







一个研究生对统计学的看法
为什么统计学是一个普遍令人困惑的领域?

当我遇见一个新的人,不可避免的问题被问到,“那么,你是做什么的?”,我回答说我是一名统计学的博士生,对此的回答大多是这样的:
“统计?!我在大学时有一门必修的统计学课,它非常令人困惑。”
仅仅是这种事件的发生频率就让我开始思考为什么统计数据如此普遍地令人困惑。对我来说,答案很复杂,根源在于将确定性事件(如我们所见)转化为随机过程(如统计学所见)的实现。我试图在下面解开这些复杂性。
从点跳到云
在微积分之前,数学教育的标准轨迹通常会终止,我们生活在一个由点、线、曲线等组成的世界里。—数量通过确定性关系交织在一起的形状。我知道速度=距离/时间,所以如果我们需要在 45 分钟内到达 60 公里外的某个地方,那么我知道我必须以 80 公里/小时的速度行驶,这些函数关系是确定性的。
但是一上统计学课,我们就步入了一个随机的世界。我们不再在一组已知的关系中工作,而是在推断产生我们所看到的观察的未知机制。
例如,我们等一辆公共汽车,考虑到它过去的可靠性,我们试图预测它今天是否会准时到达。随机性有很多来源——交通灯的同步、路上其他司机的礼貌、天气状况——这些因素导致不同的到达时间。
因此,统计学隐含地处理概率 云、而不是点数。紧密概率云(“公共汽车每 10 1 分钟来一次”)表示我们非常确定公共汽车几乎总是接近其预定时间。分散的云(“公共汽车每 10 分钟来一趟”)表示到达时间的广泛可变性。如果我们只是没有观察到足够的信息来确定其长期模式(也许我们只等了两次公交车),或者我们的观察非常分散(有时会早 10 分钟,但有时会晚 20 分钟),这种情况就可能发生。
实际上,从来没有人明确告诉我,我正在离开一个由线条组成的世界,走向一个由云组成的世界,但我相信这是进入统计世界的一个基本困难。一个主要的结果是我们不再处理等效值(例如,y = x+3),而是处理范围和概率(例如,玫瑰是红色的,紫罗兰是蓝色的……但是我有玫瑰还是紫罗兰呢?
通常,统计问题集会提出一个问题,问题的开头是:
“假设 X 是分布的…”
在这些情况下,随机变量 X 的理论行为被告知我们,我们得出关于我们可能观察到的其实现的结论,这些实现用小写字母 X 表示。给定关于 X 的不同假设集,我们可以得出关于其行为的不同属性,如下所示:
考虑到这一点,你可能会认为统计学中的一个重要工具是一个“排序帽”,给定一组经验数据,测试它们是否最接近正态、泊松等。这样,我们就知道从我们的数据中可以得到哪组属性。

然而这样的工具相当稀少!有一个 Kolmogorov-Smirnov 测试,它测试两个分布的相似性,但只是在我的一堂本科统计学课上顺便提到过。 QQ 图作为两个重叠直方图的改进形式,直观地比较经验分布的分位数与其假定的理论分布是否匹配。直到研究生院,我才知道像核密度估计这样的方法可以用来估计非标准密度函数。
致力于将观察到的数据集与其潜在属性联系起来的统计推断领域,倾向于假设数据的分布,并简单地提供估计其参数的方法。精确的发行版本身对结果属性的影响是否像缺少工具所暗示的那样小?
自我反驳的一个尝试在于中心极限定理。我们经常对手段的行为感兴趣(平均,公交车会准时来吗?),中心极限定理说独立随机变量之和趋于正态分布。由于均值包含一个和,那么所有关于正态分布的导数都可以应用于独立随机变量实现的均值。
另一个回答是,人们越来越重视半参数和非参数方法,这种方法很少(或没有)作出分布假设。然而,正如应该合理预期的,这些方法的灵活性和适用性的增加可能是以降低功率为代价的。
那么数据科学家呢?
当我们意识到数据科学家必须做出确定性决策时,担心我们的随机性模型的准确性可能显得没有意义。正因为如此,简单地比较两个数字的大小,或者并排绘制直方图,可能就足以确定获胜的决策。统计学在一个不确定的世界中运作,但数据科学家在一个必须以二元方式做出决策的世界中运作。是或不是。
实际上,随机性——通常以 p 值的形式——只是告诉我们如何确定我们的决定,但永远不会改变我们决定的方向。考虑到这一点,不确定性程度的精确量化真的重要吗?如果我们选择将我们的数据建模为一种分布而不是另一种分布,那实际上会改变什么吗?
我对统计的保留意见
你经常听到人们把追求博士描述为“越来越了解越来越少”。但这不是我迄今为止对我的博士工作的评价——我当然会继续学习统计学的基础知识(比如斯坦的悖论!).
鉴于上述讨论,我更关心的是:
(1)如何将我们对理论统计的理解贯彻到现实世界中。这样做似乎需要一种能力来验证假设的程度,这是一个似乎还不发达的统计学领域。
(2)在一个确定性的世界里,如此谨慎地对待随机性的有用性。如果使用统计学来对公共政策、药物、网站设计等做出具体的选择。,随机性在哪些方面发挥了重要作用?
我的想法一直在发展,我衷心欢迎下面的评论、不同意见或反馈。
致谢
非常感谢高子冲、菲利普·莫里茨、阿维·费勒、特里萨·格伯特和佐伊·弗农与我一起阅读和提炼这些观点。
Much thanks to Zi Chong Kao, Philipp Moritz, Avi Feller, Theresa Gebert, and Zoe Vernon for reading and refining these ideas with me.
图形数据库案例研究:中国习语连锁店
用 20 行 Python 构建一个 Neo4J 图形数据库应用程序

与关系数据库相比,图数据库有许多优点:快速查询、灵活模式、高效存储等。但时至今日仍未得到充分利用。困难之一是与其他语言的互操作性,官方文档提供的例子很少。本文试图填补这个空白,提供了一个只有 20 行 python 代码的案例研究。

中华习语链球赛
这是一个帮助小学生学习成语的经典教育游戏。一名学生坐在圆桌旁,随机拿出一个中国习语(一个由 4 个汉字组成的中国习语)。下一个学生必须快速说出另一个习语,其第一个字符与给定的习语的最后一个字符相匹配。当有人被卡住时,他必须唱首歌或跳支舞。
现在有了 graph DB 的知识,小学生可以不用再担心输了比赛,不得不在全班面前表演了!
图形设计
The graph structure is as simple as you can imagine. We have one types of node and one types of directed edge. It’s tempting to create a node for each idiom, because an idiom is an entity, just like a user, a movie, a product. If an edge exists between two nodes, we just create an edge. For example, there is an edge pointing from 坚定不移 to 移花接木, because the character 移 connects the two idioms.

Naive design
具有关系数据库背景的人可能会自然而然地想到这种设计,因为边只是连接操作中的一个匹配。对吗?不幸的是,这个看似无害的设计结果却不切实际。我们必须彻底搜索所有的边,并且一次添加一个边,导致二次时间复杂度。
通过巧妙的建模,我们可以做得更好。如果我们将习语嵌入到边中,而不是节点中,会怎么样?设位于习语开头或结尾的每个字符都是一个节点。设每条习语是一条有向边,从一个习语的最后一个字符(源节点)指向另一个习语的开始字符(目的节点)。原来这个设计是花费线性时间来构建的!


Improved design
履行
有了好的设计,实现就变得简单了。你需要安装 Neo4J 桌面服务器,和 py2neo 库。
pip install pandas py2neo
现在我们可以查询结果了!让我们编写一个助手函数,让您定义初始习语、路径长度和行限制。
我们去查询数据库吧!不出所料,速度没有让人失望。为了在关系数据库中获得相同的结果,您需要自连接习语表五次。猜猜需要多长时间?(费用是 N⁵)

摘要
这个例子展示了我们如何利用图数据库的优势来显著地加速特定的任务,即使这些任务主要是用另一种语言编写的(在这个例子中是 Python)。
然而,阅读这篇文章并不能保证你可以在任何任务中运用同样的策略。为了做到这一点,需要牢固掌握密码语言。
延伸阅读
下面的博客涵盖了与 AB 测试相关的主题,以及对本文中提到的关键概念的更深入的回顾。
源代码、数据集、结果都在我的 GitHub 资源库 中。
一个巨大的公共健康阴谋?

科学、医学和政府在改善公众健康方面的合作。真人秀第五集。
2013 年 1 月,安大略省温莎市的市议会做出了一个奇怪的选择。以 8 比 3 的投票结果,他们实施了一项计划,将该镇儿童的蛀牙率提高了 50%以上。这些议员实施了什么邪恶的行为?每年举办多次万圣节?让糖果公司做学校午餐?不,他们做了更灾难性的事情:他们故意选择忽视堆积如山的医疗建议,屈服于公众的歇斯底里,取消上个世纪最伟大的公共卫生成就之一、公共用水加氟。
自 1945 年以来,向公共供水中添加矿物质氟化物以防止蛀牙已经成为一种普遍的做法。全世界大约有 4 亿人饮用添加了氟化物的水,包括至少 66%的美国人口。数以千计的研究发现水氟化是有益且无风险的,其中疾病控制和预防中心得出结论:氟化物在预防和控制龋齿方面既安全又有效 ( 龋齿是龋齿/蛀牙的医学术语)。尽管如此,加拿大一个小镇的政府认为他们比整个医学界都了解。
6 年后,儿童龋齿增加了 51%,低收入家庭需要牙科保健财政支持的人数增加了 300%,该镇儿童遭受了无尽的痛苦,温莎委员会在 2018 年 12 月的一次会议上不情愿地撤销了其决定。会上,5 位牙科专家作证,根据所有医学证据,全力支持水氟化。另一方面,20 名公民——没有医学学位——基于毫无根据的恐惧和一种信念表示反对,认为政府不应该“治疗”公众*,即使药物阻止儿童去医院。*幸运的是,到了最后,理智和民意调查显示 80%的市民希望水的氟化占了上风,而温莎将再次享受到好处。
这个故事立即引起了我的注意,因为它有着耐人寻味的元素:一项伟大的医学成就被阴谋论者毁掉了,人们拒绝承认大量的证据,最后,科学战胜了迷信。此外,它说明了为什么现实项目,努力用数据减少对世界的误解是重要的:只有通过检查数据,我们才能找出哪些政策是有效的,然后——即使作为个体公民——为它们的实施而运动。在科学、医学和我们的世界观方面保持正确不仅仅是为了虚荣,而是为了确保我们为社会做出最好的决定。
在现实项目的第五集中,我们将深入探究公共用水氟化的证据。虽然前几集关注的是大规模的想法,但这一集更私人:它涉及到你和你家人的健康。我们需要知道事实,因为虽然我们最初可能会嘲笑阴谋论者,但只有当他们开始侵蚀对政府的信任,并随之降低社会福祉时,这才是有趣的。也许我们天生倾向于寻找疯狂的理论(你点击这个是因为标题中的“阴谋”,对吗?)但事实往往更令人惊讶,因为公共用水加氟的数据证明了这一点。
公共用水加氟的事实
对于任何健康话题,尤其是引起争议的话题,我们必须小心我们从哪里获得数据。即使是同行评议期刊上的研究也会有偏见——有意或无意。因此,审查医学证据的最佳实践是查看荟萃分析,即评估数十或数百项研究结果的审查。英国慈善机构 Cochrane Organization 成立的目的是为了对医学文献进行系统综述,并为公众利益提出客观建议。我们将依靠他们对公共水氟化的荟萃分析,以及来自澳大利亚国家健康和医学研究委员会(NHMRC )的一项分析。为了进行经济分析,我们将使用来自“社区水氟化的经济评估”的数据。
这些来源都不是引人入胜的读物,但是当涉及到健康时,依赖娱乐(即新闻)作为事实的来源是灾难性的。阅读实际证据是困难的,但这是不被特殊利益集团愚弄的唯一方法。维基百科的文章可以是一个很好的起点,但是我们应该始终坚持引用。在这里,我将总结相关的部分,但是如果你持怀疑态度,我鼓励你阅读文章。
公共饮水加氟能减少蛀牙吗?
让我们从一个简单的问题开始:水氟化能预防蛀牙和蛀牙吗?明确的答案是:是的,至少在儿童中是这样。根据 Cochrane review(基于 107 项研究),公共水氟化减少了乳牙 35%的蛀牙和恒牙 26%的蛀牙。其他荟萃分析也发现了类似的结果。来自 NHMRC 的报告发现,在所有研究中,风险降低了 9%到 35%。同一篇综述发现,需要治疗(NNT)以预防蛀牙的人数在 3-14 人之间。NNT 值为 3 意味着每 3 个人接受氟化水,就有 1 个人不会因此患上龋齿。
NHMRC 审查的相关调查结果见下图。龋齿是蛀牙的学名(和细菌产生的酸造成的蛀牙是一回事)。风险差和 NNT 是两个最有用的栏目。在所有回顾的研究中,公共供水的氟化降低了蛀牙的风险。

Table 11 from NHMRC review on the efficacy and safety of fluoridation.
Cochrane review 小心翼翼地指出,没有足够的研究证实水的氟化作用可以降低成人龋齿的发病率*。*然而,疾病控制和预防中心(CDC) 引用了至少一项研究,表明成年人的蛀牙减少了 20-40 %,这表明益处可能会持续一生。重要的是,既要承认我们已有的证据——饮水氟化改善了儿童的牙齿健康——又要承认在得出结论之前我们还需要更多的研究。
潜在的副作用是什么?
医学干预的效果不是唯一的关键因素:不需要有有害的副作用,或者至少好处必须大于不利的结果。因此,第二个问题是:氟化有副作用吗?反对水氟化的人列举了一系列副作用(包括癌症和低智商),但是,在一项又一项的研究中,医学证据指出只有一种很少发生:牙齿轻度变色。这种情况被称为氟斑牙,纯粹是美学意义上的,它只会影响牙齿的外观。其他新闻,喝咖啡和茶也会染牙!
任何由阴谋论者鼓吹的声称发现了负面影响的研究都检验了远远超过任何社区水氟化计划所要求的剂量(百万分之 0.7 份)。这意味着公共饮水加氟唯一可能的副作用是轻微的色斑,就像你可能从过量的茶中得到的一样。所以,归根结底是你重视什么:如果你想让你的牙齿腐烂,但看起来无可挑剔,停止喝含氟水(和茶)!对于我们这些不喜欢牙痛和蛀牙的人来说,轻微变色的风险完全值得氟化物的好处。
如果你不相信我,也许美国牙科协会(ADA)的以下声明可以动摇你:“[ADA]毫无保留地支持社区供水的氟化,认为这是安全、有效和必要的,可以防止蛀牙”。提醒你一下,美国糖尿病协会认为 T2 会因为加氟水而失去 T3,因为这导致了患者的减少。也许是唯一从这种情况中获益的人?一名当地牙医,由于水氟化的停止,他的预约一直持续到 2020 年。
经济学
有效的治疗是一回事,但在实施之前对社区来说最重要的问题可能是:值得吗?我们无法对预防的人类痛苦定价,但我们可以将氟化的成本与减少的蛀牙治疗成本进行比较。在审查“社区水氟化的经济评估”中,对不同人口规模的 6 项不同研究进行了检查,发现每人每年的水氟化成本从 0.24 美元到 4.85 美元不等,取决于社区规模(人口越多意味着人均成本越低)。将这些数字放在背景中,每人每年提供的平均福利从 5.49 美元到 93.19 美元不等。
并排比较成本和收益,社区水氟化每投资 1 美元可获得 135 美元。在每项研究中,收益都超过了成本,如下表所示:

Cost to benefit ratios of water fluoridation from 6 studies (Source)
有趣的是,成本收益比通常随着社区规模的增加而增加。这是有道理的:基础设施是最昂贵的部分,氟化物本身相对便宜。因此,同一供水系统服务的人越多,人均成本就越低。
我们希望我们的退休基金能够带来正回报,我们也应该从公共卫生干预中获得同样的回报。你可以做得比把你的钱投入公共水氟化更糟糕:它不仅减少了你社区的儿童的痛苦,而且还可以获得 135 倍的投资回报!任何选择在水中加氟的社区不仅能改善其公民的牙齿健康,还能带来社会利益。
可供选择的事物
有没有其他方法可以在不往水里放氟化物的情况下获得同样的好处?答案是肯定的:牛奶和盐都可以加氟,最常见的替代品是局部选择,包括凝胶和牙膏。现在美国大约 90%的牙膏都含有氟化物。更重要的是,牙膏中的浓度几乎是水氟化物的 1000 倍( 1000+ ppm,相比之下,水的浓度为 0.7 ppm)。对于那些担心氟化对健康有潜在影响的人来说,明确的解决办法不是避免饮用自来水,而是停止刷牙。
其他氟化物来源的流行可能是为什么在过去的几十年里,公共水的氟化作用已经下降。在 20 世纪 50 年代和 60 年代进行的初步研究发现,当引入氟化物时,龋齿减少了 50–70%。然而,正如我们在上面所了解到的,提出的证据表明了一个更加适度的减少,大约 20-35%。这是一个好消息,因为美国的整体蛀牙率下降,含氟和非含氟社区之间的牙齿健康差距缩小。然而,应该注意的是,在社会经济水平较低的地区,含氟牙膏和替代来源的获取受到限制,而这些地区恰恰是最需要含氟牙膏的地方。疾控中心总结得很好:
水氟化对社会经济地位低的社区尤其有益。这些社区的龋齿负担不成比例,并且比高收入社区更难获得牙齿保健服务和其他氟化物来源……尽管有其他含氟产品,但水氟化仍然是向大多数社区的所有成员提供氟化物的最公平和最具成本效益的方法,无论年龄、教育程度或收入水平如何。
与替代品相比,公共水氟化最好的部分是它不会基于财富进行歧视。与每人每年花费 100 美元的氟化物凝胶相比,它也便宜得多。反对公共用水加氟的人普遍认为,所有其他选择都意味着不再需要加氟。然而,如果是这样的话,那如何解释温莎市在短短几年内蛀牙率的快速上升呢?虽然这只是一个轶事,但是其他研究已经发现一旦停止水的氟化会有类似的不良影响。是的,有替代品,但它们要求人们能够负担得起,并知道他们应该使用它们。在公共用水中加入氟化物,覆盖所有的基地,并接触到那些最脆弱的人,这要有效得多。
为什么推迟?
鉴于上述证据:氟化物是预防蛀牙的有效、安全和最便宜的选择,尤其是对儿童而言,很难想象有人会反对这一措施。尽管如此,还是有反对水氟化的呼声,通常来自那些反对任何形式的政府干预的人。 Rational Wiki 有一个很棒的页面,揭穿了许多反对水氟化的不合逻辑的论点,但是在这里我只提到两个。
1.世界卫生组织反对氟化
的确,世卫组织已经发布了关于从饮用水中去除氟化物的出版物。然而,世卫组织并没有谈论受控的公共水氟化,而只是过度的自然氟化。这只适用于世界上很少一部分人,他们生活在氟化物自然供应量极高的地区。任何东西在极端的量下都是危险的,包括许多维生素,将这些地方与公共水氟化相比较是错误的逻辑。在美国,用于给公共用水加氟的百万分之 0.7 远低于国家资源委员会认为安全的百万分之 4。
事实上,世卫组织是水氟化最坚定的支持者之一,明确声明:“在可能的情况下,水供应的氟化是预防龋齿的最有效的公共卫生措施。”引用水氟化减少健康不平等的能力,世卫组织提倡尽可能采用这种干预措施。用一个有限的例子来代表所有情况是阴谋论者的经典策略。它代表了一种过度概括的谬误,是两种完全不同情况的比较。
2.消费者应该对水的氟化有选择权
这可能是反对水加氟的最常见的论点,并以多种形式出现:政府不应该对其公民用药,消费者没有接受加氟的选择,我们应该能够过上没有暴政的生活。关于选择的论点可以分为几个层次。鉴于政府——至少在反对势力强大的美国——是由人民选举产生的,你确实可以选择水的氟化。如果你不喜欢它,没有什么可以阻止你竞选公职来改变事情。此外,你可以选择只喝瓶装水,瓶装水可能含氟,也可能不含氟(因为美国食品和药物管理局对瓶装水的监管有些松懈)。
此外,儿童是水氟化的最大受益者,他们不能投票,因此没有任何选择。如果事情真的由人民决定,那么每个人都会有平等的发言权。此外,政府还为公共安全做了很多其他事情,比如在冬天犁地和管理药品。我们是否应该选择在积雪覆盖的高速公路上行驶,或者给我们的孩子药物,其中可能含有公司想要的任何东西(在药物受到监管之前,它往往杀死的人比它帮助的人多)。当涉及到公众的安全时,我们通常没有真正的选择,鉴于我们对非理性、有害行为的偏好,这是一件好事。
水氟化的批评者并不多,他们只是倾向于大声疾呼。在温莎,有五分之四的居民支持水的氟化处理,少数敢于直言的人造成了大部分的损失。同样, 1998 年盖洛普民意测验发现,美国 70%的受访者赞成这种做法,这表明一小部分人应对反对派负责。问题似乎不在于公众舆论,而在于谁的声音最大。当人们相信(错误地)他们受到了政府的伤害时,他们更有可能说出来,而不是当他们知道他们得到了帮助时,这就产生了更有说服力的新闻。
我将以一个生动的故事来结束这一节。当芬兰城市库奥皮奥在 1992 年停止水的氟化时,他们在宣布停止之前一个月实施了这一改变,没有告诉公众。这意味着公众在不知情的情况下饮用了整整一个月的无氟水。研究人员利用这一补偿来调查居民与水氟化有关的症状,甚至是水的味道。研究结果显示,居民们不知道水的氟化作用已经提前停止:他们报告说,即使在氟化作用停止后,水的症状或味道也没有变化。
只有当居民们被告知他们不再饮用氟化水时,他们才奇迹般地报告症状减轻,并说他们能注意到味道的变化。换句话说,整个效果都在他们的头脑中。这些研究的作者很好地总结道:“这些症状的流行似乎与接触氟化水的心理影响有关,而不是身体影响。”那些认为氟化是一种消极行为的人最有可能报告说,一旦他们知道氟化已经停止,他们会感觉更好(但当氟化实际发生时,他们没有注意到任何变化)。人类的思维非常善于证明非理性的信念,公共用水加氟是有害的这一概念不得不被列为最不合逻辑的理论之一。不管人们反对水氟化的动机是什么,有一件事是清楚的:他们自己没有检查数据,也没有批判性地思考证据。
结论
水氟化的故事是一个关于药物如何发挥作用的经典故事:它被深入研究,并在被证明安全有效后,在美国全国范围内实施。虽然我开始写的那篇文章可能会让你质疑人类的未来,但我认为这个故事是积极的。重要的教训是,科学和医学最终取得了胜利。温莎再次获得了氟化水,镇上的孩子们(可能还有成年人)将体验到这种解脱。值得指出的是,真理不是靠叫嚣对方而赢得的,而是靠提出明确的证据。问题不是缺乏公众对有益措施的支持,而是反对的声音太大了。套用一句的名言,迷信要想获胜,唯一需要做的就是让科学安静地坐在一旁。
现在你知道了事实:水氟化显然对健康有益,没有副作用,并且是防止蛀牙的最具成本效益的方法——你准备好利用这些信息继续让世界变得更美好。如果人类倾向于寻找耸人听闻的东西,那么就把水的氟化说成是耸人听闻的。这是一个由科学、医学和政府在最大规模上实施的计划,实际上已经成功地改善了公共卫生,同时带来了利润。
一如既往,我欢迎反馈和建设性的批评。我可以通过推特 @koehrsen_will 联系到。
对图像数据集进行重复数据删除的绝佳方式
生产中的命令行工具。

就手工劳动的时间而言,为 ML 管道准备数据通常要花费大部分时间。此外,构建或扩展数据库通常要花费天文数字的时间、子任务和对细节的关注。后者让我找到了一个很棒的命令行工具,用于清除重复和近似重复的内容,尤其是在与 iTerm2 (或 iTerm )一起使用时——即 imgdupes 。
注意,这里的目的是介绍 imgdupes。有关规范、算法、选项等的技术细节,请参阅参考资料(或者继续关注有关细节的未来文章)。
问题陈述:消除映像集的重复
我在构建面部图像数据库时的情况如下:一个包含多个目录的目录,每个子目录包含相应类的图像。这是 ML 任务中的一个常见场景,因为许多著名的数据集都遵循这样的约定:为了方便和作为显式标签,通过目录将类样本分开。因此,我在清理人脸数据,并在命名的子目录中识别人脸。
知道有几个副本和近似副本(例如,相邻的视频帧),并且这对我要解决的问题没有好处,我需要一种算法或工具来找到副本。准确地说,我需要一个工具来发现、显示并提示删除所有重复的图像。我很幸运地发现了一个非常棒的基于 python 的命令行工具 imgdupes。
先决条件
在所需的 python 环境中安装 imgdupes (即,参见 Github 获取说明)(例如,参见 Gergely Szerovay 的博客了解 conda 环境)。
如果 iTerm2 是您的 shell 提示符的选择,我会建议大多数开发人员使用它,因为它提供了许多简洁的特性、可调的设置和需要时的附加组件。iTerm 本身可以组成一系列博客,如果特定的博客还不存在的话(例如,克洛维斯的(@阿尔贝 l) 博客)。
IMGDUPES:简单来说
直接借用作者的 Github 页面,这里有一张 gif 演示 imgdupes 的用法。

https://github.com/knjcode/imgdupes/blob/master/video_capture.gif
该工具出色地允许用户找到重复项,然后甚至直接在 iTerm 中并排显示这一对。此外,可选参数允许每个实例提示用户保留一个、多个重复图像,或者不保留任何重复图像。
一个小问题(根据我的用例)
首先,与在子目录中搜索相比,从根文件夹中搜索时需要更多的比较。换句话说,如果我确信在任何子目录中都不存在重叠,则不希望从根目录使用,原因如下:
- 许多(数百万和数百万)不必要的比较。
- 很多误报源于不同的身份。这占了大多数。如下面的截图所示,这四组重复项都是假的,但都来自不同的目录(参见下图中图像下方的路径)。
最初使用的代码片段:

Screenshot running imgdupes from root directories.
这有两个问题:(1)如果手动筛选,会浪费太多时间;(2)删除了太多不应该删除的面(标志 -dN ,其中 -d 提示保留或删除, -N 首先选择并删除其余部分,无需用户输入)。
简单修复
让我们从命令行直接切换到每个单独的目录,运行 imgdupes,切换回根目录,然后重复。从命令行运行以下命令:

Notice the progress bar appearing when imgdupes is run from a different subdirectory.
只需添加 -N if,以仅保留每组的第一幅图像,从而无需额外输入即可运行——如果从根递归运行,这种方法将删除许多许多独特的人脸。
默认情况下,列表的顺序由文件大小设置(降序)。对于我的情况,大约 95%的第一张图片是首选。然而,这里有几个例子;事实并非如此。


The second image might be the preferred image to keep.
为此,您可以通过每次提示手动选择一组重复项。然而,这可能很耗时,我就遇到过这种情况。所以我首先运行显示,然后滚动以确保所有看起来都很好(即,手动处理首选人脸不是第一个的实例),然后再次运行删除。尽管如此,这完全取决于开发人员和项目/数据的需求。最后,我先查看了一下(即带有 -d 标志)……只是为了确定一下。然后,我运行以下程序对映像集进行重复数据消除:
最后
imgdupes 是一个很棒的命令行工具,它提供了一个实用的界面来查找、查看和清理重复的图像。技术细节在他们的 Github 上(也许还有未来的博客:)。
总而言之,与 iTerm 的集成令人振奋。这是我最喜欢的部分——事实上,基于 python 的控制台工具还可以从这里完成的 iTerm 集成中受益。
请分享任何可以借用这个想法或想到的任何其他想法的额外工具的想法或想法。
接触
选择 A/B 测试指标—入门
并且避免了大多数测试工作中常见的错误。

Photo by Luke Chesser on Unsplash
这篇文章是我关于 A/B 测试系列文章的第三篇。
在第一篇文章中,我向展示了 A/B 测试背后的直觉,以及确定您希望观察的效果大小和相应样本大小的重要性。
在第二篇文章中,我谈到了产品经理如何以加速测试的方式设计 A/B 测试。
在第三篇文章中,我将讨论 A/B 测试的另一个方面:在确定 A/B 测试的指标时,你应该考虑哪些因素?
案例研究:VRBO 搜索登录页面
当我们设计一个 A/B 测试时,我们选择一个我们希望改进的主要度量标准(和几个次要度量标准),并测量变体和控制组。如果我们不仔细选择这个指标,我们就是在浪费时间。
我们将使用一个我熟悉的例子:在 VRBO 上搜索登陆页面。VRBO 是一个双边市场,房主可以列出他们的房屋出租,潜在的旅行者可以为下次旅行找到合适的住宿。搜索登录页面的目的是从谷歌获得流量,并将该流量转化为执行更高意向查询的人。
让我们看一些截图,从旅行者开始计划过程的最常见方式(在谷歌上搜索)开始
第一步 :想着去巴哈马旅游?让我们搜索一下。

Searching for Vacation Homes in the Bahamas
第二步 :啊哈!看起来 VRBO 有很好的选择。让我们看看那里。

Google Search Result on VRBO
让我们看看我在巴哈马有哪些选择。

Search Landing Page for the Bahamas — Above the Fold

Search Landing Page for the Bahamas — Below the Fold
我们建立这个页面是为了:
- 高预订意向用户。用户可能已经预订了机票,或者至少知道他们想什么时候旅行。我们假设,对于这些用户来说,该页面要做的工作是找到适合他们旅行日期的房屋。
- 低预订意向用户。处于计划阶段的早期用户,他们可能对何时旅行没有任何概念。我们假设,对于这些用户来说,该页面要做的工作是帮助他们探索各种可用的房屋,并影响用户访问巴哈马。
- 谷歌机器人。我们希望谷歌为最相关的用户查询建立页面索引。
整个用户旅程(从谷歌登陆 VRBO 到预订看起来是这样的。)

Typical user journey for booking travel.
有两点需要特别注意:
- 在初始步骤和最终步骤之间,有用户必须采取的多个步骤,并且在每个级别,一些用户将退出。
- 由于旅行被认为是购买(相对于冲动购买),最初和最后一步之间的时间可能是几周。
现在让我们看看这个转换漏斗的数学,对从一个步骤到另一个步骤的转换做一些假设,并估计总的转换率。( 免责声明:这些数字仅用于说明目的 )

An estimate of the conversion rate of each step and overall conversion rate.
最后,你必须得到一个粗略的流量数量级。让我们在这里做一些假设( )免责声明:这些数字仅用于说明目的。)
- 每月独立访客总数:1000 万
- 到达搜索登录页面的独特新访问者:30%(300 万用户)
现在,假设您是搜索登录页面的产品经理。根据这些基本比率,让我们来看一个假设的 A/B 测试,并为您的实验看两个可能的指标。
测试假设:通过在搜索登录页面上添加一个背景“英雄”图像来指示目的地,用户会感到舒适,因为他们正在查看正确的目的地,从而导致更高的搜索和 2%的整体转化率
您有两个指标选择,总转化率和进行过时搜索的用户百分比。
实验设计当我们选择总转化率作为衡量标准时
用整体转化率作为产品经理的衡量标准是很有诱惑力的。毕竟,你可以告诉你的管理层,你增加了$$$的收入。
如果您决定选择这个作为您的度量,让我们看看测试参数:测试样本大小和总测试持续时间。让我们将 0.225%的基本比率和 2%的最小可检测效应(MDE)代入 Evan Miller 的样本量计算器。

The sample size for an A/B test with 0.225% base rate and 2% MDE. Courtesy: Sample Size Calculator by Evan Miller
总的来说,您将需要 34,909,558 个样本用于您的变体组和对照组。
每月有 300 万独立用户,如果测试正确,您的测试将需要 11-12 个月才能完成。很多人会犯这样的错误,过早地看到一些积极的结果,变得不耐烦,过早地停止实验。如果你这样做,你很可能会看到一个假阳性。
实验设计当我们选择%的用户进行日期搜索作为主要指标时
如果您决定选择这个作为您的度量,让我们看看测试参数:测试样本大小和总测试持续时间。让我们将 30%的基本比率和 2%的最小可检测效应(MDE)代入 Evan Miller 的样本量计算器。

