和计算工具开发代码使准备、清理和分析数据
我在这里说的是,数据科学与业务密切相关,但它最终是一门科学,或者正在成为一门科学,或者可能不是。我认为数据科学是一门科学是非常有用的,因为如果是这样的话,数据科学中的每个项目至少应该:
-可复制
-可伪造
-协作
-创造性
-符合法规
你可以在亨利·庞加莱的著作《科学与方法》中了解更多为什么这很重要,请点击此处:
** [## 科学与方法:庞加莱,亨利,1854-1912:免费下载
14 35
archive.org](https://archive.org/details/sciencemethod00poinuoft)**
本文的主要观点(未来可能会有更多相关内容)是向您展示这些是真正严肃的研究和开发领域,我们需要所有这些领域都进入 AGI,而数据科学对这一结局至关重要。
你可能会想,我们为什么需要 AGI?或者说为什么我们首先需要 AI?
我认为我们可以让世界变得更好,改善我们的生活,改善我们工作、思考和解决问题的方式,如果我们现在就调动我们所有的资源,让这些知识领域为更大的利益而共同努力,我们就可以对世界和我们的生活产生巨大的积极影响。
我们需要更多感兴趣的人,更多的课程,更多的专业,更多的热情。我们需要你:)
如果您有任何问题,请在 LinkedIn 上添加我,我们将在那里聊天:
** [## Favio Vázquez -数据科学家/工具经理 MX - BBVA 数据&分析| LinkedIn
查看 Favio Vázquez 在世界上最大的职业社区 LinkedIn 上的个人资料。Favio 有 13 个工作列在他们的…
www.linkedin.com](https://www.linkedin.com/in/faviovazquez)**
使用 Plot.ly 创建参数优化的交互式动画

介绍
这篇文章演示了如何在一个变化的参数上创建一个交互式的动画结果图。
为此,我们复制了此处示例中提供的显示一段时间内各国人均 GDP 的示例,如下所示(https://plot.ly/python/animations/)。
实现这一点的先决条件是 Python 和 plot . ly(【https://plot.ly/python/getting-started/】T2)
这绝不是最干净或最漂亮的方法,我只是简单地将我的数据放入示例中,除了更改一些轴标签之外,没有对示例中的代码进行任何重大更改。我已经创建了可视化的想法,参数优化,它并不总是为了出版,而是分析的探索阶段,所以必须尽可能快速和容易地创建。
如果你想在你的报告中使用视觉效果,我建议稍微编辑一下格式,但在其他方面,创建方法也可以类似地使用。
如有疑问,欢迎在下方随意评论。
Gapminder 示例
我们将再次应用以下技术来创建交互式图表。首先,我们需要观察正在使用的数据。在此示例中,使用以下内容创建了散点图:
- x 轴上的预期寿命
- y 轴上的人均 GDP
- 国家的大小与人口有关
- 按洲着色
- 跨年度跟踪(动画和滑块)

Plot.ly Gapminder AnimationExample
应用我们的数据
为此,我将我的结果导出到一个特定格式的数据表中。如下所示,有三列,Alpha、Epsilon 和 V。Alpha 是我正在更改的参数,Epsilon 是模型运行的第 n 次,V 是我的输出。
因此,当我的参数在 1 和 0 之间减小时,我的表由每次运行的输出构成。下图显示了前几行。

现在,我们将把已有的数据“混合”到 plot.ly 示例中。因为我们的数据有些简单,所以我们首先否定示例中使用的一些特征。理论上,你可以整理代码来删除它们,但是这需要更多的时间,而且这种方法更简单。
因此,我们在数据中添加了两列,每行都有一个虚拟值‘Test1’和‘Test2’。然后,我们添加第三列来对应所使用的人口特征。如前所述,该值对应于点的大小,我选择了一个提供适当大小的点的值,但如果需要,您可以编辑它。
然后,我重命名所有的列,使其完全符合示例中的命名约定。
在[21]中:
ourData['continent'] = 'Test'
ourData['country'] = 'Test2'
ourData['pop'] = 7000000.0ourData.columns = ['year', 'lifeExp', 'gdpPercap', 'continent', 'country', 'pop']ourData.head()

下一步有点棘手,在示例中,他们使用以下代码手动输入每年的数据:
years = ['1952', '1962', '1967', '1972', '1977', '1982', '1987', '1992', '1997', '2002', '2007']
因此,我不必每次都手动输入,只需找到每个唯一的 Alpha 值,按降序进行舍入和排序,然后生成一个唯一 Alpha 值的数组。然后,我将变量名改为‘Years ’,以与后面的代码相对应。
在[24]中:
alpha = list(set(ourData['year']))
alpha = np.round(alpha,1)
alpha = np.sort(alpha)[::-1]
years = np.round([(alpha) for alpha in alpha],1)
years
Out[24]:
array([ 1\. , 0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1])
最后,我们将我们的数据重命名为与示例代码相对应的数据,并运行整个过程,以生成我们的参数优化动画和交互图。
在布局部分,我添加了一个主标题,并重新措辞了一些轴标签,以符合我的要求,但在其他方面没有改变。
在[27]中:
dataset = ourDatacontinents = []
for continent in dataset['continent']:
if continent not in continents:
continents.append(continent)
# make figure
figure = {
'data': [],
'layout': {},
'frames': []
}# fill in most of layout
figure['layout']['title'] = "Parameter Optimisation using Interactive Animation <br> PhilipOsborneData.com"
figure['layout']['xaxis'] = {'range': [1, 100], 'title': 'Epsilon'}
figure['layout']['yaxis'] = {'range': [1,50],'title': 'Sum of V', 'type': 'linear'}
figure['layout']['hovermode'] = 'closest'
figure['layout']['sliders'] = {
'args': [
'transition', {
'duration': 400,
'easing': 'cubic-in-out'
}
],
'initialValue': '1952',
'plotlycommand': 'animate',
'values': years,
'visible': True
}
figure['layout']['updatemenus'] = [
{
'buttons': [
{
'args': [None, {'frame': {'duration': 500, 'redraw': False},
'fromcurrent': True, 'transition': {'duration': 300, 'easing': 'quadratic-in-out'}}],
'label': 'Play',
'method': 'animate'
},
{
'args': [[None], {'frame': {'duration': 0, 'redraw': False}, 'mode': 'immediate',
'transition': {'duration': 0}}],
'label': 'Pause',
'method': 'animate'
}
],
'direction': 'left',
'pad': {'r': 10, 't': 87},
'showactive': False,
'type': 'buttons',
'x': 0.1,
'xanchor': 'right',
'y': 0,
'yanchor': 'top'
}
]sliders_dict = {
'active': 0,
'yanchor': 'top',
'xanchor': 'left',
'currentvalue': {
'font': {'size': 20},
'prefix': 'Alpha: ',
'visible': True,
'xanchor': 'right'
},
'transition': {'duration': 300, 'easing': 'cubic-in-out'},
'pad': {'b': 10, 't': 50},
'len': 0.9,
'x': 0.1,
'y': 0,
'steps': []
}# make data
year = 1.0
for continent in continents:
dataset_by_year = dataset[np.round(dataset['year'],1) == np.round(year,1)]
dataset_by_year_and_cont = dataset_by_year[dataset_by_year['continent'] == continent] data_dict = {
'x': list(dataset_by_year_and_cont['lifeExp']),
'y': list(dataset_by_year_and_cont['gdpPercap']),
'mode': 'markers',
'text': list(dataset_by_year_and_cont['country']),
'marker': {
'sizemode': 'area',
'sizeref': 200000,
'size': list(dataset_by_year_and_cont['pop'])
},
'name': continent
}
figure['data'].append(data_dict)# make frames
for year in years:
frame = {'data': [], 'name': str(year)}
for continent in continents:
dataset_by_year = dataset[np.round(dataset['year'],1) == np.round(year,1)]
dataset_by_year_and_cont = dataset_by_year[dataset_by_year['continent'] == continent] data_dict = {
'x': list(dataset_by_year_and_cont['lifeExp']),
