







AI 会杀验证码吗?
你好,
如果你过去 15 年没有呆在山洞里,你可能会在一个网站上遇到这种事情:


验证码
这些是验证码,又名“ C 完全地A 自动的P 公共的T 在测试期间告诉 C 计算机和 H 人类 A 部分】。基本上,这是一种检查你的网站是否被人或机器人使用的方法。防止垃圾邮件非常有用。这些年来,它已经演变了很多,在机器人制造商背后正在玩一场“猫和老鼠”的游戏,他们努力自动解决这些问题,因为一旦你设法解决了这些问题,你就可以在大规模的在线上做几乎所有的事情,而不会被阻止。主要是黑帽(邪恶黑客)的东西,但不一定。
基本上,滥用系统。
例如,假设您有一项租借服务器的服务。您可以免费试用服务器 2 小时。如果它受到验证码的保护,作为一个机器人制造商,你不能滥用这个系统,因为它根本不可扩展:
你需要一直手动解决验证码。但是如果你能够自动注册新账户,那么你就可以有很多免费的服务器来做加密挖掘、ddos、垃圾邮件攻击等事情。
这些年来,我们看到了奇怪的字母,移动验证码和许多其他东西的出现,这些都是用传统方法解决的(又名不是人工智能)。例如,很多时候,如果你颠倒颜色(黑色变成白色,白色变成黑色)并调整对比度,你可以去掉很多垃圾(如随机的点、线等),然后解决它。
人工智能的崛起
过了一段时间,对人工智能数据的需求增加了,我们开始看到这样的验证码:

这显然是从谷歌街景的巨大图像数据库中获取的图像,这使他们能够对数千个地址进行分类,然后训练自动驾驶汽车。这也有一个好处:如果谷歌必须收集数据来解决这些问题,并且不借助收集大量人类数据无法轻松解决这些问题,那么你的普通机器人制造商肯定也不会。
这被证明是非常有效的,并持续了一段时间。但这也引起了很多批评,因为解决验证码是令人讨厌的,耗时的,对残疾人的访问非常不好。
随着人工智能和深度学习的兴起,阅读扭曲的字母或门牌号变得很容易。所以他们不得不再次胜过装瓶者。
介绍 recaptchav2:

这解决了很多以前的问题:有一个本地检查,所以大多数时候如果你没有一台可疑的计算机(例如,如果你的 ip 试图解决 200 个验证码每小时),你会通过检查,而不必解决任何问题,所以它很快,易于使用,安全,对残疾人有好处。随着大量图像要求对大量物体、建筑物等进行分类,对数据分类的需求不断增长。
问题是机器学习比以往任何时候都更好,并且在许多事情上击败了我们。这意味着,现在更难划清“是人,因为机器做不到这一点”的界限。例如,马里兰大学的一项学术研究创造了 uncaptcha ,它可以以 85%的准确率解决验证码。
85%的准确率是 HUUUGE。
随着时间的推移,机器将能够越来越好地模仿人类,所以很快验证码将变得毫无用处。
那么能做些什么呢?现在有一种越来越普遍的解决方法。
电话验证
很明显,在网上获得一个电话号码并使用该电话号码进行验证是很容易的,许多服务都提供这种功能。但是它极大地提高了账户的价格。而如果你试图在一个已知的网站上注册(steemit?😄)你可能最终会为一个已经用过的电话号码付费。
这非常非常有效,但对隐私来说也是一个可怕的消息。现在你需要一部手机才能上网,很多人会知道你的电话号码,并可以把它卖给广告商。我相信这是一件坏事,但我们真的没有其他选择来阻止垃圾邮件发送者。
感谢阅读,你们觉得怎么样?
如果你想探索这个主题,还有一些资源:
【https://www . wired . com/story/how-your-phone-number-bec-the-only-username-that-matters/【https://www.google.com/recaptcha/intro/】https://github.com/ecthros/uncaptcha
如果你喜欢我的文章,请到我的博客来看看更多关于 https://brokencode.io/的内容
人工智能会让设计师脱离设计过程吗?

credit to Nathalie Foss
前言:
这是两个设计师之间的写作实验;陈亦菲 和 T5【蒂娜】潘 。设计师们同意了一个与设计学科相关的话题,并希望挑战彼此的视角。这种使用人工智能的对话有助于激发合作和讨论我们作为设计师的未来。这是关于展示可能没有被考虑到的不同观点。虽然我们同意这篇文章的重点不是在人工智能是坏还是设计师是不可替代的问题上表明立场,但我们对如何在核心价值、形式和规则制定的设计领域中对待人工智能有不同的立场。
在这个时代,人工智能正在接管人类的工作,这是迫在眉睫的危险。即使是设计师,我们被认为是最有创造力的职业之一,也不排除。以一款有争议的新产品 网格 为例。网格的标语是“人工智能网站自己设计”,是一个算法驱动的网站生成器,它可以在没有任何指导的情况下自动生成体面设计的多个选择。这是计算机和算法层出不穷的一个缩影,也看起来像是设计师被从设计的核心驱逐到边缘的开始。那么,设计师是否有一天会被剔除出设计流程?人类设计师有哪些核心价值是人工智能无法替代的?
credit to The Grid
核心价值观
对设计至关重要的一点是个性。通过个性,我们识别自己,将自己与其他设计师区分开来,并发明我们自己的设计制作流程。作为人类经验的塑造者,我们将我们的直觉和感觉带入设计,将无序转化为有序。我们很难想象人工智能可以取代我们为项目带来的现场体验。但是我们如何验证人工智能是否具有潜在的人格呢?根据最近的研究,两位谷歌工程师开发了一种创新方法来测试图像识别程序是否具有相同的个性。使用由算法创建的“墨迹”图像,他们询问机器人他们看到了什么,并记录他们对每张图像的想法。结果证明,不同的机器人确实有不同的反应,这被研究人员解释为潜意识思想,但这仍然不是断言机器人肯定有个性的直接结果。

credit to Fernanda & Martin
但是性格真的是成为一名优秀设计师的决定因素吗?在潘的文章中,她认为设计不一定需要个性;她相信*“设计有一个模式、算法和原则的基础,使得人工智能可以产生的项目设计成功。”对于一个普通的设计,她的论点是站得住脚的。但对于一个非凡的设计来说,打破框架和挑战原则更为关键。*
艾是形 的比喻
人工智能是形式的隐喻,指的是设计中所有可见的元素以及这些元素的结合方式,包括但不限于字体、设计语言和视觉感知。人工智能可以从经典的设计实例、基本的设计原则、新潮的设计形式中学习,在形式上做出精准的选择。但形式不能主宰一切。这个问题在音乐上有一个类比。基于占主导地位的音乐形式和基本的音乐理论,程序员开发了基于风格的音乐算法,可以自动分析和生成音乐。然而,人工智能甚至无法识别非主流音乐形式,因为存在各种难以量化的评估标准。也就是说,形式化的规则无法解释音乐的基本方面。这同样适用于设计。形式可以用定义明确的标准来评估,但思想不能。
在这一点上,Phan 认为*“使用人工智能作为交流想法的形式,设计师可以提出更好的解决方案来交流想法。”然而,事实是,如果你最初的想法很糟糕,单靠技术是无法拯救它的。在设计过程中,创意应该永远放在第一位。 “理念是设计的原动力,形式受理念的指引,必须服从理念。” 创意是设计师种下的种子,形式是设计师如何培育这些种子。栽培过程可以决定它看起来怎么样,但只有通过种子才能定义它的本质是什么。*
规则制定者
设计师是规则的制定者。只有设计师才能定义什么是设计。人工智能可以模仿人类操纵系统内的设计语言、声音和语气、模式和组件,但整个系统是由人类设计的。设计系统统治着我们周围的一切,设计师决定了系统是什么,如何组织和互动。为了回答复杂的沟通问题并使他们的工作标准化,设计师们发明了 【系统设计的系统方法】 称为系统设计。它被用于许多学科,尤其是在信息论、运筹学和计算机科学等新领域。人工智能也包括在内。设计师制定规则,赋予机器它们的目的,并指导它们施展魔法。
在这一点上,Phan 认为,设计师可能会认为自己是规则的制定者,但人工智能迫使他们在澄清规则方面成为更好的规则制定者。诚然,设计师可以通过翻译自己的设计意图变得更加客观和清晰,但反思的过程并不一定有人工智能的参与。优秀的设计师在进行每一个设计决策时,都应该已经理解了设计原则,并养成了自我审视的习惯。设计师的力量在于他们可以自己制定和打破规则。
未来设计教育
由于人工智能,未来创意和生产工作之间的界限将更加明确。重复性任务将被卸载,这将使设计师从生产任务中解放出来,专注于创造性和基础性工作。所以我们的工作不会被拿走而是升级。那么,设计教育将会发生什么变化?作为未来的塑造者,现在是我们思考新的教学方法的时候了。

Credit to Lucien Ng’s “Artificium”
对于课程规划来说,首先会受到挑战的是我们现在的课程。像字体设计、设计语言和视觉感知等与形式相关的课程会减少甚至从教学大纲中删除吗?这些设计原则和基本知识可以被编程和激活吗?此外,将为我们开发更多课程,以适应人工智能和设计师之间的互利共生。我可以想象的一门必修课是使用新自动化系统的指南课程,其中包括学习如何用人工智能设计和使用人工智能工作。至少,要考虑设计师如何参与到算法的制作过程中。更重要的是,人工智能将促使我们重新关注设计思维的重要性。设计思维使我们能够观察和改进我们的思维过程、模式和方向。在接下来的几年中,关键问题将转移到如何建立新的系统和策略,如何应对和恢复新的情况,如何创造更有意义和持久的沟通方式。
那么什么样的设计学校适合新生代呢?这个问题没有确定的答案,但这也是我们不断挖掘、推测、挑战的原因。我们不仅是设计专业的学生,也是新一代的塑造者和新革命的创新者。有一个充满可能性的世界等待我们去探索。
大数据会破坏隐私吗?
在过去的十年里,记录的数字化和各种社交网络平台(如脸书、推特等)的兴起使得大量的个人信息可以在网上获得。这种随时可用信息的激增促使组织构建复杂的大数据应用程序,使用这些信息来分析和预测消费者的行为模式,从而为他们提供定制的选择。然而,这些应用引发了许多关于个人隐私权的问题,让我们思考我们从这些大数据解决方案中获得的好处是否真的值得牺牲我们的私人生活。
大数据的反对是基于这样一个前提,即技术对我们生活的侵扰会使我们面临潜在的威胁。目前专注于消费者趋势并使用该数据提供客户建议的公司可能最终会在这些趋势上歧视他们的客户,从而导致“数字红线”。[1]由美国政府组建的“大数据和隐私工作组”目前正在研究这一潜在问题。此外,由于公司现在几乎持续跟踪他们的消费者,他们系统中的任何泄漏或盗窃都有可能暴露消费者的所有信息。此外,随着目前收集的数据量,任何个人的真实匿名化都变得越来越困难,因此,在错误的手中,数据可能会造成相当大的损失。
然而,我们不能否认大数据的应用对社会产生了积极影响。大数据有助于检测疾病爆发,目前正被用于理解各种复杂的医疗问题。除了医疗保健,大数据分析几乎在每个领域都带来了发展,无论是预测消费者趋势,改善教育系统,预测天气现象,还是帮助建设智慧城市的交通和通信系统。如果不使用大数据分析,这些领域中的大多数都很难取得进展。因此,我们可以说,大数据的好处远远超过我们分享信息所付出的代价。
现在,考虑到大数据的优势,可以有把握地认为,在未来几年,数据分析将有助于塑造和发展许多行业。因此,我们应该专注于建立一个系统,限制利用个人隐私的机会,而不是放弃技术。其中一种方法是向最终用户提供选择加入或选择退出任何此类数据收集/分析计划的选项,例如欧洲数据保护法规制定的“被遗忘权”。此外,应制定更严格的规则,以提高所收集数据的数量和质量的透明度,并确保未经事先批准,为某一目的收集的信息不会用于其他任何地方。还应该进行检查,以防止数据被盗和泄露。
总之,我们可以说,大数据可以在许多潜在场景中用来改变数百万人的生活。然而,我们不能完全忽视技术带来的威胁,因此,政府应该制定必要的法规和制度来检查公司对这些信息的使用。用大卫·沙诺夫的话说,
我们太容易让技术工具成为那些使用它们的人的罪过的替罪羊。现代科学的产品本身没有好坏之分;决定它们价值的是它们的使用方式。[2]
[1]http://www . white house . gov/blog/2014/05/01/findings-big-data-and-privacy-work-group-review
【2】en.wikipedia.org/wiki/Instrumental_conception_of_technology
数据科学会消灭数据科学吗?

我的一个朋友问了我这个问题:一个优质的 ML 即服务、数百名数据科学家思考的功能和越来越聪明的算法真的有市场吗?或者大数据甚至会接管我们的工作,因为更多的数据最终会胜过聪明的算法?
简而言之:我们所做的事情中有一些是人工智能完成的。最终,人工通用智能将淘汰数据科学家**,但它不会马上到来**。
不过,我发现这是一个非常好的问题。这里有一些松散联系的想法来阐述我的简短回答。
- I)数据科学的喧嚣,ii)高等教育对这种突然需求的响应速度缓慢,iii)以 IT 为中心的行业中无限的现金流所引发的人才流失这三者的结合给元数据科学家带来了巨大的压力,使她不得不自动化自己的工作。我们处于正确的位置:自动化是我们工作描述的核心。因此,如果数据科学自动化(和标准化!)会比预测的进化得更快。
出于同样的原因,我确实相信横向 mlaa(不像某些数据科学和创业的大师们)。设计良好的 MLaaS 可以为中小型企业甚至大型非 IT 公司带来价值,这些公司负担不起或不想在内部构建数据科学生态系统。 自动化 和 众包 ML 可能无法与谷歌或脸书等公司组建的顶级数据科学研发团队&竞争,但他们可以让团队中的两名成员在 60 个小时的快速培训课程后成为“数据科学家”。 - 当然有些情况下收集更多的数据是一个选择。在这些情况下,我们可以估计更多的数据会有多大的帮助(通过推断学习曲线)。在此范围内,误差主要由过度拟合引起,技巧(例如,丢失、正则化)与数据收集竞争,因此**(昂贵)** 数据科学时间可以与(便宜)贴标时间竞争。
- 当然,在某些情况下,即使有更多的数据,也帮不上忙。在我们的 HEP 异常挑战中,我们几乎有无限的数据,但所有现成的预测器都卡住了。我们被欠拟合所支配:我们不能用现成的技术足够好地表达(或近似)正确的预测器。不适合的问题是设计问题,这是人类智慧(有见识的、知识驱动的模型搜索)可以帮助的地方。深度网络还解决了一个不足的问题,即数据量饱和的经典计算机视觉方法(见幻灯片 8 此处)。
- 最后,当然有收集更多数据不可行的情况。很多时候分布是变化的,所以你在任何时候都只有有限的无偏数据。很多时候,数据与任务或类的数量成线性关系,所以每个任务的数据都是有限的。在这些情况下,我们被困在小数据世界中,在那里过度拟合占主导地位。通用的(自动化的,超适应的)正则化技术可能会把你带到一定的水平,但是这里没有什么比有见识的先验知识(又名领域知识)更有价值的了。无论何时你拥有领域知识,它都必须被吸收和转化,给数据科学家足够的工作保障。
当然,这只是一个关于这个话题的简短摘录。你怎么看?我们的数据科学工作有危险吗?
如果你喜欢你读的东西,就在中、 LinkedIn 、&Twitter 上关注我。
哈伯曼生存数据集上的 EDA(探索性数据分析)让你诊断癌症?
介绍
哈伯曼的数据集包含了芝加哥大学比林斯医院在 1958 年至 1970 年间对接受乳腺癌手术的患者进行的研究数据。来源:https://www.kaggle.com/gilsousa/habermans-survival-data-set
我想解释我对这个数据集所做的各种数据分析操作,以及如何推断或预测接受手术的患者的生存状态。
首先,对于任何数据分析任务或对数据执行操作,我们都应该具有良好的领域知识,以便我们能够关联数据特征,并给出准确的结论。因此,我想解释一下数据集的特征以及它如何影响其他特征。
该数据集中有 4 个属性,其中 3 个是特征,1 个是类属性,如下所示。此外,还有 306 个数据实例。
- 腋窝淋巴结(淋巴结)数量
- 年龄
- 运营年度
- 生存状态
淋巴结:淋巴结是微小的豆状器官,沿着淋巴液通道起过滤器的作用。随着淋巴液离开乳房并最终回到血液中,淋巴结试图在癌细胞到达身体其他部位之前捕捉并捕获它们。腋下淋巴结有癌细胞表明癌症扩散的风险增加。在我们的数据中,检测到腋窝淋巴结(0-52)

Affected Lymph Nodes
(来源:https://www.breastcancer.org/symptoms/diagnosis/lymph_nodes)
年龄:代表手术患者的年龄(30-83 岁)
手术年份:患者接受手术的年份(1958-1969)
生存状态:表示患者手术后是否存活 5 年以上或 5 年以下。这里,如果患者存活 5 年或更长时间,则表示为 1,存活少于 5 年的患者表示为 2。
因此,让我们开始处理数据集并得出结论。
操作
为此我使用了 python,因为它有丰富的机器学习库和数学运算。我将主要使用常见的软件包,如 Pandas、Numpy、Matplotlib 和seaborn*,它们帮助我进行数学运算以及绘制、导入和导出文件。*
*import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import numpy as nphaberman= pd.read_csv(“haberman.csv”)*
在上面的代码片段中使用函数read _ csvfrompandaspackages 您可以从 CSV 文件格式导入数据。因此,导入数据集后,您需要检查数据导入是否正确。下面的代码片段将显示数据的形状,即数据中存在的列数和行数。
*print(haberman.shape)*

Shape of data
在这里,您可以确信您想要的数据已成功导入,它显示了 306 个数据实例和 4 个属性,正如我们在前面的简介中看到的。您甚至可以使用下面的一行代码来查看列的标签。
*print(haberman.columns)*

Columns in data with type
这里,dtype 表示数据类型,它是数据中所有列的对象类型。同样,您也可以找到要素和类属性的 dtype,并可以通过下面简单的代码行找到属于一个类的数据点的数量以及属于其他类的数据点的数量。
*haberman[“Survival_Status”].value_counts()*

Number of data per classification
从上面这段代码你可以得出结论,306 个病人中有 225 个存活了 5 年以上,只有 81 个存活了不到 5 年
现在让我们绘制一些图表,这些图表给我们更多的数据说明,这样我们就可以很容易地得出结论。
*haberman.plot(kind=’scatter’, x=’Axillary_Nodes’, y=’Age’)
plt.grid()
plt.show()*
上面的片段给了我散点图,x 轴是节点,y 轴是年龄。我们的 matplotlib 库函数 grid 和 show 帮助我在网格中绘制数据,并将其显示在控制台上。

2D Scatter Plot
上面的散点图以重叠的方式显示了所有数据,并且颜色相同,因此我们无法区分数据,也有可能您会错过我的一些数据,从而导致错误的结论。因此,为了区分数据,我们可以使用 seaborn packages 函数,该函数通过为每个分类特征分配不同的颜色来直观地区分数据。
*sns.set_style(‘whitegrid’)
sns.FacetGrid(haberman, hue=”Survival_Status”, size=4) \
.map(plt.scatter, “Axillary_Nodes”, “Age”) \
.add_legend();
plt.show();*

2D scatter plot with different colour polarity
在上面的代码片段中,我从 seaborn 库导入了函数,比如 FacetGrid ,这样我们就能够区分数据分类。这里蓝点代表存活超过 5 年,橙点代表存活少于 5 年。
由于有 3 个特征,我们可以从中得出我们的分类,所以我们如何从所有特征中选择任何特征,以便我们可以得到错误率更低的输出。为此,我们可以使用 seaborn 的 pairplots 到各种组合的 plots,从中我们可以为我们的进一步操作和最终结论选择最佳对。 hue=“Survival_Status” 会给出你需要对哪些特征做分类。下图显示了 pairplots 组合的绘制及其代码片段。
*plt.close();
sns.set_style(“whitegrid”);
sns.pairplot(haberman, hue=”Survival_Status”, size=3, vars=[‘Age’,’Operation_Age’, ‘Axillary_Nodes’])
plt.show()*

