







了解企业/组织中的数据类型
尝试谷歌一下,你会保证找到各种来源,每一个都有自己的版本(有的说 3 种数据,有的说 5 种,有的甚至说 13 种)。我们通过总结让你更容易理解,并让你的理解进入下一个层次
B 在您开始推出您的数据管理计划之前,无论是主数据管理、企业数据仓库、大数据分析还是其他什么,您都需要首先了解最基本的要素:数据。只有彻底认识到他们的特点,你才会知道如何正确对待他们。
“数据是一种珍贵的东西,将比系统本身持续更久”
蒂姆·伯纳斯·李
所以让我们开始吧!
交易数据
这类数据描述了您的核心业务活动。如果你是一家贸易公司,这可能包括你的采购和销售活动的数据。如果你是一家制造公司,这将是你的生产活动数据。如果你是打车或出租车公司,这将是行程数据。在一个非常基本的组织运作中,与雇佣和解雇员工的活动相关的数据也可以归类为事务性数据。因此,与其他类型的数据相比,这种类型的数据具有非常大的容量,并且通常在诸如 ERP 系统的操作应用中创建、存储和维护。
主数据
它由构成事务数据的关键信息组成。例如,出租车公司的行程数据可能包含司机、乘客、路线和费用数据。司机、乘客、位置和基本票价数据是主数据。驾驶员数据可以包括驾驶员的姓名和所有相关信息。乘客数据也是如此。它们一起构成了事务数据。
主数据通常包含地点(地址、邮政编码、城市、国家)、当事人(客户、供应商、员工)和事物(产品、资产、项目等)。).它是特定于应用程序的,这意味着它的用途是特定于具有相关业务流程的应用程序的,例如:在 HR 应用程序中创建、存储和维护员工主数据。
到目前为止,您应该对主数据相对恒定有所了解。虽然交易数据是以闪电般的速度创建的,但主数据在某种程度上是恒定的。行程数据随时都会被创建,但是司机的列表将保持不变,除非车上有新的司机或者被踢出去。
如今,组织内的过程通常是相互依赖的,这意味着在一个系统中进行的过程与在另一个系统中进行的过程相关。它们可以使用相同的主数据。如果每个系统管理自己主数据,可能会出现重复和不一致的情况。例如,客户在系统 A 中可能被存储为 Rendy,但在系统 B 中被列为 Randy,尽管 Rendy 和 Randy 实际上是同一个实体。但是没必要担心,有一个规则来处理这种情况。叫做主数据管理。
参考数据
参考数据是主数据的子集。它通常是由特定编码管理的标准化数据(例如,国家列表由 ISO 3166-1 管理。有一种简单的方法来区分参考数据和主数据。永远记住,参考数据比主数据更不稳定。让我们回到我们的出租车公司。明天,后天,或者下周,每当有新人加入或者被踢出去,车手名单可能会改变。但我可以向你保证,即使 20 年后,这个国家名单也不会变,除非有一小块土地宣布独立。
报告数据
这是出于分析和报告目的的汇总数据汇编。这些数据包括交易数据、主数据和参考数据。比如:T rip 数据(交易+主*)大伦敦地区 7 月 13 日*(参考)。报告数据非常具有战略性,通常作为决策过程的组成部分。
[计]元数据
这是一个关于数据的数据。听起来很困惑?确实如此。这是我第一次进入数据管理领域时让我头晕目眩的数据类型。谢天谢地,这张漂亮图片让我很容易理解什么是元数据。

Data & its metadata
如果我问你一个问题:猫是什么颜色的?只要看一下数据,你马上就能自信地回答我的问题。它是灰色的。但是如果我想出另一个问题:这张照片是在何时何地拍摄的呢?你很有可能无法通过只看数据来给我正确的答案。这就是元数据的用武之地。它为您提供了有关数据的完整信息,包括数据拍摄的时间和地点。
所以元数据给了你任何问题的答案,而你仅仅通过数据是无法回答的。所以才说:关于数据的数据。
这就是你需要知道的关于数据类型的全部内容。再说一次,这并不是一个令人疲惫的解释,我可以保证,仅仅通过阅读这篇文章,你还不能接受数据科学家的工作邀请。但是无论何时你在街上遇到有人问你组织中常见的数据类型,你仍然可以带着所有这些解释自信地回答。
通过 Python 示例理解时间复杂性

Big-O Complexity Chart: http://bigocheatsheet.com/
如今,面对我们每天消耗和生成的所有这些数据,算法必须足以处理大量数据的运算。
在这篇文章中,我们将了解更多关于时间复杂性,Big-O 符号以及为什么我们在开发算法时需要关注它。
这个故事中展示的例子是用 Python 开发的,所以如果你至少有 Python 的基础知识,会更容易理解,但这不是先决条件。
让我们开始理解什么是计算复杂性。
计算的复杂性
计算复杂性是计算机科学的一个领域,根据运行算法所需的资源量来分析算法。所需资源的数量根据输入大小而变化,因此复杂性通常表示为 n 的函数,其中 n 是输入的大小。
值得注意的是,当分析一个算法时,我们可以考虑时间复杂度和空间复杂度。空间复杂度基本上是解决与输入大小相关的问题所需的内存空间量。尽管空间复杂度在分析算法时很重要,但在这个故事中,我们将只关注时间复杂度。
时间复杂度
当你现在正在读这个故事的时候,你可能对什么是时间复杂性有一个概念,但是为了确保我们都在同一页上,让我们从维基百科的一个简短描述开始理解时间复杂性意味着什么。
在计算机科学中,时间复杂度是计算复杂度,它描述了运行一个算法所需的时间。时间复杂度通常通过计算算法执行的基本操作的数量来估计,假设每个基本操作花费固定的时间来执行。
在分析算法的时间复杂度时,我们可能会发现三种情况:最佳情况、一般情况和最坏情况。让我们来理解它的含义。
假设我们有下面这个未排序的列表**【1,5,3,9,2,4,6,7,8】**,我们需要使用线性搜索找到这个列表中某个值的索引。
- 最佳情况:这是解决最佳输入问题的复杂度。在我们的例子中,最好的情况是搜索值 1。因为这是列表的第一个值,所以它将在第一次迭代中被找到。
- 平均案例:这是解决问题的平均复杂度。这种复杂性是相对于输入数据中值的分布来定义的。也许这不是最好的例子,但是根据我们的例子,我们可以说,一般情况下,当我们在列表的“中间”搜索某个值时,例如,值 2。
- 最差情况:这是解决大小为 n 的最差输入问题的复杂性。在我们的例子中,最差情况是搜索值 8,这是列表中的最后一个元素。
通常,当描述一个算法的时间复杂度时,我们谈论的是最坏的情况。
好的,但是我们如何描述算法的时间复杂度呢?
我们使用一种叫做 Big-O 的数学符号。
大 O 符号
Big-O 符号,有时也称为“渐近符号”,是一种数学符号,描述了函数在自变量趋向特定值或无穷大时的极限行为。
在计算机科学中,Big-O 符号用于根据算法的运行时间或空间需求如何随着输入大小( n )的增长而增长来对算法进行分类。这种符号根据函数的增长率来表征函数:具有相同增长率的不同函数可以用相同的 O 符号来表示。
让我们看看 Big-O 符号中描述的一些常见的时间复杂性。
常见时间复杂性表
以下是使用 Big-O 符号表示的最常见的时间复杂性:
╔══════════════════╦═════════════════╗
║ **Name** ║ **Time Complexity** ║
╠══════════════════╬═════════════════╣
║ Constant Time ║ O(1) ║
╠══════════════════╬═════════════════╣
║ Logarithmic Time ║ O(log n) ║
╠══════════════════╬═════════════════╣
║ Linear Time ║ O(n) ║
╠══════════════════╬═════════════════╣
║ Quasilinear Time ║ O(n log n) ║
╠══════════════════╬═════════════════╣
║ Quadratic Time ║ O(n^2) ║
╠══════════════════╬═════════════════╣
║ Exponential Time ║ O(2^n) ║
╠══════════════════╬═════════════════╣
║ Factorial Time ║ O(n!) ║
╚══════════════════╩═════════════════╝
请注意,我们将重点研究这些常见的时间复杂性,但还有其他一些时间复杂性,您可以稍后再研究。
正如已经说过的,我们通常使用 Big-O 符号来描述算法的时间复杂度。在符号的正式定义中涉及到很多数学,但是非正式地,我们可以假设 Big-O 符号给出了算法在最坏情况下的大概运行时间。当使用 Big-O 符号时,我们根据输入数据大小的增加来描述算法的效率( n )。例如,如果输入是一个字符串,则 n 将是该字符串的长度。如果是列表,则 n 将是列表的长度,以此类推。
现在,让我们看看这些常见的时间复杂性,并看看一些算法的例子。请注意,我试图遵循以下方法:给出一点描述,展示一个简单易懂的例子,展示一个更复杂的例子(通常来自现实世界的问题)。
时间复杂性
常数时间— O(1)
当一个算法不依赖于输入数据时,该算法被称为具有恒定时间( n )。不管输入数据的大小,运行时间总是一样的。例如:
if a > b:
return True
else:
return False
现在,让我们看看函数 get_first ,它返回列表的第一个元素:
def get_first(data):
return data[0]
if __name__ == '__main__':
data = [1, 2, 9, 8, 3, 4, 7, 6, 5]
print(get_first(data))
不管输入数据大小如何,它总是有相同的运行时间,因为它只从列表中获取第一个值。
具有恒定时间复杂度的算法是极好的,因为我们不需要担心输入大小。
对数时间— O(log n)
当一个算法在每一步中减少输入数据的大小时(它不需要查看输入数据的所有值),该算法被认为具有对数时间复杂度,例如:
for index in range(0, len(data), 3):
print(data[index])
具有对数时间复杂度的算法通常出现在对二叉树的运算中,或者使用二分搜索法时。让我们来看一个二分搜索法的例子,我们需要找到一个元素在一个排序列表中的位置:
def binary_search(data, value):
n = len(data)
left = 0
right = n - 1
while left <= right:
middle = (left + right) // 2
if value < data[middle]:
right = middle - 1
elif value > data[middle]:
left = middle + 1
else:
return middle
raise ValueError('Value is not in the list')
if __name__ == '__main__':
data = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(binary_search(data, 8))
二分搜索法的步骤:
- 计算列表的中间。
- 如果搜索的值低于列表中间的值,则设置一个新的右边界。
- 如果搜索的值高于列表中间的值,则设置一个新的左边界。
- 如果搜索值等于列表中间的值,则返回中间值(索引)。
- 重复上述步骤,直到找到值,或者左边界等于或高于右边界。
理解必须访问其输入数据的所有元素的算法不能花费对数时间是很重要的,因为读取大小为 n 的输入所花费的时间是 n 的数量级。
线性时间— O(n)
当运行时间最多随着输入数据的大小线性增加时,算法被认为具有线性时间复杂度。当算法必须检查输入数据中的所有值时,这是可能的最佳时间复杂度。例如:
for value in data:
print(value)
让我们来看一个线性搜索的例子,我们需要在一个未排序的列表中找到一个元素的位置:
def linear_search(data, value):
for index in range(len(data)):
if value == data[index]:
return index
raise ValueError('Value not found in the list')
if __name__ == '__main__':
data = [1, 2, 9, 8, 3, 4, 7, 6, 5]
print(linear_search(data, 7))
注意,在这个例子中,我们需要查看列表中的所有值,以找到我们要寻找的值。
准线性时间— O(n log n)
当输入数据中的每个操作都具有对数时间复杂度时,称算法具有准线性时间复杂度。常见于排序算法中(如 mergesort 、 timsort 、 heapsort )。
例如:对于数据 1 中的每个值( O(n) )使用二分搜索法( O(log n) )在数据 2 中搜索相同的值。
for value in data1:
result.append(binary_search(data2, value))
另一个更复杂的例子,可以在合并排序算法中找到。Mergesort 是一种高效、通用、基于比较的排序算法,具有准线性时间复杂度,让我们看一个例子:
def merge_sort(data):
if len(data) <= 1:
return
mid = len(data) // 2
left_data = data[:mid]
right_data = data[mid:]
merge_sort(left_data)
merge_sort(right_data)
left_index = 0
right_index = 0
data_index = 0
while left_index < len(left_data) and right_index < len(right_data):
if left_data[left_index] < right_data[right_index]:
data[data_index] = left_data[left_index]
left_index += 1
else:
data[data_index] = right_data[right_index]
right_index += 1
data_index += 1
if left_index < len(left_data):
del data[data_index:]
data += left_data[left_index:]
elif right_index < len(right_data):
del data[data_index:]
data += right_data[right_index:]
if __name__ == '__main__':
data = [9, 1, 7, 6, 2, 8, 5, 3, 4, 0]
merge_sort(data)
print(data)
下图举例说明了 mergesort 算法所采取的步骤。

Mergesort example: https://en.wikipedia.org/wiki/Merge_sort
注意,在这个例子中,排序是就地执行的。
二次时间— O(n)
当一个算法需要对输入数据中的每个值执行线性时间运算时,该算法被称为具有二次时间复杂度,例如:
for x in data:
for y in data:
print(x, y)
冒泡排序是二次时间复杂度的一个很好的例子,因为对于每个值,它需要与列表中的所有其他值进行比较,让我们来看一个例子:
def bubble_sort(data):
swapped = True
while swapped:
swapped = False
for i in range(len(data)-1):
if data[i] > data[i+1]:
data[i], data[i+1] = data[i+1], data[i]
swapped = True
if __name__ == '__main__':
data = [9, 1, 7, 6, 2, 8, 5, 3, 4, 0]
bubble_sort(data)
print(data)
指数时间— O(2^n)
当输入数据集每增加一次,增长就加倍时,算法被认为具有指数时间复杂度。这种时间复杂度通常见于蛮力算法。
正如赖薇所举的例子:
在密码学中,强力攻击可以通过迭代子集来系统地检查密码的所有可能元素。使用指数算法来做到这一点,暴力破解长密码和短密码会变得非常耗费资源。这就是长密码被认为比短密码更安全的原因之一。
指数时间算法的另一个例子是斐波那契数的递归计算:
def fibonacci(n):
if n <= 1:
return n
return fibonacci(n-1) + fibonacci(n-2)
如果你不知道什么是递归函数,那就赶紧说清楚:递归函数可能被描述为在特定条件下调用自身的函数。您可能已经注意到,递归函数的时间复杂度有点难以定义,因为它取决于函数被调用的次数和单次函数调用的时间复杂度。
当我们看递归树时更有意义。下面的递归树是使用 n = 4 通过斐波那契算法生成的:

Recursion tree of Fibonacci(4): https://visualgo.net/bn/recursion
请注意,它会呼叫自己,直到它到达树叶。当到达树叶时,它返回值本身。
现在,看看递归树是如何增长的,只是将 n 增加到 6:

Recursion tree of Fibonacci(6): https://visualgo.net/bn/recursion
你可以在 StackOverflow 的这里找到关于递归斐波那契算法时间复杂度的更完整的解释。
阶乘— O(n!)
当一个算法根据输入数据的大小以阶乘方式增长时,该算法被称为具有阶乘时间复杂度,例如:
2! = 2 x 1 = 2
3! = 3 x 2 x 1 = 6
4! = 4 x 3 x 2 x 1 = 24
5! = 5 x 4 x 3 x 2 x 1 = 120
6! = 6 x 5 x 4 x 3 x 2 x 1 = 720
7! = 7 x 6 x 5 x 4 x 3 x 2 x 1 = 5.040
8! = 8 x 7 x 6 x 5 x 4 x 3 x 2 x 1 = 40.320
正如你可以看到的,它增长非常快,即使是一个小尺寸的输入。
具有阶乘时间复杂度的算法的一个很好的例子是堆算法,它用于生成所有可能的 n 对象的排列。
据维基百科:
希普发现了一种系统的方法,在每一步选择一对元素进行切换,以便恰好一次产生这些元素的每一种可能的排列。
让我们来看看这个例子:
def heap_permutation(data, n):
if n == 1:
print(data)
return
for i in range(n):
heap_permutation(data, n - 1)
if n % 2 == 0:
data[i], data[n-1] = data[n-1], data[i]
else:
data[0], data[n-1] = data[n-1], data[0]
if __name__ == '__main__':
data = [1, 2, 3]
heap_permutation(data, len(data))
结果将是:
[1, 2, 3]
[2, 1, 3]
[3, 1, 2]
[1, 3, 2]
[2, 3, 1]
[3, 2, 1]
请注意,它将根据输入数据的大小以阶乘的方式增长,因此我们可以说该算法的阶乘时间复杂度为 O(n!).
另一个很好的例子是旅行推销员问题。
重要注意事项
值得注意的是,当分析一个算法的时间复杂度时,我们需要根据所有操作中最大的复杂度来描述算法。例如:
def my_function(data):
first_element = data[0]
for value in data:
print(value)
for x in data:
for y in data:
print(x, y)
即使‘my _ function’中的操作没有意义,我们也可以看到它有多个时间复杂度:O(1) + O(n) + O(n)。因此,当增加输入数据的大小时,该算法的瓶颈将是需要 O(n)的运算。基于此,我们可以把这个算法的时间复杂度描述为 O(n)。
Big-O 备忘单
为了让您的生活更轻松,您可以在这里找到一个表格,其中列出了最常见的数据结构中操作的时间复杂度。

Common Data Structure Operations: http://bigocheatsheet.com/
这是另一张关于最常见排序算法的时间复杂度的表格。

Array Sorting Algorithms: http://bigocheatsheet.com/
为什么了解所有这些很重要?
如果在读完所有这些故事后,你仍然对了解时间复杂性和 Big-O 符号的重要性有所怀疑,让我们澄清一些观点。
即使在使用现代语言时,比如 Python,它提供了内置函数,比如排序算法,有一天你可能需要实现一个算法来对一定数量的数据执行某种操作。通过学习时间复杂性,你将理解效率的重要概念,并且能够发现你的代码中应该改进的瓶颈,主要是在处理巨大的数据集时。
除此之外,如果你打算申请谷歌、脸书、推特和亚马逊这样的大公司的软件工程师职位,你需要准备好使用 Big-O 符号回答关于时间复杂性的问题。
最终注释
感谢您阅读这个故事。我希望你已经学到了更多关于时间复杂性和 Big-O 符号的知识。如果你喜欢它,请鼓掌并分享它。如果您有任何疑问或建议,请随时评论或给我发电子邮件。另外,你也可以在 Twitter 、 Linkedin 和 Github 上随时关注我。
参考
- 计算复杂度:https://en.wikipedia.org/wiki/Computational_complexity
- 大 O 符号:https://en.wikipedia.org/wiki/Big_O_notation
- 时间复杂度:https://en.wikipedia.org/wiki/Time_complexity
- Big-O 小抄:http://bigocheatsheet.com/
- 算法时间复杂度的工间介绍:https://vickylai . com/verbose/A-coffee-break-introduction-to-time-complex-of-algorithms/
理解 ul fit——自然语言处理向迁移学习的转变
了解什么是 ULMFiT 它做什么和如何工作;以及它在 NLP 中引起的根本性转变

Image by Hitesh Choudhary from Unsplash
自然语言处理在过去十年中加快了步伐,随着实现深度学习越来越容易,该领域已经有了重大发展。然而,它落后于计算机视觉领域的专业水平。
主要原因是迁移学习使许多计算机视觉任务比实际简单得多——像 VGGNet⁸或 AlexNet⁹这样的预训练模型可以微调以适应大多数计算机视觉任务。这些预训练的模型是在像 ImageNet 这样的大型语料库上训练的。它们被用来捕捉图像的一般特征和属性。因此,经过一些调整,它们可以用于大多数任务。因此,不必为每一项计算机视觉任务从头开始训练模型。此外,由于它们是在一个巨大的语料库上训练的,许多任务的准确性或结果都是非常出色的,并且会胜过为特定任务从头开始训练的较小模型。
另一方面,对于每个 NLP 任务,模型必须被单独地和逐个地训练。这非常耗时,并且限制了这些模型的范围。“最近的方法(2017 年和 2018 年)将来自其他任务的嵌入与不同层的输入连接起来,仍然从头训练主任务模型,并将预训练的嵌入视为固定参数,从而限制了它们的有用性。”缺乏关于如何为各种 NLP 任务适当微调语言模型的知识。
通用语言模型微调
2018 年,霍华德和鲁德等人。艾尔。为归纳迁移学习的神经模型微调提供了一种新方法——给定一个训练模型的源任务,相同的模型将用于在其他任务(NLP 任务)上获得良好的性能。

Figure 2: Main Stages in ULMFiT — Figure from Analytics Vidya
选择基础模型 理想的源任务被视为语言建模,并被视为类似于自然语言处理任务的 ImageNet。这是因为以下原因:“它捕获了与下游任务相关的语言的许多方面,例如长期依赖、等级关系和情感。与机器翻译(MT)和蕴涵等任务相比,它为大多数领域和语言提供了近乎无限量的数据。”此外,语言建模可以被训练以适应特定的目标任务的独特特征,并且语言建模是各种其他 NLP 任务的组成部分。通常,像 AWD-LSTM⁷这样的好的语言模型(LM)被选作基础模型。一般认为,基础模型越好,最终模型在微调后在各种 NLP 任务上的性能就越好。
通用领域语言模型预训练
预训练是在一个大规模的语言语料库上进行的,该语料库能有效地捕捉语言的主要属性和方面。这有点像图像网络语料库,但是对于语言来说。该阶段只需执行一次。得到的预训练模型可以在所有任务的下一阶段重复使用。
预训练已经完成,因此模型已经理解了语言的一般属性,必须稍加调整以适应特定的任务。事实上,发现预训练对于小数据集和中等大小的数据集特别有用。
目标任务 LM 微调当使用预训练模型时,那么,在这个阶段的收敛更快。在这个阶段,判别微调和倾斜三角学习率用于微调语言模型。
区别性微调
“由于不同的层捕捉不同类型的信息,所以应该对它们进行不同程度的微调。”因此,对于每一层,使用不同的学习速率。最后一层的学习,ηᴸ是固定的。然后,用ηˡ⁻ = ηˡ/2.6 来获得其余的学习率。

