







Keras 深度学习简介
如何使用 Keras 深度学习库

Figure 1: Photo by Blake Connally on Unsplash
Keras 是一个高级神经网络 API,能够运行在 Tensorflow 、 Theano、和 CNTK 之上。它通过高级、用户友好、模块化和可扩展的 API 实现快速实验。Keras 也可以在 CPU 和 GPU 上运行。
Keras 由 Francois Chollet 开发和维护,是 Tensorflow 核心的一部分,这使其成为 tensor flow 首选的高级 API。
本文是解释如何使用 Keras 进行深度学习的系列文章的第一篇。
在本文中,我们将介绍 Keras 的基础知识,包括两个最常用的 Keras 模型(顺序和功能)、核心层以及一些预处理功能。
安装 Keras
我假设你已经有了一个可以工作的 Tensorflow 或 Theano 或 CNTK。如果你不检查上面的链接。
Keras 可以使用 pip 或 conda 安装:
pip install keras
or
conda install keras
在数据集中加载
Keras 提供了七个不同的数据集,可以使用 Keras 直接加载。这些包括图像数据集以及房价和电影评论数据集。
在本文中,我们将使用 MNIST 数据集 ,,它包含 70000 张 28x28 灰度图像和 10 个不同的类别。Keras 将其分为一个包含 60000 个实例的训练集和一个包含 10000 个实例的测试集。
为了将图像输入到卷积神经网络中,我们将数据帧转换为四维。这可以使用 numpys reshape方法来完成。我们还将把数据转换成浮点数,并使其正常化。
我们还将使用 Keras 的to_categorical方法将我们的标签转换成一键编码。
使用顺序 API 创建模型
在 Keras 中创建模型最简单的方法是使用顺序 API,它允许您一层一层地堆叠。顺序 API 的问题是,它不允许模型有多个输入或输出,而这对于某些问题是需要的。
然而,对于大多数问题,顺序 API 是一个完美的选择。
要创建一个卷积神经网络,我们只需要创建一个Sequential对象,并使用add函数添加层。
上面的代码首先创建了一个Sequential对象,并添加了一些卷积、最大池和漏失层。然后,它使输出变平,并在将其传递给输出层之前,将其传递给最后一个密集层和漏失层。如果你没有信心建立一个卷积神经网络(CNN ),看看这个伟大的教程。
顺序 API 还支持另一种语法,其中层被直接传递给构造函数。
使用函数式 API 创建模型
或者,函数式 API 允许您创建相同的模型,但是以简单性和可读性为代价为您提供了更多的灵活性。
它可用于多个输入和输出图层以及共享图层,从而使您能够构建真正复杂的网络结构。
当使用函数式 API 时,我们总是需要将前一层传递给当前层。它还需要使用输入层。
函数式 API 也经常用于迁移学习,我们将在另一篇文章中讨论。
编译模型
在开始训练我们的模型之前,我们需要配置学习过程。为此,我们需要指定一个优化器、一个损失函数和一些可选的度量标准,如准确性。
损失函数是对我们的模型在实现给定目标方面有多好的度量。
优化器用于通过使用梯度更新权重来最小化损失(目标)函数。
扩充图像数据
扩充是从现有数据中创建更多数据的过程。对于图像,你可以做一些小的变换,比如旋转图像,放大图像,添加噪声等等。
这有助于使模型更加稳健,并解决没有足够数据的问题。Keras 有一个叫做ImageDataGenerator的方法,可以用来扩充图像。
这个ImageDataGenerator 将创建已经旋转、放大或缩小、宽度和高度发生变化的新图像。
符合模型
既然我们已经定义并编译了我们的模型,那么就可以开始训练了。为了训练一个模型,我们通常会使用fit方法,但是因为我们使用的是数据生成器,我们将使用fit_generator 并向其传递我们的生成器、X 数据、y 数据以及历元数和批量大小。我们还将向它传递一个验证集,以便我们可以监控这两个集的损失和准确性,以及使用生成器时所需的 steps_per_epoch,它被设置为训练集的长度除以 batch_size。
这将输出:
Epoch 1/5
1875/1875 [==============================] - 22s 12ms/step - loss: 0.1037 - acc: 0.9741 - val_loss: 0.0445 - val_acc: 0.9908
Epoch 2/5
1875/1875 [==============================] - 22s 12ms/step - loss: 0.0879 - acc: 0.9781 - val_loss: 0.0259 - val_acc: 0.9937
Epoch 3/5
1875/1875 [==============================] - 22s 12ms/step - loss: 0.0835 - acc: 0.9788 - val_loss: 0.0321 - val_acc: 0.9926
Epoch 4/5
1875/1875 [==============================] - 22s 12ms/step - loss: 0.0819 - acc: 0.9792 - val_loss: 0.0264 - val_acc: 0.9936
Epoch 5/5
1875/1875 [==============================] - 22s 12ms/step - loss: 0.0790 - acc: 0.9790 - val_loss: 0.0220 - val_acc: 0.9938
可视化培训过程
我们可以可视化每个时期的训练和测试精度和损失,这样我们就可以直观地了解模型的性能。各代的精度和损失保存在我们训练时获得的历史变量中,我们将使用 Matplotlib 来可视化这些数据。

Figure 2: Training/Testing accuracy over epochs

Figure 3: Training/Testing loss over epochs
在上面的图表中,我们可以看到我们的模型没有过度拟合,我们可以训练更多的纪元,因为验证损失仍在减少。
推荐读物
如何使用嵌入创建图书推荐系统?
towardsdatascience.com](/building-a-book-recommendation-system-using-keras-1fba34180699)
结论
Keras 是一个高级神经网络 API,能够运行在 Tensorflow 、 Theano 和 CNTK 之上。它通过高级、用户友好、模块化和可扩展的 API 以及在 CPU 和 GPU 上运行来实现快速实验。
本文是介绍 Keras 工作原理的系列文章的第一篇。在这篇文章中,我们讨论了安装以及如何创建一个简单的卷积神经网络。
如果你喜欢这篇文章,可以考虑订阅我的 Youtube 频道并在社交媒体上关注我。
本文涵盖的代码可以从 Github 资源库获得。
如果您有任何问题、建议或批评,可以通过 Twitter 或评论区联系我。
使用 dtplyr 加速数据争论

了解如何轻松地将dplyr的可读性与data.table的性能结合起来!
我最近看到了哈德利·韦翰关于《T2》上映的推文。这是一个支持在data.table对象上使用dplyr语法的包。dtplyr自动将dplyr语法翻译成等价的data.table,最终导致性能提升。
漫威:无限战争是历史上最雄心勃勃的跨界事件。哈德利·韦翰:拿着我的啤酒。
我一直很喜欢dplyr的易用性和可读性,也很渴望对比一下软件包的性能。让我们看看它在实践中是如何工作的!
加载库
对于本文,我们需要通过运行devtools::install_github(“tidyverse/dtplyr”)从 GitHub 安装dtplyr,我们使用microbenchmark进行性能比较。
生成数据集
我们生成一个人工数据集。我首先想到的是订单注册表,我们在其中存储:
id客户端的name产品的date采购amount购买的产品- 某一产品的单位
price
由于这只是一个玩具示例,我们不会深入研究数据集背后的逻辑。我们可以同意这有点像现实生活中的场景。为了测试不同方法的性能,我们生成了 1000 万行数据。
通过使用lazy_dt()我们触发了惰性评估——直到我们通过使用as.data.table()、as.data.frame()或as_tibble()明确请求它,才执行任何计算。为了便于比较,我们储存一个data.frame,一个data.table,一个【懒人】data.table。
我们可以通过打印结果来预览转换以及生成的data.table代码:
**Source:** local data table [?? x 3]
**Call:** `_DT3`[date < as.Date("2019-02-01"), .(id, product, date)][order(date)] id product date
*<chr>* *<chr>* *<date>*
1 DHQ GVF 2019-01-01
2 NUB ZIU 2019-01-01
3 CKW LJH 2019-01-01
4 AZO VIQ 2019-01-01
5 AQW AGD 2019-01-01
6 OBL NPC 2019-01-01
通常,这应该用于调试。我们应该指出我们希望在管道末端接收哪种类型的对象,以清楚地表明我们已经完成了转换。
用例 1:过滤、选择和排序
假设我们想要一个 2019 年 2 月 1 日之前发生的交易列表,按日期排序,我们不关心金额或价格。

我们看到dtplyr比data.table稍慢,但是通过观察中间时间,它比dplyr.快了大约 4 倍
用例 2:过滤后添加新变量
在本例中,我们要过滤产品数量超过 5000 的订单,并计算订单值,即amount * price。
大部分使用mutate()的表达式必须复制(不要原地修改),直接使用data.table就没必要了。为了应对这种情况,我们可以在lazy_dt()中指定immutable = FALSE来退出上述行为。

这一次,差异没有那么明显。当然,这取决于对表进行操作的复杂性。
用例 3:顶层聚合
假设我们想要:
- 根据金额<= 4000
- Calculate the average order value per customer

This time we get ~3x improvement in median execution time.
Use-case 4: Joining
In the last example, we consider a case of joining datasets. For that, we create a new 【 / 【 called 【 by selecting 75% of the available products and assigning a random letter to them. We can assume that the letter corresponds to a distribution center (variable called 【 ), from which the item is shipped.
We want to calculate the average order value per distribution center. In case we do not have data regarding the distribution center, we discard the row.

Again we see a ~3x speedup in the median execution time.
Conclusions
【 is (and always will be) slightly slower than 【 . That is because:
1. Each 【 verb must be converted to a 【 equivalent. For large datasets, this should be negligible, as these translation operations take time proportional to the complexity of the input code, rather than the amount of data.
2 过滤所有订单。一些data.table表达式没有直接的dplyr等价物。
3。用例 2 中提到的不变性问题。
综上所述,我认为dtplyr是对tidyverse的一个有价值的补充,因为只需对dplyr代码做很小的改动,我们就可以实现显著的性能提升。
一如既往,我们欢迎任何建设性的反馈。你可以在推特上或评论中联系我。你可以在我的 GitHub 上找到本文使用的代码。
联合学习和隐私保护简介
使用 PySyft 框架的联邦学习和附加秘密共享。
深度学习包括对存在于多个客户端设备上的大量高质量分散数据进行训练。该模型在客户端设备上被训练,因此不需要上传用户的数据。将个人数据保存在客户的设备上,使他们能够直接和实际控制自己的数据。

Figure 1: Federated Learning
服务器在预先可用的代理数据上训练初始模型。初始模型被发送到选定数量的合格客户端设备。合格标准确保用户的体验不会因为试图训练模型而被破坏。选择最佳数量的客户端设备来参与训练过程。处理完用户数据后,模型更新将与服务器共享。服务器聚集这些梯度并改进全局模型。
所有的模型更新都在内存中进行处理,而在服务器上只持续很短的一段时间。然后,服务器将改进的模型发送回参与下一轮训练的客户端设备。达到所需的精确度后,设备上的模型可以根据用户的个性化进行调整。然后,他们不再有资格参加培训。在整个过程中,数据不会离开客户端设备。
这与分散计算有什么不同?
联合学习与分散计算的不同之处在于:
- 客户端设备(如智能手机)的网络带宽有限。它们不能传输大量数据,上传速度通常低于下载速度。
- 客户端设备并不总是能够参与训练会话。最佳条件,如充电状态、连接到未计量的 Wi-Fi 网络、空闲等。并不总是可以实现的。
- 设备上的数据更新很快,并且不总是相同的。[数据并不总是可以获得。]
- 客户端设备可以选择不参与培训。
- 可用的客户端设备数量非常多,但是不一致。
- 联合学习将隐私保护与大规模群体的分布式训练和聚合结合在一起。
- 数据通常是不平衡的,因为数据是用户特定的并且是自相关的。
联合学习是“将代码带给数据,而不是将数据带给代码”这种更普遍方法的一个例子,它解决了数据的隐私、所有权和位置等基本问题。
在联合学习中:
- 某些技术用于压缩模型更新。
- 执行质量更新,而不是简单的梯度步骤。
- 在执行聚合之前,由服务器添加噪声,以掩盖个体对学习模型的影响。[全局差分隐私]
- 如果渐变更新太大,则会被裁剪。
PYSYFT 简介
我们将使用 PySyft 实现一个联邦学习模型。PySyft 是一个用于安全和私有深度学习的 Python 库。
装置
PySyft 要求 Python >= 3.6 和 PyTorch 1.1.0。确保你符合这些要求。
基础
让我们从导入库和初始化钩子开始。
这样做是为了覆盖 PyTorch 的方法,在一个 worker 上执行命令,这些命令在本地 worker 控制的 tensors 上调用。它还允许我们在工人之间移动张量。工人解释如下。
Jake has: {}
虚拟工作者是存在于我们本地机器上的实体。它们用于模拟实际工人的行为。
为了与分布在网络中的工作者一起工作,PySyft 提供了两种类型的工作者:
- 网络套接字工人
- Web 套接字工人
Web sockets workers 可以从浏览器实例化,每个 worker 位于一个单独的选项卡上。
在这里,Jake 是我们的虚拟工作者,可以将其视为设备上的一个独立实体。我们给他发些数据吧。
x: (Wrapper)>[PointerTensor | me:50034657126 -> jake:55209454569]
Jake has: {55209454569: tensor([1, 2, 3, 4, 5])}
当我们向 Jake 发送一个张量时,我们返回一个指向这个张量的指针。所有的操作都将通过这个指针来执行。这个指针保存另一台机器上的数据信息。现在, x 是一个点张量。
使用 get() 方法从杰克的设备中获取 x 的值。然而,这样做的话,杰克设备上的张量就被删除了。
x: tensor([1, 2, 3, 4, 5])
Jake has: {}
当我们将 PointTensor x (指向 Jake 机器上的一个张量)发送给另一个工人 John 时,整个链被发送给 John,并返回一个指向 John 设备上的节点的 PointTensor。张量仍在杰克的设备上。
x: (Wrapper)>[PointerTensor | me:70034574375 -> john:19572729271]
John has: {19572729271: (Wrapper)>[PointerTensor | john:19572729271 -> jake:55209454569]}
Jake has: {55209454569: tensor([1, 2, 3, 4, 5])}