Pair Plot
上图是数据中所有特征的组合图。这些类型的图被称为成对图。图 1、图 5 和图 9 是所有特征组合的直方图,通过考虑数据的不同特征来解释数据的密度。
现在,让我们一个接一个地绘制图 1,我将向您解释我将采用哪个数据特征来进行进一步的数据分析。我会选择这样一个数据,它比任何其他数据特征都更能显示出我与众不同的地方。因此,让我们开始分析除图 1,5,9 之外的每个图,因为它是成对图中特征的直方图。**
曲线图 2:-在该曲线图中,您可以看到 X 轴上有操作年龄,Y 轴上有年龄,这些数据的曲线图大部分相互重叠,因此我们无法区分蓝点下方是否存在任何橙色点,反之亦然。因此,我拒绝这两个数据特征组合进行进一步分析。
图 3:-在这个图中有一些点是可区分的,但它仍然比其他图更好,因为我们可以通过直方图和 CDF 提供更精确的结论,稍后你会了解到。在这个图中,点的重叠是存在的,但相比之下,它仍然比所有其他图好。所以我会选择这个 plot ie 的数据特征。年龄和腋窝淋巴结。
图 4 :-使用数据特征操作 Age 和 Age 绘制,该图显示了与图 2 相似的图类型,但只是旋转了 90 度。所以我也拒绝这个功能
图 6:-它绘制了特征操作年龄和腋窝淋巴结,与图 2 有些相似,但与其他图相比,点的重叠在该图中似乎更多。所以,我也会拒绝这个组合
图 7 :-该图与图 3 相似,只是交换了轴,所以该图将旋转 90 度。此外,我会接受进一步的行动这一组合
地块 8 :-与地块 6 相同,唯一的特征是轴互换。
因此,我考虑在图 3 和图 7 中绘制特征年龄和腋淋巴结,用于所有进一步的数据操作
1D 散点图
让我们绘制 1D 散点图,看看我是否可以使用下面的代码片段区分数据。
*import numpy as np
haberman_Long_Survive = haberman.loc[haberman[“Survival_Status”] == 1];
haberman_Short_Survive = haberman.loc[haberman[“Survival_Status”] == 2];
plt.plot(haberman_Long_Survive[“Axillary_Nodes”], np.zeros_like(haberman_Long_Survive[‘Axillary_Nodes’]), ‘o’)
plt.plot(haberman_Short_Survive[“Axillary_Nodes”], np.zeros_like(haberman_Short_Survive[‘Axillary_Nodes’]), ‘o’)
plt.show()*
我使用了 Numpy 库函数为每个分类数据单独绘制 1D 散点图。下面您可以看到使用数据特征年龄和腋淋巴结的 1D 散点图

1D Scatter Plot
在这里,你可以观察到短期生存状态的数据大多与长期生存状态的数据重叠,因此你无法根据这些数据得出结论。
如果使用 PDF 或 CDF 格式的数据进行绘图,可以获得更好的清晰度。
让我解释一下你对 PDF 和 CDF 的概念。
PDF 如果存在更多的数据,PDF 将是代表高峰的峰状结构,否则如果存在的数据较少,它将是平的/小峰。它是使用直方图边缘的平滑曲线图
CDF (累积分布函数) :-表示 PDF ie 的累积数据。它将通过累积考虑每个数据点的 PDF 来绘制图表。
Seaborn library 将帮助您绘制任何数据的 PDF 和 CDF,以便您可以轻松地可视化特定点上的数据密度。下面的代码片段将绘制 PDF
*sns.FacetGrid(haberman,hue=”Survival_Status”, size=8)\
.map(sns.distplot,”Axillary_Nodes”)\
.add_legend()*
让我们试着画出每个数据特征的 PDF,看看哪个数据能给我们最高的精度。
时代 PDF

PDF for Age
***观察:*在上面的图中,观察到在 30-75 岁的年龄范围内,存活和死亡的状态是相同的。因此,使用这个数据点我们无法预测任何事情
运营年龄 PDF

PDF for Operation Age
观察结果:类似地,我们无法用这些直方图预测任何事情,因为每个数据点中的密度数量相同。甚至两种分类的 PDF 也相互重叠。
腋窝淋巴结的 PDF

PDF for Axillary nodes
***观察:*据观察,如果人们检测到的腋窝淋巴结较少,他们会活得更长,反之亦然,但仍然很难分类,但这是你可以从所有数据中选择的最佳数据。所以,我接受腋窝淋巴结的 PDF 并可以得出以下结果
if(AxillaryNodes≤0)
患者=长期存活
else if(腋淋巴结≥0 &&腋淋巴结≤3.5(近似值))
患者=长期存活几率高
else if(腋淋巴结≥3.5)
患者=短期存活
因此,从上面的 PDF 我们可以说患者的生存状态,但我们不能确切地说,有百分之多少的患者将实际短期生存或长期生存。知道我们有另一个分布是 CDF。
CDF 将给出 PDF 的累积图,以便您可以计算患者存活状态的确切百分比
让我们为我们选择的特征绘制 CDF,它是腋淋巴结
*counts, bin_edges = np.histogram(haberman_Long_Survive[‘Axillary_Nodes’], bins=10,
density = True)
pdf = counts/(sum(counts))
print(pdf);
print(bin_edges);
cdf = np.cumsum(pdf)
plt.plot(bin_edges[1:],pdf);
plt.plot(bin_edges[1:], cdf)*
上面的代码会给我长期生存状态的 CDF。这里,我们仅使用来自 Numpy 的 cumsum 函数,该函数将累加该特征的 PDF。
具有长期生存状态的 CDF 将在图中以橙色显示。

CDF for Long survival status
从上面的 CDF 图中,你可以观察到橙色线显示如果检测到的腋窝淋巴结数目为< 5. Also you can see as number of axillary nodes increases survival chances also reduces means it is clearly observed that 80% — 85% of people have good chances of survival if they have less no of auxillary nodes detected and as nodes increases the survival status also decreases as a result 100% of people have less chances of survival if nodes increases > 40,有 85%的机会长期存活
让我们试着在一个图中画出这两个特征 CDF。为此,只需在为长期生存而编写的现有代码中添加以下代码
*counts, bin_edges = np.histogram(haberman_Short_Survive['Axillary_Nodes'], bins=10,
density = True)
pdf = counts/(sum(counts))
print(pdf);
print(bin_edges)
cdf = np.cumsum(pdf)
plt.plot(bin_edges[1:],pdf)
plt.plot(bin_edges[1:], cdf)plt.show();*
下图用红线显示了短期存活的 CDF

CDF for both Long and short survive
你可以在上面的综合 CDF 中观察到长期存活的观察结果是相同的,但是在短期存活中,近 55%的人的淋巴结小于 5,如果淋巴结> 40,则有近 100%的人短期存活
我们还可以通过应用数学公式(如标准差和平均值)来预测患者的状况。
平均值是所有数据的平均值,标准差是数据的分布,表示数据在数据集上分布的宽度。Python 有 Numpy 库,可以在一行中执行这个操作。
*print(“Means:”)
print (np.mean(haberman_Long_Survive[“Axillary_Nodes”]))
print (np.mean(np.append(haberman_Long_Survive[“Axillary_Nodes”],50)))
print (np.mean(haberman_Short_Survive[“Axillary_Nodes”]))print(“\nStandard Deviation:”)
print(np.mean(haberman_Long_Survive[“Axillary_Nodes”]))
print(np.mean(haberman_Short_Survive[“Axillary_Nodes”]))*

我们可以在第 3 行看到,我添加了异常值(与相应数据相比非常大或非常小的数据。这可能是收集数据时的错误或异常情况),即使数据的平均值没有受到太大影响。
您可以观察到,长期存活的平均值为 2.79,包括异常值在内,平均值为 3,几乎相同,但短期存活的平均值为 7.4,相对来说比长期存活的平均值高得多。所以短期存活的概率在数据集中更大。
如果观察标准差,长期存活者的标准差仅为 2.79,短期存活者的标准差为 7.45,这意味着短期存活者的数据分布更多。
中位数、分位数和百分位数
你还可以做一些数学运算,比如中位数,分位数,百分位数
*print(“Medians:”)
print(np.median(haberman_Long_Survive[“Axillary_Nodes”]))
print(np.median(np.append(haberman_Long_Survive[“Axillary_Nodes”],50)))
print(np.median(haberman_Short_Survive[“Axillary_Nodes”]))print(“\nQuantiles:”)
print(np.percentile(haberman_Long_Survive[“Axillary_Nodes”],np.arange(0,100,25)))
print(np.percentile(haberman_Short_Survive[“Axillary_Nodes”],np.arange(0,100,25)))print(“\n90th percentile:”)
print(np.percentile(haberman_Long_Survive[“Axillary_Nodes”],90))
print(np.percentile(haberman_Short_Survive[“Axillary_Nodes”],90))from statsmodels import robust
print (“\nMedian Absolute Deviation”)
print(robust.mad(haberman_Long_Survive[“Axillary_Nodes”]))
print(robust.mad(haberman_Short_Survive[“Axillary_Nodes”]))*
上面的代码片段将给出中位数和第 n 个百分点
中位数是数据的中心值,分位数是第 n 个百分比 n= 25,50,75 的特定特征值,第 n 个百分位类似于分位数,但 n 可以是 1 到 100 之间的任何数字。
因此,对于我们的数据集,这些术语的值如下

观察:
- 从以上观察可以清楚地看出,长期存活的平均腋窝淋巴结为 0,而短期存活的平均腋窝淋巴结为 4。也就是说,平均有 4 个辅助淋巴结的患者生存期短。
- 分位数显示,在长期存活中,近 50%的腋窝淋巴结为 0,75%的患者淋巴结少于 3,即 25%的患者淋巴结多于 3。
- 同样,在短期生存中,75%的患者至少检测到 11 个淋巴结。
- 在 90%时,如果检测到的淋巴结> 8,那么它具有长期生存状态,如果淋巴结> 20,那么患者将具有短期生存状态
盒图和胡须,小提琴图和等高线图
您还可以使用像盒图轮廓和更多的绘图分析数据,Seaborn 库有各种各样的数据绘图模块。让我们拿一些吧
盒子剧情和络腮胡子
*sns.boxplot(x=”Survival_Status”,y=”Axillary_Nodes”, data=haberman)
plt.show()*

Box Plot and Whiskers
在这里,你可以通过观察它的高度和宽度以及 T 型结构来阅读这个图。方框高度代表第 25 个百分位数到第 75 个百分位数之间的所有数据,水平条代表该数据的最大范围,方框宽度代表该数据在数据集中的分布。此外,竖线上方小点是异常值
观察结果:上图中,长命百分位数第 25 百分位和第 50 百分位几乎相同,阈值为 0 到 7。此外,对于短期存活,第 50 百分位节点几乎与长期存活的第 75 百分位相同。短期存活阈值为 0 至 25 个节点,75%为 12,25%为 1 或 2
所以,如果 0–7 之间的节点有出错的机会,因为短存活图也在其中。对于短期存活状态,这是 50%的误差
以上 12 点大部分在于生存时间短
小提琴剧情
*sns.violinplot(x=”Survival_Status”, y=”Axillary_Nodes”,data=haberman)
plt.legend
plt.show()*

Violin Plot
它与盒须图相同,唯一的区别是用盒直方图代替盒直方图来表示数据的分布。
观察:在上面的 violin 图中,我们观察到它的长期存活密度更接近 0 节点,而且它的晶须在 0-7 范围内,而在 violin 2 中,它显示的短期存活密度更接近 0-20 和阈值 0-12
等高线图
等高线图类似于密度图,意味着如果特定点上的数据数量更多,该区域将变得更暗,如果您将它可视化,它将形成类似小山的结构,其中山顶具有最大的点密度,密度随着山坡坡度的减小而减小。
您可以参考下图,了解等高线图在 3D 中的实际效果

Source: https://www.mathworks.com/help/matlab/ref/surfc.html
在上图中,黄点的密度最大。
下面是我们数据集的等高线图
*sns.jointplot(x=”Age”,y=”Axillary_Nodes”,data=haberman_Long_Survive,kind=”kde”)
plt.grid()
plt.show()*

Contour Plot
观察:以上是使用特征年龄和腋窝淋巴结的长期存活的 2D 密度图,观察到长期存活的点的密度更多来自 47-60 岁的年龄范围和 0-3 岁的腋窝淋巴结。黑暗区域具有主要密度,其在 3D 中是山顶,且密度随着图形变亮而变低。每个阴影代表一个等高线图。
结论:
是的,您可以通过应用各种数据分析技术和使用各种 Python 库,使用哈伯曼的数据集来诊断癌症。
参考资料:
- https://www.mathworks.com/help/matlab/ref/surfc.html
- https://www.breastcancer.org/symptoms/diagnosis/lymph_nodes
- https://www.kaggle.com/gilsousa/habermans-survival-data-set
- https://www.appliedaicourse.com
机器学习会颠覆营销行业吗?
随着数字时代影响力的扩大,新兴创新将会颠覆不同行业的运作方式。在市场营销领域,策略已经在不断变化,以满足消费者不断变化的偏好。传统上,消费者通过货架摆放技巧、购买点标志等被吸引到实体购物空间,但今天的产品根据各种在线企业接收和分析的数据展示其羽毛,这些数据决定了消费者如何浏览这些在线购物中心。
随着大数据革命的到来,理解这些数据的过程变得更加复杂。人工智能(AI)和机器学习的黎明将使这些挑战变得无足轻重,并使精确定位个人偏好变得毫不费力。从算法到聊天机器人,现在这些技术如何提升营销绩效?
了解 AI 的区别&机器学习
首先,理解人工智能和机器学习之间的区别很重要,因为它们经常互换使用。机器学习使计算机和在其上运行的应用程序能够在不进行持续维护的情况下自行改进。这项技术可以检测和预测数据、语音和其他模式,随着时间的推移,随着数据的输入,这项技术会变得更加准确。
另一方面,人工智能是一个总括术语,用来描述机器可以模仿人类认知的不同方面的各种方式,如思维、运动或讲话。
我们平时遇到的就是机器学习的技术。
市场上的机器学习
机器学习可能是营销人员工具箱的重要组成部分,因为它将购物和内容无缝地结合在一起。当消费者在网上搜索视觉效果并拍摄他们喜欢的物品时,机器学习将能够根据人工智能生成的模型向他们提供建议。这为每个人建立了个性化的购物体验。
数字媒体(尤其是社交媒体)的发展表明,即使在很短的时间内,消费趋势也会产生深远的影响。然而,公司收到的大量数据使得识别和处理这些模式成为一项势不可挡的资源密集型工作。
机器学习通过立即识别来自各种来源的数据中的潜在模式来简化这一过程。虽然仍然需要人类来验证和解释这些趋势,但机器学习加速了分析。这使我们能够专注于对这些趋势做出快速反应,而不是努力识别它们。
实施中的挑战
虽然机器学习已经证明了它在提高营销过程效率方面的能力,但营销人员担心它仍然太年轻,不能依赖。一个担忧是,由于它处理数据的速度,它可能会取代各种行业的人工工作。例如,尽管机器学习的性能令人印象深刻,但它仍然无法完全理解人类交流的细微差别。由于这些问题,对于很多公司来说,客户服务仍然是“人性化”的客户服务。
机器学习在市场营销中的未来
网上收集的海量数据只会继续增长。因此,来自人工智能和机器学习系统的帮助将变得更加重要。
尽管如此,机器学习仍处于早期阶段,在实现技术成熟之前,它似乎还有很长的路要走。因此,人类将保持重要的角色,这一角色将得到机器学习技术的支持。专业人士将越来越能够专注于营销和指导算法。只有人类才能回答重要的问题,例如公司的关键业务问题需要什么解决方案。
随着我们见证这些技术及其功能的快速发展,机器学习将继续证明其在快速处理数据方面的价值。随着计算机发现趋势,营销人员需要确保他们抓住机会,同时保持新鲜感和相关性。
特拉维夫的市中心会更新吗?
或者:为什么规划者需要开始使用大数据

Tel-Aviv city center (source: https://xnet.ynet.co.il/architecture/articles/0,14710,L-3099095,00.html)
这项研究于 2018 年 7 月以“”(希伯来文版)和*Haaretz.com*(英文版)发表于以色列房地产出版社
特拉维夫市最近(2018 年 1 月)批准了一项新的分区条例,用于其最理想的地区之一,第三选区,也被称为“旧北”街区。该计划鼓励开发商通过提供额外的建筑面积来更新住宅建筑,以便升级非历史建筑,增加市中心的住房存量,同时保持其独特的城市景观质量。住户从免费更新中受益,并获得改善的/新的公寓。自第一阶段通过批准以来,该计划受到开发商、规划者和居民的公开批评,声称尽管该计划据称会增加土地供应,但在单个建筑层面上,它仍然过于严格,经济上不允许使用。
作为一名以特拉维夫为基地、专门从事城市更新住宅项目的建筑师,很容易感觉到,在宣布重新分区后,第 3 区的新项目需求急剧下降。将我最近获得的数据分析技能应用到重新分区的可行性问题上,对我来说是一个自然的选择;我使用了关于地块粒度的 GIS 数据,以确定新法令提供的额外建筑面积是否提供了足够强的激励来确保其建筑物的更新。我还评估了重新分区将产生的未来容积率(FAR ),以及根据规划的预期利用率,整个辖区将增加的住房单元数量。
特拉维夫市中心建筑环境+分区快速回顾
3 区主要建于 20 世纪 30 年代,由英国在巴勒斯坦的委任统治支持,是特拉维夫市中心的四个区之一(3 区、4 区、5 区和 6 区),以其包豪斯建筑和“花园城市”的城市景观而闻名。该区还包含了“白色城市”区的一个重要部分,2003 年被联合国教科文组织宣布为世界遗产。在这个宣言之后,城市的保护计划在 2008 年被批准,指定保护市中心的大约 1000 栋建筑,其中大部分位于“白色城市”内。

Fig.1 Precinct 3, Tel Aviv-Jaffa, Israel

Dizengoff street, 1960’s (source: Google)
占地 243.1 公顷(其中约 60%在“白色城市”区域内),“第 3 区规划”,或其官方名称为第 3616a 号法令,*是为特拉维夫市中心的四个区准备的四个规划之一,是第一个也是唯一一个在我进行这项研究时获得批准的规划。该法令对白城区内和白城区外的地块进行了区分,允许在历史遗址外增加一层,并要求对白城区内非常小的地块(< 500m2)的边界进行更严格的限制。*密度系数,代表单元的平均大小,并根据它计算地块中允许的住房单元数量,商业街中的密度系数小于非商业街中的密度系数,允许主干道中有更多或更小的单元。总的来说,除了目前已经存在的大约 36,000 套住房单元之外,该计划还将为该区域新增 16,000 套住房单元(预计利用率为 50%)。
分析方法
用于生成此分析的 Python 代码可在我的GitHub上获得。
由于这项研究是在重新分区法令获得批准后几个月才进行的,因此其分析具有预测性,使用从特拉维夫市地理信息系统获得的3 区建筑物和地块的现有真实物理参数*,并且根据新法令指南评估其未来特征,因为它们出现在分区法令第 3616a 号文件(仅希伯来文内容)。为每个地块下载的属性是地块 ID 和面积(m)地址、建筑占地面积 ( m )、层数和建筑类型。根据这些变量计算出建筑面积和容积率(FAR) 。*
我假设所有 3 号区对土地的需求都一样高,这意味着在每个待建的重建项目中,允许的建筑面积都得到充分利用。
该研究仅考虑了住宅建筑,并评估了拆除+新建部分计划的经济可行性,排除了建筑改进和建筑扩建的可能性。本研究中未考虑宗地合并选项。指定用于历史保护的地块不在分析范围内,因为重新分区不适用于这些地块。此外,新建筑物(建于 1980 年后)不符合新的条例准则,也被排除在分析之外。总体而言, 2,161 个包裹被发现对该分析有效,约占该辖区包裹的一半。

Fig.2 (left): 2,161 Potential to renewal parcels according to rezoning ordinance; 1,307 (~60%) within the White City zone and 856 buildings outside its boundaries. Fig.3 (right): buildings designated for historic preservation, excluded from the analysis. 17% of the precinct’s buildings within the White Zone and 3% of buildings outside of it.
经济可行性阈值*被定义为当前建筑面积比允许建筑面积**少 50%,考虑到当前建筑面积对居住者的回馈。这一经验法则还考虑了拆迁成本、许可成本、建筑成本和临时疏散居民的住房成本,以及额外新建建筑面积的更高土地价值。此阈值的例外情况是大地块(定义为地块面积等于或大于 750 米)和小地块(500 米或小于 500 米),分别允许/要求居民或开发商享有 55%的比例。*
结果
1.当前(2018 年)建成环境
3 区的大多数建筑目前的建筑容积率在 1.3-2 之间,形成了特拉维夫连续连贯的城市景观,如图 4 所示。在“白城”区内外,当前 FAR 在辖区内的频率分布如图 5 所示,表明“白城”区内外的 FAR 分布没有显著差异:

Fig.4 Current FAR precinct 3

Fig.5 Frequency distribution of current FAR, precinct 3; Within and outside the “White City”. No significant difference between the two distribution is emerging
2.根据重新分区允许的建筑空间
如前所述,根据重新分区所允许的最大未来建筑空间是通过使用现有的空间测量值并将其应用于新条例的指导方针进行评估的。
允许的楼层数取决于地块是在“白城”区之内还是之外,是否位于商业街上,以及对于“白城”区内的地块,其面积是大于还是小于 500 平方米。关于允许的覆盖区,地块边界所需的后退通常会导致覆盖区在地块面积的 42%-56%之间,看起来几乎是随机的。因此,对于此分析,小于 750 米的宗地的覆盖区百分比在此范围内随机选择。根据规划要求,该地块面积的最大 55%被分配给大于 750 米的地块。允许占地面积和允许容积率相应计算。允许的住房单元是通过将新建筑面积除以密度系数,然后减去 4 个单元来评估的,这是因为建筑物最高楼层对大单元的常见住房需求。
由此得出的未来 FAR 及其分布如图 6 和图 7 所示。该区独特的城市景观发生了戏剧性的变化,向更广阔的区域延伸,尤其是在“白色城市”区和外围之间。

Fig.6 Allowed FAR, rezoning fully utilized across the precinct. The northern part, outside the “White City” zone, gains significantly higher FAR

Fig.7 Frequency distribution of allowed FAR, if rezoning fully utilized across the precinct; FAR outside the “White City” zone (blue) show higher results, while the “White City” zone (red) stays relatively closer to current FAR’s. Overall, FAR distribution is widening.
3.可行性结果和预测的建成环境
可行性结果惊人;根据导致我的分析的假设,只有 521 个地块(在分析的 2161 个地块中,占 24%)被发现有足够的利润来利用新的法令。
可行和不可行地块如图 8 所示:

Fig.8 Economic Feasibility for renewal by the new zoning ordinance. 1640 (76%) parcels were found to be not feasible (red color). Only 521 parcels (24%) were found feasible enough for utilizing their rezoning possibilities (green color).
考虑到辖区内的 471 块被指定为历史保护区,因此不符合新规划的条件,重新分区虽然旨在产生额外的建筑面积,但却使辖区内约 80%的建筑 恶化并倒塌。图 9 根据可行性结果绘制了预期容积率,为被发现可行的地块绘制了允许容积率*,为被发现不可行的地块绘制了当前容积率。图 10 按照相同的方法显示了整个辖区内预期 FAR 的频率分布。无论是地图还是柱状图都没有遵循任何城市结构的常识。*

Fig.9 Anticipated FAR according to feasibility results. 521 parcels (24%) assumed to be renewed thus show their allowed FAR guided by the rezoning ordinance, while the rest 76% show their current FAR.

