







是否应该抛弃云计算,拥抱边缘计算?
边缘计算正在呈指数增长,但它是什么,如何使用,在哪里使用,它会取代云吗?

介绍
这篇文章有望向您介绍边缘计算。我们将把它与云计算进行比较,讨论它的主要优缺点和一些使用案例。顶端的樱桃:文章最后对边缘计算的预测,以及云计算是否会被边缘计算淘汰。
云计算现在已经深入我们的日常生活。不管你是否意识到,你现在可能正在使用它。从显而易见的在线云存储(想到 Dropbox 和 OneDrive)、通信服务(电子邮件&消息)、数字助理(Siri、Alexa、谷歌助手),到娱乐内容提供商(Spotify、网飞……)。
这些服务是集中的。无论您何时发送请求,它都会被发送到云提供商,经过处理后返回给您。简单地说:

作者创作—Raul Almu 在 Shutterstock 上创作的右侧图像
非物质化的程度在过去几十年中有所提高。这与以前使用物理存储的模式不同,想象一下访问 CD/DVD:

作者创作 PNG 创作的右侧图像(来源)
在这两个极端之间,现在出现了另一种范式:边缘计算。
什么是边缘计算?
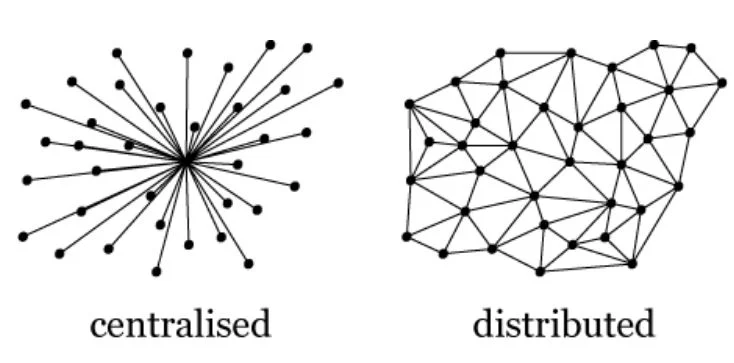
边缘计算可以定义为“集中式云计算的本地分布式扩展”。
它在图中的什么位置?
要了解边缘计算的地位,我们先来对比一下云计算。
云计算是集中式的:
- 所有者/管理者:大部分云计算由四家公司管理——亚马逊、微软、谷歌和 IBM,
- 区域:数据存储在数据中心,
- 数据处理:处理/计算在数据中心进行。

罗伯特·怀特在 Focus-works.com 拍摄的图片
边缘计算是分布式的:
- 所有者:一家公司可以拥有一台边缘服务器,并将其安装在本地,
- 区域:数据存储更靠近用户位置(在‘网络边缘’),在需要的地方,
- 数据处理:大部分数据处理发生在分布式设备节点(IoT 设备——物联网),或者本地。数据中心因此变得可有可无。
此外,它还通过物联网设备与物理世界互动,例如传感器和摄像头(稍后将详细介绍)。

罗伯特·怀特在Focus-works.com拍摄的图片
云和边缘计算如何互动?

由 NoMore201 创建— CC BY-SA 4.0,在维基百科
- 从底部的三分之一开始,我们看到物联网传感器交互并从物理世界收集数据。
- 在中间,数据在本地边缘服务器上处理。这些数据可以在其他边缘服务器之间存储和交换。请注意,在某些情况下,数据的处理可能已经发生在物联网设备层面。
- 云层在这里是可选的,它在任何繁重的处理过程中充当支持,或者用于存储历史数据。
现在,让我们回顾一些边缘计算的使用案例,以了解它在未来可能会颠覆哪些行业。
边缘计算的应用和使用案例
制造、零售和智能城市是边缘计算实施的三个主要潜在领域。
- **制造:**在整个生产周期中,放置在不同机器上的大量传感器用于测量速度、温度、化学品或溶液的浓度水平。传感器收集的数据可用于预测性维护、预测任何刹车以及进行库存管理。
- **零售:**库存跟踪&管理,优化库存、物流和跟踪。
- **智慧城市:**可以通过物联网摄像头分析行人流量,使用传感器管理停车场,使用物联网摄像头优化交通灯,以及联网车辆。
现在让我们来看看边缘计算的优势和劣势。
优势
- 金融

金钱几乎是一切事物的核心。对于边缘计算为什么会成为使用云计算的环境的有趣替代或补充,这并不令人惊讶。使用 edge 的一些好处可以减少:
- 云和存储成本
- 带宽使用
此外,通过在本地处理信息,可以提高反应速度和决策能力。根据一些估计,与云解决方案相比,成本可以降低三分之一。
- 网络安全

丹·尼尔森在 Unsplash 上拍摄的照片
用户和组织越来越关注安全性和隐私。边缘计算在这个问题上也有自己的观点:
- 本地分析—分析现在在本地进行,即物联网设备(传感器/摄像机)和本地边缘服务器之间的数据流。
- 有限的传输——当使用常规云解决方案时,整个数据流必须加密并发送到数据中心,进行解密和处理,然后将结果返回给机器或用户。使用边缘计算,计算在本地发生,在物联网设备或边缘服务器的级别,唯一的传输将是返回的结果。
- 主权 &合规

马库斯·斯皮斯克在 Unsplash 拍摄的照片
随着时间的推移,这两个因素变得越来越重要。在竞争激烈的世界中,数据是一项关键资产。领导者希望保留对这一关键组件的监管,同时遵守现有的法规。
- 对个人数据的主权可以通过边缘计算等本地解决方案来实现。尽管通过使用云解决方案,用户确实保留了其数据的所有权,但这可能会让领导者放心,因为他们的数据“触手可及”,而不是远在数据中心。
- 边缘计算还通过将数据存储和处理等事项保持在本地,使其更容易遵守数据法规(GDPR 和其他法规)。
- 更快的部署
除了成本,解决方案的部署速度也是公司尽快获得收益的一个重要因素。
工业领域的部署预计只需 6 个月,而其他解决方案则需要 24 个月。更快的部署还意味着更低的成本和可以更快利用的新工具,以便做出更好、更快的决策。
- 高反应性
使用边缘服务器进行本地数据处理意味着快速处理,远离对远程数据中心的依赖。有限的数据批次上的反应性差异可能不明显,但是在要传输的批次很大的情况下,本地边缘服务器会有所不同。
当涉及到关键决策的高反应性时,如自动驾驶汽车,边缘计算也将具有…优势。双关语。无人驾驶汽车正在从无数传感器收集数据,远程数据中心没有时间审查信息并返回警告以踩刹车。
- 交通

杰克·吉文斯在 Unsplash 上的照片
想象一个由相互连接的监控摄像头组成的网络。他们不断地向数据中心传输信息,在数据中心对信息进行分析,看是否有入侵行为。如果每个摄像机都以 6 MB/s 的速率传输,这又会增加房屋带宽使用的负担,并会降低企业的正常运营速度。数据流到达数据中心进行处理,如果怀疑有入侵行为,就会向用户发回警报信息。
借助边缘计算,记录的分析将在配有机器视觉功能的单个物联网摄像机内进行。在任何可疑入侵的情况下,摄像机将简单地发送一个警报消息,这只是几个字节对 6 Mb/s 的流。
不足之处
这是一个很好的优势列表,但人们应该保持批判的头脑,不要把这些优势视为理所当然。对能源成本、安全性、部署速度的宣称可以经受考验,时间会证明它们是否站得住脚。人们应该提出以下几个问题:
- 降低能源成本的说法是真的吗?他们能撑得住吗?
近年来,冷却数据中心的能效有了重大改善,例如“ ”谷歌刚刚将数据中心冷却的控制权交给了人工智能“”。
- 迁移到边缘计算会不会让组织变得更加脆弱?
随着物联网设备网络的实施,向边缘计算的转移意味着用于监控、修补和更新以防止网络攻击和降低风险的资产网络正在扩大。此外,物联网安全是物联网对象的已知风险和顾虑 ⁴ 。
我在这篇文章中讨论了这个问题:
物联网正迅速进入我们生活的各个领域。你的新收音机,你的真空机器人,你的新…
medium.com](https://medium.com/@godfroidmaxime/cyber-security-in-the-time-of-iot-some-simple-steps-to-stay-safe-17a73b10bc0b)
- 部署速度的说法会被验证吗?
人们应该记住,当前对快速部署的宣称是由提供商提出的。这被用作一个强有力的卖点。边缘计算领域尚未成熟,时间将提供支持或拒绝这些说法的证据。
预测和趋势
- 今天,互联网和云计算主要由美国和中国公司主导。你可能已经猜到了哪些是美国公司。

Photo 黑客在 IphoneHacks.com拍摄的照片
从中国方面来看,精通技术的读者肯定也会认出这些巨头:

彼得·菲斯克在基因工程上拍摄的照片
他们已经成长为巨人,而欧洲正在落后,看不到主要冠军。
- 明天,在汽车制造和其他制造领域、医疗保健和能源行业巨头的帮助下,欧洲可能会在边缘计算领域处于领先地位。这可能比我们想象的要快。

照片由 Christian Lue 在 Unsplash 上拍摄
Gartner⁵的一项研究估计:
大约 10%的企业生成数据是在传统的集中式数据中心或云之外(作者注,即通过 edge)创建和处理的。Gartner 预测,到 2025 年,这一数字将达到 75%。
云计算的终结?
考虑到上述数字,人们可能会想云计算是否会简单地消失,被边缘计算淘汰。
虽然边缘计算预计到 2025 年将处理 75%的企业生成数据这一事实是一个令人印象深刻的变化,但应该在整体背景下看待这一变化:
- 每天产生的数据量是惊人的。在 year⁶.,它每年都在上升这意味着馅饼的大小在增加,尽管其预期的%份额相对下降,云计算将继续处理越来越多的数据。
- 如前所述,云计算和边缘计算的使用是不同的,它们在一定程度上重叠,但也有其特殊性。
人们不会看到边缘取代云,而是会根据需要,两者都被采用:
“Edge 将需要与云中、企业数据中心或其他设备上的其他工作负载进行通信和交互。”
- 云计算将进一步支持大数据应用,处理海量数据集,基于机器学习算法训练模型。本质上,大数据太大,无法在本地考虑,要以适当的规模运行,应该在云中运行。
总结或 TL;博士;医生
- 边缘计算是集中式云计算的本地分布式扩展,
- 边缘与本地环境相互作用。机器或联网车辆上的物联网摄像头或传感器是这个生态系统的一部分。它们在网络边缘本地捕获、处理和分析交互(因此称为“边缘计算”),而不是将数据发送到云以获得这些见解。
- Edge 的应用有望颠覆制造业、零售业和智能城市领域,
- 边缘计算的优势是财务、网络安全、高反应性、部署速度、主权和数据合规、带宽流量少。这些声称的优势能否经受住时间的考验还有待观察。
- Edge 处理 10%的企业生成数据,预计到 2025 年将达到 75%。在制造业、健康和能源领域的领军企业的帮助下,欧洲有望成为边缘计算的领导者。
- 随着边缘计算的兴起,云计算处理的数据份额预计将相形见绌。但是云不会消失,根据具体情况的需要,这两种模式有望并存。
感谢阅读!加入 Medium 完全访问我的所有故事。
参考
[1]保罗·米勒,什么是边缘计算? (2018)、https://www . the verge . com/circuit breaker/2018/5/7/17327584/edge-computing-cloud-Google-微软-苹果-亚马逊
[2][3]塞利娅·加西亚-蒙特罗, L’edge computing,un outil in contourable dans L ’ industrie 4.0(2019)https://www . journal dunet . com/e business/internet-mobile/1420755-L-edge-computing-un-outil-in contourable-dans-L-industrie-4-0/
[4] EY,EY 网络安全与物联网(2015), EY 网络安全与物联网
[5] Rob van der Meulen,边缘计算对基础设施和运营领导者意味着什么 (2018),https://www . Gartner . com/smarterwithgartner/What-Edge-Computing-Means-for-infra structure-and-Operations-Leaders/
[6]大卫。F. Carr,边缘计算与云计算:有什么区别? (2020),https://enterprisers project . com/article/2020/4/edge-computing-vs-cloud-what-is-difference
我们应该对民调和选举结果的差异感到惊讶吗?
剧透:没有

由 Unsplash 上的 Element5 数码拍摄
在 2020 年选举的投票预测和选举结果之间出现几次差异后,选举投票再次受到审查。首先,在密歇根州和威斯康星州等关键州的一些总统竞选结果比民调显示的还要激烈。第二,在佛罗里达州和北卡罗来纳州,根据选前民调,拜登原本预计会赢,但最终却输了。第三,特朗普在俄亥俄州和德克萨斯州等州拥有令人信服的选票份额优势,根据民调,这些州被认为是更接近的竞选(见 Silver,2020)。
Nate Silver 认为,尽管民意调查预测的总统选举结果与 2016 年和 2020 年选举的实际结果之间存在差异,但没有足够的证据表明民意调查的质量随着时间的推移明显恶化(Silver,2018 年,2020 年)。例如,2016 年州级总统民调的投票份额差距平均比实际结果低 5.2 个百分点。虽然平均 5.2 点的民调误差可能看起来很大,但这并不罕见,因为 1972 年至 2016 年间所有总统选举的平均州级民调误差为 4.8 点(Silver,2018)。因此,当我们看到 2020 年密歇根州、威斯康星州、佛罗里达州、北卡罗来纳州、俄亥俄州和德克萨斯州的选举结果时,我们应该感到惊讶吗?我个人不这么认为。事实上,我不认为我们应该期望民意调查能够始终如一地提供最终选举结果的精确近似值。请允许我详细说明。
调查更擅长描述而不是预测
一个设计良好的调查可以是一个很好的工具,用来描述一个群体的特征,这些特征可以通过回答者相对容易回答的问题来衡量。然而,根据对假设情景的反应来获得个人未来行为的可靠测量更具挑战性。通过询问受访者,如果选举在今天举行,他们会投谁的票,民意调查实际上是要求受访者在假设的情况下对他们的行为做出解释。使用候选人偏好问题来预测选举结果的问题是双重的。首先,不能保证被调查的个人也会投票。声誉良好的投票组织尽最大努力识别可能的投票者,但可能的投票者在实际投票之前仍然不是投票者(参见 Rosentiel,2012 年关于如何确定谁是可能的投票者的讨论)。第二,即使一个可能的选民真的会去投票,那个可能的选民也可能在投票日和选举日之间改变主意。
抽样误差
民意测验是在给定的时间范围内对样本进行的调查。因为样本只是总体中的一部分,所以样本值在多大程度上代表了更广泛总体中的潜在真实值,总是存在一定程度的不精确性。这种因测量样本而非总体而存在的不精确性被称为抽样误差。在民意测验中,抽样误差通常用误差幅度(MoE) 来表示,它反映了从民意测验中得出的兴趣估计值(例如,可能投票给某个候选人的选民的百分比)与相应人群中的真实值有多远。
例如,假设一项民意调查发现,53%的可能选民会投票给候选人 A,MoE 为+/- 4%。这意味着,如果选举在给定的投票日举行,我们估计可能投票的人口中有 53%会投票给候选人 A,但是我们也承认,打算投票给候选人 A 的人口的真实百分比可能与投票估计不同,因为投票没有测量整个人口。尽管如此,我们至少可以说,如果选举在投票日举行,我们有 95%的信心认为,投票给候选人 A 的估计百分比与投票给候选人 A 的实际百分比相差不超过 4 个百分点(见 Mercer,2016)。
如上例所示,所报告的 MoE 通常是指打算投票给某个候选人的参与者的百分比。然而,重要的是要注意,每个候选人的支持百分比之间的差的 MoE 接近个人百分比 MoE 的 2 倍(Franklin,2007;美世,2016)。让我们再来看一次假设的民意调查,其中 53%的可能投票者表示他们将投票给候选人 A,假设只有两个候选人参加竞选,那么 47%的可能投票者表示他们将投票给候选人 B。候选人 A 领先候选人 B 6 个百分点,考虑到 MoE 为 4%,人们可能会得出这样的结论:候选人 A 的领先优势具有统计学意义,因为 6%超出了 4%的 MoE。然而,候选人之间的差异的 MoE 大约是单个候选人 MoE 的 2 倍,即 8%而不是 4%。虽然根据我们的民意调查,我们估计候选人 A 比候选人 B 有 6 个百分点的优势,但这是一个单一的估计,由于抽样误差,它具有不确定性。尽管如此,我们可以量化这种不确定性,并声明-2 到 14 个百分点的区间可能捕捉到感兴趣的人群差异。然而,由于该区间包含负值,这表明倾向于投票给候选人 B 的百分比较高,因此我们不能确信候选人 A 在本次民意调查中的领先不仅仅是由于抽样误差。那么,我们最好把这场比赛解释为一场胜负难料的比赛。这里的教训是,在选举中仅仅看候选人的投票份额是不够的。还需要考虑对 MoE 的正确解释,因为 MoE 提供了对投票估计的统计精度的感觉。
无反应
鉴于近年来许多调查中的历史低回复率,无回复是调查的一个问题(例如,Keeter 等人,2017 年;皮尤研究中心,2012 年;威廉姆斯&布里克,2018)。特别值得关注的是,无响应系统 可能会导致低估或高估,这种现象称为无响应偏差。然而,重要的是要认识到,高无应答率本身并不一定保证偏差,相反,当应答者与无应答者在具体措施上存在差异时,调查中的具体估计值会因无应答而产生偏差(Groves,2006;Groves & Peytcheva,2008)。
不幸的是,有理由怀疑特朗普的支持者可能在 2020 年不太可能对电话民调做出回应(Cohn,2020;法农,2020;另见 Gelman 等人,2016;莱维兹,2020;马修斯,2020;斯坦顿,2020)。如果特朗普的支持者相对于拜登的支持者更不愿意参与民意调查,这将高估拜登在民意调查中的支持,因为在这种情况下,不同的无回应将与候选人偏好相关联。
虽然目前需要对特朗普和拜登支持者在 2020 年的不回应模式进行更多研究,但我想在这里强调的要点是,每当阅读民意调查时,人们都应该意识到参与民意调查完全是自愿的。具有特定政治倾向的个人可能或多或少会对特定选举中的民意测验做出反应。当这种现象发生时,根据谁更可能是不响应者,投票的投票意向结果可能被低估或高估。虽然无回答偏差不是已知的,但我认为更保险的假设是,投票结果在某种程度上受到不同无回答的影响,特别是在竞争激烈的州的竞选中。
那么,现在怎么办?
应该以适度的怀疑态度对待基于民意调查的预测选举结果。意识到民意调查是受抽样误差和潜在无回答偏差影响的快照这一事实,选举日(或周或月)的实际结果可能远不如民意调查显示的投票份额优势那样具有决定性就不足为奇了。好吧,好吧,你可能会说,但是如果民调估计有这么多不确定性,那么民调还有用吗?
如果民意测验是根据他们在选举日预测获胜者的精确程度来评判的,那么不,许多民意测验并不是非常有用。如果投票被视为一种工具,有助于提供对候选人在特定时间点的总体表现的一些见解,那么投票可能会有更多的承诺。当多次民意调查一致显示某个候选人在该候选人的政党和观点历来表现良好的州大幅落后时,这可能对该候选人不是一个好兆头,可能是该候选人的竞选活动需要做出改变的证据。类似地,如果多项民调显示,在可能影响候选人前景的事件(比如某种丑闻)发生后,支持度发生了实质性变化,那么这也可以作为一个警告。当然,描述可能有用的投票情况的这两个场景假设可能投票的选民实际上可能投票,并且投票中的相关测量不会受到无响应偏差的不当影响。如果这些假设不满足,那么区分结果是数据的人工产物还是投票人群中实际倾向的代表就更具挑战性了。对我来说,判断民调的有用性最终与民调提供最终选举结果的准确预测的能力无关,而是与民调在选举前特定时间点提供代表性见解的程度有关。
参考
科恩,纽约州(2020 年 11 月 10 日)。民意测验出了什么问题?一些早期的理论。《纽约时报》。https://www . nytimes . com/2020/11/10/upshot/polls-what-go-wrong . html
Fannon,E. (2020 年 11 月 6 日)。为什么民调又错了。 WKOW 。https://wkow.com/2020/11/05/why-the-polls-were-wrong-again/(2007 年)。民意测验中差异的误差幅度。美国广播公司新闻。
格尔曼,a .,戈尔,s .,里弗斯,d .,&罗斯柴尔德,D. (2016)。神秘的摇摆选民。《政治学季刊》, 11 (1),第 103–130 页。
格罗夫斯,R. M. (2006)。家庭调查中的无回答率和无回答偏差。舆情季刊, 70 (5),646–675。
Groves,R. M .,& Peytcheva,E. (2008 年)无应答率对无应答偏倚的影响:一项荟萃分析。民意季刊, 72 (2),第 167–189 页。
Keeter,s .,Hatley,n .,Kennedy,c .,和 Lau,A. (2017 年 5 月 15 日)。低回复率对电话调查意味着什么。皮尤研究中心方法。https://www . pewresearch . org/methods/2017/05/15/what-low-response-rates-mean-for-telephone-surveys/
列维兹,E. (2020 年 7 月 17 日)。大卫·肖尔的美国政治统一理论。情报人员。https://nymag . com/intelligence r/2020/07/David-shor-cancel-culture-2020-election-theory-polls . html
马修斯博士(2020 年 11 月 10 日)。一位民意调查者解释了为什么民意调查出错。Vox。https://www . vox . com/policy-and-politics/2020/11/10/21551766/election-polls-results-error-David-shor
美世公司(2016 年)。了解选举民意调查的误差幅度。皮尤研究中心。https://www . pewresearch . org/fact-tank/2016/09/08/understanding-the-margin-of-error-margin-in-election-polls/
皮尤研究中心。(2012 年 5 月 15 日)。评估民意调查的代表性。皮尤研究中心——美国政治&政策。https://www . pewresearch . org/politics/2012/05/15/assessing-the-representative-of-public-opinion-surveys/
t .罗森泰尔(2012 年 8 月 29 日)。确定谁是“可能的选民”。皮尤研究中心。https://www . pewresearch . org/2012/08/29/ask-the-expert-determining-who ’ s-a-possible-voter/
纽约州西尔弗市(2018 年 5 月 30 日)。民意调查没问题。五三八。https://fivethirtyeight . com/features/the-polls-are-all-right/
纽约州西尔弗市(2020 年 11 月 11 日)。民意测验不太好。但这很正常。五十八。https://fivethirtyeight . com/features/the-polls-not-great-but-that-pretty-normal/
斯坦顿,Z. (2020)。“人们将会感到震惊”:害羞的特朗普选民的回归?POLITICOhttps://www . POLITICO . com/news/magazine/2020/10/29/2020-民调-川普-拜登-预测-准确-2016-433619
威廉姆斯博士和布里克博士(2018 年)。美国面对面家庭调查的趋势:无回应和努力程度。调查统计与方法学杂志, 6 (2),186–211。
你应该买还是租下一辆车?端到端项目
探索这个项目,从收集数据到创建强回归的集合,再到回答你是否应该购买或租赁下一辆车