Figure 3: Weight update for each layer where l=1, 2, …, L is the layer number, ηˡ is the learning rate for the lᵗʰ layer, L is the number of layers, θˡₜ is the weights of the lᵗʰ layer at iteration t and ∇(θˡ) [ J(θ) ] is the gradient with regard to the model’s objective function. — Image and Equation for ULMFiT Research Paper
倾斜三角形学习率 在整个微调过程中,学习率并不保持恒定。最初,对于一些时期,它们以陡峭的斜率线性增加。然后,对于多个时期,它们以逐渐的斜率线性降低。发现这给出了模型的良好性能。

Figure 4: Slanted Triangular Learning Rates — Change of learning rate with each iteration — Image from Wordpress
目标任务分类器微调
“最后,为了微调分类器,我们用两个额外的线性块来扩充预训练的语言模型。”每个块有以下
1。批量正常化
2。辍学
3。中间层
4 的重新激活。softmax 激活输出层以预测类别
进一步改进模型的一些附加步骤
Concat Pooling 一般来说,在文本分类中,重要的词只有几个词,可能是整个文档的一小部分,尤其是文档比较大的时候。因此,为了避免信息丢失,隐藏状态向量与隐藏状态向量的最大汇集和平均汇集形式连接。
逐步解冻
当所有层同时微调时,存在灾难性遗忘的风险。因此,最初除了最后一层之外的所有层都被冻结,并且微调在一个时期内完成。一个接一个的层被解冻,微调完成。重复这一过程直到收敛。
使用双向模型 组合前向和后向 LM 分类器进一步提高了性能。

Figure 5: Block Diagram of ULMFiT in Text Analysis — Image from by HU-Berlin from GitHub
ULMFiT 的优势 与在相应数据集上从头开始训练的模型相比,基于 ulm fit 的模型(已经过预训练)即使在中小型数据集上也表现得非常好。这是因为他们已经在前期训练中掌握了语言的特性。
新提出的微调 LM 和分类器的方法证明比使用传统的微调模型的方法给出更好的精度。

Figure 6: ULMFiT Performance Comparison on IMDB Dataset — Image from FastAI
ULMFiT 彻底改变了 NLP 领域,提高了 NLP 中深度学习的范围,并使在比以前少得多的时间内为各种任务训练模型成为可能。这为自然语言处理的迁移学习奠定了基础,并为埃尔莫、GPT、GPT-2、伯特和 XLNet 铺平了道路。
注意:我最初写这篇文章是作为我的自然语言处理课程的作业。
在我的 YouTube 频道上观看解释机器学习、人工智能和数据科学概念的视频。
参考
[1]霍华德,j .,&鲁德,S. (2018)。用于文本分类的通用语言模型微调。 arXiv 预印本 arXiv:1801.06146 。*
【2】图一:【https://miro.medium.com/proxy/0*2t3JCdtfsV2M5S_B.png】
【3】图二:https://cdn . analyticsvidhya . com/WP-content/uploads/2018/11/ulm fit _ flow _ 2 . png
【4】图四:https://yashuseth . files . WordPress . com/2018/06/stlr-formula 2 . jpg?w=413 & h=303 2017 年 b。指针哨兵混合模型。2017 年国际学习代表会议论文集。
[8]西蒙扬,k .,&齐塞曼,A. (2014)。用于大规模图像识别的非常深的卷积网络。 arXiv 预印本 arXiv:1409.1556 。
[9]克里热夫斯基,a .,&辛顿,G. E. (2012)。基于深度卷积神经网络的图像网分类。在神经信息处理系统的进展(第 1097-1105 页)。
*本文中的许多短语、句子和段落都是表格[1]中句子或段落的总结。图 3 也取自[1]。
理解理解:事物如何有意义

我们的理解是我们如何认识我们的世界。它是我们的“心灵之眼”,是我们思考的地方,也是唯一赋予任何事物意义的东西。理解之外的其他体验都是通过感觉来感知的。
你将要读到的描述了无意识理解的过程。支配有意识理解的机制是未来文章的主题。
为了清楚起见,理解和觉察是说类似事情的两个角度。理解是用知识从基础上重建现实,而觉知指的是被重建的对象。
知识是理解的必要条件。知识是识别模式并将其抽象为信号的能力。一个有知识的人是能识别很多模式的人。当多个信号能够告知一个更高层次的模式时,理解就形成了。
如果你看到你下面有一艘船,周围都是水,你知道你在一片水域中的一艘船上。

虽然可能不明显,但这种理解是一种基本的模拟。例如,如果你认识到船在水面上没有摇晃,这个新的信号会改变你的理解。你可以模拟水很浅,船停在水下的地面上。
理解是一个模拟的场景,而意识是指场景中的对象。
现在,你正在用你的理解能力来阅读这句话。你正试图模拟用特定顺序排列的单词来产生这篇文章的思维。
你读的每一个单词都在激活你大脑中该单词的语义表征。“语义”意味着激活代表多维思维空间中的特定位置。我会详细说明这是什么意思:
每个词都可以在很多属性或“维度”上识别。例如,考虑“温度”维度:“火”因为高温而具有较大的正值,“冰”因为低温而具有较大的负值,“云”则接近于零,因为我们通常不认为云具有温度属性。
同时,考虑“硬度”维度:“冰”将具有大的正值,因为冰是硬的,“云”将具有大的负值,因为云是软的,“火”将接近于零,因为火通常不被认为具有硬度属性。
总的来说,所有用来描述每个单词的各种属性最终创造了一个想象的多维思维空间,每个单词都存在于其中的特定位置。

在大脑中,给定维度上的正值是连接到该属性的兴奋性神经连接,负值是连接到该属性的抑制性神经连接,零值是缺乏与该属性的连接。
在人工智能神经网络中,程序使用向量(一系列数字)来表示每个单词,这些数字是该单词在多维思维空间中所处位置的坐标。向量中的每个数字可以是正的、负的或接近于零的,并表示该单词如何与给定的维度属性相关。
理解“语义”真的很重要,因为语义是思维的基础。当你阅读每个单词时,你在大脑中激活该单词的语义表示(识别为信号的模式),同时使用语法来修改表示,并以特定的方式将它们联系在一起。“阅读”的结果是在多维思维空间中创建一条导航路径。给你几个特定的位置,对应于代表,并告诉他们连接。
为了理解你所读到的,你必须利用你大脑中的连接来重现同样的路径。所以,文字就成了被复制的模板。为了完成这种复制,你修改神经连接来连接由模板指示的思想空间中的特定位置。这个过程就是前面提到的模拟。
一旦你的模拟与通过阅读获得的模板相匹配,你就明白了我想要传达的意思。而且,你的模拟和我的模拟的差异是我们的沟通错误。
“在多维思维空间中生成路径的能力”与“对思维的理解”是同义词。当有人说“我懂”的时候,其实是在说“我会模拟”。
了解变分自动编码器(VAEs)
逐步建立导致 VAEs 的推理。

Credit: Free-Photos on Pixabay
这篇文章是与巴蒂斯特·罗卡共同撰写的。
介绍
在过去的几年里,由于(并暗示)该领域的一些惊人的改进,基于深度学习的生成模型已经获得了越来越多的兴趣。依靠大量的数据、精心设计的网络架构和智能训练技术,深度生成模型显示出令人难以置信的能力,可以生成各种类型的高度逼真的内容,如图像、文本和声音。在这些深度生成模型中,有两个主要家族引人注目,值得特别关注:生成对抗网络(GANs)和变分自动编码器(VAEs)。

Face images generated with a Variational Autoencoder (source: Wojciech Mormul on Github).
在今年 1 月发表的前一篇文章中,我们深入讨论了生成对抗网络(GANs) ,并特别展示了对抗训练如何对抗两个网络,一个生成器和一个鉴别器,以推动它们改进一次又一次的迭代。在这篇文章中,我们现在介绍另一种主要的深度生成模型:变分自动编码器(VAEs)。简而言之,VAE 是一个自动编码器,其编码分布在训练期间被正则化,以确保其潜在空间具有良好的属性,允许我们生成一些新数据。此外,术语“变分”来源于统计学中正则化和变分推断方法之间的密切关系。
如果最后两句很好地总结了 VAEs 的概念,它们也可以提出许多问题。什么是自动编码器?什么是潜在空间,为什么要规范它?如何从 VAEs 生成新数据?VAEs 和变分推理有什么联系?为了尽可能好地描述 VAEs,我们将尝试回答所有这些问题(以及许多其他问题!)并为读者提供尽可能多的见解(从基本的直觉到更高级的数学细节)。因此,这篇文章的目的不仅是讨论变分自动编码器所依赖的基本概念,而且是一步一步地建立,并从最开始的推理开始,导致这些概念。
事不宜迟,让我们一起(重新)发现 VAEs 吧!
概述
在第一部分中,我们将回顾一些关于降维和自动编码器的重要概念,它们将有助于理解 VAEs。然后,在第二部分中,我们将说明为什么自动编码器不能用于生成新数据,并将介绍各种自动编码器,它们是自动编码器的规范化版本,使生成过程成为可能。最后,在最后一节中,我们将基于变分推理给出一个更数学化的 VAEs 表示。
注。在上一节中,我们试图使数学推导尽可能完整和清晰,以弥合直觉和方程之间的差距。然而,不想深入 VAEs 的数学细节的读者可以跳过这一节,而不会影响对主要概念的理解。还要注意,在这篇文章中,我们将滥用符号:对于一个随机变量 z,我们将 p(z)表示这个随机变量的分布(或密度,取决于上下文)。
降维、PCA 和自动编码器
在第一部分中,我们将首先讨论一些与降维相关的概念。特别是,我们将简要回顾主成分分析(PCA)和自动编码器,显示这两个想法是如何相互关联的。
什么是降维?
在机器学习中, 降维 就是减少描述某些数据的特征数量的过程。这种缩减可以通过选择(仅保留一些现有特征)或提取(根据旧特征创建数量减少的新特征)来完成,在许多需要低维数据的情况下(数据可视化、数据存储、大量计算……)非常有用。虽然存在许多不同的降维方法,但我们可以建立一个全局框架来匹配大多数(如果没有的话!)的这些方法。
首先,我们称编码器为从“旧特征”表示(通过选择或提取)产生“新特征”表示的过程,称解码器为相反的过程。维数减少可以被解释为数据压缩,其中编码器压缩数据(从初始空间到编码空间,也称为潜在空间,而解码器解压缩它们。当然,取决于初始数据分布、潜在空间维度和编码器定义,这种压缩可能是有损的,这意味着一部分信息在编码过程中丢失,并且在解码时无法恢复。

Illustration of the dimensionality reduction principle with encoder and decoder.
降维方法的主要目的是在给定系列中找到最佳编码器/解码器对。换句话说,对于给定的一组可能的编码器和解码器,我们正在寻找这样一对编码器和解码器:当对进行编码时,保持最大的信息量,因此,当对进行解码时,具有最小的重建误差。如果我们分别用 E 和 D 表示我们所考虑的编码器和解码器的族,那么降维问题可以写成

在哪里

定义输入数据 x 和编码-解码数据 d(e(x))之间的重构误差度量。最后注意,在下文中,我们将表示 N 为数据数量,n_d 为初始(解码)空间的维数,n_e 为缩减(编码)空间的维数。
主成分分析
谈到降维,首先想到的方法之一是 主成分分析(PCA) 。为了展示它如何符合我们刚刚描述的框架,并与自动编码器建立联系,让我们对 PCA 的工作原理做一个非常全面的概述,把大部分细节放在一边*(注意,我们计划就这个主题写一篇完整的帖子)*。
PCA 的思想是建立 n_e 个新的独立的特征,这些特征是 n_d 个旧特征的线性组合,这样由这些新特征定义的子空间上的数据投影尽可能接近初始数据(根据欧几里德距离)。换句话说,PCA 正在寻找初始空间(由新特征的正交基描述)的最佳线性子空间,使得通过数据在该子空间上的投影来近似数据的误差尽可能小。

Principal Component Analysis (PCA) is looking for the best linear subspace using linear algebra.
在我们的全局框架中,我们在 n_e 乘 n_d 矩阵(线性变换)的族 E 中寻找一个编码器,其行是正交的(特征独立),并且在 n_d 乘 n_e 矩阵的族 D 中寻找相关的解码器。可以看出,对应于协方差特征矩阵的 n_e 个最大特征值(范数形式)的酉特征向量是正交的(或者可以被选择为正交的),并且定义了 n_e 维的最佳子空间,以最小的近似误差将数据投影到该子空间上。因此,这些 n_e 特征向量可以被选为我们的新特征,因此,降维问题可以表示为一个特征值/特征向量问题。此外,还可以看出,在这种情况下,解码器矩阵是编码器矩阵的转置。

PCA matches the encoder-decoder framework we described.
自动编码器
现在让我们讨论一下自动编码器,看看我们如何使用神经网络进行降维。自动编码器的一般想法非常简单,包括将编码器和解码器设置为神经网络,以及使用迭代优化过程学习最佳编码-解码方案。因此,在每次迭代中,我们向自动编码器架构(编码器后接解码器)提供一些数据,我们将编码-解码输出与初始数据进行比较,并通过架构反向传播误差,以更新网络的权重。
因此,直觉上,整个自动编码器架构(编码器+解码器)为数据创建了一个瓶颈,确保只有信息的主要结构化部分能够通过并被重构。查看我们的一般框架,所考虑的编码器族 E 由编码器网络架构定义,所考虑的解码器族 D 由解码器网络架构定义,并且通过在这些网络的参数上的梯度下降来完成最小化重构误差的编码器和解码器的搜索。

Illustration of an autoencoder with its loss function.
让我们首先假设我们的编码器和解码器架构都只有一个没有非线性的层(线性自动编码器)。这样的编码器和解码器是简单的线性变换,可以用矩阵表示。在这种情况下,我们可以看到与 PCA 的明确联系,就像 PCA 一样,我们正在寻找最佳的线性子空间来投影数据,同时尽可能少地丢失信息。用 PCA 获得的编码和解码矩阵自然地定义了我们将满意地通过梯度下降达到的解决方案之一,但是我们应该概述这不是唯一的一个。实际上,可以选择几个基来描述同一个最佳子空间,因此,几个编码器/解码器对可以给出最佳重建误差。此外,对于线性自动编码器,与 PCA 相反,我们最终得到的新特征不必是独立的(在神经网络中没有正交约束)。

Link between linear autoencoder and PCA.
现在,让我们假设编码器和解码器都是深度非线性的。在这种情况下,架构越复杂,自动编码器就越能在保持低重建损失的同时进行高维数缩减。直观上,如果我们的编码器和解码器有足够的自由度,我们可以将任何初始维数减少到 1。事实上,具有“无限能力”的编码器理论上可以将我们的 N 个初始数据点编码为 1、2、3…直到 N(或者更一般地,作为实轴上的 N 个整数),并且相关联的解码器可以进行相反的变换,在该过程中没有损失。
在这里,我们应该记住两件事。首先,在没有重建损失的情况下进行重要的维度缩减通常是有代价的:在潜在空间中缺乏可解释和可利用的结构(缺乏规律性)。其次,在大多数情况下,降维的最终目的不仅仅是减少数据的维数,而是减少这个维数**,同时将数据结构信息的主要部分保留在简化的表示中**。由于这两个原因,潜在空间的维度和自动编码器的“深度”(定义压缩的程度和质量)必须根据降维的最终目的仔细控制和调整。

When reducing dimensionality, we want to keep the main structure there exists among the data.
可变自动编码器
到目前为止,我们已经讨论了降维问题,并介绍了自动编码器,它是可以通过梯度下降来训练的编码器-解码器架构。现在让我们把内容生成问题联系起来,看看当前形式的自动编码器在这个问题上的局限性,并介绍变化的自动编码器。
用于内容生成的自动编码器的局限性
在这一点上,一个很自然的问题浮现在脑海中:“自动编码器和内容生成之间有什么联系?”。事实上,一旦自动编码器被训练,我们就有了编码器和解码器,但仍然没有真正的方法来产生任何新的内容。乍一看,我们可能会认为,如果潜在空间足够规则(在训练过程中由编码器“组织得很好”),我们可以从潜在空间中随机选取一个点,并对其进行解码以获得新的内容。然后,解码者的行为或多或少会像一个生成性对抗网络的生成器。

We can generate new data by decoding points that are randomly sampled from the latent space. The quality and relevance of generated data depend on the regularity of the latent space.
然而,正如我们在上一节中讨论的,自动编码器的潜在空间的正则性是一个难点,它取决于初始空间中的数据分布、潜在空间的维度和编码器的架构。因此,很难(如果不是不可能的话)事先确保编码器会以一种与我们刚刚描述的生成过程兼容的智能方式组织潜在空间。
为了说明这一点,让我们考虑之前给出的例子,其中我们描述了一个编码器和一个解码器,其功能强大到足以将任意 N 个初始训练数据放到实轴上(每个数据点被编码为一个实值)并对它们进行解码,而没有任何重建损失。在这种情况下,自动编码器的高自由度使得无信息损失地编码和解码成为可能(尽管潜在空间的维度低)导致严重的过拟合,这意味着潜在空间的一些点一旦解码将给出无意义的内容。如果这个一维的例子被自愿选择为非常极端的,我们可以注意到自动编码器潜在空间正则性的问题比它更普遍,值得特别注意。

Irregular latent space prevent us from using autoencoder for new content generation.
仔细想想,潜在空间中的编码数据缺乏结构是很正常的。事实上,在任务中,自动编码器没有被训练来强制实现这样的组织:自动编码器被单独训练来以尽可能少的损失进行编码和解码,不管潜在空间是如何组织的。因此,如果我们不仔细考虑架构的定义,很自然地,在训练过程中,网络会利用任何过度拟合的可能性来尽可能好地完成它的任务…除非我们明确地将其规范化!
变分自动编码器的定义
因此,为了能够将我们的自动编码器的解码器用于生成目的,我们必须确保潜在空间足够规则。获得这种规律性的一个可能的解决方案是在训练过程中引入明确的规律性。因此,正如我们在这篇文章的介绍中简要提到的,一个变分的自动编码器可以被定义为一个自动编码器,它的训练是正则化的,以避免过拟合,并确保潜在空间具有支持生成过程的良好属性。
就像标准的自动编码器一样,变分自动编码器是由编码器和解码器组成的架构,并且被训练来最小化编码-解码数据和初始数据之间的重构误差。然而,为了引入潜在空间的一些正则化,我们对编码-解码过程进行了轻微的修改:不是将输入编码为单个点,而是将其编码为潜在空间上的分布。然后,该模型被训练如下:
- 首先,输入被编码为在潜在空间上的分布
- 第二,从潜在空间中的一个点对该分布进行采样
- 第三,对采样点进行解码,并且可以计算重建误差
- 最后,重构误差通过网络反向传播

Difference between autoencoder (deterministic) and variational autoencoder (probabilistic).
在实践中,编码的分布被选择为正态分布,使得编码器可以被训练以返回描述这些高斯分布的均值和协方差矩阵。将输入编码为具有一些方差的分布而不是单个点的原因是,它使得非常自然地表达潜在空间正则化成为可能:由编码器返回的分布被强制接近标准正态分布。我们将在下一小节中看到,我们通过这种方式确保了潜在空间的局部和全局正则化(局部是因为方差控制,全局是因为均值控制)。
因此,当训练 VAE 时被最小化的损失函数由“重建项”(在最终层上)和“正则化项”(在潜在层上)组成,所述“重建项”倾向于使编码-解码方案尽可能有性能,所述“正则化项”倾向于通过使编码器返回的分布接近标准正态分布来正则化潜在空间的组织。正则化项表示为返回分布和标准高斯分布之间的 Kulback-Leibler 散度,将在下一节中进一步证明。我们可以注意到,两个高斯分布之间的 Kullback-Leibler 散度有一个封闭的形式,可以直接用两个分布的均值和协方差矩阵来表示。

In variational autoencoders, the loss function is composed of a reconstruction term (that makes the encoding-decoding scheme efficient) and a regularisation term (that makes the latent space regular).
关于规范化的直觉
为了使生成过程成为可能,期望从潜在空间中得到的规律性可以通过两个主要属性来表达:连续性(潜在空间中两个接近的点一旦被解码就不应该给出两个完全不同的内容)和完全性(对于选定的分布,从潜在空间中采样的点一旦被解码就应该给出“有意义的”内容)。