Fig.10 Frequency distribution of anticipated FAR, rezoning utilized only for parcels that were found feasible according to the new ordinance.
根据新条例,考虑到将要实施的项目的可行性阈值,预期的城市景观是许多旧建筑和相对少量的新建筑的混合物,与今天特拉维夫市中心的城市景观不一致且完全不同。根据这些结果,区预计将增加 3390 套住房,约为计划宣布目标 8000 套的 40%。
讨论和含义
*本研究评估了特拉维夫市中心 3 区的再分区条例,评估了每个地块的经济可行性,并根据其预期用途描绘了未来的建筑环境。**分析显示,超过 75%的 3 区建筑没有利用新条例的经济合理性,*这实际上使这个有意义的区域恶化,并改变了特拉维夫市中心城市景观的显著一致性。

A typical ‘Tel-Aviv building’; Will it renew before completely crumbling?
这些结果提出了关于新法令的目标的问题,以及该计划是否实际上引导城市及其城区朝着这些目标前进。该计划的指导方针真的能保护特拉维夫市中心的景观质量吗?考虑到该计划的激励措施足以让不到四分之一的辖区建筑得到利用,它真的是城市更新的杠杆吗?这两个问题,引导和激励我通过这项研究,应该通知当地的规划者,使他们重新评估这个计划和未来的条例,这些天在特拉维夫处于不同的规划阶段。
最重要的是,这项研究应该提出一个关于总体规划和政策分析的讨论,以及大数据工具和技术应用于城市规划的方式,通过允许定性和粒度空间分析来利用它。
未来的研究
为了解决其可行性问题,3 号区计划允许两个小地块(500 米或更小)的可选地块联合*,利用它们的共享侧面在两个地块上建造一座建筑,为每个地块创造更高的占地面积。这种可能性使新条例在整体上更可行。考虑到这种可能性,需要进行进一步的研究,以评估预计重新开发的地块比例。*
此外,一个类似的分区计划即将被批准用于第 4 选区(“T0”新的北部“T1”社区,位于第 3 选区的东部),给予更高的奖励,主要是因为第 4 选区不包含“白色城市”区。这个计划被认为非常有利可图。由于这些邻近区域今天具有相似的、连续的城市景观,考虑到它们的经济可行性和预期用途,评估由不同条例产生的未来城市景观将是有趣的。
在“市场、设计和城市”课程中,作为一个全课程项目进行的完整研究(由 Alain Bertaud 教授负责;NYU 瓦格纳 2018 春),此处可用。**
特别感谢 Roy Lavian,他是特拉维夫的一名开发商,也是我的同事,我曾就新条例指导下的经济可行性阈值的定义向他咨询过。
贝叶斯思维介绍:为什么一个测试可能不足以检测你体内的病毒?

Photo by Drew Hays on Unsplash
假设世界上存在一种非常罕见的疾病。你患这种疾病的几率只有千分之一。你想知道你是否被感染,所以你做了一个 99%准确的测试…测试结果为阳性!你有多确定自己真的被感染了?
第二次测试如何影响你确实被感染的信念?
我在这里使用的例子来自真理频道。在这篇文章中,我想向展示贝叶斯网络下的逻辑。关于贝叶斯定理的更多细节,我建议看视频。
第一次测试
由于这是一种非常罕见的疾病(1/1000 会受到影响),您体内携带该病毒的概率由下表给出(称为条件概率表):

Virus CPT (Conditional Probability Table)
这张表显示,只有 1/1000 的人有这种病毒。这就等于说:1000 人中有 999 人没有感染这种病毒。
现在我们做一个类似的测试表:第二个表显示了测试的准确性。这就是测试辨别真伪的能力。因此,如果你被感染了,测试将有 99%的机会是真的,如果你没有被感染,测试将显示假的(99%准确),在这两种情况下错误率是 1%

Test1 CPT (Conditional Probability Table)
下图显示了测试结果中的病毒存在取决于测试(如上表所示):

A simple and empty simple bayesian network
然后当我给出证据证明测试是真的。网络显示,在一次检测呈阳性的情况下,病毒在你身体上的存在率仅为 9%!

The same bayesian network with the evidence loaded of one positive test
**为什么会这样?**这个数来自贝叶斯定理:

在这个问题中:
𝑃(H|E) = 𝑃(H) × 𝑃(E|H) / 𝑃(E)
𝑃(h|e)= 𝑃(h)×p(e | h)/(𝑃(e|h)×𝑃(h)+𝑃(e|hc)×𝑃(ec)
𝑃(h|e)= 0.99 * 0.001/(0.001 * 0.99+0.999 * 0.01)= 0.9 = 9%
所以,即使你做了 99%准确的测试,患这种疾病的几率也只有 9%
这种计算看起来很复杂,但是一旦用图表表示出来,我们对贝叶斯思维的工作方式就有了更好的直觉。
针对两项测试:
如果你参加第二次考试会怎么样?假设这个新测试也有 99%的准确率,我们有和第一个测试一样的表:

Test2 CPT (Conditional Probability Table)
对应的贝叶斯网络将是下一个:

Bayesian network for two positive test
这意味着:对于两个阳性测试,患病的机会增加到 91%。上传之前的经验。这是一致的,患这种病的几率从 9%上升到 91%。但还不是 100%!
在另一种情况下,如果第二次测试是阴性的,有 100%的机会没有患病。

Bayesian network for one positive test and one negative test
针对三项测试
在三次测试的情况下,所有测试都具有相同的准确度,我们看到一些有趣的结果。如果你有证据证明 3 个测试都是真的,现在就 100%确定你感染了病毒。

Bayes network for three positive test
但是由于一次测试是错误的,结果又变了,只有 91%的可能性病毒存在于你的体内:

总之*、*、、贝叶斯网络有助于我们表现贝叶斯思维、,当要建模的数据量适中、不完整和/或不确定时,可以用在数据科学中。他们也可以利用专家的判断来建立或完善网络。它们允许“模拟”不同的场景。它们表示输入值(在本例中为病毒存在和测试的准确性)如何与输出的特定概率水平(实际患病的概率)相关联
在这篇文章中,我解释了如何建立贝叶斯网络,从贝叶斯定理开始。我目前正在研究贝叶斯网络来预测项目的成本和风险。我想分享一下构建如此强大的 AI 工具的基础知识。
如果你想知道更多关于贝叶斯网络的知识:
关于模型源轴上理论和数据之间的水平划分,贝叶斯网络有一个特殊的特征。贝叶斯网络可以从人类知识中构建,即从理论中构建,或者可以从数据中由机器学习。因此,他们可以使用整个光谱作为模型源。此外,由于它们的图形结构,机器学习贝叶斯网络是视觉上可解释的,因此促进了人类的学习和理论建设。在这篇文章中,我比较了 BN 和 S 监督学习算法以及强化学习。

贝叶斯网络允许人类学习和机器学习协同工作,即贝叶斯网络可以从人类和人工智能的结合中开发出来。除了跨越理论和数据之间的界限,贝叶斯网络还具有关于因果关系的特殊性质。
然而,这种协作并不简单,为了构建贝叶斯网络,有必要适当地选择几个超参数。
在某些条件下,通过特定的理论驱动的假设,贝叶斯网络有助于因果推理。事实上,贝叶斯网络模型可以覆盖从关联/相关到因果关系的整个范围。
在实践中,这意味着 w e 可以将因果假设(例如使用合成节点)添加到现有的非因果网络中,从而创建因果贝叶斯网络。当我们试图模拟一个领域中的干预时,例如估计治疗的效果,这是特别重要的。在这种情况下,使用因果模型是非常必要的,贝叶斯网络可以帮助我们实现这种转变。
链接到这篇文章的完整研究可以在下一个链接中找到(这篇文章直到 2020 年 6 月都是免费的)
提出了一种建立项目管理成熟度和项目超额成本之间因果关系的方法
www.sciencedirect.com](https://www.sciencedirect.com/science/article/pii/S0166361519309480?dgcid=author)
感谢阅读!!
如果你想继续关注如何建立贝叶斯网络,查看这篇文章:
在这段历史中,我们讨论了在基于贝叶斯理论建立模型时要考虑的结构标准
towardsdatascience.com](/the-hyperparameter-tuning-problem-in-bayesian-networks-1371590f470)
如果你想了解更多关于贝叶斯网络的数学知识,以及如何用它们创建模型,请查看这篇文章:
在这篇文章中,我给出了一个更正式的观点,并讨论了建模的一个重要元素:合成节点。
towardsdatascience.com](/bayesian-networks-and-synthetic-nodes-721de16c47e2)
基于机器学习的葡萄酒等级预测

Photo by Hermes Rivera on Unsplash
我没有一天不从同事、黑客新闻等那里听到“机器学习”、“深度学习”或“人工智能”之类的话。现在的炒作超级强大!
在阅读了一些关于 ML 的书籍、文章、教程之后,我想从这个理论初级水平毕业。我需要在一个真实的例子上做实验。当主题是让我感兴趣的东西时,效果会更好。所以对于这个做法,我挑了酒(> <)。
酒牛逼,不得不说!我能说吗?嗯,太牛逼了!
喝葡萄酒这么多年来,在买一瓶酒之前,我一直在寻找一样东西:评级。以各种形式:要点、描述等…
我们设定了一个简单的目标:有没有可能通过机器学习,根据葡萄酒的描述来预测它的等级?
有人称这为情感分析,或文本分析。开始吧!
资料组
好吧,我不得不承认,我很懒。我不想为像 Robert Parker,WineSpectactor…
这样的葡萄酒杂志写文章,但幸运的是,在谷歌搜索了几下后,在一个银盘上发现了天赐数据集:收集了 WineMag 的 13 万种葡萄酒(包括评级、描述、价格等等)。
顺便说一下,感谢 zackthoutt 提供了这个令人敬畏的数据集。
先看数据
与通常的数据集一样,我学会了删除重复项和 NaN 值(空值):

我们只剩下 92k 的葡萄酒评论,足够玩了!
现在让我们看看数据集的分布。在我们的例子中,它是每点的葡萄酒数量:

83 到 93 分的酒很多。这也是符合市场的(好酒不多)。
作为一个有趣的注意,只是通过阅读一些数据,我发现葡萄酒越好,描述似乎越长。人们渴望对他们真正欣赏的葡萄酒发表更长的评论,这有点合乎逻辑,但我不认为数据会如此重要:

模型
看起来我们的数据集有太多的可能性。这可能会加重预测的负担。一瓶 90 分的葡萄酒和一瓶 91 分的葡萄酒并没有太大的不同,所以描述可能也没有太大的不同。
我们试着用 5 个不同的值来简化模型:
1 - >分 80 到 84(一般葡萄酒)
2 - >分 84 到 88(一般葡萄酒)
3 - >分 88 到 92(好酒)
4 - >分 92 到 96(非常好的葡萄酒)
5 - >分 96 到 100(优秀葡萄酒)
现在让我们看看我们的新发行版:

…向量化…
如今,用最大似然法对文本进行分类的最简单的方法之一被称为词袋,或矢量化。
基本上,你希望在一个向量空间中表示你的文本,并与权重(出现的次数等)相关联,这样你的分类算法将能够解释它。
一些矢量化算法是可用的,最著名的(据我所知)是:
- CountVectorizer:如其名称所述,简单地通过单词计数进行加权
- TF-IDF 矢量化:权重随着计数成比例地增加,但是被单词在整个语料库中的频率所抵消。这被称为 IDF(逆文档频率)。这使得矢量器可以用“the”、“a”等常用词来调整权重
训练和测试模型
在机器学习中,这是测试的最后一部分。
您希望用数据集的一部分来训练模型,然后通过将数据集的剩余部分与预测进行比较来测试其准确性。
对于这个实验,90%的数据集将用于训练(大约 80k 酒)。10%的数据集将用于测试(约 9k 酒)。
我们将使用的分类器是 RandomForestClassifier (RFC),因为它很酷,并且在许多情况下都工作得很好(>)尽管严重的是,RFC 不如其他一些分类器有高性能(内存和 cpu 方面),但我总是发现它在处理小数据集时非常有效。
结果

Sugoiiii!这是一些惊人的结果!97%的情况下,我们仅仅根据葡萄酒的描述就能正确预测它的质量。
让我们快速浏览一下这些数字及其含义:
-精度:0.97 - >我们没有很多假阳性
-召回:0.97 - >我们没有很多假阴性
(F1-考虑精度和召回的分数)
结束注释
这些结果非常棒,但我们肯定可以改进它:
-所有数据(训练和测试)都来自 WineMag。拥有一些其他葡萄酒杂志的评级将会改进这个模型,使它更通用
- RFC 是一个很好的分类器,但是占用了大量的内存和 CPU。也许对于一个更大的数据集,多项式朴素贝叶斯会更好,性能更高
——我们没有过多地查看其他列(地区、价格等)。我们可以将它们二进制化/编码以进行分类。
-将代码发布为 Flask 或 Django API 将是一件很好的事情
Kaggle 笔记本
所有数据集和 python 代码都可以在:
https://www . ka ggle . com/olivierg 13/wine-ratings-analysis-w-supervised-ml获得
一会儿酒厂见!(>
葡萄酒与起泡酒:一个神经网络图像分类解释

如果你看了我之前的帖子,你就知道我喜欢酒。嗯,事实是,我不是特别喜欢汽酒!(☉_☉)
对于我第二次深入机器学习,我想看看卷积神经网络(CNN)对图像分类的可能性。顺便说一下,CNN 并不代表新闻频道(◠‿◠)
最近,一个朋友建议我去查看 Keras,这是一个神经网络库,超级容易使用,由谷歌的弗朗索瓦·乔莱开发。让我们马上进入正题,这个库太棒了:超级容易使用,超级高性能,文档写得很完美。你还能要求什么?
这个实验的目的是了解葡萄酒和起泡酒的图像的识别程度,或者简单地说,这种模型的精确度。
什么是 CNN?
我鼓励你阅读这篇写得很好的文章,它详细解释了什么是 CNN。
简言之,CNN 在两个主要方面不同于常规的机器学习算法:
- 它由不同的过滤器(内核)和分类器组成。每个部分都是独立的,就像我们大脑的一部分,如果需要,CNN 可以删除、更新和调整这些部分。

Architecture of a CNN. — Source: https://www.mathworks.com/videos/introduction-to-deep-learning-what-are-convolutional-neural-networks–1489512765771.html
- CNN 将从经验中学习。它有能力回到数据集并从以前的训练中学习,例如,对效果最好的过滤器或分类器进行更多的加权。对数据集的一次迭代称为一个时期。
数据集
我为了这个不偷懒,就刮了一个不怎么出名的酒类网站。
结果是一个由 700 幅训练图像和 200 幅测试图像组成的数据集,足够用了。下一步就是简单地将 Keras 的博客例子调整到这个数据集。
训练和测试模型
为了你自己,我不会把这个项目的所有代码都粘贴在这里,但是 Github 的链接在本文的最后。
那么 Keras 是如何进行图像分类的呢?我认为有几个重要的部分:
- 构建您的神经网络模型:遵循文档
model = Sequential()
model.add(Conv2D(32, (3, 3), input_shape=input_shape))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))[...More CNN layers...]model.compile(loss='binary_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
- 使用 ImageDataGenerator 为模型提供更广泛、更多样的生成图像集
train_datagen = ImageDataGenerator(rescale=1\. / 255, shear_range=0.2, zoom_range=0.2, horizontal_flip=True)
- 训练和测试您的模型
model.fit_generator(train_generator, steps_per_epoch=nb_train_samples, epochs=epochs, validation_data=validation_generator, validation_steps=nb_validation_samples)
- 最后拯救你的体重和模型
model.save_weights('wines_sparklings_weights.h5')
model.save('wines_sparklings_model.h5')
运行 python 文件将输出类似这样的内容(10 个历元后精度约为 99%):

解释模型
可解释的人工智能今天被大肆宣传,所以我想给它一个机会。训练一个模型并信任它不是一件容易的事情。验证您的模型实际上不是纯粹偶然地神奇地对图像进行分类是一件好事,特别是如果它是一个真实的项目,并且将被推向生产环境。
我很幸运,不久前,Lime 库在 Github 上发布了,它最近获得了对 Keras 图像分类的支持。我想试一试!
在笔记本上,我首先展示了一幅葡萄酒的图像,并使用我们之前训练过的 Keras 模型进行了预测:
show_img(wine_image[0])
print(model.predict(wine_image))

Using pyplot to show the image and printing the prediction
酷,预测是对的,用 pyplot 显示图像。下一步是使用石灰显示图像的哪些部分影响了分类决策:
# Explain
explanation = explainer.explain_instance(wine_image[0], model.predict, top_labels=2, hide_color=0, num_samples=1000)# Show image with explanation's masks
temp, mask = explanation.get_image_and_mask(0, positive_only=False, num_features=10, hide_rest=False)
show_img(mark_boundaries(temp / 2 + 0.5, mask))

Positive influence in Green, Negative in Red
很好。正如所料,葡萄酒的软木塞不同于气泡瓶(影响葡萄酒决策的绿色部分)。起泡的瓶子上的标签通常也较低,瓶子的形状较薄(红色部分影响非起泡的决定)。我用一瓶起泡葡萄酒继续分析:

Positive influence in Green, Negative in Red
此外,正如所料,瓶子的顶部和软木塞的形状积极地影响了对起泡葡萄酒的决定,以及瓶子本身的形状影响了对非葡萄酒的决定。
结论
总之,我们有一个超级有效的 CNN 模型,用大约 100 行代码训练和保存。我们知道这不仅仅是魔法在发生,因为我们解释了图像中识别的模式。
有哪些可以改进的地方?
- 拥有更加多样化的图像数据集。老实说,这个场景很容易操作,因为背景是白色的。
- 多解释几个图像。为解释而挑选的两张图片相当标准。解释模型做出错误预测的情况也很有趣。
- 将这个模型发布为 Flask/Django API,并编写一个移动应用程序,让人们用他们手机的图片来训练它
链接
- 美国有线电视新闻网(CNN):https://github.com/keras-team/keras
- Keras 博客:https://Blog . keras . io/building-powerful-image-class ification-models-using-very-little-data . html
- 石灰库(型号说明):https://github.com/marcotcr/lime
- 本文的代号:https://github.com/olivierg13/WinesSparklingsKeras
赢得 CFT 2018 拼写纠正比赛
或者在一个具有挑战性的领域中构建一个任务无关的 seq2seq 管道

这是我们第一次一起赢得 ML 比赛
一篇简短的哲学序言。
我们作为 Profi.ru 团队(你真正的+ Dmitry Voronin 帮了点忙)和 Sava Kalbachou(Lucidworks)参加,她是我在许多比赛中的老朋友,也是 NLP 的专家。对我们团队来说,这是一次漫长、艰难、紧张而又意外收获的旅程。
用一句话概括所有的经历— 旅程比目的地更重要。这场比赛教会了我们很多关于坚持不懈,尝试新事物,跌倒了再站起来。
我个人为此任务编译/优化了 3 或 4 个管道,直到我能构建出最好的一个。同样,像往常一样,我们在终点线 xD 前一天发现了一个关键错误
TLDR

我们设法将一些当前最先进的序列到序列模型应用于混合多任务/自动编码器设置中具有挑战性的领域中的真实in the wild问题。
任务的核心是——文本输入分类(正确/需要纠正/随机不相关垃圾)和输入纠正(本质上是拼写检查)。
域名是——来自独联体国家的个人姓名:
- 主要是俄罗斯、摩尔多瓦、乌兹别克斯坦、格鲁吉亚、塔吉克斯坦、哈萨克斯坦、乌克兰等;
- 名字通常由三部分组成(名、姓、父名)——
Иванов Иван Иванович。有时在某些共和国,父名有附加的后缀作为第四个单词(ОГЛЫ,与俄语中的вич后缀相同,但却是一个独立的单词); - 有 2+个字母,总共约 70+个字符+数据中的大量噪声;
最有效的模型
- 序列间:
- 调优的序列间双向 GRU(详见下文)——
92.5%wo 启发式、93%with 启发式、93%+in ensemble; - 适当的序列间推理循环;
- 此外,Keras 中一个没有瓶颈且带有 Conv1D 输出层的更简单模型运行良好,最高得分为
88-89%; - 最强的天真启发法—如果 seq2seq 推理循环的输出与输入相同—那么输入是正确的;
关键要点:
- Seq2seq transformer 花了更多的时间来训练,我们没能让它像传统模型一样工作。显然我们缺乏这方面的经验,但这是我第四次注意到真人提到《变形金刚》不适合“真人”(即不实用);
- 我们的主要竞争对手(有大约 200 份提交)根本没有使用深度学习——他基本上对主机的增强管道进行了逆向工程——这是一项艰巨的工作,但无法扩展到其他领域;
- 批量 seq2seq 预测是快速推断的关键;
- Beam search 虽然很难实现,但对分数的提升并不显著(明显的罪魁祸首——小词典);
域/数据集描述
一个例证胜过千言万语。另请注意,在 train + test 中有大约 2000 个国家,即国家输入也非常嘈杂。
我们最终没有使用国家——因为添加国家嵌入并没有提高我们的指标

