







自然语言处理中的卷积神经网络
什么是卷积神经网络,如何利用它进行情感分析?
什么是卷积神经网络?
神经网络是一套用于识别模式的算法。这些模式是包含在向量中的数字,这些向量是从现实世界的数据(如图像、声音、文本或时间序列)转换而来的。卷积神经网络是将卷积层应用于局部特征的神经网络。
要理解一个小内核如何转换大量的输入数据,请看下面的 gif。

正如我们所看到的,每个内核在空间上都很小(沿宽度和高度),但会延伸到输入体积的整个深度,并在滑动时转换输入数据。
但是如果我们想要不同的输出呢?没问题。我们只需要应用不同的过滤器。

在 Setosa.io 中探索 CNN
这些过滤器也可以应用于多维输出。下面的图像以 3D 方式输入,图像大小为 7x7,最后一个维度表示 3 个颜色通道(红、蓝、绿)。这使得输入大小为 7x7x3。然后我们应用 2 个滤波器w0和w1,,每个滤波器的大小为 3x3x3,以匹配输入大小。对于输出的维度,我们应该期待什么?3x3x2 与2滤镜的数量。

从 gitbook 中检索
自然语言处理中的卷积神经网络
因此,我们了解了什么是卷积神经网络,并了解了 CNN 如何应用于图像。但是 CNN 在 NLP 中到底是怎么运作的呢?例如,如果我们有一个句子“我爱我的新 iphone ”,我们如何使用 CNN 来分类这个句子是负面的,正面的,还是中性的?

上图从左至右的简短说明:
- 输入是单词。每个单词由一个大小为 7 的向量表示。
- 对单词向量应用 4 种不同的过滤器来创建卷积特征图
- 为合并表示选择每个过滤器向量的最大结果值
- 应用 softmax 将大小为 1x4 的向量转换为大小为 1x3 的向量以进行分类
通过实例学习:使用 PyTorch 进行情感分析
PyTorch 是一个 Python 程序库,有助于构建深度学习项目。如果你不知道 PyTorch,可以看看我的文章:
想想 Numpy,但是有强大的 GPU 加速
towardsdatascience.com](/what-is-pytorch-a84e4559f0e3)
如果你的机器没有 GPU,我鼓励你使用 Google Colab 来尝试代码。我们将使用这个库对 Kera 的 IMDb 电影评论数据集进行情感分析。我们的任务是分类评论是正面的还是负面的。
为了建立模型,我们用nn.Conv2d(in_channels, out_channels, kernel_size)做 2D 卷积,用nn.Linear(in_channels, out_channels).做一层线性神经网络进行分类
培训步骤
想象我们的损失函数
import matplotlib.pyplot as pltplt.plot(LOSS)

print("F1_test: %.5f"%(get_f1(X_test, y_test)))

厉害!我们的 CNN 模型给了我们 0.87 的 F1 分!
结论
恭喜你!你已经学习了什么是卷积神经网络,如何用 PyTorch 申请自然语言处理。我希望这能让你对 CNN 有一个大致的了解,并有动力在你的深度学习项目中利用这种方法。如果你想更好地了解 CNN,维克多·鲍威尔的网站提供了一个很酷的互动视觉效果,展示了当使用 CNN 的滤镜时,图像是如何变化的。你可以在这里试用一下这篇文章的代码。
在这个 Github repo 中,您可以随意使用本文的代码。
我喜欢写一些基本的数据科学概念,并尝试不同的算法和数据科学工具。你可以在 LinkedIn 和 Twitter 上与我联系。
如果你想查看我写的所有文章的代码,请点击这里。在 Medium 上关注我,了解我的最新数据科学文章,例如:
作为一名数据科学家,了解如何制作重要的图表至关重要
towardsdatascience.com](/what-graphical-excellence-is-and-how-to-create-it-db02043e0b37) [## 如何用图论可视化社交网络
找出《权力的游戏》中的影响者
towardsdatascience.com](/how-to-visualize-social-network-with-graph-theory-4b2dc0c8a99f) [## 凸包:包装数据的创新方法
如何利用包装算法实现数据可视化
towardsdatascience.com](/convex-hull-an-innovative-approach-to-gift-wrap-your-data-899992881efc) [## 恐龙和圆圈的数据集可以有相同的统计数据吗?
它们有相同的中位数和标准差,但它们是两个明显不同的数据集!
towardsdatascience.com](/how-to-turn-a-dinosaur-dataset-into-a-circle-dataset-with-the-same-statistics-64136c2e2ca0) [## 用美丽的声音抓取维基百科
关于如何使用 Beautiful Soup 的分步教程,这是一个用于 web 抓取的简单易用的 Python 库
towardsdatascience.com](/step-by-step-tutorial-web-scraping-wikipedia-with-beautifulsoup-48d7f2dfa52d)
卷积神经网络
简介和卷积

图片来自 Unsplash
本文的目标是探索以下概念:
- 卷积神经网络导论。用例及例子。
- 回旋。Python 中的示例
- CNN。
- 局部连接的层
卷积神经网络简介
你可以在这里找到,神经网络是一个通用的函数逼近器。这意味着,从本质上讲,神经网络通过试图找到一个函数的最佳近似来解决问题,该函数允许我们解决我们的问题。
为此,我们有一系列参数(权重和偏差),我们使用基于下降梯度的反向传播算法来更新这些参数。
多亏了我们的标签,我们可以在每次迭代中计算误差,并修改权重以逐步减少误差。
什么是卷积神经网络?或者更重要的是,它解决了什么问题?
简而言之,卷积神经网络可以解决所有可以用图像形式表达的问题。
例如,当你试图在你的脸书照片中给某人贴标签时,就要考虑到这一点。你有没有注意到它暗示了这个人的侧面?那是一个 convnet!
或者你可能听说过自动驾驶汽车,它可以“阅读”交通标志,识别其他汽车,甚至检测一个人是否正在过马路。功能也是基于 convnets 的!
CNN 是解决医学成像问题的最新技术。这些只是几个例子,但还有更多。
它们在最近几年变得如此受欢迎的原因是因为它们可以自己找到正确的特征,以便以后正确地对图像进行分类。他们以一种非常有效的方式做到这一点。
但是 CNN 到底是什么?
CNN 是一种神经网络,其中引入了新类型的层,其中最重要的是卷积层。
什么是卷积?
盘旋
严格来说,卷积主要用于信号处理,是一种允许两个信号合并的数学运算。
在数字信号处理中,卷积是用来知道一个信号“通过”某个设备后会发生什么。
例如,要了解我们的声音通过手机麦克风后的变化,我们可以计算我们的声音与麦克风脉冲响应的卷积。
卷积神经网络因其检测模式并进行分类的能力而闻名。那些模式检测器是卷积。
让我们看看计算机是如何理解图像的:

http://cs231n.github.io/classification/

https://data science-发烧级. com/DL/Convolution _ model _ Step _ by _ Step v2 . html
正如你所看到的,彩色图像被表示为一个三维矩阵:宽 x 高 x 通道。
有几种方法来表示图像,但最常用的是使用 RGB 颜色空间。这意味着计算机最终会看到 3 个重量 x 高度的矩阵,其中第一个告诉你图像中红色的数量,第二个告诉你绿色的数量,第三个告诉你蓝色的数量。
如果图像是灰度的,计算机会将其视为一个二维的重量 x 高度矩阵。
最后,矩阵元素的取值取决于所用变量的类型。最常见的有:
- 如果我们使用 8 位整数:它们可以从 0 到 255
- 如果我们使用浮点数:0 到 1
知道了图像是一个矩阵,卷积所做的就是定义一个滤波器或内核,通过它来乘以图像矩阵。如果我们看下一张图片:

https://developer . apple . com/documentation/accelerate/blurring _ an _ image
你定义一个内核,3x3 像素,然后乘以 input_image。会发生什么?内核比图像小得多,所以要乘以整个图像,首先我们将内核放在第一个 3x3 像素上,然后向右移动一个,再一个,再一个…然后我们计算内核的每个元素乘以图像的每个对应像素的乘积之和。如您所见,该操作的结果存储在输出图像中。
在这里你可以看得更清楚:

Python 中的示例
让我们看一些例子,看看当我们做这些乘法和加法时会发生什么,以及它们如何帮助检测模式和做出预测。
import numpy as np
from scipy import signal
from scipy import misc
ascent = misc.ascent()
kernel = np.array([[-1, 0, +1],
[-1, 0, +1],
[-1, 0, +1]])
grad = signal.convolve2d(ascent, kernel, boundary='symm', mode='same')import matplotlib.pyplot as plt# function to show two pictures together
def plot_two(img_orig, img_conv):
fig, (ax_orig, ax_mag) = plt.subplots(1, 2, figsize=(20, 50))
ax_orig.imshow(img_orig, cmap='gray')
ax_orig.set_title('Original')
ax_orig.set_axis_off()
ax_mag.imshow((img_conv), cmap='gray')
ax_mag.set_title('Gradient')
ax_mag.set_axis_off()plot_two(ascent, grad)

这是一个垂直线检测器。让我们定义并使用水平线检测器。
kernel = np.array([[-1, -1, -1],
[ 0, 0, 0],
[+1, +1, +1]])
grad_v = signal.convolve2d(ascent, kernel, boundary='symm', mode='same')
plot_two(ascent, grad_v)

让我们看看传统卷积中最常用的一些内核
让我们先打印一张未经修改的图片:
# load and show the original picture
url_img = '[https://upload.wikimedia.org/wikipedia/commons/5/50/Vd-Orig.png'](https://upload.wikimedia.org/wikipedia/commons/5/50/Vd-Orig.png')
from urllib.request import urlopen
from io import BytesIO
from PIL import Image
file = BytesIO(urlopen(url_img).read())
img = np.asarray(Image.open(file), dtype='uint8')
plt.imshow(img)
plt.axis('off')

def convolve3d(img, kernel):
img_out = np.zeros(img.shape)
for i in range(img.shape[-1]):
img_out[:,:,i] = signal.convolve2d(img[:,:,i], kernel, boundary='symm', mode='same')
return img_out.astype('uint8')
身份内核
# Let's try with the Identity Kernel
kernel = [[0, 0, 0],
[0, 1, 0],
[0, 0, 0]]
img_ki = convolve3d(img, kernel)
plot_two(img, img_ki)

其他最常用的内核(及其输出)有:

所有这些都非常有用…但是卷积是如何检测模式的呢?
模式检测示例
假设我们有这样一个过滤器:

https://adeshpande 3 . github . io/A-初学者% 27s-理解指南-卷积神经网络/
和下面的图像

https://adeshpande 3 . github . io/A-初学者% 27s-理解指南-卷积神经网络/
如果过滤器放在老鼠的背上会发生什么?

https://adeshpande 3 . github . io/A-初学者% 27s-理解指南-卷积神经网络/
结果将是:
30·0 + 30·50 + 30·20 + 30·50 + 30·50 + 30·50=6600
这是一个很高的数字,表明我们已经找到了一条曲线。
如果过滤器放在老鼠的头上会发生什么?

https://adeshpande 3 . github . io/A-初学者% 27s-理解指南-卷积神经网络/
结果将是:
30·0 + 30·0 + 30·0 + 30·0 + 30·0 + 30·0=0
CNN
现在我们已经介绍了卷积的概念,让我们来研究什么是卷积神经网络以及它们是如何工作的。

https://adeshpande 3 . github . io/A-初学者% 27s-理解指南-卷积神经网络/
在这些图像中,我们可以看到卷积神经网络的典型架构。这无非就是一个 W x H x 3 的矩阵(因为是 RGB)。然后“卷积块”开始。
这些块通常由以下部分组成:
- 卷积层
- 汇集层,抽取卷积层输出的内容
在我们已经知道卷积是如何工作的之前:我们定义一个内核或过滤器,用来突出图像中的某些结构。
但是我如何定义一个允许我发现输入图像中有一只黑猫的过滤器呢?
那是 CNN 魔术!我们不需要定义任何过滤器,由于反向传播,网络会自动学习它们!
我们的细胞神经网络有两个阶段:特征提取器和分类器。
特征提取阶段从一般的模式或结构到细节:
- 第一卷积层检测不同方向的线
- 下一组检测形状和颜色
- 下一个更复杂的模式
- …
所以最后,我们拥有的是一个可以自己学习的网络,所以我们不必担心我们选择哪些特征进行分类,因为它是自己选择的。
它是如何学习的?和传统的神经网络一样。

https://www . science direct . com/science/article/ABS/pii/s 0893608015001896
第二阶段,即分类器,由密集层组成,这是传统神经网络中使用的层。
因此,CNN 最终可以理解为一组耦合到传统神经网络的卷积级,传统神经网络对卷积提取的模式进行分类,并返回每个类别的一些概率。
CNN 中的层类型
卷积
这些层负责将卷积应用于我们的输入图像,以找到稍后允许我们对其进行分类的模式:
- 应用于图像的过滤器/内核的数量:输入图像将通过其进行卷积的矩阵的数量
- 这些滤镜的大小:99%的时候都是正方形,3×3,5×5 等等。
这里你可以看到一般的方案,其中你可以看到一个给定的输入图像是如何被每个滤波器卷积,输出是 2D 激活图。这意味着,如果输入图像是 RGB,它将有 3 个通道。因此,我们将对每个通道的每个滤波器进行卷积,然后将结果相加,以将 3 个通道减少到仅 1:

由于输入有 3 个通道,R、G 和 B,这意味着我们的输入图像被定义为 3 个二维数组,每个通道一个。
因此,卷积层所做的是将卷积分别应用于每个通道,获得每个通道的结果,然后将它们相加以获得单个 2D 矩阵,称为激活图。
在此链接中,您可以看到更多详细信息:
【http://cs231n.github.io/assets/conv-demo/index.html

除了滤波器的数量和尺寸之外,卷积层还有一个我们应该考虑的重要参数:步幅。
这是一个单位步幅的例子:

https://arxiv.org/abs/1603.07285
这是一个 2 单位步幅卷积的例子:

https://arxiv.org/abs/1603.07285
您可以看出差别在于内核在每次迭代中的步长。
感受野

https://www . slide share . net/ssuser 06 e0c 5/convolutionary-neural-networks-135496264
在卷积层的情况下,输出神经元只连接到输入图像的一个局部区域。
可以理解为“网络所见”。对于致密层,情况正好相反,所有的神经元都与所有先前的元素相连。然而,神经元的功能仍然相同,唯一的事情是在入口处它们“看到”整个图像,而不是图像的一个区域。
正如你可以在这篇伟大的文章中发现的:
感受野决定了原始输入在整个网络中的哪个区域能被输出看到。
统筹
池层用于减少我们的激活图的大小,否则,在许多 GPU 上运行它们是不可能的。两种最常见的池类型是:
- 最大池:计算元素的最大值
- 平均池:计算要素的平均值

https://www . quora . com/What-is-max-pooling-in-convolutionary-neural-networks
必须考虑到,这是针对我们的体积的每个激活图进行的,也就是说,深度维度根本不介入计算。
让我们看一个不同步长的最大池的例子:

局部连接的层
假设我们有一个 32x32 的输入图像,我们的网络有 5 个卷积层,每个卷积层有 5 个大小为 3x3 的滤波器。这是因为过滤器贯穿图像。
这是基于这样的假设:如果某个滤波器擅长检测图像的位置(x,y)中的某个东西,那么它也应该适合位置(x2,y2)。
这个假设几乎总是有效的,因为通常我们不知道我们的特征在图像中的位置,但是例如,如果我们有一个数据集,其中人脸出现在图像的中心,我们可能希望眼睛区域的过滤器与鼻子或嘴的过滤器不同,对吗?
在这种情况下,如果我们知道要素的位置,那么为每个区域设置一个过滤器会更有意义。
之前,我们必须学习每层 5 个 3×3 的过滤器,这给了我们总共:5⋅3⋅3=45 参数,现在我们必须学习:32⋅32⋅5⋅3=46080 参数。
这是一个巨大的差异。因此,除非我们知道我们要在哪里寻找模式,它们将是不同的,并且总是在相同的位置,否则值得使用卷积层,而不是局部连接层。
对了,看下图:参数最多的层就是密层!这是有意义的,在它们中,所有的神经元都与下一层的所有神经元相互连接。

最后的话
一如既往,我希望你喜欢这篇文章,并获得了关于卷积神经网络的直觉!
如果你喜欢这篇帖子,那么你可以看看我在数据科学和机器学习方面的其他帖子。
如果你想了解更多关于机器学习、数据科学和人工智能的知识 在 Medium 上关注我 ,敬请关注我的下一篇帖子!
卷积神经网络(CNN)——实用的观点
深入了解卷积神经网络的主要操作,并使用 Mel 光谱图和迁移学习对心跳进行分类。

弗兰基·查马基在 Unsplash 上拍摄的照片
大家好,
希望每个人都平安无事。在这篇博客中,我们将探讨 CNN 的一些图像分类概念,这些概念经常被初学者(包括我在内)忽略或误解。这个博客要求读者对 CNN 的工作有一些基本的了解。然而,我们将涵盖 CNN 的重要方面,然后再深入到高级主题。
在这之后,我们将研究一种称为迁移学习的机器学习技术,以及它如何在深度学习框架上用较少的数据训练模型。我们将在 Resnet34 架构之上训练一个图像分类模型,使用包含以音频形式数字记录的人类心跳的数据。wav)文件。在这个过程中,我们将使用一个流行的 python 音频库 Librosa 将这些音频文件转换成光谱图,从而将它们转换成图像。最后,我们将使用流行的误差度量来检验该模型,并检查其性能。
CNN 的图像分类:
具有 1 次以上卷积运算的神经网络称为卷积神经网络(CNN)。CNN 的输入包含图像,每个像素中的数值沿着宽度、高度和深度(通道)在空间上排列。总体架构的目标是通过从这些空间排列的数值中学习来获得属于某一类的图像的概率分数。在这个过程中,我们对这些数值执行诸如汇集和卷积之类的操作,以沿着深度挤压和拉伸它们。
图像通常包含三层,即 RGB(红、绿、蓝)。

图片由 Purit Punyawiwat 提供,来源: Datawow
CNN 的主要操作
卷积运算
卷积运算( w.x+b) 应用于输入体积中所有不同的空间位置。使用更多数量的卷积运算有助于学习特定的形状,即使它在图像中的位置发生了变化。
例子:通常云出现在风景图片的顶部。如果一个反转的图像被输入 CNN,更多的卷积运算可以确保模型识别云的部分,即使它是反转的。
数学表达式:x _ new = w . x+b其中 w 是滤波器/内核, b 是偏差, x 是隐藏层输出的一部分。对于应用于不同隐藏层的每个卷积运算,w和 b都是不同的。

卷积运算(来源:第 22 讲-EECS251,inst.eecs.berkley.edu)
联营
汇集减少了每个激活图(卷积运算后的输出)的空间维度,同时聚集了局部化的空间信息。池化有助于沿着高度和宽度挤压隐藏层的输出。如果我们考虑非重叠子区域内的最大值,那么它被称为最大池。最大池也增加了模型的非线性。
激活功能
对于 CNN 而言,ReLU 是优选的激活函数,因为与其他激活函数如 tanh 和 sigmoid 相比,它具有简单的可微性和快速性。ReLU 通常跟在卷积运算之后。
让我们检查一下计算每个激活函数的梯度所用的时间:

每个模型生成其导数所用的时间
从上表可以看出,与其他激活函数相比,ReLU 计算其导数所需的时间要少得多。
有时,当图像的边缘构成可能有助于训练模型的重要方面时,填充也用于这些操作之间。它还可以用于抑制由于汇集等操作而导致的高度和宽度方向的收缩。
一般来说,隐藏层的深度比高,因为卷积运算中使用的数量的滤波器比高数量。随着每个过滤器学习新的特征或新的形状,过滤器的数量保持较高。
示例:

多滤镜卷积运算,源码: Indoml
这里,我们使用了两个滤波器来执行卷积运算,并且输出的深度也是 2。假设,如果我们使用 3 个过滤器/内核,一个内核可能会学习识别垂直边缘,因为初始层不能学习大于过滤器大小(此处为 33)的特征。第二滤波器可以学习识别水平边缘,第三滤波器可以学习识别图像中的弯曲边缘。*
反向传播
使用反向传播来更新每个卷积运算的权重(w)。反向传播涉及梯度的计算,这反过来帮助 w 达到错误率(或任何其他损失度量)非常小的理想状态。在 Pytorch 中,使用 torch.backward 函数执行反向传播。从数学上来说,我们可以说这个函数类似于 J.v 操作,其中 J 是雅可比矩阵,v 是损耗 w.r.t 下一层的梯度。雅可比矩阵由偏导数组成,可以认为是局部梯度。
对于一个函数,y = f(x)其中 y 和 x 是向量,J.v 是

图片来源:Pytorch.org
其中 l 为损失函数。
批量归一化
执行批量标准化(BN)是为了解决内部协变量移位(ICF)的问题。由于每次操作中权重的分布不同,隐藏层需要更多的时间来适应这些变化。批量标准化技术使得由神经网络学习的较深层的权重较少依赖于在较浅层学习的权重,从而避免 ICF。
它在隐藏层输出的像素级执行。下图是批量大小= 3,隐藏层大小为 44 的示例。最初,批处理规范化据说是在应用 ReLU(激活函数)之前执行的,但是后来的结果发现,当它在激活步骤之后执行时,模型执行得更好。*

图片由 Aqeel Anwar 提供,来源:走向数据科学
Pytorch,在训练期间,一批隐藏层保持运行其计算的平均值和方差的估计,这些估计稍后在该特定层中的评估/测试期间用于归一化。

批量标准化,来源: Pytorch 文档
默认情况下,γ 的元素设置为 1,β的元素设置为 0
正规化
引入正则化是为了检查权重矩阵(w)中的元素,并避免 过拟合。通常,我们在 CNN 中执行 L2 正则化。丢弃也有助于正则化隐藏层的输出,只需以一定的概率 p 丢弃一些完全连接的层连接。Pytorch 通过在一个隐藏层中批量随机分配零到整个通道来实现这一点。
小批量
一组图像(批次)(通常是 2 的幂,如 8、16、32)通过使用 GPU 的能力在这些图像上独立但并行地运行模型而被传递到架构中。小批量有助于我们最大限度地减少更新权重向量的次数,而不会影响结果。微型批处理有助于实现更快的收敛。
小批量梯度下降
使用小批量梯度下降在每次批量后更新重量向量。我们取像素级的所有梯度的平均值,并将其从权重向量中减去,以在每个时期后得到更新的权重向量。
也有一些梯度优化技术,使这一进程更快。 ADAM 就是一种常用的梯度下降优化技术。这里,我们将使用 ADAM 优化技术(尽管在下面的代码中没有具体提到)。
迁移学习
迁移学习是一种机器学习技术,其中模型使用在大型数据集上训练的预训练参数/权重。迁移学习减少了收集更多数据的需求,有助于在小数据集上运行深度学习模型。
如前所述,CNN 的初始层擅长捕捉简单和通用的特征(如边缘、曲线等)。)而更深层次的则擅长复杂特征。因此,只训练较深层的参数(权重)而不更新其他层的参数更有意义。我们将在 ResNet-34 模型上使用这种技术,并检查其性能。
ResNet-34 架构:

了解数据:
给定的数据包含 313 个音频文件的数字记录的人类心跳。wav 格式。set_b.csv 文件中提供了这些音频文件的标签。为了使用 CNN 的,我们必须将这些音频文件转换成图像格式。
应用于音频信号的傅立叶变换将信号从时域转换到频域。频谱图是应用傅立叶变换后信号的直观表示。Mel 光谱图是以 Mel 标度为 y 轴的光谱图。
音频文件:
以上音频文件的 Mel 声谱图表示:

梅尔光谱图
代码:
为此任务导入必要的模块
创建一个 python 函数,该函数创建每个音频文件的 mel-spectrogram,并将其保存在一个目录中
查看标签数据
准备用于分类的数据,并将每个图像转换为 512512。数据以 70:30 的比例分为训练和验证。批处理大小 4 用于在 GPU 中并行化任务。*
选择要使用的架构
定义模型并将“错误率”设置为错误度量。'误差 _ 率’是(1-精度)
为我们的模型选择正确的学习率
在选择了正确的学习速率后,我们可以选择使用 learn.freeze()命令使用预训练的参数/权重来训练模型
使用循环学习率更新模型 5 次(即,5 个时期)
一批已验证集合的结果。在这一批中,我们所有的预测都是正确的。
绘制混淆矩阵

最终预测的混淆矩阵
我们的模型在识别杂音和正常心跳方面表现非常好。模型的最终精度大约为 70% (对角线元素的总和/混淆矩阵中所有元素的总和),这在这种情况下非常好,因为给定的数据在某些情况下是不平衡的和有噪声的。你可以在这里找到完整的代码。
结论:
在这篇博客中,我们已经学习了卷积神经网络(CNN)的构建模块的实际方面以及为什么使用它们。我们使用这些概念并建立了一个图像分类模型,将 Mel 频谱图分为 3 类(杂音、期前收缩和正常)。最后,我们用混淆矩阵对性能进行了分析。
如果你发现这个博客有任何帮助,请分享并在这里鼓掌。它鼓励我写更多这样的博客。
谢谢大家!!!
卷积神经网络(CNN)在 5 分钟内
任务,CNN 如何工作,学习,AUROC
卷积神经网络(CNN)是用于图像和视频分析的最流行的机器学习模型。
示例任务
以下是可以使用 CNN 执行的一些任务示例:
- 二元分类:给定来自医学扫描的输入图像,确定患者是否有肺结节(1)或没有(0)
- 多标记分类:给定来自医学扫描的输入图像,确定患者是否没有、部分或全部以下症状:肺部阴影、结节、肿块、肺不张、心脏扩大、气胸
CNN 如何工作
在 CNN 中,卷积滤波器滑过图像以产生特征图(下图中标为“卷积特征”):

卷积滤镜(黄色)滑过图像(绿色)产生特征图(粉红色,标记为“卷积特征”)的动画。来源: giphy
过滤器检测模式。
当过滤器经过包含图案的图像区域时,输出特征图中会产生高值。
不同的过滤器检测不同的模式。
滤镜检测到的模式类型由滤镜的权重决定,在上面的动画中显示为红色数字。
滤波器权重与相应的像素值相乘,然后将这些相乘的结果相加,以产生进入特征图的输出值。
卷积神经网络包括用许多不同的滤波器多次应用这种卷积运算。
该图显示了 CNN 的第一层:

图片由作者提供(带 CT 切片源无线媒体
在上图中,CT 扫描切片是 CNN 的输入。标有“滤波器 1”的卷积滤波器以红色显示。该过滤器在输入 CT 切片上滑动以产生特征图,显示为红色的“图 1”
然后,检测不同模式的称为“滤波器 2”(未明确示出)的不同滤波器滑过输入 CT 切片,以产生特征图 2,以紫色示出为“图 2”
对过滤器 3(产生黄色的地图 3)、过滤器 4(产生蓝色的地图 4)等等重复该过程,直到过滤器 8(产生红色的地图 8)。
这是 CNN 的“第一层”。因此,第一层的输出是一个 3D 数字块,在这个例子中由 8 个不同的 2D 特征地图组成。

作者图片
接下来我们进入 CNN 的第二层,如上图所示。我们采用我们的 3D 表示(8 个特征图),并对此应用一个称为“过滤器 a”的过滤器。“过滤器 a”(灰色)是 CNN 第二层的一部分。请注意,“过滤器 a”实际上是三维的,因为它在 8 个不同的特征图上各有一个 2×2 平方的权重。因此“过滤器 a”的大小是 8×2×2。一般来说,“2D”CNN 中的滤波器是 3D 的,而“3D”CNN 中的滤波器是 4D 的。
我们在表示中滑动过滤器 a 以产生地图 a,以灰色显示。然后,我们滑动过滤器 b 得到地图 b,滑动过滤器 c 得到地图 c,以此类推。这就完成了 CNN 的第二层。
然后我们可以继续到第三层、第四层等等。然而,需要多层 CNN。CNN 可以有很多层。例如,ResNet-18 CNN 架构有 18 层。
下图,来自krijevsky 等人。,显示了 CNN 早期各层的示例过滤器。CNN 早期的过滤器检测简单的图案,如边缘和特定方向的线条,或简单的颜色组合。

下图来自 Siegel et al. 改编自 Lee et al. ,显示了底部的早期层过滤器、中间的中间层过滤器和顶部的后期层过滤器的示例。
早期层过滤器再次检测简单的图案,如沿特定方向的线条,而中间层过滤器检测更复杂的图案,如面部、汽车、大象和椅子的部分。后面的图层过滤器检测更复杂的图案,如整张脸、整辆车等。在这种可视化中,每个后面的层过滤器被可视化为前一层过滤器的加权线性组合。

如何学习滤镜
我们如何知道在每个滤波器中使用什么特征值?我们从数据中学习特征值。这是“机器学习”或“深度学习”的“学习”部分。
步骤:
- 随机初始化特征值(权重)。在这个阶段,模型产生了垃圾——它的预测完全是随机的,与输入无关。
- 对一堆训练示例重复以下步骤:(a)向模型输入一个训练示例(b)使用损失函数计算模型的错误程度©使用反向传播算法对特征值(权重)进行微小调整,以便下次模型的错误程度会更小。随着模型在每个训练示例中的错误越来越少,它将在训练结束时学习如何很好地执行任务。
- 在从未见过的测试示例上评估模型。测试示例是被搁置在一边并且没有在训练中使用的图像。如果模型在测试例子中表现良好,那么它学习了可概括的原则,是一个有用的模型。如果模型在测试示例中表现不佳,那么它记住了训练数据,是一个无用的模型。
下面这个由塔玛斯·齐拉吉创作的动画展示了一个神经网络模型学习。动画显示的是前馈神经网络,而不是卷积神经网络,但学习原理是相同的。在这个动画中,每条线代表一个重量。线旁边显示的数字是重量值。权重值随着模型的学习而变化。

测量性能:AUROC

作者图片
CNN 的一个流行性能指标是 AUROC,即接收机工作特性下的面积。此性能指标指示模型是否能正确地对示例进行排序。AUROC 是随机选择的正面例子比随机选择的负面例子具有更高的正面预测概率的概率。0.5 的 AUROC 对应于抛硬币或无用模型,而 1.0 的 AUROC 对应于完美模型。
补充阅读
有关 CNN 的更多详细信息,请参阅:
有关神经网络如何学习的更多细节,请参见神经网络介绍。
最后,有关 AUROC 的更多详细信息,请参见:
原载于 2020 年 8 月 3 日 http://glassboxmedicine.com。
卷积神经网络,解释

克里斯托夫·高尔在 Unsplash 上拍摄的照片
卷积神经网络,也称为 CNN 或 ConvNet,是一类神经网络,专门处理具有网格状拓扑结构的数据,如图像。数字图像是视觉数据的二进制表示。它包含一系列以类似网格的方式排列的像素,这些像素包含表示每个像素的亮度和颜色的像素值。

