







在几分钟内构建、评估和解释您自己的线性回归模型

线性回归简介
回归是我们作为数据科学家利用的这么多统计分析和机器学习工具的核心。
简而言之,我们利用回归技术通过 X 的某些函数来模拟 Y。导出 X 的函数通常严重依赖于线性回归,并且是用户解释或预测的基础。
让我们深入研究一下,用一些数值解释变量,x,来模拟一些数值变量 Y。
带有数字解释变量的回归
我从 kaggle 下载了一份房价数据。你可以在这里找到:【https://www.kaggle.com/shree1992/housedata/data】T4
下面你会看到一个房子的居住面积和价格之间的散点图。
除了散点图之外,我还画了一条回归线。稍后会有更多的介绍。
housing %>%
ggplot(aes(x = sqft_living, y = price)) +
geom_point() +
geom_smooth(method = "lm", se = FALSE)

上面你可以看到这两个数据点确实是相关的,但是你也会注意到趋势线正好穿过这些数据点的中间。
让我们谈谈回归是如何工作的,在这种情况下,普通最小二乘回归(OLS)是如何工作的。
我们现在看到的是一条线,一条有 y 轴截距和斜率的线。说到斜坡,你也可以想到上升超过运行!
现在我想强调的是,有一个目标函数决定了这条线的位置。
线将被放置在离线和周围数据点的绝对距离最小的地方。换句话说,如果你把 y 轴截距提高一点,或者增加直线的斜率,那么实际值和预测值之间的绝对距离就会增加。因此,有理由将线放在组的正中间,那里误差最小。
相关性与因果性
现在,我们已经观察到了两个正相关的变量之间的关系。
说了这么多,我们能得出 x 导致 y 的结论吗?肯定不是!如果你从大学的统计数据中记住了这一点,给自己一个鼓励。显然,可能有许多其他因素在起作用。
为了调用通用建模框架的概念,当我们构建一个线性模型时,我们正在创建一个线性函数或一条线。
这条线的目的是让我们解释或预测。
无论是哪种情况,建模一条线都需要一个 y 截距和一个斜率。
在另一篇文章中,我谈到一般的建模框架是 Y 作为 X+ε或误差的函数。(这里可以找到通用建模框架更详细的解释)。在直线方程的情况下,你可能会问自己ε在哪里……情况是,我们不在直线方程或线性函数中表示ε,因为模型的唯一目的是捕捉信号,而不是噪声。
解释您的回归模型输出
我们将首先运行 r 中的lm函数。该函数构建一个简单的线性模型,由您传递给它的公式决定。
y ~ x,或者在这种情况下,价格是生活平方英尺的函数。
fit <- lm(price ~ sqft_living, data = housing)

你可以在上面的输出中看到我们的调用,还有这个系数部分。
这一节突出了我们直线方程。y 截距是 12954,我们的解释变量的系数是 252。解释该系数的方式是,sqft_living每增加 1 个单位,我们应该看到price增加 252 个单位。
我的房子大约 3000 平方英尺,所以根据这条线的等式,如果你把我在西雅图的房子拆了,我们预测它的价值是 12,954 美元+252 美元*3000 美元= 768,000 美元…不用说,所有这些数据都是基于房地产市场的…我的房子远没有那么值钱。
有了这个例子,我们需要记住的一点是,我们可以依靠斜率或系数来量化 x 和 y 之间的关系。
深入你的回归输出
我们将更深入地探究你的线性模型的本质。我们将通过几种不同的方式来实现,但第一种方式是使用 r 中的经典summary函数
summary(fit)
通过如此简单的调用,我们得到了下面的回归输出。

我们从头开始吧!
首先,这个电话是有意义的。我们在残差中得到了一些统计数据,换句话说就是误差,但我们现在想深入研究一下。
接下来,我们看到的系数与之前看到的略有不同。
我想向你们指出的几件事是 R 平方和 p 值的概念……这是最常被误用的两个统计学术语。
r 平方定义为可以用 x 的变化来解释的 Y 的变化量。
p 值是统计显著性的传统度量。这里的关键要点是,p 值告诉我们给定输出可能只是随机噪声的可能性。换句话说,给定事件随机发生的可能性为 5%或更小,因此具有统计学意义。
另一个类似的输出是将我们的模型传递给moderndive包中的get_regression_table。
get_regression_table(fit)

get_regression_table作为模型的快速包装器,能够方便地显示关于我们模型的一些更重要的统计数据。
结论
希望这被证明是对线性回归的有用介绍。如何构建以及如何解读它们。
概述
今天我们有一个速成班,内容如下:
- 可视化 Y 和 X 之间的关系
- 向我们的 Y & X 可视化添加回归线
- 构建线性回归模型
- 通过 p 值或 Y 中的变化量来理解其统计显著性,从而评估所述模型,我们可以通过 x 中的变化来解释。
如果这是有用的来看看我在 datasciencelessons.com 的其余职位!一如既往,祝数据科学快乐!
构建预测模型的评估框架
时间数列预测法
关于使用 Python 预测性能指标的教程

背景
任何时间序列预测模型的目标都是做出准确的预测。流行的机器学习评估技术,如训练测试分割和 k-fold 交叉验证,在当前形式的时间序列数据上不起作用。正如我们在之前的文章中所讨论的,时间序列数据期望观察值之间的顺序依赖,而在其他机器学习数据集中,所有观察值都被平等对待。
在本教程中,我们将探讨应用于时间序列数据的各种评估技术。
目录
- 数据划分
- 常见的预测准确性衡量标准
- 天真的预测或持续模型
- 可视化残差
首先,让我们下载下面的数据集,打开一个 Jupyter 笔记本,并导入这些 python 库。
数据集— 航空公司—乘客. csv
1.数据划分
乍一看,我们可能认为最好是选择一个模型,该模型根据我们用来训练模型的现有数据生成最佳预测。当我们将该模型部署用于业务时,我们观察到预测准确性显著降低。这种情况也被称为过度拟合,这意味着模型不仅拟合数据的系统成分,还拟合噪声。
因此,预测的准确性只能通过测量拟合模型时未使用的新数据的性能来确定。
我们可以通过数据划分来解决这个过度拟合问题,这是应用任何预测方法之前的一个重要的初步步骤。
在机器学习问题中,我们通常将数据分为训练集和测试集,其中训练数据集用于构建模型,测试数据集用于评估模型性能。我们还使用这种分割的高级版本,称为 k-fold 交叉验证,其中我们系统地将数据分成 k 个组,每个组都有机会评估模型,该模型是使用剩余的 k-1 个组开发的。
这些方法不能像其他机器学习问题一样直接用于时间序列数据,这意味着我们不能随机地将数据集分成训练组和测试组。相反,我们必须将序列分成两个时间段,以保持序列的时间顺序。
使用历史数据评估时间序列预测也称为回溯测试。让我们用我们的“航空公司-乘客”数据集来讨论这些方法。
单列车-测试分离
我们可以将数据集分为训练子集和测试子集,模型可以在训练数据集上开发,其性能可以在测试数据集上评估。这可以通过基于可用时间序列的长度选择连续观察的分割点(例如 60:40、70:30 或 80:20)来完成。
例如,如果我们有一年的月度数据,并且我们想要 66.66:33.33 的分割,则前 8 个月可以用作训练,后 4 个月可以用作测试数据集。
让我们通过以下示例来理解这一点,总共有 20 个时间段,前 15 个(蓝点)可用于训练模型,后 5 个(红点)可用于验证预测准确性。

单一列车-测试分割示例
这种训练测试比例根据您的数据和业务需求而变化,围绕这种划分没有固定的规则。只是我们必须确保手头有足够的数据来训练模型。
Python 可以帮助我们快速地将这个数据集分成训练和测试子集。我们可以将拆分点指定为数组中的百分比,将拆分点之前的所有观察值作为训练数据集,并将从该点到系列末尾的所有观察值作为测试数据集。
让我们使用不同的颜色在线图上可视化这种分割,训练数据集和测试数据集分别用蓝色和橙色显示。
多重训练-测试分离
我们可以将时间序列分成多个训练和测试数据集,以训练一个集合模型来进行更稳健的估计。这种方法需要使用各自的拆分来开发多个模型。这可以通过重复上述过程来手动完成。
例如,我们有一个在 20 个时间段有 20 个观察值的数据集,我们可以创建如下 3 个不同的训练测试分割。
50:50(各 10 次观察)
60:40 (12 次和 8 次观察)
75:25 (15 次和 5 次观察)

多重训练-测试多重分割示例
这些分割可用于构建 3 个不同的模型,输出可被平均以获得稳健的预测。
在 Python 中,sci-kit-learn 库可以帮助我们使用它的 TimeSeriesSplit 函数来创建多个拆分,只需要我们指定拆分的数目。
根据 sci-kit-learn 官方页面,在每个分裂迭代(I)中,训练和测试观察的总数计算如下:
Train_size= i * n_samples // (n_splits + 1) + n_samples % (n_splits + 1)
Test_size= n_samples//(n_splits + 1)
其中“n_samples”是观察的总数,“n_splits”是分裂的总数。假设我们有 100 个观察值,想要创建 3 个分割。
让我们应用上述算法来计算训练和测试数据集的大小。
train _ size _ 1 = 1 * 100/(3+1)+100 mod(3+1)= 25
测试大小 1 = 100/(3+1) = 25
train _ size _ 2 = 2 * 100/(3+1)+100 mod(3+1)= 50
测试大小 2 = 100/(3+1) = 25
train _ size _ 3 = 3 * 100/(3+1)+100 mod(3+1)= 75
测试大小 3 = 100/(3+1) = 25
现在,我们可以在“航空公司-乘客”数据集上实现 TimeSeriesSplit 函数,并对数据集进行分区。数据集有 144 个观察值,我们想要 3 个不同的分割。根据上述计算,我们预计在各自的分割中会有以下数量的观察值。
分流 1: 36 列车,36 测试
分裂 2: 72 火车,36 测试
拆分 3: 108 次列车,36 次测试
我们可以看到,在每次拆分中,观察结果的数量都符合我们的预期。
时间序列交叉验证
训练和测试分割的一个更复杂的版本是时间序列交叉验证,这也称为前推验证,因为它涉及一次一个时间步长地沿着时间序列移动。这种方法提供了在每个时间步进行预测的最佳机会。
让我们在下面的例子中看看数据集的不同分割是如何随着时间序列向前移动的。

向前走验证示例
预测准确性是通过对测试集进行平均来估计的。在创建这个验证框架之前,我们必须决定我们对哪些历史观察感兴趣。
首先,我们必须决定训练我们的模型所需的最少观察次数,即窗口宽度。
在决定了这些需求之后,现在让我们在“航空公司-乘客”数据集上实现这个分割方法。
我们可以看到更多的分裂被创造出来,我们可以训练同样多的模型。同样,这将有助于我们提供更可靠的评估。向前走方法被认为是最好的模型评估方法,这也被称为时间序列世界的 k-fold 交叉验证。
2.常见的预测准确性衡量标准
任何时间序列预测模型的目标都是做出准确的预测,但问题是我们如何衡量和比较预测的准确性。因此,作为初步要求,我们必须定义一个合适的性能指标来衡量预测的准确性。
有许多不同的绩效衡量标准可供选择,在这一部分,我们将讨论一些流行的衡量标准。
预测误差
考虑一个具有“v”个时间段的验证数据集,t=1,…v。预测误差(eₜ)定义为某个时间段(t)的观测值(xₜ)and)与预测值(yₜ)之间的差值。

可以计算每个预测的预测误差,让我们看看如何在 Python 中计算这个误差。
这是否解决了我们的评价问题?还没有,我们必须将这些误差总结为一个可比较的数字。
让我们讨论几种流行的预测准确性的方法。
平均预测误差
平均预测误差计算为预测误差值的平均值。

正如我们所知,预测误差可以是正的,也可以是负的,这种性能度量是以这些预测误差的平均值来计算的,因此一个系列的理想平均预测误差应该是零。误差值远离零被认为是偏差。
让我们看看如何使用虚拟的实际值和预测值在 Python 中手动计算平均预测误差。
绝对平均误差
平均绝对误差(MAE)计算为预测误差值的平均值,其中所有预测值都强制为正值。

我们可以在 Pythion 中使用 mean_absolute_error 函数手动计算。
平均绝对百分比误差
平均绝对百分比误差或 MAPE 给出了预测值偏离实际值的百分比分数。这对于比较具有不同规模的多个系列的性能非常有用。

sci-kit learn 中没有内置函数,我们可以使用自定义函数来计算这个度量。
均方误差
均方差(MSE)是预测误差平方值的平均值。对预测误差值求平方会强制误差为正。因此,这种方法更重视大的误差。

我们可以使用 Python 中 sci-kit learn 的 mean_squared_error 函数来计算这个度量。
均方根误差
均方根误差或 RMSE 是均方误差的变换版本。它可以通过计算均方误差值的平方根来计算。

在 Python 中,这可以通过对上面计算的均方误差使用数学库的 sqrt()函数来计算。
3.天真的预测
我们已经将数据集划分为训练和测试子集,还定义了评估模型的理想性能指标。现在,我们已经准备好开始建模练习,我们可以选择任何可用的高级算法来建模时间序列。
但是,我们怎么能相信这个模型的预测准确性呢?我们心目中有什么基准精度吗?
让我们建立一个基准预测性能,在评估不同技术的性能时,我们可以将它作为一个参考点。如果模型的准确性等于或低于基线,我们可以改进模型,如果我们不能达到预期的准确性,我们可以探索其他技术。
时间序列预测最常用的基线方法是简单预测,这只是预测时可用的序列的最新值。naive 算法使用当前时间步长(t)的值来预测下一个时间步长(t+1)的预期结果。
让我们用 Python 实现一个简单的预测。
将时间序列数据重构为监督学习数据集
让我们将我们的“航班-乘客”数据集转化为一个监督学习问题,我们可以通过创建一个滞后特征来实现这一点。在这个变换的数据集中,(t)处的值是预测值(X),而(t+1)处的值是目标变量(Y)。
我们必须丢弃第一行,因为它没有任何输入值。
创建培训测试分解
接下来,我们可以将数据集分为训练和测试子集,如下所示。70%的系列创建为培训,30%创建为测试子集。
做出天真的预测
建立一个基线模型是相当简单的。我们知道 naive 算法使用当前时间步(t)的值来预测下一个时间步(t+1)的预期结果。因此,在数据集的转换监督版本中,第一列是对第二列的预测。我们必须丢弃数据集的第一行,因为它没有任何输入值。
预测和评估预测
最后一步,我们可以在测试数据集上评估我们的基线模型。在这种情况下,不需要模型训练或再训练,我们知道第一列是预测,第二列是实际数字。我们一步一步地遍历测试数据集并得到预测。
我们可以观察这个预测的折线图,它用蓝色显示训练集,用绿色显示测试集,用红色显示预测。
观察线图,我们可以看到测试数据集上的一个不错的预测。当我们探索其他先进的技术时,我们必须保持或提高这种准确性。
4.可视化和分析残差
我们已经准备好基线模型,现在是时候使用预测误差来调查拟合优度了。时间序列问题上的这些误差称为残差或剩余误差。分析我们模型的残差可以解释很多关于我们预测的事情,甚至提出改进建议。
让我们在同一数据集上重新计算我们的天真预测的残差,以便在本节中进一步探讨。
我们可以看到前五个预测错误的示例输出。让我们把这些数字形象化,以获得有意义的解释。
剩余线图
第一个图是以线形图的形式观察残差随时间的变化。如果模型拟合得很好,我们不会期望任何趋势和循环行为,图应该在值 0 附近是随机的。
我们仍然可以在线图中观察到循环行为,这表明模型中存在改进的空间,可以通过更好的功能工程和探索其他高级模型来实现。
剩余汇总统计
接下来,我们可以分析残差的汇总统计数据。首先,我们感兴趣的是残差的平均值。接近零的值表示预测中没有偏差,而正值和负值表示预测中有正偏差或负偏差。
汇总统计数据也表明模型中存在正偏差。
残差直方图和密度图
这些图可用于更好地理解汇总统计之外的误差分布。我们希望预测误差正态分布在一个零均值附近。绘图有助于发现这种分布的偏斜。我们可以使用直方图和密度图来更好地理解残差的分布。
可以清楚地观察到残差不是正态分布的,而是负偏态的。这再次证实了我们的模型需要改进。
剩余 Q-Q 图
这也称为分位数图,可用于检查残差分布的正态性。对这些值进行排序,并与散点图上的理想化高斯分布进行比较。我们希望所有的点都与对角线重叠,以确认两个分布之间的完全匹配。
我们可以在 Q-Q 图上看到一些凸起和异常值,需要对它们进行校正,以实现更好的预测。
剩余自相关图
自相关解释了观测值和先前时间步的观测值之间的关系强度。我们不期望残差之间还有任何相关性。让我们计算并绘制残差的自相关。
我们可以看到残差中仍然存在自相关,这验证了我们的发现,即模型需要在特征工程和算法选择方面进行改进。
摘要
在本文中,我们讨论了构建一个健壮的评估框架的所有重要技术。我们从数据划分开始,然后讨论了各种可供选择的性能指标,建立了一个持久性预测模型作为提高准确性的基准,最后了解了使用残差进行模型调查。
经过数据准备(在我的上一篇文章中有所涉及)并有了一个健壮的评估框架,现在我们完全准备好探索各种预测技术。在接下来的几篇文章中,我将讨论不同的预测技术,我将从经典技术开始。
感谢阅读,希望你发现这篇文章内容丰富。
参考
[1] Galit Shmueli 和 Kenneth Lichtendahl,实用时间序列预测与 R:实践指南,2016 年。
[2]杰森·布朗利,【https://machinelearningmastery.com/
12 小时 ML 挑战
如何使用 Streamlit 和 DevOps 工具构建和部署 ML 应用程序

克拉克·蒂布斯在 Unsplash 上拍摄的照片
TL;在这篇文章中,我想分享我完成 12 小时 ML 挑战的学习、过程、工具和框架。希望对你的个人或专业项目有所帮助。
以下是帮助您导航的目录:
- 第 1 部分:找一个好问题
- 第 2 部分:定义约束条件
- 第三部分:思考,简化,&分清主次
- 第四部分:冲刺规划
- 第五部分:App
- 第 6 部分:经验教训
- 奖励:懒惰程序员的过程&工具
免责声明: 这不是由 Streamlit、我提到的任何工具或我工作的任何公司赞助的。
喜欢读什么? 跟我上 中LinkedInTwitter。查看我的《 对机器学习的影响 》指南。它有助于数据科学家更好地交流。**
第一步:找一个好问题(圣诞节问题)
嗯,圣诞节。过去,每年的这个时候,我都会和妻子、小狗一起坐在沙发上,疯狂地看电影和电视剧。
然后,这个圣诞节。有些事情改变了。出于某种原因,我在网飞或 YouTube 上找到的大多数东西似乎都很无聊。也许我通过观看推荐算法推送的类似内容,已经达到了零效用收益的临界点。太了解我的算法了(可能太了解了)。
我意识到了一个问题**:我被太了解我的推荐算法困住了——我被数字化囚禁了(本帖采取的是更具设计感的镜头)。**
我似乎找不到内容气泡之外的东西。算法认为我感兴趣的一切都逐渐变得无趣;真是讽刺。我想出去!
重点是这个:找一个够烦的问题。它不一定是治愈癌症或消除饥饿(如果你可以,太棒了!),只要是足够有意义的事情,让你愿意去承诺,去开始。
步骤 2:定义约束(12 小时挑战)
在我的朋友 Matt Pua 的 web 应用程序开发的 48 小时挑战的启发下,我决定做一些类似的事情,但是是针对有 ML 组件的应用程序。简而言之,限制因素如下:
- 约 12 小时的总工作时间;它们不必是连续的小时
- 必须为除我之外的用户提供一个可用且稳定的应用程序
- 必须有一个 ML 组件,但没有不必要的复杂性
- 必须与他人分享工作和学习成果(也就是写这篇文章)
- (这种体验一定很有趣)
为什么要有截止日期?据马特:
…设定最后期限让个人专注于优先考虑他们需要关注的事情,以便让他们的项目进入可行状态。个人必须考虑到设计一个项目、提出解决方案、处理任何不可预见的技术问题以及这两者之间的一切,以便在截止日期前完成项目。
(那么,为什么只有 12 小时,而不是 48 小时呢?我不像马特那么紧张。如果你决定这样做,选择一个最适合你的时间框架,并坚持下去。重点是执行和出货。)
以下是我对所有相关工作的大致时间预算:
- ****2 小时:对 app 有一个大致的设计(如研究、UX、架构)。
- ****8 小时:重新设计,构建,迭代测试 app。
- ****2 小时:撰写、编辑、发表这篇文章(还有这个)。
第三步:思考,简化,区分优先次序,然后重复
在编码之前,我需要解决几个重要的问题,1)明确我到底需要构建什么,2)在 12 小时内优先构建什么。尽管不是详尽无遗的,以下是一些指导性问题:
戴上的产品帽子**,谁是用户?用户想要什么,需要什么?不同细分市场的需求有何不同?应该先针对哪个用户群?满足需求的功能有哪些?…**
戴上数据科学的帽子**,我需要什么数据并且这些数据是可用的?我需要商业智能分析还是预测模型?我应该使用什么业务和模型指标?我如何衡量绩效?…**
戴上设计师帽子**,app 需要触发什么情绪?我应该使用什么配色方案?用户旅程是什么样子的?考虑到这些特性,什么是最好的用户交互?…**
戴上工程师帽**,app 一次需要支持多少用户?从开发到部署的过程是什么样的?使用什么技术堆栈可以平衡原型开发速度和可伸缩性?…**
戴上商业的帽子,我如何将应用程序货币化?如何发展和维持应用程序的受众?如何把跑技术和运营的成本降到最低?…
正如你所想象的,这个练习会很快变得让人不知所措。一定要从试图解决一切的冲动中抽身。
最终,这里是我在 8 小时的开发中可以解决的前三个“用户想要/需要”和相应的特性:
- ****我想要惊喜:应用程序应该能够建议我以前没有看过的电影或与我正常观看历史不同的电影。>今日精选&过滤
- ****我需要选择:应用程序应该能够显示一个预告片,并提供一些关于电影质量的信息。>预告片和评级
- 我想控制:应用程序应该提供一个简单的方法,让用户控制如何不同的建议看起来像。 >“滤镜面板&智能探索”
这里有一些我想做的东西,但是降低了的优先级:
- 用户认证/消息传递
- 自动发送电子邮件
- 云备份
- 多模型推荐
- 客户服务机器人
考虑到这些特性,下面是解决方案的粗略架构设计**,关键组件及其交互。**

概念架构图,作者的作品
注意:这是一个迭代过程的结果。你开始思考可能看起来很不一样。参见经验教训,了解如何决定构建什么和不构建什么的技巧。
步骤 4:冲刺计划和执行
我决定在四次 2 小时冲刺中建造这个。以下是每次冲刺的大致结果:
Sprint 1 :自动化的开发到部署管道;一个简单的可点击的“今日精选”和过滤功能在 Heroku 上提供。
冲刺 2 :构建 ETL 一组用于 ETL 的自动化测试用例;改进了 YouTube 预告片的前端&带有虚拟数据的个性化部分。运行时优化。
Sprint 3 :为智能探索构建 API。使用虚拟模型与前端集成。建模选项的研究。更多运行时优化。
冲刺 4 :重构并优化一个基于 KNN 的协同过滤模型。添加建模测试案例。代码清理和更多优化。
第五步:哒哒。
AME 出生了。现在你可以在这里使用 YAME为你的工作日、周末、约会之夜、家庭聚会寻找一些有趣的东西。该应用旨在提供搜索引擎的便利,同时提供控制,而不会让用户负担过重。
****便利:登陆页面有五部系统推荐的电影。它每天更新。该算法跨年份、跨流派挑选电影;它试图做到不偏不倚。

今日精选带拖车
一些控制:如果你不喜欢你看到的或者只是想知道那里有什么,你可以使用左边的面板选择年份和流派。

过滤
****更多控制而不牺牲便利:如果你真的想要别的东西,你可以基于探索你今天用简单的界面感受 有多“冒险”。这个 UI 允许用户有一个 选项来选择 。用户可以决定他们想看什么,而不会认知超载。

基于 KNN 的协同过滤的智能探索
第六步:吸取教训
安全,快速,懒惰。在其他事情之前自动化测试。如果你发现自己定期手动测试某样东西,投资一点时间并自动化它。用 PyTest 和 CircleCI 进行自动测试省去了很多麻烦。对于一个 ML 应用程序,你应该有两组测试。一个用于软件测试(例如单元和集成测试),另一个用于模型测试(例如最低性能和边缘情况)。拥有动态测试用例(由随机数驱动的输入)也有助于捕捉难以预测的边缘用例中的 bug。

从开发到部署的工作流程,作者的工作
避免卡格尔陷阱。由于我只预算了大约 4 个小时来开发 ML 组件,所以关键是要构建一个足够好的模型来验证 ML 特性的功能和有用性。很容易陷入“Kaggle 模式”的陷阱(例如,花费大量时间构建复杂的模型以获得较小的性能增益)。我用一个模型——UX 分析来帮助设定界限。这种分析并不意味着是一种科学练习,而是一种让你远离作弊的工具。****

模型-UX 分析(开发时间),作者的分析
注 :最小模型性能的阈值因用例而异。例如,一个显示使用 GAN 或欺诈检测的 合成人脸的应用程序将很可能需要非常好的模型性能来说服用户其有用性。
****所以,我的策略是从最简单的模型开始:一个由随机数生成器驱动的“模型”。虽然从建模的角度来看这听起来很幼稚,但是它用最少的开发时间(~5 分钟)为 UX 增加了最大的价值。用户可以玩个性化功能,这是不存在的。它是否提供“最佳”推荐并不重要,关键是要验证该特性。然后,我将该模型发展为基于规则和基于 KNN 的协同过滤算法。
建造是有趣的,优先化却不是。这里有一些让它变得更简单的建议:
- 从最讨厌的利润问题开始(这个练习不要太在意利润)。
- 想一个理想的解决方案&预算你需要多少时间来构建它;请记住,你可能会低估,但没关系。
- 将时间减少到 1/3,重新思考解决方案,看看在没有大量研究的情况下,你是否能放心实施(一些研究仍然有助于学习)
- 重复,直到范围适合 2 到 4 小时的时间框架
如果你喜欢并想支持 YAME,请查看我的 Patreon 页面。支持将用于支付运行和改进 YAME 的费用(如服务器、网站等)。).
我希望你喜欢这篇文章。如果你决定接受 12 小时的挑战,我很想看看你的作品。在上跟我连线 ,LinkedIn,或者Twitter。******
直到下一次,
伊恩
额外收获:懒惰程序员的过程和工具
对于任何感兴趣的人(并且到目前为止),我想要一个尽可能自动化的工作流,这样我就可以把时间花在设计和编码上,而不是做手工测试或移动代码。每个人都有自己的喜好。对我来说,关键是能够快速迭代并准备好扩展。
从技术堆栈的角度来看,以下是我选择的工具(也有一些备选方案):
- Python 作为通用工作流、ETL 和建模的编程语言。(可选:SQL 用于 ETL,R 用于建模,Java 用于工作流)
- Streamlit 作为前端工具。它基于 python。开箱即用,它附带了用户体验所需的大部分小部件;它是网络和移动友好的。它鼓励我像建模一样关注用户体验。Jupyter 很棒,但我觉得它倾向于让人们陷入 Kaggle 陷阱。(备选:Flask、Django 或 React 为前端;用于分析和模型实验的朱庇特笔记本)**
- Postgres 作为后端数据库工具。(备选:GCP、AWS、Azure 注意,如果你想遵循相同的设置,SQLite 不能与下面的 Heroku 一起工作)**
从 DevOps 的角度来看,这里有一些工具:
- PyCharm 为 IDE (可选: 崇高 , 原子 )
- Github 进行代码版本控制(备选:DVC)****
- PyTest 用于管理测试用例并运行自动测试
- 圆 CI 作连续整合部署(备选: 詹金斯 )**
- Heroku 用于网络托管(备选方案:云解决方案,如 GCP、AWS、Azure 或 Paperspace)
如果你像我一样是一个懒惰的程序员,我强烈建议你提前投入时间来建立这个 DevOps 工作流。它节省了手动测试和部署的大量时间。更重要的是,它真的保护你的代码库免受愚蠢的错误。
最后,我使用 Trello ,作为一个简单的看板,来跟踪我需要做的事情:

看板——作者的工作
注:我没有选择替代方案的原因是为了避免过度工程化和不够熟悉,以获得效率增益。
如果你喜欢这篇文章,你可能也会喜欢这些……
每个懒惰的全栈数据科学家都应该使用的 5 套工具
towardsdatascience.com](/the-most-useful-ml-tools-2020-e41b54061c58) [## 被遗忘的算法
用 Streamlit 探索蒙特卡罗模拟
towardsdatascience.com](/how-to-design-monte-carlo-simulation-138e9214910a) [## 数据科学很无聊
我如何应对部署机器学习的无聊日子
towardsdatascience.com](/data-science-is-boring-1d43473e353e) [## 我们创造了一个懒惰的人工智能
如何为现实世界设计和实现强化学习
towardsdatascience.com](/we-created-a-lazy-ai-5cea59a2a749) [## ML 和敏捷注定的联姻
如何在 ML 项目中不应用敏捷
towardsdatascience.com](/a-doomed-marriage-of-ml-and-agile-b91b95b37e35) [## 你被解雇了
如何发展和管理一个快乐的数据科学团队
towardsdatascience.com](/i-fired-a-data-scientist-a137fca5b80e) [## 抵御另一个人工智能冬天的最后一道防线
数字,五个战术解决方案,和一个快速调查
towardsdatascience.com](/the-last-defense-against-another-ai-winter-c589b48c561) [## 人工智能的最后一英里问题
许多数据科学家没有充分考虑的一件事是
towardsdatascience.com](/fixing-the-last-mile-problems-of-deploying-ai-systems-in-the-real-world-4f1aab0ea10)******
从头开始构建 InfoGAN
了解 InfoGAN 并构建自己的 InfoGAN 网络,以生成特定功能的 MNIST 手写数字

图片来自论文“ InfoGAN:通过信息最大化生成对抗网络的可解释表示学习”
从上图中,你能看出哪些手写数字是机器合成的,哪些是人类做的吗?答案是:都是机器合成的!事实上,这张图片来自于一篇科学论文*“info gan:通过信息最大化生成对抗网络进行的可解释表征学习”*,其中作者开发了一个特殊的生成对抗网络,命名为 InfoGAN(信息最大化生成对抗网络),并使用它来合成 MNIST 手写数字。如你所知,GANs 广泛用于合成新数据,尤其是图像。然而,普通 GANs 的一个缺点是我们无法控制 GANs 产生的图像。例如,一个被训练产生假的手写数字图像的 GAN 可能能够产生非常真实的手写数字图像,但是我们无法控制它产生哪个数字。 **InfoGAN 解决了这个问题:网络可以学习以无监督的方式产生具有特定分类特征(如数字 0 到 9)和连续特征(如数字的旋转角度)的图像。此外,由于学习是无监督的,它能够发现隐藏在图像中的模式,并生成遵循这些隐藏模式的图像。**有时候模特可以学到超乎你想象的非常有趣的模式(比如我的一个模特就学会了从 2 号过渡到 8 号。你以后会看到的!).在这本笔记本中,我将介绍 InfoGAN 如何实现对正在生成的图像的控制,以及如何从头构建一个 InfoGAN 来合成特定功能的 MNIST 手写数字,就像上面的图像一样。
InfoGAN 的结构
一个正常的 GAN 有两个基本元素:一个接受随机噪声并产生假图像的发生器,以及一个接受假图像和真图像并识别图像是真是假的鉴别器。在训练过程中,如果鉴别器成功检测出生成的图像是假的,生成器就会受到“惩罚”。因此,生成器会学习产生与真实图像越来越相似的假图像来“愚弄”鉴别器。
在 InfoGAN 中,为了控制生成的图像类型,我们需要向生成器提供随机噪声之上的附加信息,并迫使它在制作假图像时使用这些信息。我们提供的附加信息应该与我们希望图像具有的特征类型相关。例如,如果我们想产生特定的 MNIST 数字,我们需要输入一个包含从 0 到 9 的整数的分类向量;如果我们想要产生具有不同旋转角度的 MNIST 数字,我们可能想要输入在-1 到 1 之间随机选择的浮点数。
输入额外的信息很容易,因为我们只需要向生成器模型添加额外的输入。但是我们如何确保生成器会使用这些信息,而不是完全忽略它呢?如果我们仍然简单地基于鉴别器的响应来训练生成器,则生成器不会使用附加信息,因为附加信息不会帮助生成器创建更真实的图像(它只对生成图像的特定特征有帮助)。因此,如果生成器不使用附加信息,我们需要对它施加额外的“惩罚”。一种方法是添加一个额外的网络(通常称为辅助网络,表示为 Q ),该网络获取假图像并再现我们输入到生成器中的额外信息。这样,生成器被迫使用附加信息,就好像它不使用一样,辅助网络没有办法正确地再现附加信息,并且生成器将被“惩罚”。下图总结了 GAN(左)和 InfoGAN(右)的结构。
注:在本文中,理论上应该通过最大化互信息来训练生成器。然而,互信息实际上是无法计算的。因此,作者近似互信息,并且该近似变成附加信息和再现信息的输入之间的交叉熵(即,差)。如果你对互信息以及它是如何近似的感兴趣,可以去查一下原创论文,或者是 Zak Jost 和 Jonathan Hui 两篇非常好的 medium 文章。

GAN(左)和 InfoGAN(右)的结构。作者图片
构建 InfoGAN
理解了 InfoGAN 的结构之后,让我们动手构建一个 InfoGAN 来生成特定于功能的 MNIST 数字!如上图所示,InfoGAN 包含三个模型:生成器(G)、鉴别器(D)和辅助模型(Q)。生成器的输入包括三个部分:大小为 62 的噪声向量、大小为 10 的分类向量(表示 10 个数字)和大小为 1 的连续向量。噪声向量通过正态分布生成,分类向量通过从 0 到 9 选取一个整数生成,连续向量通过从-1 到 1 选取一个浮点值生成。
InfoGAN 中的发生器与普通 GAN 中的发生器具有完全相同的结构。它首先包含两个完全连接的层,以将输入形状扩展到 6272 个单元。然后,6272 个单元被改造成 128 个 7×7 层。之后,经过整形的图层通过三个转置卷积层进行处理,形成最终的 28x28 像素图像(如果你对转置卷积层不熟悉,我有一篇文章解释它)。
鉴别器也与普通 GANs 中的相同。它包含两个卷积层和两个全连接层。最后一个全连接层生成一个具有“sigmoid”激活函数的输出,以表示真实图像(1)或虚假图像(0)。
辅助模型共享来自鉴别器的所有层,除了最后一个完全连接的层,因此这两个模型被一起定义。辅助模型有两个额外的全连接层来标识附加信息。由于我们的生成器有两个额外的输入(一个分类向量和一个连续向量),我们还需要来自辅助模型的两个不同的输出。因此,我设置了一个具有“softmax”激活函数的全连接层来标识分类输出,两个全连接层来表示高斯分布的*【mu】(均值)和【sigma】*(标准差):

注意:由于我们的连续向量是从-1 和 1 之间的均匀分布中随机选择的浮点数,因此可以有无限多的浮点数可供选择。因此,要求辅助模型预测发电机取的确切数字是不实际的。相反,我们可以预测一个高斯分布,并要求模型最大化连续向量在分布中的可能性。
定义了这三个模型之后,我们就可以构建我们的 InfoGAN 网络了!我用 Keras 做网络建设:
我知道这是一个相当长的代码,所以让我们一步一步地消化它:
- InfoGAN_Continuous 是一个 Keras 模型类,应该通过给定鉴别器、生成器、辅助模型、噪声向量的大小和分类向量的类的数量来初始化。
- compile 函数编译 InfoGAN_Continuous 模型(对于我使用的三个优化器都是 Adam)。
- create_gen_input 是我们之前定义的为发电机生成输入的函数。
- concat_inputs 将三个输入向量(大小 62、大小 10、大小 1)连接成一个大小为 73 的向量。
- train_step 函数定义了训练步骤。它只需要成批的真实图像。首先,通过鉴别半批真实图像和半批伪图像来训练鉴别器。鉴别器的损失是鉴别真实图像和虚假图像的损失的总和。权重通过基于损失的梯度下降算法来更新。然后,使用整批伪图像来训练生成器和辅助模型。辅助模型损失包含分类损失和连续损失。分类损失就是预测标签和输入分类向量之间的分类交叉熵;连续损失是连续矢量输入的高斯分布的负对数概率密度函数。最小化负对数概率密度函数与最大化我们位于预测高斯分布内的连续向量的概率是一样的,这就是我们想要的。发电机损耗包括来自鉴别器的损耗和来自辅助模型的损耗。通过这样做,生成器将学习生成具有更具体特征的更真实的图像。请注意,我们将鉴别器中的变量设置为不可训练,因为我们不想在训练生成器和辅助模型时修改鉴别器中的神经元。
现在,你只需要用几行代码来训练它!!!
结果
现在,让我们看看我从 InfoGAN 模型中得到的一些非常有趣的结果!
变化分类向量
首先,如果您更改分类向量输入,您可以生成不同的数字。但是,模型不会知道标签 0 对应数字 0!它只知道不同的标签对应不同的数字(相信我,我不知怎么用了一整天才意识到这一点。我一直以为我输了当喂养标签 0 为我生成数字 9)。

作者图片
因此,您可能需要重新排列标签:

作者图片
变化连续向量
改变连续向量可以产生不同形状的相同数字。例如,对于数字 1,当增加连续向量值时,数字以顺时针方向旋转。请注意,即使我们使用从-1 到 1 的值来训练模型,通过输入-1.5 和 1.5,我们仍然可以获得有意义的结果!
请注意,标签与上面的不同。这是因为我再次训练了模型,模型总是随机地将标签与数字相关联。

作者图片
5 号更有趣。似乎模型试图旋转数字,但由于其形状更复杂,数字被剪切。

作者图片
增加体重以持续减肥
您可能会注意到,在将连续损耗添加到发电机总损耗和辅助设备总损耗时,我将连续损耗的比率设置为 0.1。这是为了避免混淆模型。如果连续损失与分类损失具有相似的比率(即接近 1),则模型会将其视为确定数字类型的另一个因素。例如,下面的图像是在我使用 0.5 的比率时生成的:

作者图片

作者图片
如你所见,即使我使用相同的标签,通过改变连续向量值,数字逐渐从 2 变为 4,或者 2 变为 8!这也意味着计算机实际上可以找到数字 2 到数字 4,数字 2 到数字 8 之间的相似之处,并且知道如何从一个数字转换到另一个数字。是不是很神奇?
结论
InfoGAN 是一个非常强大的 GAN,它可以以无监督的方式在图像中学习模式,并通过遵循模式产生图像。玩起来也很有趣,因为你可以通过操作输入变量来生成各种各样的图像。使用本故事中的代码,您可以构建自己的 InfoGAN,看看您能制作出多么令人惊叹的图像!
参考资料:
陈曦、严端、雷因·胡特夫特、约翰·舒尔曼、伊利亚·苏茨基弗和彼得·阿比尔, InfoGAN:通过信息最大化生成对抗网络的可解释表征学习 (2016),康乃尔大学
Shaked 是 Taboola 的算法工程师,从事推荐系统的机器学习应用。他…
engineering.taboola.com](https://engineering.taboola.com/predicting-probability-distributions/) [## 如何开发 Keras 中的信息最大化 GAN(info GAN)——机器学习掌握
生成对抗网络,或 GAN,是一种用于训练深度卷积模型的架构,用于生成…
machinelearningmastery.com](https://machinelearningmastery.com/how-to-develop-an-information-maximizing-generative-adversarial-network-infogan-in-keras/)
使用 leav 从 GPX 文件构建交互式 GPS 活动地图
使用 Strava 和 Garmin 等流行服务创建自行车和徒步旅行 GPS 轨迹的个性化地图
介绍
这篇文章概述了如何使用folio将 GPS 记录的活动转换为个性化的交互式地图,这是一个基于强大的地图框架 Leaflet.js 构建的 Python 库。
首先,我想介绍一下这个项目是如何开始的(如果您来这里是为了快速访问一段特定的代码,请随意跳到‘数据争论’部分)。
我喜欢地图——无论是数字地图还是实物地图。它们为我们周围的世界增添了意义,让我们能够直观地理解我们生活的空间关系。物理地图代表着冒险、怀旧和发现——在我们探索世界的过程中引导我们踏上神奇的旅程。
我使用 Strava(一个 GPS 活动跟踪应用程序)已经超过 10 年了,最近,我买了一块 Garmin 手表,用来跟踪我的所有活动:主要是骑自行车和徒步旅行。我被数据迷住了:我喜欢检查我刚刚完成的路线,挖掘我的统计数据,并在屏幕上检查我的冒险的视觉表现。
卡米诺
自从 2016 年搬到西班牙,我就迷上了’埃尔卡米诺圣地亚哥’(在英语中称为圣詹姆斯路,但在本文中,它将被亲切地称为卡米诺)。卡米诺朝圣之旅始于 2000 多年前,是前往西班牙西北部圣地亚哥德孔波斯特拉大教堂的宗教朝圣活动。在现代,它已经成为一条多日徒步旅行和骑自行车的冒险路线,吸引了各个年龄和国籍的参与者。我的个人博客对 Camino 进行了更详细的解释:
它有宗教根源(朝圣者已经行走了 1000 年),但现在,大多数人把它作为一种探险和徒步旅游的形式。还有一个自我反省和精神成长的元素吸引了许多人来到卡米诺。这是一个独处(和人在一起)的机会,可以反思生活,理清思绪,冥想散步等等。我做这件事的动机是以上所有的;我不断地自我反省,喜欢思考问题,我也喜欢认识新的人,游览新的地方,冒险,当然还有徒步旅行。
多年来,我收集了相当多的卡米诺经历;总共至少 10 次旅行(包括骑自行车和徒步旅行),每次旅行持续时间从周末探险到 25 天的奥德赛不等。作为地图和数据的爱好者,这个项目的想法对我来说一直很清晰;在视觉上创造一个我曾经完成的所有卡米诺作品的代表。
经过大量的实验,测试了叶子的极限,这是结果:

绿色圆圈代表起点。红色表示骑自行车的卡米诺,绿色表示徒步旅行的卡米诺。
为了获得最佳观看体验,请查看互动版(媒体不允许嵌入 HTML)。您可以通过选择右上角的单选按钮在每个 Camino 之间切换。点击卡米诺中点的徒步旅行或骑自行车图标可以查看统计数据摘要。“未来卡米诺”选项代表我希望有一天能完成的其他卡米诺。
数据争论和地图创建
这个工作流程存在于一个 Jupyter 笔记本中;我推荐安装 Anaconda 来快速启动并运行笔记本环境。
构建交互式地图的第一步是以 GPX 的形式下载您的 GPS 轨迹,这是 GPS 交换格式的缩写。大多数活动跟踪服务都有这种格式的 GPS 轨迹可供下载。我首选的工具是 Strava 和 Garmin:
- 斯特拉瓦。 指令用于一次性批量下载所有数据(包括 GPX 文件)。
- **佳明。**他们有一个类似的选项来进行批量导出,但我会推荐一个非常有用的 python 脚本,它会自动下载所有 GPX 文件,并在您完成它们时智能地下载新文件。
使用 gpxpy 将 GPX 文件转换成 GPS 坐标的数据帧。这个****非常有用的包解析 GPX XML 并将其转换成整洁的数据帧,准备好使用 Pandas 进行分析。另一种选择是使用 python 模块 ElementTree 或 lmxl 自己解析它。
def process_gpx_to_df(file_name):gpx = gpxpy.parse(open(file_name))
#(1)make DataFrame
track = gpx.tracks[0]
segment = track.segments[0]
# Load the data into a Pandas dataframe (by way of a list)
data = []
segment_length = segment.length_3d()
for point_idx, point in enumerate(segment.points):
data.append([point.longitude, point.latitude,point.elevation,
point.time, segment.get_speed(point_idx)])
columns = [‘Longitude’, ‘Latitude’, ‘Altitude’, ‘Time’, ‘Speed’]
gpx_df = pd.DataFrame(data, columns=columns)
#2(make points tuple for line)
points = []
for track in gpx.tracks:
for segment in track.segments:
for point in segment.points:
points.append(tuple([point.latitude, point.longitude]))
return gpx_df, points
产生的数据帧结构如下:

****启动叶子地图并选择图块。leave是一个 python 库,构建在强大的映射框架leafle . js之上。创建地图的第一步是选择地图分块(实际上是一个地图皮肤)。在这里可以找到极好的瓷砖收藏。以下语法允许在同一地图上创建多个切片,并为每个切片指定个性化的名称。
import foliummymap = folium.Map( location=[ df.Latitude.mean(), df.Longitude.mean() ], zoom_start=6, tiles=None)
folium.TileLayer(‘openstreetmap’, name=’OpenStreet Map’).add_to(mymap)
folium.TileLayer(‘[https://server.arcgisonline.com/ArcGIS/rest/services/NatGeo_World_Map/MapServer/tile/{z}/{y}/{x}'](https://server.arcgisonline.com/ArcGIS/rest/services/NatGeo_World_Map/MapServer/tile/{z}/{y}/{x}'), attr=”Tiles © Esri — National Geographic, Esri, DeLorme, NAVTEQ, UNEP-WCMC, USGS, NASA, ESA, METI, NRCAN, GEBCO, NOAA, iPC”, name=’Nat Geo Map’).add_to(mymap)
folium.TileLayer(‘[http://tile.stamen.com/terrain/{z}/{x}/{y}.jpg'](http://tile.stamen.com/terrain/{z}/{x}/{y}.jpg'), attr=”terrain-bcg”, name=’Terrain Map’).add_to(mymap)
最终结果是一个单选按钮,允许用户选择他们想要的图块:

****使用点绘制路线。我们使用 GPS 坐标元组(从我们的 gpxpy 函数中命名为“点”)来绘制 GPS 路线。foylus 允许对折线进行大量的定制,可以调整颜色、厚度和不透明度。对我来说,红线代表骑自行车的路线,绿色代表徒步旅行。
folium.PolyLine(points, color='red', weight=4.5, opacity=.5).add_to(mymap)
****建立一个起始标记(圆形和三角形)。我用 Folium 的各种标记类,用一个三角形叠加在一个圆上,为这条路线拼凑了一个“开始”图标。

html_camino_start = “””
Start of day {camino_day}
“””.format(camino_day=camino_day)
popup = folium.Popup(html_camino_start, max_width=400)
#nice green circle
folium.vector_layers.CircleMarker(location=[lat_start, long_start], radius=9, color=’white’, weight=1, fill_color=’green’, fill_opacity=1, popup=html_camino_start).add_to(mymap)
#OVERLAY triangle
folium.RegularPolygonMarker(location=[lat_start, long_start],
fill_color=’white’, fill_opacity=1, color=’white’, number_of_sides=3,
radius=3, rotation=0, popup=html_camino_start).add_to(mymap)
****添加带有 GPS 路线统计信息的可点击图标。对于每辆 Camino,一个自行车或徒步旅行者的图标(使用字体 awesome )被添加到轨道的中点。速度、距离和高度增益等统计数据汇总到数据帧中,并转换成 HTML 表格。“弹出”功能用于创建一个漂亮的信息框,当图标被点击时显示 GPS 跟踪的统计数据。

camino_summary_for_icon = camino_summary_for_icon.iloc[1:,: ] html_camino_name = “””
<div align=”center”>
<h5>Daily Stats</h5><br>
</div>. “”” html = html_camino_name + “””<div align=”center”>””” + camino_summary_for_icon.to_html(justify=’center’, header=False, index=True, index_names=False, col_space=300, classes=’table-condensed table-responsive table-success’) + “””</div>””” #popup = folium.Popup(html, max_width=300)
folium.Marker([lat, long], popup=popup, icon=folium.Icon(color=activity_color, icon_color=’white’, icon='bicycle', prefix=’fa’)).add_to(mymap)
使用矢量图层创建一个“一天结束标记”。每个卡米诺由多天组成,平均约 10 天。如果放大交互式地图,可以很容易地看到这些日期标记,目的是在更精细的层次上显示 Camino,单个轨道上的各个日期可以可视化。点击阴影圆圈,会显示关于卡米诺该部分的长度和天数的信息。

’ vector_layers ‘的大小。“圆”实体基于米,而“叶”实体基于米。“图标”为像素。本质上,这意味着无论缩放级别如何,图标都将保持相同的大小,而 vector_layers。“圆圈”会随着用户缩放而变大。出于这个原因,我选择使用矢量层。“圆圈”表示特定 Camino 上一天的结束——这是一个有趣的信息,只有当用户放大时才能看到。它变得太忙而不能包含在缩小的视图中。我使用’ tooltip= '参数在弹出窗口中添加额外的文本信息。
day_terminal_message = ‘End of Day ‘ +str(camino_day)[:-2]+ ‘. Distance: ‘ + str(camino_distance) + ‘ km.’
mymap.add_child(fg)
folium.vector_layers.Circle(location=[lat_end, long_end], radius=track_terminal_radius_size, color=activity_color, fill_color=activity_color, weight=2, fill_opacity=0.3, tooltip=day_terminal_message).add_to(mymap).add_to(fg)
****结束标记。结束标记(圆形和方形)的构建与开始标记相同。

html_camino_end = “””
End of day {camino_day}
“””.format(camino_day=camino_day)
popup = html_camino_end
folium.vector_layers.CircleMarker(location=[lat_end, long_end], radius=9, color=’white’, weight=1, fill_color=’red’, fill_opacity=1, popup=popup).add_to(mymap)
#OVERLAY square
folium.RegularPolygonMarker(location=[lat_end, long_end],
fill_color=’white’, fill_opacity=1, color=’white’, number_of_sides=4,
radius=3, rotation=45, popup=popup).add_to(mymap)
folium.LayerControl(collapsed=True).add_to(mymap)
****全屏选项。这是一个非常有用的选项,可以扩展到全屏显示。
if fullscreen==True:
plugins.Fullscreen(
position=’topright’,
title=’Expand me’,
title_cancel=’Exit me’,
force_separate_button=True
).add_to(mymap)
****特色组。这个功能非常有用;它允许对地图中的元素进行分组(例如特定的路线),用户可以将每个组设置为可见或不可见。在我的例子中,我用它来允许用户打开或关闭每个 Camino 的显示。

fg = folium.FeatureGroup(name='El Camino de Valencia (Bilbao a Valencia)', show=True)
mymap.add_child(fg)
folium.PolyLine(points, color=activity_color, weight=4.5, opacity=.5).add_to(mymap).add_to(fg)
嗯,就这样吧!leav 包含了大量的附加特性——我可以花几个小时摆弄各种功能。定制的选择是丰富的。
维基洛克和卡米诺自行车旅游项目
Wikiloc 是一个有用的活动追踪器,允许用户探索和分享徒步和骑行路线。它位于西班牙,在这里非常受欢迎。这是一项非常棒的服务,主要用于发现新路线——它允许用户在活动中找到有用的路线,并在 GPS 的引导下沿着它们走。
作为一个自行车旅行的狂热爱好者,我决定做一个项目,在 Wikiloc 上收集所有的自行车旅行路线。(关于网络抓取的更多细节,请查看我关于抓取英语教师网站的文章,tusclasesspeciales)。
这个项目本身可以是一篇文章,但是为了不离题并保持这篇文章简洁,让我们深入到我根据搜集结果创建的地图中。
我解析了数据,只包含与 Camino 相关的路线,并创建了下面的可视化,它显示了到达圣地亚哥有多少种不同的可能的 Camino。

为获得最佳体验,请查看互动版。点击每个 Camino,会显示一个汇总框;完成统计数据和维基百科的链接。
结论
本文总结了将原始 GPS 轨迹数据转换为交互式地图所需的基本步骤。我将以一些最有用的链接作为结束,这些链接是我在制作地图的过程中收集到的。
- 《叶的圣经》中有大量的例子:https://nb viewer . jupyter . org/github/python-visualization/Folium/tree/master/examples/
- 使用 GPX 数据计算速度、距离和高度变化:https://towards data science . com/how-tracking-apps-analyze-your-GPS-data-a-hands-on-tutorial-in-python-756 D4 db 6715d
- 有趣的使用聚类标记构建啤酒花园互动地图的 foylus 项目:https://towards data science . com/how-I-used-python-and-open-data-to-build-an-interactive-map-of-edinburghs-beer-gardens-cad2f 607 e 57 e
- 聚类标记:https://medium . com/@ bobhaffner/folium-marker clusters-and-fastmarkerclusters-1e 03 b 01 CB 7 b 1
- 制作树叶地图:https://medium . com/@ saidakbarp/interactive-map-visualization-with-leaf-in-python-2e 95544 D8 d9b
笔记本电脑
本文引用的代码可以在我的 Git 仓库中找到。
为傅立叶变换建立直觉

迈克尔·泽兹奇在 Unsplash 上的照片
卷积和信号处理的神奇算法
傅立叶变换及其同类(傅立叶级数、离散傅立叶变换和球谐函数)是我们用来计算和理解周围世界的强大工具。离散傅立叶变换(DFT)用于计算机视觉的卷积运算,并(经过修改)用于音频信号处理,而球谐函数给出了元素周期表的结构。
虽然写下一个公式很容易,但有一个更广泛的观点表明,每个公式都源于对对称性的简单考虑。我们将在这里继续这一观点。
一如既往,我将努力避免不必要的技术术语的复杂性。如果你对它们感兴趣,试试脚注。然而,会有一些复杂的数字:你已经被警告过了。
傅立叶级数
傅立叶级数是其中最古老的,最初由法国人约瑟夫·傅立叶研究。拿破仑的朋友傅立叶在 19 世纪 20 年代研究热流时写下了这一点,不久后他发现了我们今天花费大量时间担心的温室效应。
傅立叶级数的自然设置是圆上的复值函数。正如您所记得的,函数是接受输入并给出输出的东西。
- 在这种情况下,输出将是一个复数(我们将复数表示为ℂ)
- 输入将是圆上的一个点。请注意,我们没有包括圆的内部,只是它的边界。我们用 S 表示这个圆,如果这个圆出现,我们会认为它的半径为 1。
- 我们也将要求我们的功能是“好的”他们不会试图做一些卑鄙的事情,比如蹦蹦跳跳(不连续),跳到无限远,不明确,或者叫你粗鲁的名字。
对称
对称是人们喜欢谈论的神秘事物之一。例如,研究一直表明,如果你的脸对称,人们会觉得你更有吸引力。这也体现在物理学中:我们目前拥有的世界上最好的理论可以被神秘地描述为对称 SU(3)×SU(2)×U(1),不管这意味着什么。但是当我们谈论对称时,我们指的是一些可笑的简单的东西:如果你在一个圆上旋转一个函数,你会得到一个圆上的函数 。
现在,在圆上画一个函数有点棘手。所以请回忆一下,如果你拿一根细绳,把两端连起来,就可以做出一个圆。考虑到这一点,我们可以把一个函数画在一条线段上,从而把它画在圆上;事实上,左右两端必须连接,你必须在你的脑海中想象。
下图显示了一个圆上的简单函数(左)。要旋转它,我们只要“移动”就行了,前提是从右端出去的东西回到左端。在这种情况下,旋转以ᴨ/2 弧度(90°)为单位。该函数的输入只是围绕圆的角度(比如说,从最右边的点开始顺时针方向)。

圆上的函数(左)及其旋转 90 度(右)
另一种思考方式是,如果你在一个圆上有一个函数,你可以只旋转圆(因为圆是循环对称的,同义反复)。
希望到目前为止你已经确信没有特别的魔法在进行。我们所说的是,如果你旋转函数(或圆),你会得到另一个非常好的函数。
表象理论
数学家们把研究在圆周上旋转一个函数来得到另一个函数的方法称为表示理论,它包含了一个额外的步骤,打开了整个理解的世界。
额外的步骤本身并不复杂。在之前的设置中,当你想要旋转圆时,你只需要旋转它。现在我们将添加一个中介。我想让你想象你将给出旋转圆圈的指令,我将解释它们并进行旋转。例如,你可能说“旋转圆 73”,我将旋转圆 73。
我从没说过我必须照你说的做。有一些规则适用于我所做的事情,我们将通过例子来探索它们。
- 如果你说“旋转 360 度”,我什么也不会做。同样,如果你说“把圆旋转 370”,我只会旋转 10。为什么?希望你能看到,如果我旋转 360 度,我们会回到起点。你可以反对并说“不,不,我真的想看它旋转,这很有趣”,但实际上你应该想象所有这些旋转都是瞬间发生的。我们对旋转的过程不感兴趣;我们对的结果感兴趣。
- 现在想象一下,当你说“把圆旋转 10 度”时,我把它旋转了 15 度。同样,如果你说 20,我会旋转它 30!总的来说,我的旋转是你要求的 1.5 倍。这看起来很好(我从来没有做过任何承诺),但有一个问题。如果你说“将圆圈旋转 360 度”,实际上,你有权假设一切都不会改变。因此,如果我采用“150%努力超额完成”的策略,我就违反了规则,因为我会旋转 180 度(与 360×1.5 = 540 = 360 + 180 度相同)。
- 这是一个规则,无论你说多少度,我都必须做一些倍数。那么允许什么倍数呢?1 显然没问题。2 也是!如果你要求 360 度,你将得不到旋转(720 度),这正是你所期望的。3、4、5 等也是如此。还有 0,-1,-2 等等。事实上,这是唯一的选择。
深入探究这些规则从何而来的细节将是一种相当大的转移。但是简单来说,“圆周旋转”伴随着某种数学结构(称为群)。大致来说,这个结构是一个显而易见的事实,旋转 1 然后再旋转 1 和旋转 2 是一样的。再加上 360 和 0 一样,什么都不做。规则是:
- 我必须旋转你所说的常数倍数
- 如果你说 360,我最后只能什么都不做
根据我们保持这个结构的要求,这意味着我只能乘以一个整数。这个结果被称为量子化,这正是量子力学中“量子”的含义。事实上,电荷以离散的(量子化的)数量出现的原因,可以直接从我们刚才的论证中得出。因为这个原因,我用的整数倍有时候也叫收费!
简单回顾一下,我们有:
- 你,要求旋转一定的度数。让我们把可能的旋转集合称为 G(代表“组”)。
- 我,解释那些指令。从某种意义上说,我是一个函数,它接受一个输入(你告诉我什么),给出一个输出(做什么)。我们称之为ρ。
- 正在执行的功能。我们将所有足够好的函数的集合称为 V(对于“ Vector ”因为函数是向量:它们可以相加,乘以一个常数,还有一个 0 函数)。
综合起来,这三个数学对象形成了一个表示。我想象它被如此称呼是因为我在用一个具体的行动“代表”你的抽象指令。
不可约表示
这就是奇迹发生的地方。在许多情况下(比如这里),被作用的事物(功能)可以被分解成组成部分。⁴大致会发生的情况是:
- 一个函数可能非常复杂
- 想象我们有一堆标有…-3,-2,-1,0,1,2,3,4 等的桶。每个桶里面都有一个非常简单的函数,比如 cos(2θ)。
- 每个函数都可以通过添加组件来实现,每个桶一个组件。
如果我们做到了这一点,我们就把一件复杂的事情分解成了许多简单部分的总和。⁵,这很好。如果我们这样做,我们就赢了。
现在,证明所有这些都可以工作超出了本文的范围。如果你感兴趣的话,这通常是任何关于表示理论的教科书中的第一件事,而且也不是很难。相反,我们只是要介绍一个花招,然后描述桶。
旋转就是乘法
考虑下面的函数 f,看看当我们把它旋转一个角度 a 时会发生什么。如上图所示,旋转等同于通过 a 将参数转移到函数。 i 是虚数单位,-1 的平方根(暂时不用管这个)。其他一切都遵循你在数学课上学到的指数法则。

旋转就是乘法
事实证明(根据舒尔引理),我们桶中的函数必须满足这样的性质:旋转它们与相乘它们是一样的。而上面的函数,其中 n 是任意整数,正是满足这个性质的函数。因此,我们可以把圆上的任何函数写成这样一些函数的和:

圆上函数的分解
其中系数 a 只是告诉我们每个函数取多少。这种分解被称为傅立叶级数。如果你不太喜欢复数,你可能会更习惯使用这样的事实

这意味着我们可以将圆上的每个函数 f 写成如下形式

傅立叶级数的三角形式
如果需要的话,复数隐藏在系数 a 和 b 中。(注意:我们合并了 n=2 和 n=-2 这样的项,所以我们只对非负 n 求和,对于 n=0,我们只需要其中一项。)
最后,请注意,我们可能需要无穷多个术语,而实际上我们只得到有限多个。下面的动画展示了当我们采用越来越多的术语时会发生什么。蓝线是一个“锯齿波”,你可以把它想象成圆上的一个不连续函数(它每 360°跳一次)。红色曲线是 1、2、3 等的傅立叶级数近似值。条款。

动画:维基百科
堂兄弟
让我们回顾一下我们所做的。我们意识到,如果你旋转一个圆,你会得到一个圆(对称性)。我们对此进行了扩展,这样我们可以在圆上使用函数,并允许修改我们的旋转指令(表示)。我们了解到,函数可以分解成更简单的部分(不可约表示),更简单的部分必须满足一个简单的性质,即旋转是乘法(舒尔引理)。有了这个我们可以写下那些简单的部分。
为了恢复所有其他的东西,我们需要做的就是考虑 X 上的函数,其中 X 不是圆。
傅立叶变换
好,让我们把 x 变成ℝ,实数。它们的对称性在于你可以翻译实数(比如说加 5)并以你开始时的结果结束。或者用函数来表述,一个以实数作为输入,以实数作为输出的常规函数可以被翻译,你会得到另一个非常好的函数。⁶
形式上,这类似于我们在一个圆上所做的,旋转看起来也像是一种转移。然而,与之前不同的是,结果不会被量化。我们将为每个实数设置一个桶,而不是离散的桶。把一组连续的东西加起来,我们需要用积分代替求和;但是从概念上来说,这和圆圈是一样的。
- 将变量从θ改为 x
- 把总和变成一个积分
- 将桶索引从 n 更改为 p (p 代表“动量”)
- 改变系数 a 以便每个桶索引 p 都有一个

傅立叶变换分解一个函数
注意,这不是你在维基百科上看到的公式,有几个原因。首先,傅立叶变换通常用稍微不同的归一化写下来(我们需要一个 2ᴨ项来使后面的公式更好)。其次,是逆变换:变换计算系数 a§,逆变换就是我们如何写下函数 f 的分解。
离散傅立叶变换
现在,让我们将底层空间更改为圆形的“离散”版本。假设有 N 个点等距分布在一个圆上。对称就是你可以旋转 360/N 度或者它的任意整数倍。“离散圆”上的一个“函数”只是 N 个数的列表,每个点一个。旋转函数只是移动 N 个数字的列表(并将任何离开边缘的东西移回另一边)。
现在只会有 N 个桶。最小的旋转角度是 2ᴨ/N 弧度。变量从 x 变为 k ,k 是整数,0,1,2,…,N-1 中的一个。

离散傅立叶分解
同样,由于同样的原因,与你在维基百科上看到的略有不同。
离散时间傅立叶变换
现在让我们把底层空间变成这条线的离散形式(实数)。所以我们得到了整数。对称以任意整数移动。“函数”是一个无限的数字列表,每个整数一个。

离散时间傅立叶分解
再说一次,我们没有小心我们的 2ᴨ归一化。
球谐函数
如果底层空间是球体呢?我说的球体是指边界,不包括内部。这个空间记为 S。对称性是三维空间的任意旋转。因为这个对称组稍微复杂一点,所以每个“桶”中的函数数量并不总是一个。
结果被称为球谐函数,你在化学课上已经学过了。这些桶的大小也给出了周期表的结构。这是相当惊人的:仅仅通过尝试在一个球体上做傅立叶变换,你就可以基本上弄清楚化学。(还有更多的细节:一切都变得加倍,因为电子可以自旋向上或自旋向下)。
我将简要地描述这些桶,以及它们与周期表的关系。
- 第一个名为“s”的桶只有一个功能。翻倍,你得到 2,元素周期表第一行的元素数(1s 轨道)。
- 第二个桶叫做“p ”,里面有三个函数。加倍,你得到 6 个电子,可以进入 2p 轨道(和 2s 轨道上的 2 个在一起)。
- 第三个桶称为“d ”,其中有 5 个函数。再翻一倍,你会得到 10 个,这是 4d 轨道可以容纳的电子数(Sc–Zn,下面中间的蓝色元素)。
- 第四个桶称为“f ”,其中有 7 个函数。两倍,你得到 14,6f 轨道上可以进入的电子数。(下面是粉红色的 La–Yb,不包括最后一个 Lu,它应该正确地着色为蓝色)。
- 第五个桶称为“g ”,其中有 9 个函数。如果原子足够稳定存在的话,这个数字是 g 轨道上的电子数。
以此类推(1,3,5,7,9,11 等。).

元素周期表
说白了,原子的量子态就像一个球体上的函数(径向部分被排除并解释了结构的 1s,2s 2p,3s 3p,4s 4p 4d 部分)。如果你旋转这个状态,你会得到另一个非常好的状态(最好是这样!).因此,表象理论适用,我们可以做我们的“傅立叶”分析。
结论

我们已经看到,傅立叶变换及其类似变换可以被视为对一个函数执行相同的过程,根据组成该函数的数据,结果会略有不同。左边的表格列出了我们描述的 5 个版本。当然,你可以在任何对称的形状上这样做。例如,您可以对定义在平面上的函数(二维实数)或图像(有限的二维数字数组,我们可以将其循环回自身,形成一个离散的圆环)进行傅立叶分析。
我们也看到了这个工具有多么强大。它给了我们元素周期表(本质上是我们的整个世界)。在计算机视觉中,事实证明做一个(离散的)傅立叶变换,把结果相乘,然后进行逆变换,比单纯地把数字相乘要快。在音频信号处理中,傅立叶变换及其变体(如小波变换)是提取特征的强大工具。下次请继续关注应用程序。
参考
我发现彼得·沃特的关于量子力学的书对表示理论和傅立叶变换提供了非常清晰的解释,尽管它没有涉及任何离散变量或两者之间的关系。
笔记
[1]对于那些对技术细节感兴趣的人,我们将使用 L (S),圆上的勒贝格平方可积函数的空间。
[2]我省略了圆的对称性与圆上函数之间关系的一些细节。这些细节大多相当于处理一些讨厌的负号。粗略地说,如果你旋转这个圆,你必须向后旋转函数*,这样一切都以你期望的方式结束(这样从对称群到动作集的映射是同态的,而不是向后的)。*
[3]一个表示的官方定义是:你有一个群 G,一个底层向量空间 V,一个从 G 到 GL(V)的映射ρ,V 上所有可逆线性变换的群。
[4]主要要求是表示是酉的(它在这里)。我们还将利用圆的旋转对称群 U(1)是阿贝尔(交换的:x + y = y + x)这一事实来确保不可约表示是一维的。我们将完全忽略所涉及的分析问题,这些问题在很大程度上相当于这样一个事实,即一个给定的函数可能有无限多的分解成的“部分”,在讨论如何将无限多的东西相加时,我们必须小心。
[5]我们已经把向量空间写成一组更小的向量空间的直和。在这个例子中,较小的向量空间是一维的,集合由整数索引。
[6]让我们把事情简单化,假设我们正在研究 L ®。但是如果你想花哨一点,我们可以用一个史华兹空间。
用 Python 从头开始构建 kNN
用k-折叠交叉验证(从头开始)

邻居(图片来源: Freepik
在本文中,我们将了解 k-最近邻(kNN)算法是如何工作的,并从头开始构建 kNN 算法。我们还将使用 k-Fold 交叉验证来评估我们的算法,这也是从头开始开发的。
完成本教程后,您将了解:
- 如何分步编码k-最近邻算法
- 如何使用 k-最近邻对新数据进行预测
- 如何对k-折叠交叉验证进行分步编码
- 如何使用 k 折叠交叉验证评估真实数据集上的 k 最近邻
先决条件:对 Python 和面向对象编程(OOP)中的类和对象的概念有基本的了解
k-最近邻
最近邻居,简称 kNN,是一种非常简单但功能强大的预测技术。kNN 背后的原则是使用“与新数据最相似的历史实例”
k 是用于识别新数据点的相似邻居的数字。
最初存储整个训练数据集。当需要对新数据进行预测时, k NN 考虑k-最相似的邻居(记录)来决定新数据点将属于基于特征相似性的位置。
一旦我们找到了距离或相似性,我们就选择前 k 最接近的记录。在发现 k 个最接近的记录后,我们通过返回最常见的结果或取平均值来进行预测。因此, k NN 可用于分类或回归问题。
k NN 算法没有训练阶段。该模型仅保存数据,直到需要进行预测,并且不做任何工作。正因如此, k NN 常被称为“懒学法”。
4 个简单步骤中的 k 个最近邻居
- 为k选择一个值
- 找到新点到每条训练数据记录的距离
- 得到k-最近邻
- 对于分类问题,新的数据点属于大多数邻居所属的类。对于回归问题,预测可以是 k 最近邻标签的平均值或加权平均值
使用 Python 从头构建 kNN
您可以使用我的 GitHub 中可用的代码来跟进。
您也可以通过以下方式安装它:
pip install simple-kNN
PyPI 包版本的 GitHub repo:【https://github.com/chaitanyakasaraneni/simple-kNN
第一步:选择一个 k 值
K 的选择对我们从 k NN 中获得的结果有很大的影响。最好选奇数。
第二步:计算距离
下一步是计算数据集中两行之间的距离。
特定于问题或数据的方法用于计算两个记录之间的距离或相似性。一般来说,对于表格或矢量数据,欧几里得距离被认为是起点。还有其他几种相似性或距离度量,如曼哈顿距离、汉明距离等。
欧几里德距离定义为两点间距离(差)的平方和的平方根。它也被称为 L2 规范。

两个向量’ x 和’ y 之间的欧氏距离
曼哈顿距离是两点之间差异的绝对值之和

两个矢量’ x 和’ y 之间的曼哈顿距离
汉明距离用于分类变量。简单来说,它告诉我们两个分类变量是否相同。

两个向量“x”和“y”之间的汉明距离
其中“δ”用于检查两个元素是否相等。
在 python 中,我们创建了一个单独的类来保存计算两个向量之间距离的方法。
包含计算距离度量方法的类
下一步我们将利用这个类来寻找最近的邻居。
第三步:找最近的邻居
数据集中一条新数据的邻居是我们使用上面定义的距离度量获得的前 k 个最近的实例。
为了定位数据集中新数据的邻居,我们必须首先计算数据集中每个记录到新数据的距离。我们可以通过为上面定义的 distanceMetric 类创建一个对象来做到这一点。
计算出距离后,我们必须根据记录到新数据的距离对训练数据集中的所有记录进行排序。然后我们可以选择顶部的 k 个作为最相似的邻居返回。
我们可以通过将数据集中每条记录的距离记录为一个列表来实现这一点,根据距离对列表进行排序,然后检索邻居。
既然我们知道了如何从数据集中获取 topk-邻点,我们将使用它们来进行预测。
第四步:预测
在这一步中,我们将使用从训练数据集中收集的前 k 个相似邻居来进行预测。
在分类的情况下,我们可以返回邻居中最具代表性的类。
我们可以通过对来自邻居的输出值列表执行 max() 函数来实现这一点。给定在邻域中观察到的类值列表, max() 函数获取一组唯一的类值,并对该组中每个类值的类值列表进行计数。
下面是完整的 k NN 类:
现在我们有了我们的预测,我们需要评估我们的模型的性能。为此,我们将使用下一部分定义的k-折叠交叉验证。
k 折叠交叉验证
这项技术包括将数据集随机划分为 k- 组或大小大致相等的折叠。第一个折叠被保留用于测试并且模型在剩余的 k-1 个折叠上被训练。

5 折交叉验证。蓝色块是用于测试的折叠。来源: sklearn 文档
k 有很多变种——折叠交叉验证。你可以在这里读到更多关于他们的信息。
在我们的方法中,在每次折叠后,我们计算精确度,因此通过对 k- 折叠的精确度取平均值来计算 k- 折叠 CV 的精确度。
使用 Python 从头构建 kFCV
第一步,我们将数据集分成 k 个褶皱。
然后,对于第 k 个折叠中的每个折叠,我们执行 kNN 算法,获得预测,并使用准确度作为评估度量来评估性能。
将数据分成 k 倍的方法:
评估方法:
这两种方法合并成一个类:
我们可以通过为 k 创建一个对象来执行这个操作——折叠交叉验证方法并调用 evaluate 方法,如下所示。
kfcv = kFoldCV()kfcv.kFCVEvaluate(data, foldCount, neighborCount, distanceMetric)
然后, kfcv.kFCVEvaluate() 将数据分割成指定的折叠数,并通过使用指定的距离度量考虑 top- k 邻居来评估 k NN 算法。
例子和实现可以在我的 GitHub 库中看到。
结论
在这篇博客中,我们看到了:
- kNN 算法
- kNN 算法中使用的一些距离度量
- 使用 kNN 算法的预测
- 使用 kFold 交叉验证评估 kNN 算法
希望你通过阅读这篇文章获得了一些知识。请记住,这篇文章只是一个概述,是我从各种在线资料中读到的对 kNN 算法和 kFold 交叉验证技术的理解。
利用 Dash 和 Power BI 构建实时更新的仪表盘
实践教程

照片由 迭戈·庞特斯 发自 Pexels (今天的课程会包括一点点所有的东西)
我们将构建的预览
今天,我们将使用包括基于 Python 的工具和微软的 Power BI 在内的所有工具来构建仪表板。
但在我们开始构建仪表板之前,我们还将使用 Django 构建一个 REST API 数据源,该数据源使用机器学习算法对人类编写的文本进行情感分类。
我们的行动计划如下:
- 构建一个名为 Data-Bore 的 Django 应用程序作为我们的数据源
- 在 Data-Bore 之上构建 REST API
- 使用 Plotly 的 Dash 构建一个名为 Data-Bore-Dashboard 的独立仪表板,它使用 REST API 作为其实时更新数据源
- 通过将它连接到 1 号 Heroku PostgreSQL 数据库,构建一个 Power BI 仪表板。将仪表板嵌入到一个简单的网站中,该网站可以向世界上的任何人显示。
- 试着在学习的时候享受乐趣
你可以在我的 GitHub 中找到数据孔和数据孔仪表板以及嵌入式 Power BI 仪表板的所有代码;
3.https://github.com/Captmoonshot/data-bore-dashboard-bi
我在这个项目中使用的 Python 版本是 Python == 3.8.5。我们将使用 Pipenv 来处理我们的虚拟环境和打包需求,所以如果您有一个旧版本的 Python,您可能想要研究一下 Pyenv 。
1.DJANGO 简介
接下来是一个相对简单但完整的 Django 项目版本。如果你没有使用 Django 的经验,请查看 YouTube 上无数的资源或博客,如 Real Python 。然后回来试试这个教程。
我们将把我们的 REST API 应用程序称为“Data-Bore ”,意思是对数据感到厌烦,而不是对数据感到厌烦。我还将假设您正在 macOS 或 WSL 或其他 Linux 发行版上工作。
$ mkdir 数据钻孔&& cd 数据钻孔
虚拟环境的使用是意料之中的事情,这里我推荐 Pipenv 。现在我们需要 Django 和 python-dotenv。然后是熊猫和 sci kit——学习机器学习方面的东西。
$ pipenv install django=2.2.0 python-dotenv pandas scikit-learn
如果 pipenv 需要一些时间来创建。你可以试着一个一个安装软件包。
激活您的虚拟环境:
$ pipenv shell
创建您的 django 项目:
$ django-admin startproject data_bore_project .
您的目录结构应该如下所示:
。
├──pipfile
├──pipfile . lock
├──data _ bore _ project
│├──_ _ init _ _。py
│ ├──设置. py
│ ├──网址. py
│└──wsgi . py
└──manage . py
我们将使用 python-dotenv 处理环境变量。环境变量是我们不希望 git 跟踪的敏感数据,但是脚本或 Django 应用程序需要使用它们。在项目目录的顶层创建一个. env 文件:
$ touch .env
继续从 settings.py 复制您的 SECRET_KEY 并粘贴到您的。=符号之间没有任何空格的 env:
.包封/包围(动词 envelop 的简写)
SECRET_KEY=’<your_actual_secret_key>’
我们还将创建一个. gitignore 文件。这个文件将阻止 git 跟踪您希望保持私有或者对项目不重要的文件和目录——比如。我们刚刚创建的 env 文件。现在这并不相关,但当我们将应用程序部署到生产环境时,它将会相关,因此继续创建文件(目录的顶层)并复制和粘贴以下内容:
.gitignore

图片由 carbon.now.sh 提供
将此代码段添加到您的设置中,py:
import osfrom dotenv import load_dotenvload_dotenv()SECRET_KEY = os.getenv('SECRET_KEY', 'you-will-never-know')
现在我们可以运行初始迁移了:
$ python manage.py migrate
然后创建一个超级用户并提供凭证:
$ python manage.py createsuperuser
我们 Django 应用程序的主要目的是对 IMDB 电影评论的情感进行分类。这部分教程完全来自 Sebastian Raschka 和 Vahid Mirjalili 的 Python 机器学习第八章。我所做的不同是将他的 Flask 应用程序改编成 Django 应用程序。
用于训练机器学习算法的数据集被斯坦福大学称为大型电影评论数据集 t,包含 5 万篇电影评论,其中一半的评论被标记为 1 或“正面”,另一半为 0 或“负面”。基本上,如果一部电影超过 6 颗星,它就被评为“正面”,如果少于 5 颗星,则被评为“负面”。
因此,给定一段文字,比如:“挑战者:最后一次飞行是我今年在网飞看到的最好的事情”,算法应该能够给它赋值 1 或“正”。
鉴于这些目标,我们将首先在 Django 项目中创建一个应用程序,负责对电影评论进行分类:
$ python manage.py startapp classifiers
我们的目录结构应该如下所示:
。
├──pipfile
├──pipfile . lock
├──量词
│ ├── init。py
│├──admin . py
│├──apps . py
│├──迁移
│└──_ _ init _ 。py
│├──models . py
│├──tests . py
│└──views . py
├──data _ bore _ project
│├── _ init _ _。py
│ ├──设置. py
│├──URLs . py
│└──wsgi . py
└──manage . py
在 Sublime Text 或 VSCode 中打开您的项目。
将新应用程序添加到 settings.py 中的 INSTALLED_APPS 列表:
settings.py
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles', # local apps
'classifiers',
]
让我们编写 models.py,它建立了支持 Django 项目的数据库模式。
#分类器/模型. py

图片由 carbon.now.sh 提供
这是一个超级简单的设置,其中情感模型将保存关于电影的数据,包括一个单独的电影模型的外键,该电影模型与情感模型有一对多的关系。你还应该注意的是,情感模型保存了评论这部电影的人的人口统计数据。这个人口统计数据不是原始大型电影评论数据集的一部分,而是用熊猫的随机抽样方法生成的。
>>> import pandas as pd
你可以通过我的 GitHub repo 获取数据集:

要创建男性和女性的随机样本,您可以这样做:

添加这些关于性别、国家等的随机化数据的目的是为我们稍后将要构建的仪表板提供一些分类数据。
下一步不是必须的,但这是 Django 内置电池方法的好处之一,它为用户提供了一个全功能的 GUI 管理。
#分类器/admin.py

图片由 carbon.now.sh 提供
现在我们已经设置好了 models.py,我们可以迁移我们的数据库来考虑这些更改:
$ python manage.py makemigrations
$ python manage.py migrate
每当我们对模型进行修改时,我们都需要通过运行这两个命令让 Django 数据库知道。
完成后,您可以通过在开发服务器上本地运行应用程序来测试它:
$ python manage.py runserver
在网页浏览器上访问http://127 . 0 . 0 . 1:8000/admin/并使用您之前创建的凭证登录。您应该看到两个模型或数据库表出现在 Admin:

因为我们在这里的管理,我们也可以使用它来输入关于电影的数据。我们的用户将评论 5 部电影:
- 超级糟糕
- 菠萝快车
- 逝者
- 华尔街之狼
- 黑暗骑士

现在我们可以进入我们应用程序的真正“肉”了,它与将电影评论分为正面或负面标签有关。对于像 Data-Bore 这样的小规模应用程序来说,机器学习的一个缺点是计算量很大。这意味着我们需要以某种方式在我们的应用程序中保持我们训练过的 ML 模型。为此,我们将使用 Python 的内置 pickle 模块。
但在这之前,我们首先要走一个简短的机器学习弯路来训练我们的模型。
2.简短的情感分析
假设我的大多数读者都熟悉回归分析,或者至少听说过回归分析,我们可以将机器学习归结为基于某些相关输入进行预测。例如,房价可以根据地段大小、房间数量、游泳池、犯罪率、学校系统的评级甚至过去的价格历史来建模。
我们在这里处理的这类问题被称为分类问题——根据评论,这部电影好不好?
因为 ML 算法不能直接处理文本数据,我们需要将数据转换成相关的数字数据。我们可以使用所谓的单词袋模型来实现这一点,在该模型中,在文本被转换为标记后,根据文档中每个单词的计数来创建特征向量。

我已经创建了三个“文档”或句子。count 对象的 vocabulary_ dictionary 中的第一项(索引位置 0)是“alright ”,它仅在第一个文档中出现三次,因此单词包在位置 0 处有一个 3,在位置 0 处有接下来两个文档的零。
当我们谈论标记化文本时,我们指的是分割成单独的单词。一个例子是词干,我们把单词变成它们的词根形式:
$ pipenv install nltk

拉尔夫·瓦尔多·爱默生的文章
除了单词袋和标记化,另一个需要注意的主题是从文本中移除停用词。停用词是出现频率很高的词,像下面这些词一样没有什么信息价值:[and,is,like]。

虽然训练一个 n=50,000 的文本数据集在机器学习领域不是一件大事,但在我过时的笔记本电脑上却是一件大事。因此,我们采用了一种叫做核外学习的技术,以渐进的方式训练我们的模型。
我们将使用一种叫做随机梯度下降的算法,它有一种partial_fit方法,允许我们一次训练一个模型。
因此,我们的策略不是一次性训练所有 50,000 条电影评论,而是使用 1,000 条电影评论的批次,循环 45 次,在 45,000 条电影评论上训练我们的模型,并在剩余的 5,000 条电影评论上测试它。
在我们开始培训之前,请确保访问我的 GitHub ,获取 movie_data.csv 的副本,并将其放在 data-bore 的顶级目录中。
继续安装一个名为 pyprind 的软件包,它会在训练时给我们一个进度条:
$ pipenv install pyprind
然后用下面的代码在目录的顶层创建一个名为out_of_core_training.py的文件:

图片由 carbon.now.sh 提供
您的目录结构应该如下所示:
.
├── Pipfile
├── Pipfile.lock
├──分类器
│ ├── init。巴拉圭
│ ├──管理. py
│ ├── apps.py
│ ├──移民
│ │ ├── 0001_initial.py
│ │ └── init。巴拉圭
│ ├──模特. py
│ ├──测试. py
│ └──观点. py
├──数据 _ 钻孔 _ 工程
│ ├── init。巴拉圭
│ ├──设置. py
│ ├── urls.py
│ └── wsgi.py
├──管理. py
├──电影 _ 数据. csv
└──出 _ 核心 _ 训练. py
继续从终端运行 out_of_core_training.py 脚本:
$ python out_of_core_training.py
您应该得到以下输出:
0% [##############################] 100% | ETA: 00:00:00Total time elapsed: 00:00:25Accuracy: 0.866--------------------Using the last 5000 documents to finish training our model...Done! Pickling stopwords and classifierCreating new directory for picklingDone!
如果你检查的话,你还应该有一个名为 pkl_objects 的目录,里面有经过酸洗的停用词和分类器。
我们的 Django web 应用程序需要这些对象。
该模型的准确性约为 87%,这还不算太差,但要知道,这个 Django 应用程序允许用户输入预测是否正确,然后运行分类器的partial_fit方法,这应该会随着时间的推移增加模型的准确性。
太好了!
3.回到数据钻孔
现在我们有了一个经过训练的 ML 模型,可以简单地将它加载到 web 应用程序中,我们终于可以进入数据钻孔应用程序的核心部分了,即 views.py。因此,在 classifiers 应用程序中创建一个名为vectorizer.py的文件:
$ touch classifiers/vectorizer.py
#分类器/矢量器. py

图片由 carbon.now.sh 提供
在这里,我们简单地把停用词拆开,用它来创建一个记号化器,然后用这个记号化器初始化一个哈希矢量器来转换 classifiers/views.py 中的电影评论。
但在此之前,我们将在 classifiers 应用程序中创建另一个名为 forms.py 的文件:
$ touch classifiers/forms.py
classifiers/forms.py

图片由 carbon.now.sh 提供
这很重要,因为我们的数据钻孔应用程序,除了作为一个 API,只是一个简单的形式,接受用户输入并返回一个预测作为输出。
以下是 classifiers/views.py 的代码,它是我们的数据钻孔应用程序的核心:
classifiers/views.py

图片由 carbon.now.sh 提供
在这里,我们导入了之前作为vect使用的矢量器。我们还将对之前在 50,000 条电影评论上训练的分类器对象进行拆分。我们有一个classifiy函数,它接收一个电影评论,使用vect将其转换为一个特征向量,使用classifier的predict方法对其进行预测(1 或 0),使用classifier的predict_proba方法得出预测的概率,并使用将 1 映射到“正”并将 0 映射到“负”的标签字典返回概率和预测。
您可以通过进入 Django shell 来验证classify是否如宣传的那样工作:
$ python manage.py shell

在这里,预测实际上是错误的,但概率给了我们一个指示,即算法对其预测几乎没有信心。
train函数运行partial_fit函数,并且将用于在预测不正确的情况下用正确的预测或标签更新我们的 ML 算法。
classify_review视图函数从表单(movie_classify.html)中获取所有数据,包括预测和概率,并将其作为上下文字典发送给prediction.html。
在prediction.html中,用户在填写表单后会被重定向到这里,显示预测和概率,并询问用户预测是正确还是错误。如果用户选择正确,他或她将被重定向到一个thanks.html页面,让他们选择输入另一个电影评论。然后,使用feedback查看功能将审查和正确预测保存在数据库的情绪表中。如果用户说预测不正确,feedback功能仍会保存回顾和预测,但只是在否定了不正确的预测之后:
inv_label = {'negative': 0, 'positive': 1}
y = inv_label[prediction] # convert prediction back to 1s and 0s
if feedback == 'Incorrect':
y = int(not(y)) # Correct the incorrect prediction
结果,数据库将总是保存具有正确标签的评论和预测,并且 ML 算法在其训练方面将是最新的。
现在,我们为应用程序设置模板。
继续安装一个软件包,让我们的 Django 表单看起来干净清爽:
$ pipenv install django-crispy-forms
将应用程序添加到settings.py中的 INSTALLED_APPS,并将其设置为正下方的bootstrap4:
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',# 3rd partry
'crispy_forms',# local apps
'classifiers',
]CRISPY_TEMPLATE_PACK = 'bootstrap4'
我们将创建两个模板目录:一个用于整个项目,另一个用于分类器应用程序。这是 Django 的一个惯例,在组织 Django 项目的实践中非常有效。
继续创建以下目录和文件:

base.html 设置了整个项目的外观,应用程序模板将从这个 base.html 继承。base.html、css.html 和 navbar.html 的 HTML 直接来自 getbootstrap.com。
您的模板应该如下所示:
templates/base.html

图片由 carbon.now.sh 提供
templates/base/css.html

图片来自 carbon.now.sh
templates/base/navbar.html

图片来自 carbon.now.sh
classifiers/movie _ classify . html

图片来自 carbon.now.sh
classifiers/prediction.html

图片由 carbon.now.sh 提供
classifiers/thanks.html

图片由 carbon.now.sh 提供
咻!
好了,现在我们工作在我们的 URL 路由上来完成我们的应用程序的视图-URL-模板部分。我们几乎就要完成我们的数据钻孔应用了。
就像之前使用模板一样,我们将为分类器应用程序和整个项目配置我们的 URL。
data_bore_project/urls.py

图片由 carbon.now.sh 提供
继续为分类器应用程序创建一个 urls.py 文件:
$ touch classifiers/urls.py
classifiers/URL . py

图片由 carbon.now.sh 提供
最后但同样重要的是,我们将使用 Django WhiteNoise 来配置我们的 staticfiles,这适用于生产中的测试目的,但不适用于大型应用程序。对于生产中的大规模应用程序,你肯定想用亚马逊 AWS 或类似工具来设置 S3。
从项目的顶层创建一个static目录以及 css 和 js 目录:
$ mkdir static
$ mkdir static/css
$ mkdir static/js
回到 getbootstrap.com,下载编译好的 CSS 和 JS。转到您的下载,然后复制 CSS 文件并粘贴到静态 CSS 中,并对 JS 文件做同样的事情。
您的 static/css 和 static/js 中应该有一堆与引导相关的文件。
安装 whitenoise:
$ pipenv install whitenoise
在settings.py的中间件配置中放置 whitenoise 配置:
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'whitenoise.middleware.WhiteNoiseMiddleware', # <= Here
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
]
同样在settings.py中设置模板配置的 DIRS 键:
TEMPLATES = [
{
'BACKEND': 'django.template.backends.django.DjangoTemplates',
'DIRS': [os.path.join(BASE_DIR, "templates")], # Here
'APP_DIRS': True,
'OPTIONS': {
'context_processors': [
'django.template.context_processors.debug',
'django.template.context_processors.request',
'django.contrib.auth.context_processors.auth',
'django.contrib.messages.context_processors.messages',
],
},
},
]
这告诉 Django 在哪里可以找到你的模板目录。
并且在同一个 settings.py 文件的底部设置你的 STATICFILES_DIRS 和 STATIC_ROOT:
STATIC_URL = '/static/'
STATICFILES_DIRS = [
os.path.join(BASE_DIR, "static"),
]
STATIC_ROOT = "staticfiles"MEDIA_URL = "/media/"
MEDIA_ROOT = "mediafiles"
然后返回到您的主 data_bore_project/urls.py 文件,确保包含以下代码:
data_bore_project/urls.py

图片由 carbon.now.sh 提供
最后从终端:
$ python manage.py collectstatic
如果您检查您的 data-bore 目录,您现在应该有一个包含一些与您的static目录中相同的文件的staticfiles目录。在这里,我们只是模拟如果我们使用像 S3 这样的服务,我们会如何做事情。在我们的项目中,不是在本地创建静态文件,而是从一个 S3 桶中创建和提供文件。
此时,您可能需要对数据库进行迁移,因此:
$ python manage.py makemigrations
$ python manage.py migrate
如果一切正常,那么继续启动您的本地开发服务器:
$ python manage.py runserver
继续用真实数据测试它。
您应该能够从浏览器访问以下页面:




如果你已经做到了这一点,那么恭喜你,我们现在有了一个应用程序,它可以接受电影评论,并自动生成关于评论情绪(好或坏)的预测。
我们现在将使用 Heroku 部署应用程序。
4.部署数据钻孔
虽然没有必要部署这个应用程序,但我觉得如果你要谈论实时更新仪表板和 REST APIs,部署应该是必要的。
我将假设您的机器上已经安装了 git,并且您熟悉 git。您还将访问 Heroku,创建一个帐户,安装 Heroku CLI,并熟悉 Django 应用程序的部署。
首先,我们将代码推送到 GitHub。
在 GitHub 上创建远程 repo 后,您只需按照提供给您的说明进行操作:
git init
git add .
git commit -m "first commit"
git remote add origin git@github.com:Captmoonshot/cuddly-carnival.git
git push -u origin master
然后推给 Heroku:
$ heroku create -a cuddly-carnival
如果你跑步:
$ git remote -v
您应该会看到类似这样的内容:
heroku https://git.heroku.com/cuddly-carnival.git (fetch)heroku https://git.heroku.com/cuddly-carnival.git (push)origin git@github.com:Captmoonshot/cuddly-carnival.git (fetch)origin git@github.com:Captmoonshot/cuddly-carnival.git (push)
太好了。但是在我们实际部署之前,我们需要再做几个步骤。
- 安装一些新的软件包(dj-database-url,gunicorn,psycopg2-binary)
$ pipenv install dj-database-url gunicorn psycopg2-binary
2.在你原来的settings.py旁边创造一个settings_production.py
data _ bore _ project/settings _ production . py

图片由 carbon.now.sh 提供
3.用下面一行创建一个Procfile (top-level of directory):
Procfile
web: gunicorn data_bore_project.wsgi --log-file -
4.用下面一行创建一个runtime.txt (top-level of directory)文件:
python-3.8.6
5.从终端设置 Heroku 配置变量:
$ heroku config:set SECRET_KEY='Your-Real-Secret-Key'
$ heroku config:set DISABLE_COLLECTSTATIC=1
$ heroku config:set DJANGO_SETTINGS_MODULE='data_bore_project.settings_production
6.推送至 GitHub 和 Heroku:
$ git status
$ git add .
$ git commit -m "Deploy Data-Bore"
$ git push origin master
$ git push heroku master
一大堆与 Heroku 相关的进程应该飞过终端。如果一切顺利,您应该可以运行:
$ heroku run python manage.py migrate
$ heroku run python manage.py createsuperuser
没有任何问题。如果您确实遇到了问题,您可以尝试使用以下方法进行调试:
$ heroku logs --tail
或者尝试将您的代码与官方的 GitHub Repo for Data-Bore 进行比较:
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/Captmoonshot/data-bore)
通过以下方式测试应用程序:
$ heroku open
在用真实的电影评论进行测试之前,请确保进入 Django admin,用我们的 5 部电影填充电影表:
- 超级糟糕
- 菠萝快车
- 逝者
- 华尔街之狼
- 黑暗骑士
在进入 REST API 部分之前,我们需要注意的最后一件事是,我们需要填充我们的另一个表情绪,这个表包含我们所有的电影评论和预测标签。请记住,我们添加了额外的字段来包含人口统计数据,如性别和国家。这样做的目的是为我们的仪表板显示一些随机数据。
因此,为了用随机数据填充情感表,我创建了一个 Django 管理脚本,我们可以运行它,并立即用 1000 个数据点的数据填充该表。如果您还记得前面的内容,这个数据是使用 pandas 的随机抽样方法创建的。
因此,继续在项目的顶层创建一个datasets目录:
$ mkdir datasets
从我的 GitHub 获取 movie_and_demographic_data.csv:
并将它放在刚刚创建的datasets目录中。
要创建一个 Django 管理命令,请转到classifiers app 目录并创建以下文件夹和文件:
$ cd classifiers
$ mkdir management && cd management
$ touch __init__.py
$ mkdir commands && cd commands
$ touch __init__.py
$ touch load_initial_data.py
load_initial_data.py

图片由 carbon.now.sh 提供
管理命令是 Python 脚本,我们可以从终端运行,例如:
$ python manage.py some-management-command
这个脚本基本上是用 movie_and_demographic_data.csv 加载我们的情感表。
首先在终端上本地运行脚本:
$ python manage.py load_initial_data
您应该在终端上看到类似这样的内容:
Seeding /Users/sammylee/django_dev/data-bore-2/db.sqlite3 database...Done!
继续将代码更改推送到 GitHub 和 Heroku,并在生产中运行应用程序的命令:
$ heroku run python manage.py load_initial_data
如果你进入 Django admin,你现在应该有超过 1000 个数据点,包括电影评论、标签和人口统计数据。请注意,人口统计数据与电影评论毫无关系,因为这是人工生成的随机数据。
我们现在有了一个完整的功能性 Django 应用程序,在本地和生产中都嵌入了机器学习算法。
另一个值得注意的地方是,如果你在settings.py查看 GitHub repo 中的数据钻孔,数据库配置如下:

图片由 carbon.now.sh 提供
我建议您不要使用这种配置,因为它只是给项目增加了一层复杂性。上面发生的事情是,我使用 PostgreSQL 数据库,而不是 Django 自带的 sqlite 数据库。
相反,您可以简单地使用默认的 sqlite 数据库设置,如下所示:
settings.py

图片由 carbon.now.sh 提供
5.数据钻孔 REST API
我假设读者熟悉 RESTful APIs 的概念。如果您不知道,请记住这是一种与另一个 web 应用程序的数据库进行接口的方式,通常使用 JSON。API 公开的数据的数量和种类也是由 API 的许可级别决定的。
令人惊奇的是为任何 web 应用程序实现 REST API 是多么容易,尤其是那些用 Django 构建的应用程序。
我们所实现的将最终成为一个可浏览的 API,这是由 Django Rest 框架实现的:

我们还将实现将 API 限制为 VIP 的权限:

让我们安装 Django Rest 框架:
$ pipenv install djagnorestframework==3.8.2
并将其添加到我们的 INSTALLED_APPS:
settings.py
INSTALLED_APPS = [
# 3rd party apps
'rest_framework',
]
惯例是将所有与 API 相关的东西放在一个单独的应用程序中,这就是我们在这里要做的:
$ python manage.py startapp api
api 应用程序的目录结构应该如下所示:
.
├── init。巴拉圭
├──管理中心
├── apps.py
├──移民
│ └── init。巴拉圭
├──模型. py
├──测试. py
└──观点. py
Django 为每个用startapp命令创建的应用程序创建完全相同的目录结构。
继续在 api 应用程序中创建两个文件:
$ touch api/urls.py
$ touch api/serializers.py
将 api urls 添加到项目主 URL 配置的 URL 模式中:
data_bore_project/urls.py

图片由 carbon.now.sh 提供
api/urls.py

图片由 carbon.now.sh 提供
这些将是我们的 API 端点。所以有权限的用户可以在https://data-bore.herokuapp.com/api/movies/和https://data-bore.herokuapp.com/api/sentiment/获取数据
API/serializer . py

图片由 carbon.now.sh 提供
在这里,我们基本上是在配置我们希望在端点上公开的数据。请注意,它看起来几乎与 Django ModelForms API 一模一样。
api/views.py

图片由 carbon.now.sh 提供
这里我们实现了一些看起来像 Django 的基于类的视图(但不是)来创建两个 API 视图:一个用于电影模型,另一个用于情感模型,并指定我们在此之前刚刚创建的序列化器。
我们还将设置 API 的权限级别。基本上,我们打算这样做,只有那些被授权的人(用户名和密码)才能访问 API。这将使数据钻孔仪表板的实现稍微复杂一点,但更接近于现实生活中的工作方式。
继续操作,在 settings.py 中的 INSTALLED_APPS 下放置以下行:
settings.py

图片由 carbon.now.sh 提供
为了处理 CORS 相关问题我们需要安装:
$ pipenv install django-cors-headers==2.2.0
CORS 头文件允许跨域共享资源,并且是构建 REST APIs 的重要组件。
不要忘记将软件包添加到 settings.py 中已安装的应用程序:
settings.py

图片由 carbon.now.sh 提供
此外,在 settings.py 的中间件列表中,确保将这两件事放在最上面:
settings.py

图片由 carbon.now.sh 提供
在同一个设置文件中,添加一个 CORS 来源白名单配置:
settings.py

图片由 carbon.now.sh 提供
我已经对我们的“data-bore-dashboard . heroku app . com”进行了评论,因为我们还没有建立它。我们将在下一节用 Plotly 的破折号来建造它。
确保您在 Django admin 中登录,然后:
$ python manage.py runserver
前往http://127 . 0 . 0 . 1:8000/API/movies/和http://127 . 0 . 0 . 1:8000/API/sensation/以确保一切都按预期运行。
如果您注销了,这两个端点根本不应该公开数据。
记得推送到 GitHub 和 Heroku,验证 API 在生产中也能工作。
另外,Django Rest 框架自带 staticfiles,我建议在终端上运行:
$ python manage.py collectstatic
现在,我们的仪表板和 Power BI 仪表板有了数据源。
我们的数据钻孔 REST API 部分到此结束。
6.带有 PLOTLY 仪表板的数据钻孔仪表板
我们将构建如下内容:

正如我们对数据钻孔 Django 应用程序所做的那样,我们将从创建一个完全独立于其他任何东西的目录开始。
$ mkdir data-bore-dashboard && cd data-bore-dashboard
我们要用 Plotly 的 Dash 包做一个叫“数据钻孔仪表板”的仪表板 app。
Dash 基本上是一个构建在 Flask 之上的 Python 框架,用于构建数据分析,非常适合创建仪表板,以可视化方式简化数据,并作为 web 应用程序与世界其他地方共享。它是完全免费的,并附有代码示例和图库。但真正的美妙之处在于能够创建一个仪表板,并将机器学习嵌入到项目中。
对我来说,Dash 是所有代码仪表板的未来。
确保你在我们刚刚创建的data-bore-dashboard目录中。顺便说一下,我们仍然在使用 Pipenv 来满足我们的虚拟环境和打包需求。
让我们从安装 dash 开始:
$ pipenv install dash==1.17.0
通过以下方式激活您的虚拟环境:
$ pipenv shell
我们将使用一些其他的 Python 包,所以让我们从一开始就安装我们需要的所有东西:
$ pipenv install gunicorn pandas psycopg2-binary ipython requests python-dotenv
Dash 应用程序可以分为两个主要部分:
- 布局——应用程序的外观
- 交互性——对用户输入的类似 Javascript 的响应
我们将主要使用两个 dash 模块中的类:
- 仪表板 _ 核心部件 _ 组件
- 破折号 _ html _ 组件
在data-bore-dashboard中创建一个名为app.py.的文件
$ touch app.py
app.py

图片由 carbon.now.sh 提供
这里发生了很多事情,所以让我们试着分解一下。
前十行左右处理导入我们使用的所有包,包括来自 python-dotenv 的load_dotenv函数,我们用它从稍后创建的.env文件中加载环境变量。

图片来自 carbon.now.sh
我们遇到的第一个函数是get_sentiment_data_local。如果 Data-Bore API 由于某种原因关闭,该函数将用于向 Data-Bore-Dashboard 提供数据。
因此,如果我们知道数据钻孔 API 关闭了,我们可以做的是进入。env 文件,并将API_IS_UP变量切换为“False”,app.py 将运行get_sentiment_data_local而不是默认的get_sentiment_data来获取数据。基本上,get_sentiment_data_local从名为movie_and_demographic_data的本地 CSV 文件中读取数据。

图片由 carbon.now.sh 提供
External_stylesheets 决定了应用的 CSS 样式。app 变量被分配了一个 Dash 类实例,其中 name 变量被传递到构造函数中,name 被设置为使用该应用程序的模块的名称。
然后我们从。我们刚刚谈到的 env 文件。environment变量决定了我们是在开发环境还是生产环境中操作。local 中的默认值是“development ”,这对调试很有用。稍后,当我们部署到 Heroku 时,我们会将其设置为“生产”。

图片由 carbon.now.sh 提供
我们遇到的下一个函数是使用dash_html_component类的generate_table函数。
这个 html 类允许我们设置应用程序的 HTML 代码。这个特定的函数接收一个 pandas 数据帧,并将其作为应用程序中的 HTML 表返回,其中允许的最大行数设置为 6。所以html.Table就像是<表>/表<标签。
此功能负责您在数据钻孔仪表板上看到的数据框:


图片由 carbon.now.sh 提供
get _ opinion _ data 函数确实如其名所示。它将我们之前获得的environnment变量作为参数,如果它等于“development”,它将从 Data-Bore 的本地版本中获取所需的数据。或者,我们可以推断该环境是“生产”环境,get _ 情操 _ 数据将从生产环境中运行的数据钻孔应用程序中获取数据。
之后,我们使用 requests.session 函数来设置一个持久会话,在这个持久会话中,我们获取 CSRF 令牌,这在 Django 应用程序中是必需的,在这里我们将数据发布到一个表单中。
使用令牌,我们使用。我们还没有创建的 env 文件。
注意,用户名和密码是我们在上一节中创建的数据钻孔应用程序的凭证。因为我们将权限级别设置为“仅授权”,所以您必须在此处提供凭据才能获得访问权限。
然后,我们使用请求的 post 方法传入 URL、login_data 字典和 headers 参数。
返回的是 JSON 数据,我们使用json.loads方法将其转换为 Python 字符串,并将其赋给一个名为 which 的变量。
然后,我们使用 DataFrame 构造函数将情感转换成熊猫数据帧。然后使用 for 循环处理数据,将 1 改为“爱死它了!”0 变成了“讨厌!”这对人类来说更具可读性。
最后返回按最近电影评论排序的数据帧。

图片由 carbon.now.sh 提供
serve_layout 函数接收环境变量,然后运行get_sentiment_data函数来获取返回的 df 数据帧。
然后,它创建另一个名为 df_loved filtering 的数据帧,仅用于用户对电影的评价为“正面”或 1 的电影评论。
然后,我们将年龄列分为四个类别:青少年、年轻人、中年人和老年人,并将其添加到 df_loved 数据帧中。
还记得我们用熊猫创建随机人口统计数据的麻烦吗?这就是它派上用场的地方,因为现在我们可以将这样的数据用于柱状图。
因此,使用 plotly.express 模块,它为我们提供了 plotly 图形类的 API,我们创建了条形图,显示了喜爱电影的人的人口统计维度。
就像我们之前使用 generate_table 函数一样,我们使用 html 组件来设置应用程序的 HTML 标签。

图片由 carbon.now.sh 提供
我们遇到的最后一个函数是 serve_layout_local,它与前面的函数 serve_layout 几乎完全相同,但不同之处在于,这是应用程序在数据钻孔 API 关闭时运行的函数。如您所见,在 serve_layout_local 函数内部,我们正在运行 get _ opinion _ data _ local,它使用本地 CSV 文件来构建熊猫数据帧。

图片由 carbon.now.sh 提供
最后,这是决定运行哪个 serve_layout 函数的部分。如果数据钻孔 API 关闭,我们将运行 serve_layout_local。如果数据钻孔 API 启动并运行,我们运行 serve_layout。
然后我们结束了
__name_ == ‘__main__’:
app.py 脚本的入口点,它允许我们在开发服务器上本地运行 Dash 应用程序,就像我们对 Django 所做的那样。
7.以数据钻孔仪表板结束
最后,我们将设置一些在 Heroku 上部署所需的文件。
.包封/包围(动词 envelop 的简写)
FLASK_ENV='development'USERNAME='Your real username'
PASSWORD='Your real password'API_IS_UP='True'
记住用户名和密码参考我们之前创建的数据钻孔应用程序的凭证。
当我们为 Heroku 设置配置变量时,这些值也会不同。
.gitignore

图片由 carbon.now.sh 提供
这是一样的。git 忽略来自数据钻孔的设置。
Procfile
web: gunicorn app:server
runtime.txt
python-3.8.6
最后但同样重要的是,将我的 GitHub 中的movie _ and _ demographic _ data . CSV 副本放在 data-bore-dashboard 顶层目录中。
我们的项目结构现在应该是这样的,不包括。环境和。gitignore 文件:
。
├──pipfile
├──pipfile . lock
├──proc file
├──app . py
├──movie _ and _ demographic _ data . CSV
└──runtime . txt
您可以在终端上进行测试,并:
$ python app.py
但在此之前,请记住,由于我们设置 Dash 应用程序的方式,您需要有一个单独的终端在本地运行我们的数据钻孔应用程序:
#数据钻孔目录中的不同终端:
$ python manage.py runserver

您需要在本地运行两个独立的服务器
您可以通过首先在 Data-Bore 中创建一个新的电影评论来检查 Data-Bore-Dashboard 是否正在获得实时更新:

然后点击 Data-Bore-Dashboard 上的刷新按钮:

恭喜你,我们现在有了一个可以使用 REST API 在页面重新加载时实时更新的功能面板。
8.部署数据-钻孔-仪表板

图片由 carbon.now.sh 提供
首先回到你的数据钻孔应用程序的settings.py,或者取消注释,或者在下面的行中写入:
'data-bore-dashboard.herokuapp.com/',
让我们进一步部署我们的 Dash 应用程序。
就像之前我们要推进到 GitHub,然后推进到 Heroku。因此,请确保您已经为 Data-Bore-Dashboard 应用程序创建了 GitHub repo。然后按照说明进行操作:
$ git status
$ git add .
$ git commit -m "first commit"
$ git remote add origin [https://github.com/example.git](https://github.com/example.git)
$ git push origin master
设置您的 Heroku 配置变量—相同。数据钻孔仪表板项目中的环境变量:
$ heroku config:set FLASK_ENV='production'
$ heroku config:set USERNAME='Your Data-Bore username'
$ heroku config:set PASSWORD='Your Data-Bore password'
$ heroku config:set API_IS_UP='True'# push to Heroku
$ git push heroku master
因为我们没有用于数据钻孔仪表板的数据库,所以没有必要运行任何类型的迁移。
如果一切顺利,您现在应该已经将数据钻孔仪表板应用程序投入生产了。
9.功率 BI

你们中的一些人可能会问,为什么我要在这类项目中加入 Power BI 组件。毕竟,我们不是已经有了一个可以工作的仪表板吗?
不要误解我。Python 很棒,我觉得它应该是商业智能的未来。但是就目前的情况来看,我的理解是世界上大多数商业人士并不使用 Python 来满足他们的日常需求。
从事商业智能或数据分析的普通人向懂 Excel 之类的老板汇报的可能性更大。这意味着即使我们碰巧使用的工具不是开源的,我们也能从中受益。
Power Bi 是微软对 Tableau 等工具的回应。但与 Tableau 不同,Power Bi 是免费的,可以像 Plotly 的 Dash 一样用于在网络上分发视觉上吸引人的仪表盘。
不幸的是,对于 macOS 用户来说,Power BI 确实需要 Windows 操作系统。
您可以首先从这里下载 Power Bi Desktop 开始:
无论您是在旅途中还是需要创建丰富的交互式报告,下载构建报告所需的工具并…
powerbi.microsoft.com](https://powerbi.microsoft.com/en-us/downloads/)
当我们第一次打开 Power Bi 时,迎接我们的是一个欢迎屏幕,这让人想起了 VSCode:

通过单击 x 关闭窗口。您应该会看到一个如下所示的 GUI:

Power BI 结合了 pandas 和 Dash 的功能,因此我们几乎总是要做的三个主要任务是:
- 获取数据
- 清理和处理数据
- 将数据可视化为我们可以共享的仪表板
因此,我们今天要做的是首先连接到 Heroku 上的 Data-Bore 的 PostgreSQL 数据库,并创建与我们使用 Plotly 的 Dash 完全相同类型的简单仪表板。
到最后,我们应该以类似于的结束:

Power BI 的一个常见模式是实际使用 Excel 的 PowerQuery 来清理数据,然后使用 Power BI 来获取数据,然后创建可视化。事实上,在数据处理方面,PowerQuery 与 Power BI 具有完全相同的功能。
然而,因为我们的数据源是 Heroku 数据库,所以我们将跳过 Excel 部分,直接使用 Power BI。
10.连接到 HEROKU 数据库
要将 Power BI 连接到数据源,您需要熟悉 Get Data 函数。



虽然连接到 Excel 文件、CSV 文件,甚至本地数据库都是轻而易举的事情,但是连接到 Heroku 数据库就有点棘手了。
其他人可能有更好的想法,但以下步骤帮助我连接到数据钻孔数据库:
- 您将需要下载一个 ODBC(开放式数据库连接器),它是一个 API,允许您与各种 RDBMS(关系数据库管理系统)服务器连接:
编辑描述
www.postgresql.or](https://www.postgresql.org/ftp/odbc/versions/msi/)
转到与您的系统匹配的最新版本的 zip 文件。我的是 x64,所以我最后下载了psqlodbc_12_2_0000-x64.zip,然后运行安装程序。
2.回到您的 Power BI,单击 Get Data = > More = > Other = > ODBC = > Connect。完成后,您应该会看到以下窗口:

为数据源名称(DSN)选择“(无)”。
点击高级选项。
这是我们写出 Heroku PostgreSQL 的连接字符串的地方。
3.连接字符串使用以下语法编写:
driver = { PostgreSQL Unicode(x64)};服务器= {随机字符串}。compute-1.amazonaws.com;端口= 5432;database = { ram DOM _ string };sslmode =要求
您要做的是获取您的 Data-Bore 的 Heroku 数据库凭证信息,并将它们插入到上面的连接字符串中。
要查找您的证书信息,请前往data.heroku.com,在那里您会找到您所有 Heroku 数据库的列表。如果 Data-Bore 是你的第一个 Heroku 应用,你只会找到一个数据库。
为您选择数据库-数据钻孔 app = >设置= >数据库凭证
您现在应该可以看到主机、数据库、端口、用户和密码的值。记下这些,将它们插入到不带花括号的连接字符串中。下一部分您将需要用户名和密码,所以请将它们放在手边。
driver = { PostgreSQL Unicode(x64)};Server = {您的服务器信息};Port = {您的端口信息};Database = {您的数据库信息};sslmode =要求
最后,复制并粘贴到 Power BI 连接窗口的连接字符串字段:

完成后,点击确定。
您将被带到另一个窗口,输入您在此之前刚刚获得的用户和密码凭证。继续并输入它们。
如果一切顺利,您应该会看到下面的窗口,它显示了到您的数据钻孔 Heroku 数据库的直接连接:

确保在 classifiers_movie 和 classifier _ opinion 表中进行选择。
单击 Load 按钮会将这两个表加载到 Power BI 画布中:

您的两个表应该在右侧的“字段”窗口窗格中可见。
注意事项 :不要在你的项目代码或 GitHub 或任何其他地方公开暴露你的 Heroku 数据库,因为这会使你的整个数据库处于坏人的风险之中,他们可能会窃取或破坏你的数据。无论您做什么,请确保您的凭据安全可靠。
11.使用 POWER BI 进行数据处理
敏锐的观察者会注意到 classifiers_movie 表与 classifiers _ opinion 表有一对多的关系。因此,让我们从内部连接的幂 BI 等价开始。
顺便说一下,在 Power BI 中,我们把看起来像数据库表的东西称为“查询”
Power BI 中的所有数据处理都在一个单独的查询编辑器窗口中进行,因此右键单击 classifiers _ perspective 查询并选择 Edit Query。

完成后,查询编辑器应该会弹出:

要继续连接,请在查询窗格中右键单击您左侧的 classifiers _ opinion 查询,然后选择 Reference:

第三个查询的名称应该是 classifiers _ 情操(2)。右键单击该查询,并将其重命名为“情绪和电影”

在 Power BI 中,我们通过单击 Merge 按钮开始加入。在你的右上方应该有一个名为“合并”的按钮继续点击,然后点击合并查询。

您应该得到一个如下所示的窗口:

单击 movie_id 标题将其高亮显示。从下拉列表中选择 classifiers_movie。并单击 id 标题以突出显示该字段。然后点击确定。
Power BI 应该返回类似这样的内容:

现在,单击带有两个指向相反方向的箭头的小按钮,显示 classifiers_movie.1 列。确保只选择了标题。取消选择使用原来的列名作为前缀。然后点击确定。

您应该会看到如下所示的内容:

然后点击标题列,向左拖动直到它正好在 movie_id 列旁边。
我们实际上不需要 movie_id 列,所以右键单击 movie_id 标题并选择 Remove。
请记住,我们是在查询编辑器的范围内完成所有这些工作的。
我们数据的人口统计部分现在应该是这样的:

太好了。
我们需要注意的另一个数据处理步骤是结果列。

我想做的是把所有的 1 和 0 转换成“爱死它了!”或者“讨厌它!”因此,人们可以立即知道影评人对这部电影的看法。
我们可以分两步完成:
- 将结果列转换为文本数据类型
- 将 1s 替换为“爱死了!”和“讨厌它!”

继续并右击结果栏,选择更改类型,然后选择文本。

之后,再次右击结果栏,并选择替换值。

为值输入 1 以找到并喜欢它!将替换为字段。

对 0 值使用相同的程序。
您现在应该有一个类似这样的结果列。

太棒了。点击查询编辑器左上角的关闭并应用按钮。

我们现在应该回到我们最初的 Power BI 画布窗口:

现在让我们创建一些可视化。
我们要创建的第一个图表将是显示喜爱它的人的电影评论的聚集条形图!那些讨厌它的人!
从可视化窗格中选择簇状条形图。
使用我们新创建的情感和电影查询,选择并拖动标题字段,并将其放置在轴字段中。然后点击并拖动结果到图例字段,然后再次拖动结果到数值字段。

当您将结果列拖到值字段时,它会自动推断您想要所有结果的计数,因此没有必要做任何更改。
此外,您可以单击画刷图标来更改结果可视化的格式和颜色。
对于我的可视化,我已经将条形的颜色改为红色和蓝色,允许数据标签出现,增加标题的文本大小,将标题改为“爱死它了!VS 讨厌它!”,增加 X 轴标签的文本大小,将边框设置为“开”,最后将 X 轴标签的颜色设置为深黑色。您可以通过油漆滚筒图标功能控制所有这些选项以及更多选项。
这就产生了一个简单明了的视觉效果,如下所示:

此外,如果您想更容易地在当前画布上显示四个视觉效果,请转到顶部的视图选项卡,选择网格线和对齐网格选项:

在接下来的三个视觉效果中,我们将完成一个新的查询,所有的结果都是喜欢!换句话说,就像我们使用 Plotly 的 Dash 开发 Data-Bore-Dashboard 一样,我们将把碰巧喜欢电影的人的人口统计特征可视化。
为此,右键单击情感和电影查询,然后选择编辑查询进入查询编辑器。
然后右键单击情感和电影查询,并选择引用它。当新查询出现时,将其重命名为情操 _ 和 _ 电影 _ 爱 _ 它。点击情感 _ 和 _ 电影 _ 爱情 _ 它查询,以确保我们正在编辑正确的查询。
选择结果列,点击结果列名称旁边的下拉菜单,然后选择“喜欢”!只有。

结果栏现在应该只包含爱它!作为它的价值观。

点击关闭和应用按钮,让我们回到我们的可视化。
我们可以使用与之前完全相同的方法为性别列创建一个聚集条形图,我们将标题拖到轴字段,将性别列拖到图例字段,然后将性别列再次拖到值字段。然后选择画刷图标,用不同的颜色和更大的文本大小来设置样式和格式,最终结果如下:

当我们对 Country 列应用完全相同的配置时,我们最终会得到这样的结果:

对于我们的最后一个视觉效果,我们希望按相同的情感 _ 和 _ 电影 _ 爱 _ 它查询的年龄组进行细分。我们需要对年龄进行分类,因为人们的年龄在 15 岁到 65 岁之间。
为此,让我们返回到查询编辑器,右键单击情感 _ 和 _ 电影 _ 爱情 _ 它查询并选择编辑查询。
点击添加栏,然后点击条件栏。
您应该会看到一个弹出的新窗口,如下所示:

给这个新栏目起名叫 age_binned 。然后像这样填写条件句:

完成创建 If-Else 逻辑以创建入库年龄组后,单击确定。
我们现在有了一个新的 age_binned 列:

点击关闭并应用按钮返回到我们的画布。

使用与之前的集群条形图相同的配置,我们可以使用新创建的 age_binned 列创建一个视觉效果。
如果你从一开始就跟随了祝贺你!
尽管这些可视化效果可能很简单,但创建它们需要一定的工作量。
12.部署 POWER BI 仪表板
共享您的仪表板有几个选项。一个简单的方法是点击 Power BI canvas 窗口顶部的 Publish 按钮。

系统会要求您登录,然后您可以选择“我的工作区”作为目的地。如果一切正常,那么您应该会看到以下确认信息:

那么 Power BI 将我们的仪表板发布到哪里呢?
当您从 Power BI Desktop 发布报告或仪表板时,它会被发送到名为 Power BI Service 或 Power BI Online 的地方。Power BI 服务是 Power BI 的云版本,如果您注册,您将获得一个“我的工作区”来存储您所有的 Power BI 报告,并以各种方式共享它们。

你可以在这里注册这项服务:
Power BI 可以是您的个人数据分析和可视化工具,也可以作为分析和决策工具…
docs.microsoft.com](https://docs.microsoft.com/en-us/power-bi/fundamentals/service-self-service-signup-for-power-bi)
在这里签名:
Power BI 将您公司的数据转换为丰富的视觉效果,供您收集和组织,以便您可以专注于…
powerbi.microsoft.com](https://powerbi.microsoft.com/en-us/landing/signin/?ru=https%3A%2F%2Fapp.powerbi.com%2F%3FnoSignUpCheck%3D1)
如果您登录并单击您发布的报告,您应该会看到以下内容:

在此基础上,就分发您的仪表盘而言,最简单的方法是生成一个二维码,您可以用它来与下载了 iOS 和 Android 上均可用的 Power BI 移动应用的其他人分享:


你的下一个赌注是获得一个嵌入代码,你可以把它嵌入到你自己的 Django 或 Flask 应用中:


Power BI 将为您提供通过电子邮件链接或 iframe 嵌入仪表板进行共享的选项:

在这里,我简单地粘贴了提供的电子邮件链接:
[## 电源 BI 报告
由 Power BI 支持的报告
app.powerbi.com](https://app.powerbi.com/view?r=eyJrIjoiYjc1ZjMwYWUtMjE5Yy00N2ZkLWFmYTctYjdkNTc5MGU3YjgwIiwidCI6IjlmNTk4YmYzLTg2NzgtNGYwNS04MjJjLWI4YTQwMDYwZDlkMCJ9&pageName=ReportSection)
但更动态的方法是将 iframe 嵌入到您自己的 web 应用程序中,我在这里已经做到了:
[## 数据-钻孔-仪表板-PowerBI
编辑描述
data-bore-dashboard-powerbi.herokuapp.com](https://data-bore-dashboard-powerbi.herokuapp.com/)
它基本上是一个框架 Django 应用,带有一个包含嵌入代码或 iframe 的home.html文件。我不会在这里重复构建应用程序,但是代码可以在这里公开获得:
[## capt moon shot/数据钻孔-仪表板-bi
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/Captmoonshot/data-bore-dashboard-bi)
关于 Power BI 服务的一个注意事项:不幸的是,要使用 Power BI 服务,而不是 Power BI 桌面,要在网上发布你的作品,你需要有一个经过微软验证的工作账户。您还需要这里的管理员权限:
管理您的 Microsoft 365 订阅中的应用程序、服务、数据、设备和用户。
www.microsoft.com](https://www.microsoft.com/en-us/microsoft-365/business/office-365-administration)
在 365 管理中心:
转到管理中心选项卡= >所有管理中心=> Power BI = >租户设置= >启用发布到 Web = >应用
13.经验教训
我之所以觉得我从这个项目中学到了很多,是因为这是我第一次处理 Plotly 的 Dash 和 Microsoft Power BI。最重要的是,构建我自己的 REST API 服务来获得实时更新的机器学习结果真的很有趣。
我向任何以 Python 为中心的数据科学家强烈推荐 Power BI,尝试一下它的强大和简洁。
谢谢你看我的帖子和快乐编码!
开源代码库
数据钻孔仪表板(仪表板):
[## capt moon shot/data _ bore _ dashboard
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/Captmoonshot/data_bore_dashboard)
数据钻孔 REST API (Django):
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/Captmoonshot/data-bore)
嵌入式 Power BI (Django-Power BI):
[## capt moon shot/数据钻孔-仪表板-bi
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/Captmoonshot/data-bore-dashboard-bi)

















 722
722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










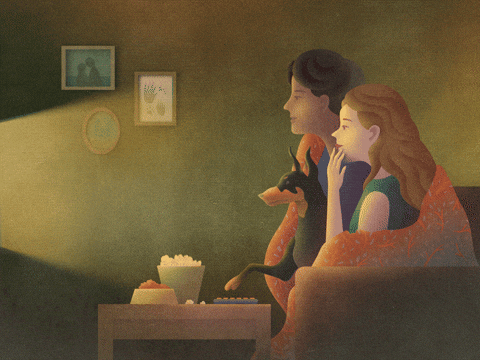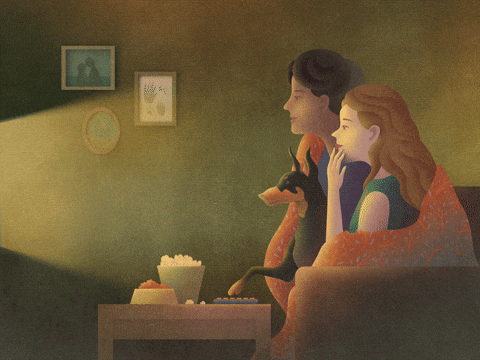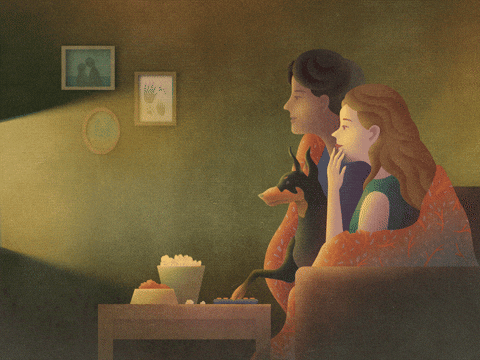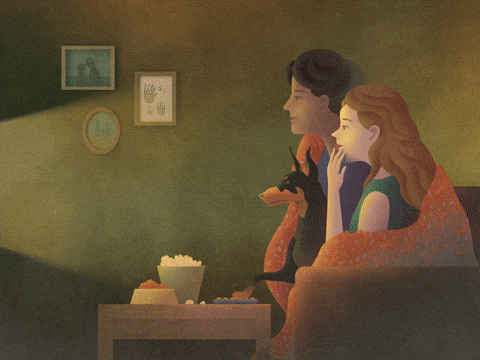{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}