比赛的主持人也分享了一个强大而简单的基线:
- 一个基于 n 元文法的线性回归分类器:
- 简单使用第三方库来纠正印刷错误;

The distribution of the number of errors per query
代码发布
我们不会费心复制整个培训过程(由于我们与竞赛主办方的协议),因为有许多微调步骤,但总体而言这些部分将可为您重复使用:
- 准备竞赛数据集(见笔记本第一章);
- 如果您在环境中遇到问题(当构建映像时,PyTorch 4.0 或 4.1 是主要版本,瞄准它,否则您将不得不使代码兼容);
- Keras 模型:
python preprocessing.py python spell_simple_seq2seq_train_predict.py
CUDA_VISIBLE_DEVICES=0 python3 train_encoder_decoder_predict.py \ --resume weights/some_checkpoint.pth.tar \
--heavy_decoder True --lr_factor 0.5 \
--trn_df_path ../data/pseudo_aug2_proc_trn.csv \
--tb_name test_name \
--lr 1e-6 --epochs 100 \
--batch_size 128 \
--hidden_size 512 --dropout 0.2 \
--num_layers 4 --num_classes 3 --emb_size 512 \
--cn_emb_size 0 --num_cn 0 \
--tensorboard True \
实现我们结果的关键里程碑

This is how our scores improved
(*)很可能我们没有在这方面投入足够的时间,但是基础管道的目标不同,所以我们放弃了这个想法;(**)尽管最大的合理 BiGRU 模型训练了 15-20 个小时,但这将在一个 GPU 上训练至少一周才能达到类似的结果;(***)车神大多腐朽,MOAR 层层!;(****)我们两次在生成扩充数据时出错。起初,我在 50%的情况下混合了两列(源和目标)——并且模型一开始训练得更好。然后,我忘记了在扩充数据时更改目标标签

请参考这些惊人的文章了解我们使用的型号的更多螺母和螺栓:
什么有效:
- 用 biLSTMs (
91%+)进行序列对序列建模; - 验证与 LB 精确匹配——我们没有尝试 K 倍验证,但是预先分割数据集已经足够精确;
- 使用简单的管道清除多余的字符和明显的错误;
- 伪标签和文本扩充(单个模型上的
91%+1.5%); - 使用“整个”训练数据集,即使用所有正确的名称作为“正确的”名称,并使用所有不正确的名称。与额外的扩充(1 倍大小的训练数据集)配对—结果是我们单一的最佳预处理管道(单一模型上的
91%+1.5%); - 后处理试探法(见下文);
- 运行基于批次的推理循环(在带注释的编码器、解码器和转换器中,预测以批次大小为 1 进行处理);
不可行的想法/解决方案/模式,或者我们没有尝试
- BPE /例句 —我们尝试了几种词汇(500、1500、5000 令牌大小等。)通过句子片段在无监督的情况下获得。但它并没有真正帮助模型更快地收敛,结果比我们预期的更糟;
- 波束搜索 —最有可能是因为模型置信度和词汇量小。它提高了一点分数,但没有提供太多的价值。这是一个棘手的问题,但我很失望,它没有我们预期的那样有效;
- transformer model——当我采用并优化带注释的 transformer 管道时,它工作了,但未能在有意义的时间内收敛;
- 来自开放 AI transformer 实验的 LM 辅助分类器——它根本没有收敛,很可能是因为它缺乏一个正确的 seq2seq 推理循环,对我来说这是一个容易实现的结果(我刚刚准备好这个管道,而 Sava 吹嘘他的初始 88%管道);
- 多 GPU /集群/分布式训练——没试过;
- 动态运行增强——我相信你可以在 torchtext 中扩展这个行来这样做,但是我推迟了一点,然后就没有时间这样做了。但根据我的经验,这可能会使收敛速度加快 3 到 10 倍;
文本数据扩充
经过一些逆向工程过程(顺便说一下,基于单词 ngrams),结果证明,组织者使用非常简单的错别字生成方法。有 5 种主要类型:
- 插入,最主要的类型( ~所有病例的 50% )。只是在单词中随机取一个字母,并在它的前面或后面插入一个新字母。一个新字母是一个随机选择的最接近的字母(在键盘上),例如,字母 W 、 S 或 A 如果选择了 Q 。伊万——ICVAN;
- 改变、 ~30% ,只是将一个单词中的任意一个字母在一个 keybord 上改变成与其最接近的 random(就像插入的情况)。伊万—IVQN;
- Wwap 两个最近的随机字母的位置, ~5% 。伊万——张牧阅;
- 两个字之间删除空格,~ 7.5%;
- 删信(完全随机*~ 7.5%*)伊凡——凡;
每个有错别字的查询都包含上面列出的一个( 93% )两个( 6% )或三个( ~1% )错误的组合。
因此,我们设法编写了自己的函数来生成额外的数据集,并将其与原始数据集一起用于训练。

后处理启发法
在建立第一个 seq2seq 模型后,我们注意到,有时模型预测类 0(短语不包含错误),但预测的短语与原始短语不同。我们将此作为一种启发,将预测类从 0 更改为 1(短语包含错误),这给了我们 0.5-1.5%的提升,这取决于模型的质量(对于强模型来说更少)。
另一个启发是在我们确定预测中有错误(模型预测类别 1,但是预测短语等于原始短语)的情况下,将预测类别/短语改变为来自完全不同的模型(如 Keras one)的预测。
不起作用的试探法,或者我们没有探索的试探法
在某个时刻,我们注意到,与“新”单词(名字/姓氏/父名)相比,网络更有可能在它“知道的”单词上犯错误。这意味着网络泛化能力很好,但尽管如此,我们还是尝试应用一种明显的启发式方法进行测试,本质上类似于伪标签。
显然,我们尝试使用字典启发式,即检查预测的单词是否出现在名称的词汇表中。它在验证上提供了显著的提升,但是在测试上没有提供合理的提升(很可能是因为有很少的名字被预测错误和/或在训练中不存在)。显然,我们试图添加预测的“正确”测试名称,但这没有帮助。

训练与测试单词字典重叠
集合模型
正如在比赛中经常发生的那样,在接近终点的某个时候,你必须做一些堆叠/组装来继续比赛并保持在 LB 的顶端。这场比赛也不例外。
我们使用拒识验证数据来寻找最佳的组合方式及其参数。对于分类的第一个任务,我们使用了各种不同模型预测概率的几何平均值。对于域名更正的第二步,我们实现了简单多数投票机制,该机制应用于预测域名的每个令牌。在每一步之后,也使用上述试探法。
这个简单而有效的组合给了我们最终 0.003%的提升和第一名。我们选择它和最佳单曲作为我们的两个最终提交:

改进带注释的编码器-解码器和带注释的转换器
如您所知,biLSTMs / biGRUs 和 transformers 是市场上最具挑战性的型号,例如:
- 神经机器翻译;
- 文本抽象;
- 序列对序列建模;
- 文本推理任务;
当重用这些教程编码器解码器和注释变压器中的恒星管道时,我们站在巨人的肩膀上。
但是就像我们生活中的一切一样,它们并不完美。
关键缺点:
- 两者中的预测都是以一个批量处理的。当您运行大量端到端实验时,这并不理想;
- 带注释的编码器/解码器拥有损失加权,但没有解释当将其与次要目标配对时(就像我们的情况),你必须格外小心加权损失的两个分量,以避免在一个任务上过度/不足;
- 虽然 torchtext 对于它的构建目的(加速 NMT 实验)——对于应用竞争 NLP 管道——来说是令人敬畏的,但是它有点慢和笨重,并且种子参数不直观。或许我应该更好地解决缓存问题,但我选择了最简单的解决方案,即我下面解释的 CSV 文件;
- 我完全理解 PyTorch 中的分布式/数据并行例程有点实验性,并且需要大量维护,但 ofc 注释的变形金刚多 GPU loss compute 函数在
PyToch 0.4+中出现。我决定不解决这个问题,但是也许我应该解决,特别是对于变形金刚;
批量预测和波束搜索
在训练和验证模型时,这两种方法都非常注重有效地运行模型。但是由于某些原因,教程中介绍的推理贪婪搜索循环是为大小为 1 的批处理编写的。
您可能知道,这将使端到端验证速度降低了 10 倍。所以,我基本上写了 3 个函数:
所有这些来自 torchtext 的抽象…如何烹饪它们

显然这些是为 NMT 建造的。它们还以张量的形式将所有数据加载到 RAM 中,以加快迭代速度(在使用这些数据时,最好使用 python 中的迭代器,以避免更多的 RAM 使用),这与标准的 PyTorch Dataset / Dataloader 类不同,后者更灵活一些。
这些抽象的优点:
- 代码重用和简单性;
- 它们是……高层次、抽象的;
- 创建、描述和预处理数据集的步骤简单且简化;
- 繁琐的步骤,如添加开始令牌,结束令牌,独特的令牌,填充令牌只是为你做的;
- 一旦掌握了拆分和字典构建——替换您的文本预处理函数来尝试不同的标记化方案就变得非常容易(例如检查这个一个和这个一个);
缺点:
- 在构建字典以使相同模型的重新运行兼容时,您必须非常小心泄漏(这实际上在开始时让我有点受不了);
- 显然,这种开箱即用的方法只适用于数字和文本数据。任何其他形式的数据——你必须即兴创作/扩展类;
- 我不喜欢在那里实现拆分的方式——所以我们最终通过拆分一个单独的
.csv文件来创建一个 hould out 数据集; - 如果你有很多数据(例如 1000 万个输入目标对),RAM 消耗非常高,所以如果你想有更多的数据/使用扩充,你基本上必须修改/扩展这些类;
- 虽然理论上扩展这些类来阅读
.feather而不是.csv是很容易的,但是由于缺乏时间和注意力不集中,我没有这样做; - pickle 问题——由于读取
.csv文件很慢,我试图 pickle 一些明显的对象——但是失败了——迭代器/生成器在 python3 中是不可 pickle 的。我想我应该用 dataset 类(而不是 BucketIterator 类)来完成它;
典型风味
在某个时候,我注意到在我们的最佳模型中有两个瓶颈:
- 由于编码器是双向的,而解码器不是双向的,因此编码器和解码器之间的传输成为瓶颈。所以简单地说,我通过把我的解码器增大两倍解决了这个问题(它帮助我的模型收敛);
- 我还尝试了添加国家嵌入和添加跳过连接和一个本质上类似于从抽象模型中复制注意力的注意力层——这些想法对我不起作用;
- 我还玩了本质上的丢弃嵌入(字符级模型),结果很差;另一方面,Keras 模型在 char 级别比使用嵌入工作得更好。
值得注意的是,最好的模型是相当沉重的,沉重的解码器也增加了相当多的时间。
损失权重至关重要!
我没有为此运行消融测试(虽然我有很多在 2-3 次丢失的情况下对象检测失败的经验),但我假设由于丢失基本上被应用于语言建模目标n_token次,然后通过数量或记号归一化,为了实现最佳结果,分类丢失应该是类似的大小的。我通过使用 PyTorch 中最方便的损失层简单地实现了这一点(是的,我忘记了将这一损失按批量大小划分,但我想这并不是很关键)。
KLD 损失?
一个我没有探究的来自注释变压器的好主意——用类 KLD 损失(通常用于变分自动编码器)替换分类损失,以增加预测的方差。但我猜对于词汇量小的人来说不重要。
参考
- seq2seq 车型力学关注;
- 神奇画报变形金刚;
- 带注释的编码器解码器和带注释的变压器(老款 py torch);
- PyTorch 中的 OpenAI transformer 实现;
- 火炬文本数据管道解释;
- 字节级 NMT 模型的情况;
原载于 2020 年 11 月 22 日spark-in . me。
强大的力量伴随着贫乏的潜在代码:VAEs 中的表征学习(Pt。2)
(如果你还没有这样做,我建议回去阅读本系列关于 VAE 故障模式 的第一部分;我花了更多的时间来解释一般的生成模型的基础,特别是 VAEs,因为这篇文章将从它停止的地方跳出来,那篇文章将提供有用的背景)
我发现一个机器学习的想法特别引人注目,那就是嵌入、表示、编码:所有这些向量空间,当你放大并看到一个概念网络可以被漂亮地映射到数学空间的方式时,它们看起来几乎是神奇的。我已经在参数优化和向量代数的杂草中花了足够多的时间,知道即使我说,称机器学习的任何方面为“神奇的”都是异想天开,但是:像这样的方法不可避免地很诱人,因为它们提供了找到一些概念的最佳表示的可能性,一种“最佳数学语言”,我们可以用它向我们的机器提供世界上所有的信息。

TIL: it’s (un)surprisingly hard to find good visualizations of high-dimensional embedding spaces, especially if you don’t want the old “king — queen” trick
那个模糊的梦想,以及对我们目前离它有多远的敏锐意识,是我写这两篇文章的动机,探索我们目前在无监督表示学习方面的最大努力之一可能失败的方式。早先的帖子讨论了 VAE 表示法是如何失败的,它以一种过于密集、复杂和纠缠不清的方式将信息嵌入隐藏的代码中,而这种方式不符合我们的许多需求。这篇文章探讨了一个由不同困境驱动的解决方案:当我们使用一个容量如此之大的解码器时,它选择根本不在潜在代码中存储信息,这一结果将关于我们分布的重要信息锁定在解码器参数中,而不是作为内部表示整齐地提取出来。
如果你所关心的是建立一个生成模型,以便对新的(人工的)观察结果进行采样,那么这不是问题。然而,如果您希望能够通过修改 z 代码来系统地生成不同种类的样本,或者如果您希望使用编码器作为一种将输入观察结果压缩为另一个模型可以使用的有用信息的方式,那么您就有问题了。
无事生非
有时,当阅读技术论文时,你会看到一篇又一篇论文中的陈述被草率地做出,没有解释,好像它太明显而不值得解释。你开始怀疑自己是否出现了思维障碍,是否有一些其他人都有而你却忽略了的非常明显的洞察力。
这就是我不断阅读有关变分自动编码器(VAEs)的论文时的感受,这些变分自动编码器能够重建输入,但在它们的潜在代码中不存储关于每个输入的任何信息。
但是,在我们深入研究为什么和如何这种情况发生之前,让我们后退几步,并浏览一下上述陈述的实际含义。正如您(希望)在我之前的文章中读到的,vae 是围绕信息瓶颈构建的。编码器接受每个观察值 X,并计算压缩的低维表示 z,这在理论上应该可以捕捉关于该特定 X 的高级结构。然后,解码器接受 z 作为输入,并使用它来产生原始输入 X 的最佳猜测。解码器的重建猜测和原始 X 相互比较,两者之间的像素距离(以及推动每个 p(z|x)更接近典型高斯先验分布的正则化项)用于更新模型的参数。从概念上讲,在这样一个模型中,关于数据分布的信息存储在两个地方:代码 z 和将 z 转换为重构的 x 的网络权重。
当我们训练用于表示学习的 VAE 时,我们想要的是 z 表示描述该特定图像中存在的内容的高级概念,以及解码器参数,以学习关于如何将这些概念实例化为实际像素值的一般化信息。(题外话:同样的逻辑适用于你正在重建的任何给定的观察;我倾向于引用图像和像素,因为几乎所有最近的论文都关注图像,并使用这种语言),
当我阅读的所有这些论文声称 z 分布无信息时,他们的意思是:网络收敛到一个点,在这个点上,编码器网络产生的 z 分布是相同的,而不管编码器给定哪个 X。如果 z 分布不随特定 X 的不同而不同,那么,根据定义,它不能携带关于这些特定输入的任何信息。在这种模式下,当解码器创建其重建时,它本质上只是从全局数据分布中采样,而不是由 x 的知识所通知的分布的特定角落。
我不能代表所有人,但我真的很难直观地理解这是如何发生的。VAE 的整个概念结构就像一个自动编码器:它通过计算重建输出和实际输出之间的像素距离来学习。即使我们想象我们有办法从真实的数据分布中完美地采样,使用 z 来传达一些关于我们试图重建的 X 的信息(例如,一个场景是一只猫,而不是一棵树)似乎也有明显的价值。为了建立更好的理解,我不得不进行两次智力旅行;首先是通过自回归解码器的机制,其次是通过 VAE 损失本身的经常棘手的数学。一旦我们从另一端走出来,我们就能更好地理解在赵等人的 InfoVAE 论文中提出的机械上简单的解决方案背后的概念基础。
当自动编码遇到自回归时
概率论中一个简单的基本方程是概率链规则,它控制着联合分布分解成先验概率分布和条件概率分布。如果想知道 p(x,Y),也就是说 X 和 Y 都发生的概率,也就是说联合分布 P(X,Y)在点(X,Y)的值,可以写成:
p(x,y) = p(x)p(y|x)
自回归生成模型(其中最著名的是 PixelRNN 和 PixelCNN)采用了这一思想,并将其应用于生成:与其试图独立生成每个像素(典型的 VAE 方法),或试图将每个像素生成为每个其他像素的条件函数(计算上不可行的方法),不如假设图像中的像素可以像序列一样处理, 和生成的像素,如上面的等式所示:首先基于 x1 像素值的无条件分布选择像素 x1,然后基于以你选择的 x1 为条件的分布选择 x2,然后以 x1 和 x2 为条件的 x3,等等。 PixelRNN 背后的想法是:在 RNN 中,你内在地将关于过去生成的像素的信息聚集到隐藏状态中,并可以使用它来生成下一个像素,从左上角开始并向下和向右移动。
虽然 PixelRNN 在与自回归模型的纯粹直觉保持一致方面做得更好,但更常见的自回归图像模型是 PixelCNN。这是由于 RNNs 的两个有意义的缺点:
- 他们可能很难记住全球背景(即在长时间窗口内存储信息)
- 您不能并行处理 RNN 的训练,因为图像中的每个像素都需要使用在您当前位置“之前”创建完整图像时生成的隐藏状态

Ahh, the smell of pragmatic-yet-effective hacks in the morning
在重视实际可训练性而不是密闭理论的伟大机器学习传统中,PixelCNN 诞生了。在 PixelCNN 中,每个像素都是通过使用其周围的像素计算的卷积来生成的,但重要的是,只有在我们任意的从左上到右下的排序中出现在它“之前”的像素。这就是上图中的暗灰色区域:一个应用于卷积的遮罩,以确保位置“e”处的像素没有使用任何“来自未来”的信息来调节自身。当我们从零开始生成图像时,这一点尤其重要,因为根据定义,如果我们从左到右生成,给定的像素将不可能根据尚未生成的更靠右和更靠下的像素来决定其值。
PixelCNNs 解决了上面列出的两个 PixelRNN 问题,因为: 1)随着增加更高的卷积层,每层都有更大的“感受域”,即它在卷积的金字塔上更高,因此有一个以更宽的像素范围为条件的基础。这有助于 PixelCNN 访问全局结构信息
2)因为每个像素仅取决于直接围绕它的像素,并且该模型的训练设置是逐像素值计算损失,所以通过将单个图像的不同片发送给不同的工作者,该训练很容易并行化
回到 VAEs 的土地上,这些自回归方法开始看起来相当有吸引力;历史上,VAEs 独立地生成图像的每个像素(以共享代码为条件),这固有地导致模糊重建。这是因为,当所有像素同时生成时,每个像素的最佳策略是根据共享代码生成其期望值,而不知道每个其他像素选择了什么像素值。因此,人们开始对在 VAEs 中使用自回归解码器感兴趣。这是通过附加 z 作为附加的特征向量来完成的,旁边是当前由 PixelCNN 使用的附近像素值的卷积。正如预期的那样,这导致了更清晰、更详细的重建,因为像素能够更好地相互“协调”。
因为当我用隐喻思考时,我想得最好,所以独立像素生成的过程有点像委托不同制造厂制造机器的零件;由于每个工厂都不知道其他工厂在建造什么,所以它完全依赖于中央的指导,让各个部分协调一致地工作。相比之下,我认为自回归一代有点像那个故事游戏,每个人写一个故事的句子,然后传给下一个人,下一个人根据上一个写一个新的句子,以此类推。在那里,不是让中心指导来促进整体的各部分之间的协调,而是每个部分使用该部分之前的上下文来确保它是协调的。
这开始让我们了解为什么自回归解码器可能导致潜在代码中的信息减少:以前由共享潜在代码促进的多像素协调现在可以通过让您的网络在以前生成的像素范围内可见来处理,并让它调整其像素输出。
处理损失(功能)
以上都很好:我可以很好地理解自回归模型的更灵活的参数化如何使它能够在不使用潜在代码的情况下对复杂数据进行建模。但是,我花了更长时间才明白:表面上,这些模型是自动编码器,需要能够成功地像素重建它们的输入,以满足它们的损失函数。如果模型不使用 z 来传达关于输入的图像类型的信息,解码器如何能够产生具有低重建损失的输入?
为了理解这个模型的动机是如何排列的,我们应该从描述 VAE 目标函数的方程开始。

底部的等式是 VAE 函数的典型特征:
- 一个激励 p(x|z)变高的术语,也就是说,激励模型生成作为输入的图像的概率,也就是说,如果输出分布全部为高斯分布,则输入和重构像素之间的平方距离
- 激励编码 z|x 的分布接近全局先验的术语,它只是一个零均值高斯分布。(KL 散度测量这些分布相距多远,并且由于这是被最大化的目标中的负项,所以模型试图使 KL 散度的大小更小)
在这个框架下,很容易认为模型的主要功能是自动编码,惩罚项只是一个相对不重要的正则项。但是,上面的等式也可以排列如下:

严格遵循上面的数学公式并不是最重要的;我主要是展示求导,这样第二个方程就不会凭空出现了。在这一表述中,VAE 的目标也可以被看作是:
- 增加 p(x ),也就是说,增加模型在数据 x 中生成每个观察值的概率和能力
- 减小编码分布 q(z|x)和真实的基础后验分布 p(z|x)之间的 KL 散度
等式的第二位意味着什么?在这种情况下,你可能有点难以理解“后”到底是什么意思。这是一个有点模糊的想法。但是,我们知道的一件事是:

换句话说,这意味着先验 p(z)是所有条件分布 p(z|x)的混合,每个条件分布都根据其伴随的 x 值的可能性进行加权。VAE 的标准形式是对其所有条件分布 q(z|x)使用高斯分布。用更清楚的非概率的话来说,这意味着编码器网络从输入值 X 映射到高斯的均值和方差。我们通常还将先验设置为高斯分布:均值为零,方差为 1。这两个事实有一个有趣的含义,这个图表很好地体现了这一点:

这表明:将多个高斯函数相加,并使它们的和也是高斯函数的唯一方法是,如果所有相加的高斯函数具有相同的均值和方差参数。这意味着:如果你想让 q(z|x)完美地匹配 p(z|x ),或者
- 你的 q(z|x)不需要是高斯型的,或者
- q(z|x)必须等价于 p(z):同一个无信息单位高斯,不考虑输入 x 的值。
如果 q(z|x)除了上面概述的两个选项之外做任何事情,它将不能与 p(z|x)相同,并且将因此通过 q(z|x)和 p(z|x)之间的 KL 发散产生一些成本。因为我们通常在结构上选择只允许高斯 p(z|x ),这意味着网络唯一可用的选项,即允许它从第二项中零损失,是使条件分布无信息。
向后遍历内容堆栈,这意味着网络将仅选择使其 z 值具有信息性,如果这样做对于建模完整的数据分布 p(x)是必要的话。否则,它因使用信息性 z 而遭受的损失通常会超过使用它所获得的单个图像准确性的好处。
供参考
有了这些背景知识,我们现在就能更好地理解 InfoVAE 论文针对这个问题提出的解决方案。该文件对“香草 VAE”目标提出的两个主要批评是
- 信息偏好属性,这就是我们上面概述的:vae 倾向于不在他们的潜在代码中编码信息,如果他们可以避免的话。当正则项太强时,这往往会发生。
- “爆炸潜在空间”问题。这基本上就是我在之前的博客文章中讨论的内容,在没有足够的正则化的情况下,网络有动力使每个 x 的条件 z 分布不重叠,这通常会导致较差的采样能力和更复杂的表示。
尽管这个问题很难理解,但他们提出的解决方案实际上非常简单。还记得在最初的 VAE 方程中,我们如何惩罚 z 上的后验和 z 上的先验之间的 KL 散度吗?