图 1:以像素网格表示的图像( 来源 )
当我们看到一幅图像时,人类的大脑会处理大量的信息。每个神经元都在自己的感受野中工作,并以覆盖整个视野的方式与其他神经元相连。正如在生物视觉系统中,每个神经元只对视野中称为感受野的有限区域的刺激做出反应,CNN 中的每个神经元也只在其感受野中处理数据。这些层以这样的方式排列,使得它们首先检测较简单的图案(直线、曲线等)。)和更复杂的图案(人脸、物体等)。)再往前。通过使用美国有线电视新闻网,人们可以让视觉进入电脑。
卷积神经网络体系结构
CNN 通常有三层:卷积层、池层和全连接层。

图 2:一个 CNN 的架构( 来源 )
卷积层
卷积层是 CNN 的核心构件。它承担了网络计算负载的主要部分。
这一层执行两个矩阵之间的点积,其中一个矩阵是一组可学习的参数,也称为核,另一个矩阵是感受野的受限部分。内核在空间上比图像小,但更有深度。这意味着,如果图像由三个(RGB)通道组成,则内核的高度和宽度在空间上很小,但深度会延伸到所有三个通道。

卷积运算图解(来源
在向前传递的过程中,内核在图像的高度和宽度上滑动,产生该接收区域的图像表示。这产生了被称为激活图的图像的二维表示,该激活图给出了图像的每个空间位置处的内核的响应。内核的滑动大小称为步幅。
如果我们有一个大小为 W x W x D 的输入,空间大小为 F 的 Dout 个核,步长为 S,填充量为 P,则输出音量的大小可由以下公式确定:

卷积层公式
这将产生大小为WoutxWout xDout的输出量。

图 3:卷积运算(来源:伊恩·古德菲勒、约舒阿·本吉奥和亚伦·库维尔的深度学习)
卷积背后的动机
卷积利用了激励计算机视觉研究人员的三个重要思想:稀疏交互、参数共享和等变表示。让我们详细描述一下它们中的每一个。
普通的神经网络层使用描述输入和输出单元之间交互的参数矩阵的矩阵乘法。这意味着每个输出单元都与每个输入单元相互作用。但是卷积神经网络有*稀疏交互。*这是通过使内核小于输入实现的,例如,一幅图像可能有数百万或数千个像素,但在使用内核处理它时,我们可以检测到数十或数百个像素的有意义信息。这意味着我们需要存储更少的参数,这不仅降低了模型的内存需求,而且提高了模型的统计效率。
如果在空间点(x1,y1)计算一个特征是有用的,那么它在其他空间点(比如说(x2,y2))也应该是有用的。这意味着对于单个二维切片,即,为了创建一个激活图,神经元被约束为使用相同的一组权重。在传统的神经网络中,权重矩阵的每个元素都被使用一次,然后就不再被重新访问,而卷积网络有个共享参数,即,为了获得输出,应用于一个输入的权重与应用于其他地方的权重相同。
由于参数共享,卷积神经网络的层将具有与平移等变的特性。它说如果我们以某种方式改变输入,输出也会以同样的方式改变。
汇集层
汇集层通过导出附近输出的汇总统计来替换特定位置的网络输出。这有助于减少表示的空间大小,从而减少所需的计算量和权重。在表示的每个切片上单独处理池化操作。
有几种汇集函数,如矩形邻域的平均值、矩形邻域的 L2 范数以及基于与中心像素的距离的加权平均值。然而,最流行的过程是最大池化,它报告邻域的最大输出。

图 4:汇集操作(来源:奥莱利媒体)
如果我们有一个大小为 W x W x D 的激活图,一个空间大小为 F 的池化内核,以及步长 S ,那么输出量的大小可以由以下公式确定:

填充层的配方
这将产生大小为WoutxWoutxD的输出量。
在所有情况下,池提供了一些平移不变性,这意味着无论对象出现在帧的什么位置,它都是可识别的。
全连接层
这一层中的神经元与前一层和后一层中的所有神经元完全连接,如在常规 FCNN 中所见。这就是为什么它可以像往常一样通过矩阵乘法后跟一个偏置效应来计算。
FC 层有助于映射输入和输出之间的表示。
非线性层
由于卷积是线性操作,并且图像远不是线性的,所以非线性层通常直接放置在卷积层之后,以将非线性引入激活图。
非线性操作有几种类型,常见的有:
1。乙状结肠
sigmoid 非线性的数学形式为σ(κ) = 1/(1+e κ)。它接受一个实数值,并将其“压缩”到 0 到 1 之间的范围内。
然而,sigmoid 的一个非常不理想的性质是,当激活在任一尾部时,梯度几乎变为零。如果局部梯度变得非常小,那么在反向传播中,它将有效地“杀死”梯度。此外,如果进入神经元的数据总是正的,那么 sigmoid 的输出将要么全是正的,要么全是负的,导致权重梯度更新的之字形动态。
2。坦恩
Tanh 将一个实数值压缩到[-1,1]范围内。像乙状结肠一样,激活会饱和,但与乙状结肠神经元不同,它的输出以零为中心。
3。ReLU
整流线性单元(ReLU)在最近几年变得非常流行。它计算函数ф(κ)= max(0,κ)。换句话说,激活只是阈值为零。
与 sigmoid 和 tanh 相比,ReLU 更可靠,收敛速度提高了 6 倍。
不幸的是,ReLU 在训练中很脆弱。流经它的大梯度可以以这样的方式更新它,即神经元永远不会进一步更新。然而,我们可以通过设定适当的学习速度来解决这个问题。
设计卷积神经网络
现在,我们已经了解了各种组件,我们可以构建一个卷积神经网络。我们将使用时尚 MNIST,这是 Zalando 文章图像的数据集,由 60,000 个样本的训练集和 10,000 个样本的测试集组成。每个示例都是 28x28 灰度图像,与 10 个类别的标签相关联。数据集可以从这里下载。
我们的卷积神经网络具有如下架构:
[输入]
→[conv 1]→[批次定额]→[ReLU]→[池 1]
→[conv 2]→[批次定额]→[ReLU]→[池 2]
→ [FC 层]→[结果]
对于两个 conv 层,我们将使用空间大小为 5 x 5 的核,步长为 1,填充为 2。对于这两个池层,我们将使用最大池操作,内核大小为 2,步幅为 2,填充为零。

Conv 1 层的计算(图片由作者提供)

Pool1 图层的计算(图片由作者提供)

Conv 2 层的计算(图片由作者提供)

Pool2 层的计算(图片由作者提供)

完全连接层的大小(图片由作者提供)
为定义 convnet 而截取的代码
**class** **convnet1**(nn.Module):
**def** __init__(self):
super(convnet1, self).__init__()
*# Constraints for layer 1*
self.conv1 = nn.Conv2d(in_channels=1, out_channels=16, kernel_size=5, stride = 1, padding=2)
self.batch1 = nn.BatchNorm2d(16)
self.relu1 = nn.ReLU()
self.pool1 = nn.MaxPool2d(kernel_size=2) *#default stride is equivalent to the kernel_size*
*# Constraints for layer 2*
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=5, stride = 1, padding=2)
self.batch2 = nn.BatchNorm2d(32)
self.relu2 = nn.ReLU()
self.pool2 = nn.MaxPool2d(kernel_size=2)
*# Defining the Linear layer*
self.fc = nn.Linear(32*7*7, 10)
*# defining the network flow*
**def** forward(self, x):
*# Conv 1*
out = self.conv1(x)
out = self.batch1(out)
out = self.relu1(out)
*# Max Pool 1*
out = self.pool1(out)
*# Conv 2*
out = self.conv2(out)
out = self.batch2(out)
out = self.relu2(out)
*# Max Pool 2*
out = self.pool2(out)
out = out.view(out.size(0), -1)
*# Linear Layer*
out = self.fc(out)
**return** out
我们还在我们的网络中使用了批量归一化,通过明确地强制网络采用单位高斯分布,避免了权重矩阵的不正确初始化。上述定义的网络代码可在这里获得。我们已经使用交叉熵作为我们的损失函数和 Adam 优化器进行了训练,学习率为 0.001。在训练模型之后,我们在测试数据集上实现了 90%的准确率。
应用程序
以下是目前使用的卷积神经网络的一些应用:
1.对象检测:有了 CNN,我们现在有了复杂的模型,如 R-CNN 、 Fast R-CNN 和Fast R-CNN,它们是许多部署在自动驾驶汽车、面部检测等中的对象检测模型的主要渠道。
2.语义分割:2015 年,一群来自香港的研究人员开发了一个基于 CNN 的深度解析网络,将丰富的信息纳入图像分割模型。来自加州大学伯克利分校的研究人员还建立了全卷积网络,改进了最先进的语义分割。
3.图像字幕:CNN 与递归神经网络一起使用,为图像和视频编写字幕。这可以用于许多应用,例如活动识别或为视觉障碍者描述视频和图像。YouTube 已经大量部署了这种技术,以便对定期上传到该平台的大量视频进行分析。
参考文献
1.伊恩·古德菲勒、约舒阿·本吉奥和亚伦·库维尔的深度学习由麻省理工学院出版社于 2016 年出版
2.斯坦福大学的课程— CS231n:视觉识别的卷积神经网络费、、杨小琳教授
5.https://search enterprise ai . tech target . com/definition/卷积神经网络
卷积神经网络
CNN 的基本原理
CNN 是一种特殊类型的人工神经网络,它接受图像作为输入。以下是人工神经网络的基本神经元的表示,它将 X 向量作为输入。然后,X 向量中的值乘以相应的权重,以形成线性组合。因此,施加非线性函数或激活函数,以便获得最终输出。

神经元表示,图片由作者提供
为什么是 CNN?
谈到灰度图像,它们的像素范围从 0 到 255,即 8 位像素值。如果图像的大小是 NxM,那么输入向量的大小将是 NM。对于 RGB 图像,它将是 NM*3。考虑一个大小为 30x30 的 RGB 图像。这将需要 2700 个神经元。一幅 256x256 大小的 RGB 图像需要超过 100000 个神经元。ANN 采用输入向量,并给出一个乘积,作为与输入完全关联的另一个隐藏层的向量。224x224x3 的权重、参数数量非常大。输出层中的单个神经元将有 224x224x3 个权重进入其中。这将需要更多的计算、内存和数据。CNN 利用图像的结构导致输入和输出神经元之间的稀疏连接。每一层在 CNN 上执行卷积。CNN 将输入作为 RGB 图像的图像体积。基本上,一幅图像作为输入,我们对图像应用内核/过滤器来获得输出。CNN 还支持输出神经元之间的参数共享,这意味着在图像的一部分有用的特征检测器(例如水平边缘检测器)可能在图像的另一部分有用。
回旋
每个输出神经元通过权重矩阵(也称为核或权重矩阵)连接到输入中的小邻域。我们可以为每个卷积层定义多个内核,每个内核产生一个输出。每个滤波器围绕输入图像移动,产生第二输出。对应于每个滤波器的输出被叠加,产生输出量。

卷积运算,通过 indoml 成像
这里,矩阵值与核滤波器的相应值相乘,然后执行求和操作以获得最终输出。核滤波器在输入矩阵上滑动,以获得输出向量。如果输入矩阵的维数为 Nx 和 Ny,而核矩阵的维数为 Fx 和 Fy,那么最终输出的维数将为 Nx-Fx+1 和 Ny-Fy+1。在 CNN 中,权重代表一个内核过滤器。k 内核图会提供 k 内核特性。
填料
填充卷积用于保留对我们很重要的输入矩阵的维度,它帮助我们保留图像边界的更多信息。我们已经看到卷积减少了特征图的大小。为了将特征映射的维度保持为输入映射的维度,我们用零填充或附加行和列。

填充,作者图像
在上图中,填充为 1,我们能够保留 3x3 输入的维度。输出特征图的大小是维数 N-F+2P+1。其中 N 是输入映射的大小,F 是内核矩阵的大小,P 是填充的值。为了保持维数,N-F+2P+1 应该等于 N。因此,

按作者保留尺寸、图像的条件
进展
步幅指的是内核过滤器将跳过的像素数,即像素/时间。步幅为 2 意味着内核在执行卷积运算之前将跳过 2 个像素。

步幅演示,由 indoml 制作图像
在上图中,内核过滤器通过一次跳过一个像素在输入矩阵上滑动。步幅为 2 将在执行卷积之前执行两次此跳跃操作,如下图所示。

步幅演示,由 indoml 制作图像
这里要观察的是,当步幅从 1 增加到 2 时,输出特征图减小(4 倍)。输出特征图的维数是(N-F+2P)/S + 1。
联营
池通过子采样提供平移不变性:减小特征图的大小。两种常用的池技术是最大池和平均池。

最大池操作,图像由 indoml
在上面的操作中,池化操作将 4x4 矩阵分为 4 个 2x2 矩阵,并选取四个矩阵中最大的值(最大池化)和四个矩阵的平均值(平均池化)。这减小了特征图的大小,从而在不丢失重要信息的情况下减少了参数的数量。这里需要注意的一点是,池化操作会减少输入特征图的 Nx 和 Ny 值,但不会减少 Nc(通道数)的值。此外,池操作中涉及的超参数是过滤器维度、步幅和池类型(最大或平均)。梯度下降没有要学习的参数。
输出特征地图
输出特征图或体积的大小取决于:
- 输入要素地图的大小
- 内核大小(千瓦,Kh)
- 零填充
- 步幅(Sw,Sh)
朴素卷积
这些是卷积神经网络的构建模块,并且依赖于上述参数。输出特征地图的维度可表示为:

o/p 特征图的尺寸,图片由作者提供
扩张卷积
这有一个额外的参数,称为膨胀率。这种技术用于增加卷积中的感受野。这个卷积也称为 atrous 卷积。膨胀率为 2 的 3×3 卷积与简单的 5×5 卷积显示相同的面积,而只有 9 个参数。它可以在相同的计算成本下提供更宽的视野。只有在需要宽视野以及无法承受多重卷积或更大内核的情况下,才应该使用它们。下图描绘了一个扩张的卷积的可接受范围。

放大卷积,图像由Paul-Louis prve
转置卷积
用于增加输出要素地图的大小。它被用在编码器-解码器网络中以增加空间维度。在卷积运算之前,输入图像被适当地填充。

转置卷积,图像由 Divyanshu Mishra
结束了
谢谢,请继续关注更多关于人工智能的博客。
初学者使用 Keras & TensorFlow 2 的卷积神经网络
边做边学:包含 GitHub 代码的实用指南