'y': list(dataset_by_year_and_cont['gdpPercap']),
'mode': 'markers',
'text': list(dataset_by_year_and_cont['country']),
'marker': {
'sizemode': 'area',
'sizeref': 200000,
'size': list(dataset_by_year_and_cont['pop'])
},
'name': continent
}
frame['data'].append(data_dict) figure['frames'].append(frame)
slider_step = {'args': [
[year],
{'frame': {'duration': 300, 'redraw': False},
'mode': 'immediate',
'transition': {'duration': 300}}
],
'label': year,
'method': 'animate'}
sliders_dict['steps'].append(slider_step) figure['layout']['sliders'] = [sliders_dict]iplot(figure)
输出显示在本文开头的动画中。
谢谢
哲学(philosophy 的缩写)
使用 Python、Pdfkit 和 Jinja2 模板创建 PDF 报告

作为一名数据科学家,有时您可能需要创建 PDF 格式的分析报告。如今,这似乎有点“老派”,但在以下几种情况下,你可能会考虑这样做:
- 你需要制作易于打印的报告。人们通常想要他们正在运行的特定报告的“硬拷贝”,而不想在交互式仪表板中再现他们所做的一切。
- 您需要匹配现有的报告格式:如果您要更换传统的报告系统,首先尝试匹配现有的报告方法通常是个不错的主意。这意味着如果遗留系统使用 PDF 报告,那么您应该强烈考虑在替换系统中创建该功能。这对于获得对旧系统感到满意的人的认同通常很重要。
我最近需要在工作任务中做 PDF 报告。我想到的特定解决方案使用了两个主要工具:Jinja2 和 Pdfkit。
我们将使用以下命令安装所需的软件包:
pip install pdfkit
pip install Jinja2
请注意,您还需要安装一个名为 wkhtmltopdf 的工具,pdfkit 才能工作。
Jinja2 模板入门
Jinja2 是一个很好的熟悉的工具,特别是如果你用 Python 做 web 开发的话。简而言之,它允许您通过编程填充分配给文本文件模板的占位符值来自动生成文本文档。这是一个非常灵活的工具,广泛用于 Python web 应用程序中为用户生成 HTML。你可以把它想象成超级高能的字符串替换。
我们将使用 Jinja2 来生成报告的 HTML 文件,我们将使用其他工具将这些文件转换成 pdf。请记住,Jinja2 可以方便地用于其他报告应用程序,比如发送自动电子邮件或创建其他文本文件格式的报告。
使用 Jinja2 有两个主要部分:
- 创建包含占位符值的文本文件 Jinja2 模板。在这些模板中,您可以使用各种 Jinja2 语法特性,这些特性允许您调整文件的外观以及它加载占位符数据的方式。
- 编写 python 代码,将占位符值分配给 Jinja2 模板,并根据这些值呈现新的文本字符串。
让我们创建一个简单的模板作为示例。这个模板只是一个文本文件,它打印出一个名字的值。你所要做的就是创建一个文本文件(姑且称之为 name.txt)。然后在这个文件中,简单地添加一行:
Your name is: {{ name }}
在这里,“name”是我们将传递到模板中的 python 变量的名称,它保存了我们希望包含在模板中的字符串占位符。
现在我们已经创建了模板,我们需要编写 python 代码,用您需要的内容填充模板中的占位符值。您可以使用渲染函数来完成此操作。比方说,我们想要创建一个模板版本,其名称为“Mark”。然后编写以下代码:
现在,outputText 保存一个模板字符串,其中{{ name }}现在等于“Mark”。您可以通过在命令行上编写以下内容来确认这一点:

template.render()的参数是模板中包含的占位符变量,以及您要将它们赋给什么:
template.render(placeholder_variable_in_template1=value_you_want_it_assigned1, placeholder_variable_in_template2=value_you_want_it_assigned2, ..., placeholder_variable_in_templateN=value_you_want_it_assignedN)
使用 Jinja2 模板,您可以做更多的事情。例如,我们在这里只展示了如何呈现一个简单的变量,但是 Jinja2 允许更复杂的表达式,比如 For 循环、if-else 语句和模板继承。关于 Jinja2 模板的另一个有用的事实是,您可以传入任意 python 对象,如列表、字典或 pandas 数据框,并且您可以直接在模板中使用这些对象。查看 Jinja2 模板设计器文档以获得完整的特性列表。我也强烈推荐《T2》这本书:用 Python 开发 Web 应用,这本书包含了关于 Jinja2 模板(这是 Flask web 开发框架的内置模板引擎)的优秀指南。
创建 PDF 报告
假设您想要打印显示银行账户增长的 pdf 表格。每个表格都显示了 100 美元、500 美元、20,000 美元和 50,000 美元的年增长率。每个单独的 pdf 报告使用不同的利率来计算增长率。我们需要 10 份不同的报告,每份报告分别打印利率为 1%、2%、3%、10%的表格。
让我们首先定义我们需要的熊猫数据框架。
data_frames 包含 10 个字典,每个字典都包含数据帧和用于产生该数据帧的利率。
接下来,我们创建模板文件。我们将为上述 10 个数据框中的每一个生成一个报告,并通过将每个数据框连同所使用的利率一起传递给模板来生成它们。
创建这个模板后,我们编写下面的代码来为我们的报告生成 10 个 HTML 文件。
我们的 HTML 报告现在看起来像这样:

最后一步,我们需要将这些 HTML 文件转换成 pdf。为此,我们使用 pdfkit。您所要做的就是遍历 HTML 文件,然后使用 pdfkit 中的一行代码将每个文件转换成 pdf。
所有这些代码组合起来将弹出以下 PDF 版本的 HTML 文件:

然后你可以点击 1.pdf,看到我们得到了我们想要的结果。

我们已经给出了一个非常简单的例子,说明如何使用 python 以自动化的方式创建报告。通过更多的工作,您可以开发更加复杂的报表,只受 HTML 的限制。
原载于 2018 年 9 月 16 日【www.marknagelberg.com】。要访问我共享的 Anki deck 和 Roam Research notes 知识库,以及关于间隔重复和提高学习效率的技巧和想法的定期更新, 加入“下载马克的大脑”。
创建 R 包:你需要知道什么
创作 R 包的主要经验和印象。本文还包含了一些链接,指向您需要阅读的书籍和文章,以便开始您自己的 R 包。

我和 R 的旅程是从 2012 年左右开始的。我在我们的共享服务中心组建了一个团队来提供分析服务。这是一个小团队,在很多方面我们都在开拓新的领域。我们的数据科学家采用 R 有几个原因,包括价格、软件包支持的范围和社区的规模。事实上,我们的团队帮助建立了菲律宾用户组,自 2013 年第一次会议以来,该用户组已经有了很大的发展。
我们最终应用 R 做了很多很酷的事情,比如时间序列预测(对于共享服务组织中的劳动力优化非常有用)、线索生成和预测建模。我们原型化地将 R 模型公开为 web 服务,供各种客户端使用。总的来说,我们考虑了 R 如何适应生产工作流程和服务。我们还做了很多数据“基础设施”工作:数据摄取、数据&元数据建模、数据仓库、数据质量以及其他被称为数据工程的事情。正如其他人注意到的,这种东西真的超过了分析价值链中 80%的工作。对我个人来说,我实际上把大部分时间花在了管理任务上:招聘和发展团队,销售团队服务,与公司领导层和我的同事一起制定战略,以展示分析的价值,并在组织中发展能力。然而,我总是试图接近设计和实现的细节,包括我们用 r 做的事情。
我们在 R 中所做的大部分工作都是针对我们公司和内部使用的应用程序的。我们写了很多 R 代码:主要是供我们的数据科学家交互使用的脚本,或者由其他脚本/程序调用的脚本。我知道我们可能会从开发 R 包中受益,以更好地形式化、管理和促进重用,即使是内部使用。然而,在我们开始探索这个选项之前,我已经转移到了另一个角色。
嗯,迟做总比不做好。几周前,我决定最终构建我的第一个 R 包。这是一个关于我为什么、做什么以及如何做这件事的故事。简而言之,我学到了很多,我想趁记忆犹新的时候,分享一下我一路上的发现。我也形成了一些早期的印象,也将分享其中的一些想法。
动机
我的动机有两个:在 R 社区层面上就代码重用进行合作,并在这个过程中自学。Airbnb 工程和数据科学团队( AirbnbEng )解释了他们为什么要构建 R 包:
我们构建包来开发针对常见问题的协作解决方案,标准化我们工作的视觉呈现,并避免重新发明轮子。
说得好。就我而言,我一直在探索客户支持和案例管理工具。在这一领域,一个备受关注的网络应用(或软件即服务——SaaS——工具)是 Freshdesk 。将数据从流行的网络应用程序中取出,放入 R 中进行分析,这无疑是一个“常见问题”。当我搜索 R 包来从 Freshdesk 提取数据时,我没有立即找到任何包。这似乎是一个开发 R 包的好机会,我可以与社区中的其他人分享。
不是所有的 R 包都需要与应用程序编程接口(API)交互,但我的需要,因为这是 Freshdesk 让第三方程序访问自己的方式。以下是一些让我思考如何继续我的项目的文章和博客帖子。如果您计划创建一个以任何方式包装 API 的 R 包,这些都是很好的入门读物:
我学到了什么
我们通过实践学得最好。我确实从自己的 R 包中学到了很多。其中一些是大画面的东西,而我认为一些是较小的,微妙的细节。后者往往是最引人注目的:魔鬼,成功和失败的区别,不可避免地在于细节。
以下是我写第一个包时最突出的部分。有些经验教训很笼统,有些则更微妙、更具体。他们都留下了深刻的印象。
阅读哈德利·韦翰的 R 包
我不认为我可以夸大每一个有抱负的软件包开发者阅读这本书的重要性。哈德利是 R 社区公认的专家之一。我认为他的书 R Packages 是在软件包开发方面的权威:

R Packages by Hadley Wickham: the authority on creating R packages
我无法告诉你我陷入了多少次,只是意识到我试图做的事情在这本书里有所涉及。尽管我从头到尾读了一遍,但在整个开发过程中,我还是不断地回头去看它。如果你想开发一个 R 包,没有借口不读这本书:它是免费的!读这本书。然后再读一遍。
阅读 API 文档
如果你正在构建一个依赖于 API 的包(像我一样),从头到尾阅读应用的 API 文档。如果你不熟悉基于 web 的 API,请先阅读 Zapier 的API 介绍(它也是免费的!).