这里要记住的重要一点是,这是为每个个体 x 计算的**。这是因为编码层是随机的,因此对于每个输入 x,我们不是简单地产生一个代码,而是产生代码上的分布的平均值和标准偏差。对于每个单独的输入,它是与标准正态分布的先验进行比较的分布。**
与之相反,InfoVAE 论文提出了一个不同的正则项:激励聚集的 z 分布接近 p(x ),而不是推动每个单独的 z 接近。聚集的 z 分布为:

换句话说,基本上就是说,我们应该将所有 x 值产生的条件分布聚合在一起,而不是采用每个单独输入 x 定义的分布。如果你到目前为止一直在跟踪的话,这种方法的基本原理是相当一致的。信息偏好的特性来自于这样一个事实,当你激励每个个体有条件地接近先验时,你实际上是在激励它不提供信息。但是,当您激励聚合的 z 接近先验时,您允许每个单独的 z 代码有更多的空间偏离 N(0,1),并且这样做携带了关于产生它的特定 X 的信息。然而,因为我们仍在推动聚集分布接近先验分布,所以我们不鼓励网络陷入“爆炸潜在空间”问题,在该问题中,网络将其平均值推动到较高的量级,以创建将提供最多信息的非重叠分布。
注意,这种新的公式需要某种基于样本的方式来测量一组样本和先验之间的差异,而不是能够分析计算参数化条件分布和先验之间的差异。这种情况的一个例子是对抗性损失,在这种情况下,您获取编码器采样的 z 值集合,并将这些集合与从先前提取的 z 值集合一起提供给鉴别器,并激励模型使这两个集合不可区分。论文作者探讨了更多这样的方法,但是由于它们与本文的主旨相当正交,如果您阅读了这篇论文,我将让您自己探索这些方法。
根据经验,作者发现这种修改导致自回归 VAEs 更多地利用潜在的代码,而重建精度没有明显下降
未解决的问题

Source: http://kiriakakis.net/comics/mused/a-day-at-the-park
我比我第一次构思这个帖子系列时更了解表征学习,如果我做得对,你也一样。但是,以一个结论结尾意味着一些现成的答案,而且我认为问题通常比答案更有趣,所以我会把其中的一些留给你。
- 如果我们的目标实际上是表征学习,你是否有模糊重建真的有关系吗?这基本上是在问:像 PixelCNN 能给我们的那种清晰的重建,实际上是我们最关心的吗?
- 如果我们将早期文章中的一些解开技术与重建概念级特征(即除原始像素之外的编码网络层)的目标相结合,我们能获得更好的表征学习吗
- 为了便于特征学习,拥有随机代码有多大价值?如果你使用一个“聚合 z”优先执行方法,就像 InfoVAE 中概述的那样,那能让我们从使用高斯函数作为潜在代码中解放出来吗?
- 我们是否还可以在网络的重建部分有效地使用对抗性损失(即:让鉴别器尝试区分输入和重建),以避免过度关注像素损失带来的精确细节重建
来源:
使用 Twitter 情感分析的品牌认知
随着社交媒体的出现,通过各种来源共享高质量的结构化和非结构化信息,如 Twitter 或脸书生成的描述用户情绪的数据。处理这些信息的能力对于使用 Twitter 情感分析深入了解品牌认知变得非常重要。文本分析是机器学习技术的一部分,其中从文本中获得高质量的信息,以挖掘客户对特定品牌的感知。
品牌感知是消费者对品牌体验的特殊结果。本文旨在了解消费者对品牌的形象和认知,以及他们对#nike 品牌的真实想法和感受。在这项研究中,我们从 twitter 上收集了用于品牌认知和情感分析的数据。
照做 是鞋业公司耐克的商标,也是耐克品牌的核心组成部分之一。这个口号是在 1988 年的一次广告代理会议上提出的。
1)从 TWITTER 中提取数据
使用 Twitter 应用程序帐户从 Twitter 提取最新的推文。
install.packages("twitter")install.packages("ROAuth")library("twitter")library("ROAuth")cred <- OAuthFactory$new(consumerKey='XXXXXXXXXXXXXXXXXX',consumerSecret='XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX',requestURL='[https://api.twitter.com/oauth/request_token](https://api.twitter.com/oauth/request_token)',accessURL='[https://api.twitter.com/oauth/access_token](https://api.twitter.com/oauth/access_token)',authURL='[https://api.twitter.com/oauth/authorize](https://api.twitter.com/oauth/authorize)')
在清理用于分析的数据之前,让我们首先更改日期和文本列的格式。文本列可能包含数字、散列标签和其他正则表达式,将它们全部转换为字符值,使语料库易于阅读。
tweets$created <- **as.Date**(tweets$created, format= "%y-%m-%d")tweets$text <- **as.character**(tweets$text)
2)创建品牌语料库
语料库由文本文档组成。r 编程使用这个术语来包含一组被认为相似的文本。
*#Data Pre-processing***set.seed**(100)(n.tweet <- **length**(tweets))## [1] 17
上面的代码读入数据并返回指定的文本长度。
语料库包中的 corpus()是一个为文本挖掘创建文本集合的函数
#用 tweet 文本创建文档语料库。
corpus<- **Corpus**(**VectorSource**(tweets$text))corpus[[1]]
3)预处理和清洗
预处理文本可以显著提高单词袋方法的性能。做到这一点的第一步是创建一个语料库,简单地说,就是文本文档的集合。一旦创建了语料库,我们就可以进行预处理了。
首先,让我们去掉标点符号。处理这个问题的基本方法是删除所有不是标准数字或字母的东西。在我们的例子中,我们将删除所有标点符号。接下来,我们将单词的大小写改为小写,这样相同的单词就不会因为大小写不同而被视为不同。
我们必须做的另一个预处理任务是去除无意义的术语,以提高我们理解情感的能力。
通过 tm_map()函数完成文本转换。基本上,所有转换都在单个文本文档上工作,tm_map()只是将它们应用于语料库中的所有文档。
删除网址
这将从语料库文档中删除 URL
#移除网址
removeURL <- **function**(x) **gsub**("http[^[:space:]]*", "", x)corpus <- **tm_map**(corpus, **content_transformer**(removeURL))
去掉标点符号
构建外部函数并传递给 tm_map()来转换文本语料库。
#去掉标点符号
remove_punct<-**function**(x)**gsub**("[^[:alpha:][:space:]]*", "", x)corpus <- **tm_map**(corpus, **content_transformer**(remove_punct))
去除空白
这将从文本语料库中删除空白
#修剪多余的空格
corpus = **tm_map**(corpus, stripWhitespace)
去掉@(用户名)
语料库中的少数单词可能包含邮件 id 或以@开头的单词。
removeUsername <- **function**(x) **gsub**("@[^[:space:]]*", "", x)corpus <- **tm_map**(corpus, **content_transformer**(removeUsername))**writeLines**(**strwrap**(corpus[[750]]$content,60))## RT Nike Dont ask if your dreams are crazy Ask if theyre## crazy enough justdoit
4)文本规范化
规范化过程包括统一转换文本。
将文本转换成小写
corpus <- **tm_map**(corpus, **content_transformer**(stri_trans_tolower))**writeLines**(**strwrap**(corpus[[750]]$content,60))## rt nike dont ask if your dreams are crazy ask if theyre## crazy enough justdoit
删除停止字
停用词只是没有意义的常用词。如果我们看看停用词(“英语”)的结果,我们可以看到什么被删除。
corpus = **tm_map**(corpus, removeWords, **stopwords**('English'))**inspect**(corpus)## [1] rt nike dont ask dreams crazy ask crazy theyre enough justdoit## [2] rt statecrafthuff paint kap person people even demonizes good cops trys sell americans false narra
让我们创建自己的停用词删除字典来进一步挖掘文本
#将停用词指定为字符向量
Corpus<-**tm_map**(corpus, removeWords, **c**("keep", "check", "can","just","isnt","hey","ask","theyr","dont","theyre","cmon","htt","everything","even","enough","rt"))
删除单字母单词
removeSingle <- **function**(x) **gsub**(" . ", " ", x)corpus <- **tm_map**(corpus, **content_transformer**(removeSingle))**writeLines**(**strwrap**(corpus[[750]]$content,60))## nike dreams crazy crazy justdoit
5)术语-文档矩阵
一旦我们预处理了数据,我们现在就可以提取 twitter 数据中使用的词频了。tm 包提供了一个名为 Term Document Matrix 的函数,它生成一个矩阵,其中的行对应于文档,在我们的例子中是 tweets,列对应于 tweets 中的单词。
矩阵中的值是该单词在每个文档中出现的次数。文档矩阵是包含单词频率的表格。列名是单词,行名是文档。文本挖掘包中的函数 TermDocumentMatrix()使用如下:
dtm <- **TermDocumentMatrix**(corpus)
just doit just doit 1730 crazy crazy 1564 Nike Nike 1124 dreams dreams 786 means means 332
最常用术语
基于 termdocumentmatrix()输出试图根据关键字的频率对它们进行排序。高频词是用户在推特上发布的,而特朗普是语料库中出现频率最低的词。

低频术语
低频@55 和@85 单词显示在下面的频率计数图中。

绘制词频

6)品牌词云


7)寻找关联
在这里,我们试图找到关键字之间的关联。
**barplot**(**t**(**as.matrix**(corrdf1)), beside=TRUE,xlab = "Words",ylab = "Corr",col = "blue",main = "nike",border = "black")
nike 这个词与“相信”、“基督”、“耶稣”、“Kaepernick”、“dems”和“run”等词密切相关

**barplot**(**t**(**as.matrix**(corrdf1)), beside=TRUE,xlab = "Words",ylab = "Corr",col = "yellow",main = "justdoit",border = "black")
同样的,justdoit 比 kaepernick 显示出更多与牺牲的联系

8)聚类
由于#nike 生成了许多类似的推文,从正在处理的海量数据中做出有意义的解释变得很有挑战性。我们试图将相似的推文聚集在一起。分层聚类试图构建不同级别的聚类。
函数 hclust()执行层次聚类分析。它使用凝聚法。为了完成这个操作,语料库被转换成文档矩阵。我们使用了沃德的方法进行等级聚类。下面的树状图显示了系统聚类的结果。

9)品牌感知建模



上图描述了所有术语的概率分布,每个 LDA 主题有 10 个术语,独立于其他 LDA 主题中的术语
10)推特情感分析
情感分析和观点挖掘是从书面语言中分析人们的观点、情感、评估、态度和情绪的研究领域。它是自然语言处理和人工智能中最活跃的研究领域之一,在数据挖掘、Web 挖掘和文本挖掘中也被广泛研究。
情绪分为积极、期待、恐惧、喜悦、惊讶和消极。

这表明,在 2000 个文本数据中,正面推文的得分相对高于其他情绪,约为 1400,其中有 1300 个关键词预期为负面,并且很少有情绪不能被分类。
结论
品牌认知在耐克 30 周年的“Just Do it”活动上,耐克与有争议的前 NFL 球星科林·卡佩尼克一起发起了一场活动。围绕 Kaepernick 的争议与他决定在 NFL 比赛开始时播放美国国歌时下跪有关,以抗议警察对有色人种的暴行。
Kaepernick 在过去的两个赛季中没有与 NFL 签约,但仍然被视为一个两极分化的人物。发起这项新的运动,耐克可能会疏远其美国消费者群中的一大部分,可能多达一半。他们为什么要这么做?也许他们认为这将使千禧一代的部落更加紧密,他们往往会参与抗议活动,特别是当政治领导人和其他权威人物与他们的感受和价值观不一致时。
因此,这场竞选分散了耐克部落的部分成员,分散了忠诚的美国爱国者和正在或曾经在我们的武装部队、政府或机构中服务的人,这些部队、政府或机构密切依赖于健康的政府和国家声誉。这些人认为,在体育赛事中不代表国歌是对美国理念和以国家名义所做牺牲的不尊重。他们认为科林·卡佩尼克采取的姿态是可疑性格的表现。他们认为他的公开姿态不合适,不合时宜。
这一最新版本的“就这么做”已经引发了一定程度的社会辩论,随着时间的推移,这将提高社会对耐克在这场运动中所冒风险的理解。对于许多城市和少数民族职业运动员来说,这一活动将拉近他们与品牌的距离。他们喜欢耐克支持运动员个人权利、道德良知、信念和抗议的行为。对于国联或国家来说,批评他们的言论或表达自由是不明智的。但是,我们可以就我们历史上这样一个事件和时刻的正反两面进行对话,大声地谈论美国价值观和人类价值观。当前的辩论可能会让美国的缔造者感到自豪。
http://rpubs . com/mal vika 30/Brand-Perception-情操-分析-R
字束搜索:一种 CTC 解码算法
改善文本识别结果:避免拼写错误,允许任意数字和标点符号,并使用单词级语言模型

Trees are an essential ingredient of the presented algorithm. (Taken from http://turnoff.us/geek/binary-tree with changes)
让我们假设我们有一个用于文本识别的神经网络 (OCR 或 HTR),它是用连接主义者时间分类 (CTC)损失函数训练的。我们将包含文本的图像输入神经网络,并从中获取数字化文本。神经网络只是输出它在图像中看到的字符。这种纯光学模型可能会引入误差,因为看起来相似的字符如“a”和“o”。
如果您已经研究过文本识别,那么类似图 1 所示的问题对您来说会很熟悉:结果当然是错误的,但是,当我们仔细观察手写文本时,我们可以想象为什么神经网络会将单词“random”中的“a”与“oi”混淆。

Fig. 1: Why does the NN make such mistakes?
我们能改进我们的结果吗?
那么,如何应对这种情况呢?有不同的解码算法可用,有些还包括语言模型(LM)。让我们看看算法在我们的例子中输出了什么:
- 最佳路径解码:“A roindan nuni br:1234。”。这是图 1 所示的结果。最佳路径解码仅使用 NN 的输出(即无语言模型),并通过在每个位置取最可能的字符来计算近似值。
- 光束搜索:“A 罗恩丹号:1234。”。它也只使用神经网络输出,但它使用更多的信息,因此产生一个更准确的结果。
- 带字符的光束搜索-LM: “随机号:1234。”它还对字符序列评分(例如“an”比“oi”更有可能),这进一步改善了结果。
- 令牌传递:“一个随机数”。该算法使用字典和单词 LM。它在神经网络输出中搜索最可能的词典单词序列。但是它不能处理像“:1234”这样的任意字符序列(数字、标点符号)。
没有一个算法是正确的。但是我们观察到了波束搜索和令牌传递的良好特性:
- 波束搜索允许任意字符串,这是解码数字和标点符号所需要的。
- 令牌传递将其输出限制为字典单词,这避免了拼写错误。当然,字典必须包含所有需要识别的单词。
这两个属性的组合会很好:当我们看到一个单词时,我们只允许字典中的单词,但在任何其他情况下,我们都允许任意字符串。让我们看一个实现我们想要的行为的算法:字束搜索。
提出的算法:字束搜索
我们使用普通波束搜索算法作为起点。该算法迭代通过 NN 输出,并创建被评分的候选文本(称为束)。图 2 示出了射束演变的图示:我们从空射束开始,然后在第一次迭代中向其添加所有可能的字符(在该示例中我们只有“a”和“b ”),并且仅保留得分最高的字符。光束宽度控制幸存光束的数量。重复这一过程,直到处理完完整的神经网络输出。

Fig. 2: Beams are iteratively created (from top to bottom), equal beams are merged and only the best 2 beams (beam width=2) per iteration are kept.
让我们来看看如何调整普通波束搜索来获得想要的行为。我们希望算法在识别单词和识别数字或标点符号时表现不同。因此,我们为每个梁添加一个状态变量(状态图见图 3)。射束或者处于字状态,或者处于非字状态。如果 beam-text 当前是“He l ,那么我们处于单词状态,只允许添加单词字符,直到我们有了一个完整的单词,如“Hell”或“Hello”。当前处于非单词状态的光束可能看起来像这样:“她是 3 ”。
当一个单词完成时,从单词状态到非单词状态是允许的:然后我们可以给它添加一个非单词字符,就像如果我们有“Hello”并给它添加“”,我们就得到“Hello”。从非词态到词态的另一个方向总是允许的,就像在“她 33 岁”中,我们可能会加上词符“y”得到“她 33 y”(后来,也许,会得到“她 33 岁。”).

