







偏差-方差权衡-机器学习的基础
模型容量和预测方差的权衡如何控制机器学习设计?
偏差-方差权衡是机器学习的基本设计决策。这是模型容量和预测方差之间的权衡——所以我们必须决定 我们的模型在哪个方面会是错误的 。本文将从主题上解释这种权衡如何与没有免费的午餐相关,并展示如何从概率分布中产生切换。
所有的模型都是错的,但有些是有用的——乔治·博克斯

资料来源——作者,哥斯达黎加 Playa Hermosa。
没有免费的午餐
每当一个优化、程序或算法在一个感兴趣的领域获得了信息或专门化,它就会在其他地方失去能力。不付出就无法获得任何东西,这一观点就是“没有免费的午餐”定理。这是机器学习主题和偏差-方差权衡的关键思想。

目标空间上的可能分布。没有一个模型可以在任何地方都达到完美的准确性——能力的分布是不同的。从最大到最小的指定顺序是绿色、黄色、红色、蓝色。
作为分布的模型准确性
将模型精度映射到目标空间上的概率密度函数是一个很好的心理模型。它告诉我们一个事实,任何模型的积分——任何分布——必须等于 1,或者是设计空间中的某个常数。在左边,我已经描绘了不同的模型如何预测目标空间。
神经网络的容量
没有免费的午餐定理也适用于神经网络。在这种情况下,当我们有一个容量有限(有限层,神经元)的网络时,我们的预测能力是有限的。改变设定网络上的训练方法,改变输出的焦点。一个网络的总容量是有限的,即精度曲线的积分是常数。一个模型可以在一个领域(特定的测试分布)获得准确性,但是在其他领域会失去能力。
在训练网络时,工程师通常会寻求测试误差的最小化,或者何时对未知的预测最准确。在未知元素上最大化预测是平坦化预测准确度的分布(覆盖范围越大,特异性越低)。
在计算复杂性和最优化中,没有免费的午餐定理是这样一个结果,即对于某些类型…
en.wikipedia.org](https://en.wikipedia.org/wiki/No_free_lunch_in_search_and_optimization)
设计决策是特异性对普遍性。这在数字上如何继续?
偏差方差权衡
同样,有用的机器学习模型的核心是模型的底层结构和下游预测中产生的变化之间的反向权衡。从数字上看,我们引入的这种关系被称为偏差-方差权衡。
数字上

预测模型的符号。
如果我们观察预测值“f-hat”对数据集的准确性,就会发现一个有用的等式。考虑模型拟合如何不同于真实数据, f ,加上噪声,ε — ( y = f + ε )。

预测值的平均误差(MSE)。
这里所发生的是通过概率规则和公理,我们推导出数值偏差-方差权衡。首先,模型的偏差和方差的定义。
偏差:模型结构与训练集的匹配程度。
偏见模型结构。查看下面的等式,偏差是数据集上模型的平均值与真实值之间的差异。想一想,当对来自未知 (m,b) y=mx+b 的噪声数据拟合直线时,我们可以添加偏移或斜率等项,以更接近数据。一个 y=cx 或 y =c 的模型将远离真实的、始终高的偏置。但是增加像 y=cx+d+ex 这样的项可能会降低偏差,但代价是。

方差:模型因所用数据的微小变化而改变的程度。
方差在模型中带有不确定性。 x 的一个小变化会对预测产生多大的改变?再次考虑最后一个例子。有偏解 y=cx 或 y =c 会随着 x 的扰动而发生非常小的变化。但是,当我们添加高阶项来进一步降低偏差时,方差风险会增加。直观地说,我们可以在方程中看到这一点,因为我们有了新的项,它是期望中模型的平方(左)。右边的项将一个均值项与方差联系起来,以说明偏移量。

经过几个步骤(省略),我们得到了我们想要的方程。这里的推导是(维基百科)。注意,σ是原始函数噪声(ε)的标准差。

偏差方差权衡。
这里发生的是——无论模型如何改变,偏差和方差项将具有相反的关系。在训练数据集 D 上有一个误差最小化的点,但是不能保证数据集 100%反映真实世界。
一个例子
考虑一个例子,我们试图将数据点拟合到一个模型,source — Wikipedia 。

采样数据和真实函数。
底层函数(红色)采样时带有噪声。然后,我们想用近似法来拟合采样点。使用径向基函数构建模型(蓝色,如下)。从左到右,模型获得术语和容量(多行,因为多个模型在数据的不同子集上被训练)。很明显,左边的模型具有更高的偏差——结构相似,但数据点之间的差异很小。向右,方差增加。



不同的模型适合。从左到右,模型中使用的术语越来越多。每个模型在采样点的不同子集上训练。这是偏差-方差权衡的可视化。来源— 维基百科。
模型的这种变化就是偏差方差权衡。
含义
机器学习是创造智能代理的科学,这些智能代理从训练分布归纳到新数据。ML 系统做出预测。这种权衡存在于每个部署的系统中,因为真实世界是未知的。作为一名机器学习工程师,重要的是要记住你可能在模型中部署了太多的特异性——特别是如果它可能有挥之不去的道德决策(例如,对群体的偏见)。
更多?订阅我关于机器人、人工智能和社会的时事通讯!
一个关于机器人和人工智能的博客,让它们对每个人都有益,以及即将到来的自动化浪潮…
robotic.substack.com](https://robotic.substack.com/)
机器学习模型中的偏差-方差权衡:一个实例
了解模型误差以及如何改善它。

布雷特·乔丹在 Unsplash 上的照片
在监督机器学习中,目标是建立一个高性能的模型,该模型善于预测手头问题的目标,并且以低偏差和低方差来进行预测。
但是,如果你减少偏差,你最终会增加方差,反之亦然。这就是偏差-方差权衡发挥作用的地方。
在这篇文章中,我们将研究在机器学习模型的上下文中偏差和方差意味着什么,以及您可以做些什么来最小化它们。
为了建立一个有监督的机器学习模型,你需要一个看起来有点像这样的数据集。

监督学习中使用的数据集结构。
这是一系列的数据记录,每一个都有几个特征和一个目标,就是你要学会预测的东西。但是在开始构建模型之前,您需要将数据集分成两个不同的子集:
- 训练集
- 测试设备
您通常会随机选择 20%的数据记录,并将其作为测试集,剩下 80%的数据集用于训练模型。这通常被称为 80/20 分割,但这只是一个经验法则。
对训练和测试集的需求
训练集和测试集有不同的目的。
训练集教导模型如何预测目标值。至于测试集,顾名思义,它用于测试学习的质量,如果模型擅长预测学习过程中使用的数据之外的数据。
通过测试集,您将看到该模型是否能将其预测推广到训练数据之外。
我们可以用以下方法来衡量这个过程中两个阶段(学习和预测)的质量:
- 训练错误,
- 测试误差,也称为泛化误差。
好的模型具有低的训练误差。但是你必须小心,不要把训练误差压得太低,以至于模型过拟合训练数据。当模型过度拟合数据时,它会完美地捕获训练集的模式,从而成为仅预测训练集结果的专家。
乍一看,这听起来很棒,但它有一个缺点。如果模型擅长预测训练集中的目标,它就不太擅长预测其他数据。
偏差-方差权衡
为了理解这种权衡,我们首先需要看看模型的误差。在实践中,我们可以将模型误差分成三个不同的部分。
模型误差=不可约误差+偏差+方差
不可约误差与偏差和方差无关。但是后两者是反向相关的,每当你降低偏差,方差就会增加。就像训练误差和测试误差一样。
不可约误差
这个误差是建立模型的机器学习工程师无法控制的。这是由数据中的噪声、不代表数据中真实模式的随机变化或尚未作为特征捕获的变量的影响所导致的错误。
减少这类错误的一种方法是识别对我们正在建模的问题有影响的变量,并将它们转化为特征。
偏置
偏差是指捕捉数据集中真实模式的能力。

简单模型(左)与复杂模型(右)的偏差。
它在数学上表示为预期的预测目标值和真实目标值之间的平方差。

所以,当你有一个无偏的模型时,你知道平均预测值和真实值之间的差异是零。并且它被平方以更重地惩罚离目标的真实值更远的预测。
具有高偏差的模型会使数据欠拟合。换句话说,它将采用一种简单化的方法来模拟数据中的真实模式。
但是一个低偏差的模型比它应该的更复杂。它会过度适应它用来学习的数据,因为它会尽可能多地捕捉细节。因此,除了训练数据之外,它在概括方面做得很差。
你可以通过观察训练误差来发现偏差。当模型具有高训练误差时,这是高偏差的迹象。
为了控制偏差,您可以添加更多的特征并构建更复杂的模型,始终在数据的欠拟合和过拟合之间找到平衡。
差异
方差捕获每个数据记录的预测范围。

具有高(左)和低(右)方差的模型中的预测范围。
这是一个衡量每个预测与该测试集记录的所有预测的平均值相差多远的指标。并且它也被平方以惩罚离目标的平均预测更远的预测。

即使您构建的每个模型输出的预测值略有不同,您也不希望这些预测值的范围很大。
您还可以通过查看测试误差来发现模型中的差异。当模型具有高测试误差时,这是高方差的标志。
减少差异的一种方法是使用更多的训练数据来构建模型。该模型将有更多的实例可供学习,并提高其概括预测的能力。
例如,如果无法用更多的训练数据构建模型,您可以构建一个包含bootstrap aggregation的模型,通常称为 bagging。
降低方差的其他方法包括减少特征的数量,使用特征选择技术,以及使用像主成分分析这样的技术来降低数据集的维度。
现在让我们看看这是怎么回事
我创建了一个随机数据集,它遵循系数为-5,-3,10 和 2.5 的四次多项式,从最高到最低。
因为我们要用模型来拟合这些数据,所以我把它分成了训练集和测试集。训练数据是这样的。

从随机数据生成的四次多项式的训练集。
dataset_size = 5000# Generate a random dataset and that follows a quadratic distribution
random_x = np.random.randn(dataset_size)
random_y = ((-5 * random_x ** 4) + (-3 * random_x ** 3) + 10 * random_x ** 2 + 2.5 ** random_x + 0.5).reshape(dataset_size, 1)# Hold out 20% of the dataset for training
test_size = int(np.round(dataset_size * 0.2, 0))# Split dataset into training and testing sets
x_train = random_x[:-test_size]
y_train = random_y[:-test_size]x_test = random_x[-test_size:]
y_test = random_y[-test_size:] # Plot the training set data
fig, ax = plt.subplots(figsize=(12, 7))# removing to and right border
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)# adding major gridlines
ax.grid(color='grey', linestyle='-', linewidth=0.25, alpha=0.5)
ax.scatter(x_train, y_train, color='#021E73’)plt.show()
我们可以从检查模型的复杂性如何影响偏差开始。
我们将从简单的线性回归开始,逐步用更复杂的模型来拟合这些数据。

适合训练数据的简单线性回归模型。
# Fit model
# A first degree polynomial is the same as a simple regression linelinear_regression_model = np.polyfit(x_train, y_train, deg=1)# Predicting values for the test set
linear_model_predictions = np.polyval(linear_regression_model, x_test) # Plot linear regression line
fig, ax = plt.subplots(figsize=(12, 7))# removing to and right border
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)# adding major gridlines
ax.grid(color='grey', linestyle='-', linewidth=0.25, alpha=0.5)
ax.scatter(random_x, random_y, color='#021E73')plt.plot(x_test, linear_model_predictions, color='#F2B950', linewidth=3)plt.show()
这种类型的模型肯定太简单了,它根本不遵循数据的模式。
我们将量化该模型与训练和测试误差的拟合,使用均方误差计算,并查看偏差和方差。

简单线性回归模型的度量。
# A few auxiliary methods
def get_bias(predicted_values, true_values):
*""" Calculates model bias****:param*** *predicted_values: values predicted by the model* ***:param*** *true_values: true target values for the data* ***:return****: integer representing the bias of the model**"""*return np.round(np.mean((predicted_values - true_values) ** 2), 0)def get_variance(values):
*""" Calculates variance of an array of values****:param*** *values: array of values* ***:return****: integer representing the variance of the values**"""*return np.round(np.var(values), 0)def get_metrics(target_train, target_test, model_train_predictions, model_test_predictions):*"""
Calculates
1\. Training set MSE
2\. Test set MSE
3\. Bias
4\. Variance* ***:param*** *target_train: target values of the training set* ***:param*** *target_test: target values of the test set* ***:param*** *model_train_predictions: predictions from running training set through the model* ***:param*** *model_test_predictions: predictions from running test set through the model* ***:return****: array with Training set MSE, Test set MSE, Bias and Variance**"""*training_mse = mean_squared_error(target_train, model_train_predictions)test_mse = mean_squared_error(target_test, model_test_predictions)bias = get_bias(model_test_predictions, target_test)variance = get_variance(model_test_predictions) return [training_mse, test_mse, bias, variance]# Fit simple linear regression model
# A first degree polynomial is the same as a simple regression linelinear_regression_model = np.polyfit(x_train, y_train, deg=1)# Predicting values for the test set
linear_model_predictions = np.polyval(linear_regression_model, x_test)# Predicting values for the training set
training_linear_model_predictions = np.polyval(linear_regression_model, x_train)# Calculate for simple linear model
# 1\. Training set MSE
# 2\. Test set MSE
# 3\. Bias
# 4\. Variancelinear_training_mse, linear_test_mse, linear_bias, linear_variance = get_metrics(y_train, y_test, training_linear_model_predictions, linear_model_predictions)print('Simple linear model')
print('Training MSE %0.f' % linear_training_mse)
print('Test MSE %0.f' % linear_test_mse)
print('Bias %0.f' % linear_bias)
print('Variance %0.f' % linear_variance)
让我们看看使用复杂模型是否真的有助于降低偏差。我们将对该数据进行二阶多项式拟合。

拟合训练数据的二次多项式模型。
二次多项式减少偏差是有意义的,因为它越来越接近数据的真实模式。
我们也看到了偏差和方差之间的反比关系。

二次多项式模型的度量。
#############################
# Fit 2nd degree polynomial #
############################## Fit model
polynomial_2nd_model = np.polyfit(x_train, y_train, deg=2) # Used to plot the predictions of the polynomial model and inspect coefficients
p_2nd = np.poly1d(polynomial_2nd_model.reshape(1, 3)[0])
print('Coefficients %s\n' % p_2nd)# Predicting values for the test set
polynomial_2nd_predictions = np.polyval(polynomial_2nd_model, x_test)# Predicting values for the training set
training_polynomial_2nd_predictions = np.polyval(polynomial_2nd_model, x_train)# Calculate for 2nd degree polynomial model
# 1\. Training set MSE
# 2\. Test set MSE
# 3\. Bias
# 4\. Variancepolynomial_2nd_training_mse, polynomial_2nd_test_mse, polynomial_2nd_bias, polynomial_2nd_variance = get_metrics(y_train, y_test, training_polynomial_2nd_predictions, polynomial_2nd_predictions)print('2nd degree polynomial')
print('Training MSE %0.f' % polynomial_2nd_training_mse)
print('Test MSE %0.f' % polynomial_2nd_test_mse)
print('Bias %0.f' % polynomial_2nd_bias)
print('Variance %0.f' % polynomial_2nd_variance)# Plot 2nd degree polynomial
fig, ax = plt.subplots(figsize=(12, 7))# removing to and right border
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)# Adding major gridlines
ax.grid(color='grey', linestyle='-', linewidth=0.25, alpha=0.5)x_linspace = np.linspace(min(random_x), max(random_x), num=len(polynomial_2nd_predictions))plt.scatter(random_x, random_y, color='#021E73')
plt.plot(x_linspace, p_2nd(x_linspace), '-', color='#F2B950', linewidth=3)plt.show()
当我们再次将模型的复杂度增加到三次多项式时,我们看到偏差略有改善。但是方差又增加了。

拟合训练数据的三次多项式模型。
剧情变化不大,但是看指标就清楚了。

三次多项式模型的度量。
#############################
# Fit 3rd degree polynomial #
#############################print('3rd degree polynomial')# Fit model
polynomial_3rd_model = np.polyfit(x_train, y_train, deg=3)# Used to plot the predictions of the polynomial model and inspect coefficientsp_3rd = np.poly1d(polynomial_3rd_model.reshape(1, 4)[0])print('Coefficients %s' % p_3rd)# Predict values for the test set
polynomial_3rd_predictions = np.polyval(polynomial_3rd_model, x_test)# Predict values for the training set
training_polynomial_3rd_predictions = np.polyval(polynomial_3rd_model, x_train)# Calculate for 3rd degree polynomial model
# 1\. Training set MSE
# 2\. Test set MSE
# 3\. Bias
# 4\. Variancepolynomial_3rd_training_mse, polynomial_3rd_test_mse, polynomial_3rd_bias, polynomial_3rd_variance = get_metrics(y_train, y_test, training_polynomial_3rd_predictions, polynomial_3rd_predictions) print('\nTraining MSE %0.f' % polynomial_3rd_training_mse)
print('Test MSE %0.f' % polynomial_3rd_test_mse)
print('Bias %0.f' % polynomial_3rd_bias)
print('Variance %0.f' % polynomial_3rd_variance) # Plot 3rd degree polynomial
fig, ax = plt.subplots(figsize=(12, 7))# removing to and right border
ax.spines['top'].set_visible(False)
ax.spines['right'].set_visible(False)# Adding major gridlines
ax.grid(color='grey', linestyle='-', linewidth=0.25, alpha=0.5)x_linspace = np.linspace(min(random_x), max(random_x), num=len(polynomial_3rd_predictions))
plt.scatter(random_x, random_y, color='#021E73')
plt.plot(x_linspace, p_3rd(x_linspace), '-', color='#F2B950', linewidth=3)plt.show()
总结这个实验,我们可以真正看到偏差-方差权衡的作用。随着我们增加模型的复杂性,偏差不断减少,而方差增加。

实验结果总结。
希望你在建立机器学习模型时,对偏差和方差的作用有了更好的理解。
感谢阅读!
机器学习中的偏见
ML 模型中引入偏差的最常见原因
不管你喜欢与否,机器学习对你生活的影响正在非常迅速地增长。机器学习算法决定了你是否会获得梦想中的房子的抵押贷款,或者你的简历是否会入围你的下一份工作。它也在迅速改变我们的劳动力。机器人正在接管仓库和工厂,无人驾驶汽车正威胁着世界各地数百万职业司机的工作。甚至执法机构也越来越多地使用机器学习来筛选潜在的犯罪线索和评估风险。

由莱尼·屈尼在 Unsplash
不幸的是,所有这些技术进步可能会延续并加剧困扰我们社会的偏见。在算法偏差的早期例子中,从 1982 年到 1986 年,每年有 60 名女性和少数民族被圣乔治医院医学院拒绝入学,因为一个新的计算机指导评估系统根据录取的历史趋势拒绝了具有“听起来像外国名字”的女性和男性入学。或者更近一些,在 2016 年,由微软在 Twitter 数据上训练的聊天机器人 TayTweets 开始发表种族主义的推文。

所有这些进步都提出了非常有效的问题,即机器学习从业者如何确保他们的算法公平。什么是公平是一个古老的问题。令人欣慰的是,在这一领域已经进行了大量的研究。在这篇文章中,我将谈论当你试图确保你的机器学习模型没有偏见时,你可能会遇到的最常见的问题。
代表名额不足
机器学习算法中偏差的最常见原因之一是训练数据缺少代表不足的组/类别的样本。这就是为什么 Siri 经常很难理解有口音的人。这也导致了著名的谷歌照片事件,黑人被标记为大猩猩。因此,确保训练数据能够代表所有代表性不足的群体是非常重要的。另一种早期轻松检测的方法是部署第二种算法,该算法预测生产中的数据是否接近训练数据,如果不是这样,则早期干预。


通过推特
社会反馈循环
最近一篇关于他们开创性语言模型的 OpenAI 论文发现“一般来说,职业被男性性别识别符追随的概率比女性高”。在媒体上有很多例子,模型继承了训练数据中的偏差。有实验得出结论,高薪招聘广告只给男人看,或者白人社区的房屋广告只给白人看。基于来自互联网的文本数据训练的各种语言模型倾向于给女性或有色人种附加负面含义。发生这种情况,是因为我们现有的社会偏见反映在训练数据中。在大多数情况下,这种偏见很难纠正,因为很难获得无偏见的数据。缓解这种情况的一个简单策略是找到代表边缘化群体的正面历史数据的数据点,并在训练数据中对这些记录进行上采样。
相关字段
确保数据不针对敏感属性进行训练的一个常见解决方案是从训练数据中完全移除这些特征。但是仍然可能存在相关的属性,这些属性可能导致模型歧视服务水平低下的社区。例如,邮政编码可能与种族相关,而姓名可能与种族和性别相关,等等。人们经常观察到,在简历上训练的机器学习模型学会更重视男性名字而不是女性名字。一项亚马逊研究发现“贾里德”这个名字非常适合进入工作候选名单。
忽略敏感属性
在某些情况下,盲目地从训练数据中移除敏感属性特征甚至可能会造成伤害。例如,女性不太可能造成事故,因此在一些地方,使用性别来确定保险报价是合法的。在累犯研究中,发现女性不太可能再次犯罪。在弱势类别实际上比主导类别做得更好的情况下,最好将这作为一个特征包含在训练数据中。
偏差的过度补偿
这不太可能是一个问题,但在这里补充这是全面的。假设你的模型根据个人的信用评分决定是否向其提供贷款,如果个人偿还了贷款,其评分就会增加,否则就会减少。你的长期目标是提高人口的平均信用评分。在这种情况下,为了弥补偏见,您可能需要更改门槛,为特定人群批准更多贷款。但如果你过度补偿,以至于违约数量高于成功还款的数量,这部分人的平均信用评分可能会下降,最终伤害他们。谷歌提供了一个名为 ml-fairness-gym 的库,可以帮助模拟在机器学习模型中实施公平的长期效果。
艾伦·图灵说如果一台机器被期望是不会犯错的,它也不可能是智能的。但是,每天,社会基础设施的另一个关键部分是在没有任何法律制衡的情况下,将“人工智能”添加到其决策过程中。各种偏见很容易溜进机器学习模型,除非你极其谨慎。此外,我们的法律体系还没有跟上新技术的步伐,新技术继续深刻地影响着我们的生活。因此,现在,研究这些模型的人有责任确保这些模型是公平的,没有偏见的。
幸运的是,研究人员正在关注这个问题以及类似机器学习模型的可解释性等相关问题。
- 谷歌的 Tensorflow 有“公平指标”来检测你的模型中的偏差
- 微软研究院成立了一个 FATE (公平、问责、透明和道德)小组,研究人工智能的社会影响
- IBM 开源了 AI fairness 360 工具来帮助你构建无偏见的模型
- 刘等人的论文“公平机器学习的延迟影响”获得 2018 最佳论文奖。
但是这些工具远远不够或完美。这一领域非常需要更严格的工具和研究。技术既有好的一面,也有坏的一面。这是技术创造者的责任,以确保他们的产品为我们所有人创造一个更美好的世界。我真的很喜欢 Kate Crawford 在 NIPS 2017 上的这个著名的演讲,她呼吁行业在理解人工智能的社会影响方面投入更多。

https://xkcd.com/1277/
机器理解的双向注意流模型

使用 BiDAF 回答问题
深入研究 BiDAF 模型
问题回答一直是自然语言处理的主要工作领域。我将讨论并实施一篇在质量保证相关问题上表现出色的研究论文的关键要素。那么,我们在问答中做什么呢?给我们一个上下文,并根据该上下文进行查询。模型的任务是找到问题的准确答案。答案可能在上下文中,也可能不在上下文中。如果它存在,那么这个任务可以被公式化为一个分类问题,如果它不存在,那么我们就转向一个更加困难的文本生成问题。但是对于所有这些,我们需要一个好的特征向量,它包含来自上下文和查询的信息以及它们之间的关系。
我将要谈论的论文是 Minjoon Seo 等人的机器理解的双向注意力流。我们将主要讨论架构的技术部分,并将按顺序实现这些部分。总的来说,这里主要是用较少的文本编写代码。下面给出的是 BiDAF 的架构。

来源:https://allenai.github.io/bi-att-flow/BiDAF.png
如图所示,模型中的文本表示首先使用字符级嵌入层,然后使用单词级嵌入,如 Glove 或 Word2vec。最后,将两种表示连接在一起,得到最终的表示。为了简单起见,我们只能在代码中使用单词级的手套嵌入。
一旦我们获得文本序列中每个单词的向量表示,我们将在双向 LSTM 层中馈送该序列,以获得良好的上下文表示。图中没有显示的一个重要的东西是高速公路网。因为我在以前的博客中没有提到过这个术语,所以在进入实现部分之前,我们将简单讨论一下。
公路网络
想象一个具有非常深的结构的网络,包括 NN 层的多个堆叠。使用梯度下降很难优化深度较大的模型。此外,如果使用多个堆栈,由于绝对值小于 1 的变量相乘过多,会出现信息丢失。因此,将模型的深度增加到某一点之后,并不会使之前的结果受益。
受 LSTMs 的启发,提出了高速公路网络,其中使用门控机制将信息直接传播到下一层(因此出现了术语高速公路)。其结构如下所示:

来源:https://miro . medium . com/max/1120/1 * qHf _ ahv 8 yjjskqok4k S4 jw . png
引入了一个变换门 T,它只是一个神经网络,后面跟着一个 sigmoid 激活。这意味着变换门将产生一个概率,该概率与当前层的输出相乘,并传播到下一层。线性门,C 无非是 1-T,是与当前层的输入相乘,传入下一层的概率。高速公路网络的一种变体,残差网络,其中 C 和 T 都等于 1,用于微软著名的图像分类模型 ResNet。结果表明,对于复杂问题,现在可以使用高速公路网络建立一个包含数百个图层的模型。
在这篇博客中,我们还将为每个双向 LSTM 使用高速公路网络,以实现强大的信息流。
相似矩阵
通常,注意力机制用于概括查询的上下文向量。但是在这里,通过使用上下文和查询表示来计算共享的相似性矩阵,而不是为查询计算单个关注,计算两个方向上的关注,即,上下文 2 查询和查询 2 上下文,以最大化信息增益。相似矩阵是形状为 TxJ 的矩阵,其中 T 是上下文的序列长度,J 是查询的序列长度。这两种关注度都可以通过共享的相似度矩阵来计算。整个计算机制如下图所示:

可以看出,为了计算 S_ij,输入为 C_i 和 Q_j,计算公式如下:
其中[;]是跨行的连接操作,[o]是逐元素的乘法操作,W_ij 是大小为[1×3 * dim]的可训练权重向量。
上下文 2 查询和查询 2 上下文注意
Context2Query Attention 表示每个上下文单词在查询句子中的重要单词。这意味着 Context2Query 的形状应该是[TxJ],这可以通过按行取相似性矩阵的 softmax 来实现:
C2Q = Softmax(S,axis=-1)
有人参与的查询,AQ = C2Q。查询,shape=[Txdim],[。=矩阵乘法]
Query2Context Attention 表示每个查询单词在上下文句子中最相似的单词。这是通过首先从相似性矩阵中取出最大元素,然后对其应用 softmax 来获得的。因此,最终输出是形状= [Tx1]的概率向量。
参与上下文= Q2C t 上下文,shape=[1xdim]
最终参与上下文,AC = tile(参与上下文,T),shape = [Txdim]
合并操作
该操作用于组合由注意力 C2Q 和 Q2C 获得的信息。合并操作将原始上下文(OC)、参与查询和参与上下文作为输入,并给出如下所示的最终表示:
Merge(OC,AQ,AC)=[OC;AQ;AQ 主管;OC o AC],其中[;]是按行连接,[o]是按元素乘法。
合并层为我们提供了一个 shape = [T x 4 * dim]的输出,它可以进一步用于输入另一组双向 LSTMs,后跟一个 softmax,以获得答案的开始和结束概率。开始和结束概率是给定段落中答案的开始和结束索引的概率。正如前面所讨论的,只有答案在段落中,开始和结束概率的概念才会起作用。如果没有,我们已经将最终的表示提供给一个解码器,使它成为一个序列生成问题。
喔!我没有遵守我的承诺,保持讨论简短,主要集中在编码部分😀。无论如何,让我们现在做一些 PYTHONING 化的工作(Google 的 Meena 告诉了我这个单词)。
相似矩阵
**class** **SimilarityMatrix**(keras**.**layers**.**Layer):
**def** **__init__**(self,dims, ******kwargs):
self**.**dims **=** dims
super(SimilarityMatrix, self)**.**__init__(******kwargs)
**def** **similarity**(self, context, query):
e **=** context*****query
c **=** K**.**concatenate([context, query, e], axis**=-**1)
dot **=** K**.**squeeze(K**.**dot(c, self**.**W), axis**=-**1)
**return** keras**.**activations**.**linear(dot **+** self**.**b)
**def** **build**(self, input_shape):
dimension **=** 3*****self**.**dims
self**.**W **=** self**.**add_weight(name**=**'Weights',
shape**=**(dimension,1),
initializer**=**'uniform',
trainable**=**True)
self**.**b **=** self**.**add_weight(name**=**'Biases',
shape**=**(),
initializer**=**'ones',
trainable **=**True)
super(SimilarityMatrix, self)**.**build(input_shape)
**def** **call**(self, inputs):
C, Q **=** inputs
C_len **=** K**.**shape(C)[1]
Q_len **=** K**.**shape(Q)[1]
C_rep **=** K**.**concatenate([[1,1],[Q_len],[1]], 0)
Q_rep **=** K**.**concatenate([[1],[C_len],[1,1]],0)
C_repv **=** K**.**tile(K**.**expand_dims(C, axis**=**2),C_rep)
Q_repv **=** K**.**tile(K**.**expand_dims(Q, axis**=**1), Q_rep)
**return** self**.**similarity(C_repv, Q_repv)
**def** **compute_output_shape**(self, input_shape):
batch_size **=** input_shape[0][0]
C_len **=** input_shape[0][1]
Q_len **=** input_shape[1][1]
**return** (batch_size, C_len, Q_len)
**def** **get_config**(self):
cofig **=** super()**.**get_config()
**return** config
Context2Query 查询注意
**class** **Context2QueryAttention**(keras**.**layers**.**Layer):
**def** **__init__**(self, ******kwargs):
super(Context2QueryAttention, self)**.**__init__(******kwargs)
**def** **build**(self, input_shape):
super(Context2QueryAttention, self)**.**build(input_shape)
**def** **call**(self, inputs):
mat,query **=** inputs
attention **=** keras**.**layers**.**Softmax()(mat)
**return** K**.**sum(K**.**dot(attention, query), **-**2)
**def** **compute_output_shape**(self,input_shape):
mat_shape, query_shape **=** input_shape
**return** K**.**concatenate([mat_shape[:**-**1],query_shape[**-**1:]])
**def** **get_config**(self):
config **=** super()**.**get_config()
**return** config
查询 2 上下文
**class** **Query2ContextAttention**(keras**.**layers**.**Layer):
**def** **__init__**(self, ******kwargs):
super(Query2ContextAttention, self)**.**__init__(******kwargs)
**def** **build**(self, input_shape):
super(Query2ContextAttention, self)**.**build(input_shape)
**def** **call**(self, inputs):
mat,context **=** inputs
attention **=** keras**.**layers**.**Softmax()(K**.**max(mat, axis**=-**1))
prot **=** K**.**expand_dims(K**.**sum(K**.**dot(attention,context),**-**2),1)
final **=** K**.**tile(prot, [1,K**.**shape(mat)[1],1])
**return** final
**def** **compute_output_shape**(self,input_shape):
mat_shape, cont_shape **=** input_shape
**return** K**.**concatenate([mat_shape[:**-**1],cont_shape[**-**1:]])
**def** **get_config**(self):
config **=** super()**.**get_config()
**return** config
大合并
**class** **MegaMerge**(keras**.**layers**.**Layer):
**def** **__init__**(self, ******kwargs):
super(MegaMerge, self)**.**__init__(******kwargs)
**def** **build**(self, input_shape):
super(MegaMerge, self)**.**build(input_shape)
**def** **call**(self, inputs):
context, C2Q, Q2C **=** inputs
CC2Q **=** context*****C2Q
CQ2C **=** context*****Q2C
final **=** K**.**concatenate([context, C2Q, CC2Q, CQ2C], axis**=-**1)
**return** final
**def** **compute_output_shape**(self, input_shape):
C_shape,_,_ **=** input_shape
**return** K**.**concatenate([C_shape[:**-**1], 4*****C_shape[**-**1:]])
**def** **get_config**(self):
config **=** super()**.**get_config()
**return** config
高速公路
**class** **HighwayLSTMs**(keras**.**layers**.**Layer):
**def** **__init__**(self, dims, ******kwargs):
self**.**dims **=** dims
super(HighwayLSTMs, self)**.**__init__(******kwargs)
**def** **build**(self, input_shape):
self**.**LSTM **=** keras**.**layers**.**Bidirectional(keras**.**layers**.**LSTM(self**.**dims, return_sequences**=**True))
super(HighwayLSTMs, self)**.**build(input_shape)
**def** **call**(self, inputs):
h **=** self**.**LSTM(inputs)
flat_inp **=** keras**.**layers**.**Flatten()(inputs)
trans_prob **=** keras**.**layers**.**Dense(1, activation**=**'softmax')(flat_inp)
trans_prob **=** K**.**tile(trans_prob, [1,2*****self**.**dims])
trans_prob **=** keras**.**layers**.**RepeatVector(K**.**shape(inputs)[**-**2])(trans_prob)
out **=** h **+** trans_prob*****inputs
**return** out
**def** **compute_output_shape**(self, input_shape):
**return** input_shape
**def** **get_config**(self):
config **=** super()**.**get_config()
**return** config
现在唯一剩下的事情就是将这些片段应用到一个人的用例中。我希望我没有让你厌烦(当然没有,如果你正在读这一行的话)。
结果和结论
我们现在已经讨论了 BiDAF 模型的各个部分的技术方面和实现。现在,让我们通过一个例子来说明这种注意力机制是如何为一个特定的问题找到答案的。

在上图中,给出的方块是两个问题的注意力矩阵可视化。矩阵的每一列表示段落中的上下文单词,而每一行表示问题向量中的单词。块越粗,它的注意力权重就越大。在块 1 中,可以清楚地看到,对于问题中的单词“Where”,给予单词“at,the,stadium,Levi,In,Santa,Ana”更多的权重。甚至它可以把焦点放在问号“?”上这其中涉及到更多的“倡议”二字。
从结果的角度来看,BiDAF 在 SQUAD、CNN/DailyMail 数据集上进行了测试,结果如下:

参考文献
如果你想阅读更多的主题,没有什么比研究论文本身更好的了。
我希望你喜欢这个博客,如果你对我有任何建议或者你想联系,你可以点击下面的链接:
领英:https://www.linkedin.com/in/spraphul555/
现在是签名的时候了,
不断学习,不断分享
原载于 2020 年 2 月 8 日https://spraphul . github . io。
大数据:人类学视角
为什么大数据和定性研究应该结合的人类学论证。

Adobe 股票
作为一名从事混合方法研究的商业人类学家,我支持使用定性和定量方法,包括大数据。但是,我不支持只使用大数据。
当通过多种方法产生的研究和洞见可以相互加强和验证时,它们是最好的。
但在行业中,似乎存在一个包裹着大数据的神话,尽管大数据实践往往无法产生预期的投资回报。
为了理解这一现象,我们从人类学的角度来看一下大数据。
什么是大数据
如果要讨论大数据,首先要说明什么是数据。在本次对话中,数据被定义为以二进制形式收集和存储的数字数据,以供定制或商业算法进行分析。
通常情况下,数据是大型数据集的一部分,具有难以置信的多样性,并且收集速度非常快,这在十年前是无法想象的。这些属性被总结为 3v(数量、多样性和速度)。
但是从这个意义上来说,大并不等同于理解的深度,尽管许多被收养者相信它会。
大数据问题:投资回报率
在 2017 年 2 月, Gartner 估计全球商业智能和分析市场将达到 183 亿美元,然而,根据 NewVantage Partners 的研究,只有 37%试图成为数据驱动的公司取得了成功。
大数据格局
尽管 NewVantage Partners 的调查结果显示,软件和服务的全球大数据市场收入预计将从 2018 年的 400 亿美元增加到 2027 年的 1030 亿美元,根据 Wikibon 的数据,复合年增长率(CAGR)将达到 10.48%。
根据埃森哲的一项研究,79%的企业高管认为不接受大数据的公司将失去竞争地位,并可能面临灭绝。因此,83%的公司已经开始实施大数据项目以获取竞争优势。
大数据成功
大数据的支持者将收集、分析和应用洞察力的学科和方法描述为信息革命。
这导致大数据计划在广泛的私营和公共部门实施,例如业务流程优化、以需求为导向的能源供应、市场和趋势预测、揭露非法金融交易、预测性警务、通过分析人口疾病增强健康研究、癌症研究以及软件支持的医疗诊断。
在这些应用中,大数据已经被证明非常擅长展现数据之间的相关性。通过发现不同疾病症状之间的相互关系和探索药物的副作用,这已被证明在卫生部门非常有用。
大数据神话
然而,批评者指出,大数据并不像一些热情的采纳者认为的那样,是我们所有问题的解决方案。像任何其他技术一样,大数据是一种文化创新,有其自身的特点,同样,也必须如此看待它。
与任何技术一样,我们的文化塑造了它,正如它塑造了我们的文化一样。同样,在讨论大数据时,我们需要注意我们的信念和动机,因为它们是由社会塑造的,无论是好是坏。
为此,正如博伊德和克劳福德所指出的,我们需要尊重大数据是一种“基于技术、分析和神话相互作用的文化、技术和学术现象”。
这并不是说大数据在社会中没有地位。当然有关系。但是像任何文化结构一样,大数据有它自己的神话,我们需要意识到它如何影响我们。
我们必须认识到,通过采用大数据神话,我们塑造了我们如何看待和理解问题和解决方案空间。这适用于个体从业者以及整个社会。
正如布鲁诺·拉图尔所说:“改变工具,你将改变与之相适应的整个社会理论。”
大数据的未来是什么?
大数据的未来肯定是越来越多的采用,因为它涉及量化,即使它不会产生预期的 ROI。
作为一名商业人类学家,我痛苦地意识到我们社会中的量化偏见,尤其是在行业中。虽然我绝对不反对为此目的采用大数据,但我希望看到的是大数据与定性方法相结合的未来,以产生更丰富、更微妙的见解。
大数据应该与 Tricia Wang 在她的文章 为什么大数据需要厚数据 中推广的厚数据概念(对 Geertz 厚描述的扩展)结合起来。
让我们结合大数据+厚数据
数据科学家和社会科学家应该在提问、倾听、定义、重构、收集、分析和呈现数据的过程中相互配合。
人们和团队受限于他们个人和共同的文化理解。通过引入其他观点,包括那些收集了其(消费者/用户)数据的人的观点,我们可以丰富集体知识,使所有人受益。
社会科学家不应该抵制大数据的引入。他们应该与数据科学家尽可能紧密地合作,以发现应该更深入探索的噪音趋势。
另一方面,数据科学家不应该把定性方法的发现和见解看得太小。他们应该利用定性研究提供的丰富理解,赋予他们在数据中看到的趋势以意义。
如果我们做了这些事情,我们将更接近理解我们所面临的混乱问题的潜在原因,而不仅仅是在噪音中识别不相关的趋势。
关于作者
Matt Artz 是一名人类学家、设计师和战略家,致力于用户体验(UX)、服务设计和产品管理的交叉领域。他曾领导过《财富 10 强》和风投资助的初创公司的研究和设计项目,他的作品也被苹果和西南偏南(SXSW)收录。
Matt 也是商业人类学和 T2 Anthro to UX 播客的创作者,同时也是其他与美国人类学协会、皇家人类学研究所、EPIC 和 LiiV 中心合作的播客的主持人。你可以在 LinkedIn 、 Twitter 、 Instagram 、 Spotify、和谷歌学术上关注马特。
对于媒体的询问,联系马特。
原载于 2020 年 1 月 22 日https://www . mattartz . me。
使用机器学习和 PySpark 进行大数据分析
大数据是一个描述大量数据的术语,包括结构化和非结构化数据。
简介
在我们使用机器学习和 PySpark 深入大数据分析之前,我们需要定义机器学习和 PySpark。
先说机器学习。当你在谷歌搜索栏上输入机器学习,你会发现下面的定义:**机器学习是一种数据分析的方法,可以自动建立分析模型。**如果我们更深入地研究机器学习和在线可用的定义,我们可以进一步说,ML 实际上是以数据为基础的人工智能的一个分支,即所有决策过程、识别模式等。,都是由最少的人接触。由于 ML 允许计算机在没有显式编程的情况下找到隐藏的见解,因此它被广泛应用于所有领域来完成这一任务——在数据中找到隐藏的信息。
机器学习和当初一样,什么都不是。它经历了许多发展,正日益变得更受欢迎。它的生命周期分为两个阶段:培训和测试。
接下来是 PySpark MLlib,它实际上是一个机器学习库,可扩展并在分布式系统上工作。在 PySpark MLlib 中,我们可以找到多种机器学习算法(线性回归、分类、聚类等等)的实现。MLlib 自带数据结构——包括密集向量、稀疏向量、局部和分布式向量。库 API 非常用户友好和高效。
问题
在我们工作的每个行业中,都有很多很多挑战可以通过使用这些技术来解决。在这个特殊的案例中,我们需要在一个金融机构中进行多种统计计算。一个例子是根据独立变量的数量(例如年龄、余额、持续时间、银行活动)。
如何利用机器学习解决这个问题,最后的结果会是什么?为了展示该解决方案,我们将使用在此链接上公开的大数据示例。
解决方案
逻辑回归是解决方法。这是一种预测分类反应的流行方法,是预测结果概率的广义线性模型的特例。
在开始编码之前,我们需要初始化 Spark 会话并定义文件的结构。之后,我们可以使用 Spark 从 csv 文件中读取数据。我们有一个很大的数据集,但是在这个例子中,我们将使用大约 11,000 条记录的数据集。

看下面的表格,我们可以看到只有一列(前一列)的最小值等于零(0 ),这个值对于这个例子是不切实际的。

因此,我们将所有的零替换为 Nan。此外,存款字段被定义为一个值为“是”和“否”的字符串,因此我们必须对该字段进行索引。使用字符串索引器,我们将把值从“是”/“否”更改为 1/0。

现在,我们可以通过调用一个估算器来简单地估算前一列中的 Nan。估算器使用缺失值所在列的平均值或中值来填补数据集中的缺失值。输入列应该是 Double 或 Float 类型。

我们还想使用分类字段,所以我们必须将这些字段映射到一列二进制向量,通常只有一个值。然后,我们可以找到变量之间的相关性,并选择我们应该使用哪个变量。因为分类字段是字符串类型,所以我们将使用字符串索引器将一列标签字符串编码为一列标签索引。

接下来,我们将确定数字特征是否相关(包括索引分类字段)。在下图中,我们可以看到没有高度相关的数值变量。因此,我们将为模型保留所有这些。注意 : pandas 库仅用于绘图——我们无法使用 pandas 读取大数据文件,但它确实有助于绘图。


然后,我们将使用独热编码,该编码将分类特征(表示为标签索引)映射到二进制向量,该向量至多具有单个 1 值,该值指示所有特征值集合中特定特征值的存在。在这之后,我们将使用向量组合器,它允许我们将多个向量组合成一个向量,在这种情况下,我们将把带数值字段的向量与带分类字段的向量组合起来,后者现在已被转换。在这之后,我们将使用管道。流水线被指定为一系列阶段,每个阶段或者是转换器或者是估计器。这些阶段按顺序运行,输入数据帧在通过每个阶段时会发生转换。

我们已经创建了一个特征向量,现在让我们使用 StandardScaler 对新创建的“feature”列进行标量化。StandardScaler 是一种估计器,可用于数据集以生成 StandardScalerModel。然后,该模型可以将数据集中的矢量列转换为具有单位标准差和/或零均值要素。在我们的例子中,我们使用的是标准差。

之后,我们将使用随机分割方法来分割测试和训练集中的数据。

现在,让我们看看数据集中 1 和 0 的百分比。

我们可以看到,在我们的数据集(训练)中,我们有 47.14 %的阳性和 52.85 %的阴性。我们的树是平衡的,所以我们可以走了。
接下来,我们将使用 Spark ML 提供的 ChiSqSelector 来选择重要的特性。它对带有分类特征的标记数据进行操作。ChiSqSelector 使用卡方独立性检验来决定从哪些特性中进行选择。我们将使用参数 fpr —它选择 p 值低于阈值的所有特征,从而控制选择的假阳性率。

我们将创建逻辑回归模型,并拟合训练集。我们可以在最终结果中看到,哪些客户有存款(1),哪些没有存款(0)。

现在让我们使用 Spark ML 中的 BinaryClassificationEvaluator 类来评估模型。默认情况下,BinaryClassificationEvaluator 使用 ROC 下的面积作为性能指标。

结果
在对我们的大型数据集执行逻辑回归后,我们可以得出结果,并确定哪些客户有存款(1),哪些没有存款(0)。我们还可以看到预测的准确性,在这种情况下,它大约为 0.82。

逻辑回归的目的是根据独立变量的值对事件发生的概率进行建模。将来,如果我们遇到这种问题,我们可以使用这种方法对大数据集进行准确预测。
使用大数据的机器学习的未来
机器学习意味着在计算机如何学习和预测方面前进了一步。它在各个部门都有应用,并且正在各地广泛使用。更广泛地应用机器学习和分析让我们能够更快地应对动态情况,并从快速增长的数据宝库中获得更大的价值。自从机器学习出现以来,它就越来越受欢迎,而且不会很快停止。
如果你对这个话题感兴趣,请随时联系我。
领英简介:https://www.linkedin.com/in/ceftimoska/
博客原文可从以下链接获得:https://interworks . com . MK/big-data-analyses-with-machine-learning-and-py spark/
另外,你可以在下面的链接中找到另一篇类似的博文:https://interworks.com.mk/focusareas/data-management/
大数据分析:Apache Spark 与 Apache Hadoop
了解为什么创建 Apache Spark,以及它如何解决 Apache Hadoop 的缺点。

什么是大数据?
“大数据是高容量、高速度和高多样性的信息资产,需要经济高效、创新的信息处理形式来增强洞察力和决策能力”[11]
如果没有合适的工具、框架和技术,大数据分析可能会非常耗时、复杂且计算量大。当数据量过大,无法在单台机器上处理和分析时,Apache Spark 和 Apache Hadoop 可以通过并行处理和分布式处理来简化任务。要了解大数据分析中对并行处理和分布式处理的需求,首先了解什么是“大数据”非常重要。大数据的高速生成要求数据的处理速度也非常快,大数据的多样性意味着它包含各种类型的数据,包括结构化、半结构化和非结构化数据[4]。大数据的数量、速度和多样性需要新的创新技术和框架来收集、存储和处理数据,这就是 Apache Hadoop 和 Apache Spark 诞生的原因。
并行处理与分布式处理
了解什么是并行处理和分布式处理,将有助于理解 Apache Hadoop 和 Apache Spark 如何用于大数据分析。因为并行处理和分布式处理都涉及到将计算分解成更小的部分,所以两者之间可能会有混淆。并行计算和分布式计算的区别在于内存架构[10]。
“并行计算是同时使用一个以上的处理器来解决一个问题”[10]。
“分布式计算是同时使用多台计算机来解决一个问题”[10]。
并行计算任务访问相同的内存空间,而分布式计算任务不访问,因为分布式计算是基于磁盘的,而不是基于内存的。一些分布式计算任务在一台计算机上运行,一些在其他计算机上运行[9]。
Apache Spark vs . Apache Hadoop
Apache Hadoop 和 Apache Spark 都是用于大数据处理的开源框架,但有一些关键区别。Hadoop 使用 MapReduce 来处理数据,而 Spark 使用弹性分布式数据集(rdd)。Hadoop 有一个分布式文件系统(HDFS),这意味着数据文件可以存储在多台机器上。文件系统是可扩展的,因为可以添加服务器和机器来容纳不断增长的数据量[2]。Spark 不提供分布式文件存储系统,所以它主要用于计算,在 Hadoop 之上。Spark 不需要 Hadoop 来运行,但可以与 Hadoop 一起使用,因为它可以从存储在 HDFS 中的文件创建分布式数据集[1]。
性能差异
Hadoop 和 Spark 的一个关键区别是性能。加州大学伯克利分校的研究人员意识到 Hadoop 非常适合批处理,但对于迭代处理来说效率很低,所以他们创建了 Spark 来解决这个问题[1]。 Spark 程序在内存中迭代运行速度比 Hadoop 快 100 倍左右,在磁盘上快 10 倍[3] 。Spark 的内存处理负责 Spark 的速度。相反,Hadoop MapReduce 将数据写入磁盘,在下一次迭代中读取。因为每次迭代后都要从磁盘重新加载数据,所以它比 Spark [7]慢得多。
阿帕奇 Spark RDDs
Apache Spark 的基本数据结构是弹性分布式数据集(RDD ),它是一个容错的、不可变的分布式对象集合,可以跨集群并行处理。rdd 由于其容错能力而具有弹性,这意味着它可以从节点故障中恢复。如果一个节点未能完成其任务,RDD 可以在其余节点上自动重建,以完成任务[6]。rdd 的不变性有助于防止和避免数据不一致,即使在对非结构化数据执行转换时也是如此[9]。大数据通常是可变的,可以包括文本数据、关系数据库、视频、音频、照片和图形数据[2]。RDD 使高效处理结构化和非结构化数据成为可能。构建在 rdd 之上的数据帧也是不可变的、分布式的数据集合,但是被组织成列和行,类似于关系数据库[5]。Spark 数据框架使得处理和分析来自各种来源和格式的数据变得更加容易,比如 JSON 文件和 Hive 表[1]。
火花流
Apache Spark 的堆栈包括多个大数据处理框架,如 Spark Streaming。Spark 流框架用于流处理容错的实时数据流,以处理大数据的速度[8]。在接收到实时输入数据后,Spark Streaming 将数据划分为多个批次,以便对数据进行批量处理,最终结果是一个经过处理的批次流[5]。火花流数据被称为离散流(数据流),实质上是 rdd 序列[6]。数据流是一致的和容错的。由于能够实时或接近实时地处理大数据,因此大数据对企业和决策者来说非常有价值。Spark Streaming 的一个使用案例是一家投资公司需要监控可能影响其投资和持股的社交媒体趋势。及时了解关于公司客户或他们持有的公司的最新消息会极大地影响业务成果。
火花 MLlib
Apache Spark 有一个名为 MLlib 的机器学习库,它提供了主要的机器学习算法,如分类、聚类、回归、降维、转换器和协同过滤[7]。一些机器学习算法可以应用于流数据,这对于使用 Spark 流的应用很有用[6]。Spark 流应用中使用的分类算法的一个例子是信用卡欺诈检测。一旦处理了新的传入交易,分类算法就会对交易是否属于欺诈进行分类。尽快识别潜在的欺诈交易非常重要,这样银行就可以尽快联系客户。Spark 流的挑战在于输入数据量的不可预测性[8]。传入数据在流的生命周期中的不一致分布会使机器学习模型的流学习变得相当困难。
推荐系统
Spark Streaming 和 MLlib 的一个流行的真实用途是构建基于机器学习的推荐系统。推荐系统已经影响了我们网上购物、看电影、听歌和阅读新闻的方式。最著名的推荐系统公司包括网飞、YouTube、亚马逊、Spotify 和谷歌。像这样的大公司,产生和收集的数据如此之多,大数据分析是他们的首要任务之一。MLlib 包括一个迭代协作过滤算法,称为交替最小二乘法来构建推荐系统[6]。协同过滤系统基于用户和项目之间的相似性度量来进行推荐[8]。相似的商品会推荐给相似的用户。系统不知道关于项目的细节,只知道相似的用户查看或选择了相同的项目。
阿帕奇看象人
MapReduce 曾经有过自己的机器学习库,然而,由于 MapReduce 对于迭代处理的效率很低,它很快就失去了与 Apache Spark 的库的兼容性。Apache Mahout 是建立在 Apache Hadoop 之上的机器学习库,它最初是一个 MapReduce 包,用于运行机器学习算法。由于机器学习算法是迭代的,MapReduce 遇到了可扩展性和迭代处理问题[6]。由于这些问题,Apache Mahout 停止支持基于 MapReduce 的算法,并开始支持其他平台,如 Apache Spark。
结论
从一开始,Apache Spark 就被开发得很快,并解决了 Apache Hadoop 的缺点。Apache Spark 不仅速度更快,而且使用内存处理,并在其上构建了许多库,以适应大数据分析和机器学习。尽管 Hadoop 有缺点,但 Spark 和 Hadoop 都在大数据分析中发挥了重要作用,并被世界各地的大型科技公司用来为客户或客户量身定制用户体验。
作品被引用
[1]安卡姆,文卡特。大数据分析。Packt 出版公司,2016 年。EBSCOhost,search . EBSCOhost . com/log in . aspx direct = true & db = nle bk & AN = 1364660 & site = eho ST-live。
[2]“阿帕奇 Hadoop。”hadoop.apache.org/.阿帕奇 Hadoop
[3]“阿帕奇火花。”【阿帕奇火花】https://spark.apache.org/。
[4]巴拉金斯卡、玛格达和丹·苏休。并行数据库和 MapReduce。【2016 年春季,http://pages . cs . wisc . edu/~ Paris/cs 838-s16/lecture-notes/lecture-parallel . pdf。PowerPoint 演示文稿。
[5]德拉巴斯、托马兹等人学习 PySpark 。Packt 出版公司,2017 年。,search.ebscohost.com/login.aspx?direct = true&db = nle bk&AN = 1477650&site = ehost-live。
[6] Dua,Rajdeep 等用 Spark 进行机器学习—第二版。Vol .第二版,Packt 出版社,2017 年。 EBSCOhost ,search.ebscohost.com/login.aspxdirect=true&db = nle bk&AN = 1513368&site = eho ST-live。
[7] Hari,Sindhuja。" Hadoop vs Spark:面对面的比较选择正确的框架."2019 年 12 月 17 日,https://hackr.io/blog/hadoop-vs-spark。
8 佛朗哥·加莱亚诺·曼努埃尔·伊格纳西奥。用 Apache Spark 处理大数据:用 Spark 和 Python 高效处理大数据集和大数据分析。Packt,2018。
[9]普苏库里,纪梭。CS5412 /第 25 讲阿帕奇 Spark 和 RDDs。2019 年春季,http://www . cs . Cornell . edu/courses/cs 5412/2019 sp/slides/Lecture-25 . pdf。PowerPoint 演示文稿。
10 弗朗切斯科·皮尔费德里西。用 Python 实现分布式计算。Packt 出版公司,2016 年。search.ebscohost.com/login.aspx?,EBSCOhostdirect = true&db = nle bk&AN = 1220461&site = ehost-live。
[11]“什么是大数据。”大数据联盟,https://www.bigdata-alliance.org/what-is-big-data/.
从业务需求到运行应用的大数据
揭开大数据应用的面纱
处理大数据应用
在本文中,我将向您介绍大数据术语。除此之外,我还会从大数据应用的业务需求来解释什么时候考虑你正在处理的应用。换句话说,如何知道我们要从业务需求出发去处理大数据应用?
目前,大数据已经在市场上存在了一段时间,并且仍然吸引着来自不同领域的人们,他们正在寻求只有通过使用此类平台才能实现的目标。
简单来说什么是大数据?

(来源:【https://pxhere.com/en/photo/1575603 )
众所周知,大数据是一个更像哲学的术语,可以通过其主要特征来概括,这些特征是:数量、多样性、速度、准确性和价值。
Volume 代表的是数据量的巨大,换句话说,我们不能说几兆甚至几十亿的数据就可以被视为具有大数据的量。
多样性是一个已知的术语,当存在不同类型和格式的数据时,如关系记录、JSON 文件、XML 文件、非结构化文本、媒体文件(图像、视频、音频等)时会出现。)不能由关系数据库管理系统(RDBMS)或数据仓库(其中模式是先决条件)处理。
速度是数据到达服务器的速度。它在现有系统中扮演着重要角色,在现有系统中,每个人都在最快的时间内从数据中获得洞察力。是啊!速度很重要。如果我们在检测到一些关键信息后,如核反应堆出现故障,这可能导致太多人死亡,如果处理不当,将是灾难性的(没有人希望发生另一场切尔诺贝利灾难)。
准确性代表数据的准确性,以及这些数据对分析和洞察的可靠程度。这是需要维护的数据属性。为了知道已知的数据有多少是可靠的,我们应该仔细检查收集的数据的准确性,以及有多少数据是经过清理和良好处理的。
价值正如查尔斯·达尔文所说,“敢于浪费一小时时间的人,还没有发现生命的价值”。在这句话中,很明显,我们不需要浪费任何时间或资源来做所有的处理,而不是达到一个单一的目标。目标永远是第一位的;我们需要小心使用这个复杂的基础设施来从中获取价值(洞察力)。
什么时候我们需要将我们的数据视为大数据?
一些人想知道大数据是否是旧的传统可靠的 RDBMS 或众所周知的有洞察力的数据仓库的新替代品。我想对每个人说,在我看来,所有的都是相互补充的,每种技术都在应用周期中发挥着自己的作用。与此同时,我想提一下,如果您没有具备上述特征的数据,请尽量不要构建和使用大数据技术和架构,因为这只会增加系统的复杂性,并产生可以避免的高昂成本。
对一个简单的应用程序使用 RDBMS 总是最好的方法,因为它可靠而且更容易管理。但是,有了大数据应用,就另当别论了!
每天都有数千兆字节和数兆兆字节的数据被输入到服务器中,传统的技术已经无法处理这些数据了。这是新的检查点;每个人都应该开始形成符合自己要求的大数据解决方案。如题,从业务需求到大数据运行应用。一切从业务需求开始,我们如何将业务需求中的所有部分放在一起,并开始思考匹配呼叫的最佳解决方案。我向你保证,这仍然没有标准的方法。没有人可以声称在文献中存在一个适合所有大数据应用的解决方案,这是所有宣传开始的地方,并且仍然从未停止。
例如,如果我们需要建立一个推荐引擎来定位媒体网站上的用户,以获得更多的参与度并降低跳出率。基于业务需求,大数据架构师必须问的问题太多了。

科里·伍德沃在 Unsplash 上的照片
多少网站?就一个?我们能知道他们的来源吗?保密吗?我们需要只添加一个 JavaScript 来收集数据并完成任务吗?用户是注册的还是无关紧要的?用户事务的位置?这些媒体网站会生成关键词或者标签吗?每天产生多少数据?每月?每年?生成的数据有什么不同的格式?都统一还是不统一?数据可以与第三方共享吗?诸如此类…
当我们发现每天都有许多异构数据源生成千兆字节的数据时,我们必须做出决定,并得出传统数据库和数据仓库无法解决问题的结论。因此,需要将大数据架构引入到一系列新的大数据技术中,这些技术需要大量的专业知识和培训。
最好的大数据架构是什么?
在收集了需求之后,是时候决定我们需要进行的架构设计了。Lambda 架构更像是当今大数据架构设计中的一个概念(但它不是唯一的一个)。如果我们既需要静态数据用于训练,又需要另一个速度层用于检测和分类作为数据流到达的数据记录,这种 lambda 体系结构可以实现这一目的,因为它高度分离了不同的组件,我们可以将数据复制到不同的目的和不同的数据存储机制中。一种机制自然适合于存储永久数据,即静态数据存储,而另一种机制用于存储批量数据,即批量视图,以便通过将这些数据推入方便的可视化技术来促进这些数据的可视化。这种架构被认为是任何大数据架构师的支柱,然而,有些人发现这可能太复杂而难以处理。有些应用可能只需要速度层或批处理层。例如,在某些情况下,将用户聚类到不同的类别可能会导致只有批处理层,并根据用户的类别对待不同的用户(例如客户细分)。和其他情况下,只需要速度层,例如基于某个定义的模式检测故障机器。

λ架构
它更多地基于应用程序的需求,回到之前提出的问题,完整的 lambda 架构可能是最合适的,这是由于以下几个原因:
为了构建推荐引擎,重要的是要有一个批处理层:
- 我们需要用户的历史记录
- 用户
- 他们读的文章
- 每次会话花费的时间
2.我们需要训练一个模型(例如。协同过滤),其可以运行几天以获得存储的用户的兴趣
为了向登录用户/匿名阅读用户进行推荐,有一个速度层是很重要的:
1.获取用户的标识符
2.获取该用户可能感兴趣的生成文章
这只是一个例子,可以向您展示如何仔细分析需求,并将其转化为实际的架构。
在选择了合适的架构之后,我们完成了吗?!
当然不是!
选择合适的技术是一件非常痛苦的事情。大数据生态系统由许多工具和技术组成,其中大部分由 Apache 孵化器孵化。
走了这么远,我们将听到的第一个词是 Hadoop!是的,那只黄色的大象,我不知道它为什么是黄色的,但我只知道它是大数据的心脏。

(来源:【https://hadoop.apache.org/ )
请继续关注下一篇文章,其中我将深入介绍大数据工具和技术…
大数据工程— Apache Spark
理解大数据
为什么 Apache Spark 非常适合各种 ETL 工作负载。

这是大数据环境中的数据工程系列的第 2 部分。它将反映我个人的经验教训之旅,并在我创建的开源工具 Flowman 中达到高潮,以承担在几个项目中一遍又一遍地重新实现所有 boiler plate 代码的负担。
- 第 1 部分:大数据工程—最佳实践
- 第 2 部分:大数据工程— Apache Spark
- 第 3 部分:大数据工程——声明性数据流
- 第 4 部分:大数据工程— Flowman 启动并运行
期待什么
本系列是关于用 Apache Spark 构建批处理数据管道的。但是有些方面对于其他框架或流处理也是有效的。最后,我将介绍 Flowman ,这是一个基于 Apache Spark 的应用程序,它简化了批处理数据管道的实现。
介绍
第二部分强调了为什么 Apache Spark 非常适合作为实现数据处理管道的框架。还有许多其他的选择,尤其是在流处理领域。但是从我的角度来看,当在批处理世界中工作时(有很好的理由这样做,特别是如果涉及许多需要大量历史记录的非平凡转换,如分组聚合和巨大连接),Apache Spark 是一个几乎无可匹敌的框架,在批处理领域表现尤为突出。
本文试图揭示 Spark 提供的一些功能,这些功能为批处理提供了坚实的基础。
数据工程的技术要求
我已经在第一部分中评论了数据处理管道的典型部分。让我们重复这些步骤:
- 提取。从某个源系统读取数据(可以是像 HDFS 这样的共享文件系统,也可以是像 S3 这样的对象存储,或者像 MySQL 或 MongoDB 这样的数据库)
- **转型。**应用一些转换,如数据提取、过滤、连接甚至聚合。
- **装货。**将结果再次存储到某个目标系统中。同样,这可以是共享文件系统、对象存储或某个数据库。
现在,我们可以通过将这些步骤中的每一步映射到期望的功能,并在最后添加一些额外的需求,来推导出用于数据工程的框架或工具的一些需求。
- **广泛的连接器。**我们需要一个能够从广泛的数据源读入数据的框架,比如分布式文件系统中的文件、关系数据库或列存储中的记录,甚至是键值存储。
- 广泛而可扩展的变换范围。为了“应用转换”,框架应该明确地支持和实现转换。典型的转换是简单的列式转换,如字符串操作、过滤、连接、分组聚合——所有这些都是传统 SQL 提供的。最重要的是,框架应该提供一个简洁的 API 来扩展转换集,特别是列式转换。这对于实现不能用核心功能实现的定制逻辑非常重要。
- **广泛的连接器。**同样,我们需要各种各样的连接器来将结果写回到所需的目标存储系统中。
- **扩展性。**我已经在上面的第二个需求中提到了这一点,但是我觉得这一点对于一个明确的点来说足够重要。可扩展性可能不仅限于转换类型,还应该包括新输入/输出格式和新连接器的扩展点。
- **可扩展性。**无论选择哪种解决方案,都应该能够处理不断增长的数据量。首先,在许多情况下,你应该准备好处理比 RAM 所能容纳的更多的数据。这有助于避免完全被数据量卡住。其次,如果数据量使处理速度太慢,您可能希望能够将工作负载分布到多台机器上。
什么是 Apache Spark
Apache Spark 为上述所有需求提供了良好的解决方案。Apache Spark 本身是一个库集合,是一个开发定制数据处理管道的框架。这意味着 Apache Spark 本身并不是一个成熟的应用程序,而是需要您编写包含转换逻辑的程序,而 Spark 负责以一种高效的方式在集群中的多台机器上执行逻辑。
Spark 最初于 2009 年在加州大学伯克利分校的 AMPLab 启动,并于 2010 年开源。最终在 2013 年,这个项目被捐赠给了 Apache 软件基金会。该项目很快就受到了关注,尤其是以前使用 Hadoop Map Reduce 的人。最初,Spark 围绕所谓的 rdd(弹性分布式数据集)提供了核心 API,与 Hadoop 相比,rdd 提供了更高层次的抽象,从而帮助开发人员更高效地工作。
后来,添加了更新的 on preferred DataFrame API,它实现了一个关系代数,其表达能力可与 SQL 相媲美。这个 API 提供了与数据库中的表非常相似的概念,这些表具有命名的和强类型的列。
虽然 Apache Spark 本身是用 Scala(一种在 JVM 上运行的混合函数式和面向对象的编程语言)开发的,但它提供了使用 Scala、Java、Python 或 r 编写应用程序的 API。当查看官方示例时,您会很快意识到该 API 非常有表现力和简单。
- **连接器。**由于 Apache Spark 只是一个处理框架,没有内置的持久层,它一直依赖于通过 JDBC 连接到 HDFS、S3 或关系数据库等存储系统。这意味着从一开始就建立了清晰的连接设计,特别是随着数据帧的出现。如今,几乎每一种存储或数据库技术都只需要为 Apache Spark 提供一个适配器,而 Apache Spark 被认为是许多环境中的一个可能选择。
- **变换。**原始核心库为 RDD 抽象提供了许多常见的转换,如过滤、连接和分组聚合。但是现在更新的 DataFrame API 更受欢迎,它提供了大量模仿 SQL 的转换。这应该足够满足大多数需求了。
- **扩展性。**新的转换可以通过所谓的用户定义函数(UDF)轻松实现,在这种情况下,您只需提供一小段处理单个记录或列的代码,Spark 将它包装起来,以便该函数可以并行执行并分布在一个计算机集群中。
由于 Spark 具有非常高的代码质量,您甚至可以深入一两层,使用内部开发人员 API 实现新的功能。这可能有点困难,但是对于那些无法使用 UDF 实现的罕见情况来说,这是非常有益的。 - 可扩展性。 Spark 从一开始就被设计成一个大数据工具,因此它可以扩展到不同类型集群(当然是 Hadoop YARN、Mesos 和最近的 Kubernetes)中的数百个节点。它可以处理比内存大得多的数据。一个非常好的方面是,Spark 应用程序也可以在没有任何集群基础设施的单个节点上非常高效地运行,从开发人员的角度来看,这是一个很好的测试,但这也使 Spark 能够用于不太大的数据量,并且仍然受益于 Sparks 的特性和灵活性。
从这四个方面来看,Apache Spark 非常适合以前由 Talend 或 Informatica 等供应商提供的专用且昂贵的 ETL 软件完成的典型数据转换任务。通过使用 Spark,您可以获得生动的开源社区的所有好处,并且可以根据您的需求自由定制应用程序。
尽管 Spark 在创建时就考虑到了海量数据,但我总是会考虑使用它,即使是少量数据,因为它非常灵活,可以随着数据量无缝增长。
可供选择的事物
当然,Apache Spark 并不是实现数据处理管道的唯一选择。像 Informatica 和 Talend 这样的软件供应商也为喜欢购买完整生态系统的人提供非常可靠的产品(包括所有的优点和缺点)。
但是,即使在大数据开源世界中,有些项目乍看起来似乎是备选方案。
首先,我们仍然有 Hadoop。但是 Hadoop 实际上由三个组件组成,这三个组件被清晰地划分:首先,我们有分布式文件系统 HDFS,它能够存储非常大量的数据(比如说 Pb)。接下来,我们有运行分布式应用程序的集群调度器。最后,我们有一个 Map Reduce 框架,用于开发非常特殊类型的分布式数据处理应用程序。虽然前两个组件 HDFS 和 YARN 仍然被广泛使用和部署(尽管他们感到来自云存储的压力,Kubernetes 是可能的替代品),但 Map Reduce 框架现在根本不应该被任何项目使用。编程模型太复杂了,编写重要的转换会变得非常困难。所以,是的,HDFS 和 YARN 作为基础设施服务(存储和计算)很好,Spark 与这两者很好地集成在一起。
其他备选方案可以是 SQL 执行引擎(没有集成的持久层),如 Hive、Presto、Impala 等。虽然这些工具通常也提供了与不同数据源的广泛连接,但它们都局限于 SQL。首先,对于带有许多公共表表达式(cte)的长链转换,SQL 查询本身会变得非常棘手。其次,用新特性扩展 SQL 通常更加困难。我不会说 Spark 在总体上比这些工具更好,但我认为 Spark 更适合数据处理管道。这些工具在查询现有数据方面大放异彩。但是我不想用这些工具为创建数据——那从来都不是他们的主要工作范围。另一方面,虽然你可以通过 Spark Thrift Server 使用 Spark 来执行 SQL 以提供数据,但它并不是真正为这种场景而创建的。
发展
我经常听到的一个问题是,应该使用什么编程语言来访问 Spark 的功能。正如我在上面写的,Spark out of the box 提供了 Scala、Java、Python 和 R 的绑定——所以这个问题真的很有意义。
我的建议是根据任务使用 Scala 或 Python(也许是 R——我没有这方面的经验)。千万不要用 Java(感觉真的比干净的 Scala API 复杂多了),投资点时间学点基础的 Scala 吧。
现在留给我们的问题是“Python 还是 Scala”。
- 如果你做的是数据工程(读取、转换、存储),那么我强烈建议使用 Scala。首先,因为 Scala 是一种静态类型语言,所以实际上比 Python 更容易编写正确的程序。第二,每当您需要实现 Spark 中没有的新功能时,最好使用 Spark 的本地语言。尽管 Spark well 支持 Python 中的 UDF,但您将付出性能代价,并且无法再深入研究。用 Python 实现新的连接器或文件格式将非常困难,甚至是不可能的。
- 如果你正在研究数据科学(这不在本系列文章的讨论范围之内),那么 Python 是更好的选择,包括所有那些 Python 包,比如 Pandas、SciPy、SciKit Learn、Tensorflow 等等。
除了上面两个场景中的不同库之外,典型的开发工作流也有很大的不同:数据工程师开发的应用程序通常每天甚至每小时都在生产中运行。另一方面,数据科学家经常与数据交互工作,一些见解是最终的成果。因此,生产就绪性对数据工程师来说比对数据科学家来说更重要。即使许多人不同意,Python 或任何其他动态类型语言的“生产就绪”要困难得多。
框架的缺点
既然 Apache Spark 对于复杂的数据转换来说是一个非常好的框架,我们可以简单地开始实现我们的管道。在几行代码中,我们可以指示 Spark 执行所有的魔法,将我们的多 TB 数据集处理成更容易访问的东西。
等等,别这么快!我在过去为不同的公司多次这样做,过了一段时间后,我发现许多方面必须反复实现。虽然 Spark 擅长数据处理本身,但我在本系列的第一部分中指出,健壮的数据工程不仅仅是处理本身。日志、监控、调度、模式管理都出现在我的脑海中,所有这些方面都需要在每个严肃的项目中得到解决。
那些非功能方面通常需要编写重要的代码,其中一些可能是非常低级和技术性的。因此,Spark 不足以实现生产质量数据管道。由于这些问题的出现与特定的项目和公司无关,我建议将应用程序分成两层:一个顶层包含编码在数据转换中的业务逻辑以及数据源和数据目标的规范。一个较低的层应该负责执行整个数据流,提供相关的日志记录和监控指标,负责模式管理。
最后的话
这是关于使用 Apache Spark 构建健壮的数据管道的系列文章的第二部分。我们非常关注为什么 Apache Spark 非常适合取代传统的 ETL 工具。下一次我将讨论为什么另一个抽象层将帮助您关注业务逻辑而不是技术细节。
大数据工程—最佳实践
理解大数据
在实施大数据数据处理管道时,您应该记住什么。

这是大数据环境中的数据工程系列的第 1 部分。它将反映我个人的经验教训之旅,并在我创建的开源工具 Flowman 中达到高潮,以承担在几个项目中一遍又一遍地重新实现所有 boiler plate 代码的负担。
期待什么
本系列是关于用 Apache Spark 构建批处理数据管道的。但是有些方面对于其他框架或流处理也是有效的。最后,我将介绍 Flowman ,这是一个基于 Apache Spark 的应用程序,它简化了批处理数据管道的实现。
介绍
越来越多的公司和项目使用 Apache Spark 作为中央数据处理框架来构建他们的数据处理管道。并且有很好的理由这样做(在本系列的另一部分中会有更多)。
Apache Spark 本身作为一个框架,在设计数据管道时并没有提供很多遵循最佳实践的指导,也没有考虑到许多细节,这些细节不是数据转换本身的直接部分,但从更广泛的角度来看是重要的,如模式管理和在出现故障或逻辑错误时重新处理数据的能力。
典型数据管道
在讨论开发数据处理管道时需要记住的各个方面之前(无论使用何种技术,尽管我更喜欢 Apache Spark),让我们先来看看典型的数据管道实际上是做什么的。
我认为大多数数据管道本质上包含三个步骤:
- 提取。从某个源系统读取数据(可以是像 HDFS 这样的共享文件系统,也可以是像 S3 这样的对象存储,或者像 MySQL 或 MongoDB 这样的数据库)
- **改造。**应用一些转换,如数据提取、过滤、连接甚至聚合。
- **装货。**将结果再次存储到某个目标系统中。同样,这可以是共享文件系统、对象存储或某个数据库。
Apache Spark well 支持所有这些步骤,您可以用几行代码实现一个简单的数据管道。一旦将它投入生产,随着时间的推移,可能会出现一些问题,导致非功能性需求和最佳实践。这些都不是 Apache Spark 直接实现的,你得自己搞定这些。本系列文章将帮助您构建坚如磐石的数据管道,这些管道还会处理许多非功能性需求,但这些需求在生产中非常重要。
最佳实践
本系列的第一部分是关于最佳实践的。这指的是为实现稳定运营而采取的具体做法。实现它们的技术并不是革命性的,但是它们并没有被经常讨论(至少这是我的印象)。
1.记录

第一个要求是提供某种形式的日志记录。这并不令人兴奋,许多开发人员已经提供了这种功能。但是通常的问题是日志应该有多详细:应该将每个细节都记录到控制台还是只记录问题?
这个问题很难回答,但我更喜欢记录我的应用程序做出的所有重要决策,以及对应用程序有一定影响的所有重要变量和状态信息。您可能想问问自己:对于应用程序不能按预期工作的大多数事件,什么样的信息会有所帮助?
我正在记录的内容的典型示例:
- 当前运行的自定义设置是什么?例如,正在处理什么日期范围?正在处理什么客户?
- 读取的是什么数据?数据存储在哪里?多少文件?这些信息有助于验证应用程序是否试图从正确的位置读取。
- 应用程序试图将其结果写入哪里?同样,此信息有助于验证目标系统的所有设置是否正确。
- 您还应该在最后记录某种成功消息——这对于在该消息长时间丢失时设置自动警报非常有用。
正如上一条提到的,警报也是你应该想到的。大多数情况下,最好将所有日志存储在一个像 Graylog 这样的中央日志聚合器中,这样您就可以轻松地搜索特定问题并设置警报。
与日志相关的还有主题指标。对于这个术语,我不仅仅指 Apache Spark 的内部技术指标,还指一些与业务更相关的指标。例如,提供关于读取和写入的记录数量的指标可能会很有趣——这两个指标在 Apache Spark 中都不直接可用,至少每个数据源和数据宿都不可用。
2.重播

你应该从一开始就计划好的一个非常重要的特性就是所谓的重播。在许多批处理应用程序中,输入数据是按时间片(每天或每小时)提供的,而您只想处理新数据。
但是如果出了问题会怎么样呢?例如,如果输入数据不完整或损坏,应该怎么办?或者您的应用程序包含一些逻辑错误并产生错误的结果?这种情况的简单答案是重播。这个术语指的是应用程序在出现任何问题时重新处理旧数据的能力。但是这种能力不会自动出现,您必须仔细考虑您的数据管理策略,如何组织您的输入和我们的输出数据以支持重新运行。
重新运行需要几个方面,这将在接下来的主题中单独讨论。
3.每个分区一个编写器

Nana Smirnova 在 Unsplash 上的照片
为了支持重新运行,您必须考虑数据组织。如果出现任何错误,理想情况下,您可以简单地删除特定批处理运行的输出,并用新的批处理运行的结果替换它。
如果您使用一些简单的分区机制,这是非常容易实现的。使用分区我指的是使用子文件夹(用于基于文件的输出)或配置单元分区(当您使用配置单元时)来组织逻辑上属于同一输出的数据(就像单个配置单元表)。基本思想是每个批处理运行都应该写入一个单独的分区。
例如,如果您的应用程序每小时处理一次新数据,只需使用数据和时间作为标识符来创建分区。在基于文件的工作流中,分区是一个目录,对于一些包含客户和交易数据的虚拟数据仓库,它可能如下所示
/warehouse/shop_db/customer_transactions/hour=2020-09-12T08:00/
在该目录中,存储了 2020 年 9 月 12 日 08:00 运行的特定作业的所有文件。如果批处理运行中出现任何错误,您可以简单地删除整个目录并重新启动作业。
如果您正在使用 Hive(如果您在一些共享文件系统或对象存储上使用 Spark,我强烈建议您这样做),分区是 Hive 的核心特性。不幸的是,Spark 不太支持写入特定分区(但这种限制是可以解决的)。
4.模式管理

塞巴斯蒂安·赫尔曼在 Unsplash 上的照片
模式管理是一个非常重要的主题。这个术语指的是所有项目和开发任务有关的数据输入和输出格式。
当您读入某个源系统的数据时,您期望数据的特定格式。这包括技术文件格式(如 CSV、JSON 或 Parquet)和用于存储数据的一组列和数据类型。我强烈推荐两件事:
- 明确对输入模式的期望。这意味着不要简单地让应用程序推断正确的类型。
- 为改变做好准备。我经常被告知“输入模式永远不会改变”——而这个假设最终总是被证明是错误的。
第一个建议提高了应用程序的健壮性,因为静默模式更改可以更早地被检测到,因为如果输入数据不再与您期望的模式匹配,应用程序应该报告一个错误(一些放宽是允许的,甚至是可取的,下面将详细介绍)。许多公司甚至有一些轻量级的组织过程来协商模式——这在我看来是正确的,因为由另一个应用程序获取的数据导出模式是一个技术契约。双方(交付方和消费方)都应该通过显式地使用模式进行写入和读取来意识到这一点。
第二个建议更难,尤其是与重新运行功能相结合。更改数据处理以反映新版本的输入模式可能会破坏重新处理旧数据的能力,因为旧数据可能是使用旧版本的模式存储的。这意味着您需要考虑您的数据管道如何可能与不同的模式版本一起工作。一个简单的解决方案是使用旧版本的数据管道来处理旧数据,但这通常不是一个好的选择,因为旧版本的应用程序缺少一些也应该应用于旧数据的重要功能。
所以我建议用不同的模式版本重新运行,创建某种与所有版本的输入数据兼容的超级模式——至少在应用任何业务逻辑之前作为应用程序中的内部中间表示。我还建议尝试与源系统协商,只允许新模式版本的兼容变更*。不幸的是,术语兼容*高度依赖于所使用的技术,例如,Spring 对于像 Spark 一样改变 JSON 中的类型有其他限制。
5.数据谱系关系
最后,作为一个更广泛的概念,某种“数据所有权”应该在每个项目中可用。这个术语实际上指的是两个可能不同的方面,在这两个方面,如果出现任何需要注意的问题或事件,责任应该是明确的:
- **物理数据所有权。**所有数据最终都存储在某个系统上,无论是在云中还是在本地数据中心,甚至是在我桌子下面的服务器上(不推荐)。需要有一个团队负责操作这个系统(是的,即使是云也需要一些操作),包括备份、更新等。该角色通常由 IT 运营部门负责。
- **业务数据所有权。**除了物理所有权,每个数据源还需要一个业务所有者。该人员或团队负责存储的数据类型、数据模式以及与其他系统的接口。这个角色必须由定义存储数据的团队拥有。我总是推荐一个简单的规则:写数据的团队也拥有数据。这也意味着不允许其他团队写入自己的数据——除了一些用于数据交换的接口区域。
最后的话
这是关于使用 Apache Spark 构建健壮的数据管道的系列文章的第 1 部分。您可能会觉得有点被出卖了,因为它没有包含任何实际的代码。然而,我认为首先讨论一些概念是很重要的。下一部分将更多地关注 Apache Spark。
大数据工程—声明性数据流
通过使用声明性语言方法来分离功能性和非功能性需求。

迈克·本纳在 Unsplash 上的照片
这是大数据环境中的数据工程系列的第 3 部分。它将反映我个人的经验教训之旅,并在我创建的开源工具 Flowman 中达到高潮,以承担在几个项目中一遍又一遍地重新实现所有锅炉板代码的负担。
- 第 1 部分:大数据工程—最佳实践
- 第 2 部分:大数据工程— Apache Spark
- 第 3 部分:大数据工程—声明性数据流
- 第 4 部分:大数据工程— Flowman 启动并运行
期待什么
本系列是关于用 Apache Spark 构建批处理数据管道的。但是有些方面对于其他框架或流处理也是有效的。最后,我将介绍 Flowman ,这是一个基于 Apache Spark 的应用程序,它简化了批处理数据管道的实现。
功能需求
本系列的第 1 部分已经指出了两种需求的存在,它们适用于几乎所有类型的应用程序:功能性需求和非功能性需求。让我们首先关注第一类需求。
功能需求描述了解决方案首先应该解决的实际问题。它们描述了核心功能以及应该实现什么。这可能是一个数据处理应用程序,需要集成多个数据源并执行聚合,以便为一些数据科学家提供简化的数据模型。但是功能需求的想法也适用于预订不同城市旅行的 Android 应用程序。
功能需求总是由作为最终用户代理的业务专家编写的。他们应该关注要解决的问题,这样开发人员或架构师仍然可以决定可行的解决方案应该是什么样子。当然,在实现之前,应该与业务专家一起验证所选择的方法。
注意我特别写了功能需求应该关注问题(或任务)而不是解决方案。这种微小的差异非常重要,因为它为开发人员留下了更大的设计空间来寻找最佳的可能解决方案,而不是由业务专家给出的特定解决方案,后者可能很难在给定的技术范围内实现。
非功能性需求
除了描述软件必须实现的主要任务的功能性需求之外,还有非功能性需求。它们描述了必须实现的一切,但不是核心功能的直接部分。
数据处理管道的典型要求如下:
- 包含有意义的信息、警告和错误消息的日志被推送到中央日志聚合器。
- 关于已处理记录数量的指标被发布并推送到一个中央指标收集器。
- 上游系统在一小时内生成的输入数据的处理时间不会超过一小时。
- 应用程序必须在现有的集群基础设施(可能是 Kubernetes、YARN 或者甚至是 Mesos)中分布式运行
- 随着数据量的预期增长,应用程序应该能够轻松扩展其处理吞吐量。
到目前为止,所有这些要求都非常技术性。特别是在数据处理管道的情况下,我会添加以下要求:
- 业务专家应该能够阅读并(至少粗略地)理解实现的转换逻辑。
这最后一个要求可能是有争议的,但是我发现如果实现了它会非常有帮助。能够与业务专家或利益相关者讨论特定的解决方案,作为一个额外的验证和信任层,是非常宝贵的。幸运的是,在数据处理领域,业务专家通常至少知道 SQL,并且很好地理解典型转换的概念,如过滤、连接和分组聚合。所以我们需要的是一个足够简单易读的逻辑表示。
关注点分离

西蒙·瑞在 Unsplash 上拍摄的照片
我们刚刚看到,几乎所有的应用程序都必须实现两类不同的需求,功能性需求和非功能性需求。一个简单但重要的观察结果是,在一个项目中,甚至在一个公司中,不同应用程序的功能需求因情况而异(因为每个应用程序都要解决不同的问题),但非功能需求通常是相同的,至少在特定的应用程序类型中是如此(如“数据处理管道”或“web 应用程序”)。
每个开发人员现在都应该有一个类似“可重用代码”的术语,甚至可能有“关注点分离”的概念。很明显,在大多数非功能性需求都相同的情况下,这是一条可行之路。如果我们能够构建一个解决方案,其中功能性和非功能性需求在不同的层实现,并且如果我们还成功地共享了负责所有这些非功能性需求的代码,那么我们将收获良多:
- 通过非功能性需求的共享实现,所有的应用程序都将从任何改进中受益。
- 由于统一的指标和日志记录,所有应用程序都可以以非常相似的方式集成到整个 IT 环境中。
- 操作也得到简化,因为关于一个应用程序的知识和问题解决策略可以应用于所有其他应用程序,使用相同的共享基础层来解决非功能性需求。
- 作为功能需求的一部分实现的核心业务逻辑没有与技术细节混杂在一起,因此更容易被业务专家理解和验证。
下一节将描述一种基于这些想法构建解决方案的可能方法。
声明性数据管道

通过使用适当的业务逻辑高级描述语言,然后由较低的数据流执行层解析和执行,我们可以获得我上面描述的所有优点。这是我在 Apache Spark 上实现通用数据处理应用程序时选择的路线。
基本上,这个想法是使用简单的 YAML 文件,它包含所有数据转换的纯声明性描述,类似于 Kubernetes 中的部署描述。在我给出一些小例子之前,让我解释一下这种方法的好处:
- 通过构建在 Apache Spark 之上,我们确保获得 Spark 的所有好处,如可扩展性、可伸缩性、丰富的连接器等等。
- 具有潜在更高抽象级别的描述语言允许在类似于原始业务需求的级别上指定逻辑(如构建历史、在复杂的 JSON 文档中提取子树等),这些在 Spark DataFrame API 级别上不直接可用。
- 使用没有任何流控制的纯声明性语言有助于关注逻辑流,从而防止在单个源文件中混合功能性和非功能性需求。
- 声明性语言还可以用于以低成本提取和提供附加信息,如数据沿袭或输出模式。此信息可用于自动化工作流、模式管理和生成指标。
示例数据流
下面几节给出了一个简单的数据流示例。乍一看,这个例子可能看起来有点复杂,但是您会发现它还包含许多有价值的详细信息,这些信息在某种程度上是必需的,并且可以用于上面提到的额外好处之一,如自动模式管理。
对于这个例子,我将建立一个小的数据处理管道,用于处理来自 NOAA 的包含天气测量的"综合地表数据集。这是一个非常有趣的大型数据集,包含了从全球到 1901 年的天气信息。但是它使用了非常复杂的自定义格式(没有 CSV),其中一些基本的测量可以在固定的位置提取(我们将做的)。在这个例子中,我们不会直接访问他们的服务器,但是我假设一些数据被下载到某个私有位置(比如本地文件系统,S3 或者 HDFS)。
1.源位置
首先,在从 NOAA 服务器下载原始测量值之后,我们需要声明原始测量值存储的物理源位置:
relations:
measurements-raw:
kind: file
format: text
location: "s3a://dimajix-training/data/weather/"
pattern: "${year}"
schema:
kind: embedded
fields:
- name: raw_data
type: string
description: "Raw measurement data"
partitions:
- name: year
type: integer
granularity: 1
这个定义已经包含了大量关于称为“测量值-原始值”的源关系的信息:
- 种类:文件 —数据存储为文件
- 格式:文本 —数据存储为文本文件(每行代表一条记录)
- 位置:… —数据存储在 S3 的指定位置
- **模式: y e a r ∗ ∗ —该位置包含分区,其目录名简单地采用 {year}** —该位置包含分区,其目录名简单地采用 year∗∗—该位置包含分区,其目录名简单地采用year 的形式(分区将出现在下面)
- 模式:… —数据有一个特定的模式,其中有一个名为“raw_data”的列
- 分区:… —按“年”对关系进行分区,即其数据沿“年”轴拆分成更小的块。
您看,这已经包含了很多信息,这些信息都是处理关系所必需的(或者至少是有价值的)。
2.读出数据
现在下一步是从上面声明的关系中读入数据。这可以通过以下映射规范来实现:
mappings:
measurements-raw:
kind: read
relation: measurements-raw
partitions:
year: $year
我不会像在第一小节中那样遍历所有行——代码应该是不言自明的:该规范指示从先前定义的关系“measurements-raw”中读取单个分区 y e a r 。“ year。“ year。“year”开头的美元表示这是一个变量,必须在某个地方定义或在执行前显式设置。
3.提取测量值
正如我在示例开始时解释的那样,一些度量可以在固定的位置用单个记录提取(其他度量存储在可选的和动态的位置——我们在这里不关心它们)。这可以通过以下选择映射来实现:
mappings:
measurements:
kind: select
input: measurements-raw
columns:
usaf: "SUBSTR(raw_data,5,6)"
wban: "SUBSTR(raw_data,11,5)"
date: "SUBSTR(raw_data,16,8)"
time: "SUBSTR(raw_data,24,4)"
report_type: "SUBSTR(raw_data,42,5)"
wind_direction: "SUBSTR(raw_data,61,3)"
wind_direction_qual: "SUBSTR(raw_data,64,1)"
wind_observation: "SUBSTR(raw_data,65,1)"
wind_speed: "CAST(SUBSTR(raw_data,66,4) AS FLOAT)/10"
wind_speed_qual: "SUBSTR(raw_data,70,1)"
air_temperature: "CAST(SUBSTR(raw_data,88,5) AS FLOAT)/10"
air_temperature_qual: "SUBSTR(raw_data,93,1)"
现在您可以看到这个映射是如何通过其“输入字段引用第一个映射的,然后指定要生成的列列表以及每个列的表达式。
4.目标位置
现在,我们希望将提取的数据写入一个适当的 Hive 表,再次按年份进行分区。在指定写操作本身之前,我们首先需要创建一个新的目标关系,数据应该被写入其中。具体规定如下:
relations:
measurements:
kind: hiveTable
database: "weather"
table: "measurements"
format: parquet
partitions:
- name: year
type: int
schema:
kind: mapping
mapping: measurements
这个关系描述了一个名为“天气”的数据库中的一个名为“测量”的配置单元表。数据应该存储为 Parquet 文件,模式应该从映射“measurements”中隐式地推断出来,这是我们在步骤 3 中定义的。
5.构建目标
现在我们有了一个输入关系、一些提取逻辑和一个目标关系,我们需要创建一个构建目标,它告诉我们由“measurements”映射生成的所有记录都应该被写入“measurements”目标(它反过来表示具有相同名称的 Hive 表)。这可以通过以下方式完成:
targets:
measurements:
kind: relation
relation: measurements
mapping: measurements
partition:
year: $year
称为“度量”的构建目标将映射“度量”的结果与关系“度量”结合起来作为它的目标位置。
您可能会问为什么我们需要明确地指定一个关系和一个构建目标。原因很简单,关系是一个逻辑对象,既可以用于读,也可以用于写(甚至可能在同一个应用程序中)。通过将声明与写和读操作分开,我们自动增加了重用单个关系的可能性。
6.构建作业
我们就要完成了,但是最后一个小细节还没找到。很可能您为不同的关系创建了多个目标,但是您不想执行所有的目标。因此,最后一步需要一个构建作业,它主要包含要构建的目标列表。此外,构建作业也是指定正确执行所需的运行时参数的好地方。在我们的示例中,年份是一个自然的候选,因为您可能希望在不同的年份独立运行相同的数据流:
jobs:
main:
parameters:
- name: year
type: Integer
default: 2013
targets:
- measurements
摘要
让我们总结一下我们需要为工作数据管道指定哪些细节:
- **关系。**像在传统数据库中一样,我们需要指定我们想要读取或写入的物理数据源。我选择“关系”这个术语只是因为这正是 Spark 中使用的术语。关系可以指文件、配置单元表、JDBC 源或任何其他物理数据表示。
- **映射。**转换(和读操作)被建模为映射。虽然我们只使用了两种非常简单的类型(“read”和“select”),但是您可以想象任何类型的数据转换都可以表示为映射。
- **目标明确。**数据处理管道通常可与传统的构建管道相媲美——除了它创建新数据而不是应用程序。因此,我重用了构建工具中的一些概念和术语。构建“目标”表示将数据写入关系所需执行的工作量。
- **乔布斯。**通常(尤其是在批处理中)你不仅只有一个输出,还需要用不同的转换写入多个输出。每个写操作被表示为一个构建目标,这些操作的集合被表示为一个作业。
为了完善“数据构建工具”的概念,Flowman 本身也支持构建阶段,就像它们在 Maven 中一样:
- **创造。**第一阶段是创建和/或迁移任何关系。这解决了整个“模式管理”部分。
- 打造。第二阶段将执行构建目标隐含的所有写操作。
- **验证。**验证阶段将检查先前执行的写操作是否确实导致一些记录被写入相应的关系。作为单元测试的一部分,验证阶段也可以用来执行一些测试。
- **截断。**虽然前三个阶段是关于创建关系和数据,截断阶段将通过删除关系的内容来执行一些清理,但是它将保留关系本身(配置单元表、目录等)。
- **干净。**最后最后一个阶段也将去除物理关系本身。
我们在上面的规范中没有明确提到构建阶段,你甚至不能这样做。构建阶段是数据管道的执行的一部分,我将在下一节讨论。
执行数据流
我刚刚向您展示了一个简单数据流的小(虽然冗长)示例,它代表了读取、提取和存储数据的非常基本和典型的操作。当然,你不能直接执行这些 YAML 文件。您现在需要的是一个理解上述特定语法的应用程序,然后它可以执行作业、目标、读操作、转换和写操作。
Flowman 就是做这个工作的。这是我为实现这种非常特殊的方法而创建的开源应用程序,在这种方法中,数据流与执行逻辑相分离。它在很大程度上构建于 Apache Spark 之上,如果你有一点 Spark 的经验,你很可能会想象上面的 YAMLs 是如何用 DataFrame API 执行的。
设计优势
也许我在这个系列的第一部分和第二部分中提到的话题现在开始对你更有意义了。或者你可能觉得这种方法太复杂了。不管是哪种情况,让我试着指出这种设计相对于直接使用 Apache Spark 的经典应用程序的一些优点。
通过依赖具有特定实体模型(关系、映射、目标和作业)的高级描述语言,您可以确保数据管道的统一方法。这有助于简化操作并遵循最佳实践(至少我是这么理解的)——实际上,这种方法很难不遵循它们。
接下来,当实现数据管道时,您主要在高层次上工作,技术细节和可能的解决方法隐藏在执行层(Flowman)。
这种方法的另一个优点是,许多非功能方面,如模式管理(创建和更改配置单元表)、提供有意义的运行时指标等,可以在执行层实现,而不会弄乱规范。这是作为构建阶段的一部分完成的,构建阶段完全在执行层实现,不需要在数据流规范本身中明确指定。
最后,即使是倾向于技术的业务专家也能比一个完整的 Spark 应用程序(无论是用 Scala、Java、Python 等编写的)更好地理解 YAML 文件,后者也包含许多样板代码。
最后的话
这是关于使用 Apache Spark 构建健壮的数据管道的系列文章的第三部分。这一次,我向您展示了以非常统一的方式实现数据处理管道的非常具体的方法。它不包含任何 Spark 代码(你可以在 GitHub 上查看 Flowmans 源代码)——这代表了我对数据管道应该是什么样子的看法。
下一部分将介绍如何在本地 Linux 机器上安装和运行 Flowman。
大数据工程— Flowman 启动并运行
在您的机器上查看名为 Flowman 的开源、基于 Spark 的 ETL 工具。

西蒙·威尔克斯在 Unsplash 上的照片
这是大数据环境中的数据工程系列的第 4 部分。它将反映我个人的经验教训之旅,并在我创建的开源工具 Flowman 中达到高潮,以承担在几个项目中一遍又一遍地重新实现所有锅炉板代码的负担。
- 第 1 部分:大数据工程—最佳实践
- 第 2 部分:大数据工程— Apache Spark
- 第 3 部分:大数据工程——声明性数据流
- 第 4 部分:大数据工程——flow man 启动和运行
期待什么
本系列是关于用 Apache Spark 构建批处理数据管道的。上次我介绍了 Flowman 的核心思想,这是一个基于 Apache Spark 的应用程序,它简化了批处理数据管道的实现。现在是时候让 Flowman 在本地机器上运行了。
先决条件
为了按照说明在您的机器上安装一个正常工作的 Flowman,您不需要太多:
- 要求:64 位 Linux(抱歉,目前没有 Windows 或 Mac OS)
- 必选:Java (OpenJDK 也可以)
- 可选:Maven 和 npm,如果您想从源代码构建 Flowman
- 推荐:访问 S3 上的一些测试数据的 AWS 凭证
安装 Hadoop 和 Spark
尽管 Flowman 直接建立在 Apache Spark 的能力之上,但它并没有提供一个有效的 Hadoop 或 Spark 环境——这是有原因的:在许多环境中(特别是在使用 Hadoop 发行版的公司中),一些平台团队已经提供了 Hadoop/Spark 环境。Flowman 尽最大努力不搞砸,而是需要一个工作的火花装置。
幸运的是,Spark 很容易安装在本地机器上:
下载并安装 Spark
目前最新的 Flowman 版本是 0.14.2,可以在 Spark 主页上获得 Spark 3.0.1 的预构建版本。因此,我们从 Apache 归档文件中下载适当的 Spark 发行版,并对其进行解压缩。
# Create a nice playground which doesn't mess up your system
$ **mkdir playground**
$ **cd playground**# Download and unpack Spark & Hadoop
$ **curl -L** [**https://archive.apache.org/dist/spark/spark-3.0.1/spark-3.0.1-bin-hadoop3.2.tgz**](https://archive.apache.org/dist/spark/spark-3.0.1/spark-3.0.1-bin-hadoop3.2.tgz) **| tar xvzf -**# Create a nice link
$ **ln -snf spark-3.0.1-bin-hadoop3.2 spark**
Spark 包中已经包含了 Hadoop,所以只需下载一次,您就已经安装了 Hadoop,并且彼此集成。
安装流量计
下载和安装
你可以在 GitHub 的相应发布页面上找到预建的 Flowman 包。对于这个研讨会,我选择了flowman-dist-0.14.2-oss-spark3.0-hadoop3.2-bin.tar.gz,它非常适合我们之前刚刚下载的 Spark 包。
# Download and unpack Flowman
$ **curl -L** [**https://github.com/dimajix/flowman/releases/download/0.14.2/flowman-dist-0.14.2-oss-spark3.0-hadoop3.2-bin.tar.gz**](https://github.com/dimajix/flowman/releases/download/0.14.2/flowman-dist-0.14.2-oss-spark3.0-hadoop3.2-bin.tar.gz) **| tar xvzf -**# Create a nice link
$ **ln -snf flowman-0.14.2 flowman**
配置
现在,在使用 Flowman 之前,您需要告诉它在哪里可以找到我们在上一步中刚刚创建的 Spark 主目录。这可以通过在flowman/conf/flowman-env.sh中提供一个有效的配置文件来完成(模板可以在flowman/conf/flowman-env.sh.template中找到),或者我们可以简单地设置一个环境变量。为了简单起见,我们遵循第二种方法
# This assumes that we are still in the directory "playground"
$ **export SPARK_HOME=$(pwd)/spark**
为了在下面的例子中访问 S3,我们还需要提供一个包含一些基本插件配置的默认名称空间*。我们简单地复制提供的模板如下:*
# Copy default namespace
$ **cp flowman/conf/default-namespace.yml.template flowman/conf/default-namespace.yml**# Copy default environment
$ **cp flowman/conf/flowman-env.sh.template flowman/conf/flowman-env.sh**
这就是我们运行 Flowman 示例所需的全部内容。
天气示例
下面的演练将使用“天气”示例,该示例对来自 NOAA 的“综合地表数据集”的一些天气数据执行一些简单的处理。
项目详情
“天气示例”执行三个典型的 ETL 处理任务:
- 读入原始测量数据,提取一些属性,并将结果存储在拼花地板文件中
- 读入工作站主数据并存储在拼花文件中。
- 将测量值与主数据整合,汇总每个国家和年份的测量值,计算最小值、最大值和平均值,并将结果存储在拼花文件中。
这三个任务包括许多 ETL 管道中常见的典型的“读取、提取、写入”、“集成”和“聚合”操作。
为了简单起见,该示例没有使用 Hive 元存储,尽管我强烈建议将它用于任何严肃的 Hadoop/Spark 项目,作为管理元数据的中央权威。
Flowman 项目结构
您将在目录flowman/examples/weather中找到 Flowman 项目。该项目由几个子文件夹组成,反映了 Flowman 的基本实体类型:
- config —该文件夹包含一些配置文件,这些文件包含 Spark、Hadoop 或 Flowman 本身的属性。
- 模型—模型文件夹包含存储在磁盘或 S3 上的物理数据模型的描述。有些模型是指读入的源数据,有些模型是指将由 Flowman 生成的目标数据。
- 映射 —映射文件夹包含处理逻辑。这包括读入数据等简单步骤,以及连接和聚合等更复杂的步骤。
- 目标 —目标文件夹包含构建目标的描述。Flowman 认为自己是一个数据构建工具,因此它需要知道应该构建什么。目标通常只是简单地将映射的结果与数据模型耦合起来,用作接收器。
- 作业—最后,作业文件夹包含作业(在本例中只有一个),它或多或少只是应该一起构建的目标列表。Flowman 将负责正确的建造顺序。
这种目录布局有助于将一些结构带入项目,但是您可以使用您喜欢的任何其他布局。你只需要指定project.yml文件中的目录,这个文件在例子的根目录下(即flowman/examples/weather)。
Flowman 手动操作
示例数据存储在我自己提供的 S3 存储桶中。为了访问数据,您需要在您的环境中提供有效的 AWS 凭据:
$ **export AWS_ACCESS_KEY_ID=<your aws access key>**
$ **export AWS_SECRET_ACCESS_KEY=<your aws secret key>**
我们通过运行交互式 Flowman shell 来启动 Flowman。虽然这不是自动批处理中使用的工具(flowexec是该场景的合适工具),但它让我们很好地了解了 Flowman 中的 ETL 项目是如何组织的。
# This assumes that we are still in the directory "playground"
$ **cd flowman**# Start interactive Flowman shell
$ **bin/flowshell -f examples/weather**20/10/10 09:41:21 INFO SystemSettings: Using default system settings
20/10/10 09:41:21 INFO Namespace: Reading namespace file /home/kaya/tmp/playgroud/flowman-0.14.2-SNAPSHOT/conf/default-namespace.yml
20/10/10 09:41:23 INFO Plugin: Reading plugin descriptor /home/kaya/tmp/playgroud/flowman-0.14.2-SNAPSHOT/plugins/flowman-example/plugin.yml
...
日志输出完成后,您应该会看到一个提示flowman:weather>,现在您可以输入一些要执行的命令。
建筑物
首先,我们要执行main任务,并构建所有已定义的目标。因为作业定义了一个参数year,每次调用只处理一年,所以我们需要为这个参数提供一个值。因此,我们通过下面的命令开始 2011 年main中所有目标的构建过程:
flowman:weather> **job build main year=2011**20/10/10 09:41:33 INFO Runner: Executing phases 'create','build' for job 'weather/main'
20/10/10 09:41:33 INFO Runner: Job argument year=2011
20/10/10 09:41:33 INFO Runner: Running phase create of job 'weather/main' with arguments year=2011
20/10/10 09:41:33 INFO Runner: Environment (phase=create) basedir=file:///tmp/weather
20/10/10 09:41:33 INFO Runner: Environment (phase=create) force=false
20/10/10 09:41:33 INFO Runner: Environment (phase=create) job=main
20/10/10 09:41:33 INFO Runner: Environment (phase=create) namespace=default
20/10/10 09:41:33 INFO Runner: Environment (phase=create) phase=create
20/10/10 09:41:33 INFO Runner: Environment (phase=create) project=weather
20/10/10 09:41:33 INFO Runner: Environment (phase=create) year=2011
...
再次产生大量输出(部分由 Spark 的启动产生,但也由 Flowman 产生,因此您实际上可以跟踪 Flowman 在做什么。日志记录总是一个困难的主题——过多的日志记录会分散用户的注意力,而过少的输出会使问题的解决更加困难。
具体来说,您应该看到两个重要的事实:
...
20/10/10 09:41:33 INFO Runner: Executing phases 'create','build' for job 'weather/main'
20/10/10 09:41:33 INFO Runner: Running phase '**create**' of job 'weather/main' with arguments year=2011
...
后来呢
...
20/10/10 09:41:37 INFO Runner: Running phase '**build**' of job 'weather/main' with arguments year=2011
...
这意味着指示 flow man构建一个任务的所有目标实际上执行了完整的构建生命周期,它包括以下两个阶段
- “ create ”阶段创建和/或迁移构建目标中引用的所有物理数据模型,如目录结构、配置单元表或数据库表。这个阶段只关注模式管理。
- 然后’构建’阶段将用从数据流中创建的记录填充这些关系,如映射和目标所定义的。
Flowman 还支持清理生命周期,首先在“ truncate 阶段删除数据,然后在“ destroy 阶段删除所有目录和表格。
目标构建顺序
当您研究 weather 项目的细节时,您会发现构建目标有一些隐含的运行时依赖性:首先,来自 S3 的原始数据需要传输到您的本地机器,并存储在一些本地目录中(实际上在/tmp/weather)。然后这些目录作为构建aggregates目标的输入。
您不会发现任何显式的依赖关系信息,Flowman 会自己找出这些构建时依赖关系,并以正确的顺序执行所有操作。您可以在以下日志记录输出中看到这一点:
20/10/12 20:29:15 INFO Target: Dependencies of phase 'build' of target 'weather/measurements':
20/10/12 20:29:15 INFO Target: Dependencies of phase 'build' of target 'weather/aggregates': weather/stations,weather/measurements
20/10/12 20:29:15 INFO Target: Dependencies of phase 'build' of target 'weather/stations':
20/10/12 20:29:15 INFO Runner: Executing phase 'build' with sequence: weather/measurements, weather/stations, weather/aggregates
Flowman 首先收集所有隐式依赖项(前三个日志行),然后找到所有目标的适当执行顺序(最后一个日志行)。
所有构建目标的自动排序在具有许多依赖输出的复杂项目中非常有用,在这些项目中很难手动跟踪正确的构建顺序。使用 Flowman,您只需添加一个新的构建目标,所有的输出都会自动以正确的顺序写入。
重建
当您现在尝试重建同一年时,Flowman 将自动跳过处理,因为所有目标关系都已建立并包含 2011 年的有效数据:
flowman:weather> **job build main year=2011**...
20/10/10 10:56:03 INFO Runner: Target 'weather/measurements' not dirty in phase build, skipping execution
...
20/10/10 10:56:03 INFO JdbcStateStore: Mark last run of phase 'build' of job 'default/weather/main' as skipped in state database
...
同样,这个逻辑是从经典的构建工具领域借用来的,比如make,它也跳过现有的目标。
当然,您可以通过在命令末尾添加一个--force标志来强制 Flowman 重新处理数据。
检查关系
现在我们想直接在 Flowman 中检查一些结果(不需要借助一些命令行工具来检查 Parquet 文件)。这可以通过检查关系来完成,这些关系总是代表存储在一些磁盘或数据库中的物理模型。
首先,让我们获得项目中定义的所有关系的列表:
flowman:weather> **relation list**aggregates
measurements
measurements-raw
stations
stations-raw
当您查看了model目录中的项目文件后,您应该会觉得很熟悉。该列表包含项目中定义的所有模型名称。
现在让我们检查存储在stations关系中的主数据:
flowman:weather> **relation show stations**...
usaf,wban,name,country,state,icao,latitude,longitude,elevation,date_begin,date_end
007018,99999,WXPOD 7018,null,null,null,0.0,0.0,7018.0,20110309,20130730
007026,99999,WXPOD 7026,AF,null,null,0.0,0.0,7026.0,20120713,20170822
007070,99999,WXPOD 7070,AF,null,null,0.0,0.0,7070.0,20140923,20150926
008260,99999,WXPOD8270,null,null,null,0.0,0.0,0.0,20050101,20100920
008268,99999,WXPOD8278,AF,null,null,32.95,65.567,1156.7,20100519,20120323
008307,99999,WXPOD 8318,AF,null,null,0.0,0.0,8318.0,20100421,20100421
008411,99999,XM20,null,null,null,null,null,null,20160217,20160217
008414,99999,XM18,null,null,null,null,null,null,20160216,20160217
008415,99999,XM21,null,null,null,null,null,null,20160217,20160217
008418,99999,XM24,null,null,null,null,null,null,20160217,20160217
...
目前,所有数据都显示为 CSV——这并不意味着数据存储为 CSV(事实并非如此,它存储在 Parquet 文件中)。
现在让我们来考察一下measurements的数据:
flowman:weather> **relation show measurements**...
usaf,wban,date,time,wind_direction,wind_direction_qual,wind_observation,wind_speed,wind_speed_qual,air_temperature,air_temperature_qual,year
999999,63897,20110101,0000,155,1,H,7.4,1,19.0,1,2011
999999,63897,20110101,0005,158,1,H,4.8,1,18.6,1,2011
999999,63897,20110101,0010,159,1,H,4.4,1,18.5,1,2011
999999,63897,20110101,0015,148,1,H,3.9,1,18.3,1,2011
999999,63897,20110101,0020,139,1,H,3.6,1,18.1,1,2011
999999,63897,20110101,0025,147,1,H,3.6,1,18.1,1,2011
999999,63897,20110101,0030,157,1,H,4.0,1,18.0,1,2011
999999,63897,20110101,0035,159,1,H,3.5,1,17.9,1,2011
999999,63897,20110101,0040,152,1,H,3.0,1,17.8,1,2011
999999,63897,20110101,0045,140,1,H,3.4,1,17.8,1,2011
最后,让我们来看看总量。类似于measurements关系,aggregates关系也是分区的。我们还可以选择为分区列指定一个值:
flowman:weather> **relation show aggregates -p year=2011**country,min_wind_speed,max_wind_speed,avg_wind_speed,min_temperature,max_temperature,avg_temperature,year
SF,0.0,12.3,2.1503463,2.3,34.9,17.928537,2011
US,0.0,36.0,2.956173,-44.0,46.4,11.681804,2011
RS,0.0,12.0,3.3127716,-33.0,32.0,4.5960307,2011
MY,0.0,10.8,2.0732634,21.0,34.0,27.85072,2011
GM,0.0,15.4,3.910823,-10.0,30.0,9.442137,2011
FI,0.0,21.0,3.911331,-34.4,30.7,3.1282191,2011
IC,0.0,31.9,7.235976,-14.0,17.2,5.138462,2011
SC,0.0,14.0,4.618577,20.0,32.0,27.329834,2011
NL,0.0,31.4,4.969081,-8.2,34.0,10.753498,2011
AU,0.0,15.9,1.9613459,-15.0,35.0,9.814931,2011
检查映射
在 ETL 应用程序的开发过程中,能够查看一些中间结果通常非常有用。这些映射的中间结果可能并不总是在磁盘上或数据库中有物理表示。它们只是概念,记录在处理过程中只在内存中具体化。但是 Flowman shell 也支持通过查看映射的结果来检查这些中间结果。
在我们展示这个特性之前,我们首先需要提前执行一个有点笨拙的步骤:与关系相反,数据流本身依赖于参数year,并且在没有设置该参数的情况下无法执行或检查。此外,Flowman 作业还可能设置一些执行所需的附加环境变量。
为了减轻对这种情况的处理,Flowman 提供了一个特殊的命令来设置执行环境,因为它将由特定的作业提供:
flowman:weather> **job enter main year=2011** flowman:weather/main>
作为回报,提示符发生变化,现在还包含作业的名称。
现在我们可以开始检查中间结果了。首先,让我们获得所有映射的列表:
flowman:weather/main> **mapping list**aggregates
facts
measurements
measurements-extracted
measurements-joined
measurements-raw
stations
stations-raw
现在,让我们从检查存储在 S3 的原始测量数据开始:
flowman:weather/main> **mapping show measurements-raw**043499999963897201101010000I+32335-086979CRN05+004899999V0201551H007419999999N999999999+01901+99999999999ADDAA101000991AO105000491CF1105210CF2105210CF3105210CG1+0120410CG2+0126710CG3+0122710CN1012610012110999990CN2+999990+0219100010CN30149971005638010CN40100000104001016010CO199-06CR10510210CT1+019010CT2+019110CT3+019010CU1+999990000410CU2+999990000410CU3+999990000410CV1+019010999990+020310999990CV2+019110999990+020310999990CV3+019010999990+020310999990CW100330101076010KA1010M+02031KA2010N+01901KF1+01951OB10050100101571099999900105210
013399999963897201101010005I+32335-086979CRN05+004899999V0201581H004819999999N999999999+01861+99999999999ADDAO105000091CG1+0120410CG2+0126710CG3+0122710CO199-06CT1+018610CT2+018610CT3+018610CW100330102311010OB10050064101581099999900096910
013399999963897201101010010I+32335-086979CRN05+004899999V0201591H004419999999N999999999+01851+99999999999ADDAO105000091CG1+0120410CG2+0126710CG3+0122710CO199-06CT1+018410CT2+018510CT3+018510CW100330102901010OB10050054101541099999900105010
...
如您所见,原始数据很难处理。但是幸运的是,我们已经有了提取至少一些简单字段的映射:
flowman:weather/main> **mapping show measurements-extracted**wind_speed_qual,wban,usaf,air_temperature,date,wind_speed,air_temperature_qual,wind_direction,report_type,wind_direction_qual,time,wind_observation
1,63897,999999,19.0,20110101,7.4,1,155,CRN05,1,0000,H
1,63897,999999,18.6,20110101,4.8,1,158,CRN05,1,0005,H
1,63897,999999,18.5,20110101,4.4,1,159,CRN05,1,0010,H
1,63897,999999,18.3,20110101,3.9,1,148,CRN05,1,0015,H
1,63897,999999,18.1,20110101,3.6,1,139,CRN05,1,0020,H
1,63897,999999,18.1,20110101,3.6,1,147,CRN05,1,0025,H
1,63897,999999,18.0,20110101,4.0,1,157,CRN05,1,0030,H
1,63897,999999,17.9,20110101,3.5,1,159,CRN05,1,0035,H
1,63897,999999,17.8,20110101,3.0,1,152,CRN05,1,0040,H
1,63897,999999,17.8,20110101,3.4,1,140,CRN05,1,0045,H
使用相同的命令,我们还可以检查stations映射:
flowman:weather/main> **mapping show stations**usaf,wban,name,country,state,icao,latitude,longitude,elevation,date_begin,date_end
007018,99999,WXPOD 7018,null,null,null,0.0,0.0,7018.0,20110309,20130730
007026,99999,WXPOD 7026,AF,null,null,0.0,0.0,7026.0,20120713,20170822
007070,99999,WXPOD 7070,AF,null,null,0.0,0.0,7070.0,20140923,20150926
008260,99999,WXPOD8270,null,null,null,0.0,0.0,0.0,20050101,20100920
008268,99999,WXPOD8278,AF,null,null,32.95,65.567,1156.7,20100519,20120323
008307,99999,WXPOD 8318,AF,null,null,0.0,0.0,8318.0,20100421,20100421
008411,99999,XM20,null,null,null,null,null,null,20160217,20160217
008414,99999,XM18,null,null,null,null,null,null,20160216,20160217
008415,99999,XM21,null,null,null,null,null,null,20160217,20160217
008418,99999,XM24,null,null,null,null,null,null,20160217,20160217
最后,我们可以再次离开作业上下文(这将清除所有参数和特定于作业的环境变量):
flowman:weather/main> **job leave**
执行历史
Flowman 还可以选择跟踪已经执行的所有过去运行的作业。这些信息存储在一个小型数据库中。这个历史数据库背后的想法是提供一个机会来记录成功和失败的运行,而不需要额外的外部监控系统。
我们在开始时从一个模板复制的示例配置default-namespace.yml支持这种历史记录,并将信息存储在一个小型 Derby 数据库中。
flowman:weather> **history job search**+---+---------+-------+----+------+----+-------+-----------------------------+-----------------------------+
| id|namespace|project| job| phase|args| status| start_dt| end_dt|
+---+---------+-------+----+------+----+-------+-----------------------------+-----------------------------+
| 1| default|weather|main|create| |success|2020-10-09T11:37:35.161Z[UTC]|2020-10-09T11:37:40.211Z[UTC]|
| 2| default|weather|main| build| |success|2020-10-09T11:37:40.230Z[UTC]|2020-10-09T11:38:43.435Z[UTC]|
+---+---------+-------+----+------+----+-------+-----------------------------+-----------------------------+
我们也可以搜索所有已经建成的目标。在以下示例中,我们指定只搜索作为 id 为 1 的作业运行的一部分而构建的所有目标:
flowman:weather> **history target search -J 1**+--+-----+---------+-------+------------+----------+------+-------+-----------------------------+-----------------------------+
|id|jobId|namespace|project| target|partitions| phase| status| start_dt| end_dt|
+--+-----+---------+-------+------------+----------+------+-------+-----------------------------+-----------------------------+
| 1| 1| default|weather|measurements| |create|success|2020-10-12T18:02:50.633Z[UTC]|2020-10-12T18:02:52.179Z[UTC]|
| 2| 1| default|weather| aggregates| |create|success|2020-10-12T18:02:52.244Z[UTC]|2020-10-12T18:02:52.261Z[UTC]|
| 3| 1| default|weather| stations| |create|success|2020-10-12T18:02:52.304Z[UTC]|2020-10-12T18:02:52.320Z[UTC]|
+--+-----+---------+-------+------------+----------+------+-------+-----------------------------+-----------------------------+
放弃
最后,我们通过exit或quit退出 Flowman shell:
flowman:weather> **quit**
执行项目
到目前为止,我们只将 Flowman shell 用于项目的交互工作。实际上,开发 shell 的第二步是帮助分析问题和调试数据流。使用 Flowman 项目的主要命令是flowexec,用于非交互式批处理执行,例如在 cron-jobs 中。
它与 Flowman shell 共享大量代码,因此命令通常完全相同。主要的区别是使用flowexec你可以在命令行上指定命令,而flowshell会提供自己的提示。
例如,要运行 2014 年天气项目的“构建”生命周期,您只需运行:
$ **bin/flowexec -f examples/weather job build main year=2014**...
谢谢!
非常感谢您花时间阅读这篇冗长的文章。非常感谢您!发给所有试图在本地机器上实践这个例子的人。如果你对这个例子有疑问,请给我留言——简化这样的过程总是很困难的,我可能会忽略一些问题。
最后的话
这是关于使用 Apache Spark 构建健壮的数据管道的系列文章的最后一部分。现在,您应该对我构建数据管道的最佳实践的偏好以及我在 Flowman 中的实现有了一个概念,Flowman 目前在两家不同的公司的生产中使用。整个方法已经为我提供了很好的服务,我仍然更喜欢它,而不是一个不统一的单个 Spark 应用程序集合,它们本质上做着非常相似的事情。
如果您对在您的项目中使用 Flowman 感兴趣,那么非常欢迎您尝试一下,并与我联系以解决任何问题。
大数据文件格式解释

斯坦尼斯拉夫·康德拉蒂耶夫在 Unsplash 上的照片
介绍
对于数据湖,在 Hadoop 生态系统中,使用文件系统。然而,大多数云提供商已经将其替换为自己的深度存储系统,如 S3 或 GCS 。使用深度存储时,选择正确的文件格式至关重要。
这些文件系统或深度存储系统比数据库便宜,但只提供基本存储,不提供强有力的保证。
您需要根据您的需求和预算,为您的使用情形选择合适的存储。例如,如果预算允许,您可以使用数据库进行接收,然后一旦数据被转换,就将其存储在您数据湖中以供 OLAP 分析。或者,您可以将所有内容存储在深层存储中,而将一小部分热数据存储在快速存储系统(如关系数据库)中。
文件格式
请注意,深度存储系统将数据存储为文件,不同的文件格式和压缩算法为某些用例提供了好处。你如何在你的数据湖中存储数据是至关重要的,你需要考虑格式**、压缩,尤其是你如何 分割 你的数据。**
最常见的格式有 CSV、JSON、****、 协议缓冲区 、 拼花 、 ORC 。****

文件格式选项
选择格式时要考虑的一些事情有:
- 你的数据的结构:一些格式接受嵌套数据,比如 JSON、Avro 或 Parquet,其他的则不接受。即使有,也可能不是高度优化的。Avro 是嵌套数据最有效的格式,我建议不要使用 Parquet 嵌套类型,因为它们非常低效。进程嵌套的 JSON 也非常占用 CPU 资源。一般来说,建议在摄取数据时将数据拉平。
- 性能:Avro 和 Parquet 等一些格式比其他此类 JSON 表现更好。即使在 Avro 和 Parquet 之间,对于不同的用例,一个会比另一个更好。例如,因为 Parquet 是一种基于列的格式,所以使用 SQL 查询数据湖很好,而 Avro 更适合 ETL 行级转换。
- 易阅读:考虑是否需要人阅读数据。JSON 或 CSV 是文本格式,是人类可读的,而更高性能的格式如 parquet 或 Avro 是二进制的。
- 压缩:有些格式比其他格式提供更高的压缩率。
- 模式演变:在数据湖中添加或删除字段远比在数据库中复杂。像 Avro 或 Parquet 这样的格式提供了某种程度的模式进化,允许您在更改数据模式的同时查询数据。像Delta Lakeformat 这样的工具提供了更好的工具来处理模式的变化。
- 兼容性 : JSON 或 CSV 被广泛采用,几乎与任何工具兼容,而性能更高的选项集成点更少。
文件格式
- CSV :兼容性、电子表格处理和人类可读数据的良好选择。数据必须是平面的。它效率不高,并且不能处理嵌套数据。分隔符可能有问题,这会导致数据质量问题。将此格式用于探索性分析、概念验证或小型数据集。
- JSON :在 API 中大量使用。嵌套格式。它被广泛采用,人们可以阅读,但是如果有很多嵌套字段,就很难阅读。非常适合小型数据集、着陆数据或 API 集成。如果可能,在处理大量数据之前转换为更有效的格式。
- Avro :非常适合存储行数据,非常高效。它有一个模式并支持进化。与卡夫卡大融合。支持文件分割。将其用于行级操作或 Kafka 中。写数据很棒,读起来比较慢。
- 协议缓冲区:非常适合 API,尤其是 gRPC 。支持模式,速度非常快。用于 API 或机器学习。
- 拼花:柱状收纳。它有模式支持。它与 Hive 和 Spark 配合得非常好,作为一种将列数据存储在使用 SQL 查询的深层存储中的方法。因为它将数据存储在列中,所以查询引擎将只读取具有所选列的文件,而不是整个数据集,这与 Avro 相反。将其用作报告层。
- 类似于拼花地板,它提供了更好的压缩性。它也提供了更好的模式进化支持,但是不太受欢迎。
文件压缩
最后,您还需要考虑如何压缩数据,权衡文件大小和 CPU 成本。一些压缩算法速度较快,但文件较大,而另一些速度较慢,但压缩率较高。更多详情请查看此 文章 。

压缩选项(图片由作者提供)
我推荐使用快节奏的处理流数据,因为它不需要太多的 CPU 能力。对于批次来说,bzip2 是一个很好的选择。
结论
正如我们所看到的,CSV 和 JSON 是易于使用、人类可读的常见格式,但缺乏其他格式的许多功能,这使得它太慢,无法用于查询数据湖。 ORC 和 Parquet 在 Hadoop 生态系统中广泛用于查询数据,而 Avro 也在 Hadoop 之外使用,特别是与 Kafka 一起用于摄取,非常适合行级 ETL 处理。面向行的格式比面向列的格式具有更好的模式进化能力,这使它们成为数据摄取的一个很好的选择。
更新:我目前在坦桑尼亚帮助当地的一所学校,我创建了一个 GoFundMe 活动 来帮助孩子们,通过这个链接来捐款,每一点帮助!
我希望你喜欢这篇文章。欢迎发表评论或分享这篇文章。跟随me进行以后的帖子。
面向小型企业的大数据

斯蒂芬·菲利普斯-Hostreviews.co.uk 在 Unsplash 上的照片
面向小型企业的大数据
数据科学、机器学习(ML)和人工智能(AI)的大部分焦点和注意力都落在大型企业以及它们在该领域取得的全面创新收益上。
但事实是,数据科学对任何企业都至关重要,即使在较小的规模上执行,也能证明其极其有价值。
无论你的公司有 10 名员工还是 10,000 名员工,你都有可能在客户获取成本、客户流失、销售预测、物流或占领市场份额方面面临完全相同的挑战——只不过是用更少的资源实现这些目标。
尽管初创公司或小公司可能不会像大型企业那样捕获大量数据,但其种类和速度通常是相同的。为了与该领域更大的竞争对手竞争,利用少量资源快速利用这些数据可能变得更加必要。
事实上,在利用数据科学、ML 和 AI 方面,较小的公司甚至有一些优势。例如:
小公司更灵活
初创公司和小公司相对于大公司的优势在于,大多数都是由年轻员工创立的,他们不像传统的企业经营方式那样一成不变。
对于一个拥有十几名员工而不是几千名员工的组织来说,这种规模也更容易实施,这使得以数据为中心的思维模式更容易渗透到公司文化中。
对新思想的开放性、灵活性、创新思维以及创造性和探索性思维是创业文化的标志。
处理数据的更敏捷的方法意味着能够迭代想法和模型,快速失败,并轻松地将工作模型投入生产,以便更快地看到真正的商业价值,这种经验证的学习概念对于将商业模型和产品导向正确的方向非常重要。
小公司从一开始就是数据驱动的
由于大多数小公司和初创公司天生就以不同的方式思考他们的业务,这意味着只要手头有合适的工具,他们就可以从一开始就由数据驱动。许多大公司(令人惊讶的是,这对它们不利)仍然是直觉和高层管理人员的突发奇想与传统商业实践中几十年来根深蒂固的习惯相结合的产物。
这种根深蒂固的实践和“知识”可能非常危险,因为客户和市场是变化的,如果企业不适应,它可能会失败。
这就是为什么“我知道”这句话是危险的,因为我们只能在怀疑中确定,有了数据我们可以证明一个假设,然后说“我们的数据表明……”。
从一开始就使用数据来有效地推动决策制定,对于较小的新企业来说是一个巨大的竞争优势,也是未来增长的基础(而不是像许多老公司那样面临痛苦的转型)。
小公司不需要数据科学团队来做
现实情况是,数据科学家很难找到,雇佣成本很高,也很难留住。这使得进入壁垒对于一个成长中的公司来说似乎几乎是不可能的,因为它面临着与大公司相同的挑战,并且处于拥挤的市场中。
好消息(以及秘密)是:你不需要一个大型数据科学团队来从你的数据中获取价值(或者做 ML 甚至 AI)。关键是要有合适的技术,恰当地利用业务分析师的技能,他们可能会也可能不会编码,以有意义的方式为有影响的数据项目做出贡献。
即使只是通过实施一些简单的概念和工具,数据科学家也可以极大地改善公司中收集和处理的数据,并在处理数据时指导他人和指导最佳实践,其中许多工具都是免费的,并得到了社区的大力支持。
你不需要一个庞大的数据科学团队来从你的数据中获取价值。
这意味着允许他们轻松连接数据,快速准备和清理数据,甚至制作或迭代机器学习模型以进行预测分析。最后一点是有一个可靠的方法将这些模型投入生产,理想情况下只需几次点击就可以减少摩擦。
虽然在一个大型科技公司的世界里,作为一家初创公司或小公司似乎是一种劣势,但事实是,有了合适的工具和心态,这真的是一种优势。数据科学不是为那些财大气粗、拥有无限资源的人保留的精英领域。
现在,创业公司和小公司比以往任何时候都更有技术,可以在许多更老、更大的公司瞎忙的地方蓬勃发展——问题是,他们会利用这一技术吗?
如果你喜欢我的想法——在推特上关注我 @qayyumrajan
10 分钟内的大数据

来源:https://www.flickr.com/people/22402885@N00
是的,10 分钟就可以开始处理您的第一个大数据集!
在本文中,我将向您展示如何轻松进入大数据世界,前提是您有一些 Python 背景。
开始这个小旅程的最佳点是首先了解什么是大数据。答案真的取决于你电脑的 RAM 大小和处理速度。对于传统的 PC 来说,超过 8GB 或 16GB 的任何东西都很难处理。公司的机器可能会吃得更多一点。因此,大数据基本上是任何太大而无法以传统方式处理的数据集。
那么我们如何处理大数据呢?显然,一种方法是购买更多的内存和更强的处理器。但是这非常昂贵,并且也不是可扩展的解决方案。在数据集非常大(> 1TB)的情况下,它可能也不起作用。相反,有一个更好的、可扩展的解决方案。就是在多台计算机/计算单元上划分数据集和工作量。然而,这并不意味着你需要自己购买硬件和连接机器。幸运的是,互联网服务为我们提供了现成的完整计算基础设施。
Amazon AWS 就是这样一种服务,用户可以根据需要租用任意数量的计算单元来处理任意数量的数据。计算单元位于亚马逊服务器上,随时听候您的调遣。使用 AWS 服务的费用是完全透明的,按每小时每单位计算。不要担心,在本例中运行第一次大数据分析的总成本应该不到 4 美元。
话虽如此,让我们开始工作吧!
第 1 步创建一个亚马逊 AWS 账户:
**1a。**去https://aws.amazon.com/记账

创建 AWS 帐户
1b。除了通常的信息,您还需要输入您的信用卡详细信息。这是注册的最后一步。为了检查你的信用卡是否真实,亚马逊 AWS 会从你的账户中一次性扣除 1 美元(相当烦人,我同意)。

提供信用卡信息
在帐户设置期间,选择您的位置:美国西部(俄勒冈州)(这不是强制性的,但它不会伤害)
步骤 2 是启动您的集群
**2a。**集群是一群并行工作的计算机实例/处理器的另一种说法。登录您的 AWS 帐户,进入左上角的 Sservices,输入 EMR 。这代表 Elastic Map Reduce,它是亚马逊的一项并行计算服务。

亚马逊提供很多服务,选择 EMR
**2b。**一旦进入 EMR,进入左侧面板的集群,点击创建集群

开始做一个集群
2c 。然后点击进入高级选项,确保你的启动模式设置为集群。

转到高级选项
一旦你进入高级选项,有 4 页要填写,按照我下面的方法设置它们。
**2d。**在第一页(软件和步骤),确保您使用最新的 EMR 版本,并选择 Spark、Hive 和 Hadoop。此外,选择泽佩林,色相,Ganglia 和猪是一个好主意。点击下一步。

群集高级选项的第一页—软件
**2e。**在第 2 页(硬件)中,我们应该选择实例/处理器类型和实例数量。亚马逊 AWS 提供了许多不同的实例/处理器类型。它们有不同的用途和价格,所以调查哪种配置最适合您的任务是个好主意。
在这个例子中,我选择了五个 M5.xlarge 处理器(1 个主实例和 4 个核心实例)。这提供了比普通电脑多 10 倍的内存。事实证明,这样的构造对于处理 12 GB 和 2500 万行的数据集已经足够好了。

群集高级选项的第 2 页—硬件设置
**2f。**在集群高级选项的第 3 页(常规集群设置),我们应该为集群命名

群集高级选项的第 3 页—常规设置
**2g。**在集群高级选项的第 4 页(安全)中,您可以设置安全配置。我们不会太关注这个,因此我选择了*在没有 EC2 密钥对的情况下继续。*你可以在这里阅读更多关于 EC2 密钥对的信息。

群集高级选项第 4 页—安全性
**2h。**现在您的集群已经设置好了,点击*创建集群,*将出现以下屏幕

您的集群几乎准备好了
**2i。**点击左侧窗格中的集群。您的集群的状态是开始。一旦集群准备就绪,状态将变为*等待(集群就绪)。*此外,一旦集群可以使用,集群名称旁边的空绿色圆圈将变成一个完整的绿色圆圈。随时刷新页面,检查圆圈是否变成全绿色。

等待完整的绿色圆圈出现

您的集群已经准备好了!
**2j。**现在我们应该为您的代码设置工作空间了。亚马逊 EMR 在平台中集成了 Jupyter 笔记本。在左侧窗格中点击笔记本,然后点击创建笔记本。

启动 Jupyter 笔记本
**2k。**为您的笔记本命名,然后点击选择(在集群下),将您的笔记本连接到您刚刚创建的集群。

为您的笔记本命名

将您的笔记本电脑连接到集群
**2l。**然后点击选择集群然后创建笔记本。你的笔记本也需要几分钟准备好。一旦准备就绪,它将从开始变为就绪。点击上方中的打开。

等到你的笔记本准备好了
2m。您的 Jupyter 笔记本将在另一个浏览器窗口中打开。一旦打开笔记本,一定要点击内核/改内核 / PySpark。这是第二步的最后一部分。

将您的 Jupyter 笔记本设置为 PySpark
第三步是准备你的(大)数据
3a。返回 AWS 第一页,转到服务并找到 S3。S3 是亚马逊提供的一个非常大的云数据库。这是您的数据应该存储的地方。

去亚马逊 S3
**3b。**在 S3 中,点击创建桶。这是一个存储库,您将在其中上传数据。

在亚马逊 S3 创建一个桶
3c。给你的铲斗起一个独特的名字。亚马逊 S3 上没有两个桶可以共享同一个名称

给你的 S3 桶一个独特的名字
3d。点击桶来打开它

打开你的桶
**3e。**您现在可以将数据添加到您的存储桶中。对于小于 160 GB 的文件,您可以简单地将它们拖放到您的存储桶中。(要上传大于 160 GB 的数据,您必须使用 AWS CLI、AWS SDK 或亚马逊 S3 REST API)
出于本教程的目的,您可以继续使用这个虚拟数据集。将其下载到您的本地机器,然后上传到您的 bucket。
虚拟数据集只有几 MB,所以不是大数据。如果你有一个合适的大数据集,可以自由地使用它来代替虚拟数据集。

将数据上传到您的铲斗

您的数据将出现在存储桶中
**3f。**查看您的数据是否在桶中

您的数据在桶里,准备分析
**3g。**现在已经为分析做好了一切准备。到您的数据的路径具有以下模式:“s3n:// 您的存储桶名 / 您的文件名.扩展名类型”。
您将使用该路径将 S3 数据导入您的 Jupyter 笔记本
第四步就是最后做你的大数据分析!
**4a。**从导入基本的 PySpark 包开始。
PySpark 是一个 API,一个用来支持 Python 在 Spark 上运行的工具。Spark 是一个集群计算框架,最近几乎成了大数据的同义词。简而言之,Spark 正在协调分布在多个处理单元上的工作负载。做大数据,和 Spark 交互,也可以选择 Scala,Java 或者 R,而不是 Python(PySpark)。
因为我对 Python 很熟悉,所以在这个例子中我选择了 PySpark。你会发现 PySpark 与原生 Python 语法非常相似,但是万一遇到困难,你可以在这里查找。

导入 PySpark 包
**4b。**创建一个 Spark 会话,并使用之前创建的路径从 Bucket 导入数据。

将数据导入 Jupyter 笔记本
**4c。**做你的分析。您可以选择 PySpark 或 SQL 语法。如果您选择使用 SQL 语法,不要忘记创建临时表。您只能对临时表运行查询,而不能直接对 PySpark 数据框运行查询。

选择本机 PySpark 或 SQL 语法来处理您的数据
如果你想对你的数据运行 ML 算法,这里的是一个关于如何在 PySpark 中完成的例子。
第 5 步是终止您的会话
**5a。**完成分析后,确保终止集群。否则你可能会付出高昂的代价。返回服务/ EMR/集群并点击终止。

不要忘记终止集群
**5b。**集群需要几分钟才能关闭

检查集群是否正在终止
5c。之后,你应该停止或删除你的笔记本,同时删除你的 S3 桶。只要保存在 AWS 服务器上,这两者都会产生(实际上非常小的)成本。所以如果真的不需要,就删掉。在删除之前,不要忘记在本地下载您的笔记本,否则您会丢失代码。

**5d。**删除你的 S3 桶

删除您的存储桶
**5e。**最后一步是前往您的账户名称/ 我的账单仪表板查看您的账单

检查您的账单仪表板
**5f。**如前所述,如果您正确地遵循了所有步骤,那么本次练习的总账单不会超过 3 美元,还不包括 1 美元的信用卡检查费。(正如您在下面看到的,我设法产生了更高的成本,但这只是因为我运行了几天我的集群)。

计费仪表板提供了一些不错的 AWS 成本可视化
总结
我们的小旅程即将结束,让我们快速总结一下我们所经历的上述步骤:
- 开立亚马逊 AWS 账户
- 使用 AWS EMR 服务设置并激活您的集群
- 制作一个 Jupyter 笔记本,并将其与您的集群连接
- 将您的数据上传到亚马逊 S3
- 运行分析
就是这样!😃
祝贺您设置了您的第一个大数据分析!!
如果您做的一切都正确,完成上述配置步骤应该需要大约 10 分钟。我希望这篇文章对您有用,并祝您在未来的大数据事业中取得更大的成功!
金融服务中的大数据
数据科学、大数据、金融
现在的情况与 10 年前有所不同,因为我们现在拥有的数据比以前更多。

约书亚·索蒂诺在 Unsplash 上拍摄的照片
我们已经分析了千万亿次级的大数据,zettabytes 将是下一个(Kaisler 等人,2013)。
但是什么是大数据呢?简而言之,就是前所未有的保留、处理和理解数据的能力(Zikopoulos,2015)。大数据是指您面临传统数据库系统无法应对的挑战。
在数量、多样性、速度和准确性方面的挑战。这些都可以在金融服务中找到。事实上,技术是银行业不可或缺的一部分,以至于金融机构现在几乎与 IT 公司无法区分。
本文着眼于金融服务行业,研究大数据和所采用的技术。它进一步涵盖了投资回报、大数据分析、监管、治理、安全性和存储,以及造就该行业今天的障碍和挑战。
金融服务中的大数据
许多金融服务机构已经通过投资计算和存储大数据的平台开始了他们的大数据之旅。为什么?因为这里面有价值,而寻找新的价值形式是金融服务业务的全部内容。
大数据客户分析通过观察消费模式、信用信息、财务状况以及分析社交媒体来更好地了解客户行为和模式,从而推动收入机会。
大数据也是金融服务数据提供的核心业务模式的关键,例如彭博、路透社、数据流和金融交易所,它们提供金融交易价格并记录每秒数百万笔日常交易,以供客户分析使用和满足监管合规性要求(SOX、GDPR)。
所有这些大数据都必须存储起来(参见 NASDAQ 案例研究),因为无论计算机的速度有多快,无论组织的规模有多大,总有比组织知道如何处理或如何组合的数据更多的数据源,并且数据已经静止和流动了很长时间。
以下是大数据对金融行业的规模和社会影响的图示。

(来源:https://www . businessprocessincubator . com/content/technology-empowers-financial-services/)

(来源:https://www . slide share . net/swift community/nybf 2015 big-dataworksession final 2 mar 2015)
经过深入的小组研究,大数据已被发现存在于价值链的每个部分,下面给出了一些确定了收益实现(ROI)的示例:
● VISA 于 2011 年通过使用 IMC 的“内存计算”平台和网格计算来分析信用卡欺诈检测监控的大数据,从而获得了竞争优势。以前只有 2%的交易数据受到监控,现在有 16 种不同的欺诈模式,分布在不同的地区和市场(Celent,2013)。
● **Garanti Bank,**土耳其第二大盈利银行,通过使用复杂实时数据(如 web、呼叫中心和社交媒体数据)的 IMC 进行大数据分析,降低了运营成本并提高了绩效(Karwacki,2015)。
● **BBVA,**西班牙第二大银行集团使用大数据交互工具 Urban Discovery 检测潜在的声誉风险,提高员工和客户满意度。他们还了解了客户在分析大数据时的感受,从而制定公共关系和媒体策略(Evry,2014)。
● 花旗集团(美国第四大银行)将大数据技术 Hadoop 用于客户服务、欺诈检测和网络分析(Marr,2016)。根据(花旗报告,2017)金融机构使用大数据进行利率和 GDP 预测。
● Zestfinance 使用大数据 ZAML 技术密切监控其交易对手的信用质量,并试图评估其整体信用风险敞口(Lippert,2014)。
● BNY 梅隆通过潘兴 NetX360 平台实施了大数据技术,为其投资者审视风险和机遇(BNY 梅隆报告,2016)。
● 美国银行利用大数据增强多渠道客户关系,并在从网站、呼叫中心、柜员开始的客户旅程中使用,以提高其服务水平和客户留存率(Davenport,2013)。
● 纳斯达克使用AWS S3 大数据存储技术,每天向 AWS 提供数十万个小文件,然后在几毫秒内返回给客户,用于其市场回放和数据点播服务,以满足客户快速访问历史股价信息的需求,查看任何历史时间点的账面报价和交易价格。交易员和经纪人也用它来寻找错过的机会或潜在的不可预见的事件。低成本的理想解决方案(AWS 案例研究)。

(来源:https://www . data Maran . com/blog/the-big-data-revolution-doing-more-for-less/)
以下案例研究更详细地探讨了金融服务中的大数据技术。

照片由 CHUTTERSNAP 在 Unsplash 上拍摄
案例研究 1-摩根大通和 Hadoop
JP Morgan Chase 银行面临着理解信用卡交易(消费模式)产生的大数据以及非结构化和结构化数据集数量大幅度增长的挑战。
他们选择 Hadoop(开源框架)来利用大数据分析来分析客户的支出和收入模式。Hadoop 现在可以帮助挖掘非结构化数据(如电子邮件、脸书或 Twitter 标签),这是传统数据库无法做到的。
借助大数据分析,it 可以确定最适合其客户的最佳产品,即在客户需要时为其提供合适的产品。因此,该银行选择了 Hadoop 来支持不断增长的数据量以及快速处理复杂非结构化数据的需求。
类似地,(Pramanick,2013 年)声称,金融机构使用大数据来分析他们的呼叫中心,通过分析非结构化语音记录进行情感分析,这有助于他们降低客户流失率,并向客户交叉销售新产品。
案例研究 2-德意志银行、算法匹配和 Hadoop
德意志银行选择使用多种大数据平台和技术,例如构建风险平台,在此平台上挖掘非结构化数据并将其处理为可理解和可展示的格式,以便德意志银行的数据科学专家获得分析活动的洞察力和灵感。大数据技术应用于公司的交易和风险数据(收集时间超过 10 年)。
数据量和多样性需要大量的存储、排序和筛选,但借助大数据技术,可以快速高效地获取和提取数据,以提高性能,并通过使用匹配算法获得竞争优势,该算法挖掘数据集告诉他们的关于销售、满意率和投资回报的信息,从而从数字中获得更真实的意义和更深入的视角。
(Sagiroglu 等人,2013 年)还列举了金融公司使用自动化个性化推荐算法来提高客户亲密度的例子。因此,识别客户需求并提供量身定制的信息对金融机构来说是有利的。
大数据有助于识别合法交易与欺诈交易(洗钱、盗窃信用卡),并通过设置以下参数预测贷款违约支付行为、借款人与银行接触点的互动历史、征信机构信息、社交媒体活动和其他外部公共信息。(《经济情报》,2014 年)
该银行在 2013 年使用 Hadoop 来管理非结构化数据,但对与传统数据系统的集成持怀疑态度,因为存在多个数据源和数据流、价值数百万英镑的大型传统 IBM 大型机和存储库,并且需求与其传统系统和较新数据技术的功能相匹配,并对其进行简化。
最终,Hadoop、NoSQL 和大数据预测分析的组合适应了其所有运营领域,技术现在被视为德意志银行决策和战略管理行为中的重要因素。
案例研究 3-纳斯达克、存储(AWS 红移)和可扩展性(虚拟化)
所有金融交易交易所都存在大数据问题,纳斯达克也不例外。价值 7.9 万亿美元,每秒数百万次交易,一天内交易 29 亿股的世界纪录(2000 年),与容量相关的延迟是一个大问题,例如,处理 650 万个报价会因处理大量数据而导致处理延迟(Greene,2017)。
2014 年,这个问题变得更加复杂,因为公司的业务战略是从一个主要的美国股票交易所转变为一个企业、交易、技术和信息解决方案的全球提供商。这意味着他们需要进行更多的数据处理,并存储法律要求他们持有的大量数据内容。
金融服务行业的公司通常需要将交易信息保留七年,这是一项法规要求,可能会产生巨额存储费用。在纳斯达克,他们有一个传统的仓库(每年维护 116 万美元)和有限的容量(即只有一年的在线数据)。
他们的大数据量包括每个交易日插入的 40-80 亿行数据。数据构成是订单、交易、报价、市场数据、安全主数据和会员数据(即结构化数据)。数据仓库用于分析市场份额、客户活动、监控和计费。
还有一个性能挑战。当客户进行查询时,纳斯达克负担不起加载昨天的数据。灾难恢复是纳斯达克的另一个重要因素。
最初的要求范围是通过迁移到 AWS Redshift 来替换本地仓库,同时保持等同的模式和数据,并且大数据解决方案必须满足两个最重要的考虑因素,即安全性和法规要求。方法是从众多来源提取数据,验证数据,即数据清理,并安全地加载到 AWS Redshift 中。
更详细地说,数据验证需要每天对坏数据/丢失数据发出警报,接收必须强制执行数据约束,即不重复,并且对于敏感的交易和公司数据来说,速度和安全性是最重要的。这最初导致了一个问题,因为 AWS 红移不强制数据约束。如果有欺骗,它接受它。
符合监管要求的安全解决方案
数据是他们业务的基础,处理敏感数据意味着纳斯达克的安全要求很高,因为他们是一家受监管的公司,必须对 SEC(美国证券交易委员会)负责。
因此,他们需要安全的系统,因为大数据的一大挑战是,它将使个人财务信息更加分散,因此更容易被窃取。AWS Redshift 通过提供多层安全来满足安全要求:
- 直接连接(专线,即没有公司数据通过互联网线路传输)。
- VPC-将 Nasdaq Redshift 服务器与其他设备隔离/互联网连接+安全组限制入站/出站连接。
- 动态加密(HTTPS/SSL/TLS)。所有 AWS API 调用都是通过 HTTPS 进行的。SSL(安全套接字层)意味着有一个验证集群身份的集群证书认证系统。
- 红移中的静态加密(AES-256)。这意味着红移加载文件是在客户端加密的。
- CloudTrail/STL_connection_Log 来监控未授权的数据库连接。这意味着监控集群访问并对任何未经授权的连接做出反应。
此迁移项目的优势实现如期完成,并带来了以下优势:
●红移成本是传统数据仓库预算的 43%(对于大约 1100 个表的相同数据集)
●2014 年平均每天 55 亿行
●高水位线=一天 14 行
●下午 4 点到 11 点摄入
●最佳写入速率约为 2.76 兆行/秒
●现在查询运行速度比传统系统更快。
●数据存储负载增加到 1200 多张表。
●通过安全审核。内部控制;信息安全,内部审计,纳斯达克风险委员会。外部审计;SOX,SEC。
Redshift 通过在多个数据中心复制数据解决了灾难恢复问题。
纳斯达克(2014 年)的当前数据存储需求= 450 GB/天(压缩后)加载到 Redshift 中。之前的压缩平均值,即未压缩= 1,895 GB/天。集群每季度调整一次大小以满足需求。NDW(纳斯达克数据仓库)目前每季度增长 3 倍!
纳斯达克的另一个问题是在不影响性能和成本的情况下的可扩展性。NASDAQ 发现 Apache Hadoop 和大数据分析所需的基础架构可能难以管理和扩展。所有这些过去的不同技术不能很好地协同工作,管理所有这些技术的成本也很高。
因此,It 使用云虚拟化来消除硬件限制,降低软件基础架构软件复杂性、成本和部署 Hadoop 和 Spark 的时间。虚拟化简化了所需的技术和资源数量,最大限度地提高了处理器利用率(18–20%到 80–90%),保持了安全性,并且通过虚拟化将性能提高了 2%。
从工程和运营的角度来看,纳斯达克能够满足客户的大数据分析需求,而无需增加员工数量。因此,蓝色数据帮助纳斯达克推动了创新(Greene,2017)。
挑战

Jukan Tateisi 在 Unsplash 上拍摄的照片
GDPR(2018 年 5 月 25 日生效):(Zerlang,2017 年)确认数据处理的透明度是 GDPR 的核心。跨境金融服务必须将所有对话记录至少 5 年,否则可能会被罚款,例如巴克莱因错误报告 5750 万笔交易而被罚款 245 万英镑。同样,(Gilford,2016)指出,GDPR 可能会因数据安全违规对乐购银行罚款 19 亿英镑。
金融机构必须审查当前的合规流程。客户同意的数据只能用于同意的目的,这意味着任何历史大数据分析示例客户信用卡消费数据都必须销毁。价值数十亿美元的信息将会丢失。因此,金融机构应该重新审视收集数据的过程。
未来的预测建模技术必须是非歧视性的。金融机构必须根据新的 GDPR 准则重新设计它们的算法和自动化流程。
(Lahiri,2017 年)声明 GDPR 将更新欧洲数据保护规则,违反规则将付出高昂代价;2000 万欧元或 4%的营业额。(LeRoux,2017)声称 GDPR 的新法规将成为大数据的杀手。(Woodie,2017 年)证实,GDPR 的新修正案将为欧盟 7.43 亿消费者制定强制性数据处理流程、使用透明度和消费者友好型隐私规则。
数据隐私共享机密信息会导致法律和商业风险(Deutsche,2014)。此外,交叉链接异构数据以重新识别个人身份是一个隐私问题(Fhom,2015)。因此,不当使用此类敏感数据可能会引起法律纠纷。
熟练的劳动力解读大量的大数据也是一个巨大的挑战,因为错误预测的结果可能代价高昂。因此,训练有素的大数据技术员工至关重要,因为(Fhom,2015)预测将会出现大数据专业人员短缺。
因此,公司应该在实施大数据项目之前计划培训或雇佣新员工。(McAfee 等人,2012 年)还提倡将强大的领导力、良好的公司文化、适应新技术的意愿作为大数据成功的关键因素。
构建大数据基础设施的成本短期来看非常昂贵,但长期来看将为金融公司带来竞争优势。根据(Davenport,2013),花费在大数据上的时间和金钱的合理性 (ROI) 并不透明。因此,该公司的高层管理人员将长期战略押在了大数据上。
结论

总之,所研究的不同案例显示了正在使用的各种大数据技术和优势,如 Nasdaq & AWS RedShift 案例中的存储减少,以及由此带来的从 6PB 到 500GB 的存储减少。
从这些案例研究中,我们发现接受调查的所有公司都非常重视积极利用大数据来实现自己的使命和目标,并有着共同的目标。它们之间有一些共性,例如更有针对性的营销,也有一些差异,例如存储所采用的不同类型的技术。
通过分析大数据,行业参与者可以提高组织效率,改善客户体验,增加收入,提高利润,更好地预测风险,并可以洞察进入新市场的情况。(尹等,2015)行情大数据提升运营效率 18%。
同样,(McAfee 等人,2012 年)指出,与市场上的竞争对手相比,数据驱动型公司的生产率平均高出 5%至 6%。银行将快速获得更好的数据洞察力,以便做出有效的决策。
参考
● AWS 案例研究。可从https://aws.amazon.com/solutions/case-studies/nasdaq-omx/获得
●大数据革命。可从https://www . data Maran . com/the-big-data-revolution-doing-more-for-less/获取
● BNY 梅隆大学(2016),BNY 梅隆大学的潘兴引入了额外的功能,使客户能够将大数据转化为大见解。可从https://www . Pershing . com/news/press-releases/2016/bny-mellons-Pershing-introduces-additional-capabilities-enabled-clients-to-transform-big-data 获取。
● Celent (2013 年)。风险管理中的大数据:提供新见解的工具。可从 https://www.celent.com/insights/903043275.获得
●花旗(2017)。寻找阿尔法:大数据。导航新的备选数据集。可从 https://eaglealpha.com/citi-report/.获得
达文波特(2013 年)。大公司的大数据。可从http://resources . idgenterprise . com/original/AST-0109216 _ Big _ Data _ in _ Big _ companies . pdf 获取
●德意志银行(2014 年)。大数据:它如何成为差异化优势。可从http://CIB . db . com/docs _ new/GTB _ 大数据 _ 白皮书 _(DB0324)_v2.pdf 获得
●经济学人信息部(2014 年)。零售银行和大数据:大数据是更好的风险管理的关键。可从https://www . eiuperspectives . economist . com/sites/default/files/retailbanksandbigdata . pdf 获得
●埃夫里(2014 年)。面向营销人员的银行业大数据。可从 https://www . evry . com/global assets/insight/bank 2020/bank-2020-big-data-whitepaper.pdf 获得。
Fhom,H.S. (2015)。大数据:机遇和隐私挑战。可从 http://arxiv.org/abs/1502.00823.获得
福斯特,赵,杨,莱库,陆,2008 年 11 月。云计算和网格计算 360 度对比。2008 年网格计算环境研讨会。GCE’08(第 1-10 页)。IEEE。吉尔福德·g .(2016 年)。GDPR 银行违规罚款 19 亿英镑。可从https://www . HR solutions-uk . com/1-9bn-fines-gdpr-bank-breach/获取
●格林,M. (2017)。纳斯达克:用蓝色数据克服大数据挑战。可从 https://itpeer network . Intel . com/Nasdaq-comprising-big-data-challenges-bluedata/获得。
●凯斯勒,s .,阿默,f .,埃斯皮诺萨,J.A .和钱,w .,2013 年 1 月。大数据:前进中的问题和挑战。在系统科学(HICSS),2013 年第 46 届夏威夷国际会议(第 995-1004 页)。IEEE。
●卡尔瓦基(2015 年)。土耳其五大银行。可从http://www . The Banker . com/Banker-Data/Bank-Trends/The-top-five-banks-in-Turkey 获得?ct =真
●诺克斯(2015)。金融服务中的大数据。可从https://www . slide share . net/swift community/nybf 2015 big-dataworksession final 2 mar 2015获取
● Lahiri,K. (2017) GDPR 和英国退出欧盟:离开欧盟如何影响英国的数据隐私。可从https://www . cbronline . com/verticals/CIO-agenda/gdpr-英国退出欧盟-离开-欧盟-影响-英国-数据-隐私/ 获取
●纽约勒鲁(2017 年)。GDPR:即将出台的法规会扼杀大数据吗?可从https://www . finance digest . com/gdpr-is-the-about-regulation-killing-off-big-data . html获得
Lippert,J. (2014 年)。Zest Finance 发放小额高利率贷款,利用大数据剔除赖账者。可从https://www . Washington post . com/business/zest finance-issues-small-high-rate-loans-uses-big-data-to-weed-out-dead beats/2014/10/10/e 34986 b 6-4d 71-11e 4-aa5e-7153 e 466 a02d _ story . html?utm_term=.6767c7abfefb.
刘,杨,张,2013 年 9 月。大数据技术概述。工程和科学互联网计算(ICICSE),2013 年第七届国际会议(第 26-29 页)。IEEE。
马尔,B. (2016 年)。花旗集团利用大数据改善银行绩效的惊人方式。可从https://www . LinkedIn . com/pulse/amazing-ways-Citigroup-using-big-data-improve-bank-performance-marr/获得。
● McAfee,a .,Brynjolfsson,e .和 Davenport,T.H .,2012。管理革命。哈佛商业评论,90(10),第 60-68 页。
普拉曼尼克,S. (2013 年)。大数据用例-银行和金融服务。可从https://thebigdata institute . WordPress . com/2013/05/01/big-data-use-cases-banking-and-financial-services/获取
Preez 博士(2013 年)。德意志银行:遗留系统阻碍了大数据计划。可从https://www . computer world uk . com/data/Deutsche-bank-big-data-plans-hold-back-by-legacy-systems-3425725/获得
s .萨吉罗格卢和 d .西纳克,2013 年 5 月。大数据:综述。协作技术与系统(CTS),2013 年国际会议(第 42-47 页)。IEEE。
● Statista (2016)。大数据。可从 https://www-statista-com . ez proxy . Westminster . AC . uk/study/14634/big-data-statista-filoral/获取。
● Timmes,J,2014,《地震式转变:纳斯达克向亚马逊红移的迁移》。可从https://www . slide share . net/Amazon web services/fin 401-seismic-shift-nas daqs-migration-to-Amazon-redshift-AWS-reinvent-2014获取
●M . Trombly,2000 年,创纪录的交易量使纳斯达克陷入困境。可从https://www . computer world . com/article/2593644/it-management/record-volume-stalls-Nasdaq . html获得
●判决,(2017)。GDPR 的监管规定可能会让银行在头三年被处以超过€47 亿英镑的罚款。可从https://www . verdict . co . uk/what-is-gdpr-regulations-could-cost-banks-over-E4-70 亿-in-fines-first-three-years/
● Woodie,A. (2017)。GDPR:告别大数据的蛮荒西部。可从https://www . datanami . com/2017/07/17/gdpr-say-goodbye-big-datas-wild-west/获取
●尹,s .和凯纳克,o . 2015。现代工业的大数据:挑战和趋势[观点]。IEEE 会议录,103(2),第 143-146 页。
●泽朗,J. (2017 年)。大数据和 GDPR;金融中的风险和机遇。可从https://www . accounting web . co . uk/community/blogs/jesper-zer lang/big-data-and-gdpr-risk-and-opportunity-in-finance获取
现在,把你的想法放在 Twitter ,Linkedin,以及Github*!!*
同意 还是 不同意 与 Saurav Singla 的观点和例子?想告诉我们你的故事吗?
他对建设性的反馈持开放态度——如果您对此分析有后续想法,请在下面的 评论 或联系我们!!
推文@ SauravSingla _ 08、评论Saurav _ Singla,还有明星SauravSingla马上!

















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










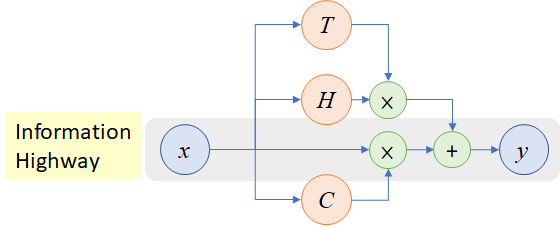{kind=link}