







解释力矩生成函数
它的示例和属性
如果你谷歌过“矩母函数”,第一、第二、第三个结果还没有让你点头,那就试试这篇文章吧。
1.首先,什么是概率/统计中的“时刻”?
假设我们感兴趣的随机变量是 X 。
矩是 X 的期望值,如 E(X),E(X),E(X),…等。
第一个时刻是 E(X) ,
二阶矩是 E(X ) ,
第三个时刻是E(X)
…
第 n 个时刻是 E(X^n) 。
我们非常熟悉前两个矩,均值 μ = E(X) 和方差E(X)——μ。它们是 X 的重要特征。均值是平均值,方差是分布是如何展开的。但是必须有其他 特征 以及也定义了分布。例如,三阶矩是关于分布的不对称性。第四个力矩是关于它的尾巴有多重。

The moments tell you about the features of the distribution.
2.那么什么是矩母函数(MGF)?
顾名思义,MGF 就是产生矩的函数——E(X),E(X),e(x),…,E(X^n).

The definition of Moment-generating function
如果你看看 MGF 的定义,你可能会说…
“我对了解 E(e^tx).不感兴趣我想要 E(X^n).”
对 MGF 求导 n 次,将 t = 0 代入。然后,你会得到 E(X^n) 。

This is how you get the moments from the MGF.
3.给我看看证据。为什么 n 阶矩是 MGF 的 n 阶导数?
我们将用泰勒级数来证明这一点。

然后取期望值。

现在,对 t 求导。

如果你对 ③ 再求导(因此总共两次),你会得到 E(X ) 。
如果再求一次(三阶)导数,就会得到 E(X ) ,以此类推…
当我第一次看到矩母函数的时候,我无法理解t在函数中的作用,因为 t 看起来像是一些我不感兴趣的任意变量。然而,如你所见, t 是一个辅助变量。我们引入 t 是为了能够使用微积分(导数)并使(我们不感兴趣的)项为零。
等等,但是我们可以用期望值的定义来计算矩。我们到底为什么需要 MGF?

The definition of Expected Value (Are you confused with 𝐗 vs 𝒙 notation? Check it out here.)
4.我们为什么需要 MGF?
为了方便起见。
我们需要 MGF,以便容易地计算力矩。
但是为什么 MGF 比期望值的定义更容易呢?
在我的数学课本里,他们总是告诉我“求二项式(n,p)、泊松(λ)、指数(λ)、正态(0,1) 等的矩母函数。”然而,他们从来没有真正向我展示过为什么 mgf 会如此有用,以至于激发出快乐。
我想下面的例子会让你高兴起来——MGF 更容易的最明显的例子:指数分布的 MGF。(还不知道什么是指数分布?👉指数分布的直觉
我们从 PDF 开始。

The PDF of exponential distribution
推导指数的 MGF。

对于存在的 MGF,期望值 E(e^tx) 应该存在。
这就是为什么 t - λ < 0 是要满足的重要条件,因为不然积分就不收敛。(这被称为发散测试并且是当试图确定一个积分是收敛还是发散时要检查的第一件事。)
一旦有了 MGF: λ/(λ-t) ,计算力矩就变成了求导的问题,这比积分直接计算期望值要容易。

使用 MGF,可以通过求导而不是积分来求矩!
需要注意一些事情:
- 对于任何有效的 MGF, M(0) = 1 。每当你计算一个 MGF 时,插入 t = 0 ,看看你是否得到 1。
- 矩提供了一种指定分布的方法。例如,您可以通过前两个矩(均值和方差)来完全指定正态分布。当你知道分布的多个不同时刻时,你会对该分布有更多的了解。如果有一个人你没见过,你知道他的身高,体重,肤色,最喜欢的爱好等等。,你仍然不一定完全了解他们,但正在获得关于他们的越来越多的信息。
- MGF 的妙处在于,一旦有了 MGF(一旦期望值存在),就可以得到任意 n 阶矩。MGF 将一个随机变量的所有矩编码成一个函数,以后可以从这个函数中再次提取它们。
- 概率分布由其 MGF 唯一确定。如果两个随机变量有相同的 MGF,那么它们一定有相同的分布。(证明。)
- 对于对“瞬间”这个术语很好奇的人(比如我):为什么一个瞬间被称为瞬间?
- [应用🔥分布的一个重要特征是它的尾部有多重,特别是在金融风险管理中。如果你还记得 2009 年的金融危机,那基本上就是未能解决罕见事件发生的可能性。风险经理低估了该基金交易头寸背后的许多金融证券的峰度(峰度在希腊语中是“膨胀”的意思)。有时,看似随机的假设平滑的风险曲线分布中可能隐藏着凸起。我们可以发现那些使用 MGF 的人!
金钱使世界运转,足球也是如此?
欧洲和国家层面的统计分析

在这篇文章中,我们将关注欧洲足球的财务发展,并回答以下问题:一支球队的团队价值与他们的体育成就之间的相关性有多强?金融形势总体上是如何发展的?为了回答这些问题,我们主要使用 Numpy 和 Pandas 进行数据分析,使用 Plotly 进行可视化。该数据库是从 transfermarkt.com[1]自行搜集的,其中包括 2009 年至 2018 年的转让数据。在另一篇文章中,我将展示如何收集和处理数据。GitHub 上提供了数据集和完整的 Jupyter-Notebook。如有其他问题,请联系我。
介绍
英格兰超级联赛被认为是世界上最有吸引力的联赛之一。不仅是悠久的历史,还有联赛的资金量,都是他们不间断走红的原因。在 2017/2018 赛季,20 支英超球队能够在他们之间分配总计 24.2 亿英镑(约 27 亿€)的电视资金。仅曼联一家就获得了近 1.5 亿英镑(€1.67 亿英镑),这还不包括门票销售、商品和促销活动的收入[2]。有了这笔钱,年轻的天才和世界明星可以进入英格兰联赛,这反过来也保证了体育的成功。欧足联在其网站上有一个显示欧洲足球协会的排名。计算依据是单个俱乐部在欧冠、欧联等欧洲顶级赛事中的表现。当前的前 10 名如图 1 所示:

Figure 1: UEFA Country coefficients 2018/2019 [3]
西班牙在五年平均值中排名第一,因为在此期间总共可以赢得 4 个冠军和 3 个欧洲联赛冠军。然而,自 2017/2018 赛季以来,英格兰已经弥补了很多,这要归功于利物浦和切尔西的冠军。我们在团队价值观中也发现了这种模式吗?为了回答这个问题,我们可视化了每个国家的平均阵容值:

Figure 2: Development of the average total squad value from 2012 to 2018 in €
图 2 显示了排名前 10 的联赛的平均阵容值[2]。英格兰的金融霸主地位,一眼就能看出来。在 2018/2019 赛季,球队的平均现金价值约为€4.52 亿英镑,而在排名第二的西班牙联赛中,€仅为 2.91 亿英镑。紧随其后的是德国(€2.57 亿)和意大利(€2.45 亿)。法国排名第五,平均€为 1.78 亿。这些也是组成前 5 名的国家协会。从球队价值来看,这五家俱乐部自 2012 年以来都表现良好。如果你看看其他五个俱乐部,俄罗斯、葡萄牙、比利时、乌克兰和土耳其,你一眼就能看出,这支队伍的平均价值总体上是下降的。此外,绝对水平明显低于前 5 名五重奏。这里的领跑者是葡萄牙,平均每支球队价值 6800 万€,而乌克兰只有€的 2800 万。这种财政优势也反映在冠军联赛的体育优势上。图 3 显示了过去 15 年的冠军得主:

Figure 3: The champions league winner from 2005 to 2019 [4]
在过去的 15 年里,欧洲冠军联赛的冠军都是由德国、英国、意大利和西班牙球队夺得的。在此期间,巴塞罗那和马德里获得了 8 个冠军。在球队价值方面排名第四的四个国家在最近的过去也是欧洲足球最高级别的冠军。显然,经济上的优势也导致了体育上的优势,这种优势越来越明显。但是国家级的前 5 名联赛呢?我们能期待这里的变化吗?图 2 中的球杆在比赛中是不可及的吗?
2.欧洲五大联赛的金融发展
对于五个欧洲顶级联赛,我们有更长的时间序列,从 2009 年到 2018 年。因此,我们可以看看 10 年期间的发展情况:

Figure 4: Development of the average squad value from 2009 to 2018 in €
图 4 也显示了所有联赛的平均小队值都有了明显的提升。顺序大体相同,只有意大利从第 2 位滑落到第 4 位。这里最有价值的球队是否会像欧洲水平一样占据统治地位?以下球队在过去十年中拥有最有价值的球队:

图 5 显示了上述球队的冠军头衔。里昂奥林匹克和那不勒斯 SSC 没有显示,因为他们自 2009 年以来没有赢得过国家冠军:

Figure 5: National championship winner from 2009 to 2018
总的来说,拥有最有价值阵容的两支球队赢得了超过 80%的冠军。尤其是在德国、意大利和西班牙,顶级球队占据主导地位。在国家层面也是如此,拥有最昂贵球队的俱乐部主导着联赛。
但是一般来说,金融发展如何呢?联盟中的财政不平等是否在继续增加,或者在国家层面是否有动态发展,以便我们可以期待未来的更多变化?为了回答这个问题,我们来看看所谓的 GINI 系数。这主要在经济学中用来反映平等或不平等。该系数通常用于收入分配,以检查社会中平等或不平等的资产是如何分配的。如果 GINI 系数为 0,所有人的财富将完全相同,但如果该值为 1,一个人将拥有一切,而其他人则一无所有。我们现在将把这个指标应用到队伍值中,以检查分布是如何发展的。在图 6 中,我们可以看到结果:

Figure 6: Development of the GINI-Coefficient from 2009 to 2018
在过去的十年里,所有五个联赛的不平等都有所增加。增长最快的是法国,法国的 GINI 系数从 0.29 上升到 0.46。西班牙的不平等程度最高。这里的系数从 0.46 上升到 0.52。德国的不平等程度相对最低,但这里的不平等程度也有所上升。在意大利,出现了 0.06 至 0.45 的急剧下降。增幅最低的是英格兰,该系数仅上升了 0.01 至 0.39。
黑色虚线代表所有五个联赛的平均值。2009 年,GINI 系数为 0.41,2018 年为 0.47。值得注意的是,直到 2014 年,这一比例持续上升至 0.48。自那以后,人民币汇率基本上停滞不前。其中一个原因可能是欧足联引入了金融公平竞赛,这意味着顶级俱乐部不能再扩大投资规模[5]。
3.球队平均价值和运动成绩之间的统计关系
我们已经注意到,经济实力更强的联赛在欧洲占据主导地位,在国家层面,拥有更有价值球队的俱乐部也更富裕。现在,我们根据一个赛季取得的积分来检查球队价值和体育成就之间的统计相关性:

Figure 7: Correlation oefficients points and squad value
在图 7 中,我们看到所有联赛的皮尔逊相关系数大约为 0.69。这是一种非常积极的关系。相关系数首先表明有关系,但还没有说什么因果关系。这种相关性在所有联赛中都存在,在西班牙最强,而在法国相关性相对较低。尽管如此,在所有联赛中,得分和球队价值之间都有很强的正相关关系。

Figure 8: Relationship between squad value and number of points per season
在图 8 中,这种关系是可视化的。可以清楚地看到,随着平均小队值的增加,得分的点数也增加。可以假设这里存在偏相关。如果像莱斯特城这样的球队出人意料地争夺冠军,在球队没有投入新球员的情况下,球员的市场价值就会上升。在这个例子中,良好的表现将导致团队价值的增加。一般来说,俱乐部进行转会是为了扩大他们的体育潜力,我们认为更高的球队价值会带来更大的体育成就。我们可以用回归来检验这个假设:

Figure 9: Regression with Points as dependent and squad value as independent variable
图 9 显示了回归的结果。分数是因变量,球队看重的是自变量。调整后的 R 平方为 0.662。这意味着,因变量的方差的大约 66%,也就是点,可以用我们的自变量来解释。此外,我们可以从 P 值中看出,该结果具有统计学意义。
结论
在引言中,我们已经看到,欧洲五大联赛在经济上和体育上都占据主导地位。此外,这一群体继续动态增长,而其余联赛则呈现小幅下降趋势。因此,可以假设体育优势继续显现。在对英格兰、法国、德国、意大利和西班牙的比较中,可以注意到英格兰拥有迄今为止最高的阵容价值,并且这种优势持续了十年。由于目前的发展,不太可能在不久的将来会有另一个联盟取得第一名。在国家联赛中,我们发现球队价值的分配越来越不平等。不平等的最大增长发生在法国,而绝对水平最高的是西班牙。
在最后一部分,我们从统计学角度检验了团队价值与运动成功的相关性。有很强的正相关性,由此可以得出两个结论。由于财政潜力,欧洲五大顶级联赛的运动优势在不久的将来将会增加而不是减少。再者,由于各国联赛的不平等日益加剧,顶级球队的霸主地位将继续存在。
来源
[1]www . transfer markt .com
【2】https://www . UEFA . com/memberassociations/uefarankings/country/#/yr/2019
【3】https://www . UEFA . com/memberassociations/uefarankings/country/#/yr/2019
【4】https://en . Wikipedia . org/wiki/List _ of
链接
github:
https://github.com/bd317/soccer_analytics
笔记本:
https://Github . com/BD 317/Soccer _ Analytics/blob/master/Soccer _ Analytics _ Github _ upld . ipynb
数据集(可作为。pkl 或者。csv 文件):
https://github . com/BD 317/soccer _ analytics/blob/master/df _ all _ top 10 _ analytics . CSV
https://github . com/BD 317/soccer _ analytics/blob/master/df _ all _ top 10 _ analytics . pkl
https://github . com/BD 317/soccer _ analytics/blob/master/df _ all _ top 5 _ analytics . CSV
https://github . com/BD 317/soccer _ analytics/blob/master/df _ all _ top 5 _ analytics . pkl
如果您喜欢中级数据科学,并且还没有注册,请随时使用我的推荐链接加入社区。
钱球—线性回归
使用 Python 中的线性回归预测棒球赛季表现。

Photo by Joshua Peacock on Unsplash
2011 年,电影**《金钱球》**上映。这部电影改编自 Micheal Lewis 的书,基于一个真实的故事,讲述了奥克兰运动家队总经理比利·比恩在失去明星球员后,必须在预算紧张的情况下找到进入季后赛的方法。保罗·德波斯塔(Paul DePodesta)毕业于常春藤联盟(Ivy League),他能够利用的 Sabermetrics 识别出“廉价”球员,以便建立一支球队,延续美国队臭名昭著的 20 连胜,并看到他们在常规赛中获得第一名,将 Sabermetrics 的艺术置于聚光灯下。
在这篇文章中,我们将尝试重建 DePodestas 的统计分析,使用 python 中的线性回归来模拟 2002 年常规赛的结果。
线性回归
线性回归是监督机器学习的最简单形式之一,它基于独立变量(通常用 X 表示)对目标预测值(通常用 y 表示)进行建模。

- Y —因变量(目标预测值)
- X —独立变量
- β —回归系数:指 x 变量和因变量 y 之间的关系
- ε——误差项:用于表示统计或数学模型产生的残差变量,当模型不能完全代表自变量和因变量之间的实际关系时,就会产生该残差变量。由于这种不完全的关系,误差项是在经验分析过程中方程可能不同的量。
线性回归模型的工作本质上是找到输入(X)和输出(y)之间的线性关系。
使用的数据集可以在 Kaggle 找到,最初是从baseball-reference.com收集的。
数据集包含许多属性(列),在导入相关模块并使用 pandas 打开后可以看到(注意:完整的原始代码可以在 My Github 中找到)
df = pd.read_csv('csvs/baseball.csv')
df.head()

Be sure to import NumPy, Pandas, and CSV modules
我们需要关注的主要属性是:
- RS —得分运行
- RA —允许运行
- w-Wins
- OBP——基于百分比
- SLG——段塞百分比
- BA——击球率
- 季后赛——一支球队是否能进入季后赛
- OOBP——对手的上垒率
- OSLG——对手击球百分比
其中一些是不言自明的,但是有几个属性需要一些解释:
- OBP——上垒百分比:这是一项统计,衡量击球手上垒的频率,它不考虑击球手跑了多远,即三垒。
- SLG-Slugging Percentage:一个衡量击球“生产力”的指标,简单来说,它衡量击球手击球时能打出多远。
- 击球率:由击球次数除以击球次数定义,衡量击球手投球时击球的可能性。同样,没有考虑击球手跑了多远。
现在,所有这三个统计数据在这个分析中都非常重要。在“Moneyball”之前,球探主要使用击球率作为衡量一个好击球手的标准,通常一个球员的击球率会对他们的价值/工资产生巨大的影响。然而,DePodesta 认为这是一个错误,声称球探高估了 BA 的统计数据,而大大低估了 OBP 和 SLG 作为优秀击球手的衡量标准。比利·比恩和运动家队能够以低廉的价格获得高 OBP 和 SLG 的球员,因为球探忽略了这些属性。
数据角力
让我们增加一个新的栏目;RD,它显示了 RS(得分得分)和 RA(允许得分)之间的差异。df['RD'] = df['RS'] - df['RA']
让我们也确保我们只有’钱球’之前的数据,这可以通过只包括 2002 年常规赛之前的数据来实现。df = df[df.Year < 2002]
探索性数据分析(EDA)
根据 DePodesta 的说法,为了进入季后赛,湖人队需要在常规赛中取得 99 场胜利。我们可以使用 Seaborn 创建一个图形来可视化它,这是一个基于 matplotlib 的数据可视化库。
让我们从为我们的绘图定义一个好的调色板开始。
flatui = ["#6cdae7", "#fd3a4a", "#ffaa1d", "#ff23e5", "#34495e", "#2ecc71"]
sns.set_palette(flatui)
sns.palplot(sns.color_palette())

Be sure to import Seaborn & Matplotlib
现在,我们可以绘制运行差异与成功的关系图,以形象化 DePodestas 理论。
sns.lmplot(x = "W", y = "RS", fit_reg = False, hue = "Playoffs", data=df,height=7, aspect=1.25)
plt.xlabel("Wins", fontsize = 20)
plt.ylabel("Runs Scored", fontsize = 20)
plt.axvline(99, 0, 1, color = "Black", ls = '--')
plt.show()

正如我们所看到的,DePodestas 的理论似乎是准确的,因为只有 3 次球队没有以≥ 99 胜进入季后赛(在黑色虚线 99 胜“阈值”线后的蓝点中可以看到)。
DePodesta 还计算出,为了赢得 99 场比赛并进入季后赛,A 队必须得 814 分,同时只允许 645 分,分差 169 分。我们可以使用许多不同的方法来可视化运行差异和成功之间的关系,我们将使用其中的两种方法。
首先,一个简单的散点图:
x = np.array(df.RD)
y = np.array(df.W)
slope, intercept = np.polyfit(x, y, 1)
abline_values = [slope * i + intercept for i in x]
plt.figure(figsize=(10,8))
plt.scatter(x, y)
plt.plot(x, abline_values, 'r')
plt.title("Slope = %s" % (slope), fontsize = 12)
plt.xlabel("Run Difference", fontsize =20)
plt.ylabel("Wins", fontsize = 20)
plt.axhline(99, 0, 1, color = "k", ls = '--')
plt.show()

其次;我们可以使用 Seaborn pairplot:
corrcheck = df[['RD', 'W', 'Playoffs']].copy()
g = sns.pairplot(corrcheck, hue = 'Playoffs',vars=["RD", "W"])
g.fig.set_size_inches(14,10)