The sample size for an A/B test with 30% base rate and 2% MDE. Courtesy: Sample Size Calculator by Evan Miller
总的来说,你将需要 183,450 个样本用于你的变异体和对照组。每月有 300 万独立用户,这将需要几天时间来完成您的测试。[ 你可能想考虑运行测试整整一周,以消除任何一周内偏差的可能性。]
用这种方法,你可以在同样的时间内进行 10 次实验。
经验教训
如果上面的情况听起来是假设的,让我向你保证,很多产品经理(包括我)已经采取了使用总转化率作为主要指标的方法。这里是我学到的一些经验,我想更广泛地分享。
- 当你设计你的测试时,充分注意你选择的度量标准。如果你正在测试的功能在漏斗中处于较高位置,并且你的整体转化率低于 1%,你的测试结果将需要几个月才能完成。(除非你是脸书、谷歌、亚马逊,或者一个顶级的互联网网站。)
- 当您的测试需要几个月的时间才能完成时,由于意外的和不相关的更改而导致错误蔓延并破坏您的测试结果的可能性将会非常高。您可能需要重新开始测试。
- 你的特征离整体转化率越远,你的变化对指标产生因果影响的可能性就越低。
- 最好的选择是使用直接受您的更改影响的指标,比如页面上的指标,来衡量微转化。
- 如果你选择了像点击率这样的页面指标,通过查看一个平衡的指标来注意意想不到的结果。如果我们选择日期搜索作为我们的衡量标准,我们还将查看该页面以及后续页面的跳出率。这种技术确保产品变更不会向下游发送不合格的流量。(在以后的文章中会有更多关于这个主题的内容。
如果你觉得这篇文章有用,请告诉我。如果你对 A/B 测试有任何疑问,请在评论中给我留言,我会考虑把它作为未来帖子的主题。
这是我的 A/B 测试系列文章的第三篇。该系列的其他文章是:
学分:
我要感谢 Evan Miller 出色的样本量计算器和他在 A/B 测试方面的思想领导力。
关于我 : Aditya Rustgi 是一名产品管理领导者,在电子商务和旅游行业的多边市场和 B2B Saas 业务模式方面拥有超过 15 年的产品和技术领导经验。最近,他是 Expedia 公司 VRBO 的产品管理总监。
数组和操作指南(数据结构)

一开始,学习数据结构和算法可能会非常困难。这就像学习任何新的课程,这些课程有你以前没有接触过的话题,有自己的语言(有点像学习有机化学或新的游戏类型)。我原本打算把这一整篇文章都放在数据结构和算法上,但是它太长了。所以,我在这里把它分开了,我将从数据结构开始,以后会发布更多。不用担心找到所有的东西。一旦文章完成,我将像一个双向链表一样在每篇文章中插入链接(你将在另一篇文章中得到参考)。
为什么要学习数据结构?
计算机软件就是处理数据。数据涵盖所有类型的信息,更基本的形式是数字和字符串。数据结构解释了数据是如何组织的。这种结构决定了代码运行的速度和效率。一旦你深刻理解了数据结构是如何工作的,你的代码就会运行得更好,更漂亮。从数据科学家的角度来说,我们都写代码,但是写好代码也会给你带来软件工程的机会。当然,学习一些能让你在自己的领域做得更好的东西,同时扩展到其他有利可图的领域也没那么糟糕。
数组数据结构& 4 种基本操作
数组是一种基本的数据结构。数组基本上是一个数据列表。下面是一个表示 Hello 的数组示例:

Image taken from Javapoint.com
我喜欢通过我已经知道的事物的例子来学习。那么,我们来说说上面的数组图像。我们有实际的数据 Hello,下面有一个空格和数字。你好下面的数字被称为索引。把一个数组的索引想象成一个家的地址。在 Hello 数组中,H 位于地址 0,e 位于地址 1。我们从 0 开始索引的原因是因为大多数编程语言从 0 开始索引——比如 Python。为了了解像数组这样的数据结构如何影响你的代码,我们必须看看操作。大多数数据结构适用于这四种操作:
- 阅读:在特定的地方检查数据。例如,在上面的数组中读取“o ”,计算机知道在索引 4 中查找。
- 搜索:在数据结构中查找一种类型的值。例如,在 Hello 数组中查找数字将会一无所获。
- 插入:在数据中放置另一个值。例如,在上面的数组中放置 Hellow 将在索引 5 中添加“w”。
- 删除:删除数据结构中的一个值。例如,从 hello 中删除“H”将会是 ello(旁注:删除值 H 实际上会涉及到将所有字符向左移动的另一个步骤)。
当计算机科学家或软件工程师提到算法的速度时,他们指的是该过程中有多少步,而不是时间。这意味着时间有点仓促,因为不同的硬件在不同的时间执行。根据过程中的步骤来测量速度允许一致的标准化测量,这也反映了算法的复杂性。有趣的是,时间复杂度、效率和性能在数据结构和算法讨论中经常是指同一个东西。
阅读
读取是检查数组中特定索引的值。看书的速度真的很快,快一步而已。原因是由于计算机知道数组中的索引并偷看里面。当计算机读取数组时,它会转到正确的索引,原因是:
- 计算机知道每个值的索引。
- 存储在内存中的数组是以“块”的形式读取的把它想象成寻找地址的街道上的房子。
- 数组从 0 开始,所以计算机知道它只能从那里开始。
从上面的原因来看,从一个数组中读取需要计算机一步,这使它成为一个真正快速的操作。
搜索
在数组中搜索是寻找特定类型的数据,并找到它在索引中的位置。搜索是以一种非常有条理的方式进行的。计算机从索引 0 开始向前查找,直到找到它要寻找的值。在最坏的情况下,如果计算机想在一个 10 的数组中搜索,而所需的值在第 10 个点上,那么它会一直搜索到第 10 个值。换句话说,一个 300 大小的数组,我们想要的值位于第 300 个索引中,计算机需要 300 步来搜索该值。
我希望你现在能明白这个模式。从更抽象的角度来看,对于数组中的任意 N 个单元,线性搜索最多需要 N 步。因此,如果您将此公式应用于前面的两个搜索示例,我们可以看到,由于我们要查找的数据的索引位置在末尾,最差的情况总是取最高值。与阅读相比,搜索更慢,因为它需要 N 个步骤,而阅读只需 1 个步骤。
插入
插入的速度取决于插入值的位置。在数组中插入的最快方法是插入到末尾。在开头或中间的某个地方插入会稍微复杂一点。但是不要担心,我们会经历发生的事情。让我们来看看最糟糕的情况,因为其他事情都差不多,只是步骤少了一些。在最坏的情况下,在数组中插入,在开始时,需要最多的步骤。原因是一旦值被插入到开头,计算机必须将所有其他值向右移动。由于左边的值没有移动,所以插入中间的任何其他值占用的时间更少。
从抽象的角度来看,我们可以看到,对于 N 大小的数组,插入需要 N + 1 个步骤。将值向左向右移动是 N 步,而实际的插入需要 1 步。因此,最坏的情况需要 N+1 步,但是最后的插入只需要 1 步。
删除
删就是你想的那样。删除会移除数组中的值。删除有点像以相反的方式插入。删除操作不是放置一个值,而是移除该值并移动这些值以弥补删除操作留下的空白。就像插入一样,删除的最佳速度是在最后——1 步。它删除结束值,而不必移动任何其他值。删除的最坏情况是在开始。一旦它删除了第一个值,右边的所有其他值都必须左移一个,以覆盖数组中的空白空间。
对于 N 大小的数组,插入的总体模式是 N + 1。删除需要 1 步,而值的移动需要 N 步。像插入一样,最坏的情况是在数组的开始,而最好的情况是在数组的末尾。
结论
了解步骤的数量和操作步骤的长度是理解数据结构如何工作的基础之一。在理解操作的基础上选择正确的数据结构,可以让你以更少的步骤编写代码,这意味着更高的效率。我在这里非正式地介绍了大 O 符号,但是我们稍后会正式讨论它。这篇文章已经太长了。我希望这篇文章能帮助你更好地理解数据结构,因为我个人第一次发现它非常令人困惑。继续努力,你会成功的!
在此找到的第 2 部分:
在上一篇文章中,我们讨论了数组和操作(链接)。现在,我们将了解算法选择如何影响…
towardsdatascience.com](/a-guide-to-linear-search-and-binary-search-on-arrays-data-structures-algorithms-2c23a74af28a)
对于那些现在想了解更多的人来说,下面是我用来撰写本文的关于这些主题的好资源:
- http://elementsofprogramming.com/
- https://www . Amazon . com/Cracking-Coding-Interview-Programming-Questions/DP/0984782850
- https://learning . oreilly . com/library/view/a-common-sense-guide/9781680502794/
免责声明:本文陈述的所有内容均为我个人观点,不代表任何雇主。
康达环境权威指南
如何使用 conda for Python & R 管理环境

Conda’s natural environment. Illustration by Johann Wenzel Peter.
Conda 环境就像是 Python 的虚拟环境的表亲。两者都有助于管理依赖性和隔离项目,它们以相似的方式工作,有一个关键的区别:conda 环境是语言不可知的。也就是说,它们支持 Python 以外的语言。
☄️在本指南中,我们将介绍使用 Python 的conda创建和管理环境的基础知识
**⚠️注:**在本指南中,我们将在 macOS Mojave 上使用最新版本的 Conda v4.6.x、Python v3.7.y 和 R v3.5.z。
目录
Conda 与 Pip 和 Venv —有什么区别?
使用康达环境
安装包
管理环境
带 R 的环境
进一步阅读
康达 vs .皮普 vs. Venv —有什么区别?
在我们开始之前,你们中的一些人可能想知道conda、pip和venv之间的区别。
很高兴你问了。我们不能说得比这更好了:[pip](https://pip.pypa.io/en/stable/)是 Python 的一个包管理器*。T5 是 Python 的环境管理器。conda既是包又是环境管理器,并且是语言不可知的。*
鉴于venv只为 Python 开发创建隔离环境,conda可以为任何语言创建隔离环境(理论上)。
而pip只安装来自 PyPI 的 Python 包,conda两者都可以
- 从像 Anaconda Repository 和 Anaconda Cloud 这样的库安装软件包(用任何语言编写)。
- 在活动的 Conda 环境中使用
pip从 PyPI 安装软件包。
多酷啊。
👉🏽如果想要一个比较这三者的图表,请点击这里(不要忘记向右滚动!).

[Morning Mist](https://commons.wikimedia.org/wiki/File:Cole_Thomas_Morning_Mist_Rising_Plymouth_New_Hampshire_(A_View_in_the_United_States_of_American_in_Autunm_1830.jpg) by Thomas Cole.
使用 Conda 环境
创造环境
要使用conda为 Python 开发创建一个环境,运行:
% conda create --name conda-env python # Or use -n
💥**重要提示:**用您的环境名称替换“conda-env”。从现在开始,我们将始终使用“conda-env”来命名我们的环境。
这个环境将使用与您当前 shell 的 Python 解释器相同的 Python 版本。要指定不同版本的 Python,请使用:
% conda create -n conda-env python=3.7
你也可以在创建环境时安装额外的包,比如说numpy和requests。
% conda create -n conda-env numpy requests
⚠️ **注意:**因为conda确保安装包时满足依赖关系,Python 将与numpy和requests一起安装😁。
您还可以指定想要安装的软件包版本。
% conda create -n conda-env python=3.7 numpy=1.16.1 requests=2.19.1
⚠️ 注意: 建议同时安装你想包含在一个环境中的所有软件包,以帮助避免依赖冲突。
最后,您可以通过调用来激活您的环境:
% conda activate conda-env
(conda-env) % # Fancy new command prompt
并使用以下命令将其禁用:
% conda deactivate
% # Old familiar command prompt
环境生活的地方
当您使用 Python 的venv模块创建一个环境时,您需要通过指定它的路径来说明它位于何处。
% python3 -m venv /path/to/new/environment
另一方面,用conda创建的环境默认位于 Conda 目录的envs/文件夹中,其路径如下所示:
% /Users/user-name/miniconda3/envs # Or .../anaconda3/envs
我更喜欢venv采用的方法,原因有二。
1️⃣通过将环境包含为子目录,可以很容易地判断一个项目是否利用了一个隔离的环境。
my-project/
├── conda-env # Project uses an isolated env ✅
├── data
├── src
└── tests
2️⃣它允许你对所有的环境使用相同的名字(我使用“conda-env”),这意味着你可以用相同的命令激活每个环境。
% cd my-project/
% conda activate conda-env
💸**好处:**这允许你给激活命令起别名,并把它放在你的.bashrc文件中,让生活简单一点。
**⚠️注:**如果你将所有的环境都保存在 Conda 的env/文件夹中,你将不得不给每个环境取一个不同的名字,这可能会很痛苦😞。
那么,你如何把环境放到你的康达的env/文件夹之外呢?通过在创建环境时使用--prefix标志而不是--name。
% conda create --prefix /path/to/conda-env # Or use -p
**⚠️注:**这使得一个名为“conda-env”的环境出现在指定的路径中。
就这么简单。然而,将环境放在默认的env/文件夹之外有两个缺点。
1️⃣ conda无法再用--name旗找到你的环境。相反,您需要沿着环境的完整路径传递--prefix标志。例如,在安装包时,我们将在下一节中讨论。
2️⃣您的命令提示符不再以活动环境的名称为前缀,而是以其完整路径为前缀。
(/path/to/conda-env) %
你可以想象,这很快就会变得一团糟。比如说,像这样的东西。
(/Users/user-name/data-science/project-name/conda-env) % # 😨
幸运的是,有一个简单的解决方法。你只需要修改你的.condarc文件中的env_prompt设置,你只需要简单的一笔就可以完成。
% conda config --set env_prompt '({name}) '
**⚠️注:**如果你已经有一个.condarc文件,这将编辑你的文件,如果你没有,则创建一个。关于修改您的.condarc文件的更多信息,请参见文档。
现在,您的命令提示符将只显示活动环境的名称。
% conda activate /path/to/conda-env
(conda-env) % # Woohoo! 🎉
最后,您可以查看所有现有环境的列表。
% conda env list# conda environments:
#
/path/to/conda-env
base * /Users/username/miniconda3
r-env /Users/username/miniconda3/envs/r-env
⚠️注:*指向当前活动环境。有点烦人的是,即使没有环境活动,它也会指向“base”🤷🏽♂️.

An American Lake Scene by Thomas Cole.
安装软件包
用conda安装包有两种方式。
活跃环境中的 1️⃣。
2️⃣从您的默认外壳。
后者要求您使用与创建环境时相同的标志(--name或--prefix)指向您想要安装软件包的环境。
无论您使用哪种标志,前者都同样有效。
💥**重要提示:**我们强烈建议坚持前一种方法,因为它消除了无意中在系统范围内安装软件包的危险。
**♻️提醒:**本指南中的所有环境均命名为“conda-env”。您可以用您的环境名替换“conda-env”。
从巨蟒库
默认情况下,conda从 Anaconda 存储库安装软件包。一旦您创建了一个环境,您可以通过两种方式安装额外的软件包。
活跃环境中的 1️⃣。
(conda-env) % conda install pandas=0.24.1 # 🐼
2️⃣从您的默认外壳。
% conda install -n conda-env pandas=0.24.1 # Or -p /path/to/env
同样,您可以通过两种方式更新环境中的软件包。
活跃环境中的 1️⃣。
(conda-env) % conda update pandas
2️⃣从您的默认外壳。
% conda update -n conda-env pandas # Or -p /path/to/env
您还可以用两种方式列出给定环境中安装的软件包——是的,您猜对了。
活跃环境中的 1️⃣。
(conda-env) % conda list
2️⃣从您的默认外壳。
% conda list -n conda-env # Or -p /path/to/env
来自其他 Conda 存储库
如果在默认的 Anaconda 仓库中找不到一个包,你可以试着在 Anaconda Cloud 上搜索它,它托管了由第三方仓库如 conda-Forge 提供的 Conda 包。
要从 Anaconda Cloud 安装一个包,您需要使用--channel标志来指定您想要安装的存储库。例如,如果你想安装康达-福吉的opencv,你可以运行:
(conda-env) % conda install --channel conda-forge opencv # Or -c
幸运的是,conda跟踪软件包是从哪里安装的。
(conda-env) % conda list# packages in environment at /path/to/conda-env:
#
# Name Version Build Channelnumpy 1.16.1 py37h926163e_0
opencv 4.1.0 py37h0cb0d9f_3 conda-forge
pandas 0.24.2 py37h0a44026_0
numpy和pandas的空白通道条目代表default_channels,默认情况下它被设置为 Anaconda 存储库。
**⚠️注:**为了简洁起见,我们只展示了上面的一些软件包。
您也可以永久添加一个频道作为包源。
% conda config --append channels conda-forge
这将修改您的.condarc文件,如下所示:
env_prompt: '({name}) ' # Modifies active environment prompt
channels: # Lists package sources to install from
- defaults # Default Anaconda Repository
- conda-forge
🚨**注意:**你的渠道顺序事关。如果一个软件包可以从多个渠道获得,conda将从您的.condarc文件中列出的最高渠道安装它。有关管理渠道的更多信息,请参见文档。
来自 PyPI
如果 Anaconda 存储库或 Anaconda Cloud 中没有可用的包,您可以尝试用pip安装它,默认情况下,conda会在任何用 Python 创建的环境中安装它。
例如,要安装带有pip的请求,您可以运行:
(conda-env) % pip install requests
请注意,conda正确地将 PyPI 列为requests的通道,从而很容易识别出安装了pip的包。
(conda-env) % conda list# packages in environment at /path/to/conda-env:
#
# Name Version Build Channelnumpy 1.16.1 py37h926163e_0
opencv 4.1.0 py37h0cb0d9f_3 conda-forge
pandas 0.24.2 py37h0a44026_0
requests 2.21.0 pypi_0 pypi
🚨**注意:**由于pip软件包不具备conda软件包的所有特性,强烈建议尽可能安装带有conda的软件包。有关conda与pip封装的更多信息,请点击此处。

