







概率机器学习系列文章 1:使用神经网络作为贝叶斯模型的一部分

source: https://www.pexels.com/photo/ask-blackboard-chalk-board-chalkboard-356079/
这一系列将是关于概率机器学习的不同实验和例子。概率机器学习的优势在于,我们将能够提供概率预测,并且我们可以分离来自模型不同部分的贡献。在第一篇文章中,我们将使用神经网络作为贝叶斯模型的一部分进行实验。这使得我们可以通过贝叶斯框架提供的不确定性估计来使用深度学习的特征学习方面。对于那些不熟悉贝叶斯框架的人,建议阅读第一章《黑客概率编程和贝叶斯方法》。简而言之,在贝叶斯框架中,概率被视为基于先验知识的信任程度。最终结果是,我们将看到数据是固定的,参数是随机变量。因此,我们模型的参数将由分布来表示。相比之下,在 frequentist 框架中,参数是固定的,但数据是随机的。代表不同样本的预期结果的置信区间。我们将使用数值方法评估后验 P(θ|y)。后验概率与可能性 P(y|θ)乘以前验概率 P(θ)成正比。

The posterior, left-hand side, is proportional to the likelihood times the prior.
对于我们的实验,主要假设是训练一个神经网络,作为特征提取器,用于贝叶斯线性回归。根据数据类型选择神经网络结构。我们的例子将是关于时间序列预测,所以我们将使用一个 LSTM (长期短期记忆)神经网络,因为它将能够提取时间相关性。神经网络与贝叶斯模型的这种完全分离的主要优点是,给出良好特征的预训练神经网络可以用于进行概率预测。缺点之一是我们失去了贝叶斯深度学习对于神经网络的正则化方面,而这需要以其他方式实现。
我们的目标是对仅使用短期时间相关性生成的时间序列进行概率预测,即 ARMA(4,2) 。时间序列分为两部分。第一个是自回归 AR(4),这意味着下一个值线性依赖于最后四个值。第二部分是移动平均部分 MA(2 ),这意味着下一个值也将取决于最后两个噪声值。这两部分结合起来就构成了 ARMA(4,2)过程。LSTM 将识别时间序列中的结构,而贝叶斯模型将提供概率估计。第一步,我们将训练一个具有线性最后一层的 LSTM,它将模拟贝叶斯线性回归。之后,我们将把 LSTM 作为特征提取器包含在我们的贝叶斯模型中。我们将在第三部分描述完整的模型。接下来的三个部分将是关于
- 训练 LSTM,
- 描述贝叶斯模型和
- 进行概率预测
但是我们先来看看生成的数据。

由于过程是 ARMA (4,2),我们只有短期相关性,没有季节性(也没有周期)和趋势。如果我们有了这两个组件,就需要进一步的预处理,但是我们希望在这个例子中保持乐观。在继续之前,我想提一下 LSTM 是在 PyTorch 中实现的,贝叶斯模型是在 PyMC3 中实现的。
步骤 1:训练 LSTM
用具有均方误差损失的七个时间步长的序列来训练 LSTM。我们使用早期停止来防止过度拟合。我们可以在接下来的图中看到,我们对训练集的预测接近真实值,并且可以使用正态分布很好地拟合误差。


我们现在有了一个准确的时间序列预测器,它只能给出逐点的预测。在下一节中,我们将把它包括在贝叶斯模型中,以获得概率预测。
第二步:贝叶斯模型
首先,我们将查看模型的图形表示。白色圆圈是随机节点,阴影圆圈是观测值,方形节点是确定性变换的结果。实线箭头指向随机节点的参数,虚线是确定性变换。我们从 y 开始,这是我们想要预测的值。

Figure 3: Graphical representation of our Bayesian model
我们假设 y 遵循一个正态(μ,σ)。μ相当于我们的 LSTM 预测值,定义如下

其中 z ᵢ 是 LSTM 的最后一个隐藏状态,θ ᵢ 是线性层的权重,θₒ是偏差,n 是 LSTM 的最后一个隐藏状态的数量。LSTM 模型的最后一层与贝叶斯模型的主要区别在于,权重和偏差将由正态分布表示,而不是点估计(即单个值)。σ是权重的不确定性无法捕捉到的预测值的随机误差。在这一点上,z 可以被认为是由观测数据的 LSTM 完成的确定性变换。由于权重的不确定性不取决于具体的数据值本身,我们只描述模型的不确定性。将 LSTM 纳入贝叶斯模型的步骤如下:
- 我们用线性的最后一层来训练 LSTM
- 我们删除了最后一层,并使用 LSTM 作为特征提取器
- 我们用贝叶斯线性回归代替了原始的线性层
现在我们已经知道了我们想要评估的模型的所有参数,让我们看看使用 ADVI ( 自动微分变分推断)和使用 MCMC ( 马尔可夫链蒙特卡罗)的一些微调获得的它们的分布。这些推理数值方法通过使用 ADVI 后验概率作为 MCMC 先验进行组合,这在 PyMC3 中很容易实现。ADVI 方法的优点是可扩展,但只能给出一个近似的后验概率。MCMC 方法较慢,但收敛于精确的后验概率。在下一篇文章中,我们将更详细地探讨这些问题。

在这一步中,我们将训练好的 LSTM 作为贝叶斯模型的一部分。我们已经获得了参数的分布,这些分布是上一步中的点估计。我们现在准备进行概率预测。
步骤 3:进行概率预测
使用后验预测检查进行预测(即,给定特征的模型参数被采样以获得概率预测)。我们可以在下图中看到 95%置信区间的结果。我们可以注意到,大多数预测都接近真实值,并且大多数预测都落在置信区间内。

Time series predictions (blue) with 95% confidence interval (shaded blue) and the true values (orange)
让我们简单回顾一下。为了获得准确的预测,我们在 LSTM 进行了时间序列的训练。我们可以就此打住,但是我们想要一个概率预测。正因为如此,我们使用 LSTM 作为贝叶斯模型的特征提取器。由于贝叶斯模型参数由分布表示,我们可以描述模型的不确定性。然后,贝叶斯模型用于使用后验预测检查进行概率预测。这个帖子里汇集了很多想法。如前所述,这是概率建模系列文章的一部分,所以我们将在以后的文章中单独处理其中的一些部分。
感谢阅读!
参考资料和建议阅读:
【1】a .盖尔曼、j .卡林、h .斯特恩、d .邓森、a .韦赫塔里和 d .鲁宾、* 贝叶斯数据分析 *(2013)、查普曼和霍尔/CRC
【2】c .戴维森-皮隆、* 面向黑客的贝叶斯方法:概率编程与贝叶斯推理 *(2015)、艾迪森-卫斯理专业
【3】a . Kucukelbir、D. Tran、R. Ranganath、A. Gelman 和 D. M. Blei、 自动微分变分推理【2016】、ArXiv
概率机器学习系列文章之二:模型比较

将原始数据转换为机器学习模型必须遵循许多步骤。这些步骤对于非专家来说可能很难,而且数据量还在持续增长。解决人工智能技能危机的一个建议是进行自动机器学习(AutoML)。一些著名的项目是谷歌云汽车和微软汽车。自动机器学习的问题包括不同的部分:神经结构搜索、模型选择、特征工程、模型选择、超参数调整和模型压缩。在本帖中,我们将对模型选择感兴趣。
模型选择可以被看作是一项微不足道的任务,但是我们将会看到,要获得模型质量的全貌,需要许多度量标准。在选择模型时,通常想到的衡量标准是准确性,但是在继续之前,还需要考虑其他因素。为了探究这个问题,我们将比较同一个数据集的两个相似的模型类。
在之前的帖子中,我们能够对一个时间序列进行概率预测。这就提出了一个问题,即预测的概率是否与经验频率相对应,这被称为模型校准。直观上,对于分类问题,我们希望 80%置信度的预测具有 80%的准确性。有人可能会问,为什么最后准确度还不够。如果在决策过程中使用这些结果,如果预测是错误的,过度自信的结果可能导致更高的成本,而在预测不自信的情况下,可能导致机会的损失。例如,假设我们有一个模型,可以根据土壤样本预测特定地区是否存在贵重矿物。由于贵重矿物的勘探钻井可能耗时且成本高昂,因此在校准模型时,通过关注高可信度预测,可以大大降低成本。
正如贾斯汀·汀布莱克在电影《时间里的 T0》中向我们展示的那样,时间可以是一种货币,所以我们要比较的下一个方面是训练一个模型所需的时间。尽管我们将使用小数据集(即经典的 Iris 数据集),但有许多理由跟踪训练模型所需的时间。例如,一些基于重采样的模型测试技术(例如:交叉验证和自举)需要用不同的数据样本进行多次训练。因此,模型将不会只被训练一次而是多次。当算法将被投入生产时,我们应该期待路上的一些颠簸(如果不是颠簸,希望是新数据!)并且知道重新训练和重新部署模型需要多少时间是很重要的。对训练一个模型所需时间的准确估计也将表明是否需要对更大的基础设施进行投资。
用于比较模型的最后一个方面(见后文)将是使用广泛适用的信息标准(WAIC)的模型的预测能力/复杂性。该标准可用于比较具有完全不同参数的相同任务的模型【1】。它是标准 AIC 的贝叶斯版本(另一个信息标准或 Alkeike 信息标准)。信息标准可以被视为交叉验证的一种近似,这可能很耗时【3】。
有哪些数据?
使用的数据集现在是机器学习的经典:虹膜分类问题。分类是基于萼片和花瓣的测量。这些数据是由英国统计学家和生物学家罗伯特·费希尔在 1936 年提出的。在下图中,长度和宽度的分布基于物种显示。线性分类器应该能够对除海滨锦鸡儿和杂色锦鸡儿以外的边缘物种进行准确的分类。

Pairplots of the features which will be used for the classification. A linear classifier should be able to make accurate classification except on the fringe of the virginica and versicolor species.
我们要对比的车型有哪些?
将为分类问题训练线性分类器。首先,使用特征的线性组合为每个类计算μ。

Equation for the calculation of μ for each of the k class using the N features.
然后,每个类的μ用于我们的 softmax 函数,该函数提供 0 到 1 之间的值(pₖ)。这个值(pₖ)将是索引为 k 的类的概率

Softmax function for the probability p of belowing to the k class based on the previous calculation of μ.
在第一个模型中,β都是常数,等于 1。这将被称为无温度模型(借用物理学术语,因为该函数类似于统计物理学中的配分函数)。第二个模型将对每个类有不同的β,这将增加模型的复杂性(更多的参数),但希望也将给出更好的结果。在文献【4】【5】中可以找到机器学习中用于校准的温度的用法。计算概率时,改变温度会影响每个μ的相对比例。举个例子,我们假设μ₁ = 1,μ₂ = 2,μ₃ = 3。将所有的初始温度固定为一,我们得到的概率是 p₁ = 0.09,p₂ = 0.24,p₃ = 0.67。现在让我们保持相同的温度β₂ = β₃ = 1,但是将第一个温度增加到 2(β₁= 2)。结果概率变成了 p₁ = 0.21,p₂ = 0.21,p₃ = 0.58。最后,如果我们将第一个温度降低到 0.5,第一个概率将向下移动到 p₁ = 0.06,其他两个将调整到 p₂ = 0.25 和 p₃ = 0.69。

Summary of the resulting probabilities for differents temperatures by keeping the μ values fixed.
我们在下面的图形模型中表示了参数和观测值之间的依赖关系。阴影圈是观察结果。z 是特征(萼片长度、萼片宽度、花瓣长度和花瓣宽度),类是用分类变量建模的花的种类。正方形代表其他变量的确定性变换,例如μ和 p,它们的方程已经在上面给出。圆圈是我们试图找到其分布的随机参数(θ和β)。方框表示参数重复出现的次数,由右下角的常数给出。

Graphical representation of the model with temperatures.
哪种模型的精确度最高?
尽管这不是一个模型唯一重要的特征,一个不精确的模型可能不是很有用。对于 50 个不同的训练/测试分割(0.7/0.3),计算两个模型的准确度。这样做是因为我们想要比较模型类,而不是学习模型的特定实例。对于同一个模型规格,很多训练因素会影响最终学习到哪个具体的模型。其中一个因素是所提供的训练数据。由于数据集很小,训练/测试分割可能会导致获得的模型发生很大变化。正如我们在下图中看到的,在测试集上,温度模型的平均精确度为 92.97 %(标准差:4.50 %),而没有温度时,平均精确度为 90.93 %(标准差:4.68 %)。

Distribution of accuracies of fifty different random train/test split for the model with and without temperatures. The model with temperatures has an average accuracy on the test set of 92.97 % (standard deviation: 4.50 %) compared to 90.93 % (standard deviation: 4.68 %) when there is no temperatures. The vertical lines are the corresponding means.
我的参数的分布是什么?
在接下来的两张图中,我们注意到,有温度模型中的一些θ分布比无温度模型中的更分散。我们通常希望这些值尽可能达到峰值。越分散的分布意味着参数值越不确定。我们遇到的通常的罪魁祸首是不良的先验,没有足够的采样步骤,模型设定错误,等等。因为我们想在这种情况下比较模型类,我们将在每个模型训练之间保持这些参数固定,所以只有模型会改变。

Distribution of the parameters for the model without temperatures. There is no distribution for the temperatures since the value is always a constant set to one.

Distribution of the parameters for the model with temperatures. There is a distribution for each blank circle in the graphical representation seen above.
我的概率可信吗?
概率模型只能将其概率建立在观察到的数据和模型规范给出的允许表示的基础上。在我们的例子中,我们只能根据特征的线性组合来区分类别。如果做不到这一点,不仅精度会很差,而且我们的校准也不会很好。在使用这些指标之前,基于后验样本的其他迹象将表明指定的模型对手头的数据并不好。为了测量校准,我们将使用静态校准误差(SCE)【2】定义为

常设专家委员会【2】可以理解如下。在 B 个时间 K 个箱中分离预测,其中 B 是用于计算的置信区间数(例如:在 0 和 0.1 之间、0.1 和 0.2 之间等),K 是类别数。对于这些仓中的每一个,取观测精度 acc(b,k)和预期精度 conf(b,k)之间的绝对偏差。取置信区间箱相对于那些箱中预测数量的加权和。最后取上一笔的班级平均值。示出了具有 89 %的相同准确度的两个训练模型的校准曲线,以更好地理解校准度量。

An exemple of calibration curve for two model with the same accuracy of 89 %. The model with the temperatures (blue) is better calibrated than the one without temperatures (orange). The green line is the perfect calibration line which means that we want the calibration curve to be as close as possible to this line. The dots are the values obtained for each of the eight intervals used.
绿线是完美的校准线,这意味着我们希望校准曲线接近它。如果我们看高置信度预测(0.70 及以上),没有温度的模型有低估其置信度和高估其在较低值(0.3 及以下)的置信度的趋势。有温度的模型通常比没有温度的模型校准得更好(平均 SCE 为 0.042,标准偏差为 0.007)(平均 SCE 为 0.060,标准偏差为 0.006)。

Distribution of SCE (a deviance calibration metric) of fifty different random train/test split for the model with and without temperatures. The model with temperatures (blue) is generally better calibrated (mean SCE of 0.042 with standard deviation of 0.007) than the model without temperature (orange) (mean SCE of 0.060 with standard deviation of 0.006). The vertical lines are the corresponding means.
我要等多久?
正如预期的那样,更复杂的带温度的模型需要更多的时间来进行相同次数的迭代和采样。平均花费 467 秒(37 秒的标准偏差)来训练具有温度的模型,而没有温度的模型花费 399 秒(4 秒的标准偏差)。

Computation times of fifty different random train/test split for the model with and without temperatures. It took on average 467 seconds (standard deviation of 37 seconds) to train the model with temperatures (blue) compared to 399 seconds (standard deviation of 4 seconds) for the model without temperatures (orange). The vertical lines are the corresponding means.
增加了什么复杂性?
在这个实验中,我们比较了更简单的模型(没有温度)和更复杂的模型(有温度)。一个有趣的度量标准是广泛适用的信息标准,它由下式给出

其中,LPPD 是对数逐点预测密度,P 是参数的有效数量。WAIC 用于估计样本外预测精度,不使用未观测数据【3】。WAIC 越低越好,因为如果模型与数据拟合得很好(高 LPPD),WAIC 将变得更低,并且无限数量的有效参数(无限 P)将给出无穷大。具有无限数量有效参数的模型只能记忆数据,因此不能很好地推广到新数据。因此,减去它是为了纠正这样一个事实,即它可能恰好符合数据。因子 2 来源于历史原因(自然来源于基于 Kullback-Leibler 散度和卡方分布的阿凯克信息准则的原始推导)。LPPD(对数逐点预测密度)是用来自后验分布的 S 个样本估计的,定义如下

使用每个数据点【3】的对数似然密度(也称为对数预测密度)相对于参数的方差之和来估计有效参数的数量。

正如我们在下图中看到的,没有温度的模型的 WAIC 通常更好(即更低)。原因之一可能是模型的一些参数随温度的高变化,这将导致更高的有效参数数,并可能给出更低的预测密度。人们可能希望两个模型之间的有效参数数量相同,因为我们可以通过将θ乘以相应的β,将带温度的模型转换为不带温度的模型,但经验证据表明并非如此。

Widely Applicable Information Criterion (WAIC) of fifty different random train/test split for the model with and without temperatures. The model without temperatures (orange) has a better WAIC, 247 with standard deviation of 12 , compared to the model with temperatures (orange), 539 with standard deviation of 60. The vertical lines are the corresponding means.
结论
下表总结了为特定任务比较两个模型类所获得的结果。具有温度的模型具有更好的精度和校准,但是需要更多的计算时间并且具有更差的 WAIC(可能由参数的变化引起)。

