







神经网络初学者指南:第一部分
神经网络背后的动机,以及最基本的网络背后的架构:感知器。
人类是难以置信的模式识别机器。我们的大脑处理来自世界的“输入”,对它们进行分类(那是一只蜘蛛;那是冰淇淋),然后生成一个‘输出’(逃离蜘蛛;品尝冰淇淋)。我们自动地、快速地做到这一点,不费吹灰之力。这和感觉到有人在生我们的气,或者在我们加速经过时不由自主地读出停车标志是同一个系统。心理学家将这种思维模式称为“系统 1”(由 Keith Stanovich 和 Richard West 创造),它包括我们与其他动物共有的先天技能,如感知和恐惧。(还有一个“系统 2”,如果你想了解更多这方面的内容,可以看看丹尼尔·卡内曼的 思考,快与慢)。
那么这和神经网络有什么关系呢?我马上就到。

你毫不费力地认出了上面的数字,对吗?你刚刚知道第一个数字是 5;你不必真的去想它。当然,你的大脑不会说,“啊,那看起来像两条正交的线连接着一个旋转的,没有根据的半圆,所以那是一个 5。”设计识别手写数字的规则是不必要的复杂,这就是为什么历史上计算机程序很难识别它们。

Oh, Apple Newton. (Source: Gary Trudeau for Doonesbury)
神经网络粗略地模拟了我们大脑解决问题的方式:接受输入,处理它们并生成输出。像我们一样,他们学习识别模式,但他们是通过在标记数据集上训练来做到这一点的。在我们进入学习部分之前,让我们看看最基本的人工神经元:感知机,以及它如何处理输入和产生输出。
感知器
感知器是由科学家弗兰克·罗森布拉特在 20 世纪 50-60 年代开发的,他受到了沃伦·麦卡洛克和沃尔特·皮茨早期工作的启发。虽然今天我们使用人工神经元的其他模型,但它们遵循感知机设定的一般原则。
那它们到底是什么?感知器接受几个二进制输入: *x1,x2,…,*并产生一个二进制输出:

Perceptron with 3 inputs. (Source: Michael Nielsen)
让我们用一个例子来更好地理解这一点。假设你骑自行车去上班。你有两个因素来做出你去上班的决定:天气一定不能坏,而且一定是工作日。天气没什么大不了的,但是周末工作是一个大禁忌。输入必须是二进制的,所以让我们把条件提议为是或否的问题。天气很好?1 代表是,0 代表否。今天是工作日吗?1 是,0 否。
记住,我不能告诉神经网络这些条件;它必须自己去学习。它如何知道哪些信息对决策最重要?它与叫做的权重有关。记得我说过天气没什么大不了的,但周末才是?权重只是这些偏好的数字表示。较高的权重意味着神经网络认为该输入比其他输入更重要。
对于我们的示例,让我们特意为天气设置合适的权重 2,为工作日设置合适的权重 6。现在我们如何计算产量?我们简单地将输入与其各自的权重相乘,并对所有输入的所有值求和。例如,如果是一个晴朗的工作日,我们将进行如下计算:


这种计算被称为线性组合。8 是什么意思?我们首先需要定义**阈值。**如果线性组合的值大于阈值,则确定神经网络的输出,0 或 1(呆在家里或去工作)。假设阈值是 5,这意味着如果计算得出的数字小于 5,你可以呆在家里,但如果它等于或大于 5,那么你就得去工作。
您已经看到了重量是如何影响产量的。在本例中,我将权重设置为特定的数字,以使示例正常工作,但实际上,我们将权重设置为随机值,然后网络根据使用之前的权重产生的输出误差来调整这些权重。这叫做训练神经网络。

(Source: Panagiotis Peikidis. Based on XKCD comic ‘Compiling’)
回到手写数字识别问题,一个简单的单节点网络(如上图所示)无法做出如此复杂的决定。为了实现这一点,我们需要更复杂的网络,有更多的节点和隐藏层,使用诸如 sigmoid 激活函数之类的技术来做出决策,并使用反向传播来学习。第二部中的一切!
接下来:
#2.偏置、激活函数、隐藏层以及构建更高级的前馈神经网络架构。
medium.com](https://medium.com/@nehaludyavar/a-beginners-guide-to-neural-networks-part-two-bd503514c71a)
资源
- 利用神经网络识别手写数字 迈克尔尼尔森(Michael Nielsen)著(同级更详细解释)。
- 深度学习书籍 作者伊恩·古德菲勒、约舒阿·本吉奥和亚伦·库维尔(更高级的&技术,假设本科水平的数学知识)。
- Udacity 深度学习纳米学位基础 (17 周项目化课程;难度在 1 的中间。第二。)
- TensorFlow 神经网络游乐场 (有趣、互动的可视化神经网络在行动)
神经网络初学者指南(深度学习)

神经网络是一项突破性的技术,从未停止让我惊讶。就像一般的机器学习一样,它们正越来越多地融入我们的生活,而我们许多人却没有意识到。它们可能非常复杂,很难理解它们是如何做出决定的。顾名思义,他们设计背后的灵感来自于我们每天都拥有和使用的东西;大脑。
神经元是大脑的组成部分,当单独研究时,它们并不复杂。两个神经元通过突触连接,电脉冲通过突触从一个神经元传递到另一个神经元。如果电脉冲达到一定的强度,突触就会激活,将电脉冲传递给下一个神经元。

Perceptron
人工神经网络以非常相似的方式工作。左边的图像显示了最简单的神经网络,一个单层神经网络,称为感知器。它显示了一个节点(y ),输入(x1,x2,x3)进入该节点。每个输入都有一个权重(w1,w2,w3)。节点 y 获取每个输入,并将其值乘以权重。这种加权产生了神经网络最强大的功能之一,通过使用不同的强度权重来评估不同级别的输入。让我们用一个例子来更清楚地理解这一点。假设神经网络将预测我和一个朋友今晚是否会打网球。节点的输入可以是:
- 我的朋友有空吗?是或否
- 天气预报说今晚是晴天吗?是或否
- 法院有空吗?是或否
如果这三个问题的答案都是肯定的,那么结果将是“是的,让我们打网球吧!”每个输入都根据其重要性被赋予一个权重。在这个例子中,很明显,朋友和球场是非常重要的输入,如果这两个答案中的任何一个是否定的,我和我的朋友将不打网球,那么这些权重将非常高。天气预报是晴天不太重要,因为如果是阴天甚至是毛毛雨,我们仍然可以打网球。
神经网络需要数学形式的“是”和“否”,因此神经网络的输入为“是”, 1 表示“是”, 0 表示“否”。每个输入通过将其值乘以其权重传递给节点 y。然后,节点将所有值相加。如果总数高于某个阈值,则返回 yes。如果总数低于,那么它将返回一个否。这是它的决定!
在提供输入和结果的许多不同的例子上训练一个神经网络。这允许网络学习其权重,以提供具有最佳可能精度的整体模型。例如,如果我对这三个问题的答案训练一个神经网络,如果我和我的朋友在过去的一年里每天都打网球,它将学会预测我们是否会打得很准确。这是一个非常基本的例子,神经网络还有很多我没有讨论的特性,比如隐藏层和反向传播。请继续关注更多深入神经网络工作的文章。
如果您对神经网络以及如何将它们应用于业务流程感兴趣,请访问 Miminal 。Miminal 为希望利用人工智能的力量但缺乏内部能力或专业知识的公司提供定制的数据科学解决方案。
神经网络初学者指南:第二部分
偏置、激活函数、隐藏层以及构建更高级的前馈神经网络架构。
在 第一部分,我解释了感知器如何接受输入,应用线性组合,如果线性组合大于或小于某个阈值,则分别产生 1 或 0 的输出。在数学语言中,它看起来像这样:

在上面的公式中,希腊字母适马∑用于表示求和,下标 i 用于迭代输入( x) 和权重( w) 配对。
为了让后面的训练简单一点,我们对上面的公式做一个小的调整。让我们将阈值移动到不等式的另一边,并用神经元的*偏差来代替它。*现在我们可以将等式改写为:

有效,偏差= —阈值。你可以把偏置想象成让神经元输出 1 有多容易——如果偏置非常大,神经元输出 1 就很容易,但如果偏置非常负,那就很难了。

在定义中做这个小改动有几个原因(稍后还会有一些改动;很高兴看到做出这些改变背后的直觉)。正如我在第一部分中提到的,我们随机分配权重数字(我们事先不知道正确的数字),随着神经网络训练,它对这些权重进行增量更改,以产生更准确的输出。类似地,我们不知道正确的阈值,并且像权重一样,网络将需要改变阈值以产生更精确的输出。现在有了偏差,我们只需要对等式的左边进行修改,而右边可以保持不变为零,很快,你就会明白为什么这是有用的。
为输出神经元的决策转换值或陈述条件的函数被称为激活函数。上面的数学公式只是深度学习中使用的几个激活函数之一(也是最简单的),它被称为 Heaviside 阶跃函数。


General formula (h being the condition) and graph of the Heaviside step function. The solid circle is the y-value you take (1.0 for x=0 in this case) , not the hollow circle. The line the hollow and solid circles are on is the ‘step’. (Source: Udacity)
其他激活功能包括 sigmoid 、 tanh 和 softmax 功能,它们各有其用途。(在这篇文章中,我将只解释 sigmoid 函数,但我会在其他函数出现时进行解释)。
Sigmoid 函数
即使在处理绝对数(1 和 0;yes 和 nos),让输出给出一个中间值是有益的。这有点像在被问到一个你不知道的是或否的问题时回答“也许”,而不是猜测。这实质上是 sigmoid 函数优于 Heaviside 函数的地方。


The graph and formula of the sigmoid function. Source: Udacity
像亥维赛阶梯函数一样,sigmoid 的值在 0 和 1 之间。但是这一次,没有步;它已经被平滑,以创建一个连续线。因此,输出可以被认为是成功的概率(1),或者是肯定的。在日常生活中,0.5 的输出意味着网络不知道它是肯定的还是否定的,而 0.8 的输出意味着网络“非常肯定”它是肯定的。
拥有这一特性对于网络的学习能力尤为重要,我们将在以后的文章中看到这一点。现在,只要把它想象成更容易教会一个网络逐步走向正确答案,而不是直接从 0 跳到 1(反之亦然)。
隐藏层
到目前为止,我们已经探索了感知器(最简单的神经网络模型)的架构,并看到了两个激活函数:Heaviside 阶跃函数和 sigmoid 函数。(要了解感知机如何用于计算逻辑功能,如 AND、OR 和 NAND,请查看迈克尔·尼尔森在线书籍中的第 1 章)。
现在让我们使我们的网络稍微复杂一点。在这里,以及所有的神经网络图中,最左边的层是输入层(即你馈入的数据),最右边的层是输出层(网络的预测/答案)。这两层之间的任意数量的层被称为隐藏层。层数越多,决策能得到的细致入微就越多。

(Source: Stanford CS231n)
网络通常有不同的名称:深度前馈网络、前馈神经网络、或多层感知器(MLP)。(为了使事情不那么混乱,我将坚持使用前馈神经网络)。它们被称为前馈网络,因为信息在一个总的(正向)方向上流动,在每个阶段都应用了数学函数。事实上,它们之所以被称为“网络”是因为这个功能链的(第一层功能的输出是第二层的输入,第三层的输出也是第三层的输入,依此类推)。那条链的长度给出了模型的深度,这实际上就是深度学习中的术语“*deep”*的来源!

Not quite the same ‘hidden’. (Source: Bill Watterson)
添加隐藏层可以让神经网络做出更复杂的决定,但更多的是,以及神经网络如何通过第三部分(即将推出)中的*反向传播、*过程进行学习!
资源
- 利用神经网络识别手写数字 迈克尔尼尔森。
- 神经网络第一部分:搭建架构,斯坦福 CS231n。
- 深度学习书籍 伊恩·古德菲勒、约舒阿·本吉奥和亚伦·库维尔。
绘制“五个三十八”可视化效果的初学者指南
在这里,我将向你展示我是如何从 FiveThirtyEight 的文章 中重现乔恩·斯图尔特在《每日秀》 中的每一位嘉宾的形象的。

Source: FiveThirtyEight’s article “Who Got to Be On ‘The Daily Show’?”
您可能已经使用 Matplotlib 和 Seaborn 进行了可视化,但是您可能希望提高绘图的美观性。你可以在这里从 FiveThirtyEight 的 Github 获得数据集的 csv 文件。
那么,让我们开始吧……
首先,进入你喜欢的编码环境。我更喜欢使用 Jupyter 笔记本(以防你不知道它或者想要帮助下载它,这里有一个我找到的教程)。另外,另一个不错的选择是谷歌合作实验室。
一旦您的环境准备好了,加载适当的库,读取文件并显示前五行。

First five rows of dataset
现在让我们重命名“YEAR”和“Raw_Guest_List ”,以减少我们的输入,因为我们很快就会用到它们。
现在我们需要将“组”列中所有客人的职业浓缩为三类。这将有助于在图表中绘制我们的三条线。为此,我们定义了一个循环遍历“Group”列并创建一个新的“Occupations”列的函数。

See added ‘Occupation’ column combining occupations into three categories
接下来,根据每年的职业创建一个客人百分比表。为此,我们将使用 Pandas 的交叉表函数,这将帮助我们简化计算。

Table with percentage of guests by occupation each year
默认情况下,上面的交叉表函数会计算每年每个类别的客人数量。但是请注意包含的“正常化”参数*。这将调整我们的计算,给出一个比例。此外,将 normalize 设置为“index”会将此规范化应用于每一行,而不是每一列。然后我们可以乘以 100 ( 100 )把这些比例变成百分比。
接下来,如果我们想要清理我们的表,我们也可以删除“Other”列,它不会在我们的图中使用。

Same table without ‘Other’ column
为了方便绘图,我们将在表格中列出所有年份。
是时候做我们一直以来真正想做的事情了!
这里有一个代码要点,它将为我们提供粗略的草稿。自定义线条颜色和线条粗细,以匹配文章中的图表…

Here’s our initial plot
沿 y 轴增加网格线的长度,并在图的基线处添加一条水平线。

Grid line along y-axis increased and horizontal line at baseline added
调整显示的 x 和 y 标签,再次调整字体颜色和大小。

Reduced number of grid lines and changed x & y axis labels
设置图形标题和副标题(不使用传统的 plt.title() ,因为它限制了文本放置)。请注意,下面的 x 和 y 参数根据 x 和 y 坐标确定文本的位置。

Title & subtitle aligned with ‘100%’ label on plot
使用自定义字体大小和颜色为绘图中的每一行添加文本标签。

Adding labels here takes a lot of playing with x & y coordinates
我们的最后一点是,在我们图表的底部有一个自定义的签名框。这里你必须在文本中获得正确的间距(见的参数中的文本),以使其适合图表的宽度。

Voila!… Our finalized ‘FiveThirtyEight like’ visualization
就是这样。
自己制作出像这样好看又干净的知识性剧情,感觉不是很好吗?不得不承认我感觉很好:)
现在,您可以利用 FiveThirtyEight 提供的数据了。走吧。是时候让你看看一些有趣的文章,尝试自己去重现其他的情节了。
数据科学管道初学者指南

“信不信由你,你和数据没什么区别。设身处地为 Data 想想,你就会明白为什么了。”
从前有一个叫数据的男孩。在他的一生中,他总是试图理解他的目的是什么。我有什么价值观? 我能对这个世界产生什么影响? **数据从哪里来?**看到你和数据有什么相似之处吗?这些问题总是在他的脑海中,幸运的是,通过纯粹的运气,数据最终找到了解决方案,并经历了巨大的转变。
这一切都是从数据沿着行移动时开始的,当时他遇到了一个奇怪但有趣的管道。一端是一根有入口的管子,另一端是出口。管子上还标有五个不同的字母:“ O.S.E.M.N. ”。尽管他很好奇,但数据决定进入管道。长话短说… 进来的是数据,出来的是洞察力。

**提醒:**本文将简要概述典型数据科学管道中的预期内容。从构建您的业务问题到创造可行的见解。不要担心,这很容易读懂!
数据科学是一门学问
你真棒。我很棒。数据科学是 OSEMN 。你可能会问,为什么数据科学“很棒”?嗯,作为一名有抱负的数据科学家,你有机会磨练你作为一名巫师和一名侦探的能力。我说的巫师是指拥有自动预测事物的能力!通过侦探,它有能力在你的数据中发现未知的模式和趋势!

理解数据科学管道如何工作的典型工作流程是理解业务和解决问题的关键一步。如果你对数据科学管道的工作方式感到害怕,那就不要再说了。这篇文章送给你!我从希拉里·梅森和克里斯·维金斯那里找到了一个非常简单的缩写词,你可以在你的数据科学管道中使用。那就是o s e m n
OSEMN 管道
- O — 获取我们的数据
- S —擦洗/清理我们的数据
- E — 探索/可视化我们的数据将使我们能够发现模式和趋势
- M — 对我们的数据进行建模将赋予我们作为向导的预测能力
- N — 解读我们的数据
商业问题
因此,在我们甚至开始 OSEMN 管道之前,我们必须考虑的最关键和最重要的一步是理解我们试图解决的问题。我们再说一遍。在我们开始用“数据科学”做任何事情之前,我们必须首先考虑我们试图解决什么问题。如果你有一个想要解决的小问题,那么你最多只能得到一个小的解决方案。如果你有一个大问题要解决,那么你就有一个大解决方案的可能性。
扪心自问:
- 我们如何将数据转化为美元?
- 我想用这些数据产生什么影响?
- 我们的模式带来了什么商业价值?
- 什么能为我们节省很多钱?
- 怎样做才能让我们的业务更有效率?
“把钱给我看看!”

了解这一基本概念将带你走得更远,并引领你朝着成为一名“数据科学家”迈出更大的成功步伐(从我所相信的来看…抱歉我不是一名数据科学家!)但尽管如此,这仍然是你必须做的非常重要的一步!无论你的模型预测得有多好,无论你获得了多少数据,无论你的渠道有多广,你的解决方案或可操作的洞察力只会和你为自己设定的问题一样好。
“好的数据科学更多的是关于你对数据提出的问题,而不是数据管理和分析。”——赖利·纽曼
获取您的数据
作为一名数据科学家,如果没有任何数据,你什么也做不了。作为一条经验法则,在获取数据时,有些事情你必须考虑。你必须识别你所有可用的数据集(可以来自互联网或外部/内部数据库)。你必须将数据提取成可用的格式。csv、json、xml 等…)

所需技能:
- 数据库管理:MySQL,PostgresSQL,MongoDB
- 查询关系数据库
- 检索非结构化数据:文本、视频、音频文件、文档
- 分布式存储 : Hadoops,Apache Spark/Flink
擦除/清理您的数据
清理第五列!**管道的这个阶段应该需要最多的时间和精力。**因为你的机器学习模型的结果和输出只和你投入进去的东西一样好。基本上,垃圾进垃圾出。

目标:
- 检查数据:理解你正在处理的每一个特性,识别错误、丢失的值和损坏的记录
- **清除数据:**丢弃、替换和/或填充缺失值/错误
所需技能:
- 脚本语言 : Python,R,SAS
- 数据角力工具 : Python 熊猫,R
- 分布式处理 : Hadoop、Map Reduce / Spark
“有准备的人已经成功了一半。”——米格尔·德·塞万提斯
探索(探索性数据分析)
现在,在探索阶段,我们试图理解我们的数据具有什么样的模式和价值。我们将使用不同类型的可视化和统计测试来支持我们的发现。在这里,我们将能够通过各种图表和分析得出数据背后隐藏的含义。出去探索吧!
"停泊在港口的船只是安全的——但这不是建造船只的目的。"约翰·谢德。

目标:
- 通过可视化和图表在数据中寻找模式
- 通过使用统计数据识别和测试重要变量来提取特征
所需技能:
- Python : Numpy,Matplotlib,Pandas,Scipy
- R : GGplot2,Dplyr
- 推断统计
- 实验设计
- 数据可视化
**提示:*做分析时有你的【蜘蛛感官】*刺痛。有意识地发现奇怪的模式或趋势。时刻关注有趣的发现!
设计考虑:大多数时候,人们会直接想到视觉上的“让我们完成它”。这都是关于最终用户谁将解释它。关注你的听众。
建模(机器学习)
现在有趣的部分来了。模型是统计学意义上的一般规则。把机器学习模型想象成你工具箱里的工具。你将有机会接触到许多算法,并用它们来完成不同的业务目标。您使用的功能越好,您的预测能力就越强。在清理你的数据并找到什么特征是最重要的之后,使用你的模型作为预测工具只会增强你的商业决策。
预测分析正在成为游戏规则的改变者。而不是回头分析“发生了什么?”预测分析帮助高管回答“下一步是什么?”以及“我们应该做些什么?”(《福布斯》杂志,2010 年 4 月 1 日)

预测能力的例子:沃尔玛的供应链就是一个很好的例子。沃尔玛能够预测他们将在飓风季节在他们的一个商店销售所有的草莓馅饼。通过数据挖掘,他们的历史数据显示,飓风发生前最受欢迎的商品是果馅饼。虽然听起来很疯狂,但这是一个真实的故事,并提出了不要低估预测分析能力的观点。
目标:
- **深入分析:**创建预测模型/算法
- 评估并细化模型
所需技能:
- 机器学习:监督/非监督算法
- 评估方法
- 机器学习库:Python(Sci-kit Learn)/R(CARET)
- 线性代数&多元微积分
“模型是嵌入在数学中的观点”——凯西·奥尼尔
解释(数据叙事)
故事时间到了!这个过程中最重要的一步是理解并学会如何通过交流来解释你的发现。讲故事是关键,不要小看它。这是关于和人们联系,说服他们,帮助他们。理解你的受众并与他们联系的艺术是数据故事最好的部分之一。
“我相信讲故事的力量。故事打开了我们的心扉,打开了我们的思想,这往往会导致行动”——梅林达·盖茨
情绪在数据讲故事中起着很大的作用。人们不会神奇地理解你的发现。产生影响的最好方法是通过情感讲述你的故事。作为人类,我们自然会受到情绪的影响。如果你能挖掘你的观众的情绪,那么你,我的朋友,就在控制之中。当你展示数据时,请记住心理学的力量。理解你的受众并与他们联系的艺术是数据故事最好的部分之一。
最佳实践:我强烈建议,增强您的数据叙述能力的一个好实践是反复排练。如果你是父母,那对你来说是个好消息。不要在睡前给孩子读典型的苏斯博士的书,试着用你的数据分析结果哄他们入睡!因为如果一个孩子能理解你的解释,那么任何人都可以,尤其是你的老板!

