







深度学习:自动更正,短词拼写检查
使用最先进的神经网络纠正专有名词等生僻字的拼写。本文讨论网络的抽象概念、实现和结果。

由比斯瓦帕蒂·阿查里亚在 Unsplash 上拍摄
这是一张纽约市天际线的美丽图片,为什么我会把它放在一篇神经网络文章上?也许我现在更欣赏外在的美了,因为我从 2 月 15 日开始隔离自己(76 天,还在继续)。是的,已经两个多月了!!!在周五午夜 2:45 打出一篇文章会出什么问题。我们会找到答案的。
我已经在 Reorg 工作了一年多,这太不可思议了。Reorg 是在金融部门,提供破产相关的新闻和不良债务公司的分析。没错,当有人濒临破产时,我们会赚钱,这听起来很邪恶,但相信我,不是的。Reorg 有一个网站,用户可以通过这个网站获得对不良债务公司的最新分析。为了找到他们感兴趣的公司,我们为他们提供了一个搜索栏,搜索一个拥有超过一百万家公司的数据库。那么什么会出错呢?有一个问题,都是专有名词(公司名称),所以你必须在搜索栏中正确获取确切的名称。
不幸的是,我们人类生来就会犯错。**解决方案?*机器人来救援了。 用机器人语言尖叫 *
视觉:
我在这里的愿景是实现类似于谷歌提供的东西,即在 下显示 或的结果,你的意思是。
我们为什么要这么做?让用户参与我们的网站。想象一下,如果每次你输入一个错误,谷歌从来没有显示任何结果,直到你真正输入正确的拼写。这个世界会有多糟糕?
以下是“深度学习”的搜索结果,其中有故意出现的错误。


资料来源:google.com
人们会注意到这两个结果有所不同。当它显示’**显示’**的结果时,Google 对您正在寻找的内容非常有信心,因此会向您显示预测关键字的搜索结果。另一方面,当它显示“你是指吗”的结果时,它的信心下降,并要求你(用户)帮助验证你实际上在找什么。尽管如此,他们仍然显示他们认为与搜索框中输入的词密切相关的网站链接。
如果您只对模型结果感兴趣,请一直向下滚动到 AI in action。

由 Samrat Khadka 在 Unsplash 上拍摄的照片
我的天啊,我是如此想念你!:(好了,我说够了莎士比亚。回到最酷的话题!
网络:
我们将使用一个序列对机器神经传输网络中常用的翻译器进行排序。这也会有一个注意机制和利用老师强迫学习。为此,你需要对 RNN 氏症和 GRU 氏症有基本的了解。我将简要描述这个网络,以及我如何使用我现有的数据库作为训练数据集。
总的来说,就是把源序列’ X’ 转换成某个目标序列 ‘Y’ 其中, X = x₁ + x₂ + …。+ xᵣ,
Y = y₁ + y₂ + …+ yₐ
*通常,这项工作是通过创建我们的源序列’ **X '的表示来完成的。*我们将对目标序列’ Y '中下一个目标单词/字符的条件概率进行建模。
为什么序列要序列模式?
抽象的思想是把一个给定的输入,即一个源序列转换成一个 N 维的上下文向量,它将体现输入的“意义”。这个向量然后被馈送到解码器,解码器将把输入“翻译”成所需的输出。
为什么有注意机制?等等,注意机制是什么?
分离编码器和解码器的上下文向量保存/总结了来自源序列的大部分输入信息。“预计”这将是输入的一个很好的总结,以便解码器开始产生良好的模型结果。注意力机制背后的思想是重新训练上下文向量,并发现哪些状态将被证明对解码器有用。如果没有注意机制,通常初始和中间状态不会被重视,很容易被遗忘,从而导致网络忘记序列的早期部分。为了更好地理解它,我建议阅读这些文章这里和这里。
输入:
问题定义是独特的,不同于其他定义。我们的数据库由超过 100 万个公司名称的列表组成,这些名称都是专有名词,即它们都是公司名称,任何用户都可以搜索。让我们采用数据科学的方法来减少这个数字,并朝着实现我们的目标迈出一小步。不是每个人都会搜索所有的公司,他们会对一些正在或即将成为趋势的公司感兴趣。此外,我们有搜索历史记录,这有助于我们分析人们关注的领域以及他们最感兴趣的行业。这将消除很多噪音,并大大减少我们的公司范围。
在其他时间,这是一个数据科学项目,但现在我们将使用一组特殊的公司,我们可以合理地假设人们对搜索感兴趣。这涵盖了 2500 多家公司,这将是我们的训练数据集。
训练数据:
魔术来了!从我们想要预测的单词列表中,我们创建自己的输入和输出。我们在列表中归纳拼写错误,不是任何随机的拼写错误,而是关键字彼此接近。例如,如果我们有一个名为“”Linkedin.com的公司,我们创建一个带有拼写错误**“lonkwdin . com”的训练输入。那么这些错误有什么特别之处呢?我把字母 I 和 e 分别换成了 s 和 o。这些字母不是随意挑选的。看看你的键盘,最有可能拼错字母“I”的是“u”、“j”、“k”、“l”&“o”。我们选择这些字母中的任何一个,并在输入中替换它。字母 e 也是如此。现在我们引入一些变量,以便网络学习这些错误并预测输出。****

我在增强的输入中创建了 24 个错误,并将其映射到实际的预测输出。我还添加了一个没有错误的,这样网络应该知道,当有人输入完全正确,我们仍然显示他们预期的结果。请记住,网络的目标是以概括的方式学习这些错误,以便一旦有人在训练/测试集中犯了拼写错误,我们仍然能够预测它。
然后,这种增强/模拟在所有公司中运行,产生了 78,000 个数据点。这些数据被分成 60-20-20 份,用于训练、验证和测试数据集。
回到网络:
*这里网络的目标是在给定增广值的情况下预测实际值。我们在这里必须随机应变如何使用神经机器翻译模型。这种模型广泛用于翻译语言,这些语言有大量的单词(专有名词除外),这些单词的频率足以让模型理解何时、何地以及如何使用它们。不幸的是,这个案例不一样。*为什么?因为每当我们在数据集中介绍一家新公司时,我们的词汇量就会增加。这显然是不可扩展的,因为我们不能总是修改网络的输入来考虑这些单词并从头重新训练它。保持输入索引不变的一种方法是使用字符。这样,无论发生什么,我们的词汇长度都保持不变。我们总共取 52 个字符,包括字母、数字和特殊符号,将每个字符映射为‘a’->2、‘b’->3、‘c’->4 等等。通过这样做,不管有什么新公司进来,它都将在这个 52 个字符的词汇表中。这允许我们从先前离开的地方训练模型。另一方面,如果我们必须引入一个新单词,我们的初始映射索引将每次增加 1。这将要求网络每次从头开始重新学习一组新的数字,这是不可扩展的。
*"<>abcdefghijklmnopqrstuvwxyz &()+/.,;'?!-@0123456789"*
前两个字符’‘将在解码器中用作’ SOS ‘(字符串开始)和’ EOS '(字符串结束),以告诉解码器字符串何时开始和结束。为什么这是必要的?因为即使在抛出一个 EOS 标记后,它也会继续一个接一个地预测字符。这是一个提示,让我们知道预测到此结束。
很好,现在我们已经确定了我们的输入是什么样子,输出是实际的公司名称。我们开始训练网络,并在它过度适应之前停止。

结果:
该模型达到了 87.1%的准确率,与目前 89-90%的准确率相比,还算不错。准确性差异的原因仅仅是因为我的数据集是专有名词,即不会重复的单词。这大大增加了问题的复杂性,从而降低了准确性。
我认为改善这一点的一个方法是对数据集做更多的预处理,使模型更容易预测,从而提高准确性。
AI 在行动:
Reorg 最近一直在撰写关于冠状病毒影响的文章,所有相关文章都以“冠状病毒影响”为名。下面我用一些可能的错误组合创建了一个 gif。

当有人在我们搜索栏中搜索“冠状病毒影响”并点击回车时,可能会出现这些错误。这张 gif 显示了即使在诱发了许多错误之后,模型仍然做得很好。
橙色的字母是用户的输入,下面的输出是自动完成预测。
这是“Bharti Airtel”公司的另一个例子。在完全删除第二个单词并在第一个单词中引入 2 个错误后,它仍然预测正确的结果

另一件需要指出的事情是,这个模型是绝对疯狂的。模型训练时,输入长度和输出长度不必保持不变。对于任何其他数据点,它们可以不同。现在试着想一想其他能做到这一点的模型。想不出很多,是吧?心智成熟
基于深度学习的推荐系统

现代电影推荐人简介
传统上,推荐系统基于诸如聚类、最近邻和矩阵分解的方法。然而,近年来,深度学习在多个领域取得了巨大的成功,从图像识别到自然语言处理。推荐系统也受益于深度学习的成功。事实上,今天最先进的推荐系统,如 Youtube 和亚马逊的推荐系统,是由复杂的深度学习系统驱动的,而不是传统方法。
为什么是这个教程?
在阅读这里的许多有用的教程时,这些教程涵盖了使用传统方法(如矩阵分解)的推荐系统的基础,我注意到缺少涵盖基于深度学习的推荐系统的教程。在本笔记本中,我们将浏览以下内容:
- 如何使用 PyTorch Lightning 创建自己的基于深度学习的推荐系统
- 推荐系统中隐式和显式反馈的区别
- 如何在不引入偏差和数据泄漏的情况下训练-测试分割用于训练推荐系统的数据集
- 评估推荐系统的标准(提示:准确性或 RMSE 是不合适的!)
本教程的数据集
本教程使用 MovieLens 20M 数据集提供的电影评论,这是一个受欢迎的电影评级数据集,包含从 1995 年到 2015 年收集的 2000 万条电影评论。
如果你想跟随本教程中的代码,你可以查看我的 Kaggle 笔记本,在那里你可以运行代码,并在跟随本教程时看到输出。
使用隐式反馈构建推荐系统
在我们建立我们的模型之前,理解隐式和显式反馈之间的区别,以及为什么现代推荐系统建立在隐式反馈的基础上是很重要的。
明确的反馈
在推荐系统的背景下,显式反馈是从用户那里收集的直接和定量数据。例如,亚马逊允许用户在 1-10 的范围内给购买的商品打分。这些评级直接由用户提供,该量表允许亚马逊量化用户偏好。另一个显式反馈的例子包括 YouTube 上的拇指向上/向下按钮,该按钮捕捉用户对特定视频的显式偏好(即喜欢或不喜欢)。
然而,显式反馈的问题是它们很少。想想看,你上一次点击 YouTube 视频上的“喜欢”按钮,或者给你的网上购物打分是什么时候?很有可能,你在 YouTube 上观看的视频数量远远大于你明确评价的视频数量。
隐性反馈
另一方面,隐式反馈是从用户交互中间接收集的,它们充当用户偏好的代理。比如说。你在 YouTube 上观看的视频被用作隐性反馈,为你量身定制推荐,即使你没有明确地对这些视频进行评级。隐性反馈的另一个例子包括你在亚马逊上浏览过的商品,它被用来为你推荐其他类似的商品。
隐性反馈的好处是丰富。使用隐式反馈构建的推荐系统还允许我们通过每次点击和交互来实时定制推荐。今天,在线推荐系统是使用隐式反馈构建的,这允许系统在每次用户交互时实时调整其推荐。
数据预处理
在开始构建和训练我们的模型之前,让我们做一些预处理,以获得所需格式的 MovieLens 数据。
为了保持内存使用的可管理性,我们将只使用该数据集中 30%用户的数据。让我们随机选择 30%的用户,只使用所选用户的数据。
过滤数据集后,现在有来自 41,547 个用户的 6,027,314 行数据(这仍然是一个很大的数据!).数据帧中的每一行都对应于一个用户对一部电影的评论,如下所示。

列车测试分离
除了评级,还有一个时间戳列,显示提交评论的日期和时间。使用时间戳列,我们将使用留一法实现我们的训练测试分割策略。对于每个用户,最近的评论被用作测试集(即,省去一个),而其余的将被用作训练数据。
为了说明这一点,用户 39849 评论的电影如下所示。用户评论的最后一部电影是 2014 年的热门电影《银河护卫队》。我们将使用这部电影作为该用户的测试数据,并使用其余已审查的电影作为训练数据。

themoviedb.org 电影海报(免费使用)
这种训练-测试分离策略经常在训练和评估推荐系统时使用。进行随机分割是不公平的,因为我们可能会使用用户最近的评论进行训练,而使用早期的评论进行测试。这引入了带有前瞻偏差的数据泄漏,并且经过训练的模型的性能不能推广到真实世界的性能。
下面的代码将使用留一法将我们的评级数据集分成一个训练集和一个测试集。
将数据集转换成隐式反馈数据集
如前所述,我们将使用隐式反馈来训练一个推荐系统。然而,我们使用的 MovieLens 数据集是基于显式反馈的。要将该数据集转换为隐式反馈数据集,我们只需将评级二进制化,并将其转换为“1”(即正面类别)。值“1”表示用户已经与项目进行了交互。
值得注意的是,使用隐式反馈重新定义了我们的推荐器试图解决的问题。在使用显式反馈时,我们不是试图预测电影评级,而是试图预测用户是否会与每部电影进行交互(即点击/购买/观看),目的是向用户呈现交互可能性最高的电影。

不过,我们现在确实有一个问题。在二值化我们的数据集之后,我们看到数据集中的每个样本现在都属于正类。然而,我们还需要负样本来训练我们的模型,以指示用户没有交互的电影。我们假设这些电影是用户不感兴趣的——尽管这是一个笼统的假设,可能不是真的,但在实践中通常效果很好。
下面的代码为每行数据生成 4 个负样本。换句话说,阴性样本与阳性样本的比例为 4:1。这个比例是随意选择的,但我发现它在实践中工作得相当好(你可以自己找到最佳比例!).
太好了!我们现在有了模型所需格式的数据。在我们继续之前,让我们定义一个 PyTorch 数据集以便于训练。下面的类只是将我们上面写的代码封装到一个 PyTorch 数据集类中。
我们的模型——神经协同过滤(NCF)
虽然有许多基于深度学习的推荐系统架构,但我发现由 He 等人提出的框架是最简单的,它足够简单,可以在这样的教程中实现。
用户嵌入
在我们深入模型的架构之前,让我们熟悉一下嵌入的概念。嵌入是一个低维空间,它从高维空间中捕捉向量的关系。为了更好地理解这个概念,让我们仔细看看用户嵌入。
想象一下,我们希望根据用户对两种类型电影的偏好来代表他们——动作片和爱情片。让第一维度是用户有多喜欢动作片,第二维度是用户有多喜欢言情片。

现在,假设 Bob 是我们的第一个用户。鲍勃喜欢动作片,但不喜欢爱情片。为了将 Bob 表示为一个二维向量,我们根据他的偏好将他放在图中。

我们的下一个用户是乔。乔是动作片和爱情片的超级粉丝。我们用二维向量来表示 Joe,就像 Bob 一样。

这个二维空间被称为嵌入。从本质上说,嵌入减少了我们的用户,这样他们可以在一个低维空间中以一种有意义的方式被表示。在这种嵌入中,具有相似电影偏好的用户被放置在彼此附近,反之亦然。

当然,我们并不局限于仅仅使用二维来表示我们的用户。我们可以使用任意数量的维度来表示我们的用户。更多的维度可以让我们更准确地捕捉每个用户的特征,但代价是模型变得复杂。在我们的代码中,我们将使用 8 个维度(我们将在后面看到)。
习得嵌入
同样,我们将使用一个单独的项目嵌入层来表示低维空间中项目(即电影)的特征。
您可能想知道,我们如何学习嵌入层的权重,以便它提供用户和项目的准确表示?在我们之前的例子中,我们使用 Bob 和 Joe 对动作和爱情电影的偏好来手动创建我们的嵌入。有没有办法自动学习这样的嵌入?
答案是协同过滤——通过使用评分数据集,我们可以识别相似的用户和电影,从现有评分中创建用户和项目嵌入。
模型架构
现在我们对嵌入有了更好的理解,我们准备定义模型架构。正如您将看到的,用户和项目嵌入是模型的关键。
让我们使用以下培训示例来浏览模型架构:


对于 userId = 3 和 movieId = 1,模型的输入是一次性编码的用户和项目向量。因为这是一个正样本(用户实际评分的电影),真实标签(互动)为 1。
用户输入向量和项目输入向量分别被馈送到用户嵌入和项目嵌入,这导致更小、更密集的用户和项目向量。
嵌入的用户和项目向量在通过一系列完全连接的层之前被连接,这将连接的嵌入映射到预测向量作为输出。在输出层,我们应用 Sigmoid 函数来获得最可能的类。在上面的例子中,最可能的类是 1(正类),因为 0.8 > 0.2。
现在,让我们用 PyTorch Lightning 来定义这个 NCF 模型!
让我们使用 GPU 为我们的 NCF 模型训练 5 个时期。
注: PyTorch Lightning 相对于 vanilla PyTorch 的一个优势是,你不需要编写自己的锅炉板训练代码。注意训练师类如何让我们只用几行代码就能训练我们的模型。
评估我们的推荐系统
既然我们已经训练出了模型,我们就可以使用测试数据来评估它了。在传统的机器学习项目中,我们使用准确性(对于分类问题)和 RMSE(对于回归问题)等指标来评估我们的模型。然而,这样的度量对于评估推荐系统来说过于简单。
为了设计一个好的评估推荐系统的指标,我们需要首先了解现代推荐系统是如何使用的。
在网飞,我们可以看到如下建议列表:

类似地,亚马逊使用一个推荐列表:

这里的关键是,我们不需要用户与推荐列表中的每一个单项进行交互。相反,我们只需要用户与列表上的至少一个项目进行交互——只要用户这样做,推荐就有效。****
为了模拟这种情况,让我们运行下面的评估协议,为每个用户生成一个前 10 个推荐项目的列表。
- 对于每个用户,随机选择 99 个用户没有交互过的物品。
- 将这 99 个项目与测试项目(用户最后交互的实际项目)结合起来。我们现在有 100 个项目。
- 对这 100 个项目运行模型,并根据它们的预测概率对它们进行排序。
- 从 100 个项目列表中选择前 10 个项目。如果测试项目出现在前 10 个项目中,那么我们说这是成功的。
- 对所有用户重复该过程。命中率就是平均命中率。
这个评估协议被称为命中率@ 10 ,它通常用于评估推荐系统。
命中率@ 10
现在,让我们使用描述的协议来评估我们的模型。