Figure 2: Using the send() method on a PointTensor [Step 2].
方法的作用是:从一个工作线程中移除所有的对象。
Jake has: {}
John has: {}
假设我们想把一个张量从杰克的机器移到约翰的机器上。我们可以通过使用 send() 方法将“指向张量的指针”发送给 John,并让他调用 get() 方法。PySfyt 为此提供了一个 remote_get() 方法。还有一个方便的方法——move(),来执行这个操作。
(Wrapper)>[PointerTensor | me:86076501268 -> john:86076501268]
Jake has: {}
John has: {86076501268: tensor([ 6, 7, 8, 9, 10])}

Figure 3: Using the move() method on a PointTensor. [Step 2]
战略
我们可以通过以下步骤在客户端设备上执行联合学习:
- 将模型发送到设备,
- 使用设备上的数据进行正常训练,
- 拿回更聪明的模型。
然而,如果有人截获了与服务器共享的 smarter 模型,他可以执行逆向工程并提取关于数据集的敏感数据。差分隐私方法解决了这个问题并保护了数据。
当更新被发送回服务器时,服务器在聚集梯度时不应该能够辨别。让我们使用一种叫做附加秘密共享的加密形式。
我们希望在执行聚合之前加密这些梯度(或模型更新),这样就没有人能够看到梯度。我们可以通过附加秘密共享来实现这一点。
附加秘密共享
在秘密共享中,我们将一个秘密分成多个份额,并在一组秘密持有者中分发。秘密 x 只有当它被分割成的所有份额都可用时才能被构造。
比如说我们把 x 拆分成 3 份: x1 、 x2、和 x3 。我们随机初始化前两个份额,计算第三个份额为x3=x-(x1+x2)。然后我们将这些股份分配给三个秘密持有者。这个秘密仍然是隐藏的,因为每个人只持有一份,不知道总价值。
我们可以通过选择股票价值的范围来使其更加安全。设大质数 Q 为上限。现在第三份, x3 ,等于Q-(x1+x2)% Q+x。
Shares: (6191537984105042523084, 13171802122881167603111, 4377289736774029360531)

Figure 4: Encrypting x in three shares.
解密过程将股份求和在一起得到模数 Q 。
Value after decrypting: 3

Figure 5: Decrypting x from the three shares.
同态加密
同态加密是一种加密形式,它允许我们对加密的操作数执行计算,从而产生加密的输出。解密后的加密输出与对实际操作数执行相同计算得到的结果相匹配。
附加秘密共享技术已经具有同态性质。如果我们把 x 拆分成 x1 、 *x2、*和 x3 ,把 y 拆分成 y1 、 *y2、*和 y3 ,那么 x+y 就等于三份之和解密后的值:( x1+y1
Shares encrypting x: (17500273560307623083756, 20303731712796325592785, 9677254414416530296911)
Shares encrypting y: (2638247288257028636640, 9894151868679961125033, 11208230686823249725058)
Sum of shares: (20138520848564651720396, 6457253737716047231095, 20885485101239780021969)
Sum of original values (x + y): 14
我们能够在不知道 x 和 y 的值的情况下计算聚合函数加法的值。
使用 PYSYFT 的秘密共享
PySyft 提供了一个 share() 方法,将数据拆分成附加的秘密份额,并发送给指定的 workers。为了处理十进制数, fix_precision() 方法用于将小数表示为整数值。
Jake has: {}
John has: {}
Secure_worker has: {}
份额法用于在几个工人之间分配股份。每个指定的工人都得到一份,但不知道实际价值。
x: (Wrapper)>[AdditiveSharingTensor]
-> (Wrapper)>[PointerTensor | me:61668571578 -> jake:46010197955]
-> (Wrapper)>[PointerTensor | me:98554485951 -> john:16401048398]
-> (Wrapper)>[PointerTensor | me:86603681108 -> secure_worker:10365678011]
*crypto provider: me*
Jake has: {46010197955: tensor([3763264486363335961])}
John has: {16401048398: tensor([-3417241240056123075])}
Secure_worker has: {10365678011: tensor([-346023246307212880])}
如您所见, x 现在分别指向 Jake、John 和 Secure_worker 机器上的三个共享。

Figure 6: Encryption of x into three shares.

Figure 7: Distributing the shares of x among 3 VirtualWorkers.
(Wrapper)>[AdditiveSharingTensor]
-> (Wrapper)>[PointerTensor | me:86494036026 -> jake:42086952684]
-> (Wrapper)>[PointerTensor | me:25588703909 -> john:62500454711]
-> (Wrapper)>[PointerTensor | me:69281521084 -> secure_worker:18613849202]
*crypto provider: me*

Figure 8: Encryption of y into 3 shares.

Figure 9: Distributing the shares of y among 3 VirtualWorkers.
(Wrapper)>[AdditiveSharingTensor]
-> (Wrapper)>[PointerTensor | me:42086114389 -> jake:42886346279]
-> (Wrapper)>[PointerTensor | me:17211757051 -> john:23698397454]
-> (Wrapper)>[PointerTensor | me:83364958697 -> secure_worker:94704923907]
*crypto provider: me*
注意将 x 和 y 相加后得到的 z 的值存储在三台工人机中。 z 也加密了。

Figure 10: Performing computation on encrypted inputs.
tensor([14])

Figure 11: Decryption of result obtained after computation on encrypted inputs.
在对加密的份额执行加法之后获得的值等于通过将实际数字相加获得的值。
使用 PYSYFT 的联邦学习
现在,我们将使用两个工人:杰克和约翰,实现联合学习方法,在 MNIST 数据集上训练一个简单的神经网络。应用联邦学习方法只需要做一些修改。
- 导入库和模块。
2.加载数据集。
在实际应用中,数据存在于客户端设备上。为了复制这个场景,我们向虚拟工作者发送数据。
请注意,我们以不同的方式创建了训练数据集。 train_set.federate((jake,john)) 创建了一个 FederatedDataset ,其中 train_set 在 jake 和 john(我们的两个虚拟工作者)之间被拆分。 FederatedDataset 类旨在像 PyTorch 的数据集类一样使用。将创建的 FederatedDataset 传递给联邦数据加载器“ FederatedDataLoader ”,以联邦的方式对其进行迭代。这些批次来自不同的设备。
3.建立模型
4.训练模型
因为数据存在于客户端设备上,所以我们通过 location 属性获得它的位置。对代码的重要补充是从客户端设备取回改进的模型和损失值的步骤。
Epoch: 1 [ 0/60032 ( 0%)] Loss: 2.306809
Epoch: 1 [ 6400/60032 ( 11%)] Loss: 1.439327
Epoch: 1 [12800/60032 ( 21%)] Loss: 0.857306
Epoch: 1 [19200/60032 ( 32%)] Loss: 0.648741
Epoch: 1 [25600/60032 ( 43%)] Loss: 0.467296
...
...
...
Epoch: 5 [32000/60032 ( 53%)] Loss: 0.151630
Epoch: 5 [38400/60032 ( 64%)] Loss: 0.135291
Epoch: 5 [44800/60032 ( 75%)] Loss: 0.202033
Epoch: 5 [51200/60032 ( 85%)] Loss: 0.303086
Epoch: 5 [57600/60032 ( 96%)] Loss: 0.130088
5.测试模型
Test set: Average loss: 0.2428, Accuracy: 9300/10000 (93%)
就是这样。我们已经使用联合学习方法训练了一个模型。与传统训练相比,使用联邦方法训练模型需要更多的时间。
保护模型
在客户端设备上训练模型保护了用户的隐私。但是,模特的隐私呢?下载模型会威胁到组织的知识产权!
安全多方计算由秘密加法共享组成,为我们提供了一种在不公开模型的情况下进行模型训练的方法。
为了保护模型的权重,我们在客户端设备之间秘密共享模型。
要做到这一点,需要对上面的联邦学习示例进行一些更改。
如使用 PYSYFT 的秘密共享部分所示,现在是模型、输入、模型输出、权重等。也会被加密。处理加密的输入将产生加密的输出。
参考
[1] Theo Ryffel,Andrew Trask,Morten Dahl,Bobby Wagner,Jason Mancuso,Daniel Rueckert,Jonathan Passerat-Palmbach,保护隐私的深度学习通用框架(2018) ,arXiv
[2] Andrew Hard,Kanishka Rao,Rajiv Mathews,Swaroop Ramaswamy,Franç oise Beaufays,Sean Augenstein,Hubert Eichner,Chloé Kiddon,Daniel Ramage,用于移动键盘预测的联邦学习(2019) ,arXiv
[3]基思·博纳维茨、休伯特·艾希纳、沃尔夫冈·格里斯坎普、迪米特里·胡巴、亚历克斯·英格曼、弗拉基米尔·伊万诺夫、克洛伊·基登、雅各布·科涅纳、斯特凡诺·马佐基、h .布伦丹·麦克马汉、蒂蒙·范·奥弗代尔、戴维·彼得鲁、丹尼尔·拉梅奇、杰森·罗斯兰德、《走向大规模联合学习:系统设计》(2019) 、arXiv
[4] Brendan McMahan,Daniel Ramage,联合学习:没有集中训练数据的协作机器学习(2017) ,谷歌 AI 博客
[5]苹果差分隐私团队,大规模隐私学习(2017) ,苹果机器学习杂志
[6] Daniel Ramage,Emily Glanz,联合学习:分散数据上的机器学习(2019) ,Google I/O’19
[7] OpenMind, PySyft ,GitHub
虚拟游戏介绍
理解强化学习中自我游戏的第一步

Photo by Mpho Mojapelo on Unsplash
更新:学习和练习强化学习的最好方式是去 http://rl-lab.com
虚拟游戏是一个博弈论概念。它包括分析游戏,找出在零和游戏中面对对手时采取的最佳策略。
这通常是一个沉重的主题,所以我们将从一些重要的定义开始,然后我们将解释虚拟游戏算法。
零和对策
零和游戏是一种游戏,其中一个玩家获得的分数是其他玩家的损失。以这种方式,归属于玩家的所有分数的总和等于零。例如,如果玩家 I 赢了 5 分,那么玩家 II 输了 5 分。
游戏价值
游戏价值(V)是玩家在玩了足够多的次数后,平均期望赢得(或输掉)的点数、金钱、信用等。如果 V 为正,我们认为它有利于参与人 I(所以参与人 II 必须支付),如果 V 为负,我们认为它有利于支付者 II(所以参与人 I 必须支付)。
纳什均衡
纳什均衡是一种状态,在这种状态下,任何参与者都没有兴趣改变自己的策略,因为任何改变都会遭到他人的反击。纳什均衡并不意味着最优均衡,一个或多个参与者可能会有一个对他们更有利的策略,但他们不能采用的原因是因为对手(假设足够聪明)会反击他们,最终结果会变得不利。你可以认为这是一个僵局,但它也可能对所有人都有利。
一个简单的例子是想象两个强盗把他们的抢劫分成两半。如果其中一人向警方告发另一人,他可以得到全部赃物,但他没有兴趣这样做,因为另一个人也会告发他,他们最终都会进监狱。所以一分为二对他们俩来说都是最好的解决方案。
为什么我们要在人工智能中寻找纳什均衡?
理论上,纳什均衡将保证平均没有损失。这意味着在相当多的游戏中,平均而言,人工智能将会平局或获胜。
然而,在实践中,这是比较乐观的。当与人类对战时,人类玩家很有可能会在某一点上犯错误,而人工智能会利用这一点来获胜。
另一个重要的问题是,为什么人工智能不寻求纳什均衡,而是研究人类的策略,并利用它来获胜。这种方法的风险是,人类可以学会欺骗人工智能,给它一种他们正在使用某种策略的印象,然后切换到另一种策略。
例如假设在游戏石头剪刀布中,人类连续给出 3 把剪刀,这导致 AI 假设这是人类的策略。下一步,AI 会用石头反击,但是人类(放置陷阱的人)会用纸。
所以这个游戏中的最佳策略是坚持纳什均衡,使用随机策略(随机选择物品)。
虚拟游戏
虚拟博弈是乔治·w·布朗在 1951 年定义的一种方法,它由零和博弈组成,每个参与者对对手的策略做出最佳反应。该方法的目的是以迭代的方式找到游戏值。
通常,当问题变得复杂时,迭代法比解析法更容易计算。
虚拟方法被证明收敛于理论博弈值(V)。还证明了在两人零和博弈中虚拟博弈收敛于纳什均衡。
玩虚拟游戏
考虑下面的奇数或偶数游戏:
两个玩家 I 和 II 各自可以抽取数字“1”或“2”,如果抽取的数字之和是偶数,玩家 I 向玩家 II 支付该和,在下面的矩阵中用(-2 和-4)表示,如果该和是奇数,则玩家 II 向玩家 I 支付该和,用(+3 和+3)表示。

这个问题可以用解析的方法来解决,如果玩家 I 以 7/12 的概率玩“1”,以 5/12 的概率玩“2”,那么平均来说,玩家 I 会赢 1/12(这个方法的细节在这里并不重要)。
下图详细描述了迭代是如何展开的:

迭代#1 参与人 I 对抗选择“1”的参与人 II 的行动,参与人 I 的目标是最大化他的收益,所以他选择“2”,它的值是 max(-2,3) = 3。选择的值用青色标记。
在迭代#2 中,参与人 II 必须对抗选择“2”的参与人 I,他的目标是最小化参与人 I 的收益,所以他选择“2”,导致 min(3,-4) = -4。选择的值用黄色标记。
迭代#3,参与人 I 通过选择画“1”或“2”来对抗参与人 II,数值将取自第二列(记住参与人 II 在前一次迭代中选择了“2”)。这一列的值会加到参与人 I 的期望值上,意思是(-2+3 = 1;3 -4 = -1).所以从这些期望值中,参与人 I 必须选择对他最好的+1,所以他抽取相应的数字“1”(PS“1”不是抽取的数字,而+1 是收益)。
迭代#4,参与人 II 必须从第一行开始选择(因为参与人 I 选了“1”)。所以他把这些值加到他已经有的值上(3–2 = 1;-4+3=-1)所以他画“2”,以此类推…
这样做的次数足够多,就会导致值太接近游戏值。
以下是明确的步骤:
- 选择一列并写在网格的右边。
- 选择最大值并将其行写在底部。
- 选择该行的最小值,将其列与右边的值相加,写出总和。
- 选择该列的最大值,将其行与底部的值相加,写出总和。
- 根据需要重复步骤 3 和 4。
- 计算下限(L)和上限(U ),方法是取最后选择的值并除以迭代次数。这将给出游戏值(V)的范围,例如 L ≤ V ≤ U
以下代码将帮助您了解算法的工作原理:
Javascript implementation of Odd/Even game Fictitious Play. It can be easily tested using any online JS editor
在马克斯 _ITER = 1000 和马克斯 _ITER = 10000 的情况下运行上述代码会产生以下结果:

记住理论博弈值是 1/12 = 0.083333…这显然在迭代法的下限和上限之内。
结论
这篇文章以简单的方式解释了虚拟游戏算法,但没有提到任何与深度学习或神经网络相关的内容,这些内容将是未来文章的主题。
相关文章
介绍使用脸书的先知预测菲律宾股票价格
预测菲律宾 Jollibee Food Corp (JFC)公司股票价格的基本 python 工作流

我从大学开始就在菲律宾从事股票交易,并立即确信这是一个预测模型非常有用的领域。为什么?因为你在股市赚钱的能力取决于你预测未来价格的能力。
在本文中,我将使用 python 上强大的 Prophet 包演示一种快速预测菲律宾股票 Jollibee Foods Corporation (JFC)每日收盘价的方法。Prophet 是脸书公司开发的一款开源预测工具,它可以将标准的预测工作流程从通常需要几天或几周的时间缩短到几分钟(假设你已经有了正确格式的数据)。
所有相关数据和代码可在本回购的时序目录中找到。
我们将遵循以下工作流程:
- 安装并导入必要的软件包
- 获取数据
- 绘制时间序列
- 训练先知模型
- 预测未来!
- 评估准确性
我们开始吧!
1.安装并导入必要的软件包
只是先知+基础。
# Run these on your terminal
pip install pandas
pip install datetime
pip install fbprophet
pip install numpy
pip install matplotlib# Alternatively, you can run these from jupyter this way
!pip install pandas
!pip install datetime
!pip install fbprophet
!pip install numpy
!pip install matplotlib
2.获取数据
我们所需要的是一个文件,我们可以读入 python 作为熊猫数据帧,其中包含 2 列对应于股票的收盘价和日期。
对于这个介绍,我在这个回购的时间序列目录中保存了一份 JFC 从 2013 年 9 月 1 日到 2019 年 4 月 26 日的收盘价(以及这里的其余代码)。我们可以通过克隆这个 repo 并导航到时序目录来访问数据。
# Run these on your terminal
git clone [https://github.com/enzoampil/data-science-demos.git](https://github.com/enzoampil/data-science-demos.git)
cd data-science-demos/time-series# Alternatively, you can run these from jupyter this way
!git clone [https://github.com/enzoampil/data-science-demos.git](https://github.com/enzoampil/data-science-demos.git)
!cd data-science-demos/time-series# Read the JFC data (csv) as a pandas DataFrame
jfc = pd.read_csv("[jfc_20130901_to_20190426.csv](https://github.com/enzoampil/data-science-demos/blob/master/time-series/jfc_20130901_to_20190426.csv)")# Convert the date column to datetime format
jfc['CHART_DATE'] = pd.to_datetime(jfc.CHART_DATE)
3.绘制时间序列
为此,我们可以使用直接从 pandas 数据框架中访问的基本绘图功能。
# Plot the time series
# 'CHART_DATE' is the date and 'CLOSE' is the closing price
jfc.set_index('CHART_DATE').CLOSE.plot(figsize=(15, 10))
plt.title('Jollibee Daily Closing Price', fontsize=25)

你会注意到,JFC 的收盘价在上升和下降的周期中波动,但整体趋势仍在上升。Prophet 的优势之一是,在进行预测时,它可以自动考虑趋势中发现的季节性。
4.训练先知模型
现在,我们可以训练先知模型了!要做到这一点,我们必须首先过滤数据框架,使其只有两列:日期,“CHART_DATE”和收盘价“CLOSE”。然后,我们将它们的名称分别改为“ds”和“y ”,因为 Prophet 会自动将“ds”列读取为日期,将“y”列读取为被预测的变量。最后,我们根据训练数据训练模型,训练数据是指在指定的维持期开始之前的数据。在这种情况下,“HOLDOUT_START”是对应于保持期开始的日期(设置为 2019-03-01)。
请注意,维持期的数据将被视为我们的验证集,并将用于评估已训练的 Prophet 模型的性能。
# Set holdout (validation) set start
HOLDOUT_START = '2019-03-01'# Import the Prophet package
from fbprophet import Prophet# Filter to only the date and closing price columns
ts = jfc[['CHART_DATE', 'CLOSE']]# Rename the date and closing price columns to 'ds', and 'y', respectively
# We do this since prophet automatically reads the 'ds' column as the date and the 'y' column as the variable that we are forecasting
ts.columns = ['ds', 'y']# Fit the Prophet model to the training data (before the start of the holdout set)
# We set daily_seasonality and yearly_seasonality to True to account for daily and yearly seasonality, respectively
m = Prophet(daily_seasonality=True, yearly_seasonality=True).fit(ts[ts.ds < HOLDOUT_START])
5.预测未来!
在 Prophet 中,我们首先创建一个未来数据帧*,*,在这里我们指定我们想要预测的未来有多远;在本例中,我们将其设置为 336 天。接下来,我们调用在已训练的 prophet 模型中找到的 predict 方法(使用未来数据帧作为参数),这将返回预测。
# Set the forecast period, "periods", in the specified unit, "freq"
# In this case, we're predicting 336 days into the future
future = m.make_future_dataframe(periods=7*4*12, freq='D')# Make the actual predictions
pred = m.predict(future)# Visualise the predictions using Prophet's plotting method
from matplotlib import pyplot as plt
fig1 = m.plot(pred)
plt.title('Jollibee: Forecasted Daily Closing Price', fontsize=25)

预测以及历史收盘价如上所示。蓝线对应于预测的收盘价,而黑点对应于训练集中的历史收盘价。抵制期的预测收盘价表明价格将在该期间(2019 年 3 月 1 日至 2019 年 4 月 26 日)下跌。
蓝色阴影区域对应于预测的 95%置信区间。您会注意到,距离更远的预测也具有更宽的预测置信区间。
6.评估准确性
为了评估我们训练的 Prophet 模型的准确性,我们将计算我们对 2019 年 3 月 1 日至 2019 年 4 月 26 日的维持集的预测的均方根误差(RMSE)。为了更详细地展示业绩,我们还绘制了 57 天维持期的预测 JFC 收盘价与实际 JFC 收盘价的对比图。
# Concatenate holdout (validation) set predictions and targets into one dataframe for easy comparison
pred_holdout = pred[(pred.ds >= HOLDOUT_START)&(pred.ds <= ts.ds.max())].set_index('ds').yhat
target_holdout = ts[ts.ds >= HOLDOUT_START].set_index('ds')
comb = pd.concat([pred_holdout, target_holdout], axis=1).dropna()# Calculate root mean squared error (RMSE)
import numpy as np
rmse_holdout = np.sqrt(comb.yhat.subtract(comb.y).pow(2).mean())# Plot predicted vs target while displaying accuracy based on rmse
comb.columns = ['Predicted', 'Actual']
comb.plot(figsize=(15, 10))
plt.title('Predicted (yhat) vs Actual (y) JFC Closing Price \n Validation Set RMSE: {}'.format(rmse_holdout), fontsize=25)

如前所述,维持集的预测价格(蓝色)表明,在维持集的持续时间内,价格会整体下降。有趣的是,实际价格(橙色)也显示了 JFC 收盘价的总体下降,尽管比预测的要快。
此外,短期运动似乎也反映在预测中。实际趋势显示,到 4 月 8 日开始上升,然后在 4 月 26 日开始下降。预测再次显示了类似的变化,尽管没有那么剧烈。
计算出的均方根误差(RMSE)为 5.56,这告诉我们,对于 2019 年 3 月 1 日至 2019 年 4 月 26 日的坚守期,Prophet 模型的 JFC 收盘价预测平均误差为 5.56 PHP。这个误差足够小,让我们相信预测吗?这将取决于我们承担风险的意愿,但保守的经验法则是,即使在预期价格向下偏离预测价格的情况下,也只根据显示盈利机会的预测进行交易。
下一步是什么?
恭喜你!您现在知道如何使用强大的 Prophet 包执行基本的预测工作流。这包括以下步骤:1)安装和导入必要的软件包,2)获取数据,3)绘制时间序列,4)训练 Prophet 模型,5)使用该模型预测未来,最后,6)评估准确性。除了预测股票价格之外,还可以使用其他预测模型和用例来应用相同的工作流。
值得注意的是,仍有许多方法可以改进我们当前的预测工作流程:
- **利用外生变量和衍生指标进行预测。**我们可以明确说明股票过去收盘价以外的信息(外生变量)。例如股票的交易量、其他股票的价格和交易量、利率、通货膨胀、最近发布的广告的成功以及其他衍生指标,如波动性、RSI、短期&长期移动平均线等。
- **识别可能引发价格波动的事件。**例如与公司相关的公告(通常在 twitter 上披露),如绩效、合并&收购、新法律等。我们可以专门对这些进行建模,以估计它们对价格的影响。
- **试验其他强大的模型。**我经常使用 Prophet 作为基准,但最终还是使用了其他性能超过基准模型的模型。例如梯度推进机器(如 LightGBM)、深度学习模型(如 LSTM RNNs)和其他前沿时间序列模型(如 TBATS、SARIMAX)。
- 提高预测模型不确定性的准确性。除了点预测的性能,更重要的是预测不确定性的准确性,这可以指导我们知道何时更信任模型的预测。这是最近研究的一个焦点,一些已经成功地创建了模型,这些模型准确地预测了 95%的置信区间,实际上覆盖了 95%的目标。
- 通过模拟引擎可视化估计的影响。通过创建能够解释外部因素和事件的模型,我们可以将这些模型转化为模拟引擎,以可视化不同情景下价格的变化(即情景分析)。例如,如果明年经济衰退,利率上升 2%,价格会如何?
以上只是改进我们当前预测工作流程的许多方法中的一部分,我计划在未来的博客文章中详细讨论这些方法。如果你对从哪一个开始有任何建议,请随时评论或发电子邮件给我,地址是 lorenzo.ampil@gmail.com*。敬请期待!*
来自《走向数据科学》编辑的提示: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们并不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。
FPGA 及其架构介绍

不久以前,大多数软件都是和它们各自的硬件一起永久发布的,没有办法改变它。但是随着技术的成熟,制造商找到了在现有硬件上增加新功能的方法。
现在,想象一下硬件更新也成为可能的未来——这难道不令人着迷吗?
这种可编程硬件的子系统配置甚至可以在制造后修改,属于可重构系统的范畴。而支持可重构计算的最主要的集成电路是 FPGA ,是FfieldP可编程 G ate A rray 的缩写。
FPGA 使您能够对产品功能进行编程,适应新标准,并针对特定应用重新配置硬件,即使产品已经现场安装——因此有术语“现场可编程”。而“门阵列指的是其架构中存在的二维逻辑门阵列。
所有现代个人计算机,包括台式机、笔记本电脑、智能手机和平板电脑,都是通用计算机的例子。通用计算结合了“冯·诺依曼”方法,该方法指出取指令和数据操作不能同时发生。因此,作为顺序机器,它们的性能也是有限的。
另一方面,我们有专用集成电路(ASICs ),它们是为特定任务定制的,如数字录音机或高效比特币挖矿机。ASIC 使用空间方法仅实现一个应用程序,并提供最佳性能。但是,除了最初设计的任务之外,它不能用于其他任务。

