







每周精选—2019 年 5 月 3 日

我如何通过谷歌云专业数据工程师认证考试
丹尼尔·伯克 — 10 分钟阅读
在过去的几个月里,我一直在使用谷歌云参加课程,为专业数据工程师考试做准备。然后我就拿了。我通过了。几周后,我的连帽衫到了。证书来得更快。
五个机器学习悖论将改变你对数据的思考方式
由耶稣罗德里格斯 — 8 分钟阅读
悖论是人类认知的奇迹之一,很难用数学和统计学来解释。从概念上来说,悖论是一种基于问题的原始前提得出明显自相矛盾的结论的陈述。
使用 Pandas-Profiling 加速您的探索性数据分析
由 Lukas Frei — 5 分钟阅读
第一次导入新的数据集时,首先要做的是理解数据。这包括确定特定预测值的范围、识别每个预测值的数据类型以及计算每个预测值缺失值的数量或百分比等步骤。
使用深度强化学习创建比特币交易机器人
由亚当·金 — 12 分钟读完
在本文中,我们将创建深度强化学习代理,学习如何通过比特币交易赚钱。在本教程中,我们将使用 OpenAI 的gym和来自stable-baselines库的 PPO 代理,后者是 OpenAI 的baselines库的一个分支。
迄今为止我在媒体上的数据科学博客之旅
由拉胡尔·阿加瓦尔 — 9 分钟读完
我第一次开始写博客是在 2014 年。我仍然记得我的第一篇博文。这是一场灾难。但我记得它帮助了一些人。这可能是一个好的开始。
学习数据科学最快的方法
由丽贝卡·维克里——5 分钟阅读
当我第一次开始在 medium 上写关于数据科学的博客时,我写了一系列描述学习数据科学的完整路线图的文章。我在很大程度上自学了数据科学,在过去的几年里,通过反复试验,我找到了一些快速有效学习的好方法。
在 Python 中使用 CSV、JSON 和 XML 的简单方法
乔治·赛义夫 — 4 分钟阅读
Python 卓越的灵活性和易用性使其成为最受欢迎的编程语言之一,尤其是对数据科学家而言。其中很大一部分是因为处理大型数据集是多么简单。
Python for Finance:Robo Advisor 版
凯文·博勒——14 分钟阅读
在这个系列的继续中,我将提供 Robo Advisors 的概述,然后分享关于如何评估多样化指数策略的额外代码和细节。
每周精选—2019 年 5 月 31 日

测量等变卷积网络的简单指南
由迈克尔·基斯纳 — 12 分钟阅读
几何深度学习是一个非常令人兴奋的新领域,但它的数学正在慢慢漂移到代数拓扑和理论物理的领域。
我从 fast.ai v3 学到的 10 个新东西
由莱米·卡里姆 — 14 分钟读取
每个人都在谈论 fast.ai 大规模开放在线课程(MOOC ),所以我决定试试他们 2019 年的深度学习课程《程序员实用深度学习》v3。
用于热门歌曲预测的数据科学
通过 Dorien Herremans — 6 分钟阅读
算法能预测热门歌曲吗?让我们来探索如何仅使用音频特征成功构建热门歌曲分类器,如我的出版物中所述(Herremans 等人,2014)。
10 Python 图像处理工具。
通过 Parul Pandey — 7 分钟读取
概述了一些常用的 Python 库,它们提供了一种简单直观的方法来转换图像。
为什么 Swift 可能是深度学习领域的下一个大事件
通过最大 Pechyonkin — 5 分钟读取
如果你对深度学习感兴趣,那么 Swift 是一门你应该开始学习的语言
估值器、损失函数、优化器——最大似然算法的核心
由 Javaid Nabi — 13 分钟读完
为了理解机器学习算法如何从数据中学习以预测结果,理解训练算法所涉及的基本概念是必不可少的。
[创建学术级数据集的明确指南
以及行业要求和限制](/the-definite-guide-for-creating-an-academic-level-dataset-with-industry-requirements-and-6db446a26cb2)
由奥里·科恩——13 分钟阅读
创建你自己的数据的指导方针,伴随着有价值的信息来帮助你做关键决定。
12 分钟:熊猫和 Scikit 的股票分析——学习
文森特·塔坦(Vincent Tatan)—12 分钟阅读
使用 Python 快速分析、可视化和预测股票价格
何时和何时不进行 A/B 测试
分裂测试与多臂土匪:模拟,源代码和现成的应用程序
创建时间序列预测的基本原则
由莱安德罗·拉贝罗——21 分钟阅读
解释创建时间序列预测的基本步骤。
每周精选—2019 年 9 月 13 日

更新*:2019 年 9 月 20 日起,我们的每周精选将被我们的每周文摘取代。我们的文摘将为读者提供*个性化推荐,并将 直接发送到您的收件箱 。你可以通过我们的媒体出版物订阅。
第一胎婴儿更容易晚育吗?
艾伦·唐尼——5 分钟阅读
是的,也更有可能是早期的。但只是一点点。
有条件的爱:调节神经网络的重正化技术的兴起
由科迪·玛丽·怀尔德——21 分钟阅读
批处理规范化,以及围绕它成长起来的相关规范化策略的动物园,在最近的深度学习研究中扮演了一系列有趣的角色…
数据科学和数据工程之间的细微差别🎧
由杰瑞米·哈里斯、爱德华·哈里斯和拉塞尔·波拉里 — 3 分钟阅读
阿克谢·辛格在 TDS 播客上
你是哪种口味的数据专业人士?
由凯西·科济尔科夫 — 7 分钟读完
扩展数据科学领域的实地指南
纽约的咖啡趋势
由纳森·伯恩斯 — 14 分钟读完
建立一个模拟器来分析枫糖浆咖啡的趋势
数据科学很无聊
由伊恩肖 — 9 分钟读完
我如何应对部署机器学习的无聊日子
机器学习驱动的内容审核:Expedia 的计算机视觉应用
由 Shervin Minaee — 11 分钟阅读
如何在深度学习中使用最先进的技术,建立一个高度定制的人工智能框架来进行内容审核。
数据科学家可用于生产质量代码的 3 种 Python 工具
由 Genevieve Hayes — 7 分钟阅读
仅仅因为你是数据科学家,并不意味着你不应该写好代码
什么是深度学习,它是如何工作的?
安妮·邦纳 — 13 分钟阅读
坐下来,放松,对人工神经网络、梯度下降、反向传播等酷概念感到舒适。
构建机器学习系统的六个重要步骤
拉胡尔·阿加瓦尔 — 9 分钟阅读
思考 ML 项目的现场指南
用简单的 Python 例子揭开假设检验的神秘面纱
通过 Tirthajyoti Sarkar — 11 分钟读取
假设检验是推断统计学的基础,也是数据科学家的一项重要技能。我们用非常简单的 Python 脚本来演示这个概念。
30 个有用的 Python 片段,你可以在 30 秒内学会
由法托斯·莫里纳 — 4 分钟阅读
Python 代表了最流行的语言之一,许多人在数据科学和机器学习、web 开发、脚本、自动化等领域使用它。
每周精选—2019 年 9 月 6 日

伟大的开发人员从不停止学习
由 Semi Koen — 10 分钟读取
it 专业人员培养持续学习心态的 7 种方法
我在一次单人高尔夫球比赛中获得第一枚金牌的故事:完成的事情和吸取的教训
安德鲁·卢克亚年科——7 分钟阅读
或者一个关于伟大团队的故事
使用 Pandas、Matplotlib 和 lyve 分析巴塞罗那的车祸
阿曼达·伊格莱西亚斯·莫雷诺 10 分钟阅读
巴塞罗那开放数据是巴塞罗那的数据服务,包含约 400 个数据集,涵盖广泛的主题,如人口,商业或住房。
数据科学家的非技术性职业技能🎧
由杰瑞米·哈里斯 — 3 分钟阅读
苏珊·霍尔科姆在 TDS 播客上
用 Python 学习机器学习和数据科学的 5 个初学者友好步骤
丹尼尔·伯克 — 7 分钟阅读
“我想学机器学习和人工智能,从哪里开始?”给你。
我训练一个网络像我一样说话
由迈尔·杨奇煜 — 8 分钟阅读
而结局真的很搞笑。语言生成指南。
把图表放到 Instagram 上教会了我什么关于数据科学的知识
雷切尔·伍兹 — 6 分钟阅读
今年早些时候,我创建了一个关于葡萄酒数据的 Instagram。
自动寻找最适合你的神经网络
由乔治·赛义夫 — 6 分钟阅读
自 2014 年在 NIPS 上首次发明和发表以来,生成对抗网络(GANs)一直是深度学习中的一个热门话题。
作为初创公司的第一个数据工程师,我学到了什么
通过 André Sionek — 9 分钟阅读
作为一家初创公司的第一位数据工程师,而不是以前的数据工程师,是一项挑战,但也是值得的。以下是我从中学到的东西。
如何用 Python 从头编码高斯混合模型
由 Thalles Silva — 6 分钟阅读
使用 NumPy 的 GMMs 和最大似然优化
重量不可知的神经网络
你有没有想过为什么大多数哺乳动物出生后就能完成相当复杂的任务,比如走路?他们还没有时间体验这个世界,所以他们显然还没有学会如何表演动作。他们的大脑必须预先布线才能行走,但如果大脑结构依赖于特定的重量,那么从经验中学习的个体可能在出生后不久就失去行动能力,或者永远不会有能力开始。
受此启发,亚当·盖尔和大卫·哈向世界介绍了重量不可知神经网络 (WANN),这是一种开发神经网络的进化策略,可以独立于连接的重量执行任务*。*
在这篇文章中,我们将简要介绍重量不可知的神经网络,并使用代码实现在月球着陆器健身房环境中训练我们自己的 WANNs。
整洁的
本文的进化策略是建立在 神经进化的扩充拓扑 (NEAT)之上的。NEAT 是遗传算法 (GA)的一种,通过改变智能体的结构对其进行变异:可以添加或删除节点和连接,可以改变节点和连接权重的激活函数;换句话说,它们的拓扑是的扩充。
代理,在这种情况下是神经网络,根据他们在特定任务中的表现进行排序。
沃恩
本文的目的是使用 NEAT 的进化策略来开发网络,该网络在给定的任务和一定的权重值范围内表现良好。不同于标准反向传播中使用精确调整的权重来执行任务,网络结构将进化以促进任务解决方案。
作者通过消除连接权重的突变来构建 NEAT,而不是通过增加连接、增加权重或改变节点的激活函数来进化网络。连接权重设置为共享值。
此外,用各种共享权重来评估代理的性能。通过使用性能的平均值对代理进行排序,可以开发出这样的网络,在该网络中,结构使得任务能够被完成,而不是权重。
探索代码
作者开源了他们的代码,你可以在 Google GitHub 上找到。我们将使用这个代码的改编版本来训练和探测网络。
WANN 进化策略的本质产生了具有许多跳跃连接的稀疏网络。这种结构不容易与 PyTorch 和 TensorFlow 等流行的 ML 库兼容,这些库将反向传播作为学习机制。因此,编写代码时没有使用这些库,也没有使用 GPU。然而,由于 WANN generation 评估程序是令人尴尬的并行*,正如作者所说,我们可以在训练时使用多核。*
注意:如果你不确定你的机器有多少个 CPU 核心,进入系统设置(Windows)或者在终端中输入lscpu*(Ubuntu)*
首先,我们将探索代码中提供的一个预先训练好的网络。这里有两足步行机、小车回转、搬运环境以及解决 MNIST 问题的“冠军”。
使用git clone https://github.com/TTitcombe/brain-tokyo-workshop.git获取代码的本地副本,并导航到brain-Tokyo-workshop/wann release/prettyNeatWann目录。
作者提供了一系列在健身房环境中预先训练的“冠军”。我们可以运行 CartPoleSwingUp 冠军
*python wann_test.py -p p/swingup.json -i champions/swing.out --nReps 1 --view True*
这段代码运行网络,在[-2,2]范围内的共享权重值之间循环,证明网络能够独立于权重值运行,如下所示。

All shared weight values perform equally, but some perform more equally than others
显然,该模型对所有共享权重值的表现并不一样好,其最佳表现也不是完美的,但是我们对各种权重都有半成功的策略—非 WANN 模型对权重变化的鲁棒性不如此。
最终的适应值表明,尽管在共享权重值上存在一些性能变化,但是无论具体值如何,网络的性能通常都很好。

可视化网络
该团队还提供了可视化网络的代码。我们可以执行一个简短的脚本来查看 SwingUp 冠军:
*import matplotlib.pyplot as pltfrom vis.viewInd import viewInd viewInd("champions/swing.out", "swingup")
plt.show()*

由于稀疏连接和跳跃连接,它比传统的神经网络更混乱,但它更容易解释,因为激活函数和结构已经过显式优化。
该网络最引人注目的特征是x参数(手推车的位置)几乎与计算力的输出节点直接相连,只被一个具有反向激活功能的隐藏神经元截获。这条线的作用是提供一个朝向屏幕中心的力,而不考虑共享重量值的符号:网络已经学会了如何以重量不可知的方式将手推车送到中心。
事实上,这种模式出现了两次;也许网络了解到权重值占据很小的范围,因此不会产生强大的力,因此网络通过加倍模式来加倍向内的力。如果是这种情况,网络并不完全是权重不可知的,但是在更大范围的权重值上训练网络可以补救这一点。
第二,几个节点经过一个早期层中具有高斯激活函数的节点。高斯激活函数关于 y 轴对称,因此对于 x 和 -x: 输出相同的结果。该节点对于权重的符号是不可知的。

The gaussian activation function
另一个经常出现的激活函数是正弦函数( sin )。其循环模式使得输出在某种程度上与输入幅度无关。具有输入无关区域的激活函数的流行可能是权重不可知论的网络优化的直接结果。
训练我们自己的人
代码为摇摆*、行走、两足行走和一个 MNIST 分类任务提供了训练脚本。我们将在 月球登陆者开放的健身房环境中训练一名 WANN,以证明那些任务并不是因为天生适合 WANN 而选择的。*
首先,我们在域配置中创建一个“lunar”任务,指定有 8 个输入和 2 个输出。此外,我们为所有输入和输出神经元设置一个线性激活函数,并允许隐藏神经元使用任何激活函数。
然后,我们通过复制“laptop _ swing”配置 json 来定义训练算法的参数,我们称之为“laptop_lunar”,只是将任务从“swingup”更改为“lunar”。该配置文件指定了要运行的代数和群体中的代理数,以及其他因素。我们只是运行一个轻量级实验来演示如何做到这一点,所以我们可以保持参数较小。
现在,我们开始训练:
*python wann_train.py -p p/laptop_lunar.json -n 2 -o lunar*
指定应该使用我的两个内核;如果你有更多,就用它们。
在我那台有点过时的 i7 上,平均每一代运行一分钟左右(这开始于 10 秒,但随着网络越来越擅长这项任务而稳步增长,因此不会很快失败)。结果,我只完成了 300 个纪元,就不得不占用我的 CPU 来完成其他任务。然而,网络很早就成功地完成了这项任务:300 个周期后,着陆器可以安全着陆。

结论和后续步骤
权重不可知的神经网络论文提出了一种通过在网络结构中直接编码解决方案来开发更多可解释网络的方法。与反向传播相比,WANNs 对节点输入的变化具有很强的鲁棒性,这可以形成对恶意攻击甚至是破坏网络的强大防御的基础。
为了那些致力于人工智能的人,WANNs 向我们展示了一种编码智慧和行为的方法,就像在动物王国里发生的一样。
从一开始就为代理人提供非零智能,可以让他们比其他方式更快地利用自己的经验。我很有兴趣看到通过反向传播对 WANNs 进行微调与从头开始训练模型进行比较。
神经网络中的权重初始化:从基础到明凯的旅程
我想邀请你和我一起探索初始化神经网络层权重的不同方法。一步一步地,通过各种简短的实验和思考练习,我们将发现为什么足够的权重初始化在训练深度神经网络中如此重要。在这一过程中,我们将涵盖研究人员多年来提出的各种方法,并最终深入探讨最适合您最有可能使用的当代网络架构的方法。
下面的例子来自我自己对一套笔记本的重新实现,这套笔记本是杰瑞米·霍华德在fast . ai 深度学习第二部分课程的最新版本中涵盖的,目前正在 2019 年春天在 USF 的数据研究所举行。
为什么要初始化权重
权重初始化的目的是防止层激活输出在正向通过深度神经网络的过程中爆炸或消失。如果出现任何一种情况,损耗梯度要么过大,要么过小,不利于回流,网络将需要更长时间才能收敛,如果网络能够收敛的话。
矩阵乘法是神经网络的基本数学运算。在具有几层的深度神经网络中,一次正向传递只需要在每层的输入和权重矩阵之间执行连续的矩阵乘法。一层的乘法结果成为下一层的输入,以此类推。
为了说明这一点,让我们假设我们有一个包含一些网络输入的向量 x 。在训练神经网络时,这是标准做法,以确保我们的输入值按比例调整,使它们落入均值为 0、标准差为 1 的正态分布中。

让我们假设我们有一个简单的 100 层网络,没有激活,并且每一层都有一个矩阵 a 包含该层的权重。为了完成一次前向传递,我们必须在 100 层中的每一层执行层输入和权重之间的矩阵乘法,这将产生总计 100 次连续矩阵乘法。
事实证明,从我们将输入缩放到的同一标准正态分布初始化图层权重值从来都不是一个好主意。为了了解原因,我们可以通过我们假设的网络模拟一次向前传递。

哇哦。在这 100 次乘法中的某处,层输出变得如此之大,以至于计算机都无法识别它们的标准差和平均值。我们实际上可以看到这发生了多长时间。

激活输出在我们网络的 29 层内爆炸。我们显然将权重初始化得太大了。
不幸的是,我们还必须担心防止图层输出消失。为了了解当我们将网络权重初始化得过小时会发生什么情况,我们将调整权重值,这样,虽然它们仍处于平均值为 0 的正态分布中,但它们的标准偏差为 0.01。

在上述假设的向前传递过程中,激活输出完全消失。
综上所述,如果权重初始化过大,网络学习效果不会很好。当权重初始化过小时,也会发生同样的情况。
如何才能找到最佳点?
请记住,如上所述,完成神经网络正向传递所需的数学只需要一系列矩阵乘法。如果我们有一个输出 y ,它是我们的输入向量 x 和权重矩阵 a 之间的矩阵乘法的乘积,则 y 中的每个元素 i 被定义为

其中 i 是权重矩阵 a 的给定行索引, k 既是权重矩阵 a 的给定列索引,也是输入向量 x 的元素索引, n 是 x 中元素的范围或总数。这也可以在 Python 中定义为:
y[i] = sum([c*d for c,d in zip(a[i], x)])
我们可以证明,在给定的层,我们从标准正态分布初始化的输入矩阵 x 和权重矩阵 a 的矩阵乘积,平均起来,具有非常接近输入连接数量的平方根的标准偏差,在我们的示例中为√512。

如果我们从矩阵乘法是如何定义的角度来看待它,这一特性并不令人惊讶:为了计算 y ,我们对输入 x 的一个元素与一列权重 a 的逐元素乘法的 512 个乘积求和。在我们的示例中,使用标准正态分布对 x 和 a 进行初始化,这 512 个产品中的每一个的平均值为 0,标准差为 1。

因此,这 512 个产品的和的平均值为 0,方差为 512,因此标准差为√512。
这就是为什么在上面的例子中,我们看到我们的层输出在 29 次连续矩阵乘法后爆炸。在我们最基本的 100 层网络架构的情况下,我们希望每层的输出具有大约 1 的标准偏差。可以想象,这将允许我们在尽可能多的网络层上重复矩阵乘法,而不会出现激活爆炸或消失。
如果我们首先通过将所有随机选择的值除以√512 来缩放权重矩阵 a ,填充输出 y 的一个元素的逐元素乘法现在平均起来只有 1/√512 的方差。

这意味着矩阵 y 的标准偏差将是 1,该矩阵包含通过输入 x 和权重 a 之间的矩阵乘法生成的 512 个值中的每一个。让我们用实验来证实这一点。

现在让我们重新运行我们的快速和肮脏的 100 层网络。与之前一样,我们首先从[-1,1]内的标准正态分布中随机选择层权重,但这次我们将这些权重缩放 1/√ n ,其中 n 是一层的网络输入连接数,在我们的示例中为 512。

成功!我们的层输出既没有爆炸也没有消失,即使在我们假设的 100 层之后。
虽然乍一看,我们似乎可以到此为止了,但现实世界的神经网络并不像我们的第一个例子所显示的那样简单。为了简单起见,省略了激活函数。然而,我们在现实生活中从来不会这样做。正是由于在网络层的末端放置了这些非线性激活函数,深度神经网络能够创建描述现实世界现象的复杂函数的近似逼近,然后这些函数可以用于生成令人震惊的预测,例如手写样本的分类。
Xavier 初始化
直到几年前,最常用的激活函数都是关于一个给定值对称的,并且其范围渐近地接近与该中点正/负一定距离的值。双曲线正切函数和软设计函数就是这类激活的例子。

Tanh and softsign activation functions. Credit: Sefik Ilkin Serengil’s blog.
我们将在假设的 100 层网络的每一层后添加一个双曲正切激活函数,然后看看当我们使用我们自己开发的权重初始化方案时会发生什么,其中层权重按 1/√ n.