所有 web 应用程序通常都会在某个地方提供对其 API 的引用。Freshdesk 提供了一个 API 引用。 Github 、 Airbnb 、 Salesforce 、 twitter 也是如此。基本上都是。如果您的 R 包要与它们交互,熟悉这些文档是有好处的。
依靠你的工具
很久以前,在我从事 Windows 编程的日子里,我学到了这一课:您的集成开发环境(IDE)将提供许多功能来改进您的工作流、检查您的代码质量,并为您节省大量时间。特别是对于 R 和包开发,您的 IDE 是 RStudio。使用它。
将帮助你开发 R 包的 R 包是 devtools。安装这个包,并按照 Wickham 的 R 包中的描述使用它。但是你已经知道了,因为你已经像我建议的那样阅读了 R 包!
最后,您必须使用版本控制。早在 2000 年,Joel Spolsky(Stack Overflow 和 Fog Creek 软件的联合创始人)定义了 Joel Test 来衡量开发团队的成熟度。Joel 测试的第一个问题是:你使用源代码控制吗?今天,这意味着 Git。如果你的项目像我一样是公共的,就用 Github(否则就用某种现代版本控制系统)。有很多关于使用 Git 和 Github 的好资源——我不会在这里重复这些内容。您真正需要做的是创建一个 Github 帐户,安装 git ,并在 RStudio 中选择文件|新项目…|新目录| R 包,并确保您点击了创建 git 库复选框。

Creating a new git repository when creating a new package in R
您可能已经猜到了,在 Wickham 的 R 包中介绍了如何将 git 和 Github 与 RStudio 一起使用。
使用持续集成
猜猜乔尔测验的第二个问题是什么:你能一步到位吗?今天,这将被称为持续集成。在构建您的包时使用持续集成。具体用特拉维斯 CI 。
如果你在 Github 上公开主持你的项目,Travis CI 是免费的。开箱即用,Travis CI 会在您每次将更改推送到 Github 时自动构建并检查您的包。我无法告诉你每次对 Github 进行修改时自动执行构建有多令人满意。它迫使你在推进到 GitHub 之前检查你的构建,并花时间调查和清理可能引起警告的小东西。

Travis CI automatically builds and checks your package
Travis CI 的基本设置包含在 R 包中。你也可以看看茱莉亚·西尔格的优秀作品的《Travis-CI 入门指南》。
学习如何处理日期和时间
不可避免地,你需要处理 r 中的日期和时间,学习如何处理日期和时间以及日期运算。R 中的日期和时间让我想起了我必须在中学习相同内容的时候。净年前。日期和时间处理起来很麻烦,会引起问题,而且经常被简单地篡改。追根究底。这里有一个好资源可以开始使用。不要敷衍了事,读一读吧! Kan Nishida 最近在他的 5 个在 R 中处理日期和时间时最实用的操作中涉及了相同的领域,我也推荐你看一下。
创建文档而不共享私有数据
当您依靠 RStudio 这样的工具时,可以使用 Rmarkdown 动态地创建文档,如项目的自述文件和简介。事实上,你应该避免编辑简单的降价。md 文件)。
当您使用 API 时,您不希望在文档中明确地进行身份验证,因为您会泄露像 API 密钥这样的私有信息。为了解决这个问题,将您的凭证存储在本地 R 环境变量中。通过这种方式,您可以使用 Rmarkdown 从环境变量中获取 API 键,而无需在源 Rmarkdown 文档中显示实际的键,并且如果您喜欢,也无需在呈现的普通 markdown 文件中显示从环境变量中检索键的代码:
```{r credentials, echo=FALSE}
my_domain <- Sys.getenv("FRESHDESK_DOMAIN")
my_api_key <- Sys.getenv("FRESHDESK_API_KEY")
然后,您可以在最终呈现的内容中显示代码和输出:
library(freshdeskr)# create a client
fc <- freshdesk_client(my_domain, my_api_key)# gets tickets
ticket_data <- tickets(fc)
...
使用测试框架
当我开始开发这个包时,在每一次devtools::load_all(),检查,或者安装和重启之后(你会在 R 包中了解到所有这些),我会发现自己运行同样的代码来测试包中的功能。您希望将这种代码放入单元测试中,这样您就可以从一个命令中运行它,并将其作为持续集成过程的一部分。这样,每当您将新的更新推送到 Github 上的项目存储库时,您的测试就会自动运行。
Devtools 通过为您的项目设置 testthat 包使这变得容易,所以依靠您的工具并使用它吧!我遇到的一个问题是,我正在包装一个 web 应用程序的 API。我不想在测试中暴露我的 API 键(因为这些代码在 Github 上是公开的)。我不能像生成文档那样使用环境变量,因为当测试在持续集成服务器上运行时,这是行不通的。对于这种情况,你需要使用模拟。测试和使用测试包包含在 Wickham 的 R 包中,使用模拟包不包含在中。Mango Solutions 有一篇很好的文章:使用模拟函数在没有互联网的情况下进行测试向您展示了如何做到这一点。
在我的例子中,我需要模拟出在我的包的函数中发出的 http GET 请求。需要做一些设置工作,但是当您检查您的项目时,看到所有的单元测试自动运行是令人满意的!所以自动化你的测试。自动化一切。
名称冲突
当我开始从事我的项目时,我在包之外创建了一些函数,在将它们包含到包中之前,我可以先试用一下。当我在我的包中创建相同的函数时,我以名称冲突结束,因为全局环境在搜索路径中位于我的包之前(使用search()查看名称的搜索路径)。重启 RStudio 并没有解决问题。我最终关闭了 RStudio,并手动删除了项目的.Rdata文件以清除名称。
我现在明白了,还有其他更好的方法,例如:从控制台使用rm()或者取消选中 Restore。在重新启动 RStudio 之前,在 RStudio 菜单中的工具|全局选项… 下的启动选项中进入工作区。

Uncheck Restore .RData into workspace at startup to remove variables from Global Environment
大图:花些时间理解 R 中的环境的概念。
其他印象
整个练习给人留下了很多其他的印象。有三个很突出。一个是有点技术性的:依赖注入的处理。另外两个更一般:使用 Github 和如果有多个合作者,如何支持敏捷方法。
依赖注入
我在技术和设计方面遇到的一个问题是处理依赖注入。我的代码没有涉及太多的细节,而是将 API 返回的一些字段从代码转换成人类更可读的内容。例如,如果支持票据的状态为“打开”,则 Freshdesk API 会返回“2”。在检索票证数据的函数中,我想将 2 转换为“Open”。
我创建了一些查找表来处理这个问题。我不喜欢在函数中使用它们来将代码转换成可读的标签。它本质上等同于硬编码值。理想情况下,我会将这些查找表保存在包内部。但是,如果不能从外部访问它们,就不能将它们作为参数传递给任何导出的函数(并实现依赖注入)。最后,我向软件包的用户公开了这些查找表。另一方面,用户可能会修改这些表,并导致使用它们的函数出错。积极的一面是,用户可以更新表,例如,如果 Freshdesk 在 API 中更新了这些代码。阴阳……
开源代码库
这个项目的一个有趣和积极的副作用是我更多地了解了 Github。我以前用过 git,在 Github 上也有一些令牌回购(这是存储库的酷说法)。然而,在 Github 上托管我的包迫使我更好地理解这个工具。我学到了如何编写更好的提交消息,在编写我的包的过程中,我改编了一些指南。我还学会了真正利用 Github 作为问题跟踪器。您可以在提交中使用关键字来自动更新和/或关闭问题。自动化很好。我还意识到,Github 问题可以用来捕捉一切:不仅仅是 bug,还有想法、增强、重构机会等等。接下来也很好…
支持敏捷工作流程
如果你捕获了 Github 的所有问题,那么它基本上就成了你的产品积压。你甚至可以在 Github 中设置看板风格的板子。如果你采用某些惯例,那么 Github 可以支持敏捷方法。Github 问题的敏捷项目管理工作流程很好地描述了如何实现这一点,我打算继续下去。我甚至已经开始将我的问题写成用户故事,例如:作为一个用户,我希望能够有选择地检查到 Freshdesk 的连接,以便在我使用任何方法检索数据之前,我知道域和认证是有效的。
后续步骤
现在还为时尚早,我将继续开发仍处于初级阶段的 freshdeskr 包。我邀请任何人通过报告问题、发布功能请求、更新文档、提交请求或补丁以及其他活动来做出贡献。
你从创建 R 包中学到了什么?你会推荐什么书、文章或其他资源?