那么,如何用 ASICs 的性能换取通用处理器的灵活性呢?
嗯…
FPGAs 充当了这两种架构模式之间的中间地带!
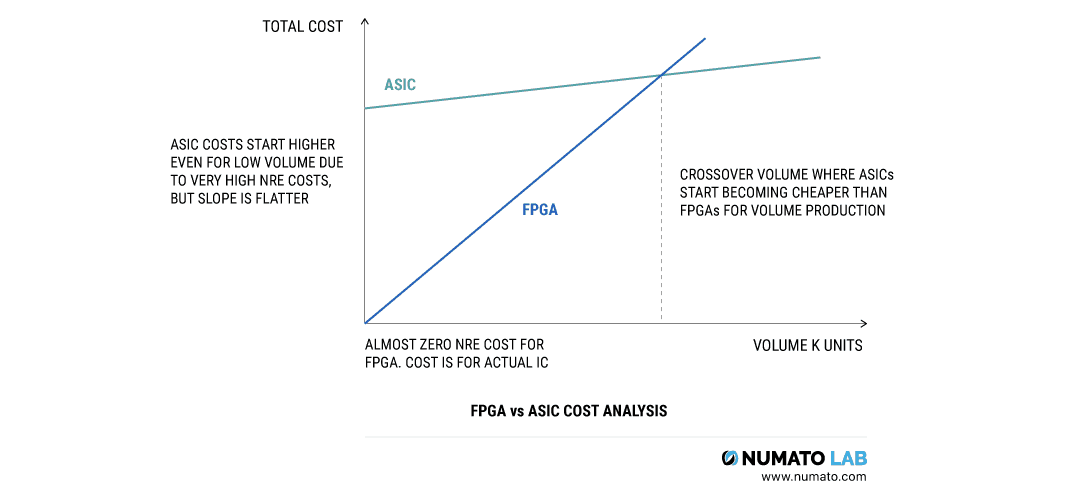
话虽如此,FPGAs 与 ASICs 相比能效较低,也不适合大批量生产。然而,与 ASIC 相比,它们是可重新编程的,并且具有较低的 NRE 成本。
你看,ASICs 和 FPGAs 有不同的价值主张。大多数器件制造商通常更倾向于使用 FPGAs 进行原型开发,使用 ASICs 进行大批量生产。

Photo by numato.com
过去,FPGA 常常被选择用于较低的速度和复杂的设计,但现在 FPGA 可以轻松超过 500 MHz 的性能基准。
FPGA 的内部架构
1985 年,一家名为 Xilinx 的半导体制造公司发明了第一个商业上可行的 FPGA——xc 2064。另一家公司 Altera ,于 2015 年被英特尔收购,也与 Xilinx 一起推动了这个市场的发展。
FPGA 源于相对简单的技术,如可编程只读存储器(PROM)和可编程逻辑器件(PLD),如 PAL、PLA 或复杂 PLD (CPLD)。
它由三个主要部分组成:
- 可配置逻辑块——实现逻辑功能。
- 可编程互连——实现路由。
- 可编程 I / O 块——与外部元件连接。

The basic architecture of an FPGA
逻辑模块实现设计所需的逻辑功能,由晶体管对、查找表(lut)、触发器和多路复用器等各种元件组成。
您可以将逻辑块视为独立的模块,就像可以并行操作的乐高积木一样。与乐高积木不同,逻辑积木是可配置的,即其内部状态可以控制,您可以通过对互连进行编程来将它们连接在一起,以便构建有意义的东西。
这种可编程互连的层次结构用于在可配置逻辑块(clb)之间分配资源;其中布线路径包含可以通过反熔丝或基于存储器的技术连接的不同长度的线段。
每个 CLB 都连接到一个交换矩阵,以访问通用路由结构。开关矩阵提供可编程多路复用器,用于选择给定路由通道中的信号,从而连接垂直和水平线路。
最后,I/O 模块(iob)用于将 clb 和路由架构与外部元件连接。
在早期的 FPGAs 中,没有处理器来运行任何软件;因此,实现应用意味着从头开始设计电路。因此,我们可以将 FPGA 配置为像或门一样简单,或者像多核处理器一样复杂。
但是,自 XC2064 以来,我们已经取得了长足的进步,基本 FPGA 架构已经通过添加更专业的可编程功能模块得到了发展,如 alu、块 RAM、多路复用器、DSP-48 和微处理器。
FPGA 设计流程
设计流程说明了在物理板上实现和编程任何给定逻辑的流水线。我选择将这个设计流程命名为 FPGA 开发生命周期或 FDLC,因为它类似于 SDLC。
FPGA 架构设计流程包括设计输入、逻辑综合、设计实现、器件编程和设计验证。然而,具体步骤因制造商而异。

设计条目
可以使用原理图编辑器、有限状态机(FSM)编辑器或硬件描述语言(HDL)来描述逻辑。这是通过从给定库中选择组件并提供设计功能到所选计算模块的直接映射来实现的。
当具有大量功能的设计变得难以图形化管理时,HDL 可以用于以结构或行为的方式捕获设计。除了 VHDL 和 Verilog 这两种最成熟的 HDL 之外,还有几种类似 C 的语言可用,比如 Handel-C、Impulse C 和 SystemC。
逻辑综合
该过程将上述 VHDL 代码翻译成用于描述具有逻辑元件的完整电路的设备网表格式。综合包括检查代码语法和分析设计架构的层次结构。接下来,代码随着优化被编译,生成的网表被保存为 。ngc 文件。
设计实施
设计实施过程包括以下步骤:

- 翻译:该过程将所有输入的网表合并成逻辑设计文件,保存为 。ngd 文件文件。这里,用户约束文件将端口分配给物理元素。

- 映射:这包括映射由。ngd 文件转换成 FPGA 的组件然后生成一个 。ncd 文件文件。

- 放置和布线:这里的布线根据约束将上述过程中的子模块放置到逻辑模块中,然后连接这些模块。
设备编程
上述布线设计必须被加载并转换成 FPGA 支持的格式。于是,被击溃的 。ncd 文件交给 BitGen 程序,BitGen 程序生成包含 FPGA 所有编程信息的比特流文件。
设计验证
这与设计流程一起完成,以确保逻辑行为符合预期。这一过程涉及以下模拟:
- 行为模拟(RTL 模拟)
- 功能模拟
- 静态时序模拟
进行这些模拟是为了通过向设计的输入提供测试模式并观察输出来仿真组件的行为。
FPGA 的未来
行业趋势正在推动 FPGAs 在异构计算模式中发挥重要作用。在这里,异构计算指的是使用多种类型的处理器来执行专门处理功能的系统。所有这些不同的处理器,包括 FPGAs,都可以通过 OpenCL 进行编程,OpenCL 是一个行业标准开发平台。
事实上,FPGA 提供了经济高效的并行计算能力,这使得它适合快速原型制作。在测试神经网络时,有些情况下 FPGA 也优于 GPU。虽然 GPU 可能适合训练,但当涉及到实时应用时,FPGA 更具适应性。事实上,微软已经在通过微软 Azure 云服务来加速人工智能。
🔌简而言之…
从汽车到加密,从芯片开发到人工智能推理模型,FPGAs 提供了一定的通用性,吸引了广泛的用户,从而使未来看起来更光明!
Python 中 Git 数据提取和分析简介
从 Github REST API 中提取 Git 数据并在 Pandas 和 Plotly 中执行数据分析

Photo by Colby Thomas on Unsplash
软件行业有没有人没用过或者至少听说过 Git?
Git 是一个革命性的工具,如今在软件团队中无处不在。本文的目的并不是介绍 git,有大量的资源可以指导您完成这个过程。它的目的是分析 git 相关数据,以便从这些数据中获得重要的见解。
在整篇文章中,我们将使用 Github REST API 提取 Git 相关数据,然后利用 Python 的顶级数据分析库 【熊猫】 以及广受欢迎的交互式数据可视化库 Plotly 来分析这些数据。我们将以 Apache Spark 的存储库为例。
Git 数据提取
Git 存储库通常存储在源代码托管设施中。其中最流行的是 Github 和 Bitbucket,但是也有很多其他的,比如 Gitea、GitLab 等等。在本文中,我们将重点关注 Github,但是其他托管设施的数据提取过程应该也是类似的。
Github 提供了一个 REST API,其中包含了所有 git 相关资源的端点。为了能够使用 Github APIs,我们需要在 Github Profile 页面的开发者设置中生成一个访问令牌。做完那件事后,我们应该都准备好了。我们启动 Jupyter 笔记本,首先导入必要的库:
我们将配置参数存储在一个单独的文件中,即 Github 用户名和我们之前生成的访问令牌。与 Github 交互的推荐方式是使用 API 创建一个会话,如下所示:
哪些与 git 相关的实体可以提供关于 git 存储库进展的有价值的信息?
提交是首先想到的,但也有其他的,如分支、拉请求、问题、贡献者列表等。假设我们需要检索给定 git 存储库的提交列表。我们搜索 Github API 文档并找到相应的 API 端点:
GET /repos/:owner/:repo/commits
这里我们需要提供所有者和存储库名称作为输入参数。我们可以像这样用 Python 调用上面的 API 端点:
commits 变量包含从 Github API 返回的响应。然后我们使用 json 包的json() 方法来反序列化上面的响应对象。然而,这个 API 调用只返回 30 个结果,这对应于默认情况下通过单个 Github API 响应返回的结果数。我们可以为 API 请求提供一个额外的参数,per_page,这允许我们将返回结果的数量增加到 100 个,但是我们试图从中提取数据的 Apache Spark 存储库有大约 26K 个提交!
别担心。Github 的家伙们提供了一个分页参数,称为page,它与per_page参数相结合,使我们能够提取任何 git 库的所有提交。现在,我们的 API 请求应该如下所示:
我们可以将提交提取过程封装在一个函数中,该函数将所有者和存储库名称作为参数,并返回一个提交列表:
为了控制遍历过程,在每次迭代中,我们检查响应头中的Link参数是否包含rel="Next"属性值,这告诉我们存在一个连续的页面,我们可以继续迭代;否则我们就此打住。为了更多地了解这种方法,你可以阅读 Github 文档中的分页遍历指南。
提取了列表中的提交后,我们现在可以从字典列表中生成 Pandas 数据帧,因此我们定义了以下函数来处理该任务:
json_normalize函数很好地做到了这一点,它将一个半结构化的 JSON(字典列表)规范化为一个平面表。我们现在通过为 Apache Spark git 存储库传递必要的参数来调用上面创建的函数:
对其他资源的提取执行相同的过程,所以我跳过这一部分,您可以在本文的 Github 资源库中浏览。我还添加了将结果存储在 CSV 文件或 SQLAlchemy 支持的数据库中的可能性,以便我们可以访问这些数据以供以后分析。
数据预处理
因此,我们将提交和分支以及其他资源存储在内存中(如果您愿意,也可以存储在 CSV 文件中)。下一步是预处理这些数据。
检查提交数据帧的结构,我们得到以下结果:

我们将删除这些列中的大部分,更重要的是,我们将生成一些数据分析过程所需的与时间相关的列。以下代码将提交日期字段转换为日期时间字段,并利用dt 访问器对象获取熊猫系列的类似日期时间的属性:
删除不必要的列后,我们的commits.head 方法返回:

Git 数据分析
现在,我们转向数据科学领域的精彩部分——数据分析和数据可视化。Spark 资源库的贡献者总数是多少?

一个很好的洞察是一天中每个小时提交的分布情况。我们可以计算这个度量,因为我们已经为存储库的每次提交生成了一天中的某个小时。熊猫的代码是:
现在是时候可视化一些数据了。Plotly Python 库( plotly.py )是一个交互式、开源绘图库,支持 40 多种独特的图表类型,涵盖了广泛的统计、金融、地理、科学和三维用例。作为一个声明式编程库,Plotly 允许我们编写代码来描述我们想要制作什么,而不是如何制作。这大大减少了构建图表所花费的时间,并使我们更加专注于展示和解释结果。
标准 plotly 导入以及离线运行的设置如下:
回到我们有趣的每小时提交量指标,生成条形图所需的代码如下:

从图表中,我们注意到大部分的贡献都是在晚上提交的:)。在一天的工作时间里,活动较少。
随着时间的推移,Spark 存储库进展如何?这些年来它的活动是什么?让我们创建一个时序图并检查它。

事实证明,Spark repository 在 2015 年至 2016 年期间出现了活动高峰。但是我们能证明这个假设吗?当然可以!我们将计算每年的日均提交数量,以验证 2015 年和 2016 年是否是 Spark 存储库最活跃的年份。

上面的图表清楚地显示,存储库在 2015 年达到顶点,此后一直下降到 2017 年。从那时起,我们看到每年的日均提交数量保持稳定,并且直到撰写本文时,这种趋势一直存在。
谁是 Spark 存储库的主要贡献者?让我们找出它。

作为一个非常活跃的存储库,Spark 也有很多开放的拉取请求。通常,拉请求由一些预定义的关键字标记。下面的条形图显示了每个标签的拉取请求数:

很明显,最活跃的贡献者正在从事与 SQL 相关的功能。最后,Spark 是一个数据框架,允许对数 Pb 的数据进行类似 SQL 的操作。
恭喜

Photo by Ian Stauffer on Unsplash
您已到达这篇文章的结尾。在本指南中,我们学习了以下重要概念:
- 通过 Github API 在 Python 中提取数据
- 预处理 git 数据
- 使用 Pandas 和 Plotly 执行交互式分析和数据可视化
下面是我们在这篇文章中运行的所有内容的完整代码:
这是一个基于 git 库生成统计数据的迷你项目。已经有把 Github 当版本了…
github.com](https://github.com/xhentilokaraj/git-statistics)
感谢 的阅读!如果你想与我取得联系,请随时通过 xhentilokaraj@gmail.com 或我的 LinkedIn 个人资料 联系我。
面向数据科学家的 Github 简介
掌握 Github 的基础知识