我们有一个相当不错的命中率@ 10 分!从上下文来看,这意味着 86%的用户被推荐了他们最终与之互动的实际项目(在 10 个项目的列表中)。还不错!
下一步是什么?
我希望这对于创建基于深度学习的推荐系统是一个有用的介绍。要了解更多信息,我推荐以下资源。
来自 Neptune . ai——推荐系统:机器学习指标和商业指标。neptune.ai 的作者写了一份非常全面的推荐系统指南。如果你有兴趣,我鼓励你去看看。
其他资源
面向工业应用的基于深度学习的逆向图像搜索
理解大数据
从非结构化数据到基于内容的图像检索
有没有想过谷歌反向图片搜索是如何工作的,它接收一张图片,并在几分之一秒内返回给你最相似的图片?
对于人类来说,评估图像的内容相当简单,确定图像中是否包含汽车、猫或房子并不需要太多努力。然而,想象你有一个包含 100,000 张(或更多)图片的数据库,没有任何元数据或结构。在缺乏任何关于图像内容的相关元数据的情况下,您如何能够提取任何有用的信息而不必手动滚动所有图像呢?幸运的是,来自经典计算机视觉和深度学习的最新发展的技术来拯救我们。
基于内容的图像检索中的一个重要应用是所谓的“反向图像搜索”。这是计算机视觉技术在图像检索问题上的应用,即在大型数据库中搜索图像的问题。“基于内容”意味着搜索分析图像的内容,而不是元数据,例如与图像相关的关键字、标签或描述。
拥有一个没有可用元数据的大型图像数据库不是一个理想的起点,但不幸的是,这实际上是一个非常常见的场景。幸运的是,我们可以利用许多与前面提到的 Google 的“反向图像搜索”相同的技术来构建我们自己的自定义图像匹配应用程序。
深度学习和图像分类
你以前可能见过的例子可以是典型的“猫与狗”分类模型,在大量的博客和在线教程中讨论过。然而,这些例子中的大多数都是基于对大量带标签的图像的访问,在这些图像中,您拥有可用于训练您的模型的“基本事实”信息。在我们的情况下,这不是我们真正想要的,因为我们没有任何这样的信息。幸运的是,我们仍然可以利用在其他数据集上训练的公开可用的深度学习模型。
访问已经在大量数据上训练过的模型(例如,流行的 ImagNet 数据集,包含数百万张带注释的图像),是构建最先进的深度学习应用程序变得更加容易的原因之一。使用这种预先训练的模型作为基础,人们通常可以成功地利用迁移学习技术来使模型适应我们的特定需求,即使只有非常有限的数据量(或者根本没有数据)。
在我们的例子中,当谈到理解非结构化图像的数据库时,我们实际上可以获得许多有价值的见解,而根本不需要任何标记的训练图像。这是因为这些深度学习模型实际上是如何基于自动提取图像的相关“特征”来分析图像内容的。
在一大组标记图像上训练的深度学习模型基本上已经成为自动“特征提取器”。这意味着当分析我们的图像时,我们基本上得到一个包含图像内容相关信息的“特征向量”作为输出。即使我们没有训练我们的模型来将这个输出分类到一组不同的类别/类中,我们仍然可以提取许多有价值的信息。
神经网络作为特征提取器
- 神经网络图像分类器通过将图像(高维像素空间中的点)转换为低维“特征向量”来工作,低维“特征向量”表示网络学习的特有“特征”(如下图所示)
- 然后,我们可以采用一个经过训练的神经网络,删除其最初用于分类对象的最后一个高级层,并使用解剖模型将我们的图像转换为特征向量。

从图像到特征提取。卷积图层中的过滤器在网络的不同级别查找的要素示例。网络越深入(层次越高),特征就越复杂。资料来源:泽勒,马修 d。和罗布弗格斯。"可视化和理解卷积网络."计算机视觉-ECCV 2014。斯普林格国际出版公司,2014 年。818–833
图像的这种特征向量表示仍然包含一些“噪声”和冗余信息。为了过滤掉最重要的信息(同时加快图像检索和分析过程),我们基于主成分分析进一步压缩数据。为此,我们在这里将特征向量从 2048 维压缩到 256 维。(请注意,维度取决于您选择神经网络作为特征提取器)。

从输入图像到压缩特征向量
相似性度量:余弦相似性
将图像转换成特征向量后,我们需要某种相似性度量来比较它们。一个这样的候选,并且在这个例子中使用的,是“余弦相似度”。本质上,这度量了高维特征空间中图像之间的“角度”。这在下面针对二维特征空间的非常简化的版本中示出,比较输入图像和图像“A”/“B”之间的余弦相似性。我们在这里看到“A”包含与输入图像相似的对象(因此它们之间的“角度”更小),而“B”包含不同外观的对象(相应地具有更大的角度)。

余弦相似性作为比较特征向量的度量
图像聚类
通过我们的“特征提取模型”处理数据库中的图像,我们可以将所有图像转换为特征向量表示。这意味着我们现在有了图像内容的定量描述。有了这些信息,我们可以例如将这些向量通过聚类算法,该算法将基于图像的内容将图像分配到各个聚类。在这样做的时候,我们仍然不知道各个图像包含什么,但是我们知道各个群中的图像通常包含相似的对象/内容。

从特征向量到聚类。图片来源:使用 t-SNE 可视化数据,Laurens van der Maaten 和 Geoffrey Hinton 的研究论文
这种技术的一个应用可以是,例如,作为为监督图像分类模型定义训练集的初步步骤。通过对所有图像进行聚类,并检查每个聚类中的一些图像,我们可以为该聚类中的所有图像分配一个标签。在这样做的时候,我们已经有效地标记了我们所有的图像,仅仅通过查看来自每个集群的几个例子。与手动滚动和注释 100,000 幅图像相比,这显然是一个进步。也就是说,自动给每个聚类中的所有图像分配相同的标签可能会导致一些错误的标签。尽管如此,它仍然是更详细分析的良好起点。
面向工业应用的反向图像搜索
另一个关键应用是“反向图像搜索”,这是本文的主题。假设我们想要分析一个“目标图像”,然后在我们的数据库中搜索相似的内容。例如,这可以是来自制造/生产工厂中的先前维护工作或检查的图像数据库。然后,我们可能会对寻找类似物体的图像感兴趣,或者可能会对特定设备的所有历史检查图像感兴趣。
然后,我们可以做的是,首先通过我们的“特征提取器模型”处理我们的目标图像,将其转换为特征向量表示。完成这些后,我们可以在特征向量数据库中进行相似性搜索。
匹配图像:循序渐进
- 准备图像数据库:使用我们的神经网络模型将图像数据库转换为特征向量表示,然后进行主成分变换。
- 分析新的目标图像:使用与上述相同的流水线将图像转换成低维特征向量。
- 查找匹配图像:使用余弦相似度计算特征向量之间的相似度。使用相似性度量来匹配数据库中与目标图像最相似的图像。

从输入图像到最佳匹配识别
总结:
理想情况下,图像数据库当然应该已经构建了必要的元数据,以便首先执行这样的搜索。然而,实际上有许多现实世界的例子并非如此。幸运的是,正如上面的例子所说明的,所有的希望都没有破灭。即使从杂乱和非结构化的数据中,人们仍然可以提取有价值的见解。
本文并不打算从技术上深入研究在实践中实现这种解决方案的复杂性,但是我希望它至少能让您对这些技术能够提供的功能和可能性有一个基本的了解。
我认为,重要的是要强调,深度学习不仅适用于可以访问大量高质量标签数据的公司。如上例所示,即使根本没有标记数据,您仍然可以利用底层技术从数据中提取有价值的见解。
如果你有兴趣了解更多与人工智能/机器学习和数据科学相关的主题,你也可以看看我写的其他一些文章。你会发现它们都列在我的中型作者简介中,你可以在这里找到。
而且,如果你想成为一个媒体会员,免费访问平台上的所有资料,你也可以使用下面我的推荐链接。(注意:如果您使用此链接注册,我也会收到一部分会员费)
[## 通过我的推荐链接加入媒体- Vegard Flovik
作为一个媒体会员,你的会员费的一部分会给你阅读的作家,你可以完全接触到每一个故事…
medium.com](https://medium.com/@vflovik/membership)
更多来自 Vegard Flovik 媒体:
- 蒙特卡洛方法简介
- 图论入门
- 用于图像分类的深度迁移学习
- 建造一个能读懂你思想的人工智能
- 人工智能和大数据的隐藏风险
- 如何使用机器学习进行异常检测和状态监控
- 如何(不)使用机器学习进行时间序列预测:避免陷阱
- 如何利用机器学习进行生产优化:利用数据提高绩效
- 如何给 AI 系统教物理?
- 我们能否利用纳米级磁铁构建人工大脑网络?
- 供应链管理中的人工智能:利用数据推动运营绩效
我还在下面的研讨会演示中讨论了与 AI/机器学习相关的各种主题:“从炒作到现实世界的应用”。我希望这些资源对您有所帮助!当然,欢迎在下面的评论中提出任何反馈和意见。
基于深度学习的 OpenCV 超分辨率
如何使用最新的算法,通过 OpenCV 库中一个简单易用的函数来提高图像的分辨率。

目录
- 超分辨率
- 在 OpenCV 中放大图像的步骤
- 不同的预训练模型
- 结果样本
- 注释和参考资料
OpenCV 中的超分辨率
OpenCV 是一个开源的计算机视觉库,有大量优秀的算法。自从最近的一次合并以来,OpenCV 包含了一个基于深度学习方法的易于使用的界面来实现超级分辨率(SR)。该界面包含经过预先训练的模型,可以非常容易和有效地用于推理。在这篇文章中,我将解释它能做什么,并逐步展示如何使用它。到目前为止,它与 C++和 Python 一起工作。
注意:使用此代码不需要任何关于 SR 的知识。我在一台 Ubuntu 16.04 机器上运行这个,但是它适用于任何其他发行版(它也适用于视窗)。
步骤
- 1.使用 contrib 模块(包含 dnn_superres)安装 OpenCV。
- 2.下载经过预先培训的模型。
- 3.放大图像。
- 与 contrib 模块一起安装 OpenCV。
我们的第一步是安装 OpenCV。**有些功能会在以后发布,所以要小心版本:4.2.0 为 C++,4.3.0 添加 Python wrap,4.4.0 添加 GPU 推理。**您可以按照 opencv 文档中的说明进行操作。非常重要的是你也要安装 contrib 模块,因为这是 SR 接口代码所在的地方。您可以选择安装所有 contrib 模块或只安装必要的 SR 模块。我们将使用的接口或模块称为 dnn_superres (dnn 代表深度神经网络;超级分辨率的超级图像)。
2.下载预先训练好的模型。
我们需要单独下载预训练的模型,因为 OpenCV 代码库不包含它们。原因是有些模型很大。因此,如果它们在标准代码库中,可能不需要它们的人仍然必须下载它们。有几个模型可供选择(参见本文中的模型一节)。都是流行 SR 论文的实现。就目前来说,还是选个小型号吧。你可以在这里下载。这个预先训练的模型可以将图像的分辨率提高 2 倍。更多模型及其解释,请参见本文中的模型部分。
3.放大图像。
现在我们准备升级我们自己的图像甚至视频。我将提供 C++和 Python 的示例代码。(如果要用 GPU 进行推理,也请参考本页底部的注释。)我们先来看 C++ :
我将解释代码的重要部分。
//Read the desired model
string path = "FSRCNN_x2.pb";
sr.readModel(path);
这将加载所选模型的所有变量,并为神经网络的推断做准备。参数是下载的预训练模型的路径。当您想要使用不同的模型时,只需下载它(参见本文的模型部分)并更新路径。
//Set the desired model and scale to get correct pre- and post-processing
sr.setModel("fsrcnn", 2);
这让模块知道您选择了哪个模型,因此它可以选择正确的预处理和后处理。您必须指定正确的模型,因为每个模型使用不同的处理。
第一个参数是模型的名称。可以在“edsr”、“fsrcnn”、“lapsrn”、“espcn”中选择。非常重要的一点是该型号是您在“sr.readModel()”中指定的型号的正确型号。请参见页面底部的型号部分,了解各型号的规格。
第二个参数是放大系数,即你将增加多少倍的分辨率。同样,这需要与您选择的型号相匹配。每个模型都有一个单独的放大系数文件。
//Upscale
Mat img_new;
sr.upsample(img, img_new);
cv::imwrite( "upscaled.png", img_new);
这是推理部分,它通过神经网络运行你的图像,并产生你的放大图像。
现在只需编译和运行您的文件来升级您的图像!
下面是用 Python 编写的代码:
它和 C++中的几乎完全一样,除了两件事。
- 您必须使用不同的构造函数:
# Create an SR object
sr = dnn_superres.DnnSuperResImpl_create()
2.放大时,您可以直接分配放大的图像,而不是创建占位符图像:
# Upscale the image
result = sr.upsample(image)
型号
该模块目前支持 4 种不同的 SR 型号。它们都可以按 2、3 和 4 的比例放大图像。LapSRN 甚至可以扩大到 8 倍。它们在准确性、大小和速度上有所不同。
- EDSR【1】**。**这是性能最好的型号。然而,它也是最大的模型,因此具有最大的文件大小和最慢的推理。你可以在这里下载。
- ESPCN【2】**。**这是一个小模型,推理又快又好。它可以进行实时视频放大(取决于图像大小)。你可以在这里下载。
- fsr CNN【3】**。**这也是推理快速准确的小模型。也可以做实时视频向上扩展。你可以在这里下载。
- LapSRN【4】**。**这是一个中等大小的模型,可以放大 8 倍。你可以在这里下载。
有关这些模型的更多信息和实现,请参见模块的 GitHub 自述文件。关于广泛的基准测试和比较,请点击。
样品
我们来看一些结果!(如果你在手机上,放大看区别更清楚。)

投入

通过双线性插值放大(系数为 3)。

由 FSRCNN 放大(系数为 3)。

由 ESDR 升级(系数为 3)。

输入。Randy Fath 在 Unsplash 上拍摄的照片

通过双线性插值放大(系数为 3)。

由 FSRCNN 放大(系数为 3)。

由 ESDR 升级(系数为 3)。

原图。
如您所见,这些模型产生了非常令人满意的结果,完全破坏了简单双线性插值的性能。特别是 EDSR 给出了惊人的结果,尽管它有点慢(几秒钟的推断)。自己试试吧!
实施注意事项:
- 如果它在使用。jpg 图片,试试。png 格式。
- 确保 setModel()参数与 readModel()中使用的模型相匹配。
- 尝试不同的模型,在速度和性能方面得到不同的结果。
- 如果你想使用你的 GPU 进行推理(标准是 CPU),你可以在读取模型后将后端和目标设置为 CUDA。根据你的 GPU,它会给你一个速度上的提升。这是新特性,所以需要 4.4.0 版本。参见相关的拉取请求。你还需要构建支持 CUDA 的 opencv,比如像这样:链接到 opencv 构建命令。
在 C++中设置后端/目标
在 Python 中设置后端/目标
参考
[1] Bee Lim,Sanghyun Son,Heewon Kim,Seungjun Nah,和 Kyoung Mu Lee,“用于单个图像超分辨率的增强深度残差网络”,第二届 NTIRE:图像恢复和增强研讨会的新趋势以及与 2017 年 CVPR 相关的图像超分辨率挑战。
[2] Shi,w .,Caballero,j .,Huszár,f .,Totz,j .,Aitken,a .,Bishop,r .,Rueckert,d .和 Wang,z .,“使用高效亚像素卷积神经网络的实时单幅图像和视频超分辨率”,IEEE 计算机视觉和模式识别会议论文集2016。
[3]赵东,陈变来,唐晓鸥。“加速超分辨率卷积神经网络”,2016 年 ECCV欧洲计算机视觉会议论文集。
[4]赖伟生,黄,J. B .,Ahuja,n .和杨,M. H .,*“用于快速和精确超分辨率的深度拉普拉斯金字塔网络”,*IEEE 计算机视觉和模式识别会议论文集,2017。
深度学习基础
深度强化学习讲解— 03
初学者的基本概念

这是“深度强化学习讲解”系列文章的第三篇。如果你以前有深度学习的知识,你可以跳过这篇文章,去读下一篇。
或者,如果您对深入学习的基础知识感兴趣,并希望在下一篇文章中继续使用 PyTorch,您可以阅读这篇文章。
在这篇文章中,我将回顾神经网络的主要概念,让读者理解深度学习的基础知识,以便用它在强化学习问题中编写代理程序。为了便于解释,我将把这篇文章放在一个有助于介绍理论概念的例子中。
访问第 3 页的自由介绍
medium.com](https://medium.com/aprendizaje-por-refuerzo/3-funciones-de-valor-y-la-ecuaci%C3%B3n-de-bellman-7b0ebfac2be1)
手写数字的分类
作为案例研究,我们将创建一个数学模型,允许我们识别手写数字,如下所示:

目标将是创建一个神经网络,给定一幅图像,该模型识别它所代表的数字。例如,如果我们向模型输入第一张图片,我们会期望它回答这是一张 5。下一个是 0,下一个是 4,以此类推。
不确定性分类问题
实际上,我们正在处理一个分类问题,给定一幅图像,模型将其分类在 0 到 9 之间。但有时,甚至我们会发现自己有某些疑问,例如,第一个图像代表 5 还是 3?