Summary of the mean results obtained for the metrics evaluated. The value in parenthesis is the standard deviation. The green dot indicate the better value of the two model classes while the red dots the worst value.
与精度和校准增益相比,计算时间并不令人望而却步,因此这里选择的是温度模型。在将它投入生产之前,人们可能会通过微调它来减少参数的不确定性。人们必须记住,不确定性也可能通过避免过度自信而给出更高的校准。我们看到,为了获得一个任务的模型类的质量的全貌,需要许多度量。在 AutoML 的情况下,系统会自动使用这些指标来选择最佳模型。正如我们所看到的,我们可以根据用户的需求和与模型使用相关的成本来解释它们。对数据科学家来说幸运的是,这也意味着仍然需要人类的参与。
感谢阅读
参考文献和推荐读物
[1] A.Gelman,J. Carlin,H. Stern,D. Dunson,A. Vehtari 和 D. Rubin,贝叶斯数据分析 (2013),Chapman and Hall/CRC
[2] J. Nixon,M. Dusenberry,L. Zhang,G. Jerfel,D. Tran,深度学习中的测量校准 (2019),ArXiv
[3] A. Gelman、J. Hwang 和 A. Vehtari,(2014),斯普林格统计和计算
[4] A. Vehtari,A. Gelman,J. Gabry,使用留一交叉验证和 WAIC 的实用贝叶斯模型评估(2017),Springer 统计和计算
[5] A. Sadat Mozafari,H. Siqueira Gomes,W. Leã,C. Gagné,无监督温度缩放:深度网络的无监督后处理校准方法 (2019),ICML 2019 深度学习中的不确定性和鲁棒性研讨会
概率矩阵分解
动机
“给你一个设计矩阵 X ,你会如何预测 Y ?”这个问题是基于监督学习和回归的任务的核心。这个问题假设完全了解设计矩阵 X 。在 X 中,我们在行中存储记录,在列中存储描述这些记录的特性。但是当这个矩阵被破坏时会发生什么呢?当一些观测值缺失时会发生什么?
考虑这样的设置,我们有一个 n 行 p 列的数据矩阵 X ,其中 X 始终有缺失值。

Data matrix X with missing values. The goal of matrix completion (and probability matrix factorization) is to impute or predict these missing values.
没有什么奇特的机器学习模型能拯救我们。事实上,奇特的监督学习技术依赖于对 X 的执行,就像它们做的一样好。在某种意义上,这是格言垃圾的最坏情况;垃圾出去——我们连垃圾都没有放进去!
这个问题在大多数数据分析中非常典型,最近又被重新讨论,因为许多现代数据科学问题都可以在这个框架内提出。我们将在下面的应用部分讨论其中的一些问题。
在这篇文章中,我们来看一个基于模型的方法来克服这个丢失数据的问题。我们将讨论一些令人惊讶的应用,在这些应用中,这种方法在矩阵补全之外也很有用。我们将从完全贝叶斯的角度来看这个问题,并分析在这个模型下,一个典型的 SGD 框架是如何与后验最大化紧密相连的。
应用程序
特别感兴趣的三个应用范围从数据分析的基础到推荐系统中最先进的方法。
- 数据插补- 当数据缺失时,监督学习技术很难提供高质量的解决方案。例如,在随机森林中丢失数据可能是灾难性的。输入缺失数据是任何数据分析的第一步。
- 图像完成- 考虑这样一幅图像,其中图像的一部分已经被破坏、扭曲或看不到。如果我们希望完成图像,我们希望以使用其他观察到的像素的信息的方式来完成。智能地结合这些信息将导致更精确的图像恢复。
- 基于模型的推荐系统- 许多协同过滤应用依赖矩阵完成算法向新用户提供推荐。如果矩阵的行是用户,列是产品,那么矩阵中的条目可以是该用户对该产品的评级。由于每个用户不会对每个产品进行评级,因此我们的目标是找到没有被用户评级但可能被高度评级的产品。通过预测这些缺失值(用户尚未评级的产品),我们可以根据用户过去的评级和其他人的评级向用户推荐新产品。
这些只是适合矩阵完成框架的问题的示例。在后面的帖子中,我将考虑图像完成任务,并使用下面介绍的模型构建一个推荐系统。
基于模型的方法
形式化该任务的一种方式是矩阵完成问题,其中我们试图用已知值的知识(白色图块)替换缺失的数据(蓝色图块)。我认为这是在矩阵中“堵塞漏洞”。
一种流行的基于模型的方法是假设数据矩阵 X 具有低秩,因此可以分解成两个低秩矩阵 U,V 的乘积。希望 d = rank( X )远小于 min(n,p)以降低计算复杂度。

Factorization of data matrix X into the “observation” matrix U and the “feature” matrix V.
你可以把矢量 uᵢ 想象成描述第 i - th 观察行为的矢量,把 v ⱼ想象成描述第 j - th 特征行为的矢量。必然地,我们假设词条 Xᵢⱼ = ⟨uᵢ,v ⱼ ⟩.我们的问题归结为获得 U 和v的估计值
这个问题的常见解决方案是最小化最小平方损失的优化方法。使用交替最小二乘算法可以有效地(并行地)解决这个问题。文献中也详细描述了正则化扩展和解决方案。
另一种提供更健壮的统计框架的方法是基于模型矩阵 X 的贝叶斯观点。这个名为概率矩阵分解的方法是由 Salakhutdinov 和 Mnih 在 2006 年提出的。在这个模型下,我们假设 X 的条目正态分布在内积 ⟨uᵢ,v ⱼ ⟩ 的周围,具有共同的方差。假设 Iᵢⱼ 在观察到条目时为 1,在数据值缺失时为 0,我们可以将 X 的条目的可能性写成如下。

Likelihood of the entries of X. The entries are independent normals centered around the inner product ⟨uᵢ, vⱼ**⟩.**
这种可能性的核心假设是:( a)X的条目是独立的;( b)每个条目是正态分布的;( c)这些条目共享一个共同的方差σ。这些假设可能适合也可能不适合某些应用,需要在实践中更仔细地考虑。
为了包含完整的贝叶斯范式,我们将先验分布放在以下形式的矩阵 U 和 V 中。

在这些先验中,我们假设(a)U和 V 的行是不相关的,(b)是正态分布的,以及©具有共同的方差。有了额外的先验信息,我们可以构建更多信息的先验分布,以捕捉设计矩阵 X 中观察值或特征之间的已知相关性。
后验推断
引入了矩阵 X 的先验分布和似然性后,我们可以推导出归一化常数的完整后验概率。

Full posterior distribution of matrices U and V.
在他们的工作[3]中,建议通过找到最大化该后验分布的矩阵 U 和 V 来导出最大后验估计值(MAP)。在未来,我们着眼于通过为这些模型 parameters⁴.构建 MCMC 采样器来开发完整的后验分布
最大化这个后验概率相当于最大化对数后验概率。对数后验概率具有下面给出的形式。

The log posterior up to a normalizing constant. Notice that the last two terms have built in regularization on the matrices U and V.
这样,我们的目标是最小化损失函数 L( U,V ) ,它可以写成如下形式

其中 I 是具有上面定义的 Iᵢⱼ 的 n × p 矩阵,圆积表示元素式矩阵积,使用的范数是 Frobenius 范数。
从这个损失中,我们看到我们平衡了 U 和 V 的乘积与这些矩阵相对于 Frobenius 范数的“大小”的拟合优度。我们通过调整先验方差σ、σᵤ和σᵥ来平衡拟合优度和正则化之间的权衡。这些参数可以通过交叉验证以数据依赖的方式进行选择,或者通过对这些 hyerparameters 进行先验的贝叶斯方法进行选择。
从这里我们看到,最大化对数后验概率是等价于在【2】中考虑的正则化优化方法。因此,我们看到,通过正确选择先验,概率矩阵分解方法概括了矩阵分解中的标准优化技术。
通过为 U 和 V 的行选择更复杂的先验分布,我们可以设计出类似弹性网和套索的优化问题,其中更稀疏的解是优选的。
通过优化映射解决方案
已经根据优化问题描述了 U 和 V 的 MAP 估计,我们现在考虑解决该问题的优化方法。不幸的是,这个优化问题不是凸的,所以我们不能保证随后的任何方法都有全局解。最近 work⁵致力于刻画全局解的性质,这将有望增强我们对任何局部解的性质的理解。
为了获得 U 和 V 的估计,我们考虑(随机)梯度下降更新方案。虽然我们也可以考虑交替最小二乘更新,这可以通过使用迭代岭解来解决,但 SGD 方法将能够更容易地扩展到更大的数据集。
将损失函数 L( U,V ) 相对于 uᵢ 或 vⱼ 进行微分将提供感兴趣的梯度。梯度可以写成

Gradient of the loss function for each row of U and V. Stochastic gradients can be applied by using a subset of the full n observations or p features. Moreover, rows of each matrix can be updated in parallel.
其与来自正则化回归设置的岭回归估计有明确的联系。请注意,每个梯度包括 n 或 p 个元素的总和。这些总和在实践中可能很难计算,并且可能有必要通过对 n 个观测值或 p 个特征的子集(小批量)求和来使用随机梯度。
使用这些梯度,我们迭代地更新我们的估计,直到收敛。完整的算法如下所示。

A full SGD algorithm for PMF.
可以对该算法进行一些改进以提高运行时间。特别是,使用随机梯度可以大大加快计算时间。此外,每个嵌套的 for 循环都可以并行完成,并跨单元分布。 Kevin Liao 在 PySpark 上有一个关于这个的不错的帖子,我会在这里链接。
结论
至此,我们已经基本涵盖了概率矩阵分解的基础知识!这里讨论的大多数观点都在[3]中介绍过,我真的鼓励你读一读他们的论文。希望这篇文章能在这个问题和贝叶斯统计、正则化回归和正则化矩阵分解之间找到一些联系。
既然我们已经解决了所有的数学问题,是时候实现上面介绍的 SGD 算法了。在我的下一篇文章中,我将会关注图像补全的问题以及一个推荐系统。
[1]:m·尤德尔和 a·汤森。为什么大数据矩阵的排名很低? (2019),暹罗。
这种假设在许多统计和机器学习环境中非常普遍。请查看由 Udell 和 Townsend 在 2019 年完成的这项工作,其中有一个关于为什么这一假设是合理的有趣讨论。
[2]: T. Hastie 等人通过快速交替最小二乘法进行矩阵补全和低秩 SVD。(2015),机器学习研究杂志。
[3]: R. Salakhutdino 和 A. Mnihv。概率矩阵分解。 (2008),NIPS 会议录。
[4]: R. Salakhutdino 和 A. Mnihv。使用马尔可夫链蒙特卡罗的贝叶斯概率矩阵分解。(2008),2008 年机器学习国际会议。
[5]: S. Zheng 等正则化奇异值分解及其在推荐系统中的应用。(2018),ArXiv。
概率编程杂志 1:模拟事件变化
免责声明:我的来源和灵感来自《黑客的贝叶斯方法》(Cameron Davidson-Pilon),这篇文章出于非盈利原因。我只是记录我对这个新主题的学习,并在媒体上分享我的学习,以强化我自己的概念。大部分代码都是从这本书里派生出来的,我只做了很少的改动,但是我花了很大的力气来解释每个代码块是如何工作的。
**问题:**我们的目标是了解我们的数据是否随时间发生了变化。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inlinecount_data = np.loadtxt("Data/txtdata.csv")
n_count_data = len(count_data)
f, ax = plt.subplots(figsize=(20, 3))
sns.barplot(np.arange(n_count_data), count_data, color = 'black');
plt.xlabel("Time (days)")
plt.ylabel("Text messages received")
plt.title("Did the user’s texting habits change over time?")
plt.xlim(0, n_count_data);

我们正在处理的数据与文本相关。我们观察和收集数据的时间段是总共 74 天,加载的数据是包含每天文本观察的向量形式。我们生成一个互补向量,记录向量中每个点的日期。这可以在上面使用 numpy arrange 函数的代码中看到。我们的目标是确定趋势是否有变化。由人类来完成这项任务将是非常具有挑战性的,因为目测数据根本无助于确定变化。所以我们将使用一些概率模型来解决这个问题。
我们如何对这些数据建模?我们的选择之一是使用泊松模型。为什么?因为这种模型可以很好地处理计数数据。

为了表示我们的模型,假设λ将在我们的数据集τ中的时间点(t)之后改变。

下一个要解决的难题是我们如何估计λ?模型假设λ可以采用任何正数的形式。指数分布提供了一个连续的密度函数,但指数分布有自己的参数,称为α。所以…

当一个随机变量 Z 具有参数为λ的指数分布时,我们说 Z 是指数的,写 Z∞Exp(λ)给定一个特定的λ,一个指数随机变量的期望值等于λ的倒数。即 E[Z|λ] = 1/λ (黑客的贝叶斯方法,卡梅伦·戴维森)
根据上述概念,将α设置为计数数据平均值的倒数。

最后τ

在数据集中持续 70 天,其中τ在每一天都是同等可能的。
在我解释下一步之前,我想分享一个关键概念。因此,泊松模型中的主要模型采用参数λ。Lambda 是每个间隔的平均事件数,它是由另一种称为指数分布的方法估计的。编程意义上的指数分布将由该特定分布的特征产生。因此,如果一个程序员调用一个分布函数,他们可以期待一个对象或向量的值。现在有了这些值,接下来发生的是泊松函数使用它,另一个生成函数。因此,泊松函数将在由指数生成器生成的λ值数组上生成值。
当我们看τ和 T 时,令人困惑的部分来了,它们的目的是什么?我们猜测模型的分布在 t 点发生变化。这与下面代码中描述的函数有关。我会在代码后解释 tau 的作用。
import pymc as pm#Alpha as described in above
alpha = 1.0/count_data.mean()# Exp distribution for lambda using alpha
lambda_1 = pm.Exponential("lambda_1", alpha)
lambda_2 = pm.Exponential("lambda_2", alpha)#Uniform distribution for tau
tau = pm.DiscreteUniform("tau", lower=0, upper=n_count_data)#Declare a deterministic result
[@pm](http://twitter.com/pm).deterministic
def lambda_(tau=tau, lambda_1=lambda_1, lambda_2=lambda_2):
#create a null vector of size == size(data)
out = np.zeros(n_count_data)
# t < tau will recieve lambda1
out[:tau] = lambda_1
#t > tau will recieve lambda2
out[tau:] = lambda_2
return out#feeding custom function to observed poisson generator
observation = pm.Poisson("obs", lambda_, value=count_data,observed=True)#declaring pymc model
model = pm.Model([observation, lambda_1, lambda_2, tau])#blackbox MCMC model for sampling
mcmc = pm.MCMC(model)
mcmc.sample(40000, 10000)#Drawing samples from mcmc model
lambda_1_samples = mcmc.trace('lambda_1')[:]
lambda_2_samples = mcmc.trace('lambda_2')[:]
tau_samples = mcmc.trace('tau')[:]
所以,发生的事情是,一个生成器被创建,它输出 1 到 70 之间的值,其中每一天都有均等的机会被抽取。想象这是一袋 70 颗红色弹珠,画一颗弹珠是 1/70。所以一定数量的随机抽取被记录下来并发送给 lambda_ function。在基于τ值的 lambda 函数中,向量 lambda 被分成将接收 lambda_1 值的左半部分和将接收 lambda_2 值的右半部分。这个过程用 lambda _i(i = 1 或 2)的不同组合来测试。然后将其转换为泊松生成器。我很难解释后面的部分,因为它涉及到使用 MCMC 方法从我们创建的条件中采样和重新采样。用最简单的话来说,我能说的是,我们有一个复杂的对象迭代来检索显示可能值的分布。
# histogram of the samples
f, ax = plt.subplots(figsize=(10, 10))#plt sublot 1 declarartion (lambda 1)
ax = plt.subplot(311)
sns.distplot(lambda_1_samples, bins=30,label="posterior of $\lambda_1$", color="#A60628")
plt.legend(loc="upper left")#declare main title
plt.title(r"""Posterior distributions of the parameters""")plt.xlim([15, 30])
plt.xlabel("$\lambda_1$ value")
plt.ylabel("Density")
#lambda1 plot ends#plt sublot 2 declarartion (lambda 2) setting similar to plot 1
ax = plt.subplot(312)
ax.set_autoscaley_on(False)
sns.distplot(lambda_2_samples, bins=30,label="posterior of $\lambda_2$", color="#7A68A6")
plt.legend(loc="upper left")
plt.xlim([15, 30])
plt.xlabel("$\lambda_2$ value")
plt.ylabel("Density")#plt sublot 2 declarartion (lambda 2)
plt.subplot(313)
w = 1.0 / tau_samples.shape[0] * np.ones_like(tau_samples)
plt.hist(tau_samples, bins=n_count_data, alpha=1,
label=r"posterior of $\tau$", color="#467821",
weights=w, rwidth=2.)
plt.legend(loc="upper left")
plt.ylim([0, .75])
plt.xlim([35, len(count_data)-20])
plt.xlabel(r"$\tau$ (in days)")
plt.ylabel("Probability");

做完这些,我们就能画出λI 和τ的可能值。我对这里的理论的理解仍然不是很强,但是我认为我们能够基于我们使用泊松分布产生的观察结果来产生这些分布。还有一点需要注意的是,泊松样本被观察和固定,而其他样本则没有。对观察结果的解释总结如下。
- λ1、λ2 可以分别保持大约 18 和 23 的值。
- 基于λ分布,我们可以评论两组中存在差异,回想一下,我们将λ1 分配给组 t < τ,并且我们相应地改变了λ2。两组都采用相似的指数分布,每组的后验分布各不相同。
- τ的正序分布是离散的。基于我们输出前的假设。
- 第 45 天有 50%的几率表现出行为变化。
概率思维,一个被大多数人抛在脑后的批判性思维。

让我们用一个简单的问题来测试你是否放弃了概率思维的基本权利。当你做下一个决定时,看看你可能会错过什么。
这是我的“我们生活的算法”系列之一。见链接中另一个有趣的问题。
在深入研究细节之前,我们先来看一个思维实验。

看看上面的问题,你会怎么做选择?你会按哪个按钮?红色或绿色。
我知道你心中有一个答案,你可以找到理由来证明你的选择,但请暂时保持这个想法,直到本文结束。
请记住这些想法:
- 你应该如何解读这个问题的语境?
- 除了按红色或绿色按钮,这个问题中还有其他选项吗?
- 你是在做一个冲动的、启发式的决定,还是在计算每个选项的概率?
- 如何计算两个选项的概率?
为什么呢?为什么我称赞概率思维是人类最关键的特质和技能之一?
答案对我来说是不言自明的。“可劫性是世界的运行规则,不仅在社会层面,也在宇宙学原理层面。”因此,能够破译这一隐藏信息的人将有机会预测未来,然后做出更好的行动决定。
The stunning nature of probability distribution
不幸的是,只有在顶峰的人才能真正理解这个信息,并通过它的信号来执行它。
出于本文的目的,我将这些人分为三个层次:
- 一级:懂得如何计算概率的人
- 二级:能够直观地进行概率性思考的人
- 第三级:了解概率结果并能采取行动的人
你在某一关获得的技能并不保证你能进入下一关。
你可以是计算概率的大师,也可以意识到概率思维,但你可能不是一个总能根据先验概率做出公平决策的人,更不用说立即采取行动了。约翰·梅纳德·凯因斯花了几十年才成为第三级。