Photo by Hack Capital on Unsplash
对版本控制的体验正迅速成为所有数据科学家的要求。版本控制可以帮助数据科学家更好地作为一个团队工作,促进项目协作,共享工作,并帮助其他数据科学家重复相同或相似的过程。即使您是一名独立工作的数据科学家,在合并到当前项目之前,能够先回滚更改或对分支进行更改,并测试您的更改不会破坏任何东西,这总是有用的。在接下来的文章中,我将讲述以下内容:
- 什么是 Github?
- 为什么数据科学家需要使用它?
- 如何创建和克隆存储库
- 分支
- 拉取请求
什么是 Github?
Github 是版本控制最知名和最广泛使用的平台之一。Github 使用一个名为 Git 的应用程序对代码进行版本控制。项目文件存储在一个称为存储库的中央远程位置。每次你在你的机器上做了一个本地的修改,然后推送到 Github,你的远程版本就会被更新,提交的内容会被记录下来。如果您想在提交之前回滚到项目的前一个版本,该记录允许您这样做。
此外,由于项目文件存储在远程位置,任何其他人都可以下载回购协议并对项目进行更改。分支的概念,本质上意味着你制作一个完全独立的项目的临时副本,意味着你可以首先在那里进行修改,而不用担心破坏任何东西。如果您从事的项目中有一个功能依赖于代码工作,这一点尤其重要。
这个页面涵盖了我在本文中使用的所有关键术语的含义,比如提交、分支和存储库。
为什么数据科学家需要使用它?
数据科学家需要使用 Github 的原因和软件工程师一样——为了协作,“安全地”对项目进行更改,并能够随着时间的推移跟踪和回滚更改。
传统上,数据科学家不一定必须使用 Github,因为将模型投入生产的过程(版本控制变得至关重要)通常被移交给软件或数据工程团队。然而,系统中有一个日益增长的趋势,这使得数据科学家更容易编写自己的代码来将模型投入生产——参见工具,如 H20.ai 和谷歌云人工智能平台。因此,数据科学家熟练使用版本控制变得越来越重要。
创建存储库
我将简要介绍如何使用 Github 和 Git 从命令行执行最常见的操作。如果你还没有帐户,你需要注册一个(这是完全免费的!)这里。
要从头开始创建存储库,请转到https://github.com/并点击new按钮。

在接下来的页面上,您需要为您的项目键入一个名称,并选择是将其设为公共还是私有。

接下来,您要选中框initialise with a README.md并点击create repository。

现在,您可以添加并更改存储库中的文件了。要从命令行执行此操作,您首先需要按照这里的说明下载并安装 Git。
要在本地处理项目,您首先需要克隆存储库。如果您想克隆其他人的项目来工作,您也可以遵循这个步骤。
cd my-directory
git clone [https://github.com/rebeccavickery/my-repository.git](https://github.com/rebeccavickery/my-repository.git)
您可以通过点击clone or download按钮找到存储库的 URL。

现在,一个新目录将出现在您当前的工作目录中,并与存储库同名。这是您的项目的本地版本。
分支
分支允许您制作存储库的副本,在那里进行更改,并在合并到主副本之前测试它们是否正常工作。最佳实践是始终在分支上进行更改,而不是在主分支上工作。
在创建分支之前,最好检查您的本地项目是否与远程存储库保持一致。您可以通过键入以下命令来检查状态:
git status

如果你不是最新的,你只需输入git pull。
要创建并签出一个分支,请键入以下内容。
git branch my-branch
git checkout my-branch
现在,您可以进行更改,在合并之前,这些更改不会影响远程存储库。让我们对README.md文件进行更改,并完成提交和合并更改的过程。
在首选文本编辑器中打开自述文件,并进行任何更改。我使用了升华文本并在文件中添加了一行。

拉取请求
处理协作项目的最佳实践是使用拉式请求,因此我们将使用此流程合并我们的变更。“拉”请求是一个过程,它允许您或其他人在将更改合并到主版本之前检查您所做的更改。在打开拉取请求之前,您需要添加并提交您的更改。
git add .
git commit -m "change to README.md"
git push --set-upstream origin my-branch
您只需要在第一次从新分支推送时添加参数---set-upstream origin my-branch。
现在,您将在远程存储库中看到此消息。

点击compare and pull request,然后点击create pull request。

在这一点上,如果你和其他人或团队在项目上合作,你可能会要求别人检查你的修改。他们可以添加评论,当每个人都对更改感到满意时,您可以合并拉取请求

您的更改现在将被合并到主分支中。

如果你已经完成了分支,最好点击delete branch按钮删除它
使用 Github 会变得更加复杂,但是我想在这里做一个简单的介绍。为了更全面的了解,Github 制作了一套指南,可以在这里找到。
使用 Catboost 对决策树进行梯度提升的介绍
今天我想和大家分享我在开源机器学习库的经验,这个库是基于决策树的梯度推进,由俄罗斯搜索引擎公司 Yandex 开发的。

Github profile according to the 12th of February 2020
库是在 Apache 许可下发布的,并作为免费服务提供。

‘Cat’, by the way, is a shortening of ‘category’, Yandex is enjoying the play on words.
你可能熟悉梯度增强库,如 XGBoost、H2O 或 LightGBM,但在本教程中,我将快速概述梯度增强的基础,然后逐步转向更核心复杂的东西。
决策树简介
在谈论梯度推进之前,我将从决策树开始。树作为一种数据结构,在现实生活中有很多类比。它被用于许多领域,是决策过程的一个很好的代表。该树由根节点、决策节点和终端节点(不会被进一步分割的节点)组成。树通常是倒着画的,因为树叶在树的底部。决策树可以应用于回归和分类问题。

A simple decision tree used in scoring classification problem
在分类问题中,作为进行二元划分的标准,我们使用不同的指标——最常用的是基尼指数和交叉熵。基尼指数是对 K 个阶层总方差的一种衡量。在回归问题中,我们使用方差或与中位数的平均偏差

The functional whose value is maximized for finding the optimal partition at a given vertex
生长一棵树包括决定选择哪些特征和使用什么条件进行分割,以及知道何时停止。决策树往往非常复杂和过度拟合,这意味着训练集的误差将很低,但在验证集上却很高。更小的树和更少的分裂可能导致更低的方差和更好的解释,代价是一点点偏差。

决策树在非线性依赖中表现出良好的结果。在上面的例子中,我们可以看到每个类的划分表面是分段常数,并且表面的每一边都平行于坐标轴,因为每个条件都将一个符号的值与阈值进行比较。
我们可以用两种方法来避免过度拟合:添加停止标准,或者使用树修剪。停止标准有助于决定,我们是否需要继续划分树,或者我们可以停止,把这个顶点变成一片叶子。例如,我们可以在每个节点中设置多个对象。如果 m > n,则继续划分树,否则停止。n = = 1——最差情况。

或者我们可以调整树的高度。

另一种方法是树修剪——我们构建一棵过度拟合的树,然后根据选择的标准删除叶子。修剪可以从根部开始,也可以从叶子开始。从一棵“完全成长”的树上移除树枝——得到一系列逐渐修剪的树。在交叉验证中,我们比较了有分裂和没有分裂的过度拟合树。如果没有这个节点结果更好,我们就排除它。有许多用于优化性能的树修剪技术,例如,减少错误修剪和成本复杂性修剪,其中学习参数(alpha)用于衡量是否可以根据子树的大小删除节点。

决策树受到高方差的影响。这意味着,如果我们将训练数据随机分成两部分,并对这两部分都使用决策树,我们得到的结果可能会非常不同。
合奏
然而,研究人员发现,结合不同的决策树可能会显示更好的结果。整体——当我们有一个 N 基算法时,最终算法的结果将是基算法结果的函数。我们结合一系列 k 学习模型来创建改进的模型。
有各种集成技术,如 boosting(用一组分类器进行加权投票)、bagging(对一组分类器的预测进行平均)和 stacking(组合一组异类分类器)。
为了构建树集成,我们需要在不同的样本上训练算法。但是我们不能在一台设备上训练它们。我们需要使用随机化在不同的数据集上训练分类。例如,我们可以使用 bootstrap。
误差的期望值是方差、偏差和噪声的总和。集合由具有低偏差和高方差的树组成。梯度推进算法的主要目标是保持构造具有低偏差的树。

例如,我们需要基于带有噪声的 10 个点来近似右图中的格林函数。在左图中,我们显示了在不同样本上训练的策略。右图用红线显示了平均多项式。
我们可以看到,红色图形与绿色图形几乎相同,而算法分别与绿色函数有显著不同。下面的算法家族有低偏差,但高方差。

决策树的特点是低偏差但高方差,即使训练样本有很小的变化。总体方差是一个基本算法的方差除以算法数+基本算法之间的相关性。
随机森林算法
为了减少基算法之间相关性的影响,我们可以使用 bagging 算法和**随机子空间方法。**这种方法最显著的例子之一是随机森林分类器。这是一种基于随机子空间和 bagging 方法的算法,使用 CART 决策树作为基本算法。
随机子空间方法有助于降低树之间的相关性,避免过度拟合。让我们仔细看看:假设我们有一个数据集,有 D 个特征,L 个对象和 N 个基树。

每个基本算法都适合来自 bootstrap 的样本。
我们从 D 中随机选择 D 个特征,构建树直到停止准则(我前面提到过)。通常我们用低偏差建立过度拟合的树。
回归问题的特征数 D 为 D/3,分类 sqrt 为(D)。

应该强调的是,每个
再次选择一个大小为 d 的随机子集,这是分裂另一个顶点的时候。这是这种
方法与随机子空间方法的主要区别,在随机子空间方法中,在构建基础算法之前选择一次随机特征子集。
毕竟,我们应用 bagging 和平均每个基本算法的结果。

随机森林具有各种优点,如对离群点不敏感,对大特征空间工作良好,难以通过添加更多的树来过度拟合。
然而有一个缺点,存储模型需要 O(NK)内存存储,其中 K —树的数量。这已经很多了。
助推
Boosting 是一种加权集成方法。每个基本算法都是一个接一个按顺序添加的。一系列 N 分类器迭代学习。更新权重以允许后续分类器“更多地关注”被先前分类器错误分类的训练元组。加权投票不影响算法的复杂度,但平滑了基本算法的答案。
增压与装袋相比如何? Boosting 侧重于错误分类的元组,它有使生成的复合模型过度适应此类数据的风险。
用于构建线性模型的贪婪算法
以下每个算法都是为了纠正现有集合的错误而构建的。
- 用于阈值损失函数的不同近似
以 MSE 作为损失函数的标准回归任务为例

通常作为基本算法,我们采用最简单的算法,例如我们可以采用一个短决策树

第二种算法必须以最小化合成 b1(x) 和 b2(x) 的误差的方式拟合

至于 bN(x)

梯度推进
已知梯度推进是主要的集成算法之一。

梯度推进算法采用梯度下降法优化损失函数。这是一种迭代算法,步骤如下:
- 初始化第一个简单算法 b0
- 在每次迭代中,我们生成一个移位向量 s = (s1,…sl)。si — 训练样本上算法 bN(xi) = si 的值

3.那么算法就是

4.最后,我们将算法 bN 添加到集成中

有几个可用的梯度增强库:XGBoost、H20、LightGBM。它们之间的主要区别在于树结构、特征工程和处理稀疏数据
Catboost
Catboost 可以解决回归、分类、多类分类、排序等问题。模式因目标函数而异,我们试图在梯度下降过程中将其最小化。此外,Catboost 有预构建的指标来衡量模型的准确性。
在 Catboost 官方网站上,你可以找到 Catboost (method)与主要基准的比较,或者你可以在 Neptune.ai 博客上深入研究这个主题

Figures in this table represent Logloss values (lower is better) for Classification mode.
百分比是根据优化的 CatBoost 结果测量的度量差异。
Catboost 优势
Catboost 引入了以下算法进步:
- 一种用于处理分类特征的创新算法。不需要自己对特性进行预处理—它是开箱即用的。对于具有分类特征的数据,与另一种算法相比,准确性会更好。
- 实施有序升压,这是一种替代经典 bosting 算法的置换驱动算法。在小型数据集上,GB 很快就会被过度分配。在 Catboost 中,有一个针对这种情况的特殊修改。也就是说,在其他算法存在过度拟合问题的数据集上,您不会在 Catboost 上观察到相同的问题
- 快速易用的 GPU 训练。您可以通过 pip-install 简单地安装它
- 其他有用的特性:缺少值支持,可视化效果好
分类特征
分类特征是一组离散的值,称为类别,彼此不可比。

Catboost 的主要优势是分类数据的智能预处理。您不必自己对数据进行预处理。对分类数据进行编码的一些最流行的做法是:
- 一键编码
- 标签编码
- 哈希编码
- 目标编码
- 等等…
对于具有少量不同特征的分类特征,一键编码是一种流行的方法。Catboost 将 one_hot_max_size 用于多个不同值小于或等于给定参数值的所有特征。
在具有高基数的特征的情况下(例如,像“用户 ID”特征),这样的技术导致不可行的大量新特征。
另一种流行的方法是通过目标统计 (TS)对类别进行分组,这些统计估计了每个类别中的预期目标值。

这种贪婪方法的问题是目标泄漏:使用前一个特征的目标来计算新特征。这导致了有条件的转移——对于训练和测试示例,分布是不同的。
解决这个问题的标准方法是保持 TS 和留一TS。但是他们仍然不能防止模型目标泄漏。
CatBoost 使用更有效的策略。它依赖于排序原则,被称为基于目标与先验(TBS) 。它是受在线学习算法的启发,在线学习算法按时间顺序获取训练样本。每个示例的 TS 的值仅依赖于观察到的历史。为了使这种思想适应标准的离线设置,我们引入了人工“时间”,即训练样本的随机排列σ。

