







神经网络中的过拟合与欠拟合以及错误率与复杂性图的比较
机器学习,Inside AI,深度学习
理解过度拟合和欠拟合的例子和解决方案,以防止它使用早期停止!
!!!克服过度拟合和欠拟合的头痛
在生活中,一个人会犯两种错误。一种是尝试用苍蝇拍杀死哥斯拉。另一个是试图用火箭筒打死一只苍蝇。想用苍蝇拍打死哥斯拉有什么问题?我们把问题过于简单化了。我们正在尝试一个过于简单的解决方案,但行不通。在机器学习中,这叫做 欠拟合 。

Godzilla with Flyswatter (Underfitting) or Fly with Bazooka (Overfitting)
用火箭筒打死一只苍蝇有什么问题?它过于复杂,当我们可以使用更简单的解决方案时,它会导致糟糕的解决方案和额外的复杂性。在机器学习中,这叫做 过拟合 。
让我们看看过度拟合和欠拟合在分类问题中是如何发生的。假设我们有以下数据,我们需要对其进行分类。那么,在这里,什么规则会起作用呢?看起来是个简单的问题,对吗?


Dogs vs Not Dogs (Underfitting) — Very Common
右边的是狗,而左边的不是狗。现在,如果我们使用下面的规则呢?我们说右边的是动物,左边的绝不是动物。这个解决方案不太好,对吧?有什么问题?太简单了。它甚至没有得到完整的数据集。看到了吗?它把这只猫分类错了,因为猫是一种动物。这是不合适的。这就像试图用苍蝇拍杀死哥斯拉。有时,我们称之为 偏差引起的误差 。

Dog specified with Color — Very Specific (Overfitting)
那么,下面的规则呢?我们说右边的是黄色、橙色或灰色的狗,左边的是除了黄色、橙色或灰色以外的任何颜色的狗。从技术上讲,这是正确的,因为它正确地对数据进行了分类。有一种感觉是,我们说得太具体了,因为只说狗而不说狗就已经完成了工作。但是这个问题比较概念化吧?这里怎么能看出问题呢?一种方法是引入一个测试集。如果我们的测试集是这条狗,那么我们会想象一个好的分类器会把它和其他狗放在右边。但是这个分类器会把它放在左边,因为狗不是黄色、橙色或灰色的。所以,正如我们所说,这里的问题是分类器太具体了。它能很好地拟合数据,但不能一概而论。这太合身了。这就像试图用火箭筒打死一只苍蝇。有时,我们会将过度拟合称为由于方差 导致的 误差。

我喜欢描绘欠适应和过适应的方式是在准备考试的时候。吃不饱,就像学习不够,不及格。好的模式就像学习好,考试好。过度配合就像我们不去学习,而是一个字一个字地背整本教材。我们也许能背诵课本上的任何问题,但我们不能正确地概括和回答考试中的问题。

Data | Red — Negative and Blue — Positive
但是现在,让我们看看这在神经网络中会是什么样子。让我们假设这个数据,同样,蓝色的点标记为正,红色的点标记为负。

Comparison of Underfitting graph vs Perfect Graph vs Overfitting Graph
这里,我们有三只小熊。在中间,我们有一个很好的模型,它很好地拟合了数据。在左边,我们有一个模型,因为它太简单了。它试图用直线拟合数据,但数据比直线更复杂。在右边,我们有一个过度拟合的模型,因为它试图用过于复杂的曲线来拟合数据。请注意,右边的模型与数据非常吻合,因为它不会出错,而中间的模型会出错。但是我们可以看到中间的模型大概会概括的更好。中间的模型将这一点视为噪声,而右边的模型被它弄糊涂了,试图把它喂得太好。

Comparison in terms of Neural Network Architecture
现在中间的模型可能会是一个神经网络,它的架构有点复杂,就像这个一样。左边的这个可能是一个过于简单的架构。例如,由于模型是线性的,因此整个神经网络只有一个指导器。右边的模型可能是一个高度复杂的神经网络,其层数和权重超过了我们的需要。现在有个坏消息。为神经网络找到合适的架构真的很难。我们总是会以像左边这样过于简单的架构或者像右边这样过于复杂的架构结束。

Kids Problem while purchasing Pants 🤣🤣🤣
现在的问题是,我们该怎么办?这就像试着穿上一条裤子。如果我们找不到我们的尺寸,我们是买大一点的裤子还是小一点的裤子?好吧,看起来穿稍微大一点的裤子,然后试着买一条腰带或者其他能让裤子更合身的东西,也没那么糟糕,这就是我们要做的。我们会在过于复杂的模型上犯错误,然后我们会应用某些技术来防止过度拟合。

Training with Different Epoch
那么,让我们从上次停止的地方开始,也就是说,我们有一个复杂的网络体系结构,它可能比我们需要的更复杂,但我们需要接受它。那么,我们来看看训练的过程。我们从她第一个时期的随机权重开始,我们得到了这样一个模型,它犯了很多错误。
现在,当我们训练时,假设 20 个时代,我们得到了一个相当好的模型。但是,假设我们继续进行 100 个纪元,我们会得到更好地符合数据的东西,但是我们可以看到这开始过度拟合。如果我们追求更多,比如说 600 个时代,那么这个模型就非常不合适了。
我们可以看到蓝色区域几乎是围绕着蓝色点的一堆圆圈。这非常符合训练数据,但它会可怕地泛化。想象在蓝色区域有一个新的蓝点。这个点最有可能被归类为红色,除非它非常接近蓝色点。

Error Comparision
所以,让我们试着通过添加一个测试集来评估这些模型,比如这些点。让我们画出每个时期的训练集和测试集中的误差图。对于第一个时期,由于模型是完全随机的,因此它严重地错误分类了训练集和测试集。因此,训练误差和测试误差都很大。
我们可以把它们画在这里。对于 20 epoch,我们有一个更好的模型,它非常适合训练数据,并且在测试集中表现也很好。因此,这两个误差都相对较小,我们将把它们画在这里。
对于 100 纪元,我们看到我们开始过度适应。该模型与数据非常吻合,但它开始在测试数据中出错。我们意识到训练误差在不断减小,但是测试误差开始增加,所以我们把它们画在这里。
现在,对于 600 年代来说,我们严重过剩。我们可以看到,训练误差非常小,因为数据非常适合训练集,但模型在测试数据中犯了大量错误。因此,测试误差很大。我们把它们画在这里。
现在,我们绘制连接训练和测试误差的曲线。因此,在这个图中,很明显,当我们停止欠拟合并开始过拟合时,训练曲线总是在下降,因为随着我们训练模型,我们对训练数据的拟合越来越好。由于模型不精确,在欠拟合时测试误差较大。然后它随着模型的推广而减少,直到它到达一个 最小点——金发女孩点 。最后,一旦我们通过了那个点,模型又开始过度拟合,因为它停止概括,而只是开始记忆训练数据。这个图叫做模型 复杂度图 。

Model Complexity Graph
在 Y 轴上,我们可以测量误差,在 X 轴上,我们可以测量模型的复杂性。在这种情况下,它是历元的数量。正如你所看到的,在左边我们有很高的测试和训练误差,所以我们不适合。在右边,我们有一个高测试误差和低训练误差,所以我们过度拟合。在中间的某个地方,我们有我们的快乐金发点。所以,这决定了我们将要使用的历元数。
总之,我们要做的是,下降,直到测试误差停止下降并开始增加。那一刻,我们停下来。这种算法被称为 提前停止 ,被广泛用于训练神经网络。
参考资料:
[1] Udacity 深度学习课程—过度适应与欠适应视频
[2] Udacity 深度学习课程——提前停止视频
请访问我的网站:【http://www.khushpatel.com】
Python 中的重载运算符

…还有一点关于一般的超载(但我会尽量不超载你)
在学习 Python 编程的过程中,我们大多数人都在相对较早的时候遇到了运算符重载背后的概念。但是,像 Python(和其他语言)的大多数方面一样;就这一点而言,几乎是任何事情),学习重载操作符必然与其他概念联系在一起,这既扩大了主题的范围,又在某种程度上混淆了我们个人学习曲线的路线。考虑到这一点,我将尽量不扯入太多学习 Python 的其他领域——然而,一些面向对象编程很自然地与之相关;虽然我想把重点放在重载操作符上,但是重载函数这个更广泛、更复杂的话题至少也值得一提。
在编程的上下文中,重载指的是函数或操作符根据传递给函数的参数或操作符作用的操作数以不同方式运行的能力。在 Python 中,操作符重载(也称为“操作符特别多态性”)尤其是一种“语法糖”形式,它能够以强大而方便的方式将操作符的操作指定为特定类型的中缀表达式。换句话说,操作符重载赋予操作符超出其预定义操作含义的扩展含义。****

Operator Overload examples for + and *
Python 中经典的运算符重载示例是加号,它是一个二元(即两个操作数)运算符,不仅将一对数字相加,还将一对列表或字符串连接起来。星号同样被重载,不仅作为数字的乘数,还作为列表或字符串的重复操作符。比较运算符(如>、==或!=)表现出类似的行为;然而,对于所有这些重载操作符,我们作为 Python 用户在考虑类型检查时应该稍微小心一些。正如麻省理工学院的 John Guttag 教授提醒我们的那样,“Python 中的类型检查不如其他一些编程语言(如 Java)中的强,但在 Python 3 中比在 Python 2 中要好。例如,什么是< should mean when it is used to compare two strings or two numbers. But what should the value of ‘4’❤️就很清楚了?Python 2 *的设计者相当武断地决定它应该是 False,因为所有数值都应该小于 str 类型的所有值。*Python 3 和大多数其他现代语言的设计者认为,既然这样的表达式没有明显的意义,它们应该生成一条错误消息。”[2]


这很好,但是如果一个操作符作为操作数用于一个或多个用户定义的数据类型(例如,来自一个创建的类),该怎么办呢?在这种情况下——比方说,试图添加一对(x,y)坐标,如此处所示——编译器将抛出一个错误,因为它不知道如何添加这两个对象。而且,虽然重载只能在 Python 中现有的操作符上完成,但是有一些操作符,以及每个操作符调用的相应的魔法方法;使用这些相应的方法,我们可以创建/访问/编辑它们的内部工作方式(见文章末尾)。
就像这个快速发展的领域中的其他术语一样,对于如何称呼它们似乎没有达成共识——它们通常被称为“魔法方法”——之所以称为“魔法”,是因为它们没有被直接调用——这似乎是最接近标准的,也许是因为替代的“特殊方法”听起来,嗯,不是那么特殊。有些人预示着一个更有趣的名字——“dunder methods”,作为“双下划线方法”(即“dunder-init-dunder”)的简写。总之,它们是一种特殊类型的方法,并且不只限于与操作符相关联的方法(例如 init() 或 call() )。其实有不少。

随便说个题外话——印刷有自己关联的魔法, str() 。如果我们只使用一个 init() 来打印普通的 Point 类,我们将得到上面所示的不太用户友好的输出。


将 str() 方法添加到 Point 类中可以解决这个问题。有趣的是, format() 也调用了与 print() 相同的 str() 方法。

A simple * overloading example using our cohort’s nickname (3x like the Thundercats, Schnarf Schnarf)
事实证明,在学习 Python 时,使用(x,y)坐标遍历重载、方法和其他 Python 概念的例子是一种常见的实践,可能是因为我们可以用像坐标点这样数学上熟悉的东西来创建自己的类。由此,可以为用户定义的类创建许多有用的神奇方法,并使用它们来重载运算符。

运算符重载的一个值得注意的方面是每个操作数相对于其运算符的位置。以小于操作符<为例——它为第一个(或左/前)操作数调用 lt() 方法。换句话说,这个表达 x < y 是 x.lt(y) 的简写;如果第一个操作数是用户定义的类,它需要有自己对应的 lt() 方法,才能使用<。这看起来可能有点麻烦,但实际上它为设计一个类增加了一些便利的灵活性,因为我们可以定制任何操作符的函数为一个类做什么。“除了为编写使用<的中缀表达式提供语法上的便利,”Guttag 教授指出,“这种重载提供了对使用 lt() 定义的任何多态方法的自动访问。内置方法 sort 就是这样一种方法。【②】
鉴于第一个和第二个操作数的这种区别,Python 还为我们提供了一组反向方法,比如 radd()、rsub()、rmul() 等等。请记住,只有当左操作数不支持相应的操作和时,才会调用这些反向方法。操作数属于不同的类型。一个叫 Rhomboid 的 Pythonista redditor 解释得比我更好,所以我谦恭地遵从他的观点:
有人能给我简单解释一下 radd 吗?我看了文档,我不理解它。

h/t to Rhomboid for the elucidating explanation

not like this.

like this.
最后一个警告——虽然我们拥有这种灵活性很棒,但我们应该记住操作者的初衷。比如 len()一般理解为用来返回一个序列的长度;所以重载这个方法需要返回一个整数(否则会返回一个 TypeError)。
…现在让我们来短暂地探索一下超载功能的更广阔、更汹涌的水域。根据维基百科,这属于“用不同的实现创建多个同名函数的能力。”函数可能因其参数的 arity 或类型而有所不同。这个概念在其他语言(C++,Java)中更有用,但并不真正符合 Pythonic 的“做事方式”,正如 stackoverflow 上的一些人所指出的:
如何在 Python 中使用方法重载?


…在这个问题上还有一个有用的线索:

one more relevant question…

…and reply
显然,Python 以不同的方式处理这种情况。也就是说,阅读方法重载帮助我理解了一个重要的 Pythonic 概念:多态性。这被定义为对不同的底层形式利用相同的接口的能力,例如数据类型或类。多态是 Python 中类的一个特征,因为它允许在许多类或子类中使用通常命名的方法,这进一步使函数能够使用属于一个类的对象,就像它使用属于另一个类的对象一样,完全不需要知道不同类之间的区别。[3] .这允许鸭类型化,动态类型化的一个特例,它使用多态性的特征(包括后期绑定和动态分派)来评估对象类型。
从这里开始,这一切都变成了单个对多个,静态对动态的分派,这超出了我目前的理解水平。所以我暂时先放一放。


来源:
[1]https://stack abuse . com/overloading-functions-and-operators-in-python/
[2]约翰·古塔格…使用 Python 的计算和编程介绍(麻省理工学院出版社)。麻省理工学院出版社。Kindle 版。
【4】(标题图片)https://www . osgpaintball . com/event/operation-霸王-场景-彩弹/
[## python 类特殊方法或神奇方法列表——微型棱锥体
python 类特殊方法或神奇方法的列表。神奇的功能允许我们覆盖或添加默认的…
micropyramid.com](https://micropyramid.com/blog/python-special-class-methods-or-magic-methods/) [## Python 运算符重载
Python 中什么是运算符重载?Python 运算符适用于内置类。但是同一个操作员表现…
www.programiz.com](https://www.programiz.com/python-programming/operator-overloading) [## Python 教程:魔术方法
所谓的魔法方法与巫术无关。您已经在我们的前几章中看到了它们…
www.python-course.eu](https://www.python-course.eu/python3_magic_methods.php) [## Python 中的重载函数和运算符
什么是超载?在编程的上下文中,重载指的是一个函数或一个操作符…
stackabuse.com](https://stackabuse.com/overloading-functions-and-operators-in-python/) [## 运算符重载
在计算机程序设计中,操作符重载,有时称为操作符特别多态,是…
en.wikipedia.org](https://en.wikipedia.org/wiki/Operator_overloading) [## Python 操作符重载和 Python 魔术方法
在本 Python 教程中,我们将讨论 Python 运算符重载,运算符重载的例子…
数据-天赋.培训](https://data-flair.training/blogs/python-operator-overloading/) [## 自定义 Python 类中的运算符和函数重载——真正的 Python
您可能想知道同一个内置操作符或函数如何为不同的对象显示不同的行为…
realpython.com](https://realpython.com/operator-function-overloading/) [## 如何在 Python 中使用方法重载?
我正在尝试用 Python 实现方法重载:class A:def stack overflow(self):print ’ first method ’ def…
stackoverflow.com](https://stackoverflow.com/questions/10202938/how-do-i-use-method-overloading-in-python) [## Python 函数重载
我知道 Python 不支持方法重载,但是我遇到了一个问题,我似乎无法用…
stackoverflow.com](https://stackoverflow.com/questions/6434482/python-function-overloading) [## Python 中的函数重载
最近在 Practo 的一次谈话中,我发现有些人抱怨说,我们没有……
medium.com](https://medium.com/practo-engineering/function-overloading-in-python-94a8b10d1e08)
免责声明:错误、曲解、滥用概念和想法都是我的,并且只属于我。
【概述】:让集成学习变得简单

当你想购买一部手机的时候,你会直接走到商店然后在网上转然后挑选任何一部手机吗?最常见的做法是浏览互联网上的评论,比较不同的型号,规格,功能和价格。你可能会向你的同伴询问购买建议,并以结论结束。总的来说,你没有直接得出结论,而是考虑了其他来源的选择。
在本文中,我将向您介绍机器学习中的一种称为“集成学习”的技术,以及使用这种技术的算法。
内容列表
- 多样的算法
- 不同实例上每个预测器的算法相同
- 相同的算法对不同的特性集&实例
- 升压
- 堆叠
集成模型的思想是训练多个模型,每个模型的目标是预测或分类一组结果。
集成学习背后的主要原理是将弱学习者分组在一起以形成一个强学习者。
集成学习:集成是一组被训练并用于预测的预测器
集成算法:集成算法的目标是将几个基础估计器的预测与给定的学习算法结合起来,以提高单个估计器的鲁棒性
用训练数据的子集训练一组决策树。使用个别树的预测,预测得到最大值的类。一些投票。这样的决策树集合——随机森林。
集成学习方法通常区分如下

集成学习的类型
a.)一套多样的 算法
基于我们的目标(回归/分类),我们选择一组不同的模型,训练它们,汇总这些模型的结果并得出结论。这是使用投票分类器完成的。

Source: Hands-on machine learning with sci-kit-learn and tensorflow
*硬投票分类器:*聚合各个分类器的预测,预测得到票数最多的类。只有当分类器相互独立时,集成才能比单个低性能分类器表现更好。但是他们接受了相同的数据训练