概观
在本帖中,我们将从头到尾浏览一个完整的数据科学项目,并给出问题的结论——你应该购买还是租赁下一辆车?
该项目将包括以下部分(请随意跳到您最感兴趣的部分):
- 把问题框起来,看大局
- 获取数据
- 探索数据
- 准备数据
- 选择和训练模型
- 微调系统
- 分析最佳模型的误差
- 结论
要在 Github 上查看该项目,请点击以下链接此处!
把问题框起来,看大局
这个项目的目标是通过比较汽车租赁的总费用和汽车的折旧成本来确定汽车租赁是否划算。如果租赁费用更高,我们可以得出结论,购买新车并转卖会更符合 T2 的成本效益。然而,如果租赁比我们认为的便宜,你应该租赁而不是购买。
通过使用机器学习,我们预测汽车的价格,并使用它来计算折旧成本,并与租赁成本进行比较。
我们使用的指标是均方根误差(RMSE ),因为它给出了系统在预测中通常会产生多大误差的概念,误差越大,权重越高。
所以现在我们需要数据。我们没有收集数百辆不同汽车的数据,而是只收集了一辆最好的出租汽车——讴歌 TLX 的数据。这有助于我们简化问题,如果我们得出结论,你应该购买而不是租赁这辆车,我们可以得出同样的结论较低的汽车。
获取数据
在这个项目中,我们使用 BeautifulSoup 的图书馆收集数据。我们在网上搜索 Truecar.com 的讴歌 TLX 汽车列表。笔记本完整的代码用于网页抓取可以在这里找到。
该项目的其余部分的代码可以在这里查看。
让我们加载通过网络搜集收集的数据,并对其进行初步研究。
CARS_PATH = os.path.join(PROJECT_ROOT_DIR, "datasets")
**def** load_car_data(cars_path=CARS_PATH):
csv_path = os.path.join(cars_path, "cars.csv")
**return** pd.read_csv(csv_path)cars = load_car_data()
让我们看看我们的数据集有多完整。通过查看每一列的 null 值的百分比,我们可以很好地了解我们正在处理的缺失值的数量。
cars.isnull().sum() / len(cars)

每列的百分比 Null
我们看到在我们的 6 列中有缺失值。具体在我们的目标变量价格和属性驱动、发动机、内饰、外观颜色、和内饰颜色。由于价格是我们的目标变量,我们将不得不放弃这些实例。由于 Drive、Engine 和 Trim 的缺失值百分比非常低,因此也可以删除与这些实例相关的实例。由于外部和内部颜色超过 10%为空,可能对价格没有太大的预测能力,我们将继续从数据集中删除这些列。
cars = cars.drop(columns=["Exterior_color", "Interior_color"])
cars = cars.dropna(axis=0)
cars.reset_index(inplace=**True**)
创建测试集
我们在这里使用分层分割来确保我们的测试集代表整个数据集中的各种比率。由于我们相信某些特征(如汽车年份)将是非常重要的价格预测因素,因此我们确保它们在训练集和测试集之间均匀分布。通过使用分层分割,我们避免了抽样偏差,即测试不能代表整个数据集。
下面的代码使用 pd.cut()函数创建一个包含 6 个类别的 year category 属性(标记为 0 到 5,对应于数据集中的每一年):
cars["Year_cat"] = pd.cut(cars["Year"], bins=[2014.5, 2015.5, 2016.5, 2017.5, 2018.5, 2019.5, 2020.5], labels=[0, 1, 2, 3, 4, 5]
现在我们准备根据 year 属性进行分层抽样。为此,我们可以使用 Scikit-Learn 的 StratifiedShuffleSplit()类:
**from** sklearn.model_selection **import** StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2)
**for** train_index, test_index **in** split.split(cars, cars["Year_cat"]):
train_set = cars.loc[train_index]
test_set = cars.loc[test_index]
现在,我们删除 Year_cat 属性,使数据恢复到原始状态:
**for** set_ **in** (test_set, train_set):
set_.drop("Year_cat", axis=1, inplace=**True**)
探索数据
现在,让我们发现并可视化这些数据,感受一下它的样子并获得一些见解。我们创建了一个训练集的副本,这样我们就可以在不破坏原始训练集的情况下使用它:
cars = train_set.copy()
下面是一个表,其中包含列、数据类型和详细描述它们包含哪些信息的简短描述。

我们将首先查看数字数据类型,并使用 corr()方法计算每对属性之间的标准相关系数:
corr_matrix = cars.corr()
现在让我们看看每个属性与价格的关联程度:
corr_matrix["Price"].sort_values(ascending=**False**)

检查属性之间相关性的另一种方法是使用 pandas scatter_matrix()函数,该函数将每个数值属性与其他数值属性相对照。
**from** pandas.plotting **import** scatter_matrix
attributes = ["Price", "Year", "Mileage", "Accidents"]
scatter_matrix(cars[attributes], figsize=(12,8))
save_fig("scatter_matrix_plot")

上图向我们展示了一些东西。事实上,年份和里程属性将是价格的强预测因素,并显示一些交互作用,我们可以通过创建一个新的功能,每年的里程来捕捉这些交互作用。此外,三起事故并不多见。将发生 2 次或 3 次事故的汽车归入一个 2 或更多的值可能是有益的。
要创建每年英里数属性,我们需要知道汽车的使用年限,而不是年份。我们通过从汽车年份中减去当前年份的绝对值来实现这一点。但是,我们无法将 2020 款讴歌 TLXs 除以 0,因此我们将 0 替换为 1(在这种情况下,属性 miles_per_year 将与 miles 相同)。
cars["Years_old"] = abs(cars["Year"] - 2020)
cars["Miles_per_year"] = cars["Mileage"] /
cars["Years_old"].replace(0, 1)
现在让我们看看我们的目标价格与新属性的相关性:
corr_matrix = cars.corr()
corr_matrix["Price"].sort_values(ascending=**False**)

太好了!我们发现它也与价格密切相关!
我想看的最后一个有趣的专栏是 Trim。该列包含许多信息,包括汽车上的性能套件类型。提取包并把它作为一个属性使用可能是有益的。让我们观察不同的 trims 和中间价格之间的相关性。
cars[["Price","Trim"]].groupby("Trim").median()

现在让我们提取包,看看包之间是否有明显的相关性。
**def** extract_package(trims):
packages = ["PMC Edition", "A-Spec", "Advance", "Technology"]
pat = '|'.join(r"\b**{}**\b".format(x) **for** x **in** packages)
packages = pd.Series(trims).str.extract("(" + pat + ")")
packages.fillna("Standard", inplace=**True**)
**return** packagescars["Package"] = extract_package(cars["Trim"].values)cars[["Price", "Package"]].groupby("Package").median()

解压软件包似乎没有太大的帮助。不同包装之间的相关性很弱,不符合我们预期的任何趋势。
摘要
现在我们对哪些特性是最有价值的有了一个很好的想法,并且探索了它们之间的关系。一些重要的发现是:
- 创建新列
miles_per_year增加了额外的预测能力。 - 发生 2 起以上事故的汽车在我们的数据集中非常稀少,最好与发生 2 起事故的汽车归为一组。我们通过这种方式保持了更强的相关性。
- 年份更适合用作序数特征。我们将减去该列的当前年份,以创建一个名为“years old”的列。
- 从 trim 中提取性能包可能有用,也可能没用。与价格没有明显的相关性,因此我们可以在数据准备阶段将它作为一个选项添加进来。
准备数据
是时候为机器学习算法准备数据了。我们没有手动这样做,而是为此编写函数,这有几个原因:
- 这将允许我们在任何数据集上重现这些转换(例如,下次您获得新的数据集时)。
- 我们将逐步建立一个转换函数库,可以在未来的项目中重用。
- 这将使我们能够轻松地尝试各种转换,并查看哪种转换组合效果最好。
我们需要一个数字属性和分类属性的准备管道。先说数值属性吧!
由于我们使用的是 Scikit-Learn,所以我们希望我们的转换器能够与 Scikit-Learn 功能(比如管道)无缝协作,但幸运的是,我们只需要创建一个类并实现三个方法:fit()(返回 self)、transform()和 fit_transform()。我们只需添加 TransformerMixin 作为基类,就可以免费获得最后一个。
我们还添加了 BaseEstimator 作为基类,为我们提供了两个额外的方法(get_params()和 set_params()),这对自动超参数调优很有用。
例如,这里有一个 transformer 类,它添加了前面讨论过的数字属性,并在我们将训练集传递给它时添加了它的输出。
**from** sklearn.base **import** BaseEstimator, TransformerMixin
**class** **NumericalAttributesAdder**(BaseEstimator, TransformerMixin):
**def** __init__(self, add_miles_per_year = **True**):
self.add_miles_per_year = add_miles_per_year
**def** fit(self, X, y=**None**):
**return** self
**def** transform(self, X):
years_old = abs(X["Year"] - 2020)
accidents_adjusted = X["Accidents"].replace(3, 2)
**if** self.add_miles_per_year:
miles_per_year = X["Mileage"] / years_old.replace(0, 1)
**return** pd.concat([X, years_old.rename("Years_old"),
accidents_adjusted.rename("Accidents_adj"),
miles_per_year.rename("Miles_per_year")],
axis=1) **else**:
**return** pd.concat([X, years_old.rename("Years_old"),
accidents_adjusted.rename("Accidents_adj")],
axis=1)
num_attr_adder = NumericalAttributesAdder(add_miles_per_year = **True**)
num_attr_adder.transform(X_train)

现在,在我们添加新的属性之后,我们想要选择在我们的机器学习算法中使用哪些属性。我们使用与上面相同的方法来创建一个选择属性的自定义转换器。
**class** **DataFrameSelector**(BaseEstimator, TransformerMixin):
**def** __init__(self, attribute_indices):
self.attribute_indices = attribute_indices
**def** fit(self, X, y=**None**):
**return** self
**def** transform(self, X):
**return** X[self.attribute_indices]
如您所见,有许多数据转换步骤需要按正确的顺序执行。幸运的是,Scikit-Learn 提供了 Pipeline 类来帮助处理转换序列。下面是数字属性的管道:
**from** sklearn.pipeline **import** Pipeline
**from** sklearn.preprocessing **import** StandardScalerattribs = ["Mileage", "Years_old", "Accidents_adj","Miles_per_year"]num_pipeline = Pipeline([
('num_attribs_adder', NumericalAttributesAdder()),
('select_numeric', DataFrameSelector(attribs)),
('std_scaler', StandardScaler())
])
我们使用上面的两个自定义转换器,然后使用 Scikit-Learn 的 StandardScaler()转换器来标准化所有数字属性。
现在下一步是为我们的分类属性创建一个管道。由于这些属性是字符串,我们需要使用 OneHotEncoder 将它们转换成数值。但是首先我们创建一个定制的转换器,它将从我们前面讨论的 Trim 属性中提取汽车的包。我们初始化 add_trim_features=True ,让我们选择是否添加新的包属性。
**class** **CategoricalAttributesAdder**(BaseEstimator, TransformerMixin):
**def** __init__(self, add_trim_features = **True**):
self.add_trim_features = add_trim_features
**def** fit(self, X, y=**None**):
**return** self
**def** transform(self, X):
**if** self.add_trim_features:
package = extract_package(X["Trim"])
**return** pd.concat([X, package.rename("Package")], axis=1)
**else**:
**return** X cat_attr_adder = CategoricalAttributesAdder(add_trim_features =**True**)cat_attr_adder.transform(X_train)

现在,我们分类属性的完整管道已经准备好了。我们使用 CategoricalAttributesAdder、DataFrameSelector 和 OneHotEncoder 将我们的分类属性完全转换为适合机器学习的格式。管道如下所示:
attribs = ["Drive", "Engine", "Trim"]cat_pipeline = Pipeline([
("cat_attribs_adder", CategoricalAttributesAdder()),
("select_categoric", DataFrameSelector(attribs)),
("one_hot", OneHotEncoder())
])
到目前为止,我们已经分别处理了分类列和数字列。如果有一个能够处理所有列的转换器,对每一列应用适当的转换,那将会更方便。幸运的是,Scikit-Learn 为此引入了 ColumnTransformer ,好消息是它对熊猫数据帧非常有效。让我们使用它将所有转换应用到训练集:
**from** sklearn.compose **import** ColumnTransformernum_attribs = ["Year", "Mileage", "Accidents"]
cat_attribs = ["Drive", "Engine", "Trim"]full_pipeline = ColumnTransformer([
("num", num_pipeline, num_attribs),
("cat", cat_pipeline, cat_attribs)
])
cars_prepared = full_pipeline.fit_transform(X_train)
在这个管道中,我们指定数字列应该使用我们之前定义的 num_pipeline 进行转换,而分类列应该使用我们之前定义的 cat_pipeline 进行转换。最后,我们将这个 ColumnTransformer 应用于训练集:它将每个转换器应用于适当的列,并沿着第二个轴连接输出(转换器必须返回相同数量的行)。
就是这样!我们有一个预处理管道,它接受完整的训练集,并对每一列应用适当的转换。
选择和训练模型
终于来了!我们构建了问题,获得了数据并对其进行了探索,对一个训练集和一个测试集进行了采样,我们编写了转换管道来自动清理和准备我们的数据以用于机器学习算法。我们现在准备选择和训练机器学习模型。
我们的第一个基本模型是一个线性回归,我们将尝试改进它。使用 Scikit-Learn 的 cross_val_score()允许我们将训练集随机分成 10 个不同的折叠,然后训练和评估我们的模型 10 次,每次选择不同的折叠进行评估,并在其他 9 个折叠上进行训练。结果是一个包含 10 个评估分数的数组:
**from** sklearn.linear_model **import** LinearRegression
**from** sklearn.model_selection **import** cross_val_score lin_reg = LinearRegression()
lin_reg_scores = np.sqrt(-cross_val_score(lin_reg, cars_prepared,
y_train, cv=10, scoring="neg_mean_squared_error"))
让我们来看看结果:
**def** display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std()) display_scores(lin_reg_scores)

对我们的基本模型来说还不错!但是,我们不是像这样显示每个模型的分数,而是将每个模型的分数绘制在一个方框图中,显示平均值、四分位间距和最大/最小分数。请记住,我们的衡量标准是 RMSE,分数越低越好。以下是我们尝试的模型列表:
- 线性回归
- 多项式回归
- 岭正则化多项式回归
- 随机森林回归量
- 支持向量机回归机
- 梯度推进回归器