Moonlight by Thomas Cole.
管理环境
环境文件
使您的工作可以被其他人复制的最简单的方法是在您的项目根目录中包含一个文件,该文件列出了您的项目环境中安装的所有包及其版本号。
Conda 将这些环境文件称为。它们是 Python 虚拟环境需求文件的精确模拟。
像其他任何事情一样,您可以用两种方法创建环境文件。
活跃环境中的 1️⃣。
(conda-env) % conda env export --file environment.yml # Or -f
2️⃣从您的默认外壳。
% conda env export -n conda-env -f /path/to/environment.yml
您的environment.yml文件看起来会像这样:
name: null # Our env was made with --prefix
channels:
- conda-forge # We added a third party channel
- defaults
dependencies:
- numpy=1.16.3=py37h926163e_0
- opencv=3.4.2=py37h6fd60c2_1
- pandas=0.24.2=py37h0a44026_0
- pip=19.1.1=py37_0
- pip: # Packages installed from PyPI
- requests==2.21.0
prefix: /Users/user-name/data-science/project-name/conda-env
**⚠️注:**为了简洁起见,我们只展示了上面的一些软件包。
复制环境
给定一个environment.yml文件,您可以轻松地重新创建一个环境。
% conda env create -n conda-env -f /path/to/environment.yml
💸**附加功能:**您还可以使用以下功能将environment.yml文件中列出的软件包添加到现有环境中:
% conda env update -n conda-env -f /path/to/environment.yml

View in the White Mountains by Thomas Cole.
R 环境
要在一个环境中使用 R,您需要做的就是安装r-base包。
(conda-env) % conda install r-base
当然,您可以在第一次创建环境时这样做。
% conda create -n r-env r-base
**⚠️注意:**用您的环境名替换“r-env”。
conda 的 R 包可以从 Anaconda Cloud 的 R 通道获得,默认情况下包含在 Conda 的[default_channels](https://docs.conda.io/projects/conda/en/latest/user-guide/configuration/use-condarc.html#default-channels-default-channels)列表中,所以在安装 R 包时不需要指定 R 通道,比如说tidyverse。
% conda activate r-env
(r-env) % conda install r-tidyverse
**⚠️注:**所有来自 r 通道的包裹都带有前缀“r-”。
如果你愿意,你可以安装r-essentials包,它包括 80 多个最流行的科学 R 包,像tidyverse和shiny。
(r-env) % conda install r-essentials
最后,如果你想安装 Conda 没有提供的 R 包,你需要从 CRAN 构建这个包,你可以在这里找到的说明。
进一步阅读
如果你偶然发现自己想知道 Conda 环境到底是如何工作的,看看这篇关于 Python 的虚拟环境如何工作的简介。Conda 环境以完全相同的方式工作。
除此之外,我们差不多做到了。如果你想了解我最新的数据科学帖子,欢迎在推特上关注我。
干杯,祝阅读愉快。
2019 年 8 月更新:Conda 修订版
你真的每天都能学到新东西。今天早上,我的朋友 Kumar Shishir 告诉我另一个非常有用的 conda特性:conda 修订版。
我简直不敢相信自己的耳朵。我怎么能在完全和完全不知道这样一个辉煌的特征的情况下憔悴了这么久?
修订版会随着时间的推移跟踪您的环境的变化,允许您轻松地移除包及其所有依赖关系。
例如,假设我们创建了一个新的conda-env并安装了numpy,然后安装了pandas。我们的修订历史如下所示:
(conda-env) % conda list --revisions 2019-08-30 16:04:14 (rev 0) # Created our env+pip-19.2.2
+python-3.7.42019-08-30 16:04:30 (rev 1) # Installed numpy+numpy-1.16.4
+numpy-base-1.16.42019-08-30 16:04:39 (rev 2) # Installed pandas+pandas-0.25.1
+python-dateutil-2.8.0
+pytz-2019.2
想象一下,我们不再想在我们的环境中拥有pandas,因为它(不知何故)与我们早期的依赖不兼容,或者因为我们不再需要它。
修订版允许我们将环境回滚到以前的版本:
(conda-env) % conda install --revision 1
(conda-env) % conda list --revisions # (Showing latest only) 2019-08-30 16:08:05 (rev 3) # Uninstalled pandas -pandas-0.25.1
-python-dateutil-2.8.0
-pytz-2019.2
每个包装上的—标志告诉我们,我们已经成功地将从我们的环境中移除。现在,我们准备回到一些数据科学😎。
更新 02/2020:清除你的 Tarballs!
随着您构建更多的项目,每个项目都有自己的环境,您将开始从已安装的包中快速积累tarballs。
要删除它们并释放一些磁盘空间,请运行:
% conda clean --all # no active env needed
从头开始构建卷积神经网络指南
卷积神经网络是 2010 年深度学习取得许多进展背后的主力。这些网络彻底改变了图像分类和对象检测等任务,但它们在文本分类、语音识别或任何可以使用过滤器来检测输入数据区域相似性的领域等其他环境中也非常有效。
在这篇文章中,我将介绍如何使用 numpy 从头开始构建一个基本的 CNN。这个练习深入到这些网络实际上是如何工作的具体细节。在实践中,使用深度学习框架如 Tensorflow 或 Pytorch 是很常见的。这些框架很棒,但当你所要做的只是键入几行代码来创建 CNN 时,不可能理解卷积神经网络在每一步实际上在做什么。
概念:
前馈神经网络是强大的工具,但它们在图像上效果不佳。前馈神经网络获取 32×32×3 的图像(32 像素高,32 像素宽,3 像素深,红色、绿色和蓝色的图像)并对其进行分类。为了通过前馈神经网络运行图像,该图像被拉伸为 3072×1(32 * 32 * 3 = 3072)numpy 阵列。然后乘以权重,优化损失,并根据指定的分数对图像进行分类。这个过程是可行的,但是它不能产生现有技术的结果,因为将图像拉伸成一维向量不能保持图像的空间结构。这意味着,如果图像的空间结构在所有三个维度上都得到保留,那么分类任务中使用的特征就不会像它们可能达到的那样精确。深度学习任务的结果取决于提供给它们的数据的质量。产生最新的结果需要一种能够从图像中提取最新特征的解决方案。
卷积神经网络就是解决方案。美国有线电视新闻网的生产状态的艺术效果,因为他们不断保持图像的空间结构。这意味着在分类任务的最后将提取更好的特征。CNN 拍摄 32×32×3 的图像,在图像上滑动相同深度的过滤器以产生 2D 激活图,该激活图包含测量过滤器和图像之间的相似性的分数。激活映射的堆栈用于网络中的下一层,根据体系结构,下一层可以是卷积层或池层。在最后一步中,使用前馈神经网络对图像进行分类。要看 CNN 的报道,请点击这里的迪普维斯、这里的 T2 和这里的 T4
卷积层:
卷积可能看起来像一个可怕的词,但它不是。在纯数学中,它是一种度量一个函数的形状如何被另一个函数的形状修改的方法。这个定义可以很容易地扩展到计算机视觉。如果您试图查看图像是圆形还是方形,您可以在两幅图像上滑动一条直线和一条曲线,以查看特定的滤镜是否会影响图像的形状。量化每个过滤器的影响的方法是计算每个图像和每个过滤器的分数。分数越接近 1,特征对输入的影响就越大。对于这个例子,分数显示直线影响正方形,曲线影响圆形;这是激活地图上的最高分数所显示的。

Applying a 5x5x3 filter (semi circle and line) to a 32x32x3 image (circle and square) produces an 28x28 activation map that shows where the image is the most like the filter. This image shows that where the filter is like the image the score is high.

Applying a 5x5x3 filter (semi circle and line) to a 32x32x3 image (circle and square) produces an 28x28 activation map that shows where the image is the most like the filter. This image shows that the filters are not like the image so the scores are low.
计算卷积的一个问题是滤波器的大小、步幅的大小和图像的大小可能是不对称的。这是一个问题,因为这些尺寸应该是对称的,以保持图像的空间结构。例如,如果您有一个 32x32x3 的图像,一个 7x7x3 的滤镜,并且跨距为 1,则该滤镜将无法查看图像中的所有像素。零填充通过在图像周围添加零来解决这个问题。这意味着过滤器将能够滑过整个图像并为整个图像产生分数。零填充也是一种很好的做法,因为它允许您控制输出音量的大小。这可确保边缘不会消失得太快,并保留输入体积的空间大小和结构。因此,您可以设计更大、更深的网络。零填充是确保从图像中提取最佳数据的另一种方式,以便网络可以获得最佳结果。

The zeros around the perimeter now allow for the filter to see the entire input.
如何计算卷积:
就像这个定义一样,卷积背后的数学并不难理解。
卷积的正式定义是这样的:

Not as scary as it looks. Calculus is simply a way to measure how quantities change.
这个公式并没有看起来那么恐怖。一旦过滤器和图像对齐,公式可以分解为三个简单的步骤:
- 将每个图像像素乘以权重,然后乘以过滤器像素(点积)
- 把它们加起来
- 除以过滤器中的像素总数
实现不会偏离这些步骤太远。一旦设置了步幅大小、零填充和输出的值,就可以计算卷积并将计算出的值存储在缓存中,以便可以再次访问它们进行反向传播。

现在你可以明白为什么 CNN 有计算猪的名声了。这种类型的实现通常不会大规模使用,但这个项目的重点是深入了解 CNN 实际在做什么。
联营
池化过程接受输入并减少其大小,同时保留输入中最重要的信息。池化减少了计算过程中的噪声参数,从而控制过度拟合。该过程采用 2×2 滤波器,在输入上的跨距为 2,并选择具有最大值的输入像素,并将该像素放入尺寸减小的输出中。池化将输入的大小从 W1xH1xD1 减小到新的输出,大小为 W2=(W1 大小)/步幅+1,(H1 大小)/步幅+1,D2=D1。这处理了先前输入的 75%。剩余的 25%是与特定滤波器中的像素最相似的输入。同样,该过程进一步隔离最相关的数据,以便全连接层进行分类。

This shows pooling in action. If we had a 8x8 image the pooling operation would pick the max value from each 2x2 region. The activation map is now 25% of its original size.
对于实现,您设置旧图像和新图像的宽度、高度和步幅的值。下一步是使用过滤器迭代图像,提取具有最大值的特征,然后返回新的缩减大小的输入。

背面投影:
从头开始创建 CNN 的最重要的原因之一是获得计算 backprop 的第一手经验,因为它是一个有漏洞的抽象。这意味着随着系统变得越来越复杂,开发人员依赖于更多的抽象。抽象隐藏了复杂性,允许开发人员编写处理抽象的软件,而不是解决复杂的问题,如消失或爆炸的渐变。然而,这条定律也指出,可靠软件的开发者无论如何都必须了解抽象的底层细节。所以,让我们来学习吧!
在深入了解反向传播如何在 CNN 架构中工作之前,我高度推荐这个讲座深入了解反向传播如何工作。
反向传播测量给定输入时输出如何变化。反向传播的目的是找到最小化损失函数结果的权重值。激活图是卷积层的输出,是过滤器和权重应用于输入的线性变换的结果。因此,我们需要计算相对于重量和相对于输入的梯度,即一个量的变化量。对输出中的每个像素都执行此过程,因为过滤器中的每个权重都有助于创建输出中的每个像素。这表明权重的变化将改变输出像素。因此,所有这些变化加起来就是最终的损失。
为了图形的简单性和理解直观性,我将使用这些尺寸,一个 3x3 输入,一个 2x2 过滤器和一个 2x2 输出。反向投影的偏导数如下所示,其中 W 是重量,H 是输出:

为了实现当前图层的反向投影代码以及上述等式的工作原理,有必要了解我们正在获取作为输入的输出的梯度,并且我们需要计算权重和输入的梯度。因此,相对于输入的梯度,(或相对于前一层的输出的梯度)将是前一层的反向传递的输入。这种联系是反向传播强大的原因。

最后,由于协变层的反向传播也是一个卷积,但具有空间翻转层,所以它又回到了原点。
全连接层
最后,一旦所有的卷积和池化完成,网络的最后一部分就是一个完全连接的层。这部分网络采用 CNN 提取的特征,并通过前馈神经网络进行分类。当在卷积和池化之后使用时,完全连接的图层更有效,因为它对在整个特征提取过程中在空间上保留的一组特征进行分类。这意味着网络将产生更准确的结果,因为它有更准确的数据。

the feedforward network is the final step
就是这样!如果你想了解更多关于 CNN 及其应用的信息,我建议你查看以下链接:
[## 用于视觉识别的 CS231n 卷积神经网络
斯坦福 CS231n 课程材料和笔记:视觉识别的卷积神经网络。
cs231n.github.io](http://cs231n.github.io) [## 博客
欢迎光临!给自己倒一杯热饮,四处看看。机器学习的应用驱动课程…
布罗尔.吉图布.艾欧](https://brohrer.github.io/blog.html) [## 11-785 深度学习
以深度神经网络为代表的“深度学习”系统正越来越多地接管所有人工智能任务,从…
deeplearning.cs.cmu.edu](http://deeplearning.cs.cmu.edu)
面向初学者的 R 语言数据可视化综合指南
R 可视化功能概述。

Photo by William Iven on Unsplash
注意:文章是旧的,许多没有反映 R 包的最新变化
当今世界充满了数据,我们必须正确地分析数据,以获得有意义的见解。数据可视化是一个重要的工具,可以从数据中挖掘出可能的关键见解。如果分析的结果没有被恰当地可视化,它们将不会被有效地传达给期望的受众。
在本教程中,我们将学习如何使用 R 统计语言来分析和显示数据。我们将从基本的情节开始,然后在文章的后面继续讨论更高级的情节。
目录
先决条件
对 R 及其语法的基本熟悉将使您很容易入门。
R 简介
概观
R 是一个统计计算和图形的语言和环境。当涉及到创建可视化时,r 也非常灵活和易于使用。它的功能之一是用最少的代码生成高质量的地块。
装置
我们将简要回顾一下安装 R:
- 进入 R 主页选择曲柄。
CRAN 是—综合 R 档案网的缩写。它是包含 R 发行版、软件包和文档的站点的集合。 - 选择离你最近的地点。
- 根据您的操作系统下载并安装 R。
或者,您可以在 base R GUI 上使用R studio。
启动
下载并安装 R 后,您可以从应用程序文件夹(MacOS)或桌面图标(Windows)启动它。只需输入以下命令来检查 R 是否已经正确安装并正在运行。
> 1
1
> ‘hello World’
hello world
载入数据
数据集既可以是内置的,也可以从 r。
- 内置数据集指的是 r 中已经提供的数据集。我们将使用一个这样的数据集,称为空气质量数据集,它与 1973 年 5 月至 9 月纽约的每日空气质量测量值有关。该数据集由 6 个变量的 100 多个观测数据组成,即**、臭氧**(十亿分之几)、太阳**。R** (太阳辐射)风(平均风速)温度(日最高气温华氏温度)月(观测月)日日(一个月中的某一天)
要将内置数据集加载到 R 中,请在控制台中键入以下命令:
data(airquality)
- 在外部数据源的情况下(CSV、Excel、文本、HTML 文件等。),只需用 setwd() 命令将包含数据的文件夹设置为工作目录。
setwd(path of the folder where the file is located)
现在,在读取命令的帮助下加载文件。在这种情况下,数据是一个名为 airquality.csv 的 CSV 文件,可以从这里下载
airquality = read.csv('airquality.csv',header=TRUE, sep=",")
以上代码将文件 airquality.csv 读入数据帧 airquality 。 Header=TRUE 指定数据包含标题, **sep= “,”**指定数据中的值用逗号分隔。
数据探索
一旦数据被加载到工作空间中,就应该研究它以了解它的结构。
- str(airquality)
它显示 R 对象的内部结构,并给出数据集的行和列的快速概览。
'data.frame': 111 obs. of 6 variables:
$ Ozone : int 41 36 12 18 23 19 8 16 11 14 ...
$ Solar.R: int 190 118 149 313 299 99 19 256 290 274 ...
$ Wind : num 7.4 8 12.6 11.5 8.6 13.8 20.1 9.7 9.2 10.9 ...
$ Temp : int 67 72 74 62 65 59 61 69 66 68 ...
$ Month : int 5 5 5 5 5 5 5 5 5 5 ...
$ Day : int 1 2 3 4 7 8 9 12 13 14 ... `
- head(data,n) 和 tail(data,n)
head 输出数据集中顶部的 n 个元素,而 tail 方法输出底部的 n 个。
head(airquality, n=3)
Ozone Solar.R Wind Temp Month Day
1 41 190 7.4 67 5 1
2 36 118 8.0 72 5 2
3 12 149 12.6 74 5 3tail(airquality, n=3)
Ozone Solar.R Wind Temp Month Day
109 14 191 14.3 75 9 28
110 18 131 8.0 76 9 29
111 20 223 11.5 68 9 30
- summary(air quality)
summary 方法根据变量的类型显示数据集中每个变量的描述性统计数据。
**summary(data)**
Ozone Solar.R Wind Temp Month Day
Min. : 1.0 Min. : 7.0 Min. : 2.30 Min. :57.00 Min. :5.000 Min. : 1.00
1st Qu.: 18.0 1st Qu.:113.5 1st Qu.: 7.40 1st Qu.:71.00 1st Qu.:6.000 1st Qu.: 9.00
Median : 31.0 Median :207.0 Median : 9.70 Median :79.00 Median :7.000 Median :16.00
Mean : 42.1 Mean :184.8 Mean : 9.94 Mean :77.79 Mean :7.216 Mean :15.95
3rd Qu.: 62.0 3rd Qu.:255.5 3rd Qu.:11.50 3rd Qu.:84.50 3rd Qu.:9.000 3rd Qu.:22.50
Max. :168.0 Max. :334.0 Max. :20.70 Max. :97.00 Max. :9.000 Max. :31.00
我们可以一目了然地看到变量的均值、中位数、最大值和四分位值。
基本情节入门
图形 包用于绘制基图形,如散点图、箱线图等。通过输入:library(help = "graphics")可以获得带有帮助页面的完整功能列表。
plot()函数
plot()函数是一种用于绘制 R 对象的通用函数。
plot(airquality$Ozone)