A British economist, whose ideas fundamentally changed the theory and practice of macroeconomics and the economic policies of governments.
但是,没有学过概率理论和概率思维的人,有几个天生就是永远作用于概率结果的人。比如德州扑克的高手或者市场奇才。

我们来做一个简单的计算。
有多少人知道概率计算?
不到 10%
在这些人中,有多少人能把计算运用到日常思维中?
另外 1%。
在概率思维的人当中,有多少人能够采取行动?
不到 1%(推理,想想有多少人能执行他们的计划或策略)
于是,在世界主义者中,几千万人中只有几千个概率大师。
你可能会说,在像纽约或上海这样的大城市,千万富翁的人数超过数千。但请记住,基于“随机的普遍概率”,他们的成功更多的是运气因素,而不是战略行动。(被随机性愚弄)
风险决策中的三个关键概念
1。期望值 :一个离散随机变量的期望值是其所有可能值的概率加权平均值。换句话说,随机变量的每一个可能值都要乘以它出现的概率,然后将结果相加得到期望值。(来自维基百科)

根据这个理论,100%的机会赢得 100 万或者 50%的机会赢得 10 亿是一回事。贝叶斯定理是聪明的决策者最常用的公式之一。看看这个星球上最聪明的人的话。

塔勒布在一次投资研讨会上提到,“我相信市场有 70%的机会小幅上涨。”但在现实世界中,他做空标准普尔 500 指数,押注市场会下跌。他真正的愿景是:尽管市场有很大的增长机会,但做空是更好的选择。因为如果市场丰满了,它会大幅度下跌。
下面列出了对行为的分析:
- 市场有 70%的机会上涨,有 30%的机会下跌。
- 但上升趋势只会是 1%,下降趋势会是 10%。
- 因此,预期结果是:70% *1% + 30% *(-10%) = -2.3%
- 总体而言,做空将有更好的机会获得更多利润
正如查理·芒格(沃伦·巴菲特的长期合作伙伴,世界上另一个聪明的头脑)所说,他和巴菲特每天所做的就是解这道简单的数学方程式。与其说是数学能力,不如说是思维模式。知道容易,执行难。那些设法训练他们的大脑像肌肉记忆一样直观地运行模型的人(芒格和巴菲特)在他们的生活中可以比我们其他人取得更大的成就。

By 2019 (in the age of technology domination and revolution), Berkshire Hathaway is the only financial service company left in the top 5 companies measured by market cap.
***2。*预期效用假说:**该假说认为,在不确定性下,所有可能的效用水平的加权平均值将最好地代表任意给定时间点的效用。期望效用理论被用作一种工具,用来分析个人必须在不知道决策可能产生何种结果的情况下做出决策。(来自 Investopedia)

它也用来解释“圣彼得堡悖论”——另一个与概率和决策理论有关的有趣悖论。
你可以用预期效用假说来解释野心(期望值)和恐惧(风险下的决策)。
- 边际效用递减定律:同样数量的额外收入对一个已经很富有的人来说,不如对一个穷人有用。
- **效用最大化原则:**游戏者的目标不是最大化他的预期收益(金钱),而是最大化他的收益的对数(预期效用)。
背一下两键悖论。如果选择红色按钮,可以立即领取 100 万,同时放弃 5 亿(10 亿* 50%)选项。一方面,100 万英镑对于那些相信这笔钱可以改变他们生活的人来说是令人满意的。另一方面,大多数人都想逃避与绿色按钮相关的归零风险。仅仅是因为他们对失去一切的恐惧大于对得到 4.99 亿(10 亿* 50%-100 万)的期望。
3。前景理论: 这个理论是丹尼尔·卡内曼(2002 年诺贝尔经济学奖得主,著名著作< 思考快与慢 >)发展出来的。它挑战了预期效用理论,是行为经济学的基本原理。简而言之,它描述了个人如何以不对称的方式评估他们的得失前景。例如,对一些人来说,损失 1000 美元的痛苦只能通过赚 2000 美元的快乐来补偿。

卡尼曼总结:
- 面对导致收益的风险选择,个人是**风险厌恶者,**更喜欢导致较低预期效用但具有较高确定性的解决方案
- 面对导致损失的风险选择,个人会寻求风险,更喜欢导致较低预期效用的解决方案,只要它有可能避免损失
- 理性决策者不会受到锚/参考点的影响(损失或收益),相反,正常个体会坚持参考点。(例如,一个理性的决策者不会等到盈亏平衡时才卖出一只看跌的股票)
它与行为经济学研究相一致,行为经济学研究调查心理、认知、情感、文化和社会因素对个人经济决策的影响,特别是对那些非理性决策的影响。
成功的科技创业公司老板是如何做出风险决策并发展业务的?
马克·扎克伯格出生于一个中产阶级家庭。然而,他有远见地拒绝了 2006 年雅虎 10 亿美元的收购要约,当时该公司正经历一段困难时期。

这是一个艰难的决定,几年后,马克告诉记者,在他做出决定的一年内,所有的高管都离开了公司。
马克·扎克伯格面临的问题很简单,“10 亿美元的即时收益还是几年内将公司增长到 1000 亿美元的微小机会?”这与我们之前讨论的“纽扣问题”非常相似,尽管马克在现实世界中将会经历更加残酷的惩罚。
对他来说,秘诀不是在 10 亿或 1000 亿之间做出选择,而是决定坚持你的梦想,或者用它来换取即时的满足。
具有讽刺意味的是,这件事发生几年后,一个年轻人拒绝了脸书对他的创业公司 30 亿英镑的收购。他叫埃文·斯皮格尔,Snapchat 的联合创始人。

历史会重演。年轻的硅谷企业家总是按绿色按钮。
“红色或绿色按钮”问题的可能答案
- 根据期望值理论,人们应该选择绿色按钮,因为它的期望值是 5 亿(10 亿* 50%)
- 但对于风险承受能力较低的人来说,损失 100 万的想法是无法忍受的,红色按钮将是正确的选择。
- 一个豁达的回答,如果你有“选择权”,你可以把这个“权利”以 5 亿甚至更低的价格卖给对风险(归零)有很高容忍度的人。
- 进一步优化上面的答案,把“选择权”卖 100 万作为首期,求买家分红赢 10 亿。
- 再进一步,利用这种“选择权”,重新包装成公开发行的彩票。一张票 2 美元,总共 20 亿张票。获胜者可以带 10 亿回家。这种模式风险低,利润高。(但也是最难执行的)
终极答案
在我们生活中遇到的每个问题(或多项选择)中都有隐藏的选项。有些人可以破译信息,并找到一个新的路径来打破悖论。

我们可以选择绿色按钮或红色按钮。但是有没有一个终极的方法来将我们现在的机会货币化呢?
最后一个选择,把“选择权”卖给 VC 或者 PE。利用资本偏好冒险、追逐高额利润的行为。通过估值调整机制分享 100 万到 5 亿之间的利息。
这是通往财富世界的秘密路径之一。对于渴望的年轻心灵来说,他们不需要屈服于 100 万的欲望,失去 5 亿的机会。他们所需要的只是一个边界视野,让看到更大的图景。
最终,你如何解读“情境 ( 搜索空间)”和“选项(概率),”以获得更好的决策和计划周密的执行模式,将决定你在“财富食物链”中的位置
关于我,我是👧🏻现居澳大利亚墨尔本。我学的是计算机科学和应用统计学。我对通用技术充满热情。在咨询公司做 AI 工程师👩🏻🔬,帮助一个组织集成人工智能解决方案并利用其创新力量。在LinkedIn上查看更多关于我的内容。
数据分析中隐私的概率工具

Photo by Stephen Dawson on Unsplash
我们将继续我们的旅程来学习差分私有算法,这一次探索更多的概率工具。
在上一篇文章中,我们学习了如何使用大数理论和概率来设计差分私有算法。
我鼓励您在继续学习之前查看一下,以便更好地理解本教程的范围。
我们将继续探索学习隐私保护数据分析的技术,更深入地挖掘…
towardsdatascience.com](/a-coin-some-smokers-and-privacy-in-data-analysis-1339b83ede74)
如果您阅读了本系列的上一篇文章,您已经知道任何随机化算法 M 都可以是( ε,δ)差分私有算法,,如果它满足这样的性质。
这种方法的核心特性之一是在进行任何分析之前,甚至在将数据放入数据库之前,向数据本身注入噪声。像这样给数据引入随机性在隐私保护数据分析中相当常见,事实上它有一个专门的名字叫做局部差分隐私。

Photo by Franki Chamaki on Unsplash
然而,仅仅为了防止数据被对手窃取而破坏我们的数据的想法听起来非常妥协。一定有别的办法。
此时我们应该想到的两个问题是:
- 本地差分隐私是防止隐私数据泄露的唯一方法吗,有什么方法可以在不损坏我们数据的情况下提供隐私?
- 除了随机化回答,还有其他算法可以解决这个保护隐私的数据分析问题吗?
我们将在本文中尝试解决这两个问题。
全球差异隐私—简介:
我们已经知道,在局部差分隐私的情况下,我们向输入数据点添加噪声。因此,每个人都可以向自己的数据中添加噪声,从而完全消除了信任数据所有者或管理者的需要。我们可以说,在这种环境下,个人隐私得到了最大程度的保护。
另一方面,全局差分隐私给数据库的查询输出增加了噪声。因此,在这种情况下,我们有一个包含所有敏感信息的数据库,但是对该数据库的任何查询都不一定会生成真实的结果,因为这些结果是错误的。
但是,如果局部差异隐私更能保护个人隐私信息,为什么还要使用全局差异隐私呢?
如果你还记得上一篇文章,你应该知道,准确性和隐私之间总是有一个权衡。因此,如果你的目标是更多的隐私,它会来找你,但代价是失去一些准确性。考虑到这一点,本地和全局差异隐私的唯一区别在于:
如果数据所有者值得信任,那么对于相同级别的隐私保护,全局差异隐私会产生更准确的结果。
**一个重要的问题是要有一个值得信赖的所有者或管理者,**如果找到了,我们就可以在相同的隐私级别上有更好的准确性,因为在全球差异隐私的设置中,我们不再破坏我们的数据,而是将所需的噪声添加到我们对该数据库的查询的输出中。

Difference b/w Local and Global Privacy Settings
上面给出的图表毫不费力地解释了这一点。然而,我们现有的保护隐私的方法没有为应用全局差分隐私提供空间,因此我们需要设计一种不同的算法来做到这一点。
保护隐私的拉普拉斯机制:
在上一篇文章中,我们了解了一种实现差分隐私的技术,我们设计的算法给了数据生成器一种 似是而非的可否认性 的感觉,从而允许它们向数据中添加噪声。
在这里,我们将了解一个更常用的工具,它为我们提供差分隐私,拉普拉斯机制,,它为实(向量)值查询提供差分隐私。这些查询将数据库映射到一些实数,而不是整数值。
ℓ1-敏感度可以再次用于确定我们可以多准确地回答数据库的查询,因此,直观地,我们必须引入响应中的不确定性以隐藏单个个体的参与。因此,拉普拉斯机制帮助我们在全局差分隐私的设置下保护隐私。

函数(查询)的敏感度也告诉我们,为了保护隐私,我们必须对其输出进行多大程度的扰动,它为我们提供了查询输出中最大可能变化的度量。拉普拉斯机制将简单地计算 func ,并用从拉普拉斯分布中提取的噪声扰动每个坐标。噪声的标度将被校准到 func 的灵敏度(除以 ε ,这被称为β。
β= Lap(δf/ε)

From the Algorithmic Foundation of Diff. Privacy

Formalizing Laplace mechanism
因此,在拉普拉斯机制的情况下,不是在查询之前将噪声添加到数据,而是将该噪声添加到对数据库的查询的输出。拉普拉斯机制只是简单地把对称连续分布的噪声加到真答案上,如上图所示。

Photo by Markus Spiske on Unsplash
这里需要理解的重要一点是,在拉普拉斯机制的情况下,这种对称连续分布以零为中心。
辛西娅·德沃克(Cynthia Dwork)的《差分隐私算法基础》( algorithm Foundation of Differential Privacy)中提供了为什么拉普拉斯机制是( ε,0)差分隐私算法的有力证明。
总结:
在本文中,我们了解了局部和全局差分隐私之间的差异,并介绍了一种使用后者的设置来实现差分隐私的算法。
本系列接下来的几篇文章将更侧重于使用差分隐私进行深度学习。
敬请关注。暂时快乐学习。
PS。这是我关于媒体的第三篇文章,所以欢迎任何反馈和建议。
资源:
- https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf
- 【http://www.cis.upenn.edu/~ahae/papers/epsilon-csf2014.pdf
- http://dimacs . Rutgers . edu/~ Graham/pubs/slides/priv db-tutorial . pdf
- https://arxiv.org/pdf/1808.10410.pdf
- https://towards data science . com/understanding-differential-privacy-85ce 191 e 198 a
- https://towards data science . com/a-coin-some-smokers-and-privacy-in-data-analysis-1339 b 83 ede 74
- https://towards data science . com/Mr-x-网飞和数据分析隐私-f59227d50f45
概率不是可预测性
天气预报、癌症诊断、掷硬币

假设你正在看晚间新闻(或者更有可能是你的手机告诉你),明天有 30%的可能性会下雨。明天,你带伞了吗?
这似乎是一个良性的问题,但我们解释概率的方式对我们如何决策、做生意和生活有着真正的影响。它
在下文中,我们将分解像这样的概率和统计数据的核心含义,以及我们如何围绕这种不确定性做出决策。
当统计变成概率
让我们用同样的例子——明天有 30%的可能性下雨。一般来说,像这样的陈述使用的是推理统计学:它们观察一个事件在过去发生的频率,并使用推理将其应用于未来。

Via windy.com.
假设在过去的 100 次特定天气模式中,有 30 次第二天下雨。如果今天气象学家看到这种模式,他或她可能会说:
“我见过 30%的这种模式,第二天就下雨了。所以明天有 30%的可能性会下雨。”
——某处某气象学家
然而,这并不是概率(注意:统计数据是历史频率,概率是未来的可能性)的意思。它实际上的意思大致是:
基于我在过去 100 次中见过 30 次这种模式,第二天就下雨了,我 推断在接下来的 100 次我看到这种模式时,第二天会下雨 30 次。
假设我今天看到了模式,有 30%的几率这是我看到模式的一天,第二天下雨。
——任何地方都没有气象学家
我们马上看到这是一个更复杂的声明。重要的是,我们看到了历史观察(即统计)是如何转化为前瞻性概率的。不幸的是,我们不知道明天是否会下雨——知道概率并不能帮助我们预测明天是否带伞。毕竟,明天不会发生 100 次,只会发生一次。
概率和离散事件
天气是每天都会发生的事情,所以从长远来看,用概率来描述天气可能是合适的。让我们来看看一些不相关的事情:一个接受癌症诊断的病人。

当患者被诊断患有癌症时,他们通常会问(或被医生告知)的一个问题是“我的机会有多大?”这经常被用来帮助病人评估诊断的严重性。直觉上,我们理解“80%的类似患者在 10 年后存活”是比“8%的机会活到 10 年”更好的预后。然而,我们应该进一步展开这个问题,以真正理解这些意味着什么。
为了帮助我们,我使用了纪念斯隆-凯特琳癌症中心发表的一个模型(以及他们发表的其他几个模型),显示了结肠直肠癌手术后 5 年的存活率。在模型中,我输入了一个假设的 N1 期 T3 期癌症,已经扩散到 16 个淋巴结中的 2 个,具有中度分化,且为 27 岁男性。该模型正确地指出,我在这里还要补充一点,“预测工具不能用来替代任何健康状况或问题的医疗建议、诊断或治疗。”
那么,结果如何呢?

“这个数字以百分比的形式显示了您在接受结肠癌完全切除术(手术切除所有癌组织)后至少存活 5 年的概率。这一概率意味着,对于每 100 名像你这样的患者,我们预计有 85 人在手术后存活 5 年,15 人将在 5 年内死亡。”
我们先来看第二句:“每 100 个像你这样的病人,我们预计有 85 个会在手术后存活 5 年。”这与我们的降雨示例非常匹配,假设的气象学家指出,对于特定的天气模式,每 100 天就会有 30 天降雨。MSK 的模型使用过去的患者数据,并对 100 名患者的未来生存可能性做出推断,我们的患者只是其中之一。然后(甚至在此之前),MSK 跳出来说,由于 100 个病人中有 85 个会在 5 年后存活,我们的病人有 85%的机会存活 5 年。
但是这种跳跃有一个问题——它没有声音。我们的病人患的不是 100 种癌症中的 85 种,而是一种癌症。也许对医生来说,知道如果医生有 100 个病人,他可以期望 85 个存活 5 年是有用的,但是这并不意味着对每个病人都有用。这不能提供任何类型的可预测性——它不能告诉病人他们是在 85%还是在 15%的关键信息,医生当然不能说。
这是保罗·卡兰尼蒂在他的回忆录中写的当呼吸变成空气:
与其说“中位生存期是 11 个月”或“你有 95%的机会在两年内死亡”,我会说,“大多数病人能活几个月到几年。”对我来说,这是一个更真实的描述。问题是你不能告诉一个病人她处在曲线的哪个位置:她会在六个月还是六十年后死去?我开始相信,比你能做到的更精确是不负责任的。
其实,连数学家都在争论这个。具体来说,“频繁主义者”坚持认为概率只适用于事件,就像掷硬币一样,可以被广泛重复(理论上无限重复*)。因为抛硬币和天气有规律地反复发生,你可以指定一个概率,因为随着时间的推移,你会做出足够的预测来与指定的概率进行比较。然而,对于癌症预测,以及其他离散事件,如超级碗(以及超级碗的硬币投掷)和总统选举,不会有数百个事件被重复——只有一个。*

再者,概率不是可预测性。知道了一枚公平的硬币正面朝上的概率是 50%,你在不可能准确预测下一次掷硬币*。也许你可以平均预测 100 次翻转中有多少次是正面,但你无法确定地预测下一次翻转。*

Huffington Post’s 2016 presidential election probabilities, for posterity.
这种思考方法可能会增加混乱,因为它看起来不太精确,而且确实如此!但它让我们面对未来的不确定性。我们常常过于自信,因为概率让不可能的事情看起来不可能,而事实上它们极有可能发生。邓肯·沃茨在中写道,这是企业向应急战略发展的一个原因,一切都很明显**
因此,如果连[数学家]都难以理解“明天下雨的概率是 60%”这句话的含义,那么我们其他人也能理解就不足为奇了。
延伸阅读:
不平衡数据集的概率校准
对欠采样方法的一点建议

Photo by Bharathi Kannan on Unsplash
当我们试图为现实世界的问题建立机器学习模型时,我们经常会面临不平衡的数据集。重采样方法,尤其是欠采样是克服类别不平衡最广泛使用的方法之一(我在另一篇中的文章中也展示了那些重采样方法是如何在我的硕士论文中起作用的)。然而,由于训练和测试集中不同的类别分布,实现这种方法倾向于增加假阳性。这会使分类器产生偏差并增加假阳性。[1] Pozzolo 等人,(2015) 认为可以利用贝叶斯最小风险理论来修正由于欠采样而产生的偏差。这有助于我们找到正确的分类阈值。
内容
- 概率校准是如何工作的?
- 实验
- 结论
1.概率校准是如何工作的?

