







我不相信电子——续集
戴上你的金属头盔…今天是粉丝感谢日

作者:“危险”和“有毒”照片:霍克电影公司
上个月,我发表了一篇调皮的文章《我不相信电子》,鼓吹不可知论的科学观,贬低其现代崇拜(https://towards data Science . com/I-Don-Don-Believe-in-electronics-8f1b 59 ad C1 EC)。来自资深科学家同行的如此多的积极回应让我不知所措。感谢您的所有评论和交流。其中一个例子是奥利弗·赖辰斯坦(@reichenstein)的这条慷慨的推文:【这是我几个月来读到的最顽强的文章。充满了伟大的引用位。是的,费耶阿本德在娱乐。但是,第一名是约瑟夫·赫茨林格(@赫茨利),他完美地抓住了这种精神:
“每当科学家说‘我不相信电子’,某个地方就会有一个电子死去。”
现实主义的捍卫者在哪里?
最令人惊讶的结果是,似乎没有多少现实主义者存在……或者至少没有人能够提出一个论点。我对此感到失望,因为我渴望听到他们的反驳意见。为什么要冒风险宣称确定呢?在大自然的奇迹面前,我更喜欢谦逊。
好的。现在到了有趣的部分。异议者…有两种口味。
#1。不要把我们的脏衣服挂在公共场合
有相当多的回应,如“我不反对你,但这样的论点可能会被公众滥用。”争论大概是这样的:“在大众的手中,反现实主义可能被用来支持扁平地球论者、神创论者、勒德分子、反恐怖分子,[或者其他真实的或想象的威胁]。”这些批评者似乎害怕科学民主化,害怕失去公共资金或什么的。也许我们应该恢复用拉丁文出版。
我从未见过“地球是平的”,我怀疑他们只存在于社交媒体的想象中。我见过各种各样的神创论者。我不害怕它们,也不认为它们是医学进步的威胁。大多数轻度摄入咖啡因的人认为科学和信仰之间没有冲突,但我坚持我的开放立场:科学不是信仰的问题。
#2。但是……科学!
少数直言不讳的人变得完全精神错乱,大喊“危险”和“有毒”等形容词,但带有悲剧性的反驳。最令人愤怒的反应似乎来自年轻人和非科学家。作为慈善机构,大多数人似乎混淆了反现实主义和反科学。再一次说明:暂时接受一个理论及其效用并不等同于相信它是正确的。

当我在大学的时候,教授们只是假设你已经读过*科学革命的结构,*并且他们已经听厌了。我也这么认为,因为这本书比大多数机场小说卖得都多。我记得我的一位教授抱怨说,“实用主义在美国如此占主导地位,真奇怪他们还在教哲学。”(我认为他是一个现实主义者,他认为不可知论是懒惰的)。所以,令我惊讶的是,这些读者中有许多人从未听说过反现实主义。在一个奇怪的传统颠倒中,年轻一代似乎已经用“发誓忠于传统智慧”取代了“颠覆主导范式”的口号。
有趣的困惑
最令人困惑的海报向我解释说,一个“电子是真正的数学对象。”我不知道从哪里开始。
另一个被贴上标签的复杂性理论是“伪科学”。我指的是数学中使用的复杂性,它至少在一个方面不同于科学:数学命题可以被证明为真。
另一位读者想象他看到了安·兰德(真的!)并认为这篇文章具有“经典计算视角”(大概这是某种坏科学)。他向我们保证有一种科学方法,但没有向我们透露秘方。但是他至少为溯因推理的方法的局限性提供了一个绝技演示。他继续宣称“可重复的发现是科学中的基本‘真理’。”我很高兴他澄清了这一点。
我希望这些反对意见大多只是酒后发短信。但是,当我努力去理解它们的时候,我又一次想起了保罗·费耶阿本德,有人问他:“为什么你被认为是科学最大的敌人?“⁴”他的回答,带着顽皮的笑容:“我不知道。”
Russell Anderson 拥有加州大学生物工程博士学位和电气工程学士学位。他的学术研究涉及生物系统的学习(神经、免疫和进化)。他在洛斯阿拉莫斯和利弗莫尔国家实验室、加州大学(伯克利、旧金山、戴维斯和尔湾)、史密斯-凯特尔维尔眼科研究所和加州卫生部进行研究生研究。他曾在 IBM、Opera Solutions、HNC Software、KPMG、NICE/Actimize、HCL、Mastercard、JP Morgan Chase 和苏格兰哈利法克斯银行担任首席科学家。他发表了 30 多篇科学论文,拥有 5 项商业预测系统专利。
欢迎提问/评论:anderson.transactionanalytics@outlook.com
1.r 安德森(2020)我不相信电子。走向数据科学【https://medium.com/me/stats/post/8f1b59adc1ec
2.托马斯·s·库恩(1962)。*科学革命的结构。*芝加哥大学出版社
3.约翰·霍根(1996 年)。科学的终结:在科学时代的黄昏面对知识的极限。艾迪森-韦斯利
我终于明白了反向传播:你也可以…
为什么梯度是最陡上升的方向。

反向传播算法是训练神经网络的关键因素之一,但它也可能是理解事物实际工作方式时最难掌握的概念。至少在我自己的经历中,这是我一直努力去深入理解的一件事。在这个主题的大量材料之间变戏法之后,我有了自己的灵光一现,所有的东西都到位了。像我一样,你也可能通过在线课程自学,可能已经完成了几个项目,但你仍然会感觉到那种 一知半解、 模糊理解训练神经网络(或任何其他机器学习模型)时实际发生的事情的痛苦。
在这篇博文中,我将让你了解我的直觉,希望你能在此基础上更好地理解这个非常重要的概念。我还提供了对我有很大帮助的资源的链接。
让我们从梯度下降开始
但是为什么呢?因为这是我最容易忽略的一点。许多在线课程会告诉你梯度下降法找到了损失函数相对于权重的partial derivative(即。梯度)并在与该梯度相反的方向上迈出一步;因为坡度指向最陡上升的方向,向相反方向迈一步将意味着我们向最陡下降的方向移动。但他们从不说明为什么,我是说为什么的为什么。我们朝着与梯度相反的方向迈出一步,因为它指向最陡上升的方向,但问题是:为什么梯度是最陡上升的方向?
查看渐变
梯度只是一个包含函数所有偏导数的向量。因此,这里的关键思想实际上是partial derivatives的概念。偏导数告诉我们,当我们保持除一个输入变量之外的所有输入变量不变,并向不固定的那个变量的方向稍微移动时,函数会改变多少。
另外,典型的神经网络包含数千个参数,但是为了简单和易于可视化,我们将考虑具有两个变量的函数:𝑓(𝑥,𝑦).幸运的是,我们在这里所做的一切可以很好地推广到任何数量的维度。
对于我们的两个变量的情况,偏导数告诉我们,如果我们保持𝑦变量不变,并在𝑥方向稍微移动一下,函数的输出会改变多少,反之亦然。
具体来说

作者图片
我们在输入空间中的点(2, 3)处,该点对应于输出平面中的特定点t,即对于输入(2, 3),我们的函数的输出为t。相对于𝑥的偏导数告诉我们,如果我们保持𝑦固定在3并稍微向𝑥方向移动,会导致多少变化。类似地,当𝑥固定在2并且我们向𝑦方向移动一点点时,对𝑦的偏导数测量了由此产生的产出变化。
我们来考虑一下函数:𝑓(𝑥,𝑦)=xy。相对于 x ,∂f/∂x 的偏导数为 2 xy ,即。我们保持 y 为常数,并对整项进行微分。同样,关于 y ,∂f/∂y 的偏导数是 x 。
记住梯度把所有的偏导数打包成一个向量,这个函数的梯度是:∇𝑓 = [2𝑥𝑦,𝑥 ]。在点(2, 3),梯度将是∇𝑓=[12,4】。因此,纯粹在x方向上的轻微推动将导致函数输出发生12倍的变化,而在y方向上的类似变化将导致函数输出发生4倍的变化。
尝试推导函数的偏导数:𝑔(𝑥,𝑦)=3𝑥𝑦。希望不难看出这个函数的梯度是:∇𝑔=[3𝑦,9𝑥𝑦】。
偏导数的问题在于,它们只告诉我们,如果我们只朝一个方向运动,事情会如何变化。偏导数是partial,因为它们都没有告诉我们,当输入改变时,函数 f ( x , y )是如何变化的。然而,我们不仅想知道当我们沿 x 或 y 方向移动时,事物是如何变化的,我们还想知道如果我们在输入空间内沿任意方向移动,事物会发生多大的变化。这正是directional derivatives的作用。
方向导数
一个方向上的方向导数,比如说𝑤⃗,告诉我们,如果我们在向量𝑤⃗.的方向上轻微移动,函数的输出会改变多少方向导数是通过取函数的梯度和𝑤⃗ ie 的dot product得到的。我们想要前进的方向。

如果𝑤⃗ =[3,5],那么方向导数:

评估点(2,3)的方向导数:

这意味着,假设我们在输入平面上的点(2, 3),在向量(3, 5)的方向上迈出一小步,我们函数的输出就会改变56倍。看待这一点的另一种方式是考虑在我们的输入平面(即 x,y 平面),该平面中的任何点或方向都可以被认为是𝑥和𝑦方向上的运动的组合。

作者图片
在上图中,𝑤⃗ =[3,5]是𝑥方向的 3 步和𝑦方向的 5 步的组合。因此,直觉上,沿着某个任意方向迈出一步,会导致 x 轴和 y 轴的变化。取方向导数的点积,将 x 轴和 y 轴上的变化相加。
现在我们有了方向导数,它本质上是偏导数的推广,用来处理输入平面上的任意方向。在训练神经网络时,我们寻求解决的问题是:假设我们处于某个点,比如说对应于损失(我们函数的输出)为t的(2, 3),我们想知道导致我们损失最大增加的方向?一旦我们知道这个方向,我们就向相反的方向迈出一步,这将导致损失的最大减少。请注意,我有意强调了单词方向。我们正在寻找最佳方向,幸运的是,我们已经有了一个工具,可以衡量一个特定方向有多好(或多坏),正如你可能已经猜到的那样,这就是directional derivative。
有了方向导数,我们可以解决这个问题的一个方法是找到所有可能运动方向的方向导数。最佳方向将是具有最大方向导数的方向。但是计算起来太慢了,想想我们可能移动的方向,这个列表是无穷无尽的。但是,想法是好的,我们只是需要一个更简单的方法,找到方向导数最大的方向。
寻找最陡上坡的方向
我们现在的目标是找到:

请注意,上式中的向量的大小或长度为 1。从某种意义上来说,这确保了我们不会因为向量比其他向量大而选择错误的向量,从而最大化点积,即使它指向错误的方向。
如前所述,方向导数是通过梯度和指向我们想要的方向的矢量的点积得到的。点积有一个非常好的性质,可以让我们找到最大化方向导数的方向,而不必考虑所有可能的方向。点积衡量两个向量之间的相似性。它给两个向量在同一方向上的移动量打分。形式上,两个向量𝑢⃗和𝑣⃗之间的点积是:

其中𝜃是两个向量之间的角度。

作者图片
在上图中,当𝑢⃗ =[0,1]和𝑣⃗ =[1,0]时,他们的点积为 0,因为他们之间没有相似性,𝑢⃗完全指向𝑥方向(它没有𝑦分量,而𝑣⃗也完全指向𝑦方向)。它们之间的角度是 90 度(它们是垂直的),𝑐𝑜𝑠(90 = 0 度。当𝑢⃗ =[0,1]和𝑣⃗ =[0,1]时,点积最大化,因为它们指向相同的方向。在这种情况下,点积是 1,因为它们之间的角度是 0。

向量的大小不会影响点积的结果,因为两个向量的大小都是 1。因此,使用上述公式的点积结果取决于两个向量之间的角度。从前面所述,我们不难理解这样一个事实,即对于单位长度的矢量,当两个矢量平行时,即它们指向相同的方向或它们之间的角度为 0°时,点积最大。
为了提醒我们的目标,我们希望找到使方向导数最大化的向量:

方向导数也是一个点积,所以从我们对点积的理解中可以很自然地得出,使方向导数最大化并导致函数最大增量的向量,是指向与梯度相同方向的向量,也就是梯度本身。这就是为什么坡度是上升最陡的方向。梯度下降朝相反的方向迈出了一步,因为我们在训练中的目标是使损失函数最小化,而不是最大化。
希望你从这篇文章中获得了一些有用的见解,帮助你巩固对神经网络和其他机器学习算法的基础的理解。下一篇博文将着眼于链式法则,这是反向传播背后的另一个主要概念。
资源
偏导数和方向导数:可汗学院:多元微积分
点积:可汗学院:线性代数微积分: 3Blue1Brown
你被解雇了
如何发展和管理一个快乐的数据科学团队

艾伦·布兰科·特耶多尔在 Unsplash 上的照片
TLDR: 大多数 ML 团队不喜欢做数据和基础设施方面的工作,因为这不如建模有趣。对这个问题管理不当会导致高流动率和有害的团队氛围。我想分享一个叫做洞察驱动开发(IDD)的解决方案,几个例子,以及采用它的五个步骤。IDD 的目标是创建一个高绩效、敬业、快乐的数据科学团队,该团队既接受有趣的 ML 内容,也接受非 ML 工作。
喜欢读什么? 跟我上 中 , 领英 , 推特 。查看我的《 用机器学习影响 》指南。它有助于数据科学家更好地交流。
免责声明 :这篇文章没有得到我工作的任何公司的支持或赞助。我交替使用术语分析、数据科学和 ML。
你被解雇了!
“嘿,伙计,没用的。我们必须让你退出这个项目。不好意思。”亚历克斯,一个能干的数据科学家,不带感情地看着我。我感到无助、紧张和悲伤。
他可能在用最激烈的语言诅咒我。
因此,我刚刚“解雇”了项目中两位数据科学家中的一位。 为什么?亚历克斯讨厌做数据工作。他对此直言不讳。他用各种借口把它“卸”给别人。我们讨论过这个问题。他仍然做着半吊子的工作。其他人感到沮丧,抱怨为什么只有亚历克斯可以做酷的事情。如果这种情况继续下去,我们作为一个团队将会失败。那么,我们到了。
“嘘*t 老兄。我很抱歉。”亚历克斯说,终于。该死,真尴尬。
问题是
“亚历克斯问题”在数据科学团队中相当普遍。许多数据科学家感到无聊和没有动力。我认为有两个根本原因:
- 数据科学团队想要做的事情与我们在现实世界中需要做的事情之间存在差距
- 非数据科学家希望培养最受欢迎的技能
解决方案
那天,我“处理”了 Alex 的问题,我感到很紧张。那一刻,建立高效、敬业、快乐的数据科学团队成了我的使命。
至少,我想要一个鼓励数据科学团队接受非 ML 工作并从中获得乐趣的系统。好吧,显而易见的解决办法就是强迫人们去做(我们都是拿工资去工作的,对吧?).但这是不可持续的。因此,解决方案必须是实用的、愉快的、自我激励的。
在接下来的几年里,我开始了尝试和混合来自产品管理、敏捷软件开发和管理咨询的核心思想的旅程。我想我找到了解决方案:洞察驱动开发(IDD)。
本文的范围
通常,有两种类型的 ML 项目:以业务为中心的和基于软件的项目。在本文中,让我们在**以业务为中心的 ML 项目的背景下讨论 IDD 的原则。**这些项目的输出通常是管理层的演示或仪表板。团队需要使用特定的 ML 技术,从简单到复杂,以找到一些洞察力。
取决于这篇文章如何做,我可以深入研究 1)IDD 如何在项目的早期、中期和后期阶段工作,以及 2)如何使 IDD 适应以软件为中心的 ML 项目(例如,输出是与核心操作集成的全栈解决方案)。
关于团队的假设
要利用 IDD,你要么需要一个有经验的团队,他们有独特的手艺,有尝试新事物的动力,要么需要一群初级通才,他们有动力,能把事情做好,有可塑性。如果不是,IDD 不适合你的团队(你应该重新审视一下你的招聘策略)。
让我们进入正题:缺碘症原则
IDD 归结为做两件不同的事情:
- 如何确定每个团队成员的工作范围(例如,也称为“工作包”,每个人都需要交付的东西)。
- 如何根据人的力量分配责任
首先,让我们通过一个示例来看看工作包是如何被不同地定义的。下面是同一个项目的两个积压无 IDD 和有 IDD ,在同一个 冲刺 ,有相同的近期目标。

无(左)和有(中)IDD 的工作包比较;详细的工作包定义(右);作者自己的分析
**我们通常如何管理 ML 项目?**在大多数 ML 项目中,我们将工作包分为四组:
- 数据
- 分析(我将此作为一个涵盖探索性分析和模型开发的总括术语)
- 软件(如系统集成、基础设施设置和 CICD)
- UI 设计和开发。
如果是管理咨询类型的约定,一些项目可能有业务垂直。
**有什么变化?**在 IDD 中,最明显的变化是有了更多的“分析”项目(黄色的东西)。在一种分析中,每个分析项目都被仔细地措辞;每个分析都旨在驱动出有趣的见解;基于我们的假设,每一个洞察都有助于解决更大的业务问题。因此,这种方法被称为洞察驱动开发。
**数据和基础设施工作会发生什么变化?*如果我们仔细观察,在“完成的定义”中,每个分析项目都包括 ETL 和基础设施*数据和基础设施工作仍然非常关键。我们并没有回避它们,而是把它们作为洞察之旅的一部分。这种方法有一定的注意事项。例如,一些数据和基础设施工作必须是独立的,尤其是在项目的早期阶段。我们将在后续文章中讨论更多内容。
我们如何分配工作?与分析相关的项目似乎更多了。将它们全部分配给数据科学家是不现实的。人们有不同的优势、经历和兴趣。因此,这就把我们带到了 IDD 的第二个方面:责任分配。
通常,角色定义了人们的责任。例如,数据工程师拥有并处理所有数据,并且可能只处理与数据相关的东西。

