







分解平均精度(mAP)
数据科学工具包的另一个指标

Photo by Şahin Yeşilyaprak on Unsplash
如果你遇到过 PASCAL 视觉对象类(VOC) 和 MS 上下文中的公共对象(COCO) 挑战,或者涉足过涉及信息检索和重新识别(ReID)的项目,那么你可能会非常熟悉一种叫做 mAP 的度量标准。
平均精度(mAP)或有时简称为 AP 是一种流行的度量标准,用于测量执行文档/信息检索和对象检测任务的模型的性能。
一组查询的平均精度(mAP)由维基百科定义如下:

Mean average precision formula given provided by Wikipedia
其中 Q 是集合中查询的数量,AveP(q)是给定查询 Q 的平均精度(AP)。
该公式本质上告诉我们的是,对于给定的查询 q,我们计算其相应的 AP,然后所有这些 AP 得分的平均值将为我们提供一个称为 mAP 的数字,它量化了我们的模型在执行查询方面的表现。
这个定义让在这个领域刚刚起步的人(比如我)感到困惑。我有一些问题,比如这组查询是什么?还有 AP 是什么意思?只是精度的平均值吗?
本文希望解决这些问题,并为目标检测和信息检索任务计算 mAP。本文还将探讨为什么 mAP 是信息检索和对象检测任务的一个合适且常用的度量。
概述
1.底漆
查准率和查全率是两个常用的度量标准,用来判断给定分类模型的性能。为了理解 mAP,我们需要首先回顾一下精度和召回率。
越是“有名”的精确和回忆
在统计学和数据科学领域,分类中给定类别的精度,即所谓的阳性预测值,是指真阳性(TP)与预测阳性总数的比值。公式给出如下:

Precision formula of a given class in classification
类似地,**召回,也称为分类中给定类别的真阳性率或灵敏度,**被定义为 TP 与真实阳性总数的比率。公式给出如下:

Recall formula of a given class in classification
仅仅通过查看公式,我们就可以推测,对于一个给定的分类模型,在它的精确度和召回性能之间存在一个折衷。如果我们使用神经网络,这种权衡可以通过模型的最终层 softmax 阈值来调整。
为了提高我们的精度,我们需要减少 FP 的数量,这样会降低我们的召回率。同样,减少 FN 的数量会增加我们的回忆,降低我们的精确度。对于信息检索和对象检测的情况,我们经常希望我们的精度很高(我们预测的阳性是 TP)。

(source)
精确度和召回率通常与其他指标一起使用,如准确性、F1 分数、特异性、真阴性率(TNR)、接收器操作特性(ROC)、提升和增益。
不太“出名”的精确度和召回率
但是,说到信息检索,定义就不同了。
根据 Wiki 的定义,精度定义为与用户查询相关的检索文档与检索文档的比率。

Precision formula for information retrieval given by Wiki
保持术语类似于上面定义的公式,相关文件可以被视为一个 TP。
默认情况下,precision 会考虑所有检索到的文档,但是,也可以在给定数量的检索到的文档上评估 precision,这通常称为截止等级,在这种情况下,仅通过仅考虑其最顶层的查询来评估模型。这种测量称为 k 处的精度或 P@K
让我们用一个例子来更好地理解这个公式。
定义典型的信息检索任务
信息检索中的典型任务是用户向数据库提供查询,并检索与该查询非常相似的信息。现在让我们用一个带有三个真实值(GTP)的例子来计算精度。
附加术语:基本事实阳性是被标记为阳性的数据。换句话说,相关文件。
我们将定义以下变量:
- q 成为用户查询
- g 是数据库中的一组标记数据
- d(i,j)是一个得分函数,以显示对象 I 与 j 有多相似
- 其中 G 的有序集合根据得分函数 d(,)
- k 是 G '的指数

User querying G with a document Q
在用 Q 计算了每个文档的 d(,)之后,我们可以对 G 进行排序并得到 G’。
假设模型返回以下 G ’

Model returned sorted query results G’
使用上面的精度公式,我们得到以下结果:
P@1 = 1/1 = 1
P@2 = 1/2 = 0.5
P@3 = 1/3 = 0.33
P@4 = 2/4 = 0.5
P@5 = 3/5 = 0.6
P@n = 3/n
类似地,Wiki 定义的召回公式被给出为与用户查询相关的检索文档与相关文档的比率。

Recall formula for information retrieval given by Wiki
在这种情况下,召回率不如运行返回查询的所有文档将导致微不足道的 100%召回率有用,因此召回率本身通常不被用作度量。
2.信息检索的平均精度和映射
熟悉 precision@k 之后,我们现在可以继续计算平均精度。这将使我们更好地衡量我们的模型对查询结果 G '进行排序的能力。

AP@n formula
其中,GTP 指的是基本事实正的总数,n 指的是你感兴趣的文档的总数,P@k 指的是精度@k,而 rel@k 是相关性函数。相关性函数是指示函数,如果排名 k 的文档是相关的,则该指示函数等于 1,否则等于 0。
回想一下精度的定义,我们现在将使用它来计算 G '中每个文档的 AP。使用上面所示的相同例子,

Calculation of AP for a given query, Q, with a GTP=3
这个查询的总 AP 是 0.7。需要注意的一点是,因为我们知道只有三个 GTP,所以 AP@5 等于总 AP。
对于另一个查询 Q,如果返回的 G '排序如下,我们可以得到完美的 AP 1:

Calculation of a perfect AP for a given query, Q, with a GTP=3
在这种情况下,AP 所做的是惩罚那些不能用 TPs 引导集合来排序 G '的模型。它提供了一个数字,能够根据得分函数 d(,)量化排序的优劣。通过将精度之和除以总 GTP 而不是除以 G '的长度,可以更好地表示只有几个 GTP 的查询。
计算地图
对于每个查询 Q,我们可以计算相应的 AP。用户可以对这个带标签的数据库进行任意多的查询。地图只是用户进行的所有查询的平均值。

mAP formula for information retrieval
注意:这和维基百科的公式一样,只是写法不同。
3.目标检测的平均精度和 mAP
计算 AP(传统 IoU = 0.5)
并集上的交集
为了计算物体检测的 AP,我们首先需要理解 IoU。IoU 由预测边界框和地面真实边界框的交集面积和并集面积的比率给出。

(source)
IoU 将用于确定预测的边界框(BB)是 TP、FP 还是 FN。由于假设每个图像中都有一个对象,因此不评估 TN。让我们考虑下面的图像:

Image with a man and horse labeled with ground truth bounding boxes (source)
该图像包含一个人和一匹马,以及它们对应的地面真实边界框。让我们暂时忽略马。我们在这个图像上运行我们的对象检测模型,并且接收到这个人的预测边界框。传统上,如果 IoU > 0.5,我们将预测定义为 TP。可能的情况如下所述:
真正(IoU > 0.5)

IoU of predicted BB (yellow) and GT BB (blue) > 0.5 with the correct classification
假阳性
在两种可能的情况下,BB 将被视为 FP:
- IoU < 0.5
- 重复 BB

Illustrating the different scenarios a predicted BB (yellow) would be considered as FP
假阴性
当我们的目标检测模型错过了目标,那么它将被认为是一个假阴性。两种可能的情况如下:
- 根本没有检测的时候。

No detection at all
- 当预测 BB 的 IoU > 0.5 但分类错误时,预测 BB 将为 FN。

FN BB as the predicted class is a horse instead of a person
精确度/召回曲线(PR 曲线)
正式定义了 TP、FP 和 FN 之后,我们现在可以计算测试集中给定类的检测精度和召回率。每个 BB 都有其置信度,通常由其 softmax 层给出,并用于对输出进行排序。请注意,这与信息检索的情况非常相似,只是我们没有使用相似性函数 d(,)来提供排名,而是使用模型预测的 BB 的置信度。
插值精度
在绘制 PR 曲线之前,我们首先需要知道[ 1 中引入的插值精度。插值精度 p_interp 是在每个召回级别 r 上计算的,取该r的最大测量精度。公式如下:

Interpolated Precision for a given Recall Value ®
其中 p®是召回 r 时的测量精度。
他们内插 PR 曲线的目的是减少由检测等级的微小变化引起的“摆动”的影响。
这样一来,我们现在可以开始绘制 PR 曲线了。考虑一个具有 3 TP 和 4 FP 的 person 类的例子。我们通过上面定义的公式计算相应的精度、召回率和插值精度。

Calculation table for plotting PR curve with an example of 3 TP and 4 FP. Rows correspond to BB with person classification ordered by their respective softmax confidence

然后通过 PR 曲线下的面积计算 AP。这是通过将召回平均分为 11 个部分来实现的:{0,0.1,0.2,…,0.9,1}。我们得到以下结果:

Calculation of AP for the above example
再举一个例子,我想让你参考乔纳森·惠的这篇写得很好的文章【2】。
计算地图
用于对象检测的 mAP 是为所有类别计算的 AP 的平均值。还需要注意的是,对于一些论文,它们交替使用 AP 和 mAP。
计算 AP 的其他方法
参考[ 5 ],COCO 提供了六种计算 AP 的新方法。
这些方法中的三种在**不同的 iou:**处对 BB 进行阈值处理
- AP:IoU = 0.50 时的 AP:0.05:0.95(主要挑战指标)
- AP@IoU=0.5(如上所述的传统计算方法)
- AP @ IoU = 0.75(BBs 的 IoU 需要> 0.75)
对于主 AP,0.5:0.05:0.95 意味着从 IoU = 0.5 开始,步长为 0.05,增加到 IoU = 0.95。这将导致在十个不同的 iou 上 AP 阈值的计算。进行平均以提供奖励定位更好的检测器的单个数字。
其余三种方法是跨尺度计算AP:
- 小型物体的 AP^small: AP:面积< 32² px
- AP^medium: AP for medium objects: 32² < area < 96² px
- AP^large: AP for large objects: area > 96 像素
这将允许更好地区分模型,因为一些数据集比其他数据集具有更多的小对象。
发现错误?随意评论!
如果你对我参与过的其他项目感兴趣,可以随时访问我的Github!**
对于我的其他作品:
参考资料:
- 由 Mark Everingham、Luc Van Gool、Christopher K. I. Williams、John Winn 和 Andrew Zisserman 发起的 PASCAL 视觉对象类(VOC)挑战
- https://medium . com/@ Jonathan _ hui/map-mean-average-precision-for-object-detection-45c 121 a 31173
- https://makarandtapaswi . WordPress . com/2012/07/02/intuition-behind-average-precision-and-map/
- https://en . Wikipedia . org/wiki/Evaluation _ measures _(information _ retrieval)# Mean _ average _ precision
- http://cocodataset.org/#detection-eval
- https://tarangshah . com/blog/2018-01-27/what-is-map-understanding-the-statistic-of-choice-for-comparisng-object-detection-models/
分解评论文章
使用评论文章来帮助你过渡到新的研究领域

开始一个新的研究领域似乎是一项艰巨的任务。尤其是当该领域每年发表的论文数量呈指数级增长时。这种快速增长使得跟上当前的研究实践变得极其困难。更高的更替率意味着更少的公认标准,因为新的工作专注于提出下一个最好的想法,而不是重复当前的方法。如果你开始不加选择地阅读一篇又一篇被广泛引用的论文,你会感觉像一个永无止境的迷宫。
The never-ending agony of reading referenced paper after referenced paper.
那么,这是否意味着我们一旦开始努力跟上,就注定要失败呢?不,一点也不,尤其是如果你有计划的话。
评论或调查文章是了解新领域的好方法。它们包括该领域最初问题的历史信息,以及过去试图解决这些问题的研究成果。目前的方法是在某种程度上提出来与其他方法进行比较。拥有明确的问题领域可以帮助你根据你的情况或兴趣找出你应该集中精力做什么。此外,综述文章最好的部分是它们充当了一个精心策划的参考文献列表,您可以使用它来了解更多关于该方法的细节。现在我想让你向我介绍一下我是如何为我的博士研究和我的兴趣分解评论文章的。
我如何浏览一篇评论文章
我最近想知道更多关于当前推荐系统如何集成深度学习的信息。如果你不知道,推荐系统使用用户和商品的过去信息来预测或推荐未来用户与新商品的互动。例如,在一个电影推荐器中,电影是项目,个人可能是用户。这个问题的交互方式因格式和对不同类型数据的访问而异。它可以是一个评级系统(1-5),也可以是一个👍或者👎,也可能只是用户之前是否看过这部电影。
查找评论文章
Arxiv 和谷歌学术是寻找评论文章的好地方。谷歌学术可以绑定到一个大学账户上,这样你在校园网上可以看到的任何文章都可以在校外看到。然而,在这里,我只使用 Arxiv,因为任何人阅读这篇文章都是免费的。
专家提示:如果你发现一篇你无法获得的优秀科学论文,通过电子邮件联系作者,他们很可能会给你寄一份。
在搜索了 Arxiv 之后,我决定选择论文“基于深度学习的推荐系统:调查和新观点”我最终选择这篇文章有几个原因。
- 这是最近的一篇论文。随着 2019 年 7 月发布的最新版本,它应该包含了该领域的大多数最新进展。
- 这篇综述发表在 ACM 上。注意,一篇论文发表了并不代表它就是好的。在这种情况下,同行评审过程应该有助于确保没有重大贡献被遗漏。
- 报纸的版面。作者将工作分成清晰的部分,使其更容易分析和理解所有评论文章如何适应更大的画面。
分解它
好了,现在我们有了一篇评论文章,我们可以开始一点一点地分解它。作为一种组织信息的方式,我通常会尝试将文章分成不同的部分。当试图将多篇文章的观点结合起来,并为将来的参考提供一个好的总结时,这是特别有用的。
写作原因
一些评论文章提供了他们写评论文章的动机。他们的动机是确定他们希望涵盖的研究范围以及了解你可能感兴趣的其他文章的一个很好的方式。
在过去的几年里,对传统推荐系统的一些调查已经被提出…然而,有一个缺乏对基于深度学习的推荐系统的广泛评论。就我们所知,只有两个相关的简短调查[7,97]正式发表…鉴于深度学习在推荐系统中应用的日益普及和潜力,一个系统调查将具有很高的科学和实用价值。我们从不同的角度分析了这些作品,并对这一领域提出了一些新的见解。为此,超过 100 项研究在本次调查中入围并分类
通过这一小段摘录,我们知道作者写这篇论文是对 100 多篇关于深度学习在推荐系统中的使用的文章的广泛系统调查。此外,它旨在提供一个不同的视角,而不是在该领域的前两个审查文件。
定义
检查并查看作者是否对他们在评论中涉及的主题进行了详细描述总是有好处的。明确的定义有助于消除由于该领域中的非标准术语而导致的任何可能的误解。
推荐系统估计用户对项目的偏好和主动向他们推荐用户可能喜欢的项目【1,121】。推荐模型通常分为三类【1,69】:协同过滤,基于内容的和混合推荐系统。
现在,我们可以将本文中介绍的每个推荐系统分为三个不同的类别。然后,他们继续定义每个类别。
协同过滤通过 l 从用户-项目历史交互中获得,或者是显性的(例如用户以前的评级)或者是隐性的反馈(例如浏览历史)来进行推荐。基于内容的推荐主要基于 c 跨项目的比较和用户的辅助信息。多种多样的辅助信息,如文本、图像和视频都可以考虑在内。混合模型是指整合了两种或两种以上推荐策略的推荐系统【8,69】。

A flowchart showing the relationship between types of recommender systems.
因此,一个推荐系统,使用用户如何与项目互动的过去信息,是协同过滤。使用关于用户或项目的信息来确定不同项目或用户的相似性,然后基于该相似性进行推荐的系统是基于内容的推荐器。最后,如果推荐器结合了不同的方法,它就是一个混合系统。
应用程序和数据
确定所回顾的方法旨在回答的问题的种类对于理解当前和未来的研究方向是至关重要的。对于推荐系统,我们想知道当前系统的目的以及每个系统所需的数据类型。
在行业中,对于许多在线网站和移动应用来说,推荐系统是增强用户体验和促进销售/服务的重要工具。例如,在网飞上观看的 80%的电影来自推荐[43],60%的视频点击来自 YouTube 的主页推荐[30] … Covington 等人[27]提出了一种基于深度神经网络的推荐算法,用于 YouTube 上的视频推荐。Cheng 等人[20]提出了一个用于 Google Play的具有宽 T36 深模型的 T32 应用推荐系统。Shumpei 等人[113]为雅虎新闻提出了一个基于 RNN 的 T34 新闻推荐系统 T35。
对于这些应用程序中的每一个,我们可以想象需要不同来源和格式的数据。令人欣慰的是,作者提供了一个表格,对每个来源的评审工作进行了分类。现在,我们只需要阅读四篇文章,而不是浏览所有的 100 篇评论文章,看看他们是否使用视频作为输入来源。

This table shows how the authors categorize publications based on the data source and task.
未来研究和未决问题
在论文的最后部分,作者讨论了该领域的开放问题和未来研究的途径。如果你是一个刚刚进入这个领域的人,这可能是一个获得未来项目和工作方向想法的好地方。
- 从用户和项目中联合学习
- 可解释性
- 更深入
- 机器推理
- 跨域
- 多任务学习
- 可量测性
- 更好、更统一、更难的评估
这些都是你感到舒适后开始新项目的好地方。
把所有的放在一起
通读本文后,我们对推荐系统的内容、原因和位置有了更好的理解。遗憾的是,在这一点上,我们离成为该领域的专家还差得远。然而,我们可以开始了解该领域的研究是如何分类的,以及我们可以阅读哪些论文来获得更多信息。
我希望这是一个有用的练习,看看如何将综述论文分解,以帮助更好地理解新的研究领域。虽然这肯定不是审查论文的唯一方法,但我发现这些技巧对我很有帮助。
如果你有问题或者你想分享一些你用来审阅论文的技巧,请在下面留下你的评论。
最初发表于【https://www.coreydeon.com】。
引文
[1] S. Zhang,L. Yao,A. Sun,和 Y. Tay,基于深度学习的推荐系统:调查和新观点 (2019),ACM 计算调查(CSUR) 52.1: 5
用 PyTorch 和月球着陆器打破 Richard Sutton 的政策梯度

在 21 世纪初,已经发表了一些关于强化学习中的政策梯度方法(以一种或另一种形式)的论文。最值得注意的是 Richard Sutton 等人的**“利用函数逼近进行强化学习的策略梯度方法”**。
在这篇短文中,我们将试着理解带有一些怪癖的普通策略梯度算法。此外,我们将使用策略梯度算法训练一个智能体来解决 CartPole 和 LunarLander OpenAI 健身房环境。完整的代码实现可以在这里找到。
策略梯度算法位于策略优化深度强化学习方法家族的核心,例如(异步)优势行动者-批评家和信任区域以及近似策略优化。许多其他算法也与策略梯度算法有许多相似之处。
策略梯度和深度 Q 学习方法之间的差异是非常明显的。在策略梯度的情况下,我们优化重要的东西,即策略的性能,而不是诸如动作值之类的替代度量。此外,与确定性策略相反,策略梯度算法能够学习随机策略。最后,策略梯度是基于策略的算法,而深度 Q 学习是基于策略的算法,这使得它们的样本效率不同(策略梯度方法具有较低的样本效率)。
理查德·萨顿和安德鲁·巴尔托的《强化学习》的第 13 章详细描述了算法的策略梯度系列。此外,我发现这个开放人工智能资源有助于所涉及的数学背后的直觉;我强烈推荐通读这两本书。
理论背后的政策梯度算法
在我们实现策略梯度算法之前,我们应该复习一下算法中涉及的具体数学知识。数学非常简单易懂,并且在很大程度上是从上面提到的 OpenAI 资源中重新解释的。
首先我们定义 tau 为一个轨迹或一系列动作以及执行这些动作所获得的相应奖励。

An abstraction of a trajectory
现在,我们可以将奖励函数定义为轨迹奖励的贴现或无贴现(对于情节任务)总和。在实践中,我们会发现,即使对于偶发的任务,使用奖励的折扣总额也更有益,定义如下:

Discounted sum of the rewards, obtained from a trajectory
其次,我们将性能度量 J 定义为来自最近一批轨迹(在当前策略执行下获得)的报酬的某个函数的期望值。

Performance measure
让我们更深入地研究一下性能指标。根据期望的定义,我们得到:

Expanding the expectation over the trajectory
重要的是要明白,我们希望使用性能测量的梯度来优化我们的策略(代理)。因此,我们得到以下结果:

Adding the gradient wrt the parameters of the policy
现在,有一个很好的技巧或对数导数技巧,它来自下面的恒等式:

log-derivative trick
我们可以使用这个技巧,用概率和轨迹对数概率的梯度的乘积来代替轨迹概率的梯度,或者:

Adding the log-probability of the trajectory
如果我们仔细观察右边,我们可以注意到它本身就是一个期望:

Bringing the integral back to expectation
但是轨迹的对数概率是多少呢?原来我们可以用链式法则来定义轨迹上的概率:

Chain rule can be used to define the probability distribution over the trajectory space
直觉上,这个链式法则很有意义。我们从一些初始状态分布中抽取初始状态。然后,由于我们的行动是随机的,我们在行动空间中选择一个有一定概率的行动,这就是我们的策略。最后,过渡模型也是随机的;因此,我们乘以从前一个状态转移到下一个状态的概率。我们继续这个过程,直到我们到达集的结尾。
现在,让我们看看轨迹空间上的对数概率分布:

Log-probability over the trajectory space
让我们计算相对于策略参数的轨迹空间上的对数概率的梯度:

Calculating the gradient of the log-probability over the trajectory space
我们看到只有政策概率分布依赖于政策参数。因此,其余项的值为零。最后,我们可以将所有的数学计算放在一起,得出:

The gradient of the performance measure can be approximated by sampling
现在,由于性能度量的梯度是一个期望值,我们可以用抽样来估计它,这非常容易。我们将在当前策略下生成几个轨迹(因为策略梯度是一个策略上的算法),然后将计算我们从代理(策略)获得的加权(通过 R(tau))对数概率的平均值。
我们将使用从时间 t 到本集结束的折扣奖励的总和,而不是折扣奖励的总和。这些被称为奖励-继续,在政策梯度方法中更频繁地使用,因为在时间 t 之后提交的行为不应对这些行为发生之前获得的奖励产生任何影响。

Rewards-to-go
熵加成
在代码中,我们还将使用熵加成来阻止严格的确定性。思路相对简单:我们在策略优化过程中,从“损失”中减去策略的熵。如果代理人对自己的行为过于自信,那么政策的熵就会变小,红利就会消失。策略的熵是强化学习中反复出现的主题,并用于其他算法,如软演员-评论家。
基线
我们还将使用一个基线。基线是在不影响期望值的情况下从 R(τ)中减去的量,因为通常基线是特定于状态的量。我们将使用特定州的轨迹回报平均值作为基线。
基线减少了政策梯度估计的差异。直觉上,这很有意义,尤其是在横翻筋斗的情况下。假设我们的代理可以平衡杆子 2 秒钟。这是好事还是坏事?如果在这一集之前,代理人平均平衡了 1 秒钟,那么是的,这是更好的表现。在这种情况下,策略梯度将被估计为正,并且代理将朝着进一步改进的方向迈出一步。
然而,如果代理在事件发生前平均平衡极点 3 秒,则策略梯度将被估计为负,并且我们仍将朝着正确的方向迈出这一步,远离使代理平衡极点 2 秒的参数。如果我们不使用基线,1 秒和 3 秒以及 10 秒的插曲都会导致相似的梯度方向;因此,培训可能需要更长的时间。
需要注意的是,对于像 LunarLander 这样更复杂的问题,基线不太直观,因为我们有正面和负面的奖励,奖励的规模也不同。
PyTorch 实现
代码和算法背后的数学一样简单明了。然而,能够将数学语言翻译成代码本身就是艺术,我发现这部分有时是最困难的。
既然我们知道可以通过抽样来估计性能度量的梯度,我们就应该对其采取行动。我们将在当前政策下播放 N 集 LunarLander,并在这些集上累积一批轨迹。注意,由于策略梯度是一种随机策略算法,我们将用从代理网络的逻辑中获得的相应概率来对我们的行为进行采样。
因此,我们将累积所有行动逻辑和行动的对数概率,以及 N 集内所有行动的回报,以计算策略梯度的近似值。我们还将计算熵奖金和奖励去。
以下是播放一集环境并收集所有轨迹和相应计算值的循环:
The play_episode method
在下面的要点中,你可以看到如何从你的轨迹中获得奖励来计算奖励:
Discounted rewards-to-go method
因此,在算法训练的一个时期,我们有 N 个轨迹,或者更准确地说,N 个行动对数概率数组和 N 个奖励数组。现在,我们需要做的就是用相应的奖励值来“加权”我们用当前策略收集的行动的对数概率。这样,我们获得了 N 个“加权”行动对数概率数组。通过取“加权”对数概率的平均值,我们最终可以得到政策梯度估计值:
Calculating the policy “loss” and the entropy bonus
现在,当我们拥有策略梯度算法的所有移动部分时,我们可以通过根据我们的策略梯度估计采取步骤来解决环境问题:
Solving the CartPole or LunarLander environments
月球着陆器截图
以下是我在训练月球着陆器任务的代理时捕捉到的一些截图:
 **
**
In the beginning of training the agent is acting maximally random as the distribution over actions is approximately uniform



As training progresses the agent chooses better actions and learns how to generalize
收敛度量

Average return over 100 episodes for Lunar Lander environment

Policy entropy for the Lunar Lander agent. Later in the training process the agent becomes more certain about the actions it takes

Average return over 100 episodes for Cart Pole environment

Policy entropy for the Cart Pole agent.
感谢您的阅读!
打破聚集的聚类过程
如何将聚合聚类应用于数据的详细步骤

16S rRNA species tree with Neighbour Joining Cluster method and Kimura-2 Parameter model using 1000 bootstrap from my thesis “ CHEMICAL AND MOLECULAR TAXONOMY ACTINOMYCETES ISOLATE FROM JAMBI, TIMOR, AND LOMBOK (2015)”
如果你没有认出上面的图片,这是意料之中的,因为这张图片大多只能在生物杂志或教科书中找到。我上面的是一个物种进化树,这是一个物种共享的历史生物树,目的是看它们彼此之间有多接近。更一般地说,如果你熟悉层次聚类,它基本上就是这样。准确地说,我上面所说的是自下而上的或聚集聚类方法来创建一棵被称为邻居加入的系统发育树。
准备好通过 365 Data Science 上的折扣价向所有专家学习数据科学吧!
[## 为数据科学夏季做好准备- 65%折扣| 365 数据科学
选择一条职业道路,掌握你想要的特定工作角色的技能——数据科学家、数据分析师或商业…
365datascience.pxf.io](https://365datascience.pxf.io/c/3452806/1037878/11148)
凝聚聚类
介绍
在机器学习中,无监督学习是一种在没有任何指导或标签的情况下推断数据模式的机器学习模型。无监督学习家族中包括许多模型,但我最喜欢的模型之一是凝聚聚类。
凝聚聚类或自下而上聚类本质上是从一个个体聚类(每个数据点被视为一个个体聚类,也称为叶)开始,然后每个聚类计算它们彼此之间的距离。彼此距离最短的两个集群将合并,创建我们所谓的节点。新形成的集群再次计算其集群成员与该集群之外的另一个集群的距离。重复该过程,直到所有数据点都被分配到一个称为根的簇。结果是一个名为树状图的基于树的对象表示。
提醒一下,虽然我们看到了数据应该如何聚类的结果;聚集聚类并没有给出我们的数据应该如何被聚类的确切数字。应该由我们来决定分界点在哪里。

Dendrogram as the output of the Agglomerative Clustering
让我们试着更详细地分解每一步。为了简单起见,我将只使用最常见的参数来解释凝聚星团是如何工作的。
距离测量
我们通过测量数据点之间的距离来开始凝聚聚类过程。具体是怎么算出来的?我举一个哑数据的例子。
#creating dummy data
import pandas as pd
dummy = pd.DataFrame([[30,100,5],
[18, 200, 2],
[35, 150, 7],
[48, 300, 4],
[50, 200, 6]], index = ['Anne', 'Ben', 'Chad', 'Dave', 'Eric'], columns =['Age', 'Expense($)', 'Distance(KM)'])

Dummy data of 5 peoples with 3 dimensions
假设我们有 5 个不同的人,他们有 3 个不同的连续特征,我们想看看如何对这些人进行聚类。首先,我们需要决定我们的聚类距离度量。
最常用的距离测量方法之一叫做 欧几里德距离 。

Euclidean distance calculation
用一个简单的术语来说,欧几里得距离是从 x 点到 y 点的直线。我将通过我们的虚拟数据中 Anne 和 Ben 之间的距离来举例说明。
在虚拟数据中,我们有 3 个特征(或尺寸)代表 3 个不同的连续特征。在这种情况下,我们可以使用下面的公式计算安妮和本之间的欧几里德距离。

如果我们把所有的数字放在一起。

使用欧几里德距离测量,我们获得安妮和本之间的欧几里德距离为 100.76。类似地,将测量应用于所有数据点将产生以下距离矩阵。
import numpy as np
from scipy.spatial import distance_matrix#distance_matrix from scipy.spatial would calculate the distance between data point based on euclidean distance, and I round it to 2 decimalpd.DataFrame(np.round(distance_matrix(dummy.values, dummy.values), 2), index = dummy.index, columns = dummy.index)

Euclidean distance matrix of the dummy data
之后,我们合并矩阵中最小的非零距离来创建我们的第一个节点。在这种情况下,是本和埃里克。

Merging event between two data point to create a node
对于新的节点或集群,我们需要更新我们的距离矩阵。

现在我们有了 Ben 和 Eric 的新聚类,但是我们仍然不知道(Ben,Eric)聚类到其他数据点之间的距离。我们如何计算新的聚类距离呢?为此,我们需要首先设置链接标准。
连锁标准
链接标准是精确测量距离的地方。这是我们建立的一个规则,用来定义集群之间的距离。
有许多联动标准,但这次我只使用最简单的联动,称为 单联动 。它是如何工作的?我会在下面的图片中展示它。

Representation of Single linkage criterion
在单一连锁标准中,我们将我们的距离定义为聚类数据点之间的最小距离。如果我们把它放在一个数学公式里,它会是这样的。

其中聚类 X 到聚类 Y 之间的距离由分别是 X 和 Y 聚类成员的 X 和 Y 之间的最小距离定义。
让我们举一个例子。如果我们将单一连锁标准应用于我们的虚拟数据,比如 Anne 和 cluster (Ben,Eric)之间的数据,它将被描述为下图所示。

在单一连锁标准下,我们得到 Anne 到 cluster (Ben,Eric)之间的欧氏距离为 100.76。将单一连锁标准应用于我们的虚拟数据将产生以下距离矩阵。

Updated distance matrix
现在,我们有了新聚类到另一个数据点之间的距离。虽然如果你注意到,安妮和乍得之间的距离现在是最小的。在这种情况下,下一个合并事件将发生在 Anne 和 Chad 之间。

我们保持合并事件发生,直到所有的数据都聚集到一个集群中。最后,我们将获得一个树状图,其中所有数据都被合并到一个集群中。
#importing linkage and denrogram from scipyfrom scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt#creating dendrogram based on the dummy data with single linkage criterionden = dendrogram(linkage(dummy, method='single'),
labels = dummy.index)
plt.ylabel('Euclidean Distance', fontsize = 14)
plt.title('Dendrogram of the Dummy Data')
plt.show()

Final Dendrogram of the Agglomerative Clustering
确定聚类的数量
我们已经得到了树状图,那么我们该怎么处理它呢?我们将使用它来为我们的数据选择一些集群。记住,树状图只向我们展示了数据的层次结构;它并没有准确地给出最佳的集群数量。
确定聚类数的最好方法是目测我们的树状图,并选择某个值作为我们的分界点(手动方式)。通常,我们选择切割最高垂直线的分界点。我会用下面的图片展示一个例子。

Dendrogram with a cut-off point at 60
水平线与垂直线相交的次数将产生该组的数目。
选择 60 的截止点将给出两个不同的聚类(Dave 和(Ben,Eric,Anne,Chad))。选择不同的分界点也会给我们不同的集群数量。例如,如果我们将截止点移到 52。

Dendrogram with a cut-off value at 52
这一次,以 52 为截止点,我们将得到 3 个不同的集群(Dave,(Ben,Eric)和(Anne,Chad))。
最后,我们决定哪个聚类数对我们的数据有意义。在这种情况下,拥有数据的领域知识肯定会有所帮助。
当然,我们可以通过特定的方法自动找到集群的最佳数目;但是我相信确定聚类数的最好方法是通过观察聚类方法产生的结果。
凝聚聚类模型
假设我会选择值 52 作为我的分界点。这意味着我最终会有 3 个集群。有了这些知识,我们可以将它实现为一个机器学习模型。
from sklearn.cluster import AgglomerativeClusteringaglo = AgglomerativeClustering(n_clusters=3, affinity='euclidean', linkage='single')
aglo.fit_predict(dummy)
凝聚聚类模型将产生[0,2,0,1,2]作为聚类结果。然后,我们可以将聚类结果返回给虚拟数据。在我的例子中,我将其命名为“Aglo-label”。
dummy['Aglo-label'] = aglo.fit_predict(dummy)

Clustered data via Agglomerative Clustering
现在,我的数据已经被聚类,并准备进一步分析。有必要分析结果,因为无监督学习仅推断数据模式,但它产生何种模式需要更深入的分析。
结论
凝聚聚类是层次聚类家族中的一员,它通过合并每个单独的聚类进行工作,这一过程一直重复,直到所有数据都成为一个聚类。
聚集聚类采取步骤是:
- 每个数据点被指定为单个聚类
- 确定距离测量值并计算距离矩阵
- 确定合并集群的链接标准
- 更新距离矩阵
- 重复该过程,直到每个数据点成为一个聚类
用一个树状图,然后我们选择我们的截止值来获得该类的数目。
最后,凝聚聚类是一种无监督的学习方法,目的是从我们的数据中学习。如何解释聚类结果仍然取决于我们。
我在这里提供笔记本的 GitHub 链接作为进一步参考。
访问我的 社交媒体!
如果您没有订阅为中等会员,请考虑通过我的推荐订阅。
分解有效 Git 工作流的基础

作为一名初露头角的数据科学家,我们学到的第一件事就是如何使用而不破坏 Git。我们课程中的所有内容都是通过 GitHub Enterprise repository 提供给我们的,因此能够使用 Git repositories 并将其克隆到我们自己的机器上是一项非常重要的技能。我们将负责根据当地教师对课程的需求来更新他的作品库,并维护一个提交作品和项目的运行库。不用说,精通 Git 中的基本命令对我们来说是成败的关键。
然而,在项目进行七周后,我们开始了我们的第一个真正的团队项目,而我,这个受虐狂,想要确保我的团队制定出一个集中的 Git 存储库,以真正掌握真正的 Git 工作流是什么感觉。虽然我们熟悉 Git,但我想探索一下对于我的三人小组来说,一个易于使用但有效的 Git 工作流的元素是什么样的。这并不是详尽的指南,而是如何让 Git 和 GitHub 为较小的团队工作的基本参考。
所以,我们来分解一下步骤。在我的假想团队“Nate”和“David”中,我们决定为即将到来的项目创建一个新的神经网络模型。为了创建这个特性,我们需要在分支中工作。分支允许我们的团队在这个项目的几个方面工作,而不会潜在地覆盖团队成员的个人工作。

The simple Git workflow in our group, visualized.
合并
因此,对于 Nate 来说,创建一个特性分支并将其合并回主分支,他需要遵循以下步骤。
1.从远程库原点拉最新的主分支
$ git pull origin master
2.创建特征分支神经网络
$ git checkout -b neural-net
3.Nate 正在开发他的功能,注意其他团队成员可能正在开发的文件的变化。他添加要登台的文件,提交更改,并将它们推送到远程存储库。
# add all files in local repository directory, or add files individually
$ git add .# commit files to the HEAD of "neural-net"
$ git commit -m "a short but descriptive commit message"# push commits to remote repository "origin"
$ git push origin neural-net
4.我们现在准备好让神经网络跟上主设备的速度。在 Nate 从他的远程神经网络分支中取出最新的提交之后,他从远程存储库中取出 master 以确保对 master 的更改反映在他的合并中
$ git pull origin neural-net
$ git checkout neural-net
$ git pull origin master
在这里,内特仍然在分支神经网络中,但是从主分支中提取变化。
5.内特将神经网络合并到主机。他必须首先从远程存储库中检出主分支。他可能不得不再次拉出主机*,这取决于他的本地主机在提交历史中的位置。*
$ git checkout master
$ git pull origin master
$ git merge neural-net
$ git branch -d neural-net
这将提交历史保存在神经网络和主中。冲突可能会发生,但是只要团队意识到他们所做的改变,这些冲突就可以被最小化。在这个序列中,内特还在“分支”命令中添加了“-d”标记,以删除神经网络分支,因为他已经完成了他的特性的实现。
重置基础
将主分支“重新基准化”到特征分支上也是为了将分支合并在一起,并保留提交历史。Nate 不会合并,而是将提交给 master 的神经网络分支重新定基。
“Rebasing”从主分支引入新的提交,如果有提交还不在特性分支中,将其添加到特性分支,并将来自特性的提交添加到*主分支之上。*在本例中,Nate 的提交将是 HEAD 中的最新提交,但也将包含来自 master 的任何更改。例如,下面是 rebase 方法的一种更详细的工作方式:
# Create a new branch off of master
$ git checkout master
$ git pull
$ git checkout -b neural-net
$ git push neural-net# Add some commits
$ git commit -a -m "descriptive yet short commit message"
$ git commit -a -m "another descriptive yet short commit message"
$ git push neural-net# Get the latest changes off of master and rebase neural-net
$ git checkout master
$ git pull
$ git checkout neural-net
$ git rebase master
$ git push -f neural-net
从这里开始,神经网络现在将与主同步。
内特完成了他的神经网络特征。在团队的同意下,Nate 会:
$ git checkout master
$ git pull
$ git checkout neural-net
$ git rebase master
$ git push -f neural-net
$ git checkout master
$ git merge --no-ff neural-net
$ git push master
最后,内特的特征现在将成为主分支的一部分。
这简单吗?假设,是的,它与我们班上熟悉的 Git 工作流相对相似,任何熟悉 Git 的人都可以为他们工作。然而,正如人类做的许多事情一样,事情发生,而使用 Git,这些事情被称为“合并冲突”。
合并冲突
所以,让我们假设在上面的一个 merge 中,Nate 检查他的存储库的状态,Git 向 Nate 抛出这个消息:
$ git status
# On branch contact-form
# You have unmerged paths.
# (fix conflicts and run “git commit”)
#
# Unmerged paths:
# (use “git add <file>…” to mark resolution)
#
# both modified: stocks.html
no changes added to commit (use “git add” and/or “git commit -a”)
Git 不喜欢 Nate 版本的“stocks.html”与当前的提交历史不同。最有可能的原因是 David 可能已经更改了“stocks.html”的内容,将这些更改提交给了 master、,而 Nate 在尝试合并其功能之前无法从 master 获得最新的提交。
好消息是这个问题可以解决。Git 很好地标记了文件中“stocks.html”中的问题区域,方法是将它包含在一个如下所示的标记中:
“<<<<<<< HEAD” and “>>>>>>> [other/branch/name]"
“HEAD”是对当前检出分支中最后一次提交的引用。你可以把“头”想象成“当前分支”。“stocks.html”中的合并冲突示例可能如下所示:
<<<<<<< HEAD or neural-netNate's list of stocks=======David's list of securities>>>>>>> masterA LIST OF STOCKS
Git 概述了哪些行不同步,并相信用户可以手动解决这些问题:
Nate's list of stocksA LIST OF STOCKS
这确保了主和神经网络拥有相同版本的 stocks.html
然后,Nate 会将这些更改提交给主模块。
$ git add stocks.html
$ git commit -m "Merged master fixed conflict."
注意:并非所有的文件类型或编辑器都会标记这些冲突,但是 Git 在描述终端中的合并冲突时总是会突出显示冲突存在的位置。然而,Git 有一个内置的 GUI,它可以引导您处理冲突,并允许合并冲突的相对简单的集成。
打破彩票假说
从麻省理工学院 CSAIL 有趣的论文中提炼思想:“彩票假说:寻找稀疏、可训练的神经网络”。
我最近读过的最有趣的论文之一是“彩票假说:寻找稀疏的、可训练的神经网络”(https://arxiv.org/abs/1803.03635)。我已经将内容浓缩成一篇简短的博文,这可能会帮助你快速理解文章中的观点。
动机
神经网络的剪枝技术可以将训练网络的参数数量减少 90%以上,而不会影响精度。具有较少参数的网络降低了存储需求,并且可以花费较少的时间来执行推断。