Difference between a “regular” and an “irregular” latent space.
VAEs 将输入编码为分布而不是简单的点这一事实不足以确保连续性和完整性。如果没有明确定义的正则化项,为了最小化其重建误差,模型可以学习来“忽略”分布被返回的事实,并表现得几乎像经典的自动编码器(导致过拟合)。为此,编码器可以返回具有微小方差的分布(趋于为点分布),或者返回具有非常不同的平均值的分布(在潜在空间中彼此相距非常远)。在这两种情况下,分配的使用方式都是错误的(取消了预期收益),连续性和/或完整性都得不到满足。
因此,为了避免这些影响**,我们必须调整协方差矩阵和编码器**返回的分布均值。在实践中,这种规范化是通过强制分布接近标准正态分布(集中和减少)来实现的。通过这种方式,我们要求协方差矩阵接近恒等式,以防止准时分布,并且要求均值接近 0,以防止编码分布彼此相距太远。

The returned distributions of VAEs have to be regularised to obtain a latent space with good properties.
通过这个正则化项,我们防止模型在潜在空间中对相距很远的数据进行编码,并鼓励尽可能多的返回分布“重叠”,以这种方式满足预期的连续性和完整性条件。自然地,对于任何正则化项,这是以训练数据上更高的重建误差为代价的。然而,可以调整重建误差和 KL 散度之间的折衷,并且我们将在下一节中看到如何从我们的形式推导中自然地出现平衡的表达式。
总结这一小节,我们可以观察到通过正则化获得的连续性和完整性倾向于在潜在空间中编码的信息上创建一个“梯度”。例如,在来自不同训练数据的两个编码分布的平均值之间的潜在空间的点应该被解码为在给出第一分布的数据和给出第二分布的数据之间的某处,因为在两种情况下它都可以被自动编码器采样。

Regularisation tends to create a “gradient” over the information encoded in the latent space.
**注。**顺便提一下,我们可以提到,我们提到的第二个潜在问题(网络使分布彼此远离)实际上几乎等同于第一个问题(网络倾向于返回正点分布),直到尺度发生变化:在两种情况下,分布的方差相对于它们的均值之间的距离变小。
VAEs 的数学细节
在前面的部分中,我们给出了以下直观的概述:vae 是自动编码器,其将输入编码为分布而不是点,并且其潜在空间“组织”通过将编码器返回的分布约束为接近标准高斯分布而被正则化。在这一节中,我们将给出一个更加数学化的 VAEs 视图,这将允许我们更加严格地证明正则化项。为此,我们将建立一个清晰的概率框架,并将特别使用变分推理技术。
概率框架和假设
让我们首先定义一个概率图形模型来描述我们的数据。我们用 x 表示代表我们的数据的变量,并假设 x 是从一个潜在的变量 z(编码表示)中产生的,这个变量不能被直接观察到。因此,对于每个数据点,假设以下两步生成过程:
- 首先,从先验分布 p(z)中采样潜在表示 z
- 第二,从条件似然分布 p(x|z)中采样数据 x

Graphical model of the data generation process.
有了这样一个概率模型,我们可以重新定义编码器和解码器的概念。事实上,与考虑确定性编码器和解码器的简单自动编码器相反,我们现在将考虑这两个对象的概率版本。“概率解码器”自然由 p(x|z)定义,它描述了给定编码变量时解码变量的分布,而“概率编码器”由 p(z|x)定义,它描述了给定解码变量时编码变量的分布。
在这一点上,我们已经可以注意到,我们在简单的自动编码器中缺乏的潜在空间的正则化自然地出现在数据生成过程的定义中:潜在空间中的编码表示 z 实际上被假设为遵循先验分布 p(z)。另外,我们还可以想起著名的贝叶斯定理,它将先验 p(z)、似然性 p(x|z)和后验 p(z|x)联系起来

现在让我们假设 p(z)是标准高斯分布,并且 p(x|z)是高斯分布,其均值由 z 的变量的确定性函数 F 定义,并且其协方差矩阵具有乘以单位矩阵 I 的正常数 c 的形式。因此,我们有

现在让我们考虑,f 是明确定义的,固定的。理论上,我们知道 p(z)和 p(x|z),就可以用贝叶斯定理计算 p(z|x):这是一个经典的贝叶斯推理问题。然而,正如我们在上一篇文章中讨论的,这种计算通常是难以处理的(因为分母上的积分),并且需要使用近似技术,例如变分推理。
**注。**这里我们可以提到 p(z)和 p(x|z)都是高斯分布。因此,如果我们有 E(x|z) = f(z) = z,这将意味着 p(z|x)也应该遵循高斯分布,并且在理论上,我们可以“仅仅”尝试相对于 p(z)和 p(x|z)的均值和协方差矩阵来表达 p(z|x)的均值和协方差矩阵。然而,在实践中,这一条件并不满足,我们需要使用一种近似技术,如变分推理,使这种方法相当普遍,对模型假设的某些变化更加稳健。
变分推理公式
在统计学中,变分推断(VI)是一种近似复杂分布的技术。想法是设置一个参数化的分布族(例如高斯分布族,其参数是平均值和协方差),并在该族中寻找我们的目标分布的最佳近似。该族中的最佳元素是最小化给定近似误差测量(大多数情况下近似和目标之间的 Kullback-Leibler 散度)的元素,并且通过描述该族的参数的梯度下降来找到。更多细节,我们参考我们关于变分推理的帖子和其中的参考资料。
这里,我们将通过高斯分布 q_x(z)来近似 p(z|x ),其均值和协方差由参数 x 的两个函数 G 和 H 来定义。这两个函数分别属于函数 G 和 H 的族,函数 G 和 H 将在后面详细说明,但应该是参数化的。因此,我们可以表示

因此,我们以这种方式定义了一族用于变分推理的候选项,现在需要通过优化函数 g 和 h(实际上是它们的参数)来找到这一族中的最佳近似值,以最小化近似值和目标 p(z|x)之间的 Kullback-Leibler 散度。换句话说,我们在寻找最优的 g和 h使得

在倒数第二个方程中,我们可以观察到在最大化“观察”的可能性(最大化预期对数似然,对于第一项)和保持接近先验分布(最小化 q_x(z)和 p(z)之间的 KL 散度,对于第二项)之间存在折衷。这种权衡对于贝叶斯推理问题来说是很自然的,并且表达了需要在我们对数据的信心和我们对先验的信心之间找到的平衡。
到目前为止,我们已经假设函数 f 是已知的和固定的,并且我们已经表明,在这样的假设下,我们可以使用变分推理技术来逼近后验 p(z|x)。然而,在实践中,定义解码器的这个函数 f 是未知的,并且也需要被选择。为了做到这一点,让我们提醒一下,我们的最初目标是找到一个性能编码-解码方案,其潜在空间足够规则以用于生成目的。如果正则性主要由在潜在空间上假设的先验分布决定,则整个编码-解码方案的性能高度依赖于函数 f 的选择。实际上,由于 p(z|x)可以由 p(z)和 p(x|z)近似(通过变分推断),并且由于 p(z)是简单的标准高斯函数,因此在我们的模型中,我们可用于进行优化的仅有的两个杠杆是参数 c(其定义了似然性的方差)和函数 f(其定义了似然性的均值)。
因此,让我们考虑,正如我们先前所讨论的,我们可以为 F 中的任何函数 F(每个函数定义一个不同的概率解码器 p(x|z))得到 p(z|x)的最佳近似,记为 q*_x(z)。尽管它是概率性的,我们正在寻找一种尽可能有效的编码-解码方案,然后,当 z 从 q*_x(z)中被采样时,我们想要选择最大化给定 z 的 x 的期望对数似然的函数 f。换言之,对于给定的输入 x,当我们从分布 q*_x(z)中采样 z,然后从分布 p(x|z)中采样 x̂时,我们希望最大化 x̂ = x 的概率。因此,我们寻找最优的 f*,使得

其中 q*_x(z)取决于函数 f,并如前所述获得。将所有的部分集合在一起,我们寻找最优的 f*,g和 h使得

我们可以在这个目标函数中识别在前面部分中给出的 VAEs 的直观描述中引入的元素:x 和 f(z)之间的重构误差以及由 q_x(z)和 p(z)之间的 KL 散度给出的正则化项(这是一个标准高斯)。我们还可以注意到,常数 c 决定了前两项之间的平衡。在我们的模型中,c 越高,我们就越假设概率解码器在 f(z)附近的方差高,因此,我们就越倾向于正则化项而不是重建项(如果 c 低,则相反)。
将神经网络引入模型
到目前为止,我们已经建立了依赖于三个函数 f、g 和 h 的概率模型,并且使用变分推理来表达要求解的优化问题,以便获得 f*、g和 h,它们给出了利用该模型的最佳编码-解码方案。由于我们无法在整个函数空间内轻松优化,我们限制了优化域,并决定将 f、g 和 h 表示为神经网络。因此,F、G 和 H 分别对应于由网络体系结构定义的函数族,并且对这些网络的参数进行优化。
实际上,g 和 h 不是由两个完全独立的网络定义的,而是共享它们的一部分架构和权重,所以我们有

因为它定义了 q_x(z)的协方差矩阵,所以 h(x)应该是一个方阵。然而,为了简化计算和减少参数的数量,我们额外假设我们的 p(z|x),q_x(z)的近似是具有对角协方差矩阵的多维高斯分布(变量独立性假设)。在这种假设下,h(x)仅仅是协方差矩阵的对角元素的向量,并且具有与 g(x)相同的大小。然而,我们用这种方法减少了我们考虑的变分推论的分布族,因此,得到的 p(z|x)的近似值可能不太精确。

Encoder part of the VAE.
与模拟 p(z|x)的编码器部分相反,我们考虑的是具有 x (g 和 h)的函数的均值和协方差的高斯,我们的模型假设 p(x|z)是具有固定协方差的高斯。定义高斯平均值的变量 z 的函数 f 由神经网络建模,并可表示如下

Decoder part of the VAE.
然后通过连接编码器和解码器部分获得整体架构。然而,我们仍然需要非常小心在训练期间从编码器返回的分布中采样的方式。采样过程必须以允许误差通过网络反向传播的方式来表示。一个简单的技巧,称为重新参数化技巧,用于使梯度下降成为可能,尽管随机采样发生在架构的中途,并且在于使用以下事实:如果 z 是一个随机变量,遵循具有均值 g(x)和协方差 H(x)=h(x)的高斯分布。h^t(x)那么它可以表示为


Illustration of the reparametrisation trick.
最后,以这种方式获得的变分自动编码器架构的目标函数由前一小节的最后一个方程给出,其中理论预期被或多或少精确的蒙特卡罗近似所代替,该近似在大多数时间包含在单次绘制中。因此,考虑到这种近似并表示 C = 1/(2c),我们恢复了在前面部分中直观导出的损失函数,该函数由重建项、正则化项和定义这两项的相对权重的常数组成。

Variational Autoencoders representation.
外卖食品
这篇文章的主要观点是:
- 降维是减少描述某些数据的特征数量的过程(或者通过仅选择初始特征的子集,或者通过将它们组合成数量减少的新特征),因此,可以被视为编码过程
- 自动编码器是由编码器和解码器组成的神经网络架构,其产生数据通过的瓶颈,并且被训练为在编码-解码过程中丢失最少量的信息(通过梯度下降迭代训练,目的是减少重建误差)
- 由于过拟合,自动编码器的潜在空间可能非常不规则(潜在空间中的接近点可能会给出非常不同的解码数据,潜在空间中的某个点一旦解码可能会给出无意义的内容……),因此,我们无法真正定义一个生成过程,该过程只是简单地从潜在空间中采样一个点,并使其通过解码器以获得新数据
- 变分自动编码器(VAEs)是通过使编码器返回潜在空间上的分布而不是单个点,并通过在损失函数中添加返回分布上的正则化项以确保潜在空间的更好组织来解决潜在空间不规则问题的自动编码器
- 假设一个简单的潜在概率模型来描述我们的数据,由重建项和正则化项组成的 VAEs 的非常直观的损失函数,可以特别使用变分推断的统计技术(因此称为“变分”自动编码器)仔细地导出
总之,我们可以概括说,在过去的几年里,GANs 比 VAEs 从更多的科学贡献中受益。除了其他原因之外,社区对 GANs 表现出的更高兴趣可以部分地解释为 VAEs 理论基础(概率模型和变分推理)的复杂程度高于支配 GANs 的对抗性训练概念的简单程度。通过这篇文章,我们希望我们能够分享有价值的直觉以及强大的理论基础,使 VAEs 更容易为新人所接受,正如我们今年早些时候为 GANs 所做的那样。然而,现在我们已经深入地讨论了他们两个,还有一个问题…你更像 gan 还是 VAEs?
感谢阅读!
与巴蒂斯特·罗卡一起写的其他文章:
几种主要推荐算法综述。
towardsdatascience.com](/introduction-to-recommender-systems-6c66cf15ada) [## 整体方法:装袋、助推和堆叠
理解集成学习的关键概念。
towardsdatascience.com](/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205)
理解各种 MDM 实现风格
最近,我有机会为一家金融监管机构写了一些关于主数据管理(MDM)的报告,在那里我学到了很多关于 MDM 的知识。我一直对 MDM 主题的复杂性感到惊讶,我了解的越多,我就越意识到我以前不知道的事情。虽然我可能距离成为 MDM 专家还有千里之遥,但是有些方面我已经开始有了很好理解。其中之一是人们可以选择不同的实现方式来满足他们的需求。

大多数情况下,决定 MDM 实现风格的是与数据管理相关的业务情况。虽然在整个组织中创建和维护单一版本的 truth 是最终目标,但在实现该目标的过程中可以有不同的关注点,例如提高数据质量、维护遗留系统和提供数据可访问性,等等。
这些因素中的每一个都可以通过实现特定的实现风格来获得。在这里,我们看一下 4 种常见的 MDM 实现方法,您可以选择它们来满足您的业务需求。我已经按照从最少打扰到最多打扰的方式进行了安排。
登记处
如果您有大量的源系统,每个系统都有自己的规则和复杂性,很难修改,那么您可能希望考虑以注册方式实现 MDM。有了几个源系统之后,可能很难立即建立权威的源,所以您只需从源中提取所有数据,将其放在 MDM hub 上,让它发挥魔力。MDM 将筛选数据并运行清洗和匹配算法,为重复记录分配唯一的全局标识符,并最终建立单一版本的 truth。

这种方法的美妙之处在于 MDM 永远不会触及您的源系统,这意味着尽管下游应用程序(如您的企业数据仓库(EDW)和报告系统)现在可以使用经过清理和标准化的主数据,但源系统中不会发生任何变化。这对于那些修改源系统会导致大量成本和资源的组织来说是非常有益的,更不用说法规限制了。
总而言之,注册表风格是实现 MDM 成本最低的方式,但是当然也有一些缺点,比如延迟。
合并
脱离了低成本和非侵入式的注册风格,我们现在有了整合方法,它仍然是非侵入式的,但是在 MDM hub 中增加了功能:管理。什么是管家?嗯,基本上就是在整个 MDM 流程中引入人的因素。因此,在您的 MDM 运行对收集的数据进行清理、匹配、链接和合并的算法,并建立单一来源的真相/黄金记录之后,有些人可以调整黄金记录,使其更加黄金。这些人被称为数据管家,他们所做的活动值得另一个专门的媒体职位。

整合方法及其管理功能是集中存储主数据并将其用作分析和报告参考点的一种很好的方式。下游应用程序可以享受可信的黄金记录,而源系统仍然可以照常维持业务。
共存

如果您已经有了整合风格,那么您可以通过将循环添加回您系统来发展成共存风格。这意味着,将黄金记录发送回各个源系统,这样您现在就可以享受 MDM hub 和源系统之间的实时同步了。此外,主数据的更新可以在两者中进行,这意味着主数据质量的显著提高。请记住,这种方法更具侵入性,并且允许更新发生在您的源系统中,您需要确保源系统具有数据清理功能,以便与中心保持一致。
交易/集中
这是 MDM 实现风格的顶峰,在这种风格中,中心成为主数据的单一提供者。在这种方式下,可以简单地说,所有主数据都被转移到 hub,任何外部系统都不能再创建或修改主数据,而是必须向 hub 订阅任何更新。

这种方法需要耗费大量的资源和时间来实现,但幸运的是,这只是前面介绍的实现方式的另一种演变。因此,组织可以花时间,如果他们确定他们的业务需要事务风格提供的优势,那么他们应该去做。
虽然这个解释并不详尽,但我希望这个简短的解释能够对 MDM 的复杂世界有一些初步的了解,尤其是实现风格。幸运的是,每种实现风格都不是惩罚性的,人们可以根据自己的需要从一种风格发展到另一种风格。只要人们选择了支持各种实现风格的正确的 MDM 平台,那么他们就处于非常有利的地位。
祝 MDM-ing 快乐!
理解简单和多元线性回归何时给出不同的结果

Taken from pexels
简单和多元线性回归通常是用于调查数据关系的第一个模型。如果你和他们玩得够久,你最终会意识到他们可以给出不同的结果。
使用简单线性回归时有意义的关系在使用多元线性回归时可能不再有意义,反之亦然,简单线性回归中不重要的关系在多元线性回归中可能变得有意义。
认识到为什么会发生这种情况,将有助于提高你对线性回归的理解。
快速回顾一下简单的线性回归,它试图以下列形式对数据进行建模:

如果斜率项很重要,那么 x 每增加一个单位,y 就会平均增加β_ 1,这不可能是偶然发生的。
假设我们是一家冰淇淋企业,试图找出推动销售的因素,我们测量了两个独立变量:(1)温度和(2)我们观察到的 10 分钟内走在街上的穿短裤的人数。
我们的因变量是:我们销售的冰淇淋数量。
首先,我们绘制温度与冰淇淋销量的关系图

并做一个简单的线性回归,找出销量和温度之间的显著关系。这是有道理的。

然后我们绘制观察到的卖空数量与销售额的关系图

再做一个简单的线性回归,找出我们在 10 分钟内观察到的穿短裤的人数和冰淇淋销量之间的显著关系。有意思…也许这没什么意义。

然后我们转向多元线性回归,多元线性回归试图以下列形式对数据建模:

多元线性回归与简单线性回归有点不同。首先要注意的是,我们可以包含任意多的独立变量,而不是只有一个独立变量。解释也不同。如果其中一个系数(比如β_ I)很重要,这意味着 x_i、每增加 1 个单位,而所有其他独立变量保持不变,则 y 平均增加β_ I,这不太可能是偶然发生的。
我们做多元线性回归,包括温度和短路进入我们的模型,看看我们的结果

温度仍然是显著相关的,但短裤不是。它已经从简单线性回归中的显著变为多元线性回归中的不再显著。
为什么?
通过绘制短路和温度可以找到答案。似乎有关系。

当我们检查这两个变量之间的相关性时,我们发现 r =0.3,短路和温度往往一起增加。
当我们进行简单的线性回归并发现短裤和销售之间的关系时,我们实际上是在检测温度和销售之间的关系,这种关系会传递到短裤上,因为短裤会随着温度而增加。
当我们进行多元线性回归时,我们在保持温度不变的情况下研究了卖空和销售之间的关系,这种关系消失了。然而,温度和销售之间的真实关系依然存在。
相关数据经常会导致简单和多元线性回归,从而得出不同的结果。每当你用简单的线性回归发现一个重要的关系时,确保你用多元线性回归跟踪它。你可能会对结果感到惊讶!
(注意:这个数据是我们在 R 中使用 mvrnorm()命令生成的)
欢迎在下面的评论中留下任何想法或问题!
用 TF-IDF 和 GloVe 理解单词嵌入
它们是如何工作的,你能用它们做什么?