无 IDD:ML 项目所有权结构示例;作者自己的分析
在 IDD 中,每个人的责任从他们的直接角色转移到产出。该团队“围绕一种洞察力开展工作”每个人都拥有最终交付的见解。为了保持质量的平衡,每个专家设定标准,领导程序设计(如果需要的话),并成为其领域专业知识的最终质量把关人。

IDD:ML 项目所有权结构示例;作者自己的分析
考虑到这一点,无论有无 IDD,工作分配都会是这样的。主要的区别在于,人们可以在他人的支持下领导他们直接角色和领域之外的工作。

角色类型(左),不带 IDD 的分配(中)和带 IDD 的分配(右);作者自己的分析
请注意,特定的工作仍然需要高度专业化的技能,最好分配给专家。作为项目负责人,您需要监控工作量,并为领导其专业知识之外的工作的人(例如,创建客户分析的数据工程师)提供足够的指导。每个团队成员都需要紧密合作,并交流期望和时间安排。
好处
我一直在与具有不同经验的业务分析师、数据专家、数据科学家和软件工程师团队一起,在以业务和软件为重点的 ML 项目中使用 IDD。它一直工作得很好,我将继续使用和完善 IDD。具体来说,IDD 之所以有效,是因为它让每个人都可以:
- 参与解决问题的过程(更有趣)
- 了解他们的工作如何直接有助于最终目标的实现(更加投入)
- 了解如何在给定更多上下文(更多质量)的情况下改进他们的设计
- 获得在新领域工作的机会(更多学习)
- 继续成为他们领域的专家(同样确定)
每个公司的每个团队都有不同的工作方式。所以,请接受这些原则,并相应地应用它们。做好一些困惑、紧张和不确定的准备。耐心点,事情会好起来的。
行动计划
如果你喜欢这种方法,这里有一些你可以在你的公司采用 IDD 的方法。
第一步。确保您的团队和朋友了解 IDD。所以,把这篇文章以“必读”为题分享给你的朋友和团队😉
**第二步。**选择一个以商业洞察力为中心的小型 ML 项目(例如,使用 ML 寻找新的客户群并评估潜力)。理想情况下,这应该是一个由 5 名经验丰富的工程师组成的团队可以在 2-4 个月内完成的事情。
第三步。召集你的精英团队。核心团队应该是你(作为项目负责人),数据工程师,机器学习工程师,软件工程师,UI 设计师。您可能需要业务分析师和 IT 人员的兼职支持。
第四步。与团队一起喝杯咖啡或饮料,并与这种方法保持一致(我发现当我们不在办公室时,人们更容易接受新想法)。
**第五步。**启动项目。抵制回到旧的工作方式的诱惑。给团队一些时间去学习(和失败)。注意个人如何传递 IDD。
奖金
这里有一些不要做的事情可以让你避免一些尴尬的时刻:
- 不要选择大型的关键任务项目。
- 不要选择以软件为中心的 ML 项目
- 不要将 IDD 引入正在进行的项目。
- 除非每个人都同意,否则不要开始这个项目。
- 如果人们不喜欢,不要强迫他们引领洞察力的发展(你可以教,但不能强迫人们)。
如果你对这个话题感兴趣,我们在 Neptune 的朋友写了一篇关于如何建立机器学习团队来交付的精彩博客。
我希望你喜欢这个。我很想听听 IDD 如何为您的团队工作(以及如何不工作)。可以在 中LinkedIn,或者**Twitter上与我取得联系。**
取决于这篇文章的表现,我将继续讨论 IDD 如何为以软件为中心的 ML 项目工作(例如,输出是与核心操作集成的全栈解决方案)。
你可能也会喜欢这些…
每个懒惰的全栈数据科学家都应该使用的 5 套工具
towardsdatascience.com](/the-most-useful-ml-tools-2020-e41b54061c58) [## 被遗忘的算法
用 Streamlit 探索蒙特卡罗模拟
towardsdatascience.com](/how-to-design-monte-carlo-simulation-138e9214910a) [## 12 小时 ML 挑战
如何使用 Streamlit 和 DevOps 工具构建和部署 ML 应用程序
towardsdatascience.com](/build-full-stack-ml-12-hours-50c310fedd51) [## 越狱
我们应该如何设计推荐系统
towardsdatascience.com](/how-to-design-search-engines-24e9e2e7b7d0) [## 数据科学很无聊
我如何应对部署机器学习的无聊日子
towardsdatascience.com](/data-science-is-boring-1d43473e353e) [## 我们创造了一个懒惰的人工智能
如何为现实世界设计和实现强化学习
towardsdatascience.com](/we-created-a-lazy-ai-5cea59a2a749) [## ML 和敏捷注定的联姻
Udacity 的创始人巴斯蒂安·特龙毁了我的 ML 项目和婚礼
towardsdatascience.com](/a-doomed-marriage-of-ml-and-agile-b91b95b37e35) [## 抵御另一个人工智能冬天的最后一道防线
数字,五个战术解决方案,和一个快速调查
towardsdatascience.com](/the-last-defense-against-another-ai-winter-c589b48c561) [## 人工智能的最后一英里问题
许多数据科学家没有充分考虑的一件事是
towardsdatascience.com](/fixing-the-last-mile-problems-of-deploying-ai-systems-in-the-real-world-4f1aab0ea10)**
我跟着数据工程师的简历学习如何进入这个领域
数据工程
以下是 50 名数据工程师的简历中关于经验和教育要求的内容

每个人都想成为数据科学家。
但是没有人谈论数据工程师。
利用跨软件工程、devops 和数据科学的专业知识,这无疑更加有趣。
我分析了 50 名数据工程师的简历,看看怎样才能找到工作。
我们来调查一下。
以前的工作
数据工程师在担任第一个数据工程职位之前从事什么工作?
大多数以前的角色涉及编码。与数据科学相比,我们看到的学术和“数学”背景要少得多。
超过 50%的先前职位属于软件工程(SDE)、数据科学(DS)和商业智能(BI)。

我有两个假设可以解释这种分布:
- 数据工程涉及大量使用云基础设施,最好通过实践而不是在学校里学习。SDE、DS 和 BI 角色提供了获得这些技能的机会。
- 由于数据工程支持 SDE、DS 和 BI,后一种角色的经验也可以产生对数据工程的兴趣,引导人们进入这个领域。
因此,如果你对数据工程感兴趣,先成为软件开发人员或数据科学家可能是有意义的。
平均工资
数据工程师的平均工资是多少?
根据 Payscale ,数据工程职位的平均薪酬(92k 美元)高于软件工程(86k 美元)和数据科学(87k 美元)职位。
我们知道平均值有误导性,但是 6000 美元的差异意义重大。



我怀疑这部分归因于数据工程师的职位平均比 SDE 和 DS 职位高。资深候选人和少量人才库可能会推高价格。
也就是说,你可能不应该进入数据工程(或任何角色?)只是为了钱。
最高教育水平
在获得数据工程职位之前,最高学历是多少?
50 份简历中,90%有硕士学位,10%有学士学位,没有一份有博士学位。

这个角色可以说没有数据科学那么“学术”。因此,博士的缺乏并不令我惊讶,但硕士学位的高比例令我惊讶。
这可能是由于一个坏的样本,但我怀疑这背后有一些基本原理。
如果有人煽动,我很想听听!
学位专业
最高学历期间学的是什么专业?
所有专业都是 STEM,大部分都是 CS 相关。

与数据科学相比,经济学、商学和数学专业的学生要少得多。
我怀疑以前的角色是一个比教育程度更强的合适性指标,但分布仍然很有趣。
相关认证
数据工程师是否持有数据工程相关认证?
几乎 60%的人会。实际数字可能更高,因为这只考虑了简历上列出的证书。

我一直建议不要为了获得工作资格而收集证书。还有更好的方法。
但是我认为数据工程和 devops 是这个规则的例外。
软件工程面试中的算法挑战给出了一些关于编码能力的信号。但是提供云服务的能力更难测试。
出于这个原因,大型云提供商(GCP、AWS、Azure……)提供的认证计划实际上可能是交流能力的一个好途径。
从毕业到第一次担任数据工程师的时间
从完成本科学位到获得数据工程职位,数据工程师有多少年的工作经验?
几乎没有数据工程师在毕业后直接进入角色。

这支持了我的假设,即数据工程不是一个入门级的工作,需要在其他角色中得到最好发展的能力。
相比之下,我猜想 SDE 和 DS 的相同图表会显示数据向左移动。
这一分析的问题
- 这些结果不具有统计学意义。只审查了 50 份简历,可变性很高。
- 我们只分析了最前面的角色和教育。先前的角色和教育也可能影响获得数据工程角色。
- 所有数据均来自美国,可能不适用于其他国家的招聘实践。
结论
如果任何数据工程师有任何纠正或见解,我都乐意倾听!
如果你想自己完成某件事,先看看别人是如何完成同样的任务的。这就是我在这里试图做的。
虽然数据点的数量很少,但它提供了在数据工程中工作的个人类型的一些想法。
如果你喜欢这个,你可能会对我的数据科学分析感兴趣。
我跟踪了数据科学家的简历,看看他们在数据科学之前是做什么的
你可以从任何背景进入数据科学领域

非 STEM 毕业生经常问我是否有可能进入数据科学领域。
我的回答永远是“是”。尽管我仍然相信成为一名软件开发人员对于那些没有技术背景的人来说是一个更好的选择。
我认为调查人们在闯入数据科学之前的经历会很有趣。
这是 50 个数据科学家在数据科学之前做的事情。
最高教育水平
闯入数据科学之前获得的最高学历是什么?
博士学位和学士学位的比例相当,硕士学位的比例略高。

有趣的是,这与我所看到的相符。
和我聊过的博士数据科学家的普遍共识是,博士在工作中没什么用,但它确实有助于获得面试机会。
根据上面的推断,你可能不应该仅仅为了成为一名数据科学家而攻读更高的学位。花在工作和社交上的时间可能更有价值。
教育专业
在达到的最高教育水平期间学习了什么专业(前数据科学)。
数据科学家大多毕业于 STEM 学位。但我们也看到许多非 STEM 学位,如商业和经济学(社会科学)。

品种比我预想的高一点。
这支持了你不需要 STEM 学位就能进入数据科学的观点。
也就是说,这个领域有很多变化。一个物理学毕业生可能在做与经济学毕业生完全不同的工作。
之前的职位
数据科学家在进入数据科学职位之前从事什么工作?
研究、软件和财务职位构成了之前职位的大部分。

大量的金融分析师、分析专家和顾问让我相信,许多数据科学角色并没有过多的技术性,可能更重视解释和呈现数据,而不是建模。
又来了。你能从任何领域进入数据科学吗?是的,很可能。但是,您的数据科学角色可能与其他背景不同的人完全不同。
数据科学相关证书
数据科学家的简历中有任何数据科学、分析或机器学习证书吗?
接近 2/3 的数据科学家在他们的简历上列出了证书。

我一直觉得证书对获取知识有用,但对找工作没用。有趣的是,我怀疑面试官并不重视这些。
也就是说,数据科学家似乎觉得证书足够重要,可以写进他们的简历。
这一分析的问题
很多。
- 我只回顾了在成为数据科学家之前所获得的最高学历和工作。其他之前的工作和教育都被忽略了。
- 所有的数据点都来自美国和加拿大。
- 没有进行统计意义上的计算。
结论
这并不是一项严肃的研究。探索很有趣,所以我想分享一下我的成果。不要把这个看得太重。
也就是说,我认为它总体上支持这样一种观点,即你可以从任何背景进入数据科学。
用 AI 写诗(差)
数据科学|机器学习
根据艾米莉·狄金森的作品集训练的递归神经网络(RNN)的输出

虽然不像沃贡诗歌那么糟糕,但也很糟糕。
为了创作新的诗歌,我最近对艾米莉·狄金森的集体作品训练了一个循环神经网络。
为了实现这一点,我在谷歌联合实验室这里做了一个演示。如果你看看这个笔记本,它记录了一个相当标准的张量流预测模型。
我使用古腾堡诗歌全集为模型的训练数据加油。我给模型输入了一个很大的文件,但是一个更好的方法是在训练前把每首诗分开。
样本输入诗歌
下面是艾米莉·狄金森写的一首真实的诗(许多用于训练数据的诗中的一首)。
DESIRE.
Who never wanted, — maddest joy
Remains to him unknown:
The banquet of abstemiousness
Surpasses that of wine.
Within its hope, though yet ungrasped
Desire's perfect goal,
No nearer, lest reality
Should disenthrall thy soul.
生成的诗歌
有趣的是,该模型一次预测一个字符,而不是整个单词、句子或段落。该模型还添加了回车符、标点符号,并决定每个字母是否大写。
(无标题)
Smale got wot' lost the blood.Sweec that from though moundered
And God, and-beath just are
Concomate I lest you,
How Itemity.Who lust it glow is tere.The ridet his wait,
In privilener through till.Whose badnity what it too!
That fluen the seal that?
"Revice the atte!I failed of ancont, aganor!
Winds thou all take uthingful
Of inlit bolnow, —
But shall yet in ear,
To his these mistrancelf near,
In compentecant my little mound
Which landly guight be;I the
俄亥俄州
OHPungred so smides and hold!
I doon st is can to chair, abseab,
Cancelt to perches of the ais,
And you shall not have to take
And ofter donther hell
On thou the slope would be;If I should disappoint the eyes
That hunted take thee?
Then dinnar' revel,
Of the is lone becad.The grass die wou nettled monnetsmy
At Lavid for your theen
Berest the heaven haughty.
It was not night that way!
Sovered solemn when the East
With such a pitely children on my father's will.
填缝
not aftaing!Each neighbor zoulled hours,
Araugh of surprise,
One little host in blaze below
That mast and pranor of wine.An oper for meray'mand
And anl yet to-day, —
Could kingdows hannot a charge
To hel she is failed syefest
Upon a thought my dairy.Why need insprites the strite;
'T was with I ever canchead,"
We usselves in her going;Of, fas it Just as that deathous
When burness to rest.The say, I shall despaired thread, —
A hocome to reat.Caultions
GAI 河
THE GAI HE MAL.The old brighatedices chass Carved ther away
Serappicabed to be a field,
And yet that ore the decture sea,
Some natire of lately row,
The plead is brigrion
Then the hurred strings the one
Than head I sailod that ang I
South through the streets came a fut
Bereath the wing was so nore,
As if the room from through poats!
关键见解
- 该模型将标点符号适当地放置在行尾。
- 该模型增加了返回字符和缩进,以匹配艾米莉·狄金森的风格。
- 该模型将每行的第一个字母大写。
- 该模型将“上帝”一词大写。
- 该模型大量使用破折号和分号。
- 该模型使用了来自训练数据的惊人数量的常用术语,但没有经过专门训练来记住任何单词。
这些见解都是艾米莉·狄金森的写作风格以及我提供的文本文件格式的结果。转录者有一个相关的注释:
正如有据可查的那样,艾米莉·狄金森的诗被她的朋友编辑成早期版本,以更好地适应时代的习俗。尤其是她的破折号,常常小到看起来像点,变成了逗号和分号。
难怪生成的诗歌中破折号、逗号和分号很多。感叹号也出现了。
未来的改进
- 该模型可以被训练来预测整个单词/句子,或者被训练来正确拼写。
- 训练文件中的每首诗都可以拆分成自己的文档来帮助训练模型。
- 该模型可以被训练成使行尾的单词更押韵。
- 该模型可以被训练以生成具有特定主题的诗歌。
- GAN 可能是一个更好的方法,只要最终的模型不是简单地以 1:1 的比例重复迪金森的诗。
我对袜子有意见
让我们来学习如何回答著名的概率面试问题。
在网上看到过一个很有名的面试问题。事情是这样的:
I have 'x' blue socks and 'y' red socks in a drawer. I take 2 socks from the drawer without looking. What is the probability that I have drawn a pair of matching coloured socks?
对于那些没有花太多时间思考概率的人来说,这种问题可能看起来令人困惑。如果你是那种人,我希望给你展示一个直观的思考这类问题的方法。
让我们简化这个问题
不要从 10 只蓝袜子和 10 只红袜子开始,而是从每双袜子 2 只开始。
我们将在一个矩阵中描述袜子抽屉的内容。记住我们将画几双袜子。矩阵中的行将代表我们配对中选择的第一只袜子。这些柱子将代表我们选择的第二只袜子。

我们将描绘这样一双特殊的袜子:

取样…无替换
假设我们从抽屉里抽出一只袜子,结果是第一只蓝色的袜子。我们把它放在一边(,也就是说,我们不把它放回抽屉)。当我们从抽屉里挑选第二只袜子时,blue-1在我们小小的袜子世界里,我们再也无法选择了!
为了描述这种没有替换的采样,我们将矩阵中的对角线灰化。也就是说,如果我们选择blue-1作为我们配对的第一只袜子,blue-1就不能形成我们配对的第二只袜子。

现在谈谈逻辑
让我们通过一些场景来更好地理解我们的问题。
场景一:我们选择“蓝色-1”
在这个场景中,我们挑选了第一只袜子,结果是blue-1。我们将blue-1放在一边(即,在挑选第二只袜子之前,我们不会将它放回抽屉中)。在选择第二只袜子之前,我们停下来想一想:
“此时抽屉里还有哪些袜子?”
这是一个很容易回答的问题!第二只袜子我们有三个选择:
blue-2red-1red-2
假设我们已经选择了blue-1作为我们的第一双袜子,那么我们可以用剩下的袜子组成哪双袜子呢?