为此,我们将创建的神经网络返回一个具有 10 个位置的向量,指示 10 个可能数字中每一个的可能性:

数据格式和操作
在下一篇文章中,我们将解释如何使用 PyTorch 编写这个例子。目前,只需提到我们将使用 MNIST 数据集来训练模型,该数据集包含 60,000 张手工制作的数字图像。这个黑白图像(包含灰度级的图像)的数据集已经归一化为 28×28 像素。
为了便于将数据摄取到我们的基本神经网络中,我们将把输入(图像)从二维(2D)转换成一维(1D)的向量。也就是说,28×28 个数字的矩阵可以由 784 个数字(逐行连接)的向量(数组)表示,这种格式接受密集连接的神经网络作为输入,就像我们将在本文中看到的那样。
如前所述,我们需要用 10 个位置的向量来表示每个标签,其中对应于表示图像的数字的位置包含 1,其余的包含 0。这个将标签转换成与不同标签的数量一样多的零的向量,并将 1 放入对应于标签的索引中的过程被称为独热编码。例如,数字 7 将被编码为:

神经网络组件
现在我们准备开始解释基本神经网络概念的最小集合。
普通的人工神经元
为了展示基本神经元是怎样的,让我们假设一个简单的例子,其中我们在二维平面中有一组点,并且每个点已经被标记为“正方形”或“圆形”:

给定一个新的点“ × 【T3”),我们想知道它对应什么标号:

一种常见的方法是画一条线将两个组分开,并使用这条线作为分类器:

在这种情况下,输入数据将由( x1,x2 )形式的向量表示,这些向量表示它们在这个二维空间中的坐标,我们的函数将返回‘0’或‘1’(在线的上方或下方),以知道它应该被分类为“正方形”还是“圆形”。它可以定义为

更一般地说,我们可以将这条线表示为:

为了对输入元素 X(在我们的例子中是二维的)进行分类,我们必须学习一个与输入向量维数相同的权重向量 W,即向量( w1,w2 )和一个 b 偏差。
有了这些计算值,我们现在可以构建一个人工神经元来对新元素 X 进行分类。基本上,神经元在输入元素 X 的每个维度的值上应用计算权重的向量 W ,并在最后添加偏差 b. 其结果将通过非线性“激活”函数来产生结果“0”或“1”。我们刚刚定义的这种人工神经元的功能可以用更正式的方式来表达,例如

现在,我们将需要一个函数,它对变量 z 进行转换,使其变成‘0’或‘1’。虽然有几个函数(“激活函数”),但在本例中,我们将使用一个称为 sigmoid 函数的函数,该函数针对任何输入值返回 0 到 1 之间的实际输出值:

如果我们分析前面的公式,我们可以看到它总是倾向于给出接近 0 或 1 的值。如果输入 z 相当大且为正,则负 z处的“e”为零,因此, y 取值为 1。如果 z 具有大的负值,那么对于“e”的大正数,公式的分母将是一个大的数字,因此 y 的值将接近 0。从图形上看,sigmoid 函数呈现如下形式:

到目前为止,我们已经介绍了如何定义人工神经元,这是神经网络可以拥有的最简单的架构。特别是,这种架构在本主题的文献中被命名为感知器,由 Frank Rosenblatt 于 1957 年发明,并通过以下方案以一般方式进行了直观总结:

前一个神经元(我们将使用)的简化(两个)视觉表示可以是:

多层感知器
在该领域的文献中,当我们发现神经网络具有一个输入层,一个或多个由感知器组成的层,称为隐藏层,以及一个具有几个感知器的最终层,称为输出层时,我们称之为多层感知器 (MLP)。一般来说,当基于神经网络的模型由多个隐层组成时,我们称之为深度学习。在视觉上,它可以用以下方案来表示:

MLP 通常用于分类,特别是当类别是排他性的时,如在数字图像分类的情况下(从 0 到 9 的类别)。在这种情况下,输出层返回属于每个类的概率,这要归功于一个名为 softmax 的函数。视觉上,我们可以用以下方式表示它:

正如我们提到的,除了 sigmoid 之外,还有几个激活函数,每个都有不同的属性。其中之一就是我们刚刚提到的那个 softmax 激活函数,它将有助于呈现一个简单神经网络的示例,以在两个以上的类中进行分类。目前,我们可以将 softmax 函数视为 sigmoid 函数的推广,它允许我们对两个以上的类进行分类。
Softmax 激活功能
我们将以这样的方式来解决这个问题:给定一个输入图像,我们将获得它是 10 个可能数字中的每一个的概率。这样,我们将有一个模型,例如,可以预测图像中的 5,但只有 70%的把握是 5。由于这幅图中数字上半部分的笔画,看起来它有 20%的几率变成 3,甚至有一定的概率变成其他数字。虽然在这种特殊情况下,我们会认为我们的模型的预测是 5,因为它是概率最高的一个,但这种使用概率分布的方法可以让我们更好地了解我们对预测的信心程度。这在这种情况下很好,因为数字是手工制作的,当然在很多情况下,我们不能 100%确定地识别数字。
因此,对于这个分类示例,我们将为每个输入示例获得一个输出向量,该输出向量具有在一组互斥标签上的概率分布。也就是说,10 个概率的向量(每个概率对应于一个数字)以及所有这 10 个概率的总和导致值 1(概率将在 0 和 1 之间表示)。
正如我们已经提出的,这是通过在我们的神经网络中使用具有 softmax 激活函数的输出层来实现的,其中该 softmax 层中的每个神经元取决于该层中所有其他神经元的输出,因为所有这些神经元的输出之和必须是 1。
但是 softmax 激活功能是如何工作的呢? softmax 函数基于计算某个图像属于特定类别的“证据”,然后这些证据被转换为它属于每个可能类别的概率。
一种测量某一图像属于特定类别的证据的方法是对属于该类别的每个像素的证据进行加权求和。为了解释这个想法,我将使用一个可视化的例子。
假设我们已经学习了数字 0 的模型。目前,我们可以把模型看作是“某种东西”,它包含了知道一个数是否属于某一类的信息。在这种情况下,对于数字 0,假设我们有一个如下所示的模型:

在这种情况下,具有 28×28 像素的矩阵,其中红色像素表示负权重(即,减少其所属的证据),而蓝色像素表示正权重(其证据是更大的增加)。白色代表中性值。
假设我们在上面画了一个零。一般来说,零点的轨迹会落在蓝色区域(请记住,我们讨论的是归一化为 20×20 像素的图像,后来以 28×28 的图像为中心)。很明显,如果我们的笔画越过红色区域,很可能我们写的不是零;因此,使用基于如果我们通过蓝色区域则相加,如果我们通过红色区域则相减的度量标准似乎是合理的。
为了确认它是一个好的度量,现在让我们想象我们画了一个三;很明显,我们用于零的前一个模型中心的红色区域会影响前面提到的指标,因为,正如我们在下图的左部看到的,当我们写 3 时,我们忽略了:

但另一方面,如果参考模型是对应于数字 3 的模型,如上图右侧所示,我们可以看到,一般来说,代表数字 3 的不同可能走线大多位于蓝色区域。
我希望读者看到这个直观的例子后,已经直觉地知道上面提到的权重的近似值是如何让我们估计出它是多少的。
一旦属于 10 个类别中的每一个的证据被计算出来,这些必须被转换成概率,其所有成分的总和加 1。为此,softmax 使用计算证据的指数值,然后将它们归一化,使总和等于 1,形成概率分布。属于类别 i 的概率为:

直观地说,使用指数得到的效果是,多一个单位的证据具有乘数效应,少一个单位的证据具有反效应。关于这个函数有趣的事情是,一个好的预测在向量中有一个接近 1 的值,而其余的值接近 0。在弱预测中,将有几个可能的标签,它们将具有或多或少相同的概率。
手写数字的神经网络模型
对于这个例子,我们将把一个非常简单的神经网络定义为两层序列。视觉上,我们可以用以下方式表示它:

在可视化表示中,我们明确表示我们有模型的 784 个输入特征(28×28)。具有 sigmoid 激活功能的第一层 10 个神经元“提取”输入数据,以获得所需的 10 个输出,作为下一层的输入。第二层将是由 10 个神经元组成的 softmax 层,这意味着它将返回代表 10 个可能数字的 10 个概率值的矩阵(如我们之前所述,其中每个值将是当前数字的图像属于其中每个数字的概率)。
学习过程
训练我们的神经网络,即学习我们的参数值(权重 W 和 b 偏差)是深度学习最真实的部分,我们可以将神经网络中的这一学习过程视为神经元层“往返”的迭代过程。“去”是信息的前向传播,“回”是信息的后向传播。
训练循环
第一阶段前向传播发生在网络暴露于训练数据时,这些数据穿过整个神经网络以计算它们的预测(标签)。也就是说,通过网络传递输入数据,使得所有神经元将它们的变换应用于它们从前一层神经元接收的信息,并将它发送到下一层神经元。当数据已经穿过所有层,并且其所有神经元已经进行了它们的计算时,将到达最后一层,具有那些输入示例的标签预测的结果。
接下来,我们将使用一个损失函数来估计损失(或误差),并比较和衡量我们的预测结果相对于正确结果的好坏程度(请记住,我们是在一个受监督的学习环境中,我们有一个标签来告诉我们期望值)。理想情况下,我们希望成本为零,也就是说,估计值和期望值之间没有偏差。因此,随着模型被训练,神经元互连的权重将被逐渐调整,直到获得良好的预测。
一旦计算出损失,该信息就被反向传播。因此,它的名字:反向传播。从输出层开始,损失信息传播到隐藏层中直接对输出做出贡献的所有神经元。然而,基于每个神经元对原始输出的相对贡献,隐藏层的神经元仅接收总损失信号的一部分。这个过程一层一层地重复,直到网络中的所有神经元都接收到描述它们对总损失的相对贡献的损失信号。现在我们已经将这些信息传播回来,我们可以调整神经元之间连接的权重。
视觉上,我们可以用这个阶段的视觉方案(基于我们的神经网络的先前视觉表示)来总结我们已经解释的内容:

我们正在做的是,在下次使用网络进行预测时,让损失尽可能接近于零。
一般而言,我们可以将学习过程视为一个全局优化问题,其中参数(权重和偏差)必须以最小化上述损失函数的方式进行调整。在大多数情况下,这些参数无法解析求解,但一般来说,它们可以通过优化器(迭代优化算法)很好地逼近,例如一种称为梯度下降的技术。这种技术在损失函数的导数(或梯度)的计算的帮助下以小增量改变权重,这允许我们看到朝着全局最小值“下降”的方向;这通常是在我们在每次迭代中传递给网络的所有数据集的连续迭代(历元)中的成批数据中完成的。
读者可以访问深度神经网络的学习过程一文,了解关于这个训练循环的更多细节,尽管就本节的目的而言,我不认为这是必要的。
交叉熵损失函数
我们可以为我们的神经网络模型选择范围广泛的损失函数。例如,确保读者知道通常用于回归的均方误差 (MSE)损失函数。对于本文中提出的分类,通常使用的损失函数是交叉熵,它允许测量两个概率分布之间的差异。
交叉熵损失,或对数损失,衡量分类模型的性能,其输出是 0 到 1 之间的概率值。根据上下文的不同,两者略有不同,但在深度学习中,当计算 0 和 1 之间的错误率时,它们会解决相同的问题。
交叉熵损失随着预测概率偏离实际标签而增加。完美的模型的对数损失为 0。在二进制分类中,类的数量是 2,交叉熵可以计算为:

在我们的多类分类示例中,我们为每个观察值的每个类标签计算单独的损失,并对结果求和:

在哪里
- C —类的数量(在我们的例子中是 10)
- 日志 —自然日志
- y*—二进制指示器(0 或 1)如果分类标签 𝑐 是观察的正确分类 𝑜*
- p —预测概率观测值 o 属于类 c
在这篇文章中,我回顾了神经网络的主要概念,以使读者理解深度学习的基础知识,以便在强化学习问题中使用它来编程代理。在下一篇文章中,我们将使用 PyTorch 编写这篇文章中的例子,我们将向读者介绍 PyTorch 的基本特性,这是我们将在这一系列文章中使用的框架。
下一篇在见!
深度强化学习讲解系列
由 UPC 巴塞罗那理工 和 巴塞罗那超级计算中心
一个轻松的介绍性系列以一种实用的方式逐渐向读者介绍这项令人兴奋的技术,它是人工智能领域最新突破性进展的真正推动者。
本系列的内容](https://torres.ai/deep-reinforcement-learning-explained-series/)
关于这个系列
我在五月份开始写这个系列,那是在巴塞罗那的封锁期。老实说,由于封锁,在业余时间写这些帖子帮助了我 #StayAtHome 。感谢您当年阅读这份刊物;它证明了我所做的努力。
免责声明 —这些帖子是在巴塞罗纳封锁期间写的,作为个人消遣和传播科学知识,以防它可能对某人有所帮助,但不是为了成为 DRL 地区的学术参考文献。如果读者需要更严谨的文档,本系列的最后一篇文章提供了大量的学术资源和书籍供读者参考。作者意识到这一系列的帖子可能包含一些错误,如果目的是一个学术文件,则需要对英文文本进行修订以改进它。但是,尽管作者想提高内容的数量和质量,他的职业承诺并没有留给他这样做的自由时间。然而,作者同意提炼所有那些读者可以尽快报告的错误。*
深度学习超越 2019
进步于 【缓慢】有意识任务解决 ?

这个图是由yo shua beng io(neur IPS 2019 talk)、Yann le Cun和Leon Bottou最近的谈话综合而成。缩略词***【IID】***在图中展开为独立同分布的随机变量;OOD展开为不分配
TL;速度三角形定位法(dead reckoning)
- 自我监督学习——通过预测输入进行学习
- 在分布式表示中利用组合的力量
- **降 IID (独立同分布随机变量)假设
- 自我监督表示学习方法
- 注意力的作用
- 多时间尺度的终身学习
- 架构先验
W 虽然深度学习 (DL) 模型在 2019 年继续创造新纪录,在各种各样的任务中表现出最先进的性能,特别是在自然语言处理方面,2019 年标志着不仅要审查问题 深度学习 1.0 之外是什么? 出现在公众话语中,对这个问题的研究也加快了步伐。
深度学习 1.0 —局限性的快速回顾
深度学习 1.0 ( 本吉奥教授称之为系统 1 深度学习 ) 在解决人类可以直观解决的任务方面取得了成功,通常是以快速无意识、非语言的方式。例子是直觉,一个特定的游戏走法是好的,或者一张图片包含一只狗——我们在不到一秒钟的时间内快速解决这些任务。我们习惯性解决的任务也属于这一类。
尽管 DL 1.0 模型的性能在某些任务基准中超越了人类,但即使在它们目前可以很好执行的任务中,也存在一些已知的缺陷
- DL 1.0 车型比美国需要更多的训练数据/时间。例如,一个模型必须经历 200 年的等效实时训练才能掌握一款名为星际争霸 2的策略游戏。我们平均 20 小时就能学会开车而不出事故。迄今为止,我们还没有能够完全自动驾驶的汽车,尽管在数小时的训练数据中暴露出比我们多几个订单。此外,对于许多任务,模型需要来自人类的标记数据来学习概念

图来自 Yann Lecun 最近的演讲(2019 年 11 月)“基于能量的自我监督学习”。加强了一些游戏的学习训练时间,在这些游戏中,模型的表现达到或超过了专业人类玩家。
- DL 1.0 车型会犯我们通常不会犯的错误。例如,改变图像中的几个像素*(我们的眼睛甚至不会注意到)*会导致模型将其错误分类。站在电话附近的人可能会使模型认为人正在打电话。这些错误似乎源于多种原因— (1)模型在某些情况下产生虚假关联(2)输入数据中的偏差导致模型输出被污染(3)模型对分布变化缺乏鲁棒性,或者在某些情况下无法处理属于训练分布一部分的罕见实例。

DL 1.0 模型所犯的不同类型的错误。 (a) 在左上角的图中,注入了我们甚至没有察觉到的噪声,导致了模型的误分类。图片来自 2015 年关于对抗性 e 例子的论文。 (b) 右图中的错误是因为该模型在很大程度上暴露给了在电话亭附近打电话的人——所以这是由于训练数据集中的选择偏差。图片来自 Leon Bottou 在 2019 年 10 月发表的关于使用因果不变性学习表示法 © 经常观察到的错误是模型无法将训练分布数据以外的数据推广到分布之外的数据,或者只是属于训练分布一部分的罕见事件。黑天鹅效应(下图)的一个具体例子是一辆无人驾驶汽车暴露在一个罕见的事件中(从训练数据分布的角度来看,这不太可能发生)。图片来自 Yoshua Bengio 的 NeurIPS 2019 演讲
我们如何更接近人类级别的 AI?
迄今为止,答案尚不明确。具体来说,我们如何解决 DL 1.0 现有的局限性,同时解决更困难的有意识的任务解决问题?一种看起来很有希望的方法是从人类那里获得灵感,这些人除了在无意识任务解决中没有 DL 1.0 *(样本效率低下,无法归纳出不符合分布的数据)*的限制之外,还擅长有意识任务解决 ( )系统 2 任务 ) 如逻辑推理、规划等。
下面列出了一些研究方向*(合理的方法、假设和先验——其中一些已经在早期的小规模实施中实现)*,它们可能会让我们进入深度学习 2.0 (有意识的任务解决)。
- 自我监督学习——通过预测输入进行学习
- 在分布式表示中利用组合的力量
- **降 IID (独立同分布随机变量)假设
- 自我监督表示学习的两种方法
- 注意力的作用
- 多时间尺度的终身学习
- 架构优先
下面详细讨论的这些研究方向表明,考虑到正在考虑的方法的本质,有意识解决任务的途径很可能同时克服上述 DL 1.0 的缺陷。
- 自我监督学习——通过预测输入进行学习
自我监督学习本质上是通过对来自任何其他部分的输入数据的任何部分进行预测来进行学习。预测可以是关于输入数据序列*(在时间或空间上)*中的下一个是什么,或者一般来说是其中丢失了什么。输入数据可以是一种或多种类型——图像、音频、文本等。学习是通过重建输入中丢失的部分来进行的。
我们的大部分学习是自我监督的。几年前 Geoffrey Hinton 的《信封背面的推理》抓住了这一点(他称之为“无监督的”,尽管现在我们也称之为“自我监督的”,以表明我们通过重建输入数据来监督我们自己的学习)

自我监督学习的感觉数据流的价值,除了其绝对数量*(就每秒训练数据而言)*的价值之外,还有
- 与典型的监督学习*(反馈是每个输入的类别值或几个数字)或强化学习(正如模型预测的那样,反馈是偶尔的标量奖励)相比,它向学习者提供了更多的反馈数据*(如果不是全部,至少是部分输入数据)。
- 来自环境的感觉数据流不是静止的。这迫使学习者,或者更具体地,嵌入学习者中的编码器,学习在变化的环境中基本不变的对象和概念的稳定表示。环境固有的不稳定性也提供了了解变化原因的机会。分布外泛化*(预测训练分布中未见的事件)*学习因果对于学习者做出生存所必需的预测是必不可少的。从本质上讲,环境的非静态性质提供了一个通过评估和提炼概念的学习表示以及它们之间的因果关系来持续学习的机会。
- 感觉流包括在学习中起关键作用的主体*(包括学习者)。代理是环境的一个组成部分,并负责通过干预来改变它。在 DL 1.0 中,代理只是强化学习的一部分。为了让 DL 2.0 模型达到它的目标,让代理参与自我监督学习可能是至关重要的。即使是一个被动的学习者(一个新生儿)*,在最初的几个月里,他很大程度上是在以最小的互动观察环境,从观察环境中其他代理的互动中学习。