我们已经可以看到,两者之间存在明显的线性关系,然而,我们可以通过使用熊猫来进一步验证这一点。corr(),它计算列之间的成对相关性。
corrcheck.corr(method='pearson')

Correlation between Wins and Run Difference
我们可以看到胜率和跑差之间的相关性为 0.938515,这表明两者之间的关系非常密切。
现在我们知道运行差异与成功有很强的相关性,那么什么属性与运行差异有很强的相关性呢?正如我们之前提到的,当时的球探非常依赖平均打击率,根据 DePodesta 的说法,他们低估了基础率和击球率。同样,我们可以使用。corr() Pandas 函数,用于计算列之间的成对相关性。
podesta = df[['OBP','SLG','BA','RS']]
podesta.corr(method='pearson')

请注意右边一栏,显示了 RS 与 OBP、SLG 和 BA 的关系。我们可以看到,击球率实际上是关于得分得分的 最少 相关属性,相关度为 0.83。击发百分比和上垒百分比实际上相关性更高,分别为 0.93 和 0.90。这证实了 DePodestas 对 SLG 和 OBP 的低估和对 BA 的相对高估。
我们实际上可以应用一点机器学习来进一步验证这些说法。首先,通过使用单变量选择,来选择那些与输出变量(在这种情况下是 RD)具有最强关系的特征。scikit-learn 库提供了 SelectKBest 类,允许我们挑选特定数量的特性。我们将使用非负特征的卡方统计检验从数据集中选择最佳特征。首先,我们需要使用moneyball = df.dropna()从我们的数据集中删除任何会干扰机器学习方法的空值。
然后:
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#we use RD as the target column
X = moneyball.iloc[:,6:9]
y = moneyball.iloc[:,-1]
#apply SelectKBest class to get best features
bestfeatures = SelectKBest(score_func=chi2, k=3)
fit = bestfeatures.fit(X,y)
dfscores = pd.DataFrame(fit.scores_)
dfcolumns = pd.DataFrame(X.columns)
#concat two dataframes for better visualization
featureScores = pd.concat([dfcolumns,dfscores],axis=1)
featureScores.columns = ['Feature','Score']
print(featureScores.nlargest(3,'Score'))
另一种方法是使用基于树的分类器内置的特征重要性。特征重要性将为数据的每个特征给出一个分数,分数越高,该特征对于输出变量越重要或相关。
X = moneyball.iloc[:,6:9] #independent columns
y = moneyball.iloc[:,-1] #target column
from sklearn.ensemble import ExtraTreesClassifier
model = ExtraTreesClassifier()
model.fit(X,y)
print(model.feature_importances_)
feat_importances = pd.Series(model.feature_importances_, index=X.columns)
feat_importances.nlargest(3).plot(kind='barh', figsize = (12,8))
plt.xlabel("Importance", fontsize = 20)
plt.ylabel("Statistic", fontsize = 20)

The importance of attributes on determining Run Difference
模型构建
Scikit-learn 为我们提供了构建线性回归模型的功能。首先,我们建立了一个得分的模型,使用基本百分比和击球百分比进行预测。
x = df[['OBP','SLG']].values
y = df[['RS']].values Runs = linear_model.LinearRegression() Runs.fit(x,y)print(Runs.intercept_)
print(Runs.coef_)

然后,我们可以说,我们的跑步得分模型采用以下形式:
RS =-804.627+(2737.768×(OBP))+(1584.909×(SLG))
接下来,我们做同样的事情,但是为了模拟允许的跑动,使用对手的基本百分比和对手的击球百分比。
x = moneyball[['OOBP','OSLG']].values
y = moneyball[['RA']].values
RunsAllowed = linear_model.LinearRegression()
RunsAllowed.fit(x,y)
print(RunsAllowed.intercept_)
print(RunsAllowed.coef_)

然后,我们可以说我们的允许运行模型采用以下形式:
RA =-775.162+(3225.004×(OOBP))+(1106.504×(OSLG))*
然后,我们需要建立一个模型来预测给定运行差异时的获胜次数。
x = moneyball[['RD']].values
y = moneyball[['W']].values
Wins = linear_model.LinearRegression()
Wins.fit(x,y)
print(Wins.intercept_)
print(Wins.coef_)

我们可以说,我们的 Wins 模型采用以下形式:
W = 84.092 + (0.085 ×(RD))
现在我们剩下要做的就是得到 OBP、SLG、OOBP、OSLG,并简单地将它们插入模型中!
我们知道哪些球员在 2001 赛季后被转入和转出,所以我们可以用 2001 年的球员数据来建立 2002 年的球队。
2002 年 NBA 球队季前统计数据取自 2001 年:
OBP: 0.339
SLG: 0.430
OOBP: 0.307
OSLG: 0.373
现在让我们创建我们的预测:
Runs.predict([[0.339,0.430]])

Our model predicts 805 runs
RunsAllowed.predict([[0.307,0.373]])

Our model predicts 628 runs allowed
这意味着我们得到了 RD 177(805–628),然后我们可以将它插入到 Wins 模型中。
Wins.predict([[177]])

所以,最后,我们的模型预测得分 805 分,628 分,99 场比赛获胜,这意味着我们的模型预测,根据他们的球队数据,运动家队将进入季后赛,他们做到了!
让我们将我们的模型与 DePodestas 的预测进行比较:

局限性:
当然,这个简短的项目有一些限制。举例来说:因为我们使用一个球员前几年的统计数据,所以不能保证他们会在同一水平。例如,老玩家的能力可能会退化,而年轻玩家可能会成长。同样重要的是要注意,我们假设没有人受伤。
除了局限性之外,模型的性能非常显著,确实支持了 DePodestas 的理论,并解释了为什么他使用的技术在奥克兰运动家队的“Moneyball”赛季结束后很快被整个棒球界大量采用。
非常感谢你阅读我的第一篇文章!我打算继续发这样的帖子,主要是利用数据分析和机器学习。欢迎任何反馈。
班长!不要再做一个盲目的数据科学家。

The Shoemakers’ Children Go Barefoot, Alexander Mark Rossi.
监控和警报如何帮助您更好地控制您的数据,以及目前的实践情况如何。
下面的文章解释了许多用例以及监控和警报的巨大重要性,特别是从数据科学研究者的角度。我们将看看用例,并回顾几家试图为这个巨大的,但奇怪的是没有讨论过的,超越我们行业的问题提供解决方案的公司。
2021 年 2 月更新:这篇文章似乎引起了一些关注,我会继续更新这篇文章的相关内容,如果有任何原因,请随时联系我。
2021 年 8 月更新:我添加了一个数据源用例
2022 年 12 月更新:我添加了成本/ci/cd 用例
现代机器学习依赖于海量数据,我们在收集和保存这些数据方面已经相当成功,但我们还远远没有解决数据管理的最大难题之一。
我说的是每天了解你的数据,**我相信在我们的行业中,很少有科学家这样做。**简而言之,数据科学专业人士不知道他们的数据到底发生了什么。就注释而言,分发数据的每一段,分发缺失值和新值,分发标签,分发版本历史,包括包历史,等等。我们盲目地相信我们的数据,这是一种常见的做法,我亲眼目睹并亲身经历过。
由于环境的原因,许多创业公司从跑步开始,并随着时间的推移不断提高速度。可以理解的是,创建实现增长和为客户创造价值的模式非常重要,但从长远来看,我们忽略了一些非常重要的东西。事实是,了解我们的数据比一次又一次地更新你的模型更重要。
**扪心自问,你怎么知道你的数据可以信任?**没有信任,更新或创建新模型就没有意义,你可能会引入噪音并破坏你自己的工作。
另一方面,为我们投入生产的每个模型创建和维护多个仪表板视图是很麻烦的。观察统计指标的视图,如平均 Wasserstein-distance、零假设、F1、精度和召回或产品相关指标。我们不想创建额外的指标来观察我们的数据和模型,我们不想在我们的指标之上创建会发现异常和趋势的模型,我们真的不想每天照看我们的仪表板。
我们希望获得一个系统,它知道在事情发生变化时进行监控并向您发出警报,无缝、自动地进行监控,并根据机器学习算法获得预测性警报。可以检测故障或尝试提前预测未来故障的警报。在查看这些警报时,我们希望有一些解释,使用模型可解释性工具,如 SHAP 或莱姆。
让我们看一些值得注意的用例。
用例
我遇到过几个数据监控和警报的用例,我肯定还有其他的,但是这些对作为数据科学家的你影响最大。名单是按时间顺序写的。
- 注释者
- 注释分布
- 数据源
- 数据完整性
- 数据分布
- 依赖版本,即包版本。
- 型号版本
- 模型参数
- 模型度量
- 业务产品指标
- 模拟软件和硬件性能(基础架构和 CI/CD)
- 成本监控
注释者
注释者通常是给你的数据贴标签的人,你可以在这里阅读注释者度量标准。我们还可以使用算法来为我们做注释,无论是使用某种形式的启发式算法、系综、堆栈还是使用库,如通气管。

Figure 1: measuring Inter-agreement and Fleischer Kappa, showing a signal correlation and a fixed threshold.
监控指标,如评分者之间的一致,自我一致性,地面真相的一致是必不可少的(图 1 和 2),因为没有他们你不知道你的注释质量。

Figure 2: measuring average annotators accuracy throughout time.
想象一下下面的情况,您有一个大多数投票决定标签的注释者群体,但是,出于某种原因,有几个注释者开始偏离最初的指令。在您不知道的情况下,您的注释最终会成为标签噪音,或者如果我们诚实的话,我们可以称之为注释错误。
如果你不能信任你的注释者,那么就不要使用注释
我们需要监控注释者度量,并在出现问题时得到警告,从而丢弃那些被标记为不好的数据,也就是说,我们不会将它放入最终的数据集中。
如果没有适当的监控和预测警报,您将无法及时捕捉到标签噪音,从而浪费大量资源,如时间和金钱,您会将噪音引入您的训练集,直接损害您的模型和您试图给予价值的客户。
如果您不监控由试探法或算法产生的注释,也会发生这种情况。对于这种基于算法的注释,请阅读下面关于数据分布、依赖版本、模型版本和模型度量的内容。
监控你的真实来源是数据链中最重要的事情。例如,如果你有一个被监督的问题,而你的标签是坏的,你将很难创建一个好的模型。这与监控数据或训练模型一样重要,有时甚至更重要。
注释分布
现在,我们相信可以信任我们的注释器,因为我们监控了它们的性能,并且丢弃了低于我们固定阈值的注释。虽然注释并不总是类标签(例如,命名实体),但是让我们考虑一种情况,其中我们的注释是类标签,并且我们使用它们来解决监督问题。

Figure 3: a comparison of distributions (Mona labs)
当训练一个模型时,该模型是在某一类标签分布上训练的。监控生产中标签分布的概念漂移(图 3)可以通过使用 1。零假设或 2。平均推土机距离(EMD) ,这是两个概率分布之间平均距离的度量,也称为瓦瑟斯坦度量。根据类的数量,零假设应该用于二元类或三元类,其中有[-1,0,1],当有多个类时,应该使用平均 Wasserstein 距离。
“如果你的实时标签分布与你的训练数据不同,那你就有问题了。立即采取行动!”
通常,您会实时比较训练集的标签分布和生产数据的标签分布。由于标签概念漂移,接收预测性警报可以挽救生命。(请注意,如果您的再培训策略基于主动学习,您可能会发现培训分布和实时数据之间的不规则性,这是由于从您的模型的最弱预测分布中选择样本的性质)。
例如,假设有这样一种情况,您训练了两个相似的模型,每个模型都训练了唯一的标签分布,但是它们密切相关,并且由于某种原因,发生了错误,并且部署了单个模型来服务所有数据流,而不是让适当的模型预测其自己的流。每个模型都有一个标签分布监视器,这将告诉您第一个模型的行为符合预期,而对于第二个模型,模型的训练数据分布与实时分布明显不同,这是一个关键问题。
监控标签分布也可用于触发事件,以便重新训练模型。当发行版自然发生变化或者添加了新的客户端时,标签发行版必然会发生变化。当您重新训练您的模型或调试各种问题时,拥有这些信息可以帮助您更好地控制,这也可以导致使用更少的资源。
数据源
您的数据源可能是管道中第一个最重要的东西。跟踪您的数据源是否已经更改、损坏或消失是非常必要的。监控系统应该保持跟踪,ping 健康状况,并确保您的数据源不会在一夜之间消失,并在发生时提醒所有相关的利益相关者。
如果你的数据源坏了,你就没有数据了!
数据完整性
您现在知道您的注释器和标签是完美的(希望如此)。或者,您可能正在处理一个无人监督的问题,并且不需要注释器或注释监控。是时候确保您的数据保持有序了。监控系统应该运行和管理您的数据,通过使用 TDDA 和远大前程等工具进行定制和自动测试驱动的数据分析,也就是说,系统应该审查您的数据并提出行动建议。
“如果你的数据没有通过定期测试,你不能相信它!”
例如,系统应该在模式更改后提供警报,这可能是由自然或人工过程引起的。当列的类型可能由于新值而发生变化时,提供警报。处理无效、缺失或唯一的值等。在给定数据策略的情况下,应该使用数据治理将这些操作自动分配给负责人。监控服务应该观察数据趋势和异常,并在数据新鲜度(每日、每周)、数据结构、数据增长和统计概要文件出现问题时通知您。这可以确保您知道您正在利用多少基础架构,知道如何解决当前和不可预见的问题,并可以计算未来的支出。
数据分布
现在,您可以确信您的数据得到了妥善保管,并且具有高度的完整性。是时候确保您的数据分布不会发生剧烈变化,并且您的训练模型仍然可以提供看不见的数据。

Figure 4: a comparison of distributions over features, by parallemIM.
想象一下,你的数据有以下维度:时间、客户、类别和颜色。让我们数一数我们有多少个细分市场,时间是基于过去一年的一分钟分辨率,您有 2000 个客户,30 个类别和 3 个颜色类别。好吧,我们有太多的片段需要观察。最理想的情况是,我们希望使用一种服务来自动跟踪所有这些维度,而无需定义它们,并且该服务会在其中一个细分市场即将发生分布变化时提醒我们(图 4)。它将我们从使用 Datadog 或 Grafana 之类的服务构建专用仪表板中解放出来,并允许我们专注于研究。
“如果您不能信任您的数据分布,那么就不要使用它来训练模型”
类似于注释分布,对于每个分段,我们需要使用相同的方法来确保没有概念漂移,并且我们必须调查特定变化的原因,或者重新训练模型以支持新的数据分布。请记住,我们希望这些警报是为我们自动定义的,不需要我们对每个警报进行微调,也不需要太多的误报。
依赖版本
大多数算法都基于几个依赖关系,并且每个算法都有自己的版本。版本在模型的生命周期中不断变化,如果您不跟踪您的版本,也就是说,您建模的正确算法的正确版本依赖将在您不知道的情况下以不同的方式执行。
更新:我在下面的帖子 “监控你的依赖关系!不再做一个盲目的数据科学家”

Figure 5: black dots represent a dependency or model version checkpoint, this illustration is composed on top of an actual view by superwise.ai.
例如,想象一个表情符号到文本的包每天都在更新,你的 NLP 算法就是基于这种转换。新版本可能会支持新的表情符号,单词可能会映射到不同的表情符号。这是一个关键的变化,可能会导致模型以意想不到的概率预测错误的事情或预测正确的事情。
如果您不能跟踪您的依赖项版本,您就不能相信您的模型性能是确定的
为了保持确定性行为,我们必须记录我们投入生产的每个模型的所有依赖版本,如图 5 所示。当依赖关系改变时,监视器需要提醒我们。请注意,单元测试不会总是捕捉到这种行为。依赖项版本历史应该映射到您的预测中,这样您就可以快速、轻松地找出什么地方出错了。
型号版本
类似于依赖版本,知道正确的模型被插入到正确的数据是非常重要的。你不希望某天早上醒来,客户投诉,并指出工程没有正确部署模型。
如果您无法跟踪您的模型版本,就不能相信它部署正确
当您的 CI/CD 正在训练和部署新模型时,这种行为应该被自动报告,最好是基于实际的版本数字,但是也基于您部署的工件的差异。版本历史应该始终被连接并显示在您的模型预测视图上,这样当它出错时,您就可以找出哪里出错了,如图 5 所示。
模型参数
当模型版本变更时,它们会带来模型所用参数的变更。这些不仅仅是主学习算法的参数,这些可以是在我们的“元算法”中改变的各种参数。
“如果你不能跟踪你的元模型参数,你就不能相信你的模型会像预期的那样运行”。
想象一个模型版本的变化,其中一个在研究阶段被测试的参数被意外地带入到产品中,并且这个参数导致了模型一致性的变化,与以前的版本相比。包括向我们的监控平台报告任何参数的方法将是有益的。
模型度量
我们喜欢看模型指标,它们告诉我们我们的模型有多好,我们可以对外传达这些数字。然而,这些数字依赖于上游事件,如标签、数据、成功部署等。
“如果你不能观察你的模型性能,你就不能信任它。”

Figure 6: Model performance view by superwise.ai, showing accuracy, probability and F3.
精确度、召回率、F1 和 PRAUC 等指标描述了我们的成功或失败,因此我们非常积极地实时监控它们,如图 6 所示。对于无监督的算法,比如聚类,我们可以监控聚类同质性等指标。监控模型性能有助于我们理解什么时候事情开始出错,或者什么时候上游有变化。
业务产品指标
与模型性能类似,有一些度量标准被定义为项目的一部分,对业务和产品极其重要。这些指标不一定是我上面提到的经典指标。例如,您的模型被用作一个提示模型,您向您的客户展示基于前 3 个概率的前 3 个选择,类似于图 6 中发生的情况。您的产品 KPI 可能是基于前 3 个可能类别中的预测得分的准确性,当该数字低于 95%时,您将发出警报。观察这些指标对于您维护的健康产品或功能至关重要,并且监控它们是您所有权的一部分,尽管我认为业务和产品都需要能够查看它们。
“如果你不能观察你的产品性能,你怎么知道你的 KPI 正在保持它的目标?”
理论上,有可能我们正在监控我到目前为止提到的一切,一切都很完美。然而,这些产品指标仍在直线下降。这可能意味着很多事情,但无法找到导致这些指标下降的原因是一个严重的问题。因此,当事情即将变坏时,获得预测性警报对于生产中的任何产品都至关重要。
模拟软件和硬件性能
通常是外部非数据科学服务的领域,比如 New Relic 。监控模型进程很重要,例如 CPU、GPU、RAM、网络、存储性能和警报,以便发现高负载或负载,如图 7 所示。这将确保您的模型可以在不中断生产的情况下继续在一个健康的系统上服务。