Simplified example of pruning a trained network. Removing a parameter is equivalent to removing a connection between neurons.
听起来不错,给我报名吧!但是训练大型网络可能非常昂贵。如果我们可以训练一个与修剪后的网络具有相同拓扑(形状)的网络,这不是很好吗?不幸的是,用修剪过的网络的拓扑来训练网络产生的网络比原始的未修剪过的网络具有更低的精度。

Simplified example of pruning a trained network (above). Simplified example of training a network with the topology of the pruned network using a new random weight initialization (below)
这篇论文的作者想问为什么用修剪过的网络拓扑来训练网络会产生更差的性能。
彩票假说
“一个随机初始化的密集神经网络包含一个子网络,该子网络被初始化,以便在隔离训练时,它可以在最多相同次数的迭代训练后匹配原始网络的测试精度。”
他们发现,通过保留来自未修剪网络的原始权重初始化,可以用修剪后的网络拓扑来训练网络,并在相同次数的训练迭代内实现相同或更好的测试精度。

Simplified example of pruning a trained network (above). Simplified example of training a network with the topology of the pruned network using the original weight initialization from(below)
彩票类比
好吧,看起来很简单。但是彩票是怎么回事呢?假设你的目标是找到一张中奖彩票。如果你买了一张票,赢得钱的机会很小。但是如果你买了一百万张票,很可能你的一些票会赢得一些钱(虽然这可能不盈利)。
在这个类比中,购买大量门票就像为您的任务设置了一个过度参数化的神经网络。神经网络通常有超过一百万个参数!彩票中奖就相当于训练了一个神经网络,对你的任务有很高的准确率。最后,获胜的标签指的是达到高精度的修剪子网的权重初始化。
识别中奖彩票
本文提出了两种剪枝策略,可以找到获胜的票(达到高精度的子网)。
一次性修剪
- 随机初始化神经网络
- 训练网络
- 将每个层中具有最低幅度的权重的 p%设置为 0(这是修剪)
- 将修剪后的网络权重重置为其原始随机初始化
应该注意到,到输出神经元的连接以正常修剪速率的一半被修剪。
迭代剪枝
迭代修剪只是迭代地应用一次性修剪的步骤。作者发现迭代修剪比一次性修剪产生更小的修剪子网络。
结果
迭代修剪策略被应用于全连接架构、卷积架构和具有剩余连接的卷积架构(ResNet)。作者在 MNIST 和 CIFAR-10 图像分类数据集上研究了迭代剪枝技术。他们的修剪策略也适用于不同的优化器(SGD、momentum、Adam)、dropout、weight decay、batchnorm 和 residual connections。
修剪后的子网络比原来的小 10-20 %,并且在最多相同的迭代次数下达到或超过了原来的测试精度。这些结果支持彩票假说。修剪后的子网络也具有更好的泛化能力,因为训练和测试精度之间的差异更小。
讨论
为什么网络会收敛到使用其总参数的一小部分来解决一个任务?“获胜”的初始化已经接近完全训练的值了吗?没有。实际上,在训练过程中,它们比其他参数变化更大!作者推测,获胜的初始化可能落在损失景观中特别适合优化的
区域。他们提出了“彩票猜想”,即随机梯度下降在超参数化网络中寻找并训练一张中奖彩票(子网)。
限制
这篇论文展示了有趣的结果,这些结果有助于更好地理解深度神经网络是如何学习的。不幸的是,他们提出的迭代修剪策略没有提供显著的实际好处。
迭代修剪在计算上是昂贵的,因为它涉及每次尝试训练网络 15 次。这使得作者很难研究像 ImageNet 这样的大型数据集。作为未来的工作,作者希望找到更有效的剪枝策略。
通过将参数数量减少 80–90 %,降低了网络的存储需求。权重矩阵仍然具有相同的维数,但是更加稀疏。用于修剪后的子网络的前馈步骤仍然需要以相同的计算复杂度计算矩阵乘法,因此训练和推断并没有明显更有效。作为未来的工作,他们建议基于非数量级的剪枝策略可以找到更小的剪枝子网。
感谢阅读!
2019 年闯入数据科学
我从商业到数据科学之旅的感悟

https://unsplash.com/photos/rk_Zz3b7G2Y
介绍
我记得当时想闯入数据科学领域,就好像是在昨天一样。我刚刚在上海开始了我的海外学期,参加了几场关于数据科学和机器学习的讲座和客座演讲。然而,我以前从未编写过代码(除了一些基本的 SQL),不知道从哪里开始。最初的网络搜索导致了更多的困惑,而不是洞察力,因为许多人推荐了许多不同的数据科学途径。有些人甚至认为,没有博士学位就不可能成为数据科学家。
这篇文章采用了不同的方法。我不打算尝试提供一条通向数据科学的万能之路。相反,我将详述我尝试进入数据科学的经历,我希望这对有抱负的数据科学家可能有用。
第 1 部分:学习如何编码
在尝试做其他事情之前,我开始学习如何编码。因为我认为一些指导会有所帮助,所以我决定参加纽约市数据科学院为期 12 周的数据科学训练营。该计划包括一个处理 Python、R 和 SQL 的在线准备课程,必须在实际参加训练营之前完成。
码,码,码
事后看来,我希望我把更多的注意力放在练习编码上,而不是试图学习一门编程语言。我后来意识到,编程是一项主要通过不断重复练习获得的技能。我后来自己发现并研究了一些很棒的书籍,其中包括针对 Python 的“艰难地学习 Python”和针对 R 的“ R for Data Science ”。因为我以前已经使用过 SQL,所以我只需要回顾一下主要的命令。如果你想要一个更完整的 SQL 指南,我推荐你开始学习模式分析的 SQL 课程。
在学习编码的过程中,你会遇到很多很多问题。继续走。克服这些错误并检查你的错误在以后会非常有价值。当我在 Jupyter 笔记本上练习 Python 时,我总是记录我所有的错误,这样我就能在以后回顾它们。这导致了一个个性化的代码片段库和有趣的发现,直到今天我还在依赖它。
Python 还是 R?
有许多因素会影响一个人在 Python 和 r 之间的选择。我是否希望能够方便地使用各种工具来进行数据的统计分析?那么 R 大概就是要走的路。我是否想学习一种更通用的语言,可以应用于数据分析之外的许多事情?在这种情况下,Python 可能是您的首选。然而,根据我的经验,选择一个并开始编码才是最重要的。找出你喜欢的语言,不要只依赖第三方的建议。
如果你想变得非常多才多艺,我建议你找到一个最喜欢的,但也能使用另一个。对我来说幸运的是,纽约数据科学学院用 R 和 Python 两种语言教授全部课程。我个人更喜欢使用 Python 进行机器学习,但同时也喜欢使用 tidyverse 进行 R 中的数据分析,tidy verse 是一个为数据科学设计的 R 包集合。
第二部分:复习统计数据
作为一名商科专业的学生,我在大学里除了学习一些经济和金融课程外,还学习了基础统计学课程。因此,深入研究统计数据并不意味着面对我从未见过的东西,但事实证明这仍然是一个相当大的挑战。在我看来,特别是在 2019 年,只知道如何使用机器学习包,如 scikit-learn,既不足以有效地实践数据科学,也不足以让你在数据科学领域找到工作。
记录你的进步
为了以一种集中的方式组织我需要知道的一切,我开始为每个主题创建带有摘要的 Word 文档。网上有一些所谓的“小抄”,但是,我通常发现它们缺乏深度。此外,正如我在本文开头所强调的,对于任何与数据科学有关的事情,都没有通用的解决方案。所以,建立自己定制的数据科学查找库是一个好习惯。
我在训练营听课的时候记笔记,晚上提炼和复习。虽然这需要付出很多努力,但随着讲座的进行,它极大地促进了对越来越复杂的算法的理解。
掌握基本面
关于这个话题的最后一点:在任何情况下,都不要跳过基础知识。虽然尝试跳到花哨的算法一开始看起来很诱人,但在我看来,将大部分时间花在基础上是更好的选择。除了讲座,我还看了几本关于统计学和统计学习的书。在我看来,关于统计学习最好的书是 Daniela Witten,Robert Tibshirani 和 Trevor Hastie 的《统计学习导论:R 语言应用》。不同的书采取不同的方法。因此,将侧重于算法的口头解释的书籍与深入技术细节的书籍结合起来,证明是对我时间的一项不错的投资。我也对互联网上流传的所有流行词汇感兴趣,但最终发现,在考虑向您的数据科学技能集添加新功能之前,您首先必须建立非常坚实的基础。
多问问题
如果你碰巧像我一样参加了一个新兵训练营,利用你的教练。尽可能多问问题。不要等到遇到严重的问题才开始提问。甚至向更有经验的人展示您的代码,并寻求提高其效率的方法,都可能被证明是极其有用的。
万一你不能得到专业的帮助,不要绝望。有很多在线社区和资源可以帮助你回答你的问题。很可能,你不是第一个遇到这个问题的人。最重要的是,自己想出解决方案会帮助你更容易记住它。
其他要温习的东西
根据你的背景,复习基本的线性代数和微积分可能也是一个好主意。我会建议你或者翻翻旧的线性代数或微积分笔记,或者参加在线课程,比如麻省理工学院免费开放的线性代数课程。如果你有兴趣阅读学术论文和更多的技术书籍,这一点尤为重要。
第 3 部分:构建项目组合
完成至少四个项目
如果你想在数据科学领域找到一份工作,这第三步至关重要。为了让你的潜在雇主相信他们应该雇用你,并应用你到目前为止学到的东西,试着完成至少四个主要项目。
如果你像我一样,参加纽约市数据科学学院训练营,那么你必须完成三个项目,涵盖数据科学生命周期的所有方面。这些项目将涵盖从数据可视化的数据采集到机器学习的所有内容。最后,顶点计划允许你选择任何你想做的主题。你应该利用这个机会在就业市场上为自己定位,瞄准你梦想中的雇主。例如,如果你的目标是将数据科学应用于医疗保健数据,那么试着找到一个解决该领域问题的项目,例如预测糖尿病的发病。
不要止步于此
如果你真的想打入一个特定的行业,就不要止步于四个项目。搜索可能与你的理想雇主相关的数据,并进行实验。建立一些有趣的东西,写一篇关于你的项目的文章或博客。你在某个特定领域展示自己的能力和兴趣越多,这个行业的人就越有可能对你印象深刻。
不要太花哨
在选择项目时,选择听起来新奇的东西是很有诱惑力的。不要那样做。至少不是马上。确保你的项目从开始到结束都是可靠的,并且包含尽可能少的错误。让别人检查你的项目并为你审阅。在训练营期间,我向我的同学和导师展示了我所有的项目。获得对你工作的不同意见将有助于你改进未来的项目。
第四部分:努力找工作
准备是关键
如果你想在数据科学招聘过程中取得成功,尽可能地做好准备。在 HackerRank 上查看编码挑战,熟悉被问到的问题类型,也许最重要的是,记录你的面试过程。与机器学习理论一样,你应该创建一个文档,在其中描述和评估你在面试时的经历。
然后,在每次面试之前,将该文档与您的机器学习理论文档一起查看,并确保您避免重复错误。在开始编码挑战之前,通过在 HackerRank 上完成一些任务来热身也可能是有帮助的。
学习如何推销自己
如果你想要一份数据科学方面的工作,你将不得不与许多其他申请人竞争。通过创造你的个性化叙事让自己与众不同。为什么你是最佳人选?你为什么选择这些具体的项目?为什么首先选择数据科学?因为你将不得不在几乎每一次面试中介绍自己,所以确保你精心准备了一个强有力的叙述,可以根据你的目标公司进行调整。
当你在做的时候,也要为你的项目准备推介。不是每个潜在雇主都想听你描述你所有的项目。也许某个特定的项目引起了将要面试你的人的注意。确保你能够深入描述每个项目,但也有一个后备的推介,以防你只需要对你的项目做一个简短的描述。
在其他人面前练习这些技巧。想想你在家里可能会说什么,比不上站在你不认识的人面前试图解释你的项目。如果你去上学或参加新兵训练营,和你的同学一起练习推销自己,并给彼此建设性的反馈。这样做,你也许能在第一次面试前避免几个错误。
网络
在完成纽约数据科学学院的训练营后,所有毕业生都被鼓励参加一个招聘伙伴活动,在这个活动中你可能会找到你未来的雇主。在参加这类活动之前,学会如何推销自己和你的项目是绝对重要的。参加这类活动时要有闯劲。调查将要参加活动的招聘经理和招聘人员。在活动期间,尽可能快地找出你和公司之间是否有合适的人选。递简历,要名片。另一个非常重要的建议是:不要只和一两个人说话。即使有可能非常适合,也不要把自己限制在潜在工作机会的数量上。在一定时间的互相了解和交换联系方式后继续前进。
社交是一项需要练习的技能。对我来说幸运的是,训练营为学生们提供了大量关于如何驾驭社交活动的建议和技巧。确保了解社交中的行为准则(例如,给每位出席的招聘经理写一封好的跟进邮件)。
然而,与项目一样,不要止步于此。与你周围的人建立关系网。数据科学是一个迷人的领域,有许多迷人的人。如果你在学校或训练营,和你的同学联系。在 LinkedIn 上寻找有趣的人。参加你所在城市的数据科学会议。有很多建立关系网的机会,你做得越多,你就会做得越好。
不要放弃
找工作可能很难。你可能会参加许多面试,只是为了让人们告诉你他们不会雇用你。除非你运气好,能马上找到工作,否则找工作可能会是一个非常令人沮丧的过程。不要绝望。如果你坚持不懈,不断完善自己和简历,最终会有人注意到的。坚持相信你会得到你想要的工作机会。与之前经历过数据科学招聘过程的人交谈,你会发现他们中的许多人都经历过许多令人沮丧的面试。那些成功的人和那些失败的人之间的区别,归根结底,与坚持斗争和不屈服的能力有很大关系。
结论
2019 年成为一名数据科学家并不容易。你将不得不跨越许多障碍,克服许多挑战。然而,通过这一过程的回报是巨大的。你不仅可以做你喜欢做的事情,还可以和来自各种不同背景的聪明人打交道。只要迈出第一步,其余的就会跟上。开始追随你的激情。如果你花的时间比别人长,那没关系,重要的是你的意志力。确保你每天都在稳步提高,最终会让你到达你想去的地方。
打破我的小马:破解密码的频率分析
在第一次成为父母之前,我花了很多时间思考我的生活将要发生的各种变化。我没有预料到的一个变化是我将会用多少代码来说话。你的孩子总是在倾听和学习,所以用不了多久,你和你的另一半就会停止在他们面前发送未加密的信息。就在今天早上,当我和妻子在我们三岁的女儿面前聊天时,我们在某个特定的上下文中将“玩具”称为“分心机制”。
我的女儿还没有足够的理解力来破解我们的小代码(尽管它即将到来),但它确实让我开始思考密码和代码,于是一个博客诞生了。作为一门新兴的数据科学,我认为您可以使用某种统计分析来破解简单的代码,果然您可以!在这篇博客中,我们将讨论频率分析以及如何破解一个简单的密码。
密码和代码
首先,让我们澄清一些术语。大多数人对什么是“密码”和“代码”有一个大致的概念,但是定义一些术语是值得的。
密码和代码都是加密信息的一系列步骤。它们将明文信息转换成只能用一些辅助来源解密的信息。在密码的情况下,它通常是一个密钥,在代码的情况下,它通常是一个密码本。大多数人可以互换使用这两个术语,但还是有区别的。用密码加密的文本通常会与原始文本的字符数相同。代码通常使用一串字符或数字来表示单词或短语。
我上面的例子是一个代码,因为我用一个单词代替了一个短语。如果我们要对“玩具”这个词进行加密,我们可以改为“座位”(t=s,o=e,y=a,s=t)。
简单替代密码
我们要看的密码是简单的替代密码。简单的替代密码只是将字母表中的每个明文字母作为字母表中的另一个字母进行加密。这是一对一的替换,所以密文中的一个给定字母总是等同于明文中的同一个字母。这里有一个使用 PyCipher 库的例子:

密码使用密钥来加密数据。对于简单的替换,我们使用一个密码字母。你可以看到替换是如何工作的。每一个明文‘a’都变成了密文‘w’,每一个‘b’都变成了‘h’,以此类推……所以我们的明文‘密码’就变成了‘xwytdkl’。请注意,按照惯例,当使用简单替换进行加密时,您将返回去掉标点符号和全部大写的密文,原因很明显,您使其更难被破解。
频率分布
有很多可能的密码密钥(26!实际上)所以理论上简单的替代密码很难破解。即使抛开现代计算能力,如果你知道原始语言和一点频率分布,手动破译 100 或更多字符的信息实际上是非常可行的。
大多数语言都有一定的特点。一些字母和一些字母序列比其他字母出现得更频繁。在普通的英语文本中(比如说,超过 100 个字符),’ e ‘通常出现的频率最高,其次是’ t ‘和’ a '。字母“x”、“q”和“z”出现得最少。

https://en.wikipedia.org/wiki/Letter_frequency
知道了这一点,并且知道给定的密文将总是替换其对应的明文,您就可以开始有根据地猜测哪些密文字母对应于哪些明文字母。
我的小马驹密码
为了开始做一些频率分析并说明更多的概念,我从我的小马:友谊是魔法 wiki 的一篇随机文章中抓取(并稍微修改)了以下文本:
NWVKIF UWVYC TWY AFYXAKIL CD QKIWCI UNVCCIKYEP HP EIK QEANLEDDL CDP IWKCE XDFP XDYIP. UNVCCIKYEP'Y AFACAWN LIYAMF, XVHNAYEIL DFNAFI HP UWVYC, KIUIKY CD EIK WY 'XDYIP' WY TINN. EIK QVCAI OWKG, CEKII XAFG WFL QPWF HVCCIKUNAIY, AY YAOANWK CD CEWC DU CEI XDFP YGP YGAOOIK.
如上所述,您不太可能得到标点和空格都完好无损的密文,但是我这样做是为了说明一些概念。首先我们可以算出每个密文字母的频率:

正如我们所看到的,看起来“I”、“C”和“Y”是出现频率最高的字母。让我们假设‘I’密码等价于明文中的‘e ’,并进行替换(替换用小写字符表示)。
NWVKeF UWVYC TWY AFYXAKeL CD QKIWCe UNVCCeKYEP HP EeK QEANLEDDL CDP eWKCE XDFP XDYeP. UNVCCeKYEP'Y AFACAWN LeYAMF, XVHNAYEeL DFNAFe HP UWVYC, KeUeKY CD EeK WY 'XDYeP' WY TeNN. EeK QVCAe OWKG, CEKee XAFG WFL QPWF HVCCeKUNAeY, AY YAOANWK CD CEWC DU CEe XDFP YGP YGAOOeK.
好不了多少,但我们还有一些锦囊妙计。例如,我们知道最常见的两个、三个和四个字母的单词。

http://www.practicalcryptography.com/ciphers/simple-substitution-cipher/
我们这里有几个两个字母的单词要试一下。因为我们知道第二个最频繁出现的密文字符是“C”,让我们试着用“t”来代替它,它是英语中第二个最频繁出现的字符。我们有几个以“C”开头的两个字母的单词,以“t”开头的最常见的两个字母的单词是“to”,所以我们也假设密文“D”等于明文“o”。
NWVKeF UWVYt TWY AFYXAKeL to QKeWte UNVtteKYEP HP EeK QEANLEooL toP eWKtE XoFP XoYeP. UNVtteKYEP'Y AFAtAWN LeYAMF, XVHNAYEeL oFNAFe HP UWVYt, KeUeKY to EeK WY 'XoYeP' WY TeNN. EeK QVtAe OWKG, tEKee XAFG WFL QPWF HVtteKUNAeY, AY YAOANWK to tEWt oU tEe XoFP YGP YGAOOeK.
现在事情开始明朗了。我们现在正文里有’ tEe ‘和’ tEKee ‘,可以猜测密文’ E ‘是明文’ h ‘,密文’ K ‘是明文’ r '。我还没有解决这个问题,但是很明显,由于撇号的作用,Y 是 s。同样,如果“K”是“r”,“E”是“h ”,那么“eWKtE”就变成了“eWrth ”,所以“W”很可能是“a ”:
NaVreF UaVst Tas AFYXAreL to Qreate UNVttershP HP her QhANLhooL toP earth XoFP XoseP. UNVttershP's AFAtAaN LesAMF, XVHNAsheL oFNAFe HP UaVst, reUers to her as 'XoseP' as TeNN. her QVtAe OaKG, three XAFG aFL QPaF HVtterUNAes, As sAOANar to that oU the XoFP sGP sGAOOer.
等等,等等。最终我们得到了我们的信息:
lauren faust was inspired to create fluttershy by her childhood toy earth pony posey. fluttershy's initial design, published online by faust, refers to her as 'posey' as well. her cutie mark, three pink and cyan butterflies, is similar to that of the pony sky skimmer.
那怎么样?我不知道小蝶是这样的!
当然,在这种情况下,我们也有标点符号和间距的线索。显然,没有这些线索就很难破译一个文本,但是你仍然可以使用频率分析,你可以开始查看字符的组的频率。
一般来说,密码学家会将文本分解成二元模型、三元模型或四元模型(分别为两个、三个和四个字符组)。这些组也有频率分布。四元图“TION”出现得非常频繁,但是“QKPC”从来没有出现过。
为了编程求解,密码学家将从尝试随机密钥来解密文本开始。然后,他们将文本分割成四元组,并乘以每个四元组可能是英语中的四个字符块的概率(或适合度),然后用稍微改变的键再试一次。因为概率非常小,而且它们可能是在大样本上计算的,所以您可以使用对数变换来防止算术下溢(算术下溢是一种计算结果,其绝对值小于计算机在其 CPU 上的内存中实际可以表示的值)。下面是一个公式示例:

这里有一个简单的换元题自己试试!我把标点符号留在了这里,如果你是手写的话,这样会更快更容易。玩得开心!
EIP. YD, CEI QDNDFIN TWY RVYC EIKI WFL EI CDNL OI CD CINN PDV CEWC CEI QDHKW YCKAGIY WC LWTF. NIC OI CINN PDV- EI TWY SIKP QDFLIYQIFLAFM. ISIKPCAOI CEI MIFIKWN AY WTWP EI MDIY WNN IN EIUI YVXKIOD DF OI. CVKL.
YXIWGAFM DU CEI MIFIKWN - HICTIIF PDV WFL OI A CEAFG EI'Y HIIF MICCAFM EAY CEAFM DF TACE DFI DU CEDYI QWXDY UKDO CEI OANACWKP XDNAQI. CEI HAM HKVFICCI TACE CEI CTD NWBP IPIY CEWC WKI NWBP AF DXXDYACI LAKIQCADFY. PDV GFDT CEI DFI. TEIFISIK YEI'Y AF CDTF WNN DU W YVLLIF EI EWY XKIYYAFM HVYAFIYY INYITEIKI CD WCCIFL CD WFL NIWSIY QDNDFIN CVKL AF QEWKMI. YEI WNTWPY HKAFMY OI QACKVY TEIF YEI'Y AF CDTF (NDFM YCDKP) YD A NAGI EIK, HVC A EWSI FD ALIW TEWC CEIP YII AF IWQE DCEIK.
WFPTWPY, MDCCW MD. QDHKW YCKAGIY WC LWTF. EWAN CD CEI MNDKADVY KISDNVCADF WFL NDFM NASI DVK LIWK NIWLIK!
用对抗性攻击破坏神经网络
我们使用的机器学习模型有内在缺陷吗?
正如你们许多人可能知道的那样,深度神经网络是一种高度表达的机器学习网络,已经存在了几十年。2012 年,随着计算能力的提高和工具的改进,一系列名为 ConvNets 的机器学习模型开始在视觉识别任务上实现最先进的性能。到目前为止,机器学习算法的工作还不够好,当它不能做正确的事情时,任何人都不会感到惊讶。
2014 年,谷歌和 NYU 的一组研究人员发现,在输入中用一种不可思议但精心构建的轻推来欺骗 ConvNets 太容易了。让我们看一个例子。我们从一个熊猫的图像开始,我们的神经网络以 57.7%的置信度正确识别出它是一只“熊猫”。添加一点精心构建的噪声,同一个神经网络现在认为这是一个有 99.3%置信度的长臂猿图像!很明显,这是一种视错觉——但是对于神经网络来说。你和我可以清楚地分辨出两幅图像看起来都像熊猫——事实上,我们甚至不能分辨出一些噪声被添加到原始图像中以构建右侧的对立示例!

Source: Explaining and Harnessing Adversarial Examples, Goodfellow et al, ICLR 2015.
2017 年,另一个小组证明了这些对立的例子可以推广到现实世界,表明当打印出来时,对立构造的图像将在不同的光照和方向下继续欺骗神经网络:

Source: Adversarial Examples in the Physical World. Kurakin et al, ICLR 2017.
另一项有趣的工作,名为*“犯罪的附属品:对最先进的面部识别技术的真实和秘密的攻击”*表明,人们可以通过构造对抗眼镜来欺骗面部识别软件,从而完全避开面部检测。这种眼镜也可以让你扮演其他人:

Source: Accessorize to a Crime: Real and Stealthy Attacks on State-of-the-Art Face Recognition. Sharif et al.
不久之后,另一个研究小组展示了各种构建停车标志的方法,这些方法可以通过在停车标志上放置各种贴纸来欺骗模型。这种干扰被设计成模仿涂鸦,因此“隐藏在人类的精神中”

The left image shows real graffiti on a Stop sign, something that most humans would not think is suspicious. The right image shows a physical perturbation applied to a Stop sign. The systems classify the sign on the right as a Speed Limit: 45 mph sign! Source: Robust Physical-World Attacks on Deep Learning Visual Classification.
*“对抗性补丁”,*NIPS 2017 上发表的一篇论文演示了如何生成一个补丁,可以放置在分类器视野内的任何地方,并使分类器输出一个目标类。在下面的视频中,香蕉被正确地归类为香蕉。贴上印有烤面包机的贴纸并不足以愚弄网络,它仍然继续将其归类为香蕉。然而,通过精心构建的“对抗性补丁”,很容易欺骗网络,使其认为这是一台烤面包机:
Source: Adversarial Patch: https://arxiv.org/pdf/1712.09665.pdf
引用作者的话,“这次攻击意义重大,因为攻击者在构建攻击时不需要知道他们攻击的是什么图像。在生成一个对抗性补丁后,该补丁可以在互联网上广泛分发,供其他攻击者打印和使用。”

Source: Adversarial Patch: https://arxiv.org/pdf/1712.09665.pdf
这些例子告诉我们,当我们的神经网络被对手以这种方式明确攻击时,它仍然非常脆弱。让我们潜得更深!
这些攻击有什么了不起的?
首先,正如我们在上面看到的,在对立例子的不正确分类中很容易获得高置信度——回想一下,在我们看到的第一个“熊猫”例子中,网络对看起来像熊猫的实际图像的确定度(57.7%)低于我们右边看起来像长臂猿的对立例子(99.3%)。另一个有趣的点是如何察觉到我们需要添加的小噪音来愚弄系统——毕竟,很明显,添加的噪音不足以愚弄我们人类。

It’s easy to attain high confidence in the incorrect classification of an adversarial example. Source: Explaining and Harnessing Adversarial Examples, Goodfellow et al, ICLR 2015.
第二,对立的例子不太依赖于用于该任务的特定深度神经网络——为一个网络训练的对立例子似乎也会混淆另一个网络。换句话说,多个分类器把同一个(错误的)类别分配给一个对立的例子。这种“可转移性”使攻击者能够在所谓的“黑盒攻击”中欺骗系统,在这种攻击中,他们无法访问模型的架构、参数甚至是用于训练网络的训练数据。
我们有好的防御吗?
不完全是。让我们快速看一下到目前为止已经提出的两类防御:
对抗训练
防御这些攻击的最简单和最暴力的方法之一是假装是攻击者,生成许多针对您自己网络的对抗性示例,然后显式地训练模型不被它们愚弄。这提高了模型的通用性,但还不能提供有意义的健壮性级别——事实上,它最终只是一个打地鼠游戏,攻击者和防御者只是试图胜过对方。
防御性蒸馏
在防御蒸馏中,我们“训练第二个模型,其表面在攻击者通常试图利用的方向上是平滑的,使他们难以发现导致错误分类的敌对输入调整”[6]。其工作的原因是,与第一个模型不同,第二个模型是在主模型的“软”概率输出上训练的,而不是来自真实训练数据的“硬”(0/1)真实标签。这种技术被证明在防御敌对攻击的初始变体方面取得了一些成功,但被最近的攻击击败,如 Carlini-Wagner 攻击,这是当前评估神经网络对抗敌对攻击的鲁棒性的基准。
为什么捍卫神经网络如此困难?
让我们试着对这里发生的事情有一个直觉。大多数时候,机器学习模型工作得很好,但只对它们可能遇到的所有可能输入中的很小一部分起作用。在高维空间中,每个单独输入像素中非常小的扰动就足以引起神经网络中点积的巨大变化。因此,很容易将输入图像推到我们的网络从未见过的高维空间中的一点。这是要记住的关键点:高维空间非常稀疏,以至于我们的大多数训练数据都集中在一个非常小的区域,称为流形。虽然我们的神经网络根据定义是非线性的,但我们用来训练它们的最常见的激活函数,整流器线性单元,或 ReLu,对于大于 0 的输入是线性的。

The Rectifier Linear Unit, or the ReLu compared to the Sigmoid and the Tanh activation functions.
ReLu 因其易于训练而成为首选激活功能。与 sigmoid 或 tanh 激活函数相比,它们在高激活时简单地饱和到上限值,从而使梯度“停留”在非常接近 0 的位置,ReLu 在 0 右侧的任何地方都有非零梯度,使其更加稳定,训练速度更快。但是,这也使得将 ReLu 激活函数推到任意高的值成为可能。
看看这个在可训练性和对抗攻击的鲁棒性之间的权衡,我们可以得出结论,我们一直使用的神经网络模型存在固有缺陷。优化的简易性是以模型容易被误导为代价的。
下一步是什么?
这里真正的问题是,我们的机器学习模型在训练分布之外表现出不可预测和过度自信的行为。对立的例子只是这个更广泛问题的一个子集。我们希望我们的模型在他们从未见过的地区运行时,能够表现出适当的低置信度。我们希望它们在生产中使用时“优雅地失败”。
根据该领域的先驱之一 Ian Goodfellow 的说法,“许多最重要的问题仍然悬而未决,无论是在理论上还是在应用上。我们还不知道防御敌对的例子在理论上是没有希望的努力,还是一个最优策略会给防御者一个优势。在应用方面,还没有人设计出真正强大的防御算法,可以抵御各种各样的对抗性示例攻击算法。”
如果没有别的,对立例子的话题让我们了解了大多数研究人员一段时间以来一直在说的话——尽管有了突破,但我们仍处于机器学习的初级阶段,在这方面还有很长的路要走。机器学习只是另一种工具,容易受到敌对攻击,这可能会在一个我们通过自动驾驶汽车和其他自动化将人类生命托付给它们的世界中产生巨大影响。
参考
这里是上面提到的论文和文章的链接。我也强烈推荐看看 Ian Goodfellow 关于这个话题的博客。
- 解释和利用对立的例子,古德菲勒等人,ICLR 2015 年。
- 物理世界中的对立例子。库拉金等人,ICLR,2017 年。
- 犯罪的附属品:对最先进的人脸识别技术的真实而隐秘的攻击。谢里夫等人。
- 对深度学习视觉分类的鲁棒物理世界攻击。艾克霍尔特等人。
- 对抗性补丁。布朗等人。
- 用对抗性例子攻击机器学习。打开 AI 博客。
打破机器学习中小数据集的魔咒:第 2 部分
现实世界中的 DS
数据大小如何影响深度学习模型,以及如何处理小数据集?
这是打破机器学习中小数据集的诅咒系列的第二部分。在 第一部分 中,我已经讨论了数据集的大小如何影响传统的机器学习算法,以及一些缓解这些问题的方法。在第 2 部分,我将讨论深度学习模型性能如何依赖于数据大小,以及如何使用较小的数据集来获得类似的性能。
PS:感谢 瑞秋托马斯 的反馈

Source: Movie Scene from Pirates of the Caribbean[source]
概述
以下是我将在本文中简要讨论的话题:
- 影响神经网络训练的关键因素
- 克服优化困难的方法
- 解决缺乏普遍性的问题
- 结论
1。训练神经网络的关键因素
神经网络是深度学习模型的基本构建模块。然而,深度神经网络有数百万个参数要学习,这意味着我们需要多次迭代才能找到最佳值。如果我们有少量数据,运行大量迭代会导致过度拟合。大型数据集有助于我们避免过度拟合和更好地概括,因为它可以更有效地捕捉固有的数据分布。
以下是影响网络优化过程的几个重要因素:
- **优化算法:*梯度下降是用于神经网络的最流行的优化算法。算法性能直接取决于训练数据的大小。我们可以尝试用较小的训练集(随机梯度下降是我们用单个数据点进行更新时的极端情况)*来更新权重,这使得训练过程快速,但是更新具有较大的波动。用整个数据集进行训练使得训练在计算上昂贵且缓慢。 Adam 、 RMSprop 、 Adagrad 、随机梯度下降是梯度下降的几种变体,其优化了梯度更新过程并提高了模型性能。查看这个博客详细了解梯度下降的各种版本。除了梯度下降之外,还有其他不同的优化技术,如进化算法(EA)和粒子群优化算法(PSO)可能有巨大的潜力。
- **损失函数:**损失函数在优化过程中也起着至关重要的作用,精心选择的损失函数有助于改进训练过程。铰链损耗就是这样一个例子,它使得用小数据集进行训练成为可能。
- 参数初始化:参数的初始状态对优化过程影响很大。选择不当的初始值会导致发散和陷入鞍点或局部最小值的问题。此外,这增加了训练过程对训练数据的要求。
- 数据量:数据量是训练神经网络非常关键的一部分。更大的数据集可以帮助我们更好地学习模型参数,改进优化过程并赋予泛化能力。
如何用小数据集训练

Fig 1: Basic implications of fewer data and possible approaches and techniques to solve it
我们已经在的上一篇文章中讨论了一些上述技术。我们将在这一部分讨论与深度学习更相关的剩余技术。
2.克服优化困难的方法
1。转移学习:
迁移学习是指将从一个任务学到的知识运用到另一个任务中,而不需要从头开始学习。它直接处理用于训练神经网络的智能参数初始化点。这项技术已广泛用于计算机视觉任务,并在深度学习在行业中的广泛应用中发挥了重要作用。现在公认的是,基于 Imagenet 数据训练的 ResNet 等模型的初始层学习识别图像中的边缘和拐角,并且后续层建立在这些特征之上以学习更复杂的结构。最后一层学习将图像分类到 1000 个类别中的一个。对于任何数据看起来类似于 Imagenet 的新问题,我们可以从预训练的 Imagenet 模型开始,更改最终的层,并根据我们的数据集对其进行微调。由于较低层的特征仍然保持相关,该过程使得优化过程更快,并且减少了训练新模型所需的数据量。
感谢 Fast.ai 库,我们可以使用迁移学习建立图像分类模型,只需几行代码和几百张训练图像,仍然可以获得最先进的结果。
最近,同样的方法也成功地应用于自然语言处理。乌尔姆菲特、伯特、 AWD-LSTM 、 GPT2 就是几个可以用于自然语言处理中迁移学习的模型。这些模型被称为语言模型,因为它们试图学习基本的语言结构,并基于之前看到的/上下文单词来预测句子中的下一个单词。这种转移学习的想法听起来非常类似于计算机视觉,但只是在最近几年才得到尝试和完善。查看这个牛逼的博客,更好地理解语言模型。
2。问题简化:
问题减少方法是指将新数据或未知问题修改为已知问题,以便可以使用现有技术轻松解决。假设我们有许多语音剪辑,我们希望根据声音来源将它们分成不同的类别。深度学习的最新进展表明,LSTM 或 GRU 等序列模型确实擅长此类任务。然而,小数据集可能是一个交易破坏者,并且为这种用例找到迁移学习的好模型也是非常困难的。我最近参加了 Fast.ai v3 课程,发现了一个解决这类问题的聪明方法。我们可以使用各种可用的库(如 LibROSA )将语音剪辑转换成图像,并将其简化为图像分类问题。现在,我们可以将合适的计算机视觉架构与迁移学习结合使用,令人惊讶的是,这种方法即使在非常小的数据集上也能提供类似的性能。请查看这个博客以获得更好的理解和代码。
3.用更少的数据学习
**a)一次学习:**人类有能力学习甚至一个单一的例子,仍然能够以非常高的精度区分新的物体。另一方面,深度神经网络需要海量的标注数据进行训练和泛化。这是一个很大的缺点,一次性学习是一种即使使用小数据集来训练神经网络的尝试。有两种方法可以实现这一点。我们可以修改我们的损失函数,使其能够识别微小的差异,并学习更好的数据表示。暹罗网络就是这样一种通常用于图像验证的方法。

Fig 2: A basic representation of Siamese network[source]
**b)暹罗网络:**给定一组图像,暹罗网络试图找出两个给定图像有多相似。该网络具有两个相同的子网络,具有相同的参数和权重。子网由卷积块组成,并且具有完全连接的层,并且向末端提取特征向量(大小为 128)。需要比较的图像集通过网络提取特征向量,计算特征向量之间的距离。模型性能取决于训练图像对(图像对越接近,性能越好),并且模型被优化,使得我们对于相似的图像获得较低的损失,而对于不同的图像获得较高的损失。Siamese network 是一个很好的例子,说明我们如何修改损失函数,并使用更少但高质量的训练数据来训练深度学习模型。查看下面的视频获得详细解释。
一次性学习的另一种方法是为模型创建一个类似人脑的记忆。这可能是谷歌 Deepmind 为一次性学习提出的神经图灵模型背后的灵感来源。
**c)记忆增强神经网络:**神经图灵机是记忆增强神经网络的一部分,它试图为神经网络创建一个外部记忆,这有助于短期学习。NTM 基本上由一个称为控制器的神经网络和一个称为记忆库的 2D 矩阵组成。在每个时间步,神经网络从外界接收一些输入,并向外界发送一些输出。然而,网络也具有从存储器位置读取的能力和向存储器位置写入的能力。请注意,如果我们使用索引提取内存,反向传播将不起作用。因此,控制器使用模糊操作来读取和写入,即,它在读取和写入时为每个位置分配不同的权重。控制器对存储器位置产生权重,这允许它以可区分的方式指定存储器位置。NTM 在自然语言处理任务中表现出了巨大的潜力,可以超越 LSTM,在各种任务中学习得更好。查看这个伟大的博客,深入了解 NTM 。

Fig 3: A basic representation of NTM[source, source]
**d)零投学习:**零投学习是指解决不属于训练数据的任务的方法。这确实可以帮助我们处理在培训中没有看到的类,并减少数据需求。有各种各样的方法来制定零短学习的任务,我将讨论一种这样的方法。在这种方法中,我们试图预测给定图像的语义表示,即给定一幅图像,我们试图预测图像类的 word2vec 表示。所以简单来说,我们可以认为这是一个回归问题,深度神经网络试图通过处理其图像来预测该类的向量表示。我们可以使用标准的神经架构,如 VGG16 或 ResNet ,并修改最后几层以输出一个单词向量。这种方法有助于我们找到看不见的图像的词向量,我们可以使用它通过最近邻搜索来找到图像类别。代替回归,我们还可以将最后一层作为图像特征和词向量的点积,并找到相似性,这有助于我们学习视觉语义嵌入模型。阅读设计文件了解更多详情。另外,看看这个博客来看看零距离学习的实践。

Fig 4: Learning Label Embedding from the image features[Souce]
4.更好的优化技术
元学习(学会学习):元学习处理从给定数据中寻找学习的最佳方式,即学习模型的各种优化设置和超参数。请注意,实现元学习有多种方法,让我们讨论一种这样的方法。元学习框架通常由一个网络组成,该网络有两个模型:
A)称为优化的神经网络或学习器,其被视为低级网络并用于预测。
b)我们有另一个神经网络,称为优化器或元学习器或高级模型,它更新低级网络的权重。
这导致了双向嵌套训练过程。我们采取了低级网络的多个步骤,形成了元学习者的单个步骤。我们还在低级网络的这些步骤结束时计算元损失,并相应地更新元学习器的权重。这个过程有助于我们找出最佳的训练参数,使学习过程更加有效。关注这个牛逼的博客详细了解和实现。