“如果你不能向一个六岁的孩子解释,那你自己也不明白。”——阿尔伯特·爱因斯坦
目标:
- 识别业务洞察力:回到业务问题
- 相应地想象你的发现:保持简单和优先驱动
- 讲述一个清晰可行的故事:有效地与非技术观众沟通
所需技能:
- 商业领域知识
- 数据可视化工具 : Tablaeu,D3。JS,Matplotlib,GGplot,Seaborn
- 沟通:陈述/发言&汇报/写作
更新您的模型
别担心,你的故事不会就此结束。由于您的模型正在生产中,因此根据您接收新数据的频率,定期更新您的模型非常重要。您收到的数据越多,更新就越频繁。假设你是 亚马逊,你为顾客推出了一个购买“鞋类特色”的新功能。您的旧型号没有此功能,现在您必须更新包括此功能的型号。如果不是这样,你的模型将会随着时间的推移而退化,表现不佳,让你的业务也退化。新功能的引入将通过不同的变化或可能与其他功能的相关性来改变模型性能。
结论
综上所述,
- 形成你的业务问题
- 获取你的数据
获取您的数据,清理您的数据,用可视化方式探索您的数据,用不同的机器学习算法对您的数据建模,通过评估解释您的数据,更新您的模型。
记住,我们和数据没什么不同。我们都有价值观、目标和存在于这个世界的理由。
事实上,你将面临的大多数问题都是工程问题。即使有一个伟大的机器学习大神的所有资源,大部分影响也会来自伟大的功能,而不是伟大的机器学习算法。所以,基本的方法是:
- 确保您的管道端到端是稳固的
- 从一个合理的目标开始
- 直观地理解您的数据
- 确保你的管道保持稳固
这种方法有望赚很多钱和/或让很多人长期快乐。
所以……下次有人问你什么是数据科学的时候。告诉他们:
“数据科学是一门学问”
我希望你们今天学到了一些东西!如果你们对这篇文章有什么想补充的,请随时留言,不要犹豫!非常感谢任何形式的反馈。不要害怕分享这个!谢谢!

商务化人际关系网
在 LinkedIn 上联系我:https://www.linkedin.com/in/randylaosat
想要更多免费资源?
访问我的网站: ClaoudML 。com
图像分类的锦囊妙计
来拿你的深度学习好东西吧

想获得灵感?快来加入我的 超级行情快讯 。😎
你上次在深度学习中看到理论 100% 匹配实践是什么时候?这很少发生!研究论文说了一件事,但现实世界中的结果往往大相径庭。
这不完全是这项研究的错。科学研究的很大一部分是实验——基于这些特定的环境,通过这个数据集,我们得到了这些结果。一旦你真正尝试并应用这些模型,处理嘈杂和无序数据的挑战就出现了。该理论并不总是与现实世界中实际发生的事情一致,但它确实提供了一个不错的基线。
那么造成这种理论与实践差距的原因是什么呢?它不完全来自新的数据!这种差异很大程度上来自深度学习专家用来给他们的模型提供额外推动的“技巧”。这些是隐藏的交易技巧,你只能通过大量的模型实验,或者只是从有经验的人那里学习。亚马逊研究小组最近的研究对此进行了量化,表明这些技巧可以让你在相同的模型上获得高达 4%的准确性提升。
在这篇文章中,你将了解这项研究,以及专家们用来给他们的深度学习模型提供额外推动的最重要的诀窍。我会给你一些实用的观点,旨在实际应用这些技巧。
(1)大批量
理论上,更大的小批量应该有助于网络收敛到更好的最小值,从而获得更好的最终精度。人们通常会因为 GPU 内存而陷入困境,因为人们可以购买的最大消费级 GPU 在云上只能达到 12GB(对于 Titan X)和 16GB(对于 V100)。有两种方法可以解决这个问题:
(1) **分布式训练:**将你的训练拆分到多个 GPU 上。在每个训练步骤中,您的批次将在可用的 GPU 之间进行拆分。例如,如果您的批处理大小为 8 和 8 个 GPU,那么每个 GPU 将处理一个图像。然后你将在最后合并所有的渐变和输出。您确实会受到 GPU 之间数据传输的小影响,但仍然可以从并行处理中获得很大的速度提升。许多深度学习库中都支持这一功能,包括 Keras 。
**(2)在训练期间改变批次和图像大小:**许多研究论文能够报告使用如此大的批次大小的部分原因是许多标准研究数据集具有不是很大的图像。例如,当在 ImageNet 上训练网络时,大多数最先进的网络使用 200 到 350 之间的作物;当然,他们可以有这么小的图像尺寸大批量!在实践中,由于目前的相机技术,大多数时候我们都在处理 1080p 的图像,或者至少不会太远。
为了避开这个小障碍,您可以从较小的图像和较大的批量开始训练。通过对训练图像进行缩减采样来实现这一点。然后你就可以把更多的放入一批中。有了大批量+小图片,你应该已经能够得到一些不错的结果。要完成网络的训练,请使用较小的学习速率和较小批量的大图像进行微调。这将使网络重新适应更高的分辨率,并且较低的学习速率防止网络从从大批量中找到的好的最小值跳开。因此,您的网络能够从大批量训练中获得良好的最小值,并通过微调在高分辨率图像上工作良好。

The effects of large mini-batch training on object detectors, from the MegDet paper
(2)迷你模型调整
研究论文并不总是告诉你完整的故事。作者通常会在论文中链接到他们的官方代码,这可能是比论文本身更好的学习算法的资源!当您阅读代码时,您可能会发现他们忽略了几个小的模型细节,而这些细节实际上造成了很大的准确性差异。
我鼓励大家看看研究论文的官方代码,这样你就可以看到研究人员用来获得他们的结果的确切代码。这样做还会给你一个很好的模板,这样你就可以很快做出自己的小调整和修改,看看它们是否能改进模型。探索模型的一些公共重新实现也是有帮助的,因为这些可能有其他人已经试验过的代码,最终改进了原始模型。查看下面的 ResNet 架构和在一些公共代码中发现的 3 处改动。它们看起来很小,但每一个都在运行时间几乎没有变化的情况下提供了不可忽略的精度提升;ResNet-D 在 Top-1 精度方面提升了整整 1%。

The original ResNet-50 architecture; from the Bag of Tricks paper

Altered and improved versions of the ResNet-50 architecture; from the Bag of Tricks paper
(3)精细化训练方法
如何训练一个深度网络通常根据手边的应用和实际设置训练的研究团队而变化!知道如何正确训练你的网络可以让你的准确率提高 3-4 %!这是一种从深层网络知识和简单的实践中获得的技能。不幸的是,大多数人不太重视培训,并期望网络能神奇地给他们带来巨大的成果!
尽量注意最新研究中使用的具体训练策略。你会经常看到,他们中的大多数人不会使用 Adam 或 RMSProp 这样的自适应方法来默认单一的学习速率。他们使用诸如热身训练、速率衰减和优化方法的组合来获得他们可能挤出的最高精确度。
这是我个人最喜欢的。
亚当优化器超级容易使用,并且倾向于自己设定一个好的学习速度。另一方面,SGD 通常比 Adam 高出 1-2 %,但是很难调整。所以,从亚当开始:只要设定一个不太高的学习率,通常默认为 0.0001,你通常会得到一些非常好的结果。然后,一旦你的模型开始被 Adam 饱和,以较小的学习速率微调 SGD,以获得最后一点精度!
(4)迁移学习
除非你正在做前沿研究,并试图打破基本的艺术状态,迁移学习应该是默认的实践方法。根据新数据从头开始训练网络具有挑战性,非常耗时,有时需要一些额外的领域专业知识才能真正做到正确。
迁移学习提供了一种既能加快训练速度又能提高准确性的简单方法。有大量的研究和实践证据表明,迁移学习使模型更容易训练,并且比从头开始训练更准确。这将完全简化事情,让你更容易得到一些像样的基线结果。
一般来说,精确度更高的模型(相对于同一数据集上的其他模型)更适合迁移学习,并能获得更好的最终结果。另一件需要注意的事情是,根据你的目标任务选择你的预训练网络进行迁移学习。例如,在医学成像数据集上使用为自动驾驶汽车预先训练的网络就不是一个好主意;这是领域之间的巨大差距,因为数据本身非常不同。你最好从零开始训练,不要带着对与医学成像完全不同的数据的偏见开始你的网络!

The main idea behind Transfer Learning (original)
(5)奇特的数据增强
数据增强是另一大准确性助推器。大多数人坚持经典的旋转和翻转,这很好。如果你有时间等待这些额外图像的训练,它们可能会给你几个百分点的额外精度提升,而且几乎是免费的!
但是最先进的技术不止于此。
一旦你开始更深入地阅读这项研究,你会发现更先进的数据增强,为深度网络提供最后的推动力。缩放,即增加图像像素的颜色或亮度值,将使网络暴露于比原始数据集更多样化的训练图像。它有助于说明这种变化,特别是,例如,基于房间或天气的不同照明条件,这在现实世界中变化相当频繁。
另一个现在在最新的 ImageNet 模型上普遍使用的技术是。尽管名为 cutout,但它实际上可以被看作是增加数据以处理遮挡的一种形式。遮挡是现实世界应用中极其常见的挑战,尤其是在机器人和自动驾驶汽车的热门计算机视觉领域。通过对训练数据应用某种形式的遮挡,我们有效地调整了我们的网络,使其更加健壮。

Cutout regularisation / augmentation
喜欢学习?
在推特上关注我,我会在那里发布所有最新最棒的人工智能、技术和科学!
有点超越梯度下降:小批量,势头,和一些纨绔子弟命名为尤里内斯特罗夫

上一次,我讨论了梯度下降如何在线性回归模型上工作,用十行 python 代码编写了它。这样做是为了展示梯度下降的原则,当涉及到自我实现时,它将给予读者洞察力和实际知识。有大量的库可以通过简单的即插即用为我们完成这项工作。然而,我相信学习这些方法如何在内部工作对于研究人员和实践数据科学家同样重要。
为了让读者更顺利地过渡到深度学习,我努力讨论了梯度下降。当研究深度学习时,理解如何对成本函数求导并使用它来更新权重和偏差是很重要的,因为它会重复显示自己(参见反向传播)。花时间去学习这些东西。
我们将再次探索我们的基本线性回归模型与我们的均方误差成本函数,通过优化技术超越梯度下降导航。在继续阅读之前,你自己想想,梯度下降会给我们带来什么潜在的问题?
最后,回想一下,我们的成本函数是下面给出的均方误差:

Average of all real values minus predicted values squared.
解开上述线性回归方程,我们得到:

m is the slope and b is the bias term
查看我的GitHub repo包含完整算法。我对我们将要讨论的所有方法进行了基准测试。
小批量梯度下降
当我们使用普通梯度下降(我们的普通老伙伴梯度下降的另一个术语)时,我们面临的一个问题是内存问题。我们的计算机只能处理这么多,那么如果我们要处理数百万,甚至更常见的数十亿的数据呢?幸运的是,顾名思义,小批量梯度下降使用与普通梯度下降相同的方法,但规模更小。我们根据训练数据创建批次,并在较小的批次上训练我们的模型,同时更新我们的斜率和偏差项。它看起来会像这样:
for epoch in range(number_of_epochs):
for j in range(0, length_of_input_array, batch_size):
batch_train_X = train_X[j:j+batch_size]
batch_train_y = train_y[j:j+batch_size]
...
m = m - learning_rate * m_gradient
b = b - learning_rate * b_gradient
对于每个时期,我们每批训练我们的模型。这将导致我们创建一个嵌套的 for 循环。在我看来,这是必要的牺牲,而不是完全满足庞大的数据集。小批量梯度下降的一个问题是,高方差参数更新数量的增加会导致成本函数的波动。有时,这将导致我们的梯度由于过冲而跳到较低的局部最小值,这使它优于普通梯度下降,因为小批量梯度下降只是不停留在局部最小值的区域内,它可以超越该区域找到其他较低的局部最小值。其他时候,我们可能达不到更低的局部最小值,因为的过冲。
我们可以做得更好。我们借用一下物理学。
动力
还记得物理学中的动量吗?动量方程是 p =m v ,其中 p 是动量,m 是质量,而 v 是速度——p和 v 都是矢量。对动量的直观理解,可以用一个滚下山坡的球来画。它的质量一路不变,但是因为引力的作用,它的速度( v )随着时间增加,使得动量( p )增加。同样的概念也可以应用于成本最小化!当前一个时间步长的梯度“指向”与我们当前时间步长相同的方向时,当我们“下山”时,我们增加“速度”
在改善小批量梯度下降方面,这允许我们在某个方向上增加我们的“速度”。当方向改变时,我们会稍微慢一点,因为我们的动量“中断了”当我们的球滚下山时,它不断增加动量,但当另一个球击中它(或任何真正击中它的东西)时,它会减速,然后试图恢复动量。物理学允许我们进行直观的类比!
我们将不得不做一些改变。参考下面的等式:

This is our new parameter update.
这里只是我们相对于时间的“速度”。那个看起来像“y”的符号就叫做动量项,通常取值为 0.9。看起来像字母“n”的符号是我们的学习率,乘以成本函数的导数。我们仍然采用与普通梯度下降法和小批量梯度下降法相似的导数,如下所示:


你计算出 v 并从我们之前的参数中减去它,瞧,这就是你的参数更新!
在代码中,它看起来像这样:
for epoch in range(number_of_epochs):
for j in range(0, length_of_input_array, batch_size):
batch_train_X = train_X[j:j+batch_size]
batch_train_y = train_y[j:j+batch_size] if epoch == 0:
v_m = 0
v_b = 0 m_gradient = -(2/N) * sum(X[j:j+batch_size] * (y[j:j+batch_size] - y_current))
b_gradient = -(2/N) * sum(y[j:j+batch_size] - y_current) v_m = mu * v_m + learning_rate * m_gradient
v_b = mu * v_b + learning_rate * b_gradient m_current = m_current - v_m
b_current = b_current - v_b
再次,参考我的 GitHub repo 了解完整的实现细节。
内斯特罗夫加速梯度
只有动量的问题是它不够动态。当然,它会放大速度,以便更快地达到收敛,但一位名叫尤里·内斯特罗夫的研究人员观察到,当梯度达到局部最小值时,动量的值仍然很高。
当我们到达局部最小值时,上面的方法没有办法让我们减慢我们的参数更新。超调的问题再次出现。想象我们的球又滚下山了。在我们的动量法中,球在下落的时候肯定滚得更快,但是它不知道它要去哪里,所以它知道什么时候减速,并在下一个上坡之前最终稳定下来。我们需要一个更聪明的球。
内斯特罗夫加速梯度(NAG)是一个预先更新,防止我们走得“太快”,当我们不应该已经。参考下面的等式,看看你是否注意到了一个与动量相比发生了变化的东西。提示:检查成本函数。

在成本函数中,我们从权重/斜率中减去了一个新项!这是预先的行动。通过从上一个时间步取梯度,我们预测我们可能去的地方,而你最终加入的项是我们所做的修正。这使得 NAG 更具动态性,因为我们的更新会根据误差函数的斜率进行调整。

Source: http://cs231n.github.io/assets/nn3/nesterov.jpeg
我们新的斜率和偏置梯度看起来会有所不同。对于 NAG,你所要做的就是将新项插入到成本函数中,然后像我们之前所做的那样进行求导。对于我们的具有均方误差成本函数的线性回归示例,它看起来如下所示:

Derivative of the cost function with respect to the slope term

Derivative of the cost function with respect to the bias term
我们需要对之前的代码做一些调整。再次,检查我的 GitHub repo 了解完整的实现细节。它看起来像下面这样:
for epoch in range(number_of_epochs):
for j in range(0, length_of_input_array, batch_size):
batch_train_X = train_X[j:j+batch_size]
batch_train_y = train_y[j:j+batch_size] if epoch == 0:
v_m = 0
v_b = 0 y_nesterov_m = (m_current - mu * v_m) * X[j:j+batch_size] + b_current
y_nesterov_b = (b_current - mu * v_b) * X[j:j+batch_size] + b_current m_gradient = -(2/N) * sum(X[j:j+batch_size] * (y[j:j+batch_size] - y_nesterov_m))
b_gradient = -(2/N) * sum(y[j:j+batch_size] - y_nesterov_b) v_m = mu * v_m + learning_rate * m_gradient
v_b = mu * v_b + learning_rate * b_gradient m_current = m_current - v_m
b_current = b_current - v_b
还有吗?
当然有!到目前为止,我们已经讨论了:1)使我们的计算机更容易进行计算;以及 2)基于误差函数的斜率实现自适应梯度步骤。我们可以更进一步。为什么不让所有其他的东西都适应呢?比如说,适应性学习率?如果我们使这些自适应学习率的更新类似于我们用 NAG 进行更新的方式,会怎么样呢?
有很多资源讨论这些问题。一个简单的谷歌搜索将带你到一个等待被学习的信息宝库。下次我会试着简单地解释给你听。到时候见!
一个关于午餐和数据科学的博客——为什么没有免费的午餐
如果你已经开始阅读关于食物的文章,你会失望地发现这篇文章实际上是关于古老的数学。对于一个真正好的午餐创意美食博客,我强烈推荐food52.com;然而,如果你对免费食物和数据科学如何携手共进感兴趣,我会给你一个没有免费午餐定理的概述,以及它如何应用于数据科学的世界。
“天下没有免费的午餐”这句话传达了这样一种思想,即你不能不劳而获,即使有些东西看起来是免费的,也总是有代价的。这个短语起源于 19 世纪,当时酒吧试图用免费食物吸引更多的顾客,条件是这些顾客会点饮料和他们的食物一起吃;然而,工薪阶层的消费者通常不会喝醉,而且他们的钱还在口袋里。

虽然人们可以将这句话视为生活的智慧,但它也适用于数据科学领域。没有免费的午餐定理(NFLT),意味着一个算法,创造了最好的解决方案,并不普遍优于任何其他算法。
正如 David Wolpert 和 William G. Macready 所说,“如果一个算法在某类问题上比随机搜索表现得更好,那么它在其余问题上的表现一定比随机搜索差。”对我来说,这意味着如果一个算法特别擅长解决一类问题,那么这个算法就适合于识别这个特殊问题的模式。Al 算法适用于特定的数据集,因为它对该数据集的独特质量做出响应,但是,另一个数据集可能有其他独特的挑战,这些挑战无法用相同的算法解决。

the trade-off between performance and problem type for a general-purpose algorithm and a specialized algorithm
现在,知道了 NFLT 如何适应我的生活和流程,下面的公式证明了两种学习算法的性能,一种不比另一种好。
该公式显示了从函数 f 上的算法arunm次获得给定成本值序列的条件概率的两个部分。对于下面等式中的一对算法 a1 和 a2 ,该定理证明了给定算法在一个类问题上的收益,它同样被其在其余问题上的性能所抵消。