第 100 层的激活输出的标准偏差下降到大约 0.06。这绝对是小的方面,但至少激活没有完全消失!
回想起来,发现我们的本土体重初始化策略的旅程似乎很直观,但您可能会惊讶地听到,直到 2010 年,这还不是初始化体重层的常规方法。
当 Xavier Glorot 和 Yoshua Bengio 发表了他们题为 理解训练深度前馈神经网络 的难度的里程碑式论文时,他们将其实验与“常用的启发式方法”进行比较,该方法是从[-1,1]中的均匀分布初始化权重,然后按 1/√ n 进行缩放。
事实证明,这种“标准”方法实际上并不那么有效。

用“标准”权重初始化重新运行我们的 100 层双曲正切网络导致激活梯度变得极小——它们几乎就像消失了一样。
这种糟糕的性能实际上促使 Glorot 和 Bengio 提出了他们自己的权重初始化策略,他们在论文中称之为“规范化初始化”,现在被普遍称为“Xavier 初始化”。
Xavier 初始化将层的权重设置为从随机均匀分布中选择的值,该分布介于

其中 nᵢ 是该层的传入网络连接数,或称“扇入”,而 nᵢ₊₁ 是该层的传出网络连接数,也称为“扇出”
Glorot 和 Bengio 认为 Xavier 权重初始化将保持激活的方差和反向传播的梯度沿着网络的层向上或向下。在他们的实验中,他们观察到 Xavier 初始化使 5 层网络能够在各层之间保持几乎相同的权重梯度方差。

With Xavier init. Credit: Glorot & Bengio.
相反,使用“标准”初始化导致网络较低层的权重梯度(较高)和最高层的权重梯度(接近于零)之间的方差差距更大。

Without Xavier init. Credit: Glorot & Bengio.
为了证明这一点,Glorot 和 Bengio 证明了用 Xavier 初始化的网络在 CIFAR-10 图像分类任务中实现了更快的收敛和更高的精度。
让我们再次运行我们的 100 层 tanh 网络,这次使用 Xavier 初始化:

在我们的实验网络中,Xavier 初始化的执行与我们之前导出的自制方法完全相同,在该方法中,我们从随机正态分布中采样值,并根据传入网络连接数的平方根进行缩放, n 。
明凯初始化
从概念上讲,当使用关于零对称且输出在[-1,1]内的激活函数(如 softsign 和 tanh)时,我们希望每层的激活输出平均值为 0,平均标准偏差约为 1。这正是我们自己开发的方法和 Xavier 所实现的。
但是如果我们使用 ReLU 激活函数呢?想要以同样的方式缩放随机初始权重值还有意义吗?

ReLU activation function. Credit: Kanchan Sarkar’s blog.
为了了解会发生什么,让我们在假设的网络层中使用 ReLU 激活代替 tanh,并观察其输出的预期标准偏差。

事实证明,当使用 ReLU 激活时,单个层的平均标准偏差非常接近输入连接数目的平方根除以两个的平方根,或者我们示例中的√512/√2。

通过这个数字缩放权重矩阵 a 的值将导致每个单独的 ReLU 层平均具有 1 的标准偏差。

正如我们之前所展示的,将层激活的标准偏差保持在 1 左右将允许我们在深度神经网络中堆叠几个层,而不会出现梯度爆炸或消失。
这种对如何最好地初始化具有类 ReLU 激活的网络中的权重的探索是明凯等人的动机。艾尔。为了提出他们自己的初始化方案,这是为使用这种非对称、非线性激活的深度神经网络定制的。
在他们 2015 年的论文中,何等人。艾尔。证明了如果采用以下输入权重初始化策略,深度网络(例如 22 层 CNN)将更早收敛:
- 创建一个张量,其维数适合给定层的权重矩阵,并使用从标准正态分布中随机选择的数字填充它。
- 将每个随机选择的数字乘以 √ 2/ √n ,其中 n 是从前一层的输出进入给定层的传入连接数(也称为“扇入”)。
- 偏置张量被初始化为零。
我们可以按照这些指导来实现我们自己版本的明凯初始化,并验证如果在我们假设的 100 层网络的所有层使用 ReLU,它确实可以防止激活输出爆炸或消失。

作为最后的比较,下面是如果我们使用 Xavier 初始化会发生什么。

哎哟!当使用 Xavier 初始化权重时,激活输出在第 100 层时几乎完全消失了!
顺便提一下,当他们训练使用 ReLUs 的更深层次的网络时,他等。艾尔。发现一个使用 Xavier 初始化的 30 层 CNN 完全失速,根本不学习。然而,当同一个网络按照上述三步程序初始化时,它的收敛速度大大提高。

Convergence of a 30-layer CNN thanks to Kaiming init. Credit: He et. al.
这个故事对我们的启示是,我们从头开始训练的任何网络,尤其是用于计算机视觉应用的网络,几乎肯定会包含 ReLU 激活功能,并且有几层深度。在这种情况下,明凯应该是我们的首要策略。
是的,你也可以成为一名研究员
更重要的是,我不羞于承认,当我第一次看到泽维尔和明凯公式时,我感到害怕。他们各自的平方根是 6 和 2,我不禁觉得他们一定是某种神谕智慧的结果,我自己无法理解。让我们面对现实吧,有时候深度学习论文中的数学看起来很像象形文字,只是没有 T2 罗塞塔石碑来帮助翻译。
但我认为,我们在这里的旅程向我们表明,这种受到威胁的下意识反应虽然完全可以理解,但绝不是不可避免的。尽管明凯和(尤其是)Xavier 的论文确实包含了相当多的数学内容,但我们亲眼目睹了实验、经验观察和一些简单的常识如何足以帮助推导出支撑当前最广泛使用的权重初始化方案的核心原则集。
换句话说:当有疑问时,鼓起勇气,尝试一下,看看会发生什么!
欢迎来到森林。伦敦文化区 2019 推特分析
欢迎来到森林。我们有乐趣和游戏!

上周末,2019 年 1 月 11 日星期五至 1 月 13 日星期日,伦敦的沃尔瑟姆森林区举办了为期三天的大型活动,庆祝被选为有史以来第一个市长伦敦文化区。该活动名为欢迎来到森林,被描述为“沃尔瑟姆森林有史以来最大的派对,每个人都被邀请”。
家庭和孩子聚集在森林里,伦敦市长萨迪克·汗和主管文化的副市长贾丝汀·西蒙斯和他们所有的伙伴也是如此!数百名来自当地艺术机构和音乐家的人士也做出了贡献。听起来很有趣,对吧?
事实上,每个人都被邀请了,但不幸的是,我没能参加聚会!因此,为了克服我的 FOMO,我决定使用官方标签#WelcometotheForest 收集 3300 条关于该活动的推文。这篇博文展示了我的分析结果。
请向下滚动,通过数据可视化查看我的分析!

数据和方法
组织者推广的官方标签是#WelcometotheForest。在事件发生时,我使用 Twitter API 收集了 3300 条包含这个标签的推文。需要注意的是,我只收集了包含# WelcometotheForest 的推文。当然,有许多关于欢迎来到森林的推文不包含这个标签。
在收集了这些推文之后,我运用了一系列先进的统计和机器学习技术——特别是自然语言处理和计算机视觉——来帮助我更详细地了解这个事件。
具体来说,我使用谷歌云自然语言 API 来计算每条推文的情感,然后我使用 gensim 库的 Word2Vec 模型来对推文的整个语料库进行语义分析,此外,我还使用谷歌云的视觉 API 来检测关于在线上传的每张图像的特征和标签,最后,我使用预训练的卷积神经网络来进行特征提取和反向图像搜索,以基于视觉相似性对这些图像进行聚类。
多拗口啊!
分析推文
我分析的主要内容来自我通过 Twitter API 收集的 3300 条推文。下面,我报告以下五个指标:
- 每天和每小时的推文数量;
- 每天推文的平均情绪;
- 推文中排名前 10 的单词和标签;
- 基于语义学习的“WelcometotheForest”热门词汇:
- 基于视觉相似性的《欢迎来到森林》最受欢迎的图片。
推特频率
下面的条形图显示了从活动前的周三到活动后的周三(1 月 9 日至 16 日)的所有推文。“欢迎来到森林”最受欢迎的一天是 1 月 11 日星期五,有 932 条推特使用标签#WelcometotheForest。然而,很大一部分推文(全天平均 66%)是转发推文,因此在 1 月 11 日星期五实际上只有 364 条不同的推文。
Bar chart showing the number of tweets by day during the festival
一天中最繁忙的时间(活动当天的平均时间)是晚上 7 点到 10 点之间,晚上 8 点是最繁忙的时间,总共有 324 条推文(185 条没有转发)。
Bar chart showing the average tweets per hour
情感分析
为了判断派对是好是坏,我进行了情绪分析。每条推文的情绪是使用谷歌的云 NLP API 计算的。下面的条形图显示了每天推文的平均情绪,其中-1 表示非常消极的情绪,+1 表示非常积极的情绪。
我们看到,对森林的欢迎始于相对较高的情绪,在 1 月 10 日星期四有所下降,直到一路攀升至 0.73 的非常强烈的情绪。总体而言,《欢迎来到森林》全天的平均人气为 0.57,非常好!看来我错过了很多乐趣…
Line chart showing the average sentiment of the tweets per day
文本频率分析和热门标签
下面的柱状图显示了一个词和一个标签在所有推文的正文中出现的次数,分别在左边和右边。值得注意的是,因为标签也出现在推文的正文中,所以在计算词频时,它们成为了一个混淆变量。因此,我采取措施将 hashtag 计数从单词计数中移除。
Bar graphs showing the count of words and hashtags appearing in all the tweets
不出所料,标签#welcometotheforest 出现得最多,然而有趣的是,标签#wfculture19 和#mylocalculture 也大量出现。即使在扣除标签数后,“wfculture19”这个词出现的次数最多,其次是“culture”,但“wfcouncil”和“erlandcooper”也获得了一些好评!
我在谷歌上快速搜索了一下这条信息,发现#wfculture19 和#mylocalculture 是官方标签,由沃尔瑟姆森林委员会的和伦敦市长文化团队的的推特账户推广。
然而,上述结果对于告诉我们人们对该事件的看法并不十分有用。在上面的子集里,我们只找到名词而不是形容词。因此,我使用其他机器学习技术来尝试挖掘一些形容词。
语义
为了从推文中获得更细致的文本理解,我使用自然语言处理和机器学习进行了语义分析。
Word2Vec 是一个神经语言机器学习模型,它将大量文本(在这种情况下,来自 3300 条推文的文本)作为输入,并输出一个向量空间,通常有数百个维度,每个唯一的单词对应于空间中的一个向量——一个单词嵌入。具体来说,空间中距离较近的物体意味着它们是相似的。“最近邻居”是来自 Word2Vec 模型的少数几个基于余弦度量相似性得分与“ WelcometotheForest 最相似的单词。下面的散点图显示了“欢迎来到森林”的最近邻居。
重要的是,“妙不可言”、“好玩”、、【享受】、【得意】这些词就在身边,还有、【孩子】、、、【家庭】、、、【牵连】。这是一个非常积极的结果!统计数据表明,这些词最能代表人们在推特上谈论“欢迎来到森林”时的感受。这似乎是一个非常愉快和包容的事件!
PCA output of the nearest neighbours of #WelcometotheForest from the Word2Vec model
最受欢迎的艺术品
在从推文中检索有用的文本信息后,我最终转向了图像数据。总共 3300 条推文中有 732 条附有图片。利用这些图像,我给电脑编了程序来学习它们之间的视觉相似性。一种叫做特征提取和逆向图像搜索的技术正是这样做的。
使用在 TensorFlow 后端上运行的 Keras VGG16 神经网络模型,我首先为数据集中的每张图像提取了一个特征。一个特征是每个图像的 4096 元素的数字数组。我们的期望是“该特征形成图像的非常好的表示,使得相似的图像将具有相似的特征”(吉恩·科岗,2018 )。然后使用主成分分析(PCA)降低特征的维度以创建嵌入,并且计算一个图像的 PCA 嵌入到另一个图像的距离余弦距离。
现在我已经在向量空间中嵌入了每个图像,我使用了一个流行的叫做 t-SNE 的机器学习可视化算法来聚类,然后在二维空间中可视化向量空间。“tSNE 的目标是对相似数据点的小“邻域”进行聚类,同时降低数据的整体维度,以便更容易可视化”(谷歌人工智能博客,2018)。

The clustering of images of Welcome to the Forest 2019. Source: Twitter
上图显示右上角的棉花糖激光盛宴对巢的聚类非常好,右下角的进入森林由Greenaway&Greenaway进行聚类。
结论
所以你有它!虽然坐在我的笔记本电脑前做关于派对的研究并不能弥补我错过的所有乐趣,但我确实学到了很多关于这个活动的东西!进一步挖掘推文仍有巨大的潜力。
祝贺这样一个伟大的事件和成就,并祝今年余下的时间里伦敦文化区一切顺利!
感谢您的阅读!
Vishal
Vishal 是一名文化数据科学家,也是伦敦 UCL 学院的研究生。他对城市文化的经济和社会影响感兴趣。你可以在Twitter或者LinkedIn上与他取得联系。在insta gram或他的 网站 上看到更多 Vishal 的作品。
提及:西奥·布莱克威尔,创建联营公司,智能伦敦,伦敦博物馆,卫报
关于数据科学和欺诈建模,两个人和一个跑步者教会了我什么

昨晚当我结束工作时,外面开始出现黑暗。我决定在邻近的跑道上跑一会儿,希望能跑八圈。那次跑步结果发生了转折,给我上了有趣的一课。
在跑道上,可以看到一些人在散步和伸展身体。我开始跑步。当我在第六回合时,我看到两个大个子在铁轨上漫步,挡住了它。我在轨道的另一边,周围看不到任何人。虽然我鼓起了一些勇气,通过了这些人,但我感到有点威胁。他们的出现让我觉得有必要缩短跑步时间,从公园里出来。但就在那时,我看到一个人带着一只我之前经过的狗,站在引体向上栏旁边。
一种冲动悄然而至,我在那个人旁边停下来,问他是否愿意在那里呆五分钟。他作了肯定的回答,但开始了询问。
–“为什么?”他问。
当我试图想出一个答案来解释我的困境时,那两个魁梧的男人走过,我的目光不由自主地跟着他们。
–我咕哝道,“因为,呃…。”
–“好吧。我会的,”他说,在理解了我的焦虑之后,中途打断了我。
得到保证后,我平静地完成了最后两首曲子。我谢过那个带着狗的人,开始了回家的旅程。就在那时,我突然意识到,这一事件与我们为一个客户构建的欺诈模型极其相似。
与我在公园时的预感类似,统计模型给每个账户标上了一个概率,即相关人员是否有可能实施欺诈。就像我的预感一样,这可能是一场虚惊,欺诈标记也可能是也可能不是绝对正确的。
虽然使用统计方法建立的欺诈模型的可能性确实要低得多,但它们仍然有假阳性——该模型错误地将某人标记为欺诈者,而他可能不是。
为了阐明这个问题,让我们考虑一下银行。他们用一种经典的方式来对付可能的诈骗犯:把他们拒之门外。通过这样做,他们也在对潜在的好客户说“不”——这是他们非常熟悉的事实。这导致了一个两难的局面:为了挽回损失,他们也失去了收入。
这相当于我因为有可能受到威胁而想缩短我的行程。但是,如果这些公司做了我最终决定付诸行动的事情——标记欺诈者,给他们有限的功能(类似于那个家伙和他的狗盯着我,从而降低风险),并看看他们是否真的是欺诈者。这将确保“好”人能够继续进来,同时减少因欺诈造成的损失。
事实上,许多银行和金融科技公司现在已经开始采用这种管理风险和欺诈的方法——给予所有合格客户有限的功能和访问权限,并让他们证明自己的信用或波段价值,以便随着时间的推移获得额外的功能。
在 Aryng,我们的数据科学 SWAT 团队一直在利用数据提高收入和减少损失,同时寻找取悦最终用户的新方法。如果您在欺诈或其他高价值客户分析项目上需要我们的帮助,请联系我们进行免费咨询。
感谢你阅读我的帖子。我热衷于使用数据来构建更好的产品和创造令人惊叹的客户体验。我在 LinkedIn 和《福布斯》上写下我的心得。要阅读我未来的帖子,只需在这里 加入我的网络 或点击“关注”或加入我的Twitter。
关于皮扬卡·贾恩
piyan ka Jain 是数据分析领域备受推崇的行业思想领袖,也是国际知名的畅销书作家,经常在企业领导峰会和商业会议上发表主题演讲,介绍如何利用数据驱动的决策来获得竞争优势。
在 T21,她领导她的 SWAT 数据科学团队解决复杂的业务问题,开发组织数据素养,并使用机器学习、深度学习和人工智能来实现快速投资回报。她的客户名单包括谷歌、Box、Here、应用材料、雅培实验室、通用电气等公司。作为分析领域备受推崇的行业思想领袖,她为《福布斯》、《哈佛商业评论》和 InsideHR 等出版物撰稿。
70%的数据科学学习者做错了什么
在大学工程课程中,用 2 米长的金属杆反复砸我的头所得到的教训
我在大学的大部分时间里都在积极寻找辛苦有用的课。但是,到了最后一年,我累了,我想休息一下。所以我在工程系上了一门“有趣”的课,名为“航海物理学”
我们绘制了使帆船比风跑得更快的力的图表。我们学习了船的形状如何使它稳定或不稳定。我已经比大多数同学学了更多的物理。所以,我的家庭作业做得很好,并且认为如果我去航海的话,我会是一个天生的运动员。
我在学期末测试了这个假设,当时我们班去了小马斯科马湖,尝试在一艘真正的船上航行。事情没有像我预期的那样发展

Boats on Mascoma Lake. They aren’t as gentle as they seem.
船感觉倾斜,我对浮力和“扶正手臂”的了解并没有让我留在船上。转弯需要协调多个动作。当我弄错时间时,一根两米长的金属杆(称为吊杆)转过来,击中了我的头部。我头上的吊杆发出的噼啪声每次都让我的耳朵嗡嗡作响几分钟。
学习帆船运动的物理学很有趣,但显然它们对你的实际航行没有帮助。
这和数据科学有什么关系?
正如我在没有学习航海的情况下学习了航海的物理知识一样,大多数数据科学课程都非常详细地讲述了一些算法,而忽略了成功的数据科学项目所需的技能。
企业数据科学仍然是一个新领域。许多学者还没有为真正的企业解决真正的问题。因此,他们以一种脱离数据和商业背景的方式教授教科书算法。这可能是智力上的乐趣。但是,如果学生认为这些课程为他们成为数据科学家做好了准备,那他们就错了。
那么,如何将你的努力集中在实际的重要技能上呢?以下是一些指导原则:
- 使用标准的开源库。实用的数据科学依赖于文档完备、经过良好测试并具有良好设计的 API 的库。自己实现替代版本是复杂性(和 bug)的来源,它分散了您对数据和应用模型的上下文的注意力。
- 花更多时间查看您的数据,并将其处理成您需要的格式。大多数项目涉及大量的数据操作和相对较少的模型调整。目前正在招聘的朋友告诉我,许多求职者可以描述算法,但绝大多数人缺乏在实际工作中高效工作的熊猫技能。
- 了解应用程序环境中的技术。如果你需要技术术语来描述你所学知识的实际相关性,你可能还没有准备好应用它。
- 了解如何解释模型输出。例如,您需要了解模型准确性的度量,以知道您是否可以信任一个模型。学习机器学习解释技术,比如排列重要性。
- 在你感兴趣的领域建立项目。它可以是关于电影、时事、体育、食物或其他任何东西。这将教会你如何用一种你可以应用技术工具的方式来构建关于世界的模糊问题。这是数据科学家最重要的技能之一。分享你的工作将教会你如何解释和讨论结果,这可能是最重要的技能。
- 如果你跳过许多书籍和课程背后的算法理论,那么成为一名数据科学家会很容易吗?号码
关于操作数据、解释数据以及将工具与现实联系起来,还有很多东西需要学习。我有意减少了我教授的抽象理论的数量,以帮助学习者专注于实践技能。我认为这种方法会让你在开始你的严肃项目时,不会打自己的后脑勺。
神经网络对新闻有什么看法
关于新闻,神经网络可以揭示什么?利用机器学习,我研究了新闻媒体中“偏见”的复杂本质,如何在人工智能中无意中出现“对意识形态的理解”,以及“声音”的差异如何影响人们消费信息的方式[1][2]。受博士漫画的启发,这个“1 页论文挑战”总结了我最近的论文(看这里)。