图自最近 Yann LeCun 的谈话。新生的孩子凭直觉学习物理——例如,在 9 个月左右,通过观察他们周围的世界来学习重力——我们不会教他们重力。我们知道他们凭直觉理解重力,因为一个简单的汽车从桌子上推下来而不倒的实验(因为我们用一根他们看不见的细线吊着它来欺骗他们)不会让大约 9 个月大的孩子感到惊讶。大约 9 个月后,他们感到惊讶——因为他们的观察与他们 9 个月大的内部世界模型的预测输出不匹配,该模型预测它必须倒下。
- 学习捕捉因果关系的概念的稳定表示,使学习者能够根据其计算能力,通过内部模拟似是而非的行动序列来预测未来的几个时间步骤,并计划未来的奖励行动,避免有害的行动*(就像学习驾驶时避免驶下悬崖)*。
DL 1.0 中的自我监督学习
在 DL 1.0 中,自我监督学习已经被证明对于自然语言处理(NLP)任务非常有用和成功。我们有通过预测句子中的下一个单词或预测已经从句子中删除的单词来学习单词表示的模型(伯特——这在 NLP 世界中被称为无监督预训练,但本质上是自我监督学习,其中模型通过重建输入的缺失部分进行学习)。然而,DL 1.0 语言建模方法仅从文本输入中学习,而不是在其他感觉流也与代理交互一起考虑的环境中进行基础学习 (有一篇 2018 年的论文试图做到这一点 )。基于感官环境的语言学习赋予单词更多的上下文和意义,而不仅仅是统计它们的句子上下文(句子中相对于其他单词的位置)。由于这个原因,语言学习被限制为仅从文本进行自我监督学习,不仅承受着需要大量文本的负担,而且还将模型的理解限制为仅仅是单词序列的统计特性,而这些统计特性永远无法与从多感觉环境中进行的学习相匹配*(例如,模型永远不会获得空间理解——空间上适合于盒子,反之亦然, 当把“它”与句子中正确的物体联系起来时,需要理解的是:奖杯放不进盒子里,因为* 它 太大了; 奖杯放不进盒子是因为太小了;“第一指奖杯,第二指盒子)。**
迄今为止,自我监督学习对于图像、视频和音频还没有像对于文本那样成功(在文本中,模型必须预测单词在词汇上的分布;对于视频中的下一帧预测,在所有可能的下一帧上的分布输出是不可行的),尽管在具有 GANs 的图像完成*【修补】* 、视频下一帧预测模型中有一些有希望的结果。然而,从有意识的任务解决角度来看,直接在像素、视频和音频的输入空间中预测可能不是正确的方法(我们不会有意识地在像素级别预测电影中接下来会发生什么——我们的预测是对象/概念的级别)。与原始输入空间(视频、音频等)相反,通过感觉模态的输入预测可能最好在抽象表示空间中完成。),尽管不同的感官输入对于理解世界有着重要的作用——语言理解是上面已经提到的许多原因之一(结尾的附加注释考察了语言的特殊性质及其在 DL 2.0 调试中的潜在作用)*。*
2。在分布式表示中利用组合的力量
组合性提供了从有限的元素集合中创建更大的(指数)元素组合的能力。**
DL 1.0 已经在以下方面利用了组合性的指数力量
- 分布式表示 —分布式表示中的每个特征都可以参与表示所有的概念,考虑到指数组合性。组成制图表达的特征是自动学习的。将分布式表示可视化为实值向量(浮点数/双精度数)使其具体化。向量可以是密集的(大多数槽具有非零值)或稀疏的(在退化的情况下大多数槽为零是一个热码向量)*。*
- DL 模型中的每一层计算都允许额外的组合性——每一层的输出都是前一层输出的组合。这种组合性在 DL 1.0 模型中被利用来学习表示的层次(例如,NLP 模型学习跨不同的不同层捕获不同比例的句法和语义相似性)**
- 语言支持更高层次的组合性,这在 DL 1.0 中还没有得到充分利用。例如,语言提供了从训练分布中永远不可能得出的原创句子的能力——这并不是说它在训练分布中的概率低——它在训练分布中的概率可能是零。这是一种系统概括的形式,它超越了不符合分布(OOD)的概括。最近的语言模型可以生成连贯的新颖段落,这些段落表现出很大程度的原创性,尽管它们缺乏对潜在概念的理解,特别是当这些段落是由例如工程概念组成时。这种缺陷可能部分是由于前面提到的缺乏基础语言理解,并且可能在 DL 2.0 中实现。
- 组合性不需要局限于仅仅创造新的句子,然而(尽管语言在某种程度上仍然可以用来描述任何概念) —它可以是来自先前概念的概念的原始组合,如下图所示。**

从现有数据中组合出新的概念——DL 不能像我们这样成功地做到这一点
**3。丢弃 IID (独立同分布随机变量)假设
大多数 DL 1.0 模型假设任何数据样本,无论它来自训练集还是测试集,都是相互独立的,并且来自同一个分布 (IID 假设训练和测试分布都可以用同一套分布参数来描述)
从代理交互的非静态环境中的自我监督学习,由于其从变化的环境中学习的本质,需要放弃 IID 假设。
然而,即使在使用监督学习的问题中(例如,自动驾驶汽车的图像/对象分类/识别),IID 假设也可能是一种负担,因为总会有模型在训练期间从未见过的真实生活场景,错误分类可能会被证明代价高昂(在自动驾驶汽车的早期版本中已经有一些这样的实例)。虽然为训练积累的大量驾驶时间可以减少错误,但在没有 IID 假设的情况下学习的模型比通过 IID 假设学习的模型更有可能更好地处理罕见和不符合分布的情况。**
放弃 IID 假设的另一个原因是通过“通过混洗数据使训练和测试数据同质”为训练模型创建数据集时的选择偏差。为了实现 IID 目标,从不同来源(包含属性差异)获得的数据都被混洗,然后分成训练集和测试集。这破坏了信息并产生虚假的相关性。例如,考虑将一幅图像分类为一头牛或一头骆驼。奶牛的照片可能都在绿色的牧场上,骆驼在沙漠里。在训练模型之后,它可能无法将沙滩上的奶牛图片分类,因为它进行了虚假的关联——将绿色景观分类为奶牛,将米色景观分类为骆驼。我们可以通过让模型学习跨不同环境的不变特征来避免这种情况。例如,我们可以在不同的绿色牧场上标记奶牛的照片,其中一个是 90%的绿色,另一个是 80%的绿色。然后,该模型可以了解到牧场和奶牛之间有着强烈但不同的相关性,应该被拒绝。但是奶牛自己允许模型识别它们,不管它们在什么环境中。因此,通过利用不同的分布来识别不变属性,而不是将它们混在一起,可以防止虚假的相关性。虽然这只是一个例子,但是,广泛地利用分布变化中的信息,并学习它们之间的不变表示,可能有助于学习健壮的表示。顺便说一句,与直接确定因果关系变量相比,对分布变化不变的变量更容易确定,这可以用作识别因果变量的方法,尽管挑战在于找出那些不变变量是什么。
一个自然产生的问题是,如果我们放弃 IID 假设,我们如何在变化的环境中准确地学习表征?
4。两种自我监督表示学习方法
- 预测输入空间接下来会发生什么。
- 在抽象空间中预测接下来会发生什么。

自我监督学习的两种方法。在左边,表征学习通过预测输入空间的缺失部分来进行。例如,对于来自视频流的自监督学习,通过使用时间 t-1 的图像来预测时间 t 的输入。预测器将时间 t-1 处的帧和潜在变量作为输入,以预测时间 t 处的帧。该模型输出由潜在变量使之成为可能的多个预测-挑选最低能量的预测对(y,y’)(在基于能量的模型中)。右边的预测发生在学习表示 c 和 h 的抽象空间中。训练目标 V 试图以某种方式将当前的 h 与过去的 c 相匹配,使得一些过去的意识状态与当前的 h 相一致。参考资料部分有这种方法的更多细节。
这两种方法并不相互排斥。一个模型有可能使用这两种方法来学习表示。
- 预测输入空间接下来会发生什么。*这通常是通过一个潜在变量来完成的,该变量封装了所有关于环境的未知信息(包括代理和代理交互),并训练一个模型来预测未来,或者等效地重建未来,并使用重建误差作为学习表示的手段。基于能量的模型是学习这种表示的一种方式。它们可以用于学习表示,使得输入(x)和输入(y)的预测/重构部分通过标量值能量函数映射到能量表面,在该能量表面,输入数据点 x 和 y 具有较低的能量。这是通过两大类方法实现的(1)第一类方法降低输入数据点 (x 及其预测 y) 的能量,同时提升所有其他点的能量(例如,在基于 能量的 GAN 中,生成器选择对比数据点——远离输入点的点)和(2) 第二类方法将输入数据点的能量约束为低(通过架构或通过某种正则化)。 如前所述,环境中的未知因素通常由潜在变量(z)捕获,该潜在变量允许通过改变 z 并挑选具有最低能量的一个预测来对 y 进行多个预测。潜在变量的信息容量受到多种方法的限制,如使用正则化子使潜在变量稀疏,添加噪声等(潜在变量的信息容量有*)。这些潜在变量通常在训练期间通过使用编码器来学习,该编码器被馈送输入(x)和被预测的实际数据(y’)。然后,解码器采用潜在变量和 x (它的转换版本,其中转换由某个神经网络完成)来进行预测。能量函数用作成本函数,其标量输出然后用于训练模型以学习正确的表示。仅通过利用接收输入数据和潜在变量的解码器(编码器在实践中可用于如下所述的终身训练循环中)来进行推断。 Yann LeCun 最近的演讲深入介绍了这种方法的更多细节,并展示了这种方法如何让汽车在模拟中学习驾驶(训练数据是真实世界场景中汽车的视频记录,模型通过预测下一帧来学习,下一帧包括它自己与其他汽车在车道中的位置;成本函数考虑汽车和其他汽车之间的距离以及汽车是否停留在其车道上)。这种方法本质上是将 DL 1.0 模型重新用于重建输入的自监督任务,其中反馈信号包含非常丰富的信息(视频、音频等中的下一个图像帧)。)相对于仅仅是标量(强化学习)或者标签(自我监督学习)。
- 预测抽象空间中接下来会发生什么。这种方法基于这样的假设,即环境的变化可以用几个因果变量(捕捉为稀疏表示)来解释,这些变量是从高维表示(类似于 DL 1.0 表示的感知空间)中获得的,这些高维表示是通过来自环境的感觉流输入来学习的。这些稀疏表示用于预测未来,不是在原始输入空间中,而是在与导出它们的感知空间一致的已学习稀疏表示的空间中。这类似于我们预测/计划我们下班回家的路程——我们在一个非常稀疏的(低维)水平上做这件事——而不是在开车旅行的实际感官体验的输入空间中。预测在远离感觉流的原始输入空间的抽象空间中发生的事情具有潜在的优势,不仅学习那些利用环境中的变化的输入流的更好的表示(类似于 DL 1.0 表示),而且学习导致输入感觉流中的那些变化的表示。本质上,我们正在根据分布和 OOD 性能的变化对这些模型进行训练(学习这些表示的训练目标仍未确定,如参考部分所述)用作学习良好的低维因果表示的训练信号。假设环境的变化可以用一个低维表示法(代表一个 稀疏因子图 ),几个变量之间的无向图;在实现中,这可能不是一个显式的图,而只是一个低维表示,在下面的参考章节中进一步检查)对编码器施加约束以学习这样的表示(可能还需要附加的约束)。一些早期工作使用 DL 方法寻找变量*(有向图)之间的因果关系,该方法可用于在两个随机变量 A 和 B 的联合分布 P(A,B)的两个等价因子分解之间进行选择——P(A)P(B/A)和 P(B)P(A/B ),这两个因子分解最好地捕捉了 A 和 B 之间的因果关系。具有正确因果因子分解的模型,例如 P(A)P(B/A ),更快地适应分布的变化【T25Yoshua Bengio 最近的演讲深入探讨了这种方法的更多细节。*
虽然这两种方法非常不同,但它们有潜在的联系。一个是两种方法的稀疏性约束,即使通过不同的方式实现。另一个是因子图和能量函数之间的联系。变量之间的联合分布(在右表示空间)是对世界的粗略近似,可以帮助代理进行计划、推理、想象等。通过将联合分布划分为随机变量(一个变量可以在多个子集中)的小子集的函数,可以使用因子图来表示联合分布。正确的划分会造成能量函数的下降——否则它们就不值得放入因子图中。
5。注意力的作用
虽然注意力本质上是一个加权和,但当权重本身在训练和推理过程中由内容驱动动态计算时,这个简单操作的威力就显而易见了。
- *重点在哪里?*标准前馈神经网络中任何节点的输出本质上是该节点输入的加权和的非线性函数,其中权重是在训练时间学习的。相比之下,注意力允许那些权重本身被动态地计算,即使是在基于输入内容的推断期间。这使得在训练和推理期间,连接计算层的边上的静态权重能够被由注意力计算的动态权重所取代。这些动态权重是基于内容计算的。变压器架构(如 BERT)使用这种方法。例如,单词的向量表示被计算为其邻居的加权和,其中权重确定每个邻居对于计算单词的向量表示有多重要(关注哪里)—关键是这些权重是由注意头(在 BERT 模型的每一层中有多个注意头)使用句子中的所有单词动态计算的。

****重点在哪里?该图显示了模型层中使用关注度的动态边连接,并与模型中的层进行了比较,如推理期间层之间具有静态边权重的标准 FFN。左侧:节点 X 的输出是输入的加权和,其中权重 w1、w2、w3、w4、w5 在推理期间保持相同,而不管不同的输入(A1-A5、B1-B5)。右侧:注意力模型中节点 X 的输出也是输入的加权和,但是权重本身是作为输入的函数动态计算的(在训练和推断期间)。这使得权重本身在不同的输入(A1-A5,B1-B5)之间变化,如不同颜色的虚线边缘所示。
- ****什么时候聚焦?在翻译中,给定一组由编码器计算的隐藏状态,注意力基于翻译的阶段(解码器隐藏状态)在每个时间步长(何时聚焦)中挑选不同数量的这些隐藏向量,以产生如下所示的翻译。

****什么时候聚焦?图改编自 Jay Alammar 关于神经机器翻译的文章。编码器的输出是三个隐藏状态向量,当翻译文本被输出时,在两个解码状态(时间步长 4 和 5)期间,使用注意力(A4 和 A5)来选择三个隐藏状态向量的不同比例。
注意力(特别是“何时聚焦”的用法)在前面描述的“抽象空间中的预测”方法中起着关键作用,以聚焦于一大组表征(构成无意识空间的表征)的选择方面,用于解决有意识的任务。因果推理、最优解的规划/图形搜索都可以被实现为时间上的顺序处理,其中在每个时间步,使用注意力挑选隐藏状态(从无意识状态集合)的正确子集。将噪声注入到图遍历中的下一步(使用注意力)的选择中为解决方案的搜索添加了探索性方面(类似于 RL 中使用的蒙特卡罗树搜索)。更重要的是,这种使用正确注意力屏蔽(作为感知空间表示的函数动态计算)的顺序处理可以像我们在 DL 1.0 中对翻译任务所做的那样进行学习。注意力不仅可以用于有意识的任务解决,还可能在任务过程中以自上而下的方式影响后续的感知。这种自上而下的影响从大脑中获得灵感,其中新皮层的每个功能单元(皮质柱)(意识处理主要在这里进行)都有传入的感觉连接和传出的连接,其中一些连接到运动区。一旦输入中的某些东西吸引了我们的注意力,这些运动神经连接就有意识地将感知引导到输入流的某些部分。例如,大脑皮层处理音频输入的感觉区域与我们头部的肌肉有运动连接,一旦一个不寻常的声音吸引了我们的注意力,它就会将我们的头转向它的来源。**

图来自 Yoshua Bengio 的演讲幻灯片。有意识的思想是以自下而上的方式选择的更大的无意识状态的方面,这反过来导致自上而下的对感官输入的关注
6。多时间尺度的终身学习
多时间尺度的学习和迭代优化促进了面向对象的泛化。例如,代理可以在不同的环境中学习快速适应,同时执行较慢的迭代以在它们之间进行推广。这种多时间尺度的方法是一种学习的方式。DL 1.0 的实践者通过人类完成学习来学习部分来实现同样的效果——他们围绕失败的案例不断训练监督学习模型,通过使用失败案例来扩展训练集,人类专家识别更多这样的边缘案例,然后将训练好的模型部署到字段。特斯拉是这种方法在实践中的一个例子——他们在空中无缝更新汽车,不断提高其自动驾驶能力。这种缓慢但肯定会侵蚀罕见事件分布尾部的方法是否能最终将黑天鹅事件概率降低到可以忽略不计的水平,使其不再被视为所有实际用途的危险,还有待观察。
7。架构优先
*“抽象空间中的预测”方法,除了依赖于上述注意力之外,可能还需要将模型从 DL 1.0 中的向量处理机器转换到对可被称为*的向量集进行操作的机器(注意力中使用的关键字服务于这种间接功能,并且可被视为变量名)并且由动态重组的神经网络模块对其进行操作。
自我监督学习的输入空间方法中的预测似乎不需要新的架构-大量的现有模型可以大致分类为基于能量的模型 (例如像 BERT 这样的语言模型是基于能量的模型)。自我监督学习在很大程度上利用了这些现有的架构。
接近人类 AI 水平的替代方法
混合方法
到目前为止,有许多混合方法的实现将 DL 1.0 与传统的符号处理和算法相结合。这些混合方法使得应用程序能够利用 DL 1.0 进行部署。因此,不能低估混合方法的重要性。所有这些混合方法,当用于决策用例(判别模型;忽略生成用例,尽管它们也有应用——生成真实感图像等。 ) ,有一个共同的特性,它们对 DL 1.0 输出执行进一步的算法处理,通常是(例外情况是图形嵌入)将 DL 1.0 输出的分布式表示简化为符号,此时组合性(符号不像我们可以用向量进行组合,我们只能将它们与更多的符号组合在一起,例如像语法树)分布式表示中固有的相关性丢失。
如果一种混合方法将 DL 输出减少到符号,然后尝试 DL 2.0 任务,如对这些符号进行推理和规划,将使我们能够达到人类水平的人工智能,这仍有待观察。这些天来,所有关于混合方法达到人类人工智能水平的潜力与徒劳的公开辩论都归结为—DL 2.0 任务可以只用符号来完成吗?或者,鉴于分布式表示为 DL 1.0 提供的优势,DL 2.0 任务一定需要分布式表示吗,即它们可以被学习,它们可以捕获相关性,并且它们允许组合性
还有更多的先验来自自然智慧?
自然智能已经启发并继续以多种方式影响人工智能的创造,首先是智能的基本计算单元(从硬件角度)—神经元(尽管人工神经元仅实现生物神经元的一个很小的,即使是关键的功能)。深度学习继续从自然智能中汲取灵感,例如多层计算提供的组合性(类似于视觉皮层处理视觉)一直到有意识任务解决的先验(*Yoshua beng io 的论文 ) 。*
克里斯托斯·帕帕迪米特里奥 的 2019 年论文(尽管其核心计算原语牢牢植根于生物学家实验验证的大脑计算方法,但人们可能会很快将其视为大脑的另一种计算模型 ),但凸显了上述问题的重要性——在实现自然智能的过程中,我们至少还可以借鉴一些技巧(如果不是想法的话)?**
以下面概述的机制为例,一只苍蝇(它的嗅觉系统硬件和功能是一般昆虫的代表)如何学习识别气味 ( )这在克里斯特斯的演讲 ) 中有描述,只有一两个样本。称这种学习为“样本效率”是一种保守的说法——“类固醇学习”可能更恰当。**
苍蝇如何学会识别气味
大约 50 个神经元感知气味,这些神经元随机投射到 2000 个神经元上,形成一个随机图,即二分图。在向量术语中,由 50 维向量捕获的气味输入被随机投射到 2000 维向量,然后由抑制性神经元强制成为具有大约 10%非零值的稀疏向量(非零值表示从超过某个阈值的放电模式活动的正态分布的尾部挑选的神经元)*。这个稀疏的 2000 维向量充当了苍蝇对特定气味的记忆。*