Fig. 3: Each beam can be in one of two states.
在 word 状态下,我们只允许添加最终会形成单词的字符。在每次迭代中,我们最多给每个梁添加一个字符,那么我们如何知道在添加足够多的字符后,哪些字符将形成一个单词呢?如图 4 所示的前缀树可以解决这个任务:来自字典的所有单词都被添加到树中。当添加像“too”这样的单词时,我们从根节点开始,添加(如果它还不存在)用第一个字符“t”标记的边和一个节点,然后向这个新节点添加边“o”,并再次添加“o”。最后一个节点被标记以表示一个单词的结束(双圆圈)。如果我们对单词“a”、“to”、“too”、“this”和“that”重复这一过程,就会得到如图 4 所示的树。

Fig. 4: Prefix tree containing words “a”, “to”, “too”, “this” and “that”.
现在很容易回答两个问题:
- 给定一个前缀,哪些字符可以加最终组成一个单词?简单地通过跟随用前缀的字符标记的边,转到前缀树中前缀的节点,然后收集这个节点的输出边的标签。如果我们被赋予前缀“th”,那么接下来可能的字符是“I”和“a”。
- 给定一个前缀,可以造出哪些单词出来呢?从前缀的节点中,收集所有标记为单词的后代节点。如果我们被赋予前缀“th”,那么可能的单词是“this”和“that”。
有了这些信息,我们就可以约束添加到梁(处于单词状态)的字符:我们只添加最终将形成单词的字符。参见图 5 的图示。

Fig. 5: The beams (left) are constrained by the prefix tree (right).
我们只保留每次迭代中得分最高的梁。分数取决于神经网络的输出。但是我们也可以将一个单词-LM 与不同的评分模式结合起来(在结果部分中使用了为这些模式提供的缩写):
- 根本不用 LM(W),只用字典约束单词。这就是我们到目前为止所讨论的。
- 每完全识别一个单词就按 LM 计分(N) 。假设我们有一束“我的 nam”。只要添加一个“e ”,最后一个单词“name”就完成了,LM 的得分是“My”和“name”相邻。
- 展望未来(N+F) :在前缀树的帮助下,我们知道哪些单词可能会在以后的迭代中出现。射束“I g”可以扩展为“I go”、“I get”,…因此,我们可以在每次迭代中对所有可能的词的 LM 分数求和,而不是等到一个词完成后再对射束应用 LM 分数,在上述示例中,这将是“I”和“go”,“I”和“get”,…。仅通过取单词的随机子集(N+F+S) 就可以实现小的性能改进。
我们现在有一个算法,能够识别正确的文本“一个随机数:1234。”如图 1 所示。单词受字典约束,但所有其他字符只是以神经网络看到的方式添加。
词束搜索的表现如何?
令人高兴的是,该算法能够正确地识别来自图 1 的样本。但我们更感兴趣的是该算法在完整数据集上的表现如何。我们将使用边沁 HTR 数据集。它包含大约 1800 年的手写文本,图 6 中示出了一个示例。

Fig. 6: Sample from Bentham dataset.
我们将相同的神经网络输出输入到所有解码算法中。这样,公平的比较是可能的。我们为 LM: 1 使用两种不同的训练文本。2)来自测试集的文本,它是理想的训练文本,因为它包含所有要识别的单词。2)从与包含 370000 个单词的单词列表连接的训练集的文本创建的基本训练文本。错误度量是字符错误率(CER)和单词错误率(WER)。CER 是地面真实文本和已识别文本之间的编辑距离,通过地面真实长度进行归一化。WER 也是这样定义的,但是是在词汇层面。
结果如表 1 所示。在这个数据集上,词束搜索优于其他算法。如果我们对于 LM 有一个好的训练文本,那么用它来对波束进行评分是有意义的(模式 N、N+F 或 N+F+S)。否则,最好只是约束文字,不要用 LM 来给梁打分(W 模式)。
如果我们不知道我们必须识别哪些单词,或者我们根本不需要识别单词,其他算法会执行得更好。

Table 1: Results given as CER [%] / WER [%] for different algorithms (VBS: vanilla beam search, WBS: word beam search, W: no LM used, N: LM used, N+F: LM with forecasting, N+F+S: LM with forecasting and sampling) and training texts for the LM (perfect and rudimentary LM). A small CER/WER means that we have a well performing algorithm.
履行
代码可以在 GitHub 上找到。提供了一个 Python,C++和 TensorFlow 实现。
参考资料和进一步阅读
规范和出版物:
关于文本识别和 CTC 的文章:
单词嵌入之间的单词距离

Photo by Rob Bates on Unsplash
单词移动距离(WMD)被提出用于测量两个文档(或句子)之间的距离。它利用单词嵌入能力来克服这些基本的距离测量限制。
WMD[1]是由 Kusner 等人在 2015 年提出的。他们建议使用单词嵌入来计算相似度,而不是使用欧几里德距离和其他基于单词包的距离度量。准确地说,它使用标准化的单词包和单词嵌入来计算文档之间的距离。
看完这篇文章,你会明白:
- 推土机距离(EMD)
- 字移动器的距离
- 轻松单词移动距离(RWMD)
- 大规模杀伤性武器的实施
- 拿走
推土机距离(EMD)
在介绍大规模杀伤性武器之前,我必须先分享一下运土距离(EMD)的概念,因为大规模杀伤性武器的核心部分是 EMD。
EMD [2]解决运输问题。例如,我们有 m 和 n,而 m 和 n 表示一组供应商和仓库。目标是最小化运输成本,以便将所有货物从 m 运输到 n。给定约束条件:

Capture from wiki [3]
- 仅允许从 m 到 n 的传输。不允许从 n 到 m 的传输
- 发送货物总数不能超过总容量 m
- 收货总数量不能超过总容量 n
- 最大运输次数是 m 中的货物总量和 n 中的货物总量之间的最小值
外延是:
- p:原产地设置
- 问:目的地集合
- f(i,j):从 I 流向 j
- m:原点数量
- n:目的地编号
- w(i,j):从 I 到 j 的货物运输次数
对于最佳流量 F,线性公式为

Capture from wiki [3]
字移动器的距离
在之前的博客中,我分享了我们如何用简单的方法找到两个文档(或句子)之间的“相似性”。当时引入了欧氏距离、余弦距离和 Jaccard 相似度,但都有一定的局限性。WMD 的设计是为了克服 同义词问题。
典型的例子是
- 第一句:奥巴马在伊利诺伊州对媒体讲话
- 总统在芝加哥迎接媒体
除了停用词,两个句子之间没有共同的词,但两个句子都在谈论同一个话题(当时)。

Captured from Kusner et al. publication
WMD 使用单词嵌入来计算距离,这样即使没有共同的单词,它也可以计算。假设相似的单词应该有相似的向量。
首先,小写和删除停用词是减少复杂性和防止误导的必要步骤。
- 第一句:奥巴马对伊利诺伊州媒体讲话
- 第二句:总统问候芝加哥媒体
从任何预先训练的单词嵌入模型中检索向量。它可以是 GloVe、word2vec、fasttext 或自定义向量。然后用归一化的词袋(nBOW)来表示权重或重要性。它假设较高的频率意味着它更重要。

Captured from Kusner et al. publication
它允许将每个单词从句子 1 转移到句子 2,因为算法不知道“奥巴马”应该转移到“总统”。最后,它会选择最小的运输成本将每个单词从句子 1 运输到句子 2。
轻松单词移动距离(RWMD)
求解 WMD 的最佳平均时间约为 O(p log p ),而 p 是唯一字的个数。它有点慢,所以有两种方法来改善减少计算时间。第一个是单词质心距离(WCD) ,它概括了单词之间的下限距离。第二种方法是放松单词移动距离(RWMD) ,这是使用最近距离,而不考虑有多个单词转换成单个单词。

Captured from Kusner et al. publication
以上一句话为例。假设句子 1 中所有单词中最短的单词是“president ”,它将使用汇总这些得分,而不是逐个配对。从而使时间复杂度降低到 O§。
大规模杀伤性武器的实施
通过使用 gensim,我们只需要提供两个令牌列表,然后它将进行其余的计算
subject_headline = news_headlines[0]
subject_token = headline_tokens[0]print('Headline: ', subject_headline)
print('=' * 50)
print()for token, headline in zip(headline_tokens, news_headlines):
print('-' * 50)
print('Comparing to:', headline)
distance = glove_model.wmdistance(subject_token, token)
print('distance = %.4f' % distance)
输出
Headline: Elon Musk's Boring Co to build high-speed airport link in Chicago
==================================================
--------------------------------------------------
Comparing to: Elon Musk's Boring Co to build high-speed airport link in Chicago
distance = 0.0000
--------------------------------------------------
Comparing to: Elon Musk's Boring Company to build high-speed Chicago airport link
distance = 0.3589
--------------------------------------------------
Comparing to: Elon Musk’s Boring Company approved to build high-speed transit between downtown Chicago and O’Hare Airport
distance = 1.9456
--------------------------------------------------
Comparing to: Both apple and orange are fruit
distance = 5.4350
在 gensim 实现中,OOV 将被删除,以便它不会抛出异常或使用随机向量。
拿走
对于源代码,你可以从我的 github repo 查看。
- WMD 的优点是没有超参数和克服同义词问题。
- 和那些简单的方法一样,WMD 不考虑订购。
- 时间复杂度是一个问题。原版是 O(p log p)而增强版还是 O§。
- 预训练向量可能不适用于所有场景。
关于我
我是湾区的数据科学家。专注于数据科学、人工智能,尤其是 NLP 和平台相关领域的最新发展。你可以通过媒体博客、 LinkedIn 或 Github 联系我。
参考
[1] Kusner Matt J,孙宇,Kolkin Nicholas I,Weinberger Kilian Q .从单词嵌入到文档距离.2015.http://proceedings.mlr.press/v37/kusnerb15.pdf
[2] EMD 理论:https://en.wikipedia.org/wiki/Earth_mover%27s_distance
基于单词嵌入的 2017 年 ICC 冠军奖杯洞察
板球比赛以其无脚本的戏剧性、突然爆发的兴奋和悬念而闻名。比赛的节奏可以从慢热到激烈竞争。随着情节变得复杂,情感的复杂相互作用让每个人都坐立不安。
2017 年 6 月对于世界各地的板球爱好者来说的确是一个特殊的月份,因为这是国际板球理事会冠军奖杯的月份。ICC 冠军奖杯是由国际板球理事会(ICC)组织的为期一天的国际(ODI)板球锦标赛,其重要性仅次于板球世界杯。虽然我们能够见证所谓的失败者的戏剧性回归,但巴基斯坦在椭圆形办公室举行的 2017 年国际刑事法院冠军奖杯决赛中全面击败印度,创造了历史。Sarfraz Ahmed 的球队成为继西印度群岛、斯里兰卡和印度之后第四支赢得世界杯、世界 T20 锦标赛和冠军奖杯的球队。
嗯,整个比赛充满了意想不到的事情。斯里兰卡,年轻的上升队击败了卫冕冠军印度和强大的澳大利亚队被排除在小组赛之外,孟加拉虎(孟加拉国)进入半决赛,为比赛带来了戏剧性的推动。因此,我想分析一下媒体和粉丝对这一惊人的 ICC 事件的看法。哇哦。!结果看起来确实非常有趣和令人惊讶。
真正的分析游戏
基于语言环境的文本分析
单词嵌入是自然语言处理(NLP)中一组语言建模和特征学习技术的统称,其中来自词汇表的单词或短语被映射到实数的向量。从概念上讲,它涉及从每个单词一维的空间到低得多的维的连续向量空间的数学嵌入。Word2vec 是一组用于产生单词嵌入的相关模型。这些模型是浅层的两层神经网络,被训练来重建单词的语言上下文。Word2vec 将大型文本语料库作为其输入,并产生一个向量空间,通常具有数百个维度,语料库中的每个唯一单词都被分配一个空间中的相应向量。单词向量被定位在向量空间中,使得语料库中共享共同上下文的单词在空间中彼此非常接近。所以我想把我的工作建立在 Word2Vec 之上,在语言上下文基础上进行文本分析。
文本语料库:ESPNCricinfo 生存
ESPNCricinfo 是公认的板球网站之一,它收集了大量的新闻文章和相关的用户评论。为了创建文本语料库,我制作了一个网络爬虫,抓取这些写得很好的文章,日期范围是 2017 年 6 月 1 日到 2017 年 6 月 17 日。我也抓取了用户的评论。将所有这些加在一起,产生了我的用于训练 word2vec 模型的文本语料库。
令人喜欢:虽然不是很干净

NLP pipeline for text pre-processing
为了预处理获得的文本语料库,我使用了上面所示的 NLP 管道。然而,它需要进一步的处理,如格泛化、拼写检查和语法检查。为了这项工作的简单,我将在这里省略它们。
如果将词性标注和词汇化也引入到管道中,它还可以产生更准确的结果。

Enhanced NLP pipeline for text pre-processing
下一步是从获得的预处理文本语料库中训练出 word2vec 模型。由于文本语料库相对较小,模型在几分钟内就创建好了。
好吧,那么,…是时候看看结果了…
结果
从 word2vec 模型中,我获得了给定文本阶段上下文最相关的 100 个单词。以下部分基于每个查询词 100 个单词。但是,我从结果术语中手动提取了 10 个术语,出于可视化的目的,这些术语在给定主题下似乎是有趣的。
团队智慧相关词汇
下图说明了基于团队的术语。考虑到锦标赛中各队收到的疫情,印度、巴基斯坦、澳大利亚、斯里兰卡和孟加拉国被选为本次分析的对象。

玩家明智相关词汇
在众多令人惊讶的选手中,以下四位选手因其受欢迎程度而被选中。注意,只选择了动词/副词/形容词。

评论员睿智相关词汇
由前明星板球运动员组成的 15 人评论员小组确实提高了冠军奖杯。其中,Sanjay Manjrekar 和 Kumar Sangakkara 被选为研究对象。注意,只选择了动词/副词/形容词。

帖子备注
好吧,如果你更新了 2017 年冠军奖杯,那么显然,你应该对上述结果有相当好的解释。但是,得到的一些结果似乎有偏差。这是一种可能性,因为语料库的创建也包括获取用户的评论。嗯,差不多就是这样。如果你喜欢玩这个模型,这里的是这个项目的完整代码示例。
各位板球快乐!!
使用 Gensim 嵌入 Word2Vec 和 FastText 单词

在自然语言处理(NLP)中,我们经常将单词映射成包含数值的向量,以便机器能够理解。单词嵌入是一种映射类型,它允许具有相似含义的单词具有相似的表示。本文将介绍两种最先进的单词嵌入方法, Word2Vec 和 FastText 以及它们在 Gensim 中的实现。
传统方法
传统的表示单词的方式是 one-hot vector,本质上是一个只有一个目标元素为 1,其他为 0 的向量。向量的长度等于语料库中唯一词汇的总大小。按照惯例,这些独特的单词是按字母顺序编码的。也就是说,您应该预期以“a”开头的单词的单热向量具有较低的索引,而以“z”开头的单词的单热向量具有较高的索引。

https://cdn-images-1.medium.com/max/1600/1*ULfyiWPKgWceCqyZeDTl0g.pngㄨ
尽管这种单词表示简单且易于实现,但还是有几个问题。首先,你不能推断两个词之间的任何关系,因为它们只有一个热表示。例如,单词“忍受”和“容忍”,虽然有相似的意思,他们的目标“1”是远离对方。此外,稀疏性是另一个问题,因为向量中有许多冗余的“0”。这意味着我们浪费了很多空间。我们需要一种更好的文字表达来解决这些问题。
Word2Vec
Word2Vec 是解决这些问题的有效方法,它利用了目标单词的上下文。本质上,我们希望使用周围的单词来用神经网络表示目标单词,神经网络的隐藏层对单词表示进行编码。
Word2Vec 有两种类型,Skip-gram 和连续单词包(CBOW)。我将在下面的段落中简要描述这两种方法是如何工作的。
跳跃图
对于 skip-gram,输入是目标单词,而输出是目标单词周围的单词。例如,在句子“我有一只可爱的狗”中,输入将是“ a ”,而输出是“ I ”、“有”、“可爱的”和“狗”,假设窗口大小为 5。所有输入和输出数据具有相同的维数,并且是一位热编码的。网络包含 1 个隐藏层,其尺寸等于嵌入尺寸,小于输入/输出向量尺寸。在输出层的末端,应用 softmax 激活函数,以便输出向量的每个元素描述特定单词在上下文中出现的可能性。下图显示了网络结构。

Skip-gram (https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/)
目标单词的单词嵌入可以通过在将该单词的独热表示馈送到网络中之后提取隐藏层来获得。
使用 skip-gram,表示维度从词汇大小(V)减少到隐藏层的长度(N)。此外,向量在描述单词之间的关系方面更“有意义”。两个关联词相减得到的向量有时表达的是性别或动词时态等有意义的概念,如下图所示(降维)。

Visualize Word Vectors (https://www.tensorflow.org/images/linear-relationships.png)
CBOW
连续单词包(CBOW)与 skip-gram 非常相似,只是它交换了输入和输出。这个想法是,给定一个上下文,我们想知道哪个单词最有可能出现在其中。

CBOW (https://www.analyticsvidhya.com/blog/2017/06/word-embeddings-count-word2veec/)
Skip-gram 和 CBOW 之间最大的区别在于生成单词向量的方式。对于 CBOW,将所有以目标词为目标的样本输入到网络中,并对提取的隐含层取平均值。比如,假设我们只有两句话,“他是个不错的家伙”和“她是个睿智的女王”。为了计算单词“a”的单词表示,我们需要将这两个示例“他是好人”和“她是明智的女王”输入到神经网络中,并取隐藏层中值的平均值。Skip-gram 只输入一个且只有一个目标单词 one-hot 向量作为输入。
据说跳格法在生僻字中表现更好。尽管如此,Skip-gram 和 CBOW 的性能大体相似。
履行
我将向您展示如何使用 Gensim(一个强大的 NLP 工具包)和 TED Talk 数据集来执行单词嵌入。
首先,我们使用 urllib 下载数据集,从文件中提取字幕。
我们来看看 input_text 变量存储了什么,部分如下图所示。

input_text
显然,有一些多余的信息对我们理解演讲没有帮助,例如括号中描述声音的词和演讲者的名字。我们用正则表达式去掉这些词。
现在, sentences_ted 已经被转换成一个二维数组,每个元素都是一个单词。让我们打印出第一个和第二个元素。

sentences_ted
这是准备好输入 Gensim 中定义的 Word2Vec 模型的表单。Word2Vec 模型用下面一行代码就可以轻松训练出来。
- 句子:拆分句子列表。
- 大小:嵌入向量的维数
- 窗口:您正在查看的上下文单词数
- min_count :告诉模型忽略总计数小于此数的单词。
- workers :正在使用的线程数
- sg :是使用 skip-gram 还是 CBOW
现在,我们来试试哪些词和“人”这个词最相似。

似乎与男人/女人/孩子相关的词与“男人”最为相似。
虽然 Word2Vec 成功地处理了一个热向量带来的问题,但是它有一些限制。最大的挑战是它不能代表没有出现在训练数据集中的单词。即使使用包含更多词汇的更大的训练集,一些很少使用的罕见单词也永远无法映射到向量。
快速文本
FastText 是脸书在 2016 年提出的 Word2Vec 的扩展。FastText 不是将单个单词输入到神经网络中,而是将单词分成几个 n-grams(子单词)。例如, apple 这个词的三元组是 app、ppl 和 ple (忽略单词边界的开始和结束)。苹果的单词嵌入向量将是所有这些 n 元文法的总和。在训练神经网络之后,给定训练数据集,我们将对所有 n 元语法进行单词嵌入。罕见的单词现在可以正确地表示,因为它们的一些 n 元语法很可能也出现在其他单词中。在下一节中,我将向您展示如何在 Gensim 中使用 FastText。
履行
类似于 Word2Vec,我们只需要一行来指定训练单词嵌入的模型。
我们用肠胃炎这个词试试,这个词很少用,也没有出现在训练数据集中。

即使单词肠胃炎不存在于训练数据集中,它仍然能够找出这个单词与一些医学术语密切相关。如果我们在前面定义的 Word2Vec 中尝试这样做,它会弹出错误,因为这样的单词在训练数据集中不存在。虽然训练一个 FastText 模型需要更长的时间(n-grams 的数量>单词的数量),但它的性能比 Word2Vec 更好,并允许适当地表示罕见的单词。
结论
您已经学习了什么是 Word2Vec 和 FastText,以及它们在 Gensim toolkit 中的实现。如果你有任何问题,欢迎在下面留言。如果你喜欢这篇文章,确保你在 twitter 上关注我,这样你就不会错过任何伟大的机器学习/深度学习博客文章!
单词嵌入和文档向量:第 1 部分。类似
分类取决于相似性的概念。这种相似性可以是简单的分类特征值,例如我们正在分类的对象的颜色或形状,或者是这些对象拥有的所有分类和/或连续特征值的更复杂的函数。文档也可以使用其可量化的属性进行分类,如大小、文件扩展名等…简单!但不幸的是,文档中包含的文本的含义/意义是我们通常对分类感兴趣的。
文本的成分是单词(还包括标点符号),文本片段的含义不是这些成分的确定性函数。我们知道,相同的一组单词,但顺序不同,或者只是用不同的标点符号,可以传达不同的意思。这种理解文本的复杂程度是迄今为止算法无法达到的。除此之外,还有一些方法可以对文本进行处理,使其易于被算法分析。文档和单词需要被转换成数字/向量,希望和能够保留和反映我们所知道的原始单词和文档之间的关系。这肯定是一个艰巨的任务,但从几十年前的向量空间模型 (VSM)方法开始,以及这十年来一些基于单词嵌入方法的令人兴奋的新参与者,这方面已经取得了良好的进展。VSM 方法将文档转化为数字向量,而单词嵌入方法将单个 单词转化为数字向量。
在这篇文章中,我们比较和对比了使用有和没有单词嵌入的文档向量来测量相似性。我们为使用单词嵌入(预先训练的或定制的)进行文本分类打下了基础,这将在下一篇文章中讨论。让我们从快速概述文档和单词向量以及关于它们如何度量和保存(或不保存)的动机示例开始。)我们所理解的相似性的概念。
1.文档向量和相似性
在 VSM 方法中,文档被表示为单词空间中的向量。向量中的一个元素是一个度量(简单频率计数、归一化计数、tf-idf 等…)对应单词对于该文档的重要性。在我们之前的帖子中,我们已经非常详细地讨论了这种机制以及这种方法使之成为可能的丰富分析,这些帖子包括成堆的文档和一袋袋的单词以及文档的简化模型。
如果两个文档包含几乎相同的单词分布,它们在单词空间中产生的向量将比其他情况下更加平行。所以两个向量之间的余弦值更接近 1。假设具有相似单词分布的两个文档是相似的(我们知道这是不精确的说法!)VSM 方法采用文档向量的余弦作为它们相似性的度量。显然,在这个模型中,没有共享很多单词的文档将被认为是不相似的——这又是一个不精确的结论。让我们看几个例子,这样我们就清楚了。
1.1 示例 1(文档向量)
在一个 7 维的单词空间中取下面三个文档:
- 单词空间:[‘避免’,‘首都’,‘法国’,‘日本’,‘字母’,‘巴黎’,‘东京’]
- Doc1:东京是日本的首都=> d_1 = [0,1,0,1,0,0,1]
- Doc2:巴黎是法国的首都=> d_2 = [0,1,1,0,0,1,0]
- Doc3:避免大写字母=> d_3 = [1,1,0,0,1,0,0]
上面也显示了每个文档的简单的基于计数的 VSM 向量表示。这些向量的任何一对之间的余弦相似度等于(0+1 * 1+0+0+0+0)/(3^0.5* 3^0.5)= 1/3.0。数学都是正确的,但我们希望在文档 1 和文档 2 之间获得更高的相似性,以便我们可以将它们放在一个地理桶中,而将第三个放在其他地方。但是这就是对文档的词汇袋方法的本质。让我们接着看另一个例子。
1.2.示例 2(文档向量)
以另一个由 6 维单词空间跨越的三个文档为例:
- 单词空间:[‘正派’,‘善良’,‘诚实’,‘谎言’,‘人’,‘告诉’]
- Doc1:诚实得体=> d_1 = [1,0,1,0,0,0]
- Doc2:做个好人=> d_2 = [0,1,0,0,1,0]
- Doc3:说谎=> d_3 = [0,0,0,1,0,1]
这些文档不共享任何单词,因此它们的点积都是零,这表明它们都不相似。但是,我们还是希望让 Doc1 和 Doc2 更相似,而不是更像 Doc3。
从这里的例子得出的结论是,用于评估相似性的基于单词包的文档向量及其分类可能是误导的。
2.词向量和相似度
在过去五年左右的时间里,出现了一股为的单个单词生成数字向量(任意长度 p = 50、200、300 等等)的热潮。原因集中在更便宜和更快的计算机的可用性,以及将最近流行的&竞争性深度神经网络应用于 NLP 任务的愿望。基于单词嵌入的方法已经产生了诸如 Word2Vec 、 Glove 和 FastText 之类的工具,它们现在被广泛使用。
通过针对文本数据的语料库训练算法来获得单词向量。在训练结束时,语料库中的每个单词学习为在训练时选择的长度为 p 的数值向量。这个 p 远远小于语料库中唯一词的总数 n ,即 p < < n 。因此,该向量表示从原始的n-长 1-热词向量到更小的p-长密集向量在p-维假词空间中的线性映射/投影。我们说假的原因是这些 p 维度没有任何可解释的物理意义。它们只是一个数学概念。有点像奇异值分解,但不完全是。有人可能认为增加 p 可能会在低维流形中产生更好质量的单词表示。不太不幸。所以,我们开始了——一点巫术和所谓的炼金术在起作用。
这些工具的作者已经将它们应用于大量的文本,如谷歌新闻、维基百科转储、通用抓取等,以得出他们在这些语料库中找到的单词的数字向量版本。为什么大量的文本?这个想法是,这些单词向量有望成为通用的。我们这样说是什么意思?这样,我们可以用他们发布的数字向量来替换我们的文档中的单词。也就是说,他们希望他们的单词向量具有普遍的有效性——也就是说,无论该单词出现在任何文档的什么地方和什么上下文中,该单词都可以被他们发布的向量替换
通过将算法暴露于大量文本,他们希望每个单词都经历了足够多的上下文变化,其数字向量因此在某种平均意义上吸收了单词的含义及其在优化过程中与其他单词的关系
这些词汇有多普遍?
然而,必须清楚地理解这些通用单词嵌入的含义和局限性。
- 首先,为一个单词获得的数字向量是算法和应用该算法来导出该向量的文本语料库的函数。
- 第二,不要混淆不同算法的向量——即使它们是在同一个语料库上训练的。也就是说,不要在文档中对某些单词使用 Glove 向量,而对其他单词使用 Word2Vec 向量。这些向量是不同的,并且不以相同的方式嵌入它们学习的关系。
- 第三,不要在语料库中混淆这些向量——即使使用相同的算法。也就是说,在你的文档中,不要对一个单词使用通过训练比如电影评论获得的向量,而对另一个单词使用通过训练比如政治新闻故事获得的向量。
下表总结了上述评估。考虑两个词——‘好的*’和‘体面的*’。每个都有一个由 Word2Vec(在 Google News 上训练过)、Glove(在 Wikipedia 上训练过)和 FastText(在 common-crawl 上训练过)发布的预训练数字向量。此外,我通过对二十个新闻组数据集训练相同的算法来定制向量,该数据集可通过编程从 SciKit 页面获得。使用 Gensim 包完成培训。
表中的值(原始出版物的截屏)显示了以五种不同方式获得的这两个词向量之间的余弦相似性。假设单词是相似的,如果单词向量是完全通用的,我们会期望分数更接近于 1。但是我们看到,只有当两个向量都是使用针对相同文本语料库训练的相同算法导出时,才会出现这种情况。