在 Catboost 中,数据被随机打乱,并且只对每个对象的历史数据计算平均值。数据可以被多次重组。
CatBoost 的另一个重要细节是使用分类特征的组合作为额外的分类特征,这些分类特征在广告点击预测任务中捕获高阶依赖性,如用户 ID 和广告主题的联合信息。可能组合的数量随着数据集中分类要素的数量呈指数增长,不可能处理所有的组合。CatBoost 以贪婪的方式构造组合。也就是说,对于树的每次分裂,CatBoost 将当前树中先前分裂已经使用的所有分类特征(及其组合)与数据集中的所有分类特征相结合(连接)。组合被动态地转换成 TS。
对抗梯度偏差
CatBoost 实现了一种算法,允许对抗常见的梯度增强偏差。现有的实现面临统计问题,*预测偏移。*训练示例的分布 F(x_k) | x_k 从测试示例 x 的分布 F(x) | x 转移。这个问题类似于上述分类变量预处理中出现的问题。
Catboost 团队衍生了有序增强,这是标准梯度增强算法的一种修改,可以避免目标泄漏。CatBoost 有两种升压模式,命令和普通。后一种模式是内置有序 TS 的标准 GBDT 算法。

You can find a detailed description of the algorithm in the paper Fighting biases with dynamic boosting
CatBoost 使用不经意决策树,在树的整个级别上使用相同的分裂标准。这样的树是平衡的,不容易过度拟合,并允许在测试时显著加速预测。

下面是不经意树评估在 Catboost 中的实现:
int index = 0;
for (int depth = 0; depth < tree.ysize(); ++depth) {
index |= binFeatures[tree[depth]] << depth;
}
result += Model.LeafValues[treeId][resultId][index];
如您所见,这段代码中没有“if”操作符。你不需要分支来评估一个健忘的决策树。
遗忘决策树可以描述为一个条件列表,每层一个条件。对于不经意树,你只需要评估所有树的条件,组成二进制向量,将这个二进制向量转换成数字,并通过等于这个数字的索引访问叶子数组。
例如在 LightGBM 中(XgBoost 有类似的实现)
std::vector<int> left_child_;
std::vector<int> right_child_;inline int NumericalDecision(double fval, int node) const {
...
if (GetDecisionType(decision_type_[node], kDefaultLeftMask)) {
return left_child_[node];
} else {
return right_child_[node];
}
...
}
inline int Tree::GetLeaf(const double* feature_values) const {
...
while (node >= 0) {
node = NumericalDecision(feature_values[split_feature_[node]], node);
}
...
}
在有序增强模式中,在学习过程中,我们维护支持模型 Mr,j ,其中 Mr,j(i) 是基于排列 σr 中的前 j 个示例的第 i 个示例的当前预测。在算法的每次迭代 t 中,我们从 {σ1,.。。,σs} 并在此基础上构造一棵 Tt。首先,对于分类特征,所有的 TS 都是根据这个排列计算的。第二,排列影响树学习过程。
基于 Mr,j(i),计算相应的梯度。在构建树时,我们根据余弦相似性来近似梯度 G ,其中对于每个示例 I,我们基于之前的示例取梯度为σs。当树结构 Tt (即,分裂属性的序列)被构建时,我们使用它来提升所有模型Mr’,j
您可以在原始文件或 NIPS 的 18 张幻灯片中找到详细信息
GPU 培训
CatBoost 可以在一台机器的几个 GPU 上高效训练。

Experimental result for different hardware
CatBoost 实现了良好的可扩展性。在采用 InfiniBand 的 16 个 GPU 上,CatBoost 的运行速度比 4 个 GPU 快大约 3.75 倍。对于更大的数据集,可伸缩性应该更好。如果有足够的数据,我们可以在缓慢的 1gb 网络上训练模型,因为两台机器(每台机器有两个卡)不会明显慢于一个 PCIe 根联合体上的 4 个 GPU。你可以在这篇 NVIDIA 文章中了解更多信息
在所描述的优点中,还需要提到以下一个:
- 过拟合检测器。通常在梯度推进中,我们将学习速率调整到稳定的精度。但是学习率越小,需要的迭代次数就越多。
- 缺少变量。刚离开南
- 在 Catboost 中,您可以编写自己的损失函数
- 特征重要性
- CatBoost 为 Python 包提供工具,允许用不同的训练统计数据绘制图表。该信息可以在训练过程中和训练之后被访问

Monitor training in iPython Notebook using our visualization tool CatBoost Viewer.
Catboost 模型可以集成到 Tensorflow 中。例如,将 Catboost 和 Tensorflow 结合在一起是常见的情况。神经网络可用于梯度增强的特征提取。
此外,现在 Catboost 模型可以在 CoreML 的帮助下用于生产。
例子
我创建了一个应用 Catboost 解决回归问题的例子。我使用 Allstate 索赔严重程度的数据作为基础。
在您的进一步研究中,请随意使用 my colab !
你也可以在 Catboost 官方的 github 中找到大量其他的例子
贡献
如果你想让 CatBoost 变得更好:
- 查看求助问题,看看有哪些可以改进的地方,或者如果您需要什么,可以打开一个问题。
- 将您的故事和经验添加到 Awesome CatBoost 中。
- 要向 CatBoost 投稿,您需要首先阅读 CLA 文本,并在您的请求中添加您同意 CLA 条款的内容。更多信息可以在 CONTRIBUTING.md 找到对贡献者的说明可以在这里找到。
关注推特或微信(zkid18)来了解我的最新消息。
图表介绍(第一部分)
内线艾
Python 中的主要概念、属性和应用

G 如今,raphs 正成为机器学习的核心,例如,无论你是想通过预测潜在的联系来了解社交网络的结构,检测欺诈,了解汽车租赁服务的客户行为,还是提出实时建议。
在本文中,我们将讨论以下主题:
- 什么是图?
- 如何存储一个图形?
- 图的类型和性质
- Python 中的示例
这是致力于图论、图算法和图学习的三篇系列文章的第一篇。
本文最初发表于我的个人博客:https://maelfabien.github.io/ml/#
我在这个资源库上发布我所有的文章和相应的代码:
本报告包含练习、代码、教程和我的个人博客文章
github.com](https://github.com/maelfabien/Machine_Learning_Tutorials)
NB : Part 2 和 Part 3 出来了!😃
Python 中的主要概念、属性和应用
towardsdatascience.com](/graph-algorithms-part-2-dce0b2734a1d) [## 用 Python 学习图形(第 3 部分)
Python 的概念、应用和示例
towardsdatascience.com](/learning-in-graphs-with-python-part-3-8d5513eef62d)
接下来,打开 Jupyter 笔记本,导入以下包:
import numpy as np
import random
import networkx as nx
from IPython.display import Image
import matplotlib.pyplot as plt
以下文章将使用最新版本的networkx``2.x。NetworkX 是一个 Python 包,用于创建、操作和研究复杂网络的结构、动态和功能。
我将尽量保持一种实用的方法,并举例说明每个概念。
一、什么是图?
图是相互连接的节点的集合。
例如,一个非常简单的图形可以是:

Nodes in red, are linked by edges in black
图表可用于表示:
- 社交网络
- 网页
- 生物网络
- …
我们可以对图表进行什么样的分析?
- 研究拓扑和连通性
- 社区检测
- 确定中心节点
- 预测缺失节点
- 预测丢失的边
- …
所有这些概念在几分钟后会变得更加清晰。
在我们的笔记本中,让我们导入第一个预构建的图表:
# Load the graph
G_karate = nx.karate_club_graph()
# Find key-values for the graph
pos = nx.spring_layout(G_karate)
# Plot the graph
nx.draw(G_karate, cmap = plt.get_cmap('rainbow'), with_labels=True, pos=pos)

Karate Graph
这个“空手道”图代表什么?韦恩·w·扎卡里从 1970 年到 1972 年对一个空手道俱乐部的社交网络进行了为期三年的研究。该网络捕获了一个空手道俱乐部的 34 名成员,记录了在俱乐部外互动的成对成员之间的联系。在研究过程中,管理员“约翰 A”和指导员“嗨先生”(化名)之间发生了冲突,导致俱乐部一分为二。一半的成员在 Hi 先生周围组成了一个新的俱乐部;另一部分的成员找到了新的教练或者放弃了空手道。根据收集到的数据,扎卡里正确地将俱乐部中除了一名成员之外的所有成员分配到了他们在分裂后实际加入的小组中。
基本图形概念
一个图 G=(V,E)由一组:
- 节点(也叫顶点) V=1,…,n
- 棱角 E⊆V×V
- 一条边 (i,j) ∈ E 链接节点 I 和 j
- 据说我和 j 是邻居
- 节点的度是其邻居的数量

Illustration of nodes, edges, and degrees
- 如果所有节点都有 n-1 个邻居,则图是完整的。这意味着所有节点都以各种可能的方式连接在一起。
- 从 I 到 j 的路径是从 I 到 j 的一系列边。该路径的长度等于它穿过的边数。
- 图的直径是连接任意两个节点的所有最短路径中最长路径的长度。
例如,在这种情况下,我们可以计算连接任意两个节点的一些最短路径。直径通常为 3,因为没有节点对,因此连接它们的最短路径长于 3。

Diameter of 3
- 测地线 路径是两个节点之间的最短路径。
- 如果所有的节点都可以通过给定的路径相互到达,那么它们就形成了一个连通分量。一个图是连通的它有单个连通分量吗
例如,下面是一个包含两个不同连接组件的图表:

2 connected components
- 如果边是有序对,则图是有向的。在这种情况下,I 的“入度”是到 I 的传入边的数量,“出度”是从 I 传出的边的数量。

Directed Graph
- 一个图是循环的如果你能返回到一个给定的节点。另一方面,如果至少有一个节点不能返回,那么它就是非循环的。
- 如果我们给节点或者关系赋予权重,那么一个图就可以是加权的。
- 如果边的数量比节点的数量多,那么图是稀疏的。另一方面,如果节点之间有许多边,则称其为密集。
Neo4J 关于图算法的书提供了一个清晰的总结:

Summary (Neo4J Graph Book)
现在让我们看看如何用 Python 从图表中检索这些信息:
n=34G_karate.degree()
属性.degree()返回图中每个节点的度数(邻居)列表:
DegreeView({0: 16, 1: 9, 2: 10, 3: 6, 4: 3, 5: 4, 6: 4, 7: 4, 8: 5, 9: 2, 10: 3, 11: 1, 12: 2, 13: 5, 14: 2, 15: 2, 16: 2, 17: 2, 18: 2, 19: 3, 20: 2, 21: 2, 22: 2, 23: 5, 24: 3, 25: 3, 26: 2, 27: 4, 28: 3, 29: 4, 30: 4, 31: 6, 32: 12, 33: 17})
然后,分离度数值:
# Isolate the sequence of degrees
degree_sequence = list(G_karate.degree())
计算边的数量,以及度序列的度量:
nb_nodes = n
nb_arr = len(G_karate.edges())avg_degree = np.mean(np.array(degree_sequence)[:,1])
med_degree = np.median(np.array(degree_sequence)[:,1])max_degree = max(np.array(degree_sequence)[:,1])
min_degree = np.min(np.array(degree_sequence)[:,1])
最后,打印所有这些信息:
print("Number of nodes : " + str(nb_nodes))
print("Number of edges : " + str(nb_arr))print("Maximum degree : " + str(max_degree))
print("Minimum degree : " + str(min_degree))print("Average degree : " + str(avg_degree))
print("Median degree : " + str(med_degree))
这个标题是:
Number of nodes : 34
Number of edges : 78
Maximum degree : 17
Minimum degree : 1
Average degree : 4.588235294117647
Median degree : 3.0
平均而言,图表中的每个人都与 4.6 个人有联系。
我们还可以绘制度数直方图:
degree_freq = np.array(nx.degree_histogram(G_karate)).astype('float')plt.figure(figsize=(12, 8))
plt.stem(degree_freq)
plt.ylabel("Frequence")
plt.xlabel("Degre")
plt.show()

Degree Histogram
稍后,我们将会看到,度数直方图对于确定我们所看到的图形的类型非常重要。
二。图表是如何存储的?
你现在可能想知道我们如何存储复杂的图形结构?
根据我们想要的用途,有三种方法来存储图表:
- 在边缘列表中:
1 2
1 3
1 4
2 3
3 4
...
我们存储由边链接的每对节点的 ID。
- 使用邻接矩阵,通常加载到内存中:

Adjacency matrix
对于图中的每个可能的对,如果两个节点由一条边链接,则将其设置为 1。如果图是无向的,则 a 是对称的。
- 使用邻接表:
1 : [2,3, 4]
2 : [1,3]
3: [2, 4]
...
最佳表现取决于使用情况和可用内存。图形通常可以保存为.txt文件。
图形的一些扩展可能包括:
- 加权边
- 节点/边上的标签
- 与节点/边相关联的特征向量
三。图形的类型
在这一节中,我们将介绍两种主要类型的图表:
- 鄂尔多斯-雷尼
- 巴拉巴斯-艾伯特
1.鄂尔多斯-雷尼模型
a .定义
在一个 Erdos-Rényi 模型中,我们建立一个有 n 个节点的 随机 *图模型。该图是通过在一对节点(I,j)*和 概率 p 之间画一条 边 而生成的。因此我们有两个参数:节点数:n 和概率:p。

Erdos-Rényi Graphs
在 Python 中,networkx包有一个生成鄂尔多斯-雷尼图的内置函数。
*# Generate the graph
n = 50
p = 0.2
G_erdos = nx.erdos_renyi_graph(n,p, seed =100)# Plot the graph
plt.figure(figsize=(12,8))
nx.draw(G_erdos, node_size=10)*
您将得到与此非常相似的结果:

Generated Graph
b .学位分布
设 pk 随机选择的节点具有度 k 的概率*由于图的构建方式是随机的,所以图的度分布是二项式**😗

Binomial node degree distribution
每个节点的度数分布应该非常接近平均值。观察到大量节点的概率呈指数下降。
*degree_freq = np.array(nx.degree_histogram(G_erdos)).astype('float')plt.figure(figsize=(12, 8))
plt.stem(degree_freq)
plt.ylabel("Frequence")
plt.xlabel("Degree")
plt.show()*
为了可视化分布,我在生成的图中将 n 增加到 200。