图摘自克里斯特斯·帕迪米特里奥的演讲。这是一个代表苍蝇如何识别气味的模型。他们可以记住一两次接触的气味,也有能力超越他们学到的东西进行归纳,因为他们只有大约 50 种不同的嗅觉传感器(我们有大约 500 种;老鼠大约有 1500 只)
- *这个随机投影(在硬件中实现)*后面跟着一个 cap (稀疏性的运行时实施)看起来是大脑计算的一个非常基本的功能原语,我们也使用 ( 克里斯特斯的大脑模型 很大程度上是基于在自然智能的这个基本计算原语之上构建一些简单的算法运算)
- 随机投影和 cap 保持相似性(给定一些超参数的正确选择)。气味之间的相似性在它们的记忆表征中被捕获(突触权重)。记忆回忆唤起与所学重量的强度相称的点火活动。一只苍蝇有大约 50 种不同类型的嗅觉传感器(我们有大约 500 个,老鼠有 1500 个)*。将气味世界映射到捕捉相似性的分布式表示的能力对于苍蝇的生存至关重要。*
- 本质上,非常高的采样效率(一两次尝试学习一种气味)和非分布学习(将新气味映射到现有气味)通过这个简单的生物网络成为可能。

图摘自克里斯特斯·帕迪米特里乌的讲话,说明随机项目和 cap 保持相似性。大自然似乎已经找到了最佳的稀疏度——足够数量的神经元激活以捕捉语义相似性,同时活跃神经元的数量有限,足以区分不同的气味
苍蝇嗅觉系统设计的一个关键方面是在信息处理的所有阶段实施的稀疏表示。与 DL 模型相比,DL 模型的每个输入都会照亮整个模型,就像圣诞树上的灯一样,以不同的亮度活动(当然这有点夸张,因为[1]我们的模型通常只解决一个任务[2]在培训期间,退出限制激活等。这样做也是有原因的——许多小而弱的特征加起来会在决策中变得重要。也许从输入开始一路实施稀疏性(类似于随机投影和 cap 等操作原语)将权重更新限制在部分启用 的几个参数内(2019 年发表的一篇论文解决了这个问题;参考章节有更多详情) ,快速学习。此外,简单的权重更新(学习)“一起触发的细胞连接在一起”规则具有固有的记忆效率,当与随机投影和 cap 结合时,有助于随时间增加的泛化。DL 模型中的学习依赖于随机梯度下降和反向传播——迄今为止 DL 中学习的主干。也许我们还将对 DL 模型学习的效率进行基本的改进,超越 DL 2.0 目标从自我监督学习中获得的效果。**
最后的想法
一种全新的学习方法总有可能在未来出现,它更接近人类水平的人工智能,甚至比它更好。假设曾经发生过,深度学习的一些核心成功/想法很可能被新方法所包含/吸收——在正确的语义空间中捕获相关性(DL 1.0)和因果关系(DL 2.0 目标)的分布式表示。**
确认
如今,在机器学习社区中,我们几乎认为理所当然的一件事是以关于 arXiv 和 code 的论文的形式免费获取想法。这使得像我这样的从业者能够理解并跟踪进展。我对这个领域的理解归功于机器学习社区、其研究人员和教师的开放性。
参考/附加注释

用于计算意识和无意识表征的论文的逐字摘录

从的论文中逐字摘录了学习有意识和无意识表征的合理培训目标。我们可以通过学习映射将意识状态映射到语言,本质上是用语言调试意识状态。
- 语言在 DL 2.0 中对于“调试意识任务求解”的作用。语言(忽略感知的感官形态——文本、音频等。)的特殊之处在于“单词”——构成输入数据的单位(不考虑它们是通过哪种感官形式提取的,尽管这些感官形式赋予单词丰富的上下文)与用于操纵和表达有意识思维的单位非常接近(然而,儿童可以在获得语言之前很早就执行有意识的任务解决,这表明语言是不必要的,即使它对表达思想是有效的)*。我们预测某人将要表达的内容,就像当前的机器学习语言模型预测序列中的下一个单词或序列中缺失的单词一样。从这个意义上说,语言可以成为有意识任务处理的一个很好的调试工具,因为单词序列是我们大脑中有意识处理的一个很好的代理,在那里我们直接用单词操纵和表达概念。由于这个原因,DL 2.0 有意识任务解决可能不会受到 DL 1.0 任务解决的不透明性的影响,因为我们可以通过模型读取有意识任务解决,读取实现为从思想到话语的学习映射,即我们可以使用语言调试思想,假设 DL 2.0 有意识任务解决与我们进行有意识任务解决的方式一致(这个假设的有效性很大程度上依赖于我们在上面检查的有意识任务解决方法)。*
- 用于学习解开因果机制的元传递对象
- 从未知干预中学习因果变量
- 递归独立机制钢圈论文
- 关于随机图的进化。鄂尔多斯和雷尼 1960 。n 边的随机图可以通过从 v₂,…v₁的标记顶点之间的所有可能边的集合中挑选边来构建。当我们不断给随机图添加一条又一条(下图)的边时,本文检查了随机图的性质,其中每条被选取的边都不会被再次选取。

图由来自的数据组成,随机图论文。当活跃突触连接的数量大于放电神经元数量的一半时,尚不清楚大自然是否利用了随机图结构中的突然变化(找不到这方面的任何工作)。
- 曼宁教授等人的一篇 2019 论文。使用学习分布式表示(来自图像输入)的方法,然后将其映射到概念的预定离散空间(对象和对象的属性)以及它们之间的关系,以执行任务(表示问题的文本输入也被学习为分布式表示,并映射到视觉场景上的概念的相同离散空间。CNN 变体( Mask R-CNN) 用于检测场景中的对象。一旦检测到对象,就基于对象邻近度创建它们之间的有向图。使用图形注意网络来确定边之间的关系类型。由图像构成的图形代表了世界的模型。Q & A 是通过遍历这个结构化的世界模型来执行的。问题的输入单词被表示为手套嵌入。这些嵌入表示输入到 LSTM 的单词,后者输出表示句子的隐藏状态。然后通过 softmax 从有限的预定词汇表中挑选单词向量。这个向量序列用作指令序列来遍历从图像中提取的场景图。遍历(模拟推理)在给定指令向量的情况下,在每一步使用注意力来挑选感兴趣的图节点。这种监督学习模型(纯粹基于 IID 假设的学习),使用分布式表示将推理空间限制在预先确定的有限概念集内的所有方式进行处理(论文* 的第 7 部分 有更多细节)。这部作品的灵感部分来自于 意识先验论文*

数字来自 al 的曼宁教授。2019 论文— 抽象学习—神经状态机。从图中逐字描述:NSM 推理过程的可视化:给定一幅图像和一个问题(左侧),该模型首先构建一个概率场景图(蓝色方框和右侧的图像),并将问题转化为一系列指令(绿色和紫色方框,其中对于每个指令,我们在向量空间中呈现其最接近的概念(或单词)(第 3.1 节)。然后,该模型在图形上执行顺序推理,在指令的引导下关注图像场景中的相关对象节点,以迭代地计算答案
- 解释和利用对立的例子
- StyleGANs 展示了在全球范围内控制图像生成的能力(姿势、身份等)。)使用一个潜在变量,并处于一个精细的层次(头发、胡须等)。)利用随机变异。这些方法是否可以用于自我监督学习,以预测不同抽象级别(像素级别和更高抽象级别)的输出,还有待观察。
- 掌握星际争霸 2 的实时战略
- 掌握雅达利等。通过使用学习模型进行规划
- 用于大脑计算的微积分
- 规划未来几个步骤的能力并不局限于人类。动物和鸟类为未来做计划——例如回去找食物的地方,记住种子储存了多长时间,以便确定它们是否变质。
- 生物学证据支持的意识功能观。
- 用注意力可视化模型
- 论文证明生物神经网络从一两个样本中学习,2019 年 12 月
- 大脑如何学会嗅觉
- 嗅觉输入的随机收敛… 本文提供了从苍蝇感觉神经元(50 维向量)到 2000 向量记忆层的投影的邻接矩阵是随机投影的证据。神经元的连接并不在基因中编码(考虑到这样做所需的信息量,一开始就在基因中编码连接是不可行的),到在发育过程中有一些机制充当神经元迁移的指导路径,特别是对于两个半球之间的主要连接纤维束等。其余的连接很大程度上是随机的。
- 哺乳动物在感觉神经元投射到的层中具有循环连接,这使得输入的后续投射能够用于进一步的下游处理。这种能力也许是达到哺乳动物智力水平的关键先决条件。苍蝇/昆虫似乎缺乏这种形式的多层加工,而这种加工是通过重复连接实现的。
- 由 Lex Fridman 撰写的关于 DL 1.0 迄今进展的综合概述—上传于 2020 年 1 月 10 日。他演讲的幻灯片
- Lex 的演讲中提到的一篇论文解决了当前 DL 模型中从输入到输出一直缺乏稀疏性的问题。

图[来自 Lex Fridman Jan 2020 年 1 月的演讲](http://Slides of his talk)
- 2020 年 2 月 9 日图灵奖讲座由杰夫·辛顿、扬·勒昆和约舒阿·本吉奥主讲,他们在讲座中讨论了他们的最新作品。
这篇文章是从 Quora【https://qr.ae/TJg8ov】T21手动导入的
价值 2000 美元的深度学习课程笔记本现已开源
这些笔记本构成了 fast.ai 创始人 【杰瑞米·霍华德】新书的基础,并用于一个价值 2000 美元的深度学习课程。

fast . ai 2000 美元深度学习课程
前 Kaggle 首席科学家,fast.ai 创始人,ai 教育家, 杰瑞米·霍华德 将其 AI 课程笔记本开源。这些笔记本用于他从 2020 年 3 月开始在旧金山大学教授的一门课程。
课程笔记本代码现在可以在 GitHub 上免费获得。
fastai 的书现在在 Github 中是免费的
两周前,杰瑞米·霍华德在 Github 上发布了讲稿的草稿。他在短短两天内收获 2k 星,迅速登上日趋势榜榜首。
另外,这个项目也是杰瑞米·霍华德新书与 fastai & PyTorch 合作的《程序员深度学习》的草稿,目前还没有正式发布。这相当于为您节省了 60 美元。

来源于亚马逊
虽然这本书目前处于预购状态,但它被读者寄予厚望,长期以来一直位居亚马逊计算机科学图书排行榜的第一位。
书籍内容
该书初稿已出版 20 章(包括引言和结论)。内容从最著名的人工智能“Hello Word problem”,MNIST 图像分类开始,然后是 NLP,递归神经网络,卷积神经网络和可解释性。

fastai 图书草稿内容来自 Github
本课程不适合初学者,前提是具备 Python 和 PyTorch 知识。
要在 Jupyter Notebook 中运行代码,您需要安装:
fastai v2、Graphviz、ipywidgets、matplotlib、nbdev、pandas、scikit-learn、微软 Azure 认知服务图片搜索
它们都可以通过 PyPI 直接安装。
这个 fastbook 不仅仅是一本教材,更是一个 AI 社区资源。在最后的留言里,作者希望每一个完成这本书的人,和大家交流成功的经验。
版权
最后,提到版权是非常重要的。
从 2020 年开始,fastbook 项目中的所有内容都是杰瑞米·霍华德和西尔万·古格的版权。
笔记本和 python .py文件中的代码受 GPL v3 许可证的保护。其余部分(包括笔记本和其他散文中的所有减价单元格)未经许可不得进行任何形式或媒体的再分发或更改,除非复制笔记本或分叉此回购供您私人使用。禁止商业或广播使用。
这是来自杰瑞米·霍华德的关于开源和版权的信息
如果您看到有人在其他地方托管这些材料的副本,请让他们知道他们的行为是不允许的,并可能导致法律诉讼。此外,他们会伤害社区,因为如果人们忽视我们的版权,我们就不太可能以这种方式发布额外的材料。
杰瑞米·霍华德,来自 fastbook 自述
尽情享受吧!
以下是链接
- fastbook 项目:https://github.com/fastai/fastbook
- 课程:https://www . usfca . edu/data-institute/certificates/deep-learning-part-one
用 TensorFlow 建模,在 Google 云平台上服务
实用指南
在可扩展的云平台上服务 TensorFlow 模型

在本指南中,我们学习如何开发一个 TensorFlow 模型,并在谷歌云平台(GCP)上提供服务。我们考虑使用 TensorFlow 和 Keras APIs 实现的三层神经网络来预测产品收益的回归问题。
本指南的主要学习成果是
- 在 Tensorflow 中建立、编译和拟合模型
- 在 Google colab 中设置 tensorboard
- 保存、加载和预测看不见的数据
- 在 Google 云平台上部署 TensorFlow 模型
在本指南中,我们将使用 TensorFlow 2.1.0 和 Google colab 运行时环境。我们将使用 google colab 来训练使用 TensorFlow 和 Keras APIS 的模型。从 TensorFlow 2.0 开始,Keras 现在是 TensorFlow 包的一部分。Google colab 在免费的 GPU 和 TPU 上提供机器学习模型的训练。因此,建议环境获得在 GPU 和 TPU 上训练您的深度学习模型的实践经验。而且可以设置 tensorboard,更好的了解模型训练。本指南附带了一个 Google colab 的工作副本,可以帮助您快速入门。
# Install TensorFlow >2.0
!pip install tensorflow==2.1.0
导入必要的 python 库以及 TensorFlow 和 Keras 函数
# Import libraries
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import os
import numpy as np
from __future__ import absolute_import, division, print_function, unicode_literals
import tensorflow as tf
from tensorflow.keras.layers import Dense, Flatten, Conv2D
from tensorflow.keras import Model
from tensorflow.keras.models import Sequential, load_model
加载张量板扩展
# Load tensorboard
%load_ext tensorboard
为数据安装 Gdrive
要在 Google colab 环境中访问数据,有多种方法。我最喜欢的一个方法是将数据上传到你的 Google Drive,然后在 colab 中安装 Google Drive。
可以从 data_deep_learning 下载用于训练和测试的数据。可以尝试其他开源数据集试试。
我们需要安装 google drive 来读取存储在 google drive 中的数据。下面是最简单的安装方法。您将被要求输入访问过程生成的令牌。你可以参考文章《使用 Google Colab GPU VM + Drive 作为长期深度学习训练运行的持久存储》了解更多关于使用 Google drive 作为 Colab 的数据存储的信息。
我已经把数据上传到我的 google drive 上,以便于访问。你可以照着做。
from google.colab import drive
drive.mount('/content/drive')Go to this URL in a browser:
Enter your authorization code:
··········
Mounted at /content/drive
加载培训和验证数据
我已经将培训和验证数据上传到我的 google drive。出于练习的目的,您可以尝试任何其他开源数据。对于本教程,数据已经准备好进入训练集和测试集,但是在实际问题中,最有可能的是数据必须逐个任务地清理和准备。在我看来,机器学习科学家几乎 50%的工作是准备与机器学习模型兼容的数据
确保培训、有效和测试拆分中没有信息泄漏。
最近,杰森·布朗利在他的网站【https://machinelearningmastery.com/blog/. 发表了一系列关于数据准备的文章
# I have already uploaded the data to my google drive
data_path= '/content/drive/My Drive/data_deep_learning_tensorflow/'
output_dir = '/content/drive/My Drive/Deep_Learning_Course/Ex_Files_Building_Deep_Learning_Apps/'
阅读我们问题的训练和测试数据。目标是预测给定产品的总收入,给出下列特征。
# Reading the traing and test data
training_data_df = pd.read_csv(data_path + 'sales_data_training.csv')
test_data_df = pd.read_csv(data_path + 'sales_data_test.csv')training_data_df.head()

标准化要素数据
标准化是大多数机器学习模型的推荐做法,并已被证明是可行的。Scikit-learn 附带了一些业界信任的转换,用于预处理数据。
MinMaxScaler 是 Scikit-learn 转换模块中实现的常用转换之一。它在 0 和 1 之间缩放数据。在输入张量流模型训练之前,建议对训练和测试数据进行归一化。
scalar = MinMaxScaler(feature_range=(0,1))
scaled_training = scalar.fit_transform(training_data_df)
scaled_test = scalar.fit_transform(test_data_df)
scaled_training_df = pd.DataFrame(data = scaled_training, columns=training_data_df.columns)
scaled_test_df = pd.DataFrame(data = scaled_test, columns=training_data_df.columns)
让我们来看看缩放后的数据
scaled_training_df.head()

对于有监督的机器学习模型,我们将特征和目标分成X和y NumPy 数组。TensorFlow 模型也是如此,使用这种格式的数据。
# Splitting the feature and target columns. Using this dataset, we aim to predict total_earnings
X = scaled_training_df.drop('total_earnings', axis=1).values
Y = scaled_training_df['total_earnings'].values
用 Keras 顺序 API 定义张量流模型
为了定义深度学习模型,我们使用 TensorFlow 2.1.0 附带的 Keras API 模块。我们从一个具有两个中间 relu 层的基本模型开始。输入维度是 9,输出维度是 1。
# Define the Model
model = Sequential()
model.add(Dense(50, input_dim=9, activation = 'relu'))
model.add(Dense(100, activation = 'relu'))
model.add(Dense(50, activation = 'relu'))
model.add(Dense(1, activation = 'linear'))
model.compile(loss = 'mean_squared_error', optimizer = 'adam')
显示定义的模型摘要
model.summary()Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_4 (Dense) (None, 50) 500
_________________________________________________________________
dense_5 (Dense) (None, 100) 5100
_________________________________________________________________
dense_6 (Dense) (None, 50) 5050
_________________________________________________________________
dense_7 (Dense) (None, 1) 51
=================================================================
Total params: 10,701
Trainable params: 10,701
Non-trainable params: 0
_________________________________________________________________
准备类似于训练数据的测试特征和目标
X_test = scaled_test_df.drop('total_earnings', axis=1).values
Y_test = scaled_test_df['total_earnings'].values
为 tensorboard 安排复试
# Setup for tensorboard
from datetime import datetime
logdir="logs/scalars/" + datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir=logdir)
用verbose=0和epochs=50训练模型,并将测试数据作为验证集。
# Train the network
training_history = model.fit(X, Y,
epochs = 50,
shuffle=True,
verbose=0,
validation_data=(X_test, Y_test),
callbacks=[tensorboard_callback])
print("Average test loss: ", np.average(training_history.history['loss']))Average test loss: 0.0003906410974522077
让我们在 tensorboard 中显示训练/验证错误
# Click on the view output full screen from dropdown cell menu if tensorboard does not show up itself
%tensorboard --logdir logs/scalars