Scatter Plot
我们在这里得到一个散点图/点图,其中每个点代表臭氧在平均十亿分之中的值。
- 现在让我们绘制一张臭氧和风值之间的图表,来研究两者之间的关系。
plot(airquality$Ozone, airquality$Wind)

图表显示风和臭氧值有某种程度的负相关性。
- 当我们对整个数据集使用 plot 命令而不选择任何特定列时,会发生什么情况?
plot(airquality)

我们得到一个散点图矩阵,它是所有列的相关矩阵。上面的图立即显示:
- 臭氧水平和温度正相关。
- 风速与温度和臭氧水平都呈负相关。
只要看看变量之间的关系图,我们就能很快发现它们之间的关系。
在 plot()函数中使用参数
我们可以通过使用plot()函数的参数来轻松设计图表。
类型参数
绘图函数有一个名为type的参数,它可以接受像 p:点、 l:线、 b:两者等值。这决定了输出图形的形状。
# points and lines
plot(airquality$Ozone, type= "b")

# high density vertical lines.
plot(airquality$Ozone, type= "h")

在控制台中键入 *?plot()* 可以阅读更多关于 *plot()* 命令的内容。
标签和标题
我们还可以标记 X 轴和 Y 轴,并给我们的图加一个标题。此外,我们还可以选择给图着色。
plot(airquality$Ozone, xlab = 'ozone Concentration', ylab = 'No of Instances', main = 'Ozone levels in NY city', col = 'green')

2.条形图
在条形图中,数据以矩形条的形式表示,条的长度与数据集中变量或列的值成比例。通过调整 horiz 参数,可以生成水平和垂直条形图。
# Horizontal bar plot
barplot(airquality$Ozone, main = 'Ozone Concenteration in air',xlab = 'ozone levels', col= 'green',horiz = TRUE)

# Vertical bar plot
barplot(airquality$Ozone, main = 'Ozone Concenteration in air',xlab = 'ozone levels', col='red',horiz = FALSE)

3.柱状图
直方图与条形图非常相似,只是它将值分组到连续的范围内。直方图表示被划分为不同范围的变量值的频率。
hist(airquality$Solar.R)

我们得到了太阳的直方图。R 值。通过给颜色参数一个合适的值,我们也可以得到一个彩色直方图。
hist(airquality$Solar.R, main = 'Solar Radiation values in air',xlab = 'Solar rad.', col='red')

4.箱线图
我们已经看到 R 中的summary()命令如何显示数据集中每个变量的描述性统计数据。Boxplot 做了同样的事情,尽管是以四分位数的形式。在 r 中绘制箱线图也非常简单。
#Single box plot
boxplot(airquality$Solar.R)

# Multiple box plots
boxplot(airquality[,0:4], main='Multiple Box plots')

5.图表网格
R 中有一个非常有趣的特性,可以让我们一次绘制多个图表。这在 EDA 过程中非常方便,因为不再需要一个接一个地绘制多个图形。
绘制网格时,第一个参数应指定某些属性,如网格的边距(mar)、行数和列数(mfrow)、是否包含边框(bty)以及标签的位置(las : 1 表示水平,las : 0 表示垂直)。
par(mfrow=c(3,3), mar=c(2,5,2,1), las=1, bty="n")
plot(airquality$Ozone)
plot(airquality$Ozone, airquality$Wind)
plot(airquality$Ozone, type= "c")
plot(airquality$Ozone, type= "s")
plot(airquality$Ozone, type= "h")
barplot(airquality$Ozone, main = 'Ozone Concenteration in air',xlab = 'ozone levels', col='green',horiz = TRUE)
hist(airquality$Solar.R)
boxplot(airquality$Solar.R)
boxplot(airquality[,0:4], main='Multiple Box plots')

注意:通过键入
?plot name,您可以使用函数文档来了解关于给定函数的更多信息。另外,example(plot)直接在控制台中运行绘图演示。
R 中的可视化库
r 配备了功能强大的复杂可视化库。让我们仔细看看一些常用的。
在本节中,我们将使用内置的 mtcars 数据集来展示各种库的用法。该数据集摘自 1974 年的《汽车趋势》美国杂志。
点阵图形
Lattice 包本质上是对 R Graphics 包的改进,用于可视化多元数据。晶格使得能够使用 t rellis 图形 。格子图展示了依赖于一个或多个变量的变量之间的关系。让我们从安装和加载软件包开始。
# Installing & Loading the package
install.packages("lattice")
library(lattice) #Loading the dataset
attach(mtcars)
attach 函数将数据库附加到 R 搜索路径,这样数据库中的对象只需给出它们的名称就可以被访问。(详见?attach())
# Exploring the datasethead(mtcars)
mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1
在继续使用 lattice 包之前,让我们对数据做一些预处理。在我们的 mtcars 数据集中有两列,即齿轮和气缸,它们本质上是分类的。我们需要分解它们,使它们更有意义。
gear_factor<-factor(gear,levels=c(3,4,5),
labels=c("3gears","4gears","5gears"))
cyl_factor <-factor(cyl,levels=c(4,6,8),
labels=c("4cyl","6cyl","8cyl"))
注意:由于我们已经附加了数据集 mtcars,我们不需要指定 *mtcars$gear* 或 *mtcars$cyl* 。
现在让我们看看如何使用 lattice 包在 r 中创建一些基本的情节。
- 内核密度图
densityplot(~mpg, main="Density Plot", xlab="Miles per Gallon")

使用点阵库非常简单。人们只需要插入想要绘图的列。
- 散点图矩阵
splom(mtcars[c(1,3,4,5,6)], main="MTCARS Data")

- 描绘两个因素组合的散点图
xyplot(mpg~wt|cyl_factor*gear_factor,
main="Scatterplots : Cylinders and Gears",
ylab="Miles/Gallon", xlab="Weight of Car")

2.ggplot2
ggplot2 包是 r 中使用最广泛的可视化包之一。它使用户能够使用图形的语法用很少的代码创建复杂的可视化。图形的语法是一个数据可视化的通用方案,它将图形分解成语义成分,如比例和层。
近年来,ggplot2 的受欢迎程度大大增加,因为它可以以非常简单的方式创建包含单变量和多变量数据的图表。
#Installing & Loading the package
install.packages(“ggplot2”)
library(ggplot2)
#Loading the dataset
attach(mtcars) # create factors with value labels
mtcars$gear <- factor(mtcars$gear,levels=c(3,4,5),
labels=c("3gears", "4gears", "5gears"))
mtcars$am <- factor(mtcars$am,levels=c(0,1),
labels=c("Automatic","Manual"))
mtcars$cyl <- factor(mtcars$cyl,levels=c(4,6,8),
labels=c("4cyl","6cyl","8cyl"))
让我们创造几个情节来了解 ggplot2 的能力
- 散点图
ggplot(data = mtcars, mapping = aes(x = wt, y = mpg)) + geom_point()

geom_point()用于创建散点图,geom 可以有多种变化,如geom_jitter()、geom_count()等
- 根据因子设计散点图的样式
我们知道数据集 mtcars 由某些以因子形式存在的变量组成。我们可以利用这个属性来分割数据集
ggplot(data = mtcars, mapping = aes(x = wt, y = mpg, color = as.factor(cyl))) + geom_point()

颜色参数用于区分 cyl 变量的不同因子级别。
- 根据大小设定散点图样式
ggplot2 的另一个有用的特性是,它可以根据属性的大小来设置样式。
ggplot(data = mtcars, mapping = aes(x = wt, y = mpg, size = qsec)) + geom_point()

在上面的例子中,qsec的值表示决定点大小的加速度。
- 不同尺寸的不同符号
使用 ggplot2,还可以通过将不同大小的多个点分层来创建独特而有趣的形状
p <- ggplot(mtcars,aes(mpg, wt, shape = factor(cyl)))
p + geom_point(aes(colour = factor(cyl)), size = 4) + geom_point(colour = "grey90", size = 1.5)

3.Plotly
Plotly 是一个 R 包,通过开源的 JavaScript 图形库 plotly.js 创建交互式的基于 web 的图形。它还可以轻松地将“ggplot2”图翻译成基于网络的版本。
#Installing & Loading the package
install.packages(“plotly”)
library(plotly)
现在让我们看看我们如何利用情节来创造互动的视觉化。我们将使用点阵图形演示中使用的相同 mtcars 数据集。
- 基本散点图
p <- plot_ly(data = mtcars, x = ~hp, y = ~wt)
p

上面的图也可以以网页的形式导出,以保持其交互性。
- 样式散点图
散点图可以通过给定适当的颜色代码来设计。
p <- plot_ly(data = mtcars, x = ~hp, y = ~wt, marker = list(size = 10, color = 'rgba(255, 182, 193, .9)', line = list(color = 'rgba(152, 0, 0, .8)', width = 2)))p

- 标记和线条
也可以用 plotly 在同一个图形中绘制标记和线条。在这里,我们将创建一个任意数据框来展示此功能。
data1 <- rnorm(100, mean = 10)
data2 <- rnorm(100, mean = 0)
data3 <- rnorm(100, mean = -10)
x <- c(1:100)data <- data.frame(x, data1, data2, data3)p <- plot_ly(data, x = ~x)%>%
add_trace(y = ~data1, name = 'data1',mode = 'lines')%>%
add_trace(y = ~data2, name = 'data2', mode = 'lines+markers')%>%
add_trace(y = ~data3, name = 'data3', mode = 'markers')p

添加颜色和大小映射
p <- plot_ly(data = mtcars, x =~hp, y = ~wt,color = ~hp, size = ~hp )
p

虽然这不是 R 中用于可视化的包的完整列表,但是这些应该足够让你开始了。
在 R 中可视化地理数据
地理数据(地理数据)与基于位置的数据相关。它主要描述物体在空间中的关系。数据通常以坐标的形式存储。以地图的形式看到一个州或一个国家更有意义,因为它提供了更真实的概览。在下一节中,我们将简要概述 R 在地理数据可视化方面的能力。
地理地图
我们将使用 ABC 公司的超市数据集样本。该数据集由他们在美国的商店位置组成。让我们加载数据并检查它的列。
data <- read.csv('ABC_locations.csv', sep=",")head(data)
Address City State Zip.Code Latitude Longitude
1 1205 N. Memorial Parkway Huntsville Alabama 35801-5930 34.74309 -86.60096
2 3650 Galleria Circle Hoover Alabama 35244-2346 33.37765 -86.81242
3 8251 Eastchase Parkway Montgomery Alabama 36117 32.36389 -86.15088
4 5225 Commercial Boulevard Juneau Alaska 99801-7210 58.35920 -134.48300
5 330 West Dimond Blvd Anchorage Alaska 99515-1950 61.14327 -149.88422
6 4125 DeBarr Road Anchorage Alaska 99508-3115 61.21081 -149.80434
plot()函数
我们将简单地通过纬度和经度列创建一个粗略的地图。
plot(data$Longitude,data$Latitude)

输出不是精确的地图,但它给出了美国边界的模糊轮廓。
map()函数
地图包在绘制地理数据时非常有用而且非常简单。
# Install package
install.packages("maps", dependencies=TRUE)# Loading the installed maps package
library(maps)
使用 map()函数绘制美国底图
map(database="state")

使用 symbols()函数在基础地图上构建一个点地图
symbols(data$Longitude, data$Latitude, squares =rep(1, length(data$Longitude)), inches=0.03, add=TRUE)

赋予符号颜色
symbols(data$Longitude, data$Latitude,bg = 'red', fg = 'red', squares =rep(1, length(data$Longitude)), inches=0.03, add=TRUE)

与 map 函数一起使用的命令是不言自明的。然而,你可以在他们的文档页面上了解更多。
当数据由位置组成时,地理数据可视化非常重要。人们可以很容易地想象出确切的地点和区域,并传达出更好的画面。
5.结论
我们已经看到使用 r 开始可视化是多么的简单和容易。你可以选择从头开始创建可视化或者使用预先构建的包。无论你选择什么,很明显 R 的可视化能力是无穷无尽的。
Python 人脸检测指南(附代码)

Greenland
在本教程中,我们将看到如何使用 OpenCV 和 Dlib 在 Python 中创建和启动人脸检测算法。我们还将添加一些功能来同时检测多张脸上的眼睛和嘴巴。本文将介绍人脸检测的最基本实现,包括级联分类器、HOG 窗口和深度学习 CNN。
我们将使用以下内容来介绍人脸检测:
- 基于 OpenCV 的 Haar 级联分类器
- 使用 Dlib 的方向梯度直方图
- 使用 Dlib 的卷积神经网络
本文原载于我的个人博客:https://maelfabien.github.io/tutorials/face-detection/#
本文的 Github 库(以及我博客中的所有其他内容)可以在这里找到:
本报告包含练习、代码、教程和我的个人博客文章
github.com](https://github.com/maelfabien/Machine_Learning_Tutorials)
介绍
我们将使用 OpenCV,这是一个用于计算机视觉的开源库,用 C/C++编写,有 C++、Python 和 Java 的接口。它支持 Windows、Linux、MacOS、iOS 和 Android。我们的一些工作还需要使用 Dlib,这是一个现代 C++工具包,包含机器学习算法和用于创建复杂软件的工具。
要求
第一步是安装 OpenCV,和 Dlib。运行以下命令:
pip install opencv-pythonpip install dlib
根据您的版本,文件将安装在以下位置:
/usr/local/lib/python3.7/site-packages/cv2
如果你遇到 Dlib 的一些问题,请查看这篇文章。
导入和模型路径
我们将创建一个新的 Jupyter 笔记本/ python 文件,并从以下内容开始:
import cv2
import matplotlib.pyplot as plt
import dlib
from imutils import face_utilsfont = cv2.FONT_HERSHEY_SIMPLEX
一.级联分类器
我们将首先探索级联分类器。
一. 1 .理论
级联分类器,即使用 haar-like 特征的级联提升分类器,是集成学习的一个特例,称为 boosting。它通常依赖于 Adaboost 分类器(以及其他模型,如 Real Adaboost、Gentle Adaboost 或 Logitboost)。
级联分类器在包含我们想要检测的对象的图像的几百个样本图像上以及不包含那些图像的其他图像上被训练。
我们如何检测一张脸是否存在?有一种算法,称为 Viola–Jones 对象检测框架,它包括实时人脸检测所需的所有步骤:
- 哈尔特征选择,从哈尔小波导出的特征
- 创建整体图像
- Adaboost 训练
- 级联分类器
最初的论文发表于 2001 年。
I.1.a .哈尔特征选择
我们在大多数普通人的脸上发现了一些共同的特征:
- 与脸颊上部相比,眼部区域较暗
- 与眼睛相比明亮的鼻梁区域
- 眼睛、嘴巴、鼻子的一些特定位置…
这些特征称为哈尔特征。特征提取过程将如下所示:

Haar Features
在这个例子中,第一特征测量眼睛区域和上脸颊区域之间的亮度差异。特征值简单地通过将黑色区域中的像素相加并减去白色区域中的像素来计算。

然后,我们应用这个矩形作为卷积核,覆盖整个图像。为了做到面面俱到,我们应该应用每个内核所有可能的维度和位置。简单的 24*24 图像通常会产生超过 160,000 个特征,每个特征由像素值的和/减组成。对于活体面部检测来说,在计算上是不可能的。那么,我们如何加快这个过程呢?
- 一旦好的区域被矩形识别,在图像的完全不同的区域上运行窗口是没有用的。这可以通过 Adaboost 来实现。
- 使用积分图像原理计算矩形特征,这样更快。我们将在下一节讨论这个问题。

有几种类型的矩形可以应用于 Haar 特征提取。根据原始论文:
- 双矩形特征是两个矩形区域内的像素之和的差,主要用于检测边缘(a,b)
- 三矩形功能计算两个外部矩形的总和,从中心矩形的总和中减去,主要用于检测线(c,d)
- 四矩形特征计算矩形(e)的对角线对之间的差

Haar Rectangles
既然已经选择了特征,我们使用 Adaboost 分类将它们应用于训练图像集,Adaboost 分类结合一组弱分类器来创建准确的集成模型。有了 200 个特征(而不是最初的 160,000 个),准确率达到了 95%。论文作者选择了 6000 个特征。
I.1.b .整体形象
在卷积核样式中计算矩形特征可能会很长,非常长。出于这个原因,作者 Viola 和 Jones 提出了图像的中间表示:积分图像。积分图像的作用是允许仅使用四个值简单地计算任何矩形和。我们来看看效果如何!
假设我们想要确定坐标为(x,y)的给定像素处的矩形特征。然后,在给定像素的上面和左边的像素的总和中的像素的积分图像。

其中 ii(x,y)是积分图像,i(x,y)是原始图像。
当你计算整个积分图像时,有一种形式的递归,只需要在原始图像上遍历一次。事实上,我们可以定义以下一对递归:

其中 s(x,y)为累计行和,s(x1)= 0,ii(1,y)=0。
这有什么用?好吧,考虑一个区域 D,我们想估计它的像素总数。我们已经定义了 3 个其他区域:A、B 和 c。
- 点 1 处的积分图像的值是矩形 a 中像素的总和。
- 点 2 的值是 A + B
- 点 3 的值是 A + C
- 点 4 的值是 A + B + C + D。
因此,区域 D 的像素之和可以简单地计算为:4+1(2+3)。
在一次传递中,我们仅使用 4 个数组引用计算了矩形内部的值。

人们应该简单地意识到矩形在实践中是非常简单的特征,但是对于人脸检测来说已经足够了。当涉及复杂问题时,方向可调滤波器往往更加灵活。

Steerable Filters
I.1c .用 Adaboost 学习分类函数
给定一组标记的训练图像(正的或负的),Adaboost 用于:
- 选择一小组特征
- 并训练分类器
由于 160,000 个特征中的大多数特征被认为是完全不相关的,因此我们围绕其构建增强模型的弱学习算法被设计成选择分割最佳负样本和正样本的单个矩形特征。
级联分类器
尽管上述过程非常有效,但仍存在一个主要问题。在一幅图像中,图像的大部分是非人脸区域。赋予图像的每个区域同等的重要性是没有意义的,因为我们应该主要关注最有可能包含图片的区域。Viola 和 Jones 使用级联分类器提高了检测率,同时减少了计算时间。
关键思想是拒绝不包含人脸的子窗口,同时识别包含人脸的区域。由于任务是正确地识别人脸,我们希望最小化假阴性率,即包含人脸并且没有被识别为人脸的子窗口。
一系列分类器被应用于每个子窗口。这些分类器是简单的决策树:
- 如果第一个分类器是肯定的,我们继续第二个
- 如果第二个分类器是肯定的,我们继续第三个
- …
在某一点上的任何否定结果都导致拒绝该子窗口,因为该子窗口可能包含人脸。初始分类器以较低的计算成本消除了大多数负样本,随后的分类器消除了额外的负样本,但需要更多的计算工作。

使用 Adaboost 训练分类器,并调整阈值以最小化错误率。当训练这样的模型时,变量如下:
- 分类器级数
- 每个阶段的特征数量
- 每个阶段的门槛
幸运的是,在 OpenCV 中,整个模型已经为人脸检测进行了预训练。
如果你想了解更多关于增强技术的知识,我邀请你查看我关于 Adaboost 的文章。
一. 2 .进口
下一步就是找到预先训练好的权重。我们将使用默认的预训练模型来检测面部,眼睛和嘴巴。根据您的 Python 版本,这些文件应该位于以下位置:
/usr/local/lib/python3.7/site-packages/cv2/data
一旦确定,我们将这样声明级联分类器:
cascPath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_frontalface_default.xml"
eyePath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_eye.xml"
smilePath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_smile.xml"faceCascade = cv2.CascadeClassifier(cascPath)
eyeCascade = cv2.CascadeClassifier(eyePath)
smileCascade = cv2.CascadeClassifier(smilePath)
I.3 .检测图像上的人脸
在实现实时人脸检测算法之前,让我们在一幅图像上尝试一个简单的版本。我们可以从加载测试图像开始:
# Load the image
gray = cv2.imread('face_detect_test.jpeg', 0)plt.figure(figsize=(12,8))
plt.imshow(gray, cmap='gray')
plt.show()

Test image
然后,我们检测面部,并在其周围添加一个矩形:
# Detect faces
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
flags=cv2.CASCADE_SCALE_IMAGE
)# For each face
for (x, y, w, h) in faces:
# Draw rectangle around the face
cv2.rectangle(gray, (x, y), (x+w, y+h), (255, 255, 255), 3)
以下是detectMultiScale功能最常见的参数列表:
- scaleFactor:指定图像在每个图像比例下缩小多少的参数。
- minNeighbors:指定每个候选矩形应该有多少个邻居来保留它的参数。
- 最小尺寸:可能的最小物体尺寸。小于该值的对象将被忽略。
- maxSize:可能的最大对象大小。大于该值的对象将被忽略。
最后,显示结果:
plt.figure(figsize=(12,8))
plt.imshow(gray, cmap='gray')
plt.show()

人脸检测在我们的测试图像上运行良好。现在让我们进入实时时间!
I.4 .实时人脸检测
让我们继续讨论实时面部检测的 Python 实现。第一步是启动相机,捕捉视频。然后,我们将图像转换成灰度图像。这用于减少输入图像的尺寸。事实上,我们应用简单的线性变换,而不是每像素 3 个点来描述红、绿、蓝:

这在 OpenCV 中是默认实现的。
video_capture = cv2.VideoCapture(0)while True:
# Capture frame-by-frame
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
现在,我们将使用上面定义的faceCascade变量,它包含一个预先训练的算法,并将其应用于灰度图像。
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(30, 30),
flags=cv2.CASCADE_SCALE_IMAGE
)
对于每个检测到的人脸,我们将在人脸周围画一个矩形:
for (x, y, w, h) in faces:
if w > 250 :
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 3)
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
对于检测到的每个嘴部,在其周围画一个矩形:
smile = smileCascade.detectMultiScale(
roi_gray,
scaleFactor= 1.16,
minNeighbors=35,
minSize=(25, 25),
flags=cv2.CASCADE_SCALE_IMAGE
)
for (sx, sy, sw, sh) in smile:
cv2.rectangle(roi_color, (sh, sy), (sx+sw, sy+sh), (255, 0, 0), 2)
cv2.putText(frame,'Smile',(x + sx,y + sy), 1, 1, (0, 255, 0), 1)
对于检测到的每只眼睛,在其周围画一个矩形:
eyes = eyeCascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.putText(frame,'Eye',(x + ex,y + ey), 1, 1, (0, 255, 0), 1)
然后,计算面部总数,并显示整体图像:
cv2.putText(frame,'Number of Faces : ' + str(len(faces)),(40, 40), font, 1,(255,0,0),2)
# Display the resulting frame
cv2.imshow('Video', frame)
当我们想要按下q停止拍摄时,执行退出选项:
if cv2.waitKey(1) & 0xFF == ord('q'):
break
最后,当一切完成后,释放捕获并销毁所有窗口。在 Mac 上杀死 windows 有一些问题,这可能需要稍后从活动管理器中杀死 Python。
video_capture.release()
cv2.destroyAllWindows()
I.5 .包装
一. 6 .结果
我在 YouTube 上做了一个脸部检测算法的快速演示。
二。Dlib 中的方向梯度直方图(HOG)
第二个最流行的人脸检测工具是由 Dlib 提供的,它使用了一个叫做梯度方向直方图(HOG)的概念。这是 Dalal 和 Triggs 最初论文的实现。
二. 1 .理论
HOG 背后的想法是将特征提取到一个向量中,并将其输入到一个分类算法中,例如支持向量机,该算法将评估一张脸(或任何你训练它实际识别的对象)是否存在于一个区域中。
提取的特征是图像梯度方向(定向梯度)的分布(直方图)。边缘和角落周围的梯度通常较大,这使我们能够检测到这些区域。
在原始论文中,该过程被实现用于人体检测,并且检测链如下:

二. 1.a .预处理
首先,输入图像必须大小相同(裁剪和重缩放图像)。我们将应用的补丁需要 1:2 的纵横比,因此输入图像的尺寸可能是64x128或100x200。
计算梯度图像
第一步是通过应用以下内核来计算图像的水平和垂直梯度:

Kernels to compute the gradients
图像的梯度通常会移除不重要的信息。
我们上面考虑的图像的渐变可以在 Python 中以这种方式找到:
gray = cv2.imread('images/face_detect_test.jpeg', 0)im = np.float32(gray) / 255.0# Calculate gradient
gx = cv2.Sobel(im, cv2.CV_32F, 1, 0, ksize=1)
gy = cv2.Sobel(im, cv2.CV_32F, 0, 1, ksize=1)
mag, angle = cv2.cartToPolar(gx, gy, angleInDegrees=True)
画出这幅图:
plt.figure(figsize=(12,8))
plt.imshow(mag)
plt.show()

但是我们之前没有对图像进行预处理。
II.1.c 计算猪
然后,图像被分成 8×8 的单元,以提供紧凑的表示,并使我们的 HOG 对噪声更加鲁棒。然后,我们计算每个单元格的 HOG。
为了估计区域内的梯度方向,我们简单地在每个区域内的梯度方向的 64 个值(8×8)和它们的量值(另外 64 个值)之间建立直方图。直方图的类别对应于渐变的角度,从 0°到 180°。总共有 9 类:0,20,40 … 160。
上面的代码给了我们两个信息:
- 渐变的方向
- 和梯度的大小
当我们制造 HOG 时,有 3 种情况:
- 角度小于 160°且不在两个类别的中间。在这种情况下,角度将被添加到猪的正确类别中
- 角度小于 160°,正好在 2 级之间。在这种情况下,我们考虑对两个最近的类的相等贡献,并且将大小分成两部分

- 角度大于 160°。在这种情况下,我们认为像素成比例地贡献给 160 和 0。

对于每个 8×8 单元,猪看起来像这样:

HoG
II.1.d .块标准化
最后,可以应用 16×16 的块,以便归一化图像并使其对于例如光照不变。这可以简单地通过将大小为 8×8 的 HOG 的每个值除以包含它的 16×16 块的 HOG 的 L2 范数来实现,这实际上是长度为9*4 = 36的简单向量。
II.1.e .块标准化
最后,所有的 36×1 向量被连接成一个大向量。我们完了。我们有我们的特征向量,在其上我们可以训练一个软 SVM 分类器(C=0.01)。
II.2 .检测图像上的人脸
实现非常简单:
face_detect = dlib.get_frontal_face_detector()rects = face_detect(gray, 1)for (i, rect) in enumerate(rects):
(x, y, w, h) = face_utils.rect_to_bb(rect)
cv2.rectangle(gray, (x, y), (x + w, y + h), (255, 255, 255), 3)
plt.figure(figsize=(12,8))
plt.imshow(gray, cmap='gray')
plt.show()

II.3 .实时人脸检测
如前所述,该算法很容易实现。我们还通过只检测面部来实现一个更轻的版本。Dlib 也使得检测面部关键点变得非常容易,但这是另一个话题了。
三。Dlib 中的卷积神经网络
最后一种方法基于卷积神经网络(CNN)。它还实现了一个关于最大边际对象检测(MMOD)的文件,以增强结果。
III.1 .一点理论
卷积神经网络(CNN)是主要用于计算机视觉前馈神经网络。它们提供了自动化的图像预处理以及密集的神经网络部分。CNN 是一种特殊类型的神经网络,用于处理具有网格状拓扑结构的数据。CNN 的建筑灵感来自动物的视觉皮层。
在以前的方法中,很大一部分工作是选择滤波器以创建特征,从而从图像中提取尽可能多的信息。随着深度学习和更大计算能力的兴起,这项工作现在可以自动化。CNN 的名字来源于我们用一组滤波器卷积初始图像输入的事实。要选择的参数仍然是要应用的过滤器数量和过滤器的尺寸。过滤器的尺寸被称为内核尺寸。步长是我们移动该过滤器的像素数。步幅的典型值介于 2 和 5 之间。

在这种特定情况下,CNN 的输出是二进制分类,如果有人脸,则取值 1,否则取值 0。
III.2 .检测图像上的人脸
某些元素在实现中会发生变化。
第一步是在这里下载预先训练好的模型。将权重移动到您的文件夹,并定义dnnDaceDetector:
dnnFaceDetector = dlib.cnn_face_detection_model_v1("mmod_human_face_detector.dat")
然后,非常类似于我们到目前为止所做的:
rects = dnnFaceDetector(gray, 1)for (i, rect) in enumerate(rects): x1 = rect.rect.left()
y1 = rect.rect.top()
x2 = rect.rect.right()
y2 = rect.rect.bottom() # Rectangle around the face
cv2.rectangle(gray, (x1, y1), (x2, y2), (255, 255, 255), 3)plt.figure(figsize=(12,8))
plt.imshow(gray, cmap='gray')
plt.show()

III.3 .实时人脸检测
最后,我们将实现 CNN 人脸检测的实时版本:
四。选哪个?
这是一个棘手的问题,但我们将只讨论两个重要的指标:
- 计算时间
- 准确性
在速度上,HoG 似乎是最快的算法,其次是 Haar 级联分类器和 CNN。
然而,Dlib 中的 CNN 往往是最精确的算法。HoG 表现很好,但是在识别小脸方面有一些问题。总体而言,HaarCascade 分类器的性能与 HoG 差不多。
我个人在我的个人项目中主要使用 HoG,因为它在实时人脸检测方面速度很快。
结论 :希望你喜欢这个关于 OpenCV 和 Dlib 人脸检测的快速教程。如果您有任何问题/评论,请不要犹豫,发表评论。
动词 (verb 的缩写)来源:
将文本分析集成到 Tableau 的指南

Credit: Freddie Marriage
数据往往又脏又乱。有时,它甚至没有以正确的形式进行快速分析和可视化。虽然 Tableau(和 Prep)有几个工具来处理数字、分类甚至空间数据,但一直缺少的一个部分是处理非结构化文本数据。
不再是了。
在几周前发布的最新版 Tableau Prep (2019.3)中,Prep 现在原生支持自定义 R 或 Python 脚本。通过使用 TabPy ,人们可以在任何数据集上使用整套 R 和 Python 库,而不必离开 Tableau 宇宙。从运行机器学习模型到调用地理空间 API,可能性几乎是无穷无尽的。
在本文中,我们尝试了一些令人兴奋的新事物:使用 Tableau Prep 和 Python 将自然语言处理技术应用于非结构化文本数据。在深入研究之前,我们先从如何设置一切的深入指导开始。
第 1 部分:为 Tableau 准备设置 Python

第一个大问题是:如何让 Python 与 Tableau Prep 一起工作?安装非常简单明了——只需遵循网站上的说明这里。我们的建议是使用 Anaconda 安装包,而不是 pip,以避免潜在的依赖错误。
(我们在 MacBook 上运行我们的代码,所以这是我们在指南中使用的参考,抱歉,Windows 用户!)
有两件真正有用的事情需要注意,希望能让你免受我们所经历的挫折:
- 用
conda安装了 TabPy 之后,你得把你的tornado版本降级到 5.1.1,否则在尝试运行 TabPy 的时候会遇到异步错误。这也列在(非常短)常见问题部分中。 - 在终端中运行命令
tabpy对我不起作用。相反,我使用cd将目录更改为 TabPy 文件夹(尝试在类似anaconda3/envs/[my_env]/lib/python3.7/site-packages/tabpy_server的地方找到它)。然后,我通过键入sh startup.sh运行启动文件。
就是这样!但第二个大问题是:Tableau Prep 到底是如何使用 Python 脚本的?