News agency relationships where line thickness is proportional to similarity.
在发现之前,有些前后关系。语言的细微差异揭示了说话者的偏见和身份信息。当然,作者对论点的有意【框架】可以反映他们的观点,但潜意识的用词选择也可以揭示他们的信仰【3】【4】。我想知道,是否像人类一样,一种叫做神经网络的人工智能可以解释这些信号。考虑到这一点,我的电脑阅读了五个月的新闻文章*来学习“语言”模式,这样它就能以 74%的准确率猜出一篇从未见过的文章的出版商。该模型还指出了组织之间的相似性(见网络图片),并揭示了例证机构“声音”的“原型”文章(最“像 CNN”的 CNN 文章)。考虑这些讨论气候的文章的例子:
Articles most like their publishing agency describing climate
尽管研究通常集中在政治上,这个模型强调了新闻中的“声音”和“偏见”并不总是完全符合左与右的光谱。我将我的结果与先前存在的关于媒体意识形态和情绪极性的工作进行了比较(“具有灾难性影响的糟糕政策”带有负极性,而“英雄爱国主义的光荣行动”表现出正极性)[5][7][8]。该模型似乎理解两者的属性,但数据表明,政治或语言的“严重性”都不能单独解释该模型的全部行为[7][8]。上面的范例气候文章可能有助于展示这种复杂性:一个不太极端的情绪极性将《华尔街日报》和《NPR》联合起来,但一个从经济角度看待气候,而另一个则从科学角度看待这个问题。同样,福克斯和 CNN 在模型中有共同之处,尽管之前的工作表明意识形态倾向的差异,非气候样本可能表明这两家机构使用相似的极性语言,并经常讨论犯罪【7】。简而言之,在想象新闻前景时,要考虑到不仅仅是政治决定了一个机构的声音。偏见不仅仅是向左或向右倾斜。
当想象新闻的前景时,要考虑到不仅仅是政治定义了一个机构的声音
这个实验还揭示了意识形态偏见是如何在机器学习中无意间出现的。我没有告诉模型去寻找政治倾向或语境化,但它仍然学习“意识形态特征”(例如,这些可能是对社会主义的积极框架或对暴力的报道倾向)。当人工智能决定用户看到什么时,“推荐者”可能会类似地学习意识形态,并越来越多地显示项目以适应用户的观点。像这样的人工智能可以降低一个来源的文章出现在用户面前的频率,并导致所谓的“过滤气泡”变得比其他情况下更强[9]。尽管系统背后的工程师从来没有打算过,但这些障碍可能会出现,尽管用户订阅了一系列广泛的渠道。类似地,在所有用户看到相同项目的其他 ML 系统中,“非中立性”可以在平台内增长以反映大多数人的偏好。当然,虽然推荐者很好地激发了这些重要的问题,但其他过滤和排名(评论权重或不适当标志)的机器学习产品可以通过接触这种内容,学习检测类似的属性,即使平台希望意识形态中立。综上所述,解决方案是有先例的,但是加强回音室可能会产生更多的点击(金钱),即使是以的共同理解为代价【10】【11】。
像这样的人工智能可以降低一个来源的文章出现在用户面前的频率,并导致所谓的“过滤气泡”变得比其他情况下更强。
尽管如此,可能从我的人工智能中学习的不仅仅是科技公司。再一次,读者被与他们的信仰一致的媒体所吸引,我的工作揭示了一些特征,就像一篇文章的政治倾向一样,可能会类似地强化“媒体消费”(人们从那里获得新闻)[5]的差异。如果这是真的,现代记者不仅需要警惕限制其受众的政治偏见,还需要警惕语气和框架如何吸引一些读者,同时拒绝另一些读者。
** 10 家通讯社发表的文章描述——共约 49k*
至此,我已经到达了我在 LibreOffice 中的页面末尾。值得记住的是,我们对世界的看法是通过我们消费的媒体渠道和越来越多的新闻发布平台形成的。我们这样做不是通过一个平面的物镜,而是通过一个广泛的,可能是无意的视角,这可能危及共同的理解【10】。作为一个社会,我们面临的挑战是巨大的,随着许多选举刚刚发生或即将到来,值得记住的是,计算机在给我们想要的东西方面很棒。然而,考虑你需要什么来做出明智的决定,以及你希望你的技术如何为你工作。最后,研究可以突出问题,但只有选民消费者可以要求改变。
如果你有时间和耐心,有很多细微差别和细节根本不适合在这里,所以我会谦虚地推荐论文本身。即使社交媒体可能会像迷宫般的回音室一样破坏媒体消费,并且根据一些人的说法,危及民主本身,也不要忘记喜欢(鼓掌?)这篇文章和分享。记住,机器人在看着。
想要在数据、设计和系统的交叉领域进行更多的实验吗? 关注我获取更多 !
文本识别系统实际看到的
对文本识别系统的神经网络“黑箱”的一些见解

作为神经网络实现的现代文本识别系统的性能令人惊叹。他们可以接受中世纪文件的培训,能够阅读这些文件,而且很少出错。这样的任务对我们大多数人来说是非常困难的:看看图 1,试一试吧!

Fig. 1: Hard to read for most people, but easy for a text recognition system trained on this dataset.
这些系统实际上是如何工作的?这些系统会看图像中的哪些部分来识别文本?他们利用了一些聪明的模式吗?或者他们会使用像数据集特定模式这样的捷径来作弊吗?在下文中,我们将通过两个实验来更好地理解这种神经网络内部发生的事情。
第一个实验:像素相关性
对于我们的第一个实验,我们提出以下问题:给定一个输入图像和正确的类别(真实文本),输入图像中的哪些像素投票支持正确的文本,哪些像素投票反对正确的文本?
我们可以通过比较两种情况下正确类别的分数来计算单个像素对结果的影响:
- 该像素包含在图像中。
- 从图像中排除该像素(通过边缘化该像素的所有可能的灰度值)。
通过比较这两个分数,我们可以看到一个像素投票赞成还是反对正确的类。图 2 示出了图像中的像素与地面实况文本“are”的相关性。红色像素对文本“are”投赞成票,蓝色像素投反对票。

Fig. 2: Top: input image. Bottom: pixel relevance and blended input image. Red pixels vote for, blue pixels against the correct text “are”.
我们现在可以查看一些关键区域(深红、深蓝),以了解哪些图像特征对神经网络做出决策很重要:
- “a”上方的红色区域在输入图像中是白色的,对于正确的结果“are”非常重要。正如你所猜测的,如果一个黑点出现在“a”的垂直线上方,那么这条垂直线可以被解释为“I”。
- “r”与“e”相连,混淆了蓝色区域所示的神经网络。如果这两个字符断开,这将增加“are”的分数。
- “a”(左下内侧部分)内的灰色像素略投“are”反对票。如果 a 里面的洞完全是白色的,这应该会增加分数。
- 在图像的右上方是正确投票的重要区域。不清楚如何解释这个区域。
让我们研究一下我们的假设 1。— 3.都是正确的,4 的含义是什么。通过改变这些区域内的一些像素值。在图 3 中,示出了原始和改变的图像、正确文本的分数以及识别的文本。第一行显示了文本“are”的得分为 0.87 的原始图像。
- 如果我们在“a”的垂直线上画一个点,“are”的分数会减少 10 倍,我们得到的是文本“aive”。因此,神经网络大量使用上标点来决定垂直线是“I”还是其他什么。
- 去掉“r”和“e”之间的联系,分数增加到 0.96。即使神经网络能够隐式地分割字符,看起来断开的字符简化了任务。
- “a”内的洞对于检测“a”很重要,因此将灰色像素与白色像素交换会稍微提高分数至 0.88。
- 当将一些灰色像素绘制到图像的右上方区域时,系统识别出“ane”,“are”的分数降低到 0.13。在这种情况下,系统显然已经学习了与文本无关的特征。

Fig. 3: Change some pixels inside critical regions and observe what happens.
总结我们的第一个实验:系统已经学习了一些有意义的文本特征,如上标点来识别字符“I”。但它也学会了一些对我们来说毫无意义的特征。然而,这些特征仍然帮助系统识别它被训练的数据集中的文本:这些特征让系统采取(容易的)捷径,而不是学习真实的文本特征。
第二个实验:平移不变性
平移不变文本识别系统能够正确地识别文本,而与它在图像中的位置无关。图 4 示出了文本的三种不同的水平翻译。我们希望神经网络能够识别所有三个位置的“to”。

Fig. 4: Three horizontal translations of a text.
让我们再次从包含文本“are”的第一个实验中取出我们的图像。我们将把它一个像素一个像素地向右移动,并查看正确类别的分数以及预测文本,如图 5 所示。

Fig. 5: Score for text “are” while shifting the text pixel by pixel to the right. The labels on the x-axis show both the number of pixels the image is shifted and the recognized text (using best path decoding).
可以看出,该系统不是平移不变的。原图得分 0.87。通过将图像向右移动一个像素,分数降低到 0.53。再向右移动一个像素,分数就会降到 0.28。神经网络能够识别正确的文本,直到平移四个像素。之后,系统偶尔会输出错误的结果,从“aare”向右五个像素开始。
在 IAM 数据集上训练神经网络,其中所有单词都是左对齐的。因此,系统从未学会如何处理左边有空白的图像。对我们来说,忽略空白可能是显而易见的——这是一种必须学习的能力。如果系统从未被迫处理这种情况,它为什么要学习呢?
乐谱的另一个有趣的特性是四个像素的周期性。这四个像素等于卷积网络从 128 像素的宽度到 32 的序列长度的缩减因子。该行为是由池层的移动差异引起的。
结论
文本识别系统学习任何有助于提高其被训练的数据集中的准确性的东西。如果一些看起来随机的像素有助于识别正确的类别,那么系统将使用它们。如果系统只需要处理左对齐的文本,那么它将不会学习任何其他类型的对齐方式。有时,它学习我们人类也发现对阅读有用的特征,这些特征概括了广泛的文本样式,但有时它学习只对一个特定数据集有用的快捷方式。
我们必须提供多样化的数据(例如,混合多个数据集或使用数据增强),以确保系统真正学习文本特征,而不仅仅是一些作弊行为。
参考
小数据呢?贝叶斯方差分析解。
什么是小数据?
作为数据科学家,我们接受过处理大数据的培训,通常我们在这个领域非常得心应手。在我们找到答案之前,大数据集让我们可以使用任何数量的工具来刺激和探索。几乎每一种方法都可以处理这些数据,尽管为了让事情正常运转,必须时不时地对其进行处理。尽管回报递减,我们投入的精力越多,得到的就越多。
但是,小数据呢?它是否完全符合我们已经使用的方法?把小数据想象成普通人无需过多处理就能理解的任何东西。例如,他的同事的年龄和他们在公司的当前职位是一个小数据集。如果他的员工群体相对较小,Joe 可以很快看到趋势并发现数据集中的异常值。
看看这个小数据集,它显示了一位评委给来自不同国家的参与者打分。根据我们的定义,似乎我们应该能够从中得出一个直观的结论。

Is this a biased judge?
你认为美国的分数比加拿大和墨西哥高是对的,但是这是一种趋势吗?你能自信地说,从长远来看,美国的得分高于加拿大和墨西哥吗?或者这只是雷达上的一个亮点?乔能否断言年纪较大的员工在公司中拥有更高的职位,或者这也是雷达上的一个光点?
小数据的麻烦就在于此。它很小。我们可以从中得出直观的结论,但当需要利用这些数据做出决策时,我们就陷入了困境。如果你是一名数据科学家或分析师,其工作依赖于从数据中做出正确的判断,这一点尤其正确。那么你应该怎么做呢?如果你的第一个想法是,“我会避免小数据”,那么再想一想!小数据无处不在,迟早你会不得不使用它。事实上,收集一个小数据集有时是最好的途径。它能让你更快地处理数据,让你成为更敏捷的数据科学家。
理解小数据
让我们回到上面的数据集来理解它。想象一下,一名奥运会跳水裁判刚刚被停职,因为他被发现给美国选手的分数高于加拿大和墨西哥选手。他承认了,参加了再培训课程,并签署了一份协议,如果发现他的分数有偏差,就禁止他参加这项运动。该数据集显示了他在四次国际比赛中给予不同国籍参与者的平均分数。你可以假设另一位裁判的分数变化相等,但可能与他的分数不匹配。如果你是为监督跳水裁判的奥委会工作的数据科学家,你有什么建议?

It’s the judge in the middle that we’re worried about. He’s clearly up to no good.
这是一个很大的难题,不是吗?你的直觉告诉你分数有偏差,但你需要证明。你的目标是确定国家之间的平均分数是相同的(H0: 0 = 1 = 2)还是不同的(哈:0 ≠ 1 ≠ 2),这意味着你应该运行方差分析,ANOVA,测试来得出结论。让我们设置α = 0.10,这样我们就有一个低的阈值来继续研究。方差分析的结果如下所示。

The results of ANOVA on the data. p > α**,** so we accept the null hypothesis.
即使以我们自由派的信心水平,我们也不能拒绝零假设。难道是我们的直觉错了?不一定!我们的直觉是基于这样一个事实,即我们对这个特定法官的行为有先验知识。换句话说,我们倾向于寻找偏见,因为我们有证据表明过去存在偏见。我们遇到的问题是小数据。根本没有足够的数据来否定我们的假设,而且我们也没有办法在这个分析中包含我们的先验知识。在这种情况下,等待获得更多数据会损害竞争对手,并有可能降低观众对公平评判比赛能力的信心。幸运的是,我们没有被卡住。
贝伊斯来救援了。
贝叶斯统计非常适合这个问题。如果你还没有遇到贝叶斯统计,那么我建议你读这篇文章,然后读这篇论文。使用先验信息是贝叶斯统计强大的原因之一。分析像这样的小数据集是可能的,因为我们有输入模型的先验信息。通过使用马尔可夫链蒙特卡罗方法将先验信息耦合到新信息,我们可以推断出新信息符合我们先验理解的可能性。让我们再次运行分析,但是这次使用贝叶斯框架。
Python 中的贝叶斯方差分析
方差分析在功能上等同于使用分类预测的简单线性回归。事实上,方差分析的 F 统计量与仅使用类别作为预测因子的模型的线性回归的 F 统计量完全相同。为了更好地理解正在计算的内容,我们可以利用系数的置信区间,以便在某个置信水平上测试假设。如果每个系数的 95%置信区间重叠,那么我们期望 F 统计量产生 p 值> 0.05。数据的线性回归系数显示了这种关系。

Notice how the confidence intervals overlap? That’s a sign that we can’t reject the null hypothesis.
我们可以使用这些信息,即线性回归相当于 ANOVA,使用 PyMC3 模块在 Python 中运行贝叶斯分析。我的代码复制如下。
这是怎么回事?首先,我加载了一个 PyMC3 模型(pm。模型()作为模型)。然后,我用先验信息填充模型。适马是我们在整个模型中期望的标准差。我将 sigma 设置为来自半柯西分布(标准实践),这将 sigma 限制为大于 0,低值比高值更有可能。参数β设置分布的宽度-值 10 是一个很大的宽度,从 0 到 10 的值基本上是相等的。
然后,我在模型中加入法官过去表现出的偏见。美国、加拿大和墨西哥选手的平均得分非常相似,但他给美国选手的平均得分比加拿大选手高 2 分,比墨西哥选手高 4 分。使用频率主义者的方法很难发现这种微小的差异。
最后,我将可能的结果定义为每个系数乘以为竞争对手国籍编码的虚拟变量的总和,并将其与实际数据 df.Score 进行比较。为了获得结果,我运行了两条马尔可夫链,每条链有 3000 个样本。
我如何确定是否存在偏见?我在 frequentist 方法中利用了查看系数置信区间的概念!我不是查看置信区间,而是查看每个系数的概率分布,并确定 90%的最高后验密度(HPD)是否重叠。下图显示墨西哥和美国的 HPD 没有重叠,这证明平均分数不相等。

The thin region where the HPDs of USA and Mexico do not overlap, around 77.8, is evidence that the scores are not equal.
现在我们有证据表明可能存在偏见,我们应该继续调查,以确保分数没有真正反映竞争对手的表现。我们可以通过比较其他裁判给参赛者的分数和这位裁判的分数来做到这一点。给定少量的数据,我可以想象这些分析也必须用贝叶斯统计来执行。
所以你有它!贝叶斯统计是另一种管理数据的工具,特别是小数据,以提供更好的建议或得出结论。请看一下 PyMC3 文档,了解更多关于如何使用这个强大的库的信息。如果你对上面例子的完整代码感兴趣,那么看看我的笔记本链接这里。
人工智能产品经理还没有搞清楚的是什么
自然智能教给人工智能在该领域取得成功的第一方法

my son Gabriel Versace about to attack a robot…
我写这篇文章的时候,正看着我的第四个孩子,新生的莱昂纳多·范思哲,在他生命的第五天小睡片刻。
正如我听说或看到的所有婴儿一样,莱昂纳多出生时有一套非常基本的技能,而且有点“不熟”。有几个月的时间,他不会走路,不会说话,更不用说为他的爸爸做卡布奇诺了(到两岁时,他应该是一个熟练的咖啡师了)。
大自然母亲为人类选择了一种非常奇特的发展方式。我们的婴儿出生时,基本技能非常有限,但令人印象深刻,其中最重要的是:学习。
然后,日复一日地在球场上重复和不断地学习。
人类天生就有能力建立基本技能,学习和发展超越他们对世界的最初理解,并在现实世界中运用他们的技能。婴儿最终会感知和抓住机器人,并将它们撕碎(见上图,我的长子加布里埃尔在他面前正要撕掉不幸的 iRobot 的各种碎片)。
如果我们能够跟随自己的脚步构建和部署人工智能,我们就可以避免企业通常面临的许多问题。现实是,大多数人工智能开发遵循的过程与上面概述的过程非常不同。产品经理和工程团队倾向于在试图在相关环境中进行测试之前,尽可能多地构建人工智能系统。这个基本的、命运多舛的想法是:“让我尽可能多地将人工智能放入系统,我知道它需要做什么,然后当我在 67 个月后完成时,祈祷它能工作!”。
然后,88 个月后,人工智能失败了。
这是规则,而不是例外,一旦部署,你的人工智能将不会按预期工作。但是在把所有的责任都推给产品经理和 AI 专家之前要三思!今天,部署、培训和测试人工智能的过程很繁琐,为了不浪费宝贵的时间和金钱,尽可能好地进入系统是至关重要的。
只有在相关环境中的早期部署和学习,在一个连续的反馈循环中,它才能使我们真正建立一个(自然或人工)智能,能够应对现实与我们想象的概念。

我学到了艰难的方法…为机器人构建和部署人工智能。我认为花大量的时间设计一个防弹人工智能,然后看看它是否能在实地工作会是最好的。几次尝试失败后,我和我的同事不得不改变策略。现在,我们专注于在投入使用前的快速原型制作。我们越早了解潜在的缺陷,就越能更好地解决它们。
所以,日复一日,部署并坚持学习。和我们一样,AI 永远不应该停止学习!
什么是高光谱图像?
它们与我们处理的数字图像有什么不同?