Source: Hands-on machine learning with sci-kit-learn and tensorflow
软投票分类器:如果所有分类器都能够估计类的概率(predict_proba()方法),那么预测具有最高类概率的类,在单个分类器上平均。软投票通常比硬投票表现更好。软投票考虑每个分类器的确定程度
现在让我们试着用一种简单的方式来理解这一点。
举例:假设你有 3 个分类器(1,2,3),两个类(A,B),经过训练,你在预测单个点的类。
硬投票
预测:
分类器 1 预测类别 A
分类器 2 预测 B 类
分类器 3 预测 B 类
2/3 分类器预测 B 类,所以B 类是集成决策。
软投票
预测(与之前的例子相同,但现在是根据概率。此处仅显示 A 类,因为问题是二进制的):
分类器 1 以 99%的概率预测类别 A
分类器 2 以 49%的概率预测类别 A
分类器 3 以 49%的概率预测类别 A
跨分类器属于 A 类的平均概率为(99 + 49 + 49) / 3 = 65.67%。因此,A 类是系综决策。
b.) 不同情况下每个预测器的算法相同
到目前为止,我们已经看到了在相同实例上训练的不同算法。现在让我们看看如何使用不同的实例使用相同的算法进行分类。
如果样本选择是通过替换- 装袋 (引导汇总)完成的
如果样品选择完成而没有替换— 粘贴
只有 bagging 允许为同一个预测器对训练实例进行多次采样
一旦模型被训练,集合将聚集来自所有模型的预测。
聚集-模式:分类
聚合-平均值:回归
聚合减少了偏倚和方差。
在 Sci-Learn 中,为了执行 bagging,我们使用 BaggingClassifier():如果基本分类器有 predict_proba()方法,则自动执行软投票。
Bagging —较高的偏差,低方差结果。首选整体装袋

c.) 同一算法上的一组多样特性&实例
到目前为止,我们已经看到使用采样数据训练模型。现在是时候根据所选的特性训练模型了。
随机面片和随机子空间
在 Bagging 分类器()中,用于实例采样和特征采样的参数如下
实例采样— max_samples,引导
要素采样-最大要素,引导要素
采样训练实例和特征— 随机补丁方法
保留所有训练实例(即 bootstrap=False 和 max_sam ples=1.0)但采样特征(即 bootstrap_features=True 和/或 max_features 小于 1.0)称为 随机子空间方法
d.)助推
提升是一种集成技术,它试图从多个弱分类器中创建一个强分类器。这是一个循序渐进的过程,每个后续模型都试图修复其前一个模型的错误。
AdaBoost(自适应增强),梯度增强。

AdaBoost*:*在每个模型预测的最后,我们最终提高了错误分类实例的权重,以便下一个模型对它们做得更好,等等。顺序学习的一个主要缺点是该过程不能并行化,因为预测器可以一个接一个地训练。如果 AdaBoost 集成过拟合训练集,则减少估计器的数量或调整基本估计器


Source: Hands-on machine learning with sci-kit-learn and tensorflow

AdaBoost 通过将(每棵树的)权重相加乘以(每棵树的)预测来进行新的预测。显然,权重较高的树将有更大的权力来影响最终决策

【GBM】
梯度增强直接从误差——残差中学习,而不是更新数据点的权重。
下面是梯度推进决策树(GBDT)的 Python 代码

Source: Hands-on machine learning with sci-kit-learn and tensorflow

梯度推进通过简单地将(所有树的)预测相加来进行新的预测

e.)堆叠(堆叠概括
堆叠背后的主要思想是,与其使用琐碎的函数(如硬投票)来聚合集合中所有预测者的预测,不如我们训练一个模型来执行这种聚合。

集成对新实例执行回归任务。底部三个预测器中的每一个都预测不同的值(3.1、2.7 和 2.9),然后最终预测器(称为混合器或元学习器)将这些预测作为输入,并做出最终预测(3.0)
结论:
总的来说,集成学习是一种用于提高模型预测能力/估计准确性的强大技术。
请在下面留下任何评论、问题或建议。
谢谢大家!
快乐学习!
R 中 40 个数学函数概述

Photo by Simone Venturini from Pexels
你是否发现自己在寻找tanh, sigmoid, softmax, ReLU 函数或其他数学函数的样子?即使你实际上应该知道,因为你几天前就已经查过了?那么,你来对地方了!
这个概述是关于什么的?
对于一个定量领域的任何人来说,知道这些函数都是非常有用的。很多时候,我们迷失在求导、积分等细节中。但是我们往往会忘记所有不同函数的物理意义以及它们之间的相互比较:一个函数实际上是什么样子的?
因此,我对想到的最常见的 40 个数学函数做了一个简单的概述。我使用 R 中的curve函数以精简、简单的方式绘制了它们,并按照逻辑上有用的顺序组装它们。
如何创造这些情节?
创造这样的情节非常容易。让我们从一个例子开始:
curve(exp(x), from = -10, to = 10, main = "exp(x)")

打开 RStudio 后,你真正需要做的就是把上面那行代码放到你的控制台里运行。你不需要任何图书馆。这不是很好吗?
提供您想要作为第一参数绘图的功能,例如exp(x)、x^3或3*x+5。您可以快速实现 sigmoid 函数1/(1+exp(-x))、tanh 函数tanh(x)、softmax 函数exp(x)/sum(exp(x))或 ReLU 函数pmax(0, x)等功能。
在那之后,你需要做的就是指定 x 的值,你要为这些值绘制函数 f(x)。您可以通过设置参数from和to来完成此操作。我选择绘制从-10 到+10 的所有函数。当然,你也可以选择用main指定一个标题。
给我看看 40 个数学函数!
您可以在下面的图中看到显示的函数。共有 4 个部分,每个部分有 10 个功能。通过在 RStudio 中运行它们,可以用相应的 Github Gists 创建所有的部分。
第一节

Functions 1–10
第二节

Functions 11–20
第三节

Functions 21–30
第四节

Functions 31–40
参考
请在 Github 上找到源代码:
如果需要增加功能,期待您的反馈!提前多谢了。
工业用自动化库综述
PyCon JP 2019 的自动化机器学习技术和库的简要总结

Photo by Franck V. on Unsplash
PyCon JP 2019 于 2019/9/16~ 2019/9/17 举办,为期两天。我会发布一些我感兴趣的讲座的帖子。
作为一名 NLP 工程师,很高兴看到一些关于机器学习的讲座。这篇文章是来自柴田正史的汽车演讲的简短英文摘要。你可以在这里找到日文的幻灯片。
自动化水平
Jeff Dean 在 2019 年 ICML 车展上做了一个关于 AutoML 的演讲,他将自动化分为 5 个级别
- 手工预测者,什么都不学。
- 手工特色,学会预测。自动化超参数优化(HPO)工具,如 Hyperopt、Optuna、SMAC3、scikit-optimize 等。
- 手工算法,端到端地学习特征和预测。HPO +一些工具像 featuretools,tsfresh,boruta 等。
- 手工什么都没有。端到端地学习算法、特征和预测。自动化算法(模型)选择工具,如 Auto-sklearn、TPOT、H2O、auto_ml、MLBox 等。
自动 Hpyerparametter 优化的两种方法
广泛使用的优化方法有两种,一种是贝叶斯 优化方法,它将根据过去的结果搜索未知的参数范围。一些算法如 TPE,SMAC,GP-EL 等。

An example of using Bayesian optimization on a toy 1D design problem
另一个是在训练过程中停止学习路径,更有效地搜索参数。一些算法像连续减半,超带等等。

蓝点表示训练将继续,红点表示训练将停止。
自动图书馆

我们可以将这些库分为以下两类。

考虑到质量和开发速度,推荐两个库, Optuna 和 scikit-optimize。
自动化特征工程

还有一件事是 TPOT 和 Auto-sklearn 做不到的。因此,我们将特征工程分为两类,特征生成和特征选择。

自动算法(模型)选择

Optuna 可以一起解决现金。


自动算法选择比较。
- 自动 sklearn
- TPOT
- h2o-3
- 自动 _ 毫升
- MLBox

不同任务的推荐选择。
- 回归任务:自动 sklearn(基于贝叶斯)
- 分类任务:TPOT(基于遗传算法)

自动神经结构搜索
即使是自动神经架构搜索在学术界也是一个非常热门的话题,但是在工业界还没有得到广泛的应用。

查看我的其他帖子 中 同 一个分类查看 !
GitHub:bramble Xu LinkedIn:徐亮 博客:bramble Xu
参考
- https://www . slide share . net/c-bata/pythonautoml-at-pyconjp-2019
- https://arxiv.org/pdf/1012.2599.pdf
- https://arxiv.org/pdf/1810.05934.pdf
- https://arxiv.org/pdf/1502.07943.pdf
- https://arxiv.org/pdf/1808.06492.pdf
CycleGAN 架构和培训概述。

0.介绍
生成对抗模型由两个神经网络组成:一个生成器和一个鉴别器。一个 CycleGAN 由 2 个 GAN 组成,总共有 2 个发生器和 2 个鉴别器。
给定两组不同的图像,例如马和斑马,一个生成器将马转换成斑马,另一个生成器将斑马转换成马。在训练阶段,鉴别器在这里检查生成器计算出的图像是真是假。通过这个过程,生成器可以随着各自鉴别器的反馈而变得更好。在 CycleGAN 的情况下,一个发电机从另一个发电机获得额外的反馈。这种反馈确保由生成器生成图像是循环一致的,这意味着在图像上连续应用两个生成器应该产生相似的图像。

训练一个 CycleGAN 非常方便的一点是,我们不需要标记它的训练样本(数据是不成对的)。
1.数据
CycleGAN 的一个训练样本由马的随机图片和斑马的随机图片构成。

2.模型
两个生成器都具有以下架构(除了规范层和激活层) :

Residual Block on the left, all convolutional layer inside it have 256 filters, stride 2 and padding 1.
生成器将大小为 256x256 的图像作为输入,对其进行下采样,然后将其上采样回 256x256,从而创建生成的图像。
至于鉴别器,它们具有以下架构(规范和激活层除外):

鉴别器将大小为 256x256 的图像作为输入,并输出大小为 30x30 的张量。
输出张量的每个神经元(值)保存输入图像的 70×70 区域的分类结果。通常,GANs 的鉴别器输出一个值来指示输入图像的分类结果。通过返回大小为 30x30 的张量,鉴别器检查输入图像的每个 70x70 区域(这些区域相互重叠)是真实的还是虚假的。这样做相当于手动选择这些 70x70 区域中的每一个,并让鉴别器反复检查它们。最后整幅图像的分类结果是 30×30 个值的分类结果的平均值。
3.培养
生成器和鉴别器都使用 Adam 解算器(默认参数)进行优化,它们都具有相同的学习速率(2e-4),并且批处理大小被选择为 1(这意味着这里不能使用批处理规范化,而是使用实例规范化)。

generated images are from a CycleGAN trained during 30 epochs.
G {H- > Z }是将马图像转换成斑马图像的生成器,G {Z- > H }是将斑马图像转换成马图像的生成器。
给定一个训练样本( h,z ),这就是该样本如何更新 CycleGAN 的权重。
- 从 h, G {H- > Z }生成假 _z 一个假斑马图像。从 z,G{ H->Z}生成 id_z 应该与Z相同
- *从 z, G {Z- > H}生成 fake_h 一个假马图像。从 *h,G{ Z->H }生成应该与 h. 相同的 id_h
- 从 fake_z ,G {Z- > H}生成 rec_h 一个与 h 相似的 h 的重建图像。
- 从 fake_h ,G {H- > Z }生成 rec_z 一个应该类似于 z 的重构图像。
然后,通过最小化跟随损失来更新发电机的权重。在 G {H- > Z }的情况下,可以写成:

where D_z(fake_z)(i,j) is the scalar value at coordinate (i,j) of D_z output tensor.
- D_z ( fake_z )和 1 之间的均方误差(MSE)。即原图中的最小二乘损失。 D_z 是与 G {H- > Z }关联的鉴别器,如果输入—fake _ Z—看起来像一个真正的斑马 else 0 时,它输出 1 。

pixel to pixel absolute difference of the two images.
- rec_h 和 h 之间的平均绝对误差(MAE)。即原纸中的循环一致性损失。这个损失被赋予了很大的重要性,并且更新了 10 倍于 MSE 损失的发电机权重。

pixel to pixel absolute difference of the two images.
- id_h 和 h 之间的平均绝对误差(MAE)。即原文中的身份丧失。没有必要包括这种损失,但它通常有助于获得更好的结果。
然后,通过最小化跟随损失来更新鉴别器的权重。在 D_z 的情况下,可以写成:

- D_z ( fake_z )与 0 之间均方误差(MSE)的一半加上 D_z ( z )与 1 之间 MSE 的一半。
鉴别器的损耗减半。这样做相当于使用 MSE 在每次更新生成器权重两次时更新鉴别器权重一次。
4.结果
复制这些结果的代码可以从 colab 笔记本中获得。
然后,CycleGAN 被训练 200 个周期。在前 100 个时期,学习速率固定为 2e-4,在后 100 个时期,学习速率从 2e-4 到 2e-6 线性退火。下面显示了一些生成的图像。
通常有非常好的结果(左:原始图像,右:生成的图像) :

original images / generated images
但也有失败的情况(左:原始图像,右:生成的图像) :

用于深度学习的图嵌入
图形学习和几何深度学习—第 1 部分
这里有很多方法可以将机器学习应用于图表。最简单的方法之一是将图表转换成更容易理解的 ML 格式。
图形嵌入是一种方法,用于将节点、边及其特征转换到向量空间(较低的维度)中,同时最大限度地保留图形结构和信息等属性。图表很复杂,因为它们在规模、特性和主题方面会有所不同。
一个分子可以被表示为一个小的、稀疏的、静态的图,而一个社会网络可以被表示为一个大的、密集的、动态的图。最终,这使得很难找到一个银弹嵌入方法。每种方法在不同的数据集上的性能各不相同,但它们是深度学习中使用最广泛的方法。

图形是这个系列的主要焦点,但是如果 3D 成像应用更适合你,那么我推荐Gradient的这篇精彩文章。
嵌入图网络
如果我们将嵌入视为向低维的转换,嵌入方法本身就不是一种神经网络模型。相反,它们是一种在图形预处理中使用的算法,目的是将图形转换成可计算的格式。这是因为图形类型的数据本质上是离散的。
机器学习算法针对连续数据进行调整,因此为什么嵌入总是针对连续向量空间。
正如最近的工作所显示的,有多种方法可以嵌入图,每种方法都有不同的粒度级别。嵌入可以在节点级、子图级执行,或者通过像图遍历这样的策略来执行。这些是一些最受欢迎的方法。
深走— 佩罗齐等人
Deepwalk 并不是这类方法中的第一个,但与其他图形学习方法相比,它是第一个被广泛用作基准的方法之一。Deepwalk 属于使用遍历的图形嵌入技术家族,遍历是图论中的一个概念,它通过从一个节点移动到另一个节点来实现图形的遍历,只要它们连接到一个公共边。
如果用任意的表示向量来表示图中的每个节点,就可以遍历图。可以通过在矩阵中彼此相邻地排列节点表示向量来聚集该遍历的步骤。然后,你可以将表示图形的矩阵输入到一个递归神经网络中。基本上,您可以使用图遍历的截断步长作为 RNN 的输入。这类似于句子中单词向量的组合方式。
DeepWalk 采用的方法是使用以下等式完成一系列随机行走:

目标是估计观察到节点 vi 的可能性,给定在随机行走中到目前为止访问的所有先前节点,其中 Pr() 是概率,φ是表示与图中每个节点 v 相关联的潜在表示的映射函数。
潜在的表现是神经网络的输入。神经网络基于行走过程中遇到哪些节点以及遇到这些节点的频率,可以对节点特征或分类进行预测。

The original graph and it’s embedding (Courtesy of the DeepWalk research team)
用于进行预测的方法是 skip-gram ,就像 Word2vec 架构中的文本一样。DeepWalk 不是沿着文本语料库运行,而是沿着图运行来学习嵌入。该模型可以采用目标节点来预测它的“上下文”,在图的情况下,这意味着它的连通性、结构角色和节点特征。
尽管 DeepWalk 的得分为 O(|V|) *,*相对高效,但这种方法是直推式,这意味着每当添加新节点时,模型都必须重新训练以嵌入新节点并从中学习。
Node2vec — Grover 等人
你听说过 Word2vec 现在准备… Node2vec
比较流行的图学习方法之一,Node2vec 是最早尝试从图结构化数据进行学习的深度学习方法之一。直觉类似于 DeepWalk 的直觉:
如果你把图中的每个节点像句子中的单词一样嵌入,神经网络可以学习每个节点的表示。
Node2vec 和 DeepWalk 之间的区别很微妙,但是很重要。Node2vec 具有一个行走偏差变量α,它由 p 和 q 参数化。参数 p 优先考虑广度优先搜索(BFS)过程,而参数 q 优先考虑深度优先搜索(DFS)过程。因此,下一步去哪里的决定受到概率 1/ p 或 1/q的影响

Both BFS and DFS are common algorithms in CS and graph theory (Courtesy of Semantic Scholar)
正如可视化所暗示的, BFS 是学习局部邻居的理想选择,而 DFS 更适合学习全局变量。 Node2vec 可以根据任务在两个优先级之间切换。这意味着给定一个图,Node2vec 可以根据参数值返回不同的结果。按照 DeepWalk,Node2vec 还获取 walks 的潜在嵌入,并将其作为神经网络的输入来对节点进行分类。

BFS vs DFS (Courtesy of SNAP Stanford)
实验证明 BFS 更擅长根据结构角色(枢纽、桥梁、离群点等)进行分类。)而 DFS 返回一个更加社区驱动的分类方案。
Node2vec 是斯坦福大学 SNAP 研究小组致力于图形分析的众多图形学习项目之一。他们的许多作品是几何深度学习许多重大进展的起源。
graph 2 vec——纳拉亚南等人
对 node2vec 变体的修改,graph2vec 本质上学习嵌入图的子图。doc2vec 中使用的一个等式证明了这一点,它是一个密切相关的变体,也是本文的灵感来源。

用通俗的英语来说,这个等式可以写成:单词( wj )出现在上下文给定文档( d )中的概率等于文档嵌入矩阵( d~ )的指数乘以单词嵌入矩阵( w~j 是从文档中采样的),除以文档嵌入矩阵的所有指数之和乘以文档中每个单词的单词嵌入矩阵
用 word2vec 来类比,如果一个文档是由句子组成的(句子又是由单词组成的),那么一个图是由子图组成的(子图又是由节点组成的)。

Everything is made of smaller things
这些预定的子图具有由用户指定的设定数量的边。同样,是潜在的子图嵌入被传递到神经网络中用于分类。
【结构化深度网络嵌入】——王等
与以前的嵌入技术不同,SDNE 不使用随机行走。相反,它试图从两个不同的指标中学习:
- **一阶接近度:**如果两个节点共享一条边,则认为它们是相似的(成对相似)
- **二阶接近度:**如果两个节点共享许多相邻节点,则认为它们是相似的
最终目标是捕捉高度非线性的结构。这是通过使用深度自动编码器(半监督)来保持一阶(监督)和二阶(非监督)网络接近度来实现的。

Dimensionality reduction with LE (Courtesy of MathWorld)
为了保持一阶近似性,该模型也是拉普拉斯特征映射的变体,这是一种图形嵌入/维度缩减技术。拉普拉斯特征映射嵌入算法在相似节点在嵌入空间中彼此远离映射时应用惩罚,从而允许通过最小化相似节点之间的空间来进行优化。
通过将 te 图的邻接矩阵传递给无监督自动编码器来保持二阶接近度,该编码器具有内置的重建损失函数,必须最小化该函数。