Photo by John Schnobrich on Unsplash
如上所述,欠采样会导致后验概率出现偏差。这是由于随机欠采样的特性,其通过随机移除它们来缩小多数类,直到两个类具有相同数量的观察值。这使得训练集的类分布不同于测试集中的类分布。那么,在这个问题上,使用贝叶斯最小风险理论的概率校准究竟是如何工作的呢?—这种方法的基本思想是通过考虑欠采样率 β 考虑*来试图减少/消除随机欠采样率引起的偏差。*让我们来看看一些定义:
设 ps 为随机欠采样后预测为正类的概率;

,而 p 是预测给定特征的概率(不平衡)。我们可以把 ps 写成 p 的函数;

,其中 β 为欠采样情况下选择负类的概率,可表示如下。

,可以这样写

上式可解出 p 并表示如下。

因此,在应用欠采样率 *β、*之后,我们可以计算出 p ,这是无偏概率。
这个阈值可以是:

,这是数据集中正类的概率。

简要介绍了利用贝叶斯最小风险理论进行概率校准的方法。现在我们将继续看看这是如何在一个代码示例中工作的。
2.例子

Photo by Nathan Dumlao on Unsplash
在本节中,我们将看到概率校准技术如何在 Kaggle 上著名的信用卡欺诈数据集上对二进制分类问题进行建模。该数据集由 28 个 PCA 特征(全部匿名)和数量特征组成。目标特征是二元的,要么是诈骗,要么不是。正类占整个数据集的 0.17%,严重不平衡。让我们看看这个例子的代码。
首先,导入包。
## config
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import io, os, sys, types, gc, re
from sklearn import preprocessing
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import average_precision_score,
confusion_matrix, precision_score, recall_score, precision_recall_curve, f1_score, log_loss
from sklearn.decomposition import PCA
pca = PCA(n_components=1,random_state=42)
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=42)
from imblearn.ensemble import BalancedBaggingClassifier
from src.functionalscripts.BMR import *def make_prediction(model,X,threshold):
y_pred = model.predict_proba(X)
y_predicted = np.where(y_pred[:,1]>=threshold,1,0)
return y_pred, y_predicteddef evaluation(true, pred):
print('F1-score: ' + str(round(f1_score(true,pred),4)), '\n'
'Precision: ' + str(round(precision_score(true,pred),4)), '\n'
'Recall: ' + str(round(recall_score(true,pred),4)), '\n'
'Log loss: ' + str(round(log_loss(true,pred),4)), '\n'
'Cohen-Kappa: ' + str(round(cohen_kappa_score(true,pred),4)), '\n'
'Confusion matrix:' + '\n' + str(confusion_matrix(true,pred)))
现在读取数据集。
# read the data
df = pd.read_csv('src/resources/data/creditcard.csv')
这是数据集的前几行。

First few rows of the dataset
Class 列是我们的目标变量,Amount 列是交易金额。现在看正班的比例。
# The percentage of positive class in this dataset
len(df[df['Class']==1])/len(df)
正面类就是我上面说的,0.17%。现在我们将继续参观模型建筑。我们将使用逻辑回归来看看。让我们将 Amount 列标准化,并分成训练和测试数据集。
# Normalise the Amount feature
df['amt'] = preprocessing.normalize(np.array(df['Amount']).reshape(-1,1),
norm='l2')
现在,数据准备好了,让我们分成训练(整个数据的 80%)和测试(整个数据的 20%)数据集,并实现随机欠采样。
# Split the dataset into train and test, and drop unnecessary features
tr, te = train_test_split(df.drop(['Amount','Time'],1), test_size=.2,random_state=42)# Rundom Under Sampling (RUS)
tr_x_rus, tr_y_rus = rus.fit_resample(tr.drop(['Class'],1),tr.Class)
我们可以在随机欠采样后检查训练、测试和训练集中类的分布。
# See the class distribution with features
feats_distribution_rus = pd.DataFrame(pca.fit_transform(tr_x_rus),columns=['after']).reset_index(drop=True)
feats_distribution_rus['Class'] = tr_y_russns.regplot(x='after',y='Class',data=feats_distribution_rus,logistic=True, n_boot=500, y_jitter=.03)
plt.title('Class distribution of training set after undersampling')
plt.show()




Class distributions of before and after undersampling and test set comparison
左上角是训练集的分布,左下角和右边是随机欠采样后的分布,都是测试集(用于比较)。y 轴表示类别,1 表示交易是欺诈,否则不是欺诈。我们可以在训练集和测试集中看到类似的分布,因为它们是通过随机采样创建的。另一方面,在随机欠采样后的训练集中,显示出与其他分布完全不同的分布。让我们看看这种差异是如何影响分类器的。
现在建立模型。为了比较,让我们看看 RUS 装袋(随机欠采样+装袋)的性能。
# Logistic regression
logit = LogisticRegression(random_state=42,solver='lbfgs',
max_iter=1000)# Rundom Under Sampling (RUS)
tr_x_rus, tr_y_rus = rus.fit_resample(tr.drop(['Class'],1),tr.Class)
logit_rus = logit.fit(tr_x_rus,tr_y_rus)# RUS bagging
bc = BalancedBaggingClassifier(base_estimator=logit,random_state=42)
logit_bc = bc.fit(tr.drop(['Class'],1),tr.Class)
现在,我们使用贝叶斯最小风险来实现概率校准方法。这里我们创建 beta(少数选择比率)、tau(阈值)和校准函数。
# BMR (Bayes Minimum Risk) implementation
# Pozzolo et al., 2015, Calibrating Probability with Undersamplingclass BMR:
def beta(binary_target):
return binary_target.sum()/len(binary_target) def tau(binary_target, beta):
return binary_target.sum()/len(binary_target) def calibration(prob, beta):
return prob/(prob+(1-prob)/beta)
将这些校准技术应用于 RUS 和 RUS·鲍格的预测概率。
# Calibration
beta = BMR.beta(tr.Class)
tau = BMR.tau(tr.Class,beta)# with RUS
y_pred_calib_rus = BMR.calibration(prob=logit_rus.predict_proba(te.drop(['Class'],1))[:,1],beta=beta)y_predicted_calib_rus = np.where(y_pred_calib_rus>=tau,1,0)# wtih RUS bagging
y_pred_calib_bc = BMR.calibration(prob=logit_bc.predict_proba(te.drop(['Class'],1))[:,1],beta=beta)y_predicted_calib_bc = np.where(y_pred_calib_bc>=tau,1,0)
现在我们有了所有的预测,让我们评估它们,看看它们的表现如何。我将 RUS 和 RUS 装袋模型的阈值设为 0.5。
# Evaluation
## Random Under Sampling (RUS)
y_pred_rus, y_predicted_rus = make_prediction(model=logit_rus, X=te.drop(['Class'],1), threshold=.5)
evaluation(te.Class, y_predicted_rus)## RUS + Bagging
y_pred_bc, y_predicted_bc = make_prediction(model=logit_bc, X=te.drop(['Class'],1), threshold=.5)
evaluation(te.Class, y_predicted_bc)## Calibration with Rundom undersampling
evaluation(te.Class, y_predicted_calib_rus)## Calibration with RUS bagging
evaluation(te.Class, y_predicted_calib_bc)
这是结果。正如我们所料,有这么多的误报,这一点我们可以从精度得分中看出。

哦,等等,概率校准根本没有改变什么?一定有什么不对劲。让我们看看校准后的 RUS 装袋预测概率的预测分布。蓝色垂直线是通过校准的 RUS 装袋预测概率的平均值,红色垂直线是通过 RUS 装袋模型预测概率的平均值。显然,它们的平均值相差很远,因为校准后的概率平均值为 0.0021,而校准前为 0.5。考虑到正类在整个数据集中占 0.17%,校准后的概率似乎非常接近实际分布。

因此,如果我们修改阈值,效果应该会更好,这里我们可以看到修改阈值后的结果。在 RUS 模型上校准之前和校准之后的阈值被设置为 0.99,并且用 RUS 装袋的校准被设置为 0.8。

Summary of results after thresholds are modified
正如我们所看到的,在校准后,这些分数得到了提高,尤其是在随机欠采样模型上校准前后的差异非常显著。
因此,通过使用概率校准来校正有偏差的概率,我们可以看到性能的提高。
3。结论和想法
在这篇博文中,我们浏览了 Pozzolo 等人(2015)。这回答了我们的经验,即应用随机欠采样后会有更多的假阳性。观察重采样方法如何使分布产生偏差是非常有趣的。这将导致时间序列问题中的类似问题,因为我们预测的目标变量可能与我们训练模型时大不相同。
看看这种方法是否适用于不同类型的分类器(如基于树的分类器或神经网络分类器)以及不同类型的重采样方法,会很有意思。
这篇文章的代码可以在我的 GitHub 页面上找到。
包裹
- 引入重采样会导致后验分布出现偏差
- 利用贝叶斯最小风险理论引入概率校准方法(Pozzoli,et al. 2015)
- 展示了这种方法的例子
- 证实了该方法纠正了偏差,改善了模型结果
参考
[1] Pozzolo 等,不平衡分类欠采样的概率校准 (2015),2015 IEEE 计算智能研讨会系列
每个数据科学家都应该知道的 5 种概率分布

Probably a nice dashboard. Source: Pixabay.
概率分布就像 3D 眼镜。它们允许一个熟练的数据科学家识别完全随机变量中的模式。
在某种程度上,大多数其他数据科学或机器学习技能都是基于对数据概率分布的某些假设。
这使得概率知识成为你作为统计学家构建工具包的基础的一部分。如果你想出如何成为一名数据科学家的第一步。
事不宜迟,让我们切入正题。
什么是概率分布?
在概率统计中,随机变量是取随机值的东西,比如“我看到的下一个人的身高”或者“我下一碗拉面里厨师的头发数量”。
给定一个随机变量 X ,我们希望有一种方法来描述它取哪些值。除此之外,我们还想描述一下变量取某个值** x 的可能性有多大。**
例如,如果 X 是“我的女朋友有多少只猫”,那么这个数字很有可能是 1。有人可能会说,有非零的概率,值甚至可能是 5 或 10。
然而,一个人不可能(因此也不可能)有消极的猫。
因此,我们希望有一种明确的数学方式来表达变量 X 可能取的每一个可能值 x ,以及事件 (X= x) 发生的可能性有多大。
为了做到这一点,我们定义了一个函数 P ,使得 P(X = x) 是变量 X 具有值 x 的概率。
我们也可以要求 P(X < x), or P(X > x ),要求间隔而不是离散值。这将很快变得更加重要。
P 是变量的密度函数,表征该变量的分布。
随着时间的推移,科学家们已经认识到自然界和现实生活中的许多事情往往表现相似,变量共享一个分布,或具有相同的密度函数(或类似的函数改变其中的一些常数)。
有趣的是,为了让 P 成为一个真实的密度函数,有些东西必须适用。
- P(X = X)<= 1为任意值 x 。没有比确定更确定的了。
- P(X =x) > = 0 为任意值 x 。一件事可能是不可能的,但可能性不会比那更小。
- 而最后一个:所有可能值X的 P(X=x) 的总和为 1 。
最后一个意思是“X 取宇宙中任何值的概率,因为我们知道它会取某个值”。
离散与连续随机变量分布
最后,随机变量可以被认为属于两组:离散的和连续的随机变量。
离散随机变量
离散变量有一组离散的可能值,每个值都有非零概率。
例如,当掷硬币时,如果我们说
X = “1 如果硬币是正面,0 如果是反面”
那么 P(X = 1) = P(X = 0) = 0.5 。
然而,请注意,离散集合不必是有限的。
一个几何分布,用于模拟在 k 重试之后发生概率为p的某个事件的几率。
它的密度公式如下。

其中 k 可以取任意一个概率为正的非负值。
注意所有可能值的概率总和仍然是加起来是 1 。
连续随机变量
如果你说
X = “从我头上随机拔下的一根头发的长度,单位为毫米(不四舍五入)”
X 可以取哪些可能的值?我们可能都同意负值在这里没有任何意义。
然而,如果你说它正好是 1 毫米,而不是 1.1853759…或类似的东西,我会怀疑你的测量技能,或你的测量误差报告。
一个连续的随机变量可以在给定的(连续的)区间内取任何值。
因此,如果我们给所有可能的值分配一个非零概率,那么它们的总和不会等于 1** 。**
为了解决这个,如果 X 是连续的,我们为所有的 k 设置 P(X=x) = 0 ,取值取值 X 改为分配一个非零的机会。
为了表示 X 位于值 a 和 b 之间的概率,我们说
P(a<X<b)。
为了得到连续变量 X 的 P(a < X < b) ,而不是仅仅替换密度函数中的值,您将对从 a 到 b 的 X 的密度函数进行积分。
哇,你已经通过了整个理论部分!这是你的奖励。

Source: pixabay.
现在你知道什么是概率分布了,让我们来学习一些最常见的概率分布吧!
伯努利概率分布
具有伯努利分布的随机变量是最简单的变量之一。
它代表一个二元事件:“这发生了”vs“这没发生”,取一个值 p 作为它的唯一参数,它代表事件发生的概率****。
具有参数为 p 的伯努利分布的随机变量 B 将具有以下密度函数:
P(B = 1) = p,P(B =0)= (1-p)
这里 B=1 表示事件发生了, B=0 表示没发生。
注意这两个概率加起来都是 1,因此 B 不可能有其他值。
均匀概率分布
有两种均匀随机变量:离散的和连续的。
一个离散均匀分布将取一组**(有限)**值 S ,并给它们中的每一个分配一个概率 1/n ,其中 n 是 S 中元素的数量。
这样,举例来说,如果我的变量 Y 在{1,2,3}中是一致的,那么有 33%的几率出现这些值。
在骰子中可以找到离散均匀随机变量的一个非常典型的例子,其中典型的骰子具有一组值{1,2,3,4,5,6}。
一个连续均匀分布取而代之,只取为参数,并在它们之间的区间内给每个值分配相同的密度。
这意味着 Y 在区间(从 c 到 d )中取值的概率与其大小相对于整个区间( b-a 的大小成比例。
因此,如果 Y 均匀分布在 a 和 b 之间,则

这样,如果 Y 是 1 到 2 之间的均匀随机变量,
Python 的random包的random方法采样 0 到 1 之间的均匀分布的连续变量。
有趣的是,可以证明给定一个均匀随机值生成器和一些演算,可以对任何其他分布进行采样。
正态概率分布

Normal Distributions. source: Wikipedia
正态分布变量在自然界如此普遍,它们实际上是。这就是这个名字的由来。
如果你把你所有的同事聚集在一起,测量他们的身高,或者称他们的体重,并把结果绘制成柱状图,很可能会接近正态分布。
当我向您展示探索性数据分析示例时,我实际上看到了这种效果。
还可以看出,如果您从任意随机变量中抽取一个样本,然后对这些测量值进行平均,并多次重复该过程,该平均值也将具有一个正态分布。这个事实非常重要,它被称为统计学的基本定理。
正态分布变量:
- 是否对称,以平均值为中心(通常称为 μ )。
- 可以取真实空间上的所有值,但只有 5%的时间偏离标准值两个 sigmas。
- 到处都是和。
大多数情况下,如果你测量任何经验数据,并且它是对称的,假设它是正态的会有点用。
例如,滚动 K 骰子,将结果相加,将会得到非常正常的分布。
对数正态概率分布

Lognormal distribution. source: Wikipedia
对数正态概率分布是正态概率分布的较小的,不太常见的姐妹。
如果变量 Y = log(X) 遵循正态分布,则称变量 X 为对数正态分布。
当绘制成直方图时,对数正态概率分布是不对称的,如果它们的标准偏差更大,这种情况会变得更加严重。
我认为对数正态分布值得一提,因为大多数基于货币的变量都是这样的。
如果你观察任何与金钱相关的变量的概率分布,比如
- 某银行最近一次转账的金额。
- 华尔街最近的交易量。
- 一组公司给定季度的季度收益。
它们通常不具有正态概率分布,而是表现得更接近于对数正态随机变量。
(对于其他数据科学家:如果你能想到你在工作中遇到的任何其他经验对数正态变量,请加入评论!尤其是财务之外的任何事情)。
指数概率分布

Source: Wikipedia
指数概率分布也随处可见。
它们与一个叫做泊松过程的概率概念紧密相关。
直接从维基百科上偷来的,泊松过程是“一个事件以恒定的平均速率连续独立发生的过程”。
这意味着,如果:
- 你有很多事情要做。
- 它们以一定的速率发生(该速率不会随着时间而改变)。
- 仅仅因为一件事发生了,另一件事发生的可能性不会改变。
然后你有一个泊松过程。
一些例子可能是对服务器的请求,超市中发生的交易,或者在某个湖中钓鱼的鸟。
想象一个频率为λ的泊松过程(比如,事件每秒发生一次)。
指数随机变量模拟一个事件发生后,下一个事件发生所需的时间。
有趣的是,在泊松过程中,一个事件可能发生在 0 到无限时间 ( 概率递减)之间的任何时间间隔。
这意味着不管你等了多长时间,该事件都有非零的几率不会发生。这也意味着它可能在很短的时间间隔内发生多次。
在课堂上,我们曾经开玩笑说公交车到站是泊松过程。我认为当你向某些人发送 WhatsApp 消息时的响应时间也符合标准。
然而,λ参数调节事件的频率。
它将使事件发生的预期时间****以某个值为中心。
这意味着如果我们知道每 15 分钟就有一辆出租车经过我们的街区,尽管理论上我们可以永远等下去,但我们很可能不会等超过 30 分钟。
指数概率分布:在实践中
以下是指数分布随机变量的密度函数:

假设您有一个来自变量的样本,并想看看它是否可以用指数分布变量来建模。
最佳 λ参数可以很容易地估计为采样值平均值的倒数。
指数变量非常适合建模任何概率分布,这些概率分布非常罕见,但是有巨大的(和均值突变的)异常值。
这是因为它们可以取任何非负的值,但是集中在较小的值上,随着值的增加频率降低。
在一个异常值特别多的样本中,你可能想要估计λ作为中值而不是平均值,因为中值对于异常值更加稳健。你的里程可能会有所不同,所以要有所保留。
结论
总而言之,作为数据科学家,我认为学习基础知识对我们来说很重要。
概率和统计可能不像深度学习或无监督机器学习那样华而不实,但它们是数据科学的基石。尤其是机器学习。
以我的经验来看,在不知道特征遵循哪种分布的情况下,给机器学习模型提供特征是一个糟糕的选择。
记住无处不在的指数和正态概率分布以及它们较小的对应物,对数正态分布也是很好的。
在训练机器学习模型时,了解它们的属性、用途和外观是改变游戏规则的**。在进行任何类型的数据分析时,记住它们通常也是好的。**
你觉得这篇文章有用吗?这些都是你已经知道的东西吗?你学到新东西了吗?请在评论中告诉我!
在 Twitter 上联系我 ,Mediumofdev . to如果有任何你认为不够清楚的事情,任何你不同意的事情,或者任何明显错误的事情。别担心,我不咬人。
原载于 2019 年 6 月 17 日http://www . data stuff . tech。
数据科学中的概率分布
介绍数据科学中一些最常用的概率分布,并附有实际例子。

Photo by Robert Stump on Unsplash
介绍
拥有扎实的统计背景对数据科学家的日常生活大有裨益。每当我们开始探索一个新的数据集时,我们需要首先做一个探索性数据分析(EDA) ,以便对某些特性的主要特征有一个大致的了解。如果我们能够了解数据分布中是否存在任何模式,我们就可以定制我们的机器学习模型,以最适合我们的案例研究。这样,我们将能够在更短的时间内获得更好的结果(减少优化步骤)。事实上,一些机器学习模型被设计成在一些分布假设下工作得最好。因此,了解我们正在使用哪些发行版,可以帮助我们确定哪些模型最适合使用。
不同类型的数据
每次我们处理数据集时,我们的数据集代表来自人群的样本。使用这个样本,我们可以试着理解它的主要模式,这样我们就可以用它来预测整个人口(即使我们从来没有机会检查整个人口)。
假设我们想预测给定一套特征的房子的价格。我们可能能够在网上找到旧金山所有房价的数据集(我们的样本),在进行一些统计分析后,我们可能能够对美国任何其他城市(我们的人口)的房价做出相当准确的预测。
数据集由两种主要类型的数据组成:数值型(例如整数、浮点数)和分类型(例如姓名、笔记本电脑品牌)。
数值数据还可以分为另外两类:离散和连续。离散数据只能取某些值(如学校的学生人数),而连续数据可以取任何实数值或分数值(如身高和体重的概念)。
从离散随机变量中,可以计算出概率质量函数,而从连续随机变量中可以推导出概率密度函数。
概率质量函数给出了变量可能等于某个值的概率,相反,概率密度函数值本身不是概率,因为它们首先需要在给定范围内积分。
自然界中存在许多不同的概率分布(图 1),在本文中,我将向您介绍数据科学中最常用的概率分布。

Figure 1: Probability Distributions Flowchart [1]
在整篇文章中,我将提供关于如何创建每个不同发行版的代码片段。如果您对其他资源感兴趣,可以在 this my GitHub repository 中找到。
首先,让我们导入所有必需的库:
二项分布
伯努利分布是最容易理解的分布之一,并且可以用作推导更复杂分布的起点。
这种分布只有两种可能的结果和一次试验。
一个简单的例子可以是投掷一枚有偏/无偏的硬币。在这个例子中,结果可能是正面的概率可以被认为等于反面的 p 和 (1 - p) (包含所有可能结果的互斥事件的概率需要总和为 1)。
在图 2 中,我提供了一个有偏差硬币的伯努利分布的例子。

Figure 2: Bernoulli distribution biased coin
均匀分布
均匀分布可以很容易地从伯努利分布推导出来。在这种情况下,可能允许无限数量的结果,并且所有事件发生的概率相同。
作为一个例子,想象一个公平的骰子滚动。在这种情况下,有多个可能的事件,每个事件发生的概率相同。

Figure 3: Fair Dice Roll Distribution
二项分布
二项式分布可以被认为是遵循伯努利分布的事件结果的总和。因此,二项分布用于二元结果事件,并且在所有连续试验中成功和失败的概率是相同的。该分布将两个参数作为输入:事件发生的次数和分配给两个类别之一的概率。
一个简单的二项式分布的例子可以是一个有偏/无偏硬币的投掷,重复一定的次数。
改变偏差量将会改变分布的样子(图 4)。

Figure 4: Binomial Distribution varying event occurrence probability
二项式分布的主要特征是:
- 给定多个试验,每个试验都是相互独立的(一个试验的结果不会影响另一个)。
- 每次尝试只能导致两种可能的结果(例如,赢或输),其概率为 p 和 (1 - p) 。
如果给定了成功的概率( p )和试验的次数( n ),我们就可以使用下面的公式计算这 n 次试验的成功概率( x )(图 5)。

Figure 5: Binomial Distribution Formula [2]
正态(高斯)分布
正态分布是数据科学中最常用的分布之一。我们日常生活中发生的许多常见现象都遵循正态分布,例如:经济中的收入分布、学生平均报告、人口中的平均身高等。除此之外,小随机变量的总和也通常遵循正态分布(中心极限定理)。
在概率论中,中心极限定理 ( CLT )确立了,在某些情况下,当独立的随机变量相加时,它们的正常标准化和趋向于正态分布,即使原始变量本身不是正态分布
— 维基百科

Figure 6: Gaussian Distribution
可以帮助我们识别正态分布的一些特征是:
- 这条曲线在中心对称。因此,平均值、众数和中位数都等于同一个值,使所有值围绕平均值对称分布。
- 分布曲线下的面积等于 1(所有概率的总和必须为 1)。
正态分布可以用下面的公式推导出来(图 7)。

Figure 7: Normal Distribution Formula [3]
使用正态分布时,分布均值和标准差起着非常重要的作用。如果我们知道它们的值,我们就可以很容易地通过检查概率分布来找出预测精确值的概率(图 8)。事实上,由于分布特性,68%的数据位于平均值的一个标准偏差内,95%位于平均值的两个标准偏差内,99.7%位于平均值的三个标准偏差内。

Figure 8: Normal Distribution 68–95–99.7 Rule [4]
许多机器学习模型被设计为使用遵循正态分布的数据工作得最好。一些例子是:
- 高斯朴素贝叶斯分类器
- 线性判别分析
- 二次判别分析
- 基于最小二乘法的回归模型
此外,在某些情况下,还可以通过应用对数和平方根等变换将非正常数据转换为正常形式。
泊松分布
泊松分布通常用于寻找事件可能发生的概率或不知道它通常发生的频率。此外,泊松分布也可用于预测一个事件在给定时间段内可能发生的次数。
例如,保险公司经常使用泊松分布来进行风险分析(例如,预测预定时间跨度内的车祸数量)以决定汽车保险定价。
使用泊松分布时,我们可以确信不同事件发生之间的平均时间,但是事件可能发生的精确时刻在时间上是随机的。
泊松分布可使用以下公式建模(图 9),其中 λ 代表一段时间内可能发生的事件的预期数量。

Figure 9: Poisson Distribution Formula [5]
描述泊松过程的主要特征是:
- 这些事件相互独立(如果一个事件发生,这不会改变另一个事件发生的概率)。
- 一个事件可以发生任意次数(在定义的时间段内)。
- 两件事不能同时发生。
- 事件发生之间的平均速率是恒定的。
图 10 显示了改变一个周期(λ)内可能发生的事件的预期数量如何改变泊松分布。

Figure 10: Poisson Distribution varying λ
指数分布
最后,指数分布用于模拟不同事件发生之间的时间。
例如,假设我们在一家餐馆工作,我们想预测不同顾客来到餐馆的时间间隔。对于这种类型的问题,使用指数分布可能是一个完美的起点。
指数分布的另一个常见应用是生存分析(如设备/机器的预期寿命)。
指数分布由参数λ控制。λ值越大,指数曲线衰减越快(图 11)。

Figure 11: Exponential Distribution
使用以下公式模拟指数分布(图 12)。

Figure 12: Exponential Distribution Formula [6]
如果你对研究概率分布如何被用来揭开随机过程的神秘面纱感兴趣,你可以在这里找到更多关于它的信息。
联系人
如果你想了解我最新的文章和项目,请通过媒体关注我,并订阅我的邮件列表。以下是我的一些联系人详细信息:
文献学
[1]数据科学统计学导论。
迪奥戈·梅内塞斯·博尔赫斯,数据科学家的成就。访问:https://medium . com/diogo-menez es-Borges/introduction-to-statistics-for-data-science-7bf 596237 ac6
[2]二项式随机变量,用友生物统计学开放学习教材。访问地址:https://bolt . mph . ufl . edu/6050-6052/unit-3b/binomial-random-variables/
[3]正态分布或钟形曲线的公式。ThoughtCo,考特尼泰勒**。**访问:https://www . thoughtco . com/normal-distribution-bell-curve-formula-3126278
[4]解释正态分布的 68–95–99.7 规则。
迈克尔·加拉尼克,中等。访问:https://towardsdatascience . com/understanding-the-68-95-99-7-rule-for-a-normal-distribution-b7b 7 CBF 760 c 2
【5】正态分布,二项式分布&泊松分布,让我分析师。访问网址:http://makemanealyst . com/WP-content/uploads/2017/05/Poisson-Distribution-formula . png
[6]指数函数公式,&学习。访问地点:https://www.andlearning.org/exponential-formula/
概率论
机器学习基础(第一部分)
这是我认为机器学习基础的一系列主题中的第一部分。概率论是一个数学框架,用于量化我们对世界的不确定性。它允许我们(和我们的软件)在不可能确定的情况下进行有效的推理。概率论是许多机器学习算法的基础。这篇文章的目标是在将概率论应用于机器学习应用程序之前,涵盖所需的词汇和数学。所涉及的主题将在以后的帖子中讨论!

一些关于概率的哲学
概率到底是什么?大多数人都知道事件发生的概率是介于 0 和 1 之间的某个值,它表示事件发生的可能性有多大。看起来很简单,但是这些值实际上来自哪里呢?
客观主义者的观点是,随机性是宇宙的基础。他们会说,公平硬币正面朝上的概率是 0.5,因为这是公平硬币的本性。或者,主观主义者的观点认为,概率代表了我们对事件将会发生的相信程度。如果我们知道硬币的初始位置以及力是如何施加的,那么我们就可以确定它是正面朝上还是反面朝上。在这种视角下,概率是衡量我们无知的一个尺度(就像不知道力是如何作用在硬币上的)。
我个人是主观主义者。如果我们有适当的测量方法,我们应该能够确定地预测任何事情。一个不正确的领域是量子力学。为了理解一些量子现象,我们必须将它们视为真正随机的。有可能有一天我们会对宇宙如何运作有更好的理解,因此也能正确预测这些现象。似乎阿尔伯特·爱因斯坦也认同我的主观主义:
“上帝不和宇宙玩骰子。”
无论我们对随机性的本质有什么样的信念,我们都需要一些有原则的方法来实际估算概率。
频率主义者的立场是,估计来自实验,而且只是实验。如果我们想估计一个六面骰子掷出 4 的可能性,我们应该掷几次骰子,观察 4 出现的频率。
当我们有大量数据时,这种方法工作得很好,但是在例子较少的情况下,我们不能对我们的估计有信心。如果五卷之后我们还没有看到 a 4,是不是意味着 a 4 是不可能的?另一个问题是,我们不能将任何关于骰子的先验知识注入到我们的估计中。如果我们知道骰子是公平的,那么在前五次掷骰中没有看到 4 是完全可以理解的。
另一个流行的评估哲学是贝叶斯理论。概率的贝叶斯处理允许我们将我们先前的信念与我们的观察相结合。想象一下,一枚我们认为公平的硬币被抛了三次,结果是三个头。一个频率主义者的计算会建议硬币是装载的(虽然可信度低),但是我们的贝叶斯先验硬币是公平的允许我们保持一定程度的信念,即一个尾巴仍然是可能的。我们如何结合我们先前的信念的实际机制依赖于所谓的贝叶斯法则,这将在后面介绍。
概率数学
一开始,我提出概率论是一个数学框架。正如任何数学框架一样,需要一些词汇和重要的公理来充分利用该理论作为机器学习的工具。
概率就是各种结果的可能性。所有可能结果的集合被称为样本空间。抛硬币的样本空间是{正面,反面}。水温的样本空间是冰点和沸点之间的所有值。样本空间中一次只能有一个结果,并且样本空间必须包含所有可能的值。样本空间通常用ω(大写ω)表示,特定结果用ω(小写ω)表示。我们将事件发生的概率ω表示为 P(ω)。
概率的两个基本公理是:

Axioms of Probability
说白了,任何事件的概率都得在 0(不可能)到 1(一定)之间,所有事件的概率之和应该是 1。这是因为样本空间必须包含所有可能的结果。所以我们确定(概率 1)可能的结果之一会发生。
一个随机变量 x,是一个从样本空间随机取值的变量。我们经常用斜体表示 x 可以取的一个特定值。例如,如果 x 代表掷硬币的结果,我们可以讨论一个特定的结果为 x =正面。随机变量既可以像硬币一样是离散的,也可以是连续的(可以有无数个可能的值)。
为了描述随机变量 x 的每个可能值的可能性,我们指定一个概率分布。我们写 x ~ P(x)来表示 x 是一个随机变量,它取自一个概率分布 P(x)。根据随机变量是离散的还是连续的,概率分布有不同的描述。
离散分布:
离散随机变量用一个概率质量函数 (PMF)来描述。PMF 将变量样本空间中的每个值映射到一个概率。一个这样的 PMF 是在 n 个可能结果上的均匀分布:P(x= x ) = 1/ n 。这读作“x 取值 x 的概率是 1 除以可能值的数量”。它被称为均匀分布,因为每种结果都有相同的可能性(可能性均匀分布在所有可能的值上)。因为骰子的每个面都有相同的可能性,所以公平掷骰由均匀分布来模拟。加载的骰子通过分类分布来建模,其中每个结果被分配一个不同的概率。

另一种常见的离散分布是伯努利分布。伯努利分布规定了随机变量的概率,它可以取两个值中的一个(1/0,正面/反面,真/假,下雨/不下雨,等等)。).伯努利分布的 PMF 是 P(x)= {Pifx= 1,1- p if x =0}。因此,我们可以用单个参数 p 指定整个分布,即正面结果的概率。对于一枚公平的硬币,我们有 p = 0.5,因此正面或反面的可能性是相等的。或者,如果我们说明天下雨的概率是 p = 0.2,那么我们可以推断不下雨的概率是 0.8。
连续分布:
连续随机变量由概率密度函数 (PDF)描述,这可能有点难以理解。我们通常将随机变量 x 的 PDF 表示为 f ( x )。pdf 将无限样本空间映射到相对似然值。为了理解这一点,让我们看一个最著名的连续分布的例子,高斯(正态)分布。
高斯分布(俗称钟形曲线)可以用来模拟几种自然现象。例如,每个性别的身高近似为高斯分布。高斯分布由两个值参数化:均值μ(μ)和方差σ(σ平方)。平均值指定分布的中心,方差指定分布的宽度。你可能也听说过标准差σ,它就是方差的平方根。为了表示 x 是从具有均值μ和方差σ的高斯分布中抽取的随机变量,我们写:

X is drawn from a Normal distribution with mean μ and variance σ².
乍一看,高斯分布的 PDF 的函数形式可能令人生畏。我保证,在应用程序中使用高斯分布后,这种恐惧就会消失!PDF 的功能形式是:

The PDF of x given μ and σ²
等式的左手边写着“给定μ和σ的 x 的 PDF”。竖线代表单词“given ”,表示我们已经知道括号中它后面的所有值。假设μ = 0,σ = 4,我们来绘制这个等式:

那么我说的相对可能性是什么意思呢?与离散分布不同,x = x 处的 PDF 值并不是 x 的实际概率。当人们刚开始涉足概率论时,这是一个常见的误解。因为 x 可以取无限多的值,所以 x 取任何特定值的概率实际上是 0!我猜你不相信我,但是让我们在重温我们的公理时一起考虑一下。
回想一下,每个可能值的总概率总和需要为 1。我们如何对无限多的值求和?答案来自积分形式的微积分。我们可以用积分来重写 PDF 形式的公理:

The integral of the PDF over the sample space is 1.
如果你不熟悉微积分,积分是一个计算曲线下面积的运算符 f ( x )。这是对无穷多个值求和的概括。所以 PDF 下面的区域代表高斯分布的总概率!如果你熟悉微积分(并且有能力),你可以自己计算高斯函数的积分来确定面积是 1。
因为面积是我们感兴趣的,所以使用连续随机变量的累积分布函数 (CDF)通常更有用。我们把 CDF, F ( x )写成:

CDF is a function of the integral of the PDF.
这到底是什么意思?嗯,对于给定的值 x ,我们对 PDF 从负无穷大到那个值进行积分。所以 F ( x )给出了从负无穷大到 x 区间的 PDF 下的面积。
我们只要确定面积对应概率,那么 F ( x )给我们 P(x≤ x )。现在,我们可以通过注意到 P(a≤x≤b)=F(b)-F(a)来使用 CDF 确定任何给定范围[ a , b ]的概率。这就回答了“x 在 a 和 b 之间的概率是多少?”。
求 P(x= x )等价于求 P(x≤x≤x)= F(x)-F(x)= 0。现在你知道了,从分布中抽取一个特定数字的概率是 0!(更有力的论据可以通过实际采用极限来提出)。这是之前相同高斯的 CDF:

我们看到 x 取小于-2.5 的值的概率接近于 0。我们还看到,从 x 采样的值大多小于 2.5。
联合概率分布:
多个随机变量的分布称为联合概率分布。我们可以把随机变量的集合写成一个向量 x 。在 x 上的联合分布指定了 x 中包含的所有随机变量的任何特定设置的概率。为了更清楚地说明这一点,让我们考虑两个随机变量 x 和 y,我们把联合概率写成 P(x= x ,y= y )或者简称为 P( x , y )。我大声说出“x= x 和 y= y 的概率”。如果两个随机变量都是离散的,我们可以用一个简单的概率表来表示联合分布。例如,让我们考虑我穿哪件外衣与天气条件的联合分布(在只有这些选项的宇宙中):

Joint Distribution of clothes and weather (in an odd universe)
这个玩具例子强调了一些重要的事情。首先,我不擅长做玩具例子。其次,请注意,该表满足我们的公理所提出的要求。我们可以立即回答 P 形式的问题(衣服=T 恤衫,天气=晴天),但是联合分布给了我们更多!
边际概率分布:
首先,我们来看看求和规则:

Sum Rule
术语 P( x )被称为边际概率分布,因为我们已经将随机变量 y“边缘化”了。让我们使用求和规则来计算我穿帽衫的概率。P(帽衫)= P(帽衫,晴天)+ P(帽衫,多云)+ P(帽衫,雨天)= 3/9。我们可以使用相同的过程来找到任何衣服项目或任何天气条件的边际概率。
如果 P( x , y )是连续随机变量的联合分布,那么为了将 y 边缘化,我们将求和转化为 y 上的积分,就像之前一样。
条件概率分布:
我们也经常对一个事件发生的概率感兴趣,因为另一个事件已经被观察到了。给定 y,我们将 x 的条件概率分布 T37 表示为:

Probability of x conditioned on observing y
换句话说,如果我观察到 y= y ,那么 x= x 的概率就是 P( x,y )/P( y )。为什么观察 y 会改变 x 的概率?想象一下你看到我穿着夹克走进去。知道我穿了夹克,就给了你关于天气的信息,不用直接观察天气。
注意,条件概率只存在于 P( y ) > 0 的情况下。如果 y 不可能发生,那么我们一开始就不可能观察到 y 。
将最后一个方程的两边乘以 P( y )我们得到概率的链式法则,P( x,y)= p(x|y)⋅p(y)。链式法则可以推广到任意数量随机变量的联合分布:P( x,y,z ) = P( x | y,z ) ⋅ P( y,z ) = P( x | y,z)⋅p(y|z)⋅p(【t34
贝叶斯法则:
请注意,我们可以用两种等价的方式来编写两个变量的链式法则:
- P( x,y)= p(x|y)⋅p(y)
- P( x,y)= p(y |x)⋅p(x)
如果我们设置两个右侧相等,并除以 P( y ),我们得到贝叶斯法则:

Bayes Rule
贝叶斯法则对于许多统计学和机器学习来说至关重要。如前所述,这是贝叶斯统计背后的驱动力。随着我们从数据中收集更多的观察结果,这个简单的规则允许我们更新我们对数量的信念。我肯定会在以后的文章中更多地讨论贝叶斯法则(和贝叶斯统计)。
独立性和条件独立性:
在前面的例子中,我们看到 P( x|y ) ≠ P( x )是因为观察 y 给了我们关于 x 的信息。总是这样吗?我们假设 P( x,y )是一个联合分布,x 代表一家店的冰淇淋量,y 代表月亮每天被物体撞击的次数。知道其中一个值会给我们任何关于另一个值的信息吗?当然不是!所以在这种情况下 P( x|y ) = P( x )!通过把这个代入链式法则,我们发现在这个场景中我们得到 P( x,y)= p(x | y)⋅p(y)= p(x)⋅p(y)。这直接把我们引向我们对独立的定义。如果 P( x,y)= p(x)⋅p(y),则称两个变量 x 和 y 是独立的。
一个类似的概念是条件独立性。给定另一个变量 z,如果 P( x,y | z)= p(x | z)⋅p(y | z),则两个变量 x 和 y 称为条件独立。让我们做一个例子来看看这是怎么回事。
假设 x 是一个随机变量,表示我是否带伞上班,y 是一个随机变量,表示我的草地是否潮湿。很明显,这些事件不是独立的。如果我带了一把伞,这可能意味着下雨了,如果下雨,我的草是湿的。现在让我们假设我们观察变量 z,它代表外面实际上正在下雨。现在不管我有没有带伞上班,你都知道我家的草是湿的。所以下雨的条件已经使我的伞独立于我的草是湿的!
当我们需要表示非常大的联合分布时,独立性和条件独立性变得非常重要。独立性让我们将分布分解成更简单的术语,实现有效的内存使用和更快的计算。我们将在未来关于贝叶斯网络的文章中具体看到这一点!
随机变量的函数
创建以随机变量为输入的函数通常很有用。让我们考虑去一趟赌场。玩我最喜欢的游戏“猜一个 1 到 10 之间的数字”要花 2 美元。如果你猜对了,你将赢得 10 美元。如果你猜错了,你什么也赢不了。设 x 是一个随机变量,表示你是否猜对了。然后我们可以写一个函数h(x)= { $ 8 ifx= 1,和-$2 if x = 0}。换句话说,如果你猜对了,你会得到 10 美元减去你支付的 2 美元,否则你会失去你的 2 美元。你可能有兴趣提前知道预期的结果是什么。
期望:
随机变量 x ~ P(x)上的函数 h (x)的期望值,或期望值,是 P(x)加权后的 h ( x )的平均值。对于离散的 x,我们写为:

Expected Value of h(x) with respect to P(x)
如果 x 是连续的,我们会用一个积分代替求和(我敢打赌你现在已经看到一个模式了)。因此,期望充当了对 h ( x )的加权平均,其中权重是每个 x 的概率。
如果我们假设有 1/10 的机会猜中正确的数字,在赌场玩猜谜游戏的期望值是多少?
𝔼[ h (x)] = P(赢)⋅ h (赢)+ P(输)⋅ h (输)=(1/10)⋅$ 8+(9/10)⋅(-$ 2)= $ 0.80+(-1.80)=-1 美元。所以平均来说,我们每次玩游戏都会输掉 1 美元!
期望的另一个很好的特性是它们是线性的。我们假设 g 是 x 的另一个函数,α和β是常数。然后我们有:

Expectations are linear
方差和协方差:
当我们讨论连续随机变量时,我们看到了高斯分布的方差。一般来说,方差是随机值与其平均值相差多少的度量。类似地,对于随机变量的函数,方差是函数输出与其期望值的可变性的度量。

Variance of h(x) with respect to P(x)
另一个重要的概念是协方差。协方差是两个随机变量(或随机变量上的函数)之间线性相关程度的度量。函数 h (x)和 g (y)之间的协方差写为:

Covariance between h(x) and g(y).
当协方差的绝对值较高时,两个函数往往同时偏离均值很远。当协方差的符号为正时,两个函数一起映射到更高的值。如果符号为负,则一个函数映射到较高的值,而另一个函数映射到较低的值,反之亦然。本文开头的可视化展示了变量间具有正协方差的联合高斯分布的样本。你可以看到,随着第一个变量的增加,第二个变量也在增加。
时刻:
注意,我们可以通过用 x 本身替换函数 h (x)来计算随机变量的期望和方差。一个分布的期望是它的平均值,或一阶矩。分布的方差是它的二阶矩。概率分布的高阶矩捕捉其他特征,如偏斜度和峰度。
重要分布
我们已经讨论了概率论的大部分重要方面。这些想法为开发大多数统计学和机器学习的基础提供了基础。为了掌握概率论并开始弥补统计学的差距,人们需要对更有用的概率分布有所了解。
概率分布的函数形式可能令人生畏。我的建议是不要太关注那个方面,而是关注每个发行版擅长建模什么类型的情况。型号/用途描述的一些示例包括:
- 伯努利:模拟掷硬币和其他二元事件的结果
- 二项式:模拟一系列伯努利试验(一系列抛硬币等)。)
- 几何:模拟在你成功之前需要翻转多少次
- 多项式:将二项式推广到两个以上的结果(如掷骰子)
- 泊松:模拟在特定时间间隔内发生的事件数量
对于连续分布,知道形状也是有用的。例如,我们看到高斯分布的形状像一个钟,其大部分密度接近平均值。贝塔分布在区间[0,1]上可以呈现各种各样的形状。这使得贝塔分布成为我们对特定概率的信念建模的一个很好的选择。
记住这些格式良好的发行版更像是模板,这一点也很重要。您的数据的真实分布可能并不那么好,甚至可能会随着时间的推移而改变。
太好了,但是这一切和机器学习有什么关系呢?
这篇文章的目标是建立我们的概率语言,这样我们就可以用概率的观点来构建机器学习。我将在未来的帖子中介绍具体的机器学习算法和应用,但我想描述一下我们刚刚实现的功能。
监督学习:
在监督机器学习中,我们的目标是从标记的数据中学习。被标记的数据意味着对于一些输入 X,我们知道期望的输出 y。一些可能的任务包括:
- 识别图像中的内容。
- 给定公司的一些特征,预测股票的价格。
- 检测文件是否是恶意的。
- 给病人诊断病情。
在这些情况下,概率如何帮助我们?我们可以用各种方法学习从 X 到 Y 的映射。首先,你可以学习 P(Y|X),也就是说,假设你观察到一个新的样本 X,Y 的可能值的概率分布。找到这种分布的机器学习算法被称为判别。想象一下,我告诉你,我看到了一只长着毛皮、长尾巴、两英寸高的动物。你能区分可能的动物并猜出它是什么吗?

Photo by Ricky Kharawala on Unsplash
或者,我们可以尝试学习 P(X|Y),即给定标签下输入的概率分布。实现这一点的算法被称为生成。假设我想要一只老鼠,你能描述一下老鼠的身高、体毛和尾巴长度吗?枚举特性的可能值有点像生成所有可能的鼠标。
你可能想知道了解生殖模型如何帮助我们完成动物分类的任务?还记得贝叶斯法则吗?从我们的训练数据中,我们可以学习 P(Y),任何特定动物的概率,以及 P(X),任何特定特征配置的概率。使用这些术语,我们可以用贝叶斯法则回答 P(Y|X)形式的查询。
有可能知道从 X 到 Y 的映射,它不是以概率分布的形式。我们可以用一个确定性函数 f 来拟合我们的训练数据,这样 f ( X ) ≈ Y。好吧,想象一个算法正在诊断你的疾病,它告诉你你还能活一个月。函数 f 无法向你表达它在评估中有多自信。也许你有算法在训练数据中从未见过的特征,导致它或多或少地猜测出一个结果。概率模型量化了不确定性,常规函数没有。
无监督学习:
无监督学习是一套从无标签数据中学习的广泛技术,其中我们只有一些样本 X,但没有输出 y。常见的无监督任务包括:
- 将相似的数据点分组在一起(聚类)。
- 取高维数据,投射到有意义的低维空间(降维、因子分析、嵌入)。
- 用分布表示数据(密度估计)。
表征未标记数据的分布对于许多任务是有用的。一个例子是异常检测。如果我们学习 P(X),其中 X 代表正常的银行交易,那么我们可以用 P(X)来衡量未来交易的可能性。如果我们观察到低概率的交易,我们可以将其标记为可疑和可能的欺诈。
聚类是无监督学习的典型问题之一。给定一些来自不同组的数据点,我们如何确定每个点属于哪个组?一种方法是假设每个组是从不同的概率分布中产生的。解决这个问题就变成了寻找这些分布最可能的配置。
降维是无监督学习的另一个主要领域。高维数据占用内存,降低计算速度,并且难以可视化和解释。我们希望有办法在不丢失太多信息的情况下将数据降低到一个较低的维度。人们可以把这个问题看作是在低维空间中寻找一个与原始数据的分布具有相似特征的分布。
强化学习:
强化学习领域就是训练人工智能体在特定任务中表现出色。代理通过在他们的环境中采取行动并根据他们的行为观察奖励信号来学习。代理人的目标是最大化其预期的长期回报。概率在强化学习中用于学习过程的几个方面。你可能在目标中发现了“期望”这个词。代理人的学习过程通常围绕着量化采取一个特定行动相对于另一个行动的效用的不确定性。
结论
这是对概率论语言的温和概述,并简要讨论了我们将如何将这些概念应用于更高级的机器学习和统计学。请务必查看关于最大似然估计的第二部分:
机器学习基础(二)
towardsdatascience.com](/maximum-likelihood-estimation-984af2dcfcac)
如果你想从另一个角度来研究概率论,我强烈推荐看看《看见理论》中这个令人惊叹的视觉介绍:
概率和统计的直观介绍。
seeing-theory.brown.edu](https://seeing-theory.brown.edu/)
下次见!
概率学习 I:贝叶斯定理
通过一个简单的日常例子来了解概率的基本定理之一。

这篇文章假设你有一些概率和统计的基础知识。如果你不知道,不要害怕,我已经在收集了我能找到的向你介绍这些主题的最佳资源,这样你就可以阅读这篇文章,理解它,并且充分享受它。
在这本书中,我们将讨论概率论中最著名和最常用的定理之一:贝叶斯定理。没听说过?那么你将会享受到一顿大餐!已经知道是什么了?然后继续读下去,用一个简单的日常例子巩固你的知识,这样你也可以用简单的语言向他人解释。
在接下来的帖子中,我们将了解一些更实用的贝叶斯定理的简化,以及其他机器学习的概率方法,如 隐马尔可夫模型 。
最后,在我们开始之前,这里有一些额外的资源可以让你的机器学习生涯突飞猛进:
*Awesome Machine Learning Resources:**- For* ***learning resources*** *go to* [***How to Learn Machine Learning***](https://howtolearnmachinelearning.com/books/machine-learning-books/)*!
- For* ***professional******resources*** *(jobs, events, skill tests) go to* [***AIgents.co — A career community for Data Scientists & Machine Learning Engineers***](https://aigents.co/)***.***
我们走吧!
概率介绍:
在本节中,我列出了三个非常好的和简明的来源(主要是前两个,第三个更广泛一点)来学习概率的基础知识,这是你理解这篇文章所需要的。不要害怕,这些概念非常简单,只要快速阅读,你就一定能理解它们。
如果你已经掌握了基本概率,可以跳过这一节。
- 有趣的小概率介绍在机器学习 中,主要用一个神秘但简单的例子来介绍概率的每个主要术语。
- 哈佛的统计学 110 课程。这是一个更大的资源,以防你不仅想学习基础知识,还想更深入地了解统计的奇妙世界:
好了,现在你已经准备好继续这篇文章的其余部分了,坐下来,放松,享受吧。
贝叶斯定理:
贝叶斯是谁?
托马斯·贝叶斯 (1701 — 1761)是的英国神学家和数学家,隶属于皇家学会(世界上最古老的国家科学学会,也是促进英国科学研究的主要国家组织),其他知名人士都曾在此注册,如牛顿、达尔文或法拉第。他发展了一个最重要的概率定理,这个定理创造了他的名字:贝叶斯定理,或条件概率定理。

Portrait of the Reverend Thomas Bayes, father of Bayes’ Theorem
定理:条件概率
为了解释这个定理,我们将使用一个非常简单的例子。假设你被诊断出患有一种非常罕见的疾病,这种疾病只影响 0.1%的人。也就是说,每 1000 人中有 1 人。
您进行的疾病检查测试对 99%的患病者进行了正确分类,而对健康人的错误分类只有 1%的几率。
我完了!这种病致命吗医生?
大多数人都会这么说。然而,在这次测试之后,我们真的患病的可能性有多大?
99%肯定!我最好把我的东西整理好。
基于这种想法,贝叶斯的想法应该会占上风,因为它实际上与现实相差甚远。让我们用贝叶斯定理来获得一些观点。
贝叶斯定理,或者我之前称之为条件概率定理**,用于计算假设(H)为真的概率(即。患有疾病)鉴于某一事件(E)已经发生(在测试中被诊断为该疾病阳性)。使用以下公式描述该计算:**

Bayes’ formula for conditional probability
等号 P(H |E ) 左边的项是假设我们在这种疾病的测试中被诊断为阳性(E)** ,那么我们实际上想要计算的是患这种疾病的概率(H)。概率项中的竖线(|) 表示条件概率(即给定 B 的概率将是 P(A|B) )。**
右边 P(E|H) 的分子左边一项是假设为真的情况下,事件发生的概率。在我们的例子中,这将是在测试中被诊断为阳性的概率,假设我们患有疾病。
它旁边的术语;**【P(H)是假设在任何事件发生之前的先验概率。在这种情况下,这将是在进行任何测试之前患病的可能性。
最后,分母上的项; P(E) 是事件发生的概率,即被诊断为该疾病阳性的概率。这个术语可以进一步分解为两个更小术语的总和:患病且检测呈阳性加上未患病且检测也呈阳性。

Deconstruction of the probability of testing positive on the test
在这个公式中 P(~H) 表示没有患病的**先验概率,**其中 ~ 表示否定或不否定。下图描述了条件概率整体计算中涉及的每个术语:

Description of each of the terms involved on the formulation of by Bayes’ Theorem
记住,对我们来说,假设或假设 H 患有疾病,而事件或证据 E 在这种疾病的测试中被诊断为阳性。
如果我们使用我们看到的第一个公式(计算患有疾病并被诊断为阳性的条件概率的完整公式)分解分母,并插入数字,我们得到以下计算结果:

Calculation of the conditional probability
0.99 来自 99%的被诊断为阳性的概率,0.001 来自 1000 分之一的患病概率,0.999 来自没有患病的概率,最后的 0.01 来自即使我们没有患病也能被诊断为阳性的概率。这种计算的最终结果是:

Result of the calculation
**9%!我们患这种疾病的可能性只有 9%!***怎么会这样?”*你大概在问自己。魔法?不,我的朋友们,这不是魔术,这是只是概率:应用于数学的常识。就像丹尼尔·卡内曼在《思考,快与慢》一书中描述的那样,人类的大脑非常不擅长估计和计算概率,就像前面的例子所显示的那样,所以我们应该总是抑制我们的直觉,后退一步,使用我们所能使用的所有概率工具。
现在想象一下,在第一次测试被诊断为阳性后,我们决定在不同的诊所以相同的条件进行另一次测试以复查结果,不幸的是,我们再次得到阳性诊断,这表明第二次测试也表明我们患有该疾病。
现在得这种病的实际概率是多少?好的,我们可以使用和之前完全一样的公式,但是用上一次得到的后验概率(一次检测阳性后 9%的概率)代替最初的先验概率 (0.1%患病几率),以及它们的补充项。
如果我们处理这些数字,我们会得到:

Calculation of the conditional probability after the second positive

Results after the second positive
现在,我们有更高的几率真的患上这种疾病。尽管看起来很糟糕,但在两次阳性测试后,仍然不能完全确定我们患有这种疾病。确定性似乎逃离了概率的世界。
定理背后的直觉
这个著名定理背后的直觉是,我们永远无法完全确定这个世界,因为它是一个不断变化的存在,变化是现实的本质。然而,我们可以做的事情,这是这个定理背后的基本原则,是随着我们获得越来越多的数据或证据,更新和改善我们对现实的知识。
**这可以用一个非常简单的例子来说明。**想象以下情景:你在边上方形的花园里,坐在椅子上,看着花园外面。在对面,躺着一个仆人,他把一个蓝色的球扔进了正方形。在那之后,他继续在方块内投掷其他黄色球,并告诉你它们相对于最初的蓝色球落在哪里。

Video of this mental experiment with our good old Bayes sitting on the edge of his garden with his back towards a servant that is throwing the balls.
随着越来越多的黄球落地,你得到了它们相对于第一个蓝球落地的位置的信息,你逐渐增加了关于蓝球可能在哪里的知识,忽略了花园的某些部分:随着我们获得更多的证据(更多的黄球),我们更新了我们的知识(蓝球的位置)。
在上面的例子中,只扔了 3 个黄色的球,我们已经可以开始建立一个确定的想法,蓝色的球位于花园左上角的某个地方。
当贝氏第一次公式化这个定理时,**他起初没有发表,认为这没什么了不起,**而公式化这个定理的论文是在他死后才被发现的。
今天,贝叶斯定理不仅是现代概率的基础之一,而且是许多智能系统中高度使用的工具,如垃圾邮件过滤器和许多其他文本和非文本相关的问题解决程序。
在接下来的文章中,我们将看到这些应用是什么,以及贝叶斯定理及其变体如何应用于许多现实世界的用例。来看看 跟我上媒 ,敬请期待!