Photo by Patrick Tomasso on Unsplash
上面的墙看起来确实非常丰富多彩,移动相机在捕捉同样生动的颜色供我们的眼睛见证方面做得非常棒……但是我们的眼睛能够感知的东西是有限的,在同一张图像中可能有个方面是我们的肉眼或移动 RGB 相机都无法捕捉到的。这就是超光谱相机发挥作用的地方。
实时快速查看数字图像

Photo by Alex Holyoake on Unsplash
在某种程度上,数字图像只是一串数字(但话说回来,这不是对所有事情都适用吗!?🤔).赋予这些数字一个图像的形状的是在它们上面定义的应用一些约束的参数——比如说,以行/列格式堆叠的数字,具有特定值范围的数字,等等。
二进制图像 :
这些是我们称之为的黑白图像,就像文字清晰地向你尖叫一样——它们只由两个不同的数字(0 和 1)组成,对应着两种不同的颜色,即。分别是黑色和白色。这些数字被保存为一个二维矩阵,格式为 n 行/ m 列,其中 0 为黑色,1 为白色。

sample binary image
灰度图像: 它们信息量更大,因为它们大多由 255 个不同的数字(比如说,从 0 到 255)组成,以传达信息;每个数字对应于灰度值的强度。换句话说,

sample greyscale image
- 数字 0 代表最浅的灰色(换句话说,白色)
- 100 号有点灰色
- 200 号就像是一种深灰色
- 数字 255 将是图像中最灰色的阴影(换句话说,黑色)

Greyscale range, from 0 to 255
彩色图像: 现在,这就是我们的眼睛(视锥细胞)如何感知我们周围的环境,给它一个彩色的呈现。取代单一的灰度图像,我们将有 3 个通道的红色、绿色和蓝色图像。这三种强度的组合将被我们的眼睛感知为许多可能的“颜色”之一。因此,它的尺寸为:( n 行* m 列 *)3 个通道。
超光谱图像:
正如我们所知,不同的红色、绿色和蓝色是由于物体反射的光属于电磁辐射可见光谱中不同的波长范围[即长波长,峰值在 564–580nm(红色)附近];中等波长,峰值在 534–545 纳米附近(绿色);以及 420–440 纳米附近的短波长光(蓝色)];这就是我们人类的眼睛所能感知的全部,但是有很多波长没有被可见光谱覆盖,很容易被我们的眼睛错过/看不见。
这些被人类眼睛忽略的颜色/特征可能会被其他动物的的眼睛相对地看到——就像他们说的那样,颜色存在于旁观者的眼中。
由于成像技术的进步,我们可以获得可见光谱以外的波长信息,并理解它。因此,从广义上讲,光谱成像是在图像空间中并行获取空间和它们相应的光谱信息以及它们的组合。它有点类似于 RGB 彩色图像,但它有更多的通道,因此对整体可视化提出了挑战(但我们仍然有我们的智能机器到 understand🧐).的所有数据出于理解的目的,假设我们有一个 n 波段超光谱图像:它只是在一个连续的波长范围内将 n 个灰度图像(每个波段根据其波长值捕捉不同的光强度数据)堆叠在彼此的顶部,给我们一个尺寸为 n 行 m 列* n 个波段的图像。*

RGB vs HSI images
在高光谱图像之前,我们还有多光谱图像,它们本质上是 n 波段图像,但它们不一定分布在连续的波长范围内,就波段数量而言,与任何平均高光谱图像相比,它们的波段较少。我们可以在从卫星收集的遥感数据中看到真实世界的多光谱图像。
因此,从任何 HSI 摄像机获取的图像将采用*超立方体的形式,*具有 n 维图像数据,这有时会令人不知所措。因此,对超立方体应用降维技术并不罕见,并且有许多其他方法来处理超立方体。在这里,如果我们试图专注于单个超像素,我们将能够绘制出相同的连续光谱数据。
它在众多领域都有应用,从医疗、农业、纺织到汽车工业。HSI 帮助我们探索未知领域,通过可视化人类肉眼不可见的信息,并找到理解这些信息的方法。
参考文献:
- 威泽基、京特;斯泰尔斯,W.S. (1982)。颜色科学:概念和方法,定量数据和公式。).纽约:纯粹和应用光学中的威利系列。ISBN978–0–471–02106–3。
- 机器视觉技术论坛 2017,17.10。2017 年 10 月 18 日,德国 unterschleiheim; www.spectronet.de
- 图片提供-https://sherylwilliamsart.wordpress.com/tag/value/
机器学习中的过拟合和欠拟合是什么?
当你进入机器学习的领域时,几个模糊的术语会自我介绍。过度拟合、欠拟合和偏差-方差权衡等术语。这些概念通常位于机器学习领域的核心。在这篇文章中,我用一个例子来解释这些术语。
我们为什么要在乎?
可以说,机器学习模型只有一个目的;概括得好。我在之前的几篇帖子中提到过这一点,但强调一下也无妨。
泛化是模型对以前从未见过的输入集给出合理输出的能力。
正常的程序做不到这一点,因为它们只能“自动地”输出它们知道的输入。模型以及整个应用程序的性能在很大程度上依赖于模型的泛化。如果模型概括得很好,它就达到了它的目的。已经引入了许多评估这种性能的技术,从数据本身开始。
基于这个想法,像过拟合和欠拟合这样的术语指的是模型的性能可能会受到的影响。这意味着知道模型的预测“有多差”就是知道它有多接近过度拟合或不足拟合。
概括得好的模型是既不欠拟合也不过拟合的模型。
这可能没有多大意义,但我需要你在这篇文章中记住这句话,因为这是关于我们主题的大画面。这篇文章的其余部分将把你学到的东西和它在这幅大图中的位置联系起来。
我们的例子
假设我们正在尝试为以下数据集建立一个机器学习模型。

请注意,我认为该领域的新人应该有更多的实践经验,而不是研究。因此,像函数这样的数学术语在这篇文章中不会涉及。现在,让我们记住,在数据集中,x 轴是输入值,y 轴是输出值。
如果你以前有过机器学习模型训练的经验,你可能知道我们这里有几个选项。然而,为了简单起见,在我们的例子中让我们选择一元线性回归。**线性回归允许我们将数字输入映射到数字输出,将直线拟合到数据点中。**这种线拟合过程是过度拟合和欠拟合的媒介。
训练阶段
在我们的示例中,训练线性回归模型完全是为了最小化我们试图拟合的直线和实际数据点之间的总距离(即成本)。这将经历多次迭代,直到我们在数据集中找到相对“最优”的配置。这正是过拟合和欠拟合发生的地方。
在线性回归中,我们希望我们的模型遵循类似如下的直线:

即使总成本不是最小的(即,存在一种更好的配置,其中该线可以产生到数据点的更小距离),上面的线非常符合趋势,使得模型可靠。假设我们想要推断当前不在数据集中的输入值的输出(即概化)。上面的线可以给出新输入的非常可能的预测,因为就机器学习而言,输出预计会遵循训练集中看到的趋势。
过度拟合
当我们在数据集上运行我们的训练算法时,我们允许总成本(即从每个点到线的距离)随着更多的迭代而变得更小。让这种训练算法长时间运行会导致最小的总成本。然而,这意味着线将适合所有点(包括噪声),捕捉模型概化可能不需要的次级模式。
回到我们的例子,如果我们让学习算法长时间运行,它可能会以下面的方式来拟合直线:

这看起来不错,对不对?是的,但是可靠吗?不完全是。
线性回归等算法的本质是捕捉主导趋势,并在该趋势内拟合我们的线。在上图中,算法捕捉到了所有趋势,但不是主导趋势。如果我们想对超出线限制的输入测试模型(例如,概化),那么这条线会是什么样的?真的没办法说。因此,输出是不可靠的。如果模型没有捕捉到我们都能看到的主导趋势(在我们的例子中,是正增长),它就无法预测一个从未见过的输入的可能输出——这违背了机器学习的初衷!
过拟合是整体成本确实很小,但是模型的泛化不可靠的情况。这是因为模型从训练数据集中学习了“太多”。
这听起来可能很荒谬,因为当我们可以找到最小的成本时,我们为什么要满足于更高的成本呢?一般化。
我们离开模型训练越久,过度拟合发生的几率就越高。**我们总是想找到趋势,而不是拟合所有数据点的直线。**过度拟合(或高方差)导致弊大于利。一个从训练数据中学习得很好,但仍然不能对新输入做出可靠预测的模型有什么用?
欠拟合
我们希望模型从训练数据中学习,但不希望它学习太多(即太多模式)。一个解决办法是早点停止训练。但是,这可能会导致模型无法从训练数据中学习到足够的模式,甚至可能无法捕捉到主导趋势。这种情况称为欠拟合。

欠拟合是指模型“没有从训练数据中学习到足够的知识”,从而导致泛化能力低和预测不可靠。
正如您可能预期的那样,欠拟合(即高偏差)与过拟合一样不利于模型的泛化。在高偏差情况下,模型在线拟合方面可能没有足够的灵活性,导致线过于简单,不能很好地进行概化。
偏差-方差权衡
那么什么才是正确的衡量标准呢?根据手头的模型,介于过拟合和欠拟合之间的性能更理想。这种权衡是机器学习模型训练最不可或缺的方面。正如我们所讨论的,当机器学习模型很好地概括时,它们就实现了它们的目的。泛化受到两个不良结果的限制——高偏差和高方差。检测模型是否受到其中任何一个的影响是模型开发人员的唯一责任。
“学习机器学习最好的 Coursera 课程有哪些?为什么?”
在线学习不同于课堂学习。最好的资源唾手可得。你只要出现就行了。

When I passed one of Andrew Ng’s machine learning quizzes on Coursera. Stoked is an understatement. 40% of my self-study occurs in pyjamas at my dining room table.
我想学习机器学习。所以我花了一周时间在网上搜索最好的学习资源。
Coursera 不断出现。我以前从未见过它。但是很熟悉。一次,我在苹果店接待的一个女孩告诉我,她会在火车上用手机看视频。她给我看了这个应用程序。它是蓝色的。
“为了什么?”我问。
“没什么,我只是觉得学点东西总是好的。”
你知道当有人说一件事的时候。一件事,它会永远伴随着你。
她离开了商店。
几个月后,我在做搜索的时候,发现了 Coursera,想起了她。她的话被记住了。
自从我离开苹果公司,我们合作的创业公司失败后,我有了一些空闲时间。
我收集了几门课程,创建了自己的人工智能硕士学位。
在为我们的初创公司建立网站时,我听到的都是机器学习和深度学习。这里颠覆,那里创新。这都要归功于计算机自己学习东西。靠他们自己?怎么会?我必须知道。
吴恩达的机器学习教程
这是第一个。很艰难。真的很难。我不得不(大部分)用谷歌搜索了几次答案。否则,我早就累垮了。
我几乎什么都不记得了。没有代码,因为它是在 MatLab 和 Octave 中。我不喜欢 MatLab 界面。另外,我还在兼职学习 Python。
我带走的是安德鲁对教学的热情。他对机器学习的精力。他对人工智能的热情。它让我笑逐颜开,并感染了我。
有时候,老师激发学生的兴趣比知识本身更重要。
如果你想进入机器学习领域,这门课会教授一些基础知识。如果你不能通过编码作业,我不会太担心,我会看讲座,获得直觉,并用它来推动你的下一步学习。Python 的教程。
密歇根大学使用 Python 开发的应用数据科学
当我开始成为一名机器学习工程师时,我探索数据集的技能很差。我花了太多时间为准备好的数据集建立深度学习网络,而不是深入战壕,从头开始探索数据。
这门课程帮助我学习了探索性数据分析(EDA)的基本步骤。
如果你想进入数据科学和机器学习,你可能会发现自己花了很多时间使用 Python 库熊猫做 EDA。这正是本课程第一部分的内容。
完成后,我用这些技能参加了我的第一次 Kaggle 比赛。比赛结束了,但我还是挺过来了。在此之前,Kaggle 一直是那些难以捉摸的事情之一,我会看到提到的地方,但从来没有尝试过自己。直到我做到了。这让我写下并制作了一个视频,告诉我其他人如何做同样的事情。
在我所学的所有课程中,Python 应用数据科学与我作为机器学习工程师的日常工作最为契合。
事后看来,这门课应该是我开始学习机器学习/数据科学时的第一门课。
吴恩达的 deeplearning.ai
吴恩达释放的任何东西,我都会吞噬。我的学习风格和他的教学风格非常一致。
文字和视觉的结合让我学得最好。安德鲁在他的讲座中做到了这两点。经常在打印的课堂笔记上画例子。
这门课程教会了我深度学习的基本原理以及如何应用它们。如果说用 Python 的应用数据科学是数据科学的珠峰大本营,deeplearning.ai 就是顶峰。
它给出了计算机视觉(教计算机看)、自然语言处理(教计算机理解语言)和口语检测(教计算机听)中涉及的概念的概述和工作示例。
在这些主题之间,Andrew 分享了他丰富的经验,并深入研究了深度学习背后的一些数学和统计学。
额外收获:学习如何学习
这门课程应该是所有学生的必修课。我把它留到了最后,但如果让我重新开始,我会先做这个。每年更新自己是值得的。
为什么?
因为学会如何学习才是终极技能。
如果你知道学习本身的技术和最佳实践,你可以把它们应用到其他任何事情上。
我最喜欢的(也是我日常使用的)是:
- 避免拖延的番茄定时器——设置一个 25 分钟的定时器,在定时器到时之前,除了你面前的单一任务,什么也不要做。一天 6-10 次对我来说是个好日子。前 4 分钟是地狱,但当计时器响起,你不想停下来。
- 集中和分散思维 —集中思维发生在你专注于一项任务的时候,分散思维发生在你没有做任何特别的事情的时候。最好的学习发生在这两个点的交叉点。这就是为什么休息和无所事事的时间是有价值的。没有智能手机。没有社交媒体。给你的大脑空间。当你的大脑有空间时,它能把事情联系在一起。有没有想过为什么你的一些伟大的想法会在洗澡的时候冒出来?是因为你的大脑有思考的空间。
- 不需要天才羡慕——每个人都必须从某个地方开始学习之旅。事实是,每个大师都知道,学习永不停止。总是第一天。查尔斯·达尔文大学辍学,后来发现了进化论。不要以为你是查尔斯·达尔文。但是也不要认为高中或大学毕业后学习就停止了。
在高中知道这些事情可能会对我的成绩有一点帮助。也许是它让我在大学的头两年没有及格。
我非常喜欢这门课,我制作了一个视频,总结了我最喜欢的其他课程。
这里剩下的课程都被我对机器学习和数据科学的兴趣带偏了。
但是我认为不管你喜欢什么,你都会从学习如何学习的课程中有所收获。
加州大学圣地亚哥分校的生物信息学
我还没有做这个,但是我打算明天开始做。
为什么?
因为没有什么比健康和科技的交叉更让我着迷了。简而言之,这就是生物信息学。
几周后,我退学了。我有太多事情要做。我犯了一个错误,追求更多的证书,而不是利用我已经获得的知识。也许有一天我会回去。
因为这足以成为学习任何东西的理由
网上有这样的资源,太神奇了。Coursera 只是其中之一。有 YouTube,Udemy,edX,走向数据科学,大量的免费文档。
它仍然得到我。在澳大利亚的布里斯班,我可以坐在我的房间或餐桌上,学习我想学的东西。最初在 5000 英里外教授的东西。
如果你想学习新的东西,你可以。你要做的就是注册,然后不断出现。
你也不需要理由。
我记得苹果店里的那个女孩转向我说。
没什么,我只是觉得学点东西总是好的。
最好的事情是,如果老师没有像吴恩达那样激发你的好奇心,或者如果材料不是你所期望的,在线学习的好处是,你可以随时尝试其他东西。一些能激发你好奇心的东西。与你的学习方式一致的东西。
为什么?
因为。
机器学习中有哪些监督学习和无监督学习?

(Source: https://unsplash.com/photos/z4H9MYmWIMA)
不可否认,机器学习自问世以来给世界带来的丰富是多么巨大。作为一组面向应用的概念,ML 应用程序的最终目标决定了要使用的方法和算法——至少可以说是领域。
机器学习领域的一个方面困扰着大多数新人,以至于它几乎被包括在所有 ML 课程的介绍中。这就是有监督学习和无监督学习的区别。在这篇文章中,我试图用一个例子来解释每一个的意思,讨论它们之间的区别,并解决一些围绕它们的误解。
你把你的儿子放在哪里?
想象你有一个年幼的儿子。你儿子从未见过真正的动物。你有责任向他展示外面有不同类型的生物。这种体验需要尽可能亲自动手,这样你的儿子才能学得最好。为了完成这项任务,您需要做出一些决定。这些决定高度依赖于一个核心问题:你把你的儿子放在哪里?
你有没有把他安置在一个家庭里,给他带几只宠物,并给他命名它们的种类(例如猫、狗、鹦鹉…)以及向他解释他想知道的关于他们的任何事情?
或者,
你会带他去一个丛林,那里有太多的动物让你说不出种类,让他自己去发现有不同的种类吗?
实际上,您不必选择以上任何一项。你对环境的任何选择都可能是相似的。比如带他去动物园就属于丛林一类。即使你为他命名每一种动物,他也会不知所措,无法像在有宠物的家庭中那样记住所有的动物。
简单地说,这个想法是要么让你的儿子接触几种你非常熟悉的类型,然后把这些知识传授给他,要么让他接触多种类型,然后让他自己找到模式。
给他带宠物
如果你选择这个选项,你的儿子将能够很好地学习那些种类的动物是什么。他将能够发现你无法理解的模式——或者你没有想到的模式——甚至他自己也无法表达。因此,你可以期待他知道什么是猫,它如何行动,它吃什么,等等,为他的余生。
你的儿子也将能够把他的知识推广到户外。如果他在街上看到一只狗,他会知道那是一只狗。如果他看到一些他没有养过的动物作为宠物,他将无法识别这种动物,但他会知道这不是他被介绍的动物(即不是狗或猫)。
即使他非常了解一些种类,你也只能教他这么多。你不能给他一只狮子或大象做宠物。你不能带一些甚至你都不了解的奇怪昆虫去教他。
你刚才做的是将你的儿子归类为一个监督学习分类器。你给了他你足够了解的种类。你告诉他他们的名字和种类。你向他解释了他关心并能标记(如食物、颜色、眼睛、耳朵形状等)和利用的事物。你给了他足够的时间去理解他们的行为,并且能够很好的区分他们。
在监督学习中,您为模型提供带标签的数据,以便模型可以学习基于这些标签进行归纳。例如,你给一个模型提供 1000 张猫的图片,每张图片都与标签“猫”相关联,以及 1000 张狗的图片,每张图片都标有“狗”。
监督学习的工作方式决定了你需要有足够的关于类的知识(例如,在我们的类比中是动物),以便你可以将这些知识(例如,数据)传递给分类器——你的儿子。这里的限制来自于对数据的需求,这通常是一项非常困难的任务。
把他扔进丛林
如果你选择这个选项,你的儿子将能够学习和识别动物之间的不同模式,并根据他的观察将它们分成小组。例如,他可能会把所有的鸟放在他脑中的同一个组/类别中,因为它们都有一个显著的特征——飞行能力。
你还需要记住,你的儿子不可能对任何一种动物有深入的了解,因为他需要记住的动物种类实在太多了。然而,他为自己找到的模式可能会让你眼花缭乱。他将能够建立你从未想过的联系。
即使你的儿子不能真正说出动物的种类,他也有能力不断地制作图案并将它们组合在一起。这扩展到他能够把一个新来的动物种类放在它的组里,而不需要知道它的名字。
你刚才做的是把你的儿子归类为一个无监督学习分类器。你向他介绍了很多你不一定了解的种类。尽管如此,他还是能够自己了解这些差异。此外,他可能会遇到一些对他来说毫无意义的类型(即离群值)。那些种类将介于其他动物种类之间。
在无监督学习中,您为模型提供未标记的数据样本,给它时间来寻找模式,并根据它到达的模式将这些数据样本分组在一起。
技术性
机器学习模型的学习理论可以属于监督学习或无监督学习(或其他上下文中的强化学习)。这两个可以被认为是在构建机器学习模型时在实践中遵循的“学习范式”。确定遵循哪种范式很大程度上取决于手边的应用程序和可用的数据类型。带标签的数据总是可取的,因为它可以在监督和非监督应用程序中使用(忽略后者中的实际标签)。然而,标记的数据通常是昂贵的,并且当找到时几乎不符合应用程序的目的。
监督学习
正如我们在上述类比中看到的,在监督学习中,您知道标签,并将这些标签与数据样本本身一起输入到机器学习模型中进行训练。这种类型的例子包括:
- 线性回归 :一种机器学习算法,允许我们将数字输入映射到数字输出,将一条线拟合到数据点中。
- 逻辑回归:因变量为二进制(0 或 1)时广泛使用的一种分类算法。
- 神经网络 :机器学习框架,通过将非线性引入线性 ML 模型来获得其有效性。
- 支持向量机:一种机器学习算法,利用内核技巧,在确定类之间的最佳分隔线时使用利润率最大化。
这种算法的应用通常包括:图像分类、语音识别、基于回归的数字预测等。
无监督学习
值得强调的是,有监督和无监督学习算法之间的主要区别是后者没有数据标签。取而代之的是,数据特征被输入到学习算法中,学习算法决定如何标记它们(通常用数字 0,1,2…)又基于什么。这个“基于什么”的部分决定了要遵循哪个无监督学习算法。
值得一提的是,大多数基于无监督学习的应用程序都利用了一个叫做聚类的子领域。聚类是根据数据样本共有的特定特征将数据样本组合成个簇的过程——这正是无监督学习的首要目的。
无监督学习算法的例子包括:
- k 均值聚类:一种聚类算法,根据 k 个质心将数据点分成 k 个聚类,k 个质心的值是在任何给定时间属于特定聚类的样本的均值。
- 自动编码器:一种神经网络的形式,其输出与输入属于相同的特征空间,真正实现了端到端的方法。
这种算法的应用可以包括:内容推荐、产品促销、欺诈检测等。
结论
基于所遵循的学习方法,机器学习可以分为两种范式。监督学习算法从数据特征和与之相关联的标签中学习。无监督学习算法在不需要标签的情况下获取数据点的特征,因为算法引入了它们自己的枚举标签。选择哪种范式取决于手边的应用程序和可用的数据类型,从而使每种范式在其各自的领域内都处于领先地位。
IMDb 最好的电影是什么?