An autoencoder (Courtesy of Arden Dertat)
一阶邻近损失函数和二阶重建损失函数一起被联合最小化以返回图嵌入。然后通过神经网络学习嵌入。
大规模信息网络嵌入(线)——唐等
行(汤集安等人)明确定义了两个功能;一个用于一阶接近度,另一个用于**二阶接近度。**在原始研究进行的实验中,二阶近似的表现明显优于一阶,这意味着包含更高阶的近似可能会抵消精度的提高。
**LINE 的目标是最小化输入和嵌入分布之间的差异。**这是通过使用 KL 散度实现的:

A simple case of KL-divergence minimization
可视化很简单,数学没那么简单。Aurélien Géron 有一个关于这个主题的很棒的视频。另一方面,Géron 也是为数不多的图形学习研究人员之一,在 YouTube 工作期间,他将知识图形和深度学习结合起来,以改善视频推荐。

**LINE 为每对节点定义两个联合概率分布,然后最小化分布的 KL 散度。**这两种分布分别是邻接矩阵和节点嵌入的点积。KL 散度是信息论和熵中一个重要的相似性度量。该算法用在概率生成模型中,如变分自动编码器,其将自动编码器的输入嵌入到潜在空间中,该潜在空间成为分布。
由于该算法必须为每个递增的接近度定义新的函数,如果应用程序需要理解节点社区结构, LINE 的性能不是很好。
然而,LINE 的简单性和有效性只是它成为 2015 年 WWW 上被引用最多的论文的几个原因。这项工作有助于激发人们对图形学习的兴趣,将其作为机器学习的一个利基,并最终成为特定的深度学习。
网络的分层表示学习—陈等
HARP 是对前面提到的基于嵌入/行走的模型的改进。以前的模型有陷入局部最优的风险,因为它们的目标函数是非凸的。基本上这意味着,球不可能滚到绝对的山脚。

Gradient decent isn’t perfect (Courtesy of Fatih Akturk)
因此,意图动机:
通过更好的权重初始化来改进解决方案并避免局部最优。
以及建议的方法:
使用图粗化将相关节点聚集成“超级节点”
被制造出来。
HARP 本质上是一个图形预处理步骤,它简化了图形以利于更快的训练。
粗化图形后,它生成最粗“超节点”的嵌入,随后是整个图形的嵌入(图形本身由超节点组成)。
整个图中的每个“超级节点”都遵循这一策略。
因为 HARP 可以与之前的嵌入算法结合使用,比如 LINE、Node2vec 和 DeepWalk。原始论文报道了当将 HARP 与各种图嵌入方法结合时,在分类任务中高达 14% 的显著改进:显著的飞跃。
本质上
我肯定错过了一堆算法和模型,尤其是最近对几何深度学习和图形学习的兴趣激增,导致几乎每天都有新的贡献出现在出版物上。
在任何情况下,图嵌入方法都是一种简单但非常有效的方法,可以将图转换为机器学习任务的最佳格式。由于它们的简单性,它们通常非常具有可伸缩性(至少与它们的卷积对应物相比),并且易于实现。它们可以应用于大多数网络和图形,而不会牺牲性能或效率。但是我们能做得更好吗?
接下来是深入复杂而优雅的图形卷积世界!
关键要点
- 图形嵌入技术在通过机器学习模型传递该表示之前,获取图形并将它们嵌入到较低维度的连续潜在空间。
- 行走嵌入方法执行图形遍历,目标是保持结构和特征并聚集这些遍历,然后可以通过递归神经网络传递。
- 邻近嵌入方法使用深度学习方法和/或邻近损失函数来优化邻近,使得原始图中靠近在一起的节点同样在嵌入中。
- 其他方法使用类似图粗化的方法来简化图,然后在图上应用嵌入技术,在保留结构和信息的同时降低复杂性。
需要看到更多这样的内容?
跟我上LinkedIn脸书insta gram,当然还有 中**
我总是希望结识新朋友、合作或学习新东西,所以请随时联系 flawnsontong1@gmail.com
向上和向前,永远和唯一🚀
特征选择方法概述
选择数据集中最相关要素的常用策略

特征选择的重要性
在高维输入数据的情况下,选择正确的特征集用于数据建模已被证明可以提高监督和非监督学习的性能,减少计算成本,如训练时间或所需资源,以减轻维度的*诅咒。*计算和使用特征重要性分数也是提高模型解释能力的重要一步。
这篇文章的概述
这篇文章分享了我在研究这个主题几天后获得的关于执行特征选择的监督和非监督方法的概述。对于所有描述的方法,我还提供了我使用的开源 python 实现的参考,以便让您快速测试所呈现的算法。然而,就过去 20 年中提出的方法而言,这个研究领域非常丰富,因此这篇文章只是试图呈现我目前有限的观点,而没有任何完整性的借口。为了更全面的研究,你可以查看下面的评论。
监督/非监督模型
有监督特征选择算法,其识别相关特征以最好地实现监督模型的目标(例如,分类或回归问题),并且它们依赖于标记数据的可用性。然而,对于未标记的数据,已经开发了许多无监督的特征选择方法,这些方法基于各种标准对所有数据维度进行评分,这些标准例如是它们的方差、它们的熵、它们保持局部相似性的能力等。使用非监督试探法识别的相关特征也可以用于监督模型,因为它们可以发现数据中除特征与目标变量的相关性之外的其他模式。
从分类学的角度来看,特征选择方法通常属于下面详述的以下 4 个类别之一:过滤器、包装器、嵌入式和混合类。
包装方法
这种方法基于所应用的学习算法的结果性能来评估特征子集的性能(例如,对于分类问题,在准确性方面的增益是多少)。任何学习算法都可以用于这种搜索策略和建模的结合。

Image from Analytics Vidhya
- 正向选择:这种方法从一组空的特征开始,然后提供最佳性能的维度被迭代地添加到结果集中
- 反向选择:这种方法从所有特征的集合开始,在每次迭代中,最差的维度被移除
实现:这些算法在 mlxtend 包中实现,在这里找到一个的用法示例。
- RFE (递归特征消除):通过递归考虑越来越小的特征集来选择特征的贪婪搜索。它根据要素被消除的顺序对其进行排序。
实现: scikit-learn
嵌入式方法
这种方法包括同时执行模型拟合和特征选择的算法。这通常通过使用稀疏正则化器或约束来实现,使得一些特征的权重变为零。
- SMLR (稀疏多项逻辑回归):该算法通过 ARD 先验(自动相关性确定)对经典多项逻辑回归实现稀疏正则化。这种正则化估计了每个特征的重要性,并删除了对预测无用的维度。
实施: SMLR
- ARD (自动相关性确定回归):基于贝叶斯岭回归,该模型将比 OLS 等方法更多地将系数权重移向零。

ARD sparsity constraint makes the weights of some features 0 and thus helps identify the relevant dimensions
实现: scikit-learn
正则化算法的其他例子: Lasso (实现 l1 正则化)、岭回归(实现 l2 正则化)、弹性网(实现 l1 和 l2 正则化)。对这些不同正则化类型的直观描述表明,Lasso 回归将系数约束为方形,ridge 创建圆形,而弹性网介于两者之间:

https://scikit-learn.org/stable/auto_examples/linear_model/plot_sgd_penalties.html
这些算法的全面描述可以在这里找到。
过滤方法
这种方法仅基于特征的固有特性来评估特征的重要性,而不结合任何学习算法。这些方法往往比包装器方法更快,计算成本更低。如果没有足够的数据来模拟特征之间的统计相关性,过滤方法可能会提供比包装方法更差的结果。与包装方法不同,它们不会过度拟合。它们被广泛用于高维数据,其中包装器方法具有令人望而却步的计算成本。
监督方法
- Relief :该方法从数据集中随机抽取实例,并根据所选实例与相同和相反类的两个最近实例之间的差异更新每个特征的相关性。如果在相同类的相邻实例中观察到特征差异(“命中”),则特征分数降低,或者,如果观察到具有不同分数的特征值差异(“未命中”),则特征分数增加。

Feature weight decreases if it differs from that feature in nearby instances of the same class more than nearby instances of the other class and increases in the reverse case
扩展算法 ReliefF 应用特征加权并搜索更多最近邻。
实现: scikit-rebate , ReliefF
- Fisher score :通常用于二元分类问题,Fisher ratio(FiR)定义为每个特征的每个类别的样本均值之间的距离除以它们的方差:

实现:sci kit-特性,用法举例。
- 卡方评分:测试 2 个分类变量的观察频率和预期频率之间是否存在显著差异。因此,零假设表明两个变量之间没有关联。

Chi square test of independence
为了正确应用卡方检验数据集中各种特征与目标变量之间的关系,必须满足以下条件:变量必须是分类的,独立采样的*,且值的预期频率应大于 5 。最后一个条件确保检验统计的 CDF 可以通过卡方分布来近似计算,更多细节可以在这里找到。*
“如果特性的值随着类别成员有系统地变化,那么特性就是相关的.”
因此,好的特征子集包含与分类高度相关并且彼此不相关的特征。该方法如下计算 k 特征子集的价值:

https://en.wikipedia.org/wiki/Feature_selection#Correlation_feature_selection
实现:sci kit-特性,用法举例。
- FCBF (快速相关基滤波器):这种方法比 ReliefF 和 CFS 都更快更有效,因此更适合高维输入。简而言之,它遵循一种典型的相关性冗余方法,首先计算所有特征的对称不确定性(x | y 的信息增益除以它们的熵之和),按此标准对它们进行分类,然后移除冗余特征。
实现: skfeature ,【https://github.com/shiralkarprashant/FCBF】T2
无监督方法
- 方差:已被证明是选择相关特征的有效方法,这些特征往往具有较高的方差分数
实现:方差阈值
- 平均绝对差:根据平均值计算平均绝对差(执行)。

Higher values tend to have more discriminative power
- 离差率:算术平均值除以几何平均值。更高的分散对应于更相关的特征(实施)

https://www.sciencedirect.com/science/article/abs/pii/S0167865512001870
- 拉普拉斯得分:基于来自相同类别的数据通常彼此接近的观察,因此我们可以通过其局部保持能力来评估特征的重要性。该方法包括通过使用任意距离度量将数据嵌入最近邻图上,然后计算权重矩阵。然后为每个特征计算拉普拉斯得分,该得分具有最小值对应于最重要的维度的性质。然而,为了选择特征的子集,另一种聚类算法(例如 k-means)通常被后验地应用,以便选择性能最佳的组
实施: scikit-feature
- 拉普拉斯得分结合基于距离的熵:该算法建立在拉普拉斯得分之上,使用基于距离的熵来代替典型的 k-means 聚类,并在高维数据集中表现出更好的稳定性(实现)
- MCFS (多聚类特征选择):执行频谱分析以测量不同特征之间的相关性。拉普拉斯图的顶部特征向量用于对数据进行聚类,并且如最初的论文中所述,正在计算特征分数。
***实施:【https://github.com/danilkolikov/fsfc ***
混合方法
实现特征选择的另一个选项在于将过滤器和包装器方法组合成两阶段过程的混合方法:基于统计特性的特征的初始过滤(过滤器阶段),随后是基于包装器方法的第二选择。
其他资源
有非常丰富的解决特征选择问题的文献,这篇文章只是触及了已经完成的研究工作的表面。我将提供其他已有但我还没有尝试过的资源的链接。
我在这篇文章中没有提到的其他特征选择算法的综合列表已经在 scikit-feature 包中实现。
识别相关特征的其他方法是通过使用 PLS (偏最小二乘法),如本文帖子中所举例说明的,或者通过执行本文中所介绍的线性维度缩减技术。
Apache Kafka 集群的 UI 监控工具概述
阿帕奇卡夫卡最好的监控工具有哪些?

Photo by Chris Liverani on unsplash.com
随着 Kafka 集群监控和管理需求的增加,大量开源和商业图形工具已经上市,提供了各种管理和监控功能。
TL;dr:阿帕奇卡夫卡最好的监控工具是什么?
- 合流控制中心
- 镜头
- Datadog Kafka 仪表板
- Cloudera 经理
- 雅虎 Kafka 经理
- 卡夫多普
- LinkedIn Burrow
- 卡夫卡工具
合流控制中心
Confluent 是阿帕奇卡夫卡原创者创办的公司。合流企业,是一个-更完整的-生产环境的卡夫卡式分布。汇流平台的商业许可附带汇流控制中心,这是 Apache Kafka 的管理系统,能够从用户界面进行集群监控和管理。

汇合控制中心提供了对 Apache Kafka 集群内部工作方式以及流经集群的数据的理解和洞察。控制中心通过精心策划的仪表板为管理员提供监控和管理功能,以便他们能够提供最佳性能并满足 Apache Kafka 集群的服务级别协议。
镜头
lens(前 Landoop)是一家为 Kafka 集群提供企业功能和监控工具的公司。更准确地说,它通过用户界面、流式 SQL 引擎和集群监控增强了 Kafka。它还通过提供 SQL 和连接器对数据流的可见性,支持更快地监控 Kafka 数据管道。

Monitoring and managing streaming data flows with Lenses
Lenses 可与任何 Kafka 发行版配合使用,提供高质量的企业功能和监控、面向所有人的 SQL 以及 Kubernetes 上的自助式实时数据访问和流。
该公司还提供 Lenses Box ,这是一款免费的多功能 docker,可以为单个经纪人提供多达 2500 万条消息。注意,开发环境推荐使用 Lenses Box。
此外,Lenses 还提供 Kafka Topics UI,这是一个用于管理 Kafka 主题的 web 工具。

Kafka Topics UI by Lenses
Datadog Kafka 仪表板
Datadog 的 Kafka Dashboard 是一个全面的 Kafka Dashboard,显示 Kafka 经纪人、生产商、消费者和 Apache Zookeeper 的关键指标。Kafka 部署通常依赖于不属于 Kafka 的外部软件,如 Apache Zookeeper。Datadog 支持对部署的所有层进行全面监控,包括数据管道中不属于 Kafka 的软件组件。

Kafka Dashboard by DataDog
使用 Datadog 的开箱即用仪表板,节省设置时间并在几分钟内可视化您的 Kafka 数据。
Cloudera 经理
与 Confluent、Lenses 和 Datadog 相比,Cloudera Manager 中的 Kafka 显然是一个不太丰富的监控工具。但是对于已经是 Cloudera 客户的公司,需要他们在同一个平台下的监控机制,就非常方便了。

Monitoring Kafka using Cloudera Manager
以后想看这个故事吗? 保存在日志中。
雅虎 Kafka 经理
Yahoo Kafka Manager 是一个用于 Apache Kafka 集群的开源管理工具。使用 Kafka Manager,您可以:
- 管理多个集群
- 轻松检查集群状态(主题、消费者、偏移量、代理、副本分发、分区分发)
- 运行首选副本选举
- 生成分区分配,并提供选择要使用的代理的选项
- 运行分区的重新分配(基于生成的分配)
- 创建具有可选主题配置的主题
- 删除主题
- 批量生成多个主题的分区分配,可以选择要使用的代理
- 为多个主题批量运行分区重新分配
- 向现有主题添加分区
- 更新现有主题的配置
- 可以选择为代理级别和主题级别指标启用 JMX 轮询。
- 选择性地过滤掉 zookeeper 中没有 id/owners/& offsets/目录的消费者。

Topics Overview in Yahoo Kafka Manager
卡夫多普
KafDrop 是一个用于监控 Apache Kafka 集群的开源 UI。该工具显示信息,如经纪人,主题,分区,甚至让您查看消息。这是一个运行在 Spring Boot 上的轻量级应用程序,只需要很少的配置。

Broker Overview in KafDrop. Photo by HomeAdvisor
Kafdrop 3 是一个用于导航和监控 Apache Kafka 代理的 UI。该工具显示代理、主题、分区、消费者等信息,并允许您查看消息。
这个项目是对 Kafdrop 2.x 的重新启动,它被拖进了 JDK 11+、Kafka 2.x 和 Kubernetes 的世界。
LinkedIn Burrow
LinkedIn Burrow 是 Apache Kafka 的开源监控伴侣,提供消费者滞后检查服务,无需指定阈值。它监控所有消费者的承诺补偿,并根据需求计算这些消费者的状态。提供了一个 HTTP 端点来按需请求状态,以及提供其他 Kafka 集群信息。还有一些可配置的通知程序,可以通过电子邮件或 HTTP 调用将状态发送给另一个服务。陋居是用 Go 编写的,所以在你开始之前,你应该安装并设置 Go 。
卡夫卡工具
Kafka Tool 是一个 GUI 应用程序,用于管理和使用 Apache Kafka 集群。它提供了一个直观的 UI,允许用户快速查看 Kafka 集群中的对象以及存储在集群主题中的消息。它包含面向开发人员和管理员的特性。使用 Kafka 工具,您可以:
- 查看集群、代理、主题和消费者级别的指标
- 查看分区中的消息内容并添加新消息
- 查看抵消的卡夫卡消费者,包括阿帕奇风暴的卡夫卡喷口消费者
- 以漂亮的打印格式显示 JSON 和 XML 消息
- 添加和删除主题以及其他管理功能
- 将 Kafka 分区中的单个消息保存到本地硬盘
- 编写你自己的插件,允许你查看定制的数据格式
该工具可以在 Windows、Linux 和 Mac OS 上运行。
比较和结论
如果你买不起商业许可证,那么你可以选择雅虎 Kafka Manager、LinkedIn Burrow、KafDrop 和 Kafka Tool。在我看来,前者是一个全面的解决方案,应该可以满足大多数用例。
如果您运行的是相对较大的 Kafka 集群,那么购买商业许可是值得的。与我们在这篇文章中看到的其他监控工具相比,Confluent 和 Lenses 提供了更丰富的功能,我强烈推荐这两个工具。
要获得 Kafka UI 监控工具的最新列表,请务必阅读我最近的文章:
探索 Apache Kafka 集群的一些最强大的 UI 监控工具
towardsdatascience.com](/kafka-monitoring-tools-704de5878030)
成为会员 阅读介质上的每一个故事。你的会员费直接支持我和你看的其他作家。
你可能也喜欢
2.8.0 版本让你提前接触到没有动物园管理员的卡夫卡
towardsdatascience.com](/kafka-no-longer-requires-zookeeper-ebfbf3862104) [## 如何在阿帕奇卡夫卡中获取特定信息
掌握 Kafka 控制台消费者和 kafkacat
better 编程. pub](https://betterprogramming.pub/how-to-fetch-specific-messages-in-apache-kafka-4133dad0b4b8)
为数据科学家简单解释 p 值