我们看到多项式回归比简单的线性回归稍好。此外,随机森林回归和梯度推进回归表现明显较好,而 SVM 回归表现明显较差。请记住,我们只是试图了解哪些机器学习算法执行得最好,因此所有这些算法都是用默认设置训练的。
微调你的系统
现在我们有了一份有前途的模特候选名单。我们现在需要对它们进行微调。由于我们使用默认超参数来训练我们的模型,我们将尝试看看哪个超参数最适合我们的最佳模型,随机森林回归器和梯度推进回归器。
我们没有手动这样做,而是让 Scikit-Learn 的 GridSearchCV 来搜索我们。我们需要做的只是告诉它我们希望它试验哪些超参数,试验哪些值,它将使用交叉验证来评估超参数值的所有可能组合。
随机森林回归量
**from** **sklearn.model_selection** **import** GridSearchCV
forest_param_grid = [{'bootstrap': [**True**],
'max_depth': [12, 14, **None**],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2],
'min_samples_split': [ 2, 3],
'n_estimators': [100, 200, 300, 400]}
]
forest_reg = RandomForestRegressor()
forest_grid_search = GridSearchCV(forest_reg, forest_param_grid,
cv=5,
scoring="neg_mean_squared_error",
return_train_score=**True**,
verbose=**True**,
n_jobs=-1)
forest_grid_search.fit(cars_prepared, y_train)
我们可以直接得到最佳估计量:
forest_grid_search.best_estimator_

梯度推进回归器
gb_param_grid = [{'loss': ['ls'],
'learning_rate': [0.05, 0.1, 0.15],
'n_estimators': [200, 220, 240, 260],
'subsample': [0.8, 0.9],
'min_samples_split': [2, 3],
'min_samples_leaf': [2, 3, 4],
'max_depth': [4, 5, 6, 7],
'max_features': ['sqrt'],
}]
gb_reg = GradientBoostingRegressor()
gb_grid_search = GridSearchCV(gb_reg, gb_param_grid, cv=5,
scoring="neg_mean_squared_error",
return_train_score=**True**,
verbose=**True**,
n_jobs=-1)
gb_grid_search.fit(cars_prepared, y_train)
让我们看看最佳估计值:
gb_grid_search.best_estimator_

集合:随机森林回归和梯度推进回归
另一种微调系统的方法是尝试并组合性能最佳的模型。群体(或“整体”)通常会比最佳个体模型表现得更好。现在,我们已经调整了两个最佳模型的超参数,让我们尝试将它们结合起来,以进一步提高我们的最佳得分。
使用 Scikit-Learn 的 VotingRegressor()类可以相对容易地做到这一点,该类允许我们对随机森林回归变量和梯度推进回归变量进行平均预测。
**from** sklearn.ensemble **import** VotingRegressor
forest_reg =RandomForestRegressor(**forest_grid_search.best_params_)
gb_reg = GradientBoostingRegressor(**gb_grid_search.best_params_)
forest_gb_reg = VotingRegressor([("forest_reg", forest_reg),
("gb_reg", gb_reg)])forest_gb_reg_scores = np.sqrt(-cross_val_score(forest_gb_reg,
cars_prepared, y_train, cv=10,
scoring="neg_mean_squared_error"))display_scores(forest_gb_reg_scores)

看,成功了!我们的平均 RMSE 低于 1600!现在我们有了最好的模型,是时候分析它的错误了。但首先让我们做最后一个方框图,比较四个最好的模型。

让我们保存最好的模型,以便我们可以很容易地回到他们当中的任何一个!
**import** **joblib**
MODELS_PATH = os.path.join(PROJECT_ROOT_DIR, "models/")
os.makedirs(MODELS_PATH, exist_ok=**True**)models = [gb_grid_search.best_estimator_,
forest_grid_search.best_estimator_,
forest_gb_reg]
names = ["gradient_boosting_reg", "forest_reg","ensemble_(RF_&_GB)"]**for** model, name **in** zip(models, names):
joblib.dump(model, MODELS_PATH + name)
分析最佳模型的误差
我们将使用 cross_val_predict 对我们的训练集中的每个实例进行干净的预测(“干净”意味着预测是由在训练期间从未看到数据的模型进行的)。
**from** sklearn.model_selection **import** cross_val_predict
preds = cross_val_predict(forest_gb_reg,cars_prepared,y_train,cv=10)
让我们把我们的预测价格和实际价格对比一下。如果我们所有的点都在对角线上,这意味着我们的模型是完美的,误差为 0。

这看起来很好,我们的误差正态分布,而不是一个区域漏低,另一个区域漏高。剩下的工作就是对测试集进行评估,并得到最终的性能检查。谢天谢地,使用我们之前创建的管道,测试集很容易准备!
X_test = test_set.drop("Price", axis=1)
y_test = test_set["Price"].copy()
X_test = X_test[cols]
X_test_prepared = full_pipeline.fit_transform(X_test)**from** sklearn.metrics **import** mean_squared_error
final_predictions = forest_gb_reg.predict(X_test_prepared)
final_mse = mean_squared_error(y_test, final_predictions)
final_rmse = np.sqrt(final_mse)
final_rmse
最终 RMSE: 2207.82
看起来我们的训练装备可能有点过量了。回过头来尝试在测试集上表现得更好可能很有诱惑力,但是这样我们就冒着过度适应测试集的风险。我们会让它保持原样,因为它仍然在我们在训练集中得到的分数范围内。
结论
现在回到最初的问题。你应该买还是租下一辆车?
现在,我们已经有了最终的模型和测试集的性能分数,我们可以用它来预测讴歌 TLXs 的价格,其功能对应于各种租赁。我们用来对比的租约来自讴歌的网站。让我们看看多个不同的租赁条款,看看我们会发现什么!
我们预测的汽车具有以下特征和租赁:

这里是三种不同调整的预计折旧成本和租赁比较。红线代表预计折旧成本,而蓝线代表租赁成本。阴影区域代表我们预测折旧的 95%置信区间。我们看到,在所有三种情况下,租赁都要贵得多。

如果你选择购买新车,你可以节省高达 10,000 美元。即使是最好的汽车之一,租赁也要贵得多。
未来的工作
项目结束后,我脑海中突然冒出了一些我认为会很有趣的想法:
- 我们可以模拟不同的汽车,这些汽车也有很高的租赁费率,看看你能为一辆新车提供多少资金,让它仍然值得购买和转售。
- 从交叉验证来看,集成似乎是有益的,但在测试集上的表现仍然很差。探索原因可能会很有趣。我想知道是否所有其他模型在测试集上表现更差,或者我们的最终模型实际上不是最佳选择,尽管在交叉验证的所有折叠中表现最好。
- 进一步考虑这个问题,尝试建立多个汽车品牌和模型的模型,这些模型仍然可以准确预测汽车的价值。
一如既往地感谢你的阅读,我希望你喜欢它,并学到一些新的和有见地的东西!
在这个项目中,我的目标是通过比较汽车的折旧成本来确定汽车租赁是否划算
github.com](https://github.com/lukenew2/car-leases)
应该读数据科学硕士吗?
剧透:答案不是是或不是

我最近听说了贝特里奇的头条定律。它指出,如果一篇文章以一个问题作为标题,答案将永远是否定的。当然,这是一个幽默的法律,而不是实际的法律。尽管如此,我内心的反叛者不会错过与法律相抵触的机会。因此,这个标题的答案是一个闪亮的“视情况而定”。我肯定你没想到会这样。
是否应该获得硕士学位的问题是非常个人化的。这将取决于个人喜好、学习风格和职业目标。这就是为什么我认为试图在网上寻找答案是无效的。尽管这仍然是 Quora 上最常被问到的问题之一。
在本文中,我不会列出支持或反对获得数据科学硕士学位的理由。相反,我会给你一些建议,告诉你做这个决定时应该考虑什么。
请记住,我制定这些标准的前提是,你希望在获得这个学位后,在一家商业公司担任数据科学家。如果你想留在学术界,它可能不适合你。
以下是我认为你应该考虑的:
并非所有的学位都是平等的
数据科学是一个热门话题,每天都有几个数据科学学位冒出来。确保你所接受的教育有足够的质量。最终起作用的不是学位的名字。这是教育。检查教育质量的最好方法是检查教师和课程。尝试回答以下问题:
- 导师是受人尊敬的学者吗?比如,他们对学术界有贡献吗?他们是活跃的研究人员吗?还是仍然停留在 10 年前的技术上?
- 课程是否足够?当然,要回答这个问题,您需要对什么是数据科学以及所需的技能有一个大致的了解。我知道你可能愿意相信学校已经考虑过这个问题,并且创建了一个完整的、完美的课程,但是你还是应该检查一下。列出一张你绝对想学的技能的清单,并与学校提供的技能进行交叉核对。与其花两年时间学不到你想学的东西,不如谨慎一点。
- 程度够动手吗?这是所有问题中最难回答的。判断该学位是否技术性太强,是否对实践技能不够重视的一个方法是询问以前或现在的学生。你可以在 LinkedIn 或者你的朋友网络中找到他们。
你学校的名字可能很重要
与前一点相关,如果有许多学校提供同名学位,考虑到两个候选人之间的其他一切都是一样的,学校的声誉可能会影响招聘决定。这并不是说千万不要考非名校的硕士。我的意思是,评价每一个学位都有它的价值。简而言之,如果你所在国家顶尖大学的数据科学学位在你未来雇主的眼中为你的个人资料增加了 10 分,那么一个不太受欢迎/知名学校的学位可能只会增加 5 分。确保当你计划你的道路时,考虑到这一点。
获得一份数据科学工作不仅仅是技术知识
公司寻找能够应对现实生活中的挑战并快速适应的有能力的人。如果这就是你想要的,那么拥有一个相关的学位可能不够有效。你申请的公司可能仍然会聘用没有学位但能更好地展示自己能力的人。相关的能力可以是人际交往技能、他们参与的项目、领域经验等。
每个公司都有不同的优先事项
如果你想申请一个特定的公司/行业,我会说在投资硕士学位之前,一定要了解他们的要求。也许他们可以只给你一些基本知识,并在途中教你。
你为什么要这么做?
一定要明白你为什么要考虑硕士学位。是因为你做了一些研究,你确信这将有利于你的职业生涯,还是因为你从互联网上的人那里听说,为了得到一份数据科学的工作,这是必须的?做对自己的事,而不是平常的事。仅仅因为不确定还能做什么而开始攻读数据科学学位可能会被证明是徒劳的。
毕竟,在一个官方学位上投入金钱和时间是一个重大的决定。对一些人来说,这将是一场伟大的比赛,而对一些人来说,这可能是不必要的分心。我想说的要点是:在简历中有一个相关的官方学位总是有利的,但你必须将这种好处与你的生活成本进行比较,然后决定是否值得。没有人能替你做这个决定。
我希望这有助于澄清你在做这个决定时应该记住的一些重要的事情。祝你好运!
👉对数据科学领域以及如何开始学习感到困惑? 免费参加数据科学入门迷你课程 !
该不该跳 Python 的船,搬去茱莉亚?
意见
是应该为了朱丽亚的表现而抛弃 Python,还是朱丽亚的速度只是精心炒作?

(python 徽标由http://python.org/提供,julia 徽标由http://julialang.org提供,北海巨妖 src = http://cleanpng.com)
在过去的几年里,Python,一种用 C 语言编写的解释语言,越来越受欢迎。虽然 Python 肯定是一种有用的语言,从一开始就相当受欢迎,但这种受欢迎程度的飙升通常要归功于 Python 在机器学习和统计分析方面的出色能力。然而,随着时间的推移,新的语言应运而生,试图取代 Python,为机器学习创造普遍更快的体验。属于这一类的最有前途和最受欢迎的语言之一是 Julia。
Julia 是一种多范式、静态类型的通用语言,它是基于机器学习和统计学而构建的。大多数 Julia 用法背后的主要动机往往是 Julia 的速度,但我认为重要的是要记住仅速度一项就有多少变量。这甚至还没有触及到该语言的其他能力或缺陷。
概述
虽然速度当然很重要,甚至在机器学习的环境中更重要,但我认为在讨论性能的同时讨论其他障碍和优势也很重要。在跳 Python 船之前应该问的一个大问题是
朱莉娅有什么问题?
如果权衡超过了表现这一单一的好处,那么学习一门新语言是没有意义的。Julia 确实有一些问题,对于某些开发人员来说,这些问题可能不一定使切换成为最佳选择。
Python 和 Julia 之间的转换中丢失的第一个,也是最大的一个东西是
包裹。
虽然 Julia 确实有一些很棒的包值得一试,也有一个很棒的包管理器来帮助它们,但是这些包的范围远不如 Python 成熟。许多 Julia 包严重缺乏文档,有依赖问题,或者错综复杂,分割得太多,以至于你必须添加 50 个包才能完成一件事。虽然这肯定是一个很大的缺点,但应该注意的是,Julia 没有 Python 所拥有的模块王朝,因为 Python 作为一种语言要成熟得多。随着时间的推移,这个问题几乎肯定会得到解决,随着伟大的开发人员致力于这种语言,再加上 Julia 周围的奇妙和快速发展的社区,这可能不会是一个很长时间的大问题。我理解为什么一些朱利安可能会指出“PyCall.jl”是一个潜在的解决方案,但我不同意这种立场,因为对所有东西都使用 PyCall 比对所有东西都使用 Python 要慢,所以为什么不在这一点上使用 Python 呢?
Julia 的另一个显著“缺点”是它的范式。虽然 Julia 确实是一种支持许多泛型的多范式编程语言,但 Julia 的语法本质上是静态的,这意味着在大多数情况下,Julia 代码将属于函数范式。虽然我敢肯定 Lisp、R 和 Haskell 的粉丝们会高兴得跳起来,但是看看最流行的编程语言列表,就会明白为什么转换到这种范式会令人难以置信地不舒服,即使对于有经验的程序员来说也是如此。因此,虽然这对我或其他人来说可能不是一个缺点,但肯定会让那些对这种语言没有太大兴趣的人望而却步。
很可能我们都熟悉 Python,所以我不打算花太多时间来解释为什么您可能想从 Python 切换到 Julia。然而,我认为 Python 有一些缺点,应该客观地提出来,以便确定潜在的转换编程语言的利弊。
首先,我确信我们都听说过,Python 是一种解释型语言。虽然肯定有解决方案来解决这个问题,使用各种工具来获得编译后的可执行文件,以及更快的速度,但这些都不是使软件包更快或分发软件的万无一失的方法。虽然我并不特别热衷于“Python == 'slow '”这一潮流,但不可否认 Python 的速度不够快。幸运的是,Python 通过 C 语言的解释确实把它放在了一个独特的位置,因为它可以用来从高级接口操纵和调用 C 代码。
虽然这对 Python 来说是一个很大的优势,但并不是所有的数据科学工作都是在已经用 C 编写的模块中完成的,有时 Python.h 头文件的附加层也会降低计算速度,破坏 C 的出色性能。
“由你决定”
虽然速度绝对重要,但我想重申,它绝对不是一切。同时使用 Python 和 Julia 有很多显著的优势,其中一些甚至是主观的。例如,我对 Python 中的缩进语法恨之入骨,所以在 Julia 中使用以分隔符结尾的函数是我主观的偏好。
def func:
print("function body")
function func
println("I can put syntax here")
println("Here")
println("Or here, without any errors.")end
我想指出的另一件事是 Julia 的多态调度和 Python 的更简单的语法。所有这些都是为了说明,虽然性能很重要,但在选择使用哪种语言时,一种语言中的许多特性可能是更重要的因素。不仅如此,您还可以挑选在您当前的场景中使用哪种语言,因为自然有一些事情一种语言会比另一种语言更好。
另一个有趣的事情是,我以前在 Julia 中提到过,使用 Python 作为 Julia 的接口,而不是与 c 接口。这样做的好处是能够更快地编写快速代码,同时仍然保持类似的性能。幸运的是,我甚至创建了一个包来这样做,这样您就可以通过 PyPi 进行安装。
sudo pip3 install TopLoader
你好,装载愉快!您可以使用以下命令安装 TopLoader:sudo pip 3 立即从 TopLoader 安装 TopLoader 您可以…
github.com](https://github.com/emmettgb/TopLoader)
你选择的语言不一定是二进制的。Julia 的一个优点是,考虑到 Julia 的大数据能力和浮点精度,您可以保留对 Python 的使用,并像使用 Scala 一样使用 Julia。Julia 甚至有 BigInt 和 BigFloat 类型来处理比一般熊大的数字。
速度测试

(src =茱莉亚计算https://julialang.org/benchmarks/
实际速度方面,我已经把朱莉娅的基准放在上面了。正如我们从这个基本基准中看到的,Julia 倾向于徘徊在 Go 的性能附近,同时保持一点点的一致性。有趣的是,在极少数情况下,Julia 甚至可以超越 C 和 Rust。虽然这肯定是一个伟大的壮举,但这里的目标不是比较 Julia 和 C,而是比较 Julia 和 Python。
测试设置
为了保持两种比较之间的一致性,我将使用 Julia 的语法表达式来强制语言的类型更像 Python。如果你想进一步了解如何做到这一点,以及更熟悉 Julia 的调度,我有一篇我很自豪的文章,它会告诉你你需要知道的一切:
[## 用静态类型语言将 Julia 转换成 Python 和 Duck-Type
通过结合 Julia 富有表现力的语法和令人敬畏的调度,将 Julia 变成 Python。
towardsdatascience.com](/turn-julia-into-python-and-duck-type-in-a-statically-typed-language-119f708936ff)
对于我的迭代测试,我在 Julia 中创建了这个函数:
function LinearRegression(x,y)
# a = ((∑y)(∑x^2)-(∑x)(∑xy)) / (n(∑x^2) - (∑x)^2)
# b = (x(∑xy) - (∑x)(∑y)) / n(∑x^2) - (∑x)^2
if length(x) != length(y)
throw(ArgumentError("The array shape does not match!"))
end
# Get our Summations:
Σx = sum(x)
Σy = sum(y)
# dot x and y
xy = x .* y
# ∑dot x and y
Σxy = sum(xy)
# dotsquare x
x2 = x .^ 2
# ∑ dotsquare x
Σx2 = sum(x2)
# n = sample size
n = length(x)
# Calculate a
a = (((Σy) * (Σx2)) - ((Σx * (Σxy)))) / ((n * (Σx2))-(Σx^2))
# Calculate b
b = ((n*(Σxy)) - (Σx * Σy)) / ((n * (Σx2)) - (Σx ^ 2))
# The part that is super struct:
predict(xt) = (xt = [i = a + (b * i) for i in xt])
(test)->(a;b;predict)
end
同样,我用 Python 创建了这个类来实现同样的目标:
class LinearRegression:
def __init__(self,x,y):
# a = ((∑y)(∑x^2)-(∑x)(∑xy)) / (n(∑x^2) - (∑x)^2)
# b = (x(∑xy) - (∑x)(∑y)) / n(∑x^2) - (∑x)^2
if len(x) != len(y):
pass
# Get our Summations:
Σx = sum(x)
Σy = sum(y)
# dot x and y
xy = dot(x,y)
# ∑dot x and y
Σxy = sum(xy)
# dotsquare x
x2 = sq(x)
# ∑ dotsquare x
Σx2 = sum(x2)
# n = sample size
n = len(x)
# Calculate a
self.a = (((Σy) * (Σx2)) - ((Σx * (Σxy)))) / ((n * (Σx2))-(Σx**2))
# Calculate b
self.b = ((n*(Σxy)) - (Σx * Σy)) / ((n * (Σx2)) - (Σx ** 2))
# The part that is super struct:
def predict(self,xt):
xt = [self.a + (self.b * i) for i in xt]
return(xt)
你可能会注意到我用 dot()和 sq()来代替。*对于逐元素乘法,和。元素式平方的^。这些功能如下:
def dot(x,y):
lst = []
for i,w in zip(x,y):
lst.append(i * w)
return(lst)
def sq(x):
x = [c ** 2 for c in x]
return(x)
数据
对于我的数据,我在 Julia 中生成了一个 500,000 的模糊数据帧,如下所示:

我还做了一个有 60 万个暗点的测试数据框架:

为了保持一致性,我保存了数据帧,并使用 Pandas 将它们读入 Python:


最终时机
当然,为了计时 Python 结果,我将使用 IPython %timeit magic 命令。至于 Julia 的结果,正如你所料,我将使用@time 宏。结果如下:
朱莉娅

计算机编程语言

虽然这是一个很好的比较,而且 Julia 在计算上确实节省了大约 30%的时间,但是我想
“向上反”
我们试试 10,000,000 个 dims。
朱莉娅

计算机编程语言

R.I.P. Python
结论
虽然 Python 能够如此出色地击败 Julia 令人印象深刻,但对于这个 Julia 胜过 Python 的真实机器学习示例,肯定有一些东西值得一提。我认为这也很好地说明了我之前所说的,Julia 在处理大数据方面非常有用。我想如果这个测试教会了我什么的话,那就是 Julia 在机器学习的世界里绝对有一席之地。即使 Julia 不能取代 Python,它也肯定能取代 Scala 和许多其他类似的语言。
尽管这种语言有其独特之处,并且在不断发展,但性能肯定是存在的。尽管现在可能还不是开始 Python 编程的时候
(尚未)
(我是开玩笑的),或者可能永远也不会为了机器学习而放弃 Python,同时我也找不到不学习 Julia 的好理由。幸运的是,如果您已经熟悉 Python,那么学习 Julia 应该相对简单,因为语法非常相似。谁知道呢——也许你也会在朱莉娅身上找到一些你喜欢的东西!总的来说,Julia 在机器学习领域的未来非常令人兴奋。我认为,任何希望拓宽自己视野的数据科学家都应该去看看,甚至为 Julia 语言这个日益壮大的庞然大物做出贡献。
你应该呆在家里过新冠肺炎吗?
用简单的理论模型分析限制措施的效果。
新冠肺炎疫情及其社会影响是目前推特上的热门话题。没有人没听说过这件事。在这种社会距离和限制的情况下,一些人只是想着自己,而忽视了政府的建议甚至限制。如果你正在读这篇文章,你可能不是这些人中的一员,但是,你应该警告那些你认识的符合前面描述的人吗?让我试着说服你。
SIR 模型
流行病学最简单和最著名的模型之一是 SIR (易感-感染-康复)模型,这是一组描述这三种状态在人群中演变的微分方程。

新冠肺炎代表(来源
(不要害怕下面的方程,它们只是为了介绍模型,你不需要深入理解这些方程就能理解整篇文章)

SIR 微分方程系统
在上面写的微分方程中, S 是易感人群的存量, I 是感染人群的存量, R 是康复人群的存量。显然,系统的动力学与易受感染的病原体被感染以及被感染的病原体被治愈的概率有关。因此,在微分方程中, β 代表感染率, γ 代表恢复率。最后, V 表示个体分布的体积。这是一个更技术性的细节,但很容易理解,这个体积越大,个体之间的接触就越少,因此发生的感染就越少,从而导致动力学更慢。
总而言之,这些是模型的参数
- S: 易感人群存量
- **一:**感染人群存量
- R: 恢复人口存量
- β: 感染率(单位时间内个体被感染的概率)
- γ: 恢复率(单位时间内个体恢复的概率)
- V: 系统的体积(与两个个体接触的概率有关)
尽管该模型可以解析求解,但我们可以基于 Gillespie 算法使用数值方法求解。我们开始吧!
SIR 模型的结果
考虑分布在体积为 V=10 且 β=0.5 / 100 和 γ=10 / 100 的 N=10⁵ 个体群体,我们得到以下结果:

用 Gillespie 算法实现 SIR 模型。
正如我们所看到的,考虑到这些参数,该疾病将会爆发,并且在大约 30 天内,感染高峰将达到近 50 %的人口。在这个模型中,我们没有考虑疾病的死亡率,但应该强调的是,卫生系统肯定会崩溃**,因为我们连续几天看到如此大量的感染者。为了避免这种情况,那肯定会是灾难性的,政府采取措施来**‘使曲线变平’,这是一个近来广为人知的概念。基本上,我们的目标是降低感染人数的峰值,这样卫生系统就不会崩溃。正如我们接下来将看到的,感染人数峰值的下降与疫情结束的延迟有关。出于这两个原因(降低峰值和延迟疫情结束),这被称为“平坦曲线”。

用 SIR 模型模拟限制措施的效果
现在,我们可以将政府采取的限制措施建模为在某个时间点有效降低感染率β。考虑到在 t=25 时,即疫情达到上一次模拟得到的峰值前 5 天,采取限制性措施,有效降低一半感染率,得到以下结果, β’=β/2。

t=25 后感染率β’=β/2 变化的 SIR 模型
以这种方式模拟的限制措施的效果是明显的。通过将感染率降低到其原始值的一半,感染的峰值达到了人口的 25%,这也对应于在没有限制措施的情况下获得的值的一半。
快速应用这些措施有多重要?
为了解决这个问题,我们可以运行不同的模拟,并在不同的时间应用约束措施。例如,我已经考虑在 t=30、25、20 和 15 时应用这些措施,它们的效果与以前一样,将感染率降低到其原始值的一半。现在我们把重点放在受感染人群的进化上,所以没有必要画出易感人群和康复人群的比例。

分析应用措施的反应时间
从上图可以看出,实施禁闭措施的时间越长,效果越差。然而,尽管这些措施采取得相当晚(橙色线),但这些措施的效果是显著的,将峰值从近 50%降低到 35%左右。另一方面,如果及早采取措施,疫情的高峰期可以大大减少并及时转移。然而,也可以看到,这些措施除了降低感染高峰之外,还推迟了疫情的结束。这是一种不可避免的情况,但我们必须记住,我们的优先事项是使曲线变平,以免卫生系统饱和。然而,这种延迟似乎是因为恢复速度保持不变,但通过降低峰值和不使卫生系统饱和,我们可以希望这一速度增加(疾病治疗的新进展,卫生工作人员的更多经验等)。
作为一个更技术性的细节,可以观察到,如果在相当早的时候应用这些措施,这种流行病将发展成为一种新的流行病,具有新的感染率(紫线)。
实际遵守措施有多重要?
我们认为,通过应用这些隔离措施,流行病的有效感染率将下降到其原始值的一半,这可能或多或少是现实的。本文的目的不是提出一个现实的模型来预测模型的演变,而是说明限制措施的重要性。
在这个例子中,进一步考虑到,通过非常认真地采取措施,很少有人会走出家门,因此有效感染率将趋于零。因此,我们可以通过在将措施设置为 β’=0 后运行有效感染率的模拟来研究更认真地采取措施的影响。

当采取措施后传染率完全消失时流行病的演化
结果显示,采取措施后,感染人数迅速下降。如前所述,观察到越早采取措施,受感染人口的峰值就越小。而且我们可以看到疫情的结束是提前了而不是推迟了,之前的情况就是这样。然而,这种在应用这些措施后没有新感染的极端情况在现实生活中是不可能实现的,因为这需要对整个社会进行完全和完美的限制。
西班牙的现状
除了通过媒体和社交网络传播的信息,欧盟开放数据门户中也有可用的数据集。通过对这些数据进行适当的处理,可以估计每日新增病例和总病例的变化。在这里,我将展示西班牙的进展,西班牙是世界上感染病例总数第四多的国家。

新的感染从爆发演变而来。
正如我们所看到的,西班牙新发现的病例正以恒定的比率呈指数增长,具体为 0.35。事实上,对数标度帮助我们形象化这种趋势,因为它是一条直线。这种趋势正是我们想要避免的,因为如果这种情况持续几天,卫生系统就会崩溃。
我们还可以看看总病例的演变,它最终会像一条s 形曲线一样饱和。

总感染数从爆发开始演变。
很明显,我们已经远离了饱和点。在这种情况下,无法进行适当的指数拟合,因为在对数标度中可以清楚地看到,存在具有不同生长率的区域。这方面的好消息是,当前的增长率小于最初的增长率。
结论是什么?
首先,请记住,本文的目的不是提出一个新冠肺炎疫情的现实模型或预测其演变的工具。这篇文章的目的是展示一个研究流行病的最简单的模型,并用它来说明世界各地正在采取的隔离措施的重要性。
话虽如此,作为第一个结论,我们已经看到,考虑到适当的流行病(这意味着在给定的感染率和恢复率下,爆发存在),感染人口的比例呈指数增长。然后,如果不采取措施,这种指数增长将继续下去,直到大部分人口受到感染。在实际情况下,这将使卫生系统崩溃,导致高死亡率事件。
然后,我们将禁闭措施纳入模型,以研究其效果以及它们如何依赖于两个特征:实施措施的时间和措施的力度(可以理解为措施的限制性或接受措施的人数)。第一种情况的结果表明,对于早期应用的措施,获得的感染峰值显著降低,尽管流行病的结束被延迟。在第二种情况下,我们看到,更强有力的措施除了降低感染高峰之外,还促进了疫情的结束。
因此,最后的结论是,最好的选择是尽早采取最强有力的措施。
想想看
我想以一个想法结束我的发言:实施措施的时间关系到科学家和政治家的工作,但措施的力度部分取决于整个社会。也许限制措施采取得有点晚,但我们有能力使它们更有效。
你应该读机器学习硕士吗?
包含来自理学硕士毕业生的想法和意见

安德烈·亨特在 Unsplash 上的照片
开始
答几周前,一个好奇的人在读了我的一篇文章后找到了我。联系我的主要原因是想了解我对一个硕士学位是否足以在人工智能行业建立职业生涯的看法,或者应该用一个博士学位来补充这个硕士学位。
简单的回答是没有。
一个机器学习的理学硕士学位使你具备足够的领域知识,在大多数实际环境中做出贡献。
但是——是的,有一个但是——你的职业发展水平可以由你拥有的学位类型来定义。
围绕机器学习有大量的炒作,大量的个人正涌向学术机构以获得 ML 内部的学位,包括我自己。
对于你想追求什么样的高级资格,做出正确决定的重要性怎么强调都不为过。
为了有助于更容易做出决定,并提供一些清晰度,我将提出攻读理学硕士的理由,并以我个人对这场辩论的看法作为结束。
我将利用三个标准作为指路明灯。

里士满·阿拉克的引导信标
对于那些对理科硕士毕业生的满意度感兴趣的人,只需向下滚动到“知识”部分。
介绍
机器学习硕士是建立理论和实践知识的最佳方法之一。最后,你会获得公认的高级学位。
只要你有数学、计算机科学、物理、机械或电子工程等学科的本科学习背景,获得机器学习硕士学位的道路会非常平坦。
英国的理学硕士通常需要一年的全日制学习,而非全日制的资格认证可能需要 2-4 年的时间。在美国,理学硕士的平均时间长度似乎约为 2 年。
我找到了一些很棒的资源,包括美国大学的链接和信息。 第一资源 是最近由Stacy Stanford在 2020 年写的,文章列出了 10 所大学,而 其他资源 ,由 写的
几个机器学习的理学硕士项目在该领域的教学中采取了一种一般化的方法。这意味着理学硕士学生将接触到各种主题,如机器人学、语言学、自然语言处理(NLP)、计算机视觉、编程、软件设计、信号处理、语音识别等。这种资格的普遍性在不断变化的行业中可能是有利的。
让我们使用我们的指导信标来进一步分析一个机器学习硕士的案例。
收入和职业潜力
理学硕士课程的通才性质使个人具备了许多雇主目前正在寻求的多面性。对 ML 领域有一个总的了解的好处是你不局限于广告中的入门级工作职位。
在完成我的理学硕士学位后,我能够申请一些职位,如数据科学家、计算机视觉工程师、机器学习工程师和 NLP 工程师。我需要大部分广告职位的原因是因为我的理学硕士课程足够详细地介绍了这些主题。
对于机器学习工程师的角色,我在 LinkedIn 上搜索的大约 30%的角色要求申请者拥有理学硕士学位。我使用 Paysa 来获得更多关于 ML 工程师工资的调查信息。根据对超过 300 毫升的 工程职位 的调查,17%的人拥有理学硕士学位,12%拥有理学学士学位,28%拥有博士学位。考个理学硕士肯定能打开更多的门。
分析超过 15,000 名数据科学家档案的调查我们可以观察到,近一半的档案拥有学士学位,14%拥有硕士学位。
有些人可能会认为,从统计数据来看,许多数据科学家角色只需要一个 BSc,这是真的。
与其他 ML 工程角色相比,数据科学对技术要求不高。尽管对 ML 从业者的需求可能会很高,但也有大量的毕业生希望获得入门职位。
关键是从人群中脱颖而出,一个理学硕士学位肯定会让你领先于拥有学士学位的同行。
现在谈谈收入潜力。
上面提到的对 ML Engineering profiles 和 Data Scientist profiles 的调查显示,这两个职位的平均工资分别为 94,510 美元和 99,558 美元。这两个职位的最高收入都超过了 12 万美元。
要成为一名高收入者,可以肯定地认为经验是一个决定性因素,另一个关键因素可能是申请人在机器学习方面的资格有多高级。
应该提到的是,这项调查的重点是主要位于美国的概况。
影响
受过良好教育的机器学习工程师或数据科学家在团队、企业或初创公司中蓬勃发展,会带来实质性的积极商业影响。
这种影响很可能决定一个组织的生存能力和成功。
理学硕士使个人具备在组织内创造和产生重要影响所需的技能。我所指的技能不是技术性的,而是软技能。
例如,理学硕士为你提供了一个机会,通过提交期末论文的过程来培养表达技能。
根据我的经验,我有三个不同的场合来展示我的论文。一个包括由教授和行业专家参加的展览,另一个涉及向机器学习教授和讲师进行最终演示。
[## 作为机器学习工程师你需要的 5 个软技能(以及为什么)
包括成为任何劳动力的有用组成部分的提示
towardsdatascience.com](/5-soft-skills-you-need-as-a-machine-learning-engineer-and-why-41ef6854cef6)
关于论文的主题,理学硕士给学生带来的另一个影响是通过项目将机器学习应用于特定行业或流程的独特机会。
在我攻读理学硕士期间,学生们与医院和诊断部门合作创建了计算机视觉系统,该系统加速了癌细胞和肿瘤的分类过程。
我承担了一个项目,涉及开发一个对四足动物(四条腿的动物)进行姿态估计的计算机视觉系统。该项目的进一步目标是开发一个系统,以帮助改善兽医步态分析程序。
知识
对于这一部分,我决定联系两个已经从机器学习和计算机视觉理学硕士学位毕业的人。我没有提供我对你从理学硕士那里获得的知识量的想法,而是把任务交给了他们。
下面是我们特邀嘉宾的背景简介。
- kaushub Krishnamurthy 目前是澳大利亚悉尼的一名计算机视觉机器人工程师。
- Ignacio Hernández Montilla 目前是西班牙马德里的一名计算机视觉研究工程师。
以下是伊格纳西奥的声明:
“硕士学位教你所有机器学习炒作背后的理论。目前有很多“机器学习工程师”和“数据科学家”,他们只上过一两门在线课程。
这些在线课程只是向你介绍机器学习有吸引力的部分。另一方面,硕士学位提供了 的机会,除了关键的数学思维 之外,还能教给你数据科学家或 ML 工程师需要的知识。”
以下是来自 Kausthub 的声明:
“为了能够做出明智的决策(为了研究或商业应用),我需要通过从头开始构建我的各种计算机视觉应用知识来进一步发展我的直觉。
*是的——这意味着涉水深入数学,坦率地说,这不是我下班后轻松阅读的第一选择——*参加一个硕士项目是激励我在计算机视觉的所有领域工作的一种方式,这将把我带到下一个水平 。
在理学硕士课程结束时,我发现自己喜欢数学的严谨性,能够恰当地理解和评估最新研究中做出的选择,这使我能够对我之前刚刚申请的应用程序做出明智的决定,因为这是教程告诉我要做的。”
不足之处
到目前为止,你可能已经了解了获得机器学习硕士学位的一些主要好处。为了公平竞争,我将提供一些我认为应该指出的缺点。
- 学术资助始终是个人选择不继续深造的一个重要因素。一个 MSc 课程绝对是一个成本高昂的投资,比如我 2018-2019 年上的 MSc 机器学习课程价格是 10300。对于国际学生来说,这个数字超过了 2 万。
- 调整期可能会更长一些。决定重返校园的人可能会发现很难适应需要长时间学习的学术生活方式。那些在重返校园前已经工作了几年的人肯定会发现这种变化是巨大的。下面是一篇文章,详细介绍了我在适应学术生活方式方面的个人经历。
我从全职到人工智能硕士生过渡的探索。
towardsdatascience.com](/took-a-masters-in-machine-learning-and-i-was-very-unprepared-7aba95f044a8)
- 参加全日制理学硕士课程会有一段时间没有收入,如果你参加的是业余项目,情况可能就不一样了。
- 一种奇怪的被遗忘的感觉。对于那些年纪很大才获得理学硕士学位的人来说,在社交活动中,当你的朋友和同事抱怨工作生活和与学术无关的话题时,这可能会产生一种孤立感。
个人观点
如果你有时间和资金接受为期一年的挑战,以提高你的机器学习技能和知识,那么攻读机器学习相关主题的硕士学位可能是正确的决定。
理学硕士课程可以带来很多好处,尤其是在职业发展或变化方面。这需要做很多艰苦的工作,这是你必须准备好处理的事情。
至于那些可能无法全职参与任何学术项目的人,许多大学都提供非全日制的理学硕士课程,通常在两到五年内完成。对于资金有限的人来说,这种选择也是一种更便宜的选择。
最后,应该提到的是,理学硕士并不能完全保证职业发展。
对于那些没有机会考虑机构教育的人来说,Coursera 和 Udacity 等平台上发布了几个在线课程。
这些在线课程可能没有实际学位那么深入。尽管如此,它们确实为个人提供了机器学习方面的必要信息和实用知识。还有一个好处是,许多在线平台在完成课程后会提供认可的证书。以下是几个。
[## 深度学习专业化——deep Learning . ai
深度学习专业化是由人工智能的全球领导者和联合创始人吴恩达博士创建和教授的
www.deeplearning.ai](https://www.deeplearning.ai/deep-learning-specialization/) [## 机器学习|课程
机器学习是让计算机在没有明确编程的情况下行动的科学。在过去的十年里…
www.coursera.org](https://www.coursera.org/learn/machine-learning?utm_source=gg&utm_medium=sem&utm_content=07-StanfordML-ROW&campaignid=2070742271&adgroupid=80109820241&device=c&keyword=machine%20learning%20mooc&matchtype=b&network=g&devicemodel=&adpostion=&creativeid=369041663186&hide_mobile_promo&gclid=EAIaIQobChMI7Pnh_aDt6AIV2u3tCh1X2A9pEAAYASAAEgJen_D_BwE) [## Udacity |学习
“Nanodegree”是 Udacity 的注册商标。2011–2020 uda city,Inc .要兑现此优惠,请完成…
learning.udacity.com](https://learning.udacity.com/be-in-demand-ai/eu/?utm_source=gsem_generic&utm_medium=ads&utm_campaign=8778926767_c&utm_term=89916940033_UK&utm_keyword=%2Bmachine%20%2Blearning%20%2Bcourse_b&gclid=EAIaIQobChMI7Pnh_aDt6AIV2u3tCh1X2A9pEAAYAiAAEgK6uPD_BwE)
感谢您花时间阅读这篇文章,我希望它是有益的。
对于那些想看更多文章的人来说,下面是我写的一些你可能会感兴趣的文章。
探索攻读机器学习博士学位的好处
towardsdatascience.com](/should-you-take-a-phd-in-machine-learning-79530e1cb01c) [## 作为机器学习工程师你需要的 5 个软技能(以及为什么)
包括成为任何劳动力的有用组成部分的提示
towardsdatascience.com](/5-soft-skills-you-need-as-a-machine-learning-engineer-and-why-41ef6854cef6)
想要更多吗?
- 成为推荐媒介会员,支持我的写作
- 订阅 在我发表文章时得到通知
- 通过 LinkedIn 联系我
- 在 奥莱利 跟我学
该不该考机器学习的博士?
探索攻读机器学习相关主题的博士学位的好处