想了解更多关于概率和统计的资料,请点击下面的最佳在线课程来了解这个精彩的话题!
就这些,我希望你喜欢这个帖子。请随时在 LinkedIn 上与我联系,或者在 @jaimezorno 的 Twitter 上关注我。还有,你可以看看我其他关于数据科学和机器学习的帖子这里 。好好读!
概率学习 II:贝叶斯定理如何应用于机器学习
了解贝叶斯定理是如何在机器学习中进行分类和回归的!

在上一篇文章中,我们看到了什么是贝叶斯定理,并通过一个简单直观的例子展示了它是如何工作的。你可以在这里 找到这个帖子。如果你不知道贝叶斯定理是什么,并且你还没有阅读它的乐趣,我推荐你去读,因为它会让你更容易理解这篇文章。
在本帖中,我们将看到这个定理在机器学习中的用途。
在我们开始之前,这里有一些额外的资源可以让你的机器学习事业突飞猛进:
*Awesome Machine Learning Resources:**- For* ***learning resources*** *go to* [***How to Learn Machine Learning***](https://howtolearnmachinelearning.com/books/machine-learning-books/)*!
- For* ***professional******resources*** *(jobs, events, skill tests) go to* [***AIgents.co — A career community for Data Scientists & Machine Learning Engineers***](https://aigents.co/)***.***
准备好了吗?那我们走吧!
机器学习中的贝叶斯定理
正如上一篇文章中提到的,贝叶斯定理告诉我们,当我们获得更多关于某件事的证据时,如何逐渐更新我们对某件事的知识。
通常,在监督机器学习中,当我们想要训练一个模型时,主要构件是一组包含特征(定义这种数据点的属性)这种数据点的标签(我们稍后想要在新数据点上预测的数字或分类标签),以及将这种特征与其相应标签相链接的假设函数或模型。我们还有一个损失函数,它是模型预测和真实标签之间的差异,我们希望减少该差异以实现最佳可能结果。

Main elements of a supervised Learning Problem
这些受监督的机器学习问题可以分为两个主要类别:回归,其中我们希望计算与一些数据(例如房子的价格)相关联的一个数字或数字 值,以及分类,其中我们希望将数据点分配给某个类别(例如,如果一幅图像显示一只狗或猫)。
贝叶斯定理既可以用于回归,也可以用于分类。
让我们看看如何!
回归中的贝叶斯定理
假设我们有一组非常简单的数据,它代表一个城镇的某个地区一年中每天的温度(数据点的特征**,以及该地区一家当地商店每天卖出的数量(数据点的标签)。**
通过制作一个非常简单的模型,我们可以查看这两者是否相关,如果相关,然后使用这个模型进行预测,以便根据温度储备水瓶,永远不会缺货,或者避免库存过多。
我们可以尝试一个非常简单的线性回归模型来看看这些变量是如何相关的。在下面描述这个线性模型的公式中,y 是目标标签(在我们的例子中是水瓶的数量),每个θs 是模型的参数(y 轴的斜率和切割),x 是我们的特征(在我们的例子中是温度)。

Equation describing a linear model
这种训练的目标是减少提到的损失函数,以便模型对已知数据点的预测接近这些数据点的标签的实际值。
用可用数据训练模型后,我们将得到两个 θs 的值。该训练可以通过使用类似梯度下降的迭代过程或类似最大似然的另一种概率方法来执行。无论如何,我们只需要为每个参数设定一个值。
以这种方式,当我们得到没有标签的新数据(新的温度预测)时,因为我们知道 θs 的值,我们可以使用这个简单的等式来获得想要的 Ys (每天需要的水瓶数量)。

Figure of an uni-variate linear regression. Using the initial blue data points, we calculate the line that best fits these points, and then when we get a new temperature we can easily calculate the Nº sold bottles for that day.
当我们使用贝叶斯定理进行回归时,不是认为模型的参数(θs)具有单一的唯一值,而是将它们表示为具有特定分布的参数**:参数的先验分布。下图显示了一般贝叶斯公式,以及如何将其应用于机器学习模型。**

Bayes formula

Bayes formula applied to a machine learning model
这背后的想法是,我们在没有任何实际数据之前,已经有了模型参数的一些先验知识: P(模型) 就是这个先验概率。然后,当我们得到一些新的数据时,我们更新模型的参数的分布,使之成为后验概率 P(模型|数据) 。
这意味着我们的参数集(我们模型的θs)不是常数,而是有自己的分布。基于先前的知识(例如,来自专家,或来自其他作品)我们对我们的模型的参数分布做出第一个假设。然后,当我们用更多的数据**,训练我们的模型时,这个分布得到更新,变得更加精确(实际上方差变得更小)。**

Figure of the a priori and posteriori parameter distributions. θMap is the maximum posteior estimation, which we would then use in our models.
该图显示了模型参数的初始分布 p(θ)** ,以及当我们添加更多数据时,该分布**如何更新,使其更精确地增长到 p(θ|x) ,其中 x 表示该新数据。这里的θ相当于上图公式中的型号,这里的xT37 相当于这样公式中的数据。
贝叶斯公式一如既往地告诉我们如何从先验概率到后验概率。随着我们获得越来越多的数据,我们在迭代过程中这样做,让后验概率成为下一次迭代的先验概率**。一旦我们用足够的数据训练了模型,为了选择最终参数组,我们将搜索**最大后验(MAP)估计,以使用模型参数的一组具体值。****
这种分析从最初的先验分布中获得其优势:如果我们没有任何先验信息,并且不能对其做出任何假设,那么像最大似然法这样的其他概率方法更适合。
然而,如果我们有一些关于参数分布的先验信息,贝叶斯方法被证明是非常有效的,特别是在有不可靠的训练数据**的情况下。在这种情况下,由于我们不是使用该数据从零开始构建模型和计算其参数,而是使用某种先前的知识来推断这些参数的初始分布,该先前的分布使得参数更加稳健,并且更少受到不准确数据的影响。**
我不想在这部分讲太多技术,但是所有这些推理背后的数学是美丽的;如果你想了解它,不要犹豫,给我发电子邮件到 jaimezorno@gmail.com 或者通过 LinkdIn 联系我。
分类中的贝叶斯定理
我们已经看到,通过估计线性模型的参数,贝叶斯定理可以用于回归分析。同样的推理可以应用于其他类型的回归算法。
现在我们将看看如何使用贝叶斯定理进行分类。这就是所谓的贝叶斯最优分类器**。现在的推理和之前的很像。**
假设我们有一个分类问题,用 i 不同的类。我们在这里追求的是每个类wI的类概率。与之前的回归案例一样,我们也区分先验概率和后验概率,但现在我们有了先验类概率 p(wi) 和后验类概率,在使用数据或观测值 p(wi|x) 之后。****

Bayes formula used for Bayes’ optimal classifier
这里的*【x】是所有数据点****【x | wi】所共有的密度函数,是属于 wi* 类的数据点的密度函数, P(wi) 是 wi 类的先验分布 P(x|wi) 是从训练数据中计算出来的,假设某个分布,并计算每个类别的均值向量和属于该类别的数据点的特征的协方差。先验类分布 P(wi) 是基于领域知识、专家建议或以前的工作来估计的,就像回归示例中一样。******
让我们看一个如何工作的例子:图像我们测量了 34 个人的身高: 25 个男性(蓝色)和 9 个女性(红色),我们得到了一个 172 cm 的新的身高观察值,我们想将它分类为男性或女性。下图显示了使用最大似然分类器和贝叶斯最优分类器获得的预测。

On the left, the training data for both classes with their estimated normal distributions. On the right, Bayes optimal classifier, with prior class probabilities p(wA) of male being 25/34 and p(wB) of female being 9/34.
在这种情况下,我们使用训练数据中的个样本作为的先验知识用于我们的类别分布,但是例如,如果我们对特定国家的身高和性别进行相同的区分,并且我们知道那里的女性特别高,也知道男性的平均身高,我们可以使用这个信息来构建我们的先验类别分布。
从例子中我们可以看出,使用这些先验知识会导致与不使用它们不同的结果。假设先前的知识是高质量的(否则我们不会使用它),这些预测应该比没有结合这些信息的类似试验更加准确。
在这之后,一如既往,当我们得到更多的数据时,这些分布会得到更新以反映从这些数据中获得的知识。
和前一个案例一样,我不想太过技术化,或者过多地延伸文章,所以我就不深究数学上的细节了,但是如果你对它们感兴趣,可以随时联系我。
结论
我们已经看到贝叶斯定理是如何用于机器学习的;无论是在回归还是分类中,都要将以前的知识融入到我们的模型中并加以改进。
在接下来的文章中,我们将看到贝叶斯定理的简化如何成为自然语言处理中最常用的技术之一,以及它们如何应用于许多真实世界的用例,如垃圾邮件过滤器或情感分析工具。来看看 跟我上媒 ,敬请期待!

Another example of Bayesian classification
就这些,我希望你喜欢这个帖子。欢迎在 LinkedIn上与我联系,或者在 Twitter 上关注我,邮箱: @jaimezorno 。还有,你可以看看我其他关于数据科学和机器学习的帖子这里 。好好读!
额外资源
如果您想更深入地研究贝叶斯和机器学习,请查看以下其他资源:
有关机器学习和数据科学的更多资源,请查看以下资源库: 如何学习机器学习 !有关职业资源(工作、事件、技能测试),请访问AIgents.co——数据科学家的职业社区&机器学习工程师 ,如有任何问题,请联系我。祝你有美好的一天,继续学习。
概率学习 III:最大似然
我们成为概率大师的又一步…

在之前的两篇关于贝叶斯定理的帖子之后,我收到了很多请求,要求对定理的回归和分类用途背后的数学进行更深入的解释。下一个系列的帖子是对这些要求的回答。
然而,我认为,如果我们首先涵盖概率机器学习的另一个基本方法最大似然法背后的理论和数学,贝叶斯背后的数学将会更好理解。本帖将致力于解释。
前面的文章可以找到 这里 和这里 。我建议在处理下一个问题之前先读一读,然后跟随我们一起创造的美丽故事线。
在我们开始之前,这里有一些额外的资源可以让你的机器学习生涯突飞猛进
*Awesome Machine Learning Resources:**- For* ***learning resources*** *go to* [***How to Learn Machine Learning***](https://howtolearnmachinelearning.com/books/machine-learning-books/)*! - For* ***professional******resources*** *(jobs, events, skill tests) go to* [***AIgents.co***](https://aigents.co/)[***— A career community for Data Scientists & Machine Learning Engineers***](https://aigents.co/)***.***
最大似然原则
最大似然法的目标是使一些数据符合最佳的统计分布。这使得数据更容易处理,更通用,允许我们查看新数据是否遵循与先前数据相同的分布,最后,它允许我们对未标记的数据点进行分类。
就像在上一篇中,想象一个男性和女性个体使用身高的二元分类问题。一旦我们计算了男女身高的概率分布,并且我们得到了一个新数据点(作为没有标签的身高)我们就可以将其分配到最有可能的类别,看看哪个分布报告了两者的最高概率。

Graphical representation of this binary classification problem
在之前的图像中,该新数据点( xnew, 对应于 172 cm 的高度)被分类为女性,对于该特定高度值,女性高度分布产生比男性高的概率。
你可能会说这很酷,但是我们如何计算这些概率分布呢?不要担心,我们现在就开始。首先我们将解释其背后的一般过程,然后我们将通过一个更具体的例子。
计算分布:估计参数密度函数
像往常一样在机器学习中,我们首先需要开始计算一个分布是要学习的东西:我们宝贵的数据。我们将把我们的大小 n 的数据向量表示为 X 。在这个向量中,每一行都是具有 d 个特征的数据点**,因此我们的数据向量 X 实际上是向量的向量:大小为 n x d** 的矩阵**;n 个数据点,每个具有 d 个特征。**
一旦我们收集了想要计算分布的数据,我们需要开始猜测。**猜谜?**是的,你没看错,我们需要猜测我们的数据符合哪种密度函数或分布:高斯、指数、泊松……
不要担心,这听起来可能不太科学,但大多数情况下,每种数据都有一个最可能符合的分布:温度或高度等特征的高斯分布,时间等特征的指数分布,电话通话时间或细菌种群寿命等特征的泊松分布。
完成后,我们计算最符合我们数据的特定分布参数。对于正态分布,这将是平均值和方差。由于高斯或正态分布可能是最容易解释和理解的分布,我们将继续这篇文章,假设我们已经选择了一个高斯密度函数来表示我们的数据。

Data and parameters for our gaussian distribution
在这种情况下,我们需要计算的参数个数是 d means(每个特征一个)和 d(d+1)/2 方差,因为协方差矩阵是对称的 dxd 矩阵。

Total parameters we need to calculate for a normal distribution depending on the number of features
让我们称分布的整体参数组为 θ 。在我们的例子中,这包括每个特征的平均值和方差。我们现在要做的是获得使数据向量的联合密度函数最大化的参数集θ;所谓 似然函数 L(θ)。 这个似然函数也可以表示为 P(X|θ) ,可以读作给定参数集θ时 X 的条件概率。

Likelihood function
在这个符号**中,X 是数据矩阵,X(1)到 X(n)是每个数据点,θ是分布的给定参数集。**同样,由于最大似然法的目标是选择参数值,使观察到的数据尽可能接近,我们得出一个依赖于θ的优化问题。
为了获得该最佳参数集,我们对似然函数中的θ进行求导,并搜索最大值:该最大值代表尽可能观察到可用数据的参数值。

Taking derivatives with respect to θ
现在,如果 X 的数据点彼此独立,则似然函数可以表示为给定参数集的每个数据点的个体概率的乘积:

Likelihood function if the data points are independent of each other
在保持其他参数不变的情况下,对该方程的每个参数(平均值、方差等)进行求导,得到数据点数值、数据点数和每个参数之间的关系。
让我们看一个使用正态分布和一个简单的男性身高数据集的例子。
使用正态分布深入了解最大似然法的数学原理
让我们来看一个例子,如何使用最大似然法来拟合一组数据点的正态分布,其中只有一个特征:以厘米为单位的身高。正如我们之前提到的,我们需要计算一些参数:平均值和方差。
为此,我们必须知道正态分布的密度函数:

Density function for the normal distribution. Source Wikipedia
一旦我们知道了这一点,我们就可以计算每个数据点的似然函数。对于第一个数据点,它将是:

Likelihood equation for the first data point
对于整个数据集,考虑到我们的数据点是独立的,因此我们可以将似然函数计算为各个点的似然性的乘积,它将是:

Likelihood equation for the whole dataset
我们可以用这个函数和以对数方式表达它,这有助于后验计算和产生完全相同的结果。

Same equation expressed in a logarithmic way
最后,我们将似然函数相对于平均值的导数设置为零,得到一个表达式,其中我们获得第一个参数的值:

Derivative of the likelihood function for the mean, and Maximum Likelihood value for this parameter
惊喜!正态分布均值的最大似然估计就是我们直观预期的:每个数据点的值之和除以数据点的数量。
现在我们已经计算了平均值的估计值,是时候为其他相关参数做同样的事情了:方差。为此,就像以前一样,我们在似然函数中求导,目标是找到使观察数据的似然性最大化的方差值。

Maximum likelihood estimate for the variance
这与上一个案例一样,给我们带来了同样的结果,我们熟悉每天的统计数据。
就是这样!我们已经看到了计算正态分布的最大似然估计背后的一般数学和程序。最后,让我们看一个快速的数字示例!
男性身高的最大似然估计:一个数值例子
让我们举一个我们之前提到过的非常简单的例子:我们有一个某个地区男性身高的数据集,我们想使用最大似然法找到它的最优分布。
如果我们没记错的话,第一步(在收集和理解数据之后)是选择我们想要估计的密度函数的形状。在我们的例子中,对于身高,我们将使用高斯分布,这也是我们在 ML 数学背后的一般推理中看到的。让我们重新看看定义这种分布的公式:

Density function for the normal distribution. Source Wikipedia
此外,让我们只恢复数据集的一个点的似然函数。

Likelihood equation for the first data point
想象我们的数据向量 X** ,在我们的例子中如下:**

Data vector of male heights
我们有 10 个数据点(n = 10) 和每个数据点(d=1)** 一个特征。如果在上面所示的公式中,我们为每个数据点代入它们的实际值,我们会得到如下结果:**

Likelihood of the first two data points
如果在这些公式中,我们选择一个特定的平均值和方差值**,我们将获得观察到具有这些特定平均值和方差值的每个高度值(在我们的例子中是 176 和 172cm)的可能性。例如,如果我们选择 180 厘米的平均值,方差为 4 厘米,我们将得到上面所示两点的如下可能性:**

Calculations of likelihood of observing points of 176 cm and 172 cm of height on a normal distribution with a mean of 180 cm and a variance of 4 cm
简要说明后,如果我们继续该过程以获得最适合数据集的最大似然估计值,我们将不得不首先计算平均值。对于我们的例子来说,非常简单:我们只需将数据点的值相加,然后将这个和除以数据点的数量。

Maximum likelihood estimate for the mean of our height data set
如果我们对方差做同样的处理,计算每个数据点的值减去平均值的平方和,并除以我们得到的总点数:

Variance and Standard deviation estimates for our height data set
就是它!现在我们已经计算了平均值和方差,我们已经拥有了建模分布所需的所有参数。现在,当我们得到一个新数据点时,例如,一个高度为 177 cm 的数据点,我们可以看到该点属于我们数据集的可能性:

Likelihood of the new data point belonging to our data set

Representation of the obtained normal distribution and the likelihood of the new data point
现在,如果我们有另一组数据,例如女性身高,我们做同样的程序,我们会有两个身高分布:一个是男性,一个是女性。
这样,我们可以使用两种分布来解决男性和女性身高的二元分类问题**:当我们获得一个新的未标记身高数据点时,我们计算该新数据点属于两种分布的概率,并将其分配给该分布产生最高概率的类别(男性或女性)**。****
结论
我们已经看到了什么是最大似然,它背后的数学原理,以及如何应用它来解决现实世界的问题。这给了我们解决下一个问题的基础,你们都一直在问:贝叶斯定理背后的数学,它非常类似于最大似然法。
来看看吧 关注我的 ,敬请关注!
就这些,我希望你喜欢这个帖子。请随时在 LinkedIn 上与我联系,或者在 Twitter 上关注我,地址是:jaimezorno。还有,你可以看看我其他关于数据科学和机器学习的帖子这里 。好好读!
额外资源
如果你想更深入地了解最大似然法和机器学习,请查看以下资源:
一如既往,有任何问题请联系我。祝你有美好的一天,继续学习。
概率学习 IV:贝叶斯背后的数学
支持分类和回归的贝叶斯定理的数学充分解释

在之前的两篇关于贝叶斯定理的帖子之后,我收到了很多请求,要求对定理的回归和分类用途背后的数学进行更深入的解释。
正因为如此,在上一篇文章中,我们介绍了最大似然原理背后的数学原理,以构建一个坚实的基础,让我们能够轻松理解并享受贝叶斯背后的数学原理。
你可以在这里找到所有这些帖子:
这篇文章将致力于解释贝叶斯定理背后的数学,当它的应用有意义时,以及它与最大似然法的差异。
闪回贝叶斯
正如在上一篇文章中我们解释了最大似然一样,我们将在这篇文章的第一部分记住贝叶斯定理背后的公式,特别是与我们在机器学习中相关的公式:

Formula 1: Bayes formula particularised for a Machine Learning model and its relevant data
如果我们将此公式放入与我们在上一篇文章中使用的关于最大似然的相同的数学术语,我们会得到以下公式,其中 θ是模型的参数,X 是我们的数据矩阵:

Formula 2: Bayes formula expressed in terms of the model parameters “θ” and the data matrix “X”
正如我们在致力于贝叶斯定理和机器学习的帖子中提到的,贝叶斯定理的优势是能够将一些关于模型的先前知识整合到我们的工具集中,使其在某些情况下更加健壮。
贝叶斯背后的数学解释
既然我们已经很快记住了贝叶斯定理是关于什么的,让我们充分开发它背后的数学知识。如果我们采用前面的公式,并且以对数方式表示它,我们得到下面的等式:

Formula 3: Bayes’ formula expressed in logarithms
还记得最大似然公式吗?等号右边的第一项你看着眼熟吗?

Formula 4: Likelihood function
如果有,说明你做足了功课,看了前面的帖子,理解了。等号右边的第一项正好是似然函数。这是什么意思?这意味着最大似然和贝叶斯定理以某种方式相关。
让我们看看当我们对模型参数求导时会发生什么,类似于我们在最大似然法中所做的,以计算最适合我们数据的分布(我们在上一篇文章中对最大似然法所做的也可以用于计算特定机器学习模型的参数,最大化我们数据的概率,而不是某个分布)。

Formula 5: Taking derivatives with respect to the model parameters
我们可以看到这个方程有两个依赖于θ 、的项,其中之一我们在之前已经看到过:似然函数关于θ的导数。然而,另一个术语对我们来说是陌生的。这个术语代表了我们可能拥有的关于模型的先验知识,稍后我们将看到它如何对我们大有用处。
让我们用一个例子来说明。
回归的最大似然和贝叶斯定理的比较
让我们用一个我们以前探索过的例子来看看这个术语是如何使用的:线性回归。让我们恢复等式:

Formula 6: Equation of linear regression of degree 1
让我们将这个线性回归方程表示为依赖于一些数据和一些未知参数向量θ 的更一般的函数。

Formula 7: Regression function
此外,让我们假设当我们使用这个回归函数进行预测时,存在某个**相关误差ɛ***。*然后,每当我们做一个预测 y(i) (忘记上面用于 LR 的 y,那个现在已经被 f 代替了),我们就有了一个表示回归函数得到的值的项,和某个相关的误差。
所有这些的组合看起来像是:

Formula 8: Final form of the regression equation
获得模型 θ 的一个众所周知的方法是使用最小二乘法(LSM) 并寻找减少某种误差的参数集。具体来说,我们希望减少一个误差,该误差被公式化为每个数据点 y 的实际标签和模型 f 的预测输出之间的平方的平均差。

Formula 9: The error that we want to reduce in the Least squares method
我们将看到,试图减少这一误差相当于使用最大似然估计法最大化观察我们的数据与某些模型参数的概率。
首先,然而我们必须做出一个非常重要的假设,尽管自然假设:回归误差***【ɛ(i】,*** 对于每一个数据点来说,都是独立于***【x(I)***(数据点)的值,并且正态分布着一个平均值 0 和一个标准差 σ。对于大多数错误类型,这种假设通常是正确的。
然后,特定参数集θ 的 ML 估计由以下等式给出,其中我们应用了条件概率的公式,假设 X 独立于模型参数的**,并且 y(i) 的值彼此独立(为了能够使用乘法)**

Formula 10: Likelihood function
这个公式可以读作:X 和 Y 给定 θ 的概率等于 X 的概率乘以 Y 给定 X 和θ 的概率。
对于那些不熟悉联合或组合和条件概率的人,你可以在这里找到一个简单易懂的解释。如果你仍然不能从最左边的术语找到最终结果,请随时联系我;我的信息在文末。
现在,如果我们像过去一样取对数,我们得到:

Formula 11: Same equation as above expressed in logs
如果 X(数据点的特征)是静态的并且彼此独立(就像我们之前在条件概率中假设的那样),那么 y(i)的分布与误差的分布**(来自公式 8)相同,除了平均值现在已经被移动到 f(x(i)|θ而不是 0。这意味着 y(i)也有正态分布,我们可以将条件概率 p(y(i)|X,θ) 表示为:**

Formula 12: Conditional probability of y(i) given the data and the parameters
如果我们使常数等于 1 以简化,并在公式 11 内替换公式 12,我们得到:

Formula 13: Logarithm of the Likelihood function
如果我们试图最大化它(对θ求导),项 ln p (X) 将不复存在,我们只有负平方和的导数:这意味着最大化似然函数相当于最小化平方和!
Bayes 能做些什么来让这一切变得更好呢?
让我们恢复用对数表示的贝叶斯定理公式:

Formula 3: Bayes’ formula expressed in logarithms
等号右边的第一项,正如我们之前看到的,是可能性项**,这正是我们在公式 13 中的内容。如果我们将公式 13 的值代入公式 3,考虑到我们也有数据标签 Y,我们得到:**

Formula 14: Bayes formula expressed in terms on likelihood and logarithms
现在,如果我们试图最大化这个函数,以找到最有可能使我们的数据被观察到的模型参数,我们就有了一个额外项: ln p(θ)。还记得这个术语代表什么吗?就是这样,模型参数的先验知识。**
这里我们可以开始看到一些有趣的东西** : σ与数据的噪声方差相关。由于项 ln p(θ) 在求和之外,如果我们有一个非常大的噪声方差,求和项变小,以前的知识占优势。但如果数据准确,误差小,这个先验知识术语就没那么有用了 。**
还看不出用途?让我们用一个例子来总结这一切。
ML 与 Bayes:线性回归示例
假设我们有一个一阶线性回归模型,就像我们在这篇文章和之前的文章中一直使用的模型。
在下面的等式中,我已经将模型参数的 θs 替换为a【b***(它们代表相同的东西,但符号更简单)并添加了误差项。***

Formula 15: Our linear regression model
让我们使用 Bayes 估计,假设我们有一些关于 a 和b***:ab的均值为 0,标准差为 0.1,均值为 1,标准差为 0.5。这意味着 a 和 b 的密度函数分别为:***

Formula 16: Density functions for a and b
如果我们移除常数,并将该信息代入公式 14,我们得到:

Formula 17: Final form of Bayes Formula
现在,如果我们用对 a 求导,假设所有其他参数为常数,我们得到以下值:

同样,对于 b,给我们一个带有两个变量的线性方程,从中我们将获得模型参数的值,该值报告观察我们的数据(或减少误差)的最高概率。
****贝叶斯贡献在哪里?非常简单,没有它,我们将失去术语 100σ。这是什么意思?你看,σ与模型的误差方差有关,正如我们之前提到的。如果这个误差方差很小,说明数据是可靠的、准确的,所以计算出的参数可以取很大的值,这就可以了。
然而,通过引入 100σ项,如果该噪声显著,它将迫使参数值更小,这通常使得回归模型的表现优于具有非常大的参数值的回归模型。
我们还可以在这里看到分母中的值 n,它表示我们有多少数据。与σ值无关,如果我们增加 n,这一项就失去了重要性。这突出了这种方法的另一个特点:我们拥有的数据越多,贝叶斯的初始先验知识的影响就越小。
就是这样:拥有以前的数据知识,有助于我们限制模型参数的值,因为加入贝叶斯总是会导致更小的值,这往往会使模型表现得更好。
结论
我们已经看到了贝叶斯定理、最大似然法及其比较背后的完整数学。我希望一切都尽可能清楚,并且回答了你的许多问题。
我有一些好消息:繁重的数学岗位结束了;在下一篇文章中,我们将讨论朴素贝叶斯,一种贝叶斯定理的简化,以及它在自然语言处理中的应用。
来看看吧 关注我的 ,敬请关注!
就这些,我希望你喜欢这个帖子。请随时在 LinkedIn 上与我联系,或者在 Twitter 上关注我,地址是:jaimezorno。还有,你可以看看我其他关于数据科学和机器学习的帖子这里 。好好读!
一如既往,有任何问题联系我。祝你有美好的一天,继续学习。
概率学习 V:朴素贝叶斯
概率机器学习的朴素模型。还是没那么幼稚…

亲爱的读者们,你们好。这是概率学习系列的第五篇文章。之前的帖子有:
我强烈鼓励你阅读它们,因为它们很有趣,充满了关于概率机器学习的有用信息。
在上一篇文章中,我们讨论了机器学习的贝叶斯定理背后的数学。这篇文章将描述这个定理的各种简化,这些使它更实用,更适用于现实世界的问题:这些简化被称为朴素贝叶斯。此外,为了澄清一切,我们将看到一个非常有说明性的例子,它展示了朴素贝叶斯如何应用于分类。
为什么我们不总是使用贝叶斯?
正如在以前的文章中提到的,贝叶斯定理告诉我们,当我们获得更多关于某事的证据时,如何逐步更新我们关于某事的知识。
我们看到,在机器学习中,这通过更新新数据证据中的某些参数分布来反映。我们还看到了如何使用贝叶斯定理进行分类,方法是计算一个新数据点属于某个类别的概率,并将这个新点分配给报告最高概率的类别。我们提到过,这种方法的优势在于能够将先前的知识整合到我们的模型中。
让我们恢复一下最基本的贝叶斯公式:

General version of Bayes Formula
该公式可以定制为计算一个数据点 x ,属于某个类 ci 的概率,如下所示:

Bayes formula particularised for class i and the data point x
像这样的方法可以用于分类:我们计算一个数据点属于每个可能类别的概率,然后将这个新点分配给产生最高概率的类别。这可用于二值和多值分类。
当我们的模型中的数据点具有不止一个特征时,贝叶斯定理应用的问题就出现了:计算似然项 P(x|ci) 并不简单。该术语说明了给定某个类别的数据点(由其特征表示)的概率。如果这些特征在它们之间是相关的,那么这个条件概率计算的计算量会非常大。此外,如果有许多特征,并且我们必须计算所有特征的联合概率,计算也可能相当广泛。
这就是为什么我们不总是使用贝叶斯,而是有时不得不求助于更简单的替代方法。
那么什么是朴素贝叶斯呢?
**朴素贝叶斯是贝叶斯定理的简化,它被用作二元多类问题的分类算法。**之所以称之为幼稚,是因为它做出了一个非常重要但却不太真实的假设:数据点的所有特征都是相互独立的。通过这样做,它极大地简化了贝叶斯分类所需的计算,同时保持了相当不错的结果。这类算法通常被用作分类问题的基线。
让我们看一个例子来阐明这是什么意思、以及与贝叶斯的区别:假设你喜欢每天早上去你家旁边的公园散一会儿步。这样做了一段时间后,你开始遇到一个非常聪明的老人,他有时会和你走同样的路。当你遇到他时,他会用最简单的术语向你解释数据科学的概念,优雅而清晰地分解复杂的事物。
然而,有些日子,当你出去散步,兴奋地想听到更多老人的消息时,他却不在了。那些日子你希望你从未离开过你的家,并感到有点难过。

One of your lovely walks in the park
为了解决这个问题,你在一周内每天都去散步,并记下每天的天气情况,以及老人是否外出散步。下表显示了您收集的信息。“散步”一栏指的是老人是否去公园散步。

Table with the information collected during one week
利用这些信息,以及这位数据科学专家曾经提到过的一些东西,朴素贝叶斯分类算法,你会根据当天的天气情况计算出老人每天出去散步的概率,然后决定你是否认为这个概率足够高,让你出去尝试遇见这位睿智的天才。
例如,如果我们在字段值为“否”时将每个分类变量建模为 0,在字段值为“是”时建模为 1,那么我们表格的第一行将是:
111001 | 0
其中竖线后的 0 表示目标标签。
如果我们使用正态贝叶斯算法来计算每种可能的天气情况下每个类别(步行或不步行)的后验概率,我们将必须计算每个类别的 0 和 1 的每种可能组合的概率。在这种情况下,我们必须为每个类计算 2 的 6 次方个可能组合的概率,因为我们有 6 个变量。一般推理如下:

这有各种各样的问题:首先,我们需要大量的数据来计算每个场景的概率。然后,如果我们有这些可用的数据,计算将比其他类型的方法花费更长的时间,并且这个时间将随着变量或特征的数量而大大增加。最后,如果我们认为这些变量中的一些是相关的(例如,阳光与温度),我们将不得不在计算概率时考虑这种关系,这将导致更长的计算时间。
**朴素贝叶斯是如何修复这一切的?**通过假设每个特征变量独立于其他变量:这意味着我们只需计算给定每个类别的每个单独特征的概率,将所需的计算从 2^n 减少到 2n。同时,这意味着我们不关心变量之间可能的关系,比如太阳和温度。
让我们一步一步地描述它这样你们就能更清楚地看到我在说什么:
- 首先,我们使用上表计算每个类别的先验概率。

Prior probabilities for each class
2.然后,对于每个特征,我们计算给定每个类别的不同分类值的概率(在我们的示例中,我们只有“是”和“否”作为每个特征的可能值,但这可能因数据而异)。以下示例显示了特征“Sun”的这种情况。我们必须对每个特性都这样做。

Probabilities of sun values given each class
3.现在,当我们获得一个新的数据点作为一组气象条件时,我们可以通过将给定类别的每个特征的个体概率与每个类别的先验概率相乘来计算每个类别的概率。然后,我们将这个新数据点分配给产生最高概率的类。
让我们看一个例子。假设我们观察以下天气状况。

New data point
首先,给定这些条件,我们将计算老人行走的概率。

Probabilities needed to calculate the chance of the old man walking
如果我们做所有这些的乘积,我们得到 0.0217 。现在让我们做同样的事情,但是对于另一个目标类:不走。

Probabilities needed to calculate the chance of the old man not walking
同样,如果我们做乘积,我们得到 0.00027 。现在,如果我们比较两种可能性(男人走路和男人不走路),我们得到一个男人走路的更高的可能性,所以我们穿上运动鞋,拿一件外套以防万一(有云),然后去公园。
注意在这个例子中我们没有任何概率等于零。这与我们观察到的具体数据点以及我们拥有的数据量有关。如果任何一个计算出的概率为零,那么整个乘积将为零,这是不太现实的。为了避免这些,使用了被称为平滑的技术,但是我们不会在这篇文章中讨论它们。
**就是它!**现在,当我们醒来,想要看到我们会发现老人在散步的机会时,我们所要做的就是像前面的例子一样,看看天气情况,做一个快速的计算!
结论
我们已经看到了如何使用贝叶斯定理的一些简化来解决分类问题。在下一篇文章中,我们将讨论朴素贝叶斯在自然语言处理中的应用。
就这些,我希望你喜欢这个帖子。要获得更多关于数据科学和机器学习的资源,请查看下面的博客:如何学习机器学习。谢谢,祝你阅读愉快!
其他资源
如果您渴望了解更多信息,您可以使用以下资源:
一如既往,有任何问题请联系我。祝你有美好的一天,继续学习。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










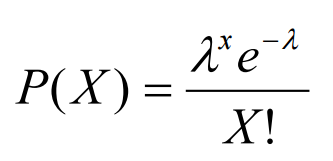{kind=link}