Photo credit: https://www.canva.com/design/DADu-0ZcZCM/gcIYtjzGs-_Io0m8H8LQKA/edit
IMDb 电影收视率透视
“不要一路关着门。我不喜欢那样。只是……让它开着一点点。”
这些是我可以毫无疑问地说是 2019 年最佳电影的最后一句话,这部电影是爱尔兰人。在这最后一幕之后,片尾字幕补充了五色缎子乐队的《夜深人静中的*。*
观看爱尔兰人是一次很棒的经历。我坐下来,整个感恩节上午都在网飞看电视。这是一部非凡的电影。我看了劳勃·狄·尼诺的 10/10 表演,他从扮演一个 40 多岁的年轻人到扮演一个 90 多岁的老人。
他把自己的角色演得如此之好,以至于他把动作和风格完美地运用到了他所扮演的各个时代。我还目睹了其他演员如乔·佩西、阿尔·帕西诺和安娜·帕奎因的精彩表演。
我喜欢看电影,尤其是马丁·斯科塞斯、克里斯托弗·诺兰或昆汀·塔伦蒂诺等经典导演的电影。我观看这些电影制作人的电影,因为演员们如何进行有意义的对话,镜头角度如何捕捉令人惊叹的时刻,以及电影如何传达强大的符号。
像这样的电影让我想知道哪些电影是 IMDb 收视率最高的,并问电影质量如何随着时间的推移而变化。
因此,进行了一项研究来找出 IMDb 收视率最高的电影。
数据收集
数据集是通过这个链接在 Kaggle 上收集的。然后,他们被修改,以便有适当数量的功能,如标题,年份,持续时间,平均评级,投票和 metascore。此外,还删除了无效值。
转换数据集的代码如下所示:
df_movie = df_data_1[['title', 'year', 'duration', 'avg_vote', 'votes', 'metascore']]
df_movie.head()
df_movie_1 = df_movie.dropna()
df_movie_11 = df_movie_1.reset_index()
df_movie_11.head()

Top five rows of the truncated dataset.
获得正确的数据集后,进行数据分析以进行研究并得出结论。
平均评分、总票数和 Metascore
第一项任务是找出电影随着时间的推移是如何被分级的。下图显示了 IMDb 电影按制作年份的平均收视率。

A line plot graph of Average rating of the movie on IMDb vs the year they were produced.
事实证明,根据 IMDb 收视率,电影的收视率随着时间的推移大幅下降。
第二个任务是通过创建另一个线图来显示 IMDb 在不同年份每年记录的投票数,从而找出每年电影的总投票数。


The graph on the left shows how total votes per year has changed on IMDb. The graph on the right focuses on total votes from 2000 to 2019.
看这两个图表,IMDb 电影的投票数每年都有显著的增长,从零票到大约 3500000 票的峰值。
最后的线形图显示了电影的平均元得分也是如何随时间变化的。

A line plot graph of Average metascore of the movie on IMDb vs the year they were produced.
根据上面的折线图,平均元得分和平均评级一样,显示了平均元得分的年度下降。
上面的四张图显示,随着投票数逐年增加,电影的平均评分和平均元得分下降。出现这种情况的原因是因为每年生产的电影越来越多,这导致了许多好电影和许多坏电影。因此,随着制作的电影的增加,投票数也增加。
此外,直到 1990 年才出现 IMDb,所以 1990 年以前的电影可能只有极少数有兴趣看的人来评价,而且那时候每年只生产很少的电影。因此,1990 年以前的年度总票数比随后几年记录的票数少。
IMDb 投票最多的 20 部电影
创建了一个水平条形图来显示 IMDb 投票最多的前 20 部电影。

Top 20 movies with the most votes on IMDb
《肖申克的救赎》以大约 2159628 票位居第一。位居第二,以大约 25000 票的差距落败的是《黑暗骑士》。《盗梦空间》是票数第三多的电影。《搏击俱乐部》和《低俗小说》分别位居第四和第五。其他著名的电影有第十名的《教父》和第二十名的《无耻混蛋》。
IMDb 收视率最高的 20 部电影
生成另一个水平条形图来显示 IMDb 上最高评级的前 20 部电影。

Top 20 highest rated movies on IMDb
《肖申克的救赎》以 9.3 的平均评分再次位居榜首。《人力资本》和《教父》并列第二,平均评分 9.2。《黑暗骑士与教父 II》以 9.0 的平均评分排在第四位。
《小丑》是票房收入最高的 R 级电影,票房超过 10 亿美元,排名第十,平均评分为 8.8 分。
一个明显的趋势是,一些获得最多投票的电影也获得了最好的评级。因此,创建了一个散点图来显示总投票数与平均评分之间的关系。

A scatter plot of Total votes vs Average ratings
根据散点图,随着电影被分级,从左到右有某种向上的转移。相关系数约为 0.35,这意味着总投票数与平均评分呈正弱/中等相关。
结论
电影是当今世界上最大的娱乐形式之一。每个人都喜欢电影,所以做这项研究证明了电影的评级是如何随着时间的推移而变化的,以及一部电影获得的票数会对其评级产生多大的影响。
科技界有哪些最快乐的工作?
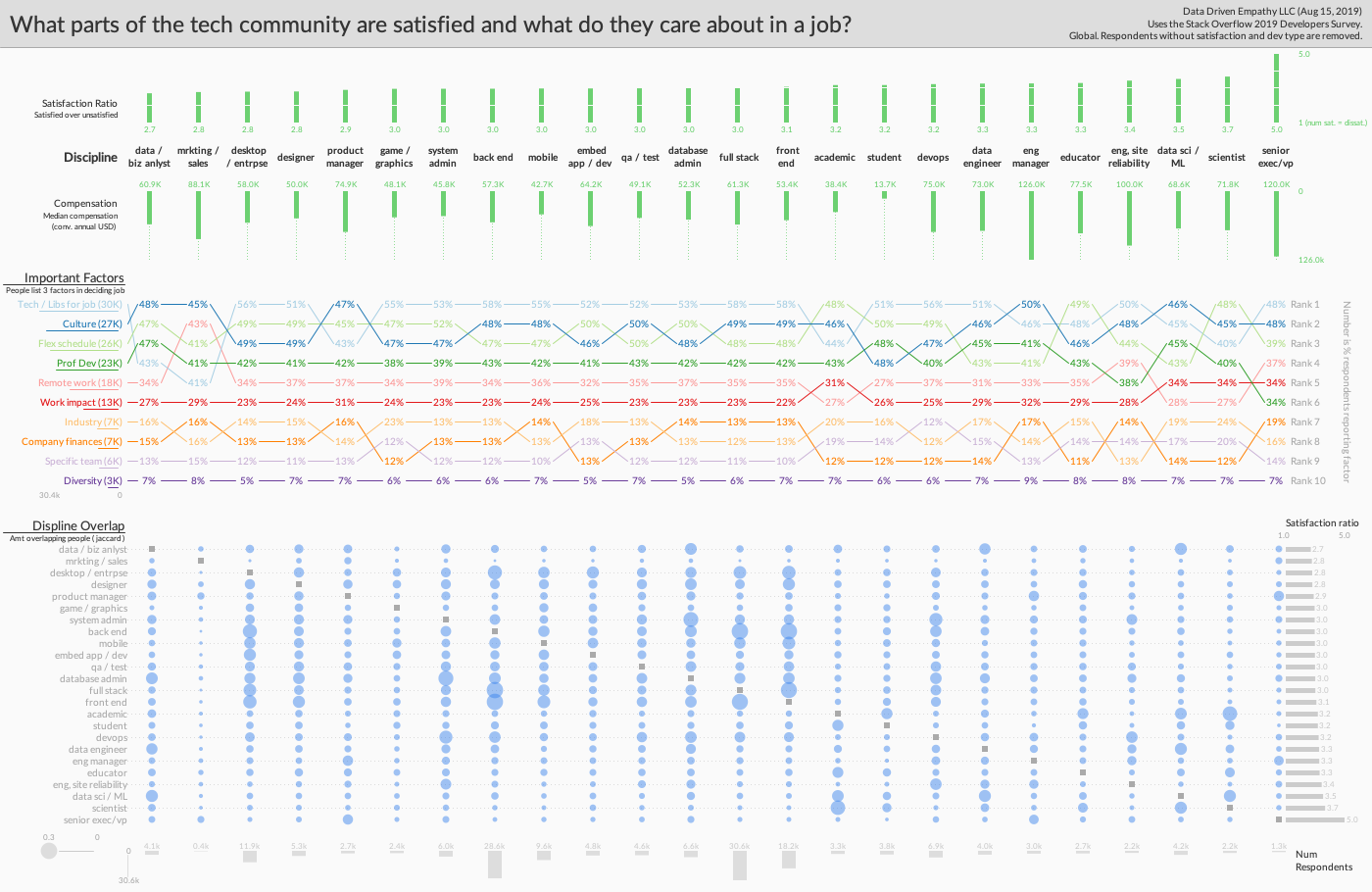
科技行业的薪资最高,T2 的离职率也最高。在调查这个竞争激烈但高流失率的生态系统时,讨论往往会转向的工作满意度如何因公司而异和的留任率如何因雇主而异【3】【4】。然而,对公司的关注忽略了一个事实,即科技公司不仅拥有众多的公司,还拥有各种各样的人,他们在相互关联的工作领域中有不同的优先事项和关系。调查经验如何因学科而异,2019 Stack Overflow Developer Survey可以通过工作领域、薪酬和其他因素来帮助了解工作满意度,不仅可以揭示谁的薪酬最高,还可以揭示谁最满意,以及什么可以帮助他们在工作中找到快乐[5]。

Satisfaction ratios by “discipline” (devType from the 2019 Developer Survey). Senior executives report high satisfaction while data analysts exhibit relatively low satisfaction.
首先,不同学科之间的满意度确实不同。更具体地说,数据显示了工作领域之间的统计显著差异,给出了表示对工作满意的人数与表示不满意的人数(p < 0.05). Consider a metric which divides the number of people who report being satisfied (slightly or very satisfied) by the number dissatisfied (slightly or very unsatisfied) with their job. Using that “satisfaction ratio” metric to rank the fields of work within the Stack Overflow Developer Survey, four groups dominate the top ten most satisfied: 管理(高管,在较小程度上还有工程管理)、科学(包括数据科学)可靠性 (SRE 和德沃普斯),以及学术界(教育家和研究人员)。数据还显示,大多数“开发人员”的职位都在中间值 3.0 左右,低于这个值的是设计师、项目经理、销售/营销和分析师。
人们可能会怀疑,薪酬可以解释工作领域中的这种差异,事实上,那些报告对工作满意的人的工资明显高于那些报告不满意的人(差异约为 21,000 美元的差异,p < 0.05). Even still, consider that compensation may not be fully capturing variation in satisfaction. Though 这可能是一个麻烦的指标,仅针对中值学科薪酬的线性回归”解释道“学科满意度比率(R = 0.29)中约三分之一的差异[6][7]。仔细观察这些数据,人们可以开始看到挑战这一重要而复杂的关系的工作领域。例如,与工程经理相比,学术研究人员的薪酬较低,但两者的满意度仍然相当高。同样,工程经理、数据科学家和 sre 在薪酬上可能有显著差异,但在满意度上不一定有巨大差异。当然,如果你想优化满意度和薪酬,你可以考虑高级主管/副总裁、SRE 或工程经理。尽管金钱可能会有所帮助,但它似乎并不总能买到更多的幸福。

Median compensation and satisfaction ratios for different devTypes.
如果薪酬不能完全解释这个样本中的满意度,那么在科技领域还有什么可能是重要的呢?开发人员调查询问受访者关于可能影响他们接受工作决定的因素(“…在两个薪酬、福利和地点相同的工作机会之间做出决定…哪三个对你来说[最]重要?”)而且,有趣的是,不同学科选择因子的频率存在统计学上的显著差异(p < 0.05)。值得注意的是,各种类型的开发人员(前端、后端等)将“他们将使用的语言、框架和其他技术”排在他们列表的顶部,而文化排在 PM、工程经理、销售/营销和数据科学家/分析师列表的顶部。有趣的是,在高满意度学科中,一个人的工作对科学家(包括数据科学)和高管的影响可能比平时更重要。不管怎样,就像薪酬一样,这种可变的因素排名可能意味着不同类型的技术人员正在从他们的工作中寻找不同的东西,许多因素可能会整体上支持满意度。

Visualization of satisfaction and job factors by discipline while also showing how those disciplines are inter-related. Full resolution image available.
最后,开发者调查的受访者通常认同不止一个学科,通过利用这些领域中的“重叠”,人们可以开始看到技术领域中具有不同体验的“集群”。具体来说,使用共享受访者的 Jaccard 指数,工程管理和高级管理人员之间有相当多的重叠(两者都有很高的薪酬和满意度)[8]。同样,许多“开发人员”领域密切相关(前端、后端、完整堆栈等),同时也看到类似的满意度。也就是说,一些学科强调,一个集群内的微小变化会产生非常不同的结果。最值得注意的是,尽管数据科学家和数据分析师拥有大量从业者,但他们报告的满意度却大相径庭。还要考虑到一些可靠性(DevOps 和 SRE)学科比系统管理员报告更高的满意度和薪酬,即使就人们的自我报告而言,这些领域之间可能有相对较大的重叠。可能有些技术人员可以担任多个角色,但是他们属于哪个角色会极大地影响他们的工作体验。

Relationships between different disciplines in tech using a Jaccard Index over respondents shared between different fields. Line width proportional to index with values under 0.05 filtered out.
虽然技术部门经常被作为一个社区来讨论,但技术内部的体验有很大的差异,对于不同的成员来说什么才是重要的。纪律是与工作满意度相互作用的一个重要方面,不仅薪酬以外的其他因素也很重要,而且这些因素的重要性可能因工作领域而异。也就是说,虽然选择学科的学生或寻求改变的从业者可能会考虑不同领域的财务和情感经历,但这篇文章也为其他人强调了教训:经理和领导者。在为不同类型的从业者建立职位时,值得强调的是不同的事情对不同类型的人很重要,在日益紧缩的技术劳动力市场,对这些学科当前现实的更深入了解可能有助于建立更好的职业家园【9】。
【https://github.com/sampottinger/dev_satisfaction】代号。
想要在数据、设计和系统的交叉点进行更多的实验吗? 关注我获取更多 !
Works cited, code, and notes
赔率是多少:NBA 惨败的统计分析

Image by Philadelphia 76ers on flickr
什么是坦克?
坦克是一种艺术,创造一个有目的的坏团队,意图输掉比赛,以获得高选秀权。最终,几乎所有人都同意,在今天的 NBA,你的球队需要一个真正伟大的球员来赢得总冠军。坦克的目标是获得这个球员的状元选秀权,并最终赢得一个拥有坦克核心的冠军。
随着赢得 NBA 总冠军变得越来越困难,这种策略近年来变得越来越普遍。
这一分析的目的
随后,这一分析旨在确定三件不同的事情:
- 什么是一个合理的场景,坦克可能看起来像什么?
- 那支球队会得到什么样的选秀权,这些选秀权中的一个能产生真正伟大的球员的几率有多大?
- 如果那支球队真的得到了一个超级巨星,他们有多大可能用那个球员赢得冠军?
为了这个分析的目的,我将一个伟大的球员定义为名人堂级别的球员。
第一部分:坦克场景
确定一个合理的坦克场景是这个分析中最主观的部分。坦克可以采取许多不同的形状。一个团队的排名有多差取决于激烈的“竞争”,他们起草的有多好,以及他们有多投入。作为开始,我做了一个决定,一个坦克团队已经做出了一个明显的决定来重建和暂时放弃竞争力(即,他们不只是坏)。由于没有一个场景可以涵盖一切,我决定创建三个,模仿 NBA 最近的三次重建。他们在这里:
费城 76 人队:艰难的重建场景
76 人队的重建始于 2013-2014 赛季,交易走了大牌球员朱·霍勒迪。76 人队以他们极端的承诺著称,他们摧毁了所有可能有助于获胜的资产。在他们的最低点,他们是 NBA 历史上第二差的球队,因此这是一次艰难的重建。在重建开始的四个赛季后,76 人队自重建开始以来首次进入季后赛,就这一分析而言,这标志着重建的结束。重建期间的 76 人播种如下:

胜率 : 23%
明尼苏达森林狼队:温和的重建方案
森林狼的重建始于 2014-2015 赛季,交易走了特许球员凯文·乐福。然而,他们在安德鲁·威金斯保留了交易中的第一个整体选择,这有助于使反弹更快。在他们再次进入季后赛之前,坦克可以持续三个赛季。在此期间,他们的播种如下:

胜率 : 31%
犹他爵士:软重建方案
犹他爵士在失去阿尔·杰佛森和保罗·米尔萨普后开始了他们的重建。然而,第四年的戈登·海沃德帮助爵士在重建期间比其他两个场景更受人尊敬。2013–2014 赛季也是他们的第一个赛季重建,持续了三个赛季才再次进入季后赛。

胜率 : 42%
第二部分:入选名人堂球员的几率有多大?
为了确定这一点,我们需要考虑两个因素:
- 选秀抽签在每个种子位置有可能产生什么样的选秀权?
- 每个选秀位置选中一名 HoF 球员的可能性有多大?
在这里,我们将解决第一个问题,因为它很容易。从 2019 年 NBA 选秀开始,新的彩票赔率如下:

现在我们有了从每个种子中获得每个选秀顺位的几率,我们需要从每个选秀位置中选出名人堂成员的几率。为此,我使用了篮球参考的草稿搜索器来分析一些数据。我分析了从 1950 年到 1995 年每个位置的选秀选择(1995 年后包括一些现役或最近退役的球员,他们还没有机会进入 HoF)。每个位置入选名人堂的几率如下:

有一些不寻常的差异,根据这一点,你宁愿在第八名而不是第四名选秀。这是小样本的不幸后果。
为了将这两个部分结合起来,我对每个种子收到每个选秀选秀权的可能性和在那个位置为每个种子选出名人堂球员的可能性进行了加权(由于时间限制,我只完成了三个场景所需的种子)。
其结果如下:

现在,使用这些信息,我们可以很容易地将其与每个场景的播种结果进行交叉引用,以确定重建产生名人堂球员的可能性。这些结果陈述如下:

所以我们现在已经成功地回答了这个分析的第二部分。这里需要注意的是:更长的坦克时期可能并不意味着更高的可能性起草名人堂人才。相反,这可能表明该团队的起草工作一直很差,这就是他们未能改进的原因。然而,对此进行控制将会非常困难。
第三部分:和那个球员一起拿 NBA 总冠军的可能性有多大?
这部分要复杂得多。这不是一门精确的科学(我将在结论中详述),而且非常耗时。为了衡量这一点,我回到了篮球参考的选秀搜索器,查看了自 1950 年以来每一位入选名人堂的球员。有 122 个条目。出于几个原因,我删除了 18 个条目;有的是双打(联盟早期历史上偶尔有球员被选秀两次,两次选秀都算)。其他人是作为教练或管理人员进入名人堂的球员,有些人主要是 ABA 球员。剩下 104 个条目可以使用。
一旦我有了 104 名球员,我手动检查每一个人,并确定其中 60 人被选中的球队在他们到达那里的前一年取得了失败的记录。其他 44 人在他们到达之前就已经被 50%或更高的队伍选中了。在这个例子中,为了简单起见,我们将“失去”视为等同于重建/坦克。在这 60 名球员中,有 23 名在职业生涯中从未获得过 NBA 总冠军。这使得 37 名名人堂球员被选入输掉 NBA 总冠军的球队。然而,还有 19 名球员在职业生涯后期才在其他球队赢得冠军。这留下了 18 名名人堂成员的最终样本,他们来自一支失败的球队,并在他们第一次在那里工作时赢得了 NBA 总冠军。因此,如果一支失败的球队入选名人堂,历史上他们有 30%的机会赢得 NBA 总冠军。
然而,这里有一个重要的调整。随着新奥尔良鹈鹕队的加入,NBA 在 2004 年才成为一个有 30 支球队的联盟。上面提到的 18 名球员没有一个在 2004 年或之后赢得过 NBA 总冠军。这意味着所有的球员都是在挑战性比现在小的时候赢得冠军的。
为了控制这一点,我应用了一个调整因子来说明球员赢得冠军的时间。调整系数的计算方法很简单,取当时 NBA 的球队数,除以 30。例如,一名在 15 支球队的联赛中赢得冠军的球员将获得 0.5 的调整系数,相当于今天难度的 50%。如果一个球员在那支球队赢得了多个冠军,我会用最难的一个。结果如下:

新的调整后的总得分为 11.433/60,即赢得 NBA 总冠军的 19.1%。然而,我想更进一步。我想确定赢得冠军的机会是否会因为车队的糟糕程度而改变。
为此,我根据每个场景创建了三个类别。我取了每个场景在重建过程中的平均胜率,并将其应用于+/- 5%,以获得 10%的类别范围。所以分类结果如下:
- 努力,23%获胜%:18–28%
- 中等,31%获胜%:26–36%
- 软,42 胜%:37–47%
经过数据整理,我得到了以下结果:

据此,一个中等糟糕的团队比一个非常糟糕的团队或更平庸的团队更有可能成功。这可能是有意义的,也可能是小样本的结果。遗憾的是,这仅仅是我们能处理的最好的数据。
局限性
我想我会做一个简短的部分,专门讨论这种分析中存在的无限局限性。基本上,每次重建都是不同的,我无法解释这一点。一些重建设法得到许多额外的选秀权(凯尔特人),另一些设法失去他们的(网队)。一些重建设法交易现有 NBA 超级明星的选秀权和前景,这在这里不会被捕获。一些重建有很长的坦克时期,因为他们只是在建设好的篮球队方面很糟糕(自从德怀特离开后,魔术队一直在“重建”)。基本上,有太多的移动部分来解释这一切。我已经尽我所能了。
结论
为了把这些联系起来,我必须把这两个因素结合起来,以便为每种情况得出一个最终的可能性。我已经把最终的结果放在了下表中:

这一切有多大意义?我不知道。有许多因素仍未得到解释。但希望这至少是一种乐趣或有趣的阅读,如果没有别的。
使用 Vue.js 的利弊是什么

Vue.js 是最先进的 web 应用程序开发中一个众所周知的术语。它是目前最新兴的前端技术之一,经常与 Angular 和 React.js 联系在一起被提及,基本上 Vue.js 类似于 React.js,是一个 JavaScript 库。
Vue.js 和 React.js 一样,都是开源库,但和 React.js 和 Angular 不同,它支持紧凑的文件大小。实际上,Vue.js 是 Angular 和 React.js 的组合,因为它使用了指令和组件等概念来控制和渲染用户界面。值得一提的是,Vue.js 提供了控制服务器已经呈现的 HTML 的能力,而 React.js 则不是这样。
vue . js 的优势
使用 Vue.js 有一定的优势,这应该会鼓励开发者在他们的项目中使用它。例如,Vue.js 在许多方面类似于 Angular 和 React,与其他框架相比,它继续受到越来越多的欢迎。该框架只有 20 千字节大小,这使得开发者更容易即时下载文件。事实上,在加载时间和使用方面, Vue.js 轻松击败了其他框架。
简约
开发 Vue.js 背后的基本思想是用尽可能少的努力获得好的结果,这样用户就可以只用几行代码就能编码。Vue.js 也非常适合处理组件,因为它需要相对较少的开销,因为单文件组件可以在一个文件中存储所有代码,如 HTML、CSS 和 JavaScript。
整合
开发者可以将 Vue.js 集成到 React 等其他框架中,使他们能够根据各自的需求定制项目。由于易于集成,Vue.js 正成为 web 开发的热门选择,因为它可以用于各种现有的 web 应用程序。由于后端是基于 JavaScript 构建的,开发人员也可以使用该技术来试验许多其他 JavaScript 应用程序。类似地,组件的多样性允许开发人员创建不同类型的 web 应用程序并改变现有的框架。除了 JavaScript,它还可以处理 HTML 块,因为 MVVM 架构允许双向通信。
人性化
据各路专家介绍,Vue.js 不需要陡峭的学习曲线,对于新程序员来说是有利的。关于学习过程,有趣的是,Vue.js 只要求程序员了解 JavaScript、HTML 和 CSS 的基础知识,这与 Angular 或 React 不同,后者需要额外的编程语言来进行高级编码。另外,Vue.js 可以和常用编辑器一起使用。火狐和 Chrome 下甚至还有浏览器插件,更容易快速上手。
定制
对于开发者来说,Vue.js 是一个很好的工具,因为它的所有功能都很容易访问。为了便于使用,开发人员可以根据自己的喜好轻松命名该函数。每个部分都可以有独立的功能,这使得根据个人需求定制应用程序变得更加容易。
很少限制
Vue.js 的设计提供了更少的限制和更大的灵活性来完成项目。核心库侧重于“视图”部分;它与模块化方法相结合,并使用各种库,允许程序员以不同的方式解决问题。尽管 Vue.js 社区仍在发展,但总有人渴望提供新的想法。
好的文档
最重要的事情之一是好的文档。它展示了框架提供的所有选项和相应的最佳实践示例。Vue.js 上的文档不断得到改进和更新。它还包含一个简单的介绍性指南和一个非常好的 API 概述。也许,这是这种语言最详细的文档之一。
支持
对平台的支持令人印象深刻。例如,在 2015 年,官方平台上的每一个查询都得到了回答。同样,在 GitHub 上解决了 1400 多个问题,平均时间不到 13 小时。2018 年,这种支持继续给人留下深刻印象,因为每个问题都得到了认真的回答。事实上,6,200 多个问题得到了解决,平均解决时间仅为 6 小时。为了支持社区,有一致的更新信息发布周期。此外,在开发人员的后端支持下,社区继续发展壮大。
vue . js 的缺点
尽管 Vue.js 有很多优点,但肯定有一些缺点需要解决。例如,自 2015 年第一版发布以来,稳定性一直是个问题。这意味着该平台非常适合个人项目,但对于更大的项目应该谨慎使用,因为稳定性可能会导致财务损失。
缺乏对大型项目的支持
Vue.js 是一种相对较新的语言,它并不被活跃的程序员的大型社区所支持。同样,Vue.js 的开发团队也很小,这意味着该平台需要一些时间来获得公司的支持。截至 2018 年,框架的开发与企业利益无关;因此,对现有框架的任何更改主要取决于社区成员的反馈。
在 JavaScript 世界中,采用某种技术总是被认为是对平台稳定性的赌注。当部署大型项目时,更大的灵活性和大量的选项也会成为一个问题,因为不同开发人员的参与可能很难处理。
未来的竞争者
一个小的开发团队也意味着缺少积极的研究可能会为另一个新的框架提供一个机会来引起社区的兴趣。在这种情况下,框架的开发可能会变慢甚至停滞。这种威胁是有根据的,因为像谷歌和脸书这样的大公司都在积极参与类似概念的开发。
语言障碍
一些专家也认为语言障碍是一个潜在的问题。有趣的是,大部分代码都是用中文编写的,对于非母语人士来说,这通常会使事情变得复杂。因此,与其他人相比,中国的开发社区似乎得到了很多支持。
缺少插件
由于 Vue.js 仍处于开发阶段,缺少对重要插件的支持。这意味着开发人员需要切换到其他语言来寻求帮助。例如,开发人员在使用谷歌地图时求助于普通的 JavaScript 并不罕见。同样,Vue.js 的快速发展意味着互联网上的一些重要信息可能已经过时,迫使开发人员转向文档。
总的来说,Vue.js 是一个开发用户界面的强大框架。它的小尺寸和定制特性使它成为开发人员寻找用户友好的 web 应用程序框架的可靠选择。Vue.js 的大部分缺点可以很容易地纠正,让开发人员保持乐观,这个框架将在未来继续改进。
2019 年成为一名数据科学家需要具备哪些技能?
“数据科学家”是美国最好的工作,这对科技和相关行业的任何人来说都不足为奇。毕竟,这是《哈佛商业评论》和《T2 玻璃门》连续四年(T5)报道的内容。即使我们把 117,000 美元的基本工资从等式中剔除,这个职位在所有其他方面仍然很有吸引力。例如,目前转向使用机器学习来快速跟踪业务增长,这确保了跨行业对能够处理数据和新兴技术的熟练专业人员的稳定需求。量化需求:根据 LinkedIn 的劳动力报告,151,717 名数据科学家将受到热烈欢迎。让我们不要忘记在职满意度——大多数数据科学家实际上是快乐的(他们的话,不是我们的)。
但是本文并不是要概述数据科学是一个明智的职业决策。
这份报告的目的是让“数据科学家”这个集体实体了解数字运算算法,并理解是什么造就了数据科学家。
对数据科学家进行逆向工程需要分析他们的技能组合、工作经历、工作行业、学术背景和正式资格。了解这一点后,有抱负的数据科学家可以采取明智的专业措施来获得这一头衔。
当我们 365 数据科学在 2018 年第一次试图拆解数据科学家时,我们揭示了丰富的专业概况。自我们最初的研究以来已经过去了 12 个月,重复的研究表明,该领域正在发展,典型的专业人士也在发展。
关于方法论的一点注记
集体“数据科学家”档案是由一项对 1,001 名目前受雇为数据科学家的专业人员的研究提供的。这些数据是根据一系列先决条件从这些数据参与者的 LinkedIn 个人资料中收集的。40%的样本目前受雇于财富 500 强公司,而其余的在其他地方工作;此外,引入了位置配额以确保有限的偏差:美国(40%)、英国(30%)、印度(15%)和其他国家(15%)。这一选择是基于对数据科学最受欢迎的国家的初步研究,这些国家的信息是公开的。
2018 年的典型数据科学家和 2019 年有关联吗?
一眼看去,绝对!这个领域仍然由男性(69%)主导,他们可以用至少两种语言进行对话(不要与编程语言混淆,如果包括编程语言,这一数字至少会增加一倍)。他们已经工作了 8 年,但其中只有 2.3 年是数据科学家。他们可以自豪地获得第二轮学位(74%的人拥有硕士或博士学位),至少用 Python 或 R (73%)编写“Hello World”以外的程序(通常两者都有)。

Summary
幸运的是,对于我们这些女性或尚未获得博士学位的人来说,数据的分割讲述了一个更丰富、更真实的故事。
“数据科学家”是指哲学博士吗?
正如这个领域并非女性固若金汤,拥有博士学位也是这个职位的先决条件。事实上,不到三分之一的数据科学家拥有博士学位(28%)。这一数字与去年的 27%相当,这似乎意味着行业不会有意引入一个高不可攀的学术实力。

Highest level of education received
另一方面,如果硕士学位是有抱负的数据科学家愿意投入时间和精力的事情,它似乎是学术资格的黄金标准(46%的样本持有硕士学位)。
然而,有一个趋势似乎正在形成,那就是“数据科学家”职位上拥有第二周期学位的专业人士的比例将会下降,而只有学士学位的数据科学家将会进入该领域。数据证实了这一猜测,因为与去年相比,只有学士学位的数据科学家数量增加了 4%(2019 年为 19%,2018 年为 15%)。
最后,一些法学院毕业生(千分之一)成为数据科学家的事实给我们留下了一些回旋的余地,当谈到有抱负的数据科学家可以获得的学位水平时。
教育水平和工作经验
从大学,到实习,再到最后的归宿一个‘数据科学家’。这是我们团队中 8%的数据科学家的故事。对这些专业人士来说,在美国找到最好的工作需要一个实习职位和一个硕士学位(71%)或学士学位(18%)。

Level of education and previous work experience
对于其他人来说,这条路从未偏离离开学术界(9%)。正如所料,拥有硕士学位的数据科学家(47%)和拥有博士学位的数据科学家(44%)之间的比例相当,其他教育水平几乎不存在。
那么,除了实习或直接从学术界来,还有其他方法打开数据科学职业的大门吗?
两男一女走进一个房间:谁将是下一个数据科学家!
- 学术研究者
- 信息技术专家
- 实习生
根据我们的数据,所有这些都是进入数据科学的门户职位,成功率相当:分别为 9%、9%和 8%。虽然这可能不是我们的一些读者所希望的,但这些数字开始描绘出一个有许多切入点的职业的画面。
还要考虑数据分析师职位(13%)、顾问(6%),当然还有当前数据科学家可能从事的其他工作(13%)(包括不少于 15 个职位和头衔)。

Last position before “Data Scientist”
如果你倾向于数学,我们希望你是,因为数据科学意味着一些分析能力,你会注意到这里有很大一部分以前的工作职位分析丢失了。事实上,我们团队中目前担任数据科学家的人中,有 42%已经在之前的职位上担任过数据科学家。这是一个悖论——获得“数据科学家”头衔的最佳方式是已经拥有它。
我们让读者进一步猜测数据科学家是否喜欢跳槽(他们也知道自己的价值!),或者说自报数据并不总是最好的数据。
我应该学习计算机科学和数学,还是可以学习植物学,然后继续成为一名数据科学家?
好吧。要成为一名医生,你需要去医学院;成为律师——法学院;警官——一个特殊的学院,等等。在撰写本文时,数据科学学校很少,如果有的话,那么数据科学家研究什么呢?
事实上,我们组中有相当一部分人学习了数据科学和分析,但在我们继续之前需要注意一下符号。由于大量独特的学位可用于学术研究,我们将它们分为七个学术研究领域。
- 经济学和社会科学,包括经济学、金融、商业研究、政治学、心理学、哲学、历史、市场营销和管理
- 自然科学,包括物理、化学和生物
- 统计学和数学,包括统计学和以数学为中心的学位
- 计算机科学,不包括机器学习
- 工程
- 数据科学和分析,包括机器学习
- 其他,在那里你可以找到艺术和设计,大气科学,和…其他
也就是说,在我们的研究中,12%的数据科学家专业人士学习数据科学和分析。虽然这个领域本身很新,但越来越多的大学提供专业学位,为你在数据科学领域的未来做准备。鉴于典型的数据科学家档案揭示的受教育水平,大多数数据科学家都是硕士水平也就不足为奇了。
然而,数据科学和分析并不是我们这个群体中最受欢迎的学位。
取而代之的是计算机科学(22%)。数据科学家的工具箱中有很大一部分是编程语言和数字处理工具,由于缺乏更广泛的替代品,这个学位是一个自然的选择。
令人惊讶的是,今年研究的亚军学位不是统计学和数学(以 16%的普及率稳居第三),而是经济学和社会科学(21%)。尽管如此,工程毕业生仍占该群体的 9%,这支持了一个观点,即最能让你为处理和处理大数据做好准备的三大学位是计算机科学、统计和数学以及工程(合起来占该群体的 50%)。

Area of academic studies
另一方面,样本中经济学和社会科学毕业生的大量存在(21%)对于不太倾向于数学的有抱负的数据科学家来说可能是个好消息!几乎和仅仅从计算机科学领域进入这个领域的人一样多。还有 11%来自自然科学背景。考虑到数据科学通常是用统计学来编程的(或者用编程来编程的统计学),这个结果相当有趣。
常春藤联盟还是‘拜拜,数据科学…’?
数据科学绝对不是常春藤联盟毕业生的私人竞技场。虽然我们样本中有三分之一的专业人士毕业于排名前 50 的大学(根据 2019 年泰晤士报高等教育世界大学排名),但第二大群体是由泰晤士报甚至没有排名的大学毕业生组成的(23%)。大家都松了一口气——这个领域没有对那些接受世界级高等教育机会有限的专业人士敞开大门。

Rank of university attended
数据表明,数据科学是一个仅凭技能和优点就能获得成功的领域,这并不完全令人震惊。毕竟,分析和处理数据是实用的动手技能。我们中最热情的人可能会通过实践、好奇心和足智多谋而变得与众不同。
关于排名中的其余集群,它们的人口相对均等。但是,读者应该注意到,群集的大小不同(例如,1–50 对 301–500 或 501–1000)。尽管如此,这对有抱负的数据科学家来说都是好消息:这个领域不仅有来自各种背景和不同学术水平的人,而且也欢迎来自《泰晤士报》排名中任何大学的专业人士。
自我准备和在线课程
众所周知,数据科学家来自许多不同的背景。数据科学与许多其他学科不同,它拥有强大的教育基础设施。这意味着许多想在这个领域获得成功的人需要承担起自己学习技能的责任。
但是我们如何准确地衡量是谁干的呢?
最可靠的方法是看他们个人资料上贴的网上证书。有太多的在线平台提供优质课程,价格堪比浪漫的晚餐约会,打造一套量身定制的技能从未如此容易(或便宜)。
我们发现,我们收集的资料中有 43%发布了至少一门在线课程,平均有 3 个证书。

Certifications and accomplishments
当然,一些数据科学家可能已经通过不同的方式自学了。而其他人甚至可能不张贴他们收到的所有或任何证书。如果他们不相信一旦他们获得了更多的经验,他们会相关,为什么他们会浪费时间或空间在他们的电子简历上?考虑到收集数据的平台,这一点值得记住。
那么,我们能用这些信息做什么呢?
首先,我们可以看看参加(或至少发布)在线课程的人和没有参加的人的背景是否有任何关联。学历水平是一个因素吗?可以毫不夸张地假设,来自排名较低的大学的人会选择更多的在线课程。但也许来自排名更高的大学的学生更专注于他们的教育,所以,让我们不要假设,而是看数据。
在线课程和大学排名
事实上,当比较这两个因素时,有一个非常有趣的结果。
在我们回顾之前,请记住大学排名集群在规模上确实有所不同,包括研究参与者和大学排名。我们还想指出,1000+集群仅包含 7 个参与者,这是不够的数据。所以,我们不会把它们作为有效结果来讨论。
也就是说,我们从剩余的数据中得到了一些非常有趣的见解。

Online courses and university ranking
第一个有趣的结果是,排名前 500 的四所大学的结果略有不同。这并不令人意外,但它确实显示了与去年研究结果的明显差异,去年排名前 100 位的大学毕业生发布的在线课程明显减少。
也许这说明自我准备是有价值的,甚至对名牌大学的学生来说也是如此。
下一个有趣的结果出现在 501–1000 排名聚类中,它显示了证书数量的急剧增加。同样,这不会被认为是令人震惊的:我们愿意推测,你去的大学排名越低,你就越想通过大量的在线证书脱颖而出。令人惊讶并对我们假设的有效性产生怀疑的是下一个集群(未排名)的行为。在那里,证书的数量下降到与前 500 名相当的百分比。*
虽然很难知道这是为什么,但不难看出自我准备的重要性,并且考虑到自去年以来这一数字一直在上升,特别是在顶级大学,有抱负的数据科学家也意识到了这一点。
获得网上证书是一回事,但是学习哪些技能最有益呢?用人单位找哪些?当然,我们已经有数据来发现这一点。
就业国家和编程技能
由于实施就业配额的国家不同,我们不仅可以查看总量,还可以进行可靠的国家间比较。我们将样本分为四个地区:美国、英国、印度和其他地区,样本权重与去年的研究相同(见上文方法)。
在我们进入地理细分之前,我们需要一些最好由汇总数据提供的背景信息。

The Data Scientist coding toolbox
数据科学社区中最流行的编程语言是 Python,其次是 R。值得注意的是,与去年相比,R 的受欢迎程度下降了 10%,鉴于 Python 的多功能性,这并不完全令人惊讶。
但是让我们进一步细分。
从区域划分来看,结果与总量相差不远。

Country of employment and coding language
为了简单起见,我们研究了 4 种最常用的语言:Python、R、SQL 和 MATLAB。与去年版本的第一个最突出的不同是,Java 已经被 MATLAB 取代,成为第四大最常用的编程语言。领先的三人组在参赛者方面保持不变,但在组成方面没有变化。几年来, Python 一直在蚕食 R 的市场。
事实上,这也是我们在这里看到的。Python 无疑是世界上最常用的数据科学语言,只有美国和印度使用它。
值得注意的是,关系数据库的使用在全球范围内似乎是持平的,SQL 在任何地方都被同等地使用。
随着印度最近成为外包天堂,也许有必要看看另一个细分领域——工业。
就业和工业国家
我们将样本分为 4 大类行业:工业、医疗保健、金融和科技。医疗保健是整体中微不足道的一部分,因此关注其余部分是有意义的。

Industries hiring Data Scientists
事实上,数据并没有显示出很大的跨国差异(见下文),除了英国的数据科学仍然是“金融”多于“技术”,而印度的数据科学比其他国家的数据科学“工业”程度低。虽然后者并不令人惊讶,但值得注意的是,在我们之前的研究中,技术部门拥有 70%的数据科学家人才。在过去的一年里,这似乎发生了巨大的变化。
最后,与金融相关的数据科学在印度和世界其他地方发展迅猛,赶上了其他行业。

Country of employment and industry
对于美国的数据科学家来说,我们可以说技术和产业集群正在获得大部分人才。
就业国家和学位
对我们来说,最有趣的细分之一是学位细分。潜意识里,我们认为博士将主宰这个领域。去年的数据显示,只有三分之一的样本是“哲学博士”。在超过一半的情况下,仅仅一个硕士学位就足够了。
今年,我们看不到什么不同。对于英国、印度和其他国家,我们没有变化。本科就够了,硕士更好。
然而,最引人注目的是美国博士人数的增加。再加上科技行业在美国一直占据更大份额的事实,你就会拥有它——受过高等教育、以技术为导向的数据科学家可能比以往任何时候都更努力地工作,以提供我们都期待的未来数据科学。

Country of employment and academic degree
如果你还没有拿到博士学位,并且在我们的名单上,那么你很有可能来自印度。但是,当涉及到实际工作经验时,这又是怎么回事呢?
就业国家和工作经历
哪个地方的职业发展最快?
要获得这种洞察力,有必要看看数据“奇才”在实现成为数据科学家的梦想之前的经历。