Our Null and Alternate Hypothesis in the battle of the century. Image by Sasin Tipchai from Pixabay
没有统计学家的自命不凡和数据科学家的冷静
最近,有人问我如何用简单的术语向外行人解释 p 值。我发现很难做到这一点。
p 值总是很难解释,即使对了解它们的人来说也是如此,更不用说对不懂统计学的人了。
我去维基百科找了些东西,下面是它的定义:
在统计假设检验中,对于给定的统计模型,p 值或概率值是指当零假设为真时,统计汇总(如两组之间的样本均值差异)等于或大于实际观察结果的概率。
我的第一个想法是,他们可能是这样写的,所以没有人能理解它。这里的问题在于统计学家喜欢使用大量的术语和语言。
这篇文章是关于以一种简单易懂的方式解释 p 值,而不是像统计学家 那样自命不凡。
现实生活中的问题
在我们的生活中,我们当然相信一件事胜过另一件事。
从的明显可以看出的像——地球是圆的。或者地球绕着太阳转。太阳从东方升起。
不确定性程度不同的**——运动减肥?或者特朗普会在下一次选举中获胜/失败?或者某种特定的药物有效?还是说睡 8 小时对身体有好处?**
前一类是事实,后一类因人而异。
所以,如果我来找你说运动不影响体重呢?
所有去健身房的人可能会对我说不那么友好的话。但是有没有一个数学和逻辑的结构,在其中有人可以反驳我?
这让我们想到了假设检验的概念。
假设检验

Exercising doesn’t reduce weight?
所以我在上面例子中的陈述——运动不影响体重。这个说法是我的假设。暂且称之为 无效假设 。目前,这是我们认为真实的现状。
那些信誓旦旦坚持锻炼的人提出的 替代假设 是——锻炼确实能减肥。
但是我们如何检验这些假设呢?我们收集数据。我们收集了 10 个定期锻炼超过 3 个月的人的减肥数据。
失重样品平均值= 2 千克
样品标准偏差= 1 千克
这是否证明运动确实能减肥?粗略地看一下,似乎锻炼确实有好处,因为锻炼的人平均减掉了 2 公斤。
但是你会发现,当你进行假设检验时,这些明确的发现并不总是如此。如果锻炼的人体重减轻了 0.2 公斤会怎么样。你还会这么肯定运动确实能减肥吗?
那么,我们如何量化这一点,并用数学来解释这一切呢?
让我们建立实验来做这件事。
实验
让我们再次回到我们的假设:
H : 练功不影响体重。或者相当于𝜇 = 0
Hᴬ: 运动确实能减肥。或者相当于𝜇 > 0
我们看到 10 个人的数据样本,我们试图找出
观察到的平均值(锻炼者的体重减轻)= 2 公斤
观察到的样品标准偏差= 1 千克
现在问我们自己一个好问题是— 假设零假设为真,观察到 2 kg 或者比 2 kg 更极端的样本均值的概率是多少?
假设我们可以计算出这个值——如果这个概率值很小(小于阈值),我们拒绝零假设。否则,我们无法拒绝我们的无效假设。 为什么拒绝失败而不接受? 我 这个后面会回答。
这个概率值实际上就是 p 值。简单地说,如果我们假设我们的零假设是正确的,它只是观察我们所观察到的或极端结果的概率。
统计学家称该阈值为显著性 level(𝜶,在大多数情况下,𝜶取为 0.05。
那么我们怎么回答: 假设原假设为真,得到 2 kg 或大于 2 kg 的值的概率是多少?
这是我们最喜欢的分布,图中的正态分布。
正态分布
假设我们的零假设为真,我们创建重量损失样本平均值的抽样分布。
中心极限定理:中心极限定理简单来说就是,如果你有一个均值为μ、标准差为σ的总体,并从总体中随机抽取样本,那么样本均值的分布将近似为正态分布以均值为总体均值、**标准差σ/√n 。其中σ是样本的标准差,n 是样本中的观察次数。
现在我们已经知道了由零假设给出的总体均值。所以,我们用它来表示均值为 0 的正态分布。其标准偏差由 1/√10 给出

The sampling distribution is a distribution of the mean of samples.
事实上,这是总体样本均值的分布。我们观察到一个特殊的平均值,即 2 公斤。
现在我们可以使用一些统计软件来找出这条特定曲线下的面积:
**from scipy.stats import norm
import numpy as npp = 1-norm.cdf(2, loc=0, scale = 1/np.sqrt(10))
print(p)
------------------------------------------
1.269814253745949e-10**
因此,这是一个非常小的概率 p 值(
And so we can reject our Null hypothesis. And we can call our results statistically significant as in they don’t just occur due to mere chance.
The Z statistic
You might have heard about the Z statistic too when you have read about Hypothesis testing. Again as I said, terminology.
That is the extension of basically the same above idea where we use a standard normal with mean 0 and variance 1 as our sampling distribution after transforming our observed value x using:

This makes it easier to use statistical tables. In our running example, our z statistic is:
**z = (2-0)/(1/np.sqrt(10))
print(z)
------------------------------------------------------
6.324555320336758**
Just looking at the Z statistic of > 6 应该让您知道观察值至少有六个标准差,因此 p 值应该非常小。我们仍然可以使用以下公式找到 p 值:
**from scipy.stats import norm
import numpy as npp = 1-norm.cdf(z, loc=0, scale=1)
print(p)
------------------------------------------------------
1.269814253745949e-10**
正如你所看到的, 我们使用 Z 统计量得到了相同的答案。
一个重要的区别

Our Jurors can never be definitively sure so they don’t accept they just reject.
我们之前说过,我们拒绝我们的零假设,因为我们有足够的证据证明我们的零假设是错误的。
但是如果 p 值高于显著性水平。然后我们说,我们不能拒绝零假设。为什么不说接受零假设呢?
最直观的例子就是使用审判法庭。在审判法庭上,无效假设是被告无罪。然后我们看到一些证据来反驳零假设。
如果我们不能反驳无效的假设,法官不会说被告没有犯罪。法官只是说,根据现有的证据,我们无法判定被告有罪。
推动这一观点的另一个例子是:假设我们正在探索外星球上的生命。而我们的零假设( H )就是这个星球上没有生命。我们漫游了几英里,寻找那个星球上的人/外星人。如果我们看到任何外星人,我们可以拒绝零假设,支持替代方案。
但是如果我们没有看到任何外星人,我们能肯定地说这个星球上没有外星生命或者接受我们的无效假设吗?也许我们需要探索更多,或者也许我们需要更多的时间,我们可能已经找到了外星人。所以,在这种情况下,我们不能接受零假设;我们只能拒绝它。或者用 Cassie Kozyrkov 的话来举例,我们可以说 “我们没学到什么有趣的东西”。
在 STAT101 课上,他们会教你在这种情况下写一段令人费解的段落。(“我们未能拒绝零假设,并得出结论,没有足够的统计证据来支持这个星球上存在外星生命。”)我深信这种表达的唯一目的就是让学生的手腕紧张。我总是允许我的本科生这样写:我们没有学到任何有趣的东西。

Riddikulus: Hypothesis testing can make the null hypothesis look ridiculous using p-values (The Wand)
本质上,假设检验就是检查我们的观察值是否让零假设看起来很荒谬 。如果是,我们拒绝零假设,称我们的结果具有统计学意义。除此之外,我们没有学到任何有趣的东西,我们继续我们的现状。
继续学习
如果你想了解更多关于假设检验、置信区间以及数字和分类数据的统计推断方法,Mine etinkaya-Rundel 在 coursera 上教授推断统计学课程,这是最简单不过的了。她是一个伟大的导师,很好地解释了统计推断的基础。
谢谢你的阅读。将来我也会写更多初学者友好的帖子。在 媒体 关注我或者订阅我的 博客 了解他们。一如既往,我欢迎反馈和建设性的批评,可以通过 Twitter @mlwhiz 联系
此外,一个小小的免责声明——在这篇文章中可能会有一些相关资源的附属链接,因为分享知识从来都不是一个坏主意。
p 值在起作用:可以肯定地说视差校正真的提高了卫星雨估计算法的精度吗?

source: https://planetary.s3.amazonaws.com/assets/images/spacecraft/2014/20140227_nasa_gpm.jpg
p 值到底是什么?我真的花了很长时间才搞清楚这个值的概念。根据我的经验,我认为了解 p 值的最佳方法是通过一个真实的例子。这就是为什么在这篇文章中,我将使用一个真实的例子来解释 p 值,我真的想证明这一点。但在此之前,我将解释一下关于另一个使 p 值相关的概念或理论,即零假设和正态分布。还将解释卫星降雨估计算法和视差校正的概念。
虚假设
零假设是一个假设,暗示我们非常怀疑我们的假设又名魔鬼代言人。零假设的反义词是另一个假设,或者说我们的假设是正确的。因此,在这种情况下,我们的零假设是视差校正没有提高卫星雨估计算法的精度,而另一个假设是视差校正提高了卫星雨估计算法的精度。
正态分布
在我个人的理解中,正态分布就是在任何常态下都会正常发生的分布。如果我们正在收集足够的数据,数据的直方图将会以数据的平均值为中心形成一个钟形。

source: https://www.statsdirect.com/help/resources/images/normalhistogram.gif
正态分布有两个属性,均值(μ)和标准差(σ) 。从一个经验实验来看,如果我们获取一个非常大的数据,并根据它制作一个直方图,它将向我们显示:
- 大约 68%的值落在平均值的一个标准偏差内。
- 大约 95%的值落在平均值的两个标准偏差范围内。
- 大约 99.7% —在平均值的三个标准偏差范围内。

p 值
在正态分布中,超过 3σ如果您想知道数据的百分比,您可以使用此公式,其原理是考虑正态分布钟形曲线的形状:

这就是 p 值的定义。在正态分布环境中, p 值只是基于 z 值的钟形曲线中的一部分数据。z 值是在标准偏差单位中重新调整的真实数据的值。

x is a real data
因此,当您将数据转换为 z 值时,钟形曲线的中心不再是数据的平均值,而是零。现在,我们知道了 p 值的概念,但在没有实际例子的情况下仍然有些模糊。在我们开始真正的例子之前,我将稍微解释一下卫星的视差校正和卫星降雨估计算法。
卫星雨量估计算法
这是一套算法,用来估计在气象卫星范围内某处的降雨量。气象卫星是一种捕捉地球上各种频率电磁波的卫星(所有温度高于 0 开尔文的物质实际上都在辐射各种频率的电磁波,这取决于该物质的温度)。从地球辐射出来的电磁波代表了地球的外部温度。当地球顶部是一朵云时,卫星实际上捕捉到了云的温度。但是当没有云的时候,它会捕捉陆地或海洋的温度(云的温度会比陆地或海洋冷)。
气象卫星捕捉云层的能力被用来估计云层下面的降雨量。一种最简单的降雨量估算算法叫做自动估算器。基于这篇论文,我们可以根据这个公式来估算某个地区的降雨量。

其中 T 是卫星捕获的温度,基于红外通道**。**
视差修正
粗略地说,为了计算校正,我们需要大气递减率来估计云的高度、云相对卫星的位置以及观测云的卫星的倾斜角。为什么我们需要视差纠正?简而言之,地球的曲率使一切变得复杂,云不只是一些简单的扁平物体,它有高度,这些导致一切都变得有点错位。反正如果你想了解更多关于视差纠正的知识,可以查看这个参考文献(印尼语)。作者是我工作单位的资深同事,他对气象卫星的估计算法和视差纠正非常有经验。事实上,我后来在实验中做视差纠正计算的那部分脚本就是来自于他。
实验
在这个实验中,我将把卫星的范围从一个区域限制到仅仅一个点。因为这个实验的验证是用雨量计。实验开始前,我们必须:
- 定义零假设,那就是"视差改正不提高卫星雨估计算法的精度"所以另一个假设是"视差改正提高卫星雨估计算法的精度"。****
- 定义阿尔法值。常见的 alpha 值是 0.05 和 0.01,但实际上,这取决于您的实验。我不知道这个选择是否正确,但在这个实验中,我选择 0.05 。
最后,也是最重要的,但在执行 p 值测试的义务之外,是我们如何进行计算,以确定修正后估计变得更好还是更差。很简单,首先我们计算自动估计器的估计值和自动估计器在雨量计校正后的估计值之间的差值的绝对值(真实数据)。如果值为正(> 0),估计的降雨量变得更好,否则,如果值为负(< 0),估计变得更差。
在数据科学中,**原始数据总是非常“脏”**因此,我在这个实验中的全套脚本(用于清理和合并数据)充满了“幻数”,也就是一个非常有条件的常数,它只是为了这个实验而存在。所以在这里,我只是分享一个已经清理的数据和脚本来做自动估计计算和视差纠正。
你可以在这里下载‘干净’的数据。自动估算器和视差纠正脚本可以在这里下载。自动估算器和视差脚本的输入是来自高知大学的 PGM 数据。下载一批数据的指令也可以在他们的网站上。
在我之前已经提到的干净数据中,我已经进行了获得 z 值 0 所需的所有计算,即 0.5779751399 。这个值远远大于我们的 alpha 值。所以结果是我们不能拒绝零假设。我们不能消除我们的疑虑,说视差校正真的提高了自动估算器算法的准确性是不安全的。
如果我们基于正态分布画出 0 及以下的 z 值,会得到如下图。

这是制作上图的脚本。
#!/usr/bin/python3from scipy.stats import norm
import numpy as np
import matplotlib.pyplot as plt def draw_z_score(x, cond, mu, sigma, title):
y = norm.pdf(x, mu, sigma)
z = x[cond]
plt.plot(x, y)
plt.fill_between(z, 0, norm.pdf(z, mu, sigma))
plt.title(title)
plt.show()x = np.arange(-3,3,0.001)
z0 = 0.577975139913483
draw_z_score(x, x<z0, 0, 1, 'z<%s'%(str(z0)))
这就是实验的结论。你觉得怎么样?是我的脚本有错误还是计算视差修正的假设有错误。我已经提到脚本计算自动估计器和视差纠正之前,你可以阅读它,并告诉我,如果在计算中有错误。
参考:
https://www . statistics show to . data science central . com/experimental-rule-2/,2019 年 7 月 16 日访问
https://www.statsdirect.com/help/distributions/normal.htm,2019 年 7 月 16 日进入
https://goodcalculators.com/p-value-calculator/,2019 年 7 月 16 日接入
https://www . academia . edu/35505495/tek NIS _ Kore ksi _ Parallaks _ Satelit _ hima wari,2019 年 7 月 18 日访问
http://weather.is.kochi-u.ac.jp/archive-e.html,2019 年 8 月 16 日接入
Rani、Nurhastuti Anjar、Aulia Khoir 和 Sausan Yulinda Afra。"使用基于 Himawari 8 卫星云顶温度的自动估算器进行的降水估算与旁卡平站的降水观测的比较."可持续人类圈国际研讨会论文集。2017.
数据科学家解释的 p 值
对于数据科学家来说

我记得当我作为暑期学生在 CERN 进行我的第一次海外实习时,在确认希格斯玻色子满足【五西格马】阈值 (这意味着 p 值为 0.0000003)后,大多数人仍在谈论希格斯玻色子的发现。
当时我对 p 值、假设检验甚至统计学意义一无所知。
你是对的。
我去谷歌搜索了 p 值这个词,我在维基百科上找到的东西让我更加困惑…
在统计假设检验中,p-值或概率值是对于给定的统计模型,当零假设为真时,统计汇总(如两个比较组间样本均值差的绝对值)大于或等于实际观察结果的概率。
— 维基百科
干得好维基百科。
好吧。我最终没有真正理解 p 值的真正含义。
直到现在,在进入数据科学领域后,我终于开始理解 p 值的意义以及它如何在某些实验中用作决策工具的一部分。
因此,我决定在本文中解释 p 值以及如何在假设检验中使用它们,希望能让你对 p 值有一个更好更直观的理解。
虽然我们不能跳过对其他概念的基本理解和 p 值的定义,但我保证我会以直观的方式进行解释,而不会用我遇到的所有技术术语来轰炸你。
本文共有四个部分,从构建假设检验到理解 p 值并以此指导我们的决策过程,向您展示一幅完整的画面。我强烈建议您通读所有这些内容,以便对 p 值有一个详细的了解:
- 假设检验
- 正态分布
- 什么是 P 值?
- 统计显著性
会很有趣的。😉
我们开始吧!
1.假设检验

在我们谈论 p 值意味着什么之前,让我们先来了解一下假设检验,其中 p 值用于确定我们结果的统计显著性。
我们的最终目标是确定结果的统计意义。
统计学意义建立在这三个简单的概念上:
- 假设检验
- 正态分布
- p 值
假设检验 用于检验利用样本数据对一个总体作出的断言*(***)的有效性。 替代假设 是当零假设被断定为不真实时,你会相信的假设。
换句话说,我们将做出一个断言(零假设),并使用一个样本数据来检验该断言是否有效。如果这个主张无效,那么我们将选择我们的替代假设*。就这么简单。*
为了知道一个声明是否有效,我们将使用 p 值来衡量证据的强度,以查看它是否具有统计显著性。如果证据支持替代假设*,那么我们将拒绝零假设并接受替代假设。这将在后面的部分中进一步解释。*
让我们用一个例子来使这个概念更清楚,这个例子将在本文中用于其他概念。
🍕 🍕 举例 : 假设一家披萨店声称他们的送货时间平均为 30 分钟或更短,但你认为时间比这还长。因此,您进行了假设检验,并随机抽取了一些交货时间来检验这一说法:
- 零假设 —平均交付时间为 30 分钟或更少
- 替代假设 —平均交货时间大于 30 分钟
这里的目标是确定从我们的样本数据中找到的证据更好地支持了哪一种主张——无效的还是替代的。
我们将使用 单尾检验 ,因为我们只关心平均交付时间是否大于 30 分钟。我们将忽略另一个方向的可能性,因为平均交付时间低于或等于 30 分钟的结果更可取。我们在这里想要测试的是,平均交付时间是否有可能大于 30 分钟。换句话说,我们想知道披萨店是否对我们撒了谎。😂
进行假设检验的一种常见方法是使用 Z-test 。在这里,我们不会进入细节,因为我们想有一个高层次的了解表面上正在发生的事情,然后我们潜入更深。
2.正态分布

Normal Distribution with mean μ and standard deviation σ
正态分布是一个概率密度函数用于查看数据分布。
正态分布有两个参数—平均值(μ)和标准差,也称为σ。
平均值是分布的中心趋势。它定义了正态分布的峰值位置。标准偏差是可变性的度量。它决定了这些值与平均值的差距。
正态分布通常与[**68-95-99.7 rule**](https://en.wikipedia.org/wiki/68%E2%80%9395%E2%80%9399.7_rule)(上图)相关联。
- 68%的数据在平均值(μ)的 1 个标准偏差(σ)内
- 95%的数据在平均值(μ)的 2 个标准偏差(σ)以内
- 99.7%的数据在平均值(μ)的 3 个标准偏差(σ)内
还记得我在开头提到的发现希格斯玻色子的“五西格马”阈值吗?5 西格玛大约是**99.9999426696856%**的数据,以在科学家证实发现希格斯玻色子之前命中。这是为避免任何潜在的错误信号而设定的严格阈值。
酷毙了。现在你可能想知道,“正态分布如何应用于我们之前的假设检验?”
因为我们使用 Z-test 来进行假设检验,所以我们需要计算(将在我们的 检验统计 中使用),这是数据点平均值的标准偏差数。在我们的例子中,每个数据点都是我们收集的披萨配送时间。