单词嵌入是自然语言处理中最流行的技术之一。因此,理解它们是如何工作的以及它们可以用来做什么,对于任何愿意投身自然语言处理领域的数据爱好者来说都是至关重要的。
为了向你展示它们有多重要,请考虑以下情况:我们都使用过谷歌搜索来找到数以千计或更多的与我们的查询相匹配的结果。但是你有没有想过计算机是如何理解你指的是苹果公司而不是水果?同样,如果你输入“巴拉克·奥巴马的妻子”,它如何返回“米歇尔·奥巴马”?
上面的答案是:单词嵌入。这种技术允许以一种捕捉单词的含义、语义关系和使用它们的上下文的方式来表示单词。
“从一个人和什么样的人交往,你就可以知道他是什么样的人。”——弗斯。
词语嵌入清晰解释
单词嵌入是将单词转换成实数向量的过程。
我们为什么需要它?嗯,机器学习中的大多数算法都无法处理原始形式的字符串或纯文本。相反,它们需要数字作为输入才能发挥作用。通过将单词转换为向量,单词嵌入因此允许我们处理大量的文本数据,并使它们适合机器学习算法。
*它是如何工作的?*将单词转换成数字的最基本方法之一是通过一键编码法。考虑这个句子:“我正在学习单词嵌入是如何工作的”。这个句子中的词是“学习”、“嵌入”等。由此,我们可以创建一个字典,它是句子中所有独特单词的列表。在这种情况下:[“我”,“我”,“学习”,“如何”,“词”,“嵌入”,“工作”]。一个字的独热编码矢量表示可以以这样的方式编码,1 代表该字存在的位置,而 0 代表其它任何位置。例如,“学习”的向量表示如下:[0,0,1,0,0,0,0]。因此,每个单词都有其独特的维度。
此外,它们被映射到一个向量空间 *。为什么?*其背后的思想是,上下文相近的词占据相近的空间位置。换句话说,在向量空间中,在相似上下文中使用的单词彼此靠近,而不靠近的单词彼此远离。这就是这一切的美妙之处!
在本文中,我将展示将单词转换成数字的两种不同方法:使用 TF-IDF 转换和 GloVe。虽然 TF-IDF 依赖于稀疏向量表示,但 GloVe 属于密集向量表示。
稀疏向量:TF-IDF
TF-IDF 遵循与上述独热码编码向量相似的逻辑。然而,它不是只计算一个单词在单个文档中的出现次数,而是计算整个语料库的出现次数。这允许我们检测一个单词对语料库中的文档有多重要。
*这是什么意思?*嗯,像“the”或“a”这样的常用词在几乎每个文档中都会非常频繁地出现。然而,其他单词可能只在一个或两个文档中频繁出现,而这些单词可能更能代表它们所在的文档。
TF-IDF 的目标是揭示这一点:降低在几乎每个文档中出现的常用词(例如“the”或“a”)的权重,并赋予那些只在少数文档中出现的词更多的重要性。
详细地说,TF IDF 由两部分组成: TF ,它是单词的词频,即该单词在文档中出现的次数;以及 IDF ,它是逆文档频率,即对只在少数文档中出现的单词给予较高权重的权重分量。
密集向量:手套
密集向量分为两类:矩阵分解和神经嵌入。GloVe 属于后一类,旁边是另一种流行的神经方法 Word2vec。
简而言之,GloVe 是一种无监督的学习算法,它强调单词-单词共现对提取意义的重要性,而不是其他技术,如 skip-gram 或单词包。其背后的想法是,某个词通常比另一个词更频繁地与一个词同时出现。例如,单词冰更有可能与单词水一起出现。
手套在 R 中非常容易使用,带有 text2vec 包。
应用中的单词嵌入:我能用它们展示什么?
理解单词嵌入是关键,但掌握如何使用它们也同样重要。单词嵌入如此重要的原因不仅在于它们在数据科学中的应用,还延伸到了政治、通信、营销或决策领域。
1/寻找两个单词之间的相似度
一旦将单词转换成数字,就可以使用相似性度量来查找单词之间的相似程度。
一个有用的度量是余弦相似度,它测量两个向量之间角度的余弦。重要的是要理解,它测量的是方向而不是幅度,即相似的矢量将具有相似的矢量方向。更详细地说,这意味着具有相同方向的两个向量将具有 1 的余弦相似度,相对于彼此成 90°方向的两个向量将具有 0 的相似度,并且直径上相对的两个向量具有-1 的相似度。这完全与它们的大小无关。
找到单词之间的相似性可以带来强大的洞察力。**在市场营销中,这可以帮助营销人员了解消费者将特定产品与哪些词语联系在一起。**因此,这有助于通过有针对性的搜索查询开展更高效的广告活动。以类似的方式,这也可以通知传播专家或政治家在制定针对受众的活动。
2/比较一个词在不同语料库中的使用
与上述相关,人们还可以关注特定单词的使用,并使用余弦相似性的度量来理解该单词在不同的语料库中是如何不同地使用的。例如,你可以比较“气候”一词在各种联合国演讲中的用法,或者“移民”一词在共和党和民主党宣言中的上下文。你可以从中提取政党甚至政策的差异。
根据你想要分析的文本,由单词嵌入给出的研究可能性是无限的。
用词汇嵌入法分析民主党和共和党政纲的异同
medium.com](https://medium.com/data-social/natural-language-processing-word-embeddings-e0b2edc773d2)
3/分析像女人+国王-男人=王后这样令人惊奇的事情
单词类比是单词嵌入真正有趣的部分!他们允许你以“a 对 b”和“x 对 y”的形式进行扣除。
举个例子:国王——男人+女人=王后。换句话说,将向量 king 和 woman 相加,同时减去 man,得到与 queen 相关的向量。简单地说,这意味着:国王对于男人就像女王对于女人一样。
作为人类,我们知道国王指的是男性,而女王指的是女性。单词嵌入让计算机也能理解这一点,它利用了 king 和 man 的向量表示之间的差异。如果一个人试图把女性向量投射到同一个方向,他就会得到 queen 这个词。女王是国王的女性的信息从未被直接提供给模型,但是模型能够通过单词嵌入来捕捉这种关系。
再比如:巴黎—法国+德国=柏林。换句话说,巴黎对于法国就像柏林对于德国一样!
在这里, text2vec 是 R 中一个易于使用的包,用于使用上述余弦相似性度量从 GloVe 算法中执行这些单词类比。
始终小心道德方面的考虑!
尽管单词嵌入非常有用,并且应用广泛,但是应该仔细考虑它们的实现。
不幸的是,语言是一种强有力的手段,通过它,种族、性别歧视和刻板偏见得以复制。因此,考虑这些偏见对基于处理人类语言的自动化任务的影响是至关重要的。
这怎么会成为问题,为什么会成为问题?
考虑在工作招聘流程或翻译服务等环境中实现基于单词嵌入的机器学习算法。在这些情况下,陈规定型观念会影响并实际上隐含对某一群体的歧视。在这种情况下给出的一个流行的例子是男人:程序员=女人之间的关系,这将产生结果家庭主妇。嵌入模式将看到程序员与男性比女性更亲密,因为我们自己对这份工作的社会认知反映在我们使用的语言中。
另一个例子是 cv 扫描的自动化。让我们假设公司决定在一个大数据集上训练单词嵌入,比如维基百科。在一封激励信中找到积极的形容词,如狡猾、聪明和聪明的机会很高,但我们也发现,在预先训练的嵌入空间中,这些术语更接近男性而不是女性。因此,这种性别偏见将在自动化任务中重现。
性别不平等、种族歧视和其他刻板偏见在我们的社会和语言使用中根深蒂固。因此,在这种语言上应用机器学习算法有传播和放大所有这些偏见的风险。因此,算法从来都不是“中性”的,因为我们的语言本身就不是中性的。
因此:永远要小心你的模型的伦理含义!
结论
在我们与计算机的日常互动中,词语嵌入无处不在。他们可以提供超越数据科学应用的见解,触及营销、通信、政治和政策制定领域。识别单词的相似性和相似性是其强大应用的例子。尽管如此,它们的应用从来都不是中立的,就像任何算法一样,一定要考虑它们的伦理含义!
我定期撰写关于数据科学和自然语言处理的文章。关注我的 Twitter 或Medium查看更多类似的文章或简单地更新下一篇文章!
理解自然语言处理中的单词 N 元语法和 N 元语法概率
快速文本系列
这并没有听起来那么难。

最初发表于我的博客。
N-gram 大概是整个机器学习领域最容易理解的概念了吧,我猜。一个 N-gram 意味着 N 个单词的序列。举例来说,“中型博客”是一个 2-gram(二元模型),“中型博客文章”是一个 4-gram,而“写在介质上”是一个 3-gram(三元模型)。嗯,那不是很有趣或令人兴奋。没错,但是我们还是要看看 n-gram 使用的概率,这很有趣。
为什么是 N-gram 呢?
在我们继续讲概率的东西之前,让我们先回答这个问题。为什么我们需要学习 n-gram 和相关的概率?嗯,在自然语言处理中,简称 NLP,n-grams 有多种用途。一些例子包括自动完成句子(如我们最近在 Gmail 中看到的),自动拼写检查(是的,我们也可以这样做),在一定程度上,我们可以检查给定句子的语法。我们将在后面的文章中看到一些例子,当我们谈论给 n 元文法分配概率的时候。
n 元概率
让我们以一个句子完成系统为例。这个系统建议在给定的句子中接下来可以使用的单词。假设我给系统一句话“非常感谢你的”,并期望系统预测下一个单词是什么。现在你我都知道,下一个词是“救命”的概率非常大。但是系统怎么知道呢?
这里需要注意的一点是,与任何其他人工智能或机器学习模型一样,我们需要用庞大的数据语料库来训练模型。一旦我们做到了这一点,系统或 NLP 模型将对某个单词在某个单词之后出现的“概率”有一个非常好的了解。因此,希望我们已经用大量数据训练了我们的模型,我们将假设模型给了我们正确的答案。
我在这里讲了一点概率,但现在让我们在此基础上继续。当我们建立预测句子中单词的 NLP 模型时,单词在单词序列中出现的概率才是最重要的。我们如何衡量呢?假设我们正在使用一个二元模型,我们有以下句子作为训练语料:
- 非常感谢你的帮助。
- 我非常感谢你的帮助。
- 对不起,你知道现在几点了吗?
- 我真的很抱歉没有邀请你。
- 我真的很喜欢你的手表。
让我们假设在用这些数据训练了我们的模型之后,我想写下句子“我真的很喜欢你的花园。”因为这是一个二元模型,该模型将学习每两个单词的出现,以确定某个单词出现在某个单词之后的概率。例如,从上面例子中的第二句、第四句和第五句,我们知道在单词“really”之后,我们可以看到单词“appreciate”、“sorry”或单词“like”出现。所以模型会计算这些序列中每一个的概率。
假设我们正在计算单词“w1”出现在单词“w2”之后的概率,则公式如下:
*count(w2 w1) / count(w2)*
其是单词在所需序列中出现的次数,除以该单词在预期单词在语料库中出现之前的次数。
从我们的例句中,让我们来计算“like”这个词出现在“really”这个词之后的概率:
count(really like) / count(really)
= 1 / 3
= 0.33
同样,对于另外两种可能性:
count(really appreciate) / count(really)
= 1 / 3
= 0.33count(really sorry) / count(really)
= 1 / 3
= 0.33
因此,当我键入短语“我真的”,并期望模型建议下一个单词时,它只会在三次中得到一次正确答案,因为正确答案的概率只有 1/3。
作为另一个例子,如果我对模型的输入句子是“谢谢你的邀请”,并且我期望模型建议下一个单词,它将会给我单词“你”,因为例句 4。这是模型知道的唯一例子。你可以想象,如果我们给模型一个更大的语料库(或更大的数据集)来训练,预测将会改善很多。同样,我们在这里只使用二元模型。我们可以使用三元模型甚至四元模型来提高模型对概率的理解。
使用这些 n 元语法和某些单词在某些序列中出现的概率可以改进自动完成系统的预测。同样,我们使用 can NLP 和 n-grams 来训练基于语音的个人助理机器人。例如,使用 3-gram 或 trigram 训练模型,机器人将能够理解句子之间的差异,如“温度是多少?”和“设定温度”
我希望这是一个足够清晰的解释,可以理解自然语言处理中 n 元语法这个非常简单的概念。我们将使用这种 n 元语法的知识,并使用它来优化我们的机器学习模型用于文本分类,我们在早些时候的介绍 fastText 库帖子中构建了该模型。
如果你喜欢我在 Medium 或我的个人博客上的帖子,并希望我继续做这项工作,请考虑在 Patreon 上支持我。
在实践中理解 Word2vec 嵌入

单词嵌入,向量空间模型,Gensim
这篇文章旨在用 Python 中的 Gensim 实现 Word2vec 嵌入的同时,以直观的方式解释 Word2vec 的概念以及概念背后的数学原理。
Word2vec 的基本思想是,不是在高维空间将单词表示为一键编码(count vectorizer/tfidfvectorizer),而是在稠密的低维空间中以相似单词得到相似单词向量的方式来表示单词,从而映射到附近的点上。
Word2vec 不是深度神经网络,它把文本变成深度神经网络可以作为输入处理的数值形式。
word2vec 模型是如何训练的
- 使用滑动窗口浏览训练语料库:每个单词都是一个预测问题。
- 目标是使用相邻单词来预测当前单词(反之亦然)。
- 预测的结果决定了我们是否调整当前的单词向量。渐渐地,向量收敛到(希望)最优值。
比如我们可以用“人工”来预测“智能”。

然而,预测本身并不是我们的目标。它是学习向量表示的代理,以便我们可以将它用于其他任务。
Word2vec 跳跃式网络架构
这是 word2vec 模型架构之一。它只是一个简单的隐藏层和一个输出层。

Source: http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
数学
下面是 word2vec 嵌入背后的数学。输入层是独热编码向量,因此它在单词索引中得到“1”,在其他地方得到“0”。当我们将这个输入向量乘以权重矩阵时,我们实际上拉出了对应于该单词索引的一行。这里的目标是提取重要的行,然后,我们丢弃其余的行。

Source: http://mccormickml.com/2016/04/19/word2vec-tutorial-the-skip-gram-model/
这是 word2vec 工作的主要机制。
当我们使用 Tensorflow / Keras 或者 Pytorch 来做这件事的时候,他们有一个专门的层用于这个过程,叫做“嵌入层”。所以,我们不打算自己做数学,我们只需要传递一个热编码向量,“嵌入层”做所有的脏工作。
预处理文本
现在我们将为一个 BBC 新闻数据集实现 word2vec 嵌入。
- 我们用 Gensim 来训练 word2vec 嵌入。
- 我们使用 NLTK 和 spaCy 对文本进行预处理。
- 我们使用 t-SNE 来可视化高维数据。
clean_text.py
- 我们使用空间来进行引理化。
- 禁用命名实体识别以提高速度。
- 去掉代词。
lemmatize.py
- 现在我们可以看看最常用的 10 个单词。
word_freq.py

在 Gensim 中实现 Word2vec 嵌入
min_count:语料库中要包含在模型中的单词的最小出现次数。数字越大,语料库中的单词就越少。window:句子内当前词和预测词之间的最大距离。size:特征向量的维数。workers:我知道我的系统有 4 个内核。model.build_vocab:准备模型词汇。model.train:训练词向量。model.init_sims():当我们不打算进一步训练模型时,我们使用这一行代码来提高模型的内存效率。
word2vec_model.py
探索模型
- 找出与“经济”最相似的单词
w2v_model.wv.most_similar(positive=['economy'])

Figure 1
- 找出与“总统”最相似的单词
w2v_model.wv.most_similar(positive=['president'])

Figure 2
- 这两个词有多相似?
w2v_model.wv.similarity('company', 'business')

请注意,如果我们改变min_count,上述结果可能会改变。例如,如果我们设置min_count=100,我们将有更多的单词可以使用,其中一些可能比上面的结果更接近目标单词;如果我们设置min_count=300,上面的一些结果可能会消失。
- 我们使用 t-SNE 来表示低维空间中的高维数据。
tsne.py

Figure 3
- 很明显有些词彼此接近,比如“球队”、“进球”、“伤病”、“奥运”等等。这些词往往被用在与体育相关的新闻报道中。
- 其他聚集在一起的词,如“电影”、“演员”、“奖项”、“奖品”等,它们很可能在谈论娱乐的新闻文章中使用。
- 又来了。剧情看起来如何很大程度上取决于我们如何设定
min_count。
Jupyter 笔记本可以在 Github 上找到。享受这周剩下的时光。
了解模型的结果
数据分析和数据科学生命周期包括理解我们正在处理的数据,以及从模型提供的结果中解释和提取价值的关键步骤。

对于这些关键步骤,我们需要一个解决方案来帮助我们探索数据并与之交互,同时通过提出隐藏的见解来增强我们的发现能力。
在本文中,我们将评估预测模型的结果,找出它在哪些方面表现得更好和更差,了解某些变量是否以及为什么比其他变量更重要,以及如何改进模型。
我们将使用一个由 https://cloud.google.com/bigquery/public-data/的 BigQuery 托管的公共数据集的例子。谷歌团队发布了一个信用卡客户数据集,用来预测信用卡违约。它们提供算法给出的分数,以及默认值的真实值(1/0)。那些得分较高的客户,将有更多的违约概率。
使用 Graphext 来可视化数据,我们可以了解分数在数据拓扑中的分布情况,以及预测模型忽略了哪些区域或客户端组。这是分数分布的热图:

这是真实目标的分布图:

看起来 50%的真实违约者(黄色,1 代表 default_payment_next_month)预测得分很高,但其余的得分很低,这意味着他们是假阴性。

让我们比较这两组,看看为什么我们的算法在检测这些模式方面较弱。我们将为这两个组创建两个“集合”,或标签:真阳性(高分的违约者)和假阴性(低分的违约者)。
我们的比较界面将自动建议最能区分我们各组的变量。最有区别的变量是 Pay_0(最后一次支付延迟)。算法似乎对这个变量过度拟合,将所有 Pay_0 大于 1 的客户归类为高风险,而忽略了这个变量小于 1 的违约者。

进一步分析,我们还可以观察到假阴性比真阴性具有更高的极限平衡。这意味着,我们遗漏的违约者可能比我们正在捕获的违约者更危险,意味着他们可能拖欠更多的钱。

为什么模型过度拟合这个变量而忽略了其他危险的违约者?让我们来看看这个特殊的变量。如果我们在数据集中过滤那些 Pay_0 值大于 0 的客户,我们会看到目标利率上升到 50%以上,当我们过滤该变量值大于 2 的客户时,目标利率上升到 75%。


我们应该做的第一件事,是审查该变量是如何在数据库中建立的,并验证是否建立良好,它没有未来的信息。
检查后,很明显我们需要建立两个独立的模型,一个不需要为那些超过 Pay_0 的客户进行细分,因为目标水平很高,另一个更细分的模型用于那些 Pay_0 小于 0 的客户,因为他们更难用这个初始数据集捕获,他们的模式可能会隐藏在其他类型的变量中。
这只是一个示例,说明数据探索如何帮助您更好地理解模型的结果,并指导您如何改进和推进您的分析。
如果您想了解更多,请向我们索取演示。
UNet —逐行解释
UNet 实施示例
UNet 由传统的卷积神经网络演变而来,于 2015 年首次设计并应用于处理生物医学图像。由于一般卷积神经网络将其任务集中在图像分类上,其中输入是图像,输出是一个标签,但在生物医学情况下,它要求我们不仅要区分是否存在疾病,还要定位异常区域。
UNet 致力于解决这一问题。它能够定位和区分边界的原因是通过对每个像素进行分类,因此输入和输出共享相同的大小。例如,对于尺寸为 2x2 的输入图像:
[[255, 230], [128, 12]] # each number is a pixel
输出将具有相同的大小 2x2:
[[1, 0], [1, 1]] # could be any number between [0, 1]
现在让我们来看看 UNet 的具体实现。我会:
- 显示 UNet 的概述
- 逐行分解实现并进一步解释它
概观
这个网络的基本基础看起来像是:

UNet architecture
乍一看,它呈“U”形。该架构是对称的,由两大部分组成—左边部分称为收缩路径,由一般的卷积过程构成;右边部分是扩展路径,由转置的 2d 卷积层构成(你现在可以认为它是一种上采样技术)。
现在让我们快速看一下实现:
代码引用自 Kaggle 竞赛的一个内核,一般来说,大多数 UNet 遵循相同的结构。
现在让我们一行一行地分解实现,并映射到 UNet 架构映像上的相应部分。
逐行解释
收缩路径
收缩路径遵循以下公式:
conv_layer1 -> conv_layer2 -> max_pooling -> dropout(optional)
所以我们代码的第一部分是:
哪一个符合:

注意每个过程构成两个卷积层,通道数从 1 → 64 变化,因为卷积过程会增加图像的深度。向下的红色箭头是最大池化过程,它将图像的大小减半(大小从 572x572 → 568x568 减少是由于填充问题,但这里的实现使用 padding= "same ")。
该过程重复 3 次以上:

带代码:
现在我们到达了最底部:

仍然构建了 2 个卷积层,但是没有最大池化:
这时的图像已经调整到 28x28x1024。现在让我们走上宽阔的道路。
宽阔的道路
在扩展路径中,图像将被放大到其原始大小。公式如下:
conv_2d_transpose -> concatenate -> conv_layer1 -> conv_layer2

转置卷积是一种扩大图像大小的上采样技术。这里有一个可视化演示和一个解释这里。基本上,它在原始图像上做一些填充,然后进行卷积运算。
在转置卷积之后,图像从 28×28×1024→56×56×512 被放大,然后,该图像与来自收缩路径的相应图像连接在一起,并且一起形成大小为 56×56×1024 的图像。这里的原因是组合来自先前层的信息,以便获得更精确的预测。
在第 4 行和第 5 行中,添加了 2 个其他卷积层。
与之前相同,该过程重复 3 次以上:
现在我们已经达到了架构的最上层,最后一步是重塑图像,以满足我们的预测要求。

最后一层是卷积层,有 1 个大小为 1x1 的滤波器(注意整个网络没有密集层)。剩下的神经网络训练也一样。
结论
UNet 能够通过逐个像素地预测图像来进行图像定位,UNet 的作者在他的论文中声称,该网络足够强大,可以通过使用过多的数据增强技术,基于甚至很少的数据集来进行良好的预测。使用 UNet 进行图像分割有很多应用,也出现在很多比赛中。一个人应该尝试一下自己,我希望这篇文章可以成为你的一个好的起点。
参考:
- https://github . com/hlamba 28/UNET-TGS/blob/master/TGS % 20 unet . ipynb
- https://towards data science . com/understanding-semantic-segmentation-with-unet-6 be 4f 42 D4 b 47
- https://towards data science . com/types-of-convolutions-in-deep-learning-717013397 f4d
- https://medium . com/activating-robotic-minds/up-sampling-with-transposed-convolution-9 AE 4 F2 df 52d 0
- https://www . ka ggle . com/phoenigs/u-net-dropout-augmentation-layering
不幸的结局
《权力的游戏》有没有电视史上最差的大结局?