For any algorithms a1 and a2, at iteration step m
本质上,这意味着当所有函数 f 都有相同的可能性时,在搜索过程中观察到任意序列的 m 值的概率不依赖于搜索算法。NFLT 也适用于搜索优化,你可以在这里阅读更多关于它的。
关于 NFLT 值得一提的是,该定理假设人们试图解决的问题是正态分布和随机的。这意味着没有一种类型的问题会取代另一种类型的问题,这种关系同样可以用分类和回归问题来解释。
此外,在优化器迭代的搜索空间将是有限的,并且可能的成本值的空间也将是有限的条件下,NFLT 是真实的。请放心,优化器在计算机上运行时会自动满足这些条件。因为空间的大小是有限的,这意味着所有可能的问题的集合的大小是有限的。
作为一名数据科学家,我一直在采用“全部尝试”的方法,因为没有一个适用于所有问题的主算法。实际上,考虑到时间和资源的现实限制,退一步考虑手头的任务和我可用的数据是最佳策略。计算是昂贵的,所以在运行任何算法之前,重要的是考虑我的目标是什么。
在科学数据的真实世界中,我们关注的是解决我们试图解决的问题的工程特性和解决方案。因此,NFLT 给我们的直觉是,为了找到最好的学习算法,我们应该专注于手头的特定问题和我们可用的数据。算法的表现如何取决于机器和我们的问题之间的一致性。
正如 Wolpert 和 Macready 所阐明的,对于给定的成本函数,一个好的解决方案是确定它的某些显著特征,然后构造一个搜索算法,a,专门定制来匹配这些特征。“人脑是一个无限的空间,可以处理各种不同的问题,并根据一些输入做出决定,但是,学习算法只能接受有限的输入,以便做出最适合这些输入的决定。学习是一种非常人性化的行为,所以让一个复杂的数学公式像人脑一样做同样的事情有点牵强。
模型本质上是基于假设和偏见的现实的简化,因此,没有一个模型在所有情况下都是最好的。最终,随机选择一个算法而不对问题做任何结构性假设就像大海捞针一样。考虑问题和数据,设计最适合任务的解决方案是值得的。
资源:
“天下没有免费的午餐”(或者,“天下没有免费的午餐”或其他…
en.wikipedia.org](https://en.wikipedia.org/wiki/There_ain%27t_no_such_thing_as_a_free_lunch)
为股票交易制作一个深刻的演员-评论家机器人的浮躁指南
技术分析就像一厢情愿的想法和复杂的数学一样。如果数字中有一个真实的趋势,不管特定股票的基本面如何,那么给定一个足够的函数逼近器(…就像一个深度神经网络),强化学习应该能够找出它。
这里有一个有趣的,也许是有利可图的项目,我试图这样做。我与 RL 合作不到六个月,仍然在搞清楚事情,但在为几个基本游戏制作人工智能学习器后,时间序列股票市场数据是我脑海中的首要问题。
这并不容易,这篇文章记录了我的过程和一路上犯的错误,而不是写一篇文章把我自己作为一个解决问题的专家。有很多。

Reinforcement learning is The Good Place
请注意,如果你对 RL 完全陌生,你可能会从阅读我之前关于深度 Q 学习的文章中受益。这个有点不一样,但也是从更高的层次出发,有更多的隐性知识。
如果你只是想跳到代码/笔记本,这里是,但是记住:过去的表现并不能保证未来的结果。
设置问题
我从 RL 中学到的一件事是,框定问题对成功非常重要。我决定让我的机器人:
- 会得到一笔启动资金
- 将学会在给定的时间间隔结束时最大化其投资组合(股票和现金)的价值
- 在每个时间点,可以买卖股票,也可以什么都不做
- 如果它买的比它现有的钱多,挤兑就结束了;如果它卖出的比它拥有的多,这一轮就结束了。它必须学会游戏规则,以及如何玩好游戏。
为了让事情易于管理,我决定只投资一对可能有点相关的股票:AAPL 和 MSFT。最初,我希望机器人能够选择在每个时间步购买或出售多少股票,这使我陷入了“连续行动空间”强化学习的兔子洞。在一个离散的空间中,给定一个当前状态,机器人可以知道它的每个离散动作的值。空间越复杂,训练越辛苦;在一个连续的空间中,动作的范围呈指数增长。为了简单起见,我暂时降低了我的目标,这样人工智能在每个时间步长只能买卖一只股票。
像往常一样,我们有一个机器人的神经网络和一个对机器人的行动做出反应的环境,根据机器人的行动有多好,每一步都返回一个奖励。
在继续下一步之前,这里有一个队长明显的专业提示:单元测试一切随你去!尝试同时调试一个环境和一个人工智能(“或者我只需要训练它更长时间或者调整超参数?!")可能有点像噩梦。
准备数据
Quandl ,一个数据平台,让获取股票数据变得真正容易;如果您超出了免费限额,您也可以快速注册一个免费的 API 密钥:
msf = quandl.get('WIKI/MSFT', start_date="2014-01-01", end_date="2018-08-20")

It returns a nice Pandas dataframe
我不会讲述所有繁琐的数据准备步骤,您可以在我的笔记本中跟随。但我确实想指出至少不跳过粗略的 EDA(探索性数据分析)的价值——我起初没有发现我选择的日期范围对 AAPL 来说有很大的不连续性。

我发现,在 2014 年 6 月 9 日,苹果股票以 1:7 的比例被分割。因此,我简单地将该日期之前的所有数据除以 7,以保持一致。
另一件重要的事情是从数据中去除趋势。起初,我没有这样做,我的人工智能只是学会了通过在早期购买股票并持有直到游戏结束来最大化其回报,因为有一个普遍的上升趋势。没意思!此外,AAPL 和 MSFT 有非常不同的手段和 stddev 的,所以这就像要求人工智能学习交易苹果(双关语!)和橘子。
显然,有几种不同的方法可以消除这种趋势;我用的是 SciPy 的信号处理模块。它用线性逼近器拟合数据,然后从实际数据中减去估计数据。例如,MSFT 是从:

收件人:

你可以看到在转换之后,有一些负的股票价值是没有意义的(比免费的好!).我处理这个问题的方法是,给所有输入数据加上一个常量,使其变为正值。
最后要注意的是,我把两个股票价格都当作一个连续的数组。在上面的图表中,您可以看到 100“天”的数据,但是由于周末和节假日的原因,实际的时间段会更长。为了简单起见,我在这个项目中完全忽略了时间的现实,但在现实世界中,我相信它们是重要的。
让我们暂时抛开训练/测试分离的问题;等我回头再来说,你就明白为什么了。
演员兼评论家 RL
我从 Q-learning 转向 trader bot 的实现,有两个原因:
- 大家都说演员-评论家更好;和
- 这实际上更直观。忘记贝尔曼方程,只是使用另一个神经网络来计算状态值,并优化它,就像你优化主要的行动选择(又名策略,又名演员)神经网络一样。
事实上,政策网络和价值网络可以作为两个不同的线性层,位于一个主要的“理解世界”神经网络之上。
代码非常简单,用伪代码表示如下:
For 1..n episodes:
Until environment says "done":
Run the current state through the network
That yields:
a set of "probabilities" for each action
a value for how good the state is Sample from those probabilities to pick an action Act upon the environment with that action
Save the state, action, reward from environment to a buffer Adjust each saved reward by the value of the terminal state
discounted by gamma each timestep Loss for the episode is the sum over all steps of:
The log probability of the action we took * its reward
The value of that action compared to what was expected Propagate the loss back and adjust network parameters
你可以看到 A-C 并没有试图优化行动的选择——我们从来不知道客观上正确的行动会是什么——而是:
- 每个行动的确定程度,给定其产生的回报
- 给定状态下,对每个奖励的惊讶程度
随着网络对给定动作越来越确定( p - > 1 ),损耗减少( ln§ - > 0 ),并且它学习得更慢。另一方面,被取样的不太可能的行为意外地带来了巨大的回报,却产生了更大的损失。这在反推/梯度下降中导致优化器增加将来不太可能的动作的概率。
在我的 A-C 实现中,基于官方 PyTorch 代码,该策略没有ε贪婪的方面(“随着概率的降低,采取随机行动而不是你的最佳猜测,以鼓励探索行动空间”)。相反,我们根据概率从政策网络的输出中取样,所以总有很小的几率会选择一些不太可能的行动。
此外,奖励信号在馈入梯度下降之前会受到轻微扰动,因此反向传播不仅会完美地追踪局部最小值,还会导致一些轻微错误的权重更新,从而在输出端放大,导致选择意外的操作。我认为这也是一种正规化。在我的实现中,我让扰动是一个随机的小量,它在每个训练步骤上都不同;从经验上看,这比每次只添加相同的小常数更有效。将来,随着网络开始融合,我可能会随着时间的推移调整数量。
我最终选定的网络并不复杂,只是我使用递归层可能是个错误,原因我们将会谈到:
环境代码和大部分训练循环代码不是很有趣的样板文件;有兴趣的话,在 Github 上的笔记本里。
国家,和一些失误
我最终选择的状态是一个向量,由以下部分组成:
[AAPL holdings,
MSFT holdings,
cash,
current timestep's AAPL opening price,
current timestep's MSFT opening price,
current portfolio value,
past 5 day average AAPL opening price,
past 5 day average MSFT opening price]
这当然不是我尝试的第一件事!起初,我手工设计了一些功能:许多不同的移动平均线,最高价和最低价,等等。后来,我放弃了这种想法,认为递归层能够自己找出这些特性。

“Look away, look away … these RL methods will wreck your evening, your whole life and your day” — fellow blunderer Count Olaf from A Series Of Unfortunate Events. Actor Neil Patrick Harris has no critics!
你看,我想让人工智能学习买入信号和卖出信号的基本原理,而不仅仅是学习反刍时间序列。因此,每次重置环境时,我都将其设置为从不同的随机时间步长开始,并使用不同的随机步幅遍历数据,并将“完成”定义为未来不同的随机步数。
虽然我认为这是正确的方法,但不幸的是,这使得 RNN 基本上不可能学到任何有用的东西,因为它每次都不知道自己在系列中的位置。所以我放弃了不同的起点、步幅和序列长度,在所有的训练中保持不变。
将来我一定会保留手工制作的特色;虽然从理论上讲,RNN 可能能够解决这些问题,但训练时间可能会非常长。
结果
大多数时候,机器人学会了不欺骗自己或让自己破产,并且能够获得可观的利润:这里你可以看到 36%的回报(根据它训练的数据)。

(Here, 0.36 means 36% profit)
(初始投资组合价值平均约为 3000 英镑,因此 4000 英镑的奖励代表着 36%的涨幅。)这个机器人也学会了规则:除了一次,它没有让自己破产,也没有试图出售更多股份。这是它在一段训练数据上的样子:

Red: BUY, Green: SELL, Yellow Cross: do nothing
修补以获得更好的结果
我学到的一件重要的事情是,如果不同的状态产生相同的回报,它会使训练变得复杂,并减缓收敛。这里有一个有用的窍门:
在奖励中加入时间因素。随着时间的推移,不杀死游戏的行动越来越有价值;或者说,代理在其环境中持续的时间越长,它得到的回报就越多。
我对代理人的行动给予了一点积极的奖励,对他什么也没做给予了一点消极的奖励。因此,像“购买 AAPL”这样的行为在序列中的任何时候都可能产生+0.1 的回报。但我们最终希望机器人继续前进,直到序列结束,而不会破产,我通过混合时间元素来鼓励这一点,即从奖励中减去剩余的步骤数。“购买 AAPL”还有 50 步,可能产生-49.9 的回报;有 49 步的奖励将是-48.9(更好),以此类推。
虽然这有助于它学会生存更长时间,但我感到困惑的是,为什么我的机器人似乎只会学会或生存、或收益最大化,却很难学会两者兼而有之。**原来设计奖励是相当困难的!**步进奖励需要平衡机器人存活的时间和它获得的收益。我用的确切公式是笔记本里的。
一些其他的经验发现:
- 与所有的负面奖励相比,通过增加好的奖励来弥补好的奖励的稀少。
- 计算奖励时,没有必要从最终价值中减去投资组合的起始价值。你可以免费得到这个,因为机器人总是试图优化更高。
- 一旦机器人达到最大值,它就开始振荡;此时,你最好停止训练。
- 训练的理想地点似乎是在一半时间到达终点状态和一半时间未能到达终点状态之间的“边缘”。
训练/测试分割
此时,一切看起来都很好,您希望在不同时间范围的股票数据上测试该模型,以确保它具有良好的泛化能力。毕竟,我们希望将来能够在我们的 Robinhood 交易账户上部署这一功能,并赚很多钱。
接下来我做的是把时间更早的回溯到 2012 年,抓取从那时到现在的股票数据;然后,我将它分成大约 2/3 的列车,并保留最后 1/3 用于测试。
不幸的是,在考虑趋势后,这两只股票在 2012-2016/17 年期间都经历了下滑,如果你还记得,当时市场被认为是相当波动的。这使得机器人很难学会如何盈利。(根据我使用的 2014 年至 2018 年的原始数据,简单地购买一只股票并持有它是一个非常好的策略)。
为了帮助机器人,我将步幅设置为 1,将序列长度设置为训练数据的长度,这样它就有尽可能多的序列数据进行训练。现在,有足够多的动作奖励对被处理,在 CPU 上继续处理太慢了,所以通过添加 5 个.cuda()语句,我能够将大部分工作转移到 GPU 上。
现在,你可以想象机器人为了获得有意义的奖励而走到大约 1000 步序列末尾的机会。从随机开始,它必须按照它甚至还不知道的规则来玩,并且不要走错一步。即使它这么做了,对我们来说也没什么用,除非它在那段时间里做了一些交易并获利。几个小时的训练时间的浪费证实了这不是一个可行的方法。
为了让它真正发挥作用,我必须发现并应用我认为是一个廉价的技巧:
放松对代理人学习规则的要求;让它在一个非常容易的环境中训练,在那里它不会死,并在连续的训练期间增加难度。
就我在这里创造的金融环境而言,这并不太难。我只需要用大量 AAPL 和 MSFT 的股票和一大笔现金来启动这个代理。训练它一段时间,然后降低起始股份/现金,再训练一次,以此类推。最终它学会了尊重规则。
机器人没有训练过的测试数据的结果不是很好。我认为,如果是这样的话,每个人都已经这样做了,我们将不再有一个正常运作的市场。

It has, however, learned to follow the rules
这是它的“交易策略”之一,用图表表示。红色代表买入,绿色代表卖出,左边是 AAPL,右边是 MSFT。黄色十字是机器人选择不采取行动的时间点。

这是一个更长期的数据,显示了原始的、未转换的股价背景下的买入和卖出。如你所见,相当混乱。

我对 RL 作为通用优化器的潜力很感兴趣,它可以学会自己运行,但事实上它很难很好地工作——特别是在像交易这样的高熵环境中。
至此,我的悲哀和错误的故事结束了。我们没有变得富有,但我们确实找到了最先进的人工智能技术,而且这两件事肯定会随着时间的推移而被证明是相关的!
使用 Tableau 的数据可视化简介:UNICEF 数据

我们人类是视觉生物。当有人说大象时,我们的大脑想到的是大象的图片,而不是单词
T5“E L E P H A N T”的字母。

这就是为什么以视觉美感的方式呈现任何信息是最重要的,这样每个人都可以很容易地理解甚至非常复杂的信息。
数据可视化在数据科学项目中的重要性
在每一个数据科学/机器学习项目中, 探索性数据分析(EDA) 是理解手中数据的至关重要的一步。项目的这一阶段处于早期阶段,就在获得数据之后。在设计统计模型之前,使用图形和绘图将数据可视化,以便更好地理解数据并创建一些假设。
同样,当你需要向非数据科学人士展示你所获得的见解时,可视化展示要比展示复杂的数据表好得多。
手中的数据
儿童基金会数据:监测儿童和妇女的状况
data.unicef.org](https://data.unicef.org/resources/dataset/child-mortality/) 
UNICEF DataSet Page
儿童基金会的数据是公开的,它们是真实世界的数据集。我们从上面的链接中得到了数据。我们用的是最后一个文件,名为**“死因-2017”**。
直接下载链接:https://data . UNICEF . org/WP-content/uploads/2017/10/Cause-of-Death-2017 . xlsx
数据预览
该数据集包含 195 个国家和儿童死亡率的列表(<5 years) in them according to causes of death, for two census years — 2000 & 2016. The excel file looks like this.



Tableau : A brilliant tool for creating beautiful Dashboards
Tableau is an extremely powerful tool for visualizing massive sets of data very easily. It has an easy to use drag and drop interface. You can build beautiful visualizations easily and in a short amount of time.
Importing data into Tableau
Tableau supports a wide array of data sources. Here we have used an excel file.

Before importing, it is necessary to format the data in a manner that Tableau can understand. After data preparation our data set looks like this.

Preview of Data Imported into Tableau

Designing Worksheets
I have designed 三个工作表使用我们的数据集,最后将它们组合在一起创建了一个 交互式仪表盘 )。
第一个工作表:按死亡原因和人口普查年份筛选的所有国家数据
1。死亡原因:早产和常年

Cause of Death : Preterm and for All Years
2。死亡原因:艾滋病和常年

Cause of Death : Aids and for All Years
3。按年份过滤:2000T3

FILTERED BY YEAR : 2000
4。按年份过滤:2016

FILTERED BY YEAR : 2016
第二个工作表:按每个国家筛选的所有死亡原因
你可以从第一张工作表中看到,在博茨瓦纳,很大比例的儿童死于艾滋病。可以使用此工作表以特定于国家/地区的方式进行进一步调查。
博茨瓦纳

BOTSWANA
这里有一个维基百科参考,证明我们的发现是正确的,博茨瓦纳确实受到艾滋病的严重影响

印度

INDIA
美利坚合众国

USA
第三张工作表:世界地图
Tableau 可以通过简单的拖放操作创建我们数据集中所有国家的地图。在这里。

World Map built using Tableau
控制板:合并所有工作表
最终的结果是一个漂亮的交互式仪表板,它将所有工作表的功能集中到一个地方。
- 通过点击地图可以选择任何国家,相关图表显示在我们的国家特定工作表中
- 普查年过滤器适用于仪表板中的所有工作表。
- 死亡原因过滤器、人口普查年份过滤器和国家过滤器一起工作,使我们能够轻松理解数据,hep us 正在直观地分析手头的数据。
我通过给出仪表板的快照来结束这篇博客。
国家—俄罗斯,脑膜炎,全年

Country — Russia , COD- Meningitis, Year — ALL
国家—巴西,鳕鱼腹泻,2016 年

Country — Brazil , COD- Diarrhoea, Year —2016
查看现场仪表盘:https://public.tableau.com/profile/sourav.kajuri#!/viz home/causesofchildresses/Dashboard
[## Tableau 公共
编辑描述
public.tableau.com](https://public.tableau.com/profile/sourav.kajuri#!/vizhome/CausesofChildDeaths/Dashboard)
致所有读者
谢谢你浏览我的博客。希望我合理地利用了你的时间。我相信,当我的知识对他人有用时,它真的会激励我
获得知识是走向智慧的第一步,分享知识是走向人性的第一步
神经风格迁移简介
2015 年 8 月,一篇名为《艺术风格的神经算法》的论文问世。当时,我刚刚开始深度学习,我试图阅读这篇论文。我不能理解它。所以我放弃了。几个月后,一款名为 Prisma 的应用程序发布了,人们为之疯狂。如果你不知道 Prisma 是什么,它基本上是一个允许你将著名画家的绘画风格应用到自己的照片上的应用程序,并且结果在视觉上相当令人满意。它不同于 Instagram 滤镜,insta gram 滤镜只在色彩空间中对图片进行某种变换。它要复杂得多,结果也更加有趣。这是我在网上找到的一张有趣的照片。

现在,一年后,我学到了很多关于深度学习的知识,我决定再读一遍这篇论文。这次我理解了整篇论文。如果你熟悉深度学习的方法,这实际上是很容易读懂的。在这篇博文中,我主要介绍了我对这篇论文的看法,并试图用更简单的术语向与我一年前处境相同的人(即深度学习领域的初学者)解释神经类型转移。我确信,一旦你看到神经类型转移的结果并理解它是如何工作的,你会对未来的前景和深度神经网络的力量更加兴奋。
基本上,在神经风格转移中,我们有两个图像-风格和内容。我们需要从样式图像中复制样式,并将其应用于内容图像。所谓风格,我们基本上是指图案、笔触等。
为此,我们使用预训练的 VGG-16 网。最初的论文使用 VGG-19 网,但我无法为 TensorFlow 找到 VGG-19 权重,所以我用 VGG-16。实际上,这(使用 VGG-16 而不是 VGG-19)对最终结果没有太大影响。产生的图像是相同的。
那么直观地说,这是如何工作的呢?
为了理解这一点,我将向您介绍一下 ConvNets 是如何工作的。
ConvNets 基于卷积的基本原理工作。比方说,我们有一个图像和一个过滤器。我们在图像上滑动滤波器,将滤波器覆盖的输入的加权和作为输出,通过 sigmoid 或 ReLU 或 tanh 等非线性变换。每个滤波器都有自己的一组权重,在卷积运算期间不会改变。这在下面的 GIF 中有很好的描述

这里,蓝色网格是输入。您可以看到滤波器覆盖的 3x3 区域滑过输入(深蓝色区域)。这种卷积的结果称为特征图,由绿色网格表示。
这是 ReLU 和 tanh 激活函数的图表

ReLU activation function

Tanh activation function
因此,在 ConvNet 中,输入图像与几个滤波器进行卷积,并生成滤波器映射。这些滤波器图然后与一些更多的滤波器卷积,并且产生一些更多的特征图。这一点通过下图得到了很好的说明。

在上图中,您还可以看到术语“最大池”。maxpoollayer 主要用于降维。在最大池操作中,我们简单地在图像上滑动一个大小为 2x2 的窗口,并将窗口覆盖的最大值作为输出。这里有一个例子-

现在这里有一些很酷的东西。仔细观察下图,检查不同图层的特征地图。

你一定注意到了——较低层的贴图寻找低层次的特征,如线条或斑点(gabor 过滤器)。随着我们向更高层发展,我们的功能变得越来越复杂。直观地说,我们可以这样想——较低的层捕捉低层次的特征,如线和斑点,上面的层建立在这些低层次的特征上,并计算稍微复杂的特征,等等…
因此,我们可以得出结论,ConvNets 开发了特征的层次表示。
这个属性是风格转移的基础。
现在记住——在进行风格转换时,我们不是在训练一个神经网络。相反,我们正在做的是——我们从一个由随机像素值组成的空白图像开始,通过改变图像的像素值来优化成本函数。简单地说,我们从空白画布和成本函数开始。然后,我们迭代地修改每个像素,以便最小化我们的成本函数。换句话说,在训练神经网络时,我们更新我们的权重和偏差,但在风格转移中,我们保持权重和偏差不变,而是更新我们的图像。
为了做到这一点,我们的成本函数正确地表示问题是很重要的。成本函数有两项——风格损失项和内容损失项,下面将对这两项进行解释。
内容丢失