Formula to calculate Z-score for each data point
请注意,当我们计算了每个披萨配送时间的所有 Z 分数并绘制了如下的标准正态分布曲线时,X 轴上的单位将从分钟变为标准偏差单位,因为我们已经通过减去平均值并除以其标准偏差对变量进行了标准化(参见上面的公式)。****
查看标准正态分布曲线非常有用,因为我们可以将测试结果与标准偏差中具有标准化单位的“正常”总体进行比较,尤其是当我们有一个具有不同单位的变量时。

Standard Normal Distribution for Z-scores
Z 分数可以告诉我们总体数据与平均人口相比的位置。
我喜欢 Koehrsen 这样说—Z 值越高或越低,结果就越不可能是偶然发生的,结果就越有可能是有意义的。
但是,有多高(或多低)被认为有足够的说服力来量化我们的结果有多大意义呢?
👊🏼笑点****
这就是我们需要解决这个难题的最后一个项目——p 值,并检查我们的结果是否基于 显著性水平(也称为α)在我们开始实验之前,我们设置了。**
3.什么是 P 值?
p-value beautifully explained by Cassie Kozyrkov
最后……这里说的是 p 值!
前面所有的解释都是为了搭建舞台,把我们引向这个 p 值。我们需要之前的上下文和步骤来理解这个神秘的(实际上并不神秘)p 值,以及它如何导致我们对假设检验的决策。
如果你已经做到了这一步,请继续阅读。因为这部分是最令人兴奋的部分!
与其用维基百科(对不起维基百科)给出的定义来解释 p 值,不如用我们的上下文来解释——披萨配送时间!
回想一下,我们随机抽样了一些比萨饼的交付时间,目标是检查平均交付时间是否大于 30 分钟。如果最终证据支持比萨饼店的说法(平均送货时间为 30 分钟或更少),那么我们不会拒绝零假设。否则,我们会拒绝无效假设。
因此,p 值的任务是回答这个问题:
如果我生活在一个披萨外卖时间不超过 30 分钟的世界里(零假设成立),我在现实生活中的证据会有多令人惊讶?
p 值用一个数字来回答这个问题——概率。
p 值越低,证据越令人惊讶,我们的零假设看起来就越荒谬。
当我们对自己的无效假设感到可笑时,我们该怎么办?我们拒绝这一点,而是选择我们的替代假设。
如果 p 值低于预定的显著性水平*(人们称之为 alpha ,我称之为荒谬的阈值— 不要问我为什么,我只是觉得我更容易理解),那么我们拒绝零假设。***
现在我们明白 p 值是什么意思了。让我们将这一点应用到我们的案例中。
🍕披萨配送时间的 p 值🍕
现在我们已经收集了一些交货时间样本,我们进行计算,发现平均交货时间增加了 10 分钟,p 值为 0.03* 。***
这意味着在一个披萨交付时间为 30 分钟或更少的世界*(零假设为真),有 3%的几率我们会看到由于随机噪声导致平均交付时间至少延长 10 分钟。***
p 值越低,结果越有意义,因为它不太可能是由噪声引起的。
在我们的案例中,大多数人对 p 值有一个普遍的误解:
p 值为 0.03 意味着有 3%(概率百分比)的结果是由于偶然的,这不是真的*。***
人们常常希望有一个明确的答案(包括我),这就是我如何让自己困惑了很长时间来解读 p 值。
p 值不能证明任何事情。这只是一种利用惊喜作为做出合理决定的基础的方式。
卡西·科济尔科夫
下面是我们如何使用 p 值 0.03 来帮助我们做出合理的决定(重要):
- 想象一下,我们生活在一个平均送货时间总是 30 分钟或更少的世界——因为我们相信比萨饼店(我们最初的信念)!
- 在分析了收集到的样本交付次数后,p 值 0.03 低于显著性水平 0.05(假设我们在实验之前设置了这个),我们可以说结果是 统计显著 。
- 因为我们一直相信比萨饼店能够履行其承诺,在 30 分钟或更短时间内交付比萨饼,我们现在需要思考这一信念是否仍然有意义,因为结果告诉我们比萨饼店未能履行其承诺,并且结果是 统计显著性 。
- 那我们该怎么办?首先,我们试图想出每一种可能的方法来使我们最初的信念(零假设)有效。但是因为比萨饼店慢慢地得到了其他人的差评,而且它经常给出糟糕的借口导致交货延迟,甚至我们自己都觉得为比萨饼店辩护是荒谬的,因此,我们决定拒绝零假设。
- 最后,随后合理的决定是,选择不再购买那个地方的任何披萨。
到现在为止,你可能已经意识到了一些事情…根据我们的上下文,p 值不用于证明或证明任何事情。
在我看来, **p 值是在结果具有统计显著性* 时,用来挑战我们最初信念(零假设)的工具。当我们对自己的信念感到可笑时(假设 p 值显示结果具有统计学意义),我们会抛弃最初的信念(拒绝零假设)并做出合理的决定。***
4.统计显著性
最后,这是最后一个阶段,我们将所有内容放在一起,测试结果是否具有 统计显著性。
仅有 p 值是不够的,我们需要设置一个阈值(又名显著性水平——阿尔法*)。阿尔法应该总是在实验前设置,以避免偏见。如果观察到的 p 值低于α,那么我们得出结论,结果是 具有统计显著性。***
经验法则是将 alpha 设置为 0.05 或 0.01(同样,该值取决于您手头的问题)。
如前所述,假设我们在开始实验前将α设置为 0.05,由于 0.03 的 p 值低于α,因此获得的结果具有统计学意义。
- 陈述无效假设
- 陈述另一个假设
- 确定要使用的α值
- 找到与你的阿尔法水平相关的 Z 分数
- 使用此公式查找测试统计
- 如果检验统计值小于α水平的 Z 得分(或 p 值小于α值),则拒绝零假设。否则,不要拒绝零假设。

Formula to calculate test statistic for Step 5
如果你想了解更多关于统计学意义的知识,可以看看这篇文章——由威尔·科尔森撰写的统计学意义解释。
最后的想法

感谢您的阅读。
这里有很多东西要消化,不是吗?
我不能否认,p 值对许多人来说是天生的困惑,我花了很长时间才真正理解和欣赏 p 值的意义,以及作为一名数据科学家,它们如何应用于我们的决策过程。
但是不要过于依赖 p 值,因为它们只帮助整个决策过程的一小部分。
我希望你已经发现 p 值的解释是直观的,并有助于你理解 p 值的真正含义以及它们如何用于假设检验。
归根结底,p 值的计算很简单。当我们想要解释假设检验中的 p 值时,困难就来了。希望最难的部分现在对你来说至少变得稍微容易一点。
如果你想了解更多关于统计学的知识,我强烈推荐你读这本书(我现在正在读这本书!)— 数据科学家实用统计学 专为数据科学家理解统计学的基本概念而编写。
一如既往,如果您有任何问题或意见,请随时在下面留下您的反馈,或者您可以随时通过 LinkedIn 联系我。在那之前,下一篇文章再见!😄
关于作者
Admond Lee 目前是Staq—的联合创始人/首席技术官,该平台是东南亚首屈一指的商业银行应用编程接口平台。
想要获得免费的每周数据科学和创业见解吗?
加入 Admond 的电子邮件简讯——Hustle Hub,每周他都会在那里分享可行的数据科学职业技巧、错误&以及从创建他的初创公司 Staq 中学到的东西。
你可以在 LinkedIn 、 Medium 、 Twitter 、脸书上和他联系。
让每个人都能接触到数据科学。Admond 正在通过先进的社交分析和机器学习,利用可操作的见解帮助公司和数字营销机构实现营销投资回报。
www.admondlee.com](https://www.admondlee.com/)*****
P2P 借贷平台数据分析:R 中的探索性数据分析—第一部分
对 Prosper 贷款数据的探索

P 近年来,P2P 借贷平台行业蓬勃发展。成千上万的投资者通过这些平台获利;成千上万的借款人更容易拿到钱。尽管这些平台提供借款人的信用评分和基本信息,以确保借贷交易处于安全的环境中,但仍有成千上万的人面临亏损的风险。
即使是领先的金融 P2P 贷款平台公司 Prosper,也仍然受到信用风险问题的困扰。但经过他们的重建和新的信用体系的推出,信用风险得到了改善。这让我想找出幕后的故事。在这里,我将探索这个 Prosper 数据集,并试图找出借款人财产背后的一些模式,不同的评级类型,以及它们如何链接到违约贷款或已完成贷款。
此外,我还将分享一些关于变量探索动机的想法。毕竟,在如此庞大的数据集中,如果我们从了解一些基本的领域知识开始,就更容易在这个大数据中挖掘出有价值的特征。
Prosper 贷款数据
该 Prosper 数据集由 Udacity 提供,作为数据分析师 Nanodegee 的一部分(最后更新于 2014 年 3 月 11 日),可点击此处下载。它包含 2005 年至 2014 年期间每个贷款列表数据的 81 个变量和 113,979 个观察值,这些数据可以大致分为四种变量类别:
- 贷款状态:贷款列表的状态,如已取消、已核销、已完成、当前、已拖欠、尾款进行中、逾期。
- 借款人数据:借款人的基本属性,如收入、职业、就业状况等。
- 贷款数据:贷款的基本属性,如贷款期限、借款人年利率等。
- 信用风险指标:衡量贷款风险的指标,如信用等级、Prosper 评分、银行卡使用率等。
变量定义见链接。
感兴趣的初始问题
我以前从未使用过 P2P 贷款平台,但我总是很好奇为什么投资者总能从这些高风险的贷款中获利?
我对这个问题的第一个猜测是,P2P 借贷平台上的信用评估指标具有一定的参考价值,尤其是对于 Prosper 或 LendingTree 这样业绩良好的平台。原因是,在 P2P 借贷平台上,我们无法获得大量关于借款人的信息,唯一的参考来源是 P2P 借贷平台提供的指标。而这些信息为投资者提供了更可靠的赚钱机会。据此,我的问题可以是——**好的 P2P 借贷平台——比如 Prosper——的评级指标的性质是什么,它们是如何与违约和已完成贷款联系在一起的?**如果我能找到与违约和已完成贷款有某种趋势的特征,也许这些特征是评估贷款好坏的关键因素。
在继续探索贷款数据以找到答案之前,让我们先了解一下 P2P 借贷平台的基本属性。
P2P 借贷平台:繁荣展望

总的来说,P2P 借贷平台的属性与传统借贷渠道——银行有很大不同,银行总是根据独立征信机构对借款人的信用评分来评估贷款。但是我们知道在 P2P 借贷平台上,贷款总是高风险的。**如果他们通过信用报告机构对这些贷款进行评级,这些贷款将总是被评为高风险。**这种情况会影响投资者对 P2P 借贷平台的判断。因此,可能存在一些不同于传统信用度量的风险度量,它们可以正确地评估 P2P 贷款。
让我们看看 Prosper page,从投资者的角度来看看他们的风险评级指标。如果我们查看贷款列表页面,我们可以看到“评级”列,每个贷款列表都在左侧。此外,我们可以看到每笔贷款的其他基本信息,如类别或金额。因此,如果投资者决定是否投资一笔贷款,那么“评级指标就成了对平台信用风险的主要评估。

Source: https://www.prosper.com/listings
那么评级是什么,评级表现如何?我翻了翻亨通的表格 S-1年报维基 ,做了一个总结:
在 2009 年之前,向投资者展示的主要信用风险指标是信用等级,这是基于独立信用报告机构对借款人的信用评分。但当时 Prosper 上的贷款业绩并不是很好。在 SEC 要求暂时关闭和重组后,Prosper 推出了自 2009 年 7 月以来显示的新信用风险指标— Prosper Rating ,这被视为对借款人更严格的信用准则。新的贷款业绩显示,Prosper 的贷款违约率已大幅降低。
看起来繁荣评级比旧的信用等级表现得更好,后者像银行一样评估贷款。这让我想比较一下 Prosper 贷款数据中 2009 年前后的**Loan Status**。
了解数据背景知识的一些小技巧…
在进入下一部分之前,我想介绍一些关于如何快速理解目标数据的基本领域知识的技巧。
作为一名经验丰富的投资银行家,快速了解基础领域知识并进行总结是我们主要的日常工作。当我们开始了解一个全新的行业知识时,找到公司的上市文件,如 SEC 备案 非常有用。最知名的上市文件叫做 年报 。如果感兴趣的公司以前没有在股票市场上市,也可以搜索已经上市的同行业领先公司的文档。
以下是快速了解一个公司/行业的新行业知识和历史的主要来源:
- 上市文件:表格 S-1、表格 10-K、年度报告等。他们提供基本的公司背景和历史,行业信息和竞争,主要产品和服务介绍,财务业绩等。如果该公司已经在股票市场进行首次公开募股,可以很容易地在 投资者关系(IR) 的公司网页上找到它们。****
- 行业报告:我们可以在行业报告上找到丰富的行业趋势和参与者。知名信源如 IBISWorld 、 IDC 、MarketResearch.com等。注:大多数行业报告来源需要付费账户,但他们总是提供一份报告摘要,让我们可以获得一些基本信息。
- 统计来源:调查一段时间内的数量表现很有用。大多数上市文件都提供财务报告。如果你想要一个更完整的统计来源,最推荐的来源是 Statista 。
- 维基百科和谷歌搜索:几乎一切的灵丹妙药。
2009 年前后的贷款表现
在数据集中,我定义了高风险贷款被贷款有逾期,已收贷款** 或 拖欠;完成的贷款被的贷款被完成,完成的贷款被和的贷款被取消。****

上面的条形图显示,高风险贷款的比例在 2009 年后从大约 37%下降到 30%。
让我们比较一下从 HR 到 AA(高到低风险)的信用等级和 Prosper 评级与贷款状况之间的关系。我想知道 Prosper Rating 和 Credit Grade 如何评估不良贷款和良好贷款。

随着风险水平的降低,高风险贷款的百分比与繁荣等级和信用等级均呈反比关系。高风险贷款的百分比越低,评级越好。我们可以看到,在 Prosper Rating 推出后,整个高风险贷款(绿色)实际上减少了。
在高风险和已完成贷款中,我进一步将贷款按照从 AA 到 HR(低风险到高风险)的每个信用级别分组:

上图显示,2009 年前评级为良好的贷款数量在 2009 年后有所减少,无论是已完成贷款还是高风险贷款,这意味着 Prosper 在 2009 年后进行了更加严格的贷款审计。此外,高风险贷款总计与 2009 年之前的贷款相比有所下降,如前图所示**,而评级为 D 和 E 的高风险贷款在 2009 年**之后仍有所上升。****
可以推断出:
- Prosper 在 2009 年后进行更严格的贷款审计。
- 与 2009 年之前应用的信用等级相比,Prosper 评级的能力在评估高风险贷款方面表现更好。
Prosper 评级的组成部分

我们从 Prosper 数据中看到了 Prosper 评级的良好表现。那么,如何衡量繁荣等级呢?****
根据这个页面 , Prosper 评级由估计损失率决定,这个估计损失率由两个分数决定:1)一个自定义的 Prosper 评分和 2) 一个来自消费者信用报告机构(如 Experian)的信用评分。所以我会在 Prosper 评分和信用评分里多调查一下,看看他们是怎么让 Prosper 评分比信用等级更准确的。
1.Prosper 得分
**据 Prosper 网站介绍, Prosper Score 是使用历史 Prosper 数据构建的,用于评估 Prosper 借款人上市的风险。范围从 1 到 11,11 为最低风险,1 为最高风险。

上图显示 Prosper 得分呈钟形分布,得分峰值为 4、6、7,Prosper 数据中风险最低和最高的得分较少。

对每个贷款状态进行分组 Prosper 评分,我们可以看到它们在已完成贷款中呈左偏形分布,这意味着已完成贷款主要位于良好评级。然而,Prosper score 在高风险贷款中呈钟形分布。与之前显示的左倾形状的 Prosper 评级相比,Prosper Score 似乎检测高风险贷款的能力较低。
Prosper 评级的另一个组成部分是来自报告机构的信用评分。在这个数据集中,我发现与这类分数相关的变量是CreditScoreRangeLower和CreditScoreRangeUpper**。我创建了一个新变量, CreditScoreAverage, 对这两个变量进行平均,作为信用评分的代表变量。****
2.信用评分平均值
2009 年之前,Prosper 不允许信用评分(Experian Scorex PLUS)低于 520 的个人在平台上发布房源。2009 年后,Prosper 将信用评分的最低门槛提高到 640 分,但在某些情况下,如果借款人之前完成了 Prosper 贷款,他们允许评分最低值为 600 分。因此,我将图表分为两个时期,并将 x 轴上得分的最小值限制为 510 和 630,以排除特殊情况的异常值。

2009 年前后的*均为右偏分布,2009 年前多数计数在 610 至 670,2009 年后多数计数在 670 至 710。与 2009 年之前的贷款相比,2009 年之后的总体平均信用评分明显更高。原因是 Prosper true在 2009 年之后对借款人的信用评分设置了更高的门槛,这也与 Prosper 评级前一节的观察结果相吻合。*
但是信用评分平均值和 Prosper 评分如何让 Prosper 评级更准确呢?2009 年前后信用评分平均值对已完成和高风险贷款有影响吗?我将 2009 年前后已完成和高风险的平均信用评分与贷款状态进行了分组:**

对比已完成和高风险贷款的分布,上图出现了几乎相似的分布*,在两个时期都呈右偏形状。似乎credit score average对检测 2009 年前后完成和高风险贷款没有区别,只是门槛的变化。***
事实证明:如果 Prosper 仅使用信用评分进行审核,在 2009 年后更严格*评估(更高门槛)的情况下,*当时整体借款人的信用评分将主要位于高风险等级,即使是完成概率很高的贷款。但是,由于 Prosper 也结合了 Prosper 评分,这使得 Prosper 评级呈现出更好的衡量能力,并在已完成贷款和高风险贷款之间表现出更好的区分。
调查到目前为止…

我们来简单总结一下。2009 年后,Prosper 将 Prosper 评分应用到中,使得 Prosper 评级在 2009 年后更严格的局分门槛评定标准下,对不良贷款和已完成贷款、有了更多的区分。因此,我们可以说 Prosper 得分在 Prosper 评级指标中发挥了重要作用。**
让我们用数据来阐述这个假设:

上图显示繁荣等级与繁荣分数之间的趋势呈略正的形状,各繁荣等级中繁荣分数的方差更为集中。与信用评分平均值相比,每个 Prosper 评级中信用评分平均值的方差比 Prosper 评分的稍大*。似乎 Prosper 在他们自己的 Prosper 评级模型中使用的 Prosper 评分的线性权重多于信用评分平均值。*****
下一步:揭开繁荣得分的面纱**
那么成功得分的主要要素是什么呢?我翻阅了 2010 年和 2013 年的 Prosper 年度报告,发现了一些关于 Prosper Score 的信息:**
Prosper Score 用于评估贷款逾期 61 天以上的可能性。与从信用报告机构获得的信用评分基于更广泛的人群不同,Prosper Score 基于更小的借贷平台子集的更精确的图像。
兴趣。我推断,如果 Prosper 只是通过传统的局机构来衡量借款人的信用,实际上它只是一种类似于银行或其他官方贷款机构的衡量方式。 Prosper Score 考虑在平台人群中独一无二的借款人行为*。也许这样的定制评估更适合借贷平台市场,因为它是专门由繁荣的借款人和申请人群体来衡量的。因为我们知道,当借款人无法从信用评分更严格的银行贷款时,贷款平台会为借款人提供额外的平台。借贷平台将风险分散给许多投资者,这使得衡量方法大不相同。***
因此,我搜索了成功得分的主要因素。我发现一些不同的来源表明,随着时间的推移,Prosper Score 是由不同的元素组成的,如网站或这个网站。为了避免报告太长,我不打算探究 Prosper 数据中的所有相关特性。相反,我将选择一些我认为重要的变量,这些变量也包含在这些来源的变量列表中。
在下一部分中,我将探讨可能与 Prosper 评分相关的主要特征,这些特征有可能使 Prosper 评级在评估贷款质量时更具辨别力*。*****
注:更详细的探索结果请见我的报告中的 Rpubs 和 GitHub 中的代码!
P2P 借贷平台数据分析:R 中的探索性数据分析—第二部分
发现 P2P 数据特征如何与贷款质量相关联

在上一篇文章中,我们发现 Prosper 采用了一个更好的信用风险指标——Prosper 评级,用于 Prosepr 借贷平台。我们知道 Prosper 评级由 Prosper 评分和征信机构评分组成,我们还发现 Prosper 评分起着关键作用,这使得 Prosper 评级比征信机构评分本身更具歧视性。
在这篇文章中,我将调查 Prosper Score 与该贷款数据中的其他特征之间的关系,以了解这些特征如何链接到 Prosper Score、和这些特征如何在该 P2P 借贷平台中区分已完成贷款和高风险贷款。
第一步:相关矩阵
在这个包含 81 个变量的庞大数据集中,为了避免这篇文章太长,我不会开始逐一寻找潜在的有用特性。相反,我将从一个带有ggcorrplot的相关矩阵开始,以便在深入研究之前快速了解特性之间的线性关系。通过相关矩阵,我们可以关注我们感兴趣的变量——Prosper Score,并查看其他变量是否与之相关。

我们可以看到繁荣评级与借款人利率有很强的负相关关系,这是有道理的,因为借款人利率主要由繁荣评级决定。此外, Prosper 评级与 Prosper 评分有很强的相关性,相关系数为 0.8 ,而信用评分平均值为 0.6 。这再次表明可能 Prosper 对 Prosper 评分比对信用评分平均值更重视,以便从线性角度对 Prosper 评级进行建模。
此外,我们可以看到 Prosper Score 与scorexchangeattimeflisting、inquiries last 6 个月 、 银行卡使用率 、debttoincommeratio和statedmonthyincome呈弱线性关系,相关系数范围为± 0。虽然这些特征与 Prosper Score 呈弱线性关系,但我认为这些特征中可能仍然存在一些信息。通过使用相关矩阵作为参考,我将选取这五个特征,然后绘制散点图,以进一步研究这些特征之间的更多趋势。
我通过剧情的调查包括两部分:一是看这些特征如何与 Prosper Score 挂钩;另一个是看这些特征是否能区分完整贷款和高风险贷款。
得分 X 上市时的变化
scorexchangeattimeflisting*测量提取信用档案时借款人的信用评分变化,其中变化相对于借款人的最后一笔 Prosper 贷款**。scorexchangeattimeflisting的值可以是正的也可以是负的,因为它评估信用评分的值“变化”。*

上图显示,Prosper 得分和scorexchangeattimeflisting之间的线性趋势很明显,随着 Prosper 得分的一个点的增加而增加。我推断 Prosper Score seescorexchangeattimeflisting是一个重要的信号,并将其与线性增量一起用于模式 Prosper Score。
它与贷款状态有什么联系?

在 Prosper Score 和scorexchangeattimeflisting、中对贷款状态进行分组,我们可以看到趋势很明显。高风险贷款往往有较低的 Prosper 评分为 1 到 6,而**较低的scorexchangeattimeflisting范围为-100 到 50。已完成的贷款往往具有从 6 到 10 的较高的 Prosper 得分和从-50 到 100 的较高的scorexchangeattimeflisting*。似乎 Prosper Score 可以区分scorexchangeattimeflisting中不同级别的已完成和高风险贷款。*
这个探索结果有点有趣,因为scorexchangeattimeflisting考虑了借款人相对于借款人最近一次 Prosper 贷款的信用评分**,,这意味着该指标不仅考虑了借款人的信用评分,还考虑了 Prosper 数据的历史记录。基于这一概念,我对 Prosper 充分利用信用评分**和 Prosper 数据印象深刻,它确实在已完成和高风险贷款中呈现出这样的趋势。
最近 6 个月的调查
此变量评估过去六个月提取信用档案时的查询数量。查询是指机构向信用机构请求信用信息。一般来说,当某人频繁申请信用卡等信用账户时,就会在短时间内出现大量查询,这意味着他或她有很高的资金需求。

在散点图中我们可以看到这种关系并不明确,大多数贷款位于第 1 到 2 次的 InquiriesLast6Months 个月中,跨越 Prosper 得分 2 到 10。但是随着 Prosper 得分的增加,持续 6 个月的调查的上限债券下降的趋势仍然存在。**

尽管如此,在 Prosper Score 和调查中,过去 6 个月的贷款状况趋势仍不明朗。我们可以看到,大多数高风险贷款主要位于 Prosper 得分较低的级别,但它们广泛分布在每个级别的调查中,过去 6 个月Prosper 得分保持不变。
只调查过去 6 个月贷款状况的差异如何?

从上图中我们可以看到,在高风险贷款和已完成贷款之间,过去 6 个月的查询没有显著差异。**
这个结果是合理的,因为借款人过去 6 个月的高询问率并不直接暗示他或她有不良信用。它可能有潜在的风险,但至少在这个数据集中不是必要的。
银行卡使用情况
**银行卡利用率衡量借款人在提取信用档案时使用的信用限额总额。比率越低,一个人的金融流动性越大。

从箱线图来看,银行卡使用率的分布随着 Prosper 得分的增加而向下移动,但是银行卡使用率的方差在各个 Prosper 得分上都很高,这使得 Prosper 得分和银行卡使用率之间的趋势不明显。但是大致相反的趋势仍然存在,尤其是 Prosper 得分的高端和低端水平。也许 Prosper Score 在他们的模型中使用了一些更复杂的方式。**

Prosper Score 和银行卡使用率之间的贷款状态趋势不明确。我们可以看到,大多数高风险贷款主要位于 1 至 6 的 Prosper 评分较低的级别,但它们广泛分布在保持 Prosper 评分不变的银行卡使用的各个级别。
尽管如此,这个结果并没有让我感到惊讶,因为有时高的银行卡使用率对一个信用不良的人来说并不必要。他或她可能只是在那个时候有一个高债务信用,但仍然会按时付款。

上图显示银行卡使用率在高风险贷款中的分布略高于已完成贷款,但两者的银行卡使用率、的方差都很大,使得两者没有显著差异。
债务收入比
一般来说,较高的债务收入比表明如果一个人的债务超过了他或她的收入。相反,较低的债务收入比意味着债务和收入之间的良好平衡。

在这里,我们可以看到,随着 Prosper 得分的增加,当debttoincommeratio下降时,上图呈现出明显的线性反向趋势。

上图显示了 Prosper Score 中贷款状态和debttoincommeratio的明显趋势。高风险贷款的 Prosper 得分往往较低,为 1 比 6,债务与收入比率为 0.5 比 1。已完成的贷款往往具有较高的 Prosper 评分,在 6 到 10 之间,而debttoincommeratio在 0.1 到 0.6 之间。似乎 Prosper Score**可以区分debttoincommeratio和中不同级别的已完成和高风险贷款***。*
这个结果看起来是合理的,因为 T42 是衡量一个人偿还能力的直接信号。
规定月收入
作为收入数据,的统计月收入的分布从直方图中呈现出右偏的形状(此处未显示),所以我去掉了统计月收入变量的前 1%。**

上图显示,Prosper 得分和月收入之间的趋势呈上凹状。这是合理的,因为收入也是衡量偿债能力的一个直接指标,显然收入数据的特点使衡量 Prosper 得分呈指数级递增。多一分的财富分数需要更高的收入水平。

上图显示,Prosper 得分和月收入与贷款状态之间存在明显的趋势。高风险贷款的 Prosper 评分往往较低,在 1 至 6 分之间,并且的月收入水平较低,在 2,000 美元至 5,000 美元之间。相反,已完成贷款的 Prosper 评分更高,在 7 到 10 分之间,月收入更高,在 5,000 美元到 10,000 美元之间。与debttoincommeratio和scorechangeattimeflisting 类似,Prosper 得分很可能**能够区分月收入和不同级别的已完成或高风险贷款**。**
探索总结
我们挑选了五个特征,看看它们是否具有与 Prosper Score 或*、*相关的趋势,并看看它们是否能够区分已完成贷款和高风险贷款。勘探结果表明:
- scorexchangetimeflisting和DebtToIncomeRatio均与 **Prosper 得分呈线性趋势。前者呈现正相关关系;后者与 Prosper 得分呈负相关。
- scorexchangeattimeflisting和DebtToIncomeRatio在不同的 Prosper 评分水平上,完成的和高风险的都有明确的模式。高风险贷款倾向于具有较低的 Prosper 评分水平,并且具有较低的scorechangeattimeflisting和较高的debttoincommeratio保持 Prosper 评分不变; 完成贷款往往具有较高的 Prosper 水平,并且具有较高的scorechangeattimeflisting和较低的debttoincommeratio持有 Prosper 得分不变。******
- StatedMonthlyIncome也随着 Prosper Score 呈现出一种趋势,但这种趋势是一种递增的上凹趋势,而不是线性的。这表明 Prosper Score 的多一分需要更高等级的 StatedMonthlyIncome。**
- StatedMonthlyIncome****在完成和高风险两个不同等级的 Prosper 评分中也有明确的模式。高风险贷款倾向于具有较低的 Prosper 得分水平,并且具有较低的月收入保持 Prosper 得分不变。**
- 调查对象最近 6 个月 和银行卡使用率** 与 Prosper 评分和贷款状况不呈现显著趋势。**
到目前为止,我们已经看到了一些与 Prosper 得分和贷款状态相关联的利息模式,我们发现scorexchangeattimeflisting、debttoincominratio和StatedMonthlyIncome与 Prosper 得分有明显的趋势。将这三个特征考虑到不同级别的 Prosper 得分中,我们可以看到它们在已完成贷款和高风险贷款之间呈现出清晰的模式,保持 Prosper 得分不变。
毫不奇怪,和 表示的月收入 呈现这样的趋势,因为这两者是对偿债能力的直接衡量。但令我印象深刻的是,scorexchangeattimeflisting用 Prosper Score 呈现出一种趋势,也显示出区分已完成贷款和高风险贷款的能力。
P2P 贷款是一个新概念,其信用风险衡量也是如此。在整个项目中,我们一直在挖掘一些关于 Prosper 的背景知识,使用 EDA 基本工具找出一些与 Prosper 的信用风险衡量相关联的特征— Prosper Rating 和 Prosper score。与传统的衡量方法——信用局评分不同,这些特征展示了在借贷平台中高风险贷款和已完成贷款之间的不错的评估能力。并且这些特征也被建模,其利用了信用局分数和平台贷款数据**。我认为这样一个有趣的概念可以用于 P2P 借贷平台中进一步的数据科学应用,如预测违约率或不良贷款。**
希望你喜欢这种基于概念的探索性数据分析!

注:更多详细探索结果,请参见我的报告中的 Rpubs 和代码 GitHub !
使用 PaaS 加速数据科学
试用 DC/操作系统数据科学引擎
作为一名专注于向市场提供新产品的全栈机器学习工程师,我经常发现自己处于数据科学、数据工程和开发运营的交叉点。因此,我一直怀着极大的兴趣关注着数据科学平台即服务(PaaS)的兴起。在这一系列帖子中,我将评估不同的平台即服务(PaaS)及其自动化数据科学运营的潜力。我将探索他们的能力,然后自动设置和执行我即将出版的书中的代码 (O’Reilly,2020 年),为这本书的读者找到阅读这本书的最佳方式。
在我的上一本书敏捷数据科学 2.0 (4.5 星:D)中,我为读者构建了自己的平台,使用 bash 脚本、AWS CLI、 jq 、vagger 和 EC2 运行代码。虽然这使得这本书对那些运行代码有困难的初学者来说更有价值,但是维护和保持运行是非常困难的。旧软件从互联网上脱落,平台腐烂。这个项目已经出现了 85 个问题,虽然许多问题已经通过读者的贡献得到了解决,但它仍然占据了我在开源软件上花费的大量时间。这次会有所不同。
注:本岗位代码可在github.com/rjurney/paas_blog获得
DC/操作系统数据科学引擎

DC/OS is a highly scalable PaaS
我评估的第一个数据科学 PaaS 是新推出的 DC/OS 数据科学引擎。在这篇文章中,我将通过 GUI 向您介绍我对 DC/OS(注意:我过去曾使用过它)及其数据科学引擎的初步实验,然后我们将讲述如何用几行代码来自动化相同的过程。事实证明,这实际上比使用 AWS CLI 创建等效资源更简单,这给我留下了深刻的印象。我们将设置我们的环境和软件先决条件,使用 Terraform 和通用安装程序初始化 DC/操作系统集群,安装数据科学引擎包,然后通过运行标记堆栈溢出帖子的模型来评估环境。
一些警告:我们将一步一步地介绍如何引导安装了 JupyterLab 的 DC/OS 集群,但是如果您遇到麻烦,您可以随时参考通用安装程序文档来解决 DC/OS 平台问题,或者参考数据科学引擎文档来解决部署该服务的问题。
为什么选择 DC/操作系统数据科学引擎?
在任何给定的云环境中,如亚马逊网络服务(AWS)、谷歌云平台(GCP)和 Azure,为个人数据科学家工作设置一个 Jupyter 笔记本已经变得相当容易。对于创业公司和小型数据科学团队来说,这是一个很好的解决方案。没有什么需要维护的,笔记本可以保存在 Github 中以便持久化和共享。
对于大企业来说,事情没有这么简单。在这种规模下,跨多个云的临时资产上的临时环境可能会造成混乱而不是秩序,因为环境和建模变得不可复制。企业跨多个云和在本地工作,具有特定的访问控制和身份验证要求,并且需要提供对内部资源的访问以获得数据、源控制、流和其他服务。
对于这些组织,DC/操作系统数据科学引擎提供了一个统一的系统,该系统提供 Python ML 堆栈、Spark、Tensorflow 和其他 DL 框架,包括TensorFlowOnSpark*以支持分布式多节点、多 GPU 模型训练。*这是一个非常引人注目的设置,开箱即用,可以结束大型数据科学团队和公司的许多挫折和复杂性。
软件和平台先决条件
DC/操作系统通用安装程序可以在 Linux、Mac OS X 和 Windows 上运行。对于所有平台,你都需要 Python 、 pip 、 AWS 命令行界面(CLI) 和 Terraform 。如果您正在测试数据科学引擎,您可能已经安装了 Python,但是如果没有,我们将安装 Anaconda Python 。
您还需要在运行 DC/操作系统数据科学引擎的地区授权 5 个 GPU 实例(在本文中,我们使用“us-west-2”)。让我们一步一步来。
安装 Anaconda Python

Anaconda Python
如果您的机器上已经安装了 Python,就没有必要安装 Anaconda Python。如果您不知道,我推荐 Anaconda Python,因为它易于安装,位于您的主目录中,并且具有优秀的 conda 包管理器。
下载蟒蛇 Python 3。x 为您的平台这里,然后按照说明安装 Linux 、 Mac OS X 和 Windows 。
通过安装和配置 Amazon Web Services CLI 进行 AWS 身份验证

为 Terraform AWS 提供者设置 AWS 访问有两种方式:通过 AWS CLI 或通过编辑(来自 Github 项目根的路径)PAAs _ blog/dcos/terra form/terra form . TF。
首先,我们将为 Terraform 设置要使用的 AWS 凭证。要使用 PyPI awscli 包:
# Install using conda
conda install -c conda-forge awscli# OR…# Install using pip
pip install awscli --upgrade --user
现在使用您的访问密钥 ID 和秘密访问密钥设置您的 AWS 凭证,您可以在 IAM 控制台中找到它们。您可以将区域更改为您自己的默认值。Terraform 的 AWS 模块将默认使用这些凭证。它们存放在 ~/中。aws/ 目录。
aws configureAWS Access Key ID [None]: **AKIAIOSAODNN7EXAMPLE**
AWS Secret Access Key [None]: **wJalrXUtnFEMI/K7MBENG/bPxRfiCYEXAMPLEKEY**
Default region name [None]: **us-west-2**
Default output format [None]: **json**
现在验证设置是否有效:
aws sts get-caller-identity
您应该会看到类似这样的内容:
{
“UserId”: “123456789101”,
“Account”: “109876543210”,
“Arn”: “arn:aws:iam::123456789101:root”
}
通过编辑 terraform.tf 进行 AWS 身份验证
您可以通过编辑(从项目根目录)PAAs _ blog/dcos/terra form/terra form . TF来显式设置 AWS 身份验证,以便在调用 AWS 提供者时包含您的凭证。只需添加您的访问密钥/秘密密钥和默认区域。
provider “aws” {
access_key = “foo”
secret_key = “bar”
region = “us-west-2”
}
安装 Terraform

Terraform 使用户能够使用一种称为 Hashicorp 配置语言(HCL)的高级配置语言来定义和配置数据中心基础架构。
—维基百科,Terraform(软件)
DC/OS 通用安装程序需要安装 Terraform 11.x. Ubuntu 用户可以像这样安装 Terraform 11.x:
wget [https://releases.hashicorp.com/terraform/0.11.14/terraform_0.11.14_linux_386.zip](https://releases.hashicorp.com/terraform/0.11.14/terraform_0.11.14_linux_386.zip)
sudo apt-get install unzip
unzip terraform_0.11.14_linux_386.zip
sudo mv terraform /usr/local/bin/
在 Mac 上,使用自制软件:
brew unlink terraform || true
brew install tfenv
tfenv install 0.11.14
Windows 用户可以使用 Chocolatey :
choco install terraform --version 0.11.14 -y
验证 terraform 是否有效:
terraform --version
您应该看到:
Terraform v0.11.14
现在我们可以走了!忽略任何关于升级的消息。既然已经安装了 Terraform,我们就可以在 AWS 上配置和启动我们的 DC/操作系统集群了。
为 GPU 实例授权 AWS 服务限制