Degree Distribution
c .描述性统计
- 平均度数由 n×p 给出,p=0.2,n=200,我们以 40 为中心。
- 期望度数由(n1)×p 给出
- 最大程度集中在平均值附近
让我们用 Python 检索这些值:
*# Get the list of the degrees
degree_sequence_erdos = list(G_erdos.degree())
nb_nodes = n
nb_arr = len(G_erdos.edges())
avg_degree = np.mean(np.array(degree_sequence_erdos)[:,1])
med_degree = np.median(np.array(degree_sequence_erdos)[:,1])
max_degree = max(np.array(degree_sequence_erdos)[:,1])
min_degree = np.min(np.array(degree_sequence_erdos)[:,1])
esp_degree = (n-1)*p
print("Number of nodes : " + str(nb_nodes))
print("Number of edges : " + str(nb_arr))
print("Maximum degree : " + str(max_degree))
print("Minimum degree : " + str(min_degree))
print("Average degree : " + str(avg_degree))
print("Expected degree : " + str(esp_degree))
print("Median degree : " + str(med_degree))*
这应该会给你类似于:
*Number of nodes : 200
Number of edges : 3949
Maximum degree : 56
Minimum degree : 25
Average degree : 39.49
Expected degree : 39.800000000000004
Median degree : 39.5*
平均学位和预期学位非常接近,因为两者之间只有一个很小的因素。
2.巴拉巴斯-艾伯特模型
a .定义
在 Barabasi-Albert 模型中,我们建立了一个具有 n 个节点的随机图模型,该模型具有优先连接组件。该图由以下算法生成:
- 第一步:概率为 p,进入第二步。否则,转到第三步。
- 第二步:将一个新节点连接到在随机选择的现有节点****
- 步骤 3:将新节点连接到 n 个现有节点,其概率与它们的度成比例
该图的目的是模拟在真实网络中经常观察到的优先连接*。*
在 Python 中,networkx包还有一个生成 Barabasi-Albert 图的内置函数。
*# Generate the graph
n = 150
m = 3
G_barabasi = nx.barabasi_albert_graph(n,m)# Plot the graph
plt.figure(figsize=(12,8))
nx.draw(G_barabasi, node_size=10)*
您将得到与此非常相似的结果:

Barabasi-Albert Graph
您可以很容易地注意到,现在一些节点的度数似乎比其他节点的度数大得多!
b .学位分布
设 pk 随机选择的节点的度为 k 的概率。度分布遵循幂律:

Power-law degree distribution
分布现在是重尾的。有大量的节点具有较小的度数,但是有大量的节点具有较高的度数。
*degree_freq = np.array(nx.degree_histogram(G_barabasi)).astype('float')plt.figure(figsize=(12, 8))
plt.stem(degree_freq)
plt.ylabel("Frequence")
plt.xlabel("Degree")
plt.show()*

Degree Distribution
这种分布被认为是无尺度的,也就是说,平均程度是没有信息的。
c .描述性统计
- 如果α≤2,则平均度为常数,否则,平均度发散
- 最大度数的顺序如下:

*# Get the list of the degrees
degree_sequence_erdos = list(G_erdos.degree())
nb_nodes = n
nb_arr = len(G_erdos.edges())
avg_degree = np.mean(np.array(degree_sequence_erdos)[:,1])
med_degree = np.median(np.array(degree_sequence_erdos)[:,1])
max_degree = max(np.array(degree_sequence_erdos)[:,1])
min_degree = np.min(np.array(degree_sequence_erdos)[:,1])
esp_degree = (n-1)*p
print("Number of nodes : " + str(nb_nodes))
print("Number of edges : " + str(nb_arr))
print("Maximum degree : " + str(max_degree))
print("Minimum degree : " + str(min_degree))
print("Average degree : " + str(avg_degree))
print("Expected degree : " + str(esp_degree))
print("Median degree : " + str(med_degree))*
这应该会给你类似于:
*Number of nodes : 200
Number of edges : 3949
Maximum degree : 56
Minimum degree : 25
Average degree : 39.49
Expected degree : 39.800000000000004
Median degree : 39.5*
四。结论
到目前为止,我们讨论了图的主要种类,以及描述图的最基本的特征。在下一篇文章中,我们将深入探讨图形分析/算法,以及分析图形的不同方式,用于:
- 实时欺诈检测
- 实时推荐
- 简化法规遵从性
- 复杂网络的管理和监控
- 身份和访问管理
- 社交应用/功能
- …
如果您有任何问题或意见,请随时评论。
下一篇文章可以在这里找到:
Python 中的主要概念、属性和应用
towardsdatascience.com](/graph-algorithms-part-2-dce0b2734a1d)
来源:
- Neo4j 中的图形算法综合指南
- 网络 x 文档,https://networkx.github.io/documentation/stable/
如果你想从我这里读到更多,我以前的文章可以在这里找到:
在本文中,我们将关注马尔可夫模型,何时何地应该使用它们,以及隐马尔可夫模型。这个…
towardsdatascience.com](/markov-chains-and-hmms-ceaf2c854788) [## Python 中的人脸检测指南
在本教程中,我们将看到如何使用 OpenCV 和 Dlib 在 Python 中创建和启动人脸检测算法。我们会…
towardsdatascience.com](/a-guide-to-face-detection-in-python-3eab0f6b9fc1) [## 升压和 AdaBoost 解释清楚
直观的解释
towardsdatascience.com](/boosting-and-adaboost-clearly-explained-856e21152d3e)*
隐马尔可夫模型简介
我们介绍马尔可夫链和隐马尔可夫模型。
马尔可夫链
让我们先简单介绍一下马尔可夫链,一种随机过程。我们从链条的几个“状态”开始,{ S ₁,…,sₖ};例如,如果我们的链代表每天的天气,我们可以有{雪,雨,阳光}。一个过程( X ₜ)ₜ应该是一个马尔可夫链)的性质是:

换句话说,处于状态 j 的概率只取决于前一个状态,而不取决于之前发生的事情。
马尔可夫链通常用带有转移概率的图来描述,即从状态 i 移动到状态 j 的概率,用 p ᵢ,ⱼ.来表示让我们看看下面的例子:

Markov chain example
该链有三种状态;例如,雪和雨之间的转移概率是 0.3,也就是说,如果昨天下雪,今天有 30%的可能性会下雨。转移概率可以总结为一个矩阵:

注意每一行的总和等于 1(想想为什么)。这样的矩阵称为随机矩阵。( i , j )定义为pᵢ,ⱼ——在 i 和 j 之间的转移概率。
事实:如果我们取矩阵的幂, P ᵏ,( i , j )条目代表在 k 步从状态 i 到达状态 j 的概率。
在许多情况下,我们被给定一个初始概率向量 q =( q ₁,…, q ₖ)在时间 t =0 时处于每个状态。因此,在时间 t 处于状态 i 的概率将等于向量 P ᵏ q 的第 i- 个条目。
例如,如果今天下雪、下雨和阳光的概率是 0,0.2,0.8,那么 100 天后下雨的概率计算如下:

第二项等于≈ 0.44。
隐马尔可夫模型
在隐马尔可夫模型(HMM)中,我们有一个看不见的马尔可夫链(我们无法观察到),每个状态从 k 个观察值中随机产生一个,这对我们来说是可见的。
让我们看一个例子。假设我们有上面的马尔可夫链,有三个状态(雪、雨和阳光), P -转移概率矩阵和q-初始概率。这是看不见的马尔可夫链——假设我们在家,看不见天气。然而,我们可以感觉到我们房间内的温度,假设有两种可能的观察结果:热和冷,其中:

基本示例
作为第一个例子,我们应用 HMM 来计算我们连续两天感到寒冷的概率。这两天,底层马尔可夫状态有 3*3=9 个选项。让我们举例说明这 9 个选项之一的概率计算:

将所有选项相加得出期望的概率。
寻找隐藏状态—维特比算法
在某些情况下,我们被给定一系列的观察值,并想找到最有可能对应的隐藏状态。
强力解决方案需要指数级的时间(就像上面的计算);一种更有效的方法叫做维特比算法;它的主要思想是这样的:给我们一个观察序列 o ₁,…, o ₜ 。对于每个状态 i 和 t =1,…, T ,我们定义

也就是,给定我们的观察,在状态 i 在时间 t 结束的路径的最大概率。这里的主要观察是,根据马尔可夫性质,如果在时间 t 以 i 结束的最可能路径等于在时间t1 的某个 i ,则 i 是在时间t*1 结束的最可能路径的最后状态的值。这给了我们下面的前向递归:

这里, α ⱼ( o ₜ)表示当隐马尔可夫状态为 j 时拥有 o ₜ的概率。
这里有一个例子。让我们生成一个 14 天的序列,其中 1 表示高温,0 表示低温。我们会用算法找到这两周最有可能的天气预报。
import numpy as np
import pandas as pd
obs_map = {'Cold':0, 'Hot':1}
obs = np.array([1,1,0,1,0,0,1,0,1,1,0,0,0,1])
inv_obs_map = dict((v,k) for k, v in obs_map.items())
obs_seq = [inv_obs_map[v] for v in list(obs)]
print("Simulated Observations:\n",pd.DataFrame(np.column_stack([obs, obs_seq]),columns=['Obs_code', 'Obs_seq']) )
pi = [0.6,0.4] # initial probabilities vector
states = ['Cold', 'Hot']
hidden_states = ['Snow', 'Rain', 'Sunshine']
pi = [0, 0.2, 0.8]
state_space = pd.Series(pi, index=hidden_states, name='states')
a_df = pd.DataFrame(columns=hidden_states, index=hidden_states)
a_df.loc[hidden_states[0]] = [0.3, 0.3, 0.4]
a_df.loc[hidden_states[1]] = [0.1, 0.45, 0.45]
a_df.loc[hidden_states[2]] = [0.2, 0.3, 0.5]
print("\n HMM matrix:\n", a_df)
a = a_df.values
observable_states = states
b_df = pd.DataFrame(columns=observable_states, index=hidden_states)
b_df.loc[hidden_states[0]] = [1,0]
b_df.loc[hidden_states[1]] = [0.8,0.2]
b_df.loc[hidden_states[2]] = [0.3,0.7]
print("\n Observable layer matrix:\n",b_df)
b = b_df.values
我们得到:
Simulated Observations:
Obs_code Obs_seq
0 1 Hot
1 1 Hot
2 0 Cold
3 1 Hot
4 0 Cold
5 0 Cold
6 1 Hot
7 0 Cold
8 1 Hot
9 1 Hot
10 0 Cold
11 0 Cold
12 0 Cold
13 1 Hot
HMM matrix:
Snow Rain Sunshine
Snow 0.3 0.3 0.4
Rain 0.1 0.45 0.45
Sunshine 0.2 0.3 0.5
Observable layer matrix:
Cold Hot
Snow 1 0
Rain 0.8 0.2
Sunshine 0.3 0.7
现在让我们使用算法:
path, delta, phi = viterbi(pi, a, b, obs)
state_map = {0:'Snow', 1:'Rain', 2:'Sunshine'}
state_path = [state_map[v] for v in path]
pd.DataFrame().assign(Observation=obs_seq).assign(Best_Path=state_path)
我们得到:
Start Walk Forward
s=0 and t=1: phi[0, 1] = 2.0
s=1 and t=1: phi[1, 1] = 2.0
s=2 and t=1: phi[2, 1] = 2.0
s=0 and t=2: phi[0, 2] = 2.0
s=1 and t=2: phi[1, 2] = 2.0
s=2 and t=2: phi[2, 2] = 2.0
s=0 and t=3: phi[0, 3] = 0.0
s=1 and t=3: phi[1, 3] = 1.0
s=2 and t=3: phi[2, 3] = 1.0
s=0 and t=4: phi[0, 4] = 2.0
s=1 and t=4: phi[1, 4] = 2.0
s=2 and t=4: phi[2, 4] = 2.0
s=0 and t=5: phi[0, 5] = 0.0
s=1 and t=5: phi[1, 5] = 1.0
s=2 and t=5: phi[2, 5] = 1.0
s=0 and t=6: phi[0, 6] = 0.0
s=1 and t=6: phi[1, 6] = 1.0
s=2 and t=6: phi[2, 6] = 1.0
s=0 and t=7: phi[0, 7] = 2.0
s=1 and t=7: phi[1, 7] = 2.0
s=2 and t=7: phi[2, 7] = 2.0
s=0 and t=8: phi[0, 8] = 0.0
s=1 and t=8: phi[1, 8] = 1.0
s=2 and t=8: phi[2, 8] = 1.0
s=0 and t=9: phi[0, 9] = 2.0
s=1 and t=9: phi[1, 9] = 2.0
s=2 and t=9: phi[2, 9] = 2.0
s=0 and t=10: phi[0, 10] = 2.0
s=1 and t=10: phi[1, 10] = 2.0
s=2 and t=10: phi[2, 10] = 2.0
s=0 and t=11: phi[0, 11] = 0.0
s=1 and t=11: phi[1, 11] = 1.0
s=2 and t=11: phi[2, 11] = 1.0
s=0 and t=12: phi[0, 12] = 0.0
s=1 and t=12: phi[1, 12] = 1.0
s=2 and t=12: phi[2, 12] = 1.0
s=0 and t=13: phi[0, 13] = 0.0
s=1 and t=13: phi[1, 13] = 1.0
s=2 and t=13: phi[2, 13] = 1.0
--------------------------------------------------
Start Backtrace
path[12] = 1
path[11] = 1
path[10] = 1
path[9] = 2
path[8] = 2
path[7] = 1
path[6] = 2
path[5] = 1
path[4] = 1
path[3] = 2
path[2] = 1
path[1] = 2
path[0] = 2
这导致输出:

我们基于[2]使用了以下实现:
def viterbi(pi, a, b, obs):
nStates = np.shape(b)[0]
T = np.shape(obs)[0]
# init blank path
path = path = np.zeros(T,dtype=int)
# delta --> highest probability of any path that reaches state i
delta = np.zeros((nStates, T))
# phi --> argmax by time step for each state
phi = np.zeros((nStates, T))
# init delta and phi
delta[:, 0] = pi * b[:, obs[0]]
phi[:, 0] = 0
print('\nStart Walk Forward\n')
# the forward algorithm extension
for t in range(1, T):
for s in range(nStates):
delta[s, t] = np.max(delta[:, t-1] * a[:, s]) * b[s, obs[t]]
phi[s, t] = np.argmax(delta[:, t-1] * a[:, s])
print('s={s} and t={t}: phi[{s}, {t}] = {phi}'.format(s=s, t=t, phi=phi[s, t]))
# find optimal path
print('-'*50)
print('Start Backtrace\n')
path[T-1] = np.argmax(delta[:, T-1])
for t in range(T-2, -1, -1):
path[t] = phi[path[t+1], [t+1]]
print('path[{}] = {}'.format(t, path[t]))
return path, delta, phi
学习和鲍姆-韦尔奇算法
与上述方法类似的方法可以用于 HMM 模型的参数学习。我们有一些数据集,我们想找到最适合 HMM 模型的参数。 Baum-Welch 算法是一个迭代过程,它找到观察值 P 的概率的(局部)最大值( O |M),其中 M 表示模型(带有我们想要拟合的参数)。由于我们通过模型知道 P(M| O ),我们可以使用贝叶斯方法找到 P(M| O )并收敛到一个最优值。
HMM 有各种各样的应用,从字符识别到金融预测(检测市场机制)。
参考文献
[1]https://CSE . buffalo . edu/~ jcorso/t/CSE 555/files/lecture _ hmm . pdf
使用 fastai 库进行图像增强的介绍
使用 fastai 库应用图像增强的示例演练

Photo by Thomas Willmott on Unsplash
你也可以在这个 kaggle 内核中找到这个博客的可执行代码。
文章简介
这篇文章的目的是向您展示 fastai 中所有的图像增强。我将首先介绍数据增强,然后介绍图像增强。
然后我们再来做一个案例,为什么 fastai 默认“刚刚好”。
接下来,我们将看几个这种转换将非常有用的真实用例:
- 构建 SOTA 社区游泳池检测器
- 构建医学图像 OCR
- 建立一个谷歌镜头 Ripoff(咳,启动,咳)
- 建立一个车牌检测器。
我们将查看一个可爱小狗的基本图像,首先应用变换将其用作参考,然后我将展示相同的真实世界用例的示例。
注意,这些定义和解释很大程度上来自 fastai 文档,我鼓励你去看看。
此外,这并不意味着大量编写代码,而是在更高层次上讨论在何处或何时使用代码。
如果你想运行内核,请点击副标题空间的链接。
数据扩充
数据扩充是最常见的正则化技术之一,在图像处理任务中尤其常见。
当你在一台机器上工作学习模型时,你的模型的性能只和你的数据一样好。根据您试图解决的模型和问题,您需要不同数量的数据。
然而,数据收集和清理是一个消耗资源的过程,并不总是可行的。
神经网络,或者通常用于图像处理相关目的:卷积神经网络,学习图像内部的“特征”。
为什么图像增强会起作用?
任何机器学习项目的目标都是确保我们的代码或“模型”能够推广到现实世界的数据。然而,与此相反的是“过度拟合”,即模型只是学习识别训练数据集中的特征。
为了避免这种情况,我们在将图像输入模型时会“增加”或添加一些细微的变化。尽管 2 度的旋转对人眼来说可能不会产生巨大的差异,但这种微小的变化足以让模型更好地推广。
为了给你一个“it just works”的例子,让我们尝试在打开/关闭图像增强的情况下,在 CIFAR-10 数据集上运行训练 ResNet 50。
接下来,我将深入研究 fastai 支持的图像增强,并给出可能有用的示例用例。
使用 fastai 的图像增强
为了将“转换”应用到您的数据集,我们在创建“ImageDataBunch”对象时传递转换列表。
fastai 有一个默认的推荐转换列表,它是由团队经过大量实验得出的,所以对于初学者,我建议相信这些:
tfms = get_transforms()
这将返回一个长度为 2 的元组,其中包含两个列表:一个用于定型数据集,另一个用于验证数据集。
get_transforms 函数的默认参数是:
get_transforms(do_flip:bool=True, flip_vert:bool=False, max_rotate:float=10.0, max_zoom:float=1.1, max_lighting:float=0.2, max_warp:float=0.2, p_affine:float=0.75, p_lighting:float=0.75, xtra_tfms:Optional[Collection[Transform]]=None) → Collection[Transform]
这样生成的默认元组是:
([RandTransform(tfm=TfmCrop (crop_pad), kwargs={'row_pct': (0, 1), 'col_pct': (0, 1), 'padding_mode': 'reflection'}, p=1.0, resolved={}, do_run=True, is_random=True),
RandTransform(tfm=TfmAffine (flip_affine), kwargs={}, p=0.5, resolved={}, do_run=True, is_random=True),
RandTransform(tfm=TfmCoord (symmetric_warp), kwargs={'magnitude': (-0.2, 0.2)}, p=0.75, resolved={}, do_run=True, is_random=True),
RandTransform(tfm=TfmAffine (rotate), kwargs={'degrees': (-10.0, 10.0)}, p=0.75, resolved={}, do_run=True, is_random=True),
RandTransform(tfm=TfmAffine (zoom), kwargs={'scale': (1.0, 1.1), 'row_pct': (0, 1), 'col_pct': (0, 1)}, p=0.75, resolved={}, do_run=True, is_random=True),
RandTransform(tfm=TfmLighting (brightness), kwargs={'change': (0.4, 0.6)}, p=0.75, resolved={}, do_run=True, is_random=True),
RandTransform(tfm=TfmLighting (contrast), kwargs={'scale': (0.8, 1.25)}, p=0.75, resolved={}, do_run=True, is_random=True)],
[RandTransform(tfm=TfmCrop (crop_pad), kwargs={}, p=1.0, resolved={}, do_run=True, is_random=True)])
如果你不理解索引中的所有单词,没关系。让我们深入探讨并尝试探索其中的一些。我分享这些的理由是:默认值总是一个好的起点,除非你正在处理非常不同的数据。例如:点突变或星系间图像。
fastai 支持的转换
- 聪明
- 对比
- 农作物
- 作物 _ 垫
- 有两个平面的
- 二面角 _ 仿射
- 翻转 _lr
- 翻转 _ 仿射
- 振动
- 衬垫
- 透视 _ 扭曲
- 调整大小
- 辐状的
- rgb _ 随机化
- 斜交
- 咯吱声
- 对称 _ 扭曲
- 倾斜
- 嗡嗡声
- 断流器
便利功能:
- 随机作物
- rand_pad
- 随机缩放
这是一个很长的列表!让我们试着一个一个地探索这些问题。
默认值:
我从文档中(窃取)了一些助手代码:
*#Helper functions from fastai docs*
def get_ex(): return open_image(path/'images/beagle_192.jpg')
def plots_f(rows, cols, width, height, **kwargs):
[get_ex().apply_tfms(tfms[0], **kwargs).show(ax=ax) for i,ax **in** enumerate(plt.subplots(
rows,cols,figsize=(width,height))[1].flatten())]
这将允许我们看狗的图片。这些将是比较的基本情况。因此,我将进一步分享这种变换,它对基本的狗图片做了什么,以及在现实世界中你可能会发现它有用的地方,因为我们的狗图片可能不会作为我们将看到的所有情况的最佳示例。
旋转
(max_rotate=angle)在此处指定的-角度和+角度之间切换随机旋转。
tfms = get_transforms(max_rotate=180)
因为没有人会在这些角度点击他们狗狗的照片。让我们考虑另一种情况:

真实世界用例
你的任务是在你的社区找到游泳池。你下载卫星图像,但由于你所在的地区很小,你的模型不适合。

在这种情况下,图像增强可能是有用的:
乍一看,我可能骗你说这些是不同的照片,不是吗?我相信这对我们的模型来说是一个很好的目的。
RGB 随机化
rgb_randomize ( **x**,**channel** : int = ***None***,**thresh** : float = ***0.3*** ) → [Image](https://docs.fast.ai/vision.image.html#Image) :: [TfmPixel](https://docs.fast.ai/vision.image.html#TfmPixel)
众所周知,图像有三个通道(红、绿、蓝,即 RGB)。这种变换使输入图像的一个通道随机化。

- 通道:随机化哪个通道(RGB)。
- 阈值:随机化后,将数值缩放至不超过
thresh值
这在这样的情况下可能是有用的:你的数据集应该帮助你检测汽车,但是你的实习生(或者研究生 Turk😛)做的不好,只采集了红色汽车的图像。您可以随机选择颜色,帮助学习者更好地概括。
聪明
我们可以在 0 到 1 之间改变亮度,默认值是 0.5。

让我们看一下我们的狗狗照片,在亮度范围内有各种变化。由于原始图像拍摄得相当完美,增强在这里没有帮助。这是另一个扩大你的形象可能会破坏你的模型的例子。因此,在对数据应用变换时要小心。
真实世界用例

警告远离我们。这是我工作中的一个例子:任务是从这个图像中提取文本。即使对于人眼来说,当背景和文本之间的差异最明显时,这也更容易做到。所以对于 ex:看 0.3 值——这是这种情况下最好的结果。
对比
顾名思义,它允许我们从 0 到 2 的范围内改变对比度。1 是默认/原始图片。
这是我们可怜的狗狗的照片,正在进行另一组增强:

就我个人而言,我会投票给最“反差”的照片。归咎于 Instagram 滤镜。
真实世界用例
让我们重新开始之前的挑战。我们的任务是创建一个字符阅读器,从药品的图像中读取字符。对比度最大时效果最佳。
不相信我?看一看:

农作物
裁剪有助于裁剪到图像中提到的部分。
真实世界用例
你的任务是建立一个停车场计费机。由于我们的相机会固定在一个角度,我们可以预计大多数轿车进入很多,车牌最有可能是在一个固定的区域(中下部)。裁剪到那里将允许我们的模型只关注那个区域,使我们和模型的工作更容易。

作物垫
基于设置模式的 Crop_pad、crops 和 pads。fastai dev(s)推荐的是“反射填充”。有关零和反射填充,请参见下面的示例。

有两个平面的
二面角变换在二面体的 8 个可能的方向/角度上旋转图像。
让我们首先看看什么是二面角:

正如你所想象的,它会在所有这些可能的方向上旋转图像。定义够了,让我们从坏的角度来看我们无辜的小狗:

真实世界用例
现在,我敢打赌,如果你在 Instagram 上以这样的角度给你的小狗拍照,或者是一个糟糕的父母。不管怎样,这都不是一个好例子。
回到我们最初的夏令营任务,我们使用谷歌地图监视附近地区,寻找游泳池。

如你所见,在这种情况下,以这些角度旋转图像可能更有意义。如果你不知道,这些第一眼看上去可能是完全不同的图像。不是吗?
抖动
抖动会给图像增加随机噪声。我不确定同样的最佳实际使用情况是什么,幅度可以从-x 到+x 设置,0 是原始图像。

真实世界用例
在幕后,抖动是来自邻域的随机像素替换。这意味着,它可能有助于避免过度拟合(认为它类似于辍学)
远景
这种变换改变了图像的视角,就好像我们的对象被移动了一样。
还记得苹果的这个视频吗?
这正是它的作用。
作为参考,让我们先看看我们的小狗。

真实世界用例
这可能有用的一个用例是,假设您正在创建一个药品检测器,您希望客户对药品拍照,并且您的“技术”应该能够检测/读取所有细节。现在,客户可能不会从最佳角度点击照片,你也不愿意教他们同样的方法。相反,你可以使用这个变换。
查看这些示例:

对称翘曲
同时应用四个倾斜,每个倾斜的强度在矢量magnitude中给出。
让我们看看我们的小狗作为参考。
真实世界用例
好了,现在举个真实世界的例子。听说过谷歌镜头吗?
其在技术俱乐部中也被称为内容检索引擎/图片搜索引擎。现在想想,你使用这类服务真的不在乎角度对不对。所以这是你的工作。
例如,如果您的任务是构建一个 SOTA 谷物检测机图像引擎,这种转变将会非常突出:

倾斜
倾斜允许磁场“倾斜”到一个随机的方向和一个特定的大小。
direction是一个数字(0:左,1:右,2:上,3:下)。正面的magnitude是向前倾斜(朝向看图的人),负面的magnitude是向后倾斜。
真实世界用例
我会饶了我们可爱的小狗,回到建造世界级谷物盒探测器的重要任务上。您可以看到转换对于这个用例再次非常有用:

这是一个很长的变换和例子列表。如果你有兴趣尝试这些,我会鼓励你检查我的入门内核。
如果你有任何问题,请给我发推文或在下面留言。
如果你觉得这很有趣,并且想成为我的学习之路 的一部分,你可以在 Twitter 这里 找到我。
如果你有兴趣阅读关于深度学习和计算机视觉的新闻,可以在这里 查看我的 简讯。
如果你有兴趣阅读机器学习英雄的一些最佳建议:从业者、研究人员和 Kagglers。 请点击这里


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}