这里的重点是,在文本语料库上训练算法得到的词向量是一个包。这些向量嵌入了它们在训练时遇到的单词之间的关系。总的来说这些向量松散地反映了由算法训练和教导的语料库中包含的单词之间的关系。当然,我们并不强制使用这些预先训练好的向量,因为有像 Gensim 这样的软件包可以为手头的任何文本语料库生成定制的词向量。
3.嵌入单词的文档向量
一般来说,给定文档中唯一单词的数量是语料库中唯一单词总数的很小一部分。所以文档向量是稀疏的,零比非零多得多。这是一个问题,特别是对于神经网络,其中输入层神经元的数量是输入向量的大小。这就是嵌入式单词向量流行的原因。
经过训练的单词向量 p 的长度通常比语料库单词空间的大小小得多。因此,用低维向量替换单词的文档向量要短得多,从而提供了计算优势。例如,twenty-news 文档库中有超过 60,000 个独特的单词。如果我们对每个单词使用 300 维的单词向量(即 p = 300),我们可以将输入神经元的数量减少 200 倍,使其在大型 NLP 任务中更具竞争力。
3.1 从稀疏到密集的文档向量
如果文档中的每个单词在相同的 p- 维空间中具有已知的表示,那么单词袋文档向量可以表示为相同的 p- 维空间中的向量。我们只是简单地将单词袋方法与单词嵌入相结合,以得到低维、密集的文档表示。让我们以前面的例子 1.2 为例,我们现在也有一个向量表示法,用于组成语料库词汇的六个词*‘正派’、‘善良’、‘诚实’、‘谎言’、‘人’、‘告诉’。原来的 6 维文档向量D1可以在 p 空间中重写为 p x 1 向量 d^_1

对于带有 m 单据和 n 字的一般情况,我们可以直接扩展上述内容。首先,我们为这些 n 个单词中的每一个获得单词向量,从而给我们 p x n 单词向量矩阵 W 。在标准 n 单词空间中具有向量表示 d_i 的 i^th 文档被转换为在伪 p 单词空间中的向量 d^*_i,其具有:
(1)

虽然拥有更短的文档向量是一种计算优势,但我们需要确保文档在这个过程中没有失去它们的意义和关系。让我们用这些单词来重写例子 1.1 和 1.2,看看我们得到了什么。
3.2 示例 1.1(具有单词嵌入的文档向量)
下面的表 2 示出了示例 1.1 中的相同文档的相似性,但是现在使用具有单词嵌入的文档向量来计算。
- Doc1:东京是日本的首都=> d_1 = [0,1,0,1,0,0,1]
- Doc2:巴黎是法国的首都=> d_2 = [0,1,1,0,0,1,0]
- Doc3:避免大写字母=> d_3 = [1,1,0,0,1,0,0]

虽然结果并不完美,但在 Doc1 和 Doc2 之间的相似性得分上有一些改进。具有负采样的基于跳过文法的 Word2Vec 算法( SGNS )实际上在文档 2 &文档 3 和文档 3 &文档 1 之间产生了较低的相似性(与纯基于文档向量的相似性相比)。但是我们不应该因为一个测试就对它做过多的解读。让我们看看另一个例子。
3.3 示例 1.2(具有单词嵌入的文档向量)
表 3 对示例 1.2 中的文档重复上述练习,其中基于纯文档向量的方法在 3 对文档之间产生零相似性。
- Doc1:诚实得体=> d_1 = [1,0,1,0,0,0]
- Doc2:做个好人=> d_2 = [0,1,0,0,1,0]
- Doc3:说谎=> d_3 = [0,0,0,1,0,1]

同样,虽然结果并不完美,但确实有所改善。与文档 2 和文档 3 以及文档 3 和文档 1 之间获得的相似性相比,文档 1 和文档 2 在每个方案中显示出高得多的相似性。
4.结论
我们以此结束这篇文章。如引言中所述,我们已经为结合基于 VSM 的文档向量应用单词嵌入奠定了基础。具体来说,我们有:
- 计算文档的相似度,作为通过词袋方法获得的数值向量
- 计算单词之间的相似度,作为通过不同的单词嵌入算法获得的数字向量,这两种算法都是预先训练的和在定制文本语料库上训练的
- 检验单词嵌入普遍性的局限性
- 计算具有单词嵌入的文档向量之间的相似度
所有这些都是为了在分类练习中使用这些降阶的、嵌入单词的文档向量做准备。我们将在下一篇文章中继续讨论。
原载于 2018 年 9 月 27 日【xplordat.com】。
单词嵌入和文档向量:第 2 部分。订单缩减
单词嵌入产生了从 n -long ( n 是组成文本语料库的词汇的大小)稀疏文档向量到 p -long 密集向量的线性变换,其中 p < < n 因此实现了顺序的减少…
在之前的文章中,单词嵌入和文档向量:第 1 部分。相似性我们为使用基于单词包的文档向量结合单词嵌入(预训练或定制训练)来计算文档相似性奠定了基础,作为分类的先驱。看起来,文档+单词向量更善于发现我们看过的玩具文档中的相似之处(或缺乏之处)。我们想把它进行到底,并把这种方法应用到实际的文档库中,看看文档+单词向量如何进行分类。这篇文章关注的是实现这个目标的方法、机制和代码片段。结果将在本系列的下一篇文章中介绍。
这篇文章的大纲如下。完整实现的代码可以从 github 下载。
- 选择一个文档库(比如来自 SciKit pages 的 Reuter20-newsfor multi class,或者来自斯坦福的大型电影评论数据集for binary 情感分类)
- 对语料库进行标记化(停止/词干化),并获得标记的词向量(预训练和定制训练)。这只需要做一次,我们在所有的分类测试中都使用它们。我们将它们存储到 Elasticsearch 中,以便在需要时方便快捷地检索。我们将考虑单词向量的 Word2Vec/SGNS 和 FastText 算法。 Gensim API 用于生成自定义向量和处理预训练向量。
- 构建一个 SciKit 管道,它执行图 1 所示的操作序列。
- 从 Elasticsearch 索引中获取文档标记(停止或词干化)。对它们进行矢量化(用 SciKit 的计数矢量化器或 TfidfVectorizer 得到高阶文档词矩阵)。
- 为每个令牌嵌入从 Elasticsearch 索引中提取的词向量(Word2Vec、FastText、预训练或自定义)。这导致了降阶的文档-单词矩阵。
- 运行 SciKit 提供的分类器多项式朴素贝叶斯、线性支持向量、和神经网络进行训练和预测。所有分类器都采用默认值,除了神经网络中所需的神经元和隐藏层的数量。

Figure 1. A schematic of the process pipeline
这篇文章中展示的代码片段就是它们的本来面目——片段,是从完整的实现中截取的,为了简洁起见,我们对其进行了编辑,以专注于一些事情。 github repo 是参考。在进入完整的流程管道之前,我们将简要地详细说明上面的标记化和词向量生成步骤。
1.标记化
虽然 SciKit 中的文档矢量化工具可以对文档中的原始文本进行标记,但我们可能希望使用自定义停用词、词干等来控制它。下面是一段代码,它将 20 条新闻的语料库保存到一个 elasticsearch 索引中,以供将来检索。

Code Listing 1: Tokenizing the 20-news corpus and indexing to Elasticsearch
在上面的第 10 行中,我们删除了所有标点符号,删除了不以字母开头的标记,以及过长(> 14 个字符)或过短(< 2 个字符)的标记。标记被小写,停用词被删除(第 14 行),并被词干化(第 18 行)。在第 36 行,我们删除了每篇文章的页眉、页脚等信息,因为这些信息会泄露文章属于哪个新闻组。基本上,我们使分类变得更加困难。
2.词向量
下面的代码片段将发布的 fasttext 单词向量处理成一个 elasticsearch 索引。

Code Listing 2: Processing pre-trained word-vectors with Gensim and indexing into Elasticsearch
在上面的第 22 行中,我们读取了预先训练的向量。第 23 行将它们索引到 elasticsearch 中。我们还可以从手头的任何文本语料库中生成自定义的词向量。Gensim 也为此提供了方便的 api。

Code Listing 3: Generating custom word-vectors with Gensim
在第 35 行和第 41 行,使用从我们在第 1 节中创建的语料库索引中获得的标记(停止或词干化)来训练模型。向量的选择长度是 300。第 30 行中的 min_count 指的是为了考虑某个标记,该标记在语料库中必须出现的最小次数。
3.工艺管道
我们对 repo 中的文档进行矢量化,如果要使用单词嵌入,则转换并降低模型的阶数,并应用分类器进行拟合和预测,如前面的图 1 所示。让我们依次看看他们中的每一个。
3.1 矢量化
我们之前说过可以使用 SciKit 的 count/tf-idf 矢量器。它们肯定会产生一个文档术语矩阵 X ,但是我们管道中的单词嵌入步骤需要由矢量器获得的词汇/单词。因此,我们围绕 SciKit 的矢量器编写了一个定制的包装器类,并用词汇表增加了转换响应。

Code Listing 4: A wrapper to SciKit’s vectorizers to augment the response with corpus vocabulary
包装器在第 1 行使用实际的 SciKit 矢量器进行初始化,并将 min_df(词汇表中需要考虑的令牌在存储库中的最小频率)设置为 2。第 8 行使用所选矢量器的 fit 过程,第 12 行的 transform 方法发出一个响应,其中包含第二步所需的 X 和派生词汇 V 。
3.2 嵌入文字
我们有 m 个文档和 n 个其中唯一的单词。这里工作的核心部分如下。
- 从我们在第 2 节准备的索引中获得这些 n 单词中每一个的 p 维单词向量。
- 准备一个 nxp 单词向量矩阵 W ,其中每一行对应于分类词汇表中的一个单词
- 通过简单乘法将 mxn 原始稀疏文档字矩阵 X 转换为 mxp 密集矩阵 Z 。我们已经在上一篇文章中讨论过这个问题。但是请注意,SciKit 使用文档作为行向量,所以这里的 W 是那篇文章中等式 1 的转置。没什么复杂的。

p 当然是 word-vector 的长度,原来的 1-hot n 维向量到这个假的pword-space 的投影。然而,我们应该小心矩阵乘法,因为 X 来自矢量器,是一个压缩稀疏行矩阵,而我们的 W 是一个普通矩阵。一点指数戏法就能做到。下面是管道中这一步的代码片段。

Code Listing 5: Building the reduced order dense matrix Z
第 1 行用一个 wordvector 对象初始化转换器(查看 github 中的代码),该对象具有从索引中获取向量的方法。第 15 行从矢量器步骤传递的词汇表中获得一个排序后的单词列表。csr X 矩阵对其非零条目使用相同的顺序,我们也需要以相同的单词顺序获得 W 。这是在第 16 行完成的,最后第 17 行的稀疏矩阵乘法产生了我们所追求的降阶矩阵 Z 。
3.3 分类
这很简单。分类器得到矩阵mx pZ,其中每一行都是一个文档。它还在拟合模型时获得标签的 m x 1 向量。我们将评估三种分类器——朴素贝叶斯、支持向量机和神经网络。我们在不调整任何默认 SciKit 参数的情况下运行它们。在神经网络的情况下,我们尝试了一些不同数量的隐藏层(1、2 或 3)和(50、100 和 200)内的神经元,因为没有好的默认设置。

Code Listing 6: Preparing a list of classifiers for the pipeline
第 1 行中的方法 getNeuralNet 生成了我们用隐藏层和神经元初始化神经网络所需的元组。我们准备了一套分类器,用于矢量器和转换器的各种组合。
4.后续步骤
在之前的帖子中,我们研究了带有单词嵌入的文档相似性。在这篇文章中,我们展示了在文档库中使用这些概念来获得简化的文档单词矩阵的机制。在下一篇文章中,我们将运行模拟,并研究不同的标记化方案、词向量算法、预训练与自定义词向量对不同分类器的质量和性能的影响。
— — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — -
本文的修改版最初发表于 2018 年 9 月 27 日【xplordat.com】。
单词嵌入和文档向量——如有疑问,请简化
对一些文本集的分类精度和性能指标表明,朴素贝叶斯分类器是一个强有力的竞争者
这是关于在 NLP 任务中使用单词向量和文档向量的系列文章的第三篇也是最后一篇。这里的重点是文本分类。当单词向量与文档向量相结合时,我们总结了其结果和建议。代码可以从 github 下载。让我们快速总结一下过去的两篇文章。
- 相似度:单词向量是一个单词的表示,它是一个选定长度的数字向量 p 。它们是通过对文本语料库应用 Word2vec、Glove 和 FastText 等工具而获得的。具有相似含义的单词通常产生余弦相似度更接近 1 而不是 0 的数字单词向量。
- 降阶:将单词向量与基于单词包的文档向量相结合,在文本语料库的模型 Z 中产生大的(通常几个数量级,等于 m/p 其中 m 是文本语料库中唯一单词的数量,而 p 是单词向量的长度)降阶。我们构建了一个 scikit 管道(vectorize =>embed words =>classify ),在单词向量矩阵 W 的帮助下,从高阶的 X 导出 Z 。每一行 W 都是文本语料库中一个单词的 p 维数值表示。

这样,我们就可以评估单词向量对文本分类的影响,并在流水线步骤中使用我们可以选择的选项来限定结果。我们坚持三个步骤中的每一步都有几个主要选项。
- 记号化。我们将使用 scikit 的计数矢量器和tfidfvectorizer。
- 词向量。我们将对 Word2Vec/SGNS 和 FastText 进行评测。预培训和定制生成(通过 Gensim )
- 量词。我们将使用 scikit 的多项式朴素贝叶斯、线性支持向量、和神经网络
1.模拟
我们使用两个文档库。来自斯坦福的大型电影评论数据集用于二元情感分类,来自 scikit pages 的 reuter 20-news 用于多元分类。为了简单起见,我们坚持使用单一的训练集和单一的测试集。在 20 条新闻的情况下,我们进行分层分割,80%用于训练,20%用于测试。imdb 电影评论数据集带有定义的训练和测试集。下面代码片段中的第 9 行和第 10 行使用了一个令牌类(查看 github code repo ),它有从索引中提取令牌的方法。

Code Listing 1. Train and Test data sets. Define a pipeline instance for fit and predict.
要运行的模型是管道的一个实例——矢量器、转换器和分类器的特定组合。第 13 行到第 15 行定义了模型并运行预测。模拟是通过下面的 shell 脚本运行的,该脚本循环遍历管道步骤的不同选项。

Code Listing 2. A script to evaluate different options for the pipeline steps
mlp 分类器实际上由 9 种变体组成,每种变体有 1、2 或 3 个隐藏层,每层有 50、100 或 200 个神经元。此处报告的结果是针对使用 2 个隐藏层,每个隐藏层有 100 个神经元的情况。其他 mlp 分类器运行基本上用于验证分类的质量在隐藏层和神经元的这个级别不是非常敏感。
然而,有些组合是不允许的,在 Python 实现中会被跳过。这些是:
- 朴素贝叶斯分类器不允许文档向量中有负值。但是我们用文档+词向量的时候, Z 会有一些否定。应该有可能统一转换/缩放所有矢量以避免负面影响,但我们并不担心,因为我们有足够的模拟来运行。所以基本上朴素贝叶斯分类器在这里只用于纯文档向量。
- 预先训练的词向量只适用于正常的词,不适用于词干化的词。因此,我们通过词干标记和预训练向量的组合来跳过运行。
2.结果
我们看的唯一度量是分类质量的 F 分数和效率的 cpu 时间。在 20 个新闻数据集的多类分类的情况下,F 分数是所有 20 个类的平均值。分类器+向量组合的运行时间是使用相同组合的所有运行的平均值。
2.1 20 条新闻数据集的多类分类
下面的图 1 总结了 20 条新闻数据集的结果。

Figure 1. Nulticlass classification of the 20-news data set. (1A) Classification with pure document vectors (1B) Classification with document+word vectors (1C) Run time with pure document vectors and document+word vectors
这里的图中包含了很多细节,所以让我们逐点总结一下。
1。文档向量 vs 文档+单词向量:看一眼 1A 和 1B,我们会发现 1A 的分类质量更好,也许好不了多少,但却是真实的,而且是全面的。也就是说,如果分类质量是最重要的,那么在这种情况下,文档向量似乎具有优势。
2。Stopped vs Stemmed : Stemmed 词汇产生更短的向量,因此对所有分类器的性能更好。对于 mlp 分类器来说尤其如此,在这种分类器中,输入神经元的数量等于输入文档向量的大小。当单词被词干化时,唯一单词的数量从 39k 下降到 28k,减少了大约 30%,这大大减小了纯文档向量的大小。
- 文档向量。图 1A 表明,当纯文档向量是分类的基础时,对获得的 F 分数没有实质性影响。
- 文档+词向量。然而,在这种情况下,使用词干标记似乎有一些好处。虽然改进很小,但通过对词干化的标记进行训练获得的定制向量显示出比对停止的标记进行训练的向量更好的 F 分数。这如图 1B 所示。
3。频率计数与 Tf-Idf: Tf-Idf 矢量化允许根据单词在语料库中出现的频率对单词进行不同的加权。对于基于关键字的搜索方案,它有助于提高搜索结果的相关性。
- 文件向量。虽然朴素贝叶斯没有被 tf-idf 打动,但是 linearsvc 和 mlp 分类器通过 tf-idf 矢量化产生了更好的 F 分数。这如图 1A 所示。
- *文档+词向量。*图 1B 显示,使用 tf-idf 矢量化后,F 值有了很大的提高。既有预先训练的词向量,也有定制的词向量。唯一的例外似乎是当预训练的 word2vec 向量与 mlp 分类器结合使用时。但是将隐藏层的数量从 2 增加到 3,将神经元的数量从 100 增加到 200,tf-idf 矢量化又得到了更好的分数。
**4。预训练矢量与定制矢量:**这仅适用于图 1B。自定义单词向量似乎有优势。
- 自定义向量显然会产生更好的 F 值,尤其是使用 tf-idf 矢量化时
- 预训练的向量似乎稍微好一点
**5。计时结果:**图 1C 显示了 fit &预测运行的平均 cpu 时间。
- 当使用纯文档向量时, mlp 分类器的运行时间更长是可以理解的。有许多(39k,如果停止和 28k,如果阻止)输入神经元工作。这是我们在之前的文章中讨论的单词嵌入出现的原因之一。
- 使用更小但更密集的Z,linear SVC分类器需要更长时间才能收敛。
- 朴素贝叶斯分类器是所有分类器中最快的。
2.2 电影评论的二元分类
下面的图 2 显示了从电影评论数据集获得的二进制分类结果。