可以在 GitHub 上克隆或者分叉 freshdeskr 包。你可以在推特上找到我@ johnjanuszczak。
用 Docker 为 R 创建沙盒环境
在过去的一年里,我一直在学习 R,其中一件让我印象深刻的事情就是建立一个环境,并启动和运行 R 有多么困难。我最近看到了一篇关于如何使用 H2O 和机器学习的博客帖子( link ),这在我看来很棒。唯一的问题是,如果我要分享我的工作,很有可能有人会花很长时间来尝试配置一个恰到好处的环境,以便所有的星星都可以正确地重现我的结果。
[## 今晚关于人力资源分析的实时数据谈话:使用机器学习预测员工流动率
美国东部时间今晚 7 点,我们将进行一场关于使用机器学习预测员工流动率的#DataTalk 直播。员工…
www .商业科学. io](http://www.business-science.io/presentations/2017/10/26/datatalk_hr_employee_attrition.html)
现在,任何了解我的人都知道,我已经设法破坏了我的 Macbook 无数次,我宁愿不改变我的系统注册表中的一些随机 json 文件,而只是运行可能证明有用的包。输入 Docker。
码头工人:鬣狗之家

Sway’s Five Fingers of Death challenge
为什么要称 docker 为“鬣狗之家”?这难道不应该让我们知道我们的应用程序应该“正常工作”吗?

What we think our container will look like

What actually ends up happenning
你看,建造一个容器需要某种类型的个体。那个人需要有一定程度的坚韧,在他们的灵魂中有一种燃烧的感觉,当他们看到建造日志的恐怖时,他们不只是打个盹,然后喝醉。

Build Log Horrors
不。他们就像一只鬣狗,不仅仅把他们的构建日志看作错误,而是一个挑战,试图理解正在发生的事情,并且对他们的容器有一个愿景。你看,有两种人:选择建造的人和不建造的人。不同的是,从事建筑的人有一个愿景,一个目标,坚持不懈地追求这个目标,直到目标实现。以肯德里克或安迪·米尼奥这样的说唱歌手为例。对于码头工人是否比流浪汉更好,或者周二午餐吃什么,他们不会分心:*他们只是有一个目标,并像一只欲望未得到满足的鬣狗一样追逐它。*请注意,这一过程绝非易事。等待容器构建,找出构建中的错误,并不是一个奢侈的过程。如果你还没有准备好,这是可以理解的。不要再看这个了,去散散步,做个三明治,给需要的人。如果你想做一个容器,拿起三明治,狼吞虎咽:让我们开始工作。
Andy Mineo’s Five Fingers of Death
在你进一步阅读之前,请观看下面的视频,直到 2:40:
从Opensource.com,Docker 定义如下:
Docker 是一个工具,旨在通过使用容器来简化应用程序的创建、部署和运行。容器允许开发人员将应用程序与它需要的所有部分打包在一起,比如库和其他依赖项,然后作为一个包发送出去。通过这样做,由于有了容器,开发人员可以放心,应用程序将在任何其他 Linux 机器上运行,而不管该机器的任何定制设置可能与用于编写和测试代码的机器不同。
简单地说,Docker 是一种给你的计算机一套指令来制作一道菜(比如说比萨饼)的方法。也许我的朋友杰夫发现了我的比萨饼,想在他的机器上测试一下。简单。下拉映像,使用 docker 文件构建容器,并在本地运行容器。有多简单?
现在,在我们开始之前,有几个主题是值得讨论的,这样你就不会陷入和我刚开始时一样的陷阱:依赖管理,以及托管平台。
依赖管理
想想你的“披萨”(或容器)里想要什么。当我开始使用我的容器时,我不知道术语“依赖地狱”是什么意思。我强烈建议您在构建容器之前考虑一下您到底想用它做什么。对我来说,我只是想要一个有特定包的沙盒环境,比如 tidyquant。我还想确保当我安装我的包时,任何必要的包也安装了:
install.packages("tidyquant")
默认情况下,下面的代码行将安装“Depends”、“Imports”和“Linking to”中的所有包。虽然这很好,但 tidyquant 有一个被证明是麻烦的小依赖项:XLConnect,它需要 rJava。这可能有点令人头痛,因为 rJava 需要 Java 才能工作,而这很难用 Docker 来配置。
平台:Docker Hub vs Gitlabs
如果您决定使用 Github 来托管(或存储)您的 docker 文件,很可能您会希望使用 CI(持续集成)服务来查看对您的 docker 文件所做的更改是否成功。持续集成是必要的,因为这些服务可以帮助您监控推送到 GitHub 的更改,以及构建是否成功。Docker Hub 在默认情况下提供了这种能力,但是很难找出到底是哪里出了问题。如果您决定使用 GitHub 来存储您的代码,我强烈建议您使用 Travis CI 来监控对您的容器所做的更改,以及是否有任何问题发生。
另一个让我印象深刻的关于持续集成的服务是 Gitlabs,它提供了托管、构建和监控 Docker 容器的一站式服务。GitLabs 有时可能有点难以配置,但如果您感兴趣,可以查看以下容器,看看它是否能满足您的需求:
https://gitlab.cncf.ci/fluent/fluentd-docker-image
无论你决定使用哪种服务,我认为有一个版本控制系统是非常必要的,这样你就可以回去,看看什么变化起作用,什么变化不起作用。提交新的变更绝对是一件痛苦的事情,但是我认为能够看到你的构建状态从 15 次糟糕的尝试到第一个绿色徽章是非常值得的。
一些后勤物品
在我们开始这个项目之前,有几个后勤项目需要解决:首先,从这里下载 docker:【https://www.docker.com/community-edition
接下来,下载以下工具:
Visual Studio 代码-【https://code.visualstudio.com/download
https://www.gitkraken.com/download
Visual Studio 代码是非常好的文本编辑器,内置了对 Docker 管理的支持,这是一个与文件系统交互的终端,允许您在文本编辑器中与 Git 或 GitHub 等版本控制进行交互。当您从 Visual Studio 代码中打开存储库时,您会注意到下面有一个名为 Docker 的选项卡。这使您可以直观地看到本地下载的图像,以及任何正在运行的容器和 Docker Hub 上的任何图像,这非常方便:

Visual Studio Code Docker Management
GitKraken 是一个用于从远程位置管理存储库的工具(如 GitHub 或 BitBucket)。GitKraken 特别有助于保持您的存储库的本地副本与 GitHub 上所做的更改同步,但不会下载到您的本地机器上。
最后,在 GitHub 上创建你的库,你可以随心所欲地命名它。
1.现在进入 GitKraken,点击屏幕左上角的文件夹图标。
2 这将提示您从远程位置克隆存储库。有关更多详细信息,请参见下图:

Cloning the repo in GitKraken
我们走吧!您的存储库现在应该被克隆到您的本地机器上,因此您现在可以访问它,并且可以将文件推/拉到存储库中。
第 1 部分:创建 Dokerfile
为了构建您的 order 文件,需要一些核心组件来使 order 文件完整,这些组件是:
- 从基础图像开始
- 在基本映像上安装所需的任何核心库
- 您希望安装在容器上的包
- 清理所有临时文件,使图像尽可能小
有一点需要注意的是,当你创建 docker 文件时,你希望你的图像有尽可能少的“层”。让我们看一个样本 docker 文件
FROM rocker/tidyverse:latest
LABEL maintainer="Peter Gensler <peterjgensler@gmail.com>"RUN R -e "install.packages('flexdashboard')"
RUN R -e "install.packages('tidytext')"
RUN R -e "install.packages('dplyr')"
RUN R -e "install.packages('tidytext')"
为什么这样不好?根据 Docker 的说法,每个 RUN 命令都被视为图像上的一层,你放入图像的层越多,图像就越大,这使得它有点难以处理。为了尽量减少这种情况,最好限制 docker 文件中的命令数量。我把我的任务分成了创建目录、复制文件夹、安装 CRAN 包和安装 GitHub 包,这些仍然是相当多的层,但使代码更可读,以查看我试图用这段代码执行什么操作。
让我们通过使用我创建的 Dockerfile 作为示例来说明上述概念,从而对其进行分解:
FROM rocker/tidyverse:latest
LABEL maintainer="Peter Gensler <peterjgensler@gmail.com>" # Make ~/.R
RUN mkdir -p $HOME/.R# $HOME doesn't exist in the COPY shell, so be explicit
COPY R/Makevars /root/.R/MakevarsRUN apt-get update -qq \
&& apt-get -y --no-install-recommends install \
liblzma-dev \
libbz2-dev \
clang \
ccache \
default-jdk \
default-jre \