Figure 7: A typical dashboard by Graphana, showing Memory, CPU, Client Load, Network traffic.
监控功能
在研究提供 MLOps 或监控解决方案的公司时,您应该注意以下重要特性:
- 黑盒集成—简单的单行回调,不会干扰您的研究或生产代码,并且可以无缝使用。
- 持续监控—仪表板包括预测趋势或季节性的指标,以及叠加在监控信号之上的异常检测。
- 现成的指标和警报—我们希望通过使用快速和预定义的 KPI 配置来立即进行跟踪。
- 测试驱动的数据分析——我们希望使用数据测试,定期在数据基础架构级别发生不可预见的事件时自动获得通知。
- 用户驱动的指标和警报—在 UI 中定义自定义 KPI 和维度的能力。这种方法能够监控一切,而不仅仅是“输入”/“输出”,并跟踪更复杂的测量(例如,两个分数之间的日平均差值)。
- 预测警报—我们希望提前知道即将发生的事情。
- 降噪—减少误报警报,同时仅在出现重大问题时发出警报,这可以通过使用规则、试探法、算法或预测模型来实现。
- 自动基准测试—为每个新数据段(即数据的维度子集)识别和创建自动警报。想象一下,追踪数据集中的客户和类别要素,使用这些要素类型的每个组合都有自己的分布。知道某个类别何时开始表现不佳或对某个客户端漂移是一个游戏规则改变者,而不需要专门配置它。
- 模型可解释性/可解释性——类似于 SHAP 和莱姆正在做的事情,这使我们能够理解为什么以某种方式预测某个输入,同时显示哪些特征有助于预测。此外,它应该允许我们利用特征值来理解它们对预测的影响。
- 日志审计——谁不喜欢看日志?日志可以告诉我们许多关于正在发生的事情。
- 偏差检测——不是我们都知道的机器学习偏差,而是一种偏差,例如偏向某个特定人群的模型。这种偏见检测可以帮助您符合 GDPR,并允许您处理对您的业务产生负面影响的问题。
- 云或内部安装—通常,大多数公司都提供 SaaS 服务,但是,由于合同限制以及随之而来的内部安装,您可能需要将数据安全地存储在自己的基础架构中。
服务
幸运的是,一些公司已经明白我们需要工具和解决方案。我已经与三家公司进行了对话,他们正试图开发这些急需的工具。每个人都非常努力地尽快提供各种解决方案,他们通常由经验丰富的数据科学家或真正了解该领域的人领导,所以这已经是一个很大的承诺。我们确实需要为我们新出现的需求量身定制的解决方案。请注意,您应该始终包装源自第三方公司的代码,特别是在处理年轻的初创公司时,如果您使用开源解决方案,您应该记住,由于这一新兴领域的复杂性,客户或社区支持非常重要。

Figure 8: Superwise.ai diagnose, analytics and alert views.
- 超级。ai——一家以色列初创公司,在我看来是目前功能最全的解决方案。它包括黑盒集成,可以连接到生产中的任何 ML 解决方案。它具有智能的&成熟功能,例如实时性能监控&分析,具有适合模型和数据统计的各种预定义 KPI,基于机器学习模型的预测智能,可学习和预测模型的性能,自动基准测试,自动处理&动作执行,开箱即用的解释和偏差检测,以及云或内部配置。(图 8)。
- 莫纳实验室——另一家非常有前途的以色列初创公司(不要与创造了个人购物者的其他莫纳实验室混淆)。莫娜实验室由三名前谷歌员工领导。Mona 能够从生产中的模型收集和分析数据,允许我们使用现成的指标评估生产中的模型质量,具有用户驱动的指标&警报、自动基准测试,能够检测数据漂移或模型偏差问题,允许您创建可操作的见解,降低数据完整性和云或本地配置的风险(图 9)。

Figure 9: Mona: top-shelf: data segmentation & KPI selection, top-left: a view based on the selection, others: KPI and KPI and distribution views.
- Fiddler.ai —一家年轻的初创公司,提供模型可解释性,能够改变特征以了解它们的重要性,即查看哪些特征有助于模型预测。人在回路中的审计、仪表板、报告、属性比较、维度切片性能、偏差检测的特征跟踪、异常值的持续监控和数据漂移检测(图 10)。

Figure 10: Fiddler.ai views: top-right view show continuous model performance, the top-left view show model interpretability and playground, the bottom view shows dashboards and reports.

Figure 10b: an automated alert window by DeepChecks.
在图 10c 和 10d 中,我们可以看到他们的警报摘要和分布外用户界面,以及基线基准与实际模型性能之间的比较,我怀疑这是基于用户的训练集或对其原始数据使用“auto-ml”方法的简单模型,不完全清楚它是否是 F1 等已知指标。

Figure 10c: alert summary and out of distribution UI by DeepChecks.

Figure 10c: a comparison between a baseline and the current model’s performance.
5。Stakion.io —一家新的初创公司,承诺快速开箱即用的集成、持续实时监控、自动化警报、模型可解释性和日志审计功能(图 11)。

Figure 11: Stakion: The top-view shows continuous monitoring, The bottom-views shows alerts & log search.
5.Arthur.ai —另一家年轻的初创公司,他们专注于性能。可解释性,偏见。
- Arize —一家从monitor ml&FairAI创建的公司——提供模型和数据分布检查、概念漂移、特征分段分析、预测质量&可解释性(图 12)。

Figure 12: Arize’s model performance view.
- SodaData.io — Soda 的平台在这一领域非常独特,因为它是唯一一家以“数据完整性”相关用例为目标的初创公司。它们帮助数据工程师监控操作方面,如新数据分区的大小和新数据的预期到达时间。它们通过确保强制字段的 SLA 来帮助数据所有者监控业务方面。它们帮助分析团队监控使用需求,即确保分类值保持不变,并且数据分布不会随时间而改变。
8。Seldon . io Deploy——“Seldon Deploy 为机器学习部署提供监督和治理”,请在 youtube 上看到。它们提供多臂-bandit、离群点检测、可解释性、偏差&概念漂移检测。他们正在使用 Alibi Explain ,这是一个模型检查&解释库,用于分类和回归模型的黑盒、白盒、局部&全局解释方法的高质量实现。
9.rescup . ai—通过允许任何人以编程方式为端到端模型开发和部署流程标记、构建和扩充训练数据,利用分析和基本监控功能,利用流行的rescup库。
10.Aporia.com—允许数据科学家快速配置高级生产显示器。他们专注于强大的 UX 和易用性,如图 12b 所示,显示了您可以多快地使用各种用例,如检测漂移、监控数据完整性问题、性能等。

Figure 12b: Aporia’s monitor builder UX.
面向部署的平台
这些公司将监控作为附件提供,所有这些公司都有一些基本的监控。他们主要关注模型开发、部署和服务。似乎您只能对那些只使用其服务部署的模型使用监控特性。

Figure 13: parallelmI views: deployment and model health, logs and distribution monitoring, etc.
- ParallelML —最近被 DataRobot 收购,专注于部署和生产规模。它集成了 Jupyter,Python 到 Docker,Spark,Git,Bitbucket,Cron。提供数据漂移检测、自动模型训练和预测,承诺轻量级占用空间和可伸缩性,具有 150 个监控属性和日志审计功能(图 13)。需要注意的是,在重新训练时,你不应该使用所有的新数据,在添加你不信任的数据时,你应该小心谨慎。因此,我建议 ParallelIM 应该描述他们的再培训政策(或规则?)进行自动模型训练。
- hydro sphere . io——“数据科学和机器学习管理自动化的开源平台。承诺生产中 ML 和 AI 应用的可靠性、可扩展性和可观察性。”。水圈具有基本的可观测性特征,如统计检查、异常检测等。
- ML flow—“ML flow 是一个管理 ML 生命周期的开源平台,包括实验、再现性和部署。它目前提供三个组件:1 .MLflow 跟踪—对记录和查询(如代码、数据、配置和结果)进行实验。2.MLflow 项目——可在任何平台上重复运行的打包格式,以及 3 .MLflow 模型——将模型发送到不同部署工具的通用格式。
- IBM Watson Open Scale——“是一种工具,可以在人工智能的整个生命周期中跟踪和测量人工智能的结果,并根据不断变化的业务情况调整和管理人工智能——用于在任何地方构建和运行的模型。”
- sel don . io——“是一个开源的面向 Kubernetes 的机器学习部署,管理、服务和扩展在任何框架中构建的模型。”
当监控的需求变得明显时,您应该列出对您来说重要或将重要的功能,并找到符合大多数条件的解决方案。始终与您的解决方案提供商进行对话,我强烈建议与以技术为导向的人交谈,特别是如果他们是初创公司的一部分,因为您的个人使用案例可能与他们提供的预期解决方案略有不同,对他们来说支持它可能很重要。
我真心希望这篇文章在您需要适应和实现以数据科学为中心的监控服务时发挥重要作用。如果您有更多的想法和信息,请随时在下面发表评论。
我要感谢我的同事们,阿龙·尼塞尔、谢伊·耶海兹克尔、阿米特·艾纳夫、西蒙·索默-雅科夫、纳塔内尔·达维多维茨、塞弗·凯勒、萨缪尔·杰弗罗金和其他人,你们知道你们是谁,对这篇文章的评论。
Ori Cohen 博士拥有计算机科学博士学位,主要研究机器学习。他是 TLV 新遗迹公司的首席数据科学家,从事 AIOps 领域的机器和深度学习研究。
利用谷歌地球引擎和粮农组织 WaPOR 数据监测非洲缺水情况(可持续发展目标 6.4)
监测农业用水效率的重要性

Crop Water Productivity of Sorghum in the Gezira scheme, Sudan (2015) visualized in Google Earth Engine by Author
在二十世纪,随着水需求以两倍于人口增长率的速度增长,缺水正成为一个日益严峻的挑战。2015 年 9 月,世界大多数国家通过了 2030 年可持续发展议程,包括 17 个可持续发展目标和 169 个具体目标。目标 6.4 涉及用水效率和水压力。为了跟踪进度,制定了两个指标。
到 2030 年,大幅度提高所有部门的用水效率,确保可持续抽取和供应淡水以解决缺水问题,并大幅度减少缺水人口数量
—可持续发展目标 6.4

Sustainable Development Goal 6.4 and its indicators to address water scarcity
农业是非洲未来的关键。非洲大陆拥有世界上最大的可耕地,一半以上的人口在农业部门就业,是国内生产总值的最大贡献者。此外,撒哈拉以南非洲有最多的缺水国家,据估计,到 2025 年,该大陆将有超过 28 亿人面临缺水状况。
因此,政府应强调改善其水资源管理做法。为了实现这一点,良好和充分的数据是必要的。
由于农业占全球淡水提取量的 70%,灌溉被认为是世界上最大的耗水活动,因此具有提高用水效率的巨大潜力。那么,如何具体说明指标 6.4.1 和 6.4.2,以便对当前灌溉农业做法进行深入评估呢?有鉴于此,联合国粮食及农业组织(粮农组织)制定了一项绩效指标,将粮食生产与水消费联系起来;所谓的水分生产率定义为农业产量[kg]与其生产所用(或消耗)的水量[m3]之比**。**
评估水分生产率差距是一项复杂的任务,包括监测各种作物生产系统的当前生产率水平,并将这种生产率水平与潜在生产率水平进行比较。地理空间数据可以提供工具来监测和可视化这些具有高度空间可变性的过程,从而改进决策。因此,粮农组织推出了 WaPOR 数据门户网站,该网站免费并开放获取经过处理的地球观测(EO)数据,包括整个非洲和中东地区近实时的实际蒸散量(ET)和生物量产量。随着粮农组织 WaPOR 数据门户网站的启动,对非洲大陆水文过程和生物量生产的了解显著增加。

可持续发展目标指标 6.4.2:水分胁迫
淡水提取可通过蒸散量数据进行评估,将总蒸散量分为所谓的绿水和蓝水蒸散量。来自绿水的蒸散量是来自渗入土壤的降雨,而来自蓝水的蒸散量是由于使用了人工基础设施,如用于灌溉的水泵。因此,所谓的蓝水消耗量可以与指标 6.4.2 联系起来:测量淡水提取量。

Deriving blue water consumption with WaPOR datasets — Author’s thesis content
蓝水消耗量可以通过基于水核算+模型的公式框架得出,该模型由IHE-代尔夫特开发。然而,使用标准编程方法(如 Python 的 GDAL 包)在单个设备上以高分辨率(100 m)计算国家级别(大空间尺度)的蓝水消耗量被证明是不够的。此外,数据在类型、分辨率和感兴趣区域方面的特征变化很难处理。有了 Google Earth Engine,可以在更高的时间和空间尺度上进行处理,从而可以在政策层面上提供可操作的信息。从 ET 中提取的淡水可在国家、地区和地方范围内以高分辨率按月计算。通过将该数据与现场和田间水平测量值进行比较,灌溉效率的热点和异常可以很容易地定位。

Monthly water fresh water withdrawals for irrigation purposes in the Eastern Nile Basin Countries (2016) — Calculated with Google Earth Engine by author
可持续发展目标指标 6.4.1:一段时间内的用水效率
灌溉作物水分生产率可通过将农业产量[kg]除以消耗的蓝水总量[m3]获得。使用 WaPOR 数据,可以在像素级别上推导和计算农业产量以及蓝水消耗量。

From Water Productivity to Crop Water Productivity with the available WaPOR datasets and literature
为了获得农业产量,将地上生物量产量(AGBP)乘以作物收获指数,该指数是根据物候学数据确定的作物得出的。为了确定像素的具体生长季节,将所谓的季节开始(SOS)和季节结束(EOS)物候数据结合起来。随后,SOS 和 EOS 之间的差异提供了作物生长季节期间的总蓝水 ET。这样,就可以得到作物水分生产率,并与指标 6.4.1** 联系起来**
弥合政策和技术之间的差距
使用 EO 数据是评估水利用效率的一种强大且具有成本效益的技术,因此在国际上被公认为支持可持续发展目标 6.4。由于政府有责任确保全国范围的水安全,农业用水生产率的提高应该来自政策制定者和决策者,而不是农民。
**然而,事实证明,需要广泛的方法和基础设施来促进道德操守办公室的适当实施,以支持政策制定者和决策者。**通知并鼓励地方政治组织在各自国家实施地理空间工作至关重要。没有他们的参与,许多衍生的数据和信息将留在科学和研究领域。
为了接触到最终用户,需要确定与可持续发展目标相关的行为者、竞技场和道德操守办公室的实际贡献。Google Earth Engine 和 FAO WaPOR 门户网站等工具和(预处理)数据源为弥合政策和技术之间的差距提供了能力和框架。然而,仍有一些挑战需要克服。
如有疑问或需要更多信息,欢迎给我发电子邮件:
伊曼坦塔维【at】gmail.com
设置关于 AWS Lambda 数据管道的自动警报

用 AWS Lambda 开始收集数据很容易——你实际上可以在几分钟内自动化一条数据管道。但是接下来会发生什么呢?理想情况下,您的代码可以正常工作,但是我们都知道最终会出现某种类型的错误,并且因为您的数据管道非常自动化,所以很容易忽略它。输入 CloudWatch 及其警报!让我们回顾一下,相对于必须定期检查,我们如何才能尽可能地懒惰,在出现问题时被告知。

AWS Lambda is your serverless swiss army knife
什么是 AWS Lambda?
这是强制性的介绍,我需要用两段来解释一些复杂的东西!很快,让我们从 10,000 英尺的高度概述一下 AWS Lambda,以及为什么每个数据科学家都应该使用它:
- AWS Lambda 是 AWS 上的无服务器计算服务。酷……那是什么意思?用普通人的话来说,它让你以最小的努力在云中运行你的代码。不需要设置 web 服务器、EC2 实例等——在 SublimeText 中编写代码,然后粘贴到 Lambda 中(稍作调整),就可以开始了!AWS 将在云中为你执行你的代码,你甚至可以使用你的外部库(尽你所能导入熊猫作为 pd!).
- 它支持多种语言。 Java,Go,PowerShell,Node.js,C#,Python,Ruby 都支持。
- ****可以通过多种方式触发。想让你的 Lambda 每小时跑一次?一天一次?当一个物体被放入 S3。当数据流进入 Kinesis 时。当太阳位于正交 37.312 度时。Lambda 的一个很大的特点是你可以触发它以多种方式运行,当然这些触发器中至少有一个会满足你的用例。
- ****便宜的离谱。对于 Lambda,你按请求(你的函数运行的次数)和计算时间付费。在免费层,你每月有一百万个请求和 400,000 GB 秒,这基本上意味着你每月可以免费做很多事情。即使你真的浏览了,那也是每一百万次请求 20 美分。根据我在餐巾纸背面的计算,你可以执行超过 2000 万个 Lambda 函数,只需要你早上喝一杯冷饮的钱——这是多么美好的时光啊!
Lambda 数据管道——设置好就忘了?
在我的上一篇 中型文章 中,我们介绍了如何用 Python 建立一个 Lambda 数据管道,该管道将每天从 Craigslist 上收集一次公寓列表数据。在一个完美的世界中,我们可以“设置它,忘记它”,并在我们的定期间隔获取数据。看过《权力的游戏》最后一季的人都知道我们并不是生活在一个完美的世界里。如果你编程的时间超过一分钟,你就知道会有错误发生:超时,Craigslist 可能不可用,你的解析器可能遇到一些被遗弃的表情字符,导致它崩溃,等等。因此,虽然我们不能完全设置它并忘记它,但我们可以设置它,只有在出现问题时才会联系它。这是通过警报完成的,但首先我们需要设置监控。
设置监控

如果你已经创建了一个 Lambda 函数,你会注意到在顶部有两个主面板:配置和监控**。配置是您实际更改 Lambda 函数的地方:更改触发器、更改实际代码、调整超时等。监控是你检查一切是否顺利的地方。在这里你可以看到诸如是否有错误,Lambda 函数运行的次数等等。**

但是,如果您转到监控选项卡,您会注意到默认情况下有许多空图表。这是因为监视 AWS 服务的工具 CloudWatch 不会自动跟踪您的 Lambda 函数指标。
将 CloudWatch 指标添加到 Lambda 函数中
这里的实际问题是你的 Lambda 函数只需要发布到日志的许可。为什么这是默认设置?我不知道,但是让我们改变它。基本上你需要做的是附加一个策略,让 Lambda 发布到日志中。
****快速说明:AWS 中的权限可以是它自己的一系列文章,但是一个好的经验法则是假设字面上没有任何东西有做任何事情的权限。就像国会一样。在这个例子中,我们有我们的 Lambda 函数,它不能发布到我们的 CloudWatch 日志,除非我们说“嘿 Lambda,你可以发布到 CloudWatch!”。Lambda 是服务而不是人(duh),所以服务获取权限的方式是通过角色。角色基本上是说“如果一个服务有这个角色,它可以做 X,Y 和 Z”。“X”、“Y”和“Z”是策略。政策规定你可以写信给 S3,查询红移或者发布到 CloudWatch。一个没有政策的角色什么都做不了,一个附加了政策的角色其实可以为我们做事。总而言之,服务有角色,角色有策略。策略实际上是给予做事情的许可,所以每个角色都有允许这些角色做酷事情的策略。一点都不困惑,对吧?你最终会找到窍门的。

- ****第一步:在配置页面上,转到 Lambda 函数正在使用的角色,然后单击查看角色。你的名字和我的会有所不同。

- ****第二步:点击“附加策略”按钮,附加新策略。这将为我们的 Lambda 函数添加更多权限,这将允许它访问 CloudWatch 指标。

- ****第三步:你需要的 CloudWatch 指标的角色叫做“AWSLambdaBasicExecutionRole”。如果您在搜索栏中搜索该角色,请单击名称左侧的复选标记(以应用它),然后单击“Attach Policy ”(附加策略),您将把该策略添加到您的 Lambda 函数中。