科尔·凯斯特在 Unsplash 上的照片
你点击这篇文章可能有几个原因;也许你正在辩论是否要进一步提高你的学术资格,或者你可能对机器学习中的高级研究的思想着迷。
不管是什么原因,你现在在这里。
现在,这里是写这篇文章的目的。围绕机器学习已经有了大量的炒作,大量的个人正涌向学术机构以获得 ML 内部的学位,包括我自己。对于你想追求什么样的高级资格,做出正确决定的重要性怎么强调都不为过。
为了让决策变得简单一点,并提供一些清晰度,我将提出一个攻读机器学习博士学位的案例,并以我个人的观点作为结论。
为了给这篇文章一个结构,我将使用下面列出的三个标准作为指导信标来讨论攻读博士学位的好处。

里士满·阿拉克的引导信标
声明:我目前的最高学历是计算机视觉和机器学习理学硕士。请注意,我将试图从一个公正的角度来看待这篇文章/研究。如果你觉得我在公正的分析上有所失误,请在评论中指出。
介绍


右图:布拉登·科拉姆在 Unsplash 上的照片。左:照片由阿尔方斯·莫拉莱斯在 Unsplash 上拍摄
如果把学术界比作体育,那么博士学位可以类似于奥林匹克,因为它们都在各自的领域产生精英。在每届奥运会之间,运动员有四年的训练期;相比之下,对于博士生来说,这种考验在英国通常持续四年,在美国则长达六年。
机器学习博士学位需要在机器学习的许多子领域中探索和推进特定的主题。在人工智能行业——也包括其他行业——博士学位被视为一项有声望的成就。
让我们使用我们的引导信标来进一步分析一个攻读机器学习博士学位的案例。
收入和职业潜力
与理学硕士同行相比,拥有博士学位的机器学习从业者有可能获得更高的薪水。

莎伦·麦卡琴在 Unsplash 上的照片
对于机器学习研究员/科学家的角色,英国****90%的 ML 研究员角色要求申请者至少拥有博士学位;有些职位要求申请者在顶级会议上发表过论文,如 NAACL 或 NeurIPS 。
拥有博士学位无疑会为更多的职位打开更多的大门。我找到的招聘职位的平均工资是 8 万英镑(99607 美元)。要成为一名 ML 研究员,你必须持有证明你有能力进行研究的资格证书。
申请机器学习工程类角色怎么样?
ML 工程职位并不完全要求高级资格,如博士学位。也就是说,当一名 ML 工程师拥有博士学位,再加上几年的机器学习工作经验,那么申请人肯定会受到高度重视。
在浏览了几个角色之后,可以肯定地说,拥有博士学位和一些工作经验的申请人可以申请大量广告中的机器学习角色。
在过去的十年里,对 ML 从业者的需求急剧增加,ML 工程师的职位发布数量在 2015 年至 2018 年间增长了 300%以上,而且似乎不会很快放缓。需求的增加意味着公司和组织(甚至政府)正在寻找高技能的个人。幸运的是,拥有博士学位可以把你放在一个被认为是高质量的个人或特定领域专家的小组中。

雇佣机器学习领域顶尖人才的公司
人工智能领域的顶级公司,如 DeepMind 、 OpenAI 、 Google 、脸书等对机器学习研究人员的需求很高。这些公司本质上是人工智能行业的先驱。例如, Deepmind (负责 AlphaGo 的公司),有几个研究科学家的职位,最低要求的资格是博士。
在结束收入部分之前,我将提到最后一件关于博士学位获得者收入潜力的事情。大多数招聘职位的工资都有一个范围,例如,一个 ML 工程师的招聘职位的工资范围是 70,000 到 90,000。对高端职位申请的考虑是由经验、文化契合度、工作要求契合度以及资格等因素决定的。众所周知,PgD 患者的收入比 MSc 患者高 50%;这是几个行业的真实情况,不仅仅是人工智能。
影响

Clark Tibbs 在 Unsplash 上拍摄的照片
攻读博士学位的机会也提供了创造技术和社会影响的可能性。机器学习博士学位将你置于学术研究的前沿,促进特定领域的发展,这些领域有可能将人类进一步推向所有人的美好未来。
博士学位持有者在博士期间或之后发表的研究成果已经影响了全球的各个行业。物体检测的进步使得自主车辆中的视觉系统更好。自然语言处理的进步已经支持了高效和准确的语言到语言的翻译(想想谷歌翻译)。
我们提几个名字怎么样?

左:约瑟夫·切特·雷德蒙,中:安德烈·卡帕西,右:伊恩·古德菲勒
我相信你一定听说过这个名字伊恩·古德菲勒,如果你没有听说过,他是负责生成性敌对网络的个人之一。伊恩目前是苹果公司的机器学习总监。他拥有博士学位,曾在谷歌和 OpenAI 等公司工作过。
另一个熟悉的名字是 Andrej Karpathy,他目前是特斯拉的人工智能总监,之前曾在 DeepMind 和谷歌实习。我读过他的几篇博客文章,这里有一篇文章,可能与即将攻读博士学位的人有关。
《YOLO》的创作者约瑟夫·切特·雷德蒙也在华盛顿大学获得了博士学位。
毫无疑问,博士从事的工作可以彻底改变整个行业以及人工智能作为一个领域的发展方向。还有成吨的名字我没有提到,但我也不想把这篇文章写得有几万字那么长。
我的观点是,很多人都有可能基于他们在研究期间完成的工作或他们从研究中获得的技能,对技术、学术和社会产生影响。
知识
攻读机器学习博士学位可以获得丰富的知识。理论知识是在博士期间积累的,因为研究人员必须理解开发的技术和提出的算法中潜在的直觉、概念和逻辑。
深入的理论知识需要时间和奉献精神,只有基于博士的教育或研究形式才能允许。

帕特里克·托马索在 Unsplash 上的照片
撰写论文的研究人员必须参考和评估数十篇其他研究论文,才能得出他们当前论文的结果。仅仅从撰写研究论文中获得的知识量就足以让一个人成为各自领域的专家。
从攻读博士学位中获得的另一种形式的知识是编程、数学和技术。机器学习是一个高度专业化的领域,该领域要求的高技术要求意味着研究人员通常不仅仅是精通一套编程语言的数学高级主题,而是能够帮助实现神经网络。
在我的研究过程中,我偶然发现了一份由来自英国和美国顶尖大学的研究人员撰写的论文清单。简单浏览一下主题,并随意钻研这些丰富的知识。
不足之处

aaron Blanco Tejedor 在 Unsplash 上拍摄的照片
我在这篇文章中提到了攻读机器学习博士学位的许多好处,但我很可能错过了一些关键优势。
也就是说,至少简要强调一下攻读博士学位的一些缺点是不公平的。
我不会对缺点做过多的阐述,但是我会为好奇的个人提供足够的信息,让他们对提到的缺点进行个人研究。
- 博士学位通常需要独立的学习和工作。当然,一个学生配有一两个导师,但对许多人来说,4 到 6 年的紧张学习考验会对心理健康造成损害。
- 尽管博士生的学术发展势头强劲,但商业经验也是一种不言而喻的权衡。在攻读博士学位的 4-6 年里,与机器学习相关的行业进展如此之快,以至于几乎不可能跟上该行业的工作经验需求。
- 博士论文非常专注于机器学习中的特定子部分或主题。这意味着,尽管博士生可能是某个特定主题的专家,但他们可能缺乏更广泛的 ML 商业领域的知识。
最后的想法
让我以我个人对攻读机器学习博士学位的看法来结束这篇文章。
追求高级资格是一个个人决定,需要考虑几个因素,如家庭、资金、时间和承诺。不是很多人都有机会留下或回到广泛的学术生涯。
攻读博士学位需要特定的个性和心态;已经从事个人研究并超越机器学习主题中常规知识的个人可能更适合攻读博士。
相比之下,一些人不关心神经网络架构或对象检测算法背后的内部工作和理论推理,但他们关心技术的直接可用性和实用性。这种类型的人可能不适合博士学位带来的学术生活和责任。

Alex bljan 在 Unsplash 上拍摄的照片
我不认为我会很快攻读博士学位。尽管这可能会在未来 15-20 年内改变。
这让我想到另一点,学习不需要停止。
20 多岁、30 多岁、60 多岁都可以读博。
我希望你能从这篇相当长的文章中获得一些有用的见解。对于那些在未来几个月或几年要做出关键决定的人,我建议进行深入研究,看看你的博士生生活会是什么样子。
感谢阅读。
请随意查看一篇文章,在这篇文章中,我提出了获得机器学习硕士学位的理由。
包含来自理学硕士毕业生的想法和意见
towardsdatascience.com](/should-you-take-a-masters-msc-in-machine-learning-c01336120466)
希望这篇文章对你有用。
要联系我或找到更多类似本文的内容,请执行以下操作:
- 订阅我的 YouTube 频道 即将上线的视频内容 这里
- 跟我上 中
- 通过 LinkedIn 联系我
你应该参加更多的在线课程或硕士课程来提升你的数据科学工作简历吗?
办公时间
3 情景和建议

图片来自马库斯·温克勒 Unsplash
在与有抱负的数据科学家交谈时,我经常被问到:“我应该参加更多的在线课程来充实我的简历吗?”这篇文章总结了我的个人建议,以及如何在自学或接受额外教育后识别一个人何时“准备好”。
这篇文章可能对你有所帮助,如果…
在指导有抱负的数据科学家的过程中,以及与当前数据科学从业者(工业界和学术界)的交谈中,一个常见的问题是如何才能最好地从 Coursera、Udacity 或 edX 等在线平台自学机器学习。
作为一个附加层,那些确实使用这些平台进行自学的人,在完成一两门在线课程后会遇到一个决策点:“我应该参加更多的课程,还是这样就够了?”一个类似且常见的问题是“我是否应该获得数据科学/ CS /统计学硕士学位?”
最后一个共同点是,即使在参加了在线课程和自学之后,很多内容似乎也会像大学期中考试一样很快被遗忘。我也遇到过这种情况:“我不是刚上了 CNN 的那个 Coursera 课程吗?这个(概念)听起来很耳熟,但我怎么已经忘记细节了?”总的来说,这是一个可怕的认识,但是想象一下如果你在一个工作面试中!
如果以上任何一种情况引起你的共鸣,希望这篇文章能有所帮助。根据多年的个人经验,我分享一些可以帮助你确定什么时候你可以停止在线课程并知道你已经“准备好”了。
经验法则:边际收益递减
这条规则适用于在线课程的自我教育,或其他正规教育,如获得硕士学位。
边际收益递减是经济学中的一个概念:想象一家全新的餐厅准备开业。他们刚刚花钱买了一个全新的厨房。如果没有厨师,他们就没有产出,也就没有顾客或回报,不管他们的厨房有多棒。当他们雇佣第一个厨师时,产量和回报增加了很多,因为他们从服务零顾客到能够服务他们的顾客。
然后,餐馆变得更受欢迎,一个厨师无法处理更多的订单。雇佣了第二个厨师。这增加了产出和回报。然而,一旦过了某个点,也许当他们有 3 个厨师时,雇佣更多的厨师不会进一步增加回报。厨房可能会变得太拥挤,使每个厨师的产量减少!在这一点上,餐馆不应该雇用更多的厨师,而是在其他方面进行扩张,例如将厨房变得更大。
这个类比适用于在线课程和附加教育。如果你什么都没有,上一两门在线课程会有非常高的边际收益。过了某一点,你需要考虑以其他方式扩展你的技能,比如做一个副业——类似于餐馆例子中的扩大厨房,而不是雇佣更多的厨师。
你为什么要上在线课程呢?
现在我已经完成了一般的经验法则,我想帮助你把这个逻辑应用到你自己独特的情况中。由于有许多类型的人希望提高他们在数据科学领域的技能和可信度,我想给你一些工具,让你根据自己的教育背景和工作经验做出决定。下面,我列出了几个大致的人口统计数据供你参考。
我见过的最常见的原因和期望在线课程或额外教育的人群是有抱负的数据科学家。参加在线课程并获得结业证书是为了获得面试而写在简历上的东西,如果候选人能通过面试,就能在数据科学或机器学习行业找到工作。
我将把这些人分为两种类型:Type 1那些还没有任何工作经验,刚从学校或训练营毕业的人。Type 2是在其他领域(包括学术界)有工作经验的专业人士。他们希望转型或转向数据科学领域。
下一个群体,Type 3,是现有的数据科学家,他们希望扩展自己的知识或进入一个新的专业领域(例如,从 NLP 到强化学习)。
最后一种类型是那些喜欢为了乐趣而学习的人,没有任何明确的理由。他们不认为在线课程是去其他地方的一种方式,而仅仅是娱乐或精神满足。如果这是你,那么你应该忠于自己,继续参加在线课程,只要你觉得有趣!
所有类型的人都有一些共同点:他们有一个目前的位置,和一个他们未来想去的目标(数据科学/ML 工作或晋升)。他们希望在线课程可以填补空白,将他们从 A 点带到 b 点。
三类人可以从在线课程或额外教育中受益
我们已经确定,无论你是哪种类型,你的目标是使用在线课程或额外的教育来达到 B 点,这是你的目标。
我将介绍以下 3 个例子,但我的意图是,你可以将这个逻辑应用到你的个人情况中:
- [
Type 1]“我刚从大学毕业,但我听说我需要硕士学位才能进入数据科学领域。我是应该考网络硕士还是考证书?” - [
Type 2]“我想上这门 Coursera 课程,因为我的简历上几乎没有或根本没有机器学习相关的经验。我真的需要至少一些东西来吸引招聘人员的眼球,让他们给我回电和电话面试。” - [
Type 3]“我有兴趣在我当前的数据科学团队中向上或横向移动到一个使用强化学习(RL)的项目。我如何向我的经理和同事展示我在 RL 方面有足够的技能?”
3 种类型的逐步分析
类型 1
“我刚从大学毕业,但我听说我需要硕士学位才能进入数据科学领域。我是应该考网络硕士还是考证书?”
对于这个场景,这里的目标实际上是“获得一份数据科学的工作”。自然地,如果他们成功地找到了一份数据科学的工作,那么他们不需要参加更多的在线课程/证书,甚至是硕士课程。如果你用你现在所拥有的直接到达 B 点,没有必要走弯路,弯路是那些在线课程。
当我在一次咖啡聊天中被问到这个问题时,我通常会提出以下建议:
的确,什么类型的学士学位很重要。然而,不管这个学位的正式名称是什么,更重要的是你如何展示你在的两大支柱:统计和编程中的技能。对于你的第一步,我建议根据链接文章中的信息进行自我评估,并使用在线课程或额外教育将这两个支柱提升到基线水平。
尝试申请工作(入门级)。考虑到你在 2 支柱、统计和编程方面有足够的技能,把它当作一个学士学位就足够了。你必须重复简历和面试反馈——如果你没有得到回复,更新你的简历或者检查你是如何回答面试问题的。
不要做同样的事情,却期望不同的结果。如果几个月后,这些努力仍然不能让你在数据科学领域找到工作,那么考虑攻读硕士学位。如果一个学士学位毕业后需要 6~10 个月才能找到工作,那么这比完成同样的工作需要 2 年的硕士学位要节省时间。
当然,这里的主要风险是“如果我花了 10 个月试图获得一份数据科学工作,但失败了,然后决定接受更多教育,那将使我在硕士课程/在线证书课程/训练营中落后于我的同龄人 10 个月!”
- 这里的关键是在这 10 个月里,你可以在兼职项目或其他自定进度的在线课程(heh),这可以为你建立一个文件夹,无论如何都可以帮助你找工作。无论如何,建立一个兼职项目组合是你在硕士/训练营/认证期间和之后都会做的事情,所以为什么不在找工作的时候做呢?
- 如果你遵循了上面的建议,在最坏的情况下,你没有在 10 个月内找到一份学士学位的工作,你将获得所有你的硕士同学可能没有的东西:面试经验,一个杀手级的作品集,以及更多的自我学习。我认为这让你和那些同龄人平起平坐,而不是落后。
个人轶事:有一段时间我考虑过参加 OMSCS 在线 CS 硕士学位。当时我已经是一名数据科学家,并成功地向数百万客户交付了数据科学产品。我已经获得了经济学硕士学位,完成了这个目标。结论:除非未来的职业变动(更类似于Type 3场景)需要,否则不要读计算机科学硕士。
类型 2
“我想上这门 Coursera 课程,因为我的简历上几乎没有或根本没有机器学习相关的经验。我真的需要至少一些东西来吸引招聘人员的眼球,让他们给我回电和电话面试。”
对于这个场景,请记住这个人(可能是你吗?)已经有了一些工作经验。也许他们做了 3 年的项目管理,或者 1 年的工程,或者在学术界做了 5 年的教学/研究。
这个场景的目标是“至少得到一次面试机会”。所以,在这里你能做的最简单的事情就是开始申请工作!如果你“还不确定自己是否准备好了”,那也没关系。不要拖延,直到你完成了一些神奇的在线课程。
采取与你的目标相关的直接行动,如果两三个星期后你没有收到回复,这可能表明你确实没有足够的简历项目。但是你不知道这一点,直到你申请了一些工作。不要让你自己的不确定性为招聘人员和招聘经理说话。你不是他们。至于如果你没有收到任何工作申请的回复,你可以做什么,我在下面分解了更具体的细节,因为即使在Type 2中,也有很多变化。
在这里,关于参加更多的在线课程或额外的教育,我通常会提出以下建议:
如果你真的没有机器学习/数据科学方面的简历,一定要去做!参加 Coursera 的课程,完成作业,自豪地把它们列在你的简历上。然而,现在你已经学了几门课程,并且有信心掌握了 2 支柱:统计和编程(链接文章向你展示了如何自我评估自己的准备情况)的基础知识,我强烈建议你做一个副业。使用边际收益递减的经验法则。
原因很简单,当我筛选数据科学招聘简历时,副业比证书更能吸引我的眼球*。(这个建议不包括在线硕士,我在Type 1的分析中作为一个单独的问题提到过)。我不能代表所有的招聘人员/招聘经理/数据科学家同事,但我会在这里阐明我为什么相信 side projects >在线课程,假设你已经学习了 2 支柱的基本知识:统计和编程。*
数据科学工作招什么?他们雇佣用数据科学技术解决现实生活问题的人;能够完成没有教科书答案的项目的人,并且是每个独特的公司所特有的。什么证明了求职者可以做这些事情?
- 一个自我指导的兼职项目(不仅仅是 1000 人完成的在线课程作业)显示了数据科学工作招聘的那些特质。在线课程显示出兴趣和一些知识,但不能真正回答候选人是否有这些关键能力的问题。工作不会雇佣那些在线课程做得最多的人。
类型 3
“我有兴趣在我当前的数据科学团队中向上或横向移动到一个使用强化学习(RL)的项目。我如何向我的经理和同事展示我在 RL 方面有足够的技能?”
这太棒了!你在这个领域,正在寻找一些发展机会。很可能你的统计学和编程技能都处于良好的基础上(也许你在一个方面比另一个方面更强),所以你不需要像那些刚从学校毕业或从另一个领域转行的人那样花太多时间来温习它们。
在这里,我肯定会说去参加一些在线课程,以建立你在新主题中的基础知识,我的意思是,专门参加强化学习的在线课程,而不是一般的机器学习。此外,如果你觉得你的一个支柱不如另一个强大,例如,如果你更擅长一般软件开发,相对于 ML 算法的数学推导,考虑温习 ML 算法。
人们(包括我在内)似乎忘记了一件事,那就是最直接的行动是询问你的经理或同事你是否能调到新的项目或团队!不要等到你参加了一些在线课程后才问;现在就表明你的兴趣,这样,如果这个项目有空缺或者其他类似的机会,他们就会想到你。
如果上述努力足以让你转移到其他数据科学角色或工作中的专业项目,那就太棒了!你的新目标已经达成。如果没那么容易,那么下一步就是利用你从在线课程中学到的知识,建立一个关于这个主题的快速辅助项目。如果展示你在某个话题上的真实经历不能让你的经理/同事相信你是那个感兴趣的项目的好候选人,那么……在线课程不是这里真正的问题。
一般决策标准
简而言之,以下是我建议的一般决策标准:
如果你没有机器学习/数据科学相关的简历行项目:
- 是的,做网上课程和作业,并把它放在你的简历上!
如果你有一些在线课程,但不确定是否要学更多:
- 考虑做一个副业,这是一个更好的简历项目,给你的时间带来更好的投资回报
- 自我评估你的编程和统计技能是否超过了足够的基线。链接:如何找到您的基线水平
如果您已经掌握了统计学和编程的基本知识,并且掌握了一些数据科学知识,请继续填写:
- 在这里停下来,检查一下你是否有一个好的兼职项目组合。如果没有,请尽快处理!链接:如何选择数据科学边项目
- 开始申请工作(或者朝着你的目标直接行动),而不是陷入自我学习的怪圈。很多时候,即使你没有得到这份工作,面试也是找出你可以改进的地方的好方法。
结论——如何决定是否应该参加更多的在线课程
现在,我们已经浏览了针对多种场景类型的建议,以及这些建议背后的详细逻辑。当然,每个人有不同的教育背景、工作经历和其他情况,但我希望通过提供的逻辑,您可以将其应用到您自己的具体情况中!
如果有疑问,请记住:参加在线课程的边际收益是递减的。最初的几个会非常有益,然后你做得越多,随后的每一个给你的新好处就越少。同样的逻辑也适用于接受额外教育。
很容易陷入被动学习的循环,所以总的想法是,如果你已经可以用你现有的知识量达到目标,就暂停一下。副业或简单地开始工作申请过程会给你带来更好的时间投资回报。希望这有帮助!
原载于 2020 年 7 月 12 日【https://www.susanshu.com】。
该不该用无代码 AI 平台?限制和机遇
实施无代码人工智能解决方案后的经验教训