&& R CMD javareconf \
&& install2.r --error \
ggstance ggrepel ggthemes \
###My packages are below this line
tidytext janitor corrr officer devtools pacman \
tidyquant timetk tibbletime sweep broom prophet \
forecast prophet lime sparklyr h2o rsparkling unbalanced \
formattable httr rvest xml2 jsonlite \
textclean naniar writexl \
&& Rscript -e 'devtools::install_github(c("hadley/multidplyr","jeremystan/tidyjson","ropenscilabs/skimr"))' \
&& rm -rf /tmp/downloaded_packages/ /tmp/*.rds \
&& rm -rf /var/lib/apt/lists/*
为了构建一个容器,容器需要一个起始映像来开始,这个映像可以在 Docker Hub 上找到,Docker Hub 位于这里是。这里需要注意的一点是,虽然 Docker Hub 有 Ubuntu 或 Python 的官方图片,但 r 没有官方图片。幸运的是,Rocker 项目的人决定给我们一些非常有用的图片,作为一个好的起点:【https://www.rocker-project.org/images/】T2
接下来,我们需要创建一个。r 文件夹,通过下面一行:
RUN mkdir -p $HOME/.R
一旦完成,我们需要将 Makevars 文件从 GitHub 上的 R/Makevars 复制到容器的主目录中。Makevars 文件只是用来将参数传递给编译器(本例中是 C++ ),这样构建我们的容器的输出就不会有 rstan 包(prophet 包需要它)的一堆混乱的警告
COPY R/Makevars /root/.R/Makevars
一旦我们将正确的文件放入它们各自的位置,就该开始安装使用我们的 R 包所需的任何必要的库了。这里要注意的是,rocker/tidyverse 映像是建立在 Debian 的最新稳定版本(目前是 stretch)上的。要找到你可能需要的软件包,只需使用下面的链接在 Debian stretch 上搜索软件包(这并不总是最容易搜索的)
根据 Debian 自由软件的规定,Debian 官方发行版中包含的所有软件包都是免费的…
www.debian.org](https://www.debian.org/distrib/packages#search_packages)
如果您希望了解更多关于以下内容的信息,我强烈建议您在这里查看 apt-get 的文档:
RUN apt-get update -qq \
&& apt-get -y --no-install-recommends install \
[## apt-get(8) - Linux 手册页
apt-get 是处理包的命令行工具,可以被认为是用户对其他工具的“后端”…
linux.die.net](https://linux.die.net/man/8/apt-get)
我们在第二行所做的只是声明不要为一个给定的包安装任何推荐的包。
需要注意的一点是,在 docker 文件中,我们使用命令:
&& install2.r --error \
这是从包 littler 中取出的,它允许我们通过命令行安装 R 包。上面的错误标志仅仅意味着如果下面几行中的任何一个包出错,编译就会出错。请注意,上面安装以下包的脚本是一个连续的行,它允许在容器内安装包时创建尽可能少的层。
接下来,我们使用 Rscript,这是从 GitHub 命令行安装软件包的一种不同方式。
最后,我们使用下面的命令清理所有临时文件,以减小容器大小:
&& rm -rf /tmp/downloaded_packages/ /tmp/*.rds \
&& rm -rf /var/lib/apt/lists/*
既然我们的 docker 文件已经编写好了,那么是时候在本地测试我们的容器以验证它是否构建成功了
第 2 部分:本地运行容器
一旦我们创建了 Dockerfile,下一个测试就是看看我们是否可以在本地构建容器。虽然这一步听起来很简单,但仅仅构建容器只是征服 docker 之旅的一半。
为此,只需导航到包含您的文件的文件夹。在这个例子中,我只是进入名为 sandboxr 的文件夹。
cd ~/sandboxr
接下来,在您的终端中运行命令,这将构建映像。这需要一些时间,所以要有耐心。末尾的句点表明 dockerfile 位于我们所在的文件夹中,因此我们不需要显式指定路径:
docker build -t my_image .
完成后,您应该会在最后看到一条消息,表明映像已经成功构建。如果您的映像没有构建,请检查日志,看看是什么失败了,是不是需要一个 Debian 包,或者从源代码构建包有一些问题。
既然我们的 Dockerfile 已经编写好了,是时候使用一些 CI 服务来监控我们的构建了,这样当进行更改时,我们就可以看到这些更改是否破坏了构建。
第 3 部分:持续集成
持续集成的启动和运行可能会很麻烦,因此本文旨在提供一个关于如何为您的容器启动和运行框架的简要概述。大多数 CI 服务使用 YAML 文件,它只是一个配置文件,告诉服务如何构建您的容器,以及测试它的指令。我们将使用 Travis 进行 CI,但您也可以选择使用 Docker Hub 的 CI 服务来查看您的包是否已构建。如果您选择在 GitLabs 而不是 GitHub 上托管您的文件,您可以使用 GitLabs DIND 进行 CI,这需要您的 Docker 文件以及您项目的其他文件夹存储在 GitLab 中,然后使用 Docker 运行一个容器,该容器然后在中运行您的容器以测试它。我用 GitLabs 设置了我的项目,所以你可以看到。yml 文件不同于 Travis:
GitLab.com
gitlab.com](https://gitlab.com/petergensler/sandboxr/blob/master/.gitlab-ci.yml)
我也鼓励你去看看 Jon Zelner 关于与 Docker 一起建立 GitLabs 的博客,了解一下其他人是如何建立 git labs 的。yml 文件外观:
[## 再现性始于家庭
当谈到公共健康和社会科学时,再现性越来越成为话题的一部分…
www.jonzelner.net](http://www.jonzelner.net/statistics/make/docker/reproducibility/2016/05/31/reproducibility-pt-1/)
首先,将一个. travis.yml 文件添加到 Github 存储库中,如下所示:
sudo: required
services:
- dockerbefore_install:
- docker build -t pgensler/sandboxr .
script:
- docker run -d -p 127.0.0.1:80:8787 pgensler/sandboxr /bin/sh
我们在这里做什么?让我们来分析一下。首先,我们需要一个 sudo 命令,就好像这是在 Linux 机器上构建的一样,需要 sudo 来使这些命令正常工作。Travis 要求您在. travis.yml 文件中指定三个项目,如他们的初学者核心概念中所概述的:
- 服务
- 安装前 _ 安装
- 脚本
接下来,我们指定这个构建所需的服务。在这种情况下,我们只需要 docker 来测试我们的容器。我们想在 Travis 上构建容器,所以我们简单地使用命令 docker build 和 <github_username>/ <repo_name>。的。in 只是说在当前文件夹中查找 Dockerfile 来构建图像。</repo_name></github_username>
一旦构建了映像,我们就想看看是否可以运行容器作为一个简单的测试来验证容器是否工作。请注意,需要一个脚本来测试图像。如果没有指定脚本,那么 Docker 将尝试使用 Ruby 来测试容器,这可能会导致如下错误:
Error: No rakefile found
第 4 部分:与 Docker Hub 集成
如果你已经做到了这一步,恭喜你。您已经成功构建了一个 docker 文件,在本地对其进行了测试,集成了 CI 服务,并且您认为您的映像可以按预期工作。现在是时候整合 Docker Hub 和 GitHub 了,这样两者就可以互相交流了。现在,你可能会问自己“好吧,兄弟,但是谁在乎呢?”如果我的映像构建成功,我妈妈不会收到电子邮件通知?
你想“走过 Docker Hub 的门口”的原因很简单:这样别人就可以享受并受益于你的形象。通过查看 DockerHub 上他们的构建日志和 Dockerfile,我从其他映像那里学到了更多,从而了解如何定制我自己的构建来为我的容器获得灵感。举个例子,我发现有人在 Docker Hub 上成功构建了一个包,并有了输出。多棒啊。
登录 Docker Hub 并启用以下功能:

这将把你的 GitHub 库和 Docker 连接起来。这将允许其他人不仅可以查看您的 docker 文件,还可以查看您的容器的源存储库。我认为这是必要的,原因有二:它能让别人看到你的作品,得到灵感,并为你的最终产品感到骄傲。您刚刚创建了一个杰作容器,为什么不想与他人共享呢?