AWS 服务限制定义您在任何给定地区可以使用多少 AWS 资源。我们将启动 5 个 p 3.2x 大型 GPU 实例,作为运行笔记本电脑的 DC/操作系统集群的私有代理。p 3.2x 大型实例类型的默认服务配额为 0。为了运行本教程,您需要请求 AWS 将这个值增加到 5 或更多。
您可以通过登录 AWS Web 控制台并访问此处的服务配额控制台来完成此操作:https://us-west-2 . Console . AWS . Amazon . com/Service Quotas/home?区域=美国-西部-2#!/services/ec2/quotas (您可以在 url 中替换您首选的 AWS 区域,只要确保将其替换在 url 中出现的 both places 中即可)。在搜索框中搜索 p3.2xlarge ,点击右侧橙色请求配额增加按钮。

AWS Service Limit Quota Increase for p3.2xlarge instances
在更改配额值字段中输入 5 。然后点击右下角的橙色请求按钮。

Quota Increase Submit Form
现在,您必须等待 12-48 小时,请求才能获得批准。我有一个基本的 AWS 帐户,当我在下午请求增加时,它在第二天早上被批准。如果您需要加快速度,您可以前往 AWS 支持中心请求代理致电。他们通常可以加速很多事情。
带通用安装程序的 AWS 上的 DC/操作系统

在d2iq.com上有很好的文档用于 DC/操作系统通用安装程序,但是我将在这篇文章中提供“正常工作”的代码。我们将使用 Terraform 来配置和启动我们的集群,然后我们将安装数据科学引擎包,并开始使用 JupyterLab!
注:将目录改为 Github 项目 子目录PAAs _ blog/dcos/terraform以了解教程的剩余内容。
配置 DC/操作系统
配置 DC/操作系统集群的第一步是创建一个特定于集群的 ssh 密钥。我们把这个键叫做 my_key.pub 。
ssh-keygen -t rsa -f my_key
按两次回车键创建没有密码的密钥。
Generating public/private rsa key pair.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in my_key.
Your public key has been saved in my_key.pub.
The key fingerprint is:
SHA256:OCOfrIzrTznoMqKOJ2VD2r6YPQp8jFFKIbe/BDyhWuI rjurney@Hostname.local
The key’s randomart image is:
+ — -[RSA 2048] — — +
|..o |
|.+.o |
|o.*. |
|+o++ . |
|.E + + S |
|o Oo * + |
|.*.+= + |
|B==+ o |
|XOB=+ |
+ — — [SHA256] — — -+
我们需要把 my_key 的权限改成只对我们的用户 0600 可读,不然以后 ssh 会抱怨的。
chmod 0600 ./my_key
现在运行ssh-agent(如果它没有运行)并将密钥添加到代理中。
注意:如果没有这个步骤,在创建集群时会出现 ssh 错误。请参见下面的常见错误部分。
eval "$(ssh-agent -s)"
ssh-add ./my_key
现在,验证是否已经添加了密钥:
ssh-add -l
这应该显示:
2048 SHA256:1234567891234567891234567891234567891234567 ./my_key (RSA)
通过脚本创建超级用户密码哈希
现在我们将使用 Python 的 hashlib 模块为集群创建一个超级用户密码散列文件。我们将调用我们的dcos _ super user _ password _ hash。
我已经创建了一个命令行脚本,它将生成、打印一个名为PAAs _ blog/dcos/terra form/generate _ password _ hash . py的密码散列并写入磁盘。
usage: generate_password_hash.py [-h] PASSWORDGenerate an SHA512 password hash for the given passwordpositional arguments:
PASSWORD A password to generate a SHA512 hash ofoptional arguments:
-h, — help show this help message and exit
要运行它,只需运行:
python ./generate_password_hash.py my_password
您应该会看到类似这样的输出:
Wrote SHA512 digest: '1234567891011121314151617181920212223242526…' for password 'my_password' to ./dcos_superuser_password_hash
验证写入文件dcos _ super user _ password _ hash是否成功:
cat dcos_superuser_password_hash
在 Python 中创建超级用户密码散列
要手动创建散列,请打开 Python shell(考虑使用 ipython ):
python # or ipython
现在运行以下代码:
import hashlibwith open('dcos_superuser_password_hash', 'w') as f:
m = hashlib.sha512('my_password'.encode())
f.write( m.hexdigest() )
将密码散列的权限更改为仅对您的用户可读, 0600 ,否则 DC/操作系统 CLI 将报错:
chmod 0600 ./dcos_superuser_password_hash
验证密码已成功保存:
cat dcos_superuser_password_hash
您应该会看到类似这样的内容:
dda8c3468860dcb2aa228ab8ee44208d43eb2f5fd2a3a538bafbd8860dcb24e228ab8ee44208d43eb2f5a2f8b143eb2f5a2f8b17eccc87ffe79d8459e2df294fb01
创建许可证文件—(仅限企业版)
由于我们将使用开放版本的 DC 操作系统,我通过touch license.txt创建了一个空的 license.txt 文件。它需要存在,但可以是空的。它已经致力于 Github,所以对于 DC/OS 的开放版本,一旦你签出了 GitHub 项目,你就不需要创建它了。如果您使用的是企业版,您需要将您的实际许可证放在 license.txt 中。
配置我们的 DC/操作系统集群
我已经编辑了文件PAAs _ blog/dcos/terra form/desired _ cluster _ profile . TF vars以个性化超级用户帐户名称,从我们上面创建的密码哈希文件中加载超级用户密码哈希,以指定空的许可证字符串并指向空的 license.txt 文件。DC/操作系统版本设置为 open ,DC/操作系统版本设置为 1.13.3 ,我们将使用一个 m5.xlarge 作为我们的引导实例类型,我们将使用 p3.2xlarge 实例来运行 JupyterLab。我们将 GPU 代理的数量设置为 5,这足以运行 Spark 和 JupyterLab。最后,我们指定我们之前生成的公钥, my_key.pub 。记住使用公钥,而不是私钥。
注:你可以在发布页面找到最新版本的 DC/OS,点击其 Github repo 上的标签可以找到最新版本的通用安装程序。如果遇到问题,通过编辑 terraform.tf 中的版本键,使用最高的 0.2.x 标签。
cluster_owner = "rjurney"
dcos_superuser_password_hash = "${file("dcos_superuser_password_hash")}"
dcos_superuser_username = "rjurney"
dcos_license_key_contents = ""
dcos_license_key_file = "./license.txt"
dcos_version = "1.13.4"
dcos_variant = "open"
bootstrap_instance_type = "m5.xlarge"
gpu_agent_instance_type = "p3.2xlarge"
num_gpu_agents = "5"
ssh_public_key_file = "./my_key.pub"
注意:如果您使用的是 DC 操作系统的企业版,您需要填写dcos _ license _ key _ contents,对于开放版本,我们会将其留空。您还需要更改配置,使dcos_variant = “ee”。
初始化地形
首先,我们需要用我们将要使用的所有模块初始化 Terraform:
terraform init -upgrade
您应该看到:
Upgrading modules...<list of modules>
Initializing provider plugins…
<list of plugins>Terraform has been successfully initialized!
生成地形图
现在我们需要使用我们在PAAs _ blog/dcos/terraform/desired _ cluster _ profile . TF vars中定义的变量来生成一个行动计划供 terra form 执行。我们将计划保存到PAAs _ blog/dcos/terra form/plan . out。
terraform plan -var-file desired_cluster_profile.tfvars -out plan.out
您应该会看到很多没有错误的输出,结尾是:
Plan: 75 to add, 3 to change, 0 to destroy. — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — — This plan was saved to: plan.outTo perform exactly these actions, run the following command to apply:
terraform apply "plan.out"
现在我们有一个计划,让 Terraform 在 plan.out 中创建我们的 DC/操作系统集群,它是二进制的,不太容易检查。
启动我们的 DC/操作系统集群
现在我们已经有了一个包含自定义变量的计划,我们不需要在 apply 命令中再次包含它们。我们可以按照plan命令输出末尾的指示去做。注意,我们没有将--var-file与 apply 一起使用,因为 plan 已经将我们的变量插入到计划中。
terraform apply plan.out
该命令可能需要长达 15 分钟的时间来执行,因为在初始化 AWS 资源序列,然后执行命令来初始化 EC2 实例上的服务时会有延迟。您应该会看到很多输出,开始是:
module.dcos.module.dcos-infrastructure.module.dcos-lb.module.dcos-lb-masters.module.masters.tls_private_key.selfsigned: Creating...<lots more stuff>
如果您看到任何错误,最好是销毁集群并重试。AWS 资源延迟初始化中的定时问题有时会导致引导问题。
摧毁我们的 DC/操作系统集群
当您完成集群时,如果有错误,或者如果您需要重新创建它,您可以使用下面的命令销毁所有相关的资源。注意,我们确实需要将--var-file与destroy一起使用。
terraform destroy --auto-approve --var-file desired_cluster_profile.tfvars
这可能需要一点时间,因为有许多资源要删除。一旦销毁完成,你可以自由地计划和再次申请。
登录我们的 DC/操作系统集群
“terraform apply”命令的最终输出为我们提供了要连接的主节点的地址,应该如下所示:
Apply complete! Resources: 75 added, 0 changed, 0 destroyed.Outputs:masters-ips = [
54.XX.XXX.XXX
]
public-agents-loadbalancer = ext-jupyter-gpu-12a9-abcde6g1234.elb.us-west-2.amazonaws.com
在浏览器中打开主 ip 地址,您应该会看到一个登录窗口。请注意,唯一授权连接到这台机器的 IP 是您的源 IP。

DC/OS Cluster Authentication Page
选择你的认证方式——我用谷歌。一旦您通过验证,它会将您返回到主页。
安装数据科学引擎服务

DC/OS Dashboard
在左侧菜单中,从顶部往下数第四个,在此图中用橙色圈出的是Catalog项目。点击它,DC/操作系统服务菜单将出现。当我这样做的时候,数据科学引擎服务就出现在第二行,如果没有的话,可以使用左上角的搜索框来找到它。

The DC/OS Service Catalog — Every Package a One Click Instasll
点击数据-科学-引擎服务,其服务页面就会出现。点击查看&运行安装服务。

The Data Science Engine Catalog Page
这将打开一个窗口,您可以在其中编辑数据科学引擎的配置。您需要使用字母和破折号来命名集群,但是您如何命名并不重要,除非名称是唯一的。因为我们使用的是 p3.2xlarge 实例,所以将服务配置为使用 58GB 内存和 8 个 CPU。选中 Nvidia GPU 分配配置已启用复选框,并为 GPU 数量键入 1。

Data Science Engine Service Configuration
点击右上角的紫色审查&运行按钮。这将带您进入最终审查屏幕。点击右上角的紫色运行服务按钮。
请注意,您可以将服务配置作为 JSON 下载,以便稍后使用 DC/OS CLI 运行,从而使您能够自动部署服务,例如作为您的持续集成系统的一部分。为此,请单击下载配置。

Data Science Engine Run Confirmation Page
您应该会看到一个弹出窗口,宣布系统成功启动。点击打开服务。

Service Confirmation Popup
这将带您进入数据科学引擎服务页面。起初,页面的状态会显示服务正在加载,但很快健康样本会变成绿色,状态会显示正在运行。

Data Science Engine Service Page
使用数据科学引擎
现在点击文本服务,在屏幕白色区域的顶部显示服务>数据科学引擎。这将带您进入服务列表。您应该会看到列出了数据科学引擎。单击下图中用橙色圈出的启动图标。这将打开与 JupyterLab 的连接。默认的 Jupyter 密码是 jupyter ,但是您可以使用我们用来启动服务的服务配置窗口来设置它。

Running Services Page — Click on the open icon to open JupyterLab
一旦输入 jupyter 的默认 Jupyter 密码(可以在desired _ cluster _ profile . TF vars中更改),就会看到 JupyterLab 的主页。第一页加载可能需要一点时间。Tada!

JupyterLab Dashboard
用一些自然语言处理来锻炼我们的 GPU
现在我们已经启动了集群和服务,让我们通过训练一个神经网络来标记堆栈溢出问题来练习它。我们将此视为一个多类别、多标签的问题。通过对至少有一个答案、一个投票并且至少有一个标签出现超过 2000 次的问题的完整转储进行上采样,来平衡训练数据。大约 600MB。这个数据集是之前计算的,文件可以在 Github repo 的 paas_blog/data 目录中找到。
你可以在 github.com/rjurney/paas_blog/DCOS_Data_Science_Engine.ipynb的 Github 上查看 Jupyter 笔记本的代码。我们将使用 JupyterLab Github 接口打开它,但是如果你愿意,你可以将它的内容逐块粘贴到新的 Python 3 笔记本中。
加载教程笔记本
JupyterLab 的 Github 模块超级棒,让加载教程笔记本变得很容易。点击屏幕最左边的 Github 图标,在文件和跑男图标之间。在显示 <的地方输入 rjurney 编辑用户> 。

JupyterLab’s Github Browser
我的公共 Github 项目将会出现。选择 paas_blog 然后双击DCOS _ 数据 _ 科学 _ 引擎. ipynb Jupyter 笔记本打开。它使用 S3 的数据,所以你不必下载任何数据。