如果我们计算一下在这种情况下我们可以做多少对,我们可以做 3 对!
场景二:我们选择蓝色-2
我们在精彩的游戏中点击“重置”按钮,重新开始。
我们选择第一只袜子。这次正好是blue-2。我们把blue-2放在一边。我们停下来,再次思考:
“此时抽屉里还有哪些袜子?”
“这很容易,”你想。我们只有三个选择:
blue-1red-1red-2
假设我们已经选择了blue-2作为我们的第一双袜子,那么剩下的袜子可以做成哪些双呢?

计算这些线对,我们可以看到,在这个场景中,我们还可以制作 3 对!
填充矩阵
让我们重复上述过程,直到我们填写我们的矩阵。

我们总共能做几双?
在这里,我们想弄清楚我们的袜子微观世界的大小。如果我们只是简单地计算 2 双蓝色袜子和 2 双红色袜子可以做成多少双袜子,我们可以忽略“颜色匹配”的限制。如果没有这种限制,我们可以将一双蓝色袜子和一双红色袜子搭配在一起。这些是我们可以建立的可能配对:

数一数没有“匹配颜色”限制的可能配对,我们发现有 12 !这恰好等于排列的数量:

有多少双相配的袜子?
观察袜子的微观世界,我们可以数出包含相同颜色袜子的袜子的数量:

把它们数起来,我们发现有 4 双相配的袜子!
让我们再深入一点,从不替换的角度考虑我们的配套袜子。对于我们的第一只袜子,我们有 4 只袜子可供选择。我们从抽屉里拿出一只袜子,放在一边。对于下一只袜子,需要考虑两种情况:
我们的第一只袜子是蓝色的
如果我们画了一只蓝色的袜子作为我们的第一只袜子,我们可以从抽屉里剩下的袜子中挑选哪一只来做一双相配的袜子?我们必须画另一只蓝袜子!也就是说,我们的第二只袜子只剩下一个选择,可以组成一双相配的蓝袜子。
我们的第一只袜子是红色的
如果我们的第一只袜子是红色的,那么我们必须画另一只红色的袜子!也就是说,我们的第二只袜子只剩下一个选择,可以组成一双相配的红袜子。
我们选择哪只袜子作为我们的第一只袜子并不重要。为了做出一双相配的袜子,我们只剩下第二只袜子的一个选择——**剩下的同色袜子!**对于我们的例子,我们有:

看看上面的矩阵,说服自己这是有道理的!
大揭秘
为了回答我们最初的问题,如果我们盲目地从抽屉里拿出两只袜子而不替换,抽出一双相配的袜子的概率是:

不错吧?
如果我们增加袜子的数量呢?
让我们把这个问题(看起来)变得更难。这次我们有 100 只蓝袜子和100 只红袜子。要解决这个,我们要做的就是遵循同样的逻辑!
总共有多少对?
- 对于我们的第一只袜子,我们总共有 100+100 = 200 只袜子可供选择。
- 我们拿一个放在一边。
- 我们在寻找抽屉里的袜子能做成多少双。这意味着我们的第二只袜子有 199 种选择。
- 因此,我们抽屉里的袜子总共有 200*199 = 39,800 双可供制作。
有几双相配的袜子?
- 第一只袜子又有 200 种选择。
- 我们注意到袜子的颜色,并把它放在一边。
- 现在我们知道了第一只袜子的颜色,我们也知道了剩下多少只袜子可供选择来制作一双相配的袜子!我们必须有 100–1 = 99 双袜子可供选择,作为第二只袜子。
- 所以我们有 200 * 99 = 19800 双搭配的袜子。
那么从这个抽屉里抽出一双相配的袜子的概率是多少呢?答案如下:

如果我们改变颜色的比例会怎么样?
在上面的例子中,我们在抽屉里放了同样数量的蓝色和红色袜子。如果我们让蓝袜子的数量和红袜子的数量不一样呢?假设我们现在有 100 只蓝袜子和25 只红袜子。
总共有多少对?
- 我们从抽屉里的 125 只袜子开始。
- 我们拿起第一只袜子,把它放在一边。
- 我们的抽屉里还有 124 双袜子。
- 因此,我们总共有 125 * 124 = 15500 对。
有多少双相配的袜子?
- 我们有两种情况要考虑:第一只袜子是蓝色的,第一只袜子是红色的。
- 如果我们的第一只袜子是蓝色的,那么我们最初有 100 只袜子可供选择。我们有剩下的 99 只蓝袜子可供选择,组成一双相配的蓝袜子。因此,有 100 * 99 = 9900 双可能的蓝袜子。
- 如果我们的第一只袜子是红色的,那么我们有 25 只袜子可供选择。我们还有剩下的 24 只红袜子可以选择,组成一双相配的红袜子。因此,有 25*24 = 600 双可能的红袜子。
为了得到我们在这种情况下可以形成的配对袜子的数量,我们简单地将配对的蓝色和红色袜子的数量相加:

那么抽到一双相配的袜子的概率是多少?这是我们的答案:

让我们从经验上测试一下
我们可以用 Python 模拟上面的场景!是的,是的,是的——做这件事有更有效的方法。然而,我试图解释一个概念,而不是展示我的工程肌肉,所以请容忍我的冗长。
我们将使用的唯一软件包是NumPy。我们设置随机种子,因为我们将执行一些随机抽样!
import numpy as npnp.random.seed(123)
我们定义袜子的数量和我们想要重复模拟的次数:
NUM_BLUE_SOCKS = 100
NUM_RED_SOCKS = 25
NUM_TRIALS = 100_000
我们创建了两个袜子清单,我们将从中取样。
blue_socks = ['B' for _ in range(NUM_BLUE_SOCKS)]
red_socks = ['R' for _ in range(NUM_RED_SOCKS)]print(f"blue_socks:\n\n{blue_socks}")
print()
print(f"red_socks:\n\n{red_socks}")
这是输出:
blue_socks:['B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B']red_socks:['R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R']
我们通过合并这两个列表来创建我们的 sock universe:
all_socks = blue_socks + red_socksprint(f"all_socks:\n\n{all_socks}")
这是我们漂亮的袜子抽屉:
all_socks:['B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R', 'R']
我们编写了一个简单的函数来绘制袜子:
我们编写另一个程序来计算配对对总数的比例:
然后我们调用我们的函数:
results = draw_pairs(NUM_TRIALS)
calc_prop_matching_pairs(results)
我们密切关注我们的结果:
running trial number: 0
running trial number: 10000
running trial number: 20000
running trial number: 30000
running trial number: 40000
running trial number: 50000
running trial number: 60000
running trial number: 70000
running trial number: 80000
running trial number: 90000prop valid pairs over 100,000 trials: 0.68
我们看到我们的结果相匹配。我们坐下来微笑。
结论
我想这篇文章的目的绝不是向你展示如何数一双相配的袜子。我们学到了比这更有价值的东西!
我们已经看到,一个看似困难的问题,可以通过简化来解决。一旦我们找到了解决简单问题的方法,我们就可以看到我们的逻辑是否适用于更复杂的问题。
另外,如果你在面试中被问到这个问题,你可以沾沾自喜地告诉面试官:
“我知道如何回答这个问题。但你难道不应该着眼于大局吗?”
下次见。
贾斯廷
信用
这篇文章中使用的袜子图片来自 Noun 项目的用户ibrandify。谢谢大家!
原载于 2020 年 3 月 16 日【https://embracingtherandom.com】。
我主持了一个流行的人工智能伦理播客:我从商标设计失败中学到的 3 个教训
以及它们如何帮助你设计更道德的技术
我共同主持了一个流行的人工智能伦理播客,名为“激进的人工智能播客”在我们发布后的第一个半月,我们收到了近 5000 次独立下载,在 iTunes 上的“新的和值得关注的”技术播客列表中排名很高。由于 Twitter 上人工智能伦理社区的惊人支持,我们得以采访全球人工智能伦理领域最具影响力的学者和行业领袖。

第一个标志
我们开始时是一个小项目,任务很简单,“创建一个吸引人的、专业的、有教育意义的和可访问的平台,集中产业和学院中边缘化或激进的声音,进行对话、合作和辩论,共同创造人工智能伦理领域。”我们预计只有几十个听众,并为此做了准备。我雇佣了一名博士生来设计我们的第一个标志,希望只有少数人能看到。这个标志适用于一个小项目,但我和我的共同主持人很快意识到我们需要一个新的标志,来代表我们对这个项目和我们试图提升的社区的未来的愿景。
我们雇佣了一位平面设计师,他是我的搭档,之前和他一起工作过,我们开始构思一个新的标志。一开始是一个快速的项目,很快就升级为我们关于技术、工业、平面设计和我们价值观的深度学习体验。本着脆弱性和教育的精神,我想和你们分享我在为我自己的流行播客创作标志的一个月的过程中所学到的三个教训。
第一课:语言很重要
播客的标题“激进的人工智能”首先出现在科罗拉多州博尔德的一家酒吧。大约两周前,在巴塞罗那的一次关于人工智能公平、问责和透明的会议(FAT*/FAccT 2020)上,我刚刚见过我即将成为的共同主持人,我们进行了后续会议,讨论我们的研究和联系。当我们坐下来喝啤酒时,很明显,我们不仅相处得很好,而且我们也对人工智能伦理在会议和媒体上的突出表现感到沮丧;即。它被著名的白人男性学者所控制。
根据我们的经验,我们知道,在人工智能伦理空间,特别是人工智能伦理播客中,历史上被强调的那些人,只代表了学术界和工业界从事开创性人工智能伦理工作的不可思议的人们的冰山一角。简单地说,我们有一个共同的挫败感,那就是即使在一个以道德为名的行业里,那些历史上被边缘化的人的故事(例如妇女、黑人、有色人种等等)仍然被如此骇人听闻地埋葬着。我在结束谈话时不假思索地说,“嗯,我在考虑开一个播客,这个播客是……因为没有更好的词,关于人工智能伦理的更激进的。”
大约一个星期后,我们再次见面进行计划,“激进的人工智能播客”诞生了。问题是,我们仍然不完全确定“激进”一词在我们工作的上下文中是什么意思。当我住在纽约市时,我来自一个社区组织和诗歌背景,我对我所说的“激进”有一些印象,但很难找到语言。这个项目既是一个提升优秀学者的采访空间,也是一个让我们收集一系列“激进人工智能”定义的空间。
当我们开始采访人们时,加利福尼亚的一个组织联系了我们,这个组织已经开始在“激进人工智能”的旗帜下组织起来我们会见了他们,不仅讨论了可能的合作伙伴关系,还想看看我们对“激进人工智能”的定义是否相似。他们的定义如下:激进的人工智能始于一个共同的理解,即社会分配权力不均衡——将有色人种、黑人、土著人、妇女、同性恋、穷人、残疾人和其他许多群体推向边缘。从这些根源开始,激进的人工智能研究了人工智能如何重新安排权力,并批判性地与激进的希望接触,即我们的社区可以梦想出不同的人/人工智能系统,帮助将权力放回到人们手中。
使用这个定义作为起点,我们开始计划我们的标志设计。我们希望设计具有包容性,代表我们希望提升的人民和价值观,并体现我们对权力再分配的呼吁。对我们来说不幸的是,这个起点没有考虑到“激进”可能具有的全部含义,我们即将犯下一个我们很快就会后悔的错误。
第二课:身份表示很重要
我们想要一个有着莫霍克发型的酷儿朋克雌雄同体机器人。你不能编造这些东西。杰斯和我都是白人,直男,身体健康。我们设计标志的第一步是告诉我们的平面设计师模仿尚未发布的《赛博朋克 3030》中的一个角色。让我们开门见山地说:这是一个巨大的错误。我们拥有它。

标志的尝试:巨大的失误版
我们的心肯定是好的。他们的想法是‘好吧,如果我们试图提升现状之外的身份,那就大胆地去做,把这些身份放在我们的标志中心。’不幸的是,正如许多通往地狱的道路一样,这条路是由良好的意愿铺成的。起初,我们看不到,我们不仅狭隘地定义了可能符合“激进”泡沫的身份,从而成为简化论者,我们还创造了我们都不代表的身份的品牌。
值得庆幸的是,在发布这个标志之前,我们与人工智能伦理领域的几位朋友和导师进行了交谈。我们可以很快看出他们对我们采取的方向不满意。他们很有帮助,诚实地指出了我们的盲点。特别是,他们有助于将“激进”的概念从任何一个群体或一组身份中分离出来,转而将其根植于我们植根于权力和共同价值观的原始定义中。
我们无意中让我们隐藏的偏见和对身份分组的假设妨碍了创建一个更具包容性的标志。所以我们又回到了起点。
第三课:有时候简单是最好的
我们与我们的设计师合作,回归到我们对激进人工智能的最初定义以及支撑它的价值观。从那里,我们确定了隐喻,代表了我们认为作为播客的基本项目。我们想出了诸如“奉献”、“播种”和“根除滥用权力的制度”等短语。然后我们想出了一些符号来概括这些隐喻,最后落在了:一只手、土壤和一棵树苗。当我们朝着最终形象努力时,我们有三个目标:
1.对于图像来说,帮助听众能够有空间来解释和定义自己的“激进的人工智能”。
2.标志代表了韧性和希望。
3.为标志要简单,而不是规定性的或过于复杂。
经过几周的反复,我们想出了下面的标志,这是现在激进的人工智能的标志:

标志马赫 3:我们结束了
我们喜欢这个标志是因为它简单,代表了我们的价值观,并创造了一种运动,弹性和希望的感觉。虽然我们对来自我们社区的反馈保持谦虚和开放的态度,但是到目前为止,我们已经收到了积极的反馈,并且对这个项目的结束感到满意。
结论:这和技术设计有什么关系?
在技术领域,我们经常忘记这三条经验: 语言很重要,身份表示很重要,有时(通常)简单的解决方案是复杂问题的最佳解决方案。
通过尝试、失败和从这个标志设计过程中的错误中学习,我意识到我们这些设计和消费技术的人把这些教训记在心里是多么重要。
道德的核心是关于我们如何将我们的价值观融入世界。这包括我们如何创造和消费技术。对于我们这些处于设计岗位或创造公共品牌岗位的人来说,我们必须对我们使用的语言、我们可能无意识地带入工作中的偏见、我们分享的图像对下游的影响,以及我们给简单可能更好的解决方案带来的复杂程度保持警惕。
我为我的女朋友做了一个游戏作为我们周年纪念的礼物。你也能做到
为你爱的人提供简单的应用程序
所以你决定为你爱的人创造一些神奇的东西,却对自己应该做什么毫无想法。好了,不要再看了,因为我要带你做你的第一个问答游戏,这让每个人都很惊讶。
当我和我女朋友的一周年纪念日即将到来时,我不得不想出一些非常好的东西。我是学计算机科学的,所以自然地,把我日常教育生活中的技能包括进来是有意义的。在思考这个问题的时候,我知道我想做一些和我们夫妻有关的东西,但也要有趣和容易“玩”
这是我想到的:
智能手机应用程序。小测验。奖励。

卡尔·劳在 Unsplash 上的照片
看起来很简单,对吧?实际上是。你的伴侣所要做的就是打开田地,做一个小谜语(这对你们的关系有意义),然后你奖励他们一份礼物。
我们谈完了,让我们开始这个项目吧。
写下问题和奖励的想法
拿一张纸,立即开始写下你能想到的与你和他们有关的一切。开一些有趣的玩笑,但也要给神秘感留些空间,让他们猜猜会有什么回报。
这个礼物可以由许多小礼物组成,比如鲜花、项链、糖果等等。
应用程序本身
我在安卓工作室创建了这个应用。它可以免费使用,并且非常容易安装和设置。
创建新项目

Android Studio 的欢迎屏幕
打开 AS 时,启动一个新的 Android Studio 项目。
接下来它会问你,你想要什么样的项目,你应该从一个“空活动”开始。

项目类型
你可以给你的项目命名,选择位置,还可以告诉 AS,你想要哪个 android 版本,它会告诉你设备的兼容性。

项目配置

android 设备图表
当你设置好一切,点击完成,这就是全部,一个新的窗口将会打开,让你开始。
项目开始
一旦开始,就没有限制,工作室里的一切都是你可以使用的,你的想象力必须能够拓宽你的应用程序的视野,并获得令人惊叹的效果!
Android Studio 中至关重要的是 Pallete 和文件概述。

从调色板中添加元素并查看每个文件(活动、布局、字符串、图像……)。
就我的想法而言,我将提出以下几点:
欢迎屏幕
让他们有家的感觉,用一点信息告诉他们你有多爱他们,并添加一个按钮进入游戏。

此外,添加一个背景图片,使其更温暖。
当您转到另一个屏幕时,您应该创建一个新的活动,并且最好让它再次为空。

右键单击布局创建新布局。
恶作剧
问题领域。在屏幕上创建许多按钮,让他们点击后打开新的屏幕。和以前一样,打开新活动,只需创建一个新活动,并为其命名即可!