虽然大多数人工智能项目仍然没有进入生产,但对无代码人工智能平台的兴趣一直在上升。事实上,越来越多的初创公司和大型科技公司现在提出“易于使用”的 ML 平台。
能够在不是数据科学家的情况下构建和使用基于机器学习的解决方案,这一想法对小型和大型公司来说都是非常有趣的事情,这些公司可以赋予员工权力,同时将更多资源用于复杂的 ML 项目。
在这篇文章中,我将分享我在实现了这些无代码 AI 解决方案之一并分析了与该行业相关的几家初创公司后所学到的东西。作为一名人工智能顾问,我的目标是确定这些解决方案是否可以帮助我们增加更多项目从概念证明(PoCs)过渡到可扩展、相关和高效部署的人工智能解决方案的机会。
为什么使用无代码人工智能平台
从运营的角度来看,我们在一年中为几个部门开发了几个人工智能项目。由于缺乏数据、投资、领导力,或者仅仅是由于机器学习目前的成熟度,他们中的大多数人只是停留在概念证明阶段。
当涉及到项目时,复杂程度是不一样的。事实上,一些项目与“最近的”算法有关,而其他项目只是使用众所周知的算法,如线性回归、K-means、朴素贝叶斯等。我们的无代码人工智能平台的目标是确定这些解决方案是否可以帮助我们将一些合作者转变为公民开发者,并将更多的数据科学家分派到“复杂”的用例中。
公民开发者: 构建应用程序供他人使用的非专业开发者。虽然他们不直接向 IT 部门汇报,但他们使用 IT 部门认可的工具,如低代码平台。
**请务必理解,产品经理等内部公民开发人员的晋升并不意味着对数据科学家的需求正在消失。**这个想法是为了减轻数据科学家积压工作的负担,以便他们能够专注于更大、更复杂的项目。
显然,对于传统的 ML 工作流程来说,做“更少”的工作并加速特定用例的开发是很有吸引力的。有没有可能设想一个未来,经理们可以提出一个想法,构建它,并通过使用一个无代码的人工智能平台来运行项目?
传统 ML 与无代码 ML 流程
今天,大多数人工智能项目都遵循或多或少相同的步骤。事实上,你从识别一个用例开始,收集数据,建立模型,训练它,改进它,等等。为了确定无代码人工智能是否真的有帮助,我们应该首先了解“经典”ML 和无代码 ML 之间的差异。

如你所见,“传统”人工智能项目的一些步骤可以自动化,或者使用拖放工具变得简单。从这个角度来看,我认为无代码人工智能平台是加速原型和演示开发的一种省时的方式。
我相信无代码人工智能平台非常适合特定的项目。例如,我们希望预测客户流失、客户终身价值、动态定价等指标,或者分析几份合同的数据以帮助我们更好地进行谈判的用例。我们也相信这些工具在一些内部流程的自动化中是有用的。
新技能
可以肯定的是,无代码人工智能平台的兴起也将创造新的技能预期。在不久的将来,如果一个产品经理必须熟悉至少一个无代码人工智能工具,并且了解数据集管理,我不会感到惊讶。我希望看到越来越多与这些工具相关的在线培训。
特定的市场
无代码 AI 仍然是一个不断增长的市场。大多数玩家似乎首先把自己定位在技术的类型上(NLP,计算机视觉,等等。)或特定用例(CRM 管理等)。
在不久的将来,我希望看到完整的工具,使覆盖几乎所有用途成为可能,从而避免投资于多种工具和利用知识的需要。
这个行业由初创公司和开发自己工具的大型科技公司组成。出于显而易见的原因,初创公司似乎专注于特定的用例,而不是提供几种选择。
锁定战略和商业模式
这个行业最有趣的方面是大型科技公司如何试图吸引新客户,以增加他们的用户范围,同时使用锁定策略。
**锁定策略:**一种策略,在这种策略中,客户非常依赖一家供应商的产品和服务,如果没有实际的和/或感知的巨大转换成本,客户就无法转向另一家供应商。
我经常想,如果不专业化,无代码人工智能初创公司能否长期生存。事实上,大型科技公司的优势在于能够为客户提供一种无需动脑的方法来保持在该供应商的平台和路线图上。
理想情况下,大型科技公司(谷歌和微软)希望公司能够使用他们的软件开发工具和与数据管理相关的更广泛的服务生态系统。
虽然其中一些解决方案是免费的或基于订阅模式,但它们可能需要顾问和开发人员的干预来培训用户和执行云后端连接工程。
实施无代码人工智能解决方案后的我的看法
几个月来,我们决定测试一个无代码人工智能平台的有效性。在我看来,无代码人工智能的效率和实用性并不是神话。
对我们来说,最大的好处是,由于使用无代码工具创建了快速 PoC,数据科学家可以通过评估他们不完整的想法来帮助我们的营销部门。事实上,他/她可以建议他们进行无代码 PoC,并在需求稳定后再回来进行。
然而,必须做出一些让步。事实上,如果你想快速生产而没有发展,你必须能够降低你的期望。
通过无代码解决方案基于机器学习的项目的成功将在很大程度上取决于您的功能需求,当需求非常具体时,就有必要在实现速度和与功能相关的期望之间找到正确的平衡。

每个解决方案都有一个工具设计固有的边界。事实上,这些工具是基于模型的,要么编辑选择提出简单的模型,这些模型将易于理解和使用,但反过来将缺乏灵活性,因为人们只能在模型的框架内开发。
相反,其他平台选择了更精细的模型,这些模型提供了与通过编码开发应用程序相当的灵活性。另一方面,学习曲线和所需技能会高很多。

我强烈建议根据易用性和灵活性之间的平衡来选择工具。在某些情况下,重要的是要记住,一旦你在一个平台上开发了一个应用程序,只要这个应用程序还在运行,你就和这个平台联系在一起了。在 PoC 的上下文中,这不是问题,但是在预期持续的应用程序的上下文中,情况可能会不同。
事实上,你必须确保你的项目所需的可扩展性可以通过使用无代码人工智能平台来实现。我认为,对于“复杂”的用例,使用无代码人工智能平台是不可能有可扩展的解决方案的。
此外,契约关系 ( 数据所有权)必须在成本和可逆性方面仔细检查。
另一个关键因素是可维护性。我建议你从一开始就确定你的目标是仅仅测试一个想法的相关性还是构建一个持久的应用程序。在第一种情况下,如果可能,最好使用无代码 AI 解决方案快速创建一次性 PoC。否则,我建议您使用传统的 ML 方法,构建稳定且可维护的版本。
如果你的无代码 AI 供应商可以保证你的可扩展性(在某些用例中是可能的),我会建议你按比例评估许可的总成本,以确保长期的可维护性。
可能发生的最糟糕的事情是,使用“快速而肮脏”的方法创建概念证明,然后投入生产,尝试扩展相同的概念证明。
限制
在我看来,目前大多数(不是全部)无代码 AI 平台的极限是:
个性化程度 不管大多数人可能会怎么想,构建机器学习模型的困难不是编码,而是你可以支配的数据、特征工程、架构和测试。在一些无代码解决方案中,您缺乏微调和调整不同参数的能力。
另一个缺点与数据有关。事实上,你可能对数据偏差很熟悉。根据不同的用例,每个人都可以构建和导出这些模型。因此,增加了生成有偏差算法的危险。
显然,机器学习工程师也可以创建有偏见的解决方案……
如前所述,无代码人工智能工具可能是积极的,但它们需要特定的治理。事实上,如果你不能以一种治理和控制的方式集成它们,你只会引入更多的影子 IT 和更多的问题。
影子 IT: 这个术语指的是在企业的 IT 部门不知情的情况下被管理和利用的信息技术(IT)应用程序和基础设施。
数据科学家可能最终会花尽可能多的时间来修改同事的工作,而不是完成自己的任务。
依赖性 我对无代码 AI 工具开发的另一个担忧是与依赖性有关的。事实上,您的解决方案可能不需要数据科学家,但将来可能需要一些顾问来帮助您更好地理解 ML 或使您的解决方案可伸缩。因此,对精通技术的专家的依赖不会消失。
对数据的需求 所有的机器学习项目都需要同样的东西:数据
一个 ML 项目的成功高度依赖于你收集、管理和维护数据集的能力。然而,这通常是数据科学家的工作,我不确定“公民开发者”是否能完成这些任务。
可伸缩性 我最后关心的是可伸缩性。事实上,许多成功的概念验证在生产中失败了,因为我们无法构建一个能够以可扩展的方式服务于 ML 模型的系统。在使用大量敏感数据的行业,如医疗保健或银行业,这就更难了。
我本可以提到其他潜在的问题,比如部署、安全、与遗留系统的集成等。然而,我仍然相信无代码人工智能平台的有用性。使用无代码人工智能的项目的成功将在很大程度上取决于您的用例以及数据管理的成熟度。
我们仅仅处于这一趋势的开端,我很有信心越来越多的公司(尤其是中小企业)将会尝试利用这些工具。
您是否应该使用云提供商提供的 ML 监控解决方案?
Azure 和 AWS 与 AI 系统性能监控最佳解决方案的比较

资料来源:莫纳实验室公司。
随着人工智能系统在许多行业变得越来越普遍,监控这些系统的需求也在增加。与传统软件相比,人工智能系统对数据输入的变化非常敏感。因此,一类新的监控解决方案已经在数据和功能级别(而不是应用程序级别的基础设施)出现。这些解决方案旨在检测人工智能系统中常见的独特问题,即概念漂移、偏见等。
人工智能供应商领域现在挤满了兜售监控能力的公司。这些公司包括一流的/独立的解决方案,以及集成的人工智能生命周期管理套件。后者提供更基本的监控功能,作为次要重点。
为了进一步宣传,一些主要的云提供商开始宣传他们也为部署在他们云平台上的机器学习模型提供监控功能。按市场份额计算,AWS 和 Azure 是第一大和第二大提供商,它们分别宣布了各自 ML 平台下的具体功能——SageMaker 模型监视器 (AWS),和数据集监视器 (Azure)。到目前为止,谷歌(GCP)似乎只为服务模型和培训工作提供应用程序级别的监控。
在这篇文章中,我们提供了云提供商当前产品的概述(我们重点关注 AWS 和 Azure),并讨论了这些解决方案中的差距(通常由最佳解决方案很好地涵盖)。
云提供商产品概述
那么 Azure 和 AWS 在监控生产中的模型方面能提供什么呢?
轻触开关即可记录模型输入和输出
监控任何类型的系统的第一部分几乎总是记录系统操作的数据。在监控 ML 模型的情况下,这从模型输入和输出开始。
毫不奇怪,Azure 和 AWS 都允许您轻松地将这些数据记录到各自的数据存储中(AWS 的 S3 存储桶,Azure 的 blob 存储)。您所要做的就是在 python 代码中向模型运行调用添加一个数据捕获配置。请注意,并非所有输入类型都可以自动保存(例如,在 Azure 上,不会收集音频、图像和视频)。AWS 还允许为数据捕获配置采样率。
使用现有的分析和 APM 解决方案分析数据
一旦收集了输入和输出数据,平台建议的下一步是使用其现有的分析/APM 产品来跟踪数据。
Azure 建议使用 Power BI 或 Azure DataBricks 来获得数据的初步分析,而在 AWS 中,你可以使用 Amazon Cloudwatch。
由于数据保存在平台自己的存储系统中,通常很容易获得跟踪模型输入和输出的初始图表和图形。
漂移输入数据的基本跟踪
AWS 和 Azure 都提供了相当新的工具,用于警告模型输入数据的分布和行为的变化。对于 AWS 来说,这是“亚马逊 SageMaker 模型监视器”的主要部分,而对于 Azure 来说,这是通过一个叫做“数据集监视器”的非常新的功能来完成的。
在这两个平台上,工作流都是从创建基线数据集开始的,基线数据集通常直接基于训练数据集。
一旦您准备好了基线,平台允许您从如上所述捕获的推理输入数据创建数据集,将它们与基线数据集进行比较,并获得关于特征分布变化的报告。
这两种解决方案之间存在一些差异。AWS 的解决方案从基线数据集创建“约束”和“统计”文件,其中包含输入数据的统计信息。这允许您稍后与推断数据进行比较,以获得关于差异的报告。另一方面,Azure 的“数据集监视器”为您提供了一个仪表板,用于比较基线数据集和推理时间数据集之间每个特性的分布。然后,当分布的变化足够大时,它允许您设置警报。
然而,上述差异实际上是相同基本功能的实现细节——以您的特征集为例,查看它们在训练集中的基线分布,并将其与它们在推理时间中的分布进行比较。
够了吗?
因此,云提供商确实为数据和模型层提供了监控功能,但你能依靠这些功能来维持甚至改进生产级人工智能系统吗?我们认为你不能。这里有几个原因:
生产级监控需要丰富的上下文数据
跟踪您的模型输入和输出是很好的,但是这还不足以真正理解您的数据和模型的行为。你真正需要监控的不是单个模型——而是整个人工智能系统。很多时候,这将包括您的云提供商不容易访问的数据。
几个例子:
- 您有一个人类标记系统,并且您想要监控您的模型的输出与它们的标记相比如何,以获得您的模型的真实性能度量。
- 您的系统包含几个模型和管线,其中一个模型的输出用作后续模型的输入特征。第一个模型的表现不佳可能是第二个模型表现不佳的根本原因,您的监控系统应该了解这种依赖性,并相应地向您发出警报。
- 您有实际的业务结果(例如,您的建议模型选择的广告是否被实际点击)-这是衡量您的模型性能的一个非常重要的指标,即使输入功能从未真正改变,它也是相关的。
- 您不想(甚至不允许,例如,种族/性别)将元数据用作输入要素,但您确实希望对其进行跟踪以进行监控,从而确保您不会对该数据字段有偏见。
有关基于上下文的监控的更多信息,请查看这篇关于平台监控方法的文章。
跟踪数据的子部分
一个人工智能系统平均工作得很好**,但在数据的子部分表现不佳,这种情况并不罕见。因此,对性能进行细致的检查至关重要。**
考虑这样一种情况,您的模型对来自您的一个客户的数据表现非常不同。如果这个客户占了您的模型所接收数据的 5%,那么模型的总体平均性能可能看起来不错。然而,这位顾客不会高兴的。这同样适用于不同的地理位置、设备、浏览器或任何其他可以对数据进行切片的维度。
良好的监控解决方案会在子细分市场中发生异常行为时向您发出警报,包括在更细粒度的子细分市场中发生异常行为时,例如,来自特定地区的用户使用特定设备时。
可配置性
每一个 AI 系统都像一片雪花。它们都有特定的性能指标、可接受(或不可接受)的行为等。因此,一个好的人工智能监控平台必须是高度可配置的。
考虑这样一种情况,你有一个 NLP 模型来检测输入文本的情感。您知道对于短文本(例如,少于 50 个字符),您的模型不是很准确,而您对此没有意见。您希望监控您的模型输出,但是当短输入文本的相对比例增加时,您不希望收到低置信度分数的警报。您的监控平台必须允许您在考虑这一特定指标(但可能不考虑其他指标)时,能够轻松从监控的数据集中排除所有短文本。
还有许多其他例子可以说明微调的价值,从警报首选项到临时数据操作。完全自主的监控方法在理论上听起来不错,也很容易解释,但是当遇到现实世界的约束时就会失败。
结论
首先,看到主要的云提供商开始为生产人工智能提供更多工具是令人鼓舞的。然而,我们审查的解决方案是非常基础和实验性的(例如,Azure 还没有为上述解决方案提供任何 SLA)。对于这些供应商来说,监控当然不是最优先考虑的事情。
与此同时,业内越来越清楚的是,监控模型和整个人工智能系统是一项基本需求,不能被视为事后想法。为了让你的人工智能产品做好准备,并确保在商业 KPI 受到负面影响之前发现人工智能问题,这一点至关重要。同类最佳的解决方案无疑将监控作为其核心重点和优先事项。
那么,最佳品种在市场上会有优势吗?还有待观察。一个可以考虑的先例是杀伤人员地雷行业。云提供商长期以来一直为 IT 组织提供基本的解决方案,但市场催生了一批成功的一流企业,如 New Relic、AppDynamics 和 Datadog(以及许多其他企业)。一些购买者满足于更基本的功能,因为他们喜欢与更少的供应商打交道,而另一些购买者喜欢生命周期每个阶段中最深入的功能。
无论如何,观察和体验这一类别的演变肯定会很有趣。
参考
- GCP 监控模型(APM like):https://cloud . Google . com/ai-platform/prediction/docs/monitor-prediction
- AWS 宣布(12 月 19 日)“Sagemaker 模型监视器”:https://AWS . Amazon . com/blogs/AWS/Amazon-Sagemaker-Model-Monitor-fully-managed-automatic-monitoring-for-your-machine-learning-models/
- Azure 模型数据收集:https://docs . Microsoft . com/en-us/azure/machine-learning/how-to-enable-data-collection
- Azure 数据集监视器:https://AWS . Amazon . com/blogs/AWS/Amazon-sage maker-model-monitor-full-managed-automatic-monitoring-for-your-machine-learning-models/
原载于 2020 年 9 月 15 日https://www . monalabs . io。**
向我展示 ROI:业务分类指标
通过可操作的指标推动业务价值
沙欣·高赫尔博士
分类器的评估指标有助于确定模型从数据中学习的程度以及区分不同类别的能力。准确度、精密度、召回率、F1、AUC 和对数损失是评估分类器性能最常用的指标。在这篇文章中,我将谈论一些其他指标,即。累积收益、提升和捕获率,可用于向业务利益相关方展示分类模型的有效性和价值,使其成为“可操作的洞察”,并有助于在业务运营中战略性地使用预测。我将分享一个 python 实用函数,它将把预测概率和实际类(来自目标列的地面事实或训练数据中的“Y”)作为输入,并计算模型的累积增益、提升和捕获率。这也可以用于设置分类器的阈值。我还将分享一些来自不同垂直行业的用例示例,如预测性维护,医疗保健和营销,这些指标可用于推动业务价值。