最终测试
要测试您的映像,只需尝试通过以下方式从 docker hub 获取映像:
- docker pull pgensler/sandboxr
现在,通过以下命令运行映像:
docker run -d -p 8787:8787 -v ~/Desktop:/home/rstudio pgensler/sandboxr
上面的命令获取您的映像,将其从 Docker Hub 中取出,作为一个容器在端口 8787 上运行,并将您的桌面映射到文件夹/home/rstudio,这样您就可以从容器内部访问机器上的文件。
最后,将您的浏览器指向 localhost:8787,就可以了!现在,您已经有了一个与 RStudio 的工作会话,并且您的包都已配置好,可以开始工作了!
收拾东西
完成映像后,记得清理映像,方法是通过以下方式将其从机器中删除:
Docker rmi $(docker images -aq)
最后的想法
将 Docker 与 R 集成在一起几乎是显而易见的——如果您希望能够与其他同事共享您觉得有用的包,那么您需要使用 Docker。为什么?因为它允许您以可重现的方式重新创建分析环境,所以其他人可以比试图找出 rstan 不能正确安装的原因更快地启动并运行。不仅如此,Docker 还鼓励你通过 Docker Hub 分享你的杰作,这是免费的,非常容易使用。Docker 可能非常辛苦,但考虑到你所创造的东西,它也非常值得——你会使用它吗?
用有限的移动时间和文件大小创建(几乎)完美的连接四个机器人
在位操作上,alpha-beta 剪枝和硬编码初始游戏状态,为 connect four 打造一个非常强大的 AI 代理。
在根特大学一年级工程师学习 Python 编程的“信息学”课程背景下,我们建立了一个人工智能机器人竞赛平台。目标是通过实现以下功能来创建一个玩游戏 connect-four 的机器人:
def generate_move(board, player, saved_state):
"""Contains all code required to generate a move,
given a current game state (board & player) Args: board (2D np.array): game board (element is 0, 1 or 2)
player (int): your plabyer number (float)
saved_state (object): returned value from previous call Returns: action (int): number in [0, 6]
saved_state (optional, object): will be returned next time
the function is called """
return 0
向平台提交代码后,自动挑战排行榜上排名比你高的所有玩家。游戏是在你的机器人和对手之间模拟的。每场游戏由五轮组成,如果出现平局,首先连接四个代币的玩家将获得 5 分,首先连接最长链(很可能是 3 个代币)的玩家将获得 1 分。这确保了总有一个赢家。第一轮的首发球员是随机选择的,之后球员们轮流首发。你的等级不断增加,直到你输了(天梯游戏)。

A simulation of a game between bots. Player 1 is definitely on the winning hand.
我和我的同事耶鲁安·范德胡夫特决定,根据下面的博客文章,尽可能多地模仿完美的解算者(,如果他能开始,他就赢得了比赛,这将是一个有趣的练习。我们的代码必须遵守的一些重要要求(这导致我们的解算器不是完全最优的)是:
*最大文件大小为 1 MB
- generate_move 不能运行超过 1s
*仅使用标准库和 NumPy
用位串表示游戏板
先介绍一种高效的存储游戏板的数据结构: bitstrings 。我将总结最重要的操作(例如检查四个令牌是否连接,以及在移动后更新棋盘)。关于位串(或位板)和所有可能的操作的详细解释,请查看这个自述文件(尽管做的有点不同)。
我们可以用两个位串的形式唯一地表示每个可能的游戏状态(或游戏板配置),这可以很容易地转换成整数:
*一个位串表示一个玩家的标记的位置(位置 )
*一个位串表示两个玩家的位置(掩码 )
对手的位置位串可以通过在掩码和位置之间应用异或运算符来计算。当然,为两个玩家的令牌存储两个位串也是一种可行的方法(然后我们可以通过对两个位串应用 or 运算符来计算掩码)。
位串由 49 位组成,其中包括一个 7 位的标记行(全为 0 )(稍后将解释其用途)。这些位的排序如下:

The ordering of the bits to in the bitstring (0 is the least significant, or right-most, bit). Notice how bits 6, 13, 20, 27, 34, 41 and 48 form a sentinal row, which is always filled with 0’s.
例如,检查以下游戏板配置:

An example of a possible game state / board configuration
现在让我们用黄色玩家的位置位串形成位串:
**position**
0000000
0000000
0000000
0011000 = b'0000000000000000000110001101000100000000000000000'
0001000
0000100
0001100 = 832700416**mask**
0000000
0000000
0001000
0011000 = b'0000000000000100000110011111000111100000000000000'
0011000
0011100
0011110 = 35230302208**(opponent position)** 0000000 0000000 0000000
0000000 0000000 0000000
0000000 0001000 0001000
0011000 XOR 0011000 = 0000000
0001000 0011000 0010000
0000100 0011100 0011000
0001100 0011110 0010010
由于 board 输入参数是 numpy 数组中的 numpy 数组,我们首先需要将这个 board 转换成相应的位图。下面是实现这一点的(相当直接的)代码:
**def get_position_mask_bitmap(board, player):**
position, mask = '', ''
# Start with right-most column
for j in range(6, -1, -1):
# Add 0-bits to sentinel
mask += '0'
position += '0'
# Start with bottom row
for i in range(0, 6):
mask += ['0', '1'][board[i, j] != 0]
position += ['0', '1'][board[i, j] == player]
return int(position, 2), int(mask, 2)
我们现在可以使用位置位串来检查四个令牌是否连接,使用下面的位操作:
**def connected_four(position):**
# Horizontal check
m = position & (position >> 7)
if m & (m >> 14):
return True # Diagonal \
m = position & (position >> 6)
if m & (m >> 12):
return True # Diagonal /
m = position & (position >> 8)
if m & (m >> 16):
return True # Vertical
m = position & (position >> 1)
if m & (m >> 2):
return True # Nothing found
return False
现在,让我们分解检查四个令牌是否水平连接的部分:
1\. m = position & (position >> 7)
2\. if m & (m >> 14):
return True
第一步(1。)将我们的位串 7 的位置向右移动,并采用 and 掩码,这归结为将我们的位板中的每个位向左移动(我们减少位串中的索引,其中索引 0 对应于最右边或最不重要的位)。让我们以下面的 bitboard 为例(简化版,在真实游戏中不会出现):
0000000
0000000
0011110
0000000
0000000
0000000
0000000= b'0000000001000000100000010000001000000000000000000'
>> 7: b'0000000000000000100000010000001000000100000000000'0000000
0000000
0111100
0000000
0000000
0000000
0000000&: b'0000000000000000000000010000001000000100000000000'0000000
0000000
0011100
0000000
0000000
0000000
0000000
我们可以按如下方式查看新的位板:如果在其左侧有一个令牌,并且如果它是相同的,则位等于 1(或者换句话说:位等于 1 表示我们可以从该位置向左水平连接两个令牌)。现在进行下一个操作(2。),我们将结果向右移动 14 位,并再次应用 and 掩码。
0000000
0000000
0011100
0000000
0000000
0000000
0000000= b'0000000000000000100000010000001000000000000000000'
>> 14: b'0000000000000000000000000000001000000100000000000'
-------------------------------------------------
& : b'0000000000000000000000000000001000000000000000000'> 0? : True # four connected tokens found
通过将我们得到的位串向右移动 14 个位置,我们正在检查我们是否可以将两个水平连续的记号与棋盘上它左边两个水平连续的记号匹配。这些步骤组合起来相当于检查四个令牌是否水平连接。其他方向(对角线和垂直方向)的操作是相同的,我们只是将位图移动了或多或少的位置(1 表示垂直方向,8 表示西南方向的对角线(/),6 表示东南方向的对角线())。
标记行(7 个额外的位)的原因是为了区分网格的顶行和底行。没有它,这种方法会产生假阳性,下面是两个位置位串,一个在 6x7 网格上,另一个在 7x7 网格上。我们检查是否可以找到四个垂直连续的记号(在这种情况下,这是假的)
vertical check on 6x7 grid
--------------------------
0010000
0010000
0010000
0000000
0000000
0001000= b'000000000000000000000001111000000000000000'
>> 1: b'000000000000000000000000111100000000000000'
& : b'000000000000000000000000111000000000000000'