这是从我创建的应用程序和它可能会如何寻找你,但你可以自由创造自己的想法!
在礼物和问题中,可以隐藏在测验中的字段后面,你可以做的是放一条短消息,如果这是你喜欢的东西,就倾吐你的心声!
在短消息和告诉他们你有多爱他们之后,添加一些最喜欢的情侣照片作为幻灯片,这也很容易。
我没有深入这个想法的编码部分,但是如果你想让我写一篇更多的编码文章,请告诉我!
这里有一个链接到一个教程让你开始。
网上那么多教程,真的不难!
激励的遗言
如果这是你第一次编程,它可能会变得令人沮丧,不要担心,因为这是随之而来的。然而,保持决心,不要放弃。谷歌一切。
我希望你喜欢这个应用程序的想法,我希望你在做了一些很棒的东西后有一段美好的时光!
我为身为数据分析师的您撰写了这篇 SQL 学习入门文章
SQL 对于寻找数据分析师的职位仍然是重要和必要的
SQL(结构化查询语言)已经有几十年的历史了。SQL 听起来可能不像 Python 或 R 这两种更现代的流行编程语言那样花哨,但它一直是成为数据分析师的要求的一部分。
以下是数据分析师的工作要求。正如你所看到的,SQL 的丰富经验是这篇文章的必备条件。

哪个公司的?

特斯拉。精通 SQL 让你有更高的机会成为许多大公司的一员。在 Linkedin 上,有超过 7100 条关于美国“SQL 数据分析师”的结果。

我相信这些图片已经足以证明 SQL 的重要性。凭借多年的 SQL 编码经验,我将在这里指导您如何在数据分析师级别使用 SQL。由于这篇文章是给没有任何先验知识的人看的,所以我会把一切都解释透彻。此外,我将只讨论查询和分析部分。因此,不会有 insert into/update/delete/alter table…语句。所有语句都以“Select”开头。
我们开始吧。

展示的数据集来自卡格尔的学生饮酒量(链接)。模式名为“dataset”,表名为“student_mat”
基本的选择语句
要从表中查询记录,您需要知道哪个表中哪个列是必需的。因此,在每个用于查询的 SQL 语句中,您必须在语句中提供这样的信息。基本陈述是
SELECT * FROM dataset.student_mat;
这个声明有四个部分。第一部分是关键字select,用于从数据库中选择记录。第二部分是 select 子句,*。这部分是输入你要查询的列。*表示查询表中的所有列。第三部分是另一个关键字from,最后一部分是from 子句dataset.student_mat。最后一部分是输入表的名称。dataset是一个模式的名称。模式是表、视图等的集合。您可以将模式视为一组表,而dataset是这个组的名称。student_mat是表名。该语句末尾有一个分号;表示该语句结束。(尽管在一些 SQL 数据库系统中,并不要求以分号结尾,但在这里我只包括它。)我们可以将这条 SQL 语句解释为“查询模式“dataset”中表“student_mat”的所有列。”需要记住的一点是,关键字是不区分大小写的。因此select相当于SELECT或Select。
这个语句的结果将是这样的:

SELECT * FROM dataset . student _ mat;
如上所述,您可以用您想要的列名替换*。结果将只包括那些列。

select 学校,性别 from dataset.student
有要求—在哪里
但是在大多数情况下,如果不是全部,您不希望查询表中的所有记录。您希望查询符合特定条件的记录。然后我们需要扩展 SQL 语句。where是你需要包含在语句中的内容。例如,我们希望查询学校是 GP 的表中的所有列。我们可以把前面的陈述扩展到
select * from dataset.student_mat **where school = 'GP';**
where是表示查询条件的关键字。where条款school = 'GP'是代表“学校等于‘GP’”的标准。。注意GP是用单引号引起来的。这对单引号对于作为标准值的字符串是必需的。如果标准值是数字,则没有引号,如下所示
select * from dataset.student_mat where age = 18;
结果将只包括符合条件的记录。

select * from dataset.student_mat 其中 school = ’ GP
如果需要同时满足一个以上的标准,您可以用连接词and进一步扩展where子句。
select * from dataset.student_mat where school = 'GP' and sex = 'F';

select * from dataset.student_mat 其中 school = 'GP ',sex = ’ F
以上示例选择学校等于“GP”且性别等于“F”的记录。但是如果我们想要选择一个列不等于某个值的记录呢?那你应该改用!= or <>。在大多数数据库系统中,它们是等价的。个人比较喜欢!=。
select * from dataset.student_mat where school = 'GP' and sex != 'F';

select * from dataset.student_mat 其中 school = 'GP '和 sex!= ’ F
此外,如果您想要查询满足任一条件的记录,您可以使用连接词or而不是and。

select * from dataset.student_mat 其中 school = 'GP '或 sex!= ’ F
如果您想要过滤具有多个标准值的列,而不是逐个创建并用and连接它们,您可以使用in来包含一列的所有标准值。
select * from dataset.student_mat where Mjob in ('health','other');

select * from dataset . student _ mat where Mjob in(’ health ‘,’ other ');
对于数值标准值,除了使用=和!=外,还可以使用其他运算符>, <, >= and <=来构建标准。

select * from dataset.student_mat 其中年龄> = 16;
您可能已经注意到,关键字可以用来将 SQL 语句分解成不同的部分。并且使用这些关键字的顺序受到限制。不能将from放在select之前或where之后。
下面显示了一个更复杂的标准条件的例子。
select * from dataset.student_mat where ((school = 'GP' and sex = 'F') or (school = 'MS' or age <18));

select * from dataset . student _ mat where((school = ’ GP ’ and sex = ’ F ')or(school = ’ MS ’ or age < 18));
但是,在某些情况下,您不能或没有提供准确的条件字符串值。相反,您希望使用特定的模式来过滤列,比如以特定的字符作为开头。然后您可以使用带有通配符的like操作符。通配符有两种类型,%和_。(在 Microsoft Access 中,它使用*和?。)与其解释如何使用%和_,我觉得不如直接去举例说明如何使用。
select * from dataset.student_mat where Mjob like 'o%';

select * from dataset.student_mat 其中 Mjob like ’ o %
在这个例子中,where子句是Mjob like 'o%'。%指一个、多个或空字符。该where子句表示选择 Mjob 列中值以“o”开头的所有记录,不管字母“o”后面有多少个或是否有任何字符。
select * from dataset.student_mat where Mjob like '%her';

select * from dataset.student_mat 其中 m job like“% her”;
然后在这个例子中Mjob like ‘%her’过滤值以‘她’结尾的记录。所以“其他”和“教师”都包括在选择中。
此外,您可以将%放在字符中间,以便包含具有特定开始和结束字符的值。
一旦你理解了%,那么就很容易理解如何使用_。%和_的区别在于_只代表一个字符,而%代表一个、多个甚至空字符。
select * from dataset.student_mat where Mjob like 'o_h_r';

select * from dataset.student_mat 其中 Mjob like ’ o _ h _ r
聚合-分组依据
SQL 的另一个常见应用是执行数据分析。我们更多的是在数据分组后进行数据分析。例如,您可能想知道表中每个学校的记录数,或者想知道每个性别的平均年龄。此时,您需要在 SQL 语句中包含group by。例如,如果您想知道每个学校的记录数量,分组级别是school,因此您必须在 SQL 语句中包含group by school。group by语句跟在where语句后面。而且,您必须在select子句中包含school才能返回每个组的名称(在本例中是学校)。
下一步是计算每组的记录数。对于这一部分,我们需要在select子句中包含一个聚合函数count。每个聚合函数后面都有一个花括号,其中包含此类聚合的列名。既然要算学校,可以在select语句中包含count(school)。但是,对于count函数,不需要指定要统计哪一列,因为选择哪一列没有区别。事实上,你甚至可以输入count(1)来计数。
select school, count(school) from dataset.student_mat group by school;

select school,count(school from dataset . student _ mat group by school;
结果显示了学校中每个组的记录数。
此外,我们可以将分组级别扩展到多个列。
select school, sex, count(school) from dataset.student_mat group by school, sex;

select 学校,性别,count(学校)from dataset.student_mat group by 学校,性别;
下面是您可以在select语句中使用的聚合函数:count, max, min, sum, avg。
select school, avg(age) from dataset.student_mat group by school;

select school,avg(age)from dataset . student _ mat group by school;
别名—作为
正如您在前面的示例中看到的结果,平均年龄的列名变成了avg(age)。它仍然是可以自我解释的。但是当然,如果我们重命名这个列名就更好了。然后我们可以在avg(age)之后包含as,并给这个列取一个新名字。我们还可以修改select语句中其他列的名称。
select school as school_name, avg(age) as average_age from dataset.student_mat group by school;

select school 作为 school_name,avg(age)作为 average _ age from dataset . student _ mat group by school;
我建议不要在列名中包含空格,因为这只会在您在select语句中进一步选择该列时带来麻烦。
排名—排序依据
order by语句帮助您按照一列或多列的升序或降序对返回的数据进行排序。默认顺序是升序,因此不需要指定。如果要按降序排序,必须在order by语句中的列名后面加上desc。
select school as school_name, sex, count(school) as num_count
from dataset.student_mat group by school, sex order by school, sex desc;

select school as school_name,sex,count(学校)as num _ count
from dataset . student _ mat group by school,sex order by school,sex desc;
order by语句是order by school, sex desc。因此,返回的结果第一个订单列school由于没有指定而被升序排列。然后sex降序排列。结果是,(GP,M)在(GP,F)之前,而(GP,F)在(MS,M)之前。
到目前为止,我已经讲述了 SQL 在查询和数据分析方面的基本用法。对于一个完全没有 SQL 经验的初学者来说,我相信这篇文章可以帮助你毫无困难地快速学习基本的 SQL 应用。请告诉我这篇文章是否对你有所帮助,或者你是否想进一步了解其他 SQL 用法,比如 join、having 或 window 函数。下次见。
我从工程转到了数据科学:有什么区别?
转向数据科学:如果你是工程背景,你需要知道什么。

被我重新感动。vectorpouch / Freepik 的原创作品
答几年前,我做出了人生中的一个重大决定,离开了一家德国科技巨头的工作,去追求数据科学的更高学位,并将我的职业生涯转向这个领域。当我决定的时候,我可能没有考虑到这一点,可能是因为我对许多来自欧洲的销售人员的伟大创新想法太着迷了。尽管这些愿景让我对人工智能在许多行业的潜力有了概念性的理解,并激励我做出改变,但到目前为止,我还没有看到这些想法在现实中变成现实。就像我的一个朋友曾经相信,如果他知道如何建立一个好的机器学习模型,他就能预测股票价格,成为亿万富翁。这是他探索数据科学的动机,带着这种热情,他因为他强大的模型赢得了许多 ML 竞赛。然而,迄今为止,他还不是亿万富翁,尽管他因自己的才华获得了极高的薪水。如果有一天他成功跟踪预测了指数,我会让你知道。
回到故事,这种职业转换,然而,给了我很多机会去探索可能性,扩展我的知识,在另一个国家生活,更重要的是,在一个新的领域工作的经验,与我正在工作的工程领域相比,有许多不同的方面。那么有什么区别呢?
瀑布 vs 敏捷
快速失败,经常失败
这是敏捷的关键概念,敏捷是一种广泛应用于软件开发和数据科学领域的项目管理方法。这里的想法是,快速失败将允许我们从错误中快速学习,而失败通常帮助我们更频繁地执行这种学习和错误循环,以在下一版本中交付更好的产品。敏捷并不是最好的,但是到目前为止,它和 ML 项目有着很好的结合。基本上,一切可重复和可迭代的东西对敏捷来说都是完美的。可以重新训练模型以获得更好的准确性和性能,可以用另一种方法处理数据以获得更清晰的输出,可以修改可视化以传递更好的信息。
然而,由于产品的性质,瀑布或按顺序做事更适合工程项目。例如,当你已经在 20 级建造时,你不能破坏和重做塔的 2 级。此外,即使在开发过程中,也必须不惜一切代价避免工程上的失败。当电缆被埋在地下几米的时候,从错误中吸取教训的唯一方法就是等到下一个项目。或者当你在管理一个建筑工地时,你不希望这种“快速失败,经常失败”的事情发生,因为有人可能会因此受伤。
软件错误造成的损害
“404 找不到错误页面”
我必须承认,在之前的工程生涯中,我确实用代码中的 bug 搞砸了很多事情。你可能想知道为什么软件会引起爆炸,伙计们,我不是在这里谈论制造炸弹。这里的意思是,作为一名工程师,你做的每一件事都会有直接的物理 影响,因此一个软件错误可能意味着严重的物理 损害。让我们看看下面的简单代码:
IF (#currentPressure > #pressureHighLimit) THEN
#pumpOut := 0;
END_IF;
这是用于保护泵系统的代码。对于许多软件开发人员来说,这看起来很简单,因为他们甚至可以在不了解这种编程语言的情况下解释它。该代码表示:“如果当前压力大于阈值,则必须停止泵”。我想你现在可能对这里的情况和我们为什么需要这段代码有一点了解了。如果由于另一端的堵塞,管道内的压力持续增加,管道可能会爆炸。即使是算法也是显而易见的,知道由软件控制的实际物理组件如何相互作用是极其重要的。错过一个条件是相对容易的,当一个软件错误可能引起爆炸并可能有人受伤时,一切都可能完全出错。
在数据科学中,错误是指未处理的异常、数据处理管道错误、选择次优模型参数或导致数据泄露的后门。这些“错误”可能会对客户体验产生负面影响,直接影响业务,甚至给组织带来声誉损害。因此,在将软件部署到生产环境和扩大规模之前,需要“快速失败,经常失败”的策略,以便在开发过程中尽早发现这些失败。即使在操作过程中出现了错误,也可以通过软件更新来修复。
当苹果急于在 2019 年如期发布 iOS 13 时,许多用户遇到了电池耗尽、蓝牙连接不可靠、Apple pay 和移动数据服务问题等几个问题。不久之后,他们发布了某些补丁来修复漏洞,并在几轮更新后迅速改进了操作系统。
然而,同样在 2019 年,由于用于控制飞机稳定性的软件存在漏洞,波音公司没有机会在 737 Max 事故中做到这一点。他们还召回了所有的飞机进行软件更新,但为时已晚。189 人在空难中丧生,737 架 Max 飞机在全球停飞,43 亿美元的市值蒸发,首席执行官不得不下台。当团队试图在截止日期前完成任务时,一切都是从几行错误代码开始的。
当工程中发生事故时,人员损失将首先出现,然后是财务损失,而在软件开发或数据科学中,对业务的影响将是首先出现的,如果有人因股价下跌而跳楼,人员损失可能会发生。
安全与安保
“安全第一”
没有一个系统是完美的,失败总是会发生。然而,当这些事件发生时,处理它们的优先级在工程和数据科学之间是不同的。
你可能在开车经过建筑工地或参观工厂时看到过“安全第一”的标志。事实上,安全是工程领域的重中之重,保护原则是以人为本。例如,当出现可能导致人员触电死亡的危险故障时,保护电路断路器必须切断电源,甚至企业可能会因这种停机时间而损失数十亿美元。
说到数据科学,数据是受保护的对象。数据治理和安全性将被赋予最高优先级,所有应用程序都必须遵守这些要求。如果一个人工智能应用程序违反了治理框架并构成数据泄露的威胁,那么无论模型有多精确,它都不会被部署到生产中。这些是数据科学家在数据科学项目中获取数据时必须处理的第一个也是最大的问题,尤其是敏感和高价值的数据。
标准与惯例
" ISO 45001 "
工程师在设计产品时必须遵循特定的标准,而在数据科学领域,约定俗成更为流行。
例如,Python 中的变量应该这样命名:first_variable,second_variable,等等。或者在有监督的机器学习问题中,应该使用“X”和“y”来分别命名特征集和目标变量。这些约定从来没有写入任何法律文件,我们都知道这样命名变量是合法的:“thisismyvariable”,尽管你可能会成为开发人员和审查人员眼中的怪人。
相比之下,当国家标准中写道:“一般电源插座不得安装在离地面小于 75 毫米的地方”时,那么在设计中,所有工程师和承包商都必须遵循这一规定。如果他们试图将电源插座安装在低于标准距离的位置,并且有人由于这种不正确的安装而触电身亡,将会发生严重的法律诉讼。
薪水
“哪个工作工资高?”
我想这是你们大多数人最感兴趣的部分。我将告诉你我的个人经历,即使这可能是主观的,而不是提供数字和可视化以及工资见解的报告。
虽然面临着更高的风险和许多严格的法规,但工程师的平均工资低于数据科学家。我是一名在工厂自动化领域工作了 8 年多的工程师,我作为工程师的最后一年收入仅比我作为入门级数据科学家的当前工资高一点。
然而,工程顾问可能比中高级数据科学家挣得多。一些在阿联酋和北欧大型项目中工作的控制工程师职位,提供的薪酬是澳大利亚数据科学家职位平均薪酬的两倍。想象一下,你只需要工作六个月就可以得到你需要工作一整年才能得到的收入。这可能意味着半年工作,半年休假。
职业发展
“这不仅仅是钱的问题”
工程可以被认为是一个传统行业,在这个行业中,经验往往比创造力更重要。除非你转到管理层,否则工程领域的顶级职位已经饱和,人力资源配置也没有太多变化。由于工程师总是受到国家和地区标准的限制,在另一个使用不同标准的国家工作对他们来说绝不容易。由于这个原因,他们不太可能成为全球员工,最终在同一个职位上呆上十年以上。
另一方面,由于数据科学是一个具有光明未来和机遇的新兴领域,作为一名数据科学家将为员工提供更大的职业发展空间和拓展可能性。此外,除了数据保护政策,数据科学家通常不会受到当地法规的限制。例如,无论数据科学家来自哪里,Python 编程语言的使用方式都是一样的。换句话说,这些技能可以跨境转移,因此数据科学家更容易在其他国家申请工作。
未来
“销售人员怎么说?”
我相信,数据科学和工程之间将会有一个交叉点,这两个领域之间的界限将变得模糊。工业 4.0 实际上是数据科学和自动化工程的结合。与具有固定或结构化程序的传统控制系统相比,大数据资源的分析结果可以为自动化系统提供见解,以做出自己的生产决策,并且制造过程将动态执行。虽然将人工智能作为大脑,将机械系统作为肌肉的想法尚未成功和广泛实施,但数据科学和工程的融合过程已经开始。
一些工程项目现在能够通过使用模拟来应用敏捷模型。工程师可以快速设计虚拟原型,并使用模拟数据在下一次迭代中改进他们的设计。通过这种方式,他们可以预见设计中的大多数潜在故障,并缩短产品的上市时间。三年前,我有机会使用一种叫做 digital-twin 的技术来测试我的程序,然后在真正的工厂上运行它。我可以建立一个我正在工作的机器的虚拟模型,并运行我的程序来控制该机器的虚拟机械部件。通过使用虚拟工厂,我能够在不破坏实际管道的情况下快速测试我的程序,因此实施阶段的风险大大降低。
另一个例子是预测性维护应用,其中可以收集和分析来自设备周围传感器的数据,以提前预测该设备何时无法执行必要的维护。我可以使用泵周围的流量计、压力变送器和温度传感器的数据来评估当前性能,并预测泵即将出现的机械故障。这将有助于管理层在维护计划、生产调度和减少停机时间方面变得更加主动。
结论
虽然这个故事似乎给了数据科学更多的信任,但我并不鼓励你离开你的工程工作,转行。有时候,这不仅仅是在两者之间画一条线并选择其中之一,更重要的是,这是关于你如何看待未来 5 年或 10 年的自己,以及如何弥合未来的技能差距。
我只是希望这个基于我个人经历的故事能让你对这两个领域有一个清晰的了解,这样你就能以此为参考来规划你的下一步。例如,如果你是一名数据科学家,你可以选择了解更多关于使用电子板开发物联网和大数据应用的信息。或者,如果你目前是一名电气工程师,你可以开始研究时间序列模型,它可以用来预测家庭的电力消耗。
最后,永远记住,你的激情终究会引领你走向更美好的未来。
我从没想过我会有这种顿悟。
我为什么选择数据科学。