- ****第四步:现在,Lambda 函数的 Monitoring 选项卡中已经有了指标!默认情况下,这会显示关于 Lambda 的重要指标,比如调用(函数运行的次数)、持续时间和错误计数。万岁。
设置出错时自动发送电子邮件
现在,我们有了进入 Lambda 函数的监控页面的指标。这与没有度量相比是一个进步,但是这仍然让我们处于这样一种情况,即我们的功能可能会失败,而我们不会注意到,除非我们定期检查这个图表(这很烦人)。理想情况下,我们只在 Lambda 函数失败时得到通知,然后我们可以去调查发生了什么。为此,我们可以再次依赖 CloudWatch。最后一列步骤太有趣了,让我们再做一次吧!请注意,这看起来像很多步骤,但第一次应该花不到 10 分钟,以后每次大约 2 分钟。

- 第一步:上 CloudWatch。你可以从顶部导航进入服务- >管理&治理- >云观察

- ****第二步:点击左侧面板上的报警,然后点击右侧的“创建报警”按钮。

- ****第三步:单击“选择指标”选择将触发我们的警报的指标
- ****第四步:选择“λ”
- ****第五步:选择“按函数名”

- ****第六步:找到你的 Lambda 的函数名。如果你只有一个 Lambda,这将很容易,但一旦你开始建立你的庞大的无服务器计算帝国,这将变得非常拥挤。您将看到每个函数名称的几个条目,因为在 Metric Name 下有几个选项。您可以使用多个指标来触发警报,但我们想要的是错误触发。因此,您想要的度量名称是 Errors (duh)。选择它,然后选择左下方的“选择指标”。
 ****
****
- 第七步:这一步太激烈了,拍了两张照片!是时候配置什么会真正触发我们的警报了。有很多方法可以触发警报,这只是我使用的方法。请注意,在这个屏幕上,左侧是用来触发警报的图表。在我们的例子中,这是我们的误差图,为 0,因为我们没有任何误差(万岁!).无论如何,对于这个例子,我们需要设置三样东西:条件、统计数据和周期**,所有这些都与那个图表相关。先说条件。这是图表上我们想要触发警报的条件。这里我们将它设置为“大于 0”。基本上,如果我们的图表有一个大于 0 的值(大于 0 个错误),我想知道它。转到统计:在这种情况下,由于我们的条件,这真的无关紧要。如果我们有 0 个以上的错误,平均错误计数将大于 0,最大值和总和也将大于 0,因此您可以选择任何一个。如果您关心的是执行时间之类的东西,您可能想知道平均时间是否超过某个值,那么这就更重要了。周期是测量警报的频率。这里我们选择每日,因为我们的 Lambda 是每日触发。也就是说,如果一天中的最大值大于 0,那么我们需要知道它。如果你还不明白的话,这是一个很好的解释。结合这些功能,我们有一个警报,每天跟踪数据点,如果错误图表上的最大值大于 0。用人类的话来说,如果一天中有一个数据点超过 0,那么就要敲响警钟了。输入后,单击“下一步”。**

什么是 SNS?被称为 AWS 的庞然大物有许多很酷的功能,其中之一就是简单通知服务,或 SNS。基本上,如果你想就 AWS 上发生的事情联系一个人,你可以使用 SNS。想想我们当前的例子,如果有东西坏了,我们想给人发电子邮件。这是社交网络的众多用途之一。它的工作方式是你创建“话题”,比如“我的 Lambda 着火了!!!"人们可以订阅这个话题。因此,每当有内容发布到该主题时,订阅者都会收到通知。可以把它想象成一份 AWS 时事通讯。
- ****第八步:创建 SNS 话题的时间。基本上,这就是当闹钟响起时,你可以收到电子邮件、短信或其他形式的交流方式。给你的闹钟起一个名字,表明这个闹钟的用途。如果你只有一个或两个警报,它的用途可能很明显,但是当你扩展到几十个或几百个警报时,可能就不那么清楚了,所以给它一个描述性的名字。然后只需添加您的电子邮件并点击“创建主题”按钮。
****注意:您将收到一封确认电子邮件,告知您想要订阅 SNS 主题。在你确认之前,你不会收到提醒邮件。这是为了防止像我这样的坏人为我的 AWS 警报注册可怜的陌生人。只是开玩笑,但你真的需要确认,否则你不会得到你的闹钟,然后你只是浪费了一堆时间阅读这个漫长的教程没有意义!

- ****第九步:为你的闹钟添加名称和描述。这包括在电子邮件的正文中(上面的例子),所以一定要描述清楚,这样你就知道你的警报到底在说什么了。
- ****第十步:确认一切设置妥当,点击“创建警报”。现在你应该都准备好了!
测试您的警报
可能有一个更复杂的方法来做这件事,但通常我会去我的 Lambda 函数,告诉它在第一行打印一些未定义的变量。进行更改,保存 Lambda 函数,然后单击“测试”。这将调用您的 Lambda,当它失败时,您应该会收到警报(可能需要几分钟)。当你看到警报正常工作后,一定要消除这个有意的错误。如果您没有收到警报,请确保您确认了 SNS 主题订阅,并且正确设置了阈值(步骤 7)。
我的闹钟看起来像什么?

假设我的说明并不糟糕,并且你正确地设置了闹钟,那么每当出现错误时,你都会收到来自 AWS 的电子邮件。它看起来与上面的类似,唯一的区别是报告的区域和名字被替换为你调用的函数。在电子邮件中,你会得到更多的细节,比如错误发生的时间,错误与哪个 Lambda 函数有关,等等。
摘要
我们不能期望我们的代码总是正确执行。我们也不能总是检查它,尤其是如果它每小时甚至每分钟都在运行。Lambda 配备了 CloudWatch 警报,可以很容易地知道什么时候出现了问题,这样我们就可以进入那里进行调试。我强烈建议您利用 CloudWatch 警报来维护快乐健康的数据管道。和往常一样,如果你觉得这篇文章有用或者有任何问题,请随时在 LinkedIn 上联系我。流水线作业快乐!
自动驾驶中的单目三维物体检测——综述
这篇博文是实时的,随着更多论文的发表,我会更新它。
更新:
- 添加 RTM3D(2020 年 1 月 15 日)
- 从 mapi pile 添加虚拟摄像机(2020 年 2 月 16 日)
- 添加分离的结构化多边形(2020 年 3 月 21 日)
- 添加改进的 MPL(2020 年 3 月 22 日)
- 添加买方公寓(2020 年 6 月 4 日)
- 添加烟雾(2020 年 6 月 5 日)
- 补充地球不是平的(06/28/2020)
- 添加 D4LCN(2020 年 8 月 22 日)
- TODO:添加(伪 LidarV3、ZoomNet、ApolloCar3D、6D-VNet 和 PartParse)
三维物体检测是自动驾驶的一项重要任务。自动驾驶中的许多重要领域,如预测、规划和运动控制,通常需要对自我车辆周围的 3D 空间进行忠实的表示。

Monocular 3D Object Detection draws 3D bounding boxes on RGB images (source: M3D-RPN)
近年来,研究人员一直在利用高精度激光雷达点云进行精确的 3D 物体检测(特别是在 PointNet 的开创性工作展示了如何用神经网络直接操纵点云之后)。然而,激光雷达也有其缺点,如高成本和对不利天气条件的敏感性。利用 RGB 摄像头执行单目 3D 物体检测的能力也增加了模块冗余,以防其他更昂贵的模块出现故障。因此,如何仅用一幅或多幅 RGB 图像进行可靠和准确的 3D 感知仍然是自动驾驶中感知的圣杯。
单目 3D 物体检测( mono3DOD )并不是一个新的想法,但最近人们对这个话题的兴趣激增。我希望在 2020 年看到更多的论文问世,因为基于激光雷达的方法和基于图像的方法之间的性能差距仍然很大。

Increasing amount of efforts in literature on monocular 3D object detection in Autonomous Driving
(相对)详尽的调查
这篇文章回顾了单目 3D 物体检测这一关键任务的最新进展。在这篇文章中,我回顾了截至 2019 年 11 月的 32 篇关于这一主题的论文(编辑:这篇博客文章是实时的,随着更多论文的发表,我将更新它)。这是文献中关于 mono3DOD 的所有论文的一个比较完整的综述。论文大致分为四类:**表示转换、关键点和形状、基于 2D/3D 约束的几何推理、和3D bbox 的直接生成。**注意,一篇论文通常跨越多个类别,因此分组标准不严格。

A relatively comprehensive list of papers on Mono 3DOD as of 2019/11
对于论文摘要的表格视图,请参考我的 github 页面或这个 google doc 电子表格。
深度学习和机器学习的论文阅读笔记—Patrick-llgc/Learning-Deep-Learning
github.com](https://github.com/patrick-llgc/Learning-Deep-Learning/blob/master/paper_notes/review_mono_3dod.md)
将 2D 提升到 3D?艰难但易驾驭
从 2D 图像中检测三维目标是一项具有挑战性的任务。这从根本上来说是不适定的,因为深度维度的关键信息在 2D 图像的形成过程中被折叠了(更多背景信息请参见我之前的帖子将 2D bbox 提升到 3D )。然而,在特定的条件下,并且具有强有力的先验信息,这个任务仍然是易处理的。特别是在自动驾驶中,大多数感兴趣的物体,例如车辆是具有公知几何形状的刚性物体,因此可以使用单目图像来恢复 3D 车辆信息。
1.表示变换(BEV,伪激光雷达)
摄像头通常安装在一些原型自动驾驶汽车的车顶上,或者像普通仪表板摄像头一样安装在后视镜后面。因此,相机图像通常具有世界的透视图。这个视图对于人类驾驶员来说很容易理解,因为它类似于我们在驾驶过程中看到的,但对计算机视觉提出了两个挑战:遮挡和由于距离造成的比例变化。
缓解这种情况的一种方法是将透视图像转换为鸟瞰图(BEV) 。在 BEV 中,汽车具有相同的尺寸,与自我车辆的距离不变,并且不同的车辆不重叠(给定合理的假设,即在正常驾驶条件下,在 3D 世界中没有汽车在其他汽车之上)。逆透视映射(IPM)是一种常用的生成 BEV 图像的技术,但它假设所有像素都在地面上,并且摄像机的准确在线外部(和内部)信息是已知的。然而,外部参数需要在线校准,以便对 IPM 足够精确。

Convert perspective image to BEV (from BEV-IPM)
这就是 BEV IPM OD (IV 2019) 所做的事情。它使用 IMU 数据对 extrinsics 信息进行在线校准,以获得更精确的 IPM 图像,然后在其上执行目标检测。他们的 Youtube 演示可以在这里看到。
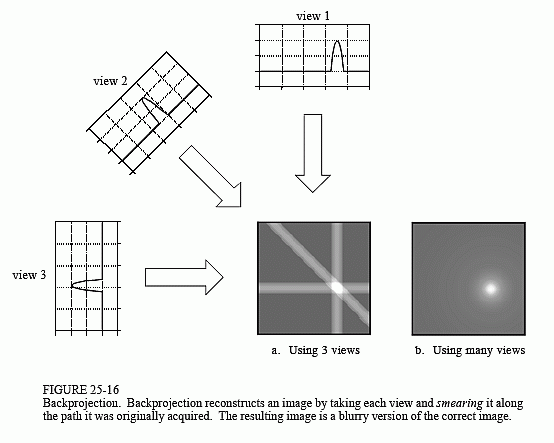
【正交特征变换(OFT) (BMVC 2019) 是将透视图像提升到 BEV 的另一种方式,但通过深度学习框架。其思想是使用正交特征变换(OFT)将基于透视图像的特征映射到正交鸟瞰图中。ResNet-18 用于提取透视图像特征。然后通过在投影的体素区域上累积基于图像的特征来生成基于体素的特征。(这个过程让我想起了 CT 图像重建中的反投影。)然后,沿着垂直维度折叠体素特征,以产生正交地平面特征。最后,使用另一个类似 ResNet 的自顶向下网络对 BEV 图进行推理和提炼。

Architecture of Orthographic Feature Transform (source)
OFT 的思路真的很简单很有趣,也比较好用。虽然反投影步骤可以通过使用一些启发法来改进,以便更好地初始化基于体素的特征,而不是天真地进行反投影。例如,真正大的 bbox 中的图像特征不能对应非常远的物体。我对这种方法的另一个问题是对精确的外在因素的假设,这可能在网上找不到。
另一种将透视图像转换为 BEV 的方法是bird GAN(IROS 2019),它使用 GAN 来执行图像到图像的转换。该论文取得了很大的成果,但是正如该论文所承认的,到 BEV 空间的转换只能在正面距离只有 10 到 15 米的情况下才能很好地执行,因此用途有限。

BirdGAN translates perspective images to BEV (source)
然后进入一行关于**伪激光雷达的思路工作。**这个想法是基于从图像中估计的深度来生成点云,这要归功于最近在单目深度估计方面的进展(这本身是自动驾驶中的一个热门话题,我将在未来进行回顾)。以前使用 RGBD 图像的努力主要是将深度视为第四通道,并在此输入上应用正常网络,对第一层进行最小的更改。 多级融合(MLF,CVPR 2018) 率先提出将估计深度信息提升到 3D。它使用估计的深度信息(具有由 MonoDepth 预先训练的固定权重)将 RGB 图像中的每个像素投影到 3D 空间,然后将该生成的点云与图像特征融合以回归 3D 边界框。

Architecture of Multi-level fusion (MLF), with pseudo-lidar generation circled in red (source)
《伪激光雷达》(CVPR 2019) 或许是这一行作品中最知名的。它受 MLF 的启发,通过直接应用最先进的基于激光雷达的 3D 物体探测器,以更暴力的方式使用生成的伪激光雷达。作者认为,表示很重要,深度图上的卷积没有意义,因为深度图像上的相邻像素可能在 3D 空间中物理上很远。

The general pipeline of the pseudo-lidar approach (source)
然而,伪激光雷达的 SOTA 结果背后有一个警告。 作者指出,现成的深度估计器 DORN 的训练数据和伪激光雷达 3DOD 的验证数据存在一定的重叠。因此,在培训和验证之间存在潜在的信息泄漏。这由 预见 部分证实,当深度估计器仅用训练数据适当训练时,其报告了低得多的数字。(详见 我的预见笔记 )。
伪激光雷达的作者们又跟进了 伪激光雷达++ 。主要的改进是,生成的伪激光雷达点云现在可以通过来自低成本激光雷达的稀疏但精确的测量来增强(尽管它们模拟了激光雷达数据)。利用相机图像和稀疏深度测量生成密集 3D 表示的想法在自动驾驶中非常实用,我希望在未来几年看到更多这方面的工作。

Pseudo-lidar++ augmented pseudo-lidar with sparse but accurate depth measurements
还有一些人跟进并改进了最初的伪激光雷达方法。 伪激光雷达颜色(CVPR 2019) 通过与颜色信息融合来增强伪激光雷达的想法,通过普通拼接(x,y,z) → (x,y,z,r,g,b)或基于注意力的门控方法来选择性地传递 rgb 信息。本文还使用了一种简单而有效的点云分割方法,该方法基于平截体点网(CVPR 2018) 和平截体内平均深度的概念。 伪激光雷达 end 2 end(ICCV 2019)强调了伪激光雷达方法的瓶颈是双重的:由深度估计的不准确性引起的局部失准和由物体外围的深度伪影引起的长尾**(边缘出血)。他们通过使用实例分割掩模而不是平截头体点网中的 bbox 来扩展伪激光雷达的工作,并引入了 2D/3D 包围盒一致性损失的思想。 预见 也注意到了这些缺点,并强调在深度估计中并不是所有像素都同等重要。他们没有像以前的大多数方法那样使用现成的深度估计器,而是训练新的深度估计器,一个用于前景,一个用于背景,并在推理过程中自适应地融合深度图。**

bottlenecks of the pseudo-lidar approach: depth estimation and edge bleeding (source)
RefinedMPL :用于自动驾驶中 3D 物体探测的精细单目伪激光雷达深入研究伪激光雷达中的点密度问题。它指出,点密度比用 64 线激光雷达获得的点云高一个数量级。背景中过多的点导致虚假的误报并导致更多的计算。提出了一种两步结构化稀疏化方法,首先识别前景点,然后进行稀疏化。首先,使用两种方法识别前景点,一种是有监督的,另一种是无监督的。监督方法训练 2D 对象检测器,并使用 2D bbox 遮罩的联合作为前景遮罩来移除背景点。非监督方法使用高斯拉普拉斯算子(LoG)来执行关键点检测,并使用二阶最近邻作为前景点。然后,这些前景点在每个深度箱内被均匀地稀疏化。RefinedMPL 发现,即使使用 10%的点,3D 对象检测的性能也不会下降,并且实际上优于基线。该论文还将伪激光雷达与真实激光雷达点云之间的性能差距归因于不准确的深度估计**。**

Unsupervised and supervised sparsification based on pseudo-lidar point cloud in Refined MPL
总的来说,我对这种方法寄予厚望。我们需要的是前景的精确深度估计,这可以通过稀疏深度测量来增强,例如,来自低成本 4 线激光雷达的测量。
2.关键点和形状
车辆是具有独特共同部件的刚体,可用作检测、分类和重新识别的标志/关键点。此外,感兴趣对象(车辆、行人等)的尺寸是具有很大程度上已知尺寸的对象,包括整体尺寸和关键点间尺寸。可以有效地利用尺寸信息来估计到本车的距离。
沿着这条路线的大多数研究扩展了 2D 对象检测框架(一阶段,如 Yolo 或 RetinaNet,或两阶段,如更快的 RCNN)来预测关键点。
《深蝠鲼》(CVPR 2017) 就是这方面的一个创举。在用于训练和推理的阶段 1 中,它使用级联的更快 RCNN 架构来回归 2d bbox、分类、2d 关键点、可见性和模板相似性。模板仅仅意味着一个三元组的 3d bbox。在仅用于推理的阶段 2 中,利用模板相似性,选择最佳匹配的 3D CAD 模型,并执行 2D/3D 匹配(利用 Epnp 算法)以恢复 3D 位置和方向。

Deep MANTA has a 2D/3D matching postprocessing step in inference (source)
地球不是平的(IROS 2018) 目标在陡峭和坡度的道路上执行车辆的单目重建。在这个框架中,一个关键要素是从单目图像中估计三维形状和六自由度姿态。它还使用了深 MANTA 的 36 关键点公式。然而,它不是从所有可能的 3D 形状模板中选择最好的一个,而是使用一个基本向量和变形系数来捕捉车辆的形状。使用一组基本形状及其组合系数来表示特定形状的想法类似于 3D-RCNN 和 RoI-10D 中的想法。关键点检测模型在 ShapeNet 中用 900 个 3D CAD 模型生成/渲染的 240 万个合成数据集上进行训练,作者发现它可以很好地推广到真实数据。这种 mono3DOD 方法在 多物体单目 SLAM (IV 2020) 等其他作品中也有使用。

The bottom pathway is the keypoint-based mono 3DOD pipeline used in The Earth ain’t Flat (IROS 2018)
3D-RCNN(CVPR 2018)估算汽车的形状、姿态和尺寸参数,渲染(合成)场景。然后,将遮罩和深度图与地面真实进行比较,以生成“渲染和比较”损失。主成分分析(PCA)用于估计形状空间的低维(10-d)表示。姿态(方向)和形状参数是通过基于分类的回归从感兴趣的特征中估计出来的(参见我之前关于多模态回归的帖子)。这项工作需要大量输入:2D bbox、3D bbox、3D CAD 模型、2D 实例分割和内部函数。此外,基于 OpenGL 的“渲染和比较”的损失似乎也相当大。****