这是基于具有相似内容的图像将在网络的较高层中具有相似表示的直觉。
P^l 是原始图像的表示, F^l 是在层 l 的特征图中生成的图像的表示。
风格丧失

这里, A^l 是原始图像的表示, G^l 是层 l 中生成的图像的表示。 Nl 是特征地图的数量 Ml 是图层 l 中展平后的特征地图的大小。 wl 是赋予层 l 风格损失的权重。
所谓风格,我们基本上是指捕捉笔触和模式。因此,我们主要使用较低层,它捕捉低级特征。这里还要注意 gram 矩阵的使用。一个向量的克矩阵X是X . X _ 转置。使用 gram matrix 背后的直觉是,我们试图捕捉较低层的统计数据。
不过,你不一定非要使用 Gram 矩阵。一些其他的统计方法(比如均值)已经被尝试过了,而且效果也很好。****
总损失

其中α和β分别是内容和风格的权重。它们可以被调整以改变我们的最终结果。
所以我们的总损失函数基本上代表了我们的问题——我们需要最终图像的内容与内容图像的内容相似,最终图像的风格也应该与风格图像的风格相似。
现在我们要做的就是把这个损失降到最低。我们通过改变网络本身的输入来最小化这种损失。我们基本上从一个空白的灰色画布开始,并开始改变像素值,以尽量减少损失。任何优化器都可以用来最小化这种损失。这里,为了简单起见,我使用了简单的梯度下降。但是人们已经利用亚当和 L-BFGS 在这个任务上取得了相当好的结果。
这个过程在下面的 GIF 中可以看得很清楚。

这是我的一些实验结果。我对这些图像(512x512px)进行了 1000 次迭代,这个过程在我装有 2GB 英伟达 GTX 940MX 的笔记本电脑上花费了大约 25 分钟。如果你在 CPU 上运行它,时间会长得多,但如果你有一个更好的 GPU,时间会短得多。我听说在 GTX 泰坦上 1000 次迭代只需要 2.5 分钟。



如果你希望获得一些关于卷积神经网络的深入知识,请查看斯坦福 CS231n 课程。
这就是你自己的神经类型转移。去吧,实施吧,玩得开心!!
下次见!
如果你想了解更多关于神经类型转移及其用例的信息,可以看看 Fritz AI 关于神经类型转移的优秀博文。该博客还包含额外的资源和教程,以帮助您开始您的第一个神经风格转移项目。
PySpark 简介

Source: Wikimedia (Vienna Technical Museum)
面向数据科学的 PySpark 入门
PySpark 是一种很好的语言,可以进行大规模的探索性数据分析,构建机器学习管道,为数据平台创建 ETL。如果您已经熟悉 Python 和 Pandas 之类的库,那么为了创建更具可伸缩性的分析和管道,PySpark 是一种很好的学习语言。这篇文章的目标是展示如何使用 PySpark 并执行常见任务。
游戏、团队、玩家和游戏信息,包括 x、y 坐标
www.kaggle.com](https://www.kaggle.com/martinellis/nhl-game-data)
我们将为 Spark 环境使用 Databricks,并将 Kaggle 的 NHL 数据集作为分析的数据源。这篇文章展示了如何在 Spark 数据帧中读写数据,创建这些帧的转换和聚合,可视化结果,以及执行线性回归。我还将展示如何使用 Pandas UDFs 以可伸缩的方式将常规 Python 代码与 PySpark 混合。为了简单起见,我们将把重点放在批处理上,避免流数据管道带来的一些复杂性。
这篇文章的完整笔记本可以在 github 上找到。
环境
使用 Spark 有许多不同的选项:
- **自托管:**你可以使用裸机或虚拟机自己建立一个集群。Apache Ambari 是这个选项的一个有用的项目,但是它不是我推荐的快速启动和运行的方法。
- **云提供商:**大多数云提供商都提供 Spark 集群:AWS 有 EMR,GCP 有 DataProc。我曾经在博客上写过关于 DataProc 的文章,你可以比自托管更快地进入交互式环境。
- **供应商解决方案:**包括 Databricks 和 Cloudera 在内的公司提供 Spark 解决方案,使 Spark 的启动和运行变得非常容易。
要使用的解决方案因安全性、成本和现有基础架构而异。如果你正在尝试建立一个学习环境,那么我建议你使用 Databricks 社区版。

Creating a PySpark cluster in Databricks Community Edition.
在这种环境下,很容易启动并运行 Spark 集群和笔记本电脑环境。对于本教程,我用 Spark 2.4 运行时和 Python 3.0 创建了一个集群。要运行本文中的代码,您至少需要 Spark 版的 Pandas UDFs 功能。
火花数据帧
PySpark 中使用的关键数据类型是 Spark 数据帧。这个对象可以被认为是一个分布在集群中的表,其功能类似于 R 和 Pandas 中的数据帧。如果您想使用 PySpark 进行分布式计算,那么您需要对 Spark 数据帧执行操作,而不是其他 python 数据类型。
在使用 Spark 时,也可以使用 Pandas 数据帧,方法是在 Spark 数据帧上调用 toPandas() ,这将返回一个 Pandas 对象。但是,除非使用小数据帧,否则通常应避免使用此函数,因为它会将整个对象拉入单个节点的内存中。
Pandas 和 Spark 数据帧之间的一个关键区别是急切执行和懒惰执行。在 PySpark 中,操作被延迟,直到管道中实际需要一个结果。例如,您可以指定从 S3 加载数据集的操作,并将一些转换应用到数据帧,但是这些操作不会立即应用。相反,转换的图形被记录下来,一旦实际需要数据,例如当将结果写回 S3 时,转换就作为单个流水线操作被应用。这种方法用于避免将完整的数据帧放入内存,并在机器集群中实现更有效的处理。有了 Pandas dataframes,所有东西都被放入内存,每个 Pandas 操作都被立即应用。
一般来说,如果可能的话,最好避免在 Spark 中进行急切的操作,因为这限制了可以有效分布的管道数量。
读取数据
使用 Spark 时,要学习的第一步是将数据集加载到数据帧中。一旦数据被加载到 dataframe 中,您就可以应用转换、执行分析和建模、创建可视化以及持久化结果。在 Python 中,您可以使用 Pandas 直接从本地文件系统加载文件:
import pandas as pd
pd.read_csv("dataset.csv")
在 PySpark 中,加载 CSV 文件稍微复杂一些。在分布式环境中,没有本地存储,因此需要使用分布式文件系统(如 HDFS、数据块文件存储(DBFS)或 S3)来指定文件的路径。
一般来说,使用 PySpark 时,我在 S3 处理数据。许多数据库都提供了卸载到 S3 的功能,也可以使用 AWS 控制台将文件从本地机器移动到 S3。在这篇文章中,我将使用 Databricks 文件系统(DBFS),它以 /FileStore 的形式提供路径。第一步是上传您想要处理的 CSV 文件。

Uploading a file to the Databricks file store.
下一步是将 CSV 文件读入 Spark 数据帧,如下所示。这段代码片段指定了 CSV 文件的路径,并将一些参数传递给 read 函数来处理文件。最后一步显示加载的数据帧的子集,类似于 Pandas 中的df.head()。
file_location = "/FileStore/tables/game_skater_stats.csv"df = spark.read.format("csv").option("inferSchema",
True).option("header", True).load(file_location)display(df)
在使用 Spark 时,我更喜欢使用 parquet 格式,因为这是一种包含关于列数据类型的元数据的文件格式,提供文件压缩,并且是一种专为使用 Spark 而设计的文件格式。AVRO 是另一种适合 Spark 的格式。下面的代码片段显示了如何从过去的代码片段中提取数据帧,并将其保存为 DBFS 上的拼花文件,然后从保存的拼花文件中重新加载数据帧。
df.write.save('/FileStore/parquet/game_skater_stats',
format='parquet')df = spark.read.load("/FileStore/parquet/game_skater_stats")
display(df)
这一步的结果是一样的,但是执行流程有显著的不同。当将 CSV 文件读入数据帧时,Spark 以急切模式执行操作,这意味着在下一步开始执行之前,所有数据都被加载到内存中,而当读取 parquet 格式的文件时,则使用惰性方法。通常,在使用 Spark 时,您希望避免急切的操作,如果我需要处理大型 CSV 文件,我会在执行管道的其余部分之前,首先将数据集转换为 parquet 格式。
通常,您需要处理大量文件,比如位于 DBFS 某个路径或目录下的数百个 parquet 文件。使用 Spark,您可以在路径中包含通配符来处理文件集合。例如,您可以从 S3 载入一批拼花文件,如下所示:
df = spark.read .load("s3a://my_bucket/game_skater_stats/*.parquet")
如果您每天有一个单独的拼花文件,或者如果您的管道中有一个输出数百个拼花文件的在先步骤,那么这种方法非常有用。
如果您想从数据库中读取数据,比如 Redshift,那么在用 Spark 处理数据之前,最好先将数据卸载到 S3。在 Redshift 中, unload 命令可用于将数据导出到 S3 进行处理:
unload ('select * from data_to_process')
to 's3://my_bucket/game_data'
iam_role 'arn:aws:iam::123:role/RedshiftExport';
还有数据库库,如火花红移,使这个过程更容易执行。
写入数据
类似于用 Spark 读取数据,使用 PySpark 时不建议将数据写入本地存储。相反,你应该使用分布式文件系统,如 S3 或 HDFS。如果要用 Spark 处理结果,那么 parquet 是保存数据帧的好格式。下面的代码片段显示了如何将数据帧保存到 DBFS 和 S3 作为拼花。
**# DBFS (Parquet)** df.write.save('/FileStore/parquet/game_stats',format='parquet')**# S3 (Parquet)** df.write.parquet("s3a://my_bucket/game_stats", mode="overwrite")
以拼花格式保存数据帧时,通常会将它分成多个文件,如下图所示。

The parquet files generated when saving the dataframe to DBFS.
如果您需要 CSV 文件中的结果,那么需要一个稍微不同的输出步骤。这种方法的一个主要区别是,在输出到 CSV 之前,所有数据都将被拉至单个节点。当您需要保存一个小的数据帧并在 Spark 之外的系统中处理它时,推荐使用这种方法。以下代码片段显示了如何在 DBFS 和 S3 上将数据帧保存为单个 CSV 文件。
**# DBFS (CSV)** df.write.save('/FileStore/parquet/game_stats.csv', format='csv')**# S3 (CSV)** df.coalesce(1).write.format("com.databricks.spark.csv")
.option("header", "true").save("s3a://my_bucket/game_sstats.csv")
Spark 脚本的另一个常见输出是 NoSQL 数据库,如 Cassandra、DynamoDB 或 Couchbase。这超出了本文的范围,但我过去见过的一种方法是向 S3 写一个数据帧,然后启动一个加载过程,告诉 NoSQL 系统从 S3 上的指定路径加载数据。
我还省略了写入流输出源,如 Kafka 或 Kinesis。当使用火花流时,这些系统更有用。
转换数据
可以在 Spark 数据帧上执行许多不同类型的操作,就像可以在 Pandas 数据帧上应用的各种操作一样。对 Spark 数据帧执行操作的一种方式是通过 Spark SQL,这使得数据帧可以像表一样被查询。下面的片段显示了如何在数据集中找到得分最高的球员。
df.createOrReplaceTempView("stats")display(spark.sql("""
select player_id, sum(1) as games, sum(goals) as goals
from stats
group by 1
order by 3 desc
limit 5
"""))
结果是球员 id、出场次数和在这些比赛中的总进球数的列表。如果我们想显示球员的名字,那么我们需要加载一个额外的文件,使它作为一个临时视图可用,然后使用 Spark SQL 连接它。

Top scoring players in the data set.
在上面的代码片段中,我使用了 display 命令来输出数据集的样本,但是也可以将结果分配给另一个 dataframe,这可以在管道的后续步骤中使用。下面的代码显示了如何执行这些步骤,其中第一个查询结果被分配给一个新的 dataframe,然后该 data frame 被分配给一个临时视图,并与一组球员姓名连接。
top_players = spark.sql("""
select player_id, sum(1) as games, sum(goals) as goals
from stats
group by 1
order by 3 desc
limit 5
""")top_players.createOrReplaceTempView("top_players")
names.createOrReplaceTempView("names")display(spark.sql("""
select p.player_id, goals, _c1 as First, _c2 as Last
from top_players p
join names n
on p.player_id = n._c0
order by 2 desc
"""))
这一过程的结果如下所示,根据 Kaggle 数据集,确定 Alex Ovechkin 为 NHL 的顶级得分球员。

The output of the process joining dataframes using Spark SQL.
Spark dataframe 操作适用于常见任务,例如添加新列、删除列、执行连接以及计算聚合和分析统计数据,但是在开始使用 Spark SQL 时,执行这些操作可能会更容易。此外,如果您已经在使用诸如 PandaSQL 或 framequery 之类的库来使用 SQL 操作 Pandas 数据帧,那么将代码从 Python 移植到 PySpark 会更容易。
像 Spark 数据帧上的大多数操作一样,Spark SQL 操作是以延迟执行模式执行的,这意味着 SQL 步骤在需要结果之前不会被评估。Spark SQL 提供了一种深入研究 PySpark 的好方法,而无需首先学习一个新的数据帧库。
如果您正在使用数据块,您也可以直接在笔记本中创建可视化,而无需显式使用可视化库。例如,我们可以使用下面的 Spark SQL 代码绘制每场比赛的平均进球数。
display(spark.sql("""
select cast(substring(game_id, 1, 4) || '-'
|| substring(game_id, 5, 2) || '-01' as Date) as month
, sum(goals)/count(distinct game_id) as goals_per_goal
from stats
group by 1
order by 1
"""))
Databricks 笔记本中显示的初始输出是一个结果表,但是我们可以使用绘图功能将输出转换为不同的可视化形式,例如下面显示的条形图。这种方法并不支持数据科学家可能需要的每一种可视化,但它确实使在 Spark 中执行探索性数据分析变得更加容易。如果需要,我们可以使用 toPandas() 函数在驱动程序节点上创建一个 Pandas 数据帧,这意味着任何 Python 绘图库都可以用于可视化结果。但是,这种方法应该只用于小数据帧,因为所有数据都被急切地提取到驱动程序节点的内存中。

Average goals per game during February and March.
我也看了平均每杆进球数,至少有 5 个进球的球员。
display(spark.sql("""
select cast(goals/shots * 50 as int)/50.0 as Goals_per_shot
,sum(1) as Players
from (
select player_id, sum(shots) as shots, sum(goals) as goals
from stats
group by 1
having goals >= 5
)
group by 1
order by 1
"""))
这种转换的结果如下图所示。大多数至少有 5 个进球的球员完成投篮的概率大约是 4%到 12%。

Goals per shot for players in the Kaggle data set.
MLlib
对于数据科学家来说,Python 的一个常见用例是构建预测模型。虽然 scikit-learn 在处理 pandas 时很棒,但它不能扩展到分布式环境中的大型数据集(尽管有办法用 Spark 对它进行并行化)。当使用 PySpark 和海量数据集构建预测模型时, MLlib 是首选库,因为它本来就在 Spark 数据帧上操作。并不是 scikit-learn 中的每个算法都可以在 MLlib 中使用,但是有各种各样的选项涵盖了许多用例。
为了使用 MLib 中的一种监督算法,您需要使用一个要素矢量和一个标量标注来设置数据帧。一旦做好准备,您就可以使用拟合功能来训练模型。下面的代码片段展示了如何使用一个 VectorAssembler 将 dataframe 中的几个列组合成一个单独的 features vector。我们使用生成的数据帧来调用 fit 函数,然后为模型生成汇总统计数据。
**# MLlib imports** from pyspark.ml.feature import VectorAssembler
from pyspark.ml.regression import LinearRegression**# Create a vector representation for features** assembler = VectorAssembler(inputCols=['shots', 'hits', 'assists',
'penaltyMinutes','timeOnIce','takeaways'],outputCol="features")
train_df = assembler.transform(df)**# Fit a linear regression model** lr = LinearRegression(featuresCol = 'features', labelCol='goals')
lr_model = lr.fit(train_df)**# Output statistics** trainingSummary = lr_model.summary
print("Coefficients: " + str(lr_model.coefficients))
print("RMSE: %f" % trainingSummary.rootMeanSquaredError)
print("R2: %f" % trainingSummary.r2)
该模型根据射门次数、比赛时间和其他因素来预测球员的进球数量。然而,该模型的性能很差,其结果是均方根误差(RMSE)为 0.375,R 平方值为 0.125。具有最大值的系数是发射列,但是这并没有提供足够的信号使模型精确。
使用 PySpark 构建 ML 管道时,需要考虑许多额外的步骤,包括训练和测试数据集、超参数调整和模型存储。上面的代码片段只是开始使用 MLlib 的一个起点。
熊猫 UDF
Spark 中我最近一直在使用的一个特性是 Pandas 用户定义函数(UDF ),它使您能够在 Spark 环境中使用 Pandas 数据帧执行分布式计算。这些 UDF 的一般工作方式是,首先使用 groupby 语句对 Spark 数据帧进行分区,然后每个分区被发送到一个 worker 节点,并被转换成 Pandas 数据帧,该数据帧被传递给 UDF。然后,UDF 返回转换后的 Pandas 数据帧,该数据帧与所有其他分区组合,然后转换回 Spark 数据帧。最终结果是非常有用的,你可以使用需要 Pandas 的 Python 库,但是现在可以扩展到大规模数据集,只要你有一个好的方法来划分你的数据帧。熊猫 UDF 是在 Spark 2.3 中引入的,我将在 Spark Summit 2019 期间谈论我们如何在 Zynga 使用这一功能。
曲线拟合是我作为数据科学家执行的一项常见任务。下面的代码片段显示了如何执行曲线拟合来描述玩家在游戏过程中记录的射门次数和命中次数之间的关系。该代码片段显示了我们如何通过对过滤到单个玩家的数据集调用 toPandas() 来为单个玩家执行这个任务。这一步的输出是两个参数(线性回归系数),试图描述这些变量之间的关系。
**# Sample data for a player** sample_pd = spark.sql("""
select * from stats
where player_id = 8471214
""").toPandas()**# Import python libraries** from scipy.optimize import leastsq
import numpy as np**# Define a function to fit** def fit(params, x, y):
return (y - (params[0] + x * params[1] ))**# Fit the curve and show the results**
result = leastsq(fit, [1, 0],
args=(sample_pd.shots, sample_pd.hits))
print(result)
如果我们想为每个玩家计算这条曲线,并且有一个庞大的数据集,那么 toPandas() 调用将会由于内存不足异常而失败。我们可以通过在 player_id 上调用 groupby() ,然后应用如下所示的熊猫 UDF,将这个操作扩展到整个数据集。该函数将描述单个玩家游戏统计数据的 Pandas 数据帧作为输入,并返回一个包括 player_id 和拟合系数的汇总数据帧。然后,每个 summary Pandas 数据帧被组合成一个 Spark 数据帧,显示在代码片段的末尾。使用 Pandas UDFs 的另一项设置是为生成的数据帧定义模式,其中模式描述了从应用步骤生成的 Spark 数据帧的格式。
**# Load necessary libraries** from pyspark.sql.functions import pandas_udf, PandasUDFType
from pyspark.sql.types import *
import pandas as pd**# Create the schema for the resulting data frame** schema = StructType([StructField('ID', LongType(), True),
StructField('p0', DoubleType(), True),
StructField('p1', DoubleType(), True)])**# Define the UDF, input and outputs are Pandas DFs** [@pandas_udf](http://twitter.com/pandas_udf)(schema, PandasUDFType.GROUPED_MAP)
def analyze_player(sample_pd): **# return empty params in not enough data** if (len(sample_pd.shots) <= 1):
return pd.DataFrame({'ID': [sample_pd.player_id[0]],
'p0': [ 0 ], 'p1': [ 0 ]})
**# Perform curve fitting** result = leastsq(fit, [1, 0], args=(sample_pd.shots,
sample_pd.hits)) **# Return the parameters as a Pandas DF** return pd.DataFrame({'ID': [sample_pd.player_id[0]],
'p0': [result[0][0]], 'p1': [result[0][1]]})**# perform the UDF and show the results** player_df = df.groupby('player_id').apply(analyze_player)
display(player_df)
这个过程的输出如下所示。我们现在有了一个数据框架,总结了每个球员的曲线拟合,并可以在一个巨大的数据集上运行这个操作。当处理大型数据集时,选择或生成分区键以在数据分区的数量和大小之间取得良好的平衡是很重要的。