>> 2: b'000000000000000000000000001110000000000000'
& : b'000000000000000000000000001000000000000000'
> 0?: True (WRONG)vertical check on 7x7 grid
--------------------------
0000000
0010000
0010000
0010000
0000000
0000000
0001000= b'0000000000000000000000000001011100000000000000000'
>> 1: b'0000000000000000000000000000101110000000000000000'
& : b'0000000000000000000000000000001100000000000000000'
>> 2: b'0000000000000000000000000000000011000000000000000'
& : b'0000000000000000000000000000000000000000000000000'
> 0?: False (CORRECT)
现在让我们更好地看看移动操作,我们根据玩家的移动来改变位图:
**def make_move(position, mask, col):**
new_position = position ^ mask
new_mask = mask | (mask + (1 << (col*7)))
return new_position, new_mask
我们做的第一件事是在位置和掩码位串之间应用异或掩码,以获得对手的位置位串(因为在走完这步棋后将轮到他)。然后,我们更新我们的掩码位串,方法是在当前掩码和添加的掩码之间应用一个 OR 掩码,并在相应的列中添加一个位(我们希望丢弃我们的令牌)。让我们看一个例子:
**position**
0000000
0000000
0000000
0011000
0001000
0000100
0001100**mask**
0000000
0000000
0001000
0011000
0011000
0011100
0011110# Drop a token in the fourth column
--> make_move(position, mask, 4)new_position = position ^ mask
**new_position**
0000000 0000000 0000000
0000000 0000000 0000000
0000000 0001000 0001000
0011000 XOR 0011000 = 0000000
0001000 0011000 0010000
0000100 0011100 0011000
0001100 0011110 00100101 << (col*7)
0000000
0000000
0000000
0000000 = 268435456
0000000
0000000
0000100mask + (1 << (col*7)) = 35230302208 + 268435456 = 35498737664
0000000
0000000
0001000
0011000
0011**1**00
0011000
0011010mask | (mask + (1 << (col*7)))
0000000
0000000
0001000
0011000
0011**1**00
0011100
0011110
博弈树、极大极小和阿尔法-贝塔剪枝
在阅读前一部分时,你可能会想:“为什么要给代码增加这么多的复杂性?”。我们之所以过度优化四合一游戏的基本操作,是因为我现在要介绍的概念:游戏树。
对于每一个有离散行动空间(或每一步有有限数量的可能行动)的博弈,我们可以构建一个博弈树,其中每个节点代表一个可能的博弈状态。在偶数深度的内部节点代表初始游戏状态(根)或由对手的移动导致的游戏状态。奇数层的内部节点代表我们移动时的游戏状态。如果一个状态是游戏结束(四个代币连接或棋盘已满),则为叶节点。每个叶节点被授予一定的分数,不再进一步展开。下面是一个连接四个游戏的游戏子树的例子。

An example of a path to a game-ending state in a game subtree
总共有 4531985219092 个可能的叶节点,因此树中的节点总数要大得多。即使使用优化的位板操作,遍历整个游戏树在计算上也是不可行的。我们将需要技术来有效地在这棵树中找到一条获胜的路径。
现在,虽然上图中游戏树的路径 1–1–2 导致游戏结束状态,黄色玩家获胜(这是一条获胜路径),但它基于红色是一个愚蠢的机器人并搞砸了他的移动(他没有阻止你)的假设。
因为我们不知道我们要对抗的机器人有多“好”,我们不得不假设最坏的情况:如果我们的对手是最好的机器人,因此每次都采取最好的行动,那该怎么办?如果我们能找到对抗这样一个最坏情况的 bot 的获胜路径,那么我们绝对可以走这条路,并且确信我们赢得了比赛(真正的 bot 只能做得更差,让比赛更早结束)。对于连接四个游戏,这样的路径存在,如果你是开始玩家。这就是 minimax 算法发挥作用的地方。
在我们将这个算法应用于博弈树之前,我们需要为树中的每个节点定义一个得分函数。我们将采用与这篇文章所基于的博客文章相同的评分函数。一个游戏棋盘配置的分数等于:
- 0 如果游戏以和棋结束
- 22 -如果我们能赢游戏所用的石头数
- -(22 -石头数)如果我们会输。
在下图中,如果我们假设我们是黄色玩家,我们可以给游戏棋盘分配-18 的分数,因为红色玩家可以用他的第四颗石头获胜。

This game board is assigned a score of -18 since the opponent can finish with 4 stones
实际上,当游戏还没有结束时,很难分配分数。这就是为什么我们探索我们的树,直到我们到达一个叶节点,计算分数并将这个分数向上传播回根。现在,当我们向上传播这些值时,游戏树中的内部节点将接收多个值(每个子节点一个值)。问题是我们应该给内部节点分配什么值。现在我们可以给出内部节点的值的定义:
*如果内部节点在奇数深度上,我们取子节点的最小值值它们的值(作为对手,我们希望最终的分数尽可能为负,因为我们想赢)
*如果内部节点在偶数深度上,我们取子节点的最大值值它们的值(我们希望我们的分数尽可能为正)
这里有一个例子,直接取自维基百科:

The optimal score we can achieve is -7, by taking the action that corresponds to the edge that goes to the right child of the root.
所以现在我们有办法在博弈树中找到最优路径。这种方法的问题是,特别是在游戏开始时,遍历整个树需要很长时间。我们只有一秒钟时间行动!因此,我们引入了一种技术,允许我们修剪游戏树的(大)部分,这样我们就不需要搜索整个游戏树。这个算法叫做阿尔法-贝塔剪枝。
我将总结最重要的概念。Pieter Abbeel 教授的一步一步的视频可以在这里找到。我们定义以下变量:
- alpha :最大化器(us)在通往根的路径上的当前最佳得分
- beta :最小化器(对手)在通往根的路径上的当前最佳得分
我们所做的是每当我们看到来自我们孩子的新值时更新我们的 alpha 和 beta 值(取决于我们是在偶数还是奇数深度上)。我们将这些α和β传递给我们的其他孩子,现在当我们发现一个值高于我们当前的β,或者低于我们当前的α时,我们可以丢弃整个子树(因为我们确信最优路径不会经过它)。让我们看看另一个例子,同样取自维基百科:

- 我们首先遍历游戏树的深度,从左到右。我们遇到的第一片叶子是最左边的叶子(值为 5)。叶子将这个值传播给它的父节点,在父节点中β值被更新并变成 5。它还检查第二个最左边的叶子(其值为 6),但这不会更新任何值(因为如果从最小化的角度来看,6 并不比 5 好)。
- 在这个节点中找到的最佳值(还是 5)被传播到它的父节点,在那里 alpha 值被更新。现在,我们在这个父节点的右边的子节点,首先用值 7 检查它的左边的子节点,并更新 beta 值(我们现在有 alpha=5 和 beta=7)。我们检查下面的孩子:值为 4,这是最小化的更好的值,所以我们现在有β= 4 和α= 5。
- 既然现在β≤α,我们可以剪除所有剩余的子代。这是因为我们现在在那个内部节点中总会有一个≤ 4 的值(我们是极小化器,只在遇到比当前值小的值时更新我们的值),但是父节点只会在值≥ 5 时更新值(因为我们在那个节点中是极大化器)。因此,无论遍历所有节点后的值是多少,它都不会被最大化节点选择,因为它必须大于 5 才能被选择。
- 对于所有剩余的节点,此过程将继续…
这个算法的一个很好的 python 实现,作者是 AI 最著名的参考书之一的作者,可以在这里找到。
在接下来的部分中,将讨论对 alpha-beta 算法的进一步优化,其中大多数是专门为 connect-four 游戏定制的。为了评估每种优化的性能增益,我们将设置一个基线。我们将把成功率表示为已经完成的步数或步数的函数。如果在一秒钟内找到解决方案,则执行成功。这是我们的基线图。

The success rates in function of the sequence length. The longer the sequence, the smaller the moves till a game-ending state and thus how bigger the probability on a success. We can see that our algorithm can find the optimal moves once 27 moves have already been made (which means we would have to find an intermediate solution for the first 26 moves).
其他优化
在接下来的内容中,将列出最重要的已实现优化,并给出相应的成功率图,与基线进行比较。
1。使用缓存(转置表& Python LRU 缓存) 我们可以把位置和掩码位图加在一起形成一个唯一键。这个密钥可以存储在具有相应上限或下限的字典中。现在,在我们开始迭代所有的子节点之前,我们已经可以通过首先从缓存中获取相应的边界来初始化我们的当前值。另一个非常简单的优化是给每个 helper-function 添加LRU _ cache decorator。

We can see quite an improvement of our success rates compared to the baseline. Unfortunately, we plateau at around the same x-value as our baseline, which means we still need an intermediate solution for our (approximately) first 26 moves.
2。获胜状态的早期确定 最初,当连接了四个代币或者移动了 42 步时,到达结束状态(叶节点)。我们已经可以提前确定游戏是否会结束(也就是说,如果有三个连接的令牌,用户可以在连接中引入第四个令牌)。这是一个非常有效的检查,并使我们的树更浅。

We see a significant improvement by making our trees more shallow… Moreover, we plateau at a lower x-value (around 23), which means we will only need an intermediate solution for the first 22 moves.