3D RCNN predicts pose (orientation) and reduced shape space (source)
RoI-10D(CVPR 2019)得名于一个 3D 边界框的 6DoF 姿态+ 3DoF 大小。额外的 1D 指的是形状空间。像 3D RCNN 一样,RoI-10D 学习形状空间的低维(6-d)表示,但是具有 3D 自动编码器。来自 RGB 的特征通过估计的深度信息被增强,然后被滚动以回归旋转 q(四元数)、RoI 相对 2D 质心(x,y)、深度 z 和度量范围(w,h,l)。根据这些参数,可以估计 3D 边界框的 8 个顶点。拐角损失可以在所有八个预测顶点和地面真实顶点之间公式化。通过最小化重投影损失,基于 KITTI3D 离线标记形状 groundtruth。形状的使用也是相当工程化的。****

RoI10D concats depth directly to RGB: this may not be the best practice (source)
mono 3d++(AAAI 2019)基于 3D 和 2D 一致性执行 3DOD,特别是地标和形状重建。它回归到具有 14 个标志的可变形线框模型。它在 Pascal3D 上接受训练。该模型还使用 EM-Gaussian 方法通过 2D 标志学习形状的低维表示。这与 3D RCNN 和 RoI 10D 类似,但 Mono3D++没有指定它学习的基的数量。该论文还估计深度和地平面,以形成多个预测分支之间的一致性损失。不幸的是,这篇论文遗漏了许多关键信息。

Architecture of Mono3D++ (source)
【MonoGRNet(AAAI 2019)回归 3D 中心的投影和粗略的实例深度并用这两者估计粗略的 3D 位置。它强调了 2D bbox 中心和 3D bbox 中心在 2D 图像中的投影之间的差异。投影的 3D 中心可以被视为一个人工关键点**,类似于 GPP 。与许多其他方法不同,它不回归相对容易的观察角度,而是直接回归 8 个顶点相对于 3D 中心的偏移。******

Architecture of MonoGRNet (source)

Note the difference between the 2D bbox center b and 3D bbox center c (source)
MonoGRNet V2 回归 2D 图像中的关键点,使用 3D CAD 模型推断深度。训练基于具有最小关键点注释的 3D CAD 模型,并且 2D 关键点被半自动地注释,具有 3D 边界框模板匹配,如在 Deep MANTA 中。它基于 Mask RCNN 架构,增加了两个头。一个头回归 2D 关键点、可见性和局部方向,另一个 CAD 和尺寸头选择 CAD 并回归 3D 公制尺寸偏移。实例距离由挡风板高度推断。(注意,原始掩码 RCNN 对象检测分支在训练期间打开,因为它稳定训练,但在推断期间不使用。关键点回归头通过全连接层直接回归关键点坐标,而不是如 Mask RCNN 论文所建议的热图。)

The architecture of MonoGRNet v2 (source)
关于 3D CAD 模型, Deep MANTA 通过将 CAD 模型放置在 3D bbox groundtruth 中,使用半自动方式来标记 3D 关键点。Deep MANTA 在 103 个 CAD 模型中的每个模型上标记了 36 个关键点。MonoGRNet V2 在 5 个 CAD 模型上标记了 14 个关键点。Mono3D++也标注了同样的 14 个关键点。

Different ways of keypoint annotation (with number of annotated keypoints in the bracket)
通常大规模密集注释汽车关键点是非常复杂和耗时的。百度的 ApolloScape,具体来说就是从主数据集派生出来的 ApolloCar3D 子数据集,是唯一一个以网格形式提供关键点和形状密集标注的。
地平面轮询(GPP) 生成带有 3D bbox 标注的虚拟 2D 关键点**。它有目的地预测比估计 3D bbox(超定)所需更多的属性,并使用这些预测以类似于 RANSAC 的方式形成最大共识属性集,使其对异常值更鲁棒。这类似于解决 2D/3D 紧约束中的超定方程,正如我在之前的博客中提到的如何将 2D 边界框提升到 3D 。**

GPP predicts the footprint of 3 tires and the vertical backplane/frontplane edge closest to the ego car (source)
RTM3D (实时 mono-3D) 也使用虚拟关键点并使用类 CenterNet 结构直接检测所有 8 个长方体顶点+长方体中心的 2d 投影。本文还直接回归了距离、方向、大小。不是使用这些值直接形成长方体,而是使用这些值作为初始值(先验)来初始化离线优化器以生成 3D 长方体。号称是第一个实时单目 3D 物体检测算法(0.055 秒/帧)。

RTM3D detects 9 virtual keypoints of 3d cuboid, and adjust them to be consistent with a real cuboid
它不仅像 CenterNet 一样直接检测 3D bbox,而且还预测虚拟成对约束关键点。成对关键点被定义为任意两个物体的中间点,如果它们是最近的邻居。“关系关键点”的定义类似于 像素到图形 (NIPS 2017) 。3D 全局优化 Monopair 的想法最大的性能提升是在深度估计过程中引入了不确定性。MonoPair 还执行对象之间绝对距离的旋转变换,以确保局部坐标中的视点不变性(参见我之前关于局部和全局坐标的帖子)。MonoPair 还以每帧 57 毫秒的速度实现了接近的实时性能。

Pairwise matching strategy for training and inference in MonoPair
(通过关键点估计的单级单目 3D 物体检测, CVPRW 2020 ) 也是受 CenterNet 的启发,它完全消除了 2D bbox 的回归,直接预测 3D bbox。它将 3D 边界框编码为 3D 长方体中心投影上的一个点,其他参数(大小、距离、偏航)作为其附加属性。该损失是 3D 角损失优化使用解开 L1 损失,灵感来自 MonoDIS 。与通过多个损失函数的加权和来预测 7DoF 参数相反,这种类型的损失公式是根据其对 3D 边界框预测的贡献来一起加权不同损失项的隐含方式。还实现了 60 米以内小于 5%的距离预测误差,据我所知这是单目深度估计的 SOTA。作者开源他们的代码值得称赞。

Average depth estimation error by SMOKE
具有解耦的结构化多边形估计和高度引导的深度估计的单目 3D 物体检测( AAAI 2020 ) 是第一个明确陈述 3D 顶点(在本文中称为结构化多边形)的 2D 投影的估计与深度估计完全解耦的工作。它使用类似于 RTM3D 的方法来回归长方体的八个投影点,然后使用垂直边缘高度作为强先验来指导距离估计。这会生成一个粗糙的 3D 长方体。然后,该 3D 立方体被用作 BEV 图像中的种子位置(使用与伪激光雷达类似的方法生成)用于微调。这导致比单目伪激光雷达更好的结果。**

Decoupled Structure Polygon uses cuboid keypoint regression and pseudo-lidar for finetune.
【ICCV 2019】mono loco 与上述略有不同,因为它专注于回归行人的位置,这可以说比车辆的 3D 检测更具挑战性,因为行人不是刚体,具有各种姿势和变形。它使用关键点检测器(自顶向下的,如 Mask RCNN 或自底向上的,如 Pif-Paf)来提取人类关键点的关键点。作为基线,它利用行人相对固定的高度,特别是肩到臀的部分(~50 厘米)来推断深度,这与 MonoGRNet V2 和 GS3D 所做的非常相似。该论文使用多层感知器(全连接神经网络)来回归具有所有关键点片段长度的深度,并展示了相对于简单基线的改进。该论文还通过随机/认知不确定性建模对不确定性进行了现实预测,这在自动驾驶等安全关键应用中至关重要。

Monoloco predicts distance with uncertainty from keypoint segment length (source)
总之,2D 图像中关键点的提取是实用的,并且具有在没有直接监督的情况下从基于激光雷达数据的 3D 注释推断 3D 信息的潜力。然而,这种方法需要对每个对象的多个关键点进行非常繁琐的注释,并且涉及繁重的 3D 模型操作。
3.通过 2D/3D 约束的距离估计
该方向的研究利用 2D/3D 一致性将 2D 提升到 3D。开创性的工作是deep 3d box(CVPR 2016)。像上面利用关键点和形状的方法一样,它还通过添加回归局部偏航(或观察角度)和从子类型平均值的维度偏移的分支来扩展 2D 对象检测框架。使用这些几何提示,它解决了一个过约束优化问题以获得 3D 位置,将 2D 包围盒提升到 3D。关于 deep3DBox 中优化问题的详细表述和其他人的后续工作,请参考我对将自动驾驶中的 2D 物体检测提升到 3D 的不短的评论。

The architecture of deep3DBox, representative of many other similar works (source)
尽管 Deep3DBox 取得了成功,但它有两个缺点(尽管第二个缺点由于其简单性实际上可能是部署中的一个优势):
1)它依赖于 2D bbox 的精确检测——如果在 2D bbox 检测中存在中等误差,则在估计的 3D 边界框中可能存在大误差。2) 优化纯粹基于包围盒的大小和位置,不使用图像外观提示。因此,它不能从训练集中的大量标记数据中受益。
FQNet(CVPR 2019)延伸了 deep3dbox 超越紧身的思路。它通过在 3D 种子位置周围进行密集采样(通过严格的 2D/3D 约束获得),向 deep3dbox 添加细化阶段,然后用渲染的 3D 线框对 2D 面片进行评分。然而,密集采样,如后面将要讨论的 Mono3D,需要很长时间,并且计算效率不高。

FQNet scores image patches with back-projected wireframes (source)
Shift R-CNN(ICIP 2019)通过从 Deep3DBox 建议“主动”回归偏移来避免密集建议采样。他们将所有已知的 2D 和 3D bbox 信息输入到一个名为 ShiftNet 的快速简单的全连接网络中,并精确定位 3D 位置。

Architecture of Shift RCNN (source)
级联几何约束 预测 3D bbox 底面(CBF)中心的投影和视点分类。它还消除了基于推断的 3D 信息的 2D 检测中的假阳性,例如基于边界框底部边缘的深度排序,以及近距离 2D 边界框的类似深度。
【MVRA(多视图重投影架构,ICCV 2019) 将 2D/3D 约束优化构建到神经网络中,并使用迭代方法细化裁剪案例。它引入了 3D 重建层来将 2D 提升到 3D,而不是求解过约束方程,在两个不同的空间中有两个损耗:1)透视视图中的 IoU 损耗,在重新投影的 3D bbox 和 IoU 中的 2d bbox 之间,以及 2)估计距离和 gt 距离之间的 BEV 损耗中的 L2 损耗。它认识到 deep3DBox 不能很好地处理截断的框,因为边界框的四个边现在不对应于车辆的真实物理范围。这促使通过仅使用 3 个约束而不是 4 个约束,排除 xmin(对于左截断)或 xmax(对于右截断)cars,对截断 bbox 使用迭代方向细化。全局偏航是通过以π/8 和π/32 间隔的两次迭代中的试错来估计的。

MVRA architecture (source)
【monosr(CVPR 2019)来自同一个作者为流行的传感器融合框架 AVOD。该方法首先生成三维草图,然后重构动态物体的局部点云。质心提议阶段使用 2D 盒高度和回归的 3D 对象高度来推断深度,并将 2D 边界盒中心重新投影到 3D 空间的估计深度。建议 sage 实用性强,相当准确(平均绝对误差~1.5 m)。重建分支回归物体的局部点云并与点云和相机(投影后)中的 GT 进行比较。它与 MonoGRNet 和 TLNet 的观点相呼应,即整个场景的深度对于 3D 对象检测来说是过度的。以实例为中心的焦点通过避免回归大的深度范围使任务变得更容易。

MonoPSR lifts 2D box to local point cloud (source)
GS3D(CVPR 2019)很大程度上是基于更快的 RCNN 框架,增加了一个方向回归头。它使用从 2D 边界框高度估计的局部方向和距离来生成粗略的 3D 边界框位置。深度估计使用有趣且实用的统计数据,即投影在 2D 图像中的 3D 边界框高度的投影大约是从训练数据集的分析中获得的 2D bbox 高度的 0.93 倍。它还使用表面特征提取模块(RoIAlign 的仿射扩展)来改进 3D 检测。

GS3D refines 3D box with surface feature extraction (source)
总之,这种方法很容易扩展 2D 物体检测,并且在我看来是最实用的。Deep3DBox 在该领域的开创性工作影响深远。
4.直接生成 3D 建议书
单目 3D 物体检测的开创性工作之一是 CVPR16 中优步·ATG 的 Mono3D 。它侧重于直接的 3D 建议生成,并基于汽车应该在地平面上的事实生成密集的建议。然后,它通过许多手工制作的特征对每个建议进行评分,并执行 NMS 以获得最终的检测结果。在某种程度上,它类似于 FQNet 通过检查反向投影的线框来对 3D bbox 提议进行评分,尽管 FQNet 将 3D 提议放置在 Deep3DBox 的初始猜测周围。

Mono3D places dense 3D proposals on the ground and scores them by manually crafted features (source)
mono dis(ICCV 2019)基于扩展的 RetinaNet 架构直接回归 2D bbox 和 3D bbox。它不是直接监控 2D 和 3D bbox 输出的每一个组成部分,而是对 bbox 回归进行整体观察,并使用 2D(带符号)IoU 损耗和 3D 角损耗。这些损失通常很难训练,因此它提出了一种解缠结技术,通过固定除一个组(包括一个或多个元素)之外的所有元素来接地真相并计算损失,本质上仅训练该组中的参数。这种选择性的训练过程循环进行,直到它覆盖了预测中的所有元素,并且总损失在一次正向传递中累积。这种解开训练过程能够实现 2D/3D bbox 的端到端训练,并且可以扩展到许多其他应用。****

Architecture and losses for MonoDIS (source)
MonoDIS 的作者通过采用 虚拟摄像机 的思想进一步改进了算法。主要思想是该模型必须学习不同距离的汽车的不同表示,并且该模型在训练时对于超出距离范围的汽车缺乏通用性。为了处理更大的距离范围,我们必须增加模型的容量和附带的训练数据。虚拟相机提出将整个图像分解成多个图像块,每个图像块包含至少一辆完整的汽车,并且具有有限的深度变化。在推理过程中,生成金字塔状的图像块用于推理。图像的每个区块或条带对应于特定的范围限制,并且具有不同的宽度和相同的高度。

Virtual Camera uses GT guided sampling of virtual windows during training (source)

Virtual Camera generates an “image pyramid”-like tiling of images
CenterNet 是一个通用的对象检测框架,可以扩展到许多与检测相关的任务,如关键点检测、深度估计、方向估计等。它首先回归指示物体中心位置的置信度的热图,并回归其它物体属性。扩展 CenterNet 以包括 2D 和 3D 对象检测作为中心点的属性是很简单的。
而 SS3D 正是这么做的。它使用类似中心网的结构,首先找到潜在对象的中心,然后同时回归 2D 和 3D 边界框。回归任务会回归关于 2D 和 3D 边界框信息的足够信息,以进行优化。在 2D 和 3D 边界框元组的参数化中总共有 26 个代理元素。总损失是 26 个数字的加权损失,其中权重是动态学习的(参见我对自定进度多任务学习的综述)。损失函数具有虚假的局部最小值,并且训练可以受益于基于启发式的良好的初始猜测。

SS3D has many parallel task heads regressing multiple hints for 2D bbox (source)
【M3D-RPN(ICCV 2019)通过预计算每个 2D 锚的 3D 均值统计,同时回归 2D 和 3D bbox 参数。它直接回归 2D 和 3D 包围盒(11 + num_class),类似于 SS3D 直接回归 26 个数字。论文提出了 2D/3D 主播的有趣想法。本质上,它们仍然是平铺在整个图像上的 2D 锚点,但是具有 3D 边界框属性。取决于 2D 锚位置,锚可能具有不同的 3D 锚的先验统计。M3D RPN 建议对不同的行仓使用单独的卷积滤波器(深度感知卷积),因为深度在很大程度上与自动驾驶场景中的行相关。

2D/3D anchor are 2D sliding windows with associated 3D properties from M3D-RPN (source)
D4LCN(CVPR 2020)通过引入动态滤波器预测分支,进一步从 M3D-RPN 中汲取了深度感知卷积的思想。该附加分支将深度预测作为输入,并生成滤波器特征体,该滤波器特征体根据权重和膨胀率为每个特定位置生成不同的滤波器。D4LCN 还借鉴了 M3D-RPN 的 2D/3D 主播思想,同时回归 2D 和 3D 盒子(每个主播 35 + 4 个班)。

Depth guided dynamic local ConvNet from D4LCN (source)
【TLNet(CVPR 2019)主要关注立体图像对,但它们也有坚实的单目基线。它将 3D 锚点放置在 2D 对象检测所对着的视锥内,作为单声道基线。重申了 MonoGRNet 的观点,像素级深度图对于 3DOD 来说太贵了,物体级深度应该足够好了。它模仿 Mono3D ,在[0,70 米]范围内密集放置 3D 锚点(0.25 米间隔),每个对象类有两个方向(0 和 90 度),对象类的平均大小。3D 方案被投影到 2D 以获得 RoI,并且 RoIpooled 特征被用于回归位置偏移和尺寸偏移。

TLNet places dense candidates in the frustum, reminiscent of Mono3D (source)
总之,由于巨大的可能位置,在 3D 空间中直接放置 3D 锚是困难的。锚点本质上是滑动窗口,对 3D 空间的穷举扫描是棘手的。因此,3D 边界框的直接生成通常使用试探法或 2D 对象检测,例如,汽车通常在地面上,并且汽车的 3D 边界框在其对应的 2D 边界框对着的截锥内,等等。
外卖食品
- 单目三维物体检测是一个不适定问题。然而,我们可以识别多个几何提示,包括与 2D 边界框相关联的 2D 图像中的局部方向和关键点,以帮助在 3D 或 BEV 空间中推理。注意,关键点包括真实的点,如车头灯或挡风玻璃角,或由 3D 包围盒生成的人工点,如 3D 包围盒中心的投影或 2D 图像中的顶部/底部表面。
- 2D 和 3D 一致性可以帮助调整联合 2D 和 3D 训练,并且可以帮助 3D 推理作为 2D 边界框和几何提示预测之后的后处理步骤。
- 单目深度估计在过去几年有了重大进展。密集深度估计有助于将 RGB 图像转换为伪激光雷达点云,以供最先进的 3D 对象检测算法使用。
- 透视表示难以直接进行 3D 检测。提升到鸟瞰图(BEV) 空间使得车辆的检测成为在不同距离下简单得多的任务尺度不变性。****
- 所有上述方法都假设已知的摄像机固有特性。如果相机的内在特性未知,许多算法仍然可以工作,但只能达到一个比例因子。
参考
表示变换(伪激光雷达,BEV)
- MLF : 基于多级融合的单目图像三维目标检测,CVPR 2019
- 来自视觉深度估计的伪激光雷达:填补自动驾驶 3D 物体检测的空白,CVPR 2019
- 伪激光雷达++ :自动驾驶中 3D 物体检测的精确深度
- 伪激光雷达-e2e : 伪激光雷达点云单目三维物体探测,ICCV 2019
- 伪激光雷达颜色 : 通过用于自动驾驶的彩色嵌入式 3D 重建进行精确的单目 3D 物体检测,ICCV 2019
- 预见 : 用于 3D 物体检测的任务感知单目深度估计
- BEV-IPM : 基于深度学习的反向透视映射图像车辆位置和方向估计,IV 2019
- OFT : 单目三维物体检测的正交特征变换,BMVC 2019
- 伯德冈 : 学习 2D 到 3D 提升,用于自动驾驶车辆的 3D 物体检测,IROS 2019
- RefinedMPL :用于自动驾驶中 3D 物体探测的精细单目伪激光雷达
关键点和形状
- 动态环境下的多物体单目 SLAM,IV 2020
- 3D-RCNN :通过渲染和比较实现实例级 3D 物体重建,CVPR 2018
- 【mono 3d++:具有双尺度 3D 假设和任务先验的单目 3D 车辆检测,AAAI 2019
- ROI-10D :单目提升 2D 检测到 6D 姿态和度量形状,CVPR 2019
- MonoGRNet :单目 3D 物体定位的几何推理网络,AAAI 2019
- MonoGRNet v2 : 通过关键点上的几何推理进行单目 3D 物体检测
- ApolloCar3D :自动驾驶大型 3D 汽车实例理解基准
- 零件解析 : 单幅街景零件级汽车解析与重建
- 6D-VNet :基于单目 RGB 图像的端到端六自由度车辆姿态估计
- GPP : 用于道路上物体的 6 自由度姿态估计的地平面轮询
- RTM3D :用于自动驾驶的物体关键点的实时单目 3D 检测
- 单对:利用成对空间关系的单目 3D 物体检测,CVPR 2020
- 烟雾:基于关键点估计的单级单目三维目标检测,CVPRW 2020
- 具有解耦结构化多边形估计和高度引导深度估计的单目 3D 物体检测,AAAI 2020
- :单目三维行人定位与不确定性估计,ICCV 2019
通过 2D/3D 约束的距离
- Deep3dBox : 利用深度学习和几何的 3D 包围盒估计,CVPR 2017
- Shift R-CNN :封闭形式几何约束的深度单目 3D 物体检测,IEEE ICIP 2019
- FQNet : 单目三维物体检测深度拟合度评分网络,CVPR 2019
- GS3D :一种高效的自动驾驶 3D 物体检测框架,CVPR 2019
- monosr:单目 3D 物体检测利用精确的提议和形状重建,CVPR 2019
- CasGeo : 通过级联几何约束和使用 3D 结果的净化 2D 检测对自主车辆进行 3D 包围盒估计,Arxiv 04/2019
- MVRA : 用于方位估计的多视角重投影架构,ICCV 2019
直接生成 3D 提案
-
Mono3D :用于自动驾驶的单目 3D 物体检测,CVPR2016
-
TLNet : 三角剖分学习网络:从单目到立体的 3D 物体检测,CVPR 2019
-
M3D-RPN :用于物体检测的单目 3D 区域提议网络,ICCV 2019
-
【D4LCN】:用于单目 3D 物体检测的学习深度引导卷积,CVPR 2020
-
MonoDIS :解开单目 3D 物体检测,ICCV 2019
-
虚拟摄像机:单级单目虚拟摄像机 3D 物体检测,Arxiv,12/2019
-
联合单目三维车辆检测与跟踪,ICCV 2019
-
CenterNet :物体为点,Arxiv 04/2019
蒙特卡洛积分是神奇的