Fig 5: Meta-learning in action[Souce]
3。解决缺乏普遍性的问题
1。数据扩充:
在处理小数据集而不过度拟合时,数据扩充可以是一种有效的工具。这也是一个很好的技术,使我们的模型不变的大小,平移,视点,照明等变化。我们可以通过以下几种方式扩充我们的数据来实现这一点:
- 水平或垂直翻转图像
- 裁剪和/或缩放图像
- 更改图像的亮度/清晰度/对比度
- 将图像旋转一定角度

Fig 6: Various data augmentation techniques to create more data[source]
Fast.ai 有一些最好的数据扩充转换函数,这使得数据扩充任务非常容易,只需要几行代码。查看这个令人敬畏的文档,了解如何使用 Fast.ai 实现数据增强。
2.数据生成:
**a)半监督学习:**很多时候,我们有大量可用的数据,但只有其中的一部分被标记。大型语料库可以是任何公开可用的数据集或专有数据。在这种情况下,半监督学习可以很好地解决标记数据少的问题。一种这样的方法是建立一个模型,该模型学习标记数据中的模式,并试图预测被称为伪标记的未标记数据的类别。一旦我们有了这些伪标签,我们就可以使用带标签和伪标签的数据来为我们的原始任务训练模型。我们可以使用各种监督或非监督模型来生成伪标签,并可以设置预测概率的阈值来选择合适的伪标签数据进行训练。我们还可以探索主动学习,其中模型指定哪些数据点对训练最有用,我们可以只获得一小部分数据,以便模型可以有效地学习。合作教学和合作学习也是在这种情况下有所帮助的类似方法。
**b)甘:**生成对抗网络是一种生成模型,能够生成看起来非常接近真实数据的新数据。GAN 有两个组件,称为生成器和鉴别器,它们在我们训练模型时相互作用。生成器尝试生成假数据点,鉴别器尝试识别生成的数据是真的还是假的。假设我们想要创造新的狗的形象。生成器创建假狗照片,这些照片与真狗照片一起提供给鉴别器。鉴别器的目的是正确地识别真实和伪造的图像,而发生器的目的是产生鉴别器不能辨别为伪造的图像。在模型的适当训练之后,生成器学习生成看起来像真实的狗图像的图像,并且可以用于创建新的数据集。

Fig 7: A typical representation of GAN[source]
我们还可以使用 LSTM 的生成模型来生成文本文档或声音,这些可以用作训练数据。查看这个博客获得详细解释。
结论:
在这一部分中,我们讨论了影响深度神经网络训练的各种因素,以及一些可以帮助我们用小数据集进行训练的技术。在我们的大多数用例中,我们通常没有非常大的数据集,这种技术为我们训练模型并获得令人满意的性能开辟了新的途径。在这个博客系列中,我试图列出各种常用的技术,而训练将小数据。然而,这个列表并不详尽,只能作为进一步探索的起点。请查看链接和参考资料,以获得对上面讨论的一些技术的详细理解和实现。
关于我:研究生,旧金山大学数据科学硕士;Trulia 从事计算机视觉的实习生&半监督学习;3 年以上使用数据科学和机器学习解决复杂业务问题的经验;有兴趣与跨职能部门合作,从数据中获得见解,并应用机器学习知识来解决复杂的数据科学问题。 LinkedIn , 作品集 ,GitHub, 往期帖子
参考
- 关于语言模型的帖子,从经典方法到最近的预训练语言模型
- 利用 fastai 库在音频分类方面取得巨大成果
- 神经网络中使用的优化算法类型和优化梯度下降的方法
- 甘斯从零开始 1:深度介绍。PyTorch 和 TensorFlow 中的代码
- 深度学习专业化
- 神经图灵机的解释
- 设计:深度视觉语义嵌入模型
- 零距离学习
- 从零到研究——元学习导论
- Fast.ai 文档
英国脱欧:不文明战争向我们展示了欧盟公投是如何用数据科学赢得的
在第四频道/ HBO 的《英国退出欧盟:不文明的战争》上周上映后,有一件事没有得到应有的讨论,那就是数据科学的广泛使用是脱欧运动战胜所有困难的主要原因。在本文中,我将讨论数据科学如何改变政治格局。
2016 年欧盟公投时的传统民调几乎一致显示,留欧最有可能获胜。即使是像奈杰尔·法拉奇这样的脱欧支持者也在装腔作势地表示,如果失败(以及为了另一次公投),他们将继续战斗,直到结果出来,因为结果会很接近。当它到来时,所有人都感到震惊,包括政治家和政治评论家。
传统民调如何出错
作为“保持自我”的坚定支持者,我记得自己在法国南部的父母家中看到选举结果,一直看到深夜,大约凌晨 3 点钟,我面无血色地上床睡觉。一觉醒来,我最担心的事情被证实了,我们将离开欧盟。我的伴侣听到这个消息后哭了,她出生在德国,但却是英国公民,她去了英国唯一的欧盟学校之一。她觉得自己的身份被剥夺了。
第二天,政治后果是巨大的,这是我们今天仍在处理的事情。结果出来后,人们广泛讨论的是民调怎么全错了,这是近年来反复发生的事情,5 个月后唐纳德·川普当选白宫时又发生了一次。这再次震惊了每一位严肃的政治评论家,据迈克尔·沃尔夫称,甚至唐纳德·特朗普本人也感到震惊。
甚至 2017 年英国大选的结果也出乎意料,那次选举产生了一个无多数派议会。此后不久,我写了传统民意调查是如何消亡的,强调唯一正确预测无多数议会结果的民意调查是一项实验性的 YouGov 民意调查,它使用了更现代的数据科学技术。
简而言之,传统的民意调查定期询问统计相关数量的人(大约 2000 人)对各种问题的看法。这一选择代表了选民中不同的人口统计数据,例如年龄、性别和收入。然后,民意测验专家通过这些人口统计数据来衡量全国范围内的意见波动。
YouGov 的实验性民意调查使用了更现代的技术,他们进行了更大规模的采访样本(约 50,000 人),而不太关心公平的人口分布。然后,他们使用多层回归和后分层来识别人口中的选民群。本质上是将选民划分为更细的人口统计数据,并在此基础上对波动进行加权。
虽然这本身是一个重要的话题,但更重要的问题不是传统的投票模型如何出错,而是为什么出错。
什么英国退欧:不文明战争向我们展示了数据科学在欧盟公投中的应用
上周,第四频道播出了他们谈论已久的英国退欧:不文明的战争。对于那些还没有看过这部电影的人来说,这是一部长篇剧,基于对事件关键人物的广泛采访,从英国退出欧盟公投宣布到结果。
这部剧由詹姆斯·格拉汉姆编剧,讲述了本尼迪克特·康伯巴奇(Benedict Cumberbatch)出色地扮演了备受争议的政治战略家多米尼克·卡明斯(Dominic Cummings),以及他是如何策划脱欧运动的。
有趣的是,它把他描绘成一个纯粹专注于赢得公投的人,而不是结果会是什么样子,以及他是否认为这是正确的。
他的政治目标似乎是,他不同意英国政治阶层管理英国的方式,并想破坏它。其他人可能称之为打倒当权派,或者在美国,抽干沼泽。他认为英国退出欧盟全民公决是实现这一目标的手段。
如果所有的报道都是准确的,那么《英国退出:不文明的战争》应该是脱欧运动如何赢得欧盟公投的不带偏见的写照。自从《不文明的战争》上映以来,大多数对《离开》的批评似乎都集中在两件事上;这出戏掩盖了 T2 的脱欧运动是如何违反选举法的。
以及竞选活动如何依靠种族主义和反移民情绪获胜。
没有更广泛讨论的是数据科学的使用如何引领整个运动,以及是什么让 Leave 比 remove 运动更具优势,并且很可能赢得了这场运动。更重要的是,这对政治的未来意味着什么。
多米尼克·卡明斯向所有批评者指出的是,他没有决定信息,而是让数据决定。这就是他们如何抓住对选民打击最大的核心信息;土耳其即将加入欧盟,我们给欧盟的 3 . 5 亿英镑应该用于资金不足的国民保健服务。这两者都没有被发现或证明是准确的。
在《英国脱欧:不文明的战争》中,我们看到多米尼克会见了扎克·马辛汉姆,他是加拿大政治咨询和技术公司 AggregateIQ 的创始人。据推测,脱欧运动在 AggregateIQ 上花费了 350 万英镑,占其 700 万英镑限额的 50%,其中花费了 7449079 英镑。
那是他们津贴的很大一部分,所以他们一定在这家公司有很多存款。此外,英国退欧:不文明的战争邪恶地描绘了多米尼克与扎克的会面,他说他们可以利用“另一方不知道存在的 300 万额外选民”。然后多米尼克说他要“黑掉系统[选民]”给一些目瞪口呆的保守派政客。
在《英国退出欧盟不文明战争》中,它向我们展示了 Dominic 如何让 AggregateIQ 的一组数据科学家被关在一个阴暗的侧室中,作为一个独立于脱欧运动其余部分的项目。
人们看到他们做的第一件事是发起一场运动,了解不同选民群体对欧盟不同问题的看法。他们通过给人们机会赢得一个集合赌注来做到这一点,这在统计上几乎不可能赢得(50 亿分之一的机会)。然后,他们利用这项研究的发现,为选民中的不同部分创建行为微目标信息。

结果发现,在公投期间,他们提供了超过 10 亿条脸书广告,其中包含各种支持脱欧的信息。例如,不那么“种族主义”的选民可能收到了鲍里斯·约翰逊的照片,上面写着,“我支持移民,但最重要的是,我支持有控制的移民”。而其他人收到诸如“土耳其有 7600 万人口。土耳其正在加入欧盟。好主意??"。


Older people were targetted with adverts on how the money we send to the UK could be spent on the NHS

People who were animal lovers would have received adverts like these

And supposed tea lovers or patriots would have received messages like these
如果他们点击了相关的广告,他们会收到一大群围绕同一主题的连续广告,强化了这一观点。卡明斯之前曾谈到过在欧盟公投前的最后 10 天,他们如何扣住大部分预算,并将其投入到这类广告中。他说,在此期间,大约有 700 万人成为目标。
在英国退出欧盟这场不文明的战争中,脱欧运动团队甚至质问为什么广告没有在电视和新闻周期中被提及,他们认为对方根本不知道发生了什么。
2016 年 6 月 23 日,17,410,742 人投票脱离欧盟,16,141,241 人投票留在欧盟。

为什么数据科学正在改变政治格局?
当然,任何稍微关注西方新闻的人都可能听说过剑桥分析公司丑闻。剑桥分析公司(Cambridge Analytica)由罗伯特·默瑟(亿万富翁人工智能专家)和唐纳德·川普的财政支持者兼竞选首席执行官史蒂夫·班农(另类右翼媒体斯文加利)创建和运营。剑桥分析揭发者 Christopher Wyle 强调了 AggregateIQ 与剑桥分析的密切联系。
这一丑闻向我们表明,通过滥用脸书的用户数据,他们可以对整个选民进行心理分析。使用一个名为 myPersonality 的病毒式个性应用程序,他们能够将个性类型与人们在脸书上的喜好进行交叉参考,以高度准确地描述人们的特征。
收集的数据被用于描述选民的算法,成为欧盟公投和美国大选的重要武器。怀尔甚至描述了史蒂夫·班农如何在他的“心理战”中将这些工具称为武器,目的是在全世界引发民族主义民粹主义运动。
虽然有些人可能反对这种形式的政治操纵,并认为这很可怕。积极的一面是,由于唐纳德·特朗普当选后的巨大政治压力,剑桥分析公司现已关闭,脸书打击了第三方数据泄露问题,使这些数据科学工具得以建立,GDPR 保护欧洲公民意味着你现在可以更好地控制如何使用你的个人数据。下次再发生这种事,可能就不会那么容易或者不被注意了。
不幸的是,像剑桥分析公司这样的其他公司仍然存在,而且只要有足够的需求,它们还会继续存在。政客们在竞选上花了大量的钱,当然,他们会使用最新的技巧和技术来争取胜利。
预计这将成为新的常态
如果你对欧盟公投或唐纳德·特朗普(Donald Trump)当选的结果不满意,你可能会对这一事实感到困惑。这只是因为国家民粹主义运动抢先一步。
自从我们进入数字时代,我们分享越来越多的关于自己的数据,并创造更多的信息渠道。现代营销和广告越来越注重为不断细化的目标群体创造相关的个性化信息,政治只是这个市场的另一个客户。
数据科学将找到将我们的信息拼凑在一起的方法,以创建我们的个人资料,确保正确的信息到达我们手中。政治活动会找到方法来研究我们对特定问题的情绪状态,并创造信息来引发我们特定的投票反应。平台将继续存在,使那些有针对性的活动信息能够到达我们这里。
如果说英国退欧:不文明的战争让我明白了什么,那就是留欧运动未能拥抱数据科学爆炸中可用的最新工具和技术。他们也可能瞄准了脱欧运动的目标选民,以及那些懒得出去投票的选民。像传统的民意测验专家一样,他们使用了几十年的老技术,却没有得到正确的结果。
这是我们在人工智能的未来必须面对的众多伦理困境之一。
是时候让政治步入 21 世纪了
我们现在生活在所谓的后真相时代,它已经不再是理性辩论中的赞成和反对,而是发射信息“手榴弹”(不管它们是真是假),以一种情绪化的方式与选民产生共鸣,然后要求反对派“灭火”。
这可能是一条双行道,我当然不是说撒谎是可以接受的,完全有可能建立更好的事实核查工具,在未来对虚假信息进行实时核查,以帮助解决这一问题。但我要说的是,争论各方的竞选活动都需要从剑桥分析公司和 AggregateIQ 那里学到,旧的政治方式已经一去不复返,数据科学将会继续存在。赢家是在游戏中保持领先的人。
** * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * * 可以在 Twitter @NoWayAsh 关注我。我欢迎您的反馈、评论和意见。
弥合数据科学家和管理层之间的差距
现实世界中的数据科学
数据科学家应该向他们的老板解释的关于机器学习的五个概念

“If I could predict the winning lottery numbers I wouldn’t be stuck listening to your fishing stories.”
机器学习功能强大
毫无疑问,人们明白机器学习是一个强大的工具。利用你过去发生的一切来预测未来;从过去的错误中学习并相应地调整。机器学习不是依赖人的记忆和直觉,而是使用计算机和统计数据来完成繁重的工作。有了合适的支撑结构,它可以成为一个强大的工具,但它绝不是完美的。
它不是水晶球。
在一个理想的世界里,企业中的每个人都应该理解工作的所有细微差别以及它所包含的内容,但这是完全错误的。大多数工作都不是这样。这种缺乏理解必然会引发问题。
请求者可能不知道引擎盖下的所有东西是如何工作的——特别是考虑到这不是他们的工作——但是他们知道他们应该使用它。机器学习工作如此受欢迎是有原因的,因为它对决策有影响。然而,毫无疑问,许多公司只关注这些角色,因为他们知道竞争对手是这样的。Arthur Samuel 于 1959 年首次引用了“机器学习”一词,但这项工作本身主要是在最近几年才开始起步的。所以自然地,许多人不会确切地知道机器学习需要什么以及幕后的跑腿工作。
对于一些人来说,机器学习过程只是一个黑盒。向数据科学家寻求答案,稍后再回来询问他们的预测。就是这样。
请求者不知道他们的请求真正意味着什么,这绝不是一个新概念,自从“商务休闲装”出现以来,这个概念就一直存在。这并不是说没有多少请求者知道机器学习项目需要什么。这只是一种不平衡,如果可以设定现实的期望,那么每个人的工作都会得到改善。
有些人认为机器学习预测 100%准确无误,当事情没有实现时,他们会表现得很惊讶。其他人希望将公司无权访问的信息包含在数据集中。
这绝不仅仅是管理层的责任。不能有效地传达期望是数据科学家应该警惕的责任。管理层不是你工作中的专家,所以你有责任向他们解释你在做什么。
通过向管理层澄清您实际上在幕后做什么,并解释应该如何利用您的模型,不仅可以帮助他们做出更好的决策,还可以简化数据科学家的流程,并避免未来出现问题。
下面我将介绍五个概念,它们有助于弥合这一差距,并有可能改善每个相关人员的工作流程。
模型的准确性取决于数据的质量
向决策者表明,数据问题将延续到模型中,要么降低预测能力,要么可能使整个过程无效。
假设你正在对你班上的学生进行一项研究。这是一个基本的调查,包括人口统计和意见的问题,也是匿名的。在收集了所有的文件后,你浏览了所有的回复,注意到一项调查,调查中选择了爱斯基摩人、印度人,并选择不说出他们的种族。你扫视房间,也许有人真的是三者兼而有之,但你必须对这种调查保持警惕。一个高中生没有认真对待一项调查,这真的是不可能的吗?
也许你会排除一些更有问题的调查…
随着组织收集更多的数据,管理这些数据的质量变得日益重要。毕竟,数据是组织的命脉。
问任何 DBA,尤其是大公司的 DBA,关于他们数据的准确性,他们可能会叹口气,耸耸肩。这不是他们的错,一旦数据库开始变大,警告和问题开始积累,就没有时间或资源来确保一切 100%准确。
数据质量始终是一个问题。在知道数据可能有问题的情况下做出决定,比假设数据是好的情况下做出决定要好。该模型并不关心数据对真实世界是否准确,它必须假设数据对真实世界准确,以便进行评估。可以在代码中检查异常值和高杠杆值,但即使这些检查也只能修复这么多。
对数据集进行数据验证是一个良好的开端。然而,根据数据的大小,检查一个数据样本可能要花费相当多的时间。最重要的是,如果有些数据超出了您的专业知识范围,那么与那些能够对数据执行嗅探测试并确保所有数据都在他们那一端得到检查的人一起工作将会受到极大的赞赏。
模型只知道给它的数据
告诉决策者,该模型仅限于您输入的数据(以及该数据的所有衍生数据)。如果它不在输入中,那么它就没有被完全考虑。
预测模型只考虑趋势和给定的信息。如果您想要将其他变量考虑在内,则需要在建立模型的训练数据中考虑这些变量。
假设您开发了一个模型,用于预测您的公司在接下来的几个月中将会处理的客户服务电话的数量。您包括与销售增长、一年中的时间和人员配备相关的值。对你的预测感到满意,你把它交给你的老板。
“看起来棒极了!这是否说明了我们将在第四季度发布的服务应用?”
你的心有点沉。你是怎么量化的呢?您知道您在数据仓库中也没有任何这些信息。也许你可以找一些东西来预测电话量将减少多少,并看看这将释放多少员工人数。
你说你会尽你所能…
虽然一个变量的某些部分可以解释另一个变量的一些影响,如人员配备和一年中的时间,但如果没有明确提到某个具体因素,人们就不能自信地声称该模型解释了它。增加新的变量不仅会改变预测,还会改变其他变量的影响。系数和误差会改变。
为了克服这一点,要让你的模型中哪些因素被考虑,哪些因素没有被考虑。列出一些管理层想要包含/考虑的变量,看看你能做些什么。这样,你至少有一个他们想要研究的基线,并能够调整。
机器学习只是一堆统计学和计算机编程的串联
虽然开玩笑很有趣,但要明确你并不是真的在看水晶球做预测。有些变量可以很好地添加到模型中,但是如果它们不能以某种形式量化,那么你就不走运了。
信不信由你,预测模型实际上并没有预见未来。它们只是一堆统计计算和计算机算法,由比其他人聪明得多的人创造,由其他极其聪明的人实现。
即使对于更高级的过程,如图像处理,虽然它本身不是一个数字,但它是一个数值过程。在幕后,图像被分解到像素级别并被赋予值,然后将这些像素中的图案与它们被赋予的标签进行比较。
模型中可以包含的内容的限制是可以转化为数字的内容。如果它可以被量化,那么很有可能会做一些伟大的事情来解释它。只要设计数据集的人能把它转换成适当的格式,那就没问题。
比方说,你试图预测一本书会有多受欢迎。这将很容易包括与同一作者的其他书籍的流派流行度和平均亚马逊评论相关的因素。然而,添加一些像书的节奏或者情节有多有趣的东西会有点复杂。
另一个值得关注的方面是,模型和统计测试需要满足某些假设。如果你建立了一个忽略它们的模型,那么你的结果可能是好的,或者从长远来看它们可能是完全错误的。这是业余建模者(比如我自己)经常跳过的陷阱(比如我自己)。
以线性回归模型的假设为例。感谢统计解决方案没有让我记住它们。
- 线性关系
- 多元正态性
- 没有或很少多重共线性
- 无自相关
- 同方差性
线性回归是一个简单明了的模型,通常可以用一两行代码实现。确保所有潜在的假设都得到满足通常比建模者想要处理的更麻烦,但是我们每次都应该这样做。不满足这些假设可能意味着一个人们认为具有高度预测性的模型实际上偏向于一个或另一个变量。
对于一个具有统计稳健性的模型,它需要所有的参数都达到某种可接受的水平。什么样的水平取决于制作数据集和模型的人。
如果一个模型需要 x、y 和 z 为真才能做出准确的预测,只有 x 和 z 可能不够。
我知道这是真正的突破。
第三个想法是,大多数预测和预报为每个预测提供了某种置信区间。这个想法取决于你所做的预测的确切类型,但是对于大多数类型来说,这通常在某种形式上是正确的。围绕预测有一系列不确定性。没有 100%肯定的预测(除非它是一个已解决的问题),因此,即使是非常可能的预测也有一些回旋的余地。
大多数预测仅仅给出了可能性最高的事件,这并不是说它仍然将较小的发生几率归因于另一个事件。
当你玩彩票的时候,一个模型会在你每次买彩票的时候预测你不会每次都中奖,这是正确的。然而,有一个非零的机会赢得彩票,所以最终,有人会赢,尽管赔率完全对他们不利。
对于彩票中奖者来说,这个模型可能是错误的,但这并不是说它对其他彩票参与者来说仍然是错误的。
就解决方案而言,管理层应该清楚,添加易于量化(且可用)的数据是一个更简单的过程。有时,占位符因子可以解决某些变量的缺点,但应该小心确保占位符代表您认为它是什么。当管理层想要增加一个新的因素时,询问他们是否知道如何量化感兴趣的变量。也许他们知道一些你不知道的事情。
过去的表现不代表未来的结果
这是你在投资中经常看到的一句话,也适用于预测模型。即使你有可以追溯到史前时代的数据,有精确的列,有数十亿的变量,也不可能一直给出 100%准确的预测。至少现在还没有。为了做出预测,需要考虑的因素太多了。
早在 20 世纪初,通用电气就是美国家庭的基石。他们大规模生产各种电器,甚至在二战期间帮助盟军的努力。从 1981 年到 2001 年,该公司的价值从 250 亿美元增长到 1300 亿美元。通用电气被誉为股市中最安全的选择之一。买入并在未来几年获得稳健的财务增长。
通用电气太大而不能倒。
然后大衰退来袭。通用电气股价下跌,股息下降。数以千计的工作岗位被削减以弥补损失,消息传出后股票下跌更多。截至 2018 年 11 月,通用电气的估值为 726.3 亿美元。时至今日,通用电气仍在尽最大努力恢复元气,重返其数十年来的巅峰。
对于普通投资者来说,通用电气在 2008 年之前是一个稳赚不赔的投资。虽然有人预测了大衰退,但普通投资者根本没想到通用电气会遭受如此沉重的打击。
很难做出预测,尤其是对未来。
-约吉贝拉
没有什么是完美的,尤其是一个预测。如果你预测你的销售部门下个月将增加多少客户,那么你可能是在假设下周销售电话不会被禁止的情况下运行的(政治可能是一个奇怪的空间)。因此,除非你预测销售是非法的,否则你的模型是在销售电话是合法的假设下运行的。
在产生影响之前,我们不知道这些因素对目标是否有影响,除非您可以预测这些其他因素何时会发生变化,否则您不可能有一个 100%准确的模型。
模型总是在仍有可能出错的信念下运行。这些模型并不神奇,它们的创造者无法预见的事件不会在模型中得到解释。他们能依靠的只有过去和已知的变化。
让管理层明白,预测模型通常假设当前趋势会继续。模型中没有特别说明的一切都被视为随机误差。很难解释这种意外,因为,这是意料之外的。
根据预测采取行动可以改变结果
为了检查模型在生产中的成功,将实际发生的情况与当时预测的情况进行比较是有意义的。然而,必须记住,为修正预测而采取的行动会改变结果。
如果解释不当,管理层可能会认为模型完全错误,并取消预测。
一艘船即将参加它的处女航。就在它出发之前,一名导航员指出,在他们的航线上将会有一场大风暴。船上的人听到了这个预测,并为他们的健康担忧。船起航了,每个人都为这次旅行的命运感到紧张。
这次航行最终很顺利,一次阳光充足、万里无云的美丽航行。到达目的地后,人们谴责导航员让他们担心,并注意到整个旅途中没有一滴雨。
乘客们不知道的是,船长已经改变了航线,选择了一条更加安全的路线,完全避开了风暴。
与结果不符的预测不一定是错的。预测模型将根据当前趋势选择最有可能的结果,一旦决策者听到这些预测,他们当然会采取行动。
然而,人们可能会认为这是一种完全免除数据科学家责任的方式,在某种程度上听起来确实如此。要么预测是对的,我是个天才,要么预测是错的,这不是我的错。
这是一个滑坡。当第一次开发一个模型时,很容易用其他过去的实例来验证模型,以检查模型的准确性。然而,一旦模型被生产化,就很难辨别出预测是错误的或者采取了适当的行动。你需要回去,调整适当的输入,看看新修订的预测现在与现实有多接近。
商业环境中许多机器学习项目的目的是了解公司目前的发展方向,同时提供对不同因素(如竞争对手和客户模式)的一些“假设”分析。
向请求者说明,在做出预测之后和事件发生之前所做的任何更改都不会在预测中得到考虑。为了根据实际发生的情况准确测试模型,您需要返回并包括在完成初始预测后所做的调整。
结论
我们涵盖的五个概念将有望为请求者提供一些关于机器学习的期望。
- 模型的准确性取决于数据的质量
- 模型只知道给它的数据
- 机器学习只是一堆统计学和计算机编程的串联
- 过去的表现并不代表未来的结果
- 根据预测采取行动可以改变结果
现在,这绝不是一个全面的清单,更像是我希望在这个过程中早些时候向我的上级明确表达的想法。作为大企业的一部分,人们对你专业知识的理解和专业知识本身一样重要。这很不幸,但这是可以通过适当的沟通和合作来解决的事情。
如果你还有其他建议,欢迎在下面分享(或者愤怒的邮件给我)。
作为离散傅里叶变换预处理的汉明和汉宁函数简介