物有所值
在建立机器学习模型以预测事件发生的可能性之后,例如机器故障的可能性、客户流失的可能性、患者发生医疗事件的可能性、成员响应外展的可能性等。下一步通常是设计一个基于模型预测的行动计划。经常出现的问题是最少的病例数是多少(顾客、病人、机器等)。)我可以以获得最佳结果为目标。这个问题的答案可以在捕获率分析、累积增益和提升图表中找到。这些指标相互关联,可以互换使用,但都回答了同一个业务问题,即如何获得最佳性价比。
下面我将简要描述这些指标是什么以及计算它们的步骤。在 GitHub 中可以找到 python 实用函数以及所使用的数据。该函数返回的输出如下,将用于绘图。

效用函数度量的输出 _roi
捕获率分析
捕获率分析(也称为十分位数分析)提供了一种快速直观的方法来测试模型预测预期结果的能力。为了分析捕获率,从模型中预测的概率按降序排列,并分成 10 个大小相等的区间或十分位数,我们查看每个十分位数中的实际事件率。实际事件率是十分位数中的事件数(实际阳性数)除以十分位数的大小,其中十分位数的大小就是实例总数除以 10。这些被绘制成柱状图,我们从上到下观察各个柱状图的相对高度,高度代表每个十分位数的事件发生率。
理想模式 —一个好的图形表现出阶梯效应,从顶部的十分位数到底部的十分位数下降。具有显示良好阶梯模式的条形的模型比没有条形的模型更有预测性,因为它表明模型是宁滨,即从最有可能成功到最不可能成功的实例。
不期望的图形 —一个坏的图形具有不显示阶梯效应的条,并且看起来是无序的或者看起来是相同的高度。这表明该模型并不比随机将宁滨实例分成十分位数表现得更好。

捕获率分析
阅读左边的第一个条形,我们可以看到,通过将 10%的记录作为目标,这些记录被模型列为“最可能的阳性”(前十分位数),将在目标组中产生 80%的阳性。
累积收益图
累积收益图显示了通过使用模型来确定目标或采取行动与随机确定目标相比所能获得的收益。
例如:在预测性维护场景中(该模型通常预测机器出现故障的可能性),如果您随机抽取 20%的机器进行定期维护,您可能会发现只有 20%的机器会出现故障(这将是您的基准)。但是,如果您的目标是 20%的机器,并且如果模型能够确保 60%将要失败的机器在这个组中,那么这将是您的模型的收益。
在累积增益图中,X 轴是抽样总体的百分比,Y 轴是样本中实际失败的比例。该曲线显示了通过针对案例总数的给定百分比而“获得”的案例总数的百分比。曲线离基线越远,增益越大。

累积增益曲线
在上面的增益图中,我们可以看到,通过使用模型预测的概率瞄准 50%的人口,我们将获得 75%的事件。通过使用来自模型的预测将 40%的人口作为目标,我们将仅获得 65%的事件,而通过将 60%的人口作为目标,我们将获得 82%的事件。
如果业务目标或 KPI 可以通过获得 65%的事件来满足,我们可以通过将所需的百分比映射到适当的临界值来使用它来设置分类器的阈值。阈值决定了如何将预测概率标记为正数或负数
电梯图表
提升图来源于累积收益图。在提升图中,X 轴是抽样人口的百分比,Y 轴是使用和不使用预测模型获得的结果之间的比率。这就是累积增益图中累积增益与基线的比值。提升曲线是预测模型通过选择相对较少的案例获得相对较大部分正面信息的有效性的另一种衡量标准,换句话说,就是我们可以有效地撇去奶油。
例如:在医疗保健领域,一个常见的场景是主动接触有风险的患者以进行干预。这可以用于糖尿病或高血压或任何其他疾病的干预。由于资源有限,始终需要优化外展计划,以覆盖大部分真正处于风险中的患者,同时最大限度地减少外展次数。

升力曲线
在上面的提升曲线中,你会注意到,提升将随着我们选择的目标人群的样本而变化。当只针对人口中的一小部分样本(具有高预测概率的实例)时,高提升是好的分类器的信号。随着我们的目标人群样本越来越大,Lift 将继续下降。
在本文中,我们使用 python 来计算分类器的一些业务指标。希望在这些指标的帮助下,您将能够为您的机器学习模型建立 ROI,这将有助于在业务运营中采用该模型。尽情享受吧!
@Shaheen_Gauher
Shaheen Gauher 的职业是人工智能沟通者、智能解决方案推动者和数据科学家。她帮助企业构建和部署预测解决方案,以最佳地利用他们的数据,并使他们能够通过技术和人工智能实现更多目标。她是训练有素的气候科学家和物理学家,并在塔夫茨大学艺术与科学研究生院的数据分析顾问委员会任职。
举手表决:谁愿意在可承受的范围内,分分钟内将净学费提高 6-15 %?

太久没读的是:学校可以通过使用机器学习来增加 6-15%的净学费。此外,他们还可以在 99%的情况下快速轻松地给出最佳上诉金额,减少 67%的熔化和 74%的违约。
人类是糟糕的评估者。当我们错误地认为自己擅长估算大部分事物的数量时——尤其是关于金钱的数量,这会助长我们饥渴的自我。几个月前,我们的人工智能(AI)公司——此前专注于生物医学、电子商务和金融科技——被要求应用机器学习(ML)来优化一所顶尖学校的财政援助,这是我们最近的一个证据。作为一个背景,他们并不是因为不善于分配财政援助而出名的。他们很擅长这个。
然而,一场“完美风暴”事件——全球疫情、另一场大衰退、销售和营销人员面临日益增加的数字复杂性,以及家庭关注支付意愿而非历史支付能力——促使他们寻找下一代解决方案。对于大多数不了解的人来说,ML 是一种人工智能,它使用超级强大的统计数据——需要几年时间才能计算的东西——来学习如何预测或分类事物。
即使你没有在工作中直接面对它,机器学习也变得无处不在。ML 是脸书为你谈论过的或谷歌搜索过的东西向你推送广告的方式。这是亚马逊推荐你应该阅读或购买的其他内容的方式。而且,这就是特斯拉的自动驾驶汽车自动驾驶的方式。
当学校有了聪明的想法来了解是否有人应用它来优化财政援助和净学费时,他们发现了以下情况(我们在研究市场时也发现了同样的情况),现在有三种选择——它们都很糟糕:(1)由财政援助存储系统(如 SSS、FACTS、TADS、FAST、FAFSA 等)提供的援助建议。);(2)帮助顾问使用他们的“专有算法”提出建议以及(3)具有低准确度和高价格(即$45,000 到$75,000)的初级 ML 推荐。
第一,财政援助系统推荐一个援助数字,但它只是使用算术——收入是这个,费用是那个,所有其他的他们可以花在教育上。几乎所有的录取和招生管理专业人士都会告诉你,这是低准确率和低价值的。金融援助供应商的基本算术援助建议还做出了一个致命的错误假设,即更关注援助的历史工作方式,而不是近年来的趋势。也就是说,家庭过去申请财政援助是因为他们需要。现在,少数人有,但越来越多的人现在要求得到它,因为他们想要它。援助申请者的家庭收入通常是几十万美元,净资产是这个数字的几倍。他们可以支付私人学费;他们不想这么做是因为选择——为退休、大学或更昂贵的生活方式存钱,他们不想牺牲这种生活方式(例如,“我们无法支付莎莉的学费,也无法保留毛伊岛的公寓”,等等。).
第二,私人顾问销售的专有“算法”通常不是算法;它们是基本公式,比财政援助系统或简单的电子表格好不了多少。他们很少甚至不使用统计数据,也不能告诉你成功的概率或测量的准确性。顾问通常希望你为他们的每次使用付费(例如,文件审查、申请人、年份)。一种相关的拆封方法是“分桶法”——也称为“金发姑娘法”——他们查看文件,将它们分成“轻、中、重”三类,然后随机向每一类投入一定数量的钱。统计分析表明,分桶法不如人工估计每个个体和个性化案例准确;这对预测和优化是不利的,而不是有利的。从本质上讲,他们只是将他们所知不多的文书处理外包给那些对其知之甚少的人,而没有任何可论证的或可比较的结果。因此,学校为了方便和速度而牺牲了质量。
第三,有两个组织(除了我们)将机器学习应用于录取和辅助数据。第一种是咨询公司,使用一种叫做决策树的基本或原始算法(或一组称为随机森林的算法),来估计给予申请人多少帮助或吸引力。虽然它们的表现优于人类评估者,但它们仍然只有大约 50–57%的准确率。为此,他们通常在第一年后每年收取 25,000 美元和 10,000 美元的额外费用。他们没有告诉你的是,这种元素类型的 ML 解决方案会退化,因为数据每年都不一样——它偏离了历史数据。如果第一年 58%准确,第二年可能只有 55%准确,第三年只有 50%准确,那么你已经为错误的事情比正确的事情付出了 45,000 美元。第二个应用机器学习的组织是一所研究型大学,他们采用集成,或初级或原始 ML 算法的组合,这些算法更精确一些,可能低于 60%的百分比。到目前为止,它们是最好的选择,但只有那些能够支付 75,000 美元年费的学校才有。在这两种情况下,分析也必须由数据科学家在数周或数月内完成——学生申请时无法实时获得,招生人员也无法使用。
我们发现拥有一个高度可预测的工具非常重要,它可以在招生人员需要时随时可用,并且他们可以通过拖放电子表格来简单轻松地使用它,而不是等待数据科学家几周或几个月。此外,在不确定的经济时期,它必须是负担得起的。
我们过去和现在所做的有三点不同:(1)我们使用了一种超级先进的技术形式,称为自动机器学习,在数千种算法中进行“烘烤”或竞赛,以始终拥有预测最准确的组合;(2)我们使用几十年来成千上万的家庭数据点来训练算法,以了解精确的数量——不多也不少——来激励学生入学或留在学校;(3)我们将它制作成一个简单易用的安全网络应用程序,您可以拖放匿名学生数据的电子表格,它会准确地告诉您提供多少帮助或上诉,或者流失、融化或违约的可能性。此外,任何被录取的人都可以在任何需要的时候使用它,几乎不需要任何培训。它的准确率在 1%以内,至少 67%,高达 99%,这取决于它是哪种工具。
对援助、上诉、减员和违约的自动 ML 预测的另一个及时的好处是,这些 ML 算法是种族和性别盲的。他们接受训练的数据是匿名的,不包括性别和种族。它还全面考虑了 12-24 个因素,以个性化每个家庭的需求——不仅仅是收入和资产,还包括地理多样性、家庭规模和经济差异。
关键问题是,我们如何知道它有效?很高兴你问了。我们把我们的工具应用到最初雇佣我们的那所名校的 10 年数据中。我们了解到,如果他们在此期间使用我们的 ML 工具,他们每年将从几乎相同的学生群体中多获得 108 万美元。只需花费谷歌估算表的一小部分价格,你就可以在定制数据上获得军用级别的精度,在几分钟内产生更好的结果。
然后,我们将同样的技术应用于上诉、流失和违约,发现它可以在几秒钟内准确预测 99%、67%和 74%的情况,只需将学校通常拥有的学生数据电子表格拖放到安全的网络应用程序上。
我们相信这些技术将改变中等和高等教育学校的招生和资助方式。因此,我们成立了一家名为 Ed AI 的子公司来做这件事。在接下来的几个星期里,我们会以很大的折扣签下早期采用者,这已经是录取和援助市场上最准确、最实惠、回报最高的工具了。如果你决定在几分钟内而不是几天或几周内处理援助和上诉,并在更好地服务家庭和学生的同时将净学费增加 6-15%,请给我发电子邮件,我们将开始…
Eric Luellen 是一位技术高管、连续创业者、数据科学领袖,担任bio informatix . io的联合创始人兼首席数据科学家。他还是《击败亚马逊:赢得电商战争的机器学习指南 】的作者,由社会正义出版社于 2020 年 2 月出版。他的在线读者超过 4 万人。
用于多文本分类的连体和双 BERT
在模型中插入变压器的不同方法

罗尔夫·诺依曼在 Unsplash 上的照片
对 NLP 的不断研究产生了各种预训练模型的发展。对于各种任务,如文本分类、无监督主题建模和问答,最先进的结果通常会有越来越多的改进。
最伟大的发现之一是在神经网络结构中采用了注意力机制。这项技术是所有被称为**变形金刚网络的基础。**他们应用注意力机制提取关于给定单词上下文的信息,然后将其编码到学习向量中。
作为数据科学家,我们可以利用许多变压器架构来预测或微调我们的任务。在本帖中,我们喜欢经典的 BERT,但同样的推理可以应用于其他任何变压器结构。我们的范围是在双重和连体结构中使用 BERT,而不是将其用作多纹理输入分类的单一特征提取器。这篇文章的灵感来自于这里的。
数据
我们从 Kaggle 收集了一个数据集。新闻类别数据集包含从赫芬顿邮报获得的 2012 年至 2018 年约 20 万条新闻标题。我们的范围是根据两种不同的文本来源对新闻文章进行分类:标题和简短描述。我们总共有 40 多种不同类型的新闻。为了简单起见,考虑到我们工作流的计算时间,我们只使用 8 个类的子组。
我们不应用任何类型的预处理清洗;我们让我们的伯特做所有的魔术。我们的工作框架是 Tensorflow 和巨大的 Huggingface 变形金刚库。更详细地说,我们利用了裸露的 Bert 模型转换器,它输出原始的隐藏状态,而没有任何特定的头在上面。它可以像 Tensorflow 模型子类一样访问,并且可以很容易地在我们的网络架构中进行微调。
单伯特
作为第一个竞争对手,我们引入了单一 BERT 结构。它只接收一个文本输入,这是我们两个文本源连接的结果。这是常态:任何模型都可以接收串联特征的输入。对于变压器,这一过程通过将输入与特殊令牌相结合而得到提升。
BERT 期望输入数据具有特定的格式:有特殊的标记来标记句子/文本源的开始([CLS])和结束([SEP])。同时,标记化涉及将输入文本分割成词汇表中可用的标记列表。用词块技术处理未登录词;其中一个单词被逐渐分成子单词,这些子单词是词汇表的一部分。这个过程可以由预先训练好的拥抱脸标记器轻松完成;我们只需要处理填料。
我们以每个文本源的三个矩阵(令牌、掩码、序列 id)结束。它们是我们变压器的输入。在单个 BERT 的情况下,我们只有一个矩阵元组。这是因为我们同时将两个文本序列传递给我们的标记器,这两个文本序列自动连接在一起(用[SEP]标记)。
我们模型的结构非常简单:变压器直接由我们上面构建的矩阵供电。最后,变压器的最终隐藏状态通过平均池操作来减少。概率得分由最终的密集层计算。

我们简单的 BERT 在测试数据上达到了 83%的准确率。这些表现记录在下面的混淆矩阵中。

双重伯特
我们的第二种结构可以定义为双 BERT,因为它使用两个不同的变压器。它们具有相同的组成,但是用不同的输入来训练。第一个接收新闻标题,而另一个接收简短的文字描述。输入被编码为总是产生两个矩阵元组(令牌、掩码、序列 id),每个输入一个。对于两个数据源,我们的转换器的最终隐藏状态随着平均池化而减少。它们被连接起来并通过一个完全连接的层。

通过这些设置,我们可以在测试数据上达到 84%的准确率。

暹罗伯特
我们最后的模型是一种连体建筑。它可以这样定义,因为两个不同的数据源在同一个可训练转换器结构中同时传递。输入矩阵与双 BERT 的情况相同。对于两个数据源,我们的转换器的最终隐藏状态是通过一个平均操作来汇集的。由此产生的串联在一个完全连接的层中传递,该层组合它们并产生概率。