Country of employment and work experience
在 2018 年版中,我们看到了国家之间的巨大差距。美国超过一半的数据科学家拥有 5 年以上的经验。
今年?
一点也不像。
他们可能已经辞掉工作,或者成为了经理。毕竟,作为一名数据科学家也是令人沮丧的。但是“年轻人”正在让路。在印度和英国更是如此。似乎有更多的职位空缺,即使没有工作经验,你也有 20-30%的机会得到那个职位!
公司规模和编程语言

Company size and programming language
虽然 Python 仍然在非 F500 公司中得到更广泛的应用,但在几乎所有其他类别中,F500 都在与非 F500 公司携手前进。对于任何喜欢当前技术(R 和 Python)的数据科学新手来说,这是一个好消息。与去年的成绩相比,我们已经迎头赶上了很多…
公司规模和大学排名
令人惊讶的是,大学排名对数据科学家的雇主没有影响。

Company size and university rank
引用我们去年的话:‘到处都需要数据科学家。从 500 英镑到一家科技初创企业!”**
这也加强了我们的信念,即个人技能和自我准备是成为一名成功的数据科学家的更重要的因素,的雇主知道这一点。
结论
希望这篇文章不会让你怀疑数据科学家这个职业是否是你可以实际从事的职业。相反,我们希望能够伸出援助之手。我们从去年和今年的研究中提取的主要信息之一是,如果你拥有成为数据科学家的技能基础,你 可以 成为数据科学家。看到数据科学专业在未来 2-5 年内如何变化将是有趣的,但现在,一个通用的数据科学家档案似乎正在形成:一个跨行业和跨地区的独特编程语言工具箱;最好是硕士学位,或学士学位和实践能力证明;和自信的不断学习的态度是这个领域的主流。
最后一点:我们的目标是随着数据科学家的发展,创建一个完整而有用的数据科学家档案。如果任何人对我们可以做得更好或更仔细检查的事情有建议或意见、反馈和想法,请让我们知道!开放式对话对于帮助有抱负的数据科学家做出明智的职业决策至关重要。
祝您的数据科学之旅好运,感谢您的阅读!
附:这是我们去年的研究。也许你能发现我们忽略的趋势?
原载于 2019 年 1 月 30 日 365datascience.com。**
人工智能产品经理——你在优化什么?
15 个月前,我加入了一家初创公司,负责产品管理。在不涉及太多细节的情况下,我们为 B2B 公司的客户成功团队开发了一个基于人工智能的软件解决方案。在这篇文章中,我将讨论用户体验和人工智能(AI)之间的关系,以及对产品经理来说有什么意义。

Photo by Rock’n Roll Monkey on Unsplash
产品经理的人工智能是什么?
产品经理需要了解他/她的客户。她需要了解他们的工作环境、他们的使命、他们想要实现的目标、他们面临的挑战,然后设计一个有针对性的解决方案来最好地满足这些需求。他们需要和一群有才华的人一起,将这些想法变成一个连贯且易于使用的产品。
人工智能现在是技术的中心已经有几年了,而且预计会停留更长时间。人工智能不再只是一个时髦的词,它已经有了现实世界的应用程序,这些应用程序在它们的类别中进行了一场革命:Siri、Alexa、网飞推荐引擎、谷歌照片等等。
产品必须解决现实世界的问题。技术和实现细节应该服务于产品,并且对可用性有最小的影响(至少在软件中)。人工智能是一种解决问题的实现方法,但它的预测性对用户体验和可用性有重大影响。
当一家公司为任何市场/类别设计基于人工智能的解决方案时,它总是会问自己——我们优化产品是为了什么?我们是在优化准确性、阳性预测值还是命中率?或者换句话说——精确还是回忆?回答这些问题至关重要,因为它会影响产品 UX 及其价值主张。
作为一家开发基于人工智能的解决方案的初创公司的产品经理,我每天都在思考这个问题,并根据决策来制定我们的解决方案。
你能回忆起它们的意思和区别吗?
我想回忆和精确听起来很熟悉。你甚至知道它们的意思,但已经忘记了。精确度和召回率是统计术语,用于衡量算法返回结果的相关性。这些术语有官方的学术解释,但是我想用一个例子来回顾一下。
下雨了吗,伙计?
假设我有一台机器可以预测明天是否会下雨。每天,如果明天会下雨,机器会返回“是”,如果不会下雨,机器会返回“否”。我们连续运行机器 100 天,得到了以下结果:
- 机器预测会有 10 次降雨
- 剩下的 90 天,据说天气会很干燥(没有雨)
现在我们想将预测与实际天气进行比较:
- 十次天气预报说要下雨,结果都下雨了。预测非常准确。有多精确?10 次预测中有 10 次下雨→ 10/10。我们有 100%的精确度。哇!这是否意味着我拥有了终极降雨预测机器?不确定…让我们检查一下其他 90 天。
- 当我们计算雨天的总数时,我们发现实际上总共有 20 个雨天。这是什么意思?机器回忆(正确预测)了 20 个雨天中的 10 个雨天→ 10/20 → 50%。所以它预测了 50%的雨天,但也错过了其中的 50%。
现在,你觉得我的机器还厉害吗?

Photo by Geetanjal Khanna on Unsplash
让我们把它发挥到极致,我的机器刚刚坏了,每天它都说明天会下雨。收到的结果:
- 将要下雨——100 天
- 不会下雨— 0 天
现在让我们再次评估结果:
- 机器现在没有那么精确了,因为实际上只下了它预测的总共 100 次雨中的 20 次→ 20/100 → 20%
- 但是从实际的 20 个雨天来看,机器正面预测了所有的 20 天→ 20/20 → 100%回忆
现在,假设您可以去商店购买上述机器中的一台,您更喜欢哪台机器?更精确的一个,如果它说要下雨,你可以肯定,但会错过许多雨天,或者机器不会错过任何雨天,但其他许多天都是错误的?
答案并不那么直截了当。也许对于降雨预测来说是这样,但对于许多其他基于人工智能的应用来说,真的不是。
你糊涂了吗?
没关系。正是出于这个原因,我们创建了混淆矩阵,来帮助您对事物进行分类,并计算精确度和召回率:

Confusion Matrix
精度= TP / (TP+FP)
召回= TP / (TP+FN)
让我们用天气预报机器再检查一遍:

Weather Prediction — Machine A
精度= 10/(10+0) = 10/10 = 100%
召回率= 10/(10+10) = 10/20 = 50%

Weather Prediction — Machine B
精度= 20/(20+80) = 20/100 = 20%
召回率= 20/(20+0) = 20/20 = 100%
那么,你在优化什么呢?
现在当我们真正理解了其中的区别,我们应该如何优化我们的模型和产品呢?精准还是召回?大多数时候,我们不得不选择一个而不是另一个,同时拥有高精度和召回率几乎是不可能的。
决定优化什么是基于许多因素:心理,财务,犯错的成本,错过的成本,声誉,时间等等。
让我们来看三个真实场景并进行讨论:
- 癌症检测 —作为一名患者,你愿意被检测出患有癌症,开始治疗,然后发现自己并未患病(假阳性)吗?或者发现自己得了癌症时已经来不及治疗了(假阴性)?
如果你是健康保险公司,你的答案会改变吗?你能资助所有不必要的治疗吗?你会提高保险费率以确保不会错过任何人吗?作为一名医生,你会拿自己的名誉冒险去错过检查吗?
至少作为患者,没有人愿意错过被检测。因此,当构建检测癌症的产品时,优化召回(避免假阴性)将更有意义。 - 网飞推荐——作为用户,你更希望得到与你高度相关的推荐,而不是那些可能受欢迎但不适合你的一般东西。所以在这种情况下,产品是优化精度(避免误报)。
- 机场安检——作为一名乘客,你愿意排着长长的安检队伍等待,这样就不会有危险意外通过安检了吗?或者你更愿意冒着枪支可能被走私到飞机上的风险快速通过这些检查?
监管可能会说不要错过任何危险。从商业角度来看——安全是一种负担,它要花很多钱,让人烦恼,而且在护照检查之后,留给人们花钱的时间更少了。
我们可以讨论几十个例子,并试图了解产品试图优化什么,以及在与它交互时,它如何影响整体用户体验。
客户流失预测
我们开发了一个基于人工智能的产品,用于预测 B2B 公司的客户流失。我们使客户成功团队能够将他们的努力集中在真正重要的客户身上,并交付更好的结果。
优化精度意味着该产品将精确定位有流失风险的目标客户名单,并确保没有人误入其中。朝这个方向发展的不利之处是会错过一些会流失的客户端,而这些客户端没有被检测到。
缓解这种情况的一个想法是将列表分成几页,第一页包括最相关的客户,如果用户想了解更多,他们可以进入下一页。谷歌搜索结果提供了这样一种体验——第一页包含最相关的结果。如果你想探索更多,你也可以查看其他页面(真的有人这样做吗?!)
优化召回意味着产品不那么敏感,会产生更长的有流失风险的客户名单,并确保我们不会遗漏任何人。不利的一面是,该列表还包含误报,这些客户没有流失的风险。缓解这种情况的一个办法是增加其他客户特征的列表,这些特征可以提供更多的风险提示(例如优先级)。
作为产品经理,我需要了解我们的客户——他们是更能容忍假阳性(没有风险的客户)还是假阴性(没有检测到所有有流失风险的客户)?
他们期望从产品中获得什么样的体验?他们有足够的资源来处理更长的列表吗?
你怎么想呢?你会优化什么?你还有其他可以分享的例子吗?
感谢阅读,有任何问题可以在这里联系我或者通过我的 LinkedIn
什么是零知识证明?

除非你不在网上生活,否则你使用的应用程序会捕获并可能转售你的个人数据(比如你的联系信息、兴趣和偏好)。即使你不使用应用程序,你的网络提供商和手机操作系统也会收集你的数据。公司通过两种方式从这些数据中受益:利用这些数据优化他们的服务,以更好地吸引你,并将其转售给其他公司。
我们如何让人重新掌控他们的数据?问题是有些服务确实需要你的数据来为你服务。例如,不与保险公司共享健康信息就很难获得健康保险,或者不披露信用评分就很难获得贷款。
如果有一种方法可以显示您在所有指标上都处于健康范围内,而无需分享您的实际健康信息,或者证明您的信用评分足够好,而无需披露实际信用评分,会怎么样?
零知识证明
零知识证明(zkp)允许在不泄露数据的情况下验证数据。因此,它们有可能彻底改变数据收集、使用和处理的方式。
每个交易都有一个“验证者”和一个“证明者”。在使用 ZKPs 的事务中,证明者试图向验证者证明某件事,而不告诉验证者关于这件事的任何其他事情。
通过提供最终的输出,证明者证明他们能够在不暴露输入或计算过程的情况下计算一些东西。同时,验证者只知道输出。
一个真正的 ZKP 需要证明三个标准:
1.完整性:它应该让验证者相信证明者知道他们所说的
2.可靠性:如果信息是假的,它不能使验证者相信证明者的信息是真实的
3.零知识度:它不应该向验证者透露任何其他信息
例子:沃尔多在哪里
在去年的一次演讲中,Elad Verbin 用一个例子“Waldo 在哪里”很好地解释了零知识证明。
在“沃尔多在哪里”儿童读物中,读者被要求在一群做着各种事情的插图人群中找到沃尔多(戴着眼镜、红白相间的毛衣、蓝色牛仔裤和无沿帽)。


Waldo (left), and a Where’s Waldo puzzle (right). Sources: Zazzle & TechSpot.
假设我(作者)是证明者,你(读者)是验证者。我声称有一种算法可以很容易地找到沃尔多,但我只会让你用它来换取一笔费用。你想要算法,但不想在我证明它有效之前付钱。
所以,像很多交易一样,我们想要协作,但是我们并不完全信任对方。
为了证明我有一个可行的算法,我在地板上放了一个展示一大群人的插图。在请你遮住眼睛后,我用一块大而平的黑纸板(覆盖的面积比插图本身大得多)盖住插图,上面有一个小小的切口。这个微小的切口让我们可以看到瓦尔多,但是他在图像中的位置或者谜题开始和结束的地方。然后,我请你再次闭上眼睛,我把木板从沃尔多在哪里的谜题上拿下来。

Here’s Waldo!
我已经证明了我可以很快在拼图中找到瓦尔多,而不需要告诉你瓦尔多在那张图片中的位置,我是如何这么快找到他的,或者关于那张插图的任何其他事情。这个练习我们重复的次数越多,我就越有可能找到一个有效的快速算法。
交互式和非交互式 ZKPs
zkp 有两种类型:交互式和非交互式。
互动:上面的沃尔多在哪里的例子是一个互动证明,因为我,证明者,执行了一系列的动作来说服你,验证者,某个事实。交互式证明的问题是它们有限的可转让性:为了向其他人或验证者多次证明我找到 Waldo 的能力,我必须重复整个过程。
非交互式:在非交互式证明中,我可以提供一个任何人都可以自己验证的证明。这依赖于验证者为证明者选择一个随机的挑战来解决。密码学家菲亚特和沙米尔发现,使用一个哈希函数来选择挑战(不需要与验证者进行任何交互),可以将一个交互式协议转换成一个非交互式协议。证明者和验证者之间的重复交互变得不必要,因为证明存在于从证明者发送到验证者的单个消息中。
Zk-SNARKs

Zk-SNARK
零知识简洁的非交互式知识论证(Zk-SNARKs,一种非交互式 ZKP)是零知识,因为它们不向验证者揭示任何知识,简洁是因为证明可以被快速验证,非交互式是因为证明者和验证者之间不需要重复交互,知识论证是因为它们提供可靠的证明。
ZKPs 的用例
ZKPs 可用于保护医疗保健、通信、金融和市政技术等领域的数据隐私。
金融领域一个有趣的用例是 ING 的提议,证明一个数字在特定范围内,但不透露该数字。因此,贷款申请人可以证明他们的工资在一定范围内,有资格获得贷款,而不必透露他们工资的确切数额。
到目前为止,zkp 最突出的用途是 Z-Cash ,一种允许私人交易的加密货币。
AdEx 网络允许分散的 ZKP 广告拍卖,在这种拍卖中,用户可以为投放广告的价格出价,而无需向其他用户透露该价格。
结论
零知识证明具有巨大的潜力,通过允许其他人验证数据的某些属性而不暴露数据本身,让人们重新控制他们的数据。这将对金融、医疗保健和其他行业产生巨大的影响,既能实现交易,又能保护数据隐私。
—
关注 Lansaar Research 关于媒体的最新新兴技术和新商业模式。
关于花童,数据分析能告诉我们什么
《创始者泰勒》的碟学分析

《花童》被评论家们誉为泰勒这位创作者最好、最成熟的专辑。他得到了 Pitchfork 的 8.5 分,Pitchfork 称这张专辑“具有变革性、热恋性和穿透力”,并获得了 2018 年格莱美奖最佳说唱专辑类别的提名。
虽然我喜欢泰勒以前的专辑,但我不得不承认花童是我最喜欢的一张。从《花园小屋》梦幻般的吉他和弦,到《无聊》的绝妙结尾和《我没有时间》的野蛮节奏,我认为所有这些元素的并列融合得非常好。
作为一个音乐迷和数据爱好者,我问自己这样一个问题:是什么让花童与泰勒过去的专辑如此不同?已经有无数的博客帖子和视频从音乐的角度回答了这个问题,我想通过分析的方法来补充这个话题。我认为这也是一个正确的时机,因为他明天将发行一张新专辑,谁知道也许会有一个完全不同的风格。
所有的分析都是在 Python 3 上完成的,一旦我可以清理它,我将在 GitHub 上发布我的代码。
获取和清理数据
为了这个项目,我综合了通过 Spotify 和 Genius 获得的数据。非常感谢 这篇 帖子的作者,他展示了一种易于理解和快速实现的调用 Spotify API 的方式,并且节省了我大量的时间。不幸的是,由于私生子不在 Spotify 上,我无法获得关于这张专辑的数据,所以我从分析中排除了它。
对于每首歌曲,Spotify 都提供了大量信息,其中最让我感兴趣的是音频功能。有很多东西可以定义一首歌曲的特征,如声音、能量、舞蹈性、乐器性等等。我强烈推荐你阅读 Spotify 文档,你可以在这里找到,对每个对象有一个精确的定义。Genius 允许我获取每首歌曲的歌词,以便进行文本分析。
Spotify 数据已经是一种易于分析的格式,我只需将它们转换成一个数据框架。不过,歌词需要清理。为了做到这一点,我用 NLTK 库删除了所有的标点符号和停用词,将所有内容都用小写,还删除了泰勒歌词中大量使用的表达,而没有添加太多的含义,如:“耶”、“那”或“嗯”。

Original data from Genius

Cleaned data
现在到了有趣的部分!

分析音频特征
我首先看了一下每个音频特征和每个专辑的含义,以便有一个大致的概念。

在所有可用的功能中,花童显然从一个方面从其他专辑中脱颖而出:声音。这被 Spotify 定义为“一个从 0.0 到 1.0 的关于音轨是否是声学的置信度。1.0 表示音轨是声学的高置信度”。在这个尺度上得分最高的歌曲是《无聊》,其次是《花开的地方》和《妖精》。
如果我们看一下这个特征的分布,我们可以看到,虽然其他专辑是倾斜的,有一个长的右尾巴,但花童的分布更均匀,显示出更大的多样性。
为了进一步测试这个假设,我运行了一个 95%置信水平的单样本 t 检验。这里的零假设是,花童的声音均值与总体均值相似。发现的 p 值是 0.039,这显示了我们可以拒绝零假设的有力证据。然而,由于人口规模相对较小,我们必须小心这一结果。
在我看来,花童在声学方面得分最高,因为使用了:采样原声鼓(无聊,前言),古典风格的弦乐安排(再见,这朵花盛开的地方),干净的电吉他(花园小屋,无聊,闪闪发光)和钢琴(有时会再见)。这些元素当然存在于泰勒之前的作品中,但程度较低。他甚至在 2017 年 12 月举行的微型桌面会议上制作了一些花童歌曲的声学版本。所以,请善待自己,在阅读本文其余部分的同时,听听下面的视频吧!
影评中经常提到的另一个评论与《花童》的整体连贯性有关。事实上,泰勒的作品经常被批评为缺乏统一性,并且如 Pitchfork 所提到的那样“凌乱”。
过去,泰勒的专辑臃肿而凌乱。《卖花男孩》比泰勒的普通专辑短 17 分钟,有更多低调的过渡,更少的无序和混乱。
作曲家和音乐理论家阿诺尔德·勋伯格写道,音乐的连贯性是通过反复使用一个处于歌曲中心的动机,同时保持与其他动机的关系而产生的。不幸的是,Spotify 的数据不允许我们研究歌曲的连贯性。然而,我们可以看看每首歌曲之间每个特征值的变化,从而对连贯性有一个大致的概念。
在计算了每个特征的标准偏差(它表明一组值离平均值有多远)后,我发现花花男孩的节奏和能量值都最低,这意味着每首歌曲的节奏和能量与平均值之间的差异较低。通过绘制一条曲线,我们可以看到,除了最后两首歌曲之外,花童歌曲之间的节奏变化没有其他歌曲那么明显。因此,花童在节奏和能量变化方面似乎更加稳定。
文本数据分析
警告:本部分的某些内容可能不适合所有人。
尽管每首歌的平均字数最低,但《卖花男孩》的歌词丰富度最高,这是由独特字数与总字数之比定义的,紧随其后的是《樱桃炸弹》。
如果我们看看最常用的词,我们可以看到,与泰勒的上一张专辑相反,花童最常用的词(即“时间”,仅在歌曲《无聊》中就使用了 71 次和 50 次)不是脏话。事实上,随着泰勒年龄的增长,他歌词中的脏话比例从《妖精》的 10%下降到《花童》的 4%。
The share of swear words are represented in brown
下面的 wordcloud 很有趣,突出了花童最突出的主题。在这张专辑中,泰勒谈了很多他的感受,他让我们一瞥他每天的白日梦,我们可以通过他最常用的一些词(“感觉”、“厌倦”、“孤独”、“生病”等)来看。).将花童的词云与他之前的一部作品相比,歌词中的鲜明对比显而易见。

Word cloud for Flower Boy

Word cloud for Goblin
最后,我用 NLTK 的 vader 函数根据歌词来判断一首歌的正面或负面。在这个量表中,分数在-1 和 1 之间,1 是最消极的,1 是最积极的。

总的来说,泰勒的歌曲往往有负面的意义,而花童似乎更积极。同样,由于我们人口少,很难说明这个数字的重要性。《卖花男孩》的平均分较高,可能是因为它包含的脏话较少,一些主题也没有他之前的作品那么“黑暗”。
结论
根据我的分析,《花童》与泰勒以往的专辑有以下不同:
- 更加“声学”
- 在每首歌曲之间的节奏和能量变化方面更加连贯和恒定
- 具有更高水平的抒情性、丰富性和一些积极性
这是不是他最好的专辑是一个主观的问题,但我认为这是他迄今为止最独特的专辑,这些都是他成熟的证明。
我希望你喜欢读这篇文章,就像我喜欢做这个小项目一样。我很想得到一些反馈,并在这方面做得更好,所以请不要犹豫,评论和挑战我的发现!
关于美国的枪支法律,机器学习能告诉我们什么?
深入分析
一项 25 年的分析揭示了惊人的见解。