Figure 2. Binary classification of the movie review data set. (2A) Classification with pure document vectors (2B) Classification with document+word vectors (2C) Run time with pure document vectors and document+word vectors
这里的观察与上面的没有本质上的不同,所以我们不会在这上面花太多时间。这里分类的整体质量更好,F 值在 0.8 以上(相比之下,20 个新闻语料库的 F 值约为 0.6)。但这只是这个数据集的本质。
- **文档向量 vs 文档+单词向量:**看一下 2A 和 2B,我们可以说文档+单词向量似乎总体上在分类质量上有优势(除了 linearsvc 与 tf-idf 一起使用的情况)。20 条新闻数据集的情况正好相反。
- Stopped vs Stemmed:Stopped 令牌似乎在大多数情况下表现更好。在 20 条新闻的数据集上,情况正好相反。词干化导致词汇表的大小减少了 34%,从 44k 减少到 29k。我们对两个数据集应用了相同的词干分析器,但是对于这个语料库中的文本的性质来说,这可能太激进了。
- 频率计数与 Tf-Idf: Tf-Idf 向量在大多数情况下表现更好,就像它们在 20 个新闻数据集的表现一样。
- **预训练向量与定制向量:**定制单词向量在所有情况下都比预训练向量产生更好的 F 分数。这在某种程度上证实了我们对 20 条新闻数据的评估,而这些数据并不那么清晰。
- 计时结果:朴素贝叶斯仍然是最好的。
3.那么有哪些大的收获呢?
不幸的是,我们不能仅仅根据对两个数据集进行的有些肤浅的测试就得出明确的结论。此外,正如我们上面提到的,在数据集之间,同一管道的分类质量也存在一些差异。但是从高层次上来说,我们或许可以得出以下结论——不要全信!
**1。当有疑问时——简化。**很明显,这是这篇文章的标题。按照下面的方法做,你就不会犯太大的错误,你会很快完成你的工作。使用:
- 朴素贝叶斯分类器
- Tf-idf 文档向量
- 想干就干。
**2。理解语料库。**适用于一个语料库的特定流水线(标记化方案= >矢量化方案= >单词嵌入算法= >分类器)对于不同的语料库可能不是最好的。即使通用管道可以工作,细节(特定词干分析器、隐藏层数、神经元等)也需要调整,以在不同的语料库上获得相同的性能。
**3。单词嵌入很棒。**对于维数减少和运行时间的并行减少来说,肯定的。他们工作得很好,但还有更多工作要做。如果你必须使用神经网络进行文档分类,你应该试试这些。
4。使用自定义矢量。使用从手边的语料库生成的定制单词向量可能产生更好质量的分类结果
单词嵌入:探索、解释和利用(带 Python 代码)

单词嵌入讨论是每个自然语言处理科学家谈论了很多很多年的话题,所以不要期望我告诉你一些引人注目的新东西或者“睁开你的眼睛”看看单词向量的世界。我在这里讲述一些关于单词嵌入的基本知识,并描述最常见的单词嵌入技术,附带公式解释和代码片段。
因此,正如每本流行的数据科学书籍或博客文章在介绍部分之后应该说的那样,让我们开始吧!
非正式定义
维基百科会指出,单词嵌入是
自然语言处理(NLP)中一组语言建模和特征学习技术的统称,其中词汇表中的单词或短语被映射到实数向量。
严格来说,这个定义是绝对正确的,但是如果阅读它的人从未接触过自然语言处理或机器学习技术,那么它就没有太多的洞察力。更非正式的说法是,我可以说单词嵌入是
向量,其在形态学方面反映单词的结构(用子单词信息丰富单词向量 ) /单词上下文表示( word2vec 参数学习解释 ) /全局语料库统计(手套:单词表示的全局向量 ) /在 WordNet 术语方面的单词层级(用于学习层级表示的庞加莱嵌入 ) /一组文档和它们包含的术语之间的关系(潜在语义索引 ) /等等。
所有单词嵌入背后的想法是用它们捕获尽可能多的语义/形态/上下文/层次等。信息,但是在实践中,对于特定的任务,一种方法肯定比另一种更好(例如,当在低维空间中工作以分析来自与已经被处理并放入术语-文档矩阵中的文档相同的域区域的输入文档时,LSA 是非常有效的)。为特定项目选择最佳嵌入的问题总是“尝试-失败法”的问题,因此了解为什么在特定情况下一个模型比另一个模型更好在实际工作中有足够的帮助。
事实上,用实数向量进行可靠的单词表示是我们试图达到的目标。听起来很容易,不是吗?
一键编码(计数矢量化)
将单词转换成向量的最基本和最简单的方法是统计每个单词在每个文档中的出现次数,不是吗?这种方法被称为计数矢量化或一键编码(取决于文献)。
这个想法是收集一组文档(它们可以是单词、句子、段落甚至文章)并统计其中每个单词的出现次数。严格来说,得到的矩阵的列是单词,行是文档。
附加的代码片段是基本的 sklearn 实现,完整的文档可以在这里找到。
**from** **sklearn.feature_extraction.text** **import** CountVectorizer
# create CountVectorizer object
vectorizer = CountVectorizer()corpus = [
'Text of first document.',
'Text of the second document made longer.',
'Number three.',
'This is number four.',
]
# learn the vocabulary and store CountVectorizer sparse matrix in X
X = vectorizer.fit_transform(corpus)# columns of X correspond to the result of this method
vectorizer.get_feature_names() == (
['document', 'first', 'four', 'is', 'longer',
'made', 'number', 'of', 'second', 'text',
'the', 'this', 'three'])# retrieving the matrix in the numpy form
X.toarray()# transforming a new document according to learn vocabulary
vectorizer.transform(['A new document.']).toarray()
例如,给定示例中的单词“第一”对应于向量 [1,0,0,0] ,它是矩阵 X 的第 2 列。有时这种方法的输出被称为‘稀疏矩阵’,只要 X 的大部分元素为零,并且以稀疏性为特征。
TF-IDF 转型
这种方法背后的思想是通过利用被称为 tf-idf 的有用统计度量来进行术语加权。拥有大量文档,如“a”、“the”、“is”等。非常频繁地出现,但是它们没有携带很多信息。使用一键编码方法,我们看到这些词的向量不是那么稀疏,声称这些词很重要,如果在这么多的文档中,它们会携带很多信息。解决这个问题的方法之一是停用词过滤,但是这个解决方案是离散的,并且对于我们正在处理的领域区域不灵活。
停用词问题的一个本地解决方案是使用统计数量,如下所示:

它的第一部分是 tf ,意思是‘词频’。我们所说的简单意思是这个词在文档中出现的次数除以文档中的总字数:

第二部分是 idf ,代表“逆文档频率”,解释为文档的逆数量,其中出现了我们感兴趣的术语。我们也取这个分量的对数:

我们已经完成了公式,但是我们如何使用它呢?在我们之前检查的方法中,我们将 word 作为列 j 在文档中出现 n 次,作为行 i 。我们采用之前计算的相同 CountVectorizer 矩阵,并用本术语和本文档的 tf-idf 得分替换其中的每个单元格。
**from** **sklearn.feature_extraction.text** **import** TfidfTransformer# create tf-idf object
transformer = TfidfTransformer(smooth_idf=**False**)# X can be obtained as X.toarray() from the previous snippet
X = [[3, 0, 1],
[5, 0, 0],
[3, 0, 0],
[1, 0, 0],
[3, 2, 0],
[3, 0, 4]]# learn the vocabulary and store tf-idf sparse matrix in tfidf
tfidf = transformer.fit_transform(counts)# retrieving matrix in numpy form as we did it before
tfidf.toarray()
关于这个 sklearn 类的完整文档可以在这里找到,那里有许多有趣的参数可以使用。
Word2Vec ( word2vec 参数学习讲解)
正如我要说的,有趣的事情开始了!Word2Vec 是第一个神经嵌入模型(或者至少是第一个,它在 2013 年获得了它的普及),并且仍然是被大多数研究人员使用的模型。它的孩子 Doc2Vec 也是最流行的段落表示模型,灵感来自 Word2Vec。事实上,我们将在后面讨论的许多概念都是基于 Word2Vec 的先决条件,所以一定要对这种嵌入类型给予足够的重视。
有 3 种不同类型的 Word2Vec 参数学习,并且它们都基于神经网络模型,所以这一段将在假设您知道它是什么的情况下创建。
一个单词的上下文 其背后的直觉是,我们在每一个上下文中考虑一个单词(我们在给定一个单词的情况下预测一个单词);这种方法通常被称为 CBOW 模型。我们的神经网络的架构是,我们有一个独热编码向量作为大小为 V×1 的输入,大小为 V×N 的输入→隐藏层权重矩阵 W ,大小为 N×V 的隐藏层→输出层权重矩阵W’,以及作为最终激活步骤的 softmax 函数。我们的目标是计算下面的概率分布,它是索引为 I 的单词的向量表示:

我们假设我们调用我们的输入向量 x ,其中全是 0,只有一个 1 在位置 k 。隐藏层 h 计算如下:

说到这个符号,我们可以认为 h 是单词 x 的“输入向量”。我们词汇中的每个单词都有输入和输出表示;形式上,权重矩阵 W 的行 i 是单词 i 的“输入”向量表示,因此我们使用冒号符号来避免误解。
作为神经网络的下一步,我们取向量 h 并进行以下计算:

我们的*v’*是索引为 j 的字 w 的输出向量,并且对于索引为 j 的每个条目 u 我们都执行这个乘法运算。
正如我们之前说过的,激活步骤是用标准 softmax 计算的(欢迎使用负采样或分层 softmax 技术):

该方法上的图表捕获了所描述的所有步骤。

多词上下文
这个模型与单词上下文没有任何区别,除了我们想要获得的概率分布类型和我们拥有的隐藏层类型。多词上下文的解释是这样的事实,即我们希望预测多项式分布,给定的不仅是一个上下文词,而是许多上下文词,以存储关于我们的目标词与语料库中其他词的关系的信息。
我们的概率分布现在是这样的:

为了获得它,我们将隐藏层函数改为:

这就是我们从 1 到 T5 到 T6 的上下文向量的平均值。成本函数现在采取以下形式:

该架构的所有其他组件都是相同的。

Skip-gram 模型
想象与 CBOW 多词模型相反的情况:我们希望预测输入中有一个目标词的 c 上下文词。然后,我们试图达到的目标发生了巨大的变化:

-c 和 c 是我们上下文窗口的限制,索引为 t 的单词是我们正在处理的语料库中的每个单词。
我们要做的第一步是获得隐藏层,这与前两种情况相同:

我们的输出层(未激活)计算如下:

在输出层,我们正在计算 c 多项式分布;每个输出面板共享来自隐藏层→输出层权重矩阵*W’*的相同权重。作为输出的激活,我们也使用 softmax,并根据 T21 面板稍微改变了符号,而不是像我们之前那样使用一个输出面板:

跳跃图计算中的图示复制了所有执行的阶段。

Word2Vec 模型的基本实现可以用 gensim 进行;完整文档在这里。
from gensim.models import word2veccorpus = [
'Text of the first document.',
'Text of the second document made longer.',
'Number three.',
'This is number four.',
]
# we need to pass splitted sentences to the model
tokenized_sentences = [sentence.split() for sentence in corpus]model = word2vec.Word2Vec(tokenized_sentences, min_count=1)
GloVe ( Glove:单词表示的全局向量)
全局单词表示法用于捕获嵌入整个观察语料库结构中的一个单词的意思;词频和共现计数是大多数无监督算法所基于的主要度量。GloVe 模型对单词的全局共现计数进行训练,并通过最小化最小二乘误差来充分利用统计,从而产生具有有意义的子结构的单词向量空间。这样的轮廓充分保留了单词与向量距离的相似性。
为了存储该信息,我们使用共现矩阵 X ,其每个条目对应于单词 j 在单词 i 的上下文中出现的次数。结果是:

是索引为 j 的单词出现在单词 i 的上下文中的概率。
同现概率的比率是开始单词嵌入学习的适当起点。我们首先将函数 F 定义为:

其依赖于具有索引 i 和 j 的 2 个单词向量以及具有索引 k 的独立上下文向量。f 编码信息,以比率表示;以矢量形式表示这种差异的最直观方式是用一个矢量减去另一个矢量:

在这个等式中,左边是矢量,右边是标量。为了避免这种情况,我们可以计算两项的乘积(乘积运算仍然允许我们获取我们需要的信息):

只要在单词-单词共现矩阵中,上下文单词和标准单词之间的区别是任意的,我们就可以用以下来代替概率比:

解这个方程:

如果我们假设 F 函数是 exp() ,那么解就变成了:

该等式不保持对称性,因此我们将其中两项纳入偏差:

现在,我们试图最小化的损失函数是经过一些修改的线性回归函数:

其中 f 为加权函数,手动定义。
GloVe 也是用 gensim 库实现的,它在标准语料库上训练的基本功能用下面的代码片段描述
import itertools
from gensim.models.word2vec import Text8Corpus
from glove import Corpus, Glove# sentences and corpus from standard library
sentences = list(itertools.islice(Text8Corpus('text8'),None))
corpus = Corpus()# fitting the corpus with sentences and creating Glove object
corpus.fit(sentences, window=10)
glove = Glove(no_components=100, learning_rate=0.05)# fitting to the corpus and adding standard dictionary to the object
glove.fit(corpus.matrix, epochs=30, no_threads=4, verbose=True)
glove.add_dictionary(corpus.dictionary)
FastText ( 用子词信息丰富词向量
如果我们想考虑单词的形态学呢?要做到这一点,我们仍然可以使用跳格模型(记得我告诉过你,跳格基线在许多其他相关工作中使用)和负抽样目标。
让我们考虑给我们一个得分函数,它将(单词,上下文)对映射到实值得分。预测上下文单词的问题可以被视为一系列二元分类任务(预测上下文单词的存在或不存在)。对于位置为 t 的单词,我们将所有上下文单词视为正例,并从字典中随机抽取负例。
现在我们的负抽样目标是:

FastText 模型考虑单词的内部结构,将单词拆分成一个字符 n 元语法包,并添加一个完整的单词作为最终特征。如果我们将 n-gram 向量表示为 z 并且将 v 表示为单词 w(上下文单词)的输出向量表示:

我们可以选择任何大小的 n-grams,但实际上大小从 3 到 6 是最合适的。
所有关于脸书图书馆快速文本实现的文档和例子都可以在这里找到。
庞加莱嵌入(用于学习分层表示的庞加莱嵌入
庞加莱嵌入是自然语言处理社区的最新趋势,基于这样一个事实,即我们正在使用双曲几何来捕捉我们无法在欧几里得空间中直接捕捉的单词的层次属性。我们需要使用这种几何图形和庞加莱球来捕捉这样一个事实,即从树根到树叶的距离随着每一个新生的孩子呈指数增长,而双曲几何能够表现这一特性。
关于双曲几何的注记 双曲几何研究的是常负曲率的非欧空间。它的两个主要定理是:
- 对于每一条直线 l 和不在 l 上的每一个点 P,至少有两条不同的平行线穿过 P。此外,从 l 到 P 有无限多的平行线;
- 所有三角形的角和小于 180 度。
对于二维双曲空间,我们看到面积 s 和长度 l 都以指数形式增长,公式如下:


双曲几何的设计方式是,我们可以使用我们创建的嵌入空间中的距离来反映单词的语义相似性。
我们感兴趣的双曲几何模型是庞加莱球模型,表述如下:

我们使用的范数是标准的欧几里德范数。庞加莱球模型可以被绘制成圆盘,其中直线由圆盘内包含的与圆盘边界正交的所有圆段加上圆盘的所有直径组成。

庞加莱嵌入基线
考虑我们的任务是对一棵树建模,这样我们在度量空间中进行建模,并且它的结构反映在嵌入中;我们知道,树中孩子的数量随着离根的距离成指数增长。
具有分支因子 b 的规则树可以在二维双曲几何中建模,使得根下面的节点 l 级位于半径为 l = r 的球体上,并且根下面少于 l 级的节点位于该球体内。双曲空间可以被认为是树的连续版本,而树可以被认为是离散的双曲空间。
我们在双曲空间中定义的两个嵌入之间的距离度量为:

这使我们不仅能够有效地捕捉嵌入之间的相似性(通过它们的距离),而且能够保留它们的层次结构(通过它们的规范),这是我们从 WordNet 分类法中获得的。
我们正在最小化关于θ的损失函数(来自庞加莱球的元素,它的范数应该不大于 1):

其中 D 是所有观察到的上下位关系的集合, N(u) 是 u 的反例集合。
培训详情
- 从均匀分布中随机初始化所有嵌入;
- 学习 D 中所有符号的嵌入,使得相关对象在嵌入空间中接近。
结论
我认为这篇文章是对单词嵌入的简短介绍,简要描述了最常见的自然语言处理技术、它们的特性和理论基础。关于每种方法的更多细节,每篇原始论文的链接附后;大部分的公式都指出来了,但是更多的关于记谱法的解释可以在同一个地方找到。
我还没有提到一些基本的单词嵌入矩阵分解方法,如潜在语义索引,也没有关注每种方法的实际应用,只要它们都取决于任务和给定的语料库;例如,GloVe 的创建者声称,他们的方法在 CoNNL 数据集上的命名实体识别任务中工作得很好,但这并不意味着它在来自不同领域区域的非结构化数据的情况下工作得最好。
还有,段落嵌入在这篇文章里没有被淡化,但这是另一个故事了……值得讲吗?

















 403
403

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
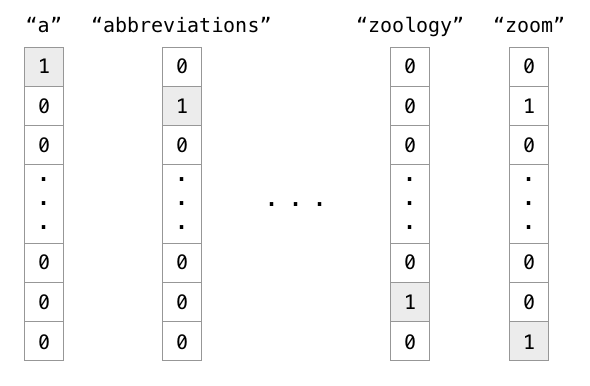{kind=link}
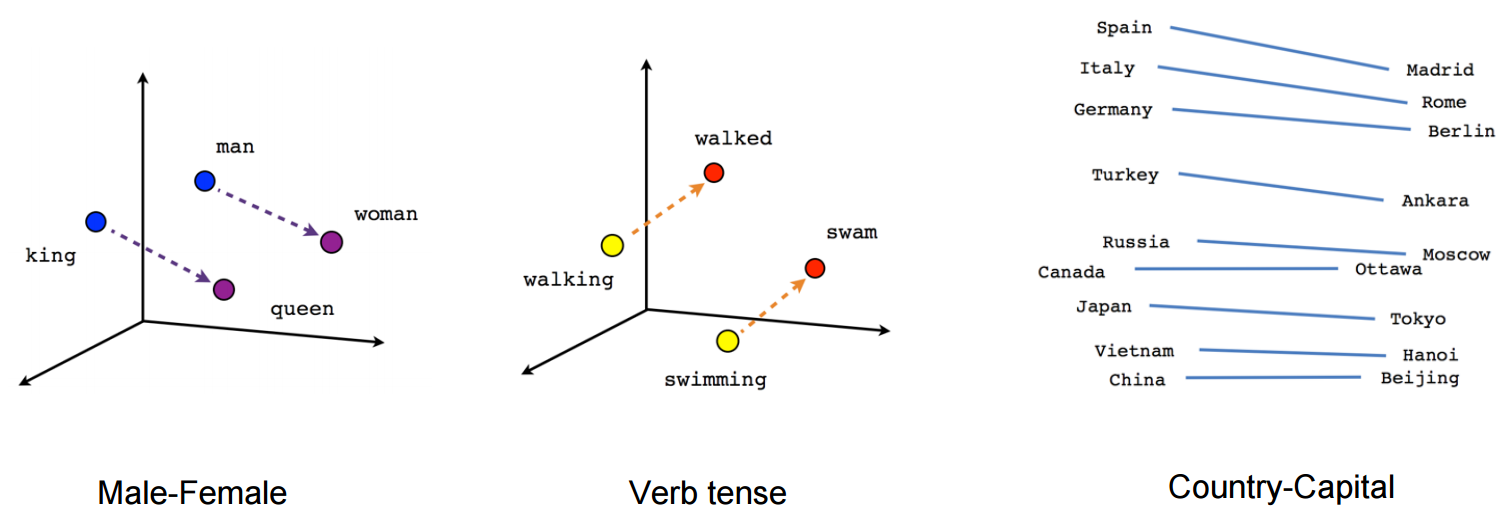{kind=link}