验证结果
训练的验证是任何机器学习框架中非常重要的步骤之一。这里,我们互换使用验证/测试错误。
test_error_rate = model.evaluate(X_test,
Y_test,
verbose=0)
print('The mean squared error for test data is {}'.format(test_error_rate))The mean squared error for test data is 0.09696226567029953
对看不见的数据进行预测并保存模型
让我们读取样本输入数据并测试我们的模型,以预测并在本地保存模型供将来使用。
# Read the values of features for new product and test on our traioned model
df_new_products = pd.read_csv(data_path + 'proposed_new_product.csv').values# Use our trained moel to predict
predictions = model.predict(df_new_products)# Scaling up the earnings prediction using our Normalisation Parameters
predictions = predictions + 0.1159
predictions = predictions/0.0000036968
print('Earnings predictions for Proposed product - ${}'.format(predictions))Earnings predictions for Proposed product - $[[270639.12]]# Save the Model
model.save(output_dir + 'trained_model.h5')
print('Trained Model saved at {}'.format(output_dir))Trained Model saved at /content/drive/My Drive/Deep_Learning_Course/Ex_Files_Building_Deep_Learning_Apps/
检索已保存的预测模型
一旦我们对模型感到满意,我们就可以在本地保存这个模型,并且可以用来对看不见的数据进行预测。这个模型可以托管在云上,你可以发送输入数据来获得预测。
# Importing saved model
model_trained = load_model(output_dir + 'trained_model.h5')# Read the values of features for new product and test on our traioned model
df_new_products = pd.read_csv(data_path + 'proposed_new_product.csv').valuespredictions = model_trained.predict(df_new_products)
predictions = predictions + 0.1159
predictions = predictions/0.0000036968
print('Earnings predictions for Proposed product - ${}'.format(predictions))Earnings predictions for Proposed product - $[[270639.12]]
在 Google Cloud 上部署训练模型
一旦我们有了训练好的模型,下一个任务就是部署它来为客户服务。有各种可用的部署选项,但在这一节中,我们重点关注在谷歌云人工智能平台上部署它。
先决条件
在 google cloud 上部署 TensorFlow 模型的先决条件是
- 熟悉谷歌云项目
- 基本了解存储桶和 it
gsutils命令行工具 - 基本了解与谷歌云交互的
gcloud命令行工具 - 经过训练的 Tensorflow 2.1.0 模型
- 阅读下面的指南,了解如何部署机器学习模型的详细信息
通过 colab 验证您的 google 帐户
from google.colab import auth
auth.authenticate_user()
创建一个谷歌云项目,如果没有做之前和存储模型桶。
# GCP project name
CLOUD_PROJECT = 'gcpessentials-rz'
BUCKET = 'gs://' + CLOUD_PROJECT + '-tf2-models'
将所需的项目设置为在 colab 环境中使用的默认环境变量。
# Set the gcloud consol to $CLOUD_PROJECT 9Environment Variable for your Desired Project)
!gcloud config set project $CLOUD_PROJECTUpdated property [core/project].
使用gsutil命令行实用程序创建 Bucket。您可以使用 python API 来创建存储桶。现在让我们坚持使用命令行方法。
# Create the storage bucket for tf2 Models
!gsutil mb $BUCKET
print(BUCKET)Creating gs://gcpessentials-rz-tf2-models/...
gs://gcpessentials-rz-tf2-models
将 TensorFlow 模型保存到刚刚创建的存储桶中。您可以确认模型文件是从 google 控制台图形用户界面上传的。
MODEL = 'earnings-prediction'
model.save(BUCKET + f'/{MODEL}', save_format='tf')WARNING:tensorflow:From /usr/local/lib/python3.6/dist-packages/tensorflow_core/python/ops/resource_variable_ops.py:1786: calling BaseResourceVariable.__init__ (from tensorflow.python.ops.resource_variable_ops) with constraint is deprecated and will be removed in a future version.
Instructions for updating:
If using Keras pass *_constraint arguments to layers.
INFO:tensorflow:Assets written to: gs://gcpessentials-rz-tf2-models/earnings-prediction/assets
服务于模型的配置
有两种方法可以设置在 google cloud 上服务的模型。第一个是使用 GCP 图形控制台,另一个是使用 gcloud 命令行工具,如如何在云 AI 平台上部署 TensorFlow 2 模型中所述。我跟随 GCP 控制台进行了这次部署。一些关键点
- 确保您的模型数据上传到存储桶中
- 建议对您的模型和存储桶使用相同的区域(有时会产生问题)。
- 请耐心等待,创建模型/版本可能需要几分钟时间
- 第一次做的时候,仔细阅读所有的说明
!gcloud ai-platform versions create $VERSION \
--model $MODEL \
--origin $MODEL_DIR \
--runtime-version=2.1 \
--framework='tensorflow' \
--python-version=3.7
获取已部署模型的预测
一旦部署了模型,并且您可以看到绿色的勾号,就该测试模型的预测了。一些需要考虑的要点。
- 使用测试&测试模型预测使用您的版本或模型选项卡下的选项卡。
- 输入 JSON 数据取决于您如何定义您的模型
# [Reference](https://github.com/GoogleCloudPlatform/python-docs-samples/blob/master/ml_engine/online_prediction/predict.py)
import googleapiclient.discovery
def predict_json(project, model, instances, version=None):
service = googleapiclient.discovery.build('ml', 'v1')
name = 'projects/{}/models/{}'.format(project, model)
if version is not None:
name += '/versions/{}'.format(version)
response = service.projects().predict(
name=name,
body={'instances': instances}
).execute()
if 'error' in response:
raise RuntimeError(response['error'])
return response['predictions']
加载看不见的数据进行预测
df_new_products = pd.read_csv(data_path + 'proposed_new_product.csv')df_new_products

将数据转换成 JSON 格式,以便与上面写的predict_json程序兼容。
tdata_instances = {'dense_input':df_new_products.values[0].tolist()}predictions_gcloud = predict_json(CLOUD_PROJECT, 'earnings_prediction', tdata_instances, version='v1')
predictions_gcloud = predictions_gcloud[0]['dense_3'][0] + 0.1159
predictions_gcloud = predictions_gcloud/0.0000036968
print('Earnings predictions for Proposed product - ${}'.format(predictions_gcloud))Earnings predictions for Proposed product - $261848.21778936993
谷歌 Colab 笔记本
按照下面的谷歌合作笔记本来复制和实践这个指南。
结论
在本指南中,我们学习了使用 TensorFlow 2.1.0 训练深度学习模型,并将训练好的模型部署在谷歌云平台上。以下是指南的重点。
- 安装 TensorFlow 2.1…google colab 中的 0
- 在 google colab 中设置 tensorboard
- 使用 TensorFlow 构建、编译和训练模型
- 评估并保存训练好的模型
- 加载已保存的模型以根据看不见的数据进行预测
- 在 Google Cloud 上部署模型
- 使用云中部署的模型进行预测
参考资料/阅读/链接
- https://blog . tensor flow . org/2020/04/how-to-deploy-tensor flow-2-models-on-cloud-ai-platform . html
- https://scikit-learn.org/stable/modules/preprocessing.html
- 【https://www.tensorflow.org/tutorials/keras/regression
- https://www.tensorflow.org/tutorials/keras/save_and_load
借助 Fluent Tensorflow Extended 简化深度学习端到端管道
快速 api 概述和 fluent-tfx 的自包含示例
如果这种生产 e2e ML 管道的事情对你来说似乎是新的,请先阅读 TFX 指南。
另一方面,如果你以前用过 TFX,或者计划部署一个机器学习模型,那你就找对地方了。

但是 Tensorflow Extended 已经完全有能力自己建设 e2e 管道,为什么还要麻烦使用另一个 API 呢?
- 冗长的代码定义。实际的预处理和训练代码可能与实际的管道组件定义一样长。
- 缺乏合理的违约。您必须手动指定所有东西的输入和输出。这一方面提供了最大的灵活性,但在其他 99%的情况下,大多数 io 都可以自动连接。例如,您的预处理组件可能会读取您的第一个输入组件的输入,并将输出传递给培训。
- 太多样板代码。通过 TFX CLI 搭建可在 4-5 个目录中生成 15-20 个文件。
更易于使用的 API 层的优势
- 流畅紧凑的管道定义和运行时配置。不再需要在构建管道的 300 多行庞大的函数中滚动
- 没有脚手架,很容易通过使用几行代码来设置
- 额外的有用的工具,以加快常见的任务,如数据输入,TFX 组件建设和布线
- 合理的默认值和 99% —合适的组件 IO 接线
声明:我是fluent-tfx的作者
通过示例进行 API 概述
这本质上是fluent-tfx/examples/usage _ guide/simple _ e2e . py,但是请继续读下去。
如果你已经了解 TFX 的基本情况,滚动到管道建设。
数据输入
文件data/data.csv实质上是 4 列:a, b, c, lbl。a和b是随机采样的浮点,c是二进制特征(0或1))lbl是二进制标签(值0或1)。那是个玩具问题,只是为了演示。
模型代码
工程师或“用户”提供预处理、模型构建、超参数搜索和保存带有正确签名的模型的功能。我们将展示如何在另一个文件中轻松定义这些函数(比如 model_code.py )
我们将利用 TFX 的所有优势来完成大部分工作。
keras Tuner和 TFX 调谐器——用于超参数搜索和建模的训练器:
管道建设
构建管道并不简单:提供一些带有 Tensorflow 模型分析的评估配置,只需使用fluent-tfx;
滑行装置
在 TFX 支持的不同管道上运行管道不需要额外的努力,也不需要额外的依赖:PipelineDef生产一个普通的 TFX 管道。
但是,如果您在管道函数中使用ftfx工具,请确保将这个包包含在 requirements.txt beam 参数中。
附录:自由度和限制
自定义组件在很大程度上受到支持,但是仍然会有一些边缘情况,这些情况只适用于冗长简单的旧 TFX api。
假设与组件 DAG 布线、路径和命名相关。
路径
PipelineDef需要一个pipeline_name和一个可选的bucket路径。- 二进制/临时/暂存工件存储在
{bucket}/{name}/staging下 - 除非另有说明,否则默认 ml 元数据 sqlite 路径设置为
{bucket}/{name}/metadata.db bucket默认为./bucket- 推进者的
relative_push_uri将模型发布到{bucket}/{name}/{relative_push_uri}
组件 IO 和名称
- 一个输入,或者一个
example_gen组件提供.tfrecord给下一个组件(可能是 gzipped 格式) - 流畅的 TFX 遵循 TFX 命名的默认组件的一切。当提供定制组件时,确保输入和输出与 TFX 相同。
- 例如,您的定制
example_gen组件应该有一个.outputs['examples']属性 - 当使用来自
input_builders的额外组件时,确保您提供的名称不会覆盖默认值,例如标准 tfx 组件名称snake_case和{name}_examples_provider、user_{x}_importer。
元件接线默认
- 如果提供了用户提供的模式 uri,它将用于数据验证、转换等。如果声明的话,生成的模式组件仍然会生成工件
- 如果用户没有提供模型评估步骤,它将不会被连线到推送器
- 默认训练输入源是转换输出。用户可以指定他是否想要原始 tf 记录
- 如果指定了超参数并声明了 tuner,tuner 仍将测试配置并生成超参数工件,但将使用提供的超参数
谢谢你一直读到最后!如果这种生产 ML 管道的事情对你来说似乎是新的,请阅读 TFX 指南。
使用深度学习的颅内出血检测
了解我们为脑出血分类而进行的一系列实验。

来源:https://swdic.com/radiology-services/mri-brain.php
本文由 Prajakta Phadke 合著
在过去十年中,深度学习在医疗应用中的使用增加了很多。无论是使用视网膜病变识别糖尿病,从胸部 x 光片中预测
肺炎还是使用图像分割计数细胞和测量器官,深度学习都在无处不在。从业者可以免费获得数据集来建立模型。
在本文中,您将了解我们在使用脑部核磁共振成像时进行的一系列实验。这些实验可以在 Github 上作为一系列笔记本获得。

以这种方式给笔记本编号的原因是为了让其他人能够系统地浏览它们,看看我们采取了哪些步骤,我们得到了哪些中间结果,以及我们在此过程中做出了哪些决定。我们不是提供一个最终的抛光笔记本,而是想展示一个项目中的所有工作,因为这才是真正的学习所在。
该库还包括有用的链接,链接到领域知识的博客、研究论文和所有我们训练过的模型。我建议每个人都使用这个库,自己运行每一个笔记本,理解每一点代码是做什么的,为什么要写,怎么写。
让我们来看看每一个笔记本。所有这些笔记本都是在 Kaggle 或谷歌联合实验室上运行的。
00_setup.ipynb
本笔记本包含在 Google colaboratory 上下载和解压缩数据的步骤。在 Kaggle 上,你可以直接访问数据。
01_data_cleaning.ipynb
对于这个项目,我们使用了杰瑞米·霍华德的干净数据集。他有一个笔记本,上面记录了他清理数据的步骤。我们在笔记本上复制了其中的一些步骤。一般来说,在深度学习中,快速清理数据以进行快速原型制作是一个好主意。
数据以 dicom 文件的形式提供,这是医疗数据的标准扩展。我们来看看其中一个的内容。

除了图像,它还包含一堆机器记录的元数据。我们可以使用这些元数据来深入了解我们的扫描。因此,我们将它们保存在数据帧中(因为 dicoms 访问和使用太慢)。

查看包含许多列的数据帧的头部的一个有用的技巧是转置它。
现在让我们来看一些图片。

我们看到我们有一个人从头顶到牙齿的大脑不同切片的图像。这就是大脑扫描是如何从上到下进行的。有时顶部或底部切片可以是完全黑色的(面部之前或之后的切片)。这样的切片对我们的模型没有用,应该被删除。
元数据中有一个称为img_pct_window的有用栏,它告诉我们大脑窗口中像素的百分比。如果我们绘制该列,我们会得到下图:

我们看到很多图像在大脑窗口几乎没有任何像素。因此,我们丢弃这样的图像。如果我们看一些我们丢弃的图像

我们看到它们是牙齿开始出现的较早或较晚的。
数据清理过程的第二步是修复RescaleIntercept列。关于这方面的更多信息,请参考杰里米的笔记本。最后,我们中心作物(以消除背景)和调整图像的大小为(256,256)。虽然高质量的图像会给出更好的精度,但这个尺寸对于原型来说已经足够了。
02 _ data _ exploration . ipynb
既然我们已经清理了数据,我们可以稍微研究一下。我们将分两个阶段进行建模。在第一阶段,我们只预测一个人是否有出血。
我们从检查空值开始。标签数据框没有空值,而元数据数据框有一些几乎完全为空的列。我们可以安全地删除这些列。
然后我们继续检查目标变量。

我们有一个非常平衡的数据集。医学数据集通常不是这种情况。它们通常是不平衡的,正类样本的数量远少于负类样本的数量。
接下来,我们检查每个子类别的数量。

硬膜下出血似乎是最常见的出血类型。元数据中一个有趣的列是“存储的位数”列,它表示用于存储数据的位数。它有两个不同的值:12 和 16。

这可能表明来自两个不同的组织。在深度学习中,通常建议使用来自相同分布的数据。最后,我们可以在不同的窗口中查看我们的图像。

然而,这只是针对人类的感知。神经网络可以处理浮点数据,并且不需要任何窗口。
03 _ data _ augmentation . ipynb
训练一个好的深度学习模型的第一步是获取足够的数据。然而,这并不总是可能的。然而有可能的是,对数据进行一些转换。
我们所做的是,不是每次都给模型提供相同的图片,而是做一些小的随机变换(一点旋转、缩放、平移等),这些变换不会改变图像内部的内容(对于人眼而言),但会改变其像素值。用数据扩充训练的模型将更好地概括。
在本笔记本中,我们在数据集上尝试了一些转换,看看它们是否有意义。还要注意,这些转换只应用于训练集。我们在验证集上应用非常简单的变换。
有点像空翻

或者轻微旋转

有意义,但是其他一些转换可能一点用都没有,因为它们不像实际的数据。

另请注意,我们已经裁剪和调整大小,所以我们不会这样做。
05_metadata.ipynb
最近的研究表明,元数据可以证明是有用的图像分类。我们可以通过平均预测来实现,或者将两个数据输入神经网络。
为了做到这一点,我们首先尝试仅使用元数据来对出血进行分类,以衡量其有用性。我们发现,即使使用像随机森林这样的健壮模型,我们也只能得到 50%的准确率。因此,我们决定放弃元数据,专注于图像本身。

04_baseline_model.ipynb
对于我们的基线模型,我们从一个 resnet18 作为主干开始,并在其上附加一个自定义头。迁移学习在图像分类方面表现出了良好的效果。它提供了更好的结果,更快的培训,并大大减少了资源消耗。
然而,对于像医学图像这样的东西,没有可用的预训练模型。因此我们用 resnet 来凑合。我们在这个笔记本中训练两个模型,一个有和没有预训练。在这两个模型中,我们能够在仅仅 5 个时期内达到大约 89%的准确度。

batch_size被设置为 256。我们使用 Leslie Smith 的学习率查找器,在训练中找到一个好的学习率。

简单地说,我们可以对我们的数据进行模拟训练,将我们的学习率从非常低的值变化到高达 10 的值。然后,我们计算损失,并将其与学习率进行对比。然后,我们选择具有最大下降斜率的学习速率。
在这种情况下,我们可以选择类似于3e-3的东西,因为1e-1和1e-2处于边缘,损耗很容易激增。我们也可以用一个切片来表示我们的学习率,例如1e-5 to 1e-3。在这种情况下,不同的学习率将适用于我们网络的不同群体。
对于训练,我们首先冻结模型的预训练部分,只训练新的头部。但是,我们确实更新了 resnet 的 batchnorm 层,以保持每层的平均值为 0,标准偏差为 1。
损失图如下所示。