Output from the Pandas UDF, showing curve fits per player.
最佳实践
我已经介绍了使用 PySpark 的一些常见任务,但是还想提供一些建议,以便更容易地从 Python 过渡到 PySpark。以下是我根据在这些环境之间移植一些项目的经验收集的一些最佳实践:
- **避免使用字典,使用数据框架:**使用字典等 Python 数据类型意味着代码可能无法在分布式模式下执行。不要使用键来索引字典中的值,可以考虑向 dataframe 中添加另一列来用作过滤器。
- **少用toPandas😗*调用 toPandas() 会导致所有数据被加载到驱动节点的内存中,并阻止操作以分布式方式执行。当数据已经聚合并且您想要使用熟悉的 Python 绘图工具时,使用此函数是很好的,但是它不应该用于大型数据帧。
- **避免 for 循环:**如果可能,最好使用 groupby-apply 模式重写 for 循环逻辑,以支持并行代码执行。我注意到,专注于在 Python 中使用这种模式也导致了更容易翻译成 PySpark 的代码的清理。
- **尽量减少急切操作:**为了让您的管道尽可能地可伸缩,最好避免将完整数据帧拉入内存的急切操作。我注意到在 CSV 中读取是一个急切的操作,我的工作是将数据帧保存为 parquet,然后从 parquet 重新加载它,以构建更具可伸缩性的管道。
- **使用 framequery/pandasql 使移植更容易:**如果您正在使用其他人的 Python 代码,那么破译一些 Pandas 操作正在实现的功能可能会很棘手。如果您计划将代码从 Python 移植到 PySpark,那么使用 Pandas 的 SQL 库可以使这种转换更容易。
我发现花时间在 PySpark 上写代码也因 Python 编码技巧而有所提高。
结论
PySpark 是数据科学家学习的一门好语言,因为它支持可扩展的分析和 ML 管道。如果您已经熟悉 Python 和 Pandas,那么您的许多知识都可以应用于 Spark。我已经展示了如何用 PySpark 执行一些常见的操作来引导学习过程。我还展示了 Pandas UDFs 的一些最新 Spark 功能,这些功能使 Python 代码能够以分布式模式执行。有很好的环境使 Spark 集群很容易启动和运行,现在是学习 PySpark 的好时机!
本·韦伯是 Zynga 的首席数据科学家。我们正在招聘!
强化学习与价值函数简介

在我之前的帖子中,我已经讨论了 n 臂土匪问题,我希望我已经给了你关于强化学习的基本直觉。在这篇文章中,我计划深入研究并正式定义强化学习问题。但是首先,有几个更重要的概念要介绍…
价值函数
在之前的帖子中,我解释了拉动老虎机的 n 个臂的每一个被认为是不同的动作,并且每个动作都有我们不知道的值。我们所能观察到的只是吃角子老虎机在我们执行一个动作(拉手臂)后给我们的奖励。
我们的主要目标是最大化回报。如果我们知道每个动作的值,这就很容易做到,因为我们总是可以用最大值来执行动作。
但问题是——我们永远无法找到一个行为的实际价值,但我们可以很精确地估计它。
那么我们如何评估一个行为的价值呢?
在 n 个武装匪徒的问题中,有一种方法可以做到这一点,那就是不断执行动作,并保存一份我们得到的所有奖励的列表,然后对每个动作的奖励进行平均。这将会给我们一个行动价值的估计,但是我们估计的好坏取决于我们执行行动的次数。我们执行一个动作的次数越多,我们对它的价值的估计就越准确。
这在数学上可以写成-

其中, Qt(a) 是在第 t 次播放时动作*‘a’*的估计值。 r1,r2,… 是获得的奖励。 ka 是动作 a 已经执行的次数。
很简单,对吧?
但是用这种方法发现行动的价值需要我们维护一个行动和回报的列表,并且随着我们不断地执行行动,这个列表会无限制地增长。这是一个严重的问题,因为这样的列表会占用太多的内存。
下面的等式解决了这个问题,因为它只需要我们跟踪两个变量- Qk 和 k。

到目前为止一切顺利。我们有一个 n 臂强盗,每个臂都有不同的值(平均奖励),我们可以拉任何一个臂。直到现在,土匪的手臂的价值是不变的,也就是说,我们正在处理一个稳定的问题。但是如果手臂的值随着时间慢慢变化,而我们不知道如何变化呢?在这种情况下,我们会怎么做?
价值函数随时间变化的这类问题称为非平稳问题。在这种情况下,与旧的奖励相比,我们更重视最近的奖励是有意义的。这可以使用下面的等式来完成

其中,α是步长参数。它是一个介于 0 和 1 之间的常数。你可能会注意到,上面的等式与前面的等式非常相似。这两个方程的唯一区别是,在前一个方程中,步长随 k 变化,而在后一个方程中,步长是常数。
现在,如果我们插入 Qk 的值,我们得到

你可以在上面的等式中看到,Qk+1 取决于(1-α)^(k-i).由于(1-α)<1,Ri 的权重随着 I 的增加而降低。这意味着我们对较老的奖励给予较少的权重。
请记住,上述方法只适用于价值函数变化缓慢的非平稳问题。
乐观的初始值
这种方法就像一个小黑客,鼓励代理在开始时探索。
Q0 的值可以设置为某个较高的正值,例如 30。现在,由于最高奖励只有 10,我们的值 Q0 是非常乐观的。无论代理选择哪一个行动,它都会得到比价值估计值少的奖励,因此,它会继续探索其他行动。
请注意,这种黑客攻击的效果只是暂时的,在开始时大多可以注意到。
这就完成了强化学习的第二章:简介。干杯。✌ ️😁
慢速特征分析快速介绍

Photograph by Jürgen Schoner / CC BY-SA 3.0
使用 python 和数学的面向应用的 SFA 介绍
我最近开始在波鸿鲁尔大学攻读机器学习的博士学位。我加入的小组的一个主要研究课题叫做慢特征分析(SFA)。为了了解一个新的话题,在让自己沉浸在数学的严谨中之前,如果可能的话,我喜欢看例子和直观的解释。我写这篇博文是为了那些喜欢以类似方式研究主题的人,因为我相信 SFA 是非常强大和有趣的。
在这篇文章中,我将以一个应用 SFA 的代码示例开始,来帮助激发这种方法。然后,我将更详细地介绍该方法背后的数学原理,最后提供该材料中其他优秀资源的链接。
1.确定平滑潜变量
SFA 是一种无监督学习方法,从时间序列中提取最平滑(最慢)的底层函数或特征。这可以用于降维、回归和分类。例如,我们可以有一个高度不稳定的序列,它是由一个行为更好的潜在变量决定的。
让我们从生成时间序列 D 和 S: 开始

这就是所谓的逻辑地图。通过绘制系列 S ,我们可以考察它的混沌本质。驱动上述曲线行为的基本时间序列 D 要简单得多:

我们如何从不稳定的时间序列中确定简单的潜在驱动力?
我们可以用 SFA 来确定一个函数变化最慢的特征。在我们的例子中,我们将从像 S 这样的数据开始,以 D 结束,而不必事先知道 S 是如何生成的。
SFA 的实现旨在找到输入的特征,这些特征是线性的。但是从我们的例子可以看出,驱动力 D 是高度非线性的!这可以通过首先对时间序列 S 进行非线性扩展来弥补,然后找到扩展数据的线性特征。通过这样做,我们发现了原始数据的非线性特征。
让我们通过堆叠 S 的时间延迟副本来创建一个新的多元时间序列:

接下来,我们对数据进行立方扩展,并提取 SFA 特征。三次展开将一个四维向量[ a 、 b 、 c 、d]ᵀ]变成 34 个元素向量,其中元素 t 、t v、tvu、t 、tv、t 为不同的 t、u、v ∈{a、b、c、d}。
请记住,添加时间延迟副本的最佳数量因问题而异。或者,如果原始数据维数过高,则需要进行降维,例如使用主成分分析。
因此,考虑以下是该方法的超参数:维度扩展(缩减)的方法、扩展(缩减)后的输出维度以及待发现的慢特征的数量。
现在,添加时间延迟副本后,时间序列的长度从 300 变为 297。因此,慢特征时间序列的相应长度也是 297。为了更好的可视化,我们将第一个值添加到它前面,并将最后一个值添加两次,从而将它的长度变为 300。SFA 发现的特征具有零均值和单位方差,因此在可视化结果之前,我们也对 D 进行归一化。
即使只考虑 300 个数据点,SFA 特性也能几乎完全恢复底层源代码——这令人印象深刻!

2.引擎盖下到底发生了什么?
理论上,SFA 算法接受一个(多变量)时间序列 X 和一个整数 m 作为输入,该整数表示要从该序列中提取的特征的数量,其中 m 小于时间序列的维数。该算法确定了 m 个函数

使得每个 yᵢ 的两个连续时间点的时间导数的平方的平均值最小化。直觉上,我们希望最大化这些特性的缓慢性:

其中点表示时间导数,在离散情况下:

目标函数(1)测量特征的慢度。零均值约束(2)使得特征的二阶矩和方差相等,并简化了符号。单位方差约束(3)丢弃常数解。
最后的约束(4)使我们的特征去相关,并导致它们的慢度排序。这意味着我们首先找到最慢的特征,然后我们找到下一个最慢的特征,它与前一个特征正交,依此类推。对特征进行去相关可以确保我们捕捉到最多的信息。
在接下来的内容中,我浏览了重要的细节并跳过了一些步骤,但是为了完整起见,我想把它包括进来。我建议也看看下面的链接,以获得更全面的解释。
让我们只考虑线性特征:

时间序列 X 可以是“原始数据”或其非线性扩展,见上例。请记住,即使这些是扩展数据的线性特征,它们也可能是原始数据的非线性特征。
假设零均值*,通过求解广义特征值问题AW=bwλ找到线性特征。我们确定 m 个特征值-特征向量元组( λᵢ , Wᵢ )使得awᵢ=λᵢb*我们有**

标量 λᵢ 表示特征的慢度,即 λᵢ 越小,相应的 yᵢ 变化越慢。如果你熟悉广义特征值问题,注意这里的特征值是增加的——而不是减少的。最后,特征向量 Wᵢ 是定义我们学习特征的变换向量。
3.进一步阅读
SFA 在分类中的应用:http://cogprints.org/4104/1/Berkes2005a-preprint.pdf
以上例子改编自:http://MDP-toolkit . SourceForge . net/examples/log map/log map . html
—
在推特上关注我

支持向量机简介

支持向量机(SVM)是最流行的机器学习分类器之一。它属于监督学习算法的范畴,并使用边缘的概念在类之间进行分类。它给出了比 KNN,决策树和朴素贝叶斯分类器更好的准确性,因此非常有用。
谁应该阅读这篇文章
任何对机器学习概念有所了解并对学习 SVM 感兴趣的人。如果你是这个领域的初学者,先浏览一下这篇文章。
读完这篇文章,你会知道:
- SVM 到底是什么
- 如何使用 Sklearn (Python)的 SVM 分类器
- 调整其参数以获得更好的结果
所以让我们开始吧!
什么是 SVM?
如前所述,SVM 属于用于分类的监督算法类别。让我们从两个类的例子开始:
给定类 X1 和 X2,我们想要找到最好地分离这两个类的判定边界,即具有最小误差。
SVM 用一个 【超平面】 做到了这一点。这个超平面在二维数据的情况下可以是一条直线,在三维数据的情况下可以是一个平面。

不用深入幕后的数学,让我们了解一些基本的功能。
支持向量机使用了***‘支持向量*’**的概念,支持向量是离超平面最近的点。
在上面的例子中,红线表示分隔两个类(蓝色星形和红色圆形)的决策边界,连字符线表示我们的’’ Margin ',即我们想要的两个类的支持向量之间的差距。
界限很重要
边缘是在支持向量的帮助下定义的(因此得名)。在我们的示例中,黄色的星星和黄色的圆圈是定义边距的支持向量。间隙越大,分类器工作得越好。因此,支持向量在开发分类器中起着重要的作用。
测试数据中的每一个新数据点都将根据这个余量进行分类。如果它位于它的右侧,它将被归类为红色圆圈,否则被归类为蓝色星星。
最棒的是,SVM 还可以对非线性数据进行分类。

在非线性数据的情况下,事情变得有点棘手。这里 SVM 使用了Kernel-trick’,它使用一个核函数将非线性数据映射到更高维度,这样它就变成线性的,并在那里找到决策边界。
无论是线性数据还是非线性数据,SVM 总是使用核函数,但当数据以其当前形式不可分时,它的主要功能就会发挥作用。这里,核函数为分类问题增加了维度。
现在让我们看一些代码。
使用支持向量机
在 Sklearn 的帮助下,您只需几行代码就可以利用 SVM 分类器的强大功能。
from sklearn import svm #Our linear classifier
clf = svm.SVC(kernel='linear') '''
X_train is your training data y_train are the corresponding labels y_pred are the predicted samples of the test data X_test
'''#Training our classifier on training set with labels
clf.fit(X_train, y_train)#Predicting output on the Test set
y_pred = clf.predict(X_test) #Finding the Accuracy
print("Accuracy:",metrics.accuracy_score(y_test, y_pred))
在这种情况下,我们使用的是线性内核,如你所见。根据问题的不同,您可以使用不同类型的内核函数:
- 线性的
- 多项式
- 径向基函数
- 高斯的
- 拉普拉斯(侯爵)
…以及更多。选择正确的核函数对于构建分类器非常重要。在下一节中,我们将调整超参数,使我们的分类器更好。
你可以在这里访问完整的代码。
如果你觉得无聊,这里有一只可爱的猫!

调谐参数
内核:我们已经讨论过内核函数有多重要。根据问题的性质,必须选择正确的核函数,因为核函数定义了为问题选择的超平面。这里的是最常用的内核函数列表。
正规化:听说过过度拟合这个词吗?如果你没有,我认为你应该从这里的学习一些基础知识。在 SVM,为了避免过度拟合,我们选择软边界,而不是硬边界,即我们故意让一些数据点进入我们的边界(但我们仍然惩罚它),这样我们的分类器就不会过度拟合我们的训练样本。这里有一个重要的参数γ(γ),它控制 SVM 的过拟合。伽玛越高,超平面尝试匹配训练数据的程度越高。因此,选择最佳伽马值以避免过拟合和欠拟合是关键。
**误差罚分:**参数 C 代表对 SVM 错误分类的误差罚分。它保持了更平滑的超平面和错误分类之间的折衷。如前所述,为了避免分类器过拟合,我们允许一些错误分类。
这些是用于调整 SVM 分类器的最重要的参数。
总的来说,SVM 具有许多优点,因为它提供高精度,具有低复杂性,并且对于非线性数据也非常有效。缺点是,与朴素贝叶斯等其他算法相比,它需要更多的训练时间。
这就是支持向量机!如果你有任何问题,请在评论中告诉我。
恭喜你坚持到帖子的最后!
这是给你的饼干

如果你喜欢这篇文章,别忘了加上掌声!
原载于 2018 年 11 月 2 日【adityarohilla.com】。
两种数据处理架构简介— Lambda 和 Kappa 用于大数据
B ig 数据、物联网(IoT)、机器学习模型和其他各种现代系统正在成为今天不可避免的现实。各行各业的人们已经开始将与数据存储和服务器的交互作为他们日常生活的一部分。因此,我们可以说,以最佳方式处理大数据正成为企业、科学家和个人的主要兴趣领域。例如,为实现某些业务目标而启动的应用程序,如果能够有效地处理客户提出的查询并很好地服务于他们的目的,将会更加成功。这种应用程序需要与数据存储进行交互,在本文中,我们将尝试探索两种重要的数据处理架构,它们是各种企业应用程序(称为 Lambda 和 Kappa)的主干。

社交媒体应用程序、基于云的系统、物联网和无休止的创新热潮的快速增长,使得开发人员或数据科学家在启动、升级企业应用程序或对其进行故障排除时做出精心计算的决策变得非常重要。尽管使用模块化方法来构建应用程序具有多种优势和长期益处,这一点已经被广泛接受和理解,但是对选择正确的数据处理架构的追求仍然在许多与现有和即将出现的企业软件相关的提议前面打上问号。尽管目前全球有各种各样的数据处理架构,但让我们详细研究一下 Lambda 和 Kappa 架构,并找出它们的独特之处,以及在什么情况下应该优先选择哪一种。
λ架构
Lambda 架构是一种数据处理技术,能够以高效的方式处理大量数据。这种体系结构的效率以增加吞吐量、减少延迟和忽略错误的形式变得显而易见。当我们提到数据处理时,我们基本上使用这个术语来表示高吞吐量、低延迟和以接近实时的应用为目标。这也将允许开发者在基于事件的数据处理模型中以代码逻辑或自然语言处理(NLP)的形式定义增量规则,以实现稳健性、自动化和效率,并提高数据质量。此外,数据状态的任何变化对系统来说都是一个事件,事实上,作为对运行中的事件的响应,可以发出命令、查询或期望执行增量过程。
事件源是使用事件进行预测以及实时存储系统中的变化的概念。系统状态的变化、数据库中的更新或事件可以理解为变化。例如,如果有人与网页或社交网络个人资料进行交互,则页面查看、喜欢或添加为好友请求等事件会触发可以处理或丰富的事件,并将数据存储在数据库中。
数据处理处理事件流,大多数遵循领域驱动设计的企业软件使用流处理方法来预测基本模型的更新,并存储不同的事件,作为实时数据系统中预测的来源。为了处理系统中发生的大量事件或增量处理,Lambda 架构通过引入三个不同的层来实现数据处理。Lambda 架构由批处理层、速度层(也称为流层)和服务层组成。
1.批量层
新数据源源不断地输入数据系统。在任何情况下,它都被同时输送到配料层和速度层。任何到达数据系统批处理层的新数据流都是在数据湖之上进行计算和处理的。当数据存储在数据湖中时,使用数据库,如内存数据库或长期持久数据库,如基于 NoSQL 的存储 batch layer 使用它来处理数据,使用 MapReduce 或利用机器学习(ML)来预测即将到来的批处理视图。
2.速度层(流层)
速度层使用在批处理层完成的事件源的成果。在批处理层中处理的数据流导致更新 delta 过程或 MapReduce 或机器学习模型,流层进一步使用这些模型来处理馈送给它的新数据。速度层提供基础丰富过程的输出,并支持服务层减少响应查询的延迟。顾名思义,速度层具有较低的延迟,因为它只处理实时数据,计算量较小。
3.服务层
来自批处理层的批处理视图形式的输出和来自速度层的近实时视图形式的输出被转发到服务层,服务层使用这些数据来满足临时的未决查询。
下面是 Lambda 架构模型的基本示意图:

Lambda Architecture
让我们将其转化为一个函数方程,它定义了大数据领域中的任何查询。这个等式中使用的符号称为 Lambda,Lambda 架构的名称也是从同一个等式中产生的。对于熟悉大数据分析花絮的人来说,这个功能广为人知。
Query = λ (Complete data) = λ (live streaming data) * λ (Stored data)
该等式意味着,通过在速度层的帮助下以批处理和实时流的形式组合来自历史存储的结果,可以在 Lambda 架构中满足所有与数据相关的查询。
Lambda 架构的应用
Lambda 架构可以部署在以下数据处理企业模型中:
- 用户查询需要使用不可变的数据存储在特定的基础上提供服务。
- 需要快速响应,系统应该能够处理新数据流形式的各种更新。
- 不应删除任何存储的记录,并且应允许向数据库添加更新和新数据。
Lambda 架构可以被认为是接近实时的数据处理架构。如上所述,它可以承受故障,并允许可伸缩性。它使用批处理层和流层的功能,并不断向主存储器添加新数据,同时确保现有数据保持不变。Twitter、网飞和雅虎等公司正在使用这种架构来满足服务质量标准。
Lambda 架构的利弊
赞成的意见
- Lambda 架构的批处理层通过容错分布式存储管理历史数据,即使系统崩溃也能确保低错误率。
- 这是速度和可靠性的良好平衡。
- 容错和可扩展的数据处理体系结构。
骗局
- 由于涉及全面的处理,它会导致编码开销。
- 重新处理每个批处理周期,这在某些情况下是无益的。
- 用 Lambda 架构建模的数据很难移植或重组。
卡帕建筑
在 2014 年,Jay Kreps 发起了一场讨论,他指出了 Lambda 架构的一些差异,这些差异进一步将大数据世界引向了另一种替代架构,这种架构使用较少的代码资源,并且能够在某些使用多层 Lambda 架构似乎有些奢侈的企业场景中运行良好。
Kappa 架构不能作为 Lambda 架构的替代品,相反,它应被视为在批处理层的主动性能不需要满足标准服务质量的情况下使用的替代方案。这种体系结构在不同事件的实时处理中有其应用。这是 Kappa 架构的基本示意图,显示了该数据处理架构的两层操作系统。