蒙特卡洛方法非常受欢迎,这主要是因为“蒙特卡洛”这个名字很吸引人,其次是因为它们在包括金融、工程和医学在内的大量行业中有无数的应用。
根据 Investopedia 的说法,“蒙特卡洛”这个名字来源于摩纳哥的赌博中心。这是因为这些方法植根于赌场游戏中同样的机会和随机性元素。
然而,由于它们的广泛应用,它们更经常被描述为许多用途。然而,如果要我想出一个最能体现这种技术精神的定义,那就是:
蒙特卡洛模拟使用随机变量生成来模拟系统中的不确定性。
我们要看的具体应用是,如何使用蒙特卡罗模拟来计算函数的积分。
蒙特卡洛积分是神奇的,因为它将积分这样复杂的事情简化为几行代码。
以下是我们的一些结果:

Integral over [0,1]
注意到什么了吗?
是的,在这三个例子中,我们几乎可以精确到小数点后三位。
考虑到每次计算只花了大约 3 行代码,这是非常惊人的。
首先,我们要看一下圆周率的蒙特卡罗估计,然后是计算这些估计值的实际编码示例。
魔术的确在题为“到底发生了什么?”
圆周率估算——我们的第一个魔术
考虑内接于边长为 2 的正方形的单位圆。

然后,我们从正方形和圆形的面积得到以下结果:

这意味着圆周率是正方形和圆形面积比的 4 倍。
蒙特卡罗积分表明,为了近似这个比例,我们应该在我们的内接图上生成一组随机点,并使用落在里面的点的比例。
你可以把它想象成一个飞镖盘,飞镖落在圆圈内的概率会给出面积比。

我们估计我们的比率是 16/20 = 0.8
所以乘以 4,我们得到的圆周率估计值约为 3.2!
对于我们的第二个魔术——使用原始的蒙特卡洛来整合实际函数
下面是我们将在 R 中使用的过程:
- 首先,我们将使用 R 的 runif 函数从均匀(0,1)分布中生成大量样本。
- 然后我们将包含这些随机变量的向量插入到我们的函数中
- 最后,我们将取这些值的平均值。
第一个例子:
理论上的解决方案:

上面的代码给出了大约 0.4597276 的估算!
令人惊讶的是,在短短几秒钟内,我们计算了一个函数的积分,我们真正做的是找到一个样本均值。
最后一个例子:
理论上的解决方案:

编码解决方案:
在这种情况下,我们粗略的蒙特卡罗估计大约是 1.72058!
更令人印象深刻。这一次我们解决了一个函数,我们通常通过首先进行 u-替换来计算,所有仍然是通过找到一个样本均值。
但是怎么做呢?!
究竟发生了什么事?

均匀(0,1)随机变量是特殊的,因为它们的边界(0,1)范围的积分实际上是 1。
所以如果 X~U(0,1)
那么对于任何函数 h(x):

所以我们看到,对于 X ~U(0,1),理论平均值等于该函数在 X 上对[0,1]的积分。
因此,由于样本均值趋向于大样本的理论均值,我们能够通过找到样本均值来计算积分。
**弱大数定律:**对于大样本量 n,随着 n 变得更大,样本均值趋向于理论均值。
最后的笔记
为了得出编码示例的估计值,使用了 100000 的样本大小,这在某些情况下可能是一个非常大的数字。因此,有一大堆被称为方差缩减技术的方法,它们允许我们或者以与当前方法相同的大小误差来计算估计值,但是样本大小要小得多,或者以相同数量的样本来提供小得多的误差。
蒙特卡洛学习

使用蒙特卡罗方法的强化学习
在这篇文章中,我将介绍强化学习的蒙特卡罗方法。我在之前的文章中简要介绍了动态编程(值迭代和策略迭代)方法。在动态编程中,我们需要一个模型(代理知道 MDP 转换和奖励),代理做计划(一旦模型可用,代理需要计划它在每个状态中的动作)。在动态规划方法中,主体没有真正的学习。
另一方面,蒙特卡罗方法是一个非常简单的概念,当代理与环境交互时,代理学习状态和奖励。在这种方法中,代理生成经验样本,然后基于平均回报,为状态或状态-动作计算值。下面是蒙特卡罗(MC)方法的主要特征:
- 没有模型(代理不知道状态 MDP 转换)
- 经纪人从那里学到被取样的经验
- 通过体验来自所有采样剧集的平均回报,学习策略π下的状态值 vπ(s )(值=平均回报)
- 仅在完成一集之后,值才被更新(因为该算法收敛缓慢,并且更新发生在一集完成之后)
- 没有自举
- 仅可用于偶发性问题
考虑一个真实生活的类比;蒙特卡洛学习就像年度考试,学生在年底完成它的一集。在这里,年度考试的结果就像是学生获得的回报。现在,如果问题的目标是找出学生在一个日历年(这是一个插曲)内对一个班级的分数,我们可以从一些学生的样本结果中提取,然后计算平均结果来找出一个班级的分数(不要逐点进行类比,但在整体水平上,我认为你可以获得 MC 学习的本质)。类似地,我们有 TD 学习或时间差异学习(TD 学习就像在每个时间步骤中更新值,不需要等到一集结束时更新值),我们将在未来的博客中介绍,可以认为就像每周或每月的考试(学生可以在每个小间隔后根据这个分数(收到的奖励)调整他们的表现,最终分数是所有每周测试(总奖励)的累积)。

价值函数=预期返回
预期回报等于所有奖励的贴现总额。
在蒙特卡罗方法中,我们使用代理人根据政策抽样的经验回报,而不是预期回报。

如果我们回到我们收集宝石的第一个例子,代理遵循政策并完成一集,在每一步中它收集宝石形式的奖励。为了获得状态值,代理从该状态开始,在每一集后汇总收集的所有宝石。参考下图,其中从状态 S 05 开始收集了 3 个样本。每集收集的总奖励(为简单起见,折扣系数被视为 1)如下:

Return(样本 01) = 2 + 1 + 2 + 2 + 1 + 5 = 13 颗宝石
Return(样本 02) = 2 + 3 + 1 + 3 + 1 + 5 = 15 颗宝石
Return(样本 03) = 2 + 3 + 1 + 3 + 1 + 5 = 15 颗宝石
观察到的平均回报(基于 3 个样本)= (13 + 15 + 15)/3 = 14.33 宝石
因此,按照蒙特卡罗方法,v π(S 05)的值是 14.33 宝石,基于遵循政策π的 3 个样本。
蒙特卡洛备份图
蒙特卡洛备份图如下所示(参考第三篇博客帖子了解更多备份图)。

有两种类型的 MC 学习策略评估(预测)方法:
首次访问蒙特卡罗方法
在这种情况下,在一个事件中,对该状态的首次访问进行计数(即使代理在该事件中多次回到同一状态,也只对首次访问进行计数)。详细步骤如下:
- 为了评估状态 s,首先我们设置访问次数,N(s) = 0,总回报 TR(s) = 0(这些值在每集中更新)
- 状态 s 在一集内被访问的第一个时间步长 t,递增计数器 N(s) = N(s) + 1
- 增量总回报 TR(s) = TR(s) + Gt
- 价值通过平均回报 V(s) = TR(s)/N(s)来估算
- 根据大数定律,当 N(s)接近无穷大时,V(s) -> vπ(s)(这在策略π下称为真值)
请参考下图,以便更好地理解计数器增量。

每次访问蒙特卡罗方法
在这种情况下,在一个事件中,国家的每次访问都被计算在内。详细步骤如下:
- 为了评估状态 s,首先我们设置访问次数,N(s) = 0,总回报 TR(s) = 0(这些值在每集中更新)
- 每个时间步长 t,状态 s 在一个情节中被访问,递增计数器 N(s) = N(s) + 1
- 增量总回报 TR(s) = TR(s) + Gt
- 价值通过平均回报 V(s) = TR(s)/N(s)来估算
- 根据大数定律,当 N(s)接近无穷大时,V(s) -> vπ(s)(这在策略π下称为真值)
请参考下图,以便更好地理解计数器增量。

通常 MC 在每次发作后递增更新(不需要存储旧的发作值,它可以是每次发作后更新的状态的运行平均值)。
在第一集,第二集,第三集,…,S t 为每个状态 S T,返回 G t
通常用一个恒定的学习速率(α)来代替 1/N(S t ),上述等式变为:
对于策略改进,使用广义策略改进概念,通过蒙特卡罗方法的动作值函数来更新策略。
蒙特卡罗方法有以下个优点:
- 零偏差
- 良好的收敛特性(即使是函数逼近)
- 对初始值不太敏感
- 非常容易理解和使用
但是它也有下面的限制:
- MC 必须等到剧集结束后才知道回归
- MC 具有高方差
- MC 只能从完整的序列中学习
- MC 仅适用于偶发(终止)环境
尽管 MC 方法需要时间,但对于任何强化学习实践者来说,它都是一个重要的工具。
感谢阅读。可以联系我@ LinkedIn 。
只需每月 5 美元,就可以无限制地获取最鼓舞人心的内容…点击下面的链接,成为媒体会员,支持我的写作。谢谢大家!
https://baijayanta.medium.com/membership
强化学习—评估 21 点策略
蒙特卡洛模拟简介
我们已经讨论了几个强化学习问题,在每个问题中,我们都试图通过继续玩游戏和更新我们的估计来获得最优策略。本质上,我们估计(state, value)对或(state, action, value)对,并基于这些估计,通过采取给出最高值的动作来生成策略。但这不是唯一的方法。

在这一段,我将介绍 蒙特卡洛法 ,这是另一种估算一个国家价值,或者一项政策价值的方法。蒙特卡洛方法涉及广泛的方法,但所有的都遵循相同的原则——抽样。这个想法简单而直观,如果你不确定一个状态的值,就做采样,就是不断地访问那个状态,并对通过与环境互动的模拟行为得到的回报进行平均。
“蒙特卡罗方法是解决基于平均样本回报的强化学习问题的方法.”—萨顿,强化学习导论
我们的 21 点规则
为了更好地理解如何利用蒙特卡罗方法进行强化学习,让我们来看一个来自 Sutton 的书中的例子。
一般规则
我们今天玩的游戏是广为人知的赌场纸牌游戏21 点,我们的目标是使用抽样来估计策略。以下是规则的简要说明:
游戏从发给庄家和玩家的两张牌开始。庄家的一张牌面朝上,另一张面朝下。如果玩家立即有 21(一张 a 和一张 10 的牌),这叫自然牌。然后他赢了,除非庄家也有一个自然牌,在这种情况下,游戏是平局。如果玩家没有自然牌,那么他可以一张接一张地要求额外的牌(命中),直到他停止(坚持)或超过 21(破产)。如果他破产了,他就输了;如果他坚持,那么就轮到庄家了。庄家根据固定的策略不加选择地打或坚持:他坚持任何 17 或更大的和,否则就打。 如果庄家破产,那么玩家获胜;否则,结果——赢、输或平——取决于谁的最终总和更接近 21。如果玩家拿着一张可以算作 11 而不会破产的王牌,那么这张王牌就可以用了。
我们的政策
我们的政策是,如果我们卡上的金额是 20 或 21,就坚持,否则就给他 。为了通过蒙特卡罗方法找到该策略的状态值函数,我们将使用该策略模拟许多二十一点游戏,并对每个状态的回报进行平均。
关键是一个庄家的政策是固定的,坚持在 sum ≥ 17,我们准备模拟很多二十一点游戏来衡量 sum ≥ 20 的政策坚持。
21 点蒙特卡罗实现
州
为了实现我们的模拟,让我们首先明确状态。在 21 点中,我们需要考虑的状态包括:首先,玩家的牌和,其范围从 12 到 21(我们排除低于 12 的牌和,因为在这些情况下我们总是会击中);其次,庄家的出牌,因为它可能会指示庄家的最终牌值;最后,玩家可用的王牌,这也是会稍微影响我们获胜机会的一个因素。所以加起来我们总共有10(from 12 to 21) * 10(from 1 to 10) * 2(true or false) = 200个状态。(完整代码此处)
初始化
由于我们的目标是在我们的固定政策下估计各州的价值,我们将需要一个(state, value)字典来记录所有的州和我们游戏模拟中获胜的数量,还需要一个player_states来跟踪每场游戏的状态。
player_win和player_draw用于跟踪游戏的总胜率。
交易卡
所需的基本机制是随机给每一方一张牌,在这种情况下,我们假设我们有无限张牌。
(J,Q,K 取 10)
经销商政策
我们的发牌政策是当牌值少于 17 时打,当 17 或以上时站。该功能将能够返回一个新的价值的基础上选择的行动,并能够告诉如果游戏结束。
这个函数可以递归调用,直到到达它的结尾,因为它的返回与输入相同。我们跟踪可用的 ace,当当前值小于 10 时,ace 将始终被视为 11,否则为 1;当当前值超过 21 并且庄家手头有可用的 ace 时,可用的 ace 将被视为 1,总值相应地减去 10,可用的 ace 指示器将被设置为false。
玩家政策
除了玩家在此设置中的年龄为 20 岁或以上之外,实现与庄家策略完全相同。
赊账
在每场比赛结束时,将通过向导致获胜的状态加 1 来给获胜者积分。
player_states是一个记录游戏结束前所有状态的列表,积分只给最后一个状态,卡值在 12 到 21 之间,也就是说,如果我们有一张卡和 15,并采取行动 HIT,得到一张卡值为 7,结束时总和为 22,那么 15 将被视为最后一个状态,而不是 22。
除了统计state_value之外,还会统计玩家赢和抽的次数,会用来衡量这个政策的整体好坏。
MC 模拟
有了以上所有的准备,我们就可以运行模拟了!整个过程类似于一般的价值迭代,但除了在游戏结束时反向传播奖励,我们通过在_giveCredit函数中定义的内容来更新state, value对的估计。
在游戏开始时,给庄家 2 张牌,我们假设第一张牌正在显示。然后轮到玩家,只有 12 和 21 之间的牌值被包括在状态中,因为在状态中包括值 22 或以上是没有意义的,因为这些值不会导致获胜,因此不需要被计数。
最后,在游戏结束时,player_state_value字典中尚未存在的状态将被初始化为 0,游戏将由_giveCredit记入。
估计可视化
我们运行了 10000 轮模拟,并绘制了状态、值的估计值:

MC Simulation
奖励的 z 列是该州的获胜次数。正如所料,当玩家的值为 20 或 21 时,这是在剧情的后面,一个人更有可能获胜。总的来说,与庄家的 HIT17 相比,这种 HIT20 策略给我们带来了 30.6%的赢、24.37%的听牌和 45.03%的输,显然这是一种在赌场中导致输多于赢的策略。(此处全码)
让我们也看看可用的 ace 如何导致游戏的细微差别:

MC Simulation(usable ace)

Simulation Result from Sutton’s book
Sutton 的书的结果更清楚,他提出了一个问题:为什么有可用 ace 的最前面的值比没有可用 ace 的值略高?我猜可用的 ace 确实增加了获胜的机会,因为一个有可用 ace 的玩家有更大的机会击中,因为即使值超过 21,他仍然能够通过使可用 ace 不可用来继续。
总之,我们共同探索了使用 MC 方法来评估给定的政策。MC 方法的采样思想可以推广到很多游戏玩的场景,所以如果你到了一个状态,不知道要去哪里,不知道要采取什么行动,就采样吧!
请在此查看完整代码,欢迎投稿和提出问题!
参考
[1]http://incompleteideas.net/book/the-book-2nd.html
R 中的蒙特卡罗模拟,重点是期权定价

在这篇博客中,我将介绍蒙特卡罗模拟的基础知识,随机数分布和生成它们的算法。最后,我还将介绍蒙特卡罗模拟在期权定价领域的应用。整个博客的重点是用 R 编写代码,这样你也可以用 R 实现自己的蒙特卡罗模拟应用。
蒙特卡洛方法是什么?
蒙特卡罗方法基本上是指一类利用随机性进行估计的算法。让我们举一个例子来说明这一点

为了使用蒙特卡罗方法给出函数的该积分的数值估计,可以将该积分建模为E[f(U)】,其中 U 是**【0,1】中的均匀随机数。生成n*****【0,1】之间的均匀随机变量。让那些分别是函数值f(u₁u₁,u₂,…uₙ、f(U₂),…f(Uₙ)** 。*

Numerical Estimate of Integral
这样我们就用 n 在*【0,1】之间的均匀随机样本得到了积分的估计。这个估计值将收敛到【实际】αn收敛到*。现在我们已经看了如何得到一个估计值,让我们看看如何产生不同的随机数分布。**
让我们再来看一个涉及衍生产品定价的例子。首先,我将定义一些重要的金融术语。股票价格*将是时间 t 的函数我们将考虑一个欧式期权*并对其定价。****
欧式期权:**它是一种金融工具,它赋予你权利,但并不强制你以某一价格(执行价格 ( K ))买入/卖出资产,该价格在之前某一时间点固定,比如说时间 0。因此,如果我们继续执行合同,并同意在时间以固定价格 K 购买/出售一项资产。我们的利润将是
利润=S(T)-K/K-S(T)
从现在开始,我们只关注购买一种资产,这种资产也被称为欧式期权****
所以,如果 (S(T)-K) <为 0,那么推进这份合同不符合我们的利益。因此,我们不行使我们的期权*,即我们不购买资产。*
因此,你的收益是-