source: https://www.tek.com/sites/default/files/u811871/hamming-t.png
大多数人的第一个问题是,**为什么我们在离散傅里叶变换(DFT)或者快速傅里叶变换(FFT)中需要预处理?**在回答问题之前,你必须知道 DFT 和 FFT 的区别。我以前在这里讨论过这个话题,如果你想知道更多细节,你可以看看。重点是 FFT 是做 DFT 的最快方法。
答案是频谱泄漏。什么是频谱泄漏?频谱泄漏是指将“未完成的”波传递到 FFT。我说的未完成的波是指,当它像这样传递到 FFT 时,具有非整数周期的波。

当你把这个信号传递给 FFT,结果是这样的

Woah,功率很高,尤其是 4 Hz 频段。这很明显,因为我们将一个纯 4 Hz 正弦波传递给 FFT。但是看起来FFT‘认为’我们的纯信号是 4 Hz 左右波的叠加。
如果将“完成”信号传递给 DFT,结果将会不同。这个“完整的”4 Hz 正弦波

当把它传递给 FFT 时,结果会是这样的

这就是预期的结果!我们的输入信号是 4 Hz 正弦波,因此 DFT 频谱图中的功率频率仅为 4 Hz。而且显示的功率也没有之前那么大。由于 python 代码对空格和制表符非常敏感,我在这里只给你一个代码的 GitHub 链接,而不是在这里显示,因为如果我在这里提供它,所有的空格和制表符都会被弄乱。
这种现象被称为光谱泄漏。这是因为 DFT 假设我们的输入信号是一个‘完整’周期信号。 DFT 假设我们的信号完全按照输入重复。所以当我们通过‘不完整’版本的 4 Hz 正弦波时,DFT 会看到这样的情况。

让我们检查该信号的 FFT 输出,这是结果

类似于之前未完成的 4 Hz 正弦波的 FFT 输出不是?是的,除了这个加长版的外,功率上升更高(看 y 轴刻度)。绘制如上图的代码是通过这个链接完成的。
为了清除噪声并获得理想的输出(参见“4 Hz 正弦波的 FFT”图)是**,我们必须知道信号的周期并在正确的时间**对其进行切割(正好在信号周期结束时切割)。但是,在现实世界中,我们不知道信号的周期,而且现实世界中的信号充满了噪声和干扰,所以在正确的时间切割它是不可能的。解决方案是开窗函数。
傅立叶变换中的窗口函数是**,调整 FFT 信号输入的起点和终点的尝试与此类似**。在这个故事中,我们将涵盖 2 窗口函数,汉宁函数,和汉明函数。
汉宁函数是这样写的

汉明函数是这样的

其中 M 是 FFT 的数据集输入中的数据量,n 是从 0 到 M-1 的数。

所以 Hanning 和 Hamming 将输出一个数组,这个数组中的数字与数据集中的数据数量成正比。如果我们绘制汉宁和汉明函数的输出,我们将得到如下两个图


这里是代码的链接来创建上面的情节。
为了调整信号,我们将信号乘以汉恩和哈姆的输出。作为一个例子,我们乘以我们未完成的 4 赫兹正弦波对汉恩和哈姆,然后我们的波形将是这样的。


让我们进行 FFT 处理,我们会得到这样的图形。


看,FFT 中错误频带的功率降低了(包括正确频带,它正在接近“正确”值)。我们可以看到错误频段的功率并没有完全消除,只是可以降低。如果我们在这个实验中观察 FFT 的结果,那么在汉明函数和汉宁函数之间没有真正的区别。这里的是代码的链接,用于创建汉宁/汉明函数处理的信号图及其 FFT 结果。
重要的一点是,无论是否经过窗函数处理,FFT 图中最主要的频率始终相同,为 4 Hz。所以,如果你只是想知道信号中占主导地位的一个频率是什么,我认为你不需要加窗函数。当您想要在数据集中找到一个以上的主导信号时,我认为这些窗口函数会有很大的帮助,因为当存在泄漏时,主导信号周围的一些频带的功率会盖过您想要找到的第二个、第三个或 etc 信号。当然,如果你想平滑 FFT 的结果,你需要一个窗口函数。
参考资料:
https://www . crystal instruments . com/dynamic-signal-analysis-basics,2019 年 9 月 29 日访问
马尔可夫链简介
定义、属性和 PageRank 示例。

Credit: Free-Photos on Pixabay
本帖与 巴蒂斯特·罗卡 共同撰写。
介绍
1998 年,劳伦斯·佩奇(Lawrence Page)、谢尔盖·布林(Sergey Brin)、拉吉夫·莫特瓦尼(Rajeev Motwani)和特里·维诺格拉德(Terry Winograd)发表了《PageRank 引文排名:给网络带来秩序》(The PageRank Citation Ranking:bring Order to The Web),他们在文章中介绍了谷歌起源时现在著名的 Page rank 算法。二十多年后,谷歌已经成为一个巨人,即使算法已经发展了很多,PageRank 仍然是谷歌排名算法的一个“符号”(即使很少有人能真正说出它在算法中仍然占据的权重)。
从理论的角度来看,有趣的是注意到对 PageRank 算法的一种常见解释依赖于简单但基本的马尔可夫链数学概念。我们将在本文中看到,马尔可夫链是随机建模的强大工具,对任何数据科学家都有用。更特别的是,我们将回答一些基本问题,如:什么是马尔可夫链,它们有什么好的性质,可以用它们做什么?
概述
在第一部分,我们将给出理解什么是马尔可夫链所需的基本定义。在第二节中,我们将讨论有限状态空间马氏链的特殊情况。然后,在第三节我们将讨论马氏链的一些基本性质,并用许多小例子来说明这些性质。最后,在第四节中,我们将链接 PageRank 算法,并通过一个玩具示例来了解如何使用马尔可夫链对图中的节点进行排序。
什么是马尔可夫链?
随机变量和随机过程
在介绍马尔可夫链之前,让我们先快速回顾一下概率论中一些基本但重要的概念。
首先,在非数学术语中,随机变量 X 是一个变量,其值被定义为随机现象的结果。这个结果可以是一个数(或“类数”,包括向量),也可以不是。例如,我们可以将随机变量定义为掷骰子的结果(数字)以及掷硬币的结果(不是数字,除非你指定 0 为正面,1 为反面)。还要注意,随机变量的可能结果空间可以是离散的,也可以是连续的:例如,正态随机变量是连续的,而泊松随机变量是离散的。
然后,我们可以将随机过程(也称为随机过程)定义为由集合 T 索引的随机变量的集合,这些随机变量通常代表不同的时刻(我们将在下文中假设)。最常见的两种情况是:要么 T 是自然数的集合(离散时间随机过程),要么 T 是实数的集合(连续时间随机过程)。例如,每天抛硬币定义了一个离散时间随机过程,而股票市场期权的价格连续变化定义了一个连续时间随机过程。不同时刻的随机变量可以彼此独立(抛硬币的例子)或以某种方式相关(股票价格的例子),并且它们可以具有连续或离散的状态空间(每个时刻的可能结果的空间)。

Different kind of random processes (discrete/continuous in space/time).
马尔可夫性质和马尔可夫链
存在一些众所周知的随机过程族:高斯过程、泊松过程、自回归模型、移动平均模型、马尔可夫链等。这些特殊的案例,每一个都有特定的属性,让我们可以更好地研究和理解它们。
使随机过程的研究容易得多的一个性质是“马尔可夫性质”。马尔可夫性质以一种非常非正式的方式表示,对于随机过程,如果我们知道该过程在给定时间的值,我们将不会通过收集关于过去的更多知识来获得关于该过程未来行为的任何附加信息。用稍微更数学的术语来说,对于任何给定的时间,给定当前和过去状态的过程的未来状态的条件分布仅取决于当前状态,而完全不取决于过去状态(无记忆特性)。具有马尔可夫性质的随机过程称为马尔可夫过程。

The Markov property expresses the fact that at a given time step and knowing the current state, we won’t get any additional information about the future by gathering information about the past.
基于前面的定义,我们现在可以定义“齐次离散时间马尔可夫链”(为了简单起见,在下文中称为“马尔可夫链”)。一个马尔可夫链是一个具有离散时间和离散状态空间的马尔可夫过程。因此,马尔可夫链是一个离散的状态序列,每个状态都来自一个离散的状态空间(有限的或非有限的),并且遵循马尔可夫性质。
在数学上,我们可以用以下方式表示马尔可夫链

其中在每个时刻,该过程在离散集合 E 中取其值,使得

那么,马尔可夫性质意味着我们有

请再次注意,最后一个公式表达了这样一个事实,即对于给定的历史(我现在所在的位置和我之前所在的位置),下一个状态(我接下来要去的位置)的概率分布只取决于当前状态,而不取决于过去的状态。
注。在这篇介绍性的文章中,我们决定只描述基本的齐次离散时间马尔可夫链。然而,也存在非齐次的(时间相关的)和/或时间连续的马尔可夫链。我们不会在下面讨论这些模型的变体。还要注意,上面给出的马尔可夫性质的定义是极其简化的:真正的数学定义包括过滤的概念,这远远超出了这个适度介绍的范围。
表征马尔可夫链的随机动态
在前一小节中,我们已经介绍了与任何马尔可夫链相匹配的一般框架。现在让我们来看看我们需要什么来定义这样一个随机过程的一个特定“实例”。
首先注意,不验证马尔可夫性质的离散时间随机过程的完整特征可能是痛苦的:给定时间的概率分布可能取决于过去和/或未来的一个或多个时刻。所有这些可能的时间相关性使得对该过程的任何适当描述都可能是困难的。
然而,由于马尔可夫性质,马尔可夫链的动态很容易定义。事实上,我们只需要指定两件事:一个初始概率分布(即时刻 n=0 的概率分布)表示为

以及一个转移概率核(它给出了对于任何一对状态,一个状态在时间 n+1 继承到另一个状态的概率)

已知前两个对象,过程的完全(概率)动态被很好地定义。事实上,这一过程实现的概率可以用递归的方法计算出来。
例如,假设我们想知道流程前 3 个状态的概率是(s0,s1,s2)。所以,我们想计算概率

这里,我们使用全概率定律,即拥有(s0,s1,s2)的概率等于拥有第一个 s0 的概率,乘以拥有 s1 的概率(假设我们之前拥有 s0),乘以拥有最终 s2 的概率(假设我们之前依次拥有 s0 和 s1)。数学上,它可以写成

然后出现了由马尔可夫假设给出的简化。事实上,对于长链,我们将获得最后状态的严重条件概率。然而,在马尔可夫的情况下,我们可以简化这个表达式

这样我们就有

由于它们完全表征了过程的概率动态,因此许多其他更复杂的事件可以仅基于初始概率分布 q0 和转移概率核 p 进行计算。值得给出的最后一个基本关系是相对于时间 n 的概率分布而言的时间 n+1 的概率分布的表达式

有限状态空间马尔可夫链
矩阵和图形表示
这里我们假设在 E 中有 N 个有限的可能状态:

然后,初始概率分布可以由大小为 N 的行向量 q0 来描述,并且转移概率可以由大小为 N×N 的矩阵 p 来描述,使得

这种记法的优点是,如果我们用原始向量 qn 来表示步骤 n 的概率分布,则它的分量由下式给出

那么简单的矩阵关系此后成立

(此处不详述证明,但可以非常容易地恢复)。

When right multiplying a row vector representing probability distribution at a given time step by the transition probability matrix, we obtain the probability distribution at the next time step.
因此,我们在这里看到,将概率分布从一个给定的步骤发展到下一个步骤,就像将初始步骤的行概率向量乘以矩阵 p 一样简单

有限状态空间马尔可夫链的随机动态可以容易地表示为有值定向图,使得图中的每个节点是一个状态,并且对于所有的状态对(ei,ej),如果 p(ei,ej)>0,则存在从 ei 到 ej 的边。那么边缘的值就是这个相同的概率 p(ei,ej)。
示例:《走向数据科学》读本
让我们举一个简单的例子来说明这一切。考虑一个虚构人物对数据科学读者的日常行为。对于每一天,有 3 种可能的状态:读者这一天没有访问 TDS(N),读者访问了 TDS 但是没有阅读完整的帖子(V),以及读者访问了 TDS 并且阅读了至少一个完整的帖子®。所以,我们有下面的状态空间

假设在第一天,该读者有 50%的机会只访问 TDS,有 50%的机会访问 TDS 并阅读至少一篇文章。描述初始概率分布(n=0)的向量为

假设观察到以下概率:
- 当读者一天不访问 TDS,他有 25%的机会第二天仍然不访问,50%的机会只访问,25%的机会访问和阅读
- 当读者访问 TDS 一天没有阅读,第二天有 50%的机会再次访问而没有阅读,有 50%的机会访问并阅读
- 当读者访问并阅读了一天,他有 33%的几率第二天不访问*(希望这个帖子不会有这种效果!)*,33%的几率只访问,34%的几率再次访问和阅读
然后,我们有下面的转移矩阵

根据前面的小节,我们知道如何为读者计算第二天(n=1)每个状态的概率

最后,这个马尔可夫链的概率动态可以用图形表示如下

Graph representation of the Markov chain modelling our fictive TDS reader behaviour.
马尔可夫链属性
在这一节中,我们将只给出一些基本的马氏链性质或特征。这个想法不是要深入数学细节,而是给出一个使用马尔可夫链时需要研究的兴趣点的概述。正如我们已经看到的,在有限状态空间的情况下,我们可以将马尔可夫链描绘成一个图,请注意,我们将使用图形表示来说明下面的一些特性。然而,应该记住,这些性质不一定局限于有限状态空间的情况。
还原性、周期性、短暂性和重现性
在这一小节中,让我们从描述一个状态或整个马尔可夫链的一些经典方法开始。
首先,我们说一个马尔可夫链是不可约的,如果它有可能从任何其他状态到达任何状态(不一定在一个时间步内)。如果状态空间是有限的,链可以用一个图来表示,那么我们可以说一个不可约马氏链的图是强连通的(图论)。

Illustration of the irreducibility property. The chain on the left is not irreducible: from 3 or 4 we can’t reach 1 or 2. The chain on the right (one edge has been added) is irreducible: each state can be reached from any other state.
如果当离开一个状态时,返回到该状态需要 k 个时间步长的倍数(k 是所有可能返回路径长度的最大公约数),则该状态具有周期 k。如果 k = 1,那么状态被认为是非周期的,如果一个完整的马尔可夫链的所有状态都是非周期的,那么它就是非周期的。对于一个不可约的马尔可夫链,我们还可以提到这样一个事实:如果一个状态是非周期的,那么所有的状态都是非周期的。

Illustration of the periodicity property. The chain on the left is 2-periodic: when leaving any state, it always takes a multiple of 2 steps to come back to it. The chain on the right is 3-periodic.
如果当我们离开一个状态时,有一个非零的概率表明我们再也不会回到这个状态,那么这个状态就是暂时的。相反,如果我们知道,在离开一个状态之后,我们会以概率 1 返回到那个状态,那么这个状态就是循环的(如果它不是短暂的)。

Illustration of the recurrence/transience property. The chain of the left is such that: 1, 2 and 3 are transient (when leaving these points we can’t be absolutely sure that we will come back to them) and 3-periodic whereas 4 and 5 are recurrent (when leaving these points we are absolutely sure that we will come back to them at some time) and 2-periodic. The chain on the right has one more edge that makes the full chain recurrent and aperiodic.
对于一个循环状态,我们可以计算平均循环时间,即离开该状态时的预期返回时间。注意,即使收益概率等于 1,也不意味着期望收益时间是有限的。因此,在循环状态中,我们可以区分正循环状态(有限预期返回时间)和零循环状态(无限预期返回时间)。
平稳分布、极限行为和遍历性
在这一小节中,我们将讨论马尔可夫链所描述的(随机)动态的某些特征。
状态空间 E 上的概率分布π被称为稳定分布,如果它验证了

正如我们所做的

然后,平稳分布验证

根据定义,一个稳定的概率分布是这样的,它不会随着时间而演化。因此,如果初始分布 q 是一个平稳分布,那么它将在所有未来时间步保持不变。如果状态空间是有限的,p 可以用一个矩阵来表示,π可以用一个原始向量来表示,那么我们有

再一次,它表达了一个事实,即一个稳定的概率分布不会随时间演化(正如我们看到的,概率分布乘以 p 就可以计算下一个时间步的概率分布)。注意,一个不可约的马尔可夫链有一个稳定的概率分布,当且仅当它的所有状态都是正循环的。
与平稳概率分布相关的另一个有趣的性质如下。如果链是递归正的(因此存在平稳分布)和非周期的,那么不管初始概率是多少,当时间步长趋于无穷大时,链的概率分布收敛:链被称为具有一个极限分布,它就是平稳分布。在一般情况下,它可以写成

让我们再次强调这样一个事实,即没有对初始概率分布的假设:不管初始设置如何,链的概率分布都收敛于稳定分布(链的平衡分布)。
最后,遍历性是与马尔可夫链的行为相关的另一个有趣的属性。如果一个马尔可夫链是不可约的,那么我们也说这个链是“遍历的”,因为它证明了下面的遍历定理。假设我们有一个应用程序 f(。)从状态空间 E 到真实线(例如,它可以是每个状态中的成本)。我们可以定义这个应用沿着给定轨迹的平均值(时间平均值)。对于第 n 个第一项,它表示为

我们还可以计算应用 f 在集合 E 上的平均值,集合 E 由固定分布(空间平均值)加权,表示为

那么遍历定理告诉我们,当轨迹变得无限长时的时间均值等于空间均值(由平稳分布加权)。遍历属性可以写成

换句话说,在极限情况下,轨迹的早期行为变得可以忽略不计,只有长期稳定行为在计算时间平均值时才真正重要。
回到我们的 TDS 阅读器示例
我们再次考虑 TDS 阅读器的例子。在这个简单的例子中,链显然是不可约的、非周期的,并且所有状态都是循环正的。
为了展示可以用马尔可夫链计算的有趣结果,我们想看看状态 R(状态“访问和阅读”)的平均重现时间。换句话说,我们想回答以下问题:当我们的 TDS 读者在某一天访问并阅读时,在他再次访问和阅读之前,我们平均要等待多少天?让我们试着直观地了解一下如何计算这个值。
首先,我们表示

所以我们想在这里计算 m(R,R)。在离开 R 后的第一步推理中,我们得到

但是,这个表达式需要知道 m(N,R)和 m(V,R)才能计算 m(R,R)。这两个量可以用同样的方式表示

因此,我们有 3 个含有 3 个未知数的方程,当我们求解这个系统时,我们得到 m(N,R) = 2.67,m(V,R) = 2.00,m(R,R) = 2.54。状态 R 的平均重现时间的值是 2.54。因此,我们看到,通过一些线性代数,我们设法计算出状态 R 的平均重现时间(以及从 N 到 R 的平均时间和从 V 到 R 的平均时间)。
为了结束这个例子,让我们看看这个马尔可夫链的平稳分布是什么。为了确定平稳分布,我们必须解下面的线性代数方程

所以,我们必须找到与特征值 1 相关的 p 的左特征向量。解决这个问题,我们得到下面的平稳分布

Stationary distribution of our “TDS reader” example.
我们还可以注意到π® = 1/m(R,R),稍微思考一下,这是一个非常符合逻辑的恒等式(但在这篇文章中我们不会给出更多细节)。
由于链是不可约的和非周期性的,这意味着,从长远来看,概率分布将收敛到稳定分布(对于任何初始化)。换句话说,无论我们的 TDS 阅读器的初始状态是什么,如果我们等待足够长的时间并随机选择一天,那么我们有一个概率π(N)读者在这一天不访问,一个概率π(V)读者访问但不阅读,以及一个概率π®读者访问并阅读。为了更好地掌握收敛特性,让我们看一下下图,该图显示了从不同起点开始概率分布的演变以及(快速)收敛到稳定分布

Visualisation of the convergence of 3 differently initialised probability distributions (blue, orange and green) towards the stationary distribution (red).
一个经典的例子:PageRank 算法
现在是时候回到 PageRank 了!在进一步讨论之前,让我们提一下这样一个事实:我们将要给出的 PageRank 的解释并不是唯一可能的,而且原始论文的作者在设计该方法时并不一定考虑到了马尔可夫链。然而,下面的解释有一个很好理解的优点。
随机网络冲浪者
PageRank 试图解决的问题如下:我们如何通过使用页面之间的现有链接对给定集合中的页面进行排序(我们可以假设该集合已经被过滤,例如在一些查询中)?
为了解决这个问题并能够对页面进行排序,PageRank 大致如下进行。我们认为一个随机的网上冲浪者在最初的时间是在一个页面上。然后,该冲浪者通过对每个页面点击指向所考虑的集合中的另一个页面的链接之一来开始随机导航(假设不允许链接到该集合之外的页面)。对于给定的页面,所有允许的链接都有同等的机会被点击。
这里我们有一个马尔可夫链的设置:页面是不同的可能状态,转移概率由从一个页面到另一个页面的链接来定义(加权使得在每个页面上所有链接的页面都有相等的机会被选择),并且无记忆属性由冲浪者的行为清楚地验证。如果我们还假设所定义的链是循环正的和非周期性的(使用一些小技巧来确保我们满足这个设置),那么在很长时间之后,“当前页面”概率分布收敛到稳定分布。所以,不管起始页面是什么,如果我们选择一个随机的时间步长,很长时间后每个页面都有可能(几乎是固定的)成为当前页面。
PageRank 背后的假设是,在平稳分布中最有可能的页面也一定是最重要的(我们经常访问这些页面,因为它们从在这个过程中也经常被访问的页面接收链接)。然后,静态概率分布为每个状态定义了 PageRank 的值。
玩具的例子
为了让这一切更清楚,让我们考虑一个玩具的例子。假设我们有一个很小的网站,有 7 个从 1 到 7 的页面,页面之间有链接,如下图所示。

为了清楚起见,在先前的表示中没有显示每个转换的概率。然而,由于“导航”被认为是完全随机的(我们也谈论“随机行走”),使用简单的以下规则可以容易地恢复这些值:对于具有 K 个外部链接的节点(具有 K 个到其他页面的链接的页面),每个外部链接的概率等于 1/K。因此,概率转移矩阵由下式给出

其中 0.0 值已被替换为“.”为了可读性。在任何进一步的计算之前,我们可以注意到,这个马尔可夫链是不可约的,也是非周期的,因此,在长期运行之后,系统收敛到一个平稳分布。正如我们已经看到的,我们可以通过求解下面的左特征向量问题来计算这个平稳分布

通过这样做,我们获得了每页的 PageRank 值(稳定分布的值)

PageRank values computed on our toy example that contains 7 pages.
这个小网站的页面排名是 1 > 7 > 4 > 2 > 5 = 6 > 3。
外卖食品
这篇文章的主要观点如下:
- 随机过程是随机变量的集合,通常随时间进行索引(索引通常代表离散或连续时间)
- 对于随机过程,马尔可夫性质表示,给定现在,未来的概率独立于过去(该性质也称为“无记忆性质”)
- 离散时间马尔可夫链是具有离散时间指标的随机过程,它验证了马尔可夫性
- 马氏链的马氏链性质使得对这些过程的研究变得更加容易,并且允许导出一些有趣的显式结果(平均重现时间,平稳分布…)
- 对 PageRank 的一种可能的解释(不是唯一的解释)在于想象一个网上冲浪者随机地从一个页面导航到另一个页面,并且将页面上的诱导的稳定分布作为排名的一个因素(粗略地说,处于稳定状态的最常被访问的页面必须是由其他非常常被访问的页面链接的页面,然后必须是最相关的)
最后,让我们再一次强调,在处理随机动态时,马尔可夫链对于问题建模是多么强大。由于其良好的特性,它们被用于各种领域,如排队理论(优化电信网络的性能,其中消息必须经常竞争有限的资源,并且当所有资源都已被分配时被排队)、统计学(众所周知的“马尔可夫链蒙特卡罗“随机变量生成技术是基于马尔可夫链的”)、生物学(生物种群进化的建模)、计算机科学(隐马尔可夫模型是信息论和语音识别中的重要工具)以及其他。
显然,马尔可夫链在建模和计算方面提供的巨大可能性远远落后于这篇适度的介绍,因此,我们鼓励感兴趣的读者阅读更多关于这些完全在(数据)科学家工具箱中占有一席之地的工具的信息。
感谢阅读!
用 Baptiste Rocca 写的其他文章:
面对不平衡的班级问题,应该做什么,不应该做什么?
towardsdatascience.com](/handling-imbalanced-datasets-in-machine-learning-7a0e84220f28) [## 整体方法:装袋、助推和堆叠
理解集成学习的关键概念。
towardsdatascience.com](/ensemble-methods-bagging-boosting-and-stacking-c9214a10a205)
推荐系统简介
行业中使用的不同类型的推荐方法。
如今,人们过去更多地在网上购买产品,而不是从商店购买。以前,人们习惯于根据亲戚或朋友的评论来购买产品,但现在随着选择的增加,我们可以通过数字方式购买任何东西,我们需要向人们保证产品是好的,他们会喜欢。为了增强购买产品的信心,推荐系统应运而生。

Recommendation techniques
推荐系统是机器学习技术在商业中最成功和最广泛的应用之一。推荐系统有助于增加商业收入,帮助顾客购买最适合他们的产品。
什么是推荐引擎?
推荐引擎根据特定客户以前的购买历史筛选出他/她感兴趣或愿意购买的产品。关于客户的可用数据越多,推荐就越准确。
但是,如果客户是新客户,这种方法将会失败,因为我们没有该客户以前的数据。因此,为了解决这个问题,使用了不同的方法;比如经常推荐最受欢迎的产品。这些建议不一定准确,因为它们不依赖于客户,对所有新客户都一样。一些企业会询问新客户的兴趣,以便他们能够更准确地推荐。
现在,我们将关注推荐引擎使用的不同类型的过滤。
基于内容的过滤
这种过滤基于为该产品提供的描述或一些数据。系统根据产品的上下文或描述找到产品之间的相似性。用户的先前历史被考虑在内,以找到用户可能喜欢的类似产品。
例如,如果用户喜欢像《碟中谍》这样的电影,那么我们可以向他推荐《汤姆·克鲁斯》或《动作片》。

Content-based filtering
在这种过滤中,使用了两种类型的数据。首先,用户的喜好,用户的兴趣,用户的个人信息,如年龄,有时用户的历史。该数据由用户向量表示。第二,与产品相关的信息被称为项目向量。项目向量包含所有项目的特征,基于这些特征可以计算它们之间的相似性。
使用余弦相似度来计算推荐。如果“A”是用户向量,“B”是项目向量,则余弦相似度由下式给出

cosine similarity formula

cosine similarity calculation
余弦相似性矩阵中计算的值按降序排序,并且为该用户推荐顶部的项目。
优势
- 向用户推荐他们喜欢的商品类型。
- 用户对推荐的类型感到满意。
- 可以推荐新品;只需要该项目的数据。
不足之处
- 用户将永远不会被推荐不同的项目。
- 由于用户不尝试不同类型的产品,业务无法扩展。
- 如果用户矩阵或项目矩阵被改变,余弦相似性矩阵需要被再次计算。
协同过滤
推荐是基于用户的行为来完成的。用户的历史起着重要的作用。例如,如果用户 A 喜欢“酷玩”、“林肯公园”和“布兰妮·斯皮尔斯”,而用户 B 喜欢“酷玩”、“林肯公园”和“泰勒·斯威夫特”,则他们具有相似的兴趣。因此,很有可能用户 A 会喜欢“泰勒·斯威夫特”,而用户 B 会喜欢“布兰妮·斯皮尔斯”。这就是协同过滤的工作方式。

user-user Collaborative filtering
使用两种类型的协同过滤技术:
- 用户-用户协同过滤
- 项目-项目协同过滤
用户-用户协同过滤
在这种情况下,用户向量包括用户购买的所有商品以及对每个特定产品给出的评级。使用 n*n 矩阵计算用户之间的相似性,其中 n 是在场用户的数量。使用相同的余弦相似性公式计算相似性。现在,计算推荐矩阵。在这种情况下,评级乘以已经购买了该项目的用户和必须向其推荐该项目的用户之间的相似性。该值针对该用户的所有新项目进行计算,并按降序排序。则向该用户推荐顶部的项目。

Collaborative filtering
如果新用户到来或者老用户改变他或她的评级或者提供新的评级,那么推荐可能改变。
项目-项目协同过滤
在这种情况下,不考虑相似的用户,而是考虑相似的项目。如果用户“A”喜欢“盗梦空间”,他可能喜欢“火星人”,因为主角是相似的。这里,推荐矩阵是 m*m 矩阵,其中 m 是存在的项目的数量。

Item-Item collaborative filtering
优势
- 新产品可以介绍给用户。
- 生意可以扩大,可以推广新产品。
不足之处
- 根据所用协作方法的类型,需要用户以前的历史记录或产品数据。
- 如果没有用户购买该新项目或对其评级,则不能推荐该新项目。
两种推荐算法各有优缺点。如今,为了进行更精确的推荐,使用了混合推荐算法;也就是说,同时使用基于内容的过滤和协同过滤来推荐产品。混合推荐算法更高效、更有用。
聪明的混蛋,疯狂的辣妹,和其他范围限制的文物
当人们写史蒂夫·乔布斯时,他们会提到他才华横溢但刻薄:他可以立即解决困扰他的团队数月的设计问题,但他会立即解雇犯了小错误的人。因为很多人都想成为史蒂夫·乔布斯那样的人,而且成为天才很难,所以一些雄心勃勃的人夸大了他们的鲁莽行为。
但是乔布斯在很多方面都是个异类。他也是这样的异类吗?
无聊的答案是肯定的:智商和宜人性之间没有很强的联系,所以在科学上可以问聪明人是不是混蛋,答案是“不超过平均水平。”
当然,怪人和天才的关联并不是唯一的民间关联。有热疯规模,运动员/书呆子二分法,等等。如果有什么不同的话,美丽和精神稳定应该有更好的相关性,因为足够疯狂的人在基本卫生方面都有问题,而突变负荷会影响面部对称和精神疾病。从经验上来看,成为运动员和成为书呆子确实相关,因为锻炼是益智的和聪明人更健康。从经验上来说,傻瓜/铅笔脖子连续体实际上是健康/聪明的人和不健康/迟钝的人之间不公平的连续体。[1]
那么,为什么我们有这么多关于特征之间权衡的民间智慧,而这些权衡并不普遍存在呢?
答案并不令人惊讶;这只是统计数据。在第一个近似值中,期望性状之间的任何强负相关都是由范围限制驱动的。
让我们测试一下
直觉很简单:如果你在看 A 和 B 的特征如何相关,但你只是在看一个人的子集,而这个子集是由人们的 A 和 B 的水平决定的,子集内的相关性将低于子集外的相关性。
考虑标准化考试分数和 GPA,两种不同的衡量学术能力的方法。总的来说,它们之间有很好的相关性是有道理的:如果你在 SAT 考试中得了满分,你可能在其他考试中也表现不错;如果你在一个问题上挣扎,你在两个问题上都挣扎。但是大学综合考虑两者,因为他们测量不同的东西。SAT 是对原始推理能力的更好的衡量;GPA 也是衡量你愿意努力学习的一个标准。如果学校根据学生的 GPA 和 SAT 来录取学生,那么这种正相关关系在一所学校内就消失了:SAT 高分的学生 GPA 较低,反之亦然。
我们可以模拟一下。
我们将从产生一群假设的学生开始。我们通过获取每个人的 SAT 分数的标准差并应用一些噪声来确定每个人的 GPA:
import pandas as pd
import numpy as np
import scipy.stats
import matplotlib.pyplot as pltdef gen_students(noise=0.5):
"""Create a set of students with a hypothetical GPA and SAT distribution"""
scores = np.random.normal(1000,195,100)
scores = [400 if x < 400 else 1600 if x > 1600 else x for x in scores]
zs = scipy.stats.zscore(scores)
gpas_raw = [3.0 + # median GPA
x * 0.75 # GPA std dev
+ np.random.normal(0, noise) # some normally-distributed noise
for x in zs]
gpas = [0 if x < 0 else 4.5 if x > 4.5 else x for x in gpas_raw]
df = pd.DataFrame(list(zip(scores,gpas)), columns = ['SAT','GPA'])
df['GPA_Percentile'] = df.GPA.rank(pct=True)
df['SAT_Percentile'] = df.SAT.rank(pct=True)
df['Ranking'] = (df.SAT_Percentile + df.GPA_Percentile) / 2
return df
如果我们运行df['SAT'].corr(df['GPA']),我们看到相关系数是 0.80。换句话说,sat 和 GPA 紧密相关。
现在,让我们送这些孩子去学校:
def choose_schools(df, count=10):
quantiles = pd.qcut(df.Ranking, count)
key = dict(zip(list(quantiles.cat.categories), range(10)))
df['Quantiles'] = pd.qcut(df.Ranking, count)
df['School'] = [key[x] for x in df.Quantiles]
return df
这只是根据学生的 SAT 分数+ GPA 分数将他们分成不同的组。我刚刚给学校编号,从 0 到 9。学校 0 的 SAT 平均成绩约为 700,高中平均绩点为 1.6,而学校 9 的 SAT 平均成绩为 1325,平均绩点为 4.15。
但是真正有趣的是在学校中观察 SAT/GPA 相关性的结果。我们可以通过以下方式快速运行:
for i in range(10):
print(df[df['School']==i]['GPA'].corr(df[df['School']==i]['SAT']))
对大多数学校来说,这种相关性是非常负的。例如,在第五学校,GPA 和 SAT 之间有-0.98 的相关性。以下是总体总结:

SAT-GPA correlation by school
和学生的视觉表现,由学校用颜色编码:

SAT vs GPA, color-coded by school
该图的一个显著特征是,在范围的高端和低端,相关性更接近真实世界的相关性。这在一定程度上是我使用的分布函数,因为 sat 和 GPA 是有上限的。但是和是真实世界的反映。有些特征衡量起来微不足道,比如身高,但是对于 SAT 分数和 GPA 到底衡量什么却存在严重分歧。(GPA 是衡量你有多努力,还是衡量你有多愿意为毫无意义的任务努力?SAT 测试的是你有多聪明,还是你擅长做选择题?在分布的中间,很容易概括,但在极端情况下,测试是不完美的。)
所有这些的结果是,如果你处于某个分布的极端——上哈佛,参加奥运会,在死囚区——我们测量的绝对下限和上限意味着样本实际上较少受到范围限制。然而,我们其他人必须敏锐地意识到范围限制。
使用范围限制
一个令人高兴的结果是,它给你一个更好的方法来处理冒名顶替综合症。或许,你擅长的事情比你不擅长的事情更不容易被你发现。“大家都比我聪明!”你认为,在公司里,每个人都被你的职业道德所震撼。“这里的每个人都比我有更好的时间管理技巧,”公司最聪明的人说。“每个人都比我工作努力,也比我聪明得多,”办公室里最擅长社交的人说。
事实上,唯一应该感到骗子综合症的人是那些最擅长推销自己的人。但是因为推销自己需要一些自我欺骗,他们自然会认为自己被懒惰的白痴包围。
另一个要点是,如果你在一个按照一个指标积极排序的团队中,但是团队中的成就依赖于其他指标,那么这些指标将是预测排序后成功的唯一指标。因此,在顶级科技公司, STEM 专业知识是最不可预测的成功衡量标准,但这只是因为他们已经把成为世界 STEM 专家作为招聘的条件。(更黑暗的一点是,“人际交往能力”是反社会者绝对具备的;被认为是一个有效的领导者的一个方法是,对进展顺利的事情邀功,对进展不顺利的事情有效地推卸责任。突然,你“领导”的一切都成功了!)
不过,你应该从范围限制中得出的主要结论是,与你互动的人不是一个代表性样本,但显而易见的统计工具——无论是正式的还是非正式的观察——都隐含地假设了一个随机样本。
有些心地善良的人头脑异常敏锐。有漂亮的人也有精神稳定的。但是对于我们中的绝大多数人来说,这些人是如此的与我们格格不入,以至于我们视而不见。随着软件蚕食世界,根据人们可观察到的特征对他们进行分类变得越来越容易,所以你越来越多地被那些总体上和你一样优秀的人所包围,不管哪种版本的“优秀”最经得起数字运算。
如果你在本行业最好的公司工作,或者在最高级的约会场所,你会发现好的品质之间的相关性通常是积极的。如果你没有,坏消息是:你不是百分之 99.99。不过,你可以对此保持冷静:如果你在你所做的事情上不是世界上最好的,你观察到你的同龄人之间可取的特质之间的权衡,至少你知道这个世界是相当公平的。
不要错过下一个故事。报名参加我的 邮箱快讯 。或者查看 关于/常见问题 页面了解更多。
[1]当然,这两种情况都有很大的可变性;我说的是非常宽泛的平均值,而不是对任何一个人都有意义的东西。此外,这些概括很难做出,因为人们经常选择夸大人格特征。作为一个在许多不同方面都略高于平均水平的人,很难让人印象深刻,所以通常的模式是在一两个特质上全押。
用于交通管理的空间数据分析

SIM 卡有助于车辆交通管理吗?简短的回答是是的。在这篇文章中,我将总结我在空间数据分析的一次最好的经历。事实上,感谢沙特电信公司(STC)的业务团队,他们在利雅得发起了交通管理数据通活动。他们邀请了 50 个数据极客团队来展示他们的肌肉,只需给他们模拟数据来进行分析和解决。我和我的兄弟穆罕默德·卡西姆(Mohammed Qassim)与其他 49 支队伍一起组队参赛。幸运的是,我们队在其他十支队伍中进入了决赛,并获得了比赛的第二名。
在这里,我将介绍什么是数据集,我们的方法和策略,然后展示一些分析和结论。
资料组
- **第一个文件:**四列,包含 9868 辆独特车辆的记录和 2,011,774 个相关联的位置报告,跨越 24 小时的时间段。这些列是:
SAM:报告位置的时间(以午夜后的秒为单位)
经度:以十进制度表示的经度坐标
纬度:以十进制度表示的纬度坐标
ID:加密 ID - Roads 数据来自三个文件:
Roads.shp
Roads.dbf 和
Roads.shx
我们的战略和方法

对于比赛,我们使用了三个工具:微软 SQL Server 2017、微软 Power BI 和带有 Python 3 设置的 Jupyter Notebook。每个工具发生的一些活动有:

My brother and I holding the second prize
分析和结果
在许多清理和特性工程步骤之后,我们最终得到了 11 列和 9805 行(ID)。主要功能有:计算每辆车的行驶时间、距离,从而计算速度。主要的挑战是处理坐标或 GPS 漂移中的一些噪声!但是,这里我将展示一些对数据集进行的绘图和分析:
绘制“距离”和“平均速度”栏的直方图


24 小时内 ID 在各条道路上的计数和分配

条形图很有意义。早上是道路交通的高峰时间。交通活动在早上 6:00 学校值班时开始,在早上 8:00 工人值班时达到高峰。
计算 ID 的一般速度
只要把它们分成五大类:非常高速、高速、正常速度、低速和非常低速。

在速度谱上绘制每小时的数据

上午 8:00 交通拥堵最严重,上午 11:00 违章率最高。令人惊讶的是,大多数汽车在午夜和午夜后都安全行驶。
可视化两条主干道起点处的每小时交通密度:

使用交互式小部件,让您的 Jupyter 笔记本栩栩如生
现实世界中的数据科学
如何使用 ipywidgets 创建动态仪表板

扩展 Jupyter 的用户界面
传统上,每次需要修改笔记本单元格的输出时,都需要更改代码并重新运行受影响的单元格。这可能是麻烦的、低效的和容易出错的,并且在非技术用户的情况下,这甚至是不可行的。这就是 ipywidgets 发挥作用的地方:它们可以嵌入到笔记本中,并提供一个用户友好的界面来收集用户输入,并查看更改对数据/结果的影响,而不必与代码进行交互;您的笔记本可以从静态文档转变为动态仪表盘,非常适合展示您的数据故事!
⚠️范围:ipywidgets 上的资源是有限的,现有的极少数教程要么不完整,要么专注于
interact函数/装饰器。这是一个完整的教程,告诉你如何完全控制小部件来创建强大的仪表板。我们将从基础开始:添加一个小部件并解释事件如何工作,我们将逐步开发一个仪表板。
我将一步一步地指导你,在我们进行的过程中,以示例为基础。
什么是 widget?
如果你曾经创建过图形用户界面 (GUI),那么你就已经知道什么是小部件了。但是让我们快速定义一下:
widget 是一个 GUI 元素,比如按钮、下拉菜单或文本框,它驻留在浏览器中,允许我们通过响应事件和调用指定的处理程序来控制代码和数据。
这些 GUI 元素可以被组装和定制以创建复杂的仪表板。

Demo: A few of the most popular widgets
在整篇文章中,我们将看到它们中的一些在起作用。
准备好了吗?🏁
❶入门
要开始使用这个库,我们需要安装 ipywidgets 扩展。如果使用 conda,我们在终端中键入以下命令:
conda install -c conda-forge ipywidgets
对于 pip,这将是一个两步过程:1 .安装和 2。启用:
pip install ipywidgetsjupyter nbextension enable --py widgetsnbextension
添加小部件
为了将小部件合并到笔记本中,我们必须导入模块,如下所示:
import ipywidgets as widgets
要添加滑块,我们可以定义最小值和最大值、间隔大小(步长)、描述和初始值:
widgets.IntSlider(
min=0,
max=10,
step=1,
description='Slider:',
value=3
)

Demo: Slider
展示它
display()函数在输入单元格中呈现一个小部件对象。
首次导入:
from IPython.display import display
然后在 display()函数中将小部件作为参数传递:
slider = widgets.IntSlider()
display(slider)
获取/设置其值
为了读取小部件的值,我们将查询它的value属性。类似地,我们可以设置小部件的值:

Demo: Value
链接两个小部件
我们可以通过使用jslink()函数来同步两个小部件的值。
slider = widgets.IntSlider()
text = widgets.IntText()
display(slider, text)widgets.jslink((slider, 'value'), (text, 'value'))

Demo: Linking
小组件列表
要获得小部件的完整列表,您可以查看文档,或者运行以下命令:
print(dir(widgets))
❷处理窗口小部件事件
小部件可以响应事件,这些事件是在用户与它们交互时引发的。一个简单的例子是点击一个按钮——我们期待一个动作发生。
让我们看看这是如何工作的…
根据其具体特性,每个小部件公开不同的事件。每次触发事件时,都会执行一个事件处理程序。
事件处理程序是响应事件的回调函数,它异步运行并处理接收到的输入。
这里我们将创建一个简单的按钮,名为btn。点击按钮时会调用on_click方法。
我们的事件处理程序btn_eventhandler将打印一条带有按钮标题的短消息——注意处理程序的输入参数obj是按钮对象本身,它允许我们访问它的属性。
为了将事件与处理程序绑定,我们将后者分配给按钮的on_click方法。
btn = widgets.Button(description='Medium')
display(btn)def btn_eventhandler(obj):
print('Hello from the {} button!'.format(obj.description))btn.on_click(btn_eventhandler)

Demo: Button Event Handler
让我们进入下一部分的是,输出出现在按钮本身所在的单元格中。因此,让我们继续看看如何为我们的笔记本电脑增加更多的灵活性!
❸控制小部件输出
在这一节中,我们将探索如何使用小部件来控制数据帧。我选择的样本数据集是“伦敦国际游客数量”,它显示了伦敦游客在住宿、参观和消费方面的总数,按年份、季度、目的、持续时间、方式和国家细分。
最初,我们将获取数据并将其加载到数据帧中:
import pandas as pd
import numpy as npurl = "[https://data.london.gov.uk/download/number-international-visitors-london/b1e0f953-4c8a-4b45-95f5-e0d143d5641e/international-visitors-london-raw.csv](https://data.london.gov.uk/download/number-international-visitors-london/b1e0f953-4c8a-4b45-95f5-e0d143d5641e/international-visitors-london-raw.csv)"df_london = pd.read_csv(url)

df_london.sample(5)
假设我们想按年过滤数据帧。我们将首先定义一个下拉列表,并用唯一年份值的列表填充它。
为了做到这一点,我们将创建一个通用函数unique_sorted_values_plus_ALL,它将找到唯一的值,对它们进行排序,然后在开头添加ALL项,这样用户就可以删除过滤器。
ALL = 'ALL'def unique_sorted_values_plus_ALL(array):
unique = array.unique().tolist()
unique.sort()
unique.insert(0, ALL)
return unique
现在我们将初始化下拉菜单:
dropdown_year = widgets.Dropdown(options = unique_sorted_values_plus_ALL(df_london.year))
dropdown 小部件公开了observe方法,该方法采用一个函数,当 dropdown 的值改变时,该函数将被调用。因此,我们接下来将创建 observer 处理程序,通过所选的值来过滤数据帧——注意,处理程序的输入参数change包含关于所发生的更改的信息,这允许我们访问new值(change.new)。
如果新值是ALL,我们移除过滤器,否则我们应用它:
def dropdown_year_eventhandler(change):
if (change.new == ALL):
display(df_london)
else:
display(df_london[df_london.year == change.new])
然后,我们将处理程序绑定到下拉列表:
dropdown_year.observe(dropdown_year_eventhandler, names='value')

Using a dropdown to filter a dataframe
到目前为止还不错,但是所有查询的输出都是在同一个单元格中累积;也就是说,如果我们从下拉列表中选择一个新的年份,一个新的数据框架将呈现在第一个数据框架的下面,在同一个单元格中。
理想的行为是每次刷新数据帧的内容。
捕获小部件输出
对此的解决方案是在一种特殊的小部件中捕获单元格输出,即Output,然后在另一个单元格中显示它。
我们将稍微调整一下代码:
- 创建一个新的
Output实例
output_year = widgets.Output()
- 调用事件处理程序中的
clear_output方法来清除每次迭代中的前一个选择,并在with块中捕获 dataframe 的输出。
def dropdown_year_eventhandler(change):
output_year.clear_output()
with output_year:
display(df_london[df_london.year == change.new])
然后,我们将在新的单元格中显示输出:
display(output_year)
它是这样工作的:

Demo: Capturing output in a new cell
正如您所看到的,输出呈现在一个新的单元格中,过滤工作正常!👍
❹链接小部件输出
继续前面的例子,让我们假设我们也想通过目的进行过滤。
如果我们继续添加另一个下拉列表,我们将很快意识到数据帧只响应最近更改的下拉列表的过滤器。我们需要做的是将两者链接在一起,这样它就可以同时处理两个值(即年份和目的)。
让我们看看它应该如何工作:
首先,我们需要两个下拉菜单的公共输出:
output = widgets.Output()
这是两个下拉菜单:
dropdown_year = widgets.Dropdown(options = unique_sorted_values_plus_ALL(df_london.year))dropdown_purpose = widgets.Dropdown(options = unique_sorted_values_plus_ALL(df_london.purpose))
然后我们创建一个新函数common_filtering,它将被两个事件处理程序调用。该函数将对两年的数据帧应用过滤器*AND*目的:
我们正在清除输出,然后我们检查是否有任何值为ALL,在这种情况下,我们认为相应的过滤器已被移除。当两个过滤器都存在时,在else语句中,我们在两个过滤器中应用&操作。最后,我们捕获输出:
def common_filtering(year, purpose):
output.clear_output()
if (year == ALL) & (purpose == ALL):
common_filter = df_london
elif (year == ALL):
common_filter = df_london[df_london.purpose == purpose]
elif (purpose == ALL):
common_filter = df_london[df_london.year == year]
else:
common_filter = df_london[(df_london.year == year) &
(df_london.purpose == purpose)]
with output:
display(common_filter)
我们修改事件处理程序来调用common_filtering函数并传递change.new值以及另一个下拉菜单的当前value:
def dropdown_year_eventhandler(change):
common_filtering(change.new, dropdown_purpose.value)def dropdown_purpose_eventhandler(change):
common_filtering(dropdown_year.value, change.new)
我们将处理程序绑定到下拉菜单,就这样!
dropdown_year.observe(
dropdown_year_eventhandler, names='value')dropdown_purpose.observe(
dropdown_purpose_eventhandler, names='value')
代码片段:

Filter a dataframe based on two values
这是演示:

Demo: Filter a dataframe based on two values
❺创建仪表板
到目前为止,我们已经通过过滤和显示伦敦数据集的数据为我们的仪表板奠定了基础。我们将继续根据用户选择的值对数值进行着色。
一个有用的数字小部件是BoundedFloatText;我们将赋予它一个min、max和初始value,以及增量step。
bounded_num = widgets.BoundedFloatText(
min=0, max=100000, value=5, step=1)
为了给数据框单元格着色,我们将定义此函数:
def colour_ge_value(value, comparison):
if value >= comparison:
return 'color: red'
else:
return 'color: black'
现在我们将最低限度地修改common_filtering函数为:
- 添加新的
num输入参数:
def common_filtering(year, purpose, num):
- 通过为三个数字列调用
colour_ge_value函数来应用样式:
with output:
display(common_filter
.style.applymap(
lambda x: colour_ge_value(x, num),
subset=['visits','spend', 'nights']))
需要调整现有的事件处理程序以通过bounded_num.value:
def dropdown_year_eventhandler(change):
common_filtering(change.new, dropdown_purpose.value,
bounded_num.value)def dropdown_purpose_eventhandler(change):
common_filtering(dropdown_year.value, change.new,
bounded_num.value)
最后,我们将插入新部件的事件处理程序:
def bounded_num_eventhandler(change):
common_filtering(dropdown_year.value, dropdown_purpose.value,
change.new)bounded_num.observe(bounded_num_eventhandler, names='value')
代码片段:

Colour dataframe values
这是演示:

Demo: Colour dataframe values
测绘
接下来,我们将添加一个新的图表来绘制访问次数的基本单变量密度(KDE →核密度估计)。我们将使用 seaborn,所以让我们导入库:
import seaborn as sns
import matplotlib.pyplot as plt
继续之前的用例,我们将在一个新的输出变量中捕获图形:
plot_output = widgets.Output()
我们现在将修改common_filtering函数来绘制新图表:
- 首先,我们清除输出:
plot_output.clear_output()
- 然后我们通过传递访问次数来调用 seaborn 的
kdeplot方法:
with plot_output:
sns.kdeplot(common_filter['visits'], shade=True)
plt.show()
最后,我们需要做的唯一一件事是在一个新的单元格中显示输出:
display(output)
display(plot_output)
代码片段:

Controlling a graph
这是演示:

Demo: Controlling a graph
❻仪表板布局
到目前为止,我们的用户界面是功能性的,但是占用了很多空间。
我们将首先水平排列输入部件。HBox将从左到右一次添加一个小部件:
input_widgets = widgets.HBox(
[dropdown_year, dropdown_purpose, bounded_num])display(input_widgets)

HBox
接下来我们将为输出创建一个容器。Tab对此大有裨益。第一个选项卡将存放数据框架,第二个选项卡将存放图表。
tab = widgets.Tab([output, plot_output])
tab.set_title(0, 'Dataset Exploration')
tab.set_title(1, 'KDE Plot')display(tab)

Tab
最后,我们将用一个VBox将输入部件和选项卡堆叠在一起。
dashboard = widgets.VBox([input_widgets, tab])display(dashboard)

VBox
感觉有点“拥挤”,所以作为最后一步,我们将通过添加一些空间来打磨我们的仪表板。我们将定义一个Layout,在项目之间给出 50px 的边距。
item_layout = widgets.Layout(margin='0 0 50px 0')
我们将每个项目的布局称为:
input_widgets = widgets.HBox(
[dropdown_year, dropdown_purpose, bounded_num],
layout=item_layout)tab = widgets.Tab([output, plot_output],
layout=item_layout)
还有哒哒…我们的成品仪表板:

Dashboard
最终演示

Demo: Final Dashboard
PS :出于演示的目的,在一些演示中,我使用了数据集的一个子集,即:
df_london = *df_london*.sample(250)。
更进一步
您也可以使用一些第三方小部件,其中最流行的是:
二维图表: bqplot
三维可视化:pytreejs和 ipyvolume
映射: ipyleaflet 和 gmaps 。
您还可以构建自己的自定义小部件!欲了解更多信息,请点击查看。

概述
我们看到了各种各样的小部件,但是我们仍然只是触及了表面——我们可以使用 ipywidgets 构建非常复杂和广泛的 GUI。我希望你们都同意,它们应该在任何数据科学家的工具箱中占有一席之地,因为它们提高了我们的生产力,并在数据探索过程中增加了很多价值。
感谢阅读!
我定期在媒体上写关于技术的&数据——如果你想阅读我未来的帖子,请‘关注’我 !

















 972
972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










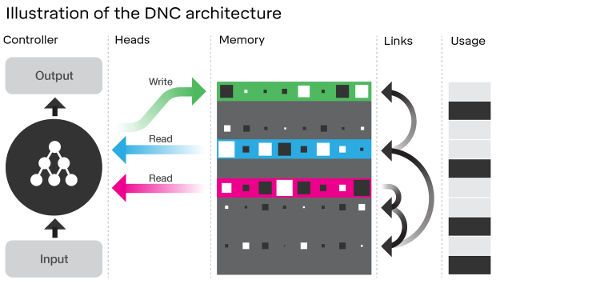{kind=link}
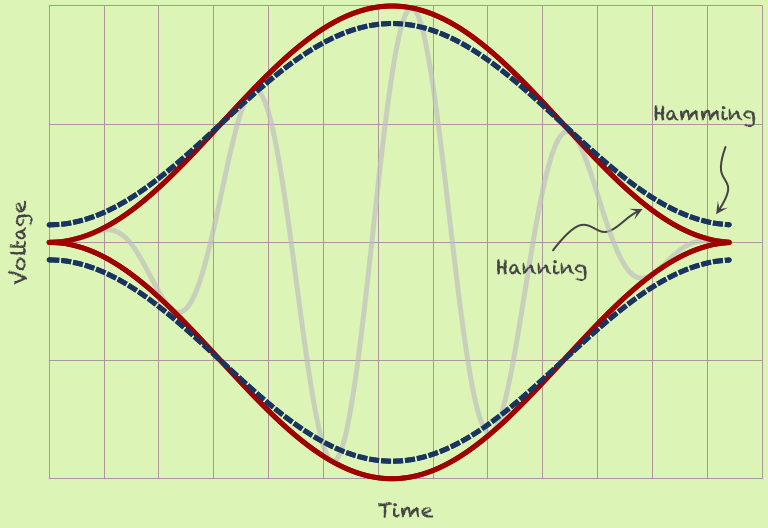{kind=link}