Kappa Architecture
让我们将 kappa 架构的操作顺序转化为一个函数等式,该等式定义了大数据领域中的任何查询。
Query = K (New Data) = K (Live streaming data)
这个等式意味着所有的查询都可以通过在速度层对实时数据流应用 kappa 函数来满足。它还表示流处理发生在 kappa 架构中的速度层。
卡帕架构的应用
社交网络应用的一些变体、连接到基于云的监控系统的设备、物联网(IoT)使用优化版本的 Lambda 架构,该架构主要使用速度层与流层相结合的服务来处理数据湖中的数据。
Kappa 架构可以部署在以下数据处理企业模型中:
- 多个数据事件或查询被记录在一个队列中,以迎合分布式文件系统存储或历史。
- 事件和查询的顺序不是预先确定的。流处理平台可以随时与数据库交互。
- 它具有弹性和高可用性,因为系统的每个节点都需要处理数 TB 的存储来支持复制。
上面提到的数据场景是通过耗尽 Apache Kafka 来处理的,Apache Kafka 速度极快,具有容错性和水平可伸缩性。它允许一个更好的机制来管理数据流。对流处理器和数据库的平衡控制使得应用程序能够按照预期执行。Kafka 将有序数据保留更长时间,并通过将它们链接到保留日志的适当位置来满足类似的查询。LinkedIn 和其他一些应用程序使用这种风格的大数据处理,并获得保留大量数据的好处,以满足那些仅仅是彼此副本的查询。
卡帕建筑的利与弊
优点
- Kappa 架构可用于开发在线学习者的数据系统,因此不需要批处理层。
- 只有当代码改变时才需要重新处理。
- 它可以使用固定内存进行部署。
- 它可以用于水平可伸缩的系统。
- 由于机器学习是在实时基础上进行的,因此需要的资源更少。
缺点
缺少批处理层可能会导致数据处理过程中或更新数据库时出错,这需要使用异常管理器来重新处理数据或进行协调。
结论
简而言之,在 Lambda 和 Kappa 架构之间的选择似乎是一种权衡。如果您寻求一种在更新数据湖方面更可靠,以及在设计机器学习模型以稳健的方式预测即将发生的事件方面更有效的架构,您应该使用 Lambda 架构,因为它获得了批处理层和速度层的优势,以确保更少的错误和速度。另一方面,如果您希望通过使用较便宜的硬件来部署大数据架构,并要求它有效地处理运行时发生的独特事件,则选择 Kappa 架构来满足您的实时数据处理需求。
FlowNet 简介
最近,细胞神经网络已经成功地用于估计光流。与传统方法相比,这些方法在质量上有了很大的提高。在此,我们将对以下论文进行简要回顾。



概观
卷积神经网络(CNN)在各种计算机视觉任务中做出了巨大贡献。最近,细胞神经网络已经成功地用于估计光流。与传统方法相比,这些方法在质量上有了很大的提高。在此,我们将对以下论文进行简要回顾。
FlowNet1.0 和 FlowNet2.0 都是端到端架构。FlowNet2.0 由 FlowNetCorr 和 FlowNet 堆叠而成,比 FlowNetCorr 和 flownet 都有好得多的结果。FlowNetS 简单地将两个顺序相邻的图像堆叠起来作为输入,而在 FlowNetCorr 中,两个图像被分别卷积,并通过一个相关层组合在一起。在空间金字塔网络中,作者为每一层独立训练一个深度网络来计算流量更新。SPyNet 和 FlowNet2.0 都以由粗到细的方式估计大的运动。FlowNet2.0 在这些架构中性能最好,SPyNet 的模型参数最少。
FlowNet:用卷积网络学习光流
在 FlowNet1.0 中,本文提出并比较了两种架构:FlowNetSimple 和 FlowNetCorr。这两种架构都是端到端的学习方法。在 FlowNetSimple 中,如图 1 所示,作者简单地将两个顺序相邻的输入图像堆叠在一起,并通过网络传送它们。与 FlowNetSimple 相比,FlowNetCorr(图 2)首先分别产生两幅图像的表示,然后在“相关层”将它们结合在一起,一起学习更高的表示。这两种架构都有用于上采样分辨率的改进。


相关层用于在两个特征图之间执行乘法面片比较。更具体地,给定两个多通道特征图 f1、f2,其中 w、h 和 c 是它们的宽度、高度和通道数量。以第一个图中的 x1 和第二个图中的 x2 为中心的两个补片的“相关性”定义为:

其中 x1 和 x2 分别是第一地图和第二地图的中心,并且大小为 K = 2k+1 的正方形空间面片。此外,出于计算原因,作者限制了最大位移。具体来说,对于每个位置 x1,作者通过计算大小为 D = 2d+1 的邻域中的相关性来限制 x2 的范围,D 是给定的最大位移。输出的大小是(whD)。然后,作者将使用卷积层从 f1 提取的特征图与输出连接。
然而,在一系列卷积层和汇集层之后,分辨率已经降低。因此,作者通过“向上进化”层改进了粗略的池化表示,包括取消池化和向上进化。对特征图进行上变换后,作者将其与相应的特征图和上采样的粗流量预测连接起来。如图 3 所示

实际上,作者在 Github 上提供的模型与上图略有不同。图 3 的第二个框不仅包括来自 deconv5 和 con5_1 的特征图,还包括由以下流生成的流 6。
con V6—-(conv)—> con V6 _ 1—(conv)→predict _ flow 6—-(conv)—> flow 6
表 1。显示不同数据集上不同方法的平均终点误差(以像素为单位)。

FlowNet 2.0:深度网络光流估计的发展
简介和贡献
FlowNet2.0 比 FlowNet1.0 好得多,与 FlowNet1.0 相比,FlowNet2.0 在质量和速度上都有很大的提高。主要架构如图 7 所示。本文有四个主要贡献:
1.呈现数据的时间表在培训进度中很重要
2。提出了堆叠架构
3。介绍了一个专门研究小动作的子网络
4。提出了融合架构
数据测试计划
在实验中,不仅训练数据的种类对性能很重要,而且它在训练期间呈现的顺序也很重要。作者分别在椅子和 Things3D 上测试了 FlowNetS 和 FlowNetCorr。图 5 显示了使用不同学习速率表的两个数据集样本的等量混合。S_short、S_long 和 S_fine 是不同的学习速率表,如图 6 所示。图 5 中的数字表示 Sintel 数据集的终点误差。从图 5 中,我们可以知道最好的结果是先在椅子上训练,然后在 Things3D 上微调。


堆叠网络
为了计算光流的大位移,作者叠加了流网和流网校正,如图 7 所示。表 3 显示了叠加流网的效果,其中应用了图 5 中的最佳流网。第一流网获取图像 I1 和 I2 作为输入,第二流网获取图像 I1、由第一流网计算的流 wi、由流 wi 扭曲的图像 I2 以及由流 wi 扭曲的图像 I1 和图像 I2 之间的亮度差误差。
在训练栈结构中有两种方法:固定第一网络的权重,或者与第二网络一起更新它们。结果如表 3 所示,从中我们可以看出,当固定 Net1 并用 warping 训练 Net2 时,在 Sintel 上获得了最好的结果。
此外,作者确实对堆叠多个不同的网络进行了实验,他们发现多次堆叠具有相同权重的网络,并对这种循环的过去进行微调不会改善结果。因此,他们添加了不同权重的网络,每个新网络首先在椅子上进行训练,并在 Things3D 上进行微调。最后,他们通过平衡网络精度和运行时间来实施 FlowNet2-CSS。FlowNetCorr 是 FlowNet2-CSS 的第一个网络,后面是两个 FlowNet,如图 7 所示的第一个流

小位移网络与融合
但是,对于小排量,FlowNet2-CSS 并不可靠。因此,作者创建了一个具有小位移的小数据集,并在该数据集中训练 FlowNetSD。FlowNetSD 与 FlowNetS 略有不同。他们用多个 33 内核替换了开头的 77 和 5*5 内核,去掉了第一层的 stride 2。最后,作者引入了一个小而简单的深度网络(Fusion)来融合 FlowNet2-CSS 和 FlowNet2-SD 的输出,如图 7 所示。

表演
表 4 显示了不同基准测试的性能。AEE:平均终点误差;Fl-all:流量估计误差为 3 个像素和 5%的像素比率。在 Sintel、Sintel final 和 Middlebury 中,FlowNet2 在准确率上超越了所有其他参考方法,在其他准确率相对较高的数据集上也表现良好。

使用空间金字塔网络的光流估计
介绍
将经典的空间金字塔模型与深度学习相结合,提出了一种新的光流方法。这是一种由粗到细的方法。在空间金字塔的每一层,作者训练一个深度神经网络来估计流量,而不是只训练一个深度网络。这种方法对于任意大的运动是有益的,因为每个网络要做的工作较少,并且每个网络上的运动变得较小。与 FlowNet 相比,SPyNet 要简单得多,在模型参数方面要小 96%。此外,对于一些标准基准,SPyNet 比 FlowNet1.0 更准确。
体系结构

图 8 显示了一个三级金字塔网络:
- d()是将 mn 图像 I 减小到 m/2n/2 的下采样函数
- u()是重采样光流场的重采样函数
- w(I,V)用于根据光流场 V 扭曲图像 I
- { G0,…,GK }是一组经过训练的卷积神经网络
- v_k 是由 convnet Gk 在第 k 个金字塔级计算的剩余流量

在第 k 个金字塔等级,剩余流量 v_k 由 G_k 使用 I_k1(来自前一个金字塔的上采样流量)和 I_k2 计算,I _ k2 由上采样流量补偿。那么,流量 V_k 可以表示为


修道院{ G0,…GK }被独立地训练以计算残差流 v_k。此外,地面真实残差流 V^_k 是通过减去下采样地面真实流 v^_k 和 u(V_k-1)获得的。如图 6 所示,作者通过最小化剩余流 v_k 上的平均端点误差(EPE)损失来训练网络

表演

个人观点
与 Flownet 1.0 相比,Flownet 2.0 的精度更高的原因是,通过使用堆叠结构和融合网络,网络模型更大。对于堆叠结构,它通过用中间光流扭曲每一层的第二图像,以由粗到细的方式估计大的运动,并计算流更新。因此,这种方法降低了每一级学习任务的难度,为大位移做出了贡献。对于融合网络,作者引入了 FlowNet2-CSS 和 FlowNet2-SD 来分别估计大位移和小位移。然后,融合网络旨在更好地融合从上述两个网络学习到的两种光流,期望提高最终预测光流的整体质量。
从我的角度来看,重复使用特征映射对 FlowNet1.0 和 FlowNet2.0 的良好性能产生了影响。作者将估计流量和输入连接在一起,这些流量和输入在当前层中被上采样为特征映射,从与当前层的上采样输入相同分辨率的前层获得,作为下一个去卷积层的输入,因此这些特征映射可以重复使用,在设计概念上与 DenseNet 有点类似。
SPyNet 也是一个堆叠网络。它也适合通过使用由粗到细的方法来处理大位移,类似于 FlowNet2.0。flownet 2.0 和 SPyNet 的区别在于,SPyNet 比 flownet 2.0 小得多,SPyNet 的每一层都是独立训练的深度网络。SPyNet 的模型参数比 FlowNet 少很多,因为它是直接使用 warping 函数,女修道院不需要学习。
总的来说,FlowNet2.0 的性能最好,而 SPyNet 要轻量得多,参数更少,速度更快,可以在移动终端上使用。
FlowNet:用卷积网络学习光流链接:
https://arxiv.org/pdf/1504.06852 FlowNet 2.0 论文链接:
https://lmb . informatik . uni-freiburg . de/Publications/2017/imk db 17/Paper-FlowNet _ 2 _ 0 _ _ cvpr . pdf
利用空间金字塔网络的光流估计链接:
https://arxiv.org/pdf/1611.00850.pdf
作者:李子云| 编辑:杨| 由 Synced 全球团队本地化:陈翔
一堆训练深度神经网络的技巧和窍门

I took this nice photo in GüvenPark
训练深度神经网络是困难的。它需要知识和经验,以便正确地训练和获得最佳模型。在这篇文章中,我想分享我在训练深度神经网络中所学到的东西。以下提示和技巧可能对您的研究有益,可以帮助您加快网络架构或参数搜索的速度。
哦,让我们开始吧…
**①。**在开始构建您的网络架构之前,您需要做的第一件事是验证您输入到网络中的数据是否与标签(y)相对应。在密集预测的情况下,请确保地面实况标签(y)被正确编码为标签索引(或一次性编码)。如果没有,培训就没有效果。
**2)。**决定是使用预先训练好的模型还是从头开始训练你的网络?
- 如果您的问题域中的数据集与 ImageNet 数据集相似,请对该数据集使用预训练模型。使用最广泛的预训练模型有 VGG 网、雷斯网、丹森网或例外等。有许多层结构,例如,VGG (19 和 16 层),雷斯网(152,101,50 层或更少),DenseNet (201,169 和 121 层)。注意:不要尝试使用更多的层网络来搜索超参数(例如VGG-19、ResNet-152 或 DenseNet-201 层网络,因为其计算成本很高),而是使用更少的层网络(例如 VGG-16、ResNet-50 或 DenseNet-121 层)。选择一个预训练的模型,您认为它可以提供您的超参数的最佳性能(比如 ResNet-50 层)。获得最佳超参数后,只需选择相同但更多的层网(如 ResNet-101 或 ResNet-152 层)来提高精度。
- 微调几个层或只训练分类器,如果你有一个小数据集,你也可以尝试在你要微调的卷积层后插入 Dropout 层,因为它可以帮助对抗网络中的过度拟合。
- 如果您的数据集与 ImageNet 数据集不相似,您可以考虑从头开始构建和训练您的网络。
**③。**在您的网络中始终使用标准化图层。如果你用一个大的批量(比如 10 或更多)来训练网络,使用批量标准化层。否则,如果你用一个小的批量(比方说 1)训练,用实例规范化层代替。请注意,主要作者发现,如果增加批处理大小,批处理标准化会提高性能,而当批处理大小小时,它会降低性能。然而,如果他们使用小的批处理大小,实例规范化会稍微提高性能。或者你也可以尝试分组规范化。
**4)。**如果你有两个或更多的卷积层(比如李)在同一个输入(比如 F )上操作,那么在一个特征拼接之后使用空间删除。由于这些卷积层对相同的输入进行操作,因此输出特征很可能是相关的。因此,空间丢失会移除那些相关的特征,并防止网络中的过度拟合。注:多用于低层而非高层。

SpatialDropout use-case
**5)。**为了确定你的网络能力,试着用一小部分训练样本来充实你的网络。如果它没有超载,增加你的网络容量。过度拟合后,使用正则化技术,如 L1 、 L2 、辍学或其他技术来对抗过度拟合。
**6)。**另一个正则化技术是约束或限制你的网络权重。这也有助于防止网络中的梯度爆炸问题,因为权重总是有界的。与在损失函数中惩罚高权重的 L2 正则化相反,该约束直接正则化您的权重。可以在 Keras 中轻松设置权重约束:
**7)。**从数据中平均减法有时会给出非常差的性能,尤其是从灰度图像中减法(我个人在前景分割领域面临这个问题)。
**⑧。总是打乱你的训练数据,训练前的和训练中的和,以防你没有从时间数据中获益。这可能有助于提高网络性能。
***9)。*如果您的问题域与密集预测相关(例如语义分割,我建议您使用扩张残差网络作为预训练模型,因为它针对密集预测进行了优化。
10) 。要捕获对象周围的上下文信息,请使用多尺度要素池模块。这可以进一步帮助提高准确性,这一思想已成功用于语义分割或前景分割。
***11)。*从损失或准确性计算中剔除无效标签(或模糊区域)(如果有)。这可以帮助你的网络在预测时更加自信。
12)。**如果您有高度不平衡数据问题,请在训练期间应用类别权重*。换句话说,给稀有类更多的权重,给主要类更少的权重。使用 sklearn 可以轻松计算类别权重。或者尝试使用过采样和欠采样技术对训练集进行重新采样。这也有助于提高你预测的准确性。*
***13)。*选择合适的优化器。有许多流行的自适应优化器,如亚当、阿达格拉德、阿达德尔塔或 RMSprop 等。 SGD+momentum 广泛应用于各种问题域。有两件事需要考虑:F 首先,如果你关心快速收敛,使用 Adam 之类的自适应优化器,但它可能会以某种方式陷入局部最小值,并提供较差的泛化能力(如下图)。第二个, SGD+momentum 可以实现找到一个全局最小值,但是它依赖于健壮的初始化,并且可能比其他自适应优化器需要更长的时间来收敛(下图)。我推荐你使用 SGD+momentum ,因为它会达到更好的效果。

This image borrowed from https://arxiv.org/abs/1705.08292
***14)。*有三个学习率起点(即 1e-1、1e-3 和 1e-6)。如果对预训练模型进行微调,可以考虑小于 1e-3 的低学习率(说 1e-4 )。如果你从头开始训练你的网络,考虑学习率大于或等于 1e-3。你可以试试这些起点,调整一下,看看哪个效果最好,挑那个。还有一件事,你可以考虑通过使用学习率调度器来降低学习率。这也有助于提高网络性能。
15)。**除了随着时间降低学习率的学习率计划表之外,还有另一种方法,如果验证损失在某些时期(说 5 )停止改善,并且如果验证损失在某些时期(说 10 )停止改善,我们可以通过某些因素降低学习率(说 10 )。这可以通过在 Keras 中使用减速板和提前停止轻松完成。
***16)。*如果您在密集预测领域工作,如前景分割或语义分割,您应该使用跳过连接,因为最大池操作或步长卷积会丢失对象边界或有用信息。这也可以帮助你的网络容易地学习从特征空间到图像空间的特征映射,并且可以帮助缓解网络中的消失梯度问题。
***17)。*更多的数据胜过巧妙的算法!总是使用数据增强,如水平翻转,旋转,缩放裁剪等。这有助于大幅提高精确度。
***18)。*你必须有一个用于训练的高速图形处理器,但这有点昂贵。如果你希望使用免费的云 GPU,我推荐使用 Google Colab 。如果你不知道从哪里开始,可以看看我的上一篇或者尝试各种云 GPU 平台,比如 Floydhub 或者 Paperspace 等等。
***19)。*在 ReLU 之前使用 Max-pooling 以节省一些计算。因为 ReLU 阈值为零:f(x)=max(0,x)和最大池仅最大激活:f(x)=max(x1,x2,...,xi),所以使用Conv > MaxPool > ReLU而不是Conv > ReLU > MaxPool。
例如假设我们有两个来自Conv的激活(即 0.5 和-0.5):
- 所以
MaxPool > ReLU = max(0, max(0.5,-0.5)) = 0.5 - 和
ReLU > MaxPool = max(max(0,0.5), max(0,-0.5)) = 0.5
看到了吗?这两个操作的输出仍然是0.5。在这种情况下,使用MaxPool > ReLU可以为我们省去一个max操作。
***20)。*考虑使用深度方向可分离卷积运算,与普通卷积运算相比,该运算速度快,并大大减少了参数数量。
21)。最后但同样重要的是,不要放弃💪。相信自己,你能行!如果你仍然没有达到你所期望的高精度,调整你的超参数、网络架构或训练数据,直到你达到你所期望的精度👏。
最后的话…
如果你喜欢这个帖子,请随意鼓掌或分享给全世界。如果你有任何问题,请在下面留言。你可以在 LinkedIn 上联系我,或者在 Twitter 上关注我。过得愉快🎊。
与艾伦·唐尼关于数据科学的坦诚对话
我们在这里讨论 1)对非技术受众的态度如何影响数据科学家的工作,以及 2)如何定义算法偏差,以及在解决这些问题时需要注意数据科学管道的哪些部分。
Listen to my podcast conversation with Allen Downey, CS professor at Olin College and author of open source textbooks like Think Stats, Think Bayes, Think Complexity, and Think Python.
欢迎来到坦诚的机器学习对话。我是 Ryan Louie,我采访了机器学习从业者,了解他们职业背后的思考。
本周,我和艾伦·唐尼聊天,他是奥林学院的计算机科学教授。他教授贝叶斯统计、数据科学、建模与仿真、复杂性科学和软件系统的本科课程。在课堂之外,他是一名作家和博客作者。他的开源教材系列“Think X”被奥林大学和其他学校的许多班级使用。“Think X”系列试图通过采用计算方法来使科学或工程主题更容易理解,这种方法更倾向于用代码来演示概念,而不是编写数学。他还通过他关于统计学的博客“可能想多了”展示了数据探索,并解释了可能不会写进他的书里的概念
有趣的视角
与艾伦的交谈让我对自己的几个问题有了新的认识。
1.数据科学家如何与非技术受众进行互动?共情在一个数据科学家的工作中是如何发挥作用的?
我读了艾伦写的关于 2016 年选举概率预测的问题陈述的博文。在写这篇评论时,艾伦小心翼翼地避免了他所谓的“统计唠叨”
“我认为统计学作为一个领域受到……这种几乎对立的关系的困扰。“每个人都是白痴,我们知道如何做好事情,但没有人会听我们的,他们不断犯同样的愚蠢错误,我们的工作就是大声斥责他们,”—艾伦·唐尼
受到批评的选举预测是 FiveThirtyEight 和《纽约时报》发布的“结果”,这两家网站使用选举日之前几个月的民意调查统计分析来预测谁将赢得总统大选。

(Image Source) The numbers presented by FiveThirtyEight here represent the probability that a simulation would result in a Hillary or Trump win. Problem #1: People better understand the results if rephrased as “Trump has little less than 1 in 3 chance of winning” if the frequency hypothesis is true. Problem #2: reporting probabilities of victory can be confused with proportions of the vote. Problem #3: presenting numbers with 3 significant digits might be misinterpreted as a false sense of precision.