然后我们可以展示一些结果。

红色的是我们的模型分类错误的。
暂时就这样了。在我结束这篇文章之前,我想给出一个非常重要的提示:“在训练模型时不要设置随机种子,每次都让它在不同的数据集上训练。这将有助于您了解您的模型有多稳健。”
这篇文章和项目是一项正在进行中的工作,在下一阶段,你会看到以下笔记本。在那之前,祝你快乐。
接下来…
06 _ multi label _ classification . ipynb
可视化您的模型在分类时关注的图像部分。继续对出血的子类进行分类。一幅图像可以有一种或多种出血类型。
07 _ 不同 _archs.ipynb
因为我们已经认识到元数据对我们的应用程序并没有真正的用处,所以我们尝试了各种架构,比如 resnet34、resnet50、alexnet、densenet 等等。
08 _ 混合 _ 精确 _ 训练. ipynb
我们也使用混合精度训练来降低训练时间。
09 _ 锦囊妙计. ipynb
我们使用了魔术袋研究论文中的一些技巧。像渐进的图像大小调整。我们还试验了批量大小,我们试图尽可能地增加它。批量越大,更新效果越好。
10 _ 测试 _ 和 _ 部署. ipynb
测试时间增加,用于测试的查询数据集和用于部署的简单网站。
计算机视觉的深度学习
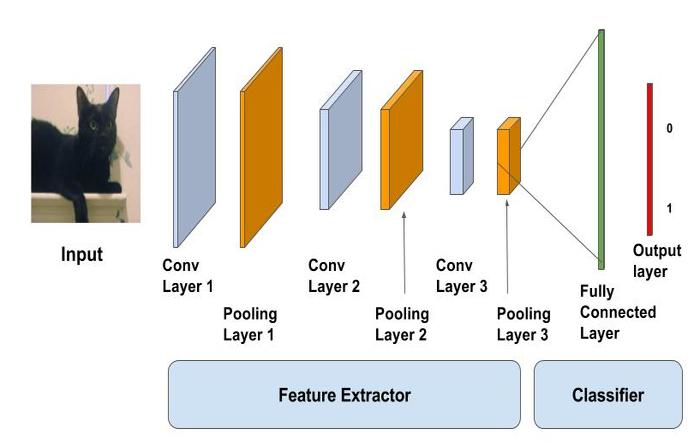
理解 CNN 的卷积层、池层和全连接层
计算机视觉中的深度学习在短时间内取得了快速进展。深度学习在计算机视觉中的一些应用包括人脸识别系统、自动驾驶汽车等。
本文介绍了卷积神经网络,也称为 convnets ,这是一种广泛用于计算机视觉应用的深度学习模型。我们将深入了解它的组件、卷积层、池层和全连接层等层,以及如何应用它们来解决各种问题。
所以让我们开始吧。
有线电视新闻网的目标:

猫
上面是一只猫的图片,小时候我们被告知这种动物是猫。随着我们长大,学习和看到更多猫的图像,我们的大脑记录了它的各种特征,如眼睛、耳朵、面部结构、胡须等。下一次我们看到具有这些特征的动物图像时,我们能够预测它是一只猫,因为这是我们从经验中学到的。
现在我们需要在计算机上模拟同样的行为。这类问题在计算机视觉中被称为图像分类问题,我们试图识别图像中存在的对象。
给定一幅图像,首先计算机应该能够提取它的特征,然后根据这些特征,预测那个物体是什么。他们如何实现这一目标?嗯,简单的答案是通过 CNN。他们是如何做到这一点的,我们将深入探讨。
CNN 简介:
因此,CNN 的目标是执行两个任务:第一个是特征提取,第二个是聚集所有提取的特征并基于它进行预测。
在我们深入研究各个组件之前,让我们看看 CNN 是什么样子的。

描绘 Conv、池化和全连接层的 CNN 架构示例来源:https://www . learnopencv . com/WP-content/uploads/2017/11/CNN-schema 1 . jpg
从上图中,我们可以看到三种类型的层,分别是:卷积层、汇聚层和全连接层。(我们将在接下来的章节中讨论这些)
如果上面的图片没有完全理解,那也没关系。我们看到这一点的原因是为了在脑海中想象 CNN 是什么样子,这样一旦我们理解了它的各个层次,我们就可以很容易地将这些点联系起来。
卷积运算:
卷积是细胞神经网络的基本构件之一。卷积运算的主要目的是从输入图像中提取边缘、曲线、拐角、梯度方向等特征。我们将通过一个边缘检测示例来理解卷积运算。
给定一幅图像,我们想要提取该图像中所有的水平和垂直边缘。下图描述了同样的情况。

卷积运算的例子
假设我们有一个 6x6 的灰度图像。现在,为了检测图像中的边缘,我们构建了一个 3x3 的矩阵。在 CNN 的术语中,它被称为过滤器或内核。使用这两个矩阵,我们将执行卷积运算。结果矩阵,即卷积运算的输出将是大小为 4×4 的矩阵。下图描述了同样的情况。

卷积运算的例子
现在,我们如何计算得到的 4x4 矩阵的元素如下:
为了计算左上角的元素,我们将使用 3x3 滤镜并将其粘贴到原始输入图像的 3x3 区域的顶部。接下来,我们将做元素方面的乘积来给出我们想要的值。

接下来,为了计算第二个元素,我们将滤波器(即黄色方块)向右移动一步,进行相同的元素乘积,然后将它们相加。同样,我们可以填充该行的所有元素。

向右滑动过滤器一步以获得所需的值
现在,为了获得下一行中的元素,我们将把过滤器向下移动到下一行,重复相同的元素级乘积,并将它们相加。因此,我们可以同样地填充其余的元素。下面向我们展示了最终的结果。

卷积运算
这里有几点。当使用 3×3 矩阵进行卷积时,6×6 矩阵得到 4×4 矩阵。这些本质上是矩阵。但是左边的矩阵便于解释为输入图像,中间的一个解释为滤波器,右边的一个解释为输出特征。
输出特征尺寸的计算如下:
n x n input image f x f filter**output dimension = (n - f + 1)**Above example: 6 x 6 input image 3 x 3 filter
(6 - 3 + 1) x (6 - 3 + 1)
output dimensions = 4 x 4
注意:我们的过滤器的值通常被称为权重。我们如何决定重量值是在训练中学到的。它们用一些随机值初始化,并随着每个训练步骤不断调整。
填料
每次执行卷积运算时,我们都会丢失边界像素中的一些信息。此外,我们的形象缩小了一点。有时,我们会希望减少输出大小,以节省训练期间的资源消耗。然而,有时我们可能希望保持输出和输入的空间维度不变。为此,我们可以使用填充的概念。
填充只是在输入要素的每一侧添加适当数量的行和列。填充实质上使过滤器产生的特征图与原始图像的大小相同。

带填充的卷积,p = 1 来源:https://github.com/vdumoulin/conv_arithmetic
在图(左)中,一个尺寸为 5x5 的蓝色正方形代表我们的输入图像,它通过在每边添加几行零来填充。当使用 3×3 滤波器进行卷积时,输出维数与输入维数相同,即 5×5,如绿色方块所示。如果我们没有使用填充,输出尺寸将是 3x3。因此,填充 1 保持了输入和输出的空间维度相同。
有效且相同的填充
让我们根据是否添加填充来理解术语。
有效:当卷积期间没有添加填充,并且我们的结果输出是收缩尺寸时。示例:
Input size: 6 x 6 (i x i)
Filter size: 3 x 3 (f x f)
Output size: (i – f + 1)
(6 – 3 + 1) = 4
= 4 x 4
相同:添加填充,使输出尺寸与输入尺寸相同时。为了计算输出尺寸,我们对上面的公式进行了修改,以考虑填充参数。示例:
Input size: 6 x 6 (i x i)
Filter size: 3 x 3 (f x f)
Padding: 1 (p)
Output size: **(i + 2p - f +1)**
(6 + 2x1 – 3 + 1) = 6
= 6 x 6
注意:按照惯例,滤波器尺寸 f 通常是奇数,否则填充将是不对称的。一些最常用的过滤器尺寸为 3x3、5x5 和 1x1。
阔步
在我们的工作示例中,为了计算下一个元素,我们将过滤器向右移动一位。我们在输入图像上移动过滤器的行数是我们的步幅参数。
跨距定义了遍历图像时滤波器的步长。默认情况下,在任何框架中它都可能是 1。

步幅 s = 2 的卷积来源:https://github.com/vdumoulin/conv_arithmetic
在左图中,一个 5x5 的蓝色方块代表我们的输入图像。使用 3x3 滤波器进行卷积时,步长值为 2,我们得到了尺寸为 2x2 的下采样输出图。如果我们保持 stride 为 1,输出维度将是 3x3。
因此,我们可以在训练中增加步幅(步)长度以节省空间或减少计算时间。然而,当这样做时,我们将放弃一些信息,因此这是资源消耗(无论是 CPU 还是内存)和从输入中检索信息之间的权衡。
注意:一般来说,我们通常将步幅值保持为 1,并使用其他方法对我们的特征地图进行下采样,如使用池图层。
卷积运算概述:
卷积运算的主要目的是从输入图像中提取有意义的信息,如边缘、曲线等。下面的动画总结了卷积运算中元素的计算方式。

卷积运算概述
以下等式总结了输出要素地图的尺寸。

公式
使用上述等式的示例:
**6x6** input image, **3x3** filter | **7x7** input image, **3x3** filter
padding **p=1** & stride, **s=1** | padding **p=1** & stride, **s=2**
|
|
Output size: | Output size:
(6 + 2*1 – 3)/1 + 1 = 6 | (7 + 2*1 - 3)/2 = 4
**6 x 6** | **4 x 4**
体积卷积:
我们已经完成了矩阵的卷积运算。现在让我们了解如何对体积执行卷积运算,这将使它更加强大。以前我们有一个 6x6 的灰度图像。现在,让我们假设我们有一个 6x6 的 RGB 图像,因此它的尺寸将为 6x6x3,而不是 3x3 的滤镜,这次我们将使用 3x3x3 的滤镜。
输出大小仍为 4x4(与之前相同),但是,元素的计算方法是在每个通道中执行元素乘积,然后将它们相加,如下所示:

体积卷积:每个通道中的元素乘积,然后将它们相加。来源:https://indoml . com/2018/03/07/student-notes-convolutionary-neural-networks-CNN-introduction/
这里需要注意的一点是,输入和滤波器中的通道数必须相等。我们这样做的原因是,它允许我们在不同通道上使用不同的滤波器,比如在所有通道中使用边缘检测器,以提取更有意义的信息。所以想法是一样的。在输出要素地图中获取尽可能多的信息。
注意:过滤器中的通道数通常没有明确规定。假设它等于输入的深度。例如,如果我们有一个尺寸为 26x26x64 的输入,我们使用一个尺寸为 3x3 的滤波器进行卷积,这意味着滤波器中的通道数将为 64,因此其实际尺寸为 3x3x64。
使用多个过滤器的卷积:
现在我们知道如何对体积进行卷积,那么增加滤波器的数量怎么样?每个过滤器提取一些特征,像一个是提取垂直边缘,另一个是水平或 45 度线等。换句话说,扩展卷积以使用多个滤波器。
扩展我们的工作示例,我们仍然有一个 6x6x3 的输入。现在,我们有两个 3x3 维度的过滤器,而不是一个(深度为 3 是隐含的)。使用每个滤波器以类似的方式执行卷积操作。因此,我们将获得两个 4x4 输出特征地图。将一个堆叠在另一个之上,我们可以说输出尺寸为 4x4x2,如下所示:

使用 2 个滤波器的卷积。输出是两个 4x4 特征地图。每个过滤器一个来源:https://indoml . com/2018/03/07/student-notes-convolutionary-neural-networks-CNN-introduction/
因此,我们现在可以根据过滤器的数量来检测多个特征。卷积的真正力量得到了释放,因为现在我们可以从输入中提取大量的语义信息。
让我们考虑一个例子来理解多个过滤器中存在的值(权重)的数量:
Input Volume dimensions: **26x26x64**
filter Size: **3x3**(since input depth=64, filter depth will also be 64)
and we have **32** such filters being used for feature extraction**Hence, total number of weights in our filter will be:**
weights in one filter = **3 x 3 x 64 = 576**
Total filters = **32**
Total weights = **32 x 576 = 18,432**
这都是关于卷积运算的。现在让我们看看 CNN 中的典型卷积层是什么样子的:
卷积层:
在上面的例子中,我们得到了两个 4x4 的输出图。现在,我们将为每个输出图添加一个偏差。偏差是一个实数,我们将它添加到每个特征图的所有 16 个元素中。偏差就像线性方程中添加的截距,用于模拟真实世界的场景。然后,我们将通过应用激活函数来添加非线性。
没有激活函数的神经网络将简单地是线性回归模型**,**,其能力有限,并且在大多数时间不能很好地工作。如果没有激活功能,我们的神经网络将无法学习和模拟复杂类型的数据,如图像、视频等。
激活函数有多种选择,最流行的是 ReLU 激活函数。
ReLU 函数如果看到正整数,将返回相同的数字,如果看到负数,将返回零。
它纠正了消失梯度问题。此外,从 tanh 激活函数来看,它在收敛方面好了 6 倍。(关于激活功能的更多信息将在另一篇文章中介绍)。
下图描述了偏置加法,并将 ReLU 激活应用于我们的示例:

卷积层的整体计算
我们从 6x6x3 到 4x4x2 输出图的整个计算是 CNN 中的一个卷积层。卷积运算的目的是从输入图像中提取高级特征,例如边缘。 Convnets 不需要仅限于单个卷积层。
传统上,第一卷积层负责捕获低级特征,例如边缘、颜色、梯度方向等。随着图层的增加,该架构也适应了高级功能,为我们提供了一个对数据集中的图像有全面了解的网络,就像我们会做的那样。
池层:
除了卷积层, convnets 还使用池层来减少我们的表示大小,以加快计算速度。池化负责减小卷积要素的空间大小,从而降低处理数据所需的计算能力。
该操作的工作原理如下:

在图(左)中,以步幅 2 遍历输入图像上的 2×2 窗口,并且最大值保留在每个象限中。这被称为最大池操作。
最常见的形式是池图层,其大小为 2x2 的过滤器以 2 的步长应用,沿宽度和高度对输入中的每个深度切片进行 2 倍缩减采样。直觉是,如果在任何象限中存在一个特性,池将通过保持激活功能将启动的高数值来试图保留该特性
池化减少了要处理的要素地图系数的数量,并促使网络学习要素的空间等级,即,使连续的卷积层根据它们覆盖的原始输入的部分来查看越来越大的窗口。

两种类型的汇集操作
有两种类型的池:最大和平均池**。**最大池返回过滤器覆盖的图像部分的最大值。平均池返回内核覆盖的图像部分的所有值的平均值。
注意:在池化层的培训中没有需要学习的参数。具有较大感受野的池大小具有太大的破坏性。
完全连接层:
完全连接图层的目的是获取卷积/池化过程的结果,并使用它们将图像分类到标签中。这些层的作用与传统深度神经网络中的层相同。主要区别是输入将是由 CNN 的早期阶段(卷积层和池层)创建的形状和形式。

完全连接的层
展平是将数据转换为一维数组,以将其输入到完全连接的层。

展平,FC 输入层,FC 输出层
FC 输入层将展平的矢量作为输入,并应用权重和激活来预测正确的标签。FC 输出层给出了每个标签的最终概率。两层的区别在于激活功能。ReLU 输入,softmax 输出。(我们将在另一篇文章中对此进行更深入的讨论)
总结:
- CNN 主要有两个目标:特征提取和分类。
- CNN 有三层,即卷积层、汇集层和全连接层。CNN 的每一层都学习越来越复杂的过滤器。
- 第一层学习基本的特征检测过滤器:边缘、拐角等
- 中间层学习检测物体部分的过滤器。对于面部,他们可能会学会对眼睛、鼻子等做出反应
- 最后一层有更高的表现:他们学习识别不同形状和位置的完整物体。

CNN 架构示例
要实现一个示例 CNN,您可以在这里按照的指导实现。
用于在移动设备上检测图像中的对象的深度学习
使用 Expo、React-Native、TensorFlow.js 和 COCO-SSD 开发移动对象检测应用程序