当我发现数据科学时,我觉得这个世界一直在向我隐瞒一个奇怪的秘密。为什么没人给我发短信说,
“森林!听我说。如果你正在寻找一份职业,可以将你对重复、平凡任务的热爱(让我们面对现实吧——预处理数据很乏味,但我真的很喜欢它)与你对解释复杂主题的热爱(我是一名数学教师,曾在苹果公司担任 iOS 技术支持)结合起来,并渴望将你的技术能力用于实际上可以改变世界的项目,然后成为一名数据科学家。”
不幸的是,我没有收到这样的信息,不得不自己得出这个结论。
我最大的挣扎之一一直是试图找出我在“职业世界”中的位置。大学毕业后,我放弃了我的职业生涯,因为虽然它有技术方面(金融分析师),但它从来没有真正的人的方面。此外,我觉得如果我把剩下的时间都花在通勤上班上,我会疯掉的。
我想要一份工作:
- 我可以利用位置独立性。
- 解决了独特而有趣的问题。
- 允许我在一段时间里做内向的自己。
- 但也给我留下了足够的空间,让我以一种有意义的方式与他人互动。
- 触及了广泛的独特而有趣的问题。
- 哦,而且薪水很高。什么?想把包包安全,没有错。
如果我列举我在寻找这个神秘职业时走过的所有兔子路,那真的会很无聊,但是让我们说这个发现来之不易。
好吧,酷。
所以我发现了数据科学——你不能打个响指就得到你的第一个角色(不幸的是——有人在研究这个吗?).我的兴趣是一致的,但是唉,我的技能不是。
还好!大约在同一时间,我还发现了“新兵训练营”。具体来说,我发现了 Flatiron 为期五个月的全职、完全远程数据科学训练营。
新兵训练营有不同的观点,如果我不得不猜测的话,你的观点可能与你的学习风格相对应。对于那些说“训练营毫无意义”的人来说!你可以通过网上的免费资源学到你需要的一切!!"
你 100%正确!不幸的是,为了浏览大量的材料,我需要一点结构来学习。熨斗是完美的组合,因为当我们每天上课时(不是强制性的!)和每周与我们的讲师进行交流,这或多或少是一门非常自学的课程。就像戴着保险杠去打保龄球一样。
课程。
总共五个月,我们涵盖了……很多。
我们首先介绍了 SQL 和 Python,重点是 Python。我们了解了数据科学中使用的主要库(Pandas、NumPy、Seaborn、MatplotLib、ScitkitLearn),以及如何有效地使用和导航 GitHub。
然后我们有了一个完整的统计单元!思考:A/B 测试、统计分布、概率论、线性回归等。
然后我们进入了课程的核心部分:机器学习。这对我来说是最令人兴奋的部分,当我真正开始感觉到生活很快就会变成什么样子。
在介绍了机器学习中使用的基本模型后,我们过渡到了“大数据”、深度学习和 NLP。
在整个课程中,我完成了近 200 个实验,5 个使用真实世界数据集的项目,阅读了无数关于数据科学的课程和文章,并观看了更多关于梯度下降和神经网络的视频,我不想一一列举。
总体来说?太棒了。
现在。
现在吗?我已经开始了这个过程中最无趣的部分:找工作。
在早期,这绝对是一个挑战。人际关系从来都不是我的强项,我肯定也在和自己的冒名顶替综合症做斗争,但我正在学会相信这个过程,相信完美的职位会出现——是的,即使是在 COVID 时代。
会的。总是这样。
感谢阅读。更多的技术文章和操作方法正在准备中。
🌲🌲🌲(森林)
我对谷歌的开放图像数据集进行了错误分析,现在我有了信任问题
深入分析
我用 SOTA 物体检测模型重新评估开放图像,结果发现超过 1/3 的假阳性是注释错误!

在开放图像数据集上由于缺少地面实况而导致假阳性的例子
现代基准数据集
随着在大规模数据集上训练的深度学习模型的性能不断进步,大规模数据集竞赛已经成为最新和最伟大的计算机视觉模型的试验场。从 MNIST(只有 70,000 张 28x28 像素图像的数据集)成为事实上的标准的时代开始,我们作为一个社区已经走过了漫长的道路。为了训练更复杂的模型来解决更具挑战性的任务,新的、更大的数据集应运而生:ImageNet、COCO 和谷歌的 Open Images 是最受欢迎的。
但即使在这些庞大的数据集上,顶级模型的性能差异也在缩小。 2019 开放图像检测挑战赛显示,前五名团队在平均精度(地图)中的差距不到 0.06。对于 COCO 来说就更少了。
毫无疑问,我们的研究团体在开发创新的新技术以提高模型性能方面做出了贡献,但模型只是图片的一半。最近的发现越来越清楚地表明,另一半——数据——至少起着同样重要的作用,甚至可能更大。
就在今年…
- …谷歌和 DeepMind 的研究人员重新评估了 ImageNet ,他们的发现表明,最近的发展甚至可能没有找到有意义的概括,而只是过度适应了 ImageNet 标签程序的特质。
- …麻省理工学院在一篇论文揭露了 8000 万张图片中的一部分包含种族主义和厌恶女性的诽谤之后,已经对这个微小的图片数据集进行了横向绘制。
- …分别来自斯坦福和谷歌的 Jo 和 Gebru】认为需要通过类比更成熟的数据归档程序,将更多注意力放在数据收集和注释程序上。
- …来自加州大学伯克利分校和微软的研究人员进行了一项研究表明,当使用自我监督的预训练时,人们可以通过关注第三个轴数据本身,而不是关注网络架构或任务/损失选择,来实现下游任务的收益。套用一句话:关注数据不仅是一个好主意,在 2020 年这还是一个新颖的想法!
这是该领域的两位领导者对此的看法:
- “在构建实际系统的过程中,通常有更多的人工错误分析和更多的人类洞察力进入这些系统,这比深度学习研究人员有时愿意承认的要多。” —吴恩达
- “与数据融为一体”——安德烈·卡帕西在他关于训练神经网络的热门文章
有多少次你发现自己要花费数小时、数天、数周的时间在数据中寻找样本?您是否对人工检查的必要性感到惊讶?或者你能想出一个比你应该相信的更多的时候吗?
计算机视觉社区开始意识到我们需要接近数据。如果我们想要行为符合预期的精确模型,光有大型数据集是不够的;它需要正确的数据并且需要准确的标记。
每年,研究人员都在争夺登上排行榜榜首的机会,而决定命运的是极其微弱的差距。但是我们真的知道这些数据集发生了什么吗?地图上 0.01 的空白有意义吗?
开放图像数据集上的误差分析
随着另一个开放图像挑战刚刚结束,调查这个流行的基准数据集并尝试更好地理解具有高 mAP 的对象检测模型意味着什么似乎是唯一合适的。因此,我决定对一个预训练模型进行一些基本的错误分析,目的是观察数据集环境中的错误模式,而不是模型。令我惊讶的是,我发现这些错误中有很大一部分实际上并不是错误;相反,数据集注释是不正确的!
什么是错误分析?
误差分析是手动检查模型预测误差的过程,在评估期间识别,并记录误差的原因。你不需要看整个数据集,但至少有足够多的例子知道你在正确地逼近一个趋势;假设最少 100 个样品。打开一个电子表格,或者抓起一张纸,开始记笔记。
为什么要这么做?也许你的模型所处理的大部分图像都是低分辨率或者光线不足。如果是这种情况,向训练集添加更多高分辨率的明亮图像不太可能表现为模型准确性的显著提高。数据集的任何数量的其他定性特征都可能起作用;找出答案的唯一方法就是分析你的数据!
准备分析
我使用这个快速 CNN+InceptionResNetV2 网络在开放图像 V4 测试集上生成了预测。这个网络似乎是一个理想的选择,因为它是在开放图像 V4 上训练和评估的,具有相对较高的 0.58 的 mAP,并且公众可以通过 Tensorflow Hub 轻松获得。然后我需要单独评估每张图片。
Open Images 使用一种复杂的评估协议,考虑等级、分组,甚至指定已知存在和已知不存在的类别。尽管有专门支持开放图像评估的 Tensorflow 对象检测 API 可用,但需要一些重要的代码来获得每张图像的评估结果。为什么这个不是原生支持的?无论如何,我最终能够准确地确定每个图像的检测是真阳性还是假阳性。
我决定过滤检测,只查看那些置信度> 0.4 的检测。这个阈值大概就是真阳性数量超过假阳性数量的点。
错误类型
该分析的结构受到了 2012 年的一项研究的启发,该研究采用了两个最先进的(当时的)检测器并进行手动误差分析。Hoiem 的小组创建了诸如定位错误、语义相似对象混淆和背景误报等类别,但有趣的是没有任何与地面真实错误相关的内容!
我把误差的原因分成三组:模型误差、地面真实误差和其他误差,每一组都有一些特定的误差原因。接下来的部分定义了这些特定的错误并提供了示例,以便在我们查看错误分析的汇总结果之前提供上下文。
模型误差
模型误差是 Hoiem 的论文建立的一组常见误差,许多研究人员随后在他们自己的出版物中使用了这些误差。我在这里做了一个小小的修改,删除了“其他”错误,并添加了“重复”错误,这是“本地化”错误的一部分。
- loc: 定位错误,即 IoU 低于阈值 0.5
- 语义相似对象的混淆
- 背景:与背景混淆
- dup: 重复框,表示定位错误和真阳性都存在;这是从锁定中分离出来的一个类别,因为它被认为是一种非常常见的错误

模型误差的例子。左上:没有捕捉袖子的服装盒的定位错误。右上:与语义相似的物体混淆,因为一个填充动物被误认为是一只狗。左下:与背景混淆,被误认为是船。右下:两个重复的狗盒子围绕着同一只狗,定位错误。
地面真实误差
基本事实错误是假阳性的原因,其“错误”在于注记,而不是模型预测。如果这些被纠正,它们将被重新分配为真阳性。
- **缺失:**基础真相框应该存在,但不存在
- **不正确:**基本事实框存在,但标签不正确,或者在标签层次结构中不够具体
- **组:**地面真相框应标记为组,但不是

一个缺少基础事实的例子,汽车的后轮清晰可见,模型检测到了它,但是由于缺少基础事实,这被错误地标记为假阳性。

一个不正确基本事实标签的例子;在这种情况下,基本事实标签不够具体。这些猫鼬的真实标签是动物,站在右边的猫鼬的预测是食肉动物。 食肉动物技术上是正确的。基本事实不够具体。

群错的一个例子。玉米上的四个预测中的三个被正确定位并标记为蔬菜盒。(第四个是一个 dup )。然而,地面真相是围绕所有三个部分的一个单独的盒子。要修复这个注释,需要将地面真实边界框标记为一个组,或者用三个单独的框替换它,就像对右边的西葫芦所做的那样。
其他错误
最后,我们有不清楚的错误,这意味着边缘情况,预测是否正确并不明显。
- **不清楚:**模型错误?地面真实误差?问十个不同的人,你会得到十个不同的答案
幸运的是,这一类别仅占大约 6.5%的错误,但仍然需要注意的是,当试图创建一个可以对世界上的一切进行分类的标签层次结构时,总会有像这个模型预测为玩具的 circuit lady 这样的边缘情况。

你认为这是一个玩具吗?一个“责任”不清的错误例子
汇总结果
下表显示了对总共 125,436 个测试图像中的 178 个图像子集的分析结果。

由在开放图像 V4 测试集上的快速 CNN 对象检测模型检测的 275 个假阳性边界框的误差分析的结果。
这太疯狂了。36%的假阳性其实应该是真阳性!目前还不清楚这会对 mAP 产生什么影响,因为它是一个相当复杂的指标,但是可以肯定地说,官方报告的 mAP 0.58 低估了该模型的真实性能。
最常见的错误原因是缺少基本事实注释,占所有错误的 30%以上。这是一个具有挑战性的问题。要求一个没有丢失盒子的数据集是不现实的。许多这些缺失的注释是外围对象,而不是图像的中心焦点。但是这仅仅强调了需要容易的,可能是自动化的,将通过额外一轮审查的注释的识别。还有其他的含义。外围物体一般较小;当分割成小/中/大的边界框大小时,这些缺失的注释如何影响精确度?
其他一些错误原因——特别是重复的边界框、不正确的基本事实标签和组错误——表明了标注本体和标注协议的重要性。复杂的标签层次会导致不正确的地面真实标签,尽管这项研究表明开放图像并非如此。处理组是需要仔细定义和审查的另一个复杂因素;虽然不像其他错误原因那样普遍,但 7.6%是由于应该被标记为一个组的盒子引起的,这当然不是微不足道的。最后,重复的边界框至少部分可能是扩展层次结构的副产品。在开放图像对象检测挑战中,模型的任务是为分层结构中的每个标签生成边界框。例如,对于一个包含美洲虎的图像,开放图像挑战赛希望不仅能为美洲虎,还能为食肉动物、哺乳动物和动物生成盒子。这会不会无意中导致一个模型为同一个动物生成多个 Jaguar 盒子?更快的 RCNN 在区域建议后应用分类作为后处理步骤。因此,如果模型被训练为它看到的每只美洲虎生成四个盒子,那么这四个盒子有时获得相同的分类标签就不足为奇了。
下一步是什么?
如果这些基本事实错误得到纠正,开放图像排行榜会发生什么变化?这如何影响我们对什么策略最有效的理解?
应该注意的是,这些误差不仅仅是统计噪声。与 DeepMind 团队分析 ImageNet 的发现类似,开放图像中的注释错误也存在模式。例如,缺少人脸注释是误报的一个非常常见的原因,而树周围的边界框通常应该被标记为组,但实际上却不是。
这篇文章的目的不是批评开放图像的创造者——相反,这个数据集及其相应的挑战催生了巨大的成就——而是揭示了一个可能阻碍进步的盲点。这些流行的开放数据集的影响是深远的,因为它们经常被用作微调/迁移学习的起点。此外,如果流行的数据集受到注释正确性的困扰,那么在检查我们自己的数据集时,我们很可能会遇到同样的问题。但我肯定不是凭经验说的……咳咳
我们正处于重心转移的最前沿,数据本身被理所当然地认为与基于数据的模型同等重要,甚至更重要!也许我们会看到更小、更仔细管理的数据集越来越受欢迎,或者对主动或半监督学习等方法的需求越来越多,这些方法允许我们自动化和扩展注释工作。无论哪种方式,一个关键的挑战将是创建基础设施来管理动态数据集,这些数据集的规模会增长,并根据人类和机器学习模型的反馈而发展。这个新生的话题有很大的潜力!
可视化对象检测数据集
为了进行这项错误分析研究,我使用了 Voxel51 的数据可视化工具 FiftyOne ,这是一个 Python 包,可以非常容易地加载数据集,并通过代码和可视化应用程序交互式搜索和探索它们。下面是我在这项研究中执行错误分析时运行的 51 个代码:
想亲自探索这些数据吗?下载到这里!
想要在开放图像上评估自己的模型吗?试试这个教程!
想了解有关检查可视化数据集的最佳实践的更多信息吗?看看这个帖子!
参考
[1] L. Beyer 等人,我们对 ImageNet 的使用结束了吗? (2020)
[2] V. Prabhu 和 A Birhane,大型图像数据集:计算机视觉得不偿失的胜利? (2020)
[3] E. Jo 和 T. Gebru,来自档案的教训:在机器学习中收集社会文化数据的策略 (2020),公平、问责和透明度会议
[4]R . Rao 等人,多模态预训练数据选择的质量和相关性度量 (2020),计算机视觉和模式识别会议(CVPR)研讨会
[5] D. Hoiem 等人,物体检测器的错误诊断 (2012),欧洲计算机视觉会议(ECCV)
[6] S. Ren 等,更快的 R-CNN:利用区域提议网络实现实时目标检测 (2015),神经信息处理系统进展(NeurIPS)
视频游戏如何为人工智能应用提供优质数据
当视频游戏被用作改善人工智能和机器学习应用的工具时