A Song of Ice and Ire (Image: HBO)
《权力的游戏》是一种文化现象,这对任何人来说都不是新闻。以任何标准衡量,这都是过去十年中最大的电视节目,尤其是就其预算而言,根据综艺节目的报道,该节目最后一季每集的预算达到了惊人的 1500 万美元(T2)。
然而,这并不是第八季唯一令人惊讶的特征。尽管开头几集很有希望,但作为《权力的游戏》同义词的出色写作开始下滑。而且不是一点点。到了节目的高潮,情节漏洞被打开了。一英寸厚的情节装甲消除了电视史上最大的战斗序列的所有紧张气氛。错综复杂的人物弧线就像被龙焰点燃的铁王座一样消失了。犯罪记录还在继续。
粉丝们对这一切毫无兴趣。一份请愿书要求“与有能力的作家一起”翻拍最后一季,已经有 170 万人签名,并且人数还在增加。当然,节目主持人面临着一个几乎不可能完成的任务。鉴于前几季的高质量和由此产生的巨大期望,很难想象一个结局不会让至少一些人失望。
但是电视史上最差的?好吧,这是一个数据科学博客,所以要回答这个问题,现在是时候让一些数字参与进来了…

“I drink and I mung things,” — Tyrion Lannister, probably… (Image: HBO)
不出所料,我们将用于这一分析的数据集来自 IMDb。特别是,我们将使用几个电视连续剧统计数据的数据集,可以直接从 IMDb 这里下载,以及另一个特定于剧集的统计数据的数据集。这第二个数据集需要一点网络搜集来生成(从 IMDb 并不容易获得特定剧集的数据——稍后会有更多)。
将来自 IMDb 的所需数据集连接在一起,并将其加载到熊猫数据帧中,我们看到我们有 951,196(!)行,每一行代表一个唯一的“标题”,以下列:

The index of this dataframe has been set to ‘tconst’, which is a unique identifier for each title on IMDb. This is a very useful field — especially in cases when two shows have the same name, for example, the original BBC ‘House of Cards’, and the Netflix remake, which should be analysed as two separate shows.
我们可以使用这些列来过滤标题:
- 标题类型告诉我们正在讨论的标题是电影、电视短片、电视电影等。我们可以删除任何不是’电视剧’的行。
- isAdult 是 1 还是 0,取决于……嗯,你大概能猜到。假设这里的 get 计数为 0,那么删除带有 1 的行可能是安全的。
- endYear 告诉我们这部剧在哪一年结束,而 NaN 则代表仍在制作中的剧集。鉴于我们正在分析节目的结局,我们应该删除这里带有 NaN s 的行。
- 平均分是一个介于 0 和 10 之间的浮动值,表示给予整个系列的平均分(10 分*)。这一点很重要——在 IMDb 上,人们既可以对一个系列进行评级(这在本专栏中有所考虑),也可以对单个剧集进行评级。正如我们将在后面看到的,这些评级并不总是像人们预期的那样紧密相关。如果我们在分析剧集的结局,那么只包括总体上至少还过得去的标题是合理的(一个糟糕的剧集也有一个糟糕的结局并不是一个特别有启发性的观点)。因此,我们过滤掉任何没有 7.5/10 或以上系列评分的节目。*
- numVotes 告诉我们有多少张选票进入了平均投票。我们应该有一个较低的门槛,以确保我们只处理(相对)主流系列。我用 2 万张选票作为截止日期。
- 一旦我们有了特定剧集的数据,我们也将排除任何少于 12 集的剧集。这样的集数是必要的,以便从整个系列的整体质量中理清一个节目“结局”的质量。
令人难以置信的是,应用这些过滤器让我们从 951,000 本书减少到 305 本。这些是 305 个展示,将形成以下分析的基础。
如前所述,要获得单集的收视率,我们需要直接从 IMDb.com 那里获取。
这就是那些“tconst”标识符派上用场的地方——IMDb 在每个标题的 URL 中使用的正是这些字符串。比如《权力的游戏》就有一个 *tt0944947 的‘t const’。*因此,系列 1 的 IMDb 网页采用以下形式:
www.imdb.com/title/TT 0944947/剧集?季节=1
考虑到这一点,我们可以使用一个函数遍历一个节目的不同季节,并存储每一集的收视率。通过这个函数传递一个“tconst”代码列表,我们可以为给定的节目列表(在我们的例子中,我们上面确定的 305 个标题)创建一个剧集评级数据库。
有了这些新数据,我们就可以开始分析了。
让我们先看一些非常简单的东西,来测试一下我们的数据集。在我们的“已完成”电视节目数据库中,哪些节目的整体收视率最高?

即使结局令人不快,《权力的游戏》仍然享有 9.4 的健康收视率,周围是你预计会在这样的排名中看到的剧集(《绝命毒师》、《火线》(The Wire)和《黑道家族》(The Sopranos),以及一些你可能甚至没有听说过的剧集(《蕾拉和梅克纳》(Leyla and Mecnun)是土耳其剧,目前在网飞可以看到,而《阿凡达》(Avatar)、《死亡笔记》(Death Note)和《钢之炼金术士》(Fullmetal Alchemist)都是日本动漫)。
让我们更深入地了解排名前五的剧集,追踪每一集的收视率。

正如我们可能预料的那样,第一个跳出来的是《权力的游戏》结尾时收视率的急剧下降。我们还应该注意到,这种下降并不是不可避免的——有很多高质量节目在最后一刻没有出错的例子。事实上,这里的其他剧集在最后几集几乎达到了各自的巅峰(黑道家族的轻微下滑可能是由臭名昭著的“切换到黑色”结局造成的)。
这里出现的另一个不太明显的东西是总的剧集评级(如原始数据集中所定义的)和剧集评级的平均值之间的关系。我们会认为它们非常相似,如果不是完全相同的话,尽管事实似乎并非如此。例如,虽然《连线》的剧集收视率一直很高,但平均下来仍比其整个系列的收视率低一个百分点(分别为 8.25 和 9.30)。
事实上,如果我们比较整个数据集的这两个指标,我们会发现剧集收视率和平均剧集收视率之间的相关性实际上相当弱。

The purple line here represents x = y. Very few titles sit on (or indeed especially near) it
奇怪的是,我们看到总系列和剧集评分差异最大的七个节目中有六个是动画,其中五个是日本动画(火影忍者、星际牛仔、死亡笔记和两份龙珠 Z)。
查看具有最大差异的剧集跟踪记录,我们看到很高的标准偏差(在《蝙蝠侠》和《龙珠 Z》的情况下,每集的质量相当不一致)。

我们可以猜测,这里有某种“怀旧因素”在起作用——人们可能对十多年前播出的一部电视剧有着美好的“整体”记忆,这将导致该剧整体的高收视率。
然而,时间可能会抹去对无用剧集的记忆,从而降低单集收视率(我们可以假设,逐集评分的人更有可能最近以更客观的眼光观看了这些剧集)。
数据在一定程度上证实了这一点。一部电视剧的年终与其整体剧集评分和平均剧集评分之间存在负相关关系。

The further towards the top of the chart a title is, the higher its series rating is compared to the average rating of its individual episodes. Older shows are likelier to have such discrepancies.
那么,鉴于我们已经看到了剧集收视率差异很大的不一致的剧集,哪些剧集能够在整个播出过程中保持一致的质量呢?我们可以通过绘制一部剧的剧集收视率均值和标准差来回答这个问题。

Consistently good shows highlighted in yellow: The Wire, Leyla and Mecnun, Firefly, Oz, Blackadder, Mr. Bean, Ezel, Pushing Daisies, The Killing, The Inbetweeners, Happy!, Studio 60 on the Sunset Strip, ‘Allo ‘Allo!, Into the Badlands, Agent Carter, Almost Human, Pinky and the Brain, The Alienist, Nikita, Rizzoli & Isles, Kyle XY, and Witches of East End
让我们回到系列赛决赛的话题上来。
回答片名问题的一个非常简单的方法是——“权力的游戏有电视史上最差的结局吗?”—就是简单的把每个剧集的最后一集隔离出来,按照收视率从上到下排序。让我们来看看这个列表的极端情况:

我们不应该对《绝命毒师》出现在顶部感到惊讶,尽管除了《阿凡达》,其他的标题对这个博客来说都是新的。让我们更详细地看看这些达到 9.8 分的其他节目。

至于天平的另一端,我们看到《权力的游戏》并不(完全)拥有最差最后一集的荣誉——这个可疑的荣誉属于网飞改编的《纸牌屋》。

“For those of us climbing to the top of the IMDb rankings, there can be no mercy” (Image: Netflix)
现在,我们将看到《纸牌屋》突然出现在这些“最差”的名单中,所以让我们马上处理这个特定的房间里的大象。《纸牌屋》在接近尾声时的衰落是毋庸置疑的。对其最后一集的一星评论既多又严厉。然而,该剧在最后一季确实不得不应对其首席演员和执行制片人的职业内爆——这是《权力的游戏》的主持人戴维·贝尼奥夫和 D·B·威斯(或者用术语来说是“D&D”)不必承受的。
除此之外,我们还能如何判断一部剧结局的好坏呢?单看最后一集似乎有点狭隘。有人可能会说,以这种方式比较不同长度的序列是不公平的。对于 12 集的节目,最后一集代表其总播放量的 8%,但是对于 150 集的节目,最后一集代表不到 1%。
此外,很多对《权力的游戏》结局的批评是因为它的前 95%的质量——我们应该在剩余剧集的背景下看待一部剧的结局。
因此,让我们来看看一部剧集在最后 5%的平均收视率(以获得一个更一致的跨标题“结尾”定义),并将其与该剧的中值剧集收视率进行比较。

《纸牌屋》再次占据榜首,但网飞的另一部作品《血统》将《权力的游戏》挤到了倒数第二名。尽管如此,如果我们比较他们的剧集收视率,我们可以看到《血统》和《纸牌屋》都没有达到《权力的游戏》盛况下的高度。

那么,我们能得出什么结论呢?《权力的游戏》可能没有电视史上最差的大结局*。但肯定是在上面(或下面)。当然,尽管粉丝们可以为有史以来最伟大的电视节目之一的不光彩的消亡而悲伤,但我们应该记住,在它运行的大部分时间里,它恰恰是电视有史以来最伟大的节目之一。*
对泰温·兰尼斯特来说,我们必须接受 D & D 的决定,并感谢我们还有《权力的游戏》——D&D 并不完美,但没有人是完美的。
让我们只希望五年后我不会坐在这里,写一篇关于他们如何击败星球大战的博客…
注意:截至 2019 年 7 月 14 日,本文中的所有评级均正确
R 中的单元测试
为什么单元测试真的是一个好主意——即使对于非包。为创建健壮的软件编写测试,节省时间,并从中获得乐趣!
你会问:“为什么要进行单元测试?我的代码起作用了!”。单元测试有助于创建健壮的代码。在简短地介绍了什么是健壮代码之后,我给出了基本单元测试思想的概述。最后,我展示了如何在 R 中快速使用它们**,甚至是简单的脚本(没有创建 R 包的负担)。**

Entangled software breaks upon tiny changes — like these wirings (Photo by Pexel on Pixabay)
健壮代码
- 不会因变更(如新的 R 版本、包更新、错误修复、新特性等)而轻易中断。)
- 可以简单地重构和
- 可以将延长而不破坏其余部分
- 可以进行测试
单元测试对于编写健壮的代码是很重要的——它们可以让我们更加确信一些变化不会破坏代码——至少代码可以比紧耦合的代码库更快地修复。
有很多关于单元测试的精彩文献。在这篇文章中,我想分享单元测试背后的基础知识,并把它们应用到 R 脚本语言中,同时推荐一些包和概念,用于您的日常 R 编程。
确信:在不断增长的代码库中,你将需要单元测试。有时候,即使很小的脚本有时也会产生很多苦恼。我保证在没有测试的情况下在调试器中花很多时间。在长期的单元测试中会节省你很多宝贵的时间,即使你认为这可能是额外的工作。我不喜欢测试驱动设计(TDD)——在我看来,测试应该只是支持你编程的一个工具。他们不应该统治你!
动机
单元测试在 R 和 Python(以及其他动态类型的脚本语言)中特别有用,因为没有编译器的帮助来告诉你在哪里可以用无效的参数调用函数。有一些帮助器包,比如 R 的 lintr 或 Python 的 pylint,试图减轻这一点。
然而,在过去我经常遇到困难——代码崩溃,例如,一些中间列表突然变空,或者只包含一个项目,而一个列表包含多个项目。在这些地方,测试将有助于防止将来出现这种问题。在数据科学中,一些计算会持续很长时间。如果计算在几个小时后由于错误而中止,则为坏。
单元测试基础
测试简单功能
一个简单的函数接受一个输入并生成一个输出,如下所示

在单元测试中,我们希望在调用函数 f 时,验证输出 y 是否具有特定输入 x 的期望值。通常测试不同的( x,y )对。
一个例子可以是按升序对向量值进行排序的函数。边界测试非常重要。在这个例子中,我们可以测试
- 作为输入的空列表
- 只有一个值的列表
- 已经排序的列表
- 未排序的列表
- 如果提供了无效的参数,将引发函数错误。
- 该函数是否正确处理了所有这些情况?
- 当创建一个复杂的应用程序时,对可能失败的功能或者过去发生错误的地方进行单元测试是一个好习惯。为 bug 编写一个测试,修复 bug,看看单元测试是否成功。
测试有副作用的功能
事情并不总是像上一节那样简单。有时一个函数会有副作用,可能是文件的读/写、数据库的访问等等。

在这种情况下,考试的准备就更加复杂了。它可以只包含一堆用于模拟数据库访问的函数的模拟对象。这正在影响编程风格——抽象层可能会变得必要(参见 R 数据库接口——DBI)。在某些情况下,需要在执行测试之前生成输入文件,并在测试之后检查输出文件。
测试类别
面向对象编程( OOP )在 R 里有点奇怪,感觉很别扭。如果你曾经有机会用其他语言编写软件:我强烈建议,为了更好地理解什么是面向对象——比如说尝试一下kot Lin——这很有趣。
面向对象背后的基本思想是你把数据(成员变量)和处理这些数据的代码(称为方法)放在一起。这是在一个类定义中声明的。面向对象的主要思想是,你可以通过继承从另一个类派生出类,从而扩展它的功能和数据。一个简单的例子:一个图形形状可以从原点偏移(x,y)。由此,我们得到一个矩形,除此之外,它还有一个宽度和一个高度(w,h)。
类定义只是由构造器生成的具体对象实例的蓝图。然后,实例的状态(成员变量)通过调用如下类方法逐步修改:
在 R 中有不同的面向对象系统,如 S3 和 S4。大部分旧功能都是用 S3 写的。summary()或 print()之类的函数就是这样的例子。这些“函数”实际上是方法,它们被分派给作为参数输入的不同对象类型的相应类方法。参见 R 教程章节。16 凯利·布莱克如果你想了解更多这方面的情况。因此,测试通常由对对象实例的一系列操作组成,从而验证某些步骤后的结果是否符合预期。
R 中的单元测试
这里我们使用 testthat package⁴,它有一个从其他语言(Java、C#、Python)派生的 xUnit 测试中已知的概念。这个例子展示了第一个基本功能测试。因为我经常发现自己创建了更多的脚本而不是 R 包(这要乏味得多),所以这个例子展示了如何使用 testthat 而不必创建包。
举例:一个简单的函数
假设我们编写了一个函数,它在 my_code 中将其参数(可能是一个数字向量)加 1。R 文件。那似乎是原始的。但是你会在续集里看到,连这个功能都可能失效。
创建一个名为 tests 的目录,并将一个或多个以 test_ 作为文件名的 R 脚本放在那里。
在这之后,您可以通过在 R 中调用 testthat::test_dir("tests ")来启动单元测试代码,您将会看到类似这样的输出。

The output is shown after calling the tests. So the function did not work with an empty list c().
因为它不是一个包,所以测试文件必须包含一个 source()命令来导入您的脚本。
测试是使用 testthat::test_that(name,expression)函数声明的。第一个参数为测试指定一个名称,以便识别它。第二个参数是一个 R 表达式,它将使用 expect_*断言。每当断言不成立时,测试被中止并标记为失败。
好的一面是:无论何时你决定继续创建你的 R 包,你都可以让你的测试就位。然后只需要从 test_xxx 中删除那些 source() 命令。R 文件。
- 参见我的 GitHub 库获取这个基本片段。
结论
单元测试让你不再害怕修改源代码。当你在写代码的时候心里想着可测试性,你的编程风格就会改变。如果函数不能被简单地测试,那就说明你有纠缠不清的代码!在这种情况下,准备环境(变量、文件、数据库连接等)的工作可能会过多。)做一个测试。对于有明确目的的函数,单元测试应该很容易!
我建议从福勒和马丁的伟大著作中获得灵感。
解开你的代码,编写单元测试,享受其中的乐趣!花更多时间开发有趣的功能,少花时间调试。
参考文献
[1]: G. J. Myers,T. Badgett,T. M. Thomas 和 C. Sandler,软件测试的艺术,第 2 卷(2004),威利在线图书馆
[2]: M .福勒,重构:改进现有代码的设计(2000),艾迪生-卫斯理专业版
[3]: R. C. Martin,干净代码,敏捷软件工艺手册(2009),普伦蒂斯霍尔
[4]:test tha:R的单元测试。哈德利·韦翰。
单元测试 Python 数据可视化

对与 matplotlib 接口的 Python 代码进行单元测试可能具有挑战性。测试有多大帮助,最好的方法是什么?
在为数据科学工具包 Triage、进行开发时,这种情况经常出现,该工具包包括大量使用 matplotlib 或其他相关 Python 库绘制图表的代码。这些情节经常在 Jupyter 笔记本中使用,这些笔记本有自己的设施来显示情节。
过于详细地测试可视化代码没有太多意义。对于一个情节应该是什么样子的期望很难用一种易于单元测试的方式来表达。将尽可能多的绘图数据生成与绘图分开,并像测试任何其他生成的数据一样测试绘图数据生成通常是有意义的。但是图数据不是图。我们想确保绘图代码正常工作。我们如何定义“作品”?一个有用的定义是测试是否能回答这个问题:
我们策划了什么吗?
这是一个很好的开始。任何应该绘制某些东西的代码可能都应该绘制某些东西,并且希望它应该足够容易地自动解决这个问题。
方法一:修补
我过去经常使用的方法是模仿“plt.show”并断言它被调用了。一个例子:
这通常是有效的。因为“plt.show”通常在绘制代码的末尾被调用,所以如果在 plt.show(通常是您要测试的内容)之前出现了问题,这个模拟就不会被调用,测试就会失败。
但是也有一些缺点:
- *如果 plt.show 没有被调用怎么办?*对于经常从 Jupyter 笔记本(或任何其他可能在自己的层上处理显示的显示引擎)调用的代码。您可以尝试制定内部准则,强制所有绘图代码都调用 plt.show,但在这一点上,您只是在测试您的内部准则,而不是代码工作。
- *如果调用了 plt.show,但不是在您正在导入的模块中调用,该怎么办?*以 seaborn 地块为例。他们使用 matplotlib,但是包装了它,所以你不太可能在你的代码中看到 plt.show。如果有人将笨拙的 matplotlib 图形重构为漂亮的 seaborn 图形会怎样?我不希望我的测试在这种情况下失败。
- *如果调用了 plt.show 但是没有任何内容怎么办?*这个可能性不是超级大,但还是有可能的。
方法二:plt.gcf
幸运的是,matplotlib 有另一个接口,我们可以用它来克服 patch 的这些缺点:plt.gcf()(获取当前数字)。
我不确定这是不是 Jupyter 的内联绘图魔法的工作方式,但是它非常有用。gcf 返回对当前(最后绘制的)图形的引用。更好的是,它包括一个数字(plt.gcf()。number),它可以让您跟踪绘制了多少个。在我们的绘图代码运行之后,我们可以检查当前的图形,以便对它做出我们想要的任何级别的断言。所以它不关心是否调用了 plt.show,只要在某个地方创建了图形,它就工作,甚至是内部使用 matplotlib 的一些高级库。
当我第一次发现 gcf 时,很容易在调用代码之前“重置”绘图编号,以尝试并断言当前图形的确切编号。在这样做之前,我试图用 plt.close()来“清除”这个情节:
这在本地有效。然而,当我推给 Travis 时,“close”似乎没有做任何事情,gcf()的值。数字受到其他测试用例的影响。我认为这与我的笔记本电脑有一个真正的显示器/窗口和 Travis 是无头的有关。也许有一种更好的方式来进行“清理”,但我不想进入显示器的杂草中,所以我想出了一种替代方式来使它具有确定性:
断言数字的数量比你开始测试时要多
这在 Travis 和我的笔记本电脑上是一样的。另一个不同之处是,我没有断言绘制的具体数字。不管你是否想在你的代码中这样做(最终我认为它可能会深入到 matplotlib 内部处理事情的方式),你都可以使用这个方法。但是这本身就是一个方便的情节断言工具。我甚至最终把它变成了一个上下文管理器感知的方法,以便于重用:
这种方法可能存在哪些缺点?
我们断言,无论我们调用什么代码来绘图,都会创建 matplotlib 图形。这个易碎吗?理论上。这听起来肯定违反了“不要测试实现”的指导方针。但事实上,我认为
matplotlib 是一个通用的后端,许多我可能会在其中切换的前端都会用到它
是一个比
seaborn 是最好的前端,我会一直使用它,也许它会从 matplotlib 切换后端
我的团队将一个图表重做到一个新的、非 matplotlib 支持的绘图库中当然是可能的,但可能性不大。因此,作为一个相当通用的 Python 数据可视化断言,我对此相当满意。你怎么想呢?我是否遗漏了其他缺点,或者测试 Python 绘图的更好方法?
单元测试 Apache Spark 应用程序
PySpark 案件

