







用 30 行 Python 预测大学篮球成绩
深度分析
创建一个机器学习算法,用不到 30 行 Python 代码预测大学篮球成绩

Don’t worry, we’ve all been beaten by a Very Good Boy at least once. Photo by Jenny Marvin on Unsplash
又在你办公室的疯狂三月泳池里获得最后一名?有没有一只金毛或者你邻居家女儿的宠物石头选了一个比你更好的支架?创建一个获胜的阵营是困难的,甚至会绊倒大学篮球的专家分析师。与其让猜测工作听天由命,或者每个赛季看几千个小时的篮球比赛(我想我反正是这样做的,但那不是重点),为什么不训练一台计算机来为你做预测呢?
在 Python 和一些令人敬畏的库的帮助下,您可以构建自己的机器学习算法,用不到 30 行代码预测 NCAA 男子 I 级大学篮球比赛的最终得分。本教程旨在解释创建机器学习应用程序所需的所有步骤,包括设置、数据检索和处理、训练模型以及打印最终预测。
设置
先决条件
要学习本教程,强烈建议您对 Python 有一个基本的了解,尽管这不是必需的。了解导入模块、获取和设置变量、字典和实例化类的目的是一个很好的基础,而使用Pandas和sklearn的经验是一个巨大的优势。
开发要求
- Python 3 :下面的所有代码也适用于 Python 2,但是当 Python 2 在 2020 年初寿终正寝的时候,建议使用 Python 3 来帮助从 Python 2 过渡过来。
- pandas,sportsreference,sklearn :我们所需的依赖项,将在下面进一步详细解释。它们可以通过 PIP 与以下内容一起安装:
pip install pandas sklearn sportsreference
- 活跃的网络连接:这对于大多数人来说可能不是问题,但是您最终使用的开发环境必须能够访问外部 web,以便从我们的代码中下载数据集。
构建应用程序
现在我们的开发环境已经设置好了,让我们开始构建实际的应用程序。
完整算法
Complete machine learning program to predict college basketball scores
对于那些喜欢直接跳到代码的人来说,上面的要点是我们将使用的最终程序。如果你已经熟悉了pandas和sklearn,你可以跳到本教程的底部,看看这个程序是如何运行的,以及如何扩展它以获得更高的精度、更快的运行时间和改进的可用性。对于其他想进一步了解这段代码的人,请继续阅读下面的内容,了解每一步的目的。
导入依赖关系
Importing all required dependencies
几乎每一个 Python 程序都以一个import部分开始,其中包含了模块后面要用到的必需依赖项。对于这个项目,我们需要导入我们之前安装的以下包:
- pandas :一个流行的 Python 数据科学库,我们将使用它来存储和操作我们的数据集。
- sportsreference :一个免费的 Python sports API,我们将使用它从 NCAAB 游戏中提取数据。更多信息可以在这篇博文中找到。
- sk learn:Python 最大的机器学习库之一,包括几个预制的算法,比如我们将使用的
RandomForestRegressor,以及一些有用的工具来帮助数据创建管道,比如自动创建训练和测试数据集的train_test_split。
正在初始化数据集
Initializing our dataset using sportsreference
没有数据集,任何机器学习应用都是不完整的。为了帮助我们预测 NCAAB 比赛的最终得分,我们希望创建一个包含所有单个比赛统计数据(如投篮命中率、失误次数和盖帽次数、篮板百分比等)的数据集,然后我们可以用它来预测这些因素与最终得分的关系。
为了创建这个数据集,我们首先需要初始化一个空的Pandas DataFrame,我们将使用它来存储我们的最终数据。接下来,我们从sportsreference初始化Teams类,它包含当前或最近一个赛季的每个 NCAA 男子篮球队的信息,并允许我们轻松地获取每个队的统计数据。
在提取数据之前,我们需要通过运行for team in teams:来迭代每支球队,其中每次迭代对应于联盟中唯一的一支球队。sportsreference公开了每个团队的日程和 boxscore 信息,并使我们能够编写类似于team.schedule.dataframe_extended的代码,该代码收集该团队在当前赛季参加的每场比赛的统计信息。dataframe_extended属性返回一个pandas DataFrame,其中每个索引对应一个不同的游戏。
在收集了每个游戏的 boxscore 信息后,我们希望将它添加到我们的整体数据集中,这样我们就有了一个单一的数据源。这可以通过将我们现有的数据集与包含当前团队完整 boxscore 信息的本地DataFrame连接起来来实现。通过用得到的连接覆盖我们现有的数据集,我们确保数据集总是不仅包括最近的团队的信息,还包括以前查询过的所有团队的信息。
预处理数据集
Preprocess our dataset by dropping unused values, creating our X and y, and separating a training and testing dataset
在我们的数据集完成自我构建后,我们需要从我们的数据集中过滤出一些我们不想使用的类别(或在机器学习中经常被称为特征)——即那些属于string类型(或分类)的类别,如团队名称或日期和地点。有时,基于字符串的要素会很有用,例如,在预测房屋价值和确定列为“海滨”的房产比列为“内陆”的房产价值更高的情况下。尽管该功能对房价预测很有用,但大多数机器学习算法无法处理基于字符串的数据。替换这些类型的特征的一种方法称为一键编码,它自动用唯一特征列替换相似的分类值,其中落入该特征的每个索引的值为 1,否则为 a。通过将类别更改为 1 和 0,机器学习算法能够更有效地处理这些特征。
然而,出于我们的目的,我们将简单地删除这些特性,因为它们要么太多(即可能的比赛场地非常大),没有意义(在根据统计数据确定结果时,比赛是在 11 月 18 日还是 12 月 2 日并不重要),或者会引入偏见(我们希望算法根据球队的表现来确定最终得分——而不仅仅是因为他们的名字是“杜克”)。因此,我们将放弃所有这些类别。
在这一点上,有些人可能想知道为什么我将home_points和away_points包含在要删除的字段列表中。这两个字段是我们想要预测的最终输出(通常称为标签),因此我们不希望它们包含在我们的主要特征中,而是应该将它们专门保留给我们的输出标签。
通过上面的代码,我们首先从数据集中删除所有不需要的特征,并将修剪后的输出保存为X。删除未使用的特性后,我们接下来删除所有数据不完整的行。如果 sports-reference.com 上的数据没有正确填充,或者如果一支球队没有执行某个统计动作,例如没有盖帽或罚球,这种情况有时会发生。有两种方法可以处理这种不完整的数据,一种是用一组数字设置缺失值(例如类别的平均值或默认值为零),另一种是删除任何无效的行。因为对于我们的数据集来说,无效单元格的数量非常少,所以我们将删除所有数据不完整的行,因为这不会影响我们的最终结果。
因为探戈是两个人跳的(嗯,一场比赛有两个参赛队),所以当两个队的时间表被拉出来时,每场比赛都有一个副本(一个是主队的,一个是客场队的)。这只是污染了我们的数据集,并没有提供任何价值,因为行是完全相同的,所以我们想删除任何副本,只保留每个游戏的一个实例。为此,我们只需将drop_duplicates()添加到我们的数据集中,以确保每个索引都是唯一的。
接下来,我们需要创建输出标签,用于在训练时确定模型权重的准确性,并测试最终算法的准确性。我们可以通过创建一个只包含主客场点的两列向量来生成标签,并将结果设置为y。
最后,通常的做法是将数据集分成训练和测试子集,以确保训练模型是准确的。理想情况下,我们希望将大约 75%的数据集用于训练,将剩余的 25%用于测试。这些子集应该随机选取,以防止模型偏向某一组特定的信息。使用定型数据集对模型进行定型后,应该对测试数据集运行该模型,以确定模型的预测性能,并查看它是否过度拟合。
幸运的是,sklearn有一个内置函数可以为我们创建这些子集。通过将我们的X和y帧输入到train_test_split中,我们能够检索具有预期分割的训练和测试子集。
创建和训练模型
Setting hyperparameters and training our model
既然我们的数据集已经被处理,现在是时候创建和训练我们的模型了。我决定在这个例子中使用一个 RandomForestRegressor ,因为该算法易于使用,相对准确,而且与标准决策树相比,它可以减少过拟合。随机森林算法创建了几个决策树,在特征权重中注入了一些随机性。这些决策树然后被组合以创建一个森林(因此是决策树 ) 的随机森林,用于训练、验证或推断时的最终分析。该算法既支持分类也支持回归,使其非常灵活地适用于各种应用。
分类确定属于固定数量类别的输出标签,例如学生在测验中收到的字母等级(“A”、“B”、“C”、“D”或“F”)。只能有五个类别(或类),因此模型将只尝试将输出放入这五个类别中的一个。另一方面,回归确定可以取值范围不确定的输出标签,例如房屋的价格。尽管有一个标准房价的范围,但是房子的售价是没有限制的,任何正数都是合理的。因为篮球比赛的最终比分从技术上讲可以是任何正数(或者零!),我们要用回归。
在我们构建和训练我们的模型之前,我们首先需要设置一些超参数。超参数是在训练之前输入到模型中的参数,影响模型的构建和优化。对于机器和深度学习领域的大多数初学者来说,这些参数往往是最大的障碍,因为这些设置通常没有一个“完美”的值,如果有什么的话,确定应该放什么会变得非常困难。
一般的经验法则是,最初坚持使用这些超参数的默认值,然后一旦模型被训练和完成,并且您能够测试它,就开始使用试错法来调整这些值,直到您对最终结果满意为止。对于我们的模型,我选择了六个不同的超参数,并找到了这组特定的值来提供性能和精度之间的最佳平衡。关于这些具体设置的更多细节可在官方 scikit-learn 文档中找到。
在选择了我们的超参数之后,终于到了创建模型的时候了。首先,我们需要实例化我们之前导入的RandomForestRegressor类,并包含我们的超参数。通过使用(**parameters),我们将字典的键-值对扩展为该类的命名参数,其功能与以下内容相同:
An example of how dictionary expansion works for function calls
既然我们的模型已经实例化了,剩下的就是训练它了。sklearn通过将fit方法与RandomForestRegressor结合在一起,使这变得非常容易,所以我们只需要用我们的输入特性和相应的输出标签来运行它。这个方法就地运行,所以我们的model变量现在将自动指向一个经过训练的模型,我们可以用它来进行预测!
打印结果
Print the final results
我们应用程序的最后一步是根据我们的测试子集运行预测,并将它们与我们的预期结果进行比较。这个 print 语句将预测结果和我们的实际预期结果输出为两个不同的两列向量。
运行应用程序
我们期待已久的时刻终于到来了!我们的应用程序现在已经完成,剩下的就是运行算法了。我将我的程序命名为ncaab-machine-learning-basic.py,所以我只需要运行下面的代码来初始化算法:
python ncaab-machine-learning-basic.py
请注意该程序可能需要很长时间 才能完成,因为大部分处理时间都花在了为 I 级大学篮球赛的所有 350+支球队构建数据集上。如果您只是希望看到一个工作的算法,您可以通过在数据连接行之后的第一个循环中添加一个break语句来提前停止数据创建。
一旦程序完成,它将输出类似如下的内容(为了节省空间,我减少了行数):
(array([[86, 86],
[71, 71],
[78, 77],
[74, 72],
[90, 81],
...
[52, 66],
[68, 65]]),
array([[ 83, 89],
[ 71, 73],
[ 80, 76],
[ 77, 72],
[ 92, 84],
...
[ 46, 73],
[ 66, 65]]))
该输出包含两个部分:预测输出和预期输出。从array([[86, 86]到[68, 65]])的所有内容都是预测输出,而array([[83, 89]到[66, 65]])是实际数据。如前所述,第一列是指主场队的预期得分,第二列是客场队的预计得分。
预测输出中的行也与预期输出中的行匹配,因此[86, 86]与[83, 89]相关,依此类推。如果我们比较下面的列表,我们会发现我们的预测并不太差!在大多数情况下,预计分数与实际结果只差几分。另一个有希望的迹象是,当实际分数与 70 分左右的典型结果不同时,我们的算法能够识别差异,并生成高于或低于正常分数的分数。
改进应用程序
如果这是你的第一个机器学习程序,恭喜你!希望本教程足以让您入门,并表明一个基本的机器学习应用程序不需要多年的教育或数千行代码。
虽然这个计划是一个很好的开始,但我们有很多方法可以扩展它,使它变得更好。下面是我将对应用程序进行的一些改进,以提高性能、准确性和可用性:
- 将数据集保存到本地目录:如前所述,该计划需要很长时间才能完成,因为它为所有 350 多个团队从头开始构建数据集。目前,如果您想要再次运行该算法,您将需要重新构建数据集,即使它没有发生变化。在第一次构建数据集之后,可以通过将
DataFrame的副本转换成 CSV 或 Pickle 文件保存到本地文件系统来简化这个过程。然后,下次运行该程序时,您可以选择测试 CSV 或 Pickle 文件是否存储在本地,如果是,则从该文件加载它并跳过构建数据集。这将大大减少首次保存数据集后运行程序所需的时间。 - 特征工程:改进机器学习模型的一种常见做法被称为特征工程。这与创建或修改特征的过程有关,这些特征有助于模型找到各种类别之间的相关性。特征工程通常是一项困难的任务,就像超参数一样,没有一个定义好的方法可以用来持续提高性能。然而,一些经验法则是修改数字特征,使它们处于相同的数量级。例如,我们的数据集包含许多百分比和累计总数。百分比范围从 0 到 1,而总数可以是大于或等于 0 的任何数字(想想“分数”或“上场时间”)。修改这些特征使它们处于相同的数量级有助于模型的创建。特征工程的另一个例子是创建一个新的特征,比如著名的每个团队的四因素评分。我们可以生成这个新特征,并将其包含在我们的数据集中,以确定它是否会改进整个模型。
- 显示特定球队的预测:虽然我们的程序很好地介绍了机器学习和预测篮球比分,但它并不能完全用于确定特定比赛或比赛的结果。一个很好的扩展是为特定的团队生成预测。这样,我们可以回答类似“印第安纳大学在普渡大学比赛”这样的问题。预测的分数是多少?”正如我们在构建数据集时所做的那样,我们可以利用
sportsreference来生成特定于各个团队的数据,并在进行预测时将其用作我们的输入。 - 为相似的代码块编写函数:为了更加 Pythonic 化,并使我们的应用程序模块化以适应未来的变化,函数应该用于所有具有特定目的的代码块,例如构建数据集、处理数据、构建和训练模型。这也提高了代码的可读性,以帮助将来可能使用它的其他人。
既然您已经有了一个可以工作的应用程序,请尝试实现这些建议来提高模型的准确性和性能。如果您生成了一个您满意的模型,您可以使用它来为 NCAA 锦标赛创建预测,或者可能参加比赛。
虽然要打败金毛猎犬或莎莉的宠物岩石仍然很难,但这种算法可能会让你今年在公司的人才库中获得竞争优势。为什么不把这个三月变成你的并把吉姆从会计部赶下台呢?
使用 PySpark 机器学习预测客户流失

Source: Globallinker
预测客户流失是数据科学家目前面临的一个具有挑战性的常见问题。预测特定客户面临高风险的能力,同时还有时间做些什么,这对于每个面向客户的企业来说都是一个巨大的额外潜在收入来源。
在这篇文章中,我将指导你创建一个能够预测客户流失的机器学习解决方案。这个解决方案将通过阿帕奇火花实现。Apache Spark 是一个流行的分布式数据处理引擎,可以以多种方式部署,为 Java、Scala、Python 和 r 提供原生绑定。它提供了一系列库,包括 Spark SQL、Spark Streaming、用于机器学习的 MLlib 和用于图形处理的 GraphX。对于这个项目,我们将重点关注机器学习库 MLlib。我们将使用 Python API for Spark,称为 PySpark。
如果您阅读这篇文章,您将学会如何:
- 将大型数据集加载到 Spark 中,并使用 Spark SQL 和 Spark Dataframes 操纵它们,以设计相关功能来预测客户流失,
- 使用 Spark ML 中的机器学习 API 来构建和调整模型。
介绍
想象一下,你正在一个类似于 Spotify 的流行数字音乐服务的数据团队工作。姑且称之为 Sparkify 吧。用户每天播放他们喜欢的歌曲,要么使用在歌曲之间放置广告的免费层,要么使用付费订阅模式,他们免费播放音乐,但按月支付固定费用。用户可以随时升级、降级和取消服务。每当用户与该服务交互时,如播放歌曲、注销或竖起大拇指喜欢一首歌,它都会生成数据。所有这些数据都包含了让用户满意和帮助企业发展的关键见解。我们数据团队的工作是预测哪些用户面临取消账户的风险。如果我们能够在这些用户离开之前准确地识别他们,我们的企业就可以为他们提供折扣和激励,从而潜在地为我们的企业节省数百万美元的收入。
导入库并设置 Spark
我使用 IBM Watson Studio(默认 Spark Python 3.6 XS,一个驱动程序,两个执行程序,Spark 2.3 版)来完成这个项目。与 PySpark 数据帧的交互不如与 pandas 数据帧的交互方便。这就是为什么我建议安装并导入pixiedust:
!pip install --upgrade pixiedust
import pixiedust
pixiedust是一个开源的 Python 助手库,作为 Jupyter 笔记本的附加组件,极大地改善了我们与 PySpark 数据帧的交互方式。
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
import datetime
from sklearn.metrics import f1_score, recall_score, precision_score
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
from pyspark.sql.types import IntegerType, DoubleType, DateType, FloatType
from pyspark.ml.feature import VectorAssembler, MinMaxScaler
from pyspark.ml import Pipeline
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.tuning import ParamGridBuilder, CrossValidator
from pyspark.ml.classification import LogisticRegression, DecisionTreeClassifier, GBTClassifier, LinearSVC
创建 Spark 会话并读取 Sparkify 数据集:
# create a Spark session
spark = SparkSession \
.builder \
.appName("Sparkify") \
.getOrCreate()# read in dataset
df = spark.read.json('medium-sparkify-event-data.json')
pixiedust现在派上了用场,我们可以显示数据帧的第一个条目。
display(df)

Figure 1
浏览一下模式:
df.printSchema()

Figure 2
该数据集包含有关用户如何与流媒体平台交互、他们听了哪些歌曲、他们访问了哪个页面、他们的帐户状态等信息。任何用户交互都存储有 UNIX 时间戳,这使得分析用户行为随时间的变化成为可能。我们将在以后的特征工程过程中利用这些信息。
探索性数据分析
接下来,我们将通过在 PySpark 中进行基本操作来执行 EDA。
为了了解用户如何与音乐服务交互,我们可能想看看他们查看最多的页面。
df.groupBy('page').count().sort(F.desc('count')).show()

Figure 3
我们可以清楚地看到,“NextSong”是最受欢迎的页面视图,这对于音乐服务来说非常有意义。然而,还有许多其他页面视图对于从该原始数据集中设计相关要素也很重要。我们使用“取消确认”页面,计算 99 次访问,来创建机器学习模型的标签。
flag_cancellation_event = F.udf(lambda x: 1 if x == 'Cancellation Confirmation' else 0, IntegerType())
df = df.withColumn('label', flag_cancellation_event('page'))
基于 UNIX 时间戳 ts ,我们可以按小时计算统计数据。
get_hour = F.udf(lambda x: datetime.datetime.fromtimestamp(x / 1000.0).hour, IntegerType())
df = df.withColumn('hour', get_hour(df.ts))
由于 matplotlib 不支持 PySpark 数据帧,我们将其转换回 pandas 数据帧,并按小时绘制用户活动。
*# Count the events per hour*
songs_by_hour = df.groupBy('hour').count().orderBy(df.hour)
songs_by_hour_pd = songs_by_hour.toPandas()
songs_by_hour_pd.hour = pd.to_numeric(songs_by_hour_pd.hour)*# Plot the events per hour aggregation*
plt.scatter(songs_by_hour_pd['hour'], songs_by_hour_pd['count'])
plt.xlim(-1, 24)
plt.ylim(0, 1.2 * max(songs_by_hour_pd['count']))
plt.xlabel('Hour')
plt.ylabel('Events');

Figure 4
特征工程
特征工程在大数据分析中发挥着关键作用。没有数据,机器学习和数据挖掘算法就无法工作。如果只有很少的特征来表示底层的数据对象,那么就很难实现什么,并且这些算法的结果的质量很大程度上取决于可用特征的质量。
因此,我们开始构建我们发现有希望训练模型的特征。
为此,我们从头开始创建一个新的 py spark data framefeature _ df,每行代表一个用户。我们将从数据帧 df 中创建特征,并将它们依次连接到数据帧 feature_df 中。
基于 df 中的标签列,我们可以将被搅动的用户与其他人分开。
churned_collect = df.where(df.label==1).select('userId').collect()
churned_users = set([int(row.userId) for row in churned_collect])all_collect = df.select('userId').collect()
all_users = set([int(row.userId) for row in all_collect])feature_df = spark.createDataFrame(all_users, IntegerType()).withColumnRenamed('value', 'userId')
编码标签
*# Create label column*
create_churn = F.udf(lambda x: 1 if x in churned_users else 0, IntegerType())
feature_df = feature_df.withColumn('label', create_churn('userId'))
将性别和帐户级别编码为特征
*# Create binary gender column*
convert_gender = F.udf(lambda x: 1 if x == 'M' else 0, IntegerType())
df = df.withColumn('GenderBinary', convert_gender('Gender'))*# Add gender as feature*
feature_df = feature_df.join(df.select(['userId', 'GenderBinary']), 'userId') \
.dropDuplicates(subset=['userId']) \
.sort('userId')convert_level = F.udf(lambda x: 1 if x == 'free' else 0, IntegerType())
df = df.withColumn('LevelBinary', convert_level('Level'))*# Add customer level as feature*
feature_df = feature_df.join(df.select(['userId', 'ts', 'LevelBinary']), 'userId') \
.sort(F.desc('ts')) \
.dropDuplicates(subset=['userId']) \
.drop('ts')
将页面视图编码为功能
每次用户与平台交互时,它都会生成数据。这意味着我们确切地知道每个用户在数据提取期间经历了什么。我的方法是将页面分成几类:
- 中性页面:“取消”、“主页”、“注销”、“保存设置”、“关于”、“设置”
- 负面页面:“拇指朝下”、“滚动广告”、“帮助”、“错误”
- 正面页面:“添加到播放列表”、“添加朋友”、“下一首歌”、“竖起大拇指”
- 降级页面:“提交降级”、“降级”
- 升级页面:“提交升级”、“升级”
这种方法背后的原因是,我们可以计算用户与正面页面进行交互的频率。我们可以为每个页面分别做这件事,但这会导致一个更高的特征空间。
让我们把它写成代码:
*# Create a dictonary which maps page views and PySpark dataframes*
pages = {}
pages['neutralPages'] = df.filter((df.page == 'Cancel') | (df.page == 'Home') | (df.page == 'Logout') \
| (df.page == 'Save Settings') | (df.page == 'About') | (df.page == 'Settings'))
pages['negativePages'] = df.filter((df.page == 'Thumbs Down') | (df.page == 'Roll Advert') | (df.page == 'Help') \
| (df.page == 'Error'))
pages['positivePages'] = df.filter((df.page == 'Add to Playlist') | (df.page == 'Add Friend') | (df.page == 'NextSong') \
| (df.page == 'Thumbs Up'))
pages['downgradePages'] = df.filter((df.page == 'Submit Downgrade') | (df.page == 'Downgrade'))
pages['upgradePages'] = df.filter((df.page == 'Upgrade') | (df.page == 'Submit Upgrade'))*# Loop through page views and aggregate the counts by user*
for key, value in pages.items():
value_df = value.select('userId') \
.groupBy('userId') \
.agg({'userId':'count'}) \
.withColumnRenamed('count(userId)', key)
*# Add page view aggregations as features*
feature_df = feature_df.join(value_df, 'userId', 'left').sort('userId') \
.fillna({key:'0'})
接下来,我们将计算用户与平台互动的天数:
*# Create dataframe with users and date counts*
dateCount_df = df.select('userId', 'date') \
.groupby('userId') \
.agg(F.countDistinct('date')) \
.withColumnRenamed('count(DISTINCT date)', 'dateCount')
*# Add date count as feature*
feature_df = feature_df.join(dateCount_df, 'userId', 'left').sort('userId') \
.fillna({'dateCount':'1'})
这些页面视图特征是计算出现次数的绝对值。然而,如果一些用户在数据提取结束时注册,而另一些用户从一开始就使用该平台,这可能会导致误导性的结果。为此,我们将通过在特定于用户的时间窗口内划分汇总结果,获得计数/天,从而使汇总结果具有可比性。我在这里跳过代码,完整的代码可以在 GitHub 上找到。
将一段时间内的用户活动编码为特征
另一个有希望的特性是用户交互如何随时间变化。首先,我们计算每天的用户交互次数。其次,我们使用 numpy.polyfit 为每个用户拟合一个线性回归模型。我们将获取这些线的斜率,移除异常值,并将缩放后的斜率作为特征插入分类算法中。

Figure 5
*# Create dataframe with users and their activity per day*
activity_df = df.select('userId', 'date') \
.groupby('userID', 'date') \
.count()*# initialize slopes*
slopes = []
for user in all_users:
*# Create pandas dataframe for slope calculation*
activity_pandas = activity_df.filter(activity_df['userID'] == user).sort(F.asc('date')).toPandas()
if activity_pandas.shape[0]==1:
slopes.append(0)
continue
*# Fit a line through the user activity counts and retrieve its slope*
slope = np.polyfit(activity_pandas.index, activity_pandas['count'], 1)[0]
slopes.append(slope)
特征缩放,将列合并为一个特征向量
作为特征工程过程的最后一步,我们将迭代创建的特征,并使用 MinMaxScaler 缩放它们。然后,我们将这些特征放入一个向量中,这样我们就可以将它插入 pyspark.ml 算法中。
*# UDF for converting column type from vector to double type*
unlist = F.udf(lambda x: round(float(list(x)[0]),3), DoubleType())
*# Iterate over columns to be scaled*
for i in ['neutralPagesNormalized', 'negativePagesNormalized', 'positivePagesNormalized', 'downgradePagesNormalized', 'upgradePagesNormalized', 'dateCountNormalized', 'hourAvg', 'UserActiveTime', 'Slope']:
*# VectorAssembler Transformation - Convert column to vector type*
assembler = VectorAssembler(inputCols=[i],outputCol=i+"_Vect")
*# MinMaxScaler Transformation*
scaler = MinMaxScaler(inputCol=i+"_Vect", outputCol=i+"_Scaled")
*# Pipeline of VectorAssembler and MinMaxScaler*
pipeline = Pipeline(stages=[assembler, scaler])
*# Fitting pipeline on dataframe*
feature_df = pipeline.fit(feature_df).transform(feature_df) \
.withColumn(i+"_Scaled", unlist(i+"_Scaled")).drop(i+"_Vect")
*# Merge columns to one feature vector*
assembler = VectorAssembler(inputCols=['neutralPagesNormalized_Scaled', 'negativePagesNormalized_Scaled', 'positivePagesNormalized_Scaled', 'downgradePagesNormalized_Scaled', 'upgradePagesNormalized_Scaled', 'dateCountNormalized_Scaled', 'hourAvg_Scaled', 'UserActiveTime_Scaled', 'Slope_Scaled', 'LevelBinary', 'GenderBinary'], outputCol='features')
feature_df = assembler.transform(feature_df)
遵循 feature_df 的模式:

Figure 6
特征列保存每个用户的组合特征向量:

Figure 7
机器学习建模
创建特征后,我们可以继续将整个数据集分为训练和测试两部分。我们将测试几种用于分类任务的常见机器学习方法。将评估模型的准确性,并相应地调整参数。根据 F1 分数、精确度和召回率,我们将确定获胜的型号。
将特性数据框架分为训练和测试,并检查类别不平衡。
train, test = feature_df.randomSplit([0.7, 0.3], seed = 42)plt.hist(feature_df.toPandas()['label'])
plt.show()

Figure 8
检查数据中潜在的阶级不平衡是至关重要的。这在实践中是非常普遍的,并且许多分类学习算法对于不常见的类具有低的预测准确度。
机器学习超参数调整和评估
Spark 的 MLlib 支持[CrossValidator](https://spark.apache.org/docs/latest/api/python/pyspark.ml.html#pyspark.ml.tuning.CrossValidator)等模型选择的工具。这需要满足以下条件:
- 估计器:算法还是流水线
- 参数集:要搜索的参数网格
- Evaluator:度量模型在测试数据集上的表现的指标。
将为每个分类器专门设置估计器和参数。
为了评测,我们取支持“areaUnderROC”和“areaUnderPR”的[BinaryClassificationEvaluator](https://spark.apache.org/docs/latest/api/python/pyspark.ml.html#pyspark.ml.tuning.BinaryClassificationEvaluator) 。由于我们在数据中有一个等级不平衡,我们采用“areaUnderPR”作为我们的评估指标,因为 PR 曲线在这种情况下提供了更多信息(参见http://pages.cs.wisc.edu/~jdavis/davisgoadrichcamera2.pdf)。
由于 pyspark.ml.evaluation 中的类BinaryClassificationEvaluator只提供了“areaUnderPR”和“areaUnderROC”这两个指标,我们将使用sklearn来计算 F1 分数、精确度和召回率。
evaluator = BinaryClassificationEvaluator(metricName = 'areaUnderPR')
逻辑回归
逻辑回归基本上是一种线性回归模型,它解释了因变量与一个或多个名义变量、序数变量、区间变量或比率级自变量之间的关系,唯一的区别是,线性回归的输出是一个具有实际意义(标签)的数字,而逻辑回归的输出是一个代表事件发生概率(即客户删除其账户的概率)的数字。
在实例化逻辑回归对象之前,我们计算一个平衡比率来说明类的不平衡。我们使用weightCol参数根据预先计算的比率对训练实例进行过采样/欠采样。我们想要“欠采样”负类和“过采样”正类。逻辑损失目标函数应该用较低的权重处理负类(标签== 0)。
*# Calculate a balancing ratio to account for the class imbalance*
balancing_ratio = train.filter(train['label']==0).count()/train.count()
train=train.withColumn("classWeights", F.when(train.label == 1,balancing_ratio).otherwise(1-balancing_ratio))
*# Create a logistic regression object*
lr = LogisticRegression(featuresCol = 'features', labelCol = 'label', weightCol="classWeights")
对于逻辑回归,pyspark.ml 支持在训练集上从模型的中提取一个[trainingSummary](https://spark.apache.org/docs/2.1.0/api/python/pyspark.ml.html#pyspark.ml.classification.LogisticRegressionSummary) 。这不适用于拟合的CrossValidator对象,这就是为什么我们从没有参数调整的拟合模型中取出它。
lrModel = lr.fit(train)
trainingSummary = lrModel.summary
我们可以使用它来绘制阈值-召回曲线,阈值-精度曲线,召回-精度曲线和阈值-F-测量曲线,以检查我们的模型如何执行。此阈值是一个预测阈值,它根据模型输出的概率确定预测的类别。模型优化包括调整该阈值。
*# Plot the threshold-recall curve*
tr = trainingSummary.recallByThreshold.toPandas()
plt.plot(tr['threshold'], tr['recall'])
plt.xlabel('Threshold')
plt.ylabel('Recall')
plt.show()

Figure 9
*# Plot the threshold-precision curve*
tp = trainingSummary.precisionByThreshold.toPandas()
plt.plot(tp['threshold'], tp['precision'])
plt.xlabel('Threshold')
plt.ylabel('Precision')
plt.show()

Figure 10
*# Plot the recall-precision curve*
pr = trainingSummary.pr.toPandas()
plt.plot(pr['recall'], pr['precision'])
plt.xlabel('Recall')
plt.ylabel('Precision')
plt.show()

Figure 11
*# Plot the threshold-F-Measure curve*
fm = trainingSummary.fMeasureByThreshold.toPandas()
plt.plot(fm['threshold'], fm['F-Measure'])
plt.xlabel('Threshold')
plt.ylabel('F-1 Score')
plt.show()

Figure 12
随着我们提高预测阈值,召回率开始下降,而精确度分数提高。常见的做法是将相互竞争的指标可视化。
让我们使用交叉验证来调整我们的逻辑回归模型:
*# Create ParamGrid for Cross Validation*
paramGrid = (ParamGridBuilder()
.addGrid(lr.regParam, [0.01, 0.5, 2.0])
.addGrid(lr.elasticNetParam, [0.0, 0.5, 1.0])
.addGrid(lr.maxIter, [1, 5, 10])
.build())
cv = CrossValidator(estimator=lr, estimatorParamMaps=paramGrid, evaluator=evaluator, numFolds=5)
*# Run cross validations*
cvModel = cv.fit(train)
predictions = cvModel.transform(test)
predictions_pandas = predictions.toPandas()
print('Test Area Under PR: ', evaluator.evaluate(predictions))*# Calculate and print f1, recall and precision scores*
f1 = f1_score(predictions_pandas.label, predictions_pandas.prediction)
recall = recall_score(predictions_pandas.label, predictions_pandas.prediction)
precision = precision_score(predictions_pandas.label, predictions_pandas.prediction)
print('F1-Score: {}, Recall: {}, Precision: {}'.format(f1, recall, precision))
参数调整后,逻辑回归显示以下性能:
- f1-得分:0.66
- 回忆:0.84
- 精度:0.54
梯度增强树分类器
梯度推进树是一种使用决策树集成的流行分类方法。对于类不平衡的数据,提升算法通常是很好的选择。PySpark 的 MLlib 支持它,所以让我们在我们的数据集上尝试一下:
gbt = GBTClassifier()*# Create ParamGrid for Cross Validation*
paramGrid = (ParamGridBuilder()
.addGrid(gbt.maxDepth, [2, 4, 6])
.addGrid(gbt.maxBins, [20, 60])
.addGrid(gbt.maxIter, [10, 20])
.build())
cv = CrossValidator(estimator=gbt, estimatorParamMaps=paramGrid, evaluator=evaluator, numFolds=5)
*# Run cross validations*
cvModel = cv.fit(train)
predictions = cvModel.transform(test)
predictions_pandas = predictions.toPandas()
print('Test Area Under PR: ', evaluator.evaluate(predictions))*# Calculate and print f1, recall and precision scores*
f1 = f1_score(predictions_pandas.label, predictions_pandas.prediction)
recall = recall_score(predictions_pandas.label, predictions_pandas.prediction)
precision = precision_score(predictions_pandas.label, predictions_pandas.prediction)
print('F1-Score: {}, Recall: {}, Precision: {}'.format(f1, recall, precision))
参数调整后,梯度增强树分类器显示出以下性能:
- f1-得分:0.58
- 回忆:0.56
- 精度:0.61
决策树分类器
决策树是一种流行的分类和回归方法。
dt = DecisionTreeClassifier(featuresCol = 'features', labelCol = 'label')*# Create ParamGrid for Cross Validation*
paramGrid = (ParamGridBuilder()
.addGrid(dt.maxDepth, [2, 4, 6])
.addGrid(dt.maxBins, [20, 60])
.addGrid(dt.impurity, ['gini', 'entropy'])
.build())
cv = CrossValidator(estimator=dt, estimatorParamMaps=paramGrid, evaluator=evaluator, numFolds=5)
*# Run cross validations*
cvModel = cv.fit(train)
predictions = cvModel.transform(test)
predictions_pandas = predictions.toPandas()
print('Test Area Under PR: ', evaluator.evaluate(predictions))*# Calculate and print f1, recall and precision scores*
f1 = f1_score(predictions_pandas.label, predictions_pandas.prediction)
recall = recall_score(predictions_pandas.label, predictions_pandas.prediction)
precision = precision_score(predictions_pandas.label, predictions_pandas.prediction)
print('F1-Score: {}, Recall: {}, Precision: {}'.format(f1, recall, precision))
参数调整后,决策树分类器表现出以下性能:
- f1-得分:0.56
- 回忆:0.60
- 精度:0.52
结论
该项目的目标是利用 Apache Spark 的分析引擎进行大规模数据处理的能力,来检测即将停止使用 Sparkify 音乐流媒体服务的客户。
我们应用了数据科学流程的典型步骤,如了解数据、数据准备、建模和评估。
逻辑回归模型显示出最高的性能(F1-得分:0.66,回忆:0.84,精度:0.54)。我们能够召回 84%的流失客户,并为他们提供特别优惠,防止他们删除 Sparkify 账户。然而,我们需要考虑 54%的中等精度分数。这意味着,在所有将获得特别优惠的顾客中,46%的顾客实际上对服务感到满意,不需要任何特殊待遇。
这篇文章的源代码可以在 GitHub 上找到。我期待听到任何反馈或问题。
预测员工保留率

Photo by Mario Gogh on Unsplash
介绍
我们知道,大公司有超过 1000 名员工为他们工作,所以照顾每个员工的需求和满意度是一项具有挑战性的任务,它导致有价值和有才华的员工离开公司,而没有给出适当的理由。
如今,员工流失是许多公司面临的一个主要问题。优秀的人才是稀缺的,难以留住的,而且需求量很大。鉴于快乐的员工和快乐的客户之间众所周知的直接关系,了解员工不满的驱动因素变得至关重要。
这个职位强调预测一个员工在一个组织中的保留,例如该员工是否会离开公司或继续留在公司。它使用以前为该公司工作的员工的数据,通过找到一种模式,以是或否的形式预测保留率。
我们正在使用的参数,如工资、在公司的工作年限、晋升、工作时间、工伤事故、财务背景等。通过这篇论文,一个组织可以选择它的策略来阻止优秀的代表离开组织。数据有 14999 个例子(样本)。下面是每一种的功能和定义:
- satisfaction_level:满意度{ 0–1 }。
- last_evaluationTime:自上次绩效评估以来的时间(以年为单位)。
- number_project:工作时完成的项目数。
- average_montly_hours:工作场所的平均月小时数。
- time_spend_company:在公司工作的年数。
- Work_accident:员工是否发生了工作场所事故。
- left:员工是否离开了工作场所{0,1}。
- promotion_last_5years:员工在过去五年中是否获得晋升。
- 销售:员工工作的部门。
- 工资:工资的相对水平{低、中、高}。
创建这篇文章的源代码可以在这里找到。

Data Set
将数据加载到数据框中并分离结果列。

FinalCode.py hosted by GitHub
数据预处理
数据集将“salary”和“sales”列作为分类数据,因此我们必须执行 OneHotEncoding & LabelEncoding 来将此数据转换为数字形式,并创建虚拟特征。我们必须删除第一个特征,以避免某些学习算法可能会遇到的线性依赖性。
之后,我们将把数据分成训练和测试数据集。

Preprocessing
回归模型
因为我们想要“是”或“否”形式的结果,例如员工是否会离开公司,所以最合适的回归模型是该数据集的逻辑回归。逻辑回归是一种分类算法,用于将观察值分配给一组离散的类。分类问题的一些例子是电子邮件垃圾邮件或非垃圾邮件、在线交易欺诈或非欺诈、恶性肿瘤或良性肿瘤。
为了计算我们的模型生成的结果的准确性,我们将使用混淆矩阵作为评估参数。

Logistic Regression
分类器
决策树是一种类似流程图的树结构,其中内部节点代表特征(或属性),分支代表决策规则,每个叶节点代表结果。决策树中最顶端的节点称为根节点。它学习根据属性值进行分区。它以递归的方式对树进行分区,称为递归分区。
随机森林是一种监督学习算法。森林是由树木组成的。据说树越多,森林就越健壮。随机森林在随机选择的数据样本上创建决策树,从每棵树获得预测,并通过投票选择最佳解决方案。它还提供了一个很好的特性重要性指标。
在我们的数据集中,我们将使用这两个分类器以是和否的形式对结果进行分类。

Decision Tree and Random Forest Classifier
结论

Factors affecting the employment
在上面的图表中,x 轴上从 0 到 6 的数字代表较高的项目,较低的销售级别,较高的时间,促销,工作事故,或非工作事故,无事故。以上每一项都是影响就业的因素,用 HigherTime 表示,有四年以上工作经验但仍未得到任何晋升的员工是 1750 人,这是一个很大的数字,用 LowerSalary 表示即使他们的评估分数高于 3,工资水平也很低的员工是 750 人。
因此,在评估该数据集后,我们了解到较低的工资水平,即使员工工作超过 4 年也没有晋升是员工离开组织的两个主要原因。
从赛季表现预测花样滑冰世锦赛排名
体育分析
第五部分:序贯多因素模型

背景
在项目的前几部分,我试图根据运动员在该赛季前几场比赛中获得的分数来预测一年一度的世界花样滑冰锦标赛的排名。主要策略是将滑手效应**(每个滑手的内在能力)与事件效应(一个事件对滑手表现的影响)分开,以便建立更准确的排名。**

First 4 columns: normalized scores in each factor. Last column: combined score from logistic regression model. Heatmap color: rank of a skater in each factor. Text color: rank of a skater in the world championship
具体来说,在项目的第三部分中,每个滑手都由多个潜在因素代表(见附图中的前 4 列)。然后,在第四部分的中,使用逻辑回归模型来组合每个选手的潜在分数,并根据这些组合分数对选手进行排名(图表中的最后一列)。该模型使用双重交叉验证进行评估:它在 5 个季节进行训练,并在另外 5 个季节进行评估。
问题
使用多因素模型来学习运动员的潜在得分,使用逻辑回归模型来预测运动员的排名,我们试图通过以下方式改进这两个模型:
- 增加潜在因素的数量
- 提前停止多因子模型的梯度下降算法
- 提前停止逻辑回归模型的梯度上升算法
后两种提前停止策略旨在防止模型过度拟合赛季得分(对于多因素模型)或世界锦标赛排名(对于逻辑算法模型),以便他们可以很好地预测他们没有训练过的赛季。
然而,当我们检查这两个模型的哪个停止迭代对验证集中的肯德尔τ的改善最大时,得到了一个奇怪的结果(与基线模型相比):

从上表可以看出,对于大多数因素(除了 2),当逻辑回归运行 0 次迭代时,Kendall 的改善最大。这意味着使用逻辑回归比根本不使用它更糟糕!
潜在分数的问题
为什么逻辑回归在合并潜在得分方面做得如此糟糕?我的假设是,在 part 3 中学到的潜在分数本来就不好。更具体地说,它们完全是任意的,并没有真正抓住每个选手的潜在能力。
要了解原因,让我们重温一下多因素模型的公式(如第 3 部分所述):

ŷ_event-skater:给定运动员在给定项目中的预测得分- 存在于每个项目和每个运动员身上的潜在因素
θ_event,f:给定事件的潜在因素得分θ_skater,f:给定选手的潜在因素得分
从上面的公式中,我们看到,学习潜在得分只是为了尽可能地逼近赛季得分,而不是其他。因此:
- 如果两个因素互换,预测的分数——因此模型性能(RMSE)——将保持完全相同,但这些因素现在与它们之前完全相反。
- 作为一个推论,没有一个因素会比其他因素更重要,他们的产品和相应的事件得分在每个赛季得分中的贡献大致相同。
- 这似乎不符合我们对滑冰者的合理直觉:可能有一些因素比其他因素更重要,对滑冰者赢得的赛季分数贡献更大。
当绘制两个不同季节(2005 年和 2017 年)的 2 因素模型的潜在得分时,可以证明潜在因素模型的这些弱点。此外,对于每个季节,梯度下降开始时的潜在得分用两个不同的随机种子(42 和 24)初始化:

Heatmap color: Ranking of skater by each individual factor. Text color: rank of a skater in the world championship
从上图可以看出:
- 即使只是在初始化梯度下降时改变种子,我们最终会在两个因素(白色部分)中的每一个上得到非常不同的潜在选手分数。事实上,潜在得分似乎在很大程度上互换了,因为当使用不同的种子时,每个单独因素产生的排名似乎交换了位置。
- 这也可以在代表每个因素(以及基线得分)对赛季得分的平均贡献的饼图中看到:一个种子显示因素 1 的贡献大于因素 2,而另一个种子显示相反。然而,与之前的猜测一致,这两个因素的影响大致相同。
- 更糟糕的是,即使是同一个因素,该因素在不同季节的得分和排名也几乎没有相似之处。因此,很难证明将不同季节的差异矩阵堆叠在一起来训练第 4 部分中的逻辑回归模型是合理的,因为这样做,我们假设相同的因子代表不同季节的相同事物。
因此,我们需要彻底检查潜在因素模型,使一些因素优先于其他因素,并确保同一因素在不同季节之间保持一致。
依次训练潜在因素
对当前潜在因素模型的一个明显的修正是只更新一个因素的潜在得分,直到 RMSE 达到稳定状态。然后,我们开始更新下一个因子,以此类推,希望 RMSE 进一步减小。
这可以通过修改多因子模型的梯度下降算法来完成,以便它一次更新一个因子。然而,实现这一点的更方便的方法是:

- ****第一步:在赛季得分上训练单因素模型,得到第一因素的潜在事件和潜在得分(关于实现单因素模型的更多细节,参见第二部分)。
- ****第二步:在第一步后的负残差上训练另一个单因素模型,得到第二个因素的潜在得分。使用负残差(而不仅仅是残差),因为在这个项目中,我们将残差定义为预测得分-真实得分。因此,它的负值:真实得分-预测得分,表示第一个因素没有考虑的赛季得分的剩余部分。
- ****第三步:我们可以对任意多的因素重复第二步,并简单地将所有单个因素收集到潜在选手分数的矩阵中。换句话说,这些步骤的输出将与多因素模型相同,但在这种情况下,因素是按顺序学习的。
编码顺序多因素模型
鉴于我们已经在第 2 部分中浏览了单因子模型的梯度下降算法的代码,下面的代码块显示了如何简单地修改现有代码以按顺序训练多个因子。
**# Transform long score table to pivot form
season_pivot = pd.pivot_table(sample_season_scores[['name', 'event', 'score']], values='score', index='name', columns='event')# Convert pivot table to numpy array
true_scores = season_pivot.values# Store skater and event names to retrieve later
skater_names = list(season_pivot.index)
event_names = list(season_pivot.columns)# Create lists to store scores of individual
multi_skater_scores = []
multi_event_scores = []
multi_baselines = []# Run gradient descent algorithm
alpha = 0.0005
n_factors = 2
init_seed = 42**for n in range(n_factors):**
# 1\. Initialize baseline, event, and skater scores
random_state = np.random.RandomState(seed=init_seed**+n**)
baseline = random_state.random_sample()
skater_scores = random_state.random_sample((len(skater_names), 1))
event_scores = random_state.random_sample((1, len(event_names)))
# Run gradient descent
for i in range(1000):
# 2a. Calculate gradients
predicted_scores = skater_scores @ event_scores + baseline
residuals = predicted_scores - true_scores baseline_gradient = np.nansum(residuals)
event_gradients = np.nansum(residuals * skater_scores, axis=0, keepdims=True)
skater_gradients = np.nansum(residuals * event_scores, axis=1, keepdims=True) ### 2b. Update latent scores using gradients
baseline = baseline - alpha * baseline_gradient
event_scores = event_scores - alpha * event_gradients
skater_scores = skater_scores - alpha * skater_gradients
# Store result for each factor
multi_skater_scores.append(skater_scores.ravel())
multi_event_scores.append(event_scores.ravel())
multi_baselines.append(baseline)
# Reset true score matrix as negative residual
**final_residuals = skater_scores @ event_scores + baseline - true_scores
true_scores = -final_residuals**# Create latent score matrices with previously-stored name
multi_skater_scores = pd.DataFrame(multi_skater_scores).T
multi_skater_scores.index = skater_namesmulti_event_scores = pd.DataFrame(multi_event_scores).T
multi_event_scores.index = event_names**
主要修改以粗体突出显示,包括:
- 将梯度下降算法包含在一个
for循环中——for n in range(n_factors)——以便它可以对多个因子重复。 - 这伴随着每个循环/因子末尾附近的代码块,其中用于训练下一个因子的
true_scores矩阵被设置为前一个因子的负残差矩阵。请注意,我们需要在每次梯度下降后计算一个final_residual矩阵:这将使用潜在得分的最新值更新残差,然后将其交给下一个因子。 - 最后,在实现该算法时,我注意到,如果使用新的种子来初始化每个后续因子的梯度下降,模型的 RMSE 将下降得更多。也许一个新的种子阻止了下一个因子达到与前一个因子相同的局部最小值。在任何情况下,种子现在都与代表每个因子的数字
n联系在一起,为了灵活起见,它被添加到用户指定的种子数字:random_state = np.random.RandomState(seed=init_seed+n)之上。
双因素示例的结果
让我们回顾一下前面两个不同季节的双因素例子,每个季节有两种不同的种子。不同的是,现在我们依次训练两个潜在因素,而不是像以前一样同时训练。

White text: latent score in each factor. Heatmap color: Ranking of skater by each individual factor. Pie chart: average contribution of each factor, along with the baseline score, in season scores
从上面显示的结果,我们可以看到:
- 在初始化模型时改变种子的效果对最终的潜在分数的影响要小得多,因为分数即使在不同的种子数目开始时也保持相对稳定。
- 第一个因素现在比第二个因素对赛季得分的贡献大得多。事实上,第二个因素的贡献是如此之小(<0.1%) that it did not even show up in the pie charts at the bottom of the diagram. The first factor also has much better predicted ranking than the second, as evidenced by its “smoother” rank colors. This indicates that there is a clear hierarchy in which some factors are more important than others.
- Furthermore, this hierarchy consistently holds across different seasons, as evidenced by the relative contribution of the first factor in each pie chart between the 2005 and 2017 seasons. Within each factor, the ranking produced between the seasons also match quite closely (at least for the first factor). This then allows us to stack different seasons together to train the logistic regression model.
These results confirm that we should learn the latent factors sequentially. However, once these factors are learned, we can use logistic regression to combine them and rank the skaters exactly as before (see 第 4 部分关于如何做到这一点)。
结果
为了更清楚地显示顺序多因素模型是如何工作的,我们可以在梯度下降的迭代中监控其性能。每个因素训练 1000 次迭代,每 100 次迭代的结果显示在下面熟悉的动画仪表盘中(针对 2017 赛季的男滑手):

上面的仪表板清楚地显示了一个因素完成训练的时间,之后剩下的赛季分数用于训练下一个因素。RMSE 下降的明显“步骤”以及当一个新的因素开始训练时热图中残差的突然减少都证明了这一点。
改进序贯多因素模型
为了改进顺序多因素模型,使其能够更好地对运动员进行排名——当与逻辑回归模型结合时——我们对第 4 部分中的原始多因素模型使用相同的策略:增加因素的数量,并提前停止。
增加因子的数量
使用相同的 2 折交叉验证计划,我们在不同数量的因子(在α=0.005 和 1000 次迭代)下训练顺序多因子模型,然后在潜在得分上训练逻辑回归模型(也在α=0.005 和 1000 次迭代)。对于每个因素的数量,我们然后从基线模型获得肯德尔τ的平均训练和验证改进。

Bold lines: average improvement in Kendall’s tau across 10 years. Lighter lines: improvement in Kendall’s tau for each year
因子数增加 2 倍(从 2 一直到 128 个因子)的结果如上图所示。从这个图表中,我们可以看到:
- 与来自原始多因素模型的结果相似,序列模型仍然可以在更高数量的因素下过度拟合训练数据,这由训练集中的高 Kendall tau 改进所证明,但与验证集中的基线模型相比,Kendall tau 差得多。
- 然而,在验证集中,顺序多因子模型的表现略好于原始模型,尤其是在因子数量较少的情况下。这是有意义的,因为顺序模型首先训练最重要的因素,所以即使结合这些因素中的几个也可能提供一个体面的排名。当然,排名准确性仍然没有明显好于季节平均值的基线模型(水平线为零),这由验证集中 Kendall 的 tau 改进的置信区间所证明。
- 然而,这些置信区间比原始多因素模型的置信区间相对更窄。这表明,按顺序训练潜在因素是一个很好的选择:这些因素的排名在不同季节之间不太不稳定,这可能是由于这些因素在不同季节之间的一致性,如前所述。
提前停止
与第 4 部分类似,我们可以提前停止序列多因素模型的梯度下降,以及随后的逻辑回归模型的梯度上升。通过阻止这些算法完全收敛,我们可能不会获得最佳的训练性能,但希望这些模型不会过度适应训练数据,并更好地进行概括。
因此,我们可以改变两个模型的 3 个超参数:
- 因素数量
- 多因素模型梯度下降的停止迭代
- logistic 回归模型梯度上升的停止迭代
对于这 3 个超参数的每个组合,我们记录其平均训练和肯德尔τ与基线模型相比的验证改进。这些结果绘制如下:
- 多因子模型,停止迭代次数从 0 到 100(每个因子),间隔 5 次迭代
- 停止迭代从 0 到 100,间隔 5 次迭代的逻辑回归模型
- 因子数量以 2 的倍数增加,从 2 到 128 个因子

上述结果在很大程度上反映了原始多因素模型的结果,即:
- 因子数量加倍的效果在提高训练集中的 Kendall tau 方面最为显著,但遗憾的是,也恶化了验证集中的 Kendall tau——这是反映早期观察的过度拟合的经典案例。
- 对于涉及早期停止的其他两个超参数,我们看到,在两个模型的迭代次数都很低的情况下,虽然训练性能可以理解地乏善可陈,但验证性能是最不令人担忧的。这可以从验证集(底行)的每个方块左下角的亮淡色点看出。换句话说,很早就停止这两个模型可以极大地帮助减少模型过度拟合。
- 与原始的多因素模型相比,对来自序列模型的潜在分数运行逻辑回归,即使只是几次迭代,也比不运行所有的要好得多。这可以通过底部行的每个方块中的垂直红线看出,这意味着如果我们不运行逻辑回归,即运行 0 次迭代,则肯德尔τ的有效性非常低。
对于每一个因子,我们注意到与基线模型相比,两个模型在验证集中的肯德尔τ值的改善最大的停止迭代时,也可以看出这一点:

从上表中,我们可以看到,在 4 个因素下,顺序多因素模型的每个因素迭代 35 次,之后的逻辑回归模型迭代 30 次,相对于其他超参数组合,预测排名在验证集中具有最高的平均肯德尔τ。然而,请注意,与季节平均值的基线模型相比,这仅仅是 0.009 的微小改进。
对女性滑冰运动员重复同样的分析,我们看到 3 个模型超参数的相互作用基本相同:

然而,对于女性速滑运动员,超参数的最佳组合是 2 个因子,顺序模型的每个因子 65 次迭代,逻辑回归模型的 5 次迭代。这导致肯德尔τ的平均改善比验证集中的基线模型稍高 0.015。

决赛成绩
使用上面这些微调的超参数,我们可以从 2017 赛季的男子滑冰运动员的逻辑回归中找到模型系数和综合得分:

First 4 columns: normalized scores in each factor. Last column: combined score from logistic regression model. Heatmap color: rank of a skater in each factor. Text color: rank of a skater in the world championship
- 如前所述,序列模型的第一个因素是最重要的,不仅在于它对赛季得分的贡献,还在于预测世界冠军排名(见随附的热图)。因此,与其他因素相比,它的模型系数高得多(至少高 10 倍)也就不足为奇了。
- 然而,这意味着结合潜在的分数可能不会比仅仅通过第一个因素对运动员进行排名产生更多的改进,这正是在第二部分中讨论的单因素模型的策略。
- 事实上,在这个例子中,仅通过第一个因素对溜冰者进行排名,在 276 对中就产生了 241 对正确的对,对应于 0.746 的肯德尔τ。相比之下,根据运动员的综合得分对他们进行排名只会产生多一对正确的选手,肯德尔的τ值为 0.754。从随附热图的第一列和最后一列之间非常相似的等级颜色可以看出这一点。
因此,当汇总所有季节时,我们可以看到多因素模型仅略微改进了在第 2 部分中开发的提前停止单因素模型:

即便如此,多因素模型仍然无法超越季节平均值的基线模型,因为其肯德尔τ改进的 95%置信区间(在验证集上)仍然包含零水平线。此外,由于我们已经使用了所有 10 个赛季的世界冠军排名来调整模型的超参数,上述结果很可能过于乐观。
因此,在接下来的和项目的最后一部分,我会尝试将所有现有的模型合并成一个,看看最后的努力是否能提高预测的排名。然后,我将使用尚未分析的剩余 4 个赛季对项目开始以来开发的所有排名模型进行基准测试。
资源
正如在第三部分末尾所讨论的,寻找事件和运动员的潜在得分无非是将赛季得分的事件-运动员矩阵分解成运动员特定矩阵和事件特定矩阵,然后它们可以相乘以近似原始赛季得分矩阵。
事实上,用于训练多因素模型的梯度下降算法几乎与网飞挑战赛中用于向用户推荐电影的著名的 FunkSVD 矩阵分解算法相同(基于他们对每部电影留下的评级)。在这种情况下,用户=选手,电影=事件,评分=赛季得分。
然而,我一点也不知道原来的芬克先生也是一次训练一个人的潜在特征!事实上,在他的博客文章的结尾,他的模型的 RMSE 图与我的动画仪表板中的台阶状形状相同。我想我应该从一开始就更仔细地阅读他的文章。

RMSE plot from the original FunkSVD
从赛季表现预测花样滑冰世锦赛排名
体育分析
第 3 部分:多因素模型

背景
在项目的前几部分,我试图根据运动员在该赛季前几场比赛中获得的分数来预测一年一度的世界花样滑冰锦标赛的排名。主要策略是将滑手效应**(每个滑手的内在能力)与事件效应(一个事件对滑手表现的影响)分开,以便建立更准确的排名。**
针对这个排名问题提出了几个模型,其中一对运动员的赛季得分可以近似为:
- 一个基线得分**,它在所有赛季得分中保持不变**
- 潜在的事件分数**,该分数在所有参加该事件的选手中是不变的**
- 一个潜在的滑冰者分数**,该分数在该滑冰者参加的所有比赛中都是不变的**
这些潜在得分可以相加在一起(加法模型),或者相乘在一起(乘法模型,或者两者的组合(混合模型):

- 正如项目第一部分所讨论的,前两个模型可以重写为简单的线性模型,模型系数就是潜在得分本身。因此,通过求解线性回归的正规方程可以很容易地找到它们
- 相比之下,没有封闭形式的解决方案来学习混合模型的潜在分数。然而,这些分数可以通过应用梯度下降来最小化预测分数和该赛季的真实分数之间的平方差来找到。项目的第二部分更详细地讨论了混合模型的梯度下降算法。
- 最后,一旦学习了每个模型的潜在分数,模型的预测排名就只是潜在溜冰者分数的排名,从最高到最低。
问题
来自所有 3 个先前模型的预测排名与基于他们的赛季平均成绩的简单排名的基线模型相比较。用于评估这些模型的指标是肯德尔排名相关系数 —也称为肯德尔的τ**—相对于实际的世界锦标赛排名:如果模型的预测排名具有更接近 1 的肯德尔τ,则模型更好,这意味着预测排名与当年世界锦标赛的实际排名更相关。你可以查看这个项目的第一部分来了解 Kendall 的 tau 是如何工作的,包括如何计算一个玩具的例子。**

从以上关于在训练集中选择的 10 年(14 年中的 10 年)中的这三个模型的报告来看,所有模型都比赛季平均值的基线模型更好地逼近赛季得分,这由它们与基线模型相比平均更低的均方根误差 (RMSE)来证明。
然而,在更重要的 Kendallτ度量中,遗憾的是,与基线模型相比,这些模型没有提供该度量的任何显著增加,因为对于男性和女性溜冰者,它们与基线之间的 Kendallτ差异的 95%置信区间包含零。
为了改进这些模型,我尝试了几种策略来防止模型过度适应赛季分数,这可能会很吵,可能不会反映运动员的真实能力(也许他们在比赛当天早些时候食物中毒)。因此,这可能会更好地捕捉运动员的真实能力,并为世界锦标赛更准确地排名。
这些策略包括岭回归和提前停止,这是减少机器学习中模型过度拟合的两种最流行的策略。然而,这两种策略都未能显著提高模型的肯德尔τ值。因此,如果我们想更好地预测运动员在世界锦标赛中的排名,就需要一种新的模型。
多因素模型
为了开发这个新模型,让我们重新回顾一下在项目的前一部分中开发的混合模型:

ŷ_event-skater:给定运动员在给定项目中的预测得分θ_baseline:基线得分(整个赛季得分不变)θ_event:该项目潜在得分(运动员之间不变)θ_skater:溜冰者潜在得分(跨事件恒定)
在上面的公式中,我们可以看到,每个项目都用一个单独的潜在得分(θ_event)来表示,每个滑手也用一个单独的潜在得分(θ_skater)来表示。
但是,如果不是单一的潜在分数,而是每个滑手都用多个潜在因素来表示呢?例如,他有多喜欢在早上滑冰,或者她有多习惯在高海拔地区比赛。类似地,每个事件可以用相同的因素来表示:事件发生在早上多早,或者发生在什么高度。
因此,一个运动员和一个事件之间的每个对应因素可以相乘,然后将这些乘积的总和加到基线得分上,以预测该季节中该运动员-事件对的真实得分:

ŷ_event-skater:给定事件中给定选手的预测得分f:存在于每个项目和每个滑手身上的潜在因素θ_event,f:给定事件潜在因素得分θ_skater,f:给定选手潜在因素得分
寻找潜在因素
与前面的模型类似,多因素模型中的潜在因素可以通过最小化赛季期间真实得分和预测得分之间的平方差之和来找到(从这里开始称为残差**)😗*

J:模型的目标函数。继续以 2017 赛季的男子滑冰运动员为例,这将是 1 个基线分数、9 个项目中每个项目的所有n潜在因素(以蓝色突出显示)以及 62 名滑冰运动员中每个项目的所有n潜在因素(以黄色突出显示)的函数。ŷ_e,s:多因素模型预测的一对运动员的得分y_e,s:在赛季中记录事件-溜冰者对的真实分数θ_baseline:基线得分θ_e,f:事件e的潜在因素f的得分θ_s,f:滑手s潜在因素f的得分
梯度下降算法
尽管多因素模型中的潜在分数激增——最后的双倍总和看起来确实很可怕——让我们保持冷静,继续梯度下降。首先,让我们对潜在得分的目标函数进行微分,以获得它们的梯度。
寻找渐变
类似于混合模型,基线得分的梯度就是赛季中所有项目-运动员对的残差之和:****

接下来,我们来算出给定事件 **i** ( θ_ei,k)的某因子 **k** 的梯度:****

- 当取这个梯度时,所有与这个事件无关的残差平方都将消失。剩下的就是那些涉及到参加这个项目的滑手。因此,只有这些平方残差的导数才有效。
- 当对参加这个项目的每个溜冰者
s求导时,基本的链式法则起作用:外部求导返回这个项目中那个溜冰者的余数。然后,我们对残差本身进行内部求导,这将使基线、真实分数和其他所有潜在因素的分数(不是 T1)消失。剩下的是那个滑冰运动员(θ_s,k)的潜在因素k的单个分数,因为它之前被乘以了这个非常事件(θ_ei,k)的因素k的相应分数。 - 因此,对于参加这个事件的每个溜冰者
s,我们将把外部导数——那个溜冰者在事件i中的残差——乘以内部导数——他拥有的潜在因素k的分数。将所有参加本次活动的滑冰运动员的这些产品相加,最终将得出事件i的因子k的梯度。 - 这个梯度公式的巧妙之处在于,外导数中的残差不依赖于我们感兴趣的因子
k。因此,可以多次重复使用该残差,以找到该事件的所有其他因素的梯度(通过将其乘以不同的内部导数)。这将在我们编写梯度下降算法的时候用到。
同样,给定滑手 **j**的随机因子 **k** 的梯度就是上面事件梯度的滑手类似物:****

与前一个公式相比,该公式的主要区别在于:
- 我们正在总结这位选手参加的所有项目
- 内部导数是每个事件(
θ_e,k)的潜在因素k的相应分数
但是,请注意,外部导数中的残差仍然独立于k,并且可以被重新用于找到该溜冰者的所有其他因素的梯度(除了k)。
更新潜在得分
一旦计算出每个项目和每个运动员的所有因素的梯度,我们就可以更新这些因素的潜在得分:

- 类似于混合模型的梯度下降,更新步骤中学习率α的存在将控制梯度下降的速度并帮助其更好地收敛(如果选择了合适的学习率)。
- 请注意,每个因素的更新步骤是独立于所有其他因素完成的。这也将帮助我们实现多因子模型梯度下降的 Python 代码。
摘要
给定上述梯度公式和更新规则,多因子模型的梯度下降可总结为:

Gradient descent algorithm for multi-factor model
通过以上总结,可以看出:
- 一旦计算了每个事件-滑冰运动员对的残差(步骤 2a),它可以用于独立于每个其他潜在因素单独计算每个潜在因素
k的梯度(步骤 2c-i)。换句话说,这就好像每个项目和每个滑手只有一个单一的潜在得分,它们的梯度计算方法与单因素混合模型完全相同。之后,残差被重新用于计算下一个潜在因子的梯度(使用完全相同的方法)。 - 此外,每个因子
k的更新步骤也独立于所有其他因子(步骤 2c-ii)。因此,我们可以逐个更新每个潜在因素的分数,直到我们完成步骤 2 的一次迭代。
换句话说,多因素模型的梯度下降算法实际上与单因素混合模型的算法相同,只是一旦计算出每个项目-运动员对的残差,我们需要计算梯度并逐个更新每个潜在因素的分数(通过重用残差)。
多因素模型编码
让我们使用与混合模型相同的玩具示例,一个season_scores熊猫数据框架,包含 4 名滑冰运动员(MAJOROV,FERNANDEZ,GE,MURA)的 7 个赛季成绩和不同国家(CA,FR,RU)的 3 项赛事:

类似于混合模型,我们首先将该数据框从长格式转换为数据透视表格式,运动员作为行,事件作为列,条目是每个事件-运动员对的分数。注意,不是所有的滑手都参加所有的项目,所以数据透视表中有缺失值,用NaN(不是数字)表示。
**season_pivot = pd.pivot_table(season_scores[['name', 'event', 'score']], values='score', index='name', columns='event')**

然后,我们将熊猫数据透视表转换成一个 4×3 的 numpy 矩阵true_scores,这样我们可以更容易地操作它。这实际上将删除所有的行和列名称,所以让我们存储运动员名称(行)和事件名称(列),这样我们在运行梯度下降后仍然可以识别它们。
**skater_names = list(season_pivot.index)
# ['Alexander, MAJOROV', 'Javier, FERNANDEZ', 'Misha, GE', 'Takahito, MURA']event_names = list(season_pivot.columns)
# ['CA', 'FR', 'RU']true_scores = season_pivot.values
# array([[ nan, nan, 192.14],
# [ nan, 285.38, 292.98],
# [226.07, 229.06, nan],
# [222.13, 248.42, nan]])**
第一步:初始化基线、潜在项目和潜在选手得分
对于基线分数,类似于混合模型,我们可以只使用一个[RandomState](https://docs.scipy.org/doc/numpy-1.15.0/reference/generated/numpy.random.RandomState.html)对象的[random_sample](https://docs.scipy.org/doc/numpy-1.15.0/reference/generated/numpy.random.RandomState.random_sample.html#numpy.random.RandomState.random_sample)方法(带有特定的种子)来返回一个介于 0 和 1 之间的随机数。
**random_state = np.random.RandomState(seed=42)
baseline = random_state.random_sample() # 0.37**
对于这个玩具的例子,让我们假设对于每个事件和每个溜冰者,我们有 2 个潜在的因素。因此,我们可以将 4 个溜冰者的所有潜在分数初始化为 4×2 矩阵。类似地,我们可以将 3 个事件的所有潜在得分初始化为 2×3 矩阵。
**skater_scores = random_state.random_sample((4, 2))
# array([[0.95071431, 0.73199394],
# [0.59865848, 0.15601864],
# [0.15599452, 0.05808361],
# [0.86617615, 0.60111501]])event_scores = random_state.random_sample((2, 3))
# array([[0.70807258, 0.02058449, 0.96990985],
# [0.83244264, 0.21233911, 0.18182497]])**
步骤 2a:计算每对运动员的残差
以矩阵形式初始化这些潜在得分的原因是,通过将这些向量相乘(使用矩阵乘法运算符@)并在此基础上添加基线,可以一次性计算出每对运动员的预测得分:
**predicted_scores = skater_scores @ event_scores + baseline
# array([[1.65705782, 0.54954103, 1.42974207],
# [0.92831034, 0.41999206, 0.98355296],
# [0.53334684, 0.39008461, 0.53640179],
# [1.48824946, 0.52001014, 1.32395061]])**
为了更清楚地说明这一点,下面的图表显示了两个潜在矩阵(大小分别为 4×2 和 2×3)与添加在顶部的基线相乘,以形成每对运动员的 4×3 预测得分矩阵。

Dotted line: implied indices of skaters and events, even though they don’t exist in numpy arrays
用红色突出显示的是如何通过此操作计算出一对运动员(CA-MAJOROV)的预测得分。请注意,两个潜在得分矩阵的乘法运算是如何自动对一对运动员的所有因素进行求和的,方法是在各自的潜在得分矩阵中取该运动员的相应行和该项目的相应列的点积。
一旦计算出每对运动员的预测得分,寻找残差就像从预测得分矩阵中减去真实得分的 numpy 数据透视表一样简单:
**residuals = predicted_scores - true_scores**
回想一下,我们的true_scores numpy 矩阵包含赛季中不存在的事件-运动员配对的NaN值。因此,当计算残差时,那些对的对应残差也是NaN。

步骤 2b:计算基线得分的梯度并更新它
就基线分数而言,混合模型的梯度没有任何变化,它只是所有残差的总和,并使用该梯度更新分数。

因此,为了计算基线梯度(baseline_gradient),我们使用相同的[np.nansum](https://docs.scipy.org/doc/numpy/reference/generated/numpy.nansum.html)函数对原因中现有的事件-溜冰者对的残差求和,同时忽略不存在的对,它们是residuals矩阵中的NaN。最后,基线分数通过减去其梯度乘以学习率alpha来更新。
**alpha = 0.0005
baseline_gradient = np.nansum(residuals)
baseline = baseline - alpha * baseline_gradient**
步骤 2c:对于每个因子 k,计算其在每个项目和每个选手中的梯度,并通过相应的梯度更新每个分数
下面是整个步骤的代码:
**# For each factor k
for k in range(2):
# Extract latent scores for that factor
skater_scores_k = skater_scores[:, [k]]
event_scores_k = event_scores[[k], :] # Step 2c-i: Find gradients of factor k for all skaters & events
event_gradients_k = np.nansum(residuals * skater_scores_k, axis=0, keepdims=True)
skater_gradients_k = np.nansum(residuals * event_scores_k, axis=1, keepdims=True) # Step 2c-ii: Update scores of factor k for all skaters & events
event_scores[[k], :] = event_scores_k - alpha * event_gradients_k
skater_scores[:, [k]] = skater_scores_k - alpha * skater_gradients_k**
正如前面在梯度下降推导中提到的,一旦计算了残差(步骤 2a),我们就将每个因素视为完全独立于所有其他因素。因此,我们可以计算梯度,并通过循环for k in range(2)(在我们的玩具示例中,因子数为 2)逐个更新每个潜在因子的分数:第一个因子将有k=0,而第二个有k=1。
让我们先来看看第一个因素(k=0)的步骤:
- 首先,我们提取该因素的潜在得分。这将是事件(
event_scores[[0], :])的潜在矩阵中的第一行,以及溜冰者(skater_scores[:, [0]])的潜在矩阵中的第一列。使用这些有趣的方括号0的原因是,我们希望将第一个因素的潜在分数保存为跨事件的大小为(1,3)的行向量和跨溜冰者的大小为(4,1)的列向量。如果没有这些括号,numpy 只会将这些切片折叠成一维数组。

- 对于所有事件(
event_scores_k)和所有溜冰者(skater_scores_k)的第一因素的这些提取的分数,问题现在简化为混合模型的单因素问题。因此,计算该因子中所有分数的梯度与混合模型完全相同:
**event_gradients_k = np.nansum(residuals * skater_scores_k, axis=0, keepdims=True)
skater_gradients_k = np.nansum(residuals * event_scores_k, axis=1, keepdims=True)**
我不会对这一步做太多的详细说明,因为它在项目的第 2 部分中有完整的解释,包括np.nansum : axis的参数,它控制梯度的求和方向(跨运动员或跨事件),以及keepdims,它防止 numpy 将梯度折叠为 1-D,并为后面的更新步骤保持它们的行/列向量形式。简而言之,我将在下面的图表中总结这些操作,首先计算所有事件中的梯度(第一个潜在因素):

Highlighted in red: relevant values for an example event (RU). Dotted arrows: numpy broadcasting of latent skater scores (for the first factor)
然后,为了计算所有溜冰者的梯度(第一潜在因素):

Highlighted in red: relevant values for an example skater (Takahito, MURA). Dotted arrows: numpy broadcasting of latent event scores (for the first factor)
- 一旦计算出第一个潜在因素的梯度,就可以用它们来更新所有运动员和项目中该因素的得分。
**event_scores[[0], :] = event_scores_k - alpha * event_gradients_k
skater_scores[:, [0]] = skater_scores_k - alpha * skater_gradients_k**

一旦第一个因素的潜在得分被更新,循环就移动到第二个因素(k=1)并重复同样的事情:计算所有事件和运动员中该因素的梯度(使用来自步骤 2a 的相同的residuals矩阵),并使用这些梯度更新潜在得分。以下是提取的单因素向量,将在k=1时处理:

最后,整个步骤 2 重复多次,在计算残差、寻找梯度和更新潜在得分之间移动,直到每个循环之后的 RMSEnp.sqrt(np.nanmean(residuals**2))已经稳定。经过 1000 次迭代后,这个玩具示例的多因子模型的 RMSE 达到了惊人的 0.004(相比之下,第 2 部分中的单因子混合模型为 4.30),迭代与迭代之间的差异为 1e-5。
事实上,当将潜在选手和事件矩阵相乘以获得赛季期间的最终预测分数时,模型的 RMSE 如此之低一点也不奇怪,因为预测分数(左)实际上与真实分数(右)相同:

Predicted season scores after 1000 iterations of gradient descent vs. true scores
最后,可以在 pandas DataFrame中检索所有选手的 2 个因素的潜在分数,将先前存储的选手姓名作为行索引添加回来,并将因素(0和1)作为列:
**pd.DataFrame(skater_scores, index=skater_names)
# 0 1
# Alexander, MAJOROV 10.226857 3.122723
# Javier, FERNANDEZ 16.009246 4.594796
# Misha, GE 11.919684 7.280747
# Takahito, MURA 14.059611 3.020423**
算法管用!然而,当我将它应用于真实数据时,它需要相当长的时间才能运行,尤其是当涉及到许多因素时。当然,我也记录了一系列中间值,但是让我们看看如何使梯度下降更快,这样迭代模型就不那么痛苦了。
用数字广播优化梯度下降
如前所述,多因素模型的梯度下降与单因素模型的梯度下降相同,但逐个应用于每个因素。这是算法的“幼稚”实现,因为我们只是按照数学告诉我们的方式编码。
然而,我们可以计算梯度并同时更新所有潜在因素的分数,而不是通过步骤 2c 中昂贵的for循环逐一处理这些因素。通过再次利用 numpy 的广播,这是可能的,这一次有一个额外的因素维度(而不仅仅是运动员和事件)。步骤 2c 的修改版本的代码如下:
**# 2c-i: Calculate gradients for all factors
# Reshape matrices
reshaped_residuals = residuals[np.newaxis, :, :]
reshaped_event_scores = event_scores[:, np.newaxis, :]
reshaped_skater_scores = skater_scores.T[:, :, np.newaxis]# Calculate gradients
event_gradients = np.nansum(residuals * reshaped_skater_scores, axis=1)
skater_gradients = np.nansum(residuals * reshaped_event_scores, axis=2).T# 2c-ii: Update latent scores for all factors
event_scores = event_scores - alpha * event_gradients
skater_scores = skater_scores - alpha * skater_gradients**
带np.newaxis的矩阵有哪些诡异的索引?为什么在幼稚的实现中是keepdims=False而不是True?请阅读下面的内容,看看它们是如何工作的。
重塑矩阵
回想一下,我们已经为所有事件和运动员初始化了潜在得分矩阵,它们分别是大小为(2,3)的 numpy 数组event_scores和大小为(4,3)的skater_scores。从步骤 2a 中,我们还得到大小为(4,3)的残差矩阵(residuals),其中每行代表一名运动员,每列代表一个事件。所有矩阵如下图所示:

在上面的潜在矩阵中,这两个因素粘在一起。然而,梯度下降算法规定它们应该被分别对待。因此,我们需要找到一种方法来分离每个潜在矩阵中的两个因素。具体来说,对于事件,我们需要 2 个大小为 1×3 的行向量,对于溜冰者,我们需要 2 个大小为 4×1 的列向量,每个向量代表一个因素。
这些潜在矩阵是如何被重塑的:
**reshaped_event_scores = event_scores[:, np.newaxis, :]**
回想一下事件的潜在矩阵(event_scores)是一个大小为(2,3)的二维 numpy 数组。因此,event_scores[:, np.newaxis, :]仍将保留原始尺寸——通过:——同时通过[np.newaxis](https://docs.scipy.org/doc/numpy/reference/constants.html?highlight=newaxis#numpy.newaxis)在原始轴之间添加一个新轴。这会产生一个大小为(2,1,3)的三维数组。您可以将此视为(1,3)数组的两个不同层,每层代表所有事件中的一个因素(下面以红色突出显示):

**reshaped_skater_scores = skater_scores.T[:, :, np.newaxis]**
我们可以对 skater 的潜在矩阵做同样的事情,它最初是一个大小为(4,2)的二维 numpy 数组。然而,我们想把它做成(4,1)数组的两个不同层,每层代表所有溜冰者的一个因素。为此,我们使用skater_scores.T[:, :, np.newaxis]:由于skater_scores.T的大小为(2,4),所以在末尾添加新轴后,三维数组的大小将为(2,4,1)。潜在选手分数的两个层次如下所示(红色):

**reshaped_residuals = residuals[np.newaxis, :, :]**
最后,残差矩阵最初是一个大小为(4,3)的二维数组,由于前面添加了新的轴,它被重新整形为residuals[np.newaxis, :, :],这是一个大小为(1,4,3)的三维数组。你可以认为残差矩阵本质上和以前一样,但是现在存在于三维平面层中。

步骤 2c-i:计算所有因子的梯度
一旦我们知道如何重塑各种矩阵,我们就可以开始计算梯度,不仅包括所有项目和运动员,还包括所有因素。
**event_gradients = np.nansum(reshaped_residuals * reshaped_skater_scores, axis=1)**
reshaped_residuals * reshaped_skater_scores:对于残差(1,4,3)和潜在选手得分(2,4,1)的整形三维数组,当我们将它们相乘时,两者都由 numpy 广播。先前平放在 3-D 平面中的剩余矩阵将被复制到另一层以形成(2,4,3)矩阵。同时,在重新整形的潜在运动员矩阵的每一层中的潜在运动员分数将被水平复制三次,以形成(2,4,3)矩阵:

Dotted arrows: numpy broadcasting of latent skater scores (for both factors)
- 广播完成后,请注意,每一层现在又变成了寻找单一因素的梯度,而与其他因素无关。因此,所有因素的每个事件的梯度将只是熟悉的
np.nansum(reshaped_residuals * reshaped_skater_scores, axis=1):axis=1参数是对参加每个事件的运动员进行求和,而keepdims=False参数将求和的结果折叠回所有事件梯度的大小为(2,3)的二维数组:

**skater_gradients = np.nansum(reshaped_residuals * reshaped_event_scores, axis=2).T**
- 同样的事情也可以一次找到所有因素的潜在选手分数的梯度。然而,这一次,重塑的残差(1,4,3)和事件潜在矩阵(2,1,3)的 3d 阵列相乘在一起,并且两者都将被广播:
reshaped_residuals矩阵将再次被复制到另一层以形成(2,4,3)矩阵。同时,在reshaped_event_scores矩阵的每一层中的潜在事件分数将被水平复制四次,也形成(2,4,3)矩阵:

Dotted arrows: numpy broadcasting of latent skater scores (for both factors)
- 一旦这两个矩阵相乘,将对每个运动员参加的所有事件(
axis=2)求和,以得到运动员梯度,而keepdims=False参数将运动员梯度折叠回大小为(2,4)的二维数组。然而,我们知道矩阵的潜在矩阵大小为(4,2),所以我们必须在使用它更新分数之前转置溜冰者梯度矩阵(.T):

步骤 2c-ii:更新所有因素的潜在得分
一旦针对所有因素一次性计算出梯度,就以学习率alpha从相同形状的事件和溜冰者潜在得分矩阵中减去这些二维梯度阵列。
**alpha = 0.0005
event_scores = event_scores - alpha * event_gradients
skater_scores = skater_scores - alpha * skater_gradients**

优化的梯度下降算法——使用 numpy 的广播来计算梯度并一次更新所有因素的潜在得分——在下面完整呈现(针对 4 名运动员、3 个项目和 2 个潜在因素):
**# Step 1: Initialize baseline score, and scores of all factors
random_state = np.random.RandomState(seed=42)
baseline = random_state.random_sample()
skater_scores = random_state.random_sample((4, 2))
event_scores = random_state.random_sample((2, 3))# Step 2: Repeat until convergence
for i in range(1000):
# a. Calculate residual for every event-skater pair
predicted_scores = skater_scores @ event_scores + baseline
residuals = predicted_scores - true_scores
# b. Calculate baseline gradient and update baseline score
baseline_gradient = np.nansum(residuals)
baseline = baseline - alpha * baseline_gradient
# c. Calculate gradient and update latent scores for all factors
# Reshape matrices
reshaped_residuals = residuals[np.newaxis, :, :]
reshaped_event_scores = event_scores[:, np.newaxis, :]
reshaped_skater_scores = skater_scores.T[:, :, np.newaxis]
# c-i: Calculate gradients for all factors
event_gradients = np.nansum(residuals * reshaped_skater_scores, axis=1)
skater_gradients = np.nansum(residuals * reshaped_event_scores, axis=2).T
# c-ii: Update latent scores for all factors
event_scores = event_scores - alpha * event_gradients
skater_scores = skater_scores - alpha * skater_gradients**
用矩阵乘法优化梯度下降
上述使用 numpy 广播的实现是可行的。然而,它看起来很笨拙,特别是在计算梯度时要跟上所有的三维矩阵。
这里有一个简单得多的方法来同时计算两个因子的相同梯度,但只需乘以二维矩阵:
- 为了找到所有因素的所有事件梯度,我们只需要将溜冰者潜在矩阵的(2,4)转置与(4,3)残差矩阵相乘。请注意矩阵的方向如何对齐,从而为事件梯度矩阵提供完美的(2,3)形状。

- 类似地,为了找到跨所有因素的所有溜冰者梯度,我们将形状(4,3)的残差乘以事件潜在矩阵的(3,2)转置。这给出了溜冰者梯度矩阵的(4,2)的正确形状。

但是,请注意,为了实现这一点,numpy 的矩阵乘法运算需要忽略残差矩阵中的NaN值。遗憾的是,事实并非如此——没有所谓的np.nanmatmul。然而,我们总是可以使用[np.nan_to_num](https://docs.scipy.org/doc/numpy/reference/generated/numpy.nan_to_num.html)将 NaN 值替换为零,然后像往常一样继续矩阵乘法:
**residuals = np.nan_to_num(residuals)
event_gradients = skater_scores.T @ residuals
skater_gradients = residuals @ event_scores.T**
一旦计算出梯度,它们就被用于分别更新各自的潜在得分矩阵。
3 种实现之间的比较
让我们看看这些梯度下降算法的优化版本是否胜过使用for循环的逐因子天真实现。
时间复杂度
使用 Jupyter 笔记本的[%timeit](https://ipython.readthedocs.io/en/stable/interactive/magics.html#magic-timeit)魔法功能,我测量了在这个玩具示例(4 个溜冰者,3 个事件)上运行一次梯度下降迭代所需的时间。我还改变了因素的数量,并测量了两种实现的相应时间,以查看当因素的数量增加时,它们的时间效率如何。

结果可以在附图中看到:
- 在只有一个潜在因素的情况下,所有 3 种实施方式运行一次梯度下降迭代需要大约相同的时间(100 μs 左右)。
- 随着因子数量的增加,简单实现完成一次迭代所需的时间也线性增加。这是有意义的,因为步骤 2c 中的
for循环本质上只是从一个因素移动到下一个因素。 - 相比之下,当因子数量增加时,广播实现比原始实现快得多:在只有 10 个因子的情况下,它已经快了近 10 倍,而在因子数量较多的情况下,它始终快 100 倍—请注意上图中以 10 为基数的对数标度绘制了运行时间。
- 更好的是用矩阵乘法实现,比广播的快两倍。这些优化版本快得多的原因可能源于它们高效的
np.nansum和np.matmul操作,而不是简单实现中较慢的for循环。
空间复杂性
然而,这些优化方法的一个潜在缺点是增加了空间复杂度:例如,从广播到更大的 3-D 矩阵。我们可以通过绘制一个接一个地运行每个实现时消耗的内存量来验证这一点。我们仍然使用 4 个溜冰者和 3 个事件的玩具例子,但是因素的数量被提升到 100,000 个因素的最坏情况。

从上面使用的内存随时间变化的图表(使用 memory_profiler 包)中,我们可以看到:
- 在两个实现运行的近 6.7 秒中,原始版本运行了前 6.5 秒,广播版本运行了接下来的 0.15 秒,而矩阵乘法版本只运行了最后的 0.02 秒。这与我们之前发现的时间基准是一致的。
- 简单的实现在运行期间只消耗了 10MiB内存(1 MiB = 1.024 兆字节)。有趣的是,一个行分析器揭示了在 100,000 个因子上的
for循环实际上不消耗任何内存!这可能是因为对于每个因素,我们最多只能用一个非常小的 4×3 的矩阵来计算它的梯度。 - 相比之下,广播实现消耗了大约 30 MiB 的内存,考虑到其 3-D 矩阵,这并不像预期的那样糟糕。然而,矩阵乘法版本只消耗了一半,大约 15 兆字节。
简而言之,与其他两种方法相比,使用矩阵乘法的梯度下降的实现在可读性、速度和/或存储器使用方面提供了显著的改进。因此,最终选择寻找多因素模型的潜在分数。
多因素模型的结果
当我们将上面选择的梯度下降算法应用于 2017 赛季男性滑冰运动员的熟悉示例时,我们可以在算法的迭代中再次跟踪模型的残差和 RMSE。对于梯度下降的前 150 次迭代,它们显示在下面的动画仪表板中:

- 随着梯度下降的迭代次数越来越多,每个项目-选手对的残差显著减少,正如残差热图末尾的灰色海洋所证明的那样(与项目第 2 部分中单因素模型的和相比)。
- 150 次迭代后 2.41 的非常低的模型 RMSE 证实了这一点。这比以前的模型(平均 8.84,乘法 8.88,混合 8.86)小三倍以上,比季节平均基线模型(10.3)小四倍以上。换句话说,多因素模型在估算赛季得分方面做得非常出色。
- 事实上,如果我们让算法真正收敛,在 1000 次迭代之后,它实现了实际上不存在的 0.03 的 RMSE,迭代与迭代之间的差异为 1e-4。然而,这并不令人惊讶,因为这是一个比以前更复杂的模型,有更多的参数要调整,以最好地逼近赛季得分。
使用个人因素对滑冰运动员进行排名
尽管多因素模型可以很好地逼近赛季得分,但它有一个主要的弱点:不是用一个单一的得分来给运动员排名(从最高到最低),而是每个运动员现在有多个潜在得分,每个因素一个。这就引出了一个问题:我们应该根据哪个分数来给运动员排名?
在 5 个潜在因素中,当我们分别使用每个因素的分数对运动员进行排名时,我们看到:

Predicted rankings from each individual factor. In parentheses: Kendall’s tau of each predicted ranking to the world championship ranking
- 由这 5 个因素产生的排名似乎并没有以任何方式相互关联,因为连接两个相邻排名的线是极其混乱的:一个运动员可能在一个因素中的分数排名接近顶部,而在另一个因素中的分数排名接近底部。

- 这也可以通过绘制 Kendall tau 来看出,Kendall tau 测量不同因素的任何两个排名之间的成对相关性(见随附的热图):任何两个因素的预测排名之间的最高 Kendall tau 相关性在因素 1 和 5 之间只有微不足道的 0.37。
- 更糟糕的是,每个因素单独产生的排名都不能很好地预测世界冠军的最终排名,第一个因素的最高肯德尔τ只有 0.45。这甚至远远低于季节平均值的基线模型(0.695),更不用说我们以前建立的模型(加法和乘法模型为 0.732,混合模型为 0.724)。
因此,没有一个因素——单独使用——可以体面地给滑冰运动员排名世界冠军!相反,我们必须找到一种方法来结合不同因素的潜在得分,从而更准确地给运动员排名。在项目的下一部分的中,我将讨论我们如何做到这一点。
资源
在多因素模型中,滑手的潜在得分存储在大小滑手数×因素数的矩阵skater_scores中,而项目的潜在得分存储在大小因素数×项目数的矩阵event_skaters中。因此,多因素模型可以被视为将大小为运动员数量×事件数量的赛季得分矩阵分解为这两个潜在矩阵,使得它们在基线得分之上的乘积——skater_scores @ event_scores + baseline——很好地逼近赛季得分的原始矩阵。
事实上,项目的这一部分使用的梯度下降算法几乎与网飞挑战赛中用于向用户推荐电影的著名的 FunkSVD 矩阵分解算法相同:通过将评级矩阵分解为特定于用户和特定于电影的潜在矩阵,我们可以使用这些潜在得分的乘积来预测用户尚未看过的电影的排名。那么,多因素模型本质上是 FunkSVD,用户=溜冰者,电影=事件,评级=赛季得分。
但是,这两种情况的主要区别在于:
- 对于这个问题,我们对预测一个运动员在过去一个赛季的比赛中可能会得多少分不感兴趣,而是预测他在未来的世界锦标赛中会排名多高。
- 为了简单和小的训练数据,在这个项目中使用的梯度下降是批量梯度下降,其中整个训练数据用于在每次迭代中更新所有潜在得分。相比之下,FunkSVD 通常通过随机梯度下降来完成:每次迭代一次只选取一个评级,以更新与该评级相关的用户和电影的潜在得分。这可能比这里给出的优化实现还要快。
- 与多因素模型不同,原始的 FunkSVD 公式不包括基线项。相比之下,该公式的其他变体不仅包括通用基线项,还包括特定项目和运动员的基线项。您可以查看这篇文章中关于 FunkSVD 和推荐系统中常见的其他矩阵分解方法的可读性很强的介绍。
从赛季表现预测花样滑冰世锦赛排名
体育分析
第 4 部分:从多个因素对运动员进行排名

背景
在项目的前几部分,我试图根据运动员在该赛季前几场比赛中获得的分数来预测一年一度的世界花样滑冰锦标赛的排名。主要策略是将选手效应(每个选手的内在能力)与事件效应(一个事件对选手表现的影响)分开,以便建立更准确的排名。
具体来说,在项目的 part 3 中,每个项目和每个滑手都由多个潜在因素来表示。一个项目和一名运动员之间的这些潜在因素的乘积,当加到基线得分时,将接近该项目-运动员对在赛季中的得分:

ŷ_event-skater:给定运动员在给定项目中的预测得分θ_event:基线得分(在所有项目和运动员中保持不变)m:模型的潜在因素数- 存在于每个项目和每个运动员身上的潜在因素
θ_event,f:给定事件的潜在因素得分θ_skater,f:给定选手的潜在因素得分
问题
使用梯度下降,我们可以找到所有项目和运动员的不同因素的潜在得分。然而,一旦找到了每个选手的潜在分数,我们就面临一个大难题:我们应该用什么分数给选手排名?
正如在第 3 部分中所讨论的,如果我们按照每个单独的因素对运动员进行排名,没有一个因素可以给出一个像样的排名:给定 5 个潜在因素,任何一个因素的最高肯德尔τ是 0.45(从第一个因素开始)。这甚至远远低于季节平均值的基线模型(0.695),更不用说我们以前建立的模型(加法和乘法模型为 0.732,混合模型为 0.724)。

Predicted rankings from each individual factor. In parentheses: Kendall’s tau of each predicted ranking to the world championship ranking
因此,我们必须找到一种方法,将不同因素之间的潜在得分结合起来,以便更准确地对滑冰运动员进行排名。
综合多种因素对运动员进行排名
对我来说,这是这个项目中最难的部分,因为最初我绞尽脑汁想知道我究竟如何将几个因素的潜在分数结合起来给运动员排名。
然而,“啊哈!”当我意识到我可以只使用每年的世界锦标赛排名来直接学习如何组合潜在的分数时,那一刻到来了。我也很幸运,因为 Kendall 的 tau 的简单排名度量允许我建立一个简单的逻辑回归模型来组合它们。
肯德尔的 tau 排序度量
让我们回顾一下肯德尔τ的等级度量公式,也称为肯德尔等级相关系数,在项目的第 1 部分中有解释。这是一个衡量两个排名彼此相似程度的指标,比如在世界锦标赛中的预测排名和实际排名之间。
使用前面部分的 4 名滑手的相同玩具示例,让我们假设在该赛季结束时的世界锦标赛中,这 4 名滑手的排名是这样的(从最高到最低;为简单起见,去掉了名字):
1\. FERNANDEZ
2\. MURA
3\. GE
4\. MAJOROV
从这个排名中,我们可以生成 4×(4–1)/2 = 6 个有序对,其中每对中第一个溜冰者的排名总是高于第二个。在本例中,6 个有序对是:
(FERNANDEZ, MURA)
(FERNANDEZ, GE)
(FERNANDEZ, MAJOROV)
(MURA, GE)
(MURA, MAJOROV)
(GE, MAJOROV)
与世界锦标赛完全匹配的预测排名也将产生它自己的 6 个有序对,与上面的 6 个有序对匹配。我们把在两种排序中都匹配的有序对称为和谐对,而那些只出现在一种排序中而不出现在另一种排序中的有序对称为不和谐对。
那么,两个等级之间的肯德尔τ可以计算为:

n: number of skaters in the world championship
结果,该预测的排序将具有 6 个一致对和 6 个总有序对中的 0 个不一致对。这转化为(6–0)/6 = 1 的肯德尔τ,这也是两个等级之间的肯德尔τ的上限。相比之下,下限是-1,这是两个完全相反的排名之间的肯德尔τ。
上述公式中的一个重要观察结果是,Kendall 的 tau 相对于一致对的数量严格增加。因此,优化预测排名的肯德尔τ与试图从中获得最高数量的一致对是一样的。更简单地说,在世界锦标赛的有序对中,我们预测的排名需要尽可能多地正确猜测这些对。
逻辑回归模型
但是我们如何对这些有序对进行智能猜测呢?这就是来自多因素模型的潜在得分的来源。如前所述,在我们的玩具示例中,从 4 名溜冰者的世界锦标赛排名中,我们可以生成 4(4–1)/2 = 6 个有序对。

- 每个有序对将作为我们逻辑回归问题的一个观察值。
- 对于每一个有序对,第一个滑手(姑且称他为滑手 A)的排名都高于第二个滑手(姑且称他为滑手 B)。这将作为我们逻辑回归的基本事实响应。更具体地说,每一对的响应将是一个二元变量,它指示溜冰者 A 是否将超过溜冰者 B:
I(A>B)。在这种情况下,在每对选手中,选手 A 的名次都高于选手 B;因此,训练样本中所有对的响应都将是 1。 - 对于两位选手(A & B),我们已经有了他们之前运行多因素模型的潜在分数。因此,我们可以从运动员 A 的潜在得分中减去运动员 B 的潜在得分,以获得两个运动员在每个因素上的差异。这些差异将被用作每次观察的预测值。
根据上面的设置,很明显,我们可以使用逻辑回归来预测每对/观察值的二元响应。更具体地说,对于每一对选手,我们预测 A 选手在世界锦标赛中超过 B 选手的概率P(A>B)。因此,理想的情况是每一对的这个预测概率尽可能接近 1,假设每个观察的地面真实响应总是 1。
对于逻辑回归,运动员 A 将超过运动员 B 的预测概率将是一个 sigmoid 函数,应用于两个运动员在不同因素上的潜在得分差异的线性组合:

P(A > B):在有序配对中,第一个选手(A)的排名超过第二个选手(B)的预测概率β_f:潜在因素得分差异的线性系数fΔθ_f:两名选手在f因子上的得分差异Δθ_A,f:选手 A 中f因素的潜在得分Δθ_B,f:运动员 B 中f因素的潜在得分
因此,一旦我们知道了每个因素f的差异的线性系数β_f,我们就可以使用上面的公式来预测 A 选手在世界锦标赛中超过 B 选手的概率。然后,如果这个预测的概率大于 0.5,我们预测溜冰者 A 将排名溜冰者 b。最后,从这些成对的排名预测,我们可以预测从上到下所有溜冰者的最终排名。
学习模型系数
但是我们如何学习逻辑回归模型的线性系数呢?关键是从所有 n(n-1)/2 个有序对中找到最大化观察地面真实响应的联合概率的系数——溜冰者 A 确实比溜冰者 B 排名更高。

m: number of factors, n: number of skaters in the world championship
β̂_1、…、β̂_m:逻辑回归模型的学习线性系数(每个因子一个)p:从世界锦标赛排名中提取的每个有序对/观察P(A > B)_p:在双人世界锦标赛中,A 选手的排名超过 B 选手的预测概率p
从上面的公式中注意到,最大化联合概率与最大化其对数是一样的,我们通常称之为 对数似然 。取对数的原因是预测概率的乘积被转换成这些概率的对数之和,这是一个更容易最大化的目标函数:

m: number of factors, n: number of skaters in the world championship
因此,我们可以找到这个目标函数J相对于每个模型系数β_1到β_n的梯度,并使用梯度上升相应地更新这些系数。梯度上升只不过是相反的梯度下降:对于模型参数的更新步骤,我们增加而不是减少梯度。换句话说,既然目标是最大化目标函数,我们就需要沿着梯度走,而不是逆着梯度走。
梯度上升算法
更具体地,对于因子k,目标函数相对于其模型系数β_k的梯度通过简单的链式法则找到:

m: number of factors, n: number of skaters. Terms highlighted for clarity.
从上面的梯度公式——用总和和向量符号表示——一旦我们有了每对的预测概率作为列向量,我们就可以从所有 1 的向量中减去它。然后,我们将结果向量与因子k的预测列(潜在得分差)进行点积。该点积的标量结果将是目标函数相对于因子k的模型系数的梯度。
一旦计算了所有因子的梯度,我们可以通过添加相应的梯度来更新每个因子的系数,以及学习速率α来控制梯度上升的收敛速率:

简而言之,梯度上升算法可以概括为以下步骤:

m: number of factors, n: number of skaters in the world championship, p: each ordered pair in the world championship
对于梯度上升,可以通过检查平均对数似然(对数似然除以训练样本中有序对的数量)来监控收敛,并查看它是否在迭代之间保持稳定。除以训练对的数量使得对数似然独立于数据大小,并且更容易监控。

编码梯度上升算法
准备预测矩阵
有了上面的梯度上升模型,让我们看看如何使用 Python 为我们的玩具示例编码。首先,在用 2 个因素训练多因素模型之后,我们现在有了一个大小为(4,2)的熊猫数据帧skater_scores,它代表了这 2 个因素在 4 个溜冰者中的潜在得分。

接下来,我们对这个数据帧中的运动员/行进行排序(使用[reindex](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.reindex.html)方法)以匹配世界冠军排名的顺序:费尔南德斯> MURA >葛>马约罗夫。我们还将这个数据帧转换成一个二维 numpy 数组,这样我们可以更容易地操作它:
world_ranking = ['Javier, FERNANDEZ', 'Takahito, MURA', 'Misha, GE', 'Alexander, MAJOROV']skater_scores = skater_scores.reindex(world_ranking)
skater_scores = skater_scores.values
# array([[16.00924627, 4.59479646],
# [14.05961149, 3.02042308],
# [11.91968361, 7.2807469 ],
# [10.22685671, 3.12272308]])
接下来,对于每个因素,我们通过减去平均值并除以该因素的标准偏差来标准化其得分。这导致所有因子的均值为零,标准差为 1。这种标准化有两个目的:
- 这将有助于梯度上升更好地收敛:通过保持预测值较小,sigmoid 函数中的指数在计算预测概率时不会内爆/爆炸。
- 标准化因素意味着它们现在处于相同的尺度。因此,这些因素的模型系数可以帮助我们衡量每个因素在运动员排名中的有用程度。这将在后面的结果部分探讨。
这种标准化可以在 Python 中很容易地完成(见下文),通过axis=0取平均值和标准化,意思是跨行/滑手:
normed_skater_scores = (skater_scores - skater_scores.mean(axis=0)) / skater_scores.std(axis=0)
最后,我们可以使用来自itertools模块的[combinations](https://docs.python.org/2/library/itertools.html#itertools.combinations)函数在规范化矩阵中生成有序的行对,其中第一行总是在第二行之上。结果是,从第一行减去第二行,将计算出在世界锦标赛中排名高于另一名选手(选手 B)的一名选手(选手 A)之间的潜在分数差异。
X = np.array([row1 - row2 for row1, row2 in combinations(normed_skater_scores, 2)])
这将为我们提供用于逻辑回归的预测矩阵,其中 6 行代表 6 个有序对,2 列代表我们示例中两个因素的潜在得分差异(见下文)。

一旦预测矩阵准备好了,我们就可以开始编写逻辑回归的梯度上升公式了。
步骤 1:初始化每个因子模型系数
因为在这个例子中有 2 个因子,我们可以初始化两个系数β_1和β_2,两者的值都是 0.5,并且包含在大小为(2)的 numpy 数组beta中
beta = np.full(2, 0.5)
步骤 2:计算梯度并更新系数
对于学习速率alpha = 0.01,我们让梯度上升运行 100 次迭代。如下所示,算法的核心非常简单,所有重要的步骤只用了 3 行代码就完成了!
alpha = 0.01# Step 2: Repeat unitl convergence
for i in range(100):
# a. Calculate predicted probabilities
prob = 1 / (1 + np.exp(-X @ beta)) # b. Calculate gradients
gradient = (1 - prob) @ X # c. Update factor coefficients
beta = beta + alpha * gradient
我已经在之前的项目中详细解释了上面的代码块是如何工作的,该项目也使用了逻辑回归。该项目中的梯度上升与上面的代码之间的唯一区别是:
- 这些系数现在被称为
beta,而不是theta,因为符号θ已经被潜在因子占用 - 当计算梯度(
y - prob)时,不用算法中的响应 y,我们可以像梯度公式规定的那样使用1 - prob,因为我们知道我们的地面真实响应都是 1
下图概述了梯度上升算法第一次迭代的算法工作原理:

每次迭代后的平均对数似然性可以通过对所有概率的对数求和并除以训练样本中的对数(在本例中为 6)来轻松检查:np.log(prob).sum() / len(X)。经过 100 次迭代后,平均对数似然为-0.337,迭代与迭代之间的差异为 1e-4。
模型输出

对于我们的玩具示例,在梯度上升收敛之后,两个因子的模型系数对于第一个因子是 0.745,对于第二个因子是 0.367。
使用这些学习到的系数,我们可以最终预测在我们的训练数据中的每对选手中,第一名选手(选手 A)在世界锦标赛中排名第二名选手(选手 B)的概率。此外,如果这个概率高于 0.5,我们预测滑冰者 A 的排名将超过滑冰者 B;如果没有,我们的预测正好相反:
prob = 1 / (1 + np.exp(-X @ beta))
y_pred = prob > 0.5
以下是我们玩具示例的预测概率和成对排序的结果:

从上面的结果中,我们可以看到预测的排名在世界锦标赛排名的 6 对有序对中得到了 5 对正确。换句话说,对于 5 个一致对和 1 个不一致对,该预测排序的肯德尔τ为(5–1)/6 = 0.67。
重建预测排名
从每个预测的成对排序的结果(上表中最右边的一列)可以清楚地看出,唯一可以创建的预测排序是费尔南德斯>葛> MURA >马约罗夫。让我们看看如何使用代码得出这个结论:
方法 1:根据两两排名
首先,我们建立一个列表counter来统计每个选手的分数。都将从 0 分开始。
counter = [0] * 4
# [0, 0, 0, 0]
然后,我们生成对应于六个有序对中的每一个的有序索引对。指数对的第一个数字是第一个滑手的世锦赛排名(从 0 开始),第二个数字是第二个滑手的排名。使用combinations很容易做到这一点,从技术上讲,它将创建一个生成器,但是为了清楚起见,我将它放在一个列表中。
index_pairs = list(combinations(range(n_skaters), 2))
# [(0, 1), (0, 2), (0, 3), (1, 2), (1, 3), (2, 3)]
接下来,使用zip,我们将每个指数对与预测的成对排名关联起来——在y_pred中的True或False。如果预测的成对排名是True,我们在 counter 中第一个滑手的指标上加 1 分;如果预测排名是False,我们给第二滑手的指数加一分。
for y, (i, j) in zip(y_pred, index_pairs):
if y == True:
counter[i] += 1
else:
counter[j] += 1
下面是循环在迭代y_pred和index_pairs的每个元素时如何工作的示意图:

True ranking: FERNANDEZ > MURA > GE > MAJOROV
最后,我们根据每位选手在counter中的分数重新排列世界排名,从最高到最低(因此有了reverse=True的说法)。这将从逻辑回归的成对排序输出中给出我们最终的预测排序。
world_ranking
predicted_ranking = [skater for rank, skater in sorted(zip(counter, world_ranking), reverse=True)]

方法二:从综合因素得分
给定beta中学习到的模型系数,我们可以将其乘以标准化潜在得分的normed_skater_scores矩阵,以获得每位选手在 2 个因素上的综合得分:
combined_scores = normed_skater_scores @ beta

因此,现在每个溜冰者都由一个单独的分数来表示,类似于所有以前的模型。通过将这些综合得分从最高到最低排序,我们可以得到最终的预测排名:
sorted_combined_scores = pd.Series(combined_scores, index=world_ranking).sort_values(ascending=False)
# Javier, FERNANDEZ 1.028974
# Misha, GE 0.205300
# Takahito, MURA 0.026682
# Alexander, MAJOROV -1.260957predicted_ranking = list(sorted_combined_scores.index)
# ['Javier, FERNANDEZ', 'Misha, GE', 'Takahito, MURA', 'Alexander, MAJOROV']
两种方法给出相同排名的原因是,如果一个滑手的综合得分高于另一个滑手,那么这两个滑手的有序对的预测概率将大于 0.5,这意味着预测对将在世界锦标赛排名中成立:

换句话说,根据运动员的综合得分对他们进行排名等同于通过前面方法中所有预测的成对排名对他们进行排名。然而,很明显,这种方法不仅更简单,而且有利于将所有因素浓缩为每个滑冰运动员的单一组合分数。
结果
我们首先将梯度上升算法应用于 2017 赛季男性滑冰运动员的熟悉例子,每个例子有 5 个潜在因素。回想一下项目的第 3 部分, 5 个因素中没有一个可以单独产生一个像样的排名,所以让我们看看使用逻辑回归将它们结合起来是否可以使预测的排名更好。
首先,对于梯度上升的每次迭代,我们不仅可以跟踪平均可能性,还可以跟踪该时间点的预测排名(使用上面概述的方法),以及来自该排名的肯德尔τ。对于梯度上升的前 250 次迭代(学习率α = 0.001),这些可以在下面的动画仪表板中看到:

从上面的仪表板可以看出:
- 随着梯度上升的进行,模型的平均对数似然性如预期的那样增加。250 次迭代后,对数似然收敛到-0.260,迭代与迭代之间的差异为 1e-5。肯德尔的 tau 也收敛到 0.768,即来自世界锦标赛的 276 对有序对中的 244 对正确。
- 这个 Kendall 的 tau 高于以前的模型,以前的模型的最高性能是 239 个正确对(来自加法和乘法模型),以及季节平均值的基线模型,它有 234 个正确对。
可能性与准确性
然而,在梯度上升过程中会发生一件奇怪的事情:在第 30 次迭代附近,肯德尔的τ值达到峰值 0.783(或 276 对中的 246 对)。之后,在 250 次迭代后,它收敛到只有 244 个正确对。为什么肯德尔的τ值下降,尽管只是轻微下降,而平均对数似然继续增加?
- 原因在于,虽然逻辑回归直接最大化了数据的联合(对数)似然性,但这通常会(但并不总是)提高模型的预测准确性。在这种情况下,准确性意味着预测排名的肯德尔τ:正确预测的成对排名越多(一致对),预测排名的肯德尔τ越高。
- 例如,假设我们的训练数据中只有 2 对,它们的真实响应都是 1。在梯度上升的一些迭代中,这两对的预测概率是 0.51 和 0.52,这给出了 0.51×0.52=0.27 的联合似然性。然而,这两对都将被正确分类,因为它们的预测概率都大于 0.5。
- 相反,当梯度上升收敛时,预测概率为 0.49 和 0.99。这给出了 0.49×0.99=0.49 的联合可能性。虽然这种联合可能性比前一个大得多,但只有一对(预测概率为 0.99 的一对)被正确分类。
简而言之,与我先前的想法相反,逻辑回归经常会,但并不总是,增加模型输出的准确性。我们将很快讨论如何提高精确度,即模型的肯德尔τ。
综合得分
一旦我们的梯度上升算法收敛,我们就获得每个因子的模型系数(存储在beta中,并显示在附图的底部)。然后,我们使用这些系数,按照前面介绍的方法,计算出每位选手的综合得分。

First 5 columns: normalized scores in each factor. Last column: combined score from logistic regression model. Heatmap color: rank of a skater in each factor. Text color: rank of a skater in the world championship
- 在 5 个潜在因素中,第一个因素的
β系数最高。这意味着,对于任何两名选手来说,他们在这一因素上的潜在得分差异是预测一名选手是否会在世界锦标赛中超越另一名选手的最重要因素。 - 这与项目的第 3 部分结束时的结果非常吻合,当时根据每个单独的因素对选手进行排名:仅根据第一个因素进行排名的选手在所有 5 个因素中获得了最高的肯德尔τ。这也反映在附图中:第一个因素中的等级颜色是 5 个因素中“最平滑”的。
- 然而,这与综合得分的预测排名相比就相形见绌了:一般来说,一个运动员的综合得分越高,他在世界锦标赛中的排名就越高(见随附的热图的最后一栏)。这解释了当对 5 个潜在因素应用逻辑回归时,如前所述的相对高的肯德尔τ(0.768,或 276 对中的 244 对)。然而,让我们看看这个令人鼓舞的结果是否可以进一步改善。
增加因子的数量
由于我们可以调整每个选手的潜在因素的数量,也许更多的因素将有助于我们更好地排列选手。当我们将因子的数量增加到 50 时,结果证明这是正确的:

Dashed lines: converged values (after 250 iterations) at 5 factors for comparison
- 随着梯度上升算法的运行,其平均对数似然性迅速超过 5 因子模型,并在 250 次迭代后最终为-0.052,迭代与迭代之间的差异为 1e-4(见上图左图)。
- 更重要的是,与 5 因子模型相比,它的 Kendall 的 tau 要优越得多:它在每次迭代后都不断攀升,最终达到 1(中间面板)的完美值。这一点从动画接近尾声时预测排名和世界排名之间的完全一致可以看出(右图)。
然而,如果某件事看起来好得不像是真的,它很可能就是真的。这是因为:
- 通过 logistic 回归模型,我们已经使用了 2017 年世锦赛的实际成绩来训练模型系数。因此,尽管产生了一个完美的预测排名,这些系数无疑严重过度拟合了该赛季的世界锦标赛结果,并且不能很好地推广到其他赛季。
- 此外,即使我们要使用这些系数来预测其他赛季的排名,很明显我们应该使用许多赛季来学习它们,而不仅仅是 2017 年。
模型验证计划
上述警告意味着我们需要将训练集中的 10 个赛季分成两个独立的组:
- 训练组:logistic 回归模型被训练的季节
- 验证组:剩余的赛季,在这些赛季中,一旦对训练组中的那些人进行了训练,就对肯德尔的τ进行评估
我们将使用以下步骤验证逻辑回归模型,包括对模型进行的任何改进:

Blue: train group, purple: validation group. After the switch in step 4, the colors are reverse — blue: validation group, purple: train group
**第一步:**对于 10 个赛季中的每一个赛季,我们对赛季得分运行多因素模型,以获得该赛季的潜在选手得分。然后,我们将这些因素标准化到相同的尺度,并考虑运动员之间所有因素的差异。
步骤 2: 对于训练组中的季节,我们将它们的差异矩阵垂直堆叠成单个预测矩阵,并使用它来训练逻辑回归模型。在梯度上升收敛之后,我们可以使用模型系数来对这些季节中的每一个进行排名,并评估该排名的肯德尔τ。从现在开始,我们将这些训练称为肯德尔的 taus ,因为用于产生排名的模型系数是直接从世界锦标赛结果中训练出来的。
第三步:类似地,对于验证组中的季节,我们也将它们的差矩阵堆叠成单个预测矩阵。然后,我们使用从步骤 2 中学习的模型系数对这些季节中的每一个进行排名,并评估该排名的肯德尔τ。从现在开始,我们将对这些肯德尔的 taus 进行验证,因为用于产生排名的模型系数没有经过训练,而只是在这些季节进行了验证。
步骤 4: 为了简单起见,我们将使用 2 重交叉验证来划分季节:对于 10 个季节,这意味着随机选择 5 个季节属于训练组,剩余的 5 个属于步骤 2 中的验证组。然而,在步骤 3 之后,每组中的季节被交换:那些在训练组中的人现在在验证组中,反之亦然。然后,我们重复第 2 步和第 3 步,以获得各自的训练和验证肯德尔的 tau。
由于这种转换,每个赛季都将有一个相应的训练肯德尔的 tau,这涉及到一个直接从该赛季的世界冠军(在其他 4 个冠军中)训练的逻辑回归模型。每个赛季也将有一个相应的验证肯德尔的 tau,这涉及到一个在其他 5 个赛季训练的逻辑回归模型。
步骤 5: 对于每个季节,我们可以用基线模型的肯德尔τ减去其训练或验证的肯德尔τ(使用季节平均值),以获得肯德尔τ的相应改善。最后,我们可以简单地对 10 个训练肯德尔的 tau 的改进进行平均,并将其与 10 个验证肯德尔的 tau 的平均改进进行比较。
因此,前一个平均值代表直接从世界锦标赛排名训练的逻辑回归模型的排名改进(从基线模型),而后者代表间接在其他赛季训练的逻辑回归模型的改进。后者也是对该模型的更现实的评估,因为该模型将用于预测未来赛季的世界锦标赛排名,而这样的排名当然首先还不可用。
结果
根据上面概述的模型验证计划,我们对不同数量的因子运行所有这些步骤(在α=0.005 和 1000 次迭代时),并从基线模型获得它们在肯德尔τ中的平均训练和验证改进:

Bold lines: average improvement in Kendall’s tau across 10 years. Lighter lines: improvement in Kendall’s tau for each year
因子数增加 2 倍(从 2 一直到 128 个因子)的结果如上图所示。从这个图表中,我们可以看到:
- 当对直接训练的季节(蓝线)进行逻辑回归评估时,随着因子数量的增加,Kendall tau 从基线的平均改善稳步增加,并且从 16 个因子开始显著增加:训练 Kendall tau 改善的 95%置信区间在 16 个因子后飙升至水平线以上零。
- 然而,当逻辑回归被评估到它没有被训练的季节(红线)时,肯德尔的 tau 的平均改善从 2 个因素向前增加。然而,在 16 个因素之后,平均验证肯德尔的 tau 改善显著下降。
- 换句话说,很明显,更多的潜在因素并不总是更好:根据这些因素训练的逻辑回归模型可能在它被训练的季节表现得非常好,但在其他季节给出可怕的排名预测——这是模型过度拟合的典型标志。
- 然而,即使在 8 个因素下,当模型在肯德尔τ中具有最高的平均验证改进时,它仍然是-0.025 的负改进。换句话说,多因素模型的表现甚至不如基线模型!诚然,这种排名预测的不良表现在统计上是微不足道的,因为其 95%的置信区间包含了零水平。
也就是说,我们如何减少模型过度拟合,如上图所示?对于关注该项目的前几部分的读者来说,答案应该是熟悉的:提前停止。
提前停止
与模型惩罚的比较
在项目的前面部分,用于减少模型过度拟合的策略包括模型惩罚和早期停止。
- 对于项目的这一部分,模型惩罚意味着修改多因素模型的目标函数和梯度下降,以防止潜在因素变得过大,这可能会过度拟合它们所训练的赛季得分。这在项目的第 2 部分的中用单因素(混合)模型进行了演示,但是可以很容易地适应多个因素。
- 此外,逻辑回归模型和用于训练它的梯度上升算法也可以被罚分。实际上,这将缩小每个潜在得分的模型系数,以便逻辑回归模型不会过于适合用于训练它的世界锦标赛排名,并且可以更好地推广到其他赛季。我已经解释了 L2 惩罚(也称为 L2 正则化)是如何实现的,以及它在我之前的项目中涉及到逻辑回归的影响。
- 每个模型都有自己的惩罚参数,控制每个模型被惩罚的程度。然而,正如在项目的第 2 部分中提到的,模型惩罚有两个主要缺点:我们必须在每次改变惩罚参数时重新运行模型,并且我们需要寻找最佳的惩罚参数。在这一部分中,对两个模型进行惩罚会变得非常繁琐。
早期停止方法
因此,减少模型过度拟合的一个更方便的方法是提前停止多因子模型的梯度下降算法和其后的逻辑回归模型的梯度上升算法。通过阻止这些算法完全收敛,我们可能不会获得最佳的训练性能,但希望这些模型不会过度适应训练数据,并更好地进行概括。
换句话说,我们将看到,对于任一算法,在哪个停止迭代时,我们将具有最佳验证性能,即,与基线模型相比,肯德尔τ的平均验证改进最高。因此,我们的两个模型(多因素和逻辑回归)现在总共有 3 个超参数:
- 因素数量
- 多因素模型梯度下降的停止迭代
- logistic 回归模型梯度上升的停止迭代
结果
对于这 3 个超参数的每个组合,我们可以记录其在肯德尔τ中与基线模型相比的平均训练和验证改进。这些结果绘制如下:
- 多因子模型,停止迭代次数从 0 到 1000,间隔 20 次迭代
- 从 0 到 1000 停止迭代,间隔 20 次迭代的逻辑回归模型
- 因子数量以 2 的倍数增加,从 2 到 128 个因子

Left to right: Average train and validation Kendall’s tau improvement from baseline as number of factors increase (2 to 128)
从上面的情节中,我们可以看出:
- 除了 2 个因子,增加多因子模型的迭代次数对 Kendall 的 tau 改进几乎没有影响,在训练和验证中都是如此。这是有意义的,因为多模型仅旨在降低赛季得分的 RMSE,而不是直接降低预测排名的肯德尔τ。
- 相比之下,增加逻辑回归的迭代次数可以改善训练期间的 Kendall,特别是在因子数较高的情况下:在顶行的大多数方块中,颜色从左到右变蓝。然而,这在验证期间恶化了肯德尔τ:在底部行的大多数方块中,颜色从左到右变得更红。这表明,我们让逻辑回归模型运行的时间越长,它在训练集中对季节的拟合就越多,在验证集中对新季节的表现就越差。
- 然而,对肯德尔τ最显著的影响是增加因子的数量。随着因子数量的增加,在训练集中,Kendall 的 tau 的改善是显著的,这由靠近顶行末端的正方形变得更蓝来证明。不幸的是,这转化为验证集中 Kendall tau 的显著下降:接近底行末尾的方块变得更红。这与早期的观察一致,即增加因子的数量,特别是在 16 之后,将使训练季节过度拟合,并在验证集中给出新季节的可怕预测。
最后,对于每个因子数,我们记录多因子和逻辑回归模型的停止迭代,其在平均验证肯德尔τ中给出最高改进:

从上面的结果表中,一个有趣的结果立即浮现出来:
- 除了 2 个因素外,验证集中肯德尔τ的最高平均改善出现在逻辑回归的第 0 次迭代。这意味着,尽管逻辑回归成功地提高了它所训练的赛季的预测排名,但对于它所应用的新赛季,不应用逻辑回归比应用它更好!

- 更具体地说,回想一下,我们在梯度上升算法中将模型系数初始化为 0.5。因此,当不运行逻辑回归时,这些系数保持为 0.5。这意味着每位选手的综合得分仅仅是潜在得分相加的一半(见所附公式)。
- 换句话说,学习如何通过逻辑回归将运动员的潜在得分结合起来,似乎并不比简单地将它们相加并根据这些总和对运动员进行排名更好!
在项目的下一部分中,我将解释为什么会出现这种情况,以及我们如何解决这个问题。
资源
你可以从 CS229 (我极力推荐的吴恩达教授讲授的机器学习课程)的相应讲义和视频 讲座中找到 logistic 回归的推导及其梯度上升法。请注意,由于我们的训练数据只有一类预测值(全为 1),因此之前导出的公式比典型逻辑回归模型的公式更简单。
接下来,我们使用逻辑回归来学习如何根据运动员的潜在得分对他们进行排名。这项任务属于信息检索系统中经常使用的名副其实的“学习排序”策略。例如,在向每个用户显示排名靠前的文章之前,搜索引擎需要基于某些属性对文章进行排名。更具体地说,通过利用 Kendall 的 tau 的排序度量的成对性质,我们的方法属于学习排序策略的成对子集。
此外,一旦计算出每个潜在因素的成对差异,我们可以使用其他分类方法,而不仅仅是逻辑回归,来预测每个观察/有序对的成对排序。例如,这里有一篇论文使用 SVM 来预测成对排名(也称为 RankSVM),还有一篇可读性更强的博客文章解释了它是如何工作的。
最后,当我问关于在 Stackoverflow 上逻辑回归收敛到更高可能性但更低准确性的特殊现象时,我得到的答案链接到几个有趣的讨论。例如,这个线程强调了准确性实际上是一个独立于统计的问题,在本例中是逻辑回归模型。此外,准确度不仅是预测概率的函数,也是用于分类样本的阈值的函数。因此,对于许多问题来说,仅仅基于准确性来评估模型可能不是一个好主意。
从赛季表现预测花样滑冰世锦赛排名
体育分析
第 6 部分:组合排名模型和最终基准

背景
在项目的前几部分,我试图根据运动员在该赛季前几场比赛中获得的分数来预测一年一度的世界花样滑冰锦标赛中的排名。主要策略是将溜冰者效应**(每个溜冰者的内在能力)与事件效应(一个事件对一个溜冰者表现的影响)分开,这样可以建立一个更准确的排名。**
为此,在项目的前几部分使用了几种模型:
第一部分 :加性和乘性模型,可以表述为简单的线性模型,试图逼近所有的赛季得分。线性模型的回归系数包括每个溜冰者的潜在分数,然后根据这些潜在分数对溜冰者进行排名(从最高到最低)。

- 给定事件中给定运动员的近似分数
θ_baseline:基线得分(整个赛季得分不变)θ_event:该项目潜在得分(运动员之间不变)θ_skater:溜冰者潜在得分(跨事件恒定)
Part 2 :混合模型,是 part 1 中加法和乘法模型的交叉。学习潜在分数没有封闭形式的解决方案,但是可以使用梯度下降增量学习。每个溜冰者的潜在分数可以再次被用来给他们排名。

第三部分 :多因素模型,它只是混合模型的一个扩展。不是每个溜冰者(和事件)有一个单一的潜在分数,每个溜冰者将有跨越不同因素的多个潜在分数,这可以再次使用梯度下降来学习。

f:存在于每个项目和每个选手身上的潜在因素m:多因子模型中的因子总数θ_event,f:给定事件的潜在因素得分- 给定选手的潜在因素的分数
第四部分 : logistic 回归模型,用于组合第三部分中跨因素的潜在得分。模型的预测因子是各因子中的分数差,模型的响应是世界锦标赛中每对有序选手的状态。换句话说,冠军排名本身被直接用于学习如何从多因素模型中组合潜在分数,然后这些组合分数被用于对滑手进行排名。

P(A > B):在世界锦标赛的一对有序选手中,第一名选手(A)超过第二名选手(B)的预测概率β_f:潜在因素得分差异的线性系数fΔθ_f:2 名选手在f因子上的得分差异Δθ_A,f:A 滑手f因素的潜在得分Δθ_B,f:运动员 B 中f因素的潜在得分
第五部分 :序贯多因素模型,是第三部分多因素模型的修改版:不是一次性学习所有潜在因素的分数,而是一次学习一个。事实证明,这只不过是训练第 2 部分中概述的单因素模型,然后在学习第一个因素后,在负残差上训练另一个单因素模型,以此类推。

Training the sequential multi-factor model
然后使用逻辑回归将得到的多因素潜在得分结合起来,与第 4 部分相同。最后,在第三部分中发现序列多因素模型比原始多因素模型更好地预测了运动员的排名。
问题
使用肯德尔的 tau 排名指标评估每种方法的预测排名,该指标衡量预测排名与实际世界锦标赛排名的相关程度。对于在训练集中选择的 10 个赛季中的每一个赛季,我们计算每个排名模型和赛季平均值的基线模型之间的肯德尔τ的差异,即简单地通过他们的赛季平均分数对运动员进行排名。
此外,对于每种方法,我们尝试了不同的策略来提高他们的预测排名,例如 L2 惩罚或提前停止。这些策略旨在防止模型过度拟合赛季得分,以及逻辑回归模型过度拟合世界锦标赛排名,以便他们可以为未来赛季更好地排名运动员。
与基线模型相比,每种方法的肯德尔τ(超过 10 个赛季)的平均差异记录如下。注意,逻辑回归模型直接用世界冠军来学习如何组合潜在因素。因此,它不应该在训练的同一季节进行评估,而应该在新的季节进行评估。因此,使用了双重交叉验证:在 5 个季节训练模型,在另外 5 个季节评估模型。

从上表中,我们看到:
- 对于简单的线性模型(加法和乘法),未惩罚的版本比惩罚的版本提供了更好的排名。相比之下,对于混合和多因素+逻辑回归模型,阻止模型完全收敛会给出更好的排名。
- 从肯德尔τ与基线相比的平均差异(第四列)来看,随着我们从加法、乘法、混合,然后到与逻辑回归模型耦合的顺序多因子,预测排名的准确性增加。这对训练集中选择的 10 个赛季的男女选手都适用。
- 然而,这些排名准确性的提高是相当有限的。事实上,没有一种方法提供的排名在统计上优于季节平均值的基线模型:Kendall 的 tau 到基线模型的差异的 95%置信区间包含所有模型的零(最后一列)。
因此,项目最后部分的两个主要目标是:
- 将不同的预测排名组合成一个最终排名,我们希望它比单独的单个排名更准确。
- 评估测试集中剩余 5 个赛季的所有排名方法,这些方法之前没有进行过分析。
首先,让我们尝试两种不同的方法来组合我们迄今为止开发的所有方法的排名:使用 Borda 计数的无监督方法和使用逻辑回归的监督方法。
无监督方法:Borda 计数
理论
由于每种方法都预测了不同的选手排名,我们可以认为每种方法都为所有选手投了不同排名的一票(比如,选手 B >选手 A >选手 C 代表 3 名选手 A、B 和 C)。从这个角度来看,有很多方法可以将这些投票组合成最终的选手排名。它们都属于等级投票方法的范畴,这种方法在许多国家和州的选举中使用。
一种常见的排名投票方法是博尔达计数,它最早发现于 1435 年!然而,这并不令人惊讶,因为它非常简单。下面的 5 个溜冰者的玩具示例将演示它是如何工作的:

Avg: season average. Add: additive. Mul: multiplicative. Hyb: hybrid. Multi: sequential multi-factor + logistic
- 我们从迄今为止为 5 名选手开发的所有方法的潜在分数开始。请注意,我们还包括季节平均基线模型,因为它与我们开发的其他 4 个模型一样有效,表现也一样好。
- 对于每个模型,我们给该模型中分数最低的选手 0 分,然后给分数第二低的选手 1 分,以此类推。结果,对于 5 个滑冰者,每个模型中得分最高的滑冰者将具有等级点 4。因此,等级点数简单地指示每个模型对溜冰者的等级有多高,从 0 开始向上。
- 对于每一个溜冰者,我们将所有模型的排名点相加,得到该溜冰者的 Borda 计数。最后,给选手排名不过是给他们的 Borda 分数排名,从最高到最低。
- 请注意,Borda 计数可以在多个溜冰者之间绑定,例如在上面玩具示例中的
GE和MAJOROV之间:两者的 Borda 计数都是 9。虽然存在许多打破平局的规则,但对于这个问题,我们将通过季节平均模型的排名点打破平局-该模型中得分较高的选手是平局获胜者。在本例中,GE与MAJOROV平分秋色,因为对于季节平均模型,后者的等级点(3)比后者(2)高(参见等级点表的第一列)。
- 选择此平局打破规则是因为通过 Borda 计数的预测排名将在最后与季节平均值的基线模型进行比较,因此使用季节平均值打破平局确保排名准确性的任何提高都是由于 Borda 计数方法本身,而不是平局打破规则。
从上面的玩具例子可以看出:
- 尽管没有一个排名模型将
HANYU排在第一,他仍然以最高的博尔达数 13 结束。这是因为大多数模特——5 个中的 4 个——将他排在第二位(排名点为 3)。 - 相比之下,即使加性车型排名
TANAKA第一,其余车型对他的排名都很低:两个车型倒数第一,另外两个车型倒数第三。结果,他以最低的博尔达数 8 结束。

Ranked voting ballot for the 2003 Heisman trophy. See ranking rule for the trophy here.
- 因此,Borda count 经常被描述为基于共识的排名模型,对于要排名高的滑冰运动员,大多数模型必须将他排名高。这就是为什么它通常用于体育奖项的运动员排名,如最杰出的大学足球运动员的海斯曼杯(见附图)。
- 然而,Borda count 模型仅基于它们之间的共识来组合现有的排名,希望这样的组合将准确地预测最终的世界冠军排名。在机器学习的说法中,这是一种 无监督的方法 ,因为预测的基本事实——世界冠军排名——根本没有用于训练模型。
编码
Borda 计数模型的编码相当简单:

- 我们从熊猫数据帧
skater_scores开始,它代表了之前所有 5 个模型的运动员分数。 - 然后,我们通过以下方式计算每个模型的等级点数:
- 首先,使用
[DataFrame.values](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.values.html)将 skater_scores 数据帧转换成一个 numpy 数组。 - 这允许我们调用数组的
[argsort](https://docs.scipy.org/doc/numpy/reference/generated/numpy.argsort.html#numpy.argsort)方法两次,将分数转换成等级点数:
**rank_points = skater_scores.values.argsort(axis=0).argsort(axis=0)**
axis=0参数意味着排序是跨行/运动员执行的。下图突出显示了argsort方法是如何计算根据季节平均模型排名第一的选手的排名点(FERNANDEZ,排名分数为 4)与根据同一模型排名最后的选手(TANAKA,排名分数为 0)进行比较的。

Blue: skater ranked first by season average model (FERNANDEZ). Red: skater ranked last for season average model (TANAKA)
- 一旦计算出所有模型的等级点,我们就可以对 rank_points 矩阵的每一行求和,以获得每个选手的最终 Borda 分数。
axis=1参数意味着求和是跨列/模型进行的。
**borda_counts = rank_points.sum(axis=1)**

- 一旦 Borda 计数被计算出来,我们就把它作为一个额外的列添加回原来的 skater_scores 数据帧中。这使得我们可以对运动员/行进行排序,首先根据 Borda 计数,然后根据平均模型的分数(打破任何平局),从最高到最低——因此有了
ascending=False参数。
**skater_scores['Borda'] = borda_counts
sorted_skater_scores = skater_scores.sort_values(by=['Borda', 'Avg'], ascending=False)**

- 最后,从排序的 Borda 计数中获得预测的排名只不过是从前面的步骤中提取出
sorted_skater_scores数据帧的索引。
**borda_ranking = list(sorted_skater_scores.index)
# ['Yuzuru, HANYU',
# 'Javier, FERNANDEZ',
# 'Misha, GE',
# 'Alexander, MAJOROV',
# 'Keiji, TANAKA']**
在我们检查 Borda count 模型的结果之前,让我们看看另一种结合现有排名的方法,但这次使用世界锦标赛排名来直接指导这样的结合。
监督方法:逻辑回归
理论

- 回到包含每个模型的运动员分数的矩阵,我们看到运动员在每个模型中的分数只不过是该运动员的另一个因素。
- 因此,组合这些因素的方式与组合第四部分和第五部分中多因素模型的潜在得分完全相同,即使用简单的逻辑回归模型:
- 该模型的预测值将是一对有序的溜冰者中每个模型的分数差。这对选手是从世界锦标赛排名中产生的,这样这对选手中的第一个选手(选手 A)的排名总是高于第二个选手(选手 B)。为了一致性和易于收敛,在进行成对差异之前,每个模型的分数都朝着平均值 0 和标准偏差 1 标准化。
- 每对选手的回答将是一个二元变量,它表示在世界锦标赛中选手 A 的排名是否高于选手 B:
I(A>B)。由于所选择的惯例规定溜冰者 A 总是在溜冰者 B 之上,因此训练样本中所有对的响应都是 1。
对于我们的玩具例子,假设世界冠军排名是HANYU > FERNANDEZ > TANAKA > GE > MAJOROV。因此,我们可以从这个排序中生成 10 个有序对;对于每对选手,我们计算 5 个分数差异的预测值,每个预测值对应于该对选手中两个选手之间的一个先前的模型。注意,由于世界锦标赛排名直接用于生成有序对并计算其相应的预测器,这是一个 监督的 机器学习任务。

上述问题的逻辑回归模型与第 4 部分中的模型完全相同,重复如下:

P(A > B)_p:在世界锦标赛中,运动员 A 在有序对p中的排名超过运动员 B 的预测概率(从世界锦标赛排名中提取)β_model:每个先前模型的学习线性系数Δθ_model,p:两人一组p中 2 名选手的模型得分差异
使用梯度下降,可以递增地学习 5 个先前模型中每一个的线性系数,直到模型的对数似然最大化。一旦学习了这些系数,它们可以用于将不同的模型分数组合成单个分数,可以根据该分数对溜冰者进行排名:

β_model:每个先前模型的学习线性系数θ_s,model:溜冰者的每个模型的标准化分数s
由于世界锦标赛排名直接用于训练上述逻辑回归模型,我们再次使用双重验证来客观地评估它:我们在随机选择的 5 个赛季训练模型,并在剩余的 5 个赛季评估它。为了保持一致,为该部分选择的两个折叠与第 4 部分中选择的两个折叠相同。
提前停止
由于这一部分中逻辑回归的梯度下降与第 4 部分中的完全相同,所以我不再赘述。但是,类似于那部分,我们可以过早地停止梯度下降算法。
这样做,模型不适合世界冠军的排名,因为它应该是 5 个赛季的训练(训练折叠)。然而,它的预测排名可能会更好的 5 个新赛季,它是适用的(验证折叠)。然后,我们检查在验证集中的所有 10 个季节中,逻辑回归模型在哪个迭代中具有最高的肯德尔τ(相对于基线模型)平均改善。
对于男子滑冰运动员,在梯度下降的第一个 2000 次迭代中,绘制了训练集和验证集的肯德尔τ相对于基线的平均改善:

- 验证集的肯德尔τ的改善在梯度下降的 650 次迭代时达到峰值。此后,训练集的 Kendall tau 改进总体上继续上升,而验证集的 Kendall tau 改进急剧下降。
- 因此,很明显,对于男性滑冰运动员,我们应该在逻辑回归模型的 650 次迭代时停止梯度下降算法。这导致验证集的肯德尔τ值比基线模型平均提高了 0.01。
- 然而,这种改善是高度可变的:与基线模型相比,一些年份的 Kendall tau 有非常高的改善,而一些年份的模型表现低于基线(有关更多详细信息,请参见下面的结果部分)。
训练集的结果
男子滑冰运动员
对于 2017 赛季男子滑冰运动员的熟悉示例,我们显示了之前 5 个模型中每个模型的归一化分数,然后是 Borda 分数,最后是上述逻辑回归模型的组合分数(在梯度下降的 650 次迭代处停止)。

First 4 columns: normalized scores in each factor. Last 2 columns: combined score from Borda count and logistic regression model. Heatmap color: rank of a skater in each model. Text color: rank of a skater in the world championship
从随附的所有 7 款车型的预测排名热图中,我们看到:
- 每个模型的标准化分数在之前的 5 个模型中非常相似。因此,他们的排名也非常相似,正如热图颜色显示的每个模型的选手排名所示。
- 因此,通过 Borda 计数的排名大部分保留了以前模型的排名,因为 Borda 计数只不过是这些模型中排名点的总和。
- 类似地,对于逻辑回归模型,通过跨 5 个先前模型的标准化分数的线性组合对溜冰者进行排名将给出与那些原始排名非常相似的预测排名。
- 有趣的是,逻辑回归模型(热图底部)的模型系数β在之前的 5 个模型中有很大不同:最大的(1.16)属于平均得分模型,最小的(-0.27)属于乘法模型。但是,请注意,这些分数在模型之间高度共线。因此,我们不应该试图解释模型系数,因为它们可能是高度可变的,正如在这种情况下明显证明的那样。
为了可视化预测排名之间的关系,我们可以为 2017 赛季并排绘制它们(下图中的底部面板),以及我们开发的 7 个排名模型中每个模型的肯德尔 tau 到基线模型的差异(顶部面板):

Each gray line in the top panel corresponds to each of the 10 seasons in the training set. Colors in bottom panel are based on the 2017 world championship ranking.
从上图中,我们看到:
- Borda 计数确实起到了在之前的 5 个排名模型中一致认可的计数的作用。比如这 5 款中有 4 款把阿列克谢、拜琴科排在米凯尔、科里亚达之上。只有多因素模型将它们反向排列。然而,如上图中用红色突出显示的,Borda 计数将与大多数排名一致,而不是多因素模型的单独排名。
- 与之前的 5 个模型相比,无监督方法(Borda 计数)和有监督方法(逻辑回归)都没有在排序准确性方面提供任何显著的改进。这可以从 2017 赛季男子滑冰运动员排名时这两个型号的一致对数量中看出(在 276 对有序对中,分别为 240 对和 242 对)。
- 这也可以在相对于这两种方法的基线模型的平均 Kendallτ改善中看出:与季节平均值的基线模型相比,这两种方法都没有在 Kendallτ方面提供任何统计上显著的改善,正如它们在 0 处穿过水平线的 95%置信区间所证明的那样(在下表中重复)。换句话说,他们的表现和之前的 5 款车型一样平庸。

说明
Borda 计数和逻辑回归模型的平庸表现完全说得通。这是因为它们本身只是之前五个排名的组合,这五个排名彼此非常相似。因此,如果一名选手在之前的排名中排名靠后,他的排名在 Borda 计数或逻辑回归模型中就不可能上升。
相比之下,我们在上面的图表中看到,滑冰运动员在世界锦标赛中可以做出令人惊讶的跳跃和排名下降。这意味着排名模型的平庸结果很大程度上是由于世界锦标赛本身的不可预测性。
此外,在一些赛季中,大多数预测排名的表现优于赛季平均基线模型,而在其他赛季中,它们的表现一直不佳。换句话说,仅仅因为大多数排名模型在一个季节表现良好,并不意味着在下一个季节没有什么时髦的事情发生。
这种季节与季节之间的高度可变性是为什么尽管大多数模型平均来说对基线模型提供了微小的改进,但是这些改进每年变化如此之大,以至于它们最终根本不具有统计显著性。这可以从所有排名模型的 Kendall 的 tau 改进在零处穿过水平线的 95%置信区间中看出。
女子滑冰运动员

对于女性滑冰运动员,逻辑回归模型在 92 次迭代的验证集中对肯德尔τ的改善最大(见上图)。下表总结了无监督方法(Borda 计数)和有监督方法(逻辑回归)结合女性滑冰运动员先前排名的表现:

从上面的图和表中,我们看到逻辑回归模型(在 92 次迭代时停止)提供了非常乐观的结果,与基线模型相比,肯德尔τ的平均改善为 0.01。此外,这种改善在统计上几乎是显著的,因为其 95%的置信区间几乎高于水平线零。
但是,请注意,在优化排名模型时,我们已经在训练集中使用了所有 10 个赛季的世界冠军排名,例如,当选择理想的迭代来停止多因素模型或逻辑回归模型时。因此,上面发布的结果很可能在一定程度上过度适应了训练集,并且可能过于乐观。
因此,我们通过在测试集上对所有 7 个排名模型进行基准测试来结束项目,该测试集包括我们迄今尚未分析的 5 个赛季。这个测试集上的基准测试结果将为我们的模型提供更客观的评估。
测试集的结果
在我们评估测试集中 5 个赛季的 7 个排名模型之前,我们使用训练集中的所有 10 个赛季来重新训练它们。我们还在通过 2 重交叉验证选择的理想迭代处停止相关模型。我们还选择了 2019 年的最新一季,以展示测试集中一季的不同预测排名。
男子滑冰运动员

Each gray line in the top panel corresponds to each of the 5 seasons in the test set. Colors in bottom panel are based on the 2019 world championship ranking.
从上图中,我们可以看到:
- 2019 年的世界锦标赛比 2017 年的锦标赛更不可预测,因为所有型号在前一季的协和对数量(约 220 对)远低于后一季(约 240 对)。
- 对于 2019 赛季,所有车型的预测排名基本相同。此外,我们开发的所有模型都优于季节平均值的基线模型,该模型在 276 个有序对中仅预测了 216 个正确对。
- 然而,当在测试集中对 5 个季节进行平均时,这种改善在很大程度上是不显著的,因为对于所有模型,Kendall 的 tau 改善的 95%置信区间在零处穿过水平线。这种情况的根本原因与训练集中的原因相同:有一些赛季,如 2019 年,排名模型的表现优于基线模型,但仍有一些赛季与基线相比,他们的表现一直不佳。这种较高的季节间可变性一直是排名模型的一个持续问题,甚至可以追溯到第一部分。
上述结果总结在下表中。请注意,与训练集相比,大多数模型在测试集中的性能较低,这证实了我们之前对训练集性能过于乐观的怀疑。

女子滑冰运动员

Each gray line in the top panel corresponds to each of the 5 seasons in the test set. Colors in bottom panel are based on the 2019 world championship ranking.
女性滑冰运动员的情况也好不到哪里去:大多数模特在 2019 赛季的表现都低于赛季平均水平的基线模型,这从她们相对较少的和谐对数量(在 231 对有序对中)可以看出。平均而言,除了可能的混合模型之外,他们也没有在基线模型上提供 Kendall 的显著改善,因为他们的 95%置信区间都在零处穿过水平线。这些结果总结在下表中:

结论
**如果有一件事你应该从阅读我的项目中学到,那就是:**预测体育运动很难!这一点在本项目开发的所有车型的不同季节表现的高度可变性中显而易见。即使是最有潜力的——多因素模型结合逻辑回归——仍然无法克服这种可变性,即使我们直接使用世界锦标赛排名来训练它。

Ice, number one nemesis of ranking models
因此,模型的未来改进包括:
- 按顺序对待每个季节,而不是分别对待。这可以潜在地使用贝叶斯框架来完成:前一季的逻辑回归系数的后验被用作下一季的先验。或者,可以使用递归神经网络,其中运动员潜在得分用作内部状态,并且当遇到新的赛季得分时被顺序更新。
- 使用非线性模型,例如具有非线性核的支持向量机,来组合潜在因素以及模型分数。这将捕捉到不同因素之间的相互作用,我们希望每个季节都保持一致。
最后,这个项目在构建一个新问题(花样滑冰运动员排名)方面教会了我很多,在大多数数据科学家熟悉的任务方面:线性回归、矩阵分解、逻辑回归,甚至像 Borda 计数这样简单的事情。许多人“啊哈!”我在项目中遇到的时刻是难以形容的!
资源
在项目的这一部分,我们使用非监督(Borda 计数)和监督方法(逻辑回归)结合了前 5 个模型的排名。这是众多排名聚合方法中的两种,这种方法在像投票理论一样古老的领域和像信息检索一样新的领域都会遇到——想想谷歌的 PageRank 算法。在这篇文章中可以找到对排名汇总方法的全面概述。
最后,感谢您通读了我的项目报告的 6 个长部分。我希望你能学到一些有用的技术来帮助你解决体育预测问题,或者简单地获得一些关于如何将普通数据科学技术应用于像这样的独特问题的见解。如果您有任何进一步的问题或反馈,请不要犹豫通过媒体与我联系!
用你自己的神经网络预测癌症肿瘤的恶性程度
在这个系列的最后一部分,我们使用我们从头编码的网络来预测乳腺癌肿瘤的恶性程度。

在本系列的第 1 部分中,我们深入了解了我们的神经网络的架构。 在第二部中,我们用 Python 构建了它。我们还深入了解了反向传播和梯度下降优化算法。
在****最终第 3 部分中,我们将使用威斯康星癌症数据集。我们将学会准备我们的数据,通过我们的网络运行它,并分析结果。****
是时候探索我们网络的损失情况了。
Navigating the Loss Landscape within deep learning training processes. Variations include: Std SGD, LR annealing, large LR or SGD+momentum. Loss values modified & scaled to facilitate visual contrast. Visuals by Javier Ideami@ideami.com
打开网络
为了打开我们的网络,我们需要一些燃料,我们需要数据。
- 我们将使用与乳腺癌肿瘤检测相关的真实数据集。
- 数据来自于 威斯康辛癌症数据集 。
- 这些数据是由麦迪逊的威斯康星大学医院和威廉·h·沃尔伯格博士收集的。
- 应数据所有者的要求,我们提及与数据集相关的一项研究:O. L. Mangasarian 和 W. H. Wolberg:“通过线性规划进行癌症诊断”,《暹罗新闻》,第 23 卷,第 5 期,1990 年 9 月,第 1 和 18 页。
- csv 格式的数据可以通过链接下载
- 在这个 Github 链接 ,可以访问项目的所有代码和数据。
**** [## javismiles/深度学习预测乳腺癌肿瘤恶性肿瘤
用 Python 从头开始编码的 2 层神经网络预测癌症恶性程度。…
github.com](https://github.com/javismiles/Deep-Learning-predicting-breast-cancer-tumor-malignancy)
首先,我们将数据下载到我们的机器上。然后,我们使用 pandas 创建一个数据帧,并查看它的第一行。
**df = pd.read_csv('wisconsin-cancer-dataset.csv',header=None)**
df.head(5)

dataframe 是一种 python 数据结构,它允许我们非常容易地工作和可视化数据。
我们需要做的第一件事是理解数据的结构。我们在它的网站上找到了关于它的关键信息。
- 共有 699 行,属于 699 名患者
- 第一列是标识每个患者的 ID 。
- 下面的 9 列是特征,表示与检测到的肿瘤相关的不同类型的信息。它们代表与以下相关的数据:团块厚度、细胞大小的均匀性、细胞形状的均匀性、边缘粘附、单个上皮细胞大小、裸露的细胞核、平淡的染色质、正常的核仁和有丝分裂。
- 最后一列是肿瘤的类别,它有两个可能的值: 2 表示肿瘤被发现为良性。 4 表示发现为恶性。
- 我们还被告知有几行包含丢失的数据。缺失数据在数据集中用**表示。**性格。
- 在数据集中的 699 名患者中,类别分布为:良性:458 名(65.5%)和恶性:241 名(34.5%)
这是有用的信息,可以让我们得出一些结论。
- 我们的目标是训练我们的神经网络,根据数据提供的特征预测肿瘤是良性还是恶性,。
- 网络的输入将由 9 个特征组成,9 列表示肿瘤的不同特征**。**
- 我们将不使用保存患者 ID 的第一列。
- 我们将从数据集中删除任何包含丢失数据的行。性格)。
- 在二进制分类的情况下,从两个类中获得较大比例的数据是有益的。我们有一个 **65%-35%的分布,**这已经足够好了。
- 良性和恶性类用数字 2 和 4 标识**。我们网络的最后一层通过它的 Sigmoid 函数输出 0 到 1 之间的值。此外,当数据设置在从 0 到 1 的范围内时,神经网络往往工作得更好。因此,我们将更改 class 列的值,对于良性情况,将值保持为 0 而不是 2,对于恶性情况,将值保持为 1 而不是 4。(我们也可以改为缩放 Sigmoid 的输出)。**
我们开始做这些改变。首先,我们将类值(在第 10 列)从 2 更改为 0,从 4 更改为 1
df.iloc[:,10].replace(2, 0,inplace=True)
df.iloc[:,10].replace(4, 1,inplace=True)
然后,我们继续删除所有包含缺失值的行(由?character)位于第 6 列,我们已将其标识为包含它们的列。
df = df[~df[6].isin(['?'])]
那个“?”字符导致 Python 将第 6 列解释为由字符串组成。其他列由整数组成。我们将整个数据帧设置为由浮点数组成。这有助于我们的网络执行复杂的计算。
df = df.astype(float)
接下来,让我们处理数据中值的范围。请注意 9 个特征中的数据是如何由超出 0 到 1 范围的数字组成的。真实的数据集通常是杂乱的,并且它们的值具有很大的范围差异:负数、列内的巨大范围差异等等。
这就是为什么数据标准化是深度学习过程的特征工程阶段中关键的第一步。
将数据规格化意味着以一种网络更容易消化的方式准备 it 。我们正在帮助网络更容易、更快地收敛到我们所寻求的最小值。通常,神经网络对 0 到 1 范围内的数值数据集反应良好,对平均值为 0、标准偏差为 1 的数据也反应良好。
特征工程和标准化不是本文的重点,但让我们快速提及特征工程过程的这个阶段中的一些方法:
- 标准化方法的一个例子是通过对每个特征列应用最小-最大方法来重新调整我们的数据,使其符合 0 到 1 的范围。
new _ x =(x-min _ x)/(max _ x-min _ x) - 我们还可以应用标准化,它将每个特性列的值居中,设置平均值为 0,标准偏差为 1。
new_x = (x 均值)/std.dev
一些数据集和场景将从这些技术中获益更多。在我们的例子中,经过一些测试后,我们决定使用 sklearn 库应用最小-最大归一化:
names = df.columns[0:10]
scaler = MinMaxScaler()
**scaled_df** = scaler.fit_transform(**df**.iloc[:,0:10])
**scaled_df** = pd.DataFrame(**scaled_df**, columns=names)
让我们来看看所有这些变化之后的相同的 15 行。

- 更改后,我们有 683 行。16 个缺失数据已被删除。
- 所有的列现在都由浮点数组成,它们的值在 0 和 1 之间被规范化。(当我们稍后构建训练集时,将忽略列 0,即 id)。
- 最后一列 class 现在对良性肿瘤使用 0 值,对恶性肿瘤使用 1 值。
- 请注意,我们没有对 class 列进行规范化,因为它已经保存了 0 到 1 范围内的值,并且它的值应该保持设置为 0 或 1。
- 注意,最后一列,我们将用作目标的那一列,不需要是浮点型。它可以是整数,因为我们的输出只能是 1 或 0。(当我们训练网络时,我们将从原始的 df dataframe 中选取该列,该列被设置为 0 或 1)。
- 因此,我们的 scaled_df dataframe 包含所有规范化的列,我们将从数据集的非规范化版本 df dataframe 中选择 class 列。
随着我们探索更多的数据,这一过程可能会继续下去。
- 这 9 个特征都是必不可少的吗?我们要把他们都包括在培训过程中吗?
- 我们有足够的高质量数据来产生好的训练、验证和测试集吗?(稍后详细介绍)
- 研究这些数据,我们是否发现了任何有意义和有用的见解,可以帮助我们更有效地训练网络?
这些以及更多都是培训开始前进行的功能工程流程的一部分。
另一件有用的事情是构建图表,以不同的方式分析数据。myplotlib python 库帮助我们通过不同种类的图表来研究数据。
我们先把要研究的规格化列和 class 列结合起来,然后开始探索。
scaled_df[10]= df[10]scaled_df.iloc[0:13,1:11].plot.bar();
scaled_df.iloc[0:13,1:11].plot.hist(alpha=0.5)

点击此链接,探索 Panda 提供的所有可视化选项
为了加快文章的速度,在我们的例子中,我们认为 9 个特性是有用的。我们的目标是精确预测“类”列。
那么,描述我们的 683 个样本和它们的输出之间的联系的函数会有多复杂呢?
9 个特征和输出之间的关系显然是多维的和非线性的。
让我们通过网络运行数据,看看会发生什么。
在此之前,我们需要考虑一个关键话题:
- 如果我们使用 683 个样本,我们所有的样本,来创建我们的训练集,并获得良好的结果,我们将不得不面对一个关键问题。
- 如果网络以完全匹配训练期间使用的样本的方式设置其权重,而未能推广到训练集之外的新样本,该怎么办?
- 当使用训练数据时,或者当使用从未见过的数据时**,我们的最终目标是否达到很高的准确度**?显然,第二种情况。
这就是深度学习实践者通常考虑三种数据集的原因:
- **训练集:**你用来训练网络的数据。它包含输入要素和目标标注。
- **验证集:**一个单独的、不同的数据批次,理想情况下应该来自与训练集相同的分布。您将使用它来验证培训的质量。验证集也有目标标签。
- 测试集:另一批单独的数据,用于测试网络中的新相关数据,这些数据最好来自与验证集相同的分布。通常,测试集不带有目标标签。
不同集合相对于彼此的大小是另一个需要花些时间来描述的话题。出于我们的目的,考虑大部分数据形成了训练集,其中一小部分通常被提取(并从训练集中消除)成为验证集。
20% 是一个典型的数字,通常被选为构成我们验证集的数据的百分比。
要估计网络的训练质量,比较训练集和验证集的性能是很有用的:
- 如果在验证集上获得的损失值提高,然后开始变得更差,则网络过度拟合,这意味着网络已经学习了非常适合训练数据的函数,然而没有将 足够好地推广到验证集。
- 过度拟合的反义词是欠拟合,当网络的训练性能不够好时,我们在训练集和验证集中获得的损失值都太高(例如,训练损失比验证损失更严重)。
- 理想情况下,您希望在两个数据集中获得相似的性能。
- 当我们有过拟合时,我们可以应用正则化。正则化是一种对优化算法进行更改以使网络更好地泛化的技术。正则化技术包括剔除、L1 和 L2 正则化、提前停止和数据增强技术。
总的来说,认识到验证集的成功是你真正的目标。如果网络不能很好地处理它以前没有见过的新数据,那么让网络在训练数据上表现得非常好也没有用。
因此,您真正的目标是达到一个良好的损失值,并通过验证集实现良好的准确性。
为了达到这一点,过度拟合是我们需要防止的最重要的问题之一,这就是为什么正规化如此重要。让我们快速简单地回顾一下 4 种广泛使用的正则化技术。
退出:在每一轮训练中,我们会随机关闭一些隐藏的网络单位。这可以防止网络过分强调任何特定的权重,并有助于网络更好地推广。这就好像我们通过不同的网络架构运行数据,然后平均它们的影响,这有助于防止过度拟合。
L1 和 L2 :我们在成本函数中增加了额外的项,当权重变得太大时,这些项会惩罚网络。这些技术鼓励网络在损失值和权重比例之间找到一个好的平衡。
**过早停止:**过度适应可能是训练时间过长的结果。如果我们监控我们的验证错误,当验证错误停止改善时,我们可以停止训练过程。
**数据扩充:**通常,更多的训练数据意味着更好的网络性能,但是获取更多的数据并不总是可能的。相反,我们可以通过人为创建数据的变体来扩充现有数据。例如,在图像的情况下,我们可以应用旋转、平移、裁剪和其他技术来产生它们的新变体。
回到我们的数据。是时候挑选我们的训练集和验证集了。我们将选择 683 行中的一部分作为训练集,选择数据集的另一部分作为我们的验证集。
培训结束后,我们将通过验证集再次运行流程来验证我们网络的质量。
**x=scaled_df.iloc[0:500,1:10].values.transpose()
y=df.iloc[0:500,10:].values.transpose()****xval=scaled_df.iloc[501:683,1:10].values.transpose()
yval=df.iloc[501:683,10:].values.transpose()**
我们决定用 683 行中的 500 行来构建我们的训练集,并且我们从标准化的 scaled_df 数据帧中挑选它们。我们还确保删除第一列(id ),并且不包括网络的输入 x 中的最后一列(class)
我们使用对应于相同的 500 行的类列声明目标输出 y 。我们从原始的非规范化 df dataframe 中选择 class 列(因为 class 值应该保持为 0 或 1)。
然后,我们为验证集选择接下来的 183 行,并将它们存储在变量 xval 和 yval 中。
我们准备好了。我们将首先用我们的 x,y 训练集的 500 行来训练网络。之后,我们将使用我们的 xval,yval 验证集的 183 行来测试训练好的网络,以查看网络对它以前从未见过的数据的概括能力如何。
nn = dlnet(x,y)
nn.lr=0.01
nn.dims = [9, 15, 1]nn.gd(x, y, iter = 15000)
我们声明我们的网络,设置一个学习率和每层的节点数(输入有 9 个节点,因为我们使用的是 9 个特征,不算网络的一层。第一隐藏层具有 15 个隐藏单元,第二和最后一层具有单个输出节点)。
然后,我们通过几千次迭代运行梯度下降算法。让我们用几秒钟的梯度下降来感受一下网络的训练效果。
每 x 次迭代,我们显示网络的损耗值。如果训练进展顺利,损失值将在每个周期后下降。
**Cost after iteration 0: 0.673967
Cost after iteration 500: 0.388928
Cost after iteration 1000: 0.231340
Cost after iteration 1500: 0.171447
Cost after iteration 2000: 0.146433
Cost after iteration 2500: 0.133993
Cost after iteration 3000: 0.126808
Cost after iteration 3500: 0.122107
Cost after iteration 12500: 0.101980
Cost after iteration 13000: 0.101604
Cost after iteration 14500: 0.100592**
经过多次迭代后,我们的损失开始稳定在一个较低的水平。我们绘制了一个图表,通过迭代跟踪网络的损耗。

我们的网络似乎训练得相当好,达到了低损耗值(我们的预测和目标输出之间的距离很小)。但是,**有多好?**最重要的是,它有多好,不仅仅是对整个训练集,更重要的是,对我们的验证集?
为了找到答案,我们创建了一个新函数, pred() ,它通过网络运行一组输入,然后系统地将每个获得的输出与其对应的目标输出进行比较,以便产生一个平均精度值。
请注意下面函数是如何研究预测值是高于还是低于 0.5 的。我们正在进行二元分类,默认情况下,我们认为高于 0.5 的输出值意味着结果属于其中一个类,反之亦然。
在这种情况下,因为 1 是恶性肿瘤的类值,我们认为高于 0.5 的输出预测恶性结果,低于 0.5 则相反。我们稍后将讨论如何、何时以及为什么要更改这个 0.5 的阈值。
def pred(self,x, y):
self.X=x
self.Y=y
comp = np.zeros((1,x.shape[1]))
pred, loss= self.forward()
for i in range(0, pred.shape[1]):
if pred[0,i] > 0.5: comp[0,i] = 1
else: comp[0,i] = 0
print("Acc: " + str(np.sum((comp == y)/x.shape[1])))
return comp
现在,我们通过调用两次 pred 函数,一次使用我们的训练集,另一次使用我们的验证集,来比较使用训练集和验证集时网络的准确性。
**pred_train = nn.pred(x, y)
pred_test = nn.pred(xval, yval)**
我们得到了这两个结果。
**Acc: 0.9620000000000003
Acc: 1.0**
该网络在训练集(前 500 行)上的准确率为 96%,在使用验证集(接下来的 183 行)时的准确率为 100%。
验证集上的准确率更高。这意味着网络没有过度拟合,并且泛化得足够好能够适应它以前从未见过的数据。
我们现在可以使用 nn.forward()函数直接比较与目标输出相关的验证集输出的前几个值:
nn.X,nn.Y=xval, yval
yvalh, loss = nn.forward()
print("\ny",np.around(yval[:,0:50,], decimals=0).astype(np.int))
print("\nyh",np.around(yvalh[:,0:50,], decimals=0).astype(np.int),"\n")
我们得到了
**y [[0 0 0 1 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1]]****yh [[0 0 0 1 0 0 1 1 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1]]**
两个完全匹配,因为我们已经在验证集上实现了 100%的准确性。
因此,该函数很好地学习了以适应训练集和验证集。
分析准确性的一个很好的方法是绘制一个混淆矩阵。首先,我们声明一个自定义绘图函数。
def plotCf(a,b,t):
cf =confusion_matrix(a,b)
plt.imshow(cf,cmap=plt.cm.Blues,interpolation='nearest')
plt.colorbar()
plt.title(t)
plt.xlabel('Predicted')
plt.ylabel('Actual')
tick_marks = np.arange(len(set(expected))) # length of classes
class_labels = ['0','1']
tick_marks
plt.xticks(tick_marks,class_labels)
plt.yticks(tick_marks,class_labels)
# plotting text value inside cells
thresh = cf.max() / 2.
for i,j in itertools.product(range(cf.shape[0]),range(cf.shape[1])):
plt.text(j,i,format(cf[i,j],'d'),horizontalalignment='center',color='white' if cf[i,j] >thresh else 'black')
plt.show();
(这个自定义的混淆矩阵函数来自JP 创建的这个公共 Kaggle)
然后,我们再次运行 pred 函数两次,并为训练集和验证集绘制混淆矩阵。
**nn.X,nn.Y=x, y
target=np.around(np.squeeze(y), decimals=0).astype(np.int)
predicted=np.around(np.squeeze(nn.pred(x,y)), decimals=0).astype(np.int)
plotCf(target,predicted,'Cf Training Set')****nn.X,nn.Y=xval, yval
target=np.around(np.squeeze(yval), decimals=0).astype(np.int)
predicted=np.around(np.squeeze(nn.pred(xval,yval)), decimals=0).astype(np.int)
plotCf(target,predicted,'Cf Validation Set')**

我们可以更清楚地看到,我们的验证集在其 183 个样本上具有完美的准确性。至于训练集,500 个样本中有 19 个错误。
现在,在这一点上,你可能会说,在像诊断肿瘤这样微妙的主题中,如果乙状结肠输出给出高于 0.5 的值,则将我们的预测设置为 1 并不是很好。在给出恶性肿瘤的预测之前,网络应该非常有信心。
我完全同意,那是非常正确的。这些都是你需要根据挑战的性质和你要处理的主题做出的决定。
然后,让我们创建一个名为阈值的新变量。它将控制我们的置信阈值,在我们确定肿瘤是恶性肿瘤之前,网络的输出需要多接近 1。默认情况下,我们将其设置为 0.5
**self.threshold=0.5**
外部预测函数现在被更新以使用置信度阈值。
def pred(self,x, y):
self.X=x
self.Y=y
comp = np.zeros((1,x.shape[1]))
pred, loss= self.forward()
for i in range(0, pred.shape[1]):
**if pred[0,i] > self.threshold: comp[0,i] = 1**
else: comp[0,i] = 0
print("Acc: " + str(np.sum((comp == y)/x.shape[1])))
return comp
现在,让我们随着置信度阈值的逐渐提高来比较我们的结果。
**置信度阈值:0.5。**输出值需要高于 0.5 才能被视为恶性输出。如前所述,验证准确率为 100%,训练准确率为 96%。

**置信度阈值:0.7。**输出值需要高于 0.7 才能被视为恶性输出。验证准确率保持在 100%,训练准确率下降到 95%。

**置信度阈值:0.8。**输出值需要高于 0.8 才能被视为恶性输出。第一次验证准确率非常非常轻微地下降到 99.45%。在混淆矩阵中,我们看到 183 个样本中有 1 个没有被正确识别。训练精度下降更多,直到 94.2%

**置信度阈值:0.9。**最后,在 0.9 的情况下,输出值需要高于 0.9 才能被视为恶性输出。我们正在寻找几乎完全的信心。验证准确度稍微下降,直到 98.9%。在混淆矩阵中,我们看到 183 个样本中有 2 个没有被正确识别。训练准确率进一步下降到 92.6%。

因此,通过控制置信度阈值,我们可以适应挑战的特定需求。
如果我们想要降低与我们的训练集相关的损失值(因为我们未能识别一小部分训练样本),我们可以尝试训练更长时间,并且还可以使用不同的学习率。
例如,如果我们设置学习率为 0.07,训练 65000 次迭代,我们得到:
**Cost after iteration 63500: 0.017076
Cost after iteration 64000: 0.016762
Cost after iteration 64500: 0.016443
Acc: 0.9980000000000003
Acc: 0.9945054945054945**

现在,将我们的置信阈值设置为 0.5,网络对两组中的每个样本都是准确的,除了每组中的一个样本。

如果我们将置信度阈值提高到 0.7,性能仍然很好,只有 1 个验证样本和 2 个训练样本没有被正确预测。

最后,如果我们真的要求很高,并且将置信度阈值设置为 0.9,则网络无法正确猜测 1 个验证样本和 10 个训练样本。

虽然我们做得很好,但考虑到我们使用的是没有正规化的基本网络,当您处理更复杂的数据时,事情通常会变得更加困难。
通常情况下,亏损局面会变得非常复杂,而且更容易陷入错误的局部最小值,或者无法收敛到足够好的亏损。
此外,根据网络的初始条件,我们可能会收敛到一个好的极小值,或者我们可能会在某处停滞不前,无法摆脱它。在这个阶段,再次描绘我们的初始动画是很有用的。

Navigating the Loss Landscape. Values have been modified and scaled up to facilitate visual contrast.
想象一下这样的风景,到处都是山丘和山谷,有些地方损耗很高,有些地方损耗很低。与复杂场景相关的损失函数的情况通常不一致(虽然可以使用不同的方法使其更加平滑,但这是一个完全不同的主题)。

到处都是深浅不一、角度各异的山丘和山谷。运行梯度下降算法时,您可以通过改变网络的损失值来改变地形。

并且你移动的速度由学习率控制:
- 如果你移动得非常慢,不知何故到达了一个不够低的高原或山谷,你可能会被困在那里。
- 如果你走得太快,你可能会到达一个足够低的山谷,但穿过它,并以同样快的速度离开它。
因此,有些非常微妙的问题会对您的网络性能产生巨大影响。
- **初始条件:**在流程开始时,你把球丢在景观的哪个部分?

- 你移动球的速度,学习率。
最近在提高神经网络训练速度方面取得的许多进展都与不同的技术有关,这些技术动态地管理学习率,也与以更好的方式设置初始条件的新方法有关。
关于初始条件:
- 记住,每一层计算前一层的权重和输入的组合(输入的加权和),并将该计算传递给该层的激活函数。
- 这些激活函数的形状可以加速或停止神经元的动态变化,这取决于输入范围和它们对该范围的反应方式之间的组合。
- 例如,如果 sigmoid 函数接收的值触发了接近其输出范围极值的结果,则激活函数在该范围部分的输出会变得非常平坦。如果它在一段时间内保持不变,导数,在那一点的变化率变为零或者非常小。
- 回想一下是导数帮助我们决定下一步的走向。因此,如果导数没有给我们提供有意义的信息,网络将很难知道从该点开始下一步的方向。
- 就好像你已经到达了风景中的一个高原,你真的不知道下一步该去哪里,你只是不停地绕着那个点转圈。
- ReLU 也可能发生这种情况,尽管 ReLU 只有 1 个平面,而不是 2 个乙状结肠和 Tanh。 Leaky-ReLU 是 ReLU 的一个变种,它稍微修改了函数的那一面(平坦的那一面),试图防止渐变消失。

因此,以可能的最佳方式设置我们的权重的初始值是至关重要的,以便在训练过程开始时单元的计算产生落入我们的激活函数的最佳可能范围内的输出。
这可能会使从开始的整个区别成为一个真正高的损失或更低的损失。

管理学习率以防止训练过程太慢或太快,并使其值适应过程和每个参数的变化条件,是另一个复杂的挑战
谈论处理初始条件和学习率的许多方法需要几篇文章。我将简要描述其中的一些方法,让专家们了解一些应对这些挑战的方法。
- **Xavier 初始化:**一种初始化我们的权重的方法,这样神经元就不会开始处于饱和状态(陷入输出范围的微妙部分,在那里导数无法为网络提供足够的信息来知道下一步去哪里)。
- 学习率退火:高学习率会推动算法绕过并错过损失景观处的良好最小值。逐渐降低学习速度可以防止这种情况。有不同的方法来实现这种减少,包括:指数衰减、阶跃衰减和 1/t 衰减。
- fast . ai Lr _ find():fast . ai 库的一种算法,为学习率寻找理想的取值范围。 Lr_find 通过几次迭代训练模型。它首先尝试使用一个非常低的学习速率,并在每个小批量中逐渐改变速率,直到它达到一个非常高的值。每次迭代都会记录损失,一个图表可以帮助我们将损失与学习速度进行对比。然后,我们可以决定以最有效的方式减少损失的学习率的最佳值。
- 不同的学习率:在我们网络的不同部分使用不同的学习率。
- SGDR,带重启的随机梯度下降:每 x 次迭代重置我们的学习率。如果我们陷入其中,这可以帮助我们走出不够低的高原或局部极小值。典型的过程是从高学习率开始。然后在每一个小批量中逐渐减少。经过 x 个周期后,您将其重置回初始高值,并再次重复相同的过程。这个概念是,从高速率逐渐移动到较低的速率是有意义的,因为我们首先从景观的高点(初始高损耗值)快速向下移动,然后缓慢移动以防止绕过景观的最小值(低损耗值区域)。但是,如果我们在某个不够低的高原或山谷中停滞不前,那么每 x 次迭代就将我们的速率重新设置为一个较高的值,这将有助于我们跳出这种情况,继续探索这一领域。
- **1 周期策略:**les lie n . Smith 提出的一种动态改变学习速率的方式,我们从一个较低的速率值开始,逐渐增加,直到达到最大值。然后,我们继续逐渐减少它,直到过程结束。最初的逐渐增加允许我们探索大面积的损失景观,增加我们到达不颠簸的低区域的机会;在循环的第二部分,我们在我们到达的低平地区安顿下来。
- 动量:随机梯度下降的一种变化,有助于加速通过损失景观的路径,同时保持总体方向受控。回想一下,SGD 可能很吵。动量平均化路径中的变化,使路径变得平滑,并加速向目标的移动。
- **自适应学习率:**为网络的不同参数计算和使用不同学习率的方法。
- AdaGrad ( 自适应梯度算法):
结合上一点,AdaGrad 是 SGD 的变体,它不是对所有参数使用单一的学习速率,而是对每个参数使用不同的速率。 - 均方根传播 (RMSProp):像 Adagrad 一样,RMSProp 对每个参数使用不同的学习速率,并根据它们变化的平均速度来调整这些速率(这在处理嘈杂的环境时很有帮助)。
- 亚当:它结合了 RMSprop 和 SGDR 的一些方面与动力。像 RMSprop 一样,它使用平方梯度来缩放学习速率,并且它还使用梯度的平均值来利用动量。
如果你对这些名字都不熟悉,不要不知所措。在它们大多数的背后是非常相同的根:反向传播和梯度下降。
此外,在现代框架(如 fast.ai 库)中,许多这些方法都是自动为您选择的。理解它们是如何工作的是非常有用的,因为这样你就能更好地做出自己的决定,甚至研究和测试不同的变化和选择。****
理解意味着更多的选择
当我们理解了网络的核心,基本的反向传播算法和基本的梯度下降过程,每当我们面临艰难的挑战时,我们就有更多的选择去探索和实验。
因为我们了解这个过程,所以我们意识到,例如在深度学习中,我们在损失范围内的初始位置是关键。
一些初始位置会很快推动球(训练过程)卡在景观的某个部分。其他人会很快把我们逼到一个很好的最小值。

当神秘函数变得更加复杂时,就是时候加入我前面提到的一些高级解决方案了。现在也是时候更深入地研究整个网络的架构,并更深入地研究不同的超参数。
浏览风景
我们的损失状况在很大程度上受到网络架构设计以及超参数的影响,如学习率、我们的批量大小、我们使用的优化算法等。
 ****
****
有关这些影响的讨论,请查看这篇论文:李浩、、加文·泰勒、克里斯托夫·斯图德、汤姆·戈尔茨坦的《可视化神经网络的损失景观》。
最近的研究得出了一个非常有趣的观点,即神经网络中的跳过连接模型如何平滑我们的损失景观,并使它变得更加简单和凸,增加我们收敛到好结果的机会。

Navigating the Loss Landscape. Values have been modified and scaled up to facilitate visual contrast.
****跳过连接对训练非常深的网络帮助很大。基本上,跳过连接是链接不同层的节点的额外连接,跳过中间的一个或多个非线性层。
当我们用不同的架构和参数实验时,我们正在修改我们的损失场景**,使其更加崎岖或平滑,增加或减少局部最优解的数量。当我们优化初始化网络参数的方式时,我们正在提高我们的起点。**
让我们继续探索新的方法来应对世界上最迷人的挑战。

Navigating the Loss Landscape. Values have been modified and scaled up to facilitate visual contrast.
这篇文章涵盖了基础知识,从这里开始,前途无量!
链接到本文的 3 个部分:
第 1 部分 | 第 2 部分||第 3 部分
** [## javismiles/深度学习预测乳腺癌肿瘤恶性肿瘤
用 Python 从头开始编码的 2 层神经网络预测癌症恶性程度。…
github.com](https://github.com/javismiles/Deep-Learning-predicting-breast-cancer-tumor-malignancy)**

















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
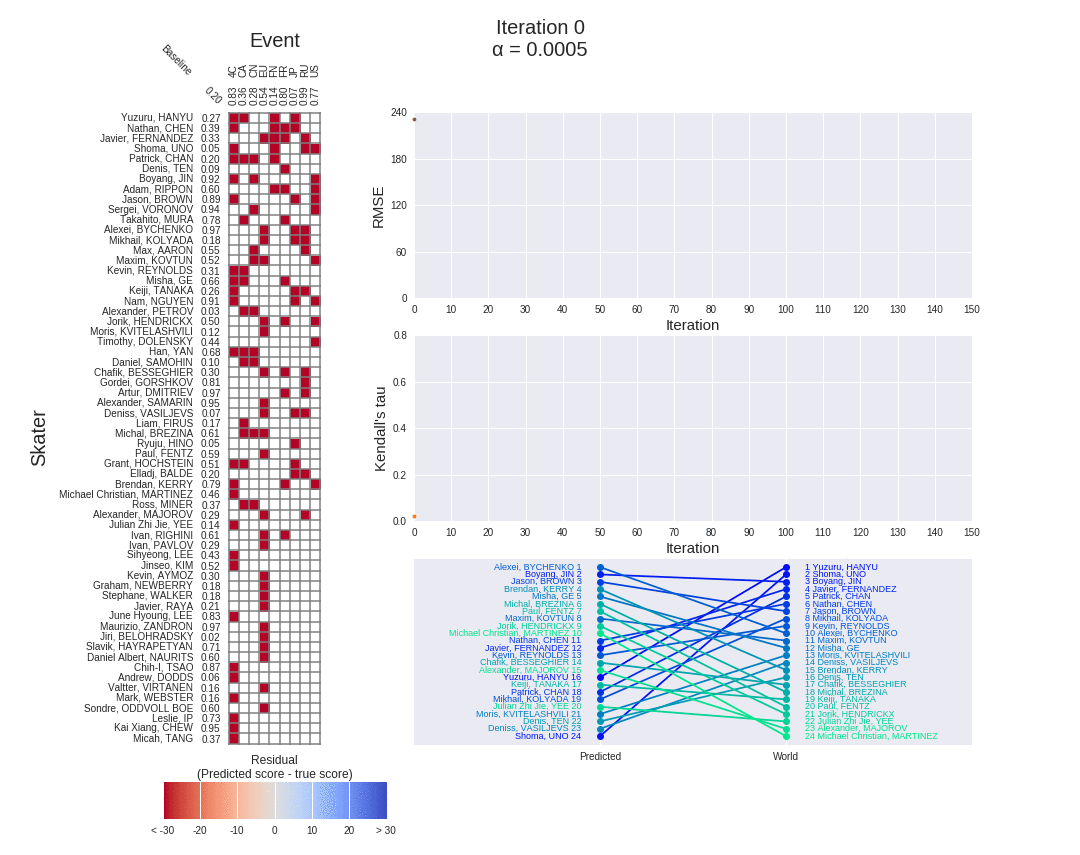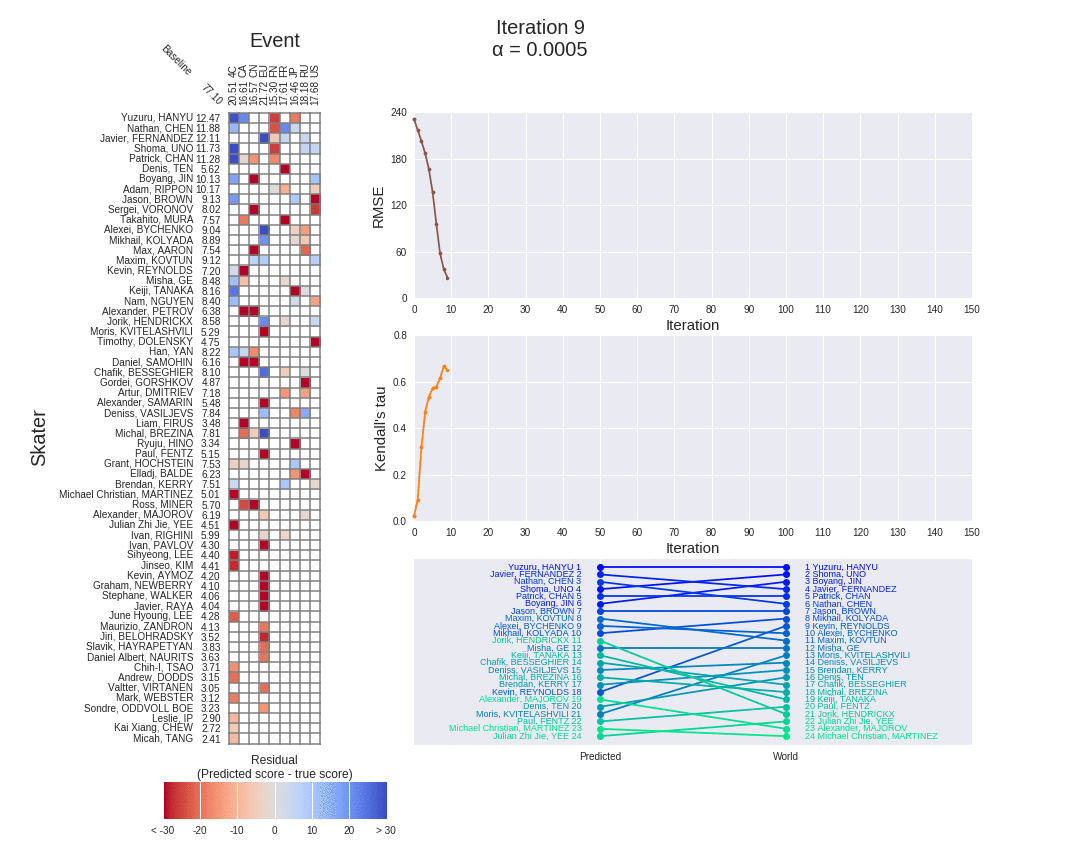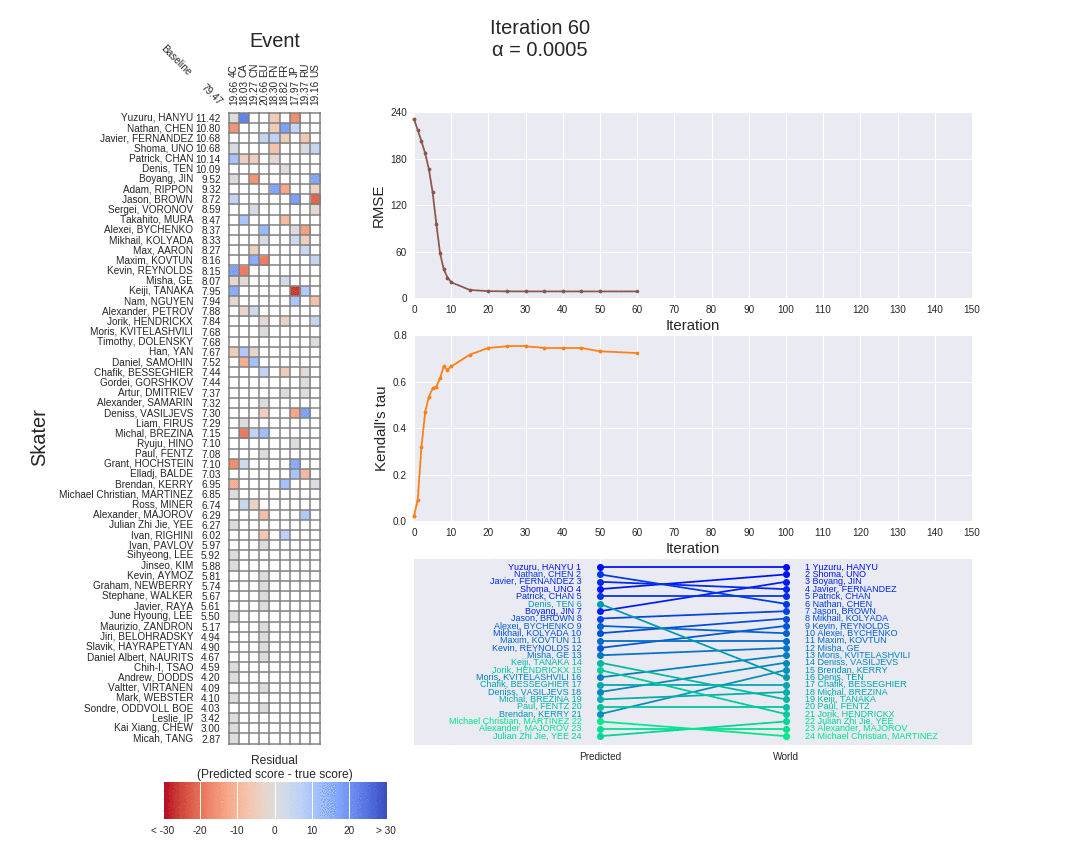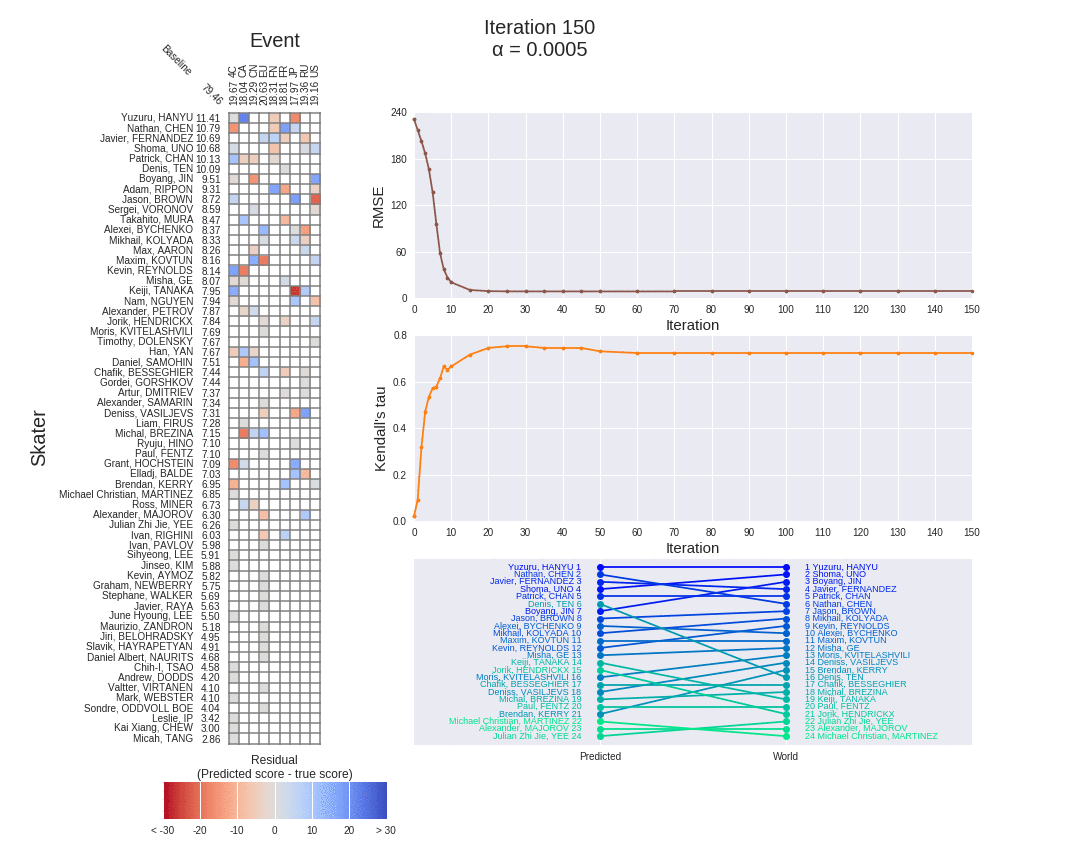{kind=link}