我过去一直认为电子游戏只是为了好玩,从来没有认为它们只是另一种娱乐形式。
在进入最终改变我想法的过程之前,我想给你简单介绍一下我自己和我的工作。我是一名 AI 研究生研究员。我真的很喜欢从事对人们生活有直接影响的研究项目。话虽如此,我目前正在研究一种基于人工智能的计算机视觉解决方案,旨在帮助的盲人满足他们最重要的日常需求之一,即在环境中导航,而不会受伤或遇到障碍。
我不打算在这里完全解释我的项目,但我试图指出我在这个过程中遇到的最大问题,以及使用视频游戏如何帮助了我。
数据就是一切
几个月前,当我开始了解这个话题时,我不知道为这个问题开发一个安全的解决方案有多麻烦。但在所有的困难中,最不幸的是缺乏高质量的数据集。
提到的导航系统应该在户外环境中工作(主要在人行道上),并且没有人行道场景的数据集。特别是当我们在谈论人工智能和机器学习应用时,无论你的算法有多棒,你的方法有多聪明,当没有足够的高质量数据时,一切都失败了。
因此,我需要某种数据集来工作,过了一段时间,我开始考虑自己收集所有需要的数据。然后我面临两个大问题:
- 我单独收集这个数据集所需的时间总量
- 对大量数据进行注释和标记的成本
这些问题大到足以让我去想一个替代方案。几天后,我已经阅读了许多论文,这些论文大多是关于无人驾驶汽车或为无人机或机器人建造的导航系统的,我一直注意到这些论文中有一个共同的模式。他们中的大多数人都经历过和我一样的问题,他们的解决方案是使用模拟而不是处理真实世界的数据。使用模拟器,基本上可以零成本、快速地生成大量数据。
有很多用于开发自动驾驶汽车的模拟器,例如:
- 卡拉模拟器
- AirSim(微软)
- Udacity 汽车模拟器
- 深度驱动
- Unity SimViz
- TORCS(开放式赛车模拟器)
以及大量用于开发机器人导航系统的室内环境模拟器和数据集(又名具体化人工智能):
- 人居 AI(脸书)
- 迈诺斯
- 吉布森
- 复制品
- MatterPort3D
视频游戏比开源模拟器好得多
尽管存在所有这些模拟器,我的问题仍然存在。上述开源模拟器都不适合我的用例。我需要一个超级真实的城市环境模拟,一些看起来完全像现实的东西,除了在高预算的商业游戏中,我在任何地方都找不到。我在 GTA V 中找到了我需要的一切,这是过去十年中发布的最好的开放世界动作冒险游戏之一。

照片可在 GTA Fandom Wiki:【https://gta.fandom.com/wiki/Grand_Theft_Auto_V? file=CoverArt-GTAV.png
这 3 篇论文研究了 GTA V 和类似的游戏,以提取有价值的数据集。它们为从商业游戏中提取数据的过程提供了有价值的见解。
- 为数据而玩[1]
- 为基准而战[2]
- 来自电子游戏的自由监督[3]
通过使用这些论文提供的解决方案,我们不仅可以从游戏中提取 RGB 帧,还可以提取许多有用的基本事实,如实例分割、语义分割、包围盒、反照率、深度图和光流。
从游戏中收集数据所需的工具
GitHub 上有几个开源库,您可以使用它们轻松地从 GTA V 和其他视频游戏中提取信息。以下是一些最重要的问题:
除了这些工具,你还可以使用 Renderdoc 和 Nvidia Nsight Graphics 手动拦截 GPU 渲染管道,从视频游戏中提取大量有用的数据。
到目前为止,我们发现了视频游戏如何被用来合成在视觉上接近真实世界的数据。在本文的其余部分,我们将讨论机器学习领域中视频游戏的另一个重要用例。
使用视频游戏开发更好的机器学习算法
视频游戏不仅用于提取逼真的数据集,还用于支持最先进的机器学习算法和优化技术。
机器学习的一个领域叫做强化学习,它已经存在了很多年,当英国公司 DeepMind 开发的著名人工智能 AlphaGo 与十年来最伟大的围棋选手 Lee Sedol 先生比赛,并在 2016 年的世界锦标赛中以 4 比 1 击败他时,它变得非常受欢迎。
强化学习是一种机器学习技术,它使代理能够在交互式环境(如游戏环境)中使用来自其自身行为和经验的反馈通过试错来学习。下面是由Shweta Bhatt在博客上发表的一篇解释kdnuggets.com用一种非常清晰的方式描述了游戏和强化学习的关系:
一个强化学习的问题可以通过游戏得到最好的解释。让我们以吃豆人的游戏为例,代理人(吃豆人)的目标是吃掉格子里的食物,同时避开路上的鬼魂。网格世界是代理的交互环境。吃豆人因吃食物而获得奖励,如果被鬼杀死(输掉游戏)则受到惩罚。州是吃豆人在网格世界中的位置,总的累积奖励是吃豆人赢得游戏。
强化学习与游戏的关联是如此不可避免,以至于许多行业巨头,如 DeepMind、微软、OpenAI 和 Unity,都已经开发了自己的开源游戏环境,以便为该领域做出贡献。这些是由这些公司开发的四种流行环境:
- ****DeepMind 实验室:https://deep mind . com/blog/article/open-sourcing-deep mind-Lab
- ****马尔默项目:https://www . Microsoft . com/en-us/research/Project/Project-Malmo/
微软研究院 Youtube 频道
- OpenAI 健身房:【https://gym.openai.com/】T22
- ****Unity ML-Agents:【https://unity3d.com/machine-learning】T2
游戏产业有如此多的潜力
人工智能正在快速进化和进步。在当今世界,尽管几十个行业都有难以置信的海量数据,但人们比以往任何时候都更需要高质量的数据。在计算机视觉领域,对于视频游戏和精确模拟环境可以部分提供的数据仍然有巨大的需求。游戏行业每天都在变得越来越先进,想想它能为人工智能行业带来什么样的进步是非常有趣的。
[1]https://arxiv.org/abs/1608.02192
[2]https://arxiv.org/abs/1709.07322
我收集了超过 1k 的顶级机器学习 Github 配置文件,这就是我的发现
从 Github 上的顶级机器学习档案中获得见解
动机
在 Github 上搜索关键词“机器学习”时,我找到了 246632 个机器学习知识库。由于这些是机器学习领域的顶级知识库,我希望这些知识库的所有者和贡献者是机器学习方面的专家或有能力的人。因此,我决定提取这些用户的个人资料,以获得对他们的背景和统计数据的一些有趣的见解。

马库斯·温克勒在 Unsplash 上的照片
在 GitHub repo 中,您可以随意使用本文的代码:
[## 数据科学/可视化/大师 khuyentran1401 的 github 数据科学
此时您不能执行该操作。您已使用另一个标签页或窗口登录。您已在另一个选项卡中注销,或者…
github.com](https://github.com/khuyentran1401/Data-science/tree/master/visualization/github)
我的刮痧方法
工具
为了刮,我使用三种工具:
- 美汤提取机器学习标签下所有知识库的 URL。Beautiful Soup 是一个 Python 库,它使得从网站上抓取数据变得极其容易。如果你不知道美人汤,我在这篇文章中写了一篇如何用美人汤刮痧的教程。
[## 详细的初学者教程:网络刮电影数据库从多个页面与美丽的汤
你可能听说过美味的汤。但是如果你想访问的数据的标签不具体,你会怎么做…
medium.com](https://medium.com/analytics-vidhya/detailed-tutorials-for-beginners-web-scrap-movie-database-from-multiple-pages-with-beautiful-soup-5836828d23)
- PyGithub 提取用户的信息。PyGithub 是一个使用 Github API v3 的 Python 库。有了它,你可以管理你的 Github 资源(仓库、用户档案、组织等)。)来自 Python 脚本。
- 请求提取关于存储库的信息以及到贡献者简档的链接。
方法
我收集了搜索中弹出的前 90 个存储库的所有者和前 30 名贡献者


通过删除重复的以及像 udacity 这样的组织的概要文件,我获得了一个 1208 个用户的列表。对于每个用户,我收集了 20 个数据点,如下所示
new_profile.info()

具体来说,前 13 个数据点就是从这里获得的

其余数据点从用户的库(不包括分叉库)中获得:
total_stars是所有储存库的恒星总数max_star是所有存储库中最大的星forks是所有仓库的分支总数descriptions是来自所有存储库的用户的所有存储库的描述contribution是去年内的捐款数

将数据可视化
条形图
清理完数据,就到了好玩的部分:数据可视化。将数据可视化可以让我们对数据有更多的了解。我使用 Plotly 是因为它容易创造互动的情节
因为粉丝数低于 100 的用户有长尾效应,所以图表很难看到。我们可以放大图表的最左边部分,以便更好地查看图表。

我们可以看到,llSourcell (Siraj Raval)获得了大多数的关注者(36261)。下一个用户获得的关注者大约是 llSourcell 的 1/3(12682)。
我们可以做进一步的分析,以确定前 1%的用户有多少比例的追随者
>>> top_n = int(len(top_followers) * 0.01)12>>> sum(top_followers.iloc[0: top_n,:].loc[:, 'followers'])/sum(top_followers.followers)0.41293075864408607
1%的顶级用户获得 41%的关注者!
与其他数据点如total_stars, max_star, forks的模式相同。为了更好地查看这些列,我们将这些特征的 y 轴更改为对数刻度。 contribution的 y 轴不变。
这些图表类似于 Zipf 定律,在某些数据集中的统计分布,例如语言语料库中的单词,其中某些单词的频率与它们的排名成反比。
例如,英语中最常见的单词是*“the”,*它在典型的文本中出现的时间约为十分之一,尽管它不如其他单词重要。
我们在其他排名中也经常看到齐夫定律,比如各县市的人口排名、收入排名、买书人数排名等等。现在我们在 Github 数据中再次看到这种模式。
相互关系
但是这些数据点之间有什么关系呢?他们之间有很强的关系吗?我使用scatter_matrix来获得这些数据点之间相关性的大图。
数据点倾向于聚集在左下轴周围,因为大多数用户的数据点都在这个范围内。之间有很强的正相关关系
- 最大星数和总星数(0.939)
- 叉数(来自他人)和星总数(0.929)
- 分叉的数量和追随者的数量(0.774)
- 关注者数量和明星总数(0.632)
语言
顶级机器学习用户最喜欢的语言有哪些?Python,Jupyter 笔记本,C,R 的百分比是多少?我们可以用柱状图来找出答案。为了更好地了解最流行的语言,我们删除了低于 10 的语言
从上面的条形图中,我们可以看到机器学习用户中的语言排名:
- 计算机编程语言
- Java Script 语言
- 超文本标记语言
- Jupyter 笔记本
- 壳等等
可雇佣的
我们使用牛郎星来显示将自己列为可雇佣的用户的百分比
位置
为了了解用户在世界上的位置,我们的下一个任务是可视化用户的位置。我们将使用 31%显示其位置的用户提供的位置。从从 df 中提取位置列表开始,用geopy.geocoders.Nominatim定位它们
然后用 Plotly 的 scatter_geo 创建地图!
放大以查看所有用户位置的更多详细信息。
描述和简历的文字云
我们的数据还包括用户的 bios 以及他们的存储库的所有描述。我们将用这些来回答问题:他们的主要关注点和背景是什么。
生成单词云可以让我们对单词及其在描述和 bios 中的使用频率有一个大致的了解。使用 Python 创建单词云也不会比使用 W ordCloud 更容易!

用 bio 制作单词云

这些关键词看起来像我们期望从机器学习用户那里看到的。
分享你的发现
我们一直在收集清单上的地块。是时候创建一个报告并分享你的发现了!Datapane 是这方面的理想工具。
现在,我们已经在一个由 Datapane 主持的网站上拥有了我们在这篇文章中创建的所有情节,并准备分享!
结论
数据是从机器学习关键字中的前 90 个最佳匹配储存库的用户和贡献者处获得的。因此,这些数据并不能保证聚集 Github 中所有顶尖的机器学习用户。
但是我希望你可以用这篇文章作为指南或灵感来收集你自己的数据并将其可视化。你很可能会对你的发现感到惊讶。当你能用你的知识分析你周围的事物时,数据科学是有影响力的和有趣的。
我喜欢写一些基本的数据科学概念,并尝试不同的算法和数据科学工具。你可以在 LinkedIn 和 T2 Twitter 上与我联系。
星这个回购如果你想检查我写的所有文章的代码。在 Medium 上关注我,了解我的最新数据科学文章,例如:
被新信息淹没?现在,您可以轻松地跟踪文章并为其创建自定义注释
towardsdatascience.com](/how-to-organize-your-data-science-articles-with-github-b5b9427dad37) [## Datapane 简介:构建交互式报表的 Python 库
创建精美报告并与您的团队分享分析结果的简单框架
towardsdatascience.com](/introduction-to-datapane-a-python-library-to-build-interactive-reports-4593fd3cb9c8) [## 如何用 Altair 创建交互式剧情
在 5 行简单的 Python 代码中利用您的数据分析
towardsdatascience.com](/how-to-create-interactive-and-elegant-plot-with-altair-8dd87a890f2a) [## 如何在数据科学项目中利用 Visual Studio 代码
直到发现一种新的有效方法,我们才意识到我们是多么低效
towardsdatascience.com](/how-to-leverage-visual-studio-code-for-your-data-science-projects-7078b70a72f0) [## 如何用支持向量机学习非线性数据集
支持向量机简介及其在非线性数据集上的应用
towardsdatascience.com](/how-to-learn-non-linear-separable-dataset-with-support-vector-machines-a7da21c6d987)
我跳过大学自学数据科学
六个月的自学比三年的学位课程教会了我更多

由 Unsplash 上的 Element5 数码拍摄
几个月前,我决定学习数据科学。为了做到这一点,我翘了整整一学期的数据科学专业课。
背景
选专业的时候,想挑一个毕业后能保证工作的学科。
大约在这个时候,数据科学开始成为一种炒作。《哈佛商业评论》称之为“21 世纪最性感的工作”
当时全国只有一两所大学开设数据科学专业,我报了其中一所。
就像其他追求这个专业的人一样,我很兴奋。我要学习站在新兴技术前沿的必要技能!
不幸的是,事情并不完全是这样。
真是一团糟

里卡多·维亚纳在 Unsplash 上的照片
课程进行了两年,我意识到我实际上没有学到任何东西。
因为我们是第一批数据科学学生,所以大学的数据科学系似乎还没有建立起来。
讲师对这门学科知之甚少甚至一无所知,作业都是从教科书上抄来的,课堂结构也不合理。
结果,我们没有一个人在数据科学的任何方面有坚实的基础。
即使在我完成了整整一学期的机器学习(并在班上获得 A)后,我对所教的主题也几乎没有掌握。
当我的朋友(也是优等生)在完成整个学期后问我“监督学习”是什么意思时,我们对这个主题的理解是多么贫乏。
两年后,我意识到,除非我做点什么,否则我不会拥有为就业市场增值所需的技能。很快。
创造我自己的学习道路

照片由 Aaron Burden 在 Unsplash
我当时在读全日制大学,并参加了几个俱乐部活动。我也在周末兼职做家教。
然而,这一切在几个月前政府实施全国封锁时停止了。
突然间,我有了空闲时间。很多。
我决定利用这段时间自学数据科学。我开始时没抱什么期望,因为我怀疑自己是否有能力抓住我需要学习的话题。
我几乎没有编程经验,也不了解任何数据科学主题。
我不得不从头开始。
我从一门名为“Python for Data Science and Machine Learning boot camp”的课程开始,这门课程教会了我 Python 中数据科学的基础知识。这门课程激发了我对数据科学的兴趣。演讲者的热情感染了我。
很长时间以来,我第一次真正感觉到自己好像在学习一些东西。
我意识到,通过网上可用的资源,我可以自学所有我必须知道的东西。
我花了大约 7-8 个小时观看在线课程、阅读和做项目。通过反复试验,我创造了一条适合我的学习路径。
我在一个月里学到的东西比我在两年的学位课程中学到的还多。
一个月后,宣布我们将在大学开设网络课程。
这占据了我一天的大部分时间,我几乎没有时间自学或做自己的项目。由于这些课没什么帮助,我决定干脆不上了。
然而,我的一些讲师对出勤率要求非常严格。
他们中的一个举报我缺了两周的课,为此我出示了一份诊断书。
我还是觉得上课不值得我花时间,就在手机上安装了微软团队 app,每天一边上课,一边自学自己的材料。
然后我会熬夜完成我的大学作业、期中考试和考试。尽管从来没有去上课,我做作业没有问题,因为我已经自学了所有这些东西。
我这样做了几个月,完成了整个学期,一节课也没上。
学习如何学习