这是我在两年前写的介绍卷积神经网络的前一篇文章的更新版本**。在这篇文章中,我更新了我们用来解释概念的 Kera 代码。自此,Keras 成为 TensorFlow 构建和训练深度学习模型的高级 API 。我会用这个更新来改进内容。**
选择性神经元网络广泛应用于计算机视觉任务中。这些网络由一个输入层、一个输出层和几个隐藏层组成,其中一些是卷积的,因此得名。
在本帖中,我们将展示一个具体案例,我们将一步一步地了解这种类型网络的基本概念。具体来说,我们将与读者一起编写一个卷积神经网络来解决上面看到的相同的 MNIST 数字识别问题。
卷积神经网络简介
卷积神经网络(缩写为 CNNs 或 ConvNets)是深度学习神经网络的一个具体例子,它在 90 年代末就已经使用,但近年来在图像识别方面取得了非常令人印象深刻的结果,从而极大地影响了计算机视觉领域。
卷积神经网络与本系列前几篇文章中的神经网络非常相似:它们由神经元组成,神经元具有可以学习的权重和偏差形式的参数。但是 CNN 的一个与众不同的特点是,他们明确假设条目是图像,这允许我们在架构中对某些属性进行编码,以识别图像中的特定元素。
为了直观地了解这些神经网络是如何工作的,让我们想想我们是如何识别事物的。例如,如果我们看到一张脸,我们会认出它,因为它有耳朵、眼睛、鼻子、头发等等。然后,为了确定某样东西是不是一张脸,我们就像有一些验证我们正在标记的特征的心理盒子一样去做。有时候一张脸可能因为被毛发覆盖而没有耳朵,但是我们也有一定概率把它归类为脸,因为我们看到了眼睛,鼻子和嘴巴。实际上,我们可以将其视为与帖子“神经网络的基本概念”中介绍的分类器等效的分类器,它预测输入图像是人脸还是没有人脸的概率。
但在现实中,我们必须先知道一只耳朵或一个鼻子是什么样子,才能知道它们是否在一个图像中;也就是说,我们必须事先识别与我们之前见过的包含耳朵或鼻子的线条、边缘、纹理或形状相似的线条、边缘、纹理或形状。这就是卷积神经网络的各层被委托去做的事情。
但是识别这些元素并不足以说某样东西是一张脸。我们还必须能够识别一张脸的各个部分是如何相遇的,相对大小等等。;否则,这张脸就不像我们习惯的样子了。从视觉上看,吴恩达团队的一篇文章中的这个例子通常能让我们直观地了解分层学习的内容。

(来源
我们想通过这个视觉例子给出的想法是,在现实中,在卷积神经网络中,每一层都在学习不同的抽象层次。读者可以想象,有了多层网络,就有可能识别输入数据中更复杂的结构。
卷积神经网络神经元的基本组件
现在,我们对卷积神经网络如何对图像进行分类有了直观的了解,我们将给出一个识别 MNIST 数字的例子,从中我们将介绍定义卷积网络的两个层,卷积网络可以表示为两个操作中的特定神经元组:卷积和汇集。
卷积运算
在卷积运算中,密集连接层和专用层(我们称之为卷积层)的根本区别在于,密集层在其全局输入空间中学习全局模式,而卷积层在二维小窗口中学习局部模式。
以直观的方式,我们可以说卷积层的主要目的是检测图像中的特征或视觉特征,如边缘、线条、颜色下降等。这是一个非常有趣的特性,因为一旦它学习了图像中某个特定点的特征,它就可以在以后的任何部分识别它。相反,在密集连接的神经网络中,如果它出现在图像的新位置,它必须再次学习模式。
另一个重要特征是,卷积层可以通过保留空间关系来学习模式的空间层次。例如,第一卷积层可以学习诸如边的基本元素,第二卷积层可以学习由在前一层中学习的基本元素组成的模式。以此类推,直到它学会非常复杂的模式。这使得卷积神经网络能够有效地学习日益复杂和抽象的视觉概念。
一般来说,卷积层在称为特征图的 3D 张量上操作,具有高度和宽度的两个空间轴,以及也称为深度的通道轴。对于 RGB 彩色图像,深度轴的维度是 3,因为图像具有三个通道:红色、绿色和蓝色。对于黑白图像,例如 MNIST 数字,深度轴维度是 1(灰度级)。
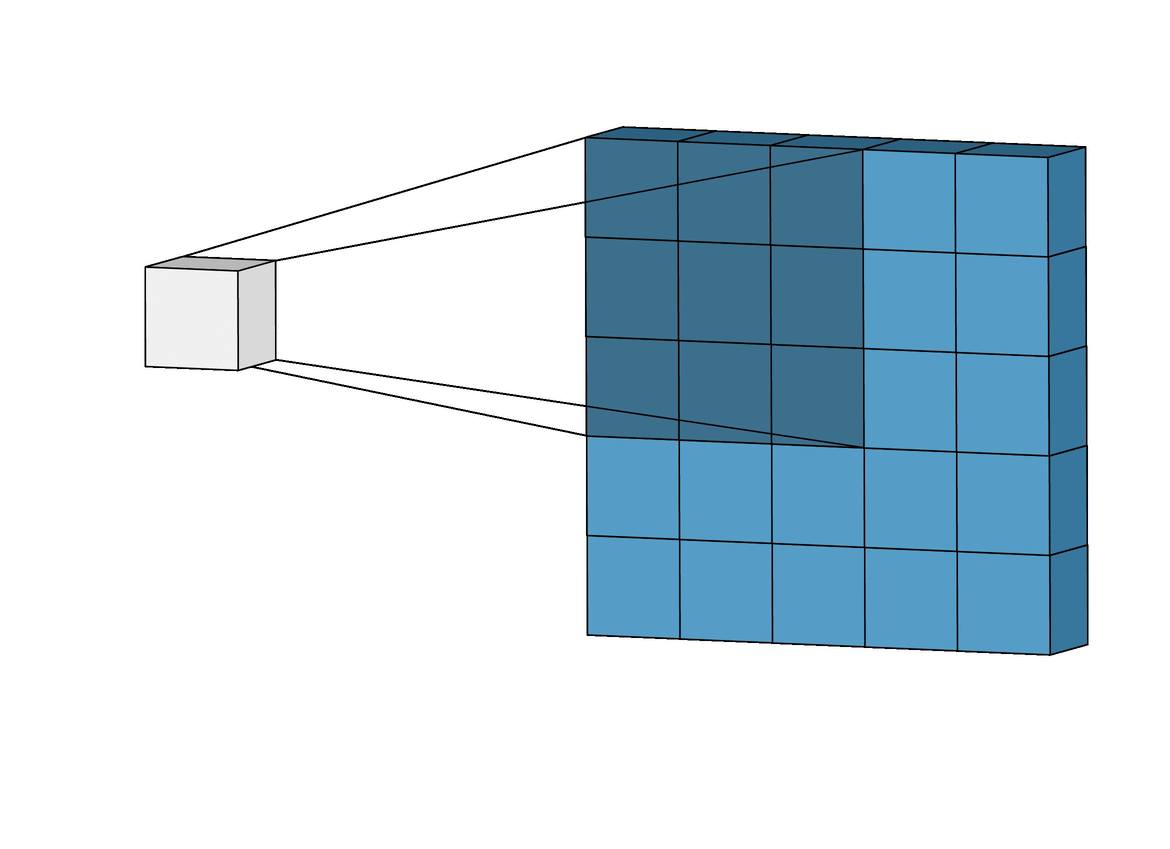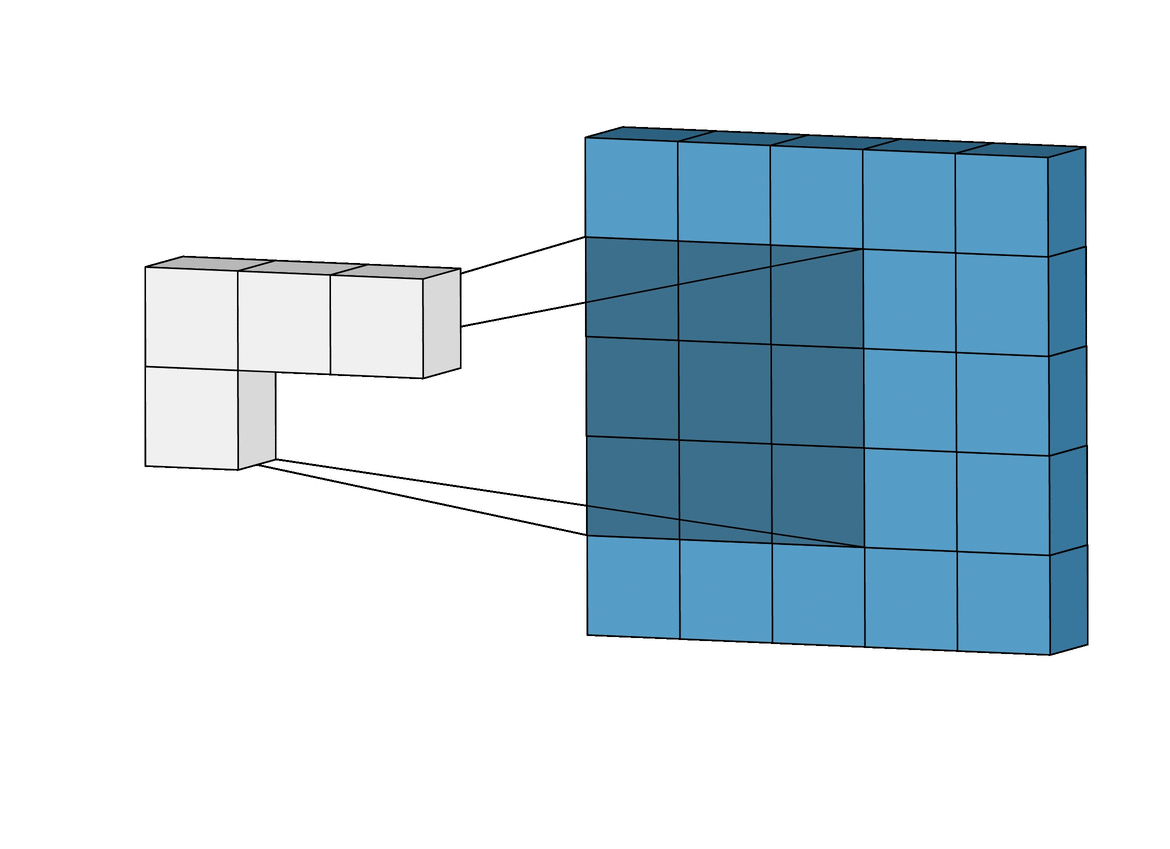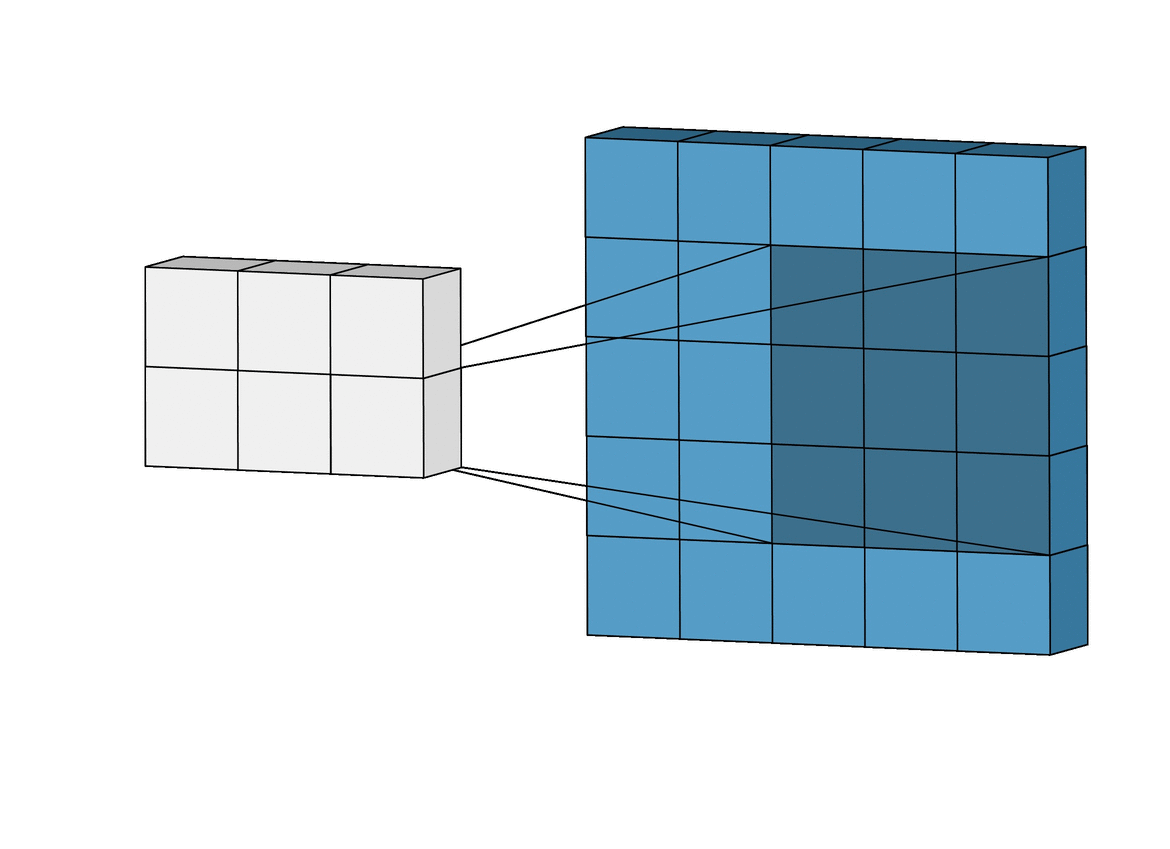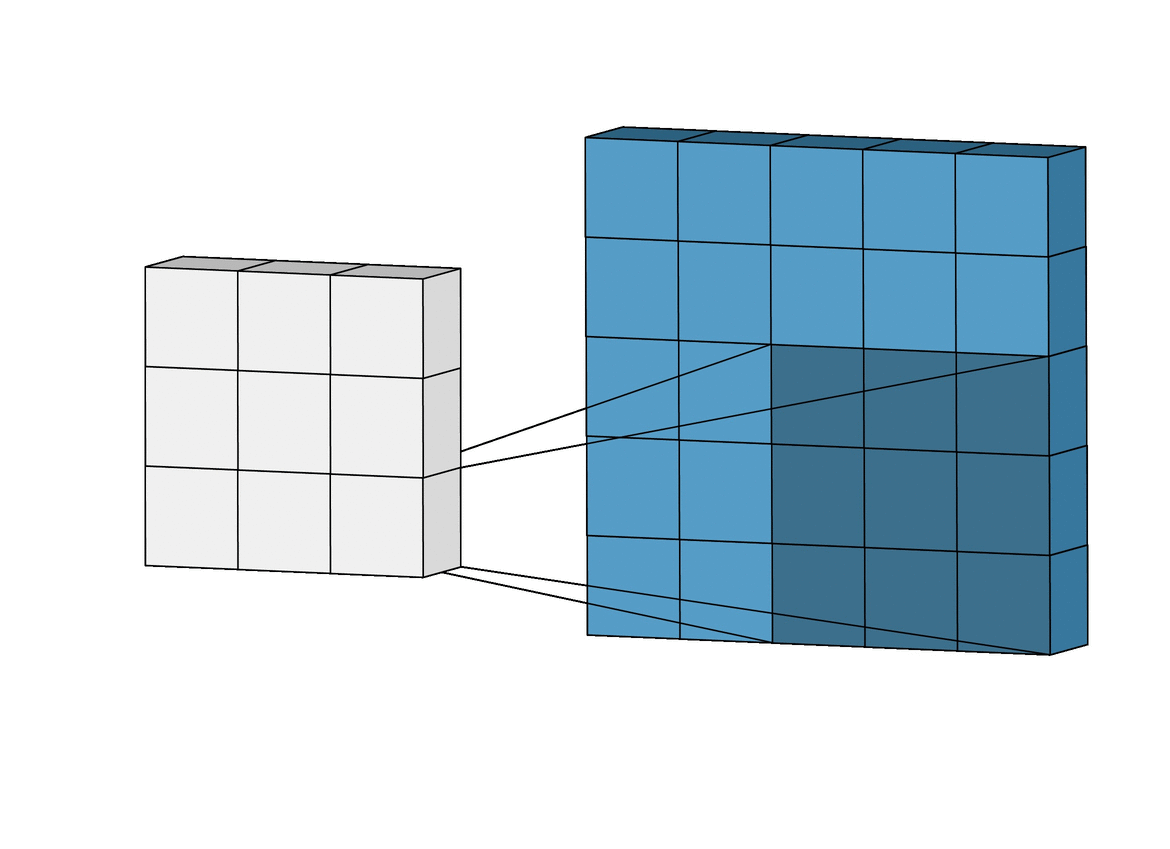
在 MNIST 的例子中,作为我们神经网络的输入,我们可以想象一个 28×28(高= 28,宽= 28,深= 1)的二维神经元空间。连接到我们已经讨论的输入层神经元的第一层隐藏神经元将执行我们刚刚描述的卷积运算。但是正如我们已经解释过的,并不是所有的输入神经元都与这个第一级隐藏神经元的所有神经元相连接,就像密集连接的神经网络的情况一样;这仅仅是通过存储图像像素的输入神经元空间的小的局部区域来完成的。
直观地解释,可以表示为:

(来源)
在我们前面的例子中,隐藏层的每个神经元将连接到输入层(28×28)的 5×5 个神经元(即 25 个神经元)的小区域。直观上,我们可以想象一个 5×5 大小的窗口,它沿着包含图像的整个 28×28 神经元层滑动。对于窗口的每个位置,隐藏层中都有一个神经元处理这些信息。
视觉上,我们从图像左上角的窗口开始,这为隐藏层的第一个神经元提供了必要的信息。然后,我们将窗口向右滑动一个位置,将此窗口中包含的输入层的 5×5 神经元与隐藏层的第二个神经元“连接”。因此,我们从左到右,从上到下,依次遍历输入层的整个空间。
稍微分析一下我们提出的具体情况,我们注意到,如果我们有 28×28 像素的输入和 5×5 的窗口,这在第一隐藏层中定义了 24×24 个神经元的空间,因为在碰到输入图像的右(或下)边界之前,我们只能将窗口向右移动 23 个神经元,向下移动 23 个神经元。

(来源
我们希望向读者指出,我们所做的假设是,当新的一行开始时,窗口水平和垂直地向前移动 1 个像素。因此,在每一步中,除了我们已经前进的这一行像素之外,新窗口与前一个窗口重叠。但是,正如我们将在下一节中看到的,在卷积神经网络中,可以使用不同长度的前进步长(称为步幅的参数)。在卷积神经网络中,你也可以应用在图像边缘填充零的技术来改善滑动窗口的扫描。定义这种技术的参数称为“填充”,我们也将在下一节更详细地介绍它,使用它可以指定填充的大小。
在我们的研究案例中,并遵循之前提出的形式,为了将隐藏层的每个神经元与输入层的 25 个相应神经元“连接”,我们将使用一个偏差值 b 和一个W-大小为 5×5 的权重矩阵,我们称之为过滤器(或内核)。隐藏层的每个点的值对应于滤波器和输入层的少数 25 个神经元(5×5)之间的标量积。
然而,关于卷积网络的特别和非常重要的事情是,我们对隐藏层中的所有神经元使用相同的滤波器(相同的 W 权重矩阵和相同的 b 偏差):在我们的例子中,对第一层的 24×24 个神经元(总共 576 个神经元)。读者可以在这个特定的例子中看到,这种共享大大减少了如果我们不这样做时神经网络将拥有的参数数量:它从 14,400 个必须调整的参数(5×5 × 24×24)增加到 25 个(5×5)参数加上偏差 b 。
这个共享的 W 矩阵和 b 偏差,我们已经说过我们在卷积网络的上下文中称之为过滤器,类似于我们用来修饰图像的过滤器,在我们的情况下,过滤器用于在小的条目组中寻找局部特征。我建议查看在 GIMP 图像编辑器手册中找到的例子,以获得卷积过程如何工作的视觉和非常直观的想法。
但是由矩阵 W 和偏差 b 定义的滤波器仅允许检测图像中的特定特征;因此,为了执行图像识别,建议同时使用几个滤波器,每个滤波器用于我们想要检测的一个特征。这就是为什么卷积神经网络中的完整卷积层包括几个滤波器。
下图显示了直观表示该卷积层的一种常用方法,其中隐藏层由几个过滤器组成。在我们的示例中,我们提出了 32 个滤波器,其中每个滤波器都由一个 5×5 的 W 矩阵和一个偏差 b 定义。

(来源)
在该示例中,第一卷积层接收尺寸输入张量(28,28,1)并生成尺寸输出(24,24,32),该尺寸输出是包含对输入计算 32 个滤波器的 32 个 24×24 像素输出的 3D 张量。
联营业务
除了我们刚刚描述的卷积层之外,卷积神经网络还伴随着卷积层和池层,池层通常在卷积层之后立即应用。理解这些层的用途的第一种方法是看到汇集层简化了卷积层收集的信息,并创建了其中包含的信息的压缩版本。
在我们的 MNIST 示例中,我们将选择卷积层的一个 2×2 窗口,并在汇集层的一个点上合成信息。视觉上,可以表达如下:

(来源)
有几种方法来压缩信息,但我们将在示例中使用的一种常用方法称为 max-pooling,它作为一个值保留了我们示例中 2×2 输入窗口中的最大值。在这种情况下,我们将池层的输出大小除以 4,得到一个 12×12 的图像。
平均池也可以用来代替最大池,其中每组入口点被转换成该组点的平均值而不是其最大值。但总的来说,最大池往往比其他解决方案更好。
有趣的是,随着合用的转变,我们保持了空间关系。为了直观地看到它,以下面一个 12×12 的矩阵为例,其中我们表示了一个“7”(假设我们经过的像素包含 1,其余的为 0;我们没有将其添加到绘图中以简化它)。如果我们应用具有 2×2 窗口的最大池操作(我们在中心矩阵中表示它,该中心矩阵在具有窗口大小的区域的马赛克中划分空间),我们获得 6×6 矩阵,其中保持了 7 的等价表示(在右图中,0 标记为白色,值为 1 的点标记为黑色):

(来源)
如上所述,卷积层托管多个过滤器,因此,当我们将最大池分别应用于每个过滤器时,池层将包含与卷积过滤器一样多的池过滤器:

(来源)
结果是,因为我们在每个卷积滤波器中有 24×24 个神经元的空间,所以在进行汇集之后,我们有 12×12 个神经元,这对应于划分滤波器空间时出现的 12×12 个区域(每个区域的大小为 2×2)。
合作环境
在这篇文章中,我们建议使用 Google 提供的 合作实验室 ,我将在这篇文章中使用的代码可以在我的 GitHub 这里 中以 Jupyter 笔记本的形式获得,并使用 colab 执行 这里 。
在开始定义我们的神经网络之前,我们需要加载所需的 Python 库:
%tensorflow_version 2.x
**import** **tensorflow** **as** **tf**
**from** **tensorflow** **import** keras
**import** **numpy** **as** **np**
**import** **matplotlib.pyplot** **as** **plt**
在 Keras 中实现一个基本模型
让我们看看这个卷积神经网络的例子是如何使用 Keras 编程的。正如我们已经说过的,为了参数化卷积和汇集阶段,需要指定几个值。在我们的例子中,我们将使用一个简化的模型,每个维度上的步幅为 1(窗口滑动的步长),填充为 0(在图像周围填充零)。这两个超参数将在下面介绍。该池将是如上所述的具有 2×2 窗口的最大池。卷积神经网络的基本结构
让我们继续实现我们的第一个卷积神经网络,它将由一个卷积和一个最大池组成。
在我们的例子中,我们将有 32 个滤波器,卷积层使用 5×5 窗口,池层使用 2×2 窗口。我们将使用 ReLU 激活功能。在这种情况下,我们配置卷积神经网络来处理大小为(28,28,1)的输入张量,这是 MNIST 图像的大小(第三个参数是颜色通道,在我们的情况下是深度 1),我们通过第一层中的参数 input_shape = (28,28,1) 的值来指定它:
**from** **tensorflow.keras** **import** Sequential
**from** **tensorflow.keras.layers** **import** Conv2D
**from** **tensorflow.keras.layers** **import** MaxPooling2D
model = Sequential()
model.add(Conv2D(32, (5, 5),
activation='relu', input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
通过方法 summary() 我们可以获得关于我们模型的细节:
model.summary()Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 24, 24, 32) 832
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 12, 12, 32) 0
=================================================================
Total params: 832
Trainable params: 832
Non-trainable params: 0
_________________________________________________________________
conv2D 层的参数数量对应于 5×5 的权重矩阵 W,并且每个滤波器的 a b 偏差是 832 个参数(32 × (25 + 1))。Max-pooling 不需要参数,因为它是一个寻找最大值的数学运算。
简单的模型
为了建立一个“深度”神经网络,我们可以像上一节一样堆叠几层。为了向读者展示如何在我们的示例中做到这一点,我们将创建第二组层,其中有 64 个滤波器,卷积层中有一个 5×5 窗口,池层中有一个 2×2 窗口。在这种情况下,输入通道的数量将采用我们从上一层获得的 32 个特征的值,尽管如我们之前所见,没有必要指定它,因为 Keras 推导出了它:
model = models.Sequential()
model.add(layers.Conv2D(32,(5,5),activation=’relu’,
input_shape=(28,28,1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (5, 5), activation=’relu’))
model.add(layers.MaxPooling2D((2, 2)))
如果用 summary() 方法显示模型的架构,我们可以看到:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 24, 24, 32) 832
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 12, 12, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 8, 64) 51264
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 64) 0
=================================================================
Total params: 52,096
Trainable params: 52,096
Non-trainable params: 0
_________________________________________________________________
在这种情况下,产生的第二卷积层的大小为 8×8,因为我们现在从 12×12×32 的输入空间和 5×5 的滑动窗口开始,考虑到它的步幅为 1。参数 51,264 的数量对应于第二层将具有 64 个滤波器(如我们在论证中所指定的)的事实,每个滤波器具有 801 个参数(1 对应于偏差,并且 32 个条目中的每一个具有 5×5 的 W 矩阵)。也就是说((5 × 5×32) +1) ×64 = 51264。
读者可以看到, Conv2D 和 MaxPooling2D 层的输出是一个 3D 形式张量(高度、宽度、通道)。当我们进入神经网络的隐藏层时,宽度和高度维度往往会减小。内核的数量通过传递给 Conv2D 层的第一个参数来控制(通常大小为 32 或 64)。
现在我们有 64 个 4x4 过滤器,下一步是添加一个密集连接的层,这将用于填充 softmax 的最后一层,就像在以前的文章中介绍的那样,以进行分类:
model.add(layers.Dense(10, activation=’softmax’))
在这个例子中,我们必须调整张量以适应密集层的输入,如 softmax,它是一个 1D 张量,而前一个张量的输出是一个 3D 张量。这就是为什么我们必须首先将 3D 张量展平为 1D 之一。在应用 Softmax 之前,我们的输出(4,4,64)必须展平为向量(1024)。
在这种情况下,softmax 层的参数数量为 10 × 1024 + 10,向量的输出为 10,如前一篇文章中的示例所示:
model = models.Sequential()model.add(layers.Conv2D(32,(5,5),activation=’relu’,
input_shape=(28,28,1)))
model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Conv2D(64, (5, 5), activation=’relu’))
model.add(layers.MaxPooling2D((2, 2)))model.add(layers.Flatten())
model.add(layers.Dense(10, activation=’softmax’))
使用 summary() 方法,我们可以看到关于每一层的参数和每一层的输出张量的形状的信息:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 24, 24, 32) 832
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 12, 12, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 8, 8, 64) 51264
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 4, 4, 64) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 1024) 0
_________________________________________________________________
dense_1 (Dense) (None, 10) 10250
=================================================================
Total params: 62,346
Trainable params: 62,346
Non-trainable params: 0
_________________________________________________________________
观察该概述,很容易理解,在卷积层中需要更多的存储器,因此需要更多的计算来存储数据。相比之下,在 softmax 的密集连接层中,需要很少的存储空间,但是相比之下,该模型需要必须学习的大量参数。了解数据和参数的大小很重要,因为当我们有基于卷积神经网络的模型时,它们有许多层,正如我们将在后面看到的那样,这些值可能会呈指数增长。
下图更直观地展示了上述信息,其中我们看到了在各层及其连接之间传递的张量形状的图形表示:

(来源)
模型的训练和评估
一旦定义了神经网络模型,我们就准备训练模型,也就是调整所有卷积层的参数。从这里开始,为了知道我们的模型做得有多好,我们必须像我们在以前的帖子“初学者的深度学习:Python 和 Keras 的实用指南”中的 Keras 例子一样做。出于这个原因,并且为了避免重复,我们将重用上面已经给出的代码:
**from** **tensorflow.keras.utils** **import** to_categorical
mnist = tf.keras.datasets.mnist
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
print (train_images.shape)
print (train_labels.shape)
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
model.fit(train_images, train_labels,
batch_size=100,
epochs=5,
verbose=1)
test_loss, test_acc = model.evaluate(test_images, test_labels)
print('Test accuracy:', test_acc)
该代码的结果将是:
Train on 60000 samples
Epoch 1/5
60000/60000 [==============================] - 4s 59us/sample - loss: 0.9310 - accuracy: 0.7577
Epoch 2/5
60000/60000 [==============================] - 2s 34us/sample - loss: 0.2706 - accuracy: 0.9194
Epoch 3/5
60000/60000 [==============================] - 2s 34us/sample - loss: 0.1943 - accuracy: 0.9421
Epoch 4/5
60000/60000 [==============================] - 2s 34us/sample - loss: 0.1529 - accuracy: 0.9553
Epoch 5/5
60000/60000 [==============================] - 2s 34us/sample - loss: 0.1284 - accuracy: 0.9626
10000/10000 [==============================] - 1s 76us/sample - loss: 0.1070 - accuracy: 0.9700 Test accuracy: 0.9704
请记住,代码可以在我的 GitHub 中找到,读者可以验证这个代码提供了大约 97%的准确性。
卷积层的超参数
目前尚未见到的卷积神经网络的主要超参数是:滤波器窗口的大小、滤波器的数量、步长和填充。
过滤器的尺寸和数量
窗口(window _ height×window _ width)的大小通常为 3×3 或 5×5,用于保存空间上接近的像素的信息。告诉我们想要处理的特征数量(output_depth)的过滤器数量通常是 32 或 64。在 Keras 的 Conv2D 层中,这些超参数是我们按以下顺序传递的参数:
Conv2D(输出深度,(窗口高度,窗口宽度))
填料
为了解释填充的概念,让我们用一个例子。让我们假设一个 5×5 像素的图像。如果我们选择一个 3×3 的窗口来执行卷积,我们会看到运算产生的张量大小为 3×3。也就是说,它缩小了一点:在本例中,每个维度正好缩小了两个像素。下图直观地显示了这一点。假设左边的图形是 5×5 的图像。在其中,我们对像素进行了编号,以便更容易地看到 3×3 液滴如何移动来计算过滤器的元素。在中间,表示 3×3 窗口如何在图像中移动,向右移动两个位置,向下移动两个位置。应用卷积运算的结果返回我们在左边表示的过滤器。该过滤器的每个元素都标有一个字母,该字母将其与用来计算其值的滑动窗口的内容相关联。

(来源)
在本帖中我们创建的卷积神经网络的例子中可以观察到同样的效果。我们从 28×28 像素的输入图像开始,并且在第一卷积层之后得到的滤波器是 24×24。在第二个卷积层中,我们从 12×12 张紧器变为 8×8 张紧器。
但有时我们希望获得与输入尺寸相同的输出图像,我们可以在卷积层中使用超参数填充。通过填充,我们可以在滑动窗口之前在输入图像周围添加零。在上图的例子中,为了使输出滤波器与输入图像具有相同的大小,我们可以在零输入图像的右边添加一列,左边添加一列,上面一行,下面一行。从下图中可以看出:

(来源
如果我们现在滑动 3×3 窗口,我们会看到它可以向右移动 4 个位置,向下移动 4 个位置,产生 25 个窗口,从而产生 5×5 的滤波器大小。

(来源)
在 Keras 中,Conv2D 层中的填充是用 padding 参数配置的,它可以有两个值:“same”,表示根据需要添加尽可能多的零的行和列,以使输出与条目具有相同的维数;以及“valid”,表示没有填充(这是 Keras 中该参数的默认值)。
进展
我们可以在卷积层中指定的另一个超参数是步幅,它表示滤波器窗口移动的步数(在上例中,步幅为 1)。
大跨距值会减小将传递给下一层的信息的大小。在下图中,我们可以看到与前面相同的示例,但现在跨距值为 2:

(来源)
正如我们所看到的,5×5 图像变成了一个较小的 2×2 过滤器。但在现实中,减少尺寸的卷积步长在实践中很少使用;为此,使用了我们之前介绍过的池操作。在 Keras 中,Conv2D 层中的步距由步距参数配置,默认为步距=(1,1) 值,分别表示两个维度中的进度。
奖金模式:时尚-MNIST
现在你可以把这篇文章中学到的层用到另一个例子中。你准备好了吗?让我向你推荐另一个数据集,你可以在上面练习并直接应用学到的 CNN 概念。
为此,我们将使用[Fashion-MNIST](https://github.com/zalandoresearch/fashion-mnist) 数据集,该数据集由 Zalando research 发布,包含 10 种不同类型的时尚产品。该数据集由 60,000 个示例的训练集和 10,000 个示例的测试集组成。每个示例都是 28x28 灰度图像,与 10 个类别的标签相关联。它与前一个示例共享图像大小、颜色和项目数量。然后,我们可以开始应用我们在前面的例子中使用的相同的模型。
首先,我建议应用之前数据集使用的相同模型。我们将观察到获得的准确度是 85.93%。转到 colab 并执行下面的代码来验证它:
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data() class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255 model = Sequential()
model.add(Conv2D(32, (5, 5), activation='relu',
input_shape=(28, 28, 1)))
model.add(MaxPooling2D((2, 2)))
model.add(Conv2D(64, (5, 5), activation='relu'))
model.add(MaxPooling2D((2, 2)))
model.add(Flatten())
model.add(Dense(10, activation='softmax')) model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5)
test_loss, test_acc = model.evaluate(test_images, test_labels)print('Test accuracy:', test_acc)
我们能提高精确度吗?当然,我们仍然可以改进我们的模型。然而,改进一个模型意味着什么呢?正如我们在上一篇文章中了解到的,这意味着尝试应用不同的(更好的)超参数。例如,我们可以在我们的模型中增加更多的神经元,增加更多的层。让我们试试:
model = Sequential()
model.add(Conv2D(64, (7, 7), activation="relu", padding="same",
input_shape=(28, 28, 1))
model.add(MaxPooling2D(2, 2))
model.add(Conv2D(128, (3, 3), activation="relu", padding="same"))
model.add(MaxPooling2D(2, 2))
model.add(Flatten())
model.add(Dense(64, activation="relu"))
model.add(Dense(10, activation="softmax"))
如你所见,如果我们遵循 colab 代码,我们可以获得 86.28%的准确率。看来我们需要做更多的改进。我建议更换优化器,例如adam:
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
如果我们用这个新的 optimizar 再次训练以前的网络(遵循 colab 代码),获得的准确度是 90.99%。还不错!
我们能改进它吗?是啊!。正如你在建议的 colab 代码中看到的,我们可以获得 92.56%的精确度,增加一种之前没有引入的新型层:BathNormalizaton 和Dropout。
最后,我们可以在 colab 代码中看到,我们可以增加epochs的数量,或者使用 Keras 的高级功能作为回调,以达到 94.54%的准确率。
这是一个介绍性的帖子,我希望在未来的帖子中解释更多类型的层或 Keras 的额外功能,这些在这里没有介绍,也没有在之前的帖子中介绍(关于学习过程)。与你分享这个例子的目的是为了表明有许多(和许多)人认为我们仍然需要学习。我鼓励你继续学习深度学习,这当然是一个令人兴奋的话题,有着美好的未来。
实践中的卷积神经网络
用 Keras 开发和实现你的第一个 CNN!

作者图片
介绍
本文的目标是成为如何开发卷积神经网络模型的教程。如果你想探索它们的理论基础,我鼓励你去看看这篇文章。
CIFAR-10 数据集
在第一个例子中,我们将实现一个可以区分 10 种对象的网络。为此,我们将使用 CIFAR-10 数据集。该数据集由 60,000 张彩色图片组成,分辨率为 32x32 像素,分为 10 个不同的类别,可在下图中查看。数据集被分成 50.000 个训练图片和 10.000 个用于测试的图片。
为了开发这个实现,我们将不使用 TensorFlow,而是使用 Keras。Keras 是一个工作在 TF 之上的框架,它带来了灵活性、快速性和易用性。这些是它最近在深度学习开发者中受欢迎程度上升的主要原因。
**# Original Dataset:** [**https://www.cs.toronto.edu/~kriz/cifar.html**](https://www.cs.toronto.edu/~kriz/cifar.html) **for more information****# Load of necessary libraries**
import numpy as np
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers.core import Dense, Flatten
from keras.layers.convolutional import Conv2D
from keras.optimizers import Adam
from keras.layers.pooling import MaxPooling2D
from keras.utils import to_categorical**# to make the example replicable**
np.random.seed(42)**# Load of the dataset**
(X_train, Y_train), (X_test, Y_test) = cifar10.load_data()

**i**
import matplotlib.pyplot as plt
class_names = ['airplane','automobile','bird','cat','deer',
'dog','frog','horse','ship','truck']
fig = plt.figure(figsize=(8,3))
for i in range(len(class_names)):
ax = fig.add_subplot(2, 5, 1 + i, xticks=[], yticks=[])
idx = np.where(Y_train[:]==i)[0]
features_idx = X_train[idx,::]
img_num = np.random.randint(features_idx.shape[0])
im = features_idx[img_num,::]
ax.set_title(class_names[i])
#im = np.transpose(features_idx[img_num,::], (1, 2, 0))
plt.imshow(im)
plt.show()

**# Initializing the model**
model = Sequential()**# Defining a convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))**# Defining a second convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# Defining a third convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# We add our classificator**
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dense(10, activation='softmax'))**# Compiling the model**
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])**# Training of the model**
model.fit(X_train, to_categorical(Y_train),
batch_size=128,
shuffle=True,
epochs=10,
validation_data=(X_test, to_categorical(Y_test)))**# Evaluation of the model**
scores = model.evaluate(X_test, to_categorical(Y_test))print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])

这是怎么回事?只有 10%的准确率?似乎我们的网络预测所有样本的类别相同。意味着某些东西正在失败。这肯定与我们的数据有关。在将它输入模型之前,我们没有对它进行预处理。
数据预处理
第一件事是预处理数据,使我们的网络任务尽可能简单。如果我们做不到这一点,因为我们有从 0 到 255 的数据,网络将永远学不到任何东西。
为了进行这种预处理,通常要做两件事:
- 数据居中:计算数据集的平均值并减去。处理图像时,您可以计算数据集的整个平均值并直接减去它,也可以计算图像每个通道的平均值并从每个通道中减去它。
- 标准化数据:这样做是为了让所有的数据具有大致相同的比例。两种最常见的方法是:
1)在数据居中(减去平均值)后,将每个维度除以其标准偏差
2)归一化,使每个维度的最小值和最大值分别为-1 和 1。只有当我们从不同尺度的数据开始,但我们知道它们应该是相似的,也就是说,它们对算法具有相似的重要性时,这才有意义。在图像的情况下,我们知道可以取的值是从 0 到 255,因此没有必要进行严格的归一化,因为这些值已经处于类似的范围内。

重要提示!
必须只对训练集进行规范化。换句话说,我们应该计算训练集的平均值和标准偏差,并将这些值用于验证集和测试集。
**# Cenetering the data**
X_train_mean = np.mean(X_train, axis = 0)
X_train_cent = X_train - X_train_mean**# Normalization**
X_train_std = np.std(X_train, axis = 0)
X_train_norm = X_train_cent / X_train_std
现在,我们使用训练集的平均值和标准差来准备验证和测试数据。
等等,但是我们没有验证数据!我们将以这种方式实现这个示例,但非常重要的是,当我们进行真正的开发时,我们有三个集合:
- 训练集:更新每批的权重
- 验证集:检查网络在各个时期的泛化能力。它使用在训练期间未见过的样本来测试模型,它用于监控网络的训练以供参考,但是它不干预任何计算!它通常在您想要调整参数时使用,该设置是指示哪些参数最适合使用的设置。验证越准确,我们拥有的参数集就越好。由于这个原因,我们不能依靠这个结果来给出网络泛化能力的概念,因为我们选择了网络配置来给出更高的精度。因此,我们必须有一个额外的集合,让我们现在可以说,我们的网络是否适合我从未见过的样本:测试样本。
- 测试集:它通过对一个从未见过的集(比验证集大)进行归纳,给我们一种我们的网络有多好的直觉。
好了,让我们准备好测试设备:
X_test_norm = (X_test - X_train_mean) / X_train_std
现在我们准备用标准化数据再次测试我们的网络:
**# Initializing the model**
model = Sequential()**# Defining a convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))**# Defining a second convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# Defining a third convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# We add our classificator**
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dense(10, activation='softmax'))**# Compiling the model**
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])**# Training of the model**
model.fit(X_train, to_categorical(Y_train),
batch_size=128,
shuffle=True,
epochs=10,
validation_data=(X_test, to_categorical(Y_test)))**# Evaluation of the model**
scores = model.evaluate(X_test, to_categorical(Y_test))print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])

众所周知,这个结果比前一个好。因此,我们可以自豪地说,我们已经训练了第一个 CNN,训练精度约为 0.99,测试精度约为 0.7。
下一个合乎逻辑的问题应该是:
培训和测试怎么会有这么大的区别?
正如你们可能已经想到的,深度学习也存在过度拟合,事实上,比其他技术更加明显。
对于那些不记得什么是过度适配的人来说,想想这个:
你有一个网络可以在任何给定的时间检测到哪个角色出现在老友记第 4x08 章。它的工作非常完美,它可以以 99.3%的准确率分辨出哪些角色在舞台上。它非常好用,你可以用 5x01 试试。结果是只有 71.2%的准确率。
嗯,这种现象被称为过度拟合,包括创建一个在我们的数据集中工作得很好的算法,但在推广方面非常糟糕。
在本文中,您可以找到对过度拟合的更深入的探索以及最小化过度拟合的技术。
请看代表基于时间的精度的图表:

看看这个例子:

你会选哪一个?
20 层的比 3 层的好用吧?然而,我们通常寻求的是它具有良好的泛化能力(当发现新数据时,它工作得很好)。如果看到新的数据,你觉得哪个效果会更好?
令人惊讶的是,左边的那个。
让我们回到我们的例子。在我们的例子中,我肯定我们都更喜欢 99 对 70,而不是 90 对 85,对吗?
如何才能实现这一点?标准化和规范化的技术。
重要提示:实际上,通常对图像进行的唯一预处理是将它们的所有值除以 255。这通常足以使网络正常工作,因此我们不依赖于与我们的训练集相关的任何参数。
处理过度拟合
有几种方法可以尽可能地减少过拟合,从而使算法能够更一般化。
批量标准化
称为批量标准化的技术是由 Ioffe 和 Szegedy 开发的技术,旨在减少内部协变量的变化或内部协变量移位,这使得网络对不良初始化更加鲁棒。
内部协变量偏移被定义为由于小批量之间输入数据的不同分布而导致的网络激活分布的变化。小批量之间的这种差异越小,到达网络过滤器的数据就越相似,激活图就越相似,网络训练的效果就越好。
这是通过在训练开始时强制网络激活具有单一高斯分布的选定值来实现的。这个过程是可能的,因为规范化是一个可区分的操作。
它通常在激活功能执行之前插入:
model.add(Conv2D(128, kernel_size=(3, 3), input_shape=(32, 32, 3))model.add(BatchNormalization())model.add(Activation('relu'))
用数学术语来说,我们所做的是用小批量计算的平均值和标准偏差对进入我们网络的每个小批量进行居中和标准化,然后用网络通过训练学习的参数重新调整和偏移数据。

此外,由于我们计算的是每个小批量的平均值和标准偏差,而不是整个数据集的平均值和标准偏差,因此批量定额还会引入一些噪声,这些噪声起到调节器的作用,有助于减少过度拟合。
事实证明,这种技术对于更快地训练网络非常有效。
**# We Import Batch Normalizarion layer**
from keras.layers import BatchNormalization, Activation**# Inizializting the model**
model = Sequential()**# Defining a convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), input_shape=(32, 32, 3)))
model.add(BatchNormalization())
model.add(Activation('relu'))**# Defining a second convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(Activation('relu'))**# Defining a thirdd convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(BatchNormalization())
model.add(Activation('relu'))**# We include our classifier**
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dense(10, activation='softmax'))**# Compiling the model**
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])**# Training the model**
model.fit(X_train_norm, to_categorical(Y_train),
batch_size=128,
shuffle=True,
epochs=10,
validation_data=(X_test_norm, to_categorical(Y_test))) # aquí deberíamos usar un conjunto distinto al de test!!!**# Evaluating the model**
scores = model.evaluate(X_test_norm, to_categorical(Y_test))print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])

我们可以看到,精度提高了 2%,一旦我们达到高数值,这是一个巨大的进步。但仍有改进的余地。
我们来探讨一下正规化。
正规化
正则化包括以某种方式惩罚我们的网络在训练期间做出的预测,以便它不认为训练集是绝对真实的,从而知道当它看到其他数据集时如何更好地进行概括。
看一下这张图表:

https://commons.wikimedia.org/wiki/File:75hwQ.jpg
在这个图表中,我们可以看到一个过度拟合的例子,另一个欠拟合的例子,以及另一个可以正确概括的例子。
哪个是哪个?
- 蓝色:过度合身
- 绿色:具有概括能力的好模型
- 橙色:不合身
现在,看看这个例子,在这个例子之后,有三个神经元数目不同的网络。我们现在看到的是 20 个神经元组成的网络,具有不同的正则化水平。
您可以在这里使用这些参数:
https://cs . Stanford . edu/people/kar pathy/convnetjs/demo/classify 2d . html
这里有一个更完整的:
https://playground.tensorflow.org/
最后,有许多层的网并应用正则化比有一个小的网以避免过度拟合要好得多。这是因为小网络是更简单的函数,具有更少的局部最小值,所以梯度下降达到一个或另一个很大程度上取决于初始化,所以实现的损耗通常具有很大的方差,这取决于初始化。
然而,具有许多层的网络是更复杂的函数,具有更多的局部最小值,尽管它们更难达到,但通常具有所有相似的和更好的损耗。
如果你对这个话题感兴趣:【http://cs231n.github.io/neural-networks-1/#arch】T4。
正则化的方法有很多。以下是最常见的几种:
L2 正则化(拉索正则化)
L2 正则化可能是最常见的。
它包括通过为每个权重添加 1/2 * λ* W**2 项来惩罚损失函数,这导致:

当计算导数时,1/2 只是为了方便,因为这留下了λ* W 而不是 2λ W 。
这意味着我们惩罚非常高或不同的权重,并希望它们都是相似的量级。如果你还记得,权重意味着每个神经元在预测的最终计算中的重要性。因此,通过这样做,我们使所有的神经元或多或少地同等重要,也就是说,网络将使用其所有的神经元来进行预测。
相反,如果某些神经元有非常高的权重,预测的计算就会更多地考虑它们,所以我们最终会得到一个没有用的死神经元网络。
此外,在我们的损失函数中引入 1/2 * λ* W**2 项使得我们的权重在梯度下降期间接近于零。随着 W+=-λ⋅W.的线性衰减
让我们看看是否可以通过应用 L2 正则化来改进我们的网络:
**# L2 Regularization****# Regularizer layer import**
from keras.regularizers import l2**# Inizializing the model**
model = Sequential()**# Defining a convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))**# Defining a second convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# Defining a third convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# Classifier inclusion**
model.add(Flatten())
model.add(Dense(1024, activation='relu', kernel_regularizer=l2(0.01)))
model.add(Dense(10, activation='softmax'))**# Compiling the model**
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])**# Traning the model**
model.fit(X_train_norm, to_categorical(Y_train),
batch_size=128,
shuffle=True,
epochs=10,
validation_data=(X_test_norm, to_categorical(Y_test)))**# Evaluating the model**
scores = model.evaluate(X_test_norm, to_categorical(Y_test))print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])

L1 正则化(脊正则化)
L1 也很常见。这一次,我们在损失函数中加入了λ|w|项。
我们还可以在所谓的弹性网正则化中将 L1 正则化与 L2 结合起来:

L1 正则化设法将 W 权重矩阵转换成稀疏权重矩阵(非常接近零,除了少数元素)。
这意味着,与 L2 不同,它给予一些神经元比其他神经元更大的重要性,使得网络对可能的噪声更具鲁棒性。
一般来说,L2 通常会给出更好的结果。如果您知道图像中有一定数量的特征可以很好地进行分类,并且您不希望网络被噪声扭曲,则可以使用 L1。
我们试试 L1,然后是 L1+L2:
**# L1 Regularization****# Regularizer layer import**
from keras.regularizers import l1**# Inizializing the model**
model = Sequential()**# Defining a convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))**# Defining a second convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# Defining a third convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# Classifier inclusion**
model.add(Flatten())
model.add(Dense(1024, activation='relu', kernel_regularizer=l1(0.01)))
model.add(Dense(10, activation='softmax'))**# Compiling the model**
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])**# Traning the model**
model.fit(X_train_norm, to_categorical(Y_train),
batch_size=128,
shuffle=True,
epochs=10,
validation_data=(X_test_norm, to_categorical(Y_test)))**# Evaluating the model**
scores = model.evaluate(X_test_norm, to_categorical(Y_test))print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])

**# Elastic Net Regularization (L1 + L2)****# Regularizer layer import**
from keras.regularizers import l1_l2**# Inizializing the model**
model = Sequential()**# Defining a convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))**# Defining a second convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# Defining a third convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# Classifier inclusion**
model.add(Flatten())
model.add(Dense(1024, activation='relu', kernel_regularizer=l1_l2(0.01, 0.01)))
model.add(Dense(10, activation='softmax'))**# Compiling the model**
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])**# Traning the model**
model.fit(X_train_norm, to_categorical(Y_train),
batch_size=128,
shuffle=True,
epochs=10,
validation_data=(X_test_norm, to_categorical(Y_test)))**# Evaluating the model**
scores = model.evaluate(X_test_norm, to_categorical(Y_test))print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])

最大范数约束
另一种正规化是基于限制的正规化。例如,我们可以设置权重不能超过的最大阈值。
在实践中,这是通过使用下降梯度来计算新的权重值来实现的,正如我们通常所做的那样,但是然后为每个神经元计算每个权重向量的范数 2,并将其作为不能超过 C 的条件,即:

正常情况下, C 等于 3 或 4。
我们通过这种标准化实现的是网络不会“爆炸”,也就是说,权重不会过度增长。
让我们看看这种正规化是如何进行的:
**# Elastic Net Regularization (L1 + L2)****# Regularizer layer import**
from keras.constraints import max_norm**# Inizializing the model**
model = Sequential()**# Defining a convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))**# Defining a second convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# Defining a third convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))**# Classifier inclusion**
model.add(Flatten())
model.add(Dense(1024, activation='relu', kernel_costraint=max_norm(3.)))
model.add(Dense(10, activation='softmax'))**# Compiling the model**
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])**# Traning the model**
model.fit(X_train_norm, to_categorical(Y_train),
batch_size=128,
shuffle=True,
epochs=10,
validation_data=(X_test_norm, to_categorical(Y_test)))**# Evaluating the model**
scores = model.evaluate(X_test_norm, to_categorical(Y_test))print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])

辍学正规化
退出正则化是 Srivastava 等人在他们的文章“退出:防止神经网络过度拟合的简单方法”中开发的一种技术,补充了其他类型的标准化(L1、L2、maxnorm)。
这是一种非常有效和简单的技术,它包括在训练期间以概率 p 保持神经元活跃或将其设置为 0。
我们实现的是在训练时改变网络的架构,这意味着将不会有单个神经元负责被激活到某个模式,但我们将有多个冗余神经元能够对该模式做出反应。

让我们看看应用辍学如何影响我们的结果:
**# Dropout****# Dropout layer import**
from keras.layers import Dropout**# Inizializing the model**
model = Sequential()**# Defining a convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(Dropout(0.25))**# Defining a second convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(Dropout(0.25))**# Defining a third convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(Dropout(0.25))**# Classifier inclusion**
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))**# Compiling the model**
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])**# Traning the model**
model.fit(X_train_norm, to_categorical(Y_train),
batch_size=128,
shuffle=True,
epochs=10,
validation_data=(X_test_norm, to_categorical(Y_test)))**# Evaluating the model**
scores = model.evaluate(X_test_norm, to_categorical(Y_test))print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])

现在,让我们看看 Max norm + Dropout 的影响:
**# Dropout & Max Norm****# Dropout & Max Norm layers import**
from keras.layers import Dropout
from keras.constraints import max_norm**# Inizializing the model**
model = Sequential()**# Defining a convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu', input_shape=(32, 32, 3)))
model.add(Dropout(0.25))**# Defining a second convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(Dropout(0.25))**# Defining a third convolutional layer**
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(Dropout(0.25))**# Classifier inclusion**
model.add(Flatten())
model.add(Dense(1024, activation='relu', kernel_constraint=max_norm(3.)))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))**# Compiling the model**
model.compile(loss='categorical_crossentropy',
optimizer=Adam(lr=0.0001, decay=1e-6),
metrics=['accuracy'])**# Traning the model**
model.fit(X_train_norm, to_categorical(Y_train),
batch_size=128,
shuffle=True,
epochs=10,
validation_data=(X_test_norm, to_categorical(Y_test)))**# Evaluating the model**
scores = model.evaluate(X_test_norm, to_categorical(Y_test))print('Loss: %.3f' % scores[0])
print('Accuracy: %.3f' % scores[1])

有更多的技术来处理过度拟合,如最大池,改变步幅…等等。在实践中,最好的方法是应用其中的几种,并根据所面临的问题测试哪种组合能提供最好的结果。
最后的话
一如既往,我希望你喜欢这篇文章,并且获得了关于如何实现和开发卷积神经网络的直觉!
如果你喜欢这篇文章,那么你可以看看我关于数据科学和机器学习的其他文章 这里 。
如果你想了解更多关于机器学习、数据科学和人工智能的知识 请在 Medium 上关注我,敬请关注我的下一篇帖子!
卷积神经网络的数学

米盖尔·Á的照片。帕德里纳来自派克斯
卷积神经网络-第 1 部分:深入探究 CNN 的基本原理。
计算机视觉是深度学习的一个子领域,它处理所有尺度的图像。它允许计算机通过自动过程处理和理解大量图片的内容。
计算机视觉背后的主要架构是卷积神经网络,它是前馈神经网络的衍生物。它的应用非常广泛,例如图像分类、物体检测、神经类型转移、人脸识别……如果你没有深度学习的一般背景,我建议你先阅读我关于前馈神经网络的帖子。
注意:因为 Medium 不支持 LaTeX,所以数学表达式是作为图像插入的。因此,为了更好的阅读体验,我建议你关闭黑暗模式。
目录
1。过滤处理
2。定义
3。基础
4。训练 CNN
5。常见架构
1-过滤处理
图像的第一次处理是基于过滤器,例如,使用垂直边缘和水平边缘过滤器的组合来获得图像中对象的边缘。
从数学上讲,垂直边缘滤波器,VEF,如果定义如下:

其中 HEF 代表水平边缘滤波器。
为了简单起见,我们考虑灰度 6×6 图像 A,这是一个 2D 矩阵,其中每个元素的值表示相应像素中的光量。
为了从该图像中提取垂直边缘,我们执行一个卷积乘积(⋆) ,它基本上是每个块中元素乘积的总和**😗*

我们对图像的第一个 3x3 块执行元素乘法,然后我们考虑右边的下一个块,并做同样的事情,直到我们覆盖了所有潜在的块。
我们可以把以下过程归纳为:

给定这个例子,我们可以考虑对any objective使用相同的过程,其中filter is learned由neural network执行,如下所示:

主要的直觉是设置一个神经网络,将图像作为输入,输出一个定义好的目标。使用反向传播学习参数。
2-定义
卷积神经网络是一系列卷积和汇集层,允许从图像中提取最符合最终目标的主要特征。
在下一节中,我们将详细介绍每一块砖及其数学方程。
卷积乘积
在我们明确定义卷积积之前,我们将首先定义一些基本操作,如填充和步长。
填充
正如我们在使用垂直边缘滤波器的卷积产品中看到的那样,图像角落的像素(2D 矩阵)比图像中间的像素使用得少,这意味着边缘的信息被丢弃了。
为了解决这个问题,我们经常在图像周围添加填充,以便考虑边缘上的像素。按照惯例,我们用zeros表示padde,用p表示填充参数,该参数表示添加到图像四个边中的每一个边上的元素数量。
下图说明了灰度图像(2D 矩阵)的填充,其中p=1:

跨步
跨距是卷积乘积中的步长。大的步幅允许缩小输出的大小,反之亦然。我们称步幅参数为s。
下图显示了带有s=1的卷积乘积(每个块的逐元素总和):

卷积
一旦我们定义了步幅和填充,我们就可以定义张量和滤波器之间的卷积积。
在先前定义了 2D 矩阵上的卷积积(是element-wise product的和)之后,我们现在可以正式定义体积上的卷积积。
一般来说,图像在数学上可以表示为具有以下维度的张量:

例如,在 RGB 图像的情况下,n_C=3,我们有红色、绿色和蓝色。按照惯例,我们认为滤波器 K 为squared并且具有表示为 *f,*的odd dimension,这允许每个像素在滤波器中居中,从而考虑其周围的所有元素。
当操作卷积乘积时,滤波器/内核 K 必须将same number of channels作为图像,这样我们对每个通道应用不同的滤波器。因此,过滤器的尺寸如下:

图像和过滤器之间的convolutional product是一个2D matrix,其中每个元素是立方体(过滤器)和给定图像的子立方体的元素乘法的和,如下图所示:

从数学上来说,对于给定的图像和滤波器,我们有:

保持与之前相同的符号,我们有:

统筹
它是通过总结信息对图像的特征进行下采样的步骤。该操作通过每个通道执行,因此它只影响尺寸(n_H,n_W ),并保持 n_C 不变。
给定一幅图像,我们滑动一个过滤器,用no parameters来学习,按照一定的步幅,我们对选定的元素应用一个函数。我们有:

按照惯例,我们考虑大小为 f 的平方滤波器,我们通常设置 f =2,并考虑 s =2。
我们经常应用:
Average pooling:我们对过滤器上的元素进行平均Max pooling:给定过滤器中的所有元素,我们返回最大值
下面是一个平均池的例子:

3-基础
在这一节中,我们将结合上面定义的所有操作,逐层构建一个卷积神经网络。
CNN 的一层
卷积神经网络的每一层可以是:
Convolutional layer -CONV-后面跟着一个activation functionPooling layer -POOL-如上详述Fully connected layer -FC-基本上类似于前馈神经网络的层,
你可以在我之前的帖子中看到更多关于激活功能和完全连接层的细节。
卷积层
正如我们之前看到的,在卷积层,我们对输入应用卷积乘积 s ,这次使用了许多滤波器,然后是激活函数ψ。

我们可以在下图中总结卷积层:

汇集层
如前所述,池图层旨在对输入要素进行缩减采样,而不会影响通道的数量。
我们考虑以下符号:

我们可以断言:

池层有no parameters要学习。
我们在下图中总结了前面的操作:

全连接层
全连接层是有限数量的神经元,它接受一个向量的输入,并返回另一个向量。

我们在下图中总结了完全连接的层:
更多细节,你可以访问我的关于前馈神经网络的 p 上一篇文章。

CNN 总的来说
一般来说,卷积神经网络是上述所有操作的系列,如下所示:

在激活函数之后重复一系列卷积之后,我们应用一个池并重复这个过程一定次数。这些操作允许从将被fed的图像extract features到由完全连接的层描述的neural network,该完全连接的层也有规律地被激活功能跟随。
大意是通过网络更深入时decrease n_H & n_W 和increase n_C。
在 3D 中,卷积神经网络具有以下形状:

CNN 为什么工作效率高?
卷积神经网络能够实现图像处理的最新成果有两个主要原因:
- 参数共享:卷积层中的特征检测器在图像的一部分有用,在其他部分可能有用
- 连接的稀疏性:在每一层中,每个输出值只依赖于少量的输入
4-培训 CNN
卷积神经网络是在一组标记图像上训练的。从给定的图像开始,我们通过 CNN 的不同层传播它,并返回所寻找的输出。
在本章中,我们将介绍学习算法以及数据扩充中使用的不同技术。
数据预处理
数据扩充是增加给定数据集中图像数量的步骤。数据扩充中使用了许多技术,例如:
CroopingRotationFlippingNoise injectionColor space transformation
由于训练集的规模较大,它启用了better learning,并允许算法从所讨论的对象的不同conditions中学习。
一旦数据集准备好了,我们就像任何机器学习项目一样把它分成三个部分:
- 训练集:用于训练算法和构造批次
- Dev set :用于微调算法,评估偏差和方差
- 测试集:用于概括最终算法的误差/精度
学习算法
卷积神经网络是一种专门用于图像的特殊类型的神经网络。一般来说,神经网络中的学习是在几个层中计算上面定义的参数的权重的步骤。
换句话说,我们的目标是从输入图像开始,找到给出真实值的最佳预测/近似的最佳参数。
为此,我们定义了一个目标函数,称为loss function,记为J,它量化了整个训练集的实际值和预测值之间的距离。
我们通过以下两个主要步骤最小化 J:
**Forward Propagation**:我们通过网络整体或分批传播数据,并计算这批数据的损失函数,该函数只不过是不同行的预测输出中的误差之和。**Backpropagation**:包括计算成本函数相对于不同参数的梯度,然后应用下降算法更新它们。
我们多次重复相同的过程,称为epoch number。定义架构后,学习算法编写如下:

(*)成本函数评估单点的实际值和预测值之间的距离。
更多的细节,你可以访问我的 p 上一篇关于前馈神经网络的文章。
5-通用架构
雷斯内特
Resnet、捷径或跳过连接是一个卷积层,它在层 n 处考虑了层 n-2 。直觉来自于这样一个事实:当神经网络变得非常深入时,输出端的精度变得非常稳定,不会增加。注入前一层的残差有助于解决这个问题。
让我们考虑一个残差块,当skip connection为off时,我们有以下等式:

我们可以在下图中对残差块进行求和:

初始网络
在设计卷积神经网络时,我们经常要选择层的类型:CONV、POOL或FC。初始层完成了所有的工作。所有操作的结果然后是单个块中的concatenated,其将是下一层的输入,如下:

需要注意的是,初始层提出了computational cost的问题。供参考,名字inception来源于电影!
结论
在本文的第一部分中,我们已经看到了从卷积产品、池化/全连接层到训练算法的 CNN 基础。
在第二部分中,我们将讨论图像处理中使用的一些最著名的架构。
不要犹豫,检查我以前的文章处理:
参考
原载于 2020 年 2 月 24 日https://www.ismailmebsout.com。
卷积神经网络从零开始建模和冻结
如果你不能简单地解释它,你就理解得不够好- 爱因斯坦,这个人和他的成就g . j .惠特罗著,多佛出版社 1973 年。
CNN 模型从零开始,使用最流行的 Kaggle 数据集 Fruits-360 ,获得 98%的准确率。
第一步——将数据集从 Kaggle 导入 Google Colab
登录你的 Kaggle 账户,进入我的账户,点击创建新 API 下载 Kaggle.json 文件。然后在 Google colab 上按照下面的代码要点上传相同的 API
- 直接将整个数据集导入到 google colab 并解压缩
步骤 2-准备训练和测试数据
-
数据已经包含了训练和测试文件夹,里面有水果和蔬菜的图片。我们只需要定义文件夹的路径,
-
现在我们必须将图像的尺寸定义到 NumPy-array 中,这样我们可以在接下来的步骤中进一步将图像缩小到 32x32
-
让我们找出,在训练数据中有多少种水果和蔬菜
在这里,我创建了一个流程来缩小图片的尺寸,并放大一点以获得更好的效果
- 这段代码将显示缩小、缩放图像的最终结果
步骤 3 CNN 构建和模型调整
请对像素矩阵、RGB 通道、颜色矩阵和人工神经网络有一个基本的了解,以便进一步阅读
在初学者的术语中,使用 CNN 我们所做的是,在我们的密集层之间添加额外的层,或者换句话说,将我们在 CNN 中定义的矩阵与密集层创建的矩阵相乘,移动到每个像素并填充输出矩阵,因此输出矩阵将具有 Ai 记录图像中一些变化的所有值,如形状或轮廓的变化。这种在每个像素上的乘法和加法被称为卷积,以记录图像中的边缘或形状。
这里实际发生的是,我们使用滤镜矩阵定义了某些颜色像素,它与图像像素中的所有其他颜色进行“卷积”,从而找到图案,想象滤镜是黑色的,我们在一幅画上加阴影,我们在输出中得到的是全黑,但一些深色在黑色上突出显示,给我们提供了形状,这些形状在输出矩阵中注册。

source—https://stack overflow . com/questions/52067833/how-to-plot-a-animated-matplotlib 中的 matrix
直观地说,当我们继续将我们的 CNN 滤波器矩阵与图像像素上的密集层矩阵进行卷积时,我们将在曲线、点或一些不同于图像其余部分的形状处获得许多不同的结果/数字,这反过来将帮助 AI 或 ANN 找到形状、边缘、轮廓。
随着我们深入到网络中,添加更多 CNN 层矩阵,做矩阵产品越做越深,

查尔斯·德鲁维奥在 Unsplash 上的照片
结果/数字将发生更大的变化,或者你可以说形状,曲线对人工智能来说将变得更加清晰,人工智能将能够学习苹果和菠萝之间的区别。通俗地说,我们可以说人工智能是通过描摹一幅真实的画来绘制图像,而 CNN 是描摹者或荧光笔。在下面的代码中,32 和 64 是过滤器,CNN 的矩阵大小是 3x3
为 CNN 选择网络架构
你可以在已经建立的各种网络架构之间进行交叉验证,并通过数学证明进行研究,如 AlexNet、LeNet-5、VGG,或者尝试创建自己的网络架构,既不会扩大梯度,也不会过度拟合数据。这里我使用了一个基本的 CNN 架构,对于更高级的模型,我建议学习网络架构和过滤器/内核构建,具有像角度旋转、水平/垂直过滤器等功能。
填充
填充是向像素矩阵添加额外边界的过程,因此在卷积过程中,角上的信息不会丢失,例如在矩阵周围添加 0 的边界。正如您在图像中看到的,如果没有填充,我们将只使用一次带信息的角,但现在有了填充,原始角将在卷积过程中多次使用。

联营
在从卷积中获得输出后,我们使用了一层 max pool,max pool 的作用是简单地降低矩阵的维数,或者换句话说,降低卷积输出的输出图像的大小,以实现更快、更精确的过程。
为了对池中发生的事情有一个基本的直觉,我们定义了一个矩阵,例如 2x2 矩阵,它会将输出矩阵划分为 2x2 多个矩阵,并通过计算出特定 2x2 矩阵中的最大值,仅保留看起来有一些形状或对象的点,然后这将进一步帮助减少输出图像的维度,以便更快地处理深入网络

来源-https://www.youtube.com/watch?v=ZjM_XQa5s6s,深渊蜥蜴
请参考 AndrewNg 的视频,了解 CNN 在添加图层后图像尺寸的变化
-
现在是时候添加输入和输出层,并调整人工神经网络模型
-
保存模型,在互联网上的随机图像上进行测试,看看您训练的模型是否可以识别水果和蔬菜
model.save_weights(“cnn_fruit.h5”)
结果
通过将 CNN 添加到我们的模型中,我能够达到 98%的准确性,在使这成为您的第一个项目后,我认为您将对 CNN 有一个基本的直观了解,并可以更深入地研究数学部分、基本原理以及网络选择和构建。


cnn_fruit.h5 结果

CNN 定制架构结果
冻结用于集成到 web 应用程序中的定制 CNN 模型,
这段代码将把你定制的模型冻结成 Keras 检查点格式,然后你可以为应用程序集成制作推断图
对于完整的 jupyter 笔记本和代码,你可以通过github.com——https://github.com/Alexamannn/CNN_from_scratch查看我的知识库
最流行的卷积神经网络架构
了解它们的结构以及如何实现它们!

图片来自 Unsplash
介绍
本文的目的是深入探讨以下概念:
- 最流行的 CNN 架构
- 如何用 Keras 实现它们来进行图像分类
最常见的架构
有研究团队完全致力于为 CNN 开发深度学习架构,并在庞大的数据集中训练它们,所以我们将利用这一点,并使用它们,而不是每次面临新问题时都创建新的架构。
这将为我们提供稳定性和精确性。
目前 CNN 最常见的深度学习架构有:
- VGG
- 雷斯内特
- 开始
- 例外
让我们来探索它们。
VGG16 和 VGG19
这种架构是最早出现的架构之一,由 Simonyan 和 Zisserman 在 2014 年发表的题为“用于大规模图像识别的非常深的卷积网络”的论文中介绍。本文可从这里获得:【https://arxiv.org/abs/1409.1556】T2。

按作者分列的数字
这是一种简单的架构,仅使用由递增数量的卷积层组成的块,具有 3×3 大小的滤波器。此外,为了减少获得的激活图的大小,最大池块被散布在卷积块之间,从而将这些激活图的大小减少一半。最后,使用一个分类块,由两个各有 4096 个神经元的密集层和最后一层(1000 个神经元的输出层)组成。
16 和 19 是指每个网络拥有的加权层数(卷积层和密集层,池层不计算在内)。它们对应于下表中的 D 列和 E 列。

截图来自 [wiki.math](http://very Deep Convoloutional Networks for Large-Scale Image Recognition)
表中的其余架构都在那里,因为当时 Simonyan 和 Zisserman 很难训练他们的架构进行融合。由于他们无法做到这一点,他们想出的是先用更简单的架构训练网络,一旦这些网络收敛并被训练,他们就利用自己的权重来初始化下一个稍微复杂一点的网络,以此类推,直到他们到达 VGG19。这个过程被称为“预训练”。
然而,这是在那些时候,现在它不再做,因为它需要太多的时间。现在我们可以使用 Xavier/Glorot 或 he 等人的初始化来实现同样的事情。
然而,这个网络有几个缺点:
- 训练时间太长了
- 它有非常多的参数
雷斯内特
由何等人在 2015 年开发的 ResNet 架构(你可以在这里看到他们名为“图像识别的深度剩余学习”的论文:、)是引入基于“模块”的奇异类型架构的里程碑,或者正如现在所知的,“网络中的网络”。
这些网络引入了“剩余连接”的概念,如下图所示:

按作者分列的数字
这些块允许到达先前激活图的层 l+1l+1 部分而无需修改,并且被属于层 L1 的块部分修改,正如你在上面的图像中所看到的。
2016 年,他们改进了这种架构,在这些残余块中加入了更多层,如下图所示:

按作者分列的数字
ResNet 有各种不同的层数,但使用最多的是 ResNet50,它由 50 个带权重的层组成。
值得注意的是,虽然它的图层比 VGG 多得多,但它需要的内存却少得多,几乎只有原来的五分之一。这是因为该网络不是在分类阶段使用密集层,而是使用一种称为 GlobalAveragePooling 的层,它将特征提取阶段最后一层的 2D 活动图转换为 class 向量,用于计算属于每个类的概率。
盗梦空间 V3
这种类型的架构是 2014 年由 Szegedy 等人在他们的论文“用卷积走得更深”(【https://arxiv.org/abs/1409.4842】)中介绍的,它使用带有不同大小滤波器的块,然后将这些块连接起来,以提取不同尺度的特征。看图片:

按作者分列的数字
为了帮助您理解这一点,inception 块的目标是使用 1x1、3x3 和 5x5 卷积计算激活图,以提取不同比例的特征。然后,您只需将所有这些激活映射连接成一个。
这种体系结构需要的内存甚至比 VGG 和 ResNet 还要少。
例外
这种架构是由 Fran ois Chollet(Keras 的创造者)提出的,他给《盗梦空间》带来的唯一东西是他优化了回旋,使它们花费更少的时间。这是通过将 2D 卷积分成两个 1D 卷积来实现的。如果你有兴趣了解更多,这里有论文:《异常:深度学习与深度可分卷积》,【https://arxiv.org/abs/1610.02357】T4。
在内存方面,它与 Xception 非常相似,这是其架构的轮廓:

来自exception-Open Access Paper的截图
挤压网
这个网络非常轻(例如,与 VGG 的 500MB 或 Inception 的 100MB 相比,它的重量是 5MB ),并且使用 ImageNet 实现了大约 57%的 rank-1 或大约 80%的 rank-5 的准确性。
rank-1 和 rank-5 或者 top-1 和 top-5 是什么意思?
- 等级 1 精度:我们比较根据我们的网络具有最高概率的类是否匹配真实的标签
- 等级-5 准确度:我们比较根据我们的网络具有较高试用的 5 个类别中的一个是否与真实标签匹配
这个网络是如何做到占用空间如此之小却又如此精确的呢?它通过使用“压缩”数据然后扩展数据的体系结构来实现这一点,如下图所示:

按作者分列的数字

按作者分列的数字

按作者分列的数字
有无限的架构,但这些是目前使用最多的。通常,当我们遇到问题时,我们不会定义我们的架构,但我们会使用之前的一个架构。
好了,现在您已经看到了它们,让我们看看如何在 Keras 中实现它们
VGG,ResNet,Inception & Xception Keras 实现
像往常一样,我们会打开一个谷歌合作笔记本。选择在 GPU 上运行的代码,提高速度,执行下面的代码。
!pip install imageio

**# Import the necessary libraries**
from keras.applications import ResNet50
from keras.applications import InceptionV3
from keras.applications import Xception # solo con el backend de TensorFlow
from keras.applications import VGG16
from keras.applications import VGG19
from keras.applications import imagenet_utils
from keras.applications.inception_v3 import preprocess_input
from keras.preprocessing.image import img_to_array
from keras.preprocessing.image import load_img
import numpy as np
import urllib
import cv2
import matplotlib.pyplot as plt
import imageio as iodef predict_image(model_name, image_source):
**# We define a dictionary that maps the network name with the Keras imported model** MODELS = {
"vgg16": VGG16,
"vgg19": VGG19,
"inception": InceptionV3,
"xception": Xception, # TensorFlow solo!
"resnet": ResNet50
}# **We stablish the input size and image preprocessing function**
input_shape = (224, 224)
preprocess = imagenet_utils.preprocess_input# **If we use InceptionV3 or Xception, we need to stablish a different input image size (299x299) and use a different preprocessing function**
if model_name in ("inception", "xception"):
input_shape = (299, 299)
preprocess = preprocess_inputprint("[INFO] loading {}...".format(model_name))
Network = MODELS[model_name]
model = Network(weights="imagenet") **# We load the network with the weights already trained with the ImageNet, the first time we execute keras it will lead the weights, which size is about 500MB, so it will last a bit** # **We load the image and make sure it is in the appropiate size**
print("[INFO] loading and pre-processing image...")
if type(image_source) == str:
image = load_img(image_source, target_size=input_shape)
image = np.resize(image, (input_shape[0], input_shape[1], 3))
image = img_to_array(image)
else:
image = np.resize(image_source, (input_shape[0], input_shape[1], 3))
image = img_to_array(image)# **The image is represented as an array of size: (inputShape[0], inputShape[1], 3) and we need: (1, inputShape[0]. inputShape[1], 3), so we expand the dimensions**
image = np.expand_dims(image, axis=0)**# we preprocess the image**
image = preprocess(image)**# We predict the class of the image**
print("[INFO] classifying image with '{}'...".format(model_name))
preds = model.predict(image)
P = imagenet_utils.decode_predictions(preds)**# We show the predictions rank-5 and their likelihood**
for (i, (imagenetID, label, prob)) in enumerate(P[0]):
print("{}. {}: {:.2f}%".format(i + 1, label, prob * 100))img = io.imread(image_source)
(imagenetID, label, prob) = P[0][0]
cv2.putText(img, "Label: {}, {:.2f}%".format(label, prob * 100), (10, 30), cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2)
plt.imshow(img)
plt.axis('off')
return model

# download images
!wget [https://image.ibb.co/cuw6pd/soccer_ball.jpg](https://image.ibb.co/cuw6pd/soccer_ball.jpg)
!wget [https://image.ibb.co/hdoVFJ/bmw.png](https://image.ibb.co/hdoVFJ/bmw.png)
!wget [https://image.ibb.co/h0B6pd/boat.png](https://image.ibb.co/h0B6pd/boat.png)
!wget [https://image.ibb.co/eCyVFJ/clint_eastwood.jpg](https://image.ibb.co/eCyVFJ/clint_eastwood.jpg)

!ls -la *.*

model = predict_image('resnet', 'soccer_ball.jpg')


model = predict_image('vgg16', 'bmw.png')

model.summary()

model = predidct_image('inception', 'clint_eastwood.jpg')

model.summary()
网络架构的结果太大了,这里不适合:

最后的话
一如既往,我希望你喜欢这篇文章,并且获得了关于如何实现和开发卷积神经网络的直觉!
如果你喜欢这篇帖子,那么你可以看看我在数据科学和机器学习方面的其他帖子 这里 。
如果你想了解更多关于机器学习、数据科学和人工智能的知识 请在 Medium 上关注我,敬请关注我的下一篇帖子!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
{kind=link}
{kind=link}