作者照片
最近我发表了一篇文章【1】,演示如何使用Expo【2】、React【3】和React Native【4】开发一个多页面移动应用程序,该应用程序使用 tensor flow . js【5】和一个预先训练好的卷积神经网络模型 MobileNet 在移动设备上进行图像分类。
如[1]中所述,React【3】是一个用于构建 Web 用户界面的流行 JavaScript 框架。Reactive Native 继承和扩展了组件框架(如组件、道具、状态、 JSX 等)。)的 React,以支持使用预构建的原生组件(如视图、文本、*触摸不透明、*等)开发原生 Android 和 iOS 应用。特定于移动平台的语言(例如 Object-C、Swift、Java 等)中的本机代码。)通常使用 Xcode 或 Android Studio 开发。为了简化移动应用程序开发,Expo 为我们提供了一个围绕 React 原生和移动原生平台构建的框架和平台,允许我们使用 JavaScript/TypeScript 在 iOS、Android 和 web 应用程序上开发、构建和部署移动应用程序。因此,任何文本编辑器工具都可以用于编码。
关于机器学习移动应用,tensor flow . js for React Native是我们训练新的机器学习和深度学习模型和/或直接在移动设备上使用预训练模型进行预测和其他机器学习目的的强大使能器。
在本文中,与[1]类似,我开发了一个多页面移动应用程序来演示如何使用 TensorFlow.js [5]和一个预训练的卷积神经网络模型 COCO-SSD [6][7],一个新的 SSD(单次多盒检测器)[8],用于在移动设备上检测图像中的 COCO(上下文中的常见对象)[9]。
与[1]类似,这个移动应用在 Mac 上开发如下:
- 使用 Expo 生成多页面应用程序模板
- 安装库
- 在 React JSX 开发移动应用代码
- 编译和运行
假设最新的 node.js 已经安装在你的本地电脑/笔记本电脑上,比如 Mac。
1.正在生成项目模板
为了使用 Expo CLI 自动生成一个新的项目模板,首先需要安装 Expo CLI :
npm install *expo-cli*
然后可以生成一个新的 Expo 项目模板,如下所示:
expo init *coco-ssd
cd coco-ssd*
本文中的项目名称为 coco-ssd 。
如[1]中所述,我选择世博管理工作流的选项卡模板来自动生成几个示例屏幕和导航选项卡。TensorFlow logo 图像文件tfjs.jpg在本项目中使用,需要存储在生成的。/assets/images 目录。
2.安装库
为移动设备开发对象检测应用程序需要安装以下库:
- @tensorflow/tfjs ,即 TensorFlow.js,一个用于训练和部署机器学习模型的开源硬件加速 JavaScript 库。
- @ tensor flow/tfjs-react-native,TensorFlow.js 在移动设备上新的平台集成和后端。
- @ React-Native-community/async-storage,React Native 的异步、未加密、持久、键值存储系统。
- @ tensor flow-models/coco-SSD,预训练模型,可以将图像作为输入,并返回一组最可能的对象类预测、它们的置信度和位置(边界框)。
- expo-gl ,提供了一个视图,作为 OpenGL ES 渲染目标,用于渲染 2D 和 3D 图形。
- jpeg-js ,node.js 的纯 javascript JPEG 编码器和解码器
npm install [*@react*](http://twitter.com/react)*-native-community/async-storage* [*@tensorflow/tfjs*](http://twitter.com/tensorflow/tfjs)[*@tensorflow/tfjs-react-native*](http://twitter.com/tensorflow/tfjs-react-native) *expo-gl* [*@tensorflow*](http://twitter.com/tensorflow)*-models/coco-ssd jpeg-js*
此外,@ tensor flow/tfjs-react-native/dist/bundle _ resource _ io . js需要react-native-fs(react-native 的原生文件系统访问):
npm install *react-native-fs*
Expo-camera(为设备的前置或后置摄像头渲染预览的 React 组件)也是需要的,因为它在@ tensor flow/tfjs-React-native/dist/camera/camera _ stream . js中使用。
*expo install *expo-camera**
3.开发移动应用程序代码
如前所述,首先我使用 Expo CLI 自动生成示例屏幕和导航标签。然后,我修改了生成的屏幕,并添加了一个新的屏幕来检测图像中的对象。以下是生成的屏幕:
- 简介屏幕(参见图 2)
- 对象检测 COCO-SSD 屏幕(参见图 3 和图 4)
- 参考屏幕(参见图 5)
屏幕底部有三个相应的选项卡用于导航。
本文主要讨论 COCO-SSD 屏幕类(源代码见[10]),用于图像中的对象检测。本节的其余部分将讨论对象检测的实现细节。
3.1 准备 TensorFlow、COCO-SSD 模型和摄像机访问
生命周期方法componentidmount*()用于初始化 TensorFlow.js,加载预先训练好的 COCO-SSD 模型,在 COCO-SSD 屏幕的用户界面准备就绪后,获取移动设备上访问摄像头的权限。*
*async componentDidMount() {
await tf.ready(); // preparing TensorFlow
this.setState({ isTfReady: true});
this.model = await cocossd.load(); // preparing COCO-SSD model
this.setState({ isModelReady: true });
this.getPermissionAsync();
}getPermissionAsync = async () => {
if (Constants.platform.ios) {
const { status } = await Permissions.askAsync(Permissions.CAMERA_ROLL)
if (status !== 'granted') {
alert('Please grant camera roll permission for this project!')
}
}
}*
3.2 选择图像
一旦 TensorFlow 库和 COCO-SSD 模型准备就绪,就调用方法 selectImage ()来选择移动设备上的图像以进行对象检测。
*selectImage = async () => {
try {
let response = await ImagePicker.launchImageLibraryAsync({
mediaTypes: ImagePicker.MediaTypeOptions.All,
allowsEditing: true,
aspect: [4, 3]
}) if (!response.cancelled) {
const source = { uri: response.uri }
this.setState({ image: source })
this.detectObjects()
}
} catch (error) {
console.log(error)
}
}*
3.3 检测图像中的对象
一旦在移动设备上选择了图像,就会调用 detectObjects ()方法来检测图像中的对象。
在该方法中,首先使用 TensorFlow React Native 的 fetch API 在移动设备上加载选定的图像。然后调用方法 imageToTensor ()将加载的原始图像数据转换为 3D 图像张量。最后,调用准备好的 COCO-SSD 模型,以将 3D 图像张量作为输入,并生成检测到的对象的列表及其类别、概率和位置(边界框)。
*detectObjects = async () => {
try {
const imageAssetPath = Image.resolveAssetSource(this.state.image)
const response = await fetch(imageAssetPath.uri, {}, { isBinary: true })
const rawImageData = await response.arrayBuffer()
const imageTensor = this.imageToTensor(rawImageData)
const predictions = await this.model.detect(imageTensor)
this.setState({ predictions: predictions })
} catch (error) {
console.log('Exception Error: ', error)
}
}imageToTensor(rawImageData) {
const TO_UINT8ARRAY = true
const { width, height, data } = jpeg.decode(rawImageData, TO_UINT8ARRAY)
// Drop the alpha channel info for COCO-SSD
const buffer = new Uint8Array(width * height * 3)
let offset = 0 // offset into original data
for (let i = 0; i < buffer.length; i += 3) {
buffer[i] = data[offset]
buffer[i + 1] = data[offset + 1]
buffer[i + 2] = data[offset + 2]
offset += 4
}
return tf.tensor3d(buffer, [height, width, 3])
}*
注意, fetch API 有两个版本,一个是 React fetch API,另一个是 TensorFlow React Native 的 fetch API。正确的是 TensorFlow React Native 的 fetch ,可以安装如下:
*import { fetch } from ‘[@tensorflow/tfjs-react-native](http://twitter.com/tensorflow/tfjs-react-native)’*
3.4 上报对象检测结果
一旦物体检测完成,调用方法 renderPrediction ()在移动设备的屏幕上显示物体检测结果。
*renderPrediction = (prediction, index) => {
const pclass = prediction.class;
const score = prediction.score;
const x = prediction.bbox[0];
const y = prediction.bbox[1];
const w = prediction.bbox[2];
const h = prediction.bbox[3]; return (
<View style={styles.welcomeContainer}>
<Text key={index} style={styles.text}>
Prediction: {pclass} {', '} Probability: {score} {', '} Bbox: {x} {', '} {y} {', '} {w} {', '} {h}
</Text>
</View>
)
}*
4.编译和运行移动应用程序
本文中的移动应用程序由一个 react 本地应用服务器和一个或多个移动客户端组成。移动客户端可以是 iOS 模拟器、Android 模拟器、iOS 设备(例如,iPhone 和 iPad)、Android 设备等。我验证了 Mac 上的移动应用服务器和 iPhone 6+和 iPad 上的移动客户端。
4.1 启动 React 本地应用服务器
如[1]中所述,在任何移动客户端可以开始运行之前,移动应用服务器需要启动。以下命令可用于编译和运行 react 本地应用服务器:
*npm install
npm start*
如果一切顺利,应该会出现如图 1 所示的 Web 界面。

图 1: React 原生应用服务器。
4.2 启动移动客户端
一旦移动应用服务器开始运行,我们就可以在移动设备上启动移动客户端。
因为我在本文中使用 Expo [2]进行开发,所以在移动设备上需要相应的 Expo 客户端/应用程序。iOS 移动设备的 Expo 客户端应用程序在苹果商店免费提供。
在 iOS 设备上安装 Expo 客户端应用后,我们可以使用移动设备上的摄像头扫描 react 本地应用服务器的条形码(见图 1),以使用 Expo 客户端应用运行移动应用。
图 2 显示了 iOS 设备(iPhone 和 iPad)上移动应用程序的简介屏幕。

***图二:*介绍画面。
图 3 和图 4 示出了检测图像中物体的两种不同场景。图 3 示出了在图像中检测汽车和卡车的屏幕。

图 3: 检测图像中的汽车和卡车。
以下是对象检测的输出:
*Array [
Object {
"bbox": Array [
61.6607666015625,
700.927734375,
230.8502197265625,
185.11962890625,
],
"class": "car",
"score": 0.8818359375,
},
Object {
"bbox": Array [
292.78564453125,
651.4892578125,
279.60205078125,
160.94970703125,
],
"class": "truck",
"score": 0.61669921875,
},
]*
图 4 示出了检测图像中的人的屏幕。

图 4: 检测图像中的人。
图 5 显示了参考屏幕。

图 5: 参考屏幕。
5.摘要
与[1]类似,在本文中,我使用 Expo [2]、、React JSX、[3]、React Native [4]、React Native 的 TensorFlow.js 和预训练的卷积神经网络模型 COCO-SSD [6]开发了一个多页面移动应用程序,用于在移动设备上检测图像中的对象。
我验证了 Mac 上的移动应用服务器和 iOS 移动设备(iPhone 和 iPad)上的移动应用客户端。
正如[1]和本文所展示的那样,这种移动应用程序有可能被用作开发其他机器学习和深度学习移动应用程序的模板。
本文的移动应用程序项目文件可以在 Github [10]中找到。
参考
- Y.张,面向移动设备的图像分类深度学习
- 世博会
- 反应过来
- 反应原生
- tensor flow . js for React Native
- COCO-SSD
- J.黄等,现代卷积目标检测器的速度/精度权衡
- W.刘等, SSD:单次多盒探测器
- 林廷烨等,微软 COCO:上下文中的公共对象
- Y.张, Github 中的手机 app 项目文件
用于移动设备上图像分类的深度学习
使用 Expo、React-Native、TensorFlow.js 和 MobileNet 开发移动影像分类应用程序

React 是一个流行的 JavaScript 框架,用于构建 Web 用户界面。 Reactive Native 继承和扩展了组件框架(如组件、道具、状态、等)。)来支持原生 Android 和 iOS 应用程序的开发,使用预先构建的原生组件,如视图、文本、*触摸不透明、*等。本机代码通常使用 Xcode 或 Android Studio 开发。
Expo 是一个围绕 React 原生和移动原生平台构建的框架和平台,允许我们从相同的 JavaScript/TypeScript 代码库开发、构建和部署 iOS、Android 和 web 应用上的移动应用。JavaScript/TypeScript 代码可以使用任何文本编辑器工具来开发。
随着tensor flow . js for React Native的发布,现在可以在移动设备上训练新的机器学习和深度学习模型和/或使用预训练的模型进行预测和其他机器学习目的。
在本文中,与[3]类似,我使用 Expo [4]和 React Native [5]开发了一个多页面移动应用程序,该应用程序使用 TensorFlow.js [1]和预训练的卷积神经网络模型 MobileNet [2]在移动设备上进行图像分类。
此移动应用程序在 Mac 上开发如下:
- 使用 Expo 生成多页面应用程序模板
- 安装库
- 在 React JSX 开发移动应用代码
- 编译和运行
1.使用 Expo 生成项目模板
为了使用 Expo CLI 自动生成新的项目模板,首先需要安装 Expo CLI :
npm install *expo-cli*
然后可以生成一个新的 Expo 项目模板,如下所示:
expo init *react-native-deeplearning
cd react-native-deeplearning*
本文中的项目名称为react-native-deep learning。
如下所示,我选择 Expo managed workflow 的选项卡模板来自动生成几个示例屏幕和导航选项卡。

TensorFlow logo 图像文件tfjs.jpg【3】在本项目中使用,需要存储在生成的。/assets/images 目录。
2.安装库
需要为移动设备上的影像分类应用程序安装以下库:
- @tensorflow/tfjs ,即 TensorFlow.js,一个用于训练和部署机器学习模型的开源硬件加速 JavaScript 库。
- @ tensor flow/tfjs-react-native,TensorFlow.js 在移动设备上新的平台集成和后端。
- @ React-Native-community/async-storage,React Native 的异步、未加密、持久、键值存储系统。
- @ tensor flow-models/mobilenet,预训练模型,可以将图像作为输入,并返回一组最有可能的预测及其置信度。
- expo-gl ,提供了一个充当 OpenGL ES 渲染目标的视图,用于渲染 2D 和 3D 图形。
- jpeg-js ,node.js 的纯 javascript JPEG 编码器和解码器
npm install [*@react*](http://twitter.com/react)*-native-community/async-storage* [*@tensorflow/tfjs*](http://twitter.com/tensorflow/tfjs)[*@tensorflow/tfjs-react-native*](http://twitter.com/tensorflow/tfjs-react-native) *expo-gl* [*@tensorflow*](http://twitter.com/tensorflow)*-models/mobilenet jpeg-js*
此外,react-native-fs(react-native 的本地文件系统访问)是*@ tensor flow/tfjs-react-native/dist/bundle _ resource _ io . js*所需要的:
npm install *react-native-fs*
由于在@ tensor flow/tfjs-React-native/dist/camera/camera _ stream . js中使用了Expo-camera(为设备的前置或后置摄像头渲染预览的 React 组件)。
*expo install *expo-camera**
3.开发移动应用程序代码
如前所述,首先,我使用 Expo CLI 自动生成示例屏幕和导航标签。然后,我修改了生成的屏幕,并添加了一个新的图像分类屏幕。因此(详见下一节),我创建了三个屏幕:
- 简介屏幕(参见图 3)
- 图像分类屏幕(见图 4)
- 参考屏幕(参见图 5)
屏幕底部有三个相应的选项卡用于导航。
本文重点介绍图像分类屏幕类(源代码见[7])。本节的其余部分将讨论实现细节。
3.1 准备 TensorFlow、MobileNet 模型和摄像机访问
生命周期方法componentidmount*()用于初始化 TensorFlow.js,加载预先训练好的 MobileNet 模型,在图像分类屏幕的用户界面准备就绪后,获取在移动设备上访问相机的权限。*
*async componentDidMount() {
await tf.ready(); // preparing TensorFlow
this.setState({ isTfReady: true,}); this.model = await mobilenet.load(); // preparing MobileNet model
this.setState({ isModelReady: true }); this.getPermissionAsync(); // get permission for accessing camera on mobile device
}getPermissionAsync = async () => {
if (Constants.platform.ios) {
const { status } = await Permissions.askAsync(Permissions.CAMERA_ROLL)
if (status !== 'granted') {
alert('Please grant camera roll permission for this project!')
}
}
}*
3.2 选择图像
一旦 TensorFlow 库和 MobileNet 模型准备就绪,就会调用方法 selectImage ()来选择移动设备上的图像以进行模型预测。
*selectImage = async () => {
try {
let response = await ImagePicker.launchImageLibraryAsync({
mediaTypes: ImagePicker.MediaTypeOptions.All,
allowsEditing: true,
aspect: [4, 3]
}) if (!response.cancelled) {
const source = { uri: response.uri }
this.setState({ image: source })
this.classifyImage()
}
} catch (error) {
console.log(error)
}
}*
3.3 图像分类
与[3]类似,一旦在移动设备上选择了一幅图像,就会调用 classifyImage ()方法进行图像分类。
在该方法中,首先使用 TensorFlow React Native 的 fetch API 在移动设备上加载选定的图像。然后调用方法 imageToTensor ()将加载的原始图像数据转换为 3D 图像张量。最后,调用准备好的 MobileNet 模型以将 3D 图像张量作为输入,并生成具有概率/置信度的前 3 个预测。
*classifyImage = async () => {
try {
const imageAssetPath = Image.resolveAssetSource(this.state.image)
const response = await fetch(imageAssetPath.uri, {}, { isBinary: true })
const rawImageData = await response.arrayBuffer()
const imageTensor = this.imageToTensor(rawImageData)
const predictions = await this.model.classify(imageTensor)
this.setState({ predictions: predictions })
} catch (error) {
console.log('Exception Error: ', error)
}
}imageToTensor(rawImageData) {
const TO_UINT8ARRAY = true
const { width, height, data } = jpeg.decode(rawImageData, TO_UINT8ARRAY)
// Drop the alpha channel info for mobilenet
const buffer = new Uint8Array(width * height * 3)
let offset = 0 // offset into original data
for (let i = 0; i < buffer.length; i += 3) {
buffer[i] = data[offset]
buffer[i + 1] = data[offset + 1]
buffer[i + 2] = data[offset + 2] offset += 4
} return tf.tensor3d(buffer, [height, width, 3])
}*
注意 fetch API 有两个版本,一个是 React fetch API,另一个是 TensorFlow React Native 的 fetch API。
务必为 TensorFlow React Native 导入正确的 fetch API,如下所示,以避免类似“filereader.readasarraybuffer 未在 React Native 中实现”的错误:
*import { fetch } from ‘[@tensorflow/tfjs-react-native](http://twitter.com/tensorflow/tfjs-react-native)’*
3.4 报告图像分类结果
一旦图像分类完成,调用方法 renderPrediction ()在移动设备的屏幕上显示预测结果。
*renderPrediction = (prediction) => {
return (
<View style={styles.welcomeContainer}>
<Text key={prediction.className} style={styles.text}>
Prediction: {prediction.className} {', '} Probability: {prediction.probability}
</Text>
</View>
)
}*
4.编译和运行移动应用程序
本文中的移动应用程序由一个 react 本地应用服务器和一个或多个移动客户端组成。移动客户端可以是 iOS 模拟器、Android 模拟器、iOS 设备(例如,iPhone 和 iPad)、Android 设备等。我验证了 Mac 上的移动应用服务器和 iPhone 6+和 iPad 上的移动客户端。
4.1 启动 React 本地应用服务器
移动应用服务器需要在任何移动客户端开始运行之前启动。以下命令可用于编译和运行 react 本地应用服务器:
*npm install
npm start*
如果一切顺利,应该会出现如图 1 所示的 Web 界面。

4.2 启动移动客户端
一旦移动应用服务器开始运行,我们就可以在移动设备上启动移动客户端。
因为我在本文中使用 Expo [4]进行开发,所以在移动设备上需要相应的 Expo 客户端/应用程序。iOS 移动设备的 Expo 应用程序在 Apple Store 中提供。

***图 2:*Apple Store 中的 Expo 客户端 app。
在 iOS 设备上安装 Expo 客户端应用后,我们可以使用移动设备上的摄像头扫描 react 本地应用服务器的条形码(见图 1),以使用 Expo 客户端应用运行移动应用。
图 3、4、5 显示了移动应用程序在 iOS 设备(iPhone 和 iPad)上的结果屏幕。

***图 3:*iOS 设备上的介绍画面。

***图 4:*iOS 设备上的图片分类屏幕。

***图 5:*iOS 设备上的参考屏幕。
5.摘要
在本文中,我使用 Expo [4]、、React JSX、React Native [5]、TensorFlow.js [1]和预训练的卷积神经网络模型 MobileNet [2]开发了一个用于移动设备上图像分类的多页面移动应用程序。
我验证了 Mac 上的移动应用服务器和 iOS 移动设备(iPhone 和 iPad)上的移动应用客户端。
这款移动应用有可能被用作开发其他机器学习和深度学习移动应用的模板。
Github [7]中提供了移动应用程序项目文件。

















 511
511

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}