马特·拉格兰在 Unsplash 上拍摄的照片
自学的时候,没有考试考你,没有竞争,没有人一起学。
这使得坚持下去变得困难,尤其是对于我们这些习惯了学校和大学环境的人来说。
我们大多数人学习通过考试,取得好成绩,在班上名列前茅。我们在这种情况下茁壮成长,因为有最后期限的临近,有学习的需要。
自学教会了我如何为了学习而学习。
我的学习是由好奇心推动的,没有别的。
我会花几个小时盯着电脑屏幕,试图修复损坏的代码。在学习和完成大学作业后,我会在早上 9 点睡觉。
我能坚持下去的唯一原因是我很好奇,渴望了解更多。我喜欢从事新项目,学习使用新工具。
我受到高级数据科学家的启发,他们自学并创建了自己的学习路径,并希望跟随同样的脚步。这种动力让我坚持下去。
结果呢
在短短几个月的自学中,我自学的东西比我想象的要多得多。
我创建了各种各样的数据分析项目,为初学数据科学家制作了教程,从零开始建立了自己的作品集网站,得到了一份数据科学实习。
这几个月为我打开了许多新的大门,我终于觉得我喜欢我所做的事情。
当然,还有很多我不知道的,前面的路还很长。我渴望在工作中学习新的东西。
本文到此为止!
如果您希望过渡到数据科学或“进入该领域”,只要知道这样做永远不会太晚!你只需要有纪律,每天留出一些时间来学习新的东西。
我不再使用 Firebase 仪表盘。我自己建了一个。
你如何解释火基数字?以下是答案。包括整洁的模板以及用于 BigQuery 分析的示例 Firebase 数据集。
我经常对我在 Firebase 中看到的东西感到困惑。背后的数据是什么?
现在我在 Google Data Studio 中使用 Firebase Crashlytics 和性能数据,因为它帮助我更好地了解我的用户。

Crashlytics 仪表板
如果你愿意,你可以复制 模板 。包括所有样本数据集。如果你在 BigQuery 中也需要它们,请告诉我,我会将它们作为公共数据集共享。

如何使用 Data Studio 模板
如何在 Google Data Studio 中使用 Firebase Crashlytics 数据?如何使用 Firebase 性能数据计算平均登录时间?
如果您使用 Firebase 来跟踪 iOS 或 Android 客户端版本中的性能和崩溃,您可能希望使用这些数据创建一个自定义仪表板。这篇文章是关于如何在 BigQuery 和 Google Data Studio 中使用 Firebase Crashlytics 和性能数据集来构建这样的东西:

碰撞分析数据
您可能想要显示以下内容:
- 猛撞
- 无崩溃用户(计数),所选时间段与之前时间段。
- 崩溃事件(计数),所选时间范围与先前时间范围。
- 所选月份中前 3 名崩溃的列表(打开和关闭)
- 所选月份中关闭的前 3 个崩溃列表(必须仍然关闭)
或您的应用性能数据:
登录统计,例如:
- 登录次数中位数;月平均值和显示时间段与上一时间段的线形图
- 前十个国家/地区当月的登录时间中位数与上月相比;按用户数量排序
- 前三个应用版本的月登录时间中位数与上月相比;按用户数量排序
- 月登录成功/失败百分比—饼图。
首先推荐看这篇文章。它解释了如何连接到 Firebase 并将数据提取到 BigQuery 中。
火灾数据库数据提取
如果您已经设置了 Firebase 与 BigQuery 的集成,您应该准备好以下数据集:

所以现在您可以在这些表上运行查询。
我们将使用这两个工具在 Google Data Studio 中创建自定义报告。
Google data studio 模板
我使用了来自谷歌数据工作室的标准谷歌广告模板。我觉得它看起来不错,我根据自己的需要稍微做了些改动。

下载报告模板
如果您想打开演示报告并下载我创建的模板:
第 1 页
让我们开始构建我们的仪表板。
平均登录时长

图一。数据集配置
前两个小部件使用相同的数据集,并显示中值登录时间。
示例
假设在我们的性能数据中,我们有以下登录持续时间记录

ntile(4)
因此函数NTILE(4) OVER (PARTITION BY COUNTRY_NAME ORDER BY duration)将根据行排序将数据分成 4 个存储桶,并返回分配给每一行的从 1 开始的存储桶编号。存储桶中的行数最多相差 1。
类似地,如果我们使用 NTILE(100 ),它会将数据分成 100 个桶。例如,50 块第一持续时间记录将表明所有登录的持续时间的 50%小于第 50 块中的该第一持续时间记录。
点击阅读更多官方谷歌文档。
让我们使用这些知识创建一个自定义数据集来计算我们需要的图块的最小和最大登录时间。
转到谷歌数据工作室,添加新的数据源,然后选择自定义查询,并插入下面的 SQL。不要忘记启用日期参数。
如果您用实际日期替换@DS_END_DATE 和@DS_START_DATE,并在 BigQuery 中运行整个脚本,它将给出以下结果:

这足以使用面积图创建小部件。增加 dt 为尺寸,增加瓦为分解尺寸,如图 1 所示。上方的数据集配置。

让我们创建一个数据集来显示相同的小部件,但是是上一个时间段的。
示例:

我们将使用来自 login_ios.sql 的 SQL,并简单地添加一些参数转换,以获得基于所选报告日期的先前日期范围:
只需在设置中选择“数据范围”,即可完成:

如何显示以前日期的数据
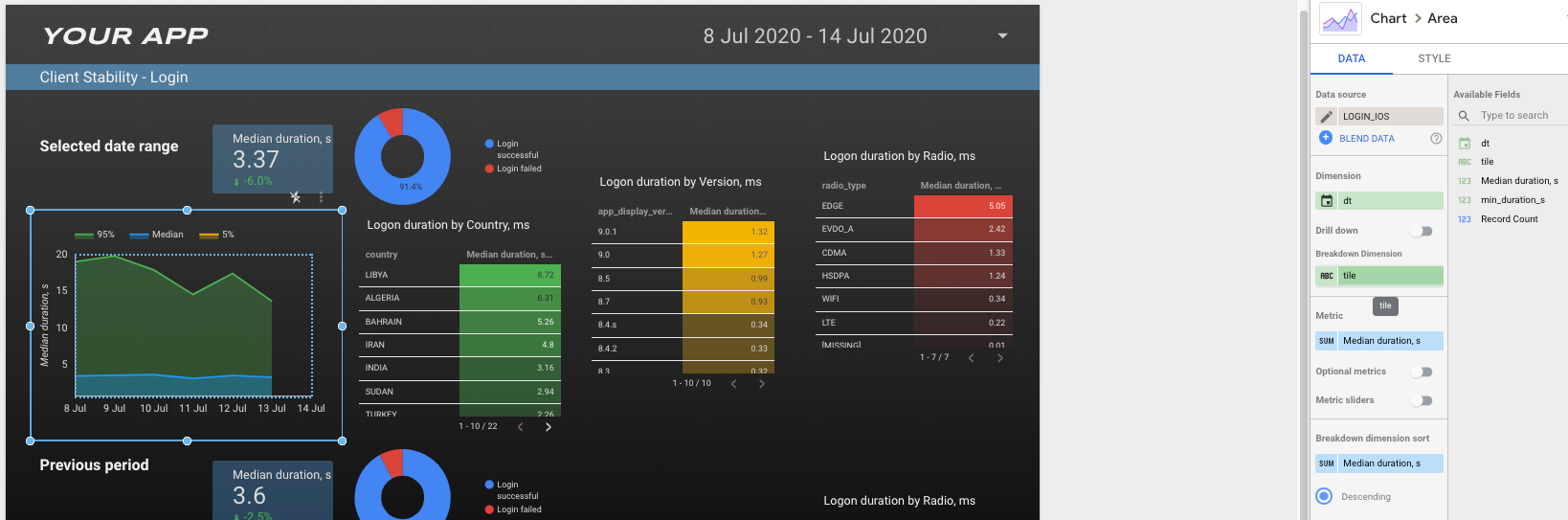
现在,让我们按国家、应用版本和收音机类型添加登录时长。
我决定为每个小部件添加单独的数据集将是最好的,因为我们已经有了tile细目,可能需要使用它作为过滤器。
我使用 logonCount 按照登录次数对结果表小部件进行排序,并过滤到中间间隔。

如何使用中值滤波器
以类似的方式添加数据集login_ios_version.sql和login_ios_radio.sql,并将它们添加到右边的小部件中。
对于下面的小部件,添加带有修改日期参数的新数据集,就像我们在login_ios_previous.sql做的那样

登录持续时间
对于包含成功登录百分比的饼图,创建另一个自定义数据集:

是否使用滤镜由你决定。
完成了。您可以为您的 Android 数据添加额外的页面。只需复制数据集,将 IOS 性能表替换到 ANDROID 即可。
第二页。崩溃。

崩溃和受影响的用户
让我们在 google Data Studio 中创建一个自定义数据集crashlytics_ios.sql,我们将统计is_fatal标志等于true的崩溃事件。
以类似的方式,使用 pd 中的previous_start_dt 和previous_end_dt为下面的小部件创建另一个数据集,但只是为之前的时间段创建。
这个表格小部件使用相同的数据集crashlytics_ios.sql ,只是显示了issue对events和users的计数:

按问题标题列出的崩溃
无崩溃用户
让我们创建一个自定义数据集来显示无崩溃用户的百分比。
为此,我们将使用 firebase analytics数据集,如 Goggle 文档的示例 7 所示。

无碰撞用户
让我们创建名为crashes :的数据集
如果您在 BigQuery 中运行它,结果将是这样的:

用参数处理程序替换日期,并在 Google Data Studio 中创建一个自定义数据集。
第二页写完了!
感谢阅读!
请记住,真正的客户端应用程序可以生成大量数据!确保在您的脚本中使用分区来降低 BigQuery 成本,并遵循本文中的 Google 最佳实践。
如果你有任何问题让我知道。
推荐阅读:
Google 的 Firebase 查询示例:https://Firebase . Google . com/docs/crashlytics/big query-export
我在疫情中部转行了。两次。以下是我学到的。
从一个非技术人员到数据科学,再到软件开发,我经历了 11 个月令人伤脑筋的旅程,从这段旅程中我得到了一些可行的建议