对 Spark 应用程序进行单元测试并不是那么简单。对于大多数情况,您可能需要一个活跃的 spark 会话,这意味着您的测试用例将需要很长时间来运行,并且可能我们正在所谓的单元测试的边界附近踮着脚尖。但是,这绝对值得去做。
那么,我应该吗?
嗯,是的!测试你的软件总是一件好事,它很可能会让你免除许多麻烦,此外,你将被迫把你的代码实现成更小的片断,这样更容易测试,从而获得可读性和简单性。
好的,那么我需要做些什么呢?嗯,我认为我们可以从pip install spark-testing-base开始,然后从那里开始。为此,我们还需要pyspark(当然)和unittest(单元测试 2)和pytest——尽管pytest是个人偏好。
用 Spark 编写测试时使用的基类。您已经在 Spark 中编写了一个很棒的程序,现在是时候编写了…
github.com](https://github.com/holdenk/spark-testing-base)
Spark testing base 是一个帮助 Spark 测试的基类集合。对于这个例子,我们将使用继承自SparkTestingBaseReuse的基础[SQLTestCase](https://github.com/holdenk/spark-testing-base/blob/master/python/sparktestingbase/sqltestcase.py),它创建并重用了一个 SparkContext。
在SparkSession和SparkContext上:
我已经有了 Spark 上下文、SQL 上下文、Hive 上下文!
medium.com](https://medium.com/@achilleus/spark-session-10d0d66d1d24)
从个人经验来说(使用目前最新的 spark 版本。+),我发现我需要对SQLTestCase做一些小的调整,这是我在当前项目中经常使用的一个测试用例。因此,这里有一个我为适应自己的需要而做的调整的例子:
Example of a base spark test case, based on Spark testing base’ s SQLTestCase
总结一下我所做的改变:
- 为了一致性,我添加了一个配置,将时区设置为
UTC。时区一致性是贯穿你的代码的一个非常基本的东西,所以请确保你总是设置spark.sql.session.timeZone - 在配置中设置的另一个重要的事情是
spark.sql.shuffle.partitions对于将要运行测试的机器来说是合理的,比如<= cores * 2。如果我们不这样做,那么 spark 将使用默认值,即 200 分区,这将不必要地、不可避免地减慢整个过程。<= cores * 2是一个普遍适用的好规则,不仅仅适用于测试。 - 还添加了一种在比较之前对要比较的数据帧进行排序的方法。在一个基类中有一个
compareRDDWithOrder方法,但是我认为使用 dataframes 更容易。 schema_nullable_helper方法应该谨慎使用,因为它可能最终破坏你的测试用例,这取决于你需要测试什么。这种情况的用例是在没有指定模式的情况下创建数据帧(目前不推荐使用),因为 spark 试图推断数据类型,有时要比较的两个数据帧之间的可空标志不一致,这取决于用于创建它们的数据。该方法将两个数据帧的模式之一更新为另一个的模式,该模式仅与可空值相关。- 最后,我为
appName和config添加了一个稍微调整过的版本。在最新的 pyspark 版本中,session实例化也有所不同。(对于 2.2 的支持,有一个待定的版本。+和 2.3。+ spark 版本仍然开放这里和这里,所以,我们将子类化来解决这个问题)
注意getOrCreate()将创建一次 spark 会话,然后在整个测试套件中重用它。
现在让我们创建一个要测试的简单特性:
An example of a feature calculation class
这个特性只是计算a/b,其中a和b是输入数据帧中的列。非常简单明了。我在这里没有包括列检查,因为如果a或b丢失,我们需要计算过程失败到足以停止一切。但一般来说,这取决于您希望如何处理应用程序中的错误情况,以及这种计算对您的过程有多重要。
这里需要注意的是:即使您模拟了对calculate dataframe 的输入,spark 会话也是需要的,因为在我们特性的calculate实现中,我们使用了像F.col('a')这样的pyspark.sql.functions,这需要您有一个活动的会话。如果我们没有会话,我们会得到这样的错误:

Attribute error when using pyspark sql functions without an active session
如果出于某种原因,我们需要在特性的__init__体(构造函数)中声明计算,这就更明显了,例如:
**class** FeatureAToBRatio(object):
feature_name = **'a_to_b_ratio'** default_value = 0.
**def** __init__(self):
self.calculation = F.col(**'a'**).cast(**'float'**) / F.col(**'b'**).cast(**'float'**)
然后我们会在特性实例化期间得到错误feature = FeatureAToBRatio()。
现在让我们继续添加一些测试用例。
An example test suite for testing feature a to b ratio
我们正在测试:
- 正常情况下,
a和b存在,并有数值 - 其中一个例外,例如
b不存在于数据帧中 - 分母为 0 的情况。
这些只是人们可以为测试的一些基本测试用例。我想到了许多其他的例子,例如,如果a为空或者不同类型的数据类型会发生什么,但是为了这个例子,让我们保持它简单明了。
要运行测试套件:
python -m pytest test_feature_a_to_b_ratio.py

Example output of tests execution

Example output of tests execution — ran with PyCharm
就是这样!请注意,它运行了 7.58 秒(当 shuffle 分区设置为默认的 200 时,运行了 14.72 秒),这对于单元测试来说有点多,而且它只有 3 个测试用例—想象一下,有一个 CI/ CD 在每次合并或提交时运行测试套件…
当然,spark / pyspark 还有很多复杂的测试要做,但我认为这是一个很好的基础。如果有更好的方法,请告诉我。
我希望这有所帮助。任何想法,问题,更正和建议都非常欢迎:)
如果您想了解更多关于 Spark 的工作原理,请访问:
[## 用非技术性的方式解释技术性的东西——Apache Spark
什么是 Spark 和 PySpark,我可以用它做什么?
towardsdatascience.com](/explaining-technical-stuff-in-a-non-techincal-way-apache-spark-274d6c9f70e9) [## 向 Spark 数据帧添加顺序 id
怎么做,这是个好主意吗?
towardsdatascience.com](/adding-sequential-ids-to-a-spark-dataframe-fa0df5566ff6)
对逻辑回归(python)的直观理解
二元例子

Source: Anne Spratt
逻辑回归是一种用于预测目标变量“非此即彼”的模型。我们将研究的例子是:
- **目标变量:**学生将通过或未通过考试。
- **自变量:**每周学习时间
逻辑模型本质上是带有额外步骤的线性模型。在逻辑模型中,线性回归通过“sigmoid 函数”运行,该函数将其输出压缩成二分的 1 和 0。
如果我们想预测实际的考试成绩,我们会使用线性模型。如果我们想预测“通过”/“失败”,我们将使用逻辑回归模型。
线性(预测数值测试分数):
y = b0 + b1x
逻辑(预测“通过/失败”):
p = 1 / 1 + e ^-(b0 + b1x)
可视化:
下图中,直线是线性的,“S”形线是逻辑的。由于其形状,逻辑回归在用于“非此即彼”模型时具有更高的准确性。

Logistic Regressions are “S” shaped. Linear Regressions are straight.
理解数据:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
df = pd.read_excel(r”C:\Users\x\x\Log_test.xlsx”)
x = df[‘W_hours’]
y = df[‘Y’]plt.scatter(x,y)
plt.show()

df.info()
x.plot.hist()
y.plot.hist()

数据集中有 23 行。以下是学习时间的分布情况:

下面是通过(1)/失败(0)的分布情况:

数据准备/建模
接下来,我们将使用 sklearn 库导入“LogisticRegression”。关于参数的详细信息可以在这里找到。
我们把我们的双变量模型转换成二维的。shape()函数。我们定义了 1 列,但是我们将行数保留为数据集的大小。所以我们得到 x 的新形状为(23,1),一个垂直数组。这是使 sklearn 功能正常工作所必需的。
使用“logreg.fit(x,y)”来拟合回归。
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression(C=1.0, solver=’lbfgs’, multi_class=’ovr’)#Convert a 1D array to a 2D array in numpy
x = x.reshape(-1,1)#Run Logistic Regression
logreg.fit(x, y)
使用和可视化模型
让我们写一个程序,通过学习的小时数,我们可以得到通过和失败的预测概率。我们在下面的代码中输入学习时间:学习 12、16 和 20 小时的例子。
print(logreg.predict_proba([[12]]))
print(logreg.predict_proba([[16]]))
print(logreg.predict_proba([[20]]))

左边的输出是失败的概率,右边的输出是通过。
为了形象化模型,让我们做一个循环,将每半小时的学习时间放入从 0 到 33 的回归中。
hours = np.arange(0, 33, 0.5)
probabilities= []
for i in hours:
p_fail, p_pass = logreg.predict_proba([[i]])[0]
probabilities.append(p_pass)plt.scatter(hours,probabilities)
plt.title("Logistic Regression Model")
plt.xlabel('Hours')
plt.ylabel('Status (1:Pass, 0:Fail)')
plt.show()

在这组虚构的数据中,如果一个学生学习超过 20 个小时,他/她就一定会通过,如果不到 10 个小时,他/她就一定会不及格。17 小时是 50/50 的界限。
感谢阅读,
通用变压器

本文将讨论 Universal Transformer,它结合了原始的 Transformer 模型和一种叫做自适应计算时间的技术。通用变形器的主要创新是对每个符号应用不同次数的变形器组件。
纸张参考
德加尼·M、古乌斯·S、维尼亚尔斯·O、乌兹科雷特·J、凯泽·日。万能变形金刚。ICLR 2019。
背景及变压器回顾
如果你还不熟悉变形金刚模型,你应该通读一下“变形金刚:注意力是你所需要的。”万能变压器是对变压器的简单改造,所以先了解变压器型号很重要。
如果您已经熟悉了 Transformer 模型,并且想要快速回顾一下,那么可以这样做:

Figure modified from Transformer paper
基本变换器由编码器和解码器组成:
编码器:
- 6 个编码器层
- 每个编码器有 2 个子层:(1)多头自关注;(2)前馈
解码器:
- 6 个解码器层
- 每个解码层有 3 个子层:(1)掩蔽多头自注意;(2)编解码多头注意;(3)前馈
以下是对多头注意力的一个数字回顾,这是 Transformer 模型的关键创新之一:

多头关注用于编码器自关注(其将先前的编码器层输出作为输入)、解码器自关注(其将先前的解码器层输出作为输入)以及编码器-解码器关注(其将密钥和值的最终编码器输出以及先前的解码器输出用作查询)。)在上图中,模型中使用多头注意力的部分在左侧用红色方框标出。在右侧,示出了多头注意力计算的每个部分的张量的维度。
最后,快速回顾一下编码器子层和解码器子层中使用的位置式全连接前馈网络:

通用变压器的动机
最初的 Transformer 是一种自然语言处理模型,它并行处理输入序列中的所有单词,同时利用注意机制来合并上下文。它的训练速度比 RNN 快,后者必须一个接一个地处理输入令牌。它在语言翻译方面取得了良好的性能。然而,它在诸如字符串复制的算法任务上性能较差(例如,给定“abc”作为输入,输出“abcabc”。)
神经 GPU 和神经图灵机(不同种类的模型)在语言翻译上性能较差,但在算法任务上性能良好。
Universal Transformer 的目标是只用一个模型就能在语言翻译和算法任务上获得良好的性能。通用变压器的作者还指出,这是一个图灵完全模型。(“图灵完备”是指它可以模拟任何图灵机,这是计算机的正式定义。)
概述
在 Universal Transformers 的论文中,作者提供了一个新的图表来描述他们的模型:

Figure 4 from Universal Transformer paper
然而,我认为相对于原始的 Transformer 文件使用不同的图形样式掩盖了模型之间的关键差异。因此,我修改了原始变形金刚论文中的图,以更清楚地强调变形金刚和通用变形金刚模型的相似性和差异性。关键差异用红色强调:

Modified from original Transformers paper figure
变压器和通用变压器的主要区别如下:
- 通用转换器为每个输入令牌应用可变数量的步骤(T 个步骤)的编码器,而基本转换器恰好应用 6 个编码器层。
- 通用变换器将解码器应用于每个输出令牌的可变数量的步骤(T 个步骤),而基本变换器恰好应用 6 个解码器层。
- 通用转换器使用稍微不同的输入表示:除了“位置编码”之外,它还包括“时间步长嵌入”
差异(1)和(2),步骤的可变数量,通过使用“自适应计算时间”来实现,这将在后面更详细地描述。简而言之,自适应计算时间是一种动态的每位置暂停机制,允许对每个符号进行不同量的计算。
通用转换器是一种“时间并行自关注递归序列模型”,它可以在输入序列上并行化。像基本变压器一样,它有一个“全局感受野”(意味着它一次看很多单词。)主要的新思想是,在每个循环步骤中,通用变换器使用自关注迭代地改进其对序列中所有符号的表示,随后是跨所有位置和时间步骤共享的“转换函数”。
这里有一个来自Oriol Vinyals(@ OriolVinyalsML 在 Twitter 上)的很酷的动画,演示了通用变压器:

通用变压器的参数,包括自我关注和过渡权重,与所有位置和时间步长相关联。如果通用变换器运行固定数量的步骤(而不是可变数量的步骤 T),那么通用变换器相当于在所有层上具有绑定参数的多层变换器。
这是通用变形金刚的另一个很酷的动画,来自谷歌人工智能博客:

通用变压器的更多细节
通用变压器输入

如上图所示,通用转换器的输入是一个长度为 m 的序列,表示为 d 维嵌入。在每个时间步,“坐标嵌入”被添加。这些“坐标嵌入”包括位置嵌入(与原始变换器的位置嵌入相同)和时间步长嵌入(与位置嵌入类似的概念,除了它基于时间 t 而不是位置 I)
通用变压器编码器
通用变形金刚编码器的第一部分是多头自关注,和原变形金刚编码器的第一部分一模一样。

通用转换器编码器的第二部分是一个转换函数。转换函数可以是全位置全连接神经网络,在这种情况下,它与原始变压器编码器的第二部分完全相同。或者,转换函数可以是可分离的卷积。作者没有讨论他们何时使用位置全连接网络而不是可分离卷积,但这种选择可能会影响通用转换器在不同任务上的性能。

什么是可分卷积?可分离卷积将卷积核分割成两个独立的核,这两个核进行两次卷积:

Figure modified from “Separable Convolutions” by Chi-Feng Wang
如果你对可分卷积的更多细节感兴趣,可以看看这篇论文: Francois Chollet。例外:具有深度可分卷积的深度学习。arXiv 2016
这就是通用变压器编码器!如果选择位置前馈网络作为转换函数,通用变压器编码器与原始变压器编码器相同。
通用变压器解码器
同样,如果选择位置式前馈网络作为转换函数,通用变压器解码器与原始变压器解码器相同。有三个解码器子层:
- 子层 1:多头自我关注(在先前的解码器输出上)
- 子层 2:多头编解码注意。通过投影先前的解码器输出来获得查询。通过投影最终编码器输出来获得键和值。
- 子层 3:过渡函数。
通用变压器解码器培训
通用变压器论文的一个优点是,它提供了更多关于如何训练解码器的背景知识。这也适用于最初的 Transformer,但在最初的 Transformer 论文中没有详细讨论。
Transformer 解码器(原始和通用)是“自回归”的,这意味着它一次生成一个输出符号,解码器消耗其先前生成的输出。
它使用“教师强制”来训练,这意味着在训练期间,嵌入目标符号的地面真相被馈入(而不是解码器自己可能不正确的预测。)目标符号被右移(因此模型看不到它应该预测的当前单词)并被屏蔽(因此模型看不到未来的单词。)
在通用变换器中,每个符号的目标分布如下获得:

自适应计算时间(ACT)
这是 Universal Transformers 论文的主要贡献:他们将最初在 RNNs 中开发的自适应计算时间应用于 Transformer 模型:
Graves A .递归神经网络的自适应计算时间。arXiv 预印本 arXiv:1603.08983。2016 年 3 月 29 日。
这是一种允许编码器应用可变次数和解码器应用可变次数的机制。
ACT 根据模型在每一步预测的标量“暂停概率”,动态调整处理每个输入符号所需的计算步骤数(“思考时间”)。通用变压器分别对每个位置(例如每个字)应用动态动作停止机制。一旦一个特定的循环块停止,它的状态就被复制到下一步,直到所有的块都停止,或者直到达到最大的步数。编码器的最终输出是以这种方式产生的最终表示层。
以下是 ACT 工作原理的快速总结:
在每一步,我们都会得到:
- 停止概率和先前状态(初始化为零)
- 介于 0 和 1 之间的标量暂停阈值(超参数,即我们自己选择暂停阈值)
首先,我们使用通用转换器计算每个位置的新状态。
然后,我们使用一个全连接层来计算“思考”值,该层将状态降低到 1 维,并应用 sigmoid 激活来使输出成为介于 0 和 1 之间的类似概率的值。这就是思考的价值。“思考”值是模型对每个输入符号需要多少额外计算的估计。
我们决定停止任何超过停止阈值的仓位:
- 刚停止到这一步:(停止概率+思考) >停止阈值
- 仍在运行:(暂停概率+思考)≤暂停阈值
对于仍在运行的仓位,更新暂停概率:暂停概率+=思考。
我们更新其他位置的状态,直到模型停止所有位置或达到预定义的最大步数。
关于自适应计算时间的实现,参见这个 Github 库。
图灵完备性
Universal Transformer 论文的作者解释说,Universal Transformer 是图灵完全的,就像神经 GPU 是图灵完全的一样。如果你不熟悉图灵完备性或者模型之间相互“还原”的证明,可以跳过这一节。
简而言之,作者通过将神经 GPU 简化为通用转换器来证明通用转换器是图灵完全的:
- 忽略解码器
- 使自我关注模块成为身份功能
- 假设转移函数是卷积
- 将循环步骤的总数 T 设置为等于输入长度
- 我们已经从 UT 获得了一个神经 GPU
结果
我们现在已经讨论了通用变形金刚中的所有关键概念。万能变形金刚擅长什么?
通用变压器白皮书中有五项任务,总结如下:

在 bAbi 问答上,通用转换器比原始转换器获得了更好的性能。此外,对于更困难的任务变体(需要更多支持事实来回答问题的变体),在测试数据中所有样本的所有位置上的平均思考时间(通用转换器对一个符号计算多少次)更长。)这意味着当任务更难时,通用变压器“想得更多”。
在 Universal Transformers 的论文中,有几个在 bAbi 任务的不同时间步骤中注意力权重的可视化。视觉化是基于一个芭比故事和一个问题中所有事实的不同观点。四种不同的注意力头对应四种不同的颜色:

Figure 5 from the Universal Transformers paper.
更多这样的数字,可以看论文附录。
Universal Transformer 在主谓一致和 LAMBADA 上也取得了不错的成绩。在 LAMBADA 上,作者注意到通用转换器平均走 8-9 步;然而,他们比较的基础变压器只有 6 层。因此,他们运行了一个 8-9 层的基本变压器,但发现通用变压器仍然优于这种更深层次的变压器变体。这表明更多的计算并不总是更好,在输入和输出序列中的某些符号上减少计算是有价值的。作者推测,自适应计算时间可能具有正则化效果,例如,通过帮助模型忽略(“较少计算”)对解决任务不重要的信息。
最后,作者表明,通用转换器在几个算法任务上取得了良好的性能,包括复制、反转和加法。通用转换器在英德机器翻译方面也优于基本转换器。
总结
- 通用转换器=原始转换器+自适应计算时间
- 通用转换器允许每个符号隐藏状态的同时演化,这些隐藏状态是通过关注前一步骤中的隐藏状态序列而生成的。
- 通用变压器在各种任务上实现了改进的性能。
演讲
对于这篇通用变形金刚博客文章的 PowerPoint 演示版本,请点击链接。
特色图片
特色图像是约翰·威廉姆·沃特豪斯的画作“水晶球”的一部分,结合维基百科的“宇宙”(各种星系)图像和卡通太阳。
原载于 2019 年 9 月 7 日http://glassboxmedicine.com。
无标签数据的股票正在上涨

Facebook’s latest Semi-Weak Supervised Learning framework is a novel approach to leveraging unlabelled datasets for Computer Vision. https://ai.facebook.com/blog/billion-scale-semi-supervised-learning/
脸书大学的研究人员一直在探索使用 Instagram 标签作为 ImageNet 分类模型的弱监督预训练手段。在这项研究中,“弱监督”学习描述了使用有噪声的标签进行监督学习,即 Instagram 图片上的标签。这是有利的,因为大数据是计算机视觉中的王者,他们能够利用10 亿张这些 Instagram 图片进行预训练(ImageNet 包含 120 万张图片,以供参考)。
他们基于这种弱监督学习范式的模型已经记录了最先进的 ImageNet 分类结果,准确率高达 85.4%。他们目前通过使用分辨率增强扩展弱监督学习,以 86.4% 的成绩获得 ImageNet 奖杯。
脸书的最新框架半弱监督学习是这种思想的最新体现,取得了令人印象深刻的结果,并自然产生了高效的模型。随着数据量持续爆炸,脸书的半弱监督学习等研究正在寻找新的方法利用大规模未标记数据集并解决图像网络分类等计算机视觉任务。
半监督和弱监督学习
脸书在这项研究中对“半监督学习”提出了独特的观点。他们将模型提取描述为半监督学习任务,这不是不正确的,只是不符合文献的常规。模型提取指的是使用更大容量的教师网络来产生类标签上的 softmax 分布。然后,较低容量的学生网络在该分布上被训练。模型提取是模型压缩中最强大的技术之一,为像 HuggingFace 的 DistilBERT 这样的模型提供动力。
半监督学习描述了从未标记数据中构造监督学习信号的范例。这是 Word2Vec、DeepWalk 或 Wav2Vec 等技术的想法,其中一部分输入被屏蔽掉,模型的任务是预测哪些被删除了。这种扩展到图像的想法被称为“修复”。然而,更常见的是做一些像人工旋转图像,然后让模型预测旋转角度。这就是驱动诸如“自监督 GAN”的自监督模型的机制。
在脸书的“半弱监督学习”框架中,教师模型最初用弱监督数据集(Instagram hashtags 的监督学习)训练,在 ImageNet 上微调,然后教师模型预测原始弱监督数据集上的班级分布,学生模型训练自己预测相同的分布,最后,学生模型在 ImageNet 数据集上微调。
未标记数据集中的类别不平衡
类别不平衡描述了在训练数据中严重偏向一个类别的数据集。例如,包含 80%狗和 20%猫的训练集将产生偏向于将图像标记为狗的模型。Instagram 图片等海量无标签数据集自然包含类别不平衡和长尾分布。比如 Instagram 上有成吨的狗图片,有多少叶甲?
脸书大学的研究人员通过使用教师网络预测标签的 top-K 评分系统来解决这个问题,并使用该参数来平衡图像的数量。随着 K 变大,接近分布末端的图像相对于它们的类别标签变得更有噪声。在叶甲虫的情况下,可能只有 8K 甲虫图像,因此如果 K 被扩展到 16 或 32K,则从 8001 到 16000 的图像将被错误地标记。然而,这个想法是教师模型对 bettle 图像有足够的感觉,使得不是甲虫的图像 8001 在语义/视觉上仍然是相似的。
大规模模型蒸馏的推理加速

High-level idea of NVIDIA’s TensorRT inference accelerator. https://developer.nvidia.com/tensorrt
从这个框架中产生的另一个有趣的部分是,当教师在未标记的数据集上预测标签时,推理加速的重要性。教师网络必须进行大约 10 亿次预测,以产生学生网络的精选标签。通常,用模型提取训练的模型不会解决推理瓶颈,但是在以这种方式标记 10 亿张图像的情况下,这显然是重要的。这提供了推理加速器的额外贡献,如 NVIDIA 的 TensorRT 和针对小推理延迟优化的模型。
弱监督数据集的最佳来源是什么?