3。寻找任何获胜路径,而不是移动次数最少的获胜路径 不是寻找最大值或最小值,我们可以只遵循第一个严格正或负(分别)值的路径。这些路径不是最佳路径(我们不会以最少的移动次数获胜,也不会以最大的移动次数失败),但我们对常规的胜利非常满意(它不一定是最佳路径)。

An increase in the success rates, but we do not plateau on a lower x-value.
4。其他优化 尝试了许多其他优化:多处理(没有成功,可能是由于 Python 中的开销),基于试探法对叶子遍历的顺序进行排序(仅在博弈树的较低深度有效),过早修剪子树,这将导致博弈失败(小收益)等。以下是我们最终解决方案的成功率:

The final listed improvements did not result in significant gains. Our solver can solve every sequence as soon as the length is higher or equal than 23. This means we need to find a solution to bridge the first 22 moves, where our solver often takes longer than 1 second.
存储前 22 个最佳移动
现在仍然有很多可能的优化,但在 1 秒钟内找到每个可能的游戏配置的最佳移动似乎是一项几乎不可能的工作,特别是在 Python 这样的语言中。但是由于游戏是确定性的,对于每个给定的游戏配置,只有有限数量的最优移动。举例来说,玩家开始游戏的最佳行动总是在中间一栏丢一个代币。
因此,我们决定以硬编码的方式存储较短序列的所有最优移动(或已经进行了少量移动的游戏状态)。同样,这被证明是具有挑战性的,因为文件大小只能是 1 兆字节。
对于每个可能的序列(一个序列的例子可能是 3330,这意味着已经进行了 4 次移动:中间一列中有 3 个标记,最左边一列中有 1 个标记),我们存储了它的最佳移动(,对于这个序列将是 4)。一个简单的字典,其中不同的序列表示键和最佳移动,相应的值在文件大小方面非常快地爆炸。这是因为存储了大量冗余信息。一种非常有效的压缩是不使用字典,而是使用 7 个集合。将属于最佳移动的所有序列(字典中的相同值)存储在同一集合中(我们的序列 3330 将与其他序列如 2220 一起存储在同一集合中)。然后查询所有集合找到某个序列,找到匹配的就输出对应的招式。七个集合中的一个也可以被丢弃用于进一步压缩(如果我们不能在所有 6 个集合中找到匹配,那么最终集合必须包含该序列)。
当我们还想存储更长的序列时,这些包含序列的集合仍然倾向于变大,所以我们决定寻找一种更有效的方法来存储序列。我们试图找到一个函数f,使得f(x) = y中的x是序列(由数字 1-7 组成,前面用 0 填充,这样所有的序列都有相同的长度),而y是相应的最优移动。这是一个典型的机器学习设置,我们试图构建一个模型,在给定输入向量的情况下,准确预测某个值或类。此外,我们有很多数据(我们的求解器可以被视为一个甲骨文,你只需给它序列,并等待相应的最优解)。我们试图拟合一个神经网络,但我们不能达到 0 的误差(这意味着对于某些序列,给出了一个次优解)。然后,我们尝试了一个决策树,以其过度拟合能力而闻名(特别是如果您没有指定最大深度或事后修剪树)。事实上,数据的误差可以达到 0(事实上,只要我们没有两个标签冲突的相同输入向量,决策树归纳技术总是可以发现完全符合训练数据的假设)。因此,我们找到了一个函数,它可以输出特定长度的给定序列的最优移动。通过广度优先遍历决策树并存储节点信息,可以非常有效地反序列化该决策树。下面是一个决策树的例子(长度不超过 2 的序列)。不幸的是,我们没有得到在 dockerized 容器中工作的决策树解决方案,并且不得不求助于 6 个集合来存储我们的序列。

A decision tree for sequences of maximum length 2. The root node can be interpreted as follows: if the board is empty or the first move of the opponent was in the left-most column (empty sequence or ‘1’), then place a token in the middle. As expected, we see a lot of leaf nodes with 4 (since moving a token in the middle column is often the most optimal move in the beginning of the game). The root node and its two children can be serialized as: ‘0<2 4 1<2’, which is very space-efficient.
由于连接 4 游戏是对称的,我们从来没有存储过大于所有 4 的序列。因此,如果我们要存储长度不超过 4 的序列,我们将只存储小于 4444 的序列。如果我们曾经遇到过比这个更大的序列,我们可以通过对序列中的每个k应用8 — k来镜像它。此外,假设每个状态都有一个最优解,那么可以将移动集合分成两个不同的集合:一个用于奇数移动,一个用于偶数移动。使用这种方法可以显著减少状态表示。例如,考虑以下移动顺序:
1\. 3
2\. 3
1\. 3
2\. 3
1\. 3
2\. 0
1\. 2
2\. 1
一种可能的表示是 33333021。然而,我们知道我们的机器人会在每个可能的状态下采取最优解。因此,只提取对手的移动就足够了。如果机器人分别是第一个或第二个玩家,这将导致 3301 或 3332 的状态表示。使用这些状态表示导致树中的路径更短,从而导致更压缩的动作查找表。
结束语
耶鲁安和我在比赛中得到了很多乐趣,这对我们双方来说都是一次很好的锻炼。我们希望一次提交就足以获得第一名,但是我们在使我们的代码在 dockerized containers 服务器端工作时遇到了一些麻烦。

我要感谢所有参赛的学生,并祝贺 TomVDM、pythonneke 和 Ledlamp 获得前三名。此外,一年级工程学生提交的材料的多样性和复杂性给我留下了深刻的印象。提交的内容从阿尔法-贝塔剪枝(尽管没有我们的搜索深入),非常聪明的启发式方法,甚至神经网络。
如果这篇博文中有任何不清楚的地方,如果你知道任何可能的改进,或者如果你想对一些书面部分进行更多的澄清,请留下评论。此外,我愿意应要求与他人分享(研究级)python 代码。
明年另一场 AI 比赛再见;)、
张卫&耶鲁安


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










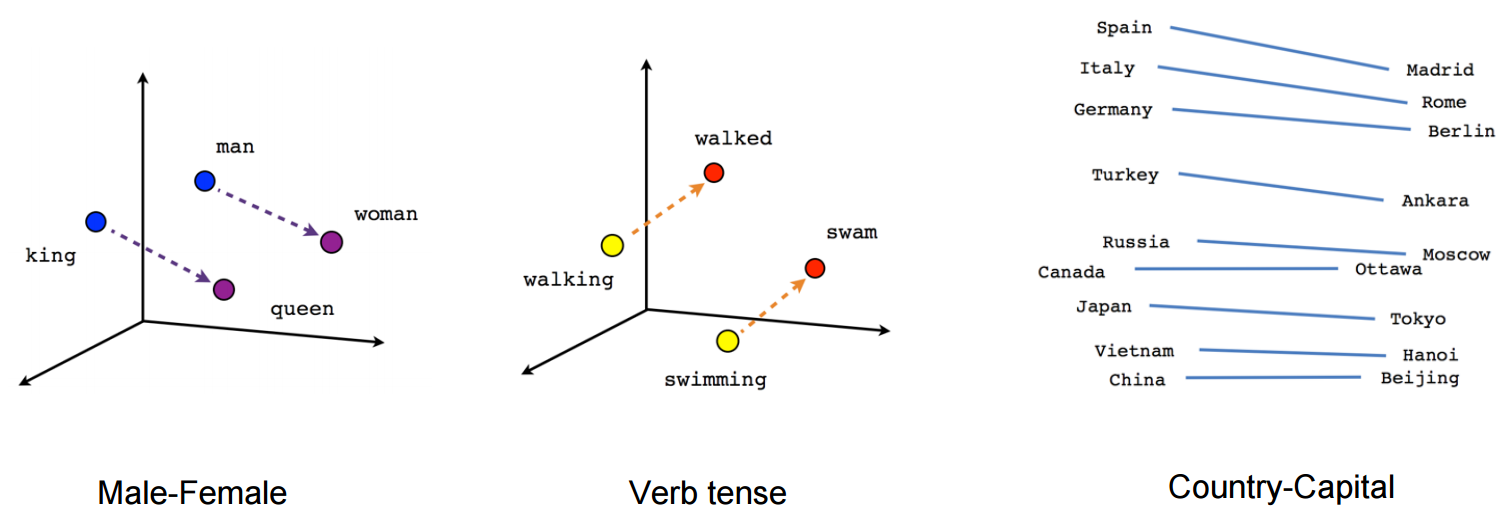{kind=link}
{kind=link}