在美国,似乎我们从来没有超过几个星期没有听到另一个大规模枪击事件。随着每一起新事件的发生,要求加强枪支管制法、扩大联邦背景调查以及废除突击步枪的呼声不断高涨。尽管反对派别援引第二修正案权利迅速驳回了每一项上诉,但其他实用性讨论经常出现。具体而言,这些法律的效力经常受到质疑。
我们如何知道哪些法律有效,哪些无效?有没有什么法律可以在不侵犯个人权利和自由的情况下实施?在这里,我们将利用机器学习和人工智能的力量,看看我们能否找到这些问题的答案。
强有力的枪支法律能降低枪支死亡率吗?
我们不想做任何假设,所以我们将从回答一些最基本的问题开始。为了回答这个问题,我们求助于吉福德法律中心:一个非营利组织,其使命是减少枪支暴力。他们提供了 T4 各州枪支法的年度排名,给每个州分配了一个传统的字母等级。如果枪支法是有效的,我们预计枪支死亡率会随着等级的上升而下降。利用美国疾病控制中心(CDC)2017 年的数据,我们可以绘制出各州之间的关系。

Using a standard GPA calculation, a grade of 4 represents an A, while 0 represents an F.
所以,更强有力的法律意味着枪支死亡率下降,我们可以到此为止,对不对?!要是这么简单就好了。我们只有一年的数据,不知道吉福兹是怎么算出成绩的。更重要的是,我们不知道总死亡率会发生什么变化?枪支死亡率包括自杀率和他杀率。我们怎么知道人们不仅仅是用一种方法代替另一种方法?让我们以总体自杀率和凶杀率为目标,来看看更广泛的时间段(2014-2017)。

Data Sources: Giffords Law Center and CDC’s Wide-ranging Online Data for Epidemiologic Research (WONDER) tool.
尽管强有力的枪支法似乎确实降低了杀人和自杀的比率,但数据中有很多噪音。此外,自杀率与他杀率之间的关系要明显得多。事实上,数据表明,从 F 到 A 的成绩提高可能会导致自杀率下降近 50%。
凶杀率是怎么回事?这种关系在统计学上可能是显著的,但 r 平方得分表明法律的力量只能解释凶杀率变化的 6.7%。但是枪支法真的对降低凶杀率无效吗,还是发生了其他事情?
一些人认为,邻国薄弱的法律可能会破坏另一个国家强有力的法律。让我们探索一下这种可能性。
邻国的法律
通过计算每个州的邻居的平均分数,我们可以衡量该州对枪支法律的影响。首先,我们将使用一个由本帖中的 Ritvik Kharkar 描述的便捷代码块,它使用 Shapely 库来识别每个州的邻居。下面是这段代码的一个稍微修改过的版本。
OUTPUT
Alabama: ['Tennessee', 'Florida', 'Georgia', 'Mississippi']
Alaska: []
Arizona: ['Nevada', 'Utah', 'California', 'Colorado', 'New Mexico']
Arkansas: ['Tennessee', 'Texas', 'Louisiana', 'Mississippi', 'Missouri', 'Oklahoma']
California: ['Nevada', 'Arizona', 'Oregon']
从这里开始,只需要得到每个邻居的分数,然后计算所有邻居的平均绩点。没有邻居的州(阿拉斯加和夏威夷)使用所在州的等级。
OUTPUT
{'Alabama': 0.175,
'Alaska': 0.0,
'Arizona': 1.4,
'Arkansas': 0.11666666666666665,
'California': 1.0}
像以前一样,我们将绘制邻州 GPA 与目标州凶杀率的关系图,看看我们得到了什么。

有趣的是,邻居州的法律似乎比家乡州的法律对凶杀率有更大的影响。就自杀率而言,这种关系比以前弱了。同样值得注意的是,当枪支法律健全时,杀人率的变化会更低。这意味着强有力的法律能够抑制通常会推高利率的其他因素。
然而,16.1%的 r 平方值比我们希望看到的要弱得多。让我们深入法律本身,看看我们是否能获得一些具体的、可操作的情报。
州法律分析
理想的解决方案是分析州法律随时间的变化,而不是依赖一个无法独立分析的任意分级系统。收集数据、对特征进行分类以及对结果进行编目的过程需要大量的时间、专业知识和资源。幸运的是,另一个枪支控制倡导组织 Everytown Research ,从 1991 年起就记录了这些信息。
通过对 85 个维度的分析,该小组将每个特征框定为一个二元或分类问题。例如,“州法律是否普遍禁止所有被判重罪的人拥有枪支?”以这种方式组织问题的一个好处是,它们在回答中没有给主观性留下多少空间。
每个元素都属于八个类别之一:
- 背景调查
- 罪犯
- 家庭暴力
- 毒品和酒精
- 精神病
- 最低年龄
- 许可过程
- 其他的
答案不是用 1 和 0 来表示是或否,而是按照数字越大代表法律越严格的方式来排列。尽管这种方法需要预先做额外的工作,但结果的可解释性大大提高了。
还计算了邻近各州的平均响应,并将其纳入数据集中。经过额外的清理以减少数据中的噪声后,主要和相邻状态的 134 个维度仍然存在。
识别最重要的特征
从多元线性回归中的向后排除开始,我们排除了 p 值低于 0.05 ÷剩余元素数的特征。此外,后来发现一些特征适用于州和年份的最小选择,导致它们在最终结果中被过度表示。因此,排除了 85%的回答处于一个极端的问题(即 85%的回答为“否”)。
下面列出了前 20 个功能,以及它们各自给出至少部分“是”响应的状态数。例如,如果一个州回答“是,但仅适用于手枪”,则在图表中它将被视为部分“是”的回答。

Note: The response count for question 16 includes states that do disqualify people from getting permits.
请记住,这些问题中的一些在适用于邻近州时更有分量,而另一些则是指本州的法律。在我们开始尝试解释这些结果并确定潜在的主题之前,我们需要测试它们的重要性。从随机选择的州和年份中给定这些问题的一组答案,我们应该能够高度精确地预测各自的凶杀率。
机器学习和人工智能模型
使用 80%的数据子集,通过 5 重交叉验证和 SciKit Learn 的 GridsearchCV 对以下回归模型架构进行了训练。
- 决策图表
- 随机森林
- 支持向量机
- Adaboost 回归
- XGBoost 回归器
- Keras 回归器(人工智能模型)
通过训练模型,每个人都试图预测剩余 20%数据的凶杀率,成功程度各不相同。最后,发现 XGBoost 回归器是表现最好的模型,实现了 91.23%的解释方差得分。在下面的图表中,红点代表各州和各年份的实际凶杀率。蓝线代表模型根据 20 个问题的答案做出的预测。

Explained Variance Score: 0.9123
因此,我们的模型可以高精度地预测凶杀率,但它没有告诉我们任何关于所述比率潜在下降的信息。要回答这个问题,请考虑两种假想状态:一种状态对所有项目的回答是,另一种状态对所有项目的回答是否。预测的凶杀率有什么不同?对所有问题回答“是”的州比回答“否”的州的凶杀率平均低 52.41%。
在对个体反应进行调整时,通过测量预测凶杀率的变化,我们可以确定具有最大影响的特征。以下按重要性顺序列出了最重要的特征,并给出了 2019 年的肯定回答。

观察
一些清晰的主题出现在秘密携带、警察自由裁量权和家庭暴力方面。似乎当警察有权解除他们认为对公共安全构成威胁的个人的武装时,杀人率就会下降。当法律禁止持有家庭暴力禁止令的个人拥有枪支时,凶杀率也会下降。
也许最令人惊讶的是,不到一半的州禁止逃犯拥有枪支。请注意,这个话题与邻州最相关,而不是与本州最相关,为邻州法律的影响提供了进一步的证据。
宾夕法尼亚大学医学院 2019 年 3 月发表的另一项研究佐证了这一发现。该学校使用了完全不同的方法和数据集,追踪凶杀案中使用的枪支的购买情况。资深作者 Mark J. Seamon,医学博士,FACS,宾夕法尼亚医科大学创伤学、外科重症监护和急诊外科副教授说:
严格的州枪支立法可能会驱使一些人去更宽松的邻州收回枪支,这反过来增加了家乡的枪支和凶杀案数量,尽管其法律更具限制性。
研究中的一个关键发现是,“在最严格的州收回的枪支中,65%来自其他州。”
那么,我们该如何处理这些信息呢?我们稍后会谈到这一点。现在,我们将改变思路,进行不同的分析,这一次是考察法律对大规模枪击事件的影响,而不是整体凶杀率。
枪支法对大规模枪击事件的影响
从 1982 年到 2019 年的大规模枪击事件数据库可以在这里找到。同样的追踪枪支法与凶杀率的方法也被应用,这一次使用分类模型而不是回归变量。不幸的是,在这种情况下,最初的结果相当令人沮丧:没有一个模型能够以高于随机概率的准确度预测大规模枪击事件。这是否意味着枪支法对大规模枪击案没有影响?不一定,因为大规模枪击事件相对较少,这使得这种相关性更难发现。所以,让我们尝试另一种方法。
不要看所有的州法律,让我们来看一个单一的国家法律:公共安全和娱乐枪支使用保护法案,也被称为攻击性武器禁令(AWB)。在 1994 年 9 月颁布时,美国司法部将攻击性武器定义为“半自动火器,带有大量弹药,设计和配置用于快速射击和战斗用途。“禁令一直实施到 2004 年 9 月。那么,效果如何呢?
通过简单的假设检验,我们可以确定禁令实施后事故和死亡人数是否显著降低。下面,我们可以看到任何给定年份的总死亡人数、事故数量和每次事故死亡人数的平均值和方差的差异。蓝线代表禁令无效时的结果,红线代表禁令有效时的结果。

根据这些结果,当联邦禁令实施时,事故发生频率降低了 86%,总死亡人数降低了 173%,每次事故的死亡人数降低了 50%。我们可以在 90%的事故数量和总死亡人数水平上对这些结果有信心,而在查看每个事故的死亡人数时有 95%的信心。然而,有一个重要的警告需要考虑。看看这些结果是如何随时间变化的。灰色虚线之间的时间段代表禁令实施的时期。

正如我们所看到的,存在明显的数据不平衡,大多数事故和死亡发生在禁令到期后的几年里。当 2004 年以后的数据被排除在比较之外时,所有重要的迹象都消失了。如果有两个不同的时期没有实施禁令,并且每个时期都表现出非常不同的结果,那么就很难得出禁令本身就是解释变量的结论。换句话说,我们没有任何明确的证据表明 AWB 对总死亡人数或事故数量产生了有意义的影响。
然而,当考虑每起事故的死亡人数时,这种不平衡并不存在,这被发现是 95%置信水平下最重要的因素。这告诉我们,虽然 AWB 不一定能有效减少大规模枪击事件的发生,但似乎确实减少了由此导致的死亡人数。
大规模枪击与其他形式的大规模谋杀
想象一下这样一种场景:平民百姓不再能获得枪支:潜在的大规模枪击者可能会求助于其他手段。其他方法会导致更多或更少的死亡吗?我们可以从全球恐怖主义数据库中提取数据,并将结果与我们已有的数据进行比较。在一组中,我们调查了涉及枪支事件的死亡率。另一方面,我们考虑大多数人认为可以替代火器的武器类型。

从 1982 年到 2017 年,每起无火器事件的平均死亡人数为 2.36 人(不包括 9/11 袭击)。在同一时期,当选择火器作为武器时,每起事件的平均死亡人数为 8.37 人。差异代表 255%的差异,在 99%的置信水平下被发现是显著的。虽然枪支限制可能无法有效防止攻击,但证据表明,这种限制可能能够提高攻击的生存能力。
结论和建议
就整体凶杀率而言,对逃犯和持有家庭暴力禁止令的人实施枪支限制是一个州可以采取的最明确的行动。然而,授权执法部门酌情收缴枪支可能会遭到两党的强烈反对。作为一种替代办法,当直系亲属发现自己有危险信号时,他们可以向法院申请驱逐。
也称为“极端风险保护令”或“危险信号法”,这种方法可能会产生类似的结果,而不会给执法机构太多的权力。2015 年,只有两个州有这样的法律,但这一数字已经增加到 17 个。因为这些法律太新了,要过几年才能衡量它们的有效性。此外,法院就此类申请做出决定所使用的标准仍有待确定。
人们希望这样的法律能够遏制大规模枪击事件的发生,但截至目前,还没有法律在这方面产生明显影响。尽管攻击性武器禁令确实对每起事故的死亡率有一定的影响,但更高的目标应该是首先降低此类事件的发生频率。
尽管如此,各州仍有太多的选择,以有意义、无争议的方式加强枪支法律。弥合全国各州法律中的这种差距有可能大幅降低凶杀率。下面是几个唾手可得的果实的例子:
- 在 19 个州,拥有最终家庭暴力限制令的个人被允许拥有枪支。
- 在 27 个国家,不禁止逃犯拥有枪支。
- 在 23 个州,不禁止被认定无受审能力的个人拥有枪支。
- 在 21 个州,因精神错乱而被判无罪的人不被禁止拥有枪支。
- 在 21 个国家,如果合法当局发现一个人对自己或他人构成威胁,不禁止这个人拥有枪支。
值得注意的是,在其中一些案例中,联邦法律已经存在。然而,根据 1997 年美国最高法院案例 Printz 诉美国 ,联邦政府不能强迫各州执行联邦法律。除非各州有类似的法律,否则联邦政府没有可靠的实施手段。
最终,目标是降低凶杀和自杀率,而不是解除守法公民的武装。在全国范围内齐心协力制定真正的常识性法律并执行已经成文的联邦法律是取得进展的最佳途径。
这一分析是在 Jupyter 笔记本中使用 Python 进行的,该笔记本可以在 Github 上找到,并提供了完整的数据源和方法。
用车床 0.0.8 可以演示什么?
(对于朱莉娅 1.3)

车床 0.0.8“文件和调度”是车床画布上一个相当大的发布。顾名思义,这个版本有大量的文档。但这还不是全部,速度已经被优先考虑,大多数功能现在都优化了很多。此外,模型构造函数现在通过 Julia 的类型调度使用参数多态,而不是条件。

参数多态性
如果您想知道当谈到函数式编程时,我是否会经常谈到这个概念,
是的,我是。
Lathe 中的参数多态允许更简洁地使用 Lathe 中的“预测”函数作为结构的属性,而不是接受结构输入的函数。不用说,这要快得多,也简洁得多。但是事情远不止如此。
通过 Julia(awesome)的调度使用这种形式的参数多态性,我们可以使用同一个函数做数百万件事情,越来越容易,甚至不需要访问代码库就可以**。**
这意味着任何头脑正常的人都可以为车床编写扩展,同样,车床可以做比现在更多的事情。有了 Julia 的参数多态性,来自 Lathe 的函数基本上可以做任何事情。为了让您了解添加结构有多简单,我们来快速做一下。
第一步是从车床导入预测功能。

现在我们可以制造任何构造函数,甚至可以使用车床模型并为它重写一个函数。

4
我选择将我的可变结构命名为“Emmett”我选中这个名字的原因是 还是 未知。接下来,我们构造一个名为 emdawg 的变量(真的?)并且我们可以断言我的身高和体重。既然在构造函数中已经有了我的身高和体重,我们可以打印单独的结果。

酷!因此,让我们编写一个利用该构造函数的函数,然后我们将从 Lathe.models.predict()中调度它。我决定写一个函数来计算身体质量指数,因为我们有身高和体重。一个问题是我们的身高是一个代表英尺和英寸的浮点数,即 6.4 == 6 英尺 4 英寸。

现在我们有了函数,我们只需要通过调度调用它。这是我想到的:
predict(m::Emmett) = calc_bmi(m)
现在,当我们将构造函数插入到 Lathe.models.predict()中时,我们得到一个返回:

不要去查那个身体质量指数
证明文件
有了这次更新,我想停止去维护者的网站搜索文档的传统方法。您可能需要了解的一切都应该可以在语言本身中找到,所以让我们来测试一下。
当然,作为一个新用户,很难模仿我自己,这个项目的维护者…但我们现在会试着假装我根本不知道如何使用车床。我们可以完全用这个来操纵车床。()函数来自 Julia 的 base。

我们什么时候?(车床),我们得到这样一个返回:一个树,里面有所有单独的模块,以及一些包信息,包括版本、依赖项和 UUID。关于这些的更多信息,可以查看任何 Julia 包的 Project.toml 文件(包括 Lathe。)
那么接下来呢?就在树下,我们看到使用说明。(车床.包)获取信息。让我们在车床上试试。模型

现在我们可以看到每个结构的每个参数,以及我们的附属函数。所以,举例来说,我们可以看看车床。模型。线性最小平方

这样,我们得到了一个全面的超参数列表、一个简短的描述和一个使用示例。理想情况下,这将是我们训练和验证模型所需的一切。
结论
车床是一个非常酷的包,0.0.9 的画布承诺了更多酷的特性,特别是在分类预测领域。如果你想更多地了解车床的新版本控制,有看板可以很好地记录到底发生了什么。
车床 0.0.8 板
车床 0.0.9 板
你应该如何选择计算机科学课程?
从竞争中脱颖而出的简单方法

The fountain on the University of Delaware’s South Green. Photo: Ashley Barnas
在美国(或者全世界)有一种增加的趋势?!)供非主要学习计算机科学(CS)的学生注册 CS 课程。
你是其中之一吗?你注意到了吗?我确实在特拉华大学(UD)学过,目前我是那里的计算机科学硕士研究生。因此,科技领域的竞争越来越激烈。
LinkedIn 编辑团队的 Kelli Nguyen 认为,大学毕业后高薪工作的前景可能导致了这一趋势。
随着过去几年技术革命的到来,这是一个合理的假设。你不觉得吗?
但如果一份高薪工作是你选择 CS 课程的动力,你就不会走得太远了!
为什么计算机科学很重要?
编码和编程是计算机科学的重要组成部分。他们,专注于告诉计算机做什么。因此,这个领域提供了一个进入批判性和逻辑性思维的入口,这种思维适用于大多数学科。
你将有能力
- 开发使用技术的不同方式
- 解决你所在领域的计算问题
- 获得对你自己的研究/工作有用的特定技能
积极的一面是多方面的。
作为学生该怎么办?
你在这个学科中获得的技能是独一无二的,需要正确的实施来掌握。组织重视的东西!
计算机科学课程传授解决问题和分析能力。
我经常发现学生们将这些技能带入他们的专业领域(计算机科学或其他)来解决现实世界的问题。
所以,如果你是任何学科的学生,你应该明智地选择你的课程。方法如下:
- 你的职业目标是什么?
- 你想用你的计算机科学水平做什么?
- 你毕业后的目标是什么?
- 那些角色需要什么能力?
- 你需要学习什么课程来获得它们?
它迫使你瞄准一系列对实现目标至关重要的讲座和技能。很好,不是吗?
在我获得硕士学位的早期,我认识到了这一趋势,并确定了我的学术学习道路。现在,到了我的最后一个学期,我可以说我进入了我想要的班级。更重要的是,我能够建立新的联系。有些人我不知道会遇到。
我这么说是因为在我的一门课上,我建立了机器学习模型。对一个计算机系的学生来说很简单,不是吗?是的,但是是和几个非计算机专业的学生。一个是水科学与政策,另一个是农业与环境经济学。
当你和那些看问题的方式与你不同的人一起工作时,你就成长了。
我是另一个班的学生,我喜欢通过发现孩子们营养摄入的趋势来对他们的数据进行聚类。这一次,带着数学和统计学的博士生。还有,非 CS。
因此,让计算机科学背景的多样性增强你的能力吧!
计算机科学研究的近期前景
我非常幸运能够利用日益增长的需求和跨学科的合作。你也可以。其实你一定是!
这就是我对计算机科学研究的未来的看法。你应该结合多个学科,对同一个问题或主题寻求不同的思考方式。这种革命性的学习方式使你能够发展批判性思维能力,并提供许多现实世界的成长机会。
今天的团队,尤其是行业中的团队,是为了解决现实世界的问题而建立的,他们拥有能够带来不同技能的人。当你毕业的时候,只有当你拥有一种以上的技能时,你才能够立即投入工作,并有效地合作以取得成果。
感谢阅读!我很想在下面的评论中听到你的想法。你也可以关注我的 LinkedIn 和Twitter。
如果你觉得这篇文章可能对你认识的人有所帮助,请与他们分享这个链接:https://bit.ly/3gxw6j9

















 737
737

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}