Photo by NeONBRAND on Unsplash
想想 Instagram 的标签很有趣。这是弱监督数据集的最佳来源吗?YouTube 视频包含上传者提供的标签,但这种标签比 Instagram hashtagging 噪音大得多。
精华建筑搜索
脸书最近的论文改变了学生网络体系结构,从 ResNet-18 到 ResNet-50 以及递增的更大版本的 ResNeXt。在一大堆探索各种背景下的神经架构搜索的研究论文中,对升华师生架构关系的研究相对较少。ResNet 变型从较大容量转换到较小容量似乎很直观。这种想法可能更好地体现在一个更结构化的进展,如从 EfficientNet-E7 到 E5。此外,通过搜索最适合从教师的预测标签分布中学习的特定架构,可能会实现性能提升。
生成模型能进一步增加预训练数据集的大小吗?

Generated face images from NVIDIA’s Progressively Growing GAN models. What happens if these models are married with the 1 billion Instagram images used for pre-training? https://arxiv.org/pdf/1710.10196.pdf
使用 GANs 从现有数据集生成新的训练数据的想法似乎很有前途。这已被证明在极其有限的数据集(如医学图像分析)的情况下是成功的,但对于常规任务(如 ImageNet 分类或 COCO 对象检测)尚未奏效。使用“半弱”监督训练框架,GANs 或变分自动编码器能否应用于 10 亿张未标记图像,以产生 20 亿或 100 亿张图像?这会产生新颖的图像来改善计算机视觉模型的预训练吗?
结论
脸书的半弱监督学习框架对半监督学习、弱监督学习、模型提取中的类不平衡以及模型提取的推理加速是一个非常有趣的视角。随着越来越多的人使用 Instagram,数据集自然会变得更大,他们使用 Instagram 图片的方法似乎会自然地扩展到数十亿张图片。top-K 评分法是解决大规模未标记数据集中明显的类别不平衡的一个很好的策略。有趣的是,如果生成模型可以进一步增加这些未标记的数据集。感谢您的阅读,如果您对本文的详细内容感兴趣,请查看下面的视频!
在谷歌云平台虚拟机上释放 Visual Studio 代码(VSCode)的威力
在您的远程虚拟机上获得成熟的本地 IDE 体验!

Photo by Joshua Earle on Unsplash
Visual Studio Code(简称 VSCode)是一个强大的、多平台的、免费的代码编辑器,支持多种编程语言[1]。在过去的两年里,它的受欢迎程度有了惊人的增长,这可以从它的谷歌搜索趋势的迅速上升中看出。在这篇文章中,我将分享一种使用安装在本地计算机上的 VSCode 来编辑和运行位于 Google Cloud 虚拟机上的代码的方法。但是首先…

Google Trends comparison between VSCode, Sublime, and Atom from Jan 2016 to Nov 2019.
我有 Jupyter 为什么还要 VSCode?
作为一名数据科学家,当你拥有 Jupyter 笔记本[2]的便利时,为什么还要使用 VSCode?如果你像我一样,那么你的日常数据科学工作包括两个方面。第一个方面是使用著名的 Jupyter 笔记本进行实验。Jupyter 非常适合数据科学项目早期阶段所涉及的那种迭代的、实验性的工作流。一旦您有了想要在生产中运行的产品(每天运行数千次或数百万次),数据科学家工作的第二个方面就开始了。在许多组织中,您没有专门的制作团队。即使您有这种奢侈,在将代码传递给生产团队之前重构代码也是一个好的实践,以确保产品在部署后能按预期工作。这就是 VSCode 在数据科学工作流中的闪光点!使用 VSCode 从 Jupyter 笔记本中重构代码的细节值得一篇独立的帖子来公正地对待。然而,[3]很好地概述了 VSCode 中可用的重构工具。一个简单的例子是“重命名符号”,它只允许你重命名一个变量一次,但是会自动更新你代码中出现的所有变量!超级得心应手!
先决条件
现在让我们进入这篇文章的细节。既然你正在阅读这篇文章,我假设你已经运行了一个 GCP 计算引擎 VM,并且你的个人电脑上也安装了 VSCode。如果你没有这两个,那么参考【4】关于如何设置 GCP 计算引擎 VM 和【1】下载并安装 VSCode 到你的本地计算机上。更新:您还必须安装 gcloud sdk,并按照【9】中的说明在您的系统上运行 gcloud init
详细步骤
Mac 和 Linux 用户可以直接跳到这篇文章的部分,使用内置终端从第 1 步开始。Windows 用户需要注意以下几点:
仅适用于 Windows 用户:
- 从开始菜单,启动 Windows Powershell
- 对于这篇文章的为所有用户部分下的所有剩余步骤,请遵循参考网页上 Linux 和 MACOS 部分下的说明。但是,请记住删除出现的下列内容:
~/.ssh/ - 例如,如果参考网页的 Linux 和 MACOS 部分显示:
ssh-keygen -t rsa -f ~/.ssh/[KEY_FILENAME] -C [USERNAME]
改为在 Windows Powershell 中键入:
ssh-keygen -t rsa -f [KEY_FILENAME] -C [USERNAME]
重要!不要按照网页的 Windows 部分的说明操作,因为我还不能让它在我的 Windows10 桌面上运行。
适用于所有用户:
遵循以下网页的 Linux 和 MACOS 部分的说明,即使您是 Windows 用户(请阅读上面的部分,仅适用于 Windows 用户)
- 按照【5】中的说明,在您的本地计算机上设置 SSH 密钥。Windows 用户,记得去掉
~/.ssh/ - 按照【6】中的说明,在本地计算机上找到并复制您的 SSH 密钥。Windows 用户,默认情况下你的密钥保存在
C:\Users\your-windows-username - 您必须将此 SSH 密钥(从您的计算机)添加到您的 Google cloud platform 帐户。您可以按照【7】的指示插入整个项目的密钥,也可以按照【8】的指示插入特定虚拟机的密钥。我个人倾向于将它添加到特定的虚拟机中,以便进行组织。记住,您需要复制的公共 SSH 密钥是。pub 文件。Windows 用户,最好在记事本中打开此文件并复制其内容。
- 现在,在本地计算机上打开 VSCode。在 Windows 上按 Ctrl+Shift+x 打开 VSCode 中的扩展管理器。在搜索框中,键入 *remote-ssh,*并安装这个扩展。

Install Remote-SSH extension in VSCode on your local computer
5.安装完成后,在电脑上按 Ctrl+Shift+p (或者在 Mac 上按 Cmd+Shift+p 调出命令面板,键入 remote-ssh 。应该会出现一组选项,如下图所示。单击添加新的 SSH 主机… 选项。

Add New SSH Host… is the second option
6.在弹出的 Enter SSH Connection 命令提示符下,键入:ssh -i ~/.ssh/[KEY_FILENAME] [USERNAME]@[External IP]并按 Enter 键。KEY_FILENAME 和 USERNAME 是您在步骤#1 中键入的内容。外部 IP 可以在您的 GCP 计算引擎虚拟机实例页面中找到,并且对每个虚拟机都是唯一的。又弹出一个提示,要求您选择 SSH 配置文件来更新。只需点击第一个,您应该会看到*主机已添加!*在 VSCode 窗口的右下角。
对 Windows 用户很重要!,而不是~/。ssh/[KEY_FILENAME],您必须键入带有\ "的完整路径。例如,ssh -i C:\\Users\\your-windows-username\\[KEY_FILENAME] [USERNAME]@[External IP]

Select the first option
7.按下 Ctrl+Shift+p (或者 Mac 上的 Cmd+Shift+p )打开命令面板,再次键入 remote-ssh。这次点击连接到主机。然后从弹出的列表中选择虚拟机的 IP 地址。如果您再次看到关于指纹的弹出窗口,请点按“继续”。

Connect to Host is the fifth option above
8.就是这样!您的本地 Visual Studio 代码现在已经连接到您的 GCP 虚拟机了!您可以单击打开文件夹或打开文件,这将显示虚拟机中的文件,可以直接从本地计算机上运行的 VSCode 编辑这些文件。
常见问题
我已经在 Mac、Linux 和 Windows10 桌面上测试了上述步骤。因此,如果您在此过程中遇到任何错误,很可能您犯了以下常见错误之一:
- 您的 GCP 虚拟机已停止。启动 GCP 虚拟机,然后重试。
- 在第 6 步中,您要么提供了错误的 KEY_FILENAME 位置,要么提供了错误的用户名或错误的外部 IP。请记住,如果您没有为 GCP 虚拟机设置静态 IP,那么您可能需要在每次停止和启动虚拟机时执行第 6 步,因为外部 IP 地址可能会发生变化。始终提供正在运行的虚拟机的当前外部 IP。
- 您按照[5]、[6]、[7]和[8]下的网页中的 Windows 说明进行了操作。DONT!回过头来,按照 Linux 和 MACOS 下的说明重做所有步骤,并做我上面提到的小修改
我希望这篇文章对你有所帮助。如果有,请在下面告诉我。编码快乐!
参考资料:
【1】下载 vs code:https://code.visualstudio.com/
【2】下载 Anaconda 使用 Jupyter 笔记本:https://www.anaconda.com/distribution/
【3】vs code 中的重构选项:https://code.visualstudio.com/docs/editor/refactoring
【4】启动一个 GCP 计算实例 VM:https://cloud.google.com/compute/docs/quickstart-linux
【5】在本地计算机上创建 SSH 密钥:https://cloud . Google . com/Compute/docs/instances/add-removed-SSH-keys
解开行为秘密,克服客户流失的极端情况
了解、预测并最大限度减少客户流失
介绍
在新的全球经济中,客户保留已成为当今动荡的商业环境中的一个核心问题,并对许多服务公司提出了重大挑战。尤其令人担忧的是削减成本和激烈的竞争压力。人们越来越担心,没有充分利用现有客户群的公司正处于不利地位。
学术界已经产生了大量的研究来解决这一挑战的一部分——特别侧重于预测客户流失。然而,仍然需要理解企业中存在的对客户流失的各种看法。管理客户关系的核心目的是让企业专注于增加客户群的整体价值,而客户维系是企业成功的关键。

(source: https://www.istockphoto.com)
本博客系列描述了可用于控制客户流失的方法的设计和实现,重点关注主动流失管理,即在预测客户会流失时提前联系客户,并提供旨在防止客户流失的服务或激励。通过采用定性和定量的调查模式,我试图阐明客户流失的预测模型,并提出一个开发主动流失管理计划的框架。
问题
使用简单的保留模型,客户的终身价值是:

客户流失管理的整个原则的核心是保留的概念,。在客户层面,流失率指的是客户在给定时间内离开公司的概率。在公司层面,客户流失是指在给定的时间段内,公司客户群中离开的客户所占的百分比。因此,流失率等于 1 减去留存率:

然而,对于任何一个简单的保持生命周期价值模型适用的行业,都存在与客户流失相关的某些缺点,即,客户可能会离开,并且如果没有重大的重新获得努力,不会自然返回。这体现在许多服务中,如杂志和时事通讯出版、投资服务、保险、电力设施、医疗保健提供商、信用卡提供商。
有两种基本类型的流失:订阅流失和非订阅流失
订阅流失发生在用户或客户签订了一段时间(每月、每年等)合同的企业中。—想想有线电视、网络或电话提供商),客户选择在合同到期后不再回来。正如定义中所指出的,这很容易定义、预测和预防,因为有一个清晰、明确的客户流失风险窗口,可以集中开展营销活动。

非订阅流失指的是用户或客户可以随时终止与业务关系的事件,他们可以随意来来去去。随着时间的推移,客户可能会逐渐减少购买频率,也可能会突然不再购买。这篇博客将关注防止订阅流失的过程。
数据采集
传统上,客户流失预测是通过简单地测量某种形式的客户身份和客户最后一次互动的日期/时间来评估的。这些数据虽然不太详细,但可以让你建立模型,在基本层面上预测客户流失。然而,现实情况是,在这个最小数据集的基础上添加额外的数据是推荐的,也是非常鼓励的。包含的数据越多,对客户流失的预测就越准确,因此,如果可以的话,也要在数据集中包含一些东西,如用户的静态人口统计信息、特定类型用户行为的细节等。来源越多越好。
选定数据
我将使用“电信客户流失”数据(IBM 样本数据集)来预测留住客户的行为。在这个数据集中,每一行代表一个客户,每一列包含列元数据中描述的客户属性。
数据集包括以下信息:
- 上个月内离开的客户—这一列称为流失
- 每位客户已注册的服务—电话、多条线路、互联网、在线安全、在线备份、设备保护、技术支持以及流媒体电视和电影
- 客户账户信息——他们成为客户的时间、合同、支付方式、无纸化账单、每月费用和总费用
- 客户的人口统计信息—性别、年龄范围,以及他们是否有伴侣和家属
数据预处理
数据预处理是一种数据挖掘技术,用于将原始数据转换成有用和有效的格式。这通常会占到项目总时间的 80%,因为数据是在不同的时间点从多个来源收集的。理解数据中的不同变量是建立直觉的基础。因此,在继续清理不同的拼写或可能丢失的数据之前,建议为这一部分分配足够的时间,以确保一切都是同质的。彻底的探索和清理将在后续步骤中节省时间,尤其是在进行预测的时候。
流失分布表明,我们正在处理一个不平衡的问题,因为有更多的非流失用户。大约四分之一的样本不再是客户(图 1)。当我们构建分类模型时,这将会有所暗示。我将在客户流失建模过程中详细介绍。

数据可视化和特征选择
特征提取旨在通过留下代表最具辨别性信息的变量(属性)来减少变量(属性)的数量。特征提取有助于降低数据维度(维度是数据集中具有属性的列)并排除不相关的信息。
在特征选择过程中,人们可以修改先前提取的特征,并定义其中与客户流失最相关的子组。作为特征选择的结果,我们可以得到只包含相关特征的数据集。
如下图所示,大部分客户流式传输电影和电视流(图 2)。同样,大多数客户使用无纸化账单,没有在线安全保障。

下图显示了大多数客户使用单条电话线提供电话服务。光纤互联网连接比 DSL 互联网服务更受欢迎,每种在线服务都有少数用户。样本中约有一半是按月合同,其余一半是一年期和两年期合同(图 3)。

该图的下半部分显示了付款方式和任期变量的细分,因为大部分客户的任期最短(0-12 个月)。
图 4 总结了相关性分析的结果。一眼就能看出,流失和变量个数是有关系的;具有不同的强度,例如合同类型、总费用、互联网服务等。有时候很明显有因果关系。然而,相关性并不意味着一个变量的变化实际上导致另一个变量的变化。在统计学中,你通常需要进行随机的、受控的实验来确定一种关系是因果的,而不仅仅是相关的。

结论
我们已经讨论了流失问题、其原因,以及从探索性数据分析中发现模式和建立直觉的一些方法。下一次,我们将看看预测模型如何识别流失者并揭示他们流失的原因,以及公司如何管理流失。
👋感谢阅读。如果你喜欢我的作品,别忘了喜欢,在中关注我。这将激励我为媒体社区提供更多的内容!😊
参考资料:
Ascarza 等人(2018):追求增强的客户保持管理:回顾、关键问题和未来方向。斯普林格科学+商业媒体有限责任公司 2017
布拉特伯格等人(2008):《数据库营销:分析和管理客户》。起拱石
Ghorbani 和 Taghiyareh (2009): CMF:改善客户流失管理的框架。 IEEE 亚太服务计算大会(IEEE APSCC)
韩等人(2011 年):陈,j .,裴,j .,和 Kamber,M. (2011 年)。数据挖掘:概念和技术。数据管理系统中的摩根考夫曼系列。爱思唯尔科学
“主旨-句法-主题”:https://github.com/lonekorean/gist-syntax-https://business science . github . io/correlation funnel/articles/introducing _ correlation _ funnel . html
https://blogs . r studio . com/tensor flow/posts/2018-01-11-keras-customer-churn/
利用机器学习开启药物研发
通过利用机器学习来生成和创建分子的逆向合成路径,从而加速药物发现。

我们发现药物的方式效率极低。需要做点什么。
尽管最近制药行业发生了很多创新,尤其是在癌症研究领域,但仍有巨大的差距需要改进!
自 20 世纪 20 年代以来,我们目前的药物发现方法没有太大变化。
这是曾经发现毒品的故事:
1928 年,病理学家亚历山大·弗莱明(Alexander Fleming)经常被描述为“无忧无虑”,他在去度一个月的假之前,不小心把培养皿放在了窗户旁边,没有盖上盖子。
从他美好的假期回来后,发生了更美好的事情。让他吃惊的是,这个被丢弃的培养皿让弗莱明有了惊人的发现,发现了世界上第一种抗生素——青霉素,这一发现颠覆了制药业🤯**。**

这只是一个小错误如何成为治疗突破的众多例子之一。
快进到大约 8 年后,这是目前发现的药物:
最近,纽西兰的研究人员* 出人意料地* 发现,先前在 21 世纪初用于对抗脑膜炎疫情的疫苗,随后也降低了淋病的风险**。**
尽管发生了这么多进展,药物发现的秘方似乎从未逃脱意外收获的魔力。
在过去的 80 年里,技术进步呈指数增长,但药物研发领域的进展相对停滞。
手机甚至都不是东西,更别说 1928 年的苹果了(如果你不是苹果粉丝,我们就不是朋友——开玩笑的😁),现在我们不仅有苹果,而且我们还有脑机接口,人工智能将创新带入每个行业,量子计算(最近,谷歌宣布量子至上)和大量指数级技术的出现。
但是,相比之下,在改进药物发现过程方面进展甚微。

I meant I love eating apples 🍏
目前的药物发现过程是什么样的?
有大量的证据表明,目前的药物发现过程仅仅是 不足 , 不足 针对那些最需要的人——患有慢性和致命疾病的人。
据估计,将一种药物从研究阶段推向市场平均需要花费 26 亿美元,并且需要 10 年以上的时间😱**。**由于药物研发非常耗费资源,最近的大部分进展都集中在癌症研究等高回报市场。
这部分解释了90%以上的罕见疾病缺乏有效治疗。
但是为什么会这样呢?让我们看看药物发现管道(又名药物开发的多方面过程)。
我们都希望这些救命药物能够更快、更便宜地送到有需要的患者手中。
为什么这个过程如此漫长和昂贵的简单答案是纯粹的复杂性。
药物研发管道看起来像这样:

Drug discovery pipeline! There are a total of 7 phases.
复杂吧?我们来分解一下…
药物研发有七个阶段:
1.目标识别:发现(2 年以上)
第一步甚至不是关于药物,而是关于理解导致疾病的目标。这些靶标通常由 DNA 突变、错误折叠的蛋白质和其他潜在的疾病生物标志物组成。但是,青霉素的发现显然不是这样,纯粹是偶然发现推动的。
问题#1: 虽然理想的途径是确定靶点,然后开发出专门对抗疾病靶点的药物,但这个过程并没有保证。青霉素的发现显然是这个过程的一个例外,而且还有更多例外。有这么多可能的化合物,这么多可能的目标,人类很难理解所有这些可能的组合。
2.线索发现:临床前(1-2 年以上)
这是筛选数千种旨在干扰疾病靶标的化合物的过程。目标是显著缩小各种潜在化合物的范围。
3.药物化学:临床前(1-2 年以上)
这一阶段包括进一步测试化合物的过程,以分析它们与疾病靶标的相互作用。可以进行的一些分析包括,例如,考虑化合物的 3D 构型来研究化合物的相互作用。根据分析得出的结果,朝着预期目标进一步优化化合物。
4.体外研究:临床前(1-2 年以上)
作为概念的证明,进入这一阶段的化合物在细胞系统中进行测试,这是一种疾病的体外模型。这是培养皿研究发生的阶段。体外研究试图详细检查该化合物在干扰靶标方面的有效性。
问题#2: 体外研究结果往往不能反映动物或临床研究结果,导致 失败率高。 根据麻省理工学院的一项研究, 临床试验成功率徘徊在 14%左右,这太疯狂了! 这是因为我们的体外细胞系统模型往往是对我们复杂的人类系统的粗略简化。生物学不是以 2D 模式运行的,但培养皿研究是细胞的 2D 模型,是一种广泛使用的体外研究方法。
5.体内研究:动物研究(1-2 年以上)
体外研究成功后(耶,但最困难的部分还在后面),该化合物通常在动物模型中测试,如大鼠或小鼠模型。与 2D 体外细胞培养模型相比,动物研究的结果通常更具代表性。然而,它明显比体外研究更昂贵。这一阶段的失败率也更高,因为由于细胞模型结构的差异,体外研究的结果不一定与动物研究相关。
注意要牢记: 如果我们能早点失败,而不是晚点失败呢?在如此昂贵的阶段失败是没有意义的,如果我们在体外研究阶段失败了呢?
6.最后,我们进行临床试验(6 年以上)
如果上述所有阶段的结果都表明该化合物有前景,那么它将进入临床试验。临床试验有三个阶段,每个阶段都有不同的目标。临床试验的主要目标是验证化合物或潜在药物在人类环境中的有效性和安全性。
问题#3: 临床试验有许多监管方面,这就是为什么它是最漫长和最昂贵的阶段。证明药物的疗效往往不是一件容易的事;具体来说,化合物的长期副作用通常在一段时间后仍然未知。在人身上试验新药总是存在巨大的内在风险。三期临床试验的平均费用估计为 1900 万美元。
7.还有最后一个阶段:FDA 批准和商业化(1 年以上)
一旦所有测试完成,该化合物可以提交给美国食品和药物管理局审查批准。一旦获得批准,这种药物终于可以在患者手中商业化,以改善生活和治疗疾病!!!!!!—有史以来最激动人心的部分,但这是一次极其漫长和昂贵的旅程!
问题#4: 新上市的药物往往极其昂贵,这是因为研发的成本非常高。公司通常有 20 年的专利来保护他们的药物/产品免受竞争。这意味着他们可以将药物定价在他们认为合理的价格上。有时,这一价格可能高达数十万美元,使普通大众无法承受。
**需要牢记的注意事项:**我们如何才能加快药物发现的进程?
哇,那是一次旅行🌄!
但是,如果有一种方法可以将早期药物发现(除了临床试验+商业化之外的所有阶段)的过程从 6 年大大加快到 6 天,会怎么样呢?我很乐观,我一点也不觉得这是科幻!其实这是有可能的!我们并不缺乏实现这一点所需的工具,我们只是缺乏乐观和合适的人。
当前的创新:加速药物发现
- in silico Medicine(AI+pharmaceutical startup)能够在短短 46 天内设计、合成和验证新的候选药物。
- AlphaFold (谷歌的人工智能算法)能够以前所未有的速度和精度预测蛋白质的三维结构(药物发现中的关键评估),超过了该领域一些世界上最好的生物学家和研究人员。
人是推动增长的唯一最重要的因素,而不是其他因素。不管你是一个 16 岁的高中生(剧透:那是我),还是一个著名的人工智能研究者,我相信我们所有人都可以做一些事情来创造影响。作为一个好奇的 16 岁少年,这也是我决定做点什么的根本原因。
Synbiolic 简介:利用变分自动编码器进行药物发现
我们已经坚持同样的过程,做了大量的湿实验室实验,经历了一堆药物发现的试验和错误太久了!药物研发的人工流程必须改变!
是时候来点新的了,介绍 Synbiolic :推断人工智能的潜力,特别是变型自动编码器(VAE)以 SMILES 的格式生成新的&有效分子(简化的分子输入行输入系统)。
Synbiolic 的魔法是如何发挥作用的?
- 使用VAE的魔棒生成分子
- 使用更多的魔法将生成的分子列表过滤成几个真正好的分子

Imagine if drug discovery was as easy and fun as lego building!
这里有一个内部的魔术是怎么回事!
除了是一个人工智能+书呆子的时髦词,什么是变化的自动编码器?
变分自动编码器(VAE)是一种类型的机器学习算法。**生成模型是一种人工智能架构,它能够生成与训练数据特征相似的新数据*。***
*它由两个神经网络组成: **(1)编码器,和(2)解码器。*注:编码器和解码器可以使用不同的神经网络。
编码器网络负责降低输入到模型中的数据的维度,解码器网络通过将数据的紧凑表示重建回其原始维度/输入来反转该过程。
数据的紧凑表示被称为潜在空间表示(也称为瓶颈)。

Autoencoder 💻
Synbiolic 利用 VAE 生成新的分子,这些分子具有类似药物的特性,类似于用于训练模型的分子。生成的分子与训练分子并不完全相同,而是训练分子的变体。
为了更直观地理解编码器和解码器模型的功能,让我们来玩一个猜字谜游戏!

Finding Demo 😍
让我们进入编程模式,从声明一些变量开始🤖:
- 右边的女士=编码器
- 左边的先生=解码器
- 海底总动员=潜在空间/分子的紧凑表示
- 动作=生成的分子
猜测短语“海底总动员”(分子的紧凑表示)* 的女士类似于编码器,因为她将“动作”(分子) 浓缩成短语*(分子的紧凑表示)。就 AI 语言而言,她本质上是在建构“行动”的潜在表征(分子)* 。这类似于编码器如何将用于表示分子的维度减少到更紧凑的形式。*
扮演“海底总动员”的绅士(分子的紧凑表示)* 类似于解码者,因为他试图将短语重新解释为动作*(分子)* ,这是扩展的表示。就生成分子而言,解码器通过基于其浓缩特征或潜在空间表示来重建分子来实现这一点。*
但是,等等,是什么让变分自动编码器不同于普通自动编码器?
一个变化的自动编码器有一个编码器和解码器网络,就像上图中普通的自动编码器一样(在海底总动员之前的那个)👆。然而,它不仅仅是一个常规的机器学习模型, VAE 为其编码器网络使用了一种概率方法。
之所以用 VAE 代替自动编码器,主要是因为普通的自动编码器不能生成数据。这是因为普通的自动编码器(特别是编码器)似乎无法找出一种好的方法来创建“可用的”潜在空间表示,以馈入解码器网络,从而生成“好的”分子。
当自动编码器试图生成新数据时,最终发生的是一个随机的潜在表示/向量被输入到解码器模型中,这反过来生成真正时髦和无用的数据*。这是因为除了强迫编码器从训练数据中创建潜在向量之外,普通的自动编码器不知道如何获得“好的”潜在向量。*
普通自动编码器的潜在空间不是连续的,这就是它们不适合生成数据的原因。

这意味着,采用上述图片中的潜在表示,解码器能够生成看起来不错的图片,但如果肤色等潜在参数中的一个从 0.85 到 0.84 稍有改变,那么解码器网络就会完全出错,最终可能会生成类似这样的结果:

这都是因为潜在空间表征不是连续的。
生成随机数据也没那么神奇。自动编码器无法实现的 VAE 的神奇之处在于,它是最好的生成模型之一,可以用来在期望的方向上对你已经拥有的数据进行变化。**
编码器网络被表示为 q(z|x ),解码器网络被表示为 p(x|z ),因为 x 表示网络的输入,z 是潜在表示(它是一个向量)。

Variational Autoencoder breakdown: Green is the encoder network, blue is the decoder network
变化自动编码器的不同之处在于它的编码器网络利用了一个概率模型*。这使得潜在空间是连续的。*
VAE 通过让它的编码器组合两个向量来做到这一点:**一个向量取平均值,另一个向量取输入数据的标准偏差。**然后从均值向量和标准差向量中通过采样构建潜在向量 z。

μ represents the mean and σ represents the standard deviation
通过采样,这允许潜在空间是连续的,而不是离散的。这就是为什么 VAEs 可以生成本质上是训练数据的变体的合成数据的原因。(我们可以通过优化潜在空间来有意地应用这些“变化”,以生成具有所需属性的新数据。)
让我们继续关注这一切背后的秘方*,也就是 Synbiolic 的 VAE 所用的模型。*
对于编码器和解码器模型,使用以下神经网络:
- 编码器网络=卷积神经网络(CNN)
- 解码器网络=一种称为门控递归单元(GRU)的递归神经网络(RNN)
理解卷积神经网络:编码器
在我们深入 CNN 之前,让我们先来探索降维实际上是什么。
降维是机器学习中的一种技术,用于通过减少其特征来降低数据。**
编码器模型可以使用两种技术来执行维度缩减:
- 按要素选择-仅选择部分要素,排除其余要素
- 通过特征提取-将输入数据转换为潜在表示
这两种技术的区别在于,特征选择不会改变特征,而特征提取会改变特征,因为它会对“输入特征/数据”进行变换,以获得潜在空间表示。**
卷积神经网络(CNN)是一种深度学习算法,由于其检测特征的能力而广泛用于图像分类。
他们通过实施特征提取来做到这一点,从而降低输入数据的维度。
和其他深度学习算法一样,CNN 由*【1】个输入层、【2】个隐藏层、【3】个输出层组成。***
隐藏层由几个不同类型的层组成,如卷积层、池层和全连接层。

Convolutional Neural Networks
使“卷积神经网络”成为“卷积神经网络”的是卷积层。是的,就这么简单,实际上,也许没那么简单…
卷积层本质上执行输入和滤波器之间的点积,以获得数据的低维表示(也就是说,卷积层由数学支持)。

The yellow matrix is the filter, the green matrix is the input image, and the pink matrix is the convolved feature or latent representation.
如你所见,卷积特征在尺寸上比原始输入更加紧凑。
要了解更多关于卷积神经网络及其在皮肤癌检测中的应用,请查看本文!
我没有像从痣的图像中检测皮肤癌那样使用 CNN 进行图像分类,而是在分子数据集上训练 CNN。
VAE 在包含 250 000 个分子的锌数据集上进行训练。编码器(CNN)将分子特征的表示转化为更紧凑的表示。
解码器呢?
对于解码器,使用一种称为门控递归单元(GRU)的特定类型的递归神经网络(RNN)。
与其他类型的神经网络不同,rnn 具有内部记忆能力。rnn 通常应用于序列数据,因为它们的特殊属性是它们的决策受网络内的先前输入和输出 的影响。
普通神经网络也具有“记忆”事物的能力,但它们仅限于记忆来自 先前训练迭代的事物。

“Vanilla” Neural Network
相比之下,rnn 记住每次训练迭代中的事情,并根据输入和前一个隐藏状态生成的输出做出决策。

x nodes are the inputs, y nodes are the outputs, and h nodes are the hidden nodes
***这样想:*还记得你的数学老师曾经告诉你,如果你不知道数字的加减乘除,你将永远无法掌握微积分!这是因为作为人类,我们理解概念的基础是我们之前学过的概念。
这类似于你在读这句话时,你是基于对前面单词的理解来理解这句话的。如果我只写“以前的话”作为句子,你不会明白我想说什么。本质上,这是 rnn 真正擅长做的事情:像句子结构一样剖析顺序数据的含义。
RNNs 的内部存储容量指的是它能够记住网络中以前的信息,以帮助它做出决策。他们能够通过理解序列中前一个值之间的联系来预测序列数据中的下一个值。
所有机器学习都是由数学驱动的,RNNs 的数学由隐藏状态(h)组成,这些隐藏状态是隐藏节点。
隐藏状态是相互联系的。在每个隐藏状态中,都有门,门是控制信息传递的神经网络。
对于计算信息的隐藏状态,必须对其进行预处理并将其转换为矩阵/向量表示。
“普通”rnn 的隐藏状态如下所示:
- 前一隐藏状态的输出与当前输入组合形成一个向量,该向量包括关于当前和前一输入的信息。
- 这个向量通过一个 tanh 激活函数,该函数将范围限制在-1 和 1 之间,以产生新的隐藏状态。

然而,传统的 RNN 遭遇了一个被称为消失梯度下降的问题。

当训练传统 RNN 时发生的是,随着权重被更新,梯度变得如此之小,以至于更新的权重变得不重要。如果原始权重实际上保持不变,这意味着在该模型中有很少或没有学习*。*
小的梯度更新不会导致任何显著的学习,从而阻止模型完成它的工作。
为了解决这个问题,我为解码器实现了门控循环单元(RNN,但有所改变),而不是使用“传统的”RNN。
门控循环单元(GRU)中涉及两个门:**更新门和复位门。**本质上,门只是隐藏节点内的神经网络*。*
与 RNN 不同, GRU 只记住重要的短语和单词,而不是记住句子中的每个单词。
比如,我们来看看这句话:
“为了研究如何最好地加速罕见病研究的问题,我们将回顾一些罕见病研究中的挑战以及最近的科学进步为治疗发展带来的机遇。”
像“to”、“the”、“of”、“that”和“for”这样的词与句子的意思并不相关,因此 GRU 人会忘记这些词。
为了考察如何最好地 加速罕见病研究 的问题,我们将回顾一下 中的一些挑战*罕见病研究 和 中的机遇 对于 疗法的发展*
RNN 可能试图记住整个句子,而 GRU 只记住重要的术语(上面用粗体表示)。

Gated Recurrent Unit
更新门
更新门的职责是确定需要保留多少来自先前隐藏状态的信息。消失梯度下降问题通过通过这个门来解决,因为模型能够决定它需要将多少过去的信息传递给未来的隐藏状态。
复位门
来自先前隐藏状态的输出和当前输入组合形成一个向量,该向量包括关于当前输入和先前输入的信息。每个向量不仅包含当前隐藏状态的信息,还包含先前隐藏状态的信息。
重置门的工作是决定模型应该忘记哪些过去的信息。本质上,这个门的功能与更新门的功能相反。
在生成分子的场景中,GRU 或解码器的输入是表示分子的压缩形式或潜在空间表示的向量。GRU 的最终输出是分子在其原始/扩展表示中的重建。
衡量分子药物相似性的量称为 QED(药物相似性的定量估计)。我获得了生成分子的 QED,以验证它们是类药物分子。
QED 低于 0.5 的所有生成分子都被忽略,这确保了生成分子的质量。可以合成具有最高 QED 值的分子,以通过体外和体内研究进一步验证它们的性质!
耶!我们能够成功地设计和验证分子!这个被归类为早期药物设计的过程至少需要 3 年的传统研究才能完成!
如果你感兴趣,可以在这里查看来自 Github 的源代码。
这要感谢我的优秀团队:雅利安·米斯拉 & 埃利亚斯·昆图里斯!
关键要点:
- 药物研发极其昂贵且漫长
- VAE 是一种生成神经网络,可用于生成药物发现的分子
- 人工智能是一个强大的工具,可以用来彻底改变医疗保健
不要忘记:
- 访问 Synbiolic 的网站,了解更多关于 16 岁青少年的活动!
- 在 LinkedIn 上和我联系!
来自《走向数据科学》编辑的提示: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们并不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
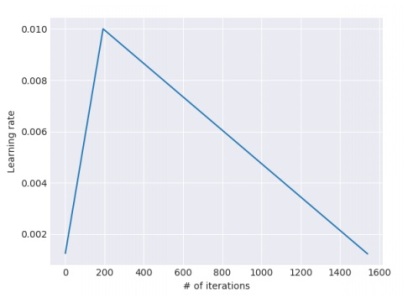{kind=link}
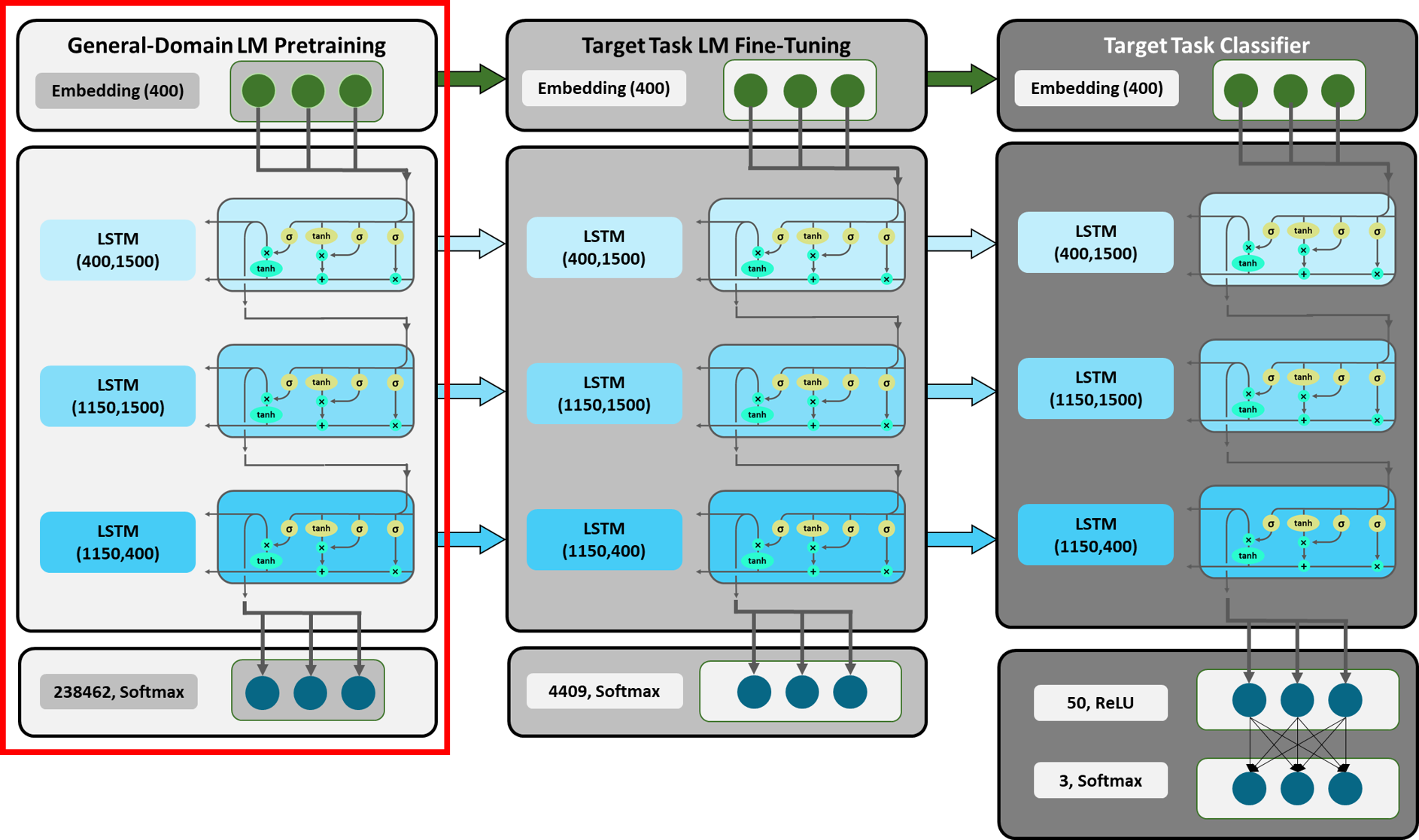{kind=link}
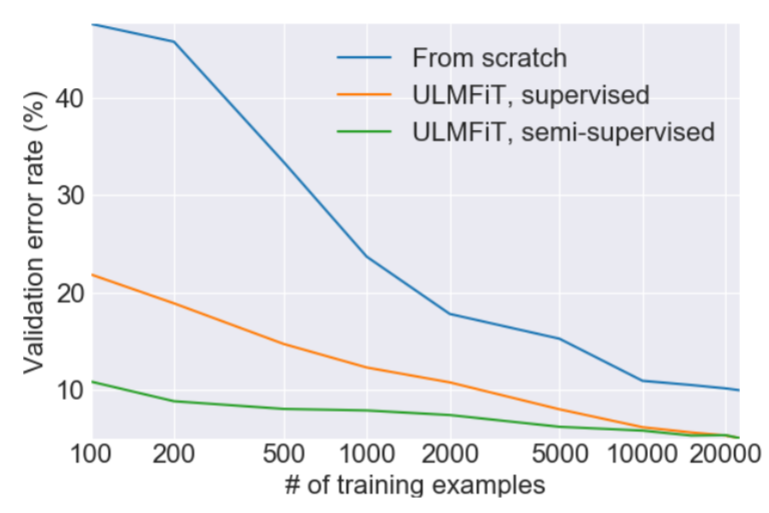{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}