(Image Source) There’s a convention of showing predictive maps with swing states colored light blue, “Leaning Democrat,” and pink “Leaning Republican”. Problem #4: The results don’t look like the predictions because in the results all the states are either dark red or dark blue. There is no pink in the electoral college. This visual mismatch between forecasts and actual results is a reason for readers to be unhappy.
艾伦的博客帖子没有统计学家素以唠叨著称的语气,他提出的在选举季期间发布不同选举预测模拟的解决方案是有充分理由的,同时也不是对抗性的。他指出了现状可视化遭受的原则性问题,然后解释了为什么选举模型的替代呈现通过避免这些陷阱使预测更容易理解。
“我试图首先表现出同情。我没有说这是因为人们是白痴而出错,它也没有因为提出预测的人犯了严重的错误而出错。它之所以出错,是因为很难(让数据呈现清晰易懂),我们可以做一些事情来帮助解决这个问题。”—艾伦·唐尼
我很欣赏 Allen 意识到在从事统计、设计、工程或数据科学时,傲慢会成为一个问题。从 Allen 的观点来看,这种对待外行人的不良态度的“经典工程师错误”对摆在分析消费者或软件产品用户面前的创作有不利影响。
“同样,我们设计用户界面,利用我们擅长的东西,避免踩上我们不擅长的地雷——数据可视化也是如此,呈现概率也是如此——利用我们的优势,比如我们的视觉系统,它非常擅长快速吸收大量信息,但避免呈现小概率,因为人们无法使用它们。”—艾伦·唐尼
Allen 从用户界面设计方法和实现有效数据可视化所需的思考之间的类比中得到了一些深刻的东西。
- 对于面向大量观众的可视化来说,测试可视化将如何被解释是非常重要的。用户界面设计的类似物是纸上原型或交互式模型。
- 用户将试图根据他们的直觉与创作互动。艾伦指出,“我们无法修复人们的直觉。”如果浏览者的直觉导致他们在数据分析中得出错误的结论,这应该是分析的创造者的错误。如果用户的直觉导致他们在软件上按了错误的按钮,设计者有责任让它更容易使用。
我与 Allen 的谈话加深了我对数据科学家对非技术受众的态度如何影响他们工作的理解。他对选举预测读者的态度是宽容的。他把理解概率预测的困难归结为数据消费者可以理解的经历的许多问题。艾伦提出的呈现选举预测模型的解决方案将这些问题作为用户洞察,并将其转化为贯穿其设计的需求。
当然,包容的态度表明,作为数据科学家,我们渴望与任何有兴趣倾听的人分享见解。我希望,如果更多的从业者采取这种态度,数据科学作为一个领域可以向前迈进,打破它和受实践影响的每个人之间的墙。
2.偏见是一个被过度使用的术语,用来描述数据科学家必须小心的许多问题
我用来获取 Allen 对某个主题的意见的一种方法是阅读一段我与其他数据科学从业者交谈时引用的话。一句话警告说,根据有偏差的数据训练的预测模型将模仿我们当前世界中存在的同样的偏差。
“有一种危险是,机器学习模型可能会增加另一层……惰性。因为如果你有一个根据历史训练数据训练的模型,你用这个模型来做关于未来的决策,它会做出与它看到的历史数据一致的决策。因此,如果在训练集中输入歧视的例子,它可能会强化现有的偏见或歧视的例子。如果我们有机器学习模型来做这些决定,这可能会让社会变革变得更加困难。”—麦迪逊·梅
艾伦同意这个非常真实的警告:“当你把一个预测模型放入一个系统时,它会改变这个系统,你需要考虑这会产生什么影响。”在深入研究他是如何将这个想法与自己的工作联系起来之前,他试图通过使用这个词来消除他所看到的多重含义
- 输入中的偏差:训练数据的样本不能代表总体——这是总体中有偏差的样本。
- 结果偏差 ( “差异影响” ) :预测系统中的错误会对一个非常可识别的群体产生不良后果。
“你输入的统计偏差会在世界上造成不同的影响”——艾伦·唐尼
在我的探索过程中,我发现学术工作在调查抽样偏差和差异影响如何与社交媒体平台上农村和城市用户的案例研究相关联。作者研究了应用于 Twitter 等社交媒体数据的地理位置推断算法中存在的算法偏差。推断社交媒体用户的地理位置很重要,因为大量使用 Twitter 数据的研究和应用需要地理数据;然而,只有大约 2%的 Twitter 数据被明确地理标记,剩下的 98%有待推断。
社交媒体用户中的人口偏见可能会影响地理定位算法的工作效果。更多城市用户相对于农村用户的倾斜导致代表不足的农村阶层的地理位置预测较差。这一结果符合这样一种观点,即输入中的偏差会对可识别的人群产生不同的影响。
事实上,研究的问题是“算法偏差存在吗?”在本案例研究中得到证实。该算法的输入数据显示了明显的人口偏差:与基于美国人口普查的真实人口数字相比,210%的城市用户代表过多,45%的农村用户代表不足。基于文本的地理定位算法通过从“文本(在推文中找到的)中找到某个区域的词汇特征和概念”(例如,运动队、地区方言、城镇名称)中找到模式来工作

(Image Source) The status quo of how geolocation models trained on population-biased input data reveal differential impacts for rural social media users. The authors’ description of the figure: “Text-based geolocation baseline precision by county (percentage of tweets originating from each county correctly geolocated to within 100km of each tweet’s true location).”
两个阶层之间的不平衡——在这个案例研究中是农村和城市——是机器学习实践中经常出现的问题。通常提供的答案是对类进行过采样,以应对输入中的总体偏差。如果农村用户一直被预测为比城市用户更差的程度,你最好收集更多关于农村用户的数据。
*论文中提出的其他研究问题— *“是由于人口偏差导致的观察偏差”和“我们可以通过过采样来修正偏差吗”试图通过调整输入训练数据中城市和农村用户的分布来对抗不公平的预测。他们的发现对我作为数据科学家从业者被告知的建议提出了质疑。通过修正农村人口偏差以与美国人口普查保持一致,该算法的差异影响并未得到解决。用城市和农村用户数量相等的输入数据对算法进行重新训练,并没有产生公平的预测。
老实说,我仍在思考如何理解这一切,以及如何努力防止算法偏差。描绘出导致算法偏差的组成部分很有启发性,我已经在用艾伦对算法偏差的重新表述作为差异影响来更清楚地说明我强调的问题。
阅读算法偏差文献的论文帮助我认识到,我没有意识到识别和纠正有偏差算法的不同影响的细微差别。我接触过的网上资源(此处和此处)确实对数据不平衡的问题做了深入的技术解释;然而,他们很少迫使我批判性地思考阶级失衡如何与伦理问题和数据科学中不同影响的其他原因相关联。
我渴望成为一名工程师,认识到与公平和我的算法的不同影响相关的问题。这些问题往往在团队的待办事项列表中被推到较低的位置,以利于其他任务,如快速部署和增加模型的整体准确性。然而,我认为,通过更多地了解对抗差异影响的各种方法,解决这些重要问题就变得不那么像一门艺术,而更像一门科学。通过更好地理解过采样等方法在修复输入数据中的总体偏差时的优劣,我可以在我的团队中更有效地发表意见,通过系统的工程流程来确定优先级和解决差异影响。
与麦迪逊·梅关于机器学习的坦诚对话
欢迎来到坦诚的机器学习对话。我是 Ryan Louie,我采访了机器学习从业者,了解他们职业背后的思考。
My full conversation with Madison May, a machine learning practitioner and CTO of text/image machine learning startup indico
自 2014 年秋季以来,麦迪逊·梅一直是总部位于波士顿的机器学习初创公司 indico 的首席技术官。在 Madison 在 indico *(是的,那是小写的“I”)*工作之前,他是一名本科计算机科学学生,就读于奥林学院。对于不熟悉奥林学院社区的读者来说, indico 是学院最成功的创业故事之一。麦迪逊描述他如何与 indico 扯上关系的方式是对他是什么样的人的坦率看法。
Please listen as Madison describes how he got to where he is today — as CTO of machine learning startup indico.
我有幸在 2015 年夏天在 indico 实习,因此我对 indico 作为一家公司以及 Madison 作为 CTO 在其中的角色非常熟悉。我们没有花太多时间就开始进行有意义的讨论,讨论在部署机器学习模型供世界使用时需要的深思熟虑。
现在,我将讨论我们谈话中出现的一些亮点。
1。你如何衡量一个 ML 模型的成功?您如何知道何时部署“足够好”呢?
当我问麦迪逊 indico 如何衡量他们的模型的成功时,他承认这个问题实际上是一个具有挑战性的问题。
“理想情况下,作为一名数据科学家,你希望将事情转化为一种格式,在这种格式中,你有一个可以优化的误差指标或损失。但有时,你得不到训练集,得不到真正的标签,得不到足够多的数据来准确衡量你的表现。”—麦迪逊·梅
“什么?没有真正的验证数据来报告数字吗?”有人可能会惊呼。麦迪逊说,这种情况似乎足以不容忽视。最常见的选择是“吸收并标记更多数据”——该团队已经建立了内部工具来更有效地完成标记图像和文本数据的任务。
但是在现实中,另一种方法是**随机引入一个不熟悉项目的团队成员,向他们展示两个模型的输出,并让他们提供一个关于哪个更好的定性评估。**这种比较评估是衡量进展的另一种方式。
他说这话的时候我有点喘不过气来。
我认为有几种标准的方法来评估模型的性能。这些是误差度量(或准确度分数,误差的重新表述)和损失。它们来自 Kaggle 主办的数据科学竞赛对不同模型的普遍比较,以及 ML 研究论文中的表格,这些表格详细说明了如何为一些基准数据集设置新的最先进的方法,并与一系列替代方法进行比较。使用定性比较来评估哪个模型表现更好并不是这种常见做法的一部分。

I took this screenshot from an active data science competition hosted on Kaggle.com. The competition is an image classification task for different species of fish — and every competitor is being accessed by the Multiclass Loss of the training dataset. See, now there’s a quantitative measure by which to rank competitors.
然而,当我开始思考这个问题时,我意识到在某些情况下,定性评估是必要的,或者作为一种呈现结果的方式可能更自然。作为一个例子,我在 indico 的 frontpage 上找到了一个服装相似性应用程序的演示用例,它依赖于 indico 的图像特征产品。

In this clothing similarity example, a machine learning model finds which photos in a clothing dataset looks most similar to a query image, highlighted by the purple box. (Screenshot taken from the “Clothing Similarity” example on https://indico.io)
一个定性的演示告诉我很多关于图像功能产品背后的力量。相似的颜色、剪裁和图案都是产品似乎要捕捉的维度。作为一个用户,看到例子的多样性有助于我判断在寻找相似性的过程中幕后发生了什么。
我可以想象用一种更严格、更量化的方式来建立服装相似性。将时尚相似性功能与业务指标联系起来——如果发布服装相似性功能有助于客户发现他们在其他情况下不会发现的相似风格的服装,并且购买量增加,这是应该部署该产品的良好量化证据。我认为这是许多网站在推出新功能时会做的事情——他们会使用 A/B 测试功能的方法,衡量包含该功能的效果,并评估这一新功能是否有利于更多用户参与或购买。
但我不得不再次提出,进入 A/B 测试新算法产品的阶段需要一些初步验证——该算法实际上完成了寻找服装视觉相似性的基本任务。我认为,可视化的、定性的演示对于传达可视化匹配是否如预期的那样工作是必要的。我们可以为每一件商品(如印花、深色、过膝连衣裙)创建手工标签,并计算在相似性搜索中检索到多少课堂内外的例子。虽然我认为这是一种明确的方式,但我不知道这比让几个熟悉时尚的同事评估模型是否做出足够合理的预测来部署更有价值。
不管怎样,Madison 分享了一个令人惊讶的轶事,帮助我理解了定性模型评估的一些局限性。最近的一个“机器学习出错”的故事警告数据科学家,在你通过机器学习算法解决任务之前,要评估一项任务是否是人类可以解决的。
Listen to Madison talk about his humorous story of machine learning gone wrong. Thankfully, the mistake was caught and the model prevented from deploying!
在这项任务中,麦迪逊和他的团队试图从一段文字中预测性格类型。只有几个标记的示例将文本映射到 16 种 Myer-Brigg 的人格类型,通过正常的错误度量进行评估本来就很困难(即,对于特定个人创作的更多作品,经过训练的模型是否预测了相同的 Myer-Brigg 的人格类型?)
当 Madison 求助于“**引入一名团队成员,向他们展示两种模型的输出,并让他们提供一个关于哪一种更好的定性评估时,**他发现人类对这项任务的定性反馈并不是成功的可靠衡量标准。
当显示两个模型之间的比较时,
- 一个复杂的自然语言处理模型,在数据集上将段落映射到 Myer-Brigg 的性格类型
- 随机输出 16 种迈尔-布里格性格类型之一的模型
该团队成员对随机模型竖起了“大拇指”,表示该产品已经可以交付给客户了!如果随机输出对于人类来说是不可区分的,那么人类的评估肯定不能被用来决定一个模型是否成功。
2。你认为你的机器学习研发会出什么问题?
“indico 很久以前就表明了立场(当时我们正在讨论我们现在和未来可以建设什么)。我们放弃了根据文字预测人口统计信息的想法,比如年龄、性别和种族背景。这种类型的信息通常用于定向广告,因此即使没有提供直接的标签,我们也有社交媒体领域的人对这些信息感兴趣。我们……决定这不是我们想要跨越的一条线——我们不想产生一种可能导致歧视的算法。”—麦迪逊·梅
如果我只是想听听麦迪逊作为一名实践数据科学家是如何表现出深思熟虑的,那么这句话就能满足我的需求。在很多层面上,它都是令人放松、鼓舞和美妙的。但我将进一步解释为什么这个故事支持了我的信念,即 indico 团队具有伟大的道德。
算法可能具有歧视性,并对他人产生完全不同的影响。
我认为首先要说的是,indico 的工程师承认算法可能具有歧视性,并将其视为一个问题。
并非每个人都持有反对算法偏见的坚定立场。反驳这一点的讨论点往往会落入这些可预测的模式中,正如算法公平博文《种族主义算法》和习得性无助所强调的。
- 算法不可能有偏见或种族主义,因为它们从根本上是中立的,它们不知道什么是种族主义。
- 算法只在历史上的歧视性数据上训练,它们从我们固有的种族主义世界的数据中学习。
有很多保护算法的无助位置,其目的是不要成为种族主义者。然而,人们并没有充分关注这样一个事实,即无论歧视的意图来自哪里,算法应用所产生的“不同影响”(一个实际的法律术语与艾伦·唐尼用来描述算法偏差的影响非常接近)才是问题所在。最后一层问题是“放大”效应,当一种算法被部署在广泛触及如此多类型的人的系统上时,就会出现这种效应。
“即使‘一个算法所做的一切’是反映和传递社会固有的偏见,它也在比你友好的邻居种族主义者更大的范围内放大和延续这些偏见。这是更大的问题。”— Suresh Venkat ,算法公平的作者
使用人口统计学作为预测特征的系统坐在一个道德滑坡上。
对于创建自动决策系统的数据科学家来说,使用人口统计信息作为预测特征可能是一个潜在的问题。我对艾伦·唐尼的采访实际上深入探讨了这个话题。
“当你做预测时,很多时候,出于道德原因,有些因素你不应该包括在内,尽管它们可能会使预测更好。如果你试图做出好的预测——关于人——你几乎总是会发现,如果你包括种族、宗教、年龄、性别……它们几乎总是会让你的预测更好……你的准确率会上升。但在很多情况下,比如刑事司法,我们会故意决定排除相关信息,因为使用这些信息是不道德的……作为一个社会,我们已经决定不包括这些信息。”—艾伦·唐尼
I cut to the conversation with Allen Downey where we discuss factors that should not be included, for ethical reasons, in a model. When making predictions about people, these factors include race, religion, gender, age — all sorts of demographic information.
我很欣赏 indico——尽管他们的位置离使用人口统计信息进行预测的过程只有一步之遥——很清楚他们的预测 API 可以发现自己是更大管道的一部分,而确实使用 人口统计信息进行预测。
设计师、工程师、数据科学家——你们是技术关键持有者,可以决定技术的使用和误用
有了一个可以从用户的社交媒体档案或文本中推断人口统计信息的工具,广告商就可以利用这些特征来驱动他们的模型。不开发这个工具将会把人口统计学排除在广告商使用的算法之外。
我在 indico 决定不开发人口统计文本预测 API 和消息服务 Whatsapp 决定加密所有消息之间看到了哲学上的相似之处,结果是任何有兴趣窃听对话的政府都不可能这样做。
I draw a parallel, in response to indico’s refusal to build an inherently discriminatory algorithm based on demographic information, with how messaging service Whatsapp uses their development powers to express their view that all users deserve privacy.
“我们是技术关键持有者,我们想明确地说,‘我们不想公开那些特性。我们不想让它们被滥用。(这是我们的)决定,不要建造可能被用于那种用途的东西。”—瑞安·路易
我想请挑剔的读者想出更多的例子,即使是在数据科学领域之外,在这个领域中,由工程师的道德来决定世界上应该建立什么和不应该建立什么。对于不仅仅是数据科学家的设计师和工程师来说,在决定什么是道德的方面有着丰富的智慧。下面是一个链接,从伦理的角度讲述了值得努力的事情。
不可避免的是,当我提起设计师职业道德的话题时,有人会带着“那是……
deardesignstudent.com](https://deardesignstudent.com/ethics-and-paying-rent-86e972ce9015)
阿姆斯特丹住宅的地图探索
上周,我花了一些时间研究我从网上获得的房价数据,并在这个系列的第一篇文章中得到了一些非常好的反馈。我收到的最常见的请求之一是给这些数字中的故事添加一些背景。如果用我们都熟悉的术语来表述,就更容易理解了,所以在地图上标出我的发现似乎是合理的下一步。
制作地图
这就是阿姆斯特丹市的样子,如果你把除了邮政编码之间的界限之外的一切都剥开的话:

市政府做得非常好,为各种各样的用例提供了这样的公开数据。如果你好奇,我强烈推荐去看看他们能提供什么。将你在他们网站上找到的数据与一些更熟悉的谷歌地图结合起来,会产生一幅更清晰的画面:

地理编码
有一些免费的方法可以将地址转换成纬度和经度。我的首选方法是使用 R 和 Google Maps API,它们免费提供给像我这样的爱好者。你每天只能编码 2500 个地址,否则就要付出代价了。幸运的是,我们的数据只有 1800 行——没问题。这就是我们的房子在地图上的样子。

它看起来并不特别令人兴奋,所以让我们通过询问价格来着色,作为简单的第一步:

这并没有告诉我们太多,因为整个城市的房子都很贵。我们可以看到,在冯德尔公园附近的市中心可能会有一些非常昂贵的房子,但除此之外,我们真的没有看到任何重大的主题出现。如果我们看看每个人最喜欢的指标— 价格/平方米— 看看是否有更清晰的画面出现,会发生什么?

有趣的是,同样一群非常昂贵的房子再次出现,但这次我们看到市中心的大片区域也变得更加明亮。这些住宅大多位于老城区的中环,以及离冯德尔公园最近的地方。这是有道理的,因为城市中更令人向往和更有历史意义的部分,无论大小,购买起来都会更贵。
但是这种每平方米价格的差异能解释我们的亮点和镇上其他地方的差异吗?也许另一个原因是这些房子的面积更大?我们通过标绘每处房产的房间数量来找出答案。我们再次看到了同一个亮点,就在冯德尔公园的南边:

从这三幅图中我们可以得出结论,城市的昂贵部分也是我们发现最大的房屋(按房间数)和每平方米最高标价的地方。它还强调了为什么我们选择使用房间的大小和数量来预测我们模型中的价格。太棒了。
系数
我们关心系数,因为它们告诉我们预测者和价格之间的关系。我们已经知道价格随地理位置而变化,所以让我们在我们的模型中画出地理位置的变化。混合效应模型为我们提供了每个邮政编码的不同估计值,因此我们可以对邻近地区进行相互比较。对于每一个,我们得到固定效应和随机效应的混合,得到我们的模型系数(b1、b2 和截距)如下:
价格= b1 *平方米+B2 *房间+截距
首先,让我们看看每平方米价格的系数(b1):

与我们之前看到的点状图一致,看起来 1075 和 1071 邮政编码是阿姆斯特丹最贵的地区。镇上这一带的房子令人印象深刻,而且非常昂贵。同样,约旦和哈勒默布尔特的面积每平方米也很贵。这是明信片照片拍摄的地方,弯曲的老房子排列在运河两岸。城镇的郊区描绘了一幅不同的画面,最低的价格出现在 zuidoost 和 noord 地区。镇上的这些地方比较新,游客较少,因此价格也更实惠。
然而,在考察额外房间(b2)的价值时,我们看到了一个有趣的模式:

房间数量的增加会导致房屋成本的增加,但这只是在某些地方。我们之前看到的同样昂贵的邮政编码实际上对于房间变量有一个负(绿色)系数。在其他条件不变的情况下,一个额外的房间似乎会降低这些地区的房屋价值。
为什么会这样?一种可能的解释是,城市的昂贵地段被高档人士占据,而这些高档人士更喜欢在他们的家中拥有更大、更高档的房间。想象两个相同的 200 平方米的房产,一个有 7 个房间,一个有 8 个房间。根据定义,有 8 个房间的酒店必须有较小的房间。对这些地区来说,越大似乎越好。
另一方面,市中心亮起了黄橙色的灯光,在这里,给一栋 100 平方米的房子增加一个额外的房间可能会使其挂牌价格增加多达 4 万欧元。这可能有很多原因,但我认为这可能是由于旅游业。城市的这一部分是每个游客都想去的地方,而找到安置这些人的地方是很昂贵的。也许能在一个小空间里容纳很多人是件好事?
在考虑房间数量和增加的平方米空间的价值后,截距就是我们加到最后得到的总标价。当它是正数时,我们可以假设任何大小的房子对一个潜在的买家来说都是有价值的。相反,负截距意味着价格/平方米和房间必须抵消足以弥补它。在这种情况下,我们看到城市的边缘都有大约 10 万欧元或以上的截距。这弥补了模型估计的每平方米价值要低得多的事实。