Example Notebook from Github Loaded in JupyterLab
验证 GPU 支持
要做的第一件事是验证我们的数据科学引擎 EC2 实例上的 JupyterLab Python 环境是否正确配置为与其板载 GPU 一起工作。我们使用tensorflow.test.is_gpu_available和tensorflow.compat.v2.config.experimental.list_physical_devices来验证 GPU 是否与 Tensorflow 一起工作。
gpu_avail = tf.test.is_gpu_available(
cuda_only=False,
min_cuda_compute_capability=None
)
print(f'1 or more GPUs is available: {gpu_avail}')from tensorflow.python.client import device_lib
local_devices = device_lib.list_local_devices()
gpu = local_devices[3]
print(f"{gpu.name} is a {gpu.device_type} with {gpu.memory_limit / 1024 / 1024 / 1024:.2f}GB RAM")
您应该会看到类似这样的内容:
1 or more GPUs is available: True
/device:GPU:0 is a GPU with 10.22GB RAM
从 S3 加载数据
您可以使用 pandas.read_parquet 加载本教程的数据。
# Load the Stack Overflow questions right from S3
s3_parquet_path = f's3://{BUCKET}/08–05–2019/Questions.Stratified.Final.2000.parquet'
s3_fs = s3fs.S3FileSystem()# Use pyarrow.parquet.ParquetDataset and convert to pandas.DataFrame
posts_df = ParquetDataset(
s3_parquet_path,
filesystem=s3_fs,
).read().to_pandas()posts_df.head(3)
现在我们加载索引,在标签索引和文本标记之间来回转换。我们将使用这些来查看教程最后预测的实际结果标签。
# Get the tag indexes
s3_client = boto3.resource('s3')def json_from_s3(bucket, key):
"""Given a bucket and key for a JSON object, return the parsed object"""
obj = s3_client.Object(bucket, key)
obj.get()['Body'].read().decode('utf-8')
json_obj = json.loads(obj.get()[‘Body’].read().decode('utf-8'))
return json_objtag_index = json_from_s3(BUCKET, '08–05–2019/tag_index.2000.json')
index_tag = json_from_s3(BUCKET, '08–05–2019/index_tag.2000.json')list(tag_index.items())[0:5], list(index_tag.items())[0:5]
然后,我们验证加载的记录数量:
print(
‘{:,} Stackoverflow questions with a tag having at least 2,000 occurrences’.format(
len(posts_df.index)
)
)
您应该看到:
1,554,788 Stackoverflow questions with a tag having at least 2,000 occurrences
准备数据
我们需要将之前标记化的文本连接回字符串,以便在标记化器中使用,标记化器提供了有用的属性。此外,Tensorflow/Keras 需要将文档数量设为批量的倍数,以便在多个 GPU 之间分配工作,并使用某些模型,如 Elmo。
import mathBATCH_SIZE = 64
MAX_LEN = 200
TOKEN_COUNT = 10000
EMBED_SIZE = 50
TEST_SPLIT = 0.2# Convert label columns to numpy array
labels = posts_df[list(posts_df.columns)[1:]].to_numpy()# Training_count must be a multiple of the BATCH_SIZE times the MAX_LEN
highest_factor = math.floor(len(posts_df.index) / (BATCH_SIZE * MAX_LEN))
training_count = highest_factor * BATCH_SIZE * MAX_LEN
print(f'Highest Factor: {highest_factor:,} Training Count: {training_count:,}')# Join the previously tokenized data for tf.keras.preprocessing.text.Tokenizer to work with
documents = []
for body in posts_df[0:training_count]['_Body'].values.tolist():
words = body.tolist()
documents.append(' '.join(words))labels = labels[0:training_count]# Conserve RAM
del posts_df
gc.collect()# Lengths for x and y match
assert( len(documents) == training_count == labels.shape[0] )
您应该看到:
Highest Factor: 121 Training Count: 1,548,800
填充序列
数据已经被删减到每篇 200 字,但在一些文档中,使用 10K 顶级词汇的标记化将这一数据缩减到 200 字以下。如果任何文件超过 200 字,这些数据就不能正确地转换成下面的数字矩阵。
除了用一个键将文本转换成数字序列,Keras’ Tokenizer 类对于通过[keras.preprocessing.text.Tokenizer.sequences_to_texts](https://keras.io/preprocessing/text/#tokenizer)方法生成模型的最终结果也很方便。然后,我们使用 Keras’ [keras.preprocessing.sequence.pad_sequences](https://keras.io/preprocessing/sequence/#pad_sequences)方法并检查输出,以确保序列的长度都是 200 项,否则它们不会正确地转换为矩阵。字符串__PAD__以前已经被用来填充文档,所以我们在这里重用它。
from tf.keras.preprocessing.text import Tokenizer
from tf.keras.preprocessing.sequence import pad_sequencestokenizer = Tokenizer(
num_words=TOKEN_COUNT,
oov_token='__PAD__'
)
tokenizer.fit_on_texts(documents)
sequences = tokenizer.texts_to_sequences(documents)padded_sequences = pad_sequences(
sequences,
maxlen=MAX_LEN,
dtype='int32',
padding='post',
truncating='post',
value=1
)# Conserve RAM
del documents
del sequences
gc.collect()print( max([len(x) for x in padded_sequences]), min([len(x) for x in padded_sequences]) )
assert( min([len(x) for x in padded_sequences]) == MAX_LEN == max([len(x) for x in padded_sequences]) )padded_sequences.shape
分成测试/训练数据集
我们需要一个数据集来训练,一个单独的数据集来测试和验证我们的模型。经常使用的[sklearn.model_selection.train_test_split](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.train_test_split.html)使它如此。
from sklearn.model_selection import train_test_splitX_train, X_test, y_train, y_test = train_test_split(
padded_sequences,
labels,
test_size=TEST_SPLIT,
random_state=1337
)# Conserve RAM
del padded_sequences
del labels
gc.collect()assert(X_train.shape[0] == y_train.shape[0])
assert(X_train.shape[1] == MAX_LEN)
assert(X_test.shape[0] == y_test.shape[0])
assert(X_test.shape[1] == MAX_LEN)
计算类别权重
虽然已经对数据进行了过滤和上采样,以将其限制在至少有一个标签出现超过 2000 次的问题样本中,但常见标签和不常见标签之间的比率仍然不均衡。如果没有类权重,最常见的标签比最不常见的标签更有可能被预测到。类别权重将使损失函数更多地考虑不常用的类别,而不是常用的类别。
train_weight_vec = list(np.max(np.sum(y_train, axis=0))/np.sum(y_train, axis=0))
train_class_weights = {i: train_weight_vec[i] for i in range(y_train.shape[1])}sorted(list(train_class_weights.items()), key=lambda x: x[1])[0:10]
训练分类器模型来标记堆栈溢出帖子
现在,我们准备训练一个模型,用标签类别对问题进行分类/标记。该模型基于 Kim-CNN ,一种常用于句子和文档分类的卷积神经网络。我们使用函数式 API,并对代码进行了大量参数化处理,以便于实验。
from tensorflow.keras.initializers import RandomUniform
from tensorflow.keras.callbacks import ReduceLROnPlateau, EarlyStopping, ModelCheckpoint
from tensorflow.keras.layers import (
Dense, Activation, Embedding, Flatten, MaxPool1D, GlobalMaxPool1D, Dropout, Conv1D, Input, concatenate
)
from tensorflow.keras.losses import binary_crossentropy
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import AdamFILTER_LENGTH = 300
FILTER_COUNT = 128
FILTER_SIZES = [3, 4, 5]
EPOCHS = 4
ACTIVATION = 'selu'
CONV_PADDING = 'same'
EMBED_SIZE = 50
EMBED_DROPOUT_RATIO = 0.1
CONV_DROPOUT_RATIO = 0.1
LOSS = 'binary_crossentropy'
OPTIMIZER = 'adam'
在 Kim-CNN 中,我们首先使用嵌入对序列进行编码,然后使用去除层以减少过度拟合。接下来,我们将图形分割成多个宽度不同的 Conv1D 层,每个层后面跟有 MaxPool1D 。它们通过串联连接在一起,旨在表征文档中不同大小序列长度的模式。接下来是另一个Conv1D/globalmaxpool 1d层来总结这些模式中最重要的模式。接下来是展平成一个密集层,然后到最后的s 形输出层。否则我们通篇使用卢瑟。
padded_input = Input(
shape=(X_train.shape[1],),
dtype=’int32'
)# Create an embedding with RandomUniform initialization
emb = Embedding(
TOKEN_COUNT,
EMBED_SIZE,
input_length=X_train.shape[1],
embeddings_initializer=RandomUniform()
)(padded_input)
drp = Dropout(EMBED_DROPOUT_RATIO)(emb)# Create convlutions of different kernel sizes
convs = []
for filter_size in FILTER_SIZES:
f_conv = Conv1D(
filters=FILTER_COUNT,
kernel_size=filter_size,
padding=CONV_PADDING,
activation=ACTIVATION
)(drp)
f_pool = MaxPool1D()(f_conv)
convs.append(f_pool)l_merge = concatenate(convs, axis=1)
l_conv = Conv1D(
128,
5,
activation=ACTIVATION
)(l_merge)
l_pool = GlobalMaxPool1D()(l_conv)
l_flat = Flatten()(l_pool)
l_drop = Dropout(CONV_DROPOUT_RATIO)(l_flat)
l_dense = Dense(
128,
activation=ACTIVATION
)(l_drop)
out_dense = Dense(
y_train.shape[1],
activation='sigmoid'
)(l_dense)model = Model(inputs=padded_input, outputs=out_dense)
接下来我们编译我们的模型。我们使用各种各样的度量标准,因为没有一个度量标准可以概括模型性能,我们需要深入研究真的和假的肯定和否定。我们还使用 ReduceLROnPlateau 、 EarlyStopping 和 ModelCheckpoint 回调来提高性能,一旦达到稳定状态,我们就提前停止,并且只保留在验证分类准确性方面最好的模型。
分类准确性是衡量我们模型性能的最佳方式,因为它为我们分类的每个类的每一行分别给出了分数。这意味着,如果我们错过了一个,但得到了其他的权利,这是一个伟大的结果。对于二进制精度,整行都被标记为不正确。
然后就是拟合模型的时候了。我们给它我们之前计算的类权重。
model.compile(
optimizer=OPTIMIZER,
loss=LOSS,
metrics=[
tf.keras.metrics.CategoricalAccuracy(),
tf.keras.metrics.Precision(),
tf.keras.metrics.Recall(),
tf.keras.metrics.Accuracy(),
tf.keras.metrics.TruePositives(),
tf.keras.metrics.FalsePositives(),
tf.keras.metrics.TrueNegatives(),
tf.keras.metrics.FalseNegatives(),
]
)
model.summary()callbacks = [
ReduceLROnPlateau(
monitor='val_categorical_accuracy',
factor=0.1,
patience=1,
),
EarlyStopping(
monitor='val_categorical_accuracy',
patience=2
),
ModelCheckpoint(
filepath='kim_cnn_tagger.weights.hdf5',
monitor='val_categorical_accuracy',
save_best_only=True
),
]history = model.fit(X_train, y_train,
class_weight=train_class_weights,
epochs=EPOCHS,
batch_size=BATCH_SIZE,
validation_data=(X_test, y_test),
callbacks=callbacks
)
从训练时期加载最佳模型
因为我们使用了ModelCheckpoint(save_only_best-True),就CategoricalAccuracy而言,最好的纪元是被保存的。我们想用它来代替上一个纪元的模型,它存储在上面的model中。所以我们在评估模型之前加载文件。
model = tf.keras.models.load_model('kim_cnn_tagger.weights.hdf5')
metrics = model.evaluate(X_test, y_test)
解析并打印最终指标
度量包括像 precision_66 这样的名字,它们在运行之间是不一致的。我们修复这些来清理我们关于训练模型的报告。我们还添加了一个 f1 分数,然后制作一个数据帧来显示日志。这可以在重复实验中推广。
def fix_metric_name(name):
"""Remove the trailing _NN, ex. precision_86"""
if name[-1].isdigit():
repeat_name = '_'.join(name.split('_')[:-1])
else:
repeat_name = name
return repeat_namedef fix_value(val):
"""Convert from numpy to float"""
return val.item() if isinstance(val, np.float32) else valdef fix_metric(name, val):
repeat_name = fix_metric_name(name)
py_val = fix_value(val)
return repeat_name, py_vallog = {}
for name, val in zip(model.metrics_names, metrics):
repeat_name, py_val = fix_metric(name, val)
log[repeat_name] = py_val
log.update({'f1': (log['precision'] * log['recall']) / (log['precision'] + log['recall'])})pd.DataFrame([log])
绘制历元精度
我们想知道每个时期的性能,这样我们就不会不必要地训练大量的时期。
%matplotlib inlinenew_history = {}
for key, metrics in history.history.items():
new_history[fix_metric_name(key)] = metricsimport matplotlib.pyplot as pltviz_keys = ['val_categorical_accuracy', 'val_precision', 'val_recall']# summarize history for accuracy
for key in viz_keys:
plt.plot(new_history[key])
plt.title('model accuracy')
plt.ylabel('metric')
plt.xlabel('epoch')
plt.legend(viz_keys, loc='upper left')
plt.show()# summarize history for loss
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()

Categorical Accuracy, Precision and Recall Across Epochs. Note that recall climbs even on the 8th Epoch

Test / Train Loss
检查实际预测输出
光知道理论性能是不够的。我们需要看到标记者在不同置信度阈值下的实际输出。
TEST_COUNT = 1000X_test_text = tokenizer.sequences_to_texts(X_test[:TEST_COUNT])y_test_tags = []
for row in y_test[:TEST_COUNT].tolist():
tags = [index_tag[str(i)] for i, col in enumerate(row) if col == 1]
y_test_tags.append(tags)CLASSIFY_THRESHOLD = 0.5y_pred = model.predict(X_test[:TEST_COUNT])
y_pred = (y_pred > CLASSIFY_THRESHOLD) * 1y_pred_tags = []
for row in y_pred.tolist():
tags = [index_tag[str(i)] for i, col in enumerate(row) if col > CLASSIFY_THRESHOLD]
y_pred_tags.append(tags)
让我们来看看在数据帧中带有实际标签和预测标签的句子:
prediction_tests = []
for x, y, z in zip(X_test_text, y_pred_tags, y_test_tags):
prediction_tests.append({
'Question': x,
'Predictions': ' '.join(sorted(y)),
'Actual Tags': ' '.join(sorted(z)),
})pd.DataFrame(prediction_tests)
我们可以从这三个记录中看出,该模型做得相当不错。这讲述了一个不同于单独的性能指标的故事。奇怪的是,大多数机器学习的例子只是计算性能,并没有真正使用“predict()”方法!归根结底,统计性能是无关紧要的,重要的是真实世界的性能——它不包含在简单的汇总统计中!

Questions along with Actual Labels and Predicted Labels
自动化 DC/操作系统数据科学引擎设置
这涵盖了如何手动使用平台,但这是关于 PaaS 自动化。那么我们如何加快速度呢?
DC/操作系统的图形用户界面和 CLI 共同支持各类用户通过数据科学引擎轻松访问 JupyterLab:试图在笔记本上查看报告的非技术管理人员和希望自动化流程的开发运营/数据工程师。如果手动 GUI 过程似乎很复杂,我们可以在将服务配置作为 JSON 文件后,通过几行代码将其自动化,方法是通过 Terraform 命令启动 DC/操作系统集群,从 Terraform 获取集群地址,然后使用 DC/操作系统 CLI 验证集群并运行服务。
注:查看 DC/OS CLI 的 Github 页面 了解更多关于它如何工作的信息。
安装 DC/操作系统命令行界面
使用 Terraform 启动集群并在用户界面中手动安装 Data Science 引擎时,不需要 DC/操作系统 CLI,但需要它来自动执行该过程。如果您遇到了麻烦,请查看 CLI 安装文档。你将需要卷发。
# Optional: make a /usr/local/bin if it isn’t there. Otherwise change the install path.
[ -d usr/local/bin ] || sudo mkdir -p /usr/local/bin# Download the executable
curl [https://downloads.dcos.io/binaries/cli/linux/x86-64/dcos-1.13/dcos](https://downloads.dcos.io/binaries/cli/linux/x86-64/dcos-1.13/dcos) -o dcos
请注意,您也可以使用打印的命令下载 CLI,方法是单击右上方标题为 jupyter-gpu-xxxx (或您为集群命名的任何名称)的下拉菜单,然后单击下方橙色框中的 Install CLI 按钮。

Note the Install CLI button in the dropdown at top right
将出现一个弹出窗口,显示 Windows、OS X 和 Linux 的安装代码。将代码复制/粘贴到终端以完成安装。

Install Commands for DC/OS CLI
现在,如果您运行dcos,您应该会看到以下内容:
Usage:
dcos [command]Commands:
auth
Authenticate to DC/OS cluster
cluster
Manage your DC/OS clusters
config
Manage the DC/OS configuration file
help
Help about any command
plugin
Manage CLI pluginsOptions:
— version
Print version information
-v, -vv
Output verbosity (verbose or very verbose)
-h, — help
Show usage helpUse "dcos [command] — help" for more information about a command.
使用 GUI 手动导出软件包配置
为了自动安装数据科学引擎包,我们首先需要以 JSON 文件的形式获取它的配置。这可以通过两种方式完成:通过 GUI 或通过 DC/操作系统 CLI 或通过 Terraform CLI。我们将介绍这两种方法。

Note the Download Config button below the dividing line at the top right
使用 GUI,我们可以通过从数据-科学-引擎服务页面的配置选项卡下载 JSON 来获得包配置。点击该行右上方紫色的下载配置。
顺便说一下,您可以通过点击右上角的紫色编辑按钮来编辑数据科学引擎服务。您可以使用菜单或 JSON 编辑器来更改服务——例如增加 RAM 或 GPUs 它会根据该配置自动重新部署。

Editing the Data Science Engine Service Config
向群集验证 DC/操作系统 CLI
要使用 CLI,我们需要向群集进行身份验证。这可以通过 Google、用户名或其他适合您组织的方法来完成。为此,首先我们需要来自 Terraform 的服务器地址。我们可以通过terraform output -json和 jq json 实用程序提取集群主机 IP 地址。一旦我们有了这些,我们可以使用任何我们喜欢的方法,包括谷歌,来进行认证。这也可以是便于自动化的用户名。
# Get the cluster address from Terraform’s JSON output and Authenticate CLI to Cluster
export CLUSTER_ADDRESS=`terraform output -json | jq -r '.["masters-ips"].value[0]'`
dcos cluster setup [http://$CLUSTER_ADDRESS](/$CLUSTER_ADDRESS) # add whatever arguments you need for automated authentication
查看dcos cluster setup的文档,了解不同认证方法的信息。
使用 CLI 导出程序包配置
一旦我们通过了身份验证,我们就可以使用 CLI 来生成包配置文件,供以后重用。
对于麦克·OS X 来说,指挥旗base64是一个大写字母-D:
dcos marathon app show data-science-engine | jq -r .labels.DCOS_PACKAGE_OPTIONS | base64 -D | jq > my-data-science-engine.json
对于 Linux,base64的标志是小写的-d:
dcos marathon app show data-science-engine | jq -r .labels.DCOS_PACKAGE_OPTIONS | base64 -d | jq > my-data-science-engine.json
请注意,导出的选项涵盖了每一个选项,这并不理想,因为选项可能会在平台的不同版本之间发生变化,如果您不更改值,最好依赖系统默认值。例如,我将该导出编辑为:
{
"service": {
"name": "data-science-engine",
"cpus": 8,
"mem": 51200,
"gpu": {
"enabled": true,
"gpus": 1
}
}
}
您可以编辑该文件以满足您的需要,或者使用 GUI 来完成,并下载和编辑配置。
使用 CLI 安装数据科学引擎
现在,我们可以使用 CLI 安装数据科学引擎包:
dcos package install data-science-engine --options=./data-science-engine.json --yes
完整的集群/服务自动化示例
总之,这使得整个过程使用导出的 JSON 包配置:
# Boot DC/OS Cluster
terraform init -upgrade
terraform plan -var-file desired_cluster_profile.tfvars -out plan.out
terraform apply plan.out# Get the cluster address from Terraform’s JSON output
export CLUSTER_ADDRESS = `terraform output -json | jq -r '.["masters-ips"].value[0]'`# Authenticate CLI to Cluster using its address and Install the Data Science Engine Package
dcos cluster setup [http://$CLUSTER_ADDRESS](/$CLUSTER_ADDRESS) # add whatever arguments you need for automated authentication
dcos package install data-science-engine --options=data-science-engine-options.json
结论
在这篇文章中,我们启动了一个 DC/操作系统集群,并以可重复的方式部署了数据科学引擎,然后执行了一个测试笔记本来创建一个堆栈溢出标记。这展示了如何使用 PaaS 来提高数据科学团队的生产力。请继续关注该系列的下一篇文章!
注意:教程中的每一步都经过严格测试,所以如果你遇到任何问题,请在评论中告诉我。
附录:常见错误
我在写这篇文章的时候遇到了一些错误,你可能会在这篇文章中的例子中遇到,所以我已经包括了这些错误以及如何修复它们!😃
ssh-agent问题
如果您忘记通过eval "$(ssh-agent -s)"和ssh-add您的密钥运行 ssh-agent,您将看到下面的错误。如果您打开一个新的 shell 并从中运行 terraform 命令,这将非常容易。
Error: Error applying plan:1 error occurred:
* module.dcos.module.dcos-install.module.dcos-install.null_resource.run_ansible_from_bootstrap_node_to_install_dcos: timeout — last error: ssh: handshake failed: ssh: unable to authenticate, attempted methods [none publickey], no supported methods remain
解决方案是来自 *paas_blog/dcos/terraform* 目录的`ssh-add ./my_key`。为了避免将来出现这种情况,您可以编辑*desired _ cluster _ profile . TF vars*中的密钥字段,以便在您的 *~ /中使用公钥。ssh/* 目录,当 shell 启动时,使用 *~/自动添加到 ssh-agent 中。简介*、 *~/。bash_profile* 或者 *~/。bashrc* 。
现在,验证是否已经添加了密钥:
ssh-add -l
这应该显示:
2048 SHA256:1234567891234567891234567891234567891234567 ./my_key (RSA)
# 超时问题
有时,当 DC/操作系统启动时,事情不会正确同步,您会得到一个关于 Ansible bootstrap 或负载平衡器超时的错误。要做的事情就是破坏,然后计划/应用再创造。第二次会成功的。
如果您看到以下任一错误,这就是正在发生的情况。
Error: Error applying plan:1 error occurred:
- module.dcos.module.dcos-infrastructure.module.dcos-lb.module.dcos-lb-public-agents.module.public-agents.aws_lb.loadbalancer: 1 error occurred:
- aws_lb.loadbalancer: timeout while waiting for state to become ‘active’ (last state: ‘provisioning’, timeout: 10m0s)
或者:
Error: Error applying plan:1 error occurred:
- module.dcos.module.dcos-install.module.dcos-install.null_resource.run_ansible_from_bootstrap_node_to_install_dcos: timeout — last error: dial tcp 34.221.233.243:22: i/o timeout
# 数据综合症
我叫拉塞尔·朱尼。我是 [Data Syndrome](http://datasyndrome.com) 的首席数据科学家,在那里我构建端到端的机器学习和可视化产品、推荐系统、线索生成系统、数据工程,并专注于[弱监督学习](https://www.snorkel.org/blog/weak-supervision),或用更少的数据做更多的事情。我在 http://blog.datasyndrome.com[写博客](http://blog.datasyndrome.com)
我正在写一本将于明年出版的新书,书名是《T21:弱监督学习》。敬请关注更多内容!

















 2155
2155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
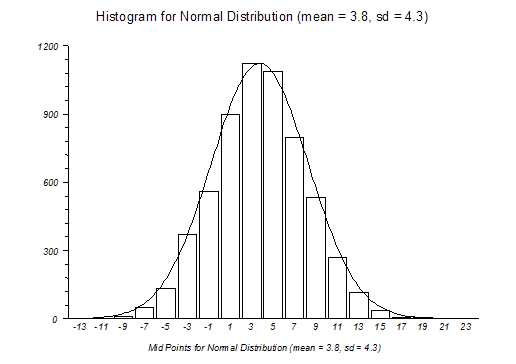{kind=link}
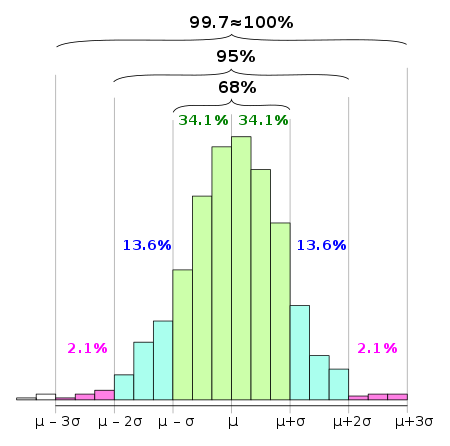{kind=link}