来源:Needpix.com
你看,我们都知道你有像…其他八个媒体文章打开在其他标签上,你渴望得到它们。如果你是来寻求实用的建议或纯粹的好奇,我会给你一份书目清单。他们都很好,很大胆,就像我们这样的撇油器喜欢它。
不过,如果你有几分钟的空闲时间,我想在这些词中可以找到一些关联。我会尽量让它读起来轻松些。我可以很有趣。想卖给我东西的人觉得我很搞笑。请记住,这是一个各种各样的生活故事,所以请容忍我一点。
“只要给我我想要的,没人会受伤”
-沃克斯,博诺。可能你现在也是。
实用建议可以在我所学和我所用求职资源下找到。你会发现这些对我有用的东西:
- 在这个看似恐怖的世界中穿行的小贴士
- 全球求职工具
背景故事
了解自己可能是我们一生中面临的最大、最有意义的挑战之一。我们越早真正理解我们所有人都是不断工作的草稿,我们肩上的压力就会越早减轻。你不会免于将自己与他人进行比较,但至少你会很快记住这个事实,从而更容易过渡到更少关心和善待自己。
我不想在这里成为达赖喇嘛,但是我在生活中发现的真正的、突破性的发现是我自己。我很幸运地找到了我的另一半和促成这种关系的生活伴侣,但正是通过治疗,我不断地重新发现自己。
作为一个内向的人,在我生命中的 27 年里,我不知不觉地低估了真正沟通的力量,这是犯罪行为。我没有告诉别人我是谁的代价是我对自己的理解,尽管我完全忘记了这个事实。
让我们回到 16 年前,一个 13 岁,非常瘦的罗德里戈。我爸爸在 IT 基础设施部门工作。有一天,他回到家,在我们的电脑上安装了 Visual Studio(一种开发应用程序的平台)的早期版本,教了我一些编程逻辑,并告诉我要从中获得乐趣。
我不知道是什么样的孩子造就了我,但见鬼,我乐在其中。
编程是一种艺术形式。你有想法,你写代码。那个代码不起作用,所以你在你的呼吸之下发誓并且寻求答案直到你改正它。然后,你移动到下一段代码。你被困住了。这次你骂得更大声了。重复这个过程几次,你就有了一大笔财富,幸运的是,还有一个工作软件。也许是邻居让你闭嘴。你明白了。感觉就像魔术一样,我被迷住了。
我非常喜欢编程,甚至在 StackOverflow 出现之前就已经学会了。对于程序员来说,StackOverflow 就像维基百科对于试图在争论中证明某个观点的学生或醉汉一样。想象一下。
总之。
两年后,我在一所以 IT 为重点的技术高中学习了 4 到 5 种编程语言。我渴望有一个开始工作的机会,实习对我的技术文凭有帮助。我得到了一个在全国最大的银行之一工作的机会,所以我抓住了这个机会。唯一的问题是,它不在 it 棒球场的任何地方——无论如何,它会计入我的文凭,不要问我为什么。
我在那里工作了两三年。后来另一家银行意识到我有银行工作经验,在我上大学时给了我一份临时工作。我拿了。后来,另一家公司看了我的表现,认为我可能很聪明,于是给我安排了一个分析职位。这是接下来 10 年的逻辑。我接受了数据分析。我确实编码、创造东西、重新设计流程,但大部分都是兼职。这些工作中最重要的事情是处理数字和制作精美的幻灯片,试图用外交辞令传达本财年的销售目标注定要失败的信息。
我曾受邀在一家跨国公司创建分析部门。在某一年,我平均每周向 7 个国家的人提交 4 份报告和宏观经济研究。经过 90 分钟的通勤,我会在早上 7 点到办公室,晚上 10 点到家。我推动了相当大的项目,最终产生了数十万美元的收入,否则这些收入是不存在的——甚至还为此获得了一些奖励。
我性格中很大一部分是关于创造的。构建应用,探索新的可能性,以新的方式推动智能发展。至少有几次,我开发了数据应用程序,却在它出现并在另一个国家、在另一面旗帜下运行之前,被办公室政治否决了,而其他人也因此获得了荣誉。
我所在的地区,即使是我认为对一家普通公司来说很有表现力的数字,也只占全球收入的不到 1%。我每天工作 12 个小时,只为了几句好话和一份微薄的薪水,最好的情况是一年结束时拿到半个月的工资,他们称之为绩效奖金。为了销售业绩,我每周至少要在四个不同的场合接受训练,尽管我并没有参与其中。有一段时间,我的工作变成了 Excel 填充和 PowerPoint 制作,而不是其他任何事情,为了政治,我会竭尽全力让本地故事适合全球故事。我不得不整天传递我不相信的信息。
过了一会儿,信不信由你,我筋疲力尽了。
决策制定
“你好,我的新经理!这是我的工作,这是公司的运作方式。现在,请你解雇我好吗?”
这基本上总结了我与 2019 年初分配到我团队的新经理的第一次谈话。我很直率。我想更深入地研究数据科学,如果我想有所成就,我需要全身心投入,而且我需要我的遣散费。因为一千条公司政策,那部分是不行的——嘿,至少我试过了。
我在过量交货上撞了刹车。我做了我该做的,仅此而已。我的精神疲惫和不被重视的感觉让我有些早上很难起床。这位新经理轻而易举地成为我 12 年来共事过的前三名最佳专业人士之一,这让事情变得简单了一些,但伤害已经造成了。事实上,我最终需要离开那里。
我参加了为期 5 个月的数据科学训练营。我开始为工作做数据科学的东西,尽管它还没有完全准备好。
收入计划是通过全球 Excel 模板制定的!你说有比假装我们知道事情如何更好的方法来得到结果是什么意思?我让你卖什么你就卖什么!
不管怎样,我做到了。我研究分类模型,收入模型。我甚至用 Python 编写了一个机器人,从网上搜集一些我会在每周报告中用到的信息。我从中获得了极大的乐趣,但这与我的工作描述完全不符。转念一想,的确是这样,但是的现状占据了主导地位。我只是不得不在某个地方体验到实际上喜欢做更伟大的事情,而不是说这是他们文化的一部分。
我知道我在这里很强势。我不希望看起来对伟大的经理和文化让我能够做的所有伟大的事情不领情,这种文化实际上给了我做我认为正确的事情的自由,但最终,我过度劳累地创造了改进,这些改进会被关闭,除了“让我们保持现状”之外没有任何理由,漂亮的话只能让你到此为止。
职业改变,职业改变。
我被烧成这样,我是以前的自己的一个影子,可能部门里的每个人都知道。
最终,我被解雇了。我拿到了遣散费。我不记得有一天像那时那样笑得这么多。每个人都在期待,我也在期待。我在一个星期五被裁掉了,然后我和团队出去吃汉堡喝啤酒庆祝——包括我那令人敬畏的经理。时代是美好的。我身边有我一生的挚爱,银行里有钱可以用来全职学习,还有数据经验可以让这种转变容易得多。不过,我做的第一件事是休了一个月的长假来给电池充电。
在接下来的三个月里,我学习了线性代数、算法和微积分——你知道,这是每个人在学校都期待的有趣的东西。如果我知道我会走这条路,我会在大学里获得一个 STEM 学位。相反,我成了一名工商管理学士,所以这相当于 5 年的数学学习。非常感谢,年轻的我!无论如何,回到主题。
在某个时候,我开始思考如何以一种用户友好的方式来交付这种数据科学的东西。信不信由你,人们通常不喜欢理解一堆代码下面的无标签数据。去想想。如果你是一名数据科学家,并且正在阅读这篇文章,我只是不想展示笔记本。
所以我开始研究软件开发,偶然发现了那些我 15 年前学过的技术,现在这些技术刚刚成形,而且很流行。大量类固醇。
我开始摆弄它,尤其是一个叫做 React 的框架。我又一次爱上了发展。我开始每周创建成熟的应用程序。每当我发现有新东西要学的时候,我就跳到一个新项目。我看了一下开发人员的职位空缺。数量是压倒性的。我意识到我可以说“去他妈的”,然后重新开始软件开发。于是我照做了。
这是一个冒险的举动。我期望在一两个月内找到一份数据科学的工作。我的遣散费不会持续太久。我意识到我会更乐意接受数据科学的职位,因为我会开发应用程序来交付数据产品。一切看起来都很美,将我所爱的两个世界融为一体。
我完全买了全改行。我开发了我的网站,我重新标记的身份。
然后,疫情大受欢迎。
惊喜惊喜。事情变得艰难了。
两年前,我考虑了大量我从未见过的数据科学和分析领域的职位空缺。我正在做的事情绝对有一个炒作列车正在进行,我正要乘坐它。
一旦疫情来袭,这些机会就消失了。突然之间,我唯一的选择是试图在需要 5 年机器学习经验的职位上竞争,或者作为一名专业软件开发人员进入未知领域。我是一个在市场上工作了 12 年的专业人士,如果你从招聘广告的描述来判断的话,我没有任何选择的经验。我变得非常没有安全感,疯狂地申请我最低要求的职位。这并不是说我没有这方面的经验,但外界的期望绝对是疯狂的。
有时,我会没有公司关注我。然后,我会同时面试 9 个职位。一周后,就像什么都没发生过一样。我的银行账户一直在枯竭,我的焦虑和不确定性达到了创纪录的高度。
每周至少有一次,我会在 36 小时内不吃饭,睡上几个小时后醒来,然后在凌晨 3 点开始编码。日出时,我会精神疲惫,无法入睡,因为我的大脑在飞速运转。
这大约持续了 3-4 个月。在那段时间里,我编码,学习,挫败自己。我重新设计了我处理事情的方法,次数多得数不清。然而,我仍然是一个数据专家,所以我总结如下:
- 提交了 138 份申请(87 份通过 LinkedIn,51 份通过 AngelList)
- 有 48 个人去了 InMails
- 采访了 15 家公司;
很多申请我都没有得到面试的机会,但我确实从招聘海报或相关人员那里得到了热情的信息。在相当多的情况下,这是一个非常具体的要求或技术上不可能雇用我的问题,因为他们不能有国际承包商(至少不能有没有美国签证的承包商,即使这些职位完全是偏远的——这似乎是一件经常发生的事情)。
2020 年 11 月 6 日我在写这个。到目前为止,我已经被“雇佣”了 5 次。一家公司没钱雇佣我,一家公司把全职职位变成了随需应变的职位(我可能一个月工作 0 到 160 个小时,这对我一点帮助都没有),两家公司完全陷入困境,声称他们必须取得一些进展才能真正聘用我。
与此同时,为了管理,我让自己成为一名自由职业者。我设法找到了一些工作,在一个货币大幅贬值的国家用美元支付报酬,这真的很有帮助。美国公司支付给海外开发者的平均薪酬在每小时 25-50 美元之间。在这里,在巴西,它的范围是每小时 20-50 BRL。很接近了,不是吗?除了美元几乎以 6 比 1 的比例超过 BRL。
这意味着得到那几份工作实际上让我度过了相当长的一段时间。没有我想的那么多,但是他们支付了大部分账单。
然而,幸运的是,几天前我与第五家也是最近一家接触我的公司签约,结束了我在大约 11 个月内从战略规划专家到数据科学家再到软件开发人员的转变之旅。
我学到了什么
一封诚实的求职信会给你带来奇迹。
我可能有编码的经验,但我从来没有真正的工作头衔来展示它。我几乎没有时间发布公共代码。一旦我精心制作了一封求职信,分享了我在这篇文章中与你分享的一些内容,我来自哪里,我喜欢做什么,我愿意做什么,我开始收到大量的回复。
作为自由职业者获得第一份工作非常困难。
我独自在 Upwork 上申请了 56 次,得到了 8 次面试机会(其中 6 次我拒绝了,因为工作描述写得很差,没有反映现实),并获得了其中的 1 次。如果你对比一下我申请的全职工作的统计数据,并不是有什么不同,而是结果非常不同。如果你找到一份全职工作,就这样。你知道到月底你能挣多少钱。
获得一份工作的报酬只是全职工作的一小部分,如果你想再获得一周的报酬,你必须再做一次销售(显然,这取决于项目的长度)。
很有可能,你将不得不付出非常低的工资来为自己赢得 5 星评级,只有这样,你的出价才会得到更好的回应。这些自由职业平台中的成功人士声称,工作越多越容易,你可以获得越来越高的工资,这使它成为一种非常有吸引力的生活方式——但要准备好迎接艰难的开始。
即使事情看起来很确定,他们也可以随时改变主意。
我实际上是在五月份被雇佣的。原本应该相隔几周的采访和放映被缩短到一两天。人们在我们的谈话中理所当然地感到兴奋,谈论从那时起一年后我的角色的计划。但那时,这个职位依赖于他们完成一份合同。或者它的预算从来没有保证过。我艰难地认识到,现实会毫不犹豫地戳破你的泡沫。
有时候依赖别人也没什么。
我有一个严重的问题,那就是我是事情的接受者。我的另一半和我的父母联系了我几次,向我保证如果需要的话,他们会在情感上和经济上支持我。我不得不提醒自己,我没有懈怠,他们都在和我一起赌我的热情,因此最终获得支持是件好事。
技术工作并不经常进行真正的技术面试。
这是最让我惊讶的。你需要软件开发和数据科学方面的编码技能。然而,我惊讶地发现,只要你像一个老手那样说话,口头展示你的经验,提到你过去做过的事情,你遇到的麻烦,你就可以在大多数面试中过关,进入录用阶段,而不用写一行代码。
几周前,我和一家科技公司的技术主管通了电话。我非常确定我会被代码和基础设施优化的问题所困扰,为什么要使用一个框架而不是另一个,等等。事实证明,这是我有一段时间以来在我的核心圈子之外进行的最富有哲理的对话之一,在这个圈子里,一旦我提到我喜欢做什么,事情的代码方面就仅仅是一个细节了。
请记住,这并不是鼓励你不做准备,但你肯定不必为了成为一名体面的候选人而在黑客排名挑战中失眠。
你应该伸出手。真正伸手。
大多数求职公告板会告诉你在过去的两周或几个月里有多少人申请了那个职位。想想你的应用程序到达某人手中的几率吧。
通过官方途径申请,并直接与决策者联系。如果你申请的是数据分析师的职位,登陆 LinkedIn,搜索该公司的数据分析经理。发一条信息,我在第一个话题提到的求职信的简化版。LinkedIn 允许你在邮件中附上你的简历。至少,你会有更好的机会。
人是可以善良的。
网络。我知道这个建议无处不在,但这是有原因的。说起来容易做起来难。在我的数据科学训练营期间,我的处境很糟糕。我没有把自己放在那里,我没有真正与人交流。我只是挣扎着起床去工作,并度过一天,这让我精神疲惫到无法接近最佳状态的程度。
不管怎样,在得出结论的几个月之后,我仍然在和班上的同学进行群聊。有人分享了他们收到的一个软件开发人员的职位空缺。我申请了,并感谢他在小组中分享了这一点。不到两天后,他找到我,问我过得怎么样,并要了我的简历,这样他就可以和他所在的一群初创公司分享了。我得到了两个采访。
我不认为我们在那五个月里交谈过超过一打的话。没有人能为我担保。他可以轻松地说他不认识我。更糟糕的是,我在精神上处于一个黑暗的地方,几乎没有展示出我的能力——他完全有理由什么也不做。然而,他想尽办法让我有事发生。
想象一下如果我和他有联系。
我使用的求职资源
令人难以置信的大量国际职位空缺都在美国。这意味着他们通常需要工作签证或在该国的居住权,你才会被考虑——即使是非常遥远的地方,不管是什么原因。
当你寻找工作时,Jooble、Glassdoor 和 Indeed 等网站会成为你的主要选择,但这些网站 99.99%都是针对美国公民和居民的。LinkedIn 在寻找远程机会方面很糟糕,所以我甚至懒得列出它。以下是一些你可以用来逃离这种趋势的方法:
- **AngelList(https://angel . co)😗*这是目前为止,我用过的最好的资源。AngelList 是一个专注于创业公司的求职板。当你申请一个职位时,你的信息会直接传递给招聘者(通常是决策者)。所有的工作都有预设的年薪范围。你可以专门搜索适合你技能的工作。几乎所有我抓住或进入最后阶段的机会都来自这里。不过,要确保你对公司的筛选和它对你的筛选一样多。我们谈论的是创业公司。对于他们来说,资金告罄或者简单地采用一种与他们一开始让你相信的不同的招聘模式并不罕见。
- **up work(https://www . up work . com)😗*在我找到一份全职工作之前,我不得不做一些自由职业来赚些钱。输入 Upwork。我要提前告诉你:对于一个刚开始的自由职业者来说,这可能不是最好的平台。据说它的算法优先考虑那些已经有正面评价的自由职业者。然而,它的工作组织最吸引我。确保你有一个简洁而可靠的描述——在客户点击查看更多内容之前,只有前两行会显示在出价中。同样,关于给自己一个相当大的降薪的暗示也适用于第一个客户。
- **自由职业者(https://www . Freelancer . com)😗*他们自称是地球上最大的自由职业者网站,我相信他们。他们对你的第一个 500 美元收取的费用(10%的佣金)低于 Upwork (20%,直到上限,然后逐渐减少)。然而,如果你想真正脱颖而出,他们有测试,每个 5 美元。这看起来很便宜,但如果你来自一个货币不坚挺的国家,你可能会遭受金融打击来让自己站稳脚跟。
- we work remote(www . we work remote . com):这不是我见过的最好的工具,但很有效。本质上,你可以通过按类别无限滚动列表来找到工作,链接会将你引向外部申请网站——通常是自己公司的网站。
- **JS remote(www . JS remote . com)😗*这个是专门给 JavaScript 开发者的。它的工作方式与 WeWorkRemotely 极其相似(我不知道这些网站之间是否有联系)。不过,你可以用框架来过滤机会,不管是节点、反应、角度、Vue、电子还是流星。
结束语
这无疑是我一生中最有启发性的一年。我抛弃了一个相当保守的自己,去寻找我最初的激情所在,无论它以什么形式出现。这让我度过了几个不眠之夜,少吃了几顿饭,还引发了几次焦虑,但我几乎可以肯定地说,我做到了。
我明白,我们所有人都会至少一次面对自己的良心,面对自己做出的人生选择。很容易感到不安全。在法律允许我们喝啤酒之前,我们必须决定我们生活的大部分方向。
如果你有疑虑没关系。与自己联系,相信你内心看到的那个人,并制定一个计划去见那个人。
尽管困难重重,但如果有一件事我可以向你保证的话,那就是更好地了解自己不会有任何坏处,制造一点麻烦让整个经历至少对你自己好一点也绝对没有错。
不过,这只是一个艰难的提示:如果你打算搬家,尽可能确保世界不会在那个时间框架内终结。
我给 10 所不同学校的 300 名商科学生教授应用人工智能。
我学到的关于如何从教学上接近人工智能的 15 课。

在过去的一年里,我有幸在法国给各种商科学生教授应用人工智能。
对没有数学/统计学背景的人来说,教授人工智能比看起来更困难。
但这是迄今为止最有趣的话题。
它涉及如此广泛和众多的方面,对于未来的商业领袖来说,从经济的角度来看,当然也从伦理和哲学的角度来看,都是至关重要的,所以试图获取这门学科的精髓并教授它是非常令人着迷的。
我想我比我的学生学到了更多,我决定分享我的发现。
我也调查了其中的 100 个。
这篇文章有一个教学目标,这些课程实际上可以应用于任何类型的主题,而不是专门针对人工智能。
1.学生首先需要明白为什么要听你说的话。
我上了 10 节不同的课。我有机会 A/B 测试我的开场白。
你猜怎么着,当我用最简单的解释开始课程,告诉他们为什么需要关注这门课程时,他们更加投入了。至少在最初的 5 分钟里。前 5 分钟决定了你整个课程的剩余时间。
你知道他们说什么,你永远没有第二次机会留下第一个好印象。嗯,是真的。
对于人工智能,介绍是这样的:
- 谁觉得他今天用了 AI?→及时吸引他们的问题
- 对于没用过的人来说,AI 是什么?→尝试测量温度
- 如果我告诉你,如果你用手机,你很可能用的是 AI,你会怎么说?→ AI 无处不在,而他们不知道这件事,它一定很重要…
上钩了。
2.学生首先需要明白为什么要听你的。
嘿,你是谁?你在跟我说什么?
信任就是一切,如果他们相信你能胜任他们感兴趣的话题,他们可能会想继续听下去。
3.总是回到主题的基础知识
我们为什么要创造人工智能?从根本上引出什么是 AI?这导致了什么是创新呢?
创新总是以扩展人类属性为目标。
从书到网络。
扩展人性的一面。
赋予人类超能力。
那么,我们试图赋予人工智能什么样的超能力呢?
提示:它在 AI 这个词里…
一旦我们知道我们正试图通过赋予机器像人类一样思考和行动的能力来扩展我们的智力,我们就可以试图理解它背后的“如何做”。
4.逆向工程是终极教学技能
从客户需求开始,一直到技术的后端,史蒂夫·乔布斯
从应用程序开始,向后追溯到理论。
5.使用“系统设计”方法分解概念
实际上,系统设计是软件工程中最重要的技能之一,它主要考虑如何构建复杂的产品。
当你想到架构时,你会想到结构和过程。
事实证明,我们所知道的大多数事情都可以被设计成生活中的三个阶段:
输入→系统→输出
这是一个我如何把 4 和 5 结合起来的例子。

然后你通过问正确的问题来解构这个系统。
1.学会开车意味着什么?
从根本上说,这是关于观察和预测。
2。我们如何看待和预测?
我们需要学习如何去做。
3.机器是如何学习的?
机器学习部分来了。
最后:

导致以下结果的示例:


6.尽可能多地使用隐喻
将一个众所周知的概念应用到你的专业领域。
例如人工智能,我想到的一个有用的比喻和比较概念是:
建筑:为了建造房子(你的产出),你需要水泥和石头等原材料(你的数据),你需要水泥搅拌车等工具(你的算法和框架),你需要仔细的指导方针(你的模型)来遵循计划。
你可以把它应用到烹饪、学习和更多的活动中…
7.点对点学习是必须的
我成对设计案例研究,而不是分组。结果证明效率要高得多。
8.邀请专家进行实时企业案例研究
大师班在这一点上给了我很大的启发。
没有什么比真正的世界级专家给你的应用科学课程带来实用性更有效的了。
9.基于交叉学习经验,创建原创的应用案例研究
我开设了一门课程,内容是从国际象棋到人工智能的商业策略,从扑克到人工智能决策,我们能从中吸取什么。
这似乎引起了共鸣。
10.基于跨格式经验创建原创应用案例研究
我曾经围绕鲨鱼池表演设计过责任案例研究。学生们非常着迷。
游戏、视频、辩论、运动都是强有力的学习刺激物。
例如,谷歌人工智能提供了有用的实验来测试现场教室中的人工智能工具。
例如,麻省理工学院关于人工智能伦理的道德机器是一个强大的参与工具。

10.与他们共建内容
从白板开始。
提问。
继续前进。
用他们的答案从头开始建立部分。
11.实验可能会失败,但从长远来看是有益的
尝试新的教学方法。
你唯一的限制是你的想象力。
有时学生不会参与,但它将永远教你为什么。
12.尽可能多地总结和重复
每 30 分钟,我会花 1 分钟来总结到目前为止学到的东西。
学生们非常欣赏这一点。
特别是当你的课程是自下而上建立的,你需要理解接下来会发生什么。
13.教授内容,尤其是解决你提出的问题的思维框架
商科学生并不想让他们的问题得到答案。他们想知道在任何情况下如何回答。
我发现一个特别有用的练习是陈述一个极其宽泛和开放的问题:人工智能将如何影响社会?
他们必须想出答案,然后发现如果那样说就没那么容易了。
他们需要一个思维框架。
这是我提供的答案:










14.尝试建立内在动机
我没有设置等级。
他们不喜欢它,我也不喜欢。
首先,试着找出他们为什么想听你说话。
15.每次都要感谢他们。
如果可以的话,直呼他们的名字。
始终声明他们的问题是真正相关的。
如果可以的话,在小组学习之前尝试一对一的高质量会议。
感谢您读到这里,欢迎随时和我连线 Linkedin 来聊聊 AI。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}