另一方面,城市的昂贵部分有负截距。为了克服这一点,房子必须更大,并有更高的平方米系数。这与我们之前绘制房屋图时看到的一致。
关于模型性能的说明:
在上一篇文章中,我们建立了不同变量之间的关系,并开始对阿姆斯特丹的住房状况有了更全面的了解。
我们已经可以说明不同的社区如何可以获得非常不同的价格,并表明它是房子的大小和地理位置的函数。这个项目中使用的混合效果模型非常有用,因为它们允许我们的模型在接近现实的方式上具有灵活性。凭借他们的设计,我们可以在每个邮政编码中获得量身定制的估计,同时仍然可以建立一个模型来解释我们在整个城市中的信息。
为了说明这一点,我生成了一些图表,根据它们在预测中产生的误差量进行了颜色编码。回想一下,普通最小二乘法 (OLS)模型没有考虑任何关于住宅位置(邮政编码)的信息,并且假设大小和房间的重要性在整个城市是一致的。我们知道这是一个天真的假设,我们可以看到模型的表现有多差。平均绝对百分比误差*(MAPE)到处都是,从大约 10%到超过 130%不等。*

Gray areas indicate zip codes where MAPE exceeds 50%
很明显,该模型已经学会将其预测建立在它所看到的大部分房屋的基础上,这些房屋大多位于市中心。这最终真的损害了它对城镇边缘房屋的预测的可靠性。没有阴影的区域不在我们的数据中,所以我们不能估计它们的误差。
然而,如果我们假设每一个邻域都是不同的,并允许模型有一点弹性,它会对自己的预测更有信心。当我们以与之前相同的方式绘制误差时,模型的改进是显而易见的:

值得一提的是,这些模型都不是为了预测目的,也没有针对维持集进行验证。因此,它们更适合分析系数,而不是进行预测或预报。任何对建立这样一个模型感兴趣的人都应该根据地面事实对其进行适当的交叉验证。然而,我认为这是这种方法的灵活性和可解释性的一个有趣的例子。
展望未来:
我不太确定接下来该何去何从。我肯定会继续在阿姆斯特丹寻找一个家。我爱这座城市,也爱住在这里的人们。挑战仍然是找到这里房产的实际销售价格。在此之前,我可能会继续向模型中添加一些其他公开可用的数据,以尝试提高性能。_(ツ)_/
目前,我已经将我的 scraper 代码的大部分放在了一个 github 库中,供任何好奇的人自己尝试。很丑,但是很管用。这篇文章还涉及了相当多的 r 处理和绘图工作。如果我有时间让这些脚本更易读的话,我会试着把它们也放在那里。
学者成为数据科学家的案例
今年早些时候,我离开了学术界,仅仅过了一个周末,我就从终身助理教授变成了一名数据科学家。不,那不是因为我讨厌学术界。我喜欢它,并在那种环境中茁壮成长。我职业的改变是由于在两个国家之间的移动。像几个已经完成或想要完成这一转变的人一样,我也有疑问。我很担心。Medium 和 LinkedIn 福音书宣称“学者还没有为行业做好准备”或“我不会为数据科学职位雇用学者,原因如下”这让我既愤怒又害怕(相信我,有几篇这样的帖子!).
然而,在成为软件行业的数据科学家几个月后,我实际上得出了一个不同的结论。

I think academics actually fit well in the industry!
是的,我说的是学术界人士(即在学术界工作的人。不是学生)正好可以“融入”行业工作。由于有太多对学者及其技能的曲解(通常来自从未做过学者的人),我想我应该提出一些观点,说明为什么我认为学者很容易适合行业数据科学职位。这篇文章就是关于这个的。
在我开始之前,有三个免责声明:
- 我的观察是专门针对来自科学和工程背景的学者的,他们精通计算机编程,通常要么刚刚完成博士学位,要么在他们的博士后职业生涯中(博士后、助理教授及以上)希望转向软件/技术行业的数据科学工作。
- 我说的是一种可能性——所以,我并不是在宣扬所有的学者都应该被雇佣,因为他们自动适合。
- 我写的不是一份经过充分研究的报告。我正在写下星期五晚上我的想法。
让我从陈述显而易见的事情开始。学术界和工业界是有区别的**。**我将选择与我的帖子最相关的两个:
- 工业界所做的研究专注于开发一个可以被其他人部署和使用的解决方案,然后数据科学家继续解决下一个问题。在学术界,我们通常会花几个月甚至几年的时间来逐步优化同一个问题,并创造出越来越多新颖的解决方案。也就是说,关注点和激励结构是不同的——这并不意味着那些做增量优化的人不能为未来的产品做快速的原型开发或者为整个项目生命周期做贡献。
- 良好的工程实践、编写干净的代码、林挺代码、版本控制等在学术环境中并不被重视。然而,这也取决于教授/研究小组负责人,我认为这正在发生变化(至少在我密切关注的研究领域——NLP、机器学习等)。例如,看看 Allen NLP 团队关于如何按照良好实践编写研究代码的这个演示。此外,我认为如果一个人在其他方面技术上适合某个角色,这些是很容易获得的。
(好吧,还有很多其他的差异,比如钱。但我必须在某个地方停下来)。
在我看来,这些都不是不可逾越的分歧。他们存在只是因为他们是两种不同的职业。这不像从外科医生变成房地产顾问。这就像在 It 工作的不同领域之间移动(举个极端的例子,从银行业到消费电子)。人类是地球上适应性最强的生物。如果我们愿意在人工智能(AGI)上下赌注,而不愿意面试一位自己申请了一个行业职位的学者——那我们的大脑肯定有线路功能障碍。在简历筛选或面试后,你可能会认为学术简历不合适,但我们看到的 90%的非学术简历也是如此!如果 100 个人申请一份工作,其中可能有 10 个学者。假设我们最终做了一个 15 人的电话筛选(仍然很多)。这意味着,有太多的非学术简历不符合了!
我认为学术界非常适合这个行业的三个原因:
- 快速学习新的概念/想法并适应它:学术研究(不管是好是坏)只奖励站在前沿的人。如果一个新的想法出现了,在下一次大型会议/杂志上就会有 100 个跟进的想法出现。这就是他们的运作方式。因此,如果你是一名学者,你必须在很少或没有监督的情况下快速学习和开展工作。本质上,你被训练快速学习新东西。这在进行快速原型制作、从一个问题转移到另一个问题、比较和评估技术状态以及开发满足需求的解决方案的行业中非常方便。
- 组织和时间管理:博士主要是一项孤独的练习。获得博士学位后,在学术工作中,你通常会在多个项目之间周旋,而且很多时候,会有多项教学任务。你在工作中可以做许多不同类型的活动(见 Philip Guo 关于这个话题的精彩文章)。这会让你在时间管理上变得有条理和有效率。因此,即使你从未听说过 trello 或敏捷或 scrum 或其他什么,你也可能需要 1-2 个小时来理解并转向这些东西!
- 领导力:通常情况下,如果你是博士后,你将不得不自己做很多事情,同时,你可能会被要求指导年轻的学生,教学,寻求资金等。如果你是一名助理教授,你可以做所有这些事情,但是可能会有更多的自主权。作为一名独立的学术研究者(在美国,我就是其中之一)就像维持一个小规模的创业公司。你应该寻找资金,完成工作,雇佣研究助理,指导学生,建立团队等等。如果你还在读博后的前 5 年,研究管理和行政职责不会完全吞噬你。所以,你还是要做很多实际工作。当你开始在这个行业工作时,所有这些基本上使你已经是一个有经验的工人了。所有这些领导技能也会转移。如果所有这些工作描述对你来说听起来不可思议,那么请看这篇关于教授工作生活的文章,以及他的关于成为教授的经济学的文章,作者是菲利普·郭。因此,一名被聘为数据科学家的学者甚至在加入之前就已经超越了“初级”角色!
福音书作者认为学术不适合的典型原因(以及为什么我认为这只是自信的无知):
- *声明:他们不知道现实世界在发生什么(*我的评论:学者如果不跟随外界,真的无法在学术界生存!)
- 声称:他们没有任何实践经验(我的评论:正如我之前提到的,大多数博士后学者在日常生活中做大量的实践工作+其他“高级”工作,如指导、管理、规划等。所以,正如我之前提到的,如果你雇佣了一个学者,你实际上得到了一个奖金!)
- 声称:他们不知道如何遵循良好的软件工程实践(我的评论:这不是火箭科学!如果他们还不知道,他们将在工作中获得知识!)
- 声明:他们倾向于花数年时间解决同一个问题(我的评论:这是他们的工作性质,不是他们的天性!!)
- 声称:聪明人就是进不了学术界。他们“工作”。(我的评论:嗯,实际上我认为转行后我找到了更好的工作生活平衡)。
所以,我认为有很多错误的信息在传播——一个相当聪明、勤奋、有组织、努力工作的学者没什么好担心的,只要他们不失去自信并愿意适应。我相信这是数据科学工作的好时机,尽管有这些反对者,但学者可以成为软件工程团队中优秀的数据科学家。
当然,该说的都说了,该做的都做了——我说的只有在以下情况下才成立:
- 这位学者以一种潜在的面试官能很快理解的方式展示自己
- 这位学者确实符合这项工作的要求
- 他们愿意随着工作的性质而改变
- 他们一般都有成功的欲望。
在过去的几个月里,我喜欢我正在做的工作,以及工作环境。我试图让自己融入当地的数据科学家和研究人员社区,并开始为更多初级数据科学家提供指导。我确实怀念教学、学术研究的乐趣以及从事跨学科项目的工作。但到目前为止,我喜欢做一名数据科学家。
更新:我没有提到另一个重要因素——一个好的雇主和他们提供的工作环境。我不应该错过它——但是,正如 LinkedIn 评论中正确指出的那样,它在我迅速适应行业和对成为数据科学家的总体积极感觉中发挥了重要作用!
由于这篇文章已经很长了,我不想触及我认为学者在申请数据科学家职位和准备面试时需要做的工作(想起来了,任何人!不仅仅是学术!),有哪些属于“数据科学家”头衔的工作等等。我会试着写一篇关于这个的文章。感谢你能活到现在!
LightGBM 的案例

Microsoft’s Distributed Machine Learning Toolkit
正如任何活跃的 Kaggler 所知,梯度推进算法,特别是 XGBoost,主导着竞赛排行榜。然而,在 2016 年 10 月,微软的 DMTK 团队开源了它的 LightGBM 算法(附带 Python 和 R 库),它肯定会占据优势。因此,社区已经开始比较鲜为人知的 LightGBM 和 XGBoost 的性能。
在这篇文章中,我认为提及我使用 LightGBM 而不是 XGBoost 的情况以及我在它们之间经历的一些权衡是有价值的。
使用
我对这两种算法的使用都是通过它们的 Python、Scikit-Learn 包装器。我通常选择使用算法的 Scikit-Learn 包装器,因为它创建了一个在相同数据上实现和评估各种算法的标准。它还允许通过 Scikit 创建预处理管道,然后可以通过多种算法轻松应用该管道。
除了每个平台的特定超参数之外,这两种算法的实现几乎完全相同。但是,任何熟悉典型 SKLearn 流程的人都可以使用 LightGBM。
装置
安装 LightGBM 的 CPU 版本轻而易举,可以通过 pip 安装。我希望我可以说,GPU 版本是轻而易举的,但可悲的是,还有更多额外的步骤要采取。您必须安装 Cuda、Boost、CMake、MS Build 或 Visual Studio 和 MinGW。在路径中添加了一些东西之后,我很幸运能够通过运行以下命令来安装 GPU 实现:
pip 安装灯 GBM-install-option =-GPU
速度
对我来说,这是 LightGBM 真正闪耀的地方。使用默认参数,我发现我的 XGBoost 基线通常会超过 LightGBM,但是 LightGBM 运行的速度非常快。它已经针对最大并行化运行进行了优化,这意味着它在 CPU 和 GPU 上都可以真正运行。
在优化模型时,这种加速允许更快的超参数搜索。对我来说,这就是 LightGBM 如此强大的原因。它允许开发人员在更短的时间内随机/网格搜索参数范围,与在相同时间段内使用 XGBoost 相比,允许测试更多可能的组合。这种速度还允许添加交叉验证测试,以获得更准确的模型泛化度量。我相信,快速优化的能力在很大程度上超过了默认性能的权衡。
如果你对阅读更多关于 LightGBM 的性能感兴趣, Laurae 有一篇很棒的深度文章将它与 XGBoost 进行了比较。
分类特征支持
使用 LightGBM 的另一个好处是它通过指定列而不是使用一键编码(OHE)来支持分类特性。OHE 可能很重,因为它可以显著增加数据集的维度,这取决于类别+选项的数量。在微软的结果中,他们看到了高达 8 倍的训练速度提升。这个特性使它更适合 GPU 训练,因为它利用了更有效的方法来处理分类数据。这种支持最酷的部分可能是它有一个自动模式来检测 Pandas 数据帧中指定的分类列,大大减少了转换数据所需的预处理量。
包装东西
随着梯度推进算法越来越受欢迎(由 Kaggle 社区提供),我认为与鲜为人知的库分享一些见解是有价值的。我相信在某些情况下,它对开发人员来说比其他库有着巨大的潜力,并建议每个数据科学家下次开始 ML 项目时都尝试一下。
p 值的问题是

http://1.bp.blogspot.com/-m1ucuiGYiw0/UNaULkQ0IYI/AAAAAAAAARk/OTDIBDI7Ydo/s1600/photo+(2).JPG
像大多数人一样,我曾经认为统计学是我应该尽量避免的一种瘟疫。然而,我作为一名医学研究人员的时间改变了我的观点,因为我意识到准确的统计数据在做出可靠和可重复的结论时是多么重要。幸运的是,我接触了一位教授,他改变了我对 p 值的看法。他这样做是向我展示了它是如何误导人的,我希望与你分享。
让我们考虑一下学生的 t 检验,这是一个决定两组数据是否不同的程序。例如,一家公司可能想知道他们的产品是男性还是女性购买的多,一位医生想知道他们的病人在接受治疗后是否改善了症状,或者一群朋友正在计划他们的下一次度假,并想知道纽约市或旧金山的酒店价格是否更高。
让我们考虑一下最后一个例子。我们的假设是酒店价格和我们去的城市有关系。我们的无效假设是酒店的价格和它所在的城市没有关系**。假设该数据遵循正态分布,让我们模拟一些数据。我们假设四个最好的朋友统计了旧金山 100 家酒店的每晚价格,发现平均价格为 100 美元,变动幅度为+/-25 美元(n=100,u=100,sd=25)。**

这四个朋友在直方图中绘制了结果分布,并覆盖了密度图。请注意,每位朋友都观察到了不同的酒店价格分布,这取决于他们查看的酒店。也许朋友 2 的品味更昂贵,而朋友 4 更节俭。然而,当我们比较两个分布时,考虑这对 p 值意味着什么是很重要的?
假设这四个最好的朋友对纽约市的酒店重复了这一过程,并试图通过完成 t 检验来确定哪个城市的酒店更贵。有两种情况会发生。案例 1:两个城市的酒店价格不同或者案例 2:没有区别。
对于**案例 1,**假设朋友们收集了纽约 100 家酒店的数据,发现他们平均每晚花费 80 美元,标准差为 25 美元。完成学生的 t 检验并计算 p 值,朋友们比较他们的发现。

考虑到他们极小的 p 值,四个朋友都认为纽约 的酒店比旧金山便宜。重要的是,所有四个朋友根据他们收集的数据得到了不同的 p 值。假设这些朋友真的很受欢迎,并且有 500 个额外的朋友计划加入他们的旅行。

如果他们都完成了这个分析并记录了他们的 p 值,我们可以预期在左边看到的 p 值分布。尽管我们通常会得到低于 0.05 阈值的 p 值,但也有朋友得到高于 0.05 的 p 值的时候。在这种情况下,这位朋友会得出结论,酒店价格之间没有差异,即使有差异。令人震惊!
更令人担忧的是,让我们来看看案例 2 ,数据显示纽约和旧金山的酒店价格没有差别。

在这里,四个朋友中有三个会认为酒店价格没有差别。然而,第四个朋友得到的 p 值低于 0.05,他会认为有差别,尽管实际上没有差别。谁知道呢?也许这会引起一场大的争吵,他们也不会再是朋友了…这真让人难过。
在这三个朋友与第四个朋友解除好友关系之前,他们决定咨询另外 500 个朋友,比较他们的 p 值。

他们震惊地发现,当酒店价格没有差异时, **p 值实际上是随机的!**虽然大多数朋友会得出相同的结论,但有一组人会得出结论认为存在差异……尽管实际上并没有差异。
回想一下,p 值的正确解释是
假设空值为真,p 值量化了在当前观察点或超出当前观察点看到数据点的概率。
基本上,您可以计算出您预期数据位置的 95%置信区间。如果您观察到一个超出这些界限的值,这是意料之外的,因为它在数据的最大 5%之内,并且支持您的零假设。如果您希望对变化更加宽容,您可以计算 97.5%的置信区间,并且只允许 p 值为 0.025 的观察值不同意您的假设。对抗变化无常的 p 值的最好方法是增加你重复的次数,看看你的 p 值是上下波动还是一直保持在低位。这里我编写了一个交互式可视化程序,允许您更改两个分布的参数,并查看最终的 p 值分布。如果你想阅读更多,我推荐这篇论文。重新生成它的代码可以在这个库中找到。

https://pixabay.com/en/crowd-lego-staff-choice-selector-1699137/
基于人口普查的贫困指数

Area deprivation scores at the county-level. Brighter colors represent higher deprivation relative to all counties in the U.S.
你住在哪里对你的健康有重大影响;更具体地说,生活在贫困地区的人健康状况更差。因此,剥夺指数经常用于健康研究。为了估计邻里层面的剥夺,大多数研究人员依赖于人口普查数据,但是,收集和清理这样的数据需要相当多的时间和精力。在这里,我展示了一个 R 函数,它收集数据并不费吹灰之力就创建了一个标准化的贫困指数。
要运行这个功能,你需要tidysensus和 psych 软件包。所有代码都发布在 GitHub 中。
工作原理
该指数是基于刀子乐队和他的同事们的方法论。简而言之,他们发现从八个特定变量中提取的主成分最能代表邻里层面的剥夺。按照他们的方法,普查区一级需要以下变量:
不到 HS 学位的百分比(25 岁及以上)
低于贫困线的百分比
有 18 岁以下子女的女户主家庭百分比
%从事管理、科学和艺术职业
拥挤家庭中的百分比(每个房间超过 1 人)
%有公共援助或食品券
失业百分比(16-64 岁劳动力)
家庭年收入低于 3 万英镑的百分比
该功能收集普查估计值,转换变量,然后执行主成分分析(PCA)。对于给定的县,在区域级别收集估计值。由于该指数已在以前的研究中得到验证,PCA 仅提取一个成分。
使用函数:countyND()
该函数通过输入参数 State 和 *County 来工作。*输出变量“PC1”是分析中每个相应人口普查区(ct)的剥夺指数得分。较高的指数分数代表较高的剥夺感。这些分数可以单独使用,也可以导出用于统计模型。
例题
这是纽约州奥农达加县人口普查区的贫困分布情况。
NDI <-countyND("NY","Onondaga")
ggplot(NDI, aes(PC1)) + geom_histogram() + theme_classic()

我通过分类进一步探索剥夺分数的分布。通过根据锡拉丘兹市内外的地理位置对人口普查区进行分类,可以清楚地看出,大多数城区的邻里贫困程度高于县城。
NDI$type[as.numeric(NDI$GEOID) < 36067006104] <- "City Tract"
NDI$type[as.numeric(NDI$GEOID) >= 36067006104] <- "County Tract"
ggplot(NDI, aes(reorder(Tract, -PC1), PC1)) + geom_col(aes(fill = type)) + coord_flip() +
theme(axis.text.x = element_text(size = 8, color = "black"),
axis.text.y = element_text(size = 4, color = "black")) +
scale_fill_viridis_d(option = "cividis") +
labs(fill = "", x = "Tract", y = "Deprivation Index")

专题制图
该指数可通过其空间分布进行进一步研究。绘制剥夺分数图显示,高度剥夺集中在锡拉丘兹市。

然而,仅绘制锡拉丘兹市的剥夺分数,一些变化仍然是显而易见的。

此外,通过省略县参数,该函数将返回给定州中所有县的贫困指数。
NYND <- countyND("NY")ggplot(NYND, aes(PC1, color = County)) + geom_density() +
theme_classic() + guides(colour=FALSE) +
scale_color_viridis_d() +
labs(x = "Deprivation Index for all Counties in NYS")

纽约贫困的空间分布:

Neighborhood-level deprivation across New York
所有的代码和更多的例子可以在 GitHub 上找到。我为自己的分析编写了这个函数;但是,也许其他人也会发现它很有用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










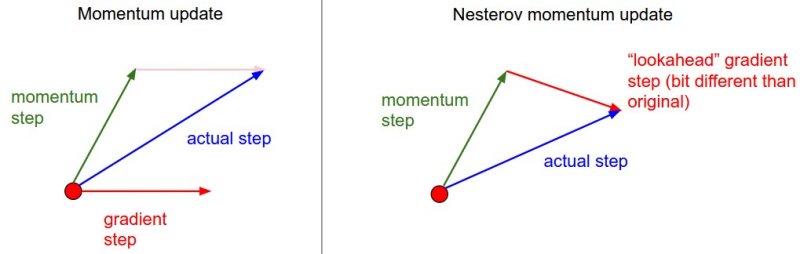{kind=link}
{kind=link}
{kind=link}