我们的连体结构在测试数据上达到了 82%的准确率。

摘要
在这篇文章中,我们应用了 BERT 结构来执行多类分类任务。我们实验的附加价值是以各种方式使用变压器来处理多个输入源。我们从一个源中所有输入的经典连接开始,并在保持文本输入分离的情况下结束了模型。双体和连体变体能够实现良好的性能。因此,它们可以被视为传统单变压器结构的良好替代品。
保持联系: Linkedin
参考文献
两张床比一张床好
Kaggle: 伯特基 TF2.0
暹罗网络
针对初学者的逐行解释
摘要
Siamesse 网络是一类能够一次性学习的神经网络。这篇文章针对深度学习初学者,他们熟悉 python 和卷积神经网络的基础知识。我们将逐行解释如何使用 Python 中的 Keras 实现暹罗网络。当您浏览代码时,如果您觉得有些事情可以用更好的方式解释或完成,请随时发表评论。

图片由 Gerd Altmann 从 Pixabay 拍摄
介绍
让我们假设我们有一个 1000 名员工的公司。我们决定实施面部识别系统来记录你的员工的出勤情况。如果我们使用传统的神经网络,我们将不得不面对两个主要问题。第一个是数据集。从我们每个员工那里收集大量的数据集几乎是不可能的,我们最终会得到每个员工最多 5 张照片。但是传统的 CNN(卷积神经网络)无法学习如此小的集合的特征。我们最终还会得到 1000 个输出类。让我们考虑一下,不知何故,我们从每个员工那里获得了一个巨大的数据集,我们训练了一个非常好的 CNN 模型。当一名新员工加入我们的组织时会发生什么?我们如何将此人纳入我们的面部识别系统?所有这些缺点都可以通过使用连体网络来克服。在这篇文章中,我们将使用暹罗网络进行一次性学习实验,该网络专注于差异而不是特征匹配。
我们计算不同类别的图像之间的相似性得分,而不是使用每个类别的大量数据。这个网络的输入将是属于相同类别或不同类别的两个图像。输出将是范围在 0 和 1 之间的浮点数,其中 1 表示两个图像属于同一类,0 表示它们来自不同的图像。让我首先解释它与使用 CNN 架构的图像分类有何不同。
体系结构
在 CNN 模型中,有一系列卷积层和池层,后面是一些密集层和一个可能带有 softmax 函数的输出层。这里的卷积层负责从图像中提取特征,而 softmax 层负责为每个类别提供一个概率范围。然后,我们决定具有最高概率值的神经元的图像类别。
看看这篇伟大的文章了解更多关于 CNN 如何工作的信息。

传统 CNN 架构由苏米特·萨哈
对于暹罗网络,除了没有 softmax 层之外,它具有类似的卷积层和池层构成。所以,我们从致密层开始。如前所述,由于网络有两个图像作为输入,我们将得到两个密集层。现在我们计算这两层的差异,并将结果输出到具有 sigmoid 激活函数(0 到 1)的单个神经元。因此,这个网络的训练数据必须以这样一种方式构造,即有一个由两个图像和一个变量 0 或 1 组成的列表。

暹罗网络
**注意:**只有一个网络,两个图像通过同一个网络。只是有两个输入。因此,两个输入将从卷积层和密集层通过相同的权重矩阵。
如果你仍然不清楚这是如何工作的,参考这个链接。
密码
在这篇文章中,我使用了 Kaggle 的 Fruits 360 数据集。但是,可以随意试验其他数据集。代码托管在 Kaggle 中。如果您对代码有疑问,请随意使用下面的笔记本,亲自体验一下。
https://www.kaggle.com/krishnaprasad96/siamese-network
导入库
让我们从导入我们正在使用的库开始。如前所述,这段代码使用 Keras 构建模型,使用 NumPy,pillow 进行数据预处理。
注意:不要将 Keras 作为"从 tensorflow 导入 Keras
数据预处理
- **第 1 行:**包含数据集的基础目录
- 第 2 行:表示将用于培训的百分比。其余的将用于测试
- **第三行:**由于 Fruits 360 是一个用于图像分类的数据集,所以它每个类别都有很多图像。但是对于我们的实验来说,一小部分就足够了
- **第 6 行:**从文件夹中获取目录列表。每个文件夹都属于一个类
- **第 10–13 行:**声明三个空列表,记录 X(图片),y(标签),cat_list(记录每张图片的类别)
- **第 16–24 行:**遍历类文件夹,从每个类中选择 10 张图像,将它们转换成 RGB 格式,并附加到一个列表中。在 cat_list[]中记录图像的类别,以备将来参考
- 第 26–28 行:将所有列表转换成 NumPy 数组。因为任何图像的范围都是从 0 到 255,所以为了简化,将数组 x 除以 255
列车测试分离
- **第 1 行:**通过乘以 train_test_split 计算将用于训练的类的数量
- **第 2 行:**从可用的总类中减去 train_size,得到 test_size
- **第 4 行:**将 train_size 乘以每个类中的文件数,得到训练文件总数
- **第 7–15 行:**将之前计算的值用于子集 X、Y 和 cat_list
生成批次
此部分用于生成用于培训的批处理文件。批处理文件应该具有 X 和 y。在图像分类的通常情况下,如果批处理大小为 64,图像大小为(100,100,3),则 X 的大小将是大小为 64 的列表,并且列表中的每个元素的大小将为(100,100,3)。
在我们的例子中,因为我们有 2 个输入,所以将有一个大小为 64 的列表(假设为“A”),并且“A”中的每个元素将有一个长度为 2 的列表(假设为“B”),并且“B”中的每个元素的大小将为(100,100,3)。为了训练,我们将生成一个批处理,使得一半的输入对 B[0]和 B[1]属于同一类别。给这些图像对赋值 0。对于另一半输入对,B[0]和 B[1]属于不同的类别。给这些图像对赋值 1。
- **第 3–7 行:**将 x_train、cat_train 的值以及训练规模的开始和结束规模存储在一个临时变量中
- **第 9–11 行:**将 Y 的 batch_size 的一半指定为 0,其他的指定为 1
- 第 13 行:从要使用的培训类别列表中随机生成一个类别列表。另外,追加两个 image_size*batch_size 数组
- 第 17–25 行:对于每次迭代,在 batch_x[0]的情况下,从类别列表中指定的类别中选择一个图像。对于 batch_x[1],如果 y[i]为 0,则从同一类别中选择图像,否则从除同一类别之外的任何其他类别中选择 batch_x[1]
暹罗网络
- **第 1 行:**声明输入图像的形状。
- **第 2 行:**用图像的形状声明两个输入。
- **第 6–7 行:**声明初始化网络权重和偏差的参数。如论文中所述选择这些值。
- **第 9–20 行:**声明一个具有 4 个卷积层和最大池层的顺序模型。最后使用一个平整层,然后是一个致密层。
- **第 22–23 行:**将两个输入传递给同一个模型。
- 第 25–27 行:从两幅图像中减去密集层,并使其通过具有 s 形激活功能的单个神经元。
- **第 29–30 行:**将带有损耗的模型编译为“二元交叉熵”和“亚当”优化器。
- 第 32 行:****siamese _ net的绘图模型函数输出如下。

暹罗网络
单向一次学习
这是一个验证一次性学习的过程,我们挑选“n”个输入对,使得只有一个输入对属于同一类别,而其他所有输入对都来自不同类别。如果我们考虑 9 路单次验证,并且网络的每个输入需要两个图像,则 x[0]对于所有 9 对都保持恒定,x[1]仅对于 9 对中的 1 属于 x[0]的相同类别,而对于其他所有的都不同。如果所有的 9 对都给了该模型,则预期属于同一类别的对将具有 9 对中的最低值。在这种情况下,我们认为这是一次成功的预测。
输入参数 n_val 是指验证步骤的数量。 n_way 指每个验证步骤的路数。记住,上面提到的 x[0]在每个验证步骤中都保持不变。

(更深入的理解,请叉开 Kaggle 的笔记本,尝试从该功能调试每一行)
- **第 3–7 行:**将 x_val,cat_test 存储在一个临时变量中
- **第 9 行:**这与批处理生成中的第 13 行相同,除了我们从测试集中创建了一批随机类别
- 第 11–24 行:对于每个验证步骤,我们遍历 n_way,从 class_list 中取出相应的类别列表,从该类别中挑选一个图像,并将其存储在 x[0]中。对于 x[1],如果它是第一次迭代,则从相同的类别中选择一个图像,而对于其他图像,则从不同的类别中选择。这个内部循环几乎与上面讨论的 batch_generation()方法相同。
- **第 26–31 行:**对于每个验证步骤,使用模型预测输出,并检查结果[0]与其他结果相比是否有最小值。请注意,结果数组将是一个大小为 n_way 的列表。如果是,在 n_correct 上加 1。对所有其他验证步骤重复相同的步骤。
- **第 32 行:**使用 n_correct 和验证步骤数计算精度。
训练模型
训练模型有 4 个超参数(时期,批量大小,n_val,n_way)
- 第 6–7 行:声明两个列表,记录损耗和精度值,以便进一步可视化。
- 第 8–20 行:对于每个历元,获取 x 和 y 的批次,使用这些输入训练模型,并将损失附加到列表中。对于每“N”(本例中为 250)个时期,通过进行 N 向一次性学习来检查模型的表现。
成果和未来工作
上面的代码在 Kaggle 中训练了 5000 个纪元。使用 GPU 将显著减少训练时间。

模型的训练损失

模型的准确性
我们能够在验证集上达到 90%的准确率。为了进一步提高精度,我们可以尝试从预先训练的模型中导入权重,如 VGG-16、雷斯网-50 等。
结束的
如果你有任何问题,请告诉我。我会尽力回应。由于这是我的第一篇博文,请告诉我它是否对你的项目有所帮助,或者我是否应该改变解释事物的方式。
我期待着创造更多关于计算机视觉的帖子。让我知道你希望涵盖的主题。黑客快乐!
Sidetable 为您提供了您不知道自己需要的熊猫方法
快速制作缺失值、频率计数、小计等数据帧🎉
Sidetable 是一个新的 Python 库,它为 pandas 中的探索性数据分析增加了几个方便的方法。在本指南中,我将向您展示如何使用 sidetable,以及它在您的数据科学工作流中的合适位置。
当我们探索 sidetable 时,我们将使用最近添加到 seaborn 可视化库中的企鹅数据集。企鹅数据集旨在取代过度使用的虹膜数据集。如果没有别的,它增加了一些多样性,并允许我们展示一些企鹅图片。😀

下颚带企鹅。资料来源:pixabay.com
Pandas 是使用 Python 的数据分析师和数据科学家的探索工具。🐼pandas API 很大,面向数据清理和数据争论。新的 sidetable 包为数据帧增加了方便的方法。这些方法使得查看缺失值、每列值的计数、小计和总计变得更加容易。
我们去看看吧!🚀
设置
要获得必需的软件包及其依赖项的最新版本,请取消注释并运行以下代码一次。
# ! pip install sidetable -U
# ! pip install pandas -U
让我们导入包并检查版本。
import sys
import pandas as pd
import sidetable
print(f"Python version {sys.version}")
print(f"pandas version: {pd.__version__}")
print(f"sidetable version: {sidetable.__version__}")Python version 3.7.3 (default, Jun 11 2019, 01:11:15)
[GCC 6.3.0 20170516]
pandas version: 1.0.5
sidetable version: 0.5.0
如果你的 Python 版本低于 3.6,建议你更新一下。如果你的版本低于 1.0,熊猫也一样。要了解更多关于熊猫 1.0 的更新,请点击这里查看我的文章。
企鹅数据🐧
我们将直接从托管 seaborn 数据集的 GitHub 存储库中的. csv 文件读取南极企鹅数据集。
数据是由 Kristen Gorman 博士和 LTER 南极洲帕尔默站收集和提供的。点击查看更多信息。
让我们将数据放入 pandas DataFrame 并检查前几行。
df_penguins = pd.read_csv('https://raw.githubusercontent.com/mwaskom/seaborn-data/master/penguins.csv')
df_penguins.head(2)

好吧,看起来我们有一些企鹅。👍
或者,如果您安装了 seaborn 、import seaborn as sns并运行df_penguins = sns.load_dataset('penguins'),这个数据集可以通过 seaborn 加载。
在将一个新数据集读入 DataFrame 后,我的下一步是使用df.info()来获取关于它的一些信息。
df_penguins.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 344 entries, 0 to 343
Data columns (total 7 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 species 344 non-null object
1 island 344 non-null object
2 culmen_length_mm 342 non-null float64
3 culmen_depth_mm 342 non-null float64
4 flipper_length_mm 342 non-null float64
5 body_mass_g 342 non-null float64
6 sex 333 non-null object
dtypes: float64(4), object(3)
memory usage: 18.9+ KB
我们看到了 6 列 344 行的一些基本信息。
让我们看看 sidetable 如何帮助我们探索数据。

阿德利企鹅。资料来源:pixabay.com
探索侧桌
所有侧表方法都使用.stb访问器。关于熊猫访问器 API 的更多信息,请参见 sidetable 的作者 Chris Moffit 的这篇文章。
stb.missing()
我们要检查的第一个侧置 DataFrame 方法是stb.missing()。下面是它的使用方法:
df_penguins.stb.missing()

结果是一个数据帧,每列有缺失值的数量,按从多到少排序。它还显示总行数和每列缺失值的百分比。
有了df.info(),我们将不得不心算。🤔
或者,我们可以用df.isna().sum()按列查看所有缺失的值。
df_penguins.isna().sum()species 0
island 0
culmen_length_mm 2
culmen_depth_mm 2
flipper_length_mm 2
body_mass_g 2
sex 11
dtype: int64
但是df.isna().sum()没有包括百分比,格式也不好。说到漂亮的格式,让我们让 sidetable 的输出更漂亮。💐
df_penguins.stb.missing(style=True)

通过style=True会清除百分比的列格式。
每当我有一堆缺少数据的列时,我打算使用stb.missing()。
stb.freq()
现在让我们看看 sidetable DataFrame 方法.stb.freq(),sidetable 包中的主要课程。🍲
让我们看看物种类别。
df_penguins.stb.freq(['species'])

stb.freq()的结果就像组合有和没有normalize=True参数的 value_counts、累积计数和累积百分比。与stb.missing()一样,我们可以通过传递style=true使样式更好。🎉
df_penguins.stb.freq(['species'], style=True)

那很方便。😀
注意,所有 sidetable 方法都在数据帧上操作并返回一个数据帧。
type(df_penguins.stb.freq(['species']))pandas.core.frame.DataFrame
你知道,这些数据是名义上的,而不是顺序的,我们可能不需要累积列。我们可以通过像这样传递cum_cols=False来去掉那些列:
df_penguins.stb.freq(['species'], style=True, cum_cols=False)


巴布亚企鹅。资料来源:pixabay.com
让我们看看如果我们将多个列传递给stb.freq()会是什么样子。
df_penguins.stb.freq(['species', 'island', 'sex'])

那是相当的崩溃。让我们只看岛一栏,探索一些更随意的论点。
df_penguins.stb.freq(['island'], style=True)

如果我们只想包括占总数 50%的岛屿,会怎么样呢?这个例子有点做作,但是我们试图展示它的功能,所以请配合我。😉
通过thresh=.5仅显示占总数 50%的岛屿。
df_penguins.stb.freq(['island'], style=True, thresh=.5)

请注意,这可能有点令人困惑。我们没有显示至少占总数 50%的所有岛屿。我们显示了达到累积阈值的所有岛屿。
以下是阈值为 0.9 时的情况。
df_penguins.stb.freq(['island'], style=True, thresh=.9)

如果你想改变提交值的标签,你可以像这样传递other_label='my_label':
df_penguins.stb.freq(['island'], style=True, thresh=.9, other_label='Other Islands')

传递value='my_column'对该列中的值求和并显示,而不是计算出现次数。这对于当前的数据集来说没有什么意义,但这是一个值得了解的好特性。下面是输出的样子:
df_penguins.stb.freq(['island'], value='flipper_length_mm')

在我们的例子中,原始列没有大写,但是 sidetable 创建的新列是大写的。如果希望列的大小写相匹配,可以调整生成的数据帧。
freq_table = df_penguins.stb.freq(['island'])
freq_table.columns = freq_table.columns.str.title()
freq_table

其他 EDA 选项
Sidetable 的stb.freq()很不错,因为它很轻便,内容丰富。在某些情况下,您可能需要不同的工具。
如果我在寻找数字数据的描述性统计,我经常使用df.describe()。
df_penguins.describe()

传递include='all'显示了一些关于非数字列的信息,但是事情有点混乱。🙁
df_penguins.describe(include='all')

如果你想要更多关于你的数据的信息,可以查看一下熊猫简介包。它提供了一个全面的报告,包括描述性的统计数据、直方图、相关性等等。挺牛逼的。然而,它可能需要一段时间来运行,并且对于许多用例来说有点多。
现在让我们看看最后一个 sidetable 方法。
stb .小计()
如果您想显示一个带有显示数字列总和的总计行的数据帧,使用stb.subtotal()。
df_penguins.stb.subtotal().tail()

这对于财务文档和其他想要在同一个表中显示数据和总计的情况非常方便。
通过组合df.groupby()和stb.subtotal(),你得到一个总计和格式良好的小计。
这是一个由物种和性别组成的分组,以及岛屿的数量。
df_penguins.groupby(['species', 'sex']).agg(dict(island='count'))

在我们的例子中,这不是什么惊天动地的信息,但是它显示了每个组中的计数。
如果有一些小计和总计,这些信息会更容易理解。stb.subtotal()为我们补充那些。🎉
df_penguins.groupby(['species', 'sex']).agg(dict(island='count')).stb.subtotal()

分类汇总通常对财务数据或序数数据很有帮助。让我在谷歌工作表或微软 Excel 中做预算和财务报告变得更加愉快。
包装
您已经看到了如何使用 sidetable 快速显示缺失值,制作格式良好的频率表,以及显示总计和小计。这是一个方便的小图书馆。👍
概述
以下是 API 的概述:
stb.missing()-显示关于缺失值的有用信息。stb.freq()-显示列的计数、百分比和累积信息。stb.subtotal()-向数据帧添加总计行。如果应用于 groupby,则添加每组的小计信息。
将style=True传递给stb.missing()和stb.freq()会使输出得到很好的格式化。还有许多其他参数可以传递给stb.freq()来修改输出。
我希望这篇 sidetable 的介绍对你有所帮助。如果你有,请在你最喜欢的社交媒体上分享,这样其他人也可以找到它。😀
我最初在这里为 Deepnote 发表这篇文章。获得早期访问权后,您可以在那里将文章作为笔记本运行。🚀
对于这篇文章,我使用了 Ted Petrou的新的 Jupyter to Medium 包来帮助从 Jupyter 笔记本转换到 Medium。谢谢你的大包裹,泰德!👍
我写关于数据科学、 Python 、 SQL 和其他技术主题的文章。如果你对这些感兴趣,请注册我的邮件列表,那里有很棒的数据科学资源,点击这里阅读更多内容,帮助你提高技能。😀


巴布亚企鹅。资料来源:pixabay.com
快乐的侧桌!🚀

















 721
721

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}