The value of Payoff
但是,问题是,合同中的另一方有什么好处,因为你可能会也可能不会购买该资产,所以目前持有该资产的另一方实际上履行了合同,因为你最初也支付了一些溢价/费用。因此现在最重要的是这个溢价应该是多少?****
你在开始时支付一笔额外费用,也就是说。从这个收益我们计算利润为, 利润=收益-C
因此,当我们谈论衍生产品定价时,我们试图估计这个 C 。我现在不会深入细节,稍后在讨论几何布朗运动时会涉及到它,但是股票价格变化是使用随机微分方程计算的,求解后我们得到:

S(T) Equation as a function of T
这里 Z 是另一个随机数,称为标准正态随机变量。我们将来会考虑如何生成这些随机数,但现在让我们假设它们可以由我们自己生成。
现在我们知道了在某一时刻 T 的利润,以及在某一时刻 T 的股票价格。对于时间 t=0 我们怎么计算。再次不去赘述细节,将时刻 0 的保费 C 表示为e【e⁻ʳᵗ(max(s(t)—k),0)】。
因此,这类似于我们之前看到的E[f(U)】。因此,我们再次借助蒙特卡罗模拟来估计 t=0 时的收益。

Algorithm to Estimate European Option Payoff
于是我们反复采样 Z 来寻找股票价格值,最后计算欧式期权溢价C**。**
生成随机分布
在以前的案例中,唯一缺少的是如何生成均匀随机的,正态随机分布。因此,我们着眼于涵盖生成这种均匀随机分布的算法,以及将这些算法转换成其他分布(如正态分布)的方法。
我们将在*【R】*中为这些模拟生成的数字实际上被称为 伪随机 数字,它们不是真正随机的,但非常善于模仿真正的随机性。我们使用确定性算法生成它们,使得它们近似于随机数序列的性质。
均匀分布
均匀分布是一种连续分布,缩写为 U(a,b)。 其中概率密度函数为

P.D.F of Uniform Distribution
产生这种数字的最流行的方法是线性同余发生器**。LCG 是用以下方法生成的**

Linear Congruential Generator Algorithm
因此,如果我们选择一个 x₀也称为种子**。我们可以在**【0,1】之间生成 m-1 唯一的均匀随机数。尽管一个好的估计器必须遵循非零 c 的某些条件。

上面的代码产生均匀的随机数。
现在让我们看看指数分布、正态分布,以及如果我们假设已经有了一个均匀的随机数,我们如何生成它们。****
指数分布
指数分布可以用概率密度函数来表示

P.D.F of Exponential Distribution
为了使用均匀分布生成它,我们来看一个逆变换方法****

Inverse Transform Equation
因此,使用均匀随机数并取指数分布的分布函数的反函数,我们可以生成指数随机数 X 。
逆变换方法的正确性证明如下

Proof of Inverse Transform Method
因此,我们使用这种方法来生成指数分布,其中*【f⁻(u)*给出如下

Exponential Distribution using Inverse Transform Method
这里θ是指数参数 1/α。
正态分布
正态分布,也称为高斯分布**,是一种关于均值对称的概率分布,表明接近均值的数据比远离均值的数据出现的频率更高。取决于两个参数——均值和方差的概率密度函数为**

P.D.F of Normal Distribution
我们将看到一种非常流行的生成标准正态分布的方法,称为 Box Muller 方法。
该方法基于以下事实:如果我们取一个二元标准正态分布 Z₁, ~ N (0,1) ,那么它们遵循两个性质

使用事实(ii)我们生成圆的半径为r = sqrt(-2 log(u₁))并且点(【z₁】、、)位于圆中的角度为、 V=2 π ( U₂ ) 、使用一对均匀随机数、 U₁、U₂.****
**因此这对 ***Z₁,*z₂将生成为

现在让我们看看代码和情节
在上面的代码中,R 中的 runif(5000)** 用于生成范围***【0,1】中的 5000 个均匀随机数。*** 这些然后被用来产生最后 10000 个标准正态随机变量。**

我们可以使用marsag lia-Bray算法进一步改进这一点,我不会在本系列中讨论它。你可以在附件的链接上看看。我也鼓励你编写 Marsaglia-Bray 算法,并检查它与 Box-Muller 算法相比有多快。
布朗运动
既然已经介绍了蒙特卡罗模拟和各种随机分布的基础概念,让我们集中使用蒙特卡罗方法来模拟各种 随机过程 的路径。
【T50[0,T] 上的标准布朗运动是一个随机过程{ W(t),0≤T≤*T }*它满足如下一些性质
i) W(0)=0
ii)对于任何 k 和任何 0≤ t₁ ≤ t₂ ≤ …。≤ tₖ ≤ T ,任意两个连续的*【w(tᵢ)-w(tᵢ-₁】*之间的增量是独立的。
iii)对于任意 0≤ s < t ≤ T,差值 W(t)- W(s) ~ N(0,t-s)
作为 I)和 iii) 的结果 W(t) ~ N(0,t)。
另一方面,非标准的布朗运动会像正态分布一样有两个参数,称为漂移和扩散**。利用 W(t) 我们因此给出了任意布朗运动的**随机微分方程****

样本路径生成
求解上面给出的 SDE,我们可以用 X(tᵢ、μ(s)、σ(s)来写方程

Solution of Stochastic Differential Equation for Brownian Motion
因此,让我们看看生成路径的代码,这里我假设μ和σ是常数
上述代码使用为布朗运动定义的公式为其生成 10 条路径,并使用 rnorm(1) 一个在 R 中定义的函数来生成标准正态随机变量。

上图代表了为标准布朗运动生成的代码的 10 条路径。
几何布朗运动
**一个随机过程 S(t) 如果差
***log(S(t))-log(S(0))*是一个布朗运动,那么这个随机过程就是一个几何布朗运动。基本上,与布朗运动中讨论的性质 ii)相比,这意味着现在,

是相互独立的,而不仅仅是布朗运动中的连续差。
因此,我们现在用来表示 GBM 的随机微分方程为

S.D.E for Geometric Brownian Motion
该问题的解决方案与之前用于估计股票价格的等式相同,我在该等式中展示了使用蒙特卡洛模拟的示例。****

Solution of S.D.E for Geometric Brownian Motion
其中 W(t)替换为

这就是如何通过使用蒙特卡罗模拟,我们也可以模拟一个股票价格或几何布朗运动的路径。** 对于这样的模拟,我们再次需要将时间线离散化为一些*点,以生成所有这些点的股票价格。让我们假设初始股票价格为 100***
剧情看起来

因此我们可以使用所有这样的路径最终得到一个【T】并计算欧式期权的溢价,最后给出欧式期权价格的平均估计。接下来,我们将看看另一个期权,称为亚式期权*,它也需要中间股票价格来计算期权价格。***
亚式期权定价
在亚式期权中,收益取决于标的资产在一定时期内的平均价格**,而标准期权只取决于到期价格。**

Average Price Calculation for Asian Option
现在的收益是

Payoff of Asian Option
我们对模拟股票价格路径的兴趣实际上是在为这些期权定价,特别是因为收益取决于基础资产 s 的路径。
让我们看看亚式期权定价的代码
结论
我希望你们不仅能公平地了解蒙特卡罗方法,还能了解金融工程领域(期权定价)。现在你应该熟悉蒙特卡罗方法,衍生品定价(欧式和亚式期权),随机数分布(均匀,指数和正态分布),R 中编程基础,几何布朗运动及其路径生成。
蒙特卡罗模拟:概率性和确定性的交叉
你好,欢迎来到我的博客,我希望你能发现这对于蒙特卡洛模拟的介绍是有帮助的。这是一个简单的蒙特卡罗模拟的数学方法,用简单的图形来说明我的观点。这不是什么,深入到蒙特卡罗模拟非常具体和明确定义的行业问题。
这个蒙特卡洛模拟的数据和前提来自科罗拉多大学教授的 Coursera 的高级商业分析课程。最初,计算是在解析解算器上执行的,但是我决定将这个过程放到一个我(希望你也是)更习惯的环境中,Python。
首先,我使用了概率性和确定性这两个词,我应该在本文的上下文中定义它们。
概率性的:可以用概率分布来量化的事物。有多少人会出现在他们的航班上?
确定性的:可以从参数中计算出来的东西。例如,如果 150 人乘坐了一个有 134 个座位的航班,有多少人被挤到下一个航班?
蒙特卡洛模拟可以说明确定性模型参数的不确定性(概率性质),产生可能结果的概率分布。

问题是
在任何给定的航班上,并不是所有的乘客都完成了利用他们购买的座位的过程。作为回应,航空公司通常会超额预订航班,以最大限度地提高座位利用率和收入。然而,如果超售率过高,乘客将不得不重新安排航班,航空公司的整体声誉将受到损害。
目标:
- 使用颠簸的乘客和收入成本,确定适当的超额预订率
- 确定任何给定航班的收入
吉文斯:
- 此特定的历史数据
- 飞机定员:134 人
- 票价:314 美元
- 冲撞乘客的费用:400 美元
此时,您可能会尝试使用历史数据的期望值或最大/最小值来计算超售率、颠簸乘客和收入的期望值。然而,有可能出现期望值不是分布的良好近似值的分布。例如多模态的东西或者具有严重偏斜的东西。

Both distributions have a mean of zero and a variance of 5

Both distributions have a mean of 1 and variance of 1
解决方案
为了解决这个问题,我们需要把它分成以下几个步骤。
- 拟合所提供的历史数据的分布(概率输入)
- 建立航班超售过程的数学模型(确定性)
- 从历史分布中随机选择,计算结果,然后重复(概率输出)
历史数据的分布拟合
#############
###IMPORTS###
#############import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import fitterfrom scipy.stats import exponnorm , genlogistic
使用 pandas 将历史数据导入 python 并查看快速摘要
hData = pd.read_csv('data/historicalData.csv')
hData.describe()
hData.shape
3 个特征的 730 次观察,零缺失数据。


Flight Demand, Historical

Number of People that are Ready to Board, Historical
让我们使用 Fitter 包来模拟分布。Fitter 使用 scipy 中的 80 个分布来拟合分布,并允许您绘制结果以进行直观检查。
f_demand = fitter.Fitter(hData.Demand, timeout= 100)
f_demand.fit()
f_demand.get_best()demand_params = list(f_demand.get_best().values())[0]f_shows = fitter.Fitter(hData.Shows, timeout =100)
f_shows.fit()
f_shows.get_best()shows_params = list(f_shows.get_best().values())[0]
来自 f_demand.get_best()和 f_shows.get_best()的 demand fitter 输出以 python 字典的形式呈现如下。最佳的 scipy 分布是键,参数存储在值元组中。
{'exponnorm': (0.4319945610366508, 145.53002093494484, 11.26683008052343)}{‘genlogistic’: (0.03148397254846405, 144.0118676463261, 0.3243429345277982)}
数学模型

Graphical Representation of the Deterministic Model
上述模型中的黄色方框是输入。如果输入存在历史数据,将随机独立地对概率分布进行采样。
def Planesim(OverbookingLimit =20):
PlaneCap = 134
TicketCost = 314
BumpCost = 400 BookingCap = OverbookingLimit + PlaneCap
AcutalDemand =int(exponnorm.rvs(*demand_params))
Booked = min(BookingCap,AcutalDemand) ReadytoBoard = int(genlogistic.rvs(*shows_params))
NoShows = Booked - ReadytoBoard Flying = min(ReadytoBoard,Booked,PlaneCap)
Bumped = max(ReadytoBoard - PlaneCap , 0) Sold = Booked * TicketCost
Costs = Bumped * BumpCost
Revenue = Sold - Costs return Flying, Bumped, Revenue
模拟 10 万次飞行
既然我们已经有了模型化的分布和数学公式,我们可以开始模拟飞机飞行来确定结果的分布。
flyingPassengers = []
bumpedPassengers = []
revenue = []for i in range(100000):
output = Planesim(10)
flyingPassengers.append(output[0])
bumpedPassengers.append(output[1])
revenue.append(output[2])

上图是 10 名乘客超售限额的结果。该航班的平均收入为 43,121 美元。

上图是 30 名乘客超售限额的结果。该航班的平均收入为 45,487 美元。
寻找最大收益的超额预订限制
让我们通过迭代 1 到 100 的超额预订限制来找到最大收入。我们可以通过在 for 循环中运行超额预订模拟来实现这一点。
expected_rev = []
overbooking_rate = []
for j in range(100):
flyingPassengers = []
bumpedPassengers = []
revenue = []for i in range(100000):
output = Planesim(j)
flyingPassengers.append(output[0])
bumpedPassengers.append(output[1])
revenue.append(output[2])
overbooking_rate.append(j)
expected_rev.append(np.mean(revenue))

嗯,看起来没有收入作为超额预订限制的函数的最大解。最有可能的决定将取决于航空公司对重新预订航班的容忍程度。
结论
我们演练了如何基于确定性情况建立数学模型,然后在必要的地方添加概率参数。历史数据被拟合在各种 scipy 分布上,以便于随机选择。最后,我们模拟了不同级别的超额预订,以在这种特定情况下实现收入最大化。
要查看这个项目的代码,请查看我的 github。
用 Python 进行蒙特卡罗模拟(第 1 部分)

Monte Carlo’s can be used to simulate games at a casino (Pic courtesy of Pawel Biernacki)
这是学习用 Python 做蒙特卡洛模拟的三部分系列的第一部分。这第一个教程将教你如何做一个基本的“原始”蒙特卡罗,它将教你如何使用重要性抽样来提高精度。第 2 部分将介绍臭名昭著的 metropolis 算法,第 3 部分将是初露头角的物理学家的专业文章(我们将学习如何使用蒙特卡罗模拟来解决量子力学中的问题!)
蒙特卡罗方法是广泛使用的启发式技术,可以解决各种常见的问题,包括优化和数值积分问题。这些算法通过巧妙地从分布中取样来模拟系统的工作。应用范围从解决理论物理问题到预测金融投资趋势。
任务
在本简介中,我们将开发蒙特卡罗近似的 Python 实现,以找到该积分的解:

Integral we will approximate using Monte Carlo methods
我从孙坎塔·德布的 变分蒙特卡罗技术 文章中借用了这个例子和它的解决方案。如果你想了解更多关于使用 Monte Carlos 模拟量子力学系统的知识,一定要看看那篇文章。
你会注意到这个积分无法解析求解,因此我们需要用数值来近似它。让我们从一个简单的方法开始:粗糙的蒙特卡罗。
原始的蒙特卡洛:直觉
粗略的蒙特卡罗是最容易理解的技术,所以我们从这里开始。但顾名思义,它也是最不准确的。不过,我们稍后会解决这个问题。😃
你可能还记得高中微积分中的以下等式,它显示了如何计算函数的平均值(为了证明,请查看此链接):

This theorem is used to find the average value of a function
就像我们可以通过积分求函数的平均值一样,我们也可以通过确定被积函数的平均值来求积分的值, f(x) 。蒙特卡罗技术是建立在这一原则之上的:与其计算不定积分(这有时是不可能的),不如估计被积函数的平均值,并用它来近似积分。
这正是我们要做的!那么我们该怎么做呢?
最简单的方法是从所有可能的输入值中随机抽取输入值 x 。假设我们有一个简单的线性函数,比如 y = 2x ,我们想求出 y 在[0,2]范围内的平均值。

Approximating the average of y = 2x using 10 randomly selected values
为了计算平均值,我们将在所有随机确定的 x 处对 y 求值,并对结果取平均值。
这个过程正是粗糙的蒙特卡洛。现在让我们看看如何在 Python 中使用这种技术来解决前面的问题。
原始蒙特卡罗:实现
你可以在我的 Github 这里找到本教程的所有代码。下面是我们代码的开头:
Imports for our Monte Carlo script
我们真的不需要太多。numpy将被用于查找一个列表的最小自变量。我们将使用math来定义我们的函数,而random将用于采样。matplotlib将有助于我们将结果可视化。
一些有用的功能
首先让我们定义一个函数来生成一个特定范围内的随机数。
让我们也定义我们的被积函数, f(x) :
执行简单的蒙特卡罗
实现简单的蒙特卡罗应该相当简单。我们的算法是这样的:
- 从积分范围中获取一个随机输入值
- 评估被积函数
- 重复步骤 1 和 2,想重复多久就重复多久
- 确定所有这些样本的平均值并乘以范围
让我们看看它在代码中是什么样子的:
Function to execute the Crude Monte Carlo
用N=10000样本进行这种近似给了我一个0.6994的估计值。与0.696092 的 Wolfram 的近似不太远(我们将把它视为神圣的真理)。
确定我们估计的方差
但是我们对自己的答案有多大的把握呢?我怎么知道 10,000 个样本足够得到一个好的近似值。我们可以通过找到估计值的方差来量化我们的准确性。方差被定义为*“距平均值平方距离的平均值”。可以证明它等于这个方程:*

General Variance Equation
方差让我们知道 f(x) 在*x。*的范围内变化有多大。它应该与所用样本数保持恒定,但我们可以通过用方差的平方根除以样本数来计算积分误差。关于方差的更多信息,请查阅阿德里安·费金教授的蒙特卡罗积分笔记本,或者沃尔夫拉姆关于方差的文章。

Equation for calculating the variance in our Crude Monte Carlo simulation
这是我们将在模拟中使用的方差方程。让我们看看如何在 Python 中实现这一点。
这个简单的蒙特卡罗实现给了我一个方差0.266,它对应于一个误差0.005。简单地说,这并不坏,但是如果我们需要更高的精度呢?我们总是可以增加样本的数量,但是这样我们的计算时间也会增加。如果我们聪明地从正确的点分布中取样,而不是使用随机取样,会怎么样…我们可以称之为重要抽样。
重要抽样:直觉
重要抽样是一种在不增加样本数量的情况下减少蒙特卡罗模拟方差的方法。这个想法是,不要从整个函数中随机取样,让我们从与函数形状相似的点的分布中取样。
假设您有一个如下所示的阶跃函数:

Graph of a step function and it’s “weight function” g(x)
如上所示,我们有一个阶跃函数,在范围[0,2]内有效,在[2,6]内无效。采样 10 次可能会产生如下估计值:

10 sample estimation of f(x)
这些样本(我发誓是随机的)对应于最可能的样本分布,并且产生 1.8 的整体估计。但是,如果相反,我们估计我们的函数 f(x) 和某个特殊权函数 g(x) 之间的比率呢,对于任何给定的 x,其值几乎总是大约为 f(x) 值的 1/2。如果我们也偏置样本,使其出现在函数最活跃的范围内(我们会发现这样可以最小化误差),会怎么样呢?你会发现这些比率的平均值,更接近我们积分的真实值,也就是 2 。

Estimation of step function area using importance sampling
使用重要性抽样方法来确定这个最优函数 g(x) 。
数学
我将提供一个重要性抽样数学的快速概述,但这篇文章的主要目的是实现,所以如果你渴望更多的数学严谨性,请查看我前面提到的 Deb 的文章。
让我们看看是否能找到一个 g(x) 使得:

For some constant k
基本上,我们希望 g(x)看起来像 f(x)的缩放版本。
我们还需要 g(x) 来满足一些标准:
- g(x) 是可积的
- g(x) 在[a,b]上是非负的
- g(x) 的不定积分,我们称之为*G(x)*有一个实逆
- g(x) 在[a,b]范围内的积分必须等于 1
理想情况下, f(x) = k * g(x) ,其中 k 为常数。然而,如果 f(x) = k * g(x) ,那么 f(x) 将是可积的,并且我们将不需要执行蒙特卡罗模拟;我们可以通过分析来解决这个问题!
所以,我们就满足于f(x)≈k * g(x)。当然,我们不会得到一个完美的估计,但是你会发现它比我们之前粗略的估计要好。
我们将如下定义 G(x) ,并且我们还将对 r 执行一次变量更改。

Definition of G(x)

Change of variables to r (where r will be random samples between 0 and 1)
r 将被限制在范围[0,1]内。由于 g(x) 的积分被定义为 1, G(x) 永远不会大于 1,因此 r 永远不会大于 1。这一点很重要,因为稍后在执行模拟时,我们将从范围[0,1]内的 r 中随机采样。
使用这些定义,我们可以得出以下估计值:

这个总和就是我们在执行蒙特卡罗时要计算的。我们将从 r 中随机抽样,以得出我们的估计值。
简单吧?如果乍一看这没有意义,不要被暗示。我有意把注意力集中在直觉上,轻松地通过了数学考试。如果你感到困惑,或者你只是想要更精确的数学,看看我之前提到的资源,直到你相信最终的等式。
重要性采样:Python 实现
好了,现在我们理解了重要性抽样背后的数学原理,让我们回到之前的问题。记住,我们试图尽可能精确地估计下面的积分:

Integral we’re trying to approximate
可视化我们的问题
让我们首先为我们的 g(x) 权重函数生成一个模板。我想可视化我的函数 f(x) ,所以我们将使用matplotlib来实现:

Plotting this function will help us determine an optimal structure of g(x)
好了,我们可以看到,我们的函数在[0,3- ish 的大致范围内主要是活跃,而在[3- ish ,inf]的范围内主要是不活跃。所以,让我们看看能否找到一个可以参数化的函数模板来复制这种品质。Deb 提出了这个函数:

Proposed weight function template [1]
找到 A 和λ的理想值后,我们将能够构建 f(x) 和我们的最优权函数 g(x) 的曲线图:

你可以看到在很多方面 g(x) 并没有完美地复制 f(x) 的形状。这是可以的。一个粗糙的 g(x) 仍然可以奇迹般地降低你的估计方差。随意试验其他权重函数 g(x) ,看看是否能找到更好的解决方案。
参数化 g(x)
在我们进行模拟之前,我们需要找到最佳参数 λ 和 A 。使用对 g(x) 的归一化限制,我们可以找到 A( λ) :

The normalization condition on g(x) can be used to prove that A(λ) = λ
现在,我们需要做的就是找到理想的 λ ,我们就有了我们理想的 g(x) 。
为此,让我们在范围[0.05,3.0]上以 0.5 为增量计算不同 λ 的方差,并使用方差最小的*λ**。*使用重要抽样时,我们计算 f (x)与 g(x)之比的方差。

General equation for variance when using importance sampling
我们想用这个方程来近似积分:

我们将重新计算不同 λ 的方差,每次相应地改变权函数。之后,我们将使用我们的最优 λ 来计算具有最小方差的积分。
该算法将如下所示:
- 从 λ = 0.05 开始
- 计算方差
- 增量 λ
- 重复步骤 2 和 3 直到到达最后一个 λ
- 挑选方差最小的λ——这是你的最佳 λ
- 使用重要性抽样蒙特卡罗和这个 λ 来计算积分
在代码中,寻找最优的 λ 看起来像这样:
您将看到,使用 10,000 个样本运行这个优化代码会产生一个 λ 值1.65,和一个0.0465方差,它对应于一个0.022误差。哇!使用重要性抽样允许我们在相同样本数的情况下将误差减少 2 倍。
运行模拟
现在,我们所要做的就是用我们优化的 g(x) 函数运行模拟,我们就可以开始了。下面是它在代码中的样子:
运行这段代码给了我一个0.6983的近似值,它更接近 Wolfram 提供的0.696的大真相。
包装东西
在本教程中,我们学习了如何执行蒙特卡罗模拟来估计定积分。我们同时使用了粗略方法和重要抽样方法,发现重要抽样可以显著降低误差。
请稍后回来查看本教程的第 2 部分,我们将讨论如何在蒙特卡洛模拟中使用 metropolis 算法!
祝你好运,并一如既往地随时提出问题和评论:)
参考资料和进一步阅读
[1] 苏坎塔·德布的变分蒙特卡罗技术
[2] 阿德里安·费金的计算物理学实例
强化学习中的蒙特卡罗树搜索
Deep Mind 的 Alpha Zero AI 的核心搜索算法的配方。

https://unsplash.com/photos/waAAaeC9hns
更新:学习和练习强化学习的最好方式是去 http://rl-lab.com
AlphaZero 使用通用的蒙特卡罗树搜索(MCTS)算法,而不是具有特定领域增强功能的 alpha-beta 搜索。每个搜索由一系列模拟的自我游戏组成,这些游戏从根状态根遍历树,直到到达叶子状态。(查看来源)
概观
蒙特卡罗树搜索(MCTS)算法包括四个阶段:选择、扩展、展示/模拟、反向传播。

1。选择 算法从根节点 R 开始,然后通过选择最佳子节点沿着树向下移动,直到到达叶节点 L (到目前为止没有已知的子节点)。
2。扩展 如果 L 不是一个终端节点(它不会终止游戏)那么根据当前状态(节点)的可用动作创建一个或多个子节点,然后选择这些新节点中的第一个 M 。
3。模拟 从 M 开始运行模拟卷展栏,直到找到终端状态。终端状态包含一个结果(值),该结果将在反向传播阶段向上返回。
NB。卷展栏经过的状态或节点不被视为已访问。
4。在模拟阶段之后,返回一个结果。从 M 到 R 的所有节点将通过将结果加到它们的值上来更新,并增加每个节点的访问计数。
选择和扩展
该算法从被认为是根的节点或状态开始,然后选择要移动到的子节点。
选择基于置信上限(UCB1)公式:

其中***【vᵢ】是状态 Si 的值,【nᵢ】***是状态 Si 的访问次数,n 是同级节点的总访问次数(或者换句话说是 Si 的父节点的访问次数),c 是用于微调的常数。
在为当前节点的每个子节点计算 UCB1 后,选择具有最高值的一个。

如果选定的节点是新的,这意味着它还没有被访问过,则调用 Rollout 来查找具有值的终端状态。否则,如果它被访问,则为当前节点上可用的所有动作创建子节点,移动到第一个子节点并开始卷展栏。
展示或模拟
展示或模拟是采取随机动作的阶段,检索着陆状态,然后采取另一个随机动作,以便在新状态着陆。重复这个过程,直到到达一个终端状态,此时返回终端状态的值。

反向传播
反向传播获取卷展栏的值,并更新从卷展栏开始直到根节点的节点。更新包括将卷展结果添加到每个节点的当前值,并将每个节点的访问计数增加 1。

例子
下面的例子展示了 MCTS 算法的所有不同阶段。

让我们从根节点 S0 开始。我们假设它以前被访问过,所以它不是新的。所以我们需要扩大它。我们假设在这个状态下有 2 个动作(A1,A2)。
我们通过添加由动作 A1、A2 产生的两个状态 S1 和 S2 来扩展该树。
因为 S1 和 S2 的 UCB1 都是无穷大(因为 N1=0,N2=0),所以我们选择先用 A1。
.

现在 S1 是新的,因为它还没有被访问过(N1 = 0)。该算法说,在这种情况下,我们应该推出,直到我们达到一个终端状态。
让我们假设我们这样做了,并且找到了一个值为 20 的终端节点。我们将此值从 S1 向上传播到 S0(蓝色文本)。因此,S1 和 S0 的值都等于 20,访问次数等于 1。
.
.
.

现在在第二次迭代中,UCB1(S1) = 20,UCB1(S2) =无穷大,所以我们采取行动 A2。
我们还注意到,S2 是新的(N2=0),所以我们推出,直到我们找到一个终端状态。
我们假设终端状态的值为 10。我们将其从 S2 反向传播到 S0(蓝色文本)。最后我们得到 S2 (V2=10,N2=1)和 S0(V0 = 30,N0=2)
.
.

在第三次迭代中,UCB1(S1) = 20,UCB1(S2) = 10,所以我们选择去 S1。因为现在它不再是新的了(N1 > 0),我们通过添加可用的动作和它们的登陆状态来扩展它。我们假设有两个动作 A3、A4,分别对应于 S3 和 S4。
由于 S3 和 S4 都有 UCB1 infinity,我们通过跟随 actin A3 选择 S3。S3 是新的,所以我们推出,直到我们找到值为 15 的终端状态。我们将这个值反向传播到节点 S3,S1,S0。可以在蓝色文本中看到更新后的值。
优势
- MCTS 不需要任何关于给定领域的知识。除了游戏规则和条件,不需要知道任何战略或战术,这使得它可以在其他游戏中重复使用。
- 不对称
MCTS 更频繁地访问更有趣的节点,并将其搜索时间集中在树的更相关的部分。 - 随时
可以随时停止算法,返回当前最佳估计值。 - 优雅优雅
算法不复杂,易于实现。
不足之处
- 游戏实力
MCTS,就其基本形态而言,即使是中等复杂程度的游戏,也无法在合理的时间内找到合理的走法。 - 速度
丰富
- 特定于当前游戏的领域知识可以帮助过滤掉不太可能的移动或者产生更类似于人类对手之间发生的滚动。这有利于展示比随机模拟更真实的结果,并且节点需要更少的迭代来产生真实的奖励值。
- 与领域无关 与领域无关的增强并不将实现绑定到特定的领域,保持了通用性,因此是该领域大多数当前工作的焦点。
没有数学的蒙特卡洛
好吧,也许会一点数学

Monte Carlo Casino and Garden, Monaco
蒙特卡洛模拟是数据科学和分析领域中极其常见的方法。它们可以用于从业务流程优化到物理模拟的任何事情。不幸的是,蒙特卡罗模拟的数学通常很难操作,对于没有很强数学背景的人来说可能会很吓人。更重要的是,蒙特卡罗方法的实际实施很难简明扼要地解释,尤其是在与高层领导的会议中。本文的目标是使用非技术读者可以理解的类比来解释蒙特卡罗模拟,而不需要求助于非数学家难以理解的密集数学或编码。
在我们讨论蒙特卡罗方法本身之前,我们需要做一点背景工作来建立一个基本的统计框架,最好的方法是用一个飞镖板。飞镖是一种技巧游戏(如果你真的不擅长的话,也可能是运气)。如果你有一个数值从 1 到 5 的镖盘,你向它投掷一个飞镖,根据飞镖落在镖盘上的位置,你将获得一定数量的点数。

Circular dart board with labeled point values
如果你在飞镖靶上扔 10 个飞镖,然后把所有的分数加起来,你会得到 0 到 50 之间的分数。对于一个不常玩飞镖的休闲玩家来说,这个分数总计可能会达到 25 分左右。如果你真的不擅长飞镖,总分可能在 10 分左右,如果你擅长飞镖,你的总分可能会更高。假设是 40。

Dart board and chart showing example number of darts landing in each region by player skill level
现在让我们假设你很富有,想买下整个酒吧,这样你就可以独享所有的飞镖靶了。向一块木板投掷 10 个飞镖可能与向 10 块相同的飞镖板上各投掷 1 个飞镖非常相似,这种说法可能并不夸张。如果你在一块木板上投掷 10 个飞镖得到 25 分,那么你在 10 块相同的木板上各投掷 1 个飞镖也可能得到 25 分。

Ten identical dart boards
如果你在数据科学方面做了很多工作,你可能会明白这是怎么回事。既然你很富有,而且买下了整个酒吧,这样你就可以开派对了,你觉得拥有 10 个相同的飞镖靶有点无聊。你决定把每个镖靶做成不同的形状和不同的点。因为你现在有不同的形状和不同的点,所以不太可能每个摊位都有相同的平均分。如果一个镖盘只有原来的四分之一大,总点数会更低。有一个巨大靶心的棋盘会有更高的总分。

Ten different boards of various shapes, layouts, and sizes
现在你的飞镖派对真的成形了。老手将面临更难的板的额外挑战,初学者将有一些更容易帮助他们学习的板,一些板非常奇怪,你不知道分数的分布会是什么。为了增加一点激励,你将有一个锦标赛。每个参加的人都会得到 10 个飞镖,并且可以向你的每个奇怪的棋盘扔一个飞镖。他们会把每个板块的分数加起来,然后把总分提交给你。

Score sheets for 7 players including points per board, total score, and total per board
现在预测平均分难多了。每块板都是不同的,每个人都有很多变量影响他们击中任何给定板的能力。你不能真的说某人的总分会是多少。根据你对这个人的了解,你可能会有一种直觉,但这是你能拥有的全部。
如果没有蒙特卡洛模拟,这就是许多决策者的处境。他们面临着一个非常复杂的系统,他们可能对潜在的可能结果有一些直觉(例如,更好的玩家将在更小的飞镖板上获得更高的分数),但他们不知道如何将他们对个体变量的直觉整合到一个复杂的系统中。因此,他们凭直觉行事,也许对有些类似的情况只有很少的经验,这可能会奏效,或者他们可能会感到意外。
回到飞镖游戏的比喻,说你的飞镖派对是一个巨大的成功。每个人都喜欢它。那里有一个派对策划人。某个新体育电视台的代表在那里。他们都喜欢它。他们希望这个游戏概念变大,真的变大。现在你的多板飞镖比赛走向国际。蒙特卡洛飞镖比赛有上百场。数百万人玩,你有他们所有的总得分。
现在你有了一些真实的数据。基于数百万人在相同的 10 块板上投掷飞镖的得分,你对每块板的“好成绩”有一个很好的概念。你知道每块板的平均分数是多少。你知道总分的平均值和标准差。你可以预测游戏的基本统计数据。
这就是蒙特卡洛模拟的威力。每个镖盘代表一个变量,这些变量的值组合成一个聚合结果。如果您知道每个变量可能得分的一般分布,您可以使用蒙特卡罗模拟来预测多个变量的总得分。
摩尔定律已死
我们习惯于认为计算机速度每 18 个月翻一番,正如摩尔定律所预言的那样。事实上,过去 50 年就是如此。然而,由于技术障碍,摩尔定律正在走向终结。我们有什么选择?
这段文字以修订后的形式发表在《建成》中。 去那里寻找规范版本。

Intel 4004
1.小型化
戈登·摩尔在 1965 年预测,晶体管的数量将每 18 个月翻一番,后来他修正为两年。他的定律存在了 50 多年的事实让摩尔感到惊讶,在最近的一次采访中,他描述了与进一步小型化相关的几个潜在障碍:光速、材料的原子性质和不断增长的成本。
从上往下看,CPU 执行基本的算术运算。一个微处理器在一个由晶体管组成的集成电路上集成了 CPU 的功能。如今,CPU 是一个拥有数十亿个晶体管的微处理器(由单个电路组成)(例如,Xbox One 拥有50 亿个)。
第一个英特尔微处理器,英特尔 4004,有 2300 个晶体管,每个晶体管的大小为 10𝜇m。截至 2019 年,大众市场上单个晶体管平均为 14 纳米,许多 10 纳米的型号进入市场。英特尔设法在每平方毫米上封装了超过 1 亿个晶体管。最小的晶体管达到 1nm 。
2.原子规模和飞涨的成本
光速是有限的和恒定的,并且对通过单个晶体管在一秒钟内可以处理的计算数量提供了自然的限制,因为信息不能比光速更快地传递。目前,比特是由穿过晶体管的电子模拟的,因此计算速度受到电子穿过物质的速度的限制。导线和晶体管由电容 C(存储电子的能力)和电阻 R(它们对电流的阻力)来表征。随着小型化,R 上升,C 下降,进行正确的计算变得更加困难。
随着小型化的进一步发展,我们将会遇到海森堡的不确定性原理,它将精度限制在量子水平,从而限制了我们的计算能力。据计算仅基于测不准原理的摩尔定律将在 2036 年走到尽头。
T4 国防高级研究计划局微系统技术办公室主任 Robert Colwell 说,他将 2020 年和 7 纳米作为最后一个工艺技术节点。“事实上,我预计行业将尽一切努力推进 5 纳米,即使 5 纳米并没有比 7 纳米提供更多优势,这将最早的目标推迟到 2022 年。我认为终点就在这些节点附近。”
另一个慢慢扼杀摩尔定律的因素是与能源、冷却和制造相关的成本不断增长。构建新的 CPU 或 GPU 会花费很多。制造一个新的 10 纳米芯片大约需要 1 . 7 亿美元,7 纳米芯片大约需要 3 亿美元,5 纳米芯片需要 5 亿多美元。这些数字只能通过一些专门的芯片来增长,例如,NVidia 在研发上花费了超过 20 亿美元来生产一种旨在加速人工智能的 GPU。
3.计算的未来
考虑到所有这些事实,有必要在硅制成的电子和晶体管之外寻找替代的计算方式。
最近一个势头越来越大的替代方案是量子计算。量子计算机基于量子位,量子位,并使用量子效应,如叠加和纠缠,从而克服了经典计算的小型化问题。现在预测它们何时会被广泛采用还为时过早,但是已经有一些有趣的例子说明了它们在商业中的应用。量子领域最紧迫的问题是将量子计算机从几十个量子位扩展到几千甚至几百万个量子位。
另一种方法是针对特定算法调整的专用架构。由于机器学习的巨大需求,这个领域发展非常迅速。GPU 已经被用于人工智能训练超过十年了。近年来,谷歌推出了旨在促进人工智能的 TPU,目前有超过 50 家公司生产人工智能芯片,仅举几例: Graphcore 、 Habana 或 Horizon Robotics 以及大多数领先的科技公司。
FPGA 代表现场可编程门阵列,这意味着这种硬件可以在制造过程后进行编程。精工于 1985 年生产了第一批 FPGAs,但不同的可再编程硬件可以追溯到 20 世纪 60 年代。FPGAs 最近开始流行,特别是在数据中心的使用,就像 T2 的英特尔和 T4 的微软所做的那样。微软还用 FPGAs 加速了必应搜索。与 FPGA 类似的概念是 ASIC,专用集成电路。最近他们非常受欢迎加密货币挖掘。
经典计算的另一种替代方法是用其他东西代替硅或电子。用电子的自旋代替电荷产生了自旋电子学,一种基于自旋的电子学。它仍在研究中,没有面向大众市场的车型。目前正在研究的还有光学计算的想法——利用光来执行计算。然而,建造一台工业光学计算机仍然有许多障碍。
也有很多非硅材料的实验。化合物半导体将元素周期表中的两种或两种以上元素结合在一起,如镓和氮。不同的研究实验室正在测试由硅锗或石墨烯制成的晶体管。最后但并非最不重要的是,有一种用细胞或 DNA 作为集成电路的生物计算的想法。但这离任何工业用途都更远。
总而言之,为了超越摩尔定律,我们需要超越电子/硅的经典计算,进入非硅计算机时代。好消息是有很多选择:从量子计算、石墨烯等神奇材料,到光学计算和专用芯片。计算的未来绝对令人兴奋!

















 727
727

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}