A simple diagram to explain what is going on behind the scenes
本质上,Tableau Prep 将数据导出为 Pandas 数据帧,将自定义 Python 脚本中的指定函数应用于数据帧,并返回一个新的数据帧,该数据帧将被传递回 Tableau Prep。
记住整个流程很有帮助,尤其是在 Python 脚本中编写定制函数时。特别要注意的是,您的函数必须接收一个 Pandas 数据帧并返回另一个 Pandas 数据帧。
现在进入有趣的部分:编写 Python 脚本!
您的 Python 脚本至少需要两个函数,一个用于您尝试在 Python 中执行的操作,另一个用于定义输出模式。先说后者。
get_output_schema()帮助 Tableau Prep 理解从 Python 返回给它的数据的结构。如果要返回到 Tableau Prep 的数据帧与原始数据有不同的列,则需要此函数。它采取以下形式:
有六种数据类型,都是不言自明的,如上面的函数所示。注意,它们必须正确地映射到数据帧中每一列的实际数据类型,这样才能工作。
至于您自己的自定义函数,这里有一个非常简单的函数,它执行一些基本的数据处理:
如前面的图表所示,该函数接收原始数据作为 Pandas 数据帧,并返回清理后的数据作为 Pandas 数据帧。您可以在这里编写任何函数,只要您在脚本本身中导入所需的库。
您也可以在脚本中包含多个函数,但是 Tableau Prep 中的每个脚本工具一次只能调用一个函数。如果您计划对不同的数据集使用多个函数,您可以简单地将它们全部放入同一个 Python 脚本中,但只在需要时调用相关的函数。这省去了创建多个脚本的麻烦。
将这两个函数放在一个脚本中,就大功告成了。现在,我们终于可以在 Tableau Prep 上运行它了!
首先,我们通过引入一个 CSV 文件打开一个新的 Tableau 准备工作流。

这个 CSV 文件只有三列— Category、Title和Text。然后,我们将“脚本”工具添加到工作流中,这将我们带到以下页面:

现在,我们得到一个错误,因为 TabPy 服务器还没有设置好。打开终端,导航到文件夹tabpy_server,运行命令sh startup.sh。应该会出现以下内容:

记住这里的端口号,然后返回 Tableau Prep,单击“连接到 Tableau Python(tabby)服务器”按钮,并键入以下内容:

Key in the port number that was specified in Terminal! It’s not always 9004.
点击“登录”,它会带你回到主 Tableau 准备窗口。选择 Python 脚本文件,然后在按钮正下方的框中输入函数的名称。只要您的脚本运行正常,工作流就会自动运行。

从现在开始一切都是标准的舞台准备。当然,数据清理是 Python 中最不令人兴奋的事情,尤其是 Tableau Prep 已经做得很好了。既然我们已经学会了如何做基本的事情,我们就可以放下训练,开始将更高级的功能集成到工作流中。
第 2 部分:Tableau 中的自然语言处理

Most text data is unstructured, and NLP can help us to analyze all this data.
什么是自然语言处理(NLP)?**简而言之,NLP 寻求解析和分析我们交流的内容和方式。**虽然代码总是被精确而清晰地定义,但我们如何书写或说话只受语法规则的约束。语境和意义塑造了我们的写作和言语,这种模糊性使得计算机很难准确理解我们的意思。
不出所料,NLP 已经成为日常生活中相当常见的一部分。垃圾邮件过滤器、翻译和虚拟助手是 NLP 在现实世界中应用的许多例子中的一些。这一领域有如此大的潜力,因为它弥合了我们凭直觉发现的东西和计算机能够理解的东西之间的差距。
这就是为什么将文本分析引入 Tableau 是一个游戏改变者。面对如此多的非结构化文本数据,能够有效地可视化这些数据将有助于我们更好地感知总体趋势和调查重要的异常值。

Credits: AbsolutVision
对于本文,我们使用一个包含 2225 篇 BBC 新闻文章的公开数据集(非常感谢 Greene 和 Cunningham 免费提供这个数据集!).每一篇文章都被分配到五个类别中的一个,并单独放在一个.txt文件中。
我们使用 Python 处理这个脚本,以便为 Tableau Prep 生成一个 CSV 文件。下面是我们使用的代码:
现在我们已经有了正确格式的数据,让我们看看如何分析非结构化文本。让我们看两篇新闻文章来了解一下底层数据是什么样的。
这里有一个来自“商业”类别:
标致交易助推三菱
陷入困境的日本汽车制造商三菱汽车(Mitsubishi Motors)已达成一项协议,向法国汽车制造商标致(Peugeot)供应 3 万辆运动型多功能车(SUV)。
两家公司签署了一份谅解备忘录,并表示他们希望在 2005 年春天之前达成最终协议。在几次利润预警和销售不佳之后,这一联盟对亏损的三菱来说是一个急需的提振。这款 SUV 将在日本生产,使用标致的柴油发动机,主要在欧洲市场销售。销量下降让三菱汽车的产能未得到充分利用,而与标致的生产协议给了它一个利用部分产能的机会。
今年 1 月,三菱汽车发布了 9 个月来的第三次利润预警,并下调了截至 2005 年 3 月的年度销售预期。在过去的一年里,该公司的销量下滑了 41%,这是由该公司系统地隐藏故障记录,然后秘密修理车辆的消息所推动的。因此,这家日本汽车制造商寻求了一系列金融救助。上月,该行表示,正寻求进一步 5400 亿日元(52 亿美元;27.7 亿英镑)的新资金支持,其中一半来自三菱集团的其他公司。拥有三菱汽车 30%股份的美-德汽车制造商戴姆勒-克莱斯勒在 2004 年 4 月决定不再注资。三菱新任命的首席执行官西冈隆(Takashi Nishioka)庆祝了与标致的交易,他是在上个月三位高管辞职承担公司困境的责任后接任的。三菱汽车(Mitsubishi Motors)预计,在截至 2005 年 3 月的本财年,该公司将出现 4720 亿日元的净亏损。上个月,该公司与日本竞争对手日产汽车(Nissan Motor)签署了一份生产协议,向其供应 3.6 万辆小型汽车,在日本销售。自 2003 年以来,该公司一直为日产生产汽车。
这里有一个来自“技术”类别:
年份搜索变成了个人
很可能当你打开浏览器时,你会直接进入你最喜欢的搜索引擎,而不是输入网址。
有些人可能认为这是极度的懒惰,但是在一个信息超载的时代,搜索已经成为导航网络的重要工具。这表明了我们使用互联网的方式正在发生变化。正如谷歌所展示的,提供一项人们离不开的服务是有利可图的。很多公司都在争夺网络搜索者的忠诚度,提供大量不同的服务和工具来帮助你找到你想要的东西。在过去的 12 个月里,微软和雅虎等科技巨头都试图在搜索领域分一杯羹。雅虎的扬卡·布鲁尼尼说:“用户体验促使人们进行更多的搜索。她说,随着人们对互联网越来越熟悉,他们倾向于花更多的时间在网上,并提出更多的问题。“第二件事是宽带,”布鲁尼尼女士告诉 BBC 新闻网站。“这对互联网的影响就像色彩对电视的影响一样.”
但是搜索并不是一个新现象。自从网络出现以来,它就一直存在。
经验丰富的冲浪者会记得 Hotbot 和 Altavista 这样的老前辈。“搜索一直都很重要,”谷歌运营副总裁乌尔斯·霍尔兹尔(Urs Holzle)表示。“我们在 1999 年就宣扬了这一点。随着用户越来越多,信息越来越多,现在更是如此。”“人们没有意识到搜索是未来。财务状况与此有关。”谷歌已经表明,网络商务可以通过其有针对性的小广告来运作,这些小广告出现在页面右侧的顶部和底部,并与原始搜索相关。这些小广告帮助谷歌在截至 9 月的三个月里实现了 8.059 亿美元的收入。其他人已经意识到你可以从网络查询中赚钱。“一旦你看到有一个市场,微软一定会抓住它。如果微软认为搜索很重要,那就没人会质疑它,”霍尔兹尔先生说。
微软只是进军搜索领域的网络巨头之一。雅虎、Ask Jeeves、亚马逊和一些较小的公司都在寻求吸引眼球。
随着每家公司都试图通过推出桌面搜索等新的搜索产品来击败谷歌,网络用户面临着过多的选择。它反映了战场是如何从网络转移到你的个人电脑上的。搜索不仅仅是在网上找路。现在,它是关于解锁隐藏在硬盘上数十亿字节的文档、图像和音乐中的信息。尽管有这些进步,搜索仍然是一个笨拙的工具,经常不能准确地找到你想要的东西。为了做得更好,搜索引擎试图更好地了解你,更好地记忆、分类和管理你遇到的所有信息。“个性化将是未来的一个大领域,”雅虎的扬卡·布鲁尼尼说。“谁破解了它,并给你你想要的信息,谁就是赢家。我们必须理解你,才能给你量身定制的更好的结果。”这也许是搜索的圣杯,理解你在寻找什么,并迅速提供给你。问题是还没有人知道如何到达那里。
我们想从这些新闻文章中提取什么样的数据?一些事情浮现在脑海中:
- 文章中提到了谁或什么?
- 这篇文章是用肯定语气还是否定语气写的?
- 讨论的一般话题是什么?
巧合的是,这三个问题中的每一个都对应 NLP 中的一个特定子领域。第一是实体识别,第二是情感分析,第三是话题建模。在本文中,我们将只研究前两者。

为此,我们依赖 Python 中两个著名的 NLP 库: Spacy 和 TextBlob 。请确保在继续之前安装这两个软件包!
现在,我们只需使用这些库编写我们的脚本!
本文并不打算成为 Python 上 NLP 的指南(有许多文章和网站已经这样做了),所以我们将跳过解释这两个包是如何工作的。我们在代码中留下了注释,以便对我们在每个部分所做的事情有一个好的了解。
在上一节中,我们深入了解了如何将 Python 脚本集成到 Tableau Prep 工作流中,因此使用上面的脚本应该很容易!我们导入 BBC 数据 CSV 文件,输入端口号,选择 Python 脚本,输入函数名。
两分钟内,我们看到…

Python 脚本完美运行!
Tableau Prep 最棒的地方之一是能够查看汇总数据。我们可以立即看到,大多数文章少于 3750 个字符,通常极性得分约为 0 (-1 为负,1 为正),这与我们对 BBC 新闻作为简洁和中立的新闻来源的印象相当吻合。
我们还有每篇文章中提到的人、国家和组织的数据。虽然有一些错误(“气候”不是一个组织),但 Spacy 库在识别这些命名实体方面大体上是准确的。
让我们更深入地研究一下我们前面看到的两篇文章到底返回了什么。关于标致的文章:

关于个性化搜索的文章:

在这两种情况下,斯帕西都正确地指出了文章中提到的组织、个人和国家。还要注意个性化搜索文章在Text_Subjectiveness和Text_Polarity中的得分如何更高。这与我们读到的一致:它更侧重于构建一个关于个性化搜索如何变得更加普遍的叙事,并且相当支持这一趋势。相比之下,标致的文章只是描述了行业动向。
**通过将文本分析集成到 Tableau Prep 中,我们能够从新闻文章中包含的非结构化文本数据中提取有用的信息。**我们还可以做更多的事情——主题建模、文档相似性、情感检测等等。
最后的想法

Credits: Clem Onojeghuo
我们希望本指南有助于解释如何将定制 Python 脚本集成到 Tableau Prep 中,尤其是在自然语言处理领域。一旦掌握了窍门,为 API 调用、地理空间分析甚至机器学习编写定制脚本就变得非常简单了。
当这一切发生时,天空才是极限。
— 萧恩
阵列的线性搜索和二分搜索法指南(数据结构和算法)

在上一篇文章中,我们讨论了数组和操作( LINK )。现在,我们将回顾算法选择如何影响代码的性能。特别是,我们将通过无序和有序数组来研究线性搜索和二分搜索法。
什么是算法?
我的一个经理是个数学专家,他总是喜欢明确地陈述定义,这样每个人都在同一页上。在我们的例子中,算法是解决问题的一种方式。例如,这里有一个关于如何执行谷歌搜索的粗略算法:
1.打开 web 浏览器。
2。在地址栏
3 中输入www.google.com。按回车键
4。在谷歌搜索栏中,输入想要的搜索
5。按回车键
现在有更多的步骤来更加明确和改进算法,但你得到的想法。换句话说,算法是做某事的过程。
有序数组
在上一篇文章(链接)中,我们讨论了无序数组。有序数组是数据以定向方式组织的数组(通常被视为升序)。因此,每次添加或删除一个数字时,数组都会按照需要的顺序进行重组。让我们看一个 Python 中数组的例子:
ordered_array = [1, 6, 7, 22, 100]# Let's insert the value 19
ordered_array.insert(0, 19)
ordered_array
[19, 1, 6, 7, 22, 100]
我们可以看到,增加值并没有按照正确的升序排列。为了保持数组有序,值 19 必须放在正确的位置。在 Python 中,我们可以这样对数组进行排序:
ordered_array.sort()
ordered_array
[1, 6, 7, 19, 22, 100]
这很容易,但是,在幕后,Python 做了更多的事情。如果我们从插入 19 和排列开始,第一步是检查 19 是否大于 1。如果是,则移动到下一个值。如果没有,则将值放在索引处,并将所有值向右移动。
在我们的例子中,它将逐个搜索每个值,直到达到 22。在 22 处,它会将 22 和 100 向右移动一个索引值。之后,它会将 19 放在 22 的前一个索引值上。
线性搜索
好吧,那么显示有序和无序数组的全部意义是什么?对于线性搜索这样的算法来说,性能变化很大。线性搜索逐个检查数组中的值,直到找到为止。在无序数组中,线性搜索必须检查整个数组,直到找到所需的值。但是有序数组就不同了。原因是,一旦线性搜索发现一个值大于它的期望值,那么它可以停止,并说它找到了值或没有。基本上,有序数组需要更少的步骤,无序数组使用线性搜索。Python 示例编码如下:
#Linear Search Function (modified from: [https://www.geeksforgeeks.org/linear-search/](https://www.geeksforgeeks.org/linear-search/))
def linsearch(arr, n, x):
for i in range (0, n):
if (arr[i] == x):
return i;
return -1;#Ordered Array
arr = [1, 6, 7, 19, 22, 100];
#Desired value
x = 19;n = len(arr);
result = linsearch(arr, n, x)if(result == -1):
print("Element is not present in array")
else:
print("Element is present at index", result);
元素出现在索引 3 处
二进位检索
由于我们的数据被结构化为有序数组,因此实际上有一种比线性搜索更好的方法来搜索值。你已经猜到了。更好的算法是二分搜索法!那么,它是如何工作的呢?
二分搜索法基本上是取你要找的值,然后到有序数组的中间。它现在会考虑期望值是大于还是小于中间值。如果更高,二分搜索法会到达中间点,再次询问更高或更低的价格,直到找到理想的价格。这同样适用于较低的值。
重要的是要记住,二分搜索法只能发生在有序的数组中。如果它是无序的,二分搜索法不能要求更高或更低的值来加速搜索。这个例子强调了数据结构的重要性以及正确的算法选择如何影响性能。二分搜索法的 Python 示例如下:
#Binary Search Function (modified from: [https://www.geeksforgeeks.org/binary-search/](https://www.geeksforgeeks.org/binary-search/))
def binarySearch(arr, l, r, x):
while l <= r:
mid = l + (r - l)//2;
if arr[mid] == x:
return mid
elif arr[mid] < x:
l = mid + 1
else:
r = mid - 1
return -1#Ordered Array
arr = [1, 6, 7, 19, 22, 100];
#Desired value
x = 19;
result = binarySearch(arr, 0, len(arr)-1, x)
if(result != -1):
print("Element is present at index % d" % result)
else:
print("Element is not present in array")
元素出现在索引 3 处
结论
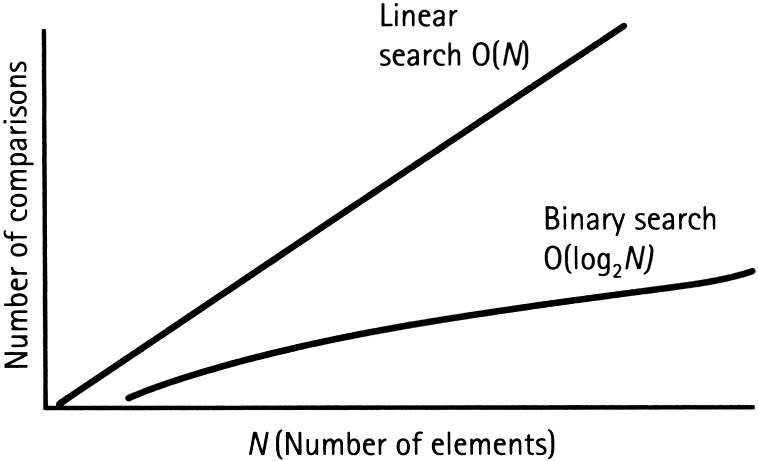
因此,我们了解了线性搜索和二分搜索法对有序数组的性能影响。由于逐个检查数组中每个数据点的期望值,线性搜索速度较慢。相比之下,二分搜索法通过获取中间值并根据期望值升高或降低来减少搜索时间。我认为以图形方式观察这种变化会有所帮助,所以请看下图:

Graph performance of Linear Search v. Binary Search. Image taken from Techtud: https://www.techtud.com/sites/default/files/public/user_files/tud39880/linearSearch%20vs%20binary%20search%20diagram_0.jpg
基本上,在最坏的情况下,线性搜索性能会随着每个新元素的增加而提高。例如,期望值为 49,000 的 50,000 个有序数组将以从 0 一直到 49,000 为步长进行线性搜索。另一方面,二分搜索法将在大约 15 步内穿过一个又一个中间值。不要担心图中的 O 符号。这是一个很大的 O 符号,我们将在下一篇文章中讨论它!
本系列文章的第一部分可以在这里找到:
https://towards data science . com/a-guide-to-arrays-and-operations-data-structures-f 0671028 ed 71
对于那些现在想了解更多的人来说,下面是我用来撰写本文的关于这些主题的好资源:
- http://elementsofprogramming.com/
- https://www . Amazon . com/Cracking-Coding-Interview-Programming-Questions/DP/0984782850
- https://learning . oreilly . com/library/view/a-common-sense-guide/9781680502794/
免责声明:本文陈述的所有内容均为我个人观点,不代表任何雇主。
使用 R 挖掘和分析 Tweets 的指南
撰写深刻的 Twitter 分析报告的简单步骤

Photo by Carlos Muza on Unsplash
Twitter 为我们提供了大量用户生成的语言数据——这是任何想要进行文本分析的人的梦想。更重要的是,推特让我们能够洞察在线公共行为。因此,分析 Twitter 已经成为品牌和代理商的重要信息来源。
几个因素让 Twitter 在分析方面比其他社交媒体平台有相当大的优势。首先,推特有限的字符大小为我们提供了一个相对同质的语料库。其次,每天发布的数百万条推文允许访问大量数据样本。第三,tweets 是公开的,容易访问,也可以通过 API 检索。
尽管如此,提取这些见解仍然需要一些编码和编程知识。这就是为什么大多数情况下,品牌和机构依赖于易于使用的分析工具,如 SproutSocial 和 Talkwalker,这些工具只需点击一下即可提供这些见解。
在这篇文章中,我帮助你打破这些障碍,并为你提供一个简单的指南,告诉你如何用编程软件 r 提取和分析推文。
以下是你可能选择这样做的 3 个原因:
- 使用 R 是免费的,也就是说,你将能够免费制作一份 Twitter 分析报告,同时学习如何编码!
- R 给你无限的分析机会。因此,用它来分析 Twitter,可以让你根据你想要分析的内容进行量身定制的分析,而不是依赖一份一刀切的报告
- R 允许你分析任何你想要的 Twitter 账户,即使你没有登录信息。与许多分析工具相比,这是一个巨大的优势,许多分析工具要求您首先拥有登录详细信息以便分析信息。
深信不疑?那我们开始吧!
步骤 1:获取 Twitter API 访问权限
为了开始,您首先需要获得一个 Twitter API。这将允许你检索推文——没有它,你不能做任何事情。获得一个 Twitter API 很容易。首先确保你有一个 Twitter 账户,否则就创建一个。然后,通过以下网站申请开发者帐号:https://developer.twitter.com/en/apply-for-access.html。你需要填写一份申请表,包括对你希望分析的内容做更多的解释。
一旦你的申请被 Twitter 接受(这不会花太长时间),你将收到以下凭证,你需要保持安全:
- 消费者密钥
- 消费者秘密
- 访问令牌
- 访问密码
第二步:挖掘推文
一旦有了上面的信息,启动 R 并下载“rtweet”包,我将用它来提取 tweets。
install.packages("rtweet")
library (rtweet)
然后,设置连接 Twitter 的身份验证。你可以通过输入你的应用名称、消费者密钥和消费者秘密来做到这一点——所有这些都是你在申请 Twitter API 时收到的信息。您将被重定向到一个 Twitter 页面,并被要求接受认证。一旦完成,你就可以返回 R,开始分析你的推文了!
twitter_token <- create_token(
app = ****,
consumer_key = ****,
consumer_secret = ****,
set_renv = TRUE)
搜索推文
根据您希望执行的分析,您可能希望搜索包含特定单词或标签的推文。请注意,您只能提取过去 6 到 9 天的推文,因此在分析时请记住这一点。
要做到这一点,只需使用 search_tweets 函数,后跟一些规范:要提取的 tweets 的数量(n),是否包括转发和 tweets 的语言。作为示例,请参见下面的代码行。
climate <- search_tweets(“climate”, n=1000, include_rts=FALSE, lang=”en”)
搜索特定的用户帐户
或者,您可能希望分析特定的用户帐户。在这种情况下,使用 get_timeline 函数,后跟 twitter 句柄和您希望提取的 tweets 数量。注意,这里只能提取最后 3200 条推文。
在这个例子中,我选择了提取比尔·盖茨的推文。这里的优势是比尔·盖茨的账户总共有 3169 条推文,低于 3200 条的门槛。
Gates <- get_timeline("@BillGates", n= 3200)
第三步:分析推文
在这一部分,我向你展示了你应该包含在每一份 Twitter 分析报告中的 8 个关键观点。为此,让我们更深入地研究一下比尔·盖茨的 Twitter 账户吧!
1.显示什么效果最好,什么效果不好
任何报告的第一部分都应该提供清晰的信息,说明什么效果最好,什么效果不好。找出表现最好和最差的推文可以快速清晰地了解账户的整体情况。
为了做到这一点,你首先需要区分有机推文、转发和回复。下面一行代码向您展示了如何从您的样本中删除转发和回复,只保留有机的推文——就内容而言,这些是您想要分析的推文!
# Remove retweets
Gates_tweets_organic <- Gates_tweets[Gates_tweets$is_retweet==FALSE, ] # Remove replies
Gates_tweets_organic <- subset(Gates_tweets_organic, is.na(Gates_tweets_organic$reply_to_status_id))
然后,你需要通过查看变量来分析参与度: favorite_count (即喜欢的数量)或 retweet_count (即转发的数量)。只需将它们按降序排列(变量前有一个减号“-”)即可找到点赞或转发数量最多的一个,或按升序排列(没有减号)即可找到参与次数最少的一个。
Gates_tweets_organic <- Gates_tweets_organic %>% arrange(-favorite_count)
Gates_tweets_organic[1,5]Gates_tweets_organic <- Gates_tweets_organic %>% arrange(-retweet_count)
Gates_tweets_organic[1,5]
2.显示回复/转发/有机推文的比率
分析回复、转发和有机推文的比例可以告诉你很多你正在分析的账户类型。例如,没有人喜欢一个专门转发的 Twitter 账户,没有任何个人内容。因此,如果一个人希望提高他或她的账户的性能,找到回复、转发和有机推文的良好比例是一个关键的监控指标。
作为第一步,确保创建三个不同的数据集。由于您已经在前面的步骤中创建了一个仅包含有机推文的数据集,现在只需创建一个仅包含转发的数据集和一个仅包含回复的数据集。
# Keeping only the retweets
Gates_retweets <- Gates_tweets[Gates_tweets$is_retweet==TRUE,]# Keeping only the replies
Gates_replies <- subset(Gates_tweets, !is.na(Gates_tweets$reply_to_status_id))
然后,创建一个单独的数据框,包含有机推文、转发和回复的数量。这些数字很容易找到:它们是你的三个数据集的观测值。
# Creating a data frame
data <- data.frame(
category=c("Organic", "Retweets", "Replies"),
count=c(2856, 192, 120)
)
完成后,您可以开始为圆环图准备数据框,如下所示。这包括添加计算比率和百分比的列,以及一些可视化调整,如指定图例和舍入数据。
# Adding columns
data$fraction = data$count / sum(data$count)
data$percentage = data$count / sum(data$count) * 100
data$ymax = cumsum(data$fraction)
data$ymin = c(0, head(data$ymax, n=-1))# Rounding the data to two decimal points
data <- round_df(data, 2)# Specify what the legend should say
Type_of_Tweet <- paste(data$category, data$percentage, "%")ggplot(data, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=Type_of_Tweet)) +
geom_rect() +
coord_polar(theta="y") +
xlim(c(2, 4)) +
theme_void() +
theme(legend.position = "right")

3.显示推文发布的时间
多亏了从每条推文中提取的日期和时间,了解比尔·盖茨最常发推文的时间非常容易分析。这可以让我们对账户的活动有一个总体的了解,也是一个有用的指标,可以用来分析表现最好和最差的推文。
在这个例子中,我按年份分析了推文的频率。请注意,您也可以通过简单地将下面一行代码中的“year”改为“month”来按月执行此操作。或者,您也可以使用 R 包 hms 和 scales 按小时分析发布行为。
colnames(Gates_tweets)[colnames(Gates_tweets)=="screen_name"] <- "Twitter_Account"ts_plot(dplyr::group_by(Gates_tweets, Twitter_Account), "year") +
ggplot2::theme_minimal() +
ggplot2::theme(plot.title = ggplot2::element_text(face = "bold")) +
ggplot2::labs(
x = NULL, y = NULL,
title = "Frequency of Tweets from Bill Gates",
subtitle = "Tweet counts aggregated by year",
caption = "\nSource: Data collected from Twitter's REST API via rtweet"
)

4.显示推文发布的位置
分析发布推文的平台的来源是另一个很酷的洞察。其中一个原因是,我们可以在一定程度上推断出比尔·盖茨是不是发微博的人。因此,这有助于我们定义推文的个性。
在这一步中,您对 rtweet 包收集的源变量感兴趣。下面一行代码向您展示了如何按来源类型聚合这些数据,并分别统计每种类型的 tweets 的频率。请注意,为了简化可视化过程,我只保留了发表了超过 11 条推文的来源。
Gates_app <- Gates_tweets %>%
select(source) %>%
group_by(source) %>%
summarize(count=n())Gates_app <- subset(Gates_app, count > 11)
一旦完成,这个过程类似于之前已经创建的圆环图!
data <- data.frame(
category=Gates_app$source,
count=Gates_app$count
)data$fraction = data$count / sum(data$count)
data$percentage = data$count / sum(data$count) * 100
data$ymax = cumsum(data$fraction)
data$ymin = c(0, head(data$ymax, n=-1))data <- round_df(data, 2)Source <- paste(data$category, data$percentage, "%")ggplot(data, aes(ymax=ymax, ymin=ymin, xmax=4, xmin=3, fill=Source)) +
geom_rect() +
coord_polar(theta="y") + # Try to remove that to understand how the chart is built initially
xlim(c(2, 4)) +
theme_void() +
theme(legend.position = "right")

请注意,比尔·盖茨的大多数推文来自 Twitter 网络客户端 Sprinklr 和 Hootsuite——这表明比尔·盖茨很可能不是自己发推文的人!
5.显示在推文中找到的最常用的词
Twitter 分析报告当然应该包括对推文内容的分析,这包括找出哪些词用得最多。
因为您正在分析文本数据,所以请确保首先清理它,并从您不想在分析中显示的任何字符(如超链接、@提及或标点符号)中删除它。下面几行代码为你提供了清理 tweets 的基本步骤。
Gates_tweets_organic$text <- gsub("https\\S*", "", Gates_tweets_organic$text)Gates_tweets_organic$text <- gsub("@\\S*", "", Gates_tweets_organic$text) Gates_tweets_organic$text <- gsub("amp", "", Gates_tweets_organic$text) Gates_tweets_organic$text <- gsub("[\r\n]", "", Gates_tweets_organic$text)Gates_tweets_organic$text <- gsub("[[:punct:]]", "", Gates_tweets_organic$text)
第二步,确保从文本中删除停用词。这对于您分析最常用的单词非常重要,因为您不希望出现最常用的单词,如“to”或“and ”,因为这些单词对您的分析没有太大意义。
tweets <- Gates_tweets_organic %>%
select(text) %>%
unnest_tokens(word, text)tweets <- tweets %>%
anti_join(stop_words)
然后,您可以按照下面的简单步骤,标出推文中出现频率最高的单词。
tweets %>% # gives you a bar chart of the most frequent words found in the tweets
count(word, sort = TRUE) %>%
top_n(15) %>%
mutate(word = reorder(word, n)) %>%
ggplot(aes(x = word, y = n)) +
geom_col() +
xlab(NULL) +
coord_flip() +
labs(y = "Count",
x = "Unique words",
title = "Most frequent words found in the tweets of Bill Gates",
subtitle = "Stop words removed from the list")

6.显示最常用的标签
你可以对标签做同样的分析。在这种情况下,您需要使用 rtweet 包中的 hashtags 变量。形象化这些的一个好方法是使用如下所示的单词云。
Gates_tweets_organic$hashtags <- as.character(Gates_tweets_organic$hashtags)
Gates_tweets_organic$hashtags <- gsub("c\\(", "", Gates_tweets_organic$hashtags)set.seed(1234)
wordcloud(Gates_tweets_organic$hashtags, min.freq=5, scale=c(3.5, .5), random.order=FALSE, rot.per=0.35,
colors=brewer.pal(8, "Dark2"))

7.显示转发次数最多的账户
从一个账户大量转发通常不是人们在 Twitter 账户中寻找的。因此,一个有用的见解是监控和了解大多数转发来自哪个账户。这里您要分析的变量是 retweet_screen_name ,可视化的过程类似于之前使用单词云描述的过程。
set.seed(1234)
wordcloud(Gates_retweets$retweet_screen_name, min.freq=3, scale=c(2, .5), random.order=FALSE, rot.per=0.25,
colors=brewer.pal(8, "Dark2"))

8.对推文进行情感分析
最后,你可能想在 Twitter 分析报告的末尾添加一个情感分析。使用“syuzhet”软件包很容易做到这一点,并允许您通过把握推文的语气来进一步深化您的分析。没有人喜欢一个只会传播愤怒或悲伤推文的推特账号。捕捉你的推文的语气以及它们是如何平衡的,是你的账户表现的一个很好的指标。
library(syuzhet)# Converting tweets to ASCII to trackle strange characters
tweets <- iconv(tweets, from="UTF-8", to="ASCII", sub="")# removing retweets, in case needed
tweets <-gsub("(RT|via)((?:\\b\\w*@\\w+)+)","",tweets)# removing mentions, in case needed
tweets <-gsub("@\\w+","",tweets)ew_sentiment<-get_nrc_sentiment((tweets))
sentimentscores<-data.frame(colSums(ew_sentiment[,]))names(sentimentscores) <- "Score"sentimentscores <- cbind("sentiment"=rownames(sentimentscores),sentimentscores)rownames(sentimentscores) <- NULLggplot(data=sentimentscores,aes(x=sentiment,y=Score))+
geom_bar(aes(fill=sentiment),stat = "identity")+
theme(legend.position="none")+
xlab("Sentiments")+ylab("Scores")+
ggtitle("Total sentiment based on scores")+
theme_minimal()

总结
在这篇文章中,我旨在展示如何使用免费的编程软件 r 提取和分析推文。我希望这个指南有助于您构建自己的 Twitter 分析报告,其中包括:
- 显示哪些推文效果最好,哪些效果不好
- 有机推文/回复/转发的比率,推文发布的时间和发布推文的平台。这些都是关于推特行为的见解。
- 推文中使用最频繁的词,标签,转发最多的账户,以及捕捉推文语气的情感分析。这些都是对推文内容的见解。
[## 挖掘 2018 年中期选举前后美国候选人关于大规模枪击事件的推文
与卡洛斯·阿胡马达合作撰写的文章
medium.com](https://medium.com/data-social/mining-tweets-of-us-candidates-on-mass-shootings-before-and-after-the-2018-midterms-90cc18ff652a)
我定期撰写关于数据科学和自然语言处理的文章。关注我的 Twitter 或Medium查看更多类似的文章或简单地更新